interesting topicscse.iitrpr.ac.in/ckn/courses/s2016/csl452/w17.pdf · 2017-03-21 · dynamic...
TRANSCRIPT

Interesting Topics
0
2
4
6
8
10
12
14
CSL452 - ARTIFICIAL INTELLIGENCE 1
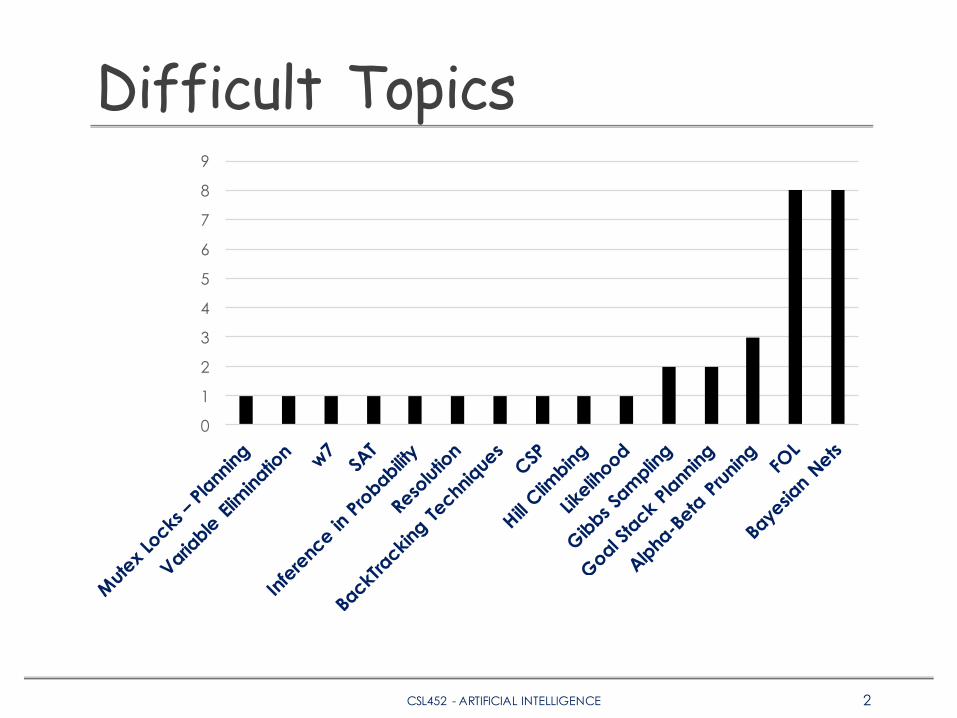
Difficult Topics
0
1
2
3
4
5
6
7
8
9
CSL452 - ARTIFICIAL INTELLIGENCE 2

Quantifying Uncertainty CSL452 - ARTIFICIAL INTELLIGENCE 3
Eating a lot of fast food (F) is widely believed to be the primary cause of obesity (O) in teenagers, and leading a sedentary (S) lifestyle being the second main cause. Higher levels of bad cholesterol (L) and blood sugar (B) are directly attributed only to obesity, while depression (D) is known to be caused by only leading a sedentary lifestyle. Assume that each variable is Boolean. Consider the 3 Bayesian nets presented in the Figure below. For each network state whether it models the domain exactly as described. State if the network has too many conditional independence assumptions and give at least one example. Similarly, state if the network misses any conditional independencies and give at least one example. (6 points)

Quantifying Uncertainty CSL452 - ARTIFICIAL INTELLIGENCE 4
Which query will variable elimination compute more efficiently and why?𝑃 𝑆|𝑙, 𝑑,𝑏, 𝑓, 𝑜 and 𝑃 𝑆 (2 points)

Quantifying Uncertainty CSL452 - ARTIFICIAL INTELLIGENCE 5
If were to use rejection sampling, which query will require more samples tocompute the probabilities with a higher degree of accuracy – 𝑃 𝑆 𝑏 or 𝑃 𝑆|𝑏, 𝑓 ,why? (2 points)

Quantifying Uncertainty CSL452 - ARTIFICIAL INTELLIGENCE 6
Assume we wanted to remove the obesity node (O). Draw the minimal Bayes netover the remaining variables that encodes the marginal distributions of the originalmodel over the remaining variables. (2 points)

Reinforcement LearningCHAPTER 21
Adapted from slides by Dan Weld, Pieter Abbeel, and Raj Rao

Reinforcement Learning
qBasic idea:oReceive feedback in the form of rewardsoAgent’s utility is defined by the reward functionoMust (learn to) act so as to maximize expected rewardsoAll learning is based on observed samples of outcomes!
Environment
Agent
Actions: aState: sReward: r
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 8

