machine learning
TRANSCRIPT

Machine Learning

What is it?
● Grew out of work in Artificial Intelligence (AI)● 1959 Arthur Samuel – Machine Learning:
● „Field of study that gives computers the ability to learn without being explicitly programmed.”
● 1998 Tom Mitchell – Well posed learning problem:● „A computer program is said to 'learn' from
experience 'E' with respect to some task 'T' and some performance measure 'P', if its performance on 'T', as measured by 'P', improves with experience 'E'.”

What is it?
● Example:● Email program
(experience)
– 'E' – watches you label emails as spam/not spam
(task)
– 'T' – classifies emails as spam/not spam
(performance)
– 'P' – fraction of emails correctly classified as spam/not spam

What is it?
● Solves complicated, underspecified problems● Some problems can't be solved directly by software
● Instead of writing a program for each problem:● Collect samples of correct input->output● Use algorithm to create a program to do the same● Program handles new cases (other than those in
the training data), retrain if new data
● Massive amounts of data + computation is cheaper than developing softwarehttp://technocalifornia.blogspot.com/2012/07/more-data-or-better-models.html

Problems for Machine Learning
● Pattern recognition● Objects in real scenes● Computer vision – facial identities / expressions● Speech recognition
– Sample sounds– Partition phonemes– Decoding – extract meaning, NLP
● Natural language

Problems for Machine Learning
● Recognizing anomalies● Unusual sequences
– Credit / phone fraud– SPAM / HAM
● Sensor readings– Power plant operation and health– Detect when actions are required

Problems for Machine Learning
● Prediction● Stock price movements (time sequence)● Currency exchange rates● Risk analytics● Sentiment analysis● Click throughs (web traffic)● Preferences
– Netflix, Amazon, Pandora, web ad targetting, etc.

Problems for Machine Learning
● Information Retrieval (database mining)● Genomics● News/Twitter data feeds● Archived data● Web clicks● Medical records● Find similar, summarize groups of material

Learning - Supervised
● Predict output given the input, train using inputs with known outputs
● Regression – target is a real number, goal is to be 'close'
● Classification – target is a class label: binary (yes/no) or multi-class (one of many)

Learning – Unsupervised
● Older texts explicitly exclude this from being learning!
● Discover good internal representation of input● Difficult to determine what the goal is
● Create a representation that can be used in subsequent supervised learning?
● Dimensionality reduction (PCA) can be used for compression or to simplify analysis
● Provide an economical high dimensional representation (binary features, real features – single largest parameter)

Learning – Reinforcement
● Select action to maximize payoff● Maximize expected sum of future rewards● Not every action results in a payoff● Apply discounting to minimize effect of far future on
present decisions
● Difficult – payoffs are delayed, critical decision points unknown, scalar payoff contains little information

Learning – Reinforcement
● Planning● Choice of actions by anticipating outcomes● Actions and planning can be interleaved
(incomplete knowledge)– Warehouse, dock management, Route
planning/replanning● Multiple simultaneous agents planning
independently– Emergency responders– http://www.aiai.ed.ac.uk/project/i-globe/resources/2007-
03-06-Iglobe/2007-03-06-Iglobe-Demo.avi

Learning – Data
● Training data [ ~60% - 80% ]● Inputs (with correct response for supervised)
● Validation data [ ~20% ]● Converge by training on multiple sets of data,
improving each time
● Test data [ ~10% - 20% ]● Not used until training and validation are complete –
measure performance with this data set

Learning – Data
● Partition randomly● Time series data use random subsequences● Training and test data should be from same
population● If feature selection or model tuning required
(e.g. PCA parameter mapping) then the tuning must be done for each training set

Learning – Training
● One iteration for each set of input data in the training data set
● Start with random parameters● Randomize input data during training● Calculate model parameters for each input● Use previous parameter values to calculate
next values using new training input

