hierarchische lineare modelle -...
TRANSCRIPT

Hierarchische lineare Modelle
(Lineare Mixed-Effects Models fur hierarchische Datenstrukturen beimetrischen Variablen)
Thomas Rusch
22. Juni 2011

Copyright c©2006 Thomas Rusch.
Permission is granted to copy, distribute and/or modify this document un-der the terms of the GNU Free Documentation License, Version 1.2 or anylater version published by the Free Software Foundation; with no InvariantSections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the li-cense is included in the section entitled
”GNU Free Documentation License“.
Die in dieser Publikation erwahnten Software- und Hardware-Bezeichnungensind in den meisten Fallen auch eingetragene Warenzeichen und unterliegenals solche den gesetzlichen Bestimmungen.
1

Inhaltsverzeichnis
1 Einleitung 5
2 Die Idee von HLM 72.1 Ein hierarchisches Modell auf zwei Ebenen . . . . . . . . . . . 72.2 Einfachere Submodelle . . . . . . . . . . . . . . . . . . . . . . 92.3 Verallgemeinerung des einfachen HLM auf zwei Ebenen . . . . 12
3 Parameterschatzung und Inferenz bei HLM 143.1 Parameterschatzung . . . . . . . . . . . . . . . . . . . . . . . 143.2 Hypothesentests . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Ein Anwendungsbeispiel 224.1 Einfache ANOVA mit Zufallseffekt . . . . . . . . . . . . . . . 234.2 Random-Coefficient Modell . . . . . . . . . . . . . . . . . . . . 254.3 Intercepts-and Slopes-as-Outcomes Modell . . . . . . . . . . . 27
5 Spezielle Anwendungsgebiete 325.1 Analyse von Longitudinaldaten und Veranderungsmessung . . 325.2 Meta-Analysen und andere Falle mit bekannter level-1 Varianz 44
6 Uberprufung der Angemessenheit von HLM 506.1 Zentrale Annahmen der HLM . . . . . . . . . . . . . . . . . . 516.2 Aufsetzen des level-1 Modells . . . . . . . . . . . . . . . . . . 526.3 Aufsetzen des level-2 Modells . . . . . . . . . . . . . . . . . . 596.4 Gultigkeit von Inferenz bei geringer Stichprobengroße . . . . . 66
7 Literaturverzeichnis 70
A R Code 74A.1 Auswertung der HSB82-Daten . . . . . . . . . . . . . . . . . . 74A.2 Auswertung der ORTHODONT-Daten . . . . . . . . . . . . . 79A.3 Auswertung der OVARY-Daten . . . . . . . . . . . . . . . . . 80
2

Tabellenverzeichnis
1 Testbare Hypothesen bei HLM . . . . . . . . . . . . . . . . . . 182 Hypothesentests bei HLM . . . . . . . . . . . . . . . . . . . . 193 Deskriptive Statistiken der Hsb82 Daten . . . . . . . . . . . . 234 Ergebnisse der einfachen ANOVA . . . . . . . . . . . . . . . . 245 Ergebnisse des Random-Coefficients Modell . . . . . . . . . . . 276 Ergebnisse des Intercept-and Slopes-as-Outcomes Modell . . . 307 Ergebnisse des Modells mit zufalligem Intercept fur die Orthodont-
Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378 Ergebnisse des Random-Coefficients Regression Modell fur die
Orthodont-Daten . . . . . . . . . . . . . . . . . . . . . . . . . 379 Ergebnisse des Modells mit AR(1)-Fehlerstruktur fur die Ovary-
Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4110 Ergebnisse der 19 Studien zum Einfluss von Lehrererwartung
auf den IQ von Schulern (nach: Raudenbush & Bryk (2002, S.211)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
11 Ergebnisse der Modelle fur die Meta-Analyse zum Einfluss vonLehrererwartung auf IQ von Schulern (nach: Raudenbush &Bryk (2002, S. 213 & 216)) . . . . . . . . . . . . . . . . . . . . 48
12 Univariate Statistiken mit bekannter Varianz (nach: Rauden-bush & Bryk (2002, S. 219)) . . . . . . . . . . . . . . . . . . . 50
13 Kofundierende Effekte der zusatzlichen Variable”ACADEMIC
BACKGROUND“ (nach: Raudenbush & Bryk (2002, S. 260)) 5514 Effekte bei Misspezifikation (nach: Raudenbush & Bryk (2002,
S. 271)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3

Abbildungsverzeichnis
1 Distanz von der Hypophyse zur pterygomaxillaren Spalte ge-gen das Alter der 11 Madchen . . . . . . . . . . . . . . . . . . 36
2 Geschatzte Wachstumskurven der 11 Madchen fur das Modellmit zufalligem Intercept . . . . . . . . . . . . . . . . . . . . . 38
3 Anzahl der Follikel mit > 10mm Durchmesser bei 11 Stutenuber einen Zyklus (±3Tage) . . . . . . . . . . . . . . . . . . . 39
4 Empirische Autokorrelationsfunktion der Residuen fur die Ovary-Daten nach Schatzung eines Modells mit unabhangigen Zu-fallseffekten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5 Plot der gefitteten und der beobachteten Werte fur die Ovary-Daten fur das Modell mit AR(1)-Fehlerstruktur . . . . . . . . 42
6 QQ-Plot der Residuen beim Intercepts and Slopes as Outco-mes Modell der HSB82-Daten . . . . . . . . . . . . . . . . . . 59
7 Scatterplot der Zufallseffekte fur offentliche und private Schu-len bei den HSB82-Daten . . . . . . . . . . . . . . . . . . . . . 64
8 QQ-Plot der Zufallseffekte beim Intercepts and Slopes as Out-comes Modell der HSB82-Daten . . . . . . . . . . . . . . . . . 65
4

1 Einleitung
In den Sozialwissenschaften und der Psychologie kommt es relativ oft vor,dass hierarchische Datenstrukturen zu untersuchen sind. So kann man zumBeispiel daran interessiert sein, wie das Mathematikwissen von Schulern vonderen soziookonomischem Status beeinflusst wird. Diese Schuler sind aber ineinen spezifischen Kontext eingebettet, z. B. der jeweiligen Klasse, die wie-derum zu einer ganz bestimmten Schule gehort, die sich in einer bestimmtenStadt eines bestimmten Landes befindet. Hierarchische Modelle, sowohl li-nearer als auch nichtlinearer Natur, stellen eine Moglichkeit dar, diese denDaten inharente hierarchische Struktur in die Analyse miteinzubeziehen.
Auch die Stichprobenerhebung kann zu so einer hierarchischen Strukturfuhren, z. B. beim Cluster-Sampling, oder das Studiendesign selbst ermoglichtkeine vollstandige Randomisierung (quasi-experimentelle Designs oder Block-designs) und fuhrt zu Daten von Personen, die in spezifische Gruppen naturli-cherweise eingebettet sind. Genauso fuhrt der Versuch, aus den Ergebnissemehrerer Studien generelle Resultate zu synthetisieren, zu einer hierarchi-schen Struktur der Daten, da die Personen Teil der jeweiligen Untersuchungensind und diese verschiedene Charakteristika aufweisen konnen. Ebenfalls alshierarchische Struktur konnen Longitudinaluntersuchungen mit wiederholtenMessungen gesehen werden, da dort die einzelnen Zeitpunkte der Messung indie Personen eingebettet sind. Diese konnen wiederum in z. B. unterschied-lichen Regionen leben, wodurch eine weitere Ebene hinzukommen kann.
Gerade die Wechselwirkungen zwischen den einzelnen Variablen auf allenEbenen und der primar interessierenden abhangigen Variablen zu untersu-chen, ist mit konventionellen Methoden nicht wirklich moglich, da etliche An-nahmen, die diese treffen, in solchen hierarchischen Strukturen nicht oder nurselten erfullt sind. Dies kann (besonders wenn diese Methoden unreflektiertangewendet werden) zu verzerrten Schatzungen fuhren - v.a. der Standard-fehler -, zu falschen Entscheidungen bei Hypothesentests, zu Informationsver-lust bei der Analyse aggregierter Daten etc. Auch die explizite Formulierungund Uberprufung bestimmter Hypothesen uber Phanomeme innerhalb undzwischen den Ebenen ist mit herkommlichen statistischen Verfahren nichtzufriedenstellend moglich. Zwar konnten manche dieser Probleme mit durch-dachten Methoden gelost werden, doch bieten HLM ein integrierteres, relativflexibles Methodenset, dass diese Probleme behandeln kann.
Im Folgenden soll die Idee hierarchischer Modelle beschrieben werden, so-wie - anhand einiger Anwendungsbeispiele - die Flexibilitat und die Vorteiledieses Zugangs verdeutlicht werden. Allerdings muss und wird auch daraufhingewiesen werden, wo die Grenzen der HLM liegen und dass deren unre-flektierte Anwendung ebenso problematisch ist, wie bei allen anderen statis-
5

tischen Methoden. Die Arbeit orientierte sich in erster Linie an den Buchernvon Raudenbush & Bryk (2002) und Pinheiro & Bates (2000).
Die Ideen und Modelle, die im Folgenden beschrieben werden, firmiertenunter einer Vielzahl von Namen in unterschiedlichen Fachgebieten, z.B. mul-tilevel linear models in der Soziologie (Goldstein, 1995), mixed-effects modelsoder random-effects models in der Biometrie (Singer, 1998; Pinheiro & Bates,2000), random-coefficient regression models in der Okonometrie (Longford,1993) oder auch covariance components models (Longford, 1987). Zwar sindalle diese nicht exakt gleich, doch sind die Unterschiede marginal und ver-schwinden durch leichte Adjustierungen der Modelle bzw. stellen Sonderfalledar. So sind HLM eine spezielle Form der mixed-effects models, bei der dieModelle auf den unterschiedlichen Ebenen getrennt spezifiziert werden. Beider Kombination der Ebenen-Modelle in ein einziges Modell und der Par-tition der Effekte in fixe und zufallige Effekte, erhalt man ein mixed-effectsmodel. Ich habe aber den Terminus HLM beibehalten, da er das Hauptan-wendungsfeld der mixed models in der psychologischen Forschung - i.e. dieAnwendung bei genesteten Datenstrukturen - meiner Ansicht nach relativgut widerspiegelt und manche mixed-effects models, die in okonometrischenoder biometrischen Untersuchungen verwendet werden, fur die Psychologienur bedingt sinnvoll sind (v.a. im Hinblick auf Interpretation und praktischeRelevanz).
Es ist auch eine Reihe von Software erhaltlich um die entsprechendenModelle zu schatzen und zu testen, z. B. HLM (Raudenbush et al. 2006),MIXREG (Hedeker & Gibbons, 1996) und VARCL (Longford, 1988). Ichbeschranke mich in dieser Arbeit auf die Verwendung des R Packages nlme(Pinheiro et al., 2006). Auch in anderen Programmen, die eine Prozedurzur Berechnung von mixed-effects models enthalten, konnen diese Modelleberechnet werden (z.B. die SAS Proc Mixed (Littel et al., 1996)).
Die Struktur der folgenden Arbeit ist dergestalt, dass zuerst die Idee derHLM anhand eines 2-Level-Modells erklart und mittels eines Beispiels veran-schaulicht wird. Danach folgen Beschreibungen unterschiedlicher Hypothesenund Verfahren zur Testung derselbigen. Anschlieıßend folgen weitere Anwen-dungen der HLM bei Meta-Analysen und in der Veranderungsmessung. Derabschließende Abschnitt konzentriert sich auf die Uberprufung der Angemes-senheit von HLM und die Grenzen dieser Methoden.
6

2 Die Idee von HLM
2.1 Ein hierarchisches Modell auf zwei Ebenen
In diesem Kapitel wird die Idee und die Logik der HLM anhand eines Bei-spiels fur 2-Level-Modelle veranschaulicht, wobei von bekannten Konzeptendes linearen Modells ausgegangen wird (ANOVA und Regression), die alsSpezialfall der HLM angesehen werden konnen.
Als Beispiel verwende ich den Einfluß einer unabhangigen Variable SES(soziookonomischer Status) eines Schulers i (i = 1...I) auf eine abhangige Va-riable MACH (Leistungen in Mathematik) in einer ganz bestimmten Schule.Unabhangig von etwaigen Operationalisierungsfragen, kann dieser durch einlineares Regressionsmodell beschrieben werden als:
Yi = β0 + β1Xi + ri, (1)
wobei β0 den Intercept (erwartete Leistung eines Schulers mit SES=0), β1 dieerwartete Anderungsrate in der Leistung bei einer Zunahme von SES um eineEinheit (wobei hier SES metrisch ist) und ri den Fehlerterm darstellt, dermit einer einzelnen Person assoziiert ist. Es gelten die Standardannahmen deslinearen Models, ri ∼ N(0, σ2). Bei diesen Daten ist es sinnvoll die erklarendeVariable zu zentrieren, damit der Intercept eine ansprechende Interpretationhat. Dies wird in folgendem gemacht, SES wird um das “Mittel“ zentriert.β0 ist nun die mittlere Leistung in Mathematik.
Wenn man nun davon ausgeht, dass die entsprechenden Daten einer ande-ren Schule ebenfalls erhoben worden sind, kann fur beide ein Modell wie in (1)erstellt werden. Die Parameter werden sich aber vermutlich unterscheiden.Falls es eine randomisierte Zuordnung der Schuler zu den Schulen gegebenhatte, konnte man aus diesen Unterschieden Schlusse uber die Schulen zie-hen, namlich in welcher Schule die Mathematikleistung hoher ist (Intercept)und welche Schule “fairer“ ist, d.h. wo der Einfluß des Status weniger großist (Slope). Was man aber vermuten kann, ist, dass die Schuler hochstwahr-scheinlich nicht zufallig den Schulen zugeordnet wurden. HLM bieten dieMoglichkeit, diese Unterschiede in der Schulerzusammensetzung der Schulenzu berucksichtigen, doch vorerst wird Randomisierung angenommen.
Man kann diese zwei Schulen als Stichprobe aus einer ganzen Populationvon Schulen sehen, in denen Intercept und Slope verschieden sind. Die Para-meter sind dann Zufallsvariablen. Angenommen es gabe eine Zufallsstichpro-be aus J Schulen einer Population, wobei J groß ist. Das Regressionsmodellinnerhalb jeder Schule j hatte dann die Form
Yij = β0j + β1j(Xij − X.j) + rij, (2)
7

wiederum mit rij ∼ N(0, σ2). Weiters wird angenommen, dass der Zufalls-vektor (β0j, β1j) bivariat normalverteilt ist, mit den Parametern
E(β0j) = γ0, V ar(β0j) = τ00
E(β1j) = γ1, V ar(β1j) = τ11
Cov(β0j, β1j) = τ01
γ0 ist der erwartete Schulmittelwert der Mathematikleistung in der Popula-tion der Schulen, γ1 die erwartete Anderungsrate in der Population, τ00 diePopulationsvarianz zwischen den Schulmitteln, τ11 die Populationsvarianzdes Slopes und τ01 die Populationskovarianz zwischen Intercept und Slope.Diese Parameter sind naturlich nicht bekannt (oder nur sehr selten), son-dern mussen aus Daten geschatzt werden - die Behandlung der Parameter indiesem Kapitel dient somit nur der Verdeutlichung der Idee und des Prinzips.
Angenommen die wahren Werte jedes Mittelwertes und Slopes pro Schuleseien bekannt. Sofern die Kovarianz nicht 0 ist, konnte man den Zusammen-hang der beiden Parameter pro Schule wiederum durch irgendwelche Varia-blen zu erklaren versuchen. So konnten Schulen mit einer hohen mittlerenLeistung, einen geringen Zusammenhang zwischen Leistung und SES haben,das entsprache einer negativen Korrelation zwischen β0j und β1j. Man kanndementsprechend ein Modell formulieren, das es ermoglicht β0j und β1j zumodellieren, z.B. anhand spezieller “ubergeordneter“ Variablen, die sich aufSchulcharakteristika beziehen (Geld, Schultyp, etc.). Eine solche Variable,Wj konnte eine Indikatorvariable sein, die 0 annimmt wenn es sich um eineoffentliche und 1 wenn es sich um eine private Schule handelt. Diese konntesowohl den Mittelwert der Leistung pro Schule als auch den Zusammenhangvon Leistung und SES beeinflussen. Ein Modell dieser Art sahe dann so aus:
β0j = γ00 + γ01Wj + u0j (3)
β1j = γ10 + γ11Wj + u1j (4)
Dabei ist γ00 die mittlere Leistung in offentlichen Schulen, γ10 die mittle-re Anderungsrate in offentlichen Schulen, γ01 und γ11 respektive sind diemittleren Differenzen zu γ00 bzw. γ10, die eine Privatschule aufweist. DieFehlerterme, u0j und u1j, sind die Einzeleffekte der Schule j auf Mittelwertbzw. Slope, bedingt auf Wj und sind normalverteilt mit Erwartungwert 0und Varianz-Kovarianz-Matrix
V C
[u0j
u1j
]=
[τ00 τ01
τ10 τ11
]= T (5)
wobei τ00 die Varianz der level-1 Intercepts, τ11 die Varianz der level-1 Slopesund τ01 die Kovarianz zwischen den level-1 Slopes und Intercepts bezeichnet.
8

In der obigen allgemeinen Formulierung sind es jeweils bedingte Varianzen-Kovarianz-Komponenten, da auf Wj kontrolliert wird.
Die Modelle (3) und (4) konnen so nicht geschatzt werden, da die β nichtbeobachtet werden. Doch wenn man (3) und (4) in (2) einsetzt, erkennt man,dass die Daten die gesamte notwendige Information zur Schatzung enthalten:
Yij = γ00 +γ01Wj + γ10(Xij − X.j) + γ11Wj(Xij − X.j)
+u0j +u1j(Xij − X.j) + rij (6)
(6) ist ein spezielles mixed-effects model fur dieses Problem. Auch sieht man,dass die Fehlerstruktur, u0j + u1j(Xij − X.j) + rij, relativ kompliziert ist,zumindest im Vergleich zu der Fehlerstruktur beim herkommlichen linearenModell. Es gibt Heteroskedastiztat und Abhangigkeiten der Fehler unterein-ander (u0j und u1j sind fur jeden Schuler in Schule j gleich). Die Schatzungfindet deshalb uber spezielle iterative ML-Methoden statt. Falls u0j und u1j
fur jedes j gleich null waren, erhielte man ein Standardregressionsmodell,d.h. die Koeffizienten auf Schulebene waren dann fixe Effekte. Gleichzeitigzeigt sich in (6), dass die angesprochene fehlende Randomisierung in die-sem Modell berucksichtigt werden kann, d.h. dadurch zu Stande kommendeVarianzkomponenten uber Zufallseffekte mitaufgenommen werden konnen.
In der Terminologie von Raudenbush & Bryk (2002) heißt Gleichung (2)das level-1 Modell; Die Gleichungen (3) und (4) gemeinsam heißen das level-2Modell und Gleichung (6) wird das kombinierte Modell genannt. Im obigenBeispiel sind die Objekte auf level-1 die Schuler und die auf level-2 die Schu-len. Die Fehler rij sind die level-1 Zufallseffekte und die u0j und u1j level-2Zufallseffekte. Dieselben Bezeichnungen gelten auch fur die Varianzen, dieKovarianz und die β und γ als Koeffizienten.
2.2 Einfachere Submodelle
Gegeben, dass es nur einen level-1 Prediktor, Xij, und nur einen level-2 Pre-diktor, Wj, gibt, ist Modell (6) bzw. (2), (3) und (4) ein vollkommen konditio-nales hierarchisches Modell und dementsprechend generell. Durch Restriktio-nen, v.a. durch Nullsetzen bestimmter Parameter, resultieren einfachere Mo-delle, von denen manche den statistischen Standardverfahren entsprechen.Im folgenden sollen ein paar dieser Modelle kurz vorgestellt werden.
Einfache ANOVA mit Zufallseffekten
Dies ist das einfachste HLM (bei Weglassen des Zufallseffektes wurde keinehierarchische Struktur mehr notwendig sein). Auf level-1 wird β1j fur alle j
9

gleich null gesetzt, wodurch (2) zu
Yij = β0j + rij (7)
wird. Die Annahmen des klassischen linearen Modells werden auch hier auflevel-1 angenommen. Das level-2 Modell ist
β0j = γ00 + u0j, (8)
und das kombinierte Modell
Yij = γ00 + u0j + rij, (9)
offenbart die ANOVA-Struktur, wobei der Gruppeneffekt hier allerdings alszufallig definiert wurde. Die Varianz der abhangigen Variablen lasst sich so-mit zerlegen in
V ar(Yij) = V ar(u0j + rij) = τ00 + σ2. (10)
Klarerweise muß die Annahme der Unkorreliertheit und somit - aus der An-nahme der Normalverteilung - Unabhangigkeit der u0j und der rij gelten,damit die Zerlegung korrekt ist. Dieses simple Modell ist in einer Analyseoft brauchbar. Erstens ergibt sich ein Punktschatzer und ein KI fur das Ge-samtmittel, desweiteren ermoglicht es eine Abschatzung, wieviel der Varianzder abhangigen Variablen auf den einzelnen Ebenen erklart werden kann. σ2
ist dabei die Varianz innerhalb der Gruppen und τ00 die Varianz zwischenden Gruppen. Damit kann dann auch der Interklassen-Korrelationskoeffizientberechnet werden, mittels
ρIC =τ00
(τ00 + σ2). (11)
Dieser misst den Varianzanteil der zwischen den level-2 Objekten auftritt.
Einfache ANOCOVA mit Zufallseffekten
Eine Erweiterung des vorher dargestellten Modells ist durch die Hinzunahmeeines Prediktors auf level-1 gekennzeichnet. Formel (2) ist hier das level-1Modell, allerdings findet eine Zentrierung um das Gesamtmittel statt. Aufder zweiten Ebene werden die Parameter γ01 und γ11 sowie der Zufallseffektu1j (∀ j) gleich null gesetzt. Das level-1 Modell sieht dann wie folgt aus
Yij = β0j + β1j(Xij −X ..) + rij,
10

und die level-2 Modelle
β0j = γ00 + u0j
β1j = γ10
Die Zentrierung um das Gesamtmittel findet deswegen statt, weil der Effektfur alle Xij fur jede Gruppe als gleich angenommen wird. Das kombinierteModell
Yij = γ00 + γ10(Xij − X..) + u0j + rij
zeigt wiederum die Ahnlichkeit zur klassischen ANOCOVA, nur dass derGruppeneffekt, u0j, als zufallig gesehen wird. Die level-1 Parameter, β0j undσ2, haben nun die zusatzliche Interpretation, dass nach den Differenzen inXij, also nach der level-1 Kovariate, adjustiert wurde.
Dieses Modell kann naturlich auch auf die Hinzunahme von level-2 Ko-variaten verallgemeinert werden, in der Formel (3) wird der Koeffizient γ01
dabei nicht auf null gesetzt. Die Annahme der ANOCOVA, dass γ10 bzw. β1j
fur jede Gruppe gleich ist, wird im nachsten Abschnitt fallen gelassen.
Random-Coefficients Regression Model
Die dargestellten Spezialfalle bisher waren random-intercept models, nun sollnoch ein Spezialfall von (6) dargestellt werden, bei dem die level-1 Slopes alszufallig uber die level-2 Objekte variierend betrachtet werden. Dies kommtauch recht haufig in der Anwendung vor. Das einfachste Modell dieser Gruppeist das random-coefficients regression model, welches auf level-1 den Interceptund (mehrere) Slope(s) als zufallig spezifiziert, aber es wird nicht versuchtderen Variation mittels unabhangiger Variablen zu erklaren. Dies war ubri-gens historisch gesehen einer der Vorlaufer der mixed-effects models und nochimmer das am weitesten verbreitete dieser Modelle (de Leeuw & Kreft, 1986).
Das level-1 Modell entspricht dabei haargenau (2), in (3) wird aber γ01
und in (4) γ11 gleich null gesetzt. Somit bleiben nur die Mittel uber die level-2 Objekte und die fur jedes Objekt j spezifische Abweichung bei Interceptund Slope ubrig. Die formelle Reprasentation der Varianz-Kovarianz-Matrixist in (5) ersichtlich, allerdings handelt es sich nun um unbedingte Varianz-Kovarianz-Komponenten, da keine Kovariaten im Modell auf level-2 enthal-ten sind. Eine weitere Verallgemeinerung, d. h. Modellierung der Variationder Koeffizienten, fuhrt dann zu den Intercepts-and-Slopes-as-Outcomes mo-dels(IaSaO) wie in (2), (3) und (4).
Die Vorgangsweise der Vereinfachung des Modells aus (6) - je nach inter-essierender Fragestellung - sollte nun nachvollziehbar sein, fur weitere Sub-modelle vgl. Raudenbush & Bryk (2002).
11

