keyword extraction for metadata annotation of learning objects lothar lemnitzer, paola monachesi...
Post on 20-Dec-2015
225 views
TRANSCRIPT

Keyword extraction for metadata annotation of
Learning Objects
Lothar Lemnitzer, Paola MonachesiRANLP, Borovets 2007

Outline
• A quantitative view on the corpora• The keyword extractor• Evaluation of the KWE

Creation of a learning objects archive • Collection of the learning material IST
domains for the LOs:1. Use of computers in education, with
sub-domains: 2. Calimera documents (parallel corpus
developed in the Calimera FP5 project, http://www.calimera.org/ )
• Result: a multilingual, partially parallel, partially comparable, domain specific corpus

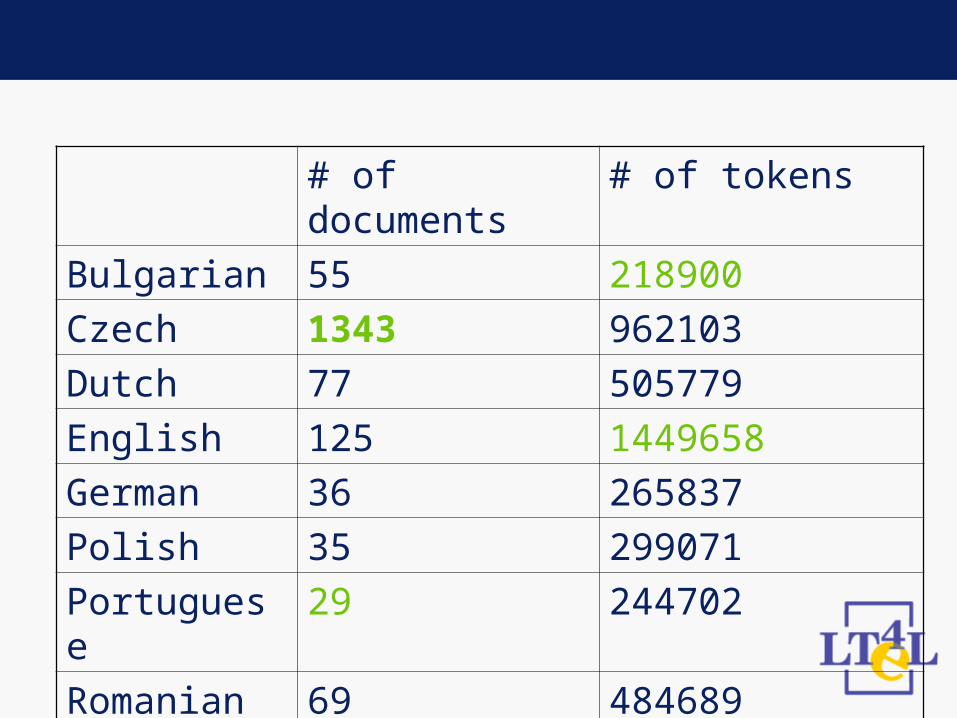
Corpus statistics – full corpus
• Measuring lengths of corpora (# of documents, tokens)
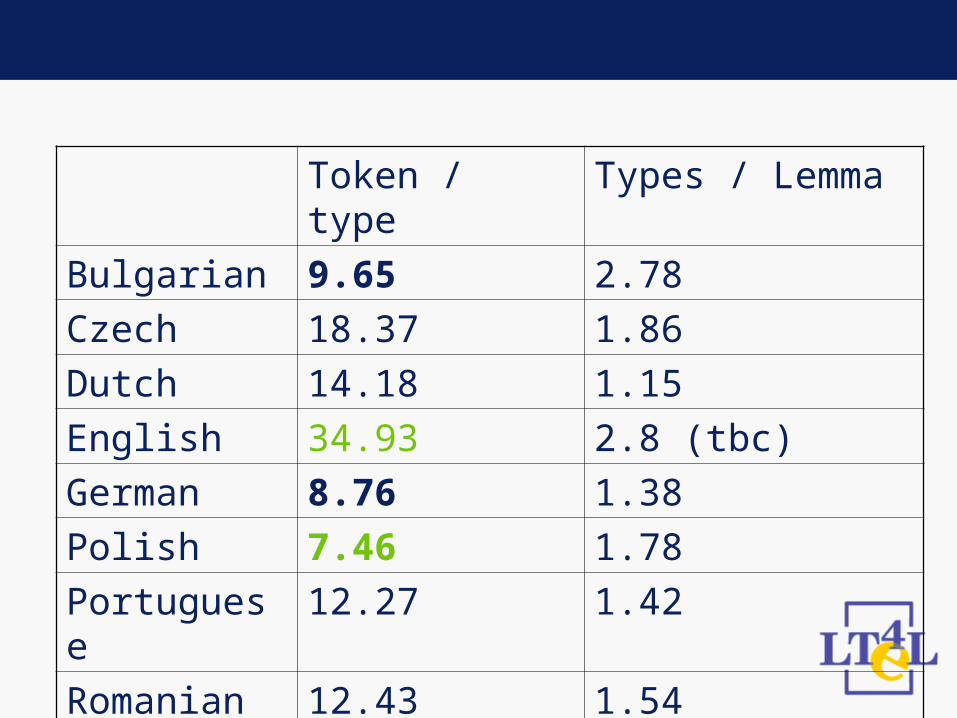
• Measuring token / tpye ratio• Measuring type / lemma ratio
# of documents
# of tokens
Bulgarian 55 218900
Czech 1343 962103
Dutch 77 505779
English 125 1449658
German 36 265837
Polish 35 299071
Portuguese 29 244702
Romanian 69 484689
Token / type Types / Lemma
Bulgarian 9.65 2.78
Czech 18.37 1.86
Dutch 14.18 1.15
English 34.93 2.8 (tbc)
German 8.76 1.38
Polish 7.46 1.78
Portuguese 12.27 1.42
Romanian 12.43 1.54

