hp-ux vxfs tuning_c01919408
DESCRIPTION
HP-UX VxFS TuningTRANSCRIPT

HP-UX VxFS tuning and performance
Technical white paper
Table of contents
Executive summary ............................................................................................................................... 2
Introduction ......................................................................................................................................... 2
Understanding VxFS ............................................................................................................................. 3 Software versions vs. disk layout versions ............................................................................................ 3 Variable sized extent based file system ............................................................................................... 3 Extent allocation .............................................................................................................................. 4 Fragmentation ................................................................................................................................. 4 Transaction journaling ...................................................................................................................... 5
Understanding your application ............................................................................................................ 5
Data access methods ........................................................................................................................... 6 Buffered/cached I/O ....................................................................................................................... 6 Direct I/O ..................................................................................................................................... 12 Concurrent I/O .............................................................................................................................. 15 Oracle Disk Manager ..................................................................................................................... 17
Creating your file system .................................................................................................................... 18 Block size ...................................................................................................................................... 18 Intent log size ................................................................................................................................ 18 Disk layout version ......................................................................................................................... 19
Mount options ................................................................................................................................... 20
Dynamic file system tunables ............................................................................................................... 24
System wide tunables ......................................................................................................................... 25 Buffer cache on HP-UX 11i v2 and earlier ......................................................................................... 25 Unified File Cache on HP-UX 11i v3 ................................................................................................. 27 VxFS metadata buffer cache ............................................................................................................ 27 VxFS inode cache .......................................................................................................................... 28 Directory Name Lookup Cache ........................................................................................................ 29
VxFS ioctl() options ............................................................................................................................ 30 Cache advisories ........................................................................................................................... 30 Allocation policies .......................................................................................................................... 30
Patches ............................................................................................................................................. 31
Summary .......................................................................................................................................... 31
For additional information .................................................................................................................. 32

2
Executive summary
File system performance is critical to overall system performance. While memory latencies are
measured in nanoseconds, I/O latencies are measured in milliseconds. In order to maximize the
performance of your systems, the file system must be as fast as possible by performing efficient I/O,
eliminating unnecessary I/O, and reducing file system overhead.
In the past several years many changes have been made to the Veritas File System (VxFS) as well as
HP-UX. This paper is based on VxFS 3.5 and includes information on VxFS through version 5.0.1,
currently available on HP-UX 11i v3 (11.31). Recent key changes mentioned in this paper include:
page-based Unified File Cache introduced in HP-UX 11i v3
improved performance for large directories in VxFS 5.0
patches needed for read ahead in HP-UX 11i v3
changes to the write flush behind policies in HP-UX 11i v3
new read flush behind feature in HP-UX 11i v3
changes in direct I/O alignment in VxFS 5.0 on HP-UX 11i v3
concurrent I/O included with OnlineJFS license with VxFS 5.0.1
Oracle Disk Manager (ODM) feature
Target audience: This white paper is intended for HP-UX administrators that are familiar with
configuring file systems on HP-UX.
Introduction
Beginning with HP-UX 10.0, Hewlett-Packard began providing a Journaled File System (JFS) from
Veritas Software Corporation (now part of Symantec) known as the Veritas File System (VxFS). You no
longer need to be concerned with performance attributes such as cylinders, tracks, and rotational
delays. The speed of storage devices have increased dramatically and computer systems continue to
have more memory available to them. Applications are becoming more complex, accessing large
amounts of data in many different ways.
In order to maximize performance with VxFS file systems, you need to understand the various
attributes of the file system, and which attributes can be changed to best suit how the application
accesses the data.
Many factors need to be considered when tuning your VxFS file systems for optimal performance. The
answer to the question “How should I tune my file system for maximum performance?” is “It depends”.
Understanding some of the key features of VxFS and knowing how the applications access data are
keys to deciding how to best tune the file systems.
The following topics are covered in this paper:
Understanding VxFS
Understanding your application
Data access methods
Creating your file system
Mount options
Dynamic File system tunables
System wide tunables
VxFS ioctl() options

3
Understanding VxFS
In order to fully understand some of the various file system creation options, mount options, and
tunables, a brief overview of VxFS is provided.
Software versions vs. disk layout versions
VxFS supports several different disk layout versions (DLV). The default disk layout version can be
overridden when the file system is created using mkfs(1M). Also, the disk layout can be upgraded
online using the vxupgrade(1M) command.
Table 1. VxFS software versions and disk layout versions (* denotes default disk layout)
OS Version SW Version Disk layout version
11.23 VxFS 3.5
VxFS 4.1
VxFS 5.0
3,4,5*
4,5,6*
4,5,6,7*
11.31 VxFS 4.1
VxFS 5.0
VxFS 5.0.1
4,5,6*
4,5,6,7*
4,5,6,7*
Several improvements have been made in the disk layouts which can help increase performance. For
example, the version 5 disk layout is needed to create file system larger than 2 TB. The version 7 disk
layout available on VxFS 5.0 and above improves the performance of large directories.
Please note that you cannot port a file system to a previous release unless the previous release
supports the same disk layout version for the file system being ported. Before porting a file system
from one operating system to another, be sure the file system is properly unmounted. Differences in
the Intent Log will likely cause a replay of the log to fail and a full fsck will be required before
mounting the file system.
Variable sized extent based file system
VxFS is a variable sized extent based file system. Each file is made up of one or more extents that
vary in size. Each extent is made up of one or more file system blocks. A file system block is the
smallest allocation unit of a file. The block size of the file system is determined when the file system is
created and cannot be changed without rebuilding the file system. The default block size varies
depending on the size of the file system.
The advantages of variable sized extents include:
Faster allocation of extents
Larger and fewer extents to manage
Ability to issue large physical I/O for an extent
However, variable sized extents also have disadvantages:
Free space fragmentation
Files with many small extents

4
Extent allocation
When a file is initially opened for writing, VxFS is unaware of how much data the application will
write before the file is closed. The application may write 1 KB of data or 500 MB of data. The size of
the initial extent is the largest power of 2 greater than the size of the write, with a minimum extent
size of 8k. Fragmentation will limit the extent size as well.
If the current extent fills up, the extent will be extended if neighboring free space is available.
Otherwise, a new extent will be allocated that is progressively larger as long as there is available
contiguous free space.
When the file is closed by the last process that had the file opened, the last extent is trimmed to the
minimum amount needed.
Fragmentation
Two types of fragmentation can occur with VxFS. The available free space can be fragmented and
individual files may be fragmented. As files are created and removed, free space can become
fragmented due to the variable sized extent nature of the file system. For volatile file systems with a
small block size, the file system performance can degrade significantly if the fragmentation is severe.
Examples of applications that use many small files include mail servers. As free space becomes
fragmented, file allocation takes longer as smaller extents are allocated. Then, more and smaller I/Os
are necessary when the file is read or updated.
However, files can be fragmented even when there are large extents available in the free space map.
This fragmentation occurs when a file is repeatedly opened, extended, and closed. When the file is
closed, the last extent is trimmed to the minimum size needed. Later, when the file grows but there is
no contiguous free space to increase the size of the last extent, a new extent will be allocated and the
file could be closed again. This process of opening, extending, and closing a file can repeat resulting
in a large file with many small extents. When a file is fragmented, a sequential read through the file
will be seen as small random I/O to the disk drive or disk array, since the fragmented extents may be
small and reside anywhere on disk.
Static file systems that use large files built shortly after the file system is created are less prone to
fragmentation, especially if the file system block size is 8 KB. Examples are file systems that have
large database files. The large database files are often updated but rarely change in size.
File system fragmentation can be reported using the “-E” option of the fsadm(1M) utility. File systems
can be defragmented or reorganized with the HP OnLineJFS product using the “-e” option of the
fsadm utility. Remember, performing one 8 KB I/O will be faster than performing eight 1 KB I/Os.
File systems with small block sizes are more susceptible to performance degradation due to
fragmentation than file systems with large block sizes.
File system reorganization should be done on a regular and periodic basis, where the interval
between reorganizations depends on the volatility, size and number of the files. Large file systems
with a large number of files and significant fragmentation can take an extended amount of time to
defragment. The extent reorganization is run online; however, increased disk I/O will occur when
fsadm copies data from smaller extents to larger ones.

