
Toward Statistical Machine Translation without Parallel Corpora
Alex Klementiev, Ann Irvine, Chris Callison-Burch, and David Yarowsky Johns Hopkins University
EACL 2012

Motivation
2
} State-of-the-art statistical machine translation models are estimated from parallel corpora (manually translated text)
} Large volumes of parallel text are typically needed to induce good models
} Manual translation is laborious and expensive
} Sufficient quantities available for only a few language pairs
} E.g. Canadian and European parliamentary proceedings
} WMT 2011 translation task: 6 languages, Google Translate - 59
BUT

Goal
3
Instead of:

Goal
4
Cheap monolingual data
+
Use cheap and plentiful monolingual data to reduce (eliminate?) the need for parallel data to induce good translation models

Summary of the Approach
5
At a very high level, translation involves:
1. Choosing correct translation of words and phrases
2. Putting the translated phrases or words in the right order
This work: extend bilingual lexicon induction to score phrasal dictionaries from monolingual data
This work: novel algorithm to estimate ordering from monolingual data
Phrase based SMT: extract / score phrasal dictionaries from sentence aligned parallel data
Phrase based SMT: extract ordering information from parallel data

Outline
6
} Motivation and summary of the approach
} Phrase-based statistical machine translation
} Weaning phrase-based SMT off parallel data
} Scoring phrases
} Extending bilingual lexicon induction
} Scoring ordering
} Novel reordering algorithm
} Experiments
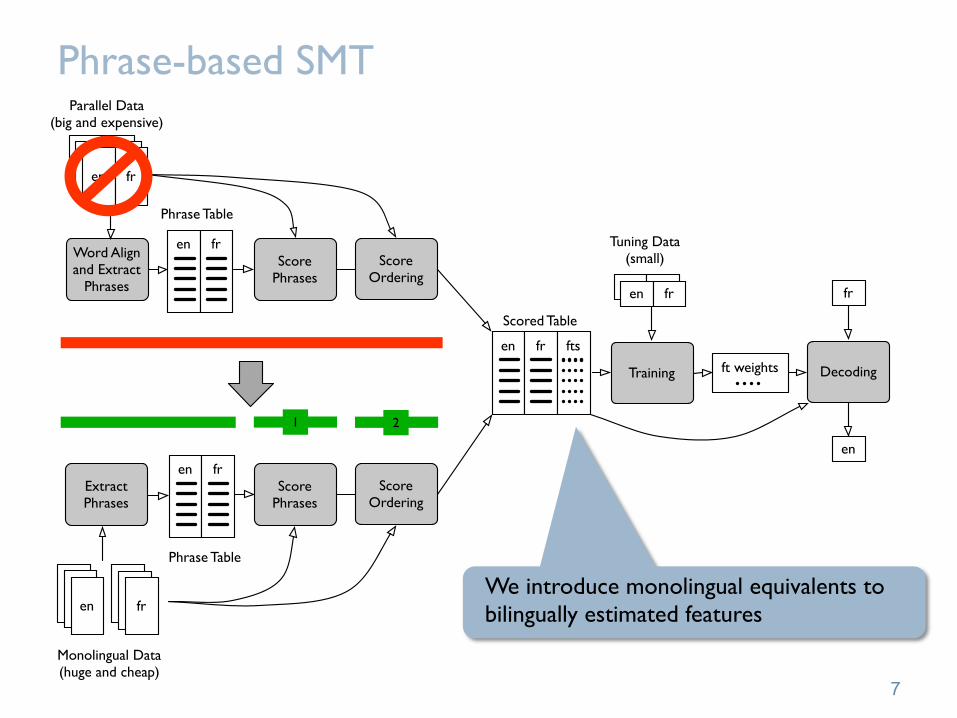
en uren uren fr
Parallel Data(big and expensive)
en uren uren fr
Parallel Data(big and expensive)
Word Align and Extract
Phrases
Phrase Table
en fr
en uren uren fr
Parallel Data(big and expensive)
Word Align and Extract
Phrases
Phrase Table
Score Ordering
en fr fts
Scored Table
