february 2007csa3050: tagging ii1 csa2050: natural language processing tagging 2 rule-based tagging...
TRANSCRIPT

February 2007 CSA3050: Tagging II 1
CSA2050: Natural Language Processing
Tagging 2
• Rule-Based Tagging• Stochastic Tagging• Hidden Markov Models (HMMs)• N-Grams

February 2007 CSA3050: Tagging II 2
Tagging 2 Lecture
• Slides based on Mike Rosner and Marti Hearst notes
• Additions from NLTK tutorials

February 2007 CSA3050: Tagging II 3
Rule-Based Tagger
• Basic Idea:– Assign all possible tags to words– Remove tags according to set of rules
if word+1 is an adj, adv, or quantifier and the following is a sentence boundary and word-1 is not a verb like “consider” then eliminate non-adv else eliminate adv.
– Typically more than 1000 hand-written rules, but may be machine-learned.

February 2007 CSA3050: Tagging II 4
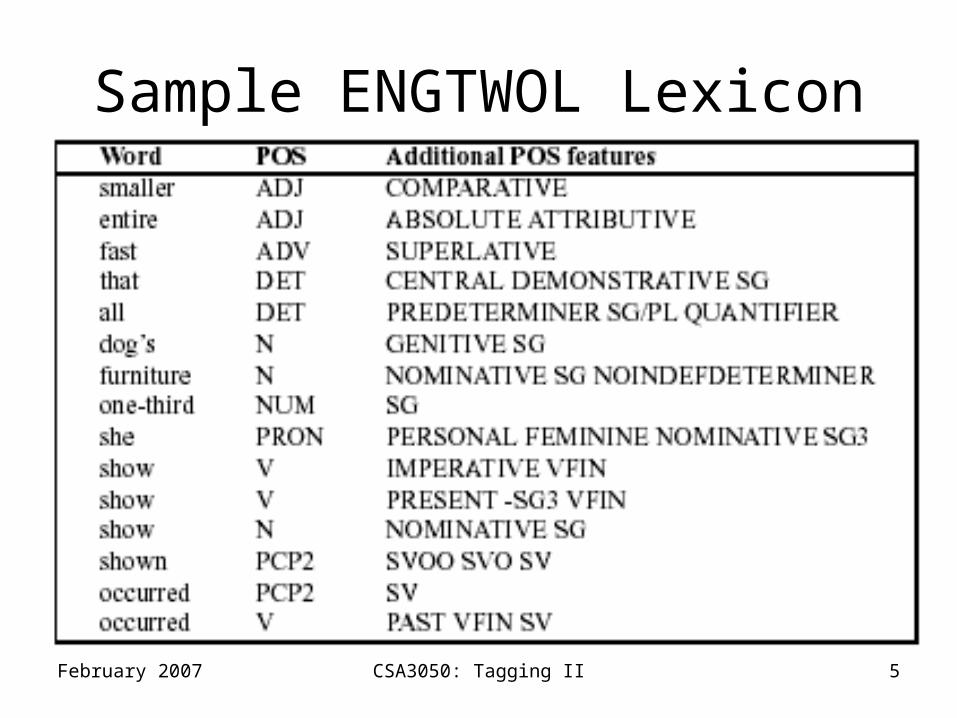
ENGTWOL
• Based on two-level morphology
• 56,000 entries for English word stems
• Each entry annotated with morphological and syntactic features
February 2007 CSA3050: Tagging II 5
Sample ENGTWOL Lexicon

February 2007 CSA3050: Tagging II 6
ENGTWOL Tagger• Stage 1: Run words through morphological
analyzer to get all parts of speech.– E.g. for the phrase “the tables”, we get the
following output:
"<the>" "the"<Def> DET CENTRAL ART SG/PL
"<tables>" "table" N NOM PL "table"<SVO> V PRES SG3 VFIN
• Stage 2: Apply constraints to rule out incorrect POSs

