handbuch zur referenzarchitektur für dell | cloudera...
TRANSCRIPT

Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4
© 2011-2015 Dell Inc.

Inhalt | 2
Inhalt
Marken ...............................................................................................................................................4
Hinweise, Vorsichtshinweise und Warnungen...........................................................................5
Glossar........................................................................................................................................ .......6
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution ..............................................................................................................................9
Zusammenfassung der Lösungsanwendungsfälle.................................................... ......9 Lösungskomponenten......................................................... ...............................................10
Support-Matrix....................................................................... ................. ...................11 Überblick zu Syncsort DMX-h............................................................................ ................11
Hadoop für Datentransformationen.................................................... ...................11 Überblick zu Cloudera Enterprise Software................................................. ...................12
Hadoop für Enterprise-Umgebungen...................................................... ..............12 Neugestaltung der Datenverwaltung.............................................................. ......13 Bestandteile..................................................................................... .... .......................13 Cloudera Enterprise Data Hub....................................................... .. .......................13
Clusterarchitektur....................................................................... ........ ..........................................15 High-Level-Knotenarchitektur........................................................................................ .. 15
Knotendefinitionen............................................................................................. ......16 Netzwerk-Fabric-Architektur................................................................................... ......... 17
Netzwerkdefinitionen........................................................................... .....................18 Dimensionierung von Clustern................................................................................. ........19
Rack............................................................................................................ ..................19 Pod....................................................................................................................... .........19Cluster.................................................................................................... .....................20 Dimensionierungsbeschränkungen............................................................... ......20
Hochverfügbarkeit................................................................................................. ..............20 Hadoop Redundanz............................................................................................... .. 20 Netzwerkredundanz........................................................................... ..................... 20 Hochverfügbare HDFS-Namensknoten............................................................ ....21 Hochverfügbarkeit des Resource Manager....................................................... ...21
Hardwarearchitektur.............................................................................................................. .......22 Serverinfrastrukturoptionen........................................................................................ .... 22
PowerEdge R730/R730xd Server...................................................................... ......22
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Inhalt | 3
Netzwerkarchitektur........................................................................................................................ .....25 Physische Netzwerkkomponenten. ................................................................................. 26
Serverknotenverbindungen................................................................................. .... 26Top-of-Rack-Switches......................................................................................... .... .26Clusteraggregations-Switches.............................................................................. .. 27 Kernnetzwerk............................................................................................................ . 29 Layer-2 und Layer-3................................................................................................ .. 29 Verwaltungsnetzwerk............................................................................................. .. 29 Netzwerkgeräte – Zusammenfassung................................................................... 30
Netzwerkkonnektivität – Zusammenfassung................................................................. 30 IPv6-Funktionen.................................................................................................... ..... 31
Syncsort Software......................................................................................................................... 32 Syncsort DMX-h Engine.................................................................................................... .. 32Syncsort Agent.................................................................................................................... . 32Syncsort DMX-h Client...................................................................................................... . 32Syncsort SILQ...................................................................................................................... . 33
Cloudera Enterprise Software.................................................................................................... . 34 Cloudera Manager............................................................................................................. . .34Cloudera RTQ (Impala)..................................................................................................... .. 34Cloudera Search.................................................................................................................. 35 Cloudera BDR..................................................................................................................... . .35 Cloudera Navigator.......................................................................................................... . ..35 Cloudera Support.............................................................................................................. . .36
Bereitstellungsmethode......................................................................................................... ......38
Anhang A: Physische Konfiguration – PowerEdge R730xd................................................. .. 39
Anhang B: Stückliste – PowerEdge R730 Knoten..................................................... .............. 41
Anhang C: Stückliste – PowerEdge R730xd 3,5-Zoll-Datenknoten................................ ....43
Anhang D: Stückliste – PowerEdge R730xd 2,5-Zoll-Datenknoten................................ ....45
Aktualisierungsverlauf................................................................................................................. . 47
Referenzen...................................................................................................................................... 48 Weitere Informationen........................................................................................................ 48
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Marken
Marken | 4
DIESES DOKUMENT DIENT AUSSCHLIESSLICH INFORMATIONSZWECKEN UND ENTHÄLT MÖGLICHERWEISE DRUCKFEHLER ODER TECHNISCHE UNGENAUIGKEITEN. DER INHALT WIRD IN DER VORLIEGENDEN FORM OHNE JEGLICHE GEWÄHRLEISTUNG (AUSDRÜCKLICH ODER IMPLIZIT) BEREITGESTELLT.
© 2011-2015 Dell Inc. Alle Rechte vorbehalten. Ohne die ausdrückliche schriftliche Genehmigung von Dell Inc. ist jedwede Vervielfältigung dieses Dokuments verboten. Wenn Sie weitere Informationen wünschen, wenden Sie sich bitte an Dell. Dell, das Dell Logo, Force10, OpenManage, PowerEdge und das Dell Emblem sind Marken von Dell Inc.
Andere unter Umständen in diesem Dokument genannte Marken und Handelsnamen verweisen auf die Inhaber dieser Marken und Namen oder auf deren Produkte. Dell erhebt keinerlei Anspruch auf Eigentumsrechte an den Marken und Handelsnamen Dritter. Dieses Dokument dient lediglich Informationszwecken. Dell behält sich das Recht vor, die hier beschriebenen Produkte jederzeit ohne Vorankündigung zu ändern. Die Angaben wurden sorgfältig zusammengestellt, dennoch kann keine ausdrückliche oder stillschweigende Haftung jeglicher Art übernommen werden.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Hinweise, Vorsichtshinweise und Warnungen
Hinweise, Vorsichtshinweise und Warnungen | 5
Ein Hinweis enthält wichtige Informationen zur effizienteren Verwendung des Systems.
Ein Vorsichtshinweis warnt vor möglichen Beschädigungen der Hardware oder vor Datenverlust, falls die Anweisungen nicht befolgt werden.
Eine Warnung verweist auf eine potenziell gefährliche Situation, die zu Sachschäden, Verletzungen oder zum Tod führen kann.
Dieses Dokument dient ausschließlich Informationszwecken und kann Druckfehler und technische Ungenauigkeiten enthalten. Der Inhalt wird wie besehen und ohne jedwede ausdrückliche oder implizite Gewährleistung zur Verfügung gestellt.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Glossar | 6
Glossar
BMC
Baseboard Management Controller
CDH
Cloudera Distribution for Apache Hadoop
Clos
Mehrstufige, nicht blockierende Netzwerkswitch-Architektur. Reduziert die Anzahl der benötigten Ports in einem Netzwerkswitch-Fabric.
DBMS
Datenbankmanagementsystem
DTK
Dell OpenManage Deployment Toolkit
EDW
Unternehmens-Datawarehouse (Enterprise Data Warehouse)
EoR
End-of-Row-Switch/Router
ETL
"Extrahieren, Transformieren, Laden" ist ein Prozess für das Extrahieren von Daten aus verschiedenen Datenquellen, das Transformieren der Daten in eine zum Speichern geeignete Struktur und das Laden der Daten in einen Datenspeicher.
HBA
Hostbusadapter
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

HDFS
Hadoop Dateisystem (Hadoop File System)
IPMI
Intelligente Plattformverwaltungsoberfläche (Intelligent Platform Management Interface)
JBOD
Typ eines Festplattenverbundsystems ("Just a Bunch of Disks")
LAG
Link-Aggregationsgruppe
LOM
Local Area Network on Motherboard
NIC
Netzwerkkarte (Netzwerk Interface Card)
OS
Betriebssystem (Operating System)
RSTP
Rapid Spanning Tree Protocol
SIEM
Verwaltung von Sicherheitsinformationen und -ereignissen (Security Information und Event Management)
THP
Transparent Huge Pages
Glossar | 7
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

ToR
Top-of-Rack-Switch/Router
VLT
Virtual Link Trunking
VRRP
Virtual Router Redundanz Protocol
YARN
Resource Manager für Hadoop Cluster
Glossar | 8
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 9
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution
Mit Dell™ | Cloudera™ | Syncsort™ Data Warehouse Optimization for ETL Offload Solution können Unternehmen die Kosten für die Transformation von Daten senken, dabei die Betriebseffizienz steigern und zugleich eine robuste, kosteffiziente, sichere und skalierbare Grundlage für die Verwaltung von Daten legen, die für fortgeschrittene Datenanalysen vorgesehen sind.
Hadoop ist zwar ein beliebtes und vielfach eingesetztes System, jedoch müssen für die Installation, Konfiguration und Ausführung von Hadoop Clustern in Produktionsumgebungen viele Aspekte beachteten werden:
• Passende Hadoop Software-Distribution und entsprechende Erweiterungen • Überwachungs- und Managementsoftware • Zuordnung von Hadoop Services zu physischen Knoten • Auswahl der geeigneten Serverhardware • Design des Netzwerk-Fabric • Dimensionierung und Skalierbarkeit • Leistung
Beim Entwurf einer Lösung für eine bestimmte Rechenlast müssen weitere Aspekte berücksichtigt werden wie die Integration mehrerer externer Tools in das Hadoop Ökosystem und eine Entwurfsoptimierung zur Anpassung an die vorgesehenen Rechenlasten.
Die Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution wurde gemeinsam von Dell, Cloudera und Syncsort entwickelt. Die Lösung umfasst alles, was notwendig ist, um mit Hadoop eine robuste ETL-Umgebung zu schaffen – Hardware, Software, Ressourcen und Services. Dieser durchgehende Lösungsansatz sorgt für eine schnellere Produktionseinführung von Hadoop für ETL-Offload, als dies normalerweise bei selbst erstellten Lösungen möglich ist.
Die Lösung basiert auf der Cloudera Distribution for Apache Hadoop (CDH), Syncsort DMX-h Software sowie Servern und Netzwerktechnologie von Dell. Sie enthält Komponenten für ein vollständiges Lösungspaket:
• Referenzarchitektur und Best Practices • Optimierte Serverkonfigurationen • Optimierte Netzwerkinfrastruktur • Cloudera Distribution for Apache Hadoop • Syncsort DMX-h ETL Software
Folgende Abschnitte enthalten ausführliche Informationen zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution:
• Zusammenfassung der Lösungsanwendungsfälle auf Seite 9 • Lösungskomponenten auf Seite 10 • Überblick zu Syncsort DMX-h auf Seite 11
• Überblick zu Cloudera Enterprise Software auf Seite 12
Zusammenfassung der Lösungsanwendungsfälle
The Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution wurde speziell für die in Tabelle 1: Lösungsanwendungsfälle auf Seite 10 beschriebenen Anwendungsfälle entwickelt:
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

XML
RDBMS
Ereignisse
Mainframe
Inte
grat
ion
Datenverarbeitung (MapReduce)
Datentransformation (DMX-H)
Datensuche (SOLR)
Datenabfrage (Impala)
Sich
erhe
it
Verw
altu
ng
Ber
eits
tellu
ng
Datensatzspeicherung (HBase)
Dateispeicherung (HDFS)
Ressourcenverwaltung (YARN)
Betriebssystem (RedHat Enterprise)
PowerEdge Server und Force10 Netzwerktechnologie
Anwendungsfall Beschreibung
ETL-Offload Auslagerung der ETL-Verarbeitung von einem RDBMS oder Unternehmens-Datawarehouse in einen Hadoop Cluster.
Optimierung des Datawarehouse Erweiterung der herkömmlichen relationalen Datenbank oder des Unternehmens-Datawarehouse mit Hadoop. Hadoop agiert als zentraler Daten-Hub für Daten jeden Typs.
Integration in DatawarehouseExtrahieren, Übertragen und Laden von Daten nach oder aus Hadoop in ein separates DBMS für erweiterte Analyse.
Hochleistungs- Datentransformationen
Umfasst Sortieren, Verknüpfen, Aggregieren, Lookup mit mehreren Schlüsseln, erweiterte Textverarbeitung, Hashing-Funktionen sowie Operationen auf Quell-, Datensatz- und Feldebene.
Aufnahme und Übersetzung von Mainframe-Daten
Lesen von Dateien direkt aus dem Mainframe sowie Parsing und Transformation der Daten – gepackt dezimal, in Abhängigkeit von, EBCDIC/ASCII, mehrformatige Datensätze und mehr – ohne Installation zusätzlicher Software im Mainframe und ohne Schreiben von zusätzlichem Code.
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 10
Tabelle 1: Lösungsanwendungsfälle
Lösungskomponenten
Abbildung 1: Lösungskomponenten auf Seite 10 zeigt die primären Komponenten in Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution.
Abbildung 1: Die Komponenten der Lösung
Die PowerEdge Server, die Force10 Netzwerktechnologie und das Betriebssystem bilden zusammen die Grundlage, auf der das ETL-Softwarepaket ausgeführt wird.