en frScore
Phrases
en uren uren fr
Parallel Data(big and expensive)
Word Align and Extract
Phrases
Phrase Table
Score Ordering
en fr fts
Scored Table
Training
en uren fr
Tuning Data(small)
en fr
ft weights
Score Phrases
Phrase-based SMT
7
en uren uren fr
Parallel Data(big and expensive)
Word Align and Extract
Phrases
Phrase Table
Score Ordering
en fr fts
Scored Table
Training Decoding
en uren fr
Tuning Data(small)
en
fr
en fr
ft weights
Score Phrases
en uren uren fr
Word Align and Extract
Phrases
Phrase Table
Score Ordering
en fr fts
Scored Table
Training Decoding
en uren fr
Tuning Data(small)
en
fr
en fr
en uren uren fr
Monolingual Data(huge and cheap)
Phrase Table
Extract Phrases
en fr
ft weights
Score Phrases
Score Ordering
Score Phrases
Parallel Data(big and expensive)
1 2
We introduce monolingual equivalents to bilingually estimated features
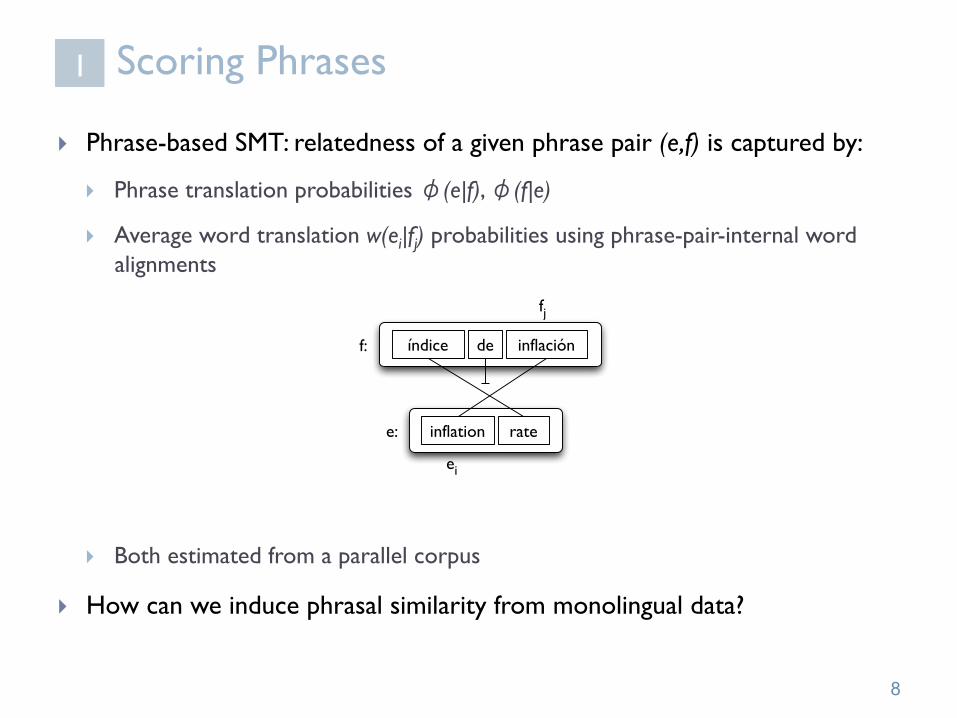
Scoring Phrases
8
} Phrase-based SMT: relatedness of a given phrase pair (e,f) is captured by:
} Phrase translation probabilities φ(e|f), φ(f|e)
} Average word translation w(ei|fj) probabilities using phrase-pair-internal word alignments
} Both estimated from a parallel corpus
} How can we induce phrasal similarity from monolingual data?
índice de inflación
inflation rate
f:
e:
fj
ei
1

Scoring Phrases: Context
9
} An old first idea [Rapp, 99]: measure contextual similarity } Words appearing in similar context are probably related } First, collect context
1
crecer
rápidamente
economíasplaneta
empleoextranjero
crecer
rápidamente
economíasplaneta
empleoextranjero
1
crecer
rápidamente
economíasplaneta
empleoextranjero
1
1
crecer
rápidamente
economíasplaneta
empleoextranjero
2
1... este número podría crecer muy rápidamente si no se modifica ...
... nuestras economías a crecer y desarrollarse de forma saludable ...
... que nos permitirá crecer rápidamente cuando el contexto ...

