lvtn cao hoc_tranducminh
TRANSCRIPT

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 1/80
-1-
MỤC LỤC
MỞ ĐẦU ............................................................................................................................2
CHƯƠ NG I: CÁC KHÁI NIỆM CƠ B ẢN V Ề M ẠNG NƠ RON..................................................4 1.1. Sơ lược v ề mạng nơron ..........................................................................................4 1.1.1. L ị ch s ử phát tri ể n ....................................................................................................4 1.1.2. Ứ ng d ụ ng...............................................................................................................6 1.1.3. C ă n nguyên sinh h ọ c ...............................................................................................6
1.2. Đơn vị xử lý ............................................................................................................8 1.3. Hàm xử lý ...............................................................................................................9
1.3.1. Hàm k ế t h ợ p...........................................................................................................9 1.3.2. Hàm kích ho ạ t (hàm chuy ể n) ...................................................................................9
1.4. Các hình trạng của mạng .....................................................................................12 1.4.1. M ạ ng truy ề n th ẳ ng................................................................................................12 1.4.2. M ạ ng h ồ i quy........................................................................................................13
1.5. Mạng học..............................................................................................................13 1.5.1. H ọ c có th ầ y .......................................................................................................... 13 1.5.2. H ọ c không có th ầ y ................................................................................................14
1.6. Hàm mục tiêu .......................................................................................................14 CHƯƠ NG II. M ẠNG NƠ RON TRUY ỀN TH ẲNG VÀ THU ẬT TOÁN LAN TRUY ỀN NGƯỢ C..16
2.1. Kiế n trúc cơ bản ...................................................................................................16 2.1.1. M ạ ng truy ề n th ẳ ng................................................................................................16 2.1.2. M ạ ng h ồ i quy........................................................................................................18
2.2. Khả năng thể hiện ................................................................................................19 2.3. V ấ n đề thiế t k ế cấ u trúc mạng .............................................................................19
2.3.1. S ố l ớ p ẩ n..............................................................................................................19 2.3.2. S ố đơ n v ị trong l ớ p ẩ n ...........................................................................................20
2.4. Thuật toán lan truy ền ngược (Back-Propagation)...............................................21 2.4.1. Mô t ả thu ậ t toán ................................................................................................... 22 2.4.2. S ử d ụ ng thu ậ t toán lan truy ề n ng ượ c......................................................................27 2.4.3. M ộ t s ố bi ế n th ể c ủ a thu ậ t toán lan truy ề n ng ượ c .....................................................31 2.4.4. Nh ậ n xét .............................................................................................................. 36
2.5. Các thuật toán tố i ư u khác...................................................................................38 2.5.1. Thu ậ t toán gi ả luy ệ n kim (Simulated annealing).......................................................38 2.5.2. Thu ậ t gi ả i di truy ề n (Genetic Algorithm)..................................................................39
CHƯƠ NG III. Ứ NG DỤNG M ẠNG NƠ RON TRUY ỀN TH ẲNG TRONG DỰ BÁO DỮ LIỆU...41 3.1. Sơ lược v ề l ĩ nh vự c dự báo dữ liệu.......................................................................41 3.2. Thu thập, phân tích và xử lý dữ liệu ....................................................................42
3.2.1. Ki ể u c ủ a các bi ế n ..................................................................................................43 3.2.2. Thu th ậ p d ữ li ệ u ...................................................................................................44
3.2.3. Phân tích d ữ li ệ u ...................................................................................................45 3.2.4. X ử lý d ữ li ệ u ......................................................................................................... 46 3.2.5. T ổ ng h ợ p .............................................................................................................48
3.3. Chương trình dự báo dữ liệu................................................................................48 3.3.1. Các b ướ c chính trong quá trình thi ế t k ế và xây d ự ng................................................48 3.3.2. Xây d ự ng ch ươ ng trình ..........................................................................................54 3.3.3. Ch ươ ng trình d ự báo d ữ li ệ u ..................................................................................69
3.4. Một số nhận xét....................................................................................................75 K Ế T LU ẬN........................................................................................................................77 TÀI LIỆU THAM KH ẢO.....................................................................................................79

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 2/80
-2-
MỞ ĐẦU
Cùng vớ i sự phát triển của mô hình kho dữ liệu (Dataware house), ở Việt nam ngày càng
có nhiều kho dữ liệu vớ i lượ ng dữ liệu r ất lớ n. Để khai thác có hiệu quả những dữ liệu
khổng lồ này, đã có nhiều công cụ đượ c xây dựng để thỏa mãn nhu cầu khai thác dữ liệu
mức cao, chẳng hạn như công cụ khai thác dữ liệu Oracle Discoverer của hãng Oracle.
Công cụ này đượ c sử dụng như một bộ phân tích dữ liệu đa năng theo nhiều chiều dữ liệu,
đặc biệt theo thờ i gian. Hay là việc xây dựng các hệ chuyên gia, các hệ thống dựa trên một
cơ sở tri thức của các chuyên gia, để có thể dự báo đượ c khuynh hướ ng phát triển của dữ
liệu, thực hiện các phân tích trên các dữ liệu của tổ chức. Mặc dù các công cụ, các hệ thống
trên hoàn toàn có thể thực hiện đượ c phần lớ n các công việc nêu trên, chúng vẫn yêu cầu
một độ chính xác, đầy đủ nhất định về mặt dữ liệu để có thể đưa ra đượ c các câu tr ả lờ i
chính xác.
Trong khi đó, các ứng dụng của mạng nơ ron truyền thẳng đượ c xây dựng dựa trên các
nhân tố ảnh hưở ng đến sự thay đổi của dữ liệu đã đượ c thực tiễn chứng minh là khá mạnh
và hiệu quả trong các bài toán dự báo, phân tích dữ liệu. Chúng có thể đượ c huấn luyện vàánh xạ từ các dữ liệu vào tớ i các dữ liệu ra mà không yêu cầu các dữ liệu đó phải đầy đủ.
Trong số các loại mạng tươ ng đối phổ biến thì các mạng neuron truyền thẳng nhiều lớ p,
đượ c huấn luyện bằng thuật toán lan truyền ngượ c đượ c sử dụng nhiều nhất. Các mạng
nơ ron này có khả năng biểu diễn các ánh xạ phi tuyến giữa đầu vào và đầu ra, chúng đượ c
coi như là các “bộ xấ p xỉ đa năng”. Việc ứng dụng của loại mạng này chủ yếu là cho việc
phân tích, dự báo, phân loại các số liệu thực tế. Đặc biệt đối vớ i việc dự báo khuynh hướ ng
thay đổi của các dữ liệu tác nghiệ p trong các cơ quan, tổ chức kinh tế, xã hội,... Nếu có thể
dự báo đượ c khuynh hướ ng thay đổi của dữ liệu vớ i một độ tin cậy nhất định, các nhà lãnh
đạo có thể đưa ra đượ c các quyết sách đúng đắn cho cơ quan, tổ chức của mình.
Luận văn này đượ c thực hiện vớ i mục đích tìm hiểu và làm sáng tỏ một số khía cạnh về
mạng nơ ron truyền thẳng nhiều lớ p, thuật toán lan truyền ngượ c và ứng dụng chúng trong
giải quyết các bài toán trong l ĩ nh vực dự báo dữ liệu.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 3/80
-3-
Tác giả xin chân thành cảm ơ n sự giúp đỡ về mặ t khoa học cũng như sự động viên của các
đồng nghiệ p trong phòng Công nghệ phần mề m trong quản lý - Viện Công nghệ thông tin
trong suố t quá trình thự c hiện luận vă n. Đặ c biệt, tác giả xin chân thành cảm ơ n TS. Lê
H ải Khôi , ng ườ i thầ y đ ã giúp đỡ các ý kiế n quý báu để tác giả có thể hoàn thành t ố t luận
vă n này.
Hà nội, tháng 12 năm 2002
Tr ần Đứ c Minh

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 4/80
-4-
CHƯƠ NG I: CÁC KHÁI NIỆM CƠ BẢN VỀ MẠNG NƠ RON
Chươ ng này đề cậ p các vấn đề sau:
1.1. Sơ lượ c về mạng nơ ron
1.2. Ðơ n vị xử lý
1.3. Hàm xử lý
1.4. Các hình tr ạng của mạng
1.5. Mạng học
1.6. Hàm mục tiêu
1.1. Sơ lượ c về mạng nơ ron
1.1.1. L ị ch sử phát tri ể n
Sự phát triển của mạng nơ ron tr ải qua cả quá trình đưa ra các khái niệm mớ i lẫn thực thi
những khái niệm này.
Dướ i đây là các mốc đáng chú ý trong lịch sử phát triển của mạng nơ ron.
• Cuối TK 19, đầu TK 20, sự phát triển chủ yếu chỉ là những công việc có sự tham gia
của cả ba ngành Vật lý học, Tâm lý học và Thần kinh học, bở i các nhà khoa học như
Hermann von Hemholtz, Ernst Mach, Ivan Pavlov. Các công trình nghiên cứu của họ
chủ yếu đi sâu vào các lý thuyết tổng quát về HỌC (Learning), NHÌN (vision) và LẬP
LUẬ N (conditioning),... và không hề đưa ra những mô hình toán học cụ thể mô tả hoạt
động của các nơ ron.
• Mọi chuyện thực sự bắt đầu vào những năm 1940 vớ i công trình của Warren McCulloch
và Walter Pitts. Họ chỉ ra r ằng về nguyên tắc, mạng của các nơ ron nhân tạo có thể tính
toán bất k ỳ một hàm số học hay logic nào!
• Tiế p theo hai ngườ i là Donald Hebb, ông đã phát biểu r ằng việc thuyết lậ p luận cổ điển
(classical conditioning) (như Pavlov đưa ra) là hiện thực bở i do các thuộc tính của từng
nơ ron riêng biệt. Ông cũng nêu ra một phươ ng pháp học của các nơ ron nhân tạo.
• Ứ ng dụng thực nghiệm đầu tiên của các nơ ron nhân tạo có đượ c vào cuối những năm
50 cùng vớ i phát minh của mạng nhận thức (perceptron network) và luật học tươ ng ứng

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 5/80
-5-
bở i Frank Rosenblatt. Mạng này có khả năng nhận dạng các mẫu. Điều này đã mở ra r ất
nhiều hy vọng cho việc nghiên cứu mạng nơ ron. Tuy nhiên nó có hạn chế là chỉ có thể
giải quyết một số lớ p hữu hạn các bài toán.
• Cùng thờ i gian đó, Bernard Widrow và Ted Hoff đã đưa ra một thuật toán học mớ i và
sử dụng nó để huấn luyện cho các mạng nơ ron tuyến tính thích nghi, mạng có cấu trúc
và chức năng tươ ng tự như mạng của Rosenblatt. Luật học Widrow-Hoff vẫn còn đượ c
sử dụng cho đến nay.
• Tuy nhiên cả Rosenblatt và Widrow-Hoff đều cùng vấ p phải một vấn đề do Marvin
Minsky và Seymour Papert phát hiện ra, đó là các mạng nhận thức chỉ có khả năng giải
quyết các bài toán khả phân tuyến tính. Họ cố gắng cải tiến luật học và mạng để có thể
vượ t qua đượ c hạn chế này nhưng họ đã không thành công trong việc cải tiến luật học
để có thể huấn luyện đượ c các mạng có cấu trúc phức tạ p hơ n.
• Do những k ết quả của Minsky-Papert nên việc nghiên cứu về mạng nơ ron gần như bị
đình lại trong suốt một thậ p k ỷ do nguyên nhân là không có đượ c các máy tính đủ mạnh
để có thể thực nghiệm.
• Mặc dù vậy, cũng có một vài phát kiến quan tr ọng vào những năm 70. Năm 1972,Teuvo Kohonen và James Anderson độc lậ p nhau phát triển một loại mạng mớ i có thể
hoạt động như một bộ nhớ . Stephen Grossberg cũng r ất tích cực trong việc khảo sát các
mạng tự tổ chức (Self organizing networks).
• Vào những năm 80, việc nghiên cứu mạng nơ ron phát triển r ất mạnh mẽ cùng vớ i sự ra
đờ i của PC. Có hai khái niệm mớ i liên quan đến sự hồi sinh này, đó là:
1. Việc sử dụng các phươ ng pháp thống kê để giải thích hoạt động của một lớ p
các mạng hồi quy (recurrent networks) có thể đượ c dùng như bộ nhớ liên hợ p
(associative memory) trong công trình của nhà vật lý học Johh Hopfield.
2. Sự ra đờ i của thuật toán lan truyền ngượ c (back-propagation) để luyện các
mạng nhiều lớ p đượ c một vài nhà nghiên cứu độc lậ p tìm ra như: David
Rumelhart, James McCelland,.... Đó cũng là câu tr ả lờ i cho Minsky-Papert.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 6/80
-6-
1.1.2. Ứ ng d ụng
Trong quá trình phát triển, mạng nơ ron đã đượ c ứng dụng thành công trong r ất nhiều l ĩ nh
vực. Dướ i đây liệt kê ra một số ứng dụng chính của mạng nơ ron:
Aerospace: Phi công tự động, giả lậ p đườ ng bay, các hệ thống điều khiển
lái máy bay, bộ phát hiện lỗi.
Automotive: Các hệ thống dẫn đườ ng tự động cho ô tô, các bộ phân tích
hoạt động của xe.
Banking: Bộ đọc séc và các tài liệu, tính tiền của thẻ tín dụng.
Defense: Định vị - phát hiện vũ khí, dò mục tiêu, phát hiện đối tượ ng,nhận dạng nét mặt, các bộ cảm biến thế hệ mớ i, xử lý ảnh radar,...
Electronics: Dự đoán mã tuần tự, sơ đồ chip IC, điều khiển tiến trình, phân
tích nguyên nhân hỏng chip, nhận dạng tiếng nói, mô hình phi tuyến.
Entertainment: Hoạt hình, các hiệu ứng đặc biệt, dự báo thị tr ườ ng.
Financial: Định giá bất động sản, cho vay, kiểm tra tài sản cầm cố, đánh
giá mức độ hợ p tác, phân tích đườ ng tín dụng, chươ ng trình thươ ng mại
qua giấy tờ , phân tích tài chính liên doanh, dự báo tỷ giá tiền tệ.
Insurance: Đánh giá việc áp dụng chính sách, tối ưu hóa sản phẩm.
.....
1.1.3. C ăn nguyên sinh học
Bộ não con ngườ i chứa khoảng 1011 các phần tử liên k ết chặt chẽ vớ i nhau (khoảng 104
liên k ết đối vớ i mỗi phần tử) gọi là các nơ ron. Dướ i con mắt của những ngườ i làm tin học,
một nơ ron đượ c cấu tạo bở i các thành phần: tế bào hình cây (dendrite) - tế bào thân (cell
body) – và sợ i tr ục thần kinh (axon). Tế bào hình cây có nhiệm vụ mang các tín hiệu điện
tớ i tế bào thân, tế bào thân sẽ thực hiện gộ p (Sum) và phân ngưỡ ng (Thresholds) các tín
hiệu đến. Sợ i tr ục thần kinh làm nhiệm vụ đưa tín hiệu từ tế bào thân ra ngoài.
Điểm tiế p xúc giữa một sợ i tr ục thần kinh của nơ ron này và tế bào hình cây của một nơ ron
khác đượ c gọi là khớ p thần kinh (synapse). Sự sắ p xế p của các nơ ron và mức độ mạnh yếu

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 7/80
-7-
của các khớ p thần kinh đượ c quyết định bở i các quá trình hóa học phức tạ p, sẽ thiết lậ p
chức năng của mạng nơ ron.
Một vài nơ ron có sẵn từ khi sinh ra, các phần khác đượ c phát triển thông qua việc học, ở
đó có sự thiết lậ p các liên k ết mớ i và loại bỏ các liên k ết cũ.
Cấu trúc của mạng nơ ron luôn luôn phát triển và thay đổi. Các thay đổi sau này có khuynh
hướ ng bao gồm chủ yếu là việc làm tăng hay giảm độ mạnh của các mối liên k ết thông qua
các khớ p thần kinh.
Mạng nơ ron nhân tạo không tiế p cận đến sự phức tạ p của bộ não. Mặc dù vậy, có hai sự
tươ ng quan cơ bản giữa mạng nơ ron nhân tạo và sinh học. Thứ nhất, cấu trúc khối tạo
thành chúng đều là các thiết bị tính toán đơ n giản (mạng nơ ron nhân tạo đơ n giản hơ n
nhiều) đượ c liên k ết chặt chẽ vớ i nhau. Thứ hai, các liên k ết giữa các nơ ron quyết định
chức năng của mạng.
Cần chú ý r ằng mặc dù mạng nơ ron sinh học hoạt động r ất chậm so vớ i các linh kiện điện
tử (10-3 giây so vớ i 10-9 giây), nhưng bộ não có khả năng thực hiện nhiều công việc nhanh
hơ n nhiều so vớ i các máy tính thông thườ ng. Đó một phần là do cấu trúc song song của
mạng nơ ron sinh học: toàn bộ các nơ ron hoạt động một cách đồng thờ i tại một thờ i điểm.Mạng nơ ron nhân tạo cũng chia sẻ đặc điểm này. Mặc dù hiện nay, các mạng nơ ron chủ
yếu đượ c thực nghiệm trên các máy tính số, nhưng cấu trúc song song của chúng khiến
chúng ta có thể thấy cấu trúc phù hợ p nhất là thực nghiệm chúng trên các vi mạch tích hợ p
lớ n (VLSI: Very Large Scale Integrated-circuit), các thiết bị quang và các bộ xử lý song
song.
Mạng nơ ron, đôi khi đượ c xem như là các mô hình liên k ết (connectionist models), là các
mô hình phân bố song song (parallel-distributed models) có các đặc tr ưng phân biệt sau:
1) Tậ p các đơ n vị xử lý;
2) Tr ạng thái kích hoạt hay là đầu ra của đơ n vị xử lý;
3) Liên k ết giữa các đơ n vị. Xét tổng quát, mỗi liên k ết đượ c định ngh ĩ a bở i một tr ọng
số w jk cho ta biết hiệu ứng mà tín hiệu của đơ n vị j có trên đơ n vị k;
4) Một luật lan truyền quyết định cách tính tín hiệu ra của từng đơ n vị từ đầu vào của
nó;

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 8/80
-8-
5) Một hàm kích hoạt, hay hàm chuyển (activation function, transfer function), xác định
mức độ kích hoạt khác dựa trên mức độ kích hoạt hiện tại;
6) Một đơ n vị điều chỉnh (độ lệch) (bias, offset) của mỗi đơ n vị;
7) Phươ ng pháp thu thậ p thông tin (luật học - learning rule);
8) Môi tr ườ ng hệ thống có thể hoạt động.
1.2. Đơ n vị xử lý
Một đơ n vị xử lý (Hình 1), cũng đượ c gọi là một nơ ron hay một nút (node), thực hiện một
công việc r ất đơ n giản: nó nhận tín hiệu vào từ các đơ n vị phía tr ướ c hay một nguồn bên
ngoài và sử dụng chúng để tính tín hiệu ra sẽ đượ c lan truyền sang các đơ n vị khác.
Σ g(a j )
x 0
x 1
x n
w j0
w jn
a j z j
j
n
i
i ji j xwa θ +=∑=1
)( j j a g z =
j
. . .
θ j
w j1
Hình 1: Đơ n vị xử lý (Processing unit)
trong đó:
xi : các đầu vào
w ji : các tr ọng số tươ ng ứng vớ i các đầu vào
θ j : độ lệch (bias)
a j : đầu vào mạng (net-input)
z j : đầu ra của nơ ron
g(x): hàm chuyển (hàm kích hoạt).
Trong một mạng nơ ron có ba kiểu đơ n vị:
1) Các đơ n vị đầu vào (Input units), nhận tín hiệu từ bên ngoài;
2) Các đơ n vị đầu ra (Output units), gửi dữ liệu ra bên ngoài;