2.3 Verallgemeinerung des einfachen HLM auf zweiEbenen
In diesem Teil wird kurz darauf eingegangen, wie ein HLM mit multipler Re-gressionsstruktur auf beiden Ebenen aussahe bzw. wie die Fehlerstrukturenauf den Ebenen verallgemeinert werden konnen.
Multiple Regressoren auf Ebene 1 und 2
Angenommen, es stehen Q Regressoren auf level-1 und Sq Regressoren auflevel-2 (Sq daher, da die Anzahl der Regressoren auf level-2 nicht zwingenddieselben sein mussen) zur Verfugung. Das allgemeine Modell sieht folgen-dermaßen aus
Yij = β0j +
Q∑q=1
βqjXqij + rij wobei rij ∼ N(0, σ2), (12)
und
βqj = γq0 +
Sq∑s=1
γqsWsj + uqj q = 1, . . . , Q. (13)
bzw. in Matrixschreibweise (pro Gruppe; fur ein Gesamtmodell fallen dieIndizes einfach weg)
Yj = Xjβj + rj, rj ∼ N(0, σ2Inj) (14)
undβj = Wjγ + uj, uj ∼ N(0,T). (15)
Yj ist ein nj×1 Vektor an Beobachtungen, Xj eine nj×(Q+1) Designmatrixvon Regressoren, βj ein (Q + 1) × 1 Vektor an unbekannten Parametern, rjein nj × 1 Vektor von Zufallsfehlern und Inj
die nj × nj Einheitsmatrix. Wj
ist eine (Q + 1) × S Matrix von Prediktoren auf level-2 (S ist hierbei dieZahl aller moglichen Pradiktoren, Sq ≤ S), die eine Blockdiagonalform hatvon der jede Zeile zu einem βqj gehort, γ ein S × 1 Vektor unbekannter fixerEffekte, uj ein (Q+ 1)× 1 Vektor der level-2 Fehler und T ist eine beliebige(Q+ 1)× (Q+ 1) Varianz-Kovarianz-Matrix.
Das kombinierte Modell erhalt man durch Einsetzen von (15) in (14).Wenn man die Struktur noch ein wenig andert, dann erhalt man eine Form,die sehr an ein mixed-effects model erinnert. Die in Xj enthaltenen level-1Variablen haben entweder einen fixen (γ) oder einen zufalligen Effekt (uj).Nun kann man eine Matrix Zj definieren, die nur diejenigen Spalten von Xj
enthalt, die mit einem Zufallseffekt assoziiert sind. Das ist typischerweise
12

eine Submatrix von Xj. Man kann die beiden Matrizen aber theoretisch auchunabhangig voneinander spezifizieren (z.B. konnten einige level-1 Variablennur einen Zufallseffekt, aber keinen fixen Effekt haben). In Xj sind dannalle Spalten, die nicht in Zj vorkommen, mit fixen Effekten assoziiert. Daskombinierte Modell sieht dann folgendermaßen aus:
Yj = XjWjγ + Zjuj + rj. (16)
Diese Formel ist der Darstellung eines mixed-effects model sehr ahnlich, derUnterschied besteht darin, dass die level-2 Designmatrix, Wj, hier explizitauftaucht. Das betont die hierarchische Struktur, was inhaltlich fur genes-tete Datenstrukturen Sinn macht. Mathematisch ist es aber aquivalent. Diemarginale Varianz von Yj ist
V ar(Yj) = ZjTZ′j + σ2Inj. (17)
Verallgemeinerung der Fehlerstrukturen
Die vorgestellten Modelle setzen unabhangige, homogene Fehler auf den bei-den Ebenen voraus. Die Erweiterung auf komplexere Fehlerstrukturen istaber relativ einfach. So konnte die level-1 Varianz fur jedes level-2 Objektverschieden sein, σ2
j , oder als Funktion einer level-1 Variable. Auch auf level-2 konnen verschieden Kovarianzstrukturen fur verschieden Subgruppen anlevel-2 Objekten modelliert werden. Die Matrix T wurde somit fur verschie-dene Subgruppen unterschiedlich aussehen. In R werden verschiedenste vor-definierte Strukturen angeboten, sowohl fur Heteroskedastie (varFunc) alsauch fur abhangige Fehler, darunter MA(q) oder AR(p) oder ARMA(p,q)-Prozesse (corStruct).
Erweiterung uber das 2-level Modell hinaus
Die bisher dargestellten Ideen sind direkt auf mehr als zwei Ebenenen ubert-ragbar. Außerdem kann durch das verallgemeinerte lineare Modell die Ideeder HLM auch auf nichtkontinuierliche abhangige level-1 Variablen, wie Haufig-keitsdaten oder kategoriale Variablen, angewendet werden. Auch die Verwen-dung nichtlinearer Modelle ist moglich. Die Modellierung selbst wird dabeinur unwesentlich komplizierter, was naturlich nicht fur die Schatzmethodengilt. Das R Package nlme bietet diese Schatzmethoden an, zumindest fur kon-tinuierliche Variablen (verallgemeinerte hierarchische lineare Modelle werdennicht unterstutzt). Dies sind allerdings schon relativ fortgeschrittene Metho-den und es soll deswegen auf Pinheiro & Bates (2000) verwiesen werden.
13

3 Parameterschatzung und Inferenz bei HLM
In diesem Abschnitt soll auf die Moglichkeiten zur Parameterschatzung imRahmen der HLM und darauf basierende Hypothesentests vorgestellt werden,wobei letzteres mehr Raum erhalt. Die Moglichkeit zur Parameterschatzungwird nur kurz abgehandelt.
3.1 Parameterschatzung
Es konnen in einem 2-level Modell 3 Arten von Parametern geschatzt werden:Die fixen Effekt, die zufalligen level-1 Koeffizienten und Varianz-Kovarianz-Komponenten. Die Schatzungen der einzelnen Parameter hangen naturlichvoneinander ab, man benotigt die Varianz-Kovarianz-Komponenten zur Be-stimmung der Koeffizienten und umgekehrt. Deshalb werden ublicherweiseiterative Prozeduren verwendet. Im folgenden wird nur kurz erwahnt, welcheSchatzmethoden es gibt, fur eine detailiertere Beschreibung sei auf Pinheiro& Bates (2000), Goldstein (1995) oder Raudenbush & Bryk (2002) verwiesen.
Fixe Effekte
Fur fixe Effekte kann man sowohl eine Punktschatzung durchfuhren, alsauch Konfidenzintervalle angeben. Prinzipiell werden die Erkenntnisse ausder Schatztheorie des linaren Modells verwendet. Fur die Schatzung von βjauf der Ebene 1 werden OLS herangezogen (ordinary least squares), fur dieSchatzung der γ, also die interessierenden fixen Effekte, GLS-Schatzer (ge-neralised least squares) basierend auf den Schatzungen der βj. Die Gewich-tung kommt aus der Inversen der (geschatzten) Varianz-Kovarianz-Matrixder Zufallseffekte plus der (geschatzten) Varianz-Kovarianz-Matrix der level-1 Fehler. Bei vollkommen balancierten Daten kann auch der OLS-Schatzer furlevel-2 verwendet werden. Ein (1-α)%-Konfidenzintervall fur die Punktschatzungγh ist
KI(1−α) = γh ± z(1−α/2)(√
(Vhh), (18)
wobei Vhh das h-te Diagonalelement der Varianz-Kovarianz-Matrix des GLS-Schatzers der fixen Effekte darstellt und z(1−α/2) das (1 − α/2)-Quantil derStandardnormalverteilung bezeichnet.
Schatzung der zufalligen level-1 Koeffizienten
Hierbei stellt sich die Frage, wie man mit diesen zufalligen Effekten verfah-ren soll, denn streng genommen durfte man sie ja nicht schatzen konnen,schließlich sind es Zufallsgroßen. Deswegen sagt man auch oft Vorhersage der
14

zufalligen Effekte, die man aber auch als Schatzung der konkreten Realisie-rungen der Zufallsvariablen interpretieren kann.
Es gibt zur Schatzung mehrere Moglichkeiten, drei seien kurz erwahnt:
• ML-Schatzung mittels GLS:
Dabei wird die gemeinsame Verteilung von Y und U und σ2 als Like-lihood herangezogen und anhand der Daten maximiert, es werden alsoalle Effekte geschatzt. In der Likelihoodfunktion ist ein “Strafterm“ furdie Schatzung des Zufallseffekts enthalten, somit ist dies ein shrinkageestimator. Fur die Matrixform aus (16) ergibt sich ein (penalisierter)GLS-Schatzer aus der gesamten Designmatrix fur die fixen Effekte undden resultierenden
”Schatzern“ der zufalligen Effekte. Der shrinkage
wirkt hierbei so, dass fur relative Prazisionsfaktoren Π (entspricht einerproportionalen Funktion der Inversen der Varianz-Kovarianz-Matrixder Zufallseffekte, T−1/(σ2)−1 = ΠTΠ) der Schatzung der Zufalls-effekte, die gegen 0 gehen, der GLS-Schatzer so gewichtet wird, dassdie Zufallseffekte mehr Gewicht bekommen (bis hin zu einer Regressi-on ohne Strafterm). Werden die relativen Prazisionsfaktoren aber groß,werden die Zufallseffekte so stark bestraft, dass sie null werden, so dasssich (16) auf eine Regression der Y auf die XjWj reduziert. Der Erwar-tungswert (bedingt auf die Zufallseffekte) der Linearkombination derfixen Effekte und den entsprechenden Kovariaten plus der Linearkom-bination der Zufallseffekte und deren entsprechenden Kovariaten heißtdann der beste, lineare, unverzerrte Pradiktor, (BLUP), den man alsgefitteten Werte bezeichnen konnte. Fur weitere Details siehe Pinheiro& Bates (2000).
• Empirische Bayes-Schatzung:
Hierbei werden im Grunde die β auf den beiden Ebenen geschatzt (mit-tels OLS auf der ersten Ebene und auf der zweiten Ebene wird derGLS-Schatzer verwendet) und miteinander anhand einer “optimalen“Gewichtungsmatrix, die man als Reliabilitatsmatrix oder Prazisionsma-trix (siehe vorher) bezeichnet, kombiniert. Dieser Schatzer ist verzerrtund zwar in Richtung des fixen Intercepts γ00. Jedoch ist sein erwarte-ter mean squared error kleiner (Lindley & Smith, 1972). Auch hierbeihandelt es sich um einen shrinkage estimator. Details sind in Rauden-bush & Bryk (2002) zu finden. Der shrinkage wirkt hier ungefahr sowie oben, aber das Konzept ist etwas verschieden, da der empirischeBayes-Schatzer explizit auf einer bayesianischen Begrundung fur denshrinkage beruht.
15

• Vollstandiger Bayes-Schatzer:
Hierbei wird nach dem Bayes’schen Zugang und mittels Markov ChainMonte Carlo geschatzt. Fur weiterfuhrende Informationen siehe Rau-denbush & Bryk (2002).
Naturlich existieren fur jeden dieser Schatzer auch Konfidenzintervalle. DasR Package nlme verwendet ML-Schatzer, wobei zwischen FML und REMLgewahlt werden kann. Fur vollstandige Bayes-Schatzung bietet sich BUGS(Bayesian Inference using Gibbs-Sampler) an (in der Windows-DistributionWinBUGS), das auch als R Package BRugs verfugbar ist.
Schatzung der Varianz-Kovarianz-Komponenten
Die Schatzung findet hierbei ublicherweise uber iterative maximum likelihoodSchatzungen statt. Dabei kann man zwei Zugange unterscheiden, auf die ichkurz eingehen mochte. Fur Methoden nach dem Bayesianischen Zugang seiauf Raudenbush & Bryk (2002, Kap. 13) verwiesen.
• Vollstandige maximum likelihood Methode (FML):
Hierbei werden die Schatzungen der fixen Effekte in die Likelihoodeingesetzt und diese wird dann maximiert (1. und 2. Ableitungen exis-tieren dadurch und Fisher Scoring oder ein Newton-Verfahren kannverwendet werden). Diese Likelihood beinhaltet also sowohl die Koef-fizienten, als auch die Varianz-Kovarianz-Komponenten. Allerdings istdiese Schatzung verzerrt, da nicht berucksichtigt wird, dass man durchdie Schatzung von γ Freiheitsgrade verliert.
• Restringierte maximum likelihood Methode (REML):
Diese berucksichtigt die geringere Anzahl an Freiheitsgraden. Es wirdnamlich die Verteilung sogenannter Fehlerkontraste (i.e. Linearkombi-nationen a′y derart, dass gilt: E(a′y) = 0; Residuen der OLS-Schatzersind ein solches Beispiel) bestimmt und diese wird als Likelihood ver-wendet. Dadurch wird auf die verlorenen Freiheitsgrade acht gegebenund die Schatzung ist weniger verzerrt. Diese Adjustierung nach derZahl der Freiheitsgrade ist auch der einzige Unterschied zwischen FMLund REML. Der mean squared error muss allerdings nicht kleiner sein.Der Nachteil dieser Methode ist, dass bei Testung auf Modellgultig-keit mittels eines Likelihood-Ratio-Tests nur Modelle verglichen werdenkonnen, die sich im Zufallseffekt und den Varianzkomponenten unter-scheiden, nicht aber Modelle, die unterschiedliche fixe Effekte postu-lieren (Hox, 1995). Trotzdem wird diese Methode in der Praxis meistbevorzugt.
16

3.2 Hypothesentests
Die Hypothesen uber die Parameter bzw. deren Schatzungen, die im letztenAbschnitt angesprochen wurden - fixe Effekte, Zufallseffekte auf level-1 unddie Varianz-Kovarianz-Komponenten - konnen im Rahmen des HLM auchgetestet werden. Dafur verwende ist die generelle Formulierung eines HLMauf level-1 hilfreich,
Yij = β0j +
Q∑q=1
βqjXqij + rij wobei rij ∼ N(0, σ2) (19)
βqj = γq0 +
Sq∑s=1
γqsWsj + uqj (20)
Wie schon bei (12) und (13) erwahnt, kann jedes βqj andere Prediktorenhaben, wodurch es pro Koeffizient Sq + 1 fixe Effekte gibt und insgesamtS =
∑q(Sq + 1) fixe Parameter im Modell enthalten sind. Fur die Fehler,
uqj, wird angenommen, dass sie multivariat normalverteilt sind, sodass
V ar(uqj) = τqq
und fur jedes Paar q und q′
Cov(uqj, uq′j) = τqq′
gilt.Hypothesen kann man nun fur jeden fixen Effekt, γqs, die zufalligen level-1
Koeffizienten, βqj, und die Varianz-Kovarianz-Parameter testen. Diese konnensich auch auf einen oder mehrere Parameter gleichzeitig beziehen. Tabelle 1gibt einen Uberblick uber die testbaren Hypothesen und Tabelle 2 verrat,welche Tests angewendet werden. Diese Tests sind im Grunde dieselben wiebei einem klassischen linearen Modellen und sollen im folgenden nochmalerwahnt werden.
Tests fur fixe Parameter
Ein-Parameter Tests Die Nullhypothese hierbei ist
H0 : γqs = c, (21)
wobei c typischerweise 0 ist. Das heisst, man testet, ob der Effekt eines level-2Prediktors einen signifikant von c verschiedenen Wert hat. Die Teststatistikist
t =γqs√Vγqs
, (22)
17

wobei γqs der maximum likelihood Schatzer fur γqs ist und Vγqs dessen geschatz-te Varianz. Da es sich um einen ML-Schatzer handelt ist diese Teststatistikasymptotisch normalverteilt, allerdings wird die t Verteilung mit J − Sq − 1Freiheitsgraden ublicherweise besser passen (Raudenbush & Bryk, 2002).
Multiparameter Tests Dieser Fall tritt beispielsweise auf, wenn man furalle level-2 Slopes testen will, ob sie 0 sind, d.h. dass eben eine Gruppenzu-gehorigkeit auf level-2 keinen Einfluss hat und somit als Prediktor aus demModell genommen werden kann. Im Beispiel von fruher hieße das, dass so-wohl offentliche als auch private Schulen ahnliche Intercepts und Slopes auflevel-1 haben (γ01 und γ11 sind 0). Die Matrixformulierung des Modells (15)hilft dabei, die Nullhypothese ist
H0 : C′γ = 0,
C′ ist hierbei eine Kontrastmatrix.Fur unbekannte Varianz V ar(βj) = ∆j, ist die Varianz von γ
V ar(γ) =(∑
W′j∆−1j Wj
)−1= Vγ.
Der Kontrastvektor C′γ, hat die Varianz
V ar(C′γ) = C′VγC = Vc,
wodurch sich die approximative Teststatistik (Raudenbush & Bryk, 2002)
H = γ′CV−1c C′γ, (23)
anbietet, die unter H0 eine asymptotische χ2-Verteilung hat, mit einer An-zahl an Freiheitsgraden, die der Anzahl der zu testenden Kontraste entspricht
Level-1Zufalls- Varianz-
Hypothesentyp Fixe Effekte Koeffizient Komponente
Ein-ParameterH0 γh = 0 βqj = 0 τqq = 0H1 γh 6= 0 βqj 6= 0 τqq > 0Multi-ParameterH0 C′γ = 0 C′β = 0 T = T0
H1 C′γ 6= 0 C′β 6= 0 T = T1
Tabelle 1: Testbare Hypothesen bei HLM
18

(Anzahl der Zeilen in C′). Multi-Parameter Tests bezuglich γ konnen in vie-lerlei Hinsicht nutzlich sein. Z.B. als globale Tests auf Zusammenhang zwi-schen kategoriellen level-2 Prediktoren und βqj-Parametern, Kontraste zwi-schen level-2 Prediktorenkategorien, um zu uberprufen ob eine level-2 Va-riable mit einer level-1 Variable wechselwirkt oder ob ein gewisses Subsetvon level-2 Prediktoren im Modell fur ein bestimmtes bqj benotigt wird. Dergroße Vorteil dieser Tests ist, dass eine Uberhohung der Risikos fur einenFehler 1. Art nicht stattfindet, wie es bei multiplen Ein-Parameter Testsder Fall ware. Auch F-Tests (allg. lineare Hypothesentests) sollten fur dieseHypothesen geeignet sein.
Falls zur Schatzung der Effekte die FML-Methode verwendet wurde, kannauch ein Likelihood-Ratio-Test verwendet werden. Raudenbush & Bryk (2002)schlagen vor ihn auf Basis der Devianz durchzufuhren. Die beiden Modelle,die miteinander verglichen werden sollen, sind zum ersten das “Nullmodell“,bei dem alle fixen Effekte, die als Hypothese 0 sind, ausgespart werden unddem “Alternativmodell“, das alle Effekte enthaltet. Die Teststatistik ist ge-geben als
D0 −D1, (24)
mit den Devianzen D0 fur das Nullmodell und D1 fur das Alternativmodell.Die beiden Devianzen sind
D0 = −2 log(L0) (25)
D1 = −2 log(L1). (26)
(24) hat eine asymptotische χ2-Verteilung mit einer Zahl an Freiheitsgra-den, die gleich der Differenz der Anzahl geschatzter Parameter in den beidenModellen ist. Große Werte fur (24) legen nahe, dass die Nullhypothese ver-worfen werden sollte, da es ein zu simples Modell um die Daten beschreiben
Level-1Zufalls- Varianz-
Hypothesentyp Fixe Effekte Koeffizient Komponente
Ein-Parameter t-Test t-Test univariate χ2
oder z-Test
Multi-Parameter allg. linearer allg. linearer Likelihood-Hypothesentest Hypothesentest Ratio-Test
Likelihood-Ratio-Test (nur FML)
Tabelle 2: Hypothesentests bei HLM
19

zu konnen darstellt. Der obige Zugang zur globalen Testung von Parameternuber Kontraste ist aber um einiges flexibler.
Tests fur die zufalligen level-1 Parameter
Ein-Parameter Tests Es kann - um beim Beispiel zu bleiben - von Inter-esse sein, ob ein Regressionskoeffizient in einer bestimmten Schule gleich nullist. Wiederum haben wir fur die Nullhypothese,
H0 : βqj = c, (27)
wobei normalerweise c = 0 ist. Die Teststatistik ist wie diejenige bei den fi-xen Effekte, namlich Schatzung durch Standardfehler der Schatzung, nur dasses nun darauf ankommt, wie die Schatzung der zufalligen Effekte zu Standekam (OLS, ML oder empirischer Bayes). Bei Verwendung der OLS-Schatzungist es der bekannte Standardfehler der Schatzung, Bei Verwendung des em-pirischen Bayes-Schatzers aber wird als “Standardfehler“ das q-te Diago-nalelement der
”Posterior-Dispersions-Matrix“ (die die Posterior-Varianzen
enthalt) der Parameter βqj verwendet. Die Teststatistik ist dann wiederumunter der Nullhypothese approximativ standardnormal verteilt (Raudenbush& Bryk, 2002). Bezuglich der verwendeten Methode zur ML-Schatzung istzu sagen, dass mittels REML ein hoherer Standardschatzfehler berechnetwerden wird, v.a. wenn die Zahl der level-2 Objekte klein ist. Das ist aberkeineswegs schlecht, sondern viel naher am
”echten“ Standardschatzfehler,
da ja bei der FML-Schatzung die fixen Effekte als bekannt vorausgesetztwerden und die Unsicherheit, die mit deren Schatzung verbunden ist, nichtmiteinfließt. Einzig fur große J ist diese Annahme sinnvoll. uberhaupt weisenRaudenbush & Bryk (2002) und auch Goldstein (1995) darauf hin, dass, egalob REML oder FML verwendet wird, die beschriebenen Tests sehr liberal(zu liberal?) sind, wenn J nicht groß ist. Zwar ist nicht bekannt, wie großJ tatsachlich sein soll, Kreft (1996) schlagt aber als Faustregel das Vorhan-densein von mind. 30 level-2 Objekten vor. Falls eine OLS-Schatzung fur βverwendet wurde, ist die Teststatistik zwar exakt t verteilt unter H0, abersehr konservativ, wenn die Stichprobengroße nicht sehr groß ist.
Multiparameter Tests Auch dies ist von der Formulierung analog zuden fixen Effekten, man nimmt β als den gesamten J(Q+ 1)× 1 Vektor der
”aufeinander gestapelten“ zufalligen Parameter, dann kann wiederum mit
Kontrasten gearbeitet werden. Die Nullhypothese ware dann,
H0 : C′β = 0.
20

Die Teststatistik (Raudenbush & Bryk, 2002) ergibt sich als
H = β′C(C′VC)−1C′β, (28)
wobei β der Vektor der geschatzten Parameter ist und V die Matrix der Stan-dardfehler der Schatzung bezeichnet. Bei OLS (falls berechenbar) ist das eineJ(Q+1)×J(Q+1) Block-Diagonalmatrix mit allen (Q+1)×(Q+1) Blockenentsprechend der bekannten Standardschatzfehlermatrix aus der Theorie li-nearer Modelle und bei Verwendung von empirischen Bayes-Schatzern ei-ne J(Q + 1) × J(Q + 1) Varianz-Kovarianz-Matrix der Koeffizienten, einevolle Matrix bei REML-Schatzungen (aufgrund der durch die fixen Effektebedingten, wechselseitigen Abhangigkeiten der Schatzungen) und bei FMLsind diese unabhangig voneinander, da die fixen Effekte als bekannt voraus-gesetzt sind. Auch hier gilt wieder die Warnung, dass die Tests (außer beiOLS-Schatzungen) zu liberal sind, wenn J nicht groß ist.
Tests fur die Varianz-Kovarianz-Komponenten
Ein-Parameter Tests Diese Tests sind sehr hilfreich, wenn es darum gehtfestzustellen, ob bestimmte level-1 Prediktoren als fix, zufallig oder nicht-zufallig variierend angesehen werden sollen. Die Nullhypothese ist dabei
H0 : τqq = 0,
wobei τqq = V ar(βqj). Wenn diese Hypothese verworfen werden muss, sollteder Koeffizient als zufallig variierend spezifiziert werden. Falls eine OLS-Schatzung moglich ist, ergibt sich nach Raudenbush und Bryk (2002) alsTeststatistik ∑
j
(βqj − γq0 −
∑Sq
s=1 γqsWsj
)2
Vqq,j, (29)
mit Vqq,j als q-tem Diagonalelement der Matrix des OLS-Standardschatzfeh-
lers Vj = σ2(X′jXj)−1. Dies Teststatistik ist asymptotisch χ2-verteilt mit
J − Sq − 1 Freiheitsgraden.Eine andere Teststatistik fur dieselbe Hypothese basiert auf dem geschatz-
ten Standardfehler der τqq aus der Inversen der Informationsmatrix. DasVerhaltnis
z =τqq√
V ar(τqq)(30)
ist asymptotisch normal erteilt, wenn es sich um einen ML-Schatzer handelt.Allerdings ist die Asymptotik hier ziemlich schlecht, v.a. fur τqq nahe null.
21