Scoring Phrases: Context
10
} An old first idea [Rapp, 99]: measure contextual similarity } Words appearing in similar context are probably related } First, collect context
} Then, project through a seed dictionary, and compare vectors
1
7
4
3
1
1
2
5
7
9
crecerexpand
activity
rápidamente
economíasplaneta
empleoextranjero
policy
7
4
37
4
dict.
1
1
2
5
7
9
crecerexpand
activity
quicklypolicy
economic
growth
employment
rápidamente
economíasplaneta
empleoextranjero
policy
crecer(projected)
7
41
1
2
5
7
9
expand
activity
quicklypolicy
economic
growth
employment
policy
crecer(projected)

Scoring Phrases: Time
11
} Second idea: measure temporal similarity } Assume, we have temporal information associated with text (e.g. news
publication dates)
} Events are discussed in different languages at the same time } Collect temporal signature
} Measure similarity between signatures (e.g. cosine or DFT-based metric)
Similar
Dissimilar
1
terrorist (en)terrorista (es)
Occ
urre
nces
terrorist (en)riqueza (es)
Occ
urre
nces
Time

Scoring Phrases: Topics
12
} Third idea: measure topic similarity } Phrases and their translations are likely to appear in the same topic } The more similar the set of topics in which a pair of phrases appears the more
likely the phrases are similar
} We treat Wikipedia article pairs with interlingual links as topics
1
Topic 1 Topic 2 Topic 3 Topic N
L1
L2
Topic 1 Topic 2 Topic 3 Topic N
L1
L2

Scoring Phrases: Orthography
13
} Fourth idea: measure orthographic similarity } Etymologically related words often retain similar spelling across languages with
the same writing system
} Transliterate for language pairs with different writing system
} Measure similarity with edit distance or a discriminative translit model
} Other ideas: burstiness, etc.
democracia democracy
Spanish English
демократия democracy
Russian Transliterated
demokratiya
English
1

