
Hochschule für Technik und Wirtschaft Dresden
Fakultät Geoinformation
Masterstudiengang Geoinformation und Management
Masterarbeit
Entwurf und Implementierung einer Offline-Replikationunter PostgreSQL
Eingereicht von
Benjamin Thurm
Seminargruppe: 11/063/71
Matrikelnummer: 33265
1. Gutachter: Prof. Dr.-Ing. F. Schwarzbach
2. Gutachter: MSc. A. Schulze (BTU Cottbus)
Eingereicht am: 25.10.2013

Inhaltsverzeichnis i
Inhaltsverzeichnis
Abbildungsverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
1 Einleitung 1
2 Open Information System for Research in Archaeology 32.1 Datenhaltung OpenInfRA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Mutter-Kind-Konzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Anforderungskatalog . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.4 Fazit Analyse Grobkonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Theoretische Grundlagen 143.1 Verteilte Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Referenzarchitektur verteilter Datenbanken . . . . . . . . . . . . . . . . . . 163.3 Replikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.4 Transaktionsverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.5 Mobile verteilte Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . . . 213.6 Architektur mobiler Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . 223.7 Abgrenzung MDBMS und VDBMS . . . . . . . . . . . . . . . . . . . . . . . 233.8 Transaktionen in mobilen verteilten Systemen . . . . . . . . . . . . . . . . . 243.9 Eventually Concistency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.10 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.10.1 Pessimistische Synchronisationsverfahren . . . . . . . . . . . . . . . 283.10.2 Optimistische Synchronisationsverfahren . . . . . . . . . . . . . . . 29
4 Technik 324.1 Native Replikation mit PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . 32
4.1.1 Standby Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.1.2 Hot-Standby-Replication . . . . . . . . . . . . . . . . . . . . . . . . . 334.1.3 Streaming-Replikation . . . . . . . . . . . . . . . . . . . . . . . . . . 334.1.4 Synchrone Replikation . . . . . . . . . . . . . . . . . . . . . . . . . . 344.1.5 Interpretation der WAL-Segmente . . . . . . . . . . . . . . . . . . . 34
4.2 PostgreSQL BDR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.3 Softwarelösungen und Erweiterungen . . . . . . . . . . . . . . . . . . . . . 36
4.3.1 Bucardo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.3.2 SymmetricDS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.3.3 ArcGIS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5 Vorüberlegungen zur Replikationskomponente 445.1 Anpassungen Datenbankschema . . . . . . . . . . . . . . . . . . . . . . . . 455.2 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475.3 Fragmentierung und Allokation der Projektdatenbank . . . . . . . . . . . . . 485.4 Synchronisation externer Dokumente . . . . . . . . . . . . . . . . . . . . . 505.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6 Implementierung 526.1 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 526.2 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.3 Konfiguration Engine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55

Inhaltsverzeichnis ii
6.4 Datenmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 566.4.1 Konfigurationstabellen . . . . . . . . . . . . . . . . . . . . . . . . . . 566.4.2 Datentabellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.5 Einrichten der Replikationshierachie eines Projekts . . . . . . . . . . . . . . 596.6 Protokollieren von Verlaufsdaten . . . . . . . . . . . . . . . . . . . . . . . . 616.7 Synchronisation externer Dokumente . . . . . . . . . . . . . . . . . . . . . 656.8 Mutterknoten einrichten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 676.9 Erstellen einer Kind-Instanz . . . . . . . . . . . . . . . . . . . . . . . . . . . 686.10 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.11 Offline-Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 726.12 Konfliktlösung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 736.13 Purging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.14 Knoten entfernen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.15 Sichern des Kommunikationswegs . . . . . . . . . . . . . . . . . . . . . . . 766.16 Test der Konfiguration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 776.17 Notwendige Erweiterungen . . . . . . . . . . . . . . . . . . . . . . . . . . . 796.18 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
7 Zusammenfassung und Ausblick 86
Konfiguration SymmetricDS-Engine v
Standardkonfiguration vii
Email xiv
Anlagenverzeichnis xx
Monographien xxii
Publikationen xxii
Webseiten xxiii
Erklärung über die eigenständige Erstellung der Arbeit xxvi

Abbildungsverzeichnis iii
Abbildungsverzeichnis
1 OpenInfRA-Informationsmdel . . . . . . . . . . . . . . . . . . . . . . . . . . 42 Anwendungsschema Projektdatenbank . . . . . . . . . . . . . . . . . . . . 53 Komplexe Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64 Instanziierung Kind-Instanz . . . . . . . . . . . . . . . . . . . . . . . . . . . 75 Exemplarische Mutter-Kind-Hierarchie . . . . . . . . . . . . . . . . . . . . . 96 Vergleich Client-Server - VDBMS . . . . . . . . . . . . . . . . . . . . . . . . 157 Referenzarchitektur Verteilter Datenbanken . . . . . . . . . . . . . . . . . . 168 Fragmentierung und Allokation einer Relation . . . . . . . . . . . . . . . . . 179 Darstellung Single- & Multi-Master-System . . . . . . . . . . . . . . . . . . 1910 Globale Transaktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2011 2-Phase-Commit-Protokoll in einem verteilten Datenbanksystem . . . . . . 2112 Dimensionen verteilter Datenbanksysteme . . . . . . . . . . . . . . . . . . 2213 Architektur mobiler verteilter Datenbanksysteme . . . . . . . . . . . . . . . 2314 Transaktionen MDBS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2515 CAP Pyramide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2716 Phasen optimistischer Synchronisation . . . . . . . . . . . . . . . . . . . . . 2917 CDC Pattern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3718 3-Tier-Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3919 ArcGIS Versionsbaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4220 ArcGIS Replikationsschema . . . . . . . . . . . . . . . . . . . . . . . . . . . 4321 Replikation externer Projektdaten . . . . . . . . . . . . . . . . . . . . . . . . 5022 SymmetricDS Systemtabellen . . . . . . . . . . . . . . . . . . . . . . . . . . 5723 SymmetricDS Verlaufstabellen . . . . . . . . . . . . . . . . . . . . . . . . . 5924 Pull- und Push-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61

Listings iv
Listings
5.1 Installation uuid-ossp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.2 Abfrage aller Themeninstanzen eines Projekts . . . . . . . . . . . . . . . . 496.1 Starten des SymmetricDS-Standalone-Service . . . . . . . . . . . . . . . . 536.2 Minimalanwendung SymmetricDS . . . . . . . . . . . . . . . . . . . . . . . 546.3 Erstellen eines SymmetricDS-Nutzers . . . . . . . . . . . . . . . . . . . . . 566.4 Konfiguration der Knoten-Hierarchie . . . . . . . . . . . . . . . . . . . . . . 606.5 Einrichten von Pull- und Push-Verbindungen . . . . . . . . . . . . . . . . . 606.6 Definition eines Datenkanals . . . . . . . . . . . . . . . . . . . . . . . . . . 626.7 Einrichten der CDC-Trigger einer replizierten Relation . . . . . . . . . . . . 636.8 Einrichten der CDC-Trigger via Wild Card . . . . . . . . . . . . . . . . . . . 636.9 Einrichten eines Router . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 646.10 Zuordnung Router - Trigger . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.11 Registrieren der Mutter-Instanz . . . . . . . . . . . . . . . . . . . . . . . . . 676.12 Registrierung symadmin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 696.13 Registrierung SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 696.14 Online-Initialisierung einer Kind-Instanz. . . . . . . . . . . . . . . . . . . . . 706.15 Hilfsfunktion Offline-Sync . . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.16 Manuelle Konfliktlösungsstrategie für Projektdaten . . . . . . . . . . . . . . 736.17 Query zum Analysieren von Konflikten im empfangenen Batch . . . . . . . 746.18 Auffinden von Konflikten in ausgehenden Batches . . . . . . . . . . . . . . 756.19 Einfache Hilfsfunktion zum Entfernen einer Kind-Instanz . . . . . . . . . . . 766.20 Hilfsfunktion Offline-Import . . . . . . . . . . . . . . . . . . . . . . . . . . . 791 SymmetricDS-Engine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v2 Standardkonfiguration Mutter-Kind-Konzept . . . . . . . . . . . . . . . . . . vii3 Ordnerstruktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xx

1 Einleitung 1
1 Einleitung
Fragt man jemanden, welche drei Dinge er auf eine einsame Insel mitnehmen würde, fällt
mit hoher Wahrscheinlichkeit der Begriff des „Internet“. Aus dem heutigen Alltag kaum
noch wegzudenken, hat sich ein ständiger Online-Zugang längst fest in das tägliche Le-
ben vieler Menschen integriert. Was hierbei jedoch oft in Vergessenheit gerät ist, dass
dies gar keine Selbstverständlichkeit darstellt. In weniger erschlossenen Gebieten ist ei-
ne stehende Internetverbindung ein kostbares Gut, das mitunter auch für Geld nicht zu
haben ist.
Besonders offensichtlich wird dieser Umstand für Fachgebiete wie der Archäologie. Wäh-
rend die Auswertung von Forschungsreisen mitunter komfortabel im Büro möglich ist, er-
folgt die eigentliche Datenerhebung im Feld. Dies ist in der Praxis schnell Ursache für
einen komplizierten Umgang mit den mühsam beschafften Daten. Unzureichende Mittel
der Datensynchronisation zwischen offline gesammelten und online geänderten Daten
stellen hier ein weit verbreitetes Problem dar. Im schlimmsten Fall kann dies bis hin zum
Datenverlust führen, wenn der Aufwand den einstweiligen Nutzen der Datenintegration
in den Grundbestand übersteigt - ein fürchterlicher Umstand, der der großen Mühe der
Datenerhebung nicht würdig ist.
Dennoch sind Mitarbeiter des Deutschen Archäologischen Instituts täglich mit diesem
Problem bei ihrer Arbeit konfrontiert. Bei Projekten wie der Pergamon-Grabung in der
Türkei, bei der Recherche in Museumsdepots und bei Forschungsreisen im Ausland sam-
meln sie neues Wissen und dokumentieren die Ergebnisse dabei in verschiedenster, zu-
meist digitaler Form. Grundlage dieser Arbeitsweise sollte ein Informationssystem sein,
das für die vielen Facetten dieser Forschung geeignet ist. Dazu gehört insbesondere
auch die Arbeit jenseits einer verlässlichen Netzwerkanbindung.
In dieser Arbeit soll daher eine Replikations- und Sychronisationslösung als Bestandteil
des digitalen Dokumentationssystems OpenInfRA Abhilfe für dieses Problem schaffen,
indem das autonome Arbeiten von einem zentralen Datenbestand ermöglicht wird. Sie
soll es dem Nutzer erlauben, online und offline mit der gleichen Anwendung zu arbei-
ten und den lokalen Datenbestand zu einem passenden Zeitpunkt mit den Änderungen
auf der zentralen Auskunftsversion abzugleichen. Erfordern die Umstände eine weitere
„Offline-Version“, für deren Einrichtung sich mit dem Internet nicht verbunden werden

1 Einleitung 2
kann, soll die Möglichkeit geschaffen werden, diese ausgehend vom lokalen Datenbe-
stand zu erstellen.
Einleitend wird daher zunächst das Informationssystem OpenInfRA vorgestellt, da es den
Ausgangspunkt dieser Betrachtung darstellt. Eine Analyse des bestehenden Grobkon-
zeptes zu OpenInfRA wird darlegen, welche Anforderungen an eine Offline-Replikation
gestellt werden. Hier soll auch das im Grobkonzept definierte sogenannte „Mutter-Kind-
Konzept“ betrachtet werden, welches das Bilden von Kind-Instanzen ausgehend vom
zentralen Datenbestand beschreibt.
Im Anschluss daran soll der aktuelle Wissensstand zu verteilten und mobilen verteilten
Datenbanken dargelegt werden, sodass davon ausgehend die optimistische Replikation
und Synchronisation betrachtet werden kann.
Ein Überblick über bereits bestehende Lösungen für das Datenbanksystem PostgreSQL
soll dann zeigen, welche davon für die Umsetzung des Mutter-Kind-Konzepts in Frage
kommen. Die im fünften Abschnitt folgenden Vorüberlegungen zum Entwurf einer Repli-
kation und Synchronisation sollen anschließend die konkrete Umsetzung einer geeigne-
ten Lösung vorbereiten.
Abschließend wird die Implementierung mit der vorher für geeignet befundenen Lösung
SymmetricDS dokumentiert. Dabei soll auch geprüft werden, inwieweit die vorher gestell-
ten Anforderungen erfüllt werden können.

2 Open Information System for Research in Archaeology 3
2 Open Information System for Research
in Archaeology
Das Open Information System for Research in Archaeology (OpenInfRA) stellt die Bemü-
hungen des Deutschen Archäologischen Instituts Berlin (DAI) dar, ein digitales Dokumen-
tationssystem für „archäologische, bauforscherische und historische Fragestellungen [zu
schaffen, das] unabhängig von konkreten Forschungsfragen“ (OpenInfRA 2013, S.6) ein-
gesetzt werden kann. Ziel ist der Entwurf und die Implementierung des Systems sowohl
für Projekte des DAI als auch für andere Institute wie Universitäten und ausländische Ko-
operationspartner. Ein großes Augenmerk liegt dabei darauf, das breite „Spektrum von
Arbeitsmethoden, Ergebnistypen und Fachobjekten“ zu berücksichtigen. (ebd., S. 27f.)
OpenInfRA ist ein Kooperationsprojekt zwischen dem Lehrstuhl für Vermessungskunde
der Brandenburgischen Technischen Universität Cottbus, dem dort ebenfalls ansässi-
gen Lehrstuhl für Datenbank- und Informationssysteme, der Fakultät Geoinformation der
Hochschule für Technik und Wirtschaft Dresden und dem Deutschen Archäologischen
Institut (DAI).
Die aktuelle Entwicklungsgrundlage für OpenInfRA stellt das Grobkonzept dar, welches
im Ergebnis dieser Arbeit zum Thema „Mutter-Kind-Konzept“ weiterentwickelt werden
soll. Es beschreibt die Sicht „auf ein neues Dokumentationssystem für archäologische
Feldforschungsprojekte [...], das einen effizienten und nachhaltigen Umgang mit For-
schungsdaten“ (ebd., S. 6) ermöglichen soll. Bisher ist es üblich, dass jedes Forschungs-
projekt am DAI mitunter „mehrere, individuell erstellte Dokumentationssyteme“ (ebd., S.
6) nutzt. Die Übernahme für andere, nachfolgende Projekte ist dabei oft - auch wenn
die Datenerfassung zumeist digital erfolgt und sich Anwendungsgebiete überschneiden
- nicht ohne erheblichen Aufwand, möglich. OpenInfRA soll dem Abhilfe schaffen und
dabei auch durch eine Offline-Replikations- und Synchronisierungskomponente die Da-
tenerfassung und digitale Projektpflege vor Ort erleichtern.
Als Grundlage der weiteren Betrachtungen wurde das bestehende OpenInfRA-Grobkon-
zept mit Hinblick auf die für die Replikationskomponente relevanten Aspekte analysiert.
In erster Linie interessiert hier natürlich die Datenhaltung. Die gewonnen Kenntnisse zur
Speicherung in einer OpenInfRA-Projektdatenbank sind aus diesem Grund im Folgenden
kurz charakterisiert. Anschließend wird das „Mutter-Kind-Konzept“ erläutert, welches die

2 Open Information System for Research in Archaeology 4
grundlegenden Überlegungen zur Umsetzung der Replikation der Projektdatenbank dar-
stellt.
2.1 Datenhaltung OpenInfRA
Für OpenInfRA ist die Open Source Datenbank PostgreSQL vorgesehen. Für das RDBMS
spricht, dass es für jedermann frei verfügbar ist, dabei plattformunabhängig implementiert
ist und mit PostGIS eine mächtige GIS-Erweiterung bietet. Eine Replikationskomponen-
te für das Informationssystem muss dementsprechend mit dieser Datenbank kompatibel
sein und den gleichen Grundsätzen folgen.
Um das erklärte Ziel zu erreichen, „einem offenen Nutzerkreis die Bearbeitung von Pro-
jekten zu ermöglichen“, wird das Datenbankschema von OpenInfRA aus einem konzep-
tuellen Anwendungsschema abgeleitet, deren „Elemente auf einer höheren Abstrakti-
onsebene modelliert werden (‚Metamodell‘)“. Zu erwarten ist, dass das generalisierte
Datenbankschema dadurch „stabil und insbesondere in hohem Maße robust gegenüber
zukünftigen projektspezifischen Anforderungen [ist]“. (OpenInfRA 2013, S. 57) Das pro-
jektspezifische Informationsmodell wird dabei wie in Abbildung 1 aus vorhandenem Do-
mänenwissen des Metamodells durch Auswahl generiert.
OpenInfRA Informationsmodell
(Metamodell)
Projektspezifisches Modell
Auswahl von Themen, Attributen und Wertelisten zur Projektinitialisierung
Abbildung 1: Ableitung des projektspezifischen Informationsmodells aus demOpenInfRA-Informationsmodell (ebd., S. 56)
Im Zusammenhang dieser Arbeit ist es wichtig in Bezug auf die grundlegende Datenhal-
tung in OpenInfRA-Systemdatenbank und der Projektdatenbank zu unterscheiden. Die
Systemdatenbank stellt alle projektübergreifenden Informationen zur Verfügung und bil-
det so das OpenInfRA-Informationsmodell ab, aus dem die konkreten projektspezifischen

2 Open Information System for Research in Archaeology 5
Informationsmodelle abgeleitet werden können. Dies geschieht in Form der Initialisierung
von Projektdatenbanken, welche ein aus der Systemdatenbank ausgewähltes „initiales
Themengerüst“ übertragen bekommen. Das Anwendungsschema der Projektdatenbank
ist in Abbildung 2 und 3 in UML-Notation dargestellt.
Abbildung 2: Anwendungsschema der Projektdatenbank (ebd.)
Die Systemdatenbank unterscheidet sich von diesem Schema im Fehlen der Klassen,
welche nur projektspezifisch relevant sind, d.h. insbesondere konkrete Themeninstanzen
und deren Daten.
Es wird klar, dass es sich auch bei diesem Vorgang der Initialisierung einer Projektdaten-
bank um eine Replikation von Daten handelt, da Informationen aus der Systemdatenbank
übertragen werden. Dieser Vorgang geschieht dabei in der Regel unidirektional und nur
einmal bei der Einrichtung der OpenInfRA Komponenten eines Projekts. Allgemeingültige
Daten, wie triviale Wertelisten und Themengerüste werden dabei direkt für die Projektda-
tenbank übernommen. Es ist gut möglich, dass während der Lebenszeit eines Projekts
beispielsweise neue nützliche Wertelisten ergänzt werden. Die automatisierte Übernah-
me all dieser Daten in die Systemdatenbank ist aber nicht vorgesehen. (OpenInfRA 2013,
S. 75)
Inwiefern in Zukunft auch beispielsweise allgemein nützliche Erweiterungen der Wertelis-
ten in den Projektdatenbanken an die Systemdatenbank verteilt werden, ist nicht geklärt.
Für diese Arbeit bedeutet dies, dass die Replikation und Synchronisation zwischen In-
stanzen der Projektdatenbank betrachtet werden muss, nicht aber die Kommunikation

2 Open Information System for Research in Archaeology 6
Abbildung 3: Komplexe Datentypen (ebd.)
zwischen der System- und Projektdatenbank. Der Vorgang der Replikation und Synchro-
nisierung zwischen verschiedenen Projektdatenbank-Instanzen ist im Grobkonzept als
Mutter-Kind-Konzept beschrieben.
2.2 Mutter-Kind-Konzept
Abgeleitet aus den Arbeitsmethodiken der durch OpenInfRA angezielten Fachgebiete der
Archäologie und archäologischen Bauforschung ist die Anforderung gewachsen, berech-
tigten Administratoren die Möglichkeit zu geben, Kopien des Projektdatenbestands anzu-
legen. Dabei soll der Projektdatenbestand der zentralen Online-Version, hier treffend als
Mutter-Instanz bezeichnet, auf die lokalen Computern oder auf einen lokalen Server der
Forschungsniederlassung kopiert werden. Diese Kopien der Projektdatenbank, in dem
Zusammenhang als Kind-Instanz bezeichnet, sollen dann in der Regel ohne eine Netz-
werkverbindung zum zentralen Repository über eine lokal installierte Offline-Version der
OpenInfRA-Anwendung nutzbar sein. Während auch Kind-Instanzen selbst neue Instan-
zen abbilden können, besitzt die Mutter-Instanz durch ihre Rolle als zentrales Portal bzw.
Auskunftssystem auf den DAI-Servern einen gewissen Sonderstatus. So entsteht eine
hierarchische Replikation von Projektdaten über mehrere Ebenen, was sprachlich unter
Umständen schwer auszudrücken ist. Um die Mutter-Instanz bei der Beschreibung der
Replikation der Projektdaten mit OpenInfRA sprachlich besser abzugrenzen wird daher
vorgeschlagen, die rein konzeptuelle Bezeichnung der Eltern-Instanz einzuführen. Die-
se Eltern-Instanz bezeichnet immer die übergeordnete Instanz in der Replikationshier-
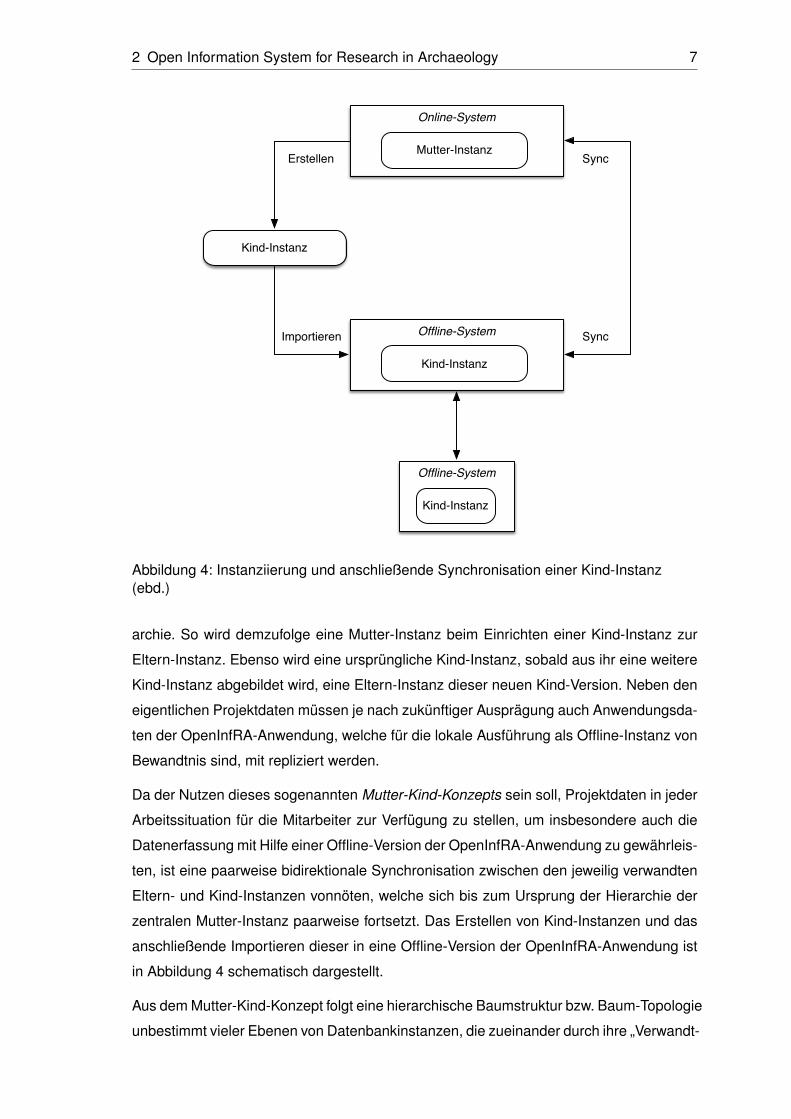
2 Open Information System for Research in Archaeology 7
Online-System
Mutter-Instanz
Offline-System
Kind-Instanz
Kind-Instanz
Erstellen
Importieren Sync
Sync
Offline-System
Kind-Instanz
Abbildung 4: Instanziierung und anschließende Synchronisation einer Kind-Instanz(ebd.)
archie. So wird demzufolge eine Mutter-Instanz beim Einrichten einer Kind-Instanz zur
Eltern-Instanz. Ebenso wird eine ursprüngliche Kind-Instanz, sobald aus ihr eine weitere
Kind-Instanz abgebildet wird, eine Eltern-Instanz dieser neuen Kind-Version. Neben den
eigentlichen Projektdaten müssen je nach zukünftiger Ausprägung auch Anwendungsda-
ten der OpenInfRA-Anwendung, welche für die lokale Ausführung als Offline-Instanz von
Bewandtnis sind, mit repliziert werden.
Da der Nutzen dieses sogenannten Mutter-Kind-Konzepts sein soll, Projektdaten in jeder
Arbeitssituation für die Mitarbeiter zur Verfügung zu stellen, um insbesondere auch die
Datenerfassung mit Hilfe einer Offline-Version der OpenInfRA-Anwendung zu gewährleis-
ten, ist eine paarweise bidirektionale Synchronisation zwischen den jeweilig verwandten
Eltern- und Kind-Instanzen vonnöten, welche sich bis zum Ursprung der Hierarchie der
zentralen Mutter-Instanz paarweise fortsetzt. Das Erstellen von Kind-Instanzen und das
anschließende Importieren dieser in eine Offline-Version der OpenInfRA-Anwendung ist
in Abbildung 4 schematisch dargestellt.
Aus dem Mutter-Kind-Konzept folgt eine hierarchische Baumstruktur bzw. Baum-Topologie
unbestimmt vieler Ebenen von Datenbankinstanzen, die zueinander durch ihre „Verwandt-

2 Open Information System for Research in Archaeology 8
schaftsverhältnisse“ verbunden sind. An der Spitze dieser Hierarchie steht immer die
Mutter-Instanz (siehe auch Abbildung 5), deren Rolle nicht übertragbar ist und auf der
durch Synchronisation entlang des sich ergebenden Graphen alle Änderungen zusam-
menlaufen. In der Praxis könnte die Nutzung folgendermaßen aussehen:
Ein leistungsstarker, zentraler Server des DAI hostet die Online-Version der OpenInfRA-
Anwendung, welche die Mutter-Instanz des Projektdatenbestands verfügt. Interessierte
Besucher könnten diese nutzen, um öffentlich zugängliche Informationen zu recherchie-
ren, während über das Internet verbundene Mitarbeiter sie für ihre Aufgaben nutzen.
Die Forschungsniederlassung, die das Projekt betreibt, installiert eine Offline-Version
der OpenInfRA-Anwendung auf einem oder mehreren Desktop-Rechnern und spielt ei-
ne Kind-Instanz auf dem zugehörigen Datenbankserver ein. Die Mitarbeiter profitieren
nun von einer höheren Lokalität der Daten und können auch ohne Internetverbindung
auf die Projektdaten zugreifen. Für den Außendienst wird aber ein Laptop benötigt, der
ebenfalls mit einer OpenInfRA-Anwendung ausgestattet wird. Im Feld erhobene und im
Büro recherchierte Daten können schließlich über eine lokale Netzwerkverbindung durch
Synchronisation zwischen Laptop und Desktop abgeglichen werden. Die Synchronisa-
tion zwischen Mutter-Instanz und den lokalen Desktop-Rechnern könnte beispielsweise
periodisch zum Ende des Arbeitstages geschehen.
Dieses Szenario ist exemplarisch in Abbildung 5 dargestellt.
Um Daten zwischen den Instanzen abzugleichen, sind zwei Verfahren vorgesehen: eine
Online-Synchronisation per Netzwerkverbindung und eine komplementäre Offline-Syn-
chronisation. Für die Synchronisation von Offline-Versionen der OpenInfRA-Anwendung
kommt auch eine temporäre Netzwerkverbindung, wie sie über ein einfaches LAN-Kabel
oder einen stationären WLAN-Router hergestellt werden kann, in Frage. Für Synchroni-
sationspartner mit einer relativ stabilen Netzwerkverbindung zueinander sollte zusätzlich
auch eine periodische Synchronisation möglich sein, die das Abweichen der Datenbe-
stände auf den Synchronisationspartner so gering wie möglich voneinander hält. Die
Offline-Synchronisation soll durch den Austausch von Synchronisationsnachrichten er-
folgen, die durch berechtigte Nutzer erstellt werden können.
Die konkreten Erwartungen, die mit dem Mutter-Kind-Konzept verbunden werden, sind
im Anforderungskatalog des Grobkonzepts näher beschrieben.

2 Open Information System for Research in Archaeology 9
Online-System
Mutter-Instanz
Offline-System
Kind-Instanz
Offline-System
Kind-Instanz
Offline-System
Kind-Instanz
DAI-Server
Desktop-Rechner
Laptop für Außendienst
Periodische Sync.On-Demand Sync.
1. Hierarchieebene
2. Ebene
3. Ebene
Abbildung 5: Die Hierarchie unter den Datenbankinstanzen folgt aus derInstanziierungsreihenfolge, deren Ausgangspunkt immer die zentrale Mutter-Instanz ist.Das Beispiel zeigt eine mögliche Konstellation, in der OpenInfRA im Rahmen einesProjekts genutzt werden könnte.
2.3 Anforderungskatalog
Für die Ableitung funktionaler und nicht-funktionaler Anforderungen werden die im Grob-
konzept definierten Anwendungsfälle genutzt. Das Mutter-Kind-Konzept und damit die
Replikation bzw. Synchronisation betreffend ist der Anwendungsfall 1.2.4 - Administration
Projekt Instanz, welcher die Abläufe bei der Verwaltung einer Projektinstanz beschreibt.
Der Vorgang fällt unter die Kategorie der Projekt-Administration, als Akteur ist der Ad-
ministrator bestimmt. Vorbedingung ist also, dass der Administrator angemeldet ist, die
benötigten Rechte für die Administration der Projekt-Instanz hat und ein entsprechendes
Projekt angelegt wurde.
Zum möglichen Ablauf der Administration sind derzeit sechs Fälle definiert:
• Das Erstellen einer Kind-Instanz eines Projektes. Die entsprechende Anforderung
AC_0280 spezifiziert dies als das Erstellen einer (Offline-)Version in unterschiedli-
chen Ausprägungen an einem ausgewähltem Speicherort mit den Wahlmöglichkei-
ten, nur den Datenbestand des Projekts zu exportieren und eventuelle Systemda-
teien und/oder Projektkonfigurationen mit einzubeziehen.

2 Open Information System for Research in Archaeology 10
• Die Möglichkeit eine Online- (AC_0300) oder Offline-Synchronisation (AC_0310)
zwischen Kind-Instanz und Mutter-Instanz durchzuführen.
• Eine Kind-Instanz auf einer Offline-Version der OpenInfRA-Anwendung importieren
bzw. installieren (AC_0320, AC_0330).
• Die für die Offline-Synchronisation vorgesehen Synchronisationsdateien (AC_0311,
AC_0312) exportieren (AC_0313).
Darüber hinaus bestehen konkrete Anforderungen im Bereich der Sicherheit, die nicht
direkt aus dem Anwendungsfall entnommen werden können. Sie betreffen die Protokol-
lierung aller Synchronisationsvorgänge durch Zeitstempel, Benutzername, der beteiligten
Instanz, dem Status der Synchronisation und einer entsprechenden Fehlermeldung bei
Misserfolg (SEC_0260). Darüber hinaus ist eine gesicherte Übertragung (SEC_0410)
bei der Synchronisation gefordert (SEC_0420), die nur ein Administrator starten darf
(SEC_0400).
Des Weiteren werden im Grobkonzept konzeptuelle Anforderungen formuliert. So be-
schreibt KT_1000 genau eine Mutter-Version des Datenbestands eines Projekts, die als
Grundlage der Erzeugung von Kind-Versionen und welche immer das Auskunftssystem
des Systems darstellt (KT_1050). Ein oder mehrere Kind-Instanzen (KT_1010) bilden
die Mutter-Instanz nach Datenbestand und projektspezifischen Eigenschaften ab. Dar-
über hinaus ist formuliert, dass die Transaktionierung zwischen Mutter und Kind-Instanz
dem optimistischen Transaktionsansatz folgen soll (KT_1031) und für die Synchronisa-
tion lange Transaktionen unterstützt (KT_1032). Die grafische Benutzeroberfläche (GUI)
soll letztendlich auf Online- und Offline-Instanzen gleich aussehen (KT_1040).
Neben den konkret für die Replikations/Synchronisationskomponente formulierten Anfor-
derungen gelten für sie die gleichen Grundsätze wie für alle Bestandteile von OpenInfRA.
Dazu zählt insbesondere, dass die Implementierung betriebssystemunabhängig für die
Systeme Microsoft Windows (XP), Mac OS X und Linux erfolgen muss (SW_0130), die
grundlegende Administration per Admin-Client vorgenommen werden kann und die ge-
nutzten Komponenten als Open Source-Software zur Verfügung stehen (SW_0140, 0160).
Der Aufbau der Komponente soll modular zum Gesamtsystem OpenInfRA erfolgen, so-
dass es möglich ist zu entscheiden, ob die Komponente Replikation für einige Projekte
gar nicht von Bewandtnis sein soll (SW_4000). Bei auftretenden Fehlern soll der Nutzer
außerdem per Statusnachricht darüber informiert werden (SW_0041). Nötige Einstellun-
gen, die für die Komponente vonnöten sind, können neben der Nutzung des Admin-Client
per Konfigurationsdateien (SW_0230) und/oder über administrative Einstellungen im Da-
tenbanksystem (SW_0240) vorgenommen werden.
Die bestehenden Anforderungen des Grobkonzepts sind im Folgenden zusammen mit

2 Open Information System for Research in Archaeology 11
ihrer ID und der Priorisierung in gekürzter Form aufgelistet:
Tabelle 2.1: Anforderungsfälle Mutter-Kind-Konzept
ID Art Anforderung Prior.
AC_0280 FA Erstellen einer Instanz eines Projektes 1AC_0300 FA Online-Synchronisation 1AC_0310 FA Offline-Synchronisation 1AC_0311 FA Erstellung SQL-Dump 2AC_0312 FA Parametrierung SQL-Dump 2AC_0313 FA Import SQL-Dump 2AC_0320 FA Import einer Kind-Version 1AC_0330 FA Installation einer (Offline-)Instanz 1
SEC_0260 NFA Protokollierung Synchronisation 1SEC_0410 NFA Datensicherheit 3SEC_0420 FA Datenübertragung 2
KT_1000 NFA Mutter-Version 1KT_1010 NFA Kind-Version 1KT_1031 NFA Optimistischer Transaktionsansatz 1KT_1032 NFA Lange Transaktionen 1KT_1040 NFA Einheitliche GUI für Online / Offline Nutzung 1KT_1050 NFA Mutter-Instanz als Auskunftssystem 1
SW_0130 FA Betriebssystem 1SW_0140 FA Client-Komponenten des Systems KOSW_0041 FA Fehlermeldungen KOSW_0230 FA Systemanpassungen über Konfigurationsdateien KOSW_0240 FA Systemanpassungen über Datenbankmanagementsys-
temKO
SW_4000 NFA Modularer Aufbau KO
2.4 Fazit Analyse Grobkonzept
Bei einer ersten Analyse des Grobkonzepts wurde der Unterschied zwischen Daten-
bankinstanzen und der Online- und Offline-Anwendung OpenInfRA durch die stringen-
te Bezeichnungen Mutter/Kind-Instanz und Online/Offline-Version besser voneinander
differenziert. Außerdem ist für den Fall der Offline-Synchronisation nun nicht mehr der
„SQL-Dump“ als Format vorgesehen, um über die entsprechenden Anforderungen die
Implementierungsmöglichkeiten nicht einzuschränken. Stattdessen wird die allgemeine-
re Formulierung „Synchronisationsdateien“ genutzt. Um die Replikationshierarchie zwi-
schen Mutter- und Kind-Instanzen und Kind- und Kind-Instanzen leichter zu beschreiben,
wurde die konzeptuelle Bezeichnung der Eltern-Instanz eingeführt, welche eine Instanz
beschreibt, die zuvor eine Kind-Instanz gebildet hat und als dessen Synchronisations-
partner auftritt. Dies dient außerdem zur besseren Abgrenzung der Sonderstellung der
Mutter-Instanz bzw. der zentralen Online-Version als Auskunftssystem.

