explotar la información noticiosa
DESCRIPTION
El centro de documentación del periódico es una riquísima fuente tanto para reportajes en profundidad como para ofrecer nuevos servicios a los lectores digitales pero se requiere una buena estructura y fuertes mecanismos de exploración (data mining), lo que se explica aquí.TRANSCRIPT


Inscripción Registro chileno de Propiedad Intelectual nº 122.264.© Raymond Colle, Santiago de Chile, 2001. Derechos reservados para todos los países.
Producido por Visagrafic, S.L.Impreso en España - Printed in Spain
Tel./Fax: (34) 91 739 88 75
ISBN: 84-0-Depósito Legal: M-
Reservados los derechos para todos los países. Ninguna parte de estapublicación, incluido el diseño de la cubierta, puede ser reproducida, almacenadao transmitida de ninguna forma, ni por ningún medio, sea éste electrónico,químico, mecánico, electro-óptico, grabación, fotocopia o cualquier ortro, sin laprevia autorización escrita por parte del autor.

INDICE
PRESENTACIONPROLOGO...... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7INTRODUCCIÓN ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
PRIMERA PARTE:BASES DE DATOS, META-INFORMACIONY "MINERÍA DE DATOS"
1. BASES DE DATOS Y SISTEMAS DOCUMENTALES AVANZADOS ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.1. Supuestos básicos..................................................... 171.2. Sistema documental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.3. ¿Banco de datos o Bodega de datos? (Data Warehouse). . . . . . . . . . 191.4. Feria y depósito de datos (Data Mart y Data Repository) . . . . . . . . . 201.5. Meta-datos.............................................................. 221.6. Análisis Visual de Datos ("VDA")................................... 231.7. Los datos, su valor y su complejidad .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.8. Tipos de bases de datos............................................... 25
1.8.1. Tipo jerárquico................................................. 251.8.2. Tipo relacional................................................. 271.8.3. BD orientada a objetos........................................ 311.8.4. Otros tipos de BD ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
1.9. Operaciones con los datos............................................ 33Conclusión................................................................... 34
2. MODELOS DE DATOS Y META-INFORMACIÓN................... 352.1. Modelo lógico.......................................................... 35
2.1.1. Modelo conceptual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.1.2. Atributos........................................................ 362.1.3. Relaciones...................................................... 362.1.4. Dominios....................................................... 38
2.2. Normalización de datos............................................... 392.2.1. Primera forma normal......................................... 392.2.2. Segunda forma normal........................................ 402.2.3. Tercera forma normal......................................... 402.2.4. Modelo canónico .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42

2.3. Diseño físico........................................................... 422.3.1. Modelo "compacto"........................................... 422.3.2. Modelo canónico .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.3.3. Modelo de datawarehouse.................................... 44
2.4. Explotación básica de los datos...................................... 462.4.1. Meta-datos compuestos....................................... 462.4.2. Explotación algebráica........................................ 472.4.3. Explotación estadística........................................ 48
Conclusión................................................................... 49
3. EXPLOTACIÓN AVANZADA O "MINERÍA DE DATOS".......... 513.1. Concepto de "Minería de Datos" ("Data Mining") . . . . . . . . . . . . . . . . . 513.2. Los métodos de Data Mining......................................... 54
3.2.1. OLAP........................................................... 543.2.2. KDD ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.3. Principios básicos .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.3.1. Reiteración .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.3.2. Temporalidad .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.4. Etapas de trabajo....................................................... 563.4.1. Fase preliminar .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.4.2. La preparación de los datos .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.4.3. La aproximación al problema ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.4.4. La secuencia básica de trabajo .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.5. Las herramientas de Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.5.1. La visualización de datos como método de análisis . . . . . . . 713.5.2. Otras herramientas............................................. 75
3.6. Algunos ejemplos de Data Mining. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 813.6.1. Las telecomunicaciones....................................... 813.6.2. El mundo de las nuevas tecnologías......................... 823.6.3. Las relaciones interpersonales .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
Conclusión................................................................... 83
SEGUNDA PARTE:BASES DE DATOS, METAINFORMACIÓNY "MINERÍA DE DATOS" EN EL PERIODISMO
4. LA INFORMATIZACION DE LA DOCUMENTACION DE PRENSA..................................................................... 87
4.1. Sistema documental periodístico..................................... 874.2. Bases para el modelamiento de datos............................... 89
4.2.1. El registro documental como conversación................. 894.2.2. Análisis genérico de referentes............................... 90
4.3. Modelamiento conceptual de los hechos noticiosos .. . . . . . . . . . . . . . 964.3.1. Actor............................................................ 954.3.2. Relator y "Vector"............................................. 954.3.3. Reseña.......................................................... 964.3.4. Núcleo de la reseña............................................ 96

4.3.5. Periféricos de la reseña .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 974.3.6. Atributos seleccionados....................................... 984.3.7. Producto.......................................................100
Conclusión..................................................................100
5. META-INFORMACION PERIODISTICA.............................1015.1. Estado inicial de la base de datos ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .102
5.1.1. Ingreso y publicación de los datos .... . . . . . . . . . . . . . . . . . . . . .1025.1.2. El problema de los actores y afectados.....................1045.1.3. Otras tablas....................................................107
5.2. Extracción de meta-información ex post facto por procedimientos comunes: estadísticas de frecuencias............107
5.2.1. Atributo "Fecha"..............................................1085.2.2. Atributo "Lugares"...........................................1095.2.3. Atributo "Descriptores temáticos"..........................1095.2.4. Atributo "Implicados"........................................1125.2.5. Atributo "Fuentes" ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1125.2.6. Producto.......................................................112
5.3. Preparación para la "Minería de Datos"............................1155.3.1. Verificación de la consistencia lógica y semántica de la
Base de Datos original.......................................1155.3.2. Traspaso de los datos de la tabla única de noticias a múltiples tablas de "tercera forma normal". ..............1155.3.3. Reestructuración de la lista de Implicados.................117
5.4. Estadísticas del nuevo total de noticias.............................1185.4.1. Atributo "Fecha"..............................................1185.4.2. Atributo "Lugares"...........................................1185.4.3. Atributo "Descriptores temáticos"..........................1215.4.4. Atributo "Implicados"........................................1215.4.5. Clases de "Implicados"......................................1215.4.6. Atributo "Fuentes" ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1225.4.7. Coeficiente de predictibilidad .... . . . . . . . . . . . . . . . . . . . . . . . . . . .122
Conclusión..................................................................129
6. "MINERIA DE DATOS" EN UN MEDIO PERIODISTICO.........1316.1.Análisis visual de datos...............................................132
6.1.1. Visualización de Descriptores...............................1326.1.2. Visualización de los Implicados repartidos por clases ...135
6.2. Coocurrencias internas...............................................1356.2.1. Coocurrencias entre Descriptores...........................1376.2.2. Coocurrencias entre Implicados .... . . . . . . . . . . . . . . . . . . . . . . . .1426.2.3. Coocurrencias entre clases de Implicados.................1426.2.4. Coocurrencias entre Lugares................................145
6.3. Coocurrencias externas ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1476.3.1. Coocurrencias entre descriptores y clases de implicados 1476.3.2. Descriptores por períodos mensuales......................1506.3.3. Implicados por períodos mensuales........................1556.3.4. Lugares y Descriptores ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .156

6.3.5. Lugares y períodos mensuales..............................1586.3.6. Lugares y clases de Implicados.............................1606.3.7. Fuentes y clases de Implicados.............................1656.3.8. Descriptores y Fuentes.......................................165
6.4. Asociaciones de tres atributos.......................................1706.4.1. Tríada Descriptor-Implicado-Lugar .... . . . . . . . . . . . . . . . . . . . .1706.4.2. Tríada Descriptor-Implicado-Fecha .... . . . . . . . . . . . . . . . . . . . .1726.4.3. Tríada Descriptor-Lugar-Fecha.............................174- [ Láminas a color ] -................................................1776.4.4. Tríada Implicado-Lugar-Fecha..............................1816.4.5. Conclusión....................................................181
6.5. Análisis multidimensional .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1826.5.1. Demultiplicación combinatoria..............................1826.5.2. Proyecciones tridimensionales..............................185
Conclusión..................................................................186
CONCLUSION................................................................1897.1. Evaluación de la experiencia.........................................189
7.1.1. Principales hallazgos.........................................1897.1.2. Ventajas y limitaciones de la visualización ................1927.1.3. Las dificultades...............................................193
7.2. El futuro de la Data Mining en el Periodismo ..... . . . . . . . . . . . . . . . .194
ANEXO Ciencias humanas y matemática...................................1971. Matemática del caos y ciencias humanas .... . . . . . . . . . . . . . . . . . . . . . . . . .1972. El concepto de "orden implicado".....................................200
GLOSARIO....................................................................203
BIBLIOGRAFIA..............................................................207

A mis amigos docentes del área de la Documentación,
especialmente los que conocí en Españay los chilenos con quienes he compartido el sueño
de introducir programas de postgradoque permitiesen a los profesionales en ejercicio
dominar herramientas más avanzadas.
A los periodistas que podrán encontrar aquínuevas herramientas de trabajo.
A Daniel,mi asesor en computación.


PROLOGO"EN BUSCA DE LA INFORMACIÓN PERSONALIZADA"
Desde mediados de los años 90 la idea de un "diario electrónico" (mal nombrepero que sigue siendo el más utilizado para describir un multimedio informativoabsolutamente novedoso) contempla -entre muchas posibilidades- la del accesopersonalizado del usuario a sistemas documentales.
Conforme a este planteamiento teórico, a partir de una nota de actualidad -porejemplo. una referencia a una intervención del Presidente de la República- elinteresado podría complementarla de inmediato con otros antecedentes. Así, si setrata de un lector extranjero, tal vez le interese saber más de la situación políticainterna del país; los motivos del discurso o la personalidad del Jefe del Estado.En cambio, un usuario local medianamente informado, querría saber la opiniónde diversos sectores políticos, estadísticas y mayores detalles sobre aspectosconcretos..
Esta es una de las ventajas más significativas de las tecnologías digitales y delacceso a la información en red: a la instantaneidad con que se entrega elencabezado noticioso, el propio usuario -o un programa adecuado a sus interesesy gustos- podría lograr acceso inmediato a una amplia gama de antecedentes. Estaprofundización debería permitirle comprender mejor la actualidad, antes inclusoque los propios periodistas hayan agregado sus análisis y comentarios.
La posibilidad existe, como se demostró en una investigación acerca del DiarioElectrónico en la que participamos en los años finales de la década pasada conotros profesores -periodistas e ingenieros- de la Universidad Diego Portales1.Pero desde entonces, a pesar de que el número de medios electrónicos en la redse ha multiplicado considerablemente, todavía no termina de concretarse demanera sistemática. Ello se debe, probablemente, a un cierta falta de interés de lasempresas informativas. La incursión de los medios impresos en esta área seinició con comprensible reticencia y todavía no se define con precisión, pese aque ya se han instalado sobre este escenario numerosos medios audiovisuales eincluso existen no pocos que no tienen asociación alguna con mediostradicionales.
Es evidente, además, que no se dispone todavía del software que facilite la puestaen práctica del concepto del link que vaya más allá del "archivo" tradicional(generalmente a través de un botón que dice: "ver ediciones anteriores") o de losenlaces externos. Y, aunque no sería difícil crearlos, la verdad es que ha faltado
7

algo que nos parece esencial: una reflexión acerca de lo que se quiere obtener yde cómo mejoraría el servicio que deben prestar los periodistas.
Ese es, sin duda, el gran aporte de esta obra.
Hay que decir, en primer lugar, que no es casual que su autor sea el doctorRaymond Colle. Su formación europea le ha hecho exigente y riguroso en unárea donde abunda la improvisación y durante años dominaron los técnicos, loshombres "prácticos", frente a los "teóricos" que aparentemente no tenían muchoqué decir. Pero no sólo eso: es, además, un auténtico pionero que desde laprehistoria de Internet -digamos, los años 80- y lo que todavía llamamos"nuevas tecnologías" ha estado preocupado del tema. Y, finalmente, hay quereconocerle la persistencia en una reflexión difícil y con pocos alicientes.
La realidad, como suele ocurrir, ha ido forzando el curso de los acontecimientos.
Todo empezó, en cierto modo, con la agonía de las viejas "morgues" de losperiódicos, donde se sepultaba el material -normalmente impreso- querecopilaban los periodistas y que después no se atrevían a botar a la basura, juntocon libros de referencia, almanaques, atlas y otros documentos. La innovacióntecnológica fue produciendo un visible, aunque paulatino cambio en los viejosarchivos que hasta entonces repletaban estantes en miles de diarios y revistas enel mundo entero.
Primero apareció el microfilm, con fichas algo engorrosas, pero más fáciles derevisar y aprovechar que los recortes de papel. Luego vino la incorporacióncreciente de la computación, dando origen a un concepto nuevo: el servicio dedocumentación, donde se encontraron en un terreno compartido periodistas ydocumentalistas. Pero es evidente que todavía falta. Habría, sin duda, mayorinterés si se comprendiera, como dice nuestro autor, que "el tiempo que seinvierte en la confección de los registros (ingreso de información) se recuperacon creces en la recuperación de la información".
El interés por recuperar información no se limita, por cierto, al periodismo y asíse explica en esta obra. Pero, por vocación y profesión, Raymond Colle terminapor entrar de lleno a los desafíos que todo esto implica para el periodismo. Y lohace tratando de responder una gran interrogante: "¿Puede el periodismobeneficiarse de la "Minería de datos"?. Su respuesta es positiva: "Como gran«consumidor» -y difusor- de información, (el periodismo) no debería quedar almargen de los aportes que estas técnicas podrían significar para sus analistas ycomentaristas; al contrario, estimamos que no puede ignorar la importancia deéstas para su labor de ahora en adelante. Nadie mejor que un medio decomunicación puede "auscultar" la vida de la sociedad y descubrir los hilos queunen los hechos y explican los éxitos y fracasos en múltiples campos".
Por haber dedicado gran parte de mi vida académica y profesional a lo que hemosdenominado el "género interpretativo", el de las explicaciones, una manera dehacer periodismo cada vez más necesaria ante la avalancha ininterrumpida de
8

información, no me cabe duda de que la respuesta afirmativa a esta pregunta delprofesor Colle es lo que hace tan importante esta obra. Nos coloca en uno de losnudos de la preocupación periodística de todos los tiempos, que se ha aceleradoy profundizado de manera creciente desde comienzos del siglo XX.
Y no solo eso. También se apunta en estas páginas a otros aspectos, tal vez enapariencia menos importantes, pero que sin duda nos han preocupado largamentea los formadores de periodistas. La falta de uniformidad en los nombres, porejemplo. Cuando el coronel Gadafi estaba de moda, se le llamaba -según laprocedencia del cable- Khadaffy, Gaddafi o de cualquier modo parecido. AlJazeera, la cadena informativa de Qatar aparece ahora incluso como Al Gazeera yno hablemos de las confusiones todavía no resueltas por el paso de los nombreschinos de la transcripción tradicional al "pinyin", ya que son muchos los quecreen que Pekín y Beijing son dos ciudades distintas y Mao Zedong un parientelejano de Mao Tse-tung.
La verdad es que este tipo de situaciones se seguirá repitiendo, como pasó antescon los apellidos rusos, transcritos por los franceses ("Lenine", "Staline", o"Moscou", por ejemplo), sin contar con los lugares y países que han cambiadode nombre, como San Petersburgo, que fue Petrogrado y luego Leningrado enmenos de un siglo antes de volver a su nombre original.
Pero si no se pueden evitar estas confusiones, lo que recomienda el sentidocomún es que cada medio tome su decisión y la respete, en vez de brindar elespectáculo de usar un nombre o una grafía distinta en cada página o sección
Para todo esto -si se usan bien- pueden ocuparse las herramientas tecnológicasque tenemos a nuestra disposición, junto con las conexiones a Internet. Lo queRaymond Colle nos dice, con insistencia, es que aprendamos a usarlas... y lasusemos.
Abraham Santibañez MartínezPeriodista.
Coordinador del Area Académica de Periodismo,Facultad de Ciencias de la Comunicación e Información,
Universidad Diego Portales.Ex-director del diario "La Nación" y de la revista "Hoy".
Premio de Periodismo 2001,Embotelladora Andina (Coca-Cola Chile),
Santiago de Chile.
1 Ver "El Portaliano on-line: El diario (sin tinta ni papel) del futuro". De Luis AlvarezBaltierra, Esteban Alvarez, Pedro Arrau Fontecilla, Miguel González Pino y AbrahamSantibáñez. Editado por la Universidad Diego Portales. Santiago. 1999.
9

10

INTRODUCCIÓN
"El conocimiento de las técnicas documentales ha dejado de ser unterreno exclusivo del documentalista o experto en Documentación paraconvertirse en una de las herramientas más eficaces del profesional de laInformación y de la Comunicación. No parece tener ya cabida alguna ennuestra llamada «sociedad de la información» el profesional maldocumentado (indocumentado) y desconocedor de las vías por las quecirculan y se accede a los conocimientos. En un mundo donde prima laespecialización, el periodista indocumentado es visto hoy día como unapersona no suficientemente preparada para afrontar con eficacia sutrabajo periodístico y, por ende, ser útil a los ojos de su medio decomunicación." 1
Dra. Ángeles López HernándezProfesora de Documentación Audiovisual, Periodística e Informativa
Departamento de Periodismo. Universidad de Sevilla
Los Sistemas Documentales cumplen una función cada día más importante y vitalen todo de tipo de organización. ¡Máxime en una empresa cuya razón de serconsiste en informar! Mucha información que era hasta hace poco (no más de 15a 20 años) del dominio "del lápiz y del papel" se ciñe hoy a formatos estándares eingresan a sistemas computacionales que facilitan no sólo su utilización posteriorsino también la obtención de "subproductos" informativos de alta importanciapara la toma de decisiones.
Por otra parte, cierto tipo de información - como la bibliográfica, científica otecnológica - que era siempre requerida pero de difícil o lenta difusión ha ganadoenormenente en posibilidades de acceso gracias a los sistemas informáticos degestión de "bases de datos" y a las redes informáticas como Internet y más aúncon la World Wide Web.
Nacidos en los Estados Unidos a principios de los 60 - junto a la tercerageneración de computadores - los sistemas documentales informatizados sólofueron cobrando una importante difusión en los 70 con el nacimiento del llamado"modelo relacional", llegando a cierta madurez en los 80. Esto explica que el
11

mercado mundial que había llegado recién a unos 500 de estos bancos deinformación en 1975 sobrepasó los 2.500 diez años después2. Así, hanempezado a tranformar los hábitos de trabajo de los docentes, investigadores,profesionales y ejecutivos: usuarios que hoy suman millones de personas en todoel mundo, cifra difícil de apreciar si se consideran las bases de datos que se usanhoy para "abastecer" páginas informativas en la WWW.
Si bien en Estados Unidos la informatización de los centros de documentación delos medios de prensa se inició en los 70, en Europa empezó a mediados de los80. Y el costo de infraestructura (especialmente para conservar grandescantidades de datos en medios magnéticos) llevó a muchos medios a constituirsistemas que estuvieran al servicio de conjuntos de empresas (como laAsociación de Editores de Periódicos en Bélgica, o el para-estatal "Banco deInformación Política de Actualidad -BIPA-" de Francia). Gracias a la posteriorevolución de los sistemas de compresión de datos y el abaratamiento de lossoportes magnéticos cada vez más potentes, casi todos cuentan hoy con Bases deDatos donde se conserva información, al menos, sobre toda publicación propia.
El desarrollo de la computación no sólo ha significado una mayor rapidez en elprocesamiento de datos y una gigantesca acumulación -y difusión- deinformaciones en todo el mundo (Se estima que solo las organizacionescientíficas almacenan cada día sobre 1Tb -terabyte- de nueva información).También, gracias al creciente poder y abaratamiento de los procesadores así comoa la investigación en Inteligencia Artificial, ha permitido el desarrollo deaplicaciones capaces de sacar partido de esas grandes cantidades de datos, en lamedida en que se conserven en formatos "normalizados".
Tal como la "matemática del caos" ha podido poner en evidencia la existencia dereglas en fenómenos aparentemente caóticos y la posibilidad de que reglassimples y cambios ínfimos puedan conducir a transformaciones enormementecomplejas, la "minería de datos" ("Data Mining") reúne hoy procedimientos quepermiten explorar grandes conjuntos de datos y sacar de ellos conocimientosnuevos que, de otro modo, permanecerían por siempre escondidos.
Aplicaciones de este tipo han permitido, por ejemplo, a la compañía de teléfonosBritish Telecom obtener invaluable información acerca de los fraudes en lasllamadas telefónicas, descubriendo -por ejemplo- que se concentraban endeterminadas zonas geográficas. También ha permitido a organismos policialesdescubrir sofisticados métodos de lavado de dinero como la petición ("limpia")de créditos para obras inmobiliarias reembolsados luego mediante dinero "sucio",y ayuda a los bancos a detectar el uso fraudulento de tarjetas de crédito cuandoaparecen operaciones que se salen de la rutina normal del dueño legítimo. En lainvestigación médica, ha permitido descubrir cómo ciertas combinaciones demédicamentos explicaban el fracaso de diversos tratamientos. Podríamos darmucho más ejemplos.Prácticamente en todas las áreas del quehacer humano,donde se acumule información, la minería de datos puede tener hoy aplicacióncomo un nuevo medio de ampliar el conocimiento, resolviendo problemas,
12

ayudando a la toma de decisiones, permitiendo una mejor comprensión de losfenómenos, llenando vacíos o facilitando proyecciones históricas.
Ante este panorama, nos surgió la pregunta: ¿puede el Periodismo beneficiarse dela "Minería de Datos"? Como gran "consumidor" -y difusor- de información, nodebería quedar al margen de los aportes que estas técnicas podrían significar parasus analistas y comentaristas: al contrario, estimamos que no puede ignorar laimportancia de éstas para su labor de ahora en adelante. Nadie mejor que unmedio de comunicación puede "auscultar" la vida de la sociedad y descubrir loshilos que unen los hechos y explican los éxitos y fracasos en múltiples campos.
En una primera serie de capítulos abordaremos conceptos generales acerca de lasbases de datos, los sistemas documentales y los métodos de procesamiento de lainformación contenida en ellos. Luego pasaremos a aplicar estos conceptos a larealidad propiamente periodística y finalizaremos dando un ejemplo completoreal, basado en la experiencia realizada con las noticias acumuladas en la base dedatos de la hiperrevista "Temas de Tecnologías Digitales de Comunicación(TDC)" del Centro de Estudios Mediales de la Universidad Diego Portales deSantiago de Chile, que hemos tenido a nuestro cargo. El lector encontrarátambién al final de la obra un Glosario que contiene todos los términos técnicosque utilizamos en nuestro texto.
13

14

Primera Parte
Bases de Datos, Meta-información
y
"Minería de datos"
15

16

1BASES DE DATOS
YSISTEMAS DOCUMENTALES AVANZADOS
En este capítulo inicial recordaremos la definición de los principales conceptosque utilizaremos. Partiremos aquí hablando de las bases de datos y los sistemasavanzados construidos a partir de éstas. Posteriormente abordaremos ladescripción de los métodos y técnicas que se encuentran hoy disponibles.
1.1. Supuestos básicos
Abordar y efectuar adecuadamente la informatización de la documentaciónperiodística no es un problema trivial, como lo hacen pensar algunas vecesvendedores de software. Lo más común en el pasado ha sido encontrarse conofertas de un tipo de sofware que retomaba cada nota o artículo publicado -en elcaso de un medio impreso- y lo archivaba "full text" en forma de fichas(registros), ofreciendo a la vez algunas facilidades de búsqueda/recuperación.Esta forma de trabajar ha sido bastante común en países anglosajones pero nopermite responder a preguntas precisas como "¿Qué dijo tal parlamentario oministro acerca de tal tema?", pregunta típica de un periodista del sector político.Tampoco llevó a la correcta implantación de un verdadero SISTEMAdocumental, el cual se compone necesariamente de múltiples archivos que se hande complementar mútuamente. Típico error sistémico sería, por ejemplo, laausencia de un Archivo Biográfico, obligando a leer numerosos registros de unarchivo "full text" de crónicas para reconstruir el currículum de algún personajepúblico.
Esto lleva por lo tanto a señalar dos condiciones básicas a tener presentes en lainformatización de la documentación periodística:
17

1. Mientras más analítica es la estructura del archivo diseñado, más fácil y másprecisamente se podrá recuperar la información buscada.
2. Es indispensable configurar un verdadero SISTEMA DOCUMENTAL, y nosolamente construir diversos tipos de archivos, de acuerdo a la intuición o lasnecesidades del momento.
De la primera condición se deriva otro principio esencial:
EL TIEMPO QUE SE INVIERTE EN LA CONFECCIÓN DE LOS REGISTROS(INGRESO DE INFORMACIÓN) SE RECUPERA CON CRECES EN LARECUPERACIÓN DE LA INFORMACIÓN.
Este es justamente el principio que infringen los modelos no-analíticos: al invertirmuy poco tiempo para confeccionar los registros (puede hacerseautomáticamente), se pierde gran cantidad de tiempo en la recuperación y sedesalienta a los usuarios debido a la cantidad de ruido informativo que se genera(registros que no responden a las preguntas que guían la búsqueda).
Pero los modelos analíticos tienen además otras ventajas, muy importantes hoy.Permiten ligar la entrada de información con nuevas formas de salida de lamisma. En efecto, cuando se cuenta con múltiples atributos (como por ejemploel nombre del "actor" de un hecho noticioso, el nombre de la institución a la cualpertenece, el tipo de acción y el tema tratado –si es una declaración–, etc.) sepueden generar estadísticas tales como "quiénes han hecho alguna declaraciónsobre tal tema, con qué frecuencia, durante tal o cual período). El trabajointerpretativo del periodista se ve grandemente facilitado. Y la misma tabla deresultados constituye un nuevo producto que, con algunos ajustes redaccionales,es también publicable. (Constituye lo que se llamaría hoy "meta-información":ver Cap.5).
Paralelamente, es posible instalar un sistema de DISEMINACIÓN de información(como se explica más adelante), aproximándose así a un sistema de "diario a lacarta", en que los suscriptores reciban boletines personalizados, de acuerdo a susintereses particulares.
1.2. Sistema documental
Sólo se puede hablar de SISTEMA DOCUMENTAL si el conjunto de archivosse estructura en forma de "espacio de información", permitiendo diversas formasde lectura de la información que contiene y contemplando la existencia derelaciones entre los distintos archivos que lo conforman.
18

El diseño de sistemas documentales debe partir del análisis de las característicaspropias e intrínsecas de los referentes (objetos y eventos) representados ademásde tener en cuenta las necesidades y los hábitos de los usuarios, es decir la formaen que los usuarios o destinatarios de la misma tenderán a requerirla. Pero loshábitos de los usuarios no pueden ser los únicos que han de guiar el diseño, porcuanto ello podría impedir un mejor aprovechamiento de la información paranuevas tareas o productos que se pueden diseñar hoy o en el futuro.
Solo un sistema documental construido de acuerdo a estos principios yadministrado con herramientas informáticas que permitan mantener relacionesentre los datos de varios archivos constituye un verdadero y provechoso"BANCO DE DATOS".
1.3. ¿Banco de datos o Bodega de datos?(DATA WAREHOUSE)
El término "BASE DE DATOS"
"se refiere a la información que una empresa u organización mantienealmacenada en el computador [...] Al usar una base de datos, todos los datosse almacenanen forma integrada, y están sujetos a un control centralizado,ejercido por un administrador de la base de datos" (P.Poblete, p.1)
Se ha utilizado algunas veces como sinónimo "Banco de datos". Sin embargo,debería hacerse una distinción entre estos dos conceptos, el "Banco" haciendomás referencia al contenido (información), mientras la "Base" -en sentidoestricto- hace referencia a la estructura lógico-matemática y al tipo de softwareutilizado, poniendo el énfasis en el carácter de "fundamento" y punto de partidasobre el cual se construye. De ahí que los programas informáticos (software) sellamen habitualmente "Sistemas de Gestión de Bases de Datos" (SGBD) y no"sistemas de gestión de bancos de datos". El concepto de SGBD también reflejaun aspecto importantísimo del sistema: la "INDEPENDENCIA" de los datos, que serefiere a que éstos son independientes del software con el cual han sidoimgresados y pueden ser modificados, representados o consultados de diversasmaneras, mediante diversas aplicaciones computacionales (Poblete, p.4).
Por ello,todo SGBD debe cumplir como mínimo las siguientes condiciones:
• 1. Las estructuras de datos (espacio informativo) son simples e independientesdel programa que genera los datos.
• 2. Varios espacios informativos -si los hay- se asocian mediante la presencia deal menos un atributo común1.
• 3. Un conjunto de operadores permite la definición, búsqueda y actualizaciónde los datos.
19

• 4. Un conjunto de requisitos de integridad define el estado coherente de la basede datos.
En los últimos años, el término "BANCO de datos" a caído prácticamente endesuso, reemplazado por "DATA WAREHOUSE"2 o "Bodega de Datos", conceptoque engloba:
• el conjunto integrado y organizado de todos los datos no volátiles (Bases deDatos) de que dispone una empresa,
• mantenidos a través del tiempo, registrando históricamente su evolución,• acompañados de herramientas capaces de administrar el conjunto y facilitar
información útil para la toma de decisiones• mediante interfaces que faciliten la consulta.
La gestión de la Bodega de Datos así concebida y adecuadamente estructurada esvital para la correcta toma de decisiones y forma parte de los "sistemas de apoyoa la decisión" o "DSS" ("Decision Support System").
La Bodega de Datos, tal como se entiende actualmente -a diferencia del antiguo"Banco de datos"- tiene dos componentes importantes:
- los datos propios (por ejemplo la información acerca de los productos,inventario, precios, etc.) y
- los datos que se recogen acerca de quienes consultan dichos datos, comopodría ser -crecientemente- quienes consultan por diversos productos en unsitio web.
Esos datos acerca de los "usuarios" de información son cada vez más valorizadospor las empresas que, más que centrarse en sus productos, se van preocupandode sus clientes (cfr. D.Marco, p.20 y vea Gráfico 1.1.). Pero, además, estoscomponentes son son datos estáticos y todos los cambios que los afectan debeser registrados de tal modo que se pueda obtener una visión HISTÓRICA de loocurrido.
1.4. Feria y depósito de datos(DATA MART y DATA REPOSITORY)
Junto al nuevo concepto de Bodega de Datos han aparecido otros como "DATAREPOSITORY", "DATA MART" y "META DATA".
El "DATA MART" , apelación que podría ser traducida por "feria de datos" o"mercado de datos", puede entenderse en dos diferentes niveles:
20

• en el interior de la institución: disponibilidad de los datos del Almacén para serconsultados e intercambiados entre todos los posibles usuarios, medianteconsultas on line o reportes periódicos (aspecto de "feria");
• externamente (DATA MARKET), es la posibilidad de intercambio -obviamente atítulo oneroso- de bases de datos entre empresas, cosa que ya observamosfrecuentemente con carteras de clientes de negocios que operan por Internet(aspecto de "mercado" o comercio).
Gráfico 1.1: Depósito y mercado de datos
Archivo de consultas
Base de datos
BODEGADE DATOS
Usuarios Internos
Usuarios Externos
"FERIA" DE DATOS
Opera-cionales
Técnicos
METADATOS
DEPOSITO DE DATOS
Explotados
Existe un creciente mercado para las informaciones sobre los clientes (cuandoestán bien clasificadas) y una presión cada vez más grande para crear estándaresinternacionales que faciliten tales intercambios. En ello compiten actualmente dosgrandes organizaciones: la MDC, o Meta Data Coalition, y el OMG, ObjectManagement Group (D.Marco, p.11).
El lenguaje XML representa una alternativa muy prometedora para laestandarización, por cuanto es independiente de toda plataforma y compatible conel HTML (el lenguaje de las "páginas web"); y los navegadores de versión 5 osuperior ya lo "entienden". Se ha de combinar con el sistema de hojas de estilo("style sheets") por cuanto no provee etiquetas destinadas a definir el despliegueen pantalla. Puede ser programado con el más simple de los procesadores detexto aunque, sin duda, aparecerán pronto aplicaciones que faciliten el desarrollopor el método WYSIWYG (producción a nivel de visualización del producto enpantalla) (cfr. D.Marco, pp.77-79). Sin embargo, se ha de tomar en cuenta que
21

el XML, al permitir la definición de sus propias "etiquetas" (definiciones deformatos), aumenta en forma importante la cantidad de meta-datos y el espacionecesario para ellos en medios digitales, ya que estas definiciones son meta-datosacerca de los meta-datos, pudiendo además generar dificultades de consistencia ala hora de crear nuevas definiciones. El auge del comercio electrónico vía web sinduda promete éxito para el XML y el OMG lo está adoptando3.
El "DATA REPOSITORY" o depósito de datos, por su parte, se compone de laBodega de Datos y, además, de todo el conocimiento ligado a ésta o que puedaser extraído mediante diversas técnicas, hoy muy sofisticadas. Éstos son losMeta-Datos (META DATA), de los cuales hemos de hablar luego y queconcentrarán especialmente nuestra atención a lo largo de la presente obra. Otracaracterística de un correcto Depósito de Datos es que ha de contener toda lainformación histórica acerca de los cambios aportados eventualmente al diseño oestructura del Almacén de Datos y de los usos que se han dado tanto al Almacéncomo al propio Depósito. Finalmente -y esto es quizás el aspecto más complejo-se espera que el Depósito también tenga la forma de una Base de datos.
1.5. Meta-datos
Los meta-datos (META DATA) son, como sugiere el nombre, "datos acerca de losdatos" o información acerca de la información. Las tarjetas bibliográficas delcatálogo de una biblioteca son meta-datos. El modelo de cada tarjeta y las reglasque ha de seguir el documentalista también son meta-datos. ¿Pero qué son losmeta-datos en los SGBD? ¿Y de qué tipos de datos o informaciones estamoshablando? ¿Cuál será su utilidad?
Los meta-datos son de dos tipos:
- La información acerca de la estructura de la información conservada en losbancos o almacenes de datos y acerca de las reglas para su ingreso,transformación y uso. Estos meta-datos han de ser definidos cuidadosamenteANTES de entrar a operar, por cuanto puede resultar extremadamente difícil ycostoso modificarlos después del ingreso de datos. Cualquier duda que surjadespués y que pueda inducir a efectuar cambios requiere un serio estudio deimpacto antes de ser llevado a cabo. La ingeniería dispone de métodos paraefectuar tales estudios y es siempre aconsejable recurrir a un especialista eneste campo. Estos meta-datos, a su vez, se subdividen en dos clases: losrelativos al sistema informático (meta-datos técnicos en sentido estricto) y losrelativos al funcionamiento de la empresa u organismo ("business meta data",que podríamos traducir por "operacionales").
- La información extraída del conjunto de los datos ingresados (meta-datos"explotados"), tratando éstos como un sistema (datos interrelacionados)mediante técnicas que van desde la estadística clásica hasta los métodos más
22

modernos de visualización y explotación ("Data Mining"), a los cuales nosreferimos en otro capítulo.
Los meta-datos son herramientas que deben poder guiar a los usuarios de losdatos: a quienes los ingresan y a quienes los consultan, tanto para encontrar unainformación puntual como para extraer información sobre el conjunto en unmomento dado o a través de la historia del sistema. Así, pueden proveer uncontexto que puede ser de gran importancia para una mejor interpretación deinformaciones puntuales.
Si, como ya lo hemos mencionado, los Almacenes de Datos son vitales para lagestión, los meta-datos son aún más importantes para la toma de decisiones anivel directivo. En este caso, es común considerar la evolución del sistema(empresa o unidad operativa) a través del tiempo: la posibilidad de manejar elDepósito de Meta-Datos incluyendo el factor histórico es por lo tantofundamental.
Pero, en la forma en que las técnicas computacionales existentes extraen losmeta-datos, éstos no son generalmente de fácil interpretación. Por este motivodeben ser acompañados de "interfaces semánticas" que faciliten su comprensiónpor parte del usuario (ejecutivo) que, generalmente, no domina los formatosmatemáticos en que se generan o la terminología correspondiente. En dichosentido, las técnicas de "visualización de datos" (proyecciones bi- otridimensionales) que permite el ordenador son una importante ayuda. Sinembargo no todo debe ser "traducido": es necesario tener en cuenta que existenmeta-datos que sólo han de manejar los expertos a cargo del sistema ("meta-datostécnicos", como por ejemplo la información sobre la estructura física de las tablasde datos), mientras otros - más generales o relativos a los resultadossignificativos para la gestión - han de ser comunicados de la forma más inteligibleque se pueda (a veces llamados "meta-datos informativos").
1.6. Análisis Visual de Datos ("VDA")
El análisis visual de datos es una técnica emergente que usa en forma intensivalas innovaciones en el campo de las interfaces gráficas y de la visualizacióncientífica de datos. Se puede considerar que las primeras aplicaciones de VDAhan sido las planillas de cálculo que venían acompañadas de un medio degraficación (como Excel). Pero la idea del VDA no es simplemente de facilitar larepresentación de funciones estadísticas, sino de ayudar al usuario a explorar losdatos y "navegar" a través de ellos de manera más interactiva. Esto suponerecurrir también a técnicas de "rendering" y de animación o incluso de"inmersión" virtual en el "espacio" tridimensional de los datos.
Usaremos ampliamente algunas técnicas de visualización en la aplicación prácticaque expondremos más adelante.
23

1.7. Los datos, su valor y su complejidad
Para concluir y sintetizar los conceptos introducidos recientemente por laingeniería de los sistemas de información, podemos mostrar en un gráfico larelación existente entre el "valor corporativo" y la complejidad de diversosconjuntos de datos a los cuales nos acabamos de referir. Adaptamos aquí ungráfico propuesto por el experto D.Marco en su libro sobre "Depósitos de Datos"(p.30).
Reflejamos en este gráfico tanto el avance de los sistemas (principalmente através del desarrollo de nuevos recursos computacionales) como su crecientecomplejidad. Pero a ésta va asociado un beneficio creciente para toda empresa y,como lo veremos más adelante, un beneficio que no se limita al campo de losvalores económicos sino que involucra en realidad todas la áreas delconocimiento en que es posible ordenar y clasificar datos (de cualquier tipo).
Gráfico 1.2. "Potencial de retorno" de los sistemas de datos
Sistemas de Control basados en Meta-Datos
Interfaz basada en Meta-Datos (VDA)
MejorDSS
Diccionariode datos
Control de calidad de datos
Complejidad
ValorCorporativo
SGBD
Bodegas de datos
Depósito de datos
24

1.8. Tipos de bases de datos
Se conocen en la actualidad al menos cuatro tipos de bases de datos de acuerdo asu estructura: el jerárquico (practicamente obsoleto), el relacional, el orientado aobjeto y el "relacional orientado a objetos", que combina los dos anteriores.
1.8.1. Tipo jerárquico
Un ejemplo típico de sistema documental jerárquico podría ser uno que acumulainformación acerca de equipos deportivos (supongamos de futbol). La raíz delárbol jerárquico sería la ANFP (Asociación Nacional de Futbol Profesional).Acerca de ella existirá un registro con una serie de datos (nombres de directivos,dirección, etc.) y la indicación de que encabeza dos agrupaciones de clubes,llamadas "Primera División" y "Segunda División" (podrían haber más).
Gráfico 1.3. Ejemplo de estructura jerárquica: ANFP
- - - - - -Tesorero
Secretario
- - - - - - - - - -
- - - - -
2a. División
1a. División
Unión Española
U. Católica
U. de Chile
Colo-Colo
- - - - - - - - - -
- - - - -
Presidente
Médico
CuerpoDirec t ivo
Entrenador
- - - - - -
CuerpoTécnico
Jugadores
Jugador 2
Jugador 1
Clubes
ANFP
Clubes
Luego tendremos un registro por cada una de estas divisiones, dónde estarán losnombres de los clubes. Los datos sobre éstos irán en registros separados, uno
25

por club. Y para cada club habrá datos generales (registro específico del club) ydatos específicos relativos a los miembros del cuerpo directivo, del cuerpotécnico y del equipo de jugadores.
Otro ejemplo de sistema documental jerárquico es el que sigue las operaciones deuna industria: supondremos que ésta se divide en "departamentos", cada uno delos cuales desarrolla ciertas funciones. Éstas implican actividades seriadas queson documentadas de diversas maneras. Así, la adquisición de materias primas esseguida del uso de las mismas, con lo cual debe ajustarse permanentemente lainformación sobre el saldo disponible a fín de ordenar a tiempo la compra de loque haga falta.
Gráfico 1.4. Ejemplo de estructura jerárquica en una empresa
- - - - -
- - - - -
Producción
Personal
Empleado 3
Empleado 2
Empleado 1Ingreso de movimientos
Funcionarios
EMPRESA
Departamentos
Mov. de materia primaMov. de productos
Informe de movimientos
Mov. de materia primaMov. de productos
Inventario demateria prima
Inventario deproductos
Contabil idadIngresosEgresos
Al mismo tiempo, el uso está determinado por la creación de los productosterminados, que deben ser sometidos a inventario y son luego vendidos. Hay porlo tanto un nuevo sistema de control de existencias, referido ahora a productosterminados, y nuevos procesos contables referidos a las ventas. Todo ello daorígen a un complejo sistema de manejo de información. El ejemplo adjuntopresenta un sistema jerárquico simplificado de archivos destinados a documentarlas señaladas operaciones y sus consecuencias sobre las existencias de materias
26

primas y productos terminados y la situación contable de la empresa. Implicaque ciertas personas deben llenar ciertos formularios cuando pasan ciertas cosas,y éstos conforman los registros de ciertos archivos, al mismo tiempo que ciertosdatos son transferidos a otros archivos (dependientes) a cargo de otras personas,donde pueden ser objeto de nuevas operaciones.
Las relaciones entre archivos estarán dadas por los atributos comunes (variablesque describen cada referente) y por reglas de "herencia" o transferencia. Pero,por principio (para efectos de economía de espacio y menor redundancia), solo secolocan en un archivo propietario ("padre") los atributos del archivo dependiente("hijo") cuyos datos constituyan la entrada (encabezado) en este último y los quedeban ser transferidos por razones operativas. Luego se agregará en eldependiente el detalle de la información. (Del archivo de mayor jerarquía se diceque es "propietario" de los de menor jerarquía).
La principal ventaja de esta estructura consiste en que la información que apareceen un registro jerárquicamente superior se aplica igualmente a todos los registrosque le son subordinados (llamados sus "descendientes"), por lo cual no deberepetirse (economía de espacio y baja redundancia), gracias al principio de"herencia". Así, no debe anotarse en la ficha de un jugador -por ejemplo- quejuega en "Primera división", ya que podemos saber a qué club pertenece y-remontando la jerarquía- que este club pertenece a la "Primera División".
Las desventajas son que el árbol jerárquico debe definirse previamente y esdifícil de modificar para insertar nuevos registros, especialmente si se utilizanmedios magnéticos de conservación, debido a la forma en que se deben intercalarlos registros de diversos niveles jerárquicos (dificultad de actualización). (Cfr.Gillenson, p.117)
Es también difícil responder con rapidez a una consulta sobre un punto específicode un registro subordinado (sobre todo si a partir de un dato subordinado seespera obtener una respuesta que es una información "heredada" de un registrode nivel superior).
1.8.2. Tipo relacional
Considerando el espacio informativo como un conjunto de datos en forma dematriz (tabla de doble entrada o conjunto de n dimensiones), podemos apelar a lateoría de conjuntos para efectuar operaciones entre diferentes espaciosinformativos si mantienen entre sí algún atributo en común. Es evidente que estaexigencia nos permite construir un conjunto intersección, un conjunto unión, unconjunto diferencia (complemento de la intersección), etc. Pero en el caso dearchivos, el mecanismo y sus resultados presenta características un poco máscomplejas (y provechosas) que en conjuntos no organizados en forma de matriz.
27

La estructura relacional 4de un sistema documental es la que considera yaprovecha estas operaciones del álgebra de conjuntos y la idea de fondo es quetodos los archivos relacionados entre sí pueden ser considerados como formandoun solo espacio informativo, en el cual pueden efectuarse múltiples operacionesde selección y de reordenamiento sin perder las relaciones entre datos definidas alconfeccionar los registros.
Gráfico 1.5.Relaciones en los dos tipos de estructuras
Relaciones en archivos jerárquicos
Relaciones en BDrelacional
1 a 1 Marido Mujer1
1
1 a n Padre Hijo1
n
m a n Lector Libron
m
La estructura relacional permite conservar aspectos de la estructura jerárquica,pero permite además operaciones lógicas y de álgebra de conjuntos sobre todossus componentes, lo cual la otra no permite.
Considerando sólo la representación lógica de un espacio informativo, es muyfácil entender la enorme cantidad de operaciones que sería posible efectuar si sepudieran mantener todos los datos en forma de tabla, independientemente de losmecanismos por los cuales se generen.
Suponiendo que los datos sean conservados adecuadamente, lo más importantees descubrir que podríamos entonces cambiar casi indefinidamente el orden delos mismos. En primera instancia, podemos elegir uno de los atributos parareordenar todos los registros en la base de datos (p.ej. orden alfabético dematerias, en un archivo bibliográfico que era ordenado por autores). Ya que las"claves" (identificadores) de los referentes son datos que van en una celdilla-como todos los otros-, no hay riesgo de perder la relación biunívoca que vinculalos registros con los referentes. (Esto implica que cambiemos de lugar las "filas"enteras y no sólo las celdillas de una columna). Del mismo modo podemoscambiar el orden de los atributos (columnas), sin que se produzcan pérdidas nierrores.
28

Gráfico 1.6. Reordenamiento
Autor Materia Título Nº
Ordenado por autorBustos, A. Medicina El hígado y la vesícula 622BPérez, J. Novela El pasajero de la noche 431PUrrutia, F. Informática Ordenadores digitales 550UZamorano, V. Informática Sistemas expertos 551Z
Ordenado por materiaUrrutia, F. Informática Ordenadores digitales 550UZamorano, V. Informática Sistemas expertos 551ZBustos, A. Medicina El hígado y la vesícula 622BPérez, J. Novela El pasajero de la noche 431P
La "estructura relacional" permite estos cambios - como también otrasoperaciones - no estando condicionada por la forma física de los archivos, lo cuales muy ventajoso por cuanto permite el uso de una gran variedad de programaspara acceder a la información. Sus ventajas están evidentemente condicionadaspor múltiples reglas que no detallaremos aquí por ser una materia técnica.
Un sistema de gestión de base de datos (SGBD) relacional exige como mínimoque:
• 1. Toda información de la Base de Datos sea representada por valores en tablas.• 2. No habrá punteros (direcciones codificadas) visibles para el usuario de tales
tablas.• 3. El sistema debe poder utilizar operadores de restricción, proyección y unión
natural sin limitaciones dependientes de condiciones internas ("Operadoresrelacionales").
Si cumple con otras dos condiciones, podrá llegar a ser "completamenterelacional":• 4. Reconoce y utiliza todos los operadores del álgebra relacional.• 5. Cumple los requisos de integridad por unicidad de clave y de constricción
referencial.
Las constricciones o exigencias básicas de los sistemas relacionales son tres,relacionadas con la "clave":
• 1. Unicidad de clave: Como un conjunto no puede tener dos veces un mismoelemento, no puede existir dos veces el mismo registro en un archivo. Sellama "clave" el conjunto mínimo de atributos cuyos valores permite identificar
29

un registro (fila de datos o "tupla" en lenguaje matemático) único, y también-indirectamente- un referente único.
• 2. Constricción de entidad (o sea de referente): Ya que debe haber un referentepara todo dato ingresado, se prohibe dejar en blanco (sin información o "valornulo") los campos (celdillas) en que debe ser registrada una clave.
• 3. Integridad de referencia: A partir de la relación biunívoca que ha de existirentre un referente y un registro (tupla o fila de datos), para ser fiel al principiogeneral de relación se debe asegurar que la clave de un archivo esté presente encualquier otro archivo con el cual se "relacione". En otras palabras, dosarchivos se relacionan correctamente cuando remiten a los mismos referentes,individualizados de la misma manera. (Esto no quiere decir que, si pasamosde un 2º a un 3º archivo, los referentes sigan siendo los mismos que para el 1ºy el 2º: podrán ser otros, pero descritos con igual clave en el 2º y 3º archivo).Esto se parece a lo que hemos visto en la estructura jerárquica. (Vea Gráfico1.7).
Gráfico 1.7. Relaciones entre Archivosde Vinos y de Consumidores
Tabla de Consumidores
Tabla de Actos de
Consumo
Tabla de Vinos
Apellido Nombre Est.Civil Nº Hijos
Clave 1
Apellido Nombre Fecha Nº Vino
Nº Vino Viña Milésº Gº alcohol
Clave 2
Clave 3
30