Learning – Bias and Variance
● Bias – algorithm errors● High bias – underfit● More training data does not help
● Variance – sensitivity to fluctuations in data● High variance – overfit● More training data likely to help
● Irreducible error - noise
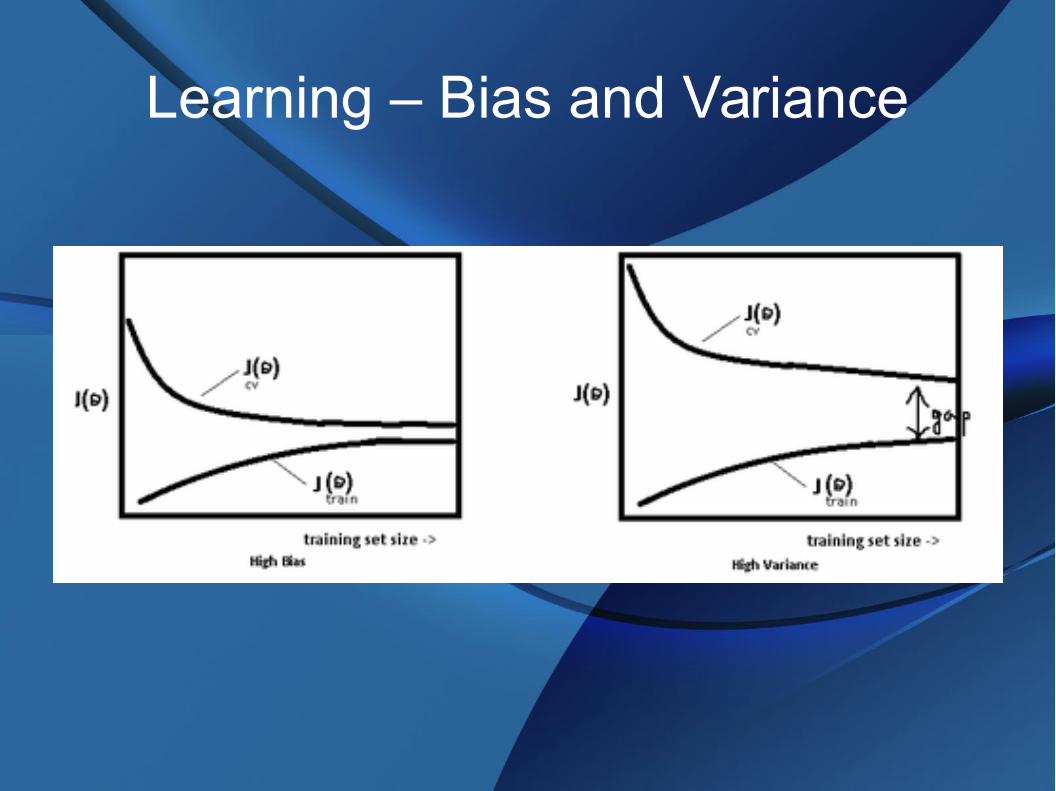
Learning – Bias and Variance

Learning – (Cross) Validation
● Validation● Holdout data for tuning model with new data● Evaluate model using holdout as test set
● Cross validation● generating models with different holdouts to avoid
overfitting● n-fold - divide data into n chunks and train n times,
treating a different chunk as the holdout each time (leave-one-out – same with chunk size of 1)
● Random subsampling – approaches leave-p-out

Learning - Improvements
● Things to do when the error is to high● Get more training data (high variance)● Try smaller sets of features (high variance)● Try getting additional features (high bias)● Add polynomial features (high bias)● Decrease smoothing parameter λ (high bias)● Increase smoothing parameter λ (high variance)

Learning – Testing
● Reserve set of data [~10% - 20% ]● Evaluate model performance with the test set● Make no further model changes● Performance evaluation
● Supervised learning – compare predictions with known results
● Predictions of unsupervised model when results can be known – even if not used in training

