diplomarbeit dependency injection als mittel zur ... · diplomarbeit dependency injection als...
TRANSCRIPT

DiplomarbeitDependency Injection als Mittel zur
Verbesserung der Softwarequalität durchzentralisierte Objekterzeugung
September 2007
Sebastian SanitzWohlwillstr. 120359 HamburgEmail: [email protected]: 4724018
Betreuer: Dr. Wolf-Gideon BleekZweitbetreuer: Prof. Dr. Winfried Lamersdorf
Universität HamburgFachbereich InformatikArbeitsbereich SoftwaretechnikVogt-Kölln-Str. 2022527 Hamburg


Inhaltsverzeichnis
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Lösungsansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Vorgehensweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Grundlagen 62.1 Begriffsklärungen und Abgrenzung . . . . . . . . . . . . . . . . . . . . 62.2 Designprinzipien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Gegenstand der Arbeit 143.1 Das CommSy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Die vorhandene Architektur . . . . . . . . . . . . . . . . . . . . . . . . . 163.3 Muster im JCommSy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.4 Ergebnisse der Vermessung . . . . . . . . . . . . . . . . . . . . . . . . . 253.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4 Lösungsansätze 334.1 Explizite Abhängigkeiten . . . . . . . . . . . . . . . . . . . . . . . . . . 334.2 Dependency Injection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.3 Dependency Injection Frameworks . . . . . . . . . . . . . . . . . . . . . 424.4 Vereinfachung der Tests durch Mock-Objekte . . . . . . . . . . . . . . . 454.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5 Beschreibung der praktischen Lösung 485.1 Ziele der Umstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485.2 Planung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515.3 Umstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
6 Ergebnis 566.1 Bewertung der Vorgehensweise . . . . . . . . . . . . . . . . . . . . . . . 566.2 Bewertung der Umstellung . . . . . . . . . . . . . . . . . . . . . . . . . 586.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
I

7 Ausblick 62
Messergebnisse 65
Literaturverzeichnis 68
Abbildungsverzeichnis 72
Tabellenverzeichnis 73
Danksagung 74
Selbstständigkeitserklärung 75
II

Kapitel 1
Einleitung
1.1 Motivation
Objektorientierte Software-Systeme sind ab einer gewissen Größe schwer zu wartenund nur mit erhöhtem Aufwand zu erweitern. Eine Ursache ist die Erzeugung vonObjekten. Sie ist in diesen Systemen meist verteilt auf den gesamten Sourcecode. EineKlasse erzeugt sich die konkreten Objekte, die es für die Erledigung ihrer Aufgabenbenötigt. Fehler schleichen sich leichter in eine Anwendung, wenn das System starkvoneinander abhängig und die Komponenten untereinander eng gekoppelt sind. DasSchreiben von Komponenten-Tests für solche Systeme kann sehr aufwendig sein. Eserfordert das Aufsetzen von vielen abhängigen anderen Komponenten.
Auf den gesamten Sourcecode sind Informationen zu konkreten Typen verteilt.Durch diese Verweise entsteht eine enge Kopplung innerhalb des Systems. Es gibtkeine Trennung von Implementation und Schnittstelle. Diese fehlende Trennung istein Anzeichen für schlechte Qualität, denn es erschwert das Testen und die Erweiter-barkeit.
Beispielhaft ist in Abbildung 1.1 dargestellt, wie ein BuecherService auf einRepository zugreift. Es erzeugt sich eine Instanz der Klasse RdbmsBuecherRepo-sitory und benutzt diese für ihre Aufgaben.
Eine Komponente die ihre abhängigen Objekte selber erzeugt, lässt sich nur schwertesten. Sämtliche abhängigen Objekte werden im Test auch erzeugt. Diese abhängi-gen Objekte können für den Test nicht durch Dummy- oder Mock-Objekte1 ersetztwerden. Es wird somit unmöglich einen Komponenten-Test für eine Klasse bzw. ei-
1Mock-Objekte sind Dummy-Objekte, die für einen Test rudimentär eine Schnittstelle implementie-ren und dabei definierte Aufrufe erwarten.
Abbildung 1.1: Direkte Abhängigkeit
1

