k-nearest neighbors search in high dimensions
TRANSCRIPT

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 1/111
k-Nearest Neighbors Search
in High Dimensions
Tomer Peled
Dan Kushnir
Tell me who your neighbors are, and I'll know who you are

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 2/111
Outline
•Problem definition and flavorsProblem definition and flavors
•Algorithms overview - low dimensions
•Curse of dimensionality (d>10..20(
•Enchanting the curseLocality Sensitive Hashing (high dimension approximate solutions(
•l2 extension
•Applications (Dan(

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 3/111
• Given: a set P of n points in Rd
Over some metric
• find the nearest neighbor p of q in P
Nearest Neighbor Search
Problem definition
Distance metric
QQ??

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 4/111
Applications
•Classification
•Clustering
•Segmentation
q?
•Indexing
•Dimension reduction
(e.g. lle(
color
Weight

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 5/111
Naïve solution
• No preprocess
•Given a query point q
– Go over all n points
– Do comparison in Rd
•query time = O(nd(
Keep in mind

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 6/111
Common solution
•Use a data structure for acceleration
•Scale-ability with n & with d is important

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 7/111
When to use nearest neighbor
High level algorithms
Assuming no prior knowledge about the underlying probability structure
complex models Sparse data High dimensions
Parametric Non-parametric
Density
estimationProbability
distribution estimation
Nearest
neighbors

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 8/111
Nearest Neighbor
min pi
∈P
dist(q,pi
)
C l o s e s t
qq??

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 9/111
r, ε - Nearest Neighbor
r
)1+ε ) r
dist(q,p1) ≤ r
dist(q,p2) ≥ (1 + ε ) r r2=(1 + ε ) r1
qq??

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 10/111
Outline
•Problem definition and flavors
•Algorithms overview - low dimensionsAlgorithms overview - low dimensions
•Curse of dimensionality (d>10..20(
•Enchanting the curseLocality Sensitive Hashing(high dimension approximate solutions(
•l2 extension
•Applications (Dan(

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 11/111
The simplest solution
•Lion in the desert

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 12/111
Quadtree
Split the first dimension into 2
Repeat iteratively
Stop when each cell
has no more than 1 data point

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 13/111
Quadtree - structure
X
Y
X1,Y1 P≥X1
P≥Y1P<X1
P<Y1
P≥X1
P<Y1
P<X1
P≥Y1
X1,Y1
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 14/111
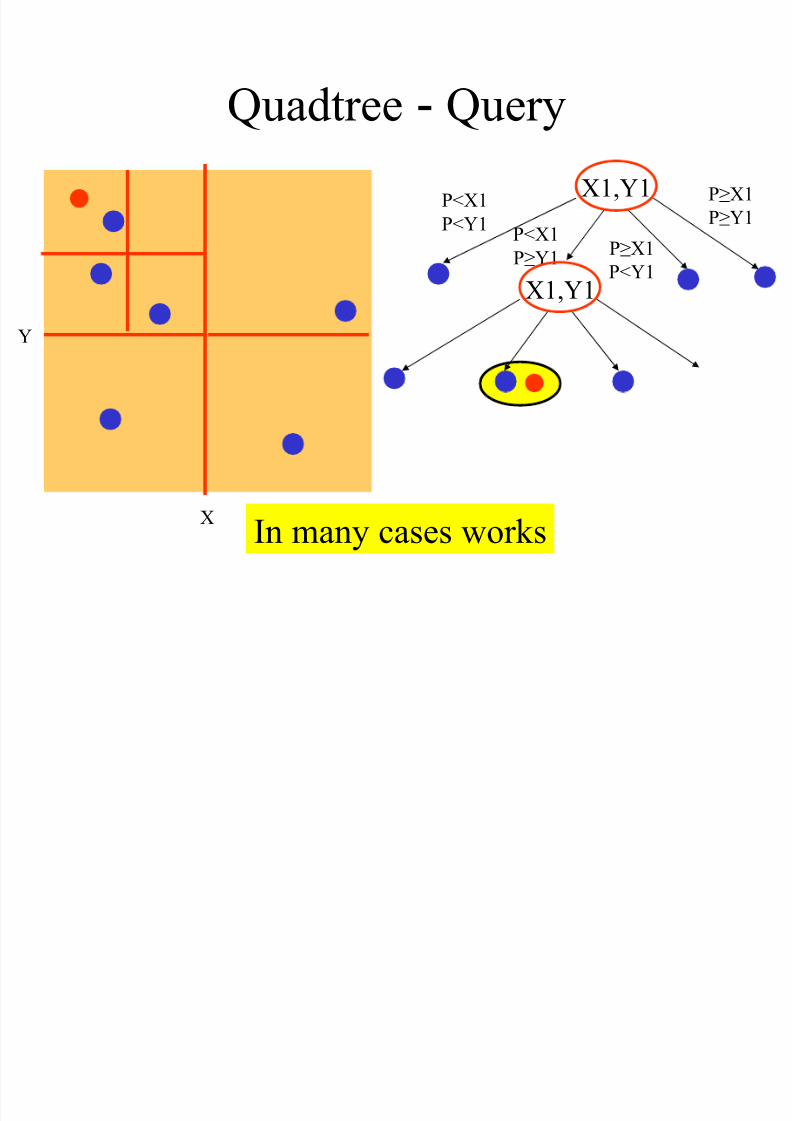
Quadtree - Query
X
Y
In many cases works
X1,Y1P<X1
P<Y1P<X1
P≥Y1
X1,Y1
P≥X1
P≥Y1
P≥X1
P<Y1
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 15/111
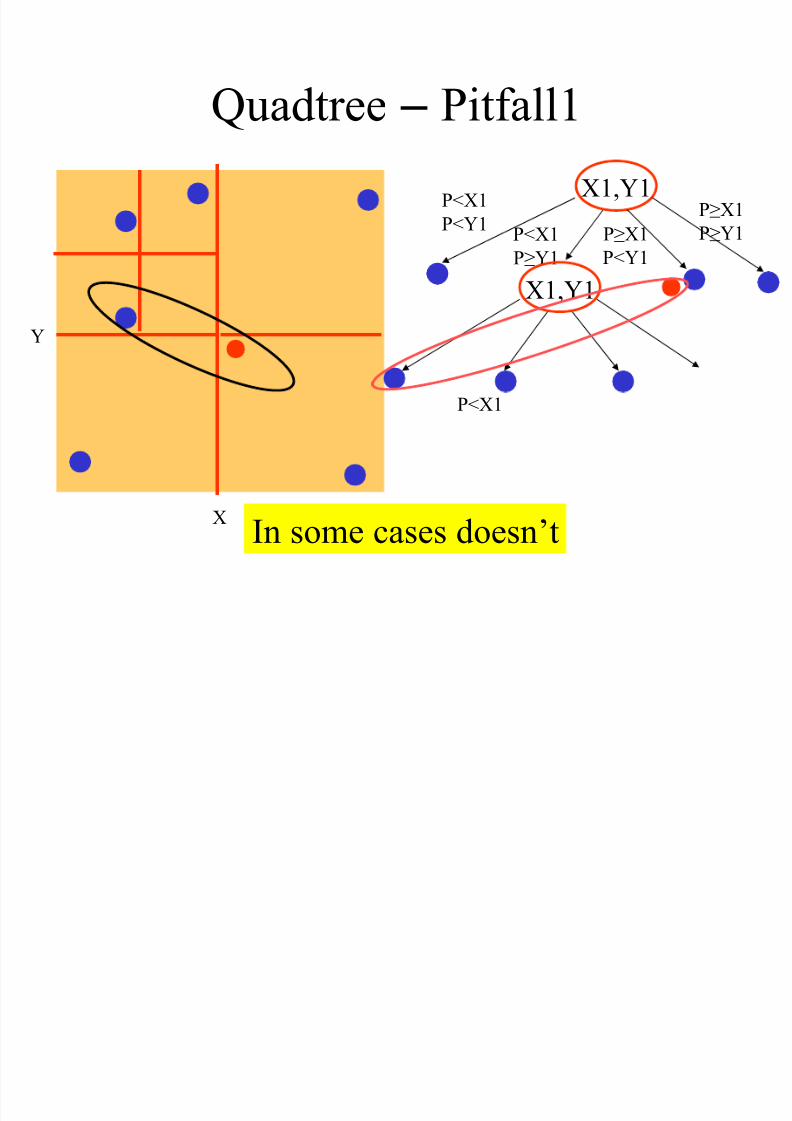
Quadtree – Pitfall1
X
Y
In some cases doesn’t
X1,Y1P≥X1
P≥Y1
P<X1
P<X1
P<Y1P≥X1
P<Y1
P<X1
P≥Y1
X1,Y1
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 16/111
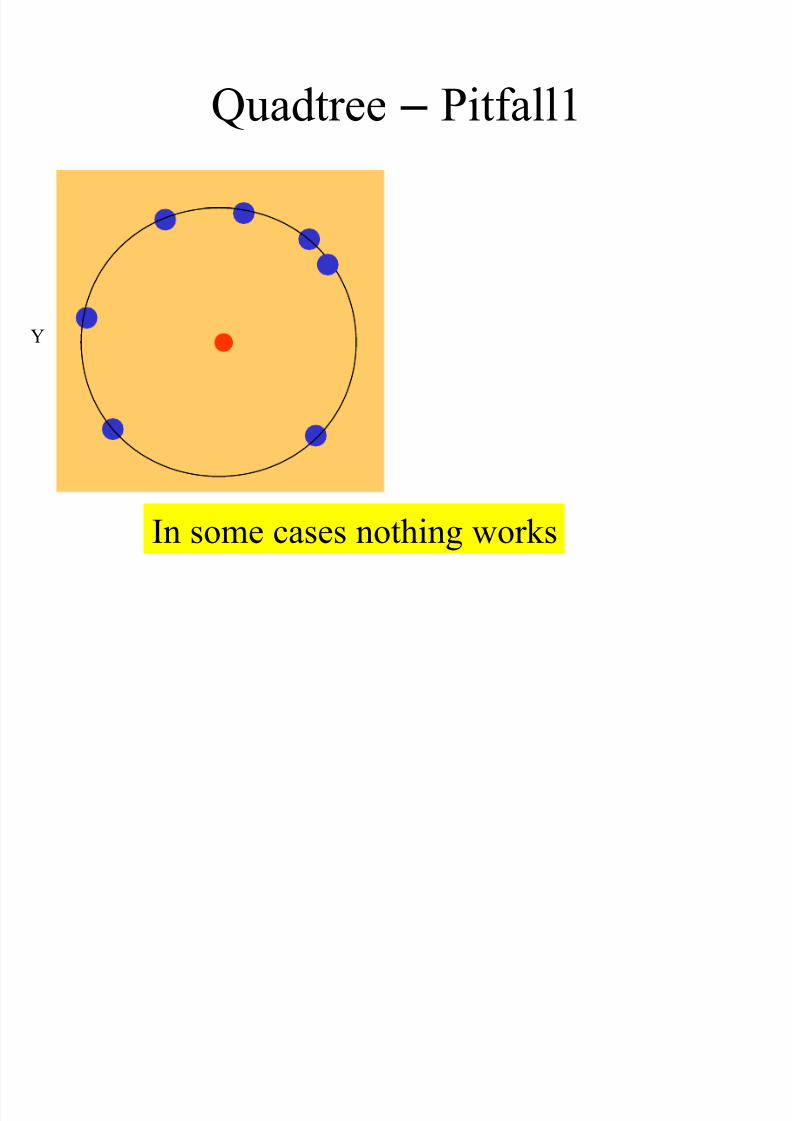
Quadtree – Pitfall1
X
Y
In some cases nothing works
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 17/111
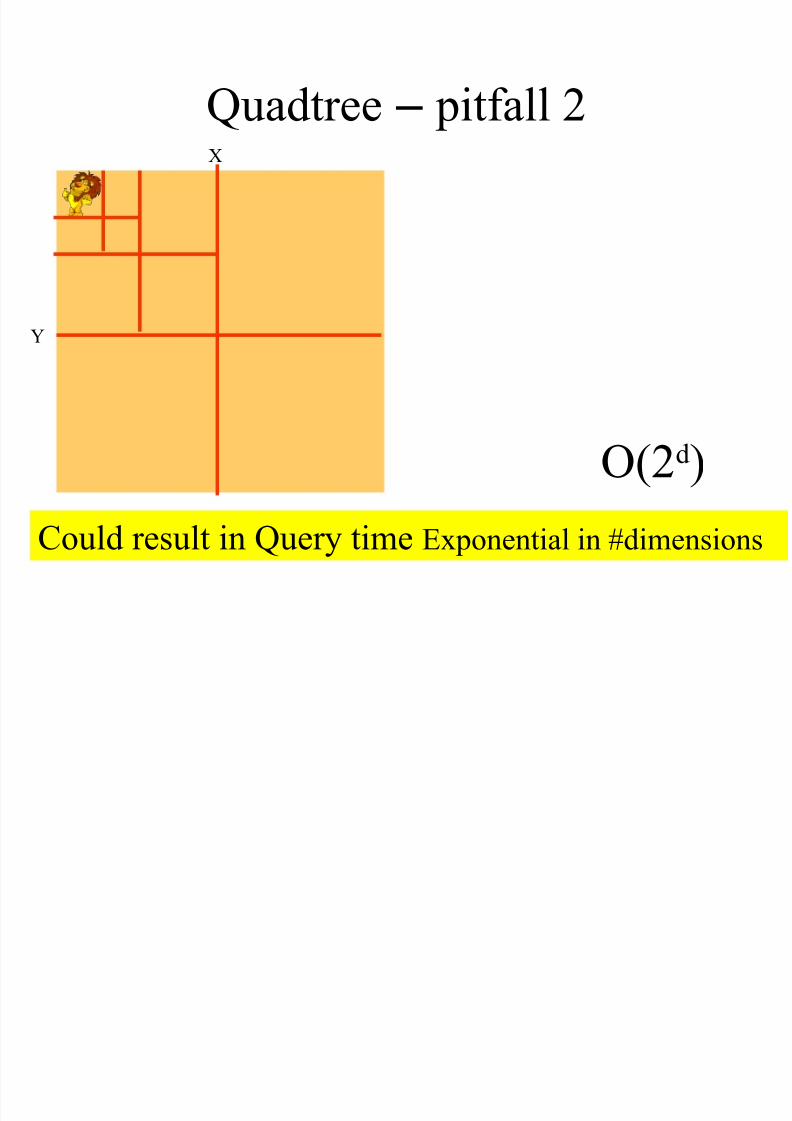
Quadtree – pitfall 2X
Y
O(2d)
Could result in Query time Exponential in #dimensions

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 18/111
Space partition based algorithms
Multidimensional access methods / Volker Gaede, O. Gunther
Could be improved

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 19/111
Outline
•Problem definition and flavors
•Algorithms overview - low dimensions
•Curse of dimensionality (d>10..20Curse of dimensionality (d>10..20((
•Enchanting the curseLocality Sensitive Hashing(high dimension approximate solutions(
•l2 extension
•Applications (Dan(

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 20/111
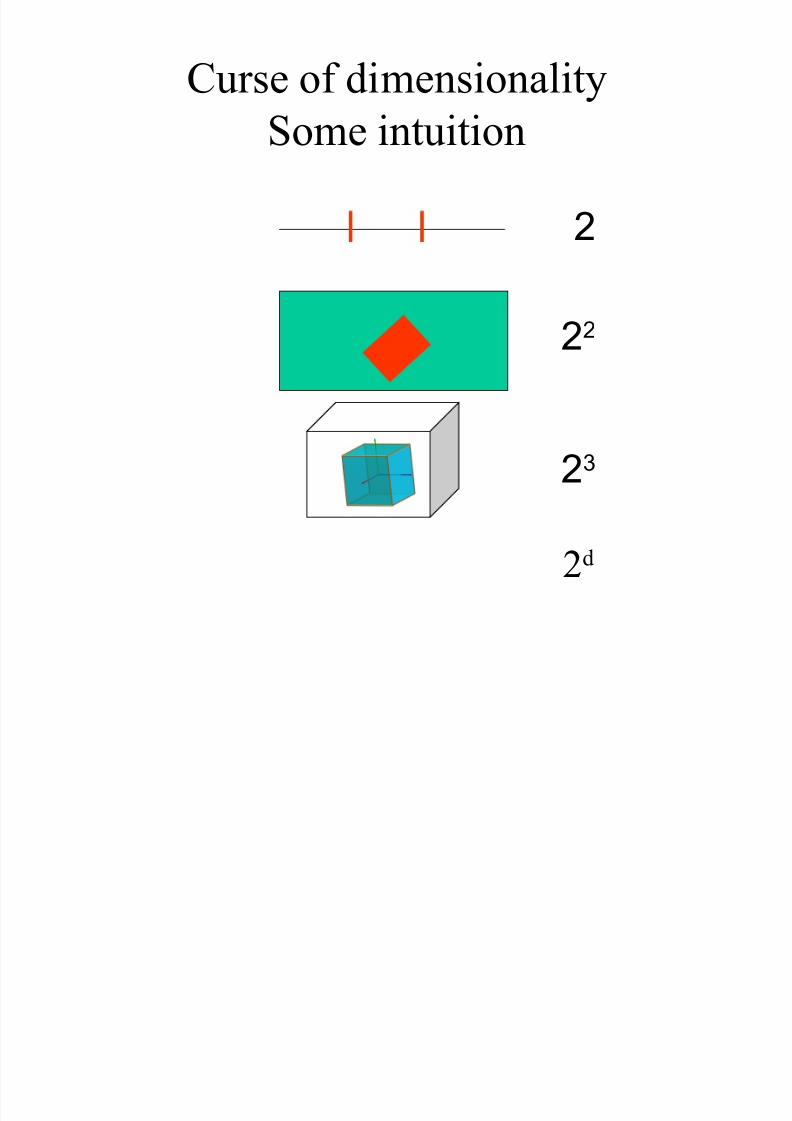
Curse of dimensionality
•Query time or spaceO(nd(
•D>10..20 worst than sequential scan
– For most geometric distributions
•Techniques specific to high dimensions are needed
• Prooved in theory and in practice by Barkol & Rabani 2000 & Beame-Vee 2002
O( min(nd, nd) ) Naive
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 21/111
Curse of dimensionality
Some intuition
2
22
23
2d