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 9/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 10/80
-10-
gọi là mức độ kích hoạt của đơ n vị (unit's activation). Loại tr ừ khả năng đơ n vị đó thuộc lớ p
ra, giá tr ị kích hoạt đượ c đưa vào một hay nhiều đơ n vị khác. Các hàm kích hoạt thườ ng bị
ép vào một khoảng giá tr ị xác định, do đó thườ ng đượ c gọi là các hàm bẹ p (squashing). Cáchàm kích hoạt hay đượ c sử dụng là:
1) Hàm đồng nhất (Linear function, Identity function )
x x g =)(
Nếu coi các đầu vào là một đơ n vị thì chúng sẽ sử dụng hàm này. Đôi khi một hằng số đượ c
nhân vớ i net-input để tạo ra một hàm đồng nhất.
g(x)
-1
0
1
-1 0 1x
Hình 2: Hàm đồng nhấ t (Identity function)
2) Hàm bướ c nhị phân (Binary step function, Hard limit function)
Hàm này cũng đượ c biết đến vớ i tên "Hàm ngưỡ ng" (Threshold function hay Heaviside
function). Đầu ra của hàm này đượ c giớ i hạn vào một trong hai giá tr ị:
<
≥=
)
)
,0
,1)(
θ
θ
x
x x g
(nÕu
(nÕu
Dạng hàm này đượ c sử dụng trong các mạng chỉ có một lớ p. Trong hình vẽ sau, θ đượ c
chọn bằng 1.
g(x)
0
1
-1 0 1 2 3
x
Hình 3: Hàm bướ c nhị phân (Binary step function)

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 11/80
-11-
3) Hàm sigmoid (Sigmoid function (logsig))
xe x g
−+=
1
1)(
Hàm này đặc biệt thuận lợ i khi sử dụng cho các mạng đượ c huấn luyện (trained) bở i thuật
toán Lan truyề n ng ượ c (back-propagation), bở i vì nó dễ lấy đạo hàm, do đó có thể giảm
đáng k ể tính toán trong quá trình huấn luyện. Hàm này đượ c ứng dụng cho các chươ ng trình
ứng dụng mà các đầu ra mong muốn r ơ i vào khoảng [0,1].
g(x)
0
1
-6 -4 -2 0 2 4 6
x
Hình 4: Hàm Sigmoid
4) Hàm sigmoid lưỡ ng cực (Bipolar sigmoid function (tansig))
x
x
e
e x g −
−
+−=
11)(
Hàm này có các thuộc tính tươ ng tự hàm sigmoid. Nó làm việc tốt đối vớ i các ứng dụng có
đầu ra yêu cầu trong khoảng [-1,1].
g(x)
-1
0
1
-6 -4 -2 0 2 4 6 x
Hình 5: Hàm sigmoid l ưỡ ng cự c
Các hàm chuyển của các đơ n vị ẩn (hidden units) là cần thiết để biểu diễn sự phi tuyến vào
trong mạng. Lý do là hợ p thành của các hàm đồng nhất là một hàm đồng nhất. Mặc dù vậy
nhưng nó mang tính chất phi tuyến (ngh ĩ a là, khả năng biểu diễn các hàm phi tuyến) làm cho

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 12/80
-12-
các mạng nhiều tầng có khả năng r ất tốt trong biểu diễn các ánh xạ phi tuyến. Tuy nhiên, đối
vớ i luật học lan truyền ngượ c, hàm phải khả vi (differentiable) và sẽ có ích nếu như hàm
đượ c gắn trong một khoảng nào đó. Do vậy, hàm sigmoid là lựa chọn thông dụng nhất.
Đối vớ i các đơ n vị đầu ra (output units), các hàm chuyển cần đượ c chọn sao cho phù hợ p
vớ i sự phân phối của các giá tr ị đích mong muốn. Chúng ta đã thấy r ằng đối vớ i các giá tr ị ra
trong khoảng [0,1], hàm sigmoid là có ích; đối vớ i các giá tr ị đích mong muốn là liên tục
trong khoảng đó thì hàm này cũng vẫn có ích, nó có thể cho ta các giá tr ị ra hay giá tr ị đích
đượ c căn trong một khoảng của hàm kích hoạt đầu ra. Nhưng nếu các giá tr ị đích không
đượ c biết tr ướ c khoảng xác định thì hàm hay đượ c sử dụng nhất là hàm đồng nhất (identity
function). Nếu giá tr ị mong muốn là dươ ng nhưng không biết cận trên thì nên sử dụng mộthàm kích hoạt dạng mũ (exponential output activation function).
1.4. Các hình trạng của mạng
Hình tr ạng của mạng đượ c định ngh ĩ a bở i: số lớ p (layers), số đơ n vị trên mỗi lớ p, và sự liên
k ết giữa các lớ p như thế nào. Các mạng về tổng thể đượ c chia thành hai loại dựa trên cách
thức liên k ết các đơ n vị:
1.4.1. M ạng truyề n thẳ ng
Dòng dữ liệu từ đơ n vị đầu vào đến đơ n vị đầu ra chỉ đượ c truyền thẳng. Việc xử lý dữ liệu
có thể mở r ộng ra nhiều lớ p, nhưng không có các liên k ết phản hồi. Ngh ĩ a là, các liên k ết mở
r ộng từ các đơ n vị đầu ra tớ i các đơ n vị đầu vào trong cùng một lớ p hay các lớ p tr ướ c đó là
không cho phép.
x 1
x 2h2
x l
h1
hm
y1
y2
yn
… … …
x 0 h0
Input Layer Hidden Layer Output Layer
bias bias
)1( jiw
)2(kjw
Hình 6: M ạng nơ ron truyề n thẳ ng nhiề u l ớ p (Feed-forward neural network)

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 13/80
-13-
1.4.2. M ạng hồi quy
Có chứa các liên k ết ngượ c. Khác vớ i mạng truyền thẳng, các thuộc tính động của mạng mớ i
quan tr ọng. Trong một số tr ườ ng hợ p, các giá tr ị kích hoạt của các đơ n vị tr ải qua quá trình
nớ i lỏng (tăng giảm số đơ n vị và thay đổi các liên k ết) cho đến khi mạng đạt đến một tr ạng
thái ổn định và các giá tr ị kích hoạt không thay đổi nữa. Trong các ứng dụng khác mà cách
chạy động tạo thành đầu ra của mạng thì những sự thay đổi các giá tr ị kích hoạt là đáng quan
tâm.
0
1 h1
l
h0
0
1
n
… … …
0
1 h1
l
h0
hm
0
1
n
… … …
Input Layer Hidden Layer Output Layer
Hình 7: M ạng nơ ron hồi quy (Recurrent neural network)
1.5. Mạng học
Chức năng của một mạng nơ ron đượ c quyết định bở i các nhân tố như: hình tr ạng mạng (số
lớ p, số đơ n vị trên mỗi tầng, và cách mà các lớ p đượ c liên k ết vớ i nhau) và các tr ọng số của
các liên k ết bên trong mạng. Hình tr ạng của mạng thườ ng là cố định, và các tr ọng số đượ c
quyết định bở i một thuật toán huấn luyện (training algorithm). Tiến trình điều chỉnh các
tr ọng số để mạng “nhận biết” đượ c quan hệ giữa đầu vào và đích mong muốn đượ c gọi là
học (learning) hay huấn luyện (training). R ất nhiều thuật toán học đã đượ c phát minh để tìm
ra tậ p tr ọng số tối ưu làm giải pháp cho các bài toán. Các thuật toán đó có thể chia làm hainhóm chính: Học có thầy (Supervised learning) và Học không có thầy (Unsupervised
Learning).
1.5.1. H ọc có thầ y
Mạng đượ c huấn luyện bằng cách cung cấ p cho nó các cặ p mẫu đầu vào và các đầu ra mong
muốn (target values). Các cặ p đượ c cung cấ p bở i "thầy giáo", hay bở i hệ thống trên đó mạng
hoạt động. Sự khác biệt giữa các đầu ra thực tế so vớ i các đầu ra mong muốn đượ c thuật

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 14/80
-14-
toán sử dụng để thích ứng các tr ọng số trong mạng. Điều này thườ ng đượ c đưa ra như một
bài toán xấ p xỉ hàm số - cho dữ liệu huấn luyện bao gồm các cặ p mẫu đầu vào x, và một
đích tươ ng ứng t, mục đích là tìm ra hàm f(x) thoả mãn tất cả các mẫu học đầu vào.
Training Data
Network
Training Algorithm
(optimization method)
ObjectiveFunction
Input Desired output
in out
Weightchanges
target
error +-
Hình 8: Mô hình H ọc có thầ y (Supervised learning model)
1.5.2. H ọc không có thầ y
Vớ i cách học không có thầy, không có phản hồi từ môi tr ườ ng để chỉ ra r ằng đầu ra của
mạng là đúng. Mạng sẽ phải khám phá các đặc tr ưng, các điều chỉnh, các mối tươ ng quan,
hay các lớ p trong dữ liệu vào một cách tự động. Trong thực tế, đối vớ i phần lớ n các biến thể
của học không có thầy, các đích trùng vớ i đầu vào. Nói một cách khác, học không có thầyluôn thực hiện một công việc tươ ng tự như một mạng tự liên hợ p, cô đọng thông tin từ dữ
liệu vào.
1.6. Hàm mục tiêu
Để huấn luyện một mạng và xét xem nó thực hiện tốt đến đâu, ta cần xây dựng một hàm
mục tiêu (hay hàm giá) để cung cấ p cách thức đánh giá khả năng hệ thống một cách không
nhậ p nhằng. Việc chọn hàm mục tiêu là r ất quan tr ọng bở i vì hàm này thể hiện các mục tiêu
thiết k ế và quyết định thuật toán huấn luyện nào có thể đượ c áp dụng. Để phát triển một hàm
mục tiêu đo đượ c chính xác cái chúng ta muốn không phải là việc dễ dàng. Một vài hàm cơ
bản đượ c sử dụng r ất r ộng rãi. Một trong số chúng là hàm tổng bình phươ ng lỗi (sum of
squares error function),
∑∑==
−= N
i
pi pi
P
p
yt NP
E 1
2
1
)(1
,
trong đó:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 15/80
-15-
p: số thứ tự mẫu trong tậ p huấn luyện
i : số thứ tự của đơ n vị đầu ra
t pi và y pi : tươ ng ứng là đầu ra mong muốn và đầu ra thực tế của mạng cho đơ n vị đầu ra thứ
i trên mẫu thứ p.
Trong các ứng dụng thực tế, nếu cần thiết có thể làm phức tạ p hàm số vớ i một vài yếu tố
khác để có thể kiểm soát đượ c sự phức tạ p của mô hình.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 16/80
-16-
CHƯƠ NG II. MẠNG NƠ RON TRUYỀN THẲNG VÀ
THUẬT TOÁN LAN TRUYỀN NGƯỢ C
Chươ ng này đề cậ p các vấn đề sau:
2.1. Kiến trúc cơ bản
2.2. Khả năng thể hiện
2.3. Vấn đề thiết k ế cấu trúc mạng
2.4. Thuật toán lan truyền ngượ c (Back-Propagation)
2.5. Các thuật toán tối ưu khác
2.1. Kiến trúc cơ bản
Để đơ n giản và tránh hiểu nhầm, mạng truyền thẳng xét trong chươ ng này là các mạng
truyền thẳng có nhiều lớ p. Kiến trúc mạng truyền thẳng nhiều lớ p (Multi-layer Feed
Forward - MLFF) là kiến trúc chủ đạo của các mạng nơ ron hiện tại. Mặc dù có khá nhiều
biến thể nhưng đặc tr ưng của kiến trúc này là cấu trúc và thuật toán học là đơ n giản và
nhanh (Masters 1993).
2.1.1. M ạng truyề n thẳ ng
Một mạng truyền thẳng nhiều lớ p bao gồm một lớ p vào, một lớ p ra và một hoặc nhiều lớ p
ẩn. Các nơ ron đầu vào thực chất không phải các nơ ron theo đúng ngh ĩ a, bở i lẽ chúng
không thực hiện bất k ỳ một tính toán nào trên dữ liệu vào, đơ n giản nó chỉ tiế p nhận các dữ
liệu vào và chuyển cho các lớ p k ế tiế p. Các nơ ron ở lớ p ẩn và lớ p ra mớ i thực sự thực hiện
các tính toán, k ết quả đượ c định dạng bở i hàm đầu ra (hàm chuyển). Cụm từ “truyềnthẳng” (feed forward) (không phải là trái ngh ĩ a của lan truyền ngượ c) liên quan đến một
thực tế là tất cả các nơ ron chỉ có thể đượ c k ết nối vớ i nhau theo một hướ ng: tớ i một hay
nhiều các nơ ron khác trong lớ p k ế tiế p (loại tr ừ các nơ ron ở lớ p ra).
Hình sau ở dạng tóm tắt biểu diễn mạng nơ ron một cách cô đọng và tránh gây ra sự hiểu
nhầm.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 17/80
-17-
Hình 9: M ạng nơ ron truyề n thẳ ng nhiề u l ớ p
trong đó:
P: Vector đầu vào (vector cột)Wi: Ma tr ận tr ọng số của các nơ ron lớ p thứ i.
(SixR i: S hàng (nơ ron) - R cột (số đầu vào))
bi: Vector độ lệch (bias) của lớ p thứ i (Six1: cho S nơ ron)
ni: net input (Six1)
f i: Hàm chuyển (hàm kích hoạt)
ai: net output (Six1)
⊕: Hàm tổng thông thườ ng.
Mỗi liên k ết gắn vớ i một tr ọng số, tr ọng số này đượ c thêm vào trong quá trình tín hiệu đi
qua liên k ết đó. Các tr ọng số có thể dươ ng, thể hiện tr ạng thái kích thích, hay âm, thể hiện
tr ạng thái kiềm chế. Mỗi nơ ron tính toán mức kích hoạt của chúng bằng cách cộng tổng các
đầu vào và đưa ra hàm chuyển. Một khi đầu ra của tất cả các nơ ron trong một lớ p mạng cụ
thể đã thực hiện xong tính toán thì lớ p k ế tiế p có thể bắt đầu thực hiện tính toán của mình bở i vì đầu ra của lớ p hiện tại tạo ra đầu vào của lớ p k ế tiế p. Khi tất cả các nơ ron đã thực
hiện tính toán thì k ết quả đượ c tr ả lại bở i các nơ ron đầu ra. Tuy nhiên, có thể là chưa đúng
yêu cầu, khi đó một thuật toán huấn luyện cần đượ c áp dụng để điều chỉnh các tham số của
mạng.
Trong hình 9, số nơ ron ở lớ p thứ nhất, và lớ p thứ hai tươ ng ứng là S1 và S2. Ma tr ận tr ọng
số đối vớ i các lớ p tươ ng ứng là W1 và W2. Có thể thấy sự liên k ết giữa các lớ p mạng thể
hiện trong hình vẽ 9: ở lớ p thứ 2, vector đầu vào chính là net output của lớ p thứ nhất.
S2x1
S1x1
n1
1
S1xR 1
R 1 x1 W1
b1
⊕
f 1
S1x1
S1x1
a1
S2x1
n2
1
S2xS1
W2
b2
⊕
f 2
S2x1
a2
P

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 18/80
-18-
Tươ ng tự như vậy, nếu thêm vào các lớ p khác nữa vào trong cấu trúc này thì lớ p mạng
cuối cùng thườ ng là lớ p cho ra k ết quả của toàn bộ mạng, lớ p đó gọi là lớ p ra (OUTPUT
LAYER).
Mạng có nhiều lớ p có khả năng tốt hơ n là các mạng chỉ có một lớ p, chẳng hạn như mạng
hai lớ p vớ i lớ p thứ nhất sử dụng hàm sigmoid và lớ p thứ hai dùng hàm đồng nhất có thể áp
dụng để xấ p xỉ các hàm toán học khá tốt, trong khi các mạng chỉ có một lớ p thì không có
khả năng này.
Xét tr ườ ng hợ p mạng có hai lớ p như hình vẽ 9, công thức tính toán cho đầu ra như sau:
a2 = f 2(W2(f 1(W1P + b1)) + b2)
trong đó, ý ngh ĩ a của các ký hiệu như đã nêu trong hình vẽ 9.
2.1.2. M ạng hồi quy
Bên cạnh mạng truyền thẳng còn có những dạng mạng khác như các mạng hồi quy. Các
mạng hồi quy thườ ng có các liên k ết ngượ c từ các lớ p phía sau đến các lớ p phía tr ướ c hay
giữa các nơ ron trong bản thân một lớ p.
Hình 10: M ột ví d ụ của mạng hồi quy
Trong hình vẽ 10, D là đơ n vị làm tr ễ đầu vào nó một bướ c.
Dế thấy r ằng, các mạng thuộc lớ p các mạng truyền thẳng dễ dàng hơ n cho ta trong việc
phân tích lý thuyết bở i lẽ đầu ra của các mạng này có thể đượ c biểu diễn bở i một hàm của
các tr ọng số và các đầu vào (Sau này, khi xây dựng các thuật toán huấn luyện ta sẽ thấy
điều này).
Sx1 a t+1
Sx1
1
SxS
Sx1 W1
b
⊕
Sx1
Sx1 D
n t+1f 1
a t
P

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 19/80
-19-
2.2. Khả năng thể hiện
Các mạng truyền thẳng cho ta một kiến trúc tổng quát thể hiện khả năng ánh xạ hàm phi
tuyến tính giữa một tậ p các biến đầu vào và tậ p các đầu ra. Khả năng thể hiện của một mạng
có thể đượ c định ngh ĩ a là khoảng mà nó có thể thực hiện ánh xạ khi các tr ọng số biến thiên.
Theo [15]:
1) Các mạng một lớ p chỉ có khả năng thể hiện các hàm khả phân tuyến tính hay các miền
phân chia đượ c (ví dụ như hàm logic AND có miền giá tr ị có thể phân chia đượ c bằng một
đườ ng thẳng trong khi miền giá tr ị của hàm XOR thì không).
2) Các mạng có hai lớ p ẩn có khả năng thể hiện một đườ ng biên phân chia tùy ý vớ i một độ
chính xác bất k ỳ vớ i các hàm chuyển phân ngưỡ ng và có thể xấ p xỉ bất k ỳ ánh xạ mịn nào
vớ i độ chính xác bất k ỳ vớ i các hàm chuyển có dạng sigmoid.
3) Một mạng có một lớ p ẩn có thể xấ p xỉ tốt bất k ỳ một ánh xạ liên tục nào từ một không
gian hữu hạn sang một không gian hữu hạn khác, chỉ cần cung cấ p số nơ ron đủ lớ n cho lớ p
ẩn. Chính xác hơ n, các mạng truyền thẳng vớ i một lớ p ẩn đượ c luyện bở i các phươ ng pháp
bình phươ ng tối thiểu (least-squares) là các bộ xấ p xỉ chính xác cho các hàm hồi quy nếu
như các giả thiết về mẫu, độ nhiễu, số đơ n vị trong lớ p ẩn và các nhân tố khác thỏa mãn. Cácmạng nơ ron truyền thẳng vớ i một lớ p ẩn sử dụng các hàm chuyển hay hàm phân ngưỡ ng là
các bộ xấ p xỉ đa năng cho bài toán phân lớ p nhị phân vớ i các giả thiết tươ ng tự.
2.3. Vấn đề thiết k ế cấu trúc mạng
Mặc dù, về mặt lý thuyết, có tồn tại một mạng có thể mô phỏng một bài toán vớ i độ chính
xác bất k ỳ. Tuy nhiên, để có thể tìm ra mạng này không phải là điều đơ n giản. Để định ngh ĩ a
chính xác một kiến trúc mạng như: cần sử dụng bao nhiêu lớ p ẩn, mỗi lớ p ẩn cần có bao
nhiêu đơ n vị xử lý cho một bài toán cụ thể là một công việc hết sức khó khăn.
Dướ i đây trình bày một số vấn đề cần quan tâm khi ta thiết k ế một mạng.
2.3.1. S ố l ớ p ẩ n
Vì các mạng có hai lớ p ẩn có thể thể hiện các hàm vớ i dáng điệu bất k ỳ, nên, về lý thuyết,
không có lý do nào sử dụng các mạng có nhiều hơ n hai lớ p ẩn. Ngườ i ta đã xác định r ằng
đối vớ i phần lớ n các bài toán cụ thể, chỉ cần sử dụng một lớ p ẩn cho mạng là đủ. Các bài
toán sử dụng hai lớ p ẩn hiếm khi xảy ra trong thực tế. Thậm chí đối vớ i các bài toán cần sử