Multiparameter Tests Hier erwahnen Raudenbush & Bryk (2002) einenLikelihood-Ratio Test, der sowohl unter REML als auch FML berechnet wer-den kann. Die Nullhypothese ware dabei
H0 : T = T0
gegen die AlternativeH1 : T = T1
wobei T0 eine reduzierte Form von T1 darstellt. Zum Beispiel konnte mandie q-te Zeile und Spalte in T1 als null vermuten. Das kann wieder uber dieDevianz gepruft werden, und die Teststatistik ist
H = D0 −D1. (31)
Die Devianz ist wie oben definiert, als −2 ∗ log(Likelihood) unter den je-weiligen Modellen. Diese Statistik ist asymptotisch χ2-verteilt mit m Frei-heitsgraden, wobei m die Differenz zwischen der Anzahl der Varianzen undKovarianzen Komponenten, die in den beiden Modellen geschatzt werden,ist. Will man diesen Test anwenden, mussen die beiden Modelle dieselbenfixen Effekte enthalten. Pinheiro und Bates (2000) weisen darauf hin, dassder Test in diesem Setting relativ konservativ sei. Bei FML-Schatzung istes daruber hinaus moglich, gleichzeitig Hypothesen uber fixe Effekte undVarianz-Kovarianz-Komponenten zu testen, ebenfalls uber den beschriebe-nen Likelihood-Ratio-Test.
4 Ein Anwendungsbeispiel
In diesem Kapitel sollen die vorher beschriebenen Konzepte anhand eines Bei-spiels konkretisiert werden. Dazu verwende ich die sogenannten High Schooland Beyond - 1982 Daten, wie sie auch in Raudenbush & Bryk (2002, Ka-pitel 4) verwendet werden. Diese Daten sind in R im package mlmRev alsdata(Hsb82) enthalten. Der kommentierte R-Code fur diese Auswertun-gen ist im Anhang zu finden. Als Ressource wurde Pinheiro & Bates (2006)verwendet.
Eine Anmerkung: Raudenbush & Bryk (2002) sowie Goldstein (1995)zahlen die Level anders als Pinheiro & Bates (2000). Bei letzteren heißt ein2-level Modell von Raudenbush & Bryk (2002) single-level model. Der Grundist, dass Pinheiro & Bates (2000) mit “level“ beschreiben, wieviele Ebenengenestet sind (Schuler in Schule), bzw. wieviele Hierarchien (z.B. Schule) esgibt. Die anderen Autoren verwenden fur “level“ die Anzahl an Ebenen, aufdenen es zufallige Variation gibt (z.B. Schuler und Schule). Die Sichtweise
22

von Pinheiro & Bates macht es einfacher, Mehrebenenmodelle zu formulieren(so hat ein 3-level Modell nur zwei genestete Gruppen).
Die High School and Beyond - 1982 Daten (Hsb82) enthalten eine re-prasentative Stichprobe US-amerikanischer offentlicher und privater Schulen(“Catholic High Schools“). Die Stichprobe enthalt Daten von 7185 Schulernund Schulerinnen, die in 160 Schulen eingebettet sind. Von denen waren 90offentlich und 70 privat. Die durchschnittliche Stichprobengroße pro Schuleist 45. Ich werde von den zur Verfugung stehenden Variablen fur das Beispielnur einen Teil verwenden. Auf der Ebene der Schuler sind dies die abhangigeVariable mAch, die Leistung eines Schulers oder einer Schulerin in einem stan-dardisierten Mathematiktest und der Prediktor SES, der soziookonomischeStatus eines Schulers oder einer Schulerin (eine zusammengesetzte Variable).Auf der Schulebene (level-2) werden die Prediktoren SECTOR, eine Indika-torvariable mit 1 fur private Schulen und 0 fur offentliche und MeanSES,der durchschnittliche ses fur die Schuler in dieser Schule verwendet. In derSprache von Goldstein oder Raudenbush & Bryk sind die Schuler die level-1Objekte und die Schulen die level-2 Objekte. Ich werde einige Modelle, die inKapitel 2 vorgestellt wurden, auf diese Daten anwenden (einfache ANOVAmit Zufallseffekt, Random Coefficients Modell und ein Intercept-and-Slopes-as-Outcomes Modell).
In Tabelle 3 sind die Mittelwerte und Standardabweichungen der Varia-blen gegeben.
Variable Mittelwert Standardabw.
Student-Level VariablenMathematikleistung mAchij 12.75 6.88Soziookonomischer Status SESj 0 0.78
Schul-Level VariablenSektor SECTORj 0.44 0.50Durchschnittlicher Schul-SES MeanSESj 0 0.41
Tabelle 3: Deskriptive Statistiken der Hsb82 Daten
4.1 Einfache ANOVA mit Zufallseffekt
Das Modell auf level-1 ist (7), das auf level-2 ist (8) und das kombinierte Mo-dell ist (9). Das kombinierte Modell ist bei Verwendung von nlme besonderswichtig aufzustellen, da es der Modellierung in R entspricht. Eine sinnvolleVorgangsweise ist es, die level-1 und level-2 Modelle wie oben aufzustellenund dann in ein kombiniertes Modell zu bringen. Dadurch ist jeder fixe undzufallige Effekt sofort sichtbar.
23

Die Modellierungssprache ist typisch S, d.h. fur ein lineares Mehrebenen-modell wird
lme(fixed,data,random)
aufgerufen. fixed ist dabei eine zweiseitige Formel die die fixen Effekte spe-zifiziert.
response ∼ 1 + x1 + x2 + . . . + xk + x1:x2 + . . . + xk:x(k-1)
random ist typischerweise eine einseitige Formel, in der die zufalligen Effekteund die Gruppierung spezifiziert werden.
random = ∼ 1 + x1 + . . . + xk | g1/ . . . /gm
Desweiteren sind noch einige spezielle Formulierungen moglich (vgl. die Hil-fedatei ?lme). Die Ergebnisse sind in Tabelle 4 aufgelistet.
KI-GrenzenFixer Effekt Koeffizient SE untere obere
Schulgesamtmittel, γ00 12.64 0.24 12.16 13.11
Sd.-Zufalliger Effekt Komponente
Schulmittel, u0j 2.94 2.60 3.32Level-1 Effekt, rij 6.26 6.15 6.36
Tabelle 4: Ergebnisse der einfachen ANOVA
Die mittlere Leistung uber alle Schulen wurde mit 12.64 geschatzt, miteinem Standardfehler von 0.24. Fur die Varianzkomponente auf dem Schuler-level ergab sich 39.15. Interessanter ist vielleicht noch die Varianz der Schul-mittelwerte um den Gesamtmittelwert. Dieser ist als 8.61 geschatzt worden.Alle diese Parameter konnen mit den entsprechenden Tests aus Kapitel 3 imHinblick auf bestimmte Hypothesen, z.B. ob die Variabilitat zwischen denSchulen von 0 verschieden ist, uberpruft werden. nlme selbst enthalt keineProzedur zur Testung der Varianz-Kovarianz-Komponenten auf 0 wie in (31),da die Schatzung ja anders ablauft als mittels OLS. Dennoch sind Likelihood-Ratio-Tests wie (33) moglich. Außerdem sind approximative Konfidenzinter-valle einzusehen. Eine 0 im Konfidenzintervall der Varianzschatzung einesZufallseffekt entspricht ca. dem Test (32) allerdings wird die Asymptotik et-was verbessert, indem der Logarithmus der Standardabweichung fur das KIverwendet und dieses auf die Originalskala zuruck transformiert wird.
24

Dieses Modell ist zwar sehr einfach, aber es erlaubt eine Schatzung derIntraklassen-Korrelation, d.h. dem Anteil an Varianz der abhangigen Va-riable, der durch die Schulen zustande kommt. In diesem Fall ist das 0.18(uber summary(modellname) sind die Standardabweichungen, die zurRechnung notig sind, zu bekommen). Geschatzte 18% der Varianz der Leis-tung beim Mathematiktest ist auf die Unterschiede zwischen Schulen zuruck-zufuhren.
4.2 Random-Coefficient Modell
Diesmal geht es um die Analyse ob und wie die Mathematikleistung vom SESder Schuler abhangt. Jede Schule wird also so gesehen, dass sie ihren eigenenIntercept und Slope fur SES hat. Dadurch sind Fragen zu beantworten, wie“Was sind die durchschnittlichen Intercepts und Slopes aller 160 Schulen?“,“Wie variieren die Regressionen zwischen den Schulen“ oder “Haben Schu-len mit einem großeren Intercept auch großere Slopes (d.h. korrelieren dieIntercepts und Slopes positiv)?“.
Das Modell auf level-1 ist
Yij = β0j + β1j(Xij − X.j) + rij. (32)
Die level-2 Modelle sind
β0j = γ00 + u0j (33)
β1j = γ10 + u1j (34)
sowie das kombinierte Modell (mixed-effects model)
Yij = γ00 + γ10(Xij − X.j) + u0j + u1j(Xij − X.j) + rij. (35)
Der Parameter γ00 bezeichnet dabei die mittlere Leistung uber alle Schulen,γ10 den mittleren Slope (Einfluss von SES auf Leistung) uber alle Schulen, u0j
ist der zufallige Effekt, der das Leistungsmittel jeder Schule als abweichendvom Gesamtmittel modelliert und u1j ist der fur jede Schule unterschiedlicheEinfluss von SES auf Leistung, also die Abweichung vom mittleren Slope einerSchule j. Das heißt, es wird davon ausgegangen, dass es einen Einfluss vonSES auf die Mathematikleistung gibt, der sich in jeder Schule unterscheidet,außerdem unterscheiden sich die Niveaus der Schulen ebenfalls.
Bei Modellierung mit der R-Funktion lme ubersetzt sich das in:
lme(mAch ∼ 1 + cses , Hsb82, random = ∼ 1 + cses | school)
25

CSES ist der um das Schulmittel zentrierte SES.Das bedeutet soviel wie: Es gibt einen generellen Intercept von Leistung
und einen generellen Einfluss von SES auf Leistung in der Population. Diessind somit fixe Effekte. Allerdings unterscheiden sich die Schulen sowohl inIntercept als auch Slope (dies sind die zufalligen Effekte), da sie als Zufallss-tichprobe einer Population von Schulen gesehen werden. Innerhalb der Schu-len unterscheiden sich die einzelnen Schuler wiederum in der Leistung unddiese Varianz wird nicht erklart. Man konnte auch vermuten, dass sich dieSchulen weiterhin im Intercept unterscheiden, aber der Slope fur alle Schulenfix, also derselbe, ist. Dann bekommt man eine ANOCOVA mit Zufallseffekt(allerdings ist dann die Zentrierung der Kovariaten um das Gesamtmittelsinnvoll, da jede Schule denselben Slope hat und dann β0j dem Gesamtmit-tel entspricht). Es soll auch noch darauf hingewiesen werden, dass es sichhierbei um ein unbedingtes Modell auf level-2 handelt, d.h. keine Kovariatenauf level-2 hinzugezogen werden. Man konnte auch sagen, dass die Variationdes Zufallseffekt nicht mit level-2 Variablen modelliert wird. Dies ist zumin-dest bei mixed-effects models ofters der Fall, es interessieren hauptsachlichfixe Effekte auf level-1 und die Variation im Zufallseffekt soll aus dem Fehlerentfernt werden (z.B. Blockdesigns). HLM und Multilevel-Modelle hingegenwerden aufgrund der spezifischen Modellformulierung auf mehreren Ebenenoft dafur verwendet, kompliziertere bedingte Modelle zu formulieren (noch-mal der Hinweis: eigentlich unterscheiden sich mixed-effects models und HLMnicht, nur der Fokus ist etwas anders). Solche bedingten Modelle sind aber re-lativ kompliziert, v.a. in der Darstellung als kombiniertes bzw. mixed-effectsmodel, da cross level -Interaktionen enthalten sind. Das nachste Kapitel gibtein solches Beispiel. Die Ergebnisse der Berechnung sind in Tabelle 5 darge-stellt.
Die Schatzung der durchschnittlichen Regressionsgleichung innerhalb derSchulen ist Intercept = 12.64 und Slope = 2.19. Der Test der Hypothese, dassSES im Durchschnitt keinen Einfluss auf die Leistung hat, fuhrt zu einem t-Wert von 17.1 (df=7024). D.h. dass - durchschnittlich gesehen - SES mit derLeistung im Mathematiktest zusammenhangt und zwar positiv.
Auch ist es moglich einen Bereich “plausibler Werte“ fur die einzelnenSchulmittel und die schulspezifischen SES-Leistung Slopes anzugeben. Dazuwird die geschatzte Standardabweichung,
√τ00 oder
√τ10, zwischen den Schu-
len herangezogen, und ein Intervall um den Punktschatzer des Gesamtmittelberechnet als,
γq0 ± z(1−ω/2)
√τqq, (36)
wobei z(1−ω/2) das (1− ω/2)-Quantil der Standardnormalverteilung bezeich-net. ω ist ublicherweise 0.95. In unserem Fall ergibt das [6.87;18.41] fur die
26

95%KI-GrenzenFixer Effekt Koeffizient SE untere obere
Mittlere Leistung insgesamt,γ00 12.64 0.24 12.16 13.12Mittlerer SES-Leistung Slope,γ10 2.19 0.13 1.94 2.44
Sd.-Zufalliger Effekt Komponente
Schulmittel, u0j 2.95 2.61 3.33SES-Leistung Slope, u1j 0.83 0.57 1.21Level-1 Effekt, rij 6.06 5.95 6.16
Korrelation der Zufallseffekte,r(u0j , u1j) 0.02 -0.05 0.09
Tabelle 5: Ergebnisse des Random-Coefficients Modell
Schulmittel,γ00, und [0.56;3.83] fur den ses-achievement Slope. 95% der Schu-len wurden erwartet in diesen Intervallen liegen.
In R wird gleich die geschatzte Korrelation der Zufallseffekte ausgegeben.Diese kann leicht in die Kovarianz als r(u0j, u1j)∗sd(u0j)∗sd(u1j) umgewan-delt werden, als 0.02*2.95*0.83=0.05, wodurch T vollstandig ware. Sieht mansich das dazugehorige KI an, scheint diese Korrelation nicht signifikant von0 verschieden zu sein. Dieser Umstand konnte genutzt werden, um eine neueVarianz-Kovarianzstruktur fur die Zufallseffekte zu definieren, wodurch we-niger Parameter geschatzt werden wurden (die pdMat-Klassen bieten dieseMoglichkeit, fur das Beispiel ware pdDiag zu verwenden). Im Anhang ist derCode dazu, der Likelihood-Ratio-Test dieser beiden Modelle gegeneinanderergibt einen p-Wert von 0.90 und somit ist das Modell mit nicht restringierterVarianz-Kovarianz-Matrix nicht uberlegen.
4.3 Intercepts-and Slopes-as-Outcomes Modell
Dies ist ein Modell um die Variablitat der Regressionskoeffizienten nicht nurzu bestimmen, sondern zu erklaren. Dafur werden auf level-2 Variablen hin-zugezogen, in diesem Fall MeanSES und SECTOR. Es soll also untersuchtwerden, welchen Einfluss der durchschnittliche SES in der Schule und dieDummyvariable
”Privatschule“ oder
”offentliche Schule“ auf die Variabilitat
hat. Dadurch soll erklart werden, warum manche Schulen eine hohere Leis-tung aufweisen und warum der Zusammenhang zwischen SES und Leistungin manchen Schulen starker ist als in anderen.
27

Das Modell auf level-1 ist
Yij = β0j + β1j(Xij − X.j) + rij, (37)
und die level-2 Modelle
β0j = γ00 + γ01W1j + γ02W2j + u0j, (38)
β1j = γ10 + γ11W1j + γ12W2j + u1j, (39)
wobei die u0j und u1j wiederum multivariat normalverteilt sind mit Erwar-tungswert von 0 und Varianz-Kovarianz-Matrix T. Deren Elemente sind nuneine Art Residualvariabilitat von Intercept und Slope zwischen den Schulen,die ubrigbleibt, wenn auf die Variablen W1j und W2j kontrolliert wird. W1j istder mittlere SES der Schule j und W2j ist eine Dummyvariable, die bezeich-net ob die j-te Schule privat (=1) oder offentlich (=0) ist. Das kombinierteModell, das zur Berechnung benotigt wird, ist dann:
Yij = γ00 + γ01W1j + γ02W2j + γ10(Xij −X .j)
+ γ11W1j(Xij −X .j) + γ12W2j(Xij −X .j)
+ u0j + u1j(Xij −X .j) + rij. (40)
Dies zeigt, dass die Mathematikleistung eines Schulers als Funktion einesGesamtmittels (γ00), eines Haupteffekts des mittleren SES der Schule (γ01)und eines Haupteffektes der Schulart (γ02) sowie eines Haupteffektes des SESeines Schulers gesehen (γ10) werden kann, daruber hinaus noch zwei cross-level -Interaktionen zwischen Schulart und SES (γ12) und mittlerem SES derSchule und SES (γ11) und einem Zufallsfehler (u0j + u1j(Xij − X.j) + rij).
Obwohl hier insgesamt nur 3 erklarende Variablen vorhanden sind, istdas obige Modell schon ein ziemlich kompliziertes mixed-effects model. V.a.die cross-level Interaktionen sind nicht einfach zu interpretieren. Daran zeigtsich, dass auch relativ einfache Zusammenhange bei HLM schnell komplexwerden konnen. Um damit umgehen zu konnen, ist ein theoriegeleitetes
”bot-
tom -up“-Vorgehen bei der Modellierung sinnvoll (siehe Kapitel 6). Auch isteine Spezifizierung der level-1 und level-2 Modelle, welche dann kombiniertwerden, sinnvoll, anstatt sofort das mixed-effects Modell aufzustellen. DasModell ubersetzt sich in R auf folgende Art (der Intercept kann auch wegge-lassen werden):
lme(mAch ∼ 1 + meanses + sector + cses + meanses:cses +sector:cses, Hsb82.g, random = ∼ 1 + cses | school)
Zwar ist das Modell eher kompliziert, doch sind damit eine Reihe von Fra-gen beantwortbar, die mit einer klassischen mehrfaktoriellen ANCOVA nicht
28

in diesem Ausmaß und numerisch richtig beantwortet werden konnten (oderpraziser, es mussten fur jede Gruppe solche ANCOVAs gerechnet werden unddabei ware die Variabilitat zwischen Schulen nicht berucksichtigt):
1. Konnen mittlerer SES und Schulart den Intercept vorhersagen undwenn ja, wie gut? Haben z.B. Schulen mit hoherem mittleren SES, kon-trolliert auf die Schulart, einen statistisch signifikant hoheren mittlerenLeistungswert? Oder unterscheiden sich private und offentliche Schu-len in der mittleren Leistung, wenn der mittlere SES konstant gehaltenwird? Dafur haben wir zwei fixe Effekte, die jeweils auf den anderenFaktor kontrolliert sind und daruber Aufschluss geben konnen.
2. Konnen mittlerer SES und Schulart den Slope zwischen den Schulenvorhersagen und wenn ja, wie gut? Kann man z.B. herausfinden, ob sichmit hoherem mittleren SES, kontrolliert auf die Schulart, die Starke desZusammenhangs zwischen SES und Mathematikleistung andert. Oderunterscheiden sich private und offentliche Schulen in der Starke diesesZusammenhangs, wenn der mittlere SES konstant gehalten wird? Dafurhaben wir ebenfalls zwei fixe Effekte, die jeweils auf den anderen Faktorkontrolliert sind und daruber Aufschluss geben konnen.
3. Wieviel Variation in Intercepts und Slopes kann durch die level-2 Pre-diktoren erklart werden, bzw. um wieviel mehr wird dadurch erklart?
Die Ergebnisse sind in Tabelle 6 dargestellt.Bezuglich der fixen Effekte sieht man, dass
”MeanSES“ positiv mit der
durchschnittlichen Leistung in den Schulen zusammenhangt, γ01=5.33. Auchder Umstand, dass eine Schule privat gefuhrt wird (“SECTOR“=1), hateinen positiven Einfluss auf die durchschnittliche Mathematikleistung in die-ser Schule, auch wenn auf
”MeanSES“ kontrolliert wird (γ02=1.23). Beide
Haupteffekte sind statistisch signifikant (Die t-Werte sind nicht dargestelltobwohl sie in R berechnet werden. Anhand der KI kann das aber auch gese-hen werden). Bei den Slopes zeigt sich eine Tendenz dahingehend, dass einhoherer mittlerer SES einer Schule (signifikant) steilere Slopes bedeutet alsbei Schulen mit niedrigerem mittleren SES (γ11=1.23). Zudem haben priva-te Schulen durchschnittlich signifikant flachere Slopes als offentliche Schulen(γ12=-1.64). Das heißt, dass private Schulen
”fairer“ dahingehend sind, wie
”SES“ und Leistung zusammenhangen, als offentliche Schulen. Weiters sind
diese auch effizienter, deren erwartete mittlere Leistung ist signifikant hoherals bei offentlichen Schulen, auch wenn der mittlere SES der Schule konstantgehalten wird. Ebenfalls ist es - unabhangig ob es sich um katholische oderoffentliche Schulen handelt - so, dass Schuler einer Schule, die einen hoheren
29

95%KI-GrenzenFixer Effekt Koeffizient SE untere obere
Modell fur das GesamtmittelIntercept, γ00 12.13 0.2 11.74 12.52Mittlerer SES, γ01 5.33 0.37 4.6 6.06Sector (Schulart),γ02 1.23 0.31 0.62 1.83
Modell fur den SES-Leistungs SlopeIntercept,γ10 2.96 0.16 2.64 3.25Mittlerer SES, γ11 1.04 0.37 0.45 1.63Sector (Schulart), γ12 -1.64 0.24 -2.11 -1.17
Sd.-Zufallige Effekte Komponente
Schulmittel, u0j 1.54 1.33 1.80SES-Leistung Slope, u1j 0.32 0 217.5Level-1 Effekt, rij 6.06 5.95 6.17
Korrelation der Zufallseffekte,r(u0j , u1j) 0.38 -0.99 0.99
Tabelle 6: Ergebnisse des Intercept-and Slopes-as-Outcomes Modell
”MEANSES“ aufweist, eine hohere durchschnittliche Leistung erzielten. Wie
auch im Modell davor hat naturlich”SES“ durchschnittlich einen signifikant
positiven Einfluss auf die Leistung in diesem Mathematiktest.Bezuglich der Zufallseffekte, so zeigt sich im Vergleich zum Random-
Coefficients Modell, das der Anteil der noch unerklarten Varianz der Inter-cepts und Slopes durch Hinzunahme der beiden Kovariaten
”MeanSES“ und
”SECTOR“ um einiges kleiner wurde (τ00=2.37 und τ11=0.10 im Vergleich zu
8.7 bzw. 0.83). Nun konnte man noch testen, ob die Varianzkomponenten si-gnifikant von 0 verschieden sind, d.h. es noch unerklarte Varianz in Interceptund Slope gibt. Fur das Schulmittel ist es tatsachlich so, die Hinzunahmeder level-2 Kovariaten hat nicht ausgereicht um die Variabilitat im Interceptvollstandig zu erklaren. Etwas uneindeutig ist das bei der Varianzkomponen-te der Slopes. Die untere 95%KI-Grenze ist ganz leicht uber 0. Allerdingsscheint hierbei ein Problem aufgetaucht zu sein, dass schon in Kapitel 3angesprochen wurde, namlich dass sehr kleine Werte fur die Varianzkompo-nenten zu instabilen Schatzern fuhren konnen und v.a. dass approximativeKI und Tests nicht verlasslich sind. Die obere 95%KI-Grenze wird mit 217.5angegeben, was nicht plausibel ist. Das durfte ein numerisches Problem ge-wesen sein. Man konnte diese Varianz aber auf 0 fixen und dann mittels ei-nes Likelihood-Ratio-Tests die beiden Modelle vergleichen (siehe Pinheiro &
30

Bates (2000) fur eine Beschreibung der Definition bestimmter fixer Varianz-Kovarianz-Komponenten). In diesem Fall ist es noch relativ leicht, da maneinfach nur den Intercept als weiterhin zufallig spezifiziert, aber den Slopeals nicht-zufallig variierend definiert. Dadurch ist die Varianz des Slopes auf0 gefixt, ebenso wie die Kovarianz zwischen Intercept und Slope (das Modellenthalt dann zwei Parameter weniger). Im Anhang ist der R-Code zu die-sem anderen Modell angefuhrt. R bietet eine einfache Moglichkeit die beidenkonkurrierenden Modelle mittels LR-Test zu vergleichen. Der Befehl
anova(ModellRestringiert,ModellGenerell)
rechnet automatisch diesen Test. Im Beispiel ist der Likelihood-Ratio-Wert1.12, was einem p-Wert von 0.57 bei einer χ2-Verteilung mit 2 Freiheitsgra-den entspricht. Demnach ist durch die Hinzunahme der Kovariaten so gutwie die gesamte Variation der Slopes erklart und ein Modell, welches denSES-Leistungs Slope mit Zufallseffekt spezifiziert, nicht dazu in der Lage,die Daten signifikant besser zu erklaren (was auch AIC und BIC bestati-gen). Hier soll nochmal darauf hingewiesen werden, dass bei Verwendung vonREML-Schatzungen nur Modelle verglichen werden konnen, die dieselben fi-xen Effekte enthalten. Sollten Modelle verglichen werden, die unterschiedlichefixe Effekte enthalten, kann das nur unter Verwendung von FML geschehen.Allerdings ist das nicht optimal. Eine Alternative stellt die Funktion simula-te.lme() dar, die die Likelihood-Ratio-Teststatistik mittels parametrischembootstrap simuliert. Das kann fur beide Schatzungsarten verwendet werden.Dann ist es moglich, eine andere als die Standard-Referenzverteilung zu fin-den, z.B. eine χ2-Verteilung mit mehr Freiheitsgraden oder eine gemischteVerteilung, um den Test etwas konservativer zu machen. Fur Details siehePinheiro & Bates (2000).
Ebenfalls moglich um einen Indikator fur die Verbesserung der Erklarungsguteeines Modells in Vergleich zu einem anderen zu bestimmen, ist die Schatzungder proportionellen Reduktion in unerklarter Varianz fur die Zufallskompo-nenten des level-1 Modells. Hier wird das Random Coefficients Model (RC)mit dem Intercept-and Slopes-as-Outcomes Modell (IaSaO) vergilchen. DerAnteil an erklarter Varianz bei βqj von RC zu IaSaO ist:
τ(RC)qq − τ (IaSaO)
τ(RC)qq
(41)
In unserem Fall ist das fur den Intercept 0.73, d.h. ein substantieller Teil(73%) der Varianz der mittleren Mathematikleistung konnte durch das IaSaO-Modell (also die Hinzunahme der Variablen
”MeanSES“ und
”SECTOR“)
erklart werden. Fur den Slope ist die Reduktion sogar noch großer, 0.85. Das
31

zeigt auch was vorher schon beschrieben wurde, namlich dass die beiden Ko-variaten beinahe die gesamte Varianz der Slopes erklaren konnen, es bleibtnur ein sehr geringer Teil unerklart. Es soll aber noch angemerkt werden,dass die Interpretation als
”erklarter Varianzanteil“ nicht analog zu R2 zu
verstehen ist. Obiges kann namlich durchaus auch negativ (und das kann beieiner Misspezifikation sehr oft der Fall sein). Allerdings ware ein negativerAnteil
”erklarter Varianz“ ein Zeichen, dass ein falsches Modell spezifiziert
wurde.
5 Spezielle Anwendungsgebiete
Im folgenden Kapitel soll besonderes Augenmerk auf zwei Bereiche gelegtwerden, in denen die Anwendung von HLM ausgesprochen hilfreich ist, umdie in den Daten enthaltene Information bestmoglich zu Nutzen. Es sinddies Meta-Analysen (bzw. generell Falle, in denen die Varianz auf der ers-ten Ebene als bekannt angenommen werden kann) sowie die Anwendung beiLongitudinaldaten und bei der Veranderungsmessung mit Wachstumskurven-modellen. HLM bieten fur beide Gebiete ein sehr flexibles und machtvollesInstrumetarium zur Analyse.
5.1 Analyse von Longitudinaldaten und Veranderungs-messung
Die Analyse von Longitudinaldaten und der Versuch, Veranderungen uber dieZeit zu erfassen, geharen zu den Gebieten, die lange Zeit durch inadaquateMethoden und Designs nur unzureichend erforscht werden konnten. Heutzu-tage gibt es adaquate Methoden, z.B. multivariate Techniken zur Analysevon Messwiederholungen oder auch Strukturgleichungsmodelle, die zur Be-antwortung gewisser Fragestellungen relativ gut geeignet sind.
Auch HLM bieten einen Rahmen an, in dem die Analyse solcher Datenerfolgen kann, wobei dieser sich durch eine sehr hohe Flexibilitat auszeich-net. So konnen lineare und nichtlineare Wachstumskurven modelliert werden,genauso wie komplexere Fehlerstrukturen auf der untersten Ebene (Heteros-kedastizitat, Autokorrelation). Es ist sogar so, dass etliche der den HLMzu Grunde liegenden Ideen speziell fur Longitudinaldaten entwickelt wur-den. Hier wird in erster Linie auf lineare Modelle ohne komplizierte Fehler-strukturen eingegangen werden, allerdings wird auch ein Beispiel vorgestellt,bei dem die UV nichtlinear transformiert wird und die Fehlerstruktur einemAR(1)-Prozess folgt. Fur eine ausfuhrliche Beschreibung der Moglichkeiten
32

