konzept, realisierung und anwendung nutzerdefinierter ... · konzept, realisierung und anwendung...
TRANSCRIPT

Konzept, Realisierung und Anwendungnutzerdefinierter Replikation in mobilen
Datenbanksystemen
Dissertation
zur Erlangung des akademischen GradesDoktor-Ingenieur (Dr.-Ing.)
vorgelegt dem Rat der Fakultät für Mathematik und Informatik derFriedrich-Schiller-Universität Jena
vonDipl.-Inf. Christoph Gollmickgeboren am 5. April 1974 in Jena

Gutachter:
1. Prof. Dr. Klaus Küspert, Friedrich-Schiller-Universität Jena
2. Prof. Dr. Hans-Jörg Schek, UMIT Innsbruck
3. Prof. Dr. Martin Welsch, IBM Deutschland GmbH, Böblingen
Tag der letzten Prüfung des Rigorosums: 6. Februar 2006
Tag der öffentlichen Verteidigung: 17. Februar 2006

Meinen Eltern


Danksagung
Meinem Doktorvater, Herrn Prof. Dr. Klaus Küspert, möchte ich dafür danken, dass ermich während des Studiums für die Datenbanken als Vertiefungsfach begeisterte und mirnach Abschluss des Studiums die Möglichkeit eröffnete, als Mitarbeiter an seinem Lehrstuhlin der Lehre zu arbeiten und zu promovieren. Im Besonderen gilt ihm mein Dank für diekontinuierliche fachliche und außerfachliche Unterstützung während meiner Zeit an derFSU Jena und darüberhinaus.
Den Herren Prof. Dr. Hans-Jörg Schek von der UMIT in Innsbruck und Prof. Dr. MartinWelsch von der IBM Deutschland GmbH in Böblingen danke ich für die Übernahme derweiteren Dissertationsgutachten.
Mein Dank gebührt den zahlreichen Studenten, die durch gute und sehr gute Studien- undDiplomarbeiten im Bereich der Produktevaluation und Implementierung, mit viel Engage-ment und fachlichen Diskussionen wesentlich zum Gelingen der Arbeit beigetragen haben.Hier seien besonders Karsten Baumgarten, Raik Bittner, Thomas Fanghänel, Matthias Lie-bisch, Frank Michels, Thomas Müller, Roman Pfender, Gennadi Rabinovitch und DavidWiese hervorgehoben. Meinen ehemaligen Kollegen in Jena danke ich für kritische Diskus-sionen und die angenehme Zeit am Lehrstuhl für Datenbanken und Informationssysteme.
Den Firmen IBM, Oracle und Sybase möchte ich für die Bereitstellung ihrer DBMS-Produkte und wichtigen Hintergrundwissens danken. Herrn Jürgen Bittner von der SQLGmbH Dresden danke ich für die Unterstützung in Produktfragen und vor allem für dievielen wertvollen Anregungen aus der Praxis. Bei Michael Rothenburger vom Büro fürForschungsförderung und -transfer der Universität Jena bedanke ich mich für die guteZusammenarbeit bei der Erstellung der Patentschrift.
Schließlich möchte ich mich ganz herzlich bei meinen Eltern bedanken, die mir durchstetig motivierende Unterstützung den Rückhalt für mein wissenschaftliches und beruflichesVorankommen gegeben haben.


Kurzfassung
Mit dem zunehmenden Einsatz tragbarer Rechner und drahtloser Kommunikation wirdbei ihren Nutzern auch der Wunsch geweckt, Informationen und Anwendungsfunktionali-tät unabhängig vom jeweiligen Aufenthaltsort immer und überall zur Verfügung zu haben.Doch trotz der Fortschritte in der Entwicklung und Verbreitung drahtloser Kommunikati-onsmedien wird ein mobiler Nutzer in vielen Szenarien nur zeitweise mit anderen Rechnernkommunizieren können (z. B. bei nicht kontinuierlicher Verfügbarkeit eines Kommunikati-onsmediums) oder wollen (z. B. bei zu hohen Kosten).
Da ein Großteil der Anwendungsdaten heute in relationalen Datenbanken gespeichert ist,muss für eine Zeit der Unverbundenheit ein Ausschnitt der Datenbank auf den mobilenClient repliziert und später bei Wiederverbindung mit dem Server synchronisiert werden.Die Auswahl und die Häufigkeit einer späteren Anpassung der Auswahl hängen dabeimaßgeblich vom zugrundeliegenden Anwendungsszenario ab. Bei Anwendungen, wie bei-spielsweise einem interaktiven mobilen Reiseinformationssystem, das seine Nutzer an derInformationsbeschaffung beteiligt, sind die Zugriffsprofile der Nutzer sehr individuell, zeit-und ortsabhängig. Da die Nutzer unabhängig sind und natürlich prinzipiell auf demselbenDatenbankausschnitt Daten pflegen können, sind häufig Änderungskonflikte zu erwarten,die geeignet behandelt werden müssen. Aktuelle kommerzielle mobile Datenbanksystemebieten für diese Anwendungen bisher keine adäquate Funktionalität und Schnittstellen.
In der vorliegenden Arbeit werden die Konzeption und Implementierung eines Dienstes zurnutzerdefinierten Replikation beschrieben. Die Schnittstellen der nutzerdefinierten Replika-tion erlauben es mobilen Datenbankanwendungen zur Laufzeit und ohne großen Program-mieraufwand, Daten per dynamischem SQL für die Replikation auf den Client auszuwählenund diese Auswahl später anzupassen. Die nutzerdefinierte Replikation ist als Erweiterungbestehender mobiler Datenbanklösungen angelegt und greift auf deren Funktionalität zurDatenübertragung und Synchronisation zurück. Eine zusätzliche Verwaltungsebene verar-beitet die dynamischen Replikationsanfragen mithilfe eines Fragmentkonzepts. Die Frag-mentverwaltung bildet, für die später damit einfachere mengenorientierte Verarbeitung,jede Anfrage auf eine Menge von Fragmenten (horizontale Partitionen mehrerer Tabellen)ab, welche in ihrer Gesamtheit die zur Replikation freigegebenen Daten repräsentieren.
Ein weiterer Schwerpunkt der Arbeit liegt auf der Erprobung der entwickelten Konzepteund Verfahren. Die nutzerdefinierte Replikation wurde dazu in einer dreistufigen Archi-tektur mit einem so genannten Replication Proxy Server (RPS) als zentralem Elementprototypisch implementiert. Die Schnittstellen und der Aufbau des RPS werden in derArbeit beschrieben. Zur Evaluation des Prototypen wurde das ebenfalls in der Arbeit be-schriebene Beispielszenario eines interaktiven mobilen Reiseinformationssystems erfolgreichumgesetzt.


Inhaltsverzeichnis
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Aufgaben und Abgrenzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.3 Gliederung der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Grundlagen 72.1 Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Das relationale Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Struktur- und Datenobjekte . . . . . . . . . . . . . . . . . . . . . . . 92.2.2 Datenmanipulationskomponente und Sichten . . . . . . . . . . . . . 112.2.3 Integritätskomponente . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Mobile Rechnersysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3.1 Mobile Rechner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3.2 Drahtlose Kommunikation . . . . . . . . . . . . . . . . . . . . . . . . 162.3.3 Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4 Mobile Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.4.1 Klassifikation für verteilte Datenbanksysteme . . . . . . . . . . . . . 202.4.2 Vergleich mit anderen vDBS . . . . . . . . . . . . . . . . . . . . . . . 212.4.3 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.5.1 ACID-Transaktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5.1.1 Korrektheitskriterium Serialisierbarkeit . . . . . . . . . . . 262.5.1.2 Reihenfolgeerhaltende und rücksetzfähige Historien . . . . . 26
2.5.2 Synchronisation in mDBS . . . . . . . . . . . . . . . . . . . . . . . . 272.5.2.1 Modell der geschlossen geschachtelten Transaktionen . . . . 282.5.2.2 Optimistische Synchronisation . . . . . . . . . . . . . . . . 302.5.2.3 Mehrbenutzeranomalien . . . . . . . . . . . . . . . . . . . . 312.5.2.4 Korrektheitskriterium Abbildisolation . . . . . . . . . . . . 33
2.5.3 Konfliktvermeidende Synchronisationsverfahren . . . . . . . . . . . . 342.5.3.1 Sperrverfahren . . . . . . . . . . . . . . . . . . . . . . . . . 352.5.3.2 Das Escrow-Verfahren . . . . . . . . . . . . . . . . . . . . . 36
i

ii INHALTSVERZEICHNIS
2.5.3.3 Das Key-Pool-Verfahren . . . . . . . . . . . . . . . . . . . . 372.5.3.4 Das Slot-Verfahren . . . . . . . . . . . . . . . . . . . . . . . 37
2.5.4 Konfliktauflösende Synchronisationsverfahren . . . . . . . . . . . . . 372.5.4.1 Datenbasierte Synchronisation . . . . . . . . . . . . . . . . 382.5.4.2 Transaktionsbasierte Synchronisation . . . . . . . . . . . . 402.5.4.3 Semantikbasierte Synchronisation . . . . . . . . . . . . . . 40
3 Die nutzerdefinierte Replikation 433.1 Auswahl von Replikaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.1 Explizite Replikation . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.1.2 Implizite Replikation . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.2 Ziele und Aufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.3 Beispieldatenbank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.4 Konzepte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.4.1 Replikationsschemadefinition . . . . . . . . . . . . . . . . . . . . . . 513.4.2 Replikat(re)definition . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.4.3 Replikationssichtengruppen und Synchronisation . . . . . . . . . . . 553.4.4 Arbeitsmodell für den Client . . . . . . . . . . . . . . . . . . . . . . 563.4.5 Zugriffszusicherungen . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.5 Stand der Technik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.6 Verwandte Arbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4 Replikatverwaltung 674.1 Relationen auf Datenbankschemata . . . . . . . . . . . . . . . . . . . . . . . 684.2 Aufgaben der Replikatverwaltung . . . . . . . . . . . . . . . . . . . . . . . . 694.3 Abhängigkeiten zwischen Schemaausschnitten . . . . . . . . . . . . . . . . . 71
4.3.1 Integritätssicherung und nutzerdefinierte Replikation . . . . . . . . . 734.3.2 Referentielle Integrität . . . . . . . . . . . . . . . . . . . . . . . . . . 744.3.3 Abstufung der Zugriffszusicherungen . . . . . . . . . . . . . . . . . . 774.3.4 Folgeänderungen und Zugriffszusicherungen . . . . . . . . . . . . . . 77
4.4 Verwaltung von Schemaausschnitten . . . . . . . . . . . . . . . . . . . . . . 784.4.1 Anfragebasierte Verwaltung . . . . . . . . . . . . . . . . . . . . . . . 784.4.2 Fragmentbasierte Verwaltung . . . . . . . . . . . . . . . . . . . . . . 79
4.4.2.1 Schemaausschnitte für die Replikation . . . . . . . . . . . . 804.4.2.2 Sperrobjekte für die Zugriffszusicherungen . . . . . . . . . . 814.4.2.3 Schemaausschnitte für die Synchronisation . . . . . . . . . 81
4.5 Schemafragmente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.5.1 Fremdschlüsselgraph . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.5.2 Fremdschlüsselpfad . . . . . . . . . . . . . . . . . . . . . . . . . . . . 844.5.3 Definition Schemafragment . . . . . . . . . . . . . . . . . . . . . . . 85

INHALTSVERZEICHNIS iii
4.5.4 Bildung der Schemafragmentierung . . . . . . . . . . . . . . . . . . . 864.6 Datenfragmente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.6.1 Definition Datenfragment . . . . . . . . . . . . . . . . . . . . . . . . 884.6.2 Bildung einer Datenfragmentierung . . . . . . . . . . . . . . . . . . . 88
4.6.2.1 Behandlung von Nullwerten . . . . . . . . . . . . . . . . . . 904.6.2.2 Prozedur SplitFrag . . . . . . . . . . . . . . . . . . . . . . . 914.6.2.3 Prozedur MergeFrag . . . . . . . . . . . . . . . . . . . . . . 97
4.6.3 Anpassung einer Fragmentierung . . . . . . . . . . . . . . . . . . . . 994.7 Verwaltung der Fragmentbeschreibungen . . . . . . . . . . . . . . . . . . . . 100
4.7.1 Die Fragmenttabellen . . . . . . . . . . . . . . . . . . . . . . . . . . 1004.7.2 Aufbau der Datenfragmenttabelle – Prozedur ToFragTable . . . . . . 1014.7.3 Übertragung der Prozeduren auf Fragmenttabellen . . . . . . . . . . 104
4.8 Anfrageverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1074.8.1 Schritt 1: Normalisierung . . . . . . . . . . . . . . . . . . . . . . . . 1094.8.2 Schritt 2: Fragmentauswahl . . . . . . . . . . . . . . . . . . . . . . . 110
4.8.2.1 Prozedur JoinToFrag . . . . . . . . . . . . . . . . . . . . . . 1114.8.2.2 Prozedur PredToFrag . . . . . . . . . . . . . . . . . . . . . . 112
4.9 Erstellen der Anfragen für die Synchronisation . . . . . . . . . . . . . . . . . 1134.9.1 Anfragen für neue Daten und die Änderungsübertragung . . . . . . . 1144.9.2 Anfrage für zu löschende Fragmente . . . . . . . . . . . . . . . . . . 1154.9.3 Benötigte Tabellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.10 Berechnung der Sperrobjekte . . . . . . . . . . . . . . . . . . . . . . . . . . 116
5 Der Replication Proxy Server 1195.1 Entwurfsziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1195.2 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1205.3 Produktauswahl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
5.3.1 Server- und RPS-DBMS . . . . . . . . . . . . . . . . . . . . . . . . . 1245.3.2 Client-DBMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1245.3.3 Programmiersprache . . . . . . . . . . . . . . . . . . . . . . . . . . . 1255.3.4 Parsergenerator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1255.3.5 Kommunikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
5.4 Nutzerverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1265.4.1 Nutzer- und Rechtekonzept des RPS . . . . . . . . . . . . . . . . . . 1275.4.2 Zugriffskontrolle durch die Anwendung . . . . . . . . . . . . . . . . . 128
5.5 Konfliktbehandlung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1295.6 Sicherheitsaspekte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1305.7 Anweisungsschnittstelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.7.1 SQL als Grundlage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1315.7.2 Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133

iv INHALTSVERZEICHNIS
5.7.3 Anweisungen zur Administration . . . . . . . . . . . . . . . . . . . . 1355.7.3.1 REGISTER CONSOLIDATED DATABASE . . . . . . . . . . . . . 1355.7.3.2 CANCEL CONSOLIDATED DATABASE . . . . . . . . . . . . . . . 1395.7.3.3 CREATE CONSOLIDATED TABLE . . . . . . . . . . . . . . . . . 1405.7.3.4 DROP CONSOLIDATED TABLE . . . . . . . . . . . . . . . . . . 1455.7.3.5 CREATE SCHEMA FRAGMENTATION . . . . . . . . . . . . . . . 1465.7.3.6 CREATE DATA FRAGMENTATION . . . . . . . . . . . . . . . . . 1475.7.3.7 START REPLICATION . . . . . . . . . . . . . . . . . . . . . . 1495.7.3.8 STOP REPLICATION . . . . . . . . . . . . . . . . . . . . . . . 1505.7.3.9 CREATE USER . . . . . . . . . . . . . . . . . . . . . . . . . . 1515.7.3.10 ALTER USER . . . . . . . . . . . . . . . . . . . . . . . . . . . 1535.7.3.11 DELETE USER . . . . . . . . . . . . . . . . . . . . . . . . . . 154
5.7.4 Anweisungen zur Anwendungsentwicklung . . . . . . . . . . . . . . . 1555.7.4.1 REGISTER REPLICA DATABASE . . . . . . . . . . . . . . . . . 1565.7.4.2 CANCEL REPLICA DATABASE . . . . . . . . . . . . . . . . . . 1575.7.4.3 CREATE REPLICATION VIEW GROUP . . . . . . . . . . . . . . 1585.7.4.4 DROP REPLICATION VIEW GROUP . . . . . . . . . . . . . . . 1595.7.4.5 CREATE REPLICATION VIEW . . . . . . . . . . . . . . . . . . 1595.7.4.6 ALTER REPLICATION VIEW . . . . . . . . . . . . . . . . . . . 1645.7.4.7 DROP REPLICATION VIEW . . . . . . . . . . . . . . . . . . . 1665.7.4.8 SYNCHRONIZE . . . . . . . . . . . . . . . . . . . . . . . . . . 167
5.8 Aufbau und Anweisungsverarbeitung . . . . . . . . . . . . . . . . . . . . . . 1695.8.1 Kernmodule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1705.8.2 Hilfsmodule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1725.8.3 Anweisungsverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . 173
5.9 Hilfsdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1745.9.1 Die RPS-Hilfsdatenbank . . . . . . . . . . . . . . . . . . . . . . . . . 1745.9.2 Hilfsdaten in der konsolidierten Datenbank . . . . . . . . . . . . . . 175
6 Beispielanwendung Hermes 1796.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
6.1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1806.1.2 Anforderungen und Lösungen . . . . . . . . . . . . . . . . . . . . . . 1806.1.3 Realisierung – Überblick . . . . . . . . . . . . . . . . . . . . . . . . . 181
6.2 Datenbankentwurf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1816.2.1 DBS-unabhängiger Datenbankentwurf . . . . . . . . . . . . . . . . . 182
6.2.1.1 Informationsangebot . . . . . . . . . . . . . . . . . . . . . . 1826.2.1.2 E/R-Modellierung . . . . . . . . . . . . . . . . . . . . . . . 183
6.2.2 Informationsgruppen . . . . . . . . . . . . . . . . . . . . . . . . . . . 1856.2.2.1 Bildung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186

INHALTSVERZEICHNIS v
6.2.2.2 Realisierungsalternativen . . . . . . . . . . . . . . . . . . . 1876.2.3 Schema der Quelldatenbank . . . . . . . . . . . . . . . . . . . . . . . 1896.2.4 Abgeleitete Schemata . . . . . . . . . . . . . . . . . . . . . . . . . . 190
6.3 Client-Anwendung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1916.3.1 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1916.3.2 Das Repository . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
6.3.2.1 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1946.3.2.2 Beispiel: Initialisierung einer Replikationssicht . . . . . . . 195
6.4 Die Arbeit mit Hermes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1976.4.1 Das Auswählen von Daten zur Replikation . . . . . . . . . . . . . . . 1976.4.2 Das Einfügen neuer Informationen . . . . . . . . . . . . . . . . . . . 200
7 Zusammenfassung und Ausblick 2057.1 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2057.2 Weiterführende Arbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
Literatur 211


Abbildungsverzeichnis
2.1 Datenbanksystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Ein mobiles Rechnersystem . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.3 Ein mobiles Datenbanksystem . . . . . . . . . . . . . . . . . . . . . . . . . . 232.4 Transaktionsverarbeitung in einem mDBS . . . . . . . . . . . . . . . . . . . 272.5 Die drei Phasen der optimistischen Synchronisation . . . . . . . . . . . . . . 302.6 Striktes Zwei-Phasen-Sperrprotokoll . . . . . . . . . . . . . . . . . . . . . . 35
3.1 E/R-Diagramm für die Beispieldatenbank . . . . . . . . . . . . . . . . . . . 503.2 Relationale Umsetzung der Beispieldatenbank . . . . . . . . . . . . . . . . . 513.3 Überblick der Konzepte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.4 Beispiel für die Freigabe aus der Quelldatenbank . . . . . . . . . . . . . . . 533.5 Beispiel für die Definition eines Replikats . . . . . . . . . . . . . . . . . . . . 533.6 Beispiele für das Ändern und Löschen eines Replikats . . . . . . . . . . . . . 553.7 Beispiel für die Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . 563.8 Arbeitsmodell der nutzerdefinierten Replikation . . . . . . . . . . . . . . . . 573.9 Verträglichkeitsmatrix der Zugriffszusicherungen . . . . . . . . . . . . . . . 59
4.1 Beispiel für Schemaabhängigkeiten . . . . . . . . . . . . . . . . . . . . . . . 724.2 Fälle der Abhängigkeit zwischen Replikationssichtengruppen . . . . . . . . . 824.3 Fremdschlüsselgraph des Beispieldatenbankschemas . . . . . . . . . . . . . . 834.4 Fremdschlüsselpfade des Beispieldatenbankschemas . . . . . . . . . . . . . . 844.5 Beispiel für Prozedur SchemaFrag . . . . . . . . . . . . . . . . . . . . . . . . 874.6 Beispielinstanz für Schemafragment S1 . . . . . . . . . . . . . . . . . . . . . 894.7 Beispielinstanz für Schemafragment S7 . . . . . . . . . . . . . . . . . . . . . 894.8 Ergebnis SplitFrag(S1, F1, F2, Land, Name, ’Thüringen’, 3) . . . . . 934.9 Ergebnis SplitFrag(S1, F1, F2, Ortschaft, Name, ’Jena’, ’Erfurt’, 3) . . . 944.10 Ergebnis SplitFrag(S1, F1, F2, F3, Land, Name, ’Bayern’, 3) . . . . . . . . 954.11 Ergebnis SplitFrag(S1, F1, F2, F3, F4, Ortschaft, Name, ’Jena’, 2) . . . . . 964.12 Ergebnis MergeFrag(S1, F1, F2, F3, F4, F5, Ortschaft, Name, ’Erfurt’, 2) . 984.13 Tabellenschemata von Schema- und Datenfragmenttabelle . . . . . . . . . . 1004.14 Tabelle sf(SF) für S1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1014.15 Tabelle df(DF) für S1 und F2, F3, F4, F5 . . . . . . . . . . . . . . . . . . . 103
vii

viii ABBILDUNGSVERZEICHNIS
4.16 Tabellenschema der Sperrobjekttabelle . . . . . . . . . . . . . . . . . . . . . 117
5.1 Architekturalternativen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1215.2 Verzweigungen in Syntaxdiagrammen . . . . . . . . . . . . . . . . . . . . . . 1345.3 Beispiel für die Anweisung RCD . . . . . . . . . . . . . . . . . . . . . . . . . 1385.4 Beispiel 1 für die Anweisung CCD . . . . . . . . . . . . . . . . . . . . . . . . 1405.5 Beispiel 2 für die Anweisung CCD . . . . . . . . . . . . . . . . . . . . . . . . 1405.6 Beispiel 1 für die Anweisung CCT . . . . . . . . . . . . . . . . . . . . . . . . 1445.7 Beispiel 2 für die Anweisung CCT . . . . . . . . . . . . . . . . . . . . . . . . 1455.8 Beispiel für die Anweisung DCT . . . . . . . . . . . . . . . . . . . . . . . . . 1465.9 Beispiel für die Anweisung CSF . . . . . . . . . . . . . . . . . . . . . . . . . 1475.10 Beispiel für die Anweisung CDF . . . . . . . . . . . . . . . . . . . . . . . . . 1495.11 Beispiel für die Anweisung STR . . . . . . . . . . . . . . . . . . . . . . . . . 1505.12 Beispiel für die Anweisung SPR . . . . . . . . . . . . . . . . . . . . . . . . . 1515.13 Beispiel 1 für die Anweisung CRU . . . . . . . . . . . . . . . . . . . . . . . . 1525.14 Beispiel 2 für die Anweisung CRU . . . . . . . . . . . . . . . . . . . . . . . . 1535.15 Beispiel 1 für die Anweisung ALU . . . . . . . . . . . . . . . . . . . . . . . . 1545.16 Beispiel 2 für die Anweisung ALU . . . . . . . . . . . . . . . . . . . . . . . . 1545.17 Beispiel für die Anweisung DEU . . . . . . . . . . . . . . . . . . . . . . . . . 1555.18 Beispiel für die Anweisung RRD . . . . . . . . . . . . . . . . . . . . . . . . . 1575.19 Beispiel für die Anweisung CRD . . . . . . . . . . . . . . . . . . . . . . . . . 1575.20 Beispiel für die Anweisung CVG . . . . . . . . . . . . . . . . . . . . . . . . . 1585.21 Beispiel für die Anweisung DVG . . . . . . . . . . . . . . . . . . . . . . . . . 1595.22 Signatur der Prozedur zur Anwendungsnutzerverwaltung bei CRV . . . . . . 1615.23 Beispiel 1 für die Anweisung CRV . . . . . . . . . . . . . . . . . . . . . . . . 1635.24 Beispiel 2 für die Anweisung CRV . . . . . . . . . . . . . . . . . . . . . . . . 1645.25 Signatur der Prozedur zur Anwendungsnutzerverwaltung bei ARV . . . . . . 1655.26 Beispiel für die Anweisung ARV . . . . . . . . . . . . . . . . . . . . . . . . . 1665.27 Beispiel für die Anweisung DRV . . . . . . . . . . . . . . . . . . . . . . . . . 1675.28 Signatur der Prozeduren zur Anwendungsnutzerverwaltung bei SYN . . . . . 1685.29 Beispiel für die Anweisung SYN . . . . . . . . . . . . . . . . . . . . . . . . . 1695.30 Modularer Aufbau des RPS . . . . . . . . . . . . . . . . . . . . . . . . . . . 1705.31 E/R-Diagramm der RPS-Hilfsdatenbank [Pfe04] . . . . . . . . . . . . . . . . 1745.32 E/R-Diagramm der Hilfsdaten in der konsolidierten Datenbank [Pfe04] . . . 178
6.1 Gliederung des Informationsangebots von Hermes . . . . . . . . . . . . . . 1826.2 E/R-Diagramm – Informationsangebot [Bau04] . . . . . . . . . . . . . . . . 1846.3 E/R-Diagramm – Bewertungen [Bau04] . . . . . . . . . . . . . . . . . . . . 1856.4 Realisierungsalternativen für Informationsgruppen . . . . . . . . . . . . . . 1886.5 Systemarchitektur der Client-Anwendung [Bau04] . . . . . . . . . . . . . . . 1926.6 Replikationssichten auf Informationsgruppen . . . . . . . . . . . . . . . . . . 193

ABBILDUNGSVERZEICHNIS ix
6.7 Alternativen für die Ortssuche . . . . . . . . . . . . . . . . . . . . . . . . . . 1976.8 Dialog zur Auswahl von Regionstypen . . . . . . . . . . . . . . . . . . . . . 1986.9 Dialog zur Auswahl von Regionen . . . . . . . . . . . . . . . . . . . . . . . . 1986.10 Dialog für die Angabe von erweiterten Bedingungen für die Ortssuche . . . 1996.11 Dialog zur Auswahl von Ortschaften . . . . . . . . . . . . . . . . . . . . . . 2006.12 Dialog zur Auswahl von Informationsgruppen . . . . . . . . . . . . . . . . . 2016.13 Informations-Browser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2026.14 Dialog zum Einfügen der Daten eines neuen Restaurants . . . . . . . . . . . 203


Tabellenverzeichnis
1.1 Vergleich traditioneller und mobilspezifischer Anwendungen . . . . . . . . . 4
2.1 Geräteklassen mobiler Rechner (Stand 2005) . . . . . . . . . . . . . . . . . . 142.2 Drahtlose Kommunikationsmedien (Stand 2005) . . . . . . . . . . . . . . . . 162.3 Vergleich verschiedener Konfigurationen . . . . . . . . . . . . . . . . . . . . 212.4 Konflikte bei datenorientierter Synchronisation . . . . . . . . . . . . . . . . 38
3.1 Vergleich der Ansätze zur Replikatauswahl . . . . . . . . . . . . . . . . . . . 483.2 Vergleich kommerzieller mobiler Datenbanklösungen . . . . . . . . . . . . . 63
4.1 Integritätssicherung und ihre Arbeitsbereiche . . . . . . . . . . . . . . . . . 734.2 Operationen und Abhängigkeiten . . . . . . . . . . . . . . . . . . . . . . . . 76
5.1 Anweisungen für den Administrator . . . . . . . . . . . . . . . . . . . . . . . 1355.2 Anweisungen für den Anwendungsprogrammierer . . . . . . . . . . . . . . . 1555.3 Kernmodule des RPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1705.4 Hilfsmodule des RPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
6.1 Informationsgruppen von Hermes . . . . . . . . . . . . . . . . . . . . . . . 1866.2 Struktur der Tabelle Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . 1896.3 Wichtige Partitionierungsspalten für die Datenfragmentbildung . . . . . . . 1916.4 Struktur der Tabelle RVG_Repository . . . . . . . . . . . . . . . . . . . . . . 1946.5 Struktur der Tabelle RV_Repository . . . . . . . . . . . . . . . . . . . . . . 195
xi


Verzeichnis der Programmtexte
4.1 Prozedur SchemaFrag mit SchemaFragRec . . . . . . . . . . . . . . . . . . . 864.2 Prozedur SplitFrag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 924.3 Prozedur MergeFrag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 974.4 Prozedur ToFragTable mit ValueToFragTable . . . . . . . . . . . . . . . . . . 1024.5 Prozedur SplitFrag auf Fragmenttabellen . . . . . . . . . . . . . . . . . . . . 1044.6 Prozedur FromFragTable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1054.7 Prozedur MergeFrag auf Fragmenttabellen . . . . . . . . . . . . . . . . . . . 1064.8 Prozedur QueryToFrag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1104.9 Prozedur JoinToFrag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1114.10 Prozedur PredToFrag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1134.11 Prozedur GetUpdNewTab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1144.12 Prozedur GetDelTab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1154.13 Prozedur GetUpdNewRI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1154.14 Prozedur CreateLockItems mit RecOverlap . . . . . . . . . . . . . . . . . . . 117
xiii


Verzeichnis der Syntaxdiagramme
4.1 Syntaxdiagramm für Replikationsanfragen (erster Teil) . . . . . . . . . . . . 1074.2 Syntaxdiagramm für Replikationsanfragen (zweiter Teil) . . . . . . . . . . . 1085.1 Optionen der Nutzerverwaltung (Administrator) . . . . . . . . . . . . . . . . 1355.2 Anweisung REGISTER CONSOLIDATED DATABASE . . . . . . . . . . . . . . . . 1365.3 Tablespace-Optionen der Anweisung RCD . . . . . . . . . . . . . . . . . . . . 1365.4 Anweisung CANCEL CONSOLIDATED DATABASE . . . . . . . . . . . . . . . . . . 1395.5 Anweisung CREATE CONSOLIDATED TABLE . . . . . . . . . . . . . . . . . . . . 1415.6 Optionen der Anweisung CCT . . . . . . . . . . . . . . . . . . . . . . . . . . 1415.7 Anweisung DROP CONSOLIDATED TABLE . . . . . . . . . . . . . . . . . . . . . 1455.8 Anweisung CREATE SCHEMA FRAGMENTATION . . . . . . . . . . . . . . . . . . 1475.9 Anweisung CREATE DATA FRAGMENTATION . . . . . . . . . . . . . . . . . . . . 1485.10 Anweisung START REPLICATION . . . . . . . . . . . . . . . . . . . . . . . . . 1495.11 Anweisung STOP REPLICATION . . . . . . . . . . . . . . . . . . . . . . . . . . 1505.12 Anweisung CREATE USER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1515.13 Rollen der RPS-Nutzerverwaltung . . . . . . . . . . . . . . . . . . . . . . . . 1515.14 Anweisung ALTER USER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1535.15 Anweisung DELETE USER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1545.16 Optionen der Nutzerverwaltung (Anwendung) . . . . . . . . . . . . . . . . . 1555.17 Anweisung REGISTER REPLICA DATABASE . . . . . . . . . . . . . . . . . . . . 1565.18 Anweisung CANCEL REPLICA DATABASE . . . . . . . . . . . . . . . . . . . . . 1575.19 Anweisung CREATE REPLICATION VIEW GROUP . . . . . . . . . . . . . . . . . 1585.20 Anweisung DROP REPLICATION VIEW GROUP . . . . . . . . . . . . . . . . . . 1595.21 Anweisung CREATE REPLICATION VIEW . . . . . . . . . . . . . . . . . . . . . 1605.22 Optionen für Zusicherungen und Konfliktbehandlung . . . . . . . . . . . . . 1605.23 Anweisung ALTER REPLICATION VIEW . . . . . . . . . . . . . . . . . . . . . . 1645.24 Optionen der Anweisung ARV . . . . . . . . . . . . . . . . . . . . . . . . . . 1655.25 Anweisung DROP REPLICATION VIEW . . . . . . . . . . . . . . . . . . . . . . 1665.26 Anweisung SYNCHRONIZE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
xv


Kapitel 1
Einleitung
Das Kapitel zeigt im ersten Abschnitt die Motivation für die Entwicklung der nutzerdefi-nierten Replikation zur Realisierung neuer mobilspezifischer Datenbankanwendungen aufund nennt im zweiten Abschnitt die dafür zu lösenden konkreten Aufgaben. Die weite-re Gliederung der Arbeit und die verwendeten typographischen Konventionen werden imletzten Abschnitt des Kapitels angegeben.
1.1 Motivation
Die rasante Entwicklung von Rechnern hin zu immer kleineren und leistungsfähigeren Ge-räten kombiniert mit der Bereitstellung drahtloser Kommunikationsmedien hat die Mög-lichkeiten der heute verfügbaren Computertechnologie um eine Dimension erweitert, dieMobilität von Rechnern. Mit dem Einsatz tragbarer Rechner und drahtloser Kommunika-tion wird bei ihren Nutzern auch der Wunsch geweckt, Informationen und Anwendungs-funktionalität unabhängig vom jeweiligen Aufenthaltsort immer und überall zur Verfügungzu haben. Mögliche Anwendungsszenarien umfassen dabei sowohl klassische Anwendungenaus dem (Arbeits-)Alltag (z. B. E-Mail-Abruf, Terminverwaltung, Anwendungen für Au-ßendienstmitarbeiter, Lagerverwaltung), als auch neue, spezifische Anwendungen, die sicherst aus der Mobilität der Nutzer heraus ergeben (z. B. ortsbezogene Dienste).
Trotz der Fortschritte in der Entwicklung und Verbreitung drahtloser Kommunikationsme-dien wird ein mobiler Nutzer, anders als sein Kollege am fest vernetzten Arbeitsplatzrech-ner, in vielen Szenarien nur zeitweise mit anderen Rechnern kommunizieren können. Dafürgibt es physikalische, wirtschaftliche und aus Sicherheitsaspekten abgeleitete Gründe:
• physikalische Gründe
Gegebene physikalische Eigenschaften des Aufenthaltsortes (z. B. Abschirmung vonFunkwellen in Gebäuden) und der mobilen Geräte selbst schränken die Möglichkeitzur kontinuierlichen Kommunikation mit anderen Rechnern ein. Beispielsweise istin Gebäuden, Tunneln oder in bergigem Gelände durch Abschirmung der Funkwel-len regelmäßig keine Funkübertragung möglich. Drahtlose Kommunikation ist zudemenergieintensiv, das Gewicht und in der Folge die Energiekapazität mobiler Gerätesind dagegen begrenzt. Ein mobiles Gerät muss mit der ihm zur Verfügung stehendenEnergie haushalten.
1

2 KAPITEL 1. EINLEITUNG
• wirtschaftliche Gründe
Wie das Beispiel UMTS zeigt, verzichten Anbieter drahtloser Medien aus wirtschaft-lichen Gründen häufig zunächst auf eine vollständige Netzabdeckung und beschrän-ken sich auf die Bereitstellung ihrer Dienste in ertragreichen Ballungsräumen. Ist amAufenthaltsort des Nutzers eine drahtlose Datenübertragung möglich, so ist diese, imVergleich zu Festnetzübertragungen, i. d. R. deutlich teurer und langsamer. Es kanndeshalb selbst bei verfügbarer Netzverbindung günstiger sein, Operationen zunächstlokal vorzubereiten, um überflüssige Datenübertragungen (bei Volumentarifen) oderVerbindungszeiten (bei Zeittarifen) zu vermeiden.
• Sicherheitsaspekte
Neben Wirtschaftlichkeitserwägungen gibt es auch aus Sicherheitsgründen gewollteVerfügbarkeitseinschränkungen drahtloser Kommunikation. Verbote gibt es teils imöffentlichen Personennahverkehr, in Flugzeugen und Krankenhäusern. Damit soll ei-ner möglichen Störung wichtiger elektronischer Geräte durch die elektromagnetischeStrahlung des Funkverkehrs vorgebeugt werden.
Ein Großteil der Anwendungsdaten ist heute in Datenbanken auf stationären Serverngespeichert, auf die über vernetzte Client-Rechner und -Anwendungen zugegriffen wird.Sind Rechner und Nutzer mobil, müssen auch die Anwendungsdaten trotz der genann-ten Einschränkungen an jedem Ort und zu jeder Zeit verfügbar und der Zugriff (lesendund ändernd) auf sie gewährleistet sein. Folglich müssen für den Fall der Verbindungsun-terbrechung Kopien benötigter Datenobjekte (Replikate) lokal auf dem mobilen Rechnergespeichert und später, nach der Wiederverbindung, mit der zentralen Datenbank auf demServer abgeglichen werden. Diese Aufgabe übernehmen Replikations- und Synchronisati-onsverfahren für Datenbanksysteme.
Gegenstand der vorliegenden Arbeit sind Verfahren zur Auswahl und Verwaltung von Re-plikaten für die lokale Datenbank des mobilen Rechners. Die Anforderungen an die Auswahlder Replikate werden vom jeweiligen Anwendungsszenario bestimmt. Anwendungsszenarienfür den mobilen Datenbankzugriff lassen sich diesbezüglich grob in zwei Klassen einteilen:traditionelle mobile Anwendungen und mobilspezifische Anwendungen [Gol00]. Für dieRealisierung traditioneller Anwendungen reichen die verfügbaren kommerziellen mobilenDatenbanklösungen i. d. R. aus, aus Sicht der Replikatauswahl und -verwaltung interessantsind die mobilspezifischen Anwendungen. Zur Verdeutlichung der Unterschiede der beidenAnwendungsklassen seien hier zwei charakteristische Beispiele gegenübergestellt:
• traditionelle mobile Anwendung: Beispiel Außendienstmitarbeiter
Im ersten Anwendungsbeispiel stattet ein Großhändler seine Außendienstmitarbeitermit mobilen Rechnern aus. Die Mitarbeiter haben die Aufgabe, mit lokalen Super-märkten Verträge für die Produkte des Großhändlers abzuschließen oder zu erneuern.Ein möglicher Tagesablauf könnte folgendermaßen aussehen: Am Morgen repliziertsich der Verkäufer die notwendigen Daten jener Supermärkte aus seinem Zuständig-keitsbereich, die er besuchen will. Vor Ort kann er die Bestellungen auf dem mobilenGerät erfassen und am Abend mit der zentralen Datenbank für die weitere Verarbei-tung durch den Innendienst synchronisieren.Die mobile Anwendung für Außendienstmitarbeiter hat eine vergleichsweise geringeKomplexität. Die aktiven Nutzer (nämlich die angestellten Verkäufer), ihr jeweili-ger exklusiver Kundenstamm und ihr Zuständigkeitsbereich sind gut bekannt. Aus

1.1. MOTIVATION 3
Sicht der Replikation arbeiten die Nutzer weitgehend auf verschiedenen Bereichender Datenbank, so dass Konflikte, hervorgerufen durch die Synchronisation inkom-patibler Änderungen auf denselben Daten, selten sind. Auch steht die Struktur derDaten, die repliziert werden müssen, fest, nur die jeweilige Kundennummer variiert.Der sichere und kontrollierte mobile Zugang zum firmeninternen Netzwerk und aufdie zentrale Datenbank kann beispielsweise über speziell konfigurierte firmeneigenemobile Rechner gewährleistet werden.
• mobilspezifische Anwendung: Beispiel interaktives Reiseinformationssystem
Ein Reiseinformationssystem versorgt seine Nutzer beispielsweise mit Informatio-nen zu Restaurants, Hotels, Straßenverhältnissen etc., abhängig vom jeweils aktuel-len Aufenthaltsort. Ein interaktives Reiseinformationssystem bezieht zusätzlich seineNutzer bei der Informationsbeschaffung mit ein. Ein möglicher Ablauf könnte wiefolgt aussehen: Ein Tourist, ausgestattet mit einem Handy, einem mobilen Rechnerund der Client-Software des Reiseinformationssystems, ist in Jena unterwegs undsucht nach einem guten Restaurant. Er repliziert sich die Daten der in der Näheliegenden Restaurants mit Hilfe einer drahtlosen Verbindung über sein Handy aufseinen mobilen Rechner. Anschließend studiert er, ohne Verbindung, die Empfehlun-gen der anderen Nutzer. Er entscheidet sich für einen Besuch der „Noll“. Auf demWeg dorthin kommt er an einem gerade neu eröffneten „Irish Pub“ vorbei, der nochnicht in der Datenbank verzeichnet ist und den er spontan ausprobieren will. Da so-wohl Essen als auch das Guinness sehr gut geschmeckt haben, fügt er die Daten desPubs in die lokale Datenbank seines mobilen Rechners ein und schreibt eine positi-ve Empfehlung für andere Nutzer. Am späten Abend im Hotel synchronisiert er dieneuen Daten mit der zentralen Datenbank des Reiseinformationssystems über denhoteleigenen kostenlosen Internetzugang.
Die Anwendung eines interaktiven Reiseinformationssystems unterscheidet sich in we-sentlichen Punkten von der Anwendung für Außendienstmitarbeiter. Die Zugriffspro-file der Nutzer sind höchst individuell, zeit- und ortsabhängig. Aus Sicht der Repli-katauswahl ändert sich der lokal benötigte Datenbankausschnitt in Bezug auf diejeweilige Situation des mobilen Nutzers. Da die Nutzer unabhängig sind und natür-lich prinzipiell auf denselben Datenobjekten arbeiten können, sind Änderungskon-flikte zu erwarten (z. B. wenn zwei Nutzer unabhängig voneinander die Daten des„Irish Pub“ erfassen und leicht verschiedene Adressen eintragen), die geeignet gelöstwerden müssen. Darüber hinaus muss die Anwendung mit einer sehr großen undständig wachsenden Anzahl „normaler“, d. h. nicht der Kontrolle als Angestellte einesUnternehmens unterworfener, Nutzer mit individueller Hardware umgehen können.Da jeder Nutzer selbst die volle Kontrolle über seinen mobilen Rechner hat, müssenbeispielsweise alle in die zentrale Datenbank einzubringenden Änderungen daraufgeprüft werden, ob sie zum zuvor replizierten Datenbankausschnitt gehören und derNutzer auch die notwendigen Änderungsberechtigungen hat.
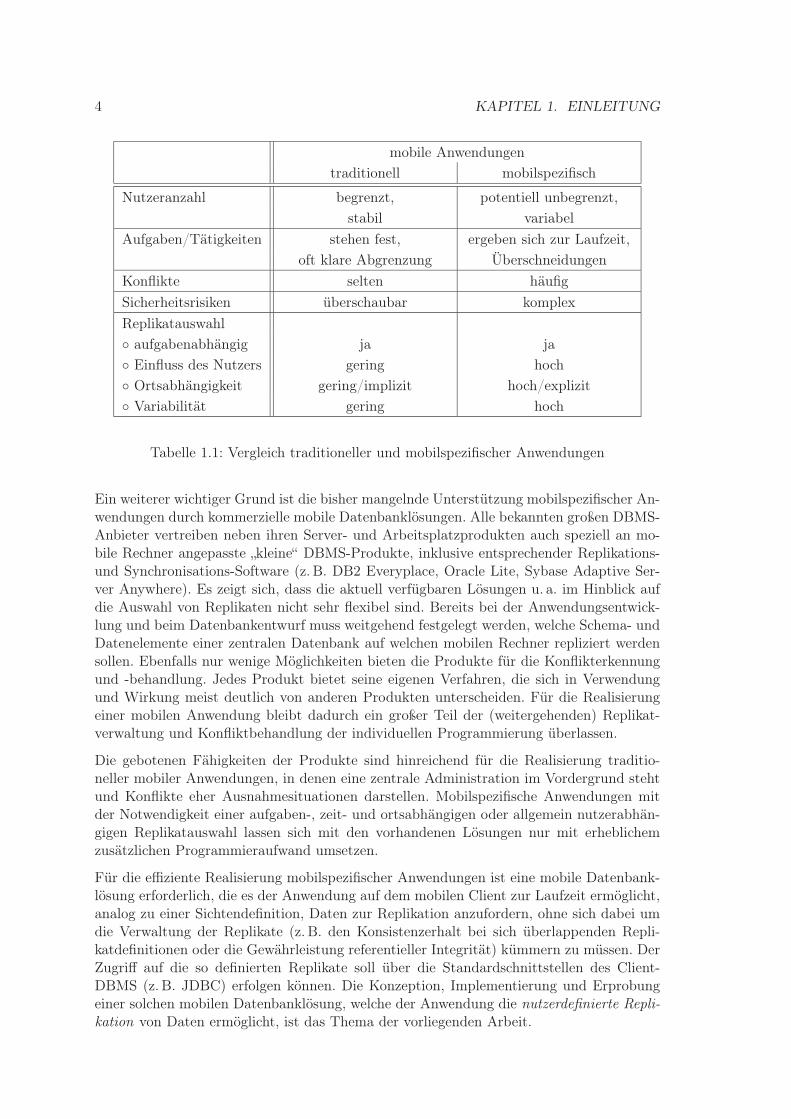
Tabelle 1.1 fasst die charakteristischen Eigenschaften beider Anwendungsklassen noch ein-mal zusammen. Ein weiteres Beispiel für Zielgruppen mobilspezifischer Anwendungen sindKatastrophenhilfskräfte [Anh01], die je nach Situation vor Ort Daten für ihre Arbeit repli-zieren und sammeln müssen. Allerdings sind solche Anwendungen bis auf Einzelprojektenoch wenig kommerziell verfügbar. Zwei mögliche Gründe sind bisher noch nicht ausgereifteGeschäftsmodelle und zu hohe Kosten für die Nutzer.
4 KAPITEL 1. EINLEITUNG
mobile Anwendungentraditionell mobilspezifisch
Nutzeranzahl begrenzt, potentiell unbegrenzt,stabil variabel
Aufgaben/Tätigkeiten stehen fest, ergeben sich zur Laufzeit,oft klare Abgrenzung Überschneidungen
Konflikte selten häufigSicherheitsrisiken überschaubar komplexReplikatauswahl aufgabenabhängig ja ja Einfluss des Nutzers gering hoch Ortsabhängigkeit gering/implizit hoch/explizit Variabilität gering hoch
Tabelle 1.1: Vergleich traditioneller und mobilspezifischer Anwendungen
Ein weiterer wichtiger Grund ist die bisher mangelnde Unterstützung mobilspezifischer An-wendungen durch kommerzielle mobile Datenbanklösungen. Alle bekannten großen DBMS-Anbieter vertreiben neben ihren Server- und Arbeitsplatzprodukten auch speziell an mo-bile Rechner angepasste „kleine“ DBMS-Produkte, inklusive entsprechender Replikations-und Synchronisations-Software (z. B. DB2 Everyplace, Oracle Lite, Sybase Adaptive Ser-ver Anywhere). Es zeigt sich, dass die aktuell verfügbaren Lösungen u. a. im Hinblick aufdie Auswahl von Replikaten nicht sehr flexibel sind. Bereits bei der Anwendungsentwick-lung und beim Datenbankentwurf muss weitgehend festgelegt werden, welche Schema- undDatenelemente einer zentralen Datenbank auf welchen mobilen Rechner repliziert werdensollen. Ebenfalls nur wenige Möglichkeiten bieten die Produkte für die Konflikterkennungund -behandlung. Jedes Produkt bietet seine eigenen Verfahren, die sich in Verwendungund Wirkung meist deutlich von anderen Produkten unterscheiden. Für die Realisierungeiner mobilen Anwendung bleibt dadurch ein großer Teil der (weitergehenden) Replikat-verwaltung und Konfliktbehandlung der individuellen Programmierung überlassen.
Die gebotenen Fähigkeiten der Produkte sind hinreichend für die Realisierung traditio-neller mobiler Anwendungen, in denen eine zentrale Administration im Vordergrund stehtund Konflikte eher Ausnahmesituationen darstellen. Mobilspezifische Anwendungen mitder Notwendigkeit einer aufgaben-, zeit- und ortsabhängigen oder allgemein nutzerabhän-gigen Replikatauswahl lassen sich mit den vorhandenen Lösungen nur mit erheblichemzusätzlichen Programmieraufwand umsetzen.
Für die effiziente Realisierung mobilspezifischer Anwendungen ist eine mobile Datenbank-lösung erforderlich, die es der Anwendung auf dem mobilen Client zur Laufzeit ermöglicht,analog zu einer Sichtendefinition, Daten zur Replikation anzufordern, ohne sich dabei umdie Verwaltung der Replikate (z. B. den Konsistenzerhalt bei sich überlappenden Repli-katdefinitionen oder die Gewährleistung referentieller Integrität) kümmern zu müssen. DerZugriff auf die so definierten Replikate soll über die Standardschnittstellen des Client-DBMS (z. B. JDBC) erfolgen können. Die Konzeption, Implementierung und Erprobungeiner solchen mobilen Datenbanklösung, welche der Anwendung die nutzerdefinierte Repli-kation von Daten ermöglicht, ist das Thema der vorliegenden Arbeit.

1.2. AUFGABEN UND ABGRENZUNG 5
1.2 Aufgaben und Abgrenzung
Für die Realisierung der geforderten nutzerdefinierten Replikation sind zunächst die zulösenden (Teil-)Aufgaben zu identifizieren. Die erste Aufgabe der Arbeit ist es, die Funk-tionalität und Schnittstellen der nutzerdefinierten Replikation zu konzipieren. Da für dieAbwicklung der Kommunikation und Datensynchronisation zwischen Datenbanken bereitsausgereifte kommerzielle Lösungen verfügbar sind, soll die nutzerdefinierte Replikation kei-ne eigenständige Lösung darstellen, sondern existierende mobile Datenbanklösungen um dieFähigkeit zur dynamischen Auswahl von Replikaten erweitern.
Bei der Konzeption müssen nicht nur die charakteristischen Eigenschaften mobilspezifischerAnwendungen, die in Abschnitt 1.1 dargestellt wurden, berücksichtigt werden, sondernauch die Eigenschaften mobiler Rechner- und Datenbanksysteme. Dazu ist als Teilaufgabeeine Analyse des Stands der Technik inklusive der Produkte durchzuführen und daraus einModell eines mobilen Rechner- und Datenbanksystems als Grundlage der nutzerdefiniertenReplikation abzuleiten.
Die zweite Aufgabe steht im Zusammenhang mit der Realisierung der nutzerdefinierten Re-plikation. Für die von den Anwendungen der mobilen Clients angeforderten Replikate musseine Verwaltungsebene bereitgestellt werden, die zunächst speichert, welcher Client welcheDaten in welchem Modus repliziert hat und anhand der gespeicherten Metainformationenu. a. effizient entscheiden kann, welche Daten zur Erfüllung einer Replikatanforderung aufeinen mobilen Client kopiert werden müssen.
Die dritte Aufgabe ist die Implementierung des Dienstes zur nutzerdefinierten Replikation.Die Implementierung soll dabei so weit wie möglich datenbanksystemunabhängig sein sowievorhandene Funktionalität und bekannte Verfahren, insbesondere zur Synchronisation undKonfliktbehandlung, einbinden. Ziel ist die Implementierung eines funktionalen Prototy-pen für eine konkrete Produktkombination, wobei die wichtigsten Funktionen vollständigimplementiert werden sollen.
Die vierte Aufgabe ist die Evaluation der nutzerdefinierten Replikation und des Prototypendurch die Implementierung des in Abschnitt 1.1 skizzierten interaktiven Reiseinformations-systems. Ziel dabei ist es, zu zeigen, dass nutzerdefinierte Replikation funktioniert und dieUmsetzung mobilspezifischer Anwendungen erheblich vereinfacht.
1.3 Gliederung der Arbeit
Die Gliederung der weiteren Arbeit orientiert sich an den im letzten Abschnitt genann-ten Aufgaben. Kapitel 2 legt durch die Einführung in das Thema mobiler Datenbank-systeme und Begriffsdefinitionen die Grundlagen für die weiteren Kapitel. Im dann folgen-den Kapitel 3 werden die Konzepte und die Funktionalität der nutzerdefinierten Replikati-on erläutert und der Stand in Technik und Forschung angegeben. Kapitel 4 beschäftigt sichausführlich mit der Verwaltung der von Clients angeforderten Replikate und beschreibtmit dem Fragmentkonzept neues prädikatbasiertes Indexierungsverfahren für relationaleDaten. In Kapitel 5 wird eine prototypische Implementierung des Dienstes zur nutzerde-finierten Replikation inklusive des Fragmentkonzepts am Beispiel der Produkte IBM DB2und Sybase Adaptive Server Anywhere beschrieben. Kapitel 6 beschreibt die Konzeptionund Umsetzung des interaktiven mobilen Reiseinformationssystems Hermes. Die Arbeit

6 KAPITEL 1. EINLEITUNG
schließt mit einer Zusammenfassung wichtiger Ergebnisse und einem Ausblick auf weiter-führende Arbeiten (Kapitel 7).
Abschließend noch einige technische Hinweise zu den im Text verwendeten Konventionen.Wichtige Begriffe bei ihrer Definition und betonte Worte werden durch Kursivschrift her-vorgehoben. Die erste Erwähnung einer Abbildung, Tabelle o. ä. wird ebenfalls hervorge-hoben. Die Bezeichungen von Prozeduren, Verfahren sowie von Tabellen- und Spaltennamenim Text werden in einer serifenlosen Schrift gesetzt. Konkrete Syntax und Werte wer-den durch Typewriter-Schrift vom übrigen Text unterschieden. Soweit es das Verständnisnicht erschwert, wird eine deutsche Fachterminologie verwendet. Nicht übersetzte englischeBegriffe werden nicht gesondert hervorgehoben.

Kapitel 2
Grundlagen
In diesem Kapitel werden grundlegende Begriffe und Konzepte von Datenbanksystemenim allgemeinen und von mobilen Datenbanksystemen im besonderen erläutert sowie die inder Arbeit verwendeten Bezeichnungen eingeführt.
2.1 Datenbanksysteme
Anwendung
Datenbanksystem (DBS)
DBMS
DBDB
...
Abbildung 2.1: Datenbanksystem
Eine Datenbank ist eine strukturierte Sammlung dauerhafter Daten, die von Anwendungs-programmen genutzt werden. Gespeichert sein können Informationen über reale oder ge-dankliche Gegenstände der Welt, wobei der betrachtete Weltausschnitt auch als Miniweltbezeichnet wird. Der Zugriff auf eine Datenbank erfolgt über die Software des Daten-bankmanagementsystems (DBMS). Das DBMS und die von ihm verwalteten Datenbankenbilden zusammen das Datenbanksystem (DBS, siehe Abbildung 2.1). Für die Arbeit mitDatenbanken muss das DBMS eine Reihe von Grundfunktionen bereitstellen [HS00]:
7

8 KAPITEL 2. GRUNDLAGEN
• Integration
Alle von Anwendungsprogrammen für die Miniwelt benötigten Daten werden aufeinheitliche Weise und ohne unnötige Redundanz vom DBMS verwaltet.
• Operationen
Für die Definition der Struktur zu speichernder Daten, das Auslesen und das Mani-pulieren von Datenbanken durch Nutzer und Anwendungen werden geeignete Ope-rationen bereitgestellt.
• Metadaten
Die Strukturen gespeicherter Daten werden in einem Datenbankkatalog abgelegt undden Anwendungen zur Verfügung gestellt.
• Benutzersichten
Benutzersichten dienen zur Bereitstellung einer an die Bedürfnisse der Anwendungbzw. des Nutzers angepasste Strukturierung der Datenbankinhalte.
• Transaktionen
Transaktionen fassen einzelne Datenbankoperationen zu Funktionseinheiten zusam-men, die als Ganzes oder gar nicht ausgeführt werden sollen. Bei erfolgreicher Aus-führung einer Transaktion werden die Änderungen in der Datenbank dauerhaft. NachFehlern im System (Systemfehler, Externspeicherfehler) muss die Dauerhaftigkeit ab-geschlossener Transaktionen gesichert bzw. wiederhergestellt werden können.
• Integritätssicherung
Die Integritätssicherung übernimmt die Gewährleistung der Konsistenz der gespei-cherten Daten und den Konsistenzerhalt ausgeführter Änderungen.
• Synchronisation des Mehrbenutzerbetriebs
Greifen mehrere Transaktionen schreibend und konkurrierend auf Daten zu, mussdieser Zugriff so synchronisiert werden, dass dadurch keine inkorrekten Daten ent-stehen.
• Datenschutz
Unautorisierte Zugriffe müssen erkannt und unterbunden werden können.
Die Anforderungen an eine Umsetzung der Grundfunktionen in einem DBMS werdenvon verschiedenen Einflussfaktoren bestimmt. Maßgeblich dafür sind neben dem zu un-terstützenden Anwendungsszenario (siehe Abschnitt 1.1) die Wahl des Datenmodells(Abschnitt 2.2), die verwendete Hardware-Infrastruktur (Abschnitt 2.3) und die damit ver-knüpfte Architektur des DBS (Abschnitt 2.4).
Welche Konsequenzen sich aus der Mobilität von Nutzern und Rechnern für die Hardware-Infrastruktur und Architektur des DBS ergeben, erläutern die angegebenen Abschnitte(vergleiche [Bar99, PB94, DH95]). Besondere Anforderungen stellt die Mobilität an dieTransaktionsverarbeitung und Synchronisation, welche im Abschnitt 2.5 genauer betrach-tet werden.

2.2. DAS RELATIONALE DATENMODELL 9
2.2 Das relationale Datenmodell
Ein logisches Datenmodell ist ein System von Konzepten zur einheitlichen Beschreibungvon Daten in einer Datenbank. Es setzt sich zusammen aus einer Struktur-, Manipulations-und einer Integritätskomponente [Dat04, Cod81]. Die Strukturkomponente beschreibt, wieObjekte der Miniwelt und ihre Beziehungen in der Datenbank repräsentiert werden. Die aufDaten in der Datenbank anwendbaren Operationen werden durch die Manipulationskompo-nente beschrieben. Die Integritätskomponente schließlich stellt Mittel zur Formulierung vonBedingungen bereit, welche die Datenbank erfüllen muss, damit die gespeicherten Datenals korrekt angesehen werden. Beispiele für logische Datenmodelle sind das hierarchischeDatenmodell, objektorientierte Datenmodelle und das relationale Datenmodell.
Die Arbeit beschränkt sich auf die Betrachtung von Datenbanksystemen, die auf dem re-lationalen Datenmodell von Codd [Cod70] basieren. Das relationale Datenmodell wird vonfast allen heute verfügbaren kommerziellen Datenbanksystemen, inklusive der für mobileRechner entwickelten Varianten (siehe Kapitel 3.5), verwendet. Es ist sehr einfach, vollstän-dig formalisiert und es steht mit der Datenbanksprache SQL (Structured Query Language,[ISO03a]) eine etablierte Umsetzung zur Verfügung (zu SQL siehe auch Kapitel 5.7.1).
Zur Verbesserung der Zusammenarbeit mit Anwendungen werden ergänzend zu den vor-handenen relationalen Konzepten zunehmend objektorientierte Eigenschaften in relationaleDBMS-Produkte und SQL integriert [Dat04, ISO03b]. Die zusätzlich bereitgestellte Funk-tionalität (z. B. komplexe Datentypen, Typhierarchien) sowie die Stärke der Integrationsind bei den objektrelationalen DBMS-Produkten heute sehr unterschiedlich ausgeprägtund oft nicht kompatibel. Die sich aus objektrelationalen Erweiterungen ergebenden zu-sätzlichen Freiheitsgrade werden hier nicht betrachtet.
In der Arbeit wird häufig auf die Begriffe und Konzepte des relationalen Modells Bezuggenommen. Aufgrund der teilweise unterschiedlichen Semantik und Verwendung von Be-zeichnungen in der Literatur und in Produkten werden die für diese Arbeit gültige Syntaxund Semantik in den folgenden Unterabschnitten definiert.
2.2.1 Struktur- und Datenobjekte
Aus mathematischer Sicht werden im relationalen Datenmodell die aus der Miniwelt zuspeichernden Daten durch Relationen repräsentiert. Relationen sind Mengen von gleichar-tig strukturierten Tupeln. Jedes Tupel beschreibt ein Objekt oder eine Beziehung in derMiniwelt. Ein Tupel wiederum besteht aus Attributwerten, welche Ausprägungen der At-tribute (der Merkmale) des zu speichernden Objekts sind. Zu jedem Attribut gehört eineDomäne (steht für Wertebereich und Datentyp), aus denen die Attributwerte stammenmüssen. Die Struktur gleichartiger Relationen wird im Relationenschema festgelegt. Rela-tionen lassen sich als Tabellen darstellen, indem man ihre Tupel als Zeilen untereinanderanordnet. Jede Spalte steht für ein Attribut; das Relationenschema entspricht gewisser-massen dem Tabellenkopf.1
Die Begriffe Tabelle, Tabellenschema, Zeile und Spalte werden in kommerziellen Daten-banksystemen, wie auch in SQL, anstatt der (mathematisch korrekten) Begriffe Relation,
1Auch wenn eine Tabellendarstellung eine künstliche Reihenfolge der Zeilen angibt, sei die Mengense-mantik von Relationen davon unberührt.

10 KAPITEL 2. GRUNDLAGEN
Relationenschema, Tupel und Attribut verwendet. Zur Erzielung einer einheitlichen Be-nennung und zur Abgrenzung gegenüber mathematischen Relationen über Objekten desrelationalen Modells (siehe Kapitel 4.1) werden in der Arbeit für den Entwurf und dieBeschreibung relationaler Datenbanken die auf Tabellen aufbauenden Bezeichnungen ver-wendet.
Ein Datenbankschema umfasst eine Menge von Tabellenschemata. Über einem Datenbank-schema können Integritätsbedingungen (z. B. Schlüssel, Fremdschlüssel oder Wertebereichs-einschränkungen) definiert werden. Eine Datenbank schließlich ist eine Ausprägung einesDatenbankschemas. Zur Adressierung von Veränderungen einer Datenbank über die Zeitwird der Begriff Datenbankzustand benutzt. Ein Datenbankzustand ist konsistent, wenn erallen Integritätsbedingungen genügt.
Formale Definitionen
In Anlehnung an [Vos00, Mai83] wird das relationale Modell wie folgt formal gefasst. EinTabellenschema T wird durch eine Menge von Spalten T = C1, . . . Cn festgelegt. Je-der Spalte Ci (1 ≤ i ≤ n) ist eine Domäne Dom(Ci) zugeordnet, aus der die Werte derSpalte v ∈ Dom(Ci) stammen müssen. Eine Instanz t(T ) eines Tabellenschemas T , alsoeine Tabelle, wird durch eine endliche Menge t = r1, . . . rm von Zeilen bestimmt. EineZeile rj (1 ≤ j ≤ m) ist eine totale Abbildung rj : T → Dom(C1) ∪ · · · ∪ Dom(Cn). DieMenge aller möglichen Zeilen über dem Tabellenschema T wird mit Row(T ) und die Men-ge aller möglichen Tabellen mit Tab(T ) bezeichnet. Ein Datenbankschema D wird durcheine endliche Menge von Tabellenschemata D = T1, . . . Tp bestimmt. Eine Instanz d(D),also eine Datenbank, wird durch eine Menge von Tabellen d = t1(T1), . . . tp(Tp) der inD enthaltenen Tabellenschemata gebildet. Die Menge der möglichen Datenbanken übereinem Datenbankschema D wird mit Dat(D) bezeichnet. Dat(D) kann durch die Formulie-rung von Integritätsbedingungen über D eingeschränkt werden (siehe Abschnitt 2.2.3 undKapitel 4.3).
Die Definition als totale Abbildung erlaubt es nicht, Zeilen zu beschreiben, in denen eineoder mehrere Spalte(n) (noch) keinen Wert aus der jeweiligen Domäne haben. Dieser Falltritt in der Praxis allerdings häufig auf und wird durch die Einführung eines so genanntenNullwerts gelöst. Die Wertebereiche der Spalten werden implizit um den datenbankweiteinheitlichen Nullwert ω erweitert, der einen normalen Wert des jeweiligen Bereichs ersetzenkann, wenn dieser nicht bekannt ist [Cod79]. Die Mengeneigenschaft von Tabellen bleibtdabei erhalten.2 Eine wichtige Anwendung des Nullwerts ist die Definition eines äußerenVerbunds (siehe Abschnitt 2.2.2).
Die Auswertung logischer Ausdrücke, in die ω eingeht, wird üblicherweise über eine drei-wertige Logik mit dem neuen Wahrheitswert Unbekannt durchgeführt [Kle03, Cod79]. EinSpezialfall stellt der Vergleich auf Gleichheit mit ω dar: es sei C = ω gdw. der Spalten-wert C der Nullwert ist. In SQL wird diese Auswertung mit dem Schlüsselwort IS NULLdurchgeführt.
2Insbesondere aus Effizienzgründen wird in der Praxis auf die erzwungene Einhaltung der Mengenei-genschaft verzichtet. Die Erweiterung auf Multimengen wird für die Arbeit nicht angewendet, da allebenötigten Operationen auf Tabellen o. B. d. A. auf Mengen ausgeführt werden können.

2.2. DAS RELATIONALE DATENMODELL 11
2.2.2 Datenmanipulationskomponente und Sichten
Die Datenmanipulation im relationalen Datenmodell wird mit Hilfe der relationalen Al-gebra und relationalen Kalkülen [HS00, Mai83] formal beschrieben. Die SELECT-Anfragender Datenbanksprache SQL basieren beispielsweise auf dem um Elemente der relationalenAlgebra erweiterten Tupelkalkül [Vos00]. Für die Arbeit mit Daten- und Schemaobjektenwird im Folgenden eine Darstellung mittels relationaler Algebra gewählt, da relationaleAusdrücke einfach zu lesen sind und sich zudem einfach in SQL-Anweisungen übersetzenlassen. Ergänzt um Basisoperationen für Änderungen, ist die Ausdrucksmächtigkeit derrelationalen Algebra ausreichend für die in der Arbeit darzustellende Semantik.
Für die Operation der relationalen Algebra gilt Abgeschlossenheit, d. h. das Resultat einerrelationalen Operation über Tabellen ist wieder eine Tabelle. Eine korrekte Kombinationrelationaler Operationen heißt relationaler Ausdruck. Anfragen an Tabellen sind nichtsanderes als relationale Ausdrücke, und die Manipulation von Daten durch Einfügen, Ändernund Löschen von Zeilen lässt sich als Abbildung von der Menge der Datenbanken in sichselbst interpretieren.
Relationale Ausdrücke und Anfragen
Sei D = T1, . . . Tm ein Datenbankschema, dann bezeichnet AD die Menge der Ausdrückeder relationalen Algebra bzgl. D. Es gilt ∀1≤i≤mTi ∈ AD. Weiter gehört rekursiv jederAusdruck E zu AD, der sich durch Anwendung einer Operation der relationalen Algebraauf Ausdrücken von AD herleiten lässt. Das Ergebnis der Anwendung eines relationalenAusdrucks E(D) bzgl. einer Datenbank d ∈ Dat(D) ist eine abgeleitete Tabelle und wirdals vE(D)(d) geschrieben, es gilt vTi(d) := ti(Ti). Die folgenden Algebraoperationen werdenin der Arbeit verwendet (mit E1, E2 ∈ AD beliebig aber fest):
• Projektion E = πT ′(E1) auf Spalten (T ′ ⊆⋃
1≤i≤m Ti)mit der Auswertung vE(d) := πT ′(vE1(d)),
• Selektion E = σp(E1) von Zeilen (p ist Selektionsbedingung)mit der Auswertung vE(d) := σp(vE1(d)),
• Kreuzprodukt E = E1 ⊗ E2
mit der Auswertung vE(d) := vE1(d) ⊗ vE2(d),
• Innerer Verbund (inner join) E = E1 p E2 (p ist Verbundbedingung)mit der Auswertung vE(d) := vE1(d) p vE2(d),
• Vereinigung E = E1 ∪ E2
mit der Auswertung vE(d) := vE1(d) ∪ vE2(d),
• Differenz E = E1 \ E2
mit der Auswertung vE(d) := vE1(d) \ vE2(d).
Auf die Angabe der genauen Definition der bekannten Operationen wird verzichtet undstattdessen auf die einschlägige Literatur verwiesen, z. B. [Vos00]. Weiter wird o. B. d. A.angenommen, dass alle Spaltennamen innerhalb eines Datenbankschemas eindeutig sind

12 KAPITEL 2. GRUNDLAGEN
(z. B. darstellbar durch Qualifikation aller Spalten durch ihr jeweiliges Tabellenschema).Diese Festlegung erlaubt den Verzicht auf eine Operation zur Umbenennung von Spalten.
Innere Verbunde sind in der Regel nicht verlustfrei, d. h. bei der Anwendung des relatio-nalen Ausdrucks gehen die Informationen in den Zeilen verloren, die nicht der Verbund-bedingung genügen. Die Ausgangstabellen lassen sich dann durch eine Projektion nichtrekonstruieren. Für die Konstruktion der Schemafragmente in Kapitel 4 wird ein verlust-freier äußerer Verbund benötigt, der sich mit Hilfe des vorher eingeführten Nullwerts wiefolgt definiert:
• Äußerer Verbund (outer join) E = E1 pE2 = E1 p E2 ∪ (E1 × Ω2) ∪ (Ω1 × E2)mit der Auswertung vE(d) := vE1(d) pvE2(d)
Dabei bezeichnet Ω1 (Ω2) ein Tabellenschema, welches dieselbe Spaltenmenge wieE1 (E2) besitzt, aber nur eine Instanz hat, in der nur eine Zeile enthalten ist, derenSpaltenwerte alle gleich ω sind.
Das Ergebnis der Ausführung eines äußeren Verbunds enthält nicht nur die zur Verbundbe-dingung passenden Zeilen, sondern auch die restlichen Zeilen der Ausgangstabellen, wobeifehlende Informationen aus der jeweils anderen Tabelle mit dem Nullwert ω aufgefülltwerden.
Für relationale Ausdrücke gibt es eine Reihe von Regeln, wie ein Ausdruck äquivalent ineinen anderen umgeformt werden kann (siehe [Vos00]). Zwei relationale Ausdrücke E1, E2 ∈AD sind äquivalent, geschrieben als E1 ≈ E2, wenn gilt ∀d∈Dat(D)(vE1(d) = vE2(d)).
Sichten
Über relationale Ausdrücke lassen sich die in den Grundfunktionen geforderten Benutzer-sichten realisieren. Der benannte Ausdruck T := E(D) ist ein abgeleitetes Tabellenschemaoder eine Sicht. Tabellenschemata, die nicht aus anderen abgeleitet sind, werden als Ba-sistabellenschemata bezeichnet. Ein Datenbankschema kann beliebig viele Basistabellen-schemata und Sichten enthalten.
Instanzen von Sichten werden normalerweise nicht gespeichert, sondern aus den Basistabel-len bei der Ausführung der Anfrage oder Änderungsoperation berechnet. Eine Ausnahmesind so genannte materialisierte Sichten. Ihr Anfrageergebnis wird vorberechnet und inder Datenbank gespeichert. Materialisierte Sichten werden zur Performance-Verbesserunghäufig wiederkehrender komplexer Anfragen eingesetzt. Dem verbesserten Anfrageverhal-ten steht ein höherer Wartungsaufwand für Änderungen gegenüber, denn wenn sich dieBasistabellen, auf die sich eine materialisierte Sicht bezieht, ändern, muss auch die Sichtangepasst werden. Materialisierte Sichten stellen einen Aspekt der kontrollierten redundan-ten Datenhaltung dar, wie sie Replikations- und Synchronisationsverfahren bereitstellen(vergleiche Abschnitt 2.5 und Kapitel 3.1).
Datenänderungen
Neben Anfragen zur Auswertung oder zur Definition abgeleiteter Tabellenschemata werdenOperationen benötigt, welche es erlauben, den Inhalt einer Datenbank zu verändern, Datenzu löschen oder neue Daten hinzuzufügen. Sei D = T, . . . mit T = C1, . . . , Cn, dann

2.2. DAS RELATIONALE DATENMODELL 13
werden, wieder in Anlehnung an [Vos00], die folgenden drei Grundoperationen auf Tab(T )eingeführt.
• Einfügen ι(t(T ); r) oder ι(t(T ); t′(T ))
Die Zeile r ∈ Row(T ) bzw. die Zeilen r ∈ t′(T ) werden durch die Operation ι in dieTabelle t(T ) eingefügt.
• Ändern µp(t(T ); Ci1 := v1, Ci2 := v2, . . .)
Die Spaltenwerte der Spalten Ci1 , Ci2 , . . . (1 ≤ i1, i2 ≤ n) der über das Selektionsprä-dikat p ausgewählten Zeilen πp(t(T )) der Tabelle t(T ) werden auf die Werte v1, v2, . . .der entsprechenden Domänen (v1 ∈ Dom(Ci1), v2 ∈ Dom(Ci2), . . . ) gesetzt.
• Löschen δp(t(T )) oder δ(t(T ); t′(T ))
Die über das Selektionsprädikat p ausgewählten Zeilen πp(t(T )) bzw. die in der Ta-belle t′(T ) enthaltenen Zeilen werden aus der Tabelle t(T ) gelöscht.
Die so definierten Grundoperationen können mittels Transaktionen (siehe Abschnitt 2.5.1)zu komplexen Operationen mit bestimmten Garantien zusammengesetzt werden. EineÜbersetzung in SQL-Anweisungen ist einfach möglich, da die Definitionen von ι, µ, δ imwesentlichen den SQL-Anweisungen INSERT, UPDATE und DELETE entsprechen.
2.2.3 Integritätskomponente
Integritätsbedingungen lassen sich formal darstellen als eine Menge von Abbildungen I =e|e : Dat(D) → Wahr, Falsch.3 Jede Abbildung e ∈ I ordnet einer Datenbank einenWahrheitswerte zu, der angibt, ob die formulierte Bedingung erfüllt ist und die Datenbankdamit einen bzgl. e konsistenten Zustand angenommen hat. Eine Datenbank erfüllt I,wenn sie alle Bedingungen e ∈ I erfüllt. Die beiden wichtigsten Integritätsbedingungenfür relationale Datenbanken sind Schlüssel und Fremdschlüssel, die wie folgt formal gefasstwerden können. Sei T ein Tabellenschema und K ⊆ T eine Spaltenmenge, dann
heißt K Schlüssel für t ∈ Tab(T ), falls gilt:
(a) ∀r1,r2∈t πK(r1) = πK(r2) =⇒ r1 = r2 und
(b) Schlüsselminimalität, d. h. für keine echte Teilmenge K ′ ⊂ K gilt (a)
Seien T, T ′ ∈ D zwei Tabellenschemata und FK ⊆ T eine Spaltenmenge, dann
heißt FK Fremdschlüssel in T , falls gilt:
(a) es existiert ein Schlüssel K ⊆ T ′ mit
(b) ∀d(D) πFK(t(T ′)) ⊆ πK(t′(T ′))
3In [Vos00] werden Integritätsbedingungen als Bestandteil des Datenbankschemas angesehen. Zuguns-ten einer einfacheren Mengendarstellung von Schemata werden die Integritätsbedingungen I hier separatbetrachtet.

14 KAPITEL 2. GRUNDLAGEN
Gibt es mehrere Schlüssel in einem Tabellenschema, so kann ein Schlüssel als Primär-schlüssel ausgezeichnet werden. Gibt es im Tabellenschema T ′ nur einen Schlüssel (denPrimärschlüssel), so kann die Fremdschlüsselbedingung geschrieben werden als T →FK T ′.Weitere Integritätsbedingungen und Regeln für die Integritätssicherung, für die hier keineformale Definition angegeben wird, werden in Kapitel 4.3.1 betrachtet.
2.3 Mobile Rechnersysteme
Die Hardware-Infrastruktur, auf der Datenbanken gespeichert und auf der das Datenbank-managementsystem ausgeführt wird, bestimmt weitere Anforderungen an die Umsetzungder Grundfunktionen. In mobilen Anwendungsszenarien geht es dabei nicht um Einzelrech-ner, sondern um das Zusammenspiel mehrerer Rechner.
Unter einem verteilten Rechnersystem wird eine Zusammenfassung von an sich autonomenEinzelrechnern verstanden, die über ein Netzwerk oder eine andere Kommunikationsin-frastruktur miteinander kommunizieren, sei es zum Datenaustausch oder zur Ausführungentfernter Dienste eines anderen Rechners. Ein mobiles Rechnersystem ist im Folgenden einverteiltes Rechnersystem bestehend aus stationären und mobilen Rechnern. Mobile Rech-ner zeichnen sich gegenüber als stationär angenommenen Rechnern dadurch aus, dass sietragbar sind und von ihrem Nutzer an verschiedenen Orten zum Einsatz gebracht werdenkönnen. Für die Kommunikation mit anderen Rechnern im Rechnersystem können sie vorOrt vorhandene Netzwerkanschlüsse nutzen oder über ein drahtloses Kommunikationsme-dium kommunizieren.
Bevor Unterabschnitt 2.3.3 das hier zugrundegelegte Modell eines mobilen Rechnersystemsund seine Eigenschaften erläutert, fassen die Unterabschnitte 2.3.1 und 2.3.2 die bei derModellierung zu berücksichtigenden Merkmale mobiler Rechner und drahtloser Kommuni-kationsmedien zusammen.
2.3.1 Mobile Rechner
Speicher Prozessor- Betriebsdauer Betriebs-leistung mit Akku (in h) system
Laptop/Notebook 512 – 2048 MB wie PC 3 – 6 wie PCHandheld/PDA 8 – 128 MB PC 2 – 16 proprietär
Mobiltelefon 1 – 32 MB ≪ PC ∼ 4 proprietär
Tabelle 2.1: Geräteklassen mobiler Rechner (Stand 2005)
Mobile Rechner sollen ihren Nutzern ermöglichen, Dienste in einem Netzwerk zu nutzenund Anwendungen lokal auszuführen, ohne an einen Ort gebunden zu sein. Tabelle 2.1enthält eine Übersicht aktueller Geräteklassen für mobile Rechner, angegeben sind heuteübliche Werte für die nutzbare Speicherkapazität und Betriebsdauer bei Akku/Batterie-Betrieb.4 Für die Hardware mobiler Rechner spielt ihre Tragbarkeit eine entscheidende
4Einen Überblick bietet beispielsweise die Webseite http://www.chip.de in der Rubrik „Die besteHardware“.

2.3. MOBILE RECHNERSYSTEME 15
Rolle. Prinzipbedingt sind dafür bei folgenden Eigenschaften, Einschränkungen in Kauf zunehmen:
• Energieversorgung und erzielbare Leistung
Mobile Rechner benötigen eine vom öffentlichen Stromnetz unabhängige Energie-quelle, mit der eine ausreichende Betriebsdauer gewährleistet werden kann. Dieseautonome Energieversorgung wird üblicherweise aus wiederaufladbaren Akkus oderBatterien bestritten. Hauptverbraucher von Energie sind Prozessor, Hauptspeicherund die drahtlose Kommunikation (siehe Abschnitt 2.3.2).
Da das Gewicht begrenzt ist, sind die bei der Energieversorgung erzielbaren Verbes-serungen abhängig von der erzielbaren Energiedichte des verwendeten Speichermedi-ums. Die Möglichkeiten der herkömmlichen Medien sind hier weitgehend ausgereizt,so dass die knappe Ressource Energie die nutzbare Speicherkapazität und Rechenleis-tung sowie die (Dauer-)Kommunikationsfähigkeit eines mobilen Rechners begrenzt.
Energieeinsparungen können durch energieeffizient konstruierte, i. d. R. dann lang-samere, Hardware oder durch Abschalten zeitweilig nicht benötigter Komponentenerreicht werden. Erst aktuelle Entwicklungen, z. B. auf dem Gebiet der Brennstoff-zellen, lassen hier in Zukunft eine Entspannung der Situation erwarten.
• Ein-/Ausgabefähigkeiten
Nicht nur das Gewicht, sondern auch die Größe eines mobilen Geräts sind beschränkt.Mit den Abmessungen verringern sich i. d. R. auch die Ergonomie und die Fähigkei-ten der Ein-/Ausgabeschnittstellen. Es gibt heute keinen Standard für Benutzer-schnittstellen mobiler Rechner; verschiedene Bildschirmtechnologien und Eingabe-geräte konkurrieren miteinander. Auf der Eingabeseite werden klassische Tastaturen(z. B. bei Laptop und Notebook) ebenso benutzt wie Stifte (z. B. beim PDA), Cursor-Kreuze oder neuerdings Spracheingabe. Anwendungsprogramme, die auf die Interak-tion mit dem Benutzer angewiesen sind, müssen die Eigenschaften der verschiedenenEin-/Ausgabeschnittstellen berücksichtigen.
• Sicherheit
In Bezug auf die Sicherheit von Daten im Zusammenhang mit der Speicherung aufeinem mobilen Rechner sind drei Aspekte zu berücksichtigen:
– Schutz vor DatenverlustStationäre Rechner befinden sich i. d. R. in so genannten kontrollierten Umge-bungen. Beispiel dafür sind Rechenzentren eines Unternehmens oder die priva-te Wohnung. Im Gegensatz dazu sind mobile Rechner vielerlei Umweltfaktoren(z. B. wechselnde Umgebungen, Transport) ausgesetzt, die zusammen das Risikovon Datenverlust, z. B. durch Beschädigung oder Diebstahl, deutlich vergrößern.Zum Schutz vor Datenverlust ist eine regelmäßige Sicherung wichtiger Daten aufstationären Rechnern geboten.
– Zugriffsschutz gegen DritteGeht ein mobiler Rechner verloren oder ist er unbeaufsichtigt, besteht das Ri-siko, dass unberechtigte Dritte Zugang zu sensiblen Daten erlangen. Das Risikolässt sich durch relativ einfach durchzuführende Maßnahmen, wie die Verschlüs-selung gespeicherter Daten [Fan02], verringern.

16 KAPITEL 2. GRUNDLAGEN
– Zugriffsschutz gegen NutzerOft vergessen wird, dass ein Schutzbedürfnis gegen unerlaubten Zugriff nichtnur gegen Dritte, sondern prinzipiell auch gegen den autorisierten Nutzer desRechners besteht. Der Nutzer auf einem nicht mit dem Netzwerk verbunde-nen Rechner außerhalb einer kontrollierten Umgebung hat prinzipiell die volleKontrolle über die installierte Hard- und Software. Auch für diesen Fall musssichergestellt sein, dass global auferlegte Zugriffsbeschränkungen nicht lokal um-gangen werden können.
2.3.2 Drahtlose Kommunikation
Reichweite max. Übertragungsrate Sendeleistung
GSM ∼ 35 km 9, 6 Kbps 2000 mWGPRS ∼ 35 km 115 Kbps 2000 mWUMTS 60 m, 1 km, 2 km 2048 Kbps, 384 Kbps, 144 Kbps 125 – 250 mW
WLAN 300 m bis 54 Mbps 100 mWBluetooth 10 – 100 m 1 – 3 Mbps 1 – 100 mW
ZigBee bis 75 m 20 Kbps, 40 Kbps, 250 Kbps Bluetooth
LAN n. a. 100 Mbps – 1 Gbps n. a.
Tabelle 2.2: Drahtlose Kommunikationsmedien (Stand 2005)
Drahtlose Kommunikationsmedien erlauben es dem mobilen Gerät, unabhängig vom Stand-ort, mit anderen Rechnern in Verbindung zu treten, Daten auszutauschen und Dienstein Anspruch zu nehmen. Tabelle 2.2 zeigt die charakteristischen Eigenschaften heute all-gemein verfügbarer drahtloser Kommunikationsmedien.5 Zum Vergleich dazu sind in derletzten Zeile die Übertragungsraten aktueller kabelgebundener Verbindungen angegeben.
Drahtlose Nahbereichskommunikation mittels Bluetooth, WLAN oder ZigBee (zweiterBlock in Tabelle 2.2) kommt i. d. R. nur in Kombination mit einem zusätzlichen drahtlo-sen Weitverkehrsnetzwerk (erster Block) oder kabelgebundenen Netzwerken zum Einsatz,weshalb sie im Folgenden nicht separat betrachtet werden soll. Allerdings ist zu beachten,dass bei der Kombination verschiedener Medien, das dann jeweils schmalbandigere Me-dium die erzielbare Übertragungsrate bestimmt. Gegenüber kabelgebundenen Netzwerkensind bei drahtloser Kommunikation die folgenden Besonderheiten und Einschränkungen zuberücksichtigen:
• Datenübertragungsraten
Im Vergleich zu kabelgebundenen Netzwerken sind die erreichbaren Datenübertra-gungsraten bei drahtloser Kommunikation deutlich geringer. In den paketvermitteln-den zellulären Mobilfunknetzen wie GPRS und UMTS kommt einschränkend hinzu,dass die angegebene maximale Übertragungsrate für alle Nutzer in einer Zelle gilt.Folglich kann die von einem Einzelnen (ohne Zusatzkosten) erzielbare Datenübertra-gungsrate in der Praxis deutlich geringer ausfallen.
5Einen Überblick und weiterführende Links bietet beispielsweise die Webseite http://www.dafu.de.

2.3. MOBILE RECHNERSYSTEME 17
• Kosten
Drahtlose Kommunikation ist teuer. Dies zum einen aufgrund der nur begrenzt ver-fügbaren Übertragungsfrequenzen und zum anderen, weil hohe Anfangsinvestitionender Betreiber beim Aufbau der Netzinfrastruktur refinanziert werden müssen.
• Energieverbrauch
Die Nutzung eines drahtlosen Netzes ist gemessen an den bei mobilen Rechnernverfügbaren Ressourcen mit einem hohem Energieverbrauch verbunden. Dabei ver-braucht das Senden mehr Energie als das Empfangen.
• Verfügbarkeit
Drahtlose Kommunikationsmedien sind deutlich fehler- und störanfälliger im Ver-gleich zu kabelgebundenen Netzen (z. B. bei schneller Bewegung oder ungünstigerTopographie des Geländes) und nicht flächendeckend verfügbar. Für die fehlendeNetzabdeckung gibt es vornehmlich zwei, weitgehend zeitlich invariante, Ursachen:
– Mobilfunknetzbetreiber verzichten aus wirtschaftlichen Gründen auf eine voll-ständige Netzabdeckung und beschränken sich auf die Dienstebereitstellung inertragreichen Ballungsräumen. Auch der Ausbau von WLAN-Hotspots konzen-triert sich auf stark frequentierte Orte, wie Flughäfen oder höherpreisige Hotels.
– Ein in den letzten Jahren immer wichtiger werdender Grund für den Verzichtauf drahtlose Kommunikation oder sogar deren Verbot (z. B. im Personennah-verkehr, in Flugzeugen oder in Krankenhäusern) sind Vorbehalte gegen eine zu-nehmende Belastung und mögliche Störungen durch elektromagnetische Emis-sionen.
• Sicherheit
Prinzipbedingt kann in Funknetzen jeder mit einem passenden Empfangsgerät ausge-stattete Nutzer die gesamte stattfindende Kommunikation in einem geographischenGebiet abhören und zur späteren Auswertung aufzeichnen. Analog zur Problematiklokal gespeicherter Daten kann der Zugriff Dritter durch eine hochwertige Verschlüs-selung der Kommunikation verhindert werden.
2.3.3 Modell
Die Abbildung 2.2 zeigt, in Anlehnung an [IB94, Zuk98], das Szenario eines mobilen Rech-nersystems, das für die Arbeit als Grundlage dienen soll. Die stationären Rechner (SR)sind über ein kabelgebundenes Netzwerk verbunden. Ein mobiler Rechner (MR) kann sichgegenüber dem System in vier verschiedenen Zuständen befinden:
1. verbunden
Im verbundenen Zustand besteht eine Kommunikationsverbindung zu den übrigenRechnern über einen stationären Rechner. Der mobile Rechner ist in der Lage, aufDaten anderer Rechner zuzugreifen und entfernte Dienste über das Netzwerk zunutzen. Der verbundene Zustand kann weiter untergliedert werden in kabelgebundeneund drahtlose Verbindung.