Scoring Phrases: Scaling Up Lex Induction
14
} Challenge in scoring phrase pairs monolingually: Sparsity
} Score the similarity of individual words within a phrase pair
} Similar to lexical weights in phrase-based SMT
} Use phrase pair internal word alignments, penalize for unaligned words
0
5
10
15
20
25
30
35
40
45
50
0 100 200 300 400 500 600
Acc
urac
y, %
Corpus frequency
Top 10
1
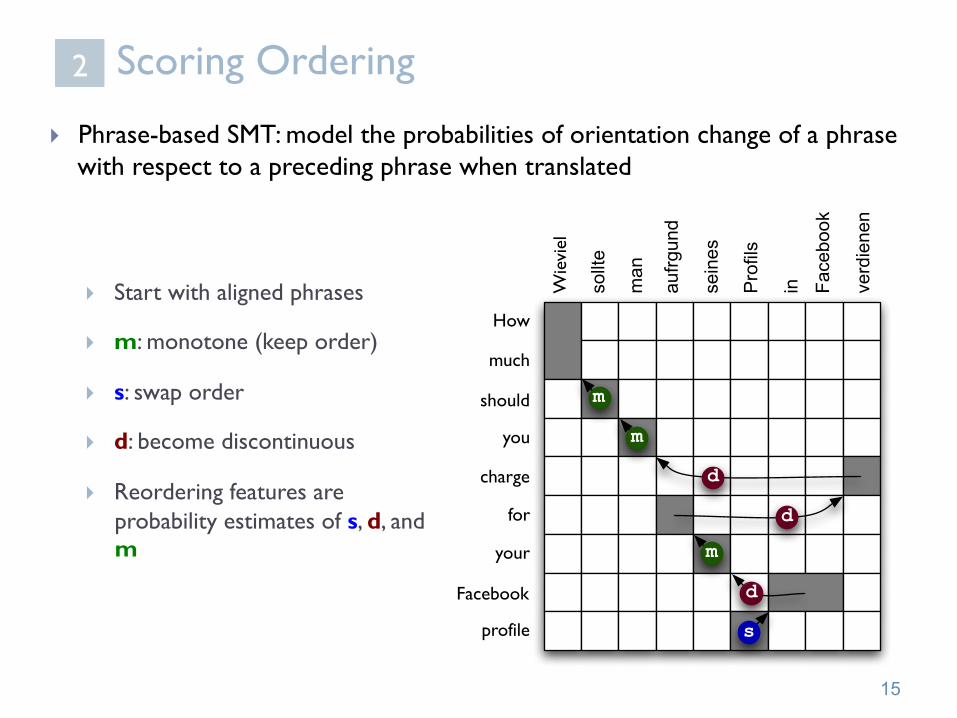
Scoring Ordering
15
} Phrase-based SMT: model the probabilities of orientation change of a phrase with respect to a preceding phrase when translated
} Start with aligned phrases
} m: monotone (keep order)
} s: swap order
} d: become discontinuous
} Reordering features are probability estimates of s, d, and m
2
Wie
viel
man
aufrg
und
sein
es
in
Face
book
How
much
sollt
e
should
you
verd
iene
n
charge
for
your
Pro
fils
profile
m
s
d
d
md
m
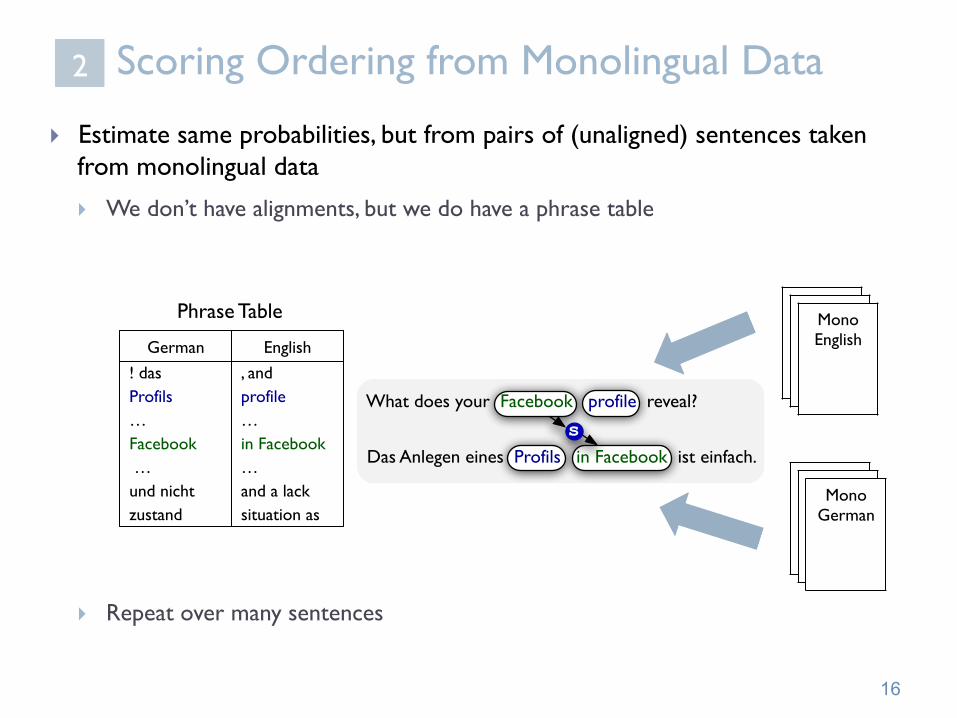
Scoring Ordering from Monolingual Data
16
} Estimate same probabilities, but from pairs of (unaligned) sentences taken from monolingual data
} We don’t have alignments, but we do have a phrase table
} Repeat over many sentences
2
What does your Facebook profile reveal?
Das Anlegen eines Profils in Facebook ist einfach.
German English ! das , and Profils profile … … Facebook in Facebook … … und nicht and a lack zustand situation as
German German Mono English
German German Mono German
Phrase Table
German English ! das , and Profils profile … … Facebook in Facebook … … und nicht and a lack zustand situation as
What does your Facebook profile reveal?
Das Anlegen eines Profils in Facebook ist einfach. s