1.8.3. BD orientada a objetos
Las bases de datos orientadas a objetos (BDOO), a la vez que combinan aspectospropios de los sistemas jerárquicos y de las BD relacionales, introducenimportantes diferencias. Un objeto es, aquí, no una mera entidad que se describesino algo que se describe y que incluye procedimientos que desencadenanacciones cuando el objeto es referenciado. Un ejemplo muy claro es un "botón"en una página web, que abre una ilustración o produce la navegación hacia otrapágina cuando es pinchado.
Gráfico 1.8: Estructura de una BDOO
TextoImagen
Foto
Página Web
Botón
Datos:
L.U.CornerR.D.Corner
Métodos:AbrirAmpliar
Datos:
ColorTrama...
Métodos:PincharORDEN
Código delprocedimiento
Pero el botón es un objeto que pertenece a (y sólo aparece en) una "página web"y comparte características con otros tipos de ilustraciones. Así, el botón pertene ala clase de las imágenes y éstas, junto con los textos, a la clase llamada "páginaweb". Así, descubrimos un conjunto de objetos de misma jerarquía quepertenecen a otros objetos de mayor jerarquía. Al igual que en las BD jerárquicas
31

opera el principio de "herencia", mediante el cual las características del "padre" setransmiten al "hijo". Pero aquí, como ya señalado, los objetos son generalmente"activos", es decir asociados a determinadas acciones, como el "pinchar" el botónha de desencadenar, por ejemplo, la apertura de otra página. Las accionesasociadas a un objeto son llamadas "métodos". Se activan mediante una orden ydesencadan un procedimiento (Ver Gráfico 1.8).
El adecuado manejo de BD orientadas a objetos plantea una considerable cantidadde dificultades técnicas y conceptuales que son objeto de una intensainvestigación (cfr. J.Navón, Cap.4, pp.1-3) y se desarrollan solamente, en laactualidad, para sistemas CAD-CAM (manufactura controlada por ordenador, apartir del diseño en la misma máquina) y CASE (sistemas de ayuda a la gestiónadministrativa). Tiene el defecto de no ajustarse al modelo de la "tercera formanormal" de los sistemas relacionales ni admitir las operaciones de álgebrarelacional que permiten manipular con mucha facilidad las BD relacionales paraextraer meta-datos.
1.8.4. Otros tipos de BD
Más recientemente, otros tipos de bases de datos han aparecido en el mercado oestán en vías de desarrollo. Entre los modelos más significativos hemos demencionar a:
• Las "Bases de Datos Relacionales Orientadas a Objetos" ("Object OrientedRelational Data Bases"), que combinan las características de las dos categoríasantes citadas. Permiten conservar datos de objetos de diferente naturaleza yestablecer relaciones entre ellos, independientemente de dicha naturaleza. Todala base de datos se transforma de este modo en una suerte de "hipermedio".Este nuevo formato es importante para el desarrollo de grandes sistemashipermediales interactivos en red ("servidores universales").
• Las "Bases de Datos Activas" o BD con reglas activas (reglas ECA:"Event -Condition - Action"). La incorporación de estas reglas a los SGBD permitencontrolar su comportamiento sin necesidad de modificar los sistemas (por locual pueden integrarse, por ejemplo, a las BD relacionales, que son las máscomunmente utilizadas). La base de la operación consiste en un sistema demonitoreo que detecta cuando ocurren determinadas condiciones, en cuyo casoaplica una regla y efectúa una acción predeterminada (p.j. poner unaadvertencia en pantalla). Las reglas pueden estar interrelacionadas (unaactivando otra en ciertas condiciones) y pueden incluir un motor de inferenciaspara realizar deducciones automáticas y darlas a conocer en el momentooportuno a uno o varios usuarios.
• Las "Bases de Datos Inteligentes", que son SGBD acompañados de recursospropios de los sistemas expertos (es decir de "bases de reglas" y de un "motorde inferencia" que permiten hacer deducciones y proyecciones a partir de los
32

datos). Con técnicas de minería de datos ("Data Mining) - ver capítulo 3 - sepuede llegar a resultados similares a partir de bases de datos relacionales.
1.9. Operaciones con los datos
Consideraremos aquí esencialmente el caso de las bases de datos relacionales,que son las que se prestan mejor para efectuar diferentes tipos de operaciones,más allá de las simples consultas.
Las operaciones relacionales tradicionales (álgebra de conjuntos) son:
• 1. la UNION: A U B = conjunto de los registros que pertenecen a la tabla A yque pertenecen a la tabla B, sin duplicación, A y B teniendo la mismaestructura.
• 2. la INTERSECCION: A Ω B = conjunto de los registros que pertenecen a lavez a las tablas A y B.
• 3. la DIFERENCIA: A - B = conjunto de los registros que pertenecen a la tablaA sin pertenecer a la tabla B.
• 4. el PRODUCTO CARTESIANO: A * B = conjunto de todos los registros quese obtengan concatenando un registro de la tabla "B" con un registro de la tabla"A".
Gráfico 1.9: Operaciones relacionales básicas
A U B A Ω B
A - B B-AAn.B1An.B2...An.Bn
A*B
A1.B1A1.B2...A1.Bn
A2.B1A2.B2...A2.Bn
...
. . .
. . .
. . .
Las operaciones relacionales especiales (que dependen del "lenguaje" de gestiónadoptado) son, típicamente:
• 5. la ADICION: Crea un nuevo registro para un archivo dado.• 6. la SUPRESION: Elimina un registro de un archivo dado.
33

• 7. la ACTUALIZACION: Permite modificar los valores de un registro.• 8. la SELECCION: arroja un conjunto de registros que cumplen con ciertas
condiciones (que son valores esperados para atributos elegidos).• 9. la PROYECCION: produce una tabla con el subconjunto obtenido al
seleccionar ciertos atributos especificados (y elimina los registros duplicados).• 10. la JUNCION ("Join"): Idéntica al Producto Cartesiano pero con conjuntos
de registros que tienen un atributo común. Pone valores nulos (blancos) en losatributos diferentes de las combinaciones donde el atributo común no tieneigual valor.
• 12. la DIVISION: produce una tabla con un subconjunto de registrosselecionados por contener valores dados para ciertos atributos (sin que en latabla queden tales atributos).
Conclusión
Como se ha podido observar, todas las operaciones que ofrece el álgebra deconjuntos y las bases de datos relacionales permiten realizar múltiplescombinaciones de los datos, ductilidad de la cual no se dispone en los sistemasjerárquicos y que es fundamental para el propósito que nos ocupa: "explotar" yextraer todo el conocimiento oculto en nuestras bases de datos. Los sistemas deBD que se inventaron con posterioridad por una parte no se han generalizado y,por otra, - en algunos casos - tienden a incluir procedimientos orientados aextraer conocimiento, pero se limitan generalmente a casos muy específicos noafines a nuestro propósito final.
NOTAS DEL CAPITULO
1 En Ámbitos 5, Revista Andaluza de Comunicación, Universidad de Sevilla, 2º semestre de2000 (http://www.ull.es/publicaciones/latina/ambitos/5/32angeles.htm).
2 Según E.H. Daniel, que se refiere a las bases de datos "disponibles públicamente" a nivelmundial, éstas han pasado de ser cincuenta y dos millones en 1975 a sumar cerca de cincobillones en los albores de los años noventa ("Quality Control of Documents", Library Trends,41 (4), 1993, pp. 644-664).
1 El "espacio informativo" es la totalidad de la información contenida en un conjunto de datos(típicamente una "tabla"). Un "atributo" es una variable de descripción de un referente (eventou objeto que se documenta).
2 "DATA WAREHOUSE" fue originalmente un producto (desarrollado por IBM), pero su nombrese ha transformado en un concepto de uso general.
3 Sin embargo no se puede considerar el desarrollo del XML como terminado y las herramientasen el mercado tienden aún a tener variaciones que producen algunas incompatibilidades.
4 Modelo creado por Edgar F.Codd y Chris Date.
34

2
MODELOS DE DATOSY META-INFORMACIÓN
Repasaremos aquí algunos conceptos básicos relativos a las estructuras y losmodelos de datos, tal como se entiende en la ingeniería de los SGBD (Sistemasde Gestión de Bases de Datos), por cuanto son parte importante de la meta-información (meta-datos anteriores) y por cuanto de la adecuada "modelización"previa de los datos depende la extracción de nuevos conocimientos acerca delespacio informativo constituído por la totalidad de los datos acumulados a travésdel tiempo (meta-datos posteriores).
2.1. Modelo lógico
2.1.1. Modelo conceptual
El modelo "conceptual" de los datos corresponde al análisis teórico de losmismos desde el punto de vista de su significado, con miras a la gestión. Sedistingue del modelo lógico y del modelo físico. El modelo "lógico" considera elsignificado de los datos y los requerimientos de información que les correspondey que podrán ser formulados por diversos usuarios. Implica por lo tanto agregara la consideración de la estructura "interna" (semántica) de los datos el estudio delos usos y usuarios que se pueden prever. El modelo "físico" define la formaconcreta en que serán conservados los datos, en función del harware y delsoftware que se han de utilizar.
El análisis conceptual considera como su objeto las "entidades" o "referentes",que son las "cosas" acerca de las cuales se conservará información en la base dedatos. Las entidades pueden ser de dos tipos:
35

- los "sujetos", u objetos cuya existencia es en principio independiente deltiempo (una persona, un bien inmobiliario); conducen a un modelo dichodescriptivo (estático);
- los "eventos", o acontecimientos, cuya característica fundamental es latemporalidad efímera (una compra, una declaración pública); conducen a unmodelo llamado transaccional (dinámico).
2.1.2. Atributos
Para describir tanto hechos noticiosos como otros referentes a los cuales puedenremitir archivos documentales, es necesario contar con un sistema constante devariables en función de las cuales se describen estos referentes. En los sistemasdocumentales estas variables pasan a llamarse "atributos" y definen distintostipos de características o componentes típicos de la descripción (por ello, ensemántica se llaman "caracteres distintivos"). Ejemplos serían: "Autor" y "Título"para libros, "Marca" y "Modelo" para autos, "Fecha" y "Lugar" para un hechonoticioso, etc.
Pero es también necesario establecer distinciones entre los objetos que deben serdocumentados, ya que los atributos variarán de acuerdo a las categorías genéricasa las cuales pertezcan éstos. Consecuentemente, distinguir el tipo de referenteobservado para luego elegir los atributos adecuados para describirlo son losprimeros pasos a realizar y constituyen la primera etapa del "modelamiento" delos datos.
Los atributos pueden ser intrínsecos, presentes explícitamente en la entidad -como identificación (nombre o título), contenido, características únicas deforma, etc. -, o extrínsecos: caracteres distintivos que fija el analista de acuerdo auna pauta - como el tema de un texto, los nombres comunes de las figuraspresentes en una foto, etc.-.1
2.1.3. Relaciones
Las entidades de un modelo de datos están relacionadas lógicamente de talmanera que forman una malla. Típicamente estas relaciones pueden ser depertenencia, de jerarquía, de cercanía o distancia espacial o temporal, desemejanza, de complementaridad, de parentezco, etc. La relación puede serbiunívoca (1 a 1), de 1 a N (uno con muchos) o de M a N (muchos con muchos).Esta tipificación -de carácter cuantitativo- es de suma importancia para el diseñode la estructura de una base de datos y determina los mayores o menores usosque se podrá hacer después de la información registrada. Esta estructura es lo quese llama "modelo entidad-relación", que conviene siempre explicitar antes deproceder a diseñar una base de datos. Generalmente se hace en forma gráfica,como lo mostraremos a continuación.
36

Ejemplo: Un socio de una mutual de salud puede haber recibido muchasprestaciones de salud (relación 1 : N de un sujeto con varios eventos), perouna determinadad prestación corresponde a un solo socio (relación 1 : 1). Asu vez, dicha prestación pertenece a una determinada categoría -supongamosque es un "ECG" -: en este sentido la relación es 1 a 1, pero la inversa no esverdadera, ya que se pueden haber realizado ECGs a muchos socios e inclusovarios al mismo socio, en diferentes fechas (relación 1 : N de la categoría a loseventos efectivos que le corresponden).
Gráfico 2.1.3 : Tipos y mallas de relaciones
Socio ECG del 1/4/991 1
ECG
Tipos dePrestaciones
PrestacionesespecíficasSujeto
1ECG del 3/6/99
1
1
1
EQUIVALE A:
Socio Prestaciones1 N
TiposN M
N
Analizando este ejemplo, a primera vista lo que determina la identificación precisade una determinada prestación es la combinación de su tipo y de su fecha. Sinembargo, sabemos que se pueden realizar muchos ECG un mismo día, por locual se requiere relacionar tres "datos" para identificar una prestación específica:un identificador único del socio (su nombre completo o su número de identidad),la fecha (incluída eventualmente la hora) y el tipo de prestación. Éstos son losatributos que conforman el modelo conceptual de este tipo de información. Porcierto se los "agrupará" y simplificará habitualmente dando a la prestación unnúmero único que la identificará y permitirá realizar diversas operaciones con losdatos. De este modo, el conjunto de datos correspondiente a una prestacióndeterminada podrá ser representada de la siguiente forma, que constituye unmodelo del registro de la misma:
Tabla 2.1.3: Registro de un evento
Nº Nombre Fecha-Hora Tipo21345 Juan Pérez Pérez 99-04-01:15.50 ECG
37

Sin embargo, sabemos que varios de estos datos podrán repetirse en el archivode todos los eventos y, además, que tendremos otros archivos que se relacionencon éste, como es el caso de los demás datos asociados al sujeto Juan Pérez P.(con su dirección, número de identidad o de socio, estado de pago de sus cuotas,etc.). Así, debemos complementar el modelo conceptual con todos los demásarchivos y definir con claridad las relaciones que existen entre los atributos detodos ellos.
Una base de datos óptima trata de evitar estas repeticiones, llegando a unaestructura más funcional a través del proceso llamado "normalización" (Ver nº2.2).
2.1.4. Dominios
Otro aspecto de los datos ha de ser tomado en cuenta en el modelamiento de lasrelaciones, especialmente con miras a extraer meta-datos y aplicar operacionestendientes a extraer nuevos conocimientos, como la data mining. Es el hecho deque los referentes o entidades pueden pertenecer a dominios totalmentediferentes. En una fábrica, el inventario de materias primas y de productosterminados pertenecen a un mismo dominio. Pero el proceso de transporte yentrega a los mayoristas o distribuidores pertenece a otro dominio. En un casocomo éste es fácil percibir la diferencia porque salta a la vista que el primero esdel tipo "sujeto" (estático) mientras el segundo es del tipo "evento" (dinámico,transaccional). Los procesos administrativos (contabilidad, manejo de personal,etc.) son también transaccionales, pero no son del mismo dominio que eltransporte. Lo mismo ocurre en nuestro ejemplo de la mutual de salud: los sociosy beneficiarios pertenecen a un dominio, los eventos que corresponden aprestaciones a otro, y las prestaciones en cuanto técnicas de intervenciónconstituyen un tercer dominio, que no se describe del mismo modo que loseventos en los cuales se aplican aunque, como lo hemos visto, existen relacionesciertas y necesarias entre estos diversos dominios.
Una buena modelización de datos debe tomar en cuenta estas diferencias paraorientar el análisis futuro de las relaciones entre los datos: en algunos casospodrán darse relaciones entre dominios diferentes, mientras en otros todas lasrelaciones de importancia (o la finalidad del análisis) se concentrarán en un sólodominio. En la investigación que describiremos más adelante (Capítulos 5 y 6) -la "explotación" de una base de datos noticiosos - nos concentramos en labúsqueda de patrones en un sólo dominio (intra-dominio), mientras en un medioperiodístico podría ampliarse la exploración a patrones inter-dominios, como porejemplo "cruzando" datos noticios con datos biográficos de los personajesimplicados.
38

2.2. Normalización de datos
2.2.1. Primera forma normal
La "normalización" del modelo de datos se realiza en tres etapas. Poner el modeloen primera forma normal significa sacar del conjunto de las entidades del modeloconceptual los atributos repetitivos. Es lo que ocurre cuando separamos ycolocamos en distintos archivos todos los datos asociados a un sujeto,distinguiendo claramente sujetos y eventos.
Ejemplo: En el caso del socio Juan Pérez, podríamos tener en una carpetatodos sus "antecedentes" (identidad, dirección, categoría socio-económica,cuotas pagadas, prestaciones recibidas, etc.). Pero es preferible crear una basede datos donde tendremos una tabla destinada a recibir los datos personales delos socios y otras más: con los datos de las cuotas cobradas, con los tipos deprestaciones, con las prestaciones efectuadas, etc.
Gráfico 2.2.1 : Primera forma normal
SocioPrestaciones
otorgadas
1 NTipos
N M
PRIMERA FORMA NORMAL:
Sujeto: Juan Pérez Pérez
Carpeta
Fecha - tipo...
NºDomicilioCategoríaBeneficiarios
Cuotas pagadas
Prestaciones otorgadas
Fecha - monto ...
Beneficiario
1 N
Pagos
1N
39

2.2.2. Segunda forma normal
Pasamos a la "segunda forma normal" cuando transformamos todas lasrelaciones M:N en relaciones 1:N. Así, en el ejemplo anterior, hemos de eliminar(transformar) las relaciones entre las prestaciones otorgadas y los tipos deprestaciones. Así, se relaciona a un socio con un tipo de prestación (que puedehaber ocurrido N veces) de la siguiente manera:
Gráfico 2.2.2 : Segunda forma normal
SEGUNDA FORMA NORMAL:
Prestacionesotorgadas
TiposN M
FORMA INICIAL
SIGNIFICADO
Tipo 1
Tipo 2
Tipo 3
Tipo 4
J.Pérez P. 1/4/99
J.Pérez P. 3/6/99
A.Ríos B. 1/4/99
Socio1 N 1N
TipoPresta-ción
2.2.3. Tercera forma normal
Para acceder a la "tercera forma normal", debemos resolver las transitividades enlos atributos (datos) repetidos, dejándolos cada uno exclusivamente en el registroque corresponde a la entidad a la cual pertenece y reemplazando eventualmentelos enlaces (relaciones) por códigos de asociación que, en sí mismo, no tienensignificado alguno (generalmente designados como "Id").
40

Gráfico 2.2.3: Tercera forma normal
Socio TipoId.
Presta-ción
DiagnósticoFecha
Gráfico 2.2.4: Modelo canónico (ejemplo)
SOCIO
NombresApellidosNºDomicilio
BENEFICIARIO
NombresApellidosNº
PRESTACIONOTORGADA
FechaDiagnóstico
PAGO
FechaMonto
1
1
1
N
N
1
N
1
1
N
CATEGORIA
TipoCargo mensual
1
N
PRESTACION
TipoValorPrestatario
N
1
Id socioId categ.
Id socioId pago
Id benefId pr/ot
Id pr/otId prest.
Id socioId benef
Id pagoId categ.
Id socioId pr/ot.
41

2.2.4. Modelo canónico
Esto nos conduce al llamado "modelo canónico", que es el modelo teórico apartir del cual se diseñará la base de datos y que incluye la lista de los atributos decada uno de los archivos (tablas) que conformarán la base de datos así como lasrelaciones entre las tablas (que pueden a su vez constituir tablas, aunquesolamente con pares de códigos -los hexágonos del gráfico-). Siguiendo nuestroejemplo, el modelo canónico podría ser como indicado en el gráfico 2.2.4.
2.3. Diseño físico
Al análisis y desarrollo del modelo conceptual de la información, tal comoacabamos de hacerlo, sigue la toma de decisión relativa a la forma concreta enque se construirá la base de datos, etapa denominada de "diseño físico". Lostipos de diseño con que nos podemos encontrar para el registro de noticias sonesencialmente tres: un modelo que podríamos llamar "compacto", quecorresponde al que se usa generalmente para bibliografías, el modelo relacionalde tercera forma normal o "canónico" y el modelo utilizado en dadtawarehouse,que es altamente redundante.
2.3.1. Modelo "compacto"
El concepto básico de este tipo de modelo consiste en establecer una relación bi-unívoca entre una entidad (un hecho noticioso en nuestro caso) y un registro de labase de datos. Este registro equivale a una "fila" o "tupla" y el conjunto conformauna única tabla, en que quedaría contenida toda la información. De este modo,todo el llamado "espacio informativo" queda representado en esta tabla, que tieneun doble orden: la secuencia de las entidades y la secuencia de los atributos,llegando a una representación teórica que corresponde a un cuadro de dobleentrada como el que se adjunta y que corresponde al llamado "modelo entidad-relación" (ver Tabla 2.3.1). En él, cada atributo tiene una posición fija,definiendo una columna de la base de datos.
Tabla 2.3.1: Estructura de tabla única
AtributosNº id. a b c d . . .
123
. . .
42

Si a alguno de los atributos, para una misma entidad, pueden corresponder variosvalores - como en el caso de los descriptores temáticos - en una tabla de este tipotenemos dos posibles soluciones: o bien (solución frecuente en archivosbiliográficos) colocar estos múltiples valores en un mismo campo de datos(celdilla de la columna correspondiente) o bien crear tantas columnas comovalores pueden ser admitidos, para respetar el principio de relación bi-unívocaentre el referente y su representación en el correspondiente registro de la base dedatos. Como ya sabemos, este tipo de tabla no está "normalizado" y, si ocurreeste tipo de multiplicidad, su tratamiento tanto estadístico como por medio de"minería de datos" es prácticamente imposible. Como lo veremos, los otrosmodelos solucionan este problema de manera diferente.
2.3.2. Modelo canónico
Ya hemos explicado detalladamente en qué consiste el modelo canónico y cómose llega a la "tercera forma normal". Esta normalización, como lo sabemos,obliga a eliminar toda redundancia y a asegurar que a cada valor de un atributocorresponda una fila en la tabla que le corresponde. La combinación quecorresponda a una multiplicidad de valores de diversos atributos podrá serobtenida mediante una operación de multiplicación lógica propia del álgebra deconjuntos. Así, por ejemplo, para una entidad con tres atributos, dos de loscuales puedan tomar múltiples valores, deberemos incluir al menos tres tablas enla base de datos:
- una tabla básica con un identificador único (preferentemente numérico) de laentidad y el atributo que sólo puede tomar un valor; si el identificador único noes numérico y secuencial, se agrega normalmente una columna más paranumerar secuencialmente las filas de la tabla;
- una tabla con tres columnas para cada uno de los otros dos atributos: unacolumna para la numeración de filas, una para el identificador único y una paralos valores del atributo.
Así, como se muestra en el Gráfico 2.3.2, el identificador único opera como"clave" relacionando las distintas tablas.
Este modelo es sumamente práctico para extraer con facilidad informaciónestadística y para asegurar la total consistencia de los datos (tema sobre el cualvolveremos en el Capítulo 6). Pero no es el más fácil de utilizar para efectuar unanálisis mediante Data Mining. Esta metodología, en efecto, recurre a un modeloque se aleja de la forma canónica, generando una gran redundancia informativa:el siguiente modelo, del cual hemos de hablar ahora.
43

Gráfico 2.3.2: Tablas asociadas en una BD normalizada (Ejemplo)
1 n
Tabla"descriptores"
id fila en 'd'id únicodescriptor
Tabla base
id únicotitulo
n
Tabla"lugares"
id fila en 'l'id únicolugar
2.3.3. Modelo de datawarehouse
Al contrario de lo que ocurre con los modelos anteriores, el sistema de base dedatos utilizado por sistemas de datawarehousing prefiere verter todos los datosen una sola tabla, aunque sea altamente redundante. Dado que la mayor parte delas "suites" de DM se enfocan hacia el datawarehousing, pocas son las queadmiten operaciones de álgebra de conjunto como para juntar y combinar datoscontenidos en varias tablas. El principio de una BD de datawarehouse se asemejaal modelo que hemos llamado "compacto", pero renuncia a la regla de relación bi-unívoca y también acepta que los atributos puedan tener diversos valores. Si estoocurre, se han de repetir los datos para representar, en varias filas, todas lascombinaciones posibles, como en los ejemplos de las Tablas 2.3.3.
Tablas 2.3.3: Estructura básica de tablas de WH
Tabla 2.3.3a: Operaciones financieras
Atributosid Nombre Cuenta Fecha Ingreso Egreso Cta.rel.1 Pérez León,
Franco120-37195-8 1999.
07.21127.374 32-81476-15
2 Pérez León,Franco
120-37195-8 1999.07.21
35.351 231-53429-7
3 Pacheco Silva,Gustavo
231-53429-7 1999.07.21
35.351 120-37195-8
. .
44
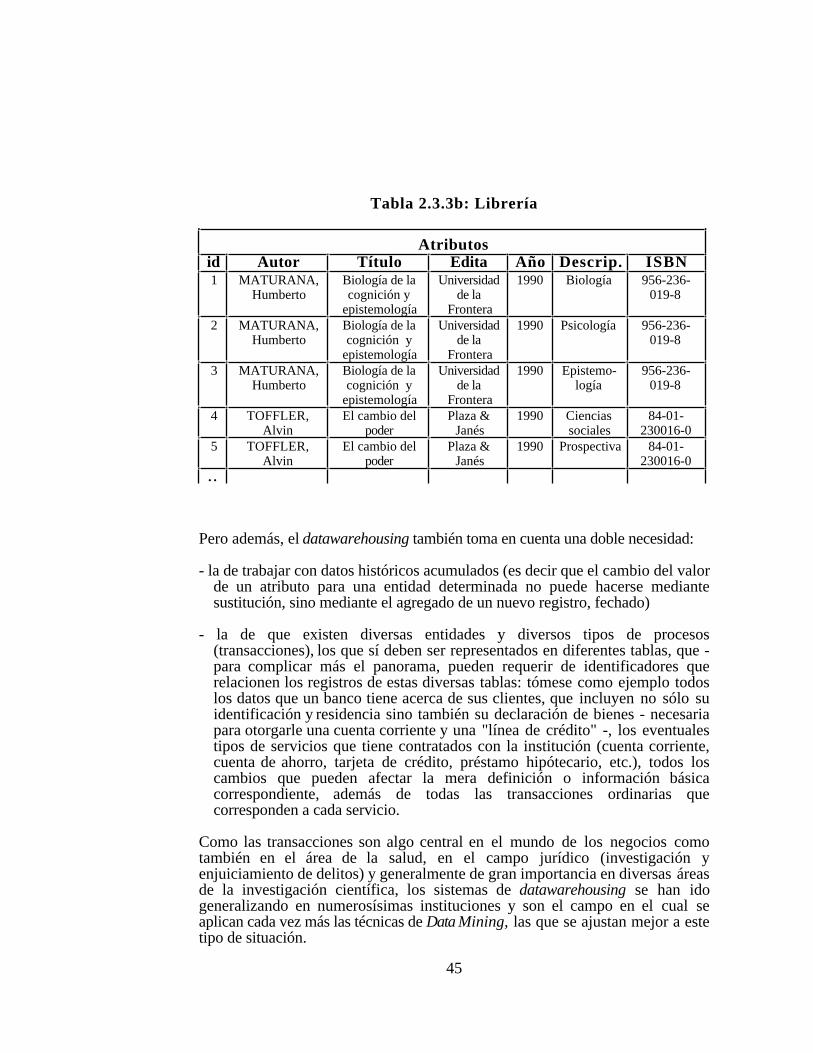
Tabla 2.3.3b: Librería
Atributosid Autor Título Edita Año Descrip. ISBN1 MATURANA,
HumbertoBiología de lacognición y
epistemología
Universidadde la
Frontera
1990 Biología 956-236-019-8
2 MATURANA,Humberto
Biología de lacognición y
epistemología
Universidadde la
Frontera
1990 Psicología 956-236-019-8
3 MATURANA,Humberto
Biología de lacognición y
epistemología
Universidadde la
Frontera
1990 Epistemo-logía
956-236-019-8
4 TOFFLER,Alvin
El cambio delpoder
Plaza &Janés
1990 Cienciassociales
84-01-230016-0
5 TOFFLER,Alvin
El cambio delpoder
Plaza &Janés
1990 Prospectiva 84-01-230016-0
. .
Pero además, el datawarehousing también toma en cuenta una doble necesidad:
- la de trabajar con datos históricos acumulados (es decir que el cambio del valorde un atributo para una entidad determinada no puede hacerse mediantesustitución, sino mediante el agregado de un nuevo registro, fechado)
- la de que existen diversas entidades y diversos tipos de procesos(transacciones), los que sí deben ser representados en diferentes tablas, que -para complicar más el panorama, pueden requerir de identificadores querelacionen los registros de estas diversas tablas: tómese como ejemplo todoslos datos que un banco tiene acerca de sus clientes, que incluyen no sólo suidentificación y residencia sino también su declaración de bienes - necesariapara otorgarle una cuenta corriente y una "línea de crédito" -, los eventualestipos de servicios que tiene contratados con la institución (cuenta corriente,cuenta de ahorro, tarjeta de crédito, préstamo hipótecario, etc.), todos loscambios que pueden afectar la mera definición o información básicacorrespondiente, además de todas las transacciones ordinarias quecorresponden a cada servicio.
Como las transacciones son algo central en el mundo de los negocios comotambién en el área de la salud, en el campo jurídico (investigación yenjuiciamiento de delitos) y generalmente de gran importancia en diversas áreasde la investigación científica, los sistemas de datawarehousing se han idogeneralizando en numerosísimas instituciones y son el campo en el cual seaplican cada vez más las técnicas de Data Mining, las que se ajustan mejor a estetipo de situación.
45

2.4. Explotación básica de los datos
Los datos pueden ser "explotados" (es decir analizados para obtener mayorconocimiento) de diversas maneras, aún antes de aplicar técnicas propias de la"minería de datos". Aún más: pueden ser preparados de tal manera que cierto tipode explotación sea posible, como es el caso del uso de tesauros para codificardescriptores, método bien conocido en el campo de la bibliotecología, que es soloun ejemplo entre los que se agrupan bajo la denominación de "meta-datoscompuestos".
2.4.1. Meta-datos compuestos
En determinados casos, los datos pueden ser agrupados con facilidad encategorías de mayor nivel de abstracción que los originales, lo cual puede ser deutilidad para guiar la exploración por medio de data mining.
Como lo acabamos de señalar, los tesauros son un importante medio de este tipode organización de datos, en este caso -además- jerarquizados en formapiramidal. De este modo se hace posible estudiar lo que ocurre con categorías demayor jerarquía (los "términos genéricos" o 'TG'), especialmente si - al efectuarconteos - los resultados a nivel último de especificidad son demasiado puntualeso dispersos. Gracias al uso de códigos numéricos y "wildchars" (claves desustitución de caracteres) se podría, por ejemplo, considerar toda la categoría"Educación" (código 1.00 del tesauro UNESCO, que se podría reemplazar por1*** o 1%, con los wildchars * o %, según el lenguaje de programación obúsqueda) en lugar de sus términos específicos como los siguientes
1.05 - Educación ambiental 1.10 - Política educativa 1.15 - Planificación educacional 1.20 - Administración educacional 1.30 - Sistemas educativos 1.35 - Instituciones educacionales 1.40 - Curriculum 1.45 - Contenidos educativos básicos 1.50 - Contenidos técnicos 1.55 - Población educacional
Se obtendría de este modo una información asociada a la categoría genérica. Peroes también posible crear otros tipos de datos compuestos. Quizás el atributo quemejor se preste para ello es el de la fecha de un evento. Recuérdese que la formacanónica del registro de una fecha sigue el orden aritmético: Año-Mes-Día (yeventualmente Hora-Minuto-Segundo). Así, basta truncar los datos originalespara obtener datos compuestos de valor categorial, clasificando y contando por
46

ejemplo los eventos por meses y años, y no solamente por días. En este caso,además, es factible realizar comparaciones, como por ejemplo entre el mismomes de diferentes años, práctica muy común en el área de la economía.
El caso de las fechas también nos permite ilustrar otra forma de crear datoscompuestos: se pueden agrupar los meses en trimestres o las fechas en estacionesy, así, comparar trimestres o estaciones de diversos años. También pueden seranalizados los días de la semana, las semanas de cada mes: ciertos eventos seagrupan al principio o al final de una semana - como los accidentesautomovilísticos en fines de semana - o de un mes (compras luego de los días depago), etc.
Pero tesauros y fechas no son los únicos casos. Numerosos datos son enrealidad compuestos, como -generalmente- los números de serie de muchosproductos (que indican modelo, tipo, cadena de fabricación o máquina que losprodujo, fecha o período, etc.), los códigos postales ("ZIP codes"), los númerosde teléfonos, etc. De todos ellos se pueden extraer informacionescomplementarias que, en determinadas circunstancias, podrían ser de sumaimportancia.
Pero este tipo de análisis, obviamente, obliga a crear nuevos campos de datos -para conservar esta nueva información - y a realizar algún procesamientoadicional. Pero un buen conocimiento previo (meta-información que forma partedel "bagage" del analista) permite descubrir con facilidad las abstracciones quepueden resultar productivas a la hora de indagar con más profundidad en elsignificado oculto en las bases de datos. Piénsese, por ejemplo, como se puedenagrupar ciudades en provincias, provincias en regiones o países en continentes yse visualizarán diversos niveles de análisis del factor geográfico aplicable enproblemas de mercadeo, de desarrollo socio-económico, de geopolítica, etc. Losejemplos son innumerables y demuestran que existen ingentes cantidades deinformación dentro de datos en apariencia simples (cfr. Westphal y Blaxton,pp.37-42).
2.4.2. Explotación algebráica
Lo anterior puede ser abordado desde otro ángulo. Los meta-datos compuestospueden ser vistos como el producto de una operación de álgebra de conjunto,llevada a cabo después de construir un modelo de datos que tome en cuentacomponentes significativos que pueden haber sido pasados por alto por eldiseñador original de la base de datos. Se trata simplemente de una operación deUnión, que corresponde a la reagrupación jerárquica (ver Gráfico 2.4.2).
47

Gráfico 2.4.2: Unión de meta-datos compuestos ("Mes de Mayo")
2000-05-18 2000-05-21
2000-05
2001-05-12 2001-05-29
2001-05
-05-
Obviamente, si podemos realizar una operación de unión, hemos de considerarque los datos compuestos se prestan para otras operaciones de álgebra deconjuntos, aunque tanto la utilidad como la factibilidad de ello podrá variar segúnel tipo de información agregada. Si consideramos, por ejemplo, que la primaverase inicia en septiembre en el hemisferio norte pero en marzo en el hemisferio sur,tendremos que intersectar región con estación para comparar los fenómenos quepudieran estar relacionados con el factor estacional. La unión de las dosintersecciones realizadas nos dará el conjunto "Primavera en el mundo" (Gráfico2.4.3).
Gráfico 2.4.3: Intersección de meta-datos compuestos ("Primavera")
-09-21 a -12-20
H.Norte
H.Sur
Primavera
-03-21 a -06-20
2.4.3. Explotación estadística
La forma más tradicional de analizar los datos consiste en recurrir a la estadística.Los principales métodos estadísticos que podemos aplicar son:
48

1. El cálculo de "marginales simples": se trata meramente de sumar lasfrecuencias de los datos de un mismo tipo (atributo) y transformarlas enporcentajes para poder efectuar comparaciones.
2. El cálculo de coeficientes de asociación o predictibilidad: aquí se trata debuscar las correlaciones entre datos correspondientes a diferentes variables(atributos). El método de cálculo varía según la naturaleza de los datos(nominales, ordinales, intervalares, aleatorios contínuos o discontínuos).
3. La extracción de coocurrencias2: técnica que construye una tabla defrecuencias de todas las combinaciones existentes de datos agrupados en pares,lo cual permite con posterioridad construir un mapa de interrelación de losmismos.
No nos extenderemos aquí sobre estos métodos ya que los desarrollaremos conejemplos en los siguientes capítulos.
Conclusión
Tener plena claridad acerca de la estructura de la información no sólo es necesariopara iniciar el diseño de un sistema documental: constituye una forma demetaconocimiento que es altamente significativa e importante para el diseño decualquier investigación que se proponga analizar la información recopilada ybuscar en su conjunto o en sus relaciones conocimientos que vayan más allá de lamera acumulación o de la posible consulta de algunos datos específicos.
NOTAS DEL CAPITULO
1 Cfr. COLLE, R.: "Documentación periodística - principios y aplicaciones", pp.25ss.2 Llamado "análisis de correspondencias" en Francia y "association analysis" en textos
maericanos sobre Data Mining.
49


3
EXPLOTACIÓN AVANZADAO "MINERÍA DE DATOS"
Vivimos en la Era de la Información. La importancia de extraer de datosexistentes un mayor conocimiento acerca de un negocio o una actividad científica- especialmente para lograr ventajas competitivas- se reconoce ampliamente en laactualidad gracias a su mayor factibilidad técnica. Cualquier empresa o institucióngrande o media dispone ya de sistemas poderosos para recolectar información yadministrarla en extensas bases de datos. Incluso empresas pequeñas yparticulares (como los investigadores en su PC de la oficina o de la casa) puedenutilizar bases de datos que se prestan para funciones avanzadas de cálculo. Sinembargo, cuando se pretende transformar estos datos en factor de éxito surge ladificultad de extraer de ellos un verdadero conocimiento acerca del conjuntosistémico que representan. Examinaremos aquí las herramientas que existen paratal propósito.
3.1. Concepto de "Minería de Datos" ("Data Mining")
Es común que grandes empresas dispongan de ingentes cantidades de datosacerca de sus operaciones, sus clientes, el mercado en el cual operan, etc. Así,también, las posibilidades de cruzar variables son numerosas y es imposibleadivinar de antemano, en muchos casos, cuales serían los cruces mássignificativos. Nuevas técnicas computacionales - agrupadas bajo el concepto de"minería de datos" o "Data Mining" - se han desarrollado y permiten descubrirlos factores que pueden ser importantes. Entre ellos se cuentan los sistemas de"descubrimiento de conocimientos en bases de datos" ("KDD": "KnowledgeDiscovery in Databases"), que no se refieren a la extracción de informaciones
51

obvias de los registros acumulados (como lo hacen los "motores de búsqueda" enla WWW) sino a un tipo particular de "meta-información": las características querelacionan de un modo inesperado - o difícil de descubrir - los valores demúltiples variables en una gran cantidad de registros.
"¿Qué mercaderías deberían promocionarse para tal cliente?¿Cuál es el la probabilidad de que cierto cliente responderá a una promoción planificada?¿Puede uno predecir las opciones más lucrativas para comprar/ vender durante la próximasesión de compra/venta?¿Este cliente faltará a un compromiso de reintegro o pago de préstamo en la fechaasignada?¿Qué diagnostico médico debe asignarse a este paciente?¿Cuán altos serán las cargas-pico de una red de energía o de teléfono?¿Por qué empiezan repentinamente a producirse mercaderías defectuosas?
Estas son todas preguntas que pueden probablemente ser contestadas si la informaciónoculta en los megabytes de su base de datos pudiera encontrarse explícitamente y serutilizada. Modelar el sistema investigado, descubriendo relaciones que conectan lasvariables en una base de datos son el objetivo de la minería de datos". (MegaputerIntelligence)
Grandes bases de datos contienen siempre - como se viene comprobando -mucha "información oculta" que es de gran valor conocer. Los métodos de DM(Data Mining) permiten descubrir esta información y transformarla en un valiosoconocimiento tanto retrospectivo (histórico) como prospectivo (proyecciones) o"comprensivo" (entender lo que ocurre), siendo así muy importante para lastomas de decisiones en las empresas, organizaciones y gobiernos. Por lo tanto,la DM es por esencia una metodología de exploración y descubrimiento. Una vezobtenido un resultado - por ejemplo un patrón de comportamiento de un posiblesujeto (natural o jurídico) - y transformado dicho resultado en modelo decontrastación para ser utilizado repetidamente con posterioridad, este nuevo uso -que también es una investigación - ya no puede ser llamado "minería de datos",porque no apunta a descubrir un conocimiento nuevo (Westphal y Blaxton, p.6)
Las razones para la popularidad creciente de la DM son esencialmente tres:
1. el creciente volumen de datos que maneja toda organización:
"Según la información del centro de investigación GTE, sólo las organizaciones científicasalmacenan cada día sobre 1 Tb (terabyte) de nueva información." (Megaputer Intelligence)
2. las limitaciones del análisis humano:
"Dos de los otros problemas que emergen cuando los analistas humanos procesan datosson la inadecuación del cerebro humano para buscar en los datos dependenciasmultifactoriales complejas y la carencia de objectividad en este análisis." (MegaputerIntelligence)
3. el bajo costo del aprendizaje automático (Machine Learning): mientras laminería de datos no elimina la participación humana para resolver la tareacompletamente, simplifica significativamente el trabajo y permite a un analista
52

que no es un profesional de las estadísticas y de la programación administrar elproceso de extraer conocimiento a partir de los datos.
Los métodos de DM son variados y el software existente incluye habitualmenteuna "batería" de programas que operan de distintas maneras y entregan distintostipos de resultados, en su mayoría acompañados de formas visuales destinadas aponer en evidencia las relaciones descubiertas. Estos métodos pueden seragrupados además en dos categorías de acuerdo a características estructurales delos datos que son fundamentales:
• manipulación de datos estructurados (caso de la mayoría de las bases de datos:se ha de conocer o definir con anticipación el formato de cada campo de dato,p.ej. numérico o de cierto número de caracteres), o
• manipulación de datos no estructurados, como son los textos (sean archivos deformato .txt, bases de datos de "texto completo" o imágenes digitalizadas).
Operaciones propias de la Minería de Datos
Los autores que abordan la DM señalan diferentes tipos de operaciones.Señalamos aquí las que hemos encontrado en diversos papers sobre el tema:
• Clasificación: encontrar una función que combina registros en una variedad decategorías discretas.
• Estimación: "llenar vacíos" (datos desconocidos) en una serie en función delvalor de los datos conocidos. Se realiza habitualmente mediante el cálculoestadístico de una "curva de regresión" (línea que recorre del mejor modoposible el conjunto de los valores conocidos).
• Predicción: descubrir un patrón a partir de ejemplos y usar el modelodesarrollado para predecir valores futuros de una determinada variable. Se basanormalmente en una etapa previa de clasificación y puede ser una extensión dela "estimación".
• Detección de relaciones: buscar las variables independientes más influyentesrelacionadas con una determinada variable dependiente.
• Modelamiento: encontrar fórmulas explícitas que describen dependencias entrediversas variables.
• Segmentación (Clustering): identificar grupos de registros que son similaresentre sí pero diferentes del resto de los datos, y especialmente las variables queproveen la mejor agrupación posible.
53

• Análisis de canasta: procesamiento de los datos de transacciones a fin deencuentrar grupos de productos que se venden bien juntos. Se buscan tambiénlas reglas de asociación que identifican el mejor producto a ofrecer con unconjunto preseleccionado de otros productos (recomendación de compra).
• Detección de desviación: determinar los cambios más importantes en algunasmedidas claves, en relación a valores esperados o previamente conocidos.
Lo normal es que estas operaciones estén acompañadas de alguna técnica quefacilite la visualización gráfica de los resultados o que utilice ésta para refinar elanálisis.
3.2. Los métodos de Data Mining
La DM no es una simple aplicación computacional de la cual existirían en elmercado varias "versiones": es esencialmente un método de trabajo, que puederecurrir a múltiples aplicaciones, siendo alguna más adecuada que otras en uncaso determinado. Tampoco es una técnica cuya aplicación lleve en formaautomática a un resultado: es - como muy bien lo señalan Westphal y Blaxton -un método de descubrimiento interactivo (p.16), especialmente adecuado en unescenario en que no se tiene la menor idea de cual podría ser el producto de lainvestigación. Por lo tanto es especialmente adecuado en los casos en que lastécnicas clásicas de análisis estadístico resultan inaplicables. Pero hemos deinsistir: las herramientas de DM no entregan nunca por sí solas ninguna solución.Todo depende del conocimiento de ellas por parte del analista y de la creatividaddel mismo.
Aunque la minería de datos incluye sin embargo, a veces, alguna técnicaestadística (como el análisis de regresión) y parte con técnicas relativamentesimples de DataWarehousing consistentes en facilitar consultas y producción deinformes ("reportes"), cuando se habla de Data Mining se apunta normalmente asus formas más avanzadas, las que se agrupan fundamentalmente en dos grandesmodos de operar: OLAP y KDD.
3.2.1. OLAP
Una metodología ya "clásica" en minería de datos es la llamada OLAP ("OnLineAnalytical Processing"). Esta metodología se centra en la base de datos de talmanera que el ordenador pueda contestar en forma rápida un conjunto deconsultas relativas a combinaciones de variables. En vez de considerar la BD enforma bidimensional (como la tradicional planilla de cálculo), OLAP permiteconsiderar cada columna de la misma como un eje en un cubo multidimensional.Para cada dimensión (atributo o variable cuyo valor representa una característica
54

de la entidad representada en el registro), OLAP calcula y registra los totales,clasificándolos y segmentándolos eventualmente en forma interactiva. Estopermite obtener una rápida visión de las informaciones que corresponden a estasclasificaciones, si el usuario sabe qué tipo de pregunta realizar, lo cual nosiempre es obvio (al contrario: en conjuntos masivos de datos, puede serextremadamente difícil formular preguntas significativas).
Pero esto no aborda ni resuelve el problema de las relaciones que pudieran existirentre el valor de un atributo y otro valor de otro atributo, y que permitirían -porejemplo- averiguar cual es el factor más decisivo o más "explicativo" de unadeterminada situación o un determinado resultado comercial. Un método másavanzado es necesario, y éste es el propósito de la metodología KDD.
3.2.2. KDD
La KDD ("Knowledge Discovery in Databases") pretende extraer unconocimiento escondido en las bases de datos "a mayor profundidad" y requiere,por lo tanto, herramientas más avanzadas. Éstas se han adquirido a través de losavances en el campo de la Inteligencia Artificial y, más precisamente, delaprendizaje automático (machine learning). La capacidad de aprendizaje artificialde KDD permite que el análisis que realiza descubra las relaciones significativas,los patrones repetitivos y las anomalías escondidos en los datos. Con estemétodo, el analista ya no necesita adivinar qué pregunta formular: el softwarebusca en forma automática todo el conocimiento que se puede extraer.
Sin embargo, como es sabido, las técnicas de Inteligencia Artificial - a las cualesrecurre-, por ahora no son aplicables en ámbitos generales (como el delperiodismo) sino sólo en dominios bien definidos, si se quieren obtener buenosresultados. Esto no quita que se hayan hecho grandes progresos en el aprendizajeautomático orientado a la inducción, lo cual es muy favorable para inducir reglasasociativas a partir de grandes conjuntos de datos, como se lo propone la mineríade datos. La intervención externa -mínima- de quienes conocen la problemática ala cual están asociados esos datos permite "afinar" el método y ajustarlo a lasnecesidades del usuario experto ("KDD supervisado"), quién podrá, con másfacilidad y precisión, interpretar los resultados.
Existe software de KDD que requiere supercomputadores o máquinas quefuncionen en paralelo. Pero también existen alternativas que ya operan enestaciones de trabajo menos costosas, generalmente al alcance de cualquierempresa mediana. Mientras tanto las herramientas que operan con OLAP están alalcance de los ordenadores personales con procesador Pentium 3 o superior,aunque - en la mayoría de los casos - exigen disponer de bastante memoria RAMy operan con más facilidad si la mayor parte de los datos son numéricos.
55

3.3. Principios básicos
3.3.1. Reiteración
El método de investigación es esencialmente reiterativo: se explora una posiblecombinación de factores y, como la primera revisión rara vez da buenosresultados - y aunque lo parezca - se vuelve a probar otra. También es normalque se apliquen varias técnicas o se recurra a diversas herramientascomputacionales (aplicaciones) para ver cual arroja los mejores resultados que -recordémoslo - han de ser nuevos conocimientos acerca de "lo que ocurre" en el"mundo" que corresponde al espacio informativo cubierto por la base de datos yacerca de lo que "se esconde" en ella.
3.3.2. Temporalidad
Una investigación de DM no puede extenderse más allá de algunos días o un parde semanas. Si no se obtienen resultados de interés en este período de tiempo, seha de volver a los supuestos iniciales o cambiar de herramienta. Sería muy raroque no se encuentre nada, pero puede ocurrir cuando los datos no sonconsistentes o son demasiado pobres, pero este tipo de situación puede serdescubierta de antemano. Si se utiliza la metodología adecuada, lo normal es queciertos patrones empiecen a aparecer de inmediato, y las reiteraciones permitiránampliarlos o reconfigurarlos practicamente "al vuelo". (cfr. Westphal y Blaxton,p.19).
3.4. Etapas de trabajo
3.4.1. Fase preliminar
1. Asegurar la disponibilidad de los datos y su coherenciaNada se podrá hacer si no se dispone de la totalidad de los datos en un formatodigital - idealmente en una o varias bases de datos - y si los datos no sonconsistentes (Si el nombre de un cliente o producto se encuentra escrito dediversas maneras, no será considerado como uno solo y el proceso de DM seráinútil). (ibidem, p.20).
2. Definir la apariencia externa del problemaPara realizar la DM, es necesario entender la problemática en la cual seinscriben los datos. No basta con querer encontrar "cualquier cosa que puedaser de interés". Es necesario figurarse ya algunas de las preguntas que sepodrían hacer u obtener y ejemplos - aunque puramente imaginarios - deposibles resultados. El proceso mismo permitirá entonces - en sus etapas
56

reiterativas - afinar el modo de enfocar los datos y los objetivos, aunque elresultado podrá ser bastante diferente de lo imaginado. (ibidem, p.21).
3. Si el problema es complejo, dividirlo en partesDe nada sirve tratar de abarcar todas las posibilidades de una sola vez. Ante lacomplejidad, más vale subdividir los objetivos y abordarlos uno por uno,eventualmente con distintas técnicas, reuniendo los resultados - si es factible yesclarecedor - en un conjunto único solamente al momento de producir uninforme final. (ibidem).
4. No olvidar nunca el destinatario final (la audiencia)¿Quiénes usarán el conocimiento nuevo extraído? ¿Con qué propósito? Estosobjetivos, que van más allá de los objetivos de la investigación en sí mismason igualmente importantes y es necesario que el analista los conozca. Por lotanto, conocer ejemplos de uso y conocer a quiénes se beneficiarán es tanimportante como oír de ellos ejemplos de resultados, cosas que, por lo demás,estarán generalmente ligadas. Pero no es lo mismo trabajar para ejecutivos(tomadores de decisión) - especialmente si tienen formación ingenieril - quepara los jueces en un tribunal o para un grupo de comentaristas del sectoreconómico, político u otro. (ibidem, p.22).
5. Vencer la inercia institucionalSi una institución solicita el trabajo, gran parte de este tipo de inercia - laresistencia al cambio - ya habrá sido vencida, aunque no ha de descuidarse larestante inercia relativa al aprovechamiento real del conocimiento obtenido.Pero si uno trabaja en una institución y sugiere introducir la minería de datoscomo una nueva forma de aproximación a la realidad y de obtención deconocimiento acerca de la misma, puede enfrentarse con una dramáticanegativa sea por desconfianza o incomprensión de los procedimientosingenieriles en general1, sea porque se estima que los cambios sugeridos porlos primeros resultados serían demasiado drásticos o costosos. Westphal yBlaxton citan el caso de compañías de seguros que, con data mining,descubrieron fraudes reiterativos - que les costaban millones - pero quedecidieron suspender la investigación y no perseguir a los culpables porque elcosto de los juicios podrían ser aún mayores.
3.4.2. La preparación de los datos
Uno de los aspectos más importantes de la minería de datos consiste enasegurarse de que los datos se encuentran en un formato adecuado, capaz de serexplorado con las herramientas existentes. El llamado "modelo de datos"(representación generalizada de la estructura de la información) será, en efecto, elque determine lo que será posible extraer.
"Un buen «minero», sabrá qué tipos y clases de patrones pueden ser identificados antes deque el primer registro de datos sea procesado. El proceso de modelamiento determina quécaracterísticas de los datos serán accesibles al usuario para el análisis. Si los datos no han
57

sido adecuadamente modelados, las relaciones críticas contenidas en el conjunto no seránrepresentadas correctamente e importantes patrones no serán detectados, reduciendo lasposibilidades de éxito." (Westphal y Blaxton, p.25)
Los pasos a seguir en esta fase son:
1. Definición de objetivosSe trata de formalizar lo constatado en la "Etapa preliminar", definiendo losobjetivos del trabajo. Se parte de las sugerencias o ejemplos formulados por elcliente, así como de la comprensión que el analista ha logrado obtener del"espacio informativo" en el cual deberá trabajar. Se tratará también de precisarsi las principales preguntas preexistentes se centran en variables específicas ono.
2. Estudio de los atributosSe verificará si algunas variables parecen por naturaleza formar parte de otras o- al contrario - descartarlas (p.ej. el estado civil "soltero" excluye normalmente"número de hijos" - salvo casos de adopción por solteros, admitidos enalgunos países -). También pueden existir variables que sería inútil incluir en labúsqueda en razón de la inexistencia de datos en muchos casos (como la no-respuesta masiva a ciertas preguntas en encuestas) o porque existe granuniformidad en los valores recopilados. De mucho interés es ampliar el análisisde la dispersión de los valores de cada variable: la posibilidad de agrupardichos valores en "bloques" discretos podría ser de gran ayuda.
3. Modelamiento de los datosEs indispensable tener presente el modelo entidad-relación (cfr. Capítulo 2). Seha de observar la estructura de los datos representada en las bases de datos oarchivos existentes, especialmente las relaciones visibles en el modelo desegunda o tercera "forma normal". Si los datos no están normalizados, seránecesario diseñar previamente este modelo. (Posteriormente, según laherramienta de minería escogida, se determinará si los datos deben sertraspasados a una BD de segunda o tercera forma normal, en caso de noestarlo, o bien a una BD redundante como las usadas en DataWarehousing).Recordando que la DM es por naturaleza reiterativa, se podrá modificar elmodelo durante el trabajo, para explorar nuevos derroteros.
4. Consideración de las fuentesSi los datos deben ser extraídos de múltiples fuentes para poder serexplotados, será necesario construir un modelo especial y, posiblemente,realizar transferencias entre bases de datos, lo cual implica un trabajo másextenso y más complejo tanto para el modelamiento como para la transferenciafísica y - sobre todo - para los indispensables controles de consistencia y lasolución de las inconsistencias.
5. Prevención del fan-out o demultiplicación combinatoriaUna de las características de los modelos transaccionales (como el que hemosde utilizar para registrar y analizar hechos noticiosos) es el efecto multiplicador
58

que tienen los atributos. Mientras más atributos se consideren y más valoresdiferentes puedan tomar dichos atributos, mayor será el efecto combinatorio y,consecuentemente la memoria y el tiempo de procesamiento requerido. Es, porlo tanto, importante proceder por pasos que vayan de menor a mayor efectocombinatorio, evaluando - a la luz de los resultados de cada etapa - laconveniencia de incluir más variables (atributos o valores). Esto significa quese debe tener claridad acerca de los "datos compuestos" (ver apartado 2.3.1)que pueden resultar de mayor interés y partir de éstos, por cuanto lasagrupaciones correspondientes reducirán la cantidad de factores que entren enel proceso combinatorio. Se parte, por lo tanto, de un modelo con bajo efectocombinatorio ("low fan out") para encontrar pistas acerca de las combinacionesmás detalladas y complejos ("higher fan out") que podrían generar nuevosdescubrimientos significativos (Westphal y Blaxton, pp.49-50).
6. Limpieza y normalización de los datosLos datos utilizados en DM provienen muchas veces de diferentes fuentes, porlo cual es indispensable asegurarse de su normalización, por ejemplotraduciendo todas las fechas al formato AAMMDD (año-mes-día), el cualpermite un fácil ordenamiento posterior. También han de eliminarse losregistros con datos nulos, asegurarse de que no quedan errores y de que lasmismas entidades han sido descritas siempre de la misma manera.
En los medios de comunicación escritos es frecuente que los nombres depersonas o instituciones sean escritos de las formas más variadas,especialmente cuando se trata de nombres extranjeros. Es indispensablefiltrar y substituir los datos cuyo valor es idéntico pero que el ordenadordiferenciará debido a alguna variación en el tipeo. Por ello resulta muchomás adecuado trabajar con datos codificados (como los tesauros dedescriptores) y tablas "look up" (donde se conserva el significado único decada código).
Formatos complejos como las imágenes y los textos largos deben serseparados, ya que no pueden ser tratados con las mismas técnicas que loscampos de datos numéricos o que contengan pocas palabras (como nombres yapellidos, o descriptores pertenecientes a un tesauro).Además, dado que el modelo de datos (especialmente si se recurrió a la "terceraforma normal") divide frecuentemente en registros de tablas separadas lasinformaciones que conciernen a una misma entidad, es necesario asegurarse deque el sistema podrá producir eventualmente nuevos registros en que todos losdatos sean reunidos, concatenándolos, para que a una entidad corresponda unsólo o varios registros con asociaciones de todos los datos relevantes.Finalmente, dado que las herramientas de DM están diseñadas para adecuarse amúltiples situaciones y plataformas, es también común que exijan que los datossean traspasados a un formato "de intercambio", como ASCII con separaciónpor comas o tabuladores (El formato .CSV es uno de los más usadosactualmente para transferir los contenidos de bases de datos). Es importante,en consecuencia, asegurarse de poder "exportar" los datos de esta manera.
59