18 KAPITEL 2. GRUNDLAGEN
SR SR
SR
MRMR
MR MR
kabelgebundenes
drahtloses
Netz
Netz1a
1b2a
2b
Abbildung 2.2: Ein mobiles Rechnersystem
(a) kabelgebundenDer mobile Rechner verfügt an seinem momentanen Aufenthaltsort über einendirekten Zugang zum kabelgebundenen Netzwerk. Der Rechner ist damit zeit-weise in seiner Mobilität eingeschränkt und kann, die Kommunikation betref-fend, wie ein stationärer Rechner im kabelgebundenen Netzwerk behandelt wer-den.
(b) drahtlosDer mobile Rechner kommuniziert ortsungebunden über ein drahtloses Kommu-nikationsmedium mit einem Rechner des kabelgebundenen Netzwerks. Es sinddie Eigenschaften drahtloser Kommunikationsmedien (siehe Abschnitt 2.3.2)zu berücksichtigen. Sie sind energieintensiv, verfügen über geringere nutzba-re Bandbreiten als kabelgebundene Netzwerkverbindungen, sind nicht überallverfügbar und teuer in der Benutzung.
2. verbindungslos
Der verbindungslose Zustand eines mobilen Rechners ist dadurch gekennzeichnet,dass keine Verbindung zu einem Netzwerk besteht und keine entfernten Dienste inAnspruch genommen werden können. Der verbindungslose Zustand kann weiter un-terteilt werden in ungewollte Unterbrechungen und gewollte Verbindungslosigkeit.
(a) ungewollt verbindungslos
Der mobile Rechner befindet sich außerhalb der Reichweite eines Kommunikati-onsmediums und ist deshalb gezwungenermaßen im verbindungslosen Zustand.
(b) gewollt verbindungslos
Der mobile Rechner befindet sich zwar innerhalb der Reichweite eines Kom-munikationsmediums, der Nutzer möchte aber dennoch nicht kommunizieren.Der vorübergehende freiwillige Verzicht auf Verbindungsmöglichkeiten kann bei-spielsweise durch fehlende Ressourcen des mobilen Rechners, durch Verbote oderin potentiell hohen Kosten begründet sein.

2.3. MOBILE RECHNERSYSTEME 19
Im Fall gewollter Verbindungslosigkeit können geeignete Maßnahmen zu deren Über-brückung (z. B. das Kopieren von Daten auf den mobilen Rechner) im vorhineingetroffen werden. Bei ungewollten Unterbrechungen, die im zeitlichen Auftreten undihrer Dauer nicht vorhersehbar sind, ist das, abgesehen von prophylaktisch und kon-tinuierlich anzuwendenden Maßnahmen (z. B. regelmäßige Synchronisation von Än-derungen), nicht möglich.
Im Unterschied zu Modellen in anderen Arbeiten (z. B. [IB94]) wird hier von der konkretenKommunikationsinfrastruktur abstrahiert und im Folgenden nur die Kommunikation zwi-schen Anwendungen bzw. Datenbanksystemen betrachtet. Ein solcher Ansatz ist für diekonzeptionelle Arbeit sinnvoll, da sich vor allem drahtlose Kommunikationsmedien ständigweiterentwickeln, ihre charakteristischen Merkmale aber weitgehend unverändert bleiben.
Das vereinfachte Modell ist aber auch insofern praxistauglich, als aktuelle drahtlose Kom-munikationsmedien gängige Protokolle für die Rechner-zu-Rechner-Kommunikation, wieTCP/IP [Tan03], unterstützen. Dadurch lassen sich Spezifika der verschiedenen Technikenund Protokolle vor der Anwendungskommunikation verbergen. Auf Protokollebene und fürdie Anwendung transparent gelöst werden können beispielsweise Zellenwechsel in zellulärenMobilfunknetzen, kurzzeitige Verbindungsunterbrechungen oder das Routing zu und vonnicht statisch adressierbaren Rechnern [Per98].
Bei Kommunikationsverbindungen wird nur die Kommunikation zwischen einem mobilenRechner und einem statisch adressierbaren Rechner im kabelgebundenen Netzwerk betrach-tet. In der Arbeit unberücksichtigt bleiben so genannte Ad-hoc-Netze, die eine direkte Kom-munikation und Dienstvermittlung zwischen mobilen Rechnern gestatten. Ad-hoc-Netzesind ein verhältnismäßig neues Forschungsgebiet, in dem noch viele grundlegende techni-sche Probleme (z. B. Dienstfindung, Routing) sowie Fragen der Datenintegrität und desDatenschutzes, die im DBS-Kontext essentiell sind, gelöst werden müssen. Einen aktuellenÜberblick zum Stand der Forschung gibt [HTK05].
In naher und auch in mittlerer Zukunft wird drahtlose Kommunikation in der Verfügbarkeiteingeschränkt und in mehrerer Hinsicht ressourcen-intensiv bleiben. Während bei kabelge-bundener Kommunikation die Verbindungsunterbrechung als seltener Fehlerfall betrachtetwird, sind längere Kommunikationsunterbrechungen bei ortsungebundener Arbeit ein Nor-malfall, seien sie vom Nutzer gewollt, um Kosten- und Ressourcen zu sparen, oder durchfehlende Netzverfügbarkeit oder Reglementierungen erzwungen.
Eine wünschenswerte Unabhängigkeit von teuren Ressourcen und unkontrollierbaren Fak-toren, wie der Verfügbarkeit eines Kommunikationsmediums, kann mit einer Strategie derAutonomie erzielt werden (vergleiche Kapitel 6.1). Die Strategie beinhaltet, dass Verbin-dungsaufnahmen auf das aus Anwendungssicht Notwendige, wie einen Datenabgleich, be-schränkt werden und, wenn immer möglich, autonom mit dem mobilen Rechner gearbeitetwird.
Eine Strategie der Autonomie, in welcher der unverbundene Zustand dominiert, hat ver-schiedene Vorteile. So kann die notwendige Kommunikation, weil in gewissen Grenzen plan-bar, über kostengünstige oder breitbandige Medien stattfinden. Auch können das Risikound die Auswirkungen einer ungewollten Verbindungsunterbrechung durch Verkürzung dergefährdeten Zeitspanne verringert werden. Eine abgebrochene Synchronisation kann wie-derholt bzw. wieder aufgesetzt oder auf später verschoben werden.

20 KAPITEL 2. GRUNDLAGEN
Voraussetzung für autonomes Arbeiten mit einer Datenbankanwendung ist, dass auch imunverbundenen Zustand ein lesender und schreibender Zugriff auf die von der Anwendungjeweils benötigten Daten gewährt werden kann. Es ist deshalb eine zentrale Anforderungan ein mobiles Datenbanksystem (siehe nächster Abschnitt) für ortsungebundene Arbeitin einem mobilen Rechnersystem, diesen Zugriff im unverbundenen Zustand und untersparsamer Nutzung von (drahtlosen) Kommunikationsmedien zur Verfügung zu stellen.
2.4 Mobile Datenbanksysteme
Datenbanksysteme werden heute nicht mehr nur als zentrales DBS (zDBS) realisiert,bei dem die Datenbank nur auf einem leistungsfähigen Rechner liegt, der alle Verar-beitung durchführt, sondern sie können die Möglichkeiten von verteilten Rechnersyste-men nutzen. Ein solches verteiltes Datenbanksystem (vDBS) besteht aus einer Menge lo-gisch zusammenhängender Datenbanken, die auf den einzelnen Komponenten des Rech-nersystems gespeichert sind. Das Datenbankmanagementsystem des vDBS (vDBMS) stelltdie rechnerübergreifenden Funktionen (z. B. Synchronisation von Änderungen) zur Verfü-gung [ÖV99, Dad96].
Ein mobiles Datenbanksystem (mDBS) ist ein verteiltes Datenbanksystem, bei dem dieDaten einer Datenbank auf mobile und stationäre Rechner eines mobilen Rechnersystemsverteilt sind. Durch die Besonderheit, dass mobile Rechner zeitweise autonom arbeiten,unterscheidet sich die Architektur eines mDBS und die Realisierung der Grundfunktionen(Abschnitt 2.1) von denen in einem verteilten Datenbanksystem auf ständig vernetztenRechnern. Je nach Anwendungsszenario und den Eigenschaften der beteiligten Rechnerund Netzwerkverbindungen haben auch vDBS verschiedene Eigenschaften.
2.4.1 Klassifikation für verteilte Datenbanksysteme
Zur Abgrenzung der unterschiedlichen Architekturen von vDBS wird in [Dad96] ein Katalogvon Merkmalen angegeben, der hier in angepasster Form Anwendung finden soll [HTK05]:
• Verteilung
Die Daten der verteilten Datenbank befinden sich nicht allein auf einem Rechner, son-dern einzelne Tabellenpartitionen oder ganze Tabellen sind auf mehreren Rechnernin jeweils lokalen Datenbanken verteilt abgelegt.
– AufteilungVerschiedene Tabellenpartitionen sind auf verschiedenen Rechnern abgelegt, sodass Anfragen über mehrere Rechner verteilt ausgeführt werden können.
– ReplikationEine Tabellenpartition ist mehrfach, kontrolliert redundant, auf verschiedenenRechnern abgelegt, so dass Anfragen an die Partition wahlweise auf verschiede-nen lokalen Datenbanken ausgeführt werden können.
• globales Datenbankschema
Der Zugriff auf die lokalen Datenbanken erfolgt über ein einheitliches globales Da-tenbankschema.

2.4. MOBILE DATENBANKSYSTEME 21
• verteilte Anfrageauswertung
Anfragen können sich über Datenbanken mehrerer Rechner erstrecken. Sie werdenvom DBS entgegengenommen, in Teilanfragen für die einzelnen Rechner übersetzt,dort jeweils ausgeführt, die Einzelergebnisse zum Endergebnis zusammengeführt undan den anfragenden Rechner zurückgeschickt.
• globale Transaktionsverarbeitung
Transaktionseigenschaften werden global über alle Rechner des Systems garantiert.
• Transparenz von Verteilung und Replikation
Vor den Anwendungsprogrammen wird die Mehrrechnersituation und die redundanteDatenhaltung verborgen.
• lokale Autonomie
Die einzelnen Rechner haben ein eigenes lokales DBMS, über das Anwendungen auchohne Verbindung zu anderen Rechnern auf lokale Datenbanken sowohl lesend als auchschreibend zugreifen können.
• Heterogenität
Das vDBS integriert verschiedene lokale Datenbanksystemprodukte oder Datenmo-delle, die von den einzelnen Rechnern genutzt werden.
2.4.2 Vergleich mit anderen vDBS
mDBS hvDBS fDBS
Aufteilung –
Replikation –
globales Schema
g → l g → l g ← lverteilte Anfragen ()
globale Transaktionen ()
Transparenz –
lokale Autonomie –
Heterogenität –
– vorhanden, () – eingeschränkt vorhanden
Tabelle 2.3: Vergleich verschiedener Konfigurationen
Zum Vergleich von vDBS-Architekturen wird untersucht, ob und inwieweit die Merkmaledes Katalogs jeweils erfüllt sind. Aus den in Abschnitt 2.3 herausgestellten Eigenschaf-ten eines mobilen Rechnersystems lassen sich die Aussagen für ein mDBS ableiten. DieTabelle 2.3 zeigt die Eigenschaften eines mDBS im Vergleich zu den zwei in der Praxis amhäufigsten eingesetzten Architekturen verteilter DBS in ständig vernetzten Umgebungen:

22 KAPITEL 2. GRUNDLAGEN
• homogen eng-integriertes verteiltes Datenbanksystem (hvDBS [Dad96])
Bei einem hvDBS agieren die einzelnen lokalen DBMS nicht autonom, sondern werdenausschließlich über das globale vDBMS gesteuert. Das vDBS tritt nach außen als einDBS mit entsprechend höherer Leistung und Fehlertoleranz auf. Die lokalen Schematawerden beim Entwurf aus dem globalen Schema abgeleitet (g → l). Anwendungengreifen nur über das globale Schema auf die Datenbank zu. Replikation wird in hvDBSsowohl zur Erhöhung der Verfügbarkeit für den Fall des Ausfalls eines Rechners bzw.einer lokalen Datenbank als auch zur Performance-Steigerung durch das Ausnutzenvon Parallelverarbeitung eingesetzt.
• föderiertes Datenbanksystem (fDBS [Con97])
Bei einem fDBS werden i. d. R. bereits bestehende lokale DBS um eine globale Kom-ponente, das föderierte DBMS, ergänzt. Bereits vorhandene lokale Schemata werdenzu einem neuen globalen Schema integriert (g ← l). Der Zugriff auf die Daten istsowohl weiter lokal (z. B. für Altanwendungen) als auch rechnerübergreifend über einglobales Schema möglich. Ein fDBS kommt zum Einsatz, wenn übergreifende Anfra-gen ohne Verlust der Autonomie möglich sein sollen, oder es dient als Vorstufe zurMigration, hin zu einem einheitlichen Datenbankschema.
Im Vergleich mit einem mDBS zeigen sich sowohl Gemeinsamkeiten als auch deutlicheUnterschiede zu den „klassischen“ vDBS-Architekturen. Eine dauerhafte Aufteilung derDaten ist in mDBS aus zwei Gründen nicht sinnvoll. Zum einen kann die Erreichbarkeit desdatenhaltenden mobilen Rechners für Anfragen nicht garantiert werden und zum anderenbesteht für die Daten ein unkalkulierbares Sicherheits- und Verlustrisiko. In einem mDBSwerden auf mobilen Rechnern nur replizierte Daten gespeichert, deren „Original“, mit demalle Änderungen abgeglichen werden müssen, auf einem stationären Rechner abgelegt ist.
Mobile Datenbanksysteme verfügen wie hvDBS und fDBS über ein globales Datenbank-schema, aus dem die mobilen Rechner jeweils einen Ausschnitt replizieren. Wie beim hvDBSergeben sich die lokalen Datenbankschemata als Ableitung aus dem globalen Schema (g→ l). Allerdings greifen Anwendungen i. d. R. über die jeweiligen lokalen Schemata auf dieDatenbank zu. Verteilte Anfragen sind i. d. R. auf den sich verbindenden mobilen Rechnerund die Rechner im kabelgebundenen Netzwerk beschränkt, da die Erreichbarkeit anderermobiler Rechner nicht garantiert werden kann.
Ebenso wie bei verteilten Anfragen ist im unverbundenen Zustand keine rechnerüber-greifende Transaktionskontrolle möglich. Unterbrechungen der Verbindung sind nicht alsFehler-, sondern als Normalfall zu betrachten. Eine Transparenz der Mehrrechnersituation,wie sie bei hvDBS und fDBS angestrebt wird, lässt sich mit mDBS nicht erreichen. Bei-spielsweise können Anfragen an Daten, die nicht auf den mobilen Rechner kopiert wurden,im unverbundenen Zustand nicht oder nicht korrekt (wenn nur Teile der benötigten Da-ten vorliegen) beantwortet werden. Damit dennoch Garantien für die Ausführung lokalerTransaktionen gegeben werden können, müssen vor der Verbindungstrennung bestimmteVorkehrungen getroffen (Konfliktvermeidung) oder Konflikte im Nachhinein bei der Syn-chronisation aufgelöst werden (Konfliktauflösung). Die Synchronisation und Konfliktbe-handlung in mobilen Datenbanksystemen ist Gegenstand von Abschnitt 2.5.
Für den unverbundenen Zustand muss der mobile Rechner über ein eigenes DBMS verfü-gen, das es ihm gestattet, autonom auf seiner lokalen Datenbank mit replizierten Daten zuarbeiten. Aufgrund der Ressourceneinschränkung mobiler Rechner bestehen aber i. d. R.

2.4. MOBILE DATENBANKSYSTEME 23
Unterschiede in der Funktionalität des DBMS und der Art der Datenspeicherung zwischenmobilen Rechnern und stationären Rechnern. Auch gibt es bei mobilen Rechnern keineStandardarchitektur, so dass auch zwischen verschiedenen mobilen Rechnern erheblicheUnterschiede vorhanden sein können. Mit beiden Ausprägungen der Heterogenität musseine mDBS umgehen können.
2.4.3 Architektur
zeitweise verbunden kabelgebundenes Netz
Anw
endu
ng DBMSServer-DBMS
DBDB
Server
Client-
ReplikationSynchronisation
Server
Replikations-Server
mobiler ClientDaten
Abbildung 2.3: Ein mobiles Datenbanksystem
Im Folgenden sei die in Abbildung 2.3 dargestellte Architektur eines mobilen Datenbank-systems zugrundegelegt, wie sie auch in kommerziellen mobilen Datenbanklösungen (ver-gleiche Abschnitt 3.5) anzutreffen ist und für die prototypische Implementierung der nut-zerdefinierten Replikation verwendet wird. Für eine Diskussion von Architekturalternativenbei der Integration der Replikations- und Synchronisationsfunktionalität sei auf Kapitel 5.2verwiesen.
Ein mDBS besteht demnach mindestens aus drei Komponenten, einem Client-DBS aufeinem mobilen Rechner, einem Server-DBS auf einem stationären Rechner und einem zu-sätzlichen beigeordneten Server für die Replikation und Synchronisation, kurz Replikations-Server, ebenfalls auf einem stationären Rechner. Zu einem mDBS gehören i. d. R. ein Server-DBS6 und viele mobile Clients, auf denen verschiedene DBMS-Produkte im Einsatz seinkönnen.
6Als Server-DBS wird o. B. d. A. ein zentrales DBS angenommen, jedes vDBS mit der Eigenschaft derTransparenz kann an seiner statt eingesetzt werden.

24 KAPITEL 2. GRUNDLAGEN
In dem beschriebenen Modell eines mDBS können die Clients zeitweise autonom agieren.Das Client-DBMS verwaltet die Client-Datenbank, im Folgenden als Replikatdatenbankbezeichnet, und stellt die Schnittstelle für die Anwendung auf dem mobilen Client bereit.Daneben können vom Client-DBMS natürlich noch weitere nicht replizierte rein lokaleDatenbanken verwaltet werden. In einem mDBS sind Replikatdatenbanken und Server-Datenbank nicht gleichberechtigt. Alle Änderungen auf einer Replikatdatenbank müssen,damit sie gültig und dauerhaft werden, in die Server-Datenbank eingebracht werden.
Die Server erfüllen im verbundenen Zustand Aufgaben für das gesamte mDBS und alleReplikatdatenbanken. Das Server-DBMS ist verantwortlich für die Dauerhaftigkeit vonÄnderungen, die Integritätssicherung und gemeinsam mit dem Replikations-Server für dieAuthentifizierung und Autorisierung der mobilen Rechner und Nutzer. Die Rechner für dasServer-DBS und den Replikations-Server müssen dabei nicht zwingend verschieden sein.
Über den Replikations-Server werden die jeweils replizierten lokalen Ausschnitte der Server-Datenbank festgelegt und verwaltet. Verfügt der Replikations-Server darüber hinaus übereine eigene Datenbank, kann er die Server-Datenbank wirksam entlasten (z. B. Stoß-zeiten für Client-Synchronisationen) und vor unerwünschten Zugriffen schützen (z. B.Firewall-Funktion), siehe Kapitel 5.2. Darüber hinaus steuert der Replikations-Server,wenn erforderlich DBMS-Produkt-übergreifend, die Datensynchronisation zwischen Server-Datenbank und Replikatdatenbanken. Die Synchronisation in mobilen Datenbanksystemenist Thema des folgenden Abschnitts.
2.5 Synchronisation
Die Arbeit mit replizierten Daten auf dem Client beinhaltet zwei Aspekte, die Auswahlder Schema- und Datenobjekte, welche auf dem Client gespeichert werden sollen, und dieregelmäßige bidirektionale Synchronisation von unverbunden durchgeführten Änderungenmittels geeigneter Synchronisationsverfahren. Eine durch den Client und seine Nutzer be-stimmte Replikatauswahl und ihre Realisierung ist der Schwerpunkt dieser Arbeit. DieAnalyse von Alternativen zur Replikatauswahl erfolgt deshalb zusammen mit der Einfüh-rung des Konzepts der nutzerdefinierten Replikation in Kapitel 3.
Für den zweiten Aspekt, die Synchronisation, werden bekannte Konzepte und Synchro-nisationsverfahren adaptiert, welche dieser letzte Abschnitt des Grundlagenkapitels ein-führt. Den Ausgangspunkt für die Beschreibung eines datenbankübergreifenden Synchro-nisationsverfahrens in einem mDBS bilden die Transaktionen und ihre Synchronisation imMehrbenutzerbetrieb, beides Grundfunktionen eines DBMS.
2.5.1 ACID-Transaktionen
Eine Transaktion fasst eine Folge logisch zusammengehörender Lese- und Schreiboperatio-nen zu einer Einheit zusammen. Der Anwendungsentwickler bzw. Benutzer spezifiziert le-diglich die sich aus der Anwendungssemantik ergebenden Operationen und legt den Beginn(Begin Of Transaction (BOT)) und das Ende (End Of Transaction (EOT)) der Transak-tion fest. Für die Ausführung von Transaktionen gelten bestimmte Garantien, z. B. dieAtomarität der Ausführung. Synchronisationsverfahren als Bestandteil der Transaktions-verwaltung sichern diese Garantien anwendungsunabhängig auch für den Fall nebenläufiger

2.5. SYNCHRONISATION 25
Ausführung von Transaktionen sowie bei Anwendungs- und Systemfehlern. Fast alle heutekommerziell verfügbaren Datenbanksysteme, inklusive der Varianten für mobile Rechner(siehe Abschnitt 3.5), bieten eine Transaktionsverwaltung, so dass im Folgenden von einertransaktionsorientierten Arbeit auf Server und Clients ausgegangen wird. Bevor auf dieBesonderheiten und notwendigen Erweiterungen für replizierte Datenhaltung und im be-sonderen für mDBS eingegangen werden kann, sollen hier zunächst wichtige Begriffe undEigenschaften „klassischer“ Transaktionen wiederholt werden [GR93].
Für klassische Transaktionen in zentralen Datenbanksystemen werden die Ausführungsga-rantien aus den ACID-Eigenschaften [HR83] abgeleitet:
• Atomarität (Atomicity)
Eine Transaktion wird entweder vollständig oder gar nicht ausgeführt (Alles-oder-Nichts-Prinzip).
• Konsistenz (Consistency)
Eine Transaktion überführt eine Datenbank von einem konsistenten Zustand in einenwiederum konsistenten Zustand, wobei nicht ausgeschlossen wird, dass während ei-ner Transaktion inkonsistente Zwischenzustände der Datenbank auftreten. Für dieIntegritätssicherung ist die Transaktion die Einheit für die Wahrung der Datenbank-konsistenz.
• Isolation (Isolation)
Jede Transaktion läuft im logischen Einbenutzerbetrieb ab. Das bedeutet, aus Sichtder Transaktion sind Änderungen anderer, nebenläufig ablaufender Transaktionenunsichtbar und für ihren Effekt unmaßgeblich.
• Dauerhaftigkeit (Durability)
Falls eine Transaktion erfolgreich beendet wurde, müssen die Änderungen in derDatenbank unabhängig von zukünftig auftretenden Fehlern „überleben“.
Eine Transaktion kann erfolgreich beendet (Commit) oder abgebrochen werden (Abort).In beiden Fällen müssen Atomarität und nach dem Commit Dauerhaftigkeit garantiertwerden. Aus Gründen der Lastverteilung speichern DBMS einerseits Änderungen bereitsvor Transaktionsende in die Datenbank (Steal -Strategie) und andererseits verzögern sie dasSchreiben bis nach dem Transaktionsende (No-Force-Strategie). Damit bei einem Transak-tionsabbruch bereits in der Datenbank gespeicherte Änderungen zurückgesetzt (Rollback)und bei einem Fehler nach dem Commit noch nicht gespeicherte Daten dauerhaft gemachtwerden können, schreiben DBMS ein Log für Änderungsoperationen und geänderte Daten(zu Protokollierungstechniken siehe [SG98, Gol98]). Benötigt werden pro Operation üb-licherweise das Vorherabbild (before image) für das Zurücksetzen und das Nachherabbild(after image) des geänderten Datenobjekts für die wiederholte Ausführung. Anzumerkenist, dass Leseoperationen im Gegensatz zu Schreiboperationen normalerweise nicht proto-kolliert werden.
Die Konsistenzeigenschaft fordert, dass spätestens beim Commit einer Transaktion alleIntegritätsbedingungen überprüft werden. Im Fall einer Verletzung sind Maßnahmen zurWiederherstellung der Konsistenz zu ergreifen, etwa durch einen Abbruch der Transaktionmit Zurücksetzen der bereits vorgenommenen Änderungen. Die Isolationseigenschaft zu

26 KAPITEL 2. GRUNDLAGEN
garantieren, ist bei Hintereinanderausführung von Transaktionen trivial. Arbeiten mehrereTransaktionen parallel auf demselben Datenbestand, muss das Synchronisationsverfahrenfür einen „wahrgenommenen Einbenutzerbetrieb“7 sorgen, beispielsweise in dem das Schrei-ben von Datenobjekten verboten wird, die zuvor von einer anderen Transaktion verwendetwurden (zu Sperrverfahren siehe Abschnitt 2.5.3.1). Entscheidungsgrundlage für eine zu-lässige nebenläufige Ausführung von Transaktionen ist das jeweils angewendete Korrekt-heitskriterium [WV01, HR01].
2.5.1.1 Korrektheitskriterium Serialisierbarkeit
Aus dem Wissen um das korrekte Ergebnis einer Hintereinanderausführung von Transak-tionen lässt sich das Korrektheitskriterium der Serialisierbarkeit ableiten. Serialisierbarkeitbedeutet (informal), dass eine nebenläufige Ausführung von Transaktionen dann korrektist, wenn sie äquivalent ist zu einer beliebigen seriellen Abfolge derselben Transaktionen.Äquivalent bedeutet hier, dass beide Transaktionsfolgen den selben Effekt haben. Die ge-bräuchlichste formale Definition der Serialisierbarkeit wird anhand von Abhängigkeitenzwischen Transaktionen wie folgt vorgenommen.
Es sei eine Historie eine lineare Abfolge von Operationen nebenläufig ausgeführter Trans-aktionen. Dann stehen zwei Operationen verschiedener Transaktionen einer Historie inKonflikt zueinander, wenn sie auf demselben Datenobjekt arbeiten und mindestens einevon ihnen eine Schreiboperation ist (Lese-Schreib- oder Schreib-Schreib-Konflikt). Über diezeitliche Abhängigkeit der Operationen lässt sich für eine gegebene Historie ein gerichte-ter Abhängigkeitsgraph aufbauen. Dessen Knoten sind alle mit Commit abgeschlossenenTransaktionen. Zwei Knoten bzw. Transaktionen tr1 und tr2 im Graphen sind durch einegerichtete Kante mit der Markierung (op1, op2) verbunden, wenn op1 ∈ tr1 und op2 ∈ tr2
in Konflikt zueinander stehen und op2 vor op1 in der Historie steht.
Die nebenläufige Ausführung von Transaktionen ist (konflikt)serialisierbar, wenn sie kon-fliktäquivalent zu einer seriellen Historie ohne Nebenläufigkeit ist. Zwei verschiedene His-torien sind konfliktäquivalent, wenn sie dieselben erfolgreich abgeschlossenen Transaktionenund denselben Abhängigkeitsgraphen haben. Es kann gezeigt werden, dass eine Historiegenau dann serialisierbar ist, wenn der zugehörige Abhängigkeitsgraph keine Zyklen auf-weist [BHG87]. Bei einer gegebenen Historie lässt sich damit durch topologische Sortierung,wenn vorhanden, die äquivalente serielle Historie bestimmen.
2.5.1.2 Reihenfolgeerhaltende und rücksetzfähige Historien
Für ein praktikables Synchronisationsverfahren reicht das Kriterium der Serialisierbarkeitallein allerdings noch nicht aus. Serialisierbarkeit garantiert zwar die Isolationseigenschaft,gibt aber keine Reihenfolge der Transaktionen vor. Es wäre also legitim, allen Lesetrans-aktionen einen längst veralteten Datenbankzustand anzubieten und sie vor allen zwischen-zeitlich durchgeführten Änderungstransaktionen einzuordnen. Will man das verhindern,muss zusätzlich gefordert werden, dass Historien reihenfolgeerhaltend sind. In reihenfolge-erhaltenden Historien sieht jede Transaktion alle Änderungen von Transaktionen, die beiihrem Start bereits mit Commit abgeschlossen hatten.
7Eine erzwungene Hintereinanderausführung von Transaktionen ist nicht praktikabel, da Verarbeitungs-unterbrechungen durch E/A-Zugriffe oder Denkzeiten in diesem Fall nicht ausgenutzt werden könnten.

2.5. SYNCHRONISATION 27
Für die Wiederherstellung von Isolation und Atomarität im Fall eines Transaktionsab-bruchs müssen die erlaubten Historien noch weiter eingeschränkt werden. Beim Abbrucheiner Transaktion tr müssen auch alle diejenigen Transaktionen abgebrochen werden, diebereits Daten gelesen haben, welche durch tr modifiziert wurden. Das wird als kaskadieren-des Rücksetzen (cascading rollback) bezeichnet, da von der Rücksetzung wiederum weitereTransaktionen betroffen sein können. Trifft das kaskadierende Rücksetzen dabei auf ei-ne Transaktion, die bereits mit Commit abgeschlossen hat und damit dauerhaft ist, darfsie nicht mehr zurückgesetzt werden. Deshalb wird gefordert, dass Historien rücksetzfähigsind. In rücksetzfähigen Historien wird eine Transaktion erst dann abgeschlossen, wenn alleTransaktionen, von denen sie modifizierte Daten gesehen hat, abgeschlossen sind.
2.5.2 Synchronisation in mDBS
Transaktionen in zentralen DBS setzen sich aus Operationen zusammen, die auf demsel-ben DBS ausgeführt werden. Synchronisationsverfahren müssen dabei „nur“ den nebenläu-figen Zugriff auf eine Datenbank koordinieren. In einem mobilen mDBS mit einer Server-Datenbank und einer oder mehreren Replikatdatenbanken müssen zusätzlich Operationenauf verschiedenen Rechnern koordiniert bzw. später bei Wiederverbindung deren Effektesynchronisiert werden. Da diese Synchronisation DBS-übergreifend erfolgen muss, ist dafürder Replikations-Server zuständig, der seine Aufgabe im Zusammenspiel mit der jeweiligenlokalen Transaktionsverwaltung ausführt.
Ist der Client Bestandteil des kabelgebundenen Netzes, kann er direkt auf der Server-Datenbank arbeiten, so dass währenddessen keine erweiterte Synchronisationsfunktionali-tät erforderlich ist. Bei einer zeitweise unverbunden Arbeit (Änderungen sind sowohl aufdem Client als auch auf dem Server möglich) sind Zeitpunkte der (gewollten) Verbindungs-trennung und -wiederaufnahme von besonderer Bedeutung für die Synchronisation in einemmDBS.
Server
mobiler Client
Zeit
Server-Transaktion tr
Client-Transaktionen tri Synchronisation
Abbildung 2.4: Transaktionsverarbeitung in einem mDBS
Es sei angenommen, dass sich der für die unverbundene Arbeit des Client benötigte Daten-bankausschnitt zum Zeitpunkt der Verbindungstrennung bereits in der Replikatdatenbankbefindet, und er aktuell und konsistent ist. Desweiteren wird zur Vereinfachung der Dar-stellung vorausgesetzt, dass zu den Zeitpunkten der Verbindungstrennung und der Wieder-

28 KAPITEL 2. GRUNDLAGEN
verbindung keine Client-Transaktionen mehr offen sind. Dann ergibt sich für einen Clientder in Abbildung 2.4 dargestellte Ablauf (die Pfeile verdeutlichen den Kontrollfluss).
Nach der Verbindungstrennung arbeitet der Client mit den zuvor replizierten Daten. Erführt dazu Transaktionen, im Folgenden als Client-Transaktionen bezeichnet, über dasdann autonome Client-DBMS auf der Replikatdatenbank aus. Da keine Verbindung be-steht, sind Datenänderungen auf dem Client zunächst für den Server unsichtbar und umge-kehrt. Erst nach einer Wiederverbindung in der Phase der Synchronisation werden die Än-derungen aller abgeschlossenen Client-Transaktionen in die Server-Datenbank eingebracht(Reintegration) und die zwischenzeitlichen Änderungen auf dem Server sowie eventuellabweichende Ergebnisse der Reintegration an den Client übertragen. Aus Sicht der Server-Datenbank kann ein Zyklus zwischen zwei Verbindungstrennungen eines mobilen Clientals eine Transaktion auf der Server-Datenbank, im Folgenden als Server-Transaktion be-zeichnet, aufgefasst werden. Im Anschluss an die Synchronisation sind die Vorbedingungenfür eine Verbindungstrennung wieder erfüllt. Es kann sich eine neue unverbundene Phaseanschließen, durch die automatisch eine neue Server-Transaktion initiiert wird.
Während Client-Transaktionen in der unverbundenen Arbeitsphase, isoliert betrachtet, denklassischen Anwendungstransaktionen entsprechen, unterscheidet sich die gesamte Server-Transaktion eines mobilen Client in Dauer, Struktur und der Ausführung von den übli-cherweise von Anwendungen durchgeführten Transaktionen. Eine Server-Transaktion ge-hört, entsprechend der unverbundenen Zeit des mobilen Client von Minuten, Stunden oderTagen, zu den langen Transaktionen [HR01]. Zum Vergleich dauern Transaktionen beidirektem Zugriff auf die Datenbank selten länger als ein paar Sekunden.
Auch ist die Server-Transaktion keine homogene Einheit, wie für Anwendungstransaktionenüblicherweise unterstellt wird. Die Operationsfolge der Server-Transaktion besitzt eine in-nere Struktur, nämlich die Zuordnung der Operationen zu einzelnen Client-Transaktionen.Die Änderungen einzelner Client-Transaktionen sind zwar nach ihrer erfolgreichen Ausfüh-rung in der Replikatdatenbank gespeichert, die allein maßgebliche (wiederholte) Ausfüh-rung auf der Server-Datenbank erfolgt erst zum Commit-Zeitpunkt der Server-Transaktion,welcher der Synchronisationsphase entspricht. Insbesondere können endgültige Prüfungenauf Verletzung der Konsistenz und Isolation durch die Server-Transaktion erst zu diesemZeitpunkt durchgeführt werden.
Die ermittelten charakteristischen Eigenschaften von Server-Transaktionen und die sichdaraus ergebenden Konsequenzen für die Arbeit eines DBS-übergreifenden Synchronisa-tionsverfahrens werden in den folgenden Unterabschnitten genauer untersucht. Als Aus-gangspunkt dient dabei ein Vergleich mit bekannten Transaktionsmodellen und Synchro-nisationsverfahren.
2.5.2.1 Modell der geschlossen geschachtelten Transaktionen
Eine so genannte geschachtelte Transaktion besteht aus einer Menge von Subtransaktionen,die ihrerseits wiederum geschachtelt sein können, und wird durch einen Transaktionsbaumbeliebiger Tiefe repräsentiert. Eine Subtransaktion wird erst dann endgültig abgeschlos-sen, wenn alle ihre Vorfahren im Transaktionsbaum erfolgreich abgeschlossen wurden. DasCommit einer Subtransaktion garantiert deshalb noch nicht die Dauerhaftigkeit, weswe-gen hierfür die Bezeichnung lokales Commit verwendet wird. Dementsprechend bezeichnetglobales Commit den erfolgreichen Abschluss der Wurzeltransaktion, der auch alle lokal

2.5. SYNCHRONISATION 29
abgeschlossenen Subtransaktionen dauerhaft macht. Subtransaktionen einer Vatertrans-aktion können parallel ausgeführt und unabhängig von der noch nicht abgeschlossenenVatertransaktion zurückgesetzt werden. Unterschieden werden geschlossen und offen ge-schachtelte Transaktionen [WS92, Mos85]. Geschlossen geschachtelte Transaktionen gebenihre Änderungen beim lokalen Commit nur an ihre Vatertransaktion und damit implizitauch an ihre Geschwister im Transaktionsbaum weiter, offen geschachtelte auch an alleanderen Transaktionen.
Vergleicht man die Struktur von Server-Transaktionen mit bekannten Transaktionsmo-dellen, so ist festzustellen, dass sich eine Server-Transaktion als geschlossen geschachtelteTransaktion beschreiben lässt. Die Server-Transaktion, welche sich zwischen zwei Synchro-nisationszeitpunkten erstreckt, entspricht der Wurzeltransaktion eines Transaktionsbaumsder Tiefe 2. Die Subtransaktionen werden von den Client-Transaktionen gebildet, wobeidiese selbst nicht geschachtelt sind.8 Bei der Server-Transaktion handelt es sich um eine ge-schlossen geschachtelte Transaktion, da unverbunden durchgeführte Änderungen erst nachder Synchronisation, die dem globalen Commit entspricht, für andere Server-Transaktionenbzw. Clients sichtbar werden.
Das lokale Commit der Client-Transaktionen in der Replikatdatenbank schließt diese nurvorläufig ab und schreibt auch nur vorläufige Daten. Bei der Ausführung auf der Replikat-datenbank ist eine Gewährleistung von Konsistenz und Isolation sowie die Prüfung von Zu-griffsrechten zunächst nur lokal für den replizierten Schemaausschnitt und die nebenläufigeAusführung von Client-Transaktionen auf einem Client möglich. Eine endgültige Prüfungder Zugriffsrechte, der Isolation gegenüber anderen Server-Transaktionen und der Inte-gritätsbedingungen kann erst nachträglich zum Synchronisationszeitpunkt erfolgen, wennwieder eine Verbindung zur Server-Datenbank besteht (ein Beispiel für eine Transaktionmit lokalem, aber nicht globalem Konsistenzerhalt enthält Abschnitt 2.5.2.4).
Das globale Commit der Server-Transaktion muss Konsistenz, Isolation, Atomarität unddie Rechtmäßigkeit der eingebetteten Client-Transaktionen und damit auch der gesamtenServer-Transaktion garantieren. Wird bei der Synchronisation eine Verletzung der Aus-führungsgarantien festgestellt, können Client-Transaktionen auch nachträglich (ggf. kaska-dierend) zurückgesetzt werden, d. h. das lokale Commit garantiert im Allgemeinen keineDauerhaftigkeit. Das gilt insbesondere auch für den Fall des Datenverlusts während des un-verbundenen Zustands vor der nächsten Synchronisation. Zur Vorbeugung können Backup-und Recovery-Verfahren (siehe z. B. [Stö01, GS02]) eingesetzt werden.
Anzumerken ist, dass die Atomarität der Server-Transaktion wegen ihrer Konstruktion fürden Konsistenzerhalt der Server-Datenbank nicht erforderlich ist. Da die zurückzunehmen-den Änderungen bereits in der Client-Datenbank sichtbar sind, müssen beim Rücksetzeneiner Client-Transaktion die geänderten Datenobjekte mit den aktuellen Daten des Ser-vers überschrieben werden. Die Wirkung der Client-Transaktion wird dadurch kompensiert.Das Kompensieren von Basisoperationen (Einfügen, Ändern, Löschen) erfolgt semantischdurch eine komplementäre Operation (z. B. Einfügen einer gelöschten Zeile). Im Folgendenwird angenommen, dass in Client-Transaktionen keine nicht kompensierbaren Operationen(z. B. Löschen einer nicht replizierten Datei) vorgenommen werden.
8Es wird angenommen, dass auf dem Client-DBS keine erweiterten Transaktionsmodelle zum Einsatzkommen.

30 KAPITEL 2. GRUNDLAGEN
2.5.2.2 Optimistische Synchronisation
Lese- Validierungs- Schreibphase
BOT EOT
Abbildung 2.5: Die drei Phasen der optimistischen Synchronisation
Synchronisationsverfahren, welche in der Erwartung weniger Konflikte deren Auftreten erstzum Commit-Zeitpunkt prüfen, werden in der Literatur unter dem Begriff optimistischeSynchronisationsverfahren (Optimistic Concurrency Control) geführt [Rah94, Här84]. DieTransaktionsverarbeitung bei optimistischer Synchronisation läuft in drei Phasen ab, derLesephase, Validierungsphase und Schreibphase (Abbildung 2.5).
Während der Lesephase findet der eigentliche Zugriff auf die Daten statt. Schreiboperatio-nen werden zunächst nur auf privaten Kopien in einem lokalen Puffer durchgeführt. DieTransaktion liest neue und bisher unveränderte Daten aus der Datenbank und veränderteDaten aus ihrem eigenen Puffer.
Zum Commit-Zeitpunkt beginnt die Validierungsphase. Hierbei wird überprüft, ob einKonflikt mit einer anderen Transaktion aufgetreten ist. Für diese Prüfung müssen vonden Transaktionen die Menge der geänderten, gelöschten oder hinzugefügten Datenobjekte(Write-Set) und die Menge der gelesenen Datenobjekte (Read-Set, es gilt Write-Set ⊆ Read-Set) bekannt sein. Gibt es einen nichtleeren Schnitt zwischen dem Read-Set der validie-renden Transaktion und dem Write-Set einer parallel ausgeführten Transaktion, ist einKonflikt erkannt (vergleiche Konfliktdefinition in Abschnitt 2.5.1.1). Anhand der Auswahlder Transaktionen, gegen die validiert wird, lassen sich optimistische Synchronisations-verfahren grob in zwei Klassen einteilen: rückwärtsorientierte Verfahren (Backward Ori-ented Optimistic Concurrency Control (BOCC)) validieren gegen alle bereits erfolgreichvalidierten Transaktionen und vorwärtsorientierte Verfahren gegen die aktuell laufendenTransaktionen.
Für Schreibtransaktionen (Write-Set ist nicht leer) erfolgt bei positiver Validierung an-schließend die Schreibphase, in der veränderte und neue Datenobjekte aus dem Pufferin die Datenbank übertragen werden. Andernfalls wird eine der in Konflikt stehendenTransaktionen abgebrochen, wobei beim BOCC-Verfahren nur die validierende Transakti-on gewählt werden kann. Die Validierungs- und Schreibphase verschiedener Transaktionenwerden serialisiert, d. h. es befindet sich immer höchstens eine Transaktion in dieser Pha-se. Das Vorgehen garantiert Serialisierbarkeit, wobei sich die Serialisierungsreihenfolge derTransaktionen unmittelbar aus den Commit-Zeitpunkten ergeben.
Angewendet auf Server-Transaktionen in einem mDBS entspricht die unverbundene Aus-führung der Client-Transaktionen der Lesephase. Den Puffer bildet die Replikatdatenbank,wobei bisher nicht verwendete Daten nicht aus der Server-Datenbank sondern ebenfalls ausdem Puffer (Benutzung der zuvor ausgewählten Replikate) gelesen werden. Die Reintegrati-on der Änderungen in die Server-Datenbank entspricht der Validierungs- und Schreibphaseeines optimistischen Synchronisationsverfahrens. Die Validierung muss dabei immer rück-wärtsorientiert erfolgen, da Änderungen anderer laufender Server-Transaktionen zum Vali-dierungszeitpunkt nicht bekannt sind. Im Falle eines erkannten Konflikts ist es hinreichend,die konfliktauslösende Client-Transaktion zurückzusetzen. In der Folge kann allerdings ein

2.5. SYNCHRONISATION 31
kaskadierendes Rücksetzen bzw. Kompensieren weiterer Client-Transaktionen erforderlichsein, die zeitlich nach der validierenden Transaktion lokal abgeschlossen und auf Daten derTransaktion zugegriffen hatten.
Dieses nachträgliche Zurücksetzen bereits lokal abgeschlossener Client-Transaktionen gilt esnach Möglichkeit zu vermeiden und stattdessen so viele Änderungen des Client wie möglichauf der Server-Datenbank dauerhaft zu machen. Dazu ist es zunächst erforderlich, genau zubestimmen, welche Mehrbenutzeranomalien bei der Validierung von Server-Transaktionenüberhaupt auftreten können und folglich als Konflikte behandelt werden müssen.
2.5.2.3 Mehrbenutzeranomalien
Phänomene bezeichnen Historien einer nebenläufigen Ausführung von Transaktionen, diedirekt oder in ihrer Folge zu einer Mehrbenutzeranomalie, das ist eine Verletzung der Isola-tionseigenschaft oder eine Inkonsistenz der Datenbank, führen können. Für die Definitionder Phänomene werden zunächst folgende Bezeichnungen eingeführt.
Es bezeichnet ri[x] (wi[x]) eine Leseoperation (Schreiboperation) von Transaktion tri aufdem Datenobjekt x. Greift eine Transaktion tri lesend oder schreibend auf eine Menge vonTabellenzeilen zu, welche einem Auswahlprädikat p genügen, so wird dafür geschrieben:ri[p] bzw. wi[p]. Als Schreiboperationen sind erlaubt: Änderungen (der geschriebene Wertwird mit wi[x := v] angezeigt), Einfügungen oder Löschungen von Datenobjekten. Daten-objekte können hier je nach Kontext ganze Tabellen, Zeilen oder Spalten sein. Schließlichsteht ci für ein Commit und ai für ein Abort der Transaktion tri. Unterschieden wer-den vier Basisphänomene, die bei unkontrolliertem Mehrbenutzerbetrieb auftreten können(Definitionen und Bezeichnungen nach [BBG+95]):
• Dirty Write (P0)
Das Schreiben „schmutziger Daten“ ist gegeben, wenn von einer Transaktion einObjekt geändert wird, das von einer noch offenen Transaktion bereits zuvor geändertwurde.
P0: w1[x] . . . w2[x] . . . ((c1 ∨ a1) ∧ (c2 ∨ a2))
Transaktion tr1 ändert das Objekt x. Transaktion tr2 ändert ebenfalls Objekt x,noch bevor tr1 beendet ist. Bricht anschließend eine der Transaktionen tr1 odertr2 ab, ist unklar, welchen korrekten Wert das Objekt x haben soll. Bei einemCommit der Transaktionen kann sogar die Konsistenz verletzt werden. Betrachtenwir zwei Objekte x und y mit der Integritätsbedingung x = y und die Historiew1[x := 1]w2[x := 2]w2[y := 2]c2w1[y := 1]c2. Beide Transaktionen für sich haltendie Integritätsbedingung ein, das Ergebnis der nebenläufigen Ausführung x = 2, y = 1ist jedoch nicht zulässig.
• Dirty Read (P1)
Das Phänomen P1 liegt vor, wenn eine Transaktion geänderte Objekte liest, derenÄnderungen von Transaktionen stammen, die noch nicht beendet sind.
P1: w1[x] . . . r2[x] . . . ((c1 ∨ a1) ∧ (c2 ∨ a2))
Transaktion tr1 ändert das Objekt x. Transaktion tr2 liest das geänderte Objekt.Wenn jetzt entweder tr1 abbricht oder Objekt x ein weiteres Mal ändert und danach

32 KAPITEL 2. GRUNDLAGEN
mit Commit abschließt, hat Transaktion tr2 eine nicht dauerhafte bzw. inkonsistenteVersion von Objekt x gelesen.
• Non-repeatable Read (P2)
Dieses Phänomen liegt vor, wenn eine Transaktion während ihrer Ausführung ohneeigene Änderungen unterschiedliche Werte eines Objektes liest
P2: r1[x] . . . w2[x] . . . ((c1 ∨ a1) ∧ (c2 ∨ a2))
Transaktion tr1 liest Objekt x. Transaktion tr2 ändert oder löscht danach Objekt xund schließt mit Commit ab. Wenn Transaktion tr1 nun versucht, Objekt x nochmalszu lesen, erhält sie einen veränderten Wert oder muss feststellen, dass Objekt x nichtmehr existiert. Arbeitet dagegen tr1 weiter mit dem gelesenen Objektwert von x undbricht tr2 ab, so liegt den weiteren Operationen von tr1 ein ungültiger Wert von xzugrunde.
• Phantoms (P3)
Phantome sind Zeilen, die durch parallele Änderungsoperationen anderer Transaktio-nen in der Ergebnismenge einer Leseoperation auftauchen oder aus ihr verschwindenkönnen. P3 kann als eine besondere Form von P2 angesehen werden.
P3: r1[P ] . . . w2[x ∈ P ] . . . ((c1 ∨ a1) ∧ (c2 ∨ a2))
Transaktion tr1 liest eine Menge von Objekten, die einem Suchprädikat p genügen.Transaktion tr2 erzeugt, ändert oder löscht Objekte, die ebenfalls das Prädikat perfüllen. Wertet jetzt tr1 das Suchprädikat erneut aus, sieht sie möglicherweise ei-ne veränderte Datenmenge. Mögliche Veränderung können sein: weniger oder mehrZeilen im Ergebnis oder andere Ergebnisse für Aggregatfunktionen.
Neben den vier Basisphänomenen gibt es drei weitere Phänomene, welche das Phänomen P2weiter differenzieren9 und für Mehrversionssysteme, wie sie mDBS darstellen, im Folgendeneine besondere Rolle spielen.
• Lost Update (P4)
Dieses Phänomen tritt auf, wenn zwei offene Transaktionen dasselbe Objekt ändernund dabei eine Änderung durch die andere überschrieben wird.
P4: r1[x] . . . w2[x] . . . w1[x] . . . c1
Transaktion tr1 liest Objekt x. Danach schreibt tr2 Objekt x. Schreibt jetzt tr1
aufgrund des gelesenen Wertes einen neuen Wert von x und schließt mit Commit ab,wird die Änderung von tr2 überschrieben und ist damit „verloren“.
• Read Skew (A5A)
Das Phänomen tritt auf, wenn zwei Datenobjekte durch eine Integritätsbedingung everknüpft sind und eine Transaktion die Datenobjekte ändert, während eine andereTransaktion die Datenobjekte liest.
A5A: r1[x] . . . w2[x] . . . w2[y] . . . c2 . . . r1[y] . . . (c1 ∨ a1)9Das heißt, für alle drei Phänomene gilt, ist P2 verboten, können sie auch nicht auftreten.

2.5. SYNCHRONISATION 33
Transaktion tr1 liest x, danach schreibt tr2 die Objekte x und y und wird beendet.Liest jetzt die noch offene Transaktion tr1 den Wert von y, kann sie möglicherweiseeine Verletzung der Bedingung e zwischen dem veralteten Wert von x und dem neuenWert von y erkennen.
• Write Skew (A5B)
Das Phänomen tritt auf, wenn zwei Datenobjekte durch eine Integritätsbedingung everknüpft sind, zwei Transaktionen einen oder beide Werte lesen und jede für sicheinen konsistenten Wert für das jeweils andere Datenobjekt schreiben.
A5B: r1[x] . . . r2[y] . . . w1[y] . . . w2[x] . . . (c1 ∧ c2)
Transaktion tr1 liest x und Transaktion tr2 liest y, danach schreibt tr1 einen Wertfür y und Transaktion tr2 einen Wert für x. Schließen jetzt beide Transaktionenerfolgreich ab, kann im Ergebnis trotzdem eine Verletzung von e vorliegen.
Das Nichtauftreten der vier Basisphänomene bzw. Historien garantiert Serialisierbarkeit.Zusätzlich werden dadurch alle nicht rücksetzfähigen und nicht reihenfolgeerhaltenden His-torien ausgeschlossen. Lässt man jetzt bewusst einzelne Phänomene zu, kann eine stu-fenweise Abschwächung der Isolation erreicht werden. DBMS-Produkte nutzen wenigerrestriktive Isolationsstufen vor allem zur Verbesserung der Performance in unkritischenAnwendungsfällen. Eine Übersicht gebräuchlicher Isolationsstufen sowie die Einführung zuder im folgenden Abschnitt erläuterten Abbildisolation gibt ebenfalls [BBG+95].
2.5.2.4 Korrektheitskriterium Abbildisolation
Transaktionen, in denen Änderungen zunächst isoliert voneinander erfolgen und erst zumCommit synchronisiert werden, so wie es bei Server-Transaktionen in mDBS der Fall ist,können mit der speziellen Isolationsstufe der Abbildisolation (snapshot isolation) ausgeführtwerden.
Die Abbildisolation definiert sich wie folgt. Jede Transaktion liest nur dauerhafte Daten ausdem Abbild (snapshot) der Datenbank, das sie zum Zeitpunkt des Transaktionsstarts (einbeliebiger Zeitpunkt vor dem ersten Lesezugriff, der als Startzeitstempel festgehalten wird)hatte. Änderungen der Transaktion werden zunächst nur auf dem Abbild durchgeführt undstehen für alle folgenden Lese- und Schreiboperationen der Transaktion zur Verfügung. Än-derungen anderer Transaktionen, die nach dem Startzeitpunkt begonnen wurden, bleibenunsichtbar.
Zum Abschluss einer abbildisolierten Transaktion müssen die isolierten Änderungen wie-der in die Datenbank reintegriert werden, was wie folgt abläuft. Will eine Transaktiontr abschließen, bekommt sie einen eindeutigen Commit-Zeitstempel, der größer ist als alleschon vergebenen Start- und Commit-Zeitstempel (Monotonie). Das Commit für tr wirdnur dann erlaubt, wenn im Zeitraum ihrer Ausführung (Startzeitstempel bis Commit-Zeitstempel) kein Commit-Zeitstempel einer anderen Transaktion liegt, die mit tr in ei-nem Schreib-Schreib-Konflikt (beide Operationen sind Schreiboperationen) steht. Diesesals First-Committer-Wins-Regel (kurz FCW-Regel) bezeichnete Vorgehen verhindert Phä-nomen P4.
Betrachten wir jetzt die anderen Phänomene. P0, P1 und A5A können trivialerweise nichtauftreten, da die isoliert ablaufende Transaktion nur Daten anderer Transaktionen sieht,

34 KAPITEL 2. GRUNDLAGEN
die vorher bereits abgeschlossen waren. Dementsprechend ist die sich bei der Reintegrationergebende Einversionshistorie reihenfolgeerhaltend und rücksetzfähig. Das Phänomen P2kann auftreten, aber nur in der speziellen Form von Phänomen A5B. Am Beispiel der fol-genden Einversionshistorie, die beim Commit einer abbildisolierten Transaktion entstehenkann, ist das leicht zu sehen:
r1[x = 50]r1[y = 50]r2[x = 50]r2[y = 50]w1[x = −40]w2[y = −40]c1c2
Besteht eine Integritätsbedingung beispielsweise darin, dass die Summe x + y positiv seinsoll, ist die Bedingung aus Sicht jeder der Transaktionen zwar erfüllt (x + y = 10), imErgebnis in der Datenbank gilt die Bedingung jedoch nicht mehr (x + y = −80). DasBeispiel lässt sich auch auf Mengen von Datenobjekten übertragen. Besteht beispielsweiseeine Begrenzung über die Anzahl vorhandener Objekte in der Datenbank und fügen dieTransaktionen unabhängig voneinander jeweils innerhalb der Grenzen neue Objekte ein,kann die Grenze in der „Summe“ überschritten werden. In diesem speziellen Fall kannfolglich Phänomen P3 (für die Einversionshistorie) nicht verhindert werden.
Die ursprüngliche Definition der Abbildisolation in [BBG+95] sieht keine Behandlung derPhänomene A5B und P3 vor. Eine solche Behandlung kann beispielsweise dadurch erfol-gen, dass bei der Reintegration alle betroffenen Integritätsbedingungen erneut auf ihreGültigkeit hin überprüft werden. Bei einem negativen Resultat wird durch die FCW-Regeldie Konsistenz wieder hergestellt (Konfliktauflösung, s. u.). Mit dieser Erweiterung kannfür abbildisolierte Transaktionen zusätzlich Serialisierbarkeit garantiert werden.
Die beschriebene Abbildisolation gilt auch für eine Server-Transaktion in einem mDBS.Der Startzeitstempel ist durch den Zeitpunkt der Verbindungsunterbrechung gegeben undder Commit-Zeitstempel wird bei der Synchronisation zugeteilt. Bleibt festzuhalten, alleindurch die isolierte Ausführung der Server-Transaktionen werden die Phänomene P0, P1und A5A ausgeschlossen. Beim Einsatz der FCW-Regel ist zu beachten, dass durch den ge-schachtelten Charakter der Server-Transaktionen nur die betroffenen Client-Transaktionen(eventuell kaskadierend) zurückgesetzt werden müssen.
Der Umgang mit den verbleibenden Phänomenen bzw. Konflikten P4 (Lost Update), A5B(Write Skew) und P3 (Phantoms) kann grundsätzlich auf zwei Arten erfolgen ([Lie03]):durch Verbot bzw. Vermeidung potentiell gefährlicher Historien (konfliktvermeidende Syn-chronisation Abschnitt 2.5.3) oder durch Erkennung und Auflösung eines Konflikts, hervor-gerufen durch eines der Phänomene, (konfliktauflösende Synchronisation Abschnitt 2.5.4)bei der Synchronisation. Da einerseits nicht alle Konflikte effizient, d. h. automatisch, lösbarsind und andererseits Verbote die Verfügbarkeit von Daten oft zu sehr einschränken, solltensich in einem mDBS beide Verfahrensklassen ergänzen und je nach Anwendungsszenariozur Wahl stehen.
2.5.3 Konfliktvermeidende Synchronisationsverfahren
Die Vermeidung von Konflikten kann durch verschiedene Vorkehrungen erzielt werden.Sie basiert auf zwei Grundprinzipien: dem Verbot potentiell gefährlicher Historien mittelsSperrverfahren und der Ausnutzung von Anwendungswissen über Datentypen und erlaubteOperationen. Sperrverfahren sind heute Stand der Technik für die Synchronisation desMehrbenutzerbetriebs in zentralen DBMS. Für mDBS sind sie nur bedingt einsetzbar,wie Unterabschnitt 2.5.3.1 zeigen wird. In den folgenden Unterabschnitten werden das

2.5. SYNCHRONISATION 35
Escrow-Verfahren, das Key-Pool-Verfahren und das Slot-Verfahren als wichtige Vertreterfür Verfahren vorgestellt, die sich Anwendungswissen für die Konfliktvermeidung zunutzemachen.
2.5.3.1 Sperrverfahren
Ziel von Sperrverfahren ist es, alle potentiell zu einem Konflikt führenden Historien neben-läufiger Transaktionen zu verhindern [GR93]. Das einfachste Sperrverfahren kennt zwei Ar-ten von Sperren, Lesesperren (shared lock) und Schreibsperren (exclusive lock). Vor jedemLese- und Schreibzugriff auf ein Datenobjekt ist für dieses eine Lese- bzw. Schreibsperreanzufordern. Lesesperren sind untereinander verträglich, während Schreibsperren mit allenanderen Sperren unverträglich sind. Trifft die Sperranforderung einer Transaktion auf eineunverträgliche Sperre, so wird die Transaktion solange in ihrer Ausführung blockiert, bisdie Sperre auf dem Datenobjekt gewährt werden kann.
Anzahl Sperren
ZeitBOT EOT
(a) ohne Preclaiming
Anzahl Sperren
ZeitBOT EOT
(b) mit Preclaiming
Abbildung 2.6: Striktes Zwei-Phasen-Sperrprotokoll
Ein Sperrverfahren, das Serialisierbarkeit und reihenfolgeerhaltende Historien garantiert,ist das Zwei-Phasen-Sperrprotokoll (Two Phase Locking, 2PL). Varianten des 2PL werdenheute in allen relationalen DBS-Produkten zur Synchronisation des Mehrbenutzerbetriebseingesetzt.
Die zwei disjunkten Phasen des 2PL sind die Anforderungsphase, während der alle Sper-ren für zu bearbeitende Datenobjekte angefordert werden müssen, und die Freigabephase,während der nicht mehr benötigte Sperren freigegeben werden. Diese Regel garantiert, dasskeine Konflikte auftreten. Allerdings zunächst nur für den fehlerfreien Betrieb, in dem je-de Transaktion erfolgreich beendet wird. Im Fall eines Zurücksetzens einer Transaktion inder Freigabephase können andere Transaktionen bereits freigegebene aber jetzt nicht mehrgültige Daten gesehen haben. Zur Vermeidung des kaskadierenden Rücksetzens müssenmindestens die Schreibsperren bis zum Ende der Transaktion gehalten werden. Diese Vari-ante des 2PL wird als striktes Zwei-Phasen-Sperrprotokoll bezeichnet (Abbildung 2.6(a)).Striktes 2PL garantiert rücksetzfähige Historien.
Beim Einsatz des 2PL zur Synchronisation von Server-Transaktionen ergibt sich der inAbbildung 2.6(b) dargestellte Ablauf. Da nach Verbindungstrennung keine Kommunika-tion mehr stattfindet, müssen alle Sperren bereits vorher gesetzt sein. Dieser Spezialfalldes strikten 2PL wird als Preclaiming bezeichnet. Die Verwendung von Preclaiming setzt

36 KAPITEL 2. GRUNDLAGEN
voraus, dass zum Zeitpunkt der Verbindungstrennung genau bekannt ist, auf welche Daten-objekte Sperren gesetzt werden müssen. Im normalen Transaktionsbetrieb ist das i. d. R.nicht gegeben. Da aber in mobilen Umgebungen vor der Verbindungstrennung eine Repli-katauswahl erfolgen muss, können in dieser Phase auf dem Server alle benötigten Sperrengesetzt werden.
Mit Hilfe von Sperren auf Datenobjekte in der Server-Datenbank lassen sich die ACID-Eigenschaften für Client-Transaktionen bei der Reintegration garantieren. Der Preis dafürist allerdings sehr hoch. Durch Sperren wird mindestens der Schreibzugriff aller anderenClients auf die replizierten Datenobjekte bis zum Abschluss der langen Server-Transaktion,vielleicht über Stunden oder sogar Tage, blockiert. Für Anwendungsszenarien, in denenhäufig auch unverbunden auf gemeinsam genutzte Datenobjekte zugegriffen werden muss,ist das 2PL ungeeignet. Für weniger häufige administrative Aufgaben (z. B. Datensiche-rung, manuelle Konsistenzprüfung und Datenbereinigung) kann auf Sperrverfahren jedochmeist nicht verzichtet werden. Auf die Besonderheiten und die Realisierung von Lang-zeitsperren wird in Kapitel 3.4.5 eingegangen.
2.5.3.2 Das Escrow-Verfahren
Das in [O’N86] erstmals vorgestellte Escrow10-Verfahren wurde für den konfliktfreien, par-allelen Zugriff mehrerer langer Transaktionen auf häufig frequentierte Spaltenwerte (hotspots) entwickelt, ohne dabei die Zeilen oder Spaltenwerte für den Änderungszugriff zusperren.
Für den Einsatz des Escrow-Verfahrens auf einer Tabellenspalte muss diese zwei Vorausset-zungen erfüllen: ihre Werte müssen für Aggregationen stehen (z. B. Bestand eines Artikelsin einem Lager) und es dürfen auf der Spalte nur die kommutativen Operationen De-krementieren und Inkrementieren verwendet werden. Sind diese Voraussetzungen erfüllt,ist es für konfliktfreie Inkrement- und Dekrementoperationen hinreichend, ein benötigtesKontingent des Spaltenwertes vorab (vor der Verbindungstrennung) zu reservieren bzw. zusperren. Die reservierten Kontingente stehen für andere Clients nicht mehr zur Verfügung.
In der Regel wird an die Gewährung der Reservierung eine Integritätsbedingung geknüpft,beispielsweise das Nichtüber- bzw. Nichtunterschreiten eines Schwellwertes. Bei einem La-gerbestand wird die untere Grenze bei 0 Artikeln und die Obergrenze bei der Höhe derLagerkapazität liegen. Damit sichergestellt ist, dass jede potentielle Verringerung oder Er-höhung des Wertes bei der Reintegration konfliktfrei, also ohne Verletzung der Integri-tätsbedingung erfolgen kann, werden vom Escrow-Verfahren sowohl der kleinste möglicheWert (Infimum) als auch der größte mögliche Wert (Supremum) für die Escrow-Spalteausgehend von allen Reservierungen gespeichert. Unterschreitet (überschreitet) das neuberechnete Infimum (Supremum) den unteren (oberen) Grenzwert, wird die Reservierungin der gewünschten Höhe abgelehnt.
Bei der Reintegration ist zu beachten, dass nicht der neue Wert der Escrow-Spalte in dieServer-Datenbank geschrieben wird, sondern die Differenz zwischen neuem und zu Beginnrepliziertem Wert dem Wert in der Server-Datenbank hinzuaddiert wird. Das Synchroni-sationsverfahren nutzt hier das Wissen um die Semantik der erlaubten Anwendungsopera-tionen.
10Escrow ist eine bei einem Dritten hinterlegte Vertragsurkunde, die erst bei Erfüllung einer Bedingungin Kraft tritt.

2.5. SYNCHRONISATION 37
Das vom Escrow-Verfahren angewandte Prinzip lässt sich auf jede andere kommutativeOperation erweitern. Auch sind in der Praxis weniger restriktive Bedingungen denkbar(Stichwort Überbuchung), allerdings kann dann keine Konfliktfreiheit mehr garantiert wer-den. Sind keine Grenzwerte vorgegeben bzw. soll deren Verletzung nicht a priori verhindertwerden (z. B. bei einer Kontoüberziehung), entfällt die Notwendigkeit zu einer Reservie-rungsanforderung.
2.5.3.3 Das Key-Pool-Verfahren
Das sogenannte Key-Pool-Verfahren wendet die vom Escrow-Verfahren bekannte Vorabre-servierung für Spalten mit Eindeutigkeitsbedingung (z. B. auf Schlüsselspalten) an. Vor derVerbindungstrennung werden dem Client eine bestimmte Anzahl von Schlüsselwerten zuralleinigen Verwendung reserviert. Unverbunden durchgeführte Einfügeoperationen, die sichder reservierten Schlüsselwerte bedienen, können bzgl. der betrachteten Eindeutigkeitsbe-dingung garantiert konfliktfrei reintegriert werden.
Voraussetzung für die Anwendung des Key-Pool-Verfahrens auf eine Spalte oder Spalten-menge ist die automatische Generierbarkeit der erlaubten Werte (i. d. R. nur bei künstlichenSchlüsseln möglich) mit einem hinreichend großen Wertevorrat. Das Key-Pool-Verfahrenist beispielsweise in [iAn04a] beschrieben.
2.5.3.4 Das Slot-Verfahren
Das Key-Pool-Verfahren hat den Nachteil, dass es nur bei künstlichen Schlüsselspalteneingesetzt werden kann. Das im Rahmen des MobiSnap-Projektes [PMC02, PBM+00] be-schriebene Slot-Verfahren erlaubt die Reservierung auch für natürliche Schlüsselspalten.Ein Beispiel wäre die Verwendung für einen Gruppenterminkalender, bei dem jeder Ein-trag für einen verplanten Termin steht. Jede Kombination aus Raum und Zeit darf dabeinur einmal vorkommen.
Die Reservierungsoperation besteht jetzt darin, vor Beginn einer unverbundenen Arbeits-phase die wahrscheinlich in Frage kommenden Termin/Raum-Kombinationen in den Grup-penterminkalender einzufügen und mit einer client-bezogenen Sperre zu belegen. DieseKombinationen dürfen von anderen Clients dann nicht mehr verwendet werden. Nach derWiederverbindung werden die tatsächlich hinzugefügten Buchungen durch eine Änderungs-operation auf der Server-Datenbank hinzugefügt und die nicht verwendeten Terminreser-vierungen wieder aus dem Kalender gelöscht.
2.5.4 Konfliktauflösende Synchronisationsverfahren
Mit Hilfe der vorgestellten Konfliktvermeidungstechniken, insbesondere mit den drei Ver-fahren, die ohne Objektsperren auskommen, kann bereits ein großer Teil der in der Praxisvorkommenden Konfliktsituationen effizient behandelt werden. Ist das Auftreten von Kon-fliktsituationen nicht vermeidbar, etwa weil Sperren die Verfügbarkeit zu stark einschränkenoder die betroffenen Spalten die erforderlichen Voraussetzungen für Escrow- und Key-Pool-Verfahren nicht erfüllen, müssen Konflikte bei der Synchronisation zunächst erkannt undanschließend aufgelöst werden. Ziel muss auch hierbei wieder sein, so viele Änderungen desClient wie möglich einzubringen, ohne die Konsistenz der Datenbank zu verletzen.

38 KAPITEL 2. GRUNDLAGEN
Das Vorgehen zur Erkennung und die Möglichkeiten zur Auflösung von Konflikten hängenmaßgeblich von den zum Server für die Synchronisation übermittelten Informationen ab.Nach der Art dieser Informationen unterscheiden wir [Lie01]: datenbasierte Synchronisati-on, transaktionsbasierte Synchronisation und semantikbasierte Synchronisation.
2.5.4.1 Datenbasierte Synchronisation
BI AI CI Operation Bedingung Konfliktart — Löschen BI = CI Löschkonflikt— Einfügen AI = CI Einfügekonflikt Ändern AI = CI Änderungskonflikt — Ändern Änderungslöschkonflikt
Tabelle 2.4: Konflikte bei datenorientierter Synchronisation
Bei der datenbasierten Synchronisation (z. B. bei Sybase Adaptive Server Anywhere, sie-he Abschnitt 3.5) werden pro geändertem Datenobjekt vom Client nur, wenn vorhanden,das Vorherabbild BI zum Zeitpunkt der letzten Synchronisation und das NachherabbildAI an den Server übermittelt (es sei angenommen, dass BI = AI). Beide Informationenlassen sich i. d. R. einfach aus dem Datenbank-Log des Client-DBMS gewinnen. Als zusätz-liche Information steht das aktuelle Abbild des Datenobjekts auf dem Server (CI, currentimage) für die Konfliktbehandlung zur Verfügung. Informationen über die „Entstehungs-geschichte“ und den Transaktionszusammenhang gehen bei datenbasierter Synchronisati-on verloren. Es können also keine einzelnen Client-Transaktionen zurückgesetzt werden(potentielle Verletzung der Atomarität). Die Konfliktbehandlung bezieht sich immer aufeinzelne Datenobjekte.
Die möglichen Konfliktsituationen zeigt Tabelle 2.4. Angegeben sind jeweils pro Konfliktartdie vorhandenen Abbilder, die daraus resultierende Gesamtoperation (die Änderungshisto-rie auf dem Client wird aggregiert) und eine Bedingung, die für den Konflikt vorliegen muss.Die dargestellten Fälle gehören zu den Auswirkungen des Phänomens P4 (Lost Update).Weitere Konflikte können in allen vier Fällen mittels einer Verletzung von Integritätsbe-dingungen durch die Phänomene P3 und A4B erkannt werden. Die Konflikterkennung und-behandlung ist dabei mindestens zweistufig, d. h. die Lösung der genannten primären Kon-fliktarten kann weitere Integritätskonflikte hervorrufen. Wird kein (neuer) Konflikt erkannt,kann das Nachherabbild, u. U. modifiziert durch eine vorangegangene Konfliktauflösung,in die Server-Datenbank übernommen werden.
Für die Auflösung von Konflikten können Regeln definiert werden. Diese können rein sche-mabasiert, also ohne Auswertung des tatsächlich zu reintegrierenden Wertes (z. B. neuerWert ist gleich AI, wenn der Nutzer Administrator ist), oder inhaltsbasiert (z. B. wennAI > 10, ist der neue Wert gleich AI, sonst CI) unter Berücksichtigung der angetroffenenWerte erfolgen. Die einzelnen primären Konfliktarten und mögliche Auflösungsalternativensollen im Folgenden etwas genauer untersucht werden:
• Löschkonflikt
Bei einem Löschkonflikt liegt die Situation vor, dass eine auf dem Client gelöschte

2.5. SYNCHRONISATION 39
Zeile zwischenzeitlich auf dem Server geändert wurde. Es ist also möglich, dass dieEntscheidung zur Löschung mit dem neuen Wert nicht erfolgt wäre. Eine Regel mussfestlegen, ob die Zeile trotzdem gelöscht werden darf oder nicht. Wenn nicht, greiftdie FCW-Regel und die Änderung wird durch Überschreiben des AI auf dem Clientdurch das CI des Servers kompensiert. Durch eine aussagekräftige Fehlermeldung(einschließlich der konfliktauslösenden Änderungen) kann dem Client die Möglichkeitgegeben werden, sein Vorgehen entsprechend zu korrigieren.
Neben dem beschriebenen Löschkonflikt gibt es noch einen Pseudo-Löschkonflikt.Dieser entsteht, wenn dieselbe Zeile sowohl auf dem Server als auch auf dem Clientgelöscht wurde. Eine explizite Auflösung muss nicht erfolgen, es kann jedoch je nachKonflikterkennung der Synchronisations-Software erforderlich sein, diese Situationauszuwerten.
• Einfügekonflikt
Ein Einfügekonflikt tritt auf, wenn sowohl auf dem Client als auch auf dem Servereine neue Zeile mit demselben Primärschlüssel, aber sonst verschiedenen Inhalten ein-gefügt werden.11 Neben der Abweisung der Client-Änderung besteht die Möglichkeit,den Konflikt durch Neuvergabe der Schlüsselwerte zu lösen. Dafür gelten dieselbenVoraussetzungen wie für das Key-Pool-Verfahren. Der Vorteil der Neuvergabe bei derSynchronisation gegenüber dem Key-Pool-Verfahren ist der Verzicht auf eine Vorab-reservierung von Schlüsselwerten. Jedoch ist neben dem Verlust der Stabilität vonPrimärschlüsselwerten der Synchronisationsaufwand erheblich größer, da auch alleabhängigen Fremdschlüsselwerte entsprechend angepasst und schließlich zurück anden Client übermittelt werden müssen.
• Änderungskonflikte
Ein Änderungskonflikt liegt vor, wenn zwei verschiedene Änderungen derselben Zeilekollidieren. Wie beim Einfügekonflikt kann hier eine Regel darüber entscheiden, wel-che der beiden neuen Zeilen „überlebt“, oder ob ein dritter berechneter Wert für dasNachherabbild (z. B. Durchschnittsbildung) verwendet wird.
Ein Änderungslöschkonflikt ist dann zu behandeln, wenn eine auf dem Client geän-derte Zeile zwischenzeitlich auf dem Server gelöscht wurde. In diesem Fall bestehtdie Option, die geänderte Zeile neu einzufügen, sofern die Semantik der Anwendunghierzu konform geht.
Die jeweils vorgeschlagenen Auflösungsalternativen zielen auf eine erfolgreiche, automati-sche Auflösung von Konflikten ab, so dass die Synchronisation bis zur nächsten Verbin-dungstrennung abgeschlossen werden kann. In kritischen Fällen kann eine Delegation aneine dritte Partei, z. B. den zuständigen Administrator, erfolgen. Bis zur manuellen Ent-scheidung sollte von der FCW-Regel Gebrauch gemacht werden, damit ein konsistenterDatenbankzustand gewährleistet ist.
Für den Vergleich der Abbilder müssen die korrespondierenden Datenobjekte, im relationa-len Fall einzelne Zeilen einer Tabelle, bei der Synchronisation durch den Replikations-Serveridentifiziert werden. Dies geschieht üblicherweise über den Primärschlüssel der Tabelle, sodass auch eine produktübergreifende Synchronisation möglich ist. Prinzipiell können hierfür
11Dieser Konflikt kann, bei Vorliegen der entsprechenden Voraussetzungen, durch Einsatz des KeyPool-oder Slot-Verfahrens vermieden werden.

40 KAPITEL 2. GRUNDLAGEN
in homogenen Umgebungen, d. h. es werden nur Produkte desselben Herstellers verwendet,auch interne Identifikatoren für Zeilen (z. B. Satznummer, RID) verwendet werden. Da allewichtigen kommerziellen mobilen Datenbanklösungen eine Identifikation über den Primär-schlüssel verwenden, wird im Folgenden diese Indentifikationsart zugrundegelegt. Folglichgehören eine Zeile in der Replikatdatenbank und eine Zeile in der Server-Datenbank zumselben Datenobjekt, wenn ihre Primärschlüsselwerte übereinstimmen.
Es ist nicht sofort offensichtlich, dass diese Konflikterkennung zu keinem unerwünschtenVerhalten führt, wenn die identifizierenden Primärschlüsselwerte selbst geändert werden.Es sind für den Ursprung einer Primärschlüsselwertänderung zwei Fälle zu betrachten:
1. Server
Wird für eine replizierte Zeile zwischenzeitlich auf dem Server der Primärschlüssel-wert geändert, entspricht die Wirkung dem Löschen einer Zeile mit dem alten Wertund dem Einfügen mit dem neuen Wert des Primärschlüssels. Eine spezielle Behand-lung konfligierender Client-Änderungen ist hierfür nicht erforderlich.
2. Client
Findet die Änderung eines Primärschlüsselwerts auf dem Client statt, so ist dieseÄnderung durch die Übertragung von BI und AI nachvollziehbar und kann zunächstwie eine normale Änderung eingebracht werden. Als nachrangiger Konflikt kann einIntegritätskonflikt auftreten und zwar dann, wenn bereits eine Zeile mit dem neuenSchlüsselwert auf dem Server existiert.
2.5.4.2 Transaktionsbasierte Synchronisation
Bei der transaktionsbasierten Synchronisation (z. B. eingesetzt bei IBM DB2, sie-he Abschnitt 3.5) werden nicht nur die kummulierten Vorher- und Nachherabbilder über-mittelt, sondern zusätzlich die Basisoperationen (Einfügen, Ändern, Löschen) und ihreTransaktionsklammern. Beide Informationen lassen sich bei den jeweiligen Datenbank-systemen aus dem Datenbank-Log des Client gewinnen. Die Erkennung von Konfliktenund die zu behandelnden Konfliktarten sind dieselben wie bei rein datenbasierter Synchro-nisation. Im Falle der Anwendung der FCW-Regel ist allerdings ein isoliertes Zurücksetzeneinzelner Transaktionen möglich, so dass die Atomarität von Client-Transaktionen erhaltenbleibt.
2.5.4.3 Semantikbasierte Synchronisation
Im Gegensatz zur daten- und transaktionsbasierten Synchronisation wird bei der seman-tikbasierten Synchronisation versucht, die Anwendungssematik, die hinter der Ausführungeiner Client-Transaktion steht, und die aus den im Log gespeicherten Basisoperationeni. d. R. nicht mehr ablesbar ist, auf dem Server nachzuvollziehen. Das Prinzip wurde in[GHOS96] unter dem Begriff Two-Tier-Replication beschrieben und in den Forschungspro-jekten Bayou [DPS+94] sowie MobiSnap ([PMC02, PBM+00], siehe Kapitel 3.6) umgesetzt.
Bei der Synchronisation werden die Client-Transaktionen auf den aktuellen Daten derServer-Datenbank erneut ausgeführt. In MobiSnap dient beispielsweise ein um prozeduraleElemente erweitertes SQL zur Spezifizierung der Transaktionssemantik. Das Ergebnis der

2.5. SYNCHRONISATION 41
erneuten Ausführung kann von dem ursprünglichen lokal erzielten Ergebnis abweichen. AlsMaß für die erfolgreiche Neuausführung wird das Ergebnis deshalb einem Akzeptanztestunterzogen (z. B. „Sitzplatz noch nicht belegt“ für eine Buchungstransaktion), der zusam-men mit der Transaktion spezifiziert werden muss. Das Akzeptanzkriterium ersetzt dieKonflikterkennung durch Abbildvergleich. Fällt der Test negativ aus, findet eine Konflik-tauflösung statt, die ebenfalls zusammen mit der Transaktion spezifiziert werden muss(z. B. Versuch, einen anderen freien Sitzplatz zu reservieren).
Semantikbasierte Synchronisation wird aktuell von keinem kommerziellen Produkt un-terstützt. Haupthemmnisse sind der notwendige veränderte Programmierstil, das Fehleneiner standardisierten Schnittstelle und die Probleme, die mit den autonomen Entschei-dungen der prozedural spezifizierten Transaktionslogik auf der Server-Seite verknüpft sind.Vergleichbare Fragestellungen und Probleme finden sich in der Softwaretechnik auf demGebiet der mobilen Agenten [BR05].


Kapitel 3
Die nutzerdefinierte Replikation
Die Konzeption und eine prototypische Implementierung der nutzerdefinierten Replikationsind Gegenstand dieses und der folgenden beiden Kapitel, die zusammen den Hauptteildieser Arbeit bilden. Das Kapitel 3 erläutert die Konzepte und die zu realisierende Funk-tionalität [Gol03c, Gol03a]. Das anschließende Kapitel 4 beschreibt die Datenstrukturenund Verfahren, welche zur Verwaltung der mit den Mitteln der nutzerdefinierten Repli-kation bestimmten Replikate benötigt werden. Kapitel 5 schließlich stellt eine konkreteImplementierung vor.
Das vorliegende Kapitel 3 gliedert sich wie folgt. Da die nutzerdefinierte Replikation dieflexible Replikatauswahl zum Ziel hat, werden im Abschnitt 3.1 zunächst die Alternativenzur Auswahl von Replikaten systematisiert. Die Definition der Aufgaben der nutzerdefinier-ten Replikation erfolgt in Abschnitt 3.2. Für die einheitliche Illustration von Sachverhaltenin den weiteren Abschnitten und Kapiteln wird ein Beispielszenario benötigt, welches inAbschnitt 3.3 vorgestellt wird. Anschließend erläutern die einzelnen Unterabschnitte desAbschnitts 3.4 die zu realisierenden Konzepte und Abläufe im Detail. Die Abschnitte 3.5und 3.6 schließlich setzen die nutzerdefinierte Replikation in Bezug zum Stand der Technikmobiler Datenbanklösungen und zu verwandten Forschungsarbeiten.
3.1 Auswahl von Replikaten
Bevor ein mobiler Client unverbunden mit seiner lokalen Replikatdatenbank arbeiten kann,müssen die dafür benötigten Daten und deren Tabellenschemata bestimmt und in die Re-plikatdatenbank kopiert bzw. dort angelegt werden. Ausgangspunkt dafür ist die Server-Datenbank. In der Regel wird in einem ersten Schritt zunächst der Ausschnitt des Server-Datenbankschemas bestimmt, welcher prinzipiell zur Replikation freigegeben ist. Anhanddieses abgeleiteten Datenbankschemas wird dann im zweiten Schritt über die individuelleAuswahl der Kopien für jeden Client entschieden. Es gibt dafür zwei prinzipielle Vor-gehensweisen [Her03], die explizite Replikation und die implizite Replikation mittels derAuswertung von Client-Anfragen. Die beiden Ansätze werden im Folgenden gegenübergestellt.
43

44 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
3.1.1 Explizite Replikation
Bei der expliziten Replikation werden vor jeder geplanten Verbindungstrennung die aufden Client zu kopierenden Daten und die dazugehörigen Schemata, analog zur Definiti-on einer materialisierten Sicht (siehe Abschnitt 2.2.2), durch einen Administrator oder dieAnwendung festgelegt. Die in dieser Weise definierten Replikate (in Produkten oft auch alsSnapshot bezeichnet) bestimmen sowohl Schema als auch, über die enthaltene Anfrage, deninitialen bzw. später möglichen Inhalt der Replikatdatenbank. Das Schema eines Replikatsmuss zunächst auf dem Client angelegt und das Replikat über eine initiale Synchronisationmit Daten versorgt werden. Anschließend kann unverbunden gearbeitet werden, der Ab-gleich mit dem Server erfolgt wiederum über eine explizit anzustoßende Synchronisation.Alle aktuellen kommerziellen mobilen Datenbanklösungen (siehe Abschnitt 3.5) verwendeneine explizite Replikation.
Analog zu Sichten werden änderbare und nicht-änderbare Replikate unterschieden. DieDefinition eines Replikats mittels einer SQL-Anfrage garantiert bei der Synchronistionzunächst nur die eindeutige Abbildung von Daten und Änderungen vom Server zu denClients. Für die lokale Änderbarkeit eines Replikats ist zusätzlich die Existenz einer Rück-abbildungsvorschrift für die Basisoperationen Einfügen, Löschen und Ändern erforderlich.
Die Frage der Rückabbildbarkeit von Änderungen auf abgeleiteten Tabellenschemata wirdin der Fachliteratur unter dem Begriff View-Update-Problem behandelt [Dat04]. In DBMS-Produkten sind i. d. R. alle Sichten bzw. Replikate, welche potentiell die eindeutige Rück-abbildbarkeit verhindernde Operationen in ihrer SQL-Anfrage wie Verbund oder Ag-gregation enthalten, standardmäßig nicht änderbar. Einige DBMS-Produkte (z. B. IBMDB2 UDB [IBM04b]) erlauben es durch das Anlegen so genannter Instead-of-Trigger, ei-gene Vorschriften für die Rückabbildung zu definieren.
Für die Zuordnung von Replikaten zu Clients gibt es verschiedene Ansätze, die, in Be-zug auf die spätere Anpassbarkeit der Replikatdefinition an die Erfordernisse des Client,unterschiedlich flexibel sind:
1. statisch, zusammen mit dem Entwurf
Replikate werden beim Entwurf der Datenbank und der Anwendung jedem Clientfest zugeordnet. Änderungen am replizierten Schemaausschnitt können nur auf demWeg einer Schemaevolution bzw. einer Änderung und Neuübersetzung der Anwen-dung erfolgen. Dieses Vorgehen eignet sich vor allem für sehr einfache homogeneund statische Szenarien, bei denen jeder Client immer den gleichen Ausschnitt derServer-Datenbank benötigt.
2. Publish/Subscribe-Verfahren
Mehr Flexibilität bietet das als Publish/Subscribe bezeichnete Verfahren. Die Publi-kationen sind einmal, beim Entwurf, definierte Replikate, deren Anfragen, analog zueingebettetem SQL, Parameter enthalten können. Oft ist es auch möglich, mehrereReplikate aufgrund gemeinsamer Semantik oder einfach für den Konsistenzerhalt zueiner Publikation zusammenzufassen. Die Clients können aus den vordefinierten Pu-blikationen auswählen, die Subskription, und instantiieren dabei eventuelle Parameterder Replikate mit aktuellen Werten. Sinnvolle Parameter sind beispielsweise der Nut-zername oder der Aufenthaltsort, vorausgesetzt diese Informationen sind Bestandteil

3.1. AUSWAHL VON REPLIKATEN 45
der zugrundeliegenden Tabellenschemata. Subsriptionen können später durch denClient angepasst werden.
3. dynamisch
Publikationen erlauben dem Client nur eine Alles-oder-Nichts-Entscheidung untervordefinierten Replikaten plus eine weitere Selektion durch die Angabe von Parame-terwerten. Die Struktur jeder Anfrage eines Replikats und insbesondere deren Selekti-onsbedingung sind festgelegt. Es ist zur Laufzeit weder möglich, einzelne Spalten vonder Replikation auszuschließen, noch eigene komplexere Selektionsbedingungen (z. B.Auswahl anhand des Inhalts verschiedener anderer Tabellen, Unteranfragen) zu defi-nieren. Am flexibelsten ist deshalb eine Lösung, welche die Definition von Replikatendurch die Anwendung mit dynamisch erzeugtem SQL erlaubt. Replikate können sowährend der Laufzeit, z. B. anhand des Informationswunsches eines Nutzers oder inBezug auf bereits replizierte Daten, neu erzeugt oder wieder gelöscht werden, wenndie Daten nicht mehr benötigt werden.
Kommerzielle mobile Datenbanklösungen unterstützen den Publish/Subscribe-Ansatz oderdie statische Zuordnung. Das freie Anlegen von Replikaten mittels SQL zur Laufzeit un-terstützt zurzeit kein Produkt (vergleiche Abschnitt 3.5).
Eine datenbankunabhängige Möglichkeit zur Auswahl eines Replikats mit dynamischemSQL bietet die RowSet-Klasse der JDBC-Datenbankschnittstelle [Bru03]. Anfrageergebnis-se werden lokal im Anwendungsspeicher abgelegt und können von der Anwendung auch oh-ne Verbindung zur JDBC-Quelle zeilenweise weiterverarbeitet werden. Die Lösung kommt,da sie von der Laufzeitumgebung der Programmiersprache bereitgestellt wird, ohne eindediziertes Client-DBMS aus. Es werden keine lokalen SQL-Anfragen unterstützt. Ände-rungen können über selbstdefinierte Methoden, die allerdings zur Übersetzungszeit bekanntsein müssen, in die JDBC-Quelle zurückgeschrieben werden.
Ein wichtiger Vorteil der expliziten Replikation besteht darin, dass über die Replikatde-finition entweder beim Entwurf oder durch die Client-Anwendung selbst der Anwendungjederzeit bekannt ist, welche Daten in der Replikatdatenbank vorhanden oder nicht vorhan-den sind. Verbindungsaufnahmen für das Anfordern neuer Daten sind also ebenso effektivsteuerbar, wie das Anstoßen einer Synchronisation – eine wesentliche Voraussetzung fürdie Unterstützung unverbundenen Arbeitens.
Demgegenüber haben alle in Produkten zu findenden Implementierungen expliziter Repli-kation, sei es die RowSet-Klasse von Java oder Publish/Subscribe-Verfahren, den Nachteil,dass verschiedene Replikate keine gemeinsame Datenbasis auf dem jeweiligen Client besit-zen. Jedes Replikat enthält seine eigenen Daten und wird, abgesehen von Zusammenfas-sungen über Publikationen, unabhängig von anderen Replikaten synchronisiert. Beinhaltenalso zwei Replikate eines Client dieselben Server-Daten, so werden diese mehrfach auf demClient gespeichert. Zur Synchronisation von unabhängig auf den beiden Replikaten durch-geführten lokalen Änderungen ist eine Verbindungsaufnahme und Synchronisation mit demServer notwendig.
Diese von den materialisierten Sichten abgeleitete Kombination von Daten und Schemaerschwert die Verwendung für dynamische Replikatdefinition. Neben der fehlenden lokalenSynchronisation von Änderungen wird beim angenommenen dynamischen Anlegen vonReplikaten auch nicht (automatisch) überprüft, ob bereits Teile der angefragten Datenauf dem Client vorhanden sind und deshalb nicht neu übertragen werden müssen. Die

46 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
Anwendung, welche in diesem Fall die Replikate anlegt, kann Konsistenz und Synchronitätzwischen Replikaten sowie eine redundanzfreie Datenhaltung erwarten. Das erfordert eine(zusätzliche) transparente Replikatverwaltung, wie sie bei impliziten Replikationsverfahrenvorhanden ist.
3.1.2 Implizite Replikation
Bei der expliziten Replikation erfolgen Definition der Replikate und der Zugriff auf sie inzwei getrennten Schritten. Die Arbeit mit Replikaten ist für die Anwendung i. d. R. nichttransparent. Anders bei der impliziten Replikation, hier werden zur Laufzeit die Anfra-gen der Client-Anwendung gegen die Server-Datenbank ausgewertet und daraus über eineReplikatverwaltungs-Software automatisch und transparent für die Anwendung ermittelt,ob und welche Daten zur Beantwortung einer Anfrage auf den Client kopiert werden müs-sen. Zusätzlich zum expliziten Anstoßen einer Synchronisation erfolgt eine implizite Syn-chronisation von Änderungen bei der Anfrageverarbeitung.
Daten und Schema sind bei der impliziten Replikation getrennt, das Schema der Repli-katdatenbank entspricht i. d. R. dem Schema des freigegebenen Ausschnitts der Server-Datenbank. Lokal gespeichert werden jedoch nur die Daten, die von Anfragen der Client-Anwendung benötigt werden, d. h. die Verwaltung der lokalen Replikatdatenbank auf demClient entspricht im Wesen der Verwaltung eines Cache-Speichers, wie er aus Speicherhier-archien bekannt ist.
Zur Replikatverwaltung gehört ein Inhaltsverzeichnis aller lokal gespeicherten Daten undeine Logik, deren primäre Aufgabe es ist, eingehende Anfragen gegen das Verzeichnis aus-zuwerten und zu entscheiden, welche Daten lokal aus der Replikatdatenbank bereitgestelltwerden können und welche über eine Verbindung zum Server von dort zusätzlich repliziertwerden müssen. Da die Replikation für die Anwendung transparent ist, müssen außerdemeine geeignete Verdrängungsstrategie sowie Methoden zur Sicherstellung der Datenkohä-renz vorhanden sein [CTO97].
Da für den Zugriff auf die Replikatdatenbank SQL-Anfragen ausgewertet werden sol-len, also ein prädikatbasierter Zugriff stattfindet, und sich zudem Client-DBMS undServer-DBMS in der Architektur unterscheiden können, sind instanzbasierte oder phy-sische Granulate, wie Tabellenzeilen und Datenbankseiten, für eine Inhaltsbeschrei-bung ungeeignet. Man greift deshalb auf prädikatbasierte Verfahren (Semantic Caching,[RD03, LKPM01, RD99, KB96, DFTJ+96]) zurück. Ein prädikatbasiertes Inhaltsverzeich-nis indiziert die in der Replikatdatenbank gespeicherten Daten anhand von Selektionsprä-dikaten, die den Inhalt vollständig beschreiben. Beim Semantic Caching werden dafür diePrädikate der gestellten Anfragen und daraus abgeleitete Prädikate verwendet.
Prädikate als Inhaltsbeschreibung besitzen gegenüber einer instanzbasierten Beschreibungzwei Vorteile. Sie sind unabhängig vom konkreten Ergebnis der Prädikatauswertung zueiner Zeit. D. h. Änderungen an den Daten selbst, sofern das Ergebnis wieder der Prä-dikatbeschreibung genügt, haben keine Auswirkungen auf die Inhaltsbeschreibung. Derzweite Vorteil liegt in der Auswertung. Bereits durch Vergleich der Selektionsprädikatevon gestellter Anfrage und Inhaltsbeschreibung kann festgestellt werden, ob eine Anfrageauch lokal beantwortbar ist oder welche (Teil-)Ergebnisse über eine Anfrage an die Server-Datenbank ermittelt werden müssen. Es müssen dazu keine Daten bzw. Schlüsselwerteübertragen werden.

