high-level programming languages: apache pig and pig latin
TRANSCRIPT

High-level Programming LanguagesApache Pig and Pig Latin
Pietro Michiardi
Eurecom
Pietro Michiardi (Eurecom) High-level Programming Languages 1 / 78
Apache Pig
Apache PigSee also the 4 segments on Pig on coursera:https://www.coursera.org/course/datasci
Pietro Michiardi (Eurecom) High-level Programming Languages 2 / 78

Apache Pig Introduction
Introduction
Collection and analysis of enormous datasets is at the heartof innovation in many organizations
I E.g.: web crawls, search logs, click streams
Manual inspection before batch processingI Very often engineers look for exploitable trends in their data to drive
the design of more sophisticated techniquesI This is difficult to do in practice, given the sheer size of the datasets
The MapReduce model has its own limitationsI One inputI Two-stage, two operatorsI Rigid data-flow
Pietro Michiardi (Eurecom) High-level Programming Languages 3 / 78

Apache Pig Introduction
MapReduce limitations
Very often tricky workarounds are required1
I This is very often exemplified by the difficulty in performing JOINoperations
Custom code required even for basic operationsI Projection and Filtering need to be “rewritten” for each job
→ Code is difficult to reuse and maintain→ Semantics of the analysis task are obscured→ Optimizations are difficult due to opacity of Map and Reduce
1The term workaround should not only be intended as negative.Pietro Michiardi (Eurecom) High-level Programming Languages 4 / 78

Apache Pig Introduction
Use Cases
Rollup aggregates
Compute aggregates against user activity logs, web crawls,etc.
I Example: compute the frequency of search terms aggregated overdays, weeks, month
I Example: compute frequency of search terms aggregated overgeographical location, based on IP addresses
RequirementsI Successive aggregationsI Joins followed by aggregations
Pig vs. OLAP systemsI Datasets are too bigI Data curation is too costly
Pietro Michiardi (Eurecom) High-level Programming Languages 5 / 78

Apache Pig Introduction
Use Cases
Temporal Analysis
Study how search query distributions change over timeI Correlation of search queries from two distinct time periods (groups)I Custom processing of the queries in each correlation group
Pig supports operators that minimize memory footprintI Instead, in a RDBMS such operations typically involve JOINS over
very large datasets that do not fit in memory and thus become slow
Pietro Michiardi (Eurecom) High-level Programming Languages 6 / 78
Apache Pig Introduction
Use Cases
Session Analysis
Study sequences of page views and clicks
Example of typical aggregatesI Average length of user sessionI Number of links clicked by a user before leaving a websiteI Click pattern variations in time
Pig supports advanced data structures, and UDFs
Pietro Michiardi (Eurecom) High-level Programming Languages 7 / 78

Apache Pig Overview
Pig Latin
Pig Latin, a high-level programming language initiallydeveloped at Yahoo!, now at HortonWorks
I Combines the best of both declarative and imperative worldsF High-level declarative querying in the spirit of SQLF Low-level, procedural programming á la MapReduce
Pig Latin featuresI Multi-valued, nested data structures instead of flat tablesI Powerful data transformations primitives, including joins
Pig Latin programI Made up of a series of operations (or transformations)I Each operation is applied to input data and produce output data→ A Pig Latin program describes a data flow
Pietro Michiardi (Eurecom) High-level Programming Languages 8 / 78
Apache Pig Overview
Example 1
Pig Latin premiere
Assume we have the following table:
urls: (url, category, pagerank)
Where:I url: is the url of a web pageI category: corresponds to a pre-defined category for the web pageI pagerank: is the numerical value of the pagerank associated to a
web page
→ Find, for each sufficiently large category, the average page rank ofhigh-pagerank urls in that category
Pietro Michiardi (Eurecom) High-level Programming Languages 9 / 78
Apache Pig Overview
Example 1
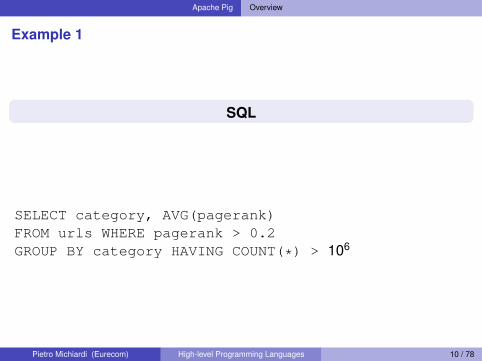
SQL
SELECT category, AVG(pagerank)FROM urls WHERE pagerank > 0.2GROUP BY category HAVING COUNT(*) > 106
Pietro Michiardi (Eurecom) High-level Programming Languages 10 / 78
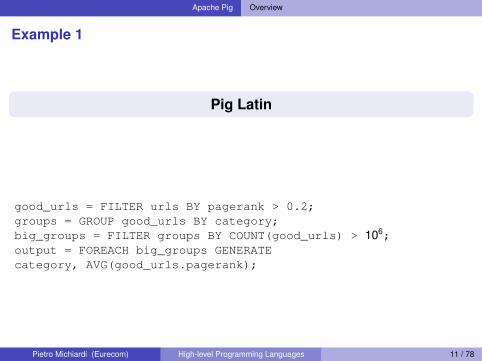
Apache Pig Overview
Example 1
Pig Latin
good_urls = FILTER urls BY pagerank > 0.2;groups = GROUP good_urls BY category;big_groups = FILTER groups BY COUNT(good_urls) > 106;output = FOREACH big_groups GENERATEcategory, AVG(good_urls.pagerank);
Pietro Michiardi (Eurecom) High-level Programming Languages 11 / 78
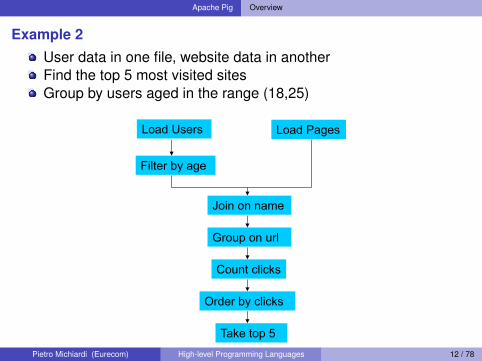
Apache Pig Overview
Example 2User data in one file, website data in anotherFind the top 5 most visited sitesGroup by users aged in the range (18,25)Why use Pig?
Suppose you have user data in one file, website data in another, and you need to find the top 5 most visited sites by users aged 18 - 25.
Load Users Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5 Pietro Michiardi (Eurecom) High-level Programming Languages 12 / 78