2 KAPITEL 1. EINLEITUNG
Abbildung 1.2: Lösung mit Factory-Muster
ne kleine Komponente aus wenigen Klassen zu schreiben. Jeder Test wird immer zueinem Integrations-Test, der das Aufsetzen von vielen Teilen des Systems erwartet.Dadurch werden Komponenten-Tests unfreiwillig schwierig aufzusetzen und zu for-mulieren.
Eine Änderung des Systems durch den Austausch einer Komponente wird er-schwert, wenn diese verteilt im System referenziert wird. Gibt es keine Trennung vonSchnittstelle und konkreter Implementierung, muss die Klasse in allen referenziertenKlassen ersetzt werden. Somit schlägt sich ein Austausch der Implementierung einerKomponente auf den gesamten Sourcecode nieder.
1.2 Lösungsansätze
Ein Versuch das Problem zu lösen ist die Verwendung von Singletons oder Factories,wie beschrieben in [GHJV94].
Hier ist es die spezielle Aufgabe einer anderen Klasse, die konkreten Objekte zuerzeugen. Die benutzende Klasse greift nur noch über die Schnittstelle auf die kon-kreten Objekte zu. Die Schnittstelle und Implementierung sind besser von einandergetrennt. Auch lässt sich die Erzeugung der konkreten Implementierung einer Kom-ponente auf weniger Teile im Sourcecode beschränken.
Das Beispiel der Factory ist in Abbildung 1.2 dargestellt. Die Klasse Buecher-Service benutzt das Repository nur noch mit der Schnittstelle BuecherReposi-tory. Für die Erzeugung ist die Klasse RepositoryFactory zuständig. Hinter derstatischen Methode erzeugeRepository wird die Erzeugung des Repositories ge-kapselt. Die Methode erzeugt ein Objekt vom Typ RdbmsBuecherRepository. DerBuecherService hat keine direkte Abhängigkeit mehr zu der konkreten Imple-mentierung RdbmsBuecherRepository.
Trotzdem lässt sich das System dadurch nicht leichter testen. Die konkreten Im-plementierungen lassen sich nicht einfach mit Mock-Objekten ersetzen. Die erzeu-gende Klasse, im Beispiel die Factory, müsste sich im Testfall anders verhalten als

1.2. LÖSUNGSANSÄTZE 3
Abbildung 1.3: Lösung mit Dependency Injection
im produktiven Betrieb.Die vorgeschlagene Lösung dieser Diplomarbeit ist eine Umstellung auf Depen-
dency Injection. Bei Dependency Injection werden Objekte nur an einer klar definier-ten Stelle im System erzeugt. Objekte benutzen nur Schnittstellen der Klassen diebenötigt werden. Das benutzende Objekt kennt trotzdem nur die Schnittstelle, nichtaber den konkreten Typ des abhängigen Objektes.
Bei Dependency Injection verwaltet ein Container die Erzeugung der Objekte.Der Container übergibt den erzeugten Objekten ihre abhängigen Objekte. Diese Über-gabe erfolgt entweder im Konstruktor oder wird per Methode gesetzt. Durch ei-ne Konfiguration des Containers wird festgelegt, welche konkreten Objekte erzeugtwerden sollen.
Informationen zu einem konkreten Typ befinden sich nicht mehr verteilt im ge-samten Sourcecode. Die Information, welche konkreten Objekte für welche Schnitt-stelle erzeugt werden soll, steht bestenfalls nur noch in der Konfiguration des Con-tainers für Dependency Injection.
Die Abhängigkeiten eines Objektes sind klar zu erkennen, entweder an der Schnitt-stelle oder dem Konstruktor. Die abhängigen Objekte werden nur noch anhand derSchnittstelle benutzt. Dadurch lassen sich diese für einen Komponenten-Test leichtdurch Dummy- oder Mock-Objekte ersetzen. Somit kann diese Komponente unab-hängig von den anderen Komponenten getestet werden.
Für eine Anpassung oder Erweiterung des Systems kann die Implementierungeines Objektes einfacher ausgetauscht werden. Die Information über den konkre-ten Typ der Implementierung befindet sich nur noch in der Konfiguration des Con-tainers. Die konkrete Implementierung der Anpassung oder Erweiterung muss die