3.2. ZIELE UND AUFGABEN 47
Die bei impliziter Replikation transparente Bereitstellung und Verwaltung replizierter Da-ten lässt eine vergleichsweise einfache Portierung bestehender Anwendungen, insbesonderesolcher mit Verwendung von dynamischem SQL, auf mobile Rechnersysteme zu. Aktuellunterstützt aber keine kommerzielle mobile Datenbanklösung implizite Replikation (ver-gleiche Abschnitt 3.5).
Die publizierten Ansätze für das Semantic Caching unterstützen das wiederholte Lesen vonDaten über die Replikatdatenbank, lokale Änderungen werden nicht betrachtet. Aufgrundder Orientierung an den Anfragen des Client (es werden nur die Zeilen und Spaltenwertegespeichert, die tatsächlich von einer Anfrage benötigt werden) sind Änderungen auf derReplikatdatenbank oft nicht eindeutig rückabbildbar. Ebenfalls nicht berücksichtigt wer-den Integritätsbedingungen, so dass sie u. U. aufgrund fehlender Daten lokal nicht geprüftwerden können oder, schlimmer noch, falsche Ergebnisse liefern würden. Es wird deshalbdavon ausgegangen, dass Änderungen, analog zu einem kabelgebundenen Client, direkt aufdem Server durchgeführt werden.
Mit der impliziten Replikation sind jedoch auch prinzipielle Probleme verbunden. SindVerbindungsaufnahmen zum Zweck der Änderung noch planbar, hängt es von der An-fragehistorie und der verwendeten Ersetzungs-/Prefetching-Strategie (siehe Hoarding-Verfahren [KR01, KP97, KS92]) ab, ob für eine neue Anfrage die benötigten Daten schon inder Replikatdatenbank gespeichert sind. Ein Nichtauffinden der Daten zwingt den mobilenClient für die Beantwortung seiner Anfrage zu einer ungeplanten Verbindungsaufnahmemit dem Server. Eine wünschenswerte Kontrolle des Nutzers bzw. der Anwendung über dieKommunikationszeitpunkte ist damit nicht möglich.
Der weiter oben als Vorteil angeführte „einfache“ Vergleich zwischen Anfrageprädikat undInhaltsbeschreibung, zur Bestimmung einer „Restanfrage“ für den Server, ist in der Praxissehr aufwändig. Der für den Vergleich notwendige Überlappungstest zwischen Prädikatenist NP-schwer, und unter Einbeziehung aller Möglichkeiten wie Ungleichheit und Bereichs-einschränkungen, NP-vollständig in der Länge der Selektionsbedingungen [GSW98, CM77].Der Aufwand kann beispielsweise durch die Einschränkung erlaubter Selektionsprädikatereduziert werden (siehe dazu Kapitel 4).
3.2 Ziele und Aufgaben
Sowohl explizite als auch implizite Replikation besitzen spezifische Nachteile, so dass siein der vorgestellten Form für die Realisierung nutzerdefinierter Replikation nicht geeignetsind. Vielmehr erscheint eine Kombination der Vorteile beider Verfahren für die Reali-sierung der in Abschnitt 1.1 aufgestellten Anforderungen mobilspezifischer Anwendungenund der gewünschten Strategie der Autonomie (siehe Abschnitt 2.3.3) sinnvoll.
In Tabelle 3.1 sind die Eigenschaften sowie die Vor- und Nachteile der beiden vorgestell-ten Ansätze zur Replikation noch einmal zusammengefasst. In der letzten Spalte sind diefür die jeweiligen Punkte als Ziel der nutzerdefinierten Replikation zu formulierenden Ei-genschaften eingetragen. Insbesondere sollen die Eigenschaften „Einfluss der Anwendung. . . “, „konsistente Änderbarkeit“ und „gemeinsame Datenbasis“ kombiniert werden. Diekonkreten (Teil-)Aufgaben eines Dienstes zur nutzerdefinierten Replikation ergeben sich
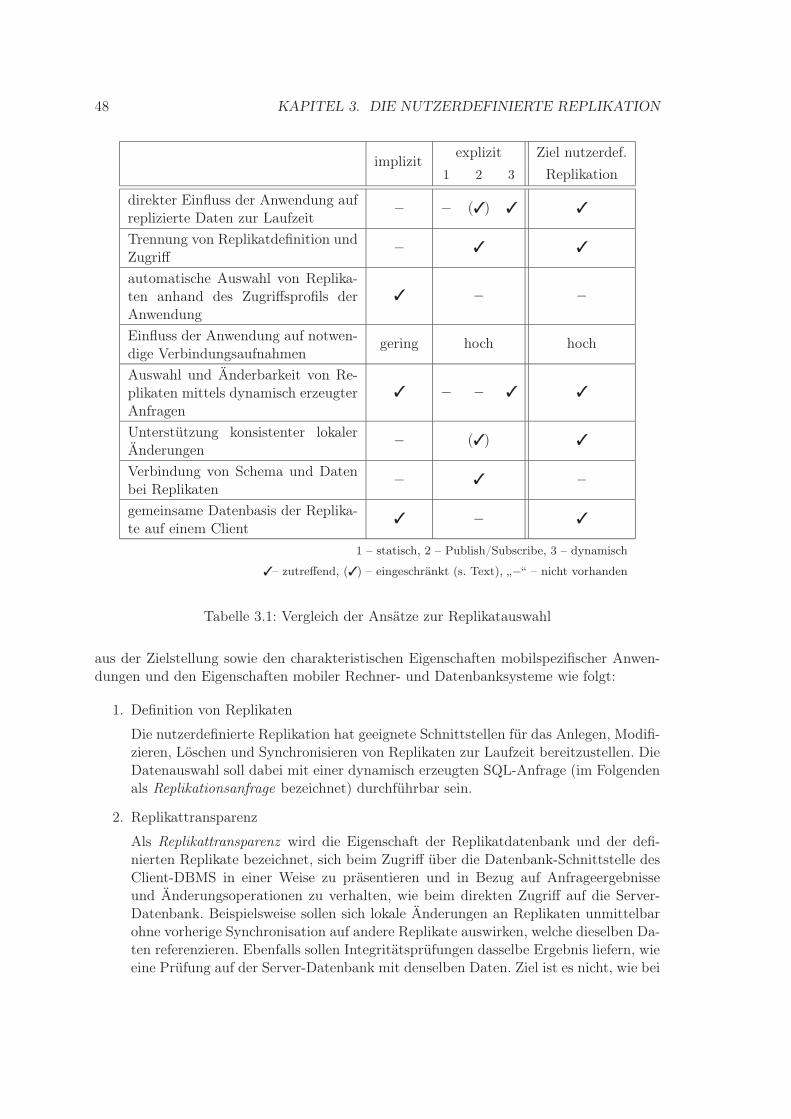
48 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
implizit explizit Ziel nutzerdef.1 2 3 Replikation
direkter Einfluss der Anwendung aufreplizierte Daten zur Laufzeit
− − ()
Trennung von Replikatdefinition undZugriff
−
automatische Auswahl von Replika-ten anhand des Zugriffsprofils derAnwendung
− −
Einfluss der Anwendung auf notwen-dige Verbindungsaufnahmen
gering hoch hoch
Auswahl und Änderbarkeit von Re-plikaten mittels dynamisch erzeugterAnfragen
− −
Unterstützung konsistenter lokalerÄnderungen
− ()
Verbindung von Schema und Datenbei Replikaten
− −
gemeinsame Datenbasis der Replika-te auf einem Client
−
1 – statisch, 2 – Publish/Subscribe, 3 – dynamisch
– zutreffend, () – eingeschränkt (s. Text), „−“ – nicht vorhanden
Tabelle 3.1: Vergleich der Ansätze zur Replikatauswahl
aus der Zielstellung sowie den charakteristischen Eigenschaften mobilspezifischer Anwen-dungen und den Eigenschaften mobiler Rechner- und Datenbanksysteme wie folgt:
1. Definition von Replikaten
Die nutzerdefinierte Replikation hat geeignete Schnittstellen für das Anlegen, Modifi-zieren, Löschen und Synchronisieren von Replikaten zur Laufzeit bereitzustellen. DieDatenauswahl soll dabei mit einer dynamisch erzeugten SQL-Anfrage (im Folgendenals Replikationsanfrage bezeichnet) durchführbar sein.
2. Replikattransparenz
Als Replikattransparenz wird die Eigenschaft der Replikatdatenbank und der defi-nierten Replikate bezeichnet, sich beim Zugriff über die Datenbank-Schnittstelle desClient-DBMS in einer Weise zu präsentieren und in Bezug auf Anfrageergebnisseund Änderungsoperationen zu verhalten, wie beim direkten Zugriff auf die Server-Datenbank. Beispielsweise sollen sich lokale Änderungen an Replikaten unmittelbarohne vorherige Synchronisation auf andere Replikate auswirken, welche dieselben Da-ten referenzieren. Ebenfalls sollen Integritätsprüfungen dasselbe Ergebnis liefern, wieeine Prüfung auf der Server-Datenbank mit denselben Daten. Ziel ist es nicht, wie bei

3.2. ZIELE UND AUFGABEN 49
der Replikationstransparenz in verteilten Datenbanksystemen (siehe Kapitel 2.4), dieMehrrechnersituation und das Potential für Konflikte durch das nur lokale Commitund die Notwendigkeit der Reintegration zu verstecken.
3. Konfliktbehandlung
Die nutzerdefinierte Replikation hat für die Behandlung der wichtigsten Konflikt-typen und -situationen geeignete Konfliktvermeidungsmethoden oder automatischeKonfliktauflösungsoptionen bereitzustellen, die bei der Definition von Replikaten aus-gewählt und vom Dienst der nutzerdefinierten Replikation durchgesetzt werden.
4. Nutzer- und Rechteverwaltung
Für die Identifikation replizierender Clients und Nutzer im Rahmen der anzubieten-den Schnittstellen sowie zur Durchsetzung von Konfliktbehandlungen und Zugriffs-beschränkungen benötigt die nutzerdefinierte Replikation eine Nutzerverwaltung mitder Möglichkeit zur Rechtevergabe. Die Nutzerverwaltung muss DBS-übergreifend(Client, Server) erfolgen und die besonderen Anforderungen mobiler Rechnersysteme(nicht vertrauenswürdige Clients, viele potentiell nicht vertrauenswürdige Nutzer)berücksichtigen.
Der Einsatzzweck der nutzerdefinierten Replikation ist die Bereitstellung replizierter Da-ten für die lokale Arbeit ohne Netzwerkverbindung. Dazu werden Schnittstellen für dasAnlegen, Modifizieren, Löschen und Anstoßen der Synchronisation von Replikaten zur Ver-fügung gestellt. Die nutzerdefinierte Replikation bietet keine eigene DBS- und Synchroni-sationsfunktionalität, vielmehr setzt sie auf einer vorhandenen mobilen Datenbanklösungauf.
Die nutzerdefinierte Replikation stellt für angeforderte Replikate über die Replikattranspa-renz zwar die Konsistenz der Replikatdatenbank sicher, welche Daten jedoch als Replikateangefordert werden, entscheidet die Anwendung bzw. ihr Nutzer. Insbesondere erfolgt auchkeine automatische Erkennung und Löschung nicht mehr auf dem Client benötigter Daten.Ebenfalls explizit, i. d. R. vom Client, muss die Synchronisation von Replikaten angestoßenwerden.
Der Zugriff auf die Replikate in der Replikatdatenbank erfolgt mit den Standardschnitt-stellen des Client-DBMS. Das erleichtert die Portierung von Anwendungen für mobile An-wendungsszenarien. Aus Sicht der Konfliktbehandlung bedeutet das, dass nur daten- undtransaktionsbasierte Synchronisations- und Konfliktauflösungsverfahren zum Einsatz kom-men können (zu Verfahren siehe Kapitel 2.5.4). Diese Einschränkung relativiert sich inder Praxis, da die allermeisten Konfliktsituationen durch Konfliktvermeidung oder sche-mabasierte Auflösungsstrategien behandelt werden können. Analog zur Einbeziehung desClient-DBMS für den Zugriff auf Replikate wird hinsichtlich der Änderbarkeit von Repli-katen auf die jeweiligen produktspezifischen Regeln und Fähigkeiten zurückgegriffen.
Mobile Datenbanklösungen sind i. d. R. heterogen zusammengesetzt, d. h. die Funktionali-tät und SQL-Schnittstelle des DBMS auf einem Client unterscheiden sich teils von denenauf anderen Clients und insbesondere von der Schnittstelle des Server. Dieser Situationbegegnet man idealerweise mit einer DBMS-unabhängigen Schnittstelle inklusive DBMS-unabhängigem SQL-Dialekt und Schematransformationsregeln. Dieses Vorgehen ist mitvertretbarem Aufwand jedoch nicht realisierbar und liegt auch außerhalb des Fokuses die-ser Arbeit. Deshalb wird bei Verwendung von SQL in der Schnittstelle der nutzerdefinierten

50 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
Replikation (z. B. in der Replikationsanfrage) immer die jeweilige SQL-Variante des Ziel-datenbanksystems verwendet.
3.3 Beispieldatenbank
Für die Illustration von Sachverhalten durch Beispiele wird ein exemplarisches Datenbank-schema benötigt, das möglichst viele Aspekte der nutzerdefinierten Replikation abdeckt.Die als Beispielszenario zugrundegelegte Miniwelt ist ein vereinfachter und angepassterAusschnitt des in Kapitel 6 beschriebenen Hermes-Anwendungsszenarios.
Land
Reisebericht Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
erhält hat
enthält
verzeichnet besitzt
eingestuftdurch
Name
BNr
Autor
Autor
Text
Text
Name Einwohner
RNr
Name
Stil
SNr
Name
(1,1)
(1,1)(1,1)
(1,1)
(0,*)
(0,*)(0,*)
(0,*)
(0,*)
(0,*)
(0,*)
(0,*)
(0,*)
(0,1)
Name
betreut
Administrator
Abbildung 3.1: E/R-Diagramm für die Beispieldatenbank
Das E/R-Diagramm für die Beispieldatenbank ist in Abbildung 3.1 angegeben. An Nutz-daten gespeichert werden können: Restaurants, Bewertungen für Restaurants, Sehenswür-digkeiten und Reiseberichte. Sehenswürdigkeiten und Restaurants sind dabei immer einerOrtschaft zugeordnet, welche wiederum in einem Land liegt. Reiseberichte können sowohlfür eine Menge von Ortschaften als auch für ganze Länder verfasst werden. Für die Be-reinigung von Daten, die von Nutzern in die Datenbank eingebracht werden, kann einAdministrator ernannt werden. Wahlweise kann seine Zuständigkeit auch auf ein bestimm-

3.4. KONZEPTE 51
tes Land beschränkt werden. Für eine bessere Lesbarkeit der späteren Beispiele wurden alsPrimärschlüssel für Ortschaft und Administrator vereinfachend jeweils die, in der Praxisnicht eindeutigen, Namen gewählt.
Land(Name)Reisebericht(Nr, Autor, Text)Ortschaft(Name, Einwohner, LName)Restaurant(RNr, Name, Stil, OName)Sehenswürdigkeit(SNr, Name, OName)Bewertung(Autor, Text, RNr)Erhält(BNr, LName)Enthält(BNr, OName)Administrator(Name, LName)
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
BNrLName
LNam
e
BNr
OName
ONameOName
RNr
LName
Abbildung 3.2: Relationale Umsetzung der Beispieldatenbank
Der E/R-Entwurf wird wie folgt in das relationale Modell abgebildet. Jeder Entitätstypwird in ein Tabellenschema überführt, gleiches gilt für die m:n-Beziehungen erhält und ent-hält. Hieraus ergibt sich das in Abbildung 3.2 angegebene relationale Datenbankschema.Alle Primärschlüssel sind wie üblich unterstrichen. Die definierten Fremdschlüsselbeziehun-gen sind zur besseren Übersicht als gerichteter Graph dargestellt, wobei die Fremdschlüs-selspalten an den Kanten vermerkt sind.
Die Spalten im Datenbankschema werden im Folgenden mit ihrem zugehörigen Tabel-lennamen durch einen Punkt getrennt qualifiziert. Weiter werden, zur Vereinfachung vonAlgebraausdrücken, Tabellennamen dabei durch einen eindeutigen Präfix abgekürzt (z. B.σO.Einwohner<100000Ortschaft mit O für Ortschaft).
3.4 Konzepte
Die Abbildung 3.3 zeigt die Konzepte der nutzerdefinierten Replikation (in Abbildungenauch als NR abgekürzt) und ihr Zusammenwirken zunächst im Überblick [Gol03b]. Dienutzerdefinierte Replikation umfasst eine administrative statische und eine von der An-wendung gesteuerte dynamische Komponente. Die statische Komponente wird von derReplikationsschemadefinition gebildet. Zur dynamischen Komponente gehören die Repli-katdefinition und die Synchronisation. Der unverbundene Zugriff auf die Replikate erfolgtdann außerhalb der nutzerdefinierten Replikation über das Client-DBMS. Die einzelnenKonzepte und Abläufe werden in den folgenden Unterabschnitten genauer erläutert.
3.4.1 Replikationsschemadefinition
Die Quelldatenbank liegt auf einem Server (im Folgenden als Quell-Server bezeichnet)im kabelgebundenen Netz. Alle Änderungen müssen, damit sie persistent und letztend-
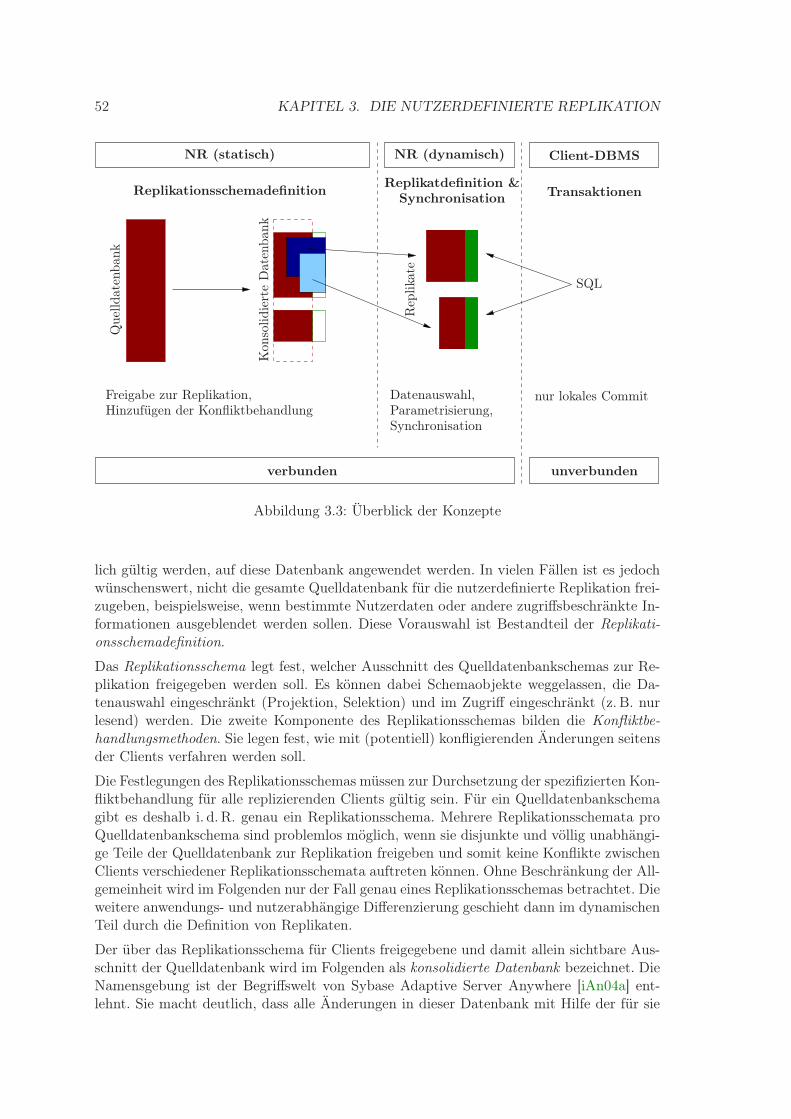
52 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
NR (statisch) NR (dynamisch) Client-DBMS
verbunden unverbunden
Replikationsschemadefinition Replikatdefinition &Synchronisation Transaktionen
Freigabe zur Replikation,Hinzufügen der Konfliktbehandlung
Datenauswahl,Parametrisierung,Synchronisation
nur lokales Commit
Que
lldat
enba
nk
Kon
solid
iert
eD
aten
bank
Rep
likat
e
SQL
Abbildung 3.3: Überblick der Konzepte
lich gültig werden, auf diese Datenbank angewendet werden. In vielen Fällen ist es jedochwünschenswert, nicht die gesamte Quelldatenbank für die nutzerdefinierte Replikation frei-zugeben, beispielsweise, wenn bestimmte Nutzerdaten oder andere zugriffsbeschränkte In-formationen ausgeblendet werden sollen. Diese Vorauswahl ist Bestandteil der Replikati-onsschemadefinition.
Das Replikationsschema legt fest, welcher Ausschnitt des Quelldatenbankschemas zur Re-plikation freigegeben werden soll. Es können dabei Schemaobjekte weggelassen, die Da-tenauswahl eingeschränkt (Projektion, Selektion) und im Zugriff eingeschränkt (z. B. nurlesend) werden. Die zweite Komponente des Replikationsschemas bilden die Konfliktbe-handlungsmethoden. Sie legen fest, wie mit (potentiell) konfligierenden Änderungen seitensder Clients verfahren werden soll.
Die Festlegungen des Replikationsschemas müssen zur Durchsetzung der spezifizierten Kon-fliktbehandlung für alle replizierenden Clients gültig sein. Für ein Quelldatenbankschemagibt es deshalb i. d. R. genau ein Replikationsschema. Mehrere Replikationsschemata proQuelldatenbankschema sind problemlos möglich, wenn sie disjunkte und völlig unabhängi-ge Teile der Quelldatenbank zur Replikation freigeben und somit keine Konflikte zwischenClients verschiedener Replikationsschemata auftreten können. Ohne Beschränkung der All-gemeinheit wird im Folgenden nur der Fall genau eines Replikationsschemas betrachtet. Dieweitere anwendungs- und nutzerabhängige Differenzierung geschieht dann im dynamischenTeil durch die Definition von Replikaten.
Der über das Replikationsschema für Clients freigegebene und damit allein sichtbare Aus-schnitt der Quelldatenbank wird im Folgenden als konsolidierte Datenbank bezeichnet. DieNamensgebung ist der Begriffswelt von Sybase Adaptive Server Anywhere [iAn04a] ent-lehnt. Sie macht deutlich, dass alle Änderungen in dieser Datenbank mit Hilfe der für sie

3.4. KONZEPTE 53
definierten Konfliktbehandlungsmethoden zusammengeführt werden.
CREATE CONSOLIDATED TABLE OrtschaftAS SELECT Name
FROM OrtschaftFOR CONSOLIDATED DATABASE cBeispielDBREAD ONLYRPS USER gollmick PWD ****
CREATE CONSOLIDATED TABLE RestaurantAS SELECT *
FROM RestaurantFOR CONSOLIDATED DATABASE cBeispielDBKEY POOL FOR RNr MAX USER KEYS 3RPS USER gollmick PWD ****
Abbildung 3.4: Beispiel für die Freigabe aus der Quelldatenbank
Die Freigabe einer Tabelle der Quelldatenbank für die Replikation erfolgt durch Anle-gen eines konsolidierten Tabellenschemas. Das Beispiel in Abbildung 3.4 zeigt die Freigabeder Tabellen Ortschaft und Restaurant unter Verwendung der Syntax der prototypischenImplementierung (siehe Kapitel 5.7.3.3). Freigegeben zur Replikation werden die Namenvon Ortschaften und alle Daten der Restaurants. Änderungen an Ortschaftsdaten sindauf Client-Seite nicht erlaubt und für Einfügungen neuer Restaurants stehen jedem Nut-zer maximal 3 Schlüsselwerte pro unverbundener Arbeitsphase zur Verfügung (Key-Pool-Verfahren). Die jeweils letzte Zeile der Anweisung enthält die Authentifizierung, die inKapitel 5.4 genauer erläutert wird.
3.4.2 Replikat(re)definition
Nach der (einmaligen) Durchführung der Replikationsschemadefinition können von mobilenClients Replikate angefordert werden. Diese werden in der jeweiligen lokalen Replikatdaten-bank abgelegt. Das Schema der Replikatdatenbank leitet sich aus dem Replikationsschemaab, wobei die client-seitige Funktionalität der ausgewählten Konfliktbehandlungsmethodenimplementiert wird. Zu einem Replikationsschema gibt es i. d. R. verschiedene Entspre-chungen als Replikatdatenbankschema, die sich durch Anpassungen an die SQL-Variantenverschiedener DBMS-Produkte unterscheiden.
CREATE REPLICATION VIEW dtRestAS SELECT *
FROM Restaurant rWHERE r.Stil = ’de’
FOR OFFLINE OPTIMISTIC READ INSERTPOOL 2 KEYSRPS USER gollmick PWD ****APPID ’***********’
Abbildung 3.5: Beispiel für die Definition eines Replikats

54 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
Replikate werden über den Client im verbundenen Zustand durch das Anlegen von Replika-tionssichten definiert. Grundlage dafür sind das lokale Replikatdatenbankschema und diekonsolidierte Datenbank. Abbildung 3.5 zeigt eine Replikationssicht für alle deutschen Re-staurants, die zum Lesen und zum optimistischen Einfügen (siehe Abschnitt 3.4.5) angefor-dert werden. Für das Einfügen werden zwei Schlüsselwerte aus dem zuvor bei der Replika-tionsschemadefinition angelegten Key-Pool reserviert (zur Syntax siehe wieder Kapitel 5).Das client-seitige Ändern und Löschen ist für dtRest nicht erlaubt.
Jede Replikationssicht bestimmt ein Replikat und es können beliebig viele, auch überlap-pende Replikationssichten auf dem Client angelegt werden. Die Replikationssicht ist dielogische Einheit der Replikation. Die Gesamtheit der von einer Anwendung zu einer Zeitgehaltenen Replikationssichten bestimmt gewissermaßen das „Fenster“ auf die konsolidierteDatenbank, auf dem unverbunden gearbeitet werden kann.
Wichtig ist die Abgrenzung einer Replikationssicht gegenüber dem Konzept der materiali-sierten Sichten. Bei der nutzerdefinierten Replikation erfolgt, wie bei impliziter Replikation,eine Trennung von Daten und Schema bei Replikaten. Tatsächlich wird von der Replikat-verwaltung nach der Synchronisation automatisch immer der Ausschnitt der konsolidiertenDatenbank als Replikatdatenbank bereitgestellt, der für die Berechnung aller angelegtenReplikationssichten und die Gewährleistung der Replikattransparenz notwendig ist. DieserAusschnitt kann größer sein, als der über Replikationssichten direkt ansprechbare Aus-schnitt (z. B. bei Fremdschlüsselbeziehungen, siehe Kapitel 4). Eine Replikationssichtende-finition hat vier Teile:
1. Replikationsanfrage
Analog zu einer klassischen Sichtendefinition erfolgt die Datenauswahl mittels ei-ner SQL-Anweisung. Die Replikationsanfrage ist immer an das lokale Replikatda-tenbankschema gerichtet und unterliegt der Notation und den Konventionen desClient-DBMS, unabhängig davon, welches Datenbanksystem für die Quelldatenbankverwendet wird.
2. Änderbarkeitsanforderung
Sollen die ausgewählten Daten lokal geändert werden, muss dafür von der Anwen-dung explizit eine Änderbarkeitszusicherung angefordert werden. Welche Vorteiledieses Vorgehen bietet und welche Zugriffszusicherungen unterstützt werden, wirdin Abschnitt 3.4.5 erläutert.
3. Parameterwerte
Für die im Replikationsschema festgelegten Konfliktbehandlungsmethoden könnenParameterwerte angegeben werden, z. B. Schlüsselwerte für das Einfügen mit demKey-Pool-Verfahren oder zu reservierende Mengen beim Escrow-Verfahren.
4. Authentisierung
Der letzte Teil der Replikationssichtendefinition besteht aus der Authentisierung vonClient und Nutzer. Die Implementierung einer Nutzerverwaltung für die nutzerdefi-nierte Replikation ist Gegenstand von Kapitel 5.4.
Das Anlegen einer Sicht ist erfolgreich, wenn die gewünschte Änderbarkeitszusicherung undKonfliktbehandlungsoptionen gewährt werden konnten. Eine naheliegende Umsetzung der

3.4. KONZEPTE 55
Replikationssicht besteht im Anlegen einer klassischen Sicht mit der Replikationsanfrageauf dem Client. Anwendungen dürfen nur über die Replikationssicht auf replizierte Datenzugreifen. Nur für den geforderten und gewährten Ausschnitt wird die Replikattransparenzgarantiert.
Ändern und Löschen einer Replikatdefinition
ALTER REPLICATION VIEW dtRestSET MODIFIABILITY TO OPTIMISTIC ALL
DROP REPLICATION VIEW dtRest
Abbildung 3.6: Beispiele für das Ändern und Löschen eines Replikats
Das hier beschriebene Konzept der nutzerdefinierten Replikation sieht keine Transaktions-klammern über mehr als eine Replikationssichtendefinition vor, d. h. jede Replikationssich-tendefinition ist unabhängig von einer anderen. Diese Vereinfachung erlaubt es, auf einekomplexe Fehlerbehandlung bei Verbindungsabbrüchen zu verzichten. Um dennoch eineatomare Änderung von Zugriffszusicherungen, Parameterwerten und Gruppenzugehörig-keit (siehe Abschnitt 3.4.3) zu gestatten, wird eine Anweisung für das Ändern eben dieserTeile der Replikationssichtendefinition bereitgestellt. Das Beispiel in Abbildung 3.6 zeigtdas Ändern der Zugriffszusicherung und das Löschen einer Replikationssicht.1
Das Löschen eines Replikats durch Löschen der Replikationssicht hat bei der nutzerde-finierten Replikation nicht zwingend das Löschen von Daten aus der Replikatdatenbankzur Folge. Das Löschen einer Sicht ist für die Replikatverwaltung ein Indikator dafür, dassdie referenzierten Daten in diesem Zusammenhang nicht mehr benötigt werden und, wennmöglich, gelöscht werden können. Werden Daten in der Replikatdatenbank von keiner Re-plikationssicht mehr referenziert, werden sie automatisch von der Replikatverwaltung ausder Replikatdatenbank entfernt.
3.4.3 Replikationssichtengruppen und Synchronisation
Die Synchronisation zwischen Server und Client wird bei der nutzerdefinierten Replikationüber eine bereitgestellte Anweisung explizit angestoßen. In bestimmten Situationen kannes sinnvoll sein, nur einen Teil der lokal vorhandenen Replikate zu synchronisieren und beiden anderen auf einer älteren, aber akzeptablen Version weiterzuarbeiten. Im Gegensatzzum Publish/Subscribe-Ansatz, bei dem der Administrator durch Zusammenfügen von Pu-blikationen global festlegt, welche Replikate gemeinsam repliziert werden sollen, kann diesbei der nutzerdefinierten Replikation ebenfalls dynamisch zur Laufzeit erfolgen. Die Fest-legung, was synchronisiert werden soll und was nicht, entscheidet die Anwendung bzw. ihrNutzer. Dafür stellt die nutzerdefinierte Replikation das Konzept der Replikationssichten-gruppe bereit.
Eine Replikationssichtengruppe ist ein „Container“ für Replikationssichten, die atomar syn-chronisiert werden sollen. Die Zuordnung der Replikationssichten zu Replikationssichten-gruppen kann dabei jederzeit zur Laufzeit geändert werden. Das Beispiel in Abbildung 3.7
1Auf die Angabe des Authentisierungsteils wird in diesem und weiteren Beispielen des Kapitels verzich-tet.

56 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
CREATE REPLICATION VIEW GROUP bsp
CREATE REPLICATION VIEW OrteAS SELECT *
FROM OrtschaftWHERE Name IN (SELECT Ort FROM Restaurant
WHERE Stil = ’de’)INTO REPLICATION VIEW GROUP bsp
ALTER REPLICATION VIEW dtRestSET REPLICATION VIEW GROUP to bsp
SYNCHRONIZE REPLICATION VIEW GROUP bsp
Abbildung 3.7: Beispiel für die Synchronisation
zeigt die Replikationssichtengruppe bsp mit den Replikationssichten Orte und dtRest, dieanschließend gemeinsam synchronisiert werden. Jede Replikationssichtengruppe kann un-abhängig von anderen Gruppen synchronisiert werden. Eine Replikationssichtengruppe istdie logische Einheit der Synchronisation. Eine sinnvolle Strategie ist es, alle Replikations-sichten, die in einer Transaktion verwendet werden, einer gemeinsamen Replikationssich-tengruppe zuzuordnen.
Da der Client in der Zusammenstellung der Replikationssichtengruppen frei ist, kann erbeispielsweise auch überlappende Sichten verschiedenen Gruppen zuordnen. Die Repli-katverwaltung sorgt dann automatisch dafür, dass dadurch die Konsistenz und atomareSynchronisation für die nicht zur Synchronisation ausgewählten Sichtengruppen nicht ge-fährdet werden (Bildung einer transitiven Hülle, siehe Kapitel 4).
3.4.4 Arbeitsmodell für den Client
Die in den vorangegangenen Abschnitten vorgestellten dynamischen Komponenten der nut-zerdefinierten Replikation sind in ein Arbeitsmodell eingebettet, an welches die Arbeit mitder nutzerdefinierten Replikation gebunden ist. Das Arbeitsmodell beschreibt alle mögli-chen Zustands- und Aktivitätsübergänge und ist in Abbildung 3.8 dargestellt.
Es werden zwei Zustände des Client unterschieden, (gewollt) unverbunden und verbun-den. Die Übergänge zwischen den Zuständen werden explizit, z. B. durch die Anwendung,herbeigeführt. Die drei Aktivitäten des Arbeitsmodells sind die Replikat(re)definition, dieSynchronisation und die Transaktionsverarbeitung, welche zyklisch durchlaufen werden. Je-de Aktivität ist in diesem Modell genau einem Verbindungszustand zugeordnet. Replikat-definitionen sind nur im verbundenen Zustand erlaubt und die Transaktionsverarbeitungerfolgt im unverbundenen Zustand.
Die nutzerdefinierte Replikation betrachtet gemäß der Zielsetzung einer Unterstützungunverbundenen Arbeitens nicht den Fall, dass der Client während einer bestehenden Ver-bindung direkt auf der Server-Datenbank arbeitet. Diese Möglichkeit besteht weitgehendorthogonal zum Arbeitsmodell und soll hier nicht betrachtet werden. Es ist jedoch zu be-achten, dass vor der Verbindungstrennung eine Synchronisation erfolgt, so dass eventuell

3.4. KONZEPTE 57
Replikat-(re)definition
Transaktions-verarbeitung Reintegration
SynchronisationDatenrück-übertragung
unverbundenerZustand
verbundenerZustand
Abbildung 3.8: Arbeitsmodell der nutzerdefinierten Replikation
direkt erzeugte Änderungen mit unverbunden durchgeführten Änderungen abgeglichen undin die Replikatdatenbank übernommen werden können.
Die Arbeit des Client beginnt im verbundenen Zustand mit der Definition eines oder meh-rerer Replikate mittels Replikationssichten. Bei der Definition werden keine Daten bewegt,sondern lediglich die Durchführbarkeit geprüft und das Replikat zur Synchronisation vor-gemerkt. Bevor mit den geforderten Daten lokal gearbeitet werden kann, muss die entspre-chende Replikationssichtengruppe synchronisiert werden.
Bei der Synchronisation werden zunächst die seit der letzten Synchronisation an Replika-ten vorgenommenen Änderungen mit der konsolidierten Datenbank abgeglichen und dabei,wenn erforderlich, einer Konfliktauflösung unterzogen (Reintegration). Anschließend wer-den die bereinigten eigenen sowie neue und geänderte Daten zurück zum Client übermittelt(Datenrückübertragung). Die vorgeschriebene Reihenfolge der Aktivitäten Reintegrationund dann Datenübertragung in einer Sitzung sichert einen konsistenten und aktuellen Da-tenbankzustand unmittelbar nach Abschluss der Synchronisation. Sind, wie zu Beginn,keine Replikate auf dem Client vorhanden oder wurden seit der letzten Verbindungsphasekeine lokalen Änderungen durchgeführt, ist die Aktivität der Reintegration leer.
Nach erfolgreichem Abschluss der Synchronisation kann die Verbindung getrennt und un-verbunden mit den Replikationssichten über das DBMS des Client gearbeitet werden. Sollenneue Daten repliziert oder nicht mehr benötigte gelöscht werden, muss die Anwendung zurAktivität der Replikatredefinition im verbundenen Zustand zurückkehren. In diesem Fallerfolgt die anschließende Reintegration auf der Grundlage der alten und die Datenrück-übertragung unter Berücksichtigung der neuen geänderten Replikatdefinitionen. Bleibendie Replikatdefinitionen unverändert und sollen nur Replikate abgeglichen werden, so kannder Zyklus unmittelbar mit der Synchronisation fortgesetzt werden.
Das hier für die nutzerdefinierte Replikation zugrundegelegte Arbeitsmodell sieht vor, dassdie komplexe Aufgabe der Replikatverwaltung auf leistungsstarken Rechnern im kabelge-

58 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
bundenen Netz durchgeführt werden kann. Dies erlaubt insbesondere eine Unterstützungauch für mobile Geräte mit geringen Ressourcen. Das bedeutet aber auch, dass Änderun-gen an Replikaten nur zusammen mit der Synchronisation und einer Verbindungsaufnahmeerfolgen können. In der Regel ist eine zentrale Prüfung, z. B. für Zugriffszusicherungen undKonfliktbehandlungsoptionen, erforderlich. In bestimmten Fällen, wenn bereits lokal alleVoraussetzungen für das Anlegen einer neuen Sicht erfüllt sind oder für das Löschen nichtmehr benötigter Daten, kann eine lokale Prüfung vorteilhaft sein. Eine entsprechende Er-weiterung des Arbeitsmodells wird in Kapitel 7.2 skizziert.
3.4.5 Zugriffszusicherungen
Wird bei einer Replikationssichtendefinition keine Zugriffszusicherung gefordert, erfolgtdie Replikation nur mit Leserechten auf die Daten. Änderbarkeitszusicherungen müssenexplizit angefordert werden, dieser Ansatz bietet im Wesentlichen zwei Chancen:
• Reduktion von Mehraufwand
Für die Erfassung lokaler Änderungen zur späteren Reintegration, für die Anwendungvon Konfliktvermeidungsmethoden und die Gewährleistung von Replikattransparenzist auf dem Client Mehraufwand sowohl an Speicherplatz als auch Rechenleistungerforderlich. Ist bei der Replikatdefinition bekannt, dass später keine Änderungendurchgeführt werden sollen, so kann, wenn keine anderen Replikatdefinitionen eserfordern, der Mehraufwand dafür vermieden werden.
• Erhöhung der Verfügbarkeit
Die explizite Angabe eines Änderungswunsches erlaubt die Einführung abgestufterÄnderbarkeitszusicherungen (s. u.) mit unterschiedlichen Einschränkungen bzgl. derVerfügbarkeit der Daten für andere Nutzer.
Die nutzerdefinierte Replikation unterscheidet drei Kategorien von Zugriffszusicherungen:
• nur lesend,
• nicht-exklusiv/optimistisch und
• exklusiv
Erhält ein mobiler Client die nicht-exklusive (optimistische) Änderbarkeitszusicherung fürangeforderte Daten, so können auch andere Clients Änderungen an diesen Daten vorneh-men. Die Verfügbarkeit der replizierten Daten für andere Nutzer wird nicht eingeschränkt.Lokal ausgeführte Transaktionen bekommen in diesem Fall nur ein lokales Commit. Beider späteren Reintegration können Konflikte auftreten, die mit Hilfe der spezifiziertenMethoden behandelt werden müssen. Die optimistische Änderbarkeitszusicherung ist derNormalfall, wenn lokale Änderungen durchgeführt werden sollen.
Zur Pflege und Kontrolle gemeinsam bearbeiteter Daten oder für spezielle Anwendungssze-narien, z. B. im wissenschaftlich-technischen Bereich sind exklusive Zugriffszusicherungenvorgesehen. Der gewährte exklusive Zugriff entspricht einem so genannten check-out der an-geforderten Daten [DGK+86, LP83]. Andere Nutzer können währenddessen die gesperrten

3.4. KONZEPTE 59
Daten weder anfordern noch synchronisieren. Im Detail sind folgende Zugriffszusicherungenvorgesehen2:
• nur lesender Zugriff (R)
• lesender und optimistisch einfügender Zugriff (RI)
• optimistischer Vollzugriff mit Lesen, Einfügen, Ändern und Löschen (RIDU)
• exklusiv lesender und einfügender Zugriff (XRI)
• exklusiver Vollzugriff mit Lesen, Einfügen, Ändern und Löschen (XRIDU)
Einem anfordernden mobilen Client kann eine Zugriffszusicherung nur dann gewährt wer-den, wenn die anderen mobilen Clients gewährten Zusicherungen dem nicht entgegenste-hen. Clients können im Rahmen der Verträglichkeitsprüfung zwischen den Zugriffszusi-cherungen für eine Replikationssicht wechseln. Dadurch ist es möglich, im Sinne maxi-maler Verfügbarkeit, immer die schwächste Zugriffszusicherung zu fordern, die für einekommende unverbundene Arbeitsphase notwendig ist. Die jeweilige Verträglichkeit oderNicht-Verträglichekeit zwischen bestehenden und neu angeforderten Zugriffszusicherungenist in Abbildung 3.9 als Matrix dargestellt.
bestehende Zugriffszusicherungeines anderen Nutzers
R RI RIDU XRI XRIDUR – –
neu angefor- RI – –derte Zugriffs- RIDU – –zusicherung XRI 1 1 1 – –
XRIDU 1 1 1 – –
Synchronisation möglich –1 –1
1 . . . Vorrang der exklusiven Zusicherung
Abbildung 3.9: Verträglichkeitsmatrix der Zugriffszusicherungen
Im Unterschied zu kurzzeitigen Sperren, die von einem DBMS auf Datenobjekte angefor-dert werden, besteht bei der Anforderung von Zugriffszusicherungen nicht die Möglichkeit,bei beobachteter Unverträglichkeit auf eine Freigabe zu warten, die eventuell Stunden inder Zukunft liegt. Eine unverträgliche Anforderung führt sofort zum Abbruch der Repli-katdefinition und einer Rückmeldung an den Client.
Aus diesem Grund ist es erforderlich, den exklusiven Zugriffszusicherungen immer Vorrangvor nicht-exklusiven Zusicherungen einzuräumen. Trifft eine exklusive Anforderung nurauf bereits bestehende nicht-exklusive Zugriffszusicherungen anderer Clients, so wird sie ge-währt. Für die Inhaber der nicht-exklusiven Zugriffszusicherungen hat das zur Konsequenz,dass Änderungen auf den betroffenen Replikaten nicht synchronisiert werden können, so-lange die exklusive Zugriffszusicherung besteht. Folglich ist eine zeitliche Begrenzung füroptimistische Zugriffszusicherungen nicht erforderlich.
2Warum genau diese Unterteilung sinnvoll ist, wird in Kapitel 4.3.2 auf Seite 74 erläutert.

60 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
Im Rahmen von mobilen Anwendungsszenarien sollten exklusive Zugriffszusicherungen aufgemeinsam genutzten Daten die Ausnahme sein. Sie sind beispielsweise für Administra-toren gedacht, die bestimmte Teile der konsolidierten Datenbank zur Wartung für dieReplikation/Synchronisation sperren wollen. Unter diesem Blickwinkel ist eine manuelleLösung von Blockierungen vertretbar. Alternativ ist eine zeitliche Befristung exklusiverZugriffszusicherungen möglich. Da Clients in der Wahl der geforderten Zugriffszusicherungzunächst frei sind, muss es möglich sein, das Recht zum exklusiven Zugriff auf bestimmteNutzer(gruppen) zu beschränken (siehe dazu Kapitel 5.4.1).
3.5 Stand der Technik
In verschiedenen Arbeiten [Mül03, Her03, Lie01, Fan00] wurden, jeweils mit unterschiedli-chen Schwerpunkten, kommerzielle mobile Datenbanklösungen untersucht. Zu einer mobi-len Datenbanklösung gehören dabei ein Client-DBMS, eine Replikations- und Synchroni-sationskomponente und ein Server-DBMS. In der Regel sind Replikationskomponente undClient-DBMS aufeinander abgestimmte Produkte desselben Herstellers. Das Server-DBMSkann in einer mobilen Datenbanklösung dagegen meist frei gewählt werden. Meist sindauch Produkte anderer Hersteller einsetzbar, solange sie eine Standardschnittstelle (z. B.ODBC oder JDBC) anbieten. Die Vorteile einer homogenen mobilen Datenbanklösung, wiez. B. der direkte Zugriff auf das systemspezifische Datenbank-Log, können in diesem Fallallerdings nicht genutzt werden.
In Tabelle 3.2 auf Seite 63 sind die Untersuchungsergebnisse zu den Schwerpunkten Repli-kation und Synchronisation (hier speziell die Konfliktbehandlung) zusammengefasst. Dieverwendete Terminologie und die jeweiligen Alternativen wurden in den vorangegangenenAbschnitten und im Kapitel 2 eingeführt bzw. werden in diesem Abschnitt noch erläutert.Die hier untersuchten Eigenschaften werden maßgeblich von der mit dem Client-DBMSkombinierten Replikationskomponente bestimmt. Zur Verbesserung der Lesbarkeit der Ta-belle sind in der ersten Spalte nur die Namen der Client-DBMS aufgeführt. Ergeben sichUnterschiede in den Eigenschaften durch verschiedene Replikationskomponenten, sind dieseentsprechend gekennzeichnet.
Die Untersuchungen erfolgten anhand von Systemhandbüchern und Sekundärliteratur, er-gänzt durch eigene praktische Evaluationen (insbesondere bei der Umsetzung der nutzerde-finierten Replikation). Zum Vergleich sind in der letzten Zeile der Tabelle die Eigenschaftendes in der Arbeit entwickelten Prototypen für die nutzerdefinierte Replikation angegeben(RPS-Prototyp, siehe Kapitel 5).
Aufgrund der schnellen Entwicklung der kommerziellen mobilen Datenbanklösungen wur-den die Angaben gegenüber den Originalarbeiten für die aktuellen Versionen der Produkteüberarbeitet und aktualisiert (Stand 2004/2005). Dabei kann festgestellt werden, dass diefür den Vergleich der Produkte untereinander und insbesondere mit dem RPS-Prototypenausgewählten Eigenschaften weitgehend auch über Versionen hinweg charakteristisch sind.Auf die Angabe weiterer technischer Eigenschaften, die einer stetigen Fortentwicklung un-terworfen sind (z. B. Umfang der unterstützten SQL-Sprachelemente), wird verzichtet. Dieevaluierten mobilen Datenbanklösungen sind (Client-DBMS in alphabetischer Reihenfol-ge):

3.5. STAND DER TECHNIK 61
• Adaptive Server Anywhere V9.0.2 (ASA)
Das DBMS Adaptive Server Anywhere ist ein vollwertiges Datenbankmanagement-system mit SQL-Schnittstelle und Transaktionsunterstützung, von Sybase speziellentwickelt für kleine, mobile Geräte mit wenig Ressourcen. Als Replikationskom-ponente stehen die Produkte SQL Remote (nur mit Sybase-Produkten als Server-DBMS) und MobiLink Synchronization Server zur Verfügung. Die genannten Pro-dukte sind Bestandteil des Software-Pakets SQL Anywhere Studio [iAn04a].
• DB2 Everyplace V8.2 (DB2e)
DB2e von IBM ist ebenfalls ein vollwertiges DBMS, das jedoch im Gegensatz zuASA als Laufzeitbibliothek für die jeweilige Betriebssystemplattform in die Client-Anwendung integriert wird. Mit einer Größe von etwa 300 KB ist DB2e auchfür sehr kleine Geräte und eingebettete Hardware geeignet. Die Replikations- undSynchronisationskomponente ist der DB2 Everyplace Sync Server, der zusammenmit dem DBMS im Software-Paket DB2 Everyplace Enterprise Edition ausgeliefertwird [IBM04a, FKL03].
• DB2 Universal Database V8.2 (DB2 UDB)
Die früher unter dem Namen DB2 Satellite Edition von IBM separat vertriebene Lö-sung für den Einsatz in stationären Außenstellen und auf mobilen Notebooks ist seitder Version 7 Bestandteil von DB2 UDB. Als Replikationskomponente wird der DB2DataPropagator eingesetzt, der ebenfalls Bestandteil von DB2 UDB ist [IBM04c].
• Oracle Database Lite 10g (Oracle Lite)
Oracle Lite ist eine Ergänzung zum Server Produkt von Oracle. Es erlaubt, wie dieanderen untersuchten Client-DBMS, die verbindungslose Arbeit auf Rechnern mitgeringen Ressourcen. Eine Synchronisation über die Mobile Server genannte Repli-kationskomponente ist nur mit einem Oracle Server-DBS möglich [Ora04a] .
Im ersten Teil der Produktevaluation, die Ergebnisse sind in den Spalten 1–4 der Tabelledargestellt, wurde untersucht, welche der in Abschnitt 3.1 erläuterten Auswahlmechanis-men für Replikate von den jeweiligen Produkten verwendet werden. Alle untersuchtenProdukte beschränken sich auf eine explizit zu spezifizierende Replikatauswahl. Gemäßdem Publish/Subscribe-Ansatz werden zunächst Daten für die Freigabe zur Replikationfestgelegt, welche anschließend von Clients ausgewählt und über Parameter instantiiertwerden können. Der RPS-Prototyp implementiert mit der nutzerdefinierten Replikation,seiner Zielsetzung nach, eine Kombination zwischen impliziter und expliziter Replikati-on, welche eine Vorauswahl für alle mobilen Clients über das Replikationsschema mittelsdynamisch generierter Replikationssichten zur Laufzeit durch den Client präzisieren lässt.
Der zweite und dritte Teil der Produktevaluation ist der Synchronisation gewidmet undgliedert sich in einen allgemeinen Teil (Spalten 5–12) und die Konfliktbehandlung (Spalten13–19). Es ist festzustellen, dass alle untersuchten Produkte in der Lage sind, nach einerobligatorischen initialen Übertragung aller benötigten Daten im Folgenden jeweils nur dieÄnderungen am Datenbankzustand zu bestimmen und zwischen Server und Client zu über-tragen. Dagegen erlauben nur ASA und der darauf aufbauende RPS-Prototyp, zur Laufzeitvon Client-Seite die zu synchronisierenden Replikate einzuschränken. Dies ist beispielsweisesinnvoll, um die Übertragung zu erwartender großer Datenvolumina auf einen günstigeren

62 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
Zeitpunkt zu verschieben, ohne dabei die Möglichkeit zur Sicherung der Dauerhaftigkeitwichtiger Änderungen zu verlieren.
Alle hier untersuchten Produkte erlauben eine verbindungsbasierte Kommunikation zurSynchronisation, d. h. es wird über einen Kommunikationskanal synchron kommuniziert.Eventuelle Abbrüche der Verbindung führen zu einem Fehlerzustand. Die Synchronisati-on muss in diesem Fall wiederaufgesetzt werden. Nach Abschluss der Kommunikation istdie Synchronsiation abgeschlossen. Eine alternative, asynchrone nachrichtenbasierte Syn-chronisation bieten ASA (mit SQL Remote) und Oracle Lite. Bei der nachrichtenbasiertenKommunikation (z. B. per E-Mail, SMS) werden die Änderungen von Server und Clientin Eingangswarteschlangen des jeweils anderen Systems geschrieben und dort nacheinan-der abgearbeitet. Nachrichtenbasierte Kommunikation hat zwei wesentliche Nachteile, somüssen Konflikte sowohl auf dem Client als auch auf dem Server behandelt werden undsie werden u. U. erst später erkannt, wenn beide Seiten schon mit den geänderten Datenweitergearbeitet haben. Nachrichtenbasierte Synchronisation eignet sich deshalb nur fürAnwendungsszenarien, in denen keine oder wenige Konflikte bei der Reintegration aufge-löst werden müssen. Für den RPS-Prototyp gelten die für ASA mit MobiLink zutreffendenEigenschaften.
Bei der Reintegration unterstützt keines der untersuchten Produkte eine semantikbasier-te Neuausführung ganzer Transaktionen. ASA, der RPS-Prototyp und DB2e übertragendie kumulierten Datenänderungen. DB2 UDB in Kombination mit dem DataPropagatorschreibt den Transaktionskontext jeder Änderung in eine Steuertabelle, so dass die Infor-mation für das Zurückrollen einzelner Client-Transaktionen und die (manuelle) Konflikt-behandlung zur Verfügung steht. Alle Produkte verlangen eine ordnungsgemäße Authenti-fizierung der Clients für eine Synchronisation. Eine ebenso wichtige automatische Prüfungder hereinkommenden Daten, per Definition unsicherer mobiler Clients, gegen die vorherfestgelegten Replikatdefinitionen findet jedoch nicht statt. Eine solche Prüfung wurde inden RPS-Prototyp integriert.
Die produktseitig vorhandenen Möglichkeiten zur Konfliktvermeidung beschränken sich beiden meisten Produkten auf „wohlgemeinte Ratschläge“ zur entsprechenden Anpassung desAnwendungsszenarios. Einzig das Sybase-Produkt ASA unterstützt die Arbeit mit Key-Pools durch entsprechende Konstrukte. Ein temporäres Sperren von Datenobjekten wirdebenfalls von keinem Produkt unterstützt. In den RPS-Prototyp wurden das Key-Pool-Verfahren sowie die Möglichkeit für exklusive Zugriffszusicherungen integriert. Für dasEscrow- und Slot-Verfahren existieren separate prototypische Implementierungen (siehedazu Kapitel 5.5).
Alle betrachteten Produkte besitzen eine automatische Konflikterkennung basierend aufden Konfliktarten aus Kapitel 2.5.4.1 und der Identifikation von Zeilen anhand ihres Pri-märschlüssels. Oracle Lite führt zusätzlich einen inhaltsunabhängigen Versionszähler fürjede Tabellenzeile, so dass auch Änderungen des Primärschlüssels, die eine Datenprüfungund eine Konflikterkennung eventuell erschweren würden, erkannt werden können. AlleProdukte bieten sowohl einfache schemabasierte Standardregeln für die Konfliktauflösung,als auch Schnittstellen für anwendungsabhängige Implementierungen. Will man bereitsfrüher in die Konfliktbehandlung eingreifen, etwa um neue, nicht automatisch erkannteKonfliktsituationen zu berücksichtigen, bietet ASA im Zusammenspiel mit MobiLink dieMöglichkeit zur Implementierung einer eigenen Konflikterkennung. Bereitgestellt werdenin diesem Fall zeilenweise alle reintegrierten Abbilder. Der RPS-Prototyp bietet über eineerweiterte SQL-Syntax die Möglichkeit, bei der Replikationsschemadefinition aus vordefi-nierten und parametrisierten Alternativen zu wählen.
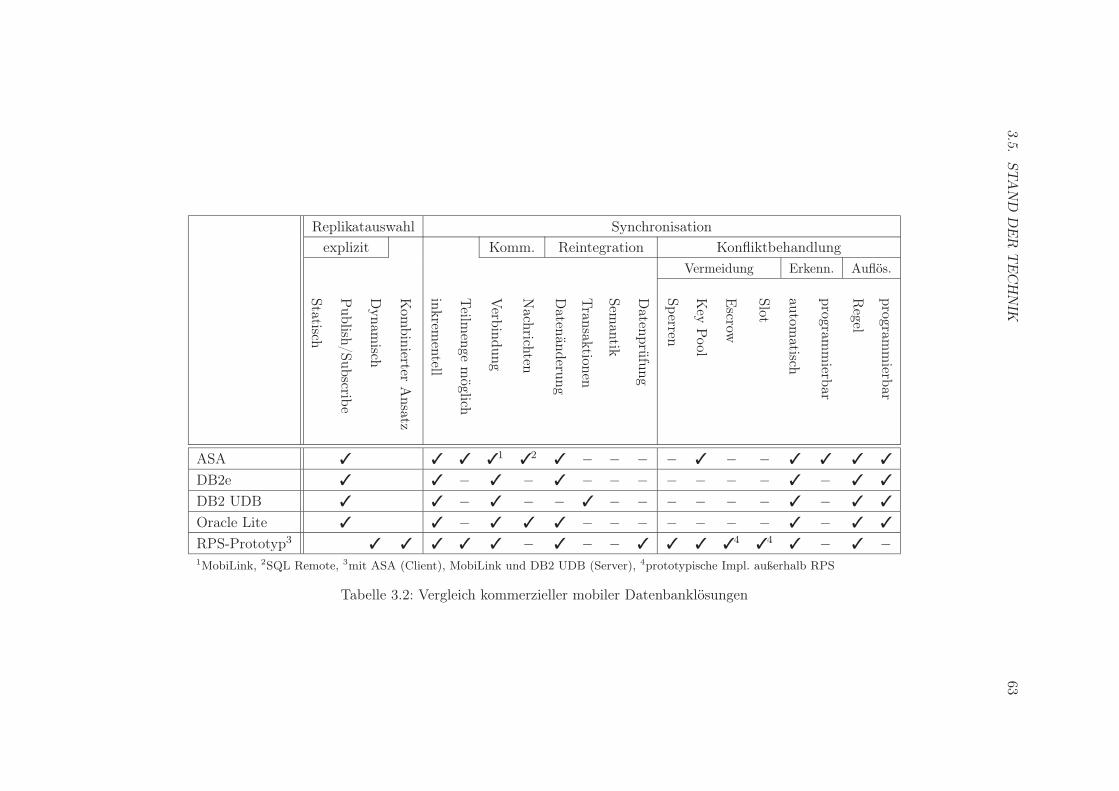
3.5.ST
AN
DD
ER
TE
CH
NIK
63
Replikatauswahl Synchronisationexplizit Komm. Reintegration Konfliktbehandlung
Vermeidung Erkenn. Auflös.
Statisch
Publish/Subscribe
Dynam
isch
Kom
binierterA
nsatz
inkrementell
Teilm
engem
öglich
Verbindung
Nachrichten
Datenänderung
Transaktionen
Semantik
Datenprüfung
Sperren
Key
Pool
Escrow
Slot
automatisch
programm
ierbar
Regel
programm
ierbar
ASA 1 2 − − − − − −
DB2e − − − − − − − − − −
DB2 UDB − − − − − − − − − −
Oracle Lite − − − − − − − − −
RPS-Prototyp3 − − − 4 4 − −1MobiLink, 2SQL Remote, 3mit ASA (Client), MobiLink und DB2 UDB (Server), 4prototypische Impl. außerhalb RPS
Tabelle 3.2: Vergleich kommerzieller mobiler Datenbanklösungen

64 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
3.6 Verwandte Arbeiten
In diesem Abschnitt sollen relevante Forschungsarbeiten vorgestellt werden, die ebenfallsLösungen für mobile Anwendungsszenarien anbieten und Bezüge zur hier betrachteten nut-zerdefinierten Replikation aufweisen. Weitere Projekte zu Einzelaspekten mobiler Daten-banksysteme, die in der Arbeit nicht im Fokus standen, z. B. erweiterte Transaktionsmo-delle mit abgeschwächten Konsistenzeigenschaften, wurden in [Her03, Lie01] evaluiert.
MobiSnap
Das bereits im Kapitel 2.5.3.4 kurz angesprochene Projekt M obiSnap [PMC02, PBM+00]von der Universidade Nova de Lisboa realisiert ein Konzept für das verbindungslose Arbei-ten mobiler Clients, es setzt dabei auf so genannte Transaktionsprogramme und Reservie-rungen. Über die Transaktionsprogramme, deren Syntax ein prozedural erweitertes SQL ist,kann die Client-Anwendung lokale Änderungen spezifizieren. Für jede Änderung müsseneine Vorbedingung, ein Akzeptanztest und Alternativen für eine Konfliktauflösung angege-ben werden. Über die Reservierungen können Anwendungen vorab bestimmte Rechte undGarantien für replizierte Daten erhalten. Neben dem Escrow-Verfahren gehört auch dieSlot-Reservierung zu den Möglichkeiten. Die Ausführung der zunächst lokal abgeschlosse-nen Transaktionsprogramme muss auf dem Server wiederholt werden. Ist die Vorbedingungbzgl. der aktuellen Daten auf dem Server erfüllt, wird die Änderung erneut durchgeführt.Anschließend entscheidet der Akzeptanztest, ob eine der spezifizierten Konfliktauflösungs-prozeduren ausgeführt werden muss. Das Ergebnis der erneuten Ausführung kann dabeivon dem Ergebnis auf dem Client abweichen.
MobiSnap bietet kein Konzept für die Auswahl zu replizierender Daten und realisiert andersals die nutzerdefinierte Replikation eine semantikbasierte Synchronisation. Diese bietet denVorteil höherer Flexibilität bei der Spezifikation der Konfliktbehandlung. Das aber zu demPreis einer sehr viel höheren Komplexität, da für jede Operation ein kleines Programmgeschrieben werden muss. Anwendungsprogramme können im Gegensatz zur nutzerdefi-nierten Replikation nicht die gewohnten SQL-Schnittstellen verwenden. Da die meisten inder Praxis auftretenden Konflikte über Reservierungen vermieden oder mit einfachen sche-mabasierten Regeln behandelt werden können, relativiert sich der Vorteil der prozeduralenKonfliktauflösung. Das in MobiSnap verwendete Konzept der Slot-Reservierungen wurdefür die nutzerdefinierte Replikation adaptiert.
Bayou
Ebenfalls auf eine Konfliktbehandlung per Transaktion und semantikbasierte Synchroni-sation setzt auch eines der ersten Projekte für mobile Datenbanksysteme, das am XeroxPARC entwickelte Bayou-System [DPS+94]. Ziel ist die Unterstützung verteilter Daten-banksysteme mit zeitweise unverbundenen Knoten. Neben der semantikbasierten Synchro-nisation sind die wesentliche Elemente von Bayou die Änderungsweiterleitung zwischen denKnotenrechnern mittels eines Anti-Entropie-Verfahrens und so genannte Session Guaran-tees. Letztere dienen dazu, einem mobilen Rechner auch beim zwischenzeitlichen Wechseldes Kommunikationspartners (vergleiche Kapitel 2.3.3) eine für ihn konsistente Sicht auf

3.6. VERWANDTE ARBEITEN 65
die globale Datenbank zu ermöglichen. Die Sitzungsgarantien sind mit verschiedenen Stufender Isolation vergleichar (vergleiche Kapitel 2.5.2).
Ein mobiles aktives Datenbanksysteme
Olaf Zukunft beschreibt in seiner Dissertation [Zuk98] die Integration von Mechanismenaktiver Datenbanksysteme in ein mobiles Datenbanksystem. Ein Schwerpunkt der Arbeitist die Entwicklung von Mechanismen und Regeln zur Adaption an veränderte Situationenmobiler Clients (z. B. Ressourcen, Ortswechsel, Netzverfügkeit). Dazu dient eine Syste-matisierung und formale Beschreibung der möglichen Eigenschaften eines mobilen Client.Weiter wurden ein neues Replikations- und Transaktionsmodell entwickelt, die zusätzlichzu Datenkopien, das Replizieren von Regeln erlauben. Die Synchronisation und Konflikt-behandlung erfolgt, wie bei den anderen bisher vorgestellten Projekten, durch Wieder-ausführung von Transaktionen und einem Akzeptanztest mit anschließender prozeduralerKonfliktauflösung.
Adaptive Replikation
In seiner Disseration beschreibt Richard Lenz Methoden zur adaptiven Replikation in ver-teilten Datenbanksystemen [Len97]. Er postuliert, dass klassische Korrektheitskriterien fürvDBMS, wie die Ein-Kopien-Serialisierbarkeit für Replikate, mit einem zu hohen Synchro-nisationsaufwand verbunden sind und außerdem für viele Anwendungsszenarien gar nichterforderlich sind. Sein Ziel ist es, durch anwendungsbezogene Abschwächung von Kon-sistenzanforderungen, die vom DBMS kontrolliert werden, eine höhere Verfügbarkeit zuerreichen.
In seinem Ansatz werden die Konsistenzanforderungen (z. B. gewünschte Aktualität der Re-plikate, Exklusivität im Zugriff) an Datenbankausschnitte der globalen Datenbank gebun-den, mit denen lokal gearbeitet werden soll. Die jeweiligen Konsistenzanforderungen und In-tegritätsbereiche (z. B. Fremdschlüsselbeziehungen über mehrere Tabellen), die überwachtwerden sollen, können von der Anwendung deskriptiv mittels erweiterten SQL-Anfragen fürso genannte Extents der globalen Datenbank spezifiziert werden. Zur Realisierung verwen-det Lenz eine Zerlegung des Datenbankschemas in disjunkte Tabellenpartitionen (Fragmen-te genannt), welche durch fortgesetzte Selektion und Projektion entstehen. Die Extents,welche sich überlappen können, und ihre Eigenschaften werden auf die Fragmente abgebil-det.
Der Ansatz ähnelt dem Fragmentkonzept der nutzerdefinierten Replikation (vergleicheKapitel 4), unterscheidet sich jedoch davon in wesentlichen Punkten. Die Anforderung vonGarantien ist bei der nutzerdefinierten Replikation immer verbunden mit der expliziten An-forderung von Daten. Durch den lokal über die Replikationsanfrage als Filter beschränktenZugriff auf die Replikatdatenbank sind Änderungen, welche aus der Sichtendefinition her-ausführen, nicht erlaubt. Damit können, solange der Client sich an die Regeln hält odereine zentrale Prüfung erfolgt, lokale Änderungen keine Zugriffszusicherungen von anderenClients verletzen. Im Ansatz von Lenz muss diese Migration von Zeilen zwischen Extentsund Fragmenten aufwändig erkannt und behandelt werden. Auch erscheint der Ansatz,Integritätsbereiche durch die Anwendung zu definieren, zwar sehr flexibel, die meistenIntegritätsbedingungen ergeben sich aber direkt aus dem Schema der Datenbank und kön-

66 KAPITEL 3. DIE NUTZERDEFINIERTE REPLIKATION
nen dementsprechend automatisch (z. B. bei der Bildung von Fragmenten) berücksichtigtwerden (siehe Kapitel 4.3).
View Holder
In [WC02] stellen die Autoren eine flexible Verwaltung materialisierter Sichten, genanntView Holder, für die Unterstützung des Lesezugriffs einer großen Zahl zeitweise unver-bundener Clients vor. Das Ziel des View-Holder-Ansatzes ist die effiziente Bereitstellungder Differenz zwischen dem aktuellen Zustand und dem Zustand eines synchronisierendenClient auf Instanzenebene. Auf einer Zwischenschicht zwischen Server und Clients werdendazu verschiedene Versionen von (materialisierten) Sichten verwaltet. Jede Sichtenversionrepräsentiert einen Zustand auf einem Client. Die View-Holder fassen dabei Sichten zuGruppen zusammen, welche von mehreren Clients benötigt werden.
Der View-Holder-Ansatz realisiert das Publish/Subscribe-Prinzip, wobei die materialisier-ten Sichten vom Client dynamisch angelegt werden können. Die Zwischenschicht, welche dieSichtenversionen speichert, dient der Performance-Verbesserung der Änderungsermittlungund Weiterleitung zu den Clients. Im Gegensatz zum Semantic Caching und zur nutzer-definierten Replikation werden die Sichtenversionen auf Instanzenebene verwaltet. Damitstehen die Differenzmengen für die Änderungsübertragung schnell zur Verfügung. Da beimView-Holder-Ansatz für die Sichten keine gemeinsame Datenbasis angestrebt wird undÄnderungen nur über den Server erfolgen dürfen, kann der andernfalls notwendige Verwal-tungsaufwand eingespart werden.

Kapitel 4
Replikatverwaltung
Die von der nutzerdefinierten Replikation erlaubte Anpassbarkeit des replizierten Daten-bankausschnitts durch dynamisch erzeugte SQL-Anfragen erfordert geeignete Verfahrenund Datenstrukturen zur Auswertung und Speicherung der Replikatdefinitionen. Zu diesemZweck wurde das so genannte Fragmentkonzept entwickelt. Im Gegensatz zum SemanticCaching werden hierbei nicht die Anfrageprädikate für die Inhaltsbeschreibung der Repli-katdatenbank verwendet, sondern vorher aus dem relationalen Schema der konsolidiertenDatenbank gebildete Partitionen, die Fragmente. Replikationsanfragen werden einmal inFragmentmengen übersetzt, welche dann stellvertretend gespeichert und weiterverarbeitetwerden.
Eine erste Version des Fragmentkonzepts wurde in [Rab03, GR03] publiziert. Jedoch ver-hinderten erhebliche Einschränkungen der veröffentlichten Variante einen praktischen Ein-satz im Prototypen (siehe Kapitel 5). Dazu zählen das Verbot der Vergleichsoperatoren=, <, >,≤,≥ in Selektionsprädikaten von Replikationsanfragen und die Notwendigkeit vonAnpassungen der Fragmentbeschreibungen beim Hinzufügen von neuen Werten für diezur Fragmentbildung verwendeten Partitionierungsspalten. Ebenfalls in der ersten Versionnicht unterstützt wurden exklusive Zugriffszusicherungen für das Einfügen neuer Daten indie Datenbank, wie sie die nutzerdefinierte Replikation vorsieht (siehe Kapitel 3.4.5).
Schließlich konnte das Fragmentkonzept u. a. in den Arbeiten [Mic04, Pfe04] entscheidendweiterentwickelt und verbessert werden. Es gelang, die Nachteile der ersten Version zu be-seitigen. Die verbesserte Datenstruktur zur Speicherung der Fragmentbeschreibungen sowiedie mit ihr verbundenen Verfahren sind zum Patent [GMP04] angemeldet. Das vorliegendeKapitel vermittelt die theoretischen Grundlagen des verbesserten Fragmentkonzepts undbeschreibt eine Realisierung basierend auf einer relationalen Speicherung der Fragment-beschreibungen. Für Beispiele kommt wieder das in Kapitel 3.3 eingeführte Szenario zumEinsatz.
Das Kapitel gliedert sich wie folgt. Abschnitt 4.1 ergänzt die in Kapitel 2.2 eingeführtenGrundlagen relationaler Datenbanksysteme um Relationen auf der Ebene der Schemata.Darauf aufbauend werden in Abschnitt 4.2 die Aufgaben der Replikatverwaltung und ins-besondere die zu berechenenden und zu speichernden Schemaausschnitte formal beschrie-ben. Zwischen verschiedenen Schemaausschnitten können Abhängigkeiten bestehen; welchedas sind und was bei der Replikation beachtet werden muss, erläutert Abschnitt 4.3. We-sentlich für die Arbeit mit replizierten Schemaausschnitten ist ihre Repräsentation in denMetadaten; die anfragebasierte und die in der Arbeit eingesetzte fragmentbasierte Verwal-
67

68 KAPITEL 4. REPLIKATVERWALTUNG
tung werden in Abschnitt 4.4 gegenübergestellt. Die Fragmente für eine fragmentbasierteVerwaltung werden in zwei Schnitten konstruiert: durch Bildung von Schemafragmenten(Abschnitt 4.5) und Datenfragmenten (Abschnitt 4.6). Die Entwicklung konkreter Verfah-ren zur Übersetzung von Replikationsanfragen in Fragmentmengen und umgekehrt benötigteine Datenstruktur zur Aufnahme der Fragmentbeschreibungen, welche in Abschnitt 4.7eingeführt wird. Die weiteren Abschnitte behandeln die einzelnen umzusetzenden Verfah-ren: Anfrageübersetzung in Fragmente (Abschnitt 4.8), Anfrageerstellung aus Fragmenten(Abschnitt 4.9) und abschließend die Sperrobjektberechnung (Abschnitt 4.10).
4.1 Relationen auf Datenbankschemata
Die Einführung in das relationale Modell und die relationale Algebra in Kapitel 2.2 be-schränkt sich auf die Definition von Operationen auf der Ebene einzelner Tabellenschemataoder der Instanzenebene. Für die Arbeit mit mehreren Datenbankschemata, wie sie beimReplizieren erforderlich ist, wird eine weitere Ebene benötigt, die zusätzlich Aussagen überdas Verhältnis von Datenbankschemata zueinander ermöglicht.
Seien D1 = T 11 , . . . , T 1
m und D2 zwei Datenbankschemata mit D = D1 ∪D2, dann lassensich die folgenden Relationen definieren:
• D1 D2: D1 ist abgeleitet aus D2, falls gilt:
Für alle Tabellenschemata T 1i ∈ D1 (1 ≤ i ≤ m) existiert ein Ausdruck Ei(D2) der
relationalen Algebra, so dass gilt: T 1i ≈ Ei(D2) bzgl. D, d. h. für alle Datenbanken
d = t1i (T 1i ), . . . ∈ Dat(D) gilt t1i = vEi(D2)(d).
– Umgekehrt heißt es D2 überdeckt D1
– D1 wird als Schemaausschnitt von D2 bezeichnet.
– Trivialerweise gilt wegen der Teilmengenbeziehung D1,D2 D.
– Beispiel:
D1 = T 1 := σO.Einwohner>1000Ortschaft,D2 = T 2 := σO.Einwohner≥500(Ortschaft Restaurant)es gilt D1 D2 mit E = πO.Name,O.Einwohner(σO.Einwohner>1000T
2)
• D1 ≈ D2: D1 und D2 sind äquivalent, falls gilt:
D1 ist abgeleitet aus D2 und D2 ist abgeleitet aus D1, formal: D1 D2 ∧ D2 D1.
• D1 D2: D1 überlappt mit D2, falls gilt:
Es existiert ein Tabellenschema T , das nicht widersprüchlich ist, also außer der leerenMenge mindestens eine weitere nicht leere Instanz besitzt (|Tab(T )| > 1), und fürdas gilt: T D1 ∧ T D2.
Beispiel:
D1 = T 1 := Ortschaft Land,D2 = T 2 := Ortschaft Restaurantes gilt D1 D2 in T := Ortschaft mitE1 = πO.Name,O.EinwohnerT
1 und E2 = πO.Name,O.EinwohnerT2

4.2. AUFGABEN DER REPLIKATVERWALTUNG 69
• D1 D2: D1 und D2 sind unabhängig, falls gilt:
D1 und D2 überlappen sich nicht, formal: ¬(D1 D2). Diese derart definierte Unab-hängigkeit bezieht sich nur auf Datenbankschemata, Integritätsbedingungen bleibendabei unberücksichtigt.
Beispiel:
D1 = T 1 := σO.Einwohner<500Ortschaft,D2 = T 2 := σO.Einwohner>500Ortschaftes gilt D1 D2
4.2 Aufgaben der Replikatverwaltung
Kommerzielle mobile Datenbanklösungen (siehe Kapitel 3.5) realisieren explizite Replika-tion und bieten ausgereifte Funktionalität für die Synchronisation bei vorgegebenen Abbil-dungsvorschriften zwischen Server-Datenbank und Replikatdatenbank. Für die Unterstüt-zung der nutzerdefinierten Replikation wird, ebenso wie bei impliziter Replikation, einezusätzliche Verwaltungsebene für die dynamisch erzeugten Replikationsanfragen benötigt.
Zusammengefasst sind die Aufgaben dieser Verwaltungsebene: die Auswertung der Re-plikationsanfragen und Änderbarkeitsanforderungen, das Buchführen über den derzeit re-plizierten Datenbankausschnitt jedes einzelnen Client und anhand dieser Information dieBereitstellung der Abbildungsvorschriften für die Synchronisation mittels einer gegebenenSynchronisations-Software. Diese informale Aufgabenbeschreibung lässt sich mit Hilfe derin Kapitel 2.2 und Abschnitt 4.1 eingeführten Bezeichnungen und Relationen für ein ge-gebenes konsolidiertes Datenbankschema K und einen gegebenen mobilen Client wie folgtformalisieren (gegliedert nach den Aktivitäten des Arbeitsmodells der nutzerdefiniertenReplikation aus Kapitel 3.4):
1. Anlegen einer neuen Replikationssicht V := EV (K)
(a) Für die lokale Berechnung von V und die Ausführung von Änderungsoperatio-nen unter Berücksichtigung der Replikattransparenz ist ein dafür hinreichenderAusschnitt des konsolidierten Datenbankschemas KV K zu bestimmen undbei erfolgreicher Ausführung der Replikatdefinition in den Metadaten für denClient zu speichern. Ein gewählter Schemaausschnitt KV ist hinreichend fürdie Berechnung von V , wenn gilt: V KV . Darüber hinaus kann ein größererAusschnitt benötigt werden, wenn Änderbarkeitszusicherungen gewährt wurden(siehe dazu Abschnitt 4.3).
Für eine effiziente Implementierung ist KV möglichst klein zu wählen.
(b) Für das Speichern gewährter Zugriffszusicherungen ist ein dafür maßgeblicherSchemaausschnitt Kl mit Kl K zu bestimmen und in den Metadaten zuvermerken. Es ist möglich, dass für die Gewährung von Zugriffszusicherungenein größerer oder auch kleinerer Schemaausschnitt betrachtet werden muss, alsfür den Zugriff auf die Replikationssicht erforderlich ist, d. h. Kl ≈ KV (sieheAbschnitt 4.3.4).
Für eine effiziente Implementierung ist Kl möglichst klein zu wählen.

70 KAPITEL 4. REPLIKATVERWALTUNG
(c) Für die geforderte Zugriffszusicherung muss geprüft werden, dass sie unter Be-rücksichtigung der gewährten Zusicherungen für andere Clients gewährt werdenkann. Das ist dann der Fall, wenn für alle von anderen Clients in unverträglicherWeise (siehe Matrix in Kapitel 3.4.5) replizierten Schemaausschnitte K′ Kgilt: K′ Kl.
(d) Sei KR K der Schemaausschnitt, der bereits auf dem Client vorhandenist, dann müssen die Schemaausschnitte KV + der neu zu replizierenden Da-ten (mit KV + KV ) und KV 0 der bereits auf dem Client vorhandenen Daten(KV 0 KV ∧ KV 0 KR) bestimmt und in den Metadaten vermerkt werden.Es muss gelten KV 0 ∪KV + ≈ KV . Diese beiden Ausschnitte werden für die Syn-chronisation (nur Änderungen für KV 0 , initiale Übertragung für KV +) benötigt.
Für eine effiziente Synchronisation ist KV + möglichst klein zu wählen.
2. Ändern der Zugriffszusicherungen
Das Ändern der Replikationsanfrage einer bestehenden Replikationssicht ist im Kon-zept der nutzerdefinierten Replikation nicht vorgesehen (siehe Kapitel 3.4). Soll derreplizierte Schemaausschnitt angepasst werden, muss die nicht mehr benötigte Sichtgelöscht und eine neue Sicht mit der geänderten Replikationsanfrage angelegt werden.Für die Änderung der Zugriffszusicherung einer bestehenden Replikationssicht mussdie neue Zugriffszusicherung für den beim Anlegen der Sicht berechneten AusschnittKl in den Metadaten gespeichert werden, sofern die Prüfung (Aufgabe 1c) positivausgefallen ist.
3. Löschen einer Replikationssicht Vn := EVn(KR)
(a) Durch Auswertung der für die Replikationssicht gespeicherten Metadaten KVn KR ist durch Abgleich mit den anderen vom Client erfolgreich definierten Re-plikationssichten (repräsentiert durch KVi K mit 1 ≤ i < n) ein löschbarerSchemaausschnitt KV −
n KVn für die Synchronisation zu bestimmen und in denMetadaten zu speichern. Für KV −
n muss gelten: ∀1≤i<nKVi KV −n , d. h. der zu
löschende Ausschnitt darf sich mit keinem für eine andere (nicht zu löschende)Sicht gepeicherten Schemaausschnitt überlappen.
Für eine effiziente Implementierung ist KV −n möglichst groß zu wählen.
(b) Die für Kl in den Metadaten gespeicherte Zugriffszusicherung der Sicht wirdaufgehoben.
4. Synchronisation einer Replikationssichtengruppe Gp
(a) Es sei KGp ≈⋃
V ∈GpKV der von Gp repräsentierte Schemaausschnitt und sei
KGi mit (1 ≤ i < p) analog definiert für die nicht zur Synchronisation an-geforderten Sichtengruppen, dann muss der tatsächlich zu synchronisierendeSchemaausschnitt Ks KGp derart bestimmt werden, dass gilt: ∀1≤i<p(Ks KGi ∨ Ks KGi). Sichtengruppen werden also, wie in Kapitel 3.4.3 gefordert,immer vollständig oder gar nicht synchronisiert.
Für eine effiziente Implementierung ist Ks möglichst klein zu wählen.
(b) Für Ks ist zu prüfen, dass keine exklusive Änderbarkeitszusicherung eines an-deren Client die Synchronisation temporär blockiert. Die Synchronisation kann

4.3. ABHÄNGIGKEITEN ZWISCHEN SCHEMAAUSSCHNITTEN 71
ausgeführt werden, wenn für alle von anderen Clients exklusiv replizierten Sche-maausschnitte Ke K gilt: Ke Ks.
(c) Es sei KRI Ks (KRIDU Ks) der jeweils größte zu synchronisierende Sche-maausschnitt mit einer gewährten RI- (RIDU-) Änderbarkeitszusicherung (ver-gleiche Kapitel 3.4.5). Bei der Reintegration ist für die vom Client übermitteltenDatenbankausschnitte (geänderte und gelöschte Daten du(DU) sowie eingefügteDaten i(I)) zu prüfen, ob für ihre zugehörigen Schemaausschnitte auch die ent-sprechenden Zugriffszusicherungen vorliegen. Das ist genau dann der Fall, wenngilt DU KRIDU und I (KRIDU ∪ KRI).
(d) Es seien V1 . . . Vq die zu Ks korrespondierenden Replikationssichten.1 Für dieÄnderungsübertragung sind aus den gespeicherten Metadaten für die Sichtendie folgenden Schemaausschnitte zu bestimmen:
• Ks0 ≈⋃
1≤i≤q KV 0i
für deren aktuelle Instanz nur die Änderungen übertragen werden,• Ks+ ≈
⋃1≤i≤q KV +
i
dessen komplette aktuelle Instanz übertragen wird und• Ks− ≈
⋃1≤i≤q KV −
i
dessen Instanz auf dem Client gelöscht wird.
Im Anschluß an die Änderungsübertragung einer Sichtengruppe wird für allebeteiligten und nicht gelöschten Replikationssichten KV 0
i = KVi , KV +i = ∅ und
KV −i = ∅ gesetzt.
(e) Aus den im vorangegangenen Schritt bestimmten Schemaausschnitten Ks0 , Ks+
und Ks− sind geeignete Skripte (i. d. R. jeweils eine SQL-Selektionsanweisung)zu generieren, die angewendet auf die aktuelle Instanz der konsolidierten Daten-bank für die Synchronisation mit einer Synchronisations-Software verwendetwerden können.
Anzumerken ist, dass die Bestimmung der geänderten Daten auf dem Client für die Rein-tegrationsphase der Synchronisation zunächst unabhängig vom replizierten Datenbank-ausschnitt und der nutzerdefinierten Replikation erfolgt und von der Synchronisations-Software zusammen mit dem Client-DBMS vorgenommen wird. Aufgabe der Replikatver-waltung ist es hierbei, die zur Reintegration an die konsolidierte Datenbank versendetenDaten daraufhin zu überprüfen, ob sie dem replizierten und zu synchronisierenden Daten-bankausschnitt entstammen und die ausgeführten Operationen den gewährten Zugriffszu-sicherungen genügen. Diese Prüfung sollte immer durchgeführt werden, da mobile Clientsals unsichere Datenquelle anzusehen sind.
4.3 Abhängigkeiten zwischen Schemaausschnitten
Abhängigkeit bedeutet für zwei Schemata, dass sie nicht getrennt synchronisiert werdenkönnen oder dürfen. Zwei Schemaausschnitte A und B sind trivialerweise abhängig, wennsie auseinander abgeleitet sind (A B oder B A) oder sich überlappen (A B).
1Diese Zuordnung ist eindeutig möglich, da Sichtengruppen atomar synchronisiert werden.