Auf der linken Seite der Abbildung sind die Datentypen aufgeführt, die in das und aus dem Hadoop System transferiert werden können. Zum Verschieben der Daten können die HDFS-API und die HDFS-Tools verwendet werden. Der Zugriff auf die Mainframe- und RDBMS-Daten erfolgt mit DMX-h, die Verarbeitung von Ereignissen mit Flume oder Kafka.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4
Kategorie Komponente Version Verfügbarer Support
Betriebssystem Red Hat EnterpriseLinux Server
6.6 Red Hat Linux Support
Betriebssystem CentOS 6.6 Dell Hardware-Support
Java Virtual Machine Sun Oracle JVM Java 7 (1.7.0_67)
Java 8 (1.8.0_11)
–
Hadoop Cloudera Distribution für Apache Hadoop(CDH)
5.4 Cloudera Support
Hadoop Cloudera Manager 5.4 Cloudera Support
Hadoop Cloudera Navigator 2.2 Cloudera Support
ETL-Engine Syncsort DMX-h 8.0 Syncsort Support
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 11
Auf der rechten Seite der Abbildung sind die Funktionen dargestellt, die im gesamten System zur Verfügung stehen. Die Administration und Verwaltung von Hadoop erfolgt über Cloudera Manager. Sicherheitsfunktionen der Enterprise-Klasse (via Apache Sentry) sind im gesamten Lösungspaket bereits integriert.
Die Hadoop Komponenten verfügen oberhalb dieser Grundlage über mehrere Funktionslayer. Mit Apache Zookeeper steht ein Koordinationslayer für die verteilte Verarbeitung im Hadoop System zur Verfügung. Das Hadoop Distributed File System (HDFS) bietet den Kernmassenspeicher für Datendateien im System. HDFS ist ein verteiltes, skalierbares, zuverlässiges und tragbares Dateisystem. Apache HBase ist ein Layer, der datensatzorientieren Massenspeicher oberhalb des HDFS bereitstellt. HBase kann als Alternative zum direkten Zugriff auf Datendateien verwendet werden. Es ist für Umgebungen optimiert, die Datenservices in Echtzeit bereitstellen, und kann parallel zum direkten Datendateizugriff eingesetzt werden.
YARN bietet ein Ressourcenverwaltungs-Framework für die Ausführung verteilter Anwendungen unter Hadoop. Die DMX-h ETL Engine wird unter Yarn ausgeführt und übernimmt die skalierbare ETL-Verarbeitung für den Cluster. Die anderen Komponenten von Cloudera Enterprise wie SOLR Search, Impala Abfragen und MapReduce Standardverarbeitung werden ebenfalls unter Yarn ausgeführt.
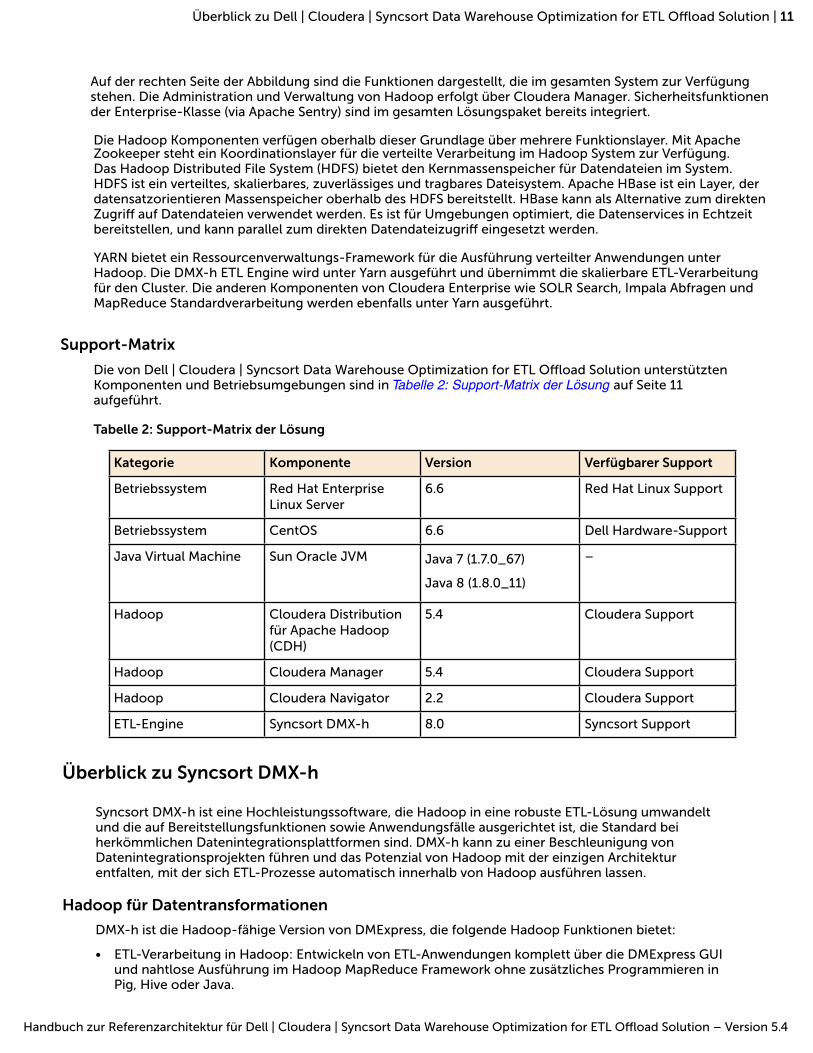
Support-Matrix
Die von Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution unterstützten Komponenten und Betriebsumgebungen sind in Tabelle 2: Support-Matrix der Lösung auf Seite 11 aufgeführt.
Tabelle 2: Support-Matrix der Lösung
Überblick zu Syncsort DMX-h
Syncsort DMX-h ist eine Hochleistungssoftware, die Hadoop in eine robuste ETL-Lösung umwandelt und die auf Bereitstellungsfunktionen sowie Anwendungsfälle ausgerichtet ist, die Standard bei herkömmlichen Datenintegrationsplattformen sind. DMX-h kann zu einer Beschleunigung von Datenintegrationsprojekten führen und das Potenzial von Hadoop mit der einzigen Architektur entfalten, mit der sich ETL-Prozesse automatisch innerhalb von Hadoop ausführen lassen.
Hadoop für Datentransformationen
DMX-h ist die Hadoop-fähige Version von DMExpress, die folgende Hadoop Funktionen bietet:
• ETL-Verarbeitung in Hadoop: Entwickeln von ETL-Anwendungen komplett über die DMExpress GUI und nahtlose Ausführung im Hadoop MapReduce Framework ohne zusätzliches Programmieren in Pig, Hive oder Java.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Merkmal Beschreibung
Hochleistungs-Daten-transformationen
Umfasst Sortieren, Verknüpfen, Aggregieren, Lookup mit mehreren Schlüsseln, erweiterte Textverarbeitung, Hashing-Funktionen sowie Operationen auf Quell-, Datensatz- und Feldebene.
Rapid Development überWindows-basierte DMX-hWorkstation
Ermöglicht die Entwicklung und den Test von MapReduce ETL Jobs lokal in Windows über eine graphische Benutzeroberfläche und die anschließende Bereitstellung in Hadoop. ExpressionBuilder unterstützt das Definieren von Datentransformationen auf der Basis von Geschäftsregeln.
Startpakete für Anwendungsfälle Beschleunigen die Hadoop Produktivität durch eine Bibliothek mit voll funktionsfähigen und wiederverwendbaren Vorlagen, z. B. zur Weblog-Verarbeitung, zur Datenänderungserfassung, zur Mainframe-Konnektivität und für Verknüpfungen, um so eigene Datenflüsse zu entwickeln.
Konnektivität von Datenquelleund Datenziel
Verbindet beliebige Quellen und Ziele mit Hadoop, einschließlich aller wichtigen DBMS, Flatfiles, XML-Dateien, Mainframe.
Aufnahme und Übersetzung von Mainframe-Daten
Lesen von Dateien direkt aus dem Mainframe sowie Parsing und Transformation der Daten – gepackt dezimal, in Abhängigkeit von, EBCDIC/ASCII, mehrformatige Datensätze und mehr – ohne Installation zusätzlicher Software im Mainframe und ohne Schreiben von zusätzlichem Code. Dem liegen 40 Jahre Erfahrung zugrunde – niemand kann das besser als Syncsort!
Dynamischer ETL-OptimiererFührt Datentransformationen und Datenfunktionen mit maximaler Geschwindigkeit auf Basis von Hunderten von proprietären Algorithmen aus. Der ETL-Optimierer wählte automatisch den besten Algorithmus aus, um die Leistung jedes einzelnen Hadoop Knotens zu maximieren, und passt sich in Echtzeit an veränderte Systembedingungen an.
Dateibasierte Metadaten-funktionen
Bietet größere Transparenz bei Auswirkungsanalyse, Data Lineage (Datenherkunft) und Ausführungsablauf ohne Abhängigkeit von Systemen anderer Anbieter wie z. B. relationalen Datenbanken.
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 12
• Beschleunigung der Hadoop Sortierung: Nahtloses Ersetzen der systemeigenen Sortierung in Hadoop MapReduce durch die Highspeed-Sortierung der DMExpress Engine für Leistungssteigerung ohne Umprogrammieren bestehender MapReduce Jobs.
• Apache Sqoop Integration: Verwenden des Sqoop Mainframe-Importanschlusses zur Übertragung von Mainframe-Daten in das HDFS.
Tabelle 3: Hauptmerkmale der DMX-h ETL Edition
Überblick zu Cloudera Enterprise Software
Cloudera Enterprise unterstützt Sie bei der Entwicklung hin zu einem datengesteuerten Unternehmen. Es bietet Zugriff auf die besten Ergebnisse der Open Source Community und auf Enterprise-Funktionen, die für einen erfolgreichen Einsatz von Apache Hadoop erforderlich sind.
Hadoop für Enterprise-Umgebungen
Cloudera Enterprise wurde speziell für geschäftskritische Umgebungen entwickelt und enthält CDH, die weltweit am häufigsten eingesetzte, Hadoop-basierte Open-Source-Plattform, sowie erweiterte Systemverwaltungs- und Datenverwaltungstools inklusive dediziertem Support und Community-Betreuung von unserem erstklassigen Team aus Hadoop Entwicklern und Experten. Cloudera ist unser Partner auf dem Weg zu Big Data.
Cloudera Enterprise mit Apache Hadoop als Kern weist folgende Eigenschaften auf:
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Produkt Beschreibung
CDHKern von Cloudera Enterprise, der Apache Hadoop mit einer Vielzahl anderer Open-Source-Projekte kombiniert, um eine zentrales, massiv-skalierbares System zu erstellen, das Massenspeicher mit einem Array an leistungsstarken Verarbeitungs- und Analyse-Frameworks verbindet.
Automatisiertes Cluster-Management –Cloudera Manager
Cloudera Enterprise enthält Cloudera Manager für die einfache Bereitstellung, Verwaltung, Überwachung und Problemdiagnose in Ihrem Cluster. Cloudera ist entscheidend für den Betrieb von Clustern nach Bedarf.
Cloudera SupportBranchenweit bester technischer Support für Hadoop.
Mit Cloudera Support erhalten Sie höhere Verfügbarkeit, schnellere Problemlösung, mehr Leistung zur Unterstützung Ihrer geschäftskritischen Anwendungen sowie schnellere Bereitstellung der für Ihre Anforderungen entscheidenden Plattformfunktionen.
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 13
• Vereinheitlicht (Unified) – ein zentrales, integriertes System, das unterschiedliche Benutzer und Anwendungsrechenlasten in einem Pool von Daten in einer gemeinsamen Infrastruktur zusammengeführt, sodass keine Daten bewegt werden müssen.
• Sicher – Perimetersicherheit, Authentifizierung, granulare Autorisierung und Datensicherung • Gesteuert – Funktionen der Enterprise-Klasse für Daten-Auditing, Data Lineage und Data Discovery • Verwaltet – nativer Hochverfügbarkeits-Massenspeicher mit Fehlertoleranz- und
Selbstreparaturfunktionen, automatischer Sicherung und Notfall-Wiederherstellung sowie erweiterter System- und Datenverwaltung
• Offen – Apache-lizenzierte Open-Source, die sicherstellt, dass Ihre Daten und Anwendungen in Ihrer Hand bleiben, sowie eine offene Plattform zum Einbinden all Ihrer vorhandenen Investitionen in Technologien und Kompetenzen
Neugestaltung der Datenverwaltung
• Eine zentrale, massiv-skalierbare Plattform zum Speichern von beliebigen Mengen und Typen von Daten in ihrer ursprünglichen Form über einen gewünschten oder benötigten Zeitraum
• Integration in vorhandene Infrastruktur und Tools
• Flexibilität zur Ausführung von unterschiedlichsten Enterprise-Rechenlasten inkl. Batchverarbeitung, interaktive SQL, Enterprise-Suche und erweiterte Analyse
• Robuste Funktionen der Enterprise-Klasse für Sicherheit, Steuerung, Datensicherung und Datenverwaltung
Mit Cloudera Enterprise können die führenden Unternehmen von heute ihre Daten in den Mittelpunkt ihrer Geschäftsaktivitäten legen, um so für mehr Transparenz und weniger Kosten zu sorgen und zugleich Risiken erfolgreich zu steuern und Datenschutzauflagen zu erfüllen.