4 KAPITEL 1. EINLEITUNG
Schnittstelle implementieren. Nur in der Konfiguration muss die angepasste oderneue Komponente registriert werden. Es ist nicht mehr nötig den gesamten Source-code bei einer Anpassung zu ändern.
Abbildung 1.3 zeigt das Beispiel umgestellt auf Dependency Injection. Der Bücher-Service bekommt ein Bücher-Repository im Konstruktor gesetzt. Der Container istzuständig für die Erzeugung von Objekten. Er kennt über seine Konfiguration diekonkreten Implementierungen. Er erzeugt in diesem Fall ein RdbmsBuecherRepo-sitory bevor er einen BuecherService erzeugt. Es gibt keine direkte oder indi-rekte Abhängigkeit mehr zwischen dem Bücher-Service und der konkreten Imple-mentierung des Bücher-Repositories.
1.3 Vorgehensweise
Für die Diplomarbeit werde ich ein bestehendes objektorientiertes System auf De-pendency Injection umstellen. Als System ist das CommSy [JJP02] ausgewählt. DerBegriff CommSy steht für „Community System“. Das CommSy ist ein webbasiertesSystem zur Unterstützung von vernetzter Projektarbeit. Teile des CommSys sind inJava implementiert. Diese werde ich umstellen auf Dependency Injection.
Hierbei möchte ich erforschen, wie bei der Umstellung eines großen objektori-entierten Systems auf Dependency Injection vorgegangen werden kann. Durch diepraktische Arbeit lassen sich Regeln ableiten, die bei einer Umstellungen zu beach-ten sind und auch für andere Projekte nützlich sind. Es werden unvermeidbar Fehlerauftreten. Wenn diese typisch sind für die Umstellung, dann werde ich diese be-schreiben und versuchen, Gegenmaßnahmen zu erörtern.
Des weiteren werde ich das System vor, während und nach der Umstellung ver-messen. Mit den Ergebnissen werde ich versuchen, die Umstellung qualitativ zu be-werten.
1.4 Aufbau der Arbeit
In Kapitel 2 werden die grundlegenden Begriffe für diese Diplomarbeit definiert. DerBegriff Software-Architektur wird mit einer Abgrenzung zu Dependency Injectionvorgestellt. Es wird der Begriff Software-Qualität definiert und als Grundlage für dieMotivation benutzt. Das Kapitel beschreibt weiter Design-Prinzipien, um eine ho-he Software-Qualität zu erreichen. Abschliessend werden die Qualitätsmerkmale fürSoftware Änderbarkeit, Wartbarkeit, Funktionalität, Zuverlässigkeit und Testbarkeitdefiniert und beschrieben, wie sich die direkte Erzeugung von Objekten im Source-code auf diese Merkmale auswirkt.
Anschließend wird in Kapitel 3 der Gegenstand der Arbeit erörtert. Es wird dasSoftware-System CommSy vorgestellt und die vorgefundene Architektur beschrie-ben. Die Software wird dort vermessen und die Ergebnisse der Vermessung inter-pretiert.

1.4. AUFBAU DER ARBEIT 5
Im Kapitel 4 werden verschiedene Lösungsansätze aufgezeigt, um direkte Er-zeugung von Objekten verteilt im Sourcecode zu zentralisieren. Dabei werden dieMuster Singleton und Plugin erörtert. Das Prinzip Dependency Injection wird dabeieingehend eingeführt.
Im Kapitel 5 wird der praktische Teil der Arbeit beschrieben. Hier stelle ich meineVorgehensweise bei der Umstellung des CommSy auf Dependency Injection vor. Da-bei erläutere ich die einzelnen Schritte, die für diese Umstellung notwendig waren.
Das Ergebnis der praktischen Arbeit wird in Kapitel 6 vorgestellt. Die Vorgehens-weise der Umstellung wird bewertet. Hier wird beschrieben und bewertet, wie sichdie Umstellung auf die Architektur und Software-Qualität des Systems ausgewirkthat.
Der Ausblick in Kapitel 7 stellt weitere Fragestellungen vor, die sich durch dieseArbeit ergeben haben, aber nicht durch diese Arbeit beantwortet wurden. Weitereverwandte Themen werden benannt.