3.4.3. La aproximación al problema
3.4.3.1. Niveles de exploración
¿Qué es lo que queremos obtener mediante data mining? Si partimos del "ModeloEntidad-Relación" que constituye habitualmente el fundamento del diseño debases de datos, estaremos sin duda tratando de descubrir nuevas relaciones entreentidades. Esto, como lo señalan Westphal y Blaxton, puede ocurrir en distintosniveles (ver Gráfico 3.1): relaciones simples desconocidas, redes o sistemas.Podemos intentar encontrar "patrones de asociación" en estos distintos niveles,que van - obviamente - de menor a mayor complejidad.
Partiremos - y podemos limitarnos a - las meras entidades, buscandocaracterísticas compartidas: esto nos conducirá a establecer relaciones entre ellas.Pero si un grupo tiene una característica común, es muy probable que existanotros conjuntos con otra característica en común. Las entidades se reagruparánasí de acuerdo a los valores diversos de un mismo atributo. Éstas son lasrelaciones que pueden poner en evidencia la más simple de las estadísticas: elconteo de frecuencias.
Gráfico 3.1: Niveles de exploración
0.Entidades
1.Relaciones
2.Redes
3.Sistemas
Pero ¿no podría ocurrir que las entidades con idéntico valor del atributo Atambién compartan - todas o parte de ellas - también un mismo valor para el
60

atributo B? En términos estadísticos, estamos ahora "cruzando" variables. Y, enla mayoría de los casos de minería de datos, la estadística clásica o "paramétrica"resulta inaplicable porque los datos (valores de las variables - o atributos ennuestro caso -) no son ni contínuos ni ordenados sino nominales, es decir consignificados representados por palabras (o incluso cifras, como los números deseries o identificadores de productos) que no representan en sí mismos ordenalguno o sólo lo representan en un enfoque semántico, como en una taxonomía oun tesauro. Debemos entonces recurrir a la estadística no-paramétrica, porejemplo al coeficiente de predictibilidad mútua lambda de Guttman para laasociación de dos variables nominales.
También podemos registrar estas relaciones como nuevas entidades y analizar, enuna nueva etapa, las relaciones que podrían mantener entre sí. Estamos ahoratrabajando con las entidades, sus relaciones y sus meta-relaciones, lo cual noslleva a un nuevo nivel: el de la red de los datos. Aquí deberíamos poder poner enevidencia el predominio de ciertos "senderos", es decir de la existencia de ciertasubestructura en el conjunto de datos. El Gráfico 3.2 ilustra esta situación y es demucho interés porque la visualización de la red muestra dos aspectossignificativos: la existencia de un "sendero" (las líneas más gruesas, quecorresponden a una mayor frecuencia) y la mayor frecuencia de las subredes decuatro componentes (los 4 cuadrados). En conocimiento de los datos reales, estasindicaciones pueden aportar un meta-conocimiento muy importante. Este es unproducto típico de la minería de datos, que podría ser imposible de captar conotras herramientas.
Gráfico 3.2: Subestructura en una red
La percepción de este doble aspecto nos llevará a un estudio más profundo yaque lo lógico, a la vista del gráfico, será preguntarnos si existe una tendenciageneralizada a que los subconjuntos formados por los cuadrados se unan entre sí,si ocurre predominantemente en forma directa (como en los 3 cuadrados del ladosuperior derecho) o si lo hacen en forma indirecta y, en este caso, mediantecuantos "pasos" intermedios. Estamos ahora analizando el conjunto en formaglobal, es decir como un sistema, y la visualización de datos (VDA) nos hafacilitado esta tarea. Las buenas aplicaciones de DM apuntan a llegar a este nivel eincluyen herramientas de VDA que han de permitir esta puesta en evidencia(Westphal y Blaxton, pp.58-60).
61

3.4.3.2. Las formas del nuevo conocimiento buscado
Otro aspecto importante a considerar es si el "espacio de datos" que exploramosimplica un conocimiento episódico - es decir relativo a una secuencia de accioneso acontecimientos - o más bien conceptual, independiente de la variable histórica.En otras palabras, ¿queremos saber "cómo son" las cosas o "qué ocurre conellas"? A lo primero corresponde el conocimiento llamado "declarativo", mientrasal segundo corresponde, en términos informáticos, el conocimiento "procedural"("episódico" en psicología cognitiva). Ambos términos - que no son los másapropiados desde el punto de vista de las ciencias cognitivas - corresponden enrealidad a distintos tipos de software. Pueden obviamente darse casos en queambos aspectos se combinan, como ocurre en el caso de la informaciónperiodística.
Si bien se ha de decidir en algunos casos si el aspecto secuencial-histórico tieneimportancia (lo habitual es que un sólo atributo - como la fecha - sea suficientepara ello), también se ha de clarificar si se pretende buscar patrones cuyaexistencia se sospecha o si, al contrario, se desea precisamente encontrar loinsospechado. En otras palabras se formularán y pondrán a prueba hipótesis obien se hará un estudio exploratorio sin ningún o casi ningún supuesto inicial.Estas opciones se enmarcan en realidad en 4 áreas de meta-conocimiento (verGráfico 3.3, traducido de Westphal y Blaxton, p.63):
Gráfico 3.3: Tipos de meta-conocimiento
Conocimientoconocido
CCDesconocimiento
conocido
DC
Conocimientodesconocido
CDDesconocimiento
desconocido
DD
- CC: "conocimiento conocido" es lo que se sabe ya acerca de los datos, antes deiniciar el proceso de DM (meta-datos previos; véase el apartado 1.5 del primercapítulo).
- DC: "desconocimiento conocido", corresponde a lo que se sabe que no sesabe, por ejemplo la frecuencia de cada valor posible de cada atributo (lasnoticias que leen realmente quienes compran su periódico, los términosintroducidos en el motor de búsqueda de su sitio web, etc.). Para esta categoríaexisten herramientas específicas de DM como los algoritmos genéticos, lasredes neuronales o los sistemas expertos.
62

- CD: el "conocimiento desconocido" es lo que no sabemos que sabemos. Estaes la situación más típica de la minería de datos: el conocimiento está ennuestras bases de datos, pero no lo sabemos y quizás no dispongamos (aún)de las herramientas adecuadas para buscarlo. La consecuencia es que - si no lobuscamos - no lo podemos utilizar, a pesar de que pueda tener un valorconsiderable, como la optimización de los servicios ofrecidos, la reducción decostos, la predicción de comportamiento de los clientes, etc. El objetivo de laDM consiste en transformar este contenido en "conocimiento conocido" (CC)lo más pronto y lo más claramente posible.
- DD: el "desconocimiento desconocido" cuyo ejemplo más típico es la ausenciade ciertos datos - que podrían ser importantes - en nuestras bases de datos. Eslo que hace más vulnerable cualquier organización y que, por lo tanto, deberíaser investigado en la forma más exhaustiva posible.
3.4.3.3. Las condiciones del trabajo de DM
Acercándonos al problema de elegir herramientas o métodos de minería de datos,hemos de preguntarnos en qué situación nos encontramos en relación a lascaracterísticas de nuestro conjunto de datos y lo que representan. Podemos estartratando con entidades (objetos o eventos) conocidos o desconocidos y dichoseventos pueden ser representados por variables cuyos valores son predecibles yacotados (variable "cerrada") o impredecibles (variable "abierta"). Esto nos da lascuatro situaciones representadas en el Gráfico 3.4 (adaptado de Westphal yBlaxton, p.67):
Gráfico 3.4: Situaciones de data mining
Reglasautomáticas
CCTop-down
Exponer patrones
CA
Bottom-upDescubrirtendencias
DCAnálisis
proactivo de amenazas
DA
Parámetros
Enti-dades
Var.cerrada Var.abierta
C
D
- CC: Entidad conocida y variables cerradas: sabemos como descubrir todos loscasos que podrían ocurrir; cualquier caso que se presente fuera de losparámetros establecidos será rechazado por el sistema (p.ej. una noticia sinfecha no podrá ser aceptada).
63

- DC: Entidad desconocida y variables cerradas: estamos aquí, en realidad,considerando meta-entidades o conocimientos que deberán surgir mediante DMdel análisis de los datos, como son las tendencias globales que se puedenextraer a partir de la acumulación de casos puntuales (bottom-up).
- CA: Entidad conocida con variables abiertas: aquí se trata de descubrir patronesdiscontínuos y los valores de una o más variables que permitirían clasificardistintas categorías de casos (por ejemplo la determinación de rangos en laasociación entre solicitudes de crédito y volúmenes de compra, o el hecho deque la mayoría de los lectores de noticias con descriptor A pasan a la lectura detextos de análisis en profundidad, mientras no ocurre lo mismo con la mayoríade los que leen noticias con descriptor B).
- DA: Entidad desconocida y variables abiertas: la minería de datos trata aquí dedescubrir prácticas desconocidas (generalmente ilegales) y el posible carácterestructurado de las mismas (como el lavado de dinero mediante numerososdepósitos que son unos pocos dólares por debajo del monto que obliga a losbancos a informar o investigar). Es el área principal de aplicación de la DM en"inteligencia" en el sentido policial o militar del término.
En esta última situación hemos introducido una perspectiva "proactiva". Implicaque se está alerta o se planea el estudio sin saber si ya ocurrieron los hechos deinterés o sin tener en cuenta esta situación. Toda minería de datos puede hacerseen forma proactiva. Pero también puede hacerse en forma "reactiva", que es elmodo opuesto o más bien complementario: aplicarse como consecuencia deldescubrimiento de casos atípicos o de la acumulación obvia de casos parecidos,que llevan a formular una hipótesis que se desea verificar, para mejorar laplanificación de las acciones o la atención de clientes, o para tomar medidasprecautorias. Responde habitualmente a la detección de una situación de crisis.Una DM reactiva puede limitarse a estudiar los casos ajustados al patróndetectado, a diferencia de la proactiva que requiere normalmente considerar latotalidad de los datos, con obvias consecuencias en materia de etapas dedesarrollo, volumen de información a tratar, duración del estudio, reiteración delmismo, etc.
3.4.4. La secuencia básica de trabajo
Las etapas principales de trabajo se señalan en el gráfico 3.5 y son esencialmentecinco: definir el problema, acceder a las estructuras de datos, combinar lasfuentes de datos, realizar la "explotación" propiamente dicha y, finalmente,exponer los resultados.
Hemos de introducirnos ahora en aspectos más concretos de la metodología,dando por supuesto que contamos ya con los datos en un "formato deintercambio" y que sabemos en que "situación" de Data Mining nos encontramos.
64

Gráfico 3.5: Etapas de trabajo
3.4.4.1. Análisis preliminar
El estudio proactivo requiere detectar primero tendencias generales y luegorefinar el análisis, para lo cual se realiza normalmente un trabajo preliminar conuna muestra de los datos (llamada "tajada proactiva") y no la totalidad de losmismos. A diferencia de los métodos estadísticos, la muestra no se elige al azarsino en función de un criterio definido en función de la naturaleza de los datos yde las combinaciones de variables que, según se estiman, podrían sersignificativas (por ejemplo un mes para datos episódicos, un tema para lecturas,una región geográfica para un sistema de reparto). Serán indicadores interesantestanto las más altas frecuencias como los casos que parecen excepcionales. Enambos casos se tratará de ver qué otras características comparten o diferencian loscasos descubiertos de esta manera con lo cual, en cierto modo, el estudioproactivo se torna en reactivo. Se turnan entonces ambos enfoques hastaconseguir los objetivos prefijados (Westphal y Blaxton, p.71).
Aún en los casos en que el inicio deba ser proactivo y no se pueda prever nadaacerca de los posibles resultados, algunas estructuras han de ser definidas a finde determinar qué datos han de ser incluídos en el análisis, ya que mientras másdatos se incluyen, más complejo, lento y exigente en poder de cómputo se vuelveel proceso. Esto es vital si la cantidad de registros supera los 25.000, segúnWestphal y Blaxton (p.85), mientras con cantidades inferiores es generalmentefactible incluir todos los datos, aunque ello también depende de las exigencias dela herramienta computacional de DM que se elija. La clave está en la posibilidadde mantener todos los datos en un sólo disco y en que la herramienta disponga desuficiente RAM para procesarlos. De lo contrario será necesaria una reducciónestructural o un trabajo con múltiples "tajadas" (cada una por separado). Paradefinir la reducción estructural se cuenta obviamente con el "modelo de datos".
65

Y, después de contar con los resultados de la explotación de la "tajada proactiva",se podrá aplicar el proceso a una muestra aleatoria - estadísticamenterepresentativa del conjunto -, para verificar si la selección estructural conduce ono a resultados de interés.
3.4.4.2. Integración o descomposición de datos
La tercera etapa señalada en el Gráfico 3.5. se refiere a la combinación de datosde diferentes fuentes. Estas fuentes pueden ser desde diferentes tablas de unamisma base de datos (caso habitual de las tablas "normalizadas") hasta reportesproveniendo de distintas empresas o investigadores. Obviamente, para suintegración, se requiere contar con un modelo de datos donde "encajen". En estecaso es indispensable verificar la consistencia (valores idénticos o compatiblespara los atributos en común), suprimir las redundancias y - eventualmente -escribir alguna rutina para ajustar los formatos o traducir ciertos códigos ypermitir de este modo que la herramienta de DM escogida opere de la mismaforma en los distintos conjuntos de datos. (Generalmente no es necesario integrartodo en una misma tabla: más bien podría reducir la eficiencia del trabajo).
Los datos numéricos son siempre los más fáciles de procesar, sean valoresaritméticos, fechas, códigos de productos u otros sistemas de clasificaciónnumérica (ISBN, tesauros, etc.). Los datos textuales pueden ser fuente de mayordificultad. Para textos largos existen herramientas de DM a las que no nosreferiremos. En el caso de textos cortos (partiendo por los nombres de personasy su direcciones), es indispensable una cuidadosa verificación de la consistencia,la cual puede ser asegurada - cada vez que sea posible - mediante el uso de unacodificación (con tablas "look up", que susbtituyen el código por su significadoen las instancias de lectura o consulta), codificación que se preferirá siemprerecurriendo a un sistema numérico, sea o no decimal2. Si no lo hizo quién diseñóla base de datos, deberá hacerlo el analista, lo cual puede transformarse en unaetapa larga y tediosa pero indispensable. En un próximo capítulo tendremos laoportunidad de comentar lo que nos ocurrió en esta fase para operar con los"implicados" en las noticias que analizáramos. Obviamente el poder trabajar contablas en "tercera forma normal" asegura en sí mismo un mayor nivel deconsistencia, aunque la multiplicación de tablas que conlleva no esnecesariamente la estructura más favorable al trabajo de minería de datos.
Un proceso que puede parecer "inverso" a la integración es la desagregación dedatos que pueden tener una parte significativa. El caso más común es el de unafecha, que tiene tres componentes: año, mes y día. Se mantendrán los tres juntossi se requiere un "análisis fino", al nivel de los días. Pero, en muchos casos, serequerirá hacer comparaciones mensuales o anuales, para lo cual cada uno deestos componentes ha de extraerse y conservarse en un campo de dato propio(generando una nueva columna en la tabla que los contiene). Lo mismo ocurre siutilizamos un tesauro: si queremos efectuar un análisis a cierto nivel jerárquico(p.ej. las categorías correspondientes a las dos o tres primeras cifras en unsistema de cinco o más cifras), deberemos copiar las cifras representativas en una
66

nueva columna, para que el software de DM pueda acceder a ellas en formadirecta.
3.4.4.3. Transferencia de datos
Aunque la "tercera forma normal" es el mejor medio para asegurar laconsistencia, evitar duplicaciones inútiles y facilitar la confección de estadísticasordinarias, no es "del gusto" de las herramientas más comunes de DM. Éstasexigen habitualmente trabajar con una tabla única, que contenga la descripcióncompleta de las entidades bajo análisis. Si, lo que es poco frecuente, cada entidadse describe con un conjunto de atributos que tienen cada uno, en cada caso, unsólo valor, se podrá confeccionar una tabla única en que cada registro secomponga de los valores de todos los atributos (método llamado "de los registroslargos").
Un ejemplo podría ser el de la Tabla 3.1. (donde podrían agregarse máscolumnas, como para incluir los nombres de los hijos, el monto del sueldomensual vigente, la dirección de e-mail -para quienes la tienen-, etc.):
Tabla 3.1. "Registros largos"
id Nombre Identidad Dirección Teléfono Conyugue1 José Alvarez
Martínez12.235.436-1 Av.Vicuña
3121,Santiago
234.21.28 Marisa SolarVicuña
2 Felipe CastroZunino
5.519.657-0 San Francisco12, Temuco
357.92.23 Clara PastorTorres
3 Andés MéndezZamorano
9.147.382-2 Esmeralda237, Iquique
0 Alicia Castrodel Pozo
Pero como, en muchos casos, existen atributos que pueden aplicarse más de unavez o tomar más de un valor para describir cada entidad (como ocurre con losdescriptores temáticos en una biblioteca), debe utilizarse un procedimientodiferente, de multiplicación de registros cortos. Esto equivale, con algunosajustes, a traspasar, una tras otra, parte o todas las tablas de tercera forma normala una tabla única destinada exclusivamente a la minería.
¿Cuáles son los ajustes que pueden ser necesarios? Los requeridos para que losdatos puedan ingresar a esa tabla única sin perder su especificidad. Lo cualimplica, generalmente, crear una columna en la cual se indica a qué tipo deatributo corresponde el conjunto traspasado (según la definición de la tabla-fuente). Obviamente, este procedimiento supone:
• que el número de columnas de las diferentes tablas-fuentes sea más o menosequivalente,
67
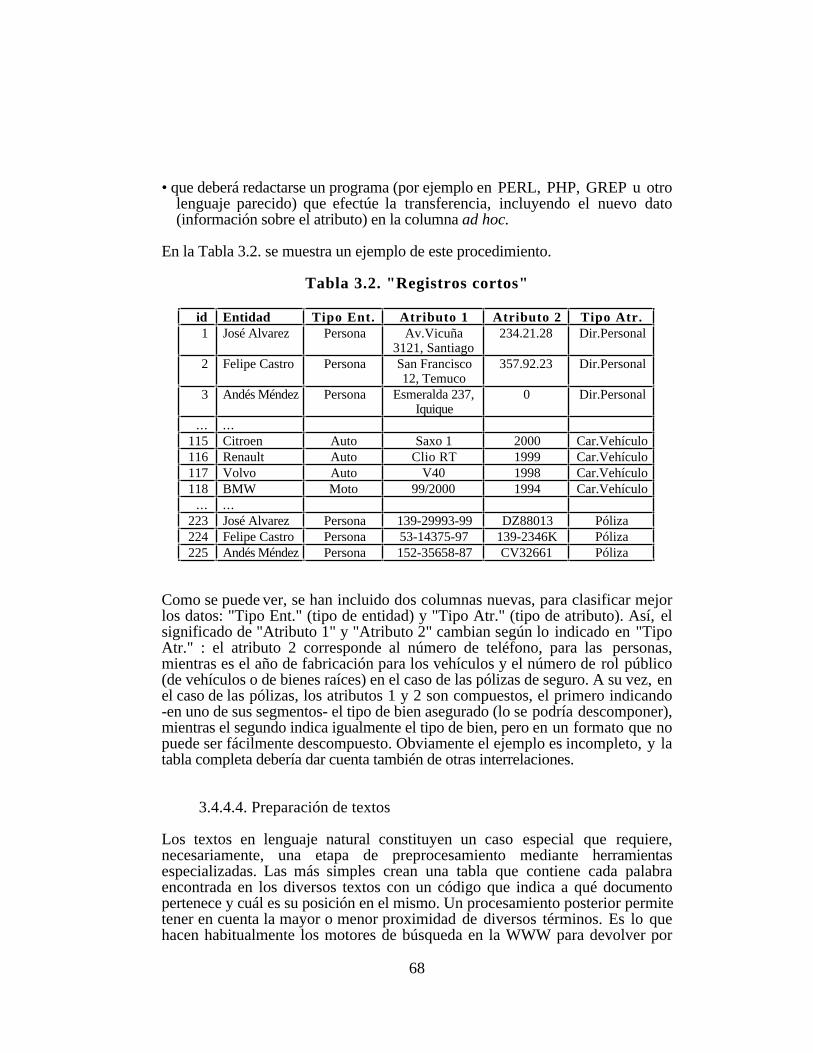
• que deberá redactarse un programa (por ejemplo en PERL, PHP, GREP u otrolenguaje parecido) que efectúe la transferencia, incluyendo el nuevo dato(información sobre el atributo) en la columna ad hoc.
En la Tabla 3.2. se muestra un ejemplo de este procedimiento.
Tabla 3.2. "Registros cortos"
id Entidad Tipo Ent. Atributo 1 Atributo 2 Tipo Atr.1 José Alvarez Persona Av.Vicuña
3121, Santiago234.21.28 Dir.Personal
2 Felipe Castro Persona San Francisco12, Temuco
357.92.23 Dir.Personal
3 Andés Méndez Persona Esmeralda 237,Iquique
0 Dir.Personal
... ...115 Citroen Auto Saxo 1 2000 Car.Vehículo116 Renault Auto Clio RT 1999 Car.Vehículo117 Volvo Auto V40 1998 Car.Vehículo118 BMW Moto 99/2000 1994 Car.Vehículo
... ...223 José Alvarez Persona 139-29993-99 DZ88013 Póliza224 Felipe Castro Persona 53-14375-97 139-2346K Póliza225 Andés Méndez Persona 152-35658-87 CV32661 Póliza
Como se puede ver, se han incluido dos columnas nuevas, para clasificar mejorlos datos: "Tipo Ent." (tipo de entidad) y "Tipo Atr." (tipo de atributo). Así, elsignificado de "Atributo 1" y "Atributo 2" cambian según lo indicado en "TipoAtr." : el atributo 2 corresponde al número de teléfono, para las personas,mientras es el año de fabricación para los vehículos y el número de rol público(de vehículos o de bienes raíces) en el caso de las pólizas de seguro. A su vez, enel caso de las pólizas, los atributos 1 y 2 son compuestos, el primero indicando-en uno de sus segmentos- el tipo de bien asegurado (lo se podría descomponer),mientras el segundo indica igualmente el tipo de bien, pero en un formato que nopuede ser fácilmente descompuesto. Obviamente el ejemplo es incompleto, y latabla completa debería dar cuenta también de otras interrelaciones.
3.4.4.4. Preparación de textos
Los textos en lenguaje natural constituyen un caso especial que requiere,necesariamente, una etapa de preprocesamiento mediante herramientasespecializadas. Las más simples crean una tabla que contiene cada palabraencontrada en los diversos textos con un código que indica a qué documentopertenece y cuál es su posición en el mismo. Un procesamiento posterior permitetener en cuenta la mayor o menor proximidad de diversos términos. Es lo quehacen habitualmente los motores de búsqueda en la WWW para devolver por
68

orden de mayor a menor relevancia las páginas web clasificadas por el motor. Seincluye habitualmente un "anti-diccionario" o lista de palabras no útiles, como losartículos, conjunciones, preposiciones, etc.
Herramientas más avanzadas permiten efectuar y registrar en forma automáticaclasificaciones temáticas, de acuerdo a pautas dadas al inicio del proceso.Algunos de estos sistemas toman en cuenta la gramática mientras otros recurren aaplicacions de Inteligencia Artificial para reconocer unidades semánticas. El costoy los requisitos de hardware varían evidentemente de acuerdo a lo avanzado delas prestaciones.
Es probable que, en el futuro y al menos en el área de la WWW, el trabajo deanalizar textos se vaya facilitando gracias a la introducción progresiva dellenguaje de definición de datos XML, compatible con el actual HTML. El XMLpermite en efecto a los creadores de documentos incluir etiquetas propias con lascuales definir componentes, como por ejemplo:
<actor>Andrés Aylwin</actor><accion>Discurso</accion><tema>Explotación de niños en supermercados</tema> etc...
Al usar con regularidad las mismas etiquetas, los documentos HTML-XMLpueden así ser tratados como si fuesen parte de una base de datos y se puedeprever incluso que nuevos navegadores de web faciliten el pasar de undocumento a otro recurriendo a tales etiquetas. La minería de datos, obviamente,se vería grandemente facilitada con documentos de este tipo, pudiendo recurrir aaplicaciones mucho más sencillas y económicas para su tratamiento.
3.4.4.5. Aplicación de las herramientas
No detallaremos aquí las herramientas que se pueden utilizar (Se enuncian en elnº 3.5). Recordemos solamente de que se trata de un proceso reiterativo, en queel analista ha de avanzar y retroceder, cambiar parámetros, definir diferentesrangos, etc. para buscar pistas. Las aplicaciones que permiten el tratamientovisual de los datos son las más apropiadas para ello y hablaremos de ellas en elapartado 3.5.2.
3.4.4.6. Presentación final de los resultados
Como sabe todo buen comunicador, el resultado real del trabajo depende de laforma en que se presenten los resultados a quiénes lo encargaron o lo tendrán queutilizar. La forma en que el "minero de datos" entiende los resultados no esnecesariamente (ni generalmente) la más adecuada. Dado que nos dirigimosesencialmente a personas que trabajan en el área de la comunicación, no nosextenderemos aquí sobre este punto. Pero, anticipando la importancia que tienen
69

los sistemas de visualización de datos en DM (tema que abordaremos en enacápite 3.6.1.2), podemos recalcar desde ya que tener cierta habilidad para eldiseño gráfico es una virtud no menor que un "minero de datos" ha de cultivarpara poder sacar el mayor partido de sus investigaciones. En este sentido, podríaser de sumo interés que estudie algunos textos sobre Lenguaje Visual y sobreInfografía.3
3.5. Las herramientas de Data Mining
En cierto modo, los "paquetes estadísticos" ya proveen las primeras herramientasde Data Mining, pero la experiencia y la intuición del analista resultanfundamentales a la hora de escoger las variables a analizar y, en particular, lasasociaciones que podrían ser significativas (p.ej. para realizar un cálculo delcoeficiente de asociación nominal-nominal, como el coeficiente de predictibilidadlambda de Guttman).
La minería de datos va mucho más lejos, recurriendo a métodos automatizados,como
- Los métodos de regresión nolineal- La programación evolutiva- Los algoritmos genéticos- Los árboles de decisión- El razonamiento basado en la memoria- Las redes neuronales
Pero dichas técnicas pueden arrojar con más facilidad resultados que informensobre tendencias generales y exigen algunas veces - como, en la mayoría de loscasos, los métodos estadísticos - que se formulen hipótesis al inicio o durante labúsqueda.
Si no se percibe una clara segmentación de las entidades y no se tiene idea deadónde llevará la exploración, lo más conveniente será escoger árboles dedecisión o redes neuronales. Pero incluso las redes neuronales podríandesembocar solamente en informaciones sobre tendencias o categorías demasiadogenerales. Por ello los métodos que incluyen la visualización de los datos son dela mayor importancia y utilidad. Permiten al mismo tiempo tener una visión deconjunto y, mediante mayor "acercamiento" o ampliación (efecto de "zoom"),explorar más detalladamente algunas zonas, descubriendo los patronesinesperados que son los que se está buscando. Hemos de recalcar aquí que losmétodos de análisis visual son un paradigma relativamente nuevo y muy diferentede los métodos analíticos estrictamente numéricos. Su potencia ha sidodescubierta solamente gracias al desarrollo de computadores suficientementepotentes, se ha formalizado principalmente en la llamada "matemática del caos" o"geometría fractal", y se ha demostrado ya ampliamente la universalidad de suaplicabilidad. (Desarrollamos este tema en el ANEXO final de la presente obra).
70

3.5.1. La visualización de datos como método de análisis
Frente a grandes tablas de datos como las que puede arrojar la más simple de lastécnicas estadísticas aplicadas a grandes conjuntos de datos, nuestra memoria seve totalmente sobrepasada. Tal como lo advirtió en una memorable conferenciaen 1956, George Miller dejó en claro que la memoria de corto plazo no es capazde almacenar más de 7±2 pequeños "trozos" (chunks) de información4, o seaentre 5 y 9 cifras de (o palabras y cifras) de una tabla. Pero, como bien lo sabenlos psicólogos cognitivos y los diseñadores gráficos, podemos - con una brevemirada - captar toda la estructura de una imagen y descubrir con facilidad susprincipales variaciones. ¿Acaso no será capaz el lector, después de mirarla en lapágina 199, de recordar la estructura básica del conjunto de Mandelbrot y nohabrá descubierto de inmediato las repeticiones presentes? Y reemplazanevidentemente centenares o miles de cifras, según el grado de ampliación odetalle escogido. Véase en la página siguiente el mapa (parcial) de un proyecto deweb, que no es más que la visualización de la información sobre loshipervínculos registrados en una base de datos a partir de la cual seconfeccionaron las páginas web (Gráfico 3.6). A pesar de la cantidad de datos,es fácil percibir los subconjuntos de vínculos (recuadros punteados) y susdiferentes características, que pueden ser revisadas en detalle si se desea.
Así, los métodos de visualización se han revelado a la vez muy eficientes yconfiables, especialmente para descubrir estructuras "encubiertas", con la ventajaadicional de hacer innecesario cualquier preconcepto y eliminar cualquierprejuicio. Pueden mostrar simultáneamente diversos patrones de relaciones,tendencias generales y casos atípicos, obteniendo una visión global de grandescantidades de datos o desmenuzando pequeños grupos de los mismos.
La visualización tiene también otra ventaja: la de poner de inmediato en evidencialos valores que se encuentran fuera de rango y, por lo tanto, corresponden adatos corruptos o casos excepcionales. Indican, por lo tanto, registros que debenser revisados, corregidos o eliminados del análisis. Pero también pueden existirvalores dentro del rango admisible pero que la imagen mostrará como separadosdel resto, es decir como anómalos. Ésta puede ser una pista de gran interés parala extracción de nuevos conocimientos. La flexibilidad del VDA permite haceraparecer estos casos al "penetrar a mayor profundidad en la mina" de datos.
En efecto, gracias a la interactividad que las aplicaciones de VDA ("Visual DataAnalysis") incluyen, el analista puede no sólo "acercarse" o "alejarse", sinotambién modificar diversos parámetros para ver cómo afectan los datos. De estemodo resulta muy fácil estudiar no sólo los patrones típicos y los casos atípicos,sino también los cambios de escenario ligados al cambio de determinadascondiciones, método que las hojas de cálculo digitales han introducido desdehace tiempo. Mientras los algoritmos de cálculo permanecen oscuros para elusuario,
71

Gráfico 3.6: Páginas de ingreso a un sitio web ludo-educativode Introducción a la Computación5
Programa
1
3f3b
4b
6b
6d
Historia
Arquitectura
Historia
Arquitectura
Lenguaje
Operaciones
Aplicaciones
Prospectiva
Inteligencia Art.
1f
5b
InteligenciaArtificial
Prospectiva
97b
95b
9b
93b 99b90b
3
2
cfin
1
Aplicaciones Operaciones
Lenguaje
Piratería
Tabla
Fin
Informática
index.html
99s
8b
c_in
Directo
Lúdico
Lúdico
72

Gráfico 3.7.Estadígrafo de dispersión
con clusters
Gráfico 3.8.Arbol jerárquico
Gráfico 3.9.Red auto-organizada
Gráfico 3.10a.Paisaje de datos
Gráfico 3.10b.Paisaje de datos
Gráfico 3.10c.Paisaje de datos
73

los resultados son de muy fácil manejo y la alteración de parámetros - con susresultados visuales - permite comprender con facilidad lo que ocurre, lo cualincrementa las probabilidades de éxito en el análisis (cfr. Westphal & Blaxton,pp.123-129).
La visualización puede hacerse de diferentes formas. Ello puede depender de laestructura de los datos y de los resultados deseados, pero también puede serconveniente explorar varias alternativas con un mismo conjunto de datos. Losformatos más comunes son los estadígrafos de dispersión que pueden conducir acategorizaciones oclusters (Gráfico 3.7), los árboles jerárquicos (Gráfico 3.8),las redes auto-organizadas (Gráfico 3.9) y los "paisajes de datos", que puedentomar varios aspectos (Gráficos 3.10 a, b y c).6 Las redes (como la 3.9 o la3.10c) son especialmente útiles porque agregan un nuevo atributo: el de lasrelaciones entre entidades, que pueden ser un importante aporte al meta-conocimiento, poniendo en evidencia entidades que aparecen como nodoscentralizadores o como puntos de articulación (o cuellos de botella) entre sub-redes (el Gráfico 3.9 muestra uno muy claro en la sub-red superior), todo lo cualrequiere obviamente interpretación en función de la naturaleza de los datos. Unaetapa muy interesante del análisis consiste en "borrar" estos datos y estudiar lasconsecuencias para el resto de la red.
Aunque nos limitamos en nuestros gráficos a trazos y tramas, por razonestipográficas, la VDA recurre también a la diferenciación por el color, además depermitir la rotación interactiva, el titileo y otros efectos visuales. Pero ladiferenciación por el color sólo puede ser aplicada a atributos que no toman másde unos seis valores porque de lo contrario se produce un efecto de "arcoiris" quehace ilegible el conjunto. Algo parecido puede ocurrir con la variación de tamaño(sea de elipses o rectángulos) que se hace difícil de percibir si los valores sonnumerosos (excepto en histogramas ordenados, con la escala apropiada).
Recordemos también que dos atributos generan gráficos de dos dimensiones. Asíque entidades con, digamos, diez atributos, generan una matriz matemática dediez dimensiones, lo cual es evidentemente imposible de graficar. Sabemos muybien que la geometría clásica - y sus gráficos - se ve limitada a las tresdimensiones (aunque existen medios para agregar, como cuarta dimensión, lavariación temporal). Por lo tanto, se deberán siempre hacer varias selecciones delos dos o tres atributos cuya combinación será visualizada7. El mismo análisis -siempre reiterativo, como lo hemos señalado ya - tiende generalmente a indicarcuáles pueden ser de mayor provecho.
Si, como ocurre en la mayoría de los casos, se trabaja con datos codificados,debe recordarse que los códigos deberán ser reemplazados por su significadopara producir la presentación final de los datos. Es importante, para ello, reducirlos términos a su forma más breve posible ya que textos largos sobre gráficostienden a hacerlos más ilegibles. También puede ocurrir que esto obligue asacrificar detalles en la vista general, reemplazando un gráfico por varios, condiferentes escalas de ampliación. Y, sin duda, habrá información que serápreferible ignorar (no representar) por cuanto sólo introduciría un factor de
74

distracción o una complejidad exagerada, haciendo más confuso el producto de lainvestigación: así, la "limpieza" de los gráficos finales ha de primar, antes que laexhaustividad.
La presentación visual de los resultados, sin embargo, no excluye la necesidad deque los datos que la sustentan también estén disponibles. Aunque sea imposiblepresentarlos, por ejemplo, en una conferencia donde se dé cuenta de losresultados, estos datos deben estar disponibles y su relación con los gráficosexhibidos debe ser clara e inequívoca. Pero esta documentación -en forma detablas o textos- constituye más un "soporte" o respaldo que el cuerpo mismo delproducto. El usuario final debe poder acceder a ella si lo desea pero no debeabrumarse con ella cuando se le entregan los resultados. Dicha entrega, por lotanto, se compone normalmente de dos partes o fases: la entrega de la "esencia"del contenido, con predominio visual, y la entrega de anexos detallados quesostienen y comprueban los elementos puestos en evidencia.
3.5.2. Otras herramientas
A diferencia de la visualización de datos, existen otras herramientas que no soninteractivas durante su aplicación sino que obligan a determinar las condicionesiniciales, lanzar la aplicación computacional - que resulta ser una "caja negra" (elusuario no sabe cómo opera) - y se observan luego los resultados (que puedenser traducidos a una forma visual) para decidir si son satisfactorios o se han demodificar los parámetros iniciales y reiterar el proceso.
La estadística descriptiva e inferencial es sin duda la herramienta conocida de máslarga data. No nos extenderemos aquí sobre estos procedimientos clásicos. Ellector encontrará ejemplos en el capítulo 5. Recalquemos, sin embargo, que estetipo de herramienta requiere datos numéricos (valores cuantificables) y,generalmente, para profundizar, la formulación de hipótesis que se ponen luego aprueba. Pero los tests estadísticos nunca podrán arrojar información sobrepatrones que se repiten en diversos segmentos o grupos de entidades: sólo sirvenpara tener una visión de conjunto y, eventualmente, hacer predicciones enrelación al comportamiento futuro del conjunto de las entidades o de la poblaciónque ellas representan. Su utilidad en DM, por lo tanto, es extremadamentelimitada.
3.5.3.1. Los árboles de decisión
Si el objetivo del análisis es efectuar clasificaciones sobre la base decombinaciones de atributos, la herramienta más adecuada es el "árbol dedecisión". Los "árboles de decisión" proceden dividiendo en subgrupos elconjunto de datos, estableciendo la existencia de reglas o relaciones que aparecenen forma sistemática. Para ello, el software busca las variables o atributos quepermiten efectuar la mayor segregación posible de las registros correspondientes
75

a las entidades, es decir las que reducen al máximo la incertidumbre (en el sentidode la teoría de la información). Pero se requiere que cada variable o atributo tengaun número muy limitado de posibles valores (idealmente menos de 4 o 5) ya que,de lo contrario, la fragmentación sería demasiado grande para que nuevasdivisiones significativas puedan aparecer en un siguiente nivel (ramificación) delárbol.
Si tomamos, por ejemplo, un análisis de la venta de vehículos - como lo hacenWestphal y Blaxton- si bien en Estados Unidos el atributo "aire acondicionado"es irrelevante (casi todos los vehículos lo tienen), no pasará lo mismo en el conosur de América, donde sí será relevante y permitirá sin duda identificar un grupoespecífico de clientes, con determinadas características socio-económicas. Esaltamente probable que este mismo grupo comprará también vehículos con mayorcilindrada, mayor cantidad de elementos de seguridad, dirección servo-asistida,etc., todos elementos que aparecerán en el árbol de decisión. Lo que no podemosprever (con nuestros conocimientos previos) y podrá revelar esta técnica es, porejemplo, si existe un color preferido y si el segmento etario o el sexo delcomprador juega algún papel, y a qué "altura" en el árbol, es decir cuál es elorden de importancia de estos factores. Este tipo de información puede ser clavepara el buen diseño de una campaña publicitaria.
Una vez elaborado el árbol con un primer conjunto de datos, se somete a pruebaverificando qué cantidad de errores se producen cuando se aplica a un nuevoconjunto. De este modo se puede establecer el grado de precisión de las reglassubyacentes, eliminando las menos significaticas. Y aprendiendo tanto de lascombinaciones que no ocurren como de las que tienen "mayor peso".
3.5.3.2. El análisis de asociaciones
Si lo que interesa son las coincidencias en los valores de algunas variables, sepreferirá la técnica de extracción de coincidencias, típica del análisis de las"canastas de compras" (sea en supermercados, sea en tiendas virtuales enInternet, por ejemplo). Puede haber muchos ejemplos de conductas que (casi)siempre ocurren juntas y que pueden estar relacionadas con variables de otranaturaleza como un sector geográfico o variables socio-económicas o culturales.Y es lo que esta herramienta pondrá en evidencia.
El análisis de asociación recurre a la construcción de una matriz de correlación enque se anota la frecuencia de coocurrencia de cada par de factores. Los datospueden ser tanto numéricos como verbales, perteneciendo a una base de datos o atextos completos, por lo que esta técnica sirve tanto en warehousing como en elanálisis de contenido. Hemos sido pioneros en su utilización para el análisis deldiscurso, creando en 1984 unsoftware de análisis de coocurrencias en textos parael Apple II y, posteriormente (1987-88), una versión para Mac OS llamada"ANATEX"8, que funcionaba en los Macintosh Plus (con 1Mb de RAM) yhemos seguido utilizando hasta el Mac OS 7.x.
76

Lo hemos utilizado numerosas veces en el campo del análisis de contenido, porejemplo en un estudio comparativo de discursos políticos en una campañaelectoral. Para este tipo de análisis, se considera la oración como el conjuntosignificativo o "entidad" y cada par de palabras en el interior de esta unidadgramatical constituye una coocurrencia. Para efectuar el análisis, se han deconfeccionar previamente un diccionario de sinónimos (términos que seránreconocidos y computados) y un "anti-diccionario" de palabras que no deben serconsideradas (como los artículos, conjunciones, etc.), cosa generalmenteinnecesaria en bases de datos normalizadas, salvo que contengan campos de textoque deban ser considerados. Obviamente lo que se puede hacer para analizar laestructura conceptual de un texto con más razón y mayor facilidad puederealizarse en el caso de los conjuntos de datos pertenecientes a un mismo atributo- o, incluso, a varios atributos - en una base de datos.
¿Cómo opera este sistema de análisis? Supongamos que disponemos de una seriede 10 términos aceptables - que representaremos aquí por las minúsculas de la'a' a la 'j' -, y que se seleccionan algunas para formar la descripción de dosentidades distintas. Dos registros podrían contener:
[Registro A:] a, c, e, g[Registro B:] b, d, f, h, i
Las coocurrencias correspondientes son, para el conjunto A:
a-c c-e e-ga-e c-ga-g
y para el conjunto B:
b-d d-f f-h h-ib-f d-h f-ib-h d-ib-i
Supongamos que, ahora, para otras entidades se efectúen las agrupaciones:
[C:] a, d, e, i, j.[D:] b, c, f, g, h.
Son nuevas coocurrencias que, al considerarse todo el super-conjunto (A, B, C,D), han de sumarse a las anteriores, para lo cual es necesario trasladar lainformación a una matriz cuadrada que tomaría la forma siguiente:
77
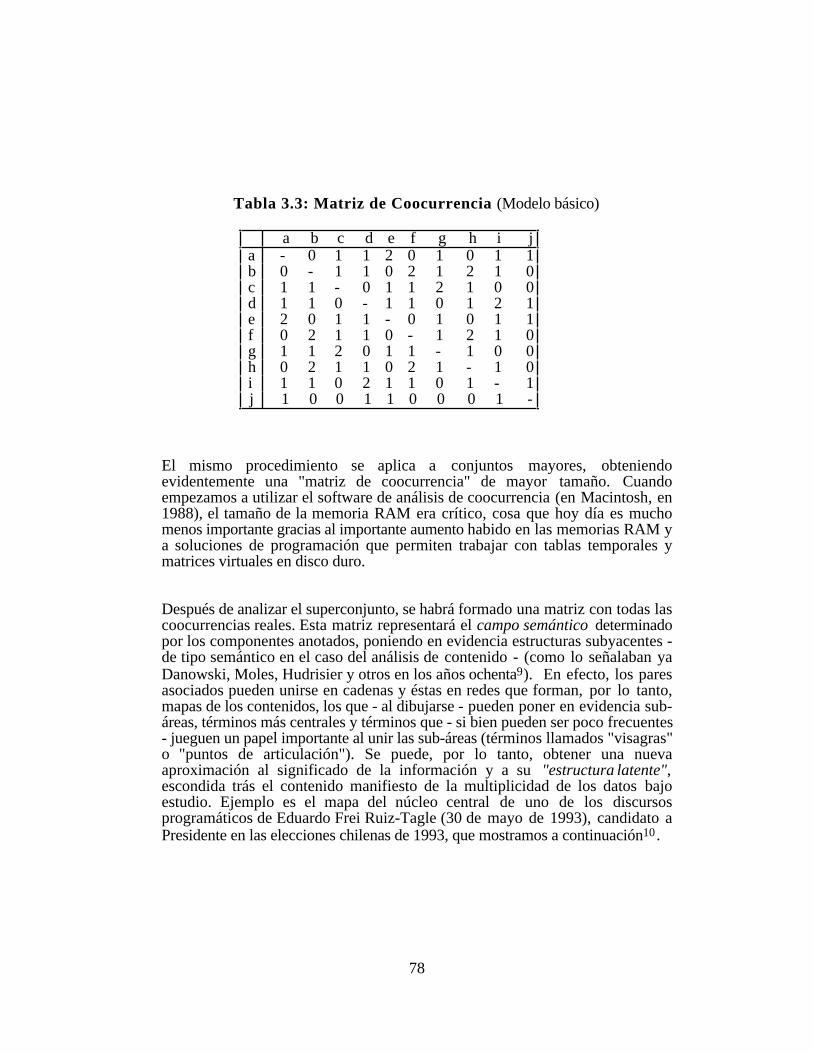
Tabla 3.3: Matriz de Coocurrencia (Modelo básico)
a b c d e f g h i j a - 0 1 1 2 0 1 0 1 1 b 0 - 1 1 0 2 1 2 1 0 c 1 1 - 0 1 1 2 1 0 0 d 1 1 0 - 1 1 0 1 2 1 e 2 0 1 1 - 0 1 0 1 1 f 0 2 1 1 0 - 1 2 1 0 g 1 1 2 0 1 1 - 1 0 0 h 0 2 1 1 0 2 1 - 1 0 i 1 1 0 2 1 1 0 1 - 1 j 1 0 0 1 1 0 0 0 1 -
El mismo procedimiento se aplica a conjuntos mayores, obteniendoevidentemente una "matriz de coocurrencia" de mayor tamaño. Cuandoempezamos a utilizar el software de análisis de coocurrencia (en Macintosh, en1988), el tamaño de la memoria RAM era crítico, cosa que hoy día es muchomenos importante gracias al importante aumento habido en las memorias RAM ya soluciones de programación que permiten trabajar con tablas temporales ymatrices virtuales en disco duro.
Después de analizar el superconjunto, se habrá formado una matriz con todas lascoocurrencias reales. Esta matriz representará el campo semántico determinadopor los componentes anotados, poniendo en evidencia estructuras subyacentes -de tipo semántico en el caso del análisis de contenido - (como lo señalaban yaDanowski, Moles, Hudrisier y otros en los años ochenta9). En efecto, los paresasociados pueden unirse en cadenas y éstas en redes que forman, por lo tanto,mapas de los contenidos, los que - al dibujarse - pueden poner en evidencia sub-áreas, términos más centrales y términos que - si bien pueden ser poco frecuentes- jueguen un papel importante al unir las sub-áreas (términos llamados "visagras"o "puntos de articulación"). Se puede, por lo tanto, obtener una nuevaaproximación al significado de la información y a su "estructura latente",escondida trás el contenido manifiesto de la multiplicidad de los datos bajoestudio. Ejemplo es el mapa del núcleo central de uno de los discursosprogramáticos de Eduardo Frei Ruiz-Tagle (30 de mayo de 1993), candidato aPresidente en las elecciones chilenas de 1993, que mostramos a continuación10 .
78