Apache Pig Overview
Example 2: in MapReduceIn MapReduce
import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.KeyValueTextInputFormat; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.RecordReader; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.SequenceFileInputFormat; import org.apache.hadoop.mapred.SequenceFileOutputFormat; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.jobcontrol.Job; import org.apache.hadoop.mapred.jobcontrol.JobControl; import org.apache.hadoop.mapred.lib.IdentityMapper; public class MRExample { public static class LoadPages extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String key = line.substring(0, firstComma); String value = line.substring(firstComma + 1); Text outKey = new Text(key); // Prepend an index to the value so we know which file // it came from. Text outVal = new Text("1" + value); oc.collect(outKey, outVal); } } public static class LoadAndFilterUsers extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String value = line.substring(firstComma + 1); int age = Integer.parseInt(value); if (age < 18 || age > 25) return; String key = line.substring(0, firstComma); Text outKey = new Text(key); // Prepend an index to the value so we know which file // it came from. Text outVal = new Text("2" + value); oc.collect(outKey, outVal); } } public static class Join extends MapReduceBase implements Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterator<Text> iter, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // For each value, figure out which file it's from and store it // accordingly. List<String> first = new ArrayList<String>(); List<String> second = new ArrayList<String>(); while (iter.hasNext()) { Text t = iter.next(); String value = t.toString(); if (value.charAt(0) == '1') first.add(value.substring(1)); else second.add(value.substring(1));
reporter.setStatus("OK"); } // Do the cross product and collect the values for (String s1 : first) { for (String s2 : second) { String outval = key + "," + s1 + "," + s2; oc.collect(null, new Text(outval)); reporter.setStatus("OK"); } } } } public static class LoadJoined extends MapReduceBase implements Mapper<Text, Text, Text, LongWritable> { public void map( Text k, Text val, OutputCollector<Text, LongWritable> oc, Reporter reporter) throws IOException { // Find the url String line = val.toString(); int firstComma = line.indexOf(','); int secondComma = line.indexOf(',', firstComma); String key = line.substring(firstComma, secondComma); // drop the rest of the record, I don't need it anymore, // just pass a 1 for the combiner/reducer to sum instead. Text outKey = new Text(key); oc.collect(outKey, new LongWritable(1L)); } } public static class ReduceUrls extends MapReduceBase implements Reducer<Text, LongWritable, WritableComparable, Writable> { public void reduce( Text key, Iterator<LongWritable> iter, OutputCollector<WritableComparable, Writable> oc, Reporter reporter) throws IOException { // Add up all the values we see long sum = 0; while (iter.hasNext()) { sum += iter.next().get(); reporter.setStatus("OK"); } oc.collect(key, new LongWritable(sum)); } } public static class LoadClicks extends MapReduceBase implements Mapper<WritableComparable, Writable, LongWritable, Text> { public void map( WritableComparable key, Writable val, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { oc.collect((LongWritable)val, (Text)key); } } public static class LimitClicks extends MapReduceBase implements Reducer<LongWritable, Text, LongWritable, Text> { int count = 0; public void reduce( LongWritable key, Iterator<Text> iter, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { // Only output the first 100 records while (count < 100 && iter.hasNext()) { oc.collect(key, iter.next()); count++; } } } public static void main(String[] args) throws IOException { JobConf lp = new JobConf(MRExample.class); lp.setJobName("Load Pages"); lp.setInputFormat(TextInputFormat.class);
lp.setOutputKeyClass(Text.class); lp.setOutputValueClass(Text.class); lp.setMapperClass(LoadPages.class); FileInputFormat.addInputPath(lp, new Path("/user/gates/pages")); FileOutputFormat.setOutputPath(lp, new Path("/user/gates/tmp/indexed_pages")); lp.setNumReduceTasks(0); Job loadPages = new Job(lp); JobConf lfu = new JobConf(MRExample.class); lfu.setJobName("Load and Filter Users"); lfu.setInputFormat(TextInputFormat.class); lfu.setOutputKeyClass(Text.class); lfu.setOutputValueClass(Text.class); lfu.setMapperClass(LoadAndFilterUsers.class); FileInputFormat.addInputPath(lfu, new Path("/user/gates/users")); FileOutputFormat.setOutputPath(lfu, new Path("/user/gates/tmp/filtered_users")); lfu.setNumReduceTasks(0); Job loadUsers = new Job(lfu); JobConf join = new JobConf(MRExample.class); join.setJobName("Join Users and Pages"); join.setInputFormat(KeyValueTextInputFormat.class); join.setOutputKeyClass(Text.class); join.setOutputValueClass(Text.class); join.setMapperClass(IdentityMapper.class); join.setReducerClass(Join.class); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/indexed_pages")); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/filtered_users")); FileOutputFormat.setOutputPath(join, new Path("/user/gates/tmp/joined")); join.setNumReduceTasks(50); Job joinJob = new Job(join); joinJob.addDependingJob(loadPages); joinJob.addDependingJob(loadUsers); JobConf group = new JobConf(MRExample.class); group.setJobName("Group URLs"); group.setInputFormat(KeyValueTextInputFormat.class); group.setOutputKeyClass(Text.class); group.setOutputValueClass(LongWritable.class); group.setOutputFormat(SequenceFileOutputFormat.class); group.setMapperClass(LoadJoined.class); group.setCombinerClass(ReduceUrls.class); group.setReducerClass(ReduceUrls.class); FileInputFormat.addInputPath(group, new Path("/user/gates/tmp/joined")); FileOutputFormat.setOutputPath(group, new Path("/user/gates/tmp/grouped")); group.setNumReduceTasks(50); Job groupJob = new Job(group); groupJob.addDependingJob(joinJob); JobConf top100 = new JobConf(MRExample.class); top100.setJobName("Top 100 sites"); top100.setInputFormat(SequenceFileInputFormat.class); top100.setOutputKeyClass(LongWritable.class); top100.setOutputValueClass(Text.class); top100.setOutputFormat(SequenceFileOutputFormat.class); top100.setMapperClass(LoadClicks.class); top100.setCombinerClass(LimitClicks.class); top100.setReducerClass(LimitClicks.class); FileInputFormat.addInputPath(top100, new Path("/user/gates/tmp/grouped")); FileOutputFormat.setOutputPath(top100, new Path("/user/gates/top100sitesforusers18to25")); top100.setNumReduceTasks(1); Job limit = new Job(top100); limit.addDependingJob(groupJob); JobControl jc = new JobControl("Find top 100 sites for users 18 to 25"); jc.addJob(loadPages); jc.addJob(loadUsers); jc.addJob(joinJob); jc.addJob(groupJob); jc.addJob(limit); jc.run(); } }
170 lines of code, 4 hours to write Hundreds lines of code; hours to write
Pietro Michiardi (Eurecom) High-level Programming Languages 13 / 78
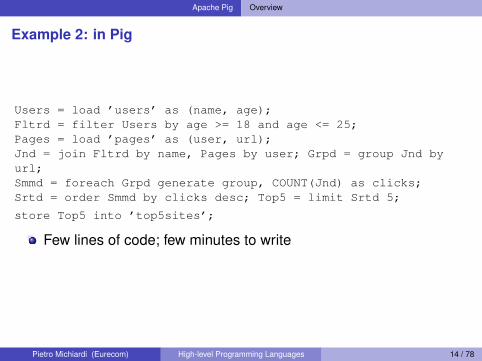
Apache Pig Overview
Example 2: in Pig
Users = load ’users’ as (name, age);Fltrd = filter Users by age >= 18 and age <= 25;Pages = load ’pages’ as (user, url);Jnd = join Fltrd by name, Pages by user; Grpd = group Jnd byurl;Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks;Srtd = order Smmd by clicks desc; Top5 = limit Srtd 5;
store Top5 into ’top5sites’;
Few lines of code; few minutes to write
Pietro Michiardi (Eurecom) High-level Programming Languages 14 / 78
Apache Pig Overview
Pig Execution environment
How do we go from Pig Latin to MapReduce?I The Pig system is in charge of thisI Complex execution environment that interacts with Hadoop
MapReduce→ The programmer focuses on the data and analysis
Pig CompilerI Pig Latin operators are translated into MapReduce codeI NOTE: in some cases, hand-written MapReduce code performs
better
Pig Optimizer2
I Pig Latin data flows undergo an (automatic) optimization phase3
I These optimizations are borrowed from the RDBMS community2Currently, rule-based optimization only.3Optimizations can be selectively disabled.Pietro Michiardi (Eurecom) High-level Programming Languages 15 / 78
Apache Pig Overview
Pig and Pig Latin
Pig is not a RDBMS!I This means it is not suitable for all data processing tasks
Designed for batch processingI Of course, since it compiles to MapReduceI Of course, since data is materialized as files on HDFS
NOT designed for random accessI Query selectivity does not match that of a RDBMSI Full-scans oriented!
Pietro Michiardi (Eurecom) High-level Programming Languages 16 / 78
Apache Pig Overview
Comparison with RDBMS
It may seem that Pig Latin is similar to SQLI We’ll see several examples, operators, etc. that resemble SQL
statements
Data-flow vs. declarative programming languageI Data-flow:
F Step-by-step set of operationsF Each operation is a single transformation
I Declarative:F Set of constraintsF Applied together to an input to generate output
→ With Pig Latin it’s like working at the query planner
Pietro Michiardi (Eurecom) High-level Programming Languages 17 / 78
Apache Pig Overview
Comparison with RDBMS
RDBMS store data in tablesI Schema are predefined and strictI Tables are flat
Pig and Pig Latin work on more complex data structuresI Schema can be defined at run-time for readabilityI Pigs eat anything!I UDF and streaming together with nested data structures make Pig
and Pig Latin more flexible
Pietro Michiardi (Eurecom) High-level Programming Languages 18 / 78