Corpus statistics – full corpus
• Bulgarian, German and Polish corpora have a very low number of tokens per type (probably problems with sparseness)
• English has by far the highest ratio• Czech, Dutch, Portuguese and
Romanian are in between• type / lemma ration reflects richness of
inflectional paradigms

Reflection
• The corpora are heterogeneous wrt to the type / token ratio
• Does the data sparseness of some corpora, compared to others, influence the information extraction process?
• If yes, how can we counter this effect?• How does the quality of the linguistic
annotation influence the extraction task?

Corpus statistics – annotated subcorpus
• Measuring lenghts of annotated documents
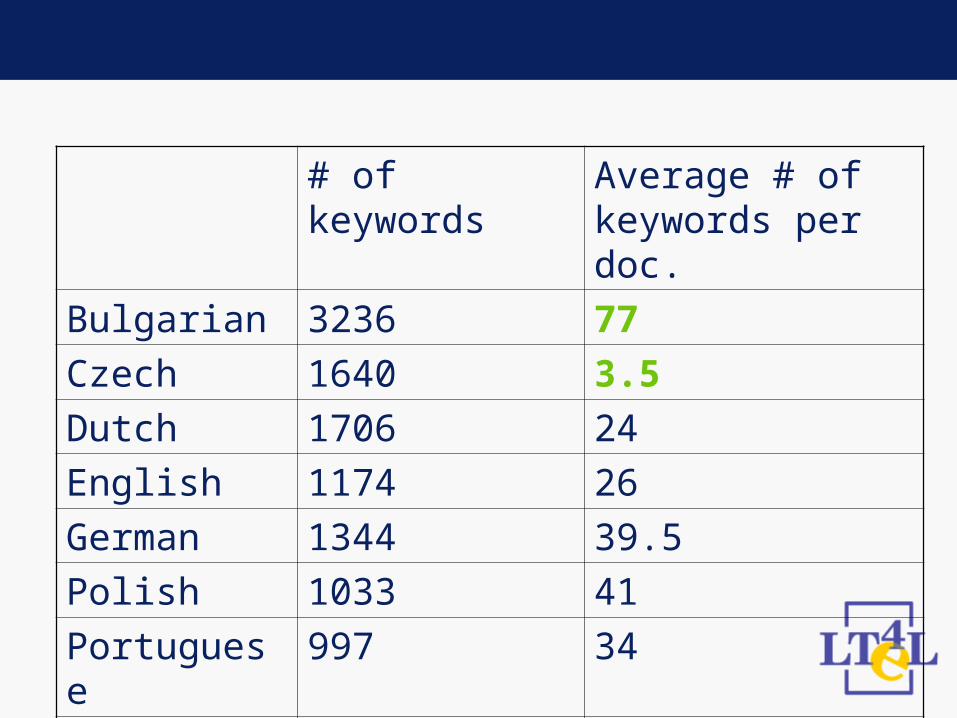