Reinforcement LearningqStill assume a Markov decision process (MDP):oA set of states 𝑠𝑆oA set of actions (per state) 𝐴oA model 𝑇(𝑠, 𝑎, 𝑠’)oA reward function 𝑅(𝑠, 𝑎, 𝑠’)
qStill looking for a policy 𝜋(𝑠)
qNew twist: don’t know 𝑇 or 𝑅oWe don’t know which states are good or what the
actions dooMust actually try actions and states out to learn
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 9

Passive Reinforcement LearningqSimplified task: policy evaluationoInput: a fixed policy 𝜋(𝑠)oYou don’t know the transitions 𝑇(𝑠, 𝑎, 𝑠’)oYou don’t know the rewards 𝑅(𝑠, 𝑎, 𝑠’)oGoal: learn the state values
qIn this case:oNo choice about what actions to takeoJust execute the policy and learn from experienceoThis is NOT offline planning! You actually take actions in the world.
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 10

Method 1- Direct Utility Estimation
qEpisodesWe are basically doing EMPIRICAL Policy Evaluation!
But we know this will be wasteful (since it misses the correlation between values of neibhoring states!)
Do DP-based policyevaluation!
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 11
We are basically doing EMPIRICAL Policy Evaluation!
But we know this will be wasteful (since it misses the correlation between values of neibhoring states!)
Do DP-based policyevaluation!
Empirical Policy Evaluation

ProblemswithDirectUtilityEstimationqAdvantagesoIt’s easy to understandoIt doesn’t require any knowledge of 𝑇,𝑅oIt eventually computes the correct average values, using just sample transitions
qDisadvantagesoIt wastes information about state connectionsoEach state must be learned separatelyoSo, it takes a long time to learn
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 12

Model-Based LearningqIdeaoLearn the model empirically (rather than only values)oSolve the MDP as if the learned model were correct
qEmpirical model learningoSimplest caseØCount the outcomes for each 𝑠, 𝑎ØNormalize to give estimate of 𝑇(𝑠,𝑎, 𝑠’)ØDiscover 𝑅 𝑠, 𝑎, 𝑠’ the first time we experience (𝑠,𝑎, 𝑠’)oMore complex learners are possible, if more domain knowledge is available
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 13
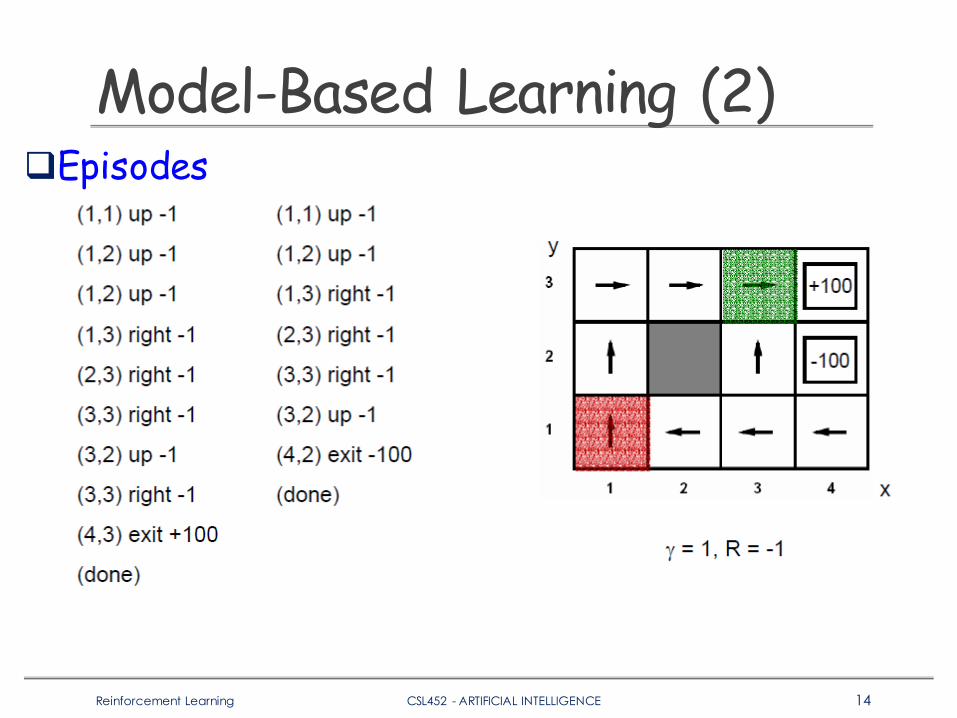
Model-Based Learning (2)qEpisodes
We are basically doing EMPIRICAL Policy Evaluation!
But we know this will be wasteful (since it misses the correlation between values of neibhoring states!)
Do DP-based policyevaluation!
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 14
We are basically doing EMPIRICAL Policy Evaluation!
But we know this will be wasteful (since it misses the correlation between values of neibhoring states!)
Do DP-based policyevaluation!