5
File system reorganization attempts to collect large areas of free space by moving various file extents
and attempts to defragment individual files by copying the data in the small extents to larger extents.
The reorganization is not a compaction utility and does not try to move all the data to the front on the
file system.
Note
Fsadm extent reorganization may fail if there are not sufficient large free
areas to perform the reorganization. Fsadm -e should be used to
defragment file systems on a regular basis.
Transaction journaling
By definition, a journal file system logs file system changes to a “journal” in order to provide file
system integrity in the event of a system crash. VxFS logs structural changes to the file system in a
circular transaction log called the Intent Log. A transaction is a group of related changes that
represent a single operation. For example, adding a new file in a directory would require multiple
changes to the file system structures such as adding the directory entry, writing the inode information,
updating the inode bitmap, etc. Once the Intent Log has been updated with the pending transaction,
VxFS can begin committing the changes to disk. When all the disk changes have been made on disk,
a completion record is written to indicate that transaction is complete.
With the datainlog mount option, small synchronous writes are also logged in the Intent Log. The
datainlog mount option will be discussed in more detail later in this paper.
Since the Intent Log is a circular log, it is possible for it to “fill” up. This occurs when the oldest
transaction in the log has not been completed, and the space is needed for a new transaction. When
the Intent Log is full, the threads must wait for the oldest transaction to be flushed and the space
returned to the Intent Log. A full Intent Log occurs very infrequently, but may occur more often if many
threads are making structural changes or small synchronous writes (datainlog) to the file system
simultaneously.
Understanding your application
As you plan the various attributes of your file system, you must also know your application and how
your application will be accessing the data. Ask yourself the following questions:
Will the application be doing mostly file reads, file writes, or both?
Will files be accessed sequentially or randomly?
What are the sizes of the file reads and writes?
Does the application use many small files, or a few large files?
How is the data organized on the volume or disk? Is the file system fragmented? Is the volume
striped?
Are the files written or read by multiple processes or threads simultaneously?
Which is more important, data integrity or performance?
How you tune your system and file systems depend on how you answer the above questions. No
single set of tunables exist that can be universally applied such that all workloads run at peak
performance.

6
Data access methods
Buffered/cached I/O
By default, most access to files in a VxFS file system is through the cache. In HP-UX 11i v2 and
earlier, the HP-UX Buffer Cache provided the cache resources for file access. In HP-UX 11i v3 and
later, the Unified File Cache is used. Cached I/O allows for many features, including asynchronous
prefetching known as read ahead, and asynchronous or delayed writes known as flush behind.
Read ahead
When reads are performed sequentially, VxFS detects the pattern and reads ahead or prefetches data
into the buffer/file cache. VxFS attempts to maintain 4 read ahead “segments” of data in the
buffer/file cache, using the read ahead size as the size of each segment.
Figure 1. VxFS read ahead
The segments act as a “pipeline”. When the data in the first of the 4 segments is read, asynchronous
I/O for a new segment is initiated, so that 4 segments are maintained in the read ahead pipeline.
The initial size of a read ahead segment is specified by VxFS tunable read_pref_io. As the process
continues to read a file sequentially, the read ahead size of the segment approximately doubles, to a
maximum of read_pref_io * read_nstream.
For example, consider a file system with read_pref_io set to 64 KB and read_nstream set to 4. When
sequential reads are detected, VxFS will initially read ahead 256 KB (4 * read_pref_io). As the
process continues to read ahead, the read ahead amount will grow to 1 MB (4 segments *
read_pref_io * read_nstream). As the process consumes a 256 KB read ahead segment from the front
of the pipeline, asynchronous I/O is started for the 256 KB read ahead segment at the end of the
pipeline.
By reading the data ahead, the disk latency can be reduced. The ideal configuration is the minimum
amount of read ahead that will reduce the disk latency. If the read ahead size is configured too large,
the disk I/O queue may spike when the reads are initiated, causing delays for other potentially more
critical I/Os. Also, the data read into the cache may no longer be in the cache when the data is
needed, causing the data to be re-read into the cache. These cache misses will cause the read ahead
size to be reduced automatically.
Note that if another thread is reading the file randomly or sequentially, VxFS has trouble with the
sequential pattern detection. The sequential reads may be treated as random reads and no read
ahead is performed. This problem can be resolved with enhanced read ahead discussed later. The
read ahead policy can be set on a per file system basis by setting the read_ahead tunable using
vxtunefs(1M). The default read_ahead value is 1 (normal read ahead).
256K 256K 256K 256K 256K
Sequential read

7
Read ahead with VxVM stripes
The default value for read_pref_io is 64 KB, and the default value for read_nstream is 1, except when
the file system is mounted on a VxVM striped volume where the tunables are defaulted to match the
striping attributes. For most applications, the 64 KB read ahead size is good (remember, VxFS
attempts to maintain 4 segments of read ahead size). Depending on the stripe size (column width)
and number of stripes (columns), the default tunables on a VxVM volume may result in excessive read
ahead and lead to performance problems.
Consider a VxVM volume with a stripe size of 1 MB and 20 stripes. By default, read_pref_io is set to
1 MB and read_nstream is set to 20. When VxFS initiates the read ahead, it tries to prefetch 4
segments of the initial read ahead size (4 segments * read_pref_io). But as the sequential reads
continue, the read ahead size can grow to 20 MB (read_pref_io * read_nstream), and VxFS attempts
to maintain 4 segments of read ahead data, or 80 MB. This large amount of read ahead can flood
the SCSI I/O queues or internal disk array queues, causing severe performance degradation.
Note
If you are using VxVM striped volumes, be sure to review the
read_pref_io and read_nstream values to be sure excessive read
ahead is not being done.
False sequential I/O patterns and read ahead
Some applications trigger read ahead when it is not needed. This behavior occurs when the
application is doing random I/O by positioning the file pointer using the lseek() system call, then
performing the read() system call, or by simply using the pread() system call.
Figure 2. False sequential I/O patterns and read ahead
If the application reads two adjacent blocks of data, the read ahead algorithm is triggered. Although
only 2 reads are needed, VxFS begins prefetching data from the file, up to 4 segments of the read
ahead size. The larger the read ahead size, the more data read into the buffer/file cache. Not only is
excessive I/O performed, but useful data that may have been in the buffer/file cache is invalidated so
the new unwanted data can be stored.
Note
If the false sequential I/O patterns cause performance problems, read
ahead can be disabled by setting read_ahead to 0 using vxtunefs(1M), or
direct I/O could be used.
Enhanced read ahead
Enhanced read ahead can detect non-sequential patterns, such as reading every third record or
reading a file backwards. Enhanced read ahead can also handle patterns from multiple threads. For
8K 8K 8K
lseek()/read()/read() lseek()/read()

8
example, two threads can be reading from the same file sequentially and both threads can benefit
from the configured read ahead size.
Figure 3. Enhanced read ahead
Enhanced read ahead can be set on a per file system basis by setting the read_ahead tunable to 2
with vxtunefs(1M).
Read ahead on 11i v3
With the introduction of the Unified File Cache (UFC) on HP-UX 11i v3, significant changes were
needed for VxFS. As a result, a defect was introduced which caused poor VxFS read ahead
performance. The problems are fixed in the following patches according to the VxFS version:
PHKL_40018 - 11.31 vxfs4.1 cumulative patch
PHKL_41071 - 11.31 VRTS 5.0 MP1 VRTSvxfs Kernel Patch
PHKL_41074 - 11.31 VRTS 5.0.1 GARP1 VRTSvxfs Kernel Patch
These patches are critical to VxFS read ahead performance on 11i v3.
Another caveat with VxFS 4.1 and later occurs when the size of the read() is larger than the
read_pref_io value. A large cached read can result in a read ahead size that is insufficient for the
read. To avoid this situation, the read_pref_io value should be configured to be greater than or equal
to the application read size.
For example, if the application is doing 128 KB read() system calls, then the application can
experience performance issues with the default read_pref_io value of 64 KB, as the VxFS would only
read ahead 64 KB, leaving the remaining 64 KB that would have to be read in synchronously.
Note
On HP-UX 11i v3, the read_pref_io value should be set to the size of the
largest logical read size for a process doing sequential I/O through cache.
The write_pref_io value should be configured to be greater than or equal to the read_pref_io value
due to a new feature on 11i v3 called read flush behind, which will be discussed later.
Flush behind
During normal asynchronous write operations, the data is written to buffers in the buffer cache, or
memory pages in the file cache. The buffers/pages are marked “dirty” and control returns to the
application. Later, the dirty buffers/pages must be flushed from the cache to disk.
There are 2 ways for dirty buffers/pages to be flushed to disk. One way is through a “sync”, either
by a sync() or fsync() system call, or by the syncer daemon, or by one of the vxfsd daemon threads.
The second method is known as “flush behind” and is initiated by the application performing the
writes.
64K 64K 64K 128K 128K
Patterned Read