• Measuring distribution of manually marked keywords over documents
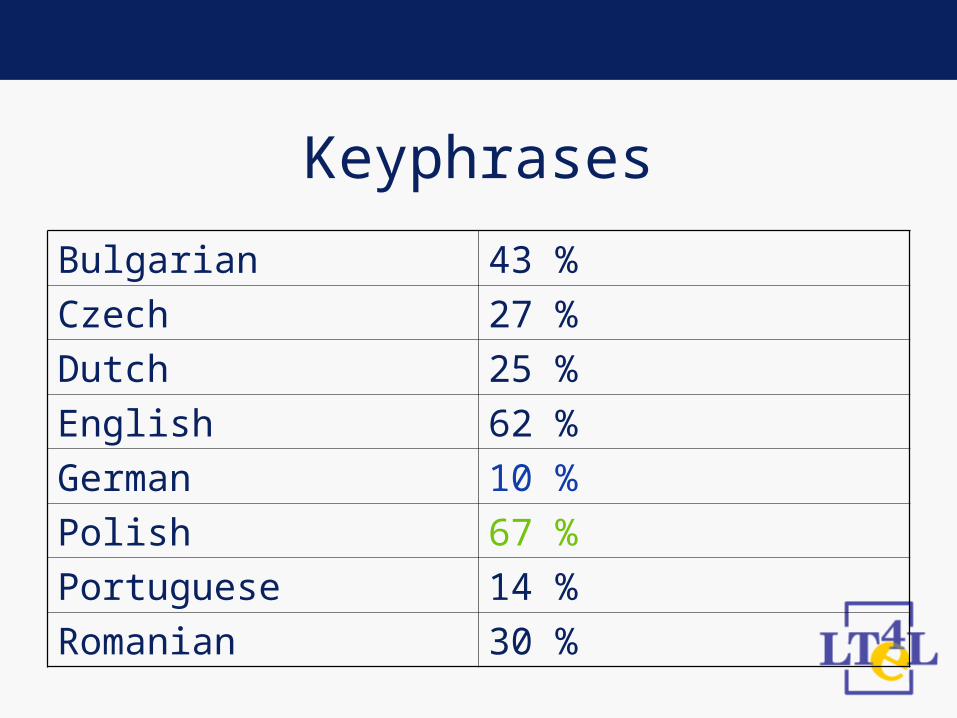
• Measuring the share of keyphrases

# of annotated documents
Average length (# of tokens)
Bulgarian 55 3980
Czech 465 672
Dutch 72 6912
English 36 9707
German 34 8201
Polish 25 4432
Portuguese 29 8438
Romanian 41 3375
# of keywords
Average # of keywords per doc.
Bulgarian 3236 77
Czech 1640 3.5
Dutch 1706 24
English 1174 26
German 1344 39.5
Polish 1033 41
Portuguese 997 34
Romanian 2555 62
Keyphrases
Bulgarian 43 %
Czech 27 %
Dutch 25 %
English 62 %
German 10 %
Polish 67 %
Portuguese 14 %
Romanian 30 %

Reflection
• Did the human annotators annotate keywords of domain terms?
• Was the task adequately contextualised?
• What do the varying shares of keyphrases tell us?