Gráfico 3.11: Mapa semántico construido sobre la base de unanálisis de coocurrencias temáticas - Campaña electoral de E.Frei
historia
Chile chileno educación
Concertacióngobierno
jóvenes
13
11
10
12
919 9
88
querer
7
partido
7
población
7
7
poder
7
trabajo
7
3.5.3.3. Las redes neuronales
Las redes neuronales son una metodología computacional comunmente utilizadapara para la identificación de patrones y la categorización, que se diferencia de lasanteriormente citadas en la ponderación del valor excitativo o inhibitorio de lasrelaciones entre los nodos que componen la red. La red se va completando ydichos valores se van modificando a medida que se presentan nuevos casos, porlo cual también se dice que es una metodología basada en el aprendizaje artificial,el cual puede ser "supervisado" o "no-supervisado".
El aprendizaje supervisado opera a partir de un conjunto de datos cuya estructuraya es conocida. Se introduce cada serie de datos, verificando la salida que arrojala aplicación. Si no es satisfactoria, se introducen factores correctivos (haydistintas maneras de hacerlo) hasta conseguir outputs satisfactorios. una vez quetodo funciona adecuadamente para todo el conjunto conocido, el aprendizaje haterminado y se puede pasar a la aplicación a nuevos datos, para detectar lospatrones aprendidos y señalar su ocurrencia. Pero en este caso no se realiza unaverdadera minería de datos, ya que se trabaja con conocimiento ya adquirido.
El aprendizaje no-supervisado, al contrario, genera su propia propuesta a partirde los datos recibidos, sin control por parte del operador. En este caso, por cadaentrada los nodos compiten entre sí para entregar un resultado y es el conjunto delas interacciones entre nodos que, ajustando cada vez su "peso" en función del
79

input, determina el output. Así, entradas semejantes activan conjuntos semejantesde nodos y refuerzan su peso, disminuyendo el de otros. De este modo se puedeconstruir un mapa que represente la fuerza de estas interconexiones: estavisualización es generalmente necesaria para poder interpretar los resultados,segmentando los datos en subconjuntos que pueden ser analizados también conotras herramientas.
El producto más conocido de esta técnica son los "mapas de Kohonen", o mapasautoasociativos ("Self Organising Maps" o SOM), desarrollados por TeuvoKohonen, a partir de 1989. El algoritmo en el cual se basan toma un conjunto Ndimensional de objetos como entrada y entrena una red neuronal que convergefinalmente a la forma de un mapa 2D de categorías en las que cada categoríaocupa un espacio proporcional a las frecuencias de sus componentes. El mapapuede tener varios niveles, apareciendo primero el más diferenciador. Si seselecciona una de las áreas representadas, se puede pasar a un segundo nivel conmás detalles (y subdivisiones) de la misma, y así sucesivamente. Los mapas deKohonen han sido utilizado en diversas aplicaciones destinadas a explorar laWorld Wide Web11 y para hacer búsquedas exclusivamente visuales en bancosde imágenes (caso de la aplicación "PicSOM"12 , de la Universidad Tecnológicade Helsinki).
Pero las redes neuronales no permiten saber las razones por las que se obtiene unresultado y no otro y, en ningún caso, permiten hacer predicciones. Estas, enmuchos casos, pueden ser limitaciones muy importantes. Pero su ventaja está enpoder trabajar en forma totalmente exploratoria, sin ninguna hipótesis previa, esdecir en su potencial para generar enfoques realmente novedosos.
3.5.3.4. Los algoritmos genéticos
Esta última herramienta se inspira en el proceso evolutivo, con sus operacionesde selección, cruzamiento y mutación. La selección se basa en la supervivenciadel individuo que se adecúa mejor a su entorno y puede así traspasar suscaracterísticas a una nueva generación. La adecuación se calcula para toda lapoblación (entidades) y los de más alta adecuación pueden reproducirseproporcionalmente, así los de menor adecuación tendrán menos copias de símismos. La selección de los que pertenezcan a una nueva generación se hacenormalmente al azar y se mantiene por lo tanto la proporción entre los más y losmenos numerosos (pero éstos se irán extinguiendo paulatinamente). En losalgoritmos más comunes la población se reemplaza completamente entre unageneración y otra y el tamaño (total) de la misma permanece constante. En otrosse puede actuar sobre algunos factores, y la población total puede crecer odecrecer.
En el cruzamiento, un nuevo individuo procede de la copia de parte de lainformación de cada uno de sus "padres". El acoplamiento se produce al azar, seasegura que todos los registros sean representados y la "reproducción" sedesarrolla de acuerdo a un factor de probabilidad que puede ser modificado.
80

Algoritmos más complejos permiten también determinar los fragmentos"dominantes" y "recesivos" de la información transmitida e introducir cierta tasade mutación (mediante error en la transmisión de los fragmentos), aunquesiempre pequeña porque una mutación leve puede - a la larga - tener efectosdevastadores. Las mutaciones habitualmente permiten ampliar el área debúsqueda de soluciones.
¿Cuál es la utilidad de esta herramienta? Fundamentalmente buscar laoptimización de las soluciones a cierto tipo de problemas. Pero exigen una granuniformidad en la estructura de los datos, porque cada atributo debe codificarseen vectores con igual número de dimensiones. Se usan generalmente para buscarcómo maximizar una rentabilidad o una combinación de características.
3.6. Algunos ejemplos de Data Mining
Las herramientas de Data Mining nacieron fundamentalmente de la ineficiencia deherramientas anteriores (como sistemas de gestión de bases de datos y hojas decálculo) para solucionar dos tipos de problemas: el análisis conducente aproyecciones útiles para la toma de decisión en materia financiera y el requeridopara extraer datos significativos para descubrir conductas ilícitas y proyectaracciones policiales para desbaratar el crimen organizado. También han sido muyimportantes en el campo de las telecomunicaciones, como lo explicaremos acontinuación. No nos extenderemos aquí citando los numerosos ejemplos deaplicaciones que ya existen en la literatura especializada. Sólo nos referiremosbrevemente a algunos casos que pueden inspirar a quienes nos interesamos porlas comunicaciones y más particularmente la información periodística.
3.6.1. Las telecomunicaciones
La telefonía es en sí misma una enorme y compleja red. Y las empresastelefónicas se han destacado por su interés por las aplicaciones de minería dedatos. Así es como la compañía británica de teléfonos (BT) pudo descubrir unagran concentración de fraudes en una limitada región geográfica de la isla. Ycompañías telefónicas americanas, en conjunto con el FBI, han podido detectarredes de apuestas ilegales viendo cómo, en determinadas fechas (coincidentescon ciertos campeonatos) un número inusual de llamados se dirigían hacia unmismo punto, donde fue descubierto el ilegal corredor de apuestas.
Pero recordemos que Internet también es una red de telecomunicaciones. El situarlos servidores con más tráfico y la densidad de las "subidas" y "bajadas" deconsultas es hoy un ejercicio que produce mapas sin gran necesidad de DM(mapas consultables en la misma World Wide Web13). Pero esta herramientapodría ser de mucha utilidad para analizar el contenido de las consultas a los
81

motores de búsqueda, especialmente si se cruzan con la localización de losclientes. Por otra parte, sabiendo que las páginas pornográficas se encuentranentre las de mayor consulta, se podría determinar si existen zonas geográficas enque son más frecuentes que otras (y ponderar en función de la concentraciónlocal de ordenadores por habitantes). Con cierto tipo de acceso a este flujo, sepodría incluso obtener más información acerca de quienes hacen las consultas,por ejemplo si lo hacen desde su hogar, desde un "ciber-café" o desde la empresadonde trabajan.
Las grandes empresas pueden fácilmente filtrar las consultas web que salen ydeterminar si corresponden efectivamente al trabajo o si tal o cual empleado seestá aprovechando de la conexión para su entretención. Hemos conocidodirectamente el caso de un funcionario de una universidad que pretendió enviar aalgunos de sus colegas y a autoridades superiores un correo electrónico anónimodenunciando supuestas irregularidades cometidas por sus jefes. Para ocultarse, lohizo desde una sala de computadores. Pero no contaba con que el número de lamáquina y la hora de envío quedaban registrados junto a su mensaje en elservidor de correo, datos que - analizando la base de datos del servidor - podíanindicar exactamente desde qué terminal de qué sala se había enviado. Y, dado queel supervisor de la sala conocía a todos los que habían ingresado en ese horario,era muy fácil descubrir el autor del anónimo que, por cierto, ya no pertenece a lainstitución.
3.6.2. El mundo de las nuevas tecnologías
La mera lectura regular de las noticias relacionadas con el desarrollo de lasnuevas tecnologías de información nos permite saber que los países que dominaneste sector son Estados Unidos, seguidos por Japón, Taiwán y Corea, así comoalgunos otros países asiáticos que fabrican componentes para empresas de paísesdesarrollados del hemisferio norte. Un trabajo de DM podría eventualmentemostrar la red de relaciones entre estos países y mostrar cuales tienen mayoresrelaciones entre sí. Y también pondría en evidencia que existe un sector en queEuropa se destaca muy claramente: el de las nuevas tecnologías de telefoníamóvil.
3.6.3. Las relaciones interpersonales
Existen múltiples casos en que pueden ser analizadas redes de relacionesinterpersonales. Westphal y Blaxton (pp.148-149) dan el ejemplo de los repartosen el cine: se puede ver cómo se forma una red de relaciones entre los actores queactuaron juntos, descubrir quiénes están más distantes y quiénes se juntan másfrecuentemente. También se hace frecuentemente este tipo de análisis paraanalizar lazos en la comunidad científica, verificando quienes aparecen como co-autores de publicaciones y quién cita a quién, especialmente en artículos de
82

revistas especializadas. Las aplicaciones de DM incluyen generalmente unaherramienta especial para detectar la existencia de estos sub-grupos.
Obviamente se puede hacer lo mismo estudiando el envío y recepción de e-mails,las relaciones mantenidas a través del teléfono, etc. además de las conocidastécnicas de análisis sociométrico en las empresas. Un caso que nos toca de máscerca es el de las personas o instituciones que aparecen involucradas en lasnoticias. Aunque existen, en este caso - como lo veremos más adelante - una grandispersión, también es posible formular e investigar la posible existencia dealgunas redes muy específicas.
Conclusión
Hemos explicado, en grandes líneas, qué es la minería de datos o Data Mining ycómo las técnicas de visualización de datos juegan en ella un papel especialmenteimportante, tanto para la exploración de los datos como para la producción depresentaciones de resultados. Aún en el caso de herramientas que no parten de lavisualización debemos subrayar la importancia de modalidades que terminan enuna representación en forma de red, como ocurre con los árboles de decisión, elanálisis de asociaciones o coocurrencias y las redes neuronales.
Los pocos ejemplos citados han de hacernos sospechar la multiplicidad de loscasos en que es posible recurrir a estas técnicas para extraer, de un conjuntoenorme de datos, conocimientos que de otro modo permaneceríanindefinidamente escondidos e inalcanzables. Ésto habría de llamarparticularmente la atención de quiénes trabajan constantemente con grandescantidades de información, como son los periodistas y documentalistas. En lossiguientes capítulos abordaremos más directamente la forma en que ellos puedensacar provecho de esta metodología para enriquecer su labor.
NOTAS DEL CAPITULO
1 ¡Lo hemos sufrido en carne en propia, nada menos que en el seno de una escuela universitaria,donde se supone que la exploración de nuevas metodologías forma parte de la labor académica!
2 Los sistemas decimales son adecuados para representar jerarquías. Pero una numeraciónaleatoria o que sigue un orden de llegadoa es igualmente válida, aunque no está cargada de una"segunda significación" como en el caso de un sistema decimal-jerárquico.
3 Podemos recomendar aquí en especial el libro de Robert Horn titulado Visual Language -Global Communication for the 21st Century", Brainbridge Island (Wa), Macro VU, 1998.
83

4 Publicada originalmente en la Psychological Review, vol.63, nº2, 1956, pp.81-96. Seencuentra en español en el Capìtulo 2 de G.Miller: "Psicología de la Comunicación" , BuenosAires, Paidos, 1973.
5 De la documentación personal del autor. Colle, R.: "Conceptos Básicos de Computación",Curso por WWW, Santiago, Pontificia Universidad Católica de Chile, 1996. (No es un mapacompleto del sitio ni de todo su componente lúdico sino, como indicado, de la mera secuenciade ingreso a los diversos capítulos). Se puede observar claramente que, en la aproximaciónlúdica, el capítulo de "Historia" es clave para poder pasar a los otros capítulos.
6 El autor dicta por Internet un curso sobre "La Imagen: Ventana al Conocimiento", dondeaborda múltiples formas - actuales y pasadas - de información científica visual. Másinformación en http://facom.udp.cl/CEM/procursos/
7 Existe sin embargo una técnica de VDA que permite representar un mayor número dedimensiones, basándose en un tipo particular de gráfico circular. Se incluye un ejemplo dedicha técnica en el Capítulo 6 (nº 6.4.3.).
8 COLLE, R., MUÑOZ, L. Y ROJAS, H.:"ANATEX", Software de Análisis de Textos paraMac OS, Santiago de Chile, Pontificia Universidad Católica, 1987-88.
9 ACOCK, A.: "Computer-aided content analysis in family research", Paper, Louisiana StateUniversity, 1985.BENZECRI, J.P. & alt.: "L'analyse des données", Dunod, Paris, 1976.DANOWSKI, J.: "A network-based content analysis methodology for computed-mediatedcommunication", art. en Communication Yearbook VI, SAGE, 1982.HUDRISIER, H.: "L'iconothèque", La Documentation Française, Paris, 1983.MOLES, A.: "Teoría de los objetos", G.Gili, Barcelona, 1974.
10 Cfr. Colle, R.: "Análisis de contenido, mapas semánticos y Teoría del Caos", Ponenciapresentada en el II Encuentro Internacional de Comunicación y Cultura, Holguín (Cuba),1997. Véase también Colle, R.: "Teoría del Caos, cognitivismo y semántica", Revista Latinade Comunicación Social, nº3, Marzo 1998. (www.ull.es/publicaciones/latina/). Otrosejemplos en Colle, R., Rozas, E. y Romo, W.: "Presnsa y moral familiar", Santiago deChile, Ed.Pontificia Universidad Católica, 1993.
11 Cfr. Dursteler, J.C.: "Mapas de Kohonen", en "InfoVis", Las Revistas de Infonomía.com, 2-5-2001, y el libro del propio Kohonen citado en nuestra Bibliografía.
12 http://www.cis.hut.fi/picsom13 Véase "An Atlas of Cyberspace", http://www.cybergeography.org/atlas/
84

Segunda Parte
Bases de datos, Metainformación
y
"Minería de Datos" en el Periodismo

86

4LA INFORMATIZACION DE LADOCUMENTACION DE PRENSA
Como lo hemos señalado en el capítulo anterior, no es posible realizar un trabajode minería de datos sin contar con un buen modelo conceptual de los mismos,cosa que, en realidad, debería hacerse antes de diseñar cualquier sistemadocumental. Partiremos aquí de algunas consideraciones generales acerca deldiseño de sistemas documentales -especialmente periodísticos-, para luegoespecificar mejor el "modelo de datos" que corresponde al caso de las noticias.
4.1. Sistema documental periodístico
Obviamente el manejo de la documentación periodística al modo de un "Almacénde Datos" no estará directa o principalmente orientado a influir en decisionesgerenciales concernientes a la empresa periodística, aunque ello no quedadescartado y sí puede influir en decisiones editoriales y en las relativas a la propiagestión de los servicios del Centro de Documentación.
Al desarrollar un banco de datos con fines periodísticos, se ha de tomar encuenta una multiplicidad de factores y, en particular, la necesidad de desagregarinformación para poder recomponer información. ¿Qué entendemos por esto? Lamédula de la información periodística es la actualidad. Pero la actualidad estácompuesta de hechos - principalmente acciones humanas - que se suceden unos aotros. Los acontecimientos son tan efímeros como los días y las horas, mientraslas personas involucradas y –más aún– los escenarios en que ocurren pertenecena un orden de permanencia muy superior.
Por otra parte, en los medios de prensa que conocemos, existe habitualmenteun vacío entre la biblioteca (atlas, libros de historia, "quién es quién",enciclopedia, etc.) y el Archivo de Crónica: vacío de información y ausencia de
87

nexos que conduzcan de un tipo de registro a otro. Para conocer los antecedentesde un personaje público, se requiere a veces revisar gran cantidad de noticias(banco de datos noticioso o carpetas de recortes); para conocer la historia recientede un país debe hacerse lo mismo pero con una cantidad aún mayor de noticiasde diversos ámbitos, lo cual puede resultar engorroso e ineficiente.
Consecuentemente una adecuada economía (de espacio y de tiempo de búsqueda)en un sistema de archivos implica separar las informaciones más permanentes delas más efímeras. Así, datos relativos a personas, instituciones, lugares,instrumentos técnicos o conceptos científicos deberán ser separados de losregistros de acontecimientos (o "Archivo de Crónica", como lo llamamos),reduciendo de este modo la longitud de éstos y facilitando las consultasnecesarias para trabajos posteriores de redacción.
Los archivos que componen un Sistema Documental Periodístico son típicamentelos siguientes (ver Gráfico 4.1):
• Crónica• Biografías• Instituciones• Geopolítico (Sistema político, estructuras ejecutiva y legislativa, etc.)• Soportes audio-visuales: audio, vídeos, fotografías• Enciclopedia (Definiciones, explicaciones de objetos, técnicas, etc. que
no estén en enciclopedias publicadas)• Estadísticas• Diseminación (Datos acerca de los lectores suscritos)
Gráfico 4.1: Sistema documental periodístico
Archivode audio
Archivofotográfico
Archivode vídeos
Archivotopológico
Archivoestadístico
Archivo dediseminación
Archivoenciclopédico
Archivoinstitucional
Archivo decrónica
Archivogeopolítico
Archivobiográfico
Archivo dedescriptores
Se observa claramente el rol central del Archivo de Crónica, donde se encuentrael texto de todas las notas publicadas. Los componentes no-verbales (no escritos)
88

se encuentran en los archivos de componentes de la primera fila: Archivos deaudio, de fotos y de vídeos. Otros cuatro archivos complementan el de Crónica yestán destinados a la navegación para reconstruir el contexto de la información:los archivos de biografías, de antecedentes geopolíticos, de estadísticas, y laenciclopedia (especialmente orientada a explicaciones de descubrimientoscientíficos, maquinarias, etc.).
Se destaca también el Archivo de Diseminación, que contiene la informaciónacerca de los perfiles de requerimientos de los suscriptores. Gracias a su enlacecon el Archivo de Descriptores y de éste con el Archivo de Crónica es posibleseleccionar las noticias para cada cliente, conforme a sus intereses declarados, enun formato compatible con el Tesauro de descriptores de la empresa. Algo apartey de uso estrictamente interno es el "Archivo topológico" que contiene lasreferencias de los artículos publicados en papel (hemeroteca)1.
Hoy todas estas informaciones pueden conservarse en bases de datos relacionalesu orientadas a objetos y estos archivos podrían ser integrados gracias a lossistemas de HIPERTEXTO e HIPERARCHIVOS, de modo que se pueda "navegar"de un archivo a otro sin siquiera tener a la vista las separaciones entre uno y otro,tal como lo hemos demostrado hace tiempo en un sistema experimental creado amediado de los años ochenta con el HyperCard de Macintosh y como lo tenemoshoy en la hiperrevista "Temas de Tecnologías Digitales de Comunicación"accesible en la World Wide Web2 y que nos sirvió para el experimento quecomentamos en la Capítulo 6.
4.2. Bases para el modelamiento de datos3
4.2.1. El registro documental como conversación
En el enfoque de la "Teoría de los actos del habla" (cfr.J.Searle), el registrodocumental ha de ser entendido como la médula de una conversación acerca delreferente. En efecto, está claro que ha de contener lo que el documentalista puedadecir del mismo y las respuestas a lo que el consultante podrá preguntar. Enalgunos casos se exigirá tal exhaustividad (especialmente en el caso de textos)que el referente estará comprendido en el registro documental (Bases de datos de"texto completo").
Pero debería parecer obvio que la mera transcripción - factible en el caso detextos - no asegura, generalmente, una adecuada respuesta. Así, por ejemplo, sise transcriben reseñas periodísticas de hechos noticiosos como "textoscompletos" sin agregar ninguna información extraída analíticamente, será muydifícil encontrar respuestas a preguntas como "¿Qué hizo el Presidente deChile?", "¿Quiénes resultaron heridos en tales tipos de atentados?", etc. Lossistemas actuales no permiten aún un análisis automático adecuado. Se requeriríaun "sistema experto" de análisis de texto para ello.
89

El análisis de los referentes requiere por lo tanto considerar la significación deéstos para las personas que se interesen por ellos. En otras palabras, todoreferente queda "definido" a partir de las conductas semánticas en que estáimplicado. Y una de estas conductas, la lingüística, constituye un modo particularde implicar al referente "en ausencia". En el caso en que esta implicación quedamediatizada por un registro documental, se crea un compromiso entre eldocumentalista y el consultante, acerca de la adecuación de la semiosis (procesode evocación y "reconocimiento" del significado). El problema centralcorresponde por lo tanto en asegurar ésta para evitar incomprensiones, es decirpara evitar "rompimientos" en la comunicación, que impidan a los usuarios de lainformación realizar las acciones posteriores que habían planeado.
4.2.2. Análisis genérico de referentes
Para resolver este problema es posible seguir dos caminos: considerarcaracterísticas genéricas de los referentes (tan generales que no dependen de unuso particular y se reflejan en el lenguaje ordinariamente ligado a ellos) yconsiderar las situaciones particulares que implican descripciones másespecíficas, para contestar preguntas más específicas.
Para describir tanto hechos noticiosos como otros referentes a los cuales puedenremitir archivos documentales, es necesario contar con un sistema constante devariables en función de las cuales se describen estos referentes (son los"atributos"). Pero es también necesario establecer distinciones entre los objetosque deben ser documentados, ya que los atributos variarán de acuerdo a lascategorías genéricas a las cuales pertenezcan éstos. Consecuentemente,distinguir el tipo de referente observado para luego elegir los atributos adecuadospara describirlo son los primeros pasos en el sentido de registrar la informaciónsignificativa.
Luego deben definirse los valores que pueden tomar los atributos. En algunoscasos, estos valores se obtienen transcribiendo datos que aparecen en el referente(por ejemplo el nombre del autor y el título de un libro). Estos son datos"intrínsecos". Pero la mayoría de las veces los datos intrínsecos no son losadecuados. Así, para representar el contenido de un libro o artículo, es pocasveces posible transcribir los datos intrínsecos, que son el texto completo. Ésteno sólo ocuparía generalmente demasiado espacio en un archivo documental:también se presta poco para las operaciones de búsqueda de información.Necesitamos habitualmente saber si se trata cierto tema en un texto o si un objetotiene determinada característica, y -generalmente- falta tiempo para leer unatranscripción o una descripción pormenorizada.
Cómo o qué atributos deben ser seleccionados para describir adecuadamente losreferentes es lo que consideraremos ahora.
90

• Identificación nominal
¿Cuáles son los atributos genéricos que pueden ser utilizados para "documentar"- es decir "representar" en un sistema documental - tanto entidades comoacontecimientos? Ambos tienen al menos un atributo común: la identificaciónnominal o "nombre común" que corresponde a una "clase" de objeto. Su valorserá el término con el cual todo observador se referirá al conjunto de ellos. Así,se describen entidades como "libros", "artículos de revistas", "personas", etc., yacontecimientos como "viajes", "declaraciones", "incendios", "accidentes", etc.
Al respecto deben hacerse dos observaciones. Primero, es posible que elidentificador nominal no permanezca en la lista de atributos considerados para elregistro que documentará cada objeto. Pero en este caso, lo normal es que pase aformar parte de la definición del archivo, como ocurre habitualmente en unabiblioteca (donde habrá archivos constituídos exclusivamente por registros delibros, por lo cual no se registra este atributo). Este atributo se transforma enidentificador de una clase de entidad.
La segunda observación dice relación con el grado de especificidad delidentificador, el cual depende obviamente de la profundidad del conocimiento(especialización) de los usuarios. Así, mientras para algunos usuarios serásuficiente identificar un objeto como "animal", para otros podría serindispensable anotar "ave", "insecto", "mamífero", etc. o usar términos aún másespecíficos. Así, el diseñador debe tener absoluta claridad en relación a losniveles de generalidad y especificidad útiles para los usuarios, lo cual se relacionacon la elección o construcción de un lenguaje documental apropiado (tesauro,lista de autoridades, taxonomía, u otro).
Si bien los acontecimientos se identifican mediante un término que designa laacción ("atentato", "conferencia de prensa", "visita", "emigración", "compra-venta", etc.), es paradojalmente poco común que se usen tales identificadorescomo atributo en un sistema documental periodístico. Sin embargo, estaidentificación ha de estar presente en algún otro campo, como el resumen o latranscripción del lead de la noticia. En consecuencia, el tratamiento dado a laidentificación nominal tiende a reflejar ya la diferencia que existe entre entidadesy acontecimientos, diferencia que lleva a modelos diferentes de análisis yestructuración de los registros, como lo veremos a continuación.
Siendo la identificación nominal el primero de los atributos requeridos paradocumentar una entidad, deben agregarse otros que también podemos considerarcomo genéricamente determinados por la naturaleza de los objetos considerados.Para ello, podemos distinguir, inspirándonos en las facetas propuestas por el"Classification Group" de Londres:
- objetos materiales (entidades físicas): entes naturales y artefactos,- objetos no-materiales: "mentefactos" y organizaciones.
91

• Entidades físicas
• Identificador propio
En el caso de los entes naturales, a los atributos ya definidos se agregará en loscasos que corresponda el identificador propio, equivalente al "nombre propio".El caso normal aquí será el de la identificación de seres humanos, en cuyo caso elnombre propio se descompone en nombres de pila y apellidos. Adicionalmentepuede ocurrir que el mismo principio se aplique a otras entidades,especialmentelos animales (p.ej. en un archivo relativo a caballos de carrera o perros de raza).
El identificador propio también es aplicable -en numerosos casos- a losartefactos: corresponde por ejemplo al número de serie de algun producto, alnúmero ISBN de un libro (considerado como entidad física), etc.
• Autoría
Pero los artefactos, siendo definidos como entidades materiales creadas por elhombre, se caracterizan necesariamente -además- por el hecho de tener uncreador o diseñador, la "AUTORÍA" siendo por lo tanto un atributo intrínseco,aunque no siempre identificable ya que existen creaciones colectivas, objetos deexistencia inmemorial, etc., y muchos objetos son de difusión tan común que yano se acostumbra señalar su autor, por lo cual tampoco constituye un atributoimprescindible. El objetivo del sistema documental, nuevamente, determinará sidebe incluirse o no.
• Función
El artefacto, por otra parte, tiene una razón de ser que corresponde a su destino, ala función que ha de cumplir. He aquí un nuevo atributo intrínseco que serámucho más frecuente registrar.
• Fundamentación
Finalmente, la razón de ser o el funcionamiento de los artefactos sólo puedecomprenderse adecuadamente recurriendo a cierto cuerpo de conocimientos quejustifica su uso y - si es el caso - explica su funcionamiento, por lo cual tambiénse desprende la existencia de un atributo que ha de permitir registrar la disciplinaque ofrece tal explicación. Proponemos llamarlo fundamentación. Sólo seincluirá ocasionalmente, cuando el objetivo del sistema documental lo requiera.
• Características físicas
Todos los objetos materiales o artefactos tienen características físicas, algunas delas cuales pueden ser relevantes para describirlos y compararlos: dimensiones,forma, peso, color, etc. Se deberá registrar todo lo que pudiera ser significativo ala hora de analizar el conjunto de la información. (El color de los objetos es, porejemplo, de suma importancia en el mercadeo de muchísimos productos.)
92

• Representaciones audio-visuales
Todos los objetos materiales tienen una forma física, por lo cual pueden serrepresentados icónicamente. Así, podemos considerar un atributo derepresentación icónica que, si bien no se utiliza aún en forma generalizada,tomará cada vez mayor importancia a medida que se difundan los mediosdigitales de conservación masiva de datos como los discos ópticos. (Esto noimplica necesariamente una graficación realista: hay muchas modalidadesposibles). También existen acontecimientos de los cuales podemos conservar unregistro sonoro o audio-visual.
Todos estos registros pueden formar parte de una base de datos orientada aobjetos o bien ser archivados en directorios especiales y su referencia ingresada auna base de datos relacional que forme parte del sistema documental.
• "Mentefactos"
Los productos de la mente, accesibles a terceros, son discursos verbales,icónicos o verbo-icónicos. Del mismo modo que los artefactos, todos tienenautoría. Y, por cierto, lo más importante es su significado o contenido, nuevoatributo propio que hemos de introducir aquí. Los mentefactos no tienen una"identificación propia" comparable con las entidades materiales, por cuanto solola totalidad de su contenido significativo los identifica plenamente. En este caso,el contenido se registraría mediante copia (atributo de transcripción) o sucondensación mediante "abstract", resumen o conjunto de descriptores temáticos.
Hay que tomar en cuenta, además, que el acto de enunciación es unacontecimiento y que, una vez registrado y conservado (mediante impresión ograbación), queda indisolublemente ligado a un soporte físico que se constituyeen artefacto. La descripción completa de una obra de la mente registrada en unsoporte implica por lo tanto tomar en cuenta los dos aspectos y sumar losatributos relevantes aplicables a artefactos y a mentefactos.
• Organizaciones
Entendemos aquí por organizaciones agrupaciones de individuos (principalmenteseres humanos) que son el producto de una especialización y de un repartoordenado de las funciones que cada individuo cumple en la agrupación. Talesorganizaciones se identifican - igual que los seres que las componen - medianteun identificador propio (nombre propio). Pero, para identificarlas másdetalladamente, resulta necesario indicar quienes son sus miembros(generalmente utilizando identificadores nominales de los mismos), cuál es laactividad que desarrolla o sea la función que cumple en la sociedad (semejante alcaso de los artefactos) y cuál es su estructura organizativa u organigrama.
93

• Acontecimientos
Como ya lo señaláramos, todo acontecimiento tiene un identificador nominal, quecorresponde al tipo de acción que tuvo lugar. Pero, además, todo acontecimientoocurre en cierto lugar del espacio y momento del tiempo: estos dos atributosconstituyen "situadores" que pertenecen a la esencia del hecho. Además, dadoque es observable, el hecho tendrá algún efecto sobre algún objeto material oalguna persona, que llamaremos afectado.
La ausencia de los atributos de lugar y momento en un archivo deacontecimientos (por ejemplo "operaciones" o "procesos" en una industria),pondrá de inmediato en evidencia que se está describiendo un "modelo" - es decirun mentefacto - y no un acontecimiento efectivo. En este caso, varios atributostípicos de los objetos que llamamos "acontecimientos" podrán estar presentes enarchivos relativos a mentefactos.
Mientras para los hechos naturales son habitualemente suficientes los atributos yamencionados como válidos para todo tipo de acontecimiento, para el caso dehechos artificiales deben agregarse otros atributos. En efecto, son hechosartificiales los que ocurren como producto de la acción humana. Por esta razón,todo hecho artificial tiene su autor - aunque pueda ser desconocido -, por lo cualvuelve a aplicarse aquí el atributo de autoría, que corresponde a quién realiza laacción, o sea al actor. Para lograr producir algún cambio observable, éste debeutilizar algún recurso físico capaz de afectar su entorno: el hecho podrá por lotanto ser descrito haciendo referencia al instrumento utilizado.
Conforme al carácter histórico de todo acontecimiento y teniendo por marco dereferencia la biología del conocimiento, tenemos que agregar que todo hechotendrá necesariamente alguna razón de ser (antecedente) y alguna consecuencia,aunque ésta puede ser trivial. Estos son dos nuevos posibles atributos paradescribir acontecimientos. Pero tienen una característica muy particular: ellosmismos son, en numerosos casos, también acontecimientos, por lo cual se hacepatente el vínculo secuencial que conforma la trama de la historicidad tanto de laspersonas como de los grupos sociales. El tratamiento más lógico de estosatributos consiste en reemplazar el valor real (descripción de los acontecimientosantecedentes y consecuentes) por "direcciones" (o punteros, en el sentidoinformático) que remitan a los correspondientes registros en el sistemadocumental.
4.3. Modelamiento conceptual de los hechos noticiosos
Definidos estos atributos, podemos preguntarnos ahora acerca de la mejormanera de representar hechos noticiosos. Esto implica un análisis de carácterlógico-semántico que es vital para el correcto diseño de un sistema documental yde registros que sean después manipulables en forma eficiente.
94

Los "centros de documentación" periodísticos comunes de hoy siguen aún,muchas veces, un modelo heredado de la hemeroteca, es decir construidos sobrela base del objeto físico (el "artículo" o recorte de prensa) - es decir un modelodescriptivo (ver apartado 2.1.1) - y no sobre la naturaleza real del referente quees en la mayoría de los casos un acontecimiento y requiere por lo tanto el uso deun modelo transaccional. Sólo una parte de la documentación periodística - y másbien anexa que central - es realmente de tipo descriptivo o sea relativo a un"sujeto" como una persona - cuya biografía se publica - o un objeto técnico -como cuando se describe algún nuevo artefacto -. La consecuencia de ello es laalta ineficiencia de los sistemas de búsqueda y recuperación de información. ¡Esimposible realizar un trabajo de data mining con datos exclusivamentedescriptivos si el referente real es de tipo transaccional! (Westphal y Blaxton,p.46).
Las exigencias de mejoramiento en este campo, especialmente para facilitar lacreación de efectivos "hipermedios informativos" obliga al análisis basado en lanaturaleza del referente - que preconizamos aquí - y, obviamente, ante todo a unacorrecta identificación de la naturaleza de dicho referente. En el caso que nosinteresa se trata de la "noticia" que es - en sí - el acontecimiento mismo y no eldiscurso acerca del mismo, el cual es sólo una forma de registrar o representar elhecho.
4.3.1. Actor
El núcleo de todo acontecimiento es la existencia de alguna acción que provoca elcambio observado. En el caso de acciones humanas, interviene alguna personaque hace que lo ocurrido sea observado (directamente) o conocido(indirectamente) por los observadores calificados que son los periodistas. A estapersona, la llamaremos el actor. El actor humano es siempre definido, aunquepueda ser momentáneamente desconocido. En otros casos - como en losfenómenos naturales -, no habrá un actor definido.
El que el actor sea definido no significa necesariamente que sea una sola personaindividualizable, aunque el observador-retransmisor (periodista) ha de tratarsiempre de identificar e individualizar lo mejor posible los actores. Podrá ocurrirque tal individualización personal no sea factible, en cuyo caso se considerará unactor colectivo, es decir un organismo, institución, o grupo social. Ejemplo: "ElMinisterio de la Vivienda financió la edificación de 37.000 viviendas sociales",donde sería imposible precisar alguna persona en particular. Se ha de considerarincompleto o "mal documentado" un relato noticioso que mencione un actorcolectivo cuando la acción corresponde obviamente a una personaindividualizable.
4.3.2. Relator y "Vector"
Puede surgir un problema de análisis cuando lo que el periodista observa es unaacción secundaria referida a otra acción -principal-, como una persona que relataun acontecimiento que él ha observado o en el cual participó. En este caso hemos
95

de considerar que el núcleo informativo (lo importante, el contenido medular) esel acontecimiento relatado por este intermediario ("fuente"). Pero la accióndirectamente observada aquí NO forma parte de este núcleo. Sólo es una suertede "soporte" que da acceso al hecho importante. Diremos que nos encontramoscon un vector de información.
Este vector será primario si quién relata es a la vez un participante en el hechoprincipal, mientras será secundario si esta persona es sólo un observador. Enambos casos se distinguirá este rol particular con el nombre de relator.
En los casos en que hay un vector, mientras el relator es quién da cuenta delhecho, el actor será quién o quiénes producen la acción constitutiva del hechonoticioso (acontecimiento relatado). En algunos casos, por lo tanto, una mismapersona podrá ser a la vez Relator y Actor (Ej.: "El dueño de la panadería relatócómo logró reducir al maleante que intentó asaltarle."). Sin embargo, cuando elsujeto del hecho es una colectividad a la cual pertenece el relator, se mantendrá ladistinción. (Ej.: "El presidente de RN, S.O.Jarpa, dijó que esa colectividad...":relator = Jarpa; actor = RN).
Será conveniente tener en cuenta estas diferencias para una más clara redacciónnoticiosa. Al revisar documentos noticiosos, habrá casos en que podrán surgirdificultades para distinguir entre relator y actor. Debe analizarse la noticia consuma prudencia cuando el texto favorece la duda.
4.3.3. Reseña
La reseña es el relato del hecho que aparece en el documento. Podrá, enconsecuencia, ser:
• directa: relato del acontecimiento por un periodista-observador (que ha sidotestigo presencial);
• indirecta: relato en que el periodista recoge las expresiones de actores, testigos orelatores que describen acciones propias, o las de una colectividad a la cualpertenecen, o las de terceros (Ej.: relatos de accidentes o delitos).
Se ha de considerar mal documentada una reseña que tiene forma directa cuando-en realidad- su origen es indirecto (e.d. si el periodista no indica que recurrió atestigos). Esto no significa que los testigos o fuentes deban ser identificados en lareseña. Si aparecen versiones de varios testigos, habrá eventualmentemultiplicidad de relatores, pero no de acontecimiento, por lo cual el núcleoinformativo ha de permanecer unitario.
4.3.4. Núcleo de la reseña
En el núcleo informativo, encontraremos habitualmente los siguientescomponentes, que pueden organizarse de diferentes maneras:
96

• el actor o sujeto que realiza la acción correspondiente al acontecimiento, y quepuede aparecer citado con nombre y apellido(s) así como con su cargo ofunción.
• la acción: es lo que realiza el actor (corresponde al verbo principal del núcleonoticioso),
• el paciente o afectado : es quién sufre las consecuencias de la acción tangible oes el destinatario directo de la acción intangible; puede aparecer citado connombre y apellido(s) así como con su cargo o función.
• el objeto de la acción : es la realidad tangible (material) o intangible que dasentido a la acción: "contenido" de una acción intangible o materialidad del actosi es una acción tangible. (¡A no debe confundir con el "instrumento"!).
El "objeto" podrá estar compuesto de dos partes:
• 1. el referente que corresponde a la entidad implicada (un objeto material, otroacontecimiento o un concepto, como el "tema" de una declaración).
• 2. la calificación, que corresponde al juicio que formula eventualmente el actoracerca del referente (o de la acción, si no hay referente).
Gráficamente, la estructura informativa aludida puede representarse como en elgráfico 4.3, agregando algunos otros elementos que pueden aparecer en lareseña:
Gráfico 4.3: Estructura de la información periodística
Objeto AfectadoLugar Fecha
Actor Acción
Instrumento
Referente
Calificación
Conceptual
Material
Destinatario
Paciente
Efecto
Relator (+ acción de relatar)
Periodista(Fuente del conocimiento público)
4 .3 .5 . Periféricos de la reseña
Aparte del núcleo antes mencionado - el cual es suficiente, si está bien redactado,para entender al menos el acontecimiento, sino para apreciar su importancia -,
97

pueden aparecer otros elementos periféricos que podemos clasificar en dosgrupos:
• los datos complementarios: explicitan brevemente el instrumento eventual, elefecto o consecuencia inmediata y el contexto del hecho. (Hasta aquí puedellegar eventualmente el llamado "lead" de la noticia).
• el desarrollo: que explica más detalladamente los datos ya mencionados. Noconsideraremos este en el procesamiento documental.
La consideración de causas y consecuencias a futuro no pertenece como tal a ladescripción del hecho mismo sino de una secuencia histórica de varios hechosconcatenados.
En nuestro libro sobre "Documentación Periodística"4, hemos incluído unexhaustivo análisis y desarrollo formal de la estructura de las reseñasperiodísticas. No es del caso reproducirlo aquí, por cuanto sólo nos interesa laestructura básica requerida para documentar el referente, la cual es idéntica a laque ha de componer la reseña.
4.3.6. Atributos seleccionados
El análisis lógico-semántico de los componentes de la información destinada a serregistrada ha de complementarse con el análisis lógico de la "conversación-tipo"que un usuario tendría con un documentalista con el fín de encontrar lo quebusca.
En el caso de hechos noticiosos, hemos de preguntarnos, en consecuencia,cuáles serían las preguntas más comunes que harían los periodistas.Encontramos por ejemplo:
- ¿Qué hizo tal persona, en tal momento o período de tiempo?- ¿Cuándo hizo tal cosa?- ¿Cuántos hechos de tal tipo ocurrieron en tal período?- ¿Qué pasó en tal país desde tal fecha?- ¿Quiénes fueron los más afectados por tal tipo de hecho?
De estas preguntas y del modo de trabajar del analista de información noticiosa,deducimos una serie de puntos de acceso o "Entradas" necesarias en el banco dedatos:
1. Fecha2. Lugar (país,ciudad)3. Actor (nombre propio)4. Objeto (=tipo de hecho/referente; clasificado por descriptores)5. Implicados (nombres propios de pacientes, destinatarios u otras personas
citadas como cuando un político se refiere a las declaraciones de otro)6. Resumen7. Fuente (referencia)
98

Gráfico 4.4: Selección de atributosATRIBUTOS
Lugar Fecha Actor Descriptores Implicados Resumen Referencia
Objeto AfectadosLugar Fecha
Actor Acción
Instrumento
Referente
Calificación
Conceptual
Material
Destinatario
Paciente
Efecto
Obtenemos así 5 atributos constitutivos, a los cuales se debe poder acceder confacilidad para encontrar respuesta a una pregunta típica. Pero el detalle de lainformación buscada, a su vez, no estará en el campo correspondiente a algunode estos atributos - ya que cada uno registra sólo un componente informativo - ydeberá aparecer en una reseña sintética, redactada en forma clara y precisa, de talmodo que el lector pueda entender exactamente qué ocurrió. Un sexto atributoserá por lo tanto el del resumen o "representación simbólica, sintética ycomprensiva del acontecimiento".
Aunque éste es un modo de evitar que el usuario deba buscar la fuente o eldocumento original de dónde procede el resumen, conviene generalmente indicarcuál es esa fuente o documento primario, ya que el usuario puede desear sabermás detalles o conocer los comentarios hechos por el relator o periodista. Enconsecuencia, se ha de registrar (7º atributo) la referencia al lugar donde aparecemás detallada la información (p.ej. diario, fecha y página en qué elacontecimiento ha sido relatado).
Un registro confeccionado de acuerdo a esta pauta podría tener la siguienteapariencia:
Fecha: 2001-04-11Lugar: Estados UnidosActor: Yahoo!Descriptores: Economía, Portal, Trabajo, Ética, Valores moralesResumen: Yahoo! Inc. anunció hoy que en el primer trimestre de 2001 registró una pérdida
neta de 11.49 millones de dólares, ó 2 centavos por acción. Despedirá 400 empleadospara sanear su situación. Con el mismo fin, la puntocom estadounidense ha lanzado unatienda electrónica de pornografía con miles de películas en formato vídeo y DVD, informóhoy el diario "Los Angeles Times".
Fuente: Mouse (La Tercera), 2001-04-11
Pero si nuestra descripción es muy detallada y precisa o nuestros datos son de"primera mano" es posible que no presente ningún interés remitir a otro
99

documento (que podría ser un borrador que destruiremos). De ello deducimosque este tipo de archivo, bien hecho, también puede ser autosuficiente y norequerir "referencia". Incluso podría constituir la fuente de la "nota" publicada,ya que es posible recurrir a procedimientos de publicación automática en páginasweb de los contenidos de la base de datos. Se puede invertir de este modo elmodo tradicional de operar, que situaba el proceso documental después de laproducción de la publicación.
4.3.7. Producto
Con los antecedentes acumulados en la forma señalada podemos - a posteriori -realizar consultas, como buscar todas la noticias relativas a un determinado tema(p.ej.: el plebiscito chileno de 1988) o las intervenciones de una determinadapersona (p.ej.: "Ricardo Lagos"), o generar informes copiando la totalidad oparte de los registros que respondan a estos criterios de búsqueda, o produciendotablas ordenadas con datos correspondientes a algunos de los atributos, comomostramos en los siguientes capítulos.
El procesamiento en Tablas nos conduce a otra posibilidad: la confección deestadísticas (Vea los capítulos 5 y 6). Todo ello podrá ser de sumo interés paraconfeccionar artículos que sinteticen la actualidad durante cierto período,expliquen antecedentes o factores contextuales, demuestren el rol preponderantede ciertas personalidades, etc.
Conclusión
Hemos recordado aquí algunos aspectos generales de la estructura de lossistemas documentales y nos hemos detenido en el análisis de la estructuralógico-semántica del hecho noticioso y de su representación, tarea esencial para elcorrecto diseño del "modelo de datos" de tipo conceptual que será la base para laexplotación o "minería" de datos que nos proponemos abordar en adelante. Peroaún sin pretender llegar a utilizar tal metodología de investigación, debemosinsistir en que toda empresa periodística debería contar con un archivo digitalconstruído sobre la base de este modelo. Como lo hemos mostrado en algunosartículos publicados con anterioridad (ver Bibliografía), dicha estructura resultaextremadamente útil especialmente para los medios que se publican online, en laWorld Wide Web.
1 Hemos descrito y ejemplificado en la práctica un sistema de este tipo en el softwaretotalmente funcional titulado "El Periodista", realizado en HyperCard para computadoresMacintosh (para el uso personal de los periodistas, no para uso masivo en un medio decomunicación).
2 http://facom.udp.cl/CEM/TDC/3 Alcances complementarios en R.Colle: "Documentación periodística".4 Ver Capítulo 6 del libro señalado.
100

5
META-INFORMACION PERIODISTICA
Como lo hemos indicado en el Capítulo 2, existe meta-información "previa", lacual corresponde al modelo de datos y a la estructura de los sistemasdocumentales, y meta-información posterior o resultante de un proceso deañálisis o cálculo (lógico - mediante operaciones de álgebra de conjuntos - oestadístico). En el capítulo pasado hemos mostrado cómo llegar a un "modelo dedatos" que permita seleccionar atributos importantes para registrar los hechosnoticiosos en una BD relacional, que es la forma más adecuada para elprocesamiento posterior. En el presente capítulo, daremos cuenta de un"procesamiento clásico" y de lo que es posible extraer ya de una base de datos detabla única, no ajustada a la "tercera forma normal". Hemos trabajado con estetipo de base de datos desde la aparición de los primeros computadores personalesen Chile, a mediados de los años ochenta.
Sin embargo, en mayo del año 2000, desarrollamos e implantamos - en el Centrode Estudios Mediales (Facultad de Ciencias de la Información y Comunicación,Universidad Diego Portales, Santiago de Chile) - un proyecto dehiperinformativo titulado "Temas de Tecnologías Digitales de Comunicación -TDC" (http://facom.udp.cl/CEM/TDC/). A partir de aquí daremos cuenta de estaexperiencia, que ha tenido como fundamentos los estudios del autor sobrerepresentación del conocimiento en hipermedios, que fueron el objeto de su tesisdoctoral (cfr. Colle, R.: "La representación...", 1999).
101

5.1. Estado inicial de la base de datos
Las noticias que publicamos no son informaciones recogidas de primera mano,sino una selección extraída de más de 60 medios de prensa, principalmenteelectrónicos (Véase la Tabla 5.2.5 y el Gráfico correspondiente, donde aparecennuestras fuentes más frecuentes).
5.1.1. Ingreso y publicación de los datos
La información recogida - y reproducida en nuestra hiperrevista para finesesencialmente académicos - es ingresada a la base de datos mediante una páginaweb conteniendo un formulario, disponible solamente para el encargado de lapublicación, cuya estructura en la primera etapa de implantación (año 2000) semuestra en el Gráfico 5.1.a.
Activado el botón de envío que se encuentra al final de dicho formulario, lanoticia es ingresada automáticamente en la tabla de noticias de nuestra BD,pasando a ser inmediatamente accesible para los lectores gracias a unacombinación de lenguaje SQL y de un sistema de pre-procesamiento (PHP) quelas extrae para su publicación en la página de "Noticias" de la revista (VerGráfico 5.1.1.b). Al margen de las Noticias se ofrece permanentemente el accesoa un diccionario y al motor de búsqueda (frame izquierdo). Se muestran siemprelas últimas 20 noticias, y el lector puede regresar en el tiempo de 20 en 20noticias o bien acceder a un motor de búsqueda y extraer las noticias de acuerdo acriterios que corresponden a los atributos representados en la base de datos1 osea:
- Fecha- Lugar (país)- Implicados (nombre de organismos o funciones de personas citadas)- Descriptores temáticos- Palabras en titulares- Palabras en el cuerpo de la noticia- Fuente periodística.
La tabla de noticias también contiene otros campos que corresponden a lossiguientes atributos:
- Id (Número único, identificatorio, que el sistema otorga en formaautomática)
- Imagen: referencia a la imagen que debe ser exhibida junto al texto,cuando la hay (URL relativa)
- Referencia a texto anexo: cuando existe un texto que complementa lanoticia (URL relativa).
102

Gráfico 5.1.1.a: Formulario de ingreso de noticia
ID:
Fecha:
Lugar:
Implicados:
Descriptores:
Título:
Texto:
Fuente:
Imagen: (Si la hay, contiene elnombre del archivo)
Textorelacionado:
(Si hay un texto más extensoanexo, contiene la URLrelativa)
Gráfico 5.1.1.b: Pantalla de noticias de la revista "TDC"
103