Scoring Ordering from Monolingual Data
17
} Estimate same probabilities, but from pairs of (unaligned) sentences taken from monolingual data
} We don’t have alignments, but we do have a phrase table
} Repeat over many sentences
2
Das
eine
s
in
ist
einf
ach
Anl
egen
Face
book
What
does
reveal
Pro
fils
profile
your
s

Scoring Phrases and Ordering: Summary
18
Phrase-based SMT Features
Phrase translation probabilities
Lexical weights
Reordering features
Monolingual Equivalents
Temporal, contextual, and topic phrase similarity
Temporal, contextual, topic, and orthographic word similarities
Reordering features estimated from monolingual data
Alternatives to features estimated from parallel corpora: we use cheap monolingual data (along with some metadata), and a seed dictionary
1,2

19
Experiments: Spanish-English
} Idealized setup: treat English and Spanish sections of Europarl as two independent monolingual corpora
} Europarl is annotated with temporal information
} Drop the idealization: estimate features from truly monolingual corpora
} Gigaword, Wikipedia for contextual and temporal
} Wikipedia for topical
} Run a series of lesion experiments:
} Begin with standard features estimated from parallel data
} Drop phrasal, lexical, and reordering features
} Replace them with the monolingually estimated counterparts
} See how much performance can be recovered
0
5
10
15
20
25 BL
EU
20
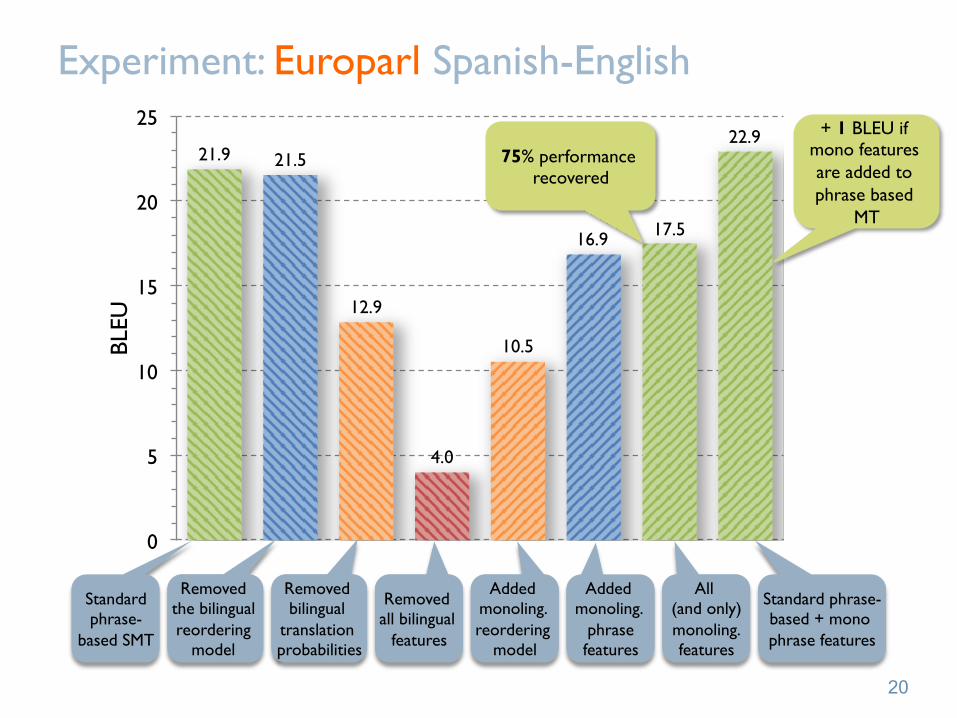
