high availability django - djangocon 2016
TRANSCRIPT

High-Availability Django
Frankie Dintino
The Atlantic


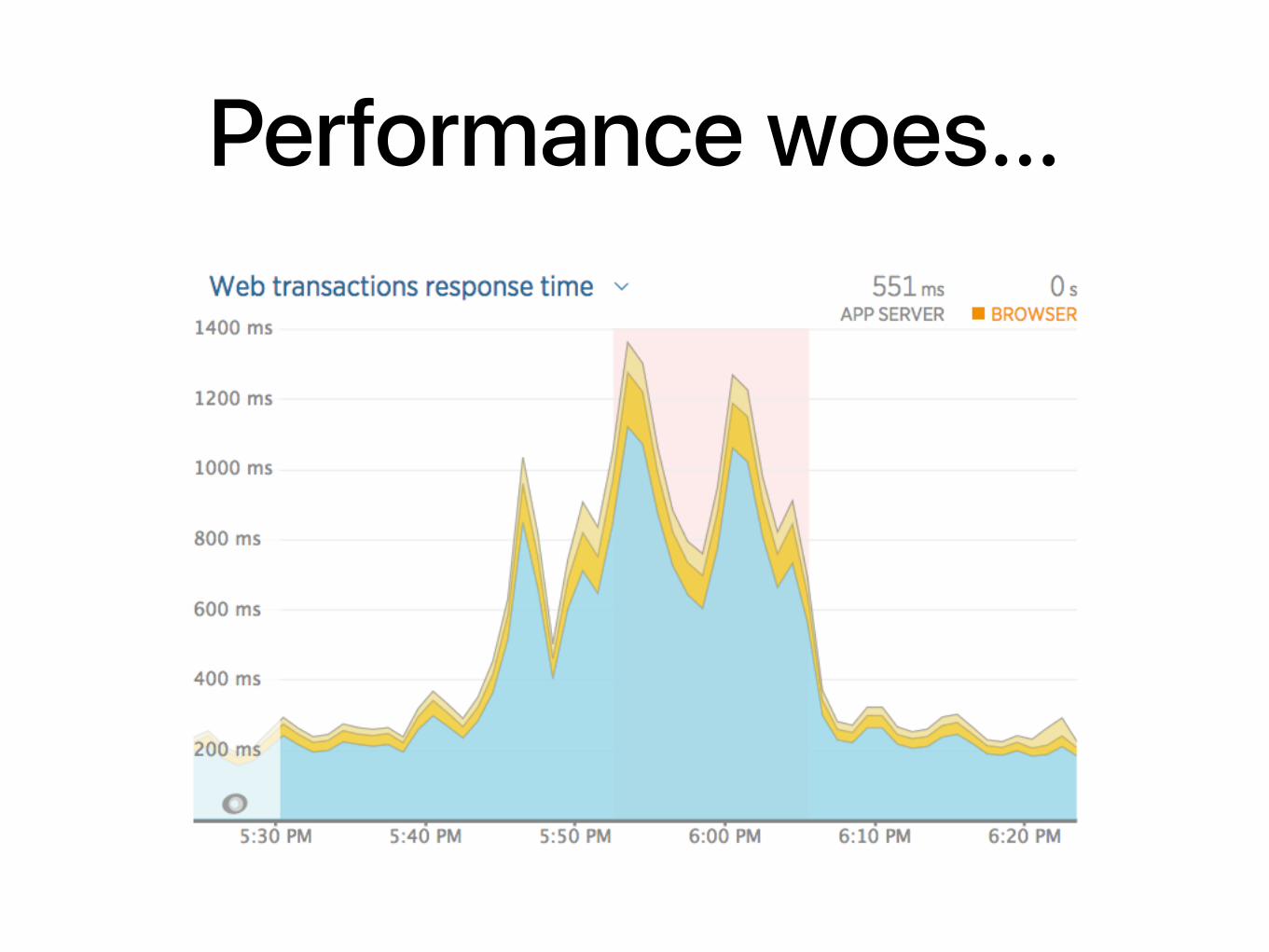
Performance woes…