Bestandteile
Tabelle 4: Enthaltene Produkte
Cloudera Enterprise Data Hub
Cloudera Enterprise bietet außerdem Support für einige fortgeschrittene Komponenten, die den Funktionsumfang von Apache Hadoop erweitern und ergänzen:
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Komponente Beschreibung
Online NoSQL – HBaseHBase ist ein verteilter Key-Value Store (Schlüsselwertedatenbank), mit dessen Hilfe Sie Echtzeitanwendungen für riesige Tabellen (Milliarden von Zeilen, Millionen von Spalten) bei schnellem, wahlfreiem Zugriff entwickeln können.
Analytic SQL – Impala Impala ist die führende MPP-SQL-Engine (Massively Parallel Processing),die speziell für Hadoop entwickelt wurde.
Suche – Cloudera SearchCloudera Search basiert auf SOLR und ermöglicht Anwendern das Abfragen und Durchsuchen von Daten in Hadoop wie mit Google oder auf einer E-Commerce-Website.
In-Memory Machine Learning und Stream-Verarbeitung – Apache Spark
Spark stellt die Funktionen für schnelle In-Memory-Analyse und Echtzeit-Stream-Verarbeitung für Hadoop bereit.
Datenverwaltung – Cloudera Navigator Cloudera Navigator bietet Funktionen für Auditing kritischer Daten, Data Lineage und Data Discovery in Enterprise-Umgebungen.
Überblick zu Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution | 14
Tabelle 5: Erweiterte Komponenten
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Admin-Knoten
Edge-Knoten
Bereitstellung Überwachung
Cloudera Manager Hadoop Clients
Node Manager Datenknoten
Datenknoten Datenknoten Datenknoten
Node Manager Datenknoten
Aktiver Resource Manager
Aktiver Namensknoten
Standby Resource Manager
Standby-Namensknoten
Journalknoten Journalknoten
Journalknoten
Aktiver Namensknoten Standby-Namensknoten Hochverfügbarkeitsknoten
Node Manager
Daten-knoten
Clusterarchitektur | 15
Clusterarchitektur
Die Gesamtarchitektur der Lösung zielt auf alle Aspekte eines Hadoop Produktionscluster ab, einschließlich Softwarelayer, physischer Serverhardware, Netzwerk-Fabric, aber auch Skalierbarkeit, Leistung und fortlaufende Verwaltung.
In diesem Abschnitt zur Clusterarchitektur sind nur die wichtigsten Aspekte der Lösungsarchitektur zusammengefasst. Ausführliche Informationen finden Sie unter:
• High-Level-Knotenarchitektur auf Seite 15 • Netzwerk-Fabric-Architektur auf Seite 17 • Dimensionierung von Clustern auf Seite 19
• Hochverfügbarkeit auf Seite 20
High-Level-Knotenarchitektur
Abbildung 2: Clusterarchitektur auf Seite 15 zeigt die Rollen der Knoten in einem Basiscluster.
Abbildung 2: Clusterarchitektur
Die Clusterumgebung besteht aus mehreren Softwareservices, die auf mehreren physischen Serverknoten ausgeführt werden. Bei der Implementierung werden den Serverknoten verschiedene Rollen zugewiesen, und jeder Knoten weist eine für seine Rolle im Cluster optimierte Konfiguration auf. Die Konfigurationen der physischen Server sind grob in zwei Klassen unterteilt: Datenknoten, welche den Großteil der Hadoop Verarbeitung übernehmen, und Infrastrukturknoten, welche die von den Clusteroperationen benötigten Services unterstützen. Ein Hochleistungs-Netzwerk-Fabric verbindet die Clusterknoten und trennt das Kerndatennetzwerk von den Verwaltungsfunktionen.
In der unterstützten Minimalkonfiguration sind sechs Knoten angegeben, wenngleich mindestens sieben Knoten empfohlen werden. Knoten können folgende Rolle haben:
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Knotenrolle Erforderlich? Hardwarekonfiguration
Administrationsknoten Optional Infrastruktur
Aktiver Namensknoten Erforderlich Infrastruktur
Standby-Namensknoten Erforderlich Infrastruktur
Hochverfügbarkeitsknoten Erforderlich Infrastruktur
Edge (oder Gateway)-Knoten Empfohlen Infrastruktur
Datenknoten 1 Erforderlich Daten
Datenknoten 2 Erforderlich Daten
Datenknoten 3 Erforderlich Daten
Clusterarchitektur | 16
Tabelle 6: Rollen von Clusterknoten
Knotendefinitionen
• Administrationsknoten: Stellt Funktionen für Clusterbereitstellung und Clusterverwaltung zur Verfügung. DerAdministrationsknoten ist in Clusterbereitstellungen optional und hängt davon ab, ob bereits eine Bereitstellungs-, Überwachungs- und Verwaltungsinfrastruktur verwendet wird.
• Aktiver Namensknoten: Führt alle Services aus, die für die Verwaltung des HDFS-Datenspeichers und die YARN Ressourcenverwaltung erforderlich sind. Er wird manchmal auch "Master-Namensknoten" genannt. Es gibt vier Services, die vorrangig auf dem aktiven Namensknoten ausgeführt werden:
• Resource Manager (zur Unterstützung der Cluster-Ressourcenverwaltung inkl. MapReduce Jobs) • NameNode (zur Unterstützung des HDFS-Datenspeichers) • Journal Manager (zur Unterstützung für Hochverfügbarkeit) • Zookeeper (zur Unterstützung der Koordination)
• Standby-Namensknoten: Bei Verwendung eines Quorum-basierten Hochverfügbarkeitsmodus werden auf diesem Knoten der Standby-Namensknotenprozess, ein zweiter Journal Manager und ein optionaler Standby Resource Manager ausgeführt. Außerdem wird auf diesem Knoten auch ein zweiter Zookeeper Service ausgeführt.
• Hochverfügbarkeitsknoten: Führt den dritten JournalNode für Hochverfügbarkeit aus – der erste und zweite JournalNode werden auf dem Master- und dem sekundäre Namensknoten bereitgestellt. Außerdem wird hier auch ein dritter Zookeeper Service ausgeführt.
• Edge-Knoten: Bietet eine Schnittstelle zwischen den im Hadoop Cluster verfügbaren Daten- und Verarbeitungskapazitäten und dem Benutzer dieser Kapazitäten an. Der Edge-Knoten ist mit dem Hauptzugriffs-LAN verbunden und wird manchmal auch "Gateway-Knoten genannt". Edge-Knoten sind optional, allerdings wird ihre Verwendung dringend empfohlen.
• Datenknoten: Führt alle Services aus, die zum Speichern von Datenblöcken auf dem lokalen Festplattenlaufwerk erforderlich sind, und führt Verarbeitungstasks auf diesen Daten aus. Es werden mindestens drei Datenknoten benötigt. Das Skalieren der Cluster erfolgt vorrangig durch Hinzufügen weiterer Datenknoten. Auf Datenknoten werden zwei Typen von Services ausgeführt:
• NodeManager Daemon (zur Unterstützung der YARN Jobausführung) • DataNode Daemon (zur Unterstützung des HDFS-Datenspeichers)
Tabelle 7: Standorte der Services auf Seite 17 beschreibt die Knotenstandorte und Knotenfunktionen der Cluster-Services.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Physischer Knoten Softwarefunktion
Administrationsknoten Bereitstellung des Betriebssystems
YUM-Repositorys
Überwachungsfunktionen
Edge-Knoten Cloudera Manager
Aktiver Namensknoten NameNode
Resource Manager
Zookeeper
Quorum-JournalNode
HMaster
Standby-Namensknoten Standby NameNode
Standby Resource Manager
Zookeeper
Quorum-JournalNode
HA-Knoten Zookeeper
Quorum-JournalNode
Datenknoten(x) DataNode
NodeManager
RegionServer
Tabelle 7: Standorte der Services
Clusterarchitektur | 17
Netzwerk-Fabric-Architektur
Die Architektur des Clusternetzwerks ist auf die Anforderungen von skalierbaren Hochleistungs-Clustern, auf Bereitstellung von Redundanz und den Zugang zu Verwaltungsfunktionen
ausgerichtet. Abbildung 3: Clusternetzwerk-Fabric-Architektur auf Seite 18 zeigt die Details:
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Logisches Netzwerk Verbindung Switch
Cluster-Datennetzwerk 10 GbE, gebündelt Zwei Top-of-Rack-Switches
Verwaltungsnetzwerk 1 GbESwitch pro Rack, dediziert oder gemeinsam mit BMC-Netzwerk verwendet
BMC/IPMI-Netzwerk 1 GbE Switch pro Rack, dediziert oder gemeinsam mit Verwaltungsnetzwerk verwendet
Edge-Netzwerk 10 GbE, optional gebündelt Top-of-Rack- oder Aggregationsswitch
Abbildung 3: Clusternetzwerk-Fabric-Architektur
Im Cluster werden vier unterschiedliche Netzwerke verwendet:
Tabelle 8: Netzwerke
Clusterarchitektur | 18
Netzwerkdefinitionen
Tabelle 9: Definitionen für Cloudera Distribution for Apache Hadoop Netzwerke auf Seite 19 enthält die Definitionen für Cloudera Distribution for Apache Hadoop Netzwerke.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4
UnternehmensrouterUnternehmensrouter
Öffentliches Netzwerk
Verbindung1Verbindung1
OptionalOptional Optional Optional
Namensknoten
Hochverfügbarkeitsknoten
Optional OptionalOptional
Edge-Knoten Datenknoten
Privates Produktions-/API-Netzwerk
iDRAC und Out-of-Band-Verwaltungsnetzwerk
Verbindung0 Verbindung0 Verbindung0
Optional für iDRAC und Out-of-Band-Verwaltung

Netzwerk Beschreibung
Cluster-DatennetzwerkDas Datennetzwerk übernimmt den Hauptteil des
Datenverkehrs innerhalb des Clusters. Dieses Netzwerk
wird innerhalb jedes Racks zusammengefasst, und Racks
werden im Cluster-Switch zusammengefasst. Duale
Verbindungen mit aktivem Lastausgleich werden von
jedem Knoten verwendet. Dies sorgt bei Ausfall eines
Kabels oder eines Switches für höhere Bandbreite und
Redundanz.
VerwaltungsnetzwerkDas Verwaltungsnetzwerk wird zur Bereitstellung von
Funktionen zum Cluster-Management und zur Cluster-
Bereitstellung verwendet.
BMC/IPMI-NetzwerkDas BMC-Netzwerk verbindet die BMC- oder iDRAC-Ports
mit den Out-of-Band-Verwaltungsports der Switches. Es
wird in einem dedizierten Switch jedes Racks aggregiert
und optional über dediziertes vLAN mit den Top-of-Rack-
oder Cluster-Switches verbunden.
Edge-NetzwerkDas Edge-Netzwerk bietet über den Top-of-Rack- oder den Cluster-Switch
Konnektivität von den Edge-Knoten zum bestehenden
Kernnetzwerk.
Tabelle 9: Definitionen für Cloudera Distribution for Apache Hadoop Netzwerke
Clusterarchitektur | 19
Die Konnektivität zwischen dem Cluster und der bestehenden Netzwerkinfrastruktur kann an bestimmte Installationen angepasst werden. Normalerweise sind Cluster-Datenknoten von allen anderen vorhandenen Netzwerken isoliert. Sie können aber freigegeben werden und optional über ein Anwendungs-Gateway oder eine Anwendungs-Firewall gerou-tet werden.
Dimensionierung von Clustern
Die Architektur ist in drei Einheiten organisiert, anhand derer bei Wachstum der Hadoop Umgebung eine Dimensio-nierung vorgenommen wird. Von der kleinsten zur größten Einheit sind das:
• Rack • Pod • Cluster Jede Einheit hat bestimmte Eigenschaften und Dimensionierungsanforderungen, die in dieser Referenzarchitektur dokumentiert sind.
Das Designziel für die Hadoop Umgebung sieht vor, dass Sie Ihre Umgebung durch Hinzufügen der benötigten zusätzlichen Kapazitäten skalieren können, ohne dass vorhandene Komponenten ausgetauscht werden müssen.
Rack
Ein Rack ist die Bezeichnung für die kleinste Einheit einer Hadoop Umgebung. Ein Rack verfügt über die notwendige Stromversorgung, die Netzwerkverkabelung und zwei Ethernet-Switches, um bis zu 15 Datenknoten zu unterstützen. Ein Rack muss über einen eigenen Stromanschluss und Platz im Rechenzentrum verfügen, muss von anderen Racks separiert sein, und sollte als Störungszone behandelt werden.
