kazuya kawakamik-kawakami.com/static/pdf/cmu_160429.pdf · lti @ carnegie mellon university...
TRANSCRIPT

LTI @ Carnegie Mellon University
Multilingual and Multimodal word representation
Kazuya Kawakami

LTI @ Carnegie Mellon University
Contents
2
Multilingual Word Representation
Multimodal Word Representation

LTI @ Carnegie Mellon University
Contents
3
Multilingual Word Representation
Multimodal Word Representation

LTI @ Carnegie Mellon University
Word Representation
• Word representation is a way to encode word semantics into vector space.- They capture syntactic and semantic similarity as geometric locality.- Analogy: King - Man + Woman = Queen
4
http://www.socher.org/ Mikolov et al. 2013
Astronomy
Color

LTI @ Carnegie Mellon University
Word Representation
• Word representation is useful for downstream tasks.- Use pre-trained word embedding as initialization of parameters.- It works well for various types of tasks.
5
POS-Tagging (Collobert et al) Parsing (Dyer et al.)
Machine Translation

LTI @ Carnegie Mellon University
Constructing Word Representation
• Distributed Word Representations are learned by - collecting concurrence statistics.- predicting surrounding context .
6
</s>
dogstudywork
shopping
appleorange
cat
….
you
hard
Lookup Table Type Level Embedding
work

LTI @ Carnegie Mellon University
Improving Word Representation
• Multilingual shared representation (Faruqui et al., 2014, Gouws et al., 2014) - Good representation capture monolingual profile and translation profile.
7
EN Monolingual FR Monolingual Shared Space

LTI @ Carnegie Mellon University
Improving Word Representation
• Multilingual shared representation with CCA (Faruqui et al., 2014). - Post Processing with alignment data .
8

LTI @ Carnegie Mellon University
Constructing Bilingual Representation
• Multilingual shared representation with joint modeling (Gouws et al., 2014 )- Joint modeling of Monolingual and Bilingual model without alignment.
9

LTI @ Carnegie Mellon University
Problem of Type Level Word Representation
• Type level embedding are not context sensitive .
10
I went to the bank to deposit my paycheck.
I went to the river bank to eat some lunch.

LTI @ Carnegie Mellon University
Token Level Representation
• To build a context sensitive model, we need to have a function of word and context.- What kind of supervisory signal is needed to tune ?
11
semantic mask word in context
Green plant
type level word representation
×
Token Level Representation
Context Word
✓
✓

LTI @ Carnegie Mellon University
Multilingual Information
• Translation disambiguate senses.
12
I went to the bank to deposit my paycheck.
I went to the river bank to eat some lunch.
Je suis allée à la banque pour déposer mon chèque de paie.
Je suis allé sur la rive pour le déjeuner.

LTI @ Carnegie Mellon University
Token Level Representation
• To build a context sensitive model, we need to have a function of word and context.- What kind of supervisory signal is needed to tune ?
13
semantic mask word in context
Green plant
type level word representation
×
Context Word
✓
✓
[ FR ] Plante

LTI @ Carnegie Mellon University
• Assuming that we have multiple senses in a single vector- We need to learn mask out or scale each elements. - The mask vector need to be sensitive to context.
What kind of function is needed ?
14
semantic mask word in context
Green plant
type level word representation
×
WordContext