9
Figure 4. Flush behind
As data is written to a VxFS file, VxFS will perform “flush behind” on the file. In other words, it will
issue asynchronous I/O to flush the buffer from the buffer cache to disk. The flush behind amount is
calculated by multiplying the write_pref_io by the write_nstream file system tunables. The default flush
behind amount is 64 KB.
Flush behind on HP-UX 11i v3
By default, flush behind is disabled on HP-UX 11i v3. The advantage of disabling flush behind is
improved performance for applications that perform rewrites to the same data blocks. If flush behind
is enabled, the initial write may be in progress, causing the 2nd write to stall as the page being
modified has an I/O already in progress.
However, the disadvantage of disabling flush behind is that more dirty pages in the Unified File
Cache accumulate before getting flushed by vhand, ksyncher, or vxfsd.
Flush behind can be enabled on HP-UX 11i v3 by changing the fcache_fb_policy(5) value using
kctune(1M). The default value of fcache_fb_policy is 0, which disables flush behind. If
fcache_fb_policy is set to 1, a special kernel daemon, fb_daemon, is responsible for flushing the dirty
pages from the file cache. If fcache_fb_policy is set to 2, then the process that is writing the data will
initiate the flush behind. Setting fcache_fb_policy to 2 is similar to the 11i v2 behavior.
Note that write_pref_io and write_nstream tunable have no effect on flush behind if fcache_fb_policy
is set to 0. However, these tunables may still impact read flush behind discussed later in this paper.
Note
Flush behind is disabled by default on HP-UX 11i v3. To enable flush
behind, use kctune(1M) to set the fcache_fb_policy tunable to 1 or 2.
I/O throttling
Often, applications may write to the buffer/file cache faster than VxFS and the I/O subsystem can
flush the buffers. Flushing too many buffers/pages can cause huge disk I/O queues, which could
impact other critical I/O to the devices. To prevent too many buffers/pages from being flushed
simultaneously for a single file, 2 types of I/O throttling are provided - flush throttling and write
throttling.
64K 64K 64K 64K 64K
Sequential write flush behind

10
Figure 5. I/O throttling
Flush throttling (max_diskq)
The amount of dirty data being flushed per file cannot exceed the max_diskq tunable. The process
performing a write() system call will skip the “flush behind” if the amount of outstanding I/O exceeds
the max_diskq. However, when many buffers/pages of a file need to be flushed to disk, if the amount
of outstanding I/O exceeds the max_diskq value, the process flushing the data will wait 20
milliseconds before checking to see if the amount of outstanding I/O drops below the max_diskq
value. Flush throttling can severely degrade asynchronous write performance. For example, when
using the default max_diskq value of 1 MB, the 1 MB of I/O may complete in 5 milliseconds, leaving
the device idle for 15 milliseconds before checking to see if the outstanding I/O drops below
max_diskq. For most file systems, max_diskq should be increased to a large value (such as 1 GB)
especially for file systems mounted on cached disk arrays.
While the default max_diskq value is 1 MB, it cannot be set lower than write_pref_io * 4.
Note
For best asynchronous write performance, tune max_diskq to a large value
such as 1 GB.
Write throttling (write_throttle)
The amount of dirty data (unflushed) per file cannot exceed write_throttle. If a process tries to perform
a write() operation and the amount of dirty data exceeds the write throttle amount, then the process
will wait until some of the dirty data has been flushed. The default value for write_throttle is 0 (no
throttling).
Read flush behind
VxFS introduced a new feature on 11i v3 called read flush behind. When the number of free pages
in the file cache is low (which is a common occurrence) and a process is reading a file sequentially,
pages which have been previously read are freed from the file cache and reused.
Figure 6. Read flush behind
64K 64K
Sequential read Read flush behind
64K
read ahead
64K 64K 64K 64K
64K 64K 64K 64K
Sequential write flush behind
64K

11
The read flush behind feature has the advantage of preventing a read of a large file (such as a
backup, file copy, gzip, etc) from consuming large amounts of file cache. However, the disadvantage
of read flush behind is that a file may not be able to reside entirely in cache. For example, if the file
cache is 6 GB in size and a 100 MB file is read sequentially, the file will likely not reside entirely in
cache. If the file is re-read multiple times, the data would need to be read from disk instead of the
reads being satisfied from the file cache.
The read flush behind feature cannot be disabled directly. However, it can be tuned indirectly by
setting the VxFS flush behind size using write_pref_io and write_nstream. For example, increasing
write_pref_io to 200 MB would allow the 100 MB file to be read into cache in its entirety. Flush
behind would not be impacted if fcache_fb_policy is set to 0 (default), however, flush behind can be
impacted if fcache_fb_policy is set to 1 or 2.
The read flush behind can also impact VxFS read ahead if the VxFS read ahead size is greater than
the write flush behind size. For best read ahead performance, the write_pref_io and write_nstream
values should be greater than or equal to read_pref_io and read_nstream values.
Note
For best read ahead performance, the write_pref_io and write_nstream
values should be greater than or equal to read_pref_io and read_nstream
values.
Buffer sizes on HP-UX 11i v2 and earlier
On HP-UX 11i v2 and earlier, cached I/O is performed through the HP-UX buffer cache. The
maximum size of each buffer in the cache is determined by the file system tunable max_buf_data_size
(default 8k). The only other value possible is 64k. For reads and writes larger than
max_buf_data_size and when performing read ahead, VxFS will chain the buffers together when
sending them to the Volume Management subsystem. The Volume Management subsystem holds the
buffers until VxFS sends the last buffer in the chain, then it attempts to merge the buffers together in
order to perform larger and fewer physical I/Os.
Figure 7. Buffer merging
The maximum chain size that the operating system can use is 64 KB. Merged buffers cannot cross a
“chain boundary”, which is 64 KB. This means that if the series of buffers to be merged crosses a 64
KB boundary, then the merging will be split into a maximum of 2 buffers, each less than 64 KB in
size.
If your application performs writes to a file or performs random reads, do not increase
max_buf_data_size to 64k unless the size of the read or write is 64k or greater. Smaller writes cause
the data to be read into the buffer synchronously first, then the modified portion of the data will be
updated in the buffer cache, then the buffer will be flushed asynchronously. The synchronous read of
the data will drastically reduce performance if the buffer is not already in the cache. For random
reads, VxFS will attempt to read an entire buffer, causing more data to be read than necessary.
64K 8K
more
8K
more
8K
more
8K
more 8K
8K
more
8K
more
8K
more

12
Note that buffer merging was not implemented initially on IA-64 systems with VxFS 3.5 on 11i v2. So
using the default max_buf_data_size of 8 KB would result in a maximum physical I/O size of 8 KB.
Buffer merging is implemented in 11i v2 0409 released in the fall of 2004.
Page sizes on HP-UX 11i v3 and later
On HP-UX 11i v3 and later, VxFS performs cached I/O through the Unified File Cache. The UFC is
paged based, and the max_buf_data_size tunable on 11i v3 has no effect. The default page size is 4
KB. However, when larger reads or read ahead is performed, the UFC will attempt to use contiguous
4 KB pages. For example, when performing sequential reads, the read_pref_io value will be used to
allocate the consecutive 4K pages. Note that the “buffer” size is no longer limited to 8 KB or 64 KB
with the UFC, eliminating the buffer merging overhead caused by chaining a number of 8 KB buffers.
Also, when doing small random I/O, VxFS can perform 4 KB page requests instead of 8 KB buffer
requests. The page request has the advantage of returning less data, thus reducing the transfer size.
However, if the application still needs to read the other 4 KB, then a second I/O request would be
needed which would decrease performance. So small random I/O performance may be worse on
11i v3 if cache hits would have occurred had 8 KB of data been read instead of 4 KB. The only
solution is to increase the base_pagesize(5) from the default value of 4 to 8 or 16. Careful testing
should be taken when changing the base_pagesize from the default value as some applications
assume the page size will be the default 4 KB.
Direct I/O
If OnlineJFS in installed and licensed, direct I/O can be enabled in several ways:
Mount option “-o mincache=direct”
Mount option “-o convosync=direct”
Use VX_DIRECT cache advisory of the VX_SETCACHE ioctl() system call
Discovered Direct I/O
Direct I/O has several advantages:
Data accessed only once does not benefit from being cached
Direct I/O data does not disturb other data in the cache
Data integrity is enhanced since disk I/O must complete before the read or write system call
completes (I/O is synchronous)
Direct I/O can perform larger physical I/O than buffered or cached I/O, which reduces the total
number of I/Os for large read or write operations
However, direct I/O also has its disadvantages:
Direct I/O reads cannot benefit from VxFS read ahead algorithms
All physical I/O is synchronous, thus each write must complete the physical I/O before the system
call returns
Direct I/O performance degrades when the I/O request is not properly aligned
Mixing buffered/cached I/O and direct I/O can degrade performance
Direct I/O works best for large I/Os that are accessed once and when data integrity for writes is
more important than performance.