Kapitel 2
Grundlagen
Die grundlegenden Begriffe für diese Diplomarbeit werden in diesem Kapitel defi-niert und voneinander abgegrenzt. In dem ersten Teil des Kapitels wird dabei dasZiel der Diplomarbeit über den Begriff der Software-Qualität motiviert. Der zwei-te Teil zeigt Design-Prinzipien zur Erreichung einer hohen Software-Qualität. DiesePrinzipien werden bei der Problembeschreibung benutzt, um typische Schwachstel-len objektorientierter Software-Systeme ohne Dependency-Injection aufzuzeigen.
2.1 Begriffsklärungen und Abgrenzung
Zunächst soll der Begriff Software-Architektur geklärt werden. In [KFBR06] wirdSoftware-Architektur wie folgt definiert:
Software-Architektur Die Software-Architektur ist die grundlegende Organisationeines Systems, dargestellt durch dessen Komponenten, deren Beziehungen zu-einander und zur Umgebung, sowie Prinzipien, die den Entwurf und die Evo-lution des Systems bestimmen.
Diese Arbeit beschäftigt sich mit der Erzeugung von Objekten innerhalb einesSoftware-Systems, also einem wichtigen Bestandteil der Software-Architektur. Füreine Software-Architektur werden von [KFBR06] Ziele definiert. Diese Ziele lassensich in drei Kategorien einteilen:
• Die vom Kunden gestellten funktionalen und qualitativen Ziele für das Pro-dukt.
• Die organisatorischen und technologischen Rahmenbedingungen der Entwick-lung.
• Die zu erwartende Flexibilität der Ziele dieser beiden Kategorien.
Diese Arbeit wird sich weniger mit den funktionalen Zielen einer Architekturbeschäftigen können, denn diese sind abhängig vom fachlichen Auftrag des Kun-
6

2.1. BEGRIFFSKLÄRUNGEN UND ABGRENZUNG 7
Abbildung 2.1: Qualitätsmerkmale
dens. Somit konzentriert sich die Arbeit auf die qualitativen Ziele der Software-Architektur. Trotzdem sollte die Software-Architektur beachten, dass ein Software-System auch auf Änderungen fachlicher Ziele flexibel reagieren muss. Diese Arbeitwird beide Ziele berücksichtigen, sowohl die Flexibilität, auf Änderungen fachlicherAnforderungen reagieren zu können, als auch das Ziel hohe Qualität zu verfolgen.
Software-Qualität
Software-Qualität wird in der Norm ISO/IEC 9126 für Softwareprodukte durch Qua-litätsmerkmale wie Funktionalität, Zuverlässigkeit, Benutzbarkeit, Effizienz, Änder-barkeit und Wartung, Übertragbarkeit beschrieben. Die einzelnen Merkmale kön-nen weiter untergliedert werden. Die Software-Qualität eines Software-Systems wirddurch diese Merkmale mit einem Qualitätsmodell beschrieben. Bewertet wird dieSoftware-Qualität durch Qualitätsindikatoren oder Metriken.
Anglehnt an die Norm ISO/IEC 9126 werden die in Abbildung 2.1 dargestelltenQualitätsmerkmale wie folgt beschrieben:
Funktionalität Bezeichnet die Fähigkeit des Software-Systems die fachlichen Aufga-ben zu erledigen. Das Merkmal Funktionalität wird unterteilt in die Submerk-male Angemessenheit, Richtigkeit und Sicherheit.
Zuverlässigkeit Unter Zuverlässigkeit wird die Wahrscheinlichkeit verstanden, mitder Software die beabsichtigten Aufgaben korrekt erledigt. Das Merkmal Zu-verlässigkeit wird unterteilt in die Submerkmale Reife, Fehlertoleranz, Robust-heit, Wiederherstellbarkeit und Konformität.
Benutzbarkeit Die Benutzbarkeit ist gegliedert in die Merkmale Verständlichkeit,Erlernbarkeit, Bedienbarkeit, Attraktivität, und Konformität.
Effizienz Die Effizienz beurteilt das Verhältnis von eingesetzten Ressourcen und derLeistung der Software. Die Effizienz wird wiederum unterteilt in Zeitverhalten,Verbrauchsverhalten und Konformität.
Änderbarkeit und Wartung Die Änderbarkeit und Wartung eines Softwaresystemsbeschreibt die Möglichkeit des Systems, auf neue fachliche oder technische An-forderungen reagieren zu können. Sie wird beschrieben durch Analysierbar-keit, Modifizierbarkeit, Stabilität und Prüfbarkeit.