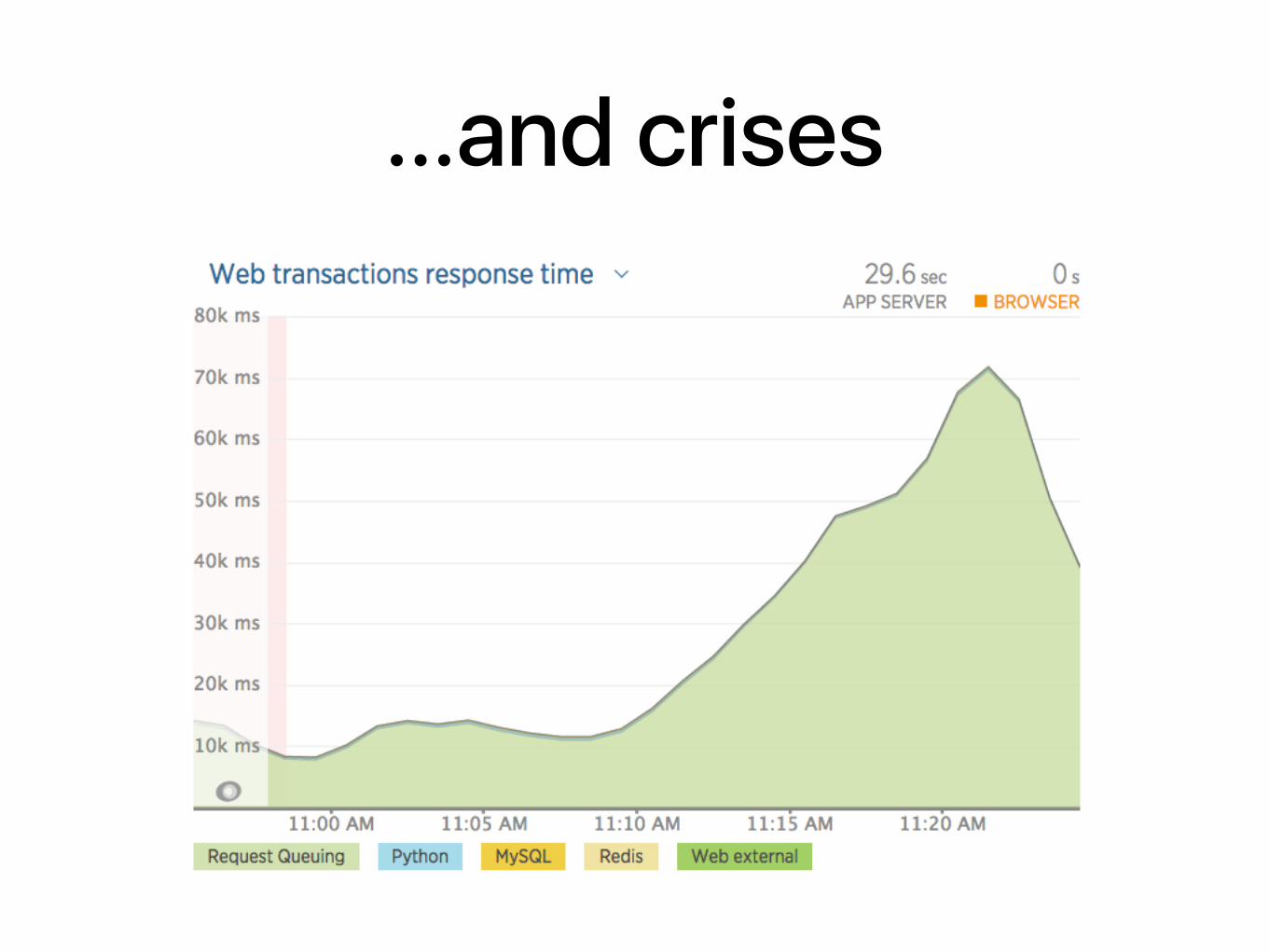
…and crises
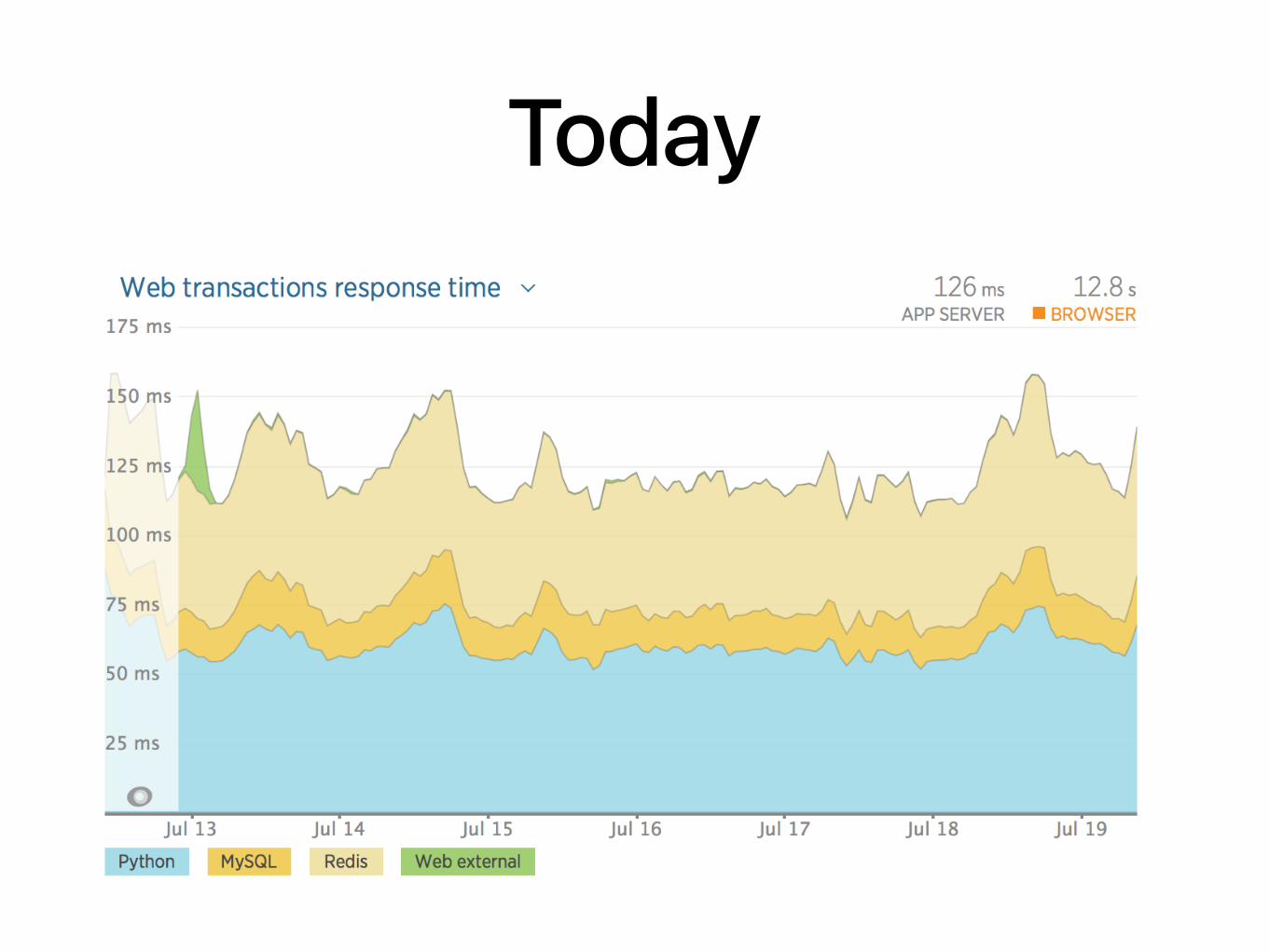
Today