13
Note
The OnlineJFS license is required to perform direct I/O when using VxFS
5.0 or earlier. Beginning with VxFS 5.0.1, direct I/O is available with the
Base JFS product.
Discovered direct I/O
With HP OnLineJFS, direct I/O will be enabled if the read or write size is greater than or equal to the
file system tunable discovered_direct_iosz. The default discovered_direct_iosz is 256 KB. As with
direct I/O, all discovered direct I/O will be synchronous. Read ahead and flush behind will not be
performed with discovered direct I/O.
If read ahead and flush behind is desired for large reads and writes or the data needs to be reused
from buffer/file cache, then the discovered_direct_iosz can be increased as needed.
Direct I/O and unaligned data
When performing Direct I/O, alignment is very important. Direct I/O requests that are not properly
aligned have the unaligned portions of the request managed through the buffer or file cache.
For writes, the unaligned portions must be read from disk into the cache first, and then the data in the
cache is modified and written out to disk. This read-before-write behavior can dramatically increase
the times for the write requests.
Note
The best direct I/O performance occurs when the logical requests are
properly aligned. Prior to VxFS 5.0 on 11i v3, the logical requests need to
be aligned on file system block boundaries. Beginning with VxFS 5.0 on
11i v3, logical requests need to be aligned on a device block boundary (1
KB).
Direct I/O on HP-UX 11.23
Unaligned data is still buffered using 8 KB buffers (default size), although the I/O is still done
synchronously. For all VxFS versions on HP-UX 11i v2 and earlier, direct I/O performs well when the
request is aligned on a file system block boundary and the entire request can by-pass the buffer
cache. However, requests smaller than the file system block size or requests that do not align on a file
system block boundary will use the buffer cache for the unaligned portions of the request.
For large transfers greater than the block size, part of the data can still be transferred using direct
I/O. For example, consider a 16 KB write request on a file system using an 8 KB block where the
request does not start on a file system block boundary (the data starts on a 4 KB boundary in this
case). Since the first 4 KB is unaligned, the data must be buffered. Thus an 8 KB buffer is allocated,
and the entire 8 KB of data is read in, thus 4 KB of unnecessary data is read in. This behavior is
repeated for the last 4 KB of data, since it is also not properly aligned. The two 8 KB buffers are
modified and written to the disk along with the 8 KB direct I/O for the aligned portion of the request.
In all, the operation took 5 synchronous physical I/Os, 2 reads and 3 writes. If the file system is re-
created to use a 4 KB block size or smaller, the I/O would be aligned and could be performed in a
single 16 KB physical I/O.

14
Figure 8. Example of unaligned direct I/O
Using a smaller block size, such as 1 KB, will improve chances of doing more optimal direct I/O.
However, even with a 1 KB file system block size, unaligned I/Os can occur.
Also, when doing direct I/O writes, a file‟s buffers must be searched to locate any buffers that
overlap with the direct I/O request. If any overlapping buffers are found, those buffers are
invalidated. Invalidating overlapping buffers is required to maintain consistency of the data in the
cache and on disk. A direct I/O write would put newer data on the disk and thus the data in the
cache would be stale unless it is invalidated. If the number of buffers for a file is large, then the
process may spend a lot of time searching the file‟s list of buffers before each direct I/O is performed.
The invalidating of buffers when doing direct I/O writes can degrade performance so severely, that
mixing buffered and direct I/O in the same file is highly discouraged.
Mixing buffered I/O and direct I/O can occur due to discovered direct I/O, unaligned direct I/O, or
if there is a mix of synchronous and asynchronous operations and the mincache and convosync
options are not set to the same value.
Note
Mixing buffered and direct I/O on the same file can cause severe
performance degradation on HP-UX 11i v2 or earlier systems.
Direct I/O on HP-UX 11.31 with VxFS 4.1
HP-UX 11.31 introduced the Unified File Cache (UFC). The UFC is similar to the HP-UX buffer cache in
function, but is 4 KB page based as opposed to 8 KB buffer based. The alignment issues are similar
with HP-UX 11.23 and earlier, although it may only be necessary to read in a single 4 KB page, as
opposed to an 8 KB buffer.
Also, the mixing of cached I/O and buffered I/O is no longer a performance issue, as the UFC
implements a more efficient algorithm for locating pages in the UFC that overlap with the direct I/O
request.
Direct I/O on HP-UX 11.31 with VxFS 5.0 and later
VxFS 5.0 on HP-UX 11i v3 introduced an enhancement that no longer requires direct I/O to be
aligned on a file system block boundary. Instead, the direct I/O only needs to be aligned on a device
block boundary, which is a 1 KB boundary. File systems with a 1 KB file system block size are not
impacted, but it is no longer necessary to recreate file systems with a 1 KB file system block size if the
application is doing direct I/O requests aligned on a 1 KB boundary.
4K 4K 8K 4K 4K
16k random write using Direct I/O
8K
Buffered
I/O
Buffered
I/O
Direct I/O
8K 8k
8 KB fs
block
8 KB fs
block
8 KB fs
block
15
Concurrent I/O
The main problem addressed by concurrent I/O is VxFS inode lock contention. During a read() system
call, VxFS will acquire the inode lock in shared mode, allowing many processes to read a single file
concurrently without lock contention. However, when a write() system call is made, VxFS will attempt
to acquire the lock in exclusive mode. The exclusive lock allows only one write per file to be in
progress at a time, and also blocks other processes reading the file. These locks on the VxFS inode
can cause serious performance problems when there are one or more file writers and multiple file
readers.
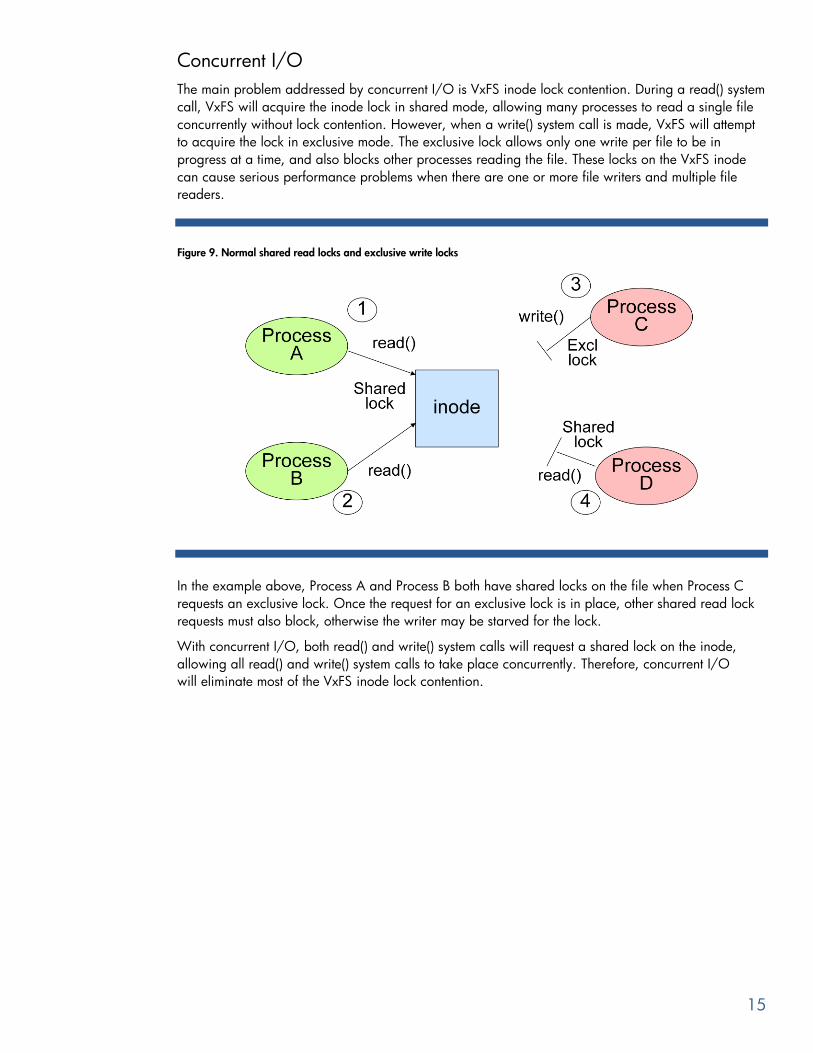
Figure 9. Normal shared read locks and exclusive write locks
In the example above, Process A and Process B both have shared locks on the file when Process C
requests an exclusive lock. Once the request for an exclusive lock is in place, other shared read lock
requests must also block, otherwise the writer may be starved for the lock.
With concurrent I/O, both read() and write() system calls will request a shared lock on the inode,
allowing all read() and write() system calls to take place concurrently. Therefore, concurrent I/O
will eliminate most of the VxFS inode lock contention.