LTI @ Carnegie Mellon University
Model
• Input gate of LSTM serve to control input. Possibly mask out unnecessary elements.
15
Workshop track - ICLR 2016
This is done by performing a softmax over the target vocabulary with the representation of the wordh
t
, as defined in the previous section. That is, we compute
u = Rh
t
+ b
0
p(f | et
, c) =exp(u
f
)Pf
02F exp(uf
0)
,
where parameters R and b
0 define the projection of the source word with context representation h
t
onto the target vocabulary F .
To obtain pairs of words in context and their lexical translations into a second language, we use un-supervised word alignment techniques (Dyer et al., 2013), to obtain high precision word alignmentsfrom a parallel corpus. While modeling alignments as latent variables, or using a soft attentionmechanism would be a reasonable alternative, word alignment is fast and the proposed trainingobjective to be easily scaled to large corpora.
Figure 2 illustrates the pre-training architecture.
<s> The plant grows </s>…..
plante
entreprise
Word in Context ( )
~~~ ~
Lexical Translation ( FR )
h
t
Figure 2: Description of cross lingual pre-training model.
3.2 PARAMETER LEARNING
The model parameters W and b as well as the word projection parameters Ve
are first pre-trainedwith the objective function:
L = �
X
(f ,e)
log p(f | e, c)
That is, we wish to find the parameters that maximize the lexical translation log probability over thewhole parallel corpus of lexical translations (f ) of a source word (e) in context (c).
When we want to transfer the model to another supervised task to predict label s 2 S for a word e incontext c, the final values of the W and b parameters are transferred and formulate a similar modelto predict label s. Using the transformation matrix S 2 R|S|⇥dh and the biases b00
2 R|S|, we maydefine the label probability as
u
0= Sh
t
+ b
00
p(s | et
, c) =exp(u0
s
)Ps
02S exp(u0s
0).
the model is training by maximizing the log likelihood of the observed label in the task.
L
0= �
X
(s,e)
log p(s | e, c) (1)
4
i
t
= �(Wxi
x
t
+W
hi
h
t�1 +W
ci
c
t�1 + b
i
)
f
t
= �(Wxf
x
t
+W
hf
h
t�1 +W
cf
c
t�1 + b
f
)
g
t
= tanh(Wxc
x
t
+W
hc
h
t�1 + b
c
)
c
t
= f
t
� c
t�1 + i
t
� g
t
o
t
= �(Wxo
x
t
+W
ho
h
t�1 +W
co
c
t
+ b
o
)
h
t
= o
t
� tanh(ct
)
FR

LTI @ Carnegie Mellon University
Multilingual Pre-Training
• We pertained our model on - EN-FR / DE / CS / FI parallel corpus.
• Pre-trained Model achieved the following perplexity.
16
Dev Perplexity
FR 3.80
DE 6.59
CS 6.30
FI 19.25

LTI @ Carnegie Mellon University
Evaluation & Result