Pod
Ein Pod ist eine aus drei Racks bestehende Installation, die von der Server- und Netzwerkdimensionierung abhängig ist. Mit einem Pod können eine ausreichende Anzahl von Hadoop Serverknoten und Netzwerk-Switches für eine minimale kommerzielle Installation unterstützt werden. Je nach Rack-Dichte kann ein Pod aus 30 bis 45 Knoten bestehen.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Servermodell Max. pro Rack Max. pro Pod Max. pro Cluster
PowerEdge R730xdDatenknoten
15 45 Bestimmung anhand der Dimensionierungskriterien
Clusterarchitektur | 20
Cluster
Ein Cluster ist eine einzelne Hadoop Umgebung, die mit einem Paar von Bereitstellungsswitches verbunden ist, welche einen Aggregationslayer für den gesamten Cluster bereitstellen. Die Größe eines Clusters kann von einem einzelnen Rack bis zu einem Satz von Pods reichen. In einem Cluster werden die Infrastrukturknoten und Verwaltungstools für den Betrieb der Hadoop Umgebung gemeinsam genutzt. Die Größe des Clusters hängt von der Kapazität des Aggregationsnetzwerks ab. Beispiel: Ein Dell™Force10™ Z9000 Aggregationsswitch kann einen größeren Cluster bedienen als ein Dell Force10 S4810 Switch.
Dimensionierungsbeschränkungen Die minimal unterstützte Konfiguration besteht aus sechs Knoten:
• Aktiver Namensknoten • Standby-Namensknoten • Hochverfügbarkeitsknoten • Drei (3) Datenknoten
Die Hardwarekonfigurationen für Infrastrukturknoten unterstützen Clusters mit Massenspeichern im Petabyte-Bereich. Hinter den Infrastrukturknoten ist die Clustergröße vorrangig eine Funktion der gewählten Serverplattform und der gewählten Festplattenlaufwerke sowie der Anzahl der Datenknoten.
Tabelle 10: Clustergrößen nach Servermodell auf Seite 20 zeigt die ungefähre Anzahl der Datenknoten pro Rack, Pod und Cluster für die verschiedenen Servermodelle. In der Praxis wird die tatsächliche Dichte pro Rack von physikalischen Beschränkungen wie Stromversorgung und Kühlung sowie von den verfügbaren Netzwerkports bestimmt.
Pro Cluster wird mindestens ein Edge-Knoten empfohlen. Große Cluster und Cluster mit hohem Datenaufkommen oder Datenraten können von zusätzlichen Edge-Knoten profitieren.
Tabelle 10: Clustergrößen nach Servermodell
Hochverfügbarkeit
Die Architektur berücksichtig Hochverfügbarkeit auf mehreren Ebenen über eine Kombination aus Hardwareredundanz und Software-Support.
Hadoop Redundanz Zur Erhöhung der Datenstabilität werden im verteilten Hadoop Dateisystem redundante Massenspeicher implementiert.
Die Daten werden auf mehrere Knoten und Racks repliziert. Dadurch stehen bei einem Festplatten- oder Knotenausfall immer mehrere Kopien der Daten zur Verfügung. Das erhöht die Zuverlässigkeit, aber auch die Leistung. Standardmäßig werden drei Replikate erstellt. Die Anzahl kann aber problemlos geändert werden. Bei Ausfall eines Knotens verwendet Hadoop automatisch Replikate – das gebündelte Netzwerk bietet ausreichend Bandbreite, um neben dem Produktionsdatenverkehr auch den durch die Replikate verursachten Datenverkehr zu bewältigen.
Hinweis: Das Jobparallelitätsmodell von Hadoop erlaubt das Skalieren auf eine größere oder kleiner Anzahl von Knoten sowie die Ausführung von Jobs, wenn Teile des Clusters offline sind.
Netzwerkredundanz
Das Produktionsnetzwerk verwendet gebündelte Verbindungen, um die Anzahl der Switches in jedem Rack zu vervielfachen. Dadurch kann bei Ausfall eines Netzwerkports, eines Netzwerkkabels oder eines Switches der Betrieb mit verringerter Kapazität fortgesetzt werden.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Clusterarchitektur | 21
Hochverfügbare HDFS-Namensknoten Die Architektur implementiert Hochverfügbarkeit für das HDFS-Verzeichnis über einen Quorum-Mechanismus, bei dem Daten kritischer Namensknoten auf mehrere physische Knoten repliziert werden. In Produktionsclustern werden üblicherweise HA-Namensknoten implementiert.
Bei Quorum-basierter HA gibt es meist zwei Namensknotenprozesse, die auf zwei physischen Servern ausgeführt werden. Zum jeweiligen Zeitpunkt ist einer der NameNodes im Modus "Aktiv", der andere im Modus "Standby". Der aktive Namensknoten ist für alle Clientoperationen im Cluster verantwortlich, während der Standby-Namensknoten einfach als Slave dient, der seinen Zustand aufrechterhält, um im Bedarfsfall einen schnellen Failover sicherstellen zu können.
Damit bei dieser Installation der Standby-Namensknoten und der aktive Namensknoten synchron bleiben, kommunizieren beide Knoten mit einer Gruppe von separaten Daemons, die sich JournalNodes nennen. Wenn der aktive Namensknoten den Namespace modifiziert, wird dies bei der Mehrheit der JournalNodes dauerhaft in einem Protokolldatensatz festgehalten.
Der Standby-Namensknoten kann diese Bearbeitungseinträge auf den JournalNodes lesen und prüft das Bearbeitungsprotokoll kontinuierlich auf Änderungen. Sobald der Standby-Namensknoten die Bearbeitungen feststellt, führt er diese auf seinem eigenen Namespace nach. Im Falle eines Failover wird vor dem Wechsel in den Status "Aktiv" geprüft, ob der Standby-Namensknoten alle auf den JournalNodes festgehaltenen Bearbeitungen nachgeführt hat. Auf diese Weise wird sichergestellt, dass der Namespace-Status vor einem Failover vollständig synchronisiert ist.
Damit der Failover schnell erfolgt, muss der Standby-Namensknoten außerdem über aktuelle Informationen zu den Speicherorten der Blocks im Cluster verfügen. Dazu ist es erforderlich, dass die DataNodes mit den Speicherorten beider NameNodes konfiguriert sind und an beide Speicherortinformationen zu den Blocks sowie Heartbeats senden.
Es sollte eine ungerade Zahl an JournalNode-Daemons (und mindestens drei davon) vorhanden sein, da Bearbeitungsprotokollmodifikationen auf die Mehrheit der JournalNodes geschrieben wird. Die JournalNode-Daemons in dieser Referenzarchitektur werden auf dem Masterknoten, dem Sekundärknoten und den HA-Knoten ausgeführt.
Hochverfügbarkeit des Resource Manager Die Architektur unterstützt Hochverfügbarkeit für den Hadoop YARN Resource Manager.
Ohne HA des Resource Manager werden bei Ausfall eines Hadoop Resource Manager auch die aktuell ausgeführten Jobs unterbrochen. Wenn Resource Manager-HA eingerichtet ist, werden Jobs bei Ausfall eines Resource Manager weiter ausgeführt.
Zudem kann nach dem Failover die Ausführung einer Anwendung ab dem letzten Zustandskontrollpunkt fortgesetzt werden. So werden beispielsweise abgeschlossenen Map-Tasks in einem MapReduce-Job bei einem anschließenden Versuch nicht noch einmal ausgeführt. Dadurch kann die Behandlung von Ereignissen wie abgestürzte Systeme oder geplante Wartungen ohne signifikante Auswirkungen auf die Leistung der gerade ausgeführten Anwendungen erfolgen.
Die HA für Resource Manager wird mittels eines Aktiv/Standby-Paares von Resource Managern implementiert. Beim Start befindet sich jeder Resource Manager im Standby-Modus: der Prozess wird gestartet, aber der Status ist nicht geladen. Beim Übergang in den aktiven Status lädt der Resource Manager den internen Status aus dem festgelegten Statusspeicher und startet alle internen Services. Der Anstoß für den Übergang in den aktiven Status kommt entweder vom Administrator oder vom integrierten Failover-Controller, wenn der automatische Failover aktiviert ist.
Hinweis: Diese Funktion ist in Produktionsclustern nicht immer implementiert.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Hardwarearchitektur | 22
Hardwarearchitektur
Bei der Dell | Cloudera Apache Hadoop Solution kommen die neuesten Serverlösungen von Dell zum Einsatz.
Serverinfrastrukturoptionen
Die Dell | Cloudera Apache Hadoop Solution umfasst folgende Serveroptionen:
• PowerEdge R730/R730xd Server auf Seite 22
PowerEdge R730/R730xd Server
Die Dell Server PowerEdge R730 und PowerEdge R730xd sind die neuesten Dell Rackserver der 13th Generation (2-Socket, 2U), die speziell für die Ausführung komplexer Rechenlasten unter Verwendung von hochskalierbaren Speicher- und E/A-Kapazitäten sowie flexiblen Netzwerkoptionen entwickelt wurden. Beide Systeme verfügen über Prozessoren der Intel®Xeon® E5-2600 v3 Produktfamilie (Haswell-EP), bis zu 24 DIMMS, PCI Express® (PCIe) 3.0-fähige Erweiterungssteckplätze sowie eine Auswahl an Netzwerkschnittstellentechnologien.
Der für allgemeine Zwecke vorgesehene PowerEdge R730 weist einen umfassend erweiterbaren Arbeitsspeicher auf (bis 768 GB) und bietet eine beeindruckende E/A-Kapazität. Der R730 kann mühelos selbst anspruchsvollste Rechenlasten wie Data Warehouses, E-Commerce, Virtual Desktop Infrastructure (VDI), Datenbanken und Hochleistungsdatenverarbeitung (HPC) bewältigen.
Zusätzlich zu den Merkmalen des PowerEdge R730 bietet der PowerEdge R730xd eine außergewöhnliche Massenspeicherkapazität. Dadurch eignet er sich insbesondere für datenintensive Anwendungen mit hohen Anforderungen an Arbeitsspeicher und E/A-Kapazität wie medizinische Bildgebung und E-Mail-Server.
Abbildung 4: PowerEdge R730 Server
Abbildung 5: PowerEdge R730xd Server – 2,5-Zoll- und 3,5-Zoll-Gehäuseoptionen
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Rechnerfunktion Infrastrukturknoten
Plattform PowerEdge R730
Prozessor 2 x Intel Xeon E5-2650 v3 2.3GHz (10 Core)
RAM (Minimum) 128 GB
Netzwerk-Tochterkarte Intel X520 DP 10 Gbit/s DA/SFP+ und I350 DP 1 Gbit/sEthernet (2 x 10 GbE, 2 x 1 GbE)
Festplatte 8 x 1 TB SATA mit 7.200 1/min, 3,5 Zoll
Massenspeicher-Controller PERC H730
RAID RAID 10
Rechnerfunktion Datenknoten Datenknoten
Plattform PowerEdge R730xd PowerEdge R730xd
Gehäuse Bis zu 12 x 3,5-Zoll-Festplatten Bis zu 24 x 2,5-Zoll-Festplatten
Prozessor 2 x Intel Xeon E5-2650 v32,3 GHz (10 Core)
2 x E5-Intel Xeon E5-2690 v32,6 GHz (12 Core)
RAM (Minimum) 128 GB 128 GB
Netzwerk-Tochterkarte Intel X520 DP 10 Gbit/s DA/SFP+, + I350 DP 1-Gbit/s-Ethernet (2 x10 GbE, 2 x 1 GbE)
Intel X520 DP 10 Gbit/s DA/SFP+, + I350 DP 1-Gbit/s-Ethernet (2 x10 GbE, 2 x 1 GbE)
Festplatte 12 x 4 TB mit 7.200 1/min NLSAS 6 Gbit/s3,5 Zoll
24 x 1,2 TB mit 10.000 1/min SAS 6 Gbit/s2,5 Zoll
Flex Bay Disk 2 x 300 GB mit 10.000 1/min SAS 6 Gbit/s2,5 Zoll
2 x 300 GB mit 10.000 1/min SAS 6 Gbit/s2,5 Zoll
Hardwarearchitektur | 23
Funktionsübersicht zum PowerEdge R730 Zu den Merkmalen des Dell PowerEdge R730 zählen:
• Intel Grantley Plattform und Intel Xeon E5-2600v3 (Haswell-EP) Prozessoren • DDR4 Arbeitsspeicher mit bis zu 2133 MT/s • 24 DIMM-Steckplätze • iDRAC8 mit Lifecycle-Controller • Netzwerk-Tochterkarten für kundeneigene LOM-Geschwindigkeit, Fabric und Marke • Vorderseitig zugängliche Hot-Plug-Festplatten • Energieeffiziente Netzteile mit Platinum-Zertifizierung
Hardwarekonfigurationen des PowerEdge R730/R730xd
Die Dell | Cloudera Apache Hadoop Solution unterstützt folgende Serverkonfigurationen:
• Tabelle 11: Hardwarekonfigurationen – PowerEdge R730 Infrastrukturknoten auf Seite 23 • Tabelle 12: Hardwarekonfigurationen – PowerEdge R730xd Datenknoten auf Seite 23
Tabelle 11: Hardwarekonfigurationen – PowerEdge R730 Infrastrukturknoten
Hinweis: Wenden Sie sich vor Änderung der empfohlenen Datenträgergröße unbedingt an Ihren Dell Account Representative.