Training - Gradient Descent
● Find minimum of a cost / performance metric
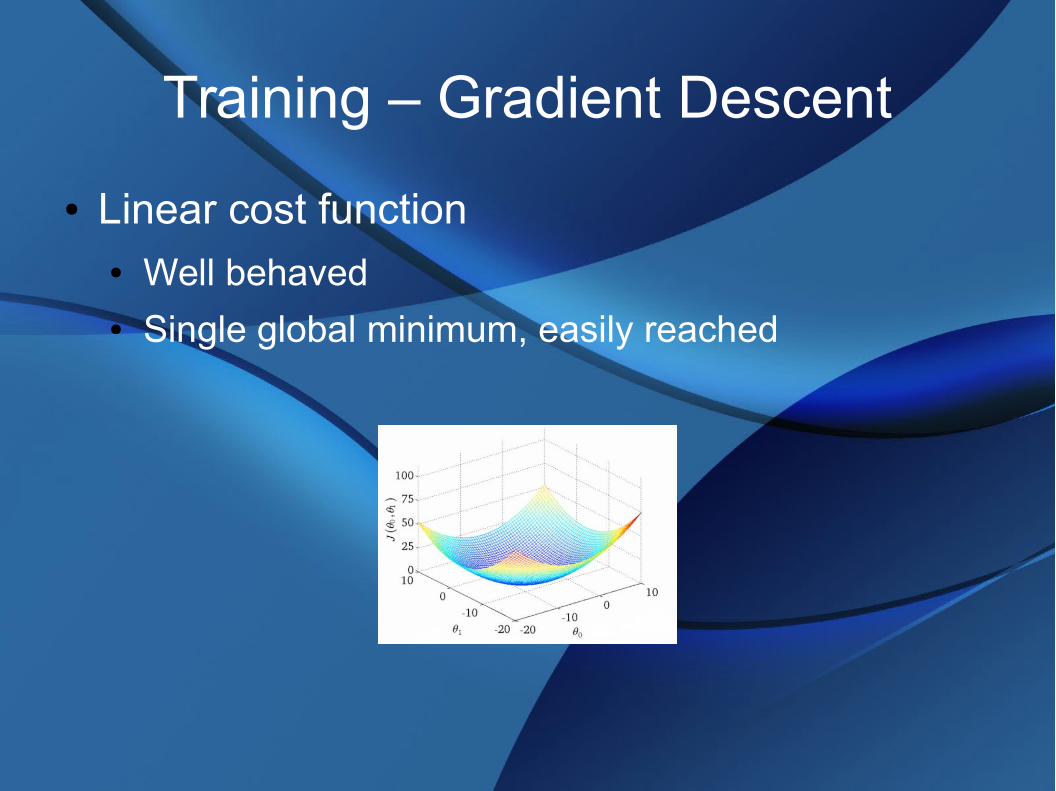
Training – Gradient Descent
● Linear cost function● Well behaved● Single global minimum, easily reached

Training – Gradient Descent
● Complex cost functions● Not well behaved● Global minimum, many local minima

Training – Gradient Descent
● Convergence speed and stability controlled by slope parameter α
● Low α ● High α

Training – k-means
● Classify data into k different groups● Start with k random points● Group data with the closest point● Move the points to the centroid of the data for that
point● Terminate when the points no longer move (or
move only a small amount)

Training – k-means

Training – k-nn
● k nearest neighbors determine classification of each element in data
● Skewed data can result in homogenous result● Use weighting to avoid this
● Training – store the training data● For each data point to be predicted
● Locate the nearest k other points– Use any consistent distance metric – l-p norms (euclidan,
manhattan distances, maximum single direction)● Assign the majority class of those nearest points

Training – k-nn

Types of Machine Learning
● Regressions● Neural Networks● Dimensionality reduction
● Support Vector Machines (SVM)● Principle Component Analysis (PCA)
● Clustering● Classification● Probabilistic – Bayes, Markov● ...others...

Regression
● Single / Multiple variable● Linear / Logistic● Regularization (smoothing) – helps to avoid
overfitting

Regression – Equations
● Linear regression hypothesis function
● Logistic regression hypothesis function
● Regularized linear regression cost function
● Regularized logistic regression cost function