February 2007 CSA3050: Tagging II 7
Examples of Constraints
• Discard all verb readings if to the left there is an unambiguous determiner, and between that determiner and the ambiguous word itself, there are no nominals (nouns, abbreviations etc.).
• Discard all finite verb readings if the immediately preceding word is to.
• Discard all subjunctive readings if to the left, there are no instances of the subordinating conjunction that or lest.
• The first constraint would discard the verb reading in the previous representation.
• There are about 1,100 constraints

February 2007 CSA3050: Tagging II 8
Example
Pavlov PVLOV N NOM SG PROPER
had HAVE V PAST VFIN SVO
HAVE PCP2 SVO
shown SHOW PCP2 SVOO SVO SV
that ADV
PRON DEM SG
DET CENTRAL SEM SG
CS
salivation N NOM SG

February 2007 CSA3050: Tagging II 9
Actual Constraint Syntax
Given input: “that”If
(+1 A/ADV/QUANT)(+2 SENT-LIM)(NOT -1 SVOC/A)
Then eliminate non-ADV tagsElse eliminate ADV tag
• this rule eliminates the adverbial sense of that as in “it isn’t that odd”

February 2007 CSA3050: Tagging II 10
3 Approaches to Tagging
1. Rule-Based Tagger: ENGTWOL Tagger(Voutilainen 1995)
2. Stochastic Tagger: HMM-based Tagger
3. Transformation-Based Tagger: Brill Tagger(Brill 1995)

February 2007 CSA3050: Tagging II 11
Stochastic Tagging
• Based on the probability of a certain tag given various possibilities.
• Necessitates a training corpus.
• Difficulties– There are no probabilities for words that are
not in the training corpus. Smoothing– Training corpus may be too different from test
corpus.

February 2007 CSA3050: Tagging II 12
Stochastic Tagging
Simple Method: Choose the most frequent tag in the training text for each word!
– Result: 90% accuracy !!– But we can do better than that by employing a
more elaborate statistical model– Hidden Markov Models (HMM) are a class of
such models.
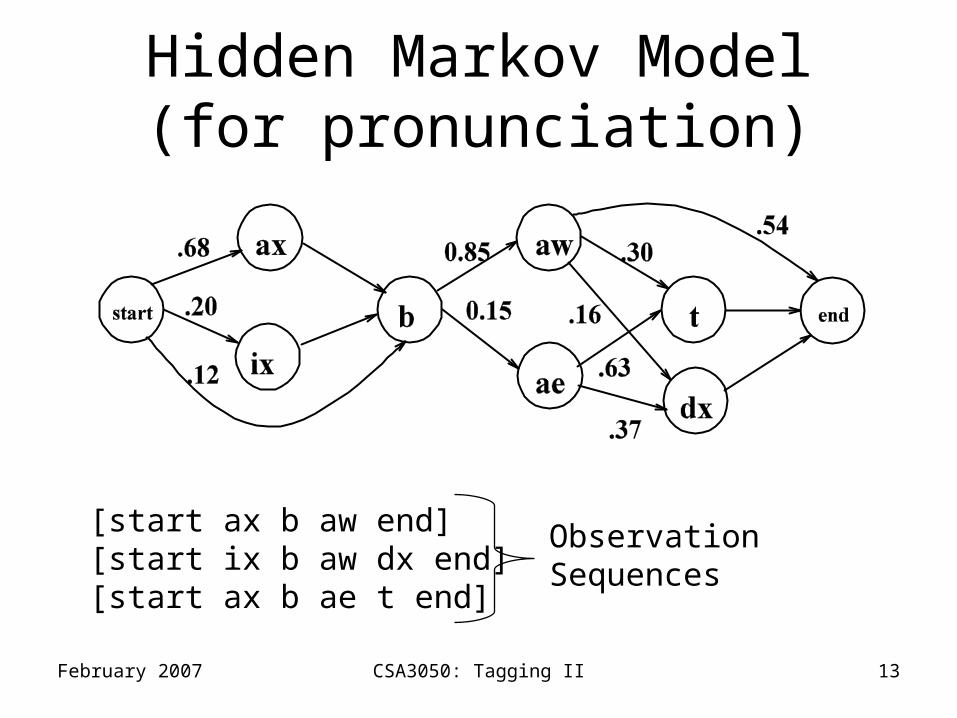
February 2007 CSA3050: Tagging II 13
Hidden Markov Model(for pronunciation)
[start ax b aw end][start ix b aw dx end][start ax b ae t end]
ObservationSequences

February 2007 CSA3050: Tagging II 14
Three Fundamental Questions for HMMs
• Given an HMM, how likely is a given observation sequence?
• Given an observation sequence, how do we choose a state sequence that best explains the observations?
• Given an observation sequence and a space of possible HMMs, how do we find the HMM that best fits the observed data?