Tabelle 12: Hardwarekonfigurationen – PowerEdge R730xd Datenknoten
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Rechnerfunktion Datenknoten Datenknoten
Massenspeicher-Controller PERC H730 PERC H730
RAID RAID 1 – FlexBay JBOD – Datenlaufwerke
RAID 1 – FlexBay JBOD – Datenlaufwerke
Hardwarearchitektur | 24
Hinweis: Wenden Sie sich vor Änderung der empfohlenen Datenträgergröße unbedingt an Ihren Dell Account Representative.
Konfigurationshinweise für PowerEdge R730xd
Anhang A: Physische Konfiguration – PowerEdge R730xd auf Seite 39 enthält das empfohlene Rack-Layout für PowerEdge R730 Cluster.
Anhang B: Stückliste – PowerEdge R730 Knoten auf Seite 41 und Anhang C: Stückliste –PowerEdge R730xd 3,5-Zoll-Datenknoten auf Seite 43 enthalten die vollständigen Stücklisten für Serverkonfigurationen mit PowerEdge R730 und PowerEdge R730xd.
Hinweise zur Dimensionierung der Massenspeicher
Bei Laufwerkskapazitäten von über 3 TB oder einer Knotenspeicherdichte von über 36 TB müssen bei der HDFS-Einrichtung bestimmte Aspekte beachtet werden. Konfigurationen dieser Größe liegen hart an der Grenze zur Hadoop Massenspeicherkapazität pro Knoten. In diesem Fall sollte die HDFS-Blockgröße auf mindestens 128 MB erhöht werden. Da bei der Berechnung sowohl die Anzahl der Dateien, als auch Blöcke pro Datei, Komprimierung und reservierter Speicherplatz berücksichtigt werden müssen, erfordert die Konfiguration eine Analyse der vorgesehenen Cluster-Nutzung und Cluster-Daten.
Eine große Dichte pro Knoten hat bei einem Knotenausfall ebenfalls Einfluss auf die Clusterleistung. Um die Leistungseinbußen in diesem Fall zu minimieren, wird für Knoten mit hoher Dichte eine gebündelte 10-GbE-Konfiguration empfohlen.
Hinweis: Ihr zuständiger Dell Mitarbeiter kann Ihnen bei diesen Abschätzungen und Berechnungen Unterstützung bieten.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

UnternehmensrouterUnternehmensrouter
Öffentliches Netzwerk
Verbindung1Verbindung1
OptionalOptional Optional Optional
Namensknoten
Hochverfügbarkeitsknoten
Optional OptionalOptional
Edge-Knoten Datenknoten
Privates Produktions-/API-Netzwerk
iDRAC und Out-of-Band-Verwaltungsnetzwerk
Verbindung0 Verbindung0 Verbindung0
Optional für iDRAC und Out-of-Band-Verwaltung
Logisches Netzwerk Verbindung Switch
Cluster-Datennetzwerk 10 GbE, gebündelt Zwei Top-of-Rack-Switches
Verwaltungsnetzwerk 1 GbE Dedizierter Switch pro Rack
BMC-Netzwerk 1 GbE Dedizierter Switch pro Rack
Edge-Netzwerk 10 GbE, optional gebündelt Top-of-Rack- oder Clusters-witch
Netzwerkarchitektur
Netzwerkarchitektur | 25
Die Architektur des ist auf die Anforderungen von skalierbaren Hochleistungs-Clustern, auf Bereitstellung von Redundanz und den Zugang zu Verwaltungsfunktionen ausgerichtet.
Die Architektur unterstützt zwei Netzwerkoptionen:
• 1 GbE • 10 GbE
Bei der 1-GbE-Option verwendet Dell Force10 S60 Switches zur Top-of-Rack-Konnektivität aller Hadoop-bezogenen Knoten. Für die 10-GbE-Option werden Dell Force10 S4810 Switches eingesetzt. Hadoop Anwendungen werden zunehmend auf 10-GbE-Servern bereitgestellt, da diese Skalierungs- und Preisvorteile bieten. Somit ist dies die empfohlene Konfiguration für neue Cluster.
Im Cluster werden vier unterschiedliche Netzwerke verwendet:
Tabelle 13: Clusternetzwerke
Jedes Netzwerk verwendet ein separates VLAN und, wenn möglich, dedizierte Komponenten. Abbildung 6: Logisches Netzwerkdiagramm von Hadoop Netzwerken auf Seite 25 zeigt die logische Struktur des Netzwerks.
Abbildung 6: Logisches Netzwerkdiagramm von Hadoop Netzwerken
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

BMC
Netzwerkarchitektur | 26
Physische Netzwerkkomponenten
Die physischen Netzwerke der Dell | Cloudera Apache Hadoop Solution bestehen aus folgenden Komponenten:
• Serverknotenverbindungen auf Seite 26 • Top-of-Rack (ToR)-Switches auf Seite 26 • Cluster-Aggregationsswitches auf Seite 27 • Kernnetzwerk auf Seite 29 • Layer-2 und Layer-3 auf Seite 29 • Verwaltungsnetzwerk auf Seite 29 • Netzwerkgeräte – Zusammenfassung auf Seite 30
Serverknotenverbindungen Serververbindungen zu den Netzwerkswitches des Datennetzwerks sind gebündelt und verwenden eine Aktiv-Aktiv-LAN-Aggregationsgruppe (LAG) in einer Lastausgleichskonfiguration. (Unter Linux ist dies Balanced-alb- oder Mode-6-Bonding.)
Die Verbindungen erfolgen zu einem Paar aus ToR-Switches, um für den Fall eines Port-, Kabel- oder Switch-Ausfalls für Redundanz zu sorgen. Die Switch-Ports werden als eine LAG konfiguriert. Jeder Server verfügt über eine zusätzliche 1-GbE-Verbindung zum Verwaltungsnetzwerk, um das Servermanagement und die Serverbereitstellung zu erleichtern.
Die Verbindungen zum BMC-Netzwerk erfolgt über eine Einzelverbindung vom BMC-Port zu einem dedizierten Switch in jeden Rack.
Edge-Knoten verfügen über ein zusätzliches Paar an 10-GbE-Verbindungen zum ToR-Switch. Diese Verbindungen unterstützen Hochleistungs-Datenaufkommen und den Clusterzugriff zwischen den Anwendungen, die auf diesen Knoten ausgeführt werden, und dem Kernnetzwerk im Rechenzentrum.
Abbildung 7: PowerEdge R730xd Knoten mit 1-GbE-Netzwerkanschlüssen
Top-of-Rack-Switches (ToR)
Jedes Rack verwendet ein Paar von Force10 S4810 Switches als Top-of-Rack-Switches. Diese Switches sind für Hochverfügbarkeit ausgelegt und verwenden Virtual Link Trunking (VLT). Mit VLT können Server ihre LAG-Schnittstellen in zwei unterschiedlichen Switches statt einem terminieren. Dies sorgt für Redundanz innerhalb des Racks, falls ein Switch ausfällt oder Wartung bei Aktiv-Aktiv-Bandbreitenauslastung erforderlich ist.
Abbildung 8: Geräte bei Einzel-Rack-Netzwerkbetrieb auf Seite 27 zeigt die Einzel-Rack-Netzwerkkonfiguration mit einem Paar von Force10 S4810 Switches zum Aggregieren des Rackdatenverkehrs.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4
Integrierte Netzwerkkarte

Gestappelt
10 GbE, gebündelt
Knoten 1
Knoten 2
Knoten 20
Rack1
Netzwerkarchitektur | 27
Abbildung 8: Geräte für Einzel-Rack-Netzwerkbetrieb
Bei einem Einzel-Rack können die Top-of-Rack-Switches als Clusteraggregationslayer fungieren. Bei größeren Clustern ist ein Clusteraggregationslayer erforderlich.
In dieser Architektur wird aus Switching-Perspektive jedes Rack als eine separate Einheit verwaltet. ToR-Switches werden nur mit Aggregations-Switches verbunden.
Clusteraggregations-Switches Cluster, die aus mindestens einem Pod bestehen, verwenden bei dieser Architektur einen der beiden folgenden Aggregations-Switches:
• Force10 S4810 • Force10 Z9000
Die Wahl hängt von der Anfangsgröße und der geplanten Skalierung ab. Das auf Force10 S4810 basierte Aggregationsdesign ist eher für kostengünstige und mittlere Skalierbarkeit geeignet. Bei diesem Design können bis zu sechs Racks oder zwei Pods verwaltet werden. Der Z9000 wird für größere Bereitstellungen empfohlen.
Aggregations-Switches werden wie ToR-Switches paarweise unter Verwendung von VLT angeschlossen. Der Uplink von jedem S4810 ToR-Switch zum Aggregationspaar hat 80 Gbit und verwendet ein Paar von 40-Gbit-Schnittstellen. Da beide S4810 Switches mit dem Aggregationspaar verbunden sind, steht jedem Rack eine Bandbreite von insgesamt 160 Gbit zur Verfügung.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Kern
VLT/VRRP
40 GbE, gebündelt 40 GbE, gebündelt
10 GbE, gebündelt 10 GbE, gebündelt
Rack 1 Rack n
Knoten 1
Knoten 2
Knoten 20 Knoten 20
Knoten 2
Knoten 1
Abbildung 9: Multi-Rack-Netzwerkbetrieb mit S4810
Netzwerkarchitektur | 28
Clusteraggregation mit S4810
Abbildung 9: Multi-Rack-Netzwerkbetrieb mit S4810 auf Seite 28 zeigt die Konfiguration für einen Multi-Rack-Cluster, der den S4810 als Clusteraggregations-Switch verwendet.
Clusteraggregation mit Force10 Z9000 Bei größeren Erstbereitstellungen wird für Bereitstellungen, bei denen eine vertikale Skalierung geplant ist, oder für Fälle, bei denen der Cluster mit anderen Anwendungen in verschiedenen Racks am gleichen Ort untergebracht werden muss, die Verwendung eines Force10 Z9000 Core-Switch empfohlen.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Layer-2 Horizontales Skalieren auf Basis von VLT Z9000 40G
Netzwerkarchitektur | 29
Der Force10 Z9000 ist ein 40-Gbit-Switch hoher Kapazität mit 32 Ports. Er kann bis zu 15 Racks mit hochdichten PowerEdge Servern aggregieren. Für die in Hadoop benötigte Rack-zu-Rack-Bandbreite ist ein 40-G-fähiger, nicht blockierender Switch geeignet. Der Force10 Z9000 kann eine kumulative Bandbreite von 1,5 TB Datendurchsatz bei Leitungsgeschwindigkeit mit maximaler Datenübertragungsrate von jedem Port bereitstellen. In den meisten Fällen muss der Force10 Z9000 nicht mit einem anderen, höherrangigen Core-Switch verbunden werden, da die Kapazität für ein Rechenzentrum mit Hunderten von Servern ausreicht.
Abbildung 10: Multi-Rack-Ansicht mit Force10 Z9000 Switches (auf Basis von Layer-2) auf Seite 29 zeigt die Konfiguration eines Multi-Rack-Clusters unter Verwendung des Z9000 als Clusteraggregations-Switch. Dies ist ein Beispiel für ein Clos-Fabric, das horizontal wächst. Dieses Verfahren zur Netzwerk-Fabric-Bereitstellung wurde bereits in Rechenzentrum der größten Internetfirmen angewendet, deren Geschäfte von Social Media bis Public Cloud reichen. Auch bei einigen der größten Hadoop-Bereitstellungen der jüngsten Zeit wurde dieser Ansatz für den Netzwerkbetrieb verwendet.
Jeder Switch in Abbildung 10: Multi-Rack Ansicht mit Force10 Z9000 Switches (auf Basis von Layer-2) auf Seite 29 bildet eine Layer-2-LAG. Das setzt voraus, dass das Force10 Z9000 Paar in der Aggregation ein VLT-Paar für HA bildet. Jetzt haben wir zwei VLT-Ebene: eine auf dem ToR für Server und die andere auf der Aggregation für die ToR-Switches.