Method 2 – Adaptive Dynamic ProgrammingqBasic ideaoLearn initial model of the environmentoSolve for the optimal policy for this model (value or policy iteration)oRefine model through experience and repeat.
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 15

Greedy ADP840 Chapter 21. Reinforcement Learning
0
0.5
1
1.5
2
0 50 100 150 200 250 300 350 400 450 500
RM
S er
ror,
polic
y lo
ss
Number of trials
RMS errorPolicy loss
1 2 3
1
2
3
–1
+1
4
(a) (b)
Figure 21.6 Performance of a greedy ADP agent that executes the action recommendedby the optimal policy for the learned model. (a) RMS error in the utility estimates averagedover the nine nonterminal squares. (b) The suboptimal policy to which the greedy agentconverges in this particular sequence of trials.
mize its long-term well-being. Pure exploitation risks getting stuck in a rut. Pure explorationto improve one’s knowledge is of no use if one never puts that knowledge into practice. In thereal world, one constantly has to decide between continuing in a comfortable existence andstriking out into the unknown in the hopes of discovering a new and better life. With greaterunderstanding, less exploration is necessary.
Can we be a little more precise than this? Is there an optimal exploration policy? Thisquestion has been studied in depth in the subfield of statistical decision theory that deals withso-called bandit problems. (See sidebar.)BANDIT PROBLEM
Although bandit problems are extremely difficult to solve exactly to obtain an optimalexploration method, it is nonetheless possible to come up with a reasonable scheme thatwill eventually lead to optimal behavior by the agent. Technically, any such scheme needsto be greedy in the limit of infinite exploration, or GLIE. A GLIE scheme must try eachGLIE
action in each state an unbounded number of times to avoid having a finite probability thatan optimal action is missed because of an unusually bad series of outcomes. An ADP agentusing such a scheme will eventually learn the true environment model. A GLIE scheme mustalso eventually become greedy, so that the agent’s actions become optimal with respect to thelearned (and hence the true) model.
There are several GLIE schemes; one of the simplest is to have the agent choose a ran-dom action a fraction 1/t of the time and to follow the greedy policy otherwise. While thisdoes eventually converge to an optimal policy, it can be extremely slow. A more sensibleapproach would give some weight to actions that the agent has not tried very often, whiletending to avoid actions that are believed to be of low utility. This can be implemented byaltering the constraint equation (21.4) so that it assigns a higher utility estimate to relatively
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 16

What Went WrongqProblem with following optimal policy for current modeloNever learn about better regions in the space if current policy neglects them
qFundamental tradeoff: exploration vs. exploitationoExploration – must take actions with suboptimal estimates to discover new rewards and increase eventual utilityoExploitation: one the true optimal policy is learned, exploration reduces utilityoSystems must explore in the beginning and exploit in the limit
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 17

Method 3 – Temporal Difference LearningqIdea – Learn from every experienceoUpdate V(s) each time we experience a transition (s, a, s’, r)oLikely outcomes s’ will contribute to updates more often
qTemporal difference learning of valuesoPolicy still fixed, still doing evaluationoMove values toward value of whatever successor occurs – maintain a running average (online mean)
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 18

Method 3 – Temporal Difference Learning (2)qModel free way to do policy evaluationqFor obtaining a new policy
qOops, we are not learning Q values!qSo why not learn them… Q Learning
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 19

Method 4 - Q-LearningqQ-Learning: sample-based Q-value iteration
qLearn Q(s,a) values as you gooReceive a sample (s,a,s’,r)oConsider your old estimate:oConsider your new sample estimate:
qIncorporate the new estimate into a running average:
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 20

Q-Learning PropertiesqWill converge to optimal policyoIf explored enoughoIf you make the learning rate small enough
qUnder certain conditionsoThe environment model doesn’t changeoStates and actions are finiteoRewards are bounded
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 21

Exploration/ExploitationqHow do force exploration?oSimplest – random actions (greedy)ØEvery time flip a coinØWith probability p, act randomlyØWith probability 1-p, act according to the current policyoProblem with random actionsØLot of unnecessary random actions once learning is completeØLower probability over timeØOther solution exploration functions.ØMulti-arm Bandit problems
Reinforcement Learning CSL452 - ARTIFICIAL INTELLIGENCE 22