Apache Pig Features and Motivations
Dataflow Language
A Pig Latin program specifies a series of stepsI Each step is a single, high level data transformationI Stylistically different from SQL
With reference to Example 1I The programmer supply an order in which each operation will be
done
Consider the following snippet
spam_urls = FILTER urls BY isSpam(url);culprit_urls = FILTER spam_urls BY pagerank > 0.8;
Pietro Michiardi (Eurecom) High-level Programming Languages 19 / 78

Apache Pig Features and Motivations
Dataflow Language
Data flow optimizationsI Explicit sequences of operations can be overriddenI Use of high-level, relational-algebra-style primitives (GROUP,FILTER,...) allows using traditional RDBMS optimizationtechniques
→ NOTE: it is necessary to check whether such optimizationsare beneficial or not, by hand
Pig Latin allows Pig to perform optimizations that wouldotherwise by a tedious manual exercise if done at theMapReduce level
Pietro Michiardi (Eurecom) High-level Programming Languages 20 / 78

Apache Pig Features and Motivations
Quick Start and Interoperability
Data I/O is greatly simplified in PigI No need to curate, bulk import, parse, apply schema, create
indexes that traditional RDBMS requireI Standard and ad-hoc “readers” and “writers” facilitate the task of
ingesting and producing data in arbitrary formats
Pig can work with a wide range of other tools
Why RDBMS have stringent requirements?I To enable transactional consistency guaranteesI To enable efficient point lookup (using physical indexes)I To enable data curation on behalf of the userI To enable other users figuring out what the data is, by studying the
schema
Pietro Michiardi (Eurecom) High-level Programming Languages 21 / 78

Apache Pig Features and Motivations
Quick Start and Interoperability
Why is Pig so flexible?I Supports read-only workloadsI Supports scan-only workloads (no lookups)→ No need for transactions nor indexes
Why data curation is not required?I Very often, Pig is used for ad-hoc data analysisI Work on temporary datasets, then throw them out!→ Curation is an overkill
Schemas are optionalI Can apply one on the fly, at runtimeI Can refer to fields using positional notationI E.g.: good_urls = FILTER urls BY $2 > 0.2
Pietro Michiardi (Eurecom) High-level Programming Languages 22 / 78

Apache Pig Features and Motivations
Nested Data Model
Easier for “programmers” to think of nested data structuresI E.g.: capture information about positional occurrences of terms in a
collection of documentsI Map<documnetId, Set<positions> >
Instead, RDBMS allows only fat tablesI Only atomic fields as columnsI Require normalizationI From the example above: need to create two tablesI term_info: (termId, termString, ...)I position_info: (termId, documentId, position)→ Occurrence information obtained by joining on termId, and
grouping on termId, documentId
Pietro Michiardi (Eurecom) High-level Programming Languages 23 / 78

Apache Pig Features and Motivations
Nested Data Model
Fully nested data model (see also later in the presentation)I Allows complex, non-atomic data typesI E.g.: set, map, tuple
Advantages of a nested data modelI More natural than normalizationI Data is often already stored in a nested fashion on disk
F E.g.: a web crawler outputs for each crawled url, the set of outlinksF Separating this in normalized form imply use of joins, which is an
overkill for web-scale dataI Nested data allows to have an algebraic language
F E.g.: each tuple output by GROUP has one non-atomic field, a nestedset of tuples from the same group
I Nested data makes life easy when writing UDFs
Pietro Michiardi (Eurecom) High-level Programming Languages 24 / 78

Apache Pig Features and Motivations
User Defined Functions
Custom processing is often predominantI E.g.: users may be interested in performing natural language
stemming of a search term, or tagging urls as spam
All commands of Pig Latin can be customizedI Grouping, filtering, joining, per-tuple processing
UDFs support the nested data modelI Input and output can be non-atomic
Pietro Michiardi (Eurecom) High-level Programming Languages 25 / 78

Apache Pig Features and Motivations
Example 3
Continues from Example 1I Assume we want to find for each category, the top 10 urls according
to pagerank
groups = GROUP urls BY category;output = FOREACH groups GENERATE category,top10(urls);
top10() is a UDF that accepts a set of urls (for each group at atime)it outputs a set containing the top 10 urls by pagerank for thatgroupfinal output contains non-atomic fields
Pietro Michiardi (Eurecom) High-level Programming Languages 26 / 78

Apache Pig Features and Motivations
User Defined Functions
UDFs can be used in all Pig Latin constructs
Instead, in SQL, there are restrictionsI Only scalar functions can be used in SELECT clausesI Only set-valued functions can appear in the FROM clauseI Aggregation functions can only be applied to GROUP BY orPARTITION BY
UDFs can be written in Java, Python and JavascriptI With streaming, we can use also C/C++, Python, ...
Pietro Michiardi (Eurecom) High-level Programming Languages 27 / 78

Apache Pig Features and Motivations
Handling parallel execution
Pig and Pig Latin are geared towards parallel processingI Of course, the underlying execution engine is MapReduceI SPORK = Pig on Spark → the execution engine need not be
MapReduce
Pig Latin primitives are chosen such that they can be easilyparallelized
I Non-equi joins, correlated sub-queries,... are not directly supported
Users may specify parallelization parameters at run timeI Question: Can you specify the number of maps?I Question: Can you specify the number of reducers?
Pietro Michiardi (Eurecom) High-level Programming Languages 28 / 78
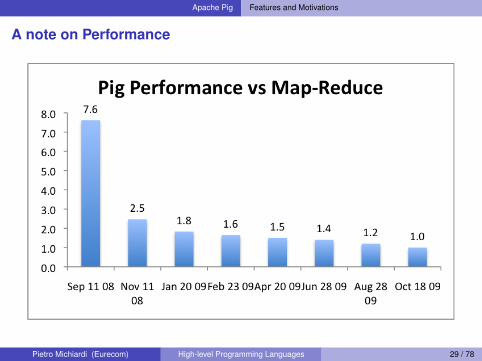
Apache Pig Features and Motivations
A note on Performance
But can it fly?
src: Olston Pietro Michiardi (Eurecom) High-level Programming Languages 29 / 78
Apache Pig Pig Latin
Pig Latin
Pietro Michiardi (Eurecom) High-level Programming Languages 30 / 78
Apache Pig Pig Latin
Introduction
Not a complete reference to the Pig Latin language: refer to [1]I Here we cover some interesting/useful aspects
The focus here is on some language primitivesI Optimizations are treated separatelyI How they can be implemented (in the underlying engine) is not
covered
Examples are taken from [2, 3]
Pietro Michiardi (Eurecom) High-level Programming Languages 31 / 78
Apache Pig Pig Latin
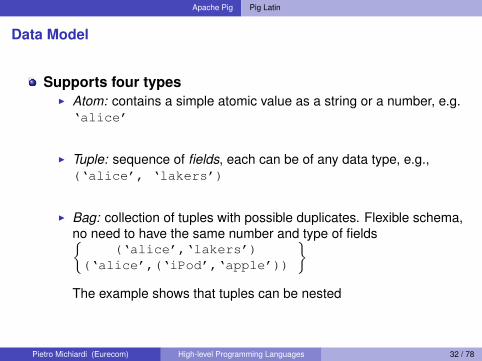
Data Model
Supports four typesI Atom: contains a simple atomic value as a string or a number, e.g.‘alice’
I Tuple: sequence of fields, each can be of any data type, e.g.,(‘alice’, ‘lakers’)
I Bag: collection of tuples with possible duplicates. Flexible schema,no need to have the same number and type of fields{
(‘alice’,‘lakers’)(‘alice’,(‘iPod’,‘apple’))
}The example shows that tuples can be nested
Pietro Michiardi (Eurecom) High-level Programming Languages 32 / 78

Apache Pig Pig Latin
Data Model
Supports four typesI Map: collection of data items, where each item has an associated
key for lookup. The schema, as with bags, is flexible.F NOTE: keys are required to be data atoms, for efficient lookup.‘fan of’ →
{(‘lakers’)(‘iPod’)
}‘age’ → 20
F The key ‘fan of’ is mapped to a bag containing two tuplesF The key ‘age’ is mapped to an atom
I Maps are useful to model datasets in which schema may bedynamic (over time)
Pietro Michiardi (Eurecom) High-level Programming Languages 33 / 78