• We evaluated our model on various types of tasks.
17
Supersense Tagging
Lexical Substitution
Word sense disambiguation
Model is fine-tuned with large supervised data.
Transfer learning scenario.
Model is fine-tuned with small supervised data.
Unsupervised scenario.
Model is just trained on parallel corpus.
Low Resource Machine Translation

LTI @ Carnegie Mellon University
Experiment & Result
• We evaluated our model on various types of tasks.
18
Supersense Tagging
Lexical Substitution
Word sense disambiguation
Model is fine-tuned with large supervised data.
Transfer learning scenario.
Model is fine-tuned with small supervised data.
Unsupervised scenario.
Model is just trained on parallel corpus.
Low Resource Machine Translation
LTI @ Carnegie Mellon University
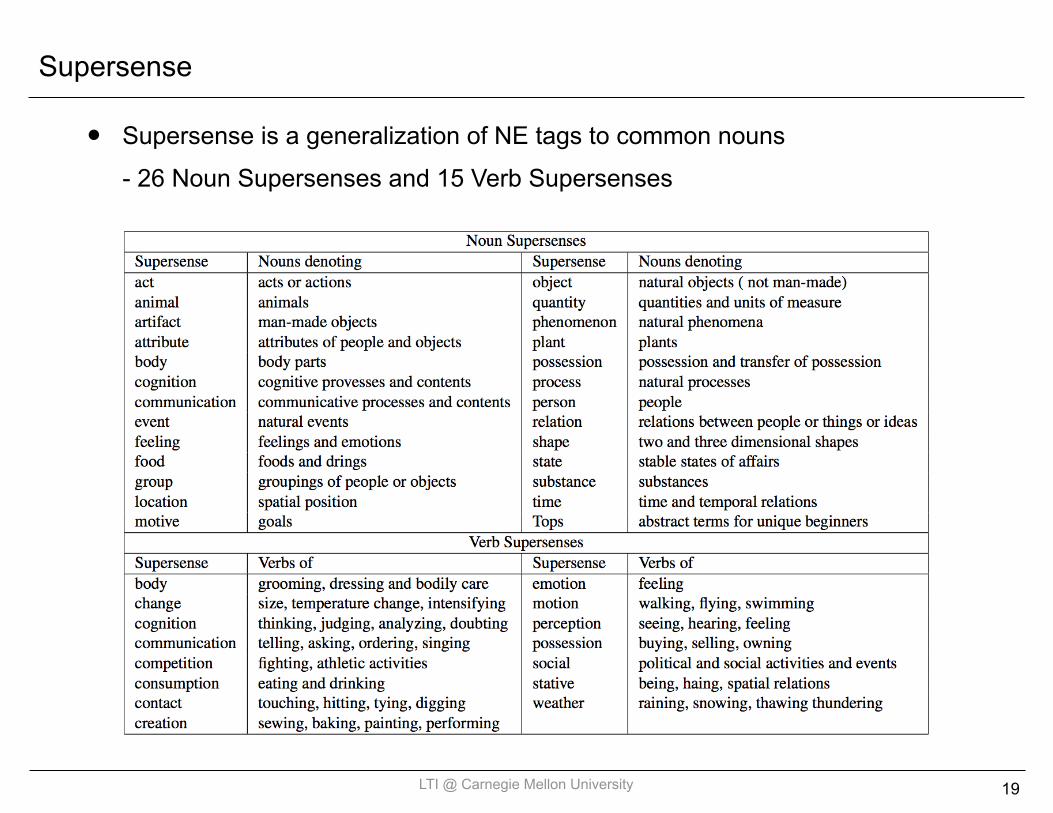
Supersense
• Supersense is a generalization of NE tags to common nouns- 26 Noun Supersenses and 15 Verb Supersenses
19

LTI @ Carnegie Mellon University
• Sequence Labeling Task which require to disambiguate senses.
• Semcor dataset and Semeval3 dataset were used. Semcor: 250,000 words of text from the Brown Corpus and a novel.
Supersense Tagging
20
artifact creation

LTI @ Carnegie Mellon University
Result
• MLP and LSTM achieved state-of-the-art result. - Cross Lingual Pre-Training provide further improvement across all languages.
21

LTI @ Carnegie Mellon University
Experiment & Result
• We evaluated our model on various types of tasks.
22
Supersense Tagging
Low Resource Machine Translation
Lexical Substitution
Word sense disambiguation
Model is fine-tuned with large supervised data.
Transfer learning scenario.
Model is fine-tuned with small supervised data.
Unsupervised scenario.
Model is just trained on parallel corpus.

LTI @ Carnegie Mellon University
Experiment
• Machine Translation in Low Resource Language- How pre-trained features are transferable to other languages?
• Malagasy and Urdu translation dataset
• Fine tune the network with small supervision
• Train baseline MT model with cdec.- Add translation probability and log translation probability - Optimized parameters of MT model with MIRA.
23
Malagasy / Urdu

LTI @ Carnegie Mellon University
Result
• Four additional features show marginal improvement across all language pairs. - The scores are average of 10 runs to deal with randomness.
24

LTI @ Carnegie Mellon University
Experiment & Result
• We evaluated our model on various types of tasks.
25
Supersense Tagging
Lexical Substitution
Word sense disambiguation
Model is fine-tuned with large supervised data.