72 KAPITEL 4. REPLIKATVERWALTUNG
Daneben können bei der nutzerdefinierten Replikation zwei Schemaausschnitte abhängigsein, wenn sie derselben Replikationssichtengruppe angehören oder zwischen ihnen Inte-gritätsbedingungen und -regeln festgelegt sind. Während die Replikationssichtengruppenexplizit von der Anwendung zur Laufzeit gebildet werden, ergänzen die Integritätsbedin-gungen das Schema der konsolidierten Datenbank und müssen von der Replikatverwaltungbei der Bestimmung des notwendigen Schemaausschnitts für eine Replikationssicht mitÄnderbarkeitszusicherung automatisch berücksichtigt werden.
Prinzipiell ist es für die Konsistenz der konsolidierten Datenbank nicht erforderlich, dassbei lokalen Änderungen Integritätsbedingungen auch auf dem Client geprüft werden. Ver-letzungen werden spätestens zum Zeitpunkt der Reintegration erkannt und mit einem ent-sprechenden Konflikt „bestraft“. Im Sinne der geforderten Replikattransparenz und zur Ver-meidung unnötiger Konflikte ist es jedoch sinnvoll, eine Integritätsprüfung soweit möglichauch auf dem Client durchzuführen, wobei diese lokale Prüfung die notwendige (erneute)Prüfung bei der Reintegration nicht ersetzen kann.
CREATE REPLICATION VIEW dtRestAS SELECT *
FROM Restaurant rWHERE r.Stil = ’de’
...
Abbildung 4.1: Beispiel für Schemaabhängigkeiten
Im Folgenden sei angenommen, dass die Prüfung auf dem Client durch Integritätsbedin-gungen und -regeln erfolgt, die, analog zur Bildung der Replikatdatenbankschemata, un-mittelbar aus denen für das konsolidierte Datenbankschema abgeleitet werden. Dadurchkann eine von den später definierten Replikationssichten unabhängige Prüfung erreichtwerden.
Für die lokale Prüfung ist es i. d. R. notwendig, mehr Daten bzw. einen größeren Sche-maausschnitt auf den Client zu replizieren, als für die lokale Berechenbarkeit einer Sichtallein erforderlich wäre. Dies soll am Beispiel der Replikationssicht dtRest in Abbildung 4.1(basierend auf dem Schema aus Kapitel 3.3 auf Seite 50) gezeigt werden; für die Sicht müs-sen mindestens repliziert werden:
• alle Zeilen der Tabelle Restaurant mit deutschen Restaurants (nur diese Zeilen sindspäter für den Client direkt zugreifbar und sichtbar),
• alle Primärschlüsselwerte der Tabelle Ortschaft, welche von den ausgewählten deut-schen Restaurants per Fremdschlüssel referenziert werden,
• alle Primärschlüsselwerte der Tabelle Land, welche von den ausgewählten Ortschaftenper Fremdschlüssel referenziert werden und,
• im Fall der Änderbarkeitsanforderung zum Ändern oder Löschen, alle Fremdschlüs-selwerte der Tabelle Bewertung, die sich auf Primärschlüsselwerte ausgewählter Re-staurants beziehen, wenn für sie on ... restrict definiert ist.
Die Auswahl der benötigten Daten basiert auf der relationalen Umsetzung der Beispielda-tenbank und berücksichtigt nur Primär- und Fremdschlüsseldefinitionen. Sind weitere In-tegritätsbedingungen, z. B. NOT NULL für weitere Spalten, definiert, müssen entsprechend

4.3. ABHÄNGIGKEITEN ZWISCHEN SCHEMAAUSSCHNITTEN 73
mehr Spalten- und Zeilenwerte zusätzlich übertragen werden. Welche Integritätsbedin-gungen bei Anwendung auf dem Client welche Auswirkungen auf den zu replizierendenSchemaausschnitt hat, wird im folgenden Unterabschnitt systematisiert.
4.3.1 Integritätssicherung und nutzerdefinierte Replikation
Integritätsbedingung oder -regel # Spalten # Zeilen # Tabellen Kl.
Datentyp 1 1 11NOT NULL 1 1 1
Default-Wert 1 1 1CHECK n 1 1 2generierte Spaltenwerte n 1 1Eindeutigkeitsbedingung n m 1 3Fremdschlüssel n m 2 4referentielle Aktionen n m 2Trigger n m k 5Kontrollanfragen der Anwendung n m k
Tabelle 4.1: Integritätssicherung und ihre Arbeitsbereiche
Die Konsistenz einer Datenbank zu Beginn und nach dem Ende einer Transaktion kannüber Integritätsbedingungen sichergestellt und mit Hilfe aktiver Integritätsregeln (z. B. re-ferentielle Aktionen) bei potentieller Verletzung wiederhergestellt werden. Tabelle 4.1 zeigteine Übersicht der heute in kommerziellen relationalen Datenbanksystemen verfügbarenMöglichkeiten zur Integritätssicherung. Für jede Bedingung oder Regel ist ihr Prüf- bzw.Arbeitsbereich angegeben. Aufsteigend nach der potentiellen Größe dieses Bereichs lassensich die Bedingungen und Regeln in fünf Klassen einteilen:
1. spalten- und zeilenlokale Bedingungen
Bedingungen der ersten Klasse lassen sich lokal auf einer Spalte einer Zeile, also aufeinem Spaltenwert, überprüfen. Im Fall einer mit NOT NULL definierten Spalte, sindfür alle geforderten Zeilen deren Spaltenwerte zu übertragen.
2. zeilenlokale Bedingungen
Bedingungen der zweiten Klasse können spaltenübergreifend sein, beziehen sich aberimmer nur auf eine Tabellenzeile.2 Für alle angeforderten Zeilen müssen die zur Prü-fung bzw. Berechnung erforderlichen Spalten mit ihren Werten auf den Client repli-ziert werden.
3. tabellenlokale Bedingungen
Bedingungen aus der dritten Klasse sind spalten- und zeilenübergreifend, beziehensich aber nur auf eine Tabelle. Zur lokalen Prüfung von Eindeutigkeitsbedingungen
2CHECK-Bedingungen werden, wie in den meisten Produkten üblich, als nicht zeilenübergreifend an-genommen.

74 KAPITEL 4. REPLIKATVERWALTUNG
(z. B. Primärschlüssel) müssen alle von den Bedingungen benötigten Spalten allerZeilen der Tabelle mit ihren Werten auf dem Client vorhanden sein.
4. tabellenübergreifende Bedingungen (maximal zwei Tabellen)
Bedingungen aus der vierten Klasse sind spalten- und zeilenübergreifend, wobei Zei-len maximal zweier Tabellen betroffen sein können. In diese Klassen gehören dieBedingungen und Regeln zur Aufrechterhaltung der referentiellen Integrität. Zur lo-kalen Prüfung bzw. Ausführung müssen die Primär- und Fremdschlüsselspalten und-werte der verknüpften Tabellenzeilen übertragen werden. Zu beachten ist, dass dieReplikation zusätzlicher Zeilen rekursiv die Replikation weitere Zeilen bzgl. Abhän-gigkeiten durch dieselbe oder andere Integritätsbedingungen nach sich ziehen kann.
5. sonstige tabellenübergreifende Bedingungen
Bedingungen der fünften Klasse haben potentiell keine Einschränkungen ihres Ar-beitsbereiches und der Folgeaktionen, inklusive berechnungsvollständiger Prozedu-ren. Im Fall von Kontrollanfragen, welche das Ergebnis einer Selektion auf bestimm-te Zustände (z. B. leeres Ergebnis) prüfen, muss der durch die Selektion bestimmteSchemaausschnitt mit auf den Client repliziert werden. Bei Triggern ist wegen derKomplexität der Prüfung und möglicher Folgeaktionen eine Eingrenzung des Arbeits-bereichs bei der Replikation nur schwer möglich. Im Zweifelsfall müssen alle Quell-und Zieltabellen bzw.-spalten komplett auf den Client repliziert werden.
Die lokale Prüfung der Integritätsbedingungen der Klassen 1 und 2 wird durch die, ver-gleichsweise wenig aufwändige, Replikation der benötigten Spalten und -werte ermög-licht. Auf die ressourcenintensive Behandlung von Eindeutigkeitsbedingungen (Klasse 3)durch Replikation aller Spaltenwerte einer Tabelle kann in der Praxis verzichtet wer-den, wenn stattdessen konfliktvermeidende Synchronisationsverfahren wie KeyPool- oderSLOT-Verfahren zum Einsatz kommen (siehe Kapitel 2.5.3), wovon im Folgenden ausge-gangen wird. Die automatische Behandlung von Fremdschlüsselbeziehungen bei der Repli-kation ist ein Schwerpunkt des später in diesem Kapitel vorgestellten Fragmentkonzeptsund wird im Abschnitt 4.3.2 einführend behandelt.
Bedingungen, die über Anfragen der Anwendung formuliert werden (Klasse 5), könnenim Rahmen der nutzerdefinierten Replikation mittels Replikationssichten realisiert wer-den. Die Unterstützung lokaler Trigger ist jedoch problematisch. Dies gilt u. a. deswegen,weil Trigger-Folgeaktionen selten idempotent sind, d. h. eine erneute Ausführung bei derReintegration kann zu einer inkonsistenten konsolidierten Datenbank führen. Gleichzeitigmüsste aber bei der Reintegration sichergestellt werden, dass über Folgeaktionen auf demClient erzeugte Daten korrekt sind. Auf eine automatische Unterstützung von Triggern(und deren Replikattransparenz) auf der Replikatdatenbank wird deshalb bei der hier be-schriebenen Replikatverwaltung verzichtet und stattdessen angenommen, dass Trigger nurauf Server-Seite ausgeführt werden.
4.3.2 Referentielle Integrität
Fremdschlüssel einer Tabelle sichern als Ausdruck einer referentiellen Integritätsbedingungdas Vorhandensein der Werte einer Spalte als Schlüsselwert in einer anderen oder dersel-ben Tabelle und werden für die relationale Umsetzung von Beziehungen zwischen Daten-bankobjekten (vergleiche E/R-Modell) eingesetzt. Die mit SQL optional spezifizierbaren

4.3. ABHÄNGIGKEITEN ZWISCHEN SCHEMAAUSSCHNITTEN 75
referentiellen Aktionen (on delete und on update) unterbinden das Löschen/Ändern vonZeilen, wenn noch abhängige Zeilen existieren (restrict), oder erlauben durch Folgeak-tionen die aktive Wiederherstellung der Konsistenz. Bei den Folgeaktionen besteht dieAuswahl zwischen kaskadierendem Löschen/Ändern (cascade) in den abhängigen bezug-nehmenden Zeilen, dem „Umhängen“ der bezugnehmenden Zeilen auf einen existierendenDefault-Schlüsselwert (default) und dem Kappen der Verbindung durch Setzen des Fremd-schlüsselwertes auf ω (set null).
Es seien im Folgenden C und P zwei Tabellenschemata. Das (Kind-)Tabellenschema Creferenziert per Fremdschlüssel das (Vater-)Tabellenschema P , dargestellt als C −→ P .Werden jetzt Teile der Tabellen c(C) oder p(P ) per Replikationssicht auf den mobilenClient repliziert, müssen eventuell zusätzliche Zeilen von c oder p mitrepliziert werden. Waszusätzlich übertragen werden muss, bestimmen die bei der Tabellendefinition spezifiziertenreferentiellen Aktionen und die dem Client lokal erlaubten Operationen:
• Lesen (R)
Der reine Lesezugriff auf p erfordert weder zusätzliche Zeilen aus c noch aus p. Wirdhingegen c zum Lesen angefordert, so müssen die referenzierten Schlüsselwerte ausTabelle p mitrepliziert werden. Solange keine Änderungen auf dem Client erlaubtsind, spielen eventuell definierte referentielle Aktionen keine Rolle.
• Einfügen (I)
Das Einfügen in p erfordert wie auch das reine Lesen keine zusätzlichen Zeilen, daneue Zeilen natürlich noch nicht referenziert sein können. Sollen Zeilen in der ab-hängigen Tabelle c lokal neu eingefügt werden, müssen die dabei aus p referenziertenSchlüsselwerte bereits repliziert sein. Das kann nicht automatisch geschehen, sonderndie Anwendung muss sicherstellen, dass zu referenzierende Zeilen aus p zuvor perReplikationssicht auf den Client übertragen wurden. Es gilt auch hier, dass Replikat-transparenz nur für den per Replikationssichtendefinitionen bestimmten Ausschnittder konsolidierten Datenbank gewährleistet werden kann. Referentielle Aktionen spie-len beim Einfügen neuer Zeilen keine Rolle.
• Löschen (D)
Das lokale Löschen von Zeilen aus der abhängigen Tabelle c erfordert keine zusätzli-chen Zeilen aus p oder c selbst. Sollen hingegen Zeilen aus der Vater-Tabelle p gelöschtwerden, hängt es von der für C spezifizierten referentiellen on-delete-Aktion ab, obweitere Zeilen benötigt werden oder nicht:
– restrictZur Prüfung, ob eine Löschung in p erlaubt ist, müssen die zu den repliziertenZeilen aus p korrespondierenden Fremdschlüsselwerte aus c mit auf den Clientrepliziert werden.
– cascadeFür die Folgelöschung abhängiger Zeilen aus c müssen diese nicht notwendiger-weise auf dem Client vorhanden sein. Diese können später bei der Reintegrationin der konsolidierten Datenbank gelöscht werden. Befinden sich abhängige Zei-len aus c auf dem Client (z. B. als Teil einer anderen Replikationssicht), werdensie gelöscht. Bei der Reintegration aller Änderungen auf p und c, einschließ-lich der per referentieller Aktion ausgelösten, kann es, je nach Reihenfolge des

76 KAPITEL 4. REPLIKATVERWALTUNG
Einbringens, durch die wiederholte Ausführung der referentiellen Aktion aufServer-Seite zu einem Pseudo-Löschkonflikt kommen (siehe Kapitel 2.5.4.1).
– set nullDas Kappen der Verbindung abhängiger Zeilen kann analog zur Folgelöschungfür nicht replizierte Zeilen bei der Reintegration ausgeführt werden. Die doppelteAusführung von set null bei der Reintegration führt zu keinem Änderungs-konflikt, da zwar das Vorherabbild nicht mit dem vorgefundenen Datenbank-zustand übereinstimmt, der Zielwert der zu ändernden Spalte aber sehr wohl(siehe Kapitel 2.5.4.1).
– set defaultWie bei cascade und set null müssen abhängige Zeilen zur Ausführung derreferentiellen Aktion nicht auf dem Client vorhanden sein. Befinden sich jedochZeilen aus c auf dem Client, deren Fremdschlüsselwerte über eine Löschung in pauf den Default-Wert gesetzt werden, muss zur Gewährleistung der referentiellenIntegrität der dazugehörige Default-Schlüsselwert aus p in der Replikatdaten-bank existieren. Das muss durch die Replikatverwaltung sichergestellt werden.Die Doppelausführung bei der Reintegration führt, analog zu set null, hier zukeinem Konflikt, da derselbe Zielwert vorliegt.
• Ändern (U)
Es gilt hier anhand der spezifizierten referentiellen Aktion dieselbe Unterscheidung zutreffen, wie beim Löschen. Ist eine Ablehnung der Änderungsoperation möglich, müs-sen zur Prüfung die Fremdschlüsselwerte aus c vorhanden sein. Anderenfalls reichtdie Durchführung der Folgeaktion auf der konsolidierten Datenbank aus, um dieKonsistenz der Datenbank sicherzustellen. Wie beim Löschen entsteht bei Doppel-ausführung der Aktion während der Reintegration kein Änderungskonflikt, da dieZielwerte der Änderung gleich sind (zu Primärschlüsselwertänderungen vergleicheKapitel 2.5.4.1).
Die Matrix in Tabelle 4.2 fasst die potentiellen Abhängigkeiten zwischen Tabellen durchIntegritätsbedingungen und -regeln noch einmal zusammen, die sich in Bezug auf die Ope-rationen auf dem Client ergeben. Links steht die Tabelle, deren Zeilen per Replikationssichtangefordert werden. Die beiden Spalten enthalten die Operationen, für die zusätzliche Zei-len jeweils aus der oben angegebenen Tabelle lokal benötigt werden.
c p
c R,I,D,Up D,U D,U
Tabelle 4.2: Operationen und Abhängigkeiten
Für die Bestimmung des Schemaausschnitts KV einer Replikationssicht V auf P oder Cmüssen jetzt je nach gewährter Zugriffszusicherung (siehe Abschnitt 4.3.3) zusätzliche Aus-schnitte der jeweils anderen Tabelle in KV aufgenommen werden. Zu beachten ist, dass diedurch referentielle Integrität erzeugten Abhängigkeiten zwischen Tabellenschemata bei derReplikation rekursiv verfolgt werden müssen.

4.3. ABHÄNGIGKEITEN ZWISCHEN SCHEMAAUSSCHNITTEN 77
So müssen zwar für kaskadierende Änderungen in p keine Zeilen aus c repliziert werden,aber eventuell Zeilen aus einer weiteren Tabelle g(G), wenn G −→ C gilt und auf G einereferentielle Aktion als restrict definiert ist. Da G per Fremdschlüssel mit C verbundenist, müssen in der Folge auch Zeilen aus C repliziert werden. Die Länge einer solchenRekursion ist dabei u. U. datenabhängig, beispielsweise wenn C und P sowie Primär- undFremdschlüssel identisch sind. Diese dabei entstehenden Fremdschlüsselpfade werden inAbschnitt 4.5 genauer untersucht.
4.3.3 Abstufung der Zugriffszusicherungen
Es ist für die Abstufung der Zugriffszusicherungen (siehe Kapitel 3.4.5) sinnvoll, die jeweilserlaubten Operationen anhand des zusätzlich auf dem Client benötigten Speicheraufwandszu differenzieren. Die Tabelle 4.2 macht diese Unterschiede deutlich.
Sollen Daten lokal nur gelesen oder neue Daten eingefügt werden, müssen zusätzliche Zei-len nur „aufwärts“ entlang der Fremdschlüsseldefinitionen hinzugenommen werden. Werteaus bezugnehmenden Tabellen werden für das Lesen und Einfügen auf dem Client nichtbenötigt. Sind Ändern und Löschen auf dem Client erlaubt, müssen zusätzlich auch bezug-nehmende Zeilen in allen abhängigen Tabellen berücksichtigt werden.
Deshalb wird neben der Zugriffszusicherung des Vollzugriffs RIDU eine Zusicherung RInur für das Einfügen und Lesen eingeführt, da hierbei auf die Übertragung von Datenbezugnehmender Tabellen verzichtet werden kann. Zusätzlich ist eine Zusicherung R fürden reinen Lesezugriff sinnvoll, da zwar genauso viele Daten wie bei RI übertragen werdenmüssen, auf die lokalen Mechanismen zur Konfliktbehandlung und die Reintegration aberverzichtet werden kann.
4.3.4 Folgeänderungen und Zugriffszusicherungen
Normalerweise sind der für den Zugriff auf eine Replikationssicht V benötigte Schemaaus-schnitt KV und der für die Zugriffszusicherung maßgebliche Schemaausschnitt Kl gleich.Es gelten davon jedoch folgende Ausnahmen.
Es sei angenommen, dass zwischen den Tabellenschemata P und C (mit C −→ P )per referentieller Aktion kaskadierende Löschungen und Änderungen auf c(C) verein-bart sind. Wird jetzt die Tabelle p über die Replikationssicht V mit einer RIDU-Änderbarkeitszusicherung auf den Client repliziert, können beim Löschen von Zeilen aus poder dem Ändern von Schlüsselwerten Änderungen an korrespondierenden Zeilen in c dieFolge sein.
Wie im vorangegangenen Abschnitt bereits festgestellt wurde, ist für kaskadierende Ände-rungen die Tabelle c lokal nicht erforderlich, ihr Schema wäre also nicht Bestandteil vonKV . Das Schema C, bzw. der von replizierten Zeilen aus p abhängige Schemaausschnitt,muss aber Bestandteil von Kl sein. Andernfalls könnten reintegrierte Änderungen von peine exklusive Änderbarkeitszusicherung verletzen, die einem anderen Client für das Ta-bellenschema C gewährt wurde.
Sieht die referentielle Aktion zwischen den abhängigen Tabellenschemata P und C dagegenein restrict vor, so muss der abhängige Schemaausschnitt von C zwar in KV enthaltensein, nicht aber in Kl, da keine Änderungen und Leseoperationen für V auf C erlaubt

78 KAPITEL 4. REPLIKATVERWALTUNG
bzw. möglich sind. Wie im Fall der Bestimmung des zu replizierenden Schemaausschnitts,müssen Abhängigkeiten rekursiv verfolgt werden.
4.4 Verwaltung von Schemaausschnitten
Die beiden vorangegangenen Abschnitte haben gezeigt, welche Schemaausschnitte bei ei-ner gegebenen Replikationssicht für die Replikation und Synchronisation benötigt werden.Wie diese Schemaausschnitte verwaltet und algorithmisch bestimmt werden sollen, ist nochoffen. Von zentraler Bedeutung für eine möglichst effiziente Implementierung der notwen-digen Prüfungen und Schemavergleiche ist die Repräsentation der Schemaausschnitte inden Metadaten.
Mindestens gespeichert werden müssen je Client die für den Zugriff auf seine Replikations-sichten (V1, . . . , Vn) benötigten Schemaausschnitte KV1 , . . . ,KVn . Die weiteren für die Syn-chronisation und die Speicherung von Zugriffszusicherungen benötigten Schemaausschnittelassen sich dann daraus ermitteln (siehe Abschnitt 4.2 und Abschnitt 4.3). Daneben sindweitere Informationen zur Konfliktbehandlung, zur Gruppenzugehörigkeit der Sichten unddie Zugriffszusicherungen selbst zu speichern, was technisch aber keine Herausforderungdarstellt.
Für die Verwaltung und Repräsentation von Schemaausschnitten gibt es verschiedene Mög-lichkeiten, in den folgenden beiden Unterabschnitten werden die anfragebasierte Verwaltungunter Nutzung der Selektionsbedingungen aus den Replikationsanfragen und die in der Ar-beit verwendete fragmentbasierte Verwaltung durch Abbildung der Selektionsprädikate aufeine Menge vorberechneter Granulate gegenübergestellt.
4.4.1 Anfragebasierte Verwaltung
Bei der anfragebasierten Verwaltung von Schemata, wie sie von den Verfahren für das Se-mantic Caching (siehe Kapitel 3.1.2) eingesetzt wird, werden die Ergebnisse der vom Clientgesendeten Anfragen auf den Client repliziert und die Selektionsprädikate der Anfragen fürden Aufbau des Inhaltsverzeichnisses verwendet. Übertragen auf die nutzerdefinierte Re-plikation sind es die Replikationsanfragen der Replikationssichten, deren Ergebnisse aufden Client repliziert und die zum Aufbau des Inhaltsverzeichnisses benutzt werden.
Für den Zugriff auf eine Replikationssicht V := EV (K) ist es jedoch keineswegs hinrei-chend, als Schemaausschnitte KV = Kl = V zu wählen. Wie Abschnitt 4.3 gezeigt hat,müssen beim Vorhandensein von Integritätsbedingungen auf dem Client zusätzliche Datenrepliziert bzw. für die Zugriffszusicherung berücksichtigt werden. Dazu muss die Repli-katverwaltung beim Anlegen der Replikationssicht den von der Selektionsformel EV aus-gewählten Schemaausschnitt auf Abhängigkeiten untersuchen und daraus neue Anfragenerzeugen, welche die zusätzlichen Schemaausschnitte dem KV und Kl hinzufügen.
Wurde KV erfolgreich bestimmt, muss geprüft werden, welcher Teil davon eventuell bereitsauf dem Client vorhanden ist und welcher Teil vom Server geholt werden muss. Dazu istein prädikatbasierter Vergleich auf Überlappung zwischen KV und allen für den Clientgespeicherten KV ′ erforderlich. Solche Prädikatvergleiche sind sehr aufwändig. Schränktman die erlaubten Selektionsformeln nicht ein und erlaubt insbesondere =-Prädikate aufInteger-Domänen, ist der Aufwand für Überlappungs- und Inklusionstests im Allgemeinen

4.4. VERWALTUNG VON SCHEMAAUSSCHNITTEN 79
Fall NP-vollständig in der Länge der Selektionsbedingungen [GSW98, CM77]. Der Aufwandmultipliziert sich mit der Anzahl der für den Client definierten Replikationssichten.
Ob die geforderten Zugriffszusicherungen gewährt werden können, muss wiederum durcheinen prädikatbasierten Überlappungstest zwischen Kl und allen anderen von Clients ex-klusiv replizierten Schemaausschnitten Kl′ ermittelt werden. Die Prüfung muss vor derGewährung einer Zugriffszusicherung und, im Fall einer optimistischen Replikation, beider Synchronisation durchgeführt werden. Der Aufwand hängt von der Anzahl der Clientsund den von ihnen exklusiv replizierten Schemaausschnitten ab.
Durch die vom Client definierten Replikationssichtengruppen werden verschiedene Sich-ten zusammengefasst, deren KV gemeinsam synchronisiert werden sollen. Da der Client indieser Zusammenfassung frei ist, die Replikatverwaltung aber sicherstellen muss, dass Re-plikationssichtengruppen ganz oder gar nicht synchronisiert werden, muss beim Zuordneneiner Sicht zu einer Gruppe geprüft werden, ob ihr KV mit Schemaausschnitten in ande-ren Gruppen überlappt. Diese eigentlich verschiedenen Gruppen müssen dann zusammensynchronisiert werden. Die Prüfung erfordert wieder einen Überlappungstest.
Schließlich müssen aus KV die zur Synchronisation verwendeten Skripte erzeugt werden.Zu beachten ist, dass nicht das Anfrageergebnis der Sicht übertragen werden soll, sonderndie Basisdaten der konsolidierten Datenbank, welche, übertragen in die korrespondierendenTabellen der Replikatdatenbank, die lokale Berechnung der Sicht und die Replikattranspa-renz ermöglichen. Wurden die Tabellenschemata von KV nicht bereits bei der Anlage derSicht entsprechend gebildet, muss die Transformation vor jeder Synchronisation erfolgen.
Bewertung
Die beschriebene anfragebasierte Speicherung weist konstruktive Schwächen auf, so dasssie für die Umsetzung der nutzerdefinierten Replikation nicht geeignet ist. Die Bestimmungder tatsächlich abhängigen Schemaausschnitte erfolgt anhand der Replikationsanfrage einerReplikationssicht, obwohl die Abhängigkeiten (auch die der Replikationssichtengruppen)wesentlich durch das feststehende Schema der konsolidierten Datenbank bestimmt werden.Es wäre also sinnvoll, die Abhängigkeiten bereits im vorhinein auf Schemaebene zu berech-nen und in einer Datenstruktur abzulegen, so dass sie nicht bei jeder Anfrageauswertungneu bestimmt werden müssen.
Ein zweites Problem stellen die häufig durchzuführenden aufwändigen Prädikatvergleicheund Transformationen von Selektionsformeln dar. Will man die Überlappungstests einfa-cher haben, muss man die erlaubten Prädikate einschränken. Das hieße für die nutzer-definierte Replikation aber, dass die Möglichkeiten für Replikationsanfragen beschnittenwerden. Der Aufwand der Prädikatvergleiche kann aber auch dadurch verringert werden,dass nicht wie beschrieben die Selektionsformeln der Anfragen selbst, sondern einfacherevorberechnete Schemaausschnitte stellvertretend gespeichert werden. Diese Überlegungenführen zur fragmentbasierten Verwaltung von Schemaausschnitten.
4.4.2 Fragmentbasierte Verwaltung
Gegeben sei ein konsolidiertes Datenbankschema K und eine Menge von TabellenschemataF = F1, . . . , Fq mit F K. Wird die Menge F so gewählt, dass F ≈ K gilt, dann

80 KAPITEL 4. REPLIKATVERWALTUNG
bezeichnet F eine Fragmentierung von K. Jedes Element von F wird im folgenden Fragmentgenannt.
Es sei KV der für die Replikation benötigte Schemaausschnitt einer Replikationssicht V .Dieser lässt sich jetzt als Teilmenge einer Fragmentierung schreiben, mit KV ⊆ F . Analoglassen sich die anderen Schemaausschnitte über Fragmentmengen repräsentieren. Bei einergegebenen Fragmentierung müssen dann anstatt der Selektionsformeln für die Schemaaus-schnitte nur die Nummern der Fragmente gespeichert werden.
Die weitere Verarbeitung und Auswertung von Schemaausschnitten erfolgt dann mit Hilfeder sie repräsentierenden Fragmentmengen. Sind Replikationssichten die logische Einheitder Replikation und die Replikationssichtengruppen die logische Einheit der Synchronisa-tion (siehe Abschnitt 3.4), so kann ein Fragment als die physische Einheit der Replikatver-waltung aufgefaßt werden.
Auch die Übersetzung einer Replikationsanfrage in eine Menge von Fragmenten erforderteinen Prädikatvergleich. Im Unterschied zur anfragebasierten Speicherung kann jedoch dieStruktur der Fragmente frei gewählt und insbesondere so konstruiert werden, dass mög-lichst viele Prädikate in Replikationsanfragen effizient ausgewertet werden können. WieFragmente konstruiert werden und die Transformation von Anfragen in Fragmentmengensind Gegenstand der Abschnitte 4.5ff.
Es lassen sich jedoch bereits anhand der Definition der Fragmentierung allgemeine Vor-schriften für die Berechnung der in Abschnitt 4.2 geforderten Schemaausschnitte angeben,was Gegenstand im weiteren Verlauf dieses Abschnitts sein soll. Die Beschreibung einesTeils der Berechnungen ist jedoch nur mit Wissen um die konkrete Struktur der Fragmen-te sinnvoll, so dass dann auf die entsprechenden Abschnitte verwiesen wird. Im Folgendensei eine gegebene Fragmentierung F = F1, . . . , Fq angenommen.
4.4.2.1 Schemaausschnitte für die Replikation
Es seien Vi (1 ≤ i ≤ n) alle auf einem Client definierten Replikationssichten und seio. B. d. A. die Sicht Vn die im Folgenden neu angelegte oder gelöschte Replikationssicht.Unabhängig von der tatsächlichen Gestalt der Fragmente lassen sich über eine Fragmen-trepräsentation für KVi die Schemaausschnitte KR (bereits auf dem Client vorhanden),KV +
n (neu zu übertragen) und KV 0n (nur Änderungen) für Vn mittels einfach durchzufüh-
render Mengenoperationen wie folgt berechnen (in Klammern jeweils die Aufgabe, welcheden Schemaausschnitt zuerst benötigt; siehe Aufgaben in Abschnitt 4.2 auf Seite 69):
• KR =⋃
1≤i<n KVi (1d)
• KV +n = KVn \ KR (1d)
• KV 0n = KVn \ KV +
n (1d)
Die Berechnung von KV −n (Aufgabe 3a) ist leider nicht so einfach, da von den Fragmenten
nicht verlangt wird, dass sie paarweise unabhängige Schemaausschnitte darstellen.3 DerSchemaausschnitt KV −
n (zu löschende Fragmente) kann deshalb nicht analog zu KV +n mit
einer Mengendifferenz bestimmt werden. Allerdings lässt sich zum Zeitpunkt der Synchro-nisation die Instanz kV −
n (KV −n ) bzw. ks−(Ks−) leicht ermitteln (siehe Abschnitt 4.9).
3Warum der Verzicht auf Unabhängigheit notwendig ist, zeigt Abschnitt 4.5.

4.4. VERWALTUNG VON SCHEMAAUSSCHNITTEN 81
4.4.2.2 Sperrobjekte für die Zugriffszusicherungen
Für die Speicherung von Zugriffszusicherungen werden auf Fragmenten aufbauende, paar-weise unabhängige Sperrobjekte benötigt. Die Fragmente selbst sind dafür nicht geeignet,da sie sich überlappen können. Andererseits sei angenommen, dass Fragmente bereits alleAbhängigkeiten, die sich aus dem Schema und den Integritätsbedingungen ergeben, berück-sichtigen. Es ist für die Definition von Sperrobjekten deshalb hinreichend, eine disjunkteZerlegung der gegebenen Fragmentmenge anhand der eingeführten Überlappungsrelati-on durchzuführen. Dabei sind transitive Abhängigkeiten zu berücksichtigen.
Es existiert dann eine Funktion l : F → P(F), die jedem Fragment ein Sperrob-jekt zuordnet mit l(F ) = LF . Seien (Fi,LFi), (Fj ,LFj ) ∈ l (mit 1 ≤ i, j ≤ q), sogilt: LFi = LFj ⇒ LFi LFj . Die Berechnung von Sperrobjekten ist Gegenstand vonAbschnitt 4.10. Ist für jedes Fragment das dazugehörige Sperrobjekte bekannt, lassen sichmit seiner Hilfe jetzt weitere Aufgaben (Nummern wieder in Klammern) lösen:
• Eine Zugriffszusicherung kann für Vn dann gewährt werden, wenn für alle F ∈ KVn
das Sperrobjekt LF (entspricht dem Kln) nicht von einem anderen Client in unver-träglicher Weise markiert ist (1b, 1c, 2, 3b).
• Die Synchronisation kann durchgeführt werden, wenn für alle F ∈ Ks
(Abschnitt 4.4.2.3) das Sperrobjekt LF nicht von einem anderen Client exklu-siv gesperrt ist (4b).
Sperrobjekte sind, wie die Fragmente, durch Prädikate beschrieben. In der Literatur gibtes eine Reihe von Ansätzen für prädikatbasierte Sperrverfahren insbesondere zur Vermei-dung des Phänomens P3 (Phantome, siehe Kapitel 2.5.2.3) bei der Transaktionsverarbei-tung [OFOL00, GR93, EGLT76]. In kommerziellen DBMS-Produkten haben sich dieseVerfahren gegenüber den sehr viel leistungsfähigeren instanzenbasierten hierarchischenSperrverfahren [HR01] und angepassten Isolationsstufen, wie der Abbildisolation (sieheKapitel 2.5.2.4), nicht durchgesetzt.
Der Performance-Nachteil durch die erforderlichen Prädikatvergleiche wiegt bei der nutzer-definierten Replikation weit weniger schwer, da sie nicht im normalen Transaktionsbetrieb,welcher ja isoliert auf dem mobilen Client erfolgt, durchgeführt werden müssen, sondernnur bei der Replikat(re)definition. Außerdem verringert die Vorberechnung der Fragmenteund Sperrobjekte, ein zentraler Vorteil der fragmentbasierten Verwaltung, den Aufwandfür die Prädikatvergleiche.
Ebenfalls wichtig ist, dass bei der Reintegration keine Phantome bzgl. der Sperrobjek-te entstehen, also Zeilen lokal eingefügt oder so geändert werden können, dass sie ausdem gewährten Bereich für die Änderbarkeitszusicherung herausfallen. Bei der nutzerdefi-nierten Replikation sind dafür zwei Mechanismen zuständig. Einerseits darf nur über dieReplikationssichten (standardmäßig mit WITH CHECK OPTION, siehe Kapitel 5.7.4.5) auf dieReplikatdatenbank zugegriffen werden und andererseits wird bei der Reintegration immergeprüft, ob die gesendeten Daten zu den replizierten Fragmenten passen.
4.4.2.3 Schemaausschnitte für die Synchronisation
Es seien Gi (1 ≤ i ≤ p) alle auf einem Client definierten Replikationssichtengruppen undsei o. B. d. A. Gp diejenige Sichtengruppe, welche im Folgenden synchronisiert werden soll.

82 KAPITEL 4. REPLIKATVERWALTUNG
KGp (für Aufgabe 4a) lässt sich einfach aus der Vereinigung der Fragmentmengen derenthaltenen Replikationssichten berechnen:
KGp =⋃
V ∈Gp
KV
Für die Berechnung des tatsächlich zu synchronisierenden Schemaausschnitts Ks (Aufga-be 4a) müssen die möglichen Abhängigkeiten zwischen den verschiedenen Replikations-sichtengruppen berücksichtigt werden. Diese können auf drei Fälle zurückgeführt werden,welche in Abbildung 4.2 dargestellt sind.
Ga
Gb
(a) 1.Fall
Ga
Gb
(b) 2.Fall
Ga
Gb
(c) 3.Fall
Abbildung 4.2: Fälle der Abhängigkeit zwischen Replikationssichtengruppen
Im ersten Fall überlappen beide Replikationssichtengruppen (Ga Gb). Wird also Ga zurSynchronisation angefordert, so muss auch Gb synchronisiert werden. Im zweiten Fall istebenfalls eine gemeinsame Synchronisation erforderlich, da zwar die Gruppen unabhän-gig sind, ihre durch Fragmentmengen repräsentierten Schemaausschnitte, die größer seinkönnen als die Gruppe selbst, aber nicht (KGa ∩ KGb = ∅ in der Fragmentrepräsentation).Der dritte Fall berücksichtigt zusätzlich die Möglichkeit einer Überlappung der Fragmenteuntereinander.
Auf der Basis von Fragmenten und Sperrobjekten lässt sich Ks über den Hilfsausdruck
Xi =⋃
F∈KGi
l(F ) ∩ KR
mit 1 ≤ i ≤ p rekursiv wie folgt bestimmen:
Ks,0 = Xp
Ks,j+1 = Ks,j ∪⋃
1≤k≤p ,KGk∩Ks,j =∅
Xk
Ks =⋃j≥0
Ks,j
Die Berechnung der verbleibenden Schemaausschnitte für die Änderungsübertragung ge-schieht einfach durch Vereinigung der entsprechenden Fragmentmengen (Aufgabe 4d). Esseien V1 . . . Vq die zu Ks korrespondierenden Replikationssichten, dann gilt:
• Ks0=
⋃1≤i≤q KV 0
i

4.5. SCHEMAFRAGMENTE 83
• Ks+=
⋃1≤i≤q KV +
i
Die weiteren Abschnitte des Kapitels konkretisieren die bisher getroffenen allgemeinenAussagen anhand einer bekannten Fragmentstruktur. Es werden die Bildung der Fragmenteund die Verfahren für ihre Verwendung bei der nutzerdefinierten Replikation erläutert.
4.5 Schemafragmente
Die bisherigen Ausführungen gingen davon aus, dass Fragmente so gebaut sind, dass sie al-le jeweils abhängigen Schemaausschnitte zusammenfassen. Die Definition eines Fragmentserfolgt deshalb in zwei Schritten, der Definition von Schemafragmenten entlang der Fremd-schlüsselbeziehungen zwischen Tabellenschemata und der Bildung von Datenfragmenten(siehe Abschnitt 4.6) durch Partitionierung von Schemafragmenten entlang ausgewählterPartitionierungsattribute.
Ein Schemafragment fasst Schemausschnitte zusammen, die per Fremdschlüsseldefinitionenverbunden sind. Bevor aber die formale Definition eines Schemafragments erfolgen kann,müssen zunächst die Strukturen genauer betrachtet werden, welche durch Fremdschlüssel-definitionen auf einem Datenbankschema entstehen, und zwar Fremdschlüsselgraphen undFremdschlüsselpfade (zu Begriffen der Graphentheorie siehe z. B. [Die00]).
4.5.1 Fremdschlüsselgraph
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
BNrLName
LNam
e
BNr
OName
ONameOName
RNr
LName
Abbildung 4.3: Fremdschlüsselgraph des Beispieldatenbankschemas
Es seien K ein konsolidiertes Datenbankschema, I die auf K definierten referentiellen Inte-gritätsbedingungen und E ⊆ K×K×I eine asymmetrische Relation mit E = (Ta, Tb, I) :Ta ∈ K referenziert Tb ∈ K per Fremdschlüsselbedingung I ∈ I. Damit lässt sichein Fremdschlüsselgraph G = (K, E) definieren. Der Fremdschlüsselgraph ist ein gerich-teter, nicht zusammenhängender Multigraph. Der zum Beispieldatenbankschema (sieheKapitel 3.3) gehörende Fremdschlüsselgraph ist in Abbildung 4.3 dargestellt. Der Fremd-schlüsselgraph der Beispieldatenbank ist ein spezieller Graph, in dem zwischen zwei Knoten

84 KAPITEL 4. REPLIKATVERWALTUNG
maximal eine Kante verläuft. Für die bessere Lesbarkeit kann deshalb im Folgenden aufdie Bezeichnung der Kanten mit den Fremdschlüsselspaltennamen verzichtet werden.
4.5.2 Fremdschlüsselpfad
Es sei G = (K, E) der Fremdschlüsselgraph zu K und I, dann bezeichnet T l ∈ Kein Blatt in G genau dann, wenn in das Tabellenschema T l keine Kanten einmünden(T∈K,I∈I(T, T l, I) ∈ E). Analog bezeichnet T r ∈ K eine Wurzel in G genau dann,wenn von T r keine weiteren Kanten ausgehen (T∈K,I∈I(T r, T, I) ∈ E). Im Graphen inAbbildung 4.3 sind beispielsweise Land und Reisebericht Wurzeln, da sie nicht Ausgangs-punkt von Fremdschlüsseldefinitionen sind. Bewertung ist ein Blatt, da die Tabelle nichtvon anderen per Fremdschlüssel referenziert wird.
Ein Weg ist eine beliebige endliche Folge von Kanten in einem Graphen. Mit den Fremd-schlüsselbedingungen als Kanten repräsentieren Wege Abhängigkeiten zwischen Tabellen-schemata, die bei der Replikation auf den Client berücksichtigt werden müssen. Ein Pfad istein spezieller Weg, in dem jeder Knoten höchstens einmal besucht wird. Gerichtete Pfademaximaler Länge, die Fremdschlüsselpfade, spielen im Folgenden eine wichtige Rolle.
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
1
2
3
4
5
6
7
Abbildung 4.4: Fremdschlüsselpfade des Beispieldatenbankschemas
Ein Fremdschlüsselpfad P (G) = (T1, e1, T2, e2, . . . , ep−1, Tp) des Fremdschlüsselgraphen Gist ein gerichteter Pfad, d. h. ∀1≤i<p∃I∈I ei = (Ti, Ti+1, I) ∈ E und ∀1≤i,j≤pi = j ⇒Ti = Tj , bei dem zusätzlich T1 ein Blatt und Tp eine Wurzel ist. Abbildung 4.4 zeigt alle7 Fremdschlüsselpfade im Beispieldatenbankschema.
Im Beispiel ist zu sehen, dass die Menge der Fremdschlüsselpfade jeden möglichen gerichte-ten Pfad im Graphen als Teilpfad enthält und damit auch jede Abhängigkeit zwischen zweiTabellenschemata erfaßt. Diese Eigenschaft, welche im Folgenden für die Konstruktion derSchemafragmente genutzt werden soll, resultiert aus der Kreisfreiheit des Beispielgraphen.Im Allgemeinen sind Fremdschlüsselgraphen aber nicht kreisfrei (siehe [HB04]). Kreise sindWege, deren Anfangs- und Endknoten gleich sind. Ein bekanntes Beispiel für einen Kreis

4.5. SCHEMAFRAGMENTE 85
ist eine Datenbank für Mitarbeiter, welche einen Chef haben, der wiederum ein Mitarbeiterist. Kreise können aber auch über mehrere Tabellenschemata gebildet werden.
Die bisherige Definition eines Fremdschlüsselpfads als endlich und insbesondere fester Län-ge schließt Kreise aus. Prinzipiell ist eine Erweiterung hin zu Fremdschlüsselwegen belie-biger und varibler Länge möglich, allerdings zum Preis der Datenabhängigkeit der Meta-daten, denn die für die Replikation zu berücksichtigende Länge eines Fremdschlüsselwegeswäre von der konkreten Datenbank abhängig. Im weiteren werden deshalb nur kreisfreieFremdschlüsselgraphen als Eingabe für die Schemafragmentierung unterstützt und der da-mit verbundene Verlust an Replikattransparenz in Kauf genommen. Die Kreisfreiheit einesFremdschlüsselgraphen G kann durch Wegnahme von Fremdschlüsseldefinitionen aus Ierzielt werden. Eine geeignete Auswahl muss der Administrator treffen.
4.5.3 Definition Schemafragment
Es sei wieder P (G) = (T1, e1, T2, e2, . . . , ep−1, Tp) ein Fremdschlüsselpfad von G, dann de-finiert das Tabellenschema S(P ) = T1 j(e1)T2 j(e2) · · · j(ep−1)Tp das Schemafragmentzu P . Dabei bildet die injektive Funktion j die Fremdschlüsselbeziehungen eineindeutigauf die dazugehörige Verbundbedingung ab. Zur Vereinfachung der Notation werden imFolgenden j(e) und e synonym verwendet, wenn der Kontext die richtige Verwendungeindeutig vorgibt.
Zu jedem Fremdschlüsselpfad korrespondiert genau ein Schemafragment. Da für die Bil-dung der Schemafragmente ein äußerer Verbund (siehe Kapitel 2.2.2) verwendet wird, gilt∀1≤i≤pTi S(P ) unter Verwendung der Ausdrücke Ei = πTiS. Weiter ist bekannt,dass jedes Tabellenschema in mindestens einem Fremdschlüsselpfad des, möglicherweisenicht zusammenhängenden, Fremdschlüsselgraphen und damit einem Schemafragment ver-treten ist. Es gilt also S =
⋃P (G) S(P ) ≈ K. Die Menge der Schemafragmente S ist eine
Fragmentierung von K. Für einen Fremdschlüsselgraphen gibt es genau ein solches S, dieFragmentierung ist also eindeutig. Für das Beispieldatenbankschema ist
S = S1 := Bewertung Restaurant Ortschaft Land,
S2 := Sehenswurdigkeit Ortschaft Land,
S3 := Enthalt Ortschaft Land,
S4 := Erhalt Land,
S5 := Erhalt Reisebericht,
S6 := Enthalt Reisebericht,
S7 := Administrator Land
Die Nummerierung entspricht dabei der Darstellung in Abbildung 4.4. Auf die Angabe derVerbundbedingungen kann im Beispielgraphen verzichtet werden, da hier zwischen zweiTabellen höchstens eine Fremdschlüsseldefinition existiert, für die implizit ihre Verwendungbei der äußeren Verbundoperation angenommen wird.
Es seien V eine Replikationssicht auf dem konsolidierten Datenbankschema K und T V ⊆ Kdie kleinste Teilmenge, für die V T V gilt, d. h. T V enthält alle und nur Tabellensche-mata, die von V zur Berechnung benötigt werden. Mit Hilfe der SchemafragmentierungS von K ergibt sich:
KV = S : S ∈ S ∧ ∃T∈T V (T S)

86 KAPITEL 4. REPLIKATVERWALTUNG
Es werden also die Daten aller derjenigen Schemafragmente auf den Client repliziert, dieeine Tabelle in ihrem Pfad enthalten, welche von der Replikationsanfrage der Sicht refe-renziert wird. Ein solcherart gewählter und replizierter Schemaausschnitt garantiert dieReplikattransparenz bzgl. der zur Definition verwendeten Fremdschlüsselbeziehungen inder Replikatdatenbank des Client.
Als Beispiel sei V := σR.Stil=′de′Restaurant definiert, dann liefert die (Schema-)Fragment-repräsentation KV = S1 den Schemaausschnitt mit dem (einzigen) Schemafragment,welches die Tabelle Restaurant enthält. Es ist leicht zu sehen, dass für alle dadurch repli-zierten Daten und auf V ausgeführten Operationen die definierte referentielle Integritäterfüllt ist und lokal geprüft werden kann.
4.5.4 Bildung der Schemafragmentierung
SchemaFrag(in G = (K, E), out S)
1: Kl = T : T ist Blatt in G2: S := ∅3: foreach T l ∈ Kl do4: S l := SchemaFragRec(T l)5: S := S ∪ S l
6: od7: return S
SchemaFragRec(in T , out S)
8: if T ist Wurzel in G do9: S := T10: else11: foreach es = (T, T s, Is) ∈ E do12: Ss := SchemaFragRec(T s)13: foreach S ∈ Ss do14: S := T esS15: od16: S := S ∪ Ss
17: od18: od19: return S
Programmtext 4.1: Prozedur SchemaFrag mit SchemaFragRec
Die im Programmtext 4.1 als Pseudo-Code dargestellte Prozedur SchemaFrag erzeugt füreinen gegebenen kreisfreien Fremdschlüsselgraphen G = (K, E) die korrespondierendeSchemafragmentierung S. Für jeden im Graphen enthaltenen Fremdschlüsselpfad wird einSchemafragment erzeugt.
Die Abbildung 4.5 zeigt den sukzessiven Aufbau der Schemafragmentierung für das Bei-spieldatenbankschema. Zuerst werden die Blätter bestimmt, welche in Abbildung 4.5(a)hellgrau umrahmt sind (Zeile 1 in SchemaFrag). Die Pfeilrichtungen symbolisieren die re-kursiven Aufrufe von SchemaFragRec (Zeilen 4,12). In Abbildung 4.5(b) haben sich dieRekursionen bis zu den Wurzeln (rechteckig umrahmt) aufgebaut, wo die eigentliche Ver-arbeitung beginnt (8). Für jede erreichte Wurzel wird ein einelementiges Schemafragmenterzeugt (9). Beim folgenden Rekursionsabbau, dargestellt in Abbildung 4.5(c), werdenschrittweise alle auf dem Fremdschlüsselpfad liegenden Tabellenschemata in die von ihnenausgehenden Schemafragmente mit der passenden Verbundbedingung aufgenommen (14).Die abschließende Schemafragmentierung entspricht der Darstellung der Fremdschlüssel-pfade in Abbildung 4.4.

4.6. DATENFRAGMENTE 87
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
(a)
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
(b)
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
(c)
Land
Reisebericht
Ortschaft
Restaurant Sehenswürdigkeit
Bewertung
Erhält
Enthält
Administrator
(d)
Abbildung 4.5: Beispiel für Prozedur SchemaFrag
4.6 Datenfragmente
Die Replikation von Instanzen ganzer Schemafragmente inklusive aller Daten aller enthalte-nen Tabellen ist zwar für die Berechnung von Replikationssichten und die Replikattranspa-renz hinreichend, aber bei weitem nicht notwendig. Für die Sicht V := σR.Stil=′de′Restaurantwäre die Replikation eines Schemaausschnitts, bestehend aus F1 := σR.Stil=′de′S1, eben-falls hinreichend, der Mehraufwand durch nicht benötigte Daten aber deutlich reduziert.
Es sei S die Schemafragmentierung von K, dann bestimmt sich die für die Replikatverwal-tung verwendete (Daten-)Fragmentierung F ≈ S durch Partitionierung von Schemafrag-menten aus S entlang ausgewählter Partitionierungsspalten und -werte. Im Gegensatz zurSchemafragmentierung ist eine Datenfragmentierung nicht eindeutig. Die Partitionierungs-spalten können je nach Anforderung der Anwendung und des zu erwartenden Zugriffsver-haltens der mobilen Clients gewählt werden. Damit verbunden ist auch die Forderung,

88 KAPITEL 4. REPLIKATVERWALTUNG
dass sich eine gegebene Fragmentierung im laufenden Betrieb an geänderte Erfordernisseanpassen lässt (siehe Abschnitt 4.6.3).
4.6.1 Definition Datenfragment
Jedes Fragment besitzt die Struktur F := σpS mit S ∈ S. Das Selektionsprädikat p kanndabei nicht beliebig gewählt werden, sondern muss bestimmten Aufbauregeln folgen, diespäter eine relationale Speicherung der Fragmentbeschreibungen und die effiziente Auswer-tung über SQL-Anfragen erlauben (siehe Abschnitt 4.7).
Es sei KS = T1, . . . , Tm mit Ti ∈ K und Ti S (1 ≤ i ≤ m) die Menge aller ausdem Schemafragemnt S ableitbaren Tabellenschemata, geordnet von der Wurzel zum Blattdes Fremdschlüsselpfades. Dann hat p die Struktur
p ≡ p1 ∧ p2 ∧ · · · ∧ pm,
wobei jedes pi genau einem Tabellenschema in KS zugeordnet ist und nur Bedingungenüber Spalten von Ti formuliert.
Sei weiter Ci,1, Ci,2, . . . , Ci,n ⊆ Ti die Menge der Spalten, die nicht Bestandteil einesFremdschlüssels von Ti sind, dann gilt weiter für die Struktur jedes pi:
pi ≡ pi,1 ∧ pi,2 ∧ · · · ∧ pi,n,
wobei jedes der pi,j nur Bedingungen für die Spalte Ci,j (1 ≤ j ≤ n) formuliert.
Fragmente können keine Bedingungen an Fremdschlüsselspalten stellen, aber an Schlüs-selspalten. Diese Festlegung verhindert im Folgenden redundante oder widersprüchlicheBedingungen, die auftreten können bzw. beseitigt werden müssten, wenn sowohl nachPrimärschlüssel- als auch korrespondierenden Fremdschlüsselspalten partitioniert wird. Re-plikationsanfragen bzgl. Fremdschlüsselspalten können dennoch effizient ausgewertet wer-den, wie das geht, zeigt Abschnitt 4.8. Für den Aufbau der Prädikate pi,j sind folgendeAlternativen erlaubt:
pi,j ≡
⎧⎪⎪⎨⎪⎪⎩
Ci,j ∈ v1, v2, . . . , vr F ist (normales) Fragment bzgl. Ci,j ,
Ci,j /∈ v1, v2, . . . , vr F ist Restfragment bzgl. Ci,j ,
Wahr keine Bedingung für Ci,j
Als Werte vk (1 ≤ k ≤ r) zugelassen sind solche der Domäne von Ci,j einschließlich desNullwerts ω. Die Kurzformen Ci,j ∈ v1, v2, . . . , vr für normale Fragmente und Ci,j /∈v1, v2, . . . , vr für Restfragmente stehen dabei vereinfachend für die Prädikate (Ci,j =v1 ∨ · · · ∨ Ci,j = vr) bzw. (Ci,j = v1 ∧ · · · ∧ Ci,j = vr).
4.6.2 Bildung einer Datenfragmentierung
Die folgende Erläuterung der Datenfragmentierung erfolgt mit Hilfe der in Abbildung 4.6und Abbildung 4.7 angegebenen Datenbankausschnitte für Schemafragment S1 und S7.Zur Verbesserung der Übersichtlichkeit sind nur die zum Verständnis wichtigen Spaltenaufgeführt, insbesondere wurde auf die Angabe von Fremdschlüsselspalten und -wertenverzichtet.

4.6. DATENFRAGMENTE 89
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 35
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 39
Thüringen
Jena Cartago sa Roland 210 Zur Noll de Roland 111
ErfurtArtemis gr Zhang 5
12 Buffalo-Bill us Chan 113 Bierbar Freundschaft de14
Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.6: Beispielinstanz für Schemafragment S1
Land AdministratorName Name
1 Thüringen Dipl.-Inf Stubing2 Bayern Dipl-Inf. Braske3 Dipl-Inf. Hansen4 Dipl.-Inf. Paulsen
Abbildung 4.7: Beispielinstanz für Schemafragment S7
Gegeben sei die folgende Fragmentmenge für das Schemafragment S1 aus dem Beispielda-tenbankschema:
F ′1 = F1,1 := σL.Name=′MV′S1,
F1,2 := σL.Name=′Bayern′S1,
F1,3 := σL.Name=′Thuringen′ ∧O.Name=′Jena′S1,
F1,4 := σL.Name=′Thuringen′ ∧O.Name=′Erfurt′S1,
F1,5 := σL.Name=′Thuringen′ ∧O.Name=′Weimar′S1
Alle Fragmente aus F ′1 entsprechen den Aufbauregeln. Die Spalten Land.Name und Ort-
schaft.Name sind die ausgewählten Partitionierungsspalten. Es ist leicht zu sehen, dass dieFragmentmenge F ′
1 für die Instanz aus Abbildung 4.6 alle Daten umfaßt. Dennoch ist dieMenge keine Fragmentierung von S1. Wird beispielsweise in die Tabelle Ortschaft eine

90 KAPITEL 4. REPLIKATVERWALTUNG
neue Zeile für die Stadt ’Gera’ eingefügt, so kann die derart erweiterte Tabelle nicht ausder Fragmentmenge abgeleitet werden.
Das Problem ließe sich dadurch beheben, dass bei jedem Hinzufügen eines Wertesfür eine Partitionierungsspalte auch ein passendes Fragment, also im Beispiel F1,6 :=σL.Name=′Thuringen′ ∧O.Name=′Gera′S1 zur Fragmentmenge hinzugefügt wird.4 Ein solches Vor-gehen wurde im ersten Entwurf des Fragmentkonzepts beschrieben [GR03, Rab03].
Die Notwendigkeit zur Anpassung der Fragmentierung bei jedem Einfügen neuer Partitio-nierungsspaltenwerte ist einerseits aufwändig und andererseits problematisch, wenn vomClient lokal neue Werte eingefügt werden. Da neue Partitionierungsspaltenwerte noch vonkeinem Fragment erfasst werden, können Abhängigkeiten zu anderen Fragmenten nichtberücksichtigt und Zugriffszusicherungen nicht geprüft werden. Das hier vorgestellte Frag-mentkonzept enthält als wesentliches Element deshalb so genannte Restfragmente.
Für jede verwendete Partitionierungsspalte wird ein Restfragment hinzugefügt, das jeweilsdie verbleibenden und potentiell einzufügenden, nicht in anderen Fragmenten erfasstenPartitionierungsspaltenwerte repräsentiert.
F1 = F1,1 := σL.Name=′MV′S1,
F1,2 := σL.Name=′Bayern′S1,
F1,3 := σL.Name=′Thuringen′ ∧O.Name=′Jena′S1,
F1,4 := σL.Name=′Thuringen′ ∧O.Name=′Erfurt′S1,
F1,5 := σL.Name=′Thuringen′ ∧O.Name=′Weimar′S1,
F1,6 := σL.Name=′Thuringen′ ∧O.Name/∈′Jena′,′Erfurt′,′Weimar′S1,
F1,7 := σL.Name/∈′MV′,′Bayern′,′Thuringen′S1
F1 ist jetzt, inklusive der beiden Restfragmente F1,6 bzgl. Ortschaft.Name und F1,7 bzgl.Land.Name, eine Fragmentierung von S1.
4.6.2.1 Behandlung von Nullwerten
Sofern keine explizite Partitionierung nach ω erfolgt, schließen die Restfragmente auch dieZeilen mit ein, deren Wert in der Partitionierungsspalte (noch) undefiniert ist. Zur Erinne-rung, ω wurde als normaler Wert den Domänen der Spalten hinzugefügt (siehe Kapitel 2.2).Diese Zuordnung ist für die Äquivalenzeigenschaft einer Fragmentierung wichtig, insbeson-dere wenn wie im Schemafragment S7 „Waisenkinder“, d. h. Zeilen mit dem Wert ω in denFremdschlüsselspalten, erlaubt sind. F7 mit
F7 = F7,1 := σL.Name=′Thuringen′S7,
F7,2 := σL.Name=′Bayern′S7,
F7,3 := σL.Name/∈′Thuringen′,′Bayern′S7
ist eine Fragmentierung von S7. Der zurzeit keinem Land zugeordnete Nutzeradminis-trator ’Dipl.-Inf. Paulsen’ aus der Instanz in Abbildung 4.7 wird in F7 durch das
4Beim Löschen eines Partitionierungsspaltenwertes ist keine Anpassung erforderlich, die entsprechendeFragmentinstanz enthält dann einfach keine Zeilen.

4.6. DATENFRAGMENTE 91
Fragment F7,3 repräsentiert, da die Partitionierungsspalte Land.Name für ihn den Nullwertannimmt (man beachte hier die Wirkung des äußeren Verbundes im Schemafragment).
Allgemein werden Waisenkinder folgendermaßen repräsentiert. Es sei tl(Tl) (1 ≤ l ≤ m) dieTabelle, welche die betrachteten Waisenkinder bezogen auf den durch das Schemafragmentrepräsentierten Fremdschlüsselpfad enthält. Dann werden diese Waisenkinder durch dieFragmente repräsentiert, welche:
(a) für alle Partitionierungsspalten Ci,j der Tabellenschemata Ti mit i < l (hin zurWurzel des Fremdschlüsselpfades) Restfragment sind
oder
(b) explizit den Nullwert ω für alle Partitionierungsspalten enthalten.
Die bisher an Beispielen demonstrierte Bildung einer Datenfragmentierung kann über diebeiden im Folgenden beschriebenen Prozeduren SplitFrag und MergeFrag implementiertwerden.
4.6.2.2 Prozedur SplitFrag
Der Programmtext 4.2 zeigt die Prozedur SplitFrag für das Aufteilen von Fragmenten ei-ner gegebenen Fragmentmenge. SplitFrag wird sowohl zum Erstellen einer initialen Frag-mentierung, als auch zur Anpassung einer gegebenen Fragmentierung verwendet (sieheAbschnitt 4.6.3). Bei Datenänderungen ist eine Anpassung der Fragmentierung zwar nichterforderlich, aber immer dann sinnvoll, wenn einzelne Fragmente zu groß werden und eineweitere Aufteilung über neue Partitionierungsspalten oder -werte möglich ist.
SplitFrag erhält als Eingabe eine Schema- und Datenfragmentierung, ein Tabellenschema T ,eine Spalte C des Tabellenschemas als Partitionierungsspalte, Partitionierungswerte V undeine Zahl min. Das Verfahren arbeitet auf einer gegebenen Instanz von K. Dabei werden alleSchemafragmente verarbeitet, welche das übergebene Tabellenschema enthalten. Ergebnisund Ausgabe ist eine angepasste Datenfragmentierung, welche neue, separate Fragmentefür die Selektionsbedingung C ∈ V enthält.
Über den Parameter min kann die Größe neuer Fragmente für eine Datenbank nach untenbegrenzt und damit die Wirksamkeit der Fragmentierung beeinflußt werden. Ein neuesFragment wird nur dann abgespalten, wenn seine Instanz, bezogen auf die aktuelle kon-solidierte Datenbank, mindestens min Zeilen enthalten würde. Die Überprüfung dieserBedingung erfolgt getrennt für jedes Schemafragment. Durch min = 0 wird der Mechanis-mus deaktiviert. Das ist beispielsweise erforderlich, wenn nach Werten partitioniert werdensoll, die noch nicht, aber absehbar in der Datenbank vorkommen. Die einzelnen Schritteder Fragmentbildung werden im Folgenden am Beispiel von Schemafragment S1 des Bei-spieldatenbankschemas und seiner Instanz aus Abbildung 4.6 erläutert.
Beispiel 1 – Initiale Fragmentierung
Der erste Aufruf sei SplitFrag(S1, S1, Land, Name, ’Thüringen’, 3). Die übergebenenFragmentmengen enthalten nur ein Schemafragment, weswegen die Schleife von Zeile 1–23

92 KAPITEL 4. REPLIKATVERWALTUNG
SplitFrag(in S ≈ K, in out F ≈ S, in T ∈ K, in C ∈ T , in V ⊆ Dom(C), in min ∈ IN)
1: foreach S ∈ S mit T ∈ KS do2: Sei FS ⊆ F mit FS ≈ S3: Mit KS = T1, . . . , Tm sei T = Ti und 1 ≤ i ≤ m4: Mit Ti = Ci,1, . . . , Ci,n sei C = Ci,j und 1 ≤ j ≤ n
Fall 1: C.T ist eine neue Partitionierungsspalte5: foreach F ∈ FS mit pi,j ≡ Wahr und |σCi,j∈V f(F )| ≥ min do6: Sei F = σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧ Wahr∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
7: F := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈V∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pmS
8: F rneu := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j/∈/∈/∈V∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
9: F := F ∪ F rneu
10: od
Fall 2: V enthält keine Partitionierungswerte11: foreach F r ∈ FS mit pi,j ≡ Ci,j /∈ V ′ und V ′ ∩ V = ∅
und |σCi,j∈V f(F r)| ≥ min do12: Sei F r = σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j/∈/∈/∈V′ ∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
13: Fnneu := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈V∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
14: F := F ∪ Fnneu
15: F r := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j/∈/∈/∈(V′∪∪∪V)∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pmS
16: od
Fall 3: V enthält Partitionierungswerte17: foreach Fn ∈ FS mit pi,j ≡ Ci,j ∈ V ′ und V ⊂ V ′
und |σCi,j∈V f(Fn)| ≥ min do18: Sei Fn = σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈V′ ∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
19: Fnneu := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈V∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
20: F := F ∪ Fnneu
21: Fn := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈(V′\\\V)∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pmS
22: od23: od
Programmtext 4.2: Prozedur SplitFrag
nur einmal durchlaufen wird. Da bisher noch keine einschränkenden Selektionsbedingungenvorhanden sind, verfährt die Prozedur nach Fall 1 ab Zeile 5.
Es werden alle vorhandenen Fragmente ermittelt, die für die Wertemenge V =’Thüringen’ mindestens 3 Einträge liefern. Ein Blick in Abbildung 4.6 zeigt, dass daseinzige bisher vorhandene Fragment für Thüringen sogar 9 Einträge ausweist – die Bedin-gung für das Abspalten ist also erfüllt.
Es werden jetzt erstens das bestehende Fragment um die Selektionsbedingung C ∈ V erwei-tert und zweitens ein neues Restfragment erzeugt und der Fragmentmenge hinzugefügt, dasalle diejenigen Zeilen des Ausgangsfragments selektiert, die gerade nicht der neuen Bedin-gung genügen. Da keine weiteren Fragmente existieren, ist die Verarbeitung hier beendet.Das Ergebnis ist in Abbildung 4.8 dargestellt.
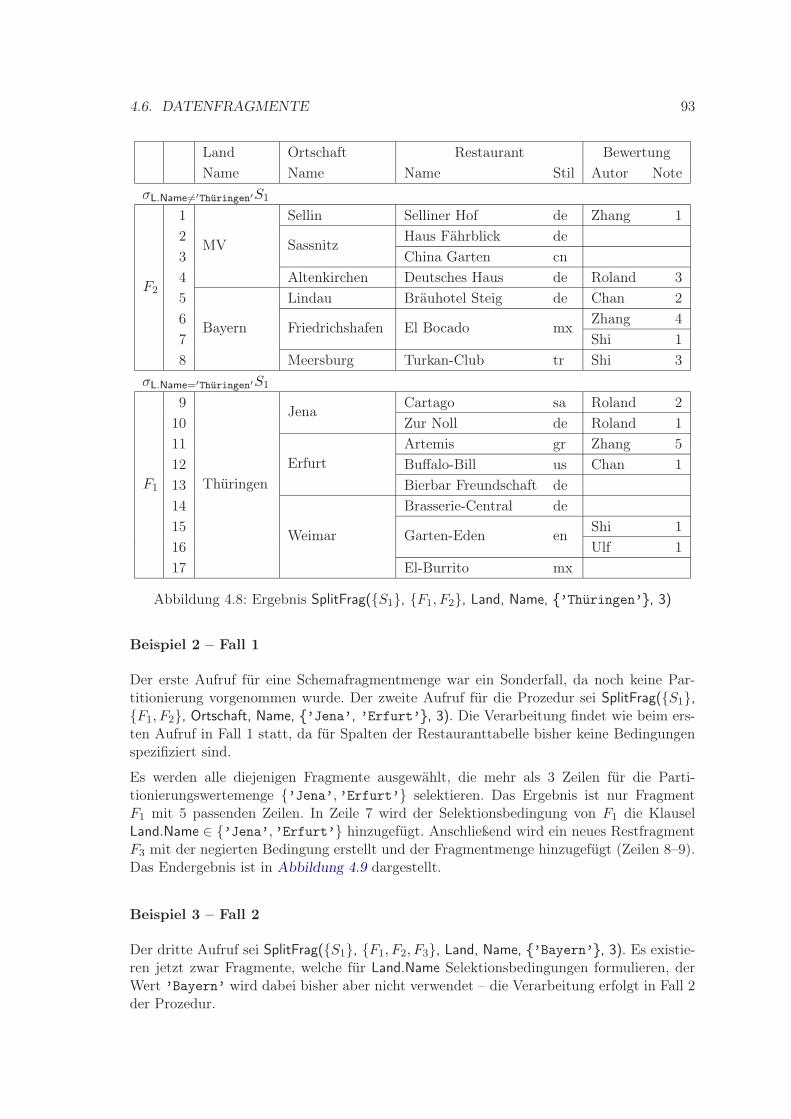
4.6. DATENFRAGMENTE 93
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
σL.Name=′Thuringen′S1
F2
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 35
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 3
σL.Name=′Thuringen′S1
F1
9
Thüringen
Jena Cartago sa Roland 210 Zur Noll de Roland 111
ErfurtArtemis gr Zhang 5
12 Buffalo-Bill us Chan 113 Bierbar Freundschaft de14
Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.8: Ergebnis SplitFrag(S1, F1, F2, Land, Name, ’Thüringen’, 3)
Beispiel 2 – Fall 1
Der erste Aufruf für eine Schemafragmentmenge war ein Sonderfall, da noch keine Par-titionierung vorgenommen wurde. Der zweite Aufruf für die Prozedur sei SplitFrag(S1,F1, F2, Ortschaft, Name, ’Jena’, ’Erfurt’, 3). Die Verarbeitung findet wie beim ers-ten Aufruf in Fall 1 statt, da für Spalten der Restauranttabelle bisher keine Bedingungenspezifiziert sind.
Es werden alle diejenigen Fragmente ausgewählt, die mehr als 3 Zeilen für die Parti-tionierungswertemenge ’Jena’, ’Erfurt’ selektieren. Das Ergebnis ist nur FragmentF1 mit 5 passenden Zeilen. In Zeile 7 wird der Selektionsbedingung von F1 die KlauselLand.Name ∈ ’Jena’, ’Erfurt’ hinzugefügt. Anschließend wird ein neues RestfragmentF3 mit der negierten Bedingung erstellt und der Fragmentmenge hinzugefügt (Zeilen 8–9).Das Endergebnis ist in Abbildung 4.9 dargestellt.
Beispiel 3 – Fall 2
Der dritte Aufruf sei SplitFrag(S1, F1, F2, F3, Land, Name, ’Bayern’, 3). Es existie-ren jetzt zwar Fragmente, welche für Land.Name Selektionsbedingungen formulieren, derWert ’Bayern’ wird dabei bisher aber nicht verwendet – die Verarbeitung erfolgt in Fall 2der Prozedur.
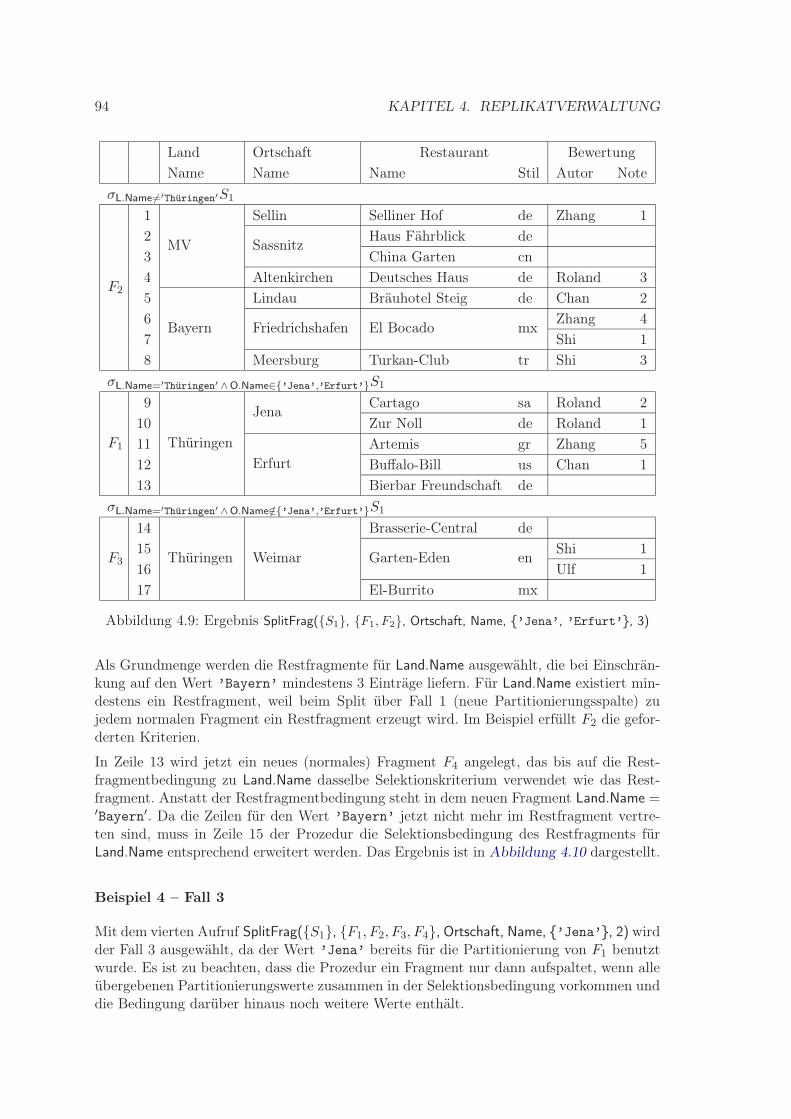
94 KAPITEL 4. REPLIKATVERWALTUNG
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
σL.Name=′Thuringen′S1
F2
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 35
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 3
σL.Name=′Thuringen′ ∧O.Name∈’Jena’,’Erfurt’S1
F1
9
Thüringen
Jena Cartago sa Roland 210 Zur Noll de Roland 111
ErfurtArtemis gr Zhang 5
12 Buffalo-Bill us Chan 113 Bierbar Freundschaft de
σL.Name=′Thuringen′ ∧O.Name/∈’Jena’,’Erfurt’S1
F3
14
Thüringen Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.9: Ergebnis SplitFrag(S1, F1, F2, Ortschaft, Name, ’Jena’, ’Erfurt’, 3)
Als Grundmenge werden die Restfragmente für Land.Name ausgewählt, die bei Einschrän-kung auf den Wert ’Bayern’ mindestens 3 Einträge liefern. Für Land.Name existiert min-destens ein Restfragment, weil beim Split über Fall 1 (neue Partitionierungsspalte) zujedem normalen Fragment ein Restfragment erzeugt wird. Im Beispiel erfüllt F2 die gefor-derten Kriterien.
In Zeile 13 wird jetzt ein neues (normales) Fragment F4 angelegt, das bis auf die Rest-fragmentbedingung zu Land.Name dasselbe Selektionskriterium verwendet wie das Rest-fragment. Anstatt der Restfragmentbedingung steht in dem neuen Fragment Land.Name =′Bayern′. Da die Zeilen für den Wert ’Bayern’ jetzt nicht mehr im Restfragment vertre-ten sind, muss in Zeile 15 der Prozedur die Selektionsbedingung des Restfragments fürLand.Name entsprechend erweitert werden. Das Ergebnis ist in Abbildung 4.10 dargestellt.
Beispiel 4 – Fall 3
Mit dem vierten Aufruf SplitFrag(S1, F1, F2, F3, F4, Ortschaft, Name, ’Jena’, 2) wirdder Fall 3 ausgewählt, da der Wert ’Jena’ bereits für die Partitionierung von F1 benutztwurde. Es ist zu beachten, dass die Prozedur ein Fragment nur dann aufspaltet, wenn alleübergebenen Partitionierungswerte zusammen in der Selektionsbedingung vorkommen unddie Bedingung darüber hinaus noch weitere Werte enthält.
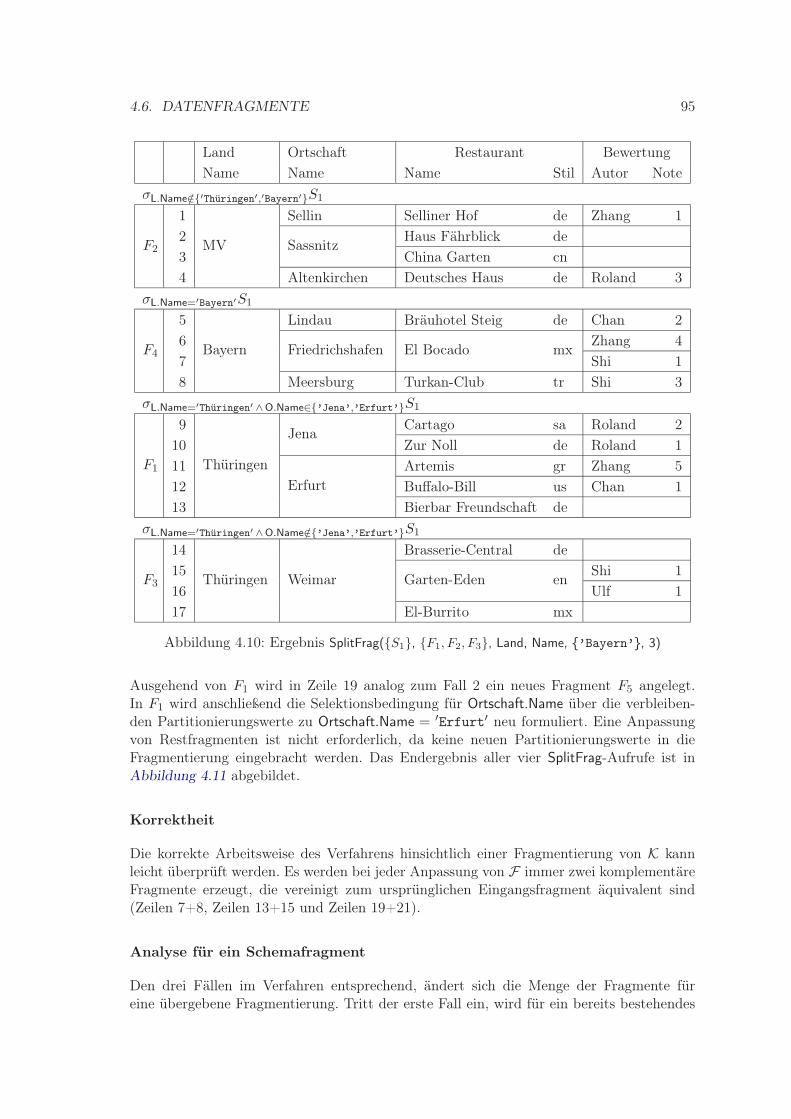
4.6. DATENFRAGMENTE 95
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
σL.Name/∈′Thuringen′,′Bayern′S1
F2
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 3
σL.Name=′Bayern′S1
F4
5
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 3
σL.Name=′Thuringen′ ∧O.Name∈’Jena’,’Erfurt’S1
F1
9
Thüringen
Jena Cartago sa Roland 210 Zur Noll de Roland 111
ErfurtArtemis gr Zhang 5
12 Buffalo-Bill us Chan 113 Bierbar Freundschaft de
σL.Name=′Thuringen′ ∧O.Name/∈’Jena’,’Erfurt’S1
F3
14
Thüringen Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.10: Ergebnis SplitFrag(S1, F1, F2, F3, Land, Name, ’Bayern’, 3)
Ausgehend von F1 wird in Zeile 19 analog zum Fall 2 ein neues Fragment F5 angelegt.In F1 wird anschließend die Selektionsbedingung für Ortschaft.Name über die verbleiben-den Partitionierungswerte zu Ortschaft.Name = ′Erfurt′ neu formuliert. Eine Anpassungvon Restfragmenten ist nicht erforderlich, da keine neuen Partitionierungswerte in dieFragmentierung eingebracht werden. Das Endergebnis aller vier SplitFrag-Aufrufe ist inAbbildung 4.11 abgebildet.
Korrektheit
Die korrekte Arbeitsweise des Verfahrens hinsichtlich einer Fragmentierung von K kannleicht überprüft werden. Es werden bei jeder Anpassung von F immer zwei komplementäreFragmente erzeugt, die vereinigt zum ursprünglichen Eingangsfragment äquivalent sind(Zeilen 7+8, Zeilen 13+15 und Zeilen 19+21).
Analyse für ein Schemafragment
Den drei Fällen im Verfahren entsprechend, ändert sich die Menge der Fragmente füreine übergebene Fragmentierung. Tritt der erste Fall ein, wird für ein bereits bestehendes
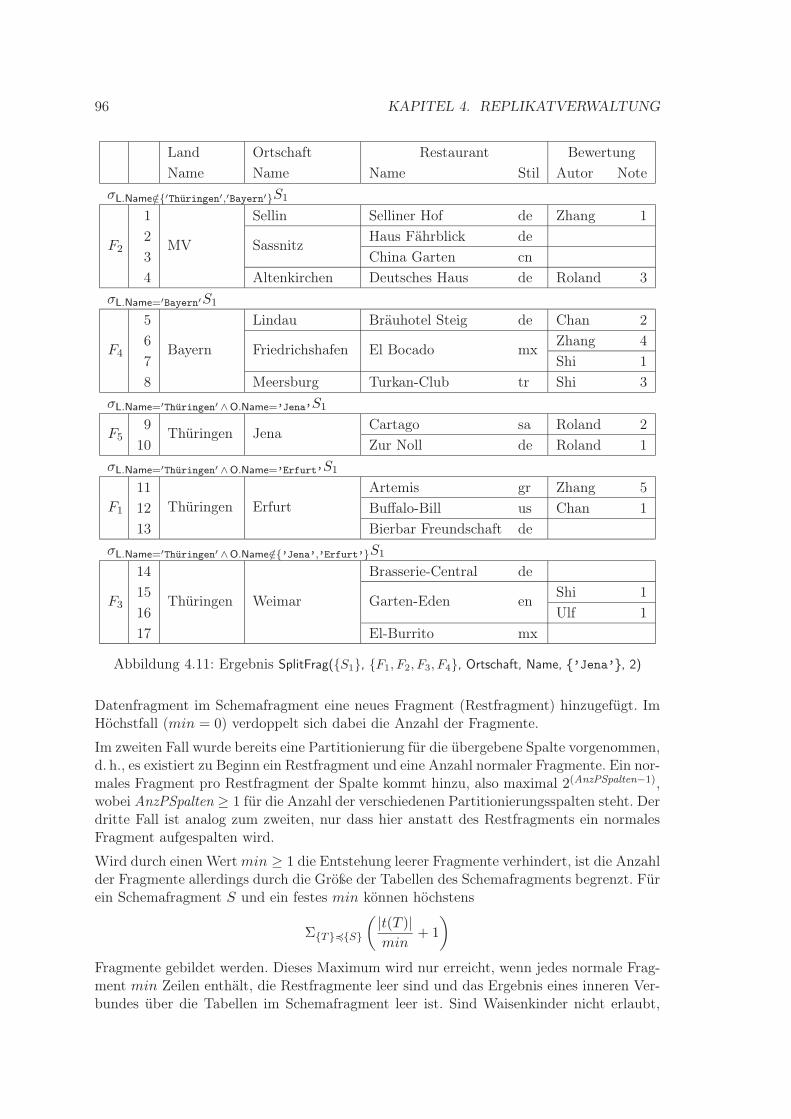
96 KAPITEL 4. REPLIKATVERWALTUNG
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
σL.Name/∈′Thuringen′,′Bayern′S1
F2
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 3
σL.Name=′Bayern′S1
F4
5
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 3
σL.Name=′Thuringen′ ∧O.Name=’Jena’S1
F59 Thüringen Jena Cartago sa Roland 2
10 Zur Noll de Roland 1σL.Name=′Thuringen′ ∧O.Name=’Erfurt’S1
F1
11Thüringen Erfurt
Artemis gr Zhang 512 Buffalo-Bill us Chan 113 Bierbar Freundschaft de
σL.Name=′Thuringen′ ∧O.Name/∈’Jena’,’Erfurt’S1
F3
14
Thüringen Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.11: Ergebnis SplitFrag(S1, F1, F2, F3, F4, Ortschaft, Name, ’Jena’, 2)
Datenfragment im Schemafragment eine neues Fragment (Restfragment) hinzugefügt. ImHöchstfall (min = 0) verdoppelt sich dabei die Anzahl der Fragmente.
Im zweiten Fall wurde bereits eine Partitionierung für die übergebene Spalte vorgenommen,d. h., es existiert zu Beginn ein Restfragment und eine Anzahl normaler Fragmente. Ein nor-males Fragment pro Restfragment der Spalte kommt hinzu, also maximal 2(AnzPSpalten−1),wobei AnzPSpalten ≥ 1 für die Anzahl der verschiedenen Partitionierungsspalten steht. Derdritte Fall ist analog zum zweiten, nur dass hier anstatt des Restfragments ein normalesFragment aufgespalten wird.
Wird durch einen Wert min ≥ 1 die Entstehung leerer Fragmente verhindert, ist die Anzahlder Fragmente allerdings durch die Größe der Tabellen des Schemafragments begrenzt. Fürein Schemafragment S und ein festes min können höchstens
ΣTS
(|t(T )|min
+ 1)
Fragmente gebildet werden. Dieses Maximum wird nur erreicht, wenn jedes normale Frag-ment min Zeilen enthält, die Restfragmente leer sind und das Ergebnis eines inneren Ver-bundes über die Tabellen im Schemafragment leer ist. Sind Waisenkinder nicht erlaubt,

4.6. DATENFRAGMENTE 97
istmaxTS |t(T )|
min+ 1
die Obergrenze für die Anzahl der Fragmente einer Fragmentierung von S, bezogen aufeine konkrete Instanz der konsolidierten Datenbank. Die Anzahl der Fragmente einer Frag-mentierung steht in einem linearen Bezug zur Größe der konsolidierten Datenbank.
4.6.2.3 Prozedur MergeFrag
MergeFrag(in out F ≈ K, in T ∈ K, in C ∈ T , in v ∈ Dom(C))
1: foreach F ∈ F do2: Sei F = σp1 ∧ ··· ∧ pmS
Fall 1: normale Fragmente3: if ∃1≤i≤m pi ≡ · · · ∨ C = v ∨ · · · do4: Mit pi ≡ pi,1 ∧ · · · ∧ pi,n sei C = Ci,j und 1 ≤ j ≤ n5: Mit pi,j ≡ Ci,j ∈ V und V ⊆ Dom(C)6: V new = V \ v7: F := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j∈∈∈Vnew ∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
8: if V new = ∅ do9: F := F \ F10: od
Fall 2: Restfragmente11: else if ∃1≤i≤m pi ≡ · · · ∧ C = v ∧ · · · do12: Mit pi ≡ pi,1 ∧ · · · ∧ pi,n sei C = Ci,j und 1 ≤ j ≤ n13: Mit pi,j ≡ Ci,j /∈ V und V ⊆ Dom(C)14: V new = V \ v15: F := σp1 ∧ ··· ∧ pi−1 ∧ (pi,1 ∧ ··· ∧ pi,j−1 ∧Ci,j/∈/∈/∈Vnew ∧ pi,j+1 ∧ ···pi,n)∧ pi+1 ∧ ··· ∧ pm
S
16: od
17: od
Programmtext 4.3: Prozedur MergeFrag
Der Programmtext 4.3 zeigt die Prozedur MergeFrag für das Zusammenführen bzw. Lö-schen von Fragmenten. MergeFrag dient der Anpassung der Fragmentierung, wenn ein-zelne Fragmente durch das Löschen von Daten zu klein oder sogar leer werden (sieheAbschnitt 4.6.3). Wie bei SplitFrag ist die Ausführung von MergeFrag allein zur Erhaltungder Fragmentierungseigenschaft bei Datenänderungen nicht erforderlich.
MergeFrag arbeitet auf einer Fragmentierung bzgl. einer konkreten Instanz von K. Darüberhinaus werden ein Tabellenschema T , eine Spalte C als Partitionierungsspalte und einPartitionierungswert v übergeben. Die Semantik der Ausführung von MergeFrag für eineMenge von Partitionierungswerten kann über den mehrmaligen Aufruf der Prozedur erzieltwerden.5 Ergebnis ist eine Fragmentierung, welche den übergebenen Partitionierungswertv in keiner Selektionsbedingung mehr enthält.
5Bei SplitFrag kann die Semantik von Fall 3 durch ein sukzessives Aufspalten nicht simuliert werden.
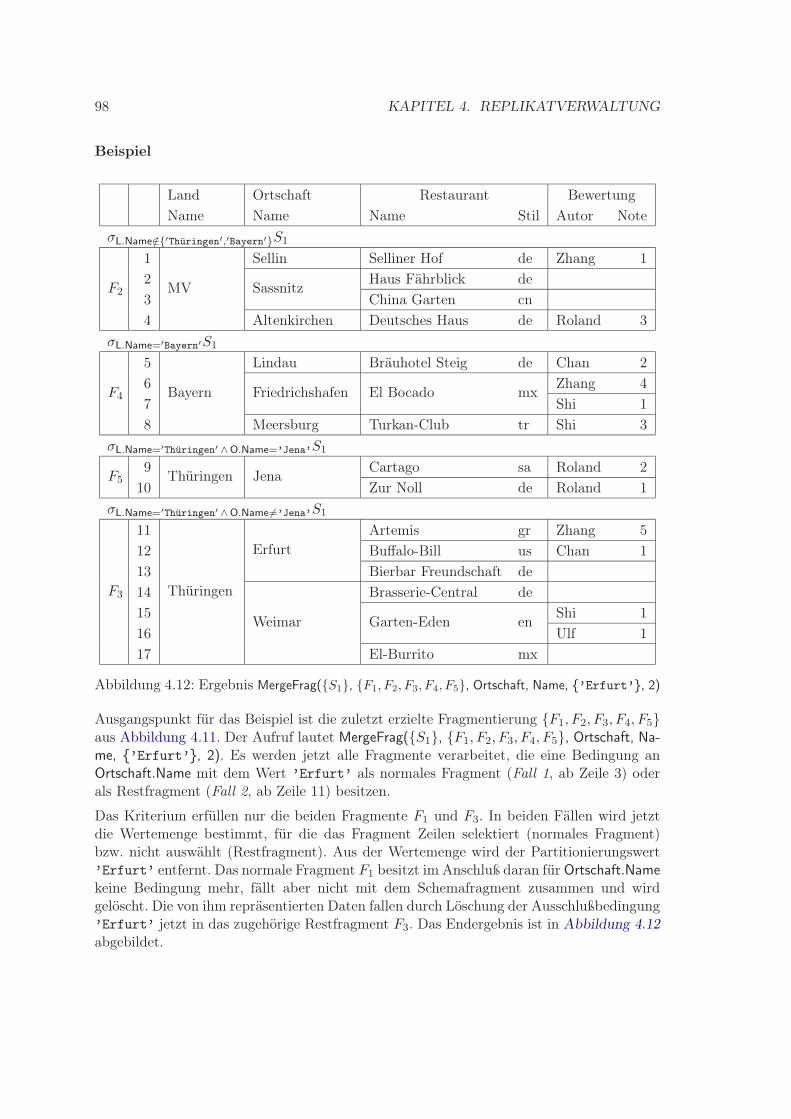
98 KAPITEL 4. REPLIKATVERWALTUNG
Beispiel
Land Ortschaft Restaurant BewertungName Name Name Stil Autor Note
σL.Name/∈′Thuringen′,′Bayern′S1
F2
1
MV
Sellin Selliner Hof de Zhang 12 Sassnitz Haus Fährblick de3 China Garten cn4 Altenkirchen Deutsches Haus de Roland 3
σL.Name=′Bayern′S1
F4
5
Bayern
Lindau Bräuhotel Steig de Chan 26 Friedrichshafen El Bocado mx Zhang 47 Shi 18 Meersburg Turkan-Club tr Shi 3
σL.Name=′Thuringen′ ∧O.Name=’Jena’S1
F59 Thüringen Jena Cartago sa Roland 2
10 Zur Noll de Roland 1σL.Name=′Thuringen′ ∧O.Name=’Jena’S1
F3
11
Thüringen
ErfurtArtemis gr Zhang 5
12 Buffalo-Bill us Chan 113 Bierbar Freundschaft de14
Weimar
Brasserie-Central de15 Garten-Eden en Shi 116 Ulf 117 El-Burrito mx
Abbildung 4.12: Ergebnis MergeFrag(S1, F1, F2, F3, F4, F5, Ortschaft, Name, ’Erfurt’, 2)
Ausgangspunkt für das Beispiel ist die zuletzt erzielte Fragmentierung F1, F2, F3, F4, F5aus Abbildung 4.11. Der Aufruf lautet MergeFrag(S1, F1, F2, F3, F4, F5, Ortschaft, Na-me, ’Erfurt’, 2). Es werden jetzt alle Fragmente verarbeitet, die eine Bedingung anOrtschaft.Name mit dem Wert ’Erfurt’ als normales Fragment (Fall 1, ab Zeile 3) oderals Restfragment (Fall 2, ab Zeile 11) besitzen.
Das Kriterium erfüllen nur die beiden Fragmente F1 und F3. In beiden Fällen wird jetztdie Wertemenge bestimmt, für die das Fragment Zeilen selektiert (normales Fragment)bzw. nicht auswählt (Restfragment). Aus der Wertemenge wird der Partitionierungswert’Erfurt’ entfernt. Das normale Fragment F1 besitzt im Anschluß daran für Ortschaft.Namekeine Bedingung mehr, fällt aber nicht mit dem Schemafragment zusammen und wirdgelöscht. Die von ihm repräsentierten Daten fallen durch Löschung der Ausschlußbedingung’Erfurt’ jetzt in das zugehörige Restfragment F3. Das Endergebnis ist in Abbildung 4.12abgebildet.