Apache Pig Pig Latin
Structure
Pig Latin programs are a sequence of stepsI Can use an interactive shell (called grunt)I Can feed them as a “script”
CommentsI In line: with double hyphens (- -)I C-style for longer comments (/* ... */)
Reserved keywordsI List of keywords that can’t be used as identifiersI Same old story as for any language
Pietro Michiardi (Eurecom) High-level Programming Languages 34 / 78
Apache Pig Pig Latin
Statements
As a Pig Latin program is executed, each statement is parsedI The interpreter builds a logical plan for every relational operationI The logical plan of each statement is added to that of the program
so farI Then the interpreter moves on to the next statement
IMPORTANT: No data processing takes place duringconstruction of logical plan → Lazy Evaluation
I When the interpreter sees the first line of a program, it confirms thatit is syntactically and semantically correct
I Then it adds it to the logical planI It does not even check the existence of files, for data load
operations
Pietro Michiardi (Eurecom) High-level Programming Languages 35 / 78

Apache Pig Pig Latin
Statements→ It makes no sense to start any processing until the whole
flow is definedI Indeed, there are several optimizations that could make a program
more efficient (e.g., by avoiding to operate on some data that lateron is going to be filtered)
The trigger for Pig to start execution are the DUMP and STOREstatements
I It is only at this point that the logical plan is compiled into a physicalplan
How the physical plan is builtI Pig prepares a series of MapReduce jobs
F In Local mode, these are run locally on the JVMF In MapReduce mode, the jobs are sent to the Hadoop Cluster
I IMPORTANT: The command EXPLAIN can be used to show theMapReduce plan
Pietro Michiardi (Eurecom) High-level Programming Languages 36 / 78

Apache Pig Pig Latin
Statements
Multi-query execution
There is a difference between DUMP and STOREI Apart from diagnosis, and interactive mode, in batch mode STORE
allows for program/job optimizations
Main optimization objective: minimize I/OI Consider the following example:A = LOAD ’input/pig/multiquery/A’;B = FILTER A BY $1 == ’banana’;C = FILTER A BY $1 != ’banana’;STORE B INTO ’output/b’;STORE C INTO ’output/c’;
Pietro Michiardi (Eurecom) High-level Programming Languages 37 / 78
Apache Pig Pig Latin
Statements
Multi-query execution
In the example, relations B and C are both derived from AI Naively, this means that at the first STORE operator the input should
be readI Then, at the second STORE operator, the input should be read again
Pig will run this as a single MapReduce jobI Relation A is going to be read only onceI Then, each relation B and C will be written to the output
Pietro Michiardi (Eurecom) High-level Programming Languages 38 / 78

Apache Pig Pig Latin
Expressions
An expression is something that is evaluated to yield a valueI Lookup on [3] for documentation
guages, including C/C++, Java, Perl and Python, so thatusers can stick with their language of choice.
2.5 Parallelism RequiredSince Pig Latin is geared toward processing web-scale
data, it does not make sense to consider non-parallel eval-uation. Consequently, we have only included in Pig Latina small set of carefully chosen primitives that can be easilyparallelized. Language primitives that do not lend them-selves to e⌅cient parallel evaluation (e.g., non-equi-joins,correlated subqueries) have been deliberately excluded.
Such operations can of course, still be carried out by writ-ing UDFs. However, since the language does not provideexplicit primitives for such operations, users are aware ofhow e⌅cient their programs will be and whether they willbe parallelized.
2.6 Debugging EnvironmentIn any language, getting a data processing program right
usually takes many iterations, with the first few iterationsusually having some user-introduced erroneous processing.At the scale of data that Pig is meant to process, a singleiteration can take many minutes or hours (even with large-scale parallel processing). Thus, the usual run-debug-runcycle can be very slow and ine⌅cient.
Pig comes with a novel interactive debugging environmentthat generates a concise example data table illustrating theoutput of each step of the user’s program. The example datais carefully chosen to resemble the real data as far as possibleand also to fully illustrate the semantics of the program.Moreover, the example data is automatically adjusted asthe program evolves.
This step-by-step example data can help in detecting er-rors early (even before the first iteration of running the pro-gram on the full data), and also in pinpointing the step thathas errors. The details of our debugging environment areprovided in Section 5.
3. PIG LATINIn this section, we describe the details of the Pig Latin
language. We describe our data model in Section 3.1, andthe Pig Latin statements in the subsequent subsections. Theemphasis of this section is not on the syntactical details ofPig Latin, but on how it meets the design goals and featureslaid out in Section 2. Also, this section only focusses onthe language primitives, and not on how they can be imple-mented to execute in parallel over a cluster. Implementationis covered in Section 4.
3.1 Data ModelPig has a rich, yet simple data model consisting of the
following four types:
• Atom: An atom contains a simple atomic value such asa string or a number, e.g., ‘alice’.
• Tuple: A tuple is a sequence of fields, each of which canbe any of the data types, e.g., (‘alice’, ‘lakers’).
• Bag: A bag is a collection of tuples with possible dupli-cates. The schema of the constituent tuples is flexible,i.e., not all tuples in a bag need to have the same numberand type of fields, e.g.,
⇤(‘alice’, ‘lakers’)`
‘alice’, (‘iPod’, ‘apple’)´
⌅
t =
„‘alice’,
⇤(‘lakers’, 1)(‘iPod’, 2)
⌅,ˆ‘age’ ⇤ 20
˜«
Let fields of tuple t be called f1, f2, f3
Expression Type Example Value for t
Constant ‘bob’ Independent of tField by position $0 ‘alice’
Field by name f3ˆ‘age’ ⇤ 20
˜
Projection f2.$0
⇤(‘lakers’)(‘iPod’)
⌅
Map Lookup f3#‘age’ 20
Function Evaluation SUM(f2.$1) 1 + 2 = 3
ConditionalExpression
f3#‘age’>18?‘adult’:‘minor’
‘adult’
Flattening FLATTEN(f2)‘lakers’, 1
‘iPod’, 2
Table 1: Expressions in Pig Latin.
The above example also demonstrates that tuples can benested, e.g., the second tuple of the bag has a nestedtuple as its second field.
• Map: A map is a collection of data items, where eachitem has an associated key through which it can belooked up. As with bags, the schema of the constituentdata items is flexible, i.e., all the data items in the mapneed not be of the same type. However, the keys are re-quired to be data atoms, mainly for e⌅ciency of lookups.The following is an example of a map:
2
4 ‘fan of’ ⇤⇤
(‘lakers’)
(‘iPod’)
⌅
‘age’ ⇤ 20
3
5
In the above map, the key ‘fan of’ is mapped to a bagcontaining two tuples, and the key ‘age’ is mapped toan atom 20.
A map is especially useful to model data sets whereschemas might change over time. For example, if webservers decide to include a new field while dumping logs,that new field can simply be included as an additionalkey in a map, thus requiring no change to existing pro-grams, and also allowing access of the new field to newprograms.
Table 1 shows the expression types in Pig Latin, and howthey operate. (The flattening expression is explained in de-tail in Section 3.3.) It should be evident that our data modelis very flexible and permits arbitrary nesting. This flexibil-ity allows us to achieve the aims outlined in Section 2.3,where we motivated our use of a nested data model. Next,we describe the Pig Latin commands.
3.2 Specifying Input Data: LOADThe first step in a Pig Latin program is to specify what
the input data files are, and how the file contents are to bedeserialized, i.e., converted into Pig’s data model. An inputfile is assumed to contain a sequence of tuples, i.e., a bag.This step is carried out by the LOAD command. For example,
queries = LOAD ‘query_log.txt’
USING myLoad()
AS (userId, queryString, timestamp);
Pietro Michiardi (Eurecom) High-level Programming Languages 39 / 78
Apache Pig Pig Latin
Schemas
A relation in Pig may have an associated schemaI This is optionalI A schema gives the fields in the relations names and typesI Use the command DESCRIBE to reveal the schema in use for a
relation
Schema declaration is flexible but reuse is awkward4
I A set of queries over the same input data will often have the sameschema
I This is sometimes hard to maintain (unlike HIVE) as there is noexternal components to maintain this association
HINT:: You can write a UDF function to perform a personalized loadoperation which encapsulates the schema
4Current developments solve this problem: HCatalogs. We will not cover this in thiscourse.
Pietro Michiardi (Eurecom) High-level Programming Languages 40 / 78
Apache Pig Pig Latin
Validation and nulls
Pig does not have the same power to enforce constraints onschema at load time as a RDBMS
I If a value cannot be cast to a type declared in the schema, then itwill be set to a null value
I This also happens for corrupt files
A useful technique to partition input data to discern good andbad records
I Use the SPLIT operatorSPLIT records INTO good_records IF temperature isnot null, bad _records IF temperature is NULL;
Pietro Michiardi (Eurecom) High-level Programming Languages 41 / 78

