Download - How to develop big data

蘇士賓 Phoenix Su

What is Big data?
從收集來的資訊,整理出對我們有用的訊息
資料量不一定很大 (但通常越多越有用)
通常要整理很久

什麼是有用的資訊?
要知道資料要用在哪裡
要知道從哪裡收集資料
要知道怎麼處理

例子
如何播出收視率高的卡通節目:
小朋友幾點放學?
平均到家所花的時間?
幾歲到幾歲最常看電視?
最喜歡看哪些類型的卡通?
收集資料:
各國中小學放學時間
各學區範圍
問卷、網路調查、訪談
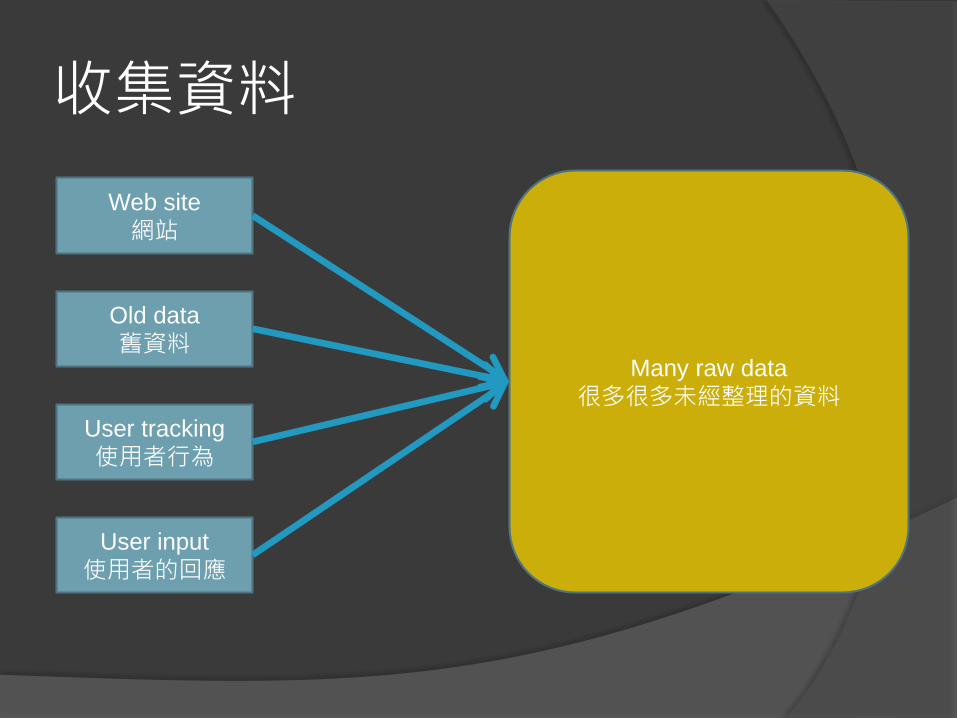