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 22/111
Outline
•Problem definition and flavors
•Algorithms overview - low dimensions
•Curse of dimensionality (d>10..20(
•Enchanting the curseEnchanting the curse
Locality Sensitive HashingLocality Sensitive Hashing(high dimension approximate solutions(
•l2 extension
•Applications (Dan(

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 23/111
Preview
•General Solution –
Locality sensitive hashing
•Implementation for Hamming space
•Generalization to l1 & l2

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 24/111
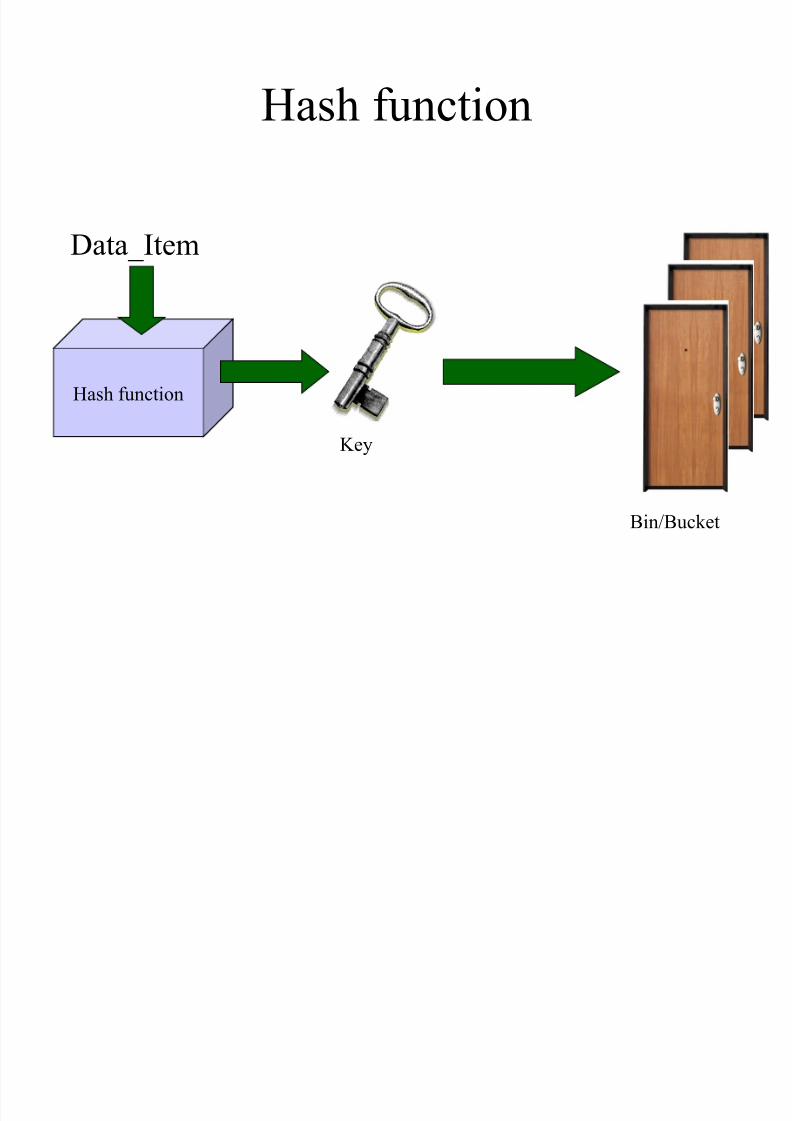
Hash function
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 25/111
Hash function
Hash function
Data_Item
Key
Bin/Bucket
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 26/111
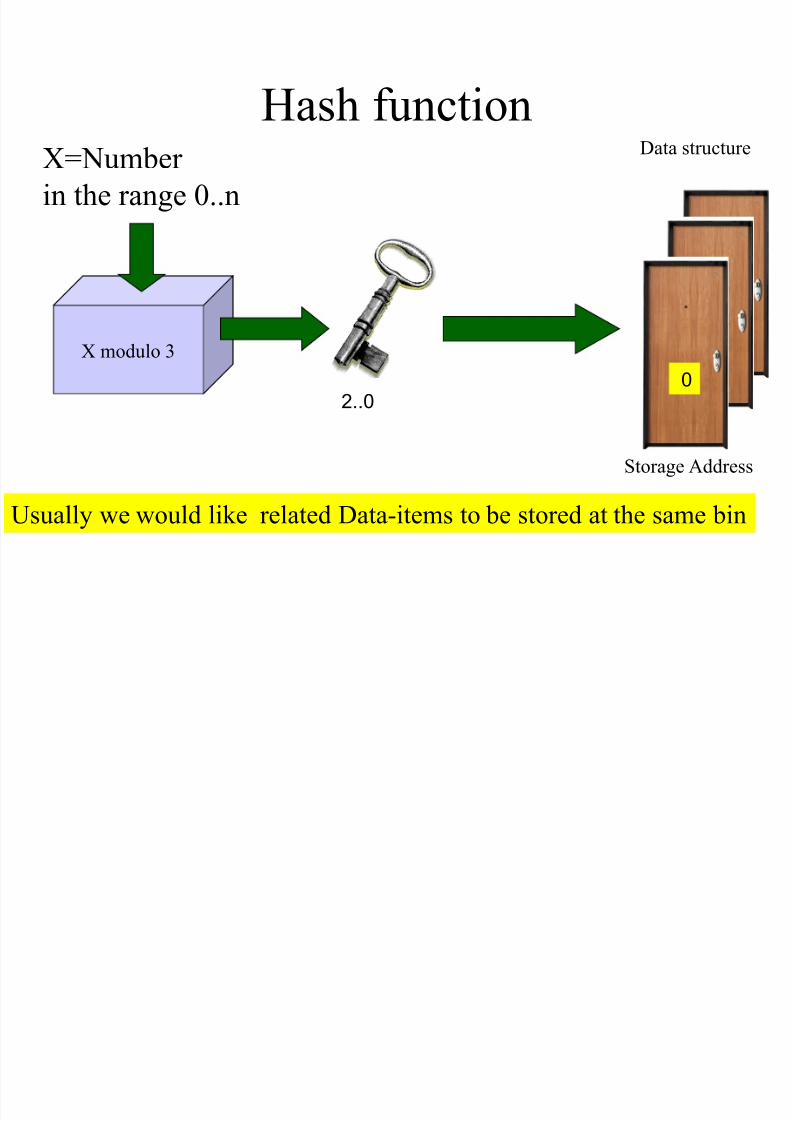
Hash function
X modulo 3
X=Number
in the range 0..n
0..2
Storage Address
Data structure
0
Usually we would like related Data-items to be stored at the same bin

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 27/111
Recall r, ε - Nearest Neighbor
r
)1+ε ) r
dist(q,p1) ≤ r
dist(q,p2) ≥ (1 + ε ) r r2=(1 + ε ) r1
qq??
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 28/111
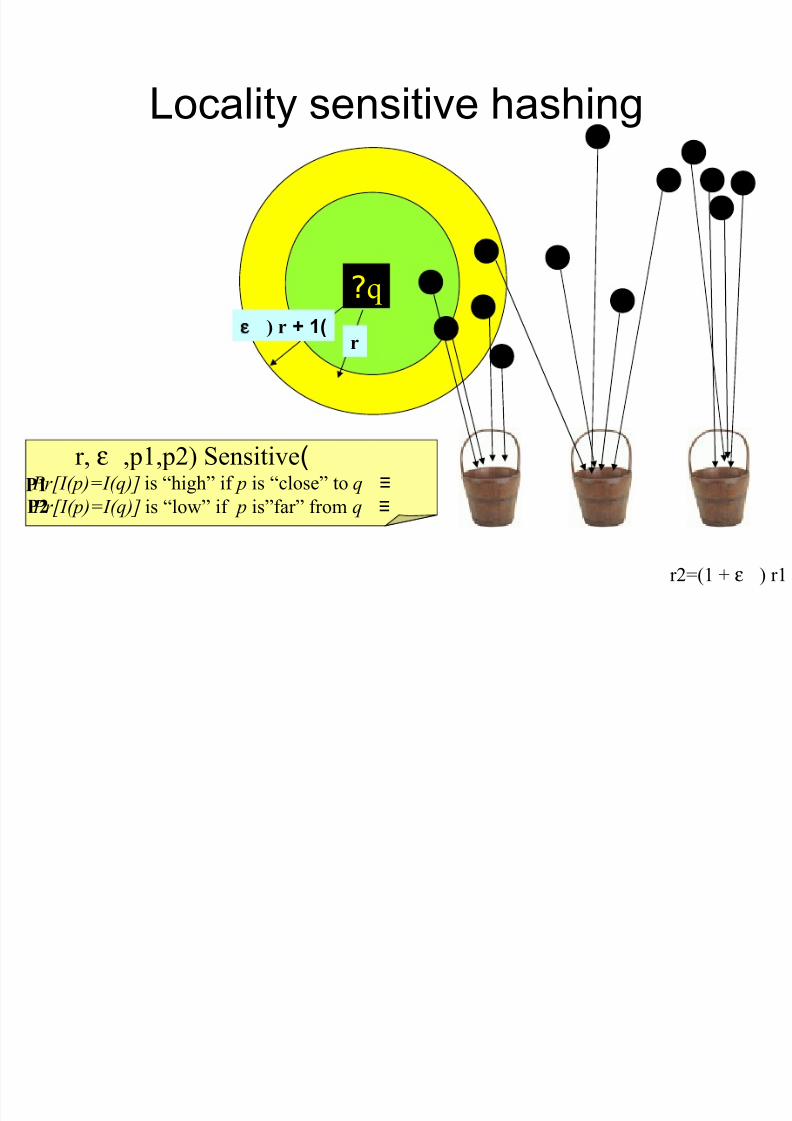
Locality sensitive hashing
r)1+) r
)r, ε ,p1,p2) Sensitive≡ Pr[I(p)=I(q)] is “high” if p is “close” to q
≡ Pr[I(p)=I(q)] is “low” if p is”far” from q
r2=(1 + ε ) r1
qq??
P1P2

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 29/111
Preview
•General Solution –
Locality sensitive hashing
•Implementation for Hamming space
•Generalization to l1 & l2