8 KAPITEL 2. GRUNDLAGEN
Übertragbarkeit Unter der Übertragbarkeit eines Software-Systems versteht mandie Fähigkeit eines Software-Systems, auf ein anderes System übertragen wer-den zu können. Sie wird beschrieben durch Anpassbarkeit, Installierbarkeit,Koexistenz, Austauschbarkeit und Konformität.
Für die weitere Arbeit wird besonders auf die Qualitätsmerkmale Zuverlässig-keit, Änderbarkeit und Wartung eingegangen. Die Bedeutung dieser Qualitätsmerk-male bezüglich der Erzeugung von Objekten in Software-Systemen wird in den nächs-ten Abschnitten dieses Kapitels erörtert.
Testen als Vorrausetzung für Zuverlässigkeit, Änderbarkeit und Wartung
Die Zuverlässigkeit eines Software-Systems, also die korrekte Erledigung der Auf-gaben, lässt sich am besten durch Software-Tests überprüfen. Indirekt sind auch dieMerkmale Änderbarkeit und Wartung von der Testbarkeit eines Systems abhängig.Je leichter ein System zu testen ist, desto einfacher ist es, dieses System auf neuefachliche oder technische Anforderungen anpassen zu können.
Testbarkeit ist somit eine der wichtigsten Vorrausetzung für die Qualitätsmerk-male Zuverlässigkeit, Änderbarkeit und Wartung. Zunächst wird der Begriff Testendefiniert, um anschließend Testbarkeit von Software näher zu betrachten.
In [Bin99] wird Testen definiert als das Ausführen eines Programmes, bzw. vonProgrammteilen, unter verschiedenen Kombinationen von Eingaben und Zustän-den, wobei erwartete und reale Ausgaben verglichen werden. Es ist insbesonderebei interaktiven Programmen praktisch unmöglich alle erdenkbaren Kombinatio-nen von Eingaben zu simulieren und mit den erwarteten Ausgaben zu vergleichen.In [Dij72] wird deshalb ausgeführt: „Man kann nur die Anwesenheit von Fehlern,nicht deren Abwesenheit beweisen“. Testen kann also nicht formal die Korrektheitvon Software beweisen, noch Evaluation oder konstruktive Kritik bei der Qualitätssi-cherung ersetzen. Das Testen von Software ist neben Analyse, Entwurf, Implementa-tion, sowie Einsatz und Wartung, Teil jeder Vorgehensweise bei der Entwicklung vonSoftwaresystemen. Nach [Bin99] werden Software-Tests unterteilt in Komponenten-,Integrations- und Akzeptanztests. Dabei wird die Größe und Zusammengehörig-keit der jeweils zu testenden Softwarekomponenten als Unterscheidungsmerkmalgewählt. Bei einem Komponententest wird eine kleine Einheit getestet. Bei objektori-entierten Systemen handelt es sich hier um eine Klasse oder mehrere eng zusammen-hängende Klassen. Fehler können lange unentdeckt bleiben, wenn keine Komponen-tentests geschrieben werden. Tests auf dieser Ebene prüfen eine wesentlich größereMenge von möglichen Eingaben und Zuständen, als dies ein Integrationstest oderSystemtest könnte. Die Zeit, bis einen Fehler gefunden wird, lässt sich deutlich redu-zieren, wenn eine zu prüfende Klasse ausgiebig durch die Entwickler getestet wird.
Das Zusammenspiel mehrerer zusammengehörender Einheiten soll beim Inte-grationstest geprüft werden. Bei der Entwicklung eines objektorientierten Systemslässt sich zwischen Komponententests und Integrationstests schwer trennen, beson-ders wenn eine Komponente von mehreren anderen Komponenten abhängt. Die Ab-hängigkeiten mehrerer Komponenten für die Integrationstests zu beschreiben, wird