收集資料
Web site
網站
Old data
舊資料
User tracking
使用者行為
User input
使用者的回應
Many raw data
很多很多未經整理的資料
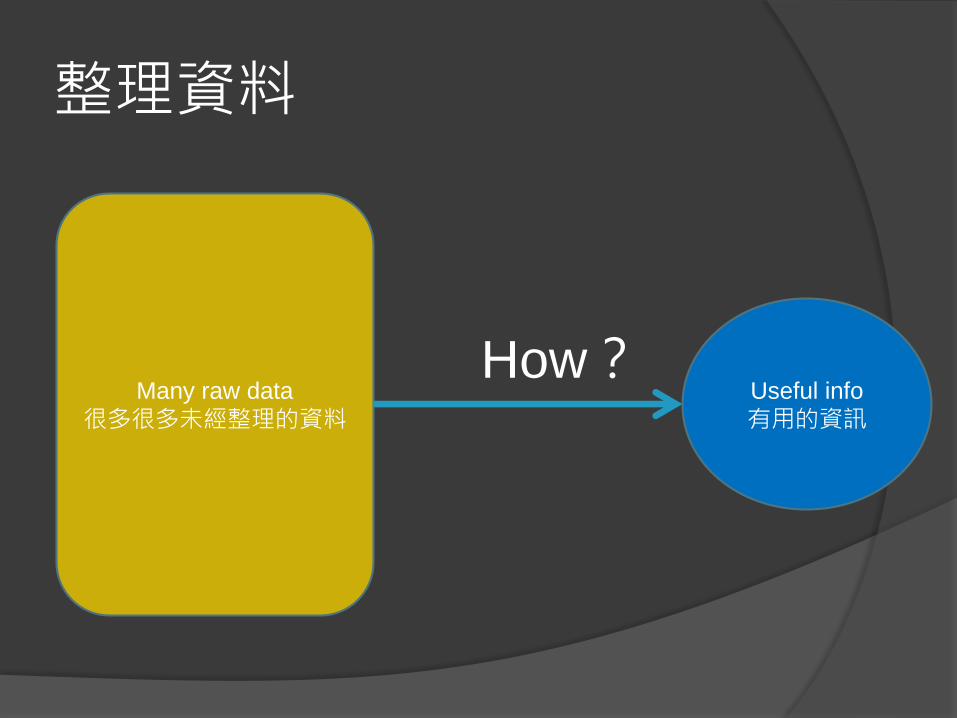
整理資料
Many raw data
很多很多未經整理的資料Useful info
有用的資訊
How?
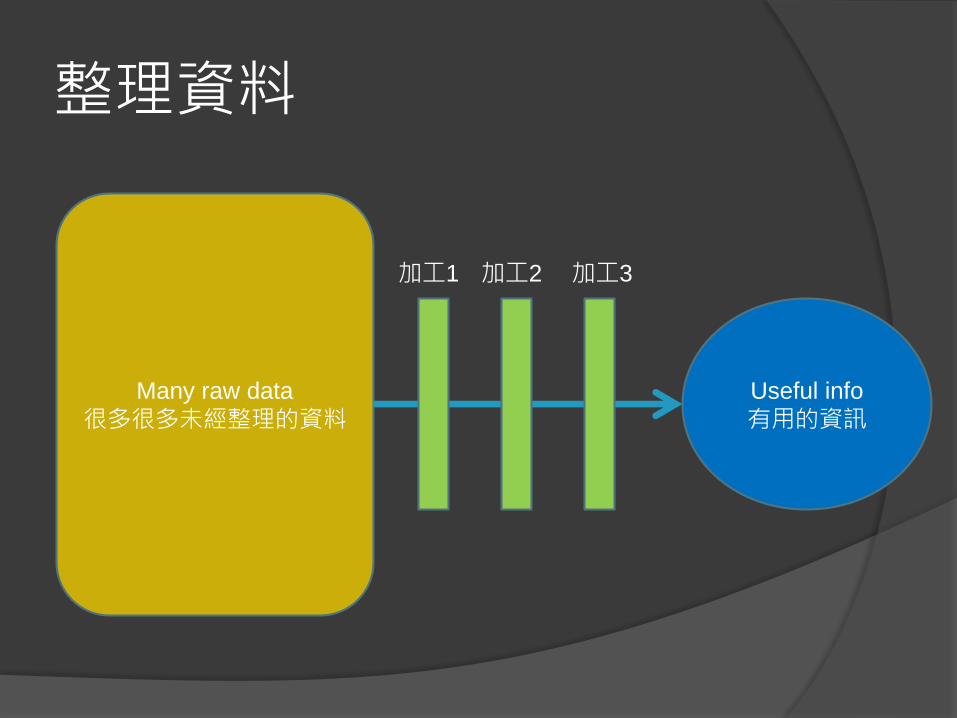
整理資料
Many raw data
很多很多未經整理的資料Useful info