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 30/111
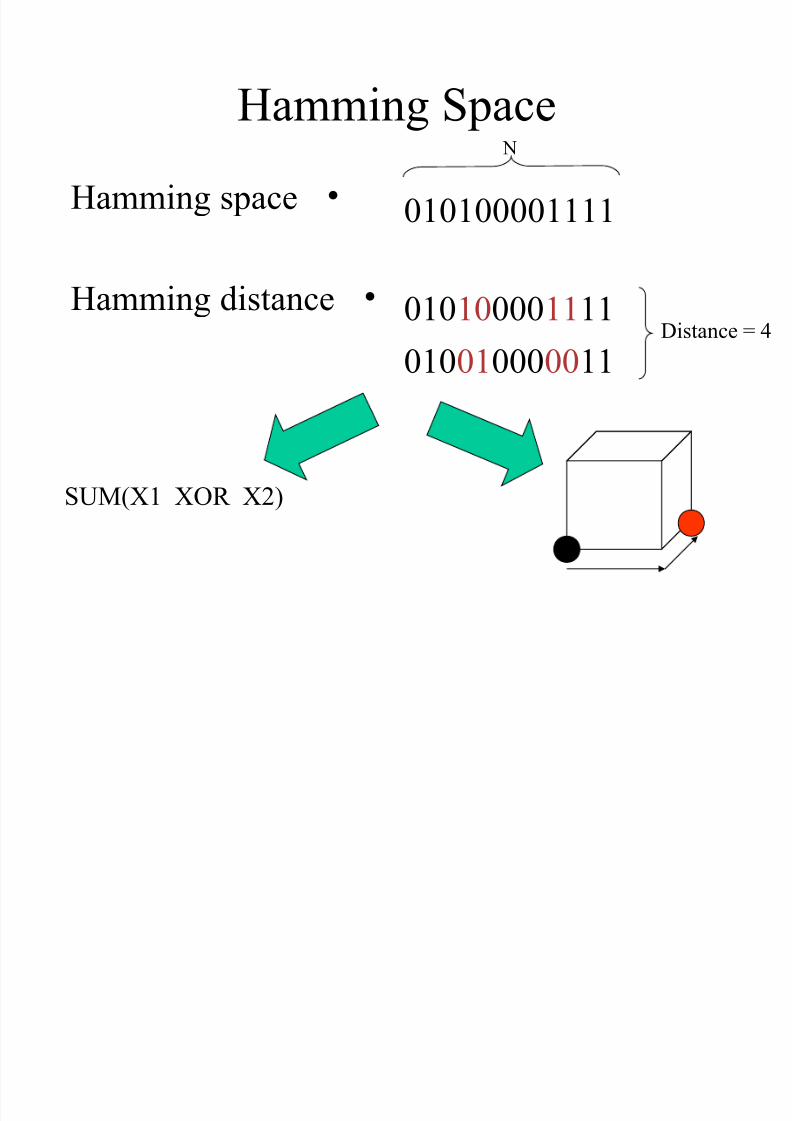
Hamming Space
•Hamming space = 2 N binary strings
•Hamming distance = #changed digits
a.k.a Signal distanceRichard Hamming
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 31/111
Hamming Space N
010100001111
010100001111
010010000011Distance = 4
•Hamming space
•Hamming distance
SUM(X1 XOR X2)
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 32/111
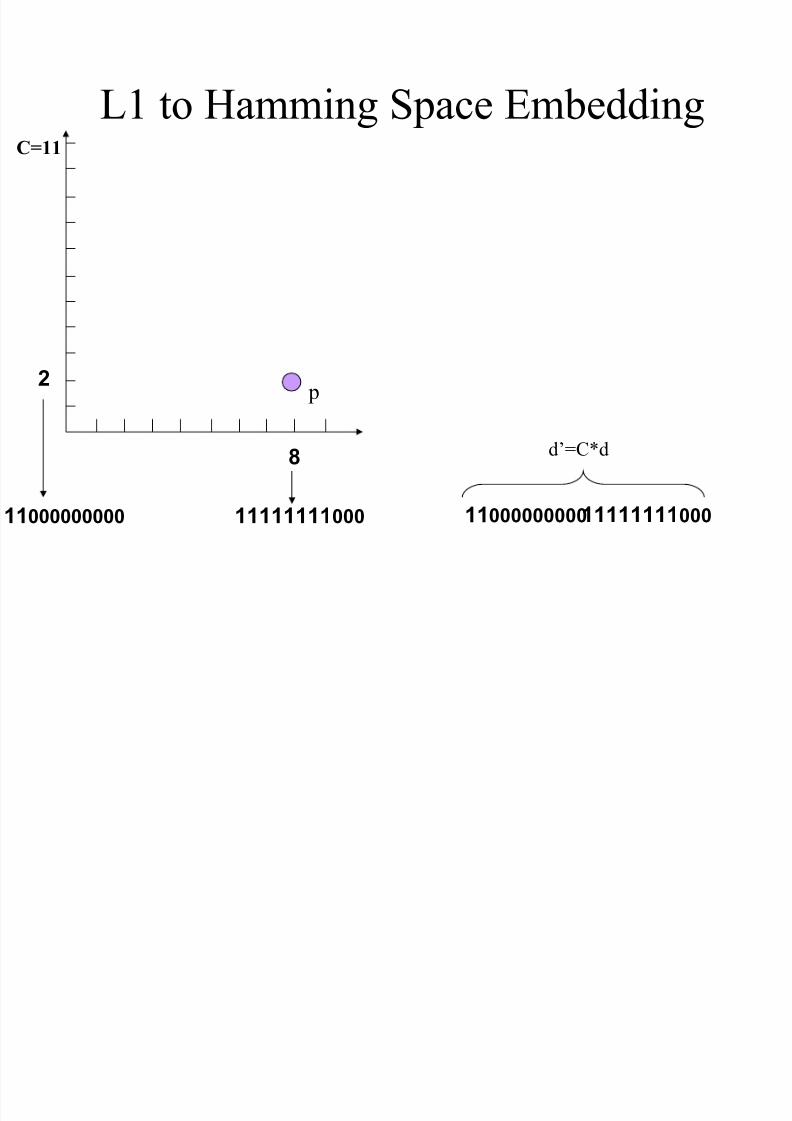
L1 to Hamming Space Embedding
p
8
C=11
1111111100011000000000
2
1111111100011000000000
d’=C*d
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 33/111
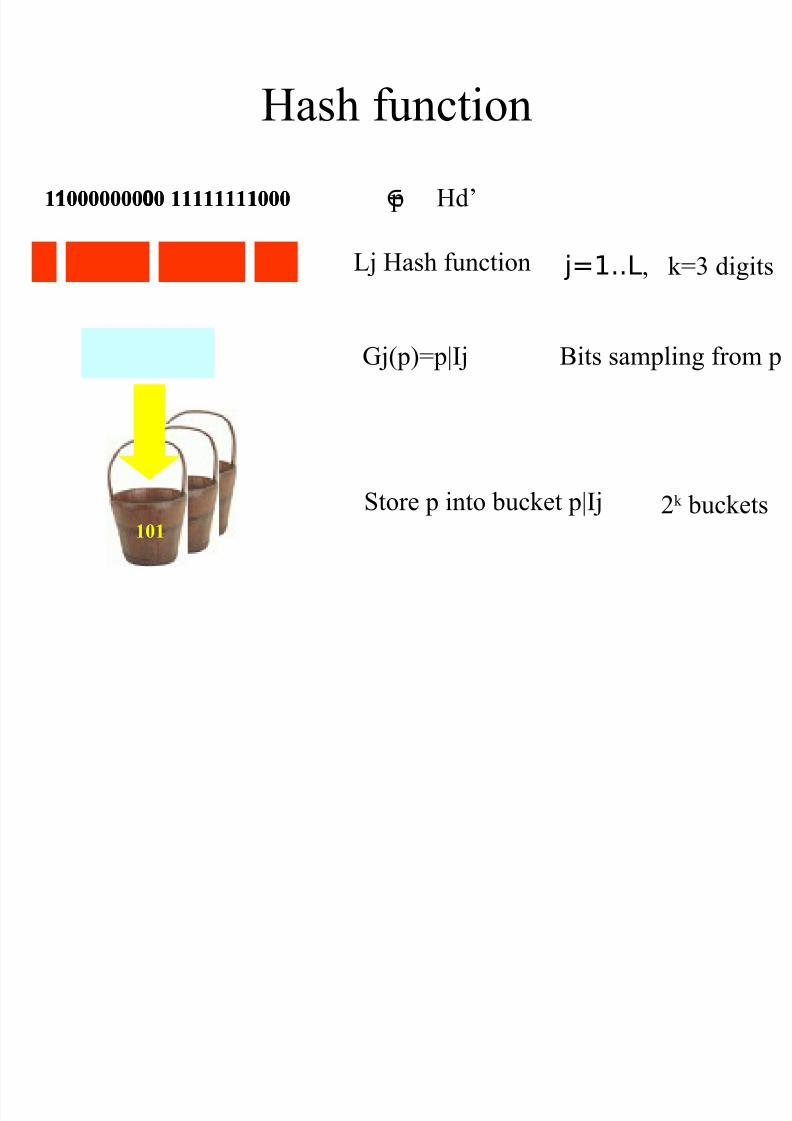
Hash function
Lj Hash function
p Hd’∈
Gj(p)=p|Ij
j=1..L, k=3 digits
Bits sampling from p
Store p into bucket p|Ij 2k buckets101
11000000000 111111110000 111000000000 111111110001
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 34/111
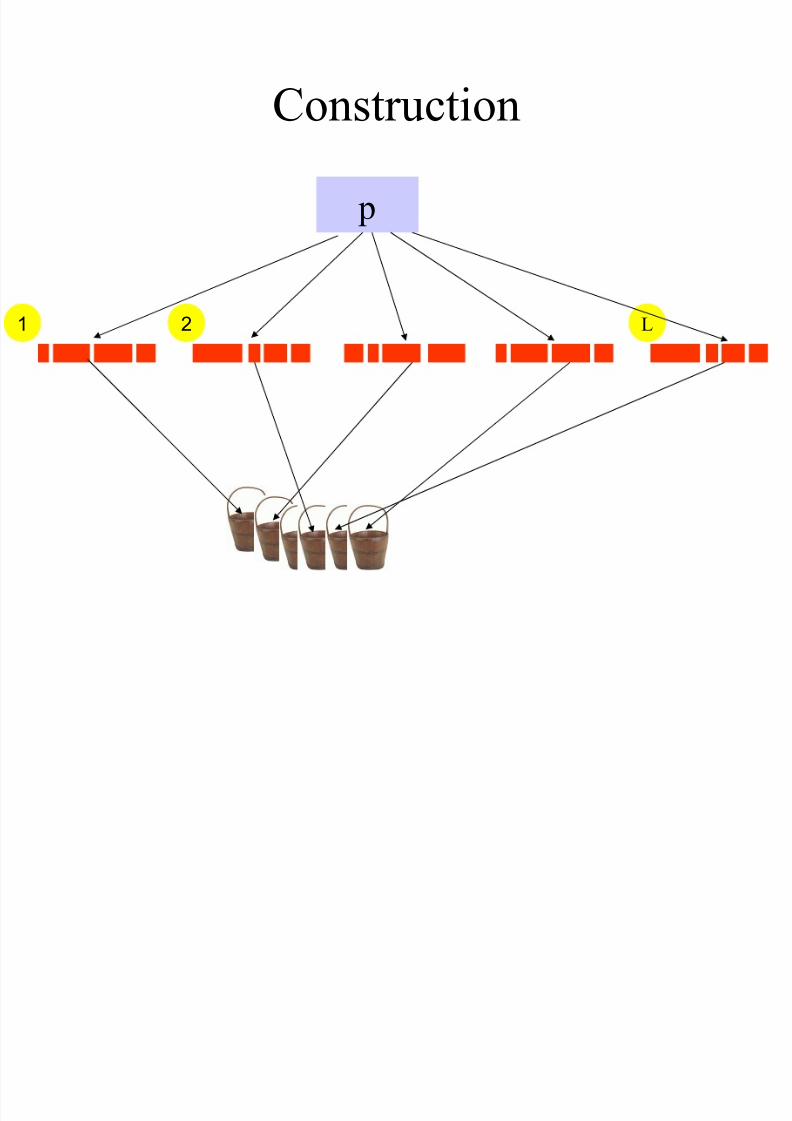
Construction
1 2 L
p
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 35/111
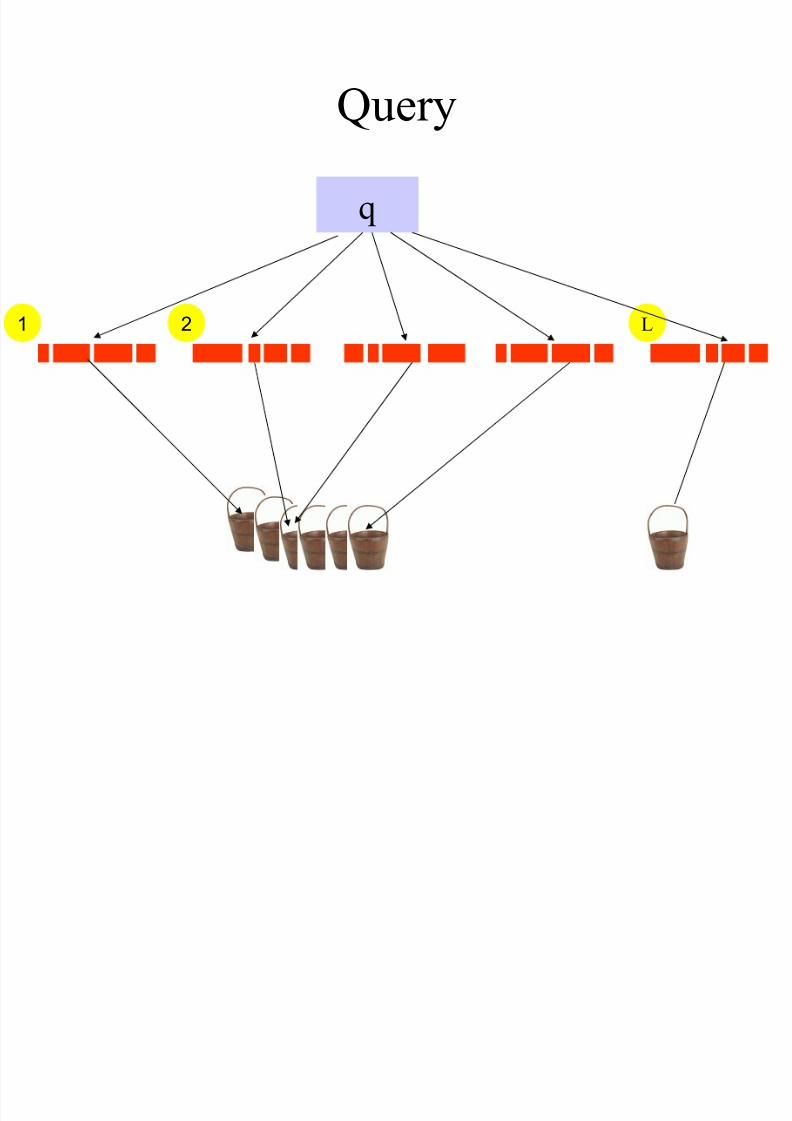
Query
1 2 L
q
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 36/111
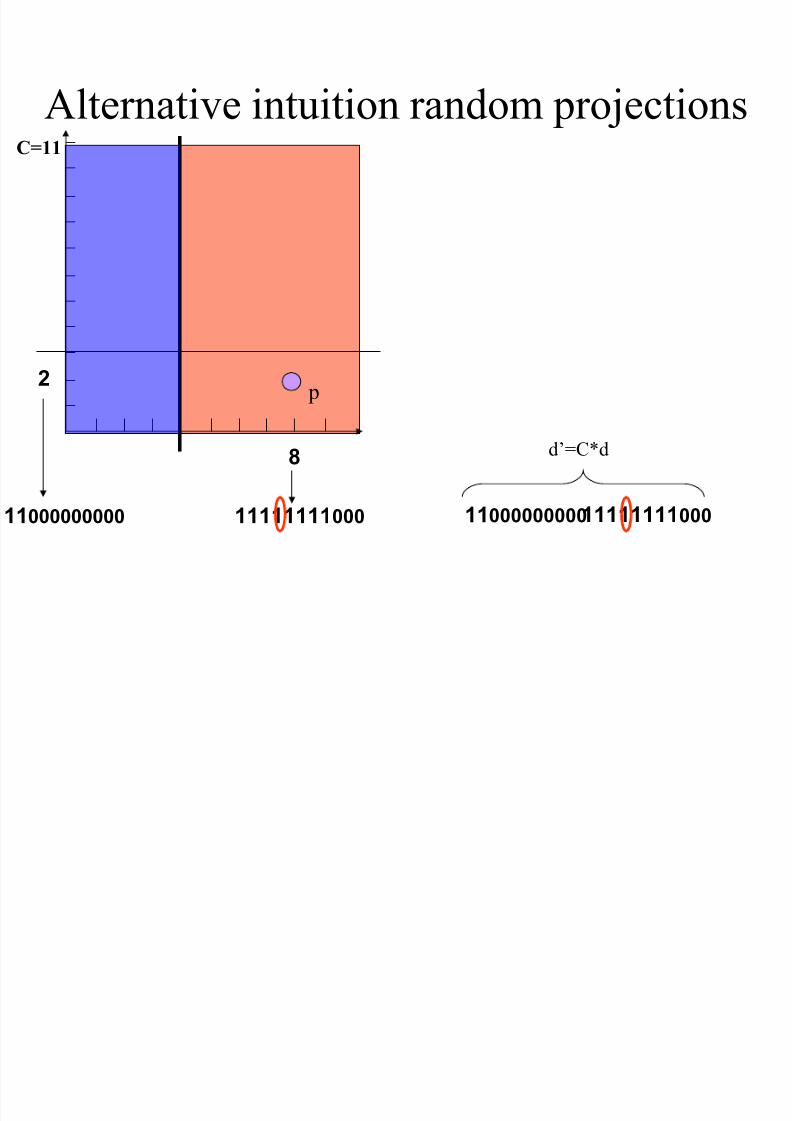
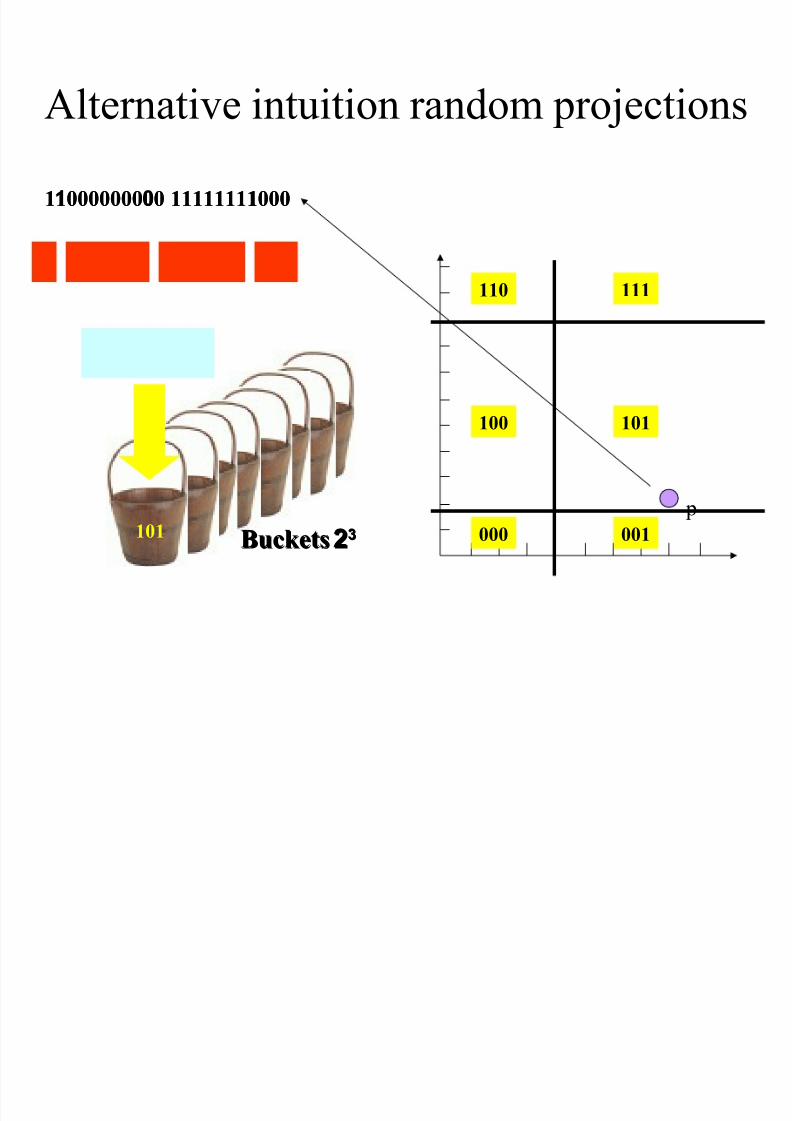
Alternative intuition random projections
p
8
C=11
1111111100011000000000
2
1111111100011000000000
d’=C*d
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 37/111
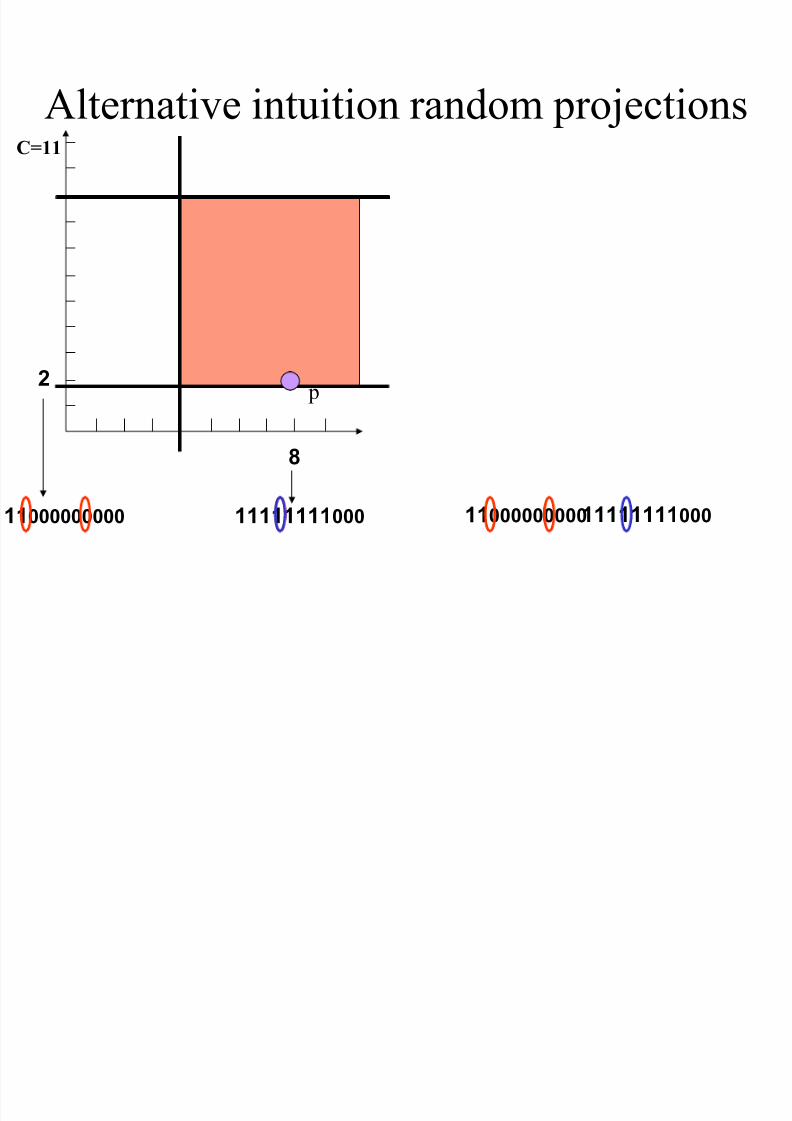
Alternative intuition random projections
8
C=11
1111111100011000000000
2
1111111100011000000000
p
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 38/111
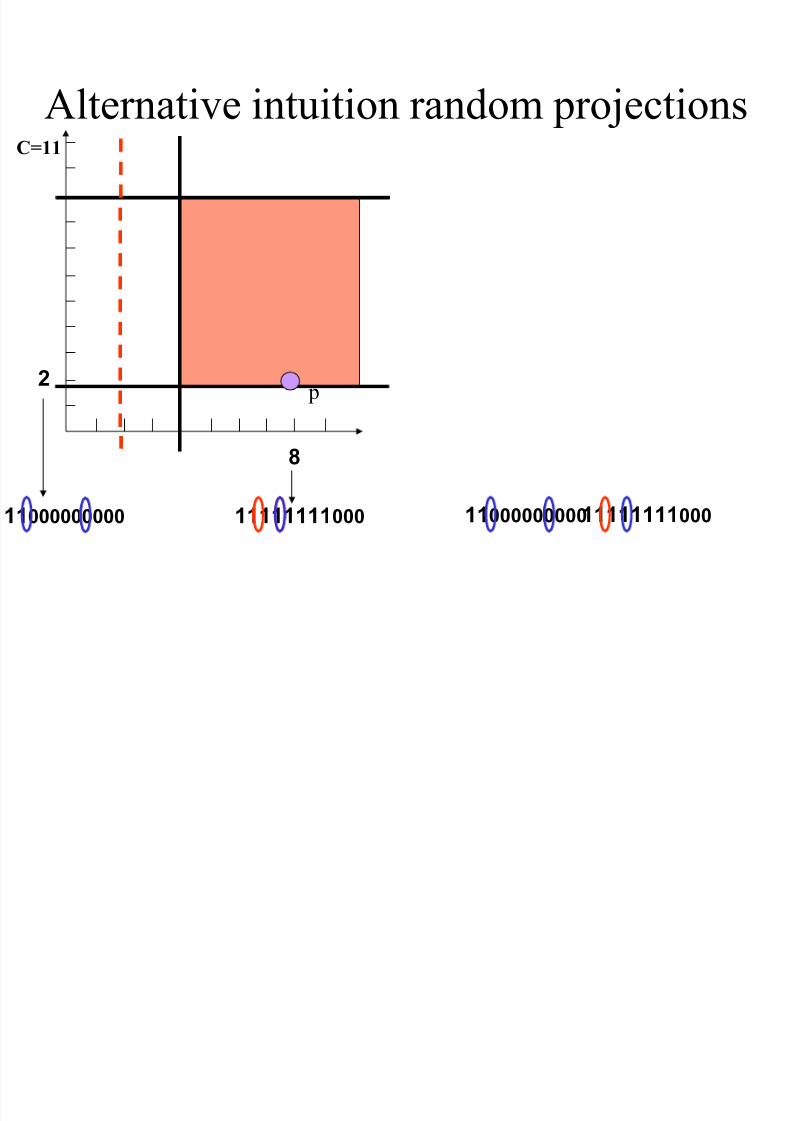
Alternative intuition random projections
8
C=11
1111111100011000000000
2
1111111100011000000000
p
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 39/111
Alternative intuition random projections
101
11000000000 111111110000 111000000000 111111110001
000
100
110
001
101
111
2233BucketsBuckets
p