Abbildung 10: Multi-Rack-Ansicht mit Force10 Z9000 Switches (auf Basis von Layer-2)
Kernnetzwerk
Der Aggregationslayer fungiert als der Netzwerkkern für den Cluster. In den meisten Fällen wird der Cluster mit einem größeren Kern innerhalb des Unternehmens verbunden sein, der in Abbildung 9: Multi-Rack Netzwerkbetrieb mit S4810 auf Seite 28 als Cloud dargestellt ist. Die Details zur Verbindung hängen vom Standort ab und müssen im Zuge der Bereitstellungsplanung ermittelt werden.
Layer-2 und Layer-3
Die Layer-2- und Layer-3-Grenzen werden entweder durch den ToR oder den Aggregationslayer gebildet. Beide Optionen haben die gleichen Auswirkungen. Rot und Blau stehen in Abbildung 10: Multi-Rack-Ansicht mit Force10 Z9000 Switches (auf Basis von Layer-2) auf Seite 29 für die Layer-2- und Layer-3-Begrenzungen. In diesem Dokument wird Layer-2 als Referenz bis zum Aggregationslayer verwendet.
Verwaltungsnetzwerk
Das Verwaltungsnetzwerk für alle Server und Switches wird in einem Dell Force10 S55 Switch aggregiert, der sich in jedem Rack des Pod befindet. Er bildet einen Uplink über eine 10-Gbit-Verbindung zu den Aggregations-Switches oder direkt zum Kern, je nachdem, wo der Split für Out-of-Band benötigt wird.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Komponente Menge
Racks gesamt 1 (6-20 Knoten)
Verwaltungs-Switch 1 x Force10 S55
Top-of-Rack-Switches 2 x Force10 S4810
Aggregations-Switch Nicht erforderlich bei Einzel-Rack
Switch-Verbindungskabel 2 x 40-Gbit-QSFP+-Kabel
Module in jedem ToR 1 x 12-2 Port-Stacking, 1 x 10G-2 Port-Uplink
Komponente Menge
Racks gesamt 3 bis 15 Racks (1–5 Pods)
Aggregationslayer-Switches 2 x Force10 Z9000
Pod-Verbindungskabel 4 x 40-Gbit-QSFP+-Kabel
Switch-Verbindungskabel 4 x 40-Gbit-QSFP+-Kabel 1 m
Beschreibung 1-GbE-Kabel erforderlich 10-GbE-Kabel mit SFP+erforderlich
Namens- und HA-Knoten 2 x Anzahl der Knoten 2 x Anzahl der Knoten
Edge-Knoten 2 x Anzahl der Knoten 4 x Anzahl der Knoten
Datenknoten 2 x Anzahl der Knoten 2 x Anzahl der Knoten
Netzwerkarchitektur | 30
Netzwerkgeräte – Zusammenfassung
Tabelle 14: Netzwerkgeräte pro Rack auf Seite 30 und Tabelle 15: Aggregation von Netzwerk-Switches für 3 oder mehr Racks auf Seite 30 enthalten alle für den Cluster-Netzwerkbetrieb erforderlichen Geräte. Tabelle 16: Netzwerkkabel erforderlich – 10-GbE-Konfigurationen auf Seite 30 zählt die für einen Cluster benötigten Kabel auf.
Tabelle 14: Netzwerkgeräte pro Rack
Tabelle 15: Netzwerk-Aggregations-Switches für 3 oder mehr Racks
Tabelle 16: Netzwerkkabel erforderlich – 10-GbE-Konfigurationen
Netzwerkkonnektivität – Zusammenfassung
Die Netzwerkverbindungen zwischen den verschiedenen Hardwarekomponenten der Lösung sind in Abbildung 11: Netzwerkverbindungen für 10 GbE auf Seite 31 dargestellt. Weitere Informationen finden Sie im Bereitstellungshandbuch für Dell | Cloudera Apache Hadoop Solution.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

UnternehmensrouterUnternehmensrouter
Öffentliches Netzwerk
Verbindung1Verbindung1
OptionalOptional Optional Optional
Namensknoten
Hochverfügbarkeitsknoten
Optional OptionalOptional
Edge-Knoten Datenknoten
Privates Produktions-/API-Netzwerk
iDRAC und Out-of-Band-Verwaltungsnetzwerk
Verbindung0 Verbindung0 Verbindung0
Optional für iDRAC und Out-of-Band-Verwaltung
Netzwerkarchitektur | 31
Abbildung 11: Netzwerkverbindungen für 10 GbE
IPv6-Funktionsumfang
Derzeit bietet die Architektur keine Unterstützung für Netzwerkkonnektivität mit IPv6.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Syncsort Software | 32
Syncsort Software
Die Datentransformationsfunktionen für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload werden von Syncsort DMX-h bereitgestellt. Syncsort DMX-h ETL Edition ist eine ETL-Hochleistungssoftware, die Hadoop in eine robustere und funktionsreichere ETL-Lösung umwandelt. Benutzer profitieren von den Vorteilen von MapReduce ohne Abstriche bei Funktionsumfang, Benutzerfreundlichkeit und typischen Anwendungsfällen von konventionellen Datenintegrationstools machen zu müssen.
Zu den Komponenten der DMX-h Softwareplattform gehören:
• DMX-h Engine • DMX-h Agent • Syncsort Clientanwendung • Syncsort SILQ
Syncsort DMX-h Engine
DMX-h ist das einzige Tool, das ETL-Prozesse nativ in Hadoop über ein steckbare Sortiererweiterung (JIRA MAPREDUCE-2454) ausführt, die von Syncsort bereitgestellt wurde und nun Teil von Apache Hadoop ist. Andere Tools generieren Code (z. B. Java, Pig, HiveQL), der die Systemleistung belasten und zu Problemen bei Wartung und Anpassung führen kann.
DMX-h ist kein Codegenerator. Stattdessen ruft Hadoop MapReduce zur Laufzeit automatisch die hoch effiziente DMX-h Engine auf, welche auf allen Knoten als integraler Teil des Hadoop Framework nativ ausgeführt wird. Nach der Bereitstellung optimiert DMX-h automatisch die Ressourcenauslastung – CPU, Arbeitsspeicher und E/A – auf jedem Knoten, um ohne weitere Anpassungen für die größtmögliche Leistung zu sorgen. Vereinfacht ausgedrückt, können durch höhere Leistung und Effizienz jedes Knotens mehr Daten in weniger Zeit und mit weniger Servern verarbeitet werden.
Syncsort Agent
Der DMX Agent wird auf einem Edge-Knoten im Hadoop Cluster ausgeführt und koordiniert den Zugriff der unter Hadoop ausgeführten DMX Engine. Der Syncsort Client verbindet sich mit dem DMX Agent, um Jobs zu initiieren.
Syncsort DMX-h Client
Der Syncsort DMX-h Client verfügt über eine intuitive grafische Benutzeroberfläche, die Benutzern das Entwickeln, Ausführen und Steuern von Datenintegrationsjobs ermöglicht.
DMX-h können auch Anwender, die keine spezialisierten MapReduce Programmierer sind, ETL-Tasks erstellen, die innerhalb des MapReduce Framework ausgeführt werden und den komplexen Java-, Pig- oder HiveQL-Code durch eine leistungsfähige und einfach zu verwendende grafische Entwicklungsumgebung ersetzen. Mit DMX-h vereinfacht die Entwickelung, Wartung und Wiederverwendung der unter Hadoop ausgeführten Anwendungen durch umfassend integrierte Transformationen und Metadatenfunktionen für weitreichendere Wiederverwendbarkeit, Auswirkungsanalyse und Data Lineage.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Syncsort Software | 33
Syncsort SILQ
SILQ ist ein webbasiertes Dienstprogramm, mit dessen Hilfe komplexe, im ETL-Stil entwickelte SQL-Jobs in DMX-h Jobs zur Ausführung unter Hadoop konvertiert werden können.
SILQ kann mehrere SQL-Dialekte lesen, einschließlich BTEQ, NZ SQL, PL/SQL und ANSI SQL-92. SILQ generiert grafische Datenflüsse, verwendet Best Practices zur Entwicklung von DMX-h Jobs und generiert automatisch ETL-Jobs, die unter Hadoop nativ ausgeführt werden.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Cloudera Enterprise Software | 34
Cloudera Enterprise Software
Die Dell | Cloudera Apache Hadoop Solution basiert auf Cloudera Enterprise, das Cloudera Distribution für Hadoop (CDH) 5.4 und Cloudera Manager enthält.
Zu den Komponenten der Cloudera Enterprise Software zählen:
• Cloudera Manager auf Seite 34 • Cloudera RTQ (Impala) auf Seite 34 • Cloudera Search auf Seite 35 • Cloudera BDR auf Seite 35 • Cloudera Navigator auf Seite 35 • Cloudera Support auf Seite 36
Cloudera Manager
Cloudera Manager wurde zur Vereinfachung und Optimierung der Administration von Umgebungen jeder Größe entwickelt. Mit Cloudera Manager können Sie das komplette Hadoop Paket einfach bereitstellen und zentral betreiben. Die Anwendung bietet Folgendes: Automatisierung des Installationsprozesses, Reduzierung der Bereitstellungszeit von Wochen auf Minuten, Cluster-weite Echtzeitansicht der ausgeführten Knoten und Services, Bereitstellung einer zentralen Konsole zur Ausführung von Konfigurationsänderungen im gesamten Cluster sowie eine vollständige Palette an Berichts- und Diagnosetools zur Optimierung von Leistung und Auslastung.
Cloudera Manager ist Bestandteil der Produktangebote Cloudera Standard und Cloudera Enterprise. Cloudera Standard bietet einen vollständigen Funktionssatz zur Bereitstellung, Konfiguration, Verwaltung, Überwachung, Diagnose und Skalierung von Clustern – dies ist der umfassendste und modernste Satz an Managementfunktionen, der derzeit angeboten wird. Wenn Sie ein Upgrade auf Cloudera Enterprise vornehmen, erhalten Sie zusätzliche Funktionen zur Integration, Prozessautomatisierung und Notfall-Wiederherstellung, die speziell für den erfolgreichen Betrieb von Clustern in Enterprise-Umgebungen ausgerichtet sind.
Cloudera RTQ (Impala)
Cloudera Impala ist eine Open-Source-Abfrage-Engine mit Massively Parallel Prozessing (MPP), die nativ in Apache Hadoop ausgeführt wird. Das von Apache lizenzierte Impala Projekt zielt auf die Einführung einer skalierbaren, parallelen Datenbanktechnologie in Hadoop ab, mit der Anwender SQL-Abfragen mit niedriger Latenz auf den in HDFS und Apache HBase gespeicherten Daten ausführen können, ohne dass die Daten vorher verschoben oder transformiert werden müssen.
Impala wurde von Grund auf für die Integration in das Hadoop Ökosystems entwickelt und unterstützt daher dieselben flexiblen Datei- und Datenformate, Metadaten-, Sicherheits- und Ressourcenverwaltungsframeworks, die auch von MapReduce, Apache Hive™, Apache Pig™ und anderen Komponenten des Hadoop Paket verwendet werden.
Während MapReduce auf die Batch-Massenverarbeitung ausgerichtet ist, wurde Impala ergänzend als unabhängiges Verarbeitungs-Framework zur Optimierung von interaktiven Abfragen entwickelt. Mit Impala können Analysten und Datenforscher nun "gedankenschnelle" Analysen in Echtzeit über SQL- oder Business-Intelligence-Tools auf den in Hadoop gespeicherten Daten ausführen.
Auf diese Weise können Massendatenverarbeitung und interaktive Abfragen über dasselbe System auf denselben Daten und Metadaten erfolgen.Dies spart Zeit und Kosten für das Migrieren der Datensets in spezielle Systeme und/oder proprietäre Formate, nur um sie analysieren zu können.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Cloudera Enterprise Software | 35
Cloudera Search
Cloudera Search stellt eine interaktive Volltextsuche für CDH bereit, der 100% Open-Source-Distribution von Cloudera, die Apache Hadoop enthält. Cloudera Search mit Apache Solr erweitert die Hadoop Plattform um eine Suchfunktion der neuesten Generation: Big Data-Suche durch skalierbare Indexierung von in HDFS und Apache HBase™ gespeicherten Daten.
Wie auch andere Hadoop Rechenlasten profitiert Cloudera Search von derselben Fehlertoleranz, Skalierung, Transparenz und Flexibilität, die durch Integration in CDH ermöglicht wird.
Seit seiner Einführung 2006 hat sich Apache Solr zum Enterprise-Standard für Open-Source entwickelt. Seine aktive und gereifte Community fördert die breite Einführung in Sparten und Branchen, was durch die funktionsreichen und erweiterbaren APIs noch unterstützt wird. Cloudera Search steigert den Mehrwert von Apache Solr durch die enge Integration und optimale Ausführung in CDH und Cloudera Manager.
Cloudera BDR
BDR ist ein Zusatzabonnement für Cloudera Enterprise, das für durchgängige Business Continuity sorgt. Wenn Sie Ihr Cloudera Enterprise Abonnement um BDR erweitern, erhalten Sie die erforderlichen Verwaltungsfunktionen und den erforderlichen Support, um maximalen Nutzen aus den leistungsfähigen Notfall-Wiederherstellungsfunktionen für CDH zu ziehen.