Neural Networks - Representation
● Nodes – compared to neurons, many inputs, one output
● Transfer characteristic – logistic function● Input from left, output to right● Layers
– Input layer, driven by numeric input values– Output layer, provides numeric output values (or
thresholded for classification output)– Hidden layers between input and output – no discernable
meaning for their values
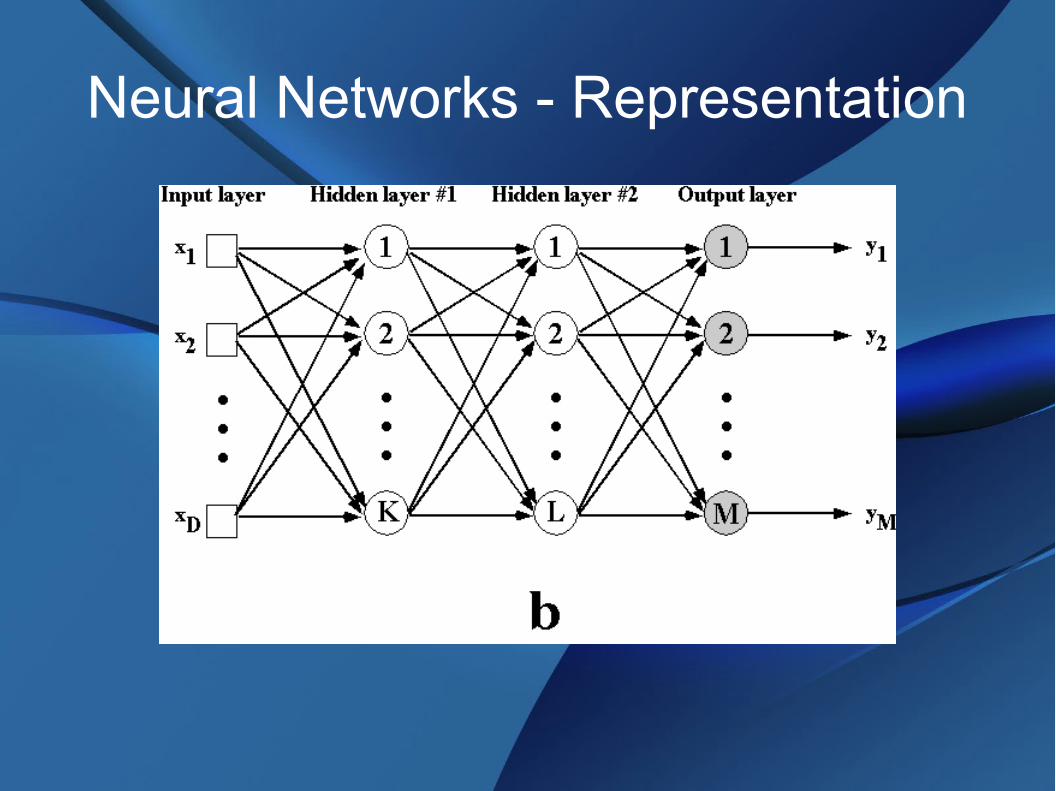
Neural Networks - Representation

Neural Networks – Learning
● Learns using gradient descent● Forward propagation – start at inputs, derive
parameters of next stage● Backward propagation – start at outputs, adjust
parameters to produce desired output

Neural Networks - Learning
● OCR training set● what does the number '2' look like when
handwritten?

Neural Networks - Learning
● Neural Network parameters are not simply interpretable

Support Vector Machines
● Supervised learning classification and regression algorithm
● Cocktail Party Problem● Many speakers, many sensors (microphones)● Classify source from the inputs
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');

Principle Component Analysis
● Unsupervised learning● Finds basis vectors for data● Largest is the 'principle' component● Center each attribute on mean for visualization,
not for prediction models● Normalized to same range to provide
comparable contributions from each factor