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 20/80
-20-
dụng nhiều hơ n một lớ p ẩn thì trong phần lớ n các tr ườ ng hợ p trong thực tế, sử dụng chỉ một
lớ p ẩn cho ta hiệu năng tốt hơ n là sử dụng nhiều hơ n một lớ p. Việc huấn luyện mạng thườ ng
r ất chậm khi mà số lớ p ẩn sử dụng càng nhiều. Lý do sau đây giải thích cho việc sử dụngcàng ít các lớ p ẩn càng tốt là:
1) Phần lớ n các thuật toán luyện mạng cho các mạng nơ ron truyền thẳng đều dựa trên
phươ ng pháp gradient. Các lớ p thêm vào sẽ thêm việc phải lan truyền các lỗi làm cho vector
gradient r ất không ổn định. Sự thành công của bất k ỳ một thuật toán tối ưu theo gradient phụ
thuộc vào độ không thay đổi của hướ ng khi mà các tham số thay đổi.
2) Số các cực tr ị địa phươ ng tăng lên r ất lớ n khi có nhiều lớ p ẩn. Phần lớ n các thuật toán tối
ưu dựa trên gradient chỉ có thể tìm ra các cực tr ị địa phươ ng, do vậy chúng có thể không tìm
ra cực tr ị toàn cục. Mặc dù thuật toán luyện mạng có thể tìm ra cực tr ị toàn cục, nhưng xác
suất khá cao là chúng ta sẽ bị tắc trong một cực tr ị địa phươ ng sau r ất nhiều thờ i gian lặ p và
khi đó, ta phải bắt đầu lại.
3) D ĩ nhiên, có thể đối vớ i một bài toán cụ thể, sử dụng nhiều hơ n một lớ p ẩn vớ i chỉ một
vài đơ n vị thì tốt hơ n là sử dụng ít lớ p ẩn vớ i số đơ n vị là lớ n, đặc biệt đối vớ i các mạng cần
phải học các hàm không liên tục. Về tổng thể, ngườ i ta cho r ằng việc đầu tiên là nên xem xét
khả năng sử dụng mạng chỉ có một lớ p ẩn. Nếu dùng một lớ p ẩn vớ i một số lượ ng lớ n các
đơ n vị mà không có hiệu quả thì nên sử dụng thêm một lớ p ẩn nữa vớ i một số ít các đơ n vị.
2.3.2. S ố đơ n v ị trong l ớ p ẩ n
Một vấn đề quan tr ọng trong việc thiết k ế một mạng là cần có bao nhiêu đơ n vị trong mỗi
lớ p. Sử dụng quá ít đơ n vị có thể dẫn đến việc không thể nhận dạng đượ c các tín hiệu đầy đủ
trong một tậ p dữ liệu phức tạ p, hay thiếu ăn khớ p (underfitting ). Sử dụng quá nhiều đơ n vị
sẽ tăng thờ i gian luyện mạng, có lẽ là quá nhiều để luyện khi mà không thể luyện mạngtrong một khoảng thờ i gian hợ p lý. Số lượ ng lớ n các đơ n vị có thể dẫn đến tình tr ạng thừa ăn
khớ p (overfitting ) , trong tr ườ ng hợ p này mạng có quá nhiều thông tin, hoặc lượ ng thông tin
trong tậ p dữ liệu mẫu (training set) không đủ các dữ liệu đặc tr ưng để huấn luyện mạng.
Số lượ ng tốt nhất của các đơ n vị ẩn phụ thuộc vào r ất nhiều yếu tố - số đầu vào, đầu ra của
mạng, số tr ườ ng hợ p trong tậ p mẫu, độ nhiễu của dữ liệu đích, độ phức tạ p của hàm lỗi, kiến
trúc mạng và thuật toán luyện mạng.
Có r ất nhiều “luật” để lựa chọn số đơ n vị trong các lớ p ẩn (xem [6]), chẳng hạn:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 21/80
-21-
• ],[ nl m∈ - nằm giữa khoảng kích thướ c lớ p vào, lớ p ra
•
3
)(2 nl
m
+
= - 2/3 tổng kích thướ c lớ p vào và lớ p ra
• l m 2< - nhỏ hơ n hai lần kích thướ c lớ p vào
• nl m ⋅= - căn bậc hai của tích kich thướ c lớ p vào và lớ p ra.
Các luật này chỉ có thể đượ c coi như là các lựa chọn thô khi chọn lựa kích thướ c của các
lớ p. Chúng không phản ánh đượ c thực tế, bở i lẽ chúng chỉ xem xét đến nhân tố kích thướ c
đầu vào, đầu ra mà bỏ qua các nhân tố quan tr ọng khác như: số tr ườ ng hợ p đưa vào huấn
luyện, độ nhiễu ở các đầu ra mong muốn, độ phức tạ p của hàm lỗi, kiến trúc của mạng
(truyền thẳng hay hồi quy), và thuật toán học.
Trong phần lớ n các tr ườ ng hợ p, không có một cách để có thể dễ dàng xác định đượ c số tối
ưu các đơ n vị trong lớ p ẩn mà không phải luyện mạng sử dụng số các đơ n vị trong lớ p ẩn
khác nhau và dự báo lỗi tổng quát hóa của từng lựa chọn. Cách tốt nhất là sử dụng phươ ng
pháp thử -sai (trial-and-error). Trong thực tế, có thể sử dụng phươ ng pháp Lự a chọn tiế n
(forward selection) hay Lự a chọn lùi (backward selection) để xác định số đơ n vị trong lớ p
ẩn.
Lựa chọn tiến bắt đầu vớ i việc chọn một luật hợ p lý cho việc đánh giá hiệu năng của mạng.
Sau đó, ta chọn một số nhỏ các đơ n vị ẩn, luyện và thử mạng; ghi lại hiệu năng của mạng.
Sau đó, tăng một chút số đơ n vị ẩn; luyện và thử lại cho đến khi lỗi là chấ p nhận đượ c, hoặc
không có tiến triển đáng k ể so vớ i tr ướ c.
Lựa chọn lùi, ngượ c vớ i lựa chọn tiến, bắt đầu vớ i một số lớ n các đơ n vị trong lớ p ẩn, sau đó
giảm dần đi. Quá trình này r ất tốn thờ i gian nhưng sẽ giúp ta tìm đượ c số lượ ng đơ n vị phùhợ p cho lớ p ẩn.
2.4. Thuật toán lan truyền ngượ c (Back-Propagation)
Cần có một sự phân biệt giữa kiến trúc của một mạng và thuật toán học của nó, các mô tả
trong các mục trên mục đích là nhằm làm rõ các yếu tố về kiến trúc của mạng và cách mà
mạng tính toán các đầu ra từ tậ p các đầu vào. Sau đây là mô tả của thuật toán học sử dụng
để điều chỉnh hiệu năng của mạng sao cho mạng có khả năng sinh ra đượ c các k ết quả
mong muốn.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 22/80
-22-
Như đã nêu, về cơ bản có hai dạng thuật toán để luyện mạng: học có thầy và học không có
thầy. Các mạng nơ ron truyền thẳng nhiều lớ p đượ c luyện bằng phươ ng pháp học có thầy.
Phươ ng pháp này căn bản dựa trên việc yêu cầu mạng thực hiện chức năng của nó và sauđó tr ả lại k ết quả, k ết hợ p k ết quả này vớ i các đầu ra mong muốn để điều chỉnh các tham số
của mạng, ngh ĩ a là mạng sẽ học thông qua những sai sót của nó.
Về cơ bản, thuật toán lan truyền ngượ c là dạng tổng quát của thuật toán trung bình bình
phươ ng tối thiểu (Least Means Square-LMS). Thuật toán này thuộc dạng thuật toán xấ p xỉ
để tìm các điểm mà tại đó hiệu năng của mạng là tối ưu. Chỉ số tối ưu (performance index)
thườ ng đượ c xác định bở i một hàm số của ma tr ận tr ọng số và các đầu vào nào đó mà trong
quá trình tìm hiểu bài toán đặt ra.
2.4.1. Mô t ả thuật toán
Ta sẽ sử dụng dạng tổng quát của mạng nơ ron truyền thẳng nhiều lớ p như trong hình vẽ 9
của phần tr ướ c. Khi đó, đầu ra của một lớ p tr ở thành đầu vào của lớ p k ế tiế p. Phươ ng trình
thể hiện hoạt động này như sau:
am+1 = f m+1 (Wm+1am + bm+1) vớ i m = 0, 1, ..., M – 1,
trong đó M là số lớ p trong mạng. Các nơ ron trong lớ p thứ nhất nhận các tín hiệu từ bênngoài:
a0 = p,
chính là điểm bắt đầu của phươ ng trình phía trên. Đầu ra của lớ p cuối cùng đượ c xem là
đầu ra của mạng:
a = aM .
2.4.1.1. Chỉ số hiệu nă ng (performance index)
Cũng tươ ng tự như thuật toán LMS, thuật toán lan truyền ngượ c sử dụng chỉ số hiệu năng
là trung bình bình phươ ng lỗi của đầu ra so vớ i giá tr ị đích. Đầu vào của thuật toán chính là
tậ p các cặ p mô tả hoạt động đúng của mạng:
{(p1, t1), (p2, t2), ..., (pQ, tQ)},
trong đó pi là một đầu vào và ti là đầu ra mong muốn tươ ng ứng, vớ i i = 1..Q. Mỗi đầu vào
đưa vào mạng, đầu ra của mạng đối vớ i nó đượ c đem so sánh vớ i đầu ra mong muốn.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 23/80
-23-
Thuật toán sẽ điều chỉnh các tham số của mạng để tối thiểu hóa trung bình bình phươ ng
lỗi:
F (x) = E [e2] = E [(t - a)2] ,
trong đó x là biến đượ c tạo thành bở i các tr ọng số và độ lệch, E là ký hiệu k ỳ vọng toán
học. Nếu như mạng có nhiều đầu ra, ta có thể viết lại phươ ng trình trên ở dạng ma tr ận:
F (x) = E [eT e] = E [(t - a)T (t - a)] .
Tươ ng tự như thuật toán LMS, xấ p xỉ của trung bình bình phươ ng lỗi như sau:
ký hiệu ( )x∧
F là giá tr ị xấ p xỉ của ( )x F thì:
( ) ( ) ( ) ),()()()()()( k k k k k k F T T eeatatx =−−=∧
trong đó k ỳ vọng toán học của bình phươ ng lỗi đượ c thay bở i bình phươ ng lỗi tại bướ c k .
Thuật toán giảm theo hướ ng cho trung bình bình phươ ng lỗi xấ p xỉ là:
( ) ( )
( ) ( ) )(,1
)(,1,
,,
++∂
−=+
+∂
−=+
∧
∧
m
i
m
i
m
i
m
ji
m
ji
m
ji
b
F k bk b
w
F k wk w
α
α
trong đó α là hệ số học.
Như vậy, mọi chuyện đến đây đều giống như thuật toán trung bình bình phươ ng tối thiểu.
Tiế p theo chúng ta sẽ đi vào phần khó nhất của thuật toán: tính các đạo hàm từng phần.
2.4.1.2. Luật xích (Chain Rule)
Đối vớ i các mạng nơ ron truyền thẳng nhiều lớ p, lỗi không phải là một hàm của chỉ các
tr ọng số trong các lớ p ẩn, do vậy việc tính các đạo hàm từng phần này là không đơ n giản.
Chính vì lý do đó mà ta phải sử dụng luật xích để tính. Luật này đượ c mô tả như sau: giả
sử ta có một hàm f là một hàm của biến n, ta muốn tính đạo hàm của f có liên quan đến một
biến w khác. Luật xích này như sau:
( )( ) ( ) ( )dw
wdn
dn
ndf
dw
wndf .=

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 24/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 25/80
-25-
( ) ( ) ( )( ) ( ) mmm
T mmmm
k k
k k
sbb
asWW
α
α
−=+
−=+ −
1
,1 1
trong đó:
∂
∂
∂
∂
∂
∂
=∂
∂=
∧
∧
∧
∧
mS
m
2
m
1
m
m
m
F
F
F
F
n
n
n
Mn
s
2.4.1.3. Lan truyề n ng ượ c độ nhậ y cảm
Bây giờ ta cần tính nốt ma tr ận độ nhậy cảm sm. Để thực hiện điều này cần sử dụng một áp
dụng khác của luật xích. Quá trình này cho ta khái niệm về sự “lan truyền ngượ c” bở i vì nó
mô tả mối quan hệ hồi quy trong đó độ nhậy cảm sm đượ c tính qua độ nhậy cảm sm+1 của
lớ p m + 1.
Để dẫn đến quan hệ đó, ta sử dụng ma tr ận Jacobi sau:
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
∂
=∂
∂
+++
+++
+++
+
+++
m
S
m
S
m
m
S
m
m
S
m
S
m
m
m
m
m
m
S
m
m
m
m
m
m
m
m
mmm
m
m
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
n
1
2
1
1
1
12
2
12
1
12
11
2
11
1
11
1
111
L
MMM
L
L
n
n
Xét phần tử (i, j) của ma tr ận trên:
( )( )m
j
m
m
jim
j
m
j
m
m
ji
m
j
m
im
jim
j
S
l
m
i
m
i
m
l i
m
j
m
i
n f wn
n f w
n
aw
n
baw
n
n
m
.1
,1
,
1,
1
11,1
++
+=
++
+
=∂
∂=
∂
∂=
∂
+∂
=∂
∂∑

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 26/80
-26-
trong đó:
( )
( )m j
m
j
m
m
j
m
n
n f
n f ∂
∂
=
•
.
Như vậy, ma tr ận Jacobi có thể viết lại như sau:
( ),1
mm
1m
m
m
nFWn
n •+
+
=∂
∂
trong đó:
( )( )
( )
( )
.
00
0000
2
1
=
•
•
•
•
m
S
m
mm
mm
mm
mn f
n f
n f
L
MMM
L
L
nF
Bây giờ ta viết lại quan hệ hồi quy cho độ nhậy cảm dướ i dạng ma tr ận:
( )( )
( )( ) .11
1
1
1
1
++•
+
∧
+•
+
∧+
∧
=
∂
∂=
∂
∂
∂
∂=
∂
∂=
mT mmm
m
T mmm
m
T
m
m
m
m F F F
sWnF
nWnF
nn
n
ns
Đến đây có thể thấy độ nhậy cảm đượ c lan truyền ngượ c qua mạng từ lớ p cuối cùng tr ở về
lớ p đầu tiên:
sM →sM - 1→......→s1.
Cần nhấn mạnh r ằng ở đây thuật toán lan truyền ngượ c lỗi sử dụng cùng một k ỹ thuật giảm
theo hướ ng như thuật toán LMS. Sự phức tạ p duy nhất là ở chỗ để tính gradient ta cần phải
lan truyền ngượ c độ nhậy cảm từ các lớ p sau về các lớ p tr ướ c như đã nêu trên.
Bây giờ ta cần biết điểm bắt đầu lan truyền ngượ c, xét độ nhậy cảm sM tại lớ p cuối cùng:
( ) ( )( ) ( )( )
M
i
iiiM
i
S
l
l l
M
i
T
M
i
M
in
aat
n
at
n
at at
n
F s
M
∂
∂−−=
∂
−∂=
∂
−−∂=
∂
∂=
∑=
∧
21
2
.
Bở i vì:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 27/80
-27-
( ) ( )M
i
M
M
i
M
i
M
M
i
M
i
M
i
i n f n
n f
n
a
n
a •
=∂
∂=
∂
∂=
∂
∂,
nên ta có thể viết:
( ) ( )M
i
M
ii
M
i n f at s•
−−= 2 .
Ở dạng ma tr ận sẽ là:
( )( )atnFs −−=•
M M
M 2 .
Tóm lại, thuật toán lan truyền ngượ c có thể phát biểu như sau:
2.4.2. S ử d ụng thuật toán lan truyề n ng ượ c
Trên đây là thuật toán lan truyền ngượ c cơ bản, sau đây ta sẽ bàn về các khía cạnh ứng
dụng của thuật toán lan truyền ngượ c như chọn lựa cấu trúc mạng, sự hội tụ và khả năng
tổng quát hóa.
THUẬT TOÁN LAN TRUY ỀN NGƯỢ C - BACK-PROPAGATION
Bướ c 1: Lan truy ền xuôi đầu vào qua mạng:
a0 = p
am+1 = f m+1 (Wm+1 am + bm+1), vớ i m = 0, 1, ..., M – 1.
a = aM
Bướ c 2: Lan truy ền độ nhậy cảm (lỗi) ngược lại qua mạng:
( )( )atnFs −−=•
M M
M 2
( )( ) 11 ++•
= mT mmm
m sWnFs , vớ i m = M – 1, ..., 2, 1.
Bướ c 3: Cuố i cùng, các trọng số và độ lệch được cập nhật bởi công thứ c sau:
( ) ( ) ( )( ) ( ) mmm
T mmmm
k k k k
sbbasWW
α
α
−=+−=+
−
11
1
.
8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 28/80
-28-
2.4.2.1. Chọn l ự a cấ u trúc mạng
Như ta đã biết, thuật toán lan truyền ngượ c có thể đượ c sử dụng để xấ p xỉ bất k ỳ một hàm
số học nào nếu như ta có đủ số nơ ron trong các lớ p ẩn. Mặc dù vậy, phát biểu trên chưa
cho ta đượ c một số cụ thể các lớ p và số nơ ron trong mỗi lớ p cần sử dụng. Ta sẽ dùng một
ví dụ để có đượ c cái nhìn chi tiết hơ n về vấn đề này.
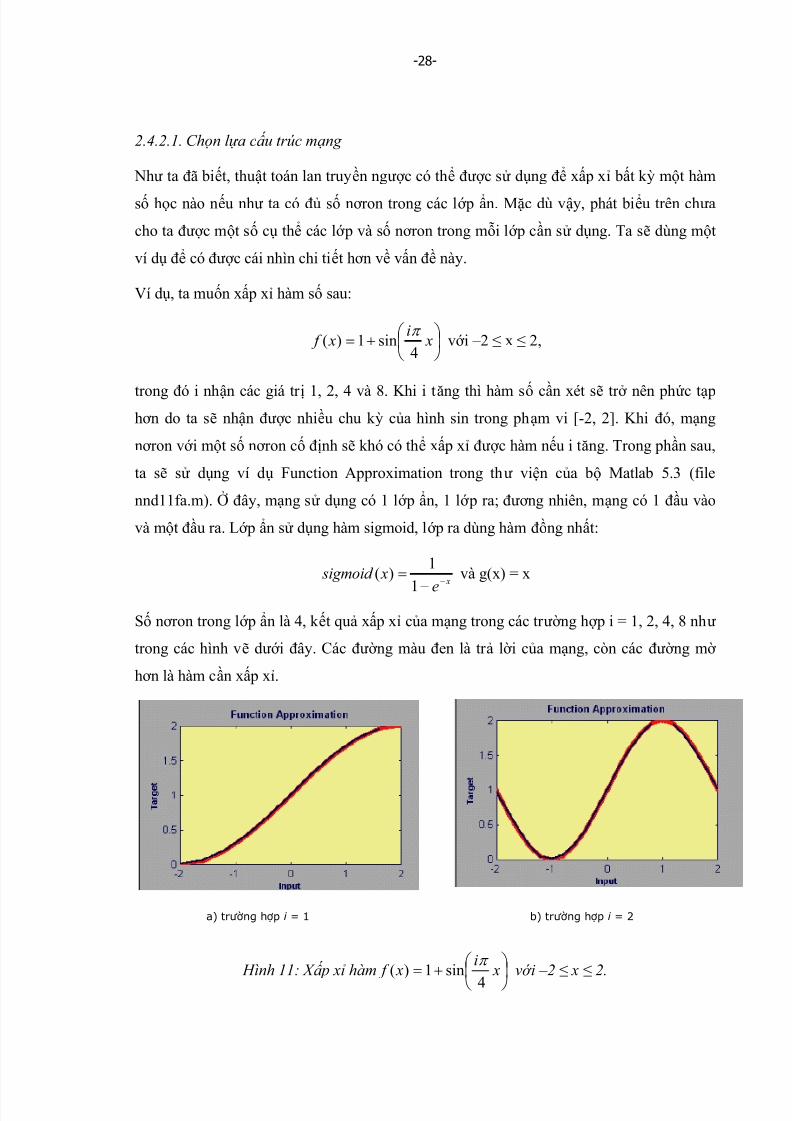
Ví dụ, ta muốn xấ p xỉ hàm số sau:
+= xi
x f 4
sin1)(π
vớ i –2 ≤ x ≤ 2,
trong đó i nhận các giá tr ị 1, 2, 4 và 8. Khi i tăng thì hàm số cần xét sẽ tr ở nên phức tạ phơ n do ta sẽ nhận đượ c nhiều chu k ỳ của hình sin trong phạm vi [-2, 2]. Khi đó, mạng
nơ ron vớ i một số nơ ron cố định sẽ khó có thể xấ p xỉ đượ c hàm nếu i tăng. Trong phần sau,
ta sẽ sử dụng ví dụ Function Approximation trong thư viện của bộ Matlab 5.3 (file
nnd11fa.m). Ở đây, mạng sử dụng có 1 lớ p ẩn, 1 lớ p ra; đươ ng nhiên, mạng có 1 đầu vào
và một đầu ra. Lớ p ẩn sử dụng hàm sigmoid, lớ p ra dùng hàm đồng nhất:
x
e
x sigmoid −
−
=
1
1)( và g(x) = x
Số nơ ron trong lớ p ẩn là 4, k ết quả xấ p xỉ của mạng trong các tr ườ ng hợ p i = 1, 2, 4, 8 như
trong các hình vẽ dướ i đây. Các đườ ng màu đen là tr ả lờ i của mạng, còn các đườ ng mờ
hơ n là hàm cần xấ p xỉ.
Hình 11: X ấ p xỉ hàm
+= xi
x f
4sin1)(
π vớ i –2 ≤ x ≤ 2.
a) trường hợp i = 1 b) trường hợp i = 2