16
Figure 10. Locking with concurrent I/O (cio)
To enable a file system for concurrent I/O, the file system simply needs to be mounted with the cio
mount option, for example:
# mount -F vxfs -o cio,delaylog /dev/vgora5/lvol1 /oracledb/s05
Concurrent I/O was introduced with VxFS 3.5. However, a separate license was needed to enable
concurrent I/O. With the introduction of VxFS 5.0.1 on HP-UX 11i v3, the concurrent I/O feature of
VxFS is now available with the OnlineJFS license.
While concurrent I/O sounds like a great solution to alleviate VxFS inode lock contention, and it is,
some major caveats exist that anyone who plans to use concurrent I/O should be aware of.
Concurrent I/O converts read and write operations to direct I/O
Some applications benefit greatly from the use of cached I/O, relying on cache hits to reduce the
amount of physical I/O or VxFS read ahead to prefetch data and reduce the read time. Concurrent
I/O converts most read and write operations to direct I/O, which bypasses the buffer/file cache.
If a file system is mounted with the cio mount option, then mount options mincache=direct and
convosync=direct are implied. If the mincache=direct and convosync=direct options are used, they
should have no impact if the cio option is used as well.
Since concurrent I/O converts read and write operations to direct I/O, all alignment constraints for
direct I/O also apply to concurrent I/O.
Certain operations still take exclusive locks
Some operations still need to take an exclusive lock when performing I/O and can negate the impact
of concurrent I/O. The following is a list of operations that still need to obtain an exclusive lock.
1. fsync()
2. writes that span multiple file extents
3. writes when request is not aligned on a 1 KB boundary
4. extending writes
5. allocating writes to “holes” in a sparse file
6. writes to Zero Filled On Demand (ZFOD) extents

17
Zero Filled On Demand (ZFOD) extents are new with VxFS 5.0 and are created by the VX_SETEXT
ioctl() with the VX_GROWFILE allocation flag, or with setext(1M) growfile option.
Not all applications support concurrent I/O
By using a shared lock for write operations, concurrent I/O breaks some POSIX standards. If two
processes are writing to the same block, there is no coordination between the files, and data modified
by one process can be lost by data modified by another process. Before implementing concurrent
I/O, the application vendors should be consulted to be sure concurrent I/O is supported with the
application.
Performance improvements with concurrent I/O vary
Concurrent I/O benefits performance the most when there are multiple processes reading a single file
and one or more processes writing to the same file. The more writes performed to a file with multiple
readers, the greater the VxFS inode lock contention and the more likely that concurrent I/O will
benefit.
A file system must be un-mounted to remove the cio mount option
A file system may be remounted with the cio mount option ("mount -o remount,cio /fs"); however to
remove the cio option, the file system must be completely unmounted using umount(1M).
Oracle Disk Manager
Oracle Disk Manager (ODM) is an additionally licensed feature specifically for use with Oracle
database environments. If the oracle binary is linked with the ODM library, Oracle will make an
ioctl() call to the ODM driver to initiate multiple I/O requests. The I/O requests will be issued in
parallel and will be asynchronous provided the disk_asynch_io value is set to 1 in the init.ora file.
Later, Oracle will make another ioctl() call to process the I/O completions.
Figure 11. Locking with concurrent I/O (cio)
ODM provides near raw device asynchronous I/O access. It also eliminates the VxFS inode lock
contention (similar to concurrent I/O).

18
Creating your file system
When you create a file system using newfs(1m) or mkfs(1m), you need to be aware of several options
that could affect performance.
Block size
The block size (bsize) is the smallest amount of space that can be allocated to a file extent. Most
applications will perform better with an 8 KB block size. Extent allocations are easier and file systems
with an 8 KB block size are less likely to be impacted by fragmentation since each extent would have
a minimum size of 8 KB. However, using an 8 KB block size could waste space, as a file with 1 byte
of data would take up 8 KB of disk space.
The default block size for a file system scales depending on the size of the file system when the file
system is created. The fstyp(1M) command can be used verify the block size of a specific file system
using the f_frsize field. The f_bsize can be ignored for VxFS file systems as the value will always be
8192.
# fstyp -v /dev/vg00/lvol3
vxfs
version: 6
f_bsize: 8192
f_frsize: 8192
The following table documents the default block sizes for the various VxFS versions beginning with
VxFS 3.5 on 11.23:
Table 2. Default FS block sizes
FS Size DLV 4 DLV 5 >= DLV6
<2TB 1K 1K 1K
<4TB1 N/A 1K 1K
<8TB N/A 2K 8K
<16TB N/A 4K 8K
<32TB N/A 8K 8K
>= 32TB2 N/A 8K 8K
For most cases, the block size is not important as far as reading and writing data is concerned (with
the exceptions regarding direct I/O alignment discussed earlier). The block size is an allocation
policy parameter, not a data access parameter.
Intent log size
The default size of the intent log (logsize) scales depending on the size of the file system. The logsize
is specified as the number of file system blocks. The table below provides details on the default size of
the Intent Log in megabytes (MB).
1 VxFS disk version layout 5 (11.23) and HP OnlineJFS license is needed to create file systems past 2TB. 2 The EBFS license is needed to create file systems past 32TB.

19
Table 3. Default intent log size
FS Size VxFS 3.5 or 4.1 or DLV <= 5 VxFS 5.0 or later and DLV >= 6
<= 8 MB 1 MB 1 MB
<= 512 MB 16 MB 16 MB
<= 16 GB 16 MB 64 MB
> 16 GB 16 MB 256 MB
For most applications, the default log size is sufficient. However, large file systems with heavy
structural changes simultaneously by multiple threads or heavy synchronous write operations with
datainlog may need a larger Intent Log to prevent transaction stalls when the log is full.
Disk layout version
As mentioned earlier, several improvements have been introduced in the disk layouts which can help
improve performance. The supported and default disk layout version will depend on the operating
system version and the VxFS version. Remember that later disk layout versions often support new
performance enhancements, such as faster performance for large directories available with disk
layout version 5.
See the manpages mkfs_vxfs(1M) and newfs_vxfs(1M) for more information on file system create
options.
Large directories
One myth about fragmentation is that a file system with a large number of small files (for example
500,000 files which are 4 KB in size or less) does not need to be defragmented. However, a file
system with thousands of small files is likely to have very large directories. Directories are good
examples of files that are often opened, extended, and closed. Therefore, directories are usually
fragmented.
“Small” is a relative term. The number of blocks taken by a directory also depends on the size of each
file name. As a general rule, consider a small directory to be one that has fewer than 10,000
directory entries.
When adding a new file to a directory or looking for a non-existent file, every directory block must be
searched. If the directory has 1000 directory blocks, then the system must do at least 1000 I/Os to
add a single file to the directory or search for a non-existent file.
Simultaneous directory searches also incur contention on the inode, extent map, or directory blocks,
potentially single-threading access to the directory. Long delays can be detected when doing multiple
„ll‟ commands on a single large directory.
Large directories can be defragmented when doing extent reorganizations, so that the directory
contains larger but fewer extents. The reorganization of a directory can relieve bottlenecks on the
indirect blocks when large directories are searched simultaneously.
VxFS 5.0 on 11i v2 and 11i v3 introduced a new indexing mechanism which avoids the sequential
scanning of directory blocks. To take advantage of this feature, the file system must be created or
upgraded to use disk layout version 7.

20
Note
To improve your large directory performance, upgrade to VxFS 5.0 or later
and run vxupgrade to upgrade the disk layout version to version 7.
Mount options
blkclear
When new extents are allocated to a file, extents will contain whatever was last written on disk until
new data overwrites the old uninitialized data. Accessing the uninitialized data could cause a security
problem as sensitive data may remain in the extent. The newly allocated extents could be initialized to
zeros if the blkclear option is used. In this case, performance is traded for data security.
When writing to a “hole” in a sparse file, the newly allocated extent must be cleared first, before
writing the data. The blkclear option does not need to be used to clear the newly allocated extents in
a sparse file. This clearing is done automatically to prevent stale data from showing up in a sparse
file.
Note
For best performance, do not use the blkclear mount option.
datainlog, nodatainlog
Figure 12. Datainlog mount option
When using HP OnLineJFS, small (<= 8k) synchronous writes through the buffer/file cache are logged
to the Intent Log using the mount option datainlog. Logging small synchronous writes provides a
performance improvement as several transactions can be flushed with a single I/O. Once the
transaction is flushed to disk, the actual write can be performed asynchronously, thus simulating the
synchronous write. In the event of a system crash, the replay of the intent log will complete the
transaction and make sure the write is completed. However, using datainlog can cause a problem if
the asynchronous write fails to complete, possibly due to a disk I/O problem. If the I/O is returned in
error, the file will be marked bad and cleaned up (removed) during the next run of fsck. While
datainlog provides a performance improvement for synchronous writes, if true synchronous writes are
needed, then the datainlog option should not be used. Also, with datainlog, the data is physically
written to the disk twice, once as part of the Intent Log and once as part of the actual data block.
I
D
Intent Log Memory
I
D
Later...