Apache Pig Pig Latin
Other relevant information
Schema propagation and mergingI How schema are propagated to new relations?I Advanced, but important topic
User-Defined FunctionsI Use [3] for an introduction to designing UDFs
Pietro Michiardi (Eurecom) High-level Programming Languages 42 / 78
Apache Pig Pig Latin
Data Processing Operators
Loading and storing data
The first step in a Pig Latin program is to load dataI Accounts for what input files are (e.g. csv files)I How the file contents are to be deserializedI An input file is assumed to contain a sequence of tuples
Data loading is done with the LOAD commandqueries = LOAD ‘query_log.txt’USING myLoad()AS (userId, queryString, timestamp);
Pietro Michiardi (Eurecom) High-level Programming Languages 43 / 78

Apache Pig Pig Latin
Data Processing Operators
Loading and storing data
The example above specifies the following:I The input file is query_log.txtI The input file should be converted into tuples using the custommyLoad deserializer
I The loaded tuples have three fields, specified by the schema
Optional partsI USING clause is optional: if not specified, the input file is assumed
to be plain text, tab-delimitedI AS clause is optional: if not specified, must refer to fileds by position
instead of by name
Pietro Michiardi (Eurecom) High-level Programming Languages 44 / 78
Apache Pig Pig Latin
Data Processing Operators
Loading and storing data
Return value of the LOAD commandI Handle to a bagI This can be used by subsequent commands→ bag handles are only logical→ no file is actually read!
The command to write output to disk is STOREI It has similar semantics to the LOAD command
Pietro Michiardi (Eurecom) High-level Programming Languages 45 / 78
Apache Pig Pig Latin
Data Processing Operators
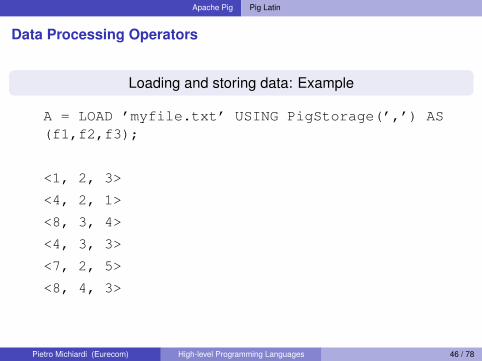
Loading and storing data: Example
A = LOAD ’myfile.txt’ USING PigStorage(’,’) AS(f1,f2,f3);
<1, 2, 3>
<4, 2, 1>
<8, 3, 4>
<4, 3, 3>
<7, 2, 5>
<8, 4, 3>
Pietro Michiardi (Eurecom) High-level Programming Languages 46 / 78
Apache Pig Pig Latin
Data Processing Operators
Per-tuple processing
Once you have some data loaded into a relation, a possiblenext step is, e.g., to filter it
I This is done, e.g., to remove unwanted dataI HINT: By filtering early in the processing pipeline, you minimize the
amount of data flowing trough the system
A basic operation is to apply some processing over everytuple of a data set
I This is achieved with the FOREACH commandexpanded_queries = FOREACH queries GENERATEuserId, expandQuery(queryString);
Pietro Michiardi (Eurecom) High-level Programming Languages 47 / 78

Apache Pig Pig Latin
Data Processing OperatorsPer-tuple processing
Comments on the example above:I Each tuple of the bag queries should be processed independentlyI The second field of the output is the result of a UDF
Semantics of the FOREACH commandI There can be no dependence between the processing of different
input tuples→ This allows for an efficient parallel implementation
Semantics of the GENERATE clauseI Followed by a list of expressionsI Also flattening is allowed
F This is done to eliminate nesting in data→ Allows to make output data independent for further parallel
processing→ Useful to store data on disk
Pietro Michiardi (Eurecom) High-level Programming Languages 48 / 78
Apache Pig Pig Latin
Data Processing Operators
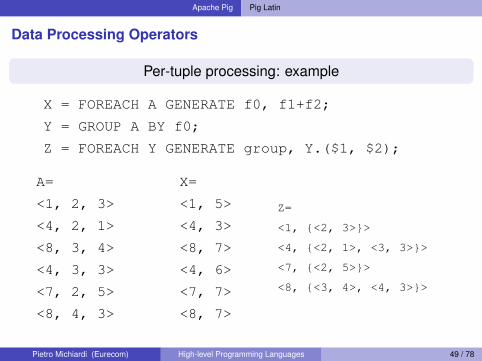
Per-tuple processing: example
X = FOREACH A GENERATE f0, f1+f2;
Y = GROUP A BY f0;
Z = FOREACH Y GENERATE group, Y.($1, $2);
A=
<1, 2, 3>
<4, 2, 1>
<8, 3, 4>
<4, 3, 3>
<7, 2, 5>
<8, 4, 3>
X=
<1, 5>
<4, 3>
<8, 7>
<4, 6>
<7, 7>
<8, 7>
Z=
<1, {<2, 3>}>
<4, {<2, 1>, <3, 3>}>
<7, {<2, 5>}>
<8, {<3, 4>, <4, 3>}>
Pietro Michiardi (Eurecom) High-level Programming Languages 49 / 78

