introduction to hadoop and cloudera, louisville bi & big data analytics meetup
TRANSCRIPT

An Introduc+on to Hadoop and Cloudera Louisville BI and Big Data Analy+cs Meetup
Ian Wrigley | Director, Educa+onal Curriculum [email protected] @iwrigley

02-‐2 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo.va.on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐3 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Tradi.onally, computa.on has been processor-‐bound – Rela+vely small amounts of data – Lots of complex processing
§ The early solu.on: bigger computers – Faster processor, more memory – But even this couldn’t keep up
Tradi+onal Large-‐Scale Computa+on

02-‐4 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ The beDer solu.on: more computers – Distributed systems – use mul+ple machines for a single job
Distributed Systems
“In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, we didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers.”
– Grace Hopper
Database Hadoop Cluster

02-‐5 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Challenges with distributed systems – Programming complexity
– Keeping data and processes in sync – Finite bandwidth – Par+al failures
Distributed Systems: Challenges

02-‐6 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Tradi.onally, data is stored in a central loca.on
§ Data is copied to processors at run.me
§ Fine for limited amounts of data
Distributed Systems: The Data BoLleneck (1)

02-‐7 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Modern systems have much more data – terabytes+ a day – petabytes+ total
§ We need a new approach…
Distributed Systems: The Data BoLleneck (2)

02-‐8 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ A radical new approach to distributed compu.ng – Distribute data when the data is stored – Run computa+on where the data is stored
Hadoop

02-‐9 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Data is split into “blocks” when loaded
§ Each task typically works on a single block – Many run in parallel
§ A master program manages tasks
Hadoop: Very High-‐Level Overview
Lorem ipsum dolor sit amet, consectetur sed adipisicing elit, ado lei eiusmod tempor etma incididunt ut libore tua dolore magna alli quio ut enim ad minim veni veniam, quis nostruda exercitation ul laco es sed laboris nisi ut eres aliquip ex eaco modai consequat. Duis hona irure dolor in repre sie honerit in ame mina lo voluptate elit esse oda cillum le dolore eu fugi gia nulla aria tur. Ente culpa qui officia ledea un mollit anim id est o laborum ame elita tu a magna omnibus et.
Lorem ipsum dolor sit amet, consectetur sed adipisicing elit, ado lei eiusmod tempor etma incididunt ut libore tua dolore magna alli quio
ut enim ad minim veni veniam, quis nostruda exercitation ul laco es sed laboris nisi ut eres aliquip ex eaco modai consequat. Duis hona
irure dolor in repre sie honerit in ame mina lo voluptate elit esse oda cillum le dolore eu fugi gia nulla aria tur. Ente culpa qui officia ledea
un mollit anim id est o laborum ame elita tu a magna omnibus et.
Slave Nodes Master

02-‐10 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Applica.ons are wriDen in high-‐level code
§ Nodes talk to each other as liDle as possible
§ Data is distributed in advance – Bring the computa+on to the data
§ Data is replicated for increased availability and reliability
§ Hadoop is scalable and fault-‐tolerant
Core Hadoop Concepts

02-‐11 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Adding nodes adds capacity propor.onally
§ Increasing load results in a graceful decline in performance – Not failure of the system
Scalability
Number of Nodes
Capacity

02-‐12 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Node failure is inevitable
§ What happens? – System con+nues to func+on – Master re-‐assigns tasks to a different node – Data replica+on = no loss of data – Nodes which recover rejoin the cluster automa+cally
Fault Tolerance
“Failure is the defining difference between distributed and local programming, so you have to design distributed systems with the expecta+on of failure.” – Ken Arnold (CORBA designer)

02-‐13 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐14 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Hadoop Cluster
§ The Hadoop Distributed File System (HDFS) is a filesystem wriDen in Java
§ Sits on top of a na.ve filesystem
§ Provides storage for massive amounts of data – Scalable – Fault tolerant – Supports efficient processing with MapReduce, Spark, and other tools
HDFS Basic Concepts
HDFS

02-‐15 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Data files are split into blocks and distributed to data nodes
How Files are Stored (1)
Block 1
Block 2
Block 3
Very Large
Data File

02-‐16 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Data files are split into blocks and distributed to data nodes
How Files are Stored (2)
Block 1
Block 2
Block 3
Block 1
Block 1
Block 1
Very Large
Data File