2 Open Information System for Research in Archaeology 12
Die Anforderung einer stetigen Online-Synchronisation in frei definierbaren Intervallen
wurde mit einer mittleren Priorität aufgenommen. Grund dafür ist, dass sie für Nieder-
lassungen mit einer stabilen Netzwerkverbindung zur Mutter-Instanz oder bei der Syn-
chronisation von niederen Ebenen der Hierarchie in lokalen Netzwerken als sehr nützlich
angesehen wird. Es kann so besser auf Bedürfnisse verschiedenster Projekte eingegan-
gen werden.
In Abschnitt 2.2 wurde der anvisierte Nutzen des Mutter-Kind-Konzepts beschrieben, die
Projektdaten autonom vom zentralen Datenbestand auf den Servern des DAI bei den
lokalen Kompetenzzentren zur Verfügung zu stellen. Dabei ist allgemein formuliert, dass
jede Kind-Instanz als Eltern-Instanz eintreten kann. In der Praxis wird die Tiefe dieser
Vererbungshierarchie eine praktikable Obergrenze haben, was für die Implementierung
einer Softwarelösung unter Umständen berücksichtigt werden darf.
Schon vor einer tiefgreifenderen Betrachtung ist klar, dass bei der Nutzung eines optimis-
tische Transaktionsansatzes und autonomen Schreiboperationen auf den Kind-Instanzen
Konflikte beim Synchronisieren möglich sind. Für OpenInfRA kann angenommen werden,
dass solche Konflikte relativ selten sind, immerhin handelt es sich um eine Anwendung,
die in erster Linie für das Sammeln von Informationen genutzt werden soll. Diese Annah-
me wird durch das in Abschnitt 2.1 beschriebene Anwendungsschema gestützt, in dem
Attribute konkreter Instanzen durch Assoziationsbeziehungen referenziert sind. Praktisch
bedeutet dies, dass die Wahrscheinlichkeit, dass zwei parallele Transaktionen die gleiche
Tabellenzeile bearbeiten, sehr gering ist. Dementsprechend stellt die manuelle Auflösung
von Konflikten bei der Synchronisation ein adäquates Mittel dar, das den Nutzern die
beste Kontrolle über die Daten bietet. Entsprechend ist im Grobkonzept die manuelle
Konfliktlösung durch Administratoren bei Synchronisationskonflikten aufgeführt.
Für die Synchronisation zwischen Datenbankinstanzen ist zu beachten, dass die Qualität
der Netzwerkverbindung stark variieren kann. Es sind deshalb Verfahren zu bevorzugen,
die lediglich diejenigen Datensätze übermitteln, die von Änderungen betroffen sind. Dies
gilt auch für die Offline-Synchronisation.
Das Mutter-Kind-Konzept beschreibt die Replikation und Synchronisation der Projektda-
ten. Gemeint sind dabei auch externe Dokumente wie Texte, Bilder und Pläne, welche
durch die OpenInfRA-Anwendung im Dateisystem abgelegt werden oder die zur Konfi-
guration der OpenInfRA-Komponenten benötigt werden. Deshalb muss beim Installieren
der Offline-Version der Anwendung bzw. beim Import der initialen Daten eine Möglichkeit
gegeben sein, externe Daten zu selektieren, die für die Projekt-Instanz bei der autono-
men Arbeit relevant sind. Die Anwendungsschicht muss dabei auf Datensätze, welche
Verknüpfungen auf externe Dateien darstellen die auf der Offline-Version nicht zur Ver-

2 Open Information System for Research in Archaeology 13
fügung stehen, ohne einen Systemfehler bzw. mit einem passenden Hinweise reagieren
können. Es ist anzunehmen, dass die Replikation und Synchronisation von externen Da-
ten nicht über eine Datenbankverbindung organisiert werden kann, sondern dass hierfür
externe Prozesse benötigt werden. Bei der Online-Synchronisation ist bei Dateien insbe-
sondere wichtig, dass diese komprimiert übertragen werden.
Die Implementierung einer Replikationskomponente für das OpenInfRA-Projekt erfordert
eine Auseinandersetzung mit der zugrundeliegenden Thematik der Replikation und Syn-
chronisation in relationalen Datenbanken. Im anschließenden Kapitel wird deshalb eine
theoretische Einführung hierzu geboten und auf mögliche Lösungsstrategien und even-
tuelle Fehlersituationen eingegangen. Im darauffolgenden Kapitel werden schließlich be-
stehende Replikationslösungen für PostgreSQL und verwandte Systeme beschrieben,
die als Ausgangspunkt oder Vorlage der Implementierung dienen könnten.

3 Theoretische Grundlagen 14
3 Theoretische Grundlagen
Das in Kapitel 2.2 beschriebene Mutter-Kind-Konzept stellt die Kommunikation zwischen
den im System befindlichen Computern dar. Als Übertragungsmedium kommt eine Ether-
netverbindung (LAN), eine Internetverbindung (WAN) aber sogar die Übertagung als
Datei in Betracht. Um die Funktion eines Computers als Kommunikationspartner in ei-
nem solchen System besser abzugrenzen, werden sie häufig als Stationen oder Knoten
bezeichnet. Um die Projektdaten verwalten zu können und so die Anforderungen des
Mutter-Kind-Konzepts zu erfüllen, muss jede der Stationen über einen lokalen Daten-
bankserver verfügen. Neben diesem Datenbankserver werden unter Umständen weitere
Services ausgeführt die für die OpenInfRA-Anwendung, sei es online oder offline, von
Belang sind. Während die einzelnen Stationen mit Hilfe der auf ihnen gespeicherten Da-
ten autonom voneinander arbeiten können, ist für die Konsolidierung von Änderungen
am Datenbestand Kommunikation vonnöten. Es handelt sich deshalb um ein Verteiltes
System, genauer ein verteiltes Datenbanksystem. Der Begriff soll im Folgenden kurz er-
läutert werden.
3.1 Verteilte Datenbanksysteme
Unter einem verteilten System versteht man in der Informatik vernetzte Computer und
Komponenten, die sich per Nachrichten über ihre Aktionen austauschen und koordinie-
ren. Die Client/Server-Architektur des World Wide Web kann beispielsweise als verteiltes
System angeführt werden, bei dem die Komponenten nebenläufig agieren, auf keine glo-
bale Uhr zurückgreifen und unter Umständen unabhängig voneinander ausfallen können.
(Coulouris, Dollimore und Kindberg 2002, S. 17f.)
In diesem Sinne beschreiben Ceri und Pelagatti (1984, S. 6f.) verteilte Datenbanken
grob als eine Sammlung von Informationseinheiten, die einen logischen Zusammen-
hang bilden, aber räumlich getrennt auf mehreren durch ein Kommunikationsmedium
verbundenen Computern verwaltet werden. Jeder dieser Computer, in diesem Zusam-
menhang als Knoten bezeichnet, nimmt dabei an mindestens einer globalen Aufgabe teil.
Die Gesamtheit der Knoten bildet das verteilte Datenbanksystem. (Mutschler und Specht
2004, S. 65f.) Abbildung 6 stellt einer verteilten Datenbank die klassische Client-Server-
Architektur gegenüber. Im Vergleich „handelt es sich [beim Client-Server-System] also
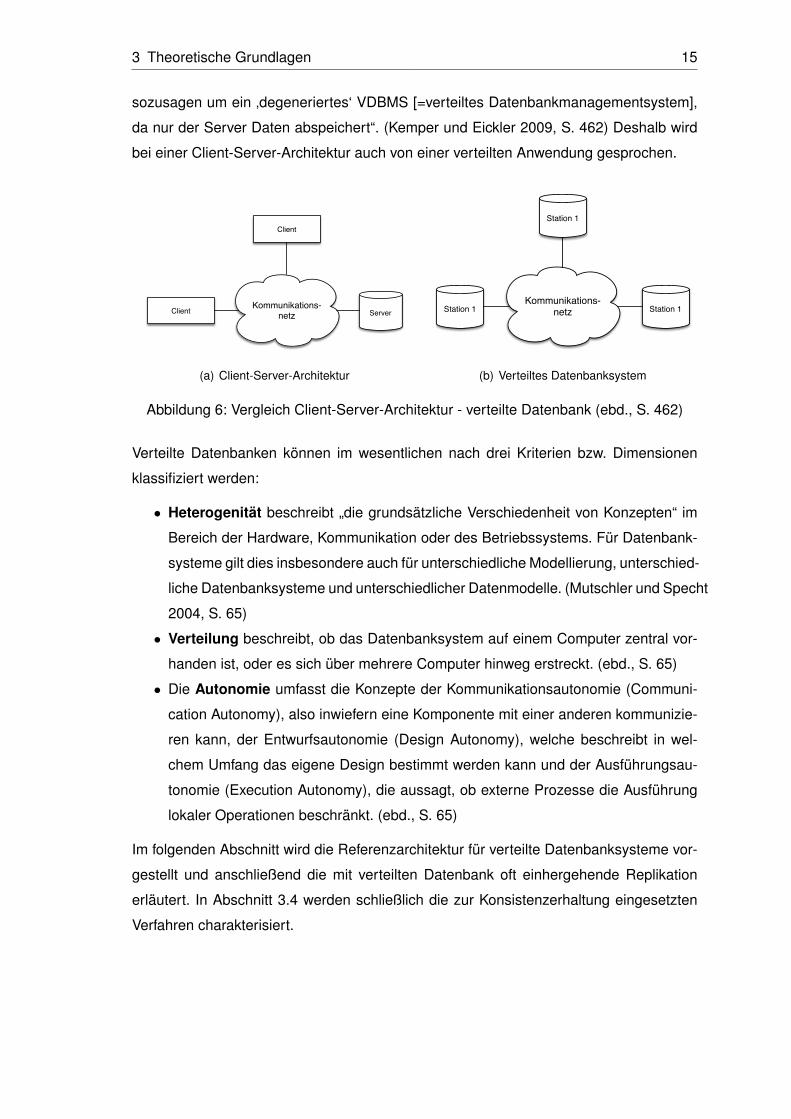
3 Theoretische Grundlagen 15
sozusagen um ein ‚degeneriertes‘ VDBMS [=verteiltes Datenbankmanagementsystem],
da nur der Server Daten abspeichert“. (Kemper und Eickler 2009, S. 462) Deshalb wird
bei einer Client-Server-Architektur auch von einer verteilten Anwendung gesprochen.
Server
Client
Client Kommunikations-netz
(a) Client-Server-Architektur
Station 1
Station 1 Station 1Kommunikations-
netz
(b) Verteiltes Datenbanksystem
Abbildung 6: Vergleich Client-Server-Architektur - verteilte Datenbank (ebd., S. 462)
Verteilte Datenbanken können im wesentlichen nach drei Kriterien bzw. Dimensionen
klassifiziert werden:
• Heterogenität beschreibt „die grundsätzliche Verschiedenheit von Konzepten“ im
Bereich der Hardware, Kommunikation oder des Betriebssystems. Für Datenbank-
systeme gilt dies insbesondere auch für unterschiedliche Modellierung, unterschied-
liche Datenbanksysteme und unterschiedlicher Datenmodelle. (Mutschler und Specht
2004, S. 65)
• Verteilung beschreibt, ob das Datenbanksystem auf einem Computer zentral vor-
handen ist, oder es sich über mehrere Computer hinweg erstreckt. (ebd., S. 65)
• Die Autonomie umfasst die Konzepte der Kommunikationsautonomie (Communi-
cation Autonomy), also inwiefern eine Komponente mit einer anderen kommunizie-
ren kann, der Entwurfsautonomie (Design Autonomy), welche beschreibt in wel-
chem Umfang das eigene Design bestimmt werden kann und der Ausführungsau-
tonomie (Execution Autonomy), die aussagt, ob externe Prozesse die Ausführung
lokaler Operationen beschränkt. (ebd., S. 65)
Im folgenden Abschnitt wird die Referenzarchitektur für verteilte Datenbanksysteme vor-
gestellt und anschließend die mit verteilten Datenbank oft einhergehende Replikation
erläutert. In Abschnitt 3.4 werden schließlich die zur Konsistenzerhaltung eingesetzten
Verfahren charakterisiert.

3 Theoretische Grundlagen 16
3.2 Referenzarchitektur verteilter Datenbanken
Ceri und Pelagatti (1984, S. 37ff.) definieren eine Referenzarchitektur verteilter Daten-
banken, welche von einem globalen Schema über das Fragmentierungsschema und dem
Zuordnungs- bzw. Allokationsschema hin zur lokalen Datenbank reicht. Die Architektur ist
in Abbildung 7 dargestellt.
globales Schema
Fragmentierungs-schema
Zuordnungs-schema
lokales Schema
lokales Schema
lokales DBMS
lokales DBMS
lokale DB lokale DB
StationsunabhängigeSchema
Abbildung 7: Referenzarchitektur Verteilter Datenbanken nach Ceri und Pelagatti (ebd.,S. 38)
Das globale Schema ist der Ausgangspunkt des Entwurfs und entspricht dem Implemen-
tierungsschema des zentralisierten Datenbankentwurfs. Für das Fragmentierungssche-
ma, der logischen Ebene der Struktur des verteilten Datenbanksystems (Mutschler und
Specht 2004, S. 68), werden sich daraus ergebende „logisch zusammenhängende Infor-
mationsmengen - hier Relationen - in (weitgehend) disjunkte Fragmente (Untereinheiten)
zerlegt.“ (Kemper und Eickler 2009, S. 463) Die Zerlegung kann dabei in horizontaler
(Zerlegung in Tupelmengen) als auch vertikaler Richtung (Projektion in Attributbereiche)
erfolgen und muss sich nach dem zu erwartenden Zugriffsverhalten richten. Es gelten im
wesentlichen drei Bedingungen für eine korrekte Fragmentierung:
• Vollständigkeit : Alle Daten der globalen Relation müssen auf Fragmente aufgeteilt
werden und dürfen bei der Fragmentierung nicht verloren gehen.

3 Theoretische Grundlagen 17
• Rekonstruierbarkeit : Globale Relationen müssen aus ihren Fragmenten wieder-
herstellbar sein.
• Disjunktheit : Fragmente müssen disjunkt zueinander sein, das heißt ein Datum ist
nicht mehreren Fragmenten zugeordnet, um Überlappungen durch das Allokations-
schema explizit zu bestimmen. (Ceri und Pelagatti 1984, S. 42; Kemper und Eickler
2009, S. 465)
Die Verteilung der Fragmente auf die einzelnen Stationen wird abschließend durch das
Allokationsschema, der physischen Ebene der Struktur einer verteilten Datenbank (Mutsch-
ler und Specht 2004, S. 65), beschrieben. Für die Zuteilung der Fragmente sind zwei
Möglichkeiten gegeben. Bei der redundanzfreien Allokation werden die Fragmente je-
weils exakt einer Station zugewiesen. Die Zuordnung erfolgt in diesem Fall möglichst nah
an der Station, die diese Daten am ehesten nutzt. Die zweite Möglichkeit besteht darin
Fragmente mehr als einer Station zuzuweisen. Man spricht nun von Allokation mit Repli-
kation. (Ceri und Pelagatti 1984, S. 39; Coulouris, Dollimore und Kindberg 2002, S. 644)
Abbildung 8 stellt die beschriebene Fragmentierung und Allokation einer Relation noch
einmal schematisch dar.
Relation
Station 1
Station 2
Fragmentierung Allokation
GlobalRelation Fragmente Physisches
Abbild
Abbildung 8: Fragmentierung und Allokation einer Relation nach Ceri und Pelagatti(1984, S. 40)
Die Allokation mit Replikation stellt ein häufig genutztes Konzept dar, welches Grundla-
ge dafür ist, Informationen ohne eine Verbindung zum zentralen Server auf Knoten zur
Verfügung zu stellen. Entsprechend soll es im Folgenden näher betrachtet werden.

3 Theoretische Grundlagen 18
3.3 Replikation
Replikate sind Kopien von Datenobjekten, also Tabellen, Tabellenpartitionen, Datensätze
oder Dateien, in verschiedenen Systemen, die konsistent zueinander gehalten werden
sollen. Geläufig ist für sie auch die Bezeichnung Snapshot oder materialisierte Sicht. Für
die Repliken verwaltenden Stationen ist der Begriff Repliken-Manager geläufig. (Coulou-
ris, Dollimore und Kindberg 2002, S.644; Saito 2005, S. 1)
Durch die beschriebene Allokation mit Replikation kann eine hohe Verfügbarkeit von Da-
ten erreicht werden. Insbesondere die Lokalität von Daten kann durch Repliken an den
entsprechenden Knoten erhöht und so die Zugriffszeit verkürzt werden, was insbeson-
dere auch für die Verfügbarkeit von Daten auf entkoppelten Knoten gilt die zeitweise
autonom vom verteilten Datenbanksystem agieren sollen. Caching und Hoarding sind
dabei verwandte Techniken bei denen Daten vervielfältigt werden. Caching beschreibt
dabei das dynamische Zwischenspeichern von angefragten Daten zur Beschleunigung
von Abfragen und der Verbindungsentlastung beim Online-Betrieb, Hoarding die Erwei-
terung dieses Verfahrens durch „vorsorgliches“ Anfordern von Daten von denen vermutet
wird, dass diese zukünftig benötigt werden. Während Caching- und Hoarding-Techniken
nur geringen Einfluss auf die Wahl der lokal bzw. offline zur Verfügung stehenden In-
formationen zulassen, erlaubt Replikation durch die in Abschnitt 3.2 beschriebene Frag-
mentierung und Allokation eine sehr genaue Auswahl der Daten. (Höpfner, Türker und
König-Ries 2005, S. 181ff.) So ist die grundsätzliche Möglichkeit der unverbundenen Ar-
beit, etwa bei archäologischen Außenarbeiten anhand der Repliken gegeben.
Werden auf mehreren Repliken-Managern Änderungen akzeptiert, also nicht nur auf ei-
nem zentralen Server, und sollen diese zu einem späteren Zeitpunkt konsolidiert werden,
spricht man von der sogenannten Multi-Master-Replikation. Das komplementäre Gegen-
stück hierzu wird als Master-Slave-Replikation bezeichnet, in der ein designierter Server
über die verbleibenden Knoten wie über Sklaven „herrscht“. Lokale Änderungen sind in
diesem Fall gar nicht möglich, oder werden im Zweifelsfall überschrieben. (Saito 2005,
S. 3; Petersen, M. J. Spreitzer u. a. 1997, S. 288) Abbildung 9 stellt die beiden Formen
exemplarisch gegenüber.
Vergleicht man die beiden Konfigurationen, ist intuitiv klar, dass ein Single-Master-Systeme
einfacher umzusetzen ist. Da Schreibzugriffe nur auf einem Knoten vorkommen können,
werden eventuelle Konflikte sofort erkannt und können dem Benutzer transparent mit-
geteilt werden. Updates müssen dann lediglich in eine Richtung transportiert werden.
Nachteilig ist jedoch die Gefahr die von einem Single Point of Failure im Master-Knoten
ausgeht. Im Gegensatz dazu kann die Multi-Master-Konfiguration diesen Nachteil durch

3 Theoretische Grundlagen 19
Slave 1 Master Slave 2
(a) Single-Master-System
Master 1 Master 2 Master 3
(b) Multi-Master-System
Abbildung 9: Exemplarische Darstellung eines Single-Master & Multi-Master-Systems inAnlehnung an Böszörmenyi und Schönig (2013, Pos. 496). Pfeile geben dieTransportrichtung von Datensätzen an.
hohe Verfügbarkeit mehrerer Knoten ausgleichen. Ähnlich wie bei der parallelen Nutzung
durch viele Clients in einer zentralisierten Datenbank, kann es aber hier zu einem kon-
kurrierenden Schreibzugriffen zwischen den Knoten kommen. (Saito 2005, S. 3) Diesem
Umstand muss durch eine Transaktionsverarbeitung und Serialisierung der Schreibvor-
gänge begegnet werden.
3.4 Transaktionsverarbeitung
Kemper und Eickler (2009) definieren den Begriff Transaktion in einem Datenbanksystem
wie folgt: „Eine Transaktion stellt eine Folge von Datenverabeitungsbefehlen (lesen, ver-
ändern, einfügen, löschen) dar, die die Datenbasis von einem konsistenten Zustand in
einen anderen - nicht notwendigerweise unterschiedlichen - konsistenten Zustand über-
führt.“ (ebd., S. 279) In diesem Zusammenhang kommt das Akronym ACID zum tragen
welches die geforderten Eigenschaften einer Transaktion beschreibt und „Kernprinzipi-
en der Architektur von relationalen Datenbanksystemen“ (Edlich u. a. 2011, S. 30) dar-
stellt:
• Atomarität (Atomicity): Eine Transaktion wird als kleinste, nicht mehr zerlegba-
re Einheit betrachtet und wird ausschließlich im Gesamten festgeschrieben. „[Sie]
muss alles oder nichts erledigen.“ (Coulouris, Dollimore und Kindberg 2002, S. 546)
Werden alle Änderungen einer Transaktion zurückgesetzt, weil sie nicht komplett
ausgeführt werden kann, so spricht man vom Zurücksetzen einer Transaktion. (Da-
dam 1996, S. 185)
• Konsistenz (Consistency): Beim Abschluss einer Transaktion muss ein konsis-
tenter Datenbestand zurückbleiben, der den Bedingungen des definierten Daten-

3 Theoretische Grundlagen 20
bankschemas genügt, dessen Integrität also nicht verletzt wird. (Dadam 1996, S.
185)
• Isolation: Parallel ausgeführte Transaktionen dürfen sich nicht gegenseitig beein-
flussen. Damit einher geht die Forderung nach der Serialisierbarkeit der parallel
ausgeführten Operationen bei der das Ergebnis der Operationen mindestens durch
eine „serielle (also nicht-überlappte) Ausführungsreihenfolge dieser Transaktionen
erzeugbar sein muss.“ (ebd., S. 185)
• Dauerhaftigkeit (Durability): Eine abgeschlossene Transaktion bleibt dauerhaft
erhalten und ihre Wirkung kann nur durch eine „kompensierende Transaktion“ auf-
gehoben werden. (Kemper und Eickler 2009, S. 283)
Die Struktur einer Transaktion besteht auch im verteilten DBS aus einer Folge von Lese-
und Schreibanweisungen, welche in Begin of Transaction und End of Transaction, bzw.
Rollback geklammert sind. In einem verteilten Datenbanksystem können dabei mehrere
Knoten beteiligt sein. Der Rechner an dem eine Transaktion gestartet wird ist dabei der
Heimatknoten und übernimmt in der Regel die Koordination der Transaktion. Finden alle
Operationen der Transaktion am Heimatknoten statt, spricht man von einer lokalen, an-
dernfalls von einer globalen Transaktion. Abbildung 10 stellt eine globale Transaktion über
drei Knoten exemplarisch dar. Bei einer globalen Transaktion muss dabei sichergestellt
werden, dass alle beteiligten Knoten getreu dem ACID-Paradigma am Ende der Transak-
tion zum selben Ergebnis kommen und die Änderungen entweder alle festschreiben oder
alle zurücknehmen. (Rahm 1994, S. 114)
T1 Knoten A
T12 Knoten CT11 Knoten B
Starte STStarte ST
Abbildung 10: Beispiel einer globalen Transaktion koordiniert durch Knoten A, welcherSubtransaktionen an Knoten B und C startet. (Darstellung nach Dadam (1996, S. 186))
Für die Koordination von verteilten Transaktionen wurden verschiedene Verfahren entwi-
ckelt. Abbildung 11 stellt das 2-Phasen-Commit-Protokoll (2PC-Protokoll) das, das aus-
gehend von einer Koordinator-Station eine Transaktion im System in zwei Phasen kom-
muniziert. Durch sie wird sichergestellt, dass eine Transaktion immer auf allen beteiligten

3 Theoretische Grundlagen 21
Agenten-Stationen akzeptiert oder abgelehnt wird, sie also auch im verteilten System ato-
mar erscheint. In allen Phasen des 2PC-Protokolls besteht dabei jedoch die Möglichkeit,
dass die Transaktion nicht nur auf Grund einer Integrationsverletzung des Datenbank-
schemas, sondern wegen einer fehlerhaften Kommunikation abgebrochen werden muss.
(Kemper und Eickler 2009, S. 485f.)
K
A3
A2
A1
K
A3
A2
A1
K
PREPARE FAILED/READY COMMIT/ABORT ACK
Abbildung 11: Nachrichtenaustausch zwischen Koordinator K und beteiligten Agentenbeim 2-Phase-Commit-Protokoll. (ebd., S. 486)
In Kapitel 2 wurde festgestellt, dass der Zweck des Mutter-Kind-Konzepts die Arbeit au-
tonom von einer ständigen Netzwerkverbindung sein soll. Dementsprechend sind restrik-
tive Verfahren wie das 2PC-Protokoll für diese Belange ungeeignet. Dementsprechend
müssen die Gedanken zum verteilten Datenbanksystem um die Komponente der Mobi-
lität ergänzt werden. Hierfür wird im Folgenden das mobile verteilte Datenbanksystem
vorgestellt.
3.5 Mobile verteilte Datenbanksysteme
Mobile Geräte, wie sie häufig bei archäologischen Arbeiten verwendet werden, insbeson-
dere „Mobile Standardcomputer“ wie Laptops, Notebooks, Subnotebooks und TabletP-
Cs können ebenfalls Bestandteil eines verteilten Datenbanksystems sein. Sie werden
treffend als mobile Knoten bezeichnet und sind zumeist über eine temporäre, drahtlose
Netzwerkverbindung in das System integriert. Sie erweitern so die Definition des ver-
teilten Datenbanksystems hin zu einem mobilen verteilten Datenbanksystem. (Höpfner,
Türker und König-Ries 2005, S. 9ff.) Durch ihre „schwache“ Anbindung sind sie häufig
vom Gesamtsystem getrennt und verursachen so Netzwerkpartitionierungen. Während
diese Fehlersituation auch bei „normalen“ Knoten eintreten kann, ist dies bei mobilen
Knoten wesentlich häufiger der Fall. (Mutschler und Specht 2004, S. 65) Die Klassifikati-
on von verteilten Datenbanksystemen lässt sich für mobile verteilte Datenbanksysteme in
der Dimension der Verteilung um den Faktor Mobilität erweitern. Abbildung 12 deutet an,

3 Theoretische Grundlagen 22
wie die Architektur des verteilten Datenbanksystems durch die oben definierten Kriterien
beeinflusst wird.
Mobilität
Verteilung
Autonomität
Heterogenität
MobileHomogene
DBMS
MobileHeterogene
DBMS
MobileMultidatenbanksysteme
Mobile HeterogeneMultidatenbanksysteme
verteilte Datenbanksysteme
Zentralisierte Datenbanksysteme
Abbildung 12: Dimensionen (mobiler) verteilter Datenbanksysteme
Die konkrete Umsetzung eines Datenbanksystems fällt dabei natürlich immer als ein
Kompromiss zwischen den Spannungsfeldern aus. Aus Abschnitt 2 ist bekannt, dass
in erster Linie die Mobilität der Nutzer und damit einhergehend ihrer Geräte interessant
ist. Darüber hinaus ist ein hoher Grad an Autonomie der Knoten gefragt, der es ihnen er-
laubt auch ohne Kontakt zum globalen System im Sinne der in Abschnitt 3.1 vorgestellten
Kommunikations- und Ausführungsautonomie Änderungen am Datenbestand vorzuneh-
men (s. auch Multi-Master-System Abschnitt 3.3). Während in Sachen Hard- und Soft-
ware potentiell ein hoher Grad an Heterogenität der Knoten durch OpenInfRA unterstützt
wird, kommt mit PostgreSQL lediglich ein Datenbanksystem zum Einsatz, auf dem das
Projektdatenbankschema installiert ist. Das spricht in diesem Punkt sowohl für eine ge-
wisse Homogenität als auch für eine geringe Design Autonomie. Allgemein lässt sich das
System als ein mobiles Datenbanksystem einordnen für das im weiteren die möglichen
Architekturen betrachtet werden sollen.
3.6 Architektur mobiler Datenbanksysteme
Für mobile Datenbanksysteme bestehen zwei grundlegende Architekturen, welche als
erweiterte Client-Server-Architektur und als Middleware-Architektur mit Replikati-

3 Theoretische Grundlagen 23
onsserver bezeichnet werden.
Mobiler Client
Sync-Client
Mobile DBMS
Mobile DB
DB-Server
Sync-Server
Server DBMS
Master-DB
Replikatauswahl
Synchronisation
(a) Erweiterte Client-Server-Architektur
Replikations-server
DB
(b) Middleware-Architektur
Abbildung 13: Architekturen mobiler Datenbanksysteme nach Höpfner, Türker undKönig-Ries (2005, S. 218f.)
Bei der erweiterten Client-Server-Architektur kommunizieren der mobile Knoten, hier als
Client bezeichnet und ein stationärer Server direkt miteinander, verfügt aber im Un-
terschied zur klassischen Client-Server-Architektur über einen eigenen Datenbankser-
ver, der die Funktion des Servers übernehmen kann, wenn keine Verbindung besteht
(vgl. Abbildung 6). „Welchen Grad der Autonomie ein mobiler Client dabei erreichen
kann, hängt von seiner Leistungsfähigkeit und den lokal gespeicherten Daten ab. Diese
reicht von einem einfachen datensatzorientierten Zugriff auf Anfrageergebnisse bis hin
zur Möglichkeit, beliebige SQL-Anfragen und Änderungsoperationen auf dem lokal re-
plizierten Datenbankausschnitt auszuführen.“ (Höpfner, Türker und König-Ries 2005, S.
218) Die Middleware-Architektur nutzt einen zwischengeschalteten Replikationsserver,
der zwischen Server und Client vermittelt. Insbesondere wenn dieser Replikationsser-
ver auch auf einen Datenbestand zugreifen kann, entlastet dies die zugeschalteten Ser-
ver und erhöht die Performanz. Die Nutzung eines eigenen Replikationsservers wird für
OpenInfRA nicht möglich sein, da nicht sichergestellt werden kann, dass mobile Knoten
immer auf diesen zugreifen können um eine Synchronisation durchzuführen. Dement-
sprechend kommt nur eine erweiterte Client-Server-Architektur in Frage.
3.7 Abgrenzung MDBMS und VDBMS
Da mobile Datenbanksysteme zeitweise entkoppelt voneinander arbeiten können, unter-
scheiden sich deren Merkmale mitunter deutlich von denen eines „einfachen“ verteilen
Datenbanksystems. In der Regel finden keine Fragmentierung der Daten auf verschie-
dene Knoten statt sondern es werden Kopien der Master-Daten eingelagert um es den
mobilen Knoten zu ermöglichen, auf diese auch im unverbundenen Zustand zuzugreifen.
Das lokale Datenbankschema wird hierfür aus dem globalen Schema abgeleitet über

3 Theoretische Grundlagen 24
Tabelle 3.1: Vergleich verteilter Datenbanksystemarchitekturen nach Höpfner, Türkerund König-Ries (ebd., S. 221)
Mobiles DBS Verteiltes DBS
Aufteilung - XReplikation X XGlobales Schema g ! l g ! lVerteilte Anfragen (X) XGlobale Transaktionen (X) XTransparenz - XLokale Autonomie X -Heterogenität X -
das der Zugriff erfolgt. Eine Besonderheit ist dabei auch, dass zumindest im unverbunde-
nen Zustand keine globale Transaktionskontrolle möglich ist. Die Verbindungsunterbre-
chung wird dabei nicht als Fehler, sondern als Normalfall angesehen, für den Konfliktver-
meidungsstrategien und Konfliktauflösungsstrategien bei der Synchronisation betrachtet
werden müssen. (Höpfner, Türker und König-Ries 2005, S. 219ff.)
Um die verschiedenen Datenbanksysteme von einander abzugrenzen, werden ihre Ar-
chitekturen in Tabelle 3.1 gegenübergestellt.
Gleicht man die Eigenschaften gegen die Anforderungen an das Mutter-Kind-Konzept ab,
ist ersichtlich, dass ein mobiles verteiltes Datenbanksystem umzusetzen ist, in dem eine
globale Transaktionierung nur bedingt umsetzbar ist, die einzelnen Datenbanksysteme
auf den Knoten dafür aber autonom arbeiten und auf heterogenen Systemen installiert
sein können. Es ist deshalb im folgenden zu klären, wie die Konsistenz des Datenbestand
trotzdem gesichert werden kann.
3.8 Transaktionen in mobilen verteilten Systemen
Transaktionen auf nicht verbundenen mobilen Knoten werden immer lokale Transaktionen
sein, welche als Subtransaktion einer langandauernden globalen Transaktion betrachtet
werden können. Daraus folgt eine geschachtelte Server-Transaktion der Tiefe 2, welche
in Abbildung 14 dargestellt ist. Die globale Server-Transaktion endet mit der Synchronisa-
tion zwischen den Änderungen die auf dem mobilen Knoten und dem stationären Server
vorgenommen wurden.
Das bedeutet zunächst, dass die lokalen Transaktionen auf dem Client nur vorläufig ab-
geschlossen sind. Die durch den lokalen Datenbankserver garantierte Konsistenz, die
durch Mehrbenutzersynchronisation gewährleistete Isolation und die Einhaltung der Zu-
griffsrechte sind an diesem Punkt also lediglich für die lokale Umgebung gesichert. Sie