5.1.2. El problema de los actores y afectados
Como se puede observar, no existen los atributos de actores y afectados: hansido agrupados en un solo campo de datos, el de "Implicados" (que incluyetambién a los sujetos o instituciones meramente citadas). Ésto ha sido el resultadode las primeras semanas de experimentación, en que se descubrió que - para estecampo peculiar de información - los límites categoriales entre actores y afectadoseran extremadamente ambigüos.
A continuación, un par de ejemplos de las dificultades de análisis que sepresentan con alta frecuencia:
• Ejemplo 1
"2000-11-27 - Bulgaria - Descubren brechas de seguridad en aplicaciones de Microsoft paraInternet - Georgi Guninski, un investigador informático búlgaro, ha anunciado eldescubrimiento de una brecha de seguridad en los Explorer 5.0 o superiores que permitecontrolar el ordenador desde Internet. El error consiste en que cualquier hacker puedeejecutar un programa a través de los archivos de ayuda comprimidos CHM o ver los archivostemporales guardados en el disco duro. (Noticias.com y CNN)."
A pesar de su aparente simplicidad, esta información es relativamente compleja.En efecto, sintetiza varios acontecimientos entrelazados, que no es posibleregistrar separadamente. Nótese que si bien Microsoft aparece como "afectado"por la revelación de errores, es - en realidad - el "actor remoto" que desencadenóel hecho noticioso de la fecha mencionada. El gráfico 5.1.2a. muestra nuestroanálisis de esta noticia. Conforme a éste, no sería muy lógico - desde el punto devista del significado - llamar a Microsoft "afectado", dado que es en realidad elque originó los problemas derivados de sus errores y que sólo han sido dados aconocer por el investigador (que, en este caso, tampoco es un simple "relator",en los términos definidos en el apartado 4.3.2).
Gráfico 5.1.2a : Noticia acerca de errores de Microsoft
Investigador estudió descubrió publicó
Actor principal
Explorer
Objeto
Microsoft
Actor remoto
programó
Fallas
Característica
104

• Ejemplo 2
"2000-09-14 - Estados Unidos - Muchas empresas punto-com desaparecerán - Un estudiode PriceWaterhouse-Coopers Consulting revela que los primeros ejecutivos de 65 empresaspunto com, aquellas que operan exclusivamente en Internet, consideran que en el plazo dedos años sólo sobrevivirán un tercio de las que hoy mantienen actividad en el negocio decomercio electrónico destinado a consumidores (B2C). Estos mismos ejecutivos semuestran algo más optimistas al evaluar el futuro de las empresas que operan comercioelectrónico entre empresas (B2B). Estiman que algo más de la mitad de estas compañíastendrán dificultades o fracasarán en los dos próximos años. En el horizonte temporal de loscinco años, las expectativas de éxito aumentan ligeramente. (Expansión)"
Aquí se puede observar nuevamente un caso de doble "actor", acompañado de undoble objeto, y este segundo objeto (las empresas del sector) sería a la vez, anuestro entender, actor y afectado (ya que generan su actividad comercial pero elretorno negativo afecta su viabilidad). Nuevamente, clasificar separadamenteactores y afectados sería una muy difícil labor.
Gráfico 5.1.2b : Noticia acerca del futuro de las "punto-com"
PriceWaterh. realizó publicó
Actor inmediato
estudio
Objeto 1
Ejecutivos
Actores remotos
opinan Pronóstico
Contenido
Empresas
Objeto 2
• Solución adoptada
La única forma que pareció resolver eficientemente las dificultades que surgían deeste modo en el ingreso de datos pareció ser la utilización de un atributo único,que hemos llamado "implicado". Obviamente la búsqueda o el análisis posteriorse vería afectado por esta decisión, que hemos tenido que tomar a nuestro pesar,ya que esperábamos inicialmente poder realizar un tratamiento "más fino",conforme al modelo lógico-semántico que hemos expuesto con anterioridad.
105

• Dispersión
Por otra parte, al avanzar en el registro de noticias, hemos visto crecer con granrapidez el número de Implicados que estabamos registrando, lo cual hizo prever -como lo demostraron las primeras estadísticas extraídas - que la dispersión de losmismos haría impracticable cualquier intento de extraer conocimiento delconjunto acumulado (considerando que cada Implicado nuevo se codificaba enforma secuencial, sin pre-clasificación alguna).
Así, al sobrepasar la cantidad de mil noticias en nuestra BD, hemos revisado lasestadísticas obtenidas y hemos establecido las siguientes reglas, que nuestroslectores podrán ajustar a sus propios casos si pretenden efectuar unprocesamiento estadístico o de Data Mining de sus datos noticiosos:
1. Eliminar todos los implicados que aparecen una sola vez (0,1%),reemplazando los identificadores propios (nombres) por identificadoresnominales (términos que designan categorías de organizaciones o depersonas). Dichas categorías se definieron teniendo en cuenta los datospresentes y experiencias realizadas durantes varios años con alumnos de uncurso de análisis de contenido.
2. En los otros casos cuya frecuencia haya sido inferior al 1%, conservarexclusivamente los nombres propios de organismos de alta relevancia en lavida pública nacional o internacional si son al mismo tiempo del sectortecnológico, ya que existe una alta probabilidad de que vuelvan a aparecer en elfuturo. Ejemplo: "Telefónica CTC Chile".
3. En los casos cuya frecuencia se sitúa entre el 1 y el 10%, conservar solamentelos nombres propios de organismos de alta relevancia nacional o internacionalaunque no sean del sector tecnológico, como por ejemplo: Corfo (Corporaciónde Fomento, de Chile), OEA (Organización de Estados Americanos), ONU,etc.
4. Todos los nombres que hayan obtenido un 10% o más se conservaron.
5. En el caso de que aparezcan nuevos nombres, se agregarán a la lista sicumplen con las reglas 2, 3 o 4. Si no es el caso, se ha propuesto tener encuenta la factibilidad de que puedan ocupar un lugar significativo en el futuroy, si es así, efectuar un ingreso "condicional" sujeto a verificación defrecuencia después de un determinado lapso de tiempo (p.ej. 6 meses) ocantidad de noticias (p.ej. revisión cada 500 noticias). Paralelamente seingresará el identificador nominal de la categoría a la cual pertenecen de talmodo que el sistema global de descripción no se vea afectado si se elimina elcódigo del identificador propio.
106

5.1.3. Otras tablas
A la tabla de noticias están anexadas (formando parte de la misma base de datos)otras tablas que contienen información también disponible en la revista:
• una tabla de "Textos": artículos (de fuentes externas), estudios (propios delCentro de Estudios Mediales) y "fichas técnicas", que aclaran o complementanlas Noticias (las cuales nunca se extienden más de unas diez líneas); estastablas contienen los atributos de autor, título, fuente, fecha y referencia (URLrelativa)
• una tabla de "Diccionario": donde se mantienen definiciones de términostécnicos y siglas; sus atributos son la entrada, la definición y el tipo (sigla otérmino).
Como ya señalado, el acceso a dicho Diccionario está siempre presente, en unacolumna separada (frame, vea la columna izquierda de la ilustración 5.1.1b),donde es posible llamar a una lista de siglas o una de términos y, a partir deéstas, consultar lo deseado. El acceso a los textos es de dos tipos: mediante unmenú de botones, también siempre presente (visible debajo del nombre de larevista y encima del título "Noticias", ver Gráfico 5.1.1b), que remite al índice decontenidos de cada sección ("Estudios", "Artículos" o "Fichas técnicas"), omediante los hipervínculos (links), que son los que se anotan en el campo de"referencia" de la tabla de noticias, cada vez que una relación útil existe, y queaparecen a continuación del cuerpo de la noticia en la página web cuandocorresponde.
5.2. Extracción de meta-información ex post facto porprocedimientos comunes: estadísticas de frecuenciaspara mil noticias
Una primera extracción de estadísticas se realizó confeccionando un programa adhoc capaz de obtenerlas a partir de la tabla única de noticias (lo cual, como hemosdicho, demostró las frecuentes inconsistencias). Reducidos los errores,obtuvimos los resultados que sintetizamos a continuación. Las cifras fueroninmediatamente traducidas en histogramas por el mismo programa - que generabauna página web con los resultados - a fin de facilitar la visión de conjunto(visualización de datos). Presentamos aquí los resultados, para cada variablemedida, solamente para las frecuencias no inferiores al 1% (para no alargarextremadamente las tablas) pero con las frecuencias totales y mediascorrespondientes a la totalidad de las noticias.
Tómese en cuenta que estas estadísticas representan nuestra información y nonecesariamente la realidad de todo lo que está ocurriendo en el mundo de las
107

tecnologías digitales, como puede ocurrir con cualquier medio de comunicación.Según estimaciones realizadas hace algunos años, un medio de prensa publicaapenas del orden del 10% de las noticias que recoge y, si se toma en cuenta loque recogen las agencias noticiosas, su propia selección de lo que efectivamentetransmiten y la selección final por los medios que publican, sólo del orden del2% del total llega al público. Sin embargo, sin desconocer que podemosintroducir algunas distorsiones en la estimación de lo que puede ser relevante (ypublicamos) versus lo que dejamos de lado, estimamos significativo que nuestrasfuentes -al completar mil noticias- han llegado a ser 69, de las cuales siete son lasmás frecuentes, superando cada una el 5% del total y quince superan el 1% (Veatabla 5.2.5).
5.2.1. Atributo "Fecha"
Las fechas se agruparon por mes y se calculó la cantidad de noticias ingresadascada mes desde el inicio del trabajo de recopilación.
Tabla 5.2.1: Frecuencia de noticias por mes
Mes Frec.2001-03* 1672001-02 1702001-01 1792000-12 1102000-11 1032000-10 962000-09 542000-08 382000-07 412000-06 262000-05 16Frec.Total 1000Frec.Media 90,91
* Mes incompleto, en el que se llegó a la noticia nº 1.000
Observaciones:
• La cifra del mes de marzo 2001 (último considerado ) no corresponde al mescompleto, ya que se limitaron los cálculos - en esta etapa - a las mil primerasnoticias registradas.
• El crecimiento del número de noticias, mes a mes, no correspondeforzosamente al aumento de noticias del área, al menos en los primeros meses
108

de trabajo, ya que el período de mayo a julio incluído fue de "marcha blanca" yla revista empezó oficialmente su publicación en el mes de agosto. En esteperíodo inicial se fueron afinando los criterios de selección. Así, al principiono se registraban noticias financieras, pero la aparición de la tendencia que sellamó posteriormente "crisis de las punto com" hizo añadir este tipo denoticias, que abundaron en el último trimestre del 2000 y en todo el períodocubierto del 2001.
Gráfico 5.2.1 : Noticias por mes de ocurrencia
0 50 100 150 200
2000-052000-062000-072000-082000-092000-102000-112000-122001-012001-022001-03
5.2.2. Atributo "Lugares"
Como "Lugar" se considera cualquier país, agregándose "Internet" para casos enque no hay otra precisión e "Internacional" cuando están involucrados más dedos países (Si son dos se registran ambos). Como se ve en la tabla adjunta,Estados Unidos domina la noticia y se explica fácilmente que Chile aparezca ensegunda posición por la importancia que hemos dado a las noticias nacionales.(Ver Tabla y Gráfico 5.2.2)
5.2.3. Atributo "Descriptores temáticos"
Nuestros descriptores temáticos corresponden al tesauro de la Unesco, quehemos ampliado agregando términos propios en las áreas de las tecnologías de lainformación. A la fecha, contábamos con uno 180 descriptores. Como era deesperar, conforme a la temática de la revista, Internet concentró gran parte de laatención. (Ver Tabla y Gráfico 5.2.3)
109

Tabla 5.2.2: Frecuencia de Lugares
Lugar Frec.Estados Unidos 444Chile 134España 84Japón 54Unión Europea 26Gran Bretaña 24Alemania 20Brasil 20Suiza 16? (Desconocido) 15Francia 13Argentina 12México 12Italia 11Otros:(1 cada uno) 115
Frec.Media 16.6Frec.Total 1000
Gráfico 5.2.2: Lugares más frecuentes
0 100 200 300 400
ItaliaMéxico
ArgentinaFrancia
?Suiza
BrasilAlemania
Gran BretañaEuropa JapónEspaña
ChileEstados Unidos
110

Tabla 5.2.3: Frecuencia de Descriptores
Descriptor Frec. % Descriptor Frec. %Internet 544 20.32 Celular 45 1.68Digital 116 4.33 Computador 45 1.68Electrónico 113 4.22 Televisión 40 1.49Comercio 99 3.70 Red 38 1.42Teléfono 94 3.51 Industria 37 1.38Derecho 88 3.29 Tecnología 33 1.23Estadística 76 2.84 Gobierno 32 1.20Sitio 64 2.39 Hardware 31 1.16Seguridad 59 2.20 Portal 30 1.12Música 58 2.17 PDA 28 1.05Telecomunicación 57 2.13 Periférico 28 1.05Software 50 1.87 Información 27 1.01Economía 47 1.76 Otros (inf. 1%) 751 28.50Web 47 1.76
Frec.Total 2677 100.00Frec.Media 9.1
Gráfico 5.2.3: Descriptores temáticos más frecuentes
0 200 400 600
InformaciónPeriférico
PDAPortal
HardwareGobierno
TecnologíaIndustria
RedTelevisión
ComputadorCelular
WebEconomíaSoftware
TelecomunicaciónMúsica
SeguridadSitio
EstadísticaDerechoTeléfono
ComercioElectrónico
DigitalInternet
111

5.2.4. Atributo "Implicados"
Hemos registrado habitualmente el nombre de los organismos o instituciones queaparacían en las reseñas noticiosas y, cuando no aparecían dicho nombre o elimplicado real solo podía ser una persona, anotamos la función o cargo de dichapersona. Esto fue elevando el número de implicados a más de 700. Basta ver(Tabla 5.2.4) que la empresa más citada - Microsoft - aparece solamente en el4,3% de los casos y que en solo 12 casos se superó el 1% del total de lasfrecuencias para confirmar la enorme dispersión de este atributo.
Como lo explicamos ya (al final del nº 5.1.2), esto nos llevó con posterioridad aintroducir reglas de selección y efectuar substituciones, para evitar la enormedispersión producida inicialmente y poder proyectar un más efectivo resultadocuando se hiciera la "minería de datos". (Ver Tabla y Gráfico 5.2.4)
5.2.5. Atributo "Fuentes"
Ya hemos comentado el caso de las fuentes: no efectuamos reporteo directo, sinoque recopilamos información "de segunda mano", en fuentes electrónicas (Web)e impresas, algunas de las cuales -a su vez- recopilan a otras. En total, hemosregistrado cerca de 70 fuentes, 7 de las cuales agrupan cada una más del 5% delas noticias, entre ellas 3 medios nacionales: "Mouse", suplemento del diario "LaTercera", de la cual recibimos la versión electrónica por e-mail; "MTG", diarioque se reparte en el metro de Santiago, y "El Mercurio", principal diario nacional,en su versión impresa.
5.2.6. Producto
Además de las definiciones correspondientes al "modelo de datos" - queconstituyen meta-datos previos - las estadísticas que hemos obtenido constituyennuevos datos que podemos conservar a su vez en una tabla. De hecho contruimostemporalmente una tabla para recibir, archivar y reordenar las frecuencias, hastatraspasarlos a un archivo de texto (para respaldo) y a una página web "estática"en que pudieran ser consultadas sin necesidad de rehacer los cálculos ni deconsultar la tabla para generar dicha página.
112

Tabla 5.2.4: Frecuencia de Implicados(previa a la reclasificación)
Implicados Frec. %Microsoft 58 4.26Wired 28 2.05Napster 26 1.91IBM 22 1.61Presidente 20 1.47Sony 20 1.47AOL 18 1.32Intel 18 1.32Palm 18 1.32Telefónica 16 1.17Ministro 14 1.03Yahoo 14 1.03Otros (inf. 1%) 1091 80.04Frec.Total 1363 100.00Frec.Media 1.9
Gráfico 5.2.4 : "Implicados" más frecuentes
YahooMinistro
TelefónicaAOLIntelPalm
PresidenteSonyIBM
NapsterWired
Microsoft
0 20 40 60
113

Tabla 5.5: Frecuencia de Noticias por Fuentes
Fuentes Frec. %Mouse (La Tercera) 179 17,9CNN 99 9,9MTG 75 7,5Noticias Intercom 74 7,4WSJI 74 7,4I Actual 61 6,1El Mercurio 57 5,7Diario TI 39 3,9El Correo Español 22 2,2Es.internet 21 2,1BPenet 18 1,8Expansión 16 1,6Ganar.com 15 1,5Cinco Días 14 1,4Clarín 13 1,3Otros (inf. al 1%) 223 22,3Frec.Total 1000 100,00Frec.Media 15.25
Gráfico 5.8: Noticias por Fuentes más frecuentes
Clarín Cinco DíasGanar.com Expansión
BPenet Es.internet
El Correo Español Diario TI
El Mercurio I Actual
WSJI Noticias Intercom
MTG CNN
Mouse (La Tercera)
0 50 100 150 200
114

5.3. Preparación para la "Minería de Datos"
Después de confeccionar, en el mes de marzo del 2001, las estadísticascorrespondientes a las mil primeras noticias de nuestra hiperrevista, decidimosconsiderar la factibilidad de aplicar a nuestra base de datos un proceso de DataMining, con el fin de conocer mejor esta metodología y sus posibles aportes en elcampo del periodismo. Nuestros primeros estudios y nuestra búsqueda desoftware especializado de libre acceso en Internet nos tomaron hasta el mes dejulio, período en que sobrepasamos la cantidad de 1.700 noticias. En esemomento iniciamos la etapa de revisión y preparación de los datos, de la cualdamos cuenta a continuación.
5.3.1. Verificación de la consistencia lógica y semántica dela Base de Datos original
Como los datos se ingresaban inicialmente por tipeo textual en los diferentescampos de datos (ver Gráfico 5.1), se introducían errores de tipeo o sereproducían inconsistencias presentes en las fuentes. Éstas constituyeron unimportante problema a la hora de extraer las primeras estadísticas. Constatamosespecialmente numerosas imprecisiones o copias erróneas de nombres depersonas o instituciones (como Bertelsmann, Bertelsman y Bertlesmann,MediaMetrix y Media Metrix, o diferencias aún mayores como BSCH y BancoSantander Central Hispano, etc.). Esto puso en evidencia la necesidad de contarcon un sistema codificado, utilizando un tesauro para los descriptores temáticos ylistas de autoridades2 para las fuentes periodísticas, los implicados y los lugaresde ocurrencia de los datos.
Por otra parte, al existir un solo campo para los descriptores (como también paralos implicados), se ingresaban inicialmente diversos términos, es decir diversosvalores, en dichos campos de datos. Esto, aunque práctico en una base de datoso archivo "doméstico", infringe las reglas de modelamiento canónico.Obviamente, si se hubiese mantenido el modelo original, se habría tenido queduplicar un registro por cada descriptor y por cada implicado, con la consiguienterepetición de todos los demás datos: esto es justamente lo que la normalizaciónimpide y soluciona, aunque con el costo de una multiplicación de tablas y unamayor complejidad - pero también flexibilidad - asociada a la necesidad derecurrir a operaciones de álgebra de conjuntos. (Veremos sin embargo, al finaldel capítulo, que la metodología OLAP requiere justamente tales repeticiones.)
5.3.2. Traspaso de los datos de la tabla única de noticias amúltiples tablas de "tercera forma normal".
Como recién señalado, se trabajó en un primer período con una base datos en quetoda la información noticiosa se vertía en una tabla única. La inclusión de unsistema codificado llevó en forma natural a crear tablas con los códigos y
115

enlazarlas con la tabla principal de noticias, así como a cambiar la interfaz deingreso de palabras por una interfaz de ingreso de códigos, excepto para el títuloy el cuerpo de la noticia (La diferencia reside exclusivamente en que la páginaweb de ingreso de datos contiene un frame para dicha finalidad y otro paraconsultar los códigos). La multiplicación de las tablas y sus interrelacioneshicieron obvia la necesidad de recurrir a la tercera forma normal, que no se habíaaplicado hasta ese momento. El modelo normalizado se expone en el gráfico5.3.2.
Gráfico 5.3.2 : Modelo normalizado de la BD de noticias
1 n
Tabla"nodescrip"
ididnoiddes
Tabla base
idtitulotextoreferenciaimagen
Tabla "nofechas"
idnofecha
Tabla"descriptores"
iddesdescriptor
Tabla"implicados"
idimimplicado
Tabla"lugares"
idluglugar
Tabla"fuentes"
idfuefuente
n
n
n
n
1n
Tabla"noimplic"
ididnoidim
Tabla"nofuente"
ididnoidfue
Tabla"nolugar"
ididnoidlug
1n
1n
1n
En la columna de la izquierda, la "Tabla base" contiene el número identificador dela noticia (id) el cual es igual a "idno" en las tablas de la columna del medio. Conexcepción de la tabla de fechas, dichas tablas contienen exclusivamente lanumeración propia - secuencial - de sus registros (id) y códigos que aseguran elenlace de cada noticia con los términos que la describen, los que se encuentran en
116

las tablas de la tercera columna - de tipo "look up" -, que contienen laequivalencia entre un código y el término legible (conforme a un tesauro o unalista de autoridades, según sea el caso).
Debido a que, con este modelo, la recuperación de datos para la producción delas páginas normales de noticias se hacía cada vez más lenta a medida queaumentaba el número de éstas (ampliándose el espacio requerido en memoriaRAM), se mantuvo además una tabla no normalizada con la estructura expuestaen la Tabla 5.3.2, que corresponde a los datos publicados secuencialmente en laspáginas web.
Tabla 5.3.2: Tabla generadora de la revista(para consultas y publicación rápidas)
Tabla "Noticias"idtítulo Campostexto iguales a laimagen (URL) Tabla "base"referenciafecha Datos enlugar forma legiblefuente
Los procedimientos programados llenan primero las tablas "normales", extraen elsignificados de los códigos y los insertan en los campos de fecha, lugar y fuentede la tabla de Noticias, lo cual permite que el sistema de extracción para lapublicación inmediata online trabaje exclusivamente sobre los campos de datos deesta única tabla.
Una vez codificados los datos y conservados en "tablas normales", resultómucho más fácil y rápido extraer las estadísticas de frecuencias correspondientesa cada uno de los atributos y se incluyó en la revista una página que permitepermanentemente solicitar estas estadísticas actualizadas al instante (onlineprocessing).
5.3.3. Reestructuración de la lista de Implicados
Esta lista creció inicialmente en forma inorgánica: a medida que aparecían nuevosnombres de instituciones o de categorías de personas, se iban agregando a lalista. Esto produjo un crecimiento cercano al de la propia tabla de "Noticias" y laestadística de frecuencias puso en evidencia la dispersión (80% de casosaparecían menos del 1% de las veces, como se puede observar en la Tabla 5.4).Por ello se decidió, tal como lo recomienda la metodología, aumentar las"autoridades" de tipo categorial y substituir por ellas las identificaciones propias
117

de instituciones que aparecían una sola o muy pocas veces en el conjunto inicialde 1.000 noticias (conforme a las reglas que hemos enunciado en el apartado5.1.2). También se eliminaron los nombres de personas que se habían incluídodebido a su particular relevancia en la temática cubierta (como "Berners-Lee" yotros próceres de Internet o de la informática), reforzándose de este modo la reglaestablecida (y publicada) para el uso del motor de búsqueda que acompaña larevista: que los nombres de personas deben ser buscados en el "cuerpo" (texto)de la noticia y no en el campo de datos "Implicados".
5.4. Estadísticas del nuevo total de noticias
Recordemos que el análisis final se realizó sobre un conjunto de 1.766 noticias.El primer paso del análisis consistió en extraer las frecuencias netas yporcentajes, para tener una visión de conjunto. También se realizó una primera"visualización de datos", para descubrir posibles tendencias y divergencias.
5.4.1. Atributo "Fecha"
Las fechas se agruparon por mes y se calculó la cantidad de noticias ingresadascada mes desde el inicio del trabajo de recopilación.
Observaciones:
• En este caso, la cifra del mes de julio 2001 (último considerado) nocorresponde al mes completo, ya que se inició el día 20 de ese mes el trabajode minería de datos.
• Como ya señalado en el capítulo anterior, el crecimiento del número denoticias, mes a mes, en el año 2000, no corresponde forzosamente al aumentode noticias del área, ya que los primeros meses fueron de "marcha blanca" y larevista empezó oficialmente su publicación en el mes de agosto. Por otra parte,la aparición, a fines del 2000, de la tendencia que se llamó posteriormente"crisis de las punto com" hizo añadir noticias financieras, las que no habíansido consideradas al principio y abundaron en el último trimestre del 2000 y entodo el período cubierto del 2001.
5.4.2. Atributo "Lugares"
Como se ve en la siguiente tabla, Estados Unidos se ha mantenido en primeraposición, seguido de Chile, debido a la importancia que hemos dado a lasnoticias nacionales. La importancia, a continuación, de España se explicaprincipalmente por razones idiomáticas pero un análisis más profundo tambiénmostraría que influye en ello la presencia de importantes inversiones españolas enpaíses iberoamericanos.
118

Tabla 5.4.1: Frecuencias de noticias por mes
Mes Frec. %2001-03 232 13,142001-05 211 11,952001-06 196 11,102001-01 179 10,142001-04 176 9,972001-02 170 9,632001-07 118 6,682000-12 110 6,232000-11 103 5,832000-10 96 5,442000-09 54 3,062000-07 41 2,322000-08 38 2,152000-06 26 1,472000-05 16 0,91TOTAL 1766 100,00
Gráfico 5.5.1: Frecuencias por fechasa. por frecuencia b. por orden cronológico
0 5 10 15
2000-052000-062000-082000-072000-092000-102000-112000-122001-072001-022001-042001-012001-062001-052001-03
%2,5
0
50
100
150
200
250
20
00
-05
20
00
-07
20
00
-09
20
00
-11
20
01
-01
20
01
-03
20
01
-05
20
01
-07
119

Tabla 5.4.2: Frecuencias de Lugares
Lugar Frec. %Estados Unidos 775 41,82Chile 235 12,68España 151 8,15Internet 112 6,04Japón 94 5,07Europa 62 3,35Internacional 44 2,37Alemania 41 2,21Inglaterra 40 2,16Latinoamérica 29 1,57?(Desconocido) 28 1,51Brasil 27 1,46Argentina 26 1,40Francia 23 1,24Suiza 20 1,08Otros (< 1% c.u.) 146 7,89TOTALES 1853 100,00
Gráfico 5.4.2: Lugares más frecuentes
5
SuizaFrancia
ArgentinaBrasil
? DesconocidoLatinoamérica
InglaterraAlemania
InternacionalEuropaJapón
InternetEspaña
ChileEstados Unidos
0 10 20 30 40 %
120

5.4.3. Atributo "Descriptores temáticos"
Para nuestras 1.766 noticias, considerando que se les podía dar a cada una entre1 y 5 descriptores, la cantidad total de descriptores ingresados fue de 4.733 (osea un promedio de 2,7 descriptores por noticia).
Comparando la totalidad de las noticias analizadas ahora con las mil primeras,observamos un ligero descenso en el porcentaje de noticias a las cuales se asocióel descriptor "Internet". Este término, sin embargo, mantiene la primera posición,junto con "Digital", aunque con un amplio margen entre ambos. En los siguientesdescriptores se observa un cambio del orden relativo, lo cual respalda la hipótesisde que no existe una constante en los hechos del sector noticioso aquíconsiderado. (Ver Tabla y Gráfico 5.4.3).
Quizás la variación más notable - aunque con una proporción de sólo 3,49% - esla aparición en tercera posición del "e-Comercio", que no aparecía en lasfrecuencias de 1% o más en las mil primeras noticias. Ello indica por lo tanto unauge significativo durante el año 2001, en comparación con el año anterior.
5.4.4. Atributo "Implicados"
Microsoft sigue apareciendo como la empresa más citada, por sobre categoríasmás generales como "Fabricante de hardware" - que es la que la sigue enimportancia -, aunque ambas corresponden solamente al 6,2 y el 5,3 % de loscasos. Esta vez, fueron 26 en lugar de 12 los casos en que se superó el 1% deltotal de las frecuencias, lo cual da cuenta de la reagrupación que tuvo lugarconforme a las nuevas reglas implantadas (señaladas en el nº 5.1.2). A pesar deellas, se observa sin embargo aún una gran dispersión (ver Tabla 5.4.4).
5.4.5. Clases de "Implicados"
Como lo explicamos ya, esta dispersión de los Implicados nos llevó conposterioridad a introducir reglas de selección y efectuar sustituciones, para evitarla enorme dispersión así producida y poder proyectar un más efectivo resultadocuando se hiciera la "minería de datos".
Junto con formular y aplicar reglas para conservar nombres propios deorganismos o reemplazarlos por categorías, creamos 16 "clases" de mayorextensión categorial y hemos procesado las noticias también en función de éstas.Las clases definidas y sus códigos son los siguientes:
10 Asociaciones 11 Asociaciones de empresas 12 Asociaciones de centros de estudios 19 Asociaciones de personas20 Organismos internacionales30 Organismos públicos
121

40 Institución o empresa 41 Organizaciones temporales 42 Empresas de asesoría o investigación 43 Instituciones de enseñanza 44 Empresas de servicios 45 Empresas de informática 46 Empresas de TI 47 Empresas de telecomunicaciones 48 Empresas financieras 49 Empresas comerciales (otras)50 Medios de comunicación90 Personas (particulares)
De este modo, sin embargo, sólo tres categorías de Implicados superan el 10%:la clase "Empresas de informática" con 27,7%, seguida por "Empresas TI" (deTecnologías de la Información) con 15,8%, y "Organismos públicos" con10,9%. (Ver Tabla y Gráfico 5.4.5).
5.4.6. Atributo "Fuentes"
Ya hemos comentado el caso de las fuentes: no efectuamos reporteo directo, sinoque recopilamos información "de segunda mano", en fuentes electrónicas (Web)e impresas, algunas de las cuales -a su vez- recopilan a otras. En total, hemosregistrado cerca de 70 fuentes, 7 de las cuales agrupan cada una más del 5% delas noticias, entre ellas 3 medios nacionales: "Mouse", suplemento de "LaTercera", de la cual recibimos la versión electrónica por e-mail; "MTG", diarioque se reparte en el metro de Santiago; y "El Mercurio", principal diario nacional,en su versión impresa. (Ver Tabla y Gráfico 5.4.6).
5.4.7. Coeficiente de predictibilidad
Es evidente que, con el tipo de datos que manejamos, muchas herramientas de laestadística común o "paramétrica" - aunque incluídas en algunas suites de DataMining - no son aplicables. Ordenando las frecuencias, no obtenemos - ni es deesperar que podamos observar - curvas de Gauss o distribuciones lineales quetengan algún sentido, fuera de los histogramas de frecuencias - ascendentes odescendentes - mostrados con anterioridad, ya que todos nuestros datos - con lasola excepción de las fechas - son "nominales", es decir no ordenados. Por ello,si queremos analizar la relación existente entre dos variables, no podemosrecurrir a las técnicas de cálculo paramétricas, sino que debemos recurrir amétodos no-paramétricos de verificación de asociación entre variables. Para elcaso de dos variables nominales, debemos recurrir al cálculo del coeficiente depredictibilidad lambda de Guttman. Dicho coeficiente nos indica en quéporcentaje se reduce el error de predicción cuando conocemos el valor de ambasvariables en comparación con la predicción que haríamos de los valores de lasegunda al conocer una sola.
122
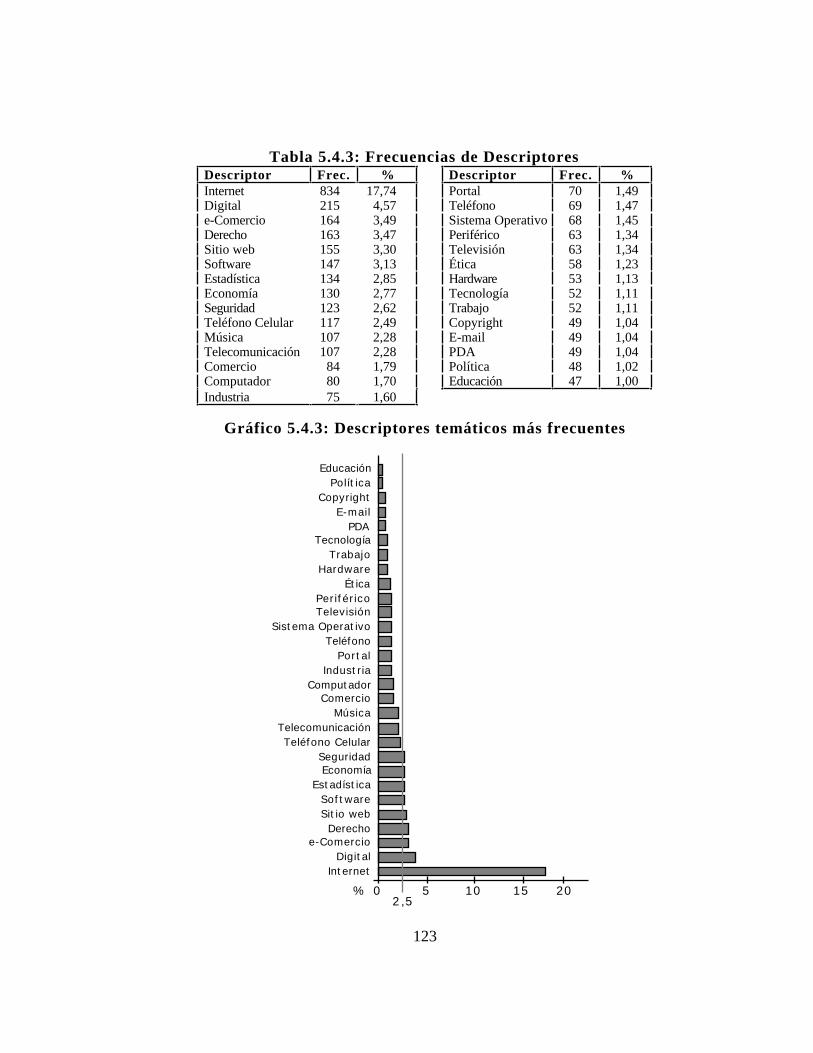
Tabla 5.4.3: Frecuencias de DescriptoresDescriptor Frec. % Descriptor Frec. %Internet 834 17,74 Portal 70 1,49Digital 215 4,57 Teléfono 69 1,47e-Comercio 164 3,49 Sistema Operativo 68 1,45Derecho 163 3,47 Periférico 63 1,34Sitio web 155 3,30 Televisión 63 1,34Software 147 3,13 Ética 58 1,23Estadística 134 2,85 Hardware 53 1,13Economía 130 2,77 Tecnología 52 1,11Seguridad 123 2,62 Trabajo 52 1,11Teléfono Celular 117 2,49 Copyright 49 1,04Música 107 2,28 E-mail 49 1,04Telecomunicación 107 2,28 PDA 49 1,04Comercio 84 1,79 Política 48 1,02Computador 80 1,70 Educación 47 1,00Industria 75 1,60
Gráfico 5.4.3: Descriptores temáticos más frecuentes
0 20% 105 15
EducaciónPolítica
CopyrightE-mail
PDATecnología
TrabajoHardware
ÉticaPeriféricoTelevisión
Sistema OperativoTeléfono
PortalIndustria
ComputadorComercio
MúsicaTelecomunicaciónTeléfono Celular
SeguridadEconomía
EstadísticaSoftwareSitio web
Derechoe-Comercio
DigitalInternet
2,5
123
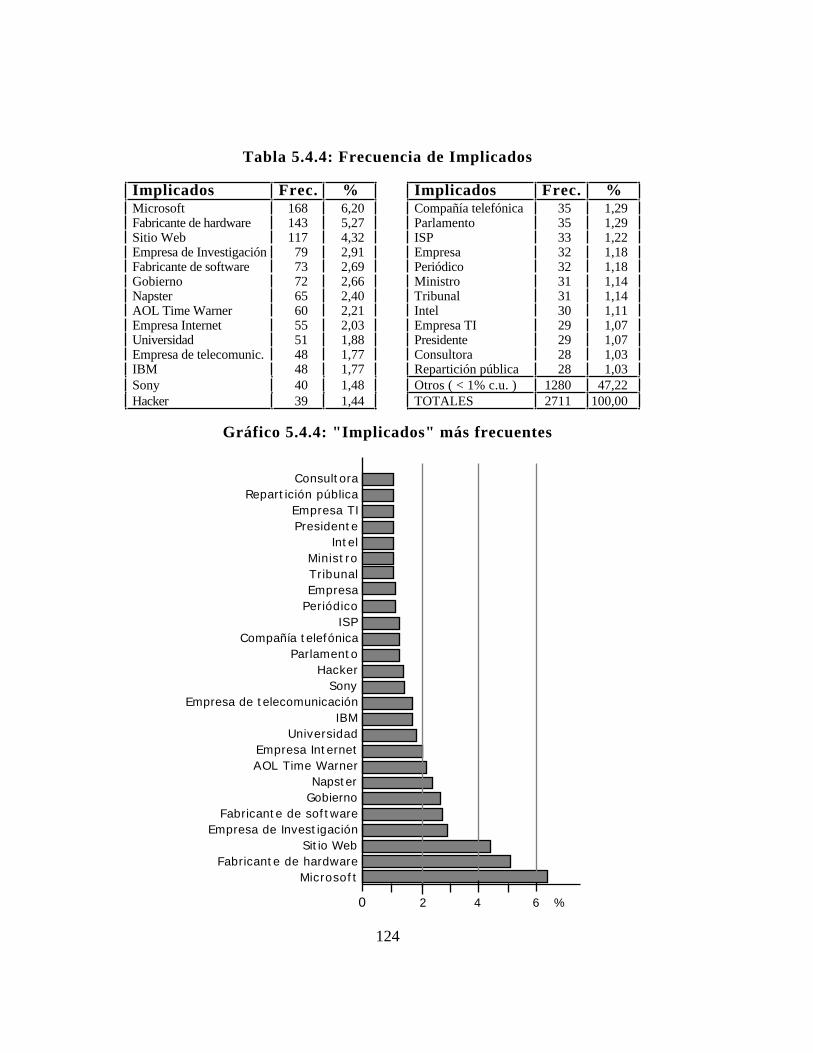
Tabla 5.4.4: Frecuencia de Implicados
Implicados Frec. % Implicados Frec. %Microsoft 168 6,20 Compañía telefónica 35 1,29Fabricante de hardware 143 5,27 Parlamento 35 1,29Sitio Web 117 4,32 ISP 33 1,22Empresa de Investigación 79 2,91 Empresa 32 1,18Fabricante de software 73 2,69 Periódico 32 1,18Gobierno 72 2,66 Ministro 31 1,14Napster 65 2,40 Tribunal 31 1,14AOL Time Warner 60 2,21 Intel 30 1,11Empresa Internet 55 2,03 Empresa TI 29 1,07Universidad 51 1,88 Presidente 29 1,07Empresa de telecomunic. 48 1,77 Consultora 28 1,03IBM 48 1,77 Repartición pública 28 1,03Sony 40 1,48 Otros ( < 1% c.u. ) 1280 47,22Hacker 39 1,44 TOTALES 2711 100,00
Gráfico 5.4.4: "Implicados" más frecuentes
ConsultoraRepartición pública
Empresa TIPresidente
IntelMinistroTribunalEmpresa
PeriódicoISP
Compañía telefónicaParlamento
HackerSony
Empresa de telecomunicaciónIBM
UniversidadEmpresa InternetAOL Time Warner
NapsterGobierno
Fabricante de softwareEmpresa de Investigación
Sitio WebFabricante de hardware
Microsoft
0 2 4 6 %
124

Tabla 5.4.5: Clases de "Implicados"
Categ.Implicados Frec. %Empresas informáticas 751 27,70Empresas de TI 428 15,79Organismos públicos 295 10,88Personas (particulares) 203 7,49Medios de comunicación 183 6,75Empresas de telecomunicaciones 165 6,09Empresas de asesoría o investig. 146 5,39Empresas comerciales (otras) 144 5,31Instituciones de enseñanza 102 3,76Organismos internacionales 97 3,58Empresas financieras 58 2,14Asociaciones de empresas 56 2,07Empresas de servicios 32 1,18Asociaciones de personas 23 0,85Organizaciones temporales 15 0,55Asociaciones de centros de estudios 13 0,48TOTALES 2711 100,00
Gráfico 6.2.5: Agrupación de "Implicados" en clases
Asoc. de centros de estudiosOrganizaciones temporales
Asociaciones de personasEmpresas de servicios
Asociaciones de empresasEmpresas financieras
Organismos internacionalesInstituciones de enseñanza
Empresas comerciales (otras)Empresas de asesoría o investig.Empresas de telecomunicaciones
Medios de comunicaciónPersonas (particulares)
Organismos públicosEmpresas de TI
Empresas de informática
0 10 20 30 %
125
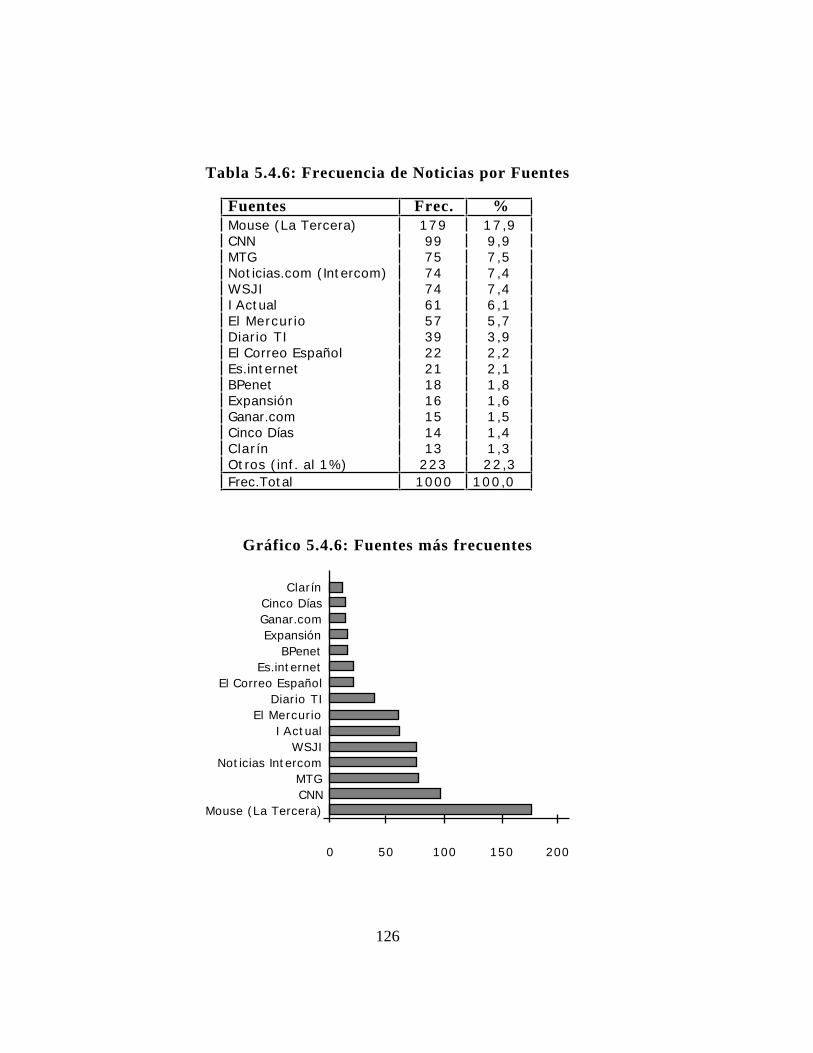
Tabla 5.4.6: Frecuencia de Noticias por Fuentes
Fuentes Frec. %Mouse (La Tercera) 179 17,9CNN 99 9,9MTG 75 7,5Noticias.com (Intercom) 74 7,4WSJI 74 7,4I Actual 61 6,1El Mercurio 57 5,7Diario TI 39 3,9El Correo Español 22 2,2Es.internet 21 2,1BPenet 18 1,8Expansión 16 1,6Ganar.com 15 1,5Cinco Días 14 1,4Clarín 13 1,3Otros (inf. al 1%) 223 22,3Frec.Total 1000 100,0
Gráfico 5.4.6: Fuentes más frecuentes
Clarín Cinco DíasGanar.com Expansión
BPenet Es.internet
El Correo Español Diario TI
El Mercurio I Actual
WSJI Noticias Intercom
MTG CNN
Mouse (La Tercera)
0 50 100 150 200
126

Trabajando por etapa, como lo sugiere la metodología de DM, hemos verificadoprimero la aplicabilidad de la fórmula a 20 noticias, luega a 100 y a 1000.
Para mantener un paralelismo con el estudio anterior, calculamos el coeficientelambda para el "cruce" de los siguientes atributos de nuestras 1.000 primerasnoticias, antes de la recodificación de las mismas . Luego lo calculamos de nuevopara las 1.766 noticias, ordenando los resultados de mayor a menorpredictividad. De modo general, como se verá a continuación, el mayor númerode noticias ha llevado a mejores coeficientes de predictibilidad.
1. Lugar - Descriptores:
1.000 Noticias: lambda = 0.031.766 Noticias: lambda = 0.03
El valor del coeficiente se ha mantenido sin variación. Indica una relaciónestrechísima entre el lugar de ocurrencia del hecho noticioso y la temática delmismo. Este resultado puede parecer bastante lógico si se considera que losprotagonistas generan, habitualmente, los mismos tipos de hechos y en el lugarde su residencia. Sin embargo nuestra percepción previa, en función de laincidencia del desplazamiento frecuente de los ejecutivos para ferias, congresos yconferencias, no nos hizo esperar tan alto grado de predictibilidad. Casos típicosde esta alta predictibilidad serían los de Japón, asociado prioritariamente a latelefonía móvil y a periféricos - como los monitores -, y Europa, que se hadestacado - en el período estudiado - por sus avances en telefonía celular.
2. Fuente - Descriptores:
1.000 Noticias: lambda = 0.051.766 Noticias: lambda = 0.04
Aquí también observamos altísimos coeficientes de predictibilidad, o sea que -conociendo la fuente - tenemos altísimas posibilidades de predecir el tema de lanoticia. Si bien este resultado no se esperaba, se ha de tomar en cuenta aquí queno se registraron todas las noticias publicadas en cada medio-fuente y que hemosintroducido una variable interviniente que actúa con gran fuerza: la selección enfunción de los objetivos de nuestra propia publicación. El resultado, por lo tanto,tiene poco valor en sí mismo y sólo representa la coherencia de nuestro propioproceso de selección.
3. Fuente - Lugar de la noticia:
1.000 Noticias: lambda = 0.131.766 Noticias: lambda = 0.10
Con el aumento de la cantidad de noticias, se produce igualmente unmejoramiento de la asociatividad. Los factores observados significan que existeuna correlación significativa - aunque no tan determinante como las anteriores -
127

entre la fuente y el lugar del hecho noticioso, lo que indica una alta importancia -para cada medio de comunicación - de las noticias locales, en desmedro de lasnoticias procedentes del extranjero. (Si la fuente es "Wired", es de esperar que lanoticia sea de Estados Unidos; si es "El Mercurio", será de Chile, etc.)
4. Descriptores - Implicados:
1.000 Noticias: lambda = 0.171.766 Noticias: lambda = 0.13
También mejorado, el coeficiente indica igualmente una alta correlación (superioral 80% de predictibilidad) entre la temática y los protagonistas de la noticia, cosapor lo demás bastante lógica ("Microsoft" implica "software" y "sistemaoperativo"; "Intel" implica "microprocesador", etc.)
5. Lugar - Implicados:
1.000 Noticias: lambda = 0.401.766 Noticias: lambda = 0.19
Para las 1.000 noticias y, en este caso, antes de la modificación del sistema decodificación de los mismos, el coeficiente -por su magnitud- obligaba a descartarla posibilidad de predecir cuales serían los protagonistas conociendo el lugar oinversamente. Sin embargo, la situación cambió radicalmente con la modificacióndel sistema de registro (y la substitución de los datos anteriores de acuerdo a lasnuevas reglas): el nuevo coeficiente está ahora dentro de un rango más aceptable,aunque no extremadamente bueno.
Es posible que influya aquí la gran cantidad de informaciones situadas en EstadosUnidos o en Chile (ver nº 6.2.2), pero compensada por la dispersión de los"Implicados", que se mantuvo bastante alta. Éste es el tipo de metaconocimientoque demuestra cómo un nuevo procesamiento (reagrupación de los "Implicados")puede arrojar una mejor información y una profundización del análisisrecurriendo a la data mining.
6. Fuente - Implicados:
1.000 Noticias: lambda = 0.431.766 Noticias: lambda = 0.11
La situación observada merece los mismos comentarios que en el caso anterior,pero el segundo coeficiente es netamente superior y casi equivalente a la relaciónFuente - Lugar.
Sintetizamos el estado de estos coeficientes de predictibilidad y su relación mútuaen el Gráfico 5.4.6, donde las líneas más gruesas indican el mayor grado depredictibilidad mútua.
128

Gráfico 5.4.7: Predictibilidad mútua de 4 atributos1.000 noticias - 1.766 noticias
Lugar
Descriptores Implicados
Fuente
0.03
0.13
0.17
0.430.05
0.40
Lugar
Descriptores Implicados
Fuente
0.03
0.10
0.13
0.110.04
0.19
Conclusión
Los meta-datos estadísticos se han transformado ahora en lo que se denominadatos compuestos, tal como los definimos en el Capítulo 2 (ver nº 2.3.1).
Lo ocurrido con la estadística de "implicados" ha sido muy significativo desdeeste punto de vista, ya que puso en evidencia que no se podrían esperarresultados de ninguna clase con el alto nivel inicial de dispersión. Aparte delvalor que representan en sí mismo estos resultados, este tipo de extracción demeta-datos ex post facto es de significativa importancia como paso intermediopara orientar el trabajo posterior.
Se ha de considerar también que el hecho de utilizar un tesauro, como en el casode nuestros descriptores temáticos, ofrece automáticamente la posibilidad detrabajar con datos compuestos, en distintos niveles de abstracción. De poderoperar con este tipo de estructuras categoriales jerarquizadas, como lo sontambién las taxonomías, la minería de datos ofrecería más niveles de búsqueda deposibles combinaciones de factores.
NOTAS DEL CAPITULO
1 La justificación del uso de una base de datos estructurada y del proceso (que llamamos"documentar antes de publicar") se encuentra en nuestra ponencia «Del "diario electrónico" al"hiperinformativo" del ciberespacio» presentada en el marco del congreso ALAIC 2000 yaccesible en Internet en http://facom.udp.cl/CEM/TDC/estudios/hiperinfo/ . Véase tambiénnuestro libro "Para informar en la WWW", Centro de Estudios Mediales, Universidad DiegoPortales, Santiago, 2001.
2 La "lista de autoridades" es una simple lista alfabética de términos autorizados, sin mayorestructuración u organización.
129