von HNLM bei Longitudinaldaten sei auf Davidian und Giltinan (1995) ver-wiesen.
Aufstellen der Modelle
Viele Fragen der Veranderungsmessung konnen mit einem HLM auf zwei Ebe-nen beantwortet werden. Auf der ersten Ebene wird die Entwicklung einerjeden Person mit einer individuellen Wachstumskurve modelliert, die durchgewisse, fur diese Person individuelle Parameter bestimmt ist. Diese Para-meter werden dann als abhangige Variablen eines Modells auf der zweitenEbene aufgefasst, welche dann von bestimmten Charakteristika einer Personbeeinflusst werden konnen. Auf Ebene 1 sind somit die multiplen Messungeneines Individuums abhangig, auf der zweiten Ebene sind die Wachstumskur-venparameter der Personen abhangig. Die multiplen Messungen sind somitin die Personen eingebettet. Diese Sichtweise hat einen sehr großen Vorteil,namlich dass es unerheblich ist, wie viele Messzeitpunkte pro Person es gibtoder wie groß der zeitliche Abstand zwischen diesen Zeitpunkten ist und obdieser fur alle Personen gleich ist (wie es beispielsweise fur MANOVA furMesswiederholungen notwendig ist).
An dieser Stelle wird die bisher eingefuhrte Notation weiter beibehalten,was sich von der Notation bei Raudenbush & Bryk (2002) unterscheidet.Diese fuhrten eine neue Notation ein, um danach drei Ebenenmodelle zubeschreiben, was in der vorliegenden Arbeit nicht gemacht wird.
Modell auf level-1 (Meßwiederholungsmodell) Es bezeichne Yti diebeobachtete Realisierung einer interessierenden Zufallsvariable zum Zeitpunktt fur die Person i. Diese wird als in den Parametern lineare Funktion einer sys-tematischen Wachstumskurve und einem Zufallsfehler gesehen. Fur Wachs-tumskurven ist es oftmals besonders sinnvoll, das systematische Wachstumals ein Polynom p-ten Grades zu reprasentieren. Das Modell auf Ebene 1 istdann:
Yti = β0i + β1iati + β2ia2ti + · · ·+ βpia
pti + rti rti ∼ N(0, σ2) (42)
fur i = 1, . . . , n Objekte. ati ist hierbei der Wert einer zeitveranderlichenVariable zum Zeitpunkt t fur Objekt i, die man als unabhangige Variableverwendet (z.B. das Alter einer Person) und βpi ist der Wachstumsparameterp fur Objekt i, assoziiert mit einem Polynom p-ten Grades (p = 0, . . . , P ).Von jedem Objekt liegen Messungen von Ti Zeitpunkten vor, wobei die An-zahl der Messungen und die Zeit zwischen den Messungen uber die Objekte
33

variieren kann. Fur die Verteilung des Fehlers wird wiederum eine einfa-che Struktur angenommen, namlich dass jeder Fehlerteil rti normalverteiltmit Mittelwert 0 und konstanter Varianz σ2 ist. Die Fehlerstruktur kann beiLongitudinaldaten aber oft kompliziertere Formen annehmen, z.B. autokor-relative Prozesse oder Heteroskedastizitat. Einen guten Uberblick uber dieVerwendung solcher Strukturen geben Pinheiro & Bates (2000).
Modell auf level-2 (Objektebenenmodell) Eine Besonderheit des obi-gen Modells ist, dass angenommen wird, dass die Wachstumsparameter uberdie Individuen variieren. Diese Variabilitat wird nun mittels eines Modellsauf der zweiten Ebene reprasentiert. Das heißt, fur jeden der P + 1 Wachs-tumskurvenparameter gilt
βpi = γp0 +
Qp∑q=1
γpqXqi + upi (43)
wobei Xqi eine erklarende Variable auf der Ebene der Objekte ist (z.B. dasGeschlecht einer Person oder eine experimentelle Bedingung wie z.B. dasKauen von Kaugummi), γpq ist der Effekt, den die Xq auf den p-ten Wachs-tumsparameter ausuben und die upi sind zufallige Effekte mit einem Mit-telwert von 0. Die P + 1 zufalligen Effekte fur Objekt i werden als mul-tivariat normalverteilt angenommen mit einer (P + 1) × (P + 1) Varianz-Kovarianzmatrix, T.
Beispiel: Lineares Wachstum Oftmals macht es Sinn, ein rein linea-res Wachstum zu unterstellen, v.a. wenn die Anzahl an Beobachtungen proPerson gering ist (z.b. 4 oder 5 Zeitpunkte). Bei einer relativ kurzen Zeitspan-ne kann ein solches Modell eine gute Approximation an ein komplizierteresWachstum sein, das aber auf Grund der geringen Zahl an Beobachtungennicht modelliert werden kann.
Bei einem linearen Modell auf der ersten Ebene reduziert sich (42) zu
Yti = β0i + β1iati + rti, rti ∼ N(0, σ2). (44)
Hier steht β1i fur die Wachstumsrate fur das Objekt i uber die beobachteteZeit und reprasentiert die erwartete Anderung innerhalb einer fixen Zeit-einheit. Der Intercept, β0i, steht fur den Wert der AV des Objekts i amZeitpunkt ati = 0. Deshalb hangt die Bedeutung des Intercept von der Ska-lierung der zeitveranderlichen Variable ab. Auf der zweiten Ebene konnensowohl der Intercept, als auch die Wachstumsrate zwischen den Objekten
34

variieren, durchaus auch als Funktion irgendwelcher Charakteristika der Ob-jekte. Somit wird das Modell (43) zu
β0i = γ00 +
Q0∑q=1
γ0qXqi+ u0i, (45)
β1i = γ10 +
Q1∑q=1
γ1qXqi+ u1i. (46)
Die Zufallseffekte u0i und u1i sind multivariat normalverteilt mit Mittel-wert 0 und Varianzen τ00 bzw. τ11 und der Kovarianz τ01. Mit einem solchenModell kann eine mittlere Wachstumskurve geschatzt werden ebenso wie dieVariabilitat der individuellen Abweichungen von dieser, es kann die Korrela-tion zwischen Intercept und Slope geschatzt und der Einfluß von Variablenauf der Objektebene erfasst werden, sowohl fur den Intercept als auch furden Slope.
Dies soll nun anhand eines Beispiels veranschaulicht werden. Die Datenstammen von Potthoff und Roy (1964, zit. nach Pinheiro & Bates, 2000).Diese erhoben die Distanz zwischen der Hypophyse und der pterygomaxilla-ren Spalte (pterygomaxillary fissure) bei Kindern alle zwei Jahre, beginnendim Alter von 8 Jahren bis zum Alter von 14 Jahren. Die Stichprobe bestandaus 26 Kindern, 16 mannlich und 11 weiblich. Hier soll nur die Substichprobeder Madchen betrachtet werden.
In Abbildung 1 sind die Messungen zu den vier Zeitpunkten fur alleMıadchen sichtbar. Diese Graphik legt die Vermutung nahe, dass die Distanzmit zunehmendem Alter wıachst und dass dieses Wachstum linear sein konn-te. Auch scheint es so zu sein, dass der Intercept von Madchen zu Madchenunterschiedlich ist. Fur den Slope ist dies nicht so eindeutig sichtbar.
Dementsprechend konnte man zwei Modelle spezifizieren, eines das einenzufalligen Intercept und einen gemeinsamen (fixen) Slope fur alle Madchenenthalt, sowie ein Modell, bei dem sowohl Intercept als auch Slope zufalligsind. Ersteres entspricht einer ANOCOVA mit Zufallseffekt, letzteres einemRandom Coefficients Regression Modell. Diese Modelle sind in Tabelle 7 undTabelle 8 dargestellt. Bei einer Analyse mit fixen Effekten waren nur Fra-gen beantwortbar, die diese spezifische Stichprobe betreffen. Die HLM aberermoglichen Inferenz uber diese Stichprobe hinaus, indem wir die Variabi-litat zwischen und innerhalb von Individuen schatzen konnen, genauso wiefixe Effekte als Schatzer fur die Population. Darin liegt eine weitere Starkevon HLM bei Veranderungsmessung.
Fur das Modell mit zufalligem Intercept zeigt sich eine Schatzung der
35
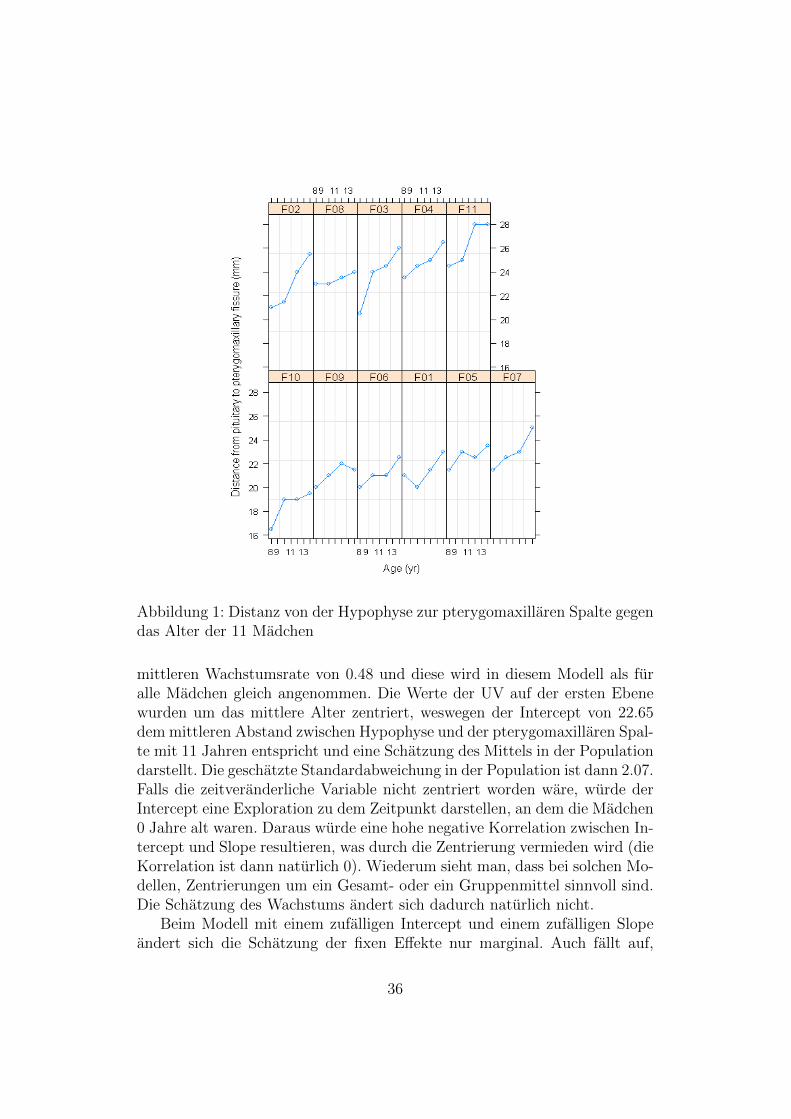
Abbildung 1: Distanz von der Hypophyse zur pterygomaxillaren Spalte gegendas Alter der 11 Madchen
mittleren Wachstumsrate von 0.48 und diese wird in diesem Modell als furalle Madchen gleich angenommen. Die Werte der UV auf der ersten Ebenewurden um das mittlere Alter zentriert, weswegen der Intercept von 22.65dem mittleren Abstand zwischen Hypophyse und der pterygomaxillaren Spal-te mit 11 Jahren entspricht und eine Schatzung des Mittels in der Populationdarstellt. Die geschatzte Standardabweichung in der Population ist dann 2.07.Falls die zeitveranderliche Variable nicht zentriert worden ware, wurde derIntercept eine Exploration zu dem Zeitpunkt darstellen, an dem die Madchen0 Jahre alt waren. Daraus wurde eine hohe negative Korrelation zwischen In-tercept und Slope resultieren, was durch die Zentrierung vermieden wird (dieKorrelation ist dann naturlich 0). Wiederum sieht man, dass bei solchen Mo-dellen, Zentrierungen um ein Gesamt- oder ein Gruppenmittel sinnvoll sind.Die Schatzung des Wachstums andert sich dadurch naturlich nicht.
Beim Modell mit einem zufalligen Intercept und einem zufalligen Slopeandert sich die Schatzung der fixen Effekte nur marginal. Auch fallt auf,
36

Fixer Effekt Koeffizient SE t-Wert
Intercept,γ00 22.65 0.63 35.69Mittlere Wachstumsrate,γ10 0.48 0.05 9.12
approx.Sd.- 95%KI-Schranke
Zufalliger Effekt Komponente untere obere
Intercept, u0i 2.07 1.31 3.26Level-1 Effekt, rti 0.78 0.61 1
Tabelle 7: Ergebnisse des Modells mit zufalligem Intercept fur die Orthodont-Daten
Fixer Effekt Koeffizient SE t-Wert
Intercept,γ00 22.65 0.63 35.69Mittlere Wachstumsrate,γ10 0.48 0.07 7.24
approx.Sd.- 95%KI-Schranke
Zufalliger Effekt Komponente untere obere
Intercept, u0i 2.08 1.32 3.25Wachstumsrate, u1i 0.16 0.07 0.38Level-1 Effekt, rti 0.67 0.5 0.9
Korrelation der Zufallseffekter(u0i,u1i) 0.53 -0.38 0.91
Tabelle 8: Ergebnisse des Random-Coefficients Regression Modell fur dieOrthodont-Daten
dass die Schatzung der Standardabweichung des Slopes relativ klein ist. Wieschon in Abbildung 1 sichtbar, sind sich die einzelnen Slopes ahnlich, wasein Modell wie in Tabelle 8 nahelegen wurde. Ein Test auf Modellvergleichzeigt das auch: Die LR-Statistik ist unter der Nullhypothese asymptotischχ2
(2)-verteilt und ein Wert von 3.79 oder mehr in 15% der Falle zu erwarten,was auf einem α = 0.05 nicht signifikant ist. Es gibt somit keinen Grund,dass kompliziertere Modell mit zufalligem Slope dem einfacheren Modell mitfixem Slope vorzuziehen. Abbildung 2 zeigt die gefitteten Wachstumskurvenfur jedes Madchen fur das Modell mit gemeinsamem Slope und zufalligemIntercept.
37

Abbildung 2: Geschatzte Wachstumskurven der 11 Madchen fur das Modellmit zufalligem Intercept
Beispiel: Zyklische Veranderung Dieses Beispiel soll die Anwendungeines
”nichtlinearen“ hierarchischen Modells1 mit Autokorrelation der level-1
Zufallseffekte zeigen . Ohne zu sehr in die statistischen Details zu gehen, sollgezeigt werden, wie flexibel dieser Zugang zur Modellierung von Veranderun-gen ist.
Die Daten stammen von Pierson und Ginther (1987; zit. nach Pinheiro&Bates, 2000). Sie erhoben die Anzahl von Eierstock-Follikel, die einen Durch-messer von mehr als 10mm haben, bei insgesamt 11 Stuten zu verschiedenenZeitpunkten wahrend des Reifungszyklus. Die Daten wurden taglich erhoben,angefangen von 3 Tagen vor dem Eisprung bis 3 Tage nach dem darauffolgen-den. Die Messungen wurden so skaliert, dass fur jede Stute zum Zeitpunkt 0und zum Zeitpunkt 1 der Eisprung stattfindet. Abbildung 3 zeigt die Anzahl
1In Wahrheit ist das naturlich kein nichtlineares Modell, da es immer noch linear inden Parametern ist. Es wird nur die UV nichtlinear transformiert, die Parameter gehennach wie vor nur linear ein.
38

Follikel gegen die Zeit fur jede Stute. Diese legt einen periodischen Verlaufder Anzahl der Follikel uber die Zeit nahe.
Abbildung 3: Anzahl der Follikel mit > 10mm Durchmesser bei 11 Stutenuber einen Zyklus (±3Tage)
Das Modell auf der ersten Ebene, das Meßwiederholungsmodell, ist
Yti = β0i + β1i sin(2πati) + β2i cos(2πati) + rti, (47)
wobei i = 1, . . . , n die Stuten bezeichnet und t = 1, . . . , Ti die Messungs-zeitpunkte. Nun ist es so, dass - obwohl die Follikel am selben Kalendartaggemessen wurden und es sich um gleichabstandige Intervalle gehandelt hat-, die Intervalle zwischen den Beobachtungen zwar sehr ahnlich, aber nichtmehr exakt gleich sind. Dies ist auf die Umskalierung zuruckzufuhren. Wirhaben es also mit einer Zeitreihe zu tun und die Daten bietet sich an umserielle Autokorrelation zu modellieren. Zuerst soll allerdings die Verteilungder rij als N(0, σ2) angenommen werden (wie bisher).
39

Das level-2 Modell ist
β0i = γ00 + u0i (48)
β1i = γ10 + u1i (49)
β2i = γ20, (50)
die Verteilung der Zufallseffekte auf der zweiten Ebene wird als unabhangignormalverteilt mit den beiden Varianzen τ00 und τ11 angenommen. Das heisst,dass die Kovarianz zwischen den zufalligen Parametern als 0 spezifiziert wird.Der Parameter β2i ist in diesem Fall fix. Die empirische Autokorrelations-funktion der Residuen nach Schatzung dieses Modells ist in Abbildung 4 zusehen.
Abbildung 4: Empirische Autokorrelationsfunktion der Residuen fur dieOvary-Daten nach Schatzung eines Modells mit unabhangigen Zufallseffekten
Dabei zeigt sich, dass die Autokorrelationen bei den lags 1 und 2 sub-stanziell hoch sind. Ein AR(p)-Modell fur die Fehlerstruktur auf der erstenEbene, also fur die Fehlerstruktur innerhalb der Gruppen, konnte sinnvoll
40

sein. Das heißt nichts anderes, als das die Beobachtungen zu verschiedenenZeitpunkten nicht unabhangig sind. In diesem Fall wird ein AR(1)-Prozessverwendet werden, da die Autokorrelation bei einem lag von 1 sehr hoch ist,aber beim lag von 2 deutlich kleiner. Ebenfalls moglich ware es aber aucheinen MA(2)-Prozess oder einen ARMA(1,1)-Prozess zu spezifizieren. EinAR(p)-Prozess innerhalb einer Gruppe hat die folgende Form, wobei rt denFehler zum Zeitpunkt t bezeichnet,
rt = ρ1rt−1 + ρ2rt−2 + · · ·+ ρprt−p + et, −1 < ρ < 1 (51)
Die et sind unabhangig und homoskedastisch und haben den Erwartungwert0. p bezeichnet den lag, d.h. wie weit die Beeinflussung zuruckreicht. Beieinem AR(1)-Prozess ist dies 1, nur die vorangegangene Beobachtung korre-liert mit derjenigen zum Zeitpunkt t. Fur Informationen uber ARMA(p,q)-Modelle sei auf Box et al. (1994) und Jones (1993) verwiesen.
95%KI-SchrankeFixer Effekt Koeffizient untere obere
γ00 12.19 10.33 14.05γ10 -2.99 -4.18 -1.79γ20 -0.88 -1.82 0.06
approx.Sd.- 95%KI-Schranke
Zufalliger Effekt Komponente untere obere
u0i 2.86 1.7 4.81u1i 1.26 0.37 4.30rti 3.50 3.02 4.07
Parameter des AR(1)-Prozess
ρ 0.57 0.43 0.69
ModellvergleichModell 1 (Unabh.) Modell 2 (AR(1))
logLikelihood -813.04 -774.72df 6 7
Likelihood-Ratio 76.63p-Wert < .0001
Tabelle 9: Ergebnisse des Modells mit AR(1)-Fehlerstruktur fur die Ovary-Daten
Die Schatzungen fur das Modell mit AR(1)-Modell fur die Fehler rti sind
41

in Tabelle 9 angegeben. Der Likelihood-Quotienten-Test weist mit einemp < 0.0001 das Modell mit Fehlern, die einem AR(1)-Prozess folgen, als demmit unabhangigen Fehlern eindeutig uberlegen aus. Auch das approximati-ve 95%Konfidenzintervall fur den Autokorrelationsparameter ρ uberdeckt 0nicht, er ist also signifikant von 0 verschieden. Eine Darstellung der beobach-teten und der gefitteten Werte ist in Abbildung 5 zu finden.
Abbildung 5: Plot der gefitteten und der beobachteten Werte fur die Ovary-Daten fur das Modell mit AR(1)-Fehlerstruktur
Zentrierung der Prediktoren In diesem Abschnitt soll noch kurz daraufeingegangen werde, wie und warum eine Zentrierung der Prediktoren auf derersten Ebene gemacht wird. Bisher wurde darauf nicht eingegangen, obwohles immer eine wichtige Uberlegung darstellt, aber bei Wachstumskurvenmo-dellen ist die Zentrierung von ganz besonderer Bedeutung.
Die Lokalisation der level-1 Prediktoren beeinflusst sowohl die Definitiondes Intercepts, die Definition der Wachstumsparameter bei Modellen mitPolynomen und die Varianzschatzungen der Wachstumsparameter.
42

Zur Veranschaulichung des Einflusses auf den Intercept soll das Beispieldes linearen Wachstums dienen. In der Formulierung des Modells (44), ist esentscheidend, wie die Kovariate skaliert ist. Ohne Zentrierung entsprache derIntercept dem erwarteten Wert der abhangigen Variable wenn ati = 0 ist, d.h.im Beispiel bei einem Alter von 0 Jahren. Wird nun ati = 0 bei einem Altervon 8 gesetzt, dann entsprache der Intercept dem
”Initialstatus“ des Kindes.
Das lasst sich so weiter machen, schlussendlich wurde im Beispiel ati = 0 beimmittleren Alter in der Beobachtungszeit gesetzt (11 Jahre). Die unterschiedli-chen Definitionen des Intercepts beeinflusst aber auch die Interpretation derVarianz des Intercepts auf der zweiten Ebene, sowie die Kovarianz zwischenSlope und Intercept. Die im Beispiel verwendete Zentrierung fuhrt dazu, dassdie Kovarianz zwischen Slope und Intercept automatisch 0 ist.
Ahnliche Uberlegungen gelten fur Modelle mit hoherwertigen Polynomen.Zentrierung um das Mittel (hier Alterti− 11) hat besondere, gunstige Eigen-schaften. Der Wert fur β1i ist nicht nur die Wachstumsrate bei einem Altervon 11, sondern auch die durchschnittliche Anderungsrate in der gesamtenDatenerhebungsperiode, die in vielen Untersuchungen von Interesse ist. Zu-dem wird die Korrelation zwischen dem linearen und dem quadratischenTerm, ati und a2
ti minimal (Pinheiro & Bates, 2000). Bei Definition des Inter-cepts als
”Initialstatus“ oder bei einem Alter von 0 wird eine starke negative
Korrelation zwischen den beiden Parametern auftauchen, die die Schatzunginstabil machen kann. Bei einem quadratischen Modell hangt die Interpreta-tion des quadratischen Terms nicht von der Lokalisation der ati ab, sehr wohlaber der Intercept und lineare Slope. Das lasst sich auch generell sagen. Beijedem polynomialen Modell ist der Term mit der hı¿1
2chsten Ordnung invari-
ant gegenuber der Zentrierung und hat somit immer dieselbe Interpretation,aber alle anderen Terme hangen von der Zentrierung ab.
Bei der Schatzung der Varianz der Wachstumsparameter ist ebenfalls dieZentrierung zu berucksichtigen. Falls die Zeitpunkte bei allen Teilnehmerndieselben sind, dann wird keine Variation beim Mittelwert einer level-1 Va-riable auftreten und somit keinen Einfluss auf die Schatzung der Varianz derWachstumsrate haben (vgl. das Beispiel der zyklischen Veranderung; dortsind die Zeitpunkte der Messung ursprunglich gleich). Es kann aber auchvorkommen, dass die Zeitpunkte systematisch uber die Teilnehmer variieren.Dann ist es notwendig eine Zentrierung um das Personenmittel durchzufuhrenund nicht um das Gesamtmittel. Eine ahnliche Vorgehensweise wurde beimBeispiel der zyklischen Veranderung gewahlt, bei dem die Daten so
”zen-
triert“ wurden, dass fur jede Stute der eine Eisprung zum Zeitpunkt 0 undder darauffolgende zum Zeitpunkt 1 stattfand. Der Eisprung fand aber nichtbei allen zum selben Zeitpunkt statt und zeigt dewegen systematische Va-riation. Die gewahlte Skalierung ermoglicht ein Vermeiden von Verzerrung
43