4.6. DATENFRAGMENTE 99
Korrektheit
Die korrekte Verarbeitung von MergeFrag hängt im Gegensatz zu SplitFrag von der vorlie-genden Fragmentierung ab. Diese kann nur garantiert werden, wenn die Fragmentierungunter Zuhilfenahme der Prozeduren SchemaFrag, SplitFrag und MergeFrag erstellt wurde.Diese Einschränkung ist erforderlich, da sich MergeFrag die spezielle Struktur der vonSplitFrag erzeugten Fragmentmengen zunutze macht (siehe auch Abschnitt 4.7).
Die ausschließliche Verarbeitung mit den hier vorgestellten Prozeduren stellt sicher, dass fürjede einschränkende Bedingung der Form C ∈ V in einem Fragment eine korrespondierendeBedingung C /∈ V in einem Restfragment existiert. Wird also bei einer Bedingung C ∈ Vim Fall 1 aus der Wertemenge ein Element entfernt, sorgt Fall 2 mit der Entfernung desPartitionierunswertes aus dem korrespondierenden Restfragment für die Wiederherstellungder Fragmentierungseigenschaft.
Trägt ein normales Fragment nicht mehr zur Unterscheidung zu anderen Fragmenten bzgl.C bei, kann es gelöscht werden. Restfragmente dürfen hingegen nicht gelöscht werden. Wirdihre Bedingung bzgl. C zu Wahr, bedeutet das, dass kein normales Fragment bzgl. C mehrexistiert bzw. später im Ablauf gelöscht wird. Eine vorangegangene Aufspaltung für C inder Fragmentierung wird damit rückgängig gemacht. Das Restfragment enthält jetzt nurnoch Bedingungen für andere Partitionierungsspalten oder fällt mit dem Schemafragmentzusammen, wenn p ≡ Wahr wird.
4.6.3 Anpassung einer Fragmentierung
Im Gegensatz zur Schemafragmentierung, welche einmal anhand des Datenbankschemasder konsolidierten Datenbank bestimmt wird und nur angepasst werden muss, wenn sichdas Schema ändert, kann es sinnvoll sein, eine initiale Datenfragmentierung regelmäßiganzupassen. Oft enthält eine Tabelle anfangs nur wenige Zeilen, welche die Partitionierungauf nur wenige Fragmente begrenzt. Im Laufe der Zeit werden neue Zeilen hinzugefügt.Enthalten diese Zeilen neue Partitionierungsspaltenwerte, so werden sie zunächst (implizit)dem jeweiligen Restfragment zugeordnet, welches im Vergleich zu den übrigen normalenFragmenten überproportional wächst. Die Folge davon ist eine Zunahme von überflüssigenDatenübertragungen beim Zugriff auf Daten, welche durch das Restfragment repräsentiertwerden.
Eine regelmäßige Anspassung der Datenfragmentierung bzgl. neuer Partitionierungswertekann über die Prozedur SplitFrag erfolgen. Da immer genau ein Fragment Ursprung einerAufspaltung ist, können dessen Eigenschaften (welche Clients haben es repliziert, zu wel-chem Sperrobjekt gehört es) sofort für die beiden neuen Fragmente übernommen werden.In Bezug auf die Bildung der Sperrobjekte kann ein Aufspalten zwei disjunkte Fragmen-te erzeugen. In diesem Fall ist zur Verbesserung der Verfügbarkeit eine Anpassung derSperrobjekte sinnvoll (siehe Abschnitt 4.10).
Dem gegenüber kann beim Löschen von Zeilen der von einem Fragment repräsentierteDatenbankausschnitt sehr klein oder (dauerhaft) leer werden. Der dadurch induzierte un-nötige Verwaltungsaufwand (ein Mehraufwand für die Datenübertragung entsteht durchleere Fragmente nicht) kann durch ein regelmäßiges Zusammenfassen bzw. Löschen über-flüssiger Fragmente mittels MergeFrag verringert werden.

100 KAPITEL 4. REPLIKATVERWALTUNG
Im Gegensatz zu SplitFrag ist bei der Ausführung von MergeFrag im laufenden Betriebfolgendes zu beachten. Wird ein Fragment gelöscht, erfolgt damit eine Verschmelzung mitdem zur betrachteten Tabellenspalte gehörenden Restfragment. Das gelöschte Fragmentwird also in allen seinen Vorkommen durch das Restfragment ersetzt. Eine solche Ersetzungkann nicht sofort erfolgen, sondern muss sukzessive für jeden replizierenden Client bei derjeweils nächsten Synchronisation durchgeführt werden. Gehörten das gelöschte Fragmentund das Restfragment verschiedenen Sperrobjekten an, was sehr wahrscheinlich der Fallist, müssen diese ebenfalls vereinigt werden. Eine solche Zusammenführung kann solangenicht erfolgen, wie verschiedene Clients jeweils nur eines der beteiligten Objekte exklusiv imZugriff haben. Eine Implementierung von MergeFrag muss deshalb vor dem Löschen einesFragments für alle betroffenen Sperrobjekte exklusive Zugriffszusicherungen erwerben.
4.7 Verwaltung der Fragmentbeschreibungen
In den vorangegangenen zwei Abschnitten wurde die Struktur der Fragmente über dieFestlegung erlaubter Selektionsprädikate und die Prozeduren SchemaFrag, SplitFrag undMergeFrag definiert. Die weitere Umsetzung des Fragmentkonzepts, insbesondere die Ent-wicklung von Verfahren zur Übersetzung von Anfragen in Fragmentmengen, erfordert dieEinbeziehung einer konkreten Repräsentation der Fragmente in einer Datenstruktur. Ei-ne solche Datenstruktur, vergleichbar mit einem Index für die konsolidierte Datenbank,ist derart zu wählen, dass damit effizient sowohl Replikationsanfragen in eine Menge kor-respondierender Fragmente übersetzt werden können, als auch aus gegebenen Fragment-mengen die zugehörigen Selektionsanweisungen für die Synchronisation ermittelt werdenkönnen.
In den folgenden Unterabschnitten wird eine Datenstruktur basierend auf relationalen Ta-bellen vorgestellt, die sich den speziellen Aufbau der Selektionsprädikate für Datenfrag-mente zunutze macht. Die relationale Ablage ist durch das Paradigma des Relational Inde-xing [KPPS03] inspiriert und bietet gegenüber einer proprietären Datenstruktur mehrereVorteile. Sie kann leicht mit jedem relationalen Datenbanksystem umgesetzt werden, istaber gleichzeitig weitgehend DBMS-unabhängig. Der Zugriff auf die Datenstruktur erfolgtmengenorientiert über Sprachmittel von SQL und kann dadurch die vom DBMS angebo-tenen Indexstrukturen sowie die Anfrageoptimierung nutzen.
4.7.1 Die Fragmenttabellen
SF(SID, Tabname, Pfadnr, FKID)DF(SID,FID, Tabname, Spaltenname, Wert, Nullind, Rest)
SF
DF
SID, Tabname
Abbildung 4.13: Tabellenschemata von Schema- und Datenfragmenttabelle
Die Datenstruktur für die Speicherung der Fragmentbeschreibungen besteht aus zwei Ta-bellen, deren Schemata und Fremdschlüsselbedingungen in Abbildung 4.13, wie sie zurVerarbeitung benötigt werden, angegeben sind. Die Tabelle sf(SF) speichert die einmal

4.7. VERWALTUNG DER FRAGMENTBESCHREIBUNGEN 101
zusammen mit dem Schema der konsolidieten Datenbank ermittelten Informationen überSchemafragmente und Fremdschlüsselpfade. In den Zeilen der für die eigentliche Anfrage-auswertung verwendeten zweiten Tabelle df(DF) werden die Pädikate für die Datenfrag-mente der aktuellen Fragmentierung abgelegt.
In einer Schemafragmenttabelle sf(SF) bekommt jedes Schemafragment eine eindeutigeIdentifikationsnummer SID. Für die im Schemafragment enthaltenen Tabellenschematawerden jeweils Bezeichnung (Tabname), die Nummer im Fremdschlüsselpfad beginnendbei der Wurzel (Pfadnr) und die ausgehende Fremdschlüsselbeziehung im Pfad über eineFremdschlüssel-ID (FKID) gespeichert.
Da jedes Tabellenschema in einem Fremdschlüsselpfad bzw. Schemafragement nur einmalenthalten sein darf, bilden SID und Tabname zusammen den Primärschlüssel von SF. DieStruktur und Semantik von Tabname und FKID sind nicht festgelegt, vielmehr hängen sievon den Konventionen des zur Verwaltung der Quell- bzw. konsolidierten Datenbank ab.Empfehlenswert ist eine Übernahme der Werte aus dem jeweiligen Datenbankkatalog. Fürdie Wurzel des Pfades ist FKID gleich ω, Nullwerte für die anderen Spalten sind nichtzulässig.
SID Tabname Pfadnr FKID
1 ’Land’ 1 ω
1 ’Ortschaft’ 2 ’LName’1 ’Restaurant’ 3 ’OName’1 ’Bewertung’ 4 ’RNr’
Abbildung 4.14: Tabelle sf(SF) für S1
Ein Verfahren zur Erstellung der Tabelle sf(SF) lässt sich sich sehr einfach aus dem Ver-fahren zur Schemafragmentbildung aus Programmtext 4.1 auf Seite 86 ableiten – auf dieAngabe der Prozedur wird deshalb hier verzichtet (siehe dazu [Mic04]). Die Schemafrag-menttabelle für das Schemafragment S1 der Beispieldatenbank ist in Abbildung 4.14 ab-gebildet. Wie die Einträge der Tabelle df(DF), mit deren Hilfe später die Auswertung derReplikationsanfragen erfolgt, aufgebaut sind, wird im Folgenden genauer erläutert.
4.7.2 Aufbau der Datenfragmenttabelle – Prozedur ToFragTable
Da die Struktur und Semantik der Einträge von df(DF) den speziellen Aufbau der Selek-tionsprädikate für Datenfragmente, wie sie mittels SchemaFrag, SplitFrag und MergeFragerzeugt werden, ausnutzt, seien dessen wesentlichen Eigenschaften noch einmal zusammen-gefasst:
1. Ein Fragment ist bzgl. einer Spalte einer Tabelle im Pfad des zugehörigen Sche-mafragments entweder Restfragement oder normales Fragment.
2. Die Bedingungen für eine Spalte C sind oder-verknüpft, falls das Fragment normalesFragment bzgl. C ist und und-verknüpft für ein Restfragment.
3. Alle Bedingungen an eine Spalte in einem Fragment sind Punktanfragen der gleichenStruktur. Für den Fall eines normalen Fragments haben sie die Form C = v und fürRestfragmente ist die Semantik C = v.

102 KAPITEL 4. REPLIKATVERWALTUNG
4. Bedingungen für verschiedene Spalten sind immer und-verknüpft.
Die Ablage der Selektionsprädikate als Zeilen in einer relationalen Tabelle ist deshalb sehreinfach. Jede Zeile der Datenfragmenttabelle repräsentiert im Folgenden einen Partitio-nierungswert (Wert). Seine Stellung im Prädikat für ein Fragment (wobei die Reihenfolgejeweils und- bzw. oder-verknüpfter Terme wegen der Kommutativität der Operationen kei-ne Rolle spielt) ist durch den Namen von Spalte (Spaltenname) und Tabelle (Tabname)sowie der Kennzeichnung, ob es sich um ein Restfragment in Bezug auf die Tabellenspaltehandelt (Rest), eindeutig bestimmt.
ValueToFragTable(in sid, in fid, in r, in T , in C,in V , in out df(DF)
)
1: if r = 0 und V = ∅ do2: foreach v ∈ V do3: if v = ω do4: ι(df;(sid, fid, T , C, v, ’X’, 0))5: else6: ι(df;(sid, fid, T , C, ω, ’X’, 0))7: od8: od9: else if r = 1 und V = ∅10: foreach v ∈ V do11: if v = ω do12: ι(df;(sid, fid, T , C, v, ’X’, 1))13: else14: ι(df;(sid, fid, T , C, ω, ’X’, 1))15: od16: od17: else18: ι(df;(sid, fid, T , C, ω, ω, 0))19: od
ToFragTable(in sid, in fid, in p,in out df(DF)
)
20: Sei p ≡ p1 ∧ · · · ∧ pm
21: foreach pi mit 1 ≤ i ≤ m do22: Sei pi ≡ pi,1 ∧ · · · ∧ pi,n
23: foreach pi,j mit 1 ≤ j ≤ n do24: if pi,j ≡ Wahr do25: ValueToFragTable(
sid, fid, 0, Ti, Ci,j , ∅, df)
26: else if pi,j ≡ Ci,j ∈ V27: ValueToFragTable(
sid, fid, 0, Ti, Ci,j , V , df)
28: else pi,j ≡ Ci,j /∈ V29: ValueToFragTable(
sid, fid, 1, Ti, Ci,j , V , df)
30: od31: od32: od
Programmtext 4.4: Prozedur ToFragTable mit ValueToFragTable
Zu beachten ist weiter, dass es für die spätere Anfrageübersetzung erforderlich ist, fürjede Spalte des Schemafragments einen Eintrag in df vorzunehmen, auch wenn das Prädi-kat des Fragments für die Spalte (noch) auf keinen Partitionierungswert einschränkt. DerGrund dafür ist, dass für die mengenorientierte Verarbeitung von Fragmenten ein Frag-ment genau dann auszuwählen ist, wenn es denselben Partitionierungswert referenziert,wie die Replikationsanfrage oder auf keinen Wert für die Spalte einschränkt (zur Anfrage-auswertung siehe Abschnitt 4.8). Dieser letztgenannte Zustand wird durch das Setzen vonω für die beiden Spalten Wert und Nullind abfragbar. Ausgenommen von der Speicherungsind Fremdschlüsselspalten, für diese erfolgt bei der Anfrageauswertung eine gesonderteVerarbeitung.
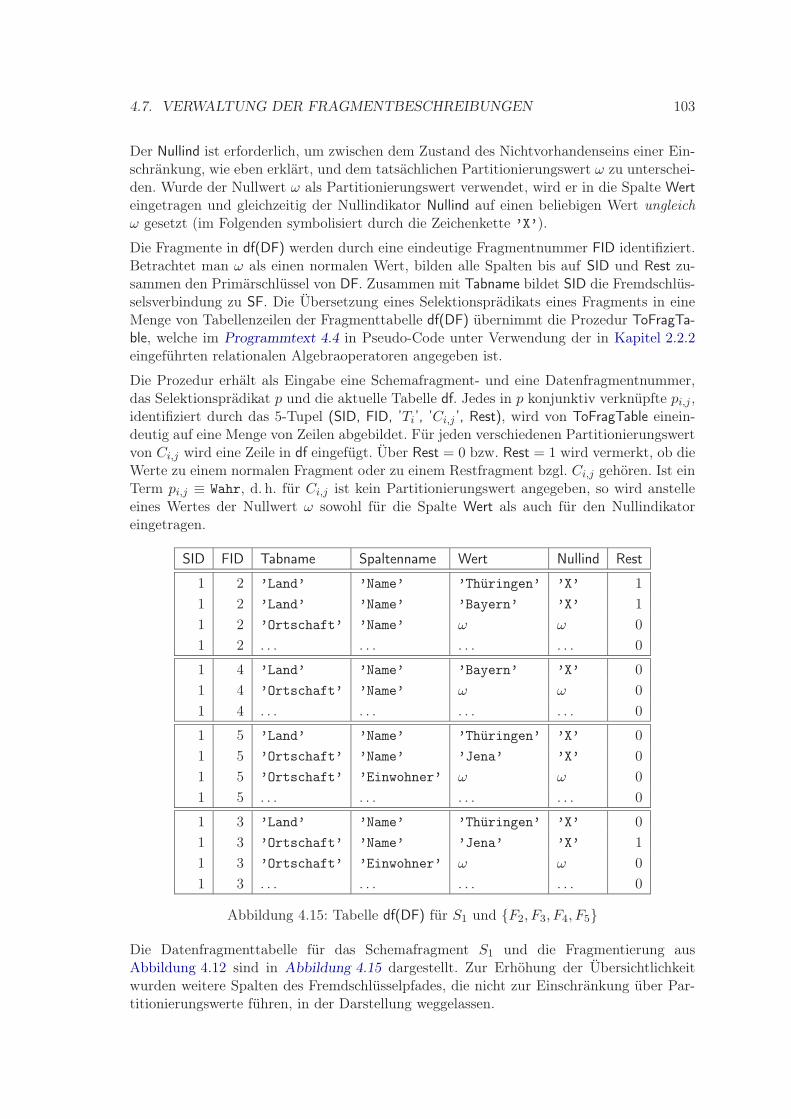
4.7. VERWALTUNG DER FRAGMENTBESCHREIBUNGEN 103
Der Nullind ist erforderlich, um zwischen dem Zustand des Nichtvorhandenseins einer Ein-schränkung, wie eben erklärt, und dem tatsächlichen Partitionierungswert ω zu unterschei-den. Wurde der Nullwert ω als Partitionierungswert verwendet, wird er in die Spalte Werteingetragen und gleichzeitig der Nullindikator Nullind auf einen beliebigen Wert ungleichω gesetzt (im Folgenden symbolisiert durch die Zeichenkette ’X’).
Die Fragmente in df(DF) werden durch eine eindeutige Fragmentnummer FID identifiziert.Betrachtet man ω als einen normalen Wert, bilden alle Spalten bis auf SID und Rest zu-sammen den Primärschlüssel von DF. Zusammen mit Tabname bildet SID die Fremdschlüs-selsverbindung zu SF. Die Übersetzung eines Selektionsprädikats eines Fragments in eineMenge von Tabellenzeilen der Fragmenttabelle df(DF) übernimmt die Prozedur ToFragTa-ble, welche im Programmtext 4.4 in Pseudo-Code unter Verwendung der in Kapitel 2.2.2eingeführten relationalen Algebraoperatoren angegeben ist.
Die Prozedur erhält als Eingabe eine Schemafragment- und eine Datenfragmentnummer,das Selektionsprädikat p und die aktuelle Tabelle df. Jedes in p konjunktiv verknüpfte pi,j ,identifiziert durch das 5-Tupel (SID, FID, ’Ti’, ’Ci,j ’, Rest), wird von ToFragTable einein-deutig auf eine Menge von Zeilen abgebildet. Für jeden verschiedenen Partitionierungswertvon Ci,j wird eine Zeile in df eingefügt. Über Rest = 0 bzw. Rest = 1 wird vermerkt, ob dieWerte zu einem normalen Fragment oder zu einem Restfragment bzgl. Ci,j gehören. Ist einTerm pi,j ≡ Wahr, d. h. für Ci,j ist kein Partitionierungswert angegeben, so wird anstelleeines Wertes der Nullwert ω sowohl für die Spalte Wert als auch für den Nullindikatoreingetragen.
SID FID Tabname Spaltenname Wert Nullind Rest
1 2 ’Land’ ’Name’ ’Thüringen’ ’X’ 11 2 ’Land’ ’Name’ ’Bayern’ ’X’ 11 2 ’Ortschaft’ ’Name’ ω ω 01 2 . . . . . . . . . . . . 0
1 4 ’Land’ ’Name’ ’Bayern’ ’X’ 01 4 ’Ortschaft’ ’Name’ ω ω 01 4 . . . . . . . . . . . . 0
1 5 ’Land’ ’Name’ ’Thüringen’ ’X’ 01 5 ’Ortschaft’ ’Name’ ’Jena’ ’X’ 01 5 ’Ortschaft’ ’Einwohner’ ω ω 01 5 . . . . . . . . . . . . 0
1 3 ’Land’ ’Name’ ’Thüringen’ ’X’ 01 3 ’Ortschaft’ ’Name’ ’Jena’ ’X’ 11 3 ’Ortschaft’ ’Einwohner’ ω ω 01 3 . . . . . . . . . . . . 0
Abbildung 4.15: Tabelle df(DF) für S1 und F2, F3, F4, F5
Die Datenfragmenttabelle für das Schemafragment S1 und die Fragmentierung ausAbbildung 4.12 sind in Abbildung 4.15 dargestellt. Zur Erhöhung der Übersichtlichkeitwurden weitere Spalten des Fremdschlüsselpfades, die nicht zur Einschränkung über Par-titionierungswerte führen, in der Darstellung weggelassen.

104 KAPITEL 4. REPLIKATVERWALTUNG
Da in der Tabelle Werte mit verschiedenen Datentypen abgelegt werden müssen, ist bei derImplementierung eine geeignete normierte Darstellung als Zeichenkette zu verwenden. DerAufbau der Werte in Spaltenname und Tabname ist dabei von den Namenskonventionen desverwendeten DBMS ahängig. Die normierte Darstellung von Zahlenwerten in der SpalteWert (z. B. in Exponentendarstellung) muss derart erfolgen, dass „=“-Vergleiche auf Wertenvon df dieselbe Aussage liefern, wie unter Verwendung des originalen Datentyps der Spalteauf der Datenbank.
4.7.3 Übertragung der Prozeduren auf Fragmenttabellen
SplitFrag(in out df(DF), in sf(SF), in T , in C ∈ T , in V , in min)
Fall 1: C.T ist eine neue Partitionierungsspalte1: foreach (sid, fid) ∈ πSID,FID(σTabname=T ∧ Spaltenname=C ∧Nullind=ωdf) do2: FromFragTable(sid, fid, df, sf, 1, ∞, S, p)3: F := σpS4: if |σC.T∈V f(F )| ≥ min do5: nfid := max(πFID(df))6: ι(df; πSID,FID:=nfid,Tabname,Spaltenname,Wert,Nullind,Rest(σFID=fid(df)))7: ValueToFragTable(sid, fid, 0, T , C, V , df)8: ValueToFragTable(sid, nfid, 1, T , C, V , df)9: δFID=fid∧Tabname=T ∧ Spaltenname=C ∧Nullind=ωdf10: od11: od
(. . . )
Programmtext 4.5: Prozedur SplitFrag auf Fragmenttabellen
Die in den vorangegangenen Abschnitten vorgestellten Prozeduren SplitFrag und Mer-geFrag zur Fragmentverwaltung lassen sich mit Hilfe der Fragmenttabellen wie im Fol-genden beschrieben umsetzen. Im Programmtext 4.5 ist die Prozedur SplitFrag aus demProgrammtext 4.2 unter Verwendung der Fragmenttabelle df(DF) und relationaler Aus-drücke und Operationen auf df(DF) skizziert. Dargestellt ist nur der Fall 1 einer neuenPartitionierungsspalte, die weiteren Fälle gestalten sich analog.
Die Verarbeitung in Fall 1 durchläuft alle Fragmente, welche für die übergebene Parti-tionsspalte C noch keine Partitionierungswerte gespeichert haben (Zeile 1). Für den an-schließend notwendigen Zugriff auf die konsolidierte Datenbank wird zunächst in einerUmkehrung von ToFragTable mittels der Prozedur FromFragTable die zum Fragment gehö-rende Selektionsanweisung erzeugt (s. u.). Werden von dem Fragment für die Menge derPartitionierungswerte V mehr als min Zeilen selektiert (Zeile 4), so erfolgt die Aufspaltungwie folgt.
Nachdem eine neue Fragmentnummer für das zukünftige Restfragment bestimmt ist, wer-den zunächst die bisherigen Einträge des aufzuspaltenden Fragments in das Restfragmentkopiert (Zeile 6). Anschließend werden die neuen Zeilen für V sowohl in das alte („positive“Bedingung) als auch in das neue Restfragment („negative“ Bedingung) mit der bereits be-kannten Prozedur ValueToFragTable eingefügt. Im letzten Schritt erfolgt das Löschen derjetzt nicht mehr benötigten Einträge für C (Zeile 10).

4.7. VERWALTUNG DER FRAGMENTBESCHREIBUNGEN 105
FromFragTable(in sid, in FID , in df(DF), in sf(SF), in pmin, in pmax, out S, out p)
1: S := πTabname(σSID=sid∧Pfadnr=pminSF)2: n := min(pmax,max(πPfadnr(σSID=sidsf)))3: foreach pmin ≤ i ≤ n do4: (tab, fkid) := πTabname,FKID(σSID=sid∧Pfadnr=isf) = ∅5: S := S j(fkid)tab
6: od
7: p := Falsch8: foreach fid ∈ FID do9: Sei h = πTabname,Spaltenname,Wert,Rest(
σSID=sid,FID=fid,Nullind =ω(πdf.∗(df df.Tabname=sf.Tabname (σSID=sid∧ pmin≤Pfadnr≤nsf))))
10: q := Wahr11: foreach (T, C, r) ∈ πTabname,Spaltenname,Rest h do12: V := πWert(σTabname=T ∧ Spaltenname=C ∧Rest=r h)13: if r = 0 do14: q := q ∧ T.C ∈ V15: else16: q := q ∧ T.C /∈ V17: od18: od19: p := p ∨ q20: od
Programmtext 4.6: Prozedur FromFragTable
Wie gesehen, ist für die Arbeit mit Fragmenttabellen auch eine Prozedur zur Generie-rung einer Selektionsformel aus einer gegebenen Fragmentbeschreibung essentiell. DieseAufgabe übernimmt die Prozedur FromFragTable, welche im Programmtext 4.6 dargestelltist. Die Prozedur erhält als Eingabe eine Schemafragmentnummer, eine Menge von Frag-mentnummern des Schemafragments, die Fragmenttabellen und eine kleinste (pmin) undgrößte (pmax) Pfadnummer. Die Pfadnummern geben an, welcher Teilpfad des Fremd-schlüsselpfades für die Ausgabe berücksichtigt werden soll. Diese Parameter werden fürdie Berechnung der Sperrobjekte (siehe Abschnitt 4.10) benötigt und sind normalerweise 1bzw. ∞, d. h. der gesamte Pfad muss berücksichtigt werden. Zurückgegeben werden die Se-lektionsformel S für das Schemafragment und das zusätzliche Prädikat p zur Beschränkungauf die gewählten Datenfragmente.
Zunächst wird S mit dem Namen der ersten Tabelle im Fremdschlüsselpfad vorbelegt (Zei-le 1). Anschließend werden in einer Schleife (Zeilen 3–6) die übrigen Tabellen mit denjeweiligen Join-Bedingungen hinzugefügt. j(fkid) steht dabei für die Verbundbedingung,die zu der mittels fkid identifizierten Fremdschlüsselbedingung gehört. Der zweite Teil derProzedur (Zeilen 7–20) ist für den Zusammenbau des Selektionsprädikats für die Daten-fragmente verantwortlich.
Das Selektionsprädikat setzt sich aus oder-verknüpften Bedingungen für die selektiertenFragmente des Schemafragments zusammen (Zeilen 7,8,19). Ein gemeinsames Prädikat ist

106 KAPITEL 4. REPLIKATVERWALTUNG
möglich, da alle Fragmente zum selben Fremdschlüsselpfad gehören. Zunächst werden jeFragment die nichtleeren Spaltenbedingungen für die zu berücksichtigenden Tabellensche-mata im Pfad in einer Sicht h ausgewählt (Zeile 9). Für jede Spalte eines normalen undRestfragments mit nichtleerer Bedingung werden in Zeile 12 die Partitionierungswerte er-mittelt. Anschließend wird je nach dem, ob es sich um eine normales oder Restfragmenthandelt, die passende Bedingung zum Teilprädikat q per Und-Verknüpfung hinzugefügt(Zeilen 13–17). Zum Abschluß der Verarbeitung eines Fragments wird q mit dem Gesamt-prädikat oder-verknüpft.
MergeFrag(in out df(DF), in T , in C ∈ T , in v)
Schritt 1: normale Fragmente1: t := σTabname=T ∧ Spaltenname=C ∧Wert=v ∧Nullind =ω ∧Rest=0df2: δ(df; t1)3: Sei h = πFID(t \ σTabname=T ∧ Spaltenname=C(df (πFIDt)))4: δ(df; df (πFIDh))
Schritt 2: Restfragmente5: t := σTabname=T ∧ Spaltenname=C ∧Wert=v ∧Nullind =ω ∧Rest=1df6: δ(df; t1)7: Sei h = πSID,FID(t \ σTabname=T ∧ Spaltenname=C(df (πFIDt)))8: foreach (sid, fid) ∈ h do9: ι(df; (sid, fid, T, C, ω, ω, 0))10: od
Programmtext 4.7: Prozedur MergeFrag auf Fragmenttabellen
Im Programmtext 4.7 ist die Prozedur MergeFrag aus dem Programmtext 4.3 mit Hilferelationaler Algebraausdrücke auf Fragmenttabellen dargestellt. Übergeben werden nebender Tabelle df(DF) als Repräsentant der Fragmentierung eine Tabellenspalte und ein Par-titionierungswert, der aus der Fragmentierung entfernt weden soll.
Im ersten Schritt (Zeilen 1–4) werden alle normalen Datenfragmente behandelt. Zuerstwerden in der Hilfstabelle t1 alle Zeilen normaler Fragmente aus der Tabelle df gespeichert,welche den übergebenen Wert v enthalten. Diese werden anschließend in Zeile 2 aus derFragmenttabelle gelöscht. In den Zeilen 3 und 4 werden alle diejenigen Fragmente bestimmt,die nach dem Löschen gar keinen Eintrag mehr für die betreffende Spalte in df besitzenund gelöscht.
Für die Restfragmente wird ab Zeile 5 in der Prozedur analog verfahren. Im Unterschied zunormalen Fragmenten dürfen Restfragemente nicht gelöscht werden, wenn keine Einträgezur übergebenen Spalte mehr vorhanden sind. In diesem Fall wird das Löschen korrigiert,in dem je eine Zeile für alle betroffenden Restfragmente eingefügt wird, welche angibt,dass für die übergebene Spalte keine Bedingung spezifiziert ist (Zeilen 8–10). Zu beachtenist, dass die Restfragmente, die keine Bedingung spezifizieren, für diese Spalte zu einemnormalen Fragment werden.

4.8. ANFRAGEVERARBEITUNG 107
4.8 Anfrageverarbeitung
restricted-select-statement
|--SELECT--+--| column-list |--+---------------------------------->‘---------*---------’
>--FROM--| table-list |------------------------------------------->
>--+-----------------------------+--------------------------------|‘--WHERE--| cnf-condition |--’
cnf-condition
.-------------------------AND-----------------------------.V |
|--+-------------------| disjunction |--------------------+--+----|‘--(--| column-list |--)--IN --| uncorrel-sub-query |--’
disjunction
.------OR--------.V |
|---------+--(----| predicate |--+--)--+--------------------------|‘-------| predicate |--------’
predicate
|--| expression |--+--| comparison |-----| expression |--+--------|‘----------------IS NULL-----------------’
Syntaxdiagramm 4.1: Syntaxdiagramm für Replikationsanfragen (erster Teil)
Eine der Hauptaufgaben der Replikatverwaltung ist die Übersetzung von SQL-Replikationsanfragen in eine sie im weiteren repräsentierende Menge von Fragmenten.Dabei ist zu berücksichtigen, dass Replikationsanfragen zur Auswahl von Replikatendienen und nicht zur Präsentation von Ergebnissen an den Nutzer. Bei der Unterstüt-zung der Anfrage-Syntax kommt es deshalb nicht darauf an, möglichst viele Konstrukteauswerten zu können, sondern sich auf die für die genaue Auswahl der zu replizierendenDaten wesentlichen Elemente, wie beispielsweise verschiedene Vergleichsoperatoren inSelektionsprädikaten und Unteranfragen, zu beschränken. Im weiteren betrachten wirdeshalb nur Anfragen, welche den folgenden Regeln gehorchen:
1. Die Anfrage ist aus den Syntaxdiagrammen 4.1 und 4.2 ableitbar.
2. Jede Tabelle der konsolidierten Datenbank wird in der Anfrage, Unteranfragen ein-gerechnet, höchstens einmal referenziert.

108 KAPITEL 4. REPLIKATVERWALTUNG
expression
|--+--table-name.col-name---+-------------------------------------|+--table-alias.col-name--+‘--constant--------------’
comparison
|--+-- = ---+-----------------------------------------------------|+-- <> --++- LIKE -++-- < ---++-- > ---++-- <= --+‘-- >= --’
uncorrel-sub-query
|--(--SELECT--| column-list |--FROM--| table-list |--------------->
>--WHERE--| cnf-condition |--)------------------------------------|
table-list
.-,-------------------------------.V |
|-----table-name--+---------------+--+----------------------------|‘--table-alias--’
column-list
.-,-------------------------------.V |
|-----column-name--------------------+----------------------------|
Syntaxdiagramm 4.2: Syntaxdiagramm für Replikationsanfragen (zweiter Teil)
3. Als Verbundbedingungen in Prädikaten einer Anfrage sind nur Terme mit der Syntaxtable-name.col-name = table-name.col-name (Gleichheitsverbund) zulässig.
4. Verbundbedingungen müssen immer vollständig angegeben werden und dürfen nichtmit anderen Prädikaten in einer Disjunktion verknüpft sein.
5. Fremdschlüsselspalten dürfen nur in Verbundbedingungen oder mit einem Konstan-tenvergleich in der Anfrage verwendet werden.
Man beachte, dass das Syntaxdiagramm für die Selektionsprädikate die konjunktive Nor-malform (KNF) vorschreibt. Darin eingebettet sind nur einfache Vergleiche sowie unkor-

4.8. ANFRAGEVERARBEITUNG 109
relierte Unteranfragen unter Verwendung der IN-Syntax erlaubt. Darüber hinaus geltennatürlich die im konkreten Fall vom DBMS vorgegebenen Syntax- und Semantik-Regeln,insbesondere für die Benennung von Tabellen und Spalten.
Neben Verbunden unterstützt die Anfragesyntax geschachtelte Unteranfragen. Dies ist er-forderlich, damit Abhängigkeiten der Datenauswahl von Daten anderer Tabellen auch inänderbaren Sichten angegeben werden können. Die Angabe möglichst vieler Abhängig-keiten in einer Replikationsanfrage ist die Voraussetzung für eine präzise Einschränkungder benötigten Fragmente. Für die Verarbeitung in der Fragmentverwaltung müssen Un-teranfragen jedoch zuerst in die (äquivalente) Verbundschreibweise transformiert werden.Diese und welche weiteren Vorverarbeitungen einer Anfrage vorgenommen werden müssen,beschreibt der folgende Unterabschnitt.
4.8.1 Schritt 1: Normalisierung
Alle Replikationsanfragen werden vor der eigentlichen Übersetzungsprozedur in eine ein-heitliche, zur Eingangsanfrage äquivalente Anfrage transformiert. Diese normalisierte Formentsteht durch (wiederholte) Anwendung der folgenden Transformationsregeln:
1. Unteranfragen → Verbunde
Jede Unteranfrage der durch die formulierten Restriktionen zugelassenen Strukturlässt sich in einen äquivalenten Verbund überführen [MS93]. Enthält die Replika-tionsanfrage eine Unteranfrage, so wird sie in eine äquivalente Anfrage mit einemVerbund transformiert, in der die Unteranfrage nicht mehr enthalten ist. Diese Er-setzung wird solange durchgeführt, bis keine Unteranfragen mehr enthalten sind.
2. Ersetzen alternativer Namen
Statt Tabellennamen können für die Qualifizierung von Spalten auch Alias-Namen(table-alias) verwendet werden. Diese werden in einem weiteren Vorverarbeitungs-schritt im Selektionsprädikat durch die zugehörigen Tabellennamen ersetzt. Diese Er-setzung führt nicht zu Mehrdeutigkeiten, da jede Tabelle nur einmal in der FROM-Listeder Anfrage vorkommen darf.
3. Vergleiche normalisieren
Jedes Prädikat der Form constant table-name.col-name wird durch ein Prädikattable-name.col-name constant ersetzt, wobei für eine der erlaubten Vergleichs-operatoren steht.
4. Bedingungen an Fremdschlüsselspalten ersetzen
In diesem Vorverarbeitungsschritt werden alle Bedingungen der Strukturtable-name.col-name constant, welche an eine Fremdschlüsselsspalte gerich-tet sind, durch eine gleiche Bedingung an die zugehörige Primärschlüsselspalte desreferenzierten Tabellenschemas ersetzt.
Die letztgenannte Vorverarbeitung stellt sicher, dass Bedingungen an Fremdschlüsselspal-ten ausgewertet werden können, obwohl Fremdschlüsselspalten nicht als Partitionierungs-spalten zugelassen sind. Durch die Verwendung eines äußeren Verbunds in den Fragment-beschreibungen und der expliziten Repräsentation von ω wird zudem sichergestellt, dass

110 KAPITEL 4. REPLIKATVERWALTUNG
später auch Waisenkinder (Bedingung table-name.col-name IS NULL) korrekt angefragtwerden können.
Die resultierende Anfrage ist zur ursprünglichen Anfrage semantisch (in Bezug auf diespätere Auswertung) äquivalent und lässt sich mit Hilfe eines Ausdrucks der relationalenAlgebra darstellen. Terme der Struktur table-name.col-name IS NULL werden dabei wiebisher als T.C = ω geschrieben. Der in der Algebra üblicherweise nicht enthaltene LIKE-Operator von SQL kann als „=“-Vergleich mit einem speziellen Textstring und speziellenAuswertungsregeln aufgefasst werden. Die Algebra-Schreibweise erlaubt u. a. die bereitsbewährte einfache Darstellung von Prozeduren in Pseudo-Code. Zusammengefasst stelltdie Vorverarbeitung für eine gegebene Replikationsanfrage folgende Informationen bereit:
• ein ausgezeichnetes Tabellenschema T für änderbare Sichtendefinitionen, welches inder ursprünglichen, nicht normalisierten Form in der ersten FROM-Klausel referenziertwird
• die Menge T der im FROM-Teil referenzierten Tabellenschemata der normalisiertenAnfrage
• das KNF-Selektionsprädikat p ≡ (p1) ∧ · · · ∧ (pm) mit pi ≡ pi,1 ∨ · · · ∨ pi,n aus derWHERE-Klausel
Die Projektionsliste ist für die Bestimmung der repräsentierenden Fragmentmenge in derdargestellten Fassung des Fragmentkonzepts nicht erforderlich, da Fragmente immer alleSpalten einer Tabelle beinhalten (siehe auch Kapitel 7.2). Die Liste der Tabellenschematawird sowohl für die Auswahl der richtigen Fragmente als auch zusammen mit dem aus-gezeichneten Tabellenschema, für das eine Änderbarkeitszusicherung gewährt werden soll,für die Erstellung der Synchronisationsanfragen (siehe Abschnitt 4.9) benötigt. Die In-formation über das Tabellenschema T wird auch für die Bereitstellung der ausgewähltenKonfliktbehandlungsmethoden verwendet.
4.8.2 Schritt 2: Fragmentauswahl
QueryToFrag(in p, in T , in sf(SF), in df(DF), out FID)
1: JoinToFrag(p, T , sf, df, FID1)2: if p ≡ Wahr do3: PredToFrag(p, sf, df, FID2)4: FID := FID1 ∪ FID2
5: od
Programmtext 4.8: Prozedur QueryToFrag
Die Auswertung der normalisierten Anfrage erfolgt mit Hilfe der Prozedur QueryToFrag,welche im Programmtext 4.8 angegeben ist. Die Prozedur erhält als Eingabe die Menge Tder in der FROM-Klausel der normierten Anfrage enthaltenen Tabellenschemata, das nor-mierte Selektionsprädikat p und die Fragmenttabellen. Ausgegeben wird die zur Anfrage

4.8. ANFRAGEVERARBEITUNG 111
passende Menge von Fragmenten. Diese kann dann in den Metadaten für die Replika-tionssicht gespeichert, mit den gewünschten Zugriffszusicherungen versehen oder für dieErzeugung von Synchronisationsanfragen (siehe Abschnitt 4.9) verwendet werden.
Da die Verbundbedingungen von p nicht über die Datenfragmenttabelle ausgewertet wer-den, sondern implizit über die Schemafragmente und die jeweiligen Fremdschlüsselpfadegegeben sind, erfolgt die Verarbeitung in zwei Schritten. Zuerst werden mittels der ProzedurJoinToFrag die Verbundbedingungen gesucht und aus dem Prädikat p entfernt. Im zweitenSchritt wird die Prozedur PredToFrag aufgerufen, sie wertet die verbliebenden Konstanten-vergleiche in p aus. Beide Prozeduren liefern eine zu berücksichtigende Fragmentmenge,die vereinigt das Endergebnis bildet.
4.8.2.1 Prozedur JoinToFrag
JoinToFrag(in out p, in T , in sf(SF), in df(DF), out FID)
1: t := σTabname∈T sf2: f := ∅3: Sei p ≡ (p1) ∧ · · · ∧ (pm)4: foreach pi mit 1 ≤ i ≤ m do5: Sei pi ≡ pi,1 ∨ · · · ∨ pi,n
6: foreach pi,j ≡ T.C v mit 1 ≤ j ≤ n do7: δTabname=T (t)8: od9: foreach pi,j ≡ T1.CT1 T2.CT2 mit 1 ≤ j ≤ n do10: Für fkid gelte j(fkid) ≡ · · · pi,j · · ·11: if σFKID=fkidf = ∅ do12: if σTabname=T1t = ∅ do13: δTabname=T1 ∧FKID=fkid(t)14: else15: δTabname=T2 ∧FKID=fkid(t)16: od17: ι(f, πFKID(σFKID=fkid(sf)))18: od19: pi := pi,1 ∨ · · · ∨ pi,j−1 ∨ pi,j+1 ∨ · · · ∨ pi,n
20: od21: if pi ≡ Wahr do22: p := p1 ∧ · · · ∧ pi−1 ∧ pi+1 ∧ · · · ∧ pm
23: od24: od25: FID := πFID(t t.SID df)
Programmtext 4.9: Prozedur JoinToFrag
Die Prozedur JoinToFrag ist im Programmtext 4.9 angegeben. Sie erhält dieselben Parame-ter wie die Prozedur QueryToFrag, wobei p während der Verarbeitung angepasst wird. DieProzedur hat, wie schon angesprochen, zwei Aufgaben: Sie soll alle Verbundbedingungen

112 KAPITEL 4. REPLIKATVERWALTUNG
aus p identifizieren und entfernen sowie alle Tabellen bzw. Tabellenverbunde identifizie-ren, für welche keine zusätzliche einschränkende Bedingung in p angegeben wurde. Fürletztere müssen die Fragmente aller Schemafragmente zurückgegeben werden, welche diekorrespondierenden Tabellenschemata in ihrem Fremdschlüsselpfad enthalten.
Die Hilfstabelle t nimmt dazu zunächst alle Tabellenschemata aus T mit ihren zugehörigenSchemafragmentnummern auf. Anschließend erfolgt die Verarbeitung für alle Disjunktionenund ihre Terme innerhalb von p, das in konjunktiver Normalform gegeben ist. In denZeilen 6–20 werden alle die Tabellen identifiziert, an die eine Bedingung gestellt wird. Essind zwei Fälle zu unterscheiden: es handelt sich um einen Konstantenvergleich (Schleife inZeilen 6–8) oder eine Verbundbedingung (Zeilen 9–20). Beide Fälle werden hintereinanderabgearbeitet.
Im ersten Fall wird das identifizierte Tabellenschema aus der Hilfstabelle gelöscht, wobei ∈ =, =, <, >, =,≥. Es verbleiben alle die Tabellenschemata in t, an die keine Konstan-tenbedingung oder eine Verbundbedingung gestellt wird. Im zweiten Fall müssen zunächstdie Fremdschlüsseldefinition bestimmt werden, welche die Verbundbedingung enthält (Zei-le 10). Anschließend wird eines der beteiligten Tabellenschemata aus der Hilfstabelle ge-löscht, welches dort noch gespeichert ist. Wobei das Löschen nur dann erfolgt, wenn derselbeVerbund (bei mehreren Bedingungen) nicht schon verarbeitet wurde (Zeilen 11 und 17).
Dieses Verfahren signalisiert, ob zu den Verbundbedingungen mindestens eine Konstanten-bedingung an eine beteiligte Tabelle gestellt und im vorangegangenen Schritt verarbeitetwurde, andernfalls verbleibt immer ein Tabellenschema eines Fremdschlüssel(teil)pfades int. Zum Abschluss des zweiten Falls wird die Verbundbedingung aus p gelöscht. In Zeile 25schließlich werden alle Fragmente von Schemafragmenten bestimmt und als Ergebnis derVerarbeitung zurückgegeben, welche die in t verbliebenden Tabellenschemata enthalten.
4.8.2.2 Prozedur PredToFrag
Die verbliebenen Konstantenbedingungen verarbeitet die im Programmtext 4.10 angegebe-ne Prozedur PredToFrag. Es werden das durch die Prozedur JoinToFrag veränderte Prädikatund die Fragmenttabellen an die Prozedur übergeben, Rückgabeparameter ist eine Mengevon Fragmentnummern.
Die Verarbeitung erfolgt pro Fremdschlüsselpfad bzw. Schemafragment. Die Ergebnisse (zuberücksichtigende Fragmentnummer) pro Schemafragment werden vereinigt (Zeilen 2,21).Innerhalb der äußeren Schleife erfolgt die Verarbeitung zunächst pro Disjunktion. Die je-weils pro Disjunktion erzielte Ergebnismenge an Fragmenten wird, da die Terme konjunktivverknüpft sind, zum Schnitt gebracht (Zeilen 3,19). Die Ergebnisse der einzelnen Termeder Disjunktionen wiederum werden vereinigt (Zeilen 6,17).
Für die Verarbeitung der Terme T.Cv schließlich erfolgt eine dreifache Fallunterscheidungnach :
1. Fall: Punktanfrage mit „=“
Bestimme alle normalen Fragmente, die v als Partitionierungswert besitzen oder fürdie Spalte C keinen Partitionierungswert haben (Nullind = ω). Hinzugenommen wer-den dazu alle Restfragmente für die Spalte (Zeile 9). Wieder abgezogen werden davonalle die Restfragmente, welche v als Partitionierungswert haben und nach der Seman-tik von Restfragmenten ihn deshalb nicht referenzieren (Zeile 10).

4.9. ERSTELLEN DER ANFRAGEN FÜR DIE SYNCHRONISATION 113
PredToFrag(in p, in sf(SF), in df(DF), out FID)
1: FID := ∅2: foreach sid ∈ πSIDsf do3: foreach pi mit 1 ≤ i ≤ m do4: FID2 := ∅5: Sei pi ≡ pi,1 ∨ · · · ∨ pi,n
6: foreach pi,j ≡ T.C v mit 1 ≤ j ≤ n do7: Sei h = σTabname=T ∧ Spaltenname=Cdf8: if ∈ = do9: FID1 := πFID(σ(Rest=0∧ (Wert=v ∨Nullind=ω))∨Rest=1h)10: FID1 := FID1 \ πFID(σRest=1∧Wert=v ∧Nullind =ωh)11: else if ∈ = do12: FID1 := πFID(σ(Rest=1∧ (Wert=v ∨Nullind=ω))∨Rest=0h)13: FID1 := FID1 \ πFID(σRest=0∧Wert=v ∧Nullind =ωh)14: else if ∈ <, >,≤,≥ do15: FID1 := πFID(σ(Rest=0∧ (Wertv ∨Nullind=ω))∨Rest=1h)16: od17: FID2 := FID2 ∪ FID1
18: od19: if i = 1 do FID3 := FID2 else FID3 := FID3 ∩ FID2 od20: od21: FID := FID ∪ FID3
22: od
Programmtext 4.10: Prozedur PredToFrag
2. Fall: negierte Punktanfrage mit „ =“
Wie Fall 1 nur mit normalen und Restfragmenten in vertauschten Rollen (Zei-len 12,13).
3. Fall: obere/untere Schranke mit <, >,≤,≥Analog zu Fall 1 bis Zeile 15. Nur dürfen die hinzugenommenen Restfragmente nichtweiter eingeschränkt werden, da alle (zukünftigen) Werte innerhalb und außerhalbspezifizierter Bereiche (z. B. T.C < v1 ∧ T.C > v2) zunächst vom Restfragmentaufgenommen werden.
4.9 Erstellen der Anfragen für die Synchronisation
Für die Synchronisation von Daten mit Hilfe der gegebenen Synchronisations-Softwaremuss die Fragmentverwaltung der nutzerdefinierten Replikation verschiedene Anfragen be-reitstellen, welche bei gegebener Fragmentauswahl jeweils eine bestimmte Datenmenge se-lektieren. Dies sind, siehe Abschnitt 4.4.2, Anfragen für:
• die Änderungsübertragung
• neue Daten

114 KAPITEL 4. REPLIKATVERWALTUNG
• zu löschende Fragmente
Bei gängiger Synchronisations-Software für relationale Datenbanken erfolgt die Synchro-nisation von Daten tabellenbasiert, d. h. für jede zu synchronisierende Tabelle muss eineentsprechende Anfrage bereitgestellt werden. Welche Tabellen tatsächlich benötigt werden,zeigt Abschnitt 4.9.3. Es kommt zunächst darauf an, Anfragen zu bilden, welche für eineFragmentmenge die Projektion auf eine Tabelle durchführen.
4.9.1 Anfragen für neue Daten und die Änderungsübertragung
GetUpdNewTab(in sf(SF), in df(DF), in FID , in T , out E)
1: E := 2: foreach sid ∈ πSID(σFID∈FID ∧Tabname=T df) do3: FromFragTable(sid, FID , df, sf, 1, ∞, S, p)4: if E = do E := σpS else E := E ∪ σpS od5: od6: E := πT.∗E
Programmtext 4.11: Prozedur GetUpdNewTab
Zwischen den Anfragen zur Änderungsübertragung für bereits replizierte Fragmente undfür neue Daten besteht kein konzeptueller Unterschied, unterschiedlich sind lediglich die zuberücksichtigenden Fragmentmengen. Die Prozedur GetUpdNewTab (Programmtext 4.11)erstellt die gewünschte Projektion. Übergeben werden der Prozedur die Fragmenttabellen,eine Menge von Fragmentnummern (entweder für neue oder abzugleichende Fragmente)und ein Tabellenschema T für die Projektion. Zurückgegeben wird ein Ausdruck der rela-tionalen Algebra.
Da die Fragmente zu verschiedenen Schemafragmenten gehören können, werden zunächstfür jedes Schemafragment der übergebenen Fragmentmenge, welches T enthält, mittels derProzedur FromFragTable der Tabellenverbund und das Selektionsprädikat bestimmt (Zei-le 3). Die Vereinigung der Algebraausdrücke für alle Schemafragmente (Zeile 4) ergibt eineAnfrage, welche die Gesamtmenge der zu berücksichtigenden Daten (über Fremdschlüsselund Partitionierungswerte) referenziert. Abschließend erfolgt in Zeile 6 die Ergänzung derProjektion auf die Tabellenspalten von T für die Verwendung bei der Synchronisation.
Die dargestellte Prozedur GetUpdNewTab ist generisch gehalten. In der Praxis wird es fürdie Synchronisation i. d. R. ausreichen, abschließend die Primärschüsselspaltenwerte dergewünschten Tabellenzeilen bereitzustellen. Unberücksichtigt bleibt der Abgleich mit denSynchronisationszeitstempeln im Falle einer reinen Änderungsübertragung (neue, gelöschteund geänderte Zeilen vorhandener Fragmente). Die Verwaltung dieser Zeitstempel obliegtder Synchronisations-Software. Wie diesbezüglich das Zusammenspiel mit einem konkretenProdukt aussehen kann, zeigt [Mic04].
Die Prozedur GetUpdNewTab ist auch für den Abgleich aufgrund von DML-Operationengelöschter Zeilen verantwortlich, nicht jedoch für das Löschen von Daten, welche aufgrundlokal nicht mehr benötigter Fragmente vom Client entfernt werden sollen. Diese Aufgabeübernimmt die im Folgenden beschriebene Prozedur GetDelTab.

4.9. ERSTELLEN DER ANFRAGEN FÜR DIE SYNCHRONISATION 115
4.9.2 Anfrage für zu löschende Fragmente
GetDelTab(in sf(SF), in df(DF), in FIDr, in FIDd, in T , out E)
1: GetUpdNewTab(sf, df, FIDd, T , Ed)2: GetUpdNewTab(sf, df, FIDr, T , Er)3: E := Ed \ Er
Programmtext 4.12: Prozedur GetDelTab
Aufgrund der Tatsache, dass die von Fragmenten referenzierten Datenbankausschnitte nichtdisjunkt sein müssen, können nicht einfach alle Daten, die von nicht mehr benötigtenFragmenten referenziert werden, auf dem Client gelöscht werden. Ausgenommen bleibenmüssen die Tabellenzeilen, welche noch zu anderen verbleibenden Fragmenten gehören. Dasberücksichtigt die Prozedur GetDelTab, welche im Programmtext 4.12 angegeben ist.
Die Übergabeparameter sind analog zur Prozedur GetUpdNewTab mit dem Unterschied,dass zwei Fragmentmengen benötigt werden, die auf dem Client verbleibenden oder neuenFragmente (FIDr) und die auf dem Client aufgrund des Löschens von Replikationssichtennicht mehr benötigten Fragmente (FIDd). Im Ablauf werden für beide Fragmentmengenzunächst mittels GetUpdNewTab die Anfragen berechnet. Im Ergebnis werden beide Aus-drücke über die Mengendifferenz verknüpft. Stellt man die so gewonnene Anfrage an dieReplikatdatenbank, erhält man genau die Zeilen von T , welche auf dem Client gelöschtwerden dürfen.
4.9.3 Benötigte Tabellen
GetUpdNewRI(in sf(SF), in df(DF), in FID , in T , out E)
1: T := T2: E := 3: foreach sid ∈ πSID(σFID∈FID ∧Tabname=T df) do4: n := πPfadnr(σSID=sid∧Tabname=T sf)5: T := T ∪ πTabname(σSID=sid∧Pfadnr<nsf)6: od
7: foreach T ∈ T do8: GetUpdNewTab(sf, df, FID , T , E)9: E := E ∪ E10: od
Programmtext 4.13: Prozedur GetUpdNewRI
Es sei eine Replikationssicht gegeben, welche Spalten des Tabellenschemas T einbezieht, so-wie die korrespondierende Fragmentmege FID . Die Fragmente sind die Verwaltungseinheitfür die Replikation und es werden Zugriffszusicherungen auf der Grundlage von Fragment-mengen gewährt. Für die Gewährleistung von Replikattransparenz für T auf dem mobilen

116 KAPITEL 4. REPLIKATVERWALTUNG
Client werden allerdings nicht immer alle Tabellen der Fremdschlüsselpfade für die Frag-mente aus FID benötigt. Welche in Bezug auf die geforderten Zugriffszusicherungen unddie definierten referentiellen Aktionen erforderlich sind, hat Abschnitt 4.3 gezeigt.
In jedem Fall, für die Gewährleistung der Fremdschlüsseldefinitionen, benötigt werden aus-gehend von T die Daten aller Tabellen bis zur Wurzel jedes Pfades. Ist die Zugriffszusiche-rung auf das Lesen und Einfügen (RI-Zusicherung) beschränkt, werden keine weiteren Da-ten benötigt. Die Prozedur GetUpdNewRI im Programmtext 4.13 bestimmt für diesen Falldie Anfragen. GetUpdNewRI erhält als Eingabe die Fragmenttabellen, eine Fragmentmengeund ein Tabellenschema, für welche eine RI-Änderbarkeitszusicherung gewährt wurde. Zu-rückgegeben wird eine Menge von Anfragen für alle benötigten Tabellen.
Im ersten Schritt (Zeilen 3–6) werden für jedes beteiligte Schemafragement (das T enthält)die Tabellenschemata bestimmt, die sich von T aus aufwärts entlang des Pfades (kleinerePfadnummer) befinden. Die Gesamtmenge aller dieser Tabellenschemata einschließlich Tist Ausgangspunkt für den zweiten Schritt von Zeile 7–10. Hier wird für jede Tabelle mitHilfe der bereits bekannten Prozedur GetUpdNewTab die benötigte Anfrage bestimmt.
Ausgeführt werden muss GetUpdNewRI für jedes Tabellenschema, das von einer Replika-tionssicht verwendet wird. Analog lassen sich die, hier nicht dargestellten, Prozeduren fürgelöschte Fragmente und eine RIDU-Änderbarkeitszusicherung bilden. Bei letzerer ist zubeachten, dass nur für die Tabelle, für welche das Änderungsrecht gewährt wurde, Tabel-lendaten abwärts entlang der Fremdschlüsselpfade benötigt werden. Für alle übrigen in derSicht verwendeten Tabellen, die beispielsweise zur Einschränkung des AnfrageergebnissesVerwendung finden, müssen, wenn nicht andere Sichten zusätzliche Rechte auf sie besitzen,nur die Tabellendaten aufwärts im Pfad mitberücksichtigt werden.
4.10 Berechnung der Sperrobjekte
Mit Hilfe der bisher vorgestellten Prozeduren für das Transformieren von Anfragen inFragmentmengen und umgekehrt ist es jetzt einfach, ein Verfahren für die Berechnungvon Sperrobjekten anzugeben. Grundlage ist die Überlegung, alle sich transitiv überlap-penden Fragmente zu einer Klasse und damit einem Sperrobjekt zusammenzufassen (sieheAbschnitt 4.4.2.2). Beim Überlappungstest ist für ein gegebenes Fragment zu prüfen, obsein von ihm repräsentierter Ausschnitt des konsolidierten Datenbankschemas, in der Formvon Anfragen an die einzelnen Tabellen des Fremdschlüsselpfades, andere Fragmente beider Anfrageübersetzung auswählt.
Im Hinblick auf ein möglichst kleines Kl (siehe Abschnitt 4.2) kann dieser Ansatz noch ver-bessert werden. Wie man anhand der Schemafragmentierung des Beispieldatenbanksche-mas (Abbildung 4.14 auf Seite 101) erkennen kann, würden sich für die Bespieldatenbankmaximal 16 Sperrobjekte ergeben. Dies liegt daran, dass die Tabelle Land in allen Sche-mafragmenten vorhanden ist und es nur 16 Bundesländer und damit Partitionierungswertefür die Spalte Land.Name gibt. Andererseits ist der Inhalt von Land naturgemäß höchststatisch, so dass die Tabelle bei der Überlappungsberechnung nicht berücksichtigt werdenmuss.
Die Prozedur CreateLockItems zur Berechnung der Sperrobjekte (Programmtext 4.14) er-hält als Eingabe deshalb zusätzlich zu den beiden Fragmenttabellen eine Menge von Tabel-lenschemata T , welche bei der Überlappungsberechnung unberücksichtigt gelassen werden

4.10. BERECHNUNG DER SPERROBJEKTE 117
CreateLockItems(in sf(SF), in df(DF), in T , out li(LI))
1: lid := 12: foreach fid ∈ πFIDdf3: if σFID=fidli = ∅ do4: FID := fid5: RecOverlap(sf, df, FID , T )6: foreach fid2 ∈ FID do7: ι(li;(lid, fid2))8: od9: lid := lid + 110: od11: od
RecOverlap(in sf(SF), in df(DF), in out FID , in T )
12: FID2 := FID13: foreach sid ∈ πSID(σFID∈FIDdf) do14: foreach (tab, i) ∈ πTabname,Pfadnr(σSID=sid∧Tabname/∈T sf)15: FromFragTable(sid, FID , df, sf, i, i, S, p)16: QueryToFrag(p, tab, sf, df, FID3)17: FID2 := FID2 ∪ FID3
18: od19: od20: if (FID2 \ FID) = ∅ do21: FID := FID2
22: RecOverlap(sf, df, FID , T )23: od
Programmtext 4.14: Prozedur CreateLockItems mit RecOverlap
LI(LID, FID)
Abbildung 4.16: Tabellenschema der Sperrobjekttabelle
sollen. Für T wird angenommen, dass die enthaltenen Tabellen, bis auf Ausnahmefälle,nicht geändert werden dürfen und deshalb weder bei den Zugriffszusicherungen noch beider gemeinsamen Synchronisation von Replikationssichtengruppen berücksichtigt werdenmüssen. Ausgabe der Prozedur ist eine Tabelle mit Paaren aus Sperrobjekt und Fragment.Das Schema der Sperrobjekttabelle ist in Abbildung 4.16 angegeben.
Es werden nacheinander alle Fragmente durchlaufen, welche noch keinem Sperrobjekt zu-geordnet wurden (Zeilen 2,3). Bei jedem Durchlauf werden zu dem Fragment alle transitivüberlappenden Fragmente mittels der Prozedur RecOverlap (s. u.) hinzugefügt (Zeilen 4,5).Für die so ermittelte Menge von Fragmenten werden die Zeilen für das neue Sperrobjekt indie Tabelle li eingefügt (Zeilen 6–8). Zwei Fragmente überlappen sich, wenn sie ein gemein-sames Tabellenschema im Fremdschlüsselpfad besitzen und dieselben Daten referenzierenkönnen. Das Auffinden aller zu einem Fragment überlappenden Fragmente funktioniertdeshalb wie folgt.

118 KAPITEL 4. REPLIKATVERWALTUNG
Für jedes Schemafragment und für jede Tabelle im jeweiligen Pfad, mit Ausnahme dernicht zu berücksichtigenden Tabellenschemata aus T , wird eine verkürzte Anfrage erzeugt(Zeile 15). Die Anfrage enthält nur Bedingungen an die ausgewählte Tabelle. Das ist er-forderlich, da die Anfrageübersetzung mittels QueryToFrag nur passende Schemafragmenteselektiert, welche den Teilpfad, wie ihn die Verbundbedingungen aus S vorgeben, enthal-ten. Durch die tabellenweise Verarbeitung ist sichergestellt, dass alle Schemafragmente,welche das betrachtete Tabellenschema enthalten, in Zeile 16 der Prozedur berücksichtigtwerden. Ebenso ist, im Gegensatz zum Ergebnis der Prozedur GetUpdNewTab, eine Verar-beitung getrennt nach Schemafragmenten erforderlich, da in der hier vorgestellten Fassungvon QueryToFrag SQL-Anfragen mit UNION-Operation nicht als Eingabe erlaubt sind (sieheAbschnitt 4.8).
Die durch QueryToFrag gewonnenen neuen Fragmente werden der Menge, welche späterdas Sperrobjekt bildet, hinzugefügt. Im dem Fall, dass nach Durchlaufen beider Schleifengegenüber der Eingabe neue Fragmente selektiert wurden, erfolgt ein rekursiver Aufruf(Zeile 22). Andernfalls ist die Verarbeitung beendet.
Eine zukünftig weitere Verfeinerung der Sperrgranulate ist möglich, wenn zusätzlich inAbhängigkeit von der jeweils zu sperrenden Tabelle, auf welche sich die Änderbarkeitszusi-cherung bezieht, von referentiellen Aktionen und des jeweiligen Fremdschlüsselpfades (sieheAbschnitt 4.3.4) Tabellen unberücksichtigt bleiben. Die dabei entstehenden Sperrobjektekönnten dann allerdings nicht mehr zur Berechnung der Überlappung von Replikations-sichtengruppen (siehe Abschnitt 4.4.2.3) eingesetzt werden, da auf den zusätzlich nichtberücksichtigten Tabellen Änderungen auf Server-Seite erfolgen können, die zu den Clientsübertragen werden müssen.
Änderung von Sperrobjekten
Für den Fall, dass zwei Fragmente, die zuvor unterschiedlichen Sperrobjekten angehör-ten, zusammengefasst werden, so sind auch deren jeweilige Sperrobjekte zu einem Objektzusammenzufassen. Beim Aufspalten eines Fragments können, aber müssen keine zwei dis-junkte(n) Sperrobjekte entstehen; andere Sperrobjekte sind nicht betroffen. Die Prüfungkann dadurch erfolgen, dass, eingeschränkt auf die Fragmentmenge des ursprünglichenSperrobjektes, die Sperrobjektberechnung mittels CreateLockItems wiederholt wird.

Kapitel 5
Der Replication Proxy Server
Die bisher theoretisch eingeführten Konzepte wurden im Rahmen der vorliegenden Ar-beit und zuarbeitender Studien- und Diplomarbeiten [Mic04, Wie04, Pfe04, Bit04, Rab03,Mül03] prototypisch implementiert. Der Dienstanbieter für die nutzerdefinierte Replikationerhielt den Namen Replication Proxy Server (im Folgenden kurz RPS). Auf der Software-Seite setzt der RPS auf der Funktionalität bestehender kommerzieller mobiler Datenbank-lösungen auf und ergänzt sie als nebengeordneter Server um die Schnittstellen und dieFunktionalität der nutzerdefinierten Replikation. Die Entwurfsentscheidungen, die darausresultierende Architektur, die Schnittstellen für Administrator und Anwendung, wichtigeImplementierungsaspekte sowie der Datenbankentwurf für die Verwaltungsinformationendes RPS werden in diesem Kapitel erläutert. Für Beispiele findet wieder das aus Kapitel 3.3bekannte Beispieldatenbankschema Verwendung.
Das Kapitel ist wie folgt gegliedert. Im ersten Abschnitt 5.1 wird zunächst erläutert, wel-che Ziele mit dem Prototypen verfolgt werden und welche Architektur und Produkte fürdie Implementierung geeignet sind. Der Abschnitt 5.2 diskutiert Architekturalternativenund stellt die gewählte Soft- und Hardware-Architektur für den RPS-Prototypen vor. Wel-che Produkte für die Implementierung des Prototypen zum Einsatz kommen erläutertAbschnitt 5.3. Im folgenden Abschnitt 5.4 wird das Nutzer- und Rechtekonzept des RPSvorgestellt. Abschnitt 5.5 beschreibt die für den Prototypen implementierte Konfliktbe-handlung. Der daran anschließende Abschnitt 5.6 geht auf Sicherheitsaspekte ein, welchebeim Umgang mit mobilen Clients berücksichtigt werden müssen. Den umfangreichstenTeil des Kapitels bildet der Abschnitt 5.7, er stellt die Funktionalität des RPS anhand derSprachschnittstelle vor. Der Abschnitt 5.8 des Kapitels geht im Überblick auf den modula-ren Aufbau des RPS und die Anweisungsverarbeitung ein. Wie und welche Hilfsdaten vomRPS gespeichert werden, erläutert Abschnitt 5.9.
5.1 Entwurfsziele
Die in Kapitel 3 gestellten Aufgaben an einen Dienst zur nutzerdefinierten Replikation unddas in Kapitel 4 eingeführte Fragmentkonzept sollen in einer prototypischen Implementie-rung umgesetzt werden. Mit der Umsetzung werden zwei Hauptziele verfolgt, erstens dieRealisierbarkeit der vorgeschlagenen Konzepte zu zeigen und zweitens hinreichend Funk-tionalität bereitzustellen, welche eine Umsetzung des ebenfalls im Rahmen dieser Arbeit
119

120 KAPITEL 5. DER REPLICATION PROXY SERVER
entwickelten Reiseinformationssystems Hermes (siehe Kapitel 6) ermöglicht. Darüber hin-aus werden die folgenden Entwurfsziele verfolgt:
• einfache Integration
Der Prototyp soll sich mit geringem Aufwand (Konfiguration, Programmieraufwand)in eine bestehende mobile Datenbanklösung aus mobilen Clients und stationärenServern sowie eventuell weiteren Komponenten zur Replikation und Synchronisationintegrieren lassen.
• Einfachheit
Die Implementierung des Prototypen soll sich auf die zur Realisierung der nutzer-definierten Replikation notwendige neue Funktionalität beschränken. Wenn immermöglich, sind bereits vorhandene Komponenten, beispielsweise als Teil einer kom-merziellen mobilen Datenbanklösung, zu verwenden.
• leichte Anpassbarkeit und Erweiterbarkeit
Die Implementierung muss leicht an verschiedene Datenbanksystemprodukte undClient-Plattformen anpassbar sein und die Möglichkeit bieten, noch fehlende Funk-tionalität später modular hinzuzufügen.
• adäquate Schnittstellen
Die Schnittstellen sollen so umgesetzt werden, dass sie für den Anwendungsprogram-mierer leicht verständlich und handhabbar sind und die Konstrukte der von SQL hergewohnten Struktur und Arbeitsweise entsprechen.
• Sicherheit
Ein wichtiges Ziel für die Implementierung ist die Erzwingung und Überwachungder von der nutzerdefinierten Replikation vorgesehenen verschiedenen Zugriffszusi-cherungen und Konfliktbehandlungsmethoden unter Berücksichtigung potentiell un-zuverlässiger Nutzer und unsicherer mobiler Clients.
Von untergeordneter Bedeutung für die Implementierung des Prototypen sind eine gu-te Performance und die Unterstützung aller bisher konzeptionell vorgestellter Funktio-nalität. Diese Aspekte sollten in weiterführenden Arbeiten berücksichtigt werden (sieheKapitel 7.2).
5.2 Architektur
Für die Implementierung des Prototypen müssen eine Software- und Hardware-Architekturfestgelegt werden. Für die Software ergeben sich grundsätzlich die folgenden zwei Archi-tekturansätze:
• in das Server-DBMS integriert oder
• als unabhängiger Server.
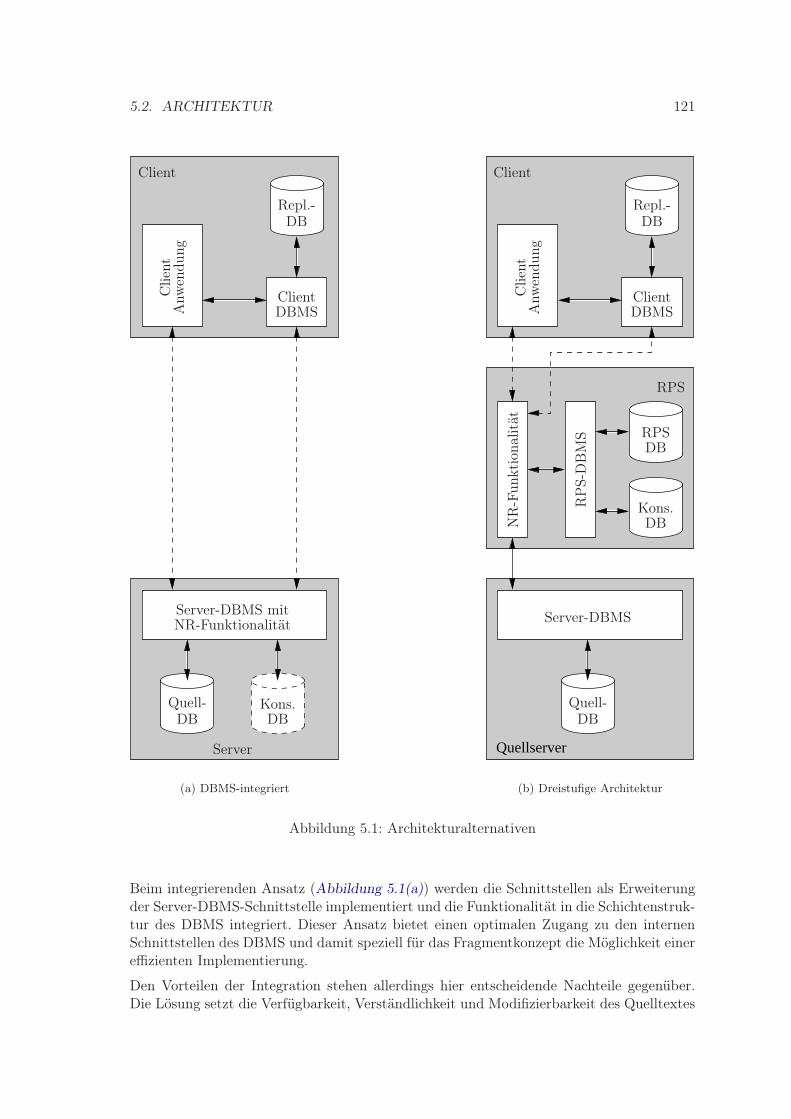
5.2. ARCHITEKTUR 121
Clie
ntClient
Client
Server
Anw
endu
ng
DB
DB DB
DBMS
Quell- Kons.
Repl.-
Server-DBMS mitNR-Funktionalität
(a) DBMS-integriert
Quellserver
Clie
nt
Client
Client
RPS
RPS
Anw
endu
ng
DB
DB
DB
DB
DBMS
Quell-
Kons.
Repl.-
NR
-Fun
ktio
nalit
ät
RP
S-D
BM
S
Server-DBMS
(b) Dreistufige Architektur
Abbildung 5.1: Architekturalternativen
Beim integrierenden Ansatz (Abbildung 5.1(a)) werden die Schnittstellen als Erweiterungder Server-DBMS-Schnittstelle implementiert und die Funktionalität in die Schichtenstruk-tur des DBMS integriert. Dieser Ansatz bietet einen optimalen Zugang zu den internenSchnittstellen des DBMS und damit speziell für das Fragmentkonzept die Möglichkeit einereffizienten Implementierung.
Den Vorteilen der Integration stehen allerdings hier entscheidende Nachteile gegenüber.Die Lösung setzt die Verfügbarkeit, Verständlichkeit und Modifizierbarkeit des Quelltextes

122 KAPITEL 5. DER REPLICATION PROXY SERVER
für das verwendete DBMS voraus. Ein weiterer mit der Integration allgemein verbundenerSchwachpunkt liegt in der geringen Flexibilität einer Implementierung. Die Funktionalitätist auf das jeweilige DBMS zugeschnitten und kann nicht ohne weiteres übertragen werden,wenn ein anderes Server-DBMS zum Einsatz kommen soll. Gerade in mobilen Umgebungenwerden aber oft verschiedene Server- und Client-DBMS-Produkte kombiniert. Kommerzi-elle mobile Datenbanklösungen tragen dem Rechnung, in dem sie die Synchronisations-funktionalität in einen separaten Server auslagern.
Die Bereitstellung der Funktionalität in einem separaten Replication Proxy Server(Abbildung 5.1(b)) ermöglicht eine weitgehend DBMS-unabhängige Implementierung undRückgriff auf die externen Schnittstellen der Datenbanksysteme. Die Entwurfsziele, einfa-che Integration und leichte Anpassbarkeit sowie die Erweiterbarkeit, sind nur mit diesemAnsatz erreichbar, weshalb er für die Software-Architektur des Prototypen ausgewähltwurde. Anwendungen auf mobilen Clients, welche die Möglichkeiten der nutzerdefiniertenReplikation für eine Quelldatenbank nutzen möchten, müssen sich mit dem RPS verbindenund die dort angebotene Schnittstelle nutzen. Der RPS kann dabei zwischen verschiedenenQuell- und Replikatdatenbanken und sogar verschiedenen DBS-Produkten vermitteln.
Es bleibt die zweite Frage zu diskutieren, wie der RPS bzgl. Server und Client-Rechnerpositioniert werden soll. Grundsätzlich stehen hier wiederum zwei Ansätze zur Verfügung:
• als Software-Komponente auf dem Quell-Server oder
• in einer dreistufigen Architektur mit eigener Hardware.
Die Entscheidung fiel zugunsten einer dreistufigen Architektur mit einem eigenständigenRechner und eigener unabhängiger Datenhaltung für den RPS (siehe Abbildung 5.1(b)).Dabei wird die konsolidierte Datenbank, welche die vom Administrator bei der Definitiondes Replikationsschemas für mobile Clients freigegebenen Schema- und Datenobjekte einerQuelldatenbank repräsentiert, im Datenbanksystem des RPS repliziert gespeichert.
Die gewählte Architektur aus eigenständigem RPS und materialisierter konsolidierterDatenbank bietet die folgenden Vorteile gegenüber einer reinen Software-Lösung mit di-rekter Verbindung zwischen Replikatdatenbanken und Quelldatenbank:
• Schutz der Quelldatenbank
Mobilen Nutzern kann der direkte Zugriff auf den Quell-Server verboten werden. Zu-griff auf Daten der Quelldatenbank sind dann nur auf dem „Umweg“ über den (ver-trauenswürdigen) RPS möglich. Bei der Synchronisation zwischen Quelldatenbankund konsolidierter Datenbank können von mobilen Nutzern reintegrierte Änderun-gen zunächst auf dem RPS gesammelt und einer zusätzlichen Prüfung unterzogenwerden, bevor eine Weiterleitung an den Quell-Server erfolgt. Sicherheitskritischeund vertrauliche Daten, die bei der Definition des Replikationsschemas ausgeblendetwurden, sind dann auf dem RPS nicht vorhanden.
• Entlastung des Quell-Server
Der RPS führt selbständig den Datenabgleich mit den Clients durch und behandeltKonflikte zwischen verschiedenen mobilen Clients. Zum Quell-Server werden nur dieresultierenden Änderungen weitergeleitet. Das Aggregieren von Änderungen mehrerermobiler Clients und ein verzögerter Datenabgleich mit dem Quell-Server erlauben es,

5.2. ARCHITEKTUR 123
Lastspitzen vom Quell-Server fernzuhalten, die durch viele zeitlich nahe beieinanderliegende Synchronisationen durch mobile Clients entstehen können.
• Verfügbarkeit
Die materialisierte konsolidierte Datenbank erhöht natürlich auch die Verfügbarkeitder Daten für die Clients. Ist die Quelldatenbank zeitweilig nicht erreichbar, etwa we-gen Wartungsarbeiten oder weil eine lokale Anwendung alle Ressourcen beansprucht,kann das durch den RPS zeitweise maskiert werden.
• Optimierung der konsolidierten Datenbank
Das interne Schema der konsolidierten Datenbank kann für die Anforderungen dernutzerdefinierten Replikation optimiert werden. Auch müssen Zugriffsstrukturen, wiedas Fragmentkonzept und Funktionalität für die Konfliktbehandlung zwischen mo-bilen Clients, nur auf dem RPS existieren.
• Positionierung und Vernetzung mehrerer RPS
Die Platzierung des RPS ist unabhängig vom Standort des Quell-Server und kanngeographisch nahe bei den zu unterstützenden mobilen Clients erfolgen. Aus dieserFunktion als lokaler Ansprechpartner und aus der im Punkt 1 genannten Schutzfunk-tion leitet sich auch der Namensbestandteil Proxy ab.
Werden mehrere RPS geographisch verteilt und über eine dann mehrstufige Replika-tion vernetzt, läßt sich eine skalierbare Infrastruktur aufbauen. Erste Ideen für dieVerwendung einer Hierarchie von RPSn wurden in [Gol02, Gol01] veröffentlicht (sieheauch Kapitel 7.2).
Wie der Argumentation zu den einzelnen Vorteilen zu entnehmen ist, ist eine Umsetzungdes RPS in der genannten Form nur sinnvoll, wenn der Datenabgleich mit dem Quell-Serverasynchron erfolgt. Es können folglich beim Abgleich mit Daten der Quelldatenbank Konflik-te mit Änderungen entstehen, die von „normalen“ Anwendungen und Clients durchgeführtwurden. Diese Konflikte sind insofern problematisch, als dass sie erst nach vermeintlich er-folgreicher Synchronisation des betroffenen mobilen Clients erkannt und behandelt werdenkönnen. Für die Behandlung derartiger Konflikte bieten sich hauptsächlich die folgendenOptionen an:
• Erhöhen der Synchronisationsfrequenz
Wird der Datenabgleich mit dem Quell-Server in zeitlich kürzeren Abständen durch-geführt, vermindert sich die Konfliktwahrscheinlichkeit aber gleichzeitig auch derNutzen des asynchronen Abgleichs. Es gilt, hierbei anhand der Zugriffsprofile einausgewogenes Maß zu finden.
• Konfliktvermeidungsverfahren
Es können die aus Kapitel 2.5.3 bekannten Konfliktvermeidungsverfahren verwen-det werden. Das Key-Pool-Verfahren läßt sich leicht mehrstufig auslegen, indemdie für den RPS verfügbaren Schlüsselmengen eingeschränkt werden. Sind poten-tiell konfligierende Zugriffe normaler Clients selten, kann eine Zusatz-Software aufdem Server Sperranforderungen auf gefährdete Datenobjekte in exklusive Änderbar-keitszusicherungen auf dem RPS transformieren. Zur Programmierung einer solchen

124 KAPITEL 5. DER REPLICATION PROXY SERVER
Software-Komponente ist allerdings der Zugang zur internen Sperrverwaltung desServer-DBMS notwendig.
• Verwerfen RPS-seitiger Änderungen
Normale Clients sind den mobilen Clients häufig übergeordnet in der Weise, dassihre Änderungen immer „überleben“ müssen. Ein mobiler Nutzer wiederum kann einespäter zurückgesetzte eigene Änderung theoretisch nicht von einer zwischenzeitlicherfolgten Folgeänderung unterscheiden. Wenn es also semantisch sinnvoll ist und dieIntegrität der Datenbank dadurch nicht gefährdet wird, bietet die First-Committer-Wins-Regel (siehe Kapitel 2.5.2.4) häufig eine praktikable Lösung.
Die aufgeführten Optionen können einzeln oder in Kombination eingesetzt werden. WelcheOptionen verwendet werden, ist schlussendlich abhängig von der konkreten Anwendungund sollte konfigurierbar sein. Da der Fokus der Implementierung des RPS auf der Client-RPS-Replikation liegt, beschränken wir uns beim Prototypen auf den Einsatz der First-Committer-Wins-Regel für die Konfliktbehandlung zwischen Quell-Server und RPS.
5.3 Produktauswahl
In diesem Abschnitt werden die für die Implementierung eingesetzten Produkte und Tech-nologien kurz vorgestellt und ihre Auswahl für den Prototypen jeweils begründet. Einekurze Beschreibung der DBMS-Produkte ist in Kapitel 3.5 zu finden.
5.3.1 Server- und RPS-DBMS
Dank der dreistufigen Architektur kann das DBMS-Produkt für die Datenhaltung desRPS frei gewählt werden. Die Implementierung des RPS erfolgt mit DB2 Universal Da-tabase V8.1 (kurz DB2) auf AIX 5.2. Im praktischen Einsatz muss der RPS, bei Bedarfparallel, mit verschiedenen Quell-Server-DBS zusammenarbeiten können. Für den Proto-typen beschränken wir uns auf die Unterstützung von DB2. Diese Entscheidung erlaubtdie Vermeidung zusätzlicher Fehlerquellen, die das Zusammenspiel verschiedener Produktezwangsläufig mit sich bringt. Als Produkt für die Synchronisation zwischen Quelldaten-bank und konsolidierter Datenbank wird der im Lieferumfang von DB2 enthaltene DB2DataPropagator verwendet.
5.3.2 Client-DBMS
Als Client-DBMS soll ein Produkt eingesetzt werden, welches auf verschiedenen mobilenHardware-Plattformen und insbesondere auch auf Rechnern der Handheld-Klasse lauffä-hig ist. DB2 Universal Database scheidet deshalb als Client-DBMS aus. Ein Einsatz vonDB2 Everyplace ist ebenfalls nicht möglich, da dessen Funktionalität zu eingeschränkt ist.Beispielsweise unterstützt DB2 Everyplace das Sichtenkonzept nicht, welches aber für dieRealisierung der Replikationssichten zwingend benötigt wird. Die Wahl fiel auf AdaptiveServer Anywhere von Sybase (verwendet wurde Version 8.0.2), da es von den untersuchtenmobilen Datenbanklösungen die Anforderungen am besten erfüllt.

