douban linguist
DESCRIPTION
Douban LinguistTRANSCRIPT

Douban-Linguistby liluo

关于我
• liluo@github
• liluoliluo@douban
• liluoliluo@twitter

Linguist 是什么?

从视觉上看是这样的
Github 之前的版本 (⺫⽬目前⾖豆瓣在⽤用)
Github 现在的版本

Douban-linguist 是这样描述的

Github-linguist README

Linguist 可以做什么
• 编程语⾔言检测 • 语法⾼高亮 • 代码仓库编程语⾔言统计
• 统计时忽略通⽤用第三⽅方库\特定⺫⽬目录代码
• 检测是否⽣生成⽂文件

Linguist 是如何检测语⾔言的?

• 遍历⺫⽬目录下所有⽂文件
• 忽略以 . 开头的⺫⽬目录, 忽略⼆二进制⽂文件/⽣生成⽂文件(如 coffeescript ⽣生成的 js)/压缩⽂文件(如 jquery.min.js)/通⽤用的第三⽅方类库(如 bootstrap)
• 对余下的⽂文件进⾏行分析并汇总
当输⼊入路径是⺫⽬目录时
当输⼊入路径是⽂文件时
• 根据⽂文件扩展名查找(数据源⾃自samples.json, languages.yml)
• 未匹配到时返回空(None)
• 匹配到⼀一个结果时将其返回
• 匹配到多个结果时分析⽂文件内容

算法: statistical classifier (之前⽂文档中写的是 Bayesian classifier)
分析内容
• 使⽤用 Tokenizer 将内容转为 tokens
• 拿 tokens 分别与所有(根据扩展名)匹配到的编程语⾔言的 Tokens 进⾏行⽐比较, 将概率最⼤大编程语⾔言判定为结果

根据 samples/ ⺫⽬目录下的⽂文件统计(训练) 得来的
编程语⾔言的 Tokens

languages.yml & samples.json

Douban-Linguist

因为 Code
2012年5⽉月 !
@huanghuang: !我们需要两个库 grit 和 linguist

然后...

断篇了.

时光荏苒, 莺⻜飞草⻓长到了
2013年01⽉月

准备⼯工作

Ruby Python 替代 #
pygments.rb pygments !前者是后者的 Ruby 封装实现
mime-types mimetypes Python 内置
escap_utils urllib 毫⽆无鸭梨
charlock_holmes ? 先⾛走着
计划时对依赖处理是这样想的

开始动⼿手
• git init
• cp blabla
• added blabla
• unittest blabla

Code 来需求了!!!
• 移动组: PR diff 中不需要显⽰示 .pbxproj, .mobileprovision
• 前端组: 统计时不计⼊入压缩版本以及 coffeescript ⽣生成⽂文件
判断是否⽣生成⽂文件

先把这个弄了给它⽤用

继续~

遭遇 CharlockHolmes

• 尝试过 Chardet, 但是只能检测编码
• 尝试过 mimetypes.guess_type(file) 检测是否⼆二进制⽂文件, 不靠谱!!!
• 还尝试过下⾯面这样:

但是好纠结...
要是有 ICU 的 Python 实现就美好了...
好像是能解决?
可是不会写 C 扩展 > . <
求给⼒力, 求 + 1

@XTao 来了!!!

发布第⼀一个版本 v0.0.1

Python mimetypes 怪怪的
此恨绵绵⽆无绝期...