6
"MINERIA DE DATOS"EN UN MEDIO PERIODISTICO
Una experiencia con más de 1.700 noticiassobre Tecnología Digital
Como señalado en el capítulo anterior, en el mes de julio 2001 iniciamos laadaptación de nuestra base de datos a las formas normales y extraímos las nuevasestadísticas correspondientes a las noticias acumuladas hasta esa fecha. Luego delas modificaciones que señaláramos, aplicamos diversas herramientas de DM almaterial informativo acumulado, trabajando con un duplicado de la base de datosreestructurada que alimenta a la revista en línea "TDC", la cual contenía 1.766noticias al momento del traspaso (noticias que van del 4 de mayo 2000 al 20 dejulio 2001).
Siguiendo los pasos sugeridos en la metología de la minería de datos (Capítulo 3,nº 3.4), definimos nuestro objetivo como
"descubrir conjuntos de hechos y relaciones entre características de los mismos quepuedan ser la expresión de tendencias o situaciones significativas que trascienden elcarácter puntual de cada hecho noticioso y podrían merecer un estudio global más profundopor parte de un periodista especializado en el área".
Apuntamos, por lo tanto, al "conocimiento desconocido", o sea al conocimientoque está en nuestra base de datos pero que no sabemos que está ni cómo está.Como lo hemos dicho, ésta es la situación más típica de la minería de datos.
Hemos hecho el análisis de los atributos y el modelamiento de datos en elCapítulo 4 (nº 4.3) y hemos realizado una exploración inicial de los datos en elCapítulo 5. Falta ahora preparar más adecuadamente los datos para los procesosque pretendemos realizar y pasar luego a la aplicación de las herramientas queestuvieron a nuestro alcance. En dicha aplicación, partimos de lo expuesto en el
131

capítulo pasado, es decir con las herramientas exentas de efecto combinatorio(estadísticas comunes, actualizadas para el conjunto de datos ahora más amplio yhecho más consistente) y pasamos luego a considerar progresivamente lascombinaciones más detalladas y complejas, pasando de un menor a un mayorefecto combinatorio ("fan out").
6.1.Análisis visual de datos
El análisis visual de los datos, como lo hemos señalado, es una herramienta queno sólo puede complementar la investigación sino guiarla hacia derroterosimprevistos pero altamente deseables de descubrir. Esto es posible en lasdiversas etapas. Obviamente es la técnica más adecuada para poner en evidencialas redes de relaciones o asociaciones de datos y dedicaremos los siguientesapartados a las redes que hemos descubierto.
Pero, si bien la visualización se inicia en realidad con la graficación de losprimeros resultados estadísticos, tal como lo hemos hecho en el numeral anterior,podemos también recurrir a ella para descubrir otros aspectos de la informaciónque estamos analizando. Particularmente clarificador al respecto, en una etapainicial, es el tratamiento visual de las tablas de descriptores y la clasificación deImplicados por categorías, que mostraremos aquí. A pesar de que estos gráficostienen obviamente dos dimensiones en el papel, corresponden al análisis de unasola dimensión del espacio informativo, o sea del espacio multidimensional en elcual constituye un eje cada uno de los atributos diferentes del identificador propio- o "llave primaria" - de cada de entidad. Desde este punto de vista, nuestroespacio informativo (también llamado habitualmente "cubo de datos", a pesar detener generalmente más de tres dimensiones) cuenta con 5 dimensiones, ya queson 5 los atributos que hemos considerado (Fecha, Lugar, Descriptor, Implicadoy Fuente).
6.1.1. Visualización de Descriptores
La visualización de datos muestra claramente la fuerte presencia de los temasrelativos a Internet (ver Gráfico 6.1.1a) y la irregularidad de aparición de losotros temas. Esta visualización se obtiene con facilidad dado que los descriptoresson codificados numéricamente mediante un tesauro. Así, al código deldescriptor corresponde el eje vertical (Y), mientras en el eje horizontal (X) se vandesplegando las sucesivas noticias, repetidas cada una tantas veces cuantosdescriptores tengan. Hemos tenido que reducir aquí en tamaño el gráficocompleto y limitarlo a 4.000 puntos (1.600 noticias) por limitaciones delsoftware utilizado, mientras la tabla completa se compone de 4.733 puntos (porlos 4.733 descriptores registrados en relación a las 1.766 noticias).
132

Gráfico 6.1.1a: 4000 descriptores aplicados (1600 noticias)
En el gráfico 6.1.1a, el eje horizontal (X) corresponde a la secuencia de ingreso de las noticias(los números corresponden a un descriptor por noticia), mientras el eje vertical corresponde alcódigo numérico de los diversos descriptores, de acuerdo al tesauro utilizado. A cada noticiapueden corresponder de 1 a 5 posiciones en X, según la cantidad de descriptores que le fueronatribuídos. Se explica a continuación (Gráf.6.1.1b) con algunos ejemplos cómo se interpretanlos códigos del eje Y.
133

Gráfico 6.1.1b: Interpretación
0
10000
20000
30000
40000
50000
60000
70000
Internet<
<
<
Educación
Optica (fibra)
< Música
< Etica
< Hardware
< Economía/Comercio< Gobierno
Informática<
Gráfico 6.1.1c: Descriptores de "Comunicación"(abarcando todas las noticias)
50000
51000
52000
53000
54000
55000Software
HardwareRedes
Internet
134

Sin embargo, se observa claramente la agrupación de ciertos tipos de datos,principalmente en la franja de 50 a 59.000, numeración que corresponde a"Comunicación", y más particularmente en torno a las subdivisiones 52040("Internet"), 54100 ("Software") y 54500("Hardware"). Obviamente estos datoscoinciden con las estadísticas de frecuencias que ya hemos extraído, pero seprestan para sugerir un análisis más acucioso de algunas agrupaciones de datos.
Así, por ejemplo, descubierta la concentración en el rango de códigos de los50.000, podemos reorganizar la visualización reagrupando todos los casos quecorresponden a este rango, prescindiendo del orden histórico de las noticias yprefiriendo la agrupación de acuerdo al código (tesauro). Esto nos lleva alGráfico 6.1.1c, que cubre la totalidad de las noticias de la categoría"Comunicación" y permite visualizar mejor lo que ya sabíamos por la estadísticade frecuencias: gran concentración para "Internet" (52040), y otra concentraciónen el rango de los 54000, especialmente 54100 ("Software"), 54500("Hardware" y sus subdivisiones) y 54600 ("Redes").
6.1.2. Visualización de los Implicados repartidos por clases
Hemos explicado antes cómo la multiplicidad y dispersión de los "Implicados"registrados inicialmente nos había llevado a definir reglas de selección yagrupación, primero conservando los nombres propios de los más frecuentes yreeemplazando a los otros por términos de categorías muy específicas y,posteriormente, confeccionando una clasificación reducida a 16 clases. Podemosvisualizar el resultado observando cómo, a lo largo de las 1.766 noticias, lostérminos identificando a los Implicados se han ido agrupando en las 16 clasesdefinidas y comprobar de este modo lo acertado que fue subdividir la clase "40",que corresponde a instituciones y empresas privadas, como lo demuestra elGráfico 6.1.2.
6.2. Coocurrencias internas
Aún manteniéndonos en la "primera dimensión" del "cubo de datos", podemosrecurrir a cálculos que nos permitirán establecer la RED DE RELACIONES que seforma entre los diferentes valores de un mismo atributo, teniendo en cuenta quevarios atributos pueden tomar más de un valor para cada entidad (El sistemapermite que un hecho noticioso sea calificado por uno a cinco descriptorestemáticos, por ejemplo).
Entramos de este modo en otro tipo de análisis visual, apelando a la gráfica deredes, para lo cual hemos de considerar la coocurrencia de términos asociados auna misma entidad. Como lo hemos explicado en el acápite 3.5.3.2, estocorresponde al análisis de coocurrencia, que consiste en considerar pares decomponentes, midiendo la simultaneidad de su aparición en conjuntossignificativos predeterminados.
135

Gráfico 6.1.2: Implicados repartidos por clases
0
10
20
30
40
5090
01
00
20
03
00
40
05
00
60
07
00
80
09
00
Las cifras de 0 a 900 (en realidad de 1 a 853) del eje horizontal corresponden al código numérico de los identificadores de Implicados, los cuales tienen una numeración aleatoria y discontínua.
136

Hemos utilizamos una nueva versión de nuestro software "ANATEX" (esta vezen PHP, sobre base de datos mySQL) para analizar las coocurrencias de losdescriptores entre sí y de los implicados entre sí (coocurrencias "internas").Posteriormente analizaremos asociaciones entre atributos diferentes, lo cualllamamos "coocurrencias "externas" y corresponde a la combinación de DOSdimensiones del cubo de datos.
6.2.1. Coocurrencias entre Descriptores
Para las 1.762 noticias, obtuvimos 4.763 coocurrencias agrupadas en 1.378pares diferentes para los 190 descriptores utilizados. En la Tabla 6.2.1mostramos las coocurrencias cuyas frecuencias fueron iguales o superiores a 10(El corte en esta cantidad sólo se debe, aquí, a limitaciones tipográficas).
Como era de esperar, siendo "Internet" el descriptor más frecuente de las noticiassobre Tecnologías Digitales de Comunicación (ver Tabla 5.4.3), aparece tambiéncomo central en las coocurrencias. Aparece a su vez asociado a varios otrosdescriptores, como "Estadística", "e-Comercio", "Derecho", "Música","Seguridad", "Sitio Web", etc. (ver Tabla 6.2.1, a continuación).
Con las frecuencias superiores a 16, confeccionamos una red de relaciones(Gráfico 6.2.1) que nos presenta una imagen de la estructura del "camposemántico" así constituido. En dicho mapa intentamos traducir la frecuencia deasociación tanto en el grosor del trazo como en su longitud (las uniones menosfrecuentes presentan un trazo más delgado y más largo siempre que sea posible),además de anotar la cifra exacta junto al vector correspondiente.
Podemos observar cómo la fuerte cadena triple "Internet - Música - Digital" sevincula con "Copyright", con "Sitio Web" y también con "Derecho" y éste a suvez con "Ética". Se forma así un sub-campo integrado por "Copyright - Derecho- Internet - Música - Digital - Sitio Web", todo lo cual conforma un área noticiosaque es posible explicar principalmente como producto de los juicios que afectaronal sitio "Napster" y los acuerdos entre compañías discográficas para estructurarotros canales de distribución.
También se cierren triángulos que unen "Internet - Estadística - e-Comercio" e"Internet - Estadística - Economía" (lo cual podría corresponder principalmente alos resultados económicos del año), "Internet - Economía - Industria", "Internet -Software - Seguridad", etc.
Existen más relaciones de menor frecuencia pero, en la mayoría de los casos,llevan a incluir más términos en el grafo e interrelaciones que ya se hace difícilincluir en una escala que permita la legibilidad. Ésto nos indica que hemos puestoen evidencia ya las que constituyen el núcleo temático más sólido del cuerponoticioso analizado. Un buen gráfico final podría obtenerse eliminando lasrelaciones bi-unívocas exclusivas para dejar solamente los conceptos multi-
137

vinculados (con arcos que cierran figuras geométricas), como en el ejemplo delGráfico 6.2.1b.
Tabla 6.2.1: Frecuencias de Coocurrencia de DescriptoresTérminos Frec. Términos Frec.Internet & Estadística 94 Video & Internet 15e-Comercio & Internet 90 Digital & Video 15Derecho & Internet 86 Teléfono & Telecomunic. 15Digital & Internet 84 Teléfono Celular & PDA 15Digital & Música 81 Derecho & Software 15Seguridad & Internet 69 e-Comercio & Economía 15Internet & Música 61 Internet & Lenguaje 14Sitio web & Internet 58 Virus & Internet 14Economía & Internet 53 Periférico & Computador 14Software & Internet 46 Privacidad & Internet 14Internet & Ética 43 e-Comercio & Derecho 14Portal & Internet 43 Internet & Teleducación 13Comercio & Internet 34 Internet & Cine 13Internet & Educación 33 Internet & Publicidad 13Teléfono Celular & Internet 33 ISP & Internet 13Televisión & Internet 30 Periférico & Internet 13Telecomunicación & Internet 29 Derecho & Industria 13Política & Internet 27 Derecho & Digital 13Software & Industria 26 Economía & Software 13Digital & Fotografía 26 Economía & Derecho 13Disco & Digital 26 Internet & Comunicación 12Teléfono & Internet 26 Buscador & Internet 12Copyright & Internet 26 Tecnología & Internet 12Copyright & Digital 26 Seguridad & Informática 12Sitio web & Música 25 Hardware & Software 12Copyright & Música 25 Procesador & Microchip 12Digital & Televisión 24 PDA & Internet 12Desarrollo & Internet 22 Red WAN & Internet 12Trabajo & Internet 22 Privacidad & Derecho 12Digital & Sitio web 21 Economía & Telecomunic. 12Economía & Industria 20 e-Comercio & Seguridad 12Internet & Medicina 19 e-Comercio & Digital 12Derecho & Ética 19 e-Libro & Internet 11Derecho & Sitio web 19 Seguridad & Virus 11Trabajo & Economía 19 Derecho & E-mail 11Internet & Información 18 Comercio & Sitio web 11Internet & Industria 18 Comercio & Digital 11Seguridad & Software 18 Comercio & Economía 11Desarrollo & Tecnología 18 Valor moral & Ética 10Computador & Internet 17 Internet & Valor moral 10Derecho & Música 17 Internet & Com. Interperson. 10Derecho & Seguridad 17 Sitio web & Estadística 10Economía & Estadística 17 Periodismo & Internet 10e-Comercio & Estadística 17 E-mail & Internet 10e-Comercio & Sitio web 17 Sistema Operat. & Software 10Internet & Entretención 16 Digital & Archivo 10Red & Internet 16 Digital & Software 10
138

Gráfico 6.2.1: Red de relaciones entre Descriptores
Internet
Estadística
Música Digital
61
e-Comercio
Seguridad
69
Economía53
Educación
43
Televisión
33
Sitioweb
33
58
Teléfono
Ética
43
Software46
Medicina
29
Telecomunicación
22
Teléfonocelular
27
Derecho
81
Información
18 19
25
22
Trabajo
17
25
86
Copyright
26
30
Fotografía
26
Industria
26
17
Política
Comercio34
Desarrollo
26
Portal
26Disco
24
21
20
1919
19
17
Computador
18
17
17
18
139

Gráfico 6.2.1b: Red de relaciones entre Descriptores
Internet
EstadísticaMúsica Digital
61
e-Comercio
Seguridad
69
Economía53
Televisión
Sitioweb
58
Ética 43
Software
46
Derecho
81
25
2225
Copyright
26
30
Industria
26
21
2019
19
19
17
18
17
18
Trabajo
26
17
24
17
17
En el caso de los Descriptores también puede ser ilustrativo el análisis de lasmetafrecuencias (frecuencias de frecuencias, o sea cuantas veces se repite cadafrecuencia de coocurrencia):
Tabla 6.2.1b: MetafrecuenciasFrec. 94 a 46 1 c.u.Frec.43 2 Frec.20 1 Frec.10 17Frec.34 1 Frec.19 4 Frec.9 16Frec.33 2 Frec.18 4 Frec.8 11Frec.30 1 Frec.17 6 Frec.7 21Frec.29 1 Frec.16 2 Frec.6 20Frec.27 1 Frec.15 6 Frec.5 30Frec.26 6 Frec.14 5 Frec.4 79Frec.25 2 Frec.13 9 Frec.3 118Frec.24 1 Frec.12 12 Frec.2 215Frec.22 2 Frec.11 6 Frec.1 766Frec.21 1
140

Salvo 2 excepciones, por sobre la Frecuencia 26 sólo aparecen pares una vezcada una, mientras por sobre la Frecuencia 19 existen sólo 5 casos en queaparecen pares más de una vez. Entre 19 y 6, las cifras progresan con ciertaregularidad, mientras suben muy rápidamente después, para dispararse en lospares únicos (766, o sea 16 % de los pares existentes).
Un análisis visual de estas cifras, recurriendo a una curva logarítmica, muestrauna progresión bastante regular con algunas excepciones, como la frecuencia 26que quiebra la línea por exceso y la 16, la 11 y la 8 por defecto (Gráfico 6.2.1c).Son estos "quiebres" que se consideran habitualmente como umbrales paradeterminar hasta donde llegar en la confección de los mapas de relaciones ografos de asociación y, por lo tanto, teníamos la opción de detenernos en lafrecuencia 26 o luego en la 17 (como hicimos) por el quiebre en la frecuencia 16,siendo el siguiente umbral la 12, por el quiebre producido por la frecuencia 11(pero exigía un gráfico más extenso, que no se habría podido leer en estaspáginas). Las frecuencias altas (parecidas al caso de 12 veces la frecuencia 12aquí) también pueden sugerir la presencia de casos especiales que podría serconveniente analizar como grupo separado.
Gráfico 6.2.1c: Distribución de cantidades de Frecuencias
1
10
100
1000
1 4 7
10
13
16
19
22
26
30
43
58
81
90
Sin embargo estos datos, salvo por la ayuda que representan al momento deelegir los límites de un mapa, no resultan significativos en relación al "fondo" ocontenido de la información propiamente tal. Los citamos solamente porqueapuntan a un tipo de análisis (DM) más elaborado, cuya aplicación podemos ver
141

en el tratamiento gráfico, aunque no se puede asegurar que siempre darán pistastan claras para definir los límites de un mapa. Sin embargo, en otros estudios,también podrían resultar de interés en relación al problema de fondo.Utilizaremos de modo habitual este procedimiento para definir los límites devisualización de nuestros gráficos de redes.
Antes de proseguir, hemos de recordar que si bien hemos trabajado con 190descriptores - y comprobamos aquí que ha sido una cantidad suficiente (y queincluso no aparecen algunos que están en nuestro tesauro), los mediosperiodísticos suelen usar de tres a cinco mil, para describir adecuadamente lamultiplicidad de hechos que "cubren". En este caso, la visualización en pantalladel uso de los mismos puede ser una herramienta efectiva para afinar laestructuración de su Tesauro. Trabajando con diferentes escalas de visualizaciónes, además, posible descubrir eventuales fluctuaciones temáticas en diversosperíodos de tiempo, como lo veremos en el apartado sobre coocurrencias"externas".
6.2.2. Coocurrencias entre Implicados
Comparado con el primer análisis, realizado con mil noticias y más de 700"Implicados" diferentes, la recategorización permitió trabajar con sólo 216identificadores de "Implicados". Las frecuencias de asociación sin embargo, sonrelativamente bajas e incluimos en la Tabla solamente las iguales o superiores a 5.(Hubo 1395 casos, que se agruparon en 960 pares diferentes).
En el correspondiente gráfico, además de observar el papel central de "Microsoft"- lógico de acuerdo a la estadística de frecuencias antes calculada -, podemos verel rol también central de "Fabricante de hardware" y "Fabricante de software".Nos parece interesante ver cómo el término "Tribunal" aparece como conectorentre Napster y Microsoft, empresas de muy diferente tamaño y poder, pero quehan estado involucradas en los casos judiciales de mayor eco durante el períodobajo estudio. (Ver Tabla y Gráfico 6.2.2)
6.2.3. Coocurrencias entre clases de Implicados
Pero nuestro siguiente paso en la recategorización de "Implicados" consistió enreunirlos en clases de mayor extensión, las cuales fueron 16. En este caso lascoocurrencias se agruparon en 574 pares diferentes. Presentamos la tabla de losresultados en que las asociaciones tuvieron una frecuencia superior a 6. En lagraficación, tuvimos que detenernos en la frecuencia 10, en razón de la escala deimpresión, pero -por análisis de frecuencias- el umbral lógico, después de 11,podría haber sido 7 o 6.
142

Tabla 6.2.2. Frecuencias de Coocurrencia de ImplicadosTérminos Frec FrecMicrosoft & AOL Time Warner 13 Presidente & Gobierno 5Napster & Discográfica 13 RealNetworks & Microsoft 5Fabricante de software & MicrosoftTribunal & Microsoft
1211
Sitio Web & Empresa deInvestigación 5
Fabricante de hardware & IBM 11 Sitio Web & Napster 5Sitio Web & Empresa InternetMicrosoft & Gobierno
98
Compañía telefónica & Empresade telecomunic. 5
Tribunal & Napster 7 Yahoo! & AOL Time Warner 5Fabricante de hardware & SonyEntel & Empresa de
7 Yahoo! & MicrosoftFabricante de software & IBM
55
telecomunicación 6 Fabricante de hardware & Hitachi 5Ministro & Gobierno 6 Fabricante de hardware & Intel 5EMI & AOL Time WarnerIntel & AMD
55
Fabricante de hardware &Microsoft 5
Intel & IBM 5 Fabricante de hardware & Palm 5Microsoft & IBMNapster & Bertelsmann
55
Fabricante de hardware &Fabricante de software 5
Gráfico 6.2.2: Red de relaciones entre Implicados
AOL TimeWarner
Discográfica
Napster
13
Fabricantede software Microsoft
13
11
Tribunal
11
EmpresaInternet
SitioWeb
9
IBM
Empresa de Investigación
5
5
7
5
12
Fabricantede hardware
Sony
7
EMI
Intel
AMD
5
Bertelsmann5
RealNetworks 5
55
Yahoo!
5
5
5
Hitachi
5
5 5
Palm
5
5
Empresa detelecomunic.
Entel
Compañíatelefónica
6
5
Gobierno
Ministro6
Presidente
5
143

En el umbral 11, se obtenía un grafo bastante más simple y, al agregar lafrecuencia 10, se hizo necesario redistribuir varios nodos para facilitar la lecturade los arcos.
El gráfico nos permite observar que hay aquí tres grandes "focos": Las"Empresas Informáticas", las "Empresas TI" (de Tecnologías de la Información)y los "Organismos públicos". En efecto, el gráfico pone mucho más demanifiesto los múltiples vínculos que asocian estas tres clases de Implicados conlas otras. Ésta es una importante ventaja de la visualización.
Tabla 6.2.3 "Implicados" asociados por clases
Términos FrecEmpresas TI & Empresas informáticas 54Empresas comerciales & Empresas TI 42MCM & Empresas informáticas 42MCM & Empresas TI 41Personas & Org.públicos 40Empresas TI & Org.públicos 31Empresas informáticas & Org.públicos 30Empresas telecomunic. & Empresas informáticas 25Empresas comerciales & Empresas informáticas 20Personas & Empresas informáticas 18Empresas TI & Empresas ases./investig. 17Org.públicos & Org.internacionales 16Empresas informáticas & Empresas ases./investig. 16Personas & Empresas TI 14Empresas telecomunic. & Org.públicos 13MCM & Empresas comerciales 13Empresas TI & Asoc.empresas 12Empresas telecomunic. & Empresas TI 12MCM & Empresas ases./investig. 11Empresas financieras & Empresas informáticas 10Empresas financieras & Empresas TI 10Empresas comerciales & Org.públicos 10MCM & Org.públicos 10Instit.enseñanza & Org.públicos 9Empresas comerciales & Org.internacionales 9Personas & MCM 8MCM & Empresas telecomunic. 7Personas & Empresas ases./investig. 7Personas & Empresas comerciales 7
144

Gráfico 6.2.3: Mapa de clases coocurrentes de "Implicados"
EmpresasInformáticas
42
25
Empresas TI
EmpresasComerciales
20
54
EmpresasTelecomun.
Personas
MCM
OrganismosPúblicos
42
41
31
40
30
18
EmpresasAses./Inv.
16
1413
OrganismosInternac.
16
17
13Asociac.
Empresas
12
12
11
EmpresasFinancieras
10 10
10
10
6.2.4. Coocurrencias entre Lugares
Este tipo de coocurrencia es evidentemente muy bajo, dado que en pocos casosaparecen involucrados varios países. Por esta misma razón, salvo el casodominante de Internet asociado con algún país (fundamentalmente EstadosUnidos), podía ser de interés ver en qué casos aparecían más de una ocasionalasociación. Estados Unidos, Japón, España y Chile - que aparecieron como losmás frecuentes - son también los más centrales en el grafo de relaciones.
Aunque las frecuencias son muy bajas, es interesante ver como España pareceservir de "visagra" para unir el grupo centrado en Chile con el centrado enEstados Unidos.
145

Tabla 6.2.4: Frecuencias de Coocurrencia de Lugares
Pares asociados Frec.Internet & Estados Unidos 20Japón & Estados Unidos 6España & Latinoamérica 4Estados Unidos & Canadá 2Latinoamérica & Estados Unidos 2España & Estados Unidos 2Brasil & Estados Unidos 2Chile & España 2Chile & Italia 2Chile & Inglaterra 2Chile & Argentina 2Internet & España 2Pares que aparecen 1 sola vez 31
Gráfico 6.2.4: Red de relaciones entre Lugares
Estados Unidos
Chile
España
Internet20
Japón
6
2
Latinoamérica4
Canadá2
22 2 2 Brasil
Italia
2Inglaterra
Argentina
2
2
No corresponde analizar las eventuales coocurrencias "internas" entre Fuentes,ya que no se anota cuando varias varias fuentes se refieren a la misma noticia (seregistra la primera o la más precisa) y sólo se han registrado ocasionalmente dosfuentes cuando era necesario complementar la información de una con la otra.
146

6.3. Coocurrencias externas
Después de estudiar las coocurrencias dentro de una mismo dimensión de datos,podemos ahora pasar al análisis de las relaciones entre dos dimensiones,buscando las asociaciones entre pares de atributos diferentes. Nuevamente hemosde crear las tablas de frecuencias y transformar éstas en redes de relaciones peroéstas tendrán ahora dos tipos diferentes de componentes, correspondientes a dostipos de atributos cada vez.
6.3.1. Coocurrencias entre descriptores y clases deimplicados
Se dieron 2.227 combinaciones, que se agruparon en 618 pares diferentes. Losresultados aparecen en la siguiente Tabla, para las frecuencias superiores a 10,cifra que corresponde a uno de los posibles umbrales de visualización. No hemosindicado en el gráfico las frecuencias, para facilitar más su visualización.
Aparecen aquí dos términos más centrales (con más vínculos): "Internet" comotema (descriptor) y "Empresas Informáticas" como tipo de implicados. Podemosagregarles "Empresas TI" (de Tecnologías de la Información), "Personas","Organismos públicos", "Empresas de Telecomunicación", "Empresascomerciales" y "Empresas de asesoría o investigación", que son las clases conmás de un vínculo.
Paralelamente y además de "Internet", los Descriptores que aparecen con más deuna relación son "Telecomunicaciones", "Seguridad", "Derecho", "Teléfonocelular", "Música", "Digital" y "e-Comercio". Esto nos conduce al gráficosimplificado 6.3.1b, que constituye la síntesis más clara de lo hallado.
Si comparamos ahora este gráfico con los gráficos de coocurrencias internas delos atributos que lo componen, podríamos volver atrás y simplificar estosgráficos anteriores de acuerdo a la presente selección, lo cual ayudaría a unamejor visión de lo realmente relevante. Como señalado en la metodología, esteproceso de "ida y vuelta" es típico - e importante - en la minería de datos.
Llama la atención aquí que no aparece "Fabricantes de Software", categoría a lacual pertenece Microsoft y que se diferencia de "Empresas Informáticas" ennuestra clasificación (expuesta en el Nº 5.3.3).
147

Tabla 6.3.1: Asociación entre descriptores y clases de implicados
Términos Frec.Internet & Empresas TI 64Internet & Empresas informáticas 47Software & Empresas informáticas 42Internet & Org.públicos 40Internet & Personas 38Internet & MCM 34Digital & Empresas informáticas 34Estadística & Empresas ases./investig. 31Derecho & Org.públicos 31Sitio web & Empresas TI 29Internet & Empresas ases./investig. 27Sistema Operativo & Empresas informáticas 26Computador & Empresas informáticas 25Internet & Instit.enseñanza 23Internet & Empresas comerciales 23Digital & Empresas TI 22Periférico & Empresas informáticas 22Teléfono Celular & Empresas informáticas 22Industria & Empresas informáticas 21Internet & Org.internacionales 21Internet & Empresas telecomunic. 20Portal & Empresas TI 20Música & Empresas TI 19Telecomunicación & Empresas telecomunic. 19PDA & Empresas informáticas 19e-Comercio & Empresas TI 18Teléfono Celular & Empresas telecomunic. 17Hardware & Empresas informáticas 15Política & Org.públicos 15e-Comercio & Empresas ases./investig. 14Televisión & Empresas informáticas 13Seguridad & Org.públicos 13Seguridad & Personas 13Teléfono & Empresas telecomunic. 13Telecomunicación & Org.públicos 12e-Comercio & Empresas financieras 12Fotografía & Empresas informáticas 11Música & Empresas comerciales 11Procesador & Empresas informáticas 11Derecho & Personas 11
148
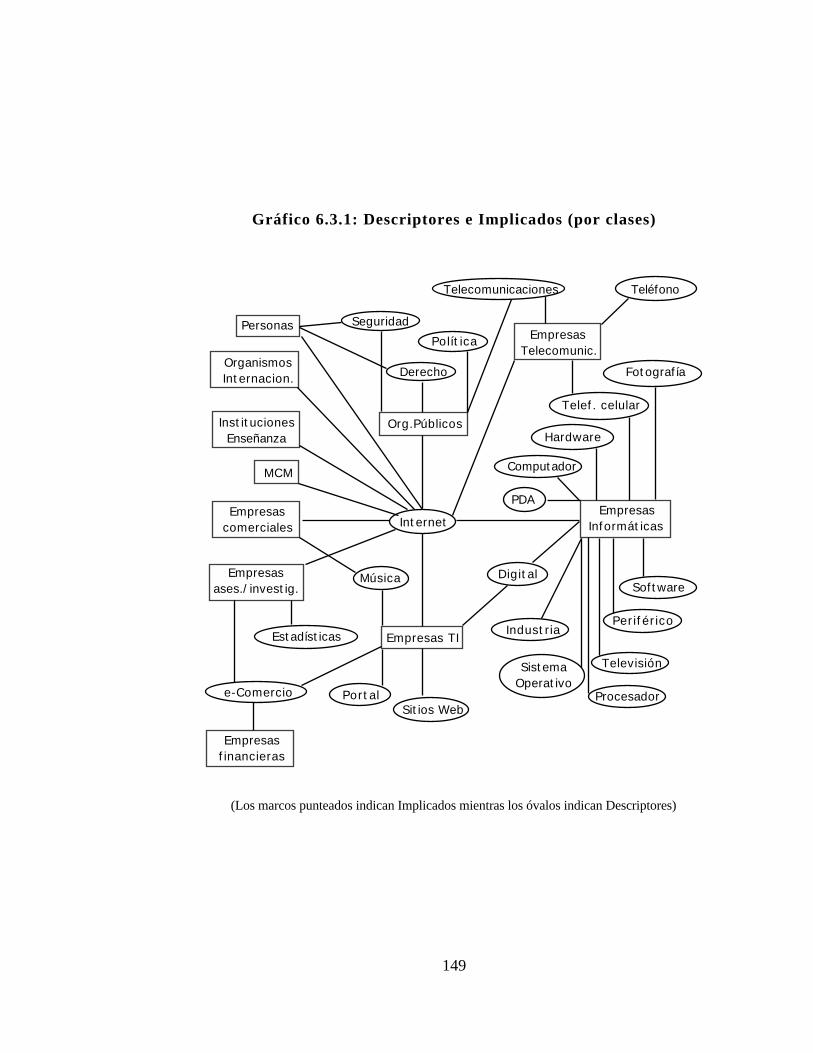
Gráfico 6.3.1: Descriptores e Implicados (por clases)
InstitucionesEnseñanza
MCM
Empresasases./investig.
e-Comercio
Telef. celular
Derecho
Org.Públicos
InternetEmpresas
Informáticas
OrganismosInternacion.
Digital
Empresas TI
Software
SistemaOperativo
EmpresasTelecomunic.
Empresascomerciales
Personas
Telecomunicaciones
Estadísticas
Portal
Música
IndustriaPeriférico
Computador
PDA
Sitios Web
Política
Hardware
Televisión
Seguridad
Teléfono
Empresasfinancieras
Fotografía
Procesador
(Los marcos punteados indican Implicados mientras los óvalos indican Descriptores)
149

Gráfico 6.3.1b: Descriptores y clases de Implicadoscon relaciones múltiples
Org.Públicos
Internet
Empresas TI
EmpresasInformáticas
EmpresasTelecomunic.
Empresascomerciales
Personas
Empresasases./investig.
Telecomunicaciones
e-Comercio
Música Digital
Telef. celular
Derecho
Seguridad
6.3.2. Descriptores por períodos mensuales
Dada la cantidad de descriptores aplicables (190) y el estrecho número de mesescubiertos (14) era lógico encontrar frecuencias bastante bajas, al menos entérminos porcentuales. La siguiente tabla da cuenta de los casos en que seobtuvieron frecuencias mensuales iguales o superiores a 20 (cifra elegidasolamente en razón de espacio).
Como se podrá ver, la primera cifra aparece comparativamente muy elevada ycorresponde a noticias relacionadas con Internet en marzo de 2001. Y todas lasfrecuencias superiores al 1% del total corresponden a Internet, lo cual nos llevó ahacer un análisis más detallado de la evolución mensual de las noticias en estesector (ver Gráfico 6.3.2).
Si aislamos y ordenamos por mes las frecuencias correspondientes a "Internet",podemos ver con claridad el fuerte crecimiento correspondiente a los primerosmeses del año (Gráfico 6.3.2a), que corresponde, por otra parte, a la curvaevolutiva general que hemos visto al calcular las frecuencias totales (Gráfico6.2.1b). Lo interesante sería poder verificar a futuro si esta tendencia se repite enotros años.
150

Tabla 6.3.2: Descriptores por mes
Términos Frec. %Internet & Marzo 2001 117 2,50Internet & Febrero 2001 97 2,07Internet & Enero 2001 91 1,94Internet & Mayo 2001 82 1,75Internet & Abril 2001 70 1,49Internet & Junio 2001 61 1,30Internet & Diciembre 2000 60 1,28Internet & Octubre 2000 53 1,13Internet & Noviembre 2000 53 1,13Internet & Septiembre 2000 41 0,87Digital & Enero 2001 34 0,73Sitio web & Mayo 2001 32 0,68e-Comercio & Marzo 2001 32 0,68Internet & Julio 2001 30 0,64Internet & Agosto 2000 29 0,62Software & Junio 2001 29 0,62Software & Mayo 2001 28 0,60Digital & Marzo 2001 26 0,55Economía & Abril 2001 26 0,55Internet & Julio 2000 24 0,51Digital & Julio 2001 24 0,51Derecho & Febrero 2001 24 0,51e-Comercio & Enero 2001 23 0,49Digital & Junio 2001 22 0,47Teléfono Celular & Marzo 2001 22 0,47Comercio & Junio 2001 22 0,47Sitio web & Junio 2001 21 0,45Digital & Abril 2001 21 0,45Sitio web & Julio 2001 20 0,43Digital & Febrero 2001 20 0,43Derecho & Marzo 2001 20 0,43Comercio & Mayo 2001 20 0,43Otros 3414 72,82
TOTALES 4688 100,00
Sabemos por otra parte (ver Estadísticas del nº 5.4.3) que "Digital" fue elsegundo descriptor más frecuente. Si analizamos su aparición por mes,obtenemos la evolución descrita en el Gráfico 6.3.2b. Podemos ver que en enero2001 hubo un alza mayor, aunque con un repunte en marzo.
151

Gráfico 6.3.2a: Noticias acerca de Internet por mes
0
20
40
60
80
100
120
20
00
05
20
00
06
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
Gráfico 6.3.2b: Noticias "digitales" por mes
0
5
10
15
20
25
30
35
20
00
06
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
152
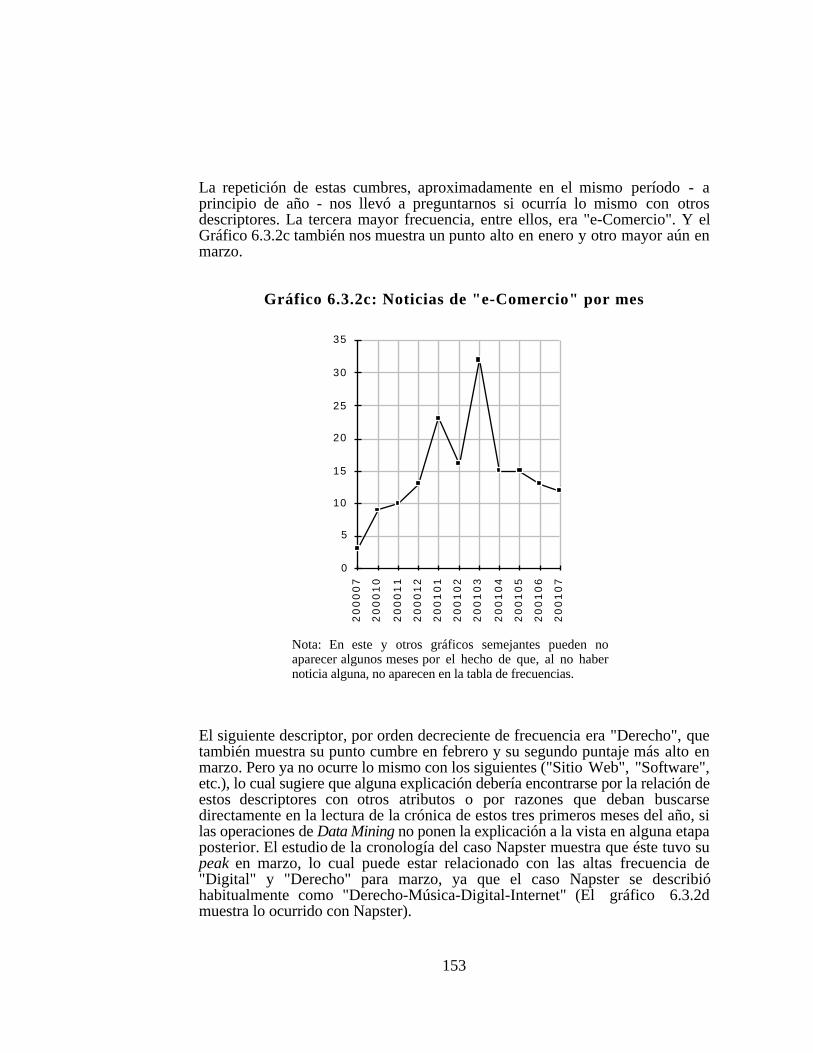
La repetición de estas cumbres, aproximadamente en el mismo período - aprincipio de año - nos llevó a preguntarnos si ocurría lo mismo con otrosdescriptores. La tercera mayor frecuencia, entre ellos, era "e-Comercio". Y elGráfico 6.3.2c también nos muestra un punto alto en enero y otro mayor aún enmarzo.
Gráfico 6.3.2c: Noticias de "e-Comercio" por mes
0
5
10
15
20
25
30
35
20
00
07
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
Nota: En este y otros gráficos semejantes pueden noaparecer algunos meses por el hecho de que, al no habernoticia alguna, no aparecen en la tabla de frecuencias.
El siguiente descriptor, por orden decreciente de frecuencia era "Derecho", quetambién muestra su punto cumbre en febrero y su segundo puntaje más alto enmarzo. Pero ya no ocurre lo mismo con los siguientes ("Sitio Web", "Software",etc.), lo cual sugiere que alguna explicación debería encontrarse por la relación deestos descriptores con otros atributos o por razones que deban buscarsedirectamente en la lectura de la crónica de estos tres primeros meses del año, silas operaciones de Data Mining no ponen la explicación a la vista en alguna etapaposterior. El estudio de la cronología del caso Napster muestra que éste tuvo supeak en marzo, lo cual puede estar relacionado con las altas frecuencia de"Digital" y "Derecho" para marzo, ya que el caso Napster se describióhabitualmente como "Derecho-Música-Digital-Internet" (El gráfico 6.3.2dmuestra lo ocurrido con Napster).
153

Gráfico 6.3.2d: "Napster" por mes
0
2
4
6
8
10
12
14
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
Gráfico 6.3.3a: Microsoft por mes
0
5
10
15
20
25
30
20
00
06
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
154

6.3.3. Implicados por períodos mensuales
Al referirnos al caso de los juicios contra Napster, hemos entrado en el análisisde lo ocurrido - a través del tiempo - con los "Implicados". Aunque algunoscasos particulares, como el ya citado, pueden ser útiles de investigar,consideraremos aquí solamente los de más alta frecuencia, como lo hemos hechoen el caso de los descriptores. En esta perspectiva, descubriremos que Microsoft- el Implicado más citado - fue especialmente objeto de noticias en marzo, mayo yjunio de 2001, con cifras ampliamente superiores a las del año 2000 (Gráfico6.3.3a). Se han juntado aquí noticias relativas tanto a los juicios que se le siguenen Estados Unidos y Europa cuanto al lanzamiento de nuevos productos yreacciones de expertos al respecto.
El siguiente "Implicado" más frecuente era el conjunto de los "Fabricantes desoftware". En este caso, las frecuencias más altas se encuentran en enero y juniode 2001 (Gráfico 6.3.3b).
Gráfico 6.3.3b: "Fabricantes de software" por mes
0
5
10
15
20
25
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
155

En el caso de "Sitio Web", que tiene la tercera mayor frecuencia, la curvaevolutiva es fluctuante, pero muestra un alza importante en los últimos meses delestudio y a pesar de que el último, recordémoslo, se cubrió solo hasta el día 20(Gráfico 6.3.3 c). Tanto en este caso como en el anterior, y considerando que elnúmero total de noticias registradas en junio y julio 2001 estuvo en descenso (vernº 6.2.1), se ha de concluir que se ha presentado una coyuntura muy especial enestos dos meses, que merecería también un estudio más profundo.
Gráfico 6.3.3c: "Sitios Web" por mes
0
5
10
15
20
25
20
00
08
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
6.3.4. Lugares y Descriptores
Obtuvimos aquí 1.881 casos de coocurrencia para los 190 descriptores y 57nombres de lugares, casos que se agruparon en 598 pares diferentes, con unafrecuencia máxima de 162 para el descriptor Internet asociado a Estados Unidos.Todas las asociaciones con frecuencias iguales o superiores a 10 que enlistamosaquí se concentran en 5 países: Estados Unidos, Chile, España, Europa, Japón,además de la "ubicua" Internet, como lo hacía esperar la estadística de frecuenciasgeográficas netas. (No calculamos los porcentajes que, como ya lo hemosmostrado, son extremadamente bajos, además de no permitir comparación algunacon otros resultados).
156

Tabla 6.3.4: Coocurrencias entre Descriptores y Lugares
Términos Frec. Internet & Estados Unidos 162 Música & Estados Unidos 74 Internet & Chile 52 Estadística & Estados Unidos 45 Internet & España 38 Industria & Estados Unidos 33 Internet & Internet 29 Sistema Operativo & Estados Unidos 27 Ética & Estados Unidos 26 Software & Estados Unidos 22 Sitio web & Estados Unidos 20 Educación & Chile 17 Telecomunicación & Chile 17 Hardware & Estados Unidos 16 Estadística & Chile 15 Internet & Europa 14 Memoria & Estados Unidos 12 Informática & Estados Unidos 12 Internet & Japón 12 Sitio web & Chile 12 Telecomunicación & Estados Unidos 12 Televisión & Estados Unidos 12 e-Libro & Estados Unidos 12 Información & Estados Unidos 11 Estadística & Internet 11 Publicidad & Estados Unidos 11 Educación & Estados Unidos 10 Lenguaje & Estados Unidos 10 Cine & Estados Unidos 10 Computador & Estados Unidos 10
Las irregularidades en la evolución de las frecuencias -que pueden indicar útilesumbrales para la visualización- se encuentran en las frecuencias 17, 12 y 7.Deberíamos haber utilizado la frecuencia 12 como límite de visualización pero,como se observa en la Tabla, en 10 aparece el descriptor "Educación", que nospermite cerrar una red que muestra un vínculo más entre Chile y Estados Unidos.Hemos ubicado y marcado especialmente, en el gráfico, los componentes queforman la red que enlaza Estados Unidos y Chile, compuesto de 5 descriptores(los que, por esta exclusiva razón, hemos puesto en letra cursiva). Nos pareceque éste es uno de los resultados menos previsibles que nuestra DM puso enevidencia y serían pistas interesantes para un análisis de periodismointerpretativo.
157
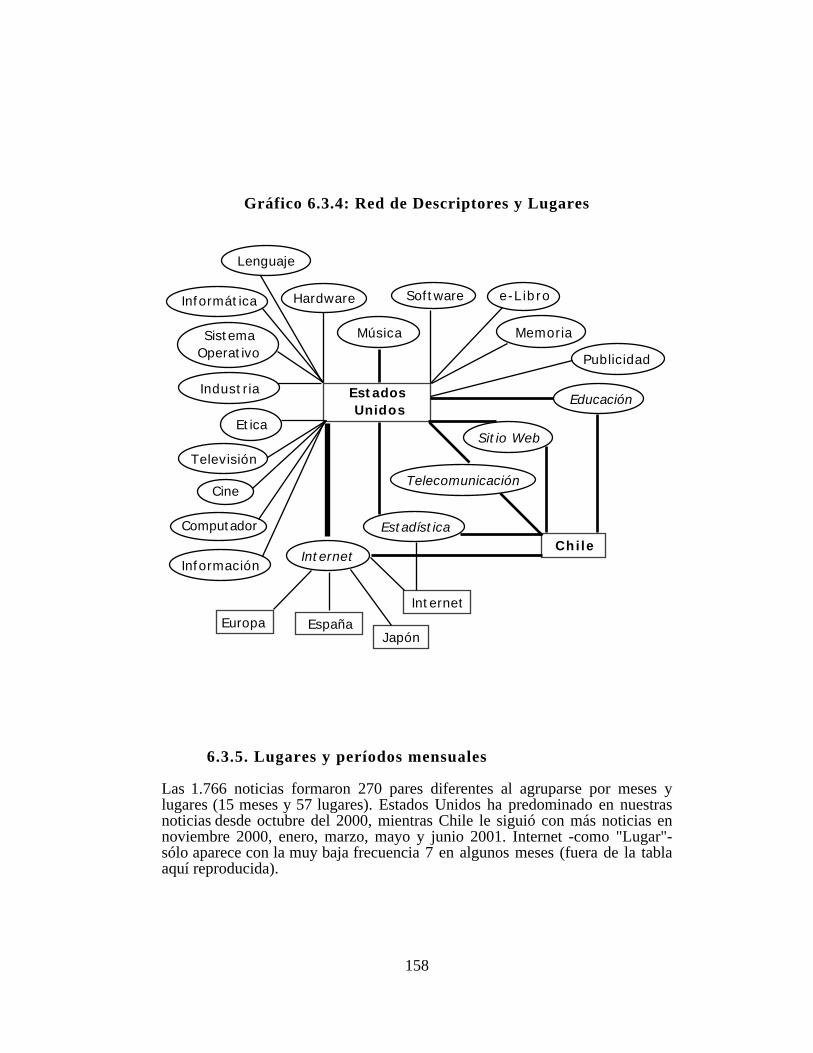
Gráfico 6.3.4: Red de Descriptores y Lugares
Estados Unidos
Chile
España
Internet
JapónEuropa
Internet
SistemaOperativo
Música
Estadística
Industria
Telecomunicación
Etica
SoftwareHardware
Sitio Web
Educación
Computador
Memoria
Informática
Televisión
e-Libro
Información
Publicidad
Lenguaje
Cine
6.3.5. Lugares y períodos mensuales
Las 1.766 noticias formaron 270 pares diferentes al agruparse por meses ylugares (15 meses y 57 lugares). Estados Unidos ha predominado en nuestrasnoticias desde octubre del 2000, mientras Chile le siguió con más noticias ennoviembre 2000, enero, marzo, mayo y junio 2001. Internet -como "Lugar"-sólo aparece con la muy baja frecuencia 7 en algunos meses (fuera de la tablaaquí reproducida).
158

Tabla 6.3.5: Reparto geográfico mensual
Términos Frec.Estados Unidos & Marzo 2001 94Estados Unidos & Junio 2001 85Estados Unidos & Mayo 2001 81Estados Unidos & Enero 2001 79Estados Unidos & Febrero 2001 76Estados Unidos & Abril 2001 75Estados Unidos & Julio 2001 51Estados Unidos & Octubre 2000 48Estados Unidos & Diciembre 2000 46Estados Unidos & Noviembre 2000 42Chile & Mayo 2001 34Chile & Enero 2001 31Chile & Junio 2001 26Chile & Noviembre 2000 23Chile & Marzo 2001 23Estados Unidos & Septiembre 2000 22Chile & Diciembre 2000 22Estados Unidos & Julio 2000 18Estados Unidos & Agosto 2000 17España & Octubre 2000 17España & Marzo 2001 17Chile & Abril 2001 17Estados Unidos & Junio 2000 16España & Mayo 2001 16Internet & Mayo 2001 15España & Junio 2001 14España & Febrero 2001 13Chile & Julio 2001 13Japón & Febrero 2001 13Internet & Junio 2001 13España & Noviembre 2000 12Japón & Marzo 2001 12Internacional & Mayo 2001 12Europa & Abril 2001 11Chile & Febrero 2001 11Japón & Junio 2001 11Europa & Mayo 2001 10España & Enero 2001 10España & Abril 2001 10España & Julio 2001 10Internet & Abril 2001 10
En Estados Unidos, la mayor cantidad de noticias se registró en marzo y junio de2001, mientras en Chile la frecuencia más alta corresponde a mayo y enero. Elgráfico (construído a partir de la tabla completa) -en que se comparan los trespaíses con mayores frecuencias- muestra claramente la amplia diferencia entreellos. Obviamente las noticias de España son menores debido a que no se
159

registran las noticias que se estiman demasiado "localistas", a diferencia de las deChile, por ser el país sede de nuestra universidad.
Nuevamente hay que observar aquí que se requeriría la información de variosaños para ver en qué medida alguna estacionalidad puede estar influenciando losresultados. (Recordemos que nuestros tres primeros meses son pocorepresentativos debido a que corresponden a la puesta en marcha de nuestrarevista.)
Gráfico 6.3.5: Evolución de la cantidad de noticiasde Estados Unidos, Chile y España
0
10
20
30
40
50
60
70
80
90
100
20
00
05
20
00
06
20
00
07
20
00
08
20
00
09
20
00
10
20
00
11
20
00
12
20
01
01
20
01
02
20
01
03
20
01
04
20
01
05
20
01
06
20
01
07
EE.UU.
Chile
España
6.3.6. Lugares y clases de Implicados
Obtuvimos aquí un total de 1.692 coocurrencias, que se agrupan en 248 paresdiferentes, asociando 57 Lugares con nuestras 16 clases de Implicados. Laevolución de las frecuencias es irregular entre las 23 y 8, como se puede apreciaren la siguiente tabla, por lo cual el umbral de graficación puede situarse encualquier punto entre estas cifras (Nos detuvimos en la frecuencia 9).
160