5.3. PRODUKTAUSWAHL 125
Der für die Server-Kommunikation eingesetzte DB2 DataPropagator kann nicht für die Syn-chronisation zwischen Clients und RPS eingesetzt werden, da Adaptive Server Anywhereals Client-DBMS von der aktuellen DataPropagator-Version 8.1 nicht unterstützt wird.Von Sybase werden für den asynchronen Datenabgleich die beiden Produkte SQL Remoteund MobiLink angeboten. Nur MobiLink unterstützt als Server-DBMS andere Produkteals die von Sybase, weswegen es für die Implementierung ausgewählt wurde.
5.3.3 Programmiersprache
Anwendungen, denen durch den Einsatz eines RPS die Verwendung nutzerdefinierter Re-plikation ermöglicht werden soll, richten sich gewöhnlich an große Nutzergruppen. Diesegreifen über mobile Clients mit i. d. R. sehr unterschiedlichen Plattformen auf den RPS zu.Unter den verfügbaren Programmiersprachen ist Java als einzige für nahezu alle Betriebs-systeme und (mobilen) Plattformen mit kompatiblen Schnittstellen verfügbar. Zur Schaf-fung einer einheitlichen Programmierumgebung für Client- und Server-Komponenten er-folgt die gesamte Implementierung des RPS-Prototypen und der Beispielanwendung Her-mes (siehe Kapitel 6) vollständig mit der Java 2 Standard Edition von Sun Microsystemsin der Version 1.4.1 [Sun03a].
5.3.4 Parsergenerator
Für die vom RPS als Schnittstelle zu den Anwendungen angebotene Sprache (sieheAbschnitt 5.7) wird eine Software für die lexikalische Analyse (Lexer) und die anschlie-ßende syntaktische Auswertung (Parser) benötigt [Teu03]. Der Parser erstellt aus einergültigen Anweisung und den übergebenen Parametern das ausführbare Anweisungsobjekt.Für die Implementierung stehen eine Reihe von Parsergeneratoren für Java zur Verfügung(beispielsweise JavaCC [Sun03b], CUP [HFAW02] und Jikes [IBM03]). Als Eingabe er-halten sie eine in Backus Naur Form (BNF, [ISO96]) formatierte Sprachbeschreibung underzeugen daraus Java-Klassen für Lexer und Parser, die in eigene Programme eingebundenwerden können.
Es gibt zwei Prinzipien für Parser, top-down-Analyse und bottom-up-Analyse. bottom-up-Parser unterstützen mehr Grammatiken wohingegen sich Grammatiken für top-down-Parser intuitiver aufschreiben lassen. Da die zu unterstützende Grammatik keine besonde-ren Anforderungen an den Parser stellt, wird der top-down-Parsergenerator JavaCC in derVersion 3.2 verwendet. JavaCC unterstützt die erweiterte BNF und der erzeugte Parserbesitzt einen integrierten Lexer. JavaCC erlaubt außerdem als Ausgabe des Lexer soge-nannte Special Token. Diese speziellen Zeichen werden vom Parser zwar verarbeitet, tragenaber keine semantische Information und haben keinen Einfluss auf den weiteren Verlauf derAnalyse. Die Special Token können benutzt werden, um in RPS-Konstrukten eingebetteteSQL-Anweisungen als Ganzes zu extrahieren und später an ein DBMS weiterzuleiten, ohnesie einer syntaktischen Analyse unterziehen zu müssen.
5.3.5 Kommunikation
Für den lokalen Zugriff auf die Datenbanken findet die standardisierte JDBC -Schnittstelle [FEB03] Verwendung. Die eingesetzten Treiber werden dabei aus der

126 KAPITEL 5. DER REPLICATION PROXY SERVER
Gruppe der sogenannten Typ-2-Treiber gewählt, da diese für viele gängige Datenbank-managementsysteme verfügbar sind und durch direkte Aufrufe der DBMS-API schnelleDatenbankzugriffe ermöglichen.
Für die Netzwerkkommunikation des RPS mit den mobilen Clients (nicht für die Synchro-nisation, s. u.) werden sichere, mit Secure Sockets Layer (SSL, [IET96]) in der Version 3.0verschlüsselte Socket-Verbindungen genutzt. Als Alternative stehen eine Implementierungmit Java Remote Method Invocation (RMI) und das Schreiben eines eigenen erweitertenJDBC-Typ-4-Treibers (vergleiche [Bei97]) zur Wahl. Die von RMI gebotenen Vorteile trans-parenter Methodenaufrufe und automatischer Übertragung serialisierter Objekte könnenbeim RPS nicht genutzt werden, da pro Verbindung lediglich wenige Anweisungen (Repli-katdefinitionen und Synchronisationsaufrufe) sowie in der anderen Richtung Statusinfor-mationen übermittelt werden. Die Kommunikation bei der Synchronisation findet über dievon den MobiLink und DataPropagator unterstützten Schnittstellen statt.
5.4 Nutzerverwaltung
Für den Betrieb von Datenbanken im allgemeinen und besonders in mobilen Umgebungenist ein durchsetzbares Nutzer- und Rechtekonzept von entscheidender Bedeutung (sieheKapitel 3.2). Für die Durchführung von datenbankübergreifenden Administrationsaufga-ben (z. B. das Anlegen konsolidierter Datenbanken) ist ein von den beteiligten DBMS un-abhängiges Nutzerkonzept erforderlich. Der RPS verfügt deshalb über eine eigenständigeDBMS-unabhängige Nutzerverwaltung [Wie04, Pfe04].
Zusätzlich wäre eine Übernahme von Rechten und Nutzern des Server-DBMS auf die konso-lidierte Datenbank und weiter auf die Replikatdatenbanken vorstellbar. Bei der prototypi-schen Implementierung wird darauf verzichtet, folgende Gründe sind für diese Entscheidungausschlaggebend:
• Heterogenität und Sicherheit
Kommerzielle Datenbanksysteme implementieren die Nutzer- und Rechteverwaltungunterschiedlich. Produkte für die Synchronisation gehen außerdem meist von einerkontrollierten Umgebung aus, d. h. sie verzichten ebenfalls auf eine Übernahme vonRechten und verwenden für die Synchronisation einen eigenen ausgezeichneten Nutzermit weitgehenden Lese- und Schreibrechten auf die zu synchonisierenden Datenban-ken. Da der RPS in der Lage sein muss, die Rechte für verschiedene Produkte aufClients und Server durchzusetzen, wäre im Falle einer Übernahme eine komplexeTransformation und u. U. sogar Emulation erforderlich.
• fehlende Funktionalität
Die Nutzer- und Rechtekonzepte der meisten verfügbaren kommerziellen Daten-banksysteme können nicht effektiv mit sehr großen und in ihrer Zusammenset-zung stark schwankenden Nutzermengen umgehen. Auch erlauben die meisten kei-ne Rechtevergabe auf der Ebene einzelner Tabellenzeilen, wie es für das Slot-Konfliktvermeidungsverfahren erforderlich ist [Wie04, Bit04]. In solchen Fällen müss-te die Autorisierung und Authentisierung über die Anwendung sichergestellt werden.
Die für die nutzerdefinierte Replikation in [Wie04] implementierte Lösung sieht ein zwei-stufiges Nutzer- und Rechtekonzept für den RPS vor. Die erste Stufe bildet ein rollenba-

5.4. NUTZERVERWALTUNG 127
siertes Rechtekonzept, das vom RPS selbst angeboten wird und die Autorisierung undAuthentisierung eines mobilen Client und einer Replikatdatenbank übernimmt. Die zweite,optionale Stufe wird von der Anwendung bereitgestellt und sorgt ergänzend zum RPS fürdie Autorisierung und Authentisierung einzelner Nutzer beim Zugriff auf die konsolidierteDatenbank. Die Durchsetzung der zweiten Stufe übernimmt ebenfalls der RPS, er stelltdazu Schnittstellen und Standardmethoden bereit, die von der Anwendung überschriebenwerden können.
Als weitere, hier nicht separat aufgeführte, „0.Stufe“ kann man die Freigabe vonkonsolidierten Tabellen zum Ändern, für den lesenden Zugriff oder ohne Client-Replikationsmöglichkeit auffassen. Durch diese Differenzierung können sensible Daten ver-steckt oder vor Änderungen durch mobile Nutzer geschützt werden. Die weitere client- undnutzerabhängige Feinabstimmung erfolgt dann über das zweistufige Nutzer- und Rechte-konzept.
5.4.1 Nutzer- und Rechtekonzept des RPS
Die erste Aufgabe einer Nutzerverwaltung ist die eindeutige Identifikation von Nutzern.Damit eine mobile Anwendung oder ein Administrator über die RPS-Anweisungen aufdie konsolidierte Datenbank zugreifen können, wird eine RPS-Nutzerkennung benötigt. Eswerden zwei Typen von Nutzerkennungen unterschieden, Client-Nutzer und Administrato-ren. Beide Typen bestehen aus einem Namen und einem Passwort, den Client-Nutzern istzusätzlich genau eine konsolidierte Datenbank zugeordnet. Über Client-Nutzerkennungenkann ein Client Replikationssichten anlegen und synchronisieren. Administratoren könnenadministrative Aufgaben auf dem RPS durchführen, aber keine Replikate anfordern.
Zu beachten ist, dass die Client-Nutzerkennungen bei der Synchronisation zur Identifika-tion einer Replikatdatenbank und ihrer gespeicherten Daten auf einem bestimmten Clientverwendet werden. Sollen für einen realen Nutzer mehrere Replikatdatenbanken auf einemoder mehreren Clients für ein und dieselbe konsolidierte Datenbank angelegt werden, sinddafür, wie auch für die Arbeit mit mehreren konsolidierten Datenbanken, verschiedene Nut-zerkennungen erforderlich. Die Zuordnung von realen Nutzern zu RPS-Nutzerkennungenkann über die Anwendung erfolgen.
Die zweite Aufgabe der Nutzerverwaltung ist die Zugriffskontrolle. Für RPS-Nutzer kommteine einfache rollenbasierte Zugriffskontrolle [FK92] zum Einsatz. Bei dieser Art der Zu-griffskontrolle stehen nicht die Nutzer, sondern die durch sie durchzuführenden Aufgabenim Vordergrund. Nutzern, die aufgrund ihrer Aufgaben und Verantwortlichkeiten über diegleichen Rechte verfügen sollen, wird dann eine bestimmte Rolle, die meist einer benanntenZusammenfassung von Einzelrechten entspricht, zugeordnet. Eine rollenbasierte Zugriffs-kontrolle ist dann geeignet, wenn es eine potentiell große Zahl von Nutzern zu verwalten,aber nur eine kleine, feste Menge von Rechtekombinationen zu vergeben gilt. Beide Kri-terien treffen auf den RPS zu. Entsprechend den bereits eingeführten zwei Nutzertypenwerden zwei Basisrollen unterschieden, die wiederum in weitere im Folgenden beschriebenespezifische Rollen gegliedert sind.
• Administration
– Systemadministration
Nur Inhaber dieser Rolle dürfen konsolidierte Datenbanken für die Replikation

128 KAPITEL 5. DER REPLICATION PROXY SERVER
mit Quelldatenbanken registrieren und wieder löschen.1 Außerdem dürfen Nut-zer mit dieser Rolle alle zur Verwaltung einer konsolidierten Datenbank nötigenAnweisungen aufrufen, neue RPS-Nutzer anlegen, ihnen Rollen gewähren undentziehen, die Zuordnung zu einer konsolidierten Datenbank vornehmen undRPS-Nutzer löschen. Standardmäßig existiert auf dem RPS eine spezielle Sys-temadministrationskennung („Root“-Nutzer), die nicht gelöscht werden kann.
– Replikationsadministration
Inhaber dieser Rolle dürfen alle zur Verwaltung einer konsolidierten Datenbanknötigen Anweisungen aufrufen. Dazu gehört das Anlegen von konsolidierten Ta-bellen und das Starten und Stoppen des Datenabgleichs zwischen den Daten-banken.
– Replikationskontrolle
Inhaber dieser Rolle dürfen den Datenabgleich zwischen den Datenbanken star-ten und stoppen, haben ansonsten aber keinen Zugriff auf die Quell- oder kon-solidierte Datenbank.
• Client-Nutzer
– Nutzeradministrator
Inhaber dieser Rolle dürfen auf der ihnen zugeordneten konsolidierten Daten-bank alle zur Replikation von Daten auf den mobilen Client benötigten An-weisungen ausführen. Dazu gehören u. a. das Registrieren und Löschen einerReplikatdatenbank, die Erstellung von Replikationssichten und Replikations-sichtengruppen sowie das Starten der Synchronisation mit dem RPS. Nur in derRolle eines Nutzeradministrators dürfen Daten der konsolidierten Datenbankmit exklusivem Zugriff repliziert werden.
– Replikationsnutzer
Inhaber dieser Rolle haben dieselben Rechte wie ein Nutzeradministrator mitder Ausnahme, dass sie Daten nur optimistisch replizieren dürfen.
Die Zuordnung zu einer der Basisrollen/Nutzertypen erfolgt nicht explizit sondern implizitdurch Zuordnung einer konsolidierten Datenbank zu einer Nutzerkennung.2 Das vorge-schlagene Nutzerkonzept unterscheidet Client-Nutzer anhand des Rechts zur Replikationmit exklusivem Zugriff, womit eine diesbezügliche Forderung aus Kapitel 3.4.5 erfüllt wird.Die Prüfung der Zugriffserlaubnis erfolgt beim Ausführen von RPS-Anweisungen und beider Synchronisation.
5.4.2 Zugriffskontrolle durch die Anwendung
Das RPS-Nutzerkonzept stellt grundlegende Funktionalität zur Zugriffskontrolle für dieAdministration, Steuerung und Definition der Replikation bereit. Der Zugriff von Clients
1Dazu muss der Nutzer mit dieser Rolle passende Zugriffsrechte auf der Quelldatenbank und für dievorgesehene konsolidierte Datenbank über eine dort jeweils definierte Nutzerkennung verfügen.
2Vergebene Rollen für Client-Nutzer gelten somit immer für eine konsolidierte Datenbank.

5.5. KONFLIKTBEHANDLUNG 129
auf die Daten der konsolidierten Datenbank wird bis auf die Einschränkungsmöglichkei-ten beim Anlegen konsolidierter Tabellen und die Anwendung des Slot-Verfahrens nichtreglementiert.
Ein Replikationsnutzer kann auf einer zum Ändern freigegebenen konsolidierten Tabelleim Rahmen seiner für die Replikationssicht geforderten Änderbarkeitszusicherung und derfür alle Nutzer geltenden Konfliktbehandlungsmethoden alle Zeilen bearbeiten. Wird ei-ne differenziertere Rechtevergabe für die konsolidierte Datenbank benötigt, so bietet diezweite Stufe der Anwendung die Möglichkeit, eine eigene Zugriffskontrolle für ein eigenesNutzerkonzept zu ergänzen.
Eine optionale anwendungsspezifische Zugriffskontrolle ist nur für datenselektierende und-manipulierende Anweisungen auf der konsolidierten Datenbank sinnvoll, also für das An-legen von Replikationssichten, das Ändern von Zusicherungen und für die Synchronisation.Da die Zugriffskontrolle für die Ausführung dieser Anweisungen auf dem RPS erfolgt, mussdie Anwendung dem RPS Prozeduren bereitstellen, welche die Authentisierung und Au-torisierung durchführen. Die Namen und Signaturen der Prozeduren werden vom RPSvorgegeben (eine kurze Beschreibung erfolgt in Abschnitt 5.7.4.5 und Abschnitt 5.7.4.8,eine ausführliche Beschreibung findet sich wieder in [Wie04]).
Die Umsetzung erfolgt mittels Stored Procedures, die in der konsolidierten Datenbank ab-gelegt werden, wobei vereinfachend davon ausgegangen wird, dass auf eine Datenbanknur eine Anwendung zugreift bzw. bei mehreren Anwendungen dieselbe Nutzerverwaltungverwendet wird. Der Aufruf der Prozeduren erfolgt immer nach der RPS-seitigen Zugriffs-kontrolle. Werden von der Anwendung keine eigenen Prozeduren bereitgestellt, ist für dieZugriffserlaubnis ausschließlich die RPS-Nutzerverwaltung maßgeblich.
5.5 Konfliktbehandlung
Für den RPS wurden die aus Kapitel 2.5 bekannten Konfliktvermeidungsverfahren Key-Pool für einspaltige Primärschlüssel, das Escrow-Verfahren für Spalten mit Mengenseman-tik und das Slot-Verfahren prototypisch implementiert und eine Sprachschnittstelle spezi-fiziert [Bit04, Wie04, Lie03]. Ebenfalls umgesetzt wurde die, als Konfliktvermeidungsver-fahren anzusehende, Möglichkeit, Daten für den exklusiven Zugriff anzufordern (exklusiveZugriffszusicherung, siehe Kapitel 3.4.5).
Während das Key-Pool-Verfahren vergleichsweise einfach umzusetzen ist, da es von denverwendenten Produkten unterstützt wird, erfordern das Escrow- und Slot-Verfahren eigeneImplementierungen. Das in der Originalpublikation [O’N86] beschriebene Escrow-Verfahrenwurde in der Arbeit [Bit04] für relationale Datenbanken adaptiert und implementiert.Die Darstellung der relationalen Umsetzung in ihren Details würde hier zu weit führen,stattdessen sei neben den bereits genannten Arbeiten auf den Beitrag [BG04] verwiesen,der eine Zusammenfassung der wesentlichen Implementierungsaspekte enthält.
Die Umsetzung des Slot-Verfahrens erfordert auf Server-Seite die Möglichkeit zu client-bezogenen Rechten und Sperren auf einzelne Zeilen einer Tabelle. Zurzeit bieten nur Zu-satzprodukte für wenige DBMS-Produkte (z. B. Oracle Label Security [Ora04b]) eine sol-che Funktionalität an. Eine DBMS-unabhängige Implementierung auf dem RPS wurdein [Bit04] entwickelt und ist dort ausführlich beschrieben.

130 KAPITEL 5. DER REPLICATION PROXY SERVER
Im RPS-Prototypen selbst, welcher für die Implementierung von Hermes (siehe Kapitel 6)als Grundlage dient, fand nur das Key-Pool-Verfahren, die First-Committer-Wins-Regel zurKonfliktbehandlung und die Gewährung exklusiver Zugriffszusicherungen Eingang, weswe-gen die im Abschnitt 5.7 vorgestellte Sprachschnittstelle nur die Syntax für diese Verfahrenenthält.
5.6 Sicherheitsaspekte
Durch den Betrieb der mobilen Endgeräte außerhalb der Kontrolle des RPS stellen Zugriffedurch mobile Clients ein potentielles Sicherheitsrisiko dar. Gefährdet sind die Vertraulich-keit sensibler Daten, die Integrität der konsolidierten Datenbank und die Verfügbarkeitvon Ressourcen. Nach der Art der Gefährdung werden zwei Schutzbedarfskategorien un-terschieden:
1. Schutz vor normalen DBMS-Aktivitäten, dazu gehören z. B. alle Änderungen un-ter Umgehung von Replikationssichten und Konfliktvermeidungsverfahren auf demClient. Weiter wird untergliedert in:
(a) Schutz vor unbefugter Manipulation durch berechtigte Nutzer vorsätzlich oderdurch Bedienfehler
(b) Schutz vor unbefugter Manipulation durch nicht berechtigte Nutzer
2. Schutz vor Hacker-Aktivitäten, dazu gehören geänderte Synchronisationsanfragen(siehe Kapitel 4.9), manipulierte Log-Einträge und eine kompromittierte Client-Software.
Alle in die prototypische Implementierung des RPS integrierten Maßnahmen und Möglich-keiten haben zumindest die Gewährleistung der Schutzbedarfskategorie 1 zum Ziel. EineAbwehr gezielter Hackerangriffe erfordert hingegen professionelle Schutzmechanismen undwird im Rahmen dieser Arbeit nicht behandelt. An dieser Stelle sei auf [OS02] verwiesen,wo entsprechende Maßnahmen eingehend betrachtet werden. Die für die Schutzbedarfs-kategorie 1 im einzelnen zu treffenden Vorkehrungen für Synchronisation und Konfliktbe-handlung, die über eine einfache Zugriffskontrolle und die architekturbedingten Vorteileder Dreistufigkeit hinausgehen, sind die folgenden:
• Synchronisation
Alle bei der Synchronisation vom Client übermittelten Daten sind potentiell korrum-piert und gefährden die Integrität der konsolidierten Datenbank. Es dürfen deshalbnur Daten in die konsolidierte Datenbank übernommen werden, welche unter Beach-tung der Sichtendefinitionen, der gewährten Zugriffszusicherungen und der Konflikt-behandlungsmethoden erfolgt sind. Dies wird durch den RPS gewährleistet, indemalle Vor- und Nachherabbilder einer Tabelle anhand der für den Client vom RPSgespeicherten Menge der zum Ändern replizierten Fragmente3 gefiltert werden. Fürdie Erstellung der dazu notwendigen Anfragen kann die Prozedur GetUpdNewTab ausKapitel 4.9.1 verwendet werden. Durch eine Prüfung der Vorherabbilder gegen diese
3Es ist zu beachten, dass die Gewährung von Zugriffszusicherungen immer für ganze Fragmente erfolgt.

5.7. ANWEISUNGSSCHNITTSTELLE 131
Anfragen kann sogar verhindert werden, dass durch Manipulation des Log mit Ände-rungen auf Daten Bezug genommen wird, für die der ändernde Zugriff nicht erlaubtwar [Bit04, Pfe04]. Weitere u. U. zeilenabhängige Prüfungen können durch die vonAnwendungen implementierbaren Prozeduren für die Zugriffskontrolle durchgeführtwerden.
• Konfliktbehandlung
Die Konfliktbehandlung beim RPS beruht zu einem großen Teil auf der Vermeidungvon Konflikten durch Vorabreservierungen von Ressourcen. Bei der Reintegrationmuss für alle Änderungen, die mit vorher reservierten Ressourcen durchgeführt wur-den (z. B. Schlüssel beim Key-Pool-Verfahren), deren Gültigkeit für den synchroni-sierenden Client geprüft werden [Bit04].
5.7 Anweisungsschnittstelle
Die Umsetzung der Funktionalität des RPS ist eng mit der Schnittstelle verbunden, überderen Anweisungen sie aufgerufen und gesteuert wird. Beides soll deshalb in diesem Ab-schnitt zusammen und jeweils mit Beispielen untersetzt erläutert werden. Der dargestellteSchnittstellenentwurf basiert u. a. auf den Vorarbeiten in [Mül03, Lie03, Pfe04], wobei An-passungen an den neuesten Stand der Prototypentwicklung vorgenommen wurden.
5.7.1 SQL als Grundlage
Das relationale Datenmodell wird in Produkten über die Datenbanksprache SQL reali-siert. Die am Markt verfügbaren (relationalen) DBMS-Produkte implementieren jeweils ei-ne mehr oder weniger zur SQL-Norm [ISO03a] kompatible Variante der Datenbanksprache.Es ist deshalb naheliegend, die Schnittstelle zu den Funktionen des RPS an SQL anzuleh-nen und wo es sinnvoll erscheint, SQL-Konstrukte zu übernehmen und zu erweitern. SQLunterscheidet mehrere Anweisungskategorien4:
• Anweisungen zur Datendefinition DDL (Data Definition Language)
Hierzu zählen beispielsweise Anweisungen für das Anlegen und Löschen von Tabel-lendefinitionen CREATE TABLE bzw. DROP TABLE aber auch produktspezifische Anwei-sungen wie CREATE DATABASE oder CREATE TABLESPACE.
• Anweisungen zur Datenmanipulation DML (Data Manipulation Language)
Die DML enthält die Anfrageanweisung SELECT und die Anweisungen für das Änderneiner Datenbank: INSERT, DELETE und UPDATE.
• Anweisungen zur Daten(fluss)kontrolle DCL (Data Control Language)
In diese Kategorie fallen die Anweisungen zur Transaktionssteuerung (COMMIT,ROLLBACK) und Rechteverwaltung (GRANT, REVOKE).
4Die SQL-Norm kennt nur DDL, DML und die Programmiersprachenanbindung, in der Praxis wirdjedoch oft feiner unterteilt.

132 KAPITEL 5. DER REPLICATION PROXY SERVER
• Anweisungen für die Programmierspracheneinbettung
Die hier kategorisierten Anweisungen werden für die Verarbeitung von Anfrageer-gebnissen und den Zugriff auf die Datenbank aus Anwendungsprogrammen herausbenötigt, z. B. DECLARE CURSOR, OPEN, FETCH und CLOSE.
• Anweisungen für die interen Ebene und die Administration
Hierunter fallen beispielsweise CREATE INDEX, CREATE PARTITION, BACKUP undRESTORE. Die Anweisungen dieser Kategorie gehören nicht zur Norm und sind deshalbstark produktabhängig.
Während sich für die Datendefinition und die Datenmanipulation die SQL-Norm weitge-hend etabliert hat, existieren für die Replikation und insbesondere die (schemabasierte)Konfliktbehandlung zurzeit noch keine einheitliche Sprachschnittstellen. In [Sut00] wur-den von Herb Sutter Normungs-Aktivitäten in dieser Richtung angestoßen, aber bis heutekein Sprachvorschlag veröffentlicht. In DBMS-Produkten sind sehr verschiedene, i. d. R. nurteilweise über Sprachmittel adressierbare, Lösungen anzutreffen. Mit der Implementierungdes RPS-Prototypen ist ein Sprachvorschlag für die nutzerdefinierte Replikation verbun-den, der auch als Ausgangsbasis für eine Normung dienen könnte. Der Vorschlag umfasstdie folgenden Anweisungensgruppen:
• Administration
– Replikationsschemadefinition (z. B. CREATE CONSOLIDATED TABLE),
– Replikatverwaltung (z. B. CREATE SCHEMA FRAGMENTATION)
– Replikationssteuerung (z. B. START REPLICATION)
– Nutzerverwaltung (z. B. CREATE USER)
• Anwendungsentwicklung
– Replikatdefinition (z. B. CREATE REPLICATION VIEW),
– Replikationssteuerung (z. B. SYNCHRONIZE)
Unter Verwendung der vorgenannten Kategorisierung gehören die Anweisungen für dieReplikationsschemadefinition und die Replikatdefinition zur DDL, die Anweisungen zurReplikationssteuerung und Nutzerverwaltung zur DCL und die Replikatverwaltung zurinternen Ebene. Die DML für den Zugriff auf die Replikationssichten steuert das jeweiligeClient-Datenbankmanagementsystem bei.
Im Unterschied zur Implementierung einer Sprachschnittstelle für ein DBMS muss beimEntwurf berücksichtigt werden, dass verschiedene Datenbankmanagementsysteme mit ver-schiedenen SQL-Dialekten über die Schnittstelle des RPS angesprochen werden. Beispiels-weise muss die in einer Replikationssichtendefinition übergebene Replikationsanfrage so-wohl auf der Replikat-, als auch auf der konsolidierten Datenbank ergebnisgleich ausführbarsein. Das Problem lässt sich aus Sicht des RPS auf zwei Wegen adressieren:
1. Das Bereitstellen einer eigenen einheitlichen Syntax und Semantik, die in alle SQL-Dialekte automatisch übersetzt wird.

5.7. ANWEISUNGSSCHNITTSTELLE 133
2. DBMS-abhängige Sprachelemente nur soweit zu definieren, wie es das Zusammenspielvon Quell- und konsolidierter Datenbank mit den Replikadatenbanken erfordert. Dieweiteren Regeln gibt das jeweilige DBS-Produkt vor, welches diese auch prüft.
Eine Vereinheitlichung von Syntax und Semantik kann nicht Aufgabe des RPS sein undwürde in der Praxis zu erheblichen Einschränkungen im Funktionsumfang führen (müssen).Für die Sprachschnittstelle des RPS wird deshalb der zweite Weg eingeschlagen und diefolgenden Regeln DBMS-abhängig zur Prüfung „durchgereicht“ und behandelt:
• Konventionen für Namen und Bezeichner, die sich auf Schema- und Datenobjekte inDatenbanken beziehen,
• Voraussetzungen für die erfolgreiche Anweisungsausführung (insbesondere Sichtenän-derbarkeitskriterien) und
• das Ergebnis der Anweisungsausführung, das eventuell weitere manuelle Schritte er-fordert (siehe z. B. Abschnitt 5.7.3.1).
Desweiteren werden insbesondere für die Ansteuerung der Replikationslösungen produkts-pezifische Anweisungselemente (z. B. Tablespace-Definitionen) benötigt. Diese produktab-hängigen Sprachelemente wurden für die in Abschnitt 5.3 ausgewählten Produkte ausge-arbeitet und werden im jeweiligen Abschnitt erklärt.
Der vorliegende Sprachvorschlag ist nicht vollständig. Ausgearbeitete Sprachmittel fürFunktionalität, die nicht mehr Eingang in den Prototypen gefunden hat, wurden in diefolgende Beschreibung nicht aufgenommen. Dies betrifft vor allem die erweiterten Mög-lichkeiten zur Konfliktbehandlung. Die dazugehörigen Schnittstellenbeschreibungen findensich in [Bit04, Lie03]. Ebenso wären Erweiterungen für die zukünftige Unterstützung wei-terer produktspezifischer Konstrukte erforderlich.
5.7.2 Notation
Die Konventionen für die Beschreibung der Anweisungen des RPS sind die folgenden. Derzu einer einzelnen Anweisung gehörende Abschnitt gliedert sich in fünf Teile:
• Syntaxdiagramm (s. u.)
• Beschreibung von Bedeutung und Wirkung der Anweisung
• die zur Ausführung erforderlichen Rollen (siehe Abschnitt 5.4.1)
• Beschreibung der Parameter
• Beispiele
Die Syntax der Anweisungen wird nicht, wie in der SQL-Norm [ISO03a] üblich, in BNFdargestellt, sondern mit Hilfe von Syntaxdiagrammen, wie sie beispielsweise in [IBM04b]verwendet werden. Syntaxdiagramme zeichnen sich gegenüber anderen Darstellungsformen

134 KAPITEL 5. DER REPLICATION PROXY SERVER
durch eine einfachere Lesbarkeit und Verständlichkeit aus und eignen sich damit gut fürdie didaktische Vermittlung der Konzepte und als Referenz für den Anwendungsentwickler.
Die Syntaxdiagramme sind der Linie folgend von oben nach unten und auf einer Ebenejeweils von links nach rechts zu lesen (Abbildung 5.2). Der Anfang einer Anweisung wirddurch >> und das Ende einer Anweisung durch >< markiert. Das Symbol -> drückt aus,dass die Anweisung auf der nächsten Zeile fortgesetzt wird. Entsprechend kennzeichnet >-eine Fortsetzung der Anweisung von der vorangegangenen Zeile.
Schlüsselwörter (z. B. CREATE) werden durchgehend mit Großbuchstaben dargestellt. FürVariablen (z. B. column-name) werden ausschließlich Kleinbuchstaben und das Symbol -(Bindestrich) verwendet. Das Symbol - (Bindestrich) tritt dabei nur innerhalb eines Va-riablennamens auf und auch dort nicht mehrfach direkt nacheinander, da ein mehrfachesVorkommen dieses Symbols (z. B. --) als Trennung benutzt wird.
Wahlmöglichkeiten, Optionen und Wiederholungen werden (wie allgemein üblich) mit Hilfevon Verzweigungen dargestellt (Abbildung 5.2). Existiert bei mehreren optionalen Wahl-möglichkeiten eine Default-Möglichkeit, so wird diese im Syntaxdiagramm dadurch hervor-gehoben, dass der entsprechende Pfad oberhalb der Hauptlinie verläuft.
>>------required-item--------+--required-choice-1--+--->‘--required-choice-2--’
>----+-----------------+-----+---------------------+--->‘--optional-item--’ +--optional-choice-1--+
‘--optional-choice-2--’
.-,-----------------..--default-choice---. V |
>---+-------------------+--------repeatable-item--+---><‘--optional-choice--’
>>-----required_item-----------| parameter-block |----><
parameter-block
|--+--parameter1--------------------+------------------|‘--parameter2--+--parameter3--+--’
‘--parameter4--’
Abbildung 5.2: Verzweigungen in Syntaxdiagrammen
Teile eines Syntaxdiagramms, die wiederum durch ein eigenes Syntaxdiagramm dargestelltwerden, sind von den Symbolen -| und |- eingeschlossen. Wird beispielsweise durch einseparates Syntaxdiagramm definiert, wofür parameter-block steht, so ist dies im über-geordneten Syntaxdiagramm durch -| parameter-block |- dargestellt. Diese Vorgehens-weise erlaubt es, Anweisungsteile außerhalb des globalen Syntaxdiagramms zu definieren,um so eine höhere Lesbarkeit und Übersichtlichkeit zu erreichen. Zudem eröffnet sich dieMöglichkeit, häufig verwendete Anweisungsteile lediglich einmal zu definieren, um sie dannin verschiedenen Syntaxdiagrammen verwenden zu können.

5.7. ANWEISUNGSSCHNITTSTELLE 135
Anweisung Kurzform AbschnittREGISTER CONSOLIDATED DATABASE RCD 5.7.3.1CANCEL CONSOLIDATED DATABASE CCD 5.7.3.2CREATE CONSOLIDATED TABLE CCT 5.7.3.3DROP CONSOLIDATED TABLE DCT 5.7.3.4CREATE SCHEMA FRAGMENTATION CSF 5.7.3.5CREATE DATA FRAGMENTATION CDF 5.7.3.6START REPLICATION STR 5.7.3.7STOP REPLICATION SPR 5.7.3.8CREATE USER CRU 5.7.3.9ALTER USER ALU 5.7.3.10DELETE USER DEU 5.7.3.11
Tabelle 5.1: Anweisungen für den Administrator
5.7.3 Anweisungen zur Administration
user-management-admin
|---RPS--USER--rps-user-name--PWD--rps-password-----------|
Syntaxdiagramm 5.1: Optionen der Nutzerverwaltung (Administrator)
Für die Bereitstellung von konsolidierten Datenbanken, die Freigabe von Daten über kon-solidierte Tabellen, die Nutzerverwaltung und Konfliktbehandlung sowie die Steuerung derReplikation stellt die Sprachschnittstelle des RPS die in Tabelle 5.1 angegebenen Anwei-sungen zur Verfügung.
Die Schnittstelle des RPS kennt keine Sitzungen, in denen eine einmal erfolgte Authenti-sierung für mehrere Anweisungen verwendet werden kann. Bei jeder Anweisung muss derNutzer explizit durch die obligatorische Angabe von RPS-Nutzerkennung und Passwort(Syntaxdiagramm 5.1) authentisiert werden. Es ist zu beachten, dass in der prototypi-schen Implementierung auf verteilte Transaktionsverarbeitung zwischen Quelldatenbankund konsolidierter Datenbank verzichtet wurde. Datenbankzugriffe erfolgen je Anweisungund Datenbank in einer lokalen Transaktion, die bei fehlerfreier Ausführung mit implizitemCommit abgeschlossen wird.
5.7.3.1 REGISTER CONSOLIDATED DATABASE
Mit Hilfe der Anweisung REGISTER CONSOLIDATED DATABASE wird eine auf dem RPS be-reits existierende Datenbank als konsolidierte Datenbank registriert, wobei ihr eindeutigeine Datenbank des Quell-Servers als zu Grunde liegende Quelldatenbank zugeordnet wird.Durch die erfolgreiche Ausführung der Anweisung werden vom RPS alle nötigen Vorkehrun-gen für den fortlaufenden Datenabgleich zwischen konsolidierter Datenbank und zu Grundeliegender Quelldatenbank getroffen. Der fortlaufende Datenabgleich kann anschließend mit

136 KAPITEL 5. DER REPLICATION PROXY SERVER
>>--REGISTER CONSOLIDATED DATABASE--cons-db-name---------->
>---USER--cons-user-name--PWD--cons-password-------------->
>---SOURCE--source-db-name-------------------------------->
>---USER--source-user-name--PWD--source-password---------->
>---+------------------------------------------------+---->‘--TABLESPACES--| full-table-space-assignment |--’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.2: Anweisung REGISTER CONSOLIDATED DATABASE
full-table-space-assignment
|---+----------------------------------------+------------>‘--SOURCE CAPTURE IN--source-capture-ts--’
>---+-----------------------------------------+----------->‘--SOURCE UOW IN--source-unit-of-work-ts--’
>---+------------------------------------+---------------->‘--CONS CAPTURE IN--cons-capture-ts--’
>---+-------------------------------------+--------------->‘--CONS UOW IN--cons-unit-of-work-ts--’
>---+--------------------------------+-------------------->‘--CONS APPLY IN--cons-apply-ts--’
>---+----------------------------+------------------------>‘--MOBILINK IN--mobilink-ts--’
>---+--------------------------------------+--------------|‘--MOBILINK LONG IN--mobilink-long-ts--’
Syntaxdiagramm 5.3: Tablespace-Optionen der Anweisung RCD
der Anweisung START REPLICATION (Abschnitt 5.7.3.7) gestartet werden. Die Syntax derAnweisung ist in Syntaxdiagramm 5.2 dargestellt.
Erforderliche Rolle
Systemadministration

5.7. ANWEISUNGSSCHNITTSTELLE 137
Beschreibung der Parameter
cons-db-nameDer Parameter übergibt den Namen der konsolidierten Datenbank. Auf dem RPSmuss eine Datenbank mit dem angegebenen Namen existieren. Es ist nicht zulässig,ein und dieselbe Datenbank des RPS als konsolidierte Datenbank mehrerer Quellda-tenbanken zu registrieren.
Bei der Verwendung von DB2 mit dem DataPropagator für den Abgleich zwischenQuelldatenbank und konsolidierter Datenbank muss die Datenbank leer und der Da-tenbankkonfigurationsparameter LOGRETAIN auf RECOVERY gesetzt sein. Dies wirdnicht automatisch durch den RPS vorgenommen, da hierfür ein vollständiges Backupnotwendig ist und dessen Durchführung im Verantwortungsbereich des Administra-tors liegt.
Wird für die Synchronisation zwischen dem RPS und den mobilen Clients Mobi-Link eingesetzt, so muss die Seitengröße des Standard-Tablespace (USERSPACE1) derkonsolidierten DB2-Datenbank 8 KB betragen. Des Weiteren müssen im Verzeichnissqllib der DB2-Instanz auf dem RPS alle von MobiLink benötigten Prozedurdefi-nitionen in Form von Java-Klassendateien vorhanden sein (siehe [iAn04b]).
cons-user-name, cons-passwordÜber die beiden Parameter werden Name und zugehöriges Passwort des Datenbank-nutzers angegeben, mit dem der RPS auf die konsolidierte Datenbank zugreifen kann.Der angegebene Datenbanknutzer muss existieren und die erforderlichen Rechte fürdie Datenbank besitzen. Im Falle von DB2 sind die Rechte eines Datenbankadminis-trators erfoderlich (siehe [IBM04c]). Die übergebenen Daten werden für den zukünf-tigen Zugriff vom RPS gespeichert.
source-db-nameDer Parameter enthält den Namen der entfernten Quelldatenbank, die als Quellefür die neu registrierte konsolidierte Datenbank verwendet werden soll. Auf demQuell-Server muss eine Datenbank mit dem angegebenen Namen existieren. EineQuelldatenbank kann Grundlage mehrerer konsolidierter Datenbanken sein.
source-user-name, source-passwordDie beiden Parameter geben Namen und Passwort des Datenbanknutzers an, mit demder kontinuierliche Datenabgleich auf der Quelldatenbank eingerichtet und durchge-führt werden kann. Dieser Datenbanknutzer muss in der Quelldatenbank existierenund über alle benötigten Rechte auf dieser Datenbank verfügen. Im Falle von DB2und DataPropagator ist das Recht eines Datenbankadministrators erforderlich (siehe[IBM04c]).
TABLESPACES (bei Verwendung von DB2, DataPropagator und MobiLink)Dieses optionale Syntaxelement (Syntaxdiagramm 5.3) ermöglicht eine explizite Zu-ordnung von Tablespaces für die Daten des kontinuierlichen Datenabgleichs zwischendem Quell-Server und dem RPS und für die Synchronisation der mobilen Clients.Alle mit diesem optionalen Parameter spezifizierten Tablespaces müssen bereits inder konsolidierten Datenbank bzw. der Quelldatenbank existieren. Wird für eine derfolgenden Tablespace-Optionen kein Tablespace angegeben, so wird der Standard-Tablespace (USERSPACE1) verwendet.

138 KAPITEL 5. DER REPLICATION PROXY SERVER
source-capture-tsgibt den Tablespace an, der in der Quelldatenbank für Hilfstabellen verwendetwird, die für das Auswerten der Änderungsinformationen beim fortlaufendenDatenabgleich zwischen dem RPS und der Quelldatenbank benötigt werden.
source-unit-of-work-tsgibt den Tablespace an, der in der Quelldatenbank für die beim fortlaufendenDatenabgleich benötigten Kenndaten zu übertragender Transaktionen verwen-det wird.
cons-capture-tsgibt den Tablespace an, der in der konsolidierten Datenbank für Hilfstabellenverwendet wird, die für das Auswerten der Änderungsinformationen beim fort-laufenden Datenabgleich zwischen dem RPS und der Quelldatenbank benötigtwerden.
cons-unit-of-work-tsgibt den Tablespace an, der in der konsolidierten Datenbank für die beim fortlau-fenden Datenabgleich benötigten Kenndaten zu übertragender Transaktionenverwendet wird.
cons-apply-tsgibt den Tablespace an, der in der konsolidierten Datenbank für Hilfstabellenverwendet wird, die zur Steuerung und Durchführung des fortlaufenden Daten-abgleichs zwischen dem RPS und der Quelldatenbank benötigt werden.
mobilink-tsgibt den Tablespace an, der in der konsolidierten Datenbank für Hilfstabellenverwendet wird, die zur Steuerung und Durchführung der Synchronisation durchdie mobilen Clients benötigt werden.
mobilink-long-tsgibt den Tablespace an, der in der konsolidierten Datenbank für LONG-Datenderjenigen Hilfstabellen verwendet wird, die zur Steuerung und Durchführungder Synchronisation durch die mobilen Clients benötigt werden.
Beispiel
REGISTER CONSOLIDATED DATABASE cBeispielDB USER cAdmin PWD abcSOURCE BeispielDB USER sAdmin PWD xyz
TABLESPACESSOURCE CAPTURE IN SourceTSSOURCE UOW IN SourceTSCONS CAPTURE IN ConsTSCONS UOW IN ConsTSCONS APPLY IN ConsTSMOBILINK LONG IN LongTS
Abbildung 5.3: Beispiel für die Anweisung RCD
Registrieren der Quelldatenbank BeispielDB als konsolidierte Datenbank cBeispielDB mitSpezifizierung konkreter Tablespaces für die Aufnahme von Hilfstabellen für DataPropa-

5.7. ANWEISUNGSSCHNITTSTELLE 139
gator und MobiLink (Abbildung 5.3). Die verwendeten Tablespaces lauten dabei für denDataPropagator in der Quelldatenbank jeweils SourceTS und in der konsolidierten Daten-bank ConsTS. Für MobiLink findet der Standard-Tablespace USERSPACE1 sowie für LONG-Spalten der Tablespace LongTS Verwendung.
5.7.3.2 CANCEL CONSOLIDATED DATABASE
>>--CANCEL CONSOLIDATED DATABASE--cons-db-name------------>
>---+-----------------+----------------------------------->‘--FORCE REPLICA--’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.4: Anweisung CANCEL CONSOLIDATED DATABASE
Die Anweisung CANCEL CONSOLIDATED DATABASE dient zur Deregistrierung einer registrier-ten konsolidierten Datenbank. Die Zuordnung zwischen dieser Datenbank und der ihr zuGrunde liegenden Quelldatenbank wird aufgehoben, wobei alle für den fortlaufenden Da-tenabgleich zwischen beiden Datenbanken getroffenen Vorkehrungen rückgängig gemachtwerden. Der Zugriff auf die konsolidierte Datenbank erfolgt mit dem Nutzernamen undPasswort, die bei der Registrierung angegeben wurden. Die Syntax der Anweisung ist inSyntaxdiagramm 5.4 dargestellt.
Die Registrierung einer konsolidierten Datenbank kann nur gelöscht werden, wenn der fort-laufende Datenabgleich zwischen der konsolidierten Datenbank und der ihr zu Grunde lie-genden Quelldatenbank und die Replikation mit den Clients nicht aktiv ist. Zum Stoppendes Datenabgleichs kann die Anweisung STOP REPLICATION (Abschnitt 5.7.3.8) benutztwerden. Die Anweisung entfernt nur eine frühere Registrierung, die als konsolidierte Daten-bank registrierte Datenbank und zum Zeitpunkt der Ausführung noch bestehende konso-lidierte Tabellen in der konsolidierten Datenbank werden nicht gelöscht. Zu beachten ist,dass eine „Wiederverwendung“ konsolidierter Tabellen nach einer erneuten Registrierungder Datenbank als konsolidierte Datenbank nicht möglich ist, da anzulegende konsolidierteTabellen noch nicht in der Datenbank existieren dürfen (siehe Abschnitt 5.7.3.3).
Noch bestehende Replikatdatenbanken der Clients werden bei der erfolgreichen Ausführungdieser Anweisung ebenfalls deregistriert. Die mobilen Nutzer können für diese Replikatda-tenbanken somit keine RPS-Anweisungen mehr ausführen und ihren lokalen Datenbestandnicht mehr mit der konsolidierten Datenbank synchronisieren.
Erforderliche Rolle
Systemadministration
Beschreibung der Parameter
cons-db-nameDer Parameter übergibt den Namen der zu deregistrierenden konsolidierten Daten-

140 KAPITEL 5. DER REPLICATION PROXY SERVER
bank. Eine konsolidierte Datenbank dieses Namens muss zuvor durch die AnweisungREGISTER CONSOLIDATED DATABASE registriert worden sein.
Diese Datenbank muss in der RPS-Datenbank als konsolidierte Datenbank verzeich-net sein. Es dürfen konsolidierte Tabellen in der konsolidierten Datenbank enthaltensein. Diese bleiben in der deregistrierten konsolidierten Datenbank bestehen und wer-den nicht gelöscht. Es dürfen keine Replikatdatenbanken für die konsolidierte Daten-bank registriert sein. Soll die konsolidierte Datenbank trotz der Referenzierung durchReplikatdatenbanken deregistriert werden, so muss der optionale Parameter FORCEREPLICA spezifiziert werden.
FORCE REPLICADieses optionale Syntaxelement gibt an, dass die konsolidierte Datenbank auch dannderegistriert werden soll, wenn sie noch von Replikatdatenbanken referenziert wird.Wird FORCE REPLICA weggelassen, führt das Vorhandensein von zugeordneten Repli-katdatenbanken zu einem Fehler.
Beispiel 1
CANCEL CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.4: Beispiel 1 für die Anweisung CCD
Deregistrieren der konsolidierten Datenbank cBeispielDB (Abbildung 5.4). Falls noch Repli-katdatenbanken für diese konsolidierte Datenbank registriert sind, wird eine Fehlermeldungausgegeben.
Beispiel 2
CANCEL CONSOLIDATED DATABASE cBeispielDBFORCE REPLICA
Abbildung 5.5: Beispiel 2 für die Anweisung CCD
Deregistrieren der konsolidierten Datenbank cBeispielDB (Abbildung 5.5). Alle zu diesemZeitpunkt für die konsolidierte Datenbank registrierten Replikatdatenbanken werden au-tomatisch deregistriert.
5.7.3.3 CREATE CONSOLIDATED TABLE
Die Anweisung CREATE CONSOLIDATED TABLE dient zum Anlegen einer konsolidierten Ta-belle. Die Anweisung kann nur ausgeführt werden, wenn der fortlaufende Datenabgleichmit dem Quell-Server deaktiviert ist. Im Falle der erfolgreichen Ausführung werden allefür die Replikation benötigten Hilfstabellen angelegt und die deklarierten Konfliktbehand-lungsmethoden eingerichtet. Konsolidierte Tabellen können auf Basistabellen und Sichtenaufsetzen. In der prototypischen Implementierung werden Sichten als Quellen wie Basista-bellen behandelt und ihr Inhalt auf dem RPS materialisiert. Die Syntax der Anweisung istin den Syntaxdiagrammen 5.5 und 5.6 dargestellt.

5.7. ANWEISUNGSSCHNITTSTELLE 141
>>--CREATE CONSOLIDATED TABLE--cons-table-name------------>
.-,--------------------.V |
>---AS SELECT--+-----source-column-name--+--+------------->‘-------------*--------------’
>---FROM--source-table-name------------------------------->
>---+------------------------------+---------------------->‘--WHERE--simple-where-clause--’
>---FOR CONSOLIDATED DATABASE--cons-db-name--------------->
>---+------------------------------------------------+---->‘--TABLESPACES--| part-table-space-assignment |--’
.------------READ ONLY------------.>---+---------------------------------+------------------->
+--| conflict handling methods |--+‘------NO CLIENT REPLICATION------’
>---+---------------------------+------------------------->‘--EXPIRY IN--expire-hours--’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.5: Anweisung CREATE CONSOLIDATED TABLE
part-table-space-assignment
|---+------------------------------------------------+---->‘--SOURCE CHANGE DATA IN--source-change-data-ts--’
>---+------------------------------+---------------------->‘--CONS DATA IN--cons-data-ts--’
>---+--------------------------------------------+--------|‘--CONS CHANGE DATA IN--cons-change data-ts--’
conflict handling methods
|--KEY POOL FOR--key-column--MAX USER KEYS--user-keys----->
>--+-----------------------------+-----------------------><‘--START WITH KEY--start-key--’
Syntaxdiagramm 5.6: Optionen der Anweisung CCT

142 KAPITEL 5. DER REPLICATION PROXY SERVER
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration
Beschreibung der Parameter
cons-table-nameDer Parameter enthält den Namen der anzulegenden konsolidierten Tabelle. In derkonsolidierten Datenbank darf noch keine Tabelle mit diesem Namen existieren. Esdürfen ferner auch die folgenden Tabellennamen nicht vergeben sein:
• <cons-table-name>_X
• <cons-table-name>_H
• <cons-table-name>_B
• <cons-table-name>_A
Sollten die Tabellennamen nach dem Anhängen der obigen Suffixe die vom DBMSvorgegebene Maximallänge für Tabellennamen überschreiten, so wird der Bestandteil<cons-table-name> für diese Hilfstabellen am Ende entsprechend gekürzt und an-schließend mit dem jeweiligen Suffix versehen. Bei der Verwendung von DB2 ist fürcons-table-name die Angabe eines Schemanamens nicht zulässig. Als Schemanamewird für alle konsolidierten Tabellen der konsolidierten Datenbank das Schema RPSverwendet.
cons-db-nameDer Parameter übergibt den Namen der konsolidierten Datenbank, in der die konsoli-dierte Tabelle angelegt werden soll.5 Auf dem RPS muss eine konsolidierte Datenbankmit dem angegebenen Namen registriert sein.
source-column-nameÜbergibt die Liste der Spaltennamen der Quelltabelle, die in der konsolidierten Ta-belle enthalten sein soll (Projektion). Jede Spalte der Quelltabelle darf nur einmal inder Spaltenliste der neuen konsolidierten Tabelle enthalten sein. Alternativ zu einerListe von Spaltennamen kann wie üblich der Stern (*) als Synonym für die Auswahlaller Spalten der Quelltabelle spezifiziert werden.
Aufgrund von Einschränkungen des DataPropagator ist es nicht möglich, bei derAusführung der Anweisung CREATE CONSOLIDATED TABLE Spaltennamen der Quell-tabelle für die konsolidierte Tabelle umzubenennen. Um dies zu erreichen, ist in derQuelldatenbank eine Sicht mit entsprechend abgeänderten Spaltennamen anzulegenund für diese anstatt der Basistabelle eine konsolidierte Tabelle zu erstellen.
Wird für die konsolidierte Tabelle nicht READ ONLY und nicht NO CLIENTREPLICATION spezifiziert (s. u.), so müssen Änderungen in der konsolidierten Tabelle
5Da die Anweisung vom RPS (und nicht von einem DBMS) ausgeführt wird, muss die betreffendeDatenbank explizit spezifiziert werden.

5.7. ANWEISUNGSSCHNITTSTELLE 143
an die Quelltabelle übertragen werden. In diesen Fällen einer (durch Clients) änder-baren konsolidierten Tabelle müssen alle Primärschlüsselspalten und all diejenigenQuelltabellenspalten in der Projektion enthalten sein, für die NOT NULL spezifiziertwurde und keine Standardwerte (DEFAULT) verfügbar sind.
source-table-nameDer Paramter übergibt dem RPS den Namen einer existierenden Tabelle in der Quell-datenbank, deren Inhalt für die Replikation durch Clients als konsolidierte Tabelleverfügbar sein soll. Als Quelltabelle können Basistabellen und Sichten verwendet wer-den. Aufgrund der primärschlüsselbasierten Identifikation von Zeilen für die Synchro-nisation müssen Tabellen, die als Quelle benutzt werden sollen, einen Primärschlüsselbesitzen.
Beim Einsatz von DataPropagator und DB2 ist zusätzlich folgendes zu beachten. DieDatenbankoption DATA CAPTURE CHANGES muss für die Quelltabelle aktiviert sein,damit der DataPropagator die Aufzeichnungen im Datenbank-Log für den kontinu-ierlichen Datenabgleich verwenden kann. Wird die optionale Qualifikation des Ta-bellennamens mit einem Schema weggelassen, so wird implizit das im Rahmen vonREGISTER CONSOLIDATED DATABASE mit dem Nuzternamen assoziierte Schema ver-wendet.
simple-where-clauseMit Hilfe der hier spezifizierten Bedingung können Tabellenzeilen von der Replika-tion ausgeschlossen werden (Selektion). Die Auswahlbedingung darf sich nur auf diedurch source-table-name spezifizierte Quelltabelle beziehen und keine Unteranfra-gen enthalten.
TABLESPACES (bei Verwendung von DB2, DataPropagator und MobiLink)Dieses optionale Syntaxelement ermöglicht eine explizite Angabe von Tablespaces fürdie Hilfstabellen, die für die Arbeit des fortlaufenden Datenabgleichs der konsolidier-ten Tabelle mit dem Quell-Server erforderlich sind.
source-change-data-tsgibt den Tablespace an, der in der Quelldatenbank für Tabellen zur Aufnahmevon Änderungsdaten für den fortlaufenden Datenabgleich verwendet wird.
cons-data-tsgibt den Tablespace an, der in der konsolidierten Datenbank für das Anlegender konsolidierten Tabelle verwendet wird.
cons-change-data-tsgibt den Tablespace an, der in der konsolidierten Datenbank für Tabellen zurAufnahme von Änderungsdaten für den fortlaufenden Datenabgleich verwendetwird.
READ ONLY (Default)Das optionale Syntaxelement definiert die konsolidierte Tabelle für nur lesende Re-plikation durch Clients.
NO CLIENT REPLICATIONKonsolidierte Tabellen mit dieser Option sind für den Client unsichtbar und könnennicht repliziert werden. Diese Option wird für Tabellen benötigt, die zwar für die

144 KAPITEL 5. DER REPLICATION PROXY SERVER
korrekte Arbeitsweise der konsolidierten Datenbank notwendig sind, aber nicht zurReplikation durch Clients freigegeben werden sollen (z. B. Freigabe bestimmter Nut-zerdaten wie Name, E-Mail-Adresse, aber Verbergen von Passwörtern zur Authen-tifizierung auf dem RPS). Werden weder READ ONLY noch NO CLIENT REPLICATIONspezifiziert, ist die konsolidierte Tabelle durch Clients replizier- und auch änderbar.
KEY POOL FORDas optionale Syntaxelement wählt die Konfliktvermeidungsmethode KeyPool fürdas client-seitige Einfügen neuer Zeilen aus. Die implementierte Variante erlaubt nureinspaltige Schlüssel.
key-columnübergibt dem RPS die Spalte, für welche ein KeyPool eingerichtet werden soll.Die Spalte muss in der konsolidierten Tabelle existieren und Primärschlüsselsein. Beim Einsatz von DB2 muss die Spalte vom Typ BIGINT oder einem dazukompatiblen Integer-Datentyp sein.
user-keysgibt an, wie viele Schlüsselwerte ein Nutzer zu einer Zeit maximal für die kon-solidierte Tabelle reservieren kann.
start-keygibt optional an, bei welchem Schlüsselwert die Reservierung von Werten be-ginnen soll. Wird die Angabe weggelassen, so beginnt die Reservierung beimSchlüsselwert 0.
expire-hoursDieser optionale Parameter übergibt dem RPS einen Richtwert, nach wie vielen Stun-den Replikationssichten, die auf dieser konsolidierten Tabelle basieren, wieder syn-chronisiert werden sollten. Diese Information wird den Metadaten der auf dieser Ta-belle basierenden Replikationssichten hinzugefügt und kann auf dem Client abgerufenwerden. Darüber hinaus stellt er keine Verpflichtung dar. Basiert eine Replikations-sicht auf mehreren konsolidierten Tabellen, so gilt für sie der minimale Wert allerzugrundeliegenden konsolidierten Tabellen.
Beispiel 1
CREATE CONSOLIDATED TABLE RestaurantAS SELECT *
FROM RestaurantFOR CONSOLIDATED DATABASE cBeispielDBEXPIRY IN 168
Abbildung 5.6: Beispiel 1 für die Anweisung CCT
Erstellen einer konsolidierten Tabelle Restaurant in der konsolidierten Datenbank cBei-spielDB für eine Quelltabelle Restaurant (Abbildung 5.6). Es werden alle Spalten ausge-wählt. Das den mobilen Nutzern empfohlene maximale Synchronisationsintervall beträgteine Woche.

5.7. ANWEISUNGSSCHNITTSTELLE 145
Beispiel 2
CREATE CONSOLIDATED TABLE Orte10000AS SELECT NameFROM BspSchema.OrtschaftWHERE Einwohner > 10000
FOR CONSOLIDATED DATABASE cBeispielDBTABLESPACES
SOURCE CHANGE DATA IN Ortschaft_CD_TSCONS DATA IN Userspace1CONS CHANGE DATA IN Orte10000_CD_TSREAD ONLY
Abbildung 5.7: Beispiel 2 für die Anweisung CCT
Erstellen einer konsolidierten Tabelle Orte10000 in der konsolidierten Datenbank cBei-spielDB (Abbildung 5.7). Diese basiert auf der Quelltabelle BspSchema.Ortschaft und selek-tiert den Namen der Orte, welche mehr als 10000 Einwohner haben. Die Änderungstabellenwerden in eigenen Tablespaces angelegt (für die konsolidierte Tabelle Orte10000_CD_TSund für die Quelltabelle Ortschaft_CD_TS). Die konsolidierte Tabelle selbst wird imStandard-Tablespace Userspace1 angelegt. Für die konsolidierte Tabelle wird READ ONLYspezifiziert, da sie für mobile Nutzer nicht änderbar sein soll.
5.7.3.4 DROP CONSOLIDATED TABLE
>>--DROP CONSOLIDATED TABLE--cons-table-name-------------->
>---FROM CONSOLIDATED DATABASE--cons-db-name-------------->
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.7: Anweisung DROP CONSOLIDATED TABLE
Die Anweisung DROP CONSOLIDATED TABLE dient dazu, eine konsolidierte Tabelle zu lö-schen. Eine konsolidierte Tabelle kann nur gelöscht werden, wenn der fortlaufende Daten-abgleich zum Server gestoppt ist und auf der zu löschenden konsolidierten Tabelle keine Re-plikationssichten mehr definiert sind. Die Syntax der Anweisung ist in Syntaxdiagramm 5.7dargestellt. Die im Rahmen der Registrierung für diese Tabelle erstellten Schema- und Da-tenelemente werden gelöscht.
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration

146 KAPITEL 5. DER REPLICATION PROXY SERVER
Beschreibung der Parameter
cons-table-nameDieser Parameter übergibt den Namen der zu löschenden konsolidierten Tabelle. DieTabelle muss in der ebenfalls übergebenen konsolidierten Datenbank (s. u.) vorhandensein.
cons-db-nameDer zweite Parameter übergibt den Namen einer existierenden konsolidierten Daten-bank, aus der die konsolidierte Tabelle gelöscht werden soll.
Beispiel
DROP CONSOLIDATED TABLE RestaurantFROM CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.8: Beispiel für die Anweisung DCT
Löschen der konsolidierten Tabelle Restaurant aus der konsolidierten Datenbank cBei-spielDB (Abbildung 5.8).
5.7.3.5 CREATE SCHEMA FRAGMENTATION
Zum Durchführen der Schemafragmentbildung wird dem Replikationsadministrator die An-weisung CREATE SCHEMA FRAGMENTATION zur Verfügung gestellt. Die Anweisung führt aufdem RPS die Prozedur SchemaFrag (siehe Kapitel 4.5) aus und legt die Schemafragment-tabelle an. Eine zuvor bereits existierende Datenfragmentierung wird bei der Ausführunggelöscht. Die Ausführung kann nur erfolgen, wenn auf der konsolidierten Datenbank keineReplikationssichten definiert sind. Die Syntax der Anweisung ist im Syntaxdiagramm 5.8dargestellt.
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration
Beschreibung der Parameter
cons-db-nameDer erste Parameter übergibt den Namen einer existierenden konsolidierten Daten-bank, für welche die Schemafragmentbildung durchgeführt werden soll.

5.7. ANWEISUNGSSCHNITTSTELLE 147
>>--CREATE SCHEMA FRAGMENTATION--------------------------->
>---FOR CONSOLIDATED DATABASE--cons-db-name--------------->
>---+-----------------------------------------------+----->‘--IGNORE REF CONSTRAINTS--| constraint-list |--’
>---| user-management-admin |----------------------------><
constraint-list
.-,-----------------.V |
|------constraint-name--+---------------------------------|
Syntaxdiagramm 5.8: Anweisung CREATE SCHEMA FRAGMENTATION
constraint-listDer zweite Parameter ist eine Liste von referentiellen Integritätsbedingungen, die beider Schemafragmentbildung ignoriert werden sollen, beispielsweise zur Erfüllung derBedingung von Kreisfreiheit des Fremdschlüsselgraphen. Die Struktur des Namenseiner Fremdschlüsselbeziehung (constraint-name) ist abhängig von der Darstellungim Katalog des jeweiligen DBMS für den RPS.
Beispiel
CREATE SCHEMA FRAGMENTATIONFOR CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.9: Beispiel für die Anweisung CSF
Erstellen der Schemafragmentierung für die Beispieldatenbank (Abbildung 5.9), wobei allefür das Datenbankschema definierten referentiellen Integritätsbedingungen berücksichtigtwerden.
5.7.3.6 CREATE DATA FRAGMENTATION
Zur Erstellung und späteren Anpassung einer Datenfragmentierung wird dem Replikati-onsadministrator die Anweisung CREATE DATA FRAGMENTATION zur Verfügung gestellt. DieAnweisung führt auf dem RPS die Prozeduren SplitFrag und MergeFrag (siehe Kapitel 4.6)aus und legt, wenn noch nicht vorhanden, eine Datenfragmenttabelle an. Die Ausführungerfordert eine vorangegangene Bildung der Schemafragmentierung. Die Syntax der Anwei-sung findet sich in Syntaxdiagramm 5.9.

148 KAPITEL 5. DER REPLICATION PROXY SERVER
>>--CREATE DATA FRAGMENTATION----------------------------->
>---FOR CONSOLIDATED DATABASE--cons-db-name--------------->
>---ON TABLE--table-name--COLUMN--column-name------------->
>---+---------------------------------+------------------->| .-,-----------. || V | |‘--VALUES--(----part-value--+--)--’------------------->
>---+--SPLIT--min-value--+-------------------------------->‘--MERGE-------------’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.9: Anweisung CREATE DATA FRAGMENTATION
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration
Beschreibung der Parameter
cons-db-nameDer erste Parameter übergibt den Namen einer existierenden konsolidierten Daten-bank, für welche die Datenfragmentbildung durchgeführt werden soll.
table-name, column-nameDie Parameter übergeben den Namen einer Tabelle und einer Spalte dieser Tabellein der konsolidierten Datenbank, für welche eine Datenfragmentbildung durchgeführtwerden soll.
part-valueOptional kann der Anweisung eine Liste von Partitionierungsspaltenwerten für dieFragmentbildung mitgegeben werden. Wird kein Partitionierungsspaltenwert spezifi-ziert, erfolgt das Aufteilen oder Zusammenführen von Fragmenten für alle aktuellenWerte der übergebenen Spalte in der konsolidierten Datenbank.
min-valueSoll eine Aufteilung von Fragmenten erfolgen (SPLIT), so wird über diesen Parameterdie minimale Zeilenzahl eines neuen Fragments festgelegt.

5.7. ANWEISUNGSSCHNITTSTELLE 149
Beispiel
CREATE DATA FRAGMENTATIONFOR CONSOLIDATED DATABASE cBeispielDBON TABLE Land COLUMN Name
Abbildung 5.10: Beispiel für die Anweisung CDF
Erstellen der Datenfragmentierung für die Spalte Name des Tabellenschemas Land für alleaktuellen Werte der Spalte in der Beispieldatenbank ohne Beschränkung der Fragmentgröße(Abbildung 5.10).
5.7.3.7 START REPLICATION
>>--START REPLICATION---+---SERVER---+-------------------->‘---CLIENT---’
>---FOR CONSOLIDATED DATABASE--cons-db-name--------------->
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.10: Anweisung START REPLICATION
Die Anweisung START REPLICATION dient sowohl zum Initiieren des fortlaufenden Da-tenabgleichs zwischen einer konsolidierten Datenbank und der ihr zu Grunde liegendenQuelldatenbank als auch zum Starten der Replikation mit den Clients. Von der Anweisungbetroffen sind alle zum Zeitpunkt der Anweisungsausführung in der Datenbank enthaltenenkonsolidierten Tabellen.
Nach dem Registrieren einer konsolidierten Datenbank muss für diese die Replikation je-weils für Quell-Server und Clients explizit gestartet werden. Ist das Starten der Client-Replikation erfolgreich, können Clients anschließend Replikationssichten über den konsoli-dierten Tabellen definieren. Damit Clients keine veralteten Daten replizieren, sollte immerzuerst die Replikation mit dem Quell-Server und danach erst die Replikation mit den Cli-ents aktiviert werden. Die Syntax der Anweisung ist in Syntaxdiagramm 5.10 dargestellt.
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration
oder
Replikationskontrolle

150 KAPITEL 5. DER REPLICATION PROXY SERVER
Beschreibung der Parameter
SERVER, CLIENTDie Syntaxoptionen spezifizieren, ob Replikation mit dem Quell-Server oder demClient aktiviert werden soll.
cons-db-nameDer Parameter übergibt den Namen der existierenden konsolidierten Datenbank, fürdie die Replikation aktiviert werden soll.
Beispiel
START REPLICATION SERVERFOR CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.11: Beispiel für die Anweisung STR
Starten des kontinuierlichen Datenabgleichs zwischen der konsolidierten Datenbank cBei-spielDB und der ihr zugrundeliegenden Quelldatenbank (Abbildung 5.11).
5.7.3.8 STOP REPLICATION
>>--STOP REPLICATION----+---SERVER---+-------------------->‘---CLIENT---’
>---FOR CONSOLIDATED DATABASE--cons-db-name--------------->
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.11: Anweisung STOP REPLICATION
Die Anweisung STOP REPLICATION dient zum Anhalten des kontinuierlichen Datenab-gleichs mit dem Server und zum Stoppen der Client-Replikation. Wurde die Client-Replikation gestoppt, können Clients weder neue Replikationssichten anlegen/ändern nochDaten synchronisieren. Die Syntax der Anweisung ist in Syntaxdiagramm 5.11 dargestellt.
Erforderliche Rolle
Systemadministration
oder
Replikationsadministration
oder
Replikationskontrolle

5.7. ANWEISUNGSSCHNITTSTELLE 151
Beschreibung der Parameter
SERVER, CLIENTDie Syntaxoptionen spezifizieren, ob Replikation mit dem Quell-Server oder demClient deaktiviert werden soll.
cons-db-nameDer Parameter übergibt den Namen der existierenden konsolidierten Datenbank, fürdie die Replikation deaktiviert werden soll.
Beispiel
STOP REPLICATION SERVERFOR CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.12: Beispiel für die Anweisung SPR
Stoppen des kontinuierlichen Datenabgleichs zwischen der konsolidierten Datenbank cBei-spielDB und der ihr zugrundeliegenden Quelldatenbank (Abbildung 5.12).
5.7.3.9 CREATE USER
Die Anweisung CREATE USER dient zum Erstellen eines neuen RPS-Nutzers. Die Syntaxder Anweisung ist in Syntaxdiagramm 5.12 dargestellt.
>>--CREATE USER--user-name--PWD--user-password------------>
>---+-------------------------------+--------------------->‘--WITH ROLES--| role-list |--’
>---+-------------------------------------------+--------->‘--FOR CONSOLIDATED DATABASE--cons-db-name--’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.12: Anweisung CREATE USER
role-list
.-,-----------.V |
|---+--role-name--+---------------------------------------|
Syntaxdiagramm 5.13: Rollen der RPS-Nutzerverwaltung
Erforderliche Rolle
Systemadministration

152 KAPITEL 5. DER REPLICATION PROXY SERVER
Beschreibung der Parameter
user-nameDer Parameter übergibt den neuen Nutzernamen.
user-passwordDer zweite Parameter übergibt das Passwort, mit dem sich der neue Nutzer anmeldenmuss.
role-nameEine optionale Liste von Rollenbezeichnern (Syntaxdiagramm 5.13) legt die (initia-len) Rechte des neuen Nutzers beim Zugriff auf RPS-Anweisungen fest. MöglicheRollennamen sind:
• RPS_ADM_SYSTEMsteht für die Rolle „Systemadministration“
• RPS_ADMsteht für die Rolle „Replikationsadministration“
• RPS_CTRLsteht für die Rolle „Replikationskontrolle“
• EXCL_CLIENTsteht für die Rolle „Nutzeradministrator“
• CLIENTsteht für die Rolle „Replikationsnutzer“
Für eine Erläuterung der Bedeutung der Rollen und den mit ihnen verbundenenRechten sei auf Abschnitt 5.4.1 verwiesen.
cons-db-nameDer optionale Parameter übergibt den Namen der existierenden konsolidierten Daten-bank, für die der neue Nutzer angelegt und mit den unter WITH ROLES angegebenenRechten versehen wird. Jeder Nutzer kann maximal einer konsolidierten Datenbankzugeordnet werden. Wird der Parameter nicht angegeben, sind bei der Rollenverga-be nur die datenbankunabhängigen Rollen RPS_ADM_SYSTEM, RPS_ADM und RPS_CTRLerlaubt.
Beispiel 1
CREATE USER Reisender_007 PWD ****WITH ROLES CLIENT
FOR CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.13: Beispiel 1 für die Anweisung CRU
Anlegen eines Replikationsnutzers mit dem Namen Reisender_007 und einem Passwort fürdie konsolidierte Datenbank cBeispielDB (Abbildung 5.13). Der Nutzer hat die Berechti-gung, alle für Replikationsnutzer vorgesehenen RPS-Dienste aufzurufen. Eine Möglichkeit,exklusive Zugriffszusicherungen zu erhalten, besteht für ihn nicht.

5.7. ANWEISUNGSSCHNITTSTELLE 153
Beispiel 2
CREATE USER Repl_Admin PWD ****WITH ROLES RPS_ADM,
EXCL_CLIENTFOR CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.14: Beispiel 2 für die Anweisung CRU
Anlegen eines Replikationsadministrators mit dem Namen Repl_Admin und einem Pass-wort für die konsolidierte Datenbank cBeispielDB (Abbildung 5.14). Der Nutzer hat dieBerechtigung, alle sowohl für die Verwaltung der konsolidierten Datenbank als auch fürderen Replikationsnutzung angebotenen RPS-Dienste aufzurufen. Darüber hinaus hat erdie Berechtigung, exklusive Zugriffszusicherungen zu erhalten.
5.7.3.10 ALTER USER
Die Anweisung ALTER USER dient zum Ändern der Nutzerdaten eines bestehenden RPS-Nutzers. Die Syntax der Anweisung ist in Syntaxdiagramm 5.14 dargestellt.
>>--ALTER USER--user-name--------------------------------->
>---+---------------------+--+----------------------+----->‘-GRANT-| role-list |-’ ‘-REVOKE-| role-list |-’
>---+-------------------------------------------+--------->‘--SET CONSOLIDATED DATABASE--cons-db-name--’
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.14: Anweisung ALTER USER
Erforderliche Rolle
Systemadministration
Beschreibung der Parameter
user-nameDer Parameter übergibt den Namen eines existierenden Nutzers, dessen Rechte ge-ändert werden sollen.
GRANTDie im Anschluss an dieses optionale Syntaxelement spezifizierten Rollen(Syntaxdiagramm 5.13) werden den Rollen des Nutzers hinzugefügt.
REVOKEDie im Anschluss an dieses optionale Syntaxelement spezifizierten vom Nutzer be-sessenen Rollen (Syntaxdiagramm 5.13) werden ihm entzogen.

154 KAPITEL 5. DER REPLICATION PROXY SERVER
cons-db-nameDer optionale Parameter übergibt den Namen einer existierenden konsolidiertenDatenbank, für die der Nutzer die neuen und alten Rollen abzüglich der entzoge-nen Rollen erhalten soll. Die Rechte für die ursprünglich zugewiesene konsolidierteDatenbank gehen verloren. Wird der Parameter nicht angegeben, sind beim Hinzu-fügen (GRANT) von Rollen nur dann datenbankabhängige Rollen (replication_user,exclusive_replication_user) erlaubt, wenn der Nutzer zuvor einer konsolidiertenDatenbank zugewiesen worden war.
Beispiel 1
ALTER USER Reisender_008SET CONSOLIDATED DATABASE cBeispielDB
Abbildung 5.15: Beispiel 1 für die Anweisung ALU
Zuordnen des Nutzers Reisender_008 zur konsolidierten Datenbank cBeispielDB(Abbildung 5.15). Alle Client-Dienste, die vom Nutzer fortan aufgerufen werden, richtensich an diese konsolidierte Datenbank.
Beispiel 2
ALTER USER Nutzer_4711GRANT EXCL_CLIENT REVOKE CLIENT
Abbildung 5.16: Beispiel 2 für die Anweisung ALU
Entziehen der Rolle CLIENT und Gewähren der Rolle EXCL_CLIENT für den Nutzer Nut-zer_4711 (Abbildung 5.16). Dieser kann daraufhin für die ihm zugeordnete konsolidierteDatenbank exklusive Zugriffszusicherungen anfordern.
5.7.3.11 DELETE USER
Die Anweisung DELETE USER dient zum Löschen eines bestehenden RPS-Nutzers. Die Syn-tax der Anweisung ist in Syntaxdiagramm 5.15 dargestellt.
>>--DELETE USER--user-name-------------------------------->
>---| user-management-admin |----------------------------><
Syntaxdiagramm 5.15: Anweisung DELETE USER
Erforderliche Rolle
Systemadministration

5.7. ANWEISUNGSSCHNITTSTELLE 155
Beschreibung der Parameter
user-nameDer Parameter übergibt den Namen eines existierenden Nutzers, der gelöscht werdensoll.
Beispiel
DELETE USER Nutzer_4711
Abbildung 5.17: Beispiel für die Anweisung DEU
Löschen des Nutzers Nutzer_4711 (Abbildung 5.17).
5.7.4 Anweisungen zur Anwendungsentwicklung
Anweisung Kurzform AbschnittREGISTER REPLICA DATABASE RRD 5.7.4.1CANCEL REPLICA DATABASE CRD 5.7.4.2CREATE REPLICATION VIEW GROUP CVG 5.7.4.3DROP REPLICATION VIEW GROUP DVG 5.7.4.4CREATE REPLICATION VIEW CRV 5.7.4.5ALTER REPLICATION VIEW ARV 5.7.4.6DROP REPLICATION VIEW DRV 5.7.4.7SYNCHRONIZE SYN 5.7.4.8
Tabelle 5.2: Anweisungen für den Anwendungsprogrammierer
user-management-client
|---RPS--USER--rps-user-name--PWD--rps-password----------->
>---+-----------------------------------+-----------------|‘--APPID--"application-identifier"--’
Syntaxdiagramm 5.16: Optionen der Nutzerverwaltung (Anwendung)
Für die Registrierung von Replikatdatenbanken, das Anlegen von Replikationssichten undReplikationssichtengruppen sowie die Durchführung der Synchronisation stellt der RPSdem Anwendungsprogrammierer die in Tabelle 5.2 angegebenen Anweisungen zur Verfü-gung. Die Zuordnung der Anweisungen zu konsolidierten Datenbanken erfolgt implizit überdie vorher vom Administrator zu treffende Zuordnung von RPS-Nutzern zu konsolidiertenDatenbanken (siehe Abschnitt 5.7.3.9).
Analog zu den Anweisungen für die Administration muss auch für die Anwendungsan-weisungen jeder Nutzer explizit durch die obligatorische Angabe von RPS-Nutzerkennung

156 KAPITEL 5. DER REPLICATION PROXY SERVER
und Passwort (Syntaxdiagramm 5.16) authentisiert werden. Zusätzlich kann einapplication-identifier übergeben werden. Der String wird vom RPS nicht ausgewertet,sondern im Anschluß an eine erfolgreiche Autorisierung mit der RPS-Nutzerkennung an diezur Anweisung gehörende Prozedur für die Anwendungsauthentisierung und -autorisierungweitergeleitet. Der application-identifier kann beispielsweise Anwendungsnutzernameund verschlüsseltes Passwort enthalten.
Auch für die Anwendungsanweisungen gilt, dass je Anweisung und Datenbank (möglichsind konsolidierte Datenbank und Replikatdatenbank) die Ausführung in einer lokalenTransaktion erfolgt, die bei fehlerfreier Ausführung mit implizitem Commit abgeschlos-sen wird. Müssen client-seitige Aktionen rückgängig gemacht werden, so sind sie durchdie entsprechenden Anweisungen zu kompensieren. Beispielweise kann ein versehentlichesAnlegen einer Replikationssicht ohne großen Aufwand durch ein anschließendes Löschender Sicht rückgängig gemacht werden. Sofern zwischen den beiden Anweisungen keine Syn-chronisation erfolgte, werden dabei keine Anwendungsdaten übertragen.
5.7.4.1 REGISTER REPLICA DATABASE
>>--REGISTER REPLICA DATABASE--replica-db-name------------>
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.17: Anweisung REGISTER REPLICA DATABASE
Die Anweisung REGISTER REPLICA DATABASE dient zur Verknüpfung einer existierendenDatenbank auf dem Client als Replikatdatenbank mit einer konsolidierten Datenbank aufdem RPS. Vorausetzung ist, dass dem RPS-Nutzer auf dem RPS eine konsolidierte Daten-bank zugeordnet ist. Die konsolidierte Datenbank ist über den Nutzer eindeutig identi-fiziert. Durch die erfolgreiche Ausführung der Anweisung werden vom RPS alle nötigenVorkehrungen für den Datenabgleich zwischen dieser Replikatdatenbank und der ihr zuGrunde liegenden konsolidierten Datenbank getroffen. Dazu gehört das Anlegen der, zu-nächst leeren, Replikattabellen basierend auf dem Schema der konsolidierten Datenbank.
Für die Replikatdatenbank wird die Standardreplikationssichtengruppe STRDRVG angelegt,welcher all diejenigen Replikationssichten zugeordnet werden, die nicht explizit einer ande-ren Replikationssichtengruppe angehören (siehe Abschnitt 5.7.4.5). Anschließend könnenReplikationssichten auf dem Schema der Replikatdatenbank definiert werden. Die Syntaxder Anweisung ist in Syntaxdiagramm 5.17 dargestellt.
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer

5.7. ANWEISUNGSSCHNITTSTELLE 157
Beschreibung der Parameter
replica-db-nameDer Parameter übergibt den Namen der Replikatdatenbank. Auf dem Client musseine leere Datenbank mit dem angegebenen Namen existieren. Darüber hinaus darfdie über den Namen replica-db-name referenzierte Datenbank für den Client nochnicht als Replikatdatenbank registriert sein.
Beispiel
REGISTER REPLICA DATABASE C:\dbhome\MeineWelt.db
Abbildung 5.18: Beispiel für die Anweisung RRD
Registrieren der Adaptive Server Anywhere Replikatdatenbank MeineWelt für die dem aus-führenden Nutzer zugeordnete konsolidierte Datenbank (Abbildung 5.18).
5.7.4.2 CANCEL REPLICA DATABASE
Die Anweisung CANCEL REPLICA DATABASE dient dazu, die Registrierung der Replikatda-tenbank eines Nutzers wieder aufzuheben. Bei erfolgreicher Ausführung werden alle Maß-nahmen, die für den Datenabgleich zwischen konsolidierter und Replikatdatenbank getrof-fen wurden, rückgängig gemacht. Die Deregistrierung einer Replikatdatenbank hat zur Fol-ge, dass auch alle zu ihr gehörenden Replikationssichten, Replikationssichtengruppen undReplikattabellen gelöscht werden. Die Syntax der Anweisung ist in Syntaxdiagramm 5.18dargestellt.
>>--CANCEL REPLICA DATABASE------------------------------->
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.18: Anweisung CANCEL REPLICA DATABASE
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Beispiel
CANCEL REPLICA DATABASE
Abbildung 5.19: Beispiel für die Anweisung CRD

158 KAPITEL 5. DER REPLICATION PROXY SERVER
Deregistrieren der vom Nutzer registrierten Replikatdatenbank (Abbildung 5.19). Die An-gabe einer Datenbank ist nicht erforderlich, da jedem Nutzer höchstens eine Replikatda-tenbank zugeordnet sein kann.
5.7.4.3 CREATE REPLICATION VIEW GROUP
Die Anweisung CREATE REPLICATION VIEW GROUP dient zum Erstellen einer Replikations-sichtengruppe in der Replikatdatenbank des mobilen Clients, die durch den Nutzer ein-deutig identifiziert ist. Für den Nutzer muss eine Replikatdatenbank registriert sein. Re-plikationssichten, die in der Replikatdatenbank neu angelegt werden, können dieser Re-plikationssichtengruppe zugeordnet werden (Abschnitt 5.7.4.5). Für bereits existierendeReplikationssichten ist ein expliziter Wechsel in diese Replikationssichtengruppe möglich(Abschnitt 5.7.4.6). Die Syntax der Anweisung ist in Syntaxdiagramm 5.19 dargestellt.
>>--CREATE REPLICATION VIEW GROUP--rv-group-name---------->
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.19: Anweisung CREATE REPLICATION VIEW GROUP
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Beschreibung der Parameter
rv-group-nameDer Parameter übergibt den Namen der neuen Replikationssichtengruppe. Unterrv-group-name darf noch keine Replikationssichtengruppe exsistieren und der re-siervierte Name STRDRVG darf nicht benutzt werden.
Beispiel
CREATE REPLICATION VIEW GROUP Alles_zu_Jena
Abbildung 5.20: Beispiel für die Anweisung CVG
Erstellen einer Replikationssichtengruppe mit dem Namen Alles_zu_Jena(Abbildung 5.20).