有用的資訊
加工2加工1 加工3
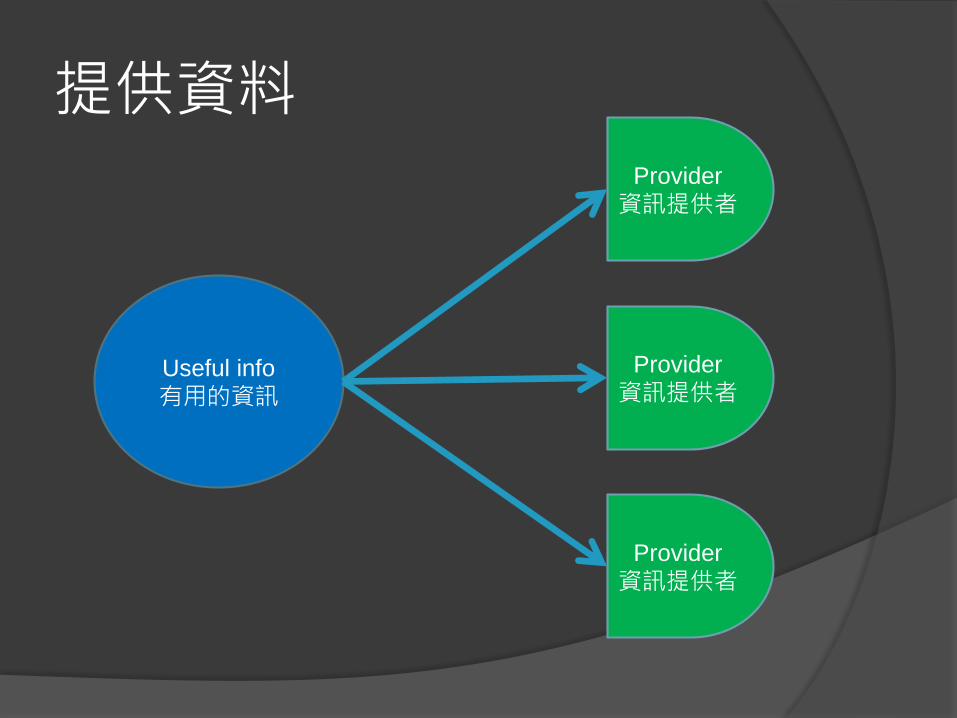
提供資料
Useful info
有用的資訊
Provider
資訊提供者
Provider
資訊提供者
Provider
資訊提供者
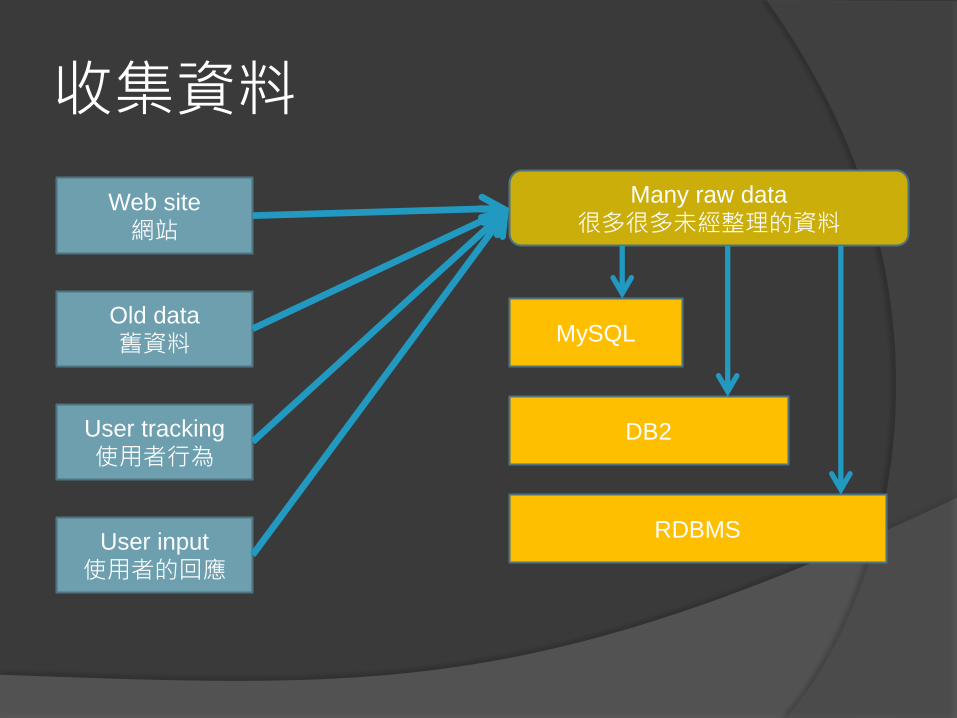
收集資料
Web site
網站
Old data
舊資料
User tracking
使用者行為
User input
使用者的回應
Many raw data
很多很多未經整理的資料
MySQL
DB2
RDBMS