First steps
• Monitoring and profiling: understand your bottlenecks
• Tackle the “easy” stuff first: query optimization, caching
• Don’t neglect front-end performance

Profiling
• Hosted services: New Relic, Opbeat
• django-debug-toolbar, django-silk
• cProfile / pyprof2calltree / KCacheGrind for masochists
• WSGI middleware

Monitoring
• Downtime notifications: Alertra, New Relic, Opbeat, Chartbeat
• Nagios and its many forks, Zabbix

Caching• Use a CDN
• Proxy cache (Nginx, Squid, Varnish)
• {% cache %}, @cached_property, CachedStaticFilesStorage, cached template loader
• Page caching frameworks
• ORM caching: a mixed bag

Query optimization
• .prefetch_related(), .select_related()
• prefetch_related_objects() for generic foreign keys
• .values() and .values_list() where it counts, if possible
• Database parameter tuning, judicious indexing

Throwing more hardware at the problem also works.
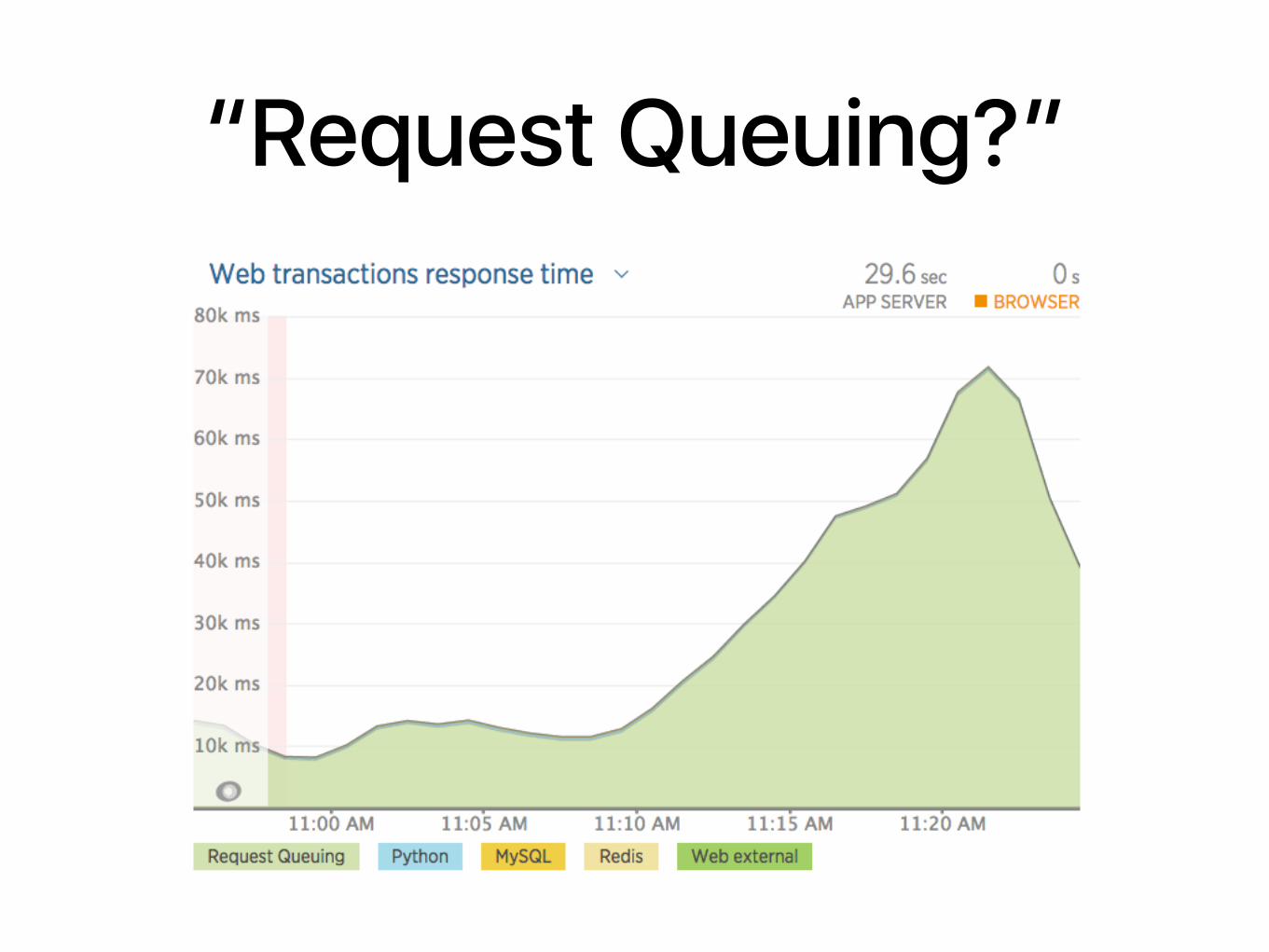
“Request Queuing?”
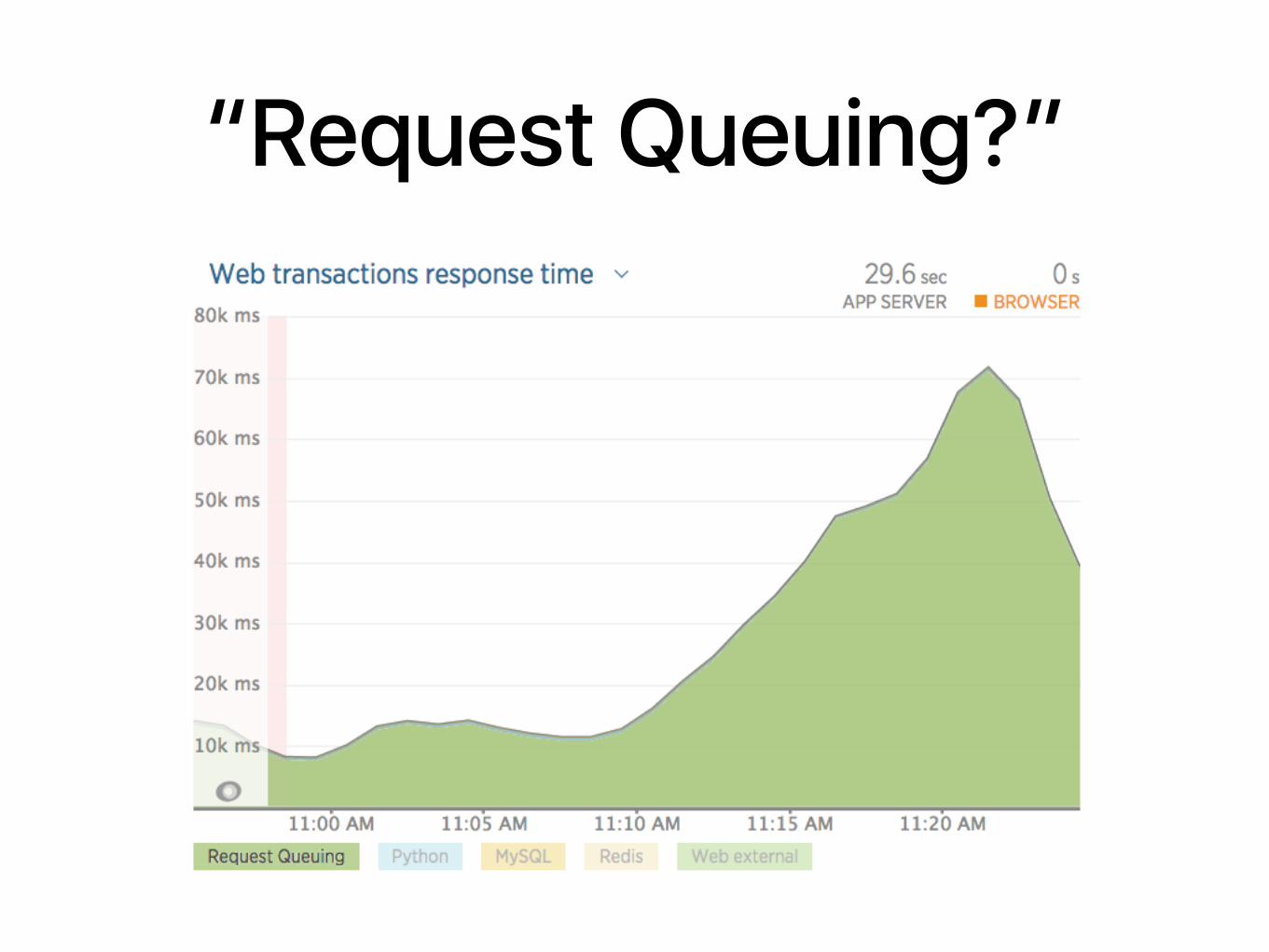
“Request Queuing?”
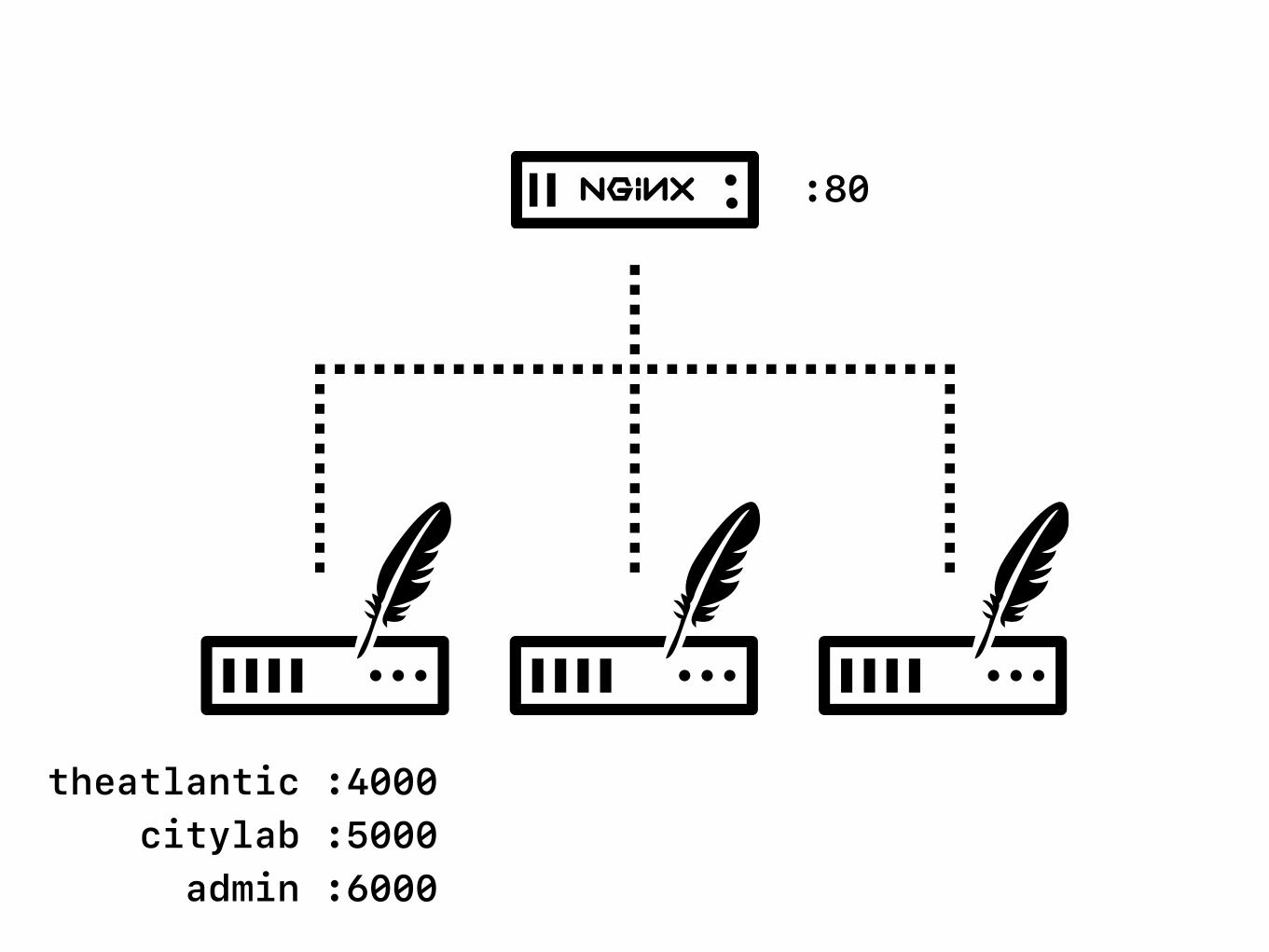
theatlantic :4000 citylab :5000 admin :6000
:80