aufgrund der Variation des Eisprungs.
5.2 Meta-Analysen und andere Falle mit bekannterlevel-1 Varianz
Ein weiteres Anwendungsfeld von HLM findet sich bei der zusammenfassen-den Untersuchung von mehreren, ahnlichen Studien, auch
”Meta-Analyse“
genannt (Glass, 1976). Die wichtigste Frage bei Meta-Analysen ist die Kon-sistenz von Ergebnissen. Wenn jedes Experiment denselben Effekt produziert,ist es sinnvoll die einzelnen Ergebnisse in einer gemeinsamen Effektstarken-Schatzung zusammenzufassen. Wenn jedoch die Ergebnisse der einzelnen Stu-dien inkonsistent sind, ist es die Aufgabe der Meat-Analyse festzustellen,warum das so sein konnte. Dies ist die Frage danach, welche Charakteristi-ken der Versuchsanordnung, der untersuchten Personen, der Methodik derUntersuchungen diese Unterschiede in den Ergebnisse vorhersagen konnen.
Eines der zentralen Probleme bei der Beurteilung, ob Ergebnisse kon-sistent sind oder nicht, ist, dass selbst dann wenn jede Studie einen ge-meinsamen,
”wahren“ Effekt produzierte, dessen Schatzung zwischen den
Studien variiert. Solche Variationen tauchen naturlich auch dann auf, wennalle Studien exakt dasselbe Design implementieren und Zufallsstichprobenaus derselben Population verwenden. Es ist dann Aufgabe des Untersucherszwischen Variationen bei den geschatzten Effekten (wo auch der Fehler auf-grund der Stichprobenziehung dazuzahlt) und Variation, die die Inkonsistenzder Ergebnisse reflektiert, zu unterscheiden. Falls nun eine solche Inkonsis-tenz auftaucht, konnen Modelle formuliert werden, die versuchen diese zuerklaren. Wieder gehort dazu die Frage nach Varianzkomponenten, also wie-viel des Fehlers ist Fehler aufgrund der Stichprobe und wieviel ist durch echteInkonsistenz, die ein Modell nicht erklaren kann, bedingt.
Die HLM sind ein nı¿12tzliches Methodenset fur die Beantwortung solcher
Fragen im Rahmen einer Meta-Analyse. Sie ermoglichen eine Schatzung desdurchschnittlichen Effektes uber Studien, eine Schatzung der Varianz des Ef-fektstarkenparameters, Abschatzung der Residualvarianz der Effektstarken-parameter fur jedes lineare Modell und eine Vorhersage von Studieneffektenanhand der Informationen anderer Studien.
Hier soll auf die Anwendung von HLM bei Meta-Analysen in denen eineinzelner, standardisierter Effekt pro Studie von Interesse ist eingegangenwerden. Eine Verallgemeinerung dieses Zugangs auf die Situation, dass dieVarianz auf der ersten Ebene bekannt ist, folgt anschließend. Fur die Anwen-dung von HLM auf komliziertere Meta-Analysen, bei denen mehrere Statis-tiken von Interesse sind bzw. mehrere abhangige Variablen interessieren, sei
44

auf Raudenbush & Bryk (2002) verwiesen.
Modelle fur Meta-Analysen
Die Sichtweise von Meta-Analysen als HLM ist relativ einleuchtend, da dieseDaten hierarchisch strukturiert sind. Objekte sind in Studien eingebettet undModelle werden benotigt, um die Variation auf der Ebene der Studienobjekteund auf der Ebene der Studien miteinzubeziehen.
Von den bisher dargestellten Anwendungen unterschiedet sich dieser Falldadurch, dass die Rohdaten aus den einzelnen Untersuchungen meistens nichtzuganglich sind und dass oftmals unterschiedliche Messungen der abhangigenVariablen verwendet werden, obwohl sie dasselbe Konstrukt erfassen sollen.Um das zweite Problem zu losen, wurden zahlreiche, standardisierte Messun-gen fur Effekte entwickelt. Cooper & Hedges (1994) geben einen Uberblickuber viele dieser Statistiken.
Level-1 Modell Die Verwendung von HLM soll anhand des standardisier-ten Mittelwertunterschiedes und anhand der standardisierten Effektstarkevon Korrelationen erklart werden.
Das Modell auf der ersten Ebene, also innerhalb der Studien ist einfach(der Terminologie von Raudenbush & Bryk (2002) folgend),
dj = δj + ej, ej ∼ N(0, Vj). (52)
Hierbei steht j = 1, . . . , J fur die Studien. Das dj ist irgendeine standardi-sierte Effektstarke aus Studie j, δj der dazugehorige Parameter und Vj istdie Varianz der dj als Schatzer fur δj.
Z.B. kann das dj der standardisierte Mittelwertsunterschied sein,
dj =Y Ej − Y Cj
Sj, (53)
wobei Y Ej der Mittelwert der AV der Experimentalgruppe in Studie j ist,Y Cj ist dasselbe in der Kontrollgruppe und Sj ist die gepoolte Standardab-weichung innerhalb der Gruppen. Die dj sind somit in Einheiten der Stan-dardabweichung angegeben. dj ist eine Schatzung des entsprechenden Popu-lationsparameter, δj, und die Genauigkeit dieser Schatzung hangt von denStichprobengroßen der Gruppen ab, also nEj fur die Experimentalgruppe undnCj fur die Kontrollgruppe. Hedges (1981, zitiert nach Raudenbush & Bryk(2002)) zeigte, dass dj fur einen fixen Wert δj approximativ unverzerrt istund eine bedingte Verteilung von,
dj|δj ∼ N(δj, Vj), (54)
45

mit2
Vj =nEj + nCjnEjnCj
+δ2j
2(nEj + nCj), (55)
hat. Laut Raudenbush & Bryk (2002) ist es gangige Praxis in Formel (55) djfur δj zu substituieren und Vj als bekannt anzunehmen.
Ein weiteres Beispiel ware die standardisierte Effektstarke der Korrelationrj,
dj =1
2log
(1 + rj1− rj
), (56)
mit
Vj =1
nj − 3. (57)
nj ist hierbei die Stichprobengroße die in der j-ten Studie verwendet wurde.
Level-2 Modell Beim Modell auf Studienebene hangt der”wahre“, un-
bekannte Parameter, δj, von bestimmten Charakteristika der Studie j undeinem Level-2 Zufallsfehler ab. In die bisherige Modellsprache ubersetzt heißtdas,
δj = γ0 + γ1W1j + · · ·+ γSWSj + uj (58)
= γ0 +∑s
γsWsj + uj, uj ∼ N(0, τ) (59)
Die W1j, . . . ,WSj bezeichnen gewisse Charakteristiken der Studie, die dieseEffektgroßen beeinflussen, die γ0, . . . , γS sind deren Regressionskoeffizientenund die uj sind level-2 Zufallseffekte.
Das kombinierte Modell lasst sich dann schreiben als
dj = γ0 +∑s
γsWsj + uj + ej, (60)
wobei die dj normalverteilt sind,
dj ∼ N(γ0 +∑s
γsWsj, τ + Vj). (61)
Das heißt,V ar(dj) = τ + Vj = ∆j. (62)
2Bei Raudenbush & Bryk (2002) ist die Formel anders angegeben. Dort ist im zweitenBruch der Nenner als 2(nEj + nEj
) angefuhrt, was 4nEj entsprache. Ich glaube, dass essich dabei um einen Druckfehler handelt und meine Korrektur richtig ist.
46

Bei diesen Arten von Problem wird die Schatzung allgemein etwas einfa-cher, da jedes Vj als bekannt angenommen wird. Es ist somit nur noch notig,eine Varianzkomponente zu schatzen, namlich τ . In der R-Implementierungvon nlme ist es leider nicht moglich, ein fixes oder mehrere fixe σ2 vorzuge-ben, der Fehler wird immer geschatzt. Fur eine Analyse dieser Art muss somitauf das Programm HLM (Raudenbush, Bryk & Congdon, 2005) zuruckge-griffen werden. Auch die SAS Proc Mixed (Littel et al. 1996) erlaubt fixelevel-1 Varianzen.
Beispiel: Effekt von Lehrererwartungen auf Schuler-IQ Rauden-bush (1984; zitiert nach Raudenbush & Bryk (2002)) verwendete 19 Studien,die sich mit der Frage beschaftigten, ob und wie die Erwartung von Lehrerndie
”intellektuelle Leistungsfahigkeit“ von Schulern beeinflußt. In allen die-
sen Studien bestand die Experimentalgruppe aus Schulern, fur die bei denLehrern
”hohe“ Erwartungen induziert wurden. Die Kontrollgruppe waren
Schuler, deren Lehrer keine experimentell manipulierte Erwartungshaltunghatten. In Tabelle 10 sind die Ergebnisse der 19 Studien angegeben.
Kontakt Effektstarke StandardfehlerStudie (in Wochen) dj se(dj)
Rosenthal et al. (1974) 2 0.03 0.125Conn et al. (1968) 3 0.12 0.147Jode & Cody (1971) 3 -0.14 0.167Pellegrini & Hicks (1972) 0 1.18 0.373Pellegrini & Hicks (1972) 0 0.26 0.369Evans & Rosenthal (1969) 3 -0.06 0.103Fielder et al. (1971) 3 -0.02 0.103Claiborn (1969) 3 -0.32 0.220Kester & Letschworth (1972) 0 0.27 0.164Maxwell (1970) 1 0.80 0.251Carter (1970) 0 0.54 0.302Flowers (1966) 0 0.18 0.223Keshock (1970) 1 -0.02 0.289Henrickson (1970) 2 0.23 0.290Fine (1972) 3 -0.18 0.159Greiger (1970) 3 -0.06 0.167Rosenthal & Jacobson (1968) 1 0.30 0.139Fleming & Anttonen (1971) 2 0.07 0.94Ginsburg (1970) 3 -0.07 0.174
Tabelle 10: Ergebnisse der 19 Studien zum Einfluss von Lehrererwartung aufden IQ von Schulern (nach: Raudenbush & Bryk (2002, S. 211))
47

Man kann erkennen, dass in den Studien teilweise stark unterschiedlicheErgebnisse resultierten. Die Schatzung der Effektstarke variiert zwischen -0.32 und 1.18. Allerdings haben die Studien mit den extremsten Ergebnisseneinen relativ hohen Standardfehler der Schatzung, was auf eine geringe Stich-probengroße schließen laßt. Die folgenden Analysen sind aus Raudenbush &Bryk (2002) entlehnt und stellen zum Einen ein unbedingtes Modell dar, umdie Variabilitat der
”wahren Effektstarke“ abzuschatzen und zum Anderen
ein bedingtes Modell, dass versucht, diese Variabilitat durch die Zeit, die dieLehrer mit den Schulern verbrachten, zu erklaren.
Das unbedingte Modell ist denkbar einfach, es wird die mittlere Effektstarkegeschatzt, sowie eine assoziierte Varianz dieser Effektstarke, d.h.
dj = δj + ej (63)
δj = γ0 + uj. (64)
Die Ergebnisse sind im oberen Teil der Tabelle 11 dargestellt.
Unbedingtes Modell
Fixer Effekt Koeffizient SE t
γ0 0.083 0.052 1.62Varianz-
ZufalligerEffekt Komponente df χ2 p-Wert
uj 0.019 18 35.85 0.009
Bedingtes Modell
Fixer Effekt Koeffizient SE t
γ0 0.407 0.087 4.67Kontakt,γ1 -0.157 0.036 -4.38
Varianz-Zufalliger Effekt Komponente df χ2 p-Wert
uj 0.000 17 16.57 > 0.5
Tabelle 11: Ergebnisse der Modelle fur die Meta-Analyse zum Einfluss vonLehrererwartung auf IQ von Schulern (nach: Raudenbush & Bryk (2002, S.213 & 216))
Die geschatzte Effektstarke, γ0, ist mit 0.083 ziemlich gering. Die Schulerder Experimentalgruppe sind im Durchschnitt nur 0.083 Standardabweichun-gen uber den Schulern der Kontrollgruppe. Die geschatzte Varianz dieser
48

Effektstarke jedoch, τ , ist mit 0.019 relativ groß, das sind 0.138 Standard-abweichungen. Es ist also substantielle Variabilitat in den Daten, die es zuerklaren gilt.
Raudenbush (1984) stellte die Theorie auf, dass die Tauschung der Leh-rer entsprechend der Experimentalbedingung nur dann wirklich funktioniert,wenn die Lehrer die Schuler gar nicht kennen. Sollte aber der Lehrer schoneine mehr oder weniger starke Uberzeugung bezuglich des Schulers haben,so wird die experimentelle Manipulation diese Uberzeugungen nicht erset-zen. Dies wurde operationalisiert, indem die Zeit, in denen der Lehrer mitdem Schuler Kontakt hatte, erhoben worden ist (in Wochen). Mit einem be-dingten Modell, dass auf den Einfluss von Kontakt zwischen Lehrern undSchulern kontrolliert, wurde versucht, die hohe Variabilitat uber die Studienzu erklaren.
Das Modell auf Ebene 1 ist dasselbe wie beim unbedingten Modell, aufEbene 2 kommt jetzt aber noch ein fixer Effekt der Kovariate hinzu:
δj = γ0 + γ1W1j + uj, uj ∼ N(0, τ) (65)
wobei γ0 nun die erwartete Effektstarke fur eine Studie ohne vorhergehendenKontakt bezeichnet, γ1 die erwartete Differenz in der Effektstarke zwischenzwei Studien, die sich um eine Woche vorhergehenden Kontakts unterscheidenund uj die Abweichung der Effektstarke von Studie j von der erwarteten, diedurch die Kovariate nicht erklart wird. Die Kovariate W1j nimmt die Werte0,1,2 oder 3 an, je nachdem ob 0, 1, 2 oder mehr Wochen Kontakt vor derStudie zwischen Schuler und Lehrer herrschte.
Die Ergebnisse sind im unteren Teil von Tabelle 11 dargestellt. Es zeigtsich - der Vermutung entsprechend -, dass die Effekte der Versuchsbedingungin den Studien kleiner waren, bei denen die Lehrer mit den Schulern Kon-takt vor dem Experiment hatten. Fur Studien ohne vorhergehenden Kontaktist der geschatzte Effekt, γ0, am großten. Mit jeder weiteren Woche Kon-takt sinkt der erwartete Effekt um -0.157. Fur Studien mit mehr als 2 Wo-chen Kontakt heißt das, dass eigentlich Effektstarken um 0 erwartet werden.Auch fallt auf, dass ein großer Teil der geschatzten Varianz der
”wahren Ef-
fektstarke“ durch die Kovariate erklart werden kann, die Punktschatzung furτ ist praktisch 0.
Probleme mit bekannter Level-1 Varianz
Meta-Analysen sind ein wichtiger Spezialfall von Problemen, bei denen dieVarianz auf der ersten Ebene als bekannt angenommen werden kann. DieGruppierung ist bei dieser etwas allgemeineren Klasse nicht auf unterschiedli-che Studien beschrankt, sondern kann auch anhand andere Kriterien vorhan-
49

den sein (z.B. wieder Schulen). Der entscheidende Unterschied zu den bisherbehandelten HLM ist eben, dass aus irgendwelchen Grunden die Variabilitatdes Fehlers auf der ersten Ebene als bekannt vorausgesetzt werden kann undsomit nicht geschatzt werden muss. Die Statistiken, die zur Beantwortungder Forschungsfrage herangezogen werden, konnen vielerart sein, sie werdenaber fur jedes level-2 Objekt separat berechnet. Oftmals kann mittels geeig-neter Transformationen die Quasi-Normalitat und die Annahme bekannterVarianz verbessert werden (z.B. die Fisher Transformation der Korrelation,Formel (56)). Einen Uberblick uber einige haufig gebrauchte Statistiken, de-ren Schatzer und deren approximativer Stichprobenvarianz ist in Tabelle 12gegeben. Die Modelle aus (52) und (59) sind fur alle diese Statistiken ver-wendbar. Diese Uberlegung lasst sich in weiterer Folge auch auf multivariateFalle verallgemeinern, bei denen mehrere interessierende Statistiken fur ver-schiedene abhangige Variablen betrachtet werden (vgl. Raudenbush & Bryk(2002)).
Parameter, δj Schatzer, dj app. Varianz, Vj
Stand. µE−µCσpooled
xE−xCSpooled
nE+nCnEnC
+ d2
2(nE+nC)
Mittelwertsdiff.
Korrelation 12 log
(1+ρ1−ρ
)12 log
(1+r1−r
)1
n−3
Logit log(
p1−p
)log(
p1−p
)1
np(1−p)
Log(sd) log(σ) log(S) + 12df
12df
(df=Freiheitsgradevon S)
Tabelle 12: Univariate Statistiken mit bekannter Varianz (nach: Raudenbush& Bryk (2002, S. 219))
6 Uberprufung der Angemessenheit von HLM
Dieses Kapitel beschaftigt sich mit Moglichkeiten, die spezifizierten Modellezu uberprufen, v.a. in Hinblick auf getroffene Annahmen, Modellselektionund der Gultigkeit von inferenzstatistischen Aussagen bei geringer Stichpro-bengroße. Gerade in der unreflektierten Anwendung der vorgestellten Kon-zepte zeigen sich große Gefahren fur Aussagen basierend auf HLM.
50

Naturlich ist es obligatorisch vor jeder Analyse mit HLM die Daten zuinspizieren, seien es univariate Analysen auf Ausreißer, marginaler Vertei-lung etc., bivariate Analysen, wie Korrelationen und plots zur Abschatzungetwaiger nichtlinearer Zusammenhange und so weiter. Auch Standardver-fahren auf level-1 - wie Einfachregressionen - geharen dazu, da auch level-2Objekte Ausreißer sein konnen und so weiter. Es sollte kein HLM spezifiziertund gerechnet werden, bevor solche Analysen durchgefuhrt wurden.
R bzw. S-Plus bietet einige Tools zur Modelldiagnostik an, v.a. Modell-plots. Darunter fallen plots der Residuen, der geschatzten Werte und dergeschatzten Zufallseffekte. Der Aufruf ist relativ einfach
plot(lmeObject,...)
Dieser Befehl produziert per default einen plot der Residuen gegen die ge-fitteten Werte fur die gesamte Stichprobe. Weitere Moglichkeiten sind imR-Code im Anhang oder bei Pinheiro & Bates (2000) zu finden.
6.1 Zentrale Annahmen der HLM
Wie beim klassischen linearen Modell beruhen auch HLM auf einer Reihe vonAnnahmen, die teilweise relativ strikt sind. Was dann noch dazu kommt, istdass auf jeder Ebene solche Annahmen getroffen werden und die Gefahr einerMisspezifikation des Modells steigt. Daruber hinaus kann eine Misspefizifika-tion (v.a. der Fehlerstruktur bzw. der zufalligen Effekte allgemein) auf einerEbene auch Einfluß auf die Ergebnisse auf der oder den anderen Ebenen ha-ben, so konnen korrelierte Fehler auf level-2 die Schatzungen auf level-1 starkverzerren. In diesem Kapitel werden diese Annahmen v.a. in Hinblick auf diefixen Effekte, deren Standardfehler und die inferenzstatistischen Aussagendikutiert, da sie meist von besonderem Interesse sind, teilweise werden aberauch Implikationen fur die Inferenz bei den zufalligen Koeffizienten und denVarianz-Kovarianz-Komponenten besprochen werden. Hierfur verwende ichErgebnisse von Raudenbush & Bryk (2002), die auf ahnlichen Daten beruhen,wie in Kapitel 4 verwendet.
Die Modelle auf beiden Ebenen sind
Yij = β0j + β1j(SES)ij + rij, (66)
sowieβ0j = γ00 + γ01(MEAN SES)j + γ02(SECTOR)j + u0j, (67)
undβ1j = γ10 + γ11(MEAN SES)j + γ12(SECTOR)j + u1j, (68)
51

als spezifische Falle der Gleichungen (12) und (13).Die Annahmen, die fur das HLM gelten sind:
1. Jeder Fehler, rij, ist unabhangig normalverteilt mit Mittelwert 0 undVarianz σ2 fur jedes level-1 Objekt i innerhalb jedes level-2 Objektesj. Formal: rij ∼ iid N(0, σ2).
2. Die level-1 Prediktoren, Xqij, sind unabhangig von den rij,d. h. Cov(Xqij, rij) = 0 ∀q.
3. Die Q + 1 Fehlervektoren auf level-2 sind multivariat normalverteilt,jeder mit Mittelwert 0 und einer spezifischen Varianz, τqq, und einerspezifischen Kovarianz zwischen den zufalligen Elementen q und q′ vonτqq′ . Die Zufallsfehler-Vektoren sind aber unabhangig zwischen den Jlevel-2 Objekten, d.h. uj = (u0j, ..., uQj)
′ ∼ iid N(0,T).
4. Die level-2 Prediktoren, Wsj, uber alle Q + 1 Gleichungen sind un-abhangig von allen Fehlern, uqj, d.h. Cov(Wsj, uqj) = 0 ∀ (Wsj, uqj).
5. Die Fehler auf level-1 und level-2 sind unabhangig, d.h.Cov(rij, uqj) = 0 ∀ q.
6. Die Prediktoren der einen Ebene sind unabhangig von den Zufallsef-fekten der anderen Ebene, d.h. Cov(Xqij, uq′j) = 0 ∀ q, q′ undCov(Wsj, rij) = 0.
Annahmen 2, 4 und 6 betreffen den Zusammenhang zwischen dem struk-turell deterministischen Teil (X und W) und den Fehlern. Sie hangen mitder Frage zusammen, ob das Modell richtig spezifiziert wurde. Verletzungendieser Annahmen beeinflussen den Bias der Schatzung von γqs, d.h. von ih-nen hangt ab, ob E(γqs) = γqs ist. Annahmen 1,3 und 5 beziehen sich nurauf die zufalligen Komponenten, rij und uqj. Sie hangen mit der Konsistenzder Schatzungen fur se(γqs) zusammen, der Genauigkeit der βqj (v.a. des
empirischen Bayes-Schatzers), der σ2 und T sowie der Hypothesentests undKonfidenzintervalle.
Folgend wird jede dieser Annahmen diskutiert, wobei von level-1 zu level-2 ubergegangen wird. Gleichzeitig kann man diesen Abschnitt als das vonRaudenbush & Bryk (2002) vorgeschlagene “Rezept“, Modelle aufzusetzenund korrekt zu spezifizieren, ansehen.
6.2 Aufsetzen des level-1 Modells
Hierbei ist es wichtig, dass dies theoriegeleitet erfolgt. Diese Theorie sollteeine relativ geringe Anzahl an Prediktoren nahelegen und andere Prediktoren
52

ausschließen. Die Fragen, die damit zusammenhangen, sind, ob eine Varia-ble Xq uberhaupt im Modell enthalten sein sollte und wie deren Koeffizientspezifiziert werden soll (als fix, zufallig oder nicht-zufallig variierend).
Eine vorgeschlagene Vorgangsweise ist es, zuerst alle level-2 Prediktorenin der Analyse außen vor zu lassen und unbedingte Modelle auf level-1 zuschatzen. Eine Vorgangsweise derart, dass von einem saturierten Modell aus-gegangen wird und mittels Ruckwarts-Selektion Prediktoren ausgeschlossenwerden, ist nicht zielfuhrend, da dafur sehr große Stichproben auf level-1 undlevel-2 notwendig waren (die Schatzung mittels OLS ware hochstwahrschein-lich instabil und die benotigten Iterationen sehr groß und ein saturiertesHLM mit lauter Zufallseffekten hatte eine enorme Anzahl an Parameter, diegeschatzt werden mussten, vgl. etwas weiter unten). Außerdem konnte leichtein overfit resultieren, bei dem die Varianz in zuviele nicht-signifikante Teilezerlegt werden wurde. Raudenbush & Bryk (2002) schlagen eine Vorwarts-selektion vor, bei der von einem ganz simplen Modell (z.B. der EinfachenANOVA mit Zufallseffekten) ausgegangen und das Modell sukzessive erwei-tert wird.
Empirische Methoden zur Aufstellung eines level-1 Modells
Besonders interessant auf level-1 sind ublicherweise die Fragen, ob der fixe Ef-fekt vonXqij signifikant ist und ob es Anzeichen dafur gibt, dass die Slopes he-terogen sind (i.e. V ar(βq) > 0). Fur letzteres konnen in der Punktschatzungτqq und dem entsprechenden Test aus Kapitel 3 Anhaltspunkte gefunden wer-den. Auch interessant in diesem Zusammenhang ist die geschatzte Verlass-lichkeit der OLS-Schatzer (Raudenbush & Bryk, 2002).
Eine niedrige Verlasslichkeit (z.B. < 0.05) bedeutet, dass die zu schatzen-den Varianzen nahe bei 0 sein werden. Das bringt computationale Problememit sich. Eine geringe Verlasslichkeit ist ein Indiz dafur den entsprechendenKoeffizienten als fix oder nicht-zufallig variierend zu spezifizieren.
Auch eine immer gute Moglichkeit zur Diagnose von Problemen sinddie Korrelationen zwischen den level-1 Koeffizienten. Bei hoher Korrelation,Quasi-Multikollinearitat, sollte das Modell vereinfacht werden, z.B. indemman zufallige Effekte auf 0 fixiert (kann problematisch sein, wenn dieser einesubstanzielle Variabilitat hat) oder indem man lineare Restriktionen aufsetzt(z.B. indem man ein Faktorenmodell auf die level-2 Zufallskomponenten auf-setzt (Miyazaki, 2000)).
Generell muss bei der Spezifizierung von level-1 Koeffizienten als zufalligachtgegeben werden. Die Anzahl an Varianz-Kovarianz-Komponenten, diein einem Modell mit zwei Ebenen geschatzt werden mussen, sind m(m +1)/2 + 1, wobei m die Anzahl der zufalligen level-1 Prediktoren darstellt.
53