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 40/111
k samplings
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 41/111
Repeating
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 42/111
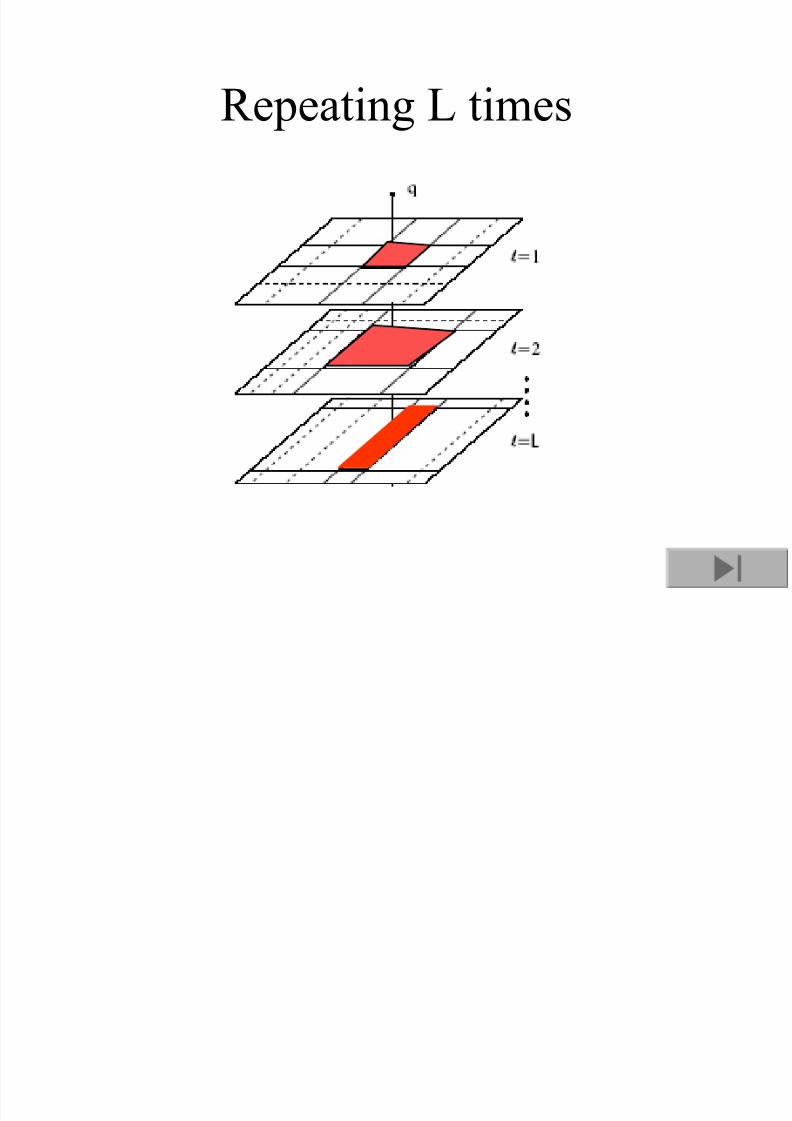
Repeating L times
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 43/111
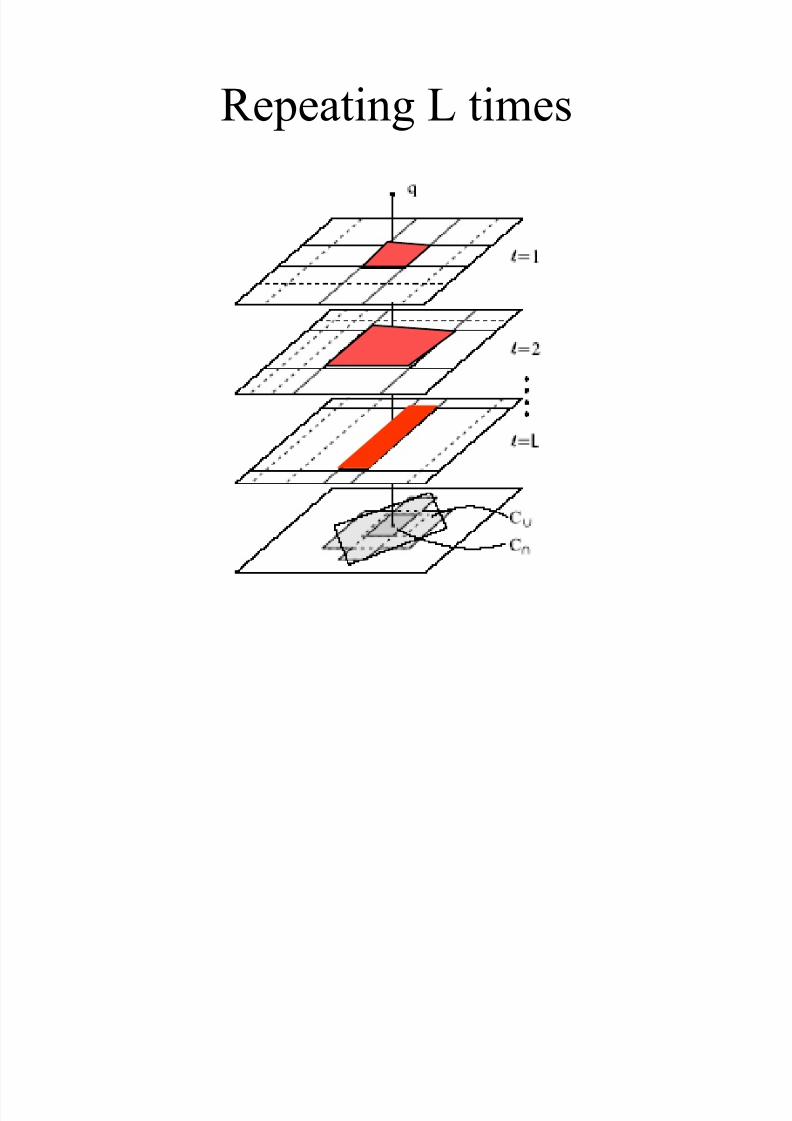
Repeating L times
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 44/111
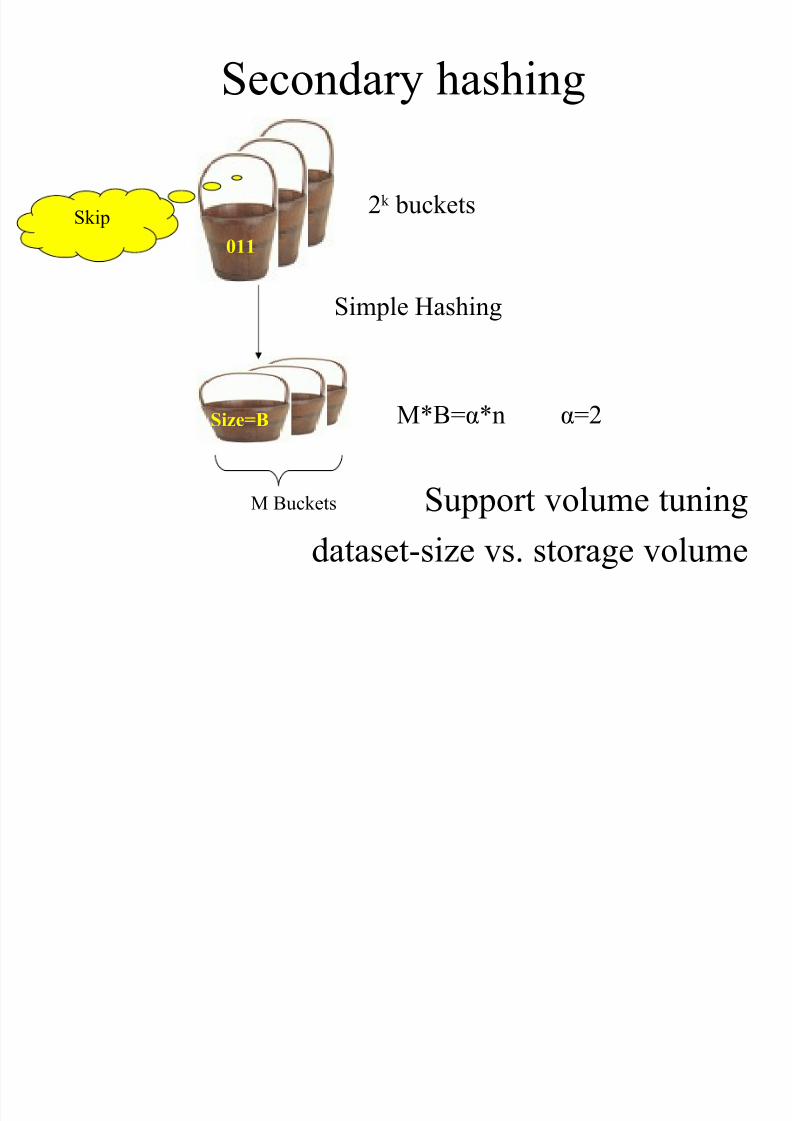
Secondary hashing
Support volume tuning
dataset-size vs. storage volume
2k buckets
011
Size=B
M Buckets
Simple Hashing
M*B=α*n α=2
Skip
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 45/111
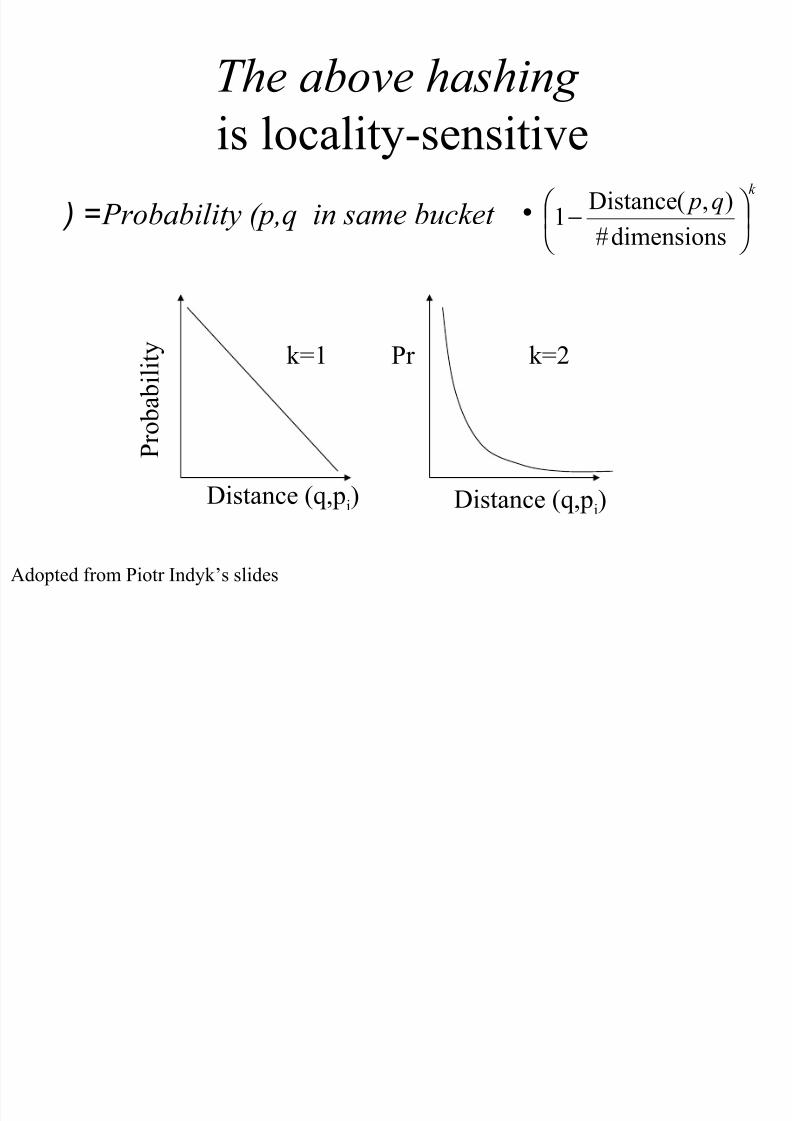
The above hashing
is locality-sensitive• Probability (p,q in same bucket ( =
k=1 k=2
Distance (q,pi) Distance (q,pi)
P r o b
a b
i l i
t y Pr
Adopted from Piotr Indyk’s slides
k q p
−
dimensions#
),(Distance1

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 46/111
Preview
•General Solution –
Locality sensitive hashing
•Implementation for Hamming space
•Generalization to l2

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 47/111
Direct L2 solution
• New hashing function
•Still based on sampling
•Using mathematical trick
•P-stable distribution for Lp distance
•Gaussian distribution for L2 distance
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 48/111
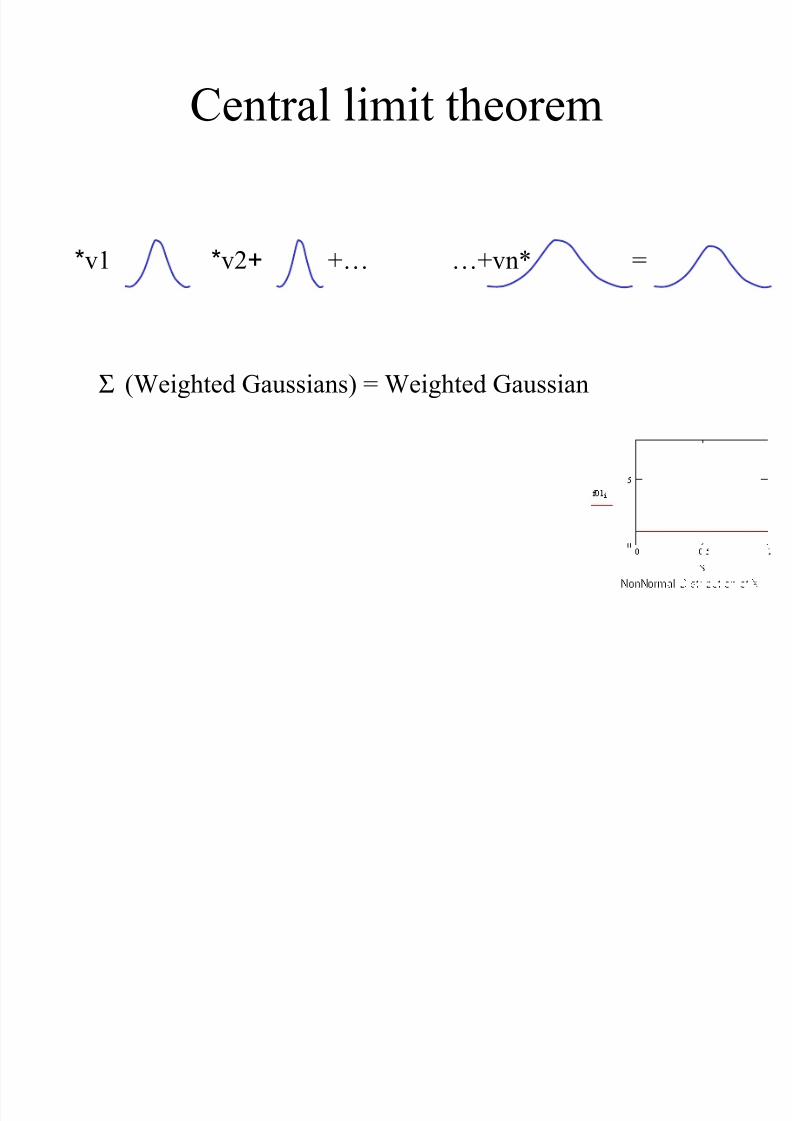
Central limit theorem
v1* +v2* …+vn* =+…
Σ (Weighted Gaussians) = Weighted Gaussian

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 49/111
Central limit theorem
v1
..vn
= Real Numbers
X1:Xn = Independent Identically Distributed
(i.i.d)
+v2* X2 …+vn* Xn =+…v1* X1
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 50/111
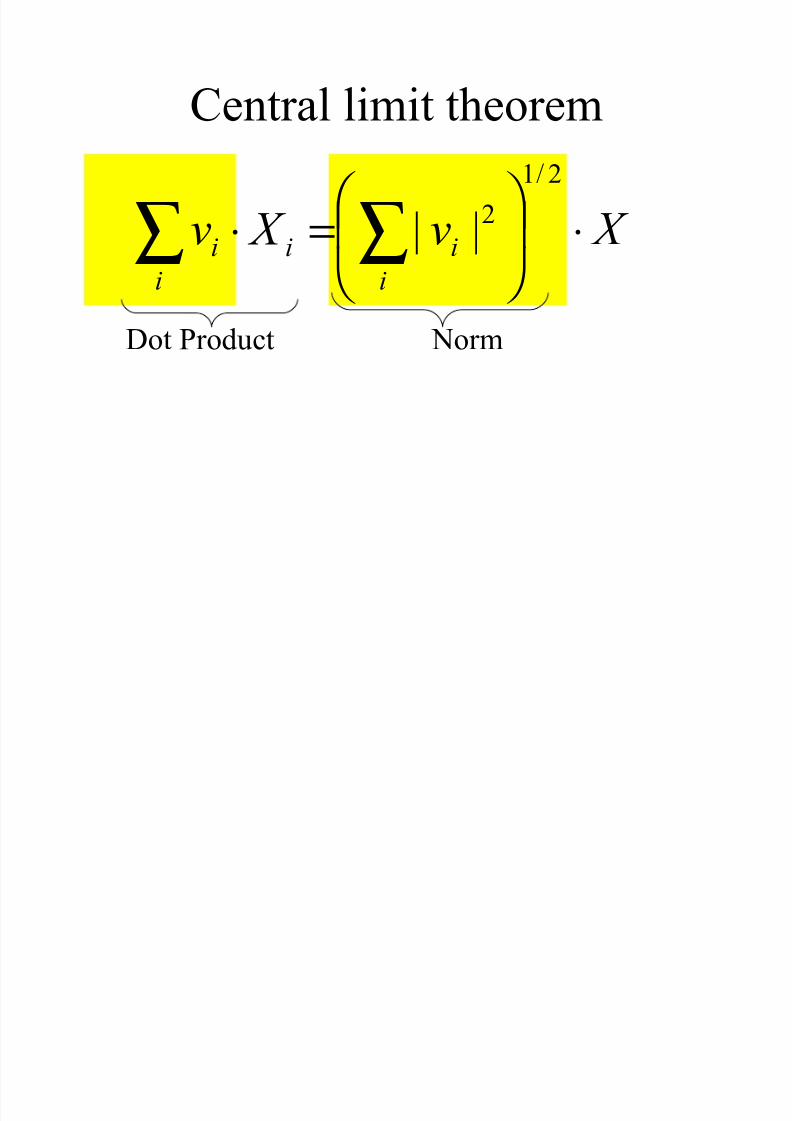
Central limit theorem
X v X v
i
i
i
ii ⋅
=⋅ ∑∑
2/1
2||
Dot Product Norm