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 29/80
-29-
Hình 11: X ấ p xỉ hàm
+= xi
x f 4
sin1)(π
vớ i –2 ≤ x ≤ 2.
Khi ta tăng số nơ ron trong lớ p ẩn lên thì khả năng xấ p xỉ hàm số của mạng sẽ tốt hơ n.
Chẳng hạn, xét tr ườ ng hợ p sử dụng 9 nơ ron trong lớ p ẩn và i = 8 ta có đượ c k ết quả sau:
Hình 12: X ấ p xỉ hàm
+= x
i x f
4sin1)(
π vớ i –2 ≤ x ≤ 2 khi t ă ng số nơ ron.
Điều đó có ngh ĩ a là nếu ta muốn xấ p xỉ một hàm số mà có số điểm cần xấ p xỉ là lớ n thì ta
sẽ cần số nơ ron lớ n hơ n trong lớ p ẩn.
2.4.2.2. S ự hội t ụ
Trong phần trên ta đã thấy các tr ườ ng hợ p mạng nơ ron không tr ả lại k ết quả chính xác mặc
dù thuật toán lan truyền ngượ c đã thực hiện tối thiểu hóa trung bình bình phươ ng lỗi. Điều
c) trường hợp i = 4 d) trường hợp i = 8
trường hợp i = 8 và số nơron lớp ẩn = 9

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 30/80
-30-
đó là do khả năng của mạng bị giớ i hạn bở i số nơ ron trong lớ p ẩn. Tuy nhiên, cũng có
tr ườ ng hợ p mà thuật toán lan truyền ngượ c không cho ta các tham số có thể dẫn đến k ết
quả chính xác nhưng mạng vẫn có thể xấ p xỉ đượ c hàm số. Điều này xảy ra là do tr ạng tháikhở i đầu của mạng, sau khi luyện, mạng có thể r ơ i vào điểm cực tiểu toàn cục hoặc r ơ i vào
điểm cực tiểu địa phươ ng.
Cần chú ý r ằng trong thuật toán trung bình bình phươ ng tối thiểu, điểm cực tr ị toàn cục là
luôn tồn tại bở i lẽ hàm trung bình bình phươ ng lỗi của thuật toán trung bình bình phươ ng
tối thiểu là một hàm bậc hai, hơ n nữa, do là hàm bậc hai nên đạo hàm bậc hai của hàm lỗi
sẽ là hằng số, do vậy mà độ cong của hàm theo một hướ ng cho tr ướ c là không thay đổi.
Trong khi đó, thuật toán lan truyền ngượ c áp dụng cho các mạng nhiều lớ p sử dụng cáchàm chuyển phi tuyến sẽ có nhiều điểm cực tr ị địa phươ ng và độ cong của hàm lỗi có thể
không cố định theo một hướ ng cho tr ướ c.
2.4.2.3. S ự t ổ ng quát hóa (Generalization):
Trong phần lớ n các tr ườ ng hợ p, mạng nơ ron truyền thẳng nhiều lớ p đượ c luyện bở i một số
cố định các mẫu xác định sự hoạt động đúng của mạng:
{(p1, t1), (p2, t2), ..., (pQ, tQ)},trong đó, pi là các đầu vào, tươ ng ứng vớ i nó là các đầu ra mong muốn ti. Tậ p huấn luyện
này thông thườ ng là thể hiện của số lớ n nhất các lớ p có thể các cặ p. Một điều r ất quan
tr ọng là mạng nơ ron có khả năng tổng quát hóa đượ c từ những cái nó đã học. Nếu có đượ c
điều đó, mặc dù dữ liệu có nhiễu thì mạng vẫn có khả năng hoạt động tốt (tr ả lại k ết quả
gần vớ i đích mong muốn).
“Để một mạng có khả năng tổng quát hóa tốt, nó cần có số tham số ít hơ n số dữ liệu có
trong tậ p huấn luyện” ([4]). Trong các mạng nơ ron, cũng như các bài toán mô hình hóa, ta
thườ ng mong muốn sử dụng một mạng đơ n giản nhất có thể cho k ết quả tốt trên tậ p huấn
luyện.
Một cách khác đó là dừng luyện mạng tr ướ c khi mạng xảy ra tình tr ạng thừa ăn khớ p. K ỹ
thuật này liên quan đến việc chia tậ p dữ liệu thu đượ c thành ba tậ p: tậ p huấn luyện sử dụng
để tính toán gradient và cậ p nhật các tr ọng số của mạng, tậ p kiểm định đượ c dùng để kiểm
tra điều kiện dừng của mạng và tậ p kiểm tra đượ c sử dụng để so sánh khả năng tổng quát
hóa của mạng đối vớ i các bộ tham số của mạng sau các lần huấn luyện.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 31/80
-31-
2.4.3. M ột số bi ế n thể của thuật toán lan truyề n ng ượ c
Ta đã xem xét một số đặc điểm của thuật toán lan truyền ngượ c sử dụng k ỹ thuật giảm theo
hướ ng. Mạng sử dụng thuật toán này tồn tại nhượ c điểm: r ơ i vào điểm cực tiểu địa phươ ng
đối vớ i mạng nơ ron truyền thẳng nhiều lớ p sử dụng các hàm chuyển phi tuyến. Hơ n nữa,
khi thực hiện luyện mạng bằng cách đưa từng mẫu vào, sau đó thực hiện cậ p nhật tham số,
sẽ làm ảnh hưở ng đến quá trình học các mẫu khác. Do đó, một phươ ng pháp để tăng tốc độ
hội tụ là sử dụng phươ ng pháp học cả gói (batch training), ngh ĩ a là tất cả các mẫu đượ c
đưa vào mạng, sau đó mớ i thực hiện cậ p nhật các tham số. Bây giờ ta sẽ xem xét một số
biến thể của thuật toán lan truyền ngượ c sử dụng phươ ng pháp học cả gói nhằm vượ t qua
các nhượ c điểm này.
2.4.3.1. S ử d ụng tham số bướ c đ à (Momentum)
Đây là một phươ ng pháp heuristic dựa trên quan sát k ết quả luyện mạng nhằm làm tăng tốc
độ hội tụ của thuật toán lan truyền ngượ c dựa trên k ỹ thuật giảm nhanh nhất. Thuật toán
lan truyền ngượ c cậ p nhật các tham số của mạng bằng cách cộng thêm vào một lượ ng thay
đổi là:
∆Wm
(k ) = - αsm
(am – 1
)T
,
∆bm(k ) = - αsm .
Khi áp dụng thuật toán lan truyền ngượ c có sử dụng bướ c đà, phươ ng trình trên thay đổi
như sau:
∆Wm(k ) = γ∆Wm(k - 1) – (1 - γ) αsm (am – 1) T ,
∆bm(k ) = γ∆bm(k - 1) - (1 - γ) αsm .
Ngườ i đa đã chứng tỏ r ằng khi sử dụng tham số bướ c đà thì hệ số học có thể lớ n hơ n r ất
nhiều so vớ i thuật toán lan truyền ngượ c chuẩn không sử dụng tham số bướ c đà trong khi
vẫn giữ đượ c độ tin cậy của thuật toán. Một điểm khác nữa là khi sử dụng tham số bướ c đà
thì sự hội tụ của thuật toán sẽ đượ c tăng tốc nếu như thuật toán đang đi theo một hướ ng
bền vững (chỉ đi xuống trong một khoảng dài).

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 32/80
-32-
2.4.3.2. S ử d ụng hệ số học biế n đổ i:
Trong thực tế, các hàm hiệu năng có dạng biểu diễn hình học là không đồng đều, có lúc có
dạng phẳng (hàm không thay đổi giá tr ị hoặc thay đổi r ất ít) hoặc có dạng phễu (giá tr ị của
hàm thay đổi r ất nhanh khi thay đổi tham số đầu vào). Nếu ta chỉ sử dụng hệ số học cố
định thì có thể sẽ tốn thờ i gian tại các vùng phẳng. Vì vậy, tư tưở ng của thuật toán lan
truyền ngượ c sử dụng hệ số học biến đổi là khi gặ p vùng phẳng thì tăng hệ số học lên và
ngượ c lại khi gặ p vùng dạng phễu thì giảm hệ số học đi.
Ngườ i ta đã đưa ra r ất nhiều phươ ng pháp để thực hiện điều trên, ở đây chỉ nêu ra một cách
biến đổi hệ số học dựa trên hiệu năng của mạng (có thể tham khảo ở [9]).
Bướ c 1: Nếu bình phươ ng lỗi trên toàn bộ tậ p huấn luyện tăng một số phần tr ăm cho tr ướ c
ξ (thông thườ ng là từ 1% cho đến 5%) sau một lần cậ p nhật tr ọng số, thì bỏ qua việc cậ p
nhật này, hệ số học đượ c nhân vớ i một số hạng ρ nào đó (vớ i 0 < ρ < 1) và tham số bướ c
đà (nếu có sử dụng) đượ c đặt bằng 0.
Bướ c 2: Nếu bình phươ ng lỗi giảm sau một lần cậ p nhật tr ọng số, thì cậ p nhật đó là chấ p
nhận đượ c và hệ số học đượ c nhân vớ i một số hạng nào đó > 1, nếu tham số bướ c đà đã bị
đặt bằng 0 thì đặt lại giá tr ị lúc đầu.
Bướ c 3: Nếu bình phươ ng lỗi tăng một lượ ng < ξ, thì cậ p nhật tr ọng số là chấ p nhận đượ c,
nhưng hệ số học không thay đổi và nếu tham số bướ c đà đã bị đặt bằng 0 thì đặt lại giá tr ị
lúc đầu.
Các thuật toán heuristic luôn cho ta sự hội tụ nhanh hơ n trong một số bài toán, tuy nhiên
chúng có hai nhượ c điểm chính sau đây:
Thứ nhấ t , việc sửa đổi thuật toán lan truyền ngượ c cần có thêm một số tham số, trong khi
trong thuật toán lan truyền ngượ c chuẩn chỉ yêu cầu có một tham số đó là hệ số học. Một
số thuật toán sửa đổi cần đến năm hoặc sáu tham số, trong khi hiệu năng của thuật toán khá
nhạy cảm đối vớ i những thay đổi của các tham số này. Hơ n nữa việc chọn lựa các tham số
lại độc lậ p vớ i bài toán đặt ra.
Thứ hai, các thuật toán sửa đổi có thể không hội tụ trong một số bài toán mà thuật toán lan
truyền ngượ c chuẩn có thể hội tụ đượ c.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 33/80
-33-
Ngườ i ta đã thấy r ằng cả hai nhượ c điểm nêu trên thườ ng xảy ra khi sử dụng các thuật toán
sửa đổi phức tạ p hơ n (yêu cầu nhiều tham số hơ n).
2.4.3.3. S ử d ụng phươ ng pháp Gradient k ế t hợ p:
Nhắc lại phươ ng pháp gradient k ết hợ p bao gồm các bướ c sau:
1. Chọn hướ ng bắt đầu ngượ c vớ i gradient (p0 = -g0).
2. Thực hiện một bướ c (∆xk = (xk+1 - xk ) = αk pk ). Chọn αk để tối thiểu hàm theo hướ ng
tìm kiếm đã chọn. Có thể chọn như sau:
k k T k
k
T
k
k p A p
p g
−=α
(phươ ng trình trên đượ c suy ra bằng cách chọn αk để tối thiểu hóa hàm F(xk + αk pk ). Để
thực hiện, ta lấy đạo hàm của F theo αk , đặt bằng 0 ta sẽ thu đượ c phươ ng trình trên.)
3. Chọn hướ ng tiế p theo dựa vào một trong ba phươ ng trình tính βk .
1−∆∆∆
=k
k k
p g
g g β
T
1-k
T
1-k hoặc1−
=k
k k
g g
g g β
T
1-k
T
k hoặc1−
∆=
k
k k
g g
g g β
T
1-k
T
1-k .
4. Nếu thuật toán chưa hội tụ thì quay lại bướ c 2.
Phươ ng pháp này không thể áp dụng tr ực tiế p trong việc luyện mạng nơ ron, bở i lẽ hàm chỉ
số hiệu năng trong nhiều tr ườ ng hợ p không ở dạng bậc hai. Điều này ảnh hưở ng đến thuật
toán này như sau:
Thứ nhất, ta không thể sử dụng phươ ng trình:
k k T k
k
T
k
k p A p
p g
−=α
để tối thiểu hóa hàm theo đườ ng thẳng (xk + αk pk ) như trong bướ c thứ 2.
Thứ hai, điểm cực tiểu chính xác sẽ không thể đạt tớ i đượ c một cách bình thườ ng sau một
số hữu hạn bướ c và do vậy thuật toán sẽ phải đượ c thiết lậ p lại sau một số hữu hạn bướ c.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 34/80
-34-
Vấn đề tìm kiếm điểm cự c tiểu:
Ta cần có một thuật toán tổng quát để tìm điểm cực tiểu của một hàm số theo một hướ ng
cụ thể nào đó. Việc này liên quan đến hai thao tác: một là xác định tần số (interval
location) và giảm tần số. Mục đích của bướ c xác định tần số là tìm kiếm tần số khở i đầu có
chứa điểm cực tiểu. Bướ c giảm tần số sau đó giảm kích thướ c của tần số cho đến khi tìm ra
điểm cực tiểu vớ i một độ chính xác nào đó.
Ta sẽ sử dụng phươ ng pháp so sánh hàm để thực hiện bướ c xác định tần số. Thủ tục này
đượ c mô tả trong hình vẽ 13. Ta bắt đầu bằng cách tính chỉ số hiệu năng tại một điểm khở i
đầu nào đó (điểm a1 trong hình vẽ), điểm này chính là giá tr ị của chỉ số hiệu năng vớ i các
tham số hiện tại của mạng.
Bướ c tiế p theo là tính giá tr ị hàm chỉ số hiệu năng tại điểm thứ 2, thể hiện bở i điểm b1
trong hình vẽ cách điểm khở i đầu một đoạn là ε theo hướ ng tìm kiếm p0.
Hình 13: Xác định t ần số .
Sau đó, ta tiế p tục tính giá tr ị của hàm hiệu năng tại các điểm bi có khoảng cách đến điểmkhở i đầu gấ p đôi điểm tr ướ c. Quá trình này sẽ dừng lại nếu như giá tr ị của hàm tăng lên so
vớ i điểm tr ướ c đó (trong hình vẽ là điểm b3 và b4). Đến đây, ta biết r ằng điểm cực tiểu sẽ
r ơ i vào khoảng giữa [a5, b5]. Ta không thể thu hẹ p thêm tần số nữa bở i lẽ điểm cực tiểu có
thể r ơ i vào vùng [a3, b3] hoặc [a4, b4].
Bây giờ ta tiế p tục bướ c thực hiện giảm tần số, ta sẽ lấy ít nhất là hai điểm c, d trong
khoảng [a5, b5] để có thể thực hiện việc này (nếu chỉ lấy 1 điểm thì ta khó có thể xác định
đượ c liệu điểm cực tiểu sẽ nằm trong vùng nào!). Có nhiều cách để chọn các điểm trên, ở
ε
b5 a5
b4 a4
b3 a3
b2 a2
b1 a1
2ε
4ε8ε

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 35/80
-35-
đây ta sẽ sử dụng phươ ng pháp gọi là: Golden Section search. Phươ ng pháp này cố gắng
thực hiện tìm kiếm sao cho số lần phải tính giá tr ị của hàm là ít nhất (tại mỗi một bướ c ta
đều cần phải tính giá tr ị của hàm).
Hình 14: Giảm kích thướ c của t ần số không chắ c chắ n.
Trong hình vẽ trên, điểm a sẽ đượ c bỏ qua và điểm c sẽ tr ở thành cận bên trái. Sau đó, một
điểm c mớ i sẽ đượ c đặt vào vùng của điểm c và d cũ. Mẹo mực ở đây là chọn điểm c sao
cho tần số của sự không chắc chắn sẽ đượ c giảm đi càng nhanh càng tốt.
Thuật toán Golden Section search như sau:
a bc a bc d
a) T ần số không được giảm b) Điểm cự c tiểu phải nằm giữ ac và b.
Golden Section search
τ = 0.618
Đặt c 1 = a 1 + (1 - τ) (b 1 – a 1 ), F c = F (c 1).
d 1 = b 1 - (1 - τ) (b 1 – a 1 ), F d = F (d 1).
Với k = 1, 2, ...., lặp lại các bước sau:
Nế u F c < F d thì:
Đặt a k + 1 = a k ; b k + 1 = d k ; d k + 1 = c k ;
c k + 1 = a k + 1 + (1 - τ) (b k + 1 – a k + 1)
F d = F c ; F c = F (c k + 1)
Ngược lại
Đặt a k + 1 = c k ; b k + 1 = b k ; c k + 1 = d k ;
d k + 1 = b k + 1 - (1 - τ) (b k + 1 – a k + 1)
F c = F d ; F d = F (d k + 1)
K ế t thúc chừ ng nào (b k + 1 – a k + 1) < tol