收集資料
因為資料未經整理,所以無法預期未來會如何「找資料」
使用 RDBMS 可以固定資料型態,查詢或儲存都方便
可分成多台 RDBMS 存放,只要知道資料如何取出即可
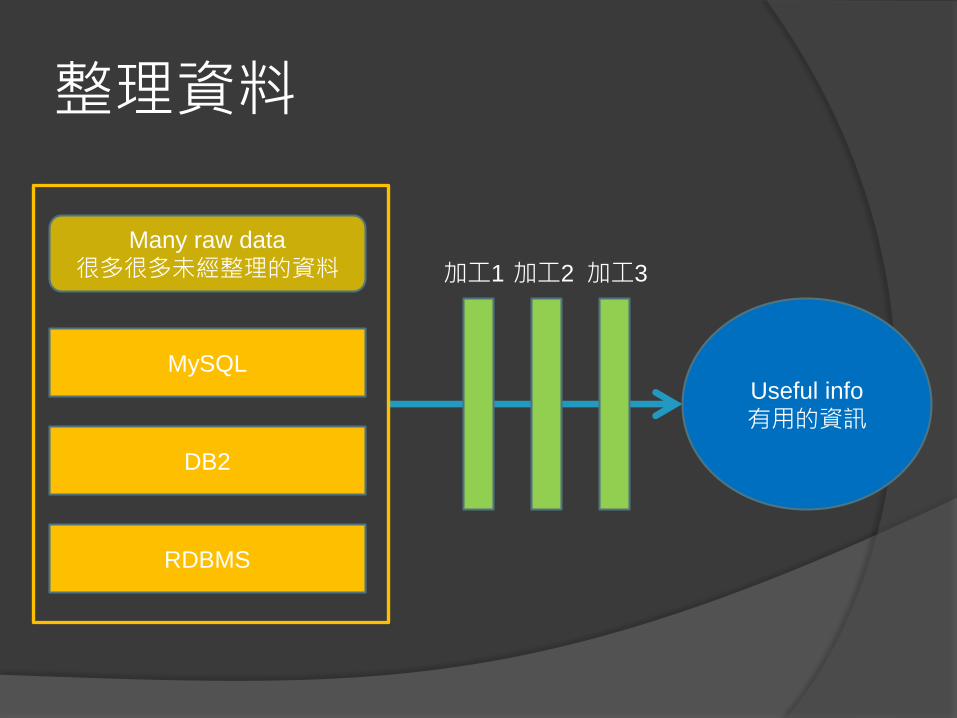
整理資料
Useful info
有用的資訊
加工2 加工3
Many raw data
很多很多未經整理的資料
MySQL
DB2
RDBMS
加工1
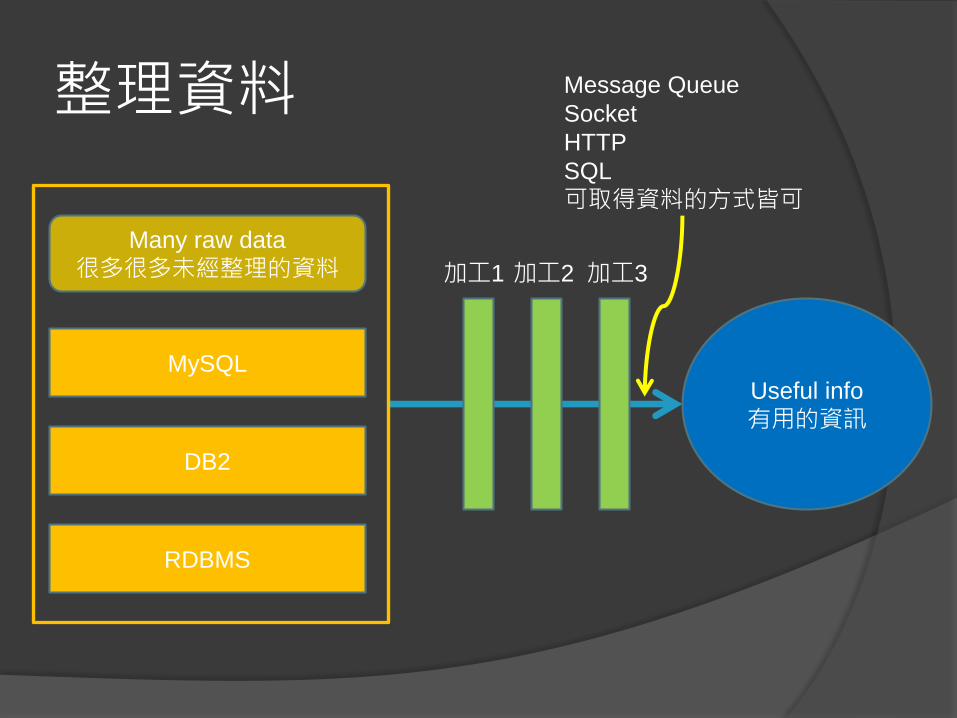
整理資料
Useful info
有用的資訊
加工2 加工3