Apache Pig Pig Latin
Data Processing Operators
Per-tuple processing: Discarding unwanted data
A common operation is to retain a portion of the input dataI This is done with the FILTER commandreal_queries = FILTER queries BY userId neq‘bot’;
Filtering conditions involve a combination of expressionsI Comparison operatorsI Logical connectorsI UDF
Pietro Michiardi (Eurecom) High-level Programming Languages 50 / 78
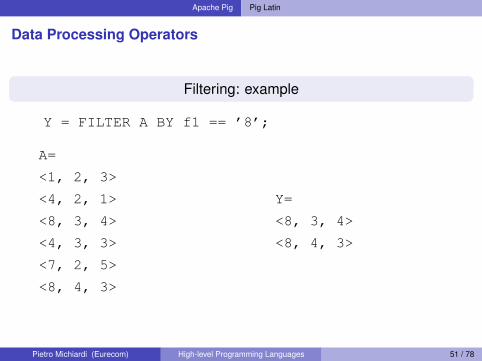
Apache Pig Pig Latin
Data Processing Operators
Filtering: example
Y = FILTER A BY f1 == ’8’;
A=
<1, 2, 3>
<4, 2, 1>
<8, 3, 4>
<4, 3, 3>
<7, 2, 5>
<8, 4, 3>
Y=
<8, 3, 4>
<8, 4, 3>
Pietro Michiardi (Eurecom) High-level Programming Languages 51 / 78
Apache Pig Pig Latin
Data Processing Operators
Per-tuple processing: Streaming data
The STREAM operator allows transforming data in a relationusing an external program or script
I This is possible because Hadoop MapReduce supports “streaming”I Example:C = STREAM A THROUGH ‘cut -f 2’;which use the Unix cut command to extract the second filed ofeach tuple in A
The STREAM operator uses PigStorage to serialize anddeserialize relations to and from stdin/stdout
I Can also provide a custom serializer/deserializerI Works well with python
Pietro Michiardi (Eurecom) High-level Programming Languages 52 / 78
Apache Pig Pig Latin
Data Processing Operators
Getting related data together
It is often necessary to group together tuples from one ormore data sets
I We will explore several nuances of “grouping”
Pietro Michiardi (Eurecom) High-level Programming Languages 53 / 78
Apache Pig Pig Latin
Data Processing Operators
The GROUP operator
Sometimes, we want to operate on a single datasetI This is when you use the GROUP operator
Let’s continue from Example 3:I Assume we want to find the total revenue for each query string.
This writes as:grouped_revenue = GROUP revenue BY queryString;query_revenue = FOREACH grouped_revenue GENERATEqueryString, SUM(revenue.amount) AS totalRevenue;
I Note that revenue.amount refers to a projection of the nestedbag in the tuples of grouped_revenue
Pietro Michiardi (Eurecom) High-level Programming Languages 54 / 78
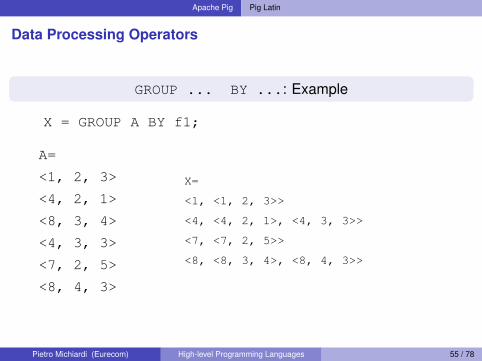
Apache Pig Pig Latin
Data Processing Operators
GROUP ... BY ...: Example
X = GROUP A BY f1;
A=
<1, 2, 3>
<4, 2, 1>
<8, 3, 4>
<4, 3, 3>
<7, 2, 5>
<8, 4, 3>
X=
<1, <1, 2, 3>>
<4, <4, 2, 1>, <4, 3, 3>>
<7, <7, 2, 5>>
<8, <8, 3, 4>, <8, 4, 3>>
Pietro Michiardi (Eurecom) High-level Programming Languages 55 / 78
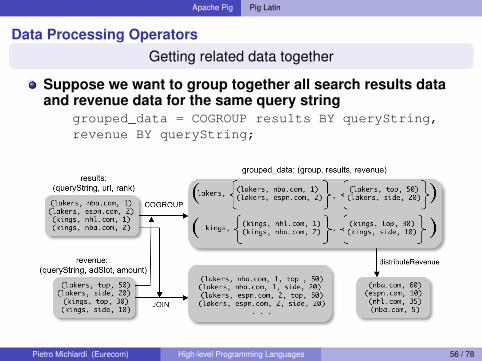
Apache Pig Pig Latin
Data Processing OperatorsGetting related data together
Suppose we want to group together all search results dataand revenue data for the same query string
grouped_data = COGROUP results BY queryString,revenue BY queryString;
Figure 2: COGROUP versus JOIN.
advertisement slots, the average amount of revenue made bythe advertisements for that query string at that slot. Thento group together all search result data and revenue data forthe same query string, we can write:
grouped_data = COGROUP results BY queryString,
revenue BY queryString;
Figure 2 shows what a tuple in grouped_data looks like.In general, the output of a COGROUP contains one tuple foreach group. The first field of the tuple (named group) is thegroup identifier (in this case, the value of the queryString
field). Each of the next fields is a bag, one for each inputbeing cogrouped, and is named the same as the alias of thatinput. The ith bag contains all tuples from the ith inputbelonging to that group. As in the case of filtering, groupingcan also be performed according to arbitrary expressionswhich may include UDFs.
The reader may wonder why a COGROUP primitive is neededat all, since a very similar primitive is provided by the fa-miliar, well-understood, JOIN operation in databases. Forcomparison, Figure 2 also shows the result of joining ourdata sets on queryString. It is evident that JOIN is equiv-alent to COGROUP, followed by taking a cross product of thetuples in the nested bags. While joins are widely applicable,certain custom processing might require access to the tuplesof the groups before the cross-product is taken, as shown bythe following example.
Example 3. Suppose we were trying to attribute searchrevenue to search-result urls to figure out the monetary worthof each url. We might have a sophisticated model for doingso. To accomplish this task in Pig Latin, we can follow theCOGROUP with the following statement:
url_revenues = FOREACH grouped_data GENERATE
FLATTEN(distributeRevenue(results, revenue));
where distributeRevenue is a UDF that accepts search re-sults and revenue information for a query string at a time,and outputs a bag of urls and the revenue attributed to them.For example, distributeRevenue might attribute revenuefrom the top slot entirely to the first search result, while therevenue from the side slot may be attributed equally to allthe results. In this case, the output of the above statementfor our example data is shown in Figure 2.
To specify the same operation in SQL, one would haveto join by queryString, then group by queryString, andthen apply a custom aggregation function. But while doingthe join, the system would compute the cross product of thesearch and revenue information, which the custom aggre-gation function would then have to undo. Thus, the wholeprocess become quite ine⇤cient, and the query becomes hardto read and understand.
To reiterate, the COGROUP statement illustrates a key dif-ference between Pig Latin and SQL. The COGROUP state-ments conforms to our goal of having an algebraic language,where each step carries out only a single transformation(Section 2.1). COGROUP carries out only the operation ofgrouping together tuples into nested bags. The user cansubsequently choose to apply either an aggregation functionon those tuples, or cross-product them to get the join result,or process it in a custom way as in Example 3. In SQL,grouping is available only bundled with either aggregation(group-by-aggregate queries), or with cross-producting (theJOIN operation). Users find this additional flexibility of PigLatin over SQL quite attractive, e.g.,
“I frankly like pig much better than SQL in somerespects (group + optional flatten works betterfor me, I love nested data structures).”– Ted Dunning, Chief Scientist, Veoh Networks
Note that it is our nested data model that allows us tohave COGROUP as an independent operation—the input tu-ples are grouped together and put in nested bags. Sucha primitive is not possible in SQL since the data model isflat. Of course, such a nested model raises serious concernsabout e⌅ciency of implementation: since groups can be verylarge (bigger than main memory, perhaps), we might buildup gigantic tuples, which have these enormous nested bagswithin them. We address these e⌅ciency concerns in ourimplementation section (Section 4).
3.5.1 Special Case of COGROUP: GROUPA common special case of COGROUP is when there is only
one data set involved. In this case, we can use the alter-native, more intuitive keyword GROUP. Continuing with ourexample, if we wanted to find the total revenue for eachquery string, (a typical group-by-aggregate query), we canwrite it as follows:
Pietro Michiardi (Eurecom) High-level Programming Languages 56 / 78
Apache Pig Pig Latin
Data Processing Operators
The COGROUP command
Output of a COGROUP contains one tuple for each groupI First field (group) is the group identifier (the value of thequeryString)
I Each of the next fields is a bag, one for each group beingco-grouped
Grouping can be performed according to UDFs
Next: a clarifying example
Pietro Michiardi (Eurecom) High-level Programming Languages 57 / 78
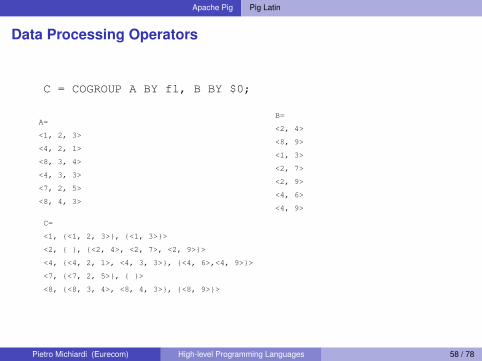
Apache Pig Pig Latin
Data Processing Operators
C = COGROUP A BY f1, B BY $0;
A=
<1, 2, 3>
<4, 2, 1>
<8, 3, 4>
<4, 3, 3>
<7, 2, 5>
<8, 4, 3>
B=
<2, 4>
<8, 9>
<1, 3>
<2, 7>
<2, 9>
<4, 6>
<4, 9>
C=
<1, {<1, 2, 3>}, {<1, 3>}>
<2, { }, {<2, 4>, <2, 7>, <2, 9>}>
<4, {<4, 2, 1>, <4, 3, 3>}, {<4, 6>,<4, 9>}>
<7, {<7, 2, 5>}, { }>
<8, {<8, 3, 4>, <8, 4, 3>}, {<8, 9>}>
Pietro Michiardi (Eurecom) High-level Programming Languages 58 / 78
Apache Pig Pig Latin
Data Processing Operators
COGROUP vs JOIN
JOIN vs. COGROUPI Their are equivalent: JOIN == COGROUP followed by a cross
product of the tuples in the nested bags
Example 3: Suppose we try to attribute search revenue tosearch-results urls → compute monetary worth of each url
grouped_data = COGROUP results BY queryString,revenue BY queryString;url_revenues = FOREACH grouped_data GENERATEFLATTEN(distrubteRevenue(results, revenue));
I Where distrubteRevenue is a UDF that accepts search resultsand revenue information for each query string, and outputs a bag ofurls and revenue attributed to them
Pietro Michiardi (Eurecom) High-level Programming Languages 59 / 78
Apache Pig Pig Latin
Data Processing OperatorsCOGROUP vs JOIN
More details on the UDF distribute RevenueI Attributes revenue from the top slot entirely to the first search resultI The revenue from the side slot may be equally split among all
results
Let’s see how to do the same with a JOINI JOIN the tables results and revenues by queryStringI GROUP BY queryStringI Apply a custom aggregation function
What happens behind the scenesI During the JOIN, the system computes the cross product of the
search and revenue informationI Then the custom aggregation needs to undo this cross product,
because the UDF specifically requires so
Pietro Michiardi (Eurecom) High-level Programming Languages 60 / 78
Apache Pig Pig Latin
Data Processing Operators
COGROUP in details
The COGROUP statement conforms to an algebraic languageI The operator carries out only the operation of grouping together
tuples into nested bagsI The user can the decide whether to apply a (custom) aggregation
on those tuples or to cross-product them and obtain a JOIN
It is thanks to the nested data model that COGROUP is anindependent operation
I Implementation details are trickyI Groups can be very large (and are redundant)
Pietro Michiardi (Eurecom) High-level Programming Languages 61 / 78
Apache Pig Pig Latin
Data Processing Operators
JOIN in Pig Latin
In many cases, the typical operation on two or more datasetsamounts to an equi-join
I IMPORTANT NOTE: large datasets that are suitable to be analyzedwith Pig (and MapReduce) are generally not normalized
→ JOINs are used more infrequently in Pig Latin than they are in SQL
The syntax of a JOINjoin_result = JOIN results BY queryString,revenue BY queryString;
I This is a classic inner join (actually an equi-join), where each matchbetween the two relations corresponds to a row in thejoin_result
Pietro Michiardi (Eurecom) High-level Programming Languages 62 / 78