February 2007 CSA3050: Tagging II 15
Two Observation Sequences for Tagging
N N P D N
Time flies like an arrow
V V P D N
February 2007 CSA3050: Tagging II 16
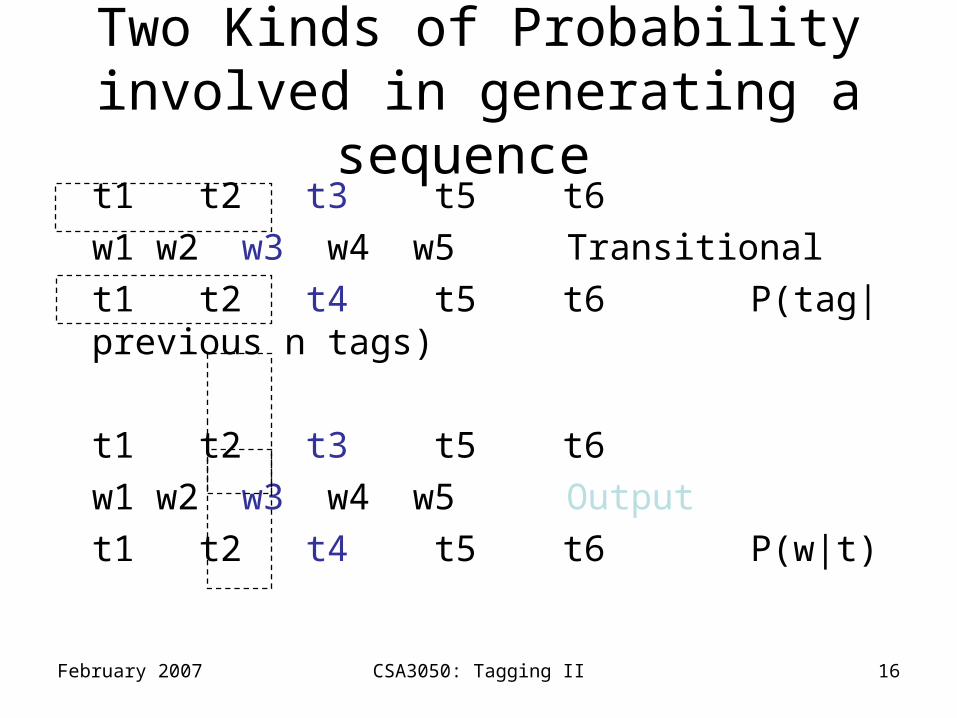
Two Kinds of Probability involved in generating a sequence
t1 t2 t3 t5 t6
w1 w2 w3 w4 w5 Transitional
t1 t2 t4 t5 t6 P(tag|previous n tags)
t1 t2 t3 t5 t6
w1 w2 w3 w4 w5 Output
t1 t2 t4 t5 t6 P(w|t)

February 2007 CSA3050: Tagging II 17
Simplifying Assumptions cannot handle all phenomena
• Limited Horizon: a given tag depends only upon a N previous tags – usually N=2.– central embedding?
The cat the dog the bird saw bark meowed.– long distance dependencies
It is easy to consider it impossible for anyone but a genius to try to talk to Chris.
• Time (sentence position) invariance: (P,V) may not be equally likely at beginning/end of sentence

February 2007 CSA3050: Tagging II 18
Estimating N-gram probabilities
• To estimate the probability that “Z” appears after “XY”:– count how many times “XYZ” appears
= A– count how many times “XY” appears = B– Estimate = A/B
• Same principle applies for tags
• We can use these estimates to rank alternative tags for a given word.