Cloudera BDR vereinfacht die Konfiguration und Verwaltung von Richtlinien für die Notfall-Wiederherstellung der in CDH gespeicherten Daten. BDR bietet Ihnen folgende Möglichkeiten:
• Zentrale Konfiguration und Verwaltung des Workflows zur Notfall-Wiederherstellung von Dateien (HDFS) und Metadaten (Hive) über eine übersichtliche, grafische Benutzeroberfläche
• Konsistente Einhaltung von Service Level Agreements (SLAs) und geforderten Wiederherstellungszeiten (RTOs) durch vereinfachte Verwaltung und Prozessautomatisierung
BDR umfasst:
• Zentrale Verwaltung der HDFS-Replikation durch Cloudera Manager • Zentrale Verwaltung der Hive Replikation durch Cloudera Manager
• Cloudera Support zu Geschäftszeiten oder rund um die
Uhr Hauptfunktionen von BDR:
• Definition von Replikationsrichtlinien auf Datei- und Verzeichnisebene • Zeitplanung für Replikationsjobs • Überwachung des Fortschritts über eine zentrale Konsole • Erkennung von Differenzen zwischen Primär- und Sekundärsystem(en)
Cloudera Navigator
Navigator ist ein Zusatzabonnement für Cloudera Enterprise, welches das erste voll integrierte Datenverwaltungstool für Cloudera Enterprise bereitstellt. Navigator wurde zur Bereitstellung aller für Administratoren, Datenverwalter und Datenanalysten erforderlichen Funktionen zur Sicherung, Steuerung und Auswertung der großen Mengen an verschiedenartigsten in CDH gesammelten Daten entwickelt.
Die erste Version von Cloudera Navigator (v1.0) war speziell auf Datensicherheitsprobleme ausgerichtet, mit denen vor allem stark regulierte Branche wie Finanzdienstleister, Gesundheitswesen und Regierung konfrontiert sind. Sie enthält einen vollständigen Satz an Auditing-Funktionen für alle CDH Komponenten, die Daten speichern.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Merkmal Beschreibung
Flexible Support-ZeitenAuswahl zwischen Support zu Geschäftszeiten oder rund um die Uhr je nach SLA-Anforderungen.
Überprüfung der Konfiguration Überprüfung, ob Ihr Hadoop-Cluster auf Ihre Umgebung abgestimmt ist.
Eskalation und Problembehebung Lösen von Supportfällen mit maximaler Effizienz.
Umfassende Knowledge Base Erweitern Sie Ihr Hadoop Wissen mithilfe Hunderter Artikel und technischer Hinweise.
Support für zertifizierte Integration Verbinden Sie Ihre Hadoop Cluster mit Ihren bestehenden Datenanalysetools.
Proaktive Benachrichtigung Bleiben Sie auf dem neuesten Stand bei Entwicklungen und Ereignissen.
Cloudera Enterprise Software | 36
Das Navigator Abonnement erlaubt den Zugriff auf alle Funktionen der Cloudera Navigator Anwendung. Navigator bietet folgende Vorteile:
• Speicherung sensibler Daten in CDH unter Gewährleistung von Compliance mit gesetzlichen Vorschriften und internen Auditrichtlinien
• Verifizierung von Zugriffsberechtigungen auf Dateien und Verzeichnisse
• Verwaltung einer vollständigen Audithistorie über den Zugriff auf Daten in HDFS, Hive und HBase
• Berichterstattung über Datenzugriffe nach Benutzer und Typ
• Integration in SIEM-Tools anderer
Anbieter Navigator enthält Folgendes:
• Zentrales Auditmanagement und Berichterstellung für HDFS, Hive und HBase
• Cloudera Support zu Geschäftszeiten oder rund um die
Uhr Hauptmerkmale von Cloudera Navigator:
• Konfiguration von Auditinformationen für HDFS, HBase und Hive
• Zentrale Ansicht für Datenzugriff und Berechtigungen
• Einfache Abfrageansicht mit Filtern für Datentypen oder Zugriffsmuster
• Export der vollständigen oder gefilterten Audithistorie zur Integration in SIEM-Tools anderer Anbieter
Cloudera Support
Mit zunehmendem Einsatz von Hadoop und einer steigenden Zahl von Gruppen und Anwendungen, die in Produktion gehen, werden Ihre Hadoop Anwender ein höheres Leistungs- und Konsistenzniveau erwarten. Der proaktive Support auf Produktionsebene von Cloudera bietet Administratoren die Fachkompetenz und Reaktionsschnelligkeit, die sie benötigen.
Cloudera Support umfasst Folgendes:
Tabelle 17: Merkmale von Cloudera Support
Mit Cloudera Enterprise können Sie das Know-how Ihrer Teams mit dem Know-how von Cloudera zur vollen Entfaltung bringen und so Ihr Hadoop System in einen effizienten Betrieb überführen. Dank integrierter Prognosefunktionen können Änderungen in der Hadoop Infrastruktur rechtzeitig erkannt und somit ein zuverlässiger Betrieb gewährleistet werden.
Cloudera Enterprise vereinfacht die Ausführung von Open-Source Hadoop in Produktionsumgebungen durch:
• Vereinfachung und Beschleunigung der Hadoop Bereitstellung • Reduzierung der mit der Einführung von Hadoop in die Produktion verbundenen Kosten und Risiken • Zuverlässiger Betrieb von Hadoop in der Produktionsumgebung mit wiederholbarem Erfolg
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

• Anwendung von SLAs auf Hadoop • Mehr Kontrolle über Bereitstellung und Verwaltung von Hadoop Clustern
Cloudera Enterprise Software | 37
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Bereitstellungsmethode
Bereitstellungsmethode | 38
Im Bereitstellungshandbuch für Dell | Cloudera Apache Hadoop Solution wird ein Bereitstellungs-Workflow vorgeschlagen, der sich auf diese Referenzarchitektur bezieht.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

RU RACK1 RACK2 RACK3
42 R1 – Switch 2: Force10S4810
R2 – Switch 2: Force10S4810
R3 – Switch 2: Force10S4810
41 R1 – Switch 1: Force10S4810
R2 – Switch 1: Force10S4810
R3 – Switch 1: Force10S4810
40 Kabelführung Kabelführung Kabelführung
39 Kabelführung Kabelführung Kabelführung
38 Master-Namensknoten:PowerEdge R730xd oder PowerEdgeR730
Edge01: PowerEdgeR730xd oder PowerEdgeR730
R3 – Switch 1: Force10S4810
R3 – Switch 2: Force10S4810
37
36 Kabelführung Kabelführung Kabelführung
35 Kabelführung Kabelführung Kabelführung
34
33
Admin-KnotenPowerEdge R730xd oderPowerEdge R730
Sekundärer NamensknotenPowerEdge R730xd oderPowerEdge R730
HA-Knoten: PowerEdgeR730xd oder PowerEdgeR730
32 R1 – S55 iDRAC Verwaltungsswitch
R2 – S55 iDRAC Verwaltungsswitch
R3 – S55 iDRAC Verwaltungsswitch
21–31 Leer Leer Leer
20
19
R1 – Gehäuse 10:PowerEdge R730xd
R2 – Gehäuse 10:PowerEdge R730xd
R3 – Gehäuse 10:PowerEdge R730xd
18
17
R1 – Gehäuse 09:PowerEdge R730xd
R2 – Gehäuse 09:PowerEdge R730xd
R3 – Gehäuse 09:PowerEdge R730xd
16
15
R1 – Gehäuse 08:PowerEdge R730xd
R2 – Gehäuse 08:PowerEdge R730xd
R3 – Gehäuse 08:PowerEdge R730xd
14
13
R1 – Gehäuse 07:PowerEdge R730xd
R2 – Gehäuse 07:PowerEdge R730xd
R3 – Gehäuse 07:PowerEdge R730xd
12
11
R1 – Gehäuse 06:PowerEdge R730xd
R2 – Gehäuse 06:PowerEdge R730xd
R3 – Gehäuse 06:PowerEdge R730xd
10
9
R1 – Gehäuse 05:PowerEdge R730xd
R2 – Gehäuse 05:PowerEdge R730xd
R3 – Gehäuse 05:PowerEdge R730xd
Anhang A: Physische Konfiguration – PowerEdge R730xd | 39
Anhang A: Physische Konfiguration – PowerEdge R730xd
Tabelle 18: Rackkonfiguration – PowerEdge R730xd (oder PowerEdge R730/PowerEdge R730xd)
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

RU RACK1 RACK2 RACK3
87R1 – Gehäuse 04:PowerEdge R730xd
R2 – Gehäuse 04:PowerEdge R730xd
R3 – Gehäuse 04:PowerEdge R730xd
65R1 – Gehäuse 03:PowerEdge R730xd
R2 – Gehäuse 03:PowerEdge R730xd
R3 – Gehäuse 03:PowerEdge R730xd
43R1 – Gehäuse 02:PowerEdge R730xd
R2 – Gehäuse 02:PowerEdge R730xd
R3 – Gehäuse 02:PowerEdge R730xd
21R1 – Gehäuse 01:PowerEdge R730xd
R2 – Gehäuse 01:PowerEdge R730xd
R3 – Gehäuse 01:PowerEdge R730xd
Anhang A: Physische Konfiguration – PowerEdge R730xd | 40
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Menge SKU Komponente
1 210-ACXU PowerEdge R730 Server
1 591-BBCH PowerEdge R730/R730xd Motherboard
1 350-BBEO Gehäuse mit bis zu acht 3,5-Zoll-Festplatten
1 340-AKKB PowerEdge R730 Versand
1 338-BFFF Intel Xeon E5-2650 v3 2,3 GHz, 25 MB Cache, 9,60 GT/sQPI, Turbo, HT, 10C/20T (105 W) max. Speicher 2.133 MT/s
1 374-BBGM Upgrade auf zwei Intel Xeon E5-2650 v3 2,3 GHz, 25 MBCache, 9,60 GT/s QPI, Turbo, HT, 10C/20T (105 W)
1 370-ABUF 2.133 MT/s RDIMMs
1 370-AAIP Leistungsoptimiert
8 370-ABUG 16 GB Dual-Rank-RDIMM mit 2.133 MT/s und vierfacher Datenbreite
1 619-ABVR Kein Betriebssystem
1 421-5736 Keine Medien erforderlich
1 780-BBJS Kein RAID für H330/H730/H730P (1–16 HDDs oder SSDs)
1 405-AAEG Integrierter PERC H730 RAID-Controller, 1 GB Cache
8 400-AEEZ Hot-Plug-fähige 3,5-Zoll-SATA-Festplatte mit 1 TB, 6 Gbit/s und 7.200 1/min, 13 GB
1 540-BBBB Intel X520 DP 10 Gbit/s DA/SFP+, + I350 DP 1-Gbit/s-Ethernet, Network-Tochterkarte
1 330-BBCR R730/xd PCIe Riser 1, rechts
1 330-BBCQ R730 PCIe Riser 3, links
1 330-BBCO R730/xd PCIe Riser 2, Mitte
1 540-BBHY Intel X520 DP 10-Gigabit-DA/SFP+-Serveradapter, Low-Profile
1 450-ADWS Hot-Plug-fähiges, redundantes 750-W-Netzteil (1+1, dual)
2 450-ACSL C13 zu C14, PDU-Stil, 10 AMP, 0,6 m (2 Fuß) Netzkabel, Argentinien
1 384-BBBL BIOS-Leistungseinstellungen
1 770-BBBR ReadyRails: Einschubschienen mit Kabelführungsarm
1 350-BBEJ Blende
1 429-AAPS DVD+/-RW, SATA, intern
1 631-AAJG Dokumentation der elektronischen Anlage und OpenManage DVD-Kit PowerEdge R730/xd
2 374-BBHM Standard-Kühlkörper für PowerEdge R730/R730xd
Anhang B: Stückliste – PowerEdge R730 Knoten | 41
Anhang B: Stückliste – PowerEdge R730 Knoten
Tabelle 19: Aktiver Namensknoten, Standby-Namensknoten, Admin-Knoten, Edge-Knoten und HA-Knoten – PowerEdge R730
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Menge SKU Komponente
1 370-ABWE Leer-DIMM für System mit 2 Prozessoren
1 385-BBHO iDRAC8 Enterprise – integrierter Dell Remote Access Controller,Enterprise
1 332-1286 US Order
1 976-8711 ProSupport: 7x24 techn. HW/SW-Support und Assistenz, 3 Jahre
1 989-3439 Dell ProSupport. Informationen zum technischen Support finden Sie unter http://support.dell.com/ProSupport oder rufen Sie 1-800-945-3355 an.