Classification
● Logistic partitioning - data

Classification
● Logistic partitioning – classification boundary
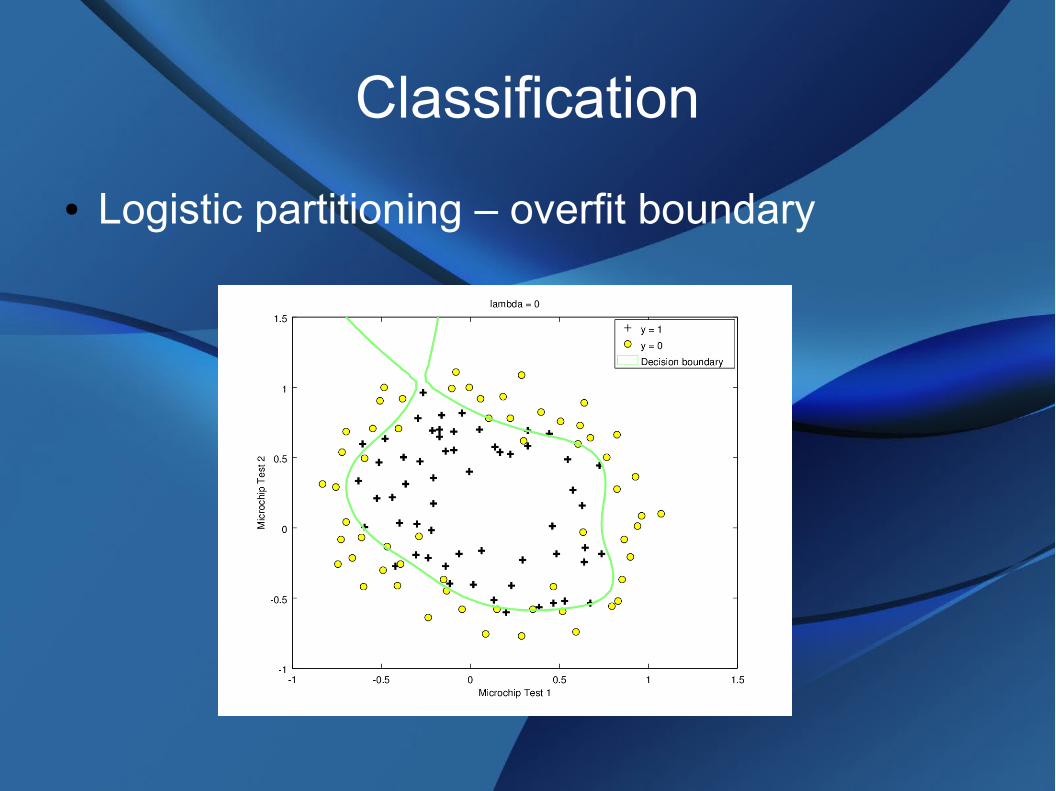
Classification
● Logistic partitioning – overfit boundary

