Download - ASCP Data Collection Technical Workshop GOOD

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 1111////14141414
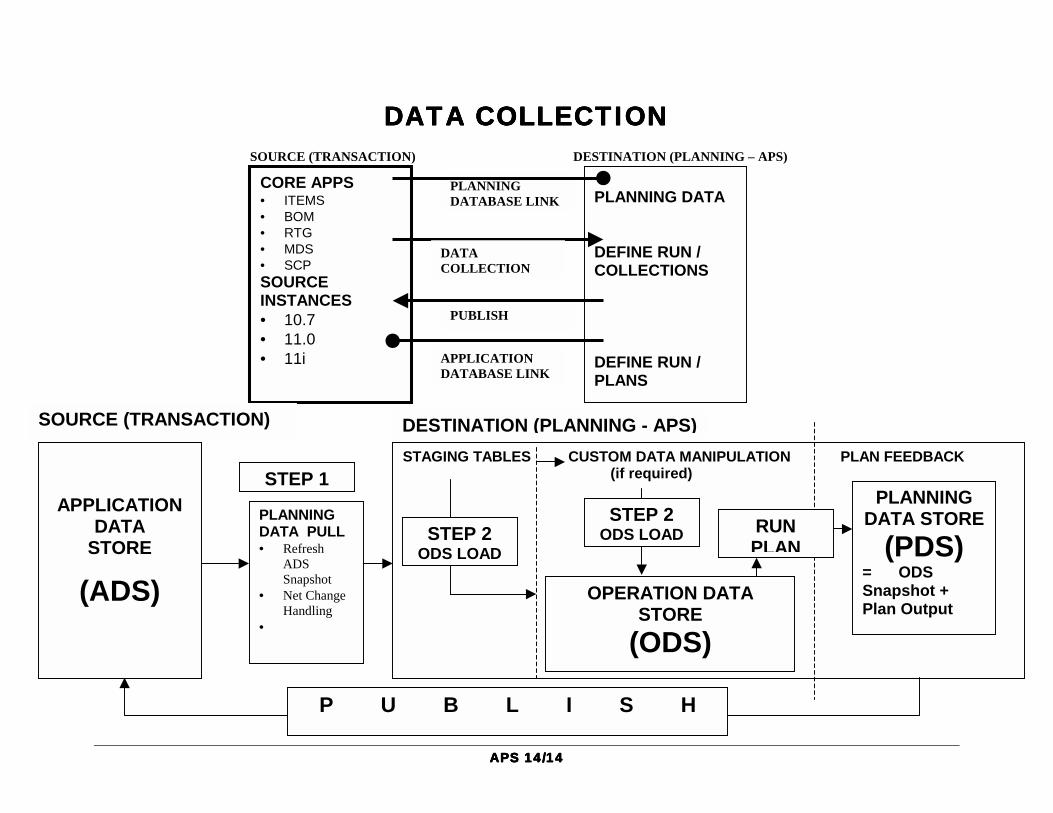
Data Collection Technical Workshop Sanjeev Kale Oracle Corporation Introduction This paper focuses on understanding Data collection architecture. Data Collection is a process that pulls data from designated data sources into its planning data store. The Data collection process consists of the ‘pull process’ and ‘Operational Data Store (ODS) load process’. Note: This document is intended for use as a reference document. Certain sections of the text are intentionally repeated throughout the document, so that each section can be read and understood independently of one another. This document is designed to supplement Oracle Advanced Supply Chain Planning and Oracle Global ATP Server User’s Guide and other APS training class notes. Overview of Running Collections Data Collection programs move data from the source instance into staging tables where data integrity is checked before being loaded into APS instances Operational Data store. Pull Data programs move the data from the staging tables to the APS instances Operational Data store. The user has the flexibility in determining when the snapshot of information from the transaction system (Source Instance) should be taken, and in deciding what information to capture with each run of Data Collection. The data collection program can be set to run upon submission of a job request, and at specified time intervals, and to collect different type of information with different frequency e.g. Dynamic data such as sales order can be collected frequently, while static data such as department resources can be collected at longer intervals.
Definitions Oracle Applications Data Store (ADS) Represents all the source data tables used to build and maintain the planning data store within Oracle ASCP. It represents a single source data instance. E.g. transaction system (Source Instance) Operational Data Store (ODS) Part of Oracle ASCP that represents all the planning data tables that act as destinations for the collected data from each of the data sources (both ADS and Legacy). This acts as the input for the snapshot portion of the planning process. ODS and PDS share the same physical tables where a special plan identifier (for example, -1) is used for distinction. Planning Data Store (PDS) Represents all the tables within Oracle ASCP which encompass those in the ODS and other output tables from planning, including copies/snapshots of the input data used for the current planning run striped by the appropriate plan identifier. Data Collection Data collection consists of the following:

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 2222////14141414
Pull program Collects the data from the ADS, and stores the data into the staging tables. This pull program is a registered AOL concurrent program that could be scheduled and launched by a system administrator. If you are using a legacy program, you must write your own pull program. The pull program performs the following major processes.
��Refresh snashots. �� Launch the pull Workers to perform
pulls from the appropriate source tables and insert the data in the Staging tables.
ODS Load A PL/SQL program which performs the data transform and moves the data from the staging tables to the ODS. This collection program is a registered AOL concurrent program that could be scheduled and launched by the system administrator. The Launch_Monitor procedure performs the following major processes: �� Key Transformation - Generate new
local ID for global attributes such as items, category set, vendor, vendor site, customer and customer site.
�� Launch the ODS Load Workers to perform Create, Update, and Delete operations for each entity in ODS (MSCPDCW).
�� Recalculate the sourcing history based on the latest sourcing information and the data from transaction systems.
�� Recalculate the net resource availability based on the calendars, shifts and department resources information.
�� Purge the data in the Staging tables (MSCPDCP).