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 51/111
Norm Distance
X vu X v X ui
ii
i
ii
i
ii ⋅
−=⋅−⋅ ∑∑∑
2/1
2||
Featuresvector 1
Featuresvector 2 Distance

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 52/111
Norm Distance
X vu X v X ui
ii
i
ii
i
ii ⋅
−=⋅−⋅ ∑∑∑
2/1
2||
DotProduct
DotProduct Distance
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 53/111
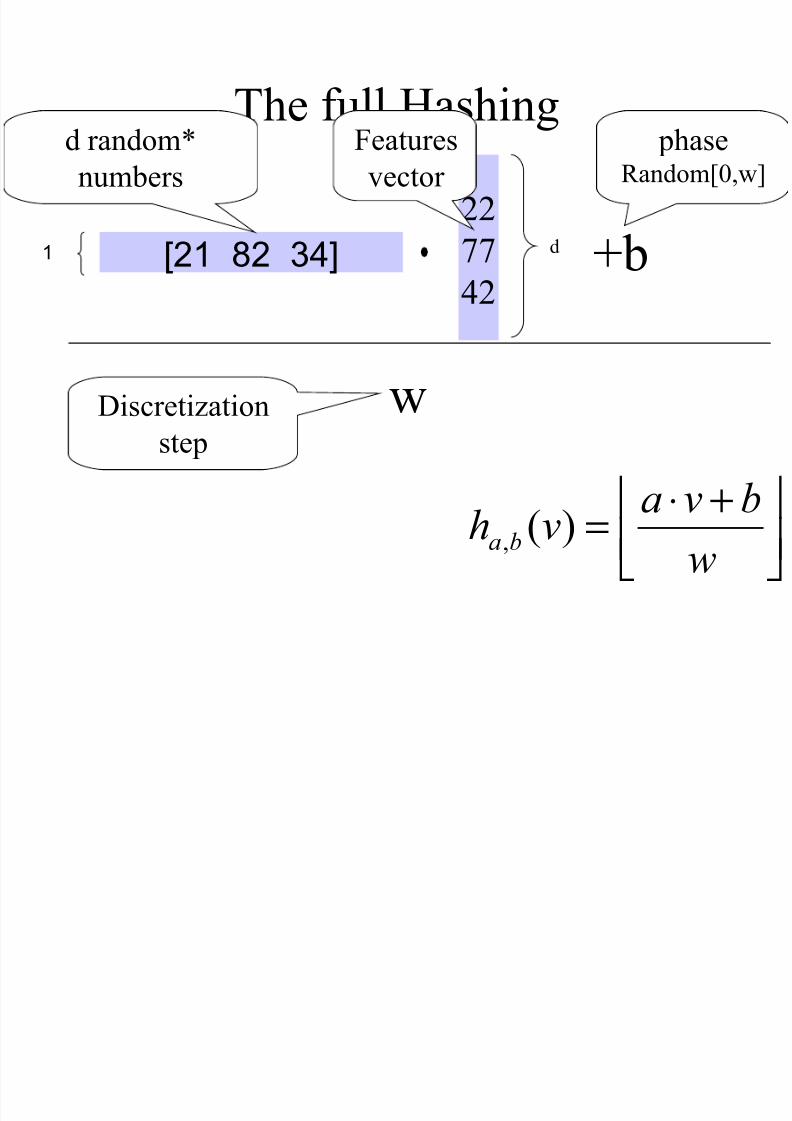
The full Hashing
+⋅=
w
bvavh ba )(,
]34 82 21[1
22
77
42
d
d random*numbers
+b
phaseRandom[0,w]
wDiscretization
step
Featuresvector
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 54/111
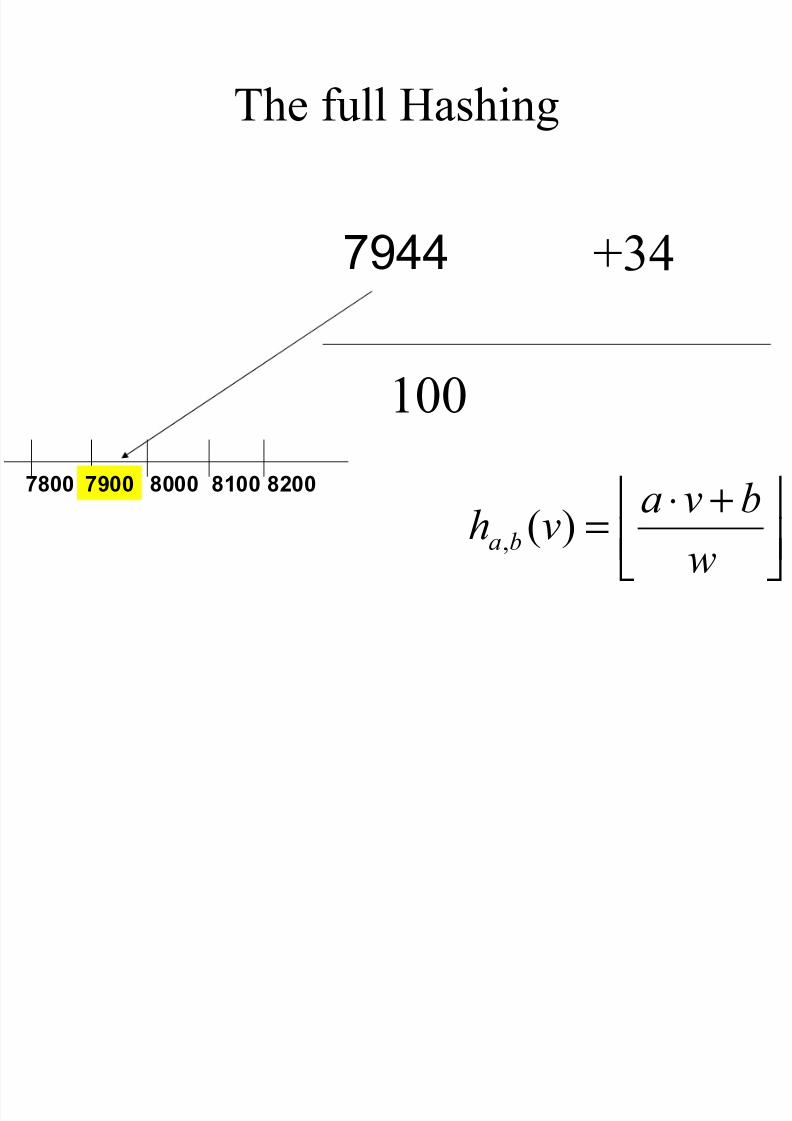
The full Hashing
+⋅=
w
bvavh ba )(,
+34
100
7944
7900 8000 8100 82007800

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 55/111
The full Hashing
+⋅=
w
bvavh ba )(,
+34
phaseRandom[0,w]
100Discretization
step
7944
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 56/111
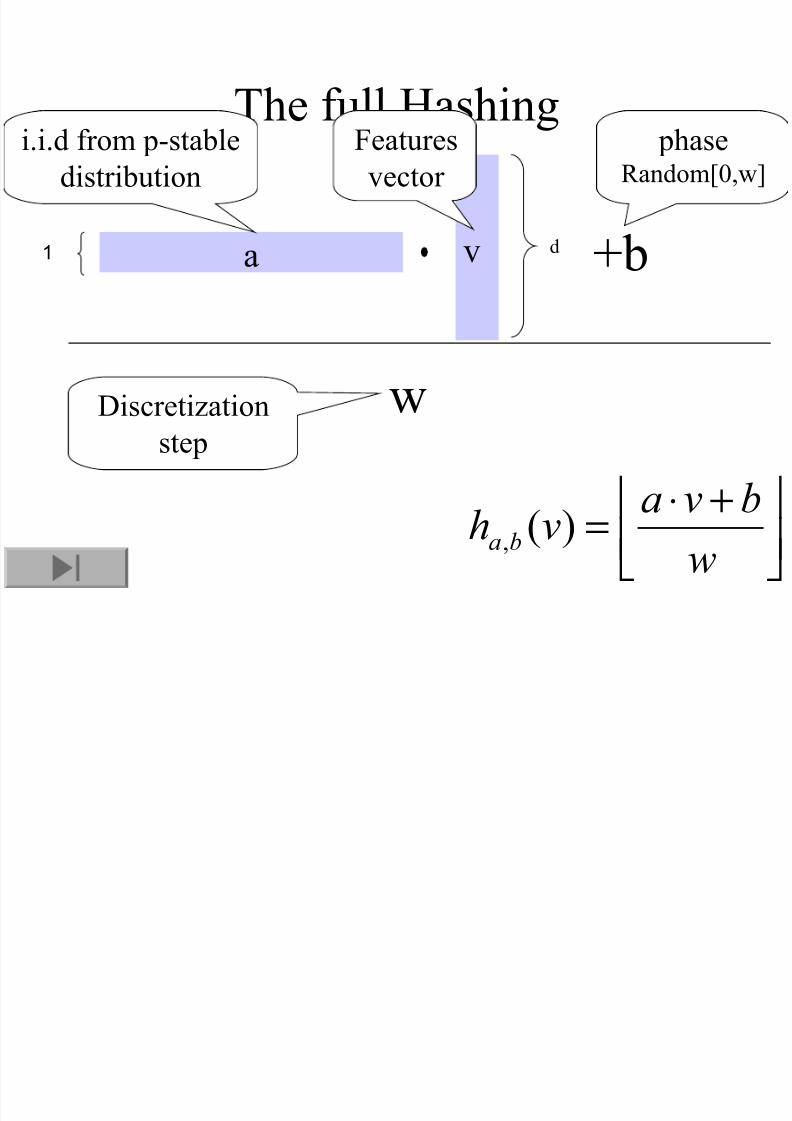
The full Hashing
+⋅=
w
bvavh ba )(,
a1 v d
i.i.d from p-stabledistribution
+b
phaseRandom[0,w]
wDiscretization
step
Featuresvector

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 57/111
Generalization: P-Stable distribution
•L p p=eps..2
•Generalized
Central Limit Theorem•P-stable distribution
Cauchy for L2
•L2
•Central Limit Theorem
•Gaussian (normal)
distribution

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 58/111
P-Stable summary
•Works for
•Generalizes to 0<p<=2
•Improves query time
Query time = O (dn1/(1+ ε )log(n) ) O (dn1/(1+ ε )̂ 2 log(n) )
r, ε - Nearest Neighbor
Latest results
Reported in Email by
Alexander Andoni

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 59/111
Parameters selection
•90%Probability Best quarry time performance
For Euclidean Space
L

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 60/111
Parameters selection…
For Euclidean Space
•Single projection hit an ε - Nearest
Neighbor with Pr=p1
•k projections hits an ε - Nearest Neighbor with Pr=p1k
•L hashings fail to collide with Pr=(1-p1k )L
•To ensure Collision (e.g. 1-δ≥90%(
•1- )1- p1k )L≥ 1-δ)1log(
)log(
1
k p
L−
≥δ
L
K
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 61/111
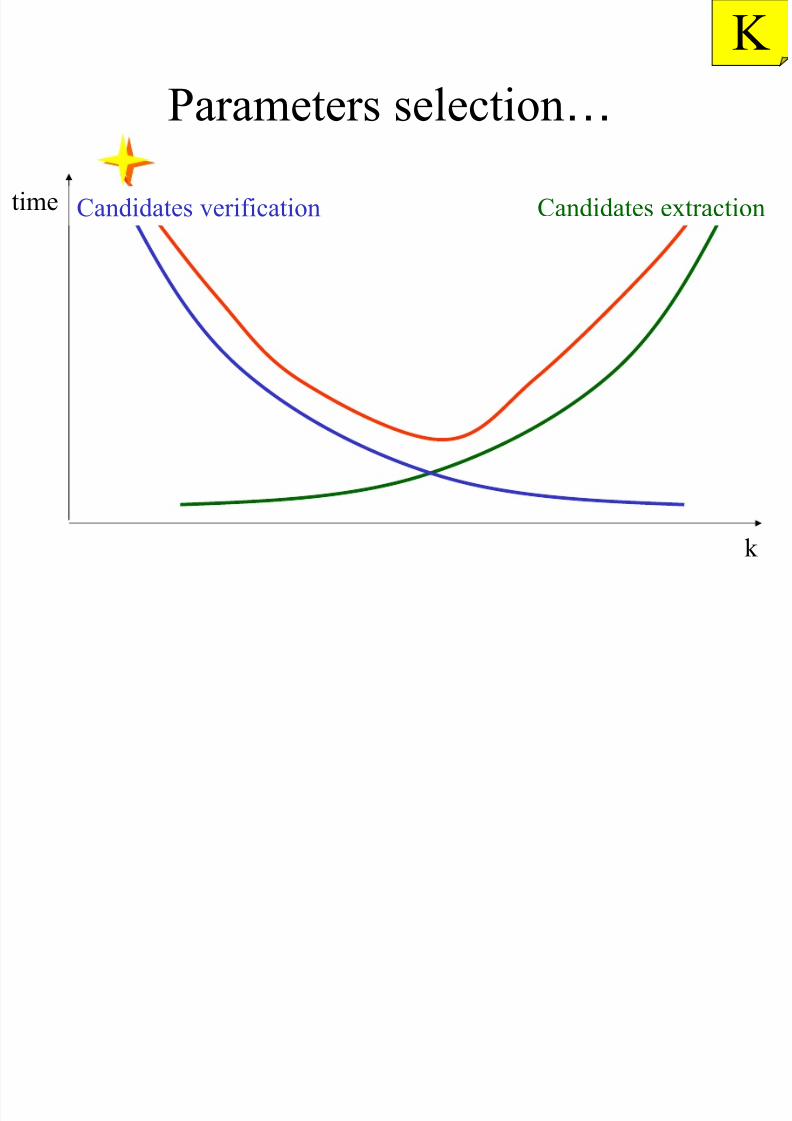
…Parameters selection
K
k
time Candidates verification Candidates extraction

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 62/111
Better Query Time than Spatial Data Structures
Scales well to higher dimensions and larger data size( Sub-linear dependence )
Predictable running time
Extra storage over-head
Inefficient for data with distances concentrated aroundaverage
works best for Hamming distance (although can begeneralized to Euclidean space)
In secondary storage, linear scan is pretty much all wecan do (for high dim)
requires radius r to be fixed in advance
Pros. & Cons.
From Pioter Indyk slides

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 63/111
Conclusion
•.. but at the end
everything depends on your data set
•Try it at home – Visit:
http://web.mit.edu/andoni/www/LSH/index.html
– Email Alex [email protected] – Test over your own data
(C code under Red Hat Linux(
LSH A li i

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 64/111
LSH - Applications• Searching video clips in databases .("Hierarchical, Non-Uniform Locality Sensitive
Hashing and Its Application to Video Identification“, Yang, Ooi, Sun).
• Searching image databases (see the following).
• Image segmentation (see the following).
• Image classification (“Discriminant adaptive Nearest Neighbor Classification”, T. Hastie, R Tibshirani).
• Texture classification (see the following).
• Clustering (see the following).
• Embedding and manifold learning (LLE, and many others)
• Compression – vector quantization.
• Search engines (“LSH Forest: SelfTuning Indexes for Similarity Search”, M. Bawa, T. Condie, P. Ganesan”).
• Genomics (“Efficient Large-Scale Sequence Comparison by Locality-Sensitive Hashing”, J. Buhler).
• In short: whenever K-Nearest Neighbors (KNN) areneeded.
M i i

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 65/111
Motivation
• A variety of procedures in learningrequire KNN computation.
• KNN search is a computational
bottleneck.• LSH provides a fast approximate solution
to the problem.
• LSH requires hash function construction
and parameter tunning.
Outline

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 66/111
Outline
Fast Pose Estimation with Parameter Sensitive
Hashing G. Shakhnarovich, P. Viola, and T. Darrell.
• Finding sensitive hash functions.
Mean Shift Based Clustering in High
Dimensions: A Texture Classification ExampleB. Georgescu, I. Shimshoni, and P. Meer
• Tuning LSH parameters.
• LSH data structure is used for algorithmspeedups.
Fast Pose Estimation with Parameter Sensitive

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 67/111
Given an image x, what are the
parameters θ, in this image?
i.e. angles of joints, orientation of the body,
etc.
The Problem:
HashingG. Shakhnarovich, P. Viola, and T. Darrell
iθ