Classification
● Logistic partitioning – underfit boundary

Classification - Performance

Classification - Performance
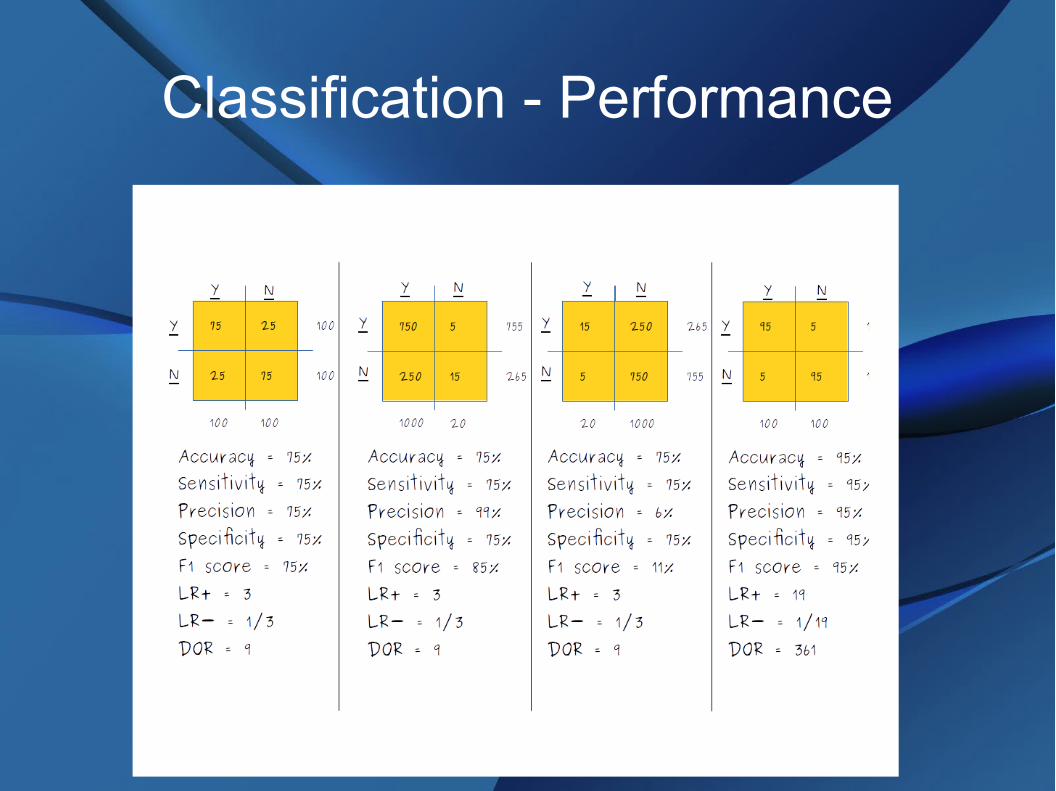
Classification - Performance
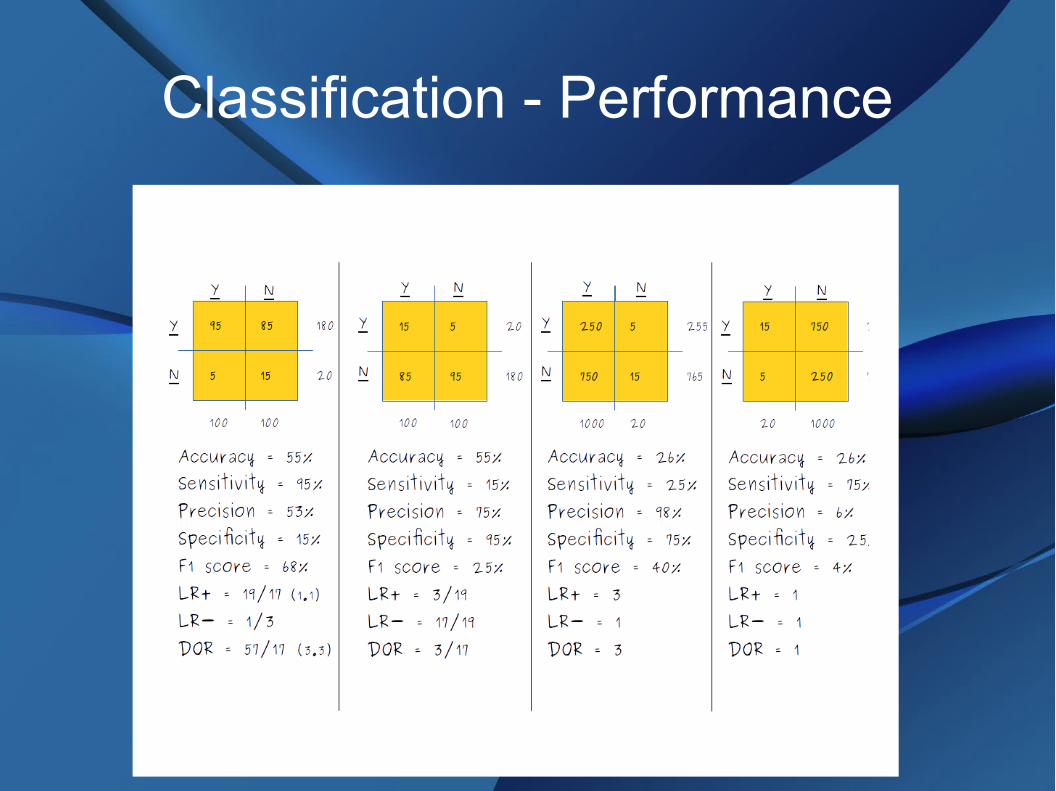
Classification - Performance