Collection Workbench Collection Workbench is a centralized data repository providing collected data from the source. Data from different source instances can be viewed using the Collection Workbench. The functionality here is similar to the Planner Workbench functionality. The collection
workbench is used to verify that the intended data has been collected – If necessary, troubleshoot errors in data collection and rerun the data collection program. Data Collection Setup Steps The Data Collection can be implemented in two configurations – Centralized configuration and Decentralized or Distributed configuration. Centralized configuration is where the transaction (Source) instance and destination (APS) instance is on the same instance. Decentralized configuration is where the transaction (Source) instance and Destination (APS) instance are two different instances. These two instances could be on different machines. Depending on the type of configuration that is selected, the setup steps will change. E.g. For Centralized configuration there is no need to set up database links, whereas in Decentralized configuration, the database links will have to be set up before proceeding with any other setup steps.
The Oracle APS setup for data collection involves three steps ��Establish database links ��Define Instances / Associate
Organizations from where the data is being pulled.
��Specify parameters for the data to be collected from each instances for each named request set
Database Links The Planning Database Link is defined by the database administrator on the APS (destination) planning instance. There are two Database links created. One on the source instance that points to the destination instance (known as the Application Database Link). One on the destination instance that points to the

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 3333////14141414
source instance (known as the Planning Database Link). Both the links are bidirectional. The Planning Database link is used for ��Data collection from transaction source
to the planning instance. �� When an action, such as releasing a
planned order or requisition, occurs in the APS planning system, the data is “published” to the transaction instance. The first step in this process is to send a signal via the Planning database link to the transaction instance. This initiates a remote procedure that pulls the planned order or requisition from the planning instance to the transaction instance.
The Application Database link is used for • Completing the “Publishing” process. • The remote procedure that pulls the
planned order or requisition record from the planning instance to the transaction instance does so by using the Application Database link.
Centralized vs. Distribution Configuration
• This refers to the deployment of planning and ERP modules.
• In Centralized deployment, planning and ERP modules are in one machine and in the same database instance.
• In the Distributed configuration, planning and ERP modules are on different database instances and are usually on different machines.
Centralized vs. Decentralized Planning
• This has nothing to do with the way the planning and ERP modules are deployed. This has to do with whether you are planning all orgs in an enterprise together or separately.
• In centralized planning, you plan all orgs in ONE PLAN.
• In decentralized planning, you plan different subsets of orgs in different
• plans and link them up by feeding the supply schedule of one org as demand schedule of another.
Example of a Database link Following database link is created in Source instance: In source (Application Database Link) ============================= create public database link APSconnect to apps identified by appsusing 'APS.world'; Following database link is created in Planning instance: In APS (Planning Database Link) ========================= create public database link vis1153connect to apps identified by appsusing 'vis1153.world'; Test the APS link as follows: In APS SQL*Plus: ==================== select sysdate from dual@vis1153; Test the source link as follows: In vis1153 SQL*Plus: ==================== select sysdate from dual@aps; These are the tnsnames.ora entries needed to connect to both instances: APS.world = (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=aps)(PORT=1523))(CONNECT_DATA=(SID=APS)))
vis1153.world = (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=aps.us.oracle.com)(PORT=7500))(CONNECT_DATA=(SID=vis1153)))
Define Instances Navigation path for defining the instances.

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 4444////14141414
Advanced Supply Chain Planner �Setup�Instances The Database Administrator uses this form to setup instance names and to specify the release version of the source database, Application Database link and Planning Database link associated with the instance names.
Complete the following Field and Flag in the Application Instance Window. Set up Organizations by clicking on the Organizations Button. The Organizations window lists the organization within the instance. To enable data collection for an organization within an instance, select the enabled check box. The database links can be confirmed by running the following SQL scripts after the instances are defined. In vis1153 SQL*Plus ================ Select db_linkfrom dba_db_linkswhere db_link = 'APS';
DB_LINK-------APS
select m2a_dblink,a2m_dblinkfrom mrp_ap_apps_instances;
MRP_AP_APPS_INSTANCES table points to the destination (APS) instance. It will always have only one row.
M2A_DBLINK A2M_DBLINK----------- -----------vis1153 APS In vis1153 SQL*Plus ================
Select db_linkfrom dba_db_linkswhere db_link = 'vis1153';
DB_LINK-------vis1153
select m2a_dblink,a2m_dblinkfrom msc_apps_instances; MSC_APPS_INSTANCES table will list all the source instances from which destination (APS) instance can pull data from.
M2A_DBLINK A2M_DBLINK----------- -----------vis1153 APS
Specify parameters for the data to be collected Data Pull Parameters – In the data pull parameter form, specify the data to retrieve from the selected instance. The complete refresh flag works in conjunction with the other data Yes/No flags listed lower in the form. When Complete Refresh is set to Yes, all the original data in the Operational Data Store (ODS) will be purged. Then the data that have flags set to yes are collected and inserted into the ODS.
FIELD/FLAG DESCRIPTION Instance Code Choose from Multiple instances Instance Type Discrete, Process, Discrete and
Process or Other. If the source is discrete, only the discrete entites are collected. IF Process, then only OPM related entities are collected
Version Unique version for the specified instance
Application Database Link
A link to connect to the Application database to Oracle ASCP
Planning Database Link
A link to connect to the Oracle ASCP to the Application database
Enable Flag Select this option to enable the collection Process
GMT Difference The difference between instance time zone and GMT

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 5555////14141414
Example 1: Complete Refresh = Yes(Complete Refresh Mode), Pull Items = Yes, Pull BOM/Routings = No – After theData collection, the ODS will contain items but no information about bills and routings. When Complete Refresh is set to No (Incremental Refresh - Net Change mode), then the data collection is performed in incremental refresh mode Net Change. The data existing in the ODS is not purged. The data that have flags set to Yes will be refreshed.
Example 2 Complete Refresh = No, Pull Items = Yes, Pull BOM/Routings = No – After the data collection, the ODS will contain refreshed item information and the same bills or routings information that existed before the incremental refresh occurred. In the incremental refresh mode, net changes of the following entities is supported.
1) Item: new item and item attribute changes
2) BOM/Routing: Any change in BOM/Routing, except for substitute components. In the case of using alternate/simultaneous resources, the change of the resource step number is not supported.