02-‐17 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Data files are split into blocks and distributed to data nodes
§ Each block is replicated on mul.ple nodes (default 3x)
How Files are Stored (3)
Block 1
Block 2
Block 3
Block 1
Block 3
Block 2
Block 3
Block 1
Block 3
Block 1
Block 2
Block 2
Very Large
Data File
02-‐18 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
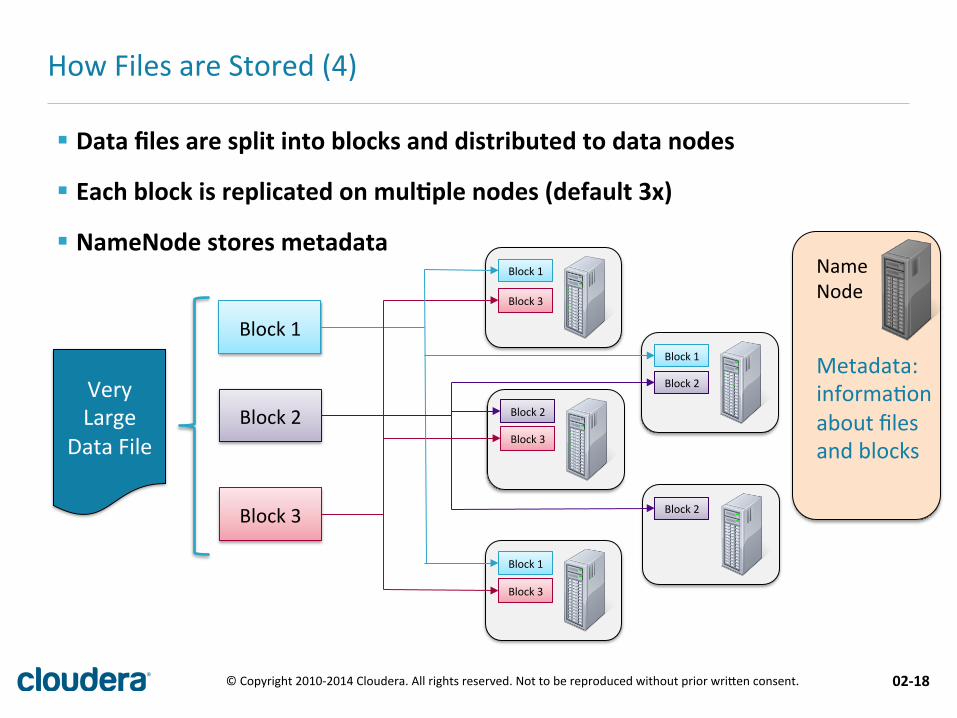
§ Data files are split into blocks and distributed to data nodes
§ Each block is replicated on mul.ple nodes (default 3x)
§ NameNode stores metadata
How Files are Stored (4)
Name Node
Block 1
Block 2
Block 3
Block 1
Block 3
Block 2
Block 3
Block 1
Block 3
Block 1
Block 2
Block 2
Metadata: informa+on about files and blocks
Very Large
Data File