Classification - Performance
● Receiver Operating Characteristic (ROC)● Location of classification performance● Perfect predictions indicated in upper left corner● Up and to the left means better● Diagonal from lower left to upper right indicates
performance equivalent to random guessing
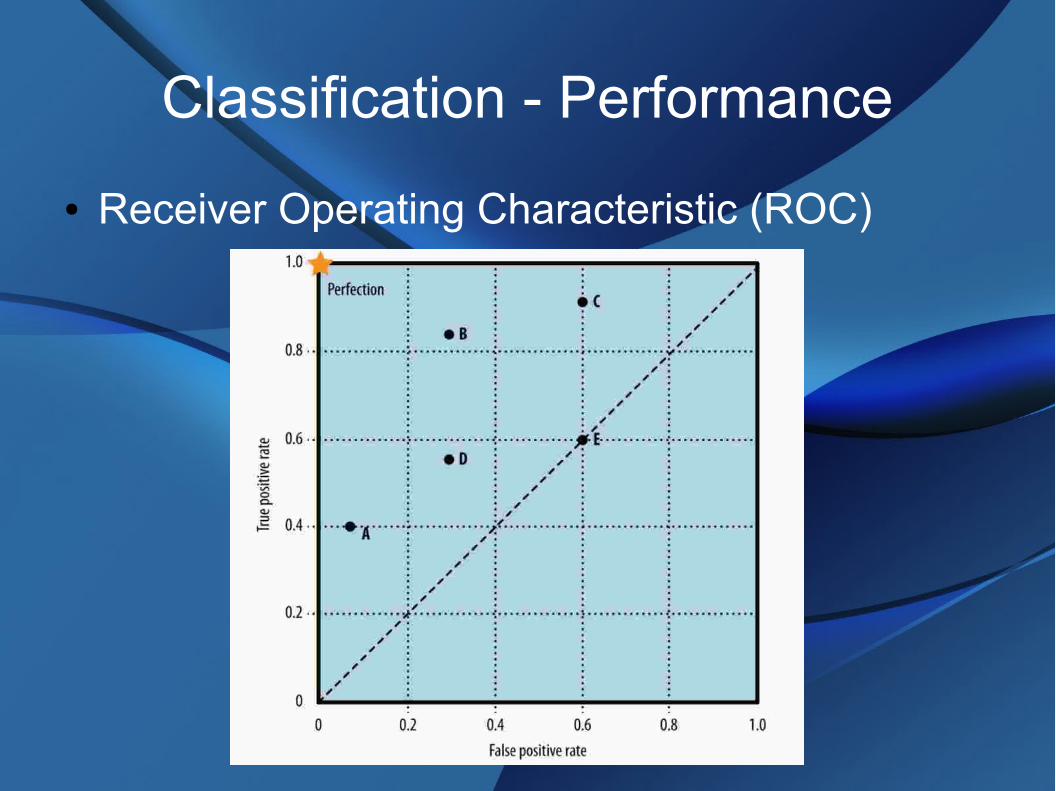
Classification - Performance
● Receiver Operating Characteristic (ROC)

Classification - Performance
● Area Under the Curve (AUC)● ROC chart with curves applied● Classifications based on thresholds for continuous
random variables● Curve is parametric plot with the threshold as the
varying parameter● AUC is a scalar summary of predictive value
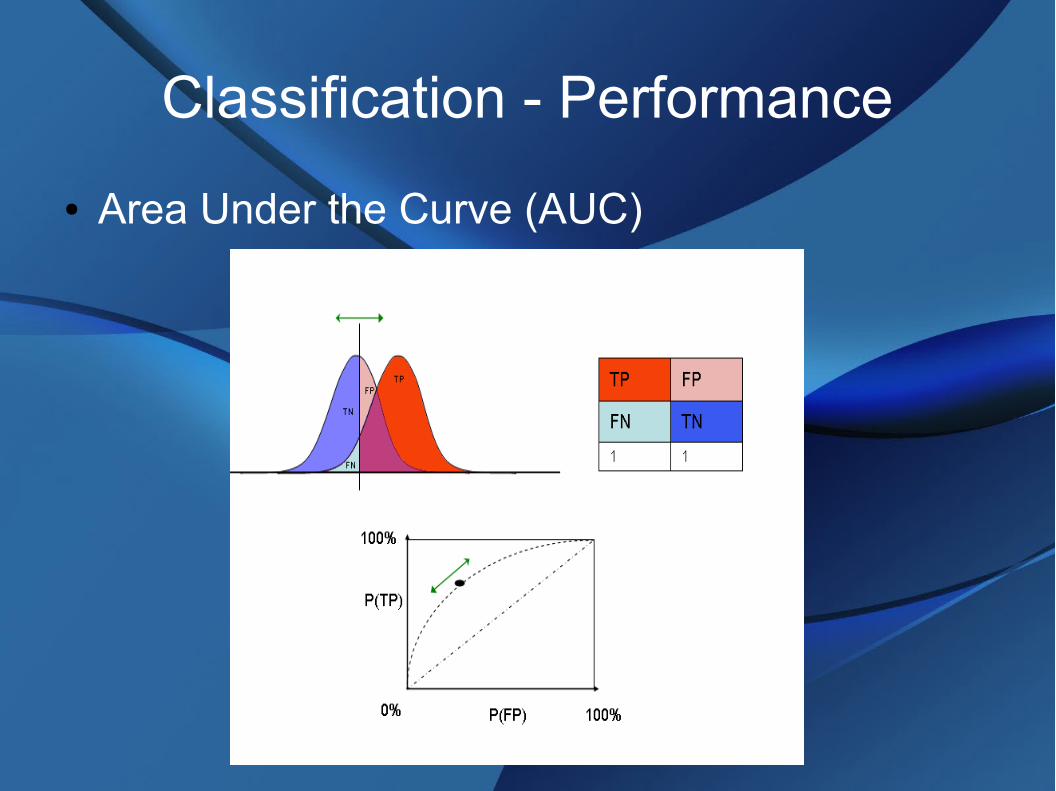
Classification - Performance
● Area Under the Curve (AUC)