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 68/111
Ingredients
• Input query image with unknown angles
(parameters).
• Database of human poses with known angles.• Image feature extractor – edge detector.
• Distance metric in feature space d x.
• Distance metric in angles space:
∑=
−−=m
i
iid 1
2121 )cos(1),( θ θ θ θ θ
Example based learning
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 69/111
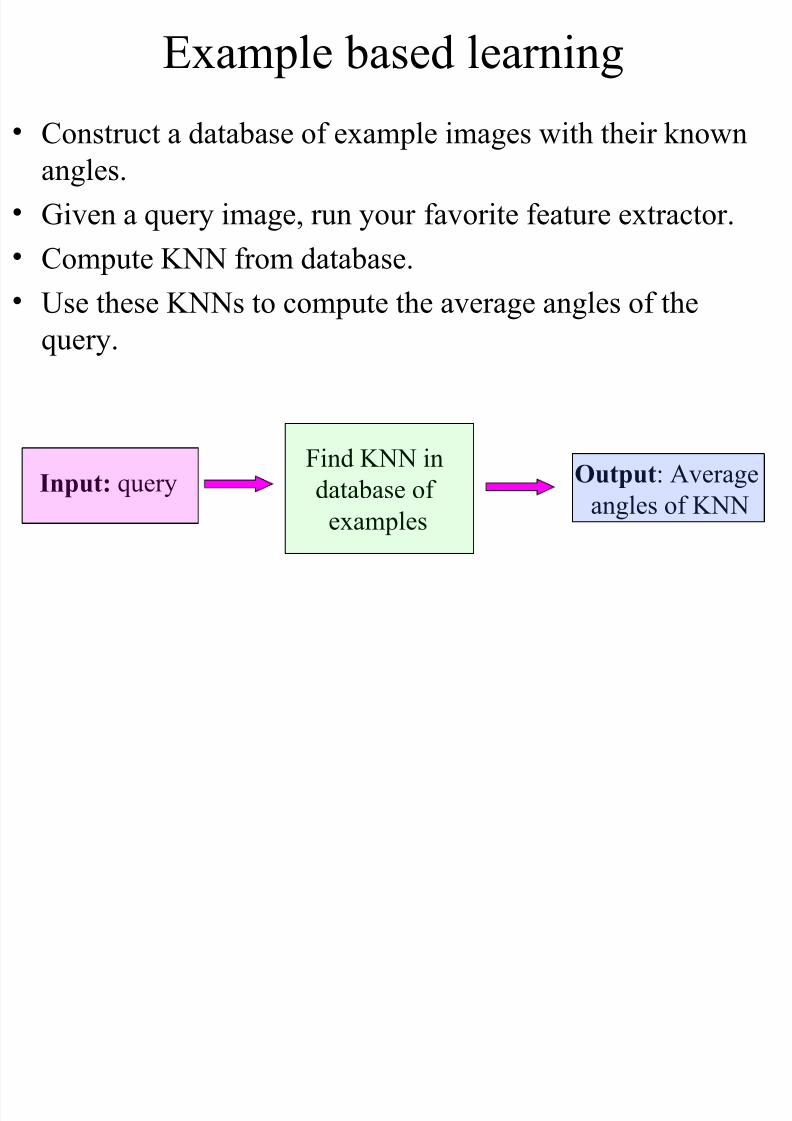
Example based learning
•Construct a database of example images with their knownangles.
• Given a query image, run your favorite feature extractor.
• Compute KNN from database.
• Use these KNNs to compute the average angles of the
query.
Input: queryFind KNN in
database of
examples
Output: Average
angles of KNN
The algorithm flow
8/9/2019 k-Nearest Neighbors Search in High Dimensions
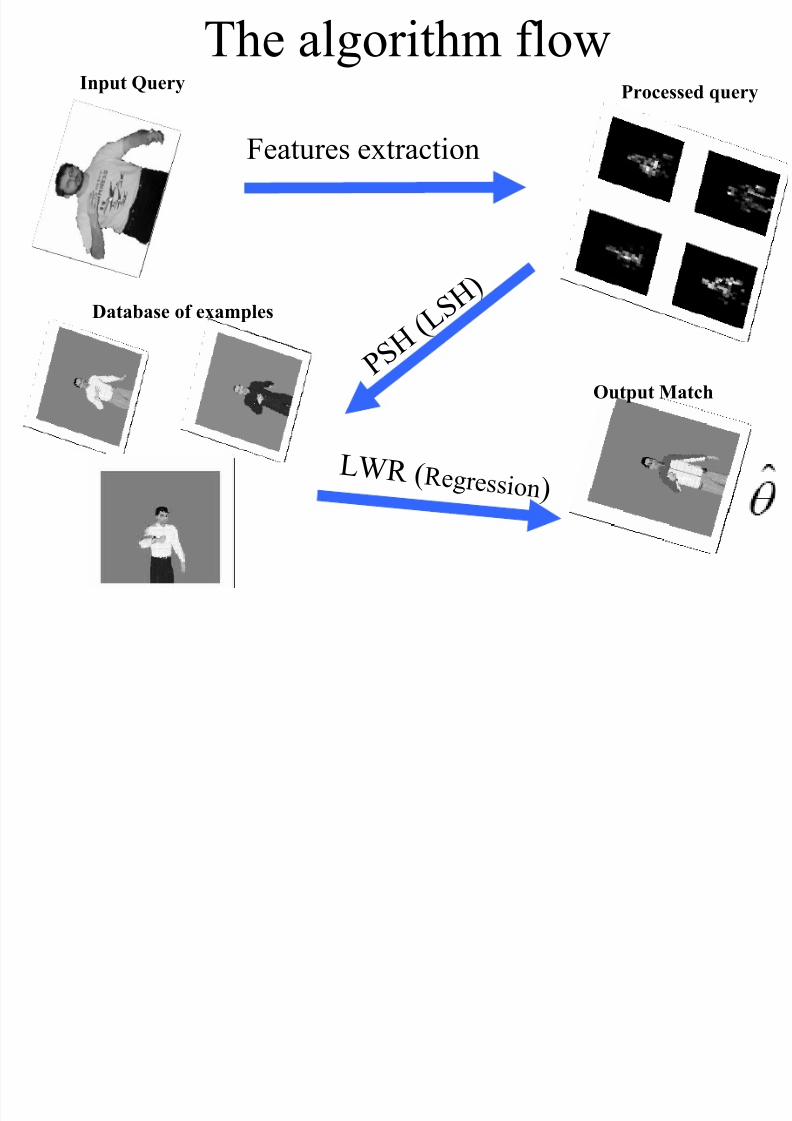
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 70/111
Input Query
Features extraction
Processed query
P S H
( L S H )Database of examples
The algorithm flow
LW R ( R e g r e ssion )
Output Match
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 71/111
The image features
BA
∑= A x x 4/107 )(
,4
3 ,
2 ,
4 ,0
π φ
π π π
Image features are multi-
scale edge histograms:
Feature Extraction PSH LWR
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 72/111
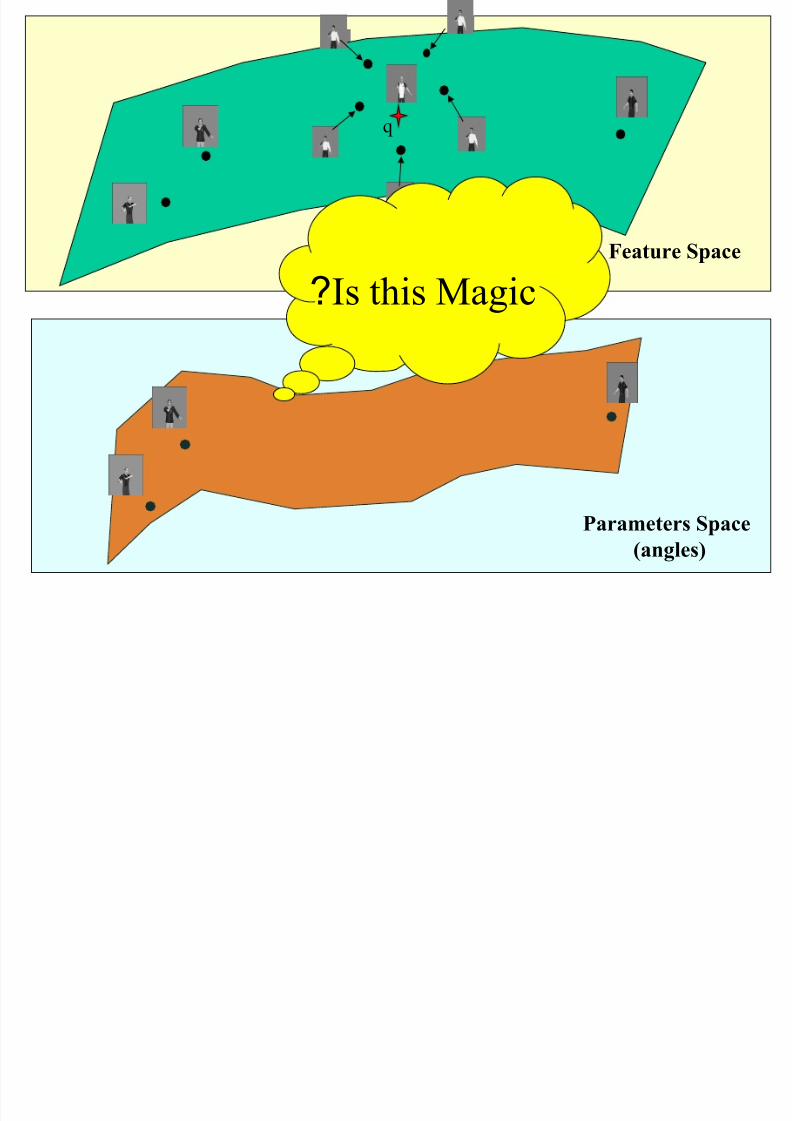
PSH: The basic assumption
There are two metric spaces here: feature space ( )
and parameter space ( ).
We want similarity to be measured in the angles
space, whereas LSH works on the feature space.
• Assumption: The feature space is closely
related to the parameter space.
xd
θ d
Feature Extraction PSH LWR
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 73/111
Insight: Manifolds
• Manifold is a space in which
every point has a neighborhood
resembling a Euclid space.
• But global structure may be
complicated: curved.
• For example: lines are 1D
manifolds, planes are 2Dmanifolds, etc.
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 74/111
Parameters Space
(angles)
Feature Space
q
Is this Magic?
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 75/111
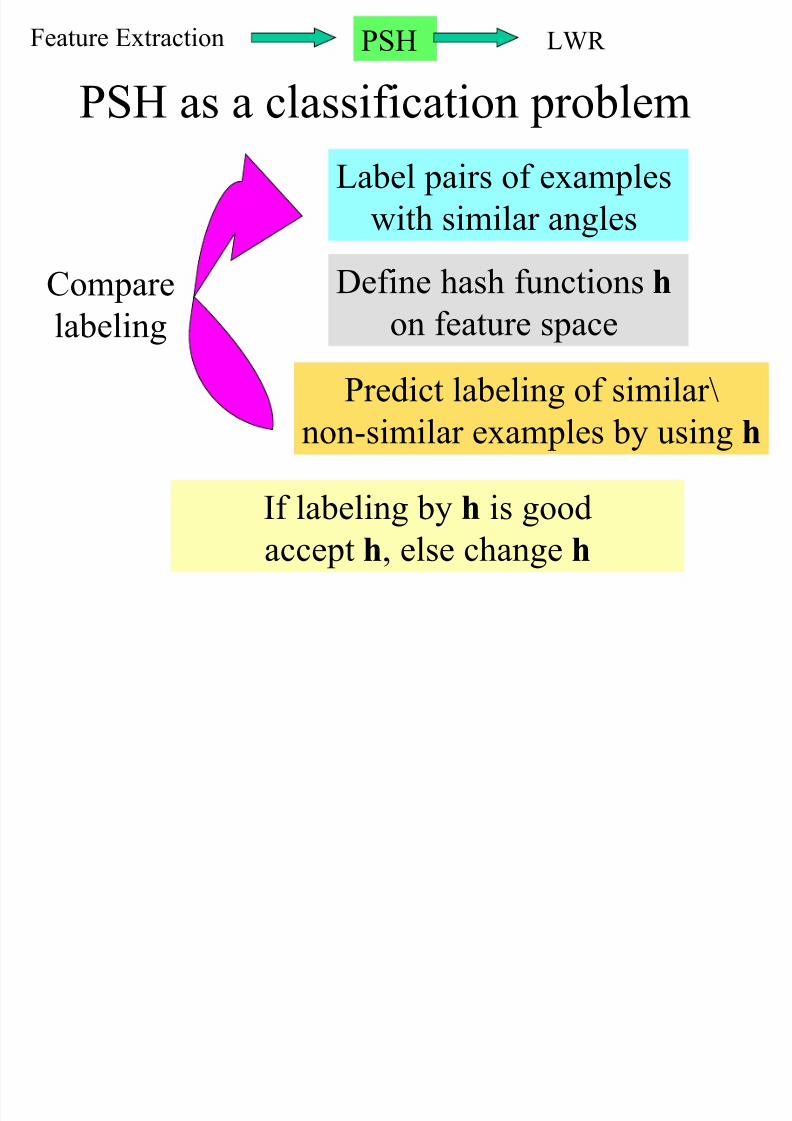
Parameter Sensitive Hashing (PSH)
The trick:
Estimate performance of different hash functionson examples, and select those sensitive to :
The hash functions are applied in feature space
but the KNN are valid in angle space.
θ d
Feature Extraction PSH LWR
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 76/111
Label pairs of examples
with similar angles
Define hash functions h on feature space
Predict labeling of similar\
non-similar examples by using h
Comparelabeling
If labeling by h is good
accept h, else change h
PSH as a classification problem
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 77/111
+1 +1 -1 -1
(r=0.25)
Labels:
+>−
<+=
)1(),(if 1
),(if 1y
:labeledis
),x(),,(xexamplesof pair A
ij
ji
ε θ θ
θ θ
θ θ
θ
θ
r d
r d
ji
ji
ji
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 78/111
>+=
otherwise 1-
T(x)if 1)(,
φ φ xh T
A binary hash function:features
−
=+
= otherwise 1
if 1
ˆ
labelsePredict th
,, )(xh )(xh
) ,x(x y
jT iT
jih
φ φ
Feature
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 79/111
s.constrainties probabilitwith thelabeling
truethe predictsthat*T besttheFind
:themseparateor bin
samein theexamples both placewill,T hφ
θ
)( xφ T
Feature Extraction PSH LWR

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 80/111
Local Weighted Regression (LWR)
• Given a query image, PSH returnsKNNs.
• LWR uses the KNN to compute a
weighted average of the estimatedangles of the query:
β * = arg min b d q xi Î N ( x0 )å (g( x i,b),q i)K (d X ( x i, x0))
dist . weight
1 244 34 4

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 81/111
Results
Synthetic data were generated:
• 13 angles: 1 for rotation of the torso, 12 for
joints.• 150,000 images.
• Nuisance parameters added: clothing,
illumination, face expression.
• 1 775 000 example pairs

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 82/111
1,775,000 example pairs.
• Selected 137 out of 5,123 meaningful features
(how??):18 bit hash functions (k ), 150 hash tables (l ).
• Test on 1000 synthetic examples:• PSH searched only 3.4% of the data per query.
• Without selection needed 40 bits and
1000 hash tables.
Recall:P1 is prob of positive
hash.
P2 is prob of bad hash.
B is the max number of
pts in a bucket.

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 83/111
Results – real data
• 800 images.
• Processed by a segmentation algorithm.
• 1.3% of the data were searched.
R l l d

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 84/111
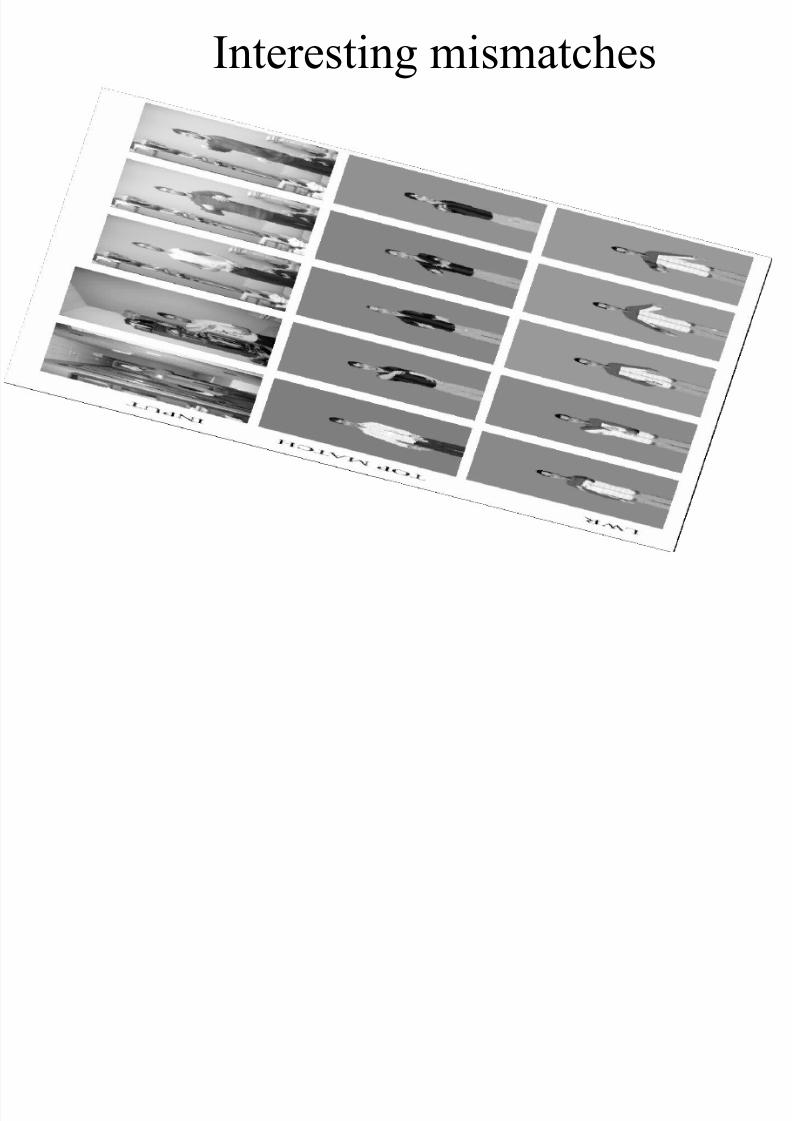
Results – real data
Interesting mismatches
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 85/111
Interesting mismatches

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 86/111
Fast pose estimation - summary
• Fast way to compute the angles of human
body figure.
• Moving from one representation space toanother.
• Training a sensitive hash function.
• KNN smart averaging.
Food for Thought

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 87/111
Food for Thought
• The basic assumption may be problematic(distance metric, representations).
• The training set should be dense.
• Texture and clutter.• General: some features are more important
than others and should be weighted.