02-‐19 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
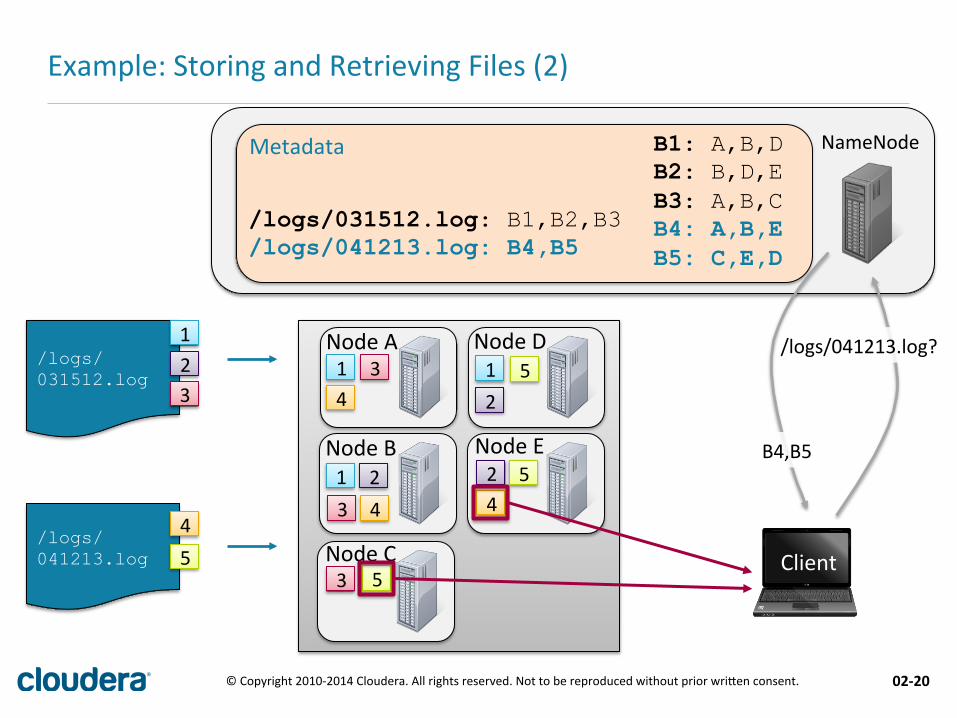
Example: Storing and Retrieving Files (1)
NameNode Metadata
/logs/031512.log: B1,B2,B3 /logs/041213.log: B4,B5
B1: A,B,D B2: B,D,E B3: A,B,C B4: A,B,E B5: C,E,D
/logs/ 031512.log
1
/logs/ 041213.log
3
45
2
Node C 3 5
Node E 5
42
Node A
41 3
2Node B
31
4
Node D 12
5
Client
/logs/041213.log?
B4,B5
02-‐20 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Example: Storing and Retrieving Files (2)
NameNode Metadata
/logs/031512.log: B1,B2,B3 /logs/041213.log: B4,B5
B1: A,B,D B2: B,D,E B3: A,B,C B4: A,B,E B5: C,E,D
/logs/ 031512.log
1
/logs/ 041213.log
3
45
2
Node C 3 5
Node E 5
42
Node A
41 3
2Node B
31
4
Node D 12
5
Client
/logs/041213.log?
B4,B5

02-‐21 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ HDFS performs best with a modest number of large files – Millions, rather than billions, of files – Each file typically 100MB or more
§ Files in HDFS are “write once” – Files can be replaced but not changed
Important Notes About HDFS

02-‐22 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ The Mapper – Each Map task (typically) operates on a single HDFS block – Map tasks(usually) run on the node where the block is stored
§ Shuffle and Sort – Sorts and consolidates intermediate data from all mappers – Happens amer all Map tasks are complete and before Reduce tasks start
§ The Reducer – Operates on shuffled/sorted intermediate data (Map task output) – Produces final output
MapReduce
Map
Reduce
Shuffle and Sort

02-‐23 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion
02-‐24 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
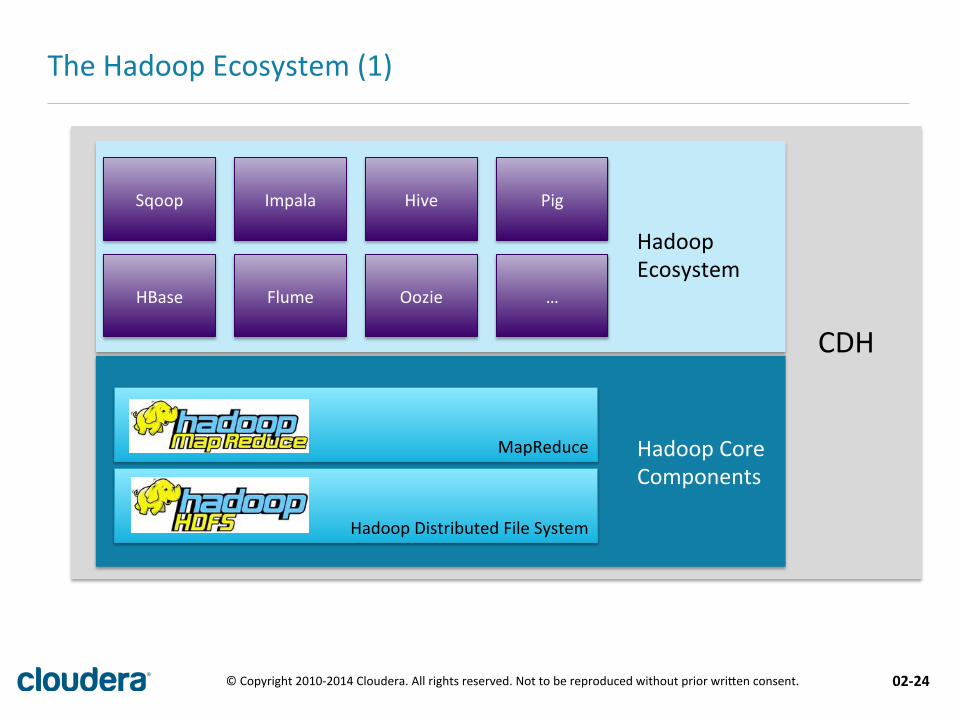
Hadoop Distributed File System
MapReduce
Hive Pig Impala Sqoop
The Hadoop Ecosystem (1)
Oozie … Flume HBase
Hadoop Ecosystem
Hadoop Core Components
CDH