1 976-8710 Mission Critical-Paket: 4-stündig 7x24 Vor-Ort-Service mit Notfallensendung, 3 Jahre
1 976-8709 MISSION CRITICAL-PAKET: Erweiterte Services, 3 Jahre
1 976-8706 Begrenzter Dell Hardware-Service plus Vor-Ort-Service
1 900-9997 Vor-Ort-Installation abgelehnt
Anhang B: Stückliste – PowerEdge R730 Knoten | 42
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Menge SKU Komponente
1 210-ADBC PowerEdge R730xd Server
1 591-BBCH PowerEdge R730/R730xd Motherboard
1 338-BFFF Intel Xeon E5-2650 v3 2,3 GHz, 25 MB Cache, 9,60 GT/sQPI, Turbo, HT, 10C/20T (105 W) max. Speicher 2.133 MT/s
1 350-BBEW Gehäuse mit bis zu 12 3,5-Zoll-Festplatten und zwei 2,5-Zoll-Flex Bay-Festplatten
1 340-AKPM PowerEdge R730xd Versand
1 374-BBGM Upgrade auf zwei Intel Xeon E5-2650 v3 2,3 GHz, 25 MBCache, 9,60 GT/s QPI, Turbo, HT, 10C/20T (105 W)
1 370-ABUF 2.133 MT/s RDIMMs
1 370-AAIP Leistungsoptimiert
8 370-ABUG 16 GB Dual-Rank-RDIMM mit 2.133 MT/s und vierfacher Datenbreite
1 619-ABVR Kein Betriebssystem
1 421-5736 Keine Medien erforderlich
1 780-BBLH Kein RAID für H330/H730/H730P (1-24 HDDs oder SSDs)
1 405-AAEG Integrierter PERC H730 RAID-Controller, 1 GB Cache
12 400-AEGHHot-Plug-fähige 3,5-Zoll-NLSAS-Festplatte mit 4 TB, 6 Gbit/s und 7.200 1/min, 13 GB
2 400-AEOC2,5-Zoll-SAS-Flex Bay-Festplatte mit 300 GB, 6 Gbit/s und 10.000 1/min, 13 GB
1 540-BBBB Intel X520 DP 10 Gbit/s DA/SFP+, + I350 DP 1-Gbit/s-Ethernet, Network-Tochterkarte
1 330-BBCO R730/xd PCIe Riser 2, Mitte
1 330-BBCR R730/xd PCIe Riser 1, rechts
1 450-ADWS Hot-Plug-fähiges, redundantes 750-W-Netzteil (1+1, dual)
2 492-BBDH C13 zu C14, PDU-Stil, 12 AMP, 0,6 m (2 Fuß) Netzkabel, Nordamerika
1 384-BBBL BIOS-Leistungseinstellungen
1 770-BBBQ ReadyRails: Einschubschienen ohne Kabelführungsarm
1 350-BBEJ Blende
1 631-AAJG Dokumentation der elektronischen Anlage und OpenManage DVD-KitPowerEdge R730/xd
1 800-BBDM UEFI BIOS
2 374-BBHM Standard-Kühlkörper für PowerEdge R730/R730xd
Anhang C: Stückliste – PowerEdge R730xd 3,5-Zoll-Datenknoten | 43
Anhang C: Stückliste – PowerEdge R730xd 3,5-Zoll- Datenknoten
Tabelle 20: Datenknoten – PowerEdge R730xd 3,5"
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Menge SKU Komponente
1 370-ABWE Leer-DIMM für System mit 2 Prozessoren
1 385-BBHO iDRAC8 Enterprise – integrierter Dell Remote Access Controller,Enterprise
1 332-1286 US Order
1 976-9010 MISSION CRITICAL-PAKET: erweiterte Services, 3 Jahre
1 989-3439Dell ProSupport. Informationen zum technischen Support finden Sie unter http://support.dell.com/ProSupport oder rufen Sie 1-800-945-3355 an.
1 976-9007 Begrenzter Dell Hardware-Service plus Vor-Ort-Service
1 976-9011 Mission Critical-Paket: 4-stündig 7x24 Vor-Ort-Service mit Notfallensendung, 3 Jahre
1 976-9012 ProSupport: 7x24 techn. HW/SW-Support und Assistenz, 3 Jahre
1 900-9997 Vor-Ort-Installation abgelehnt
Anhang C: Stückliste – PowerEdge R730xd 3,5-Zoll-Datenknoten | 44
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4
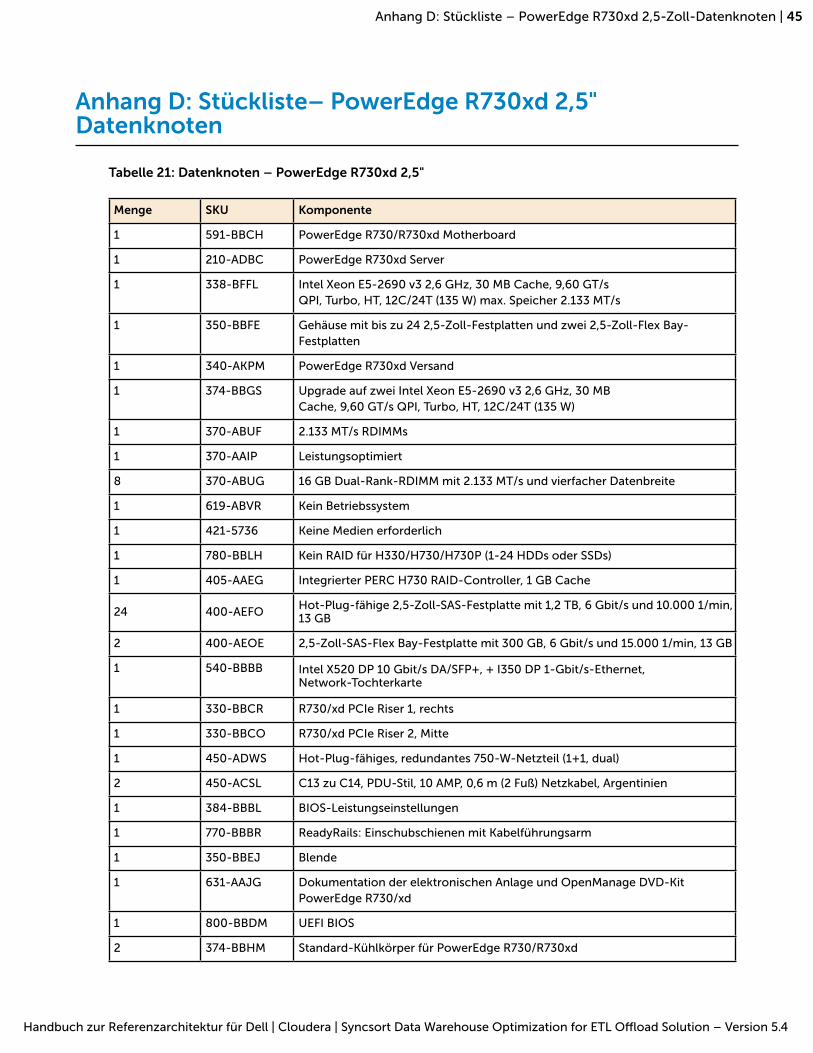
Menge SKU Komponente
1 591-BBCH PowerEdge R730/R730xd Motherboard
1 210-ADBC PowerEdge R730xd Server
1 338-BFFL Intel Xeon E5-2690 v3 2,6 GHz, 30 MB Cache, 9,60 GT/sQPI, Turbo, HT, 12C/24T (135 W) max. Speicher 2.133 MT/s
1 350-BBFE Gehäuse mit bis zu 24 2,5-Zoll-Festplatten und zwei 2,5-Zoll-Flex Bay-Festplatten
1 340-AKPM PowerEdge R730xd Versand
1 374-BBGS Upgrade auf zwei Intel Xeon E5-2690 v3 2,6 GHz, 30 MBCache, 9,60 GT/s QPI, Turbo, HT, 12C/24T (135 W)
1 370-ABUF 2.133 MT/s RDIMMs
1 370-AAIP Leistungsoptimiert
8 370-ABUG 16 GB Dual-Rank-RDIMM mit 2.133 MT/s und vierfacher Datenbreite
1 619-ABVR Kein Betriebssystem
1 421-5736 Keine Medien erforderlich
1 780-BBLH Kein RAID für H330/H730/H730P (1-24 HDDs oder SSDs)
1 405-AAEG Integrierter PERC H730 RAID-Controller, 1 GB Cache
24 400-AEFOHot-Plug-fähige 2,5-Zoll-SAS-Festplatte mit 1,2 TB, 6 Gbit/s und 10.000 1/min, 13 GB
2 400-AEOE 2,5-Zoll-SAS-Flex Bay-Festplatte mit 300 GB, 6 Gbit/s und 15.000 1/min, 13 GB
1 540-BBBB Intel X520 DP 10 Gbit/s DA/SFP+, + I350 DP 1-Gbit/s-Ethernet, Network-Tochterkarte
1 330-BBCR R730/xd PCIe Riser 1, rechts
1 330-BBCO R730/xd PCIe Riser 2, Mitte
1 450-ADWS Hot-Plug-fähiges, redundantes 750-W-Netzteil (1+1, dual)
2 450-ACSL C13 zu C14, PDU-Stil, 10 AMP, 0,6 m (2 Fuß) Netzkabel, Argentinien
1 384-BBBL BIOS-Leistungseinstellungen
1 770-BBBR ReadyRails: Einschubschienen mit Kabelführungsarm
1 350-BBEJ Blende
1 631-AAJG Dokumentation der elektronischen Anlage und OpenManage DVD-KitPowerEdge R730/xd
1 800-BBDM UEFI BIOS
2 374-BBHM Standard-Kühlkörper für PowerEdge R730/R730xd
Anhang D: Stückliste – PowerEdge R730xd 2,5-Zoll-Datenknoten | 45
Anhang D: Stückliste– PowerEdge R730xd 2,5" Datenknoten
Tabelle 21: Datenknoten – PowerEdge R730xd 2,5"
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Menge SKU Komponente
1 370-ABWE Leer-DIMM für System mit 2 Prozessoren
1 385-BBHO iDRAC8 Enterprise –integrierter Dell Remote Access Controller,Enterprise
1 332-1286 US Order
1 976-9012 ProSupport: 7x24 techn. HW/SW-Support und Assistenz, 3 Jahre
1 976-9007 Begrenzter Dell Hardware-Service plus Vor-Ort-Service
1 976-9011 Mission Critical-Paket: 4-stündig 7x24 Vor-Ort-Service mit Notfallensen-dung, 3 Jahre
1 989-3439Dell ProSupport. Informationen zum technischen Support finden Sie unter http://support.dell.com/ProSupport oder rufen Sie 1-800-945-3355 an.
1 976-9010 MISSION CRITICAL-PAKET: Erweiterte Services, 3 Jahre
1 900-9997 Vor-Ort-Installation abgelehnt
Anhang D: Stückliste – PowerEdge R730xd 2,5-Zoll-Datenknoten | 46
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Aktualisierungsverlauf
Folgende Änderungen wurden an diesem Handbuch seit Version 5.1 vorgenommen:
• Aktualisiert für die Verwendung von PowerEdge R730 und R730xd Servern der 13. Generation • Aktualisiert für Cloudera Enterprise 5.3 • Support für FlexBay-Laufwerke hinzugefügt • Poddimensionierung geklärt
Aktualisierungsverlauf | 47
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4

Referenzen
Quellen | 48
Weitere Informationen finden Sie unter http://www.dell.com/hadoop.
Wenn Sie zusätzliche Hilfe zu Services oder zur Implementierung benötigen, wenden Sie sich bitte an Ihren
zuständigen Dell Vertriebsmitarbeiter.
Weitere Informationen
Weitere Informationen zur Dell | Cloudera Apache Hadoop Lösung finden Sie unter http://www.dell.com/
hadoop. © 2011-2015 Dell Inc. Alle Rechte vorbehalten. Mit Marken bzw. Handelsnamen wird in diesem
Dokument unter Umständen auf die juristischen Personen, die die Marken und Namen beanspruchen, oder
auf deren Produkte verwiesen. Alle Angaben sind zum Zeitpunkt der Veröffentlichung korrekt, können
jedoch jederzeit ohne Vorankündigung geändert werden und unterliegen der Verfügbarkeit. Dell und
Tochterunternehmen von Dell haften nicht für Druckfehler, fehlerhafte Abbildungen oder Auslassungen.
Es gelten die allgemeinen Verkaufs- und Servicebedingungen von Dell, die auf Anfrage erhältlich sind.
Gesetzliche Verbraucherrechte des Kunden werden durch die Serviceangebote von Dell nicht berührt.
Dell, das DELL Logo, das Dell Emblem und PowerEdge sind Marken von Dell Inc.
Handbuch zur Referenzarchitektur für Dell | Cloudera | Syncsort Data Warehouse Optimization for ETL Offload Solution – Version 5.4