21
Using datainlog has no affect on normal asynchronous writes or synchronous writes performed with
direct I/O. The option nodatainlog is the default for systems without HP OnlineJFS, while datainlog is
the default for systems that do have HP OnlineJFS.
mincache
By default, I/O operations are cached in memory using the HP-UX buffer cache or Unified File Cache
(UFC), which allows for asynchronous operations such as read ahead and flush behind. The mincache
options convert cached asynchronous operations so they behave differently. Normal synchronous
operations are not affected.
The mincache option closesync flushes a file‟s dirty buffers/pages when the file is closed. The close()
system call may experience some delays while the dirty data is flushed, but the integrity of closed files
would not be compromised by a system crash.
The mincache option dsync converts asynchronous I/O to synchronous I/O. For best performance the
mincache=dsync option should not be used. This option should be used if the data must be on disk
when write() system call returns.
The mincache options direct and unbuffered are similar to the dsync option, but all I/Os are
converted to direct I/O. For best performance, mincache=direct should not be used unless I/O is
large and expected to be accessed only once, or synchronous I/O is desired. All direct I/O is
synchronous and read ahead and flush behind are not performed.
The mincache option tmpcache provides the best performance, but less data integrity in the event of a
system crash. The tmpcache option does not flush a file‟s buffers when it is closed, so a risk exists of
losing data or getting garbage data in a file if the data is not flushed to disk in the event of a system
crash.
All the mincache options except for closesync require the HP OnlineJFS product when using VxFS 5.0
or earlier. The closesync and direct options are available with the Base JFS product on VxFS 5.0.1
and above.
convosync
Applications can implement synchronous I/O by specifying the O_SYNC or O_DSYNC flags during
the open() system call. The convosync options convert synchronous operations so they behave
differently. Normal asynchronous operations are not affected when using the convosync mount option.
The convosync option closesync converts O_SYNC operations to be asynchronous operations. The
file‟s dirty buffers/pages are then flushed when the file is closed. While this option speeds up
applications that use O_SYNC, it may be harmful for applications that rely on data to be written to
disk before the write() system call completes.
The convosync option delay converts all O_SYNC operations to be asynchronous. This option is
similar to convosync=closesync except that the file‟s buffers/pages are not flushed when the file is
closed. While this option will improve performance, applications that rely on the O_SYNC behavior
may fail after a system crash.
The convosync option dsync converts O_SYNC operations to O_DSYNC operations. Data writes will
continue to be synchronous, but the associated inode time updates will be performed asynchronously.
The convosync options direct and unbuffered cause O_SYNC and O_DSYNC operations to bypass
buffer/file cache and perform direct I/O. These options are similar to the dsync option as the inode
time update will be delayed.
All of the convosync options require the HP OnlineJFS product when using VxFS 5.0 or earlier. The
direct option is available with the Base JFS product on VxFS 5.0.1.

22
cio
The cio option enables the file system for concurrent I/O.
Prior to VxFS 5.0.1, a separate license was needed to use the concurrent I/O feature. Beginning with
VxFS 5.0.1, concurrent I/O is available with the OnlineJFS license. Concurrent I/O is recommended
with applications which support its use.
remount
The remount option allows for a file system to be remounted online with different mount options. The
mount -o remount can be done online without taking down the application accessing the file system.
During the remount, all file I/O is flushed to disk and subsequent I/O operations are frozen until the
remount is complete. The remount option can result in a stall for some operations. Applications that
are sensitive to timeouts, such as Oracle Clusterware, should avoid having the file systems remounted
online.
Intent log options
There are 3 levels of transaction logging:
tmplog – Most transaction flushes to the Intent Log are delayed, so some recent changes to the file
system will be lost in the event of a system crash.
delaylog – Some transaction flushes are delayed.
log – Most all structural changes are logged before the system call returns to the application.
Tmplog, delaylog, log options all guarantee the structural integrity of the file system in the event of a
system crash by replaying the Intent Log during fsck. However, depending on the level of logging,
some recent file system changes may be lost in the event of a system crash.
There are some common misunderstandings regarding the log levels. For read() and write() system
calls, the log levels have no effect. For asynchronous write() system calls, the log flush is always
delayed until after the system call is complete. The log flush will be performed when the actual user
data is written to disk. For synchronous write() systems calls, the log flush is always performed prior to
the completion of the write() system call. Outside of changing the file‟s access timestamp in the inode,
a read() system call makes no structural changes, thus does not log any information.
The following table identifies which operations cause the Intent Log to be written to disk synchronously
(flushed), or if the flushing of the Intent Log is delayed until sometime after the system call is complete
(delayed).

23
Table 4. Intent log flush behavior with VxFS 3.5 or above
Operation log delaylog tmplog
Async Write Delayed Delayed Delayed
Sync Write Flushed Flushed Flushed
Read n/a n/a n/a
Sync (fsync()) Flushed Flushed Flushed
File Creation Flushed Delayed Delayed
File Removal Flushed Delayed Delayed
File Timestamp changes Flushed Delayed Delayed
Directory Creation Flushed Delayed Delayed
Directory Removal Flushed Delayed Delayed
Symbolic/Hard Link Creation Flushed Delayed Delayed
File/Directory Renaming Flushed Flushed Delayed
Most transactions that are delayed with the delaylog or tmplog options include file and directory
creation, creation of hard links or symbolic links, and inode time changes (for example, using
touch(1M) or utime() system call). The major difference between delaylog and tmplog is how file
renaming is performed. With the log option, most transactions are flushed to the Intent Log prior to
performing the operation.
Note that using the log mount option has little to no impact on file system performance unless there
are large amounts of file create/delete/rename operations. For example, if you are removing a
directory with thousands of files in it, the removal will likely run faster using the delaylog mount option
than the log mount option, since the flushing of the intent log is delayed after each file removal.
Also, using the delaylog mount option has little or no impact on data integrity, since the log level does
not affect the read() or write() system calls. If data integrity is desired, synchronous writes should be
performed as they are guaranteed to survive a system crash regardless of the log level.
The logiosize can be used to increase throughput of the transaction log flush by flushing up to 4 KB at
a time.
The tranflush option causes all metadata updates (such as inodes, bitmaps, etc) to be flushed before
returning from a system call. Using this option will negatively affect performance as all metadata
updates will be done synchronously.
noatime
Each time a file is accessed, the access time (atime) is updated. This timestamp is only modified in
memory, and periodically flushed to disk by vxfsd. Using noatime has virtually no impact on
performance.
nomtime
The nomtime option is only used in cluster file systems to delay updating the Inode modification time.
This option should only be used in a cluster environment when the inode modification timestamp does
not have to be up-to-date.

24
qio
The qio option enables Veritas Quick I/O for Oracle database.
Dynamic file system tunables
File system performance can be impacted by a number of dynamic file system tunables. These values
can be changed online using the vxtunefs(1M) command, or they can be set when the file system is
mounted by placing the values in the /etc/vx/tunefstab file (see tunefstab(4)).
Dynamic tunables that are not mentioned below should be left at the default.
read_pref_io and read_nstream
The read_pref_io and read_nstream tunables are used to configure read ahead through the buffer/file
cache. These tunables have no impact with direct I/O or concurrent I/O. The default values are good
for most implementations. However, read_pref_io should be configured to be greater than or equal to
the most common application read size for sequential reads (excluding reads that are greater than or
equal to the discovered_direct_iosz).
Increasing the read_pref_io and read_nstream values can be helpful in some environments which can
handle the increased I/O load on the SAN environment, such as those environments with multiple
fiber channel paths to the SAN to accommodate increased I/O bandwidth. However, use caution
when increasing these values as performance can degrade if too much read ahead is done.
write_pref_io and write_nstream
The write_pref_io and write_nstream tunables are used to configure flush behind. These tunables have
no impact with direct I/O or concurrent I/O. On HP-UX 11i v3, flush behind is disabled by default,
but can be enabled with the system wide tunable fcache_fb_policy. On 11i v3, write_pref_io and
write_nstream should be set to be greater than or equal to read_pref_io and read_nstream,
respectively.
max_buf_data_size
The max_buf_data_size is only valid for HP-UX 11i v2 or earlier. This tunable does not impact direct
I/O or concurrent I/O. The only possible values are 8 (default) and 64. The default is good for most
file systems, although file systems that are accessed with only sequential I/O will perform better if
max_buf_data_size is set to 64. File systems should avoid setting max_buf_data_size to 64 if random
I/Os are performed.
Note
Only tune max_buf_data_size to 64 if all file access in a file system will be
sequential.
max_direct_iosz
This max_direct_iosz tunable controls the maximum physical I/O size that can be issued with direct
I/O or concurrent I/O. The default value is 1 MB and is good for most file systems. If a direct I/O
read or write request is greater than the max_direct_iosz, the request will be split into smaller I/O
requests with a maximum size of max_direct_iosz and issued serially, which can negatively affect
performance of the direct I/O request. Read or write requests greater than 1 MB may work better if
max_direct_iosz is configured to be larger than the largest read or write request.