Transfer learning scenario.
Model is fine-tuned with small supervised data.
Unsupervised scenario.
Model is just trained on parallel corpus.
Low Resource Machine Translation

LTI @ Carnegie Mellon University
Lexical substitution
• Identifying meaning-preserving substitutes for a target word given a context.- Purely evaluate the quality of token representation in unsupervised setting.
• Semeval-2007 Shared Task, Task 10.- the most widely used for the evaluation of lexical substitution.- 10 sentences extracted from a web corpus for each of 201 target words.
26
This will help the younger generation to know and understand better its neighbors living just on the other ||| side ||| of the Mediterranean .
Gattlinburg , Tennessee is a touristy town to stay in on the north ||| side ||| of the park .
boundary fringe position edge
Annotation Count 2 1 1 1
bank flank divide shore edge
Annotation Count 1 1 1 1 1
LTI @ Carnegie Mellon University
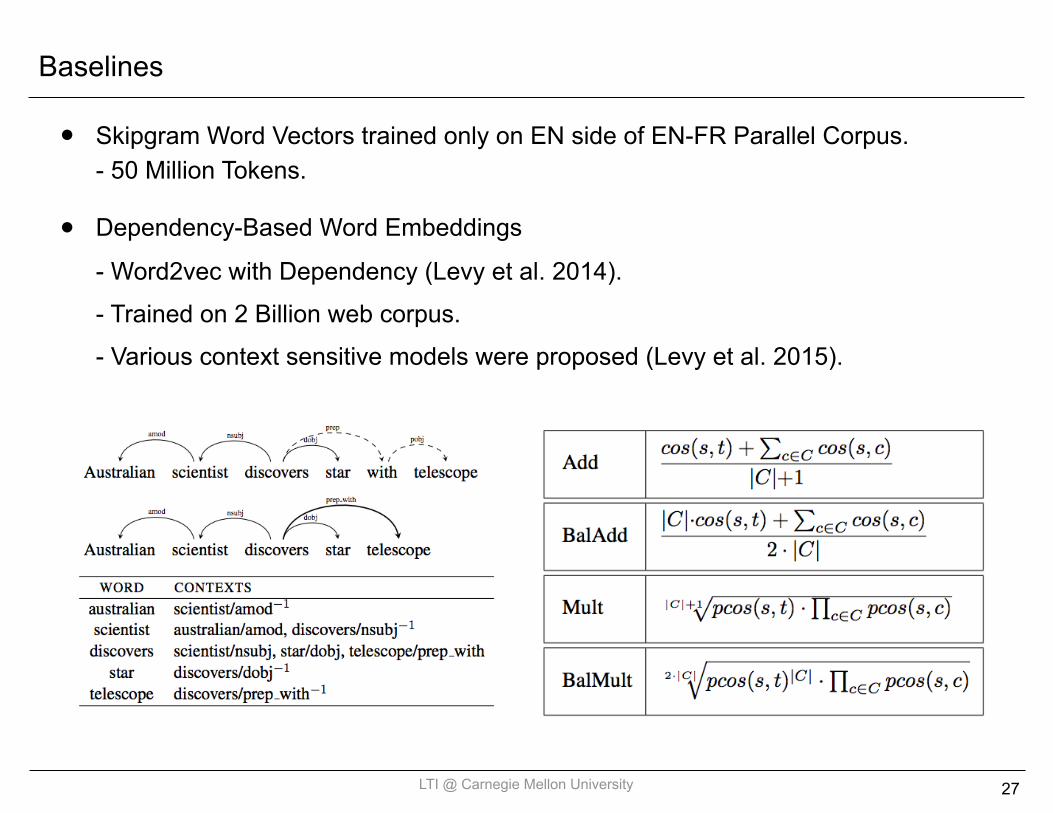
Baselines
• Skipgram Word Vectors trained only on EN side of EN-FR Parallel Corpus.- 50 Million Tokens.
• Dependency-Based Word Embeddings- Word2vec with Dependency (Levy et al. 2014). - Trained on 2 Billion web corpus. - Various context sensitive models were proposed (Levy et al. 2015).
27

LTI @ Carnegie Mellon University
Result
• Our model outperformed baseline model & the model trained on large dataset- Improved precision score by 2 points for best and best mode evaluation.- The improvement is consistent across all languages.
28
LTI @ Carnegie Mellon University
Evaluation & Result
• We evaluated our model on various types of tasks.
29
Supersense Tagging
Lexical Substitution
Word sense disambiguation
Model is fine-tuned with large supervised data.
Transfer learning scenario.
Model is fine-tuned with small supervised data.
Unsupervised scenario.
Model is just trained on parallel corpus.
Low Resource Machine Translation

LTI @ Carnegie Mellon University
Analysis
30
They built a large plant to manufacture automobiles.
Let’s plant flowers in the garden. plantes planter végétal cultiver
usine installation plante centrale

LTI @ Carnegie Mellon University
Analysis
• Effect of Cross Lingual Pre-Training- Pre-training provide good initialization for both tasks.
31
Super Sense Tagging Low-Resource MT (MG)

LTI @ Carnegie Mellon University
Contents
32
Multilingual Word Representation
Multimodal Word Representation

LTI @ Carnegie Mellon University
Multimodal Word Representation
• Multimodal word representation has been investigated intensively.- Image caption generation with Attention (Xu et al. 2015)- Image generation from caption (Elman et al. 2016)