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 36/80
-36-
Trong đó tol là độ chính xác chấ p nhận đượ c do ngườ i sử dụng đưa vào.
Thiết lập lại thuật toán
Thuật toán gradient k ết hợ p còn cần phải sửa đổi thêm một chút nữa tr ướ c khi áp dụng để
luyện cho mạng nơ ron. Đối vớ i hàm bậc 2, thuật toán sẽ hội tụ đến điểm cực tiểu sau nhiều
nhất n bướ c, trong đó n là số các tham số cần tối thiểu hóa. Chỉ số hiệu năng trung bình
bình phươ ng lỗi của mạng nơ ron truyền thẳng nhiều lớ p không phải ở dạng bậc 2, do vậy
thuật toán sẽ không hội tụ sau n bướ c lặ p. Những phát triển ở phía trên không chỉ ra hướ ng
tìm kiếm tiế p theo sau khi n bướ c lặ p hoàn thành. Có nhiều cách để thực hiện, nhưng ta chỉ
cần áp dụng một cách đơ n giản nhất đó là đặt lại hướ ng tìm kiếm tr ở lại hướ ng ban đầu của
thuật toán giảm nhanh nhất sau khi n bướ c lặ p đã hoàn thành.
2.4.4. Nhận xét
Thuật ngữ “lan truyền ngượ c” đượ c sử dụng có vẻ như không phù hợ p lắm đối vớ i thuật
ngữ truyền thẳng và thườ ng gây hiểu nhầm. Lan truyền ngượ c thực chất là là một k ỹ thuật
toán học sử dụng để tính toán lỗi trong các hệ thống toán học phức tạ p, chẳng hạn như một
mạng nơ ron. Nó là một trong các thuật toán gradient tươ ng tự như là các thuật toán theo
gradient theo các cách tiế p cận của Trí tuệ nhân tạo. Các thuật toán đó ánh xạ hàm vào bề mặt ba chiều, vớ i các mặt lồi, lõm. Phụ thuộc vào bài toán cụ thể, điểm lõm (cực tiểu) của
một bề mặt thể hiện hiệu năng tốt hơ n cho đầu ra.
Việc luyện mạng theo phươ ng pháp học có thầy liên quan đến cách thức đưa các mẫu học
từ miền của bài toán vào mạng, các mẫu này sẽ đượ c phân chia thành các tậ p huấn luyện
và tậ p kiểm định. Mạng đượ c khở i tạo các tr ọng số là các số ngẫu nhiên, sau đó, các tr ọng
số này sẽ đượ c điều chỉnh cho phù hợ p vớ i tậ p huấn luyện. Tậ p kiểm định sẽ đượ c dùng để
xác định xem liệu mạng có thành công trong việc xác định đầu ra từ đầu vào mà nó chưađượ c luyện. Mạng sẽ đượ c đưa vào một tậ p con các mẫu, mỗi mẫu một lần, sau khi nó đã
đượ c “nhìn” tất cả các mẫu, nó sẽ phải thực hiện điều chỉnh các tr ọng số bằng cách tính
toán các lỗi xảy ra. Quá trình này đượ c lặ p lại cho đến khi mạng đượ c luyện đủ. Kích
thướ c của tậ p con đượ c giớ i hạn bở i số lần lặ p, có thể là trùng vớ i kích thướ c của tậ p mẫu
học, nếu không như vậy thì cần phải xác định thứ tự đưa các mẫu vào cho mạng học một
cách ngẩu nhiên.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 37/80
-37-
Giá tr ị của lỗi đượ c tính bở i phươ ng pháp trung bình bình phươ ng của giá tr ị kích hoạt;
ngh ĩ a là nó đượ c tính bằng cách bình phươ ng hiệu của giá tr ị đầu ra mong muốn và đầu ra
thực sự, sau đó tính trung bình trong tất cả các nơ ron đầu ra. Có thể xác định cách điềuchỉnh các tr ọng số để có thể giảm đượ c lỗi bằng cách tính các đạo hàm từng phần (đạo hàm
theo hướ ng) của lỗi. Số các bướ c cần thực hiện theo hướ ng đó đượ c gọi là mức độ học
(tham số học-learning rate), nếu quá lớ n, giá tr ị cực tr ị có thể bị bỏ qua, nếu quá nhỏ thì
phải mất nhiều thờ i gian để đạt tớ i điểm cực tr ị.
Nhượ c điểm lớ n nhất của thuật toán lan truyền ngượ c truyền thống đó là nó bị ảnh hưở ng
r ất lớ n của gradient địa phươ ng, không cần thiết phải đi đườ ng thẳng. Ví dụ, nếu như cực
tr ị toàn cục nằm ở cuối vùng lõm và điểm hiện tại là bên cạnh, phía trên điểm lõm, khi đóthuật toán lan truyền ngượ c sẽ thực hiện một bướ c theo hướ ng mà gradient lớ n nhất, vượ t
qua vùng lõm. Một khi nó phát hiện các cạnh khác của của vùng lõm, nó sẽ chạy theo
đườ ng zic zắc tiến, lùi tạo ra các bướ c nhỏ tớ i đích. Đườ ng này sẽ lớ n gấ p hàng nghìn lần
so vớ i đườ ng ngắn nhất, và do đó, thờ i gian học cũng sẽ lớ n gấ p r ất nhiều lần. Thuật toán
lan truyền ngượ c chuẩn có thể đượ c tăng cườ ng bằng cách thêm tham số bướ c đà
(momentum) vào phươ ng trình. Hiệu ứng này sẽ lọc ra ngoài các cực tr ị địa phươ ng và cho
phép khả năng tìm ra cực tr ị toàn cục lớ n lên.
Khoảng bướ c, hay mức độ học, của thuật toán lan truyền ngượ c chuẩn là cố định, điều này
dẫn đến việc thuật toán tìm xung quanh điểm cực tiểu trong khi đó, thuật toán không thể
tìm chính xác điểm thấ p nhất trong hai gradient. Ngh ĩ a là nó đi xuống một bướ c, vượ t qua
điểm cực tiểu và đứng ở nửa trên phía bên kia. Phươ ng pháp gradient k ết hợ p (Conjugate
Gradient) cho phép thuật toán học thực hiện các bướ c nhỏ tăng dần khi nó tiế p cận điểm
cực tiểu, như vậy, nó có thể đạt tớ i điểm gần vớ i điểm cực tiểu thực sự r ất nhanh chóng.
Mặc dù phươ ng pháp tối ưu gradient giảm (gradient descent) dùng trong thuật toán lan
truyền ngượ c chuẩn đượ c sử dụng r ộng rãi và đượ c thực tế chứng minh là thành công trong
r ất nhiều ứng dụng, nó cũng còn tồn tại các nhượ c điểm:
1) Hội tụ r ất chậm
2) Không đảm bảo là sẽ hội tụ tại điểm cực tr ị toàn cục
R ất nhiều các nhà nghiên cứu [3][9][11][12][20] đã đưa ra các cải tiến cho phươ ng pháp
gradient như là: sửa đổi động các tham số học hay điều chỉnh độ dốc của hàm sigmoid,...

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 38/80
-38-
Trong các hoàn cảnh thích hợ p, các phươ ng pháp tối ưu khác có thể là tốt hơ n thuật toán
gradient. Nhiều thuật toán hội tụ nhanh hơ n là thuật toán gradient trong một số tr ườ ng hợ p
trong khi một số khác hứa hẹn xác suất hội tụ đến điểm cực tr ị toàn cục lớ n hơ n[20].
Một trong số các phươ ng pháp tối ưu có thể thay thế cho phươ ng pháp gradient đó là
Phươ ng pháp gradient k ết hợ p (Conjugate Gradient), đó là phươ ng pháp cực tiểu theo
hướ ng. Tối thiểu hóa theo một hướ ng d đặt hàm E tớ i chỗ mà gradient của nó là vuông góc
vớ i d . Thay vì theo hướ ng gradient tại từng bướ c, một tậ p gồm n hướ ng đượ c xây dựng
theo cách k ết hợ p vớ i các hướ ng khác, tối thiểu hóa theo một trong số các hướ ng làm hỏng
giá tr ị tối thiểu hóa theo một trong các hướ ng tr ướ c đó.
Phươ ng pháp Gradient sử dụng đạo hàm bậc hai (Ma tr ận Hessian), như trong phươ ng
pháp Newton, có thể r ất hiệu quả trong một số tr ườ ng hợ p. Nếu sử dụng đạo hàm bậc nhất,
các phươ ng pháp đó sử dụng một xấ p xỉ tuyến tính địa phươ ng của bề mặt lỗi (error
surface), Các phươ ng pháp bậc hai, sử dụng xấ p xỉ bậc hai. Do các phươ ng pháp như vậy
đều sử dụng thông tin đạo hàm bậc nhất và bậc hai theo đúng công thức, các thuộc tính hội
tụ địa phươ ng là r ất tốt. Tuy vậy, chúng đều không thực tế bở i lẽ việc tính toàn bộ ma tr ận
Hessian có thể là r ất tốn kém trong các bài toán có phạm vi r ộng.
2.5. Các thuật toán tối ư u khác
Cực tr ị địa phươ ng có thể xảy ra trong tr ườ ng hợ p mạng không đượ c huấn luyện một cách
tối ưu, trong nhiều tr ườ ng hợ p, các cực tr ị này là chấ p nhận đượ c. Nếu ngượ c lại, mạng cần
đượ c huấn luyện lại cho đến khi hiệu năng tốt nhất có thể đượ c tìm ra. Mặc dù vậy, có các
k ỹ thuật đã đượ c thiết k ế nhằm làm tăng hiệu quả của quá trình học của mạng, trong đó bao
gồm Thuật toán giả luyện kim hoặc thuật giải di truyền (Masters 1993). Các phươ ng pháp
này có thể giúp vượ t qua đượ c cực tr ị địa phươ ng đã đượ c ứng dụng thành công trong một
số vấn đề.
2.5.1. Thuật toán gi ả luyệ n kim (Simulated annealing)
K ỹ thuật tôi là một quá trình luyện kim, trong đó sự sắ p xế p ngẫu nhiên của các phân tử
cácbon trong thép đượ c chuyển đổi thành một kim loại có cấu trúc lớ p ít giòn hơ n. Quá
trình này bao gồm việc nung kim loại ở một nhiệt độ r ất cao và sau đó làm lạnh từ từ. Các
phân tử ở nhiệt độ cao có mức năng lượ ng cao, là cho các phân tử này chuyển động. Khi
mà nhiệt độ giảm đi, các chuyển động cũng giảm đi và chúng đượ c sắ p xế p thành các lớ p.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 39/80
-39-
Ý tưở ng này đượ c áp dụng vào các thuật toán huấn luyện cho mạng nơ ron. Nhiệt độ đượ c
coi như là hệ số học đượ c giảm dần. Ý tưở ng ở đây là nếu mạng gặ p phải một điểm cực tr ị
địa phươ ng thì nó sẽ đượ c “rung” (shake) để có thể thoát khỏi cực tr ị địa phươ ng. Nếu như “nhiệt độ” đượ c giữ không đổi thì hệ sẽ chỉ chuyển từ một điểm cực tr ị địa phươ ng này
sang một điểm cực tr ị địa phươ ng khác và khó có thể ổn định. Nếu khả năng nhảy đượ c
giảm đều thì mạng sẽ có xu hướ ng đạt đến đượ c điểm cực tr ị toàn cục. Và một khi mạng
đạt đến điểm cực tr ị toàn cục thì mức rung sẽ không đủ để có thể khiến cho mạng bỏ qua
nó.
Rõ ràng thuật toán giả luyện kim có dáng dấ p của một thuật toán huấn luyện vớ i hệ số học
biến đổi, tuy nhiên, hệ số học trong thuật toán này đượ c giảm dần trong khi, thuật toánhuấn luyện sử dụng hệ số học biến đổi sẽ làm tăng hay giảm hệ số học tùy thuộc vào tình
huống cụ thể khi sai số khi học là tăng hay giảm.
2.5.2. Thuật gi ải di truyề n (Genetic Algorithm)
Đây thực chất là một thuật toán tìm kiếm điểm tối ưu trong không gian của các tham số.
Thuật toán di truyền là k ỹ thuật bắt chướ c sự chọn lọc tự nhiên và di truyền. Trong tự
nhiên, các cá thể khỏe, có khả năng thích nghi tốt vớ i môi tr ườ ng sẽ đượ c tái sinh và nhân
bản trong các thế hệ sau.
Trong giải thuật di truyền, mỗi cá thể đượ c mã hóa bở i một cấu trúc dữ liệu mô tả cấu trúc
gien của mỗi cá thể đó, gọi là nhiễ m sắ c thể . Mỗi nhiễm sắc thể đượ c tạo thành từ các đơ n
vị gọi là gien. Chẳng hạn như là một chuỗi nhị phân, tức là mỗi cá thể đượ c biểu diễn bở i
một chuỗi nhị phân.
Giải thuật di truyền sẽ làm việc trên các quần thể gồm nhiều cá thể. Một quần thể ứng vớ i
một giai đoạn phát triển đượ c gọi là một thế hệ. Từ thế hệ đầu đượ c tạo ra, giải thuật ditruyền bắt chướ c chọn lọc tự nhiên và di truyền để biến đổi các thế hệ. Giải thuật di truyền
sử dụng các toán tử: tái sinh (reproduction): các cá thể tốt đượ c đưa vào thế hệ sau dựa
vào độ thích nghi đối vớ i môi tr ườ ng của mỗi cá thể (xác định bở i hàm thích nghi-fitness
function); toán tử lai ghép (crossover): hai cá thể cha, mẹ trao đổi các gien để tạo ra hai
cá thể con; toán tử đột biến (mutation): một cá thể thay đổi một số gien để tạo thành cá
thể mớ i. Việc áp dụng các toán tử trên đối vớ i các quần thể là ngẫu nhiên.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 40/80
-40-
Thuật toán di truyền bắt đầu bằng việc khở i tạo quần thể ban đầu, sau đó thực hiện lặ p lại
các bướ c: sinh ra thế hệ mớ i từ thế hệ ban đầu bằng cách áp dụng các toán tử lai ghép, đột
biến, tái sinh; đánh giá thế hệ mớ i sinh ra; cho đến khi điều kiện k ết thúc đượ c thỏa mãn.Khi thuật toán dừng, cá thể tốt nhất đượ c lựa chọn làm nghiệm cần tìm.
Có thể thấy, thuật toán di truyền có liên quan đến k ỹ thuật tìm kiếm điểm tối ưu. Thực
chất, nó có thể coi như là một k ỹ thuật khác để huấn luyện mạng nơ ron để giải quyết các
bài toán. Nó liên quan đến việc mã hóa các tham số của mạng nơ ron bằng các nhiễm sắc
thể. Các tham số ban đầu đượ c khở i tạo ngẫu nhiên nhiều lần tạo ra quần thể ban đầu. Khi
đó, hàm thích nghi của các cá thể (tậ p các tr ọng số) đượ c xác định bằng cách tính toán lỗi
đầu ra của mạng. Nếu điều kiện dừng thỏa mãn thì quá trình huấn luyện dừng lại, nếukhông, sẽ thực hiện các toán tử chọn lọc, lai ghép, đột biến trên các cá thể để tạo ra quần
thể mớ i [1] [20]. Các nghiên cứu cho thấy r ằng thuật toán di truyền có thể đượ c xem như
một thuật toán tốt dùng để huấn luyện mạng.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 41/80
-41-
CHƯƠ NG III. Ứ NG DỤNG MẠNG NƠ RON TRUYỀN THẲNG TRONG
DỰ BÁO DỮ LIỆU
Chươ ng này đề cậ p các vấn đề sau:
3.1. Sơ lượ c về l ĩ nh vực dự báo dữ liệu
3.2. Thu thậ p, phân tích và xử lý dữ liệu
3.3. Chươ ng trình dự báo dữ liệu
3.4. Một số nhận xét
3.1. Sơ lượ c về l ĩ nh vự c dự báo dữ liệu
Ngườ i ta đã chứng tỏ r ằng không có một phươ ng pháp luận hoàn hảo trong tiế p cận các bài
toán bằng cách sử dụng mạng nơ ron huấn luyện bở i thuật toán lan truyền ngượ c. Ta có
nhiều điều cần cân nhắc, lựa chọn để có thể thiết lậ p các tham số cho một mạng nơ ron:
Số lớ p ẩn
Kích thướ c các lớ p ẩn
Hằng số học (beta)
Tham số momentum (alpha)
Khoảng, khuôn dạng dữ liệu sẽ đưa vào mạng
Dạng hàm squashing (không nhất thiết phải là hàm sigmoid)
Điểm khở i đầu (ma tr ận tr ọng số ban đầu)
Tỷ lệ nhiễu mẫu (tăng khả năng tổng quát hóa cho mạng).
Việc dự báo dữ liệu là một bài toán r ất phức tạ p, cả về số lượ ng dữ liệu cần quan tâm cũng
như độ chính xác của dữ liệu dự báo. Do vậy, việc cân nhắc để có thể chọn đượ c mô hình
phù hợ p cho việc dự báo dữ liệu là một việc r ất khó khăn (chỉ có thể bằng phươ ng pháp
thử-sai). Tuy nhiên, thuật toán lan truyền ngượ c là thuật toán đượ c ứng dụng r ất r ộng rãi

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 42/80
-42-
trong các l ĩ nh vực: nhận dạng, phân lớ p, dự báo… đã đượ c thực tế chứng tỏ là một công cụ
tốt áp dụng cho các bài toán trong l ĩ nh vực dự báo dữ liệu.
Do đặc tr ưng về độ phức tạ p dữ liệu, các dữ liệu đầu ra thườ ng là các con số (mảng các số)
dấu phảy động cho nên việc lựa chọn cấu trúc mạng phù hợ p thườ ng là sử dụng phươ ng
pháp thử-sai (trial and errors). Đồng thờ i cần phải chuẩn hóa (loại bỏ các dữ liệu sai, thừa,
đưa chúng về đoạn [0,1] hoặc [-1,1],...) các dữ liệu đầu vào và đầu ra để mạng có khả năng
học tốt hơ n từ các dữ liệu đượ c cung cấ p.
Trong việc dự báo dữ liệu, nếu dữ liệu ở nhiều khoảng thờ i gian khác nhau đượ c đưa vào
mạng để huấn luyện thì việc dự báo chính xác là r ất khó nếu như mục đích là dự báo chính
xác 100% dữ liệu trong tươ ng lai. Ta chỉ có thể có đượ c k ết quả dự báo vớ i một mức độ
chính xác nào đó chấ p nhận đượ c.
3.2. Thu thập, phân tích và xử lý dữ liệu
Dữ liệu đóng một vai trò r ất quan tr ọng trong các giải pháp sử dụng mạng nơ ron. Chất
lượ ng, độ tin cậy, tính sẵn có và phù hợ p của dữ liệu đượ c sử dụng để phát triển hệ thống
giúp cho các giải pháp thành công. Các mô hình đơ n giản cũng có thể đạt đượ c những k ết
quả nhất định nếu như dữ liệu đượ c xử lý tốt, bộc lộ đượ c các thông tin quan tr ọng. Bêncạnh đó, các mô hình tốt có thể sẽ không cho ta các k ết quả mong muốn nếu dữ liệu đưa
vào quá phức tạ p và r ắc r ối.
Việc xử lý dữ liệu bắt đầu bằng việc thu thậ p và phân tích dữ liệu, sau đó là bướ c tiền xử
lý. Dữ liệu sau khi qua bướ c tiền xử lý đượ c đưa vào mạng nơ ron. Cuối cùng, dữ liệu đầu
ra của mạng nơ ron qua bướ c hậu xử lý, bướ c này sẽ thực hiện biến đổi k ết quả tr ả về của
mạng nơ ron sang dạng hiểu đượ c theo yêu cầu của bài toán (Hình 15). Sau đây, trong các
mục tiế p theo, ta sẽ đi vào xem xét từng bướ c trong quá trình xử lý dữ liệu.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 43/80
-43-
Hình 15: X ử lý d ữ liệu
3.2.1. Ki ể u của các bi ế n
Các biến dữ liệu có thể đượ c chia thành hai loại dựa trên các đặc điểm, tính chất của chúng
(Có thể tham khảo ở [2][5][6][10][13][14]):
3.2.1.1. Biế n phân loại (Categorical Variables)
Các biến này thườ ng không có thứ tự xác định, ngh ĩ a là giữa chúng không xác định đượ c
các phép toán như: “lớ n hơ n” hay “nhỏ hơ n”. Các biến này nằm trong các giá tr ị đưa vào
không có giá tr ị số nhưng đượ c gán các giá tr ị số trong đầu vào. Ví dụ, biến “kiểu màu”, có
thể nhận các giá tr ị “đỏ”, ”xanh”, và “vàng” là một biến phân loại. Giớ i tính cũng là biến
kiểu này. Các dữ liệu số cũng có thể thuộc loại này, ví dụ như: “mã vùng”, “mã nướ c”.
Các biến thuộc loại này có thể đượ c đưa vào mạng bằng sơ đồ mã hóa 1-of-c (1-of-c
encoding scheme), sơ đồ này mã hóa các giá tr ị của biến thành các xâu nhị phân có chiều
dài bằng số các giá tr ị mà biến có thể nhận trong phạm vi bài toán. Một bit sẽ đượ c bật lên
tuỳ theo giá tr ị của biến, các bit còn lại sẽ đượ c đặt bằng 0. Trong ví dụ trên, biến “kiểu
màu” cần ba biến vào, tươ ng ứng vớ i ba màu đượ c thể hiện bằng các xâu nhị phân: (1,0,0),
(0,1,0) and (0,0,1).
Một cách khác để mã hóa các biến phân loại là thể hiện tất cả các giá tr ị có thể vào một
biến đầu vào liên tục. Ví dụ, các giá tr ị “đỏ”, ”xanh”, và “vàng” có thể đượ c thể hiện bở i
Thu thập, phân
tích dữ liệu
Ti ền xử lý
Mạng nơron
Hậu xử lý