Keyword extraction
• Good keywords have a typical, non random distribution in and across documents
• Keywords tend to appear more often at certain places in texts (headings etc.)
• Keywords are often highlighted / emphasised by authors
• Keywords express / represent the topic(s) of a text

Modelling Keywordiness
• Linguistic filtering of KW candidates, based on part of speech and morphology
• Distributional measures are used to identify unevenly distributed words– TFIDF– (Adjusted) RIDF
• Knowledge of text structure used to identify salient regions (e.g., headings)
• Layout features of texts used to identify emphasised words and weight them higher
• Finding chains of semantically related words

Challenges
• Treating multi word keywords (= keyphrases)
• Assigning a combined weight which takes into account all the aforementioned factors
• Multilinguality: finding good settings for all languages, balancing language dependent and language independent features

Treatment of keyphrases
• Keyphrases have to be restricted wrt to length (max 3 words) and frequency (min 2 occurrences)
• Keyphrase patterns must be restricted wrt to linguistic categories (style of learning is acceptable; of learning styles is not)

KWE Evaluation 1
• Human annotators marked n keywords in document d
• First n choices of KWE for document d extracted
• Measure overlap between both sets• measure also partial matches

KWE Evaluation – Overlap
Settings• All three statistics have been tested• Maximal keyphrase length set to 3
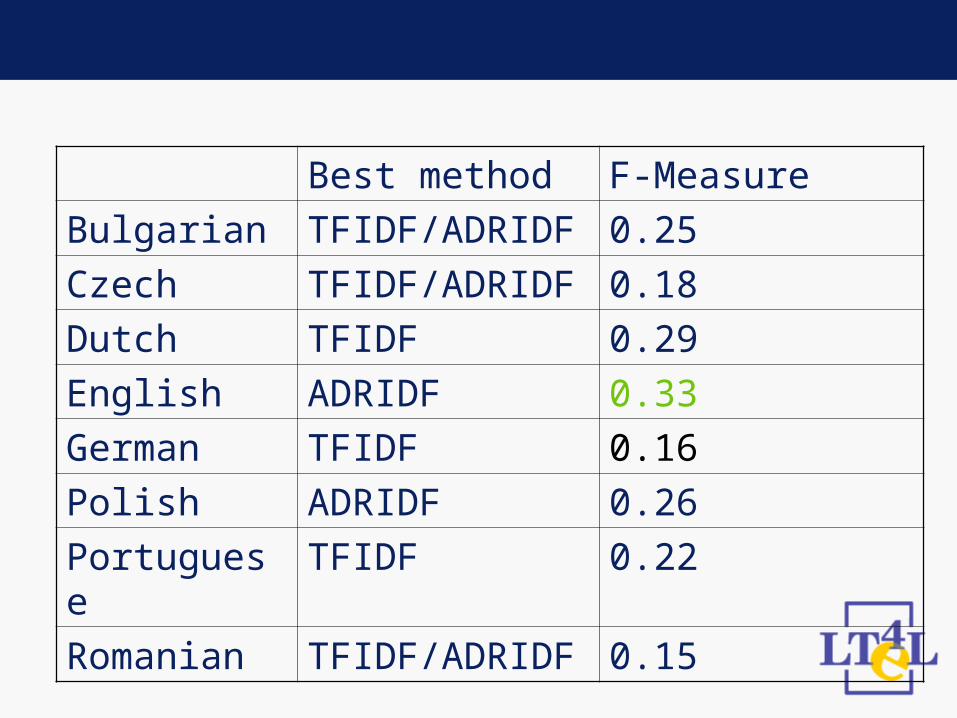
Best method F-Measure
Bulgarian TFIDF/ADRIDF 0.25
Czech TFIDF/ADRIDF 0.18
Dutch TFIDF 0.29
English ADRIDF 0.33
German TFIDF 0.16
Polish ADRIDF 0.26
Portuguese TFIDF 0.22
Romanian TFIDF/ADRIDF 0.15

Reflection
• Is it correct to use the human annotation as „gold standard“
• Is it correct to give a weight to partial matches?