33
A group of people sitting on a boat in the water.

LTI @ Carnegie Mellon University
Multimodal Word Representation
• Multimodal word representation has been investigated intensively.- Image caption generation with Attention (Xu et al. 2015)- Image generation from caption (Elman et al. 2016)
34

LTI @ Carnegie Mellon University
Color
• We focused on specific type of visual modality: Color.
35

LTI @ Carnegie Mellon University
Word-Color Association
• Word-Color Association has been investigated in cognitive science and psychology.
• Stroop Effect (Stroop 1935)“ Which is Red ? “
36

LTI @ Carnegie Mellon University
Word-Color Association
• Word-Color Association has been investigated in cognitive science and psychology.
• Stroop Effect (Stroop 1935) “ Which is Red ? “
37
Red Blue

LTI @ Carnegie Mellon University
Word-Color Association
• Word-Color Association has been investigated in cognitive science and psychology.
• Stroop Effect (Stroop 1935) “ Which is Red ? “
• Brain information processing (del Prado Martinetal. 2006; Simmons et al. 2007)- Usually our brain use different regions to perceive various modalities. - Visual cortex: vision - Broca’s area: language- Color words activates the same brain regions as color is perceived.
• Word-Color have association with polarity (Mohammad. 2014)
38
Red Blue

LTI @ Carnegie Mellon University
Word-Color Association
39
color = F (word)

LTI @ Carnegie Mellon University
Dataset
• We collected 776k sample from a design website COLORLovers- Users give name to RGB Values.- The dataset contains 776,364 pairs with 581,483 unique word name.
40

LTI @ Carnegie Mellon University
Color Regression Model
• Character Level LSTM
• Embedding Dimension: 300d, Hidden Dimension: 300d.
• Loss Function
41
i
t
= �(Wxi
x
t
+W
hi
h
t�1 +W
ci
c
t�1 + b
i
)
f
t
= �(Wxf
x
t
+W
hf
h
t�1 +W
cf
c
t�1 + b
f
)
g
t
= tanh(Wxc
x
t
+W
hc
h
t�1 + b
c
)
c
t
= f
t
� c
t�1 + i
t
� g
t
o
t
= �(Wxo
x
t
+W
ho
h
t�1 +W
co
c
t
+ b
o
)
h
t
= o
t
� tanh(ct
)
ht = [�!ht;
�!ct ]
L = ||y � y||2
y = �(Wh+ b) W 2 R3⇥600,b 2 R3

LTI @ Carnegie Mellon University
Color Space
• Lab Space is suitable for gradient base learning.
42
RGB Space Lab Space
- Discrete Space- RED, GREEN BLUE (255, 255, 255)- Addition, Subtraction is valid
- Continuous Space- L, a, b- Euclidian Distance -> Human perception
L represents lightness, a the position between red/magenta and green, and b the position between yellow and blue.

LTI @ Carnegie Mellon University
Dataset