Apache Pig Pig Latin
Data Processing Operators
JOIN in Pig Latin
JOINs lend themselves to optimization opportunitiesI Active development of several join flavors is on-going
Assume we join two datasets, one of which is considerablysmaller than the other
I For instance, suppose a dataset fits in memory
Fragment replicate joinI Syntax: append the clause USING “replicated” to a JOIN
statementI Uses a distributed cache available in HadoopI All mappers will have a copy of the small input→ This is a Map-side join
Pietro Michiardi (Eurecom) High-level Programming Languages 63 / 78
Apache Pig Pig Latin
Data Processing Operators
MapReduce in Pig Latin
It is trivial to express MapReduce programs in Pig LatinI This is achieved using GROUP and FOREACH statementsI A map function operates on one input tuple at a time and outputs a
bag of key-value pairsI The reduce function operates on all values for a key at a time to
produce the final result
Examplemap_result = FOREACH input GENERATEFLATTEN(map(*));key_groups = GROUP map_results BY $0;output = FOREACH key_groups GENERATE reduce(*);
I where map() and reduce() are UDFs
Pietro Michiardi (Eurecom) High-level Programming Languages 64 / 78

Apache Pig Pig Execution Engine
The Pig ExecutionEngine
Pietro Michiardi (Eurecom) High-level Programming Languages 65 / 78

Apache Pig Pig Execution Engine
Pig Execution Engine
Pig Latin Programs are compiled into MapReduce jobs, andexecuted using Hadoop5
OverviewI How to build a logical plan for a Pig Latin programI How to compile the logical plan into a physical plan of MapReduce
jobs
Optimizations
5Other execution engines are allowed, but require a lot of implementation effort.Pietro Michiardi (Eurecom) High-level Programming Languages 66 / 78

Apache Pig Pig Execution Engine
Building a Logical Plan
As clients issue Pig Latin commands (interactive or batchmode)
I The Pig interpreter parses the commandsI Then it verifies validity of input files and bags (variables)
F E.g.: if the command is c = COGROUP a BY ..., b BY ...;, itverifies if a and b have already been defined
Pig builds a logical plan for every bagI When a new bag is defined by a command, the new logical plan is a
combination of the plans for the input and that of the currentcommand
Pietro Michiardi (Eurecom) High-level Programming Languages 67 / 78

Apache Pig Pig Execution Engine
Building a Logical Plan
No processing is carried out when constructing the logicalplans
I Processing is triggered only by STORE or DUMPI At that point, the logical plan is compiled to a physical plan
Lazy execution modelI Allows in-memory pipeliningI File reorderingI Various optimizations from the traditional RDBMS world
Pig is (potentially) platform independentI Parsing and logical plan construction are platform obliviousI Only the compiler is specific to Hadoop
Pietro Michiardi (Eurecom) High-level Programming Languages 68 / 78