Tabla 6.3.6: Asociación entre Lugares y clases de Implicados
Términos Frec.Estados Unidos & Empresas informáticas 288Estados Unidos & Empresas TI * 114Estados Unidos & Org.públicos 85Chile & Org.públicos 73Estados Unidos & Empresas ases./investig. 68Japón & Empresas informáticas 55España & Empresas TI 35Estados Unidos & MCM 33Internet & Empresas TI 30Chile & Asoc.empresas 26Estados Unidos & Personas 25Chile & Empresas TI 24Estados Unidos & Instit.enseñanza 23Europa & Org.internacionales 23Estados Unidos & Org.internacionales 21Internacional & Empresas informáticas 18Estados Unidos & Empresas telecomunic. 17España & Empresas informáticas 17Estados Unidos & Empresas comerciales 16Chile & Empresas informáticas 16Chile & Empresas telecomunic. 16Chile & Personas 16Internet & Empresas ases./investig. 14España & Instit.enseñanza 13Alemania & Empresas informáticas 13Internet & Empresas informáticas 13España & Empresas telecomunic. 12España & Org.públicos 11Chile & Instit.enseñanza 11Desconocido & Empresas informáticas 11Estados Unidos & Asoc.empresas 10España & MCM 10Estados Unidos & Empresas servicios 9Internet & Personas 9Bélgica & Org.internacionales 8Chile & Empresas ases./investig. 8Japón & Empresas telecomunic. 8
* TI = Tecnologías de la Información
161

Gráfico 6.3.6: Asociación entre Lugares y clases de Implicados
Org.Públicos
Empresas TI
EmpresasInformáticas
EmpresasTelecomunic.
Empresas TI
OrganismosInternacion.
InstitucionesEnseñanzaMCM
Personas
Empresasases./investig.
InternetInternacional
Chile
Japón
Alemania
Empresascomerciales
Estados Unidos
Asociac.deEmpresas
Empresasases./investig.
España
Empresas deServicios
Los resultados son bastante semejantes a los obtenidos para las coocurrenciasentre Lugares y Descriptores. Es interesante ver en este gráfico como se cierra lared que une a España con Estados Unidos y con Chile: aparecen dos subredescon elementos comunes, cosa que sería interesante estudiar y comentar másdetenidamente en un análisis periodístico. Para mayor evidencia simplificamos elgráfico dejando solamente los elementos comunes:
162

Gráfico 6.3.6a: España, Chile y Estados UnidosPrincipales clases de Implicados comunes
Org.Públicos
Empresas TI
EmpresasInformáticas
EmpresasTelecomunic.
InstitucionesEnseñanza
Chile
Estados Unidos
España
El gráfico 6.3.6 muestra también las diferencias entre las clases de Implicadosque aparecen en las noticias de cada país, al menos en lo que puedan interesarlocalmente en el caso de Chile e internacionalmente en el caso de los demáspaíses o lugares. Es especialmente claro el caso de Estados Unidos, asociadoprincipalmente con numerosas empresas informáticas y de otros tipos, mientrasen el caso local de Chile el interés se centra mucho más en los OrganismosPúblicos (esencialmente iniciativas de gobierno) y se da proporcionalmente másimportancia a las Personas e Instituciones de Enseñanza. Parece bastante claroque la diferencia no se debe, en este caso, exclusivamente a criterios selectivosdel editor de la hiperrevista "TDC" sino efectivamente a coyunturas nacionalesdiferentes. El gráfico 6.3.6a pone estos hechos mejor en evidencia, siendo otrabuena muestra de lo aportado por nuestra minería de datos.
En la Tabla 6.3.6a hemos incluído España dada la situación especial puesta enevidencia por el Gráfico 6.3.6, pero no incluimos este país en el Gráfico 6.3.6bpara visualizar mejor la diferencia comentada entre Estados Unidos, paísdesarrollador de tecnología, y Chile, país usuario de tecnología, que cuentaademás con nuestro interés local. España aparece como un tercero, dependienteen gran parte de Estados Unidos a la vez que controlador de empresas chilenas ydesarrollador de algunos servicios para todo el área hispanoamericano (lo cualafecta e interesa también a Chile). Este nuevo gráfico deja muy claro que,mientras Estados Unidos se destaca por la importancia de las EmpresasInformáticas, Chile lo hace por el rol de los Organismos Públicos, lo cualcorresponde a la importancia dada por el gobierno al tema de las nuevastecnologías digitales en la política y los planes de desarrollo del país.
163

Tabla 6.3.6a: Clases de Implicados(Porcentajes comparados)
Clases% enUSA
% enCHILE
% enESPAÑA
Org.públicos 11,7 32,3 8,2Asoc.empresas 1,4 11,5 2,2Empresas TI * 15,6 10,6 26,1Empresas informáticas 39,5 7,1 12,7Empresas telecomunic. 2,3 7 ,1 9,0Personas 3,4 7 ,1 3,7Instit.enseñanza 3,2 4,9 9,7Empr. ases./investig. 9,3 3,5 3,0Empresas comerciales 2,2 3,1 3,0MCM 4,5 2,7 7,5Asoc.centros de estudios 0,0 2,2 2,2Org.internacion. 2,9 2,2 4,5Org.temporales 1,0 1,8 0,0Empresas financieras 1,0 1,8 1,5Asoc.personas 0,8 1,3 5,2Empresas servicios 1,2 0,9 1,5
100,0 100,0 100,0
* Empresas de Tecnologías de la Información
Gráfico 6.3.6b: Clases de Implicados en Chile vs. Estados Unidos
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
40,0
Aso
c.em
pres
as
Aso
c.ce
ntro
s de
estu
dios
Aso
c.pe
sona
s
Org
.inte
rnac
ion.
Org
.públic
os
Org
.tem
pora
les
Em
pr.
ases
./in
vest
ig.
Inst
it.e
nseñ
anza
Empre
sas
serv
icio
sEm
pre
sas
info
rmát
icas
Em
pre
sas
TI
Empre
sas
tele
com
unic
.Em
pre
sas
finan
ciera
sEm
pre
sas
com
erci
ales
MC
M
Pers
ona
s
USA
CHILE
164

6.3.7. Fuentes y clases de Implicados
¿Existe algún indicio de que nuestras Fuentes discriminan las noticias en funciónde ciertos tipos de Implicados? Ésta es la pregunta que podríamos hacernos aquí,especialmente considerando que gran parte de nuestras fuentes son mediosperiodísticos no especializados pero que tienen una sección dedicada a latecnología. Sin embargo, se debe tener en cuenta que nuestra publicación "TDC"realiza a su vez una selección y descarta las noticias que no corresponden alámbito que pretende cubrir. Por lo tanto, los resultados están sesgados debido alcriterio editorial de nuestra hiperrevista.
A partir de la Tabla 6.3.7 hicimos un análisis visual ordenando de diversasmaneras los datos de la Tabla. Para asegurar una mejor comparación, calculamosel porcentaje relativo ponderado de tipos de Implicados señalados para cadafuente en particular (sólo para fuentes apareciendo repetidamente en dicha Tabla),a partir de lo cual obtuvimos el gráfico 6.3.7 que pone en evidencia que la CNN,Mouse, Noticias.com y el Wall Street Journal arrojan porcentajes similares, conun "modo" relativo a las Empresas Informáticas, lo cual es claramente laexpresión de la tendencia general de la información ya que este indicadorcorresponde a la frecuencia más alta para el total de las noticias (Ver Tabla6.2.5). MTG tiene rangos muy próximos entre sí, lo cual no permite conclusiónalguna, mientras las noticias recogidas de Wired se refieren más frecuentemente aOrganismos públicos, lo cual puede ser un sesgo, pero probablemente deresponsabilidad del editor de TDC (sabiendo que la proporción de noticias que seextraen de Wired es muy baja en comparación con las recibidas).
6.3.8. Descriptores y Fuentes
Para los 190 descriptores y las 76 fuentes, hemos obtenido 1.835 asociaciones,repartidas en 757 pares diferentes. La cantidad de frecuencias idénticas es, en elpresente caso, bastante irregular y sólo se observa un crecimiento rápido -sinquiebres- a partir de la frecuencia 7. Sin embargo, paramos en la frecuencia 10por razones de legibilidad del gráfico.
Podemos ver aquí que la revista Mouse (del diario "La Tercera de la Hora") hasido referenciada en TDC esencialmente en relación a temas de Internet, deMúsica y Estadísticas. La CNN sólo aparece con alta frecuencia en relación aInternet. El análisis de la evolución cronológica de las fuentes muestra, por otraparte, un cambio en la CNN, disminuyendo fuertemente sus noticias sobreTecnologías Digitales en el año 2001, lo cual puede explicar su aparenteaislamiento temático en el gráfico 6.3.8.
165

Tabla 6.3.7: Asociación entre Fuentes y clases de Implicados
Términos Frec.Mouse (La Tercera) & Empresas informáticas 104Noticias.com & Empresas informáticas 99Mouse (La Tercera) & Org.públicos 70CNN & Empresas informáticas 47El Mercurio & Empresas informáticas 46Mouse (La Tercera) & Empresas TI 44WallStreet Journal Interactivo & Empresas informáticas 44Noticias.com & Empresas TI 37Wired & Org.públicos 35Mouse (La Tercera) & Empresas ases./investig. 23Mouse (La Tercera) & Org.internacionales 22Noticias.com & Org.públicos 22I Actual & Empresas ases./investig. 21Wired & Empresas informáticas 21BPenet & Empresas informáticas 18MTG & Org.públicos 18WallStreet Journal Interactivo & Empresas TI 17CNN & Empresas TI 16MTG & Empresas informáticas 16Wired & Empresas TI 16I Actual & Empresas informáticas 15Noticias.com & Empresas ases./investig. 15Diario TI & Empresas informáticas 14El Mercurio & Empresas TI 13Mouse (La Tercera) & MCM 13Noticias.com & Empresas telecomunic. 13CNN & Org.públicos 12Mouse (La Tercera) & Asoc.empresas 12Mouse (La Tercera) & Personas 12Noticias.com & Empresas comerciales 12Wired & Personas 12Navegante.com & Empresas TI 12MTG & Empresas TI 11WallStreet Journal Interactivo & Empresas telecomunic. 11CNN & Personas 10Diario TI & Empresas ases./investig. 10I Actual & Empresas TI 10Mouse (La Tercera) & Empresas financieras 10MTG & Asoc.empresas 10Noticias.com & Org.internacionales 10Wired & MCM 10
166

Gráfico 6.3.7: Frecuencias de Clases de Implicadossegún Fuentes (% relativo)
0
10
20
30
40
50
60
70
80
90
CNNCNNCNNCNN
MouseMouseMouseMouseMouseMouseMouseMouseMouse
MTGMTGMTGMTG
Noticias.comNoticias.comNoticias.comNoticias.comNoticias.comNoticias.comNoticias.com
WallStreet J.WallStreet J.WallStreet J.
WiredWiredWiredWiredWired
Tipos
% relativo
167

Tabla 6.3.8: Asociación entre Descriptores y Fuentes
Términos Frec.Internet & Mouse (La Tercera) 87Internet & CNN 44Internet & Noticias.com 41Estadística & Mouse (La Tercera) 24Internet & WallStreet Journal Interactivo 24Internet & Wired 24Internet & El Mercurio 22Música & Mouse (La Tercera) 20Internet & I Actual 20Música & Noticias.com 18Estadística & Noticias.com 16Internet & MTG 16Estadística & I Actual 15Internet & Diario TI 14Industria & Mouse (La Tercera) 13Sitio web & Mouse (La Tercera) 13Música & Wired 12Sistema Operativo & Mouse (La Tercera) 12Educación & Mouse (La Tercera) 11Industria & WallStreet Journal Interactivo 11Telecomunicación & Noticias.com 11Internet & BPenet 10Internet & Navegante.com 10Software & Mouse (La Tercera) 10
Hemos hecho además el ejercicio de combinar estos datos con las coocurrenciasinternas de Descriptores (Ver nº 6.2.1), lo cual muestra que, en el actual gráfico,sólo "Sistema operativo" y "Telecomunicación" quedan aislados, mientras"Industria" se empareja con "Software" y tanto este último como los restantes seasocian con "Internet" (ver curvas punteadas del Gráfico 6.3.8b).
Si analizamos de otra forma la tabla de todas las frecuencias de asociación entreDescriptores y Fuentes superiores a 1 - es decir en que los temas aparecieron másde una vez -, podremos observar que los medios en que hemos encontrado lamayor diversidad y repetición de temas son diez, partiendo por Mouse,Noticias.com (Intercom) y Wired (Tabla 6.3.8b).
168

Gráfico 6.3.8: Red de Descriptores y Fuentes
Mouse
CNN
Wired Noticias.comWSJI
El Mercurio
Internet
SistemaOperativo
Música
Estadística
Industria
Telecomunicación
SoftwareSitio Web
Educación
I Actual
MTGDiario TI BPenet
Navegante
Gráfico 6.3.8b: Red acumulativa de interrelaciones(Fuentes y Descriptores entre sí)
Mouse
Wired Noticias.comWSJI
Internet
SistemaOperativo
Música
Estadística
Industria
Telecomunicación
SoftwareSitio Web
Educación
I Actual
169

Tabla 6.3.8b: Diversidad de temas en las Fuentes
Fuentes TemasMouse 48Noticias.com 38Wired 26CNN 25El Mercurio 21MTG * 18WallStreet Journal Interactivo 18I Actual 11Navegante.com (El Mundo) 10Diario TI 9
* "MTG" cambió de nombre a "Metro Diario", momento apartir del cual dejamos de utilizarlo como fuente (siendoincompatible para nosotros su horario de distribución).
6.4. Asociaciones de tres atributos
El último Gráfico presentado (6.3.8b) nos ha introducido en realidad en unanueva etapa de investigación: la de las relaciones tri- o multidimensionales (entretres o más atributos o ejes del espacio de datos). Para el tratamiento de lastríadas, utilizamos un sistema semejante al utilizado para las "coocurrenciasexternas" entre dos atributos. Más adelante (ver nº 6.5) hablaremos brevementedel análisis multidimensional basado en otros procedimientos. No abordaremosaquí todas las combinaciones triádicas posibles (que son diez), sino las cuatroque nos partecieron más relevantes y más prometedoras.
6.4.1. Tríada Descriptor-Implicado-Lugar
Partiremos considerando las asociaciones o coocurrencias entre Descriptores,Implicados y Lugares. Para optimizar el ordenamiento, colocamos primero elLugar -que tiene el menor número de posibles valores diferentes, luego elImplicado y finalmente el Descriptor (donde hay mayor diversidad de posiblesvalores). Obtuvimos 4.668 tríadas, 1.274 de las cuales aparecieron más de unavez.
En la Tabla 6.4.1 mostramos las frecuencias superiores a 17, por ordendecreciente. Nos detenemos en este número por ser el primer posible umbral devisualización (y el único que define una tabla cuya longitud no exceda una páginade este libro).
170

Tabla 6.4.1: Tríadas Lugar-Implicados-Descriptores
Tríadas FrecEstados Unidos + Microsoft + Software 56Estados Unidos + Microsoft + Internet 50Estados Unidos + Napster + Música 47Estados Unidos + Napster + Digital 43Estados Unidos + Napster + Internet 34Estados Unidos + Empresa de Investigación+ Internet 33
Estados Unidos + Microsoft + SistemaOperativo 32
Estados Unidos + Sitio Web + Internet 28Estados Unidos + Napster + Copyright 21Estados Unidos + Fabricante de software +Software 21
Estados Unidos + Microsoft + Seguridad 20Estados Unidos + Napster + Sitio web 20Estados Unidos + Sitio Web + Sitio web 20Estados Unidos + AOL Time Warner +Internet 18
Estados Unidos + Tribunal + Derecho 18Estados Unidos + Fabricante de software +Internet 18
Estados Unidos + Fabricante de hardware +Hardware 18
La primera observación es que, en este rango, solamente aparecen hechosocurridos en Estados Unidos (el país que aparece con mayor frecuencia, segúnconsta en nuestras estadísticas, ver nº 5.4.2) o, eventualmente, en dicho país yotro más, o situados a la vez en Internet, ya que se pueden registrar dos Lugaresen el campo de datos correspondiente. Sabemos por otra parte (ver nº 6.2.4) quelos Implicados más frecuentes son "Microsoft", "Fabricantes de Software","Sitios Web" y "Empresas de Investigación", y los Descriptores más frecuentes(ver nº 6.2.3) "Internet" y "Digital". No es extraño, por lo tanto, volver aencontrarlos aquí. Pero se destacan algunas novedades, como la ausencia en lastríadas más frecuentes de temas tan frecuentes como "e-Comercio" o la bajaaparición de "Derecho". Tampoco está aquí "Gobierno", que - en la estadísticabásica - aparece en total 72 veces (más que "Napster").
Para la visualización, optamos por el sistema de gráficos de tres columnas, quees sin duda el más adecuado para representar este tipo de vínculos. La principalventaja de este tipo de gráfico es su legibilidad, ya que permite evitar numerosasrepeticiones y pone fácilmente en evidencia los nodos (valores de atributos) másconectados. Su desventaja es que sólo permite trazar los vectores que unen dosde las tres series: se asume que los vectores que unen la primera con la tercera
171

columna son "absorbidos" o contenidos en los que unen la primera con lasegunda y ésta con la tercera, pero no hay una correspondencia exacta, por locual se pierde cierto nivel de detalle. En el nº 6.4.3 mostraremos otro tipo degráfico, que conserva las tres clases de vectores de asociación, pero al costo deun lectura más difícil (especialmente en una escala pequeña y sin colores, adiferencia de lo que ocurre en la pantalla del ordenador).
Gráfico 6.4.1: Tríadas Lugar-Implicados-Descriptores
EstadosUnidos
MicrosoftSoftware
Napster
Empresa deInvestigación
Sitio Web
Fabricantede software
AOL TimeWarner
Tribunal
Fabricantede hardware
Hardware
Internet
Seguridad
Sitio Web
Música
Digital
Sistema Operativo
Copyright
Derecho
El gráfico 6.4.1 pone en evidencia que existen tres puntos de concentración denexos, aparte del lugar de ocurrencia de los hechos noticiosos: "Microsoft" y"Napster", como Implicados, además de "Internet" como Descriptor. Tanto esteGráfico como los que siguen nos confirman que Microsoft y Napster han sidolos protagonistas más detacados de los meses considerados, ambos afectados poracciones en justicia, aunque Microsoft también genera otras noticias al anunciarnuevos productos y ser objeto de múltiples denuncias por fallas de seguridad oataques de virus, lo cual aparece en las descriptores "Software" y "Seguridad".
6.4.2. Tríada Descriptor-Implicado-Fecha
En este caso pudimos extraer 5.339 tríadas, de las cuales 1.460 aparecían más deuna vez. La Tabla 6.4.2 recoge las que tuvieron una frecuencia superior a 8, unode los posibles umbrales de visualización.
172

El Gráfico 6.4.2a muestra la red de relaciones que puede extraerse de dicha tabla.Vemos aquí una "decantación" de los gráficos 6.2.1 y 6.2.2 que presentaban lascoocurrencias internas de Descriptores e Implicados.
Tabla 6.4.2: Tríadas Fechas-Implicados-DescriptoresTríada Frec.2001-07 + Sitio Web + Sitio web 222001-06 + Microsoft + Software 182001-05 + Microsoft + Software 152001-03 + Microsoft + Internet 142001-03 + Napster + Música 132001-03 + Napster + Digital 132000-11 + Sitio Web + Internet 122001-05 + Microsoft + Sistema Operativo 122001-05 + Sitio Web + Internet 122001-06 + Sitio Web + Internet 122001-05 + Sitio Web + Sitio web 112000-12 + Empresa de Investigación + Internet 102001-02 + Empresa de Investigación + Internet 102001-03 + Gobierno + Internet 102001-03 + Napster + Internet 102001-07 + Microsoft + Software 102001-01 + Empresa de e-comercio + e-Comercio 92001-03 + Napster + Copyright 92001-03 + Sitio Web + Internet 92001-04 + Napster + Música 92001-05 + Microsoft + Comercio 92001-06 + Sitio Web + Sitio web 92001-07 + Sitio Web + Internet 92001-07 + Fabricante de hardware + Digital 9
Los Gráficos 6.4.2b y c muestran el cubo tridimensional con la ubicación de lospuntos (pequeños cuadrados) correspondientes a este mismo grupo de tríadastomando como coordenadas los valores de los tres atributos que las conforman(Hacen abstracción de las variaciones de frecuencia). El software "GVA"utilizado -del cual hablaremos más en detalle en el nº 6.5 - permite girar el cubo yenfocarlo desde múltiples ángulos. Presentamos aquí dos vistas del mismo,enfrentando alternativamente los dos ejes del plano horizontal. Se observanclaramente las agrupaciones de Descriptores en la franja correspondiente a"Internet", "Software" y "Sistema Operativo" (Gráfico 6.4.2b en láminas a color)y de fechas a fines del 2000 y en julio 2001 (Gráfico 6.4.2c en láminas a color),mientras en ambos gráficos se ve (eje Y) cómo hay una mayor concentración dedescriptores en el rango de los 400, en que están "Microsoft" y "Napster".
173

No presentamos este tipo de gráfico para las otras tríadas debido a que no haysuficiente diversidad de "Lugares", por lo cual los gráficos tridimensionales(difíciles de interpretar si no se pueden hacer girar, como en la pantalla delordenador) no aportan prácticamente nada a los bidimensionales.
Gráficos 6.4.2a: Tríadas Fechas-Implicados-Descriptores
2000-11
2000-12
2001-01
2001-02
2001-03
2001-04
2001-05
2001-06
2001-07
Sitio Web Sitio Web
Microsoft
Software
Internet
NapsterMúsica
Digital
Sistema Operativo
Empresa deInvestigación
Empresa dee-comercio
E-comercio
Copyright
Comercio
Fabricantede hardware
Gobierno
6.4.3. Tríada Descriptor-Lugar-Fecha
La extracción de esta tríada arrojó 2.467 casos, de los cuales 1.495 aparecieronmás de una vez. Exponemos y graficamos las que arrojaron frecuenciassuperiores a 20. Dominan claramente aquí los hechos centrados en EstadosUnidos y que podían describirse mediante el conjunto "Música-Digital-Internet",lo cual alude claramente, otra vez, al caso del juicio contra Napster y otroshechos correlacionados, como los acuerdos entre empresas discográficas paradesarrollarsus propios sitios de distribución de música digital y la aparición de otros sitiosque empezaron a facilitar el intercambio de música que Napster ya no podíasatisfacer. De este modo, sumando la información que aparece así con la arrojadapor etapas anteriores, vemos claramente la aparición de un "cluster", es decir deun subconjunto de informaciones fuertemente ligadas entre sí, lo cual es otro de
174

los productos esperados de la minería de datos. Por otra parte, se puede observarque podría haber ocurrido algo especial en marzo, que justifique la densidad de latríada "2001-03 + España + Internet", la cual podría considerarse para otroestudio periodístico específico.
Aprovecharemos el hecho de que ésta sea la Tabla con las mejores agrupacionespara mostrar otro tipo de gráfico frecuentemente usado - y generado en formaautomática - en Data Mining. Se trata de la "agrupación circular": se divide uncírculo de acuerdo al número de atributos considerados (tres en nuestro caso) ycada fragmento de acuerdo al número de valores tomados por estos atributos, loscuales se anotan en la circunferencia. Luego se unen entre sí de acuerdo a losvínculos de asociación revelados por el cálculo. Apuntando sobre cada vector, sepueden leer sus características (qué valores une y con qué frecuencia) y sepueden seleccionar diversos colores para una mejor diferenciación tanto de losvectores como de los atributos. Aquí hemos utilizado líneas enteras y punteadas,así como diferentes estilos para los atributos. (Ver Gráfico 6.4.3b en láminas acolor).
Este tipo de gráfico permite incluir con mayor facilidad los vínculos que cierrenlas tríadas, mientras en el gráfico de columnas (que se ha de confeccionarmanualmente) los terceros vectores cruzarían por sobre los términos de lacolumna central (razón por la cual no se incluyen).
Tabla 6.4.3: Tríadas Fechas-Lugares-Descriptores
Tríadas Frec. Frec.2001-03 + EE.UU. + Internet 81 2001-05 + EE. UU. + Sitio web 282001-01 + EE.UU. + Internet 73 2001-07 + EE.UU. + Digital 272001-02 + EE.UU. + Internet 62 2000-11 + Chile + Internet 262000-12 + EE.UU. + Internet 56 2001-01 + Chile + e-Comercio 262001-04 + EE.UU. + Internet 54 2000-08 + EE.UU. + Internet 252001-04 + EE.UU. + Digital 51 2001-03 + Estados UU. + Derecho 252001-04 + EE.UU. + Música 48 2001-06 + Chile + Internet 252001-05 + EE.UU. + Internet 46 2001-03 + España + Internet 242001-06 + EE.UU. + Internet 42 2001-05 + EE.UU. + Comercio 232000-10 + EE.UU. + Internet 40 2001-07 + EE.UU. + Sitio web 232000-11 + EE.UU. + Internet 36 2001-07 + EE.UU. + Software 232001-01 + EE.UU. + Digital 35 2000-09 + EE.UU. + Internet 222001-01 + Chile + Internet 35 2000-12 + Chile + Internet 222001-03 + EE.UU. + e-Comercio 35 2001-03 + Chile + Telecomunicac. 222001-06 + EE.UU. + Software 34 2001-04 + EE.UU. + Economía 222001-06 + EE.UU. + Sistema Oper. 30 2001-03 + EE.UU. + Digital 212001-07 + EE.UU. + Internet 30 2001-05 + EE.UU. + Software 212001-04 + EE.UU. + e-Comercio 28 2001-05 + Chile + Internet 21
175

Gráfico 6.4.3: Tríadas Fechas-Lugares-Descriptores
2000-11
2000-12
2001-01
2001-02
2001-03
2001-04
2001-05
2001-06
2001-07
Chile
Sitio Web
Software
Internet
EstadosUnidos
Música
Digital
Sistema Operativo
E-comercio
Telecomunicación
Comercio
España
2000-10
2000-09
2000-08
Derecho
Economía
Hardware
Tecnología
Gráfico 6.4.4: Tríadas Fechas-Lugares-Implicados
2000-11
2000-12
2001-01
2001-02
2001-03
2001-04
2001-05
2001-06
2001-07
Sitio Web
Microsoft
Napster
Empresa deInvestigación
Fabricante de software
Fabricantede hardware
AOL TimeWarner
EstadosUnidos
2000-10 Suecia Científico
Internet
176
Gráficos 6.4.2b y c: Proyección tridimensional6.4.2b: Descriptores en plano frontal (Eje X)
(Implicados en eje Y)
6.4.2c: Meses en plano frontal (Eje Z)
177

Gráfico 6.4.3b: Tríadas F-L-D (Forma circular)
2000-11
2000-12
2001-01
2001-02
2001-03
2001-04
2001-05
2001-06
2001-07
Chile
Sitio Web
Software
Internet
EstadosUnidos
Música
Digital
SistemaOperativo
E-comercio
Telecomunicación
Comercio
España
2000-10
2000-09
2000-08
Derecho
Economía
Hardware
Tecnología
Gráfico 6.5.2: Noticias ordenadas por descriptor,implicado y fuente
178
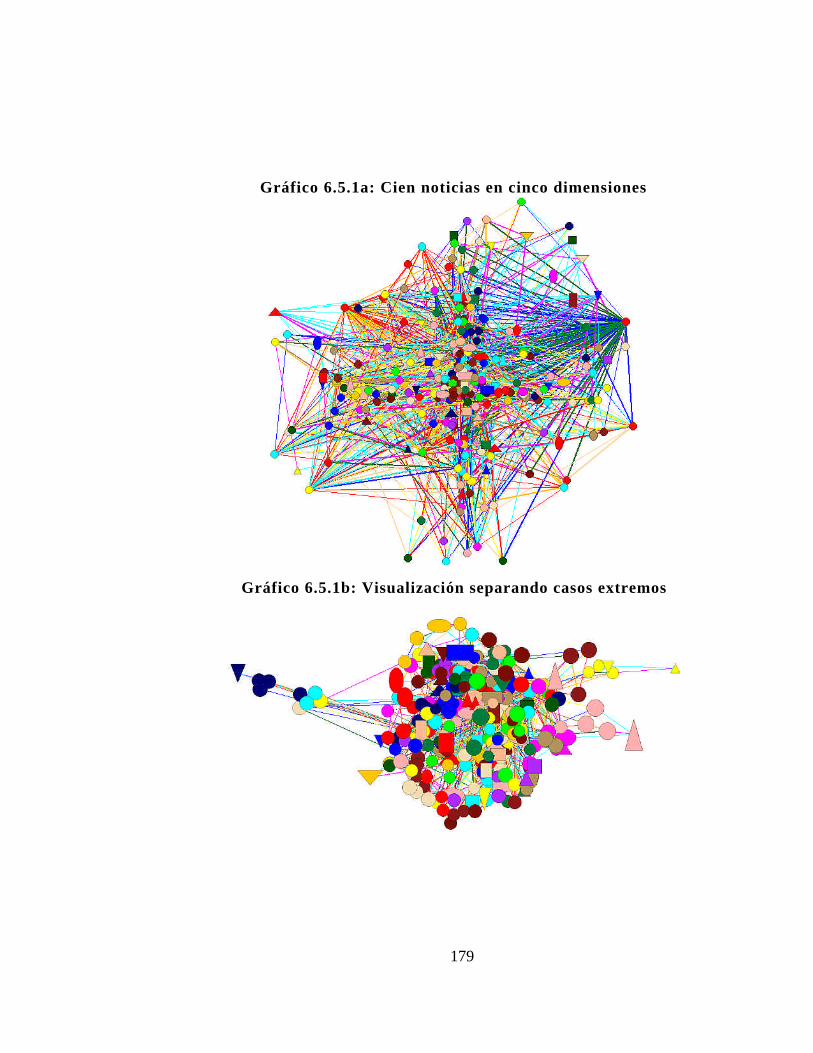
Gráfico 6.5.1a: Cien noticias en cinco dimensiones
Gráfico 6.5.1b: Visualización separando casos extremos
179

Conjunto de Mandelbrot
Arriba: el contorno del conjunto completo. Abajo: ampliación de unfragmento de su perímetro. Se puede ver claramente que en el centrodel mismo vuelve a aparecer la figura del conjunto completo. Lomismo ocurre con la ampliación de cualquiera de los aparentes"tentáculos" que lo conforman.
180

6.4.4. Tríada Implicado-Lugar-Fecha
Considerando ahora los vínculos entre Implicados, Lugares y Fechas, obtuvimos 1.839tríadas, de las cuales 1.728 ocurren más de una vez. Seleccionamos las superiores a 18 pornuestro procedimiento habitual, transcribimos la tabla correspondiente y confeccionamos elgráfico de tres columnas.
Tabla 6.4.4: Tríadas Fechas-Lugares-Implicados
Tríadas Frec.2001-03 + Estados Unidos + Napster 572001-05 + Estados Unidos + Microsoft 572001-06 + Estados Unidos + Microsoft 552001-03 + Estados Unidos + Microsoft 442001-07 + Estados Unidos + Fabricante de hardware 432001-01 + Estados Unidos + Fabricante de hardware 422001-07 + Estados Unidos + Microsoft 392001-05 + Estados Unidos + Sitio Web 372000-11 + Estados Unidos + Fabricante de hardware 352001-04 + Estados Unidos + Microsoft 342001-04 + Estados Unidos + Napster 342001-06 + Estados Unidos + Fabricante de hardware 332001-02 + Estados Unidos + Microsoft 322001-07 + Estados Unidos + Sitio Web 322001-05 + Estados Unidos + Napster 312001-07 + Internet + Sitio Web 312001-06 + Estados Unidos + Napster 272001-07 + Estados Unidos + Fabricante de software 262001-02 + Estados Unidos + Empresa de Investigación 242001-03 + Estados Unidos + Fabricante de software 212000-10 + Suecia + Científico 202000-11 + Estados Unidos + Microsoft 202001-01 + Estados Unidos + Microsoft 202001-02 + Estados Unidos + Napster 192001-06 + Estados Unidos + AOL Time Warner 19
6 .4 .5 . Conclusión
Tal como se puede observar, se produce cierta redundancia entre los diversos gráficos y, amedida que hemos avanzado, los aportes novedosos han ido en cierto modo disminuyendo ohan confirmado hallazgos anteriores. Esto quiere decir que ya hemos puesto en evidencia losresultados más importantes. Proseguir con otras tríadas (quedan otras seis posiblescombinaciones) no aporta ningún descubrimiento nuevo y por ello no las incluimos. Esto esalgo que el analista debe examinar con cuidado y depende en gran parte del orden en que decideexplorar las asociaciones. Creemos que, en nuestro caso, podríamos haber empezado por latríada Descriptor-Implicado-Fecha que ha sido, a nuestro juicio, la más rica de explorar. Elnúmero de tríadas encontradas (5.339) ha sido el mayor de todos (corresponde al 65,7 % de
181

las tuplas de la tabla OLAP) al mismo tiempo que las frecuencias de repetición han sido las másbajas (la mayor era sólo de 22) y ambos datos podrían ser indicios de situaciones de interés.
Al mismo tiempo, la tríada más frecuente, de todas las consideradas, ha aparecido 81 veces ycorresponde a "2001-03 + Estados Unidos + Internet". He aquí otro dato específico que podríaser de mucho interés para extender la investigación más propiamente periodística: ¿Qué fue loque hizo de marzo del 2001 un mes tan especial, en relación al tema "Internet", en EstadosUnidos?
6.5. Análisis multidimensional
Para esta etapa, utilizamos el software GVA: Generic Visualization Architecture, aplicación depropósito general en el campo de la minería de datos basada en visualización. Ha sidodesarrollada por United Information Systems Inc. bajo el patrocinio de la Oficinanorteamericana para la Política de Control de Drogas (Office of National Drug Control Policy).Su primer destino ha sido por lo tanto la investigación del crimen organizado y del lavado dedinero, pero ha sido puesta a disposición de toda la comunidad académica internacional yorganismos sin fines de lucro para la libre investigación en todos los campos de la DataMining.Puede funcionar practicamente con cualquier sistema operativo por cuanto fue escrito enlenguaje Java1. Aunque el manual no especifica exigencias mínimas de RAM ni tamañomáximo de la base de datos manejable, nos hemos encontrado con serias limitaciones quecomentamos a continuación y nos obligaron a trabajar solamente con una muestra muy parcialpara ilustrar algunas de las operaciones más avanzadas que facilita.
6.5.1. Demultiplicación combinatoria
En el Tercer Capítulo hemos comentado entre otras cosas el problema que surge con lademultiplicación de los registros de datos al asegurar la combinatoria de las variables queinteresan para el análisis (nº 3.4.2). Decíamos que, mientras más atributos se consideren y másvalores diferentes puedan tomar dichos atributos, mayor será el efecto combinatorio ("fan out")y, consecuentemente la memoria y el tiempo de procesamiento requerido.
Hemos de partir aquí construyendo una tabla especial según el modelo del Datawarehousing ydel método OLAP ("OnLine Analytical Processing"), tabla que se aleja de la "tercera formaformal" y debe contener todas las combinaciones posibles de los valores de los atributos paracada entidad analizada. En nuestro caso, hemos de considerar los atributos y factores dedemultiplicación que aparecen en la Tabla 6.5.1 y conducen a una estimación preliminar de latransformación de las 1.766 noticias en más de 10.000 "tuplas" o registros combinatorios delos datos que las describen.
1 Algunas funciones no operan si se utiliza el browser Explorer como interfaz, por cuanto Microsoft no respetatodas las especificaciones del Java original.
182

Tabla 6.5.1: Estimación de "fan out"Casos posibles
Atributos a incluir: MáximoPromedioestimado
Identificador de la Noticia 1 1Fecha 1 1Lugar 2 1Descriptores 5 3Implicados 5 2Fuentes 2 1Combinatoria * 1 noticia 100 6Combinatoria * 1766 not. 176.600 10.596
En realidad, construída nuestra tabla de tipo OLAP (solamente con los códigos numéricoscorrespondientes a los valores de los atributos señalados), las 1.766 noticias dieron origen a8.127 tuplas (filas de datos) y no las 10.596 que habíamos estimado (Ver Tabla 6.5.1a, con lacombinatoria correspondiente a las 5 primeras noticias).
Tabla 6.5.1a: Tabla OLAP de 5 noticias
Id.N. Descrip. Implic. Mes Lugar Fuente1 54116 47 2000-05 2 11 54510 849 2000-05 2 11 54510 47 2000-05 2 11 54116 849 2000-05 2 13 52056 10 2000-05 3 203 52040 10 2000-05 3 204 53052 428 2000-05 2 204 53052 79 2000-05 2 204 53052 47 2000-05 2 204 53052 210 2000-05 2 204 53052 585 2000-05 2 205 60500 660 2000-05 90 195 54570 660 2000-05 90 19
Sin embargo, nuestro software GVA no nos permitió cargar más de 500 tuplas,correspondientes a 190 noticias, siendo además imposible procesar a éstas considerando las 5dimensiones2. Limitándonos a las 100 primeras noticias, podemos demostrar de inmediato elefecto combinatorio mediante el Gráfico 6.5.1a (Láminas a color), que superpone en el planolas cinco dimensiones a las cuales podríamos aspirar a llegar, aunque solamente para estamínima cantidad de noticias. Considérese también que utilizamos una pantalla a color (miles)de una resolución horizontal de 1024 pixeles. La imagen ha tenido por lo tanto quetransformarse y reducirse para caber en estas páginas.
El software procede en forma automática para buscar la configuración general más adecuada.El usuario puede además intervenir para hacer girar y estirar manualmente el gráfico. A pesar
2 Trabajamos con un Pentium III a 750Mgz, con 64 Mb de RAM. Tómese en cuenta que necesitábamos usar enparalelo una aplicación de captura de imagen ya que GVA no permite guardar las imágenes en formatostraspasables a formatos de preimpresión.
183

de lo compacto del resultado aquí ilustrado en el Gráfico 6.5.1a3 (ver láminas a color), sepuede observar que se produce un importante punto de confluencia hacia el extremo derecho."Pinchando" en este punto, se obtiene - en otra ventana - la información correspondiente y sedescubre de este modo que se encuentran allí, en realidad, dos noticias: la 15 y la 100, quetranscribimos a continuación:
"(15) 4-05-2000 - Alemania - Reporteros biónicos - Ingenieros de la unidad de investigación y desarrollo deSiemens (Alemania) predijeron que, de aquí al año 2010, es probable que los reporteros lleven implantesbiónicos que transmitirán directamente las imágenes y los sonidos que perciban. Los sensores seinsertarán en los nervios ópticos y auditivos, mientras la unidad de transmisión podrá estar injertada en loshombros. (Reuters)"
"(100) 20-08-2000 - Noruega - Noruega crea completo sistema de educación "online" para adultos - El paísescandinavo anunció la semana pasada la creación de The Competence Network, el primer sistema deeducación para adultos íntegramente en internet. En el proyecto participan cincuenta organizaciones y hasido promovido por las Federaciones de Comercio, Negocios e Industria del país. The Competence Networkse compone de varios dominios por los que acceder a sistemas de educación y especialización desde losgrados más básicos hasta el nivel universitario. El proyecto está especialmente dedicado a los adultos quepor cualquier razón no hayan dispuesto de educación primaria. La Red supone un ahorro substancial en losgastos que el sistema educativo noruego, un país donde la educación a distancia es una cuestión básicapor la dispersión de la población. (Noticias.com)."
También aparecen el descriptor 27010 (Biotecnología) y los Implicados 582 (Siemens) y 731(Red de teleducación), según los datos que nos entrega el GVA. Salta a la vista que no parecehaber conexión directa entre ambas noticias. Y como lo han mostrado las etapas anteriores denuestra investigación ni este descriptor ni estos implicados aparecen entre los más frecuentes.Resulta obvio por lo tanto que esta área requiere un mayor análisis, primero visual y luego,quizás, numérico. Sin duda existen otras noticias, escondidas detrás de las identificadas (yaque existe superposición tridimensional), y se deben modificar algunos parámetros paraobtener la separación adecuada.
Hemos utilizado para ello la capacidad del software para reforzar las agrupaciones reales,alejando las más débiles, y, como se puede observar en los extremos del gráfico 6.5.1b (verláminas a color), las noticias con escasas asociaciones se alejan progresivamente del resto(ocurriendo por un lado con las antes señaladas y - en el extremo opuesto - con otro par denoticias). Son, por lo tanto, una muestra de casos excepcionales y no de las tendenciascentrales. Pero esto mismo, en algunos casos, puede ser un hallazgo de la mayor importancia.No lo podemos asegurar aquí, por cuanto debemos recordar que graficamos solamente lasrelaciones de las 100 primeras noticias. (Podemos sin embargo creer que esta conclusión escierta, sobre la base del conocimiento que tenemos del cuerpo completo de contenidos.)
Como lo señala la metodología de trabajo, queda así claramente demostrado que es importanteproceder por pasos, yendo de menor a mayor efecto combinatorio, para evaluar - a la luz de losresultados de cada etapa - la conveniencia de combinar más atributos. Pero también ha de haberquedado claro que un acercamiento multidimensional completo puede arrojar resultadosinteresantes, sea al poner en evidencia agrupaciones especialmente "fuertes" o clusters (que,aquí, hemos descubierto en etapas anteriores), sea exhibiendo los "casos excepcionales", quepueden igualmente ser de muchísima importancia y significación.
También queda demostrada la importancia de las etapas por las que hemos pasadoanteriormente, especialmente de análisis uni- y bidimensional mediante una aplicación de usomás simple. Algunas "suites" de oficina incluyen hoy planillas de cálculo que tienen útiles
3 Las diferentes figuras de este gráfico -círculos, triángulos, etc.- corresponden cada una a un tipo determinado deatributo. Hemos eliminado las "etiquestas" de identificación, que esconderían parte de la estructura general deinterrelaciones que se observa aquí.
184

herramientas de visualización bi- y tridimensional, además de incluir o permitir la adición decomandos "macro" que permiten realizar en parte funciones y etapas básicas de minería dedatos. Pero una investigación que quiera realmente extraer conocimiento nuevo escondido enuna totalidad compleja requiere necesariamente de herramientas especiales como las quepermiten extraer redes bi- y tridimensionales así como clusters .
6.5.2. Proyecciones tridimensionales
En el apartado 6.4.2. hemos mostrado ya el cubo que puede ser utilizado en el GVA para situarlas entidades de acuerdo a los valores de tres de sus atributos. El Gráfico 6.5.2 (ver láminas acolor) muestra las 100 primeras noticias, ubicadas tridimensionalmente en función de losvalores de sus Descriptores, Implicados y Fuentes. Solo mostramos los puntoscorrespondientes a cada una, mientras la aplicación también permite ver los vínculos (vectores)que las unen en función de sus atributos (pero que es practicamente imposible de traspasar a unmedio impreso).
Se puede observar muy claramente cómo la mayor parte de las noticias se agrupa en una misma"tajada" del cubo, en el rango de los Descriptores "50.000" (que corresponden al términogenérico -o categoría- "Comunicación"), mientras se dispersan ampliamente sobre el eje de losImplicados. Veríamos igualmente, al girar el cubo, la dispersión que se produce en relación alas Fuentes, no visible en este gráfico debido a que las Fuentes corresponden al eje de laprofundidad (Z) y se confunde en parte con la "altura" (Y) de los Implicados.
Conocemos en gran parte estos datos, gracias a las etapas anteriores de análisis. Lo importanteaquí es ver que, al hacer rotar el cubo, no aparece en ningún momento ninguna "mancha" enque se concentren grandes cantidades de entidades (noticias), fuera del área ya señalada deDescriptores. Trabajando con la totalidad de las noticias debería aparecer el cluster másdefinido que hemos encontrado antes ("Música-Digital-Internet" en Estados Unidos y en elsegundo trimestre de 2001). La dispersión restante corresponde a nuestro entender a la típicadiversidad de los hechos humanos - de sus actores y localización - reflejados en la informaciónnoticiosa. Así podemos formular la hipótesis de que - llegados al presente nivel de análisis (congran agregación de datos) - lo que más podemos esperar y de lo que más podemos sacarpartido es, como lo hemos visto en los gráficos de 5 dimensiones, de los "casosexcepcionales". Éstos nos pueden señalar áreas de baja cobertura periodística, de baja"resonancia social" o - lo que sería más grave - de descuido en el manejo de la pauta editorialdel medio de prensa.
Al no disponer de la capacidad computacional necesaria para manipular en formamultidimensional la totalidad de nuestras noticias, no podemos desgraciadamente sacar másconclusiones y nuestra investigación ha de concluir aquí. Pero, teniendo en cuenta las otrasmanipulaciones que hemos realizado - y de las cuales no vale la pena dar cuenta aquí, ya queson variantes de lo ya expuesto - podemos asegurar que no aparecen nuevas informacionesrelevantes que no estén ya en las etapas anteriores de análisis. Sólo nos faltaría, como señaladoen los párrafos precedentes, encontrar más "casos excepcionales" o marginales. Si bien dichoscasos están sugeridos ya en el análisis estadístico de los descriptores temáticos y de losimplicados, existe cierta multiplicidad de casos únicos, los que sólo pueden ser calificados yseleccionados como "excepcionales" y dignos de mayor estudio cuando se tiene acceso a susrelaciones triádicas o multidimensionales. Por su parte las principales relaciones y el clusterdescubiertos han sido expuestos y graficados en los análisis de las coocurrencias externas ytriádicas.
185

Conclusión
Hemos mostrado los principales tipos de gráficos con los cuales es posible trabajar, faltandosolamente una buena ilustración multidimensional de clusters debido a una falta de podercomputacional, de modo que el lector podrá - así lo esperamos - formarse una idea de losconocimientos que la metodología expuesta es capaz de extraer de una base de datos como laque hemos analizado. (Los resumimos en el siguiente capítulo).
Los resultados expuestos son comunmente imposibles de obtener en sistemas dedocumentación periodística concebidos de otra manera y sin las herramientas aquí descritas.Los sistemas construídos del modo señalado y que se utilicen para desarrollar"hiperinformativos" (diarios o revistas en Web) permitirían además enlazar los acontecimientosque formen una secuencia, facilitando el conocimiento de los antecedentes y las consecuenciasde cada uno, a medida que se desarrolla la Historia.
Ligando además la base de datos noticiosa con otras bases de datos como las de biografías o depaíses (haciendo un "clic" sobre el nombre de un país se podría obtener una descripción de sugeografía política o de su sistema de gobierno), se aseguraría que el lector de cualquier lugardel mundo sea capaz de colocar la noticia en su contexto y explicarse, en cualquier momento,lo que está pasando en un país muy alejado de su propio lugar de residencia. En un mundo deeconomía global, éste es un "valor de uso" que, sin duda, puede asegurar el éxito de unaempresa periodística que esté al día con las últimas tendencias y posibilidades de la "Era de laInformación" o, más aún, de la nueva "Era del Conocimiento".
186

7
CONCLUSION
7.1. Evaluación de la experiencia
Empezaremos aquí resumiendo brevemente los principales hallazgos que produjonuestra investigación. Sin duda los primeros - que proceden de la confección delas estadísticas iniciales - no presentan grandes sorpresas, pero al avanzar en losprocedimientos y en la complejidad del análisis hemos visto aparecer otrasinformaciones que aportaron el conocimiento nuevo que estabamos buscando.Luego trataremos de adoptar una visión crítica y ponderar el valor de estosaportes en comparación con el esfuerzo que significa obtenerlos.
7.1.1. Principales hallazgos
Conclusiones Fuente
Basadas en Estadísticas iniciales1. El mes de marzo 2001 ha sido especialmente abundante
en información del área considerada.Estadística
(5.4.1)2. Estados Unidos es sin lugar a dudas el lugar privilegiado
en materia de Tecnologías Digitales.Estadística
(5.4.2)3. No existe una constante en los hechos del sector
noticioso aquí considerado.Estadística
(5.4.3)4. El tema del "e-Comercio" tuvo un auge significativo
durante el año 2001Estadística
(5.4.3)5. La categoría de las "Empresas de informática" ha sido la
que apareció con mayor frecuencia.Estadística
(5.4.5)6. La fuente que ha aportado más información ha sido
"Mouse", suplemento del diario nacional "La Tercera".Estadística
(5.4.6)
187

7. Existe una relación estrechísima entre el lugar deocurrencia del hecho noticioso y la temática del mismo.
Estadística(5.4.7)
8. Existe una relación estrecha entre Descriptores eImplicados.
Estadística(5.4.7)
9. Un nuevo procesamiento (como el realizado en lareagrupación de los "Implicados") puede arrojar unamejor información y una profundización del análisisrecurriendo a la data mining.
Estadística(5.4.7)
Visualización inicial10. La visualización de datos muestra claramente la fuerte
presencia de los temas relativos a Internet y otraconcentración en relación a "Software", "Hardware" y"Redes", mientras se observa mayor irregularidad en laaparición de los otros temas.
Análisis visual(6.1.1)
Coocurrencias internas11. Desde el estudio de las primeras coocurrencias, se puso
en evidencia la existencia de un "campo noticioso"especial, que concentra los hechos asociados a los juiciosque afectaron al sitio "Napster" y los acuerdos entrecompañías discográficas para estructurar otros canales dedistribución.
Coocurrenciasinternas(6.2.1)
12. Microsoft aparece frecuentemente asociada a "Tribunal"y se encuentra unida con Napster a través de dichotérmino, con lo cual se destacan a ambas empresas porhaber estado involucradas en los casos judiciales demayor eco durante el período bajo estudio.
Coocurrenciasinternas(6.2.2)
13. Reagrupados en clases, los Implicados de mayorrelevancia han sido las "Empresas Informáticas", las"Empresas TI" (de Tecnologías de la Información) y los"Organismos públicos".
Coocurrenciasinternas(6.2.3)
Coocurrencias externas14. "Internet" como tema (descriptor) y "Empresas
Informáticas" como tipo de implicados aparecen comomás centrales en las relaciones entre estos dos tipos deatributos.
Coocurrenciasexternas(6.3.1)
15. Sorpende la ausencia de la clase de Implicados"Fabricantes de Software" en la serie de frecuencias másaltas de coocurrencias entre Descriptores y Clases deImplicados.
Coocurrenciasexternas(6.3.1)
188