02-‐25 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Hive Pig Impala Sqoop
§ CDH includes many Hadoop Ecosystem components
§ Following are more details on some of the key components
The Hadoop Ecosystem (2)
Oozie … Flume HBase
Hadoop Ecosystem

02-‐26 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ CDH (Cloudera’s Distribu.on, including Apache Hadoop) – 100% open source, enterprise-‐ready distribu+on of Hadoop and related projects – The most complete, tested, and widely-‐ deployed distribu+on of Hadoop – Integrates all key Hadoop ecosystem projects
CDH

02-‐27 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐28 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ HBase: database layered on top of HDFS – Provides interac+ve access to data
§ Stores massive amounts of data – Petabytes+
§ High throughput – Thousands of writes per second (per node)
§ Handles sparse data well – No wasted space for a row with empty columns
§ Limited access model – Op+mized for lookup of a row by key rather than full queries – No transac+ons: single row opera+ons only
HBase: The Hadoop Database
HDFS

02-‐29 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
RDBMS HBase
Transactions Yes Single row only
Query language SQL get/put/scan (or use Hive or Impala)
Indexes Yes Row-key only
Max data size TBs PBs
Read/write throughput (queries per second)
Thousands Millions
HBase vs RDBMS

02-‐30 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Use plain HDFS if… – You only append to your dataset (no random write) – You usually read the whole dataset (no random read)
§ Use HBase if… – You need random write and/or read – You do thousands of opera+ons per second on TB+ of data
§ Use an RDBMS if… – Your data fits on one big node – You need full transac+on support – You need real-‐+me query capabili+es
When To Use HBase

02-‐31 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra.on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐32 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ What is Flume? – A service to move large amounts of data in real +me – Example: storing log files in HDFS
§ Flume is – Distributed – Reliable and available – Horizontally scalable – Extensible
Flume: Real-‐+me Data Import

02-‐33 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Flume: High-‐Level Overview
Agent Agent Agent
Agent Agent
Agent(s)
Agent
compress encrypt
• Pre-‐process data before storing • e.g., transform, scrub, enrich
• Store in any format • Text, compressed, binary, or custom sink
• Collect data as it is produced • Files, syslogs, stdout or custom source
Agent
• Process in place • e.g., encrypt, compress
• Write in parallel • Scalable throughput
HDFS

02-‐34 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Sqoop: SQL to Hadoop – Transfers data between RDBMS and HDFS – Uses a command-‐line tool or applica+on connector – Allows incremental imports – Supports virtually all RDBMSs which speak JDBC
– Custom connectors available for some RDBMSs for increased speed
Sqoop: Exchanging Data With RDBMSs
HDFS
Sqoop
RDBMS

02-‐35 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Data Center Integra+on
File Server
Relational Database(OLTP)
Data Warehouse(OLAP)
Web/App Servers
Hadoop ClusterSqoop
Flume hadoop fs
Sqoop

02-‐36 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐37 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Apache Spark is a fast, general engine for large-‐scale data processing on a cluster
§ Originally developed at AMPLab at UC Berkeley
§ Open source Apache project
§ Provides several benefits over MapReduce – Faster – BeLer suited for itera+ve algorithms
– Can hold intermediate data in RAM, resul+ng in much beLer performance
– Easier API – Supports Python, Scala, Java
– Supports real-‐+me streaming data processing
Apache Spark