3) Supply/Demand: Any change in supply/demand, includes onhand quantities and hard reservations.
4) Resource: a) The department resource
capacity changes defined in the simulation set.
b) WIP line resource changes c) WIP job's resource
requirement changes. d) Supplier's capacity changes
In the Data pull parameters form the number of workers to be employed can be specified. ODS Load Paramters – Following parameters are specified.
In the ODS Load parameters form the number of workers to be employed can be specified. Recalculate Net Resource Availability (NRA) parameter – If a new resource is defined or the availability of a resource has changed on the transaction (source) instance, then the Recalculate Net Resource Availability (NRA) field on the ODS load parameter should be set to Yes. Recalculate Sourcing History parameter – Choose to allow sourcing history to affect allocation of orders among external supply

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 6666////14141414
sources. Setting the Recalculate Sourcing History flag to Yes will cause the sourcing history to be recalculated.
The Data Collection Process To understand the Data Collection process first we need to understand the architecture of the data in the source instance. For that we need to understand the following. Snapshot - A snapshot is a replica of a target master table at a single point-in-time. Whereas multimaster replication tables are continuously being updated by other master sites, Snapshots are updated by one or more master tables via individual batch updates, known as a refresh, from a single master site. The following Snapshots are defined in the source instance. For each snapshot there is a synonym defined. Using these synonym and other production tables in the source instance there are various views created.
SNAPSHOT NAME SYNONYM NAME MTL_SUPPLY_SN MRP_SN_SUPPLY
MTL_U_SUPPLY_SN MRP_SN_U_SUPPLY MTL_U_DEMAND_SN MRP_SN_U_DEMAND MTL_SYS_ITEMS_SN MRP_SN_SYS_ITEMS MTL_OH_QTYS_SN MRP_SN_OH_QTYS
MTL_MTRX_TMP_SN MRP_SN_MTRX_TMP MTL_DEMAND_SN MRP_SN_DEMAND
BOM_BOMS_SN MRP_SN_BOMS BOM_INV_COMPS_SN MRP_SN_INV_COMPS BOM_OPR_RTNS_SN MRP_SN_OPR_RTNS BOM_OPR_SEQS_SN MRP_SN_OPR_SEQS BOM_OPR_RESS_SN MRP_SN_OPR_RESS
BOM_RES_CHNGS_SN MRP_SN_RES_CHNGSMRP_SCHD_DATES_SN MRP_SN_SCHD_DATESWIP_DSCR_JOBS_SN MRP_SN_DSCR_JOBS
WIP_WREQ_OPRS_SN MRP_SN_WREQ_OPRSWIP_FLOW_SCHDS_SN MRP_SN_FLOW_SCHDS
WIP_WOPRS_SN MRP_SN_WOPRS WIP_REPT_ITEMS_SN MRP_SN_REPT_ITEMSWIP_REPT_SCHDS_SN MRP_SN_REPT_SCHDS
WIP_WLINES_SN MRP_SN_WLINES PO_SI_CAPA_SN MRP_SN_SI_CAPA
OE_ODR_LINES_SN MRP_SN_ODR_LINES When the data in transaction (Source) instance is – added or changed. The changes are reflected in the snapshots after the
Refresh Snapshot process completes successfully. This can be illustrated with an example. In the example we will see the flow of data for a given Bill of Material. The following BilI is defined in the source instance.
SK-DCTEST01 SK-DCTEST02 - Component SK-DCTEST03 - Component
Once this bill is defined the following tables are populated. SELECT ASSEMBLY_ITEM_ID ITEM_ID,
SEGMENT1,BOM.ORGANIZATION_ID ORG_ID,BILL_SEQUENCE_ID BILL_SEQ_ID
FROM BOM_BILL_OF_MATERIALS BOM,MTL_SYSTEM_ITEMS MTL
WHERE ASSEMBLY_ITEM_ID = 8307AND BOM.ORGANIZATION_ID =
MTL.ORGANIZATION_IDAND ASSEMBLY_ITEM_ID =
INVENTORY_ITEM_ID;
ITEM_ID SEGMENT1 ORG_ID BILL_SEQ_ID------- ----------- ------ -----------
8307 SK-DCTEST01 207 18328 SELECT COMPONENT_ITEM_ID ITEM_ID,
SEGMENT1,COMPONENT_QUANTITY COMPONENT_QTY
FROM BOM_INVENTORY_COMPONENTS COMPS,MTL_SYSTEM_ITEMS MTL
WHERE BILL_SEQUENCE_ID = 18328AND MTL.ORGANIZATION_ID = 207AND COMPONENT_ITEM_ID =
INVENTORY_ITEM_ID;
ITEM_ID SEGMENT1 COMPONENT_QTY------- ----------- -------------
8309 SK-DCTEST02 28317 SK-DCTEST03 2
There are three Snapshots involved in this example. MTL_SYS_ITEMS_SN for Items, BOM_BOMS_SN for bill material header, and BOM_INV_COMPS_SN. For each of these snapshots there is a synonym created Viz;MRP_SN_SYS_ITEMS, MRP_SN_BOMS, and MRP_SN_INV_COMPS respectively. If you run the following SQL scripts before the Refresh Snapshot Process is run, you will get zero rows returned. If you run the same scripts after the Refresh Snapshot Process is successfully run, it will return some rows.