16. La importancia de "Internet" se destaca aún más en elanálisis cronológico, apareciendo un fuerte aumento en elmes de marzo de 2001. Los tres primeros meses de esteaño arrojan también tasas muy altas de algunos otrostemas, lo cual indica la conveniencia de un estudioposterior más detallado, sea con DM sea volviendo alcontenido informativo.
Coocurrenciasexternas(6.3.2)
17. Microsoft siguió siendo un importante foco de atencióndespués de marzo del 2001, especialmente en mayo yjunio, aunque menos en relación al juicio que se le sigue,como se ve confirmado por el análisis de tríadas.
Coocurrenciasexternas
(binarias ytriádicas)
(6.3.3 y 6.4.2)18. Se ha presentado una coyuntura muy especial en los
meses de junio y julio 2001, en que se destaca "SitioWeb" como Implicado, lo cual merecería un estudio másprofundo.
Coocurrenciasexternas(6.3.3)
19. No sorprende en absoluto que Estados Unidos sea ellugar más frecuentemente asociado al tema "Internet". Síes destacable que su interés por algunos otros temas(Descriptores) sea compartido con Chile.
Coocurrenciasexternas(6.3.4)
20. Considerando Lugares y clases de Implicados, se puedeobservar que se cierra una red que une a España conEstados Unidos y con Chile, compuesta de dos subredescon elementos comunes, cosa que sería interesanteestudiar y comentar más detenidamente en un análisisperiodístico.
Coocurrenciasexternas(6.3.6)
21. Mientras Estados Unidos se destaca por la importanciade las Empresas Informáticas, Chile lo hace por el rol delos Organismos Públicos, lo cual corresponde a laimportancia dada por el gobierno al tema de las nuevastecnologías digitales en la política y los planes dedesarrollo del país.
Coocurrenciasexternas(6.3.6)
22. El análisis de la evolución cronológica de las fuentesmuestra un cambio en la CNN, disminuyendofuertemente sus noticias sobre Tecnologías Digitales en elaño 2001.
Coocurrenciasexternas(6.3.8)
23. Los medios en que hemos encontrado la mayordiversidad y repetición de temas son principalmenteMouse, Noticias.com y Wired.
Coocurrenciasexternas(6.3.8)
Tríadas24. Existen tres puntos de concentración de asociaciones,
aparte del lugar de ocurrencia de los hechos noticiosos(Estados Unidos): "Microsoft" y "Napster" comoImplicados e "Internet" como Descriptor.
Tríadas(6.4.1)
189
25. El análisis de las tríadas Descriptor-Lugar-Fechaconfirma la importancia del caso "Napster" pero lo amplíaal conjunto descrito por "Música-Digital-Internet", enEstados Unidos y en el segundo trimestre de 2001,formándose un cluster.
Tríadas(6.4.3)
26. Podría haber ocurrido algo especial en marzo, quejustifique la densidad de la tríada "2001-03 + España +Internet", la cual podría considerarse para un estudioperiodístico específico.
Tríadas(6.4.3)
27. La tríada más frecuente, de todas las consideradas, haaparecido 81 veces y corresponde a "2001-03 + EstadosUnidos + Internet". Merecería también una investigaciónperiodísticas para buscar su explicación.
Tríadas(6.4.5)
Análisis multi-dimensional28. El análisis multidimensional, a pesar de limitarse a cien
noticias, puso en eviencia la existencia de noticias concaracterísticas excepcionales. La aplicación a la totalidaddel cuerpo noticioso recogido podría poner más casos enevidencia, los que merecen sin duda una atenciónespecial. Los "casos excepcionales" pueden señalar áreasde baja cobertura periodística, de baja "resonancia social"o de descuido en el manejo de la pauta editorial del mediode prensa.
Análisis multi-dimensional
(6.5)
Como se puede observa en esta tabla, hemos encontrado reiteradas pruebas de laimportante cobertura de prensa que tuvieron Microsoft y Napster. Comoconsecuencia de ello, la Revista TDC realizó un estudio en profundidad de amboscasos y confeccionó para cada uno un Dossier publicado en línea (ampliando,conforme al hallazgo 25, el caso Napster a la tecnología P2P de la cual ha sido unimportante exponente y que ha conocido un importante auge).
7.1.2. Ventajas y limitaciones de la visualización
El lector se habrá dado cuenta de la inmensa cantidad de cálculos realizados por elordenador y de la enorme cantidad de datos que nos entregó en forma tabular, apesar de que hemos incluido una mínima fracción de los mismos. Pero lo másimportante es que se haya dado de cuenta de la ventaja de recurrir a las técnicasde visualización.
El gráfico pone mucho mejor de manifiesto los múltiples vínculos que asocian losvalores de los diversos atributos, o sea de la manera en que las noticias puedenrelacionarse entre sí. La visualización, no sólo es útil para determinar áreas querequieren mayor profundización del análisis o ajustes en la secuencia y las etapasde reiteración propias de este tipo de estudio: permite además descubrir tantoagrupaciones muy peculiares (los clusters) como casos excepcionales, lo que - en
190

ambos casos - constituye un metaconocimiento de la mayor importancia. Ésta esuna importante ventaja.
Sin embargo, una gran cantidad de datos produce rápidamente una saturación delespacio visual disponible (habitualmente una pantalla de ordenador) y esindispensable recurrir a operaciones lógicas complementarias, tales como lafijación de umbrales y la eliminación de situaciones intermedias, para encontrar yexhibir las agrupaciones más fuertes o bien los casos marginales que pudieran serindicadores de casos extraordinarios particularmente relevantes o indicadores deerrores de procedimiento en la recopilación de la información que ingresa a labase de datos. Si bien estos procedimientos restrictivos forman parte de lametodología y llevan a obtener los nuevos conocimientos buscados, tienengeneralmente el costo de ser muy difícilmente graficables en presentacionesbidimensionales.
Es una de las razones por las cuales las "suites" de Data Mining incorporanfacilidades asociadas a la gráfica tridimensional, como la rotación en pantalla, y -las más avanzadas - incluso técnicas de realidad virtual, que permiten manipulardirectamente los componentes mediante el guante digital, visualizar el cubomediante visión estereoscópica (con un visor especial) e incluso "penetrar" en élpara mirarlo desde diversos ángulos desde su interior y no solamente desde elexterior. Este tipo de aplicación no se ha difundido aún en forma masiva, perosin duda lo hará muy pronto debido a las enormes ventajas que supone parasuperar las actuales limitaciones de las proyecciones planas.
7.1.3. Las dificultades
La minería de datos, como se habrá visto, no está al alcance de todos. No sólo serequiere cierta familiarización con los métodos estadísticos tradicionales, sinotambién - y sobre todo - con el análisis de sistemas y la gestión avanzada debases de datos. También hemos descubierto la necesidad de poder intervenir en eltraspaso de los datos desde una BD o un conjunto de tablas a otra tabla oconjunto de tablas y, para ello, nuestro conocimiento de lenguajes deprogramación (en este caso PHP y SQL) han sido fundamentales. Por esta razónes necesario insistir en que, en el trabajo periodístico, es esencial un trabajo deequipo, en que colaboren estrechamente periodistas (editores) y analistas desistemas familiarizados con los métodos de Data Mining.
También, como lo hemos recalcado, es indispensable que el Sistema Documentaldel medio de prensa tenga el formato adecuado. Si no es así y la empresa deseapoder beneficiarse a futuro de los aportes de la DM y de los avances en estecampo, será necesario pasar por una etapa de transformación del modelo de datosy traspaso de los contenidos de la BD, lo cual puede requerir la elaboración de unprograma ad hoc de transferencia, involucrando costos adicionales. Pero estamosconvencidos de que el resultado valdrá la pena y de que el futuro de la empresapodría depender de ello (Ver apartado 7.2).
191

Para referirnos más directamente a nuestra propia experiencia, podemos indicarque teníamos felizmente una larga experiencia en materia de análisis decoocurrencias en textos, graficación de redes y diseño de bases de datos (VerBibliografía). También dominábamos algunos lenguajes de programación, lo cualresultó esencial a la hora de preparar los datos. La dificultad más importante conla cual nos hemos encontrado fue al usar el software GVA para el análisismultidimensional, no sólo en razón de la aparente escasez de memoria RAM denuestro PC, sino por la escasa documentación que acompaña el programa, ya quemuchas funciones y cuadros de diálogo (especialmente de modificación deparámetros) no están documentados. Incluso la versión que obtuvimos en CDincluía funciones que aparecían como "en desarrollo" en el manual disponible enInternet (funciones que resultaron muy útiles). Sólo un estudio muy detallado delos ejemplos incluídos y múltiples pruebas con diferentes modelos de datospermitieron que, después de varios días de ensayo, aprendiendo de nuestroserrores, lograramos por fin manejarlo lo suficiente como para poder extraer losejemplos incluídos en este libro.
En muchos casos, también, hemos preferido realizar muchos gráficos de redes amano, especialmente para obtener una versión escalable que se ajustara al tamañode la presente publicación. Pero ésto no es en sí una dificultad de la herramienta,sino un problema del medio de comunicación que estamos utilizando. La pantalladel ordenador permite cambiar la escala, mostrar y esconder parte de lainformación, manipular los colores, girar los objetos, etc. pero en una resoluciónque no es la más adecuada para la imprenta.
7.2. El futuro de la Data Mining en el Periodismo
Aunque las aplicaciones de minería de datos han sido - hasta ahora - utilizadascon gran provecho en el campo de la industria, la economía y el comercio, comotambién en algunas investigaciones científicas, hemos de considerar que elPeriodismo es uno de los sectores que maneja la más grande y más variadacantidad de información. Obviamente la DM no es una herramienta de utilidadpara el reportero que está al acecho de las noticias que se generan día a día. Peropara el analista de un sector determinado, podría transformarse en unaherramienta de la mayor utilidad para comprender lo que está ocurriendo y tratarde visualizar los posibles derroteros de una determinada secuencia de hechos oencontrar relaciones entre hechos aparentemente inconexos. Si el Servicio deDocumentación de un medio de comunicación cuenta por lo tanto con una base dedatos adecuadamente estructurada, una aplicación de Data Mining podríatransformarse en una herramienta de primerísima importancia, como hemospretendido demostrarlo aquí.
En la investigación que hemos descrito, nos hemos concentrado en la búsquedade patrones en un sólo dominio y en el área temática cubierta por un medio deprensa muy especializado. En un medio periodístico de cobertura más amplia,
192

que disponga de todo un sistema documental como el que también hemospropuesto, podría ampliarse la exploración no sólo a relaciones entre áreastemáticas más diversas sino a patrones inter-dominios, como por ejemplo"cruzando" datos noticiosos con datos biográficos de los personajes implicados,datos históricos o económicos de empresas, datos geo- o socio-políticos, etc.Los resultados podrían ser muchísimo más ricos que lo que hemos podidomostrar aquí, aunque también implicarían procesos más largos y más complejos.Pero la principal lección es ésta: se ha de disponer de un modelo de datos - y deun sistema documental - adecuado, de algunas herramientas bien escogidas yalguna persona capacitada para manejarlas.
No dudamos de que el futuro del periodismo, y en particular del periodismoespecializado, depende en gran parte de la capacidad de las empresas paraintegrar este tipo de herramientas. El lector de hoy, cada vez más culto, requieretambién cada vez más visiones de conjunto y explicaciones profundas que sólo lepueden dar periodistas especializados, no sólo conocedores de las disciplinasinvolucradas (ciencias políticas, economía, antropología social, etc.) sino capacesde utilizar nuevas herramientas de investigación como las que hemos expuesto,sea en forma personal sea en equipo con analistas que dominen mejor dichosinstrumentos.
En la "Era de la Información" - o "Era del Conocimiento", como algunosempiezan a llamarla, a raíz del avance en métodos como los aquí expuestos - losintereses de los usuarios (ya no se habla de "lectores" o "televidentes") se definencomo "valor de uso", y éste determina la aceptación del medio informativo.Dicho "valor de uso" es función del conocimiento que ya tiene el usuario y delque se le podrá agregar, más que de la información en sí, y depende así tanto delusuario como del emisor. El conocimiento nuevo que pueda adquirir un usuariodepende de modo vital de su comprensión del contexto de la información. Paraello requiere de "información con valor agregado" (IVA) y ésta depende de laoferta, por parte del emisor, de relaciones entre múltiples informaciones.
Así se constituye "Información con Valor de Uso" (IVU), la cual se compone de:
• IVAp: Información con valor agregado por el periodista experto.• IVC: Información con valor cognitivo = información inicial + informaciones
complementarias (obtenidas a través de los hipervínculos) + conocimientosprevios del usuario.
• IVCA: IVC ampliada gracias a aplicaciones informáticas avanzadas (DataMining, Sistemas expertos, Inteligencia Artificial)
Todo esto lleva a concebir el esquema 7.2 de valoración de la información.
El acercamiento de las metodologías del trabajo científico-cognitivo y delquehacer periodístico es hoy una exigencia cada vez más importante,especialmente porque el público exige cada vez un mayor rigor en el trabajoinformativo. Sin este rigor, el hombre con responsabilidades sociales (políticas,empresariales, profesionales, etc.) no se encuentra preparado para interpretar la
193

realidad y ajustar sus decisiones al contexto en que debe actuar. Esto haceindispensable que la prensa cuente con una base documental más sólida, mejorestructurada y de más fácil acceso, con todos los "enlaces" entre documentos quepermitan a los nuevos usuarios comprender adecuadamente la informaciónnoticiosa. Por ello, la IVCA requiere el trabajo conjunto de equipos deprofesionales altamente capacitados y con conocimientos multidisplinarios.
Gráfico 7.2: El valor de la Información
Ingeniería cognitivaIVCA
DATOS
INFORMACION (en bruto)
Periodismoclásico
IVAp (Periodismo interpretativo)
IVC (Informaciones HT) Periodismo/web
IVC
IVU
VALOR CRECIENTE
* HT significa en forma hipertextual.
Para terminar
El periodismo especializado del futuro se está transformando cada vez más enuna suerte de "ingeniería del conocimiento" y su éxito dependerá también de lacapacidad de los profesionales y de los medios periodísticos por ofrecer a susclientes una información con real "valor agregado", el cual crece en formaproporcional a la cantidad y extensión de las relaciones entre los hechosrelatados, siempre que dichas relaciones sean puestas en evidencia por quienespuedan tener acceso al "espacio informativo" completo y explorarlo debidamente.En ello los métodos matemáticos, particularmente los desarrollados por la"ingeniería de sistemas" tienen y seguirán teniendo sin duda una importanciafundamental, como también la tendrán los métodos generados por lainvestigación sobre Inteligencia Artificial. Comentamos en ANEXO el rol de losmétodos matemáticos en las Ciencias Humanas y particularmente los que hanpermitido descubrir un orden en fenómenos que parecían anteriormente caóticos.La Data Mining es tributaria de estos avances y es conveniente que los periodistasy documentalistas tengan algunas nociones acerca de estas nuevas dimensionesde la investigación que, como se ha demostrado, enriquece el conocimiento en lasáreas más diversas del conocimiento.
194

ANEXO
Ciencias humanas y matemática
La lógica y la matemática han presidido a nuestro trabajo y tendrán un lugar cadavez más importante en el futuro de los medios periodísticos como lo sugierenuestra alusión a la "ingeniería del conocimiento". Quizás pueda parecer extrañoa quiénes han sido formado en una concepción más "literaria" del periodismo.Sin embargo no parecerá extraño a quiénes tengan formación en el campo de lasciencias humanas, ya que - en éstas - los métodos estadísticos han estadopresente desde hace decenios. Pero, en el campo del periodismo, difícilmentepueden esperarse que aparezcan fenómenos que puedan ser agrupados yrepresentados mediante "curvas normales" y, como lo hemos señalado, losmétodos paramétricos son de poca utilidad.
El surgimiento de las noticias, representaciones de acontecimientos de lanaturaleza o de hechos producidos por el ser humano, no tiene nada de aleatorioni tampoco ninguna regularidad, ya que todos responden a diversas y complejasconjunciones de causas. Sin embargo, bajo su apariencia caótica, existe un ordenmuy preciso que es el que algunos científicos, como David Bohm, han llamado"orden implicado". Lo que hace la Data Mining es tratar de encontrar factores quepongan el orden en evidencia o, en términos de Bohm: pasar del "ordenimplicado" al "orden explicado".
El concepto de orden implicado, que desarrollaremos a modo de conclusión, paramostrar cómo los métodos matemáticos pueden ayudarnos a entender losfenómenos que son objeto de estudio de las ciencias humanas, es a su vez unaampliación de los conceptos de la "matemática del caos", área que la computaciónha permitido desarrollar debido a su enorme poder de cálculo.
1. Matemática del caos y ciencias humanas
1.1. El orden en el caos
El concepto de matemático de "caos" se aleja del concepto común especialmenteporque tiende a mostrar que bajo la apariencia de caos existe, en muchos casos,
195

un cierto orden, que corresponde a la existencia de reglas que, si bien pueden sermuy simples, pueden generar un producto extraordinariamente complejo. Así,por ejemplo, si se miran de muy lejos los movimientos de una familia en unpicnic parecerán caóticos, aunque corresponden a reglas de comportamientocomunes y propias de costumbres humanas. Sin embargo, cualquier humano quecomparta nuestra cultura y se acerque lo suficiente para distinguir algunos objetosy comportamientos típicos interpretará correctamente lo que ocurre. Pero existennumerosas situaciones en que no conocemos las "reglas del juego" y losacontecimientos permanecen oscuros.
Es lo que Mitchell Feigenbaum puso en evidencia al plantear que para entendercómo la mente humana entresaca algo del caos de la percepción, hay que entenderde qué manera el desorden produce universalidad. Al comparar la evolución dediferentes funciones matemáticas que producen bifurcaciones llegó finalmente(1976) a una teoría y un procedimiento matemático aplicable en forma universal.Este trabajo llevó a realizar el 1º Congreso sobre "Ciencia del Caos" en Como,Italia (1977) y las pruebas matemáticas definitivas las produjo Oscar Lanford IIIen 1979.
La base formal de estos conocimientos fue establecida por Edward Lorenz(meteorólogo del MIT) cuando publicó, en 1963, "Deterministic NonperiodicFlow" sobre el comportamiento no-lineal de un sistema de 3 ecuaciones linealescorrespondiente a un modelo simplificado de dinámica de fluídos. Este trabajofue "redescubierto" en 1972 por James Yorke, quien lo difundió y lo analizó conRobert May, matemático, biólogo y ecólogo. Analizando matemáticamente elcomportamiento de la ecuación - que May puso en evidencia - Yorke probó quecualquier sistema unidimensional (como el de la curva logística), si muestra enalgún momento un período (bloque reiterado) regular de 3, mostrará a la vezciclos regulares - aunque de extensión variable - y también ciclos caóticos. Asíhizo el gran descubrimiento de que "sistemas sencillos hacen cosas complejas",el que dió a conocer en el artículo "Period Three Implies Chaos" (1975). Sedescubrieron luego efectos similares en genética, economía, dinámica de fluídos,epidemiología y fisiología, los que resumió y publicó May en "SimpleMathematical Models" (Nature, 1976, p.467, citado por Lewin, pp.111-115).
Benoit Mandelbrot encontró luego una estructura regular al comparar - endiferentes escalas - las evoluciones de los precios del algodón en todo el sigloXIX, como también en la evolución de las rentas (publicado en "The FractalGeometry of Nature", 1977). Encontró aspectos parecidos en secuencias deerrores en la transmisión computacional de datos, en las crecidas del Nilo, en laforma de las nubes y de las costas. En 1975 inventó el término "fractal", que seaplica a la representación geométrica de este tipo de fenómeno. En un fractal, lascuencas corresponden a atractores (funciones poderosas que parecen mantener unfenómeno dentro de ciertos límites, hasta que la suma de pequeños cambios es talque su evolución se "libera" o, a la inversa, que conduce la suma de cambios aun estado aparentemente más estable). Los límites entre cuencas ponen enevidencia que la frontera entre "la calma y la catástrofe" es más complicada de
196

todo lo que se puede imaginar. (Ver Gráficos "Conjunto de Mandelbrot" enLáminas a color).
Arnold Mandell, siquiatra, descubrió un comportamiento caótico en enzimas delcerebro. Sus trabajos apuntan a reconocer que el funcionamiento de la mentetambién tiene una estructura fractal tanto en su base fisiológica como en laestructura semántica.
"Con el caos o sin él, los científicos cognoscitivos honestos no pueden establecer ya unmodelo de la mente como una estructura estática. Reconocen una jerarquía de escalas,desde la neurona en adelante, que brinda la oportunidad al juego recíproco de macroescalasy microescalas, tan peculiar de la turbulencia fluida y de otros procesos dinámicoscomplejos." (Gleick, p.298)
John Hubbard, investigador de la Universidad de Cornell, demostró la existenciade una continuidad lineal de todos los elementos de un gráfico fractal, con infinitavariedad (en una repetición sólo aparente a grandes rasgos). Y las investigacionesmuestran que todos los fractales parecen terminar en el conjunto de Mandelbrot,confirmándose el principio de universalidad asociado a la matemática del caos(cfr. Gleick, p.236).
1.2. La frontera del caos
Hacia 1980, Steven Wolfram descubrió que, aparte de los ahora conocidos tresestados "clásicos" de los sistemas dinámicos (estable, periódico y el nuevo"caótico") existe un cuarto estado, en el límite entre orden y caos. Tres añosdespués, Chris Langton pudo mostrar que esta cuarta clase es la que exige elmayor volumen de cálculo y el manejo de la mayor cantidad de información. Ahí,en la zona de transición entre orden y caos, "se presiente que el tratamiento de lainformación constituye uno de los elementos importantes de la dinámica de unsistema". Norman Packard, que hacía investigaciones paralelas, dió a este cuartoestado el nombre de "frontera del caos". Investigó cómo el proceso evolutivo seencuentra en esta área y descubrió - con autómatas celulares y reglas que semodifican mediante un algoritmo genético - que las reglas de cambios internos semodifican solas en la dirección de una eficiencia máxima, siempre más cerca dellímite del caos (Lewin, pp.56-60).
Las leyes de los sistemas abiertos de alta complejidad (como lo son el Universo ytambién el sistema social) indican que esta situación - en la "frontera del caos" -es pasajera y ha de conducir sea a una destrucción del sistema sea a un salto haciaun orden superior, donde una nueva complejidad será regulada por nuevas reglasde ordenamiento. Al mismo tiempo una serie de inventos de la época evolutivaanterior desaparecerán y otros, en una nueva relación, se profundizarán yextenderán para sostener el nuevo sistema ("salto cualitativo").
Así, los fenómenos sociales - y entre ellos los hechos que constituyen noticias -se enmarcan sea en el "caos" (en el sentido antes definido) sea en la "frontera del
197

caos". En ambos casos existe un sistema regulatorio compuesto defactores (cuya cantidad e importancia es variable) que puede serdifícil descubrir sin el apoyo de métodos matemáticos. Esto significa -y sin duda nadie lo negaría - que en toda acción humana existe cierto orden, peroque éste no siempre es visible. Aún más, puede ser muy difícil de descubrir. Estotiene mucho que ver con el concepto de "orden implicado", que también surgióde la física y se aplica perfectamente a las ciencias humanas.
2. El concepto de "orden implicado"
El concepto de orden implicado ha sido formulado por el físico David Bohm aprincipios de los años ochenta.
"El orden implicado puede ilustrarse con la ayuda del siguiente experimento: consideremosdos cilindros de cristal concéntricos, el interior fijo y el exterior capaz de girar lentamente.Llenamos el espacio entre los cilindros con un líquido viscoso, como la glicerina. Cuando sele da vueltas al cilindro exterior, éste arrastra consigo casi a la misma velocidad al fluido quetiene al lado, mientras que el fluido más próximo al cilindro interior permanece prácticamenteen reposo. Así, el fluido de diferentes partes se mueve en proporciones diferentes, y deesta manera, cualquier pequeño elemento de glicerina termina finalmente alargándose en unhilo largo y fino. Si ponemos en el líquido una gota de tinta insoluble, podremos seguir elmovimiento de algún pequeño elemento, observando cómo la gota va siendo alargada en unhilillo que llega a hacerse tan fino que resulta invisible.
A primera vista, uno tiende a pensar que la gota de tinta ha quedado totalmente mezclada enla glicerina, de modo que su orden inicial se ha perdido y es ahora aleatorio o caótico. Peroimaginemos que giramos ahora el cilindro exterior en la dirección contraria. Si el fluido esmuy viscoso, como sucede con la glicerina, y no giramos el cilindro demasiado rápido,entonces el elemento del fluido volverá exactamente sobre sus pasos. En determinadomomento, el elemento adquirirá nuevamente su forma original, y la gota de tinta pareceráhaber surgido de la nada. (De hecho, se han llevado a cabo experimentos como éste, y elefecto resulta bastante espectacular.) Está claro que lo que se consideraba una pérdida deorden caótico o aleatorio era de hecho un orden escondido de grado alto, que se generó apartir de un orden inicial simple, el de la gota que sufría los efectos de la rotación del cilindro.De la misma manera, este orden escondido se transformó de nuevo en el orden originalsimple cuando se giró nuevamente el cilindro en sentido contrario. Hay una claracorrespondencia entre este orden escondido y lo tratado en el capítulo anterior sobre cómopuede haber muchas veces un orden escondido en lo que parece ser azar o aleatoriedad."(Bohm y Peat, pp.193-194)
Para "desenvolver" la trama de los acontecimientos humanos y encontrar el "hiloconductor" se necesitaría dominar - hoy en un nivel practicamente inalcanzable -amplios conocimientos conjuntos de historia, de economía, de sociología, deantropología, de psicología, etc. Así, los cientistas sociales ya no puedenprescindir de los métodos matemáticos más avanzados. Encontrar el ordenimplicado obliga a adoptar un enfoque que la ingeniería informática ha llamado"ingeniería reversa" , es decir tomar un producto y encontrar cómo ha sidofabricado1, y la minería de datos es una forma de ingeniería reversa.
198

Bohm vió con claridad que todo conocimiento profundo supone hoy eldescubrimiento de un orden implicado, como lo señala Peat:
"Hasta aquí sólo se han discutido procesos materiales en términos de orden implicado. Peroel conocimiento tiene mucho más de orden implicado que la materia. Esto se trataba concierto detalle en el libro de Bohm La totalidad y el orden implicado." (Bohm y Peat, p.207)
El pensamiento humano, en sí mismo, releva de un orden asociado al aparentefuncionamiente caótico de millones de neuronas. También lo es la comunicacióna través del lenguaje:
"Para empezar, está claro que el pensamiento se encuentra definitivamente en el ordenimplicado. La palabra misma, implicado, que significa envuelto, sugiere que un pensamientoenvuelve a otro y que un tren de pensamiento es de hecho un proceso en el que se vaenvolviendo una sucesión de implicaciones. Esto no es del todo diferente al procesodescrito por la función de Green2, o a lo que ocurre en un juego de vídeo. Además,pensamientos y sensaciones se envuelven mutuamente, y a su vez éstos dan lugar adisposiciones que se desenvuelven en acciones físicas y en más pensamientos ysentimientos.
También el lenguaje es un orden envuelto. El significado está envuelto en la estructura dellenguaje, y se desenvuelve en pensamiento, sensación y todas las actividades que yahemos tratado antes. En la comunicación, el significado se desenvuelve en la totalidad de lacomunidad, y de la comunidad pasa a desenvolverse en cada persona. Así, existe unarelación interna entre los seres humanos, y entre el individuo y la sociedad como un todo. Laforma explicada de todo esto es la estructura de la sociedad, y la implicada es el contenidode la cultura, que se extiende al conocimiento de cada persona. Lo que por un lado son lasociedad y las formas explicadas de la cultura se envuelve de manera inseparable en lo quees por el otro lado el conocimiento de cada individuo social. Por ejemplo, las leyes,costumbres y limitaciones de la sociedad no operan de hecho como fuerzas externas,ajenas a la gente sobre la que actúan, sino que son la expresión de la naturaleza misma deesa gente y, a su vez, llevan consigo una contribución a esta naturaleza.
Es evidente que el orden implicado del conocimiento opera en muchos niveles, que estánrelacionados entre ellos de la misma manera que lo están el orden implicado y elsuperimplicado del campo cuántico o del juego de computadora. Por ejemplo, al hablar de larazón en los capítulos anteriores se mostró cómo un nivel de pensamiento organiza el nivelsiguiente. Esto puede seguir así hasta producir una estructura que puede desarrollarseinfinitamente, con varios tipos de circuitos relativamente cerrados. Esto implica que elconocimiento se organiza gracias a un orden generativo cuya totalidad es, de muchasmaneras, semejante a la totalidad de los órdenes generativo e implicado que organiza lamateria." (Bohm y Peat, pp.207-208)
Ser de carne y hueso, material y espiritual, el hombre es tributario de la materiaque lo constituye. Pero, como lo ha mostrado la física cuántica, la naturaleza dela materia es mucho más compleja de lo que se pensaba. Tiene su ordenimplicado en el cual grandes físicos, como Kapra y Bohm, y grandes fisiólogos,como el premio Nobel John Eccles, reconocen la importancia de su vertienteespiritual. Y, extrañamente, la matemática es la que mejor llega a representartanto las variables básicas de la física como - al parecer - de lo específicamentehumano.
199

No dudemos entonces en utilizar esta herramienta para investigar los fenómenoshumanos, no sólo en economía sino también en historia o en la más cercanacrónica que manejan los periodistas.
1 El concepto original de ingeniería reversa está ligado al análisis de aplicacionescomputacionales, siendo el objetivo descubrir el "programa fuente" a partir del producto finalcompilado (es decir utilizable por la máquina pero ya no legible por parte del ser humano).
2 Fórmula matemática vinculada con la matemática del caos.
200

GLOSARIO
Algoritmo: conjunto de comandos formulados para solucionar un problema enun número limitados de pasos.
ANSI: acrónimo de American National Standard Institute.Aplicación: Sinónimo de "programa" o software destinado a realizar una
determinada tarea.API: acrónimo de "Application Programming Interface" o interfaz de una
aplicación, que forma parte de su programa.ASCII: acrónimo de "American Standard for Computer Information
Interchange"; se refiere a los códigos que corresponden a todos los signos ycomandos que pueden ser enviados desde el teclado del ordenador, los quetambién son los conservados en los diferentes medios de almacenaje (discoduro, CD-ROM, diskete, etc.).
Atributo: propiedad o característica de una entidad o referente cuyo valor seingresa en una base de datos como información acerca de dicho referente
Batch: modo de procesamiento de datos secuencial y no interactivo.BD: acrónimo de "Base de datos".Browser: "navegador" o visualizador de páginas web.CASE: acrónimo de "Computer aided software engineering": método de
ingeniería con ayuda del computador (Se aplica, por ejemplo, a sistemas deayuda a la gestión de empresas u organizaciones, como el diseño de bases dedatos (SGBD) o de herramientas de ayuda a la toma de decisiones "DSS").
Cliente/servidor: sistema de relaciones -a través de una red- entre doscomputadores que efectúan operaciones complementarias. El "servidor" es elque contiene los datos o las aplicaciones que soportan todo el sistema, mientrasel "cliente" dispone de una aplicación más limitada que le permite la consulta yeventualmente el envío de datos o el uso de la aplicación.
Clustering: en estadísticas indica una acción de reagrupación de datos enfunción de uno o varios criterios de clasificación o selección; en informáticaimplica que dos o más tablas de una base de datos se guarden físicamente enforma adyacente para obtener un mejor rendimiento cuando se han deconsultar simultáneamente.
CPU: acrónimo de "Central Processing Unit", unidad central de proceso oprocesador; es el corazón del computador.
Cubo de datos: forma de acumulación de datos utilizada para consultas yanálisis mdiante herramientas OLAP.
Data marts: "mercados de datos", referido en primera instancia a un conjuntode datos construído de tal modo que facilite el acceso y uso por "usuariosfinales", e.d. no expertos en estructuras de bases de datos.
Data mining: "minería" o explotación de datos, conjunto de operaciones dediversos tipos que se pueden realizar para explorar relaciones, tendencias yproyecciones en conjuntos de datos de grandes dimensiones.
201

Data warehouse: "bodega" de datos; es el conjunto integrado de los datos novolátiles, almacenados históricamente, de que dispone una empresa,organizados para permitir consultas por un usuario final.
DBMS: acrónimo de "Data Base Management System"; vea SGBD.DDL: acrónimo de "Data Definition Language" o lenguaje utilizado para definir
una base de datos.Depósito de datos: Bodega de Datos más todo el conocimiento ligado a ésta o
que pueda ser extraído mediante diversas técnicas.Diccionario de datos: conjunto de las definiciones o especificaciones de las
categorías de datos y sus relaciones.DSS : acrónimo de "Decision Support System" o sistema de ayuda a la toma de
deciciones.ECA: acrónimo de "Event - Condition - Action"; sistema de reglas que
determinan cierta acción cuando un evento cumple una determinada condición.EDI: acrónimo de "Electronic Data Interchange"; estándar para el intercambio
electrónico de información entre computadores, especialmente para efectuaroperaciones comerciales.
Espacio medial: entorno informativo que conecta a la gente con lugares yobjetos reales o imaginarios.
ETL: acrónimo de "Extraction, transformation and load". Las herramientas ETLestán destinadas a facilitar al recolección de datos desde diferentes fuentes eingresarlos en una nueva base de datos.
Firewall: sistema que permite aislar de Internet todo o parte de los contenidosde un computador o de una red local, permitiendo sólo el acceso en casoscalificados (controlados).
GUI: acrónimo de "Graphic user interface", interfaz gráfica para el usuario.Hipermedio: Colección de palabras-claves, gráficos, imágenes, vídeos y
sonidos vinculados en forma asociativa; usada para presentar informacióndigital de tales maneras que un usuario las pueda explorar en forma interactiva.
HTML: acrónimo de "HyperText Marking Language" , lenguaje que define laforma de exhibición de los contenidos de una página web.
HTTP: acrónimo de "HyperText Transfer Protocol", estándar de transmisión delcontenido de páginas web.
IA: acrónimo de Inteligencia Artificial.Indexación: técnica que permite optimizar el acceso a los registros en una base
de datos.Integridad: propiedad de una base de datos que asegura la precisión y
consistencia de la información que contiene.Intranet: sistema interconectado de las redes locales de ordenadores de una
organización.Java: lenguaje de programación desarrollado por Sun Microsystems con la
propiedad de poder ser utilizado en forma independiente del sistema operativo(UNIX, Mac OS, Windows u otro).
Lista de autoridades: lista alfabética de términos cuya utilización se autorizapara describir referentes en un sistema documental (se entiende que no sepueden utilizar términos que no están en la lista).
Llave: dato o combinación de datos utilizado para identificar o ubicar un registroen una BD.
202

Llave externa: identificador único utilizado para conectar una tabla de una BDrelacional con otra, sin ser "llave primaria".
Llave primaria: porción del inicio de cada registro de una BD que permiteencontrar con rapidez dicho registro en un sistema indexado.
Meta-datos: todos los datos y conocimientos que una organización posee acercade la información que maneja, tanto en archivos (de ordenadores u otros) comoen la memoria de las personas que en ella participan.
Modelamiento de datos: actividad tendiente a definir la representación de laestructura de los datos bajo la forma de diagramas.
OLAP: acrónimo de "Online Analytical Processing", tipo de aplicación quepermite la manipulación multidimensional de los datos y su visualizaciónmediante una interfaz gráfica.
Programa: secuencia de instrucciones que indican al ordenador qué operacionesrealizar.
Protocolo: conjunto de reglas que determinan el comportamiento de lasfunciones propias de una comunicación digital.
Realidad virtual: simulación que utiliza información para proveer experienciasmultisensoriales; pueden ser creadas mediante generación computarizada deimágenes en el espacio medial.
Registro: conjunto de los datos que representan a un mismo referente en unatabla de datos.
SGBD: acrónimo de "sistema de gestión de base de datos".SQL: acrónimo de "Structured Query Language", lenguaje informático utilizado
pata comunicar con sistemas de bases de datos.Tabla: Conjunto de datos en que cada ítem puede ser identificado en forma
inambigüa mediante una llave. (A cada ítem corresponde un "registro" -fila o"tupla" de la tabla-).
TCP/IP: acrónimo de "Transmission Control Protocol / Internet Protocol",protocolo de transmisión de datos en Internet.
Tesauro o thesaurus: lista jerarquizada (y generalmente codificada) detérminos organizados en clases y subclases, que se utilizan para describirreferentes en un sistema documental.
URL: acrónimo de "Uniform Resource Locator", dirección de un "recurso" en laWWW (normalmente un ordenador).
VDA: acrónimo de "Visual Data Analysis" o análisis visual de datos; técnicabasada en la transformación de datos numéricos en sistemas de coordenadasque permiten diversas formas de representación gráfica.
WWW: acrónimo de "World Wide Web", parte de Internet dedicada a latransmisión de información de carácter multimedial (formato HTML).
XML: acrónimo de "Extended Marking Language", lenguage de definición dedatos compatible con el HTML y la WWW.
203

204

BIBLIOGRAFIA
ANDREWS, K.: "Applying hypermedia research to the World Wide Web",Workshop on Hypermedia Research, Hypertext '96 Conference,Washington, 1996, http:www.iicm.edu/apphrweb
ARDISSONO, L. - LESMO, L. & SESTERO, D.:"Updating the User Model onthe Basis of the Recognition of the User's Plans", Paper, 4th InternationalConference on User Modeling (UM94), Hyannis, Cape Cod, Mass.,Agosto 1994.
BARROS, O.:"Manual de diseño lógico de sistemas de informaciónadministrativos", Santiago de Chile, Ed. Universitaria, 3º ed. 1987.
BENDER, W. & MACNEIL, R.: "Design of electronic information", Paper,Cambridge (Mass.), MIT Media Laboratory, (http://www.media.mit.edu/),1997(?)
BETTETINI, G. y COLOMBO, F.: "Las nuevas tecnologías de lacomunicación", Barcelona, Paidos, 1995.
BIEBER, M., VITALI, F., ASHMAN, H., BALASUBRAMANIAN, V.,OINAS-KUKKONEN, H.: "Fourth generation hypermedia: some missinglinks for the World Wide Web", International Journal of Human-ComputerStudies, v. 47, 1997, pp.31-65.
BOHM, D. & PEAT, D.: “Ciencia, orden y creatividad”, Barcelona, Kairos,1988.
BROWN, J. & alt.: "Visualization. Using Computer Graphics to Explore Dataand Present Information", New York, John Wiley, 1995.
BRUSILOVSKY, P. & BEAUMONT, I.: "Adaptive Hypertext andHypermedia", Paper, 4th International Conference on User Modeling(UM94), Hyannis, Cape Cod (Mass.), Agosto 1994.
CABIN, Ph.& col.: "La communication: état des savoirs", Auxerre, PUF-Sciences Humaines, 1998.
CHESNAIS, P., MUCKLO M., SHEENA, J.: "The Fishwrap personalizednews system", Paper, Cambridge (Mass.), MIT Media Laboratory,(http://www.media.mit.edu/) 1997(?).
COLOMBO, F.: "Ultimas noticias sobre el periodismo", Barcelona, Anagrama,1997.
COLLE, R.:- "Para informar en la WWW", Centro de Estudios Mediales, UniversidadDiego Portales, Santiago, 2001.- "Teoría del Caos, cognitivismo y semántica", Revista Latina deComunicación Social, nº3, Marzo 1998. (www.ull.es/publicaciones/latina/)- "Análisis de contenido, mapas semánticos y Teoría del Caos", Ponenciapresentada en el II Encuentro Internacional de Comunicación y Cultura,Holguín (Cuba), 1997.
205

- "Documentación periodística", Santiago, Pontificia Universidad Católicade Chile, 1992.-"Tecnologías de la Información", Santiago de Chile, Esc. de PeriodismoPUC, 1989.
COLLE, R., MUÑOZ, L. Y ROJAS, H.:"ANATEX", Software de Análisis detextos para Mac OS, Santiago de Chile, Pontificia Universidad Católica,1987-88.
COLLE, R., ROZAS, E. y ROMO, W.: "Prensa y moral familiar", (Informefinal de un Proyecto de Análisis de Contenido), Santiago de Chile,Ed.Pontificia Universidad Católica, 1993.
CORNEJO, C. & ARCEU, A.: "Mecanismos psicológicos de reducción de lacomplejidad del entorno", en Estudios Sociales 82, 1994, pp.141-158.
DATE, C.J.: "Introduction to Data Base Systems", Addison-Wesley, 7ª ed.2000.
DAVIS, S. & BOTKIN, J.: "The coming of knowledge-based business",Harvard Business Review, Sept-October 1994, pp.165-170.
DE PABLOS, J.M.:"El «periódico» en línea", en Unicarta, 1996, nº78, pp.5-12.DRETSKE, F.: "Conocimiento e información", Barcelona, Salvat
(Bibl.Científica), 1989.EHRLICH, M.F. JOHNSON-LAIRD, P. & alt.: "Les modèles mentaux:
Approche cognitive des représentations", Paris, Masson, 183p.ELMASRI, E. & NAVATHE, S: "Sistemas de bases de datos, Conceptos
fundamentales", Addison-Wesley Iberoamericana, 1997.GAINES,B.R., SHAW, M.L.G.: "Knowledge acquisition, modelling and
inference through the World Wide Web", International Journal of Human-Computer Studies, 1997, nº46, pp.729-759.
GARDARIN, G. & VALDURIEZ, P.: "Bases de données relationnelles", Paris,Eyrolles, 1988.
GILLENSON, M.: "Introducción a las bases de datos", México, McGraw Hill,1988.
GLEICK, J.: "Caos - La creación de una ciencia", Barcelona, Seix Barral,1988.
HORN, R.: "Visual Language - Global Communication for the 21st Century",Brainbridge Island (Wa), Macro VU, 1998.
IKEDA, K.:"A social psychological approach to the networked reality", Tokyo,Department of Social Psychology, The University of Tokyo Hongo, 1994.
KAMBA, T., SAKAGAMI, H. & KOSEKI, Y.: "Anatagonomy: a personalizednewspaper on the World Wide Web", en Human-Computer Studies 1997,v.46 nº6, pp.789-803.
KOHONEN,T.: "Self-Organizing Maps", Berlín, Springer, 3ª ed. 2001.KUDYBA, S. & HOPTROFF, R.: "Data Mining and Business Intelligence: A
Guide to productivity", Idea Group Publishing, 2001.LANDOW, G.: - "The Rhetoric of Hypermedia: Some Rules for Authors",
Journal of Computing in Higher Education, 1989, nº1, pp.173-198." - "Hipertexto - La convergencia de la teoría crítica contemporánea y latecnología", Barcelona, Paidos, 1995.
206

LASICA, J.D.:"Net Gain: How online news sites can strengthen the relationshipof journalism with its resistive audience", American Journalism Review,1996, vol.18, nº9, pp.20-33.
LEVY, P.: "Les technologies de l'intelligence", Paris, La Découverte, 1990.LEWIN, R., "La complexité", Paris, Intereditions, 1994.LOPEZ H., A.: "La documentación, herramienta básica del periodista y del comunicador", en Ámbitos 5, Revista Andaluza de Comunicación, Universidadde Sevilla, 2º semestre de 2000, http://www.ull.es/publicaciones/latina/ambitos/5/32angeles.htmMARCO, D.: "Meta Data Repository - A Full Lifecycle Guide", New York,
Wiley, 2000.NORMAN, D. & DRAPER, S.: "User centered system design - New
perspectives on human-computer interaction", Hillsdale (NJ), LawrenceErlbaum Associates, 1986.
NORMAN, D. & LINDSAY, P.: "Introducción a la psicología cognitiva",Madrid, Tecnos, 2º ed. 1983.
PEREZ, V. & PINO, J.: "Estructuras de datos y organizaciones de archivos",Santiago de Chile, Ed. Universitaria, 6º ed.1990.
POBLETE, P.: "Bases de Datos", Santiago de Chile, CIISA, 59p.SHNEIDERMAN, B.: "Designing information-abundant web sites: issues and
recomendations", International Journal of Human-Computer Studies, 1997,nº47, pp.5-29.
THURAISINGHAM, B.: "Data Mining: Technologies, Techniques, Tools andTrends", CRC Press, 1998.
WEISS, S. & INDURKHYA, N.: "Predictive Data Mining", MorganKauffmann, 1997.
WESTFAL, Ch. & BLAXTON, T.: "Data mining solutions", New York,Wiley, 1998.
Fuentes sobre Data Mining consultadas en Internet
- David P. Bock: "Computer Graphics II" (http://woodall.ncsa.uiuc.edu/dbock/Class/csc232/LectureNotes.htm)- SRA: "Knowledge Discovery Solutions"
(http://www.knowledgediscovery.com)- "Data Mining", IT Horizons, vol.2, n.2 (http://www.cambashi.com/dm-
role.htm)
Software libre o de demostración en Internet
- "ARMiner Project", año 2000, (http://www.cs.umb.edu/~laur/ARMiner/)- "CBA: Classification Based on Association", 1998, National University of
Singapore ([email protected])- "Cluster-Senses", 2000, (http://inf.tu-dresden.de/~dk17/cluster-senses/)
207

- "FDEP: a Program for Inducing Functional Dependencies from relations",2000, (http://www.cs.bris.ac.uk/~flach/fdep)
- "Generic Visualization Architecture (GVA)", United Information Systems,Inc. (hhtp://www.unitedis.com/gva)
- "MCLUST/EMCLUST Model-Based Classification Software", 2001,(http://www.stat.washington.edu/fraley/mclust/soft.shtml)
- "PolyAnalyst: Data Mining System", Megaputer Intelligence Inc.(http://www.megaputer.com)
- "Rosetta. A Rough Set Toolkit for Analysis of Data", 2000,(http://www.idi.ntnu.no/~aleks/rosetta/)
- "VisDB: A Visual data Mining and Database Exploration System", 1996,(http://www.dbs.informatik.uni-muenchen.de/dbs/projekt/visdb/visdb.html)
208

TABLA DE GRAFICOS
1.1: Depósito y mercado de datos...................................... 211.2: "Potencial de retorno" de los sistemas de datos................. 241.3: Ejemplo de estructura jerárquica: ANFP......................... 251.4: Ejemplo de estructura jerárquica en una empresa .. . . . . . . . . . . . . . 261.5: Relaciones en los dos tipos de estructuras....................... 281.6: Reordenamiento..................................................... 291.7: Relaciones entre Archivos de Vinos y de Consumidores .. . . . . 301.8: Estructura de una BDOO........................................... 311.9: Operaciones relacionales básicas.................................. 332.1.3: Tipos y mallas de relaciones .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.2.1: Primera forma normal............................................ 392.2.2: Segunda forma normal........................................... 402.2.3: Tercera forma normal............................................ 412.2.4: Modelo canónico (ejemplo) .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412.3.2: Tablas asociadas en una BD normalizada (Ejemplo)......... 442.4.2: Unión de meta-datos compuestos .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482.4.3: Intersección de meta-datos compuestos........................ 483.1: Niveles de exploración............................................. 603.2: Subestructura en una red........................................... 613.3: Tipos de meta-conocimiento....................................... 623.4: Situaciones de data mining. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.5: Etapas de trabajo.................................................... 653.6: Páginas de ingreso a un sitio web ludo-educativo .. . . . . . . . . . . . . 723.7: Estadígrafo de dispersión con clusters . . . . . . . . . . . . . . . . . . . . . . . . . . . 733.8: Arbol jerárquico..................................................... 733.9: Red auto-organizada................................................ 733.10: Paisaje de datos.................................................... 733.11: Mapa semántico construido sobre la base de un análisis de
coocurrencias temáticas............................................ 794.1: Sistema documental periodístico.................................. 884.3: Estructura de la información periodística......................... 974.4: Selección de atributos .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 995.1.1.a: Formulario de ingreso de noticia............................1035.1.1.b: Pantalla de noticias de la revista "TDC"....................1035.1.2a : Noticia acerca de errores de Microsoft......................1045.1.2b : Noticia acerca del futuro de las "punto-com"..............1055.2.1 : Noticias por mes de ocurrencia ... . . . . . . . . . . . . . . . . . . . . . . . . . . . .1095.2.2: Lugares más frecuentes.........................................1105.2.3: Descriptores temáticos más frecuentes........................1115.2.4 : "Implicados" más frecuentes..................................1135.2.5: Noticias por Fuentes más frecuentes..........................1145.3.2 : Modelo normalizado de la BD de noticias ..... . . . . . . . . . . . . . .1165.5.1: Frecuencias por fechas..........................................119

5.4.2: Lugares más frecuentes.........................................1205.4.3: Descriptores temáticos más frecuentes........................1235.4.4: "Implicados" más frecuentes...................................1245.4.5: Agrupación de "Implicados" en clases........................1255.4.6: Fuentes más frecuentes.........................................1265.4.7: Predictibilidad mútua de 4 atributos...........................1296.1.1a: 4000 descriptores aplicados...................................1336.1.1b: Interpretación...................................................1346.1.1c: Descriptores de "Comunicación".............................1346.1.2: Implicados repartidos por clases...............................1366.2.1: Red de relaciones entre Descriptores..........................1396.2.1b: Red de relaciones entre Descriptores .... . . . . . . . . . . . . . . . . . . . .1406.2.1c: Distribución de cantidades de Frecuencias..................1416.2.2: Red de relaciones entre Implicados............................1436.2.3: Mapa de clases coocurrentes de "Implicados" ...............1456.2.4: Red de relaciones entre Lugares...............................1466.3.1: Descriptores e Implicados (por clases)........................1496.3.1b: Descriptores y clases de Implicados con relaciones múltiples........................................................1506.3.2a: Noticias acerca de Internet por mes..........................1526.3.2b: Noticias "digitales" por mes..................................1526.3.2c: Noticias de "e-Comercio" por mes...........................1536.3.2d: "Napster" por mes.............................................1546.3.3a: Microsoft por mes..............................................1546.3.3b: "Fabricantes de software" por mes .... . . . . . . . . . . . . . . . . . . . . . .1556.3.3c: "Sitios Web" por mes..........................................1566.3.4: Red de Descriptores y Lugares ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1586.3.5: Evolución de la cantidad de noticias de Estados Unidos,
Chile y España...................................................1606.3.6: Asociación entre Lugares y clases de Implicados............1626.3.6a: España, Chile y Estados Unidos: Principales clases de
Implicados comunes...............................................1636.3.6b: Clases de Implicados en Chile vs. Estados Unidos........1646.3.7: Frecuencias de Clases de Implicados según Fuentes........1676.3.8: Red de Descriptores y Fuentes.................................1696.3.8b: Red acumulativa de interrelaciones .... . . . . . . . . . . . . . . . . . . . . . .1696.4.1: Tríadas Lugar-Implicados-Descriptores .... . . . . . . . . . . . . . . . . . .1726.4.2a: Tríadas Fechas-Implicados-Descriptores....................1746.4.2b y c: proyección tridimensional (a color)......................1776.4.3: Tríadas Fechas-Lugares-Descriptores.........................1766.4.3b: Tríadas F-L-D (Forma circular)..............................1786.5.1a: Cien noticias en cinco dimensiones..........................1796.5.1b: Visualización separando casos extremos....................1796.5.2: Noticias ordenadas por descriptor, implicado y fuente
(3D, color) .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1787.1: El valor de la Información ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .194Anexo: Conjunto de Mandelbrot.......................................180