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 88/111
Food for Thought: Point Location in
Different Spheres (PLDS(
• Given: n spheres in Rd , centered at P={p1 ,…,p
n }
with radii {r 1 ,…,r
n } .
• Goal: given a query q, preprocess the points in P
to find point pithat its sphere ‘cover’ the query q.
qpi
r i
Courtesy of Mohamad Hegaze
Mean-Shift Based Clustering in High Dimensions: A

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 89/111
Motivation:
• Clustering high dimensional data by using local
density measurements (e.g. feature space).• Statistical curse of dimensionality:
sparseness of the data.• Computational curse of dimensionality:
expensive range queries.• LSH parameters should be adjusted for optimal
performance.
Mean Shift Based Clustering in High Dimensions: A
Texture Classification ExampleB. Georgescu, I. Shimshoni, and P. Meer
Outline

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 90/111
Outline
• Mean-shift in a nutshell + examples.
Our scope:
• Mean-shift in high dimensions – using LSH.
• Speedups:
1. Finding optimal LSH parameters.
2. Data-driven partitions into buckets.
3. Additional speedup by using LSH data structure.
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 91/111
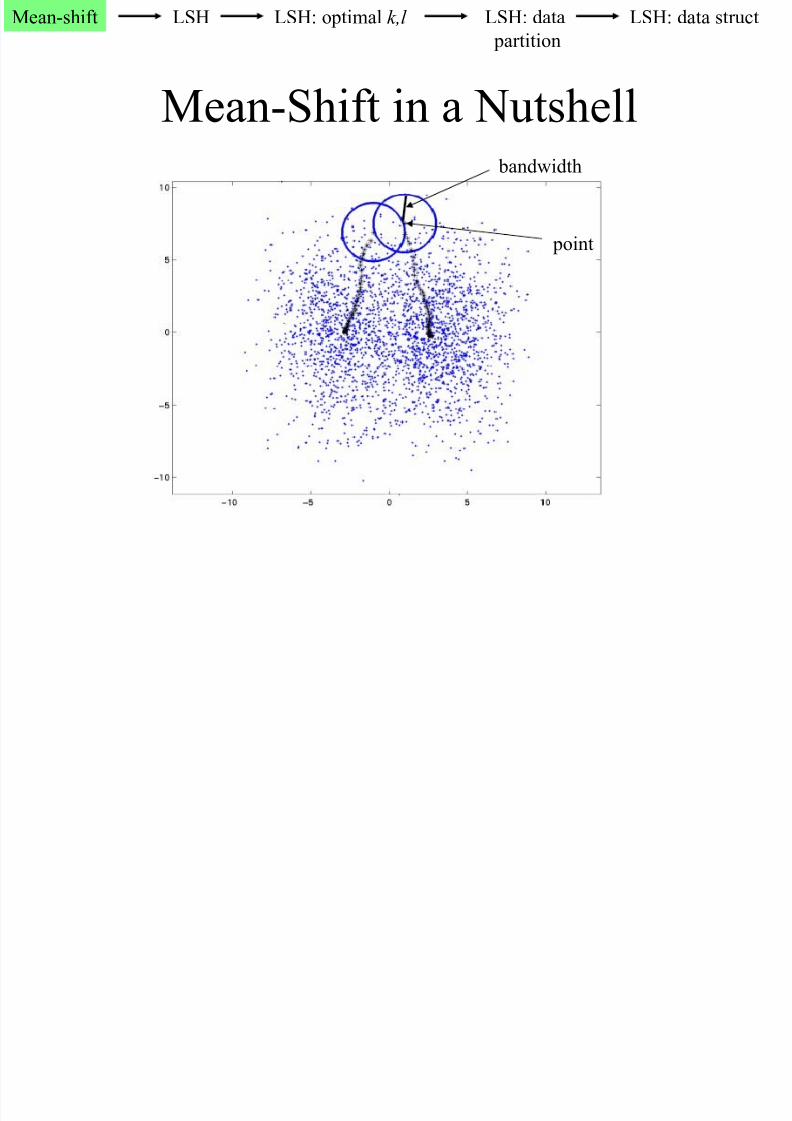
Mean-Shift in a Nutshell bandwidth
point
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 92/111
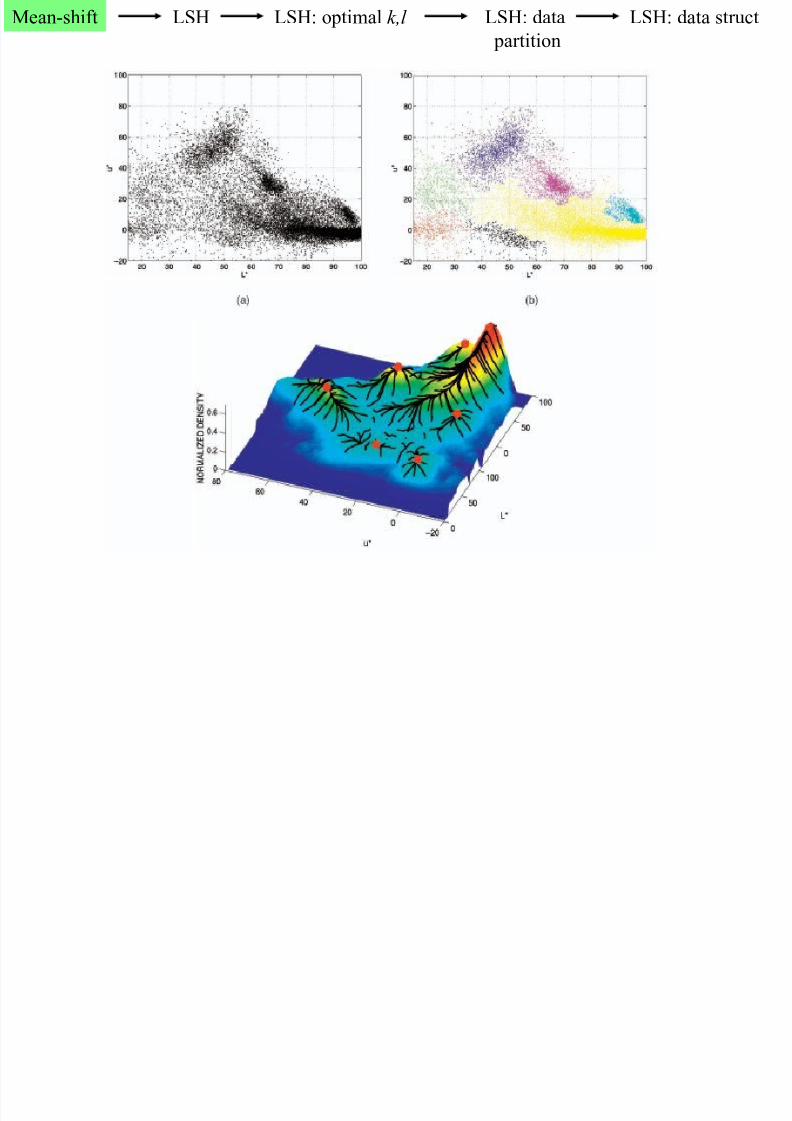
KNN in mean-shift
Bandwidth should be inversely proportional to the
density in the region:
high density - small bandwidth
low density - large bandwidth
Based on k th nearest neighbor of the point
The bandwidth is
Adaptive mean-shift vs. non-adaptive.
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 93/111
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 94/111
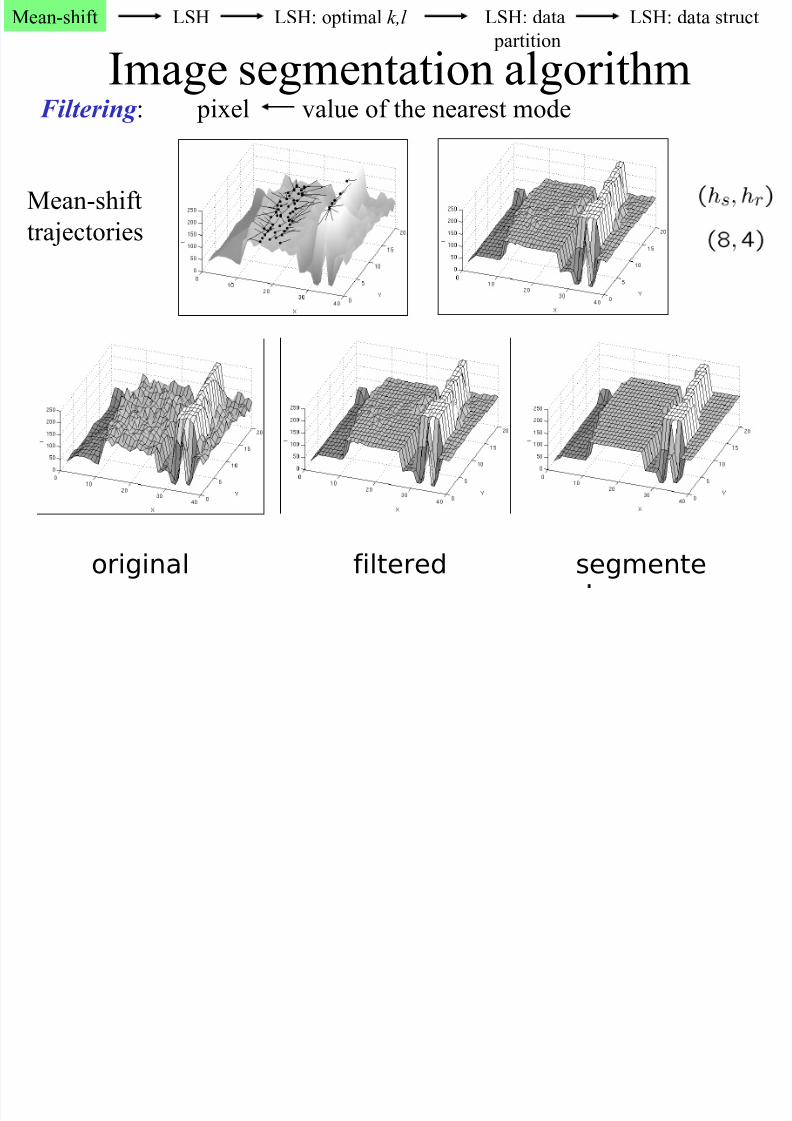
Image segmentation algorithm
1. Input : Data in 5D (3 color + 2 x,y) or 3D (1 gray +2 x,y)2. Resolution controlled by the bandwidth: hs (spatial), hr (color)
3. Apply filtering
3D:
Mean-shift: A Robust Approach Towards Feature Space Analysis. D. Comaniciu et. al. TPAMI 0’
Image segmentation algorithm
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 95/111
Image segmentation algorithm
original segmentefiltered
Filtering : pixel value of the nearest mode
Mean-shift
trajectories
Filtering examples
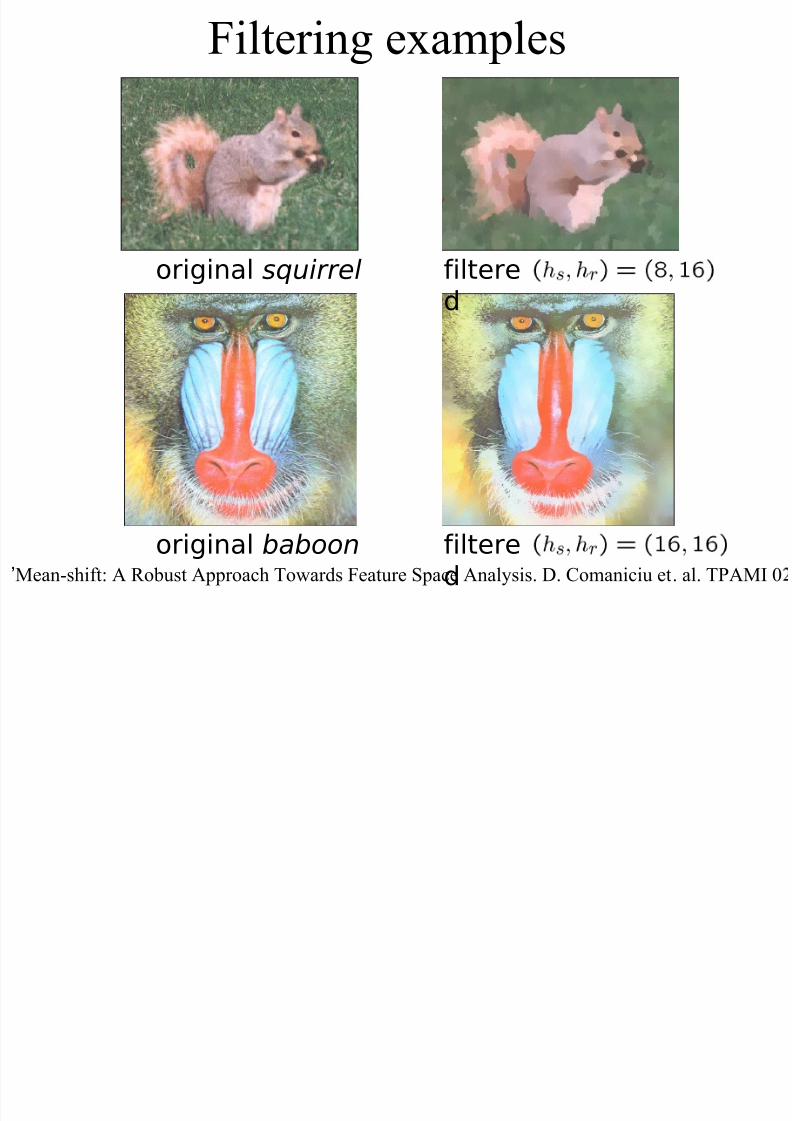
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 96/111
original squirrel filtere
d
original baboon filtere
dMean-shift: A Robust Approach Towards Feature Space Analysis. D. Comaniciu et. al. TPAMI 0’
Segmentation examples
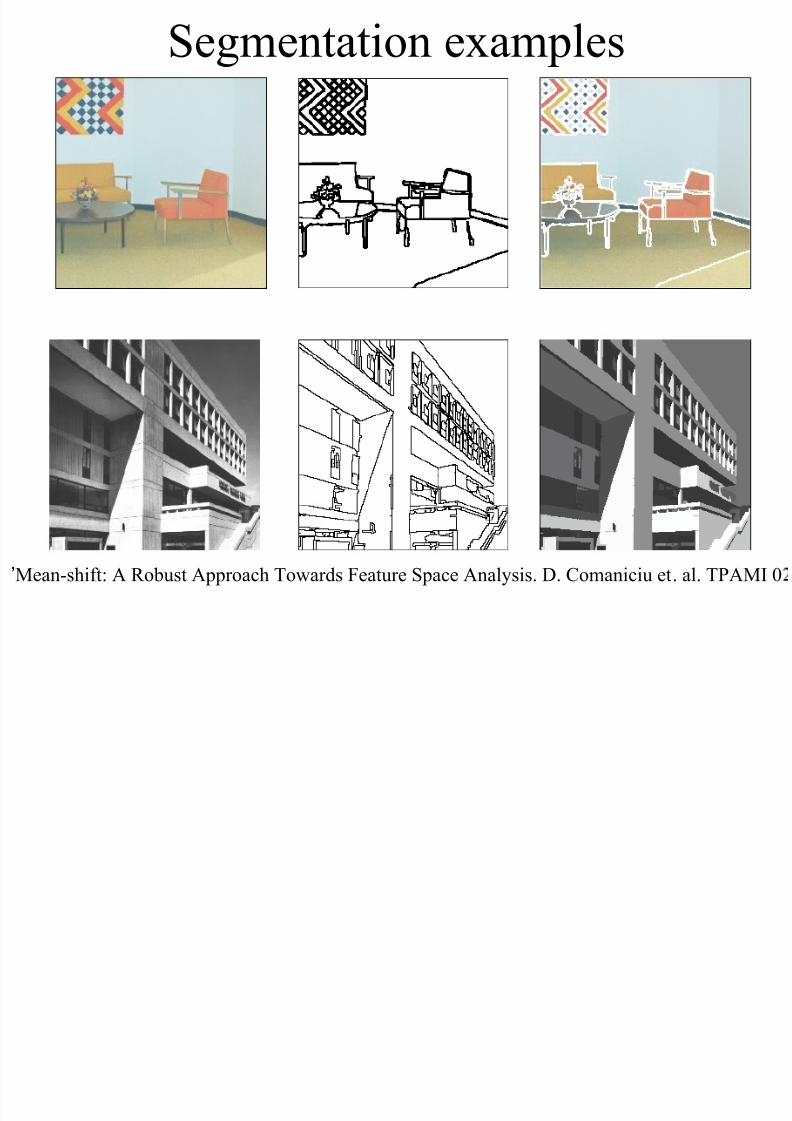
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 97/111
Mean-shift: A Robust Approach Towards Feature Space Analysis. D. Comaniciu et. al. TPAMI 0’
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 98/111
Mean-shift in high dimensions
Computational curse of dimensionality:
Statistical curse of dimensionality:
Expensive range queries implemented with LSH
Sparseness of the data variable bandwidth
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
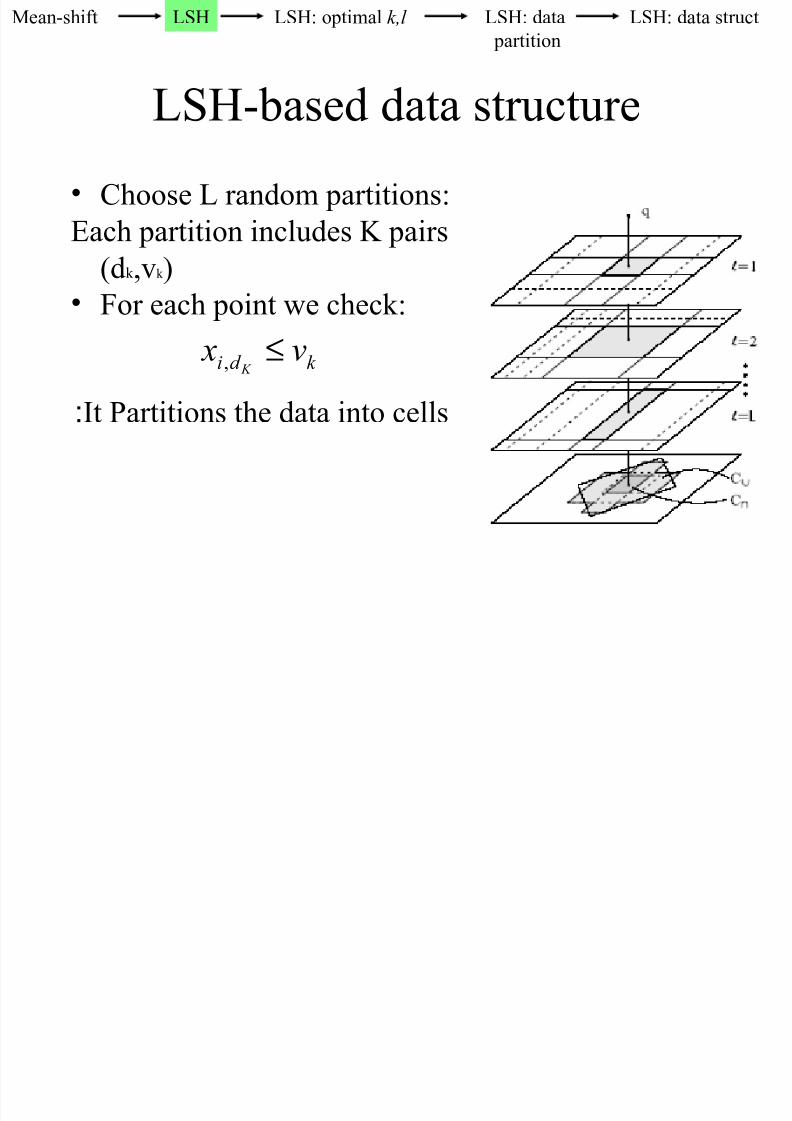
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 99/111
LSH-based data structure
• Choose L random partitions:
Each partition includes K pairs
(dk ,vk )
• For each point we check:
k d i v x K ≤,
It Partitions the data into cells:
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
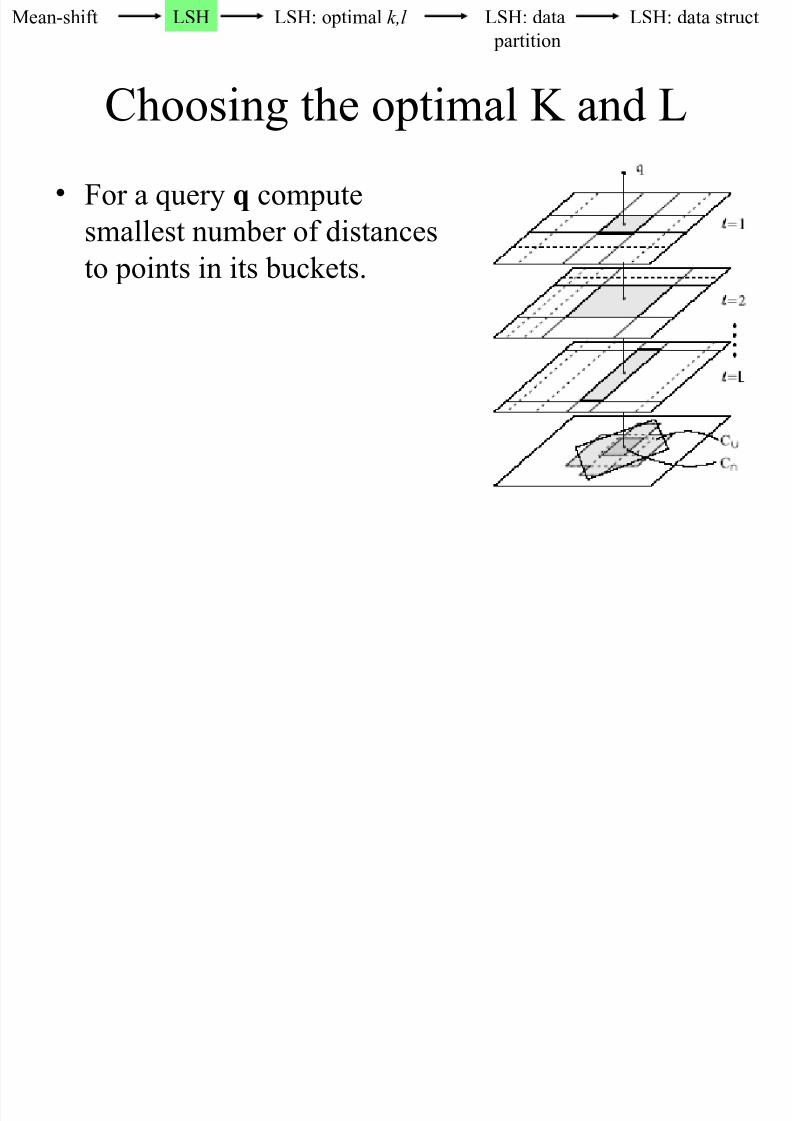
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 100/111
Choosing the optimal K and L
• For a query q compute
smallest number of distances
to points in its buckets.
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 101/111
pointsextraincludemight bigtooisLif but
missed, bemight pointssmalltooisLIf
cell.ain pointsof number smaller k Large
∪⇒⇒⇒
C
l
l
C C
d
C
LN N
d K n N
≈
+≈
∪
−)1/(
∪
∩
C
C
structure.datatheof resolutionthedetermines
decreases. butincreasesincreasesLAs
∩
∩∪
C
C C
Choosing optimal K and L
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 102/111
Choosing optimal K and LDetermine accurately the KNN for m randomly-selected
data points.
distance (bandwidth)
Choose error threshold ε
The optimal K and L should satisfy
the approximate distance
Choosing optimal K and L
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 103/111
Choosing optimal K and L
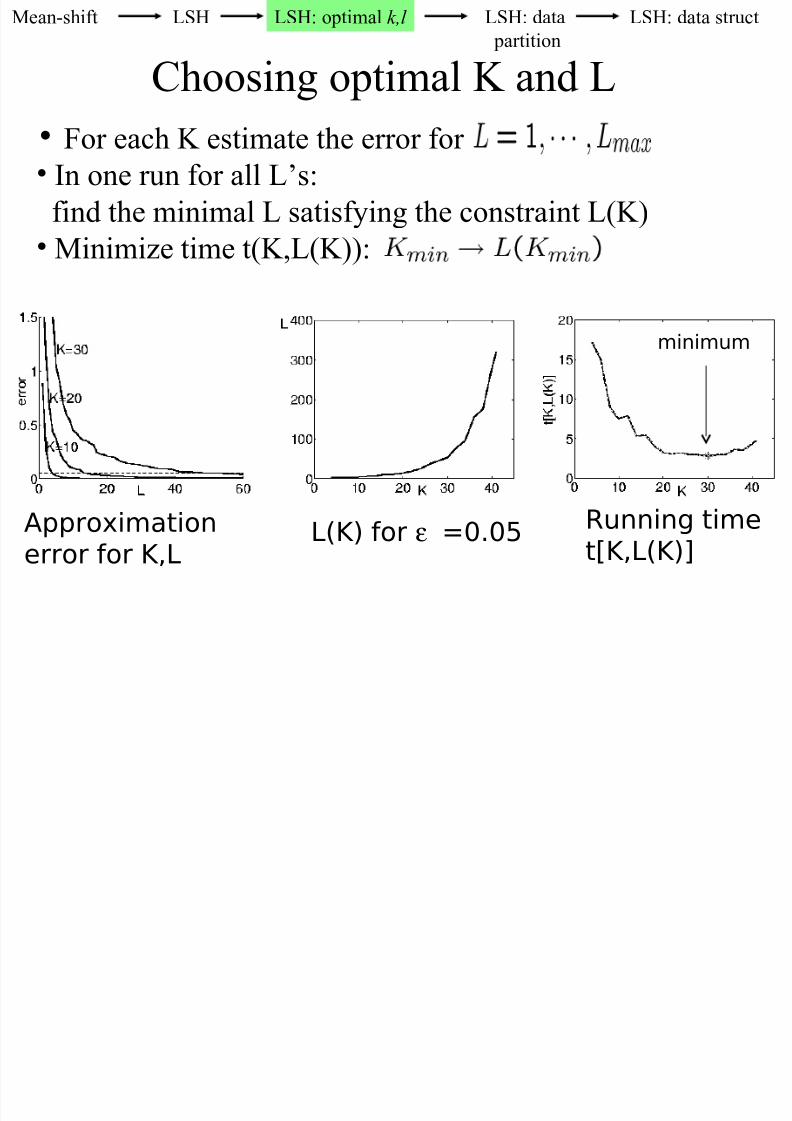
• For each K estimate the error for • In one run for all L’s:
find the minimal L satisfying the constraint L(K)• Minimize time t(K,L(K)):
minimum
Approximationerror for K,L
LK( for ε =0.05 Running timet[K,LK(]
d i i i
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 104/111
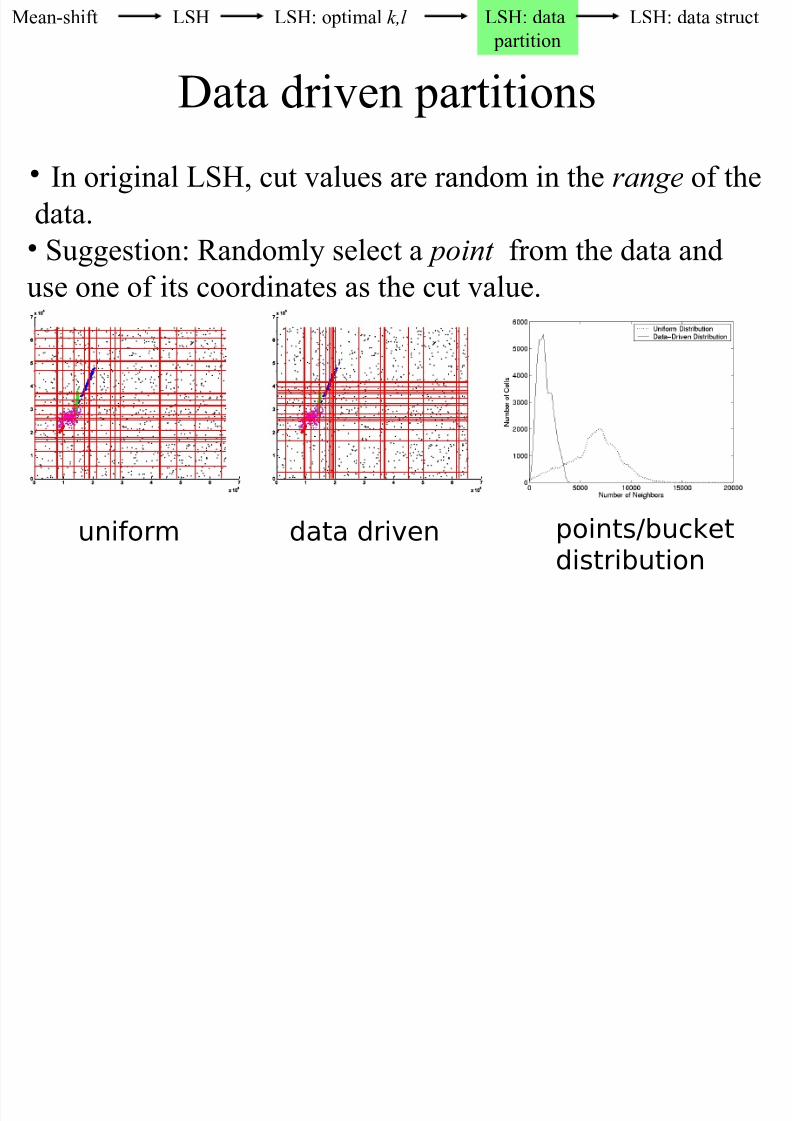
Data driven partitions
• In original LSH, cut values are random in the range of the
data.• Suggestion: Randomly select a point from the data and
use one of its coordinates as the cut value.
uniform data driven points/bucket
distribution
Additi l d
Mean-shift LSH: optimal k,l LSH: data partition
LSH LSH: data struct