Many raw data
很多很多未經整理的資料
MySQL
DB2
RDBMS
加工1
Message Queue
Socket
HTTP
SQL
可取得資料的方式皆可
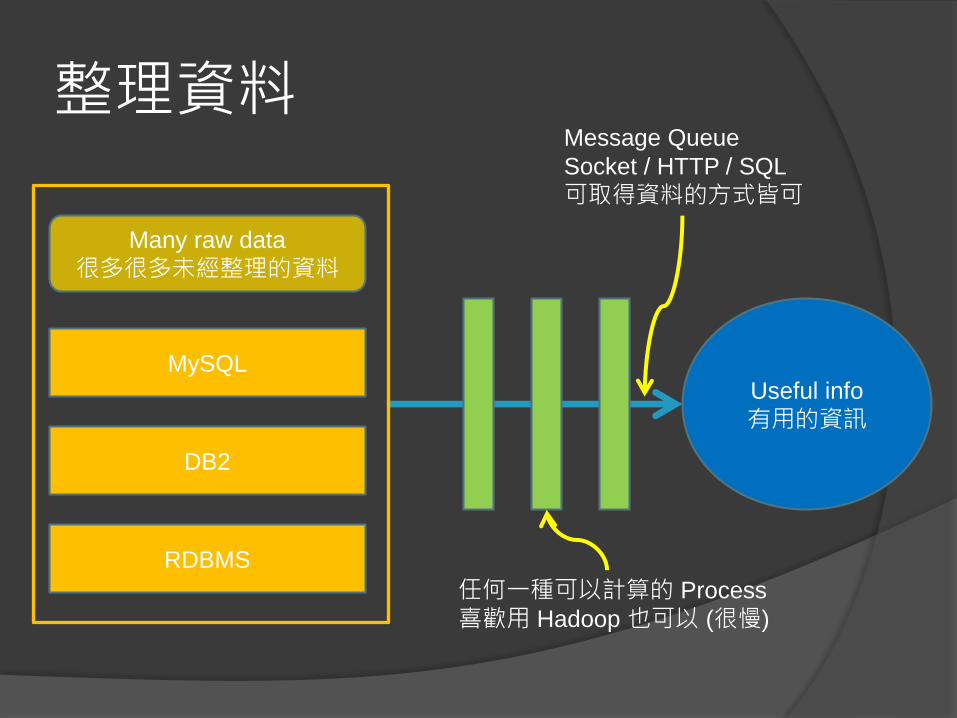
整理資料
Useful info
有用的資訊
Many raw data
很多很多未經整理的資料
MySQL
DB2
RDBMS
Message Queue
Socket / HTTP / SQL
可取得資料的方式皆可
任何一種可以計算的 Process
喜歡用 Hadoop 也可以 (很慢)