Diese Zahl wachst quadratisch (o(2)) mit der Zahl an Zufallskomponenten.Zur Schatzung wird dann sehr viel mehr Dateninformation benotigt.
Allerdings muss ein τqq dass laut deskriptiver Analyse vermutlich bei 0ist, nicht heißen, dass der assoziierte Effekt zwangslaufig fix ist. Er kannja auch auf level-2 als nicht-zufallig variierend angesehen werden. Wenn estheoretische Grunde gibt das anzunehmen, sollte auf jeden Fall ein level-2Modell fur die entsprechenden βqj spezifiziert werden.
Weiters ist es von Bedeutung, ob ein level-1 Prediktor uberhaupt insModell gehı¿1
2rt. Eine Variable zu “loschen“ darf nur dann passieren, wenn es
keinen Hinweis auf heterogene Koeffizienten oder einen fixen Effekt gibt. Beieinem linearen Zusammenhang zwischen abhangiger Variable und Prediktor,kann dieser einfach ins Modell aufgenommen werden und sein Koeffizient aufSignifikanz gepruft werden um zu entscheiden, ob er ins Modell gehort.
Probleme bei Misspezifikation
Ein großes Problem bei Misspezifikation ist es, wenn ein Prediktor nicht inden deterministischen Teil des Modells aufgenommen wird (und somit Fehlerist), obwohl er mit der abhangigen Variable und einem anderen Prediktorzusammenhangt. Dann ist Annahme 2 verletzt, da der Fehlerterm nicht mehrunabhangig von den Prediktoren sein kann und die Schatzungen fur die βwerden verzerrt sein. Auch die level-2 Modelle fur diese β werden verzerrtsein.
Konsequenzen einer level-1 Misspezifikation fur level-2 Schatzun-gen Beim Intercept Modell (35) ist es bekannt (Raudenbush & Bryk, 2002),dass, wenn eine wichtige level-1 Kovariate nicht spezifiziert wird, es zu ernst-haften Verzerrungen in der Schatzung von level-2 Prediktoren des Interceptskommt. Zum Beispiel, bei den Daten aus Kapitel 4 gibt es noch eine zusatzli-che Variable, “ACADEMIC BACKGROUND“, die bei den Analysen bishernicht berucksichtigt wurde. Falls diese Variable mit “Mathematikleistung“zusammenhangt und Schuler offentlicher und Privatschulen sich unterschei-den, was deren Werte bei dieser neuen Variablen anbetrifft, dann sind dieSchatzungen des Effektes von “SECTOR“ auf β0j in den vorherigen Ana-lysen verzerrt. Raudenbush und Bryk (2002) schlagen vor, die Verzerrungdadurch zu entfernen, dass man auf level-1 “ACADEMIC BACKGROUND“(mit Zentrierung um den Gruppenmittelwert) hinzunimmt. Die Schatzungist dann nach dem Effekt dieser Variable adjustiert, da der Schulmittelwertvon “ACADEMIC BACKGROUND“ auf level-2 als Prediktor fur den In-tercept fungiert. Alternativ ware es auch moglich die Variable zentriert umdas Gesamtmittel in das level-1 Modell aufzunehmen. Der erste Vorschlag
54

ist aber besser, wenn die Slopes von “ACADEMIC BACKGROUND“ alszufallig gesehen werden.
Beim Slope Modell (36) sind bei Misspezifikationen auf Ebene 1 kompli-ziertere Konsequenzen zu erwarten, als beim Intercept. Die formale Ableitungdieser ist bei Raudenbush & Bryk (2002) zu finden. Hier seien sie nur ex-emplarisch an dem Beispiel veranschaulicht. Angenommen in (34) hatte dieVariable “ACADEMIC BACKGROUND“ aufgenommen werden mussen. Ta-belle 13 stellt die Schatzungen fur das ursprungliche und das nun erweiterteModell einander gegenuber3.
ursprungliches Modell mitModell kofundierender Variable
Fixer Effekt Koeff. se Koeff. se
Modell fur Schulmittel,β0j
Intercept,γ00 13.73 0.20 13.74 0.20MeanSES,γ01 4.54 0.48 4.55 0.48SECTOR,γ02 0.83 0.20 0.83 0.20
Modell fur SES Slopes,β1j
Intercept,γ10 1.78 0.16 1.13 0.16MeanSES,γ11 0.68 0.38 0.29 0.36SECTOR,γ12 -0.58 0.16 -0.39 0.15
Modell fur Akad. Hintergrund Slopes,β2j
Intercept,γ20 - - 2.14 0.09
Tabelle 13: Kofundierende Effekte der zusatzlichen Variable”ACADEMIC
BACKGROUND“ (nach: Raudenbush & Bryk (2002, S. 260))
Formal ist “ACADEMIC BACKGROUND“ eine kofundierende Variableauf Ebene 1, sie hangt sowohl mit den anderen UV als auch mit der AVzusammen. Wie ersichtlich, andern sich die Schatzungen fur das InterceptModell so gut wie gar nicht, wenn “ACADEMIC BACKGROUND“ hinzu-genommen wird (zentriert um das Gruppenmittel). Jedoch andern sich diegeschatzten Effekte im Slope Modell substanziell. Fur γ10 (mittlerer SES Slo-pe innerhalb der Schulen) ist es intuitiv pausibel, dass die Schatzung kleinerist, wenn auf “ACADEMIC BACKGROUND“ kontrolliert wird, da SES und
3Es handelt sich aber um etwas andere Daten als in Kapitel 4, sowie um andere Para-metrisierungen. Die Schatzungen konnen also nicht mit denen der HSB82-Daten numerischverglichen werden. Zur Darstellung der Konzepte eignen sie sich jedoch gut. Die Wertewurden aus Raudenbush & Bryk (2002) entlehnt.
55

die neue Variable positive Wirkung auf die AV haben und selbst auch mitein-ander positiv zusammenhangen. Die Grunde fur die Verzerrungen bei γ11 undγ12 sind etwas komplizierter. Es handelt sich hierbei um cross-level interac-tion effects (Raudenbush & Bryk, 2002), da sie Interaktionen von Variablen,die auf unterschiedlichen Ebenen angesiedelt sind, einschließen (auf level-2MeanSES und SECTOR und auf level-1 SES). Raudenbush und Bryk (2002)erwahnen die Bedingungen unter denen eine level-1 UV konfundierend aufdie Inferenz von cross-level interactions wirkt. Dort ist auch der Beweis zufinden. Es sind dies:
1. Die entfernte Variable muss mit Y zusammenhangen, wenn auf anderePrediktoren im Modell kontrolliert wird.
2. Die entfernte Variable muss mit einem im Modell inkludierten X zu-sammenhangen.
3. Der Zusammenhang zwischen entfernter Variable und X muss selbstvon Objekt zu Objekt variieren und die Starke des Zusammenhangszwischen entfernter Variable und X muss zudem mit einem level-2 Pre-diktor zusammenhangen.
Im Beispiel sind alle diese Bedingungen erfullt und dementsprechend andernsich die Schatzungen bei Hinzunahme von “ACADEMIC BACKGROUND“.Zur Diagnose ob die Bedingungen zutreffen, kann fur Bedingung 1 bspw. ei-ne Regressionsanalyse von Y auf die Prediktoren “SES“ und “ACADEMICBACKGROUND“ verwendet werden. Bedingungen 2 und 3 konnen uberpruftwerden, indem man ein random coefficients model verwendet, das “ACADEMICBACKGROUND“ durch “SES“ vorhersagt. Ist der mittlere Slope, γ01, signi-fikant, durfte Bedingung 2 erfullt sein und wenn es Hinweise auf Variabilitatder β1j (Variabilitat im vorigen Zusammenhang uber die Schulen) gibt, unddass diese Slopes mit den Schulvariablen (“SECTOR“ und “MeanSES“) zu-sammenhangen, wird wahrscheinlich Bedingung 3 erfullt sein.
Konsequenzen einer level-2 Misspezifikation fur level-1 Schatzun-gen Wenn ein “geloschter“ level-2 Prediktor mit einem level-1 Prediktorzusammenhangt, wird der geschatzte Koeffizient des level-1 Prediktors ver-zerrt sein. Das bedeutet Cov(Xqij, uq′j) 6= 0. Dieses Problem kann gelostwerden, indem man den level-1 Prediktor um das Gruppenmittel zentriert(da eine solche Kovarianz eine Funktion der Kovarianz zwischen dem Grup-penmittel Xqj und dem zufalligen level-2 Prediktor ist). Auch ginge es, dasGruppenmittel Xqj als Kovariate in jedes level-2 Modell aufzunehmen. Diese
56

beiden Vorgangsweisen legen eine Prufung dieser Misspezifikation nahe, in-dem man ein Modell mit und eines ohne Zentrierung um das Gruppenmitteldes level-1 Prediktors schatzt und die Schatzungen vergleicht. Unterscheidetsich der fixe level-1 Koeffizient nicht stark in den beiden Modellen, ist dasModell nicht anfallig fur diese Art von Verzerrung.
Meßfehler bei level-1 Prediktoren Bisher wurde immer davon ausge-gangen, dass die Prediktoren ohne Messfehler erhoben wurden. Falls aberz.B. die Messung von “SES“ fehlerbehaftet ist, werden die Schatzer fur β1j
und γ10 verzerrt sein (bei mehr erklarenden Variablen alle Slopes die mitMeßfehler behaftet sind). Fur die cross-level interactions, γ11 und γ12, wirdnur dann ein Bias auftreten, wenn die Verlasslichkeit der “SES“ Messungvon Schule zu Schule unterschiedlich ist und diese Variation in der Verlass-lichkeit mit einem oder mehr level-2 Prediktoren im Modell zusammenhangt(Raudenbush & Bryk, 2002).
Uberprufen der Annahmen uber level-1 Zufallseffekte
Varianzhomogenitat Es wird meistens eine gemeinsame Varianz, σ2, furdie Fehler auf level-1 angenommen. Diese Annahme ist aber wichtig zu uber-prufen. Falls - entgegen der Annahme - die level-1 Varianz zufallig uber dielevel-2 Objekte schwankt, wird die Konsequenz nur gering sein. Es findet kei-ne Verzerrung statt und auch die Standardfehler werden sehr robust sein (Ka-sim & Raudenbush, 1998). Falls aber die Varianzen systematisch als Funkti-on von level-1 oder level-2 Prediktoren abhangen, konnen die Auswirkungengravierend sein. Grunde fur Heterogenitat konnen sein:
• Wichtige level-1 Prediktoren sind nicht im Modell enthalten.
• Der Effekt eines level-1 Prediktors, der zufallig oder nicht-zufallig va-riiert, wurde falschlicherweise als fix spezifiziert.
• Die Daten von einem oder mehreren Objekten sind schlecht, z.B. Ko-dierungsfehler.
• Nicht-Normalitat der Daten, v.a. “heavy tails“.
Diese moglichen Quellen sollten uberpruft werden, bevor eine komplizierte-re Varianzannahme getatigt wird. Das kann mittels eines standardisiertenMaßes fur die Abweichung pro Gruppe j uberpruft werden (Raudenbush &Bryk, 2002):
dj =ln(S2
j )−[∑
fj ln(S2j )/∑fj]√
2/fj, (69)
57

wobei Sj die geschatzte Residualstandardabweichung in Gruppe j ist und fjdie damit assoziierte Zahl an Freiheitsgraden bezeichnet. Eine Teststatistikfur Homogenitat ist dann
H =∑
d2j , (70)
welche unter der Nullhypothese der Homogenitat asymptotisch einer χ2-Verteilung mit J − 1 Freiheitsgraden folgt. Indiziert ist dieser Test bei nor-malverteilten Daten und einer Stichprobengroße pro Gruppe von uber 10(Bartlett & Kendall, 1946). Auch ein Likelihood-Ratio Test kann benutztwerden um Heterogenitat zu uberprufen. Dazu wird ein Modell mit homo-gener Varianz als restriktives Modell eines generelleren Falles mit komplexerFehlerstruktur (z.B. unterschiedliche Varianzen σ2
j fur alle J level-2 Objekte)angesehen. Die Devianzstatistik zeigt auf ob durch das restriktivere Modelleine signifikant schlechtere Erklarung der Daten erfolgt. Hier muss aber auchdarauf hingewiesen werden, dass solche standardisierten Residuen und Hete-rogenitatsstatistiken sehr stark von einer Normalverteilung der beobachtetenDaten abhangen.
Im Anhang ist fur die HSB82-Daten eine Reihe von Befehlen und Moglich-keiten fur graphische Uberprufung dieser Annahme angefuhrt (allerdings eig-nen sich diese plots aufgrund der hohen Zahl an Schulen nicht sehr gut zurVeranschaulichung).
Im Allgemeinen ist die Verletzung der Homogenitatsannahme fur dieSchatzung der level-2 Effekte ja nicht so schlimm. Aber Heterogenitat kannauf eine mogliche Misspezifikation des level-1 Modells hinweisen und diesekann wiederum sehr schwerwiegende Konsequenzen haben.
Annahme normalverteilter Daten Durch die Erweiterung der bisherdargestellten Theorie auf verallgemeinerte lineare Modelle ist es moglich auchandere Wahrscheinlichkeitsverteilungen zu spezifizieren.
Es kann aber auch sein, dass man kontinuierliche abhangige Variablen hatund ein lineares Modell sich aufdrangt, die Annahme der Normalverteilungaber nicht haltbar ist. In diesem Fall wird die Schatzung der level-2 Effektenicht verzerrt werden, aber ein Bias auf beiden Ebenen fur die Standardfehlerund somit die inferenzstatistischen Methoden nach sich ziehen. Allerdingsist noch wenig daruber bekannt, wie sich das im Falle von HLM auswirkt(Raudenbush & Bryk, 2002).
Eine Uberprufung dieser Annahme kann mittels QQ-plots fur jede Gruppej untersucht werden oder gepooled bei großen J (dafur mussen aber dieVarianzen homogen sein). Fur die HSB82-Daten nach fitten des Intercepts-and-Slopes-as-Outcomes Modells ist der QQ-Plot in Abbildung 6 zu sehen. Es
58

zeigt sich, dass”schwere Enden“ vorherrschen, weswegen inferenzstatistische
Aussagen nur sehr vorsichtig getroffen werden sollten.
Abbildung 6: QQ-Plot der Residuen beim Intercepts and Slopes as OutcomesModell der HSB82-Daten
Naturlich sind auch Signifikanztests zur Verteilungsanpassung moglich.Die Transformation der abhangigen Variable oder der Prediktoren konnteauch eine annahernde Normalitat der Fehlerverteilung ermoglichen.
6.3 Aufsetzen des level-2 Modells
Vieles von dem, was bei level-1 genannt wurde, gilt auch bei level-2. Die Mo-dellierung sollte theoriegeleiteten Hypothesen uber Zusammenhange auf derzweiten Ebene folgen. Wiederum schlagen Raudenbush & Bryk (2002) eineVorwartsselektion vor, da die Zahl der level-2 Objekte fur alles andere ubli-cherweise zu klein ist und daruber hinaus Multikollinearitat auf dieser Ebeneleicht auftreten kann (man beachte das Beispiel mit der Mathematikleistung
59

von Schulern in Schulen; denkbare Schulvariablen durften stark miteinanderkorellieren, z.B. Region in der sich die Schule befindet und mittlerer SES).
Beim level-2 Modell sollte darauf geachtet werden, dass es nicht allzukompliziert wird, da sonst eine enorm große Stichprobe erforderlich wird. Beiklassischer multipler Regression ist eine bekannte Faustregel, dass fur jedenPrediktor mindestens 10 Beobachtungen zur sinnvollen Schatzung benotigtwerden. Das gilt in diesem Fall nur fur level-1. Da die Koeffizienten derlevel-1 Prediktoren als abhangige Variablen der level-2 Prediktoren gesehenwerden konnen, musste die Faustregel nochmal angewandt werden, d.h manbrauchte zur Schatzung eines Parameters auf level-2 10 level-2 Objekte, diewiederum jeweils 10 Beobachtungen pro level-1 Prediktor enthalten mussten.Offensichtilich steigt diese Zahl sehr schnell sehr rapide an, und dabei giltobiges nur fur den unwahrscheinlichen Fall, dass alle β absolut unabhangigvoneinander sind.
Falls hierarchische Modelle sowohl zufallige Intercepts als auch zufalligund nicht-zufallig variierende Slopes enthalten, sollte damit begonnen wer-den, zuerst ein vorlaufiges Modell fur den Intercept, β0j, aufzustellen undzu schatzen, bevor Modelle fur die Slopes geschatzt werden. Dies ist ana-log zu der Vorgangsweise bei linearen Modellen sich zuerst die Haupteffekteanzuschauen, bevor irgendwelche Interaktionseffekte untersucht werden. Beihierarchischen linearen Modellen ist in erster Linie die Interaktion zwischenden Ebenen interessant (cross-level interactions), was naturlich nicht heisst,dass keine Wechselwirkungen auf den Ebenen mitmodelliert werden konnen.
Empirische Methoden zur Aufstellung eines level-2 Modells
Den starksten Hinweis einen level-2 Prediktor in das Modell aufzunehmenliefert die Starke seines geschatzten Effekts und dessen t-Wert (um oder unter1 ist ein Zeichen fur das Entfernen aus dem Modell).
Analyse der Residuen Eine gute exploratorische Moglichkeit zur Mo-delluberprufung ist es, sich die Residuen auf level-2 genauer anzusehen. Dazugeharen Korrelationen der Residuen gegen potentielle level-2 Variablen, oderauch plots um den funktionalen Zusammenhang, der zu diesen Korrelationenfuhrt, sichtbar zu machen. Auch eine gute Idee ist es, die Residuen gegen diePrediktoren im vorlaufigen Modell zu plotten. Damit kann uberpruft werdenob die Annahme einer linearen Struktur fur jedes level-2 Modell Sinn macht.
t-to Enter Statistik Eine weitere Moglichkeit zur Entscheidung, ob po-tentielle Variablen in das level-2 Modell aufgenommen werden sollen, bietetdie approximative “t-to-enter“ Statistik ( vgl. Raudenbush & Bryk, 2002).
60

Dabei wird eine simple univariate Regression der Residuen aus jeder der Q+1Gleichungen auf die W-Variablen, die Kandidaten fur die Aufnahme in dasModell sind, gerechnet. Allerdings werden diese Regressionskoeffizienten denEffekt von W-Variablen unterschatzen, der auftritt, wenn die Variable imModell enthalten ist. Glucklicherweise wird aber auch deren Standardfehlerunterschatzt - um ca. denselben Faktor - (Raudenbush & Bryk, 2002), sodassdie t-to-enter Statistik einen relativ guten Hinweis auf die Konsequenzen derAufnahme gibt. Naturlich ist diese Statistik nur approximativ, da es sich jaeigentlich um ein multivariates Problem handelt, mit multiplen Prediktorenund korrelierten Fehlern. Trotzdem werden diese Werte meistens eine guteAbschatzung erlauben welche einzelne Kandidatenvariable als nachstes ineine der level-2 Gleichungen aufgenommen werden sollte.
Probleme bei Misspezifikation
Die korrekte Spezifizierung jedes der Q + 1 level-2 Modelle fuhrt dazu, dassder Fehlerterm, uqj, fur jede Gleichung als unkorreliert mit den Prediktorendieser Gleichung angenommen werden kann. Das heißt, dass jeder entferntePrediktor nicht mit den anderen Prediktoren im Modell zusammenhangt.Daraus kann man auch die Annahme ableiten, dass jeder Prediktor, Wj, ohneMeßfehler erhoben wurde. Falls eine konfundierende Variable aber entferntwird, wird die Schatzung eines oder mehrerer der level-2 Prediktoren verzerrtsein, wie stark hangt von dem Zusammenhang mit den anderen Prediktorenund dem Einfluss auf die abhangige Variable ab.
Dazu kommt, dass eine Misspezifikation einer Gleichung zu verzerrtenSchatzungen einer anderen Gleichung fuhren kann, selbst wenn diese korrektspezifiziert wurde. Zu diesem Bias kommt es durch die Korrelation zwischenden Fehlern in der korrekt und inkorrekt spezifizierten Gleichung. Methodeneinen solchen Bias zu entdecken folgen weiter unten.
Konsequenzen einer level-2 Misspezifikation Wiederum sollen die Ge-fahren anhand des Beispiels verdeutlicht werden. Wir nehmen an, Gleichun-gen (34), (35) und (36) sind korrekt spezifiziert. Tabelle 14 gibt somit die“korrekten“ Schatzungen in der ersten Spalte an. Angenommen, man ent-fernt “Mean SES“ als Prediktor fur den Intercept auf level-2 (bzw. hat ver-gessen ihn uberhaupt aufzunehmen), was naturlich falsch ist unter obigerAnnahme. Die zweite Spalte in Tabelle 14 zeigt die veranderten, “falschen“Schatzungen. Da “Mean SES“ und “SECTOR“ postiv korreliert sind, fuhrtdie “Loschung“ von “MeanSES“ zu einer Uberschatzung des
”SECTOR“- Ef-
fekts bei der Intercept Gleichung um fast das Doppelte! Auch die Schatzun-gen des “SES“-Slope sind von Verzerrungen betroffen. γ11, der Koeffizient
61

von “MeanSES“, ist um 40% gestiegen. Die Misspezifikation des Intercept-modells hat auch zu einer Verzerrung im korrekt spezifizierten Slope-Modellgefuhrt, da die Fehler der beiden Modelle korreliert sind.
ursprungliches Modell ohne”Spezifik-
Modell MeanSES ationstest“
FixerEffekt Koeff. se Koeff. se Koeff. se
Modell fur Schulmittel,β0j
Intercept,γ00 13.73 0.20 12.90 0.23 12.90 0.23MeanSES,γ01 4.53 0.48 - - - -SECTOR,γ02 0.83 0.20 1.56 0.23 1.56 0.23
Modell fur SES Slopes,β1j
Intercept,γ10 1.78 0.16 1.82 0.16 1.80 0.15MeanSES,γ11 0.68 0.38 0.93 0.38 0.73 0.34SECTOR,γ12 -0.58 0.16 -0.62 0.16 -0.61 0.14
Tabelle 14: Effekte bei Misspezifikation (nach: Raudenbush & Bryk (2002, S.271))
Eine Spezifikationsuberprufung Aufgrund der großen Sensibilitat derHLM auf solche Misspezifikationen - die hier leider auch relativ leicht, v.a. aufder zweiten Ebene, auftreten konnen - schlagen Raudenbush & Bryk (2002)eine Methode vor um zu sehen, ob Misspezifikation auftritt. Diese basiert dar-auf, dass die Koeffizientenschatzungen fur Intercept- und Slope-Gleichungendann unabhangig sind (und somit auch nicht von Misspezifikationen bei deranderen Gleichung beeinflusst), wenn die Summe der Stichprobenkovarianzzwischen β0j und β1j und die Kovarianz zwischen den wahren β0j und β1j nullsind. Zwar wird das nicht wirklich vorkommen, aber es kann als Basis fur ei-ne Uberprufung verwendet werden. Indem man die level-1 Prediktoren umihr Gruppenmittel zentriert, ergibt sich eine Stichprobenkovarianz mit demIntercept von 0. Und eine Restriktion dieses Slopes auf einen Fehler von 0ergibt eine Parameterkovarianz von Slope und Intercept von ebenfalls 0. Diesfuhrt zu einer Uberprufungsmoglichkeit, ob die Schatzungen in jeder level-2Gleichung durch Misspezifikation verandert wurden. In Tabelle 14 ist das inder funften Spalte zu sehen. Die Unterschiede zwischen Spalte 3 und 5 fur“MeanSES“ weisen auf eine mogliche Misspezifikation des Intercept-Modellsmit fehlendem “MeanSES“ hin. Allerdings soll hier noch erwahnt werden,dass ein Modell mit einer auf null gefixten level-2 Varianz nur fur den Zweckeiner Spezifikationsuberprufung verwendet werden soll, da die Prazision der
62

γ-Koeffizienten dadurch stark uberschatzt wird (deshalb sind auch die Stan-dardfehler in Spalte 6 kleiner als in Spalte 2).
Eine verzerrte Schatzung in einer korrekt spezifizierten Gleichung auflevel-2 durch eine Misspezifikation in einer anderen, sowie korrelierte Fehlerzwischen den beiden, kann weitestgehend vermieden werden, indem man furalle level-2 Gleichungen dieselben Prediktoren fur alle Q+1 Gleichungen ver-wendet. Genauer, wenn dasselbe Prediktorset in jeder Gleichung verwendetwird und wenn die Daten perfekt balanciert (d.h. jede Schule hat dieselbeStichprobengroße an Schulern und dieselben SES-Kategorien) sind, dann sinddie Schatzungen der level-2 Koeffizienten im Slope-Modell unabhangig vonden level-2 Koeffizienten im Intercept-Modell und somit findet keine Ver-zerrung statt. Im unbalancierten Fall wird das asymptotisch der Fall sein(Raudenbush & Bryk, 2002). Fur ein Beispiel bei dem ein balancierter Falleinem nicht balancierten Fall gegenuber gestellt wird siehe Pinheiro & Bates(2000) bzw. Milliken & Johnson (1992).
Meßfehler bei level-2 Prediktoren Da Meßfehler als spezielle Falle desMisspezifikationsproblem gesehen werden konnen, gilt das oben genannteauch dafur (Raudenbush & Bryk, 2002). Generell gilt, dass, wenn ein Pre-diktor mit Meßfehler erhoben wurde, sein Koeffizient und wahrscheinlich deranderer Prediktoren verzerrt sein werden. Explizite Meßmodelle mit latentvariable models ermoglichen es aber, auf den Bias zu kontrollieren.
Uberprufen der Annahmen uber level-2 Zufallseffekte
Varianzhomogenitat Die Annahme ist, dass die Varianz der level-2 Zu-fallseffekte homogen zwischen den J Objekten ist. Die Annahme kann bei-spielsweise in den HSB82-Daten verletzt sein, wenn offentliche Schulen mehrVarianz bei den Zufallskoeffizienten aufweisen, als private Schulen. In Abbil-dung 7 ist ein Scatterplot der Zufallseffekte nach den Sektoren dargestellt.Man sieht, dass private Schulen (
”catholic“) eine etwas großere Streuung
aufweisen.Fur die fixen Effekte hieße das, dass die Schatzung der Effekte nicht mehr
mit der optimalen Gewichtungsmatrix stattfindet, wodurch der Schatzer we-niger effizient ist. Er bliebe aber unverzerrt. Fur die Zufallseffekte wurde sichebenfalls ein erhohter mean squared error ergeben, da der shrinkage nichtmehr stimmt.
Die Annahme gleicher Varianzen in T kann formal getestet werden, undzwar mittels eines Likelihood-Ratio-Tests auf Gleichheit der Matrizen in denSubgruppen. Die weitere Vorgangsweise ist dann sehr ahnlich zu der in Ka-pitel 5.2.
63