2.1. BEGRIFFSKLÄRUNGEN UND ABGRENZUNG 9
durch die Arbeit adressiert und eine einfache Lösung mit Dependency Injection an-geboten.
Der Systemtest soll das fertige System als Ganzes prüfen. Hierbei wird nicht nurdie Funktionalität des Systems anhand der Ein- und Ausgaben und das Zusammen-spiel der verschiedenen Komponenten geprüft. Zusätzlich wird überprüft, ob dienichtfunktionalen Anforderungen erfüllt werden, wie z.B. die Performanz.
Testbarkeit
In dem vorigem Abschnitt wurde behauptet das Testen und eine einfachere Testbar-keit das Erreichen hoher Qualität erleichtert. Durch Tests können adressierte Fehlerausgeschlossen werden. Je leichter ein Software-System zu testen ist, desto eher lässtsich mit diesem System eine hohe Qualität bzgl. der Merkmale Zuverlässigkeit, Än-derbarkeit und Wartung erreichen. Es muss nun genauer betrachtet werden, welcheVorraussetzungen für eine einfache Testbarkeit notwendig sind und warum dies zuguter Qualität führt.
Bei einem Test wird ein Teil der Software ausgeführt. Um diesen Teil, bzw. dieseKomponente auszuführen, muss diese eventuell initialisert werden. Beim Test mussbetrachtet werden, welche Klasse getestet wird und welche abhängigen Klassen indieser Komponente benutzt werden. Es kann von den abhängigen Typen mehre-re Ausprägungen geben. Es ist wichtig, dass der Test direkt nur die zu testendeKomponente überprüft und nicht indirekt die abhängigen Klassen oder Komponen-ten. Das wird am Beispiel aus der Einführung in Abbildung 1.1 verdeutlicht. DerKomponenten-Test für den Bücherservice soll nur den Bücherservice testen, nichtaber das BuecherRepository. Ein BücherService benutzt ein BuecherRepo-sitory, insofern muss dieser bei der Ausführung der Tests für den BuecherSer-vice vorhanden sein. Das BuecherRepository ist die abhängige Komponente, esmuss sich vor der Ausführung in einem eindeutigen und definierten Zustand befin-den, um Aussagen über die zu erwartenden Ergebnisse zu machen. Es kann sogarvon Vorteil sein, eine andere Implementierung für den Test zu benutzen. Wenn z.B.das BuecherRepository auf eine Datenbank zugreift, dann ist es einfacher dasBuecherRepository durch eine Mock- oder Dummy-Implementierung zu erset-zen, die nicht auf die Datenbank zugreift. Der Test für den BuecherService sollnur den BuecherService prüfen, nicht aber das BuecherRepository oder gardie Datenbank und deren Zustand. Für den eigentlichen Test ist es also wichtig zuwissen, welches BuecherRepository benutzt wird und in welchem Zustand sichdie abhängige Komponente befindet.
Das Beispiel hat gezeigt, das für den Test einer Klasse oder einer Komponentedie abhängigen Klassen oder Komponenten wichtig sind. Diese abhängigen Klassenmüssen leicht zu initialisieren sein, damit die Klasse einfach getestet werden kann.Ein Komponenten-Test wird erleichtert, wenn sich abhängige Komponenten mit we-nig Aufwand durch andere Implementierungen ersetzen lassen. Das eine abhängigeKomponente leicht ausgetauscht werden kann, ist ein direktes Indiz für eine leich-te Erweiterbarkeit und Änderbarkeit und somit für bessere Qualität der Software.Es zeigt sich also, dass einfache Testbarkeit zu einem besseren Design führt. Ein-

10 KAPITEL 2. GRUNDLAGEN
fache Testbarkeit und eindeutige Abhängigkeiten fördern gute Strukturierung undErweiterbarkeit.
2.2 Designprinzipien
Für die Erstellung qualitativ hochwertiger Software haben sich über die Zeit be-stimmte Design-Prinzipien in der Softwaretechnik als nützlich herausgestellt. In die-sem Abschnitt wird eine Auswahl bekannter, aus der Literatur entlehnter Designprin-zipien vorgestellt. Hierbei soll auch die Frage geklärt werden, wie groß eine Kom-ponente sein darf. Wieviele Klassen dürfen zu einem Modul gehören und welcheKlassen gehören zu welchen Modulen?
Die Auswahl der Design-Prinzipien habe ich aufgrund von eigener Erfahrungaus realen Projekten vorgenommen. Dieser Abschnitt wird diese Prinzipien vorstel-len und erörtern, warum diese Designprinzipien zu hoher Qualität beitragen. Diegewählten Design-Prinzipien werden bei den Ergebnissen der Arbeit in Kapitel 5wieder betrachtet. Dort wird analysiert, welche Auswirkung die Prinzipien auf diegewählte Lösung haben.
Lose Kopplung
Lose Kopplung ist ein fester Begriff in der Softwaretechnik. In [YC79] wird Kopp-lung und Kohäsion als Beziehungen zwischen und innerhalb von Modulen beschrie-ben. Unter Kopplung versteht man die Abhängigkeiten zwischen Modulen bzw. dieWahrscheinlichkeit, wenn ein Modul verändert wird, dass abhängige Module ange-passt werden müssen. Die Kohäsion beschreibt die Abhängigkeiten innerhalb einesModuls.
Lose Kopplung führt zu schmalen Schnittstellen zwischen den Modulen. Je mehrsich Module untereinander kennen, desto enger sind sie gekoppelt. Je weniger dieModule voneinander kennen, desto loser sind sie gekoppelt.
Single-Responsibility-Principle
Das Single-Responsibility-Principle wird von Robert C. Martin in [Mar03] beschrie-ben: „A class should have only one reason to change“.
Das Prinzip beschreibt, dass eine Klasse genau nur eine Verantwortung habenund daher genau nur eine Abstraktion abdecken soll. Hätte eine Klasse mehrere Ver-antwortlichkeiten, dann würde es auch mehrere Gründe geben, warum sich die Klas-se ändern könnte.
Änderungen an dieser Verantwortlichkeit sollen dann nur an dieser einen Klassegemacht werden müssen oder die Klasse muss aufgeteilt werden. Eine Klasse kannmehrere Verantwortungen im Laufe der Zeit bekommen, wenn die funktionalen An-forderungen eines Systems im Laufe der Zeit heranwachsen. Dann wird es an derZeit, diese unterschiedlichen Verantwortungen auf mehrere Klassen aufzuteilen.