整理資料
加工可以做好幾次,例如:
第一次加工:小朋友放學時間(16:00)
第二次加工:小朋友放學+回家時間(16:00+30分)
第三次加工:小朋友放學+回家+寫功課時間(16:00+30分+30分)
可以得到一個結果是, 16:00~17:00 小朋友最有可能在電視機前面,這時候播出卡通效果最好

整理資料
還可以做好幾種不同觀點的加工:
女生比較乖,寫功課特別快,所以16:00~16:30 適合播女孩子看的卡通;男生的卡通則放在 16:30~17:00 播
有的小朋友住比較遠或比較愛玩,功課寫很久來不及看,所以可以推出錄製卡通的服務

發現重點了嗎?

得到什麼結果
跟如何整理資料
很有關係
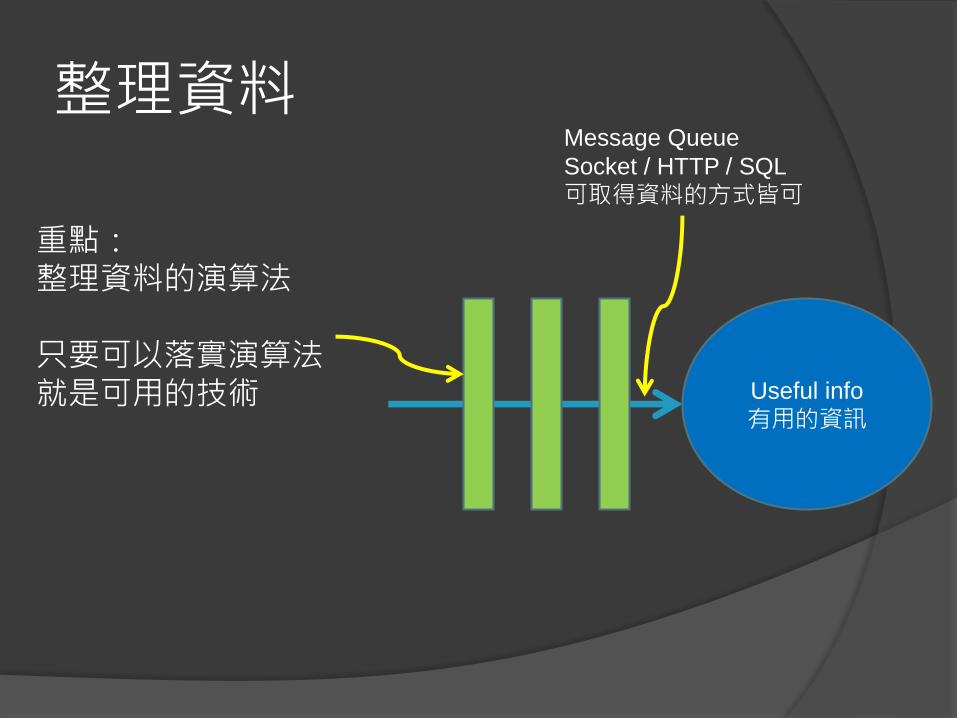
整理資料
Useful info
有用的資訊
Message Queue
Socket / HTTP / SQL
可取得資料的方式皆可
重點:整理資料的演算法
只要可以落實演算法就是可用的技術
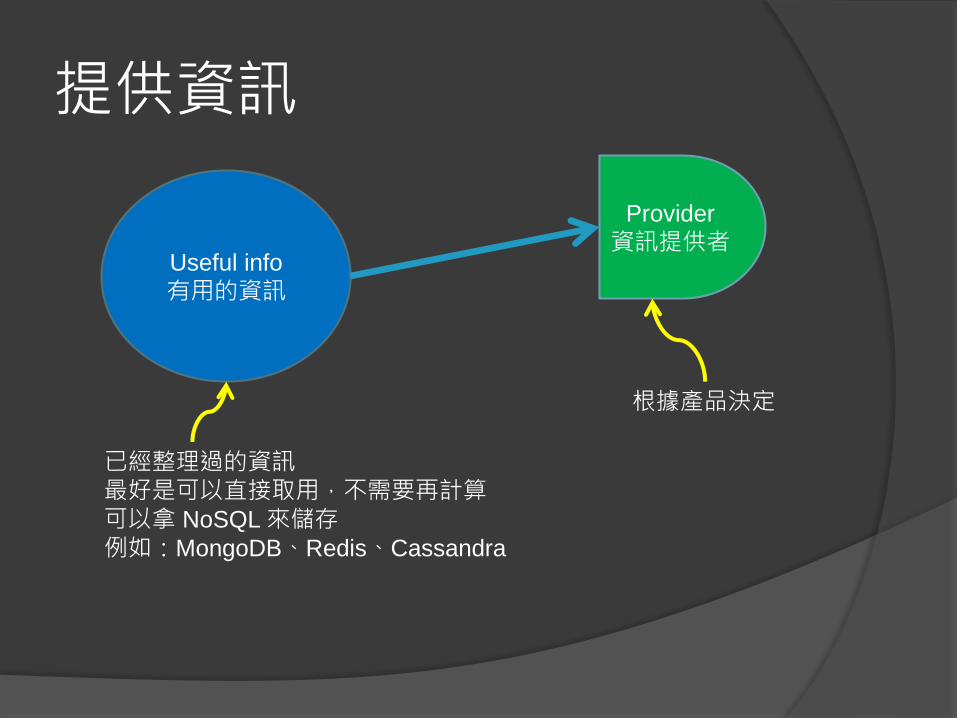
提供資訊
Useful info
有用的資訊
Provider
資訊提供者
根據產品決定
已經整理過的資訊最好是可以直接取用,不需要再計算可以拿 NoSQL來儲存例如:MongoDB、Redis、Cassandra

所以你需要….
1. Target –想達到什麼目的
2. Data Source –要從哪裡收集資料
3. Data Store for raw data –要把 Raw Data
放在哪裡
4. Algorithm –如何整理資料
5. Data Processor –幫你整理資料的工具
6. Data Store for useful data –存放整理過的資料
7. Provider –提供資料的平台

現在知道怎麼做 Big Data 了嗎?