Abbildung 7: Scatterplot der Zufallseffekte fur offentliche und private Schulenbei den HSB82-Daten
Normalverteilungsannahme Die Schatzung der fixen Effekte bleibt un-beeinflusst von einer Verletzung dieser Annahme auf Ebene 2. Aber wenndie level-2 Zufallseffekte schwere Enden haben, werden Hypothesentests undKonfidenzintervalle sehr sensibel auf die Ausreißer reagieren. Wenn die Nor-malverteilungsannahme ganz klar verletzt ist, dann sind sie sogar gar nichtmehr angemessen. Wie sich diese Verletzungen auswirken, liegt an der Art derechten Verteilung. Seltzer (1993) bietet einen Uberblick uber verschiedensteVerletzungen und deren Auswirkung.
Die Normalverteilungsannahme auf level-2 zu uberprufen, ist relativ schwer,da die level-2 AVs, βqj, nicht direkt beobachtet werden, sondern selbst nurgeschatzt sind. Es kann versucht werden, die Residuen zu plotten um nachAusreißern zu suchen. Auch konnen sie mit der marginalen Standardabwei-chung standardisiert werden und mittels QQ-plot gegen die Standardnormal-verteilung geplottet werden, dafur ist aber eine relativ große Stichprobe proGruppe, nj, notwendig um halbwegs sicher zu sein. Fur die HSB82-Daten ist
64

dies in Abbildung 8 dargestellt. Es zeigt sich, dass die Annahme der Normal-verteilung der level-2 Zufallseffekte angemessen ist.
Abbildung 8: QQ-Plot der Zufallseffekte beim Intercepts and Slopes as Out-comes Modell der HSB82-Daten
Ein weiteres Problem bei der Modellkontrolle ist, dass die Q+1 korrelier-ten Zufallseffekte pro Objekt geschatzt werden. Die beobachtete MahalanobisDistanz (sozusagen die Distanz zwischen den geschatzten Residuen fur jedeGruppe, relativ zur erwarteten Distanz aufgrund des Modells) pro Objektkann gegen die aufgrund der Normalverteilungsannahme Erwarteten geplot-tet werden, um das Ausmaß der Abweichung von der Normalverteilung zubestimmen oder um nach Ausreißern zu suchen. Dafur gibt es auch einenTest, denn diese Statistik ist bei großen Stichproben annahernd χ2-verteiltmit Q + 1 Freiheitsgraden unter Annahme der Gultigkeit der Normalvertei-lung (Raudenbush & Bryk, 2002).
Robuste Standardehler Da in den meisten Anwendungen v.a. die fixenEffekte, γ, interessieren und inferenzstatistische Aussagen uber diese von
65

Annahmen uber die Verteilung der Zufallseffekte teilweise abhangen, sollnoch kurz erwahnt werden, dass mit der Verwendung robuster Standardfeh-ler (“Huber-korrigierte“ Standardfehler) die Sensitivitat der Inferenzen aufVerletzung der Verteilungsannahmen uberpruft werden konnen. Fur weitereInformationen sei auf Raudenbush & Bryk (2002) verwiesen.
6.4 Gultigkeit von Inferenz bei geringer Stichproben-große
Im Spezialfall komplett balancierter Daten gilt die statistische Standardtheo-rie fur Inferenz uber die fixen Effekte bei kleinen Stichproben, z.B. wird dergeschatzte Wert eines fixen Effekts, dividiert durch seinen geschatzten Stan-dardfehler, exakt t-verteilt sein. Exakte Inferenz in diesem Fall ist moglich,da der Punktschatzer fur den fixen Effekt nicht von den Varianzkomponentenabhangt.
Im unbalancierten Regelfall muss man sich auf die Theorie großer Stich-proben der asymptotischen Statistik stutzen. Schatzungen der fixen Effekteund deren Standardfehler hangen von den Punktschatzungen jeder Varianz-oder Kovarianzkomponente im Modell ab. Die genaue Stichprobenvertei-lung der resultierenden Schatzer ist nicht bekannt. Bei Verwendung der ML-Schatzung jedoch, gibt es eine Menge Theorie uber deren Eigenschaften beigroßen Stichproben. Die Frage ist jetzt, wie gut diese Theorie in diesemZusammenhang funktioniert. Die Schatzung von fixen Effekten, der Varianz-Kovarianz-Komponenten und der Zufallsseffekte wird kurz im Folgenden ab-gehandelt und anhand der einfachen ANOVA mit Zufallseffekten veranschau-licht.
Inferenz uber die fixen Effekte
Die Schatzungen fixer Effekte sind fur jede Stichprobengroße unverzerrt, je-doch sind im unbalancierten Fall die Schatzungen ihrer Standardfehler ubli-cherweise zu klein und damit sind die Hypothesentests zu liberal.
Der Punktschatzer fur γ00 bei der einfaktoriellen ANOVA mit Zufallseffektist:
γ00 =
∑(Vj + τ00)−1Y .j∑
(Vj + τ00)−1, (71)
mitVj = σ2/nj
66

undY .j =
∑Yij/nj
Der geschatzte Standardfehler fur γ00 ist
[V (γ00)]1/2 =[∑
(Vj + τ00)−1]−1/2
. (72)
Man sieht, dass im Allgemeinen der Punktschatzer γ00 und dessen geschatz-ter Standardfehler Funktionen der geschatzten Werte fur σ2 und τ00 sind. Imbalancierten Fall ist das nicht der Fall, wodurch die Teststatistik
γ − γ0√MSB/nJ
, (73)
eine exakte t-Verteilung mit J − 1 Freiheitsgraden unter H0 : γ = γ0 hat.MSB bezeichnet dabei die mittlere Quadratsumme zwischen den Gruppen,der Nenner entspricht dem Standardfehler.
Fur den unbalancierten Fall jedoch gibt es keinen solchen exakten Test.Jedoch - wenn die σ2 und die τ00 ML-Schatzer sind - ist die asymptotischeVerteilung von
Z =γ − γ0√V (γ)
(74)
standardnormal. Wie schon in Kapitel 3 erwahnt wird allerdings im An-wendungsfall die Verwendung einer t-Verteilung oftmals besser sein (Fotiu,1989).
Desweiteren wird die Schatzung fur V (γ00) negativ verzerrt sein. Die wah-re Varianz von γ00 ist
V ar(γ00) = Em[V arc(γ00|τ00, σ2)] + V arm[Ec(γ00|τ00, σ
2)], (75)
wobei Em und V arm Momente der gemeinsamen Verteilung der τ00 und σ2
und Ec und V arc Momente der bedingten Verteilung von γ00 gegeben τ00 undσ2 sind. Letzteres ist die Verzerrung bei ML-Schatzung und im balanciertenFall Null. Im unbalancierten Fall wird dieser Term gegen null konvergieren,wenn J unendlich groß wird. Schatzungen im unbalancierten Fall bei geringenStichprobengroßen werden also verzerrt sein.
Raudenbush & Bryk (2002) erwahnen jedoch, dass in vielen Anwendun-gen, wenn die Unbalanciertheit nicht gravierend ist, dieser Bias sehr klein seinwird. Bei moderater oder kleiner Große von J auf level-2 wird die Große desBias durch die Sensitivitat der γ00 auf verschiedene Gewichtungen bestimmt.Aus Gleichung (47) ist das ersichtlich, die Schatzung fur γ00 ist ein gewich-tetes Mittel basierend auf (Vj + τ00)−1. Wenn nun τ00 gegen null geht, wird
67

sich die Schatzung γ00 dem gewichteten Mittelwert∑njY .j/
∑nj annahern.
Fur ein τ00, das sich nicht null annahert, wird γ00 =∑λjY .j/
∑λj sein, mit
λj = τ00/[τ00 + (σ2/nj)]. Somit zeigt sich, dass wenn τ00 zunimmt, strebtλj gegen 1 und γ00 nahert sich dem Gesamtmittel
∑Y .j/J an. Wenn das
gewichtete Mittel nun stark von diesem Gesamtmittel verschieden ist, wirdder Bias in (48) groß werden und die Schatzungen fur V (γ00) zu klein sein.
Aus den beiden dargestellten Umstanden leiten Raudenbush & Bryk(2002) folgende Vorschlage bei der Schatzung der fixen Effekte her:
• Verwendung der t-Verteilung fur Tests von Hypothesen uber γ
• Uberprufung der Sensitivitat der γ Schatzer auf die Wahl des Gewich-tungsschemas. Bei Insensitivitat kann V (γ) als Schatzung des Stan-dardfehlers problemlos verwendet werden.
• Bei Sensitivitat auf das Gewichtungsschema sollten die Tests als zuliberal angesehen werden und das auch in der Interpretation der Er-gebnisse berucksichtigt werden.
Inferenz uber die Varianzkomponenten
Auch Inferenz uber σ2 und T hangt von der Theorie uber die Asymptotik desML-Schatzers ab. Generell kann man sagen, dass Punktschatzungen fur σ2
meist ziemlich genau sein werden. Unter der Annahme eines konstanten σ2 furjedes Objekt, ist die Prazision des Schatzers abhangig von der Gesamtstich-probengroße und die ist typischerweise relativ groß. Auch Likelihood-RatioTests und Standardfehler fur σ2 werden verlasslich sein.
Probleme tauchen auf, wenn fur σ2 angenommen wird, dass es zwischenden level-2 Objekten verschieden ist. Dann ist die Stichprobengroßen in jedemObjekt nj fur die Prazision veranwortlich und die Schatzung nur bei großennj verlasslich.
Fur die Varianzkomponenten T hangt die Genauigkeit der Schatzungvon J , der Anzahl an level-2 Objekten ab. Standardfehlerschatzungen furT benotigen große J um glaubwurdig zu sein, v.a. wenn die geschatztenVarianzen nahe bei 0 sind.
In Hinblick auf Tests fur die Elemente von T (vgl. Kapitel 3) gilt eben-falls, dass diese auf der asymptotischen Theorie beruhen. Raudenbush & Bryk(2002) erwahnen jedoch, dass die Verwendung von Teststatistiken, die auf dengeschatzten Standardfehlern der Varianz-Komponenten beruhen, bei kleinenStichprobengroßen besonders ungenau ist. Diese beruhen darauf, dass einsymmetrisches Konfidenzintervall um die Punktschatzung konstruiert wird.Da aber in den meisten Fallen die Likelihood nicht symmetrisch sein wird,
68

sondern stark schief, sind diese Ergebnisse nicht verlasslich, v.a. wenn diewahre Varianz klein ist, also in den Fallen, wo man den Test am meisten ver-wendet. Auch bei der Verwendung der Likelihood-Ratio-Statistik zum Testob eine oder mehrere Varianz-Komponenten null sind, kann es laut Pinheiro& Bates (2000) ein Problem geben. Dieser wird namlich unter dieser Null-hypothese besonders konservativ sein, eine falsche Nullhypothese wird alsoeher nicht verworfen.
Alle Tests fur Elemente von T hangen asymptotisch von J ab, d.h. auchbei unendlich großen nj sind die Test nur dann genau, wenn J groß ist. Aller-dings ist die Forschung in diesem Bereich noch nicht so weit fortgeschritten,dass verbindliche Aussagen uber die Effekte kleiner Stichprobengroßen derlevel-2 Objekte getroffen werden konnen. Auf die Faustregel von Kreft (1996)wurde ja schon in Kapitel 3 hingewiesen.
Inferenz uber die zufalligen level-1 Koeffizienten
Einiges davon wurde schon in Kapitel 3 erwahnt. Exakte Tests und Kon-fidenzintervalle fur einzelne Koeffizienten konnen mittels separaten OLS-Schatzungen pro Objekt berechnet werden. Allerdings werden die Intervalleziemlich groß sein und die Tests sehr konservativ ausfallen. Bei Verwendungempirischer Bayes-Schatzer tritt der umgekehrte Fall auf, die Intervalle wer-den zu eng und und die Tests zu liberal ausfallen, da die Unsicherheit uberden Schatzer nicht mitberucksichtigt wird.
69

7 Literaturverzeichnis
Bartlett, M.S.,& Kendall, D.G. (1946). The statistical analysis of variances-heterogeneity and the logarithmic transformation. Journal of the Royal Sta-tistical Society, (Suppl.8),128-138.
Box, G.E.P., Jenkins, G.M., & Reinsel, G.C. (1994). Time series analysis:forecasting and control.(3rd Edition). San Francisco: Holden-Day.
Carter, D.L. (1970). The effect of teacher expectations on the self-esteemand academic performance of seventh grade students. Dissertation AbstractsInternational, 31, 4539-A. (University Microfilms No. 7107612).
Claiborn, W. (1969). Expectancy effects in the classroom: A failure toreplicate. Journal of Educational Psychology, 60, 377-383.
Conn, L.K., Edwards, C.N. Rosenthal, R., & Crowne, D. (1968). Percep-tion of emotion and response to teachers’ expectancy by elementary schoolchildren. Psychological Reports, 22, 27-34.
Cooper, H., & Hedges, L. (Editors). (1994). The handbook of researchsynthesis. New York: Russell Sage Foundation.
Davidian, M.,& Giltinan, D.M. (1995). Nonlinear models for repeatedmeasurement data, London: CHapman & Hall.
de Leeuw, J.,& Kreft, I.G.G. (1986). Random Coefficient Models for Mul-tilevel Analysis. Journal of Educational Statistics, 11, 57-86.
Evans, J. & Rosenthal, R. (1969). Interpersonal self-fulfilling prophecies:Further extrapolations from the laboratory to the classroom. Proceedings ofthe 77th Annual Convention of the American Psychological Association, 4,371-372.
Fielder, W.R., Cohen, R.D., & Feeney, S. (1971). An attempt to replicatethe teacher expectancy effect. Psychological Reports, 29, 1223-1228.
Fine, L. (1972). The effects of positive teacher expectancy on the readingachievement of pupils in grade two. Dissertation Abstracts International, 33,1510-A. (University Microfilms No. 7227180).
Fleming, E., & Anttonen, R. (1971). Teacher expectancy or my fair lady.American Educational Research Journal, 8, 241-252.
Flowers, C.E. (1966). Effects on an arbitrary accelerated group placementon the tested academic achievement of educationally disadvantaged students.Dissertation Abstracts International, 27, 991-A. (University Microfilms No.6610288)
Fotiu, R.P. (1989). A comparison of the EM and data augmentation al-gorithms on simulated small sample hierarchical data from research and edu-cation. Unpublished doctoral dissertation, Michigan State University, EastLansing.
70

Ginsburg, R.E. (1970). An examination of the relationship between te-acher expectations and student performance on a test of intellectual fun-tioning. Dissertation Abstracts International, 31, 3337-A. (University Micro-films No. 710922)
Glass, G.V. (1976). Primary, secondary, and meta-analysis of research.Educational Researcher, 5, 3-8.
Goldstein, H. (1995). Multilevel statistical models.(2nd Edition). NewYork: John Wiley.
Greiger, R.M., II. (1970). The effects of teacher expectancies on the in-telligence of students and behaviors of teacher. Dissertation Abstracts Inter-national, 31, 3338-A. (University Microfilms No. 7114791)
Hedeker, D., & Gibbons, R. (1996). MIXREG: A computer program formixed-effects regression analysis with autocorrelated errors. Computer Me-thods and Programs in Biomedicine, 49, 157-176.
Hedges, L.V. (1981). Distribution theory for Glass’s estimator of effectsize and related estimators. Journal of the American Statistical Association,74, 311-319.
Henrickson, H.A.(1970). An investigation of the influence of teacher ex-pectation upon the intellectual and academic performance of disadvantagedchildren. Dissertation Abstracts International, 31, 6278-A. (University Mi-crofilms No. 7114791)
Hox, J.J. (1995). Applied multilevel analysis.(2nd Edition). Amsterdam:TT-Publikaties.
Jones, R.H. (1993). Longitudinal data with serial correlation: a state-spaceapproach. London: Chapman & Hall.
Jose, J., & Cody, J. (1971). Teacher pupil interaction as it relates toattempted changes in i teacher expectancy of academic ability achievement.American Educational Research Journal, 8, 39-49.
Kasim, R., & Raudenbush, S. (1998). Application of Gibbs sampling tonested variance components models with heterogenous with-in group varian-ce. Journal of Educational and Behavioral Statistics, 20 (4),93-116.
Keshock, J.D. (1970). An ivestigation of the effects of the expectancyphenomenon upon the intelligence, achievement, and motivation of inner-cityelementary school children. Dissertation Abstracts International, 32, 243-A.(University Microfilms No. 7119010)
Kester, S.W. & Letchworth, G.A. (1972). Communication of teacher ex-pectations and their effects on achievement and attitudes of secondary schoolchildren. Journal of Educational Research, 66, 51-55.
Kreft, I.G.G. (1996). Are multilevel techniques necessary? An overview,including simulation studies. London: Institute of Education, Multilevel Mo-dels Project, University of London.
71

Lindley, D.V., & Smith, A.F.M. (1972). Bayes estimates for the linearmodel. Journal of the Royal Statistical Society, Series B, 34, 1-41.
Littel, R., Milliken, G., Stroup, W., & Wolfinger, R. (1996). SAS systemfor mixed models. Cary, NC: SAS Institute Incorporated.
Longford, N. (1987). A fast scoring algorithm for maximum likelihoodestimation in unbalanced models with nested random effects. Biometrika,74 (4),817-827.
Longford, N. T. (1988). Fisher scoring algorithm for variance componentanalysis of data with multilevel structure. In R.D. Bock (Ed.), Multilevelanalysis of educational data (pp. 297-310). Orlando, FL: Academic Press.
Longford, N. (1993). Random coefficients models. Oxford: Clarendon.Maxwell, M.L. (1970). A study of the effects of teachers’ expectations on
the IQ and academic performance of children.Dissertation Abstracts Inter-national, 31, 3345-A. (University Microfilms No. 710125).
Milliken, G.A. & Johnson, D.E. (1992). Analysis of messy data. Volume1: Designed experiments. London: Chapman & Hall.
Miyazaki, Y. & Raudenbush, S.W. (2000). A test for linkage of multiplecohorts from an accelerated longitudinal design. Psychological Methods, 5 (1),44-63.
Pelligrini, R., & Hicks, R. (1972). Prophecy effects and tutorial instructionfor the disadvantaged child. American Educational Research Journal, 9, 413-419.
Pierson, R.A. & Ginther, O.J. (1987). Follicular population dynamicsduring the estrus cycle of the mare. Animal Reproduction Science, 14, 219-231.
Pinheiro, J.C. & Bates, D.M. (2000). Mixed-effects models in S and S-Plus. New York: Springer.
Pinheiro, J.C., Bates, D.M., DebRoy, S. & Sarkar, D. (2006). nlme: Linearand nonlinear mixed effects models. R package version 3.1-73.
Potthoff, R.F. & Roy, S.N. (1964). A generalized multivariate analysis ofvariance model useful especially for growth curve problems. Biometrika, 51,313-326.
R Development Core Team (2006). R: A language and environment forstatistical computing. R Foundation for Statistical Computing, Vienna, Aus-tria. ISBN 3-900051-07-0, URL http://www.R-project.org.
Raudenbush, S.W. (1984). Magnitude of teacher expectancy effects onpupil IQ as a function of the credibility of expectancy induction: A synthesisof findings from 18 experiments. Journal of Educational Psychology, 76 (1),85-97.
Raudenbush, S.W. & Bryk, A.S. (2002). Hierarchical linear models: appli-cations and data analysis methods. (2nd Edition). Newbury Park, CA: Sage.
72

Raudenbush, S.W., Bryk, A.S., & Congdon, R.T. (2005). HLM 6: Hier-archical linear and nonlinear modelling. Chicago: Scientific Software Interna-tional.
Rosenthal, R., Baratz, S., & Hall, C.M. (1974). Teacher behavior, tea-cher expectations, and gains in pupils’ rated creativity. Journal of GeneticPsychology, 124, 115-121.
Rosenthal, R., & Jacobson, L. (1968). Pygmalion in the classroom. NewYork: Holt, Rinehart & Winston.
Seltzer, M. (1993). Sensitivity analysis for fixed effects in the hierarchi-cal model: A Gibbs sampling approach. Journal of Educational Statistics,18 (3),207-235.
Singer, J.D. (1998). Using SAS PROC MIXED to fit multilevel models,hierarchical models and individual growth models. Journal of Educationaland Behavioral Statistics, 23 (4),323-355.
73

A R Code
A.1 Auswertung der HSB82-Daten
#### R-Code fur die Auswertung der HIGH SCHOOL AND BEYOND - 1982 Daten aus
##Kapitel 4
##
## Der Ausruck "#NOT RUN" bezeichnet eine Veranschaulichung der Befehle und
## Moglichkeiten in R, wobei es sich allerdings um Code handelt, der
## a) eine Funktion beschreibt, die nicht fur die Auswertung im Text verwendet
## wurde
## c) fur den Datensatz nicht sinnvoll ist
## d) eine Alternative zu anderen Befehlen darstellt
####
library ( nlme ) #ladt das benotigte Package "nlme", das die Funktionen enthalt
library ( mlmRev ) #ladt das benotigte Package "mlmRev", das die Daten enthalt
data ( Hsb82 ) #ladt die Daten High School and Beyond - 1982
Hsb82 < - do.call ( "data.frame" , Hsb82 ) #Zuschreibung der Hsb82 Daten mit
#Klassenattribut "data.frame"
###Beschreibungen der Daten und Deskriptive Statistik
str ( Hsb82 ) #Auflistung der Variablen, ihrer Abstufungen und Spezifikationen
summary ( Hsb82 ) #Deskriptive Statistiken der Variablen des Hsb82 Datensatzes
formula ( Hsb82 ) #Formelobjekt der Hsb82 Daten; wird spater geandert
gsummary ( Hsb82 , group = Hsb82 $ school , invariant = FALSE ) #gruppierte deskriptive
#Statistiken, nach der
#Gruppe "Schule",
#invariant = FALSE gibt alle
#Variablen aus, TRUE nur die
#Konstanten in der Gruppe
####Erstellen des groupedData Object erleichtert teilweise die Funktionsaufrufe;
# ist optional aber empfehlenswert
Hsb82.g1 < - groupedData ( mAch ~ 1 | school , data = Hsb82 ) #Neues Objekt des Klassen-
#attributs "groupedData" mit
#veranderter Modellformel
Hsb82.g < - groupedData ( mAch ~ ses | school , data = Hsb82 ) #Neues Objekt des Klassen-
#attributs "groupedData" mit
#veranderter Modellformel
# NOT RUN
plot ( Hsb82.g ) #Wurde einen Trellis-Plot nach der Modellformel fur jede Gruppe
#erstellen; hier sind zuviele Gruppen
xyplot ( mAch [ 1 : 1046 ] ~ ses [ 1 : 1046 ] | school [ 1 : 1046 ] , #ist eine Alternative zum
data = Hsb82.g , type = c ( "p" , "r" ) ) #plot(groupedData); wurde die
#ersten 1046 Beobachtungen nach
#Gruppe plotten mit einer Reg-
#ressionsgeraden
bwplot ( mAch ~ school , data = Hsb82.g ) #wurde Boxplots der Mathematikleistung fur
#die einzelnen Schulen;
bwplot ( mAch [ 1 : 1046 ] ~ school [ 1 : 1046 ] , data = Hsb82.g ) #Boxplots der Mathematiklei-
#stung der ersten 1046 Beobach-
74

#tungen
# End NOT RUN
####Modelle
##Einzelregressionen nach Gruppe;
# NOT RUN
G.Reg < - lm.List ( mAch ~ ses | school , data = Hsb82 ) #Einzelne Regressionen fur Leist-
#ung auf SES fur jede Schule; zu
#umfangreich hier
summary ( G.Reg ) #Ausgabe der 160 Einzelregressionen
plot ( G.Reg , resid ( . , type = "pool" ) ~ fitted ( . ) | school , abline = 0 ) #Plots der Residuen
#gegen die gefittet-
#en Werte in den ein-
#zelnen Regressionen
#End NOT RUN
##Hierarchische lineare Modelle;
#Das ANOVA mit Zufallseffekt-Modell
Mod.rAN < - lme ( #lme() ist die Funktion fur das lin-
mAch ~ 1 , Hsb82.g , random = ~ 1 | school #eare mixed effect modell; in der
) #Formel steht: Fixer Intercept, eine
#Zufallseffekt des Intercepts nach
#Schule
# NOT RUN
Mod.rAN < - lme ( Hsb82.g1 ) #Durch die Formel von groupedData wird dasselbe wie
#oben gerechnet; lme() ubernimmt die Formel aus dem
#Objekt
#End NOT RUN
summary ( Mod.rAN ) #Zusammenfassung der Schatzung
anova ( Mod.rAN ) #F-Tests der Parameter
intervals ( Mod.rAN ) #Konfidenzintervalle fur die Parameter
#NOT RUN
plot ( Mod.rAN ) #Diagnostikplot der Residuen gegen die gefitteten Werte;
#eindeutige Heteroskedastizitat zwischen den Gruppen
plot ( Mod.rAN , resid ( . , type = "p" ) ~ fitted ( . ) | school , abline = 0 ) #Diagnostikplot der
#Residuen gegen die
#gefitteten Werte na-
#ch Schule; Sollte
#homoskedastisch wer-
#den
#End NOT RUN
ran.sd < - 2.934966
Ic.rANC < - ran.sd ^ 2 / ( ran.sd ^ 2 + Mod.rANC $ sigma ^ 2 ) #Berechnung des Interkorrelations-
#koeffizienten
# NOT RUN
Mod.rANC < - lmer ( mAch ~ 1 | school , Hsb82.g ) #Alternative Modellierung mit lmer()
#ist die lme-Funktion neu, Zufalls-
#effekte werden in der 1. Formel dir-
#ekt spezifiziert
summary ( Mod.rANC )
#MEANS AS OUTCOMES MODELL
Mod.mao < - lme ( mAch ~ 1 + meanses , Hsb82.g , random = ~ 1 | school ) #Means as outcomes
75