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 44/80
-44-
các giá tr ị số 0.0, 0.5, và 1.0. Điểm không tốt của phươ ng pháp này là nó tạo ra một tr ật tự
nhân tạo trên dữ liệu mà trên thực tế, thứ tự này không hề có. Nhưng đối vớ i các biến vớ i
một số lượ ng lớ n các phân loại, phươ ng pháp này có thể giảm r ất nhiều số đơ n vị đầu vào.
3.2.1.2. Biến có thứ tự (Ordinal Variables)
Các biến này có xác định thứ tự tự nhiên. Chúng có thể đượ c chuyển tr ực tiế p thành các
giá tr ị tươ ng ứng của một biến liên tục vớ i một tỷ lệ nào đó.
3.2.2. Thu thậ p d ữ li ệ u
Bướ c thực hiện thu thậ p các dữ liệu bao gồm ba nhiệm vụ chính:
3.2.2.1. Xác định yêu cầu d ữ liệu
Điều đầu tiên cần thực hiện khi lậ p k ế hoạch thu thậ p dữ liệu ta là xác định xem các dữ liệu
nào là cần thiết để có thể giải quyết bài toán. Về tổng thể, có thể cần sự tr ợ giúp của các
chuyên gia trong l ĩ nh vực của bài toán cần giải quyết. Ta cần phải biết: a) Các dữ liệu chắc
chắn có liên quan đến bài toán; b) Các dữ liệu nào có thể liên quan; c) Các dữ liệu nào là
phụ tr ợ . Các dữ liệu có liên quan và có thể liên quan đến bài toán cần phải đượ c xem là các
đầu vào cho hệ thống.
3.2.2.2. Xác định nguồn d ữ liệu
Bướ c k ế tiế p là quyết định nơ i sẽ lấy dữ liệu, điều này cho phép ta xác định đượ c các ướ c
lượ ng thực tế về những khó khăn và phí tổn cho việc thu thậ p dữ liệu. Nếu ứng dụng yêu
cầu các dữ liệu thờ i gian thực, những ướ c lượ ng này cần tính đến khả năng chuyển đổi các
dữ liệu tươ ng tự thành dạng số.
Trong một số tr ườ ng hợ p, ta có thể chọn lựa dữ liệu mô phỏng từ các tình huống thực tế.
Tuy nhiên, cần phải quan tâm đến độ chính xác và khả năng thể hiện của dữ liệu đối vớ icác tr ườ ng hợ p cụ thể.
3.2.2.3. Xác định l ượ ng d ữ liệu
Ta cần phải ướ c đoán số lượ ng dữ liệu cần thiết để có thể sử dụng trong việc xây dựng
mạng. Nếu lấy quá ít dữ liệu thì những dữ liệu này sẽ không thể phản ánh toàn bộ các thuộc
tính mà mạng cần phải học và do đó mạng sẽ không có đượ c phản ứng mong đợ i đối vớ i
những dữ liệu mà nó chưa đượ c huấn luyện. Mặt khác, cũng không nên đưa vào huấn luyện

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 45/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 46/80
-46-
3.2.4. X ử lý d ữ li ệ u
3.2.4.1. Dẫ n nhậ p về xử lý d ữ liệu
Khi những dữ liệu thô đã đượ c thu thậ p, chúng cần phải đượ c chuyển đổi sang các khuôn
dạng phù hợ p để có thể đưa vào luyện mạng. Ở bướ c này, ta cần thực hiện các công việc
sau:
Kiể m tra tính hợ p l ệ d ữ liệu (Data validity checks)
Việc kiểm tra tính hợ p lệ sẽ phát hiện ra các dữ liệu không thể chấ p nhận đượ c mà nếu sử
dụng chúng thì sẽ cho ra các k ết quả không tốt. Ví dụ, ta có thể kiểm tra khoảng hợ p lệ của
dữ liệu về nhiệt độ không khí của một vùng nhiệt đớ i chẳng hạn. Ta mong muốn các giá tr ị trong khoảng từ 5oC đến 40oC, do đó, các giá tr ị nằm ngoài khoảng này rõ ràng là không
thể chấ p nhận đượ c.
Nếu có một mẫu cho một phân bố sai của dữ liệu (ví dụ, nếu phần lớ n dữ liệu đượ c thu
thậ p ở một ngày trong tuần) ta cần xem xét nguyên nhân của nó. Dựa trên bản chất của
nguyên nhân dẫn đến sai lầm, ta có thể hoặc phải loại bỏ các dữ liệu này, hoặc cho phép
những thiếu sót đó. Nếu có các thành phần quyết định không mong muốn như là các xu
hướ ng hay các biến thiên có tính chất mùa vụ, chúng cần đượ c loại bỏ ngay.
Phân hoạch d ữ liệu (Partitioning data)
Phân hoạch là quá trình chia dữ liệu thành các tậ p kiểm định, huấn luyện, và kiểm tra.
Theo định ngh ĩ a, tậ p kiể m định đượ c sử dụng để xác định kiến trúc của mạng; các tậ p huấ n
luyện đượ c dùng để cậ p nhật các tr ọng số của mạng; các tậ p kiể m tra đượ c dùng để kiểm
tra hiệu năng của mạng sau khi luyện. Ta cần phải đảm bảo r ằng:
a)
Tậ p huấn luyện chứa đủ dữ liệu, các dữ liệu đó phân bố phù hợ p sao cho có thể biểu diễn các thuộc tính mà ta muốn mạng sẽ học đượ c.
b) Không có dữ liệu trùng nhau hay tươ ng tự nhau của các dữ liệu trong các tậ p dữ
liệu khác nhau.
3.2.4.2. Tiề n xử lý
Về mặt lý thuyết, một mạng nơ ron có thể dùng để ánh xạ các dữ liệu thô đầu vào tr ực tiế p
thành các dữ liệu đầu ra. Nhưng trong thực tế, việc sử dụng quá trình tiền xử lý cho dữ liệu

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 47/80
-47-
thườ ng mang lại những hiệu quả nhất định tr ướ c khi những dữ liệu này đượ c đưa vào
mạng. Có r ất nhiều k ỹ thuật liên quan đến tiền xử lý dữ liệu. Tiền xử lý dữ liệu có thể là
thực hiện lọc dữ liệu (trong dữ liệu biến thiên theo thờ i gian time-series) hay các phươ ng pháp phức tạ p hơ n như là các phươ ng pháp k ết xuất, trích chọn các đặc tr ưng từ dữ liệu
ảnh t ĩ nh (image data). Bở i lẽ việc chọn thuật toán dùng trong tiền xử lý dữ liệu là phụ
thuộc vào ứng dụng và bản chất của dữ liệu, cho nên, các khả năng lựa chọn là r ất lớ n. Tuy
nhiên, mục đích của các thuật toán tiền xử lý dữ liệu thườ ng tươ ng tự nhau, như sau (Xem
chẳng hạn [6]):
1) Chuyển đổi dữ liệu về khuôn dạng phù hợ p đối vớ i đầu vào mạng nơ ron - điều này
thườ ng đơ n giản hóa quá trình xử lý của mạng phải thực hiện trong thờ i gian ngắn hơ n.Các chuyển đổi này có thể bao gồm:
• Áp dụng một hàm toán học (hàm logarit hay bình phươ ng) cho đầu vào;
• Mã hóa các dữ liệu văn bản trong cơ sở dữ liệu;
• Chuyển đổi dữ liệu sao cho nó có giá tr ị nằm trong khoảng [0, 1].
• Lấy biến đổi Fourier cho các dữ liệu thờ i gian.
2) Lựa chọn các dữ liệu xác đáng nhất - việc lựa chọn này có thể bao gồm các thao tác đơ n
giản như lọc hay lấy tổ hợ p của các đầu vào để tối ưu hóa nội dung của dữ liệu. Điều này
đặc biệt quan tr ọng khi mà dữ liệu có nhiễu hoặc chứa các thông tin thừa. Việc lựa chọn
cẩn thận các dữ liệu phù hợ p sẽ làm cho mạng dễ xây dựng và tăng cườ ng hiệu năng của
chúng đối vớ i các dữ liệu nhiễu.
3) Tối thiểu hóa số các đầu vào mạng - giảm số chiều của dữ liệu đầu vào và tối thiểu số
các mẫu đưa vào có thể đơ n giản hóa đượ c bài toán. Trong một số tr ườ ng hợ p - chẳng hạn
trong xử lý ảnh – ta không thể nào đưa tất cả các dữ liệu vào mạng. Ví dụ như trong ứng
dụng nhận dạng ảnh, mỗi một ảnh có thể chứa hàng triệu điểm ảnh, khi đó rõ ràng là không
khả thi nếu sử dụng nhiều đầu vào như vậy. Trong tr ườ ng hợ p này, việc tiền xử lý cần thực
hiện giảm số đầu vào của dữ liệu bằng cách sử dụng các tham số đơ n giản hơ n chẳng hạn
như sử dụng các tham số vùng ảnh và tỷ lệ chiều dài/chiều cao. Quá trình này còn gọi là
trích chọn dấu hiệu ( feature extraction) [14].

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 48/80
-48-
3.2.4.3. H ậu xử lý
Hậu xử lý bao gồm các xử lý áp dụng cho đầu ra của mạng. Cũng như đối vớ i tiền xử lý,
hậu xử lý hoàn toàn phụ thuộc vào các ứng dụng cụ thể và có thể bao gồm cả việc phát
hiện các tham số có giá tr ị vượ t quá khoảng cho phép hoặc sử dụng đầu ra của mạng như
một đầu vào của một hệ khác, chẳng hạn như một bộ xử lý dựa trên luật. Đôi khi, hậu xử lý
chỉ đơ n giản là quá trình ngượ c lại đối vớ i quá trình tiền xử lý.
3.2.5. T ổ ng hợ p
Trong thực tế khi xây dựng các mạng nơ ron ứng dụng trong l ĩ nh vực dự báo dữ liệu, việc
áp dụng các phươ ng pháp tiền xử lý dữ liệu đầu vào (và sau đó áp dụng phươ ng pháp hậu
xử lý để biến đổi đầu ra về dạng phù hợ p) giúp ích r ất nhiều trong các ứng dụng. Như đã
nêu ở trên, có r ất nhiều các phươ ng pháp có thể áp dụng cho dữ liệu ở quá trình tiền xử lý
cũng như hậu xử lý. Các phươ ng pháp này thực sự hiệu quả cho các bài toán cụ thể bở i lẽ
chúng làm giảm bớ t đi độ phức tạ p của dữ liệu đầu vào, từ đó làm giảm thờ i gian học của
mạng nơ ron.
Các phươ ng pháp xử lý dữ liệu còn phụ thuộc vào công việc thu thậ p, phân tích và lựa
chọn dữ liệu đầu vào cho mạng. Đây cũng là yếu tố quyết định cho sự thành công của cácứng dụng mạng nơ ron. Việc dữ liệu đượ c chuẩn hóa tr ướ c khi đưa vào mạng huấn luyện có
thể làm giảm bớ t thờ i gian mạng học, làm tăng độ chính xác cho dữ liệu dự báo. Điều này
r ất có ý ngh ĩ a bở i lẽ thuật toán lan truyền ngượ c khi thực thi r ất tốn thờ i gian!
3.3. Chươ ng trình dự báo dữ liệu
3.3.1. Các bướ c chính trong quá trình thi ế t k ế và xây d ự ng
Tr ướ c hết, dướ i đây nêu ra các bướ c chính trong quá trình thiết k ế và xây dựng một ứng
dụng dựa trên mạng nơ ron. Có r ất nhiều vấn đề cần phải xem xét khi xây dựng mạng nơ ron
nhiều lớ p sử dụng thuật toán lan truyền ngượ c:
Tiề n xử lý d ữ liệu
Tần số của dữ liệu: hàng ngày, hàng tuần, hàng tháng hay hàng quý.
Kiểu dữ liệu: các chỉ số k ỹ thuật hay các chỉ số căn bản.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 49/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 50/80
-50-
• số nơ ron trong các lớ p ẩn.
• số nơ ron đầu ra.
• các hàm chuyển.
vi) Xác định tiêu chuẩn đánh giá (hàm lỗi)
vii) Huấn luyện mạng.
viii) Thực thi trong thực tế.
Trong khi thực hiện, không nhất thiết phải theo thứ tự các bướ c mà có thể quay lại các
bướ c tr ướ c đó, đặc biệt là ở bướ c huấn luyện và lựa chọn các biến.
Bướ c 1: Chọn l ự a các biế n
Trong bài toán dự báo các dữ liệu thươ ng mại thì các học thuyết kinh tế có thể giúp chọn
lựa các biến là các chỉ số kinh tế quan tr ọng. Đối vớ i một bài toán cụ thể cần thực hiện xem
xét các vấn đề lý thuyết mà từ đó sẽ xác định đượ c các nhân tố ảnh hưở ng đến bài toán. Tại
bướ c này trong quá trình thiết k ế, điều cần quan tâm đó là các dữ liệu thô từ đó có thể phát
triển thành các chỉ số quan tr ọng. Các chỉ số này sẽ tạo ra các đầu vào cho mạng.
Bướ c 2: Thu thậ p d ữ liệu
Cần xem xét khả năng có thể thu thậ p đượ c các dữ liệu. Các dữ liệu k ỹ thuật có thể thu
thậ p đượ c dễ dàng hơ n là các dữ liệu cơ bản. Mặt khác, các dữ liệu sau khi thu thậ p cần
đượ c kiểm tra tính hợ p lệ của chúng. Đồng thờ i, các dữ liệu bị thiếu sót cần đượ c xử lý cẩn
thận, có thể bỏ qua chúng hoặc giả sử r ằng các dữ liệu bị thiếu đó không thay đổi so vớ i dữ
liệu tr ướ c nó. Bướ c 3: Tiề n xử lý d ữ liệu
Tiền xử lý dữ liệu liên quan đến việc phân tích và chuyển đổi giá tr ị các tham số đầu vào,
đầu ra mạng để tối thiểu hóa nhiễu, nhấn mạnh các đặc tr ưng quan tr ọng, phát hiện các xu
hướ ng và cân bằng phân bố của dữ liệu. Các đầu vào, đầu ra của mạng nơ ron hiếm khi
đượ c đưa tr ực tiế p vào mạng. Chúng thườ ng đượ c chuẩn hóa vào khoảng giữa cận trên và
cận dướ i của hàm chuyển (thườ ng là giữa đoạn [0;1] hoặc [-1;1]).

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 51/80
-51-
Các phươ ng pháp phổ biến có thể là:
SV = ((0.9 - 0.1) / (MAX_VAL - MIN_VAL)) * (OV - MIN_VAL)
hoặc đưa về khoảng giữa giá tr ị min và max:
SV = TFmin + ((TFmax - TFmin) / (MAX_VAL - MIN_VAL)) * (OV - MIN_VAL)
trong đó:
SV: Giá tr ị sau khi biến đổi
MAX_VAL: Giá tr ị lớ n nhất của dữ liệu
MIN_VAL: Giá tr ị nhỏ nhất của dữ liệuTFmax: Giá tr ị lớ n nhất của hàm chuyển
TFmin: Giá tr ị nhỏ nhất của hàm chuyển
OV: Giá tr ị ban đầu
Bướ c 4: Phân chia t ậ p d ữ liệu
Trong thực tế, khi huấn luyện, ngườ i ta thườ ng chia tậ p dữ liệu thành các tậ p: Huấn luyện,
kiểm tra và kiểm định (ngoài các mẫu). Tậ p huấn luyện thườ ng là tậ p lớ n nhất đượ c sử dụng để huấn luyện cho mạng. Tậ p kiểm tra thườ ng chứa khoảng 10% đến 30% tậ p dữ liệu
huấn luyện, đượ c sử dụng để kiểm tra mức độ tổng quát hóa của mạng sau khi huấn luyện.
Kích thướ c của tậ p kiểm định cần đượ c cân bằng giữa việc cần có đủ số mẫu để có thể
kiểm tra mạng đã đượ c huấn luyện và việc cần có đủ các mẫu còn lại cho cả pha huấn
luyện và kiểm tra.
Có hai cách thực hiện xác định tậ p kiểm tra. Một là lấy ngẫu nhiên các mẫu từ tậ p huấn
luyện ban đầu. Lợ i điểm của cách này là có thể tránh đượ c nguy hiểm khi mà đoạn dữ liệu
đượ c chọn có thể chỉ điển hình cho một tính chất của dữ liệu (đang tăng hoặc đang giảm).
Hai là chỉ lấy các dữ liệu ở phần sau của tậ p huấn luyện, trong tr ườ ng hợ p các dữ liệu gần
vớ i hiện tại là quan tr ọng hơ n các dữ liệu quá khứ.
Bướ c 5: Xác định cấ u trúc mạng
Phươ ng pháp thực hiện xây dựng mạng nơ ron bao gồm việc xác định sự liên k ết giữa các
nơ ron, đồng thờ i xác định cấu trúc của mạng bao gồm số lớ p ẩn, số nơ ron trong từng lớ p.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 52/80
-52-
Tuy nhiên, các thực nghiệm cho thấy r ằng, số lớ p ẩn sử dụng trong mạng không nên vượ t
quá 4 lớ p. Ngoài ra, không có phươ ng pháp nào có thể chọn đượ c số tối ưu các nơ ron sử
dụng trong lớ p ẩn. Mặc dù vậy cũng có một số phươ ng pháp cho ta lựa chọn ban đầu. Nhưng để có đượ c số tối ưu các nơ ron trong các lớ p ẩn thì ngườ i phát triển mô hình cần
phải thực hiện nhiều thí nghiệm để có đượ c nó. Bên cạnh đó, việc chọn lựa số các đầu vào
mạng cũng mang một tính chất quyết định đến cấu trúc của mạng để có đượ c khả năng
tổng quát hóa tốt.
Ta có thể thực hiện lựa chọn số nơ ron trong các lớ p ẩn bằng cách bắt đầu bằng một số nào
đó dựa trên các luật. Sau khi thực hiện huấn luyện, kiểm tra lỗi tổng quát hóa của từng cấu
trúc, có thể tăng hoặc giảm số các nơ ron.
Bất k ể phươ ng pháp nào thì luật tổng quát nhất là thực hiện chọn cấu trúc mạng cho ta lỗi
tổng quát hóa trên tậ p dữ liệu huấn luyện là nhỏ nhất. Khi thực hiện điều chỉnh, nên giữ
các tham số còn lại không thay đổi để tránh tạo ra các cấu trúc khác có khả năng đưa lại
các phức tạ p không cần thiết trong quá trình lựa chọn số tối ưu các nơ ron trong lớ p ẩn.
Bướ c 6: Xác định tiêu chuẩ n đ ánh giá
Hàm đượ c sử dụng để đánh giá mạng thườ ng là hàm trung bình bình phươ ng lỗi. Các hàmkhác có thể là hàm độ lệch nhỏ nhất (least absolute deviation), hiệu phần tr ăm (percentage
differences), bình phươ ng nhỏ nhất bất đối xứng (asymetric least squares),... Tuy nhiên,
các hàm này có thể không phải là hàm đánh giá chất lượ ng cuối cùng cho mạng. Phươ ng
pháp đánh giá các giá tr ị dự báo hay đượ c sử dụng là giá tr ị trung bình tuyệt đối phần tr ăm
lỗi (mean absolute percentage error - MAPE).
Chẳng hạn trong các hệ thống bán hàng, các giá tr ị dự báo của mạng nơ ron sẽ đượ c chuyển
sang tín hiệu mua hoặc bán tùy thuộc vào một tiêu chuẩn xác định tr ướ c đó.
Bướ c 7: Huấ n luyện mạng
Huấn luyện mạng học các dữ liệu bằng cách lần lượ t đưa các mẫu vào cùng vớ i những giá
tr ị mong muốn. Mục tiêu của việc huấn luyện mạng đó là tìm ra tậ p các tr ọng số cho ta giá
tr ị nhỏ nhất toàn cục của chỉ số hiệu năng hay hàm lỗi.
Vấn đề đặt ra là khi nào thì ngừng huấn luyện. Có hai quan điểm trong vấn đề này. Quan
điểm thứ nhất cho r ằng chỉ nên ngừng huấn luyện chừng nào không có tiến triển nào của