3 Theoretische Grundlagen 25
Server
MobilerClient
Zeit
Client-Transaktionen Synchronisation
Server-Transaktion
Abbildung 14: Transaktionen in mobilen Datenbanksystemen. (ebd., S. 226)
werden erst beim Wiedereintritt des mobilen Knoten in das System zum Zeitpunkt der
Synchronisation mit dem Server zum Abschluss gebracht und damit dauerhaft. Unter
Berücksichtigung des bereits vorgestellten ACID-Paradigmas wird somit klar, dass für
den globalen Datenbestand in der Zeit zwischen den Synchronisationphasen die An-
forderung an Konsistenz gelockert ist, da der Datenbestand zwischen Client und Server
unterschiedlich ausfällt. Diese Erkenntnis wurde durch Eric Brewer im sogenannten CAP-
Theorem für verteilte System beschrieben und kann analog für mobile verteilte Systeme
betrachtet werden.
3.9 Eventually Concistency
Im Jahr 2000 stellte Eric A. Brewer das sogenannte CAP-Theorem auf, welches zwei
Jahre später durch Seth Gilbert und Nancy Lynch formal bestätigt werden konnte, und
die gewünschten Eigenschaften eines verteilten Systems wie folgt beschreibt:
• Konsistenz (Consistency): Die Definition zur Konsistenz im Sinne das CAP-Theo-
rems ist analog zu der des bereits bescriebenen ACID-Paradigmas. Die verteil-
te Datenbank ist nach einer Transaktion in einem konsistenten Zustand. Dies be-
deutet, dass nach einer Änderung im verteilten Datenbanksystem, auch alle Kno-
ten diese Änderung in nachfolgenden Leseoperationen widerspiegeln. (Edlich u. a.
2011, S. 31)
• Verfügbarkeit (Availability): Die Verfügbarkeit beschreibt eine „akzeptable Reakti-
onszeit“ für einen konkreten Anwendungsfall. Beispielsweise könnte eine hochak-

3 Theoretische Grundlagen 26
tive E-Commerce-Plattform eine Verfügbarkeit in Millisekunden definieren. (Edlich
u. a. 2011, S. 32) Für ein verteiltes System, das einer schwankenden Netzwerk-
verbindung unterliegt, ist aber auch die bloße Anforderung nach Verfügbarkeit in-
nerhalb des entkoppelten Teilnetzes denkbar, also die Möglichkeit auch hier eine
Antwort auf Anfragen zu bekommen.
• Ausfalltoleranz (Partition Tolerance): Ausfalltoleranz beschreibt die Fähigkeit des
Systems den Ausfall eines Knotens zu kompensieren und weiterhin auf Anfragen
zu reagieren. (ebd., S. 32)
Die Vermutung Brewers war es, dass die Eigenschaften Konsistenz, Verfügbarkeit und
Ausfall- bzw. Partitionstoleranz in einem verteilten System nie in vollem Maße gemein-
sam erfüllt werden können. Infolge dessen müsse bei der Architektur eines jeden ver-
teilten Systems ein Kompromiss zwischen diesen Größen gewählt werden, wobei die
Abstufungen der „Wahl“ dabei nicht absolut sind. Ein Beispiel hierfür ist ein Cluster aus
Relationalen Datenbanksystemen welches in der Regel auf eine Kombination aus abso-
luter Konsistenz und hoher Verfügbarkeit (CA) setzen wird. Es können also Netzwerk-
partitionierung weniger gut kompensiert werden. Für Anwendungen, in denen hingegen
der Ausfall eines von der Transaktion unberührten Servers nicht dazu führen darf, dass
eine Änderung verloren geht, wird die Kombination aus Konsistenz und Partitionstoleranz
(CP ) präferiert. Ein gutes Beispiel hierfür ist die Anwendung im Finanzwesen, bei der z.B.
Überweisungen immer zielführend sein müssen. (Brewer 2000; Gilbert und Lynch 2002;
Vogels 2009)
Für eine Anwendung wie OpenInfRA, welche durch eine fehlende Netzwerkverbindung
in Teilnetze partitioniert wird und das Daten in diesen Teilnetzen trotzdem „verfügbar“
machen will, folgt aus dem Theorem, dass in erster Linie die Konsistenzbedingungen
gelockert werden müssen. In der in Abbildung 15 gezeigten CAP-Pyramide bewegt man
sich nun auf der Kante AP . Dies unterstreicht die getroffenen Feststellungen zur Transak-
tionierung in mobilen verteilten Systemen, bei denen bei einer langen Server-Transaktion
ein inkonsistenter Zustand zwischen Client und Server gebilligt wird.
Um eine bessere Betrachtung der Konsistenz in verteilten Systemen zu ermöglichen,
wurde deshalb das alternative Konsistenzmodell BASE durch Brewer vorgeschlagen. BA-
SE steht für Basically Available, Soft State und Eventually Consistent. In diesem Modell
wird die Konsistenz der Verfügbarkeit untergeordnet, indem sie als ein „Übergangspro-
zess“, statt wie bisher als ein fester Zustand nach einer Transaktion betrachtet wird. Das
bedeutet, dass BASE-Systeme letztendlich Konsistenz erreichen, der konkrete Zeitpunkt
jedoch an dem dies geschieht ist aber unbestimmt. Für diesen Sachverhalt setzt sich
der Begriff „eventual consistency“ durch. (Edlich u. a. 2011, S. 32) Bei dieser besonderen
Form der schwachen Konsistenz wird durch das System lediglich garantiert, dass wenn

3 Theoretische Grundlagen 27
Konsistenz (C)
Verfügbarkeit (A) Partitionstoleranz (P)
Abbildung 15: Nach dem durch Brewer beschriebenem CAP-Theorem muss jedesverteilte System einen Kompromiss zwischen Konsistenz, Verfügbarkeit undAusfalltoleranz eingehen. Bildlich darstellen lässt sich dies an einem Spannungsdreieck,an dessen Kanten sich die Systeme einordnen lassen.
keine neuen Änderungen der Daten hinzukommen und sich alle Knoten über Änderun-
gen ausgetauscht haben, letztendlich alle Änderung in einer Abfrage reflektiert werden.
(Vogels 2009)
3.10 Synchronisation
Wie im zentralisierten Datenbanksystem ist es auch nötig die Änderungen nebenläufi-
ger Transaktionen einer langen Server-Transaktion zu einem Schedule zu konsolidieren,
die die Transaktionshistorien der Knoten zusammenführt und dabei die Konsistenz des
Datenbestands wahrt. Sie schützen wie bei der Mehrbenutzersynchronisation auf einer
zentralisierten Datenbank vor sogenannten Mehrbenutzeranomalien hervorgerufen durch
Phänomene. Das resultierende Schedule ist nur dann serialisierbar, wenn diese Phäno-
mene ausgeschlossen werden können:
• Dirty Write (P0): Eine Transaktion ändert eine Zeile, die bereits durch eine parallele
Transaktion geändert wurde. Beim Zurückrollen einer dieser Transaktionen ist nun
nicht klar, welcher Wert den korrekten Zustand darstellt.
• Dirty Read (P1): Eine Transaktion T2 liest einen Wert einer nicht abgeschlossenen
Transaktion T1. Wird T1 zurückgerollt, hat T2 einen nicht konsistenten Zustand
gelesen.
• Non-repeatable Read (P2): Eine Transaktion liest aufgrund einer parallel ausgeführ-
ten Transaktion bei wiederholtem Zugriff unterschiedliche Werte. P2 kann in weitere
Phänomene differenziert werden:
– Phantoms (P3): Stellt einen Sonderfall von P2 dar, bei dem durch wiederholte
Anwendung eines Suchprädikats unterschiedliche Wert zustande kommen.

3 Theoretische Grundlagen 28
– Read Skew (A5A): Eine Transaktion T liest zwei durch eine Integritätsbedin-
gung verknüpfte Objekte a und b. b wird dabei durch eine konkurrierende
Transaktion verändert noch bevor T b gelesen hat und stellt unter Umständen
die Verletzung einer Integritätsbedienung fest.
– Write Skew (A5B): Zwei konkurrierende Transaktionen lesen zwei durch Inte-
gritätsbedingungen verknüpfte Objekte und ändern jeweils eines dieser Ob-
jekte. Beim Abschluss beider Transaktionen ist es nun möglich, das die Inte-
gritätsbedienung im Ergebnis verletzt ist.
• Lost Update (P4): Zwei offene Transaktionen ändern denselben Wert und schließen
erfolgreich ab, wodurch einer der Werte sofort überschrieben wird. (Höpfner, Türker
und König-Ries 2005, S. 233ff.)
Um die Isolation der Transaktionen zu gewährleisten und diese Anomalien zu umge-
hen, kann im Zusammenhang von mobilen verteilten Systemen die Snapshot-Isolation
angewandt werden. Dabei wird mit dem Start einer Server-Transaktion ein Snapshot
(s.a. Abschnitt 3.3) der Daten auf dem Client kreiert, auf den alle folgenden Lese- und
Schreiboperationen angewandt werden. Änderungen lokaler Transaktionen des jeweils
anderen Knoten bleiben so unsichtbar, sodass die Anomalien P0, P1, P2 und A5A nicht
auftreten können. Zum Abschluss der Transaktion muss der Snapshot nun wieder mit
der Datenbank synchronisiert werden. Die Transaktion erhält dafür einen eindeutigen
Zeitstempel der monoton steigend und größer als alle bereits vergebenen Zeitstempel
sein muss. Anomalie P4 wird umgangen, wenn die Transaktion nur dann akzeptiert wird,
wenn kein Commit-Zeitstempel anderer Transaktionen zwischen ihren Start- und Commit-
Zeitstempeln liegt und durch keine Schreiboperationen in Konflikt steht. Nicht verhindert
werden, können jedoch die Anomalien P3 und A5B, welche erst bei der Synchronisation
der Transaktionen erkannt werden können. (ebd., S. 236)
Für die Synchronisation wird dabei in die Gruppen der pessimistischen und der optimis-
tischer Verfahren unterschieden, die im Folgenden betrachtet werden.
3.10.1 Pessimistische Synchronisationsverfahren
Pessimistische Synchronisationsverfahren zielen darauf ab, Konflikte bereits von vorn-
herein zu vermeiden. „Sie verhindern bereits während der Ausführung einer Transaktion
das Auftreten unerlaubter Schedules.“ (ebd., S. 226)
Das bekannteste Verfahren ist hier das 2-Phasen-Sperrprotokoll, bei dem für jeden Lese-
und Schreibzugriff Sperren auf die betroffenen Datenobjekte angefordert werden. Poten-
tiell konkurrierende Transaktionen, die auf gesperrte Objekte zugreifen wollen, werden

3 Theoretische Grundlagen 29
dann solange blockiert, bis wiederum die benötigte Sperre auf das Objekt gewährt wird.
Die Serialisierbarkeit von Transaktionen wird bei dem Verfahren durch die strikte Tren-
nung in zwei Phasen gesichert: der Anforderung von Sperren und der Freigabe gehalte-
ner Sperren.
Um die in Abschnitt 3.8 beschriebenen langen Server-Transaktionen mit diesem Verfah-
ren zu unterstützen, müssten vor dem „Offlinegehen“ der mobilen Knoten Sperren auf die
benötigten Datenobjekte eingerichtet werden. Dies ist durch das Wissen über die Alloka-
tion der Objekte möglich, bedeutet aber, dass diese Objekte für eine lange Zeit nicht zur
Verfügung stehen werden.
Ein in der Praxis gebräuchliches Verfahren welches auf dem 2-Phasen-Sperrprotokoll
begründet, ist das Check-out/Check-in-Verfahren. Hier wird das Konzept der flüchtigen
Sperren um sogenannte Langzeitsperren erweitert, welche dauerhaft eingelagert wer-
den können. Dabei wird beim „Check-out“ eines mobilen Knoten von Datenobjekten
zur entkoppelten Arbeit vermerkt, dass diese ausschließlich gelesen werden dürfen und
Sperranfragen paralleler Transaktionen nicht blockiert, sondern abgebrochen werden müs-
sen. Bei der Reintegration der Änderungen auf dem Client ist es durch die vorher einge-
holten Sperren möglich die ACID-Eigenschaften der langen Transaktion zu sichern.
Ein erheblicher Nachteil bei der Nutzung von konfliktvermeidenden Strategien ist es, dass
insbesondere Datenobjekte auf die häufig gemeinsam zugegriffen werden muss durch
Sperren der langen Server-Transaktionen nicht verfügbar sein können. Das macht sie in
solchen Fällen zu einer schlechten Wahl.
3.10.2 Optimistische Synchronisationsverfahren
Optimistische Transaktionsverfahren können eingesetzt werden, wenn Sperrverfahren für
die Server-Transaktion nicht geeignet sind, etwa wenn hierdurch die Verfügbarkeit der
Daten eingeschränkt wäre. Es wird davon ausgegangen, dass Konflikte eher selten auf-
treten und erkannt werden können, weshalb sie deshalb nicht proaktiv verhindert, son-
dern nach Auftreten entdeckt und gelöst werden. Die dabei zu durchlaufenden Phasen
der Lese-, Validierungs- und Schreibphase sind in Abbildung 16 dargestellt.
BOT EOT
Lese- Validierungs- Schreib-phase
Abbildung 16: Die Phasen der optimistischen Synchronisation (ebd., S. 226)

3 Theoretische Grundlagen 30
Tabelle 3.2: Mögliche Konflikte bei datenorientierter Synchronisation (ebd., S. 237)
BI AI CI Operation Bedingung Konfliktart
X - X Löschen BI 6= CI Löschkonflikt- X X Einfügen AI 6= CI EinfügekonfliktX X - Ändern ÄnderungslöschkonfliktX X X Ändern BI 6= CI ^ AI 6= CI Änderungskonflikt
Die Lesephase stellt hier die Zeit dar, in der der mobile Knoten nicht mit einem stationären
Knoten verbunden ist. Änderungen werden lokal akzeptiert, aber erst beim Wiedereintritt
in das globale System, d.h. im Augenblick des Commits der Server-Transaktion, validiert.
Konflikte mit bereits beendeten Transaktionen werden dabei rückwärtsgerichtet aufge-
deckt. Sind keine Konflikte festzustellen, werden die lokalen Änderungen in der Schreib-
phase übertragen. Andernfalls muss die entsprechende Client-Transaktion lediglich zu-
rückgesetzt werden. Um mit dem Zurücksetzen nicht alle Änderungen dieser Transaktion
zu verlieren, werden dabei Synchronisationsalgorithmen genutzt, die maßgeblich durch
die zur Synchronisation zur Verfügung gestellten Informationen geprägt sind.
Beim Prinzip der datenorientierte Synchronisation werden für jede Änderungen Vorher-
(BI; before image) und Nachherabbilder (AI; after image) der betroffenen Objekte über-
mittelt. Diese können miteinander und gegen den aktuellen Stand auf dem Server (CI;
current image) verglichen werden, um Konflikte aufzudecken. Zur Identifikation der Ob-
jekte in Datenbanksystemen dient dafür in der Regel der Primärschlüssel der Zeile, die-
sem kommt also eine besondere Rolle zu. Tabelle 3.2 schlüsselt mögliche Konfliktsituatio-
nen auf und zeigt unter welchen Bedingungen sie aufgedeckt werden. Die Konfliktlösung
kann nun durch schema- oder inhaltsbasierende Regeln definiert werden, die auf die
Objekte angewandt werden. Alternativ ist das manuelles Eingreifen möglich bei dem eine
Konfliktlösung bestimmt und die Transaktion zu einem späteren Zeitpunkt neu ausgeführt
wird.
Die in der Tabelle beschriebenen Löschkonflikte treten auf, wenn auf einem mobilen Kno-
ten Zeilen gelöscht wurden, diese aber in der Zwischenzeit auf der Server-Datenbank
durch ein Update betroffen waren. Einfügekonflikte entstehen, wenn in beiden beteiligten
Datenbanken der derselbe Primärschlüssel genutzt wurde. In diesem Fall muss ein neuer
Primärschlüssel zugewiesen und der Client-Datenbank vermittelt werden. Die ebenfalls
aufgeführten Änderungskonflikte bestehen zwischen Datensätzen, die in beiden Daten-
banken bearbeitet wurden. Änderungslöschkonflikte bilden das logische Gegenstück zu
Löschkonflikten, bei denen die betreffende Zeile auf der Server-Datenbank gelöscht wur-
de. In der Regel besteht hier die Lösung darin, die betroffene Zeile wiederherzustellen.
(Höpfner, Türker und König-Ries 2005, S. 238)

3 Theoretische Grundlagen 31
Bei der transaktionsorientierten Synchronisation wird der datenorientierte Ansatz um In-
formationen zur Art der ausgeführten Operation (Einfügen, Ändern, Löschen) und die
lokalen Transaktionsklammern erweitert. So ist es möglich, bei der Synchronisation und
dem Zurücksetzen von Client-Transaktionen die Atomarität dieser zu erhalten. (Höpfner,
Türker und König-Ries 2005, S. 239)
Die semantikbasierte Synchronisation ersetzt den Vergleich der before, after, und current
images mit einem Akzepttanztest. Die Client-Transaktion wird auf dem Server erneut aus-
geführt und muss dabei diesem Test genügen, um als valide erachtet zu werden. Sollte
dies nicht der Fall sein, wird eine Konfliktbehandlung angestoßen, die Teil der Synchroni-
sationsinformation ist. Die semantische Synchronisation kann dadurch von anwendungs-
spezifischen Informationen profitieren und so intelligentere Entscheidungen treffen. (ebd.,
S. 239)
In diesem Kapitel wurde das Konzept der verteilten Datenbanken vorgestellt und den
Anforderungen des Mutter-Kind-Konzepts entsprechend um die Problematik der mobilen
verteilten Datenbank ergänzt. Es wurde gezeigt, dass für mobile Knoten keine zentral
kontrollierte Transaktionierung möglich ist und deshalb die „abbildisolierte Transaktionie-
rung“ zutragen kommen muss, bei der der gemeinsame Datenbestand zwischen Server
und Client nach einer unbestimmt langen Zeit letztendlich wieder synchronisiert werden
muss. Im folgenden Kapitel soll nun auf die technischen Möglichkeiten um das Daten-
banksystem PostgreSQL eingegangen werden, um zu prüfen ob bzw. welche Implemen-
tierung für die Umsetzung des Mutter-Kind-Konzepts genutzt werden kann.

4 Technik 32
4 Technik
Während die Entwicklung von PostgreSQL nunmehr 20 Jahre zurückreicht, ist Replikation
als Kernkomponente für das Datenbanksystem erst 2008 in den Fokus der Hauptentwick-
ler gefallen. Tom Lane, einer der führenden Köpfe für PostgreSQL, beschreibt die Gründe
hierfür in einer Nachricht an die Community:
„Historically the project policy has been to avoid putting replication into core
PostgreSQL, so as to leave room for development of competing solutions,
recognizing that there is no ‚one size fits all‘ replication solution. However, it
is becoming clear that this policy is hindering acceptance of PostgreSQL to
too great an extent, compared to the benefit it offers to the add-on replication
projects.“ (Lane 2008)
Aus dieser Einsicht hervorgehend bietet PostgreSQL native Optionen die im Folgenden
dieses Kapitels kurz beschrieben werden sollen. Anschließend werden Implementierun-
gen Dritter vorgestellt, die während der Bearbeitung als mögliche Lösungswege ausge-
macht wurden. Abschließend wird die Umsetzung der Replikation im proprietären GIS-
System Esri ArcGIS betrachtet.
4.1 Native Replikation mit PostgreSQL
PostgreSQL bietet das Verfahren der Physical Log Shipping Replication (PLSR), bei dem
die durch das Datenbanksystem angelegte Write-Ahead-Log-Dateien (WAL) zu den an-
gebundenen Servern versandt werden. Die Datenbanktabellen müssen für diese Form
der Replikationstechnik nicht angepasst werden und die Konfiguration erfolgt durch den
Administrator in Konfigurationsdateien des Datenbankservers.
Die WAL-Dateien befinden sich in einer PostgreSQL-Installation im Verzeichnis pg_xlog
des Datenverzeichnis ($PGDATA). Sie stellen für einen PostgreSQL-Server das Logbuch
der Datenänderungen dar und werden in erster Linie für die Recovery-Komponente der
Datenbank genutzt. Sollte der Server also durch eine Fehlersituation unerwartet been-
det werden, kann die Konsistenz der Daten durch Wiedereinspielen der WAL-Einträge
wiederhergestellt werden. Da das Write-Ahead-Log immer alle Änderungen des Daten-
bankclusters enthält, wird bei der Replikation mit Hilfe dieser Dateien auch immer der

4 Technik 33
gesamte Cluster vervielfältigt. Die aktuell zur Verfügung stehenden Replikationstechni-
ken werden im Folgenden kurz skizziert.
4.1.1 Standby Server
Zum Bereitstellen eines Standby-Servers werden die WAL-Dateien an einen oder mehre-
re verbundene Server übertragen. Die Synchronisation erfolgt dabei asynchron und in der
Regel nachdem ein WAL-Segment die vorgesehene Dateigröße erreicht hat. Beim Emp-
fänger wird das WAL-Segment anschließend durch Nutzung der Recovery-Komponente
des Datenbankservers interpretiert und der neue Datenbestand sequentiell hergestellt.
Der Sender der WAL-Segmente fungiert hier als Master des Replikationsclusters der die
Slave-Server „beliefert“. Die Standby-Server dienen in erster Linie als Backup und zur
Sicherung der Hochverfügbarkeit. Fällt der Master-Server aus, kann einer der Standby-
Server als sein Nachfolger auserkoren werden. (PostgreSQL Global Development Group
2013f)
4.1.2 Hot-Standby-Replication
Bei der Hot-Standby-Replication stehen die Standby-Server für Anfragen zur Verfügung,
so dass sie als Read-only Server genutzt werden können. Durch den Parameter hot
standby wird der Server dabei für Queries verfügbar gemacht, sobald dieser die dazu
nötigen WAL-Daten vom zentralen Master-Server eingelesen hat. Es besteht aber auch
in dieser Konfiguration keine Möglichkeit, Schreibzugriffe an einen solchen Read-only
Server zu richten. (ebd.)
4.1.3 Streaming-Replikation
Sowohl für Standby als auch Hot-Standby-Server gilt, dass das „Lag“, also die Zeit bis
zum Herstellen des aktuellsten Datenbestands auf dem vorgeschalteten Master-Server,
die Dauer bis zum Erhalt und zur Auswertung der WAL-Segmente ist. Um den Daten-
bestand des Standby-Servers möglichst nah dem des Master-Servers zu halten, steht
seit PostgreSQL 9.0 die sogenannte Streaming-Replication zur Verfügung. Dabei werden
über eine stehende Verbindung zwischen Master und Standby einzelne WAL-Einträge
übertragen, bzw. „gestreamt“. So muss mit der Übertragung nicht gewartet werden bis
das gesamte WAL-Segment abgeschlossen ist. Auch hier erfolgt die Replikation asyn-
chron, immer erst nach dem Abschluss einer Transaktion. Dieses Verfahren wird mit Be-
zug zum WAL-Log auch als Physical log streaming replication bezeichnet. (ebd.)

4 Technik 34
Durch eine Kombination aus Archivierung der WAL-Segmente an einem sicheren Ort und
der Streaming-Replikation auf einen Slave kann ein effektives Failover konfiguriert wer-
den, das den Produktiveinsatz sichert. (PostgreSQL Global Development Group 2013f)
4.1.4 Synchrone Replikation
Als Erweiterung der Streaming Replication ist es möglich, eine Reihe von Servern für
eine synchrone Replikation zu konfigurieren. Dabei wird nach dem 2-Phase-Commit-
Verfahren bei jeder Transaktion darauf gewartet, dass diese durch jeden beteiligten Ser-
ver bestätigt wurde und damit im WAL-Log des Servers vorhanden ist, bevor sie akzep-
tiert wird. (ebd.)
Im vorhergehenden Kapitel wurde beschrieben, wie Client-Transaktionen beim Ende ei-
ner lange Server-Transaktionen in einem mobilen verteilten Datenbanksystem durch das
Auswerten der am Client vorgenommenen Änderungen synchronisiert werden können.
Da die WAL-Dateien des PostgreSQL-Servers ein Protokoll der Änderungen auf dem
Server darstellt, soll im Folgenden geprüft werden, ob sie ebenfalls für diesen Zweck
genutzt werden können.
4.1.5 Interpretation der WAL-Segmente
WAL-Dateien eines PostgreSQL-Servers haben stets die gleiche, durch die Konfigurati-
on vorgegebene Dateigröße (i.A. 16MB) und werden aus Performancegründen sequen-
tiell geschrieben. Wird durch eine Menge von Transaktionen die definierte Größe er-
reicht, wird eine neue Datei mit einem inkrementierten Dateinamen begonnen. In einer
Standardkonfiguration werden veraltete, durch Checkpoints bereits übergangene WAL-
Dateien in der Regel „recycelt“, d.h. überschrieben. Durch Setzen des wal_level der
Postgres-Konfiguration auf archive ist es möglich, dieses Überschreiben zu unterbinden
und die WALs zu archivieren. (Böszörmenyi und Schönig 2013, Pos. 696ff. PostgreSQL
Global Development Group 2013i,e)
Jede Änderung wird in WALs vermerkt noch bevor sie in die eigentlichen Datenbank-
dateien im Verzeichnis base eingetragen werden. Die Protokollierung erfolgt dabei nicht
etwa in Form von SQL-Statements, sondern enthält unter anderem die veränderten Zei-
lenwerte und Indizes in Form von Datenseiten. Checksummen für jeden Eintrag werden
genutzt, um die Integrität der Einträge zu sichern. Die beschriebenen nativen Replikati-
onsmöglichkeiten von PostgreSQL sind dadurch sehr effektiv, da die Einträge an konkre-
te physische Adressen im Datenverzeichnis übertragen werden können. Außerdem fällt
das WAL ohnehin im Standarddatenbankbetrieb an, sodass dessen Nutzung also keinen

4 Technik 35
„Overhead“ darstellt. Schwierig für dritte Anwendungen, die hiervon profitieren wollen ist
aber, dass das konkrete Statement, das zum WAL-Eintrag geführt hat, nicht rekonstru-
ierbar ist, also kein verwertbares Transaktionsprotokoll aus Vorher- und Nachherwerten
geführt wird, wie es in Abschnitt 3.10 zur Optimistischen Synchronisation beschrieben
ist. Darüber hinaus ist das Format abhängig von der PostgreSQL-Version, kann sich mit
jeder Implementierung ändern und ist lediglich durch den Source-Code selbst dokumen-
tiert. (Böszörmenyi und Schönig 2013, Pos. 1165ff.)
Bei allen verfügbaren nativen Replikationsmethoden von PostgreSQL, die vorgestellten
wurden, handelt es sich um Konstellation der Master-Slave-Replikation. Es ist so nicht
möglich, Änderungen auf den Slave-Servern in den Primärknoten zurückzuspielen, ge-
schweige denn Transaktionen auf autonomen Knoten zuzulassen. Im Folgenden soll da-
her das Projekt BDR vorgestellt werden, das sich der Herausforderung einer nativen
Master-Master-Replikation mit PostgreSQL stellt und dies ändern will.
4.2 PostgreSQL BDR
Das Feature BiDrectional Replication steht als Community-Projekt unter aktiver Entwick-
lung. Es soll mit Version 9.4 als Kernkomponente Bestandteil von PostgreSQL werden.
Es handelt sich dabei um die Implementierung einer asynchronen Multi-Master-Repli-
kationslösung, ähnlich der bereits bestehenden Streaming Replikation. Für BDR wurde
dafür eine eigenes WAL-Level namens logical geschaffen, das im Unterschied zu dem
in Abschnitt 4.1 bereits beschriebenen WAL-Format Informationen enthält, um logische
Abfolgen von Änderungen auszulesen und über die normale Datenbankverbindung an
verbundene Server zu senden. Man spricht hier deshalb von einer Logical log strea-
ming replication. Die Übertragung ist dabei einseitig gerichtet, kann aber zu einer bidi-
rektionalen Replikation ausgebaut werden, indem die Replikation ausgehend von beiden
beteiligten Datenbanken konfiguriert wird. Ein weiterer Unterschied besteht in der Gra-
nularität, mit der eine Replikation möglich wird. Bestehende Methoden von PostgreSQL
erlauben nur die Replikation des gesamten Datenbankcluster - mit BDR soll dies jedoch
auf Ebene der einzelnen Datenbanken möglich sein, wobei die Übertragung synchron
und asynchron erfolgen kann. Beim letzteren wird der konsistente Zustand zwischen den
Synchronisationspartnern im Sinne der bereits beschrieben eventually consistancy her-
gestellt, dessen „Lag“ der Synchronisation dabei beliebig groß sein kann, solange es
möglich ist die logischen WAL-Segmente zu archivieren die für das „aufholen“ der Syn-
chronisationspartner nötig ist. (BDR Project 2013)
Im Moment handelt es sich bei BDR um „work in progress“. Wie in jedem optimistischen

4 Technik 36
Replikationssystem können auch hier Konflikte zwischen den Datenbeständen auftreten.
Konkurrierende Updates werden deshalb nach der Last-Wins-Strategie aufgelöst, d.h. die
zuletzt aufgetretene Änderung dominiert die vorhergehenden. Bei „divergent conflicts“,
also Konflikten, die Unique Index-Checks widersprechen, wird im Moment die Replikation
beendet und der Vorgang geloggt.
Die Installation von BDR ist im aktuelen Zustand nur durch Kompilieren eines Forks des
PostgreSQL-Quellcodes möglich und damit relativ aufwändig. Auch ist nicht genau ab-
sehbar, in welcher Form die Master-Master-Replikation wirklich als Core-Komponente in
PostgreSQL integriert sein wird, womit sie für ein Produktivsystem im Moment nicht in
Frage kommt.
4.3 Softwarelösungen und Erweiterungen
Neben der in PostgreSQL durch WAL-Shipping umgesetzten Master-Slave-Replikation
bietet eine größere Menge externer Projekte und Erweiterungen verschiedene Replika-
tionskonzepte, die mit PostgreSQL genutzt werden können. Da, wie in Abschnitt 4.1 be-
schrieben, die durch PostgreSQL geschriebenen WAL-Dateien momentan nicht für eine
externe Interpretation des Transaktionsprotokolls dienen können, begründen sich die-
se Lösungen auf eigenen Umsetzungen des sogenannten Change Data Capture (CDC)
Design-Pattern. Dieses Pattern wird genutzt, um Änderungen zu identifizieren und auf ei-
ne Art und Weise festzuhalten, die es ermöglicht, sie durch eine Anwendung oder durch
den Nutzer interpretieren zu lassen. In der Regel wird eine relationale Darstellungsform
für die Speicherung angestrebt. (Oracle 2005; Microsoft o.D.[b]) Die Art der Aufzeichnung
unterscheidet sich dabei in ihrem Umfang und umfasst im Wesentlichen eine oder eine
Kombination der folgenden Vorgehensweisen:
• Zeitstempel als Attribut der Tabelle
• Versionsnummern als Attribute der Tabellen
• Statusindikatoren als Attribute der Tabellen
• Änderungsprotokollierung durch Trigger
• Eventbasierte Programmierung in der Anwendungsebene
Insbesondere die ersten drei genannten Varianten werden häufig in einer Kombination
eingesetzt, um komplizierte Abfragen hinsichtlich des Einbringungszeitpunkts in Kombi-
nation mit dem Status von Tabellenzeilen zu ermöglichen. Sie eignet sich dadurch be-
sonders für Systeme, die aus Änderungen am Datenbestand einen semantischen Nut-
zen ziehen können. Der „Zustand“ der Daten wird hier zum Bestandteil der betreffenden
Entität. Eine konkrete Historie der Änderungen wird dabei aber nicht erstellt.

4 Technik 37
Die beiden letzteren Verfahren sind etwas komplexer. Die triggerbasierende Änderungs-
protokollierung ist mit dem Schreiben eines Transaktionsprotokolls vergleichbar. Durch
die Nutzung von Datenbanktrigger können bei einer Änderung an einer konfigurierten
Tabelle konkrete Spaltenwerte und Metadaten gesammelt werden, die je nach Imple-
mentierung in Log-Tabellen hinterlegt werden. Dadurch bleibt das Wissen um eine vor-
genommene Änderung auch nach einem erneuten Überschreiben der Zeile erhalten. Mit
Bezug auf die in Abschnitt 3.10 beschriebenen optimistischen Synchronisationstechniken
ist ersichtlich, dass dieses Verfahren sich für derlei Auswertungen besonders gut eignet,
da entsprechend der Fähigkeiten des Datenbanksystems beliebig viele Informationen
zusammengestellt werden können. Abbildung 17 stellt das „loggen“ von Änderungen ex-
emplarisch dar.
Abbildung 17: Durch die Nutzung der triggerbasierten Änderungsprotokollierung ist esmöglich, ein Transaktionsprotokoll zu führen. In der Darstellung werden Änderungen anzwei verschiedenen Tabellen in einer „Log-Tabelle“ protokolliert. (Long 2012)
Die eventbasierte Änderungsprotokollierung gleicht im wesentlichen der triggerbasier-
ten Protokollierung. Statt Datenbanktrigger werden jedoch bestimmte Zustände oder Ak-
tionen durch die Anwendungsebene erkannt und überlassen es dieser, entsprechende
Protokollmaßnahmen zu übernehmen. Diese Implementierung ist vielseitiger einsetzbar,
stellt aber eine Lösung der Anwendungsentwicklung, nicht der Datenbanktechnik dar.
Die folgende Tabelle soll einen Überblick über eine Teil der zum Zeitpunkt der Schriftset-
zung offenkundig aktiven Open Source-Projekten ermögliche, die eine Form der Replika-
tion mit PostgreSQL ermöglichen (PostgreSQL Wiki 2013):
Für die Replikation und Synchronisation in einem mobilen verteilten Datenbanksystem
kommen nur asynchrone Replikationssysteme in Frage. Da eine Multi-Master-Replikation
zwischen den Instanzen der Projektdatenbank gefordert ist, spielen nur diese Lösungen
für die weitere Betrachtung eine Rolle.