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 7777////14141414
SELECT COUNT(*)FROM MRP_SN_BOMSWHERE ASSEMBLY_ITEM_ID = 8307;
COUNT(*)----------
0
SELECT COUNT(*)FROM MRP_SN_INV_COMPSWHERE BILL_SEQUENCE_ID = 18328;
COUNT(*)----------
0
Additionally, there are some views created on the snapshot synonyms which are used in the data collections process to load the data from the source instance into the ‘MSC staging’ tables. In this example, there are two views that are used to load the Bill of Material data into the staging tables. They are
MRP_AP_BOMS_V and MRP_AP_BOM_COMPONENTS_V
After the Refresh Snapshot Process is successfully run, run the following SQL scripts. SELECT ASSEMBLY_ITEM_ID ITEM_ID,
SEGMENT1,BOM.ORGANIZATION_ID ORG_ID,BILL_SEQUENCE_ID
BILL_SEQ_IDFROM MRP_AP_BOMS_V BOM,
MTL_SYSTEM_ITEMS MTLWHERE ASSEMBLY_ITEM_ID = 8307AND BOM.ORGANIZATION_ID =
MTL.ORGANIZATION_IDAND ASSEMBLY_ITEM_ID =
INVENTORY_ITEM_ID;
ITEM_ID SEGMENT1 ORG_ID BILL_SEQ_ID------- ----------- ------ -----------
8307 SK-DCTEST01 207 36656 SELECT COMPS.INVENTORY_ITEM_IDITEM_ID,
SEGMENT1,USAGE_QUANTITY
USAGE_QTYFROM MRP_AP_BOM_COMPONENTS_V COMPS,
MTL_SYSTEM_ITEMS MTLWHERE MTL.INVENTORY_ITEM_ID =
COMPS.INVENTORY_ITEM_IDand MTL_ORGANIZATION_ID = 207and BILL_SEQUENCE_ID = 36656;
ITEM_ID SEGMENT1 USAGE_QTY------- ----------- ---------
8317 SK-DCTEST03 28309 SK-DCTEST02 2
If you look at the LOAD_BOM procedure for data pull, it pulls the Bill of Material data from the above two views and populates the following two staging tables.
MSC_ST_BOMS and MSC_ST_BOM_COMPONENTS
After the data pull is complete, and before the purge staging process is started, the following SQL scripts can be run. SELECT ASSEMBLY_ITEM_ID ITEM_ID,
SEGMENT1,BOM.ORGANIZATION_ID ORG_ID,BILL_SEQUENCE_ID
BILL_SEQ_IDFROM MSC_ST_BOMS BOM,
MTL_SYSTEM_ITEMS MTLWHERE ASSEMBLY_ITEM_ID = 8307AND BOM.ORGANIZATION_ID =
MTL.ORGANIZATION_IDAND ASSEMBLY_ITEM_ID =
INVENTORY_ITEM_ID;
ITEM_ID SEGMENT1 ORG_ID BILL_SEQ_ID------- ----------- ------ -----------
8307 SK-DCTEST01 207 36656 SELECT COMPS.INVENTORY_ITEM_IDITEM_ID,
SEGMENT1,USAGE_QUANTITY
USAGE_QTYFROM MSC_ST_BOM_COMPONENTS COMPS,
MTL_SYSTEM_ITEMS MTLWHERE MTL.INVENTORY_ITEM_ID =
COMPS.INVENTORY_ITEM_IDand MTL.ORGANIZATION_ID = 207and BILL_SEQUENCE_ID = 36656
ITEM_ID SEGMENT1 USAGE_QTY------- ----------- ---------
8317 SK-DCTEST03 28309 SK-DCTEST02 2
If you look at the LOAD_BOM procedure for ODS data load, it pulls the Bill of Material data from the above two staging tables and populates the following two tables.

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 8888////14141414
MSC_BOMS MSC_BOM_COMPONENTS
Before the data is populated in the above tables, there is a process of Key transformation that takes place where the Source Inventory Item Id are Mapped to the inventory Item Id’ in the Planning instance. For Inventory item Id, the mapping is stored in the following table:
MSC_ITEM_ID_LID
SELECT SR_INVENTORY_ITEM_ID SR_ITEM_ID,INVENTORY_ITEM_ID ITEM_ID
FROM MSC_ITEM_ID_LIDWHERE sr_inventory_item_id IN
(8307,8309,8317);
SR_ITEM_ID ITEM_ID---------- -------
8307 23338309 23348317 2335
SELECT INVENTORY_ITEM_ID ITEM_ID,
ITEM_NAME,SR_INVENTORY_ITEM_ID SR_ITEM_ID,ORGANIZATION_ID ORG_ID
FROM MSC_SYSTEM_ITEMSWHERE ITEM_NAME LIKE 'SK-DC%';
ITEM_ID ITEM_NAME SR_ITEM_ID ORG_ID------- ----------- ---------- ------
2333 SK-DCTEST01 8307 2072334 SK-DCTEST02 8309 2072335 SK-DCTEST03 8317 207
Finally the Bill of Material data is now in the ODS data store. SELECT ASSEMBLY_ITEM_ID ITEM_ID,
ITEM_NAME,BOM.ORGANIZATION_ID ORG_ID,BILL_SEQUENCE_ID BILL_SEQ
FROM MSC_BOMS BOM,MSC_SYSTEM_ITEMS MTL
WHERE ASSEMBLY_ITEM_ID = 2333AND BOM.ORGANIZATION_ID =
MTL.ORGANIZATION_IDAND ASSEMBLY_ITEM_ID =
INVENTORY_ITEM_ID;
ITEM_ID ITEM_NAME ORG_ID BILL_SEQ_ID------- ----------- ------ -----------
2333 SK-DCTEST01 207 36656
SELECT COMPS.INVENTORY_ITEM_ID ITEM_ID,
ITEM_NAME,COMPS.ORGANIZATION_ID ORG_ID,USAGE_QUANTITY
USAGE_QTYFROM MSC_BOM_COMPONENTS COMPS,
MSC_SYSTEM_ITEMS MTLWHERE BILL_SEQUENCE_ID = 36656AND COMPS.INVENTORY_ITEM_ID =
MTL.INVENTORY_ITEM_IDAND COMPS.ORGANIZATION_ID =
MTL.ORGANIZATION_ID;
ITEM_ID ITEM_NAME ORG_ID USAGE_QTY------- ----------- ------ ---------
2334 SK-DCTEST02 207 22335 SK-DCTEST03 207 2
User has the flexibility in determining when a snapshot of information from the source system should be taken, and in deciding what information to capture with each job. The data collection program can be set to run upon submission of a job request, and at specified time intervals, and to collect different types of information with different frequencies. For example, dynamic data such as sales orders can be collected frequently, while static data, such as department resources, can be collected at longer intervals. The objective is to set up data collection as needed to create a current replica of information for the APS system to use in its model. To a degree, this is a self-balancing decision. In the incremental refresh (net change) mode, collection workers can detect and collect only changed data. The data will be at least as old as the job run time. Data collection process is run as a request set. Data can be collected from only one instance with each request set. Request sets are divided into one or more ”stages” which are linked to determine the sequence in which your requests are run. Each stage consists of one or more requests that you want to run in parallel (at the same time in any order). To run requests in sequence, you assign requests to different stages, and then link the stages in the order you want the requests to run.