2.2. DESIGNPRINZIPIEN 11
Abbildung 2.2: Klient ist nicht offen und geschlossen
Open-Closed-Principle
Das Prinzip wird von Bertrand Meyer in [Mey97] beschrieben. Es besagt, dass einModul offen sein soll für Erweiterungen, aber geschlossen für Veränderungen. Damitist die Grundlage für die Eigenschaften objektorientierter Software bzgl. Erweiterbar-keit und Wiederverwendung beschrieben.
Wie kann nun ein Modul gleichzeitig offen für Erweiterungen und geschlossenfür Änderungen sein? Die Erweiterung eines Moduls ist nötig, wenn neue fachli-che Anforderungen erfordern, dass das Modul um neues Verhalten erweitert wird.Das Modul soll geschlossen sein gegen Änderungen. Die Erweiterungen sollen mög-lich sein, ohne das der Sourcecode oder die Bibliothek des Moduls geändert werdenmuss.
Die Erweiterung kann erreicht werden über die Implementierung abstrakter Klas-sen. Das Modul bietet eine abstrakte Klasse an, über deren Implementierung das Ver-halten des Moduls erweitert werden kann, ohne es zu verändern.
Die Abbildung 2.2 zeigt ein einfaches Design, das nicht dem open-closed-principleentspricht. Der Klient und der Anbieter sind konkrete Klassen. Wenn der Klient einenanderen Anbieter benutzen soll, dann muss dafür der Klient verändert werden undden anderen Anbieter direkt benennen.
Die Abbildung 2.3 zeigt dagegen ein Design das dem open-closed-principle ent-spricht. Der Klient benutzt nur die abstrakte Klasse KlientenSchnittstelle. Dieabstrakte Klasse KlientenSchnittstelle bietet abstrakte Methoden an. DieseKlasse und deren Methoden werden von einer konkreten Klasse, dem Anbieter, im-plementiert. Soll nun der Klient einen anderen Anbieter benutzen, so kann eine an-dere Implementierung der KlientenSchnittstelle benutzt werden. Für dieseErweiterung muss der Klient nicht geändert werden, trotzdem ist er offen für Erwei-terungen.
Vertragsmodell
Das Vertragsmodell wird von Bertrand Meyer in [Mey97] genau beschrieben. Es wirdauch häufiger unter dem Namen Design-by-Contract oder abgekürzt als DBC ge-führt. Mit dem Vertragsmodell führt Meyer eine Beziehung zwischen zwei Objektenein, die aus Zusicherung, Vorbedingung, Nachbedingung und Invarianz besteht.

12 KAPITEL 2. GRUNDLAGEN
Abbildung 2.3: Klient ist beides, offen und geschlossen (Strategy-Muster)
Liskov-Substitution-Principle
Das Liskov-Substitution-Principle wurde von Barbara Liskov in dem Artikel [LW94]beschrieben. Es sagt aus, dass Typen ersetzbar sein sollen durch Subtypen. Ursprüng-lich ist es eine Definition von Typisierung und eine Einordnung, was Subtypen sind.Das ist nicht zu verwechseln mit der