4 Technik 38
Tabelle 4.1: Auswahl von Open Source-Replikationslösungen für PostgreSQL
Programm Lizenz Typ Replikationsmethodik Kommunikation
Pgpool-II BSD Middleware Master-Slave synchronSlony BSD Trigger Master-Slave asynchronBucardo BSD Trigger Multi-Master asynchronLondiste BSD Trigger Master-Slave asynchronSymmetricDS GPL Trigger Multi-Master asynchronPostgres-R BSD PostgreSQL-Fork Multi-Master synchron
4.3.1 Bucardo
Bucardo ist ein asynchrones Replikationssystem das ab Version 5 sowohl Master-Slave
als auch Multi-Master-Replikation für PostgreSQL verspricht. Es setzt die triggerbasier-
te Änderungensprotokollierung ein, bei der die Primärschlüssel der jeweiligen Zeilen in
Delta-Tabellen vermerkt werden, die von Änderungen betroffen sind. Ein externer Pro-
zess ist dann dafür zuständig aus den Delta-Tabellen eine Liste von Änderungen zu
erstellen, die für die Synchronisation zum Sychronisationspartner übertragen werden
müssen. Diese Funktionsweise wird als lazy data capture bezeichnet. Werden anhand
gleicher Primärschlüssel Konflikte erkannt, wird anhand einer konfigurierten Konfliktlö-
sungsstrategie gehandelt.
Die datenbankseitigen Komponenten sind in PL/Perl bzw. PL/PerlU umgesetzt und sind
so nicht an das Betriebssystem gebunden. Für den ebenfalls in Perl implementierten
Bucardo-Daemon gilt dies jedoch nicht, das Ausführen auf Windows ist nicht möglich.
Zwar ist für die Replikation egal, ob der Replikationsservice auf dem gleichen Server
ausgeführt wird - er kann im Sinne der Middleware-Architektur von einem dritten Server
ausgeführt werden - für eine autonom agierende Offline-OpenInfRA-Anwendung ist dies
allerdings nicht geeignet.
4.3.2 SymmetricDS
SymmetricDS ist eine quelloffene Replikations- und Synchronisationslösung und wird un-
ter der Open Source Lizenz General Public License (GPL) version 3.0 vertrieben. Kom-
merzielle Produkte, die die Lösung unter der Lesser General Public License (LGPL) in-
tegrieren wollen, müssen das Produkt lizenzieren. Die Firma JumpMind, welche die Ent-
wicklung der Software fördert, bietet in diesem Fall technischen Support.
Ein Vorteil von SymmetricDS ist, dass es eine flexible Konfiguration von Replikation und
Synchronisation zwischen Datenbanken erlaubt. Der Synchronisationsservice selbst ist
in Java programmiert und wird betriebssystemunabhängig auf jedem Client ausgeführt.
4 Technik 39
Durch die Nutzung der standardisierten JDBC-API ist es möglich, Daten in heterogenen
Systemen zu replizieren und zu synchronisieren, wobei die Synchronisationsrichtung da-
bei frei bestimmt werden kann. Zu den unterstützten Datenbanksystemen gehören Oracle
Database, IBM DB2, Microsoft SQL Server, MySQL als sowie PostgreSQL. (JumpMind
Inc. 2013c)
Die Konfiguration des Replikationsschemas erfolgt über Systemtabellen, die auf der Da-
tenbankinstanz installiert werden. Über sie lässt sich eine Replikationshierarchie anhand
von Knoten-Gruppen definieren, zu denen die an der Replikation teilnehmenden Daten-
bankinstanzen zugeordnet werden. Die Tiefe der Hierarchie ist dabei nicht begrenzt und
die Synchronisation erfolgt immer entlang dieser vorgegebenen Beziehungen. Zur Kom-
munikation dient das HTTP- bzw. HTTPS-Protokoll, über das Synchronisationsnachrich-
ten komprimiert in einem einfachen CSV-Format übertragen werden. Abbildung 18 zeigt
eine Konfiguration aus drei Hierarchieebenen, die als ein typische SymmetricDS-Setup
beschrieben wird.
Abbildung 18: SymmetricDS-Replikationshierachie (Long u. a. 2013, S. 25)
Änderungen am replizierten Datenbestand werden nach dem CDC-Pattern in einer Ver-
laufstabelle geloggt. Dies umfasst unter anderem einen monoton steigenden Zeitstem-
pel, Schema und Name der betreffenden Tabelle, die neuen und alten Spaltenwerte im
CSV-Format sowie die lokale Transaktions-ID des ausführenden Datenbankservers. Die-

4 Technik 40
se Änderungen werden in sogenannte Batches zusammengefasst, die der Replikations-
hierarchie folgend an die Eltern- bzw. Kind-Instanzen addressiert sind. Die Synchronisa-
tion erfolgt dabei nach dem in Abschnitt 3.10.2 beschriebenem transaktionsorientierten
Verfahren. Konflikte werden durch datensatzorientiertes Vergleichen der erwarteten und
vorgefundenen Spalten aufgedeckt und können manuell oder nach verschiedenen Stra-
tegien gelöst werden. Da Änderungen in den Tabellen über Trigger geloggt werden, muss
nach der Initialisierung des Knoten der Synchronisationsserver nicht laufen, wenn ohne-
hin keine Verbindung zu einem anderen Knoten möglich oder erwünscht ist. Der lokale
Synchronisationsservice eines Knoten wird durch einfache Parameterdateien konfigu-
riert. Durch Anlegen mehrere Dateien mit unterschiedlichen Parametern können beliebig
viele dieser Engines auf dem Client bzw. Server ausgeführt werden, welche die Synchro-
nisation jeweils einer Datenbank übernehmen. (Long 2012)
Seit Version 3.5 unterstützt SymmetricDS die bidirektionale Synchronisation von Datei-
en und Ordnern. Die Übertragung erfolgt dabei komprimiert als Zip-Archiv, welches auf
Seiten des Empfängers entpackt wird. Durch den Einsatz von Java Bean Shell-Scripts
(BeanShell o.D.), kann auch die Datei-Synchronisation betriebssystemunabhängig erfol-
gen und wird ebenfalls über das HTTP-Protokoll abgewickelt. (Long u. a. 2013, S. 69ff.)
4.3.3 ArcGIS
Esri ArcGIS stellt die wohl verbreitetste kommerzielle GIS-Lösung der Industrie dar und
wird derzeit als Version 10.2 vertrieben. PostgreSQL kann mit ArcGIS als relationales
Backend genutzt werden und so an der Replikation der Geodatenbank teilnehmen. (Esri
2013a, S. 27, 2013b, S. 5) Zur Verfügung stehen dabei drei grundlegende Varianten:
• Check-in/Check-out-Replikation (s.a. Abschnitt 3.10): Erlaubt es Daten in eine wei-
tere Geodatenbank zu kopieren, zu editieren und anschließend wieder in die El-
terninstanz zu importieren. Damit endet der Lifecycle der Replikation und ein neues
Checkout/Checkin-Replika muss für weitere Editiervorgänge angelegt werden.
• Uni-direktionale Synchronisation: Die Synchronisation ist im Sinne einer Master-
Slave-Konfiguration einseitig gerichtet und kann über unbestimmt viele Synchroni-
sationsvorgänge hinweg bestehen.
• Bi-direktionale Synchronisation: Änderungen werden im Sinne einer Master-Mas-
ter-Replikation beidseitig synchronisiert und die Replikation kann wie bei der uni-
direktionalen Replikation unbestimmt lang bestehen. (Zeiler und Murphy 2010, S.
261)

4 Technik 41
Grundlage für jede dieser Formen der Replikation mit ArcGIS ist die Versionierung der
Daten in einer ArcSDE-Datenbank. Esri beschreibt den Grundgedanken einer Version
als eine Art Sicht bzw. Schnappschuss der Datenbank zu einem bestimmten Zeitpunkt,
unabhängig von der aktuellen „Default“-Version, also dem Originalzustand des Datenbe-
stands. So werden parallele Editiervorgänge und lange Transaktionen effektiv voneinan-
der isoliert und können sich nicht gegenseitig durch Sperren behindern. Dies entspricht
effektiv der in Abschnitt 3.10 beschriebenen Snapshot-Isolation. Versionen können die in
ihrer Reihenfolge weniger restriktiv werdenden Zugriffslevel Private, Protected und Pu-
blic zugewiesen bekommen. Private erlaubt lediglich dem „Besitzer“ der Version auf sie
zuzugreifen. Protected und Public erlauben es anderen Nutzer lesend bzw. lesend &
schreibend mit der Version zu arbeiten. (Zeiler und Murphy 2010, S. 248ff.)
Implementiert ist die Versionierung durch Versionierungstabellen, sogenannte Delta-Ta-
bellen bestehend aus einer Hinzufügen- (A; Adds) und einer Löschen-Tabelle (D; Dele-
tes). Diese spiegeln die Änderungen an den Versionen wieder und werden beim Einfügen
mit eindeutigen, monoton steigenden Zeitstempeln versehen. Da sich auch die Basisope-
ration Ändern aus den Operationen Löschen und Einfügen konstruieren lässt, sind diese
beiden Tabellen ausreichend, um jeden Schreibvorgang zu protokollieren. Jedes versio-
nierte Dataset wird hierfür mit eigenen Delta-tabellen assoziiert. Da jede Änderung pro-
tokolliert wird, können die Delta-Tabellen so auch für eine Undo/Redo-Funktion genutzt
werden. (ebd., S. 248ff.)
Die Versionierung in ArcGIS beschränkt sich nicht auf eine aus der Default-Version abge-
leiteten Ebene, sondern kann beliebig in die Tiefe verschachtelt werden, d.h. es können
Kinder-Versionen (child version) aus Eltern-Versionen (parent version) abgeleitet wer-
den. Daraus folgend spricht man von einem Versionenbaum (s. Abbildung 19), in dem
jede Version einem bestimmten Zweck bei der Bearbeitung zugewiesen werden kann.
Um Änderungen in Versionen entlang der Vererbungshierachie des Versionenbaums zu
kommunizieren, wird ein zweistufiges Verfahren eingesetzt, bei dem Änderungen aus
der Zielversion in der Editierversion zusammengeführt werden und anschließend an die
Zielversion „geposted“ werden. Beim Zusammenführen werden etwaige Konflikte durch
Nutzung der in Abschnitt 3.10 beschriebenen datenorientierten Synchronisation aufge-
deckt. Die dafür nötigen Informationen können den Änderungstabellen der Datasets ent-
nommen werden. Nachdem dieser Vorgang abgeschlossen ist, sind alle Änderungen der
Zielversion mit den lokalen Änderungen in der Editierversion vorhanden. Diese werden
nun im zweiten Schritt an die Zielversion gesendet und dort übernommen, womit beide
Versionen identisch sind. (ebd., S. 251ff.)

4 Technik 42
Defaultversion
Planningversion
Operationsversion
West extensionversion
East extensionversion
Circuit 1version
Circuit 2version
Abbildung 19: ArcGIS Versionsbaum (ebd., S. 252)
Da insbesondere das Editieren in vielen verschiedenen Versionen zu einem großen Da-
tenumsatz in den Delta-tabellen führt, bietet ArcGIS die Möglichkeit, die Geodatenbank
zu komprimieren. Dabei werden nicht mehr benötigte Änderungsstände aus den Delta-
Tabellen gelöscht. (Zeiler und Murphy 2010, S. 255)
Die Replikation von Geodatenbanken ist ein Mechanismus der ArcGIS-Software und un-
abhängig vom eingesetzten Datenbanksystem, d.h. es ist möglich, eine Replikation ein-
zurichten, bei denen der relationale Unterbau zur ArcSDE-Geodatenbank unterschied-
lich ist. Für eine bidirektionale Synchronisation ist dabei die Nutzung einer ArcSDE-
Datenbank Pflicht, da nur diese Versionierung, wie sie zuvor beschrieben wurde, un-
terstützt. Die File- oder Personal-Geodatenbanken die durch ArcGIS-Desktop angeboten
werden, sind hierfür nicht geeignet. Bei der Einrichtung einer Replikation werden zwei
Replikat-Versionen erstellt, von der eine an das child replica, dem neuen Kind-Knoten,
übertragen wird und eine beim parent replica verbleibt. (Esri 2013d) Abbildung 20 zeigt,
wie sich der zuvor vorgestellte Versionsbaum nun über mehrere Geodatenbanken er-
streckt.
Das Erstellen und Synchronisieren von Replikas ist mit ArcGIS sowohl offline als auch
über eine Netzwerkverbindung möglich. Um beispielsweise ein Replika einzurichten, das
zur aktuellen Datenbank keine Verbindung aufbauen kann, ist es möglich diesen als
XML-Dokument zu exportieren und auf dem Zielcomputer schließlich zu importieren. Die
Synchronisation zwischen den Partnern verläuft auf gleich Art und Weise, je nach Kon-
figuration ein- oder beidseitig, wobei hier nicht nur die konkreten Änderungen in Form
von data change messages ausgetauscht werden müssen, sondern auch acknowledg-
ment messages, welche dem Sender bestätigen, das Änderungen akzeptiert wurden und
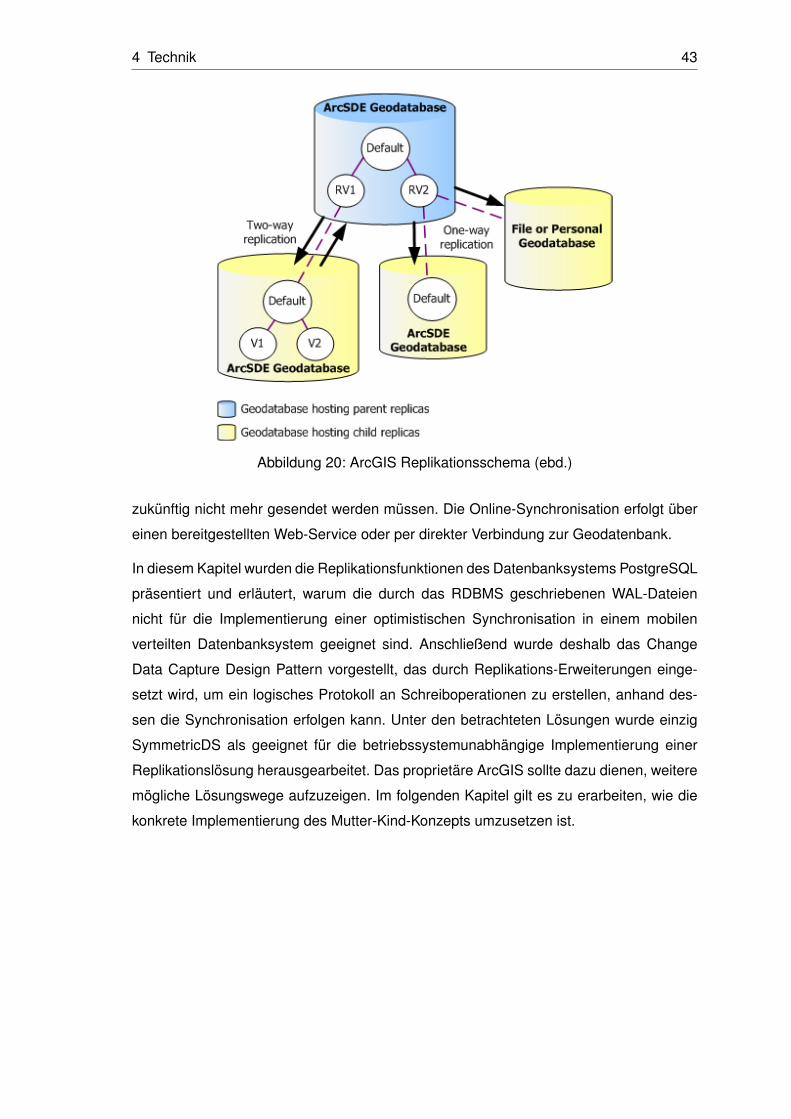
4 Technik 43
Abbildung 20: ArcGIS Replikationsschema (ebd.)
zukünftig nicht mehr gesendet werden müssen. Die Online-Synchronisation erfolgt über
einen bereitgestellten Web-Service oder per direkter Verbindung zur Geodatenbank.
In diesem Kapitel wurden die Replikationsfunktionen des Datenbanksystems PostgreSQL
präsentiert und erläutert, warum die durch das RDBMS geschriebenen WAL-Dateien
nicht für die Implementierung einer optimistischen Synchronisation in einem mobilen
verteilten Datenbanksystem geeignet sind. Anschließend wurde deshalb das Change
Data Capture Design Pattern vorgestellt, das durch Replikations-Erweiterungen einge-
setzt wird, um ein logisches Protokoll an Schreiboperationen zu erstellen, anhand des-
sen die Synchronisation erfolgen kann. Unter den betrachteten Lösungen wurde einzig
SymmetricDS als geeignet für die betriebssystemunabhängige Implementierung einer
Replikationslösung herausgearbeitet. Das proprietäre ArcGIS sollte dazu dienen, weitere
mögliche Lösungswege aufzuzeigen. Im folgenden Kapitel gilt es zu erarbeiten, wie die
konkrete Implementierung des Mutter-Kind-Konzepts umzusetzen ist.

5 Vorüberlegungen zur Replikationskomponente 44
5 Vorüberlegungen zur
Replikationskomponente
Aus den vorhergehenden Betrachtungen lässt sich schließen, dass das Mutter-Kind-
Konzept ein mobiles verteiltes Datenbanksystem beschreibt. Die Mutter-Instanz stellt da-
bei den stationären Server-Knoten dar. Entsprechend fungieren die Kind-Instanzen als
Client-Knoten im Sinne der erweiterten Client-Architektur. Das Abbilden der Kind-Instanz
durch das Übertragen des aktuellen Datenbestands kommt dem Erstellen eines Snaps-
hots der Mutter-Instanz gleich. Die Arbeit mit dieser in einer vom zentralen Datenbestand
entkoppelten Umgebung stellt somit eine lange Server-Transaktion dar, welche mit der
Synchronisationsphase zwischen Mutter und Kind-Instanz endet. Diese Sicht lässt sich
auf die Beziehung Eltern-Instanz/Kind-Instanz verallgemeinern, bei der jeweils die Eltern-
Instanz als Server im Sinne der langen Server-Transaktion eintritt.
Aus den bestehenden Anforderungen ist bekannt, dass ein optimistischer Transaktions-
ansatz gefordert ist, also keine Sperrverfahren angewandt werden dürfen, um beim Er-
stellen einer Kind-Instanz den Datenbestand der Eltern-Instanz weiter bearbeiten zu kön-
nen. Daraus ist zu schließen, dass sich die Konsistenz des Datenbestands zwischen
diesen Knoten durch Änderungen voneinander entfernt. Die Konsistenz des lokalen Da-
tenbestands wird bei Client-Transaktionen durch die Mechanismen des lokalen Daten-
banksystems gesichert. Da die entkoppelte Kind-Instanz ein Schnappschuss bzw. eine
Version der Eltern-Instanz darstellt und keine Kommunikation zwischen den Instanzen
stattfindet, kann ein Großteil der möglichen Phänomene von parallelen Transaktionen
auf Höhe der langen Server-Transaktion durch die sich daraus ergebende abbildisolier-
te Transaktionierung ausgeschlossen werden (vgl. Abschnitt 3.10). Um am Ende der
Server-Transaktion schließlich die Konsistenz zwischen den Synchronisationspartnern
herzustellen, muss ein optimistisches Synchronisationsverfahren zum Einsatz kommen.
Dabei muss die lange Server-Transaktion rückwärts gerichtet ausgewertet werden um
eventuelle Konflikte aufzudecken.
Wird die Synchronisation entlang der Netztopologie durchgeführt, ist gewährleistet, dass
schließlich alle Informationen auf der Auskunftsinstanz, der Mutter-Instanz, zusammen-
laufen. In Abschnitt 3.10 wurde festgestellt, dass bei der Synchronisation die Konflik-
te Löschkonflikt, Einfügekonflikt, Änderungslöschkonflikt und Änderungskonflikt auftreten

5 Vorüberlegungen zur Replikationskomponente 45
können. Lediglich Einfügekonflikte bzw. Schlüsselkonflikte lassen sich dabei auch ohne
Sperrverfahren effektiv verhindern.
5.1 Anpassungen Datenbankschema
Insbesondere das Auftreten von Einfügekonflikten ist bei der Nutzung der OpenInfRA-
Anwendung wahrscheinlich, wenn einfache Sequenzen als Primärschlüsselgeneratoren
eingesetzt werden. In Abschnitt 2.4 wurde bereits beschrieben, dass gerade ein hohes
Aufkommen an Einfüge-Operationen für OpenInfRA erwartet wird. Da Primärschlüssel in
einem verteilten System einen hohe Wert besitzen und das Ändern von Primärschlüsseln
in Datenbanken allgemein zu vermeiden ist, sollte dieses Problem früh berücksichtigt
werden. Mögliche Lösungsstrategien werden in Tabelle 5.1 exemplarisch aufgezeigt:
Tabelle 5.1: Mögliche Konfliktvermeidungsstrategien bei Primärschlüsselgenerationohne zentrale Kontrolle. (M = Mutter-Instanz; K = Kind-Instanz; : = Neue Spalte)
Strategie Beispiel
Seriennummernblöcke M = {1..1000},K = {1001..2000}Eindeutiges Inkrement M = {1, 11, 21},K = {2, 12, 22}Zusammengesetzter PK M = {(1 : M)};K = {(1 : K)}Namespacing M = {“M1”, “M2”..};K = {“K1”, “K2”..}UUID {214ee93a� 1af0� 448f � 98b3� 59a71498bca2}
Das Zuweisen von Nummernblöcken ist ein einfaches Verfahren, aber ungünstig, wenn
nicht abgeschätzt werden kann, wie hoch das Aufkommen an Einfügeoperationen am
Kind-Knoten sein wird, da so der Block unvorhergesehen erschöpft werden kann. Dies gilt
vor allem, wenn die Instanz selbst auch als Eltern-Instanz eintritt und so den Zahlenraum
„aufteilen“ muss. Eine großer Nummernblock würde hier Abhilfe schaffen, kann aber bei
unvorhergesehenen Ereignissen das Grundproblem nicht ausschließen. Das Zuweisen
von eindeutigen Inkrementen hat im Grunde die gleichen Vor- und Nachteile, wobei hier
die Schrittweite beachtet werden muss. Die Nutzung von zusammengesetzten Schlüs-
seln, bei denen eine Spalte die ID der ausführenden Instanz repräsentiert, erhöht aber
den ohnehin schon großen Aufwand, der durch Fremdschlüsselverknüpfungen entsteht.
Sinnvoll erscheint deshalb die Nutzung von sogenannten Universally Unique Identifiers
(UUID). Das sind nach standardisierten Verfahren (s. Force (2005) sowie ISO ISO/IEC
9834-8:2008) generierte 16 Byte Zahlen, welche für die Nutzung in verteilten Systemen
entwickelt wurden. Es ist möglich, UUIDs ohne zentralisierte Kontrolle parallel zu gene-
rieren, ohne dass eine realistische Chance besteht, dass die gleich Zahl zweimal auftritt.
UUID wird als Standard-Datentyp durch PostgreSQL unterstützt und liefert die Extension

5 Vorüberlegungen zur Replikationskomponente 46
„uuid-ossp“, welche entsprechende Generatorfunktionen zur Verfügung stellt. Das Listing
5.1 präsentiert den Ablauf. (PostgreSQL Global Development Group 2013g,h)
1 create extension "uuid -ossp";
2 select uuid_generate_v4 ();
3 uuid_generate_v4
4 --------------------------------------
5 2d7d1b5c -eaa6 -4919 -909b -5103 ff803039
6 (1 row)
Listing 5.1: Installation der PostgreSQL-Extension „uuid-ossp“ und Generierung einer
UUID Version 4.
Das in Abschnitt 4.3.3 beschriebene GIS-System ArcGIS setzt ebenfalls auf eine UUID-
Spalte, hier als Globally Unique Identifier (GUID) bezeichnet, um Zeilen über mehrere
Geodatenbanken hinweg identifizieren zu können. Es schließt so die Entstehung von
Schlüsselkonflikten in einer verteilten Umgebung aus. Das Datenbanksystem Microsoft
SQL Server setzt ebenfalls auf GUID-Spalten für die Identifizierung in replizierten Tabel-
len. (Esri 2013c; Microsoft 2013)
Ein Nachteil beim Einsatz des Datentyps ist der höhere Speicherbedarf von 16 Byte
gegenüber 4 bzw. 8 Byte für Integer bzw. Big Integer. Dennoch überwiegen die Vortei-
le, denn für das OpenInfRA-Projekt wären beispielsweise Themenausprägungen, The-
meninstanzen, Wertelisten und Attributtypen nicht nur innerhalb eines Projekts über alle
bestehenden Instanzen eindeutig identifiziert, sondern global über alle Projektdatenban-
ken hinweg, ohne dass eine Koordination vonnöten ist. Zu beachten ist, dass UUIDs
nicht sequentiell generiert werden. Da PostgreSQL Indizes aber generell nicht clustert
(PostgreSQL Global Development Group 2013d) und das bestehende Datenschema sich
ohnehin nicht dazu eignet, Bereichsabfragen über die Primärschlüssel zu formulieren,
stellt dies kein Problem dar.
Noch ein weiterer Vorteil spricht für die Nutzung von UUIDs. Da für jede verbreitete Pro-
grammiersprache standardkonforme Implementierungen der Generatorfunktionen beste-
hen, kann die Schlüsselgeneration sicher sowohl auf Seiten der Datenbank als auch
durch die Anwendung geschehen. Aus diesen Gründen muss das Datenbankschema
entsprechend angepasst werden. Im Rahmen dieser Arbeit wurde dies an dem im Mo-
ment bestehenden Datenbankschema und den zur Verfügung stehenden Importfunktio-
nen für DAI-Projekte durchgeführt.

5 Vorüberlegungen zur Replikationskomponente 47
5.2 Synchronisation
Um nur die nötigsten Informationen bei der Synchronisation auszutauschen und so den
Übertragungsaufwand zwischen den Stationen so gering wie möglich zu halten, sollten
lediglich Verlaufsdaten für den Synchronisationsalgorithmus genutzt werden. In Abschnitt
4.1 wurde verdeutlicht, warum das Write-Ahead-Log, das durch PostgreSQL erstellt wird,
nicht genutzt werden kann, um Änderungen zwischen Eltern- und Kind-Instanz zu syn-
chronisieren. Dementsprechend muss eine Form des Change Data Capture zur Anwen-
dung kommen, bei der Änderungen durch Datenbanktrigger protokolliert werden. Da ein
hohes Verhältnis von Einfügeoperationen gegenüber Updateoperationen erwartet wird,
ist die Nutzung von Status und Zeitstempelspalten an den replizierten Tabellen ineffek-
tiv. Darüber hinaus wird ein Großteil der Zeilen dieses Attribut nie nutzen, sodass die
Änderung des Anwendungsschemas der Projektdatenbank deshalb vermieden werden
sollte.
Für die Synchronisation kommt deshalb die transaktionsorientierte Synchronisation in
Frage, wie sie bereits in Abschnitt 3.10 vorgestellte wurde. Hier wird Vorher- (OLD) und
Nachherbild (NEW) auf dem Empfänger der Synchronisationsdaten mit dem aktuellen Zu-
stand verglichen. Eine semantikbasierte Synchronisation erscheint ungeeignet, da das
generalisierte Datenmodell hier zu viel Verantwortung in der Anwendungsschicht suchen
würde. Mit jeder Abfrage müssten entsprechende Bedingungen formuliert werden, die
für die Operation einzuhalten sind und die angeben, wie eventuelle Konflikte aufzulösen
sind. Da ohnehin eine manuelle bzw. interaktive Konfliktlösung vorgesehen ist, ist dies
überflüssig.
In 4.3.3 wurde gezeigt, dass das proprietäre ArcGIS die Replikation auf die Versionierung
der Daten begründet, welche über separate Delta-Tabellen umgesetzt ist. Eine komplette
Versionierung der Projektdaten ist aber nicht vorgesehen (Schäfer 2013) und erleichtert
den Schritt hin zu einem sequentiell geschriebenem Transaktionsprotokoll in relationaler
Form. Sequentiell daher, um die lokale Abfolge der Transaktionen auch auf dem Syn-
chronisationspartner in dieser Reihenfolge auszuführen und so die kausale Ordnung der
Operationen beizubehalten. Zusätzlich sollte die lokale Transaktions-ID hinterlegt sein,
um Operationen über diese zu gruppieren und auf dem Empfänger atomar auszuführen,
sie also auch dort in eine Transaktion bzw. eine Sub-Transaktion der Synchronisation zu
klammern. Für das Loggen können Datenbanktrigger eingesetzt werden, die den repli-
zierten Tabellen zugeordnet sind und in der Reihenfolge protokollieren, in der sie durch
Änderungen in der Tabelle auslösen.
Bei der Synchronisation kann so schließlich das seit der letzten Synchronisation entstan-

5 Vorüberlegungen zur Replikationskomponente 48
dene Transaktionsprotokoll an den Synchronisationspartner übertragen und ausgewertet
werden. Beim Durchführen jeder Operation wird dabei entsprechend der in Tabelle 3.2
definierten Regeln überprüft, ob ein Konflikt vorliegt. Ist dies der Fall, muss die Transak-
tion und der Synchronisationsvorgang abgebrochen werden, andernfalls kann die Trans-
aktion abgeschlossen werden. Wird dieser Vorgang auf beiden Synchronisationspart-
nern erfolgreich durchgeführt, sind die Datenbankinstanzen konsistent zueinander. Tritt
ein Konflikt auf, das heißt wurde auf beiden Instanzen das gleiche Tupel verändert, sind
die Transaktionen nicht serialisierbar (vgl. Abschnitt 3.10) und die Synchronisation muss
abgebrochen werden. Um die lokalen Transaktionen des Clients an diesem Punkt nicht
zu verlieren, muss eine Konfliktlösung durchgeführt werden, bei der entschieden wird,
welcher Wert für dieses Tupel den richtigen darstellt. Um einen konsistenten Zustand auf
beiden Datenbankinstanzen herzustellen muss sichergestellt werden, dass beide Syn-
chronisationspartner bei der Konfliktlösung zum gleichen Ergebnis kommen.
Da das auflaufende Transaktionsprotokoll nach einer erfolgreichen Synchronisation nicht
mehr benötigt wird und unnötig Ressourcen des Datenbankservers verbraucht, sollte es
regelmäßig „gesäubert“ werden. Dies kann aber erst dann geschehen, wenn alle zu die-
ser Instanz in Beziehung stehenden Knoten die Synchronisation bis zu diesem Punkt
abgeschlossen haben. Dementsprechend ist neben dem Austausch der lokalen Opera-
tionen auch eine Erfolgsmeldung nötig, welche ebenfalls protokolliert wird und die erfolgte
Synchronisation bestätigt.
5.3 Fragmentierung und Allokation der Projektdatenbank
Aus Abschnitt 3.2 ist bekannt, dass sich das Fragmentierungs- und Allokationsschema
einer verteilten Datenbank aus dem globalen Schema ableitet. Für eine OpenInfRA-
Projektdatenbank ist dies das hoch generalisierte Anwendungsschema bzw. das daraus
abgeleitete Datenbankschema, welches in Abschnitt 2.1 vorgestellt wurde. Eine vertikale
Fragmentierung der Relationen ist hier nicht sinnvoll möglich ohne den Grundsatz der
Vollständigkeit zu verletzten. Interessanter ist ohnehin die Fragmentierung in horizonta-
ler Richtung. Das heißt, das Zuweisen von Teilprojekten eines Projekts welche im Feld
bearbeitet werden sollen zu einem Fragment um dieses schließlich auf einen mobilen
Computern zu replizieren. Problematisch sind an dieser Stelle die vielen referentiellen
Beziehungen und Selbstbeziehungen, die durch das generalisierte Schema entstehen.
Während es beispielsweise trivial ist, die Relation „Projekt“ auf Selbstbeziehungen, also
Teilprojekte, zu prüfen und daraus die Menge der Themenausprägungen zu bestimmen,
gestaltet sich dies für weiter assoziierte Klassen schwieriger. Listing 5.2 demonstriert

5 Vorüberlegungen zur Replikationskomponente 49
dies für alle Themeninstanzen eines imaginären Projekts mit der ID 1. Hier ist es nötig,
die Selbstbeziehung der Klasse Themeninstanz zu berücksichtigen und über die Relati-
on „Themeninstanz_x_Themeninstanz“ zu prüfen, ob diese zu einer anderen Instanz in
Beziehung steht:
1 -- Projekt und dessen Teilprojekte
2 WITH p AS (
3 SELECT "Id"
4 FROM "Projekt"
5 WHERE "Id" = 1
6 OR "Teilprojekt_von" = 1
7 ),
8 -- Betroffene Themenausprägungen
9 ta AS (
10 SELECT ta."Id"
11 FROM "Themenauspraegung" ta
12 INNER JOIN p ON ta."Projekt_Id" = p."Id"
13 -- Themeninstanzen der Themenausprägungen
14 ), ti_pre AS (
15 SELECT ti."Id"
16 FROM "Themeninstanz" ti
17 INNER JOIN ta ON ti."Themenauspraegung_Id" = ta."Id"
18 )
19 -- Beziehungen Themeninstanzen ersten Grades
20 SELECT ti_x_ti."Themeninstanz_2" AS "Id"
21 FROM "Themeninstanz_x_Themeninstanz" ti_x_ti
22 INNER JOIN ti_pre ON ti_x_ti."Themeninstanz_1" = ti_pre."Id"
23 UNION
24 SELECT "Id" from ti_pre;
Listing 5.2: Abfrage aller Themeninstanzen eines Projekts
In diesem Query ist jedoch noch nicht berücksichtigt, dass auch die in Beziehung ste-
hende Instanz eigene Beziehungen pflegt und dabei insbesondere auch einer anderen
Themenausprägung angehören kann, welche unter Umständen abermals einem anderen
Projekt zugeteilt ist. Diese rekursiven Beziehungen müssen beachtet werden, da sonst
Fremdschlüsselverletzungen auftreten werden. Neben dieser Schwierigkeit steht hier der
rein praktische Nutzen in Frage, wenn auch auf Offline-Instanzen Beziehungen zwischen
Themeninstanzen hergestellt werden sollen, die nicht dem gewählten Teilprojekt angehö-
ren. (s.a. Email Schäfer (2013)) Entsprechend sollte der relationale Projektdatenbestand
nicht fragmentiert werden.