02-‐38 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ MapReduce – Widely used, huge investment already made – Supports and supported by many complementary tools – Mature, well-‐tested
§ Spark – Flexible – Elegant – Fast – Supports real-‐+me streaming data processing
§ Over .me Spark will supplant MapReduce as the general processing framework used by most organiza.ons
Spark vs Hadoop MapReduce

02-‐39 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐40 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ The mo.va.on: MapReduce is powerful but hard to master
§ Even Spark requires a developer who can code in Scala or Python
§ A solu.on: Hive and Pig – Built on top of MapReduce
– Currently being ported to run on top of Spark for beLer performance
– Leverage exis+ng skillsets – Data analysts who use SQL – Programmers who use scrip+ng languages
– Open source Apache projects – Hive ini+ally developed at Facebook – Pig Ini+ally developed at Yahoo!
Hive and Pig: High Level Data Languages

02-‐41 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ What is Hive? – HiveQL: An SQL-‐like interface to Hadoop
Hive
SELECT * FROM purchases WHERE price > 10000 ORDER BY storeid

02-‐42 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ What is Pig? – Pig La.n: A dataflow language for transforming large data sets
Pig
purchases = LOAD "/user/dave/purchases" AS (itemID, price, storeID, purchaserID);
bigticket = FILTER purchases BY price > 10000; ...

02-‐43 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ High-‐performance SQL engine for vast amounts of data – Similar query language to HiveQL – 10 to 50+ +mes faster than Hive, Pig, or MapReduce
– Effec+vely, provides ‘real +me’ results
§ Impala runs on Hadoop clusters – Data stored in HDFS – Does not use MapReduce
§ Developed by Cloudera – 100% open source, released under the Apache somware license
Impala: High Performance Queries

02-‐44 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Choose the best solu.on for the given task – Mix and match as needed
§ MapReduce – Low-‐level approach offers flexibility, control, and performance – More +me-‐consuming and error-‐prone to write – Choose when control and performance are most important
§ Pig, Hive, and Impala – Faster to write, test, and deploy than MapReduce – BeLer choice for most analysis and processing tasks
Which to Choose? (1)

02-‐45 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Use Impala when… – You have analysts familiar with SQL – You need near real-‐+me responses to ad hoc queries – You have structured data with a defined schema
§ Use Hive or Pig when… – You need support for custom file types, or complex data types
§ Use Pig when… – You have developers experienced with wri+ng scripts – Your data is unstructured/mul+-‐structured
§ Use Hive When… – Your data is structured and you are performing long-‐running, batch jobs
Which to Choose? (2)

02-‐46 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Comparing Pig, Hive, and Impala
Descrip.on of Feature Pig Hive Impala
SQL-‐based query language No Yes Yes
Schema Op+onal Required Required
Supports user-‐defined func.ons Yes Yes Yes
Extensible file format support Yes Yes No
Query speed Slow Slow Fast
Accessible via ODBC/JDBC No Yes Yes

02-‐47 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Probably not, if the RDBMS is used for its intended purpose
§ Rela.onal databases are op.mized for: – Rela+vely small amounts of data – Immediate results – In-‐place modifica+on of data
§ Pig, Hive, and Impala are op.mized for: – Large amounts of read-‐only data – Extensive scalability at low cost
§ Pig and Hive are beDer suited for batch processing – Impala and RDBMSs are beLer for interac+ve use
Do These Replace an RDBMS?

02-‐48 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Analysis Workflow Example
Import Transaction Datafrom RDBMS
Sessionize WebLog Data with Pig
Analyst using Impala shell for ad hoc queries
Analyst using Impala via BI tool
Sentiment Analysis on Social Media with Hive
Hadoop Cluster with Impala
Generate Nightly Reports using Pig, Hive, or Impala