February 2007 CSA3050: Tagging II 19
Data Used for Training a Hidden Markov Model
• Estimate the probabilities from relative frequencies. – Transitional probabilities: probability that a
sequence of tags t1, ... tn is followed by a tag t
P(t|t1..tn) = count(t1..tnfollowed by t)/count(t1..tn)
– Output probabilities: probability that a given tag t will be realised as a word w: P(w|t) = count(w tagged as t)/count(t)

February 2007 CSA3050: Tagging II 20
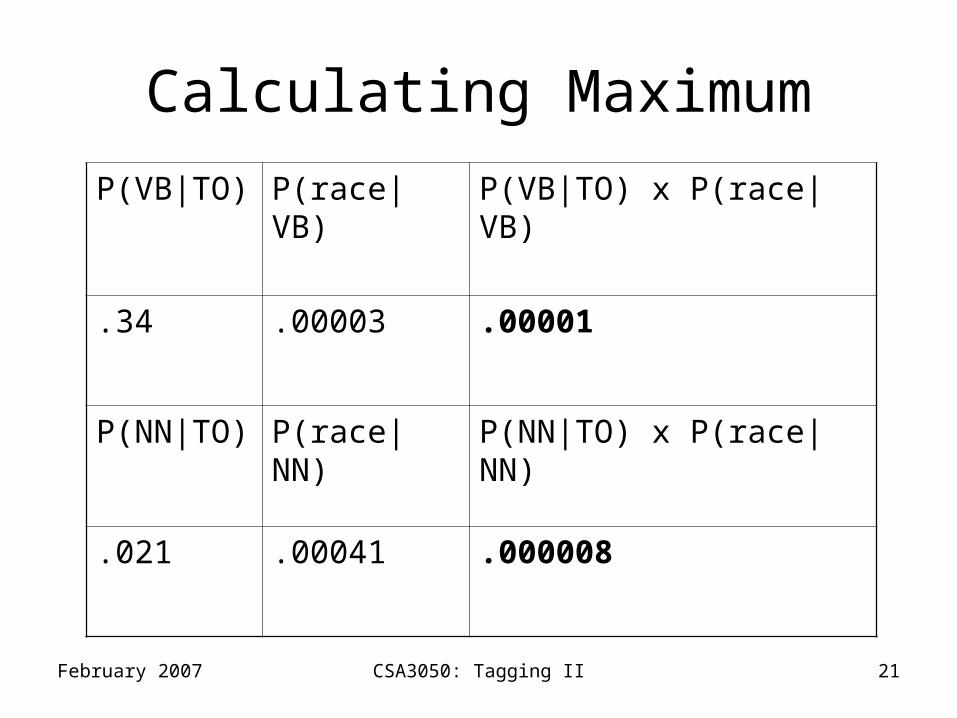
An Example• Secretariat/NNP is/VBZ expected/VBN
to/TO race/VB tomorrow/NN• People/NNS continue/VBP to/TO inquire/VB
the DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
• Consider first sentence; choose betweenA = to/TO race/VBB = to/TO race/NN
• We need to choose maximum probability:– P(A) = P(VB|TO) × P(race|VB)– P(B) = P(NN|TO) × P(race|NN)]
February 2007 CSA3050: Tagging II 21
Calculating Maximum
P(VB|TO) P(race|VB) P(VB|TO) x P(race|VB)
.34 .00003 .00001
P(NN|TO) P(race|NN) P(NN|TO) x P(race|NN)
.021 .00041 .000008

February 2007 CSA3050: Tagging II 22
Remarks• We have shown how to calculate the most
probable tag for one word.• Normally we are interested in the most
probable sequence of tags for the entire sentence.
• The Viterbi algorithm is used to calculate the entire sentence probability
• Have a look at:• http://en.wikipedia.org/wiki/Viterbi_algorithm• For a quick introduction… (PDF on website)

February 2007 CSA3050: Tagging II 23
Next Sessions…
• Transformation Based Tagging
• Chunking