hadoop ecosystem and low latency streaming architecture
TRANSCRIPT

Hadoop Ecosystem and Low Latency Streaming Architecture
InSemble Inc. http://www.insemble.com

Agenda
What is Big Data and why it is relevant ?1
Flume, Kafka and Storm 4
Reference Architecture for Low Latency Streaming3
Hadoop Ecosystem2
Demo5

Big Data Definitions
• Wikipedia defines it as “Data Sets with sizes beyond the ability of commonly used software tools to capture, curate, manage and process data within a tolerable elapsed time”
• Gartner defines it as Data with the following characteristics– High Velocity– High Variety– High Volume
• Another Definition is “Big Data is a large volume, unstructured data which cannot be handled by traditional database management systems ”

Why a game changer
• Schema on Read– Interpreting data at processing time– Key, Values are not intrinsic properties of data but chosen by
person analyzing the data• Move code to data
– With traditional, we bring data to code and I/O becomes a bottleneck
– With distributed systems, we have to deal with our own checkpointing/recovery
• More data beats better algorithms

Enterprise Relevance
• Missed Opportunities– Channels – Data that is analyzed
• Constraint was high cost– Storage – Processing
• Future-proof your business– Schema on Read – Access pattern not as relevant – Not just future-proofing your architecture

Hadoop Ecosystem
Source: Apache Hadoop Documentation

Hadoop 2 with YARN
Source: Hadoop In Practice by Alex Holmes

Big Data Journey
➢ Real time Insight from all channels➢ IT is key differentiator for your business➢ Perfect alignment of Business and IT
➢ Ad Hoc Data Exploration➢ Batch, Interactive, Real time use cases➢ Predictive Analytics, Machine Learning
➢ Consolidated Analytics➢ ETL ➢ Time Constraints
➢ Security standards defined➢ Governance Standards Defined➢ Integrated with the Enterprise
➢ Evaluate Business Benefits➢ Understand Ecosystem➢ Identify Platform
Aware of Benefits
Execute
Expand
Managed
Optimized
- Scout for Opportunities
- Pilot project
- Multiple Use cases
- Governance Model
- Core competency
Journey Over Time
Busi
ness
Val
ue
Effects
GREAT
GOOD

Real time Stream Processing Architecture with Hadoop

Flume Architecture
• Distributed system for collecting and aggregating from multiple data stores to a centralized data store
• Agent is a JVM that hosts the Flume components
• Channel will store message until picked by a sink
• Different types of Flume sources
• Source and Sink are decoupled

Consolidation Architecture

Multiplexing Architecture

Kafka Introduction
• Messaging System which is distributed, partitioned and replicated• Kafka brokers run as a cluster• Producers and Consumers can be written in any language

Topic
• Ordered, immutable sequence numbers• Retains messages until a period of time• “Offset” of where they are is controlled by the consumer• Each partition is replicated and has “leader” and 0 or more “follower”.
R/W only done on leader

Producers and Consumers
• Producer controls which partition messages goes to• Supports both Queuing and Pub/Sub
– Abstraction called Consumer group• Ordering within Partition
– Ordering for subscriber has to be done with only one subscriber to that partition

Storm Introduction
• Distributed real time computational system–Process unbounded streams of data–Can use multiple programming languages–Scalable, fault-tolerant and guarantees that data will be processed
• Use Cases–Real time analytics, online machine learning–Continuous Computation–Distributed RPC–ETL
• Concepts–Topology–Spouts–Bolts
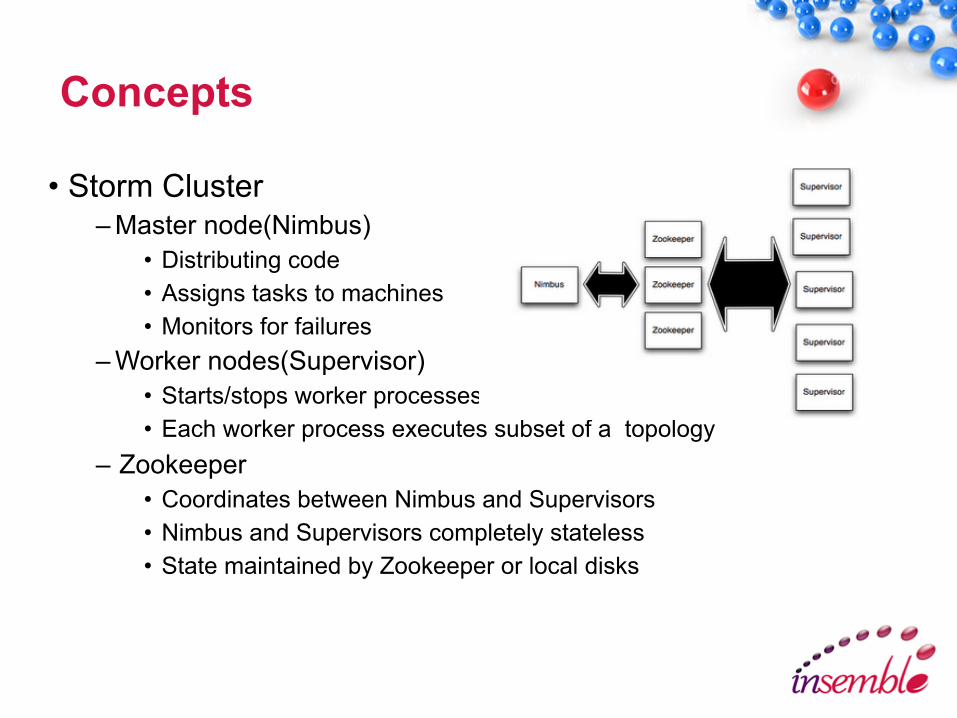
Concepts
• Storm Cluster– Master node(Nimbus)
• Distributing code • Assigns tasks to machines • Monitors for failures
– Worker nodes(Supervisor) • Starts/stops worker processes • Each worker process executes subset of a topology
– Zookeeper• Coordinates between Nimbus and Supervisors • Nimbus and Supervisors completely stateless • State maintained by Zookeeper or local disks

Details
• Stream – Unbounded sequence of tuples
• Spout(write logic)– Source of stream. Emits tuples
• Bolt(write logic)– Processes streams and emits tuples
• Topology– DAG of spouts and bolts – Submit a topology to a Storm cluster – Each node runs in parallel and parallelism is controlled

Stream groupings
• Tells a topology how to send tuples between two components• Since tasks are executed in parallel, how do we control which tasks the
tuples are being sent to

Why Use Twitter as Data Source

Demo - Twitter TopN Trending Topic
• Method 1 — Flume with interceptor• Method 2 — Storm with custom Twitter
Spout• Method 3 — Flume + Kafka + Storm

Demo - Twitter TopN Trending Topic
• Use Flume Twitter Source to ingest data and publish event to Kafka topic
• Use Kafka as messaging backbone• Use Storm as an Real-Time event processing
system to calculate TopN trending topic• Use Redis to store the TopN Result• Use Node.js/JQuery for visualization

Flow Chart

Demo: Start Redis Server

Demo: Start Node.js server

Demo: Start Storm

Demo: Start Flume Agent

Demo: Storm Console Output

Demo: Trending Result

Flume Agent — Source

Flume Agent — Channel

Flume Agent — Sink

Storm Topology Design

Submit Topology to Storm Production Cluster

Submit Topology to Test Cluster

ParseTweetBolt Code

ParseTweetBolt Code

ParseTweetBolt Code