Finally…
Summary CSL452 - ARTIFICIAL INTELLIGENCE 23

End Semester Exam -LogisticsqWhen – Saturday, 30/4, 2.00-4.00pmqWhere– L2qOne A4 cheat sheet is allowed.oBring calculators
qSame pattern as mid-semester examoDefinitions, examplesoProblem formulationoAlgorithm traceoNumericals
qWhat to read – lecture slides, class notes, Chapters 8-10,13-14,16-17, quizzes, and practice problems.
Summary CSL452 - ARTIFICIAL INTELLIGENCE 24

Review Chapter 8 & 9qFirst Order LogicoRepresentationØSyntax and Semantics
qRepresenting a problem in FOLqPropositional Vs FOL inferenceqUnification and LiftingqForward and Backward ChainingqResolution
Summary CSL452 - ARTIFICIAL INTELLIGENCE 25

Review Chapter 10qClassical PlanningoDefinition
qApproaches to planning as a state space searchoProgression searchoRegression searchoGoal stack planning
qPlanning graphsoGraph plan algorithmØRepresentation, construction and inference
qRefer to Rich and Knight – Chapter 13
Summary CSL452 - ARTIFICIAL INTELLIGENCE 26

Review Chapter 13qBasics of ProbabilityoAxioms
qJoint distributionoInference using full joint distribution tables
qIndependenceqBayes RuleoRelevance of Bayes rule
Summary CSL452 - ARTIFICIAL INTELLIGENCE 27

Review Chapter 14qProbabilistic ReasoningqBayesian NetworksoProblem formulation and semanticsoConstruction of Bayes netsoConditional Independence properties
qExact InferenceoEnumerationoVariable Elimination
qApproximate InferenceoSampling – Prior(Direct), Rejection, Likelihood (Importance), Gibbs
Summary CSL452 - ARTIFICIAL INTELLIGENCE 28

Review Chapter 16qBasics of Utility TheoryoProperties of UtilitiesoHow to define utilities
qUtility FunctionsqDecision Networks
Summary CSL452 - ARTIFICIAL INTELLIGENCE 29

Review Chapter 17qMarkov Decision Process – sequential decision problemsoDefinitionoValues, Q states, Policy
qValue IterationoBellman equation/updates
qPolicy IterationoPolicy evaluationoPolicy update
qPartially Observable MDPs
Summary CSL452 - ARTIFICIAL INTELLIGENCE 30
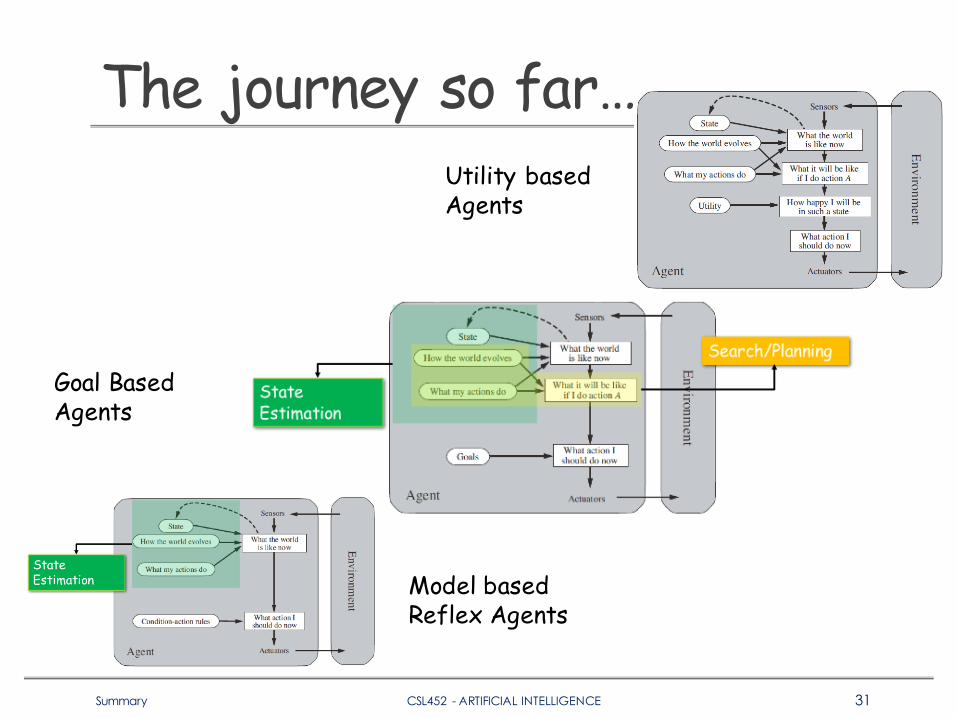
The journey so far…
Summary CSL452 - ARTIFICIAL INTELLIGENCE 31
Model based Reflex Agents
Goal Based Agents
Utility based Agents