5 Vorüberlegungen zur Replikationskomponente 50
5.4 Synchronisation externer Dokumente
Anders ist dies für externe Dateien die mit dem Datenbestand verknüpft sind. Es ist an-
zunehmen, dass diese Daten im Verhältnis zur Datenbank sehr viel mehr Speicherplatz
in Anspruch nehmen werden. Der Import dieser Daten auf einem Laptop ist damit sowohl
praktisch als auch technisch unmöglich. Die Zuordnung der externen Daten zu Teilprojek-
ten könnte dabei anhand der zugrundeliegenden Ordnerstruktur organisiert werden, wie
dies in Abbildung 21 verdeutlicht wird, welche von der Anwendung beim Upload bestimmt
wird.
Mutter-Instanz
Projektdatenbank
Teilprojekt A Teilprojekt B
Kind-Instanz
Projektdatenbank
Teilprojekt B
Abbildung 21: Replikation externer Projektdaten
Für die Replikation und Synchronisation von externen Dokumenten im Dateisystem kön-
nen die für relationale Datenbanken beschriebenen Mechanismen nicht eingesetzt wer-
den. Einzig die Verweise, die durch die OpenInfRA-Anwendung in der Datenbank ange-
legt werden, werden deshalb durch die Datenbanksynchronisation übermittelt. Um ins-
besondere bei Außendiensten gesammelte Informationen wie Bilder und Pläne an die
Büros, bzw. letztendlich an die Auskunftsversion zu übermitteln, ist ein externer Prozess
nötig, der diese Aufgabe neben der Datenbanksynchronisation übernimmt.
Denkbar wäre der Einsatz einer Versionskontrolle wie Git, dessen komplexe Funktions-
weise durch die Oberfläche der Anwendung verschleiert wird. Problematisch dabei ist
allerdings, dass es sich zuerst um Binärdaten (JPEG, PDF) handeln wird, die für die
Synchronisation anfallen. Ein Großteil dieser Dateien wird nach dem Anlegen nicht wie-
der verändert werden, sondern hat in erster Linie dokumentarischen Nutzen. Eine Ver-
sionierung dieser Daten im Dateisystem würde deshalb schnell zu „Datenmüll“ führen,
der unnötig Speicherplatz verbraucht.
Eine Alternative stellt das Auslesen der Änderungszeiten dar, gewissermaßen eine Adap-
tion des zeitspaltenbasierten Change Data Capture für Dateien. Diese Änderungszeiten
können in der Datenbank hinterlegt und bei einem Synchronisationsvorgang abgeglichen

5 Vorüberlegungen zur Replikationskomponente 51
werden. Der Transfer der Dateien muss wiederum von einem externen Prozess übernom-
men werden, der einen entsprechenden Komprimierungsalgorithmus anwendet.
5.5 Zusammenfassung
Zusätzlich zu den in in Kapitel 2 zusammengetragenen Anforderungen können aus den
im vorangegangenen Kapitel gewonnenen Informationen neue Anforderungen formuliert
werden, die durch die Replikationskomponente von OpenInfRA erbracht werden müssen,
um das Mutter-Kind-Konzept umzusetzen. Sie beziehen sich in erster Linie auf die Syn-
chronisation und die Lösung von Synchronisationskonflikten, aber auch auf administrative
Funktionen, wie das Ändern der Host-Adresse einer Eltern-Instanz, um für mobile Knoten
sicherzustellen, dass diese eine Verbindung herstellen können. Die überarbeiteten und
neuen Anforderungen AC_0280 bis AC_0371 sind im Anforderungskatalog ergänzt. Dar-
über hinaus wurde der Anforderungsfall „Administration Projektinstanz“ angepasst, um
auch neue Anforderungen zu berücksichtigen.
In Anbetracht der Umstände, dass OpenInfRA nicht nur eine einfache Synchronisati-
on von Datenbanken, sondern auch eine Synchronisation von externen Dateien benö-
tigt, ist es offensichtlich, dass die in Abschnitt 4.3.2 vorgestellte Synchronisationslösung
SymmetricDS die logische Wahl sein muss. Es wurde deshalb basierend auf diesem
System eine Standardkonfiguration entwickelt, die individuell angepasst auf das jeweilige
Projekt für die Replikation der Projektdaten genutzt werden soll. Die Vorgehensweise ist
dabei im folgenden Kapitel ausführlich dokumentiert.

6 Implementierung 52
6 Implementierung
Die Replikations- und Synchronisationslösung SymmetricDS wurde bereits in Abschnitt
4.3.2 kurz vorgestellt und als gute Lösung für OpenInfRA eingeschätzt. Die Implementie-
rung bzw. Konfiguration soll daher im Folgenden dokumentarisch beschrieben werden.
Dafür wird zuerst darauf eingegangen, auf welche Art und Weise die Software in die
OpenInfRA-Anwendung integriert werden kann, wie die Konfiguration für ein Projekt er-
folgt und schließlich wie die Synchronisation zwischen den Instanzen durchgeführt wird.
Anschließend werden auch administrative Funktionen erläutert. Die hier vorgestellte Kon-
figuration wird als Template bereitgestellt, das für den Betrieb eines jeden Projekts ange-
passt werden kann.
6.1 Installation
Aktuell ist Version 3.5.10 der Synchronisationslösung SymmetricDS veröffentlicht. Die-
se kommt in der hier vorgestellten Implementierung zum Einsatz. Grundvoraussetzung
für die Installation und anschließende Ausführung ist die Java SE Runtime Environment
(JRE) ab Version 5, welche als kostenloser Download sowohl für Microsoft Windows und
Apple OSX als auch kompiliert für die meisten Linux Distributionen bereit gestellt wird
(http://www.java.com/en/download/). Unterstützt wird neben anderen Datenbanksys-
temen PostgreSQL ab der Version 8.2.5. Die aktuelle Version der Dokumentation zu
SymmetricDS gibt fälschlicherweise an, dass für die Nutzung mit PostgreSQL die Nut-
zervariablenklasse symmetric in der postgresql.conf des Datenbankservers aktiviert
werden muss. (Long u. a. 2013, S. 148) Die Möglichkeit dieser Einstellung wurde aber ab
Version 9.2 von PostgreSQL ersatzlos und abwärtskompatibel gestrichen. (PostgreSQL
Global Development Group 2012) Neben der nachfolgend beschriebenen Installation der
Systemtabellen von SymmetricDS und der Konfiguration müssen für aktuelle Versionen
des Datenbanksystems also keine weiteren Anpassungen am Server selbst vorgenom-
men werden.
Die Installation bzw. das Ausführen von SymmetricDS kann auf drei Arten geschehen
und ist durch die Implementierung in Java betriebssystemunabhängig. Am einfachsten
ist dabei die direkte Nutzung der mitgelieferten ausführbaren Dateien, im Folgenden
als Standalone-Installation bezeichnet. Dafür wird das nach dem Download entpackte

6 Implementierung 53
SymmetricDS-Verzeichnis lediglich an dem gewünschten Ort auf dem Computer abge-
legt. Neben dem eigentlichen Synchronisationsservice werden weitere Tools zur Konfi-
guration und für den Import und Export im Unterverzeichnis bin mitgeliefert. Sie sind in
der anschließenden Tabelle kurz erläutert.
Tabelle 6.1: Ausführbare Dateien einer SymmetricDS-Installation
Bezeichnung Beschreibung
sym Starten/Stoppen des SymmetricDS-Synchronisationsservicessymadmin Konfiguration und Registrierung von Knotendbimport Import Datenbankschemadbexport Export Datenbankschemadbfill Testdatengeneratorsym_service.initd Linux/OSX-Daemonsym_service.bat Windows-Service
Die sym_service.*-Skriptdateien können genutzt werden, um SymmetricDS auf unixoi-
den Systemen als Daemon bzw. auf der Windows-Plattform als Service auszuführen. Ist
dies nicht gewünscht, also soll der Synchronisationsservice beispielsweise nur bei einer
aktiven Internetverbindung gestartet werden, kann er direkt über das Java-Programm sym
kontrolliert werden. Bei dieser Nutzungsart wird ein integrierter Jetty-Webserver gestar-
tet, über den die Kommunikation zwischen den Knoten abgewickelt wird. Das Starten des
Dienstes erfolgt in diesem Fall per nachfolgendem Kommando:
1 ./sym --port 9090
Listing 6.1: Starten des SymmetricDS-Standalone-Service
Alternativ hierzu ist es möglich, den Service als Web Application Archive (WAR) zu in-
stallieren. In diesem Fall müssen die benötigten Java-Bibliotheken und Konfigurations-
dateien entsprechend der Java-Servlet-Spezifikation (s. Sun Microsystems Inc. (2011))
in die Verzeichnisstruktur des Archivs aufgenommen werden. Die Nutzung eines WAR-
Archivs ist insbesondere dann sinnvoll, wenn bereits ein Anwendungsserver wie Apache
Tomcat ausgeführt wird. Das Archiv kann in dem Fall durch den Anwendungsserver gela-
den, gestartet und gestoppt werden, während dessen Web-Server statt dem integrierten
Jetty-Server genutzt wird.
Die dritte Möglichkeit besteht darin, SymmetricDS direkt in eine Java-Anwendung zu in-
tegrieren. Die quelloffene Bibliothek ist gut dokumentiert (s. JumpMind Inc. (2013b)) und
stellt eine Reihe von Interfaces bereit, die es erlauben, die Funktionsweise zu erweitern.
Der Standalone-Client stellt nichts anderes als eine Benutzerschnittstelle zu den durch
diese Bibliotheken definierten Klassen und Methoden dar. Listing 6.2 gibt ein Minimalbei-
spiel vor, wie der Service programmatisch ausgeführt werden kann.

6 Implementierung 54
1 import org.jumpmind.symmetric.SymmetricWebServer;
2
3 public class StartSymmetricEngine {
4 public static void main(String [] args) throws Exception {
5 SymmetricWebServer node = new SymmetricWebServer("classpath ://
properties/pergamon000.properties");
6 node.start (9090);
7 }
8 }
Listing 6.2: Minimalanwendung zum Starten des SymmetricDS
Synchronisationsservices
6.2 Funktionsweise
SymmetricDS nutzt Datenbanktrigger, um Verlaufsdaten (Knoten-ID, Schema, Tabelle,
Primärschlüsselspalten, alte Spaltenwerte, neue Spaltenwerte, Zeitpunkt) zu sammeln
und setzt damit das Change Data Capture-Design Pattern um. Diese Informationen wer-
den entsprechend der an einem Knoten registrierten Synchronisationspartner in soge-
nannte Batches verteilt, die in Form von CSV-Dateien versendet werden. Auf Seiten des
Empfängers werden diese Dateien interpretiert und anschließend als eine Transaktion
ausgeführt. Durch die monoton steigende Batch-ID und die mit übermittelte Knoten-ID
wird dabei sichergestellt, dass diese nur in ihrer kausalen Reihenfolge ausgeführt wer-
den, auch wenn mehr als ein Batch vom Sender empfangen wird. Werden Konflikte fest-
gestellt, können diese entweder via einer automatisierten Konfliktlösung bearbeitet wer-
den (Priorität Sender, etc.), oder die Synchronisation wird abgebrochen und die Transakti-
on zurückgerollt. So ist sichergestellt, dass die Datenbank in einem konsistenten Zustand
verbleibt. Die empfangenen Batches werden damit nicht verworfen, sondern warten ledig-
lich auf eine manuelle Konfliktlösung, bevor sie beim nächsten Synchronisationsvorgang
angewandt werden. So müssen Verlaufsdaten nur ein mal übertragen werden.
Die externen Prozesse, genannt Jobs, die für die Synchronisation ausgeführt werden
müssen, können unabhängig voneinander konfiguriert und gestartet werden. Die wich-
tigsten sind hier der Router -Job, welcher durch die Trigger gesammelte Verlaufsdaten
in Batches zuteilt, sowie die Pull und Push-Jobs, welche für die Übertragung zuständig
sind. Es ist nicht nötig, dass diese Prozesse ausgeführt werden, wenn lediglich Verlaufs-
daten gesammelt werden sollen. Es reicht, wenn sie für eine Synchronisation gestartet
werden.

6 Implementierung 55
6.3 Konfiguration Engine
Der Replikations- und Synchronisationsprozess, der durch den SymmetricDS-Dienst an-
gestoßen wird, ist auf Höhe sogenannter Engines definiert, welche eine Verbindung der
Java-Anwendung zur Datenbank beschreiben. Es ist möglich, mehrere Engines durch
einen Java-Prozess auf einem Computer und über einen Port zu betreiben. Anfragen
richten sich dabei an eine REST-API unter der konfigurierten Synchronisations-URL, über
die die Engine angesprochen wird. Lokale Datenbanken lassen sich dabei ebenso unter-
einander adressieren. Die Verbindungsparameter werden in einfachen Java-Properties-
Dateien vorgenommen, deren grundlegenden Einstellungen in der folgenden Tabelle zu-
sammengefasst sind:
Tabelle 6.2: Die wichtigsten Startup-Einstellungen einer SymmetricDS-Engine
Bezeichnung Kurzbeschreibung
engine.name Name der Engine zur Identifikation in der JVMgroup.id ID der Knoten-Gruppeexternal.id Sekundärer Identifikator dieses Knotensregistration.url URL, die durch die Engine zur Registrierung kontaktiert wirdsync.url Eigene Synchronisations-URL der Enginedb.driver Klassenname des JDBC-Treibersdb.url JDBC-URL zur Datenbankverbindungdb.user Datenbanknutzer für Zugriff durch die Enginedb.password Password
Die Properties-Dateien werden beim Start einer Engine ausgewertet, wobei sie in ei-
ner Standalone-Installation im Unterverzeichnis $SYM/engines gesucht werden. In einem
WAR-Archiv sind sie unter WEB-INF/classes zu platzieren. Eine typische Konfiguration
zur Anwendung auf der Mutter-Instanz bzw. auf deren Kinder-Instanzen wurde erstellt
und ist im Anhang 7 beigefügt.
Die Registrierungs-URL dient beim Einrichten der Replikationshierarchie zur Verbindungs-
aufnahme mit der Eltern-Instanz. Ein neu startender Synchronisationsserver wird prüfen,
ob die SymmetricDS-Systemtabellen im gewählten Datenbankschema installiert sind,
dies unter Umständen nachholen und anschließend diese URL ansprechen, um um eine
Registrierung zu bitten. Wird diese gewährt, werden zuerst die auf der Eltern-Instanz vor-
liegenden Konfigurationsdaten übertragen. Anhand dieser Konfiguration wird entschie-
den, welche Datenbanktrigger installiert werden müssen, um Verlaufsdaten für die Syn-
chronisation zu sammeln.
Die Wurzel der Replikationshierarchie, bzw. der Mutter-Instanz, hat natürlich keinen Zu-
griff auf eine Registrierungs-URL. Auf dieser Instanz wird vielmehr die erste Konfiguration

6 Implementierung 56
vorgenommen, bevor sie als ein Knoten der Synchronisation definiert wird. Dieser Schritt
wird in Abschnitt 6.8 eingehender erläutert.
Da der Synchronisationsservice Änderungen am Datenbestand durchführen und Daten-
banktrigger an den entsprechenden Tabellen installieren muss, sollte ein eigener Daten-
banknutzer hierfür eingerichtet werden. So ist es auch möglich zu bestimmen, in welches
Datenbankschema die Systemtabellen des Services installiert werden sollen. Standard-
mäßig werden diese im Schema public angelegt. Um dies zu verhindern, kann dem
SymmetricDS-Datenbanknutzer ein Standardsuchpfad zugewiesen werden, wie dies in
Listing 6.3 demonstriert wird.
1 # Unter der Annahme dass die SymmetricDS -Systemtabellen
2 # im Schema ’sym’ installiert werden sollen
3 CREATE USER sym_user LOGIN PASSWORD ’secr3t ’;
4 GRANT USAGE ON SCHEMA sym TO sym_user;
5 GRANT CREATE ON SCHEMA sym TO sym_user;
6 ALTER USER sym_user SET SEARCH_PATH TO sym ,public ,pg_catalog;
Listing 6.3: Erstellen eines SymmetricDS-Nutzers
Neben diesen Nutzerrechten braucht der SymmetricDS-Datenbanknutzer das Recht auf
Tabellen, die repliziert werden sollen, zuzugreifen und an ihnen Tabellentrigger zu kre-
ieren. Das Einrichten des Datenbanknutzers muss mit jeder Installation der OpenInfRA-
Anwendung auf dem lokalen Datenbankserver durchgeführt werden. Damit sind alle Vor-
kehrungen getroffen, um die Replikation und Synchronisation einzurichten.
6.4 Datenmodell
SymmetricDS stellt ein umfassendes Datenmodell zur Verfügung, über welche die Re-
plikation und Synchronisation feingranular konfiguriert werden kann. Für einen Überblick
sind in Abbildung 22 die wichtigsten hierfür genutzten Entitäten gegeben und ihre Be-
ziehungen untereinander dargestellt. Die Übersicht soll in erster Linie dazu dienen, die
folgenden Erläuterungen nachvollziehbar zu machen. Eine detailliertere Aufstellung wird
in der Dokumentation geboten. (Long u. a. 2013, S. 99ff.)
6.4.1 Konfigurationstabellen
• Node: Die Tabelle enthält die Definition der Datenbankinstanzen, die an der Syn-
chronisation teilnehmen. Während eine durch den Nutzer selbst gewählte externe
ID (external_id) den Knoten entsprechend seiner Domäne identifiziert, wird eine

6 Implementierung 57
Node
Node Identity
Node Security
Node Group
Node Group Link
Router Trigger_Router Trigger
Channel
Node Channel Ctl
Abbildung 22: ER-Diagramm der zur Konfiguration von SymmetricDS genutztenSystemtabellen. (ebd., S. 99)
eindeutige Knoten-ID (node_id) genutzt, um die Instanz im System zu erkennen.
Darüber hinaus werden in dieser Tabelle die Gruppenzugehörigkeiten der Knoten
zugeteilt.
• Node Security: Neben den Authentifizierungsparametern der Knoten, die mit die-
ser Instanz kommunizieren dürfen, wird hier verwaltet, ob für einen Server die Re-
gistrierung geöffnet wurde, er diese bereits abgeschlossen hat und ein initialer Da-
tenbestand gesendet wurde.
• Node Identity: Enthält lediglich eine einzige Zeile, die die Identität des Knoten an-
hand seiner node_id repräsentiert. Für die Mutter-Instanz der Replikationshierar-
chie wird diese Zeile händisch eingetragen. Alle nachfolgenden Instanzen erhalten
ihre „Identität“ mit der Registrierung bei einem Elternknoten.
• Node Group: Enthält die Definition der verschiedenen Knoten-Gruppen, die zur
Kategorisierung der Knoten genutzt werden kann. Typisch ist eine hierarchische
Topologie. Die Zuordnung konkreter Knoten in Gruppen erfolgt in der Tabelle „No-
de“.
• Node Group Link: Zuordnung der Kommunikationswege zwischen Knoten-Gruppen
nach Pull-, in diesem Zusammenhang als Wait (W) bezeichnet, und Push-Verfahren
(P). Ohne einen „Link“ zwischen den Gruppen ist keine Synchronisation zulässig.
Sollen Daten bidirektional zwischen den Gruppen ausgetauscht werden, müssen
für beide Richtungen Tupel angelegt werden.
• Channel: Kanäle kategorisieren abgeschlossene Einheiten von Verlaufsdaten, die
unabhängig voneinander synchronisiert werden sollen. Fehler bei der Synchronisa-

6 Implementierung 58
tion eines Kanals lassen andere davon unberührt.
• Node Channel Control: Dient der Kontrolle der Synchronisationskanäle auf Ebene
der einzelnen Knoten.
• Trigger: Über die Entität „Trigger“ werden die konkreten Tabellentrigger definiert,
die durch den Synchronisationsservice in der Datenbank installiert werden. Dabei
lässt sich insbesondere auch bestimmen, ob nur eine Teilmenge der Operationen
INSERT, UPDATE und DELETE zu CDC-Protokolleinträgen führen soll.
• Router: Über Router lässt sich der Vorgang des „Batching“ konfigurieren. Hier wird
eingestellt, wie der Synchronisationsservice im Betrieb die Verlaufsdaten in Bat-
ches zuweist, die letztendlich an die Synchronisationspartner gesendet werden.
• Trigger_Router: Hierbei handelt es sich um eine Join-Tabelle, welche die Verbin-
dung zwischen den Datenbanktriggern und den Routern herstellt.
• Conflict: Die Tabelle „Conflict“ dient der Definition der Art der Konflikterkennung
und -lösung auf Höhe der Kanäle.
Die initiale Konfiguration der Replikation erfolgt auf dem Mutter-Knoten. Änderungen an
der Konfiguration werden ausgehend von diesem Knoten an alle Kind-Instanzen bei der
Synchronisation in einem separaten Kanal übertragen. Neben diesen Konfigurationsta-
bellen dient eine Reihe weiterer Tabellen zur Organisation des Transaktionsprotokolls und
der Durchführung des Synchronisationsvorgangs. Die Entitäten sind mit ihren Beziehun-
gen in Abbildung 23 dargestellt.
6.4.2 Datentabellen
• Data: Enthält die Captured Data Changes, die durch Trigger aufgezeichnet wurden.
Dabei wird neben der Art der Operation, die zur Änderung geführt hat, den neuen
und alten Attributwerten auch diejenige Knoten-ID gesichert, auf der die Änderung
stattgefunden hat. Darüber hinaus wird die interne Transaktions-ID des Datenbank-
servers hinterlegt, um bei der Synchronisation Änderungen atomar zu gruppieren
und einzuspielen. Der Zeitpunkt der Protokollierung wird zur Information mit der lo-
kalen Uhrzeit und einer logischen Zeit in Form eines monoton steigenden Zählers
versehen.
• Data Event: Daten-Events stellen die Zuordnung zwischen den lokalen protokollier-
ten Änderungen und den Empfängern dieser Änderungen dar. Da über die Zuord-
nung von Triggern und Router eine feingranulare Kontrolle darüber besteht, welcher
Knoten welche Änderungen empfangen soll, ist diese Zuordnung hier nötig.
• Outgoing Batch: Ein Batch ist eine abgeschlossene Einheit von Operationen, die
lokal protokolliert wurden und für die Synchronisation an einen Empfänger gesen-

6 Implementierung 59
Node
Node Channel Ctl
Outgoing Batch
Node CommunicationData Event
Data Trigger History
TriggerChannel
Incoming Batch
Incoming Error
Abbildung 23: ER-Diagramm der an der Protokollierung von Änderungen undSynchronisation beteiligten Systemtabellen. (ebd., S. 100)
det werden. Data-Events referenzieren Outgoing Batches.
• Incoming Batch: Enthält von Synchronisationspartnern empfangene Batches und
stellt so das logische Gegenstück zu Outgoing Batches dar.
• Incoming Error: Als Incoming Error werden Operationen vermerkt, welche in ei-
nem Batch empfangen wurden und im Konflikt zum lokalen Datenbestand stehen.
6.5 Einrichten der Replikationshierachie eines Projekts
Um die Replikation der Projektdaten im Sinne des Mutter-Kind-Konzepts umzusetzen,
wird im Folgenden damit begonnen, eine Standardkonfiguration zu erstellen, die für die
Nutzung bei den jeweiligen Projekten leicht angepasst werden kann. Dafür werden Kind-
Instanzen als Knoten in Knoten-Gruppen, auch als Tier bezeichnet, geordnet und durch
Einträge in der Tabelle Node Group bekannt gemacht. Für die prototypische Implemen-
tierung für ein OpenInfRA Projekt wurden vier Hierarchieebenen vorgesehen, die in der
Praxis etwa durch die Mutter-Instanz auf einem zentralen Server, Desktop-Rechner im
Büro und Laptops für die Feldarbeit belegt werden können (s.a. Abbildung 5). Damit steht
eine weitere Ordnungsebene gewissermaßen als Backup zur Verfügung. Die Definition

6 Implementierung 60
weiterer Tier kann zu einem späteren Zeitpunkt erfolgen und ist in ihrer Tiefe unbegrenzt.
Das folgende Listing 6.4 zeigt die vorgeschlagene Konfiguration:
1 INSERT INTO sym_node_group (
2 node_group_id ,
3 description ,
4 create_time ,
5 last_update_by ,
6 last_update_time
7 ) VALUES
8 (’mother ’, ’Mutter -Instanz - Zentraler Server ’, current_timestamp ,
current_user , current_timestamp),
9 (’office ’, ’2. - Desktop ’, current_timestamp , current_user ,
current_timestamp),
10 (’mobile ’, ’3. - Laptops für Au ß endienst ’, current_timestamp , current_user
, current_timestamp),
11 (’rover’, ’4. - Laptops für Au ß endienst ’, current_timestamp , current_user ,
current_timestamp);
Listing 6.4: Konfiguration der Knoten-Hierarchie
Nachdem die Hierarchie angelegt wurde, gilt es den Datenfluss zwischen den Ebenen als
Synchronisation zu definieren. Hierzu dient die Tabelle Node Group Link, in der Verbin-
dungen nach dem Push- (P) oder Pull-Verfahren (W) eingefügt werden. Für eine bidirektio-
nale Synchronisation sind jeweils ein Eintrag für den Down- und den Upstream zwischen
Eltern- und Kind-Instanz nötig. Für Offline-Instanzen ist hier das Push-Verfahren geeig-
net, welches diese zum Einleiten der Synchronisation verpflichtet. Die Eltern-Instanz war-
tet damit auf eine Kontaktaufnahme der Kind-Instanz. Diese führt zur Synchronisation je-
weils eine Pull-Anweisung durch, bei der sie Änderungen vom Eltern-Knoten einholt, und
eine „Push“-Anweisung, bei der sie die lokalen Änderungen übermittelt. Die Reihenfol-
ge bestimmt dabei, auf welchem Knoten eventuelle Synchronisationskonflikte bearbeitet
werden.
1 INSERT INTO sym_node_group_link (
2 source_node_group_id ,
3 target_node_group_id ,
4 data_event_action ,
5 create_time ,
6 last_update_by
7 ) VALUES
8 (’office ’, ’mother ’, ’P’, current_timestamp , current_user),
9 (’mother ’, ’office ’, ’W’, current_timestamp , current_user),
10 (’mobile ’, ’office ’, ’P’, current_timestamp , current_user),

6 Implementierung 61
11 (’office ’, ’mobile ’, ’W’, current_timestamp , current_user),
12 (’rover’, ’mobile ’, ’P’, current_timestamp , current_user),
13 (’mobile ’, ’rover ’, ’W’, current_timestamp , current_user);
Listing 6.5: Einrichten von Pull- und Push-Verbindungen
Der Unterschied zwischen Pull- und Push-Verfahren lässt sich am folgenden Sequenzdia-
gramm besser nachvollziehen. Sie unterscheiden sich insbesondere durch den Einsatz
der HTTP-Verben GET, POST, PUT und HEAD.
Eltern-InstanzKind-Instanz
Push
OK to Push? (HTTP HEAD)
Push (HTTP PUT)
Pull
Pull (HTTP GET)
ack (HTTP POST)
Abbildung 24: Einsatz der HTTP-Verben beim Synchronisationsvorgang. (Darstellungnach Long (2012))
6.6 Protokollieren von Verlaufsdaten
Um Änderungen in den Tabellen zu loggen, werden Datenbanktrigger eingesetzt, die
die Zeilenattribute in der Reihenfolge der Ausführung in die Verlaufstabelle Data eintra-
gen. Jeder Trigger ist dabei einem „Datenkanal“ (engl. Channel) zugeordnet, der die Än-
derungen bei der Übertragung und Synchronisation gegenüber Änderungen in anderen
Kanälen isoliert. Wird einer dieser Kanäle ausgebremst, weil beispielsweise ein Konflikt
bei der Synchronisation aufgetreten ist, hat dies so keinen Einfluss auf andere Kanä-
le. Zu beachten ist, dass insbesondere Trigger der Tabellen einem gemeinsamen Kanal
zugeordnet werden müssen, welche in einer Fremdschlüsselbeziehung zueinander ste-
hen, einen semantischen Zusammenhang bilden und deren Änderungen auch auf dem
Synchronisationspartner in der gleichen Reihenfolge ausgeführt werden müssen. So ist
vermeidbar, dass die Synchronisation später aufgrund eines fehlenden Fremdschlüssels
scheitert. Mit der Installation der Systemtabellen und der Initialisierung bestehen bereits

6 Implementierung 62
die Kanäle default und config, welche die Synchronisation der Konfigurationsparameter
kapseln. Für die Projektdaten der OpenInfRA-Anwendung soll ein eigener Kanal definiert
werden.
1 INSERT INTO sym_channel (
2 channel_id ,
3 processing_order ,
4 max_batch_size ,
5 max_batch_to_send ,
6 enabled ,
7 batch_algorithm ,
8 description ,
9 create_time , last_update_by , last_update_time
10 ) VALUES (
11 ’project_data ’,
12 100,
13 10000,
14 100,
15 1,
16 ’default ’,
17 ’Projektdaten des Projekts Pergamon ’,
18 current_timestamp , current_user , current_timestamp
19 );
Listing 6.6: Definition eines Datenkanals
Listing 6.6 zeigt die hierfür vorgeschlagene Konfiguration. Die processing_order gibt
an, in welcher Reihenfolge die Kanäle übertragen und synchronisiert werden sollen. Die
Standardkanäle default (Priorität 0) und config (Priorität 1) sollten eine höhere Priori-
tät behalten, um sicherzustellen, dass geänderte Einstellungen zuerst ihren Weg auf die
Repliken-Manager finden. Darüber hinaus wird definiert, wie viele Änderungen in einer
Übertragungseinheit zusammengefasst werden sollen. Ein zu kleiner max_batch_size
würde zu einer unnötig großen Menge an Batches führen. Ein Wert von 10000 Ände-
rungen, bzw. 10000 Schreibvorgängen erscheint hingegen vertretbar und entspricht dem
vorgeschlagenen Standard. Der batch_algorithm bestimmt, auf welche Art und Weise
die lokalen Transaktionsklammern bei der Bildung der Batches berücksichtigt werden.
Zur Verfügung stehen die Algorithmen transactional, nontransactional und default.
Ersteres diktiert genau eine Transaktion in einen Batch und ignoriert damit den Wert für
die maximale Batch-Größe. Nontransaktional bewirkt das Gegenteil, das heißt Transak-
tionsklammern werden komplett ignoriert, wodurch die Atomarität einer Transaktion über
die Grenzen der maximalen Batch-Größe verloren gehen kann. Default stellt den hier ge-
eignetsten Algorithmus dar, bei dem einerseits die Transaktionsklammern beim Routing

6 Implementierung 63
berücksichtigt und andererseits mehrere Transaktionen einem Batch zugewiesen werden,
bis dieser „voll“ ist.
Nun können dem Kanal entsprechende Trigger zugeordnet werden, wie es im Folgenden
demonstriert wird:
1 -- CDC -Trigger
2 INSERT INTO sym_trigger (
3 trigger_id ,
4 source_schema_name ,
5 source_table_name ,
6 channel_id ,
7 last_update_time , last_update_by , create_time
8 )
9 VALUES (
10 ’PT_FreeText ’,
11 ’Projektdatenbank_v10 ’,
12 ’PT_FreeText ’,
13 ’project_data ’,
14 current_timestamp , current_user , current_timestamp
15 );
Listing 6.7: Einrichten der CDC-Trigger einer replizierten Relation
Bei einem umfassenden Datenmodell, das über mehrere Datenbankinstanzen repliziert
werden soll, wird die Definition von Triggern auf die Art, wie sie in Listing 6.7 demonstriert
ist, schnell unübersichtlich, da hier jede einzelne Tabelle bedacht werden muss. Wird
ohnehin das gesamte Schema verteilt, können ähnlich der Regex-Notation die zu diesem
Zweck verfügbaren Wild Card-Zeichen genutzt werden, um mehrere Tabellen gleichzeitig
mit einzubeziehen. Für die Konfiguration für die OpenInfRA-Projektdatenbank bietet sich
die Ausweitung auf alle Tabellen im Schema der Projektdatenbank an. In diesem Fall ist
das folgende Listing maßgeblich:
1 INSERT INTO sym_trigger (
2 trigger_id ,
3 source_schema_name ,
4 source_table_name ,
5 channel_id ,
6 sync_on_incoming_batch ,
7 create_time , last_update_by , last_update_time
8 ) VALUES
9 (’project_data_trigger ’,
10 ’Projektdatenbank_v10 ’,
11 ’*’,