upstream theatlantic { server apps1:4000;
server apps2:4000; server apps3:4000;
}
upstream citylab { server apps1:5000;
# ... }

upstream theatlantic_stage { server apps1:4500;
server apps2:4500; server apps3:4500;
}
upstream citylab_stage { server apps1:5500;
# ... }
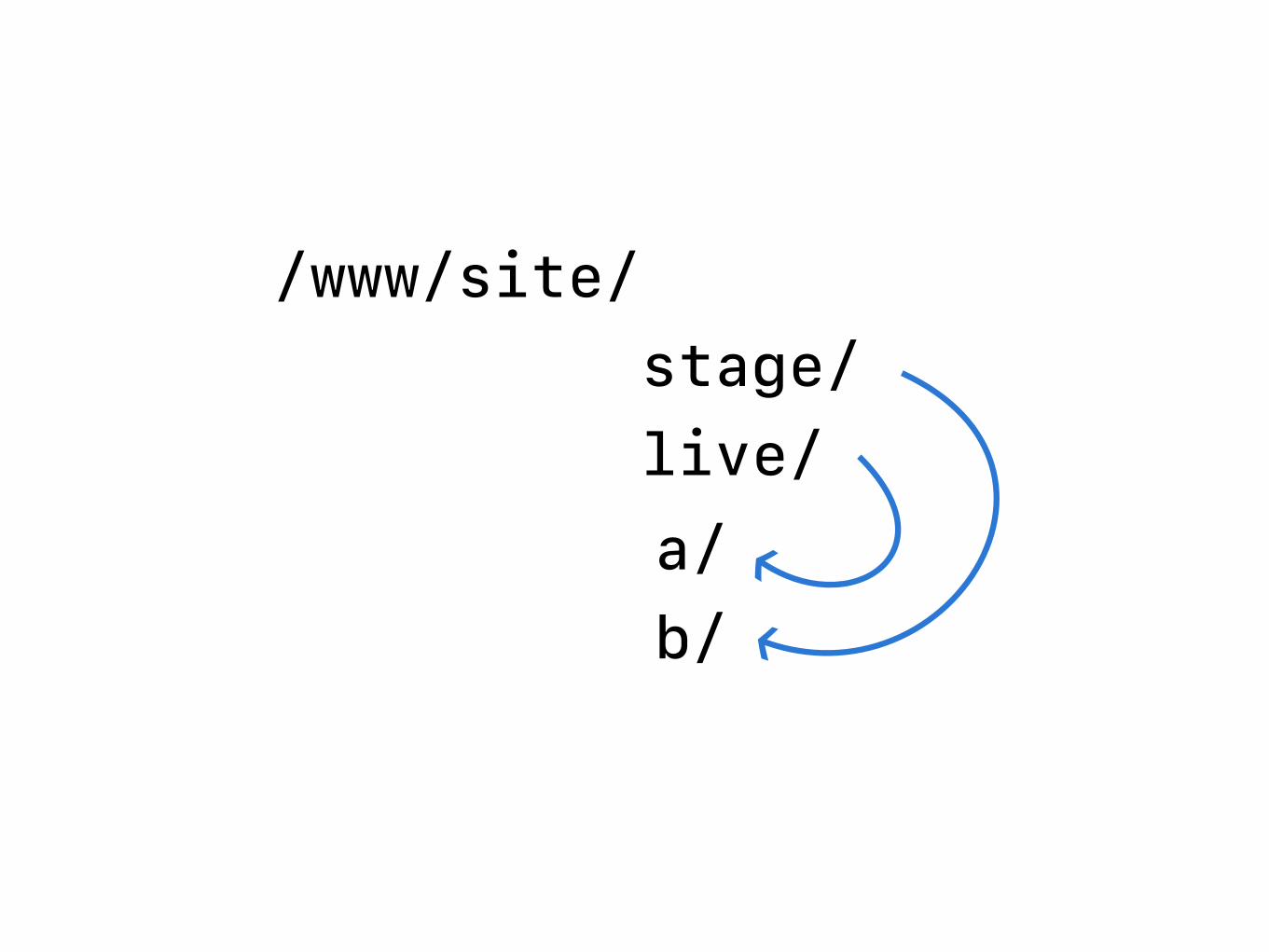
/www/site/ stage/ live/ a/ b/
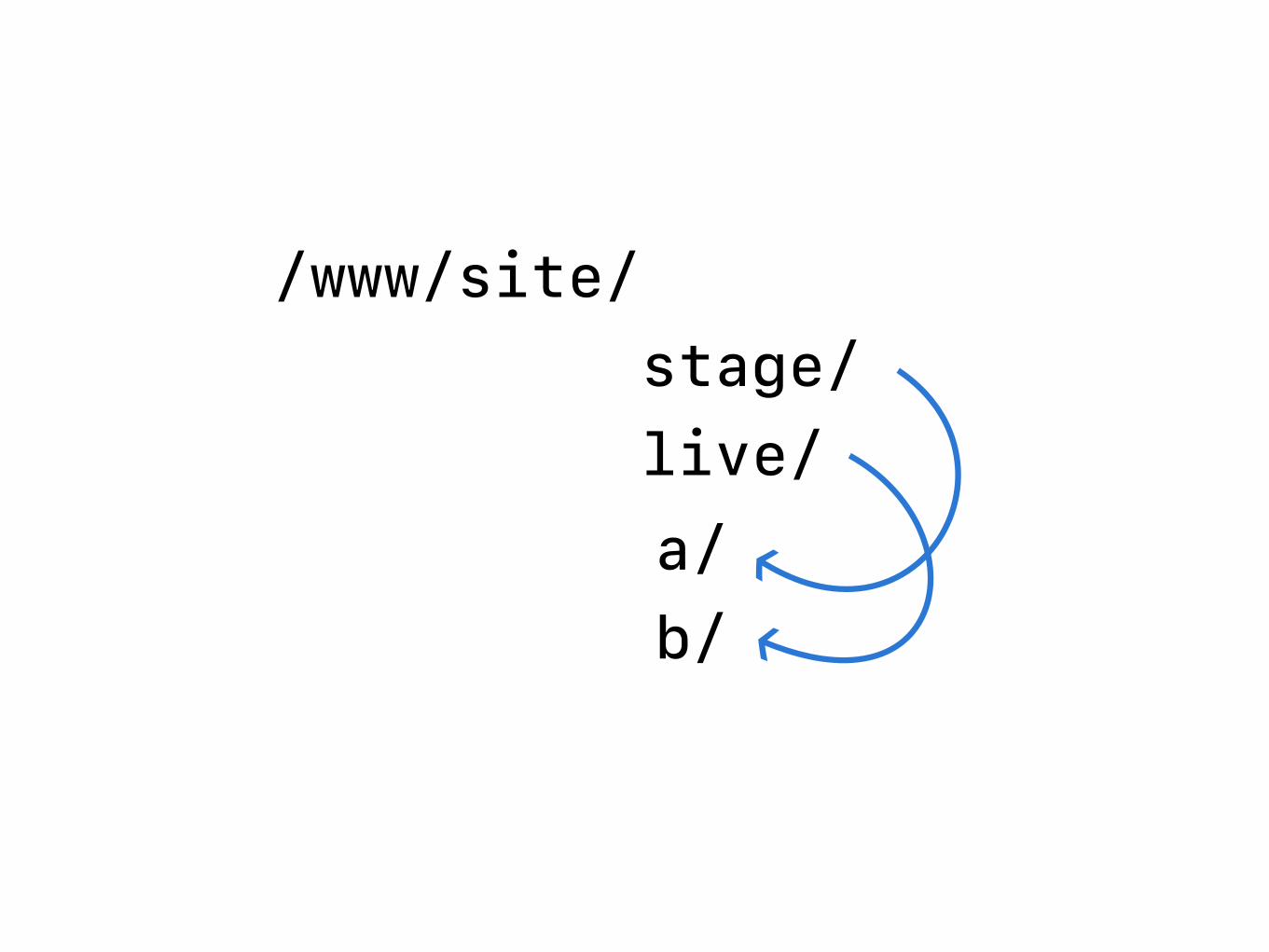
/www/site/ stage/ live/ a/ b/

Basic principles
• “a” and “b” repositories are always “production-ready.”
• Force as much Django code to load as possible before defining def application() in your WSGI file.
• Before swapping the upstreams, “warm up” the workers with concurrent HTTP requests.

mod_wsgi vs. uWSGI

mod_wsgi
• In general, comparable performance
• Runs on Apache HTTP server
• Mostly the work of a single developer
• Documentation terminally out-of-date
• Important configuration options missing or only discoverable in the release notes

uWSGI
• Broad and active community
• Very thorough documentation (overwhelming, in fact)
• Highly configurable







github.com/hadjango
@frankiedintino

High-Availability Django