5.7. ANWEISUNGSSCHNITTSTELLE 159
5.7.4.4 DROP REPLICATION VIEW GROUP
Die Anweisung DROP REPLICATION VIEW GROUP dient zum Löschen einer existierenden Re-plikationssichtengruppe. Für den Nutzer muss eine Replikatdatenbank registriert sein. DasLöschen einer Replikationssichtengruppe ist nur zulässig, wenn ihr keine Replikationssich-ten mehr angehören. Die Standardreplikationssichtengruppe kann nicht gelöscht werden.Die Syntax der Anweisung ist in Syntaxdiagramm 5.20 dargestellt.
>>--DROP REPLICATION VIEW GROUP--rv-group-name------------>
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.20: Anweisung DROP REPLICATION VIEW GROUP
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Beschreibung der Parameter
rv-group-nameDer Parameter übergibt den Namen der zu löschenden Replikationssichtengruppe.Die über rv-group-name referenzierte Replikationssichtengruppe muss existieren unddarf nicht identisch mit der Standardreplikationssichtengruppe sein.
Beispiel
DROP REPLICATION VIEW GROUP Alles_zu_Jena
Abbildung 5.21: Beispiel für die Anweisung DVG
Löschen der Replikationssichtengruppe mit dem Namen Alles_zu_Jena (Abbildung 5.21).
5.7.4.5 CREATE REPLICATION VIEW
Die Anweisung CREATE REPLICATION VIEW dient zum Erstellen einer Replikationssichtin der Replikatdatenbank des mobilen Clients. Die Syntax der gesamten Anweisungist in den Syntaxdiagrammen 5.21 und 5.22 dargestellt. Das Syntaxdiagramm derim Prototypen erlaubten Replikationsanfragen (restricted-select-statement) ist inKapitel 4.8 auf Seite 107 angegeben. Grundlage ist das Schema der Replikatdatenbank. Fürdie erfolgreiche Ausführung muss für den Nutzer eine Replikatdatenbank registriert sein.Wird ein änderbarer Zugriff gefordert (OPTIMISTIC... oder EXCLUSIVE...), müssen füreine Gewährung folgende drei Bedingungen erfüllt sein:

160 KAPITEL 5. DER REPLICATION PROXY SERVER
>>--CREATE REPLICATION VIEW--rv-name---------------------->
>---AS--restricted-select-statement----------------------->
>---FOR OFFLINE--| requested actions |-------------------->
.--WITH CHECK OPTION--.>---+---------------------+------------------------------->
‘---NO CHECK OPTION---’
>---+----------------------------------------------+------>‘--INTO REPLICATION VIEW GROUP--rv-group-name--’
>---+------------------------------------+---------------->‘--| conflict handling parameters |--’
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.21: Anweisung CREATE REPLICATION VIEW
requested actions
|-----+--READ--------------------+------------------------|+--OPTIMISTIC READ INSERT--++--OPTIMISTIC ALL----------++--EXCLUSIVE READ INSERT---+‘--EXCLUSIVE ALL-----------’
conflict handling parameters
|---POOL--number-keys--KEYS-------------------------------|
Syntaxdiagramm 5.22: Optionen für Zusicherungen und Konfliktbehandlung
1. Die Replikationssicht basiert ausschließlich auf Replikattabellen, deren zugehörigekonsolidierte Tabellen änderbar sind.
2. Die für die Replikationssicht anzulegende lokale Sicht ist entsprechend der Sichtenän-derbarkeitskriterien des Client-DBMS änderbar. In der prototypischen Implementie-rung darf im FROM-Teil der Replikationsanfrage nur eine Replikattabelle referenziertwerden (Unteranfragen im WHERE-Teil sind möglich).
3. Die anderen mobilen Clients gewährten Änderbarkeitszusicherungen stehen der Ge-währung der Änderbarkeitszusicherung nicht entgegen (Kapitel 3.4.5).
Im Anschluss an eine erfolgreiche Ausführung steht in der Replikatdatenbank eine Sichtmit den folgenden Eigenschaften zur Verfügung:

5.7. ANWEISUNGSSCHNITTSTELLE 161
1. Die Sicht basiert auf den Replikattabellen, welche sich in der entsprechenden Repli-katdatenbank des mobilen Client befinden.
2. Der Name der Sicht ist mit dem Namen der Replikationssicht identisch.
3. Zur Datenauswahl wird bei der Sichtdefinition die angegebene Replikationsanfrageverwendet.
4. Bei der Sichtdefinition wird genau dann WITH CHECK OPTION spezifiziert, wenn beider Definition der Replikationssicht nicht die Option NO CHECK OPTION gewählt wur-de.
Bevor die für die Replikationssicht angelegte lokale Sicht zum unverbundenen Arbeiten ge-nutzt werden kann, muss die zugehörige Replikationssichtengruppe synchronisiert werden.
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Anwendungsauthentisierung und -autorisierung
Optional kann von der Anwendung eine Stored Procedure (im Prototyp für DB2) mit derin Abbildung 5.22 angegebenen Signatur bereitgestellt werden. Der Prozedur werden vomRPS übergeben: der RPS-Nutzername, das restricted-select-statement aus der Sich-tendefinition, die angeforderte Zusicherung und der Identifikator für die Anwendungsnut-zerverwaltung. Als Rückgabe enthält der Parameter authorized genau dann das ZeichenY, wenn die Ausführung der Anweisung von der Anwendung autorisiert ist. Optional kannein maximal 256 Zeichen langer Meldungstext zurückgegeben werden, der vom RPS an dieAnwendung weitergegeben wird.
CREATE PROCEDURE CRT_RV_AUTHORITY_CHECK (IN RPS_user_name VARCHAR(128),IN select_stmt VARCHAR(4096),IN requested_action VARCHAR(22),IN Appl_ID VARCHAR(128),OUT authorized CHAR(1),OUT msg VARCHAR(256)
)
Abbildung 5.22: Signatur der Prozedur zur Anwendungsnutzerverwaltung bei CRV
Beschreibung der Parameter
rv-nameDieser Parameter übergibt den Namen der neu zu erstellenden Replikationssicht. In

162 KAPITEL 5. DER REPLICATION PROXY SERVER
der Replikatdatenbank des mobilen Client darf noch keine Tabelle, Sicht oder Re-plikationssicht mit diesem Namen existieren. Zulässig sind genau diejenigen Namen,die auch zur Bezeichnung einer in der Replikatdatenbank anzulegenden Sicht gewähltwerden können.
restricted-select-statementAnalog zur Definition einer Sicht wird nach dem Schlüsselwort AS eine Anfrage ange-geben, welche zur Spalten- und Zeilenauswahl genutzt wird. Mit Hilfe dieser Replika-tionsanfrage wird spezifiziert, welche Daten der zu Grunde liegenden konsolidiertenDatenbank für die unverbundene Arbeit benötigt werden. Für die Replikationsan-frage gilt das Syntaxdiagramm 4.1 aus Kapitel 4.8 und die Konventionen des Client-DBMS.
WITH CHECK OPTION, NO CHECK OPTIONDie Default-Option WITH CHECK OPTION besitzt für änderbare Replikationssichtendieselbe Wirkung, wie beim Einsatz in Verbindung mit der Definition einer änder-baren Sicht mit dem Client-DBMS. Aktiviert dient diese Option zur Integritäts-sicherung. Über die Spezifizierung von NO CHECK OPTION kann, beispielsweise zurPerformance-Verbesserung, die Prüfung explizit deaktiviert werden. Es gilt aber zubeachten, dass dann versehentlich durchgeführte unerlaubte Änderungen zu Daten-verlust, zu Konflikten bei der Synchronisation oder sogar zu Inkonsistenzen in derReplikatdatenbank führen können. Die Option ist ohne Bedeutung, wenn die Repli-kationssicht explizit oder implizit durch ihre Definition nur lesenden Zugriff erlaubt.
rv-group-nameDieser optionale Parameter gibt den Namen einer existierenden Replikationssichten-gruppe an, der die neu erstellte Replikationssicht zugeordnet werden soll. Wird dieOption INTO REPLICATION VIEW GROUP nicht spezifiziert, wird die anzulegende Re-plikationssicht der Standardreplikationssichtengruppe STRDRVG zugeordnet.
FOR OFFLINEMit Hilfe dieses Syntaxelements wird eine Zugriffszusicherung für die Replikations-sicht angefordert. Kann die gewünschte Zugriffszusicherung vom RPS auf Grundentgegenstehender anderen Clients gewährter Zugriffszusicherungen nicht gewährtwerden, so ist die Replikationssichtdefinition gescheitert.
READfordert die von der Replikationssicht referenzierten Daten ausschließlich zumLesen an. Änderungen sind in der angelegten lokalen Sicht folglich nicht zu-lässig und es werden vom RPS, falls keine anderen Sichten änderbar sind, aufden referenzierten Tabellen keine Vorkehrungen zur Konfliktbehandlung undReintegration von Daten getroffen.
OPTIMISTIC READ INSERTMit diesem Syntaxelement wird neben dem Lesezugriff die Möglichkeit zum un-verbundenen optimistischen Einfügen gefordert. Für die Reintegration von Än-derungen über diese Replikationssicht kommen die beim CREATE CONSOLIDATEDTABLE festgelegten Konfliktbehandlungsmethoden für das Einfügen zum Ein-satz.

5.7. ANWEISUNGSSCHNITTSTELLE 163
OPTIMISTIC ALLMit diesem Syntaxelement wird der optimistische Vollzugriff (Lesen, Einfü-gen, Ändern, Löschen) für die unverbundene Arbeit mit der Replikationssichtgefordert. Für die Reintegration von Änderungen kommen die beim CREATECONSOLIDATED TABLE festgelegten Konfliktbehandlungsmethoden zum Einsatz.
EXCLUSIVE READ INSERTMit diesem Syntaxelement wird neben dem Lesezugriff die Möglichkeit zumunverbundenen exklusiven Einfügen gefordert. Die Gewährung dieser Zugriffs-zusicherung beinhaltet die Garantie, dass kein Nutzer außer dem Inhaber derZugriffszusicherung Zeilen in die konsolidierte Tabelle einfügen kann. Nur Nut-zer, die über die Rolle „Nutzeradministrator“ verfügen, dürfen diese Zusicherungfordern.
EXCLUSIVE ALLMit diesem Syntaxelement wird der exklusive Vollzugriff (Lesen, Einfügen, Än-dern, Löschen) für die unverbundene Arbeit mit der Replikationssicht gefor-dert. Die Gewährung dieser Zugriffszusicherung beinhaltet die Garantie, dasskein Nutzer außer dem Inhaber der Zugriffszusicherung Zeilen in die konsoli-dierte Tabelle einfügen, im gewählten Ausschnitt verändern oder löschen kann.Änderungen können unabhängig von den spezifizierten Konfliktbehandlungsme-thoden garantiert konfliktfrei reintegriert werden. Nur Nutzer, die über die Rolle„Nutzeradministrator“ verfügen, dürfen diese Zusicherung fordern.
POOL number-keys KEYSDer optionale Parameter legt fest, wieviele Schlüsselwerte für das Einfügen in dieReplikationssicht reserviert werden sollen. Der Parameter darf nur angegeben werden,wenn
1. eine änderbare Replikationssicht vorliegt und
2. die Konfliktbehandlungsoption KeyPool bei der Definition der der Replikatta-belle zugrundeliegenden konsolidierten Tabelle spezifiziert wurde.
Ist der in number-keys angegebene Wert größer als die vom Replikationsadminis-trator bei der Erstellung der konsolidierten Tabelle spezifizierte maximale Anzahlvon Schlüsselwerten je Nutzer, so wird number-keys implizit auf die dort festgelegteMaximalanzahl herabgesetzt.
Beispiel 1
CREATE REPLICATION VIEW Rest_in_ThueringenAS SELECT r.Name, r.Stil
FROM Restaurant r, Ortschaft oWHERE r.OName = o.Name
AND o.LName = ’Thueringen’FOR OFFLINE READ
Abbildung 5.23: Beispiel 1 für die Anweisung CRV

164 KAPITEL 5. DER REPLICATION PROXY SERVER
Erstellen der Replikationssicht Rest_in_Thueringen zur Replikation von Daten zu Restau-rants im Bundesland Thüringen (Abbildung 5.23). Es werden jeweils der Name und derStil ausgewählt. Es sollen im unverbundenen Zustand keine Daten geändert werden, somitwird die Replikationssicht als nur zum Lesen gefordert (FOR OFFLINE READ). Die Replika-tionssicht wird der Standardreplikationssichtengruppe der Replikatdatenbank des Nutzershinzugefügt.
Beispiel 2
CREATE REPLICATION VIEW Reise_in_ThueringenAS SELECT *
FROM Reisebericht bWHERE b.Nr IN (
SELECT BNrFROM Erhaelt eWHERE e.LName = ’Thueringen’
)FOR OFFLINE OPTIMISTIC READ INSERTINTO REPLICATION VIEW GROUP Alles_zu_ThueringenPOOL 1 KEYS
Abbildung 5.24: Beispiel 2 für die Anweisung CRV
Erstellen einer änderbaren Replikationssicht Reise_in_Thueringen für das Hinzufügen ei-nes Reiseberichts zum Bundesland Thüringen (Abbildung 5.24). Die Sicht muss dafür mitder Änderbarkeitszusicherung OPTIMISTIC READ INSERT ausgestattet werden und es mussein Schlüsselwert für das Einfügen angefodert werden. Die Replikationssicht wird der Re-plikationssichtengruppe für Thüringen (Alles_zu_Thueringen) zugeordnet. Damit die Sichtlokal änderbar ist, muss anstatt eines Verbunds eine Unteranfrage verwendet werden.
5.7.4.6 ALTER REPLICATION VIEW
>>--ALTER REPLICATION VIEW--rv-name----------------------->
>---+------------------------------------------------+---->‘--SET REPLICATION VIEW GROUP TO--rv-group-name--’
>---+-----------------------------------------------+----->‘--SET MODIFIABILITY TO--| requested actions |--’
>---+------------------------------------------+---------->‘--| alter conflict handling parameters |--’
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.23: Anweisung ALTER REPLICATION VIEW

5.7. ANWEISUNGSSCHNITTSTELLE 165
alter conflict handling parameters
|---POOL--number-keys--KEYS---------------+---------------|
Syntaxdiagramm 5.24: Optionen der Anweisung ARV
Die Anweisung ALTER REPLICATION VIEW dient zum Ändern der Zugriffszusicherungen,Replikationssichtengruppenzuordnung und Konfliktbehandlungsparameter. Für den Nut-zer muss eine Replikatdatenbank registriert sein. Die Syntax der Anweisung ist in denSyntaxdiagrammen 5.23 und 5.24 dargestellt. Die Bedingungen für die Forderung von Zu-griffszusicherungen entsprechen denen bei CREATE REPLICATION VIEW (Abschnitt 5.7.4.5).Wird die Replikationssicht einer anderen Replikationssichtengruppe zugeordnet, muss dieneue Gruppe zunächst synchronisiert werden, damit die Sicht benutzt werden kann.
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Anwendungsauthentisierung und -autorisierung
CREATE PROCEDURE ALTER_RV_AUTHORITY_CHECK (IN RPS_user_name VARCHAR(128),IN select_stmt VARCHAR(4096),IN requested_action VARCHAR(22),IN Appl_ID VARCHAR(128),OUT authorized CHAR(1),OUT msg VARCHAR(256)
)
Abbildung 5.25: Signatur der Prozedur zur Anwendungsnutzerverwaltung bei ARV
Die Parameter der Prozedur ALTER_RV_AUTHORITY_CHECK (Abbildung 5.25) sind gleichden Parametern von CRT_RV_AUTHORITY_CHECK, so dass auf die Beschreibung dort(Abschnitt 5.7.4.5) verwiesen wird.
Beschreibung der Parameter
rv-nameDieser Parameter übergibt den Namen der zu ändernden Replikationssicht. In derReplikatdatenbank des Client muss eine Replikationssicht mit diesem Namen existie-ren.
rv-group-nameDieser optionale Parameter gibt den Namen einer existierenden Replikationssichten-gruppe an, der die Replikationssicht neu zugeordnet werden soll.

166 KAPITEL 5. DER REPLICATION PROXY SERVER
SET MODIFIABILITY TODem optionalen Syntaxelement folgend wird die neue Zugriffszusicherung für die Re-plikationssicht spezifiziert (siehe Abschnitt 5.7.4.5). Kann die spezifizierte Zugriffs-zusicherung nicht gewährt werden, so wird die Änderung über ALTER REPLICATIONVIEW zurückgewiesen und es gilt die zuvor spezifizierte Zugriffszusicherung weiter.
POOL number-keys KEYSDer optionale Parameter legt fest, wieviele Schlüsselwerte für das Einfügen in dieReplikationssicht reserviert werden sollen. Es gelten dieselben Bedingungen wie beimAnlegen einer Replikationssicht (siehe Abschnitt 5.7.4.5).
Beispiel
ALTER REPLICATION VIEW Rest_in_ThueringenSET REPLICATION VIEW GROUP TO Alles_zu_Thueringen
Abbildung 5.26: Beispiel für die Anweisung ARV
Neuzuordnen der bestehenden Replikationssicht Rest_in_Thueringen zur Replikationssich-tengruppe Alles_zu_Thueringen, die bereits in der Replikatdatenbank des Nutzers existiert(Abbildung 5.26).
5.7.4.7 DROP REPLICATION VIEW
>>--DROP REPLICATION VIEW--rv-name------------------------>
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.25: Anweisung DROP REPLICATION VIEW
Die Anweisung DROP REPLICATION VIEW dient zum Löschen einer existierenden Replika-tionssicht. Für den Nutzer muss eine Replikatdatenbank registriert sein. Die Syntax derAnweisung ist in Syntaxdiagramm 5.25 dargestellt.
Die von der CREATE REPLICATION VIEW-Anweisung angelegte lokale Sicht wird mit erfolg-reichem Löschen der Replikationssicht entfernt. Hierfür maßgeblich sind die Regeln für dasLöschen von Sichten im Client-DBMS. Die von der Replikationssicht referenzierten Datenin den Replikattabellen werden, sofern sie nicht noch von anderen Replikationssichten benö-tigt werden, bei der nächsten Synchronisation der zugehörigen Replikationssichtengruppeauf dem Client gelöscht.
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer

5.7. ANWEISUNGSSCHNITTSTELLE 167
Beschreibung der Parameter
rv-nameDieser Parameter übergibt den Namen der zu löschenden Replikationssicht. In derReplikatdatenbank des Client muss eine Replikationssicht mit diesem Namen existie-ren.
Beispiel
DROP REPLICATION VIEW Rest_in_Thueringen
Abbildung 5.27: Beispiel für die Anweisung DRV
Löschen der Replikationssicht Rest_in_Thueringen (Abbildung 5.27).
5.7.4.8 SYNCHRONIZE
.-ALL------------------------------------.>>-SYNCHRONIZE-+----------------------------------------+->
| .-,-----------. || V | |‘-REPLICATION VIEW GROUP---rv-grp-name---’
>---+--------------+-------------------------------------->‘---ROLLBACK---’
>---| user-management-client |---------------------------><
Syntaxdiagramm 5.26: Anweisung SYNCHRONIZE
Die Anweisung SYNCHRONIZE dient zum Anstoßen der Synchronisation zwischen der kon-solidierten Datenbank und der Replikatdatenbank des Client. Die Syntax der Anweisungist in Syntaxdiagramm 5.26 dargestellt. Für den Nutzer muss eine Replikatdatenbank re-gistriert sein.
Bei der Synchronisation wird eine Menge von Replikationssichtengruppen gemeinsam syn-chronisiert und zwar mindestens alle explizit angegebenen oder alle (Schlüsselwort ALL) Re-plikationssichtengruppen. Zur Konsistenzsicherung kann es erforderlich sein, mehr als dieexplizit geforderten Replikationssichtengruppen zu synchronisieren (siehe Kapitel 4.4.2.3).Nach erfolgreicher Synchronisation gehören die von Replikationssichten der synchronisier-ten Replikationssichtengruppen benötigten Daten zu einem transaktionskonsistenten Da-tenbankzustand.
Der konkrete Synchronisationsablauf ist abhängig vom verwendeten Client-DBMS undSynchronisationsprodukt. Beim Einsatz von MobiLink werden zunächst tabellenweise Än-derungen vom Client an den RPS übertragen, der Konfliktbehandlung unterzogen undschließlich die Ergebnisse plus die Änderungen vom RPS, ebenfalls tabellenweise, zum

168 KAPITEL 5. DER REPLICATION PROXY SERVER
Client übertragen (zur Arbeit mit MobiLink siehe auch [Mül03]). Für die Datenübertra-gung bei der Synchronisation stellt die Replikatverwaltung basierend auf den betroffenenReplikationssichten bzw. Fragmenten entsprechnede Anfragen bereit (siehe Kapitel 4.9).Reintegration und Datenrückübertragung erfolgen jeweils in einer Transaktion auf derkonsolidierten Datenbank. Kommt es zu einem Fehler bei der Reintegration oder der Da-tenübertragung, bricht die Synchronisation ab, und die Transaktion wird zurückgesetzt.
Erforderliche Rolle
Nutzeradministrator
oder
Replikationsnutzer
Anwendungsauthentisierung und -autorisierung
CREATE PROCEDURE SACC_<tabname> (IN RPS_user_name VARCHAR(128),IN Appl_ID VARCHAR(128)OUT authorized CHAR(1),OUT msg VARCHAR(256)
)
Abbildung 5.28: Signatur der Prozeduren zur Anwendungsnutzerverwaltung bei SYN
Optional kann die Anwendung für jede änderbare konsolidierte Tabelle eine Stored Pro-cedure mit der in Abbildung 5.28 angegebenen Signatur bereitstellen. SACC steht als Ab-kürzung für Synchronize Access Control Check und <tabname> ist durch den Namen derkonsolidierten Tabelle zu ersetzen, für welche die Prozedur die Autorisierung vornehmensoll.
Zusätzlich zu den Informationen in den Parametern (siehe Abschnitt 5.7.4.5) werden vomRPS in den Tabellen <tabname>_A und <tabname>_B die Vorher- bzw. Nachherabbilderder zu reintegrierenden Änderungen zur Verfügung gestellt. Jede Prozedur, die zu einerTabelle gehört, für die Änderungen reintegriert werden, wird nach der RPS-Autorisierungund vor der Konfliktbehandlung einmal ausgeführt. Schlägt eine Autorisierung fehl, so wirddie gesamte Synchronisation abgebrochen und die Transaktion zurückgesetzt.
Beschreibung der Parameter
ALL (Default)Das optionale und Default-Syntaxelement gibt an, dass alle Replikationssichtengrup-pen des RPS-Nutzers synchronisiert werden sollen.
rv-grp-nameÜber diesen optionalen Parameter werden explizit die Replikationssichtengruppenfestgelegt, die (mindestens) gemeinsam synchronisiert werden sollen.

5.8. AUFBAU UND ANWEISUNGSVERARBEITUNG 169
ROLLBACKWird das optionale Syntaxelement angegeben, werden alle zu reintegrierenden Ände-rungen des Client bei der Synchronisation verworfen und durch die Datenübertragungauf den Stand der konsolidierten Datenbank (zurück-)gesetzt. Eventuell abweichen-de, beim Anlegen konsolidierter Tabellen spezifizierte, Konfliktbehandlungmethodenwerden nicht verwendet.
Beispiel
SYNCHRONIZE REPLICATION VIEW GROUP Alles_zu_Thueringen
Abbildung 5.29: Beispiel für die Anweisung SYN
Synchronisieren der Replikationssichtengruppe Alles_zu_Thueringen (Abbildung 5.29).Durch Abhängigkeiten zwischen Replikationssichten bzw. Überlappungen ihrer Fragment-mengen oder Fragmente können außerdem weitere Replikationssichtengruppen von der Syn-chronisation betroffen sein.
5.8 Aufbau und Anweisungsverarbeitung
Die beiden folgenden Abschnitte erläutern im Überblick den Aufbau und die Funktionswei-se des RPS-Prototypen sowie die Speicherung der Metadaten. Für eine ausführliche Dar-stellung der Implementierung und des objektorientierten Entwurfs sei auf [Pfe04, Mic04]verwiesen.
Im Sinne einer leichten Anpassbarkeit und Erweiterbarkeit des RPS erfolgt seineImplementierung modular und objektorientiert. Abbildung 5.30 zeigt die Kernmodule(Tabelle 5.3 auf Seite 170) und Hilfsmodule (Tabelle 5.4 auf Seite 172) des RPS und ih-re möglichen Kommunikationsverbindungen untereinander und mit den anderen Kom-ponenten der Dreistufenarchitektur. Auf der linken Seite sind die beiden Zugangswegezur Funktionalität des RPS aufgezeigt. Der erste Weg führt über eine Klassenbibliothek(RPS Client), welche einer Anwendung auf einem Client die Methoden für das Absendenvon Anweisungen an den RPS bereitstellt. Der zweite Weg ist ein Kommandozeilenpro-gramm (RPS CLP), das, in der Regel auf der RPS-Hardware installiert, den adminis-trativen Zugang zum RPS gewährt. Über das Kommandozeilenprogramm können keineClient-Anweisungen ausgeführt werden.
Die Nachrichtenübermittlung wird über Methodenaufrufe realisiert. Jedes Modul verfügtüber klare Schnittstellen und Aufgaben. Den Kern des RPS bilden diejenigen Module,die für die Ausführung der Anweisungen der nutzerdefinierten Replikation verantwortlichsind (im Bild dunkel hinterlegt). Unterstützt werden die Kernmodule von Hilfsmodulen,die Zusatzfunktionen und die systemspezifische Funktionalität anbieten. Hilfsmodule ori-entieren sich am Mediator-Entwurfsmuster [GHVJ94] und sind austauschbar. Auch ist esmöglich, von einem Hilfsmodul verschiedene Implementierungen bereitzustellen, z. B. fürjedes unterstützte DBMS-Produkt.
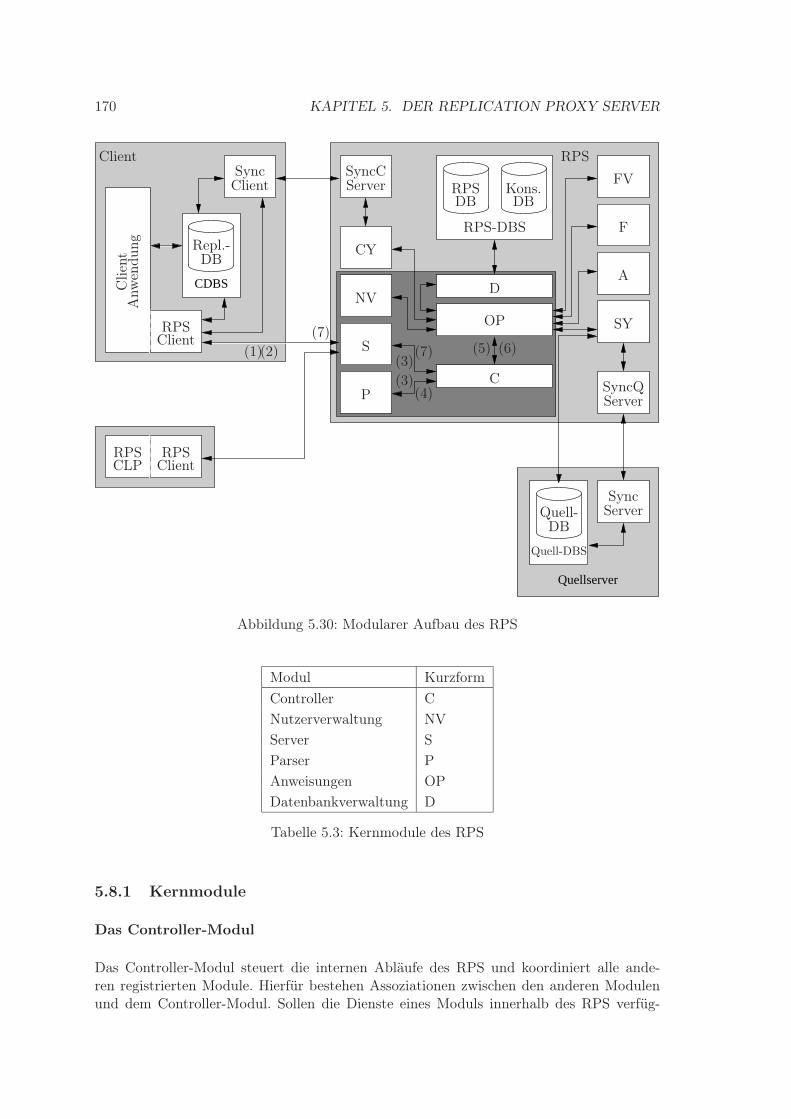
170 KAPITEL 5. DER REPLICATION PROXY SERVER
CDBS
Quellserver
C
NV
S
P
OP
D
F
FV
SY
CY
A
Clie
nt
Client
Client
Client
Client
RPS
RPS
RPS RPS
RPS
CLP
Server
Server
Server
Anw
endu
ng
Sync
Sync SyncC
SyncQ
DB
DBDB
DB
Kons.
Quell-
RPS-DBS
Quell-DBS
Repl.-
(1)(2)
(3)(3)
(4)
(5) (6)(7)
(7)
Abbildung 5.30: Modularer Aufbau des RPS
Modul KurzformController CNutzerverwaltung NVServer SParser PAnweisungen OPDatenbankverwaltung D
Tabelle 5.3: Kernmodule des RPS
5.8.1 Kernmodule
Das Controller-Modul
Das Controller-Modul steuert die internen Abläufe des RPS und koordiniert alle ande-ren registrierten Module. Hierfür bestehen Assoziationen zwischen den anderen Modulenund dem Controller-Modul. Sollen die Dienste eines Moduls innerhalb des RPS verfüg-

5.8. AUFBAU UND ANWEISUNGSVERARBEITUNG 171
bar gemacht werden, so muss dieses beim Controller registriert werden. Dieser instantiiertdaraufhin das Modul und vermittelt dessen Dienste innerhalb des RPS. Auf diese Weisewird eine Entflechtung der wechselseitigen Beziehungen zwischen den dienstanbietendenund dienstkonsumierenden Modulen erreicht.
Das Nutzerverwaltungsmodul
Aufgabe des Nutzerverwaltungsmoduls ist die Authentisierung der Nutzer des RPS unddie Autorisierung der von ihnen angestoßenen Aktionen. Hierfür werden dem RPS zumeinen Möglichkeiten zur Verifikation von Nutzerkennungen und Passwörtern bereitgestellt,zum anderen werden Methoden zur Sicherstellung von Berechtigungen im Kontext des rol-lenbasierten Rechtekonzepts angeboten. Diese beinhalten die Möglichkeit, Nutzern Rollenzuzuweisen und zu entziehen und das Vorhandensein einer für eine Anweisung notwendigenRolle zu überprüfen. Die Zugriffe auf Nutzer- und Berechtigungsdaten erfolgen mit Hilfedes Controller-Moduls über das Datenbankverwaltungsmodul.
Das Server-Modul
Das Server-Modul ist die Schnittstelle des RPS zu den mobilen Clients, über die die-se Anweisungen an den RPS absetzen können. Das Server-Modul verwaltet die Socket-Verbindungen der mobilen Clients mit dem RPS. Eingehende Anweisungen leitet das Mo-dul an das Controller-Modul zur Ausführung weiter. In der Gegenrichtung werden alle vomController-Modul zurückgelieferten Rückgabewerte an die mobilen Clients weitergeleitet.
Das Parser-Modul
Das Parser-Modul nimmt einen Anweisungstext entgegen, prüft die Syntax auf Korrekt-heit und instantiiert eine Objektrepräsentation der Anweisung, welche anhand des An-weisungstyps ermittelt und mit den extrahierten Parameterwerten initialisiert wird. Dasfertige Objekt wird vom Parser an das Controller-Modul übergeben und durch dieses zurAusführung gebracht.
Das Anweisungsmodul
Das Anweisungsmodul enthält für jede Anweisung des RPS eine Klasse. Die Klassen sind sokonzipiert, dass sich ihre instantiierten und initialisierten Anweisungsobjekte selbständigausführen können. Dazu greifen sie auf die von den Modulen über den Controller angebo-tenen Dienste zu. Dadurch ist es einfach möglich, neue Anweisungen hinzuzufügen, ohneSeiteneffekte auf die anderen Module des RPS auszuüben.
Das Datenbankverwaltungsmodul
Das Datenbankverwaltungsmodul stellt die Verbindung zu den verschiedenen Datenbankendes RPS her (konsolidierte Datenbank und RPS-Hilfsdatenbank). Der jeweils verwendete

172 KAPITEL 5. DER REPLICATION PROXY SERVER
Modul KurzformFragmentierer FFragmentverwaltung FVServer-Synchronisation SYClient-Synchronisation CYAnwendungskomponenten A
Tabelle 5.4: Hilfsmodule des RPS
Datenbanktreiber wird gekapselt6 und Methoden für den Aufbau einer Datenbankverbin-dung, für das Absetzen von DDL- und DML-Anweisungen sowie für das Abschliessen undZurückrollen von Transaktionen zur Verfügung gestellt. Alle relevanten Meldungen desDBMS werden an das aufrufende Modul zurückgegeben.
5.8.2 Hilfsmodule
Das Fragmentierer-Modul
Das Fragmentierer-Modul stellt innerhalb des RPS die in Kapitel 4 ausführlich erläuterteFunktionalität des Fragmentkonzepts bereit. Darunter fallen die folgenden Aufgaben:
• Erstellung und Anpassung der Fragmentierung
• Ermittlung und Bereitstellung von Sperrobjekten auf Basis der Fragmentierung
• Umsetzung von Datenbankanfragen auf die von ihnen betroffenen Fragmentmengen
• Umsetzung von Fragmentbeschreibungen auf SQL-Anweisungen zur Ermittlung derdurch die Fragmente repräsentierten Datensätze in der Datenbank.
Das Fragmentverwaltungsmodul
Die zwei Aufgaben des Fragmentverwaltungsmoduls sind:
• Verwaltung (Zuteilung und Speicherung) von Fragmenten der mobilen Clients ent-sprechend ihren Replikationsanfragen.
• Verwaltung und Sicherstellung der Einhaltung von Zugriffszusicherungen.
Das Server-Synchronisationsmodul
Das Server-Synchronisationsmodul kapselt die gesamte Funktionalität zur Bereitstellung,Durchführung und Überwachung des kontinuierlichen Datenabgleichs zwischen den Quell-Servern und den konsolidierten Datenbanken. Hierzu gehört beispielsweise die Einrichtungder Replikationsumgebung und die Parametrisierung des asynchronen Datenabgleichs.
6In der voliegenden prototypischen Implementierung des RPS werden ausschließlich JDBC-Treiber ver-wendet.

5.8. AUFBAU UND ANWEISUNGSVERARBEITUNG 173
Den eigentlichen Datenabgleich stellt das Server-Synchronisationsmodul nicht selbst zurVerfügung, sondern bindet hierfür eine externe Synchronisationsanwendung ein. Im vorlie-genden Prototypen ist das der DB2 DataPropagator.
Das Client-Synchronisationsmodul
Das Client-Synchronisationsmodul stellt die Funktionalität für die Synchronisation dermobilen Clients zur Verfügung. Hierzu gehören neben der eigentlichen Einrichtung undÜberwachung der Synchronisation insbesondere die Erfüllung spezieller Anforderungen,die sich aus der nutzerdefinierten Replikation ergeben. So müssen sowohl die vom Repli-kationsadministrator spezifizierten Konfliktbehandlungsmethoden angewandt werden, alsauch eine Überprüfung auf Einhaltung der Fragmentgrenzen beim Reintegrieren von Datendurch die Clients stattfinden (siehe Sicherheitsaspekte in Abschnitt 5.6).
Wie beim Server-Synchronisationsmodul führt das Client-Synchronisationsmodul den ei-gentlichen Datenabgleich nicht selbst durch, sondern setzt hierfür eine externe Synchroni-sationsanwendung ein. Im vorliegenden Prototypen ist das Sybase MobiLink.
Das Anwendungskomponentenmodul
Diese Modul verwaltet die von den Anwendungen implementierten Prozeduren zur anwen-dungsgesteuerten Zugriffskontrolle.
5.8.3 Anweisungsverarbeitung
Der prinzipielle Ablauf bei der Verarbeitung einer vom Client initiierten Anweisungsver-arbeitung vom Verbindungsaufbau durch den Client bis zur Rückmeldung durch den RPSist der folgende (Nummern in Abbildung 5.30):
1. Der mobile Client baut über den RPS-Client eine Verbindung zum RPS auf, die vomServer-Modul etabliert wird.
2. Die Anweisung wird vom Client über die offene Verbindung an das Server-Modul desRPS übermittelt.
3. Das Server-Modul leitet die Anweisung mittels Controller-Modul an das Parser-Modul weiter.
4. Im Parser-Modul wird für die Anweisung eine Objektrepräsentation instantiiert undinitialisiert und anschließend dem Controller-Modul übergeben.
5. Das Controller-Modul aktiviert die Selbstausführung des Anweisungsobjektes.
6. Das Anweisungsobjekt führt sich unter Zuhilfenahme der Dienste der anderen RPS-Module selbständig aus und gibt Rückgabewerte an das Controller-Modul zurück.
7. Der Controller reicht die Rückgabewerte über das Server-Modul an den aufrufendenmobilen Client bzw. die RPS-Client-Software zurück.
Anschließend kann der mobile Client weitere Anweisungen an den RPS senden oder dieVerbindung trennen. Für detailierte Fallbeispiele der Anweisungsausführung in Schritt 6anhand von Sequenzdiagrammen sei auf [Pfe04] verwiesen.

174 KAPITEL 5. DER REPLICATION PROXY SERVER
5.9 Hilfsdaten
Für die Arbeit des RPS werden Daten und Schemaelemente benötigt, die Informationenspeichern z. B. über registrierte Datenbanken, von Clients angelegte Replikationssichtenund zu verwendende Konfliktbehandlungsmethoden. Diese Hilfsdaten werden vom RPS inden konsolidierten Datenbanken, den Replikatdatenbanken der Clients und einer separatenRPS-Hilfsdatenbank abgelegt.
Welche Daten vom RPS gespeichert werden müssen, ist auch abhängig von den verwen-deten DBS-Produkten auf Quell- und Client-Seite und besonders von den Synchronisati-onsprodukten. Die im folgenden beschriebene Datenmodellierung ist deshalb bis zu einemgewissen Grad spezifisch für die verwendeten Produkte DB2/DataPropagator und Adapti-ve Server-Anywhere/MobiLink. Für eine Beschreibung der von den eingesetzten Synchro-nisationsprodukten selbst zusätzlich benötigten Hilfsdaten sei auf [Mül03] verwiesen.
5.9.1 Die RPS-Hilfsdatenbank
CON_DBNAME
CON_DBUSER
CON_DBPWD
RC_DBNAME
SRC_DBUSER
SRC_DBPWD
CON_DATABASE assignedtois
hasML_SRVNAME ML_PORTNR
ACTIVATED DP_APPLYQ CLIENT_ID PASSWORD
USER
ROLEROLENAME
(0,1)
(0,*)
(0,*)
(0,*)
Abbildung 5.31: E/R-Diagramm der RPS-Hilfsdatenbank [Pfe04]
In der RPS-Hilfsdatenbank werden alle anwendungs- und datenbankunabhängigen Datendes RPS abgelegt. Dazu gehören die Informationen über konsolidierte Datenbanken unddie Nutzerverwaltung des RPS. Die Daten der RPS-Hilfsdatenbank sind nur RPS-seitigverfügbar und nicht zur Replikation durch Clients freigegeben. Abbildung 5.31 zeigt dasE/R-Diagramm der RPS-Hilfsdatenbank. Die Namen von Entitätstypen und Attributenentsprechen den Namen der Tabellen und Spalten in der relationalen Umsetzung (siehedazu [Pfe04]).
Entitätstyp CON_DATABASE
Der Entitätstyp CON_DATABASE repräsentiert die vom RPS für jede registrierte kon-solidierte Datenbank vorliegenden Informationen. Dazu gehören der Name der registrier-

5.9. HILFSDATEN 175
ten konsolidierten Datenbank (CON_DBNAME) als Primärschlüsselattribut und der Nameder Quelldatenbank (SRC_DBNAME). Damit bei späteren Zugriffen durch den RPS undauch der Synchronisations-Software nicht jedesmal erneut vom Nutzer eine Nutzerkennungeingegeben werden muss, werden eine gültige Nutzername/Passwort-Kombination sowohlfür die konsolidierte Datenbank (Attribute CON_DBUSER und CON_DBPWD) als auchfür die Quelldatenbank (Attribute SRC_DBUSER und SRC_DBPWD) gespeichert. DerWert des Attributs ACTIVATED gibt Auskunft darüber, ob der kontinuierliche Datenab-gleich zwischen Quelldatenbank und konsolidierter Datenbank aktiviert ist. Für die Durch-führung der Client-Synchronisation mit MobiLink müssen der Name ML_SRVNAME)des Synchroninsations-Server und dessen Zugriffsport (ML_PORTNR) gespeichert wer-den [iAn04b].
Entitätstyp USER
Die Entitäten in USER stehen für jeweils einen Nutzer der RPS-Nutzerverwaltung. DieNutzerkennung und das Passwort werden in den Attributen CLIENT_ID7 (Primärschlüs-selattribut) und PASSWORD gespeichert. Ein Nutzer kann höchstens einer konsolidiertenDatenbank zugeordnet sein, für die er Anweisungen ausführen darf.
Entitätstyp ROLE
Die Rollen der Nutzerverwaltung des RPS werden durch Entitäten des Typs ROLE re-präsentiert. Eine Rolle ist durch einen eindeutigen Namen ROLENAME gekennzeichnet.Benutzer erlangen die mit einer Rolle assoziierten Berechtigungen, indem sie durch eineBeziehung mit dieser Rolle verknüpft werden. Eine Rolle kann dabei an mehrere Nutzervergeben werden und ein Nutzer kann mehrere Rollen innehaben (m:n-Beziehung).
5.9.2 Hilfsdaten in der konsolidierten Datenbank
In der konsoliderten Datenbank selbst werden die zu den konsolidierten Tabellen und denreplizierenden Clients gehörenden Hilfsdaten abgelegt. Abbildung 5.32 auf Seite 178 zeigtdas E/R-Diagramm der Hilfsdaten in der konsolidierten Datenbank, die bei der Regis-trierung einer Datenbank als konsolidierte Datenbank angelegt werden. Nicht angegebensind die Schemaelemente für die Konfliktbehandlung (z. B. Tabellen für die Schlüsselwer-te beim KeyPool-Verfahren), für eine Beschreibung sei auf [Bit04] verwiesen. Ebenfallsnicht im Diagramm sind die in Beziehung zum Entitätstyp FRAGMENT stehenden weite-ren Hilfsdaten des Fragmentierers, die bereits in Kapitel 4 vorgestellt wurden. Die Namenvon Entitätstypen und Attributen entsprechen wieder den Namen, welche für die Tabel-lendefinitionen verwendet wurden.
Im Gegensatz zur RPS-Hilfsdatenbank stehen die zur konsoliderten Datenbank gehören-den Hilfsdaten im Modus READ ONLY für die nutzerdefinierte Replikation durch Clientszur Verfügung. Damit ein effizienter Zugriff möglich ist, sollte vom Administrator eineFragmentierung für die Spalte CLIENT_ID der Tabelle REPL_DATABASE (zum gleichnamigenEntitätstyp) durchgeführt werden.
7Durch die Namenswahl wird verdeutlicht, dass eine RPS-Nutzerkennung zur eindeutigen Identifikationeines Client verwendet wird.

176 KAPITEL 5. DER REPLICATION PROXY SERVER
Entitätstyp CON_TABLE
Der Entitätstyp CON_TABLE repräsentiert die durch den Replikationsadministratorangelegten konsolidierten Tabellen der konsolidierten Datenbank. Gespeichert werdender Name der konsoliderten Tabelle (Primärschlüssel CON_TABNAME) und der voll-ständige (DB2-)Name der (einen) zugrundeliegenden Quelltabelle (SRC_TABNAME,SRC_TABSCHEMA). Weiter werden gespeichert die Selektionsanweisung (PREDICATE)und die boolschen Attribute zur Kennzeichnung der konsolidierten Tabelle entweder alsnur lesbar (READ_ONLY) oder nicht durch Clients replizierbar (NO_CLIENT_REPL).Die den Clients empfohlene Auffrischungszeit in Stunden ist im Attribut EXPIRY_HOURSerfasst. Weitere Schemainformationen zu einer konsolidierten Tabelle (z. B. Spaltennamenund Integritätsbedingungen) können dem Datenbankkatalog der konsolidierten Datenbankentnommen werden.
Entitätstyp RPL_DATABASE
Im Entitätstyp RPL_DATABASE werden alle für die konsolidierte Datenbank von Clientsregistrierten Replikatdatenbanken gespeichert. Abgelegt sind der Name der lokalen Re-plikatdatenbank und als Primärschlüssel der RPS-Nutzername (CLIENT_ID), für den dieRegistrierung erfolgte. Jede konsolidierte Tabelle, die von einer Replikationssicht des Clientbenötigt wird, muss einmalig für die Synchronisation und gegebenenfalls für Konfliktver-meidungstechniken initialisiert werden. Um zu protokollieren, dass eine konsolidierte Ta-belle für eine Replikatdatenbank bereits initialisiert wurde, wird eine Beziehung zwischender konsolidierten Tabelle und der Replikatdatenbank gespeichert.
Entitätstyp REPLICATIONVIEW
Die Replikationssichten werden durch den Entitätstyp REPLICATIONVIEW repräsen-tiert. Der Name der Sicht (RV_NAME) bildet den Primärschlüssel. Aus der erfolgrei-chen Replikationssichtendefinition übernommen werden die gewährte Zugriffszusicherung(ACTION) und die boolsche Angabe über die Änderbarkeit der Sicht auf dem Client(VIEW_IS_UPDATEABLE). Der Synchronisationsstatus (RELEASED) gibt an, ob eine Re-plikationssicht nach der Erstellung oder einer Änderung mittels ALTER REPLICATION VIEWbereits synchronisiert wurde.
Eine Replikationssicht gehört immer zu genau einer Replikatdatenbank und ihr könneneine oder mehrere konsolidierte Tabellen zugrundeliegen. Die Tabellennamen werden zurBestimmung der Synchronisationsanfragen benötigt (siehe Kapitel 4.9). Außerdem ist diekonsolidierte Tabelle besonders gekennzeichnet, für welche eine Änderbarkeitszusicherunggefordert wurde (MAIN_TABLE).
Eine Replikationssicht ist genau einer Replikationssichtengruppe (s. u.) zugeordnet, ent-weder explizit bei der Definition oder implizit der Standardgruppe. Zur Bestimmung derDaten für die Synchronisation werden für jede Replikationssicht die von ihr referenziertenFragmente gespeichert.
Entitätstypen FRAGMENT, LOCK_ITEM
Der Entitätstyp FRAGMENT repräsentiert die zu den Replikationssichten gehörenden Frag-mente. Der Primärschlüssel ist die Datenfragmentnummer (F_ID). Die zugehörige Tabelle

5.9. HILFSDATEN 177
in der relationalen Umsetzung referenziert die in Kapitel 4.7 eingeführten Fragmentta-bellen. Für jedes Fragment, das eine Sicht referenziert, wird für die zugehörige Replikat-datenbank in einer Beziehung der Zeitpunkt der letzten Synchronisation des Fragmentes(SYNC_TIME) gespeichert. Diese Information wird bei der Ansteuerung von MobiLink be-nötigt. Für die Verwaltung der Zugriffszusicherungen und die abhängige Synchronisationvon Replikationssichtengruppen werden die vorberechneten Informationen zu Sperrobjek-ten (LOCK_ITEM) über eine Beziehung referenziert (siehe Kapitel 4.10).
Entitätstyp RVGROUP
Die Informationen zu den Replikationssichttengruppen werden in RVGROUP modelliert.Der Name der Gruppe RVGROUPNAME ist der Primärschlüssel. Mit dem boolschen At-tribut COMPOUND_CHANGED wird festgehalten, dass sich die Überlappung der Replika-tionssichtengruppe mit anderen Replikationssichtengruppen möglicherweise geändert hat(z. B. durch Hinzufügen einer Replikationssicht). Die Neuberechnung der Überlappung er-folgt nicht sofort, sondern erst bei der nächsten Synchronisation. Jede Replikationssichten-gruppe ist genau einer Replikatdatenbank zugeordnet. Über die rekursive m:n-Beziehungwird die transitive Überlappungsrelation, die sich aus den Fragmentüberlappungen berech-nen läßt (siehe Kapitel 4.4.2.3), für den schnellen Zugriff redundant gespeichert.
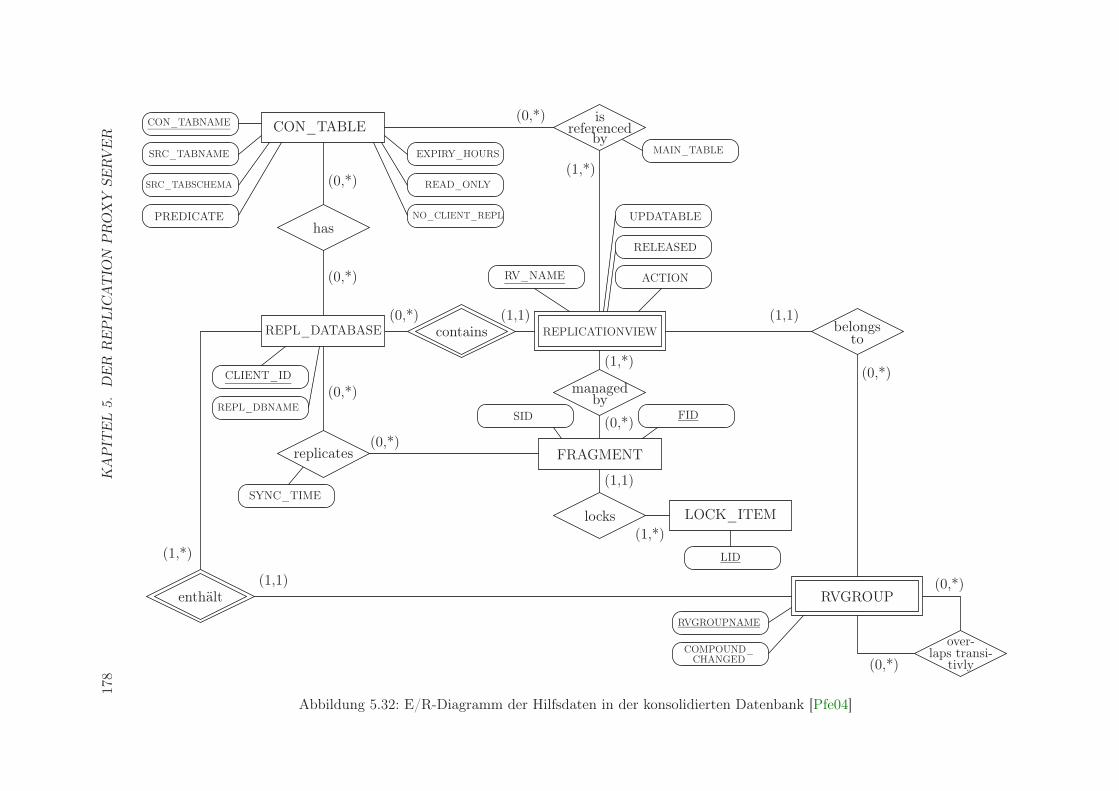
178
KA
PIT
EL
5.D
ER
RE
PLI
CA
TIO
NP
RO
XY
SERV
ER
enthält
MAIN_TABLE
has
isreferenced
by
by
over-laps transi-
tivly
contains
replicates
belongsto
locks
managed
CON_TABNAME
SRC_TABNAME
SRC_TABSCHEMA
PREDICATE
EXPIRY_HOURS
READ_ONLY
NO_CLIENT_REPL
CON_TABLE
REPL_DATABASE
CLIENT_ID
REPL_DBNAME
REPLICATIONVIEW
ACTION
RELEASED
UPDATABLE
RV_NAME
FRAGMENT
SID
LOCK_ITEM
LID
RVGROUP
RVGROUPNAME
COMPOUND_CHANGED
FID
SYNC_TIME
(1,1)(1,1)
(1,1)
(1,1)
(1,*)
(1,*)
(1,*)
(1,*)
(0,*)
(0,*)
(0,*)
(0,*)(0,*)
(0,*)
(0,*)
(0,*)
(0,*)
(0,*)
Abbildung 5.32: E/R-Diagramm der Hilfsdaten in der konsolidierten Datenbank [Pfe04]

Kapitel 6
Beispielanwendung Hermes
In diesem Kapitel werden wichtige Entwurfs- und Implementierungsaspekte des datenbank-gestützten interaktiven mobilen Reiseinformationssystems Hermes1 vorgestellt. Hermessetzt das in Kapitel 1.1 als Beispiel für mobilspezifische Anwendungen skizzierte Reisein-formationssystem mit Hilfe der Möglichkeiten nutzerdefinierter Replikation und des RPS-Prototypen um.
Hermes wurde im Rahmen mehrerer Studien- und Diplomarbeiten entworfen und imple-mentiert [Wie04, Bau04, Bau03]. Die parallel zur Konzeption der nutzerdefinierten Re-plikation stattfindende Entwicklung von Hermes gestattete es, Konzepte frühzeitig zuerproben und durch Rückkopplung mit der Anwendung weiterzuentwickeln und zu verbes-sern. Die wichtigsten Ergebnisse der Anwendungsentwicklung fasst das vorliegende Kapitelzusammen. Für eine ausführliche Dokumentation von Hermes sei jedoch auf die zitiertenArbeiten verwiesen.
Das weitere Kapitel gliedert sich wie folgt. Der erste Abschnitt 6.1 erläutert die Idee vonHermes, daraus resultierende Anforderungen und gibt einen Überblick zur Realisierung,die in den daran anschließenden Abschnitten genauer betrachtet wird. Abschnitt 6.2 er-läutert den Datenbankentwurf. Die Client-Anwendung und das Repository zur Verwal-tung von Replikationssichten werden in Abschnitt 6.3 vorgestellt. Abschließend wird imAbschnitt 6.4 die Arbeit mit der Hermes-Client-Anwendung an Beispielen verdeutlicht.
6.1 Grundlagen
Hermes ist ein Reiseinformationssystem „von Nutzern für Nutzer“. Im Gegensatz zu klassi-schen elektronischen Touristenführern mit einem zentralen Informationsanbieter und vielenKonsumenten, werden bei Hermes die Nutzer selbst durch das Sammeln und Einbrin-gen von Daten vor Ort am Aufbau und an der Pflege des Informationsangebotes betei-ligt [BG03]. Zentral bereitgestellt wird nur das Gerüst mit einer Grundmenge an Infor-mationen, z. B. die nur selten anzupassenden geographischen und politischen Basisdatenüber Landschaften und Orte. Der Großteil der eigentlichen Reiseinformationen zu Sehens-würdigkeiten, Hotels oder gastronomischen Einrichtungen wird dann von den Nutzern imLaufe der Zeit ergänzt und aktualisiert.
1[griech. Mythologie] Götterbote, Schutzgott des Verkehrs
179

180 KAPITEL 6. BEISPIELANWENDUNG HERMES
6.1.1 Motivation
Die aktive Beteiligung der Nutzer an der Ausgestaltung des Informationsangebots bietetgegenüber rein zentral gewarteten Informationen mehrere Vorteile:
• Das Informationsangebot entspricht den Interessen der Nutzer, es kann also ein hoherRelevanzgrad für die angebotenen Informationen erreicht werden.
• Der erhebliche Aufwand für die Beschaffung, Korrektur und Aktualisierung der In-formationen kann auf viele Nutzer verteilt werden. Vorstellbar ist auch, dass Hotel-und Restaurantbetreiber selbst Eintragungen in Hermes vornehmen, die dann vonihren Gästen bewertet und kontrolliert werden.
• Die Attraktivität des Reiseinformationssystems für die Nutzer (und damit auch seineAkzeptanz) wird gefördert, denn jeder kann durch seinen eigenen Beitrag zu einem„Teil des Projekts“ werden.
6.1.2 Anforderungen und Lösungen
Das „Funktionieren“ von Hermes in der Praxis setzt allerdings voraus, dass sich viele Nut-zer mit breit gefächerten Interessen an der Informationsbeschaffung beteiligen. Die primäreZielgruppe von Hermes sind technisch interessierte und mit tragbaren Rechnern (PDAs,aber auch Notebooks) ausgestattete Touristen und Geschäftsreisende. Eine ausreichendeAkzeptanz in diesen Zielgruppen lässt sich indes nicht allein durch das bereits genannteGemeinschaftsgefühl erzielen, hier zählen handfeste Kriterien, wie Kosten, Verfügbarkeitund Qualität des Informationsangebots.
Den wesentlichen Kostenfaktor bei der Benutzung von Hermes stellen die Kommunikati-onskosten dar. Die Hermes-Strategie zur Reduktion von Kommunikationskosten beinhal-tet zwei Elemente:
1. Die volle Kontrolle des Nutzers darüber, wann, wo und wie Daten ausgetauscht wer-den und
2. die prinzipielle Verfügbarkeit eines Großteils an Funktionalität auch im unverbunde-nen Zustand, wobei der Nutzer auch hier die Kontrolle darüber hat, welche Datendazu lokal auf seinem mobilen Rechner gespeichert werden.
Beide Elemente zusammen ermöglichen dem Nutzer die gezielte Ausnutzung günstigerKommunikationsmedien (z. B. eines kostenlosen WLAN-Hotspots im Hotel) für den not-wendigen Datenabgleich sowie das zwischenzeitliche verbindungslose Lesen und gegebe-nenfalls Bearbeiten der Informationen, wenn kein geeignetes Kommunikationsmedium zurVerfügung steht.
Eine jederzeitige Verfügbarkeit der Hermes-Funktionalität unabhängig von verfügbarenKommunikationmedien ist aber nicht nur aus Kostengründen ein entscheidender Akzep-tanzfaktor. Wenn Nutzer animiert werden sollen, Informationen beispielsweise über Re-staurants, Sehenswürdigkeiten oder Straßenverhältnisse für Hermes zu sammeln, mussdas zeitnah und direkt vor Ort möglich sein.

6.2. DATENBANKENTWURF 181
Für die Erzielung und Aufrechterhaltung eines nützlichen und qualitativ hochwertigenInformationsangebots sind Anreizsysteme zur Begrenzung reinen Konsumverhaltens (eineVerfahrensübersicht gibt [ON03]) sowie eine ständige Prüfung der Inhalte u. a. auf Aktuali-tät und Konsistenz notwendig. Die Prüfung kann beispielsweise vom Reiseinformationsan-bieter selbst oder besser noch von qualifizierten Nutzern, vergleichbar mit den Moderatorenin Internetforen, durchgeführt werden. Aufgrund des Ziels einer technischen Demonstrati-on wurden die beiden genannten Punkte bei der Umsetzung von Hermes ausgeklammert.Sie wären jedoch relevant für den Fall einer Weiterentwicklung hin zu einem einsatzfähigenProdukt (siehe auch Kapitel 7.2).
6.1.3 Realisierung – Überblick
Das Informationsangebot von Hermes wird in einer relationalen Datenbank gespeichert.Der Zugriff auf die Daten erfolgt über eine Anwendung und ein mobiles Datenbanksystem,deren Client-Komponenten der Nutzer auf sein mobiles Gerät installieren muss. Alle vomNutzer benötigten Daten werden über die Hermes-Anwendung ausgewählt und anschlie-ßend mit dem Dienst zur nutzerdefinierten Replikation über die Sprachschnittstelle des RPSauf das mobile Gerät repliziert. Der Lese- und Schreibzugriff erfolgt dann ausschließlichunverbunden auf lokalen Daten. Sollen oder müssen Daten mit der konsolidierten Daten-bank abgeglichen werden, wird von der Client-Anwendung die Synchronisation angestoßen,wobei die Aufnahme einer Verbindung zum Server vom Nutzer bestätigt werden muss.
Die Anwendung wurde vollständig in Java implementiert, so dass eine vergleichsweise leich-te Portierung auf unterschiedliche Hardware-Plattformen möglich ist. Sie verwendet denin Kapitel 5 vorgestellten Prototypen des RPS. Die Architektur der Anwendung und aus-gewählte Implementierungsaspekte sind Gegenstand von Abschnitt 6.3. Der sich anschlie-ßende Abschnitt 6.2 geht zunächst näher auf den Entwurf der Datenbank zur Speicherungdes Informationsangebots ein sowie auf die Besonderheiten bei Verwendung der nutzerde-finierten Replikation.
6.2 Datenbankentwurf
Der Datenbankentwurf für mobile Anwendungen bei Verwendung der nutzerdefiniertenReplikation und des RPS ist komplexer als das Entwurfsverfahren für klassische daten-bankbasierte Anwendungen und gliedert sich allgemein in die folgenden Teilaufgaben:
1. DBS-unabhängiger Datenbankentwurf
Der Entwurf dient als Basis für die Ableitung der weiteren DBS-abhängigen Sche-mata.
2. Bestimmung logischer Einheiten der Replikatauswahl
Die Einheiten der Replikatauswahl werden anhand des zu erwartenden Zugriffsprofilsder Anwendung ermittelt und legen fest, welche Daten getrennt repliziert werdenkönnen oder welche immer gemeinsam aktualisiert werden müssen.
3. Erstellen eines relationalen Datenbankschemas für den Quellserver

182 KAPITEL 6. BEISPIELANWENDUNG HERMES
4. Erstellen des konsolidierten Datenbankschemas für den RPS
Dazu gehören die Auswahl der Konfliktbehandlungsmethoden, die Wahl passen-der Partitionierungsspalten und -werte für die Fragmentierung sowie ggf. die Im-plementierung der Prozeduren für die zweite Stufe der Nutzerverwaltung (sieheKapitel 5.4.2).
5. Erstellen der Replikatdatenbankschemata für die verschiedenen Client-DBMS
Die Schritte 1 und 3 sind nur erforderlich und möglich, wenn, wie bei Hermes, eine neueAnwendung und Datenbank erstellt werden. Da alle mobilspezifischen Einstellungen undAbläufe im Schema der konsolidierten Datenbank und der Client-Anwendung festgelegtwerden, lassen sich mit der nutzerdefinierten Replikation aber auch existierende Datenban-ken und Anwendungen um den Zugriff durch mobile Clients erweitern. In den folgendenUnterabschnitten werden die einzelnen Entwurfsschritte am Beispiel von Hermes genauererläutert.
6.2.1 DBS-unabhängiger Datenbankentwurf
Dem DBS-unabhängigen Entwurf, der in der Praxis oft verkürzt oder ganz weggelassenwird, kommt bei der Neuentwicklung mobiler Datenbankanwendungen eine besondere Be-deutung zu, da durch die mögliche Vielfalt der mobilen Clients (Hardware- und Softwa-re) verschiedene Datenbanksysteme mit unterschiedlichen Fähigkeiten unterstützt werdenmüssen. Bevor der Datenbankentwurf für Hermes vorgestellt wird, beschreibt der nach-folgende Unterabschnitt kurz die zugrundegelegte Miniwelt und das Informationsangebotvon Hermes.
6.2.1.1 Informationsangebot
Region
Ort
Gebäude
Hotel Restaurant
Öffentliche Einrichtung Kulturelle Einrichtung
Historisches Gebäude
Navigationsdaten
nutzererstellbare(Basis-)Daten
Abbildung 6.1: Gliederung des Informationsangebots von Hermes
Das Informationsangebot von Hermes ist hierarchisch strukturiert in Navigationsdatenund nutzererstellbare Daten (Abbildung 6.1). Die Navigationsdaten dienen zur Datenaus-

6.2. DATENBANKENTWURF 183
wahl im Informationsangebot und umfassen Regionsdaten (z. B. Länder, Bundesländer,Landkreise) und Grundinformationen zu Ortschaften. Dazu gehören auch bekannte Rei-serouten (z. B. „Weinstraße“), die Orte untereinander verbinden. Navigationsdaten könnenausschließlich zum lesenden Zugriff repliziert werden und werden vom Anbieter bereitge-stellt.
Den überwiegenden Teil des Informationsangebots bilden nutzererstellbare Daten, die vonden mobilen Nutzern zusammengetragen und in die Quelldatenbank eingebracht werden.Prinzipiell können nutzererstellbare Daten von allen Hermes-Nutzern (natürlich auch demAnbieter selbst) verändert, ergänzt oder auch gelöscht werden. Es wird weiter unterschiedenzwischen Basisdaten und Bewertungsdaten, die auf Navigations- und Basisdaten Bezugnehmen.
Zu den Basisdaten gehören die Informationen zu Gebäuden, Hotels, Restaurants, kulturel-len Einrichtungen (z. B. Museen, Theater), historischen Gebäuden (z. B. Burgen, Denkmä-ler) und öffentlichen Einrichtungen (z. B. Rathaus, Polizeistation). Abgespeichert werdenkönnen neben dem Namen und der Adresse eines Gebäudes z. B. Speisekarten bei Restau-rants, Zimmerpreise von Hotels, Öffnungszeiten und i. d. R. noch eine Beschreibung alsFreitext.
Zu den Bewertungsdaten gehören z. B. positive oder negative Empfehlungen für Restau-rants sowie Reiseberichte über Ortschaften. Die meisten Objekte des Informationsangebotslassen sich zudem über ein einfaches Notensystem von 1 (sehr gut) bis 5 (schlecht) bewer-ten. Bewertet werden können das Kulturangebot und der Besuchswert eines Ortes, dieQualität, der Service und die Speisekarte eines Restaurants, Reiseberichte anderer Nut-zer, der Service und die Ausstattung eines Hotels sowie der Besuchswert von kulturellenEinrichtungen und historischen Gebäuden.
Es sei angemerkt, dass die hier für die prototypische Implementierung ausgewählten In-formationen nur eine Auswahl dessen darstellen, was über ein interaktives mobiles Rei-seinformationssystem angeboten und verwaltet werden kann. Aus unserer Sicht sinnvolleErweiterungen des Angebots sind u. a. Informationen zu aktuellen Veranstaltungen undVerkehrsinformationen (z. B. aktuelle Baustellen, günstige Anfahrtswege).
6.2.1.2 E/R-Modellierung
Die Abbildung 6.2 enthält einen Ausschnitt des zum Informationsangebot gehörenden E/R-Diagramms. Das E/R-Diagramm für die Bewertungsmöglichkeiten ist in Abbildung 6.3separat dargestellt (die Semantik wird in Abschnitt 6.2.3 erläutert). Aus Gründen derÜbersichtlichkeit wurde auf die Angabe der Attribute verzichtet. Welche Informationenjeweils gespeichert werden können, ist in der Tabelle 6.1 für die Informationsgruppen(Abschnitt 6.2.2) zusammengefasst. Für eine detaillierte Beschreibung aller Entitäts- undBeziehungstypen, die hier zu weit führen würde, sei auf [Bau04] verwiesen.
Theoretisch ist die E/R-Modellierung unabhängig von einem möglichen replizierenden Zu-griff auf die spätere relationale Datenbank. In der Praxis sollten jedoch beim Neuentwurf,im Hinblick auf einen effizienten Einsatz der nutzerdefinierten Replikation, zumindest diefolgenden Punkte beachtet werden:
• künstliche Primärschlüssel
Für alle Entitätstypen nutzererstellbarer Daten empfiehlt sich die Verwendung ei-nes (einattributigen) künstlichen Primärschlüssels. Das erlaubt den Einsatz des
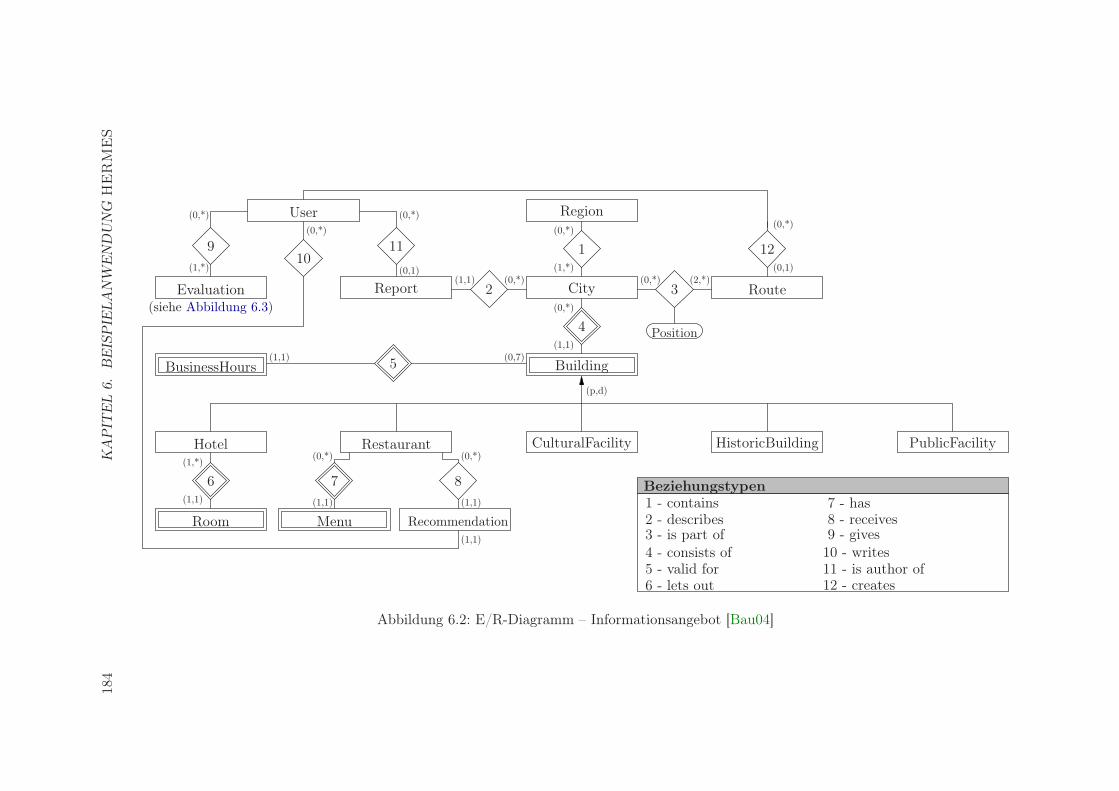
184
KA
PIT
EL
6.B
EIS
PIE
LAN
WE
ND
UN
GH
ER
MES
Region
City
Building
Report Route
Position
Hotel
Room
Restaurant
Menu
CulturalFacility HistoricBuilding PublicFacility
BusinessHours
User
Recommendation
Evaluation(0,1) (0,1)
(0,*)(0,*)(0,*) (0,*)
(0,*)(0,*)
(0,*) (0,*)
(0,*)
(0,*)
(1,1)
(1,1) (1,1)
(1,1)
(1,1)
(1,1)(1,1)
(1,*)
(1,*)
(1,*)
(0,7)
(2,*)
(p,d)
(siehe Abbildung 6.3)
1
2 3
4
5
6 7 8
910
11 12
Beziehungstypen1 - contains2 - describes3 - is part of4 - consists of5 - valid for6 - lets out
7 - has8 - receives9 - gives
10 - writes11 - is author of12 - creates
Abbildung 6.2: E/R-Diagramm – Informationsangebot [Bau04]

6.2. DATENBANKENTWURF 185
City Report
Hotel Restaurant
Menu
CulturalFacility HistoricBuilding
Evaluation
(0,1)
(0,1) (0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)
(0,1)(0,1)
(0,1)
(0,1)
(0,1)
(0,1)(0,1)
(0,1)(0,1)
(1,1)
1 2 3 4 5 6 7
8 9 10 11
Beziehungstypen1 - rates hotel service2 - rates hotel equipment3 - rates restaurant service4 - rates restaurant ambience5 - rates restaurant quality6 - rates cultural facility
7 - rates historic building8 - rates city visit9 - rates city culture10 - rates report11 - rates menu item
Abbildung 6.3: E/R-Diagramm – Bewertungen [Bau04]
Keypool-Verfahrens zur Vermeidung von Einfügekonflikten (siehe Kapitel 2.5.3.3).Das Keypool-Verfahren ist den Alternativen für „natürliche“ Primärschlüssel, Slot-Verfahren oder Änderungskonfliktauflösung vorzuziehen, da es konfliktfreie Einfü-gungen ohne einen zusätzlichen Prüf- oder Vorbereitungsschritt ermöglicht.
• optionale Attribute
Bei der Modellierung muss beachtet werden, dass die Werte aller Attribute, derenAngabe obligatorisch ist, bei der Replikationsanforderung auf den Client kopiert undbei einer Neueingabe durch den Nutzer oder über einen Standardwert eingetragenwerden müssen. Zur Erhöhung der Flexibilität bei der Bildung logischer Einheitenfür die Replikatauswahl (siehe Abschnitt 6.2.2) und damit indirekt zur Reduktionder zu übertragenden Datenmengen, sind Attribute, falls möglich und sinnvoll, alsoptional auszulegen.
6.2.2 Informationsgruppen
Die physischen Einheiten der Replikatauswahl sind die Fragmente. Mit ihrer Hilfe sichertder RPS automatisch die Konsistenz und Vollständigkeit der replizierten Daten basierendauf den Informationen des Datenbankschemas. Über die logischen Einheiten der Replikat-auswahl, im Folgenden als Informationsgruppen bezeichnet, bestimmt die mobile Anwen-dung. Informationsgruppen legen fest, welche Daten dem Nutzer gemeinsam zur Replikati-on angeboten werden und welche optional (auch zu einem späteren Zeitpunkt) auswählbarsind.
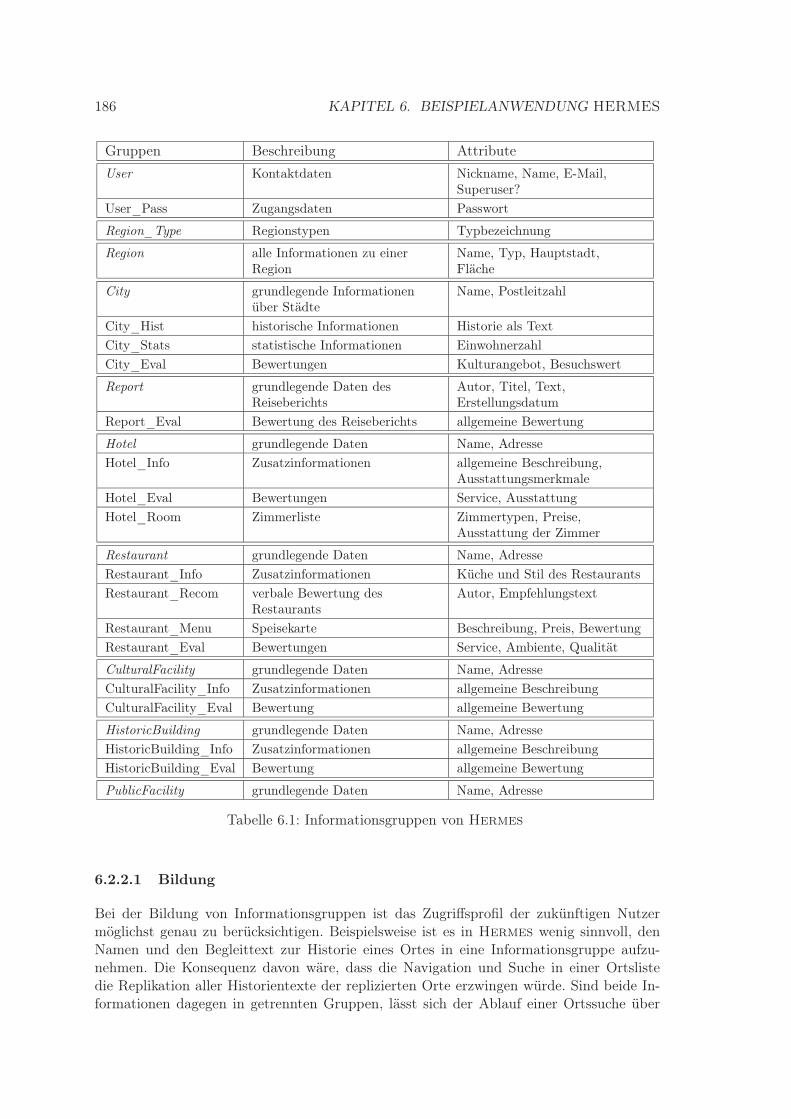
186 KAPITEL 6. BEISPIELANWENDUNG HERMES
Gruppen Beschreibung AttributeUser Kontaktdaten Nickname, Name, E-Mail,
Superuser?User_Pass Zugangsdaten Passwort
Region_Type Regionstypen Typbezeichnung
Region alle Informationen zu einerRegion
Name, Typ, Hauptstadt,Fläche
City grundlegende Informationenüber Städte
Name, Postleitzahl
City_Hist historische Informationen Historie als TextCity_Stats statistische Informationen EinwohnerzahlCity_Eval Bewertungen Kulturangebot, Besuchswert
Report grundlegende Daten desReiseberichts
Autor, Titel, Text,Erstellungsdatum
Report_Eval Bewertung des Reiseberichts allgemeine Bewertung
Hotel grundlegende Daten Name, AdresseHotel_Info Zusatzinformationen allgemeine Beschreibung,
AusstattungsmerkmaleHotel_Eval Bewertungen Service, AusstattungHotel_Room Zimmerliste Zimmertypen, Preise,
Ausstattung der Zimmer
Restaurant grundlegende Daten Name, AdresseRestaurant_Info Zusatzinformationen Küche und Stil des RestaurantsRestaurant_Recom verbale Bewertung des
RestaurantsAutor, Empfehlungstext
Restaurant_Menu Speisekarte Beschreibung, Preis, BewertungRestaurant_Eval Bewertungen Service, Ambiente, Qualität
CulturalFacility grundlegende Daten Name, AdresseCulturalFacility_Info Zusatzinformationen allgemeine BeschreibungCulturalFacility_Eval Bewertung allgemeine Bewertung
HistoricBuilding grundlegende Daten Name, AdresseHistoricBuilding_Info Zusatzinformationen allgemeine BeschreibungHistoricBuilding_Eval Bewertung allgemeine Bewertung
PublicFacility grundlegende Daten Name, Adresse
Tabelle 6.1: Informationsgruppen von Hermes
6.2.2.1 Bildung
Bei der Bildung von Informationsgruppen ist das Zugriffsprofil der zukünftigen Nutzermöglichst genau zu berücksichtigen. Beispielsweise ist es in Hermes wenig sinnvoll, denNamen und den Begleittext zur Historie eines Ortes in eine Informationsgruppe aufzu-nehmen. Die Konsequenz davon wäre, dass die Navigation und Suche in einer Ortslistedie Replikation aller Historientexte der replizierten Orte erzwingen würde. Sind beide In-formationen dagegen in getrennten Gruppen, lässt sich der Ablauf einer Ortssuche über

6.2. DATENBANKENTWURF 187
den Namen mit anschließendem Hinzufügen der Begleittexte nur für ausgewählte Orterealisieren. Das Beispiel zeigt, dass die Informationsgruppenbildung nicht losgelöst vonden zu implementierenden Abläufen betrachtet werden kann. Genauer, über die Informati-onsgruppen werden die Navigation und die Ein-/Ausgabemasken im Informationsangebotbestimmt.
Ebenfalls mit Hilfe der Informationsgruppen werden die Schemaausschnitte unterschie-den, welche später mit verschiedenen Modi zur Client-Replikation ausgestattet werdensollen. Beispielsweise ist es für gespeicherte Nutzerdaten erforderlich, die Zugangsda-ten (Nutzername, Passwort) von den Kontaktdaten (z. B. E-Mail-Adresse) zu trennen.Erstere müssen auf dem RPS in der konsolidierten Datenbank vorliegen, dürfen abernicht auf die mobilen Clients replizierbar sein (Modus no client replication, sieheKapitel 5.7.3.3 auf Seite 140).
Das Informationsangebot von Hermes unterteilt sich in die in Tabelle 6.1 angegebenenGruppen. Hervorgehoben ist jeweils die zu einem Sachverhalt obligatorische Informations-gruppe, die bei einer Auswahl in jedem Fall repliziert wird. In Hermes bilden die Infor-mationsgruppen gleichzeitig auch die kleinste Einheit für die Erfassung neuer Basis- undBewertungsdaten. Für das Hinzufügen eines neuen Gebäudes, egal welchen Typs, müssenalso zunächst nur sein Typ, sein Name und die Adresse bekannt sein. Weitere Angabenkönnen später mit Hilfe der optionalen Informationsgruppen hinzugefügt werden.
6.2.2.2 Realisierungsalternativen
Für die Umsetzung der Informationsgruppen mit dem RPS-Prototypen gibt es drei Alterna-tiven: mit Replikationssichten, im konsolidierten Datenbankschema und beim relationalenEntwurf.
1. Replikationssichten (Abbildung 6.4(a))
Bei dieser Umsetzungsalternative bleiben die Informationsgruppen beim relationalenDatenbankentwurf zunächst unberücksichtigt, d. h. die Abbildung der Entitäts- undBeziehungstypen auf das relationale Modell erfolgt nach den üblichen Regeln. DieBildung der Informationsgruppen geschieht allein durch die Anwendung mit Hilfeentsprechender Replikationssichtendefinitionen zur Laufzeit.
Die Entkopplung der Informationsgruppen vom Datenbankschema bietet maximaleFlexibilität, da sie individuell für jeden mobilen Client zusammengestellt und zurLaufzeit angepasst werden können.
2. konsolidiertes Datenbankschema (Abbildung 6.4(b))
Bei dieser Alternative wird das Quelldatenbankschema ebenfalls direkt aus dem E/R-Entwurf abgeleitet. Die Informationsgruppen werden durch das Anlegen geeigneterkonsolidierter Tabellen (Projektionen der Quelltabellen) und zusätzlicher Fremd-schlüsselverknüpfungen umgesetzt.
Die Gruppenbildung im Schemaentwurf der konsolidierten Datenbank legt die In-formationsgruppen für alle Nutzer fest. Eine Anpassung durch Schemaänderung istdennoch vergleichsweise einfach möglich, da die konsolidierte Datenbank nur repli-zierte Daten enthält.

188 KAPITEL 6. BEISPIELANWENDUNG HERMES
Gruppe 1
Gruppe 2
Gruppe 1 Gruppe 2Gruppe 1 Gruppe 2
konsolidierte Tabelle QuelltabelleReplikationssichten
(a) Replikationssichten
Gruppe 1
Gruppe 2
Gruppe 1 Gruppe 2Gruppe 1
Gruppe 2
konsolidierte Tabellen QuelltabelleReplikationssichten
Fremdschlüssel
(b) Konsolidierte Tabellen
Gruppe 1
Gruppe 2
Gruppe 1
Gruppe 2
Gruppe 1
Gruppe 2
konsolidierte Tabellen QuelltabellenReplikationssichten
FremdschlüsselFremdschlüssel
(c) Relationaler Entwurf
Abbildung 6.4: Realisierungsalternativen für Informationsgruppen
3. relationaler Entwurf (Abbildung 6.4(c))
Diese Alternative entspricht dem Vorgehen bei Alternative 2, nur werden die Infor-mationsgruppen bereits beim Entwurf der Quelldatenbank berücksichtigt.
Die Festlegung der Informationsgruppen erfolgt global für alle konsolidierten Daten-banken, Anwendungen und Nutzer. In der Regel entspricht das konsolidierte Daten-bankschema dann dem Schema der Quelldatenbank.
Für die Auswahl des richtigen Verfahrens sind die folgenden zwei Fragen zu beantworten:
1. Ist das Quelldatenbankschema bereits fest vorgegeben (z. B. bei Verwendung durchandere Anwendungen)?
2. Gibt es verschiedene Möglichkeiten zur Informationsgruppenbildung und sollen meh-rere von ihnen darstellbar sein?
Im Falle einer Antwort „Ja“ auf die erste oder auf die zweite Frage, scheidet Alternative 3für die Umsetzung aus, da sie eine Modifikation des Quelldatenbankschemas erfordert.