6 Implementierung 64
12 ’project_data ’,
13 1,
14 current_timestamp , current_user , current_timestamp);
Listing 6.8: Einrichten der CDC-Trigger via Wild Card
Nachdem die neue Konfiguration durch den Synchronisationsservice erkannt wurde, wer-
den die entsprechenden Datenbanktrigger an den Tabellen installiert und Änderungsope-
rationen schließlich in der Verlaufstabelle „Data“ protokolliert. Die zuvor beschriebenen
Router dienen an dieser Stelle letztendlich dazu, zu bestimmen, welche Änderungen an
welche Knoten-Gruppe übertragen werden sollen. Dem Attribut sync_on_incoming_batch
kommt hier eine besondere Wichtigkeit zu. Es bewirkt, dass bei der Synchronisation emp-
fangene Änderungen bei der Anwendung auf den lokalen Datenbestand wieder neue
CDC-Events triggern und die resultierenden Verlaufsdaten an die entsprechend nachfol-
genden Ebenen der Replikationshierarchie weitergeleitet werden können. Um hier eine
zirkuläre Beziehung zwischen Sender und Empfänger zu verhindern, wird die Knoten-ID
des Senders berücksichtigt. Listing 6.9 demonstriert einen Router zwischen den Hierar-
chieebenen mother, also der Mutter-Instanz, als Sender und office als Empfänger.
Die Join-Tabelle Trigger_Router erlaubt letztlich eine feingranulare Konfiguration, die be-
stimmt, welche lokalen Änderungen an welche Knoten-Gruppe gesendet werden sollen.
Die initial_load_order gibt dabei an, in welcher Reihenfolge diese Konfiguration beim
Senden des initialen Datenbestands bedient wird. Der initial_load_select erlaubt nur
bestimmte Zeilen der Tabelle beim Übermitteln des ersten Datenbestands zu berücksich-
tigen, also die Tabelle zu fragmentieren.
1 INSERT INTO sym_router (
2 router_id ,
3 source_node_group_id ,
4 target_node_group_id ,
5 router_type ,
6 create_time , last_update_by , last_update_time
7 )
8 VALUES (
9 ’mother_2_office ’,
10 ’mother ’,
11 ’office ’,
12 ’default ’,
13 current_timestamp , current_user , current_timestamp
14 );
15
16 INSERT INTO sym_trigger_router (
17 trigger_id ,

6 Implementierung 65
18 router_id ,
19 initial_load_order ,
20 initial_load_select ,
21 create_time , last_update_by , last_update_time
22 )
23 VALUES (
24 ’project_data_trigger ’,
25 ’mother_2_office ’,
26 100,
27 null ,
28 current_timestamp , current_user , current_timestamp
29 );
Listing 6.9: Einrichten eines Router
Ähnlich der Konfiguration zur Synchronisation von Änderungen in der Datenbank verhält
sich die Konfiguration externer Daten. Dies kann genutzt werden, um sowohl externe Pro-
jektdate, als auch externe Konfigurations- oder Systemdateien zwischen den Instanzen
zu synchronisieren.
6.7 Synchronisation externer Dokumente
Die Konfiguration der Synchronisation externer Dokumente und Dateien erfolgt ebenfalls
über die SymmetricDS-Systemtabellen. Die Logik bei der Vorgehensweise ist der Daten-
banksynchronisation sehr ähnlich. Statt CDC-Trigger über die Tabelle Trigger einzurich-
ten, werden Java BeanShell Scripts über die Tabelle File Trigger definiert. Der File Tra-
cker Job untersucht darauf periodisch die definierten Ordner und gleicht Zeitstempel und
Checksummen der Dateien ab. Dabei kann zusätzlich nach Dateiname und -endung gefil-
tert werden, um beispielsweise nur PDF-Pläne von der Mutter-Instanz auf Kind-Instanzen
zu replizieren. Auch dieser Prozess muss im Offline-Betrieb auf den Kind-Instanzen nicht
durchgehend ausgeführt werden, sondern begnügt sich mit dem Auslesen der Ände-
rungszeitpunkte der Dateien vor der Synchronisation. Durch die Nutzung von BeanShell-
Skripten, welche über die lokale Java JVM ausgeführt werden, ist der Service betriebs-
systemunabhängig. Das Hinzufügen, Ändern und Löschen von Dateien wird in der Tabel-
le „File Snapshot“ durch Dateipfad, Dateiname, CRC32-Checksumme und weitere Merk-
male verbucht. Wie bei der Definition „normaler“ Tabellentrigger, werden die File Trigger
über bereits zuvor definierte Router (s. Abschnitt 6.6) an die designierten Empfänger
vermittelt.
Listing 6.10 zeigt die Definition eines File-Triggers für den Medienordner eines Teilpro-
jekts und die Zuordnung zu einem der bereits zuvor definierten Router. Die Synchronisa-

6 Implementierung 66
tion weiterer Ordner bspw. für externe Konfigurationsdateien der OpenInfRA-Anwendung
kann auf die gleiche Weise erfolgen.
1 -- File Trigger
2 INSERT INTO sym_file_trigger (
3 trigger_id ,
4 base_dir ,
5 recurse ,
6 includes_files ,
7 excludes_files ,
8 sync_on_create , sync_on_modified , sync_on_delete ,
9 before_copy_script ,
10 after_copy_script ,
11 create_time , last_update_by , last_update_time
12 ) VALUES (
13 ’baalbek_directory ’,
14 ’../ OpenInfRA/Media/baalbek ’,
15 1,
16 ’*.pdf’,
17 null ,
18 1,1,1,
19 ’targetBaseDir = System.getEnv ().get(" OPENINFRA_MEDIA_BAAL ");’,
20 null ,
21 current_timestamp , current_user , current_timestamp
22 );
23
24 -- Trigger -Router
25 INSERT INTO sym_file_trigger_router (
26 trigger_id ,
27 router_id ,
28 enabled , initial_load_enabled ,
29 target_base_dir ,
30 conflict_strategy , create_time , last_update_by , last_update_time
31 )
32 VALUES
33 (
34 ’baalbek_directory ’,
35 ’mother_2_office ’,
36 1, 1,
37 ’’,
38 ’SOURCE_WINS ’,
39 current_timestamp , current_user , current_timestamp
40 );
Listing 6.10: Zuordnung Router - Trigger

6 Implementierung 67
Die Spalten before_copy_script und after_copy_script erlauben die Definition eige-
ner BeanShell Skripte, die auf dem Empfänger-Knoten ausgeführt werden. So kann bei-
spielsweise über die Java-Klasse System auf die Environment-Variablen des Systems
zugegriffen werden, um den Zielpfad der Dateien bei der Synchronisation zu bestimmen.
Es ist so möglich, die unterschiedlichen Konventionen der Pfadangabe zwischen Win-
dows und unixoiden Systemen zu berücksichtigen und schließlich im Skript die Variable
targetBaseDir anzupassen.
Die Übertragung der zu synchronisierenden Dateien erfolgt als Zip-Archiv gepackt über
den konfigurierten Web-Server. Auf Seite des Empfängers wird das Archiv entpackt, das
enthaltene BeanShell Skript interpretiert und die Dateien anschließend an ihren relativen
Pfad verschoben. Dabei wird geprüft, ob das Ablegen der Datei einen Konflikt verur-
sacht. Sollte dem so sein, kann eine Priorisierung der bestehenden oder empfangenen
Datei bestimmt werden (Spalte conflict_strategy). Zu beachten ist, dass hierdurch das
Überschreiben der Dateien verursacht werden kann, wenn beide Instanzen diese verän-
dert haben. Die Anwendungsebene sollte hier sicherstellen, dass bei Änderungen neue
Versionen angelegt werden.
Damit ist die Konfiguration der Replikationshierarchie und des Datenflusses beendet und
die Mutter-Instanz eines Projekts kann für die Replikation eingerichtet werden.
6.8 Mutterknoten einrichten
Der Root-Knoten bzw. die Mutter-Instanz der Replikationshierarchie muss bei der Ein-
richtung einer Replikation händisch initialisiert werden. Dafür wird der Knoten im System
„registriert“, indem in den Tabellen Node und Node Security entsprechende Einträge vor-
genommen werden. Anschließend kann die Identität des Mutter-Knoten in der Tabelle
Node Identity zugewiesen werden. Bei der Erstellung von Kind-Instanzen wird dieser
Vorgang automatisch durch die Registrierung an einer Eltern-Instanz durchgeführt.
1 -- Mutter -Instanz definieren
2 INSERT INTO sym_node (
3 node_id ,
4 node_group_id ,
5 external_id ,
6 sync_enabled ,
7 schema_version
8 ) VALUES (
9 ’pergamon -mother -000’,
10 ’mother ’,

6 Implementierung 68
11 ’pergamon -mother -000’,
12 1,
13 ’10’
14 );
15
16 INSERT INTO sym_node_security (
17 node_id ,
18 node_password ,
19 registration_time ,
20 initial_load_time ,
21 created_at_node_id
22 ) VALUES (
23 ’pergamon -mother -000’,
24 ’secr3t ’,
25 current_timestamp ,
26 current_timestamp ,
27 ’pergamon -mother -000’
28 );
29
30 -- Identität zuweisen
31 INSERT INTO sym_node_identity VALUES (’pergamon -mother -000’);
Listing 6.11: Registrieren der Mutter-Instanz
Durch das Setzen der Attribute registration_time und initial_load_time wird der
Knoten beim Starten des Synchronisationsservices als „aktiv“ erkannt und steht nun für
die Kontaktaufnahme bereit.
6.9 Erstellen einer Kind-Instanz
Die Voraussetzung zum Erstellen einer Kind-Instanz ist eine initialisierte Elterninstanz,
welche für die Registrierung erreichbar ist. Auf dem Computer müssen ein Datenbank-
server und der SymmetricDS-Service installiert sein (s. Abschnitt 6.1). Für das Laden
der Projektdaten ist außerdem eine initialisierte Datenbank mit dem Projektdatenschema
vonnöten.
Das Erstellen einer Kind-Instanz ist dem Erstellen einer Mutter-Instanz sehr ähnlich. Hier-
für wird für die neue Instanz „die Registierung geöffnet“, indem an der gewählten Eltern-
Instanz identifizierende Einträge in den Tabellen Node und Node Security gemacht wer-
den. Diese Registrierung am Eltern-Knoten kann entweder durch SQL oder über das Tool
symadmin erfolgen:

6 Implementierung 69
1 ./ symadmin --engine pergamon -mother -000 open -registration office pergamon -
office -001
Listing 6.12: Öffnen der Registrierung eines Kind-Knoten am Eltern-Knoten per
symadmin
1 INSERT INTO sym_node (
2 node_id ,
3 node_group_id ,
4 external_id ,
5 sync_enabled ,
6 schema_version
7 )
8 VALUES (’pergamon -office -001’, ’office ’, ’pergamon -child -101’, 1, ’10’);
9
10 INSERT INTO sym_node_security (
11 node_id ,
12 node_password ,
13 registration_enabled ,
14 registration_time ,
15 initial_load_time ,
16 created_at_node_id
17 )
18 VALUES (’pergamon -office -001’, ’secr3t ’, 1, null , null , ’pergamon -mother
-000 ’);
Listing 6.13: Öffnen der Registrierung eines Kind-Knoten am Eltern-Knoten per SQL
Nachdem diese Einstellungen vorgenommen wurden, kann der Synchronisationsservice
auf dem Kind-Knoten gestartet werden. Dieser wird den Kontakt über die definierte Re-
gistrierungs-URL (s. Abschnitt 6.3) aufnehmen und die Registrierung mit der Eltern-
Instanz abschließen. Die Kind-Instanz erhält damit eine registration_time und be-
kommt eine eigene node_id zugewiesen. Enthält die Konfiguration Trigger, welche durch
einen Eintrag in der Tabelle Trigger_Router auf diese Instanz zutreffen, werden diese
automatisch an den entsprechenden Tabellen installiert.
Um letztendlich die Projektdaten selbst auf dem neuen Knoten zur Verfügung stellen zu
können, muss der Datenbestand vom Elternknoten an diesen übermittelt werden. Dazu
dient das sogenannte „initial load“-Event, das auf dem Elternknoten auf mehreren We-
gen ausgelöst werden kann. Für eine Standalone-Installation kann wiederum das Kom-
mandozeilentool symadmin genutzt werden. Alternativ hat das Aktivieren des Attributs
initial_load_enabled in der Node Security-Tabelle den gleichen Effekt.

6 Implementierung 70
1 -- symadmin
2 ./ symadmin --engine pergamon -mother -000 reload -node pergamon -office -001
3
4 -- SQL
5 UPDATE sym.sym_node_security
6 SET initial_load_enabled = 1
7 WHERE node_id = ’pergamon -child -101’;
Listing 6.14: Online-Initialisierung einer Kind-Instanz.
Durch dieses Flag werden beim nächsten Synchronisationsvorgang alle Daten an die
Kind-Instanz übermittelt, welche durch die Konfiguration der Trigger und Router für die-
se von Bewandtnis sind. Außerdem wird für diesen Knoten anschließend das Attribut
initial_load_time gesetzt, was ihn dazu berechtigt, selbst Registrierungen anzuneh-
men.
Soll ein großer Datenbestand übertragen werden, ist es unter Umständen besser, die-
sen manuell auf der Kind-Instanz einzuspielen. Dafür werden die betreffenden Tabellen
am Elternknoten exportiert, die Registrierung für die designierte Kind-Instanz geöffnet
und die Datensätze schließlich am Kind-Knoten importiert. Für den Export können so-
wohl die Datenbankfunktionen (pg_dump) als auch die durch SymmetricDS zur Verfügung
gestellten Funktionen genutzt werden, welche leichter in eine Anwendung zu integrieren
sind. Statt nun ein Reload-Event nach der Registrierung auszulösen, muss lediglich das
Attribut initial_load_time in der Tabelle Node Security auf die Exportzeit gesetzt wer-
den. Die Einstellung ist nicht zwingend für die Synchronisation zwischen diesen beiden
Partnern notwendig, allerdings ist es dem neuen Kind-Knoten nur mit einem definierten
Initialisierungszeitpunkt möglich, selbst Registrierungen zuzulassen. Durch Öffnen der
Registrierung beim Export der Projektdaten ist die Eltern-Instanz angehalten, Verlaufs-
daten für die neue Kind-Instanz zu sammeln, die zwischen Import und und Abschluss der
Registrierung anfallen. So ist sichergestellt, dass nach der Synchronisation ein konsis-
tenter Zustand zwischen den Instanzen herrscht.
Alternativ zum manuellen Registrieren der Kind-Knoten kann für einen Eltern-Knoten in
der Properties-Datei die Einstellung auto.registration aktiviert werden, welche die Re-
gistrierung automatisch öffnet, wenn eine neue Instanz diese kontaktiert. Hinzu kommt
die Möglichkeit, mit jeder neuen Registrierung den entsprechenden Datenbestand zu
übertragen, ohne dies explizit starten zu müssen. Hierzu dient die Einstellung auto.reload.
Um sicherzustellen, dass der Kind-Knoten keine Daten enthält, die vom initialen Bestand
abweichen, können die Tabellen durch initial.load.delete.first geleert werden.

6 Implementierung 71
6.10 Synchronisation
Die Synchronisation erfolgt beim Starten des Synchronisationsservices bzw. anschlie-
ßend nach den konfigurierten Intervallen der Pull- bzw. Push-Jobs. Durch die Nutzung
des HTTP-Protokolls kann anhand des HTTP-Header-Felder Content-Length bzw. Con-
tent-MD5 sichergestellt werden, dass das gesamte CSV-Dokument korrekt übertragen
wurde. Der Transport erfolgt dabei komprimiert und, entsprechend der Konfiguration des
Web Servers, verschlüsselt. Tabelle 6.3 gibt Aufschluss über die wichtigsten Parame-
ter.
Tabelle 6.3: Konfigurationsparameter Synchronisation
Parameter Beschreibung
job.route.cron Gibt an, wie oft die aufgelaufenen Verlaufsdaten zu Batches zuge-ordnet werden sollen.
job.push.cron Gibt an, wie oft die definierte Push-Synchronisationen eingeleitetwerden soll.
job.pull.cron Gibt an, wie oft die definierte Pull-Synchronisationen eingeleitetwerden soll.
Soll die Synchronisation für eine Offline-Instanz komplett pausiert werden, ist es lediglich
nötig, den Synchronisationsdienst zu stoppen. Änderungen werden weiterhin durch die
Datenbanktrigger aufgezeichnet. Sobald der Synchronisationsservice wieder gestartet
wird, werden die aufgelaufenen Änderungen in Batches organisiert und eine Synchroni-
sation gestartet. Es ist möglich, den Synchronisationsservice stetig gestartet zu lassen,
auch wenn keine Datenverbindung verfügbar ist. Die Synchronisation wird dann entspre-
chend der definierten Cron-Jobs mit der nächsten Gelegenheit ausgeführt.
Da das periodische Synchronisieren nicht in jedem Fall sinnvoll ist, wurde das Konso-
lentool symadmin um Hilfsfunktionen zum manuellen Starten des Push- und Pull-Jobs
erweitert (s. Listing 6.15). Vor einem „Push“ wird ein Routing-Vorgang eingeleitet, der
angelaufene Änderungen in Batches zusammenfasst. Anschließend werden die Batches
an die Eltern-Instanz übermittelt. Die Implementierung ist dabei denkbar einfach, da auf
bestehende Service-Schnittstellen zurückgegriffen werden kann. So lässt sich nicht nur
der Zeitpunkt kontrollieren, an dem eine Synchronisation durchgeführt wird, sondern es
kann auch entschieden werden, ob potentiell konfliktverursachende Operationen einge-
holt werden sollen, um diese lokal zu lösen.
1 private void pushNode(CommandLine line , List <String > args) {
2 ISymmetricEngine engine = getSymmetricEngine ();
3 engine.getRouterService ().routeData(true);
4 engine.getPushService ().pushData(true);

6 Implementierung 72
5 }
6
7 private void pullNode(CommandLine line , List <String > args) {
8 ISymmetricEngine engine = getSymmetricEngine ();
9 engine.getPullService ().pullData(true);
10 }
11
12 private void syncNode(CommandLine line , List <String > args) {
13 pullNode(line , args);
14 pushNode(line , args);
15 }
Listing 6.15: Hilfsfunktionen zum manuellen Senden und Empfangen von
Synchronisationsdaten. (Paket org.jumpmind.symmetric.SymmetricAdmin.java)
6.11 Offline-Synchronisation
Die Offline-Synchronisation stellt keine Standardfunktion von SymmetricDS dar, kann
aber über die bestehenden Funktionen realisiert werden. Batches werden dafür als CSV-
Dateien in das Dateiverzeichnis exportiert und auf der Gegenseite importiert. Es handelt
sich dabei um das gleiche Format, das für die Online-Synchronisation angewandt wird.
Beim Import ist dann darauf zu achten, dass Batches immer in der sequentiellen Reihen-
folge ihrer ID ausgeführt werden.
1 ./ symadmin --engine pergamon -mother -000 export -batch pergamon -child -001 178
178. csv
2 ./ symadmin --engine pergamon -child -001 import -batch 178. csv
Um zu verhindern, dass der bereits offline importierte Batch ein weiteres Mal bei einer
Online-Synchronisation an den Empfänger versendet wird, und damit unnötiger Netz-
werktraffic entsteht, kann der Status in der Tabelle outgoing_batches auf „OK“ gesetzt
werden. Dies sollte aber nur dann geschehen, wenn sichergestellt ist, dass der Batch
wirklich abgearbeitet wurde. Ein mehrfacher Import durch den Empfänger ist durch die
Identifizierung per Node-Id und Batch-ID nicht möglich. Diese Vorgehensweise ist ver-
gleichbar mit der in Abschnitt 4.3.3 vorgestellten manuellen Synchronisation mit Arc-
GIS.

6 Implementierung 73
6.12 Konfliktlösung
Natürlich können auch bei der Synchronisation mit SymmetricDS Konflikte auftreten, die
entsprechend behandelt werden müssen. In der Standardeinstellung wird SymmetricDS
bei einem Konflikt probieren, die empfangene Änderung auf den lokalen Datenbestand
anzuwenden, indem die Operation semantisch angepasst wird. Das bedeutet, dass für
ein Tupel, das in einer Relation unvorhergesehen schon vorhanden ist, ein INSERT in ein
UPDATE und ein UPDATE bei einem nicht vorhandenen Datensatz in ein INSERT gewan-
delt wird. Das Löschen eines bereits entfernten Datensatzes wird lediglich geloggt. Wäh-
rend diese Funktionsweise für eine unidirektionale Synchronisation passend sein kann,
ist dies für Projektdaten der OpenInfRA-Anwendung nicht geeignet, da keine Kontrolle
stattfindet, ob Attribute vor Anwendung der Operation zwischen den Synchronisations-
partnern divergieren und lokale Änderungen im Sinne eines Lost Update überschrieben
werden.
Besser ist hier eine Konflikterkennung, die nicht nur die Primärschlüssel vergleicht, son-
dern dafür auch die Spaltenwerte berücksichtigt. In Abschnitt 6.10 wurde dies bereits als
datensatzbasierte Synchronisation definiert. Die Konfliktlösung soll manuell erfolgen, um
dem Nutzer volle Kontrolle über Änderungen zu geben. Hierfür können entsprechende
Strategien in der Tabelle Conflict definiert werden:
1 INSERT INTO sym.sym_conflict (
2 conflict_id ,
3 source_node_group_id ,
4 target_node_group_id ,
5 target_channel_id ,
6 detect_type ,
7 resolve_type ,
8 ping_back ,
9 create_time , last_update_by , last_update_time
10 )
11 VALUES
12 ( ’manual_mother_2_office ’,
13 ’mother ’,
14 ’office ’,
15 ’project_data ’, -- Kanal der Projektdaten
16 ’use_old_data ’, -- Verwende Spaltenwerte vor Änderung zum Abgleich
17 ’manual ’, -- Fehler loggen und auf Nutzerinteraktion warten
18 ’SINGLE_ROW ’, -- Ping Back der Zeile zum Sender nach Konfliktlösung
19 current_timestamp , current_user , current_timestamp
20 );
Listing 6.16: Manuelle Konfliktlösungsstrategie für Projektdaten

6 Implementierung 74
In der in Listing 6.16 gezeigten Konfiguration wird eine manuelle Konfliktlösung auf Höhe
des Projektdatenkanals project_data definiert. So ist der Nutzer angehalten, den Kon-
flikt aufzulösen bevor die empfangenen Änderungen eingespielt werden. Dies garantiert
die Konsistenz des Datenbestands bei voller Kontrolle über die semantische Integrität.
Die Konfliktlösung erfolgt auf Seiten des Empfängers mit Hilfe der Tabellen Incoming
Batch und Incoming Batch Error. Der nachfolgende Query gibt unter anderem Informatio-
nen über den Grund des Konflikts, die betreffende Tabelle, die erwarteten Spaltenwerte,
die beim Sender vor der Änderung bestanden (old_data) und die Spaltenwerte, die neu
eingebracht werden sollen (row_data).
1 SELECT err.*, bat.sql_state , bat.sql_code , bat.sql_message
2 FROM sym_incoming_error AS err
3 INNER JOIN sym_incoming_batch AS bat
4 ON bat.batch_id = err.batch_id
5 AND bat.node_id = err.node_id
6 WHERE bat.status = ’ER’;
7
8 -- Result
9 batch_id = 194
10 node_id = 000
11 failed_row_number = 1
12 failed_line_number = 1
13 target_catalog_name =
14 target_schema_name = Projektdatenbank_v8
15 target_table_name = Landkodierung
16 event_type = U
17 binary_encoding = BASE64
18 column_names = Id ,Landkodierung
19 pk_column_names = Id
20 row_data = "29201d46 -32d1 -4290 -9551 -99 b85e6c6c7c","USA"
21 old_data = "29201d46 -32d1 -4290 -9551 -99 b85e6c6c7c","RUS"
22 cur_data =
23 resolve_data =
24 resolve_ignore =
25 conflict_id = manual_strategy
26 create_time = 2013 -10 -09 16:01:25.955
27 last_update_by = symmetricds
28 last_update_time = 2013 -10 -09 16:01:25.955
29 sql_state = CONFLICT
30 sql_code = -999
31 sql_message = Detected conflict while executing UPDATE on
Projektdatenbank_v8.Landkodierung. The primary key data was: {Id =29201
d46 -32d1 -4290 -9551 -99 b85e6c6c7c }.

6 Implementierung 75
Listing 6.17: Query zum Analysieren von Konflikten im empfangenen Batch
Bis ein solcher Konflikt gelöst ist, werden auf dem betreffenden Kanal zu dem betref-
fenden Knoten keine Batches mehr eingespielt, um die Konsistenz des Datenbestands
zu sichern. Batches werden in diesem Fall nur empfangen, sodass beim Fortsetzen der
Synchronisation an diesem Punkt die Kausalität der Änderungen beibehalten wird. Lö-
sen lässt sich der Konflikt über die Attribute resolve_data oder resolve_ignore. So ist
es möglich, die Attribute zu hinterlegen, die beim nächsten Synchronisationsversuch statt
der in Konflikt stehenden Werte genutzt werden sollen. Alternativ lässt sich die Änderung
ignorieren, beispielsweise da der in der Datenbank hinterlegte Wert dem neuen bereits
gleicht. Die in Listing 6.16 vorgenommene Einstellung ping_back bewirkt, dass die Kon-
fliktlösung beim nächsten Synchronisationsvorgang an den Sender übermittelt und auch
dort als normale Änderung angewandt wird. So ist die Konsistenz zwischen den Synchro-
nisationspartnern wiederhergestellt.
Neben der Konfliktbehandlung beim Empfänger besteht auch die Möglichkeit, Konflikte
auf Seiten des Senders zu bearbeiten. Um Konflikte in ausgehenden Batches aufzude-
cken, wird wiederum das Attribut error_flag in der Tabelle Outgoing Batch genutzt. Es
wird beim Synchronisationsvorgang auf „wahr“ bzw. 1 gesetzt, wenn durch den Empfän-
ger gemeldet wird, dass ein Konflikt ansteht. Über die Batch-ID kann dann nach der ent-
sprechenden Änderung, die den Fehler verursacht, in der Tabelle Data gefiltert werden.
Allgemein ist die Behandlung beim Empfänger vorzuziehen, da auf Seiten des Senders
nur die Möglichkeit besteht, die Änderung oder den gesamten Batch zu ignorieren.
1 -- Batch mit Konflikt bestimmen
2 SELECT * FROM sym_outgoing_batch WHERE error_flag = 1;
3
4 -- Änderung finden die den Konflikt verursacht
5 -- Annahme das Batch 13 im vorhergehenden Schritt bestimmt wurde
6 SELECT * FROM sym_data WHERE data_id IN
7 (SELECT data_id FROM sym_data_event WHERE batch_id=’13’);
Listing 6.18: Auffinden von Konflikten in ausgehenden Batches
Während ein ausgehender Batch einen Konflikt auf einem anderen Knoten verursacht,
ist der lokale Betrieb nicht beeinträchtigt. Die Synchronisation mit anderen Knoten kann
ebenfalls fortgesetzt werden.

6 Implementierung 76
6.13 Purging
Für jede Änderung in den replizierten Tabellen fallen Daten in der Data-Tabelle an. Hinzu
kommen entsprechende Einträge in den Tabellen Data Event, Outgoing und Incoming
Batch und weitere Metadaten. Nachdem die Synchronisation erfolgreich durchgeführt
wurde, sind diese Daten nur noch für die Analyse der Vorgänge von Interesse. Um al-
so Speicherplatz zu sparen, macht es Sinn, diese zu entfernen. Hierfür wird auf jeder
Engine periodisch oder manuell der sogenannte „Purge“-Job ausgeführt, welcher Infor-
mationen über den Status der Batches mit den Informationen verwandter Knoten und
definierten Routern verknüpft und die bereits auf allen Synchronisationspartnern ange-
wandten Verlaufsdaten löscht. Dieser Vorgang ist vergleichbar mit dem Komprimieren der
Geodatenbank, wie sie für ArcGIS in Abschnitt 4.3.3 beschriebene wurde.
6.14 Knoten entfernen
Um einen nicht mehr benötigten oder anderweitig verloren gegangenen Knoten aus dem
System zu entfernen, genügt es, ihn aus den Tabellen seines Elternknoten zu entfernen.
Der in Abschnitt 6.13 beschriebene Purge-Job wird Metadaten und an diesen Knoten
adressierte Batches entfernen und Speicherplatz freigeben. Dieser Vorgang ist unwider-
ruflich, da folgende Änderungen auf dem Eltern-Knoten nicht mehr in Batches an diesen
Knoten adressiert werden. Soll der Computer also später wieder als eine Instanz einge-
richtet werden, muss sie neu registriert werden. Listing 6.19 demonstriert das Entfernen
eines Knoten.
1 CREATE OR REPLACE FUNCTION sym_delete_node(text)
2 RETURNS void AS $body$
3 DELETE FROM sym_node_security WHERE node_id = $1;
4 DELETE FROM sym_node_host WHERE node_id = $1;
5 DELETE FROM sym_node WHERE node_id = $1;
6 $body$ LANGUAGE SQL STRICT VOLATILE;
Listing 6.19: Einfache Hilfsfunktion zum Entfernen einer Kind-Instanz
6.15 Sichern des Kommunikationswegs
Insbesondere bei der Synchronisation mit der zentralen Mutter-Instanz ist eine verschlüs-
selte Datenübertragung wünschenswert. Wird die Instanz über einen bestehenden Web-

6 Implementierung 77
Server abgewickelt (s. Abschnitt 6.1), ist es möglich, die auf diesem Server konfigurierten
SSL-Zertifikate zu nutzen und so die Verbindung zu diesem Server zu verschlüsseln. Die
Java-Runtime sucht nach diesen Zertifikaten in der Regel im Keystore der Java-Installa-
tion. Je nach Gestalt des OpenInfRA-Clients müssen die für die Anwendung generierten
SSL-Keys hier importiert, oder der Java-Pfad entsprechend angepasst werden, um auf
ein lokales Keystore zu verweisen. Um die Synchronisation und Registrierung schließ-
lich über das HTTPS-Protokoll abzuwickeln, genügt es, die entsprechenden Sync- und
Registrierungs-URLs der betreffenden Engines anzupassen. Wird die Synchronisation
über einen bestehenden Anwendungsserver ausgeführt, kann die dort konfigurierte Ver-
schlüsselung genutzt werden.
Alternativ zur Sicherung per SSL besteht die Möglichkeit, die Kontaktaufnahme per HTTP-
Authentifizierung zu sichern. Dieser Weg ist natürlich einfacher zu konfigurieren, stellt
aber nur innerhalb einer „vertrauten“ Umgebung eine Alternative dar. Die Konfiguration
erfolgt via der Parameter http.basic.auth.username bzw. http.basic.auth.password
auf Höhe der Engine.
6.16 Test der Konfiguration
Die in den vorhergehenden Schritten vorgestellte Konfiguration wurde in verallgemeiner-
ter Form als SQL-Skript verfasst und soll, ähnlich wie beim Erstellen des initialen The-
mengerüsts, für eine neue Projektdatenbank für jedes Projekt individuell anpassbar sein.
Das Mutter-Kind-Konzept ist mit einer Vererbungstiefe von vier Ebenen bedacht, kann
aber durch die Administratoren beliebig erweitert werden. Das Hinzufügen neuer Ebenen
ist auch zu einem späteren Zeitpunkt möglich. Die Konfiguration sollte dabei in der Regel
auf der Mutter-Instanz erfolgen, wodurch sie bei der Synchronisation im System verteilt
wird. Die Registrierung neuer Kind-Instanzen kann an einem beliebigen Knoten erfolgen.
Soll die Kind-Instanz aus dem System entfernt werden, muss lediglich die Definition des
Knoten an seiner Eltern-Instanz gelöscht werden.
Da bei der Entwicklung von SymmetricDS bereits Regressionstests zur Anwendung kom-
men, wurde hier davon abgesehen, „Standardszenarien“ der Implementierung zu testen.
Um die Eignung der Konfiguration speziell für OpenInfRA zu prüfen, wurde sie anhand
einer 3-Ebenen Hierarchie mit den bestehenden und neu formulierten Anforderungen ab-
geglichen. Dafür kam das in Tabelle 6.4 gezeigte Setup zum Einsatz, für das der Vorgang
der Initialisierung im Folgenden kurz beschrieben ist.
Auf jedem der Knoten wurde PostgreSQL installiert, eine Datenbank angelegt und ein
entsprechender SymmetricDS-Nutzer erstellt (s. Abschnitt 6.1). Als Datengrundlage diente

6 Implementierung 78
Tabelle 6.4: Testkonfiguration
ID Ebene OS PostgreSQL Eltern-Instanz
000 0 Ubuntu Linux 12.04 VM 9.2101 1 Mac OSX 10.8.3 9.3.1 000102 1 Mac OSX 10.8.3 9.3.1 000201 2 Windows 8.1 9.2 101
ein Testdatenbestand des Pergamon-Projekts, der für das in Abschnitt 5.1 beschriebene
angepasste Datenbankschema generiert wurde und als „initiales Themengerüst“ dienen
soll. Die Engine der Mutter-Instanz wurde für eine automatische Registrierung und Initia-
lisierung von Kind-Instanzen konfiguriert.
Mit dem Start der Engine auf der Mutter-Instanz wurden die SymmetricDS-Systemtabel-
len in das für den Replikationsnutzer definierte Datenbankschema installiert. Anschlie-
ßend wurde die vorhergehend entwickelte Standard-Konfiguration für drei Replikations-
ebenen angepasst und als SQL-Skript auf dem Datenbankserver ausgeführt. Nach dem
Schreiben der Konfiguration wird mit dem nächsten Start des Synchronisationsservices
die Installation der Tabellentrigger ausgelöst. Das Projektdatenschema ist damit erfolg-
reich für das Protokollieren von Schreibvorgängen in der Verlaufstabelle Data eingerichtet
und der Ausgangzustand der Mutter-Instanz ist hergestellt.
Das Einrichten der ersten Hierarchieebene zeigt sich problemlos. Durch Starten des Syn-
chronisationsservices für Knoten 101 und 102 wird die Registrations-URL der Mutter-
Instanz angesprochen und die Registrierung abgeschlossen. Nach der Synchronisation
der Konfigurationsdaten werden die Projektdaten übertragen, wodurch der Projektdaten-
bestand nun zwischen allen drei Instanzen konsistent ist.
Für das Einrichten der mobilen Kind-Instanz wurde der in Abschnitt 6.9 beschriebene,
alternative Weg des manuellen Imports genutzt. Dafür wurde die Registrierung auf dem
Knoten 101 geöffnet und anschließend ein SQL-Dump des Projektdatenschemas über
die Datenbankfunktion pg_dump exportiert. Nach dem Import des Schemas auf dem Lap-
top wurde der Synchronisationsservice gestartet, welcher die Registrierung am Eltern-
Knoten erfolgreich abschließt.
Mit dieser Konfiguration wurden die erstellten Anforderungen als Orientierung genutzt,
um zu prüfen, inwiefern sie momentan erfüllt werden können. Synchronisationsvorgänge
wurden sowohl manuell, als auch per Cron-Job ausgeführt. Die Ergebnisse beziehen sich
dabei auf die Funktion der Synchronisationslösung. Als Datengrundlage wurde ein Test-
datenbestand des Pergamon-Projekts genutzt, der auf Grundlage des in Abschnitt 5.1
beschriebenen angepassten Datenbankschemas erstellt und durch willkürlich generierte
Geometrien ergänzt wurde.