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 9999////14141414
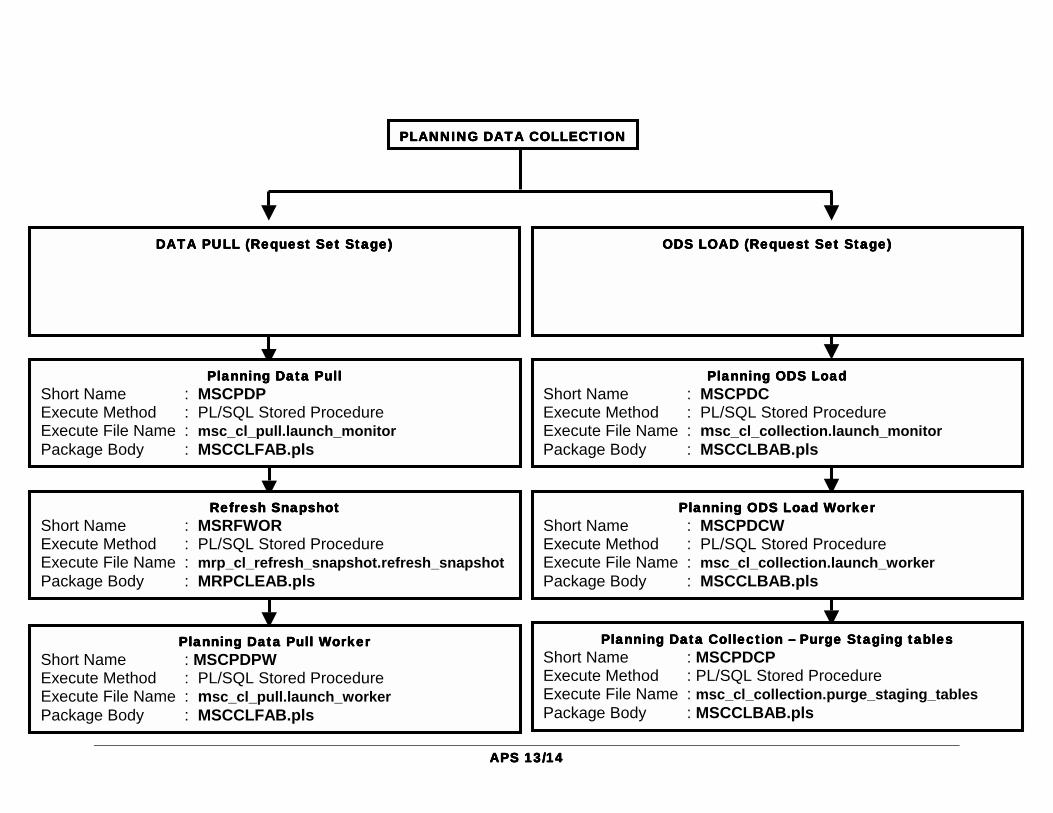
The concurrent manager allows only one stage in a request set to run at a time. When one stage is complete, the following stage is submitted. A stage is not considered to be complete until all of the requests in the stage are complete. One advantage of using stages is the ability to run several requests in parallel and then move sequentially to the next stage. In Data collection there are two stages, Data Pull Stage and ODS Load Stage. In the Data Pull Stage – Planning Data Pull, Refresh Snapshot and Planning Data Pull Worker requests are run. In the ODS Load Stage – Planning ODS Load, Planning ODS Load Worker, and Planning Data Collection Purge Staging tables requests are run. Six different processes comprise the structure of Data Collection process. Each of these processes are launched during the Data collection run.
Planning Data Pull (MSCPDP) Planning Data Pull is launched by Data Pull Stage. This is the process which launches and then controls the remaining Data Pull processes (Refresh Snapshot and Planning Data pull worker). The number of workers launched is determined by the parameter defined in the Data Pull parameters. The Planning Data Pull program maintains a list of tasks, and communicates with workers so that it has a constant picture of the status of each task. Using this list, the Data Pull program assigns the next task to available workers.
• Complete refresh – Ignores the most
recent refresh data and collects all data. • Incremental refresh – Collects only the
incremental changes since the most recent refresh.
Refresh Snapshot (MSRFWOR) Refresh Snapshot Process consistently refreshes one or more snapshots. The refresh snapshot uses Oracle's replication management API’s following packages: DBMS_SNAPSHOT.REFRESH. A Comma-separated list of snapshots is provided and the Type of refresh to perform for each snapshot listed; 'F' or 'f' indicates a fast refresh, 'C' or 'c' indicates a complete refresh. The refresh snapshot process is started, and purge the staging tables process is also submitted while the refresh snapshot process is running. For purging the staging tables, the MSC_CL_COLLECTION.PURGE_STAGING_TABLES_SUB procedure is called. The purpose of calling this procedure is that there is a COMMIT after every task – If the previous data pull failed then there would be data left in the staging tables.
Planning Data Pull Worker (MSCPDPW) As of now there are 35 tasks that are performed by the Planning Data Pull worker. These tasks are submitted one by one to the worker. Each task pulls the data from the appropriate source tables and inserts the data in the Staging tables. The Planning Data Pull workers communicate with Planning Data Pull program via the use of database pipes. Messages sent between processes on database pipes include new tasks, task completion messages, etc.