Mod.mao < - lmer ( mAch ~ meanses + ( 1 | school ) , Hsb82 ) #Alternative Formulierung
summary ( Mod.mao )
# End NOT RUN
#RANDOM COEFFICIENTS MODELL
Mod.rc < - lme ( mAch ~ 1 + cses , Hsb82.g , random = ~ 1 + cses | school ) #Random Coe-
#fficients
#Modell
summary ( Mod.rc )
anova ( Mod.rc )
intervals ( Mod.rc )
Mod.rc.Okorr < - update ( Mod.rc , random = pdDiag ( ~ cses ) ) #Random Coefficients Model
#mit Kovarianz auf 0 gefixt
#update() rechnet ein lme
#mit denselben fixen Effe-
#kten und anderen Zufalls-
#effekten, kann gut fur
#Modellierung verwendet
#werden
anova ( Mod.rcOkorr , Mod.rc ) #Likelihood Ratio Test der beiden Modelle mit/
#ohne Kovarianz = 0
# NOT RUN
Mod.rc < - lmer ( mAch ~ cses + ( cses | school ) , Hsb82 ) #Alternative mit lmer()
summary ( Mod.rc )
#End NOT RUN
#INTERCEPTS AND SLOPES AS OUTCOMES
Mod.IaSaO < - lme (
mAch ~ 1 + meanses + sector + cses
+ meanses : cses + sector : cses , Hsb82.g , random = ~ 1 + cses | school #Das ist das
) #kombinierte
#Modell in R
#ubersetzt.
#Schon, oder?
summary ( Mod.IaSaO )
intervals ( Mod.IaSaO ) #KI des Zufallseffekt von cses weist auf eventu-
#elle fixen Effekt hin
anova ( Mod.IaSaO )
Mod.IaSaOAlt < - lme (
mAch ~ 1 + meanses + sector + cses
+ meanses * cses + sector * cses , Hsb82.g , random = ~ 1 | school #cses wird als fix
) #spezifiziert, nicht
#mehr zufallig. Hı¿ 12t-
#te auch "update(Mod.IaSao,random=~1|school)" sein konnen
anova ( Mod.IaSaOAlt , Mod.IaSaO ) #Vergleich der Modelle mit/ohne Zufallsef-
#fekt von cses
prop.I < - ( ( 2.946 ) ^ 2 - ( 1.5426 ) ^ 2 ) / ( 2.946 ) ^ 2 #Erklarter Varianzanteil von IaSaO
#im Vergleich zu RC beim Intercept
prop.S < - ( ( 0.833 ) ^ 2 - ( 0.318 ) ^ 2 ) / ( 0.833 ) ^ 2 #Erklarter Varianzanteil von IaSaO
#im Vergleich zu RC beim Intercept
# NOT RUN
LRT.sim < - simulate.lme ( Mod.rc , Mod.IaSaO , nsim = 100 , seed = 2 ) #Funktion fur parametr-
76

#ischen Bootstrap
#(nsim=100 Durchgange)
#zur LR-Statistik bei
#verschiedenen fixen Ef-
#fekten und REML Schat-
#zung
plot ( LRT.sim , df = c ( 3 , 4 , 5 ) ) #QQ-Plots der Chi^2-Verteilungen mit 3,4,5 df
#sowie gewichtete Mischungen gegen die LR-Stat-
#istik aus dem Bootstrap.
#Sollte auf Gerade liegen, denn sonst zu kon-
#servativ oder liberal fur den Test
fitted ( Mod.IaSaO , level = 0 : 1 ) #Die gefitteten Werte als Summe der geschatz-
#ten fixen und Zufallseffekte. Sind also die BLUPS.
#level gibt die Ebene an, wobei hier 0 das Modell
#auf level 1 und 1 das auf level 2 benennt
plot ( fitted ( Mod.IaSaO , level = 0 ) )
points ( fitted ( Mod.IaSaO , level = 1 ) , pch = 20 , col = "red" ) #Overlay der gefitteten Wer-
#te fur jede Person auf lev-
#el 1 und 2.
plot ( Hsb82 $ school , Hsb82 $ mAch , col = "blue" ) #Overlay der Boxplots nach Schule
#und der gefitteten Werte nach
#Schule aus beiden levels; Man
#sieht zwar nicht mehr viel, aber
#eine Idee der BLUPS gibt es
points ( Hsb82 $ school , fitted ( Mod.IaSaO , level = 0 ) , pch = 20 , col = "green" )
points ( Hsb82 $ school , fitted ( Mod.IaSaO , level = 1 ) , pch = 20 , col = "red" )
##Modelldiagnose fur IaSaO (Anmerkung: Ich beschreibe hier nur plots; naturlich
#waren auch tests moglich, aber solche Hypothesentests sind nicht optimal und es
# kam mir noch nie unter, dass eine Entscheidung anhand eines plots von einem
#Test richtigerweise korrigiert wurde
resid ( Mod.IaSaO , level = c ( 0 , 1 ) , type = "pearson" ) #Residuen
plot ( resid ( Mod.IaSaO , level = 0 ) , pch = 20 , col = "green" ) #Overlay der standardisierten
#Residuen fur jede Person auf
#level 1 und 2.
points ( resid ( Mod.IaSaO , level = 1 ) , pch = 20 , col = "red" )
abline ( 1 , 0 )
#Residuen auf Ebene 1 + ein Beispiel fur Modelladjustierung anhand der Diagnose;
# ist aber nur exemplarisch, hatte ich nicht gleich gesehen
plot ( Mod.IaSaO ) #plot aller residuen nach gefitteten Werten; eindeutig
#heteroskedastisch
plot ( Mod.IaSaO , resid ( . , type = "p" ) ~ fitted ( . ) )
plot ( Mod.IaSaO , resid ( . , type = "p" ) ~ fitted ( . ) | school ) #plot der residuen nach ge-
#fitteten werte fur jede Gru-
#ppe; man sieht nicht soviel
#aber dieHeteroskedastizitat
#ist weniger
plot ( Mod.IaSaO , mAch ~ fitted ( . ) , abline = c ( 0 , 1 ) ) #Plot der beobachteten gegen
#die gefitteten Werte
77

plot ( Mod.IaSaO , school ~ resid ( . ) , abline = 0 ) #Plot der Residuen nach Schule;
#tun wir so, als ware etwas mehr
#Heterosked. da (furs beispiel);
#alternatives Modell mit unter-
#schiedlicher Gewichtung von Gru-
#ppen in der Varianzschatzung
plot ( Mod.IaSaO , school ~ resid ( . ) | sector , abline = 0 ) #Nach Schule und Sector;
#zeigt, dass etwas Dis-
#persionen etwas unter-
#schiedlich in den Sek-
#toren (zumindest tun
#wir so furs beispiel)
#ist; konnte man in Mo-
#dell aufnehmen, indem
#man die Varianzschatzung
#gewichtet nach Sector
#(wird)
#Anm: Die Heteroskedastizitat habe ich mehr oder weniger im Modell gesucht, mehr
#Heterosked. fand ich nicht; reicht aber aus wie man unten sieht
#NOT RUN
Mod.IaSaO.sec < - update ( Mod.IaSaO , weights = varIdent ( form = ~ 1 | sector ) ) # Gewichtung
#der Varianz-
#Kovarianz-
#Matrix, so
#dass unters-
#chiedliche Var-
#ianz in den S
#ektoren
#moglich ist
anova ( Mod.IaSaO , Mod.IaSaO.sec ) #Besseres Modell!
plot ( Mod.IaSaO.sec , school ~ resid ( . ) , abline = 0 ) #schaut schon besser aus
plot ( Mod.IaSaO.sec , school ~ resid ( . ) , abline = 0 )
plot ( Mod.IaSaO , school ~ resid ( . ) , abline = 0 )
plot ( Mod.IaSaO.sec , mAch ~ fitted ( . ) )
#End NOT RUN
#Normalverteilung auf Ebene 1
qqnorm ( Mod.IaSaO , abline = c ( 0 , 1 ) ) #QQ-Plot der Residuen innerhalb der Grup-
#pen. Zeigt, dass wir heavy tails haben
#(aber symmetrisch). Das wird die Schat-
#zung wenig beeinflussen, aber die
#Inferenz schon. Dafur musste dann eine
#T Verteilung mit wenig df als Fehlerstr-
#uktur verwendet werden (geht in R)
#Annahmen uber die Zufallseffekte
random.effects ( Mod.IaSaO ) #Ausgabe der geschatzten BLUPS der Zufalls-
#effekte der Gruppen
qqnorm ( Mod.IaSaO , ~ ranef ( . ) , id = 0.10 ) #QQ-Plot der Zufallseffekte; id
#schreibt die Beobachtungsnummer fur
#alle standardisierten Residuen, die
78

#großer als das 1-id/2
#Standardnormal-Quantil sind; In die-
#sem Fall ist NV-Annahme schon halbweg
#passend, nur der Intercept, hat ein
#paar Abweichler; bei mehr Ebenen kann
# man mit level=x das ausgeben was man
# haben will
pairs ( Mod.IaSaO , ~ ranef ( . ) ) #Scatterplot der zufallseffekte; Korrlation
#wird bei summary(model) ausgegeben
pairs ( Mod.IaSaO , ~ ranef ( . ) | sector ) #Scatterplot der zufallseffekte nach Sector;
#pruft Homogenitatsannahme der Zufallseffekt
#-Verteilung in Subgruppen; weist ein bis-
#schen auf das hin was oben als alternatives
#Modell mit unterschiedlicher Gewichtung
#gemacht wurde; Die offentlichen Schulen ha-
#ben eine etwas hohere Varianz der NV
A.2 Auswertung der ORTHODONT-Daten
###############################################################################
#### R-Code fur die Auswertung der ORTHODONT Daten aus Kapitel 5
####
library ( nlme ) #Ladt die benotigte Bibliothek nlme
data ( Orthodont ) #Ladt die benotigten Daten
names ( Orthodont ) #Damit lasst sich auf die Namen der Variablen auch direkt
#zugreifen
levels ( Orthodont $ Sex ) #Darstellung der Faktorstufen von Geschlecht
OrthFem < - Orthodont [ Orthodont $ Sex = = "Female" , ] #Auswahl der weiblichen Teistich
#probe
plot ( OrthFem ) #Plotten der Daten
OrthFemMod1 < - lmList ( distance ~ age , data = OrthFem ) #Lineare Regressionen fur jedes
#Madchen
OrthFemMod2 < - update ( OrthFemMod1 , distance ~ I ( age - 11 ) ) #Dasselbe mit zentrierten
#UV; Der Befehl I() andert
#die Daten aber nicht
OrthFemMod3 < - lme ( distance ~ I ( age - 11 ) , data = OrthFem , #Das HLM mit zufalligem
random = ~ 1 | Subject ) #Intercept aber fixem Slope
summary ( OrthFemMod3 ) #Zusammenfassung des Modells
OrthFemMod4 < - update ( OrthFemMod3 , #Das HLM mit zufalligem Intercept
random = ~ I ( age - 11 ) | Subject ) #und Slope
summary ( OrthFemMod4 ) #Zusammenfassung des Modells
anova ( OrthFemMod3 , OrthFemMod4 ) #Modellvergleich
plot ( augPred ( OrthFemMod3 , aspect = "xy" , grid = T ) #Plot der gefitteten Werte
79

A.3 Auswertung der OVARY-Daten
###############################################################################
#### R-Code fur die Auswertung der OVARY Daten aus Kapitel 5
####
library ( nlme ) #ladt die benotigte Bibliothek
data ( Ovary ) #ladt die benotigten Daten
plot ( Ovary ) #Plot der Daten
Ov.Mod1 < - lme ( follicles ~ sin ( 2 * pi * Time ) + cos ( 2 * pi * Time ) , #HLM mit nichtlinear trans-
data = Ovary , random = pdDiag ( ~ sin ( 2 * pi * Time ) ) ) #formierter UV zur zyklischen
#Veranderungsmodellierung;
#Zufallseffekt: Intercept
#und die sinus-Funktion;
#pdDiag() sagt, dass die
#beiden Zufallseffekte als
#unabhangig angenommen werden
ACF ( Ov.Mod1 ) #empirische Autokorrelations-
#funktion
plot ( ACF ( Ov.Mod1 , maxLag = 10 ) , alpha = 0.01 ) #plot der Autokorrelationsfunktion bei
#lag 10 und mit Signifikanzbandern
Ov.Mod2 < - update ( Ov.Mod1 , correlation = corAR1 ( ) ) #Spezifikation eines AR(1)-Prozes-
#ses fur die Fehler auf Level 1
anova ( Ov.Mod1 , Ov.Mod2 ) #Modellvergleich
plot ( augPred ( Ov.Mod2 ) , grid = T ) #Plot der gefitteten Werte
80

GNU Free Documentation License
Version 1.2, November 2002Copyright c© 2000,2001,2002 Free Software Foundation, Inc.
51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies of this licensedocument, but changing it is not allowed.
Preamble
The purpose of this License is to make a manual, textbook, or other func-tional and useful document “free” in the sense of freedom: to assure everyonethe effective freedom to copy and redistribute it, with or without modifyingit, either commercially or noncommercially. Secondarily, this License preser-ves for the author and publisher a way to get credit for their work, while notbeing considered responsible for modifications made by others.
This License is a kind of “copyleft”, which means that derivative worksof the document must themselves be free in the same sense. It complementsthe GNU General Public License, which is a copyleft license designed for freesoftware.
We have designed this License in order to use it for manuals for freesoftware, because free software needs free documentation: a free programshould come with manuals providing the same freedoms that the softwaredoes. But this License is not limited to software manuals; it can be usedfor any textual work, regardless of subject matter or whether it is publishedas a printed book. We recommend this License principally for works whosepurpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, thatcontains a notice placed by the copyright holder saying it can be distributedunder the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditionsstated herein. The “Document”, below, refers to any such manual or work.Any member of the public is a licensee, and is addressed as “you”. You acceptthe license if you copy, modify or distribute the work in a way requiringpermission under copyright law.
81

A “Modified Version” of the Document means any work containing theDocument or a portion of it, either copied verbatim, or with modificationsand/or translated into another language.
A “Secondary Section” is a named appendix or a front-matter sectionof the Document that deals exclusively with the relationship of the publishersor authors of the Document to the Document’s overall subject (or to relatedmatters) and contains nothing that could fall directly within that overallsubject. (Thus, if the Document is in part a textbook of mathematics, aSecondary Section may not explain any mathematics.) The relationship couldbe a matter of historical connection with the subject or with related matters,or of legal, commercial, philosophical, ethical or political position regardingthem.
The “Invariant Sections” are certain Secondary Sections whose titlesare designated, as being those of Invariant Sections, in the notice that saysthat the Document is released under this License. If a section does not fit theabove definition of Secondary then it is not allowed to be designated as Inva-riant. The Document may contain zero Invariant Sections. If the Documentdoes not identify any Invariant Sections then there are none.
The “Cover Texts” are certain short passages of text that are listed,as Front-Cover Texts or Back-Cover Texts, in the notice that says that theDocument is released under this License. A Front-Cover Text may be at most5 words, and a Back-Cover Text may be at most 25 words.
A “Transparent” copy of the Document means a machine-readable copy,represented in a format whose specification is available to the general public,that is suitable for revising the document straightforwardly with generic texteditors or (for images composed of pixels) generic paint programs or (fordrawings) some widely available drawing editor, and that is suitable for inputto text formatters or for automatic translation to a variety of formats suitablefor input to text formatters. A copy made in an otherwise Transparent fileformat whose markup, or absence of markup, has been arranged to thwart ordiscourage subsequent modification by readers is not Transparent. An imageformat is not Transparent if used for any substantial amount of text. A copythat is not “Transparent” is called “Opaque”.
Examples of suitable formats for Transparent copies include plain ASCIIwithout markup, Texinfo input format, LaTeX input format, SGML or XMLusing a publicly available DTD, and standard-conforming simple HTML,PostScript or PDF designed for human modification. Examples of transpa-rent image formats include PNG, XCF and JPG. Opaque formats includeproprietary formats that can be read and edited only by proprietary wordprocessors, SGML or XML for which the DTD and/or processing tools arenot generally available, and the machine-generated HTML, PostScript or
82

PDF produced by some word processors for output purposes only.The “Title Page” means, for a printed book, the title page itself, plus
such following pages as are needed to hold, legibly, the material this Licenserequires to appear in the title page. For works in formats which do not haveany title page as such, “Title Page” means the text near the most prominentappearance of the work’s title, preceding the beginning of the body of thetext.
A section “Entitled XYZ” means a named subunit of the Documentwhose title either is precisely XYZ or contains XYZ in parentheses follo-wing text that translates XYZ in another language. (Here XYZ stands fora specific section name mentioned below, such as “Acknowledgements”,“Dedications”, “Endorsements”, or “History”.) To “Preserve the Tit-le” of such a section when you modify the Document means that it remainsa section “Entitled XYZ” according to this definition.
The Document may include Warranty Disclaimers next to the noticewhich states that this License applies to the Document. These WarrantyDisclaimers are considered to be included by reference in this License, butonly as regards disclaiming warranties: any other implication that these War-ranty Disclaimers may have is void and has no effect on the meaning of thisLicense.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either com-mercially or noncommercially, provided that this License, the copyright no-tices, and the license notice saying this License applies to the Document arereproduced in all copies, and that you add no other conditions whatsoeverto those of this License. You may not use technical measures to obstruct orcontrol the reading or further copying of the copies you make or distribute.However, you may accept compensation in exchange for copies. If you distri-bute a large enough number of copies you must also follow the conditions insection 3.
You may also lend copies, under the same conditions stated above, andyou may publicly display copies.
3. COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have prin-ted covers) of the Document, numbering more than 100, and the Document’slicense notice requires Cover Texts, you must enclose the copies in covers
83

that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts onthe front cover, and Back-Cover Texts on the back cover. Both covers mustalso clearly and legibly identify you as the publisher of these copies. The frontcover must present the full title with all words of the title equally prominentand visible. You may add other material on the covers in addition. Copyingwith changes limited to the covers, as long as they preserve the title of theDocument and satisfy these conditions, can be treated as verbatim copyingin other respects.
If the required texts for either cover are too voluminous to fit legibly,you should put the first ones listed (as many as fit reasonably) on the actualcover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numberingmore than 100, you must either include a machine-readable Transparent co-py along with each Opaque copy, or state in or with each Opaque copya computer-network location from which the general network-using publichas access to download using public-standard network protocols a completeTransparent copy of the Document, free of added material. If you use thelatter option, you must take reasonably prudent steps, when you begin dis-tribution of Opaque copies in quantity, to ensure that this Transparent copywill remain thus accessible at the stated location until at least one year afterthe last time you distribute an Opaque copy (directly or through your agentsor retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of theDocument well before redistributing any large number of copies, to give thema chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document underthe conditions of sections 2 and 3 above, provided that you release the Mo-dified Version under precisely this License, with the Modified Version fillingthe role of the Document, thus licensing distribution and modification of theModified Version to whoever possesses a copy of it. In addition, you must dothese things in the Modified Version:
A. Use in the Title Page (and on the covers, if any) a title distinct from thatof the Document, and from those of previous versions (which should, ifthere were any, be listed in the History section of the Document). Youmay use the same title as a previous version if the original publisher ofthat version gives permission.
84

B. List on the Title Page, as authors, one or more persons or entitiesresponsible for authorship of the modifications in the Modified Version,together with at least five of the principal authors of the Document (allof its principal authors, if it has fewer than five), unless they releaseyou from this requirement.
C. State on the Title page the name of the publisher of the ModifiedVersion, as the publisher.
D. Preserve all the copyright notices of the Document.
E. Add an appropriate copyright notice for your modifications adjacent tothe other copyright notices.
F. Include, immediately after the copyright notices, a license notice givingthe public permission to use the Modified Version under the terms ofthis License, in the form shown in the Addendum below.
G. Preserve in that license notice the full lists of Invariant Sections andrequired Cover Texts given in the Document’s license notice.
H. Include an unaltered copy of this License.
I. Preserve the section Entitled “History”, Preserve its Title, and add toit an item stating at least the title, year, new authors, and publisher ofthe Modified Version as given on the Title Page. If there is no sectionEntitled “History” in the Document, create one stating the title, year,authors, and publisher of the Document as given on its Title Page, thenadd an item describing the Modified Version as stated in the previoussentence.
J. Preserve the network location, if any, given in the Document for publicaccess to a Transparent copy of the Document, and likewise the networklocations given in the Document for previous versions it was based on.These may be placed in the “History” section. You may omit a networklocation for a work that was published at least four years before theDocument itself, or if the original publisher of the version it refers togives permission.
K. For any section Entitled “Acknowledgements” or “Dedications”, Pre-serve the Title of the section, and preserve in the section all the sub-stance and tone of each of the contributor acknowledgements and/ordedications given therein.
85

L. Preserve all the Invariant Sections of the Document, unaltered in theirtext and in their titles. Section numbers or the equivalent are not con-sidered part of the section titles.
M. Delete any section Entitled “Endorsements”. Such a section may notbe included in the Modified Version.
N. Do not retitle any existing section to be Entitled “Endorsements” orto conflict in title with any Invariant Section.
O. Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendicesthat qualify as Secondary Sections and contain no material copied from theDocument, you may at your option designate some or all of these sectionsas invariant. To do this, add their titles to the list of Invariant Sections inthe Modified Version’s license notice. These titles must be distinct from anyother section titles.
You may add a section Entitled “Endorsements”, provided it containsnothing but endorsements of your Modified Version by various parties–forexample, statements of peer review or that the text has been approved byan organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, anda passage of up to 25 words as a Back-Cover Text, to the end of the list ofCover Texts in the Modified Version. Only one passage of Front-Cover Textand one of Back-Cover Text may be added by (or through arrangementsmade by) any one entity. If the Document already includes a cover text forthe same cover, previously added by you or by arrangement made by thesame entity you are acting on behalf of, you may not add another; but youmay replace the old one, on explicit permission from the previous publisherthat added the old one.
The author(s) and publisher(s) of the Document do not by this Licensegive permission to use their names for publicity for or to assert or implyendorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released underthis License, under the terms defined in section 4 above for modified versions,provided that you include in the combination all of the Invariant Sectionsof all of the original documents, unmodified, and list them all as Invariant
86

Sections of your combined work in its license notice, and that you preserveall their Warranty Disclaimers.
The combined work need only contain one copy of this License, and mul-tiple identical Invariant Sections may be replaced with a single copy. If thereare multiple Invariant Sections with the same name but different contents,make the title of each such section unique by adding at the end of it, inparentheses, the name of the original author or publisher of that section ifknown, or else a unique number. Make the same adjustment to the sectiontitles in the list of Invariant Sections in the license notice of the combinedwork.
In the combination, you must combine any sections Entitled “History”in the various original documents, forming one section Entitled “History”;likewise combine any sections Entitled “Acknowledgements”, and any secti-ons Entitled “Dedications”. You must delete all sections Entitled “Endorse-ments”.
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other docu-ments released under this License, and replace the individual copies of thisLicense in the various documents with a single copy that is included in thecollection, provided that you follow the rules of this License for verbatimcopying of each of the documents in all other respects.
You may extract a single document from such a collection, and distributeit individually under this License, provided you insert a copy of this Licenseinto the extracted document, and follow this License in all other respectsregarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT
WORKS
A compilation of the Document or its derivatives with other separateand independent documents or works, in or on a volume of a storage ordistribution medium, is called an “aggregate” if the copyright resulting fromthe compilation is not used to limit the legal rights of the compilation’s usersbeyond what the individual works permit. When the Document is included inan aggregate, this License does not apply to the other works in the aggregatewhich are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copiesof the Document, then if the Document is less than one half of the entire
87

aggregate, the Document’s Cover Texts may be placed on covers that bracketthe Document within the aggregate, or the electronic equivalent of covers ifthe Document is in electronic form. Otherwise they must appear on printedcovers that bracket the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may distribu-te translations of the Document under the terms of section 4. ReplacingInvariant Sections with translations requires special permission from theircopyright holders, but you may include translations of some or all InvariantSections in addition to the original versions of these Invariant Sections. Youmay include a translation of this License, and all the license notices in theDocument, and any Warranty Disclaimers, provided that you also includethe original English version of this License and the original versions of thosenotices and disclaimers. In case of a disagreement between the translationand the original version of this License or a notice or disclaimer, the originalversion will prevail.
If a section in the Document is Entitled “Acknowledgements”, “Dedica-tions”, or “History”, the requirement (section 4) to Preserve its Title (secti-on 1) will typically require changing the actual title.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document exceptas expressly provided for under this License. Any other attempt to copy,modify, sublicense or distribute the Document is void, and will automaticallyterminate your rights under this License. However, parties who have receivedcopies, or rights, from you under this License will not have their licensesterminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS
LICENSE
The Free Software Foundation may publish new, revised versions of theGNU Free Documentation License from time to time. Such new versions willbe similar in spirit to the present version, but may differ in detail to addressnew problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. Ifthe Document specifies that a particular numbered version of this License “or
88

any later version” applies to it, you have the option of following the termsand conditions either of that specified version or of any later version thathas been published (not as a draft) by the Free Software Foundation. If theDocument does not specify a version number of this License, you may chooseany version ever published (not as a draft) by the Free Software Foundation.
ADDENDUM: How to use this License for
your documents
To use this License in a document you have written, include a copy of theLicense in the document and put the following copyright and license noticesjust after the title page:
Copyright c© YEAR YOUR NAME. Permission is granted to co-py, distribute and/or modify this document under the terms ofthe GNU Free Documentation License, Version 1.2 or any laterversion published by the Free Software Foundation; with no Inva-riant Sections, no Front-Cover Texts, and no Back-Cover Texts.A copy of the license is included in the section entitled “GNUFree Documentation License”.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts,replace the “with . . . Texts.” line with this:
with the Invariant Sections being LIST THEIR TITLES, with theFront-Cover Texts being LIST, and with the Back-Cover Textsbeing LIST.
If you have Invariant Sections without Cover Texts, or some other com-bination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we re-commend releasing these examples in parallel under your choice of free soft-ware license, such as the GNU General Public License, to permit their usein free software.
89