KWE Evaluation - IAA
• Participants read text (Calimera „Multimedia“)
• Participants assign keywords to that text (ideally not more than 15)
• KWE produces keywords for text• IAA is measured over human annotators• IAA is measured for KWE / human ann.
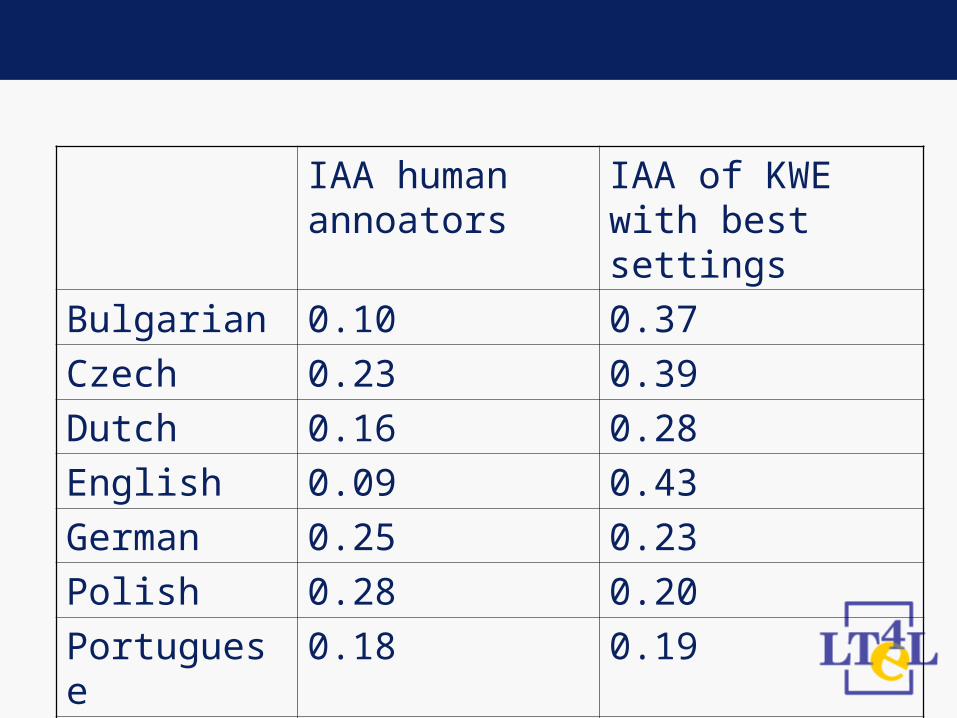
IAA human annoators
IAA of KWE with best settings
Bulgarian 0.10 0.37
Czech 0.23 0.39
Dutch 0.16 0.28
English 0.09 0.43
German 0.25 0.23
Polish 0.28 0.20
Portuguese 0.18 0.19
Romanian 0.20 0.26

KWE Evaluation – Judging adequacy
• Participants read text (Calimera „Multimedia“)
• Participants see 20 KW generated by the KWE and rate them
• Scale 1 – 4 (excellent – not acceptable)
• 5 = not sure
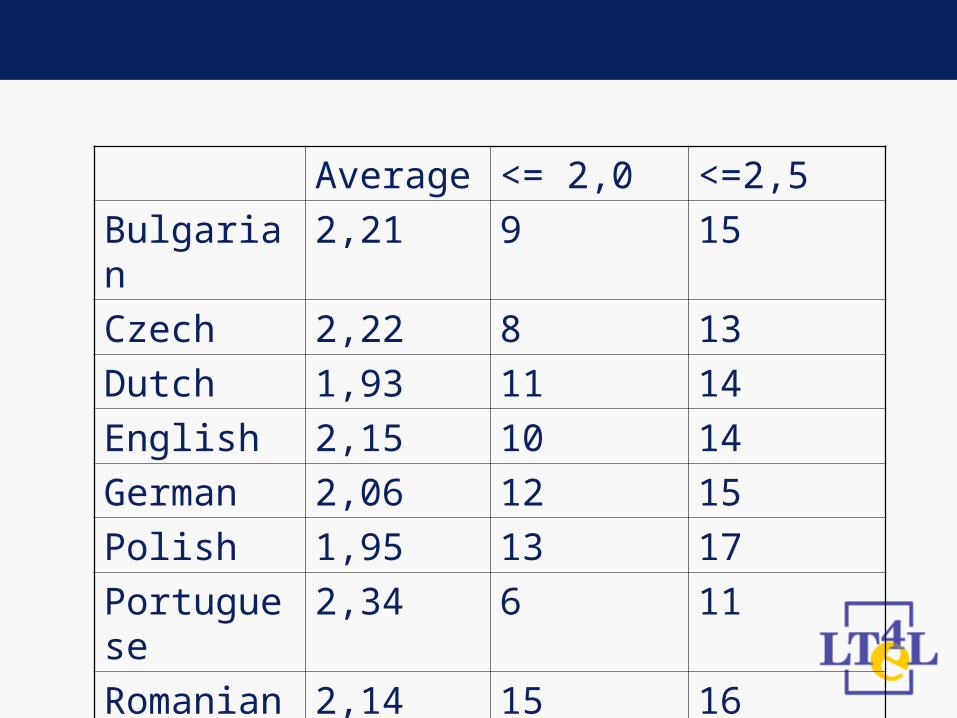
Average <= 2,0 <=2,5
Bulgarian 2,21 9 15
Czech 2,22 8 13
Dutch 1,93 11 14
English 2,15 10 14
German 2,06 12 15
Polish 1,95 13 17
Portuguese
2,34 6 11
Romanian 2,14 15 16