CONCURRENT PROGRAM
SHORT NAME
Planning Data Pull MSCPDP Refresh Snapshot MSRFWOR Planning Data Pull Worker MSCPDPW Planning ODS Load MSCPDC Planning ODS Load Worker
MSCPDCW
Planning Data Collection – Purge Staging tables
MSCPDCP

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 10101010////14141414
Please refer to the appendix for a complete list of tasks and procedures called. Planning ODS Load (MSCPDC) Planning Data load is launched by Planning ODS Load process. This is the process which launches and then controls the remaining Data load processes. Key transformation takes place here before the source data is made is available to APS. Key transformation takes place only for Items, Categories, Suppliers, and Customers. ��Key Transformation – To track data
entities back to the source instance, APS transforms each unique ID within APS. This process is called as Key Transformation. Generate new local ID for global attributes such as items, category set, vendor, vendor site, customer and customer site.
�� Launch the ODS Load Workers to perform Create, Update, and Delete operations for each entity in ODS (MSCPDCW).
�� Recalculate the sourcing history based on the latest sourcing information and the data from transaction systems.
Recalculate the net resource availability based on the calendars, shifts and department resources information.
The Planning Data load program maintains a list of tasks, and communicates with workers so that it has a constant picture of the status of each task. Using this list, the Data load program assigns the next task to available workers. Planning ODS Load Worker (MSCPDCW) As of now there are 25 tasks that are performed by the Planning ODS Load worker. These tasks are submitted one by one to the worker. Each task pulls the data from the appropriate staging tables and inserts the data into the ODS tables.
MRP:Cutoff Date Offset Months profile option is used for resource availability. Please refer to the appendix for a complete list of tasks and procedures called.
Planning Data Collection – Purge Staging Tables (MSCPDCP) The data in the staging tables is purged after the planning ODS load is successfully completed. The data collection process will attempt to purge the already extracted data and any data orphaned as a result of a termination of the Data Collection process. MRP:Purge Batch Size profile option is used to determine the number of records to be deleted at a time. The tables which are purged by the Purge Staging tables process are: • MSC_ST_BOM_COMPONENTS • MSC_ST_BOMS • MSC_ST_DEMANDS • MSC_ST_ROUTINGS • MSC_ST_COMPONENT_SUBSTITUTES • MSC_ST_ROUTING_OPERATIONS • MSC_ST_OPERATION_RESOURCES • MSC_ST_OPERATION_RESOURCE_SEQS • MSC_ST_PROCESS_EFFECTIVITY • MSC_ST_OPERATION_COMPONENTS • MSC_ST_BILL_OF_RESOURCES • MSC_ST_BOR_REQUIREMENTS • MSC_ST_CALENDAR_DATES • MSC_ST_PERIOD_START_DATES • MSC_ST_CAL_YEAR_START_DATES • MSC_ST_CAL_WEEK_START_DATES • MSC_ST_RESOURCE_SHIFTS • MSC_ST_CALENDAR_SHIFTS • MSC_ST_SHIFT_DATES • MSC_ST_RESOURCE_CHANGES • MSC_ST_SHIFT_TIMES • MSC_ST_SHIFT_EXCEPTIONS • MSC_ST_NET_RESOURCE_AVAIL • MSC_ST_ITEM_CATEGORIES • MSC_ST_CATEGORY_SETS • MSC_ST_SALES_ORDERS • MSC_ST_RESERVATIONS • MSC_ST_SYSTEM_ITEMS • MSC_ST_DEPARTMENT_RESOURCES • MSC_ST_SIMULATION_SETS • MSC_ST_RESOURCE_GROUPS • MSC_ST_SAFETY_STOCKS • MSC_ST_DESIGNATORS • MSC_ST_ASSIGNMENT_SETS

APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 11111111////14141414
• MSC_ST_SOURCING_RULES • MSC_ST_SR_ASSIGNMENTS • MSC_ST_SR_RECEIPT_ORG • MSC_ST_SR_SOURCE_ORG • MSC_ST_INTERORG_SHIP_METHODS • MSC_ST_SUB_INVENTORIES • MSC_ST_ITEM_SUPPLIERS • MSC_ST_SUPPLIER_CAPACITIES • MSC_ST_SUPPLIER_FLEX_FENCES • MSC_ST_SUPPLIES • MSC_ST_RESOURCE_REQUIREMENTS • MSC_ST_TRADING_PARTNERS • MSC_ST_TRADING_PARTNER_SITES • MSC_ST_LOCATION_ASSOCIATIONS • MSC_ST_UNIT_NUMBERS • MSC_ST_PROJECTS • MSC_ST_PROJECT_TASKS • MSC_ST_PARAMETERS • MSC_ST_UNITS_OF_MEASURE • MSC_ST_UOM_CLASS_CONVERSIONS • MSC_ST_UOM_CONVERSIONS • MSC_ST_BIS_PFMC_MEASURES • MSC_ST_BIS_TARGET_LEVELS • MSC_ST_BIS_TARGETS • MSC_ST_BIS_BUSINESS_PLANS • MSC_ST_BIS_PERIODS • MSC_ST_ATP_RULES • MSC_ST_PLANNERS • MSC_ST_DEMAND_CLASSES • MSC_ST_PARTNER_CONTACTS Package Body Procedures for the Data Collection process. PACKAGE NAMEPACKAGE NAMEPACKAGE NAMEPACKAGE NAME DESCRIPTIONDESCRIPTIONDESCRIPTIONDESCRIPTION
MSCCLAAB.pls MSCCLAAS.pls
This package executes the task assigned by the Pull worker.
MSCCLBAB.pls MSCCLBAS.pls
This package collects data from staging tables to ODS.
MSCCLFAB.pls MSCCLFAS.pls
This package launch the pull program’s Monitor/Worker processes.
MSCCLJAB.pls MSCCLJAS.pls
This package is used to exchange partitions with the tables.
MRPCLEAB.pls MRPCLEAS.pls
This package launches the Refresh Snapshot process.
MRPCLHAB.pls MRPCLHAS.pls
This package has some functions used while collections.