6 Implementierung 79
Die Online-Synchronisation hat sich als sehr funktional ergeben und kann alle Anfor-
derungen erfüllen. Änderungen werden auch dann zuverlässig synchronisiert, wenn die
beteiligten Knoten lange Zeit nicht erreichbar waren, oder viele Änderungen eingebracht
wurden. Beim Test der Offline-Synchronisation sind jedoch Fehler aufgetreten. Die zur
Verfügung stehende Import-Anweisung ignoriert die Knoten-ID des Senders und interpre-
tiert so alle eingespielten Änderungen als lokal entstandene. Infolgedessen werden diese
Änderungen nun auch an den Sender rückadressiert und es entstehen beim nächsten
Synchronisieren Einfügekonflikte. Dieses Problem konnte mit der in Listing 6.20 präsen-
tierten Hilfsfunktion behoben werden. Sie ist ebenfalls über das Konsolentool symadmin
zugänglich.
1 private void importBatchFromNode(CommandLine line , List <String > args)
throws Exception {
2 IDataLoaderService service = getSymmetricEngine ().getDataLoaderService ();
3 String sourceId = popArg(args , "Source ID");
4 String sourceGroupId = popArg(args , "Node Group ID");
5 Node node = new Node(sourceId , sourceGroupId);
6 System.out.println(sourceId + ": " + sourceGroupId);
7 InputStream in = null;
8 if (args.size() == 0) {
9 in = System.in;
10 } else {
11 in = new FileInputStream(args.get (0));
12 }
13 service.loadDataFromPush(node , in, System.out);
14 System.out.flush();
15 in.close ();
16 }
Listing 6.20: Hilfsfunktion import-from-node zum Offline-Import von
Synchronisationsnachrichten
Im Folgenden sind die zuvor definierten Anforderungen an die Replikations- und Syn-
chronisationlösung für OpenInfRA der aktuellen Funktionalität der Implementierung ge-
genübergestellt.
6.17 Notwendige Erweiterungen
Bei der Erarbeitung der hier vorgestellten Standard-Konfiguration wurde lediglich die
Standalone-Installation (s. Abschnitt 6.1) genutzt, dessen Tool symadmin um nötige Funk-
tionen erweitert wurde. Der Grund hierfür ist, dass zum gegenwärtigen Zeitpunkt nicht
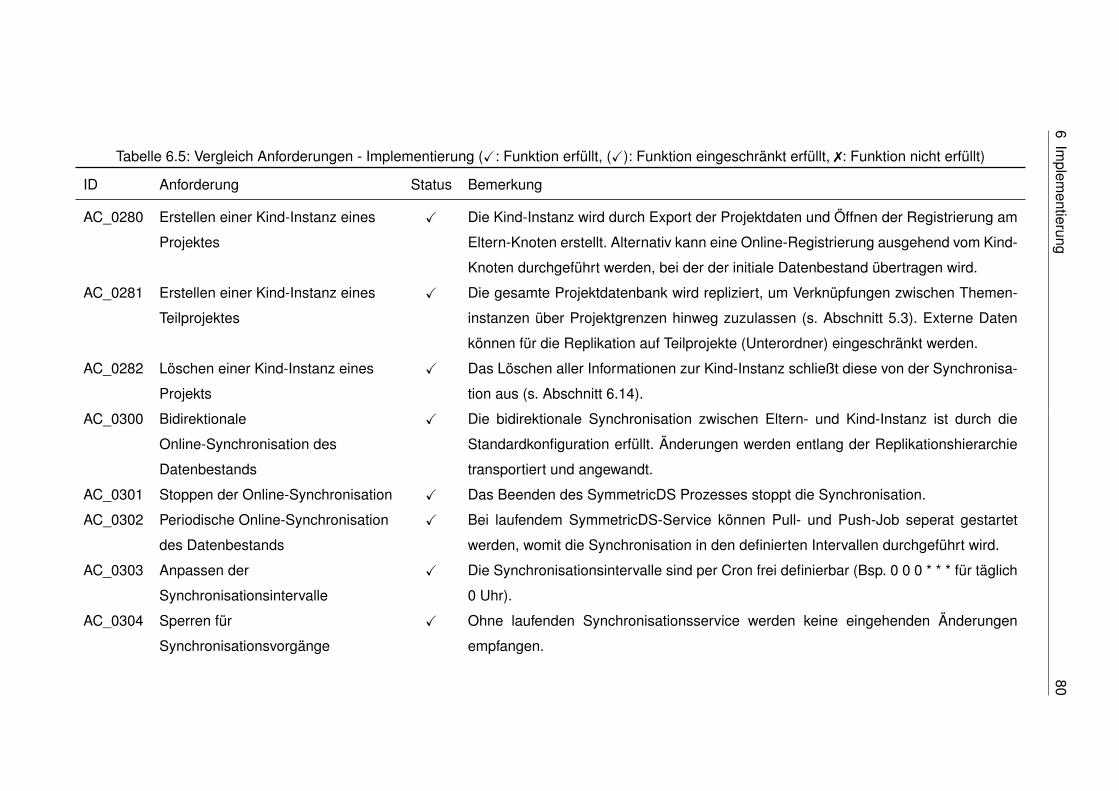
6Im
plementierung
80
Tabelle 6.5: Vergleich Anforderungen - Implementierung (X: Funktion erfüllt, (X): Funktion eingeschränkt erfüllt, 7: Funktion nicht erfüllt)
ID Anforderung Status Bemerkung
AC_0280 Erstellen einer Kind-Instanz eines
Projektes
X Die Kind-Instanz wird durch Export der Projektdaten und Öffnen der Registrierung am
Eltern-Knoten erstellt. Alternativ kann eine Online-Registrierung ausgehend vom Kind-
Knoten durchgeführt werden, bei der der initiale Datenbestand übertragen wird.
AC_0281 Erstellen einer Kind-Instanz eines
Teilprojektes
X Die gesamte Projektdatenbank wird repliziert, um Verknüpfungen zwischen Themen-
instanzen über Projektgrenzen hinweg zuzulassen (s. Abschnitt 5.3). Externe Daten
können für die Replikation auf Teilprojekte (Unterordner) eingeschränkt werden.
AC_0282 Löschen einer Kind-Instanz eines
Projekts
X Das Löschen aller Informationen zur Kind-Instanz schließt diese von der Synchronisa-
tion aus (s. Abschnitt 6.14).
AC_0300 Bidirektionale
Online-Synchronisation des
Datenbestands
X Die bidirektionale Synchronisation zwischen Eltern- und Kind-Instanz ist durch die
Standardkonfiguration erfüllt. Änderungen werden entlang der Replikationshierarchie
transportiert und angewandt.
AC_0301 Stoppen der Online-Synchronisation X Das Beenden des SymmetricDS Prozesses stoppt die Synchronisation.
AC_0302 Periodische Online-Synchronisation
des Datenbestands
X Bei laufendem SymmetricDS-Service können Pull- und Push-Job seperat gestartet
werden, womit die Synchronisation in den definierten Intervallen durchgeführt wird.
AC_0303 Anpassen der
Synchronisationsintervalle
X Die Synchronisationsintervalle sind per Cron frei definierbar (Bsp. 0 0 0 * * * für täglich
0 Uhr).
AC_0304 Sperren für
Synchronisationsvorgänge
X Ohne laufenden Synchronisationsservice werden keine eingehenden Änderungen
empfangen.

6Im
plementierung
81
AC_0310 Offline-Synchronisation des
Datenbestands
(X) Der Import und Export von Batches in CSV-Dateien funktioniert, wobei der mehr-
malige Import zu keinen Nebeneffekten führt. Beim Import muss die Hilfsfunktion
import-from-node genutzt werden, um zirkuläre Beziehungen bei der folgenden Syn-
chronisation auszuschließen. Die Offline-Synchronisation externer Daten ist im Mo-
ment nicht möglich.
AC_0311 Export von
Offline-Synchronisationsdateien
(X) Der Export und Offline-Synchronisationsdaten ist möglich, erfordert aber die konkrete
Nennung der Batch-ID. Die Funktion muss um einen massenhaften Export aller ausste-
henden Batches an einen Knoten erweitert werden, um die Nutzbarkeit zu verbessern.
AC_0312 Parametrierung von
Offline-Synchronisationsdateien
X s. AC_0311
AC_0313 Import Synchronisationsnachricht (X) Der Import von Batches ist möglich. (s.a. AC_0311).
AC_0320 Import einer Kind-Instanz X Eine Kind-Instanz kann manuell aus einem Datenbank-Dump oder über eine Online-
Synchronisation importiert werden (s.a. AC_0280).
AC_0321 Online-Import einer Kind-Instanz X Nach dem Öffnen der Registrierung einer Kind-Instanz am Eltern-Knoten ist es mög-
lich, den Datenbestand entsprechend der Konfiguration zu übertragen (s.a. AC_0320).
AC_0330 Installation einer
OpenInfRA-Offline-Version
7 Die Installationsprozedur der OpenInfRA-Anwendung als Offline-Version ist Bestand-
teil der Anforderungen an das Basissystem. Die Replikationskomponente sollte hier
als Modul mit installiert werden können. Die Installation als Standalone-Komponente
ist ohne Erweiterung möglich.
AC_0340 Lösen von
Synchronisationskonflikten
X Mögliche Konflikte werden erkannt und ohne Nebeneffekt auf den Datenbestand auf-
geführt. Die Synchronisation von ausstehenden Änderungen wird nach Lösen des
Konflikts fortgesetzt.

6Im
plementierung
82
AC_0341 Synchronisieren von gelösten
Konflikten
X Durch die Einstellung ping_back der Konfliktlösungsstrategie für Projektdaten, wird die
Konfliktlösung mit der nächsten Synchronisation übertragen und auf dem Synchroni-
sationspartner angewandt.
AC_0350 Synchronisationskonflikte anzeigen X Das Auflisten der Konflikte kann über die Tabelle incoming_error sowie über die Ta-
belle outgoing_batch erfolgen.
AC_0351 Synchronisationskonflikte
bearbeiten
X incoming_error erlaubt die Definition neuer Spaltenwerte bzw. das Ignorieren des
Konflikts, wenn die aktuellen Spaltenwerte die korrekte Lösung darstellen. Die Syn-
chronisation wird daraufhin fortgesetzt.
AC_0352 Synchronisationskonflikte von
Geometriedaten bearbeiten
(X) Die Bearbeitung ist wie für AC_0351 möglich. Für die Lösung von Konflikten ist aber
eine Verknüpfung mit dem WebGIS-Client sinnvoll, um eine korrekte Lösungsstrategie
formulieren zu können.
AC_0360 Anpassen von
Synchronisationsparametern
X Parameter können über die Properties der Engine, oder über die Konfigurationstabel-
len angepasst werden.
AC_0370 Hinweis auf Synchronisationskonflikt X Konflikte werden generell geloggt und können so für den zukünftigen Admin-Client
aufbereitet werden.
AC_0371 Protokolle zu
Synchronisationsvorgängen
X Der Erfolg- oder Misserfolg der Synchronisationsvorgänge wird anhand des Status der
einzelnen Batches vermerkt. Darüber hinaus wird eine Log-Datei über Synchronisati-
onsvorgänge geführt.

6 Implementierung 83
klar ist, wie die OpenInfRA-Anwendung konkret implementiert werden wird, die Entwick-
lung einer Benutzeroberfläche aber davon abhängig ist. Wird das Basissystem eben-
falls in Java programmiert, ist die Integration von SymmetricDS als Modul mit den hier
vorgestellten Funktionalität einfach und der entsprechende Entwicklungsaufwand gering.
Sollte eine andere Technologie zur Anwendung kommen, beispielsweise ein klassischer
LAMP-Stack, können Adapter wie mod_jk genutzt werden, um SymmetricDS beispiels-
weise über einen Tomcat Servlet-Container in die Konfiguration einzugliedern.
Neben der Frage zur Integration der Lösung sind die folgenden Anpassungen bzw. Er-
weiterungen ausstehend, die bei der Weiterentwicklung zu klären sind.
• Für die Lösung von Synchronisationskonflikten muss eine passendes Nutzerschnitt-
stelle zur Verfügung gestellt werden. In der Regel wird der Vorgang auf Seiten des
Empfängers eingeleitet. Dieser kann über die Tabelle Incomming Error abfragen,
welche Relation betroffen ist und so ein passendes Interface herleiten. Für die Lö-
sung von Konflikten bei Geometriedaten ist zu überlegen, ob der OpenInfRA-Web-
GIS-Client um entsprechende Funktionen erweitert werden kann.
• Während die Grundfunktionalität der Offline-Synchronisation funktioniert, ist der
Export einzelner Batches im Moment aufwendig (manuelle Auswahl Eltern-ID und
Batch-ID). Allgemein lässt sich anhand der Tabelle Outgoing Batches leicht abfra-
gen, welche Synchronisationsdaten an einen gewählten Knoten übertragen werden
sollen. Es sollte möglich sein, alle nötigen CSV-Dateien als Zip-Archiv zu exportie-
ren, sodass diese leichter für die Übermittlung per Wechseldatenträger oder Email
dienen können. Auf Seiten des Empfänger sollte wiederum der Import dieses Zip-
Archivs möglich sein, wobei auf die entwickelte Hilfsfunktion zurückgegriffen wer-
den kann.
• Die Offline-Synchronisation externer Projektdaten ist im Moment nicht möglich. Hier
lassen sich ebenfalls die bestehenden Funktionen nutzen, die ohnehin zur Anwen-
dung kommen, wenn diese für die Online-Synchronisation als Zip-Paket vorberei-
tet werden. Dabei sollte ebenfalls das konfigurierte BeanShell-Skript mit exportiert
werden, um die Pfadangaben beim Import auf dem Empfänger wiederherzustellen.
Die aufgeführten Erweiterungen bauen auf bereits bestehenden Funktionen auf, das
heißt es ist zu erwarten, dass bereits bestehende Klassen und Methoden bzw. die zur
Verfügung stehenden Schnittstellen der SymmetricDS-Bibliotheken genutzt werden kön-
nen. Der Aufwand der Implementierung wird daher als gering eingeschätzt.

6 Implementierung 84
6.18 Fazit
Neben der hier vorgestellten Lösung mit SymmetricDS wurde die prototypische Ent-
wicklung einer Replikationskomponente als PostgreSQL-Extension unternommen. Da die
SymmetricDS-Lösung schließlich als überlegen eingestuft wurde, wurde darauf verzich-
tet, diese Implementierung näher zu beschreiben. Allgemein basiert sie auf denselben
Grundsätzen der triggerbasierten Protokollierung von Schreiboperationen im replizierten
Datenbestand und dem Austausch des so entstandenen Verlaufsprotokolls. Eine wesent-
liche Überlegung bei der Umsetzung dieser Lösung war es, auf externe Komponenten zu
verzichten und so die Anforderungen bei der Installation und Nutzung zu reduzieren.
Dabei fielen letztendlich entscheidende Nachteile ins Gewicht, die für die Nutzung von
SymmetricDS sprachen und hier kurz als abschließendes Fazit vergleichend aufgeführt
werden sollen.
Die Eigenentwicklung pg_sengi nutzt die PostgreSQL-Extension dblink, um eine Verbin-
dung zu anderen Servern aufzunehmen und Log-Einträge auszutauschen. SymmetricDS
nutzt hingegen einen Webserver für die Übertragung, der Daten ähnlich wie beim Auf-
rufen einer normalen Website auf Seiten des Senders komprimiert und auf Seiten des
Empfängers entpackt. Bei der Synchronisation langer Server-Transaktionen werden die
Batch-Dateien dabei zusätzlich im Dateisystem zwischengespeichert und nicht direkt aus
der Datenbank gestreamt. So kommt ein effektiveres Übertragungsverhalten zustande
und die Dauer einer Synchronisation wird massiv reduziert. Hinzu kommt der Vorteil der
Entlastung des Datenbankservers durch den SymmetricDS-Service, der die erfolgreiche
Übertragung der Daten gewährleistet und bei einem Fehler eventuell neu einleitet. Ohne
einen externen Prozess, der als Mittler auftritt, besteht nur die Möglichkeit, die Über-
tragung in eine Transaktion zu klammern, welche im Ernstfall neu begonnen werden
muss. Gerade in einer Netzwerkumgebung mit schlechter Verbindung oder hoher Aus-
fallrate sind dies Vorteile, die für einen Einsatz von SymmetricDS für die Replikation von
OpenInfRA-Projektdaten sprechen.
Darüber hinaus hat die Kommunikation der Synchronisation über einen Web-Server auch
eine positiven Sicherheitsaspekt. Während beim Verbinden mit dblink eine direkte Da-
tenbankverbindung aufgebaut wird, die damit auch im Netzwerk verfügbar sein muss, ist
dies bei der Nutzung eines Middleware-Layers in Form eines Webservers nicht nötig. Hier
muss die Datenbank nur lokal durch die von SymmetricDS eröffnete JDBC-Verbindung
verfügbar sein. Die Gefahr eines Exploits der Datenbank wird dadurch stark reduziert.
Neben diesen Aspekten ist der Aufwand der Eigenentwicklung einer Replikations- und
Synchronisationskomponente auch durch die zusätzlichen Anforderung in Bezug auf ex-

6 Implementierung 85
terne Projektdateien zu groß, als das bereits bestehenden Lösungen übergangen werden
dürfen. Dies deckt sich mit der Forderung, keine Nischenprodukte für das Endprodukt
einzusetzen, um die Nutz- und Wartbarkeit der OpenInfRA-Anwendung allgemein zu er-
höhen.
Letztlich stellt sich die hier vorgestellte Implementierung des Mutter-Kind-Konzepts per
SQL-Skript einfach dar und kann leicht auf die verschiedenen Bedürfnisse der Projekte
des DAI angepasst werden. Wird dabei die entwickelte Standardkonfiguration genutzt,
kann sie beim Prozess der Initialisierung einer neuen Projektdatenbank schnell umge-
setzt werden. Die noch nötigen Anpassungen zur Offline-Synchronisation stellen gegen-
über dem zu erwartenden Nutzen einen vertretbaren Aufwand dar.

7 Zusammenfassung und Ausblick 86
7 Zusammenfassung und Ausblick
Inhalt dieser Arbeit sollte es sein, die Offline-Replikation des Datenbestands im Sinne
des Mutter-Kind-Konzepts für das Informationssystem OpenInfRA umzusetzen. Hierfür
wurde zuerst das OpenInfRA-Grobkonzept analysiert und herausgestellt, welche Anfor-
derungen eine Replikation und Synchronisation erfüllen müssen. Dabei wurden insbe-
sondere das Prinzip der Datenhaltung und des Mutter-Kind-Konzeptes unter Einführung
des Begriffs der Eltern-Instanz erläutert. Bereits an dieser Stelle wurden der Anforde-
rungskatalog und das Grobkonzept erweitert, um die zu entwickelnde Lösung daran zu
orientieren. Dies umfasste unter anderem die Konfliktidentifizierung und -lösung bei der
Synchronisation von Projektinstanzen. Dabei wurde festgestellt, dass eine manuelle Kon-
fliktlösungsstrategie ein adäquates Mittel darstellt, das dem Nutzer ausreichend Kontrolle
über die Daten ermöglicht. Darüber hinaus wurde dargelegt, dass nicht nur das Problem
der Synchronisation von Datensätzen eine Rolle spielt, sondern auch die Synchronisation
externer Dateien berücksichtigt werden muss.
Um eine Lösung zu finden, die all den beschriebenen Anforderungen gerecht wird, wurde
im zweiten Abschnitt dieser Arbeit der aktuelle Wissensstand zu verteilten mobilen Da-
tenbanken und deren Synchronisation erarbeitet. Dabei wurde deutlich, dass durch die
Autonomie der am Mutter-Kind-Konzept beteiligten Instanzen keine zentralisierte Trans-
aktionierung möglich ist, aber von einer Snapshot-Isolation zwischen Eltern- und Kind-
Instanz ausgegangen werden kann, deren lokale Änderungen durch eine optimistische
Synchronisation paarweise konsolidiert werden können.
Zur Umsetzung dieser „optimistischen Transaktionierung“ wurden anschließend die nati-
ven Replikationsfunktionen von PostgreSQL betrachtet. Es wurde festgestellt, dass das
Mutter-Kind-Konzept nicht mit den nativ zur Verfügung stehenden Mitteln umgesetzt wer-
den kann. Deshalb wurde geprüft, ob sich das im Datenbankbetrieb anfallende Write-
Ahead-Log für die logische Auswertung der Schreiboperationen eignet. Da dies nicht
der Fall war, wurde das Change-Data-Capture Entwurfsmuster vorgestellt, welches es
ermöglicht, Änderungen am Datenbestand nachzuverfolgen, was eine wichtige Voraus-
setzung einer asynchronen Synchronisation ist. Anschließend wurden Softwarelösungen
vorgestellt, die dieses Entwurfsmuster umsetzen und damit eine Multi-Master-Replikation
mit PostgreSQL ermöglichen.

7 Zusammenfassung und Ausblick 87
Im darauf folgenden Kapitel wurden die gewonnenen Erkenntnisse genutzt, um eine mög-
liche Umsetzung der Offline-Replikation zu beschreiben. Dabei wurde die Anpassung
des Datenbankschemas zur Nutzung von universal identifizierbaren Identifikatoren vor-
geschlagen. Es zeigte sich, dass die Fragmentierung des Projektdatenbankschemas für
die praktische Nutzung nicht sinnvoll ist, dafür aber die Möglichkeit gegeben sein muss,
nur einen Teil der externe Daten auf Kind-Instanzen zu replizieren. Aufgrund dieser Ein-
schätzung wurde die zuvor vorgestellte Lösung SymmetricDS als geeignet für die Imple-
mentierung des Mutter-Kind-Konzepts für OpenInfRA befunden.
Im letzten Abschnitt der Arbeiten erfolgte eine Vorstellung der Konzepte von SymmetricDS
und eine Erläuterung der Konfiguration. Zusätzlich wurde eine erweiterbare Standardkon-
figuration für die Nutzung mit OpenInfRA erarbeitet und um Funktionen zum manuellen
Einleiten einer Synchronisation und dem Offline-Import von Synchronisationsdaten er-
gänzt. Anschließend wurde die Konfiguration in Hinblick auf die gestellten Anforderungen
geprüft. Hier konnte festgestellt werden, dass Anpassungen für die zweckmäßige Offli-
ne-Synchronisation vorgenommen werden müssen. Dies betrifft in erster Linie die Offline-
Synchronisation von externen Dateien. Bei einem kurzen Vergleich mit der prototypischen
Eigenentwicklung pg_sengi wurden die Vorteile der Nutzung der bestehenden Software-
komponente SymmetricDS für OpenInfRA in Sachen Sicherheit, Performanz und Zuver-
lässigkeit herausgestellt, die für die Integration in das Kernsystem sprechen. Letztendlich
zeigte sich, dass sämtliche Anforderungen bis auf die Offline-Synchronisation von exter-
nen Dateien durch die Implementierung mit SymmetricDS erfüllt werden konnten.
Sobald geklärt ist, welche Technologie für die Umsetzung des OpenInfRA-Basissystems
eingesetzt werden, kann damit begonnen werden, die vorgestellte Lösung als Erweite-
rung dessen zu integrieren. Die Hauptaufgabe wird dabei sein, die Komplexität der Konfi-
guration für den Nutzer zu vereinfachen, die Parametrisierung über den geplanten Admin-
Client umzusetzen und ein logisches Interface für die Lösung von Synchronisationskon-
flikten anzubieten.
Mit dieser Erweiterung sind jedoch nicht nur die Voraussetzungen der Offline-Replikation
der Projektdaten mit OpenInfRA erfüllt. Viel wichtiger ist der Beitrag zur Arbeitserleichte-
rung in der Archäologie, der durch eine so ermöglichte zunehmende Unabhängigkeit von
stehenden Internetanbindungen geschaffen wird.

Konfiguration SymmetricDS-Engine v
Konfiguration SymmetricDS-Engine
1 # Naming
2 engine.name =000
3 group.id=mother
4 external.id=mother
5 schema.version =10
6
7 auto.registration=true
8 auto.reload=true
9
10 # URLs
11 registration.url=http:// 192.168.1.16:9090/ sync /000
12 sync.url=http:// 192.168.1.16:9090/ sync /000
13
14 # DB Connection
15 db.driver=org.postgresql.Driver
16 db.url=jdbc:postgresql:// localhost/openinfra?stringtype=unspecified
17 db.user=sym_user
18 db.password=secr3t
19 db.pool.initial.size=1
20 db.pool.max.active =10
21
22 # Routing
23 start.route.job=true
24 job.route.cron=0 0 * * * *
25 # job.routing.period.time.ms =30000
26
27 # Push
28 start.push.job=false
29 push.thread.per.server.count =3
30 job.push.cron=0 * * * * *
31 # job.push.period.time.ms =180000
32
33 # Pull
34 start.pull.job=false
35 pull.thread.per.server.count =3
36 job.pull.cron=0 * * * * *
37 # job.pull.period.time.ms =180000
38
39 # Purging

Konfiguration SymmetricDS-Engine vi
40 start.purge.job=true
41 job.purge.incoming.cron=0 0 0 * * *
42 job.purge.outgoing.cron=0 0 0 * * *
43 job.purge.datagaps.cron=0 0 0 * * *
44 purge.retention.minutes =1440
45
46 # Heartbeat
47 start.heartbeat.job=true
48 job.heartbeat.period.time.ms =10000
49 heartbeat.sync.on.push.period.sec =300000
50
51 # Watchdog
52 start.watchdog.job=false
53 job.watchdog.period.time.ms =3600000
54
55 # Propagation
56 auto.registration=true
57 auto.reload=true
58
59 # File
60 start.file.sync.tracker.job=true
61 job.file.sync.tracker.cron=0 * * * * *
62
63 start.file.sync.pull.job=false
64 job.file.sync.pull.cron=0 * * * * *
65
66 start.file.sync.push.job=false
67 job.file.sync.pull.cron=0 * * * * *
Listing 1: SymmetricDS-Engine

Standardkonfiguration vii
Standardkonfiguration
1 /**
2 * Standardkonfiguration für OpenInfRA -Projekte
3 *
4 * {{ projektname }} - Eindeutiger Namen des Projekts
5 * {{ schema }} - Name des Datenbankschemas der Projektdaten
6 * {{ version }} - Schemaversion der Projektdatenbank
7 * {{ password }} - Passwort der Mutter -Instanz
8 * {{ Media }} - Ordner für Mediendateien
9 * {{ Config }} - Ordner für Konfigurationsdateien
10 */
11 BEGIN;
12
13 -- Standardschema für Systemtabellen
14 SET SEARCH_PATH TO sym;
15
16 -- Konfigurationstabellen leeren
17 DELETE FROM sym_trigger_router;
18 DELETE FROM sym_router;
19 DELETE FROM sym_node_group_link;
20 DELETE FROM sym_node_group;
21 DELETE FROM sym_node_identity;
22 DELETE FROM sym_node_security;
23 DELETE FROM sym_node;
24 DELETE FROM sym_trigger;
25 DELETE FROM sym_channel;
26
27 -- Hierarchiebenen bzw. Knoten -Gruppen anlegen
28 INSERT INTO sym_node_group (
29 node_group_id ,
30 description ,
31 create_time ,
32 last_update_by ,
33 last_update_time
34 ) VALUES
35 (’mother ’, ’Mutter -Instanz - Zentraler Server ’, current_timestamp ,
current_user , current_timestamp),
36 (’office ’, ’2. Ebene - Lokale Online/Offline -Instanzen ’, current_timestamp ,
current_user , current_timestamp),

Standardkonfiguration viii
37 (’mobile ’, ’3. Ebene - Laptops für Au ß endienst ’, current_timestamp
, current_user , current_timestamp),
38 (’rover’, ’4. Ebene - Laptops für Au ß endienst ’, current_timestamp
, current_user , current_timestamp);
39
40 -- Knotengruppen verlinken
41 -- Downstream pushed zu Upstream
42 INSERT INTO sym_node_group_link (
43 source_node_group_id ,
44 target_node_group_id ,
45 data_event_action ,
46 create_time ,
47 last_update_by
48 ) VALUES
49 (’office ’, ’mother ’, ’P’, current_timestamp , current_user),
50 (’mother ’, ’office ’, ’W’, current_timestamp , current_user),
51 (’mobile ’, ’office ’, ’P’, current_timestamp , current_user),
52 (’office ’, ’mobile ’, ’W’, current_timestamp , current_user),
53 (’rover’, ’mobile ’, ’P’, current_timestamp , current_user),
54 (’mobile ’, ’rover ’, ’W’, current_timestamp , current_user);
55
56 -- Initialisierung der Mutter -Instanz der Replikationshierarchie
57 INSERT INTO sym_node (
58 node_id ,
59 node_group_id ,
60 external_id ,
61 sync_enabled ,
62 schema_version
63 ) VALUES (
64 ’mother -{{ projektname }}’,
65 ’mother ’,
66 ’mother -{{ projektname }}’,
67 1,
68 ’{{ version }}’
69 );
70
71 INSERT INTO sym_node_security (
72 node_id ,
73 node_password ,
74 registration_time ,
75 initial_load_time ,
76 created_at_node_id
77 ) VALUES (
78 ’mother -{ projektname}’,
79 ’{{ password }}’,
80 current_timestamp ,

Standardkonfiguration ix
81 current_timestamp ,
82 ’mother -{{ projektname }}’
83 );
84
85 INSERT INTO sym_node_identity VALUES (’mother -{{ projektname }}’); -- Identit
ät zuweisen
86
87 -- Synchronisationskanal
88 INSERT INTO sym_channel (
89 channel_id ,
90 processing_order ,
91 max_batch_size ,
92 max_batch_to_send ,
93 enabled ,
94 batch_algorithm ,
95 description ,
96 create_time ,
97 last_update_by ,
98 last_update_time
99 ) VALUES (
100 ’project_data ’,
101 100,
102 10000,
103 100,
104 1,
105 ’default ’,
106 ’Projektdaten des Projekts {{ projektname }}’,
107 current_timestamp ,
108 current_user ,
109 current_timestamp
110 );
111
112 -- Änderungstrigger
113 INSERT INTO sym_trigger (
114 trigger_id ,
115 source_schema_name ,
116 source_table_name ,
117 channel_id ,
118 sync_on_incoming_batch ,
119 create_time ,
120 last_update_by ,
121 last_update_time
122 ) VALUES
123 (’project_data_trigger ’, ’{{ schema }}’, ’*’, ’project_data ’, 1,
current_timestamp , current_user , current_timestamp);
124

Standardkonfiguration x
125 -- Router
126 INSERT INTO sym_router (
127 router_id ,
128 source_node_group_id ,
129 target_node_group_id ,
130 router_type ,
131 create_time ,
132 last_update_by ,
133 last_update_time
134 ) VALUES
135 (’mother_2_office ’, ’mother ’, ’office ’, ’default ’, current_timestamp ,
current_user , current_timestamp),
136 (’office_2_mother ’, ’office ’, ’mother ’, ’default ’, current_timestamp ,
current_user , current_timestamp),
137 (’office_2_mobile ’, ’office ’, ’mobile ’, ’default ’, current_timestamp ,
current_user , current_timestamp),
138 (’mobile_2_office ’, ’mobile ’, ’office ’, ’default ’, current_timestamp ,
current_user , current_timestamp),
139 (’mobile_2_rover ’, ’mobile ’, ’rover’, ’default ’, current_timestamp ,
current_user , current_timestamp),
140 (’rover_2_mobile ’, ’rover’, ’mobile ’, ’default ’, current_timestamp ,
current_user , current_timestamp);
141
142 -- Trigger Router Links
143 INSERT INTO sym_trigger_router (
144 trigger_id ,
145 router_id ,
146 enabled ,
147 initial_load_order ,
148 create_time ,
149 last_update_by ,
150 last_update_time
151 ) VALUES
152 (’project_data_trigger ’, ’mother_2_office ’, 1, 100, current_timestamp ,
current_user , current_timestamp),
153 (’project_data_trigger ’, ’office_2_mother ’, 1, 200, current_timestamp ,
current_user , current_timestamp),
154 (’project_data_trigger ’, ’office_2_mobile ’, 0, 300, current_timestamp ,
current_user , current_timestamp),
155 (’project_data_trigger ’, ’mobile_2_office ’, 0, 400, current_timestamp ,
current_user , current_timestamp),
156 (’project_data_trigger ’, ’mobile_2_rover ’, 0, 500, current_timestamp ,
current_user , current_timestamp),
157 (’project_data_trigger ’, ’rover_2_mobile ’, 0, 600, current_timestamp ,
current_user , current_timestamp);
158

Standardkonfiguration xi
159 -- Conflict Resolution
160 INSERT INTO sym.sym_conflict (
161 conflict_id ,
162 source_node_group_id ,
163 target_node_group_id ,
164 target_channel_id ,
165 detect_type ,
166 resolve_type ,
167 ping_back ,
168 create_time ,
169 last_update_by ,
170 last_update_time
171 )
172 VALUES
173 (’manual_mother_2_office ’, ’mother ’, ’office ’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp),
174 (’manual_office_2_mother ’, ’office ’, ’mother ’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp),
175 (’manual_office_2_mobile ’, ’office ’, ’mobile ’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp),
176 (’manual_mobile_2_office ’, ’mobile ’, ’office ’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp),
177 (’manual_mobile_2_rover ’, ’mobile ’, ’rover’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp),
178 (’manual_rover_2_mobile ’, ’rover ’, ’mobile ’, ’project_data ’, ’
use_old_data ’, ’manual ’, ’SINGLE_ROW ’, current_timestamp , current_user ,
current_timestamp);
179
180 -- File Sync
181 INSERT INTO sym_file_trigger (
182 trigger_id ,
183 base_dir ,
184 recurse ,
185 includes_files ,
186 excludes_files ,
187 sync_on_create ,
188 sync_on_modified ,
189 sync_on_delete ,
190 before_copy_script ,
191 after_copy_script ,
192 create_time ,