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 53/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 54/80
-54-
muốn theo thờ i gian. Tần số thực hiện huấn luyện lại mạng cần hợ p lý sao cho mạng có thể
đạt đượ c tr ạng thái hoạt động tốt nhất.
3.3.2. Xây d ự ng chươ ng trình
Về tổng thể, chươ ng trình dự báo dữ liệu đượ c xây dựng dựa trên các cơ sở lý thuyết đã
nêu trên. Mạng sử dụng trong bài toán dự báo dữ liệu là mạng truyền thẳng nhiều lớ p, đượ c
huấn luyện bở i thuật toán lan truyền ngượ c sửa đổi (có sử dụng tham số bướ c đà) để tăng
khả năng tổng quát hóa và thờ i gian hội tụ. Về tổng thể, các mạng nơ ron truyền thẳng
nhiều lớ p đượ c huấn luyện bở i thuật toán lan truyền ngượ c cần có khả năng linh hoạt đáp
ứng đượ c nhiều bài toán. (Chú ý r ằng điều này có thể thực hiện đượ c bằng cách xây dựng
cấu trúc chươ ng trình phù hợ p). Điều quan tr ọng là xác định đượ c các biến chi phối trong
bài toán, khả năng sẵn có của dữ liệu (hàng ngày, hàng tháng hay quý, năm),...
Ở đây nêu ra một ví dụ của bài toán dự báo dữ liệu: Bài toán dự báo khả năng sử dụng
khí ga
“Trong ngành công nghiệ p ga, việc dự báo khả năng sử dụng hàng ngày hay hàng giờ là r ất
cần thiết đối vớ i các công ty, giúp họ tối ưu đượ c sự phân phối phục vụ của họ đối vớ i
khách hàng. Đối vớ i các công ty đườ ng ống, việc dự báo khả năng tiêu thụ có thể giúp xácđịnh các ảnh hưở ng đến hoạt động của hệ thống đườ ng ống, từ đó có thể đáp ứng đượ c nhu
cầu và dự báo khả năng tiêu thụ trong tươ ng lai. Nó cũng có thể giúp họ tìm ra cách tốt
nhất để tối thiểu hóa chi phí điều hành, đáp ứng đượ c nhu cầu. Một quyết định cần phải
tăng thêm hay rút bớ t lượ ng ga để có thể phù hợ p vớ i yêu cầu phải đượ c đưa ra bất k ể tình
tr ạng lưu tr ữ hiện tại. Một lý do khác là lượ ng ga chảy trong hệ thống là không đượ c xác
định chính xác. Nói một cách khác, khác hàng có quyền để lại một lượ ng ga lưu tr ữ tại nhà
mà không phải thông báo. Do vậy, khả năng này cũng cần phải đượ c xem xét. ”
Rõ ràng là từ các nguyên nhân trên, cần phải xây dựng một hệ dự báo tin cậy dựa trên các
yếu tố lậ p k ế hoạch hoạt động.
Dự đoán khả năng sử dụng ga mượ n ý tưở ng từ bài toán dự báo lượ ng tiêu thụ điện, bài
toán đã áp dụng mạng nơ ron thành công cho việc dự báo lượ ng tiêu thụ trong 1 cho đến 24
giờ (Xem chẳng hạn [6][18]). Việc dự báo lượ ng tiêu thụ ga có một sự tươ ng tự nhất định
đối vớ i các bài toán khác như: điện, nướ c, đồng thờ i cũng có những đặc điểm riêng: nó
chứa đựng các dự báo cho các khoảng thờ i gian trùng vớ i các chu k ỳ k ế lậ p hoạch cho việc

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 55/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 56/80
-56-
hàng sử dụng đồng thờ i cả hai loại nhiên liệu này. Nếu giá ga cao hơ n giá dầu thì nhu
cầu về ga có khuynh hướ ng giảm và ngượ c lại.
Những hiệu ứng trên là những thứ có thể xác định đượ c số lượ ng và do vậy có thể là các
đối tượ ng xem xét để sử dụng như là các đầu vào của mạng để huấn luyện và thực hiện dự
báo. Có các nhân tố khác, chẳng hạn như các giao ướ c hợ p đồng rõ ràng có một ảnh
hưở ng rõ r ệt đối vớ i nhu cầu sử dụng, nhưng chúng r ất khó có thể đượ c định lượ ng và do
đó không thể coi chúng như là các tham số ảnh hưở ng.
3.3.2.2. Mô hình d ự báo:
Dữ liệu vào
Dữ liệu vào sử dụng trong mô hình này đượ c thu thậ p từ khách hàng, có thể là từ một cơ sở
dữ liệu tác nghiệ p của họ hay một dạng lưu tr ữ nào đó. Các dữ liệu lịch sử mà chúng ta
quan tâm đượ c lưu tr ữ dướ i dạng sau:
Ngày Giờ Nhiệt độ Tốc độ gió Sử dụng
02-08-1998 00 37 3 1168
02-08-1998 01 37 9 121302-08-1998 02 37 6 1316
02-08-1998 03 37 3 1417
02-08-1998 04 37 3 1534
02-08-1998 05 37 5 1680
02-08-1998 06 36 5 1819
02-08-1998 07 34 6 1967
Tiền xử lý
Vớ i các dữ liệu đã cho, có thể thiết lậ p mô hình phản ánh bở i sáu hiệu ứng sau:
1) Nhiệt độ: Chính là giá tr ị thực của nó.
2) Tốc độ gió: Thể hiện bằng giá tr ị thực của nó.
3) Giờ trong ngày: Thể hiện 24 tiếng trong ngày: 0, 1, 2… 23

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 57/80
-57-
4) Ngày trong tuần: Thể hiện các ngày Chủ nhật, thứ Hai, thứ Ba, thứ Tư, thứ Năm, thứ
Sáu, thứ Bảy bằng các số 0, 1, 2, 3, 4, 5, và 6 tươ ng ứng.
5) Ngày cuối tuần: thể hiện thứ Hai, thứ Ba, thứ Tư, thứ Năm, thứ Sáu bở i 0; thứ Bảy và
Chủ nhật bở i 1.
6) Tháng trong năm: thể hiện 12 tháng trong năm bở i các giá tr ị từ 0 đến 11.
Rõ ràng là các hiệu ứng 1) và 2) là các biến có thứ tự. Giá tr ị của chúng có thể đượ c đưa
vào mạng như chúng vốn có. Các hiệu ứng còn lại là các biến phân loại. Ta biết r ằng, đối
vớ i các biến phân loại, chúng ta có thể sử dụng phươ ng pháp mã hóa 1-of-c (sẽ phải dùng
1+1+24+7+2+12= 47 đơ n vị đầu vào), hoặc phươ ng pháp one-effect-one-unit (chỉ dùng có
1+1+1+1+1+1=6 đơ n vị đầu vào) ( Xem l ại M ục 3.2.1).
Ở đây chúng ta sử dụng cách thứ hai, mặc dù chúng gây ra một tr ật tự nhân tạo trên các giá
tr ị nhưng chúng giảm đi r ất nhiều số lượ ng các đầu vào, từ đó có thể làm đơ n giản mô
hình.
Tậ p dữ liệu có thể đượ c tạo ra bằng cách sử dụng bảng tính, các dữ liệu theo khuôn dạng
nói trên sẽ đượ c mã hóa thành dạng dướ i đây:
Nhiệt
độ Tốc độ gió Giờ
Ngày trong
tuần
Ngày cuối
tuầnTháng Sử dụng
37 3 00 6 1 1 1168
37 9 01 6 1 1 1213
37 6 02 6 1 1 1316
37 3 03 6 1 1 1417
37 3 04 6 1 1 1534
37 5 05 6 1 1 1680
36 5 06 6 1 1 1819
34 6 07 6 1 1 1967

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 58/80
-58-
Ngoài ra, các dữ liệu chưa tốt cũng cần đượ c xử lý, chẳng hạn như các giá tr ị nằm ngoài
khoảng giá tr ị thực tế,... Tất cả dữ liệu đầu vào đượ c đưa về khoảng [0,1].
Kiến trúc mạng
Mạng bao gồm một lớ p ra, một lớ p ẩn. Rõ ràng là chỉ có duy nhất một đơ n vị ở đầu ra -
lượ ng tiêu thụ. Số đầu vào đượ c cố định, phụ thuộc vào số nhân tố ảnh hưở ng đượ c sử
dụng. Số đơ n vị trong lớ p ẩn đượ c xác định bằng cách huấn luyện vớ i một số tậ p kiểm tra.
Mạng sẽ yêu cầu một số đơ n vị trong lớ p ẩn vừa đủ để có thể học đượ c các đặc tr ưng tổng
quát về mối quan hệ giữa các nhân tố đầu vào và đầu ra. Mục tiêu của chúng ta là làm sao
chỉ phải sử dụng số các đơ n vị trong lớ p ẩn càng ít càng tốt, đồng thờ i vẫn duy trì đượ c khả
năng của mạng có thể học đượ c mối quan hệ giữa các dữ liệu. Như đã nêu, sử dụng nhiều
hơ n một lớ p ẩn không tăng đáng k ể độ chính xác của các dự báo.
Các hàm kích hoạt của các đơ n vị trong lớ p ẩn là các hàm sigmoid. Đối vớ i các đơ n vị ở
lớ p ra có thể là hàm sigmoid hoặc hàm đồng nhất. Ta sẽ chọn hàm đồng nhất.
Cài đặt thuật toán lan truyền ngượ c
Mạng đượ c huấn luyện bằng thuật toán lan truyền ngượ c. Hàm lỗi trung bình bình phươ ng
đượ c sử dụng:
∑=
−=n
k
k k yt E 1
2)(2
1.
Như đã nêu trên, hàm chuyển của các đơ n vị lớ p ẩn là hàm sigmoid:
xe x g
−+=
1
1)( .
Hàm này có một đặc tr ưng r ất có ích đó là đạo hàm của nó có thể biểu diễn dướ i dạng sau:
))(1)(()( x g x g x g −=′ .
Các hàm trên trên có thể dễ dàng cài đặt vớ i ngôn ngữ Visual Basic 6.0 của hãng
Microsoft:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 59/80
-59-
Public Function sigmoid (x As Double) As Double
If (x > 50) Then
sigmoid = 1
ElseIf (x < -50) Then
sigmoid = 0
Else
sigmoid = 1 / (1 + Exp(-x))
End If
End Function
Public Function sigmoidDerivative (x As Double) As Double
sigmoidDerivative = x * (1 - x)
End Function
Bướ c đầu tiên của thuật toán lan truyền ngượ c đó là: truyền xuôi ( forward propagation)
Public Sub forward_prop()
Dim i As Integer, j As Integer, k As Integer
Dim aTemp() As Double, aTmp() As Double
' Đặt đầu vào cho lớp ẩn
layers(0).Set_Inputs inputs
For i = 0 To numOfLayers - 1
layers(i).calc_out
layers(i).getOutputs aTemp
If i + 1 < numOfLayers Then
layers(i + 1).Set_Inputs aTemp
End If
Next
End Sub
Trong đó, các hàm Set_Inputs, calc_out, getOutputs là các hàm thành phần của lớ p
layers, lớ p (class) dành biểu diễn cho các lớ p mạng.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 60/80
-60-
Các hàm đó như sau:
Public Sub calc_out ()
Dim i, j, k As Integer
Dim acc As Double
acc = 0
For j = 0 To numOutputs - 1
For i = 0 To numInputs - 1
k = i * numOutputs
If Weights(k + j) * Weights(k + j) > 100000 Then
Debug.Print "Trọng số tăng quá lớn ...!"
Exit For
End If
outputs(j) = Weights(k + j) * inputs(i) + bias(j)
acc = acc + outputs(j)
Next
If layerType = 0 Then
outputs(j) = acc
ReDim Preserve predicted_values(j)
predicted_values(j) = acc
outValue = acc
Else
outputs(j) = sigmoid(acc)
End If
acc = 0
Next
End Sub
Public Sub Set_Inputs (ByRef nIns)
Dim i As Integer

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 61/80
-61-
For i = 0 To numInputs - 1
inputs(i) = nIns(i)
Next
End Sub
Public Sub getOutputs(ByRef nOut)
Dim i
For i = 0 To numOutputs - 1
ReDim Preserve nOut(i)
nOut(i) = outputs(i)
Next
End Sub
Bướ c thứ hai của thuật toán là lan truyền ngượ c lỗi ( Backward propagation). Đối vớ i đơ n
vị ở lớ p ra, lỗi δ đượ c cho bở i phươ ng trình:
k k k t y −=δ ,
trong khi đó, đối vớ i các đơ n vị lớ p ẩn, lỗi δ đượ c tính bở i công thức:
∑=
−=c
k
k kj j j j w z z 1
)1( δ δ .
Các đạo hàm tươ ng ứng vớ i các tr ọng số của lớ p ẩn và lớ p ra:
i j
ji
xw
E δ =
∂∂
và jk
kj
z w
E δ =
∂∂
.
Ta sử dụng thuật toán giảm theo gradient (gradient descent algorithm) vớ i tham số bướ c đà
để cậ p nhật tr ọng số:
Public Sub backward_prop(ByRef tongLoi As Double)
Dim i As Integer
Dim OE() As Double
‘ Tính toán lỗ i đầu ra
layers(numOfLayers - 1).calc_error tongLoi

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 62/80
-62-
For i = numOfLayers - 2 To 0 Step -1
' Truy ền ng ượ c lỗ i đầu ra v ề các lớ p tr ướ c nó
layers(i + 1).getBack_errors OE
layers(i).setOutput_errors OE
‘ Thự c hiện tính toán lỗ i cho lớ p đ ó
layers(i). mid_calc_error
Next
End Sub
Các hàm calc_error, getBack_errors, setOutput_errors, mid_calc_error là các hàm
thuộc lớ p (class) layers đượ c cài đặt như sau:
Public Sub calc_error(ByRef error)
' Hàm này được sử dụng cho lớp ra
Dim i, j, k As Integer
Dim acc As Double, total_error As Double
acc = 0
total_error = 0
For j = 0 To numOutputs - 1
ReDim Preserve output_errors(j)
output_errors(j) = expected_values(j) - outputs(j)
total_error = total_error + output_errors(j)
Next
error = total_error
For i = 0 To numInputs - 1
ReDim Preserve back_errors(i)
k = i * numOutputs
For j = 0 To numOutputs - 1
back_errors(i) = Weights(k + j) * output_errors(j)

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 63/80
-63-
acc = acc + back_errors(i)
Next
back_errors(i) = acc
acc = 0
' Lỗ i lan truy ền ng ượ c lại đượ c nhân v ớ i đạo hàm của hàm chuy ển
back_errors(i) = back_errors(i) * sigmoidDerivative(inputs(i))
Next
End Sub
Public Sub mid_calc_error()
' Sử dụng cho lớp ẩn
Dim i, j, k As Integer
Dim acc As Double
acc = 0
For i = 0 To numInputs - 1
ReDim Preserve back_errors(i)
k = i * numOutputs
For j = 0 To numOutputs - 1
back_errors(i) = Weights(k + j) * output_errors(j)
acc = acc + back_errors(i)
Next
back_errors(i) = acc
acc = 0
' Lỗ i lan truy ền ng ượ c lại đượ c nhân v ớ i đạo hàm của hàm chuy ển
back_errors(i) = back_errors(i) * sigmoidDerivative(inputs(i))
Next
End Sub
Public Sub setOutput_errors(OE)
Dim i
For i = 0 To numOutputs - 1

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 64/80

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 65/80
-65-
k = i * numOutputs
For j = 0 To numOutputs - 1
delta = beta * output_errors(j) * inputs(i)
+ alpha * past_deltas(k + j)
Weights(k + j) = Weights(k + j) + delta
ReDim Preserve cum_deltas(k + j)
cum_deltas(k + j) = cum_deltas(k + j) + delta
Next
Next
' C ậ p nhật độ lệch
For j = 0 To numOutputs - 1
deltaB = beta * output_errors(j) + alpha * past_deltas_B(j)
bias(j) = bias(j) + deltaB
ReDim Preserve cum_deltas_B(j)
cum_deltas_B(j) = cum_deltas_B(j) + deltaB
Next
End Sub
Các tham số past_deltas và cum_deltas đượ c cậ p nhật mỗi khi một chu k ỳ huấn luyện
mớ i bắt đầu bở i thủ tục updateMomentum của lớ p (class) network .
Public Sub updateMomentum()
Dim i
For i = 0 To numOfLayers - 1
layers(i).updateMomentum
Next
End Sub
Thủ tục này thực chất là tráo đổi giá tr ị cum_deltas và past_deltas của từng lớ p.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 66/80
-66-
Public Sub updateMomentum()
Dim i, j, k
‘ Tráo đổi các vector deltas
swapVector past_deltas, cum_deltas
swapVector past_deltas_B, cum_deltas_B
For i = 0 To numInputs - 1
k = i * numOutputs
For j = 0 To numOutputs - 1
ReDim Preserve cum_deltas(k + j)
cum_deltas(k + j) = 0
Next
Next
For j = 0 To numOutputs - 1
ReDim Preserve cum_deltas_B(j)
cum_deltas_B(j) = 0
Next
End Sub
Sau đây là toàn bộ thủ tục huấn luyện của mạng nơ ron:
Public Sub train()
Dim tot_err As Double, num As Integer
currentError = 0.9999
Dim MaxCycles As Integer, i As Integer, j As Double, k As Integer
MaxCycles = 15000
i = 0
j = 0
tot_err = 0
ReDim predictValue(numOfPatterns - 1)
ReDim arrMSE(50)

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 67/80
-67-
'Hiển thị các màn hình theo dõi lỗ i và đồ thị khi huấn luy ện
FrmPlot.Show
mseUpdate.Show
Do While True And Not stopTraining
updateMomentum
‘ Lấy mẫ u thứ i trong tậ p huấn luy ện đ ã chuẩn bị sẵ n
get_patterns i
' Đặt vector thứ i cho mạng biết
setNumPatterns i
setStatusText 1, "Training..."
' Truy ền xuôi
forward_prop
predictValue(i) = layers(numOfLayers - 1).getoutValue
' Truy ền ng ượ c lỗ i
backward_prop currentError
' Tính toán lỗ i
tot_err = tot_err + currentError * currentError
Set_currentCycle CLng(j)
' Thự c hiện cậ p nhật tr ọng số
update_weights
' T ăng số thứ tự vector mẫ u sẽ đọc vào lên 1
i = i + 1
DoEvents
If i = numOfPatterns Then
' N ếu đ ã kết thúc một chu kỳ
i = 0
j = j + 1
' Tính toán lỗ i trung bình bình phươ ng

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 68/80
-68-
MSE = sqr(tot_err) / numOfPatterns
ReDim Preserve arrMSE(UBound(arrMSE) + 1)
arrMSE(UBound(arrMSE)) = MSE
'Thự c hiện cậ p nhật các đồ thị mỗ i 50 chu kỳ
If NumOfCycles Mod 50 = 0 Then
FrmPlot.update
mseUpdate.update
DoEvents
ReDim arrMSE(0)
DoEvents
End If
If Abs(MSE) < errorToleranceRate Then
'N ếu lỗ i trung bình bình phươ ng nhỏ hơ n hệ số thứ lỗ i
'thì kết thúc huấn luy ện
Set_currentCycle CLng(j)
setcurrentError currentError
DoEvents
setstopTraining True
End If
MSE = 0
tot_err = 0
NumOfCycles = NumOfCycles + 1
End If
Loop
setStatusText 1, "DONE!!!!!!!!!"
'Ghi lại các ma tr ận tr ọng số
write_weights
setStatusText 2, "Cycle number: " & CStr(j)
setStatusText 3, "Total error: " & Abs(currentError)
8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 69/80
-69-
Set_currentCycle CLng(j)
FrmPlot.update
DoEvents
End Sub
Các mẫu đượ c tuần tự đưa vào mạng để huấn luyện.
Sự tổng quát hóa của mạng
Một phần dữ liệu đượ c sử dụng như là tậ p kiểm tra, tậ p này sẽ không đượ c sử dụng trong
quá trình huấn luyện. Trong quá trình huấn luyện trên tậ p dữ liệu huấn luyện, sự tổng quá
hóa đối vớ i các dữ liệu kiểm tra đượ c hiển thị đồng thờ i dựa trên các tham số hiện tại củamạng.
3.3.3. Chươ ng trình d ự báo d ữ li ệ u
Màn hình ban đầu của chươ ng trình