• We collected 776k sample from a design website COLORLovers- Users give name to RGB Values.- The dataset contains 776,364 pairs with 581,483 unique word name.
• The color names (no-overlap with training data) used in - R Language: 66 Unique Name-Color Pair- Paint company Sherwin-Williams: 956 Unique Name-Color Pair
43

LTI @ Carnegie Mellon University
Result
• LSTM with Memory and BiLSTM, DeepLSTM equally performed well.- Significant improvement over Unigram, Bigram model.
44
MSE Error on Each Dataset.

LTI @ Carnegie Mellon University
Color Turing Test
• Human evaluation- Which color is better described by the term RED ?- 100 Turkers who are not color blind.
• Human selected model prediction for R, Paint Datasets (less noisy data).
45
Examples of Questionnaire Examples of Color Blind Test

LTI @ Carnegie Mellon University
Analysis: Character
• Character by character prediction show how our model read words.
46

LTI @ Carnegie Mellon University
DEMO
47
http://colorlab.us

LTI @ Carnegie Mellon University
Analysis: Leaned Representation
• 2D-PCA Plot of learned representation.
48

LTI @ Carnegie Mellon University
• Not all of the word have association with Color.- What type of word have strong association with color ?
• Colorized all words in wordnet (117,659 unique words).- Strength of color association is defined as distance from mean color, beige.
Analysis: Word Color Association
49
Mean Distance from mean prediction for each POS, NOUN/VERB Supersenses
LTI @ Carnegie Mellon University
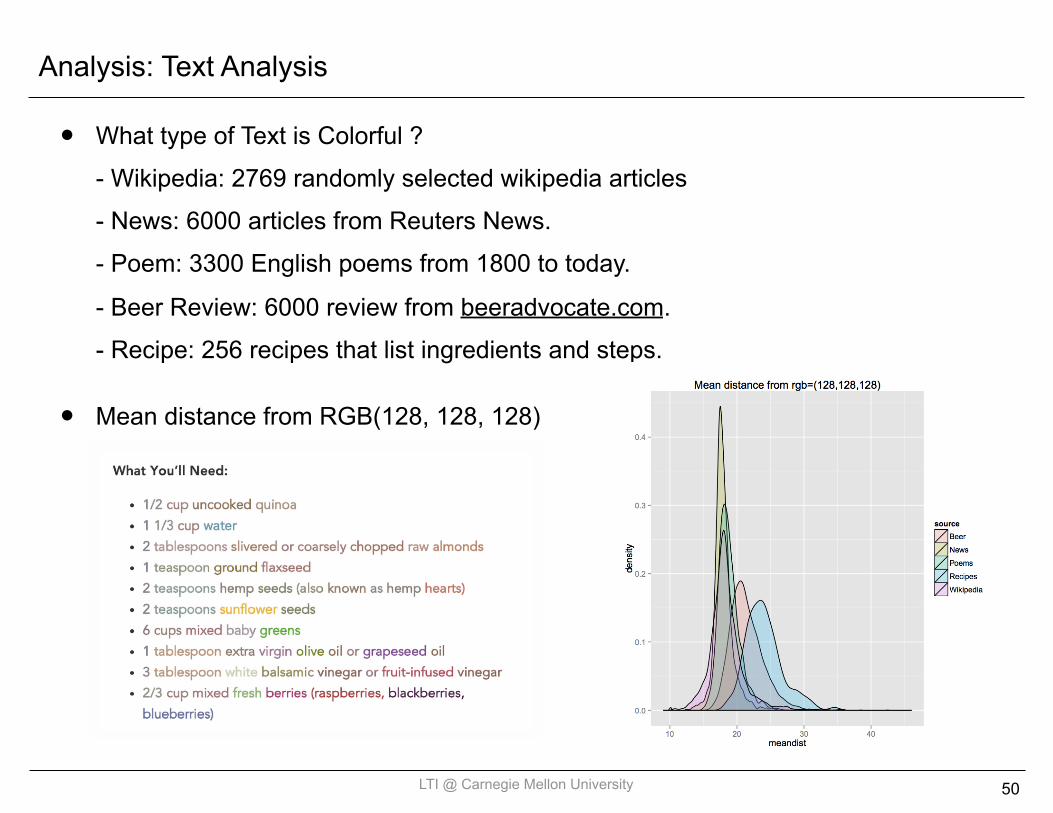
Analysis: Text Analysis
• What type of Text is Colorful ?- Wikipedia: 2769 randomly selected wikipedia articles- News: 6000 articles from Reuters News.- Poem: 3300 English poems from 1800 to today.- Beer Review: 6000 review from beeradvocate.com.- Recipe: 256 recipes that list ingredients and steps.
• Mean distance from RGB(128, 128, 128)
50

LTI @ Carnegie Mellon University
Analysis: Vision
51
• What happen if we use color of word to find object form images?- For noun chunks, we first predict color of word.- Take images which have the noun phrase in caption.- Computer Pixel-wise distance from color of word.

LTI @ Carnegie Mellon University
Analysis: Vision
52
Oranges

LTI @ Carnegie Mellon University
Analysis: Vision
53
Bananas

LTI @ Carnegie Mellon University
Analysis: Vision
54
A yellow bag

LTI @ Carnegie Mellon University
Analysis: Vision
55
The grass

LTI @ Carnegie Mellon University
Acknowledgement
56
Chris Dyer Noah Smith Bryan Routledge

LTI @ Carnegie Mellon University
Thank you very much !