Apache Pig Pig Execution Engine
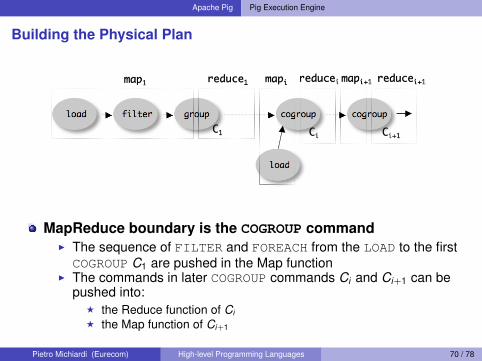
Building the Physical Plan
Compilation of a logical plan into a physical plan is “simple”I MapReduce primitives allow a parallel GROUP BY
F Map assigns keys for groupingF Reduce process a group at a time (actually in parallel)
How the compiler worksI Converts each (CO)GROUP command in the logical plan into
distinct MapReduce jobsI Map function for (CO)GROUP command C initially assigns keys to
tuples based on the BY clause(s) of CI Reduce function is initially a no-op
Pietro Michiardi (Eurecom) High-level Programming Languages 69 / 78
Apache Pig Pig Execution Engine
Building the Physical Plan
an open-source project in the Apache incubator, and henceavailable for general use.
We first describe how Pig builds a logical plan for a PigLatin program. We then describe our current compiler, thatcompiles a logical plan into map-reduce jobs executed usingHadoop. Last, we describe how our implementation avoidslarge nested bags, and how it handles them if they do arise.
4.1 Building a Logical PlanAs clients issue Pig Latin commands, the Pig interpreter
first parses it, and verifies that the input files and bags be-ing referred to by the command are valid. For example, ifthe user enters c = COGROUP a BY . . ., b BY . . ., Pig veri-fies that the bags a and b have already been defined. Pigbuilds a logical plan for every bag that the user defines.When a new bag is defined by a command, the logical planfor the new bag is constructed by combining the logical plansfor the input bags, and the current command. Thus, in theabove example, the logical plan for c consists of a cogroupcommand having the logical plans for a and b as inputs.
Note that no processing is carried out when the logicalplans are constructed. Processing is triggered only when theuser invokes a STORE command on a bag. At that point, thelogical plan for that bag is compiled into a physical plan,and is executed. This lazy style of execution is beneficialbecause it permits in-memory pipelining, and other opti-mizations such as filter reordering across multiple Pig Latincommands.
Pig is architected such that the parsing of Pig Latin andthe logical plan construction is independent of the execu-tion platform. Only the compilation of the logical plan intoa physical plan depends on the specific execution platformchosen. Next, we describe the compilation into Hadoopmap-reduce, the execution platform currently used by Pig.
4.2 Map-Reduce Plan CompilationCompilation of a Pig Latin logical plan into map-reduce
jobs is fairly simple. The map-reduce primitive essentiallyprovides the ability to do a large-scale group by, where themap tasks assign keys for grouping, and the reduce tasksprocess a group at a time. Our compiler begins by convertingeach (CO)GROUP command in the logical plan into a distinctmap-reduce job with its own map and reduce functions.
The map function for (CO)GROUP command C initially justassigns keys to tuples based on the BY clause(s) of C; thereduce function is initially a no-op. The map-reduce bound-ary is the cogroup command. The sequence of FILTER, andFOREACH commands from the LOAD to the first COGROUP op-eration C1, are pushed into the map function correspondingto C1 (see Figure 3). The commands that intervene betweensubsequent COGROUP commands Ci and Ci+1 can be pushedinto either (a) the reduce function corresponding to Ci, or(b) the map function corresponding to Ci+1. Pig currentlyalways follows option (a). Since grouping is often followedby aggregation, this approach reduces the amount of datathat has to be materialized between map-reduce jobs.
In the case of a COGROUP command with more than oneinput data set, the map function appends an extra field toeach tuple that identifies the data set from which the tupleoriginated. The accompanying reduce function decodes thisinformation and uses it to insert the tuple into the appro-priate nested bag when cogrouped tuples are formed (recallFigure 2).
Figure 3: Map-reduce compilation of Pig Latin.
Parallelism for LOAD is obtained since Pig operates overfiles residing in the Hadoop distributed file system. We alsoautomatically get parallelism for FILTER and FOREACH oper-ations since for a given map-reduce job, several map and re-duce instances are run in parallel. Parallelism for (CO)GROUPis achieved since the output from the multiple map instancesis repartitioned in parallel to the multiple reduce instances.
The ORDER command is implemented by compiling intotwo map-reduce jobs. The first job samples the input todetermine quantiles of the sort key. The second job range-partitions the input according to the quantiles (thereby en-suring roughly equal-sized partitions), followed by local sort-ing in the reduce phase, resulting in a globally sorted file.
The inflexibility of the map-reduce primitive results insome overheads while compiling Pig Latin into map-reducejobs. For example, data must be materialized and replicatedon the distributed file system between successive map-reducejobs. When dealing with multiple data sets, an additionalfield must be inserted in every tuple to indicate which dataset it came from. However, the Hadoop map-reduce im-plementation does provide many desired properties such asparallelism, load-balancing, and fault-tolerance. Given theproductivity gains to be had through Pig Latin, the asso-ciated overhead is often acceptable. Besides, there is thepossibility of plugging in a di�erent execution platform thatcan implement Pig Latin operations without such overheads.
4.3 Efficiency With Nested BagsRecall Section 3.5. Conceptually speaking, our (CO)GROUP
command places tuples belonging to the same group intoone or more nested bags. In many cases, the system canavoid actually materializing these bags, which is especiallyimportant when the bags are larger than one machine’s mainmemory.
One common case is where the user applies a distribu-tive or algebraic [8] aggregation function over the result ofa (CO)GROUP operation. (Distributive is a special case ofalgebraic, so we will only discuss algebraic functions.) Analgebraic function is one that can be structured as a treeof subfunctions, with each leaf subfunction operating over asubset of the input data. If nodes in this tree achieve datareduction, then the system can keep the amount of datamaterialized in any single location small. Examples of al-gebraic functions abound: COUNT, SUM, MIN, MAX, AVERAGE,VARIANCE, although some useful functions are not algebraic,e.g., MEDIAN.
When Pig compiles programs into Hadoop map-reducejobs, it uses Hadoop’s combiner feature to achieve a two-tiertree evaluation of algebraic functions. Pig provides a specialAPI for algebraic user-defined functions, so that custom userfunctions can take advantage of this important optimization.
MapReduce boundary is the COGROUP commandI The sequence of FILTER and FOREACH from the LOAD to the firstCOGROUP C1 are pushed in the Map function
I The commands in later COGROUP commands Ci and Ci+1 can bepushed into:
F the Reduce function of CiF the Map function of Ci+1
Pietro Michiardi (Eurecom) High-level Programming Languages 70 / 78

Apache Pig Pig Execution Engine
Building the Physical Plan
Pig optimization for the physical planI Among the two options outlined above, the first is preferredI Indeed, grouping is often followed by aggregation→ reduces the amount of data to be materialized between jobs
COGROUP command with more than one input datasetI Map function appends an extra field to each tuple to identify the
datasetI Reduce function decodes this information and inserts tuple in the
appropriate nested bags for each group
Pietro Michiardi (Eurecom) High-level Programming Languages 71 / 78

Apache Pig Pig Execution Engine
Building the Physical Plan
How parallelism is achievedI For LOAD this is inherited by operating over HDFSI For FILTER and FOREACH, this is automatic thanks to MapReduce
frameworkI For (CO)GROUP uses the SHUFFLE phase
A note on the ORDER commandI Translated in two MapReduce jobsI First job: Samples the input to determine quantiles of the sort keyI Second job: Range partitions the input according to quantiles,
followed by sorting in the reduce phase
Known overheads due to MapReduce inflexibilityI Data materialization between jobsI Multiple inputs are not supported well
Pietro Michiardi (Eurecom) High-level Programming Languages 72 / 78
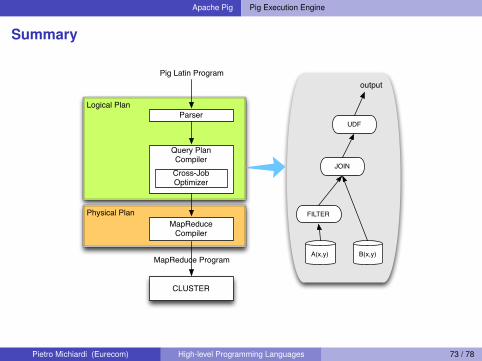
Apache Pig Pig Execution Engine
Summary
Physical Plan
Logical PlanParser
Query PlanCompilerCross-JobOptimizer
MapReduceCompiler
CLUSTER
Pig Latin Program
MapReduce ProgramB(x,y)A(x,y)
FILTER
JOIN
UDF
output
Pietro Michiardi (Eurecom) High-level Programming Languages 73 / 78

Apache Pig Pig Execution Engine
Single-program Optimizations
Logical optimizations: query planI Early projectionI Early filteringI Operator rewrites
Physical optimization: execution planI Mapping of logical operations to MapReduceI Splitting logical operations in multiple physical onesI Join execution strategies
Pietro Michiardi (Eurecom) High-level Programming Languages 74 / 78

Apache Pig Pig Execution Engine
Efficiency measures
(CO)GROUP command places tuples of the same group innested bags
I Bag materialization (I/O) can be avoidedI This is important also due to memory constraintsI Distributive or algebraic aggregation facilitate this task
What is an algebraic function?I Function that can be structured as a tree of sub-functionsI Each leaf sub-function operates over a subset of the input data→ If nodes in the tree achieve data reduction, then the system can
reduce materializationI Examples: COUNT, SUM, MIN, MAX, AVERAGE, ...
Pietro Michiardi (Eurecom) High-level Programming Languages 75 / 78

Apache Pig Pig Execution Engine
Efficiency measures
Pig compiler uses the combiner function of HadoopI A special API for algebraic UDF is available
There are cases in which (CO)GROUP is inefficientI This happens with non-algebraic functionsI Nested bags can be spilled to diskI Pig provides a disk-resident bag implementation
F Features external sort algorithmsF Features duplicates elimination
Pietro Michiardi (Eurecom) High-level Programming Languages 76 / 78

References
References
Pietro Michiardi (Eurecom) High-level Programming Languages 77 / 78
References
References I
[1] Pig wiki.http://wiki.apache.org/pig/.
[2] C. Olston, B. Reed, U. Srivastava, R. Kumar, , and A. Tomkins.Pig latin: A not-so-foreign language for data processing.In Proc. of ACM SIGMOD, 2008.
[3] Tom White.Hadoop, The Definitive Guide.O’Reilly, Yahoo, 2010.
Pietro Michiardi (Eurecom) High-level Programming Languages 78 / 78