25
read_ahead
The default read_ahead value is 1 and is sufficient for most file systems. Some file systems with non-
sequential patterns may work best if enhanced read ahead is enabled by setting read_ahead to 2.
Setting read_ahead to 0 disables read ahead. This tunable does not affect direct I/O or concurrent
I/O.
discovered_direct_iosz
Read and write requests greater than or equal to discovered_direct_iosz are performed as direct I/O.
This tunable has no impact if the file system is already mounted for direct I/O or concurrent I/O. The
discovered_direct_iosz value should be increased if data needs to be cached for large read and write
requests, or if read ahead or flush behind is needed for large read and write requests.
max_diskq
The max_diskq tunable controls how data from a file can be flushed to disk at one time. The default
value is 1 MB and must be greater than or equal to 4 * write_perf_io. To avoid delays when flushing
dirty data from cache, setting max_diskq to 1 GB is recommended, especially for cached storage
arrays.
write_throttle
The write_throttle tunable controls how much data from a file can be dirty at one time. The default
value is 0, which means that write_throttle feature is disabled. The default value is recommended for
most file systems.
Extent allocation policies
Since most applications use a write size of 8k or less, the first extent is often the smallest. If the file
system uses mostly large files, then increasing the initial_extent_size can reduce file fragmentation by
allowing the first extent allocation to be larger.
However, increasing the initial_extent_size may actually increase fragmentation if many small files
(<8k) are created, as the large initial extent is allocated from a large free area, then trimmed when
the file is closed.
As extents are allocated, they get progressively larger (unless the file is trimmed when it is closed).
Extents will grow up to max_seqio_extent_size blocks (default 2048 blocks). The
max_seqio_extent_size file system tunable can be used to increase or decrease the maximum size of
an extent.
qio_cache_enable
The qio_cache_enable tunable enables Cached Quick I/O for file systems mounted for Quick I/O
(qio).
System wide tunables
Several system wide tunables are available which can be modified to enhance performance. These
tunables help control enhanced read ahead, buffer cache, the VxFS Inode Cache, and the Directory
Name Lookup Cache (DNLC) and can be tuned with the kctune(1M) command.
Buffer cache on HP-UX 11i v2 and earlier
dbc_min_pct / dbc_max_pct
The system tries to keep frequently accessed data in special pages in memory called the buffer cache.
The size of the buffer cache can be tuned using the system wide tunables bufpages and/or nbuf for
static buffer cache, and dbc_max_pct and dbc_min_pct for dynamic buffer cache. Dynamic buffer

26
cache grows quickly as new buffers are needed. The buffer cache is slow to shrink, as memory
pressure must be present in order to shrink buffer cache.
Figure 13. HP-UX 11iv2 buffer cache tunables
The buffer cache should be configured large enough to contain the most frequently accessed data.
However, processes often read large files once (for example, during a file copy) causing more
frequently accessed pages to be flushed or invalidated from the buffer cache.
The advantage of buffer cache is that frequently referenced data can be accessed through memory
without requiring disk I/O. Also, data being read from disk or written to disk can be done
asynchronously.
The disadvantage of buffer cache is that data in the buffer cache may be lost during a system failure.
Also, all the buffers associated with the file system must be flushed to disk or invalidated when the file
system is synchronized or unmounted. A large buffer cache can cause delays during these operations.
If data needs to be accessed once without keeping the data in the cache, various options such as
using direct I/O, discovered direct I/O, or the VX_SETCACHE ioctl with the VX_NOREUSE option
may be used. For example, rather than using cp(1) to copy a large file, try using dd(1) instead using
a large block size as follows:
# dd if=srcfile of=destfile bs=1024k
On HP-UX 11i v2 and earlier, cp(1) reads and writes data using 64 KB logical I/O. Using dd, data
can be read and written using 256 KB I/Os or larger. The large I/O size will cause dd to engage the
Discovered Direct I/O feature of HP OnlineJFS and the data will be transferred using large direct I/O.
There are several advantages of using dd(1) over cp(1):
Transfer can be done using a larger I/O transfer size
Buffer cache is bypassed, thus leaving other more important data in the cache.
Data is written synchronously, instead of asynchronously, avoiding large buildup of dirty buffers
which can potentially cause large I/O queues or process that call sync()/fsync() to temporarily
hang.
Note
On HP-UX 11i v3, the cp(1) command was changed to perform 1024 KB
logical reads instead of 64 KB, which triggers discovered direct I/O similar
to the dd(1) command mentioned above.
dbc_min_pct dbc_max_pct
Memory

27
Unified File Cache on HP-UX 11i v3
Filecache_min / filecache_max
The Unified File Cache provides a similar file caching function to the HP-UX buffer cache, but it is
managed much differently. As mentioned earlier, the UFC is page-based versus buffer-based. HP-UX
11i v2 maintained separate caches, a buffer cache for standard file access, and a page cache for
memory mapped file access. The UFC caches both normal file data as well as memory mapped file
data, resulting in a unified file and page cache.
The size of the UFC is managed through the kernel tunables filecache_min and filecache_max. Similar
to dbc_mac_pct, the default filecache_max value is very large (49% of physical memory), which
results in unnecessary memory pressure and paging of non-cache data. The filecache_min and
filecache_max values should be evaluated for the appropriate values based on how the system is
used. For example, a system may have 128 GB of memory, but the primary application is Oracle and
the database files are mounted for Direct I/O. So the UFC should configured be to handle the non-
Oracle load, such as setting the filecache_max value to 4 GB of memory.
fcache_fb_policy
The fcache_fb_policy tunable controls the behavior of the file system flush behind. The default value of
0 disables file system flush behind. The value of 1 enables file system flush behind via the fb_daemon
threads, and a value of 2 enables “inline” flush behind where the process that dirties the pages also
initiates the asynchronous writes (similar to the behavior in 11i v2).
VxFS metadata buffer cache
vxfs_bc_bufhwm
File system metadata is the structural information in the file system, and includes the superblock,
inodes, directories blocks, bit maps, and the Intent Log. Beginning with VxFS 3.5, a separate
metadata buffer cache is used to cache the VxFS metadata. The separate metadata cache allows
VxFS to do some special processing on metadata buffers, such as shared read locks, which can
improve performance by allowing multiple readers of a single buffer.
By default, the maximum size of the cache scales depending on the size of memory. The maximum
size of the VxFS metadata cache varies depending on the amount of physical memory in the system
according to the table below:
Table 5. Size of VxFS metadata buffer cache
Memory Size (MB)
VxFS Metadata
Buffer Cache (KB)
VxFS Metadata Buffer Cache
as a percent of memory
256 32000 12.2%
512 64000 12.2%
1024 128000 12.2%
2048 256000 12.2%
8192 512000 6.1%
32768 1024000 3.0%
131072 2048000 1.5%
28
The kernel tunable vxfs_bc_bufhwm specifies the maximum amount of memory in kilobytes (or high
water mark) to allow for the buffer pages. By default, vxfs_bc_bufhwm is set to zero, which means the
default maximum sized is based on the physical memory size (see Table 5).
The vxfsstat(1M) command with the -b option can be used to verify the size of the VxFS metadata
buffer cache. For example:
# vxfsstat -b /
: :
buffer cache statistics
120320 Kbyte current 544768 maximum
98674531 lookups 99.96% hit rate
3576 sec recycle age [not limited by maximum]
Note
The VxFS metadata buffer cache is memory allocated in addition to the HP-
UX Buffer Cache or Unified File Cache.
VxFS inode cache
vx_ninode
VxFS maintains a cache of the most recently accessed inodes in memory. The VxFS inode cache is
separate from the HFS inode cache. The VxFS inode cache is dynamically sized. The cache grows as
new inodes are accessed and contracts when old inodes are not referenced. At least one inode entry
must exist in the JFS inode cache for each file that is opened at a given time.
While the inode cache is dynamically sized, there is a maximum size for the VxFS inode cache. The
default maximum size is based on the amount of memory present. For example, a system with 2 to 8
GB of memory will have maximum of 128,000 inodes. The maximum number of inodes can be tuned
using the system wide tunable vx_ninode. Most systems do not need such a large VxFS inode cache
and a value of 128000 is recommended.
Note also that the HFS inode cache tunable ninode has no affect on the size of the VxFS inode cache.
If /stand is the only HFS file system in use, ninode can be tuned lower (400, for example).
The vxfsstat(1M) command with the -i option can be used to verify the size of the VxFS inode cache:
# vxfsstat -i /
: :
inode cache statistics
58727 inodes current 128007 peak 128000 maximum
9726503 lookups 86.68% hit rate
6066203 inodes alloced 5938196 freed
927 sec recycle age
1800 sec free age
While there are 128007 inodes currently in the VxFS inode cache, not all of the inodes are actually
in use. The vxfsstat(1M) command with the -v option can be used to verify the number of inodes in
use:
# vxfsstat -v / | grep inuse
vxi_icache_inuseino 1165 vxi_icache_maxino 128000