6.2. DATENBANKENTWURF 189
Geht die Anwendungsentwicklung von einem gegebenen Quelldatenbankschema aus (Ant-wort „Ja“ auf die erste Frage), stehen Alternative 1 und 2 zur Wahl. Bei einer Antwort „Ja“auf die zweite Frage sollte mit Alternative 1 gearbeitet werden. Existiert nur eine Informa-tionsgruppenkonfiguration und ist das Quelldatenbankschema nicht vorgegeben (Antwort„Nein“ auf beide Fragen), ist Alternative 3 die beste Lösung. Sie sichert, dass die Daten-bankschemata entlang der Replikationshierarchie äquivalent sind.
Für Hermes ist aufgrund der Neuentwicklung die relationale Umsetzung nicht vorgegebenund es existiert nur eine Informationsgruppenkonfiguration für alle Nutzer. Die Informati-onsgruppen werden deshalb nach Alternative 3 direkt beim relationalen Entwurf angelegt,wobei jede Informationsgruppe als eine Tabelle realisiert wird.
Es sei angemerkt, dass die Flexibilität der Alternative 1 (Replikationssichten) nur ausge-nutzt werden kann, wenn sich die logische Gruppenbildung auch auf der Ebene der Frag-mente widerspiegelt. Das wiederum setzt voraus, dass die Replikatverwaltung des RPS auchmit vertikalen Tabellenpartitionen effizient umgehen kann. Dazu ist eine Erweiterung desFragmentkonzepts erforderlich, die im RPS-Prototypen implementierte Version verwaltetausschließlich horizontale Partitionen (siehe Kapitel 4). Bei Verwendung der Alternative 2oder 3 kann durch die Zerlegung in Informationsgruppen an Tabellengrenzen auch mit deraktuellen Version des Fragmentkonzepts eine effiziente Umsetzung erreicht werden.
6.2.3 Schema der Quelldatenbank
Alle Anwendungsdaten von Hermes werden in einer DB2-Datenbank gespeichert, die imKontext der nutzerdefinierten Replikation die Quelldatenbank darstellt. Die relationaleUmsetzung der E/R-Modellierung erfolgt entlang der Informationsgruppen. Jede Informa-tionsgruppe wird in eine Tabelle übersetzt, ergänzt um die korrespondierenden Tabellender verbleibenden Entitätstypen (User, Evaluation) und Hilfstabellen zur Umsetzung vonm:n-Beziehungstypen und mengenwertigen Postleitzahlen.
Spaltenname Datentyp Beschreibung
EvalNo INTEGER PrimärschlüsselGrade_1 INTEGER Anzahl Note 1 (beste Note)Grade_2 INTEGER Anzahl Note 2Grade_3 INTEGER Anzahl Note 3Grade_4 INTEGER Anzahl Note 4Grade_5 INTEGER Anzahl Note 5 (schlechteste Note)
CalculatedGrade DECIMAL(5,1)P5
i=1 Gradei∗iP5i=1 Gradei
Tabelle 6.2: Struktur der Tabelle Evaluation
Da sie eine zentrale Rolle bei der Auswahl von Replikaten spielt, soll die Bewertungstabel-le Evaluation (Tabelle 6.2) genauer vorgestellt werden. Jede Zeile der Tabelle steht für dieBewertung eines Sachverhalts (z. B. einen Reisebericht) und speichert für jede Note (von 1bis 5), wie oft sie von Nutzern gegeben wurde. Eine zusätzliche, berechnete Spalte enthältdie Durchschnittsbewertung (CalculatedGrade) auf eine Stelle nach dem Komma genau.Für die Berechnung der Durchschnittsbewertung wird die von DB2 angebotene Spalten-bedingung GENERATED ALWAYS AS in Kombination mit einer nutzerdefinierten Funktion

190 KAPITEL 6. BEISPIELANWENDUNG HERMES
verwendet. Diese Konstruktion ist erforderlich, da CalculatedGrade später als Partitionie-rungsspalte angegeben werden soll, Fragmente in der verwendeten Version der Fragment-verwaltung aber nur über Basistabellen gebildet werden können. Über Hilfstabellen undPrimär-/Fremdschlüsselbeziehungen ist die Tabelle Evaluation sowohl mit dem zu bewerten-den Sachverhalt, als auch mit den bewertenden Nutzern verbunden (siehe E/R-Diagrammin Abbildung 6.3 und Beispiel in Abschnitt 6.3.2). Dadurch kann sichergestellt werden,dass jeder Nutzer nur jeweils eine Bewertung abgibt. Der vollständige relationale Entwurfder Quelldatenbank ist in [Bau04] angegeben.
Das Vorgehen bei der Modellierung der Quelldatenbank unterscheidet sich prinzipiell nichtvon dem bei einer rein zentralen Datenbankanwendung. In der Praxis resultieren jedochEinschränkungen aus dem notwendigen Zusammenspiel verschiedener Datenbanksystemeund durch die verwendeten Replikationsprodukte für den Datenabgleich. Beispielsweisesollte darauf geachtet werden, dass die relationale Umsetzung von Datentypen und Inte-gritätsbedingungen auf den weiteren Stufen (RPS und mobile Clients) semantisch äquiva-lent oder zumindest restriktiver erfolgen kann. Ist das nicht möglich, besteht die Gefahr,dass Integritätsverletzungen erst bei der Reintegration auf der Quelldatenbank als Konflikterkannt werden.
6.2.4 Abgeleitete Schemata
Die Erstellung des Schemas der konsolidierten Datenbank umfasst drei Schritte:
1. Definition der konsolidierten Tabellen und dabei Festlegung des Replikationsmodussowie Auswahl und Konfiguration der Konfliktbehandlungsmethoden
2. Gegebenenfalls Bereitstellung der Prozeduren für die zweite Stufe der Nutzerverwal-tung
3. Auswahl geeigneter Partitionierungsspalten für die Fragmentierung der konsolidier-ten Datenbank.
Für Hermes entsprechen die Definitionen der konsolidierten Tabellen denen des Quellda-tenbankschemas. Der Replikationsmodus lässt für alle Tabellen, bis auf die Nutzer- undNavigationsdaten, das unverbundene Ändern durch Nutzer zu. Für das Einfügen neuernutzererstellbarer Daten werden künstliche Schlüssel in Verbindung mit dem Keypool-Verfahren verwendet. Alle anderen Konflikte werden über die first-commiter-wins-Regelaufgelöst.
Für Hermes wurden in [Wie04] eine eigene Nutzerverwaltung entwickelt und entsprechen-de Prozeduren (siehe Kapitel 5.4.2) implementiert. Die auf dem RPS gespeicherten Zu-gangsdaten sind für die Clients nicht les- und replizierbar. Die bereitgestellten Prozedurensorgen für die Authentifizierung der Hermes-Nutzer vor dem Zugriff auf die konsolidierteDatenbank. Eine ausführliche Dokumentation der Hermes-Nutzerverwaltung kann in derzitierten Arbeit nachgelesen werden.
Für die Fragmentierung müssen alle Spalten als Partitionierungsspalten angegeben wer-den, die von Nutzern oder Hermes selbst direkt für Selektionen in Replikationsanfragenverwendet werden können. Indirekte Selektionen über mehrere Tabellen und Fremdschlüs-selspalten (z. B. in Replikationsanfragen mit Verbunden und Unteranfragen) werden von

6.3. CLIENT-ANWENDUNG 191
Tabelle Part.-Spalte
City ZIPCodeName
Hotel_Room ShowerPhoneTV
Restaurant_Info StyleCuisine
Evaluation CalculatedGrade
Tabelle 6.3: Wichtige Partitionierungsspalten für die Datenfragmentbildung
der Fragmentverwaltung automatisch aufgelöst. Die wichtigsten Partitionierungsspaltensind in Tabelle 6.3 angegeben.
Als Minimalwert für die Fragmentgröße bei der Bildung der Datenfragmentierung wird,mit Ausnahme der Bewertungstabelle Evaluation, der Wert 1 verwendet. Das bedeutet, fürjeden Wert der Partitionierungsspalte in der Datenbank wird, wenn der Wert nicht bereitsin einem einzelnen Fragment abgebildet ist (z. B. wenn ein Ort nur eine Postleitzahl hat),ein separates Fragment angelegt.
Die Durchschnittsbewertung (CalculatedGrade) in der Tabelle Evaluation wird als Selekti-onskriterium benötigt und ist deshalb eine Partitionierungsspalte. Aus Effizienzgründenhat die minimale Fragmentgröße bei der Tabelle Evaluation den Wert 5, so dass erst dannein neues Fragment gebildet wird, wenn mindestens fünf Bewertungen eine bestimmteDurchschnittsbewertung besitzen.
Die Tabellenschemata der Client-Datenbanken entsprechen im Wesentlichen denen des kon-solidierten Datenbankschemas. Dieser Schritt soll hier deshalb nicht gesondert betrachtetwerden.
6.3 Client-Anwendung
Die in Java implementierte Client-Anwendung ist die Schnittstelle des Hermes-Reiseinformationssystems für den Nutzer. Über sie wählt er Daten zur Replikation aus,gibt neue Daten ein und startet die Synchronisation. Der folgende Abschnitt gibt einenÜberblick zu ihrer Architektur und erläutert die Funktionsweise des Repository für diedynamische Verwaltung von Replikationssichten und -gruppen.
6.3.1 Architektur
Der Client-Anwendung liegt die in Abbildung 6.5 angegebene Architektur zugrunde, welchedie folgenden drei Komponenten unterscheidet:
• Datenbankschnittstelle
Die Datenbankschnittstelle ermöglicht der Anwendung die Kommunikation mit derlokalen Datenbank, in der die replizierten Daten gespeichert sind. Sie übernimmt

192 KAPITEL 6. BEISPIELANWENDUNG HERMES
GUI
RSG-Instanzen
DB-Schnittstelle
Anfrage-ergebnisse Änderungensoperationen
lokale Anfragen
Lokale Datenbank
RPS-Anweisungen
RSG/RS-Initialisierungen→
←BestätigungRPS-Schnittstelle
RPS-Rück-meldungen
RPS
RSG - Replikationssichtengruppe
RS - Replikationssicht
Abbildung 6.5: Systemarchitektur der Client-Anwendung [Bau04]
dazu von der GUI-Komponente (s. u.) erzeugte Replikationssichten und Replikati-onssichtengruppen sowie Änderungsoperationen und führt sie mit Hilfe der RPS-Schnittstelle und des Repository (siehe Abschnitt 6.3.2) aus. In der Gegenrich-tung werden die Ergebnisse und Statusmeldungen der Ausführung an die GUI-Komponente zurückgegeben.
• RPS-Schnittstelle
Die RPS-Schnittstelle übernimmt die Kommunikation mit dem Replication ProxyServer und wird von der Anwendung ausschließlich über die Datenbankschnittstellegenutzt. Sie übermittelt Anweisungen an den RPS und wertet die von ihm zurück-gegebenen Meldungen aus.
• GUI-Komponente
Die GUI-Komponente (Graphical User Interface) ermöglicht dem Nutzer ein komfor-tables Arbeiten mit den replizierten Daten. Sie wertet die Eingaben des Nutzers aus,erzeugt entsprechende Replikationsanfragen und stellt die Ergebnisse lokaler Anfra-gen auf dem Bildschirm dar. Neu eingegebene Informationen werden über die Daten-bankschnittstelle zunächst in die lokale Replikatdatenbank geschrieben und müssenzur Erlangung der Dauerhaftigkeit mit der konsolidierten Datenbank synchronisiertwerden. Die Synchronisation wird ebenfalls über die GUI-Komponente gesteuert.
6.3.2 Das Repository
Für die Arbeit mit replizierten Daten werden von der Anwendung Replikationssichtengrup-pen und Replikationssichten je nach Auswahl des Nutzers dynamisch angelegt, zugeord-net und wieder gelöscht. Dafür bilden die Informationsgruppen (siehe Abschnitt 6.2.2) dieGrundlage. Zu jeder Informationsgruppe können auf einem Client verschiedene Replikati-

6.3. CLIENT-ANWENDUNG 193
onssichten definiert werden, die sich in der Wahl des Ortes, der vom Nutzer übergebenenFilterbedingung (z. B. Auswahl nach Bewertung) und der Änderbarkeitszusicherung unter-scheiden können.
CREATE REPLICATION VIEW Rest_01AS SELECT *
FROM RestaurantWHERE RestaurantNo IN (
SELECT BldgNoFROM BuildingWHERE CityNo IN (
SELECT CityNoFROM CityWHERE Name = ’Jena’
))AND RestaurantNo IN (
SELECT RestaurantNoFROM Restaurant_InfoWHERE Style IN (’de’,’it’)
)FOR OFFLINE OPTIMISTIC ALLPOOL 2 KEYS...
CREATE REPLICATION VIEW Rest_02AS SELECT *
FROM RestaurantWHERE RestaurantNo IN (
SELECT BldgNoFROM BuildingWHERE CityNo IN (
SELECT CityNoFROM CityWHERE Name = ’Jena’
))AND RestaurantNo IN (
SELECT RestaurantNoFROM Restaurant_EvaluationWHERE Service IN (
SELECT EvalNoFROM EvaluationWHERE CalculatedGrade
<= 3.0)
)FOR OFFLINE READ...
Abbildung 6.6: Replikationssichten auf Informationsgruppen
Das Beispiel in Abbildung 6.6 zeigt die Definition zweier Replikationssichten für den OrtJena. Die erste, änderbare Replikationssicht steht für die Informationsgruppe der grund-legenden Daten für Restaurants, wobei nur Restaurants aus Jena mit deutscher oder ita-lienischer Küche repliziert werden. Über die zweite Replikationssicht werden Daten fürRestaurants aus Jena repliziert, welche beim Service mindestens die Durchschnittsnote 3von allen bewertenden Nutzern erhalten haben. Beide Replikationssichten referenzierenDaten derselben Informationsgruppe, haben aber verschiedene Auswahlbedingungen undReplikationsmodi.
Die Fragmentverwaltung auf dem RPS stellt dabei sicher, dass Fremdschlüsselbeziehungenin der Client-Datenbank erfüllt werden und keine Daten doppelt übertragen werden, die vonbeiden Replikationssichten referenziert werden (z. B. italienische Restaurants in Jena miteiner Service-Bewertung von 2.0). Damit die Fragmentverwaltung effizient arbeiten kann,müssen die im Beispiel zur Selektion verwendeten Tabellenspalten, das sind City.Name, Re-staurant_Info.Style und Restaurant_Evaluation.Service, als Partitionierungsspalten definiertsein (siehe Abschnitt 6.2.4).
Die Synchronisation in Hermes erfolgt immer pro Ort, d. h. alle Replikationssichten, dieDaten zu einem Ort auswählen, werden in einer Replikationssichtengruppe zusammenge-

194 KAPITEL 6. BEISPIELANWENDUNG HERMES
fasst und damit gemeinsam synchronisiert. Die Zusammensetzung der Replikationssichten-gruppen hängt von der Menge der zu einem Ort definierten Replikationssichten ab undist demzufolge ebenso dynamisch wie die Auswahlbedingungen der Replikationsanfragenselbst.
Die Verwaltung der Replikationssichten und -gruppen erfolgt in einem Repository, das inGestalt zweier Tabellen in der Client-Datenbank gespeichert ist. Das Repository realisiertauf sehr einfache Art ein Inhaltsverzeichnis für Replikationssichten auf der Grundlage tex-tueller Gleichheit der Replikationsanfragen. Wird nach einer Auswahl durch den Nutzerauf der GUI-Komponente keine passende Replikationssicht im Repository gefunden, musseine neue Sicht über die Verbindung zum RPS angelegt werden. Die Fragmentverwaltungsorgt im Hintergrund für die Vermeidung einer mehrfachen Datenübertragung. Andern-falls können die Daten einer existierenden Sicht verwendet werden, wobei der Nutzer dieMöglichkeit hat, diese vor der Nutzung über den RPS zu synchronisieren.
Aufgrund des systematischen Aufbaus der Anfragen aus der Definition der Informations-gruppen und den Nutzereingaben ist der Fall zweier äquivalenter, aber textuell unterschied-licher Replikationsanfragen, der eine unnötige Verbindungsaufnahme zur Folge haben kann,sehr unwahrscheinlich. Die Auflösung einer echten Inklusionsbeziehung, d. h. die angefor-derten Daten sind bereits in einer vorhandenen Sicht enthalten, ist bei der prototypischenImplementierung nur über die Replikatverwaltung auf dem RPS möglich. Die dazu erfor-derliche Verbindungsaufnahme könnte durch eine Ausweitung der Replikatverwaltung aufden Client vermieden werden (siehe Kapitel 7.2).
6.3.2.1 Aufbau
Spaltename Datentyp Beschreibung
BaseName VARCHAR(50) Basisname der Sichtengruppe,Teil des Primärschlüssels
Suffix INTEGER Suffix zur Generierung eindeutiger Namen fürGruppen, Teil des Primärschlüssels
LastSync TIMESTAMP Zeitpunkt der letzten SynchronisationGlobalExpiration TIMESTAMP Zeitpunkt des Ablaufs der Gültigkeit der
Gruppe
Tabelle 6.4: Struktur der Tabelle RVG_Repository
In der Tabelle RVG_Repository (Tabelle 6.4) werden Informationen zu den durch die An-wendung angelegten Replikationssichtengruppen (Replication View Group, RVG) gespei-chert. Der BaseName einer Replikationssichtengruppe ist von der Anwendung prinzipiellbeliebig wählbar, muss jedoch eindeutig sein. Der Suffix dient gemeinsam mit dem BaseNa-me zur Generierung von eindeutigen Namen für die Registrierung der Gruppen beim RPS.Die Namen werden durch Verkettung von BaseName und Suffix erzeugt, die gemeinsamauch den Primärschlüssel für die Tabelle RVG_Repository bilden. Der Zeitstempel LastSyncdient zur Speicherung des letzten Zeitpunkts der Synchronisation einer Sichtengruppe undkann dem Nutzer der Anwendung ggf. als Hinweis zum Alter der replizierten Daten zurVerfügung gestellt werden. Die Spalte GlobalExpiration gibt das „Verfallsdatum“ der in derReplikationssichtengruppe enthaltenen Replikationssichten an. Dieser Wert kann vom RPS
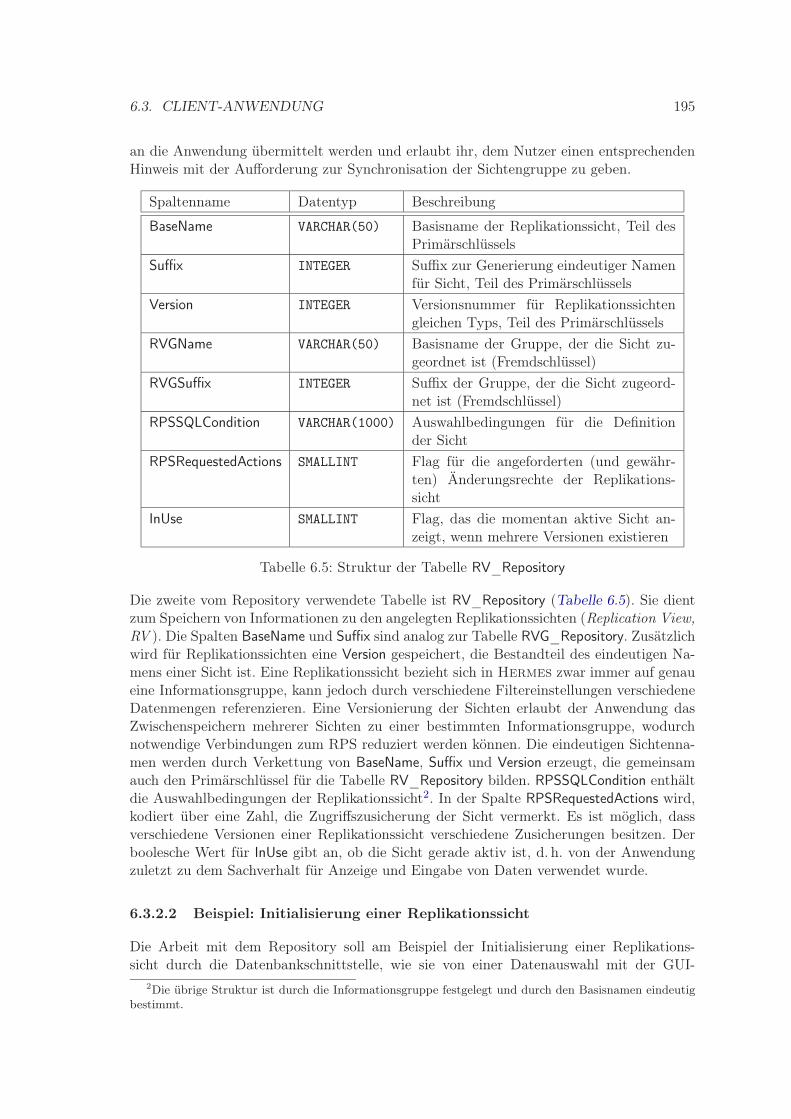
6.3. CLIENT-ANWENDUNG 195
an die Anwendung übermittelt werden und erlaubt ihr, dem Nutzer einen entsprechendenHinweis mit der Aufforderung zur Synchronisation der Sichtengruppe zu geben.
Spaltenname Datentyp Beschreibung
BaseName VARCHAR(50) Basisname der Replikationssicht, Teil desPrimärschlüssels
Suffix INTEGER Suffix zur Generierung eindeutiger Namenfür Sicht, Teil des Primärschlüssels
Version INTEGER Versionsnummer für Replikationssichtengleichen Typs, Teil des Primärschlüssels
RVGName VARCHAR(50) Basisname der Gruppe, der die Sicht zu-geordnet ist (Fremdschlüssel)
RVGSuffix INTEGER Suffix der Gruppe, der die Sicht zugeord-net ist (Fremdschlüssel)
RPSSQLCondition VARCHAR(1000) Auswahlbedingungen für die Definitionder Sicht
RPSRequestedActions SMALLINT Flag für die angeforderten (und gewähr-ten) Änderungsrechte der Replikations-sicht
InUse SMALLINT Flag, das die momentan aktive Sicht an-zeigt, wenn mehrere Versionen existieren
Tabelle 6.5: Struktur der Tabelle RV_Repository
Die zweite vom Repository verwendete Tabelle ist RV_Repository (Tabelle 6.5). Sie dientzum Speichern von Informationen zu den angelegten Replikationssichten (Replication View,RV ). Die Spalten BaseName und Suffix sind analog zur Tabelle RVG_Repository. Zusätzlichwird für Replikationssichten eine Version gespeichert, die Bestandteil des eindeutigen Na-mens einer Sicht ist. Eine Replikationssicht bezieht sich in Hermes zwar immer auf genaueine Informationsgruppe, kann jedoch durch verschiedene Filtereinstellungen verschiedeneDatenmengen referenzieren. Eine Versionierung der Sichten erlaubt der Anwendung dasZwischenspeichern mehrerer Sichten zu einer bestimmten Informationsgruppe, wodurchnotwendige Verbindungen zum RPS reduziert werden können. Die eindeutigen Sichtenna-men werden durch Verkettung von BaseName, Suffix und Version erzeugt, die gemeinsamauch den Primärschlüssel für die Tabelle RV_Repository bilden. RPSSQLCondition enthältdie Auswahlbedingungen der Replikationssicht2. In der Spalte RPSRequestedActions wird,kodiert über eine Zahl, die Zugriffszusicherung der Sicht vermerkt. Es ist möglich, dassverschiedene Versionen einer Replikationssicht verschiedene Zusicherungen besitzen. Derboolesche Wert für InUse gibt an, ob die Sicht gerade aktiv ist, d. h. von der Anwendungzuletzt zu dem Sachverhalt für Anzeige und Eingabe von Daten verwendet wurde.
6.3.2.2 Beispiel: Initialisierung einer Replikationssicht
Die Arbeit mit dem Repository soll am Beispiel der Initialisierung einer Replikations-sicht durch die Datenbankschnittstelle, wie sie von einer Datenauswahl mit der GUI-
2Die übrige Struktur ist durch die Informationsgruppe festgelegt und durch den Basisnamen eindeutigbestimmt.

196 KAPITEL 6. BEISPIELANWENDUNG HERMES
Komponente ausgelöst wird, skizziert werden.
1. Registrierung der Replikationssicht im Repository prüfen
Im Repository werden alle Informationen der im Laufe der Anwendungsnutzung vomRPS angeforderten Replikationssichten gespeichert. Soll eine Replikationssicht in-itialisiert werden, prüft die Datenbankschnittstelle zunächst, ob eine entsprechendeReplikationssicht schon einmal beim RPS angefordert wurde. Dies ist genau dannder Fall, wenn ein Repository-Eintrag mit den folgenden Eigenschaften existiert:
(a) BaseName entspricht dem Basisnamen der zu initialisierenden Sicht
(b) Suffix entspricht dem Suffix der zu initialisierenden Sicht
(c) RVGName entspricht dem Basisnamen der Sichtengruppe, zu der die Sicht gehört
(d) RPSSQLCondition entspricht der WHERE-Klausel der zu initialisierenden Sicht
2. Wiederverwendung einer bereits existierenden Replikationssicht
Sind alle Bedingungen aus (1) erfüllt, kann die bereits in der lokalen Datenbank exis-tierende Version der Replikationssicht wiederverwendet werden, wenn die folgendenzusätzlichen Bedingungen erfüllt sind:
(a) RPSRequestedActions entspricht den für die zu initialisierende Sicht vergebenenZugriffszusicherungen.
(b) GlobalExpiration ist nicht gesetzt (Nullwert) bzw. der angegebene Zeitpunkt istnoch nicht erreicht.
Die Initialisierung geht dann sofort zu Schritt (5) über. Ist die Bedingung (b) aus (2)jedoch nicht erfüllt, muss eine Synchronisation der Replikationssicht bzw. der da-zugehörenden Gruppe erfolgen. Nach der Synchronisation wird ebenfalls mit Schritt(5) fortgefahren. Ist keine Wiederverwendung möglich, wird die Initialisierung derReplikationssicht, abhängig davon, welche Bedingung(en) nicht erfüllt war(en), mitSchritt (3) oder (4) fortgesetzt.
3. Änderung einer bereits existierenden Replikationssicht
Ist nur die Bedingung (a) aus (2) nicht erfüllt, es existiert also eine Sicht, welche diegeforderten Daten enthält, jedoch wurden nicht die passenden Zugriffszusicherungenfür sie angefordert, muss keine neue Replikationssicht angelegt werden. Es reicht aus,die Zugriffszusicherungen mit der Anweisung ALTER REPLICATION VIEW anzupassen.Dazu ist eine Synchronisation und eine Verbindung mit dem RPS erforderlich.
4. Anforderung einer neuen Replikationssicht
Kann bei der Initialisierung einer Replikationssicht weder eine bereits vorhandeneSicht wiederverwendet noch durch Änderung der Zugriffszusicherungen entsprechendangepasst werden, muss die Replikationssicht angelegt und ihre Gruppe synchroni-siert werden.
5. abschließende Initialisierung der Replikationssicht
Die Initialisierung einer Replikationssicht wird mit Übertragung der referenziertenDaten aus der lokalen Datenbank in ein Ergebnismengenobjekt für die Weiterverar-beitung durch die GUI-Komponente abgeschlossen.

6.4. DIE ARBEIT MIT HERMES 197
Werden Replikationssichten oder ganze Replikationssichtengruppen nicht mehr benötigt,beispielsweise weil der Nutzer den Ort gewechselt hat, kann die Anwendung diese aus demRepository entfernen. Damit verbunden ist auch das Löschen der betroffenen Sichten bzw.Sichtengruppen beim RPS mit Hilfe der Anweisungen DROP REPLICATION VIEW bzw. DROPREPLICATION VIEW GROUP.
6.4 Die Arbeit mit Hermes
Die folgenden beiden Unterabschnitte beschreiben an Beispielen und illustriert durch Bild-schirmdarstellungen der Client-Anwendung die Auswahl von Daten und das Einfügen neuerDaten in das Informationsangebot von Hermes.
6.4.1 Das Auswählen von Daten zur Replikation
Das Auswählen von Daten zur Replikation beginnt bei Hermes immer mit der Auswahlder Ortschaften, für die Informationen bereitgestellt werden sollen. Dazu stehen dem Nut-zer drei verschiedene Möglichkeiten der Ortssuche zur Verfügung, die in Abbildung 6.7schematisch dargestellt sind.
Regionsbasierte Ortssuche Routenbasierte Ortssuche Kenndatenortssuche
Regionstyp auswählen
Region(en) auswählen
Route auswählen
Kenndaten eingeben
Kenndaten eingeben
Ort(e) auswählen
Daten auswählen
Abbildung 6.7: Alternativen für die Ortssuche
Am Beispiel der regionsbasierten Ortssuche soll der Ablauf verdeutlicht werden. Die Su-che beginnt mit der Auswahl eines Regionstyps (Abbildung 6.8) aus einer Liste mit denTypen, die dem Hermes-System bekannt sind. Die dazu benötigten Daten werden beider ersten regionsbasierten Ortssuche auf den mobilen Client repliziert, d. h. es werden ei-ne Replikationssichtengruppe und darin eine Replikationssicht für die InformationsgruppeRegion_Type angelegt und synchronisiert. Mittels „Aktualisieren“ kann der Nutzer jeder-zeit eine manuelle Synchronisation der Daten mit dem RPS durchführen. Durch „Weiter“gelangt er zum nächsten Dialog.
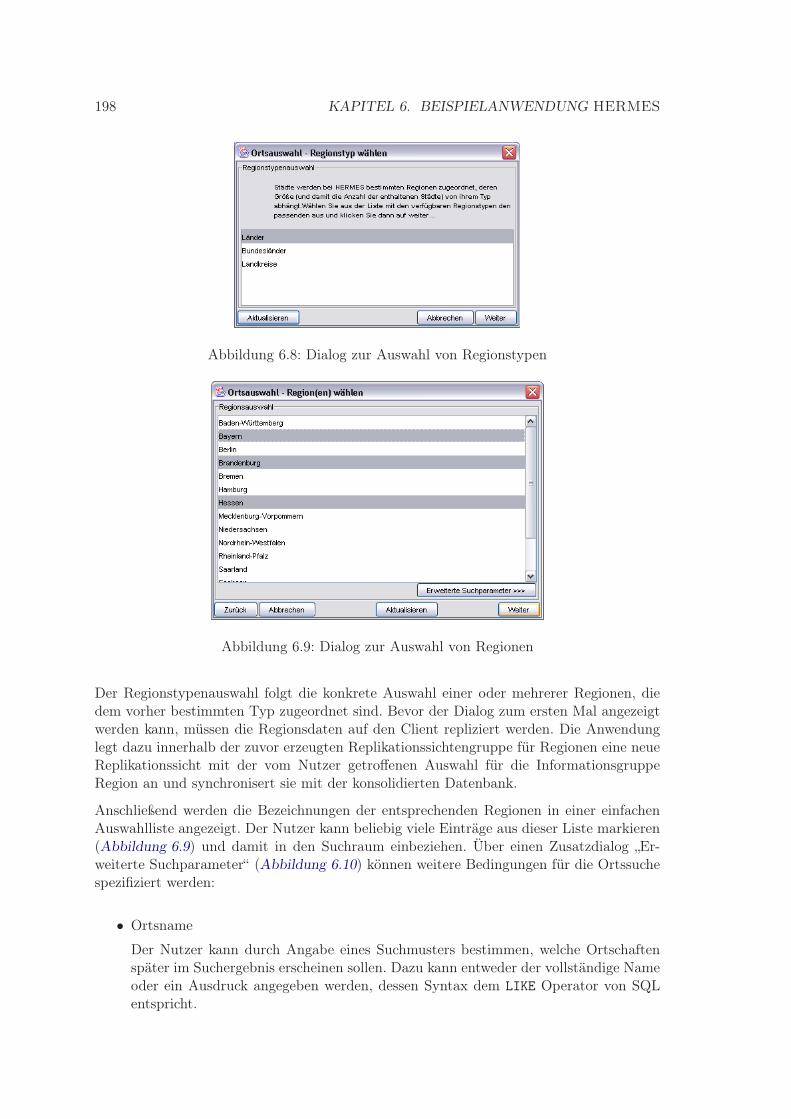
198 KAPITEL 6. BEISPIELANWENDUNG HERMES
Abbildung 6.8: Dialog zur Auswahl von Regionstypen
Abbildung 6.9: Dialog zur Auswahl von Regionen
Der Regionstypenauswahl folgt die konkrete Auswahl einer oder mehrerer Regionen, diedem vorher bestimmten Typ zugeordnet sind. Bevor der Dialog zum ersten Mal angezeigtwerden kann, müssen die Regionsdaten auf den Client repliziert werden. Die Anwendunglegt dazu innerhalb der zuvor erzeugten Replikationssichtengruppe für Regionen eine neueReplikationssicht mit der vom Nutzer getroffenen Auswahl für die InformationsgruppeRegion an und synchronisert sie mit der konsolidierten Datenbank.
Anschließend werden die Bezeichnungen der entsprechenden Regionen in einer einfachenAuswahlliste angezeigt. Der Nutzer kann beliebig viele Einträge aus dieser Liste markieren(Abbildung 6.9) und damit in den Suchraum einbeziehen. Über einen Zusatzdialog „Er-weiterte Suchparameter“ (Abbildung 6.10) können weitere Bedingungen für die Ortssuchespezifiziert werden:
• Ortsname
Der Nutzer kann durch Angabe eines Suchmusters bestimmen, welche Ortschaftenspäter im Suchergebnis erscheinen sollen. Dazu kann entweder der vollständige Nameoder ein Ausdruck angegeben werden, dessen Syntax dem LIKE Operator von SQLentspricht.

6.4. DIE ARBEIT MIT HERMES 199
Abbildung 6.10: Dialog für die Angabe von erweiterten Bedingungen für die Ortssuche
• Postleitzahl
Damit kann die Postleitzahl oder ein Suchmuster analog zum Ortsnamen für die indas Suchergebnis einzuschließenden Ortschaften spezifiziert werden.
• Einwohnerzahl
Für alle Ortschaften sind die Einwohnerzahlen verfügbar und deshalb können dieseals weitere Bedingung in das Suchergebnis einbezogen werden. Es kann eine Unter-und/oder Obergrenze für die Einwohnerzahl angegeben werden.
• Bewertungen
Ein Ort kann in Hermes mit zwei Bewertungen (Besuchswert und Kulturangebot)versehen sein. Durch die Angabe von Mindestbewertungen für einen oder beide Wertekann das Suchergebnis weiter auf solche Ortschaften eingeschränkt werden, die jeweilsdie angegebenen Mindestnoten aufweisen.
Der Auswahl der Regionen folgt ein Dialog, der alle Ortschaften zur weiteren Verfeinerungder Suche bereitstellt, die in den ausgewählten Regionen enthalten sind und den zusätzlichangegebenen Bedingungen genügen (Abbildung 6.11). Sind die Ortsnamen der Regionenlokal noch nicht vorhanden, müssen die Daten der Informationsgruppe City mittels einerReplikationssicht vom RPS angefordert werden. Der Nutzer kann anschließend aus der Listeeinen oder mehrere Orte auswählen, für die er dann im nächsten Dialog (Abbildung 6.12)bestimmen kann, welche optionalen Informationsgruppen jeweils angefordert werden sollen.
Die Baumansicht in der linken Hälfte des Dialogs enthält die Namen aller Ortschaften,die der Nutzer zuvor ausgewählt hat. Die rechte Seite des Dialogs enthält einige Register-karten, wobei jede von ihnen Informationsgruppen für ein bestimmtes Objekt (kulturelleEinrichtungen, öffentliche Einrichtungen, historische Gebäude, Reiseberichte, Restaurantsoder Hotels) zur Auswahl bereitstellt. Die Informationsgruppen können zur Replikationauf den mobilen Client markiert werden. Der Nutzer kann dabei sowohl eine globale Aus-wahl für alle Orte als auch für einzelne Orte separat durchführen. Lokale Einstellungenüberschreiben dabei globale Parameterwerte.

200 KAPITEL 6. BEISPIELANWENDUNG HERMES
Abbildung 6.11: Dialog zur Auswahl von Ortschaften
Wenn alle Einstellungen abgeschlossen sind, wird mit „Auswahl abschließen“ die Übertra-gung der Daten für die ausgewählten Informationsgruppen gestartet. Die Anwendung legtdazu für jeden ausgewählten Ort, wenn noch nicht vorhanden, eine Replikationssichten-gruppe an und ordnet ihnen, jeweils zu den markierten Informationsgruppen, Replikati-onssichten zu.
Für die Darstellung der lokal verfügbaren Informationen wird das Hauptfenster der Anwen-dung in zwei Bereiche unterteilt (Abbildung 6.13). Die Baumansicht (links) zeigt an, fürwelche Städte Informationen in der lokalen Datenbank gespeichert sind. Jede Stadt wirdim Baum durch einen entsprechenden Knoten repräsentiert, dessen Blätter die verfügbarenObjekte darstellen. Im rechten Teil des Hauptfensters werden für die in der Baumansichtausgewählten Objekte deren lokal verfügbare Daten angezeigt.
Mit „Neu“ gelangt man in einen Dialog zur Eingabe neuer Daten für das aktuell ausgewählteObjekt. „Ändern“ erlaubt das Verändern der angezeigten Informationen. Über „Löschen“werden die Daten des ausgewählten Objekts aus dem Informationsangebot gelöscht. AlleÄnderungen erfolgen zunächst lokal und werden bei der nächsten Synchronisation zumRPS übertragen.
6.4.2 Das Einfügen neuer Informationen
Am Beispiel eines neuen Restaurants soll das Hinzufügen von Informationen verdeut-licht werden. Für das Einfügen der Daten eines neuen Restaurants wird der Dialog inAbbildung 6.14 verwendet. Bevor der Dialog zur Verfügung steht, muss der Nutzer zu-nächst passende Restaurantdaten auf seinen mobilen Client replizieren. Das ist erfoderlich,um die notwendige Einfügezusicherung und die Schlüsselwerte für den Key-Pool zu erhal-ten. Eingefügt werden dürfen dann nur Restaurants, die der dabei spezifizierten Auswahl-bedingung genügen. Für jede angeforderte Informationsgruppe wird eine Replikationssicht

6.4. DIE ARBEIT MIT HERMES 201
Abbildung 6.12: Dialog zur Auswahl von Informationsgruppen
mit Lese- und Einfügeberechtigung angefordert bzw. wiederverwendet und der Replikati-onssichtengruppe des Ortes zugeordnet.
Bei der Neueingabe muss der Anwender die Basisinformationen (Name, Adresse) des Re-staurants angeben, alle weiteren Informationen sind optional und können ggf. später er-gänzt oder ganz weggelassen werden. Der Dialog ist in verschiedene Bereiche unterteilt, diejeweils Daten zu einer bestimmten Informationsgruppe aufnehmen (Reihenfolge von linksoben nach rechts unten):
• Basisinformationen
Die Angaben in dieser Gruppe sind, bis auf die Telefonnummer, obligatorisch, deshalbkann ein neues Restaurant nicht ohne diese Informationen erstellt werden.
• Zusatzinformationen
Als Zusatzinformationen optional angegeben werden können der Stil und die kulina-rische Ausrichtung des Restaurants.
• Empfehlung
Der Nutzer kann den Informationen über das Restaurant optional eine Empfehlungin Textform hinzufügen.
• Bewertungen
In diesem Abschnitt des Dialogs kann der Nutzer für die drei Bewertungsmöglich-keiten eines Restaurants (Service, Qualität und Ambiente) bereits beim Erstellenentsprechende Noten verteilen.

202 KAPITEL 6. BEISPIELANWENDUNG HERMES
Abbildung 6.13: Informations-Browser
• Speisekarte
Dieser Teil des Dialogs ermöglicht das einfache Erstellen einer Speisekarte, dafür ge-dacht, andere Nutzer auf besondere oder preiswerte Gericht aufmerksam zu machen.Um der Speisekarte einen neuen Punkt hinzuzufügen, müssen dessen Bezeichnungund Preis angegeben werden. Optional kann auch eine Bewertung vergeben werden.Mit der Schaltfläche wird der neue Punkt der Speisekarte hinzugefügt.
• Öffnungszeiten
Dieser Abschnitt ermöglicht die Angabe der Öffnungszeiten des Restaurants. Es kön-nen für jeden Tag zwei Öffnungszeitenbereiche vergeben werden, falls das Restaurantnicht durchgehend geöffnet hat. Alle markierten Einträge werden beim Einfügen desRestaurants in die Datenbank gespeichert. Ist keine Auswahlbox aktiviert, werdenkeine Öffnungszeiten für das Restaurant gespeichert.
Damit die lokal neu hinzugefügten Daten auch den anderen Nutzern von Hermes zugäng-lich werden, muss der Datenbestand des mobilen Clients mit der konsolidierten Datenbanksynchronisiert werden. Die Synchronisation kann nur für alle replizierten Objekte einerStadt gemeinsam erfolgen.
Der Nutzer kann die Synchronisation über die Auswahl des entsprechenden Menüpunktsin einem Kontextmenü starten. Die Anwendung verbindet sich daraufhin mit dem RPS
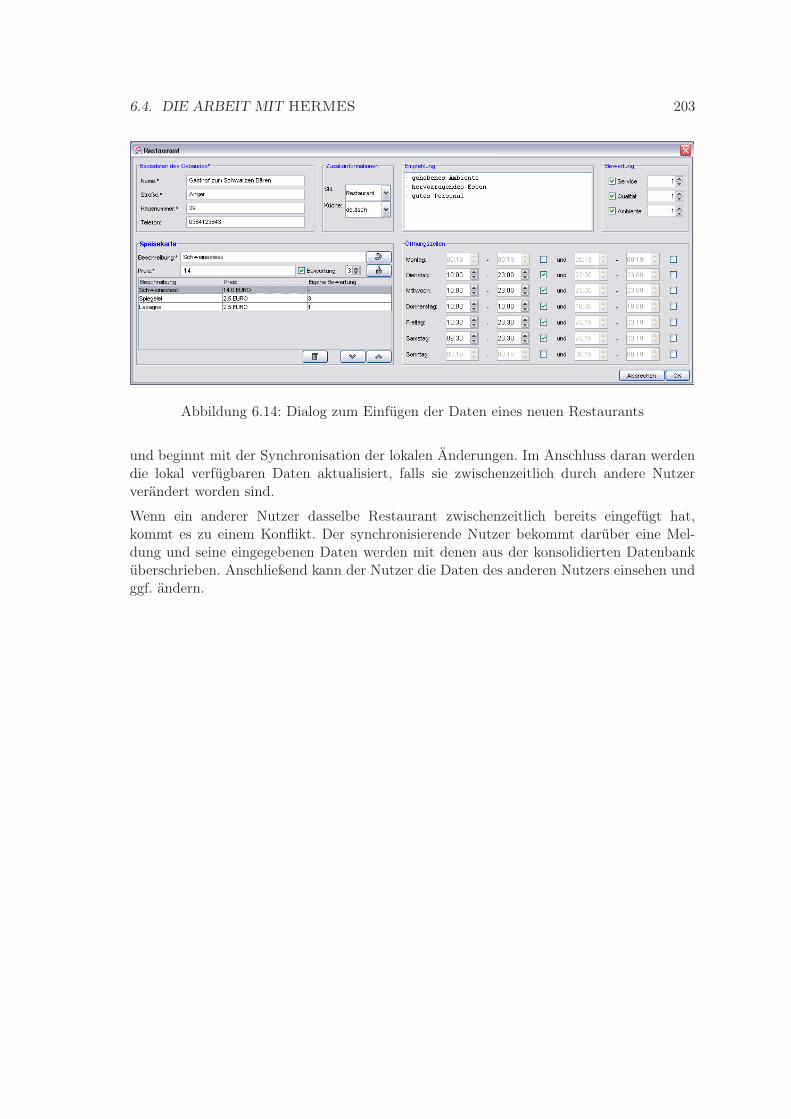
6.4. DIE ARBEIT MIT HERMES 203
Abbildung 6.14: Dialog zum Einfügen der Daten eines neuen Restaurants
und beginnt mit der Synchronisation der lokalen Änderungen. Im Anschluss daran werdendie lokal verfügbaren Daten aktualisiert, falls sie zwischenzeitlich durch andere Nutzerverändert worden sind.
Wenn ein anderer Nutzer dasselbe Restaurant zwischenzeitlich bereits eingefügt hat,kommt es zu einem Konflikt. Der synchronisierende Nutzer bekommt darüber eine Mel-dung und seine eingegebenen Daten werden mit denen aus der konsolidierten Datenbanküberschrieben. Anschließend kann der Nutzer die Daten des anderen Nutzers einsehen undggf. ändern.


Kapitel 7
Zusammenfassung und Ausblick
7.1 Ergebnisse
In der vorliegenden Arbeit wurden die Konzeption und Implementierung eines Dienstes zurnutzerdefinierten Replikation beschrieben. Die Verwendung nutzerdefinierter Replikationerlaubt es mobilen Datenbankanwendungen zur Laufzeit und ohne großen Programmier-aufwand, Daten per dynamischem SQL für die Replikation auf den Client auszuwählen unddiese Auswahl später anzupassen. Die nutzerdefinierte Replikation erweitert damit die teilsunflexible und unkomfortable Replikatverwaltung aktueller kommerzieller mobiler Daten-banklösungen. Die gewonnene Flexibilität gestattet es auch, anspruchsvolle mobilspezifi-sche Anwendungen, wie ein interaktives mobiles Reiseinformationssystem, vergleichsweiseschnell umzusetzen.
Technisch wurde die nutzerdefinierte Replikation als Erweiterung bestehender mobiler Da-tenbanklösungen angelegt. Dies bietet den Vorteil, auf eine ausgereifte Funktionalität inProdukten, vor allem zur Datenübertragung und Synchronisation, zurückgreifen zu können.Die nutzerdefinierte Replikation ist dabei so konzipiert, dass die Replikation über unter-schiedliche DBMS-Produkte als Server- und Client-DBMS möglich ist. Ebenfalls adressiertwurde die Problematik oft nur rudimentär vorhandener und zudem in Auswahl und Funk-tionalität über Produkte hinweg sehr unterschiedlicher Konfliktbehandlungsmethoden. Dienutzerdefinierte Replikation bietet eine einheitliche Schnittstelle zu den wichtigsten Kon-fliktbehandlungsmethoden für relationale Datenbanken, so dass auch dafür der Anwendungkein zusätzlicher Programmieraufwand entsteht.
Die nutzerdefinierte Replikation wurde prototypisch implementiert. Es konnte anhand dererfolgreichen Umsetzung des Reiseinformationssystem Hermes gezeigt werden, dass dienutzerdefinierte Replikation die an sie gestellten Erwartungen erfüllt und die prototypischeImplementierung funktioniert. Im Folgenden werden die wesentlichen Ergebnisse der Arbeitaus den zentralen Kapiteln noch einmal kurz aufgeschlüsselt.
Konzeption (Kapitel 3)
Die nutzerdefinierte Replikation bietet eine Reihe von Konzepten zur dynamischen Auswahlund Anpassung des von einem mobilen Client replizierten Datenbankausschnitts. Dazu zäh-len zuerst die Replikationssichten, die analog zu den bekannten Sichtendefinitionen mittels
205

206 KAPITEL 7. ZUSAMMENFASSUNG UND AUSBLICK
einer Replikationsanfrage in SQL festlegen, welche Daten der Server-Datenbank auf demClient sichtbar und zugreifbar sein sollen. Zusätzlich kann die Anwendung dabei den Zu-griffsmodus (z. B. lesend oder ändernd) festlegen und die Konfliktbehandlungsmethode(n)für unverbundene Änderungen und deren spätere Synchronisation auswählen.
Welche Daten für eine Replikationssicht tatsächlich repliziert werden müssen, hängt bei-spielsweise davon ab, welche Daten bereits auf dem Client gespeichert sind und welcheFremdschlüsselbedingungen durch Replikation zusätzlicher Daten erfüllt werden müssen.Die Arbeit mit replizierten Daten erfolgt mit den Standard-Schnittstellen des Client-DBMSüber lokal angelegte Sichten, welche zu den Replikationssichten korrespondieren. Die Re-plikatverwaltung sorgt dafür, dass sich der Zugriff auf den sichtbaren Datenbankausschnittin Bezug auf Anfrageergebnisse und Änderungsoperationen wie ein direkter Zugriff aufdie Server-Datenbank verhält (Replikattransparenz, siehe Replikatverwaltung unten). Dienutzerdefinierte Replikation bietet dagegen keine Transparenz der Unverbundenheit. DieAnwendung bzw. der Nutzer muss sich bewusst sein, dass unverbunden durchgeführte Än-derungen erst nach Wiederaufnahme der Verbindung zum Server und einer erfolgreicherSynchronisation inklusive Konfliktbehandlung dauerhaft werden.
Die Synchronisation wird bei der nutzerdefinierten Replikation vom mobilen Client ange-stoßen und gestattet ihm so, die dafür notwendige Verbindungsaufnahme zum Server zukontrollieren. Für die Synchronisation können Replikationssichten zu Gruppen zusammen-gefasst werden, welche immer gemeinsam synchronisert werden. Im Umkehrschluss heißtdas, der Client kann, wenn gewünscht, Replikationssichten gezielt von der Synchronisationausnehmen und damit das Übertragungsvolumen optimieren. Unabhängig von der Grup-penzuordnung sorgt die Replikatverwaltung der nutzerdefinierten Replikation immer fürdie Konsistenz der replizierten Daten.
Replikatverwaltung (Kapitel 4)
Für die Verwaltung der Replikationssichten wurde in Form des Fragmentkonzepts eine zu-sätzliche Verwaltungsebene entworfen und implementiert. Die Fragmentverwaltung werteteine in SQL gestellte Replikationsanfrage aus und bestimmt, ob sie erfüllt werden kann(z. B. bei einer bestehenden Sperre auf den angeforderten Daten) und welche Daten neuoder für welche nur ihre Änderungen auf den mobilen Client repliziert werden müssen.Ebenso entscheidet sie, welche Daten beim Löschen einer Replikationssicht nicht mehr vonanderen Sichten des Client referenziert werden und demzufolge gelöscht werden können.
Das Fragmentkonzept ist ein neues prädikatbasiertes Indexierungsverfahren für relationaleDaten und wurde im November 2004 [GMP04] zum Patent angemeldet. Eine Fragmentie-rung unterteilt eine relationale Datenbank zunächst in Schemafragmente, welche jeweilsTabellenschemata zusammenfassen, die über Fremdschlüsselbedingungen verknüpft sind.Damit wird später sichergestellt, dass bei der Bestimmung der Ergebnismenge einer Repli-kationsanfrage auch die jeweils per Fremdschlüssel abhängigen Tabellenzeilen berücksich-tigt werden (Replikattransparenz bzgl. Fremdschlüsselbedingungen). Im zweiten Schrittwerden die Schemafragmente anhand häufig zur Selektion in Replikationsanfragen verwen-deter Tabellenspalten horizontal partitioniert.
Die nach dem Verfahren erzeugte Fragmentierung einer relationalen Datenbank ist immervollständig und ihre Beschreibung unabhängig von den gespeicherten Daten. Die Fragmen-te müssen nur angepasst werden, wenn sich Partitionierungsspalten ändern oder Fragmente

7.2. WEITERFÜHRENDE ARBEITEN 207
ungünstige Größen annehmen. Die einfache Speicherung der Fragmentbeschreibung in einerDatenbanktabelle erlaubt eine effiziente Transformation aller wichtigen SQL-Prädikate (in-klusive Ungleichheit und Bereichsanfragen) und des Gleichheitsverbunds in die korrespon-dierenden Fragmentmengen, die anschließend, datenunabhängig, den replizierten Daten-bankausschnitt eines Client repräsentieren.
Prototypische Implementierung (Kapitel 5)
Die prototypische Implementierung realisiert die nutzerdefinierte Replikation auf Basis derDBMS-Produkte DB2 Universal Database (Server), Sybase Adaptive Server Anywhere(Client) und Sybase MobiLink (Synchronisationssoftware). Realisiert wurde die nutzerde-finierte Replikation in einer dreistufigen Architektur mit einem sogenannten ReplicationProxy Server (RPS) als zentralem Element, welches die Replikation zwischen einem Serverund mehreren mobilen Clients steuert. Mit Hilfe der Fragmentverwaltung werden die Re-plikationsabbildungen zwischen Server und Clients jeweils berechnet, die anschließend vonder Synchronisationssoftware für den Abgleich verwendet werden.
Der RPS bietet für die Konzepte der nutzerdefinierten Replikation eine an SQL angelehntedeskriptive Sprachschnittstelle. Zudem werden alle zur Replikation freigegebenen Datender Quelldatenbank noch einmal in einer konsolidierten Datenbank als Kopie auf demRPS gespeichert. Der Client greift somit nicht direkt auf die Quelldatenbank, sondernausschließlich über den RPS auf freigegebene Daten zu. Die Vorteile dieser Architektur, wieSchutz und Entlastung der Quelldatenbank sowie die Möglichkeit, das Datenbankschemader konsolidierten Datenbank u. a. für die Fragmentverwaltung zu optimieren, überwiegendie Nachteile auf Grund eines zusätzlichen Replikationschritts.
Reiseinformationssystem Hermes (Kapitel 6)
Durch die prototypische Implementierung des RPS und die Realisierung des interakti-ven mobilen Reiseinformationssystems Hermes konnte die Tauglichkeit der entwickeltenKonzepte überprüft werden. Hermes unterscheidet sich von anderen elektronischen Tou-ristenführern dadurch, dass die Nutzer in die Beschaffung und Aktualisierung der Inhaltemit einbezogen werden. Jeder kann so Informationen zu Hermes beisteuern und veralteteund fehlerhafte Daten korrigieren. Dies ermöglicht eine hohe Relevanz und „Nutzernähe“des Informationsangebots.
Bei Hermes sind die von Nutzern gelesenen und geschriebenen Daten hochgradig zeit-,orts- und situationsabhängig. Da Nutzer möglichst wenig dazu gezwungen werden sollen,eine aktive Netzverbindung für die Nutzung verfügbar zu haben, setzt Hermes konsequentauf Replikation und unverbundenes Arbeiten. Eine Umsetzung dieser Anwendung ohneeine Unterstützung für dynamische Replikatauswahl und -verwaltung wäre mit den heuteverfügbaren mobilen Datenbanklösungen sehr aufwändig. Die Arbeit hat gezeigt, dass sichHermes mit Hilfe der nutzerdefinierten Replikation sehr einfach realisieren lässt.
7.2 Weiterführende Arbeiten
Mit der vorliegenden Arbeit betrachten wir die Entwicklung an den vorgestellten Konzeptennicht als abgeschlossen, vielmehr gibt es verschiedene Ansatzpunkte für Erweiterungen und

208 KAPITEL 7. ZUSAMMENFASSUNG UND AUSBLICK
eine Verbesserung der Konzepte und Implementierungen. Im Folgenden werden zunächstverschiedene Ansätze kurz skizziert. Zum Abschluss des Abschnitts sollen die Vorteile undFragestellungen eines erweiterten Arbeitsmodells für die nutzerdefinierte Replikation an-diskutiert werden.
Die Definition der zu replizierenden Daten mittels Replikationsanfrage erfolgt in der vor-liegenden Konzeption der nutzerdefinierten Replikation mit SQL-Konstrukten der beteilig-ten DBMS-Produkte. Speziell für den Ortsbezug in Anfragen wäre eine Erweiterung derSprachschnittstelle und der Fragmentverwaltung um neue Prädikate wünschenswert, wel-che den aktuellen Aufenthaltsort des Nutzers und die Zeit implizit mit einbeziehen können,z. B. „Selektiere alle italienischen Restaurants im Umkreis von 500m“ oder „Welche kultu-rellen Veranstaltungen am Aufenthaltsort beginnen in den nächsten zwei Stunden?“. DieRealisierung setzt voraus, das auf dem RPS entsprechende geographische Informationengespeichert sind und der Client seinen momentanen Aufenthalts ermitteln kann (z. B. mitGPS). Vorschläge für die Behandlung und Auswertung ortsabhängiger Anfragen wurdenu. a. in [SDK01] gemacht.
Die in der Arbeit vorgestellte Replikatverwaltung verwendet für die Fragmentbildung nurhorizontale Tabellenpartitionen. Das bedeutet, dass immer eine komplette Tabellenzeilerepliziert werden muss (z. B. inklusive langer Beschreibungstexte), auch wenn eine Repli-kationsanfrage nur einen Teil der Spalten einer Tabelle benötigt. Dabei ebenfalls unberück-sichtigt bleiben bisher Unterschiede in den Möglichkeiten und Ressourcen der verschiedenenmobilen Clients. Beispielsweise könnte für ein sehr ressourcenarmes mobiles Gerät anstatteines farbigen Bildes (als Spaltenwert) ein kurzer Beschreibungstext übertragen werden(zu Möglichkeiten der Datenreduktion bei der Replikation siehe [Hen04]). Diese Frage-stellungen sind insbesondere relevant für Anwendungsszenarien, in denen das Schema derQuelldatenbank bereits vorgegeben ist. In diesen Fällen liegt die Aufgabe beim RPS undder Replikatverwaltung, geeignete Mittel für die Behandlung heterogen zusammengesetzterClient-Populationen bereitzustellen. Ein erster Ansatz zur Erweiterung des Fragmentkon-zepts für vertikale Tabellenpartitionen wurde in [Mic04] diskutiert.
Eine Erweiterung des RPS-Ansatzes hin zu einer hierarchischen Vernetzung geographischverteilter Replication Proxy Server wird in [Gol02] vorgeschlagen. Bei dieser Erweiterungspeichert ein einzelner RPS nur noch den Ausschnitt der Quelldatenbank, den die Nutzerin seinem Zuständigkeitsbereich benötigen. Gemeinsam verwendete Daten werden jeweilsam niedrigsten RPS in der Hierarchie verwaltet, der den Aufenthaltsort aller beteiligtenNutzer überdeckt. Die Zuständigkeit eines RPS wechselt dabei mit der Bewegung derNutzer. Da die in mobilen Anwendungsszenarien angefragten Daten oft eine sehr starkeLokalität aufweisen, lässt sich mit diesem Vorgehen auch für sehr große und regional weitverteilte Nutzerzahlen eine hochverfügbare und skalierbare Infrastruktur aufbauen.
Für die Arbeit wurde eine funktionale Evaluation der Konzepte durchgeführt. Performance-Fragestellungen wurden bei der Architektur des RPS berücksichtigt, standen aber sonstnicht im Fokus der Arbeit. Ein nächster Schritt sollte die Überprüfung und eventuellVerbesserung der Leistungsfähigkeit und Skalierbarkeit der entwickelten Verfahren undDatenstrukturen sein. Dazu dienen könnte ein Simulationsmodell für ein mobiles Daten-banksystem, erstellt auf der Basis von Simulationswerkzeugen und Netzwerksimulatoren.Eine Übersicht und Gegenüberstellung geeigneter Modelle und Werkzeuge ist in [Her02] zufinden.

7.2. WEITERFÜHRENDE ARBEITEN 209
Das Reiseinformationssystem Hermes wurde in der Arbeit nur als Beispielanwendungvorgestellt. Es bietet jedoch unserer Ansicht nach Potential für eine Weiterentwicklungbis hin zu einem kommerziellen Produkt. Dazu sind noch eine Reihe von Verbesserungensowohl bei der Anwendung selbst als auch im RPS notwendig. Es müssen verschiedeneClient-DBMS und Client-Hardware mit unterschiedlichen Ressourcen unterstützt werden.Zusätzliche Konfliktbehandlungsmethoden müssen in den RPS integriert werden und esmuss ein Anreizsystem geschaffen werden, welches das Verhältnis von abgerufenen undbeigesteuerten Daten austariert (siehe beispielsweise [ON03]). Wünschenswert wäre zudemeine Erweiterungsmöglichkeit des Informationsangebots durch die Nutzer. Das heißt, Nut-zer sollen selbst neue Informationsgruppen erfassen können, die dann als Tabellen in derDatenbank gespeichert werden.
Vorschlag für ein erweitertes Arbeitsmodell
Das Arbeitsmodell der nutzerdefinierten Replikation ist so strukturiert, dass die gesam-te Logik der Replikatverwaltung auf Rechnern im festen Netz durchgeführt wird. DiesesModell entlastet mobile Clients von komplexen Aufgaben und erlaubt damit die Unterstüt-zung auch für mobile Geräte mit geringen Ressourcen. Ein Nachteil dieses Arbeitsmodellsist offensichtlich, dass Replikationssichten immer über eine Verbindung zum RPS angelegtwerden müssen, auch wenn die gewünschten Daten bereits vollständig und mit akzeptablerAktualität auf dem Client gespeichert sind.
Stehen auf dem Client genügend Ressourcen für die Verarbeitung von Replikationsanfragenzur Verfügung, kann das Arbeitsmodell dahingehend erweitert werden, im Rahmen der be-reits bestehenden Zugriffszusicherungen (siehe Kapitel 3.4.5) auch unverbunden bestimmteReplikat(re)definitionen zuzulassen. Das bietet den Vorteil, zunächst rein lokal und ohneVerbindung überprüfen zu können, ob eine gewünschte Replikationssicht angelegt werdenkann oder nicht. Nur im zweiten Fall ist anschließend eine Verbindungsaufnahme erfor-derlich. Damit eine Replikationssicht V ohne Verbindung zur konsolidierten Datenbankerfolgreich angelegt oder geändert werden kann, müssen folgende Bedingungen erfüllt sein:
1. V muss lokal berechenbar sein, d. h. mindestens die zur Ausführung der Replikati-onsanfrage benötigten Daten (Fragmentmenge F) müssen in der Replikatdatenbankgespeichert sein.
2. V wurde mit Zugriffszusicherung R angelegtoderfür alle Fragmente F ∈ F gilt in Abhängigkeit von der geforderten Änderbarkeitszu-sicherung für V :
(a) RI: Für F wurde eine der Änderbarkeitszusicherungen RI, RIDU, XRI oderXRIDU gewährt.
(b) RIDU: Für F wurde eine der Änderbarkeitszusicherungen RIDU oder XRIDUgewährt.
(c) XRI: Für F wurde eine der Änderbarkeitszusicherungen XRI oder XRIDU ge-währt.
(d) XRIDU: Für F wurde die Änderbarkeitszusicherung XRIDU gewährt.

210 KAPITEL 7. ZUSAMMENFASSUNG UND AUSBLICK
Eine lokale Replikationssichtendefinition kann also dann erfolgreich sein, wenn alle benötig-ten Daten bereits in derselben oder mit einer höheren Zugriffszusicherung angefordert undgenehmigt wurden. Mit Hilfe des Fragmentkonzepts lässt sich diese Prüfung einfach durch-führen, alle von der Anfrage benötigten Fragmente müssen mit einer passenden Zugriffs-zusicherung und demselben Aktualisierungszeitstempel bereits auf dem Client gespeichertsein. Diese Prüfung setzt allerdings voraus, dass die zur Fragmentverwaltung benötigteFunktionalität (z. B. Anweisungsparser) und Ausschnitte der Fragmenttabellen auch aufdem Client vorhanden sind.
Das Konzept der Restfragmente, das auf RPS-Seite die Vollständigkeit einer Fragmen-tierung der konsolidierten Datenbank garantiert, kann analog dazu benutzt werden, diejeweils nicht in der Replikatdatenbank gespeicherten Daten zu referenzieren. Trifft eineunverbunden angelegte Replikationssicht auf ein solches (lokales) Restfragment, ist eineAnfrage beim Replication Proxy Server erforderlich. Dabei werden dann, wie bei der rei-nen Server-Variante, nur die zusätzlich notwendigen Fragmente übertragen und die lokalenRestfragmente aktualisiert.
Es kann abschließend festgehalten werden, dass gerade für die Realisierung neuer mobi-ler Datenbankanwendungen eine über die bisher in Produkten zu findende Funktionalitäthinausgehende Unterstützung für die Arbeit mit replizierten Daten notwendig ist. Die vor-liegende Arbeit hat mit der nutzerdefinierten Replikation, dem Fragmentkonzept und demReplication Proxy Server einen Beitrag dazu geleistet. Es wäre wünschenswert, dass diebegonnene Arbeit in zukünftigen Forschungsprojekten, wofür ein Ausblick auf möglicheThemen gegeben wurde, fortgesetzt wird.

Literaturverzeichnis
[Anh01] C. Anhalt. Telepräsenz-Anwendungen im Rettungswesen. In Tagungsband derGI-Informatiktage 2001, Bad Schussenried, Seiten 299–302, 2001. 3
[Bar99] D. Barbará. Mobile Computing and Databases – A Survey. IEEE Transactionson Knowledge and Data Engineering, 11(1):108–117, Januar/Februar 1999. 8
[Bau03] K. Baumgarten. Konzeption und Schemaentwurf eines interaktiven mobilen Rei-seinformationssystems. Studienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, März 2003. 179
[Bau04] K. Baumgarten. Implementierung eines interaktiven mobilen Reiseinformations-systems. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-UniversitätJena, August 2004. viii, 179, 183, 184, 185, 190, 192
[BBG+95] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil und P. O’Neil. ACritique of ANSI SQL Isolation Levels. In M. J. Carey und D. A. Schneider(Hrsg.), Proceedings of the 1995 ACM SIGMOD International Conference onManagement of Data, San Jose, CA, USA, Band 24(2) aus ACM SIGMODRecord, Seiten 1–10, New York, NY, USA, Juni 1995. ACM Press. 31, 33, 34
[Bei97] M. Beigl. MODBC - A Middleware for Accessing Databases from Mobile Com-puters. In Proceedings of the 3rd Cabernet Plenary Workshop, Rennes, France,1997. 126
[BG03] K. Baumgarten und C. Gollmick. Konzeption eines interaktiven mobilen Reise-informationssystems. In Tagungsband zum Workshop „Mobilität und Informati-onssysteme“ des GI-Arbeitskreises Mobile Datenbanken und Informationssystem,Zürich, Schweiz, Technical Report Nr. 422, Seiten 22–31. Departement Informa-tik, Institut für Informationssysteme, ETH Zürich, Oktober 2003. 179
[BG04] R. Bittner und C. Gollmick. Implementierung von Konfliktvermeidungstechni-ken für den mobilen Datenbankzugriff. In Tagungsband zum Workshop „Grund-lagen und Anwendungen mobiler Informationstechnologie“ des GI-ArbeitskreisesMobile Datenbanken und Informationssysteme, Heidelberg, Preprint Nr. 4/2004,Seiten 13–22. Fakultät für Informatik, Universität Magdeburg, Februar 2004.129
[BHG87] P. A. Bernstein, V. Hadzilacos und N. Goodman. Concurrency Control andRecovery in Database Systems. Addison-Wesley, Reading, MA, 1987. 26
211

212 LITERATURVERZEICHNIS
[Bit04] R. Bittner. Implementierung wichtiger Konfliktbehandlungstechniken für denmobilen Datenbankeinsatz. Studienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, April 2004. 119, 126, 129, 131, 133, 175
[BR05] P. Braun und W. Rossak. Mobile Agents: Basic Concepts, Mobility Models andThe Tracy Toolkit. dpunkt.verlag, Heidelberg, 2005. 41
[Bru03] J. Bruce. JDBC RowSet Implementations. SUN Microsystems, Palo Alto, CA,USA, April 2003. 45
[CM77] A. K. Chandra und P. M. Merlin. Optimal Implementation of Conjunctive Que-ries in Relational Data Bases. In Proceedings of the 9th Annual ACM Symposiumon Theory of Computing, Boulder, Colorado, USA, Seiten 77–90. ACM Press,1977. 47, 79
[Cod70] E. F. Codd. A Relational Model of Data for Large Shared Data Banks. Com-munications of the ACM, 13(6):377–387, Juni 1970. 9
[Cod79] E. F. Codd. Extending the Data Base Relational Model to Capture More Mea-ning. ACM Transactions on Database Systems, 4(4):397–434, 1979. 10
[Cod81] E. F. Codd. Data Models in Database Management. ACM SIGMOD Record,11(2):112–114, 1981. 9
[Con97] S. Conrad. Föderierte Datenbanksysteme: Konzepte der Datenintegration.Springer-Verlag, Berlin/Heidelberg, 1997. 22
[CTO97] J. Cai, K.-L. Tan und B. C. Ooi. On Incremental Cache Coherency Schemesin Mobile Computing Environments. In A. Gray und P. Å. Larson (Hrsg.),Proceedings of the 13th International Conference on Data Engineering, Seiten114–123, Washington, DC, USA, 1997. IEEE Computer Society. 46
[Dad96] P. Dadam. Verteilte Datenbanken und Client/Server-Systeme — Grundlagen,Konzepte, Realisierungsstrukturen. Springer-Verlag, Berlin, 1996. 20, 22
[Dat04] C. J. Date. An Introduction to Database Systems. Addison-Wesley, Reading,MA, 8. Auflage, 2004. 9, 44
[DFTJ+96] S. Dar, M. J. Franklin, B. Tór Jónsson, D. Srivastava und M. Tan. Seman-tic Data Caching and Replacement. In Proceedings of the 22th InternationalConference on Very Large Data Bases (VLDB’96), Seiten 330–341, Mumbai(Bombay), India, September 1996. Morgan Kaufmann Publishers. 46
[DGK+86] U. Deppisch, J. Günauer, K. Küspert, V. Obermeit und G. Walch. Überlegun-gen zur Datenbank-Kooperation zwischen Server und Workstations. In Tagungs-band der 16. GI-Jahrestagung I, Berlin, Band 126 aus Informatik-Fachberichte,Seiten 565–580. Springer-Verlag, 1986. 58
[DH95] M. Dunham und A. Helal. Mobile Computing and Databases: Anything New?ACM SIGMOD Record, 24(4):5–9, Dezember 1995. 8
[Die00] R. Diestel. Graphentheorie. Springer-Verlag, Heidelberg, 2. Auflage, September2000. 83

LITERATURVERZEICHNIS 213
[DPS+94] A. Demers, K. Petersen, M. Spreitzer, D. Terry, M. Theimer und B. Welch.The Bayou Architecture: Support for Data Sharing among Mobile Users. InProceedings of the Workshop on Mobile Computing Systems and Applications,Seiten 2–7, Santa Cruz, CA, USA, Dezember 1994. 40, 64
[EGLT76] K. P. Eswaran, J. Gray, R. A. Lorie und I. L. Traiger. The Notions of Consis-tency and Predicate Locks in a Database System. Communications of the ACM,19(11):624–633, 1976. 81
[Fan00] T. Fanghänel. Vergleich und Bewertung kommerzieller mobiler Datenbank-systeme. Studienarbeit, Institut für Informatik, Friedrich-Schiller-UniversitätJena, September 2000. 60
[Fan02] T. Fanghänel. Using Encryption for Secure Data Storage in Mobile DatabaseSystems. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-UniversitätJena und IBM Silicon Valley Lab, San Jose, CA, USA, September 2002. 15
[FEB03] M. Fisher, J. Ellis und J. Bruce. JDBC API Tutorial and Reference. Addison-Wesley, 3. Auflage, 2003. 125
[FK92] D. Ferraiolo und R. Kuhn. Role-Based Access Control. In Proceedings of the 15thNational Computer Security Conference, Baltimore MD, USA, Seiten 554–563,1992. 127
[FKL03] T. Fanghänel, J. S. Karlsson und T. Y. Cliff Leung. DB2 Everyplace DatabaseRelease 8.1: Architecture and Key Features. Datenbank-Spektrum, 5:9–15, 2003.61
[GHOS96] J. Gray, P. Helland, P. O’Neil und D. Shasha. The Dangers of Replication anda Solution. In Proceedings of the ACM SIGMOD International Conference onManagement of Data, Seiten 173–182, Montreal, Quebec, Canada, Juni 1996.40
[GHVJ94] E. Gamma, R. Helm, J. Vlissides und R. Johnson. Design Patterns: Elements ofReusable Object Oriented Software. Addison Wesley, Reading, MA, USA, 1994.169
[GMP04] C. Gollmick, F. Michels und R. Pfender. Datenstruktur sowie Verfahren zurAuswahl und Verwaltung von Daten für die Replikation zwischen Datenbanken,Friedrich-Schiller-Universität Jena, Antrag auf Erteilung eines Patents, AZ: 102004 058 213.0, November 2004. 67, 206
[Gol98] C. Gollmick. Analyse, Visualisierung und Auswertung von DB2-Log-Einträgen.Studienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Sep-tember 1998. 25
[Gol00] C. Gollmick. Anwendungsklassen und Architektur Mobiler Datenbanksysteme.In Tagungsband zum 12. Workshop „Grundlagen von Datenbanken“, Plön,Deutschland, Bericht Nr. 2005, Seiten 36–40, Christian-Albrechts-UniversitätKiel, Juni 2000. 2

214 LITERATURVERZEICHNIS
[Gol01] C. Gollmick. Unterstützung mobiler Clients durch erweiterte Client/Server-Datenbanksysteme. In Tagungsband zum 13. GI-Workshop „Grundlagen vonDatenbanken“, Gommern, Deutschland, Preprint Nr. 10/2001, Seiten 43–47. Fa-kultät für Informatik, Universität Magdeburg, Juni 2001. 123
[Gol02] C. Gollmick. Using Replication Proxy Servers for Scalable Mobile DatabaseAccess. In Proceedings of the EDBT 2002 Ph.D. Workshop, Prag, TschechischeRepublik, Seiten 115–118. Matfyzpress, März 2002. 123, 208
[Gol03a] C. Gollmick. Client-Oriented Replication in Mobile Database Environments.Jenaer Schriften zur Mathematik und Informatik Math/Inf/08/03, Institut fürInformatik, Friedrich-Schiller-Universität Jena, Mai 2003. 43
[Gol03b] C. Gollmick. Nutzerdefinierte Replikation zur Realisierung neuer mobiler Daten-bankanwendungen. In Tagungsband der 10. GI-Fachtagung Datenbanksystemefür Business, Technologie und Web (BTW), Leipzig, Band P-26 aus Lecture No-tes in Informatics, Seiten 453–462. Springer-Verlag, Februar 2003. 51
[Gol03c] C. Gollmick. Replication in Mobile Database Environments: A Client-OrientedApproach. In Proceedings of the 14th International Workshop on Database andExpert Systems Applications (DEXA’03), Prag, Tschechische Republik, Seiten980–982. IEEE Computer Society, September 2003. 43
[GR93] J. Gray und A. Reuter. Transaction Processing: Concepts and Techniques. Mor-gan Kaufmann Publishers, San Mateo, CA, USA, 1993. 25, 35, 81
[GR03] C. Gollmick und G. Rabinovitch. Fragmentbildung zur Unterstüung der nutzer-definierten Replikation. In Post-Proceedings of the Workshop Scalability, Per-sistence, Transactions - Database Mechanisms for Mobile Applications, Karlsru-he, Band P-43 aus Lecture Notes in Informatics, Seiten 79–93. Springer-Verlag,April 2003. 67, 90
[GS02] C. Gollmick und U. Störl. Algorithmen für Parallelität bei Backup und Restorein Datenbanksystemen. Informatik Forschung und Entwicklung, 17(4):157–166,Dezember 2002. 29
[GSW98] S. Guo, W. Sun und M. A. Weiss. Addendum to “On Satisfiability, Equivalence,and Implication Problems Involving Conjunctive Queries in Database Systems”.IEEE Transactions on Knowledge and Data Engineering, 10(5):863, September1998. 47, 79
[Här84] T. Härder. Observations on Optimistic Concurrency Control Schemes. Infor-mation Systems, 9(2):111–120, 1984. 30
[HB04] T. Härder und A. Bühmann. Datenbank-Caching - Eine systematische Analysemöglicher Verfahren. Informatik Forschung und Entwicklung, 19(1):2–16, 2004.84
[Hen04] T. Henke. Untersuchung von Möglichkeiten zur Reduktion von Datenmengenund Übertragungszeiten in mobilen Arbeitsumgebungen. Studienarbeit, Institutfür Informatik, Friedrich-Schiller-Universität Jena, Mai 2004. 208

LITERATURVERZEICHNIS 215
[Her02] M. Herzig. Evaluation von Modellen und Tools zur Simulation des mobilenDatenzugriffs. Studienarbeit, Institut für Informatik, Friedrich-Schiller-Univer-sität Jena, April 2002. 208
[Her03] M. Herzig. Alternativen und Erweiterungen zum Modell der nutzerdefiniertenReplikation. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universi-tät Jena, Oktober 2003. 43, 60, 64
[HFAW02] S. E. Hudson, F. Flannery, S. Ananian und D. Wang. CUP Parser Generatorfor Java (Version 1.0). Princeton University, 2002. Version 1.0. 125
[HR83] T. Härder und A. Reuter. Principles of Transaction–Oriented Database Reco-very. ACM Computing Surveys, 15(4):287–317, Dezember 1983. 25
[HR01] T. Härder und E. Rahm. Datenbanksysteme: Konzepte und Techniken der Im-plementierung. Springer-Verlag, Berlin, 2. Auflage, 2001. 26, 28, 81
[HS00] A. Heuer und G. Saake. Datenbanken: Konzepte und Sprachen, 2. aktualisierteund erweiterte Auflage. International Thomson Publishing, Bonn, 2000. 7, 11
[HTK05] H. Höpfner, C. Türker und B. König-Ries. Mobile Datenbanken und Informa-tionssysteme - Konzepte und Techniken. dpunkt.verlag, Heidelberg, Juli 2005.19, 20
[iAn04a] iAnywhere, A Sybase Company. Adaptive Server Anywhere SQL-Benutzerhand-buch (Version 9.0.2), Oktober 2004. 37, 52, 61
[iAn04b] iAnywhere, A Sybase Company. iAnywhere MobiLink Benutzerhandbuch (Ver-sion 9.0.2), Oktober 2004. 137, 175
[IB94] T. Imielinski und B. Badrinath. Mobile Wireless Computing: Challenges in DataManagement. CACM, 37(10):18–28, 1994. 17, 19
[IBM03] IBM Corporation. Jikes Parser Generator (Version 1.3), 2003. Version 1.3. 125
[IBM04a] IBM Corporation. IBM DB2 Everyplace Application Development Guide – Ver-sion 8.2, 1. Auflage, August 2004. 61
[IBM04b] IBM Corporation. IBM DB2 SQL Reference Volume 1/2 – Version 8.2, 2004.44, 133
[IBM04c] IBM Corporation. IBM DB2 Universal Database – Replication Guide and Re-ference (Version 8.2), 2004. 61, 137
[IET96] Internet Engineering Task Force (IETF). The SSL3.0 Protocol Version 3.0,November 1996. 126
[ISO96] International Organization for Standardization, Genf. Information technology– Syntactic Metalanguage – Extended BNF, 1996. ISO/IEC 14977:1996, FinalDraft International Standard (FDIS). 125
[ISO03a] International Organization for Standardization, Genf. Information technology –Database languages – SQL – Part 1: Framework (SQL/Framework), Dezember2003. 9, 131, 133

216 LITERATURVERZEICHNIS
[ISO03b] International Organization for Standardization, Genf. Information technology –Database languages – SQL – Part 2: Foundation (SQL/Foundation), Dezember2003. 9
[KB96] A. M. Keller und J. Basu. A Predicate-based Caching Scheme for Client-ServerDatabase Architectures. The VLDB Journal, 5(1):35–47, Januar 1996. 46
[Kle03] H.-J. Klein. Null Values in Relational Databases and Sure Information Ans-wers. In Proceedings of 2nd International Workshop on Semantics in Databases,Dagstuhl, Revised Papers, Band 2582 aus Lecture Notes in Computer Science,Seiten 119–138. Springer-Verlag, 2003. 10
[KP97] G. H. Kuenning und G. J. Popek. Automated Hoarding for Mobile Computers.In W. M. Waite (Hrsg.), Proceedings of the 16th ACM Symposium on OperatingSystems Principles, Seiten 264–275, New York, NY, USA, 1997. ACM Press. 47
[KPPS03] H.-P. Kriegel, M. Pfeifle, M. Pötke und T. Seidl. The Paradigm of RelationalIndexing: a Survey. In Tagungsband der 10. GI-Fachtagung Datenbanksystemefür Business, Technologie und Web (BTW), Leipzig, Band P-26 aus LectureNotes in Informatics, Seiten 285–304. Springer-Verlag, Februar 2003. 100
[KR01] U. Kubach und K. Rothermel. Ein Hoarding-Verfahren für ortsbezogene In-formationen. Informatik Forschung und Entwicklung, 16(4):189–199, November2001. 47
[KS92] J. J. Kistler und M. Satyanarayanan. Disconnected Operation in the Coda FileSystem. ACM Transactions on Computer Systems (TOCS), 10(1):3–25, Februar1992. 47
[Len97] R. Lenz. Adaptive Datenreplikation in verteilten Systemen. Teubner, Leipzig,1997. 65
[Lie01] M. Liebisch. Evaluation von Transaktionsmodellen und transaktionsorientiertenReintegrationsstrategien für mobile Datenbanksysteme. Studienarbeit, Institutfür Informatik, Friedrich-Schiller-Universität Jena, Dezember 2001. 38, 60, 64
[Lie03] M. Liebisch. Synchronisationskonflikte beim mobilen Datenbankzugriff: Vermei-dung, Erkennung, Behandlung. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Februar 2003. 34, 129, 131, 133
[LKPM01] L. Li, B. König-Ries, N. Pissinou und K. Makki. Strategies for Semantic Ca-ching. In Proceedings of 12th International Conference of Database and ExpertSystems Applications (DEXA), München, Band 2113 aus Lecture Notes in Com-puter Science, Seiten 284–298. Springer-Verlag, 2001. 46
[LP83] R. A. Lorie und W. Plouffe. Complex Objects and Their Use in Design Tran-sactions. In Proceedings of the ACM SIGMOD International Conference on En-gineering Design Applications, Seiten 115–121, Silver Spring, MD, USA, 1983.IEEE Computer Society Press. 58
[Mai83] D. Maier. The Theory of Relational Databases. Computer Science Press, Rock-ville, MD, USA, 1983. 10, 11

LITERATURVERZEICHNIS 217
[Mic04] F. Michels. Implementierung des Fragmentkonzepts für die nutzerdefinierteReplikation. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Univer-sität Jena, August 2004. 67, 101, 114, 119, 169, 208
[Mos85] J. E. B. Moss. Nested Transactions: An Approach to Reliable Distributed Com-puting. MIT Press, Cambridge, MA, 1985. 29
[MS93] J. Melton und A. R. Simon. Understanding The New SQL: A complete guide.Morgan Kaufmann Publishers, Inc., San Francisco, 1. Auflage, 1993. 109
[Mül03] T. Müller. Architektur und Realisierung eines Replication Proxy Server zur Un-terstützung neuartiger mobiler Datenbankanwendungen. Diplomarbeit, Institutfür Informatik, Friedrich-Schiller-Universität Jena, April 2003. 60, 119, 131,168, 174
[OFOL00] P. O’Neil, A. Fekete, E. O’Neil und D. Liarokapis. A New Hybrid Predicate-Assertion-Index-Locking (PAX) Algorithm to Prevent Transactional Phantoms.Technischer Bericht, University of Massachusetts, Boston, USA, 2000. 81
[O’N86] P. E. O’Neil. The Escrow Transactional Method. ACM Transactions on DatabaseSystems, 11(4):405–430, 1986. 36, 129
[ON03] P. Obreiter und J. Nimis. A Taxonomy of Incentive Patterns - The DesignSpace of Incentives for Cooperation. In Proceedings of the 2nd Internatio-nal Workshop on Agents and Peer-to-Peer Computing (AP2PC’03), Melbourne,Australia, Band 2872 aus Lecture Notes in Computer Science, Seiten 89–100.Springer-Verlag, 2003. 181, 209
[Ora04a] Oracle Corporation. Oracle Database Lite, Developer’s Guide 10g (10.0.0), Juni2004. 61
[Ora04b] Oracle Corporation. Oracle Label Security Administrator’s Guide (Release 10),2004. 129
[OS02] M. S. Olivier und D. L. Spooner. Database and Application Security XV –Fifteenth Annual Working Conference on Database and Application Security,International Federation for Information Processing (IFIP), Volume 87. KluwerAcademic Publishers, Boston, USA, 2002. 130
[ÖV99] M. T. Özsu und P. Valduriez. Principles of Distributed Database Systems. Pren-tice Hall, Upper Saddle River, NJ, 2. Auflage, 1999. 20
[PB94] E. Pitoura und B. Bhargava. Building Information Systems for Mobile Environ-ments. In Proceedings of the 3rd International Conference on Information andKnowledge Management, Seiten 371–378, November 1994. 8
[PBM+00] N. M. Preguica, C. Baquero, F. Moura, J. L. Martins, R. Oliveira, H. Joao,J. O. Pereira und S. Duarte. Mobile Transaction Management in MobiSnap. InProceedings of the 2000 ADBIS-DASFAA Symposium on Advances in Databa-ses and Information Systems, Special Sessions on Mobile Database Technology(LNCS 1884), Seiten 379–386, September 2000. 37, 40, 64

218 LITERATURVERZEICHNIS
[Per98] C. E. Perkins. Mobile IP – Design Principles and Practices. Addison-WesleyWireless Communication Series. Addison-Wesley, 2. Auflage, 1998. 19
[Pfe04] R. Pfender. Entwurf und Implementierung eines Replication Proxy Server zurUnterstützung nutzerdefinierter Replikation in mobilen Datenbankszenarien. Di-plomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, April2004. viii, 67, 119, 126, 131, 169, 173, 174, 178
[PMC02] N. Preguiça, J. L. Martins und M. Cunha. An SQL-based Mobile DatabaseCombining Conflict Avoidance and Conflict Resolution. Technischer Bericht,Departamento de Informática, Universidade Nova de Lisboa, Portugal, 2002.37, 40, 64
[Rab03] G. Rabinovitch. Replikatverwaltung bei der nutzerdefinierten Replikation. Stu-dienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Dezem-ber 2003. 67, 90, 119
[Rah94] E. Rahm. Mehrrechner-Datenbanksysteme. Addison-Wesley, Bonn, 1994. 30
[RD99] Q. Ren und M. H. Dunham. Using Clustering for Effective Management ofa Semantic Cache in Mobile Computing. In S. Banerjee, P. K. Chrysanthisund E. Pitoura (Hrsg.), Proceedings of the 1st ACM International Workshop onData Engineering for Wireless and Mobile Access, Seiten 94–101, New York,USA, 1999. ACM Press. 46
[RD03] Q. Ren und M. H. Dunham. Semantic Caching and Query Processing. Tran-sactions on Knowledge and Data Engineering, 15(1):192–210, Januar 2003. 46
[SDK01] A. Y. Seydim, M. H. Dunham und V. Kumar. Location Dependent QueryProcessing. In Proceedings of the 2nd ACM International Workshop on DataEngineering for Wireless and Mobile Access, Santa Barbara, CA, USA, Seiten47–53. ACM Press, Mai 2001. 208
[SG98] U. Störl und C. Gollmick. Methoden und Werkzeuge zur quantitativen Untersu-chung von Backup- und Recovery-Algorithmen in Datenbanksystemen. MMB-Mitteilungen, 34:14–19, 1998. 25
[Stö01] U. Störl. Backup und Recovery in Datenbanksystemen. TEUBNER-TEXTE zurInformatik. B. G. Teubner Verlagsgesellschaft, Stuttgart, Leipzig, Wiesbaden,2001. 29
[Sun03a] Sun Microsystems. Java 2 Platform Standard Edition (J2SE), 2003. 125
[Sun03b] Sun Microsystems. Java Compiler Compiler (JavaCC) – The Java Parser Ge-nerator (Version 3.2), 2003. Version 3.2. 125
[Sut00] H. Sutter. ISO Project Proposal for Replication, ISO/IEC JTC 1/SC 32 WG3,Januar 2000. 132
[Tan03] A. S. Tanenbaum. Computernetzwerke. Pearson Studium, München, 2003. 19
[Teu03] N. Teubert. Realisierung einer Parserkomponente für die Anweisungen des Rep-lication Proxy Server. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, September 2003. 125

LITERATURVERZEICHNIS 219
[Vos00] G. Vossen. Datenmodelle, Datenbanksprachen und Datenbank-Management-Systeme. Oldenbourg, München, 4. Auflage, 2000. 10, 11, 12, 13
[WC02] S. Weissman Lauzac und P. K. Chrysanthis. View Propagation and Inconsis-tency Detection for Cooperative Mobile Agents (CoopIS’02). In Proceedings ofthe 2002 Confederated International Conferences DOA, CoopIS and ODBASE:On the Move to Meaningful Internet Systems, Band 2519 aus Lecture Notes inComputer Science, Seiten 107–124. Springer-Verlag, Heidelberg, Oktober 2002.66
[Wie04] D. Wiese. Nutzerverwaltung und datenbasierte Rechtevergabe für mobile Da-tenbankanwendungen. Studienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Mai 2004. 119, 126, 129, 179, 190
[WS92] G. Weikum und H.-J. Schek. Concepts and Applications of Multi-level Transac-tions and Open Nested Transactions. In A. K. Elmagarmid (Hrsg.), DatabaseTransaction Models for Advanced Applications, Seiten 515–553. Morgan Kauf-mann Publishers, San Mateo, CA, USA, 1992. 29
[WV01] G. Weikum und G. Vossen. Transactional Information Systems: Theory, Algo-rithms, and Practice of Concurrency Control and Recovery. Morgan KaufmannPublishers, San Francisco, CA, USA, 2001. 26
[Zuk98] O. Zukunft. Integration mobiler und aktiver Datenbankmechanismen als Basisfür die ortsungebundene Vorgangsbearbeitung, Dissertation. Logos-Verlag, Ber-lin, 1998. 17, 65


Selbständigkeitserklärung
Ich erkläre, dass ich die vorliegende Arbeit selbständig und nur unter Verwendung derangegebenen Hilfsmittel und Literatur angefertigt habe.
Heidelberg/Jena, 4. November 2005


Lebenslauf
Persönliche Daten
Name Christoph Friedrich Gollmick
Geburtsdatum 5. April 1974
Geburtsort Jena
Schulische und universitäre Ausbildung
1981 – 1989 Polytechnische Oberschule „Grete Unrein“ in Jena
1989 – 1993 Mathematisch-naturwissenschaftlich-technischer Spezialschulteil desCarl-Zeiss-Gymnasiums in Jena, Abschluss mit Abitur
1994 – 1999 Diplomstudium Informatik mit Nebenfach Wirtschaftswissenschaftenan der Friedrich-Schiller-Universität Jena, Vertiefungsrichtung: Prak-tische Informatik, Schwerpunkt: Datenbanksysteme, Abschluss alsDiplom-Informatiker1997 Aufnahme in die Studienstiftung des deutschen Volkes
Zivildienst und beruflicher Werdegang
1993 – 1994 Zivildienst beim Deutschen Roten Kreuz in Jena
1999 – 2004 Wissenschaftlicher Mitarbeiter am Lehrstuhl für Datenbanken undInformationssysteme der Fakultät für Mathematik und Informatik,Friedrich-Schiller-Universität Jena
seit 2004 Entwickler für SAP NetWeaver BI auf MS SQL Server in der Abtei-lung Microsoft Platforms der SAP AG, Walldorf
Heidelberg/Jena, 4. November 2005