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 70/80
-70-
Chươ ng trình đượ c xây dựng bao gồm các mục thực đơ n: Tệp, Thiết đặt, Xem cấu hình,
Dự đoán. Sau đây, các đặc tr ưng chính của hệ thống sẽ đượ c mô tả chi tiết.
3.3.3.1. Màn hình nhậ p các tham số cho mạng.
Chức năng này cho phép ngườ i sử dụng nhậ p các tham số đầu vào cho mạng như: Số lớ p
mạng, Số đầu vào, Hệ số học,... Sau khi ngườ i sử dụng đã nhậ p xong các mục, cần nhấn
nút lệnh GO để thực hiện nhậ p cấu trúc cho mạng.
Sau khi đã nhậ p xong xuôi các tham số, nhấn OK để ghi lại các tham số vừa nhậ p. Tại đây,
các tham số cho mạng nơ ron đượ c gán các giá tr ị, đồng thờ i, các bộ dữ liệu huấn luyện và
kiểm tra cũng đượ c đọc vào bộ đệm chươ ng trình, tiền xử lý.
Các tệ p dữ liệu là các tệ p có cấu trúc:
- Các tr ườ ng dữ liệu đượ c phân cách bở i dấu “;”
- Tr ườ ng dữ liệu dự báo là tr ườ ng cuối cùng.
- Sau tr ườ ng dữ liệu dự báo không cần phải có dấu “;”.
- Tệ p dữ liệu không đượ c có các khoảng tr ống ở phía cuối. Nếu có thì cần đượ c loại
bỏ.
Ví dụ:
Tệ p dữ liệu có dạng như sau:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 71/80
-71-
Các dữ liệu sau khi đượ c đọc vào sẽ đượ c chuẩn hóa về khoảng [0,1] theo phươ ng pháp:
SV = ((0.9 - 0.1) / (MAX_OF_EXP - MIN_OF_EXP)) * (OV - MIN_OF_EXP),
trong đó:
SV: Scaled Value - Giá tr ị sau khi biến đổi
OV: original Value - Giá tr ị ban đầu
MAX_OF_EXP, MIN_OF_EXP: Giá tr ị lớ n nhất vào nhỏ nhất của tậ p các
giá tr ị
0.9, 0.1: Giá tr ị “lớ n nhất” và “nhỏ nhất” của hàm sigmoid.
3.3.3.1. Huấ n luyện mạng.
Sau khi qua bướ c thiết lậ p các thông số cho mạng, có thể bắt đầu huấn luyện mạng. để thực
hiện điều này, chọn: Thiết đặt\Huấn luyện mạng (Train network). Màn hình ban đầu thể
hiện tr ạng thái của việc huấn luyện có dạng sau:
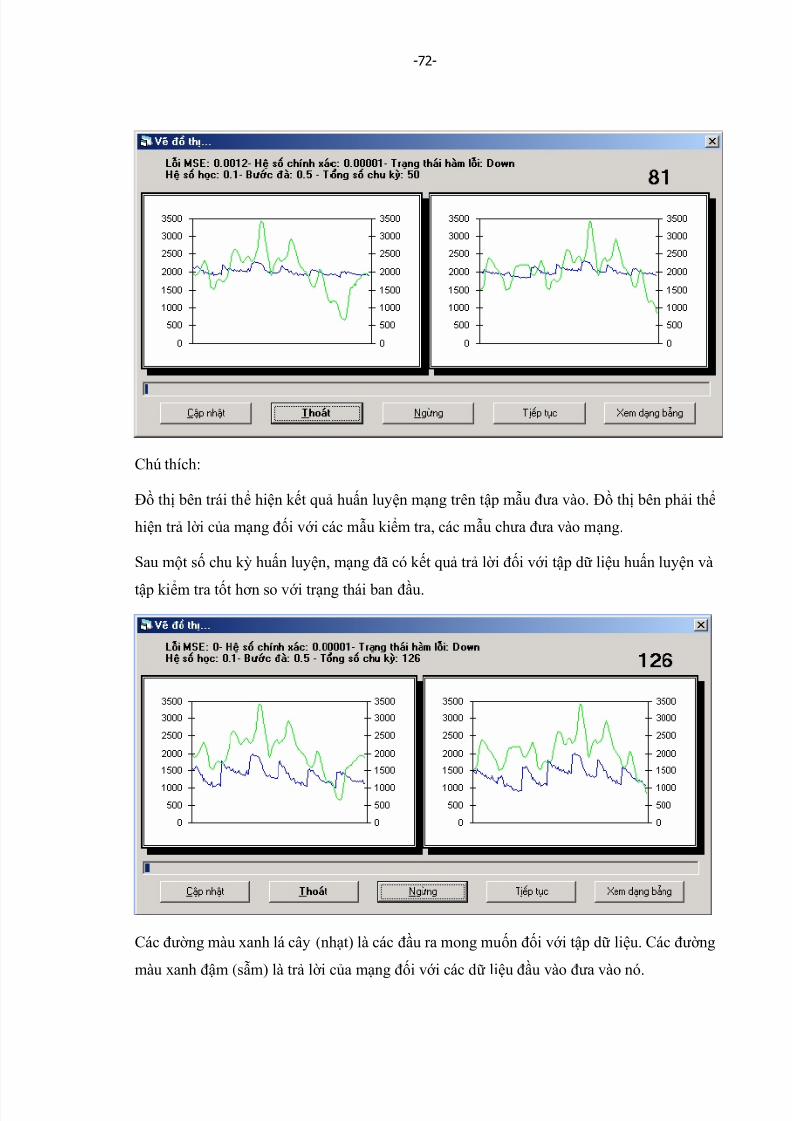
8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 72/80
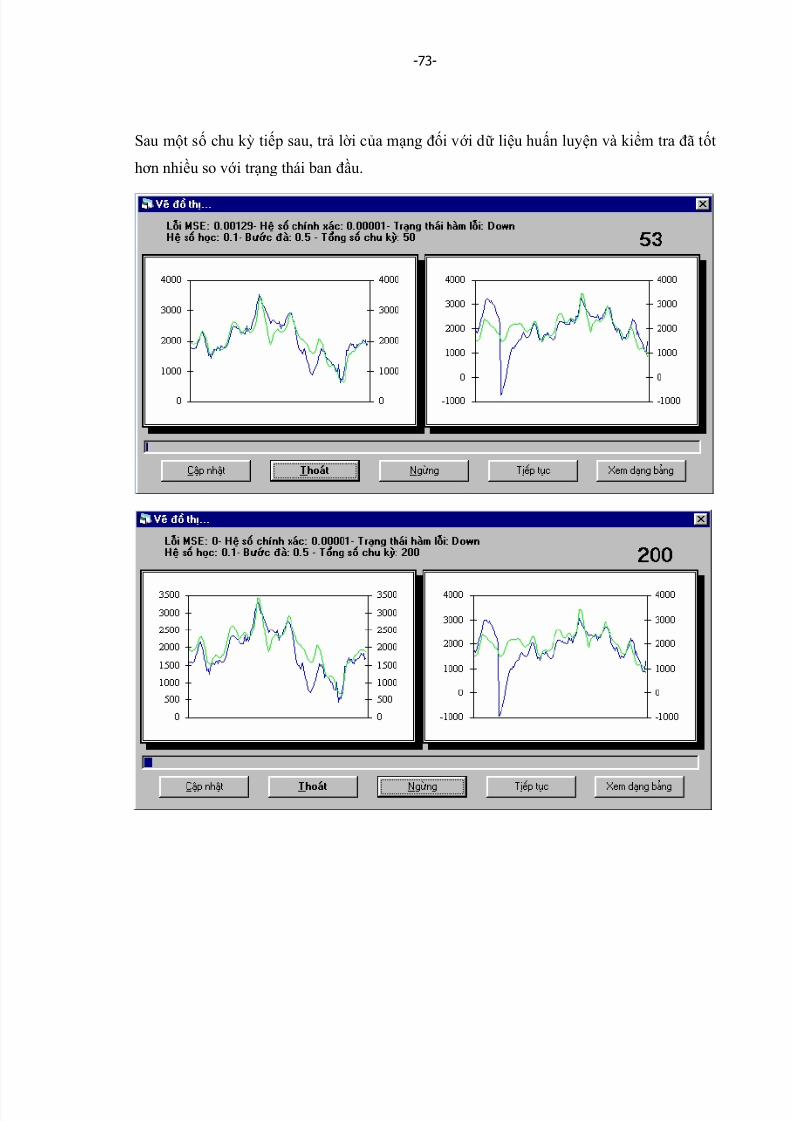
8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 73/80
-73-
Sau một số chu k ỳ tiế p sau, tr ả lờ i của mạng đối vớ i dữ liệu huấn luyện và kiểm tra đã tốt
hơ n nhiều so vớ i tr ạng thái ban đầu.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 74/80
-74-
Có thể thấy, lỗi MSE đượ c giảm sau một thờ i gian huấn luyện, đồng thờ i khả năng tổng
quát hóa của mạng đối vớ i các dữ liệu chưa đượ c “ biết” cũng đã tốt lên.
3.3.3.3. Dự báo d ữ liệu.
Sau khi mạng đã đượ c huấn luyện, có thể sử dụng để dự báo dữ liệu. Chỉ cần xác định tệ p
chứa dữ liệu và thực hiện dự báo. Màn hình như sau:

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 75/80
-75-
3.4. Một số nhận xét
Mạng bị ảnh hưở ng r ất nhiều từ tr ạng thái khở i đầu của các tham số. Trong quá trình
học, mạng cố gắng điều chỉnh các tham số sao cho tổng bình phươ ng lỗi là nhỏ nhất. Khả
năng hội tụ của mạng phụ thuộc vào các tham số khở i đầu, còn khả năng tổng quát hóa thì
lại phụ thuộc r ất nhiều vào dữ liệu đầu vào. Nếu dữ liệu đầu vào quá nhiều (!) thì có thể
dẫn tớ i tình tr ạng luyện mạng mất r ất nhiều thờ i gian và khả năng tổng quát hóa kém, nếu
quá ít dữ liệu thì sai số sẽ tăng.
Ngoài đặc tr ưng về dữ liệu, một đặc tr ưng khác trong quá trình huấn luyện mạng cần
quan tâm là nếu số lần thực hiện điều chỉnh các tham số của mạng quá ít sẽ dẫn đến tình
tr ạng là khả năng tổng quát hóa của mạng r ất kém. Bở i vậy, số chu k ỳ các mẫu đưa vào
mạng cần đượ c xem xét phải lớ n hơ n một ngưỡ ng nào đó (từ vài nghìn cho đến vài chục
nghìn lần).
Để có thể xem xét, đánh giá đượ c khả năng tổng quát hóa của mạng, cần thực hiện phân
chia tậ p dữ liệu thành các tậ p: huấn luyện (training set) và tậ p kiểm tra (test set). Tậ p các
dữ liệu thử sẽ không đưa vào để kiểm tra hoạt động của mạng để đảm bảo sự khách quan.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 76/80
-76-
Một vấn đề nữa đối vớ i mạng nơ ron đó là khả năng r ơ i vào các điểm cực tr ị địa phươ ng.
Như chúng ta đã biết, thuật toán Lan truyền ngượ c lỗi không đảm bảo sẽ cho ta điểm cực
tr ị toàn cục. Nếu r ơ i vào điểm cực tr ị địa phươ ng, ta sẽ phải bắt đầu huấn luyện lại, điềunày sẽ khiến cho mạng nơ ron sẽ không thể áp dụng đượ c trong thực tế đối vớ i các bài toán
yêu cầu độ chính xác cao trong thờ i gian tối thiểu. Do đó, giải pháp sử dụng hệ số học biến
đổi là một trong các hướ ng để có thể vượ t qua đượ c nhượ c điểm trên. Ngoài ra, nếu dữ liệu
phân bố không đều trên từng mẫu thì khả năng tổng quát hóa cũng không tốt.
Một điều nữa, là mạng có khả năng sẽ không thể đạt đượ c đến tr ạng thái mong muốn,
mà có thể nó sẽ bỏ qua điểm cực tr ị. Để có thể tránh điều này, không nên đặt hệ số học quá
lớ n (cỡ 0.1 chẳng hạn), cũng như hệ số bướ c đà quá lớ n (chẳng hạn = 0.5) (do đặc tr ưngcủa thuật toán lan truyền ngượ c sử dụng tham số bướ c đà).
Như đã nêu trên, để đảm bảo khả năng có thể đạt đến điểm cực tiểu, số các đơ n vị trong
lớ p ẩn cần đủ lớ n. Tuy nhiên, nếu số các đơ n vị trong lớ p ẩn vượ t quá một ngưỡ ng nào đó
thì khả năng tổng quát hóa của mạng sẽ kém, bở i lẽ sau khi huấn luyện mạng có xu hướ ng
ghi nhớ tất cả các mẫu đã đượ c học. Khi đó, nên xem xét đến khả năng sử dụng thêm một
lớ p ẩn nữa vớ i số nơ ron nhỏ (vài nơ ron) và giảm bớ t số nơ ron ở lớ p ẩn thứ nhất.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 77/80
-77-
K ẾT LUẬN
Mạng nơ ron có thể đượ c huấn luyện để xấ p xỉ các hàm bất k ỳ mà không cần biết tr ướ c sự
liên hệ của các đầu vào đối vớ i đầu ra. Chúng có thể hoạt động như một bộ nhớ tự liên hợ p
bằng cách sử dụng các dữ liệu đặc thù cho các ứng dụng, bài toán trong các l ĩ nh vực cụ
thể. Đó là đặc tr ưng đem lại cho mạng nơ ron lợ i thế đối vớ i các mô hình khác, đặc tr ưng
thứ lỗi.
Trong luận văn này, chúng tôi xem xét các thuộc tính của mạng nơ ron truyền thẳng và quátrình xác định các đầu vào, kiến trúc của mạng phục vụ cho một bài toán cụ thể. Chúng tôi
cũng đã xây dựng một hệ chươ ng trình dự báo dữ liệu nhằm áp dụng các vấn đề lý thuyết
đã tìm hiểu. Các thí nghiệm cho thấy, nếu như đượ c huấn luyện tốt trên tậ p các dữ liệu đầy
đủ và hoàn thiện vớ i các tham số đượ c lựa chọn cẩn thận thì k ết quả dự báo có thể chính
xác đến 90%. Chươ ng trình cũng cung cấ p khả năng lưu lại tậ p các tham số, tr ọng số và
các độ lệch sau những lần huấn luyện thành công và nạ p lại các tham số này để sử dụng
khi dự báo dữ liệu.
Tuy nhiên, luận văn này mớ i chỉ xem xét đến các khía cạnh tổng thể về mạng nơ ron truyền
thẳng nhiều lớ p và vấn đề dự báo dữ liệu trong khoảng thờ i gian ngắn (short-term
forecasting) và trung bình (mid-term forecasting). Tuy nhiên, ứng dụng của các vấn đề lý
thuyết thể hiện trong hệ chươ ng trình đượ c xây dựng hoàn toàn có thể áp dụng cho các bài
toán dự báo trong thờ i gian dài (long-term forecasting) vớ i một số sửa đổi trong thuật toán
huấn luyện.
Cần nhấn mạnh r ằng, để có thể dự báo đượ c dữ liệu, ta cần sử dụng các dữ liệu lịch sử để
huấn luyện và có thể cả các dữ liệu dự báo của các đầu vào (Ví dụ như: dự báo nhiệt độ
ngày hôm sau,...). Ngườ i ta cũng đã chỉ ra r ằng mạng nơ ron truyền thẳng nhiều lớ p có khả
năng tốt nhất trong dự báo trong khoảng thờ i gian ngắn.
Mạng nơ ron truyền thẳng nhiều lớ p có thể sử dụng trong r ất nhiều bài toán dự báo trong
các l ĩ nh vực khác: dự báo lượ ng sử dụng điện, nướ c, thị tr ườ ng chứng khoán, lưu lượ ng
giao thông và lượ ng sản phẩm bán ra chừng nào các mối quan hệ giữa các đầu vào và đầu

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 78/80
-78-
ra có thể thấy đượ c và đưa vào trong mô hình. Tuy vậy, không tồn tại một mô hình chung
thích hợ p cho tất cả các bài toán dự báo trong thực tế. Đối vớ i mỗi một bài toán, cần thực
hiện phân tích cặn k ẽ, cụ thể các dữ liệu trong phạm vi và sử dụng các tri thức thu thậ pđượ c để có thể xây dựng đượ c một mô hình thích hợ p. Các phân tích và các tri thức thu
thậ p đượ c luôn có ích trong việc lựa chọn các đầu vào, mã hóa các đầu vào này hoặc quyết
định cấu trúc của mạng, đặc biệt khi mà dữ liệu trong l ĩ nh vực đó chỉ có giớ i hạn.
Thuật toán lan truyền ngượ c chuẩn đượ c sử dụng trong việc huấn luyện mạng nơ ron truyền
thẳng nhiều lớ p đã chứng tỏ khả năng r ất tốt thậm chí đối vớ i cả các bài toán hết sức phức
tạ p. Mặc dù vậy, để có đượ c khả năng như vậy, ta cần mất r ất nhiều thờ i gian để huấn
luyện, điều chỉnh các tham số của mạng (thậm chí cả đối vớ i các bài toán có cấu trúc hếtsức đơ n giản). Điều này luôn là tr ở ngại đối vớ i các bài toán trong thực tế, do vậy, các
thuật toán cải tiến cần đượ c áp dụng để tăng khả năng hội tụ của mạng khi huấn luyện.
Luận văn này đượ c thực hiện nhằm làm sáng tỏ những vấn đề lý thuyết về mạng nơ ron
truyền thẳng nhiều lớ p, thuật toán lan truyền ngượ c, các bướ c cần thực hiện khi phân tích,
thiết k ế và xây dựng ứng dụng cho bài toán dự báo dữ liệu, đồng thờ i xây dựng một
chươ ng trình ứng dụng nhằm mục đích thể hiện các vấn đề lý thuyết đã nêu. Chắc chắn
luận văn này vẫn còn những thiếu sót, chúng tôi r ất mong nhận đượ c những ý kiến đóng
góp nhằm hoàn thiện hơ n nữa hiểu biết của mình.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 79/80
-79-
TÀI LIỆU THAM KHẢO
[1]. Đ. M. Tườ ng, Trí tuệ nhân t ạo, NXB Khoa học và K ỹ thuật, 2002.
[2]. Dipti Srinivasan, A. C. Liew, John S., P. Chen, Short term forecasting using neural
network approach, IEEE 91TH0374-9/91/0000-0012, pp 12-16, 1991.
[3]. Drucker H., Cun Y. L., Improving Generalization Performance using Double
Backpropagation, IEEE Transactions on neural netwoks, Vol. 3, No. 6, November 1992.
[4]. Hagan M. T., Demuth H. B., Beale M., Neural networks design, PWS Publishing
Company, Boston, Ma, 1996.
[5]. Haykin, S., Neural networks, a comprehensive foundation, Macmillan New York, Ny
1994.
[6]. Kaastra, I., & Boyd, M. - Designing a neural network for forecasting financial and
economic time series - Neurocomputing 10 (1996), pp 215-236.
[7]. Kesmir C., Nussbaum A. K., Schild H., Detours V., Brunak S., Prediction of
proteasome cleavage motifs by neural networks, Protein engineering , Vol 15-No 4, pp
287-196, 2002.[8]. Kolen J. F., Pollack J. B., Back Propagation is Sensitive to Initial Condition, Technical
Report , Laboratory for artificial intelligence Research-The ohio State university.
[9]. Lawrence S., C. L. Giles, a. C. Tsoj, What size Neural Netwwork Gives optimal
Generalization? Convergence Properties of Backpropagation, Technical Report , Institute
for Advanced Computer Studies - University of Maryland College Park, June 1996.
[10]. Morioka Y., Sakurai K., Yokoyama A. Sekine Y., Next day peak load forecasting
using a Multilayer neural network with an additional Learning, IEEE, 0-7803-1217-1/93,
1993.
[11]. Oh S.H., Lee Yj., A modified error function to improve the error Back-Propagation
algorithm for Multi-layer perceptrons, ETRI Journal Vol 17, No 1, April 1995
[12]. Ooyen A. V., Nienhuis B., Improving the Convergence of the Back-Propagation
algorithm, Neural Networks, Vol. 5, pp. 465-471, 1992.

8/6/2019 LVTN Cao Hoc_TranDucMinh
http://slidepdf.com/reader/full/lvtn-cao-hoctranducminh 80/80
-80-
[13]. Poh, H. L., Yao, J. T., & Jašic T., Neural Networks for the Analysis and Forecasting
of Advertising and Promotion impact - International Journal of intelligent Systems in
accounting, Finance & Management. 7 (1998), pp 253-268.
[14]. Rao, Valluru B. and Rao, Hayagriva V., C++ Neural Networks and Fuzzy Logic,
MIS Press, 1993.
[15]. Ripley B.D., Pattern Recognition and Neural Networks, Cambridge university Press,
1996.
[16]. Sullivan, R., Timmermann, A. & White, H., Dangers of data-driven inference: the case
of calendar effects in stock returns, Discussion Paper , University of California, San Diego,
Department of economics, 7/1998.
[17]. Swingler K., Financial Predictions, Some Pointers, Pitfalls, and Common errors,
Technical Report, Center for cognitive and computational neuroscience - Stirling University,
July 14, 1994.
[18] Takashi O., Next day’s peak load forecasting using an artificial neural network, IEEE
0-7803-1217-1/93, pp 284-289, 1993.
[19] T. Masters, Practical Neural Network Recipes in C++. Academic Press, Inc., 1993.
[20]. UdoSeiffert, Michaelis B., On the gradient descent in back-propagation and its
substitution by a genetic algorithm, Proceedings of the IASTED International Conference
Applied informatics 14-17/02/2000, InnsBruck, Austria.
[21]. Vogl. P. T., Mangis J. K., Zigler A. K., Zink W. T. and Alkon D. L., “Accelerating the
convergence of the back-propagation method”, Biological Cybernetics, vol.59, pp 256-264,
09/1988.