Important SQL scripts Following are the SQL scripts that are used to create to the database objects used in the Data Collection Process. The following SQL Scripts are for reference only; They are provided here for debugging purposes. Snapshot Logs Create Snapshot
Tables BOMMPSNL.sql BOMMPSNP.sqlMTLMPSNL.sql MTLMPSNP.sqlMRPMPSNL.sql MRPMPSNP.sqlWIPMPSNL.sql WIPMPSNP.sqlPOMPSNAL.sql POMPSNAP.sqlOEMPSNAL.sql OEMPSNAP.sql Create Synonyms Create Views MRPMPSNS.sql MRPMPCRV.sql Create Triggers MRPMPCRT.sql About the Author Sanjeev Kale is a Sr. Technical Analyst for Oracle Worldwide Customer Support in Orlando, Florida. He currently supports the entire Manufacturing suite of products including Master Scheduling/MRP, Work in Process, Cost Management, and Bill of Material.
APSAPSAPSAPS---- Data Collection Data Collection Data Collection Data Collection 12121212////14141414
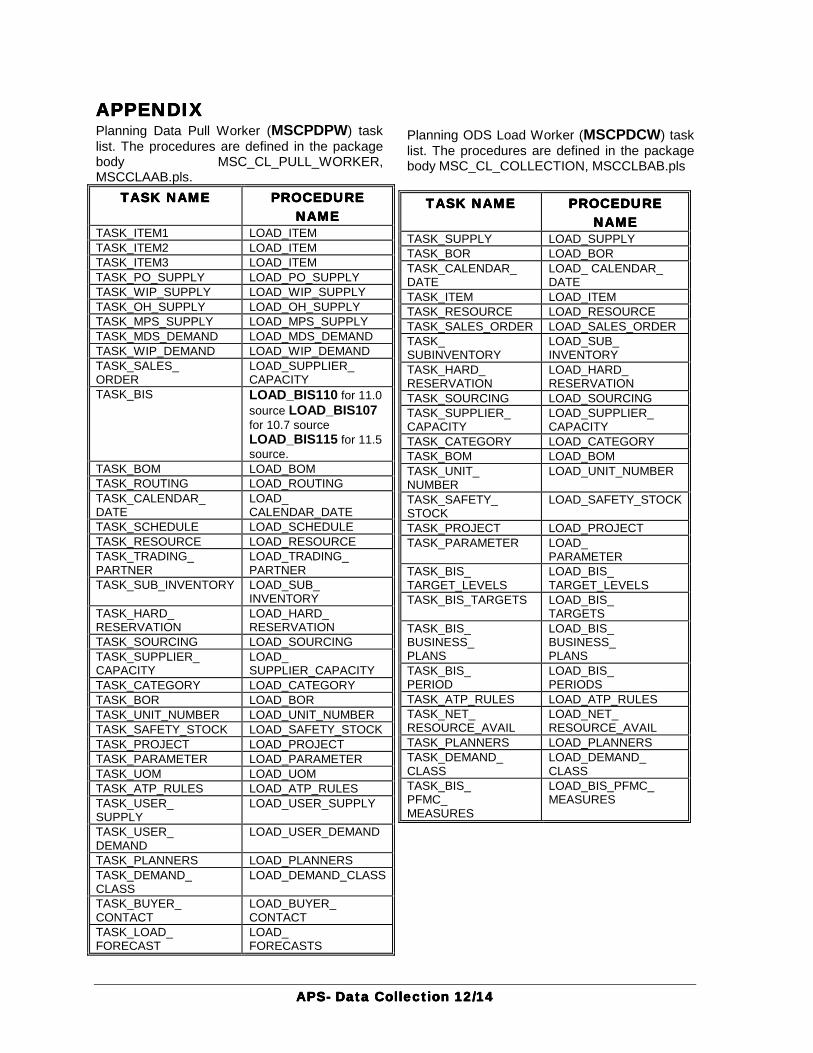
APPENDIXAPPENDIXAPPENDIXAPPENDIX Planning Data Pull Worker (MSCPDPW) task list. The procedures are defined in the package body MSC_CL_PULL_WORKER, MSCCLAAB.pls.
TASK NAMETASK NAMETASK NAMETASK NAME PROCEDUREPROCEDUREPROCEDUREPROCEDURE NAMENAMENAMENAME
TASK_ITEM1 LOAD_ITEM TASK_ITEM2 LOAD_ITEM TASK_ITEM3 LOAD_ITEM TASK_PO_SUPPLY LOAD_PO_SUPPLY TASK_WIP_SUPPLY LOAD_WIP_SUPPLY TASK_OH_SUPPLY LOAD_OH_SUPPLY TASK_MPS_SUPPLY LOAD_MPS_SUPPLY TASK_MDS_DEMAND LOAD_MDS_DEMAND TASK_WIP_DEMAND LOAD_WIP_DEMAND TASK_SALES_ ORDER
LOAD_SUPPLIER_ CAPACITY
TASK_BIS LOAD_BIS110 for 11.0 source LOAD_BIS107 for 10.7 source LOAD_BIS115 for 11.5 source.