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 105/111
Additional speedup
aggregate)anof typealikeis(Cmode.same thetoconvergewillCin pointsallthatAssume
∩
∩
∪
∩
C
C
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 106/111
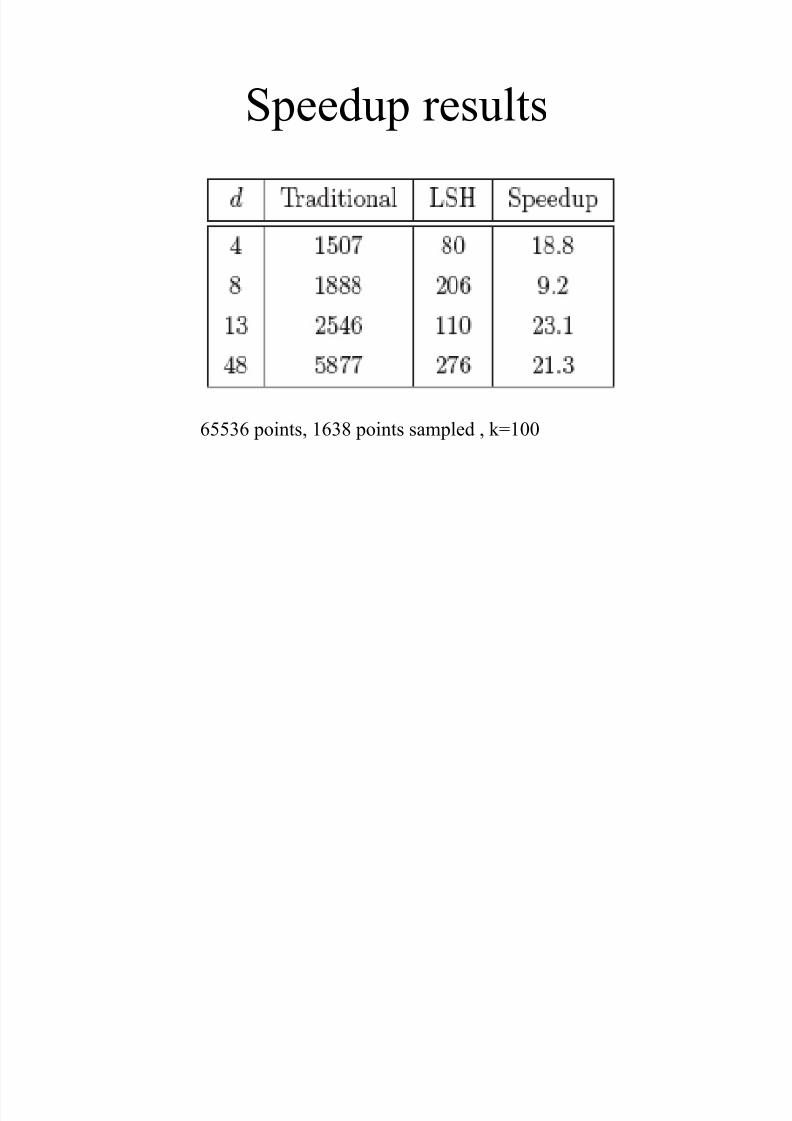
Speedup results
65536 points, 1638 points sampled , k=100
Food for thought
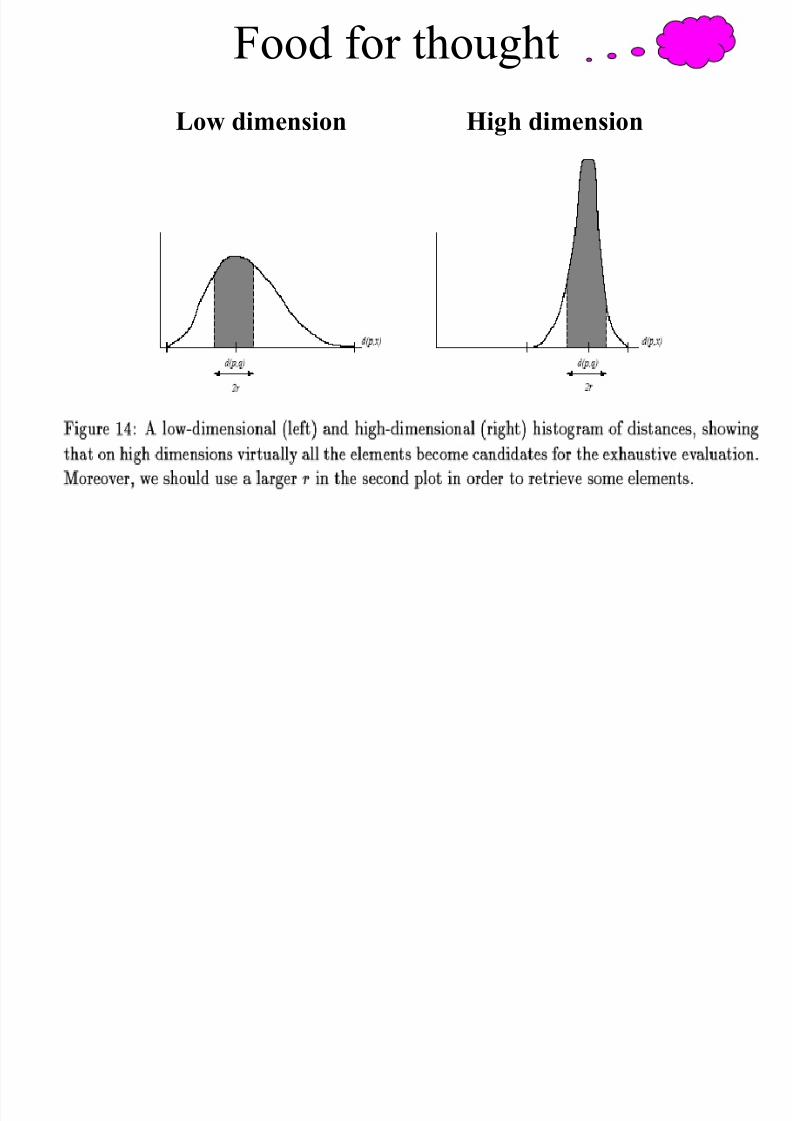
8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 107/111
Low dimension High dimension
A thought for food…

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 108/111
g
• Choose K, L by sample learning, or take the traditional.
• Can one estimate K, L without sampling?
• A thought for food: does it help to know the data
dimensionality or the data manifold?
• Intuitively: dimensionality implies the number of hash
functions needed.
• The catch: efficient dimensionality learning requires KNN.
15:30cookies…..
Summary

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 109/111
Summary
• LSH suggests a compromise on accuracy for thegain of complexity.
• Applications that involve massive data in high
dimension require the LSH fast performance.• Extension of the LSH to different spaces (PSH).
• Learning the LSH parameters and hash
functions for different applications.

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 110/111
Conclusion
• ..but at the end
everything depends on your data set
• Try it at home – Visit:
http://web.mit.edu/andoni/www/LSH/index.html
– Email Alex Andoni [email protected] – Test over your own data
(C code under Red Hat Linux )

8/9/2019 k-Nearest Neighbors Search in High Dimensions
http://slidepdf.com/reader/full/k-nearest-neighbors-search-in-high-dimensions 111/111
Thanks
• Ilan Shimshoni (Haifa).
• Mohamad Hegaze (Weizmann).
• Alex Andoni (MIT).• Mica and Denis.