移植⼀一个 Python 版本吧
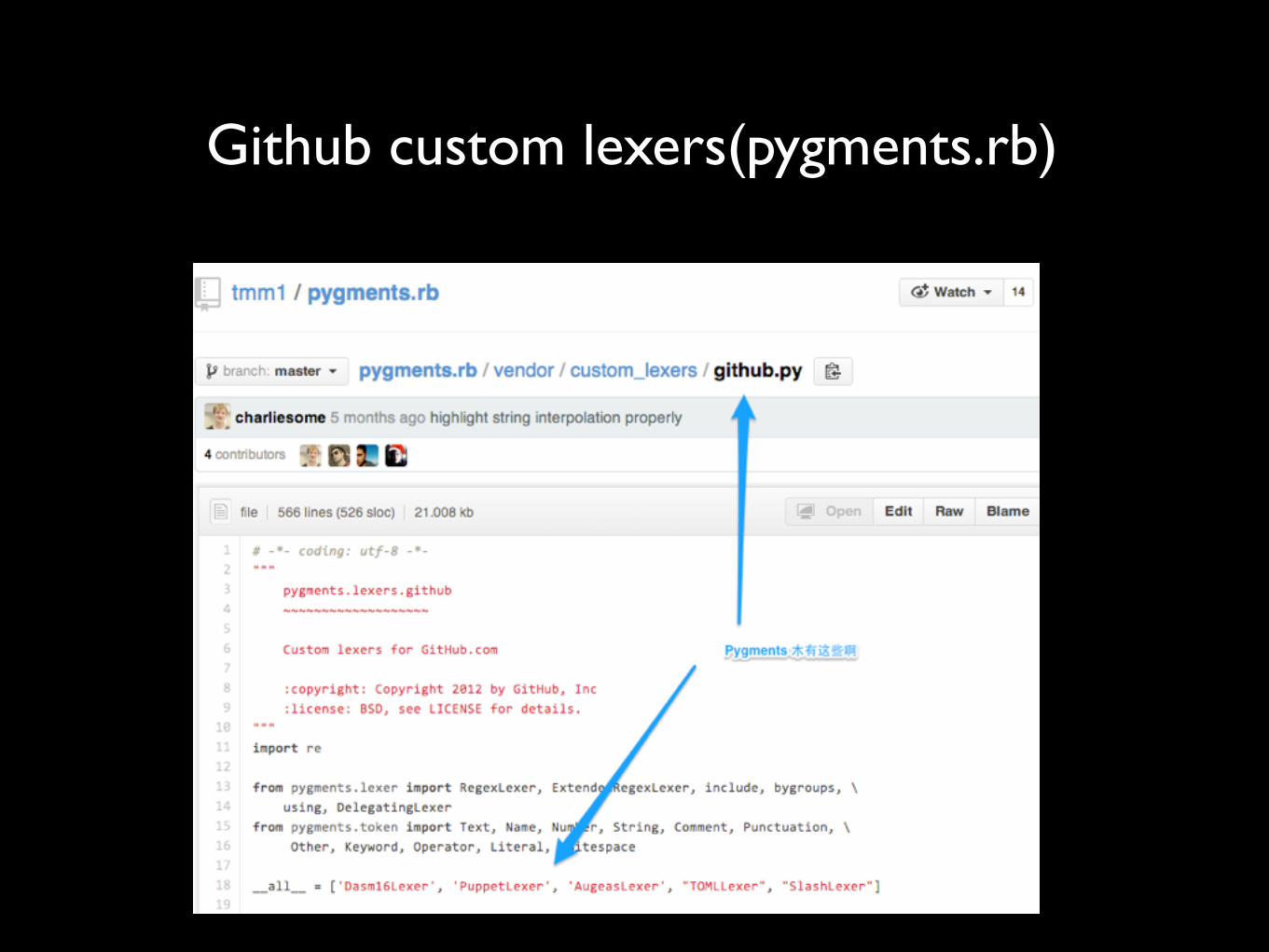
Github custom lexers(pygments.rb)

写个 Pygments 插件

某天发现性能好差!!!
• ⽐比 Github-linguist 慢了 2~4 倍多 (不太记得具体数据了)
• 跑 unittest 要 20s 左右

捉⿁鬼(1)

捉⿁鬼(2)

捉⿁鬼(3)

捉⿁鬼(4)

• 和 @xtao 讨论是 Python 正则性能问题
• 需要⼀一个⾼高性能的 Python 版本的StringScanner
捉⿁鬼(5)

于是, 有了 scanner
Like 不只是说说, 正则引擎使⽤用 oniguruma. (Ruby 正则引擎就是它)

Scanner 带来的性能提升
Travis-ci 中使⽤用 Scanner 前后对⽐比
github-linguist 与使⽤用 Scanner 后的douban-linguist 对⽐比
注: 减少的 22 个 test case ⻅见 https://github.com/douban/linguist/blob/eba200742c9f7ebd433b7aa73774381b80ddb0fa/tests/test_strscan.py

感谢 Scanner 的作者
赞美 Code Team, @XTao!!!

发布版本 v0.1.0

⻢马上就讲完了, 别捉鸡...

Douban-linguist 最新进展 在等 Pygments release 新版本

与 Github-linguist 作者
• Drinkup
• Pull Request

2013 Drinkup@北京
• 咨询 Linguist 与 Github 交互实现 !
!
• 问我 Python 版有没⽐比 Ruby 快 !
• 告诉他提了个 pull request
PUSH > HOOK > QUEUE > (PULL) > CALCULATE > CALLBACK

提 Pull Request (1)
Drinkup 当天晚上被 merge

提 Pull Request (2)

提 Pull Request (3)

就是这样了.

相关链接
• https://github.com/douban/linguist
• https://github.com/douban/PyCharlockHolmes
• https://github.com/liluo/mime
• https://github.com/liluo/pygments-github-lexers
• https://github.com/cuteio/scanner
• https://github.com/github/linguist

End.