Standardkonfiguration xii
193 last_update_by ,
194 last_update_time
195 ) VALUES (
196 ’media_directory ’,
197 ’{{Media }}’,
198 1,
199 ’*.jpeg ,*.jpg ,*.pdf’,
200 null ,
201 1,1,1,
202 ’targetBaseDir = "{{ Media }}"’,
203 null ,
204 current_timestamp ,
205 current_user ,
206 current_timestamp
207 );
208
209 INSERT INTO sym_file_trigger (
210 trigger_id ,
211 base_dir ,
212 recurse ,
213 includes_files ,
214 excludes_files ,
215 sync_on_create ,
216 sync_on_modified ,
217 sync_on_delete ,
218 before_copy_script ,
219 after_copy_script ,
220 create_time ,
221 last_update_by ,
222 last_update_time
223 ) VALUES (
224 ’config_directory ’,
225 ’{{ Config }}’,
226 1,
227 ’*.txt ,*. properties ,*. config ,*. conf’,
228 null ,
229 1,1,1,
230 null ,
231 null ,
232 current_timestamp ,
233 current_user ,
234 current_timestamp
235 );
236
237 INSERT INTO sym_file_trigger_router (
238 trigger_id ,

Standardkonfiguration xiii
239 router_id ,
240 enabled ,
241 initial_load_enabled ,
242 target_base_dir ,
243 conflict_strategy ,
244 create_time ,
245 last_update_by ,
246 last_update_time
247 )
248 VALUES
249 (’config_directory ’, ’mother_2_office ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
250 (’config_directory ’, ’office_2_mobile ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
251 (’config_directory ’, ’mobile_2_router ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp);
252 (’media_directory ’, ’mother_2_office ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
253 (’media_directory ’, ’office_2_mobile ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
254 (’media_directory ’, ’mobile_2_router ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
255 (’media_directory ’, ’office_2_mother ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
256 (’media_directory ’, ’mobile_2_office ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp),
257 (’media_directory ’, ’rover_2_mobile ’, 1, 1, ’’, ’SOURCE_WINS ’,
current_timestamp , current_user , current_timestamp);
258
259 CREATE OR REPLACE FUNCTION sym_delete_node(text)
260 RETURNS void AS $body$
261 DELETE FROM sym_node_security
262 WHERE node_id = $1;
263 DELETE FROM sym_node_host
264 WHERE node_id = $1;
265 DELETE FROM sym_node
266 WHERE node_id = $1;
267 $body$ LANGUAGE SQL STRICT VOLATILE;
268
269 COMMIT;
Listing 2: Standardkonfiguration Mutter-Kind-Konzept

Email xiv
Von: Benjamin Thurm An: Felix Falko Schäfer, Frank Henze, Philipp Gerth
Kopie: Alexander Schulze, Frank Schwarzbach
11. Juni 2013
Sehr geehrter Herr Schäfer, sehr geehrter Herr Gerth, sehr geehrter Herr Henze,
ich habe ein paar Fragen zusammengestellt, die für die Replikation der OpenInfRA-
Projektdatenbanken von Wichtigkeit sind. Ich würde mich freuen, wenn Sie mir diese
beantworten können:
1. Das Attribut „Sichtbarkeit“ kann durch den Projektadministrator im Zuge der Projekti-
nitialisierung auf „0“ gesetzt werden. Dadurch können vordefinierte Attributwerte, die in
einem Projekt (zunächst) als nicht zutreffend angesehen werden, ausgeblendet werden.
(S.59)
Liegt die Verantwortung über die Sichtbarkeit auch nach der Projektinitialisierung aus-
schließlich beim Projektadministrator? Falls dem so ist, kann hier beim Initialisieren von
Kind-Instanzen aus der Projektdatenbank davon abgesehen werden, diese Daten mit zu
replizieren. Dieser Schritt würde bei einem nachträglichen Aktivieren nachgeholt wer-
den.
2. Alle Wertelisten sind projektspezifisch erweiterbar, wobei die Erweiterungen nach Zu-
stimmung durch den System-Administrator auch anderen Projekten zur Verfügung ge-
stellt werden können. (S.59)
Für das Zurückschreiben von Daten aus der Projektdatenbank ist im Moment kein kon-
kreter Mechanismus vorgesehen. Das heißt, dass alle Klassen, die im Systemschema
vorhanden sind - nach aktuellem Stand im Grunde alles, was nicht direkt mit den kon-
kreten Themeninstanzen verbandelt ist - mit dem Systemschema abgeglichen werden
können. Dies gilt damit auch für die Wertelisten. Ist es nötig, hier einen „Schalter“ zu
führen, der bestimmt, welche Wertelisten vom Systemadministrator übernommen wer-
den sollen/dürfen? Oder ist hier eher die konkrete Kommunikation Systemadministrator-
Projektadministrator vorgesehen, bei der die Übernahme solcher Daten besprochen wird?
3. Beim Abbilden von Kinderinstanzen aus dem initialen Themengerüst der Projektda-
tenbank könnte unter Umständen darauf verzichtet werden, den gesamten Bestand der

Email xv
Daten zu übertragen. Wäre hier die Differenzierung nach Teilprojekten sinnvoll? Dar-
aus resultiert natürlich auch, dass diese Instanz anschließend nur dazu genutzt werden
kann, aus ihr den gleichen eingeschränkten Datenbestand in eine eventuelle Kinderin-
stanz abzubilden. Der Nutzen einer solchen Funktion ist sicherlich abhängig von der zu
erwartenden Datenmenge. Vorteile wären hier unter anderem ein geringerer Kopierauf-
wand (siehe auch externe Bilder, Dokumente) und eine physikalische Zugriffssicherung
bei Diebstahl/Verlust. Die benötigte Logik für diesen Vorgang kann zum Nachteil wer-
den, insbesondere wenn Themeninstanzen auf Themeninstanzen verweisen, die nicht
Bestandteil des Teilprojekts sind. Ärgerlich wäre natürlich auch, wenn der Datenbestand
für die Arbeit im Feld zu großzügig eingegrenzt wurde.
4. Um die Bearbeitung von Daten durch mehrere Nutzer im verteilten System zu er-
möglichen, müssen die Arbeitsschritte versioniert werden. Dies ermöglicht als Neben-
effekt auch ein Undo/Redo während der Arbeit an der Instanz. Beim abschließenden
Übernehmen der Änderungen würden diese „Zwischenstände“ lokal verbleiben und peri-
odisch gelöscht. Ihr Nutzen ist danach zweifelhaft und sie verursachen entsprechenden
Speicherbedarf. Ist eine projektweite Historie sinnvoll?
5. Außerdem würde mich für einige Einschätzungen interessieren, die beschreiben, wie
die Vorraussetzungen vor Ort aussehen können. In welcher Größenordnung bewegen
sich die Projekte in Sachen Mitarbeiter und genutzter Computer? Welche Betriebssyste-
me kommen zum Einsatz (Win, *unix, OSX)? Werden die Rechner in jedem Fall durch
DAI o.ä. administriert oder durch die Nutzer selbst?
Mit freundlichen Grüßen,
Benjamin Thurm
Von: Felix Falko Schäfer An: Benjamin Thurm
Kopie: Frank Henze, Philipp Gerth, Alexander Schulze, Frank Schwarzbach
11. Juni 2013
Lieber Herr Thurm,
ich erlaube mir mal Ihnen zu antworten, in der Hoffnung, dass ich auch die Meinung der
anderen richtig treffe:
1. Das Attribut „Sichtbarkeit“ kann durch den Projektadministrator im Zuge der Projekti-
nitialisierung auf „0“ gesetzt werden. Dadurch können vordefinierte Attributwerte, die in
einem Projekt (zunächst) als nicht zutreffend angesehen werden, ausgeblendet werden.

Email xvi
(S.59) Liegt die Verantwortung über die Sichtbarkeit auch nach der Projektinitialisierung
ausschließlich beim Projektadministrator? Falls dem so ist, kann hier beim Initialisieren
von Kind-Instanzen aus der Projektdatenbank davon abgesehen werden, diese Daten
mit zu replizieren. Dieser Schritt würde bei einem nachträglichen Aktivieren nachgeholt
werden.
Ja, die Sichtbarkeit wird ausschließlich von dem Projektadmin festgelegt. Nutzer müssen
sich ggf. an diesen wenden, wenn sie etwas ein-/ausblenden wollen.
2. Alle Wertelisten sind projektspezifisch erweiterbar, wobei die Erweiterungen nach Zu-
stimmung durch den System-Administrator auch anderen Projekten zur Verfügung ge-
stellt werden können. (S.59) Für das Zurückschreiben von Daten aus der Projektdaten-
bank ist im Moment kein konkreter Mechanismus vorgesehen. Das heißt, dass alle Klas-
sen, die im Systemschema vorhanden sind - nach aktuellem Stand im Grunde alles, was
nicht direkt mit den konkreten Themeninstanzen verbandelt ist - mit dem Systemsche-
ma abgeglichen werden können. Dies gilt damit auch für die Wertelisten. Ist es nötig,
hier einen „Schalter“ zu führen, der bestimmt, welche Wertelisten vom Systemadminis-
trator übernommen werden sollen/dürfen? Oder ist hier eher die konkrete Kommunikation
Systemadministrator-Projektadministrator vorgesehen, bei der die Übernahme solcher
Daten besprochen wird?
So ganz verstehe ich die Frage nicht bzw. würden den Fall etwas anders beschreiben, da
ich nicht die Zustimmung des System-Admins für die Weitergabe erforderlich halte bzw.
mir nicht klar ist, nach welchen Kriterien er seine Zustimmung gibt oder nicht. Konkret
stelle ich mir folgenden Ablauf vor (der evtl. falsch oder zu kompiziert sein kann): - Der
Projektadmin für Projekt 1 fügt an Werteliste X einen neuen Wert ein - Dieser Wert wird
dem Gesamtbestand aller für Werteliste X zulässigen Werte hinzugefügt, ist aber nur
bei Projekt 1 unmittelbar aktiviert und sichtbar - Für die anderen Projekte werden die
Projektadmins informiert (sagen wir mal für den Moment durch eine manuell verfasste
email des Sys-Admins), dass es einen neuen Wert gibt, der nun potentiel auch von den
anderen Projekten verwendet werden kann - Wenn die Projektadmins nach der Nachricht
dies tun wollen, können sie den Wert auch für ihr konkretes Projekt freischalten. ==>
insgesamt kommt es hier also auf die konkrete Kommunikation Sys- und Projekt-Admins
an.
3. Beim Abbilden von Kinderinstanzen aus dem initialen Themengerüst der Projektda-
tenbank könnte unter Umständen darauf verzichtet werden, den gesamten Bestand der
Daten zu übertragen. Wäre hier die Differenzierung nach Teilprojekten sinnvoll?
Ja, auf alle Fälle. Es kann sogar der Regelfall sein, dass eine Kindinstanz nur für ein
Teilprojekt erzeugt werden muss.

Email xvii
Daraus resultiert natürlich auch, dass diese Instanz anschließend nur dazu genutzt wer-
den kann, aus ihr den > gleichen eingeschränkten Datenbestand in eine eventuelle Kin-
derinstanz abzubilden. Der Nutzen einer solchen Funktion ist sicherlich abhängig von
der zu erwartenden Datenmenge. Vorteile wären hier unter anderem ein geringerer Ko-
pieraufwand (siehe auch externe Bilder, Dokumente) und eine physikalische Zugriffssi-
cherung bei Diebstahl/Verlust. Die benötigte Logik für diesen Vorgang kann zum Nach-
teil werden, insbesondere wenn Themeninstanzen auf Themeninstanzen verweisen, die
nicht Bestandteil des Teilprojekts sind. Ärgerlich wäre natürlich auch, wenn der Datenbe-
stand für die Arbeit im Feld zu großzügig eingegrenzt wurde.
Ja, das sehe ich auch als ein Probem an. Evtl. ist es möglich alle Themeninstanzen ei-
nes Telprojektes zu nehmen plus alle außerhalb des Teilprojektes, auf die verwiesen wird.
Das ist aber auch nur z.T. gut, weill es Verweise, die während der Offlinearbeit erfolgen,
z.T. verhindert. Ggf. muss man alle Themeninstanzen für eine Kindversion eines Teil-
projektes verwenden, aber die externen Bilder, Dokumente, etc., die nicht zu Teilprojekt-
Themeniinstanzen gehören, weglassen.
Insgesamt schwierig und ich befürchte erst die Praxisi wird zeigen, was wirklich praktika-
bel ist - sowohl für den Forscher als auch für den Synchronisationsprozess.
4. Um die Bearbeitung von Daten durch mehrere Nutzer im verteilten System zu er-
möglichen, müssen die Arbeitsschritte versioniert werden. Dies ermöglicht als Neben-
effekt auch ein Undo/Redo während der Arbeit an der Instanz. Beim abschließenden
Übernehmen der Änderungen würden diese „Zwischenstände“ lokal verbleiben und peri-
odisch gelöscht. Ihr Nutzen ist danach zweifelhaft und sie verursachen entsprechenden
Speicherbedarf. Ist eine projektweite Historie sinnvoll?
M.E. nicht. Ich kann mir kaum einen Fall vorstellen, wo es sinnvoll ist, auf eine ältere Ver-
sion eines Themeninstanz zurückgreifen zu wollen. Ich würde das wenn überhaupt durch
regelmäßige Backups (Datenbankdumps) lösen, auf die im Notfall durch den Projektad-
min zurückgriffen werden kann, wenn Theminstanzen gelöscht oder einzelne Attribute
falsch überschrieben wurden.
5. Außerdem würde mich für einige Einschätzungen interessieren, die beschreiben, wie
die Vorraussetzungen vor Ort aussehen können. In welcher Größenordnung bewegen
sich die Projekte in Sachen Mitarbeiter und genutzter Computer?
Kind-Instanzen können von 1 Person mit 1 Laptop (z.B. Forscher nimmt Objekte in ei-
nem Museumskeller auf) bis hin zu ca. 15 Personen an 10 Rechnern in einem lokalen
Netzwerk reichen (so z.B. in Pergamon als eines der „großen“ Feldforschungsprojekte)
Welche Betriebssysteme kommen zum Einsatz (Win, *unix, OSX)?

Email xviii
Primär wohl Win, OSX ganz wenig und *unix gar nicht (Ich kenne keinen Archäologen,
der mit *unix-Systemen arbeitet, schon gar nicht bei Feldforschungen ...).
Werden die Rechner in jedem Fall durch DAI o.ä. administriert oder durch die Nutzer
selbst?
Unterschiedlich: Wenn DAI-Projekt dann Administration durch das DAI, wenn aber OpenInfRA
von nicht DAI- Projekten genutzt wird (z.B. im Rahmen von TOPOI der FU & HU Berlin),
dann ist die Administartion vielfältig ...
Ich hoffe, meine Antworten helfen Ihnen ein wenig weiter. Ansonsten bitte Rückfragen.
Beste Grüße,
Felix Schäfer
Von: Philipp Gerth An: Felix Falko Schäfer
Kopie: Benjamin Thurm, Frank Henze, Philipp Gerth, Alexander Schulze, Frank Schwarz-
bach
11. Juni 2013
Lieber Herr Thurm,
generell schließe ich mich Felix’ Antworten an, habe aber noch einige Anmerkungen:
Welche Betriebssysteme kommen zum Einsatz (Win, *unix, OSX)?
Primär wohl Win, OSX ganz wenig und *unix gar nicht (Ich kenne keinen Archäologen,
der mit *unix-Systemen arbeitet, schon gar nicht bei Feldforschungen ...).
Ansonsten spielt in anderen Ländern teilweise Linux eine größere Bedeutung und insbe-
sondere ArcheOS könnte hier eine größere Rolle spielen, in der man thereotisch sicher
auch OpenInfRA einbinden könnte, was ein Deploy auf Rechnern natürlich erheblich er-
leichtert: http://www.archeos.eu
Android wird aber vermutlich zukünftig in der Archäologie eine größere Rolle spielen, wo-
bei das eher Kaffeesatzlesen ist, da es im Moment kaum angewendet wird. IOS wird sich
hier aber m.E. wegen der Restriktionen für Feldforschungen nicht durchsetzen, während
aber der Nutzen von Tablets für Feldforschungen potenziell sehr groß ist. Das soll aber
kein Aussschlusskriterium sein, lediglich ein Hinweis auf eine wahrscheinliche zukünfti-
ge Entwicklung. Meine Hoffnung/Bemühungen für ein mögliches Nachfolgeprojekt wäre
vermutlich auch in diesem Bereich.

Email xix
Werden die Rechner in jedem Fall durch DAI o.ä. administriert oder durch die Nutzer
selbst?
Unterschiedlich: Wenn DAI-Projekt dann Administration durch das DAI, wenn aber OpenInfRA
von nicht DAI- Projekten genutzt wird (z.B. im Rahmen von TOPOI der FU & HU Berlin),
dann ist die Administartion vielfältig ...
Prinzipiell gehe ich davon aus, daß sich die Administration von OpenInfRA nur größere In-
stitute „leisten“ können, da hierzu immer eine Person mit IT verstand notwendig sein wird.
Ob es dann aber in der Summe für die Institute nicht leichter ist auf den DAI Bus aufzu-
springen, wird die Zeit dann zeigen. Ob es gelingen wird eine eigene größere Open Sour-
ce Community aufzubauen, die dann ähnlich QGIS und co die Entwicklung voran treibt,
wage ich zu bezweifeln, da die Zielgruppe viel kleiner und auch weniger IT affin ist. Von
daher denke ich wird OpenInfRA später administrativ und (weiter-)entwicklungstechnisch
nur von Institutionen, Exellenzclustern und wirklich großen Instituten (wovon es vll ein
halbes Dutzend in Deutschland gibt) zu tragen sein.
Schöne Grüße,
Philipp Gerth

Anlagenverzeichnis xx
Anlagenverzeichnis
1 |-- Masterarbeit_Benjamin_Thurm.pdf
2 |-- Anhang -A_Anwendungsfälle_Überarbeitung.odt
3 |-- Anhang -B_Anforderungskatalog_Überarbeitung.xls
4 |-- Datenbankschema
5 | |-- 1_UUID_v10_Relationen.sql
6 | |-- 2_UUID_v10_Standardwerte.sql
7 | |-- 3_UUID_v10_Funktionen.sql
8 |-- Grobkonzept_Ergänzungen_Thurm.odt
9 |-- PostgreSQL Extension pg_sengi
10 | |-- pg_sengi
11 | |-- vclock
12 |-- Standardkonfiguration
13 | |-- SymOpenInfRA.sql
14 | |-- child.properties
15 | |-- mother.properties
16 |-- SymmetricDS Anpassungen
17 | |-- SVN
18 | |-- SymmetricAdmin.java
19 | |-- symmetric -client -3.5.10. jar
20 | |-- user -guide.pdf
21 |-- Test
22 | |-- Config.sql
23 | |-- UUID_Import.sql
24 | |-- UUID_Migrationsergebnis.sql
25 |-- Webseiten
26 |-- BDR Project (2013) - BDR Project - PostgreSQL wiki
27 |-- BeanShell (o.D.) - Lightweight Scripting for Java
28 |-- Cottbus , BTU (2013) CISAR
29 |-- Esri (2013a) - ArcGIS 10.2 for Desktop Functionality Matrix.pdf
30 |-- Esri (2013b) - ArcGIS 10.2 for Server Functionality Matrix.pdf
31 |-- Esri (2013c) - ArcGIS Help 10.2 - Preparing data for replication
32 |-- Esri (2013d) - ArcGIS Help 10.2 - Replica creation and versioning
33 |-- FileMaker Inc. (2013b) - FileMaker Pro -Funktionen | FileMaker Pro
12
34 |-- FileMaker , Inc. (2013a) - Database syncing - an overview of
approaches | FileMaker
35 |-- Internet Engineering Task Force (2005) - RFC 4122 - A Universally
Unique IDentifier (UUID) URN Namespace
36 |-- JumpMind (2013a) - Editions

Anlagenverzeichnis xxi
37 |-- JumpMind (2013b) - SymmetricDS API 3.5.5
38 |-- Keating (2001) - Challenges Involved in Multimaster Replication
39 |-- Lane (2008) - Core team statement on replication in PostgreSQL
40 |-- Long (2012) - How SymmetricDS Works
41 |-- Microsoft (2013) - Mergereplikation
42 |-- Microsoft - Nachverfolgen von Datena ?\210 nderungen (SQL Server)
43 |-- Microsoft - U?\210 ber Change Data Capture (SQL Server)
44 |-- Oracle (2005) - Change Data Capture
45 |-- Postgres (2010) - Postgres -R: a database replication system for
PostgreSQL
46 |-- Postgres (2012) - PostgreSQL: Documentation: devel: Release 9.2
47 |-- Postgres (2013a) - PostgreSQL: PostgreSQL 9.3 Pressemappe
48 |-- Postgres (2013b) - PostgreSQL: Documentation: 9.3: Transaction
Isolation
49 |-- Postgres (2013e) - PostgreSQL: Documentation: 9.3: Introduction
50 |-- Postgres (2013f) - PostgreSQL: Documentation: 9.3: Log -Shipping
Standby Servers
51 |-- Postgres (2013g) - PostgreSQL: Documentation: 9.3: UUID Type
52 |-- Postgres (2013h) - PostgreSQL: Documentation: 9.3: uuid -ossp
53 |-- Postgres (2013i) - PostgreSQL: Documentation: 9.0: Write -Ahead
Logging (WAL)
54 |-- Sun Microsystems (2011) - The Java Community Process(SM) Program -
JSRs: Java Specification Requests - detail JSR# 315
55 |-- Test Anything Protocoll (2007) - Test Anything Protocol
56 |-- Wheeler (2013) - pgTAP: Unit Testing for PostgreSQL
Listing 3: Ordnerstruktur

Monographien xxii
Monographien
Abeck, Sebastian u. a. (2003). Verteilte Informationssysteme. 2. Aufl. Heidelberg:dpunkt.verlag.
Böszörmenyi, Zoltan und Hans-Jürgen Schönig (Aug. 2013). PostgreSQL Replication.Birmingham: Packt Publishing Ltd.
Ceri, Stefano und Giuseppe Pelagatti (1984). Distributed Databases - Principles and Sys-tems. Computer Science Series. McGraw-Hill Book Company.
Coulouris, George, Jean Dollimore und Tim Kindberg (2002). Verteilte Systeme. 3. Aufl.München: Pearson Studium.
Dadam, Prof. Dr. Peter (1996). Verteilte Datenbanken und Client-, Server-Systeme.Grundlagen, Konzepte und Realisierungsformen. Berlin: Springer-Verlag.
Edlich, Stefan u. a. (2011). NoSQL. Einstieg in die Welt nichtrelationaler Web 2.0 Daten-banken. Carl Hanser Verlag München.
Höpfner, Hagen, Can Türker und Birgitta König-Ries (2005). Mobile Datenbanken undInformationssysteme - Konzepte und Techniken. dpunkt.verlag.
Kemper, Prof. Dr. Alfons und Dr. André Eickler (2009). Datenbanksysteme. Eine Einfüh-rung. 7. Aufl. München: Oldenbourg Wissenschaftsverlag GmbH.
Mutschler, Bela und Günther Specht (2004). Mobile Datenbanksysteme. Springer-VerlagBerlin Heidelberg.
Rahm, Erhard (1994). Mehrrechner-Datenbanksysteme. 1. Auflage. Addison-Wesley Pu-blishing Company.
Zeiler, Michael und Jonathan Murphy (2010). Modeling Our World. 2. Aufl. Redlands: EsriPress.
Publikationen
Anderson, Ross (2001). „Distributed Systems“. In: A Guide to Building Dependable Dis-tributed Systems. Wiley Computer Publishing. Kap. Distributed Systems, S. 115–135.
Demers, Alan u. a. (1994). The Bayou Architecture: Support for Data Sharing amongMobile Users. Techn. Ber. Palo Alto, California 94304 U.S.A.: Xerox Palo Alto ResearchCenter.
Esri (9. Juli 2007). An Overview of Distributing Data with Geodatabases. White paper.Redlands: Esri.
Fidge, Colin J. (1988). „Timestamps in Message-Passing Systems That Preserve thePartial Ordering“. In: Australian Computer Science Communications.
Gilbert, Seth und Nancy Lynch (2002). „Brewer’s Conjecture and the Feasibility of Con-sistent Available Partition-Tolerant Web Services“. In: In ACM SIGACT News.

Webseiten xxiii
Lamport, Leslie (1978). „Time, Clocks, and the Ordering of Events in a Distributed Sys-tem“. In: Communications of the ACM. Hrsg. von R. Stockton Gaines. Bd. 21. 7, S. 558–565.
Lamprecht, Jana (Aug. 2008). „Konzeption und Implementierung eines Intermittently Syn-chronized Database System für paläoanatomische Anwendungen“. Diplomarbeit. Mün-chen: Ludwig Maximilians Universität München.
Long, Eric u. a. (2013). SymmetricDS User Guide. v3.5.
Meijden, Chris van der (2012). OSSOBOOK. Spicing archaeo related sciences witharchaeo-informatics. Präsentation. ArchaeoBioCenter.
OpenInfRA, Projektteam (2013). „OpenInfRA. Grobkonzept für ein webbasiertes Informa-tionssystem zur Dokumentation archäologischer Forschungsprojekte“. unveröffentlicht.Arbeitsstand V2.2. Cottbus und Dresden.
Petersen, Karin, Mike J. Spreitzer u. a. (1997). „Flexible Update Propagation for WeaklyConsistent Replication“. In: SOSP ’97 Proceedings of the sixteenth ACM symposiumon Operating systems principles, S. 288–301.
Petersen, Karin, Mike Spreitzer u. a. (1996). „Bayou: Replicated Database Services forWorld-wide Applications“. In: In Proceedings 7th SIGOPS European Workshop. ACM,S. 275–280.
Rabinovich, Michael, Narain Gehani und Alex Kononov (1995). „Scalable Update Propa-gation in Epidemic Replicated Databases“. In: In Proceedings of the 5th InternationalConference on Extending Database Technology. Springer, S. 207–222.
Saito, Yasushi (2000). Optimistic Replication Algorithms. White Paper. International Sym-posium on Distributed Computing.
– (2005). „Optimistic replication“. In: ACM Computing Surveys 37, S. 42–81.
Schäfer, Felix Falko (11. Juni 2013). Re: Replikation OpenInfRA - Allgemeine Fragen.Email.
Shah, Jignesh (2013). Best Practices for HA and Replication for PostgreSQL in Virtuali-zed Enviroments. Präsentation. vPostgres Team und VMware.
Vogels, Werner (2009). „Eventually Consistent“. In: Communications of the ACM. Bd. 52.2.
Webseiten
BDR Project (3. Mai 2013). URL: http://wiki.postgresql.org/wiki/BDR_Project (besucht am29. 09. 2013).
BeanShell (o.D.). BeanShell - Lightweight Scripting for Java. URL: http://www.beanshell.org.
Brewer, Eric A. (2000). Towards Robust Distributed Systems. URL: http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf (besucht am 02. 09. 2013).
Cottbus, BTU (2. Sep. 2013). CISAR. Ein modulares Informationssystem für Archäolo-gie und Bauforschung. BTU Cottbus. URL: http : / / www. tu - cottbus . de / cisar / cisar /beschreibung.html (besucht am 02. 09. 2013).

Webseiten xxiv
Esri (2013a). ArcGIS 10.2 for Desktop Functionality Matrix. URL: http://www.esri.com/software / arcgis / arcgis - for - desktop / ~ / media / Files / Pdfs / library / brochures / pdfs /arcgis102-desktop-functionality-matrix.pdf (besucht am 15. 10. 2013).
– (2013b). ArcGIS 10.2 for Server Functionality Matrix. URL: http : / / www. esri . com /software / arcgis / arcgis - for - desktop / ~ / media / Files / Pdfs / library / brochures / pdfs /arcgis102-desktop-functionality-matrix.pdf (besucht am 15. 10. 2013).
– (2013c). ArcGIS Help 10.2 - Preparing data for replication. URL: http : / / resources .arcgis . com / en / help / main / 10 . 2 / index . html # /Preparing _ data _ for _ replication /003n000000z5000000/ (besucht am 15. 10. 2013).
– (9. Okt. 2013d). Replica creation and versioning. URL: http://resources.arcgis.com/en/help/main/10.2/index.html#/Replica_creation_and_versioning/003n000000vr000000/(besucht am 15. 10. 2013).
FileMaker, Inc. (15. Apr. 2013a). Database syncing. An overview of approaches. URL:http://help.filemaker.com/app/answers/detail/a_id/7720/~/database-syncing---an-overview-of-approaches (besucht am 01. 09. 2013).
– (2013b). FileMaker Pro-Funktionen. URL: http://www.filemaker.de/products/filemaker-pro/all-features.html (besucht am 01. 09. 2013).
Force, Internet Engineering Task (Juli 2005). RFC 4122: A Universally Unique IDenti-fier (UUID) URN Namespace. URL: http : / / tools . ietf . org / html / rfc4122 (besucht am08. 10. 2013).
Group, Postgres Global Development (2010). About Postgres-R. URL: http: / /postgres-r.org/about/about (besucht am 29. 09. 2013).
JumpMind Inc. (2013a). Editions. URL: http://www.jumpmind.com/products/symmetricds/editions.
– (2013b). SymmetricDS API 3.5.5. URL: http://www.symmetricds.org/doc/3.5/javadoc/(besucht am 10. 10. 2013).
– (9. Sep. 2013c). SymmetricDS - Open Source Database Replication. URL: http://www.symmetricds.org.
Keating, Brian (2001). Challenges Involved in Multimaster Replication. URL: http://www.dbspecialists.com/files/presentations/mm_replication.html (besucht am 27. 09. 2013).
Lane, Tom (29. Mai 2008). Core team statement on replication in PostgreSQL. URL: http://www.postgresql.org/message- id/[email protected] (besucht am28. 09. 2013).
Long, Eric (15. Sep. 2012). How SymmetricDS Works. URL: http://www.symmetricds.org/docs/how-to/how-symmetricds-works (besucht am 28. 09. 2013).
Microsoft (o.D.[a]). Nachverfolgen von Datenänderungen (SQL Server). URL: http : / /technet.microsoft.com/de-de/library/bb933994.aspx.
– (o.D.[b]). Über Change Data Capture (SQL Server). URL: http://technet.microsoft.com/de-de/library/cc645937.aspx.
– (2013). Mergereplikation. URL: http://technet.microsoft.com/de-de/library/ms152746.aspx (besucht am 22. 10. 2013).
Oracle (2005). Oracle Database Data Warehousing Guide. Change Data Capture. URL:http : / / docs.oracle .com/cd /B19306_01 /server.102 /b14223 /cdc .htm (besucht am15. 10. 2013).
PostgreSQL Global Development Group (10. Sep. 2012). PostgreSQL Documentation:Release 9.2. URL: http : / /www.postgresql . org /docs /devel / static / release - 9 - 2 .html(besucht am 07. 10. 2013).

Webseiten xxv
PostgreSQL Global Development Group (9. Sep. 2013a). PostgreSQL 9.3 Pressemappe.URL: http://www.postgresql.org/about/press/presskit93/de/ (besucht am 25. 09. 2013).
– (2013b). PostgreSQL Documentation. Concurrency Control. Transaction Isolation. URL:http : / / www. postgresql . org / docs / current / static / transaction - iso . html (besucht am26. 09. 2013).
– (2013c). PostgreSQL Documentation. Concurrency Control. Introduction. URL: http://www.postgresql.org/docs/current/static/mvcc-intro.html (besucht am 26. 09. 2013).
– (2013d). PostgreSQL Documentation: Cluster. URL: http://www.postgresql.org/docs/9.3/static/sql-cluster.html (besucht am 17. 10. 2013).
– (2013e). PostgreSQL Documentation: Continuous Archiving and Point-in-Time Reco-very (PITR). URL: http://www.postgresql.org/docs/9.3/static/continuous-archiving.html(besucht am 27. 09. 2013).
– (2013f). PostgreSQL Documentation: Log-Shipping Standby Servers. URL: http://www.postgresql.org/docs/9.3/static/warm-standby.html (besucht am 27. 09. 2013).
– (2013g). PostgreSQL Documentation: UUID Type. URL: http : / /www.postgresql .org /docs/9.3/static/datatype-uuid.html (besucht am 15. 10. 2013).
– (2013h). PostgreSQL Documentation: uuid-ossp. URL: http://www.postgresql.org/docs/9.3/static/uuid-ossp.html (besucht am 08. 10. 2013).
– (2013i). PostgreSQL Documentation: Write-Ahead Logging (WAL). URL: http: / /www.postgresql.org/docs/9.0/static/wal-intro.html (besucht am 27. 09. 2013).
PostgreSQL Wiki (5. Okt. 2013). Replication, Clustering, and Connection Pooling. URL:http : / /wiki . postgresql . org /wiki /Replication , _Clustering , _and_Connection_Pooling(besucht am 05. 10. 2013).
Sun Microsystems Inc. (9. März 2011). JSR 315: Java Servlet 3.0 Specification. URL:http://jcp.org/en/jsr/detail?id=315 (besucht am 06. 10. 2013).
Test Anything Protocol (29. Mai 2007). URL: http://testanything.org/wiki/index.php/Main_Page (besucht am 06. 09. 2013).
Wheeler, David E. (6. Sep. 2013). pgTAP: Unit Testing for PostgreSQL. URL: http://pgtap.org (besucht am 06. 09. 2013).

Erklärung über die eigenständige Erstellung der Arbeit xxvi
Erklärung über die eigenständigeErstellung der Arbeit
Hiermit erkläre ich, dass ich die vorgelegte Arbeit mit dem Titel
„Entwurf und Implementierung einer Offline-Replikation unter PostgreSQL“
selbständig verfasst, keine anderen als die angegebenen Quellen und Hilfsmittel benutztsowie alle wörtlich oder sinngemäß übernommenen Stellen in der Arbeit als solche unddurch Angabe der Quelle gekennzeichnet habe. Dies gilt auch für Zeichnungen, Skizzen,bildliche Darstellungen sowie für Quellen aus dem Internet.
Mir ist bewusst, dass die Hochschule für Technik und Wirtschaft Dresden Prüfungsarbei-ten stichprobenartig mittels der Verwendung von Software zur Erkennung von Plagiatenüberprüft.
Ort, Datum Benjamin Thurm