Natural Language Processing
● Text processing● Modeling
● Generative models – generate observed data from hidden parameters– N-gram, Naive Bayes, HSMM, CFG
● Discriminative models – estimate probability of hidden parameters from observed data– Regressions, maximum entropy, conditional random
fields, support vector machines, neural networks

NLP - Language Modeling
● Probability of sequences of words (fragments, sentences)
● Markov assumption● Product of each element probability conditional on
small preceding sequence– N-grams: bigrams: single preceding word, trigrams: two
preceeding words

NLP - Information Extraction
● Find and understand relevant parts of texts● Gather information from many sources● Produce structured representation
● Relations, knowledge base● Resource Description Framework (RDF)
● Retrieval● Finding unstructured material in a large collection● Web/email search, knowledge bases, legal data,
health data, etc.
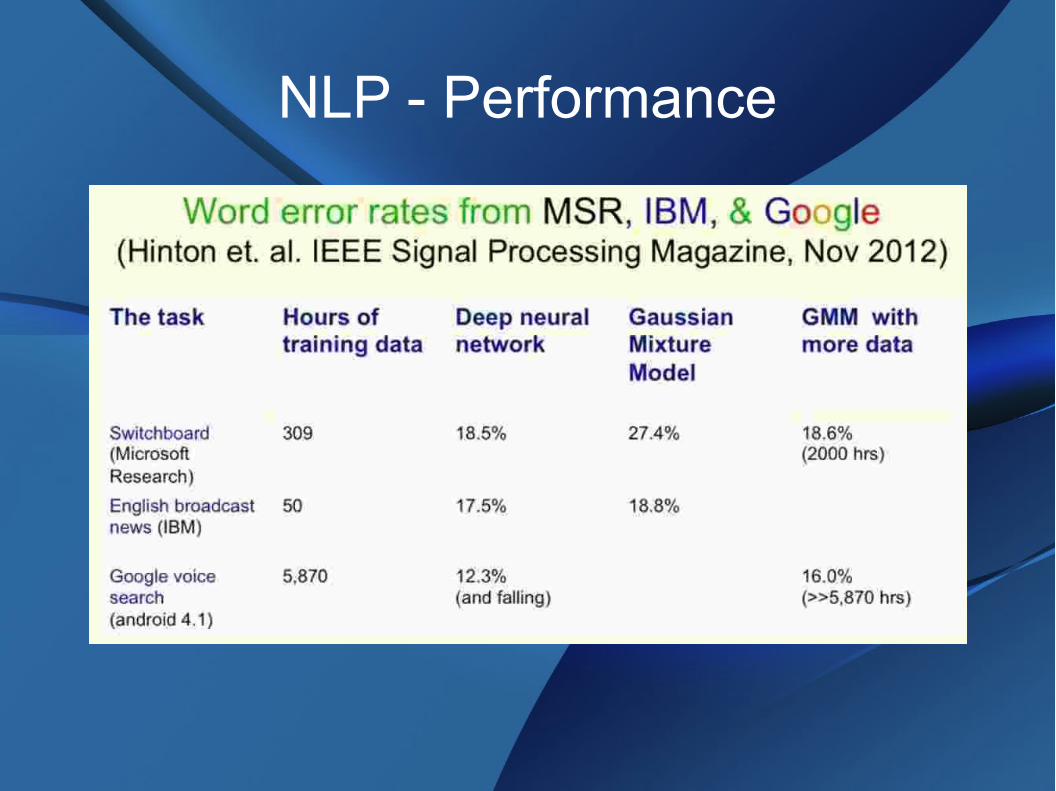
NLP - Performance