Experiment: Europarl Spanish-English
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
75% performance recovered
21.9 21.5
12.9
4.0
10.5
16.9 17.5
22.9 + 1 BLEU if mono features are added to phrase based
MT
Standard phrase-
based SMT
Removed the bilingual reordering
model
Removed bilingual
translation probabilities
Removed all bilingual
features
Added monoling. reordering
model
Added monoling.
phrase features
All (and only) monoling. features
Standard phrase-based + mono phrase features
0
5
10
15
20
25 BL
EU
0
5
10
15
20
25 BL
EU
21
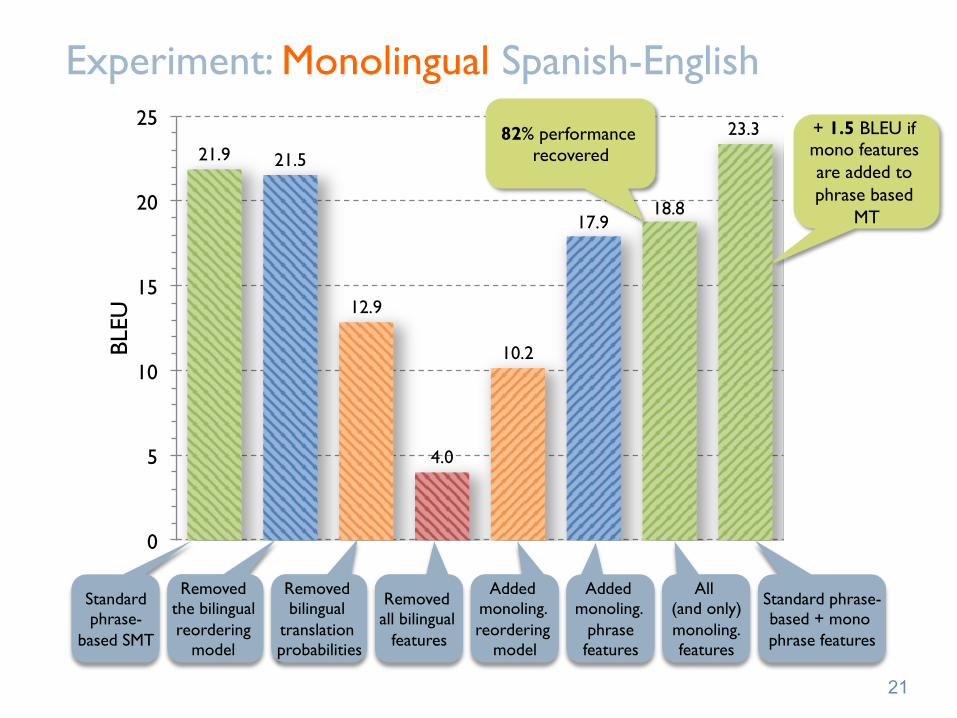
Experiment: Monolingual Spanish-English
82% performance recovered 21.9 21.5
12.9
4.0
10.2
17.9 18.8
23.3 + 1.5 BLEU if mono features are added to phrase based
MT
Standard phrase-
based SMT
Removed the bilingual reordering
model
Removed bilingual
translation probabilities
Removed all bilingual
features
Added monoling. reordering
model
Added monoling.
phrase features
All (and only) monoling. features
Standard phrase-based + mono phrase features

22
} Can recover substantial portion of the lost performance in lesion experiments
} Consistently improve performance when added to the phrase-based setup
Conclusions
Monolingual data takes us a long way toward inducing good translation models
Important direction for languages lacking sufficient (or any) parallel data
} True for most languages
} Monolingual data is plentiful and growing