29
Note
When setting vx_ninode to reduce the JFS inode cache, use the -h option
with kctune(1M) to hold the change until the next reboot to prevent
temporary hangs or Serviceguard TOC events as the vxfsd daemon
become very active shrinking the JFS inode cache.
vxfs_ifree_timelag
By default, the VxFS inode cache is dynamically sized. The inode cache typically expands very
rapidly, then shrinks over time. The constant resizing of the cache results in additional memory
consumption and memory fragmentation as well as additional CPU used to manage the cache.
The recommended value for vxfs_ifree_timelag is -1, which allows the inode cache to expand to its
maximum sizes based on vx_ninode, but the inode cache will not dynamically shrink. This behavior is
similar to the former HFS inode cache behavior.
Note
To reduce memory usage and memory fragmentation, set
vxfs_ifree_timelag to -1 and vx_ninode to 128000 on most systems.
Directory Name Lookup Cache
The Directory Name Lookup Cache (DNLC) is used to improve directory lookup performance. By
default, the DNLC contains a number of directory and file name entries in a cache sized by the
default size of the JFS Inode Cache. Prior to VxFS 5.0 on 11i v3, the size of the DNLC could be
increased by increasing the size of vx_ninode value, but the size of the DNLC could not be
decreased. With VxFS 5.0 on 11i v3, the DNLC can be increased or decreased by tuning the
vx_ninode value. However, the size of the DNLC is not dynamic so the change in size will take effect
after the next reboot.
The DNLC is searched first, prior to searching the actual directories. Only filenames with less than 32
characters can be cached. The DNLC may not help if an entire large directory cannot fit into the
cache, so an ll(1) or find(1) of a large directory could push out other more useful entries in the cache.
Also, the DNLC does not help when adding a new file to the directory or when searching for a non-
existent directory entry.
When a file system is unmounted, all of the DNLC entries associated with the file system must be
purged. If a file system has several thousands of files and the DNLC is configured to be very large, a
delay could occur when the file system is unmounted.
The vxfsstat(1M) command with the -i option can be used to verify the size of the VxFS DNLC:
# vxfsstat -i /
: :
Lookup, DNLC & Directory Cache Statistics
337920 maximum entries in dnlc
1979050 total lookups 90.63% fast lookup
1995410 total dnlc lookup 98.57% dnlc hit rate
25892 total enter 54.08 hit per enter
0 total dircache setup 0.00 calls per setup
46272 total directory scan 15.29% fast directory scan
While the size of the DNLC can be tuned using the vx_ninode tunable, the primary purpose of
vx_ninode it to tune the JFS Inode Cache. So follow the same recommendations for tuning the size of
the JFS inode cache discussed earlier.

30
VxFS ioctl() options
Cache advisories
While the mount options allow you to change the cache advisories on a per-file system basis, the
VX_SETCACHE ioctl() allows an application to change the cache advisory on a per-file basis. The
following options are available with the VX_SETCACHE ioctl:
VX_RANDOM - Treat read as random I/O and do not perform read ahead
VX_SEQ - Treat read as sequential and perform maximum amount of read ahead
VX_DIRECT - Bypass the buffer cache. All I/O to the file is synchronous. The application buffer must
be aligned on a word (4 byte) address, and the I/O must begin on a block (1024 KB) boundary.
VX_NOREUSE - Invalidate buffer immediately after use. This option is useful for data that is not
likely to be reused.
VX_DSYNC - Data is written synchronously, but the file‟s timestamps in the inode are not flushed to
disk. This option is similar to using the O_DSYNC flag when opening the file.
VX_UNBUFFERED - Same behavior as VX_DIRECT, but updating the file size in the inode is done
asynchronously.
VX_CONCURRENT - Enables concurrent I/O on the specified file.
See the manpage vxfsio(7) for more information. HP OnLineJFS product is required to us the
VX_SETCACHE ioctl().
Allocation policies
The VX_SETEXT ioctl() passes 3 parameters: a fixed extent size to use, the amount of space to reserve
for the file, and an allocation flag defined below.
VX_NOEXTEND - write will fail if an attempt is made to extend the file past the current reservation
VX_TRIM - trim the reservation when the last close of the file is performed
VX_CONTIGUOUS - the reservation must be allocated in a single extent
VX_ALIGN - all extents must be aligned on an extent-sized boundary
VX_NORESERVE - reserve space, but do not record reservation space in the inode. If the file is
closed or the system fails, the reservation is lost.
VX_CHGSIZE - update the file size in the inode to reflect the reservation amount. This allocation
does not initialize the data and reads from the uninitialized portion of the file will return unknown
contents. Root permission is required.
VX_GROWFILE - update the file size in the inode to reflect the reservation amount. Subsequent
reads from the uninitialized portion of the file will return zeros. This option creates Zero Fill On
Demand (ZFOD) extents. Writing to ZFOD extents negates the benefit of concurrent I/O.
Reserving file space insures that you do not run out of space before you are done writing to the file.
The overhead of allocating extents is done up front. Using a fixed extent size can also reduce
fragmentation.
The setext(1M) command can also be used to set the extent allocation and reservation policies for a
file.
See the manpage vxfsio(7) and setext(1M) for more information. HP OnLineJFS product is required to
us the VX_SETEXT ioctl().

31
Patches
Performance problems are often resolved by patches to the VxFS subsystem, such as the patches for
the VxFS read ahead issues on HP-UX 11i v3. Be sure to check the latest patches for fixes to various
performance related problems.
Summary
There is no single set of values for the tunable to apply to every system. You must understand how
your application accesses data in the file system to decide which options and tunables can be
changed to maximize the performance of your file system. A list of VxFS tunables and options
discussed in this paper are summarized below.
Table 6. List of VxFS tunables and options
newfs
mkfs
Mount
Option
File system
tunables
System wide
tunables
per-file attributes
bsize
logsize
version
blkclear
datainlog
nodatainlog
mincache
convosync
cio
remount
tmplog
delaylog
log
logiosize
tranflush
noatime
nomtime
qio
read_pref_io
read_nstream
read_ahead
write_pref_io
write_nstream
max_buf_data_size
max_direct_iosz
discovered_direct_iosz
max_diskq
write_throttle
initial_extent_size
max_seqio_extent_size
qio_cache_enable
nbuf
bufpages
dbc_max_pct
dbc_min_pct
filecache_min
filecache_max
fcache_fb_policy
vxfs_bc_bufhwm
vx_ninode
vxfs_ifree_timelag
VX_SETCACHE
VX_SETEXT

For additional information
For additional reading, please refer to the following documents:
HP-UX VxFS mount options for Oracle Database environments,
http://h20195.www2.hp.com/V2/GetDocument.aspx?docname=4AA1-9839ENW&cc=us&lc=en
Common Misconfigured HP-UX Resources,
http://bizsupport1.austin.hp.com/bc/docs/support/SupportManual/c01920394/c01920394.pdf
Veritas™ File System 5.0.1 Administrator’s Guide (HP-UX 11i v3),
http://h20000.www2.hp.com/bc/docs/support/SupportManual/c02220689/c02220689.pdf
Performance Improvements using Concurrent I/O on HP-UX 11i v3 with OnlineJFS 5.0.1 and the HP-
UX Logical Volume Manager,
http://h20195.www2.hp.com/V2/GetDocument.aspx?docname=4AA1-5719ENW&cc=us&lc=en
To help us improve our documents, please provide feedback at
http://h20219.www2.hp.com/ActiveAnswers/us/en/solutions/technical_tools_feedback.html.
© Copyright 2004, 2011 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein.
Oracle is a registered trademarks of Oracle and/or its affiliates.
c01919408, Created August 2004; Updated January 2011, Rev. 3