TASK_BOM LOAD_BOM TASK_ROUTING LOAD_ROUTING TASK_CALENDAR_ DATE
LOAD_ CALENDAR_DATE
TASK_SCHEDULE LOAD_SCHEDULE TASK_RESOURCE LOAD_RESOURCE TASK_TRADING_ PARTNER
LOAD_TRADING_ PARTNER
TASK_SUB_INVENTORY LOAD_SUB_ INVENTORY
TASK_HARD_ RESERVATION
LOAD_HARD_ RESERVATION
TASK_SOURCING LOAD_SOURCING TASK_SUPPLIER_ CAPACITY
LOAD_ SUPPLIER_CAPACITY
TASK_CATEGORY LOAD_CATEGORY TASK_BOR LOAD_BOR TASK_UNIT_NUMBER LOAD_UNIT_NUMBER TASK_SAFETY_STOCK LOAD_SAFETY_STOCK TASK_PROJECT LOAD_PROJECT TASK_PARAMETER LOAD_PARAMETER TASK_UOM LOAD_UOM TASK_ATP_RULES LOAD_ATP_RULES TASK_USER_ SUPPLY
LOAD_USER_SUPPLY
TASK_USER_ DEMAND
LOAD_USER_DEMAND
TASK_PLANNERS LOAD_PLANNERS TASK_DEMAND_ CLASS
LOAD_DEMAND_CLASS
TASK_BUYER_ CONTACT
LOAD_BUYER_ CONTACT
TASK_LOAD_ FORECAST
LOAD_ FORECASTS
Planning ODS Load Worker (MSCPDCW) task list. The procedures are defined in the package body MSC_CL_COLLECTION, MSCCLBAB.pls
TASK NAMETASK NAMETASK NAMETASK NAME PROCEDUREPROCEDUREPROCEDUREPROCEDURE NAMENAMENAMENAME
TASK_SUPPLY LOAD_SUPPLY TASK_BOR LOAD_BOR TASK_CALENDAR_ DATE
LOAD_ CALENDAR_ DATE
TASK_ITEM LOAD_ITEM TASK_RESOURCE LOAD_RESOURCE TASK_SALES_ORDER LOAD_SALES_ORDER TASK_ SUBINVENTORY
LOAD_SUB_ INVENTORY
TASK_HARD_ RESERVATION
LOAD_HARD_ RESERVATION
TASK_SOURCING LOAD_SOURCING TASK_SUPPLIER_ CAPACITY
LOAD_SUPPLIER_ CAPACITY
TASK_CATEGORY LOAD_CATEGORY TASK_BOM LOAD_BOM TASK_UNIT_ NUMBER
LOAD_UNIT_NUMBER
TASK_SAFETY_ STOCK
LOAD_SAFETY_STOCK
TASK_PROJECT LOAD_PROJECT TASK_PARAMETER LOAD_
PARAMETER TASK_BIS_ TARGET_LEVELS
LOAD_BIS_ TARGET_LEVELS
TASK_BIS_TARGETS LOAD_BIS_ TARGETS
TASK_BIS_ BUSINESS_ PLANS
LOAD_BIS_ BUSINESS_ PLANS
TASK_BIS_ PERIOD
LOAD_BIS_ PERIODS
TASK_ATP_RULES LOAD_ATP_RULES TASK_NET_ RESOURCE_AVAIL
LOAD_NET_ RESOURCE_AVAIL
TASK_PLANNERS LOAD_PLANNERS TASK_DEMAND_ CLASS
LOAD_DEMAND_ CLASS
TASK_BIS_ PFMC_ MEASURES
LOAD_BIS_PFMC_ MEASURES
APS APS APS APS 13131313////14141414
PLANNING DATA COLLECTIONPLANNING DATA COLLECTIONPLANNING DATA COLLECTIONPLANNING DATA COLLECTION
DATA PULL (Request Set Stage)DATA PULL (Request Set Stage)DATA PULL (Request Set Stage)DATA PULL (Request Set Stage)
Planning Data PullPlanning Data PullPlanning Data PullPlanning Data Pull Short Name : MSCPDP Execute Method : PL/SQL Stored Procedure Execute File Name : msc_cl_pull.launch_monitor Package Body : MSCCLFAB.pls
Refresh SnapshotRefresh SnapshotRefresh SnapshotRefresh Snapshot Short Name : MSRFWOR Execute Method : PL/SQL Stored Procedure Execute File Name : mrp_cl_refresh_snapshot.refresh_snapshotPackage Body : MRPCLEAB.pls
Planning Data Pull WorkerPlanning Data Pull WorkerPlanning Data Pull WorkerPlanning Data Pull Worker Short Name : MSCPDPW Execute Method : PL/SQL Stored Procedure Execute File Name : msc_cl_pull.launch_worker Package Body : MSCCLFAB.pls
ODS LOAD (Request Set Stage)ODS LOAD (Request Set Stage)ODS LOAD (Request Set Stage)ODS LOAD (Request Set Stage)
Planning ODS LoadPlanning ODS LoadPlanning ODS LoadPlanning ODS Load Short Name : MSCPDC Execute Method : PL/SQL Stored Procedure Execute File Name : msc_cl_collection.launch_monitor Package Body : MSCCLBAB.pls
Planning ODS Load WorkerPlanning ODS Load WorkerPlanning ODS Load WorkerPlanning ODS Load Worker Short Name : MSCPDCW Execute Method : PL/SQL Stored Procedure Execute File Name : msc_cl_collection.launch_worker Package Body : MSCCLBAB.pls
Planning Data Collection Planning Data Collection Planning Data Collection Planning Data Collection –––– Purge Staging tables Purge Staging tables Purge Staging tables Purge Staging tables Short Name : MSCPDCP Execute Method : PL/SQL Stored Procedure Execute File Name : msc_cl_collection.purge_staging_tables Package Body : MSCCLBAB.pls
APS APS APS APS 14141414////14141414
DATA COLLECTIONDATA COLLECTIONDATA COLLECTIONDATA COLLECTION SOURCE (TRANSACTION) DESTINATIO
CORE APPS• ITEMS • BOM • RTG • MDS • SCP SOURCE INSTANCES • 10.7 • 11.0 • 11i
PLANNI DEFINECOLLEC DEFINEPLANS
PLANNING DATABASE LINK
DATA COLLECTION
PUBLISH
APPLICATION DATA
STORE
(ADS)
STAGING TABLES CUSTOM DA (if req
PLANNING DATA PULL • Refresh
ADS Snapshot
• Net Change Handling
•
OPERAS
(O
STEP 1
STEP 2 ODS LOAD
STEPODS LO
APPLICATION DATABASE LINK
P U B L I S
SOURCE (TRANSACTION) DESTINATION (PLANNING -
N (PLANNING – APS)
NG DATA
RUN / TIONS
RUN /
TA MANIPULATION PLAN FEEDBACKuired)
TION DATA TORE DS)
2 AD
PLANNING DATA STORE
(PDS) = ODS Snapshot + Plan Output
RUN PLAN
H
APS)