20 kw First 5 kw
First 10 kw
Bulgarian 2,21 2,54 2,12
Czech 2,22 1,96 1,96
Dutch 1,93 1,68 1,64
English 2,15 2,52 2,22
German 2,06 1,96 1,96
Polish 1,95 2,06 2,1
Portuguese
2,34 2,08 1,94
Romanian 2,14 1,8 2,06
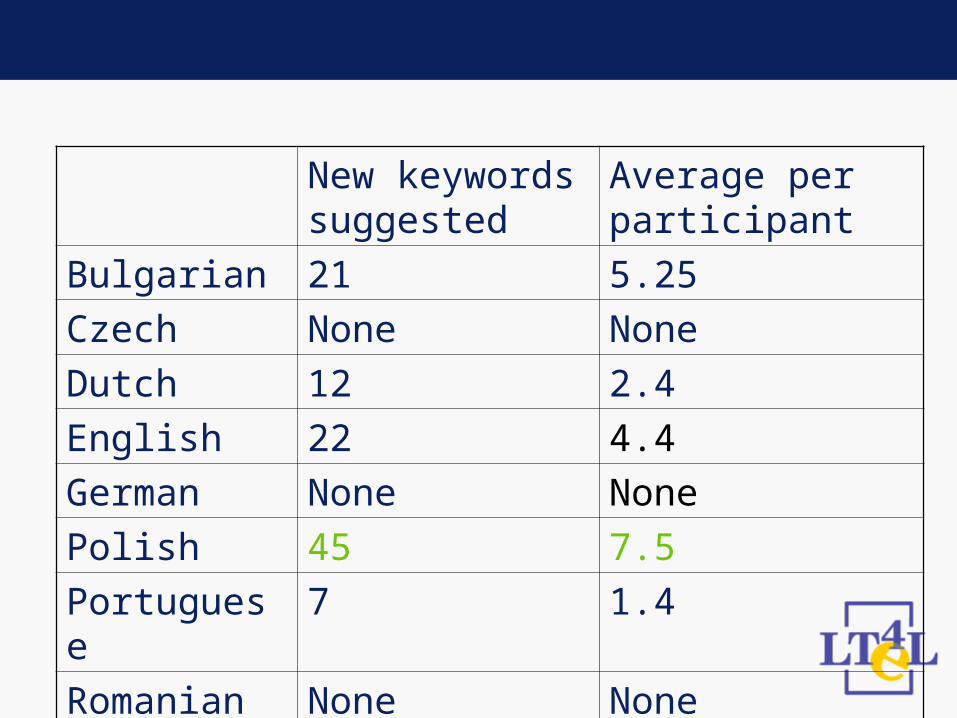
New keywords suggested
Average per participant
Bulgarian 21 5.25
Czech None None
Dutch 12 2.4
English 22 4.4
German None None
Polish 45 7.5
Portuguese 7 1.4
Romanian None None

Reflection
• How should we treat the „not sure“ decisions (quite substantial for a few judges)
• What do the added keywords tell us? Where are they in the ordered list of recommendations?

Conclusions
• Evaluation of a KWE in a multilingual environment and with diverse corpora is more difficult than expected beforehand
• Now we have the facilities for a controlled development / improvement of KWE
• Quantitative evaluation has to be accompanied by validation of the tool