02-‐49 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora.on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion
02-‐50 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
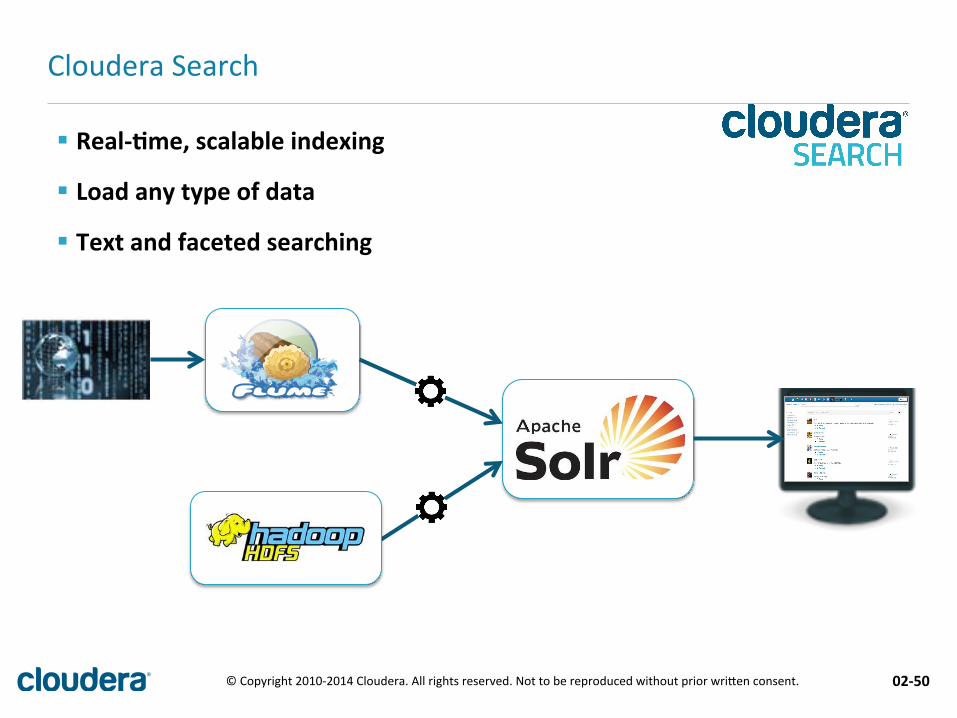
§ Real-‐.me, scalable indexing
§ Load any type of data
§ Text and faceted searching
Cloudera Search

02-‐51 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Cloudera Search Example: TwiLer Feed Search
Itera+ve search using facets
Full text search

02-‐52 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐53 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Pujng Hadoop into produc.on requires stringent up.mes
§ Clusters are made up of a large number of hosts – Each host runs mul+ple Hadoop services – Difficult to know the status of everything
§ Inevitable issues will arise with hardware and sokware
§ Keeping track of the cluster becomes an issue – Are all hosts healthy and working? – Am I using all of the best prac+ces for the service? – Is there a performance issue for a host or service? – Is the cluster secure?
Reducing Complexity With Cloudera Manager

02-‐54 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ Cloudera Manager is a purpose-‐built applica.on designed to make the administra.on of Hadoop simple and straighmorward – Automates the installa+on of a Hadoop cluster – Quickly adds and configures new services on a cluster – Provides real-‐+me monitoring of cluster ac+vity – Produces reports of cluster usage – Manages users and groups who have access to the cluster – Integrates with your exis+ng enterprise monitoring tools
§ Cloudera Manager Express Edi.on – Free
§ Cloudera Enterprise – Cloudera Manager plus support – Contact us for pricing
What Is Cloudera Manager?

02-‐55 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Cloudera Manager Dashboard

02-‐56 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Health Status and Char+ng

02-‐57 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
Presenta+on Topics
An Introduc.on to Hadoop and Cloudera
§ The Mo+va+on for Hadoop
§ ‘Core Hadoop’: HDFS and MapReduce
§ CDH and the Hadoop Ecosystem
§ Data Storage: HBase
§ Data Integra+on: Flume and Sqoop
§ Data Processing: Spark
§ Data Analysis: Hive, Pig, and Impala
§ Data Explora+on: Cloudera Search
§ Managing Everything: Cloudera Manager
§ Conclusion

02-‐58 © Copyright 2010-‐2014 Cloudera. All rights reserved. Not to be reproduced without prior wriLen consent.
§ There are several more projects in CDH – We support all the key elements you need
§ Virtually all the BI vendors who integrate with Hadoop are cer.fied on CDH
§ We haven’t even talked about security! – CDH includes Kerberos integra+on for authen+ca+on – Cloudera Enterprise provides all the security you need, whatever your industry – Recently achieved PCI cer+fica+on
§ Download the QuickStart VM to get started in a single VM
§ Try Cloudera on a real cluster for free
§ All available at cloudera.com/live
Conclusion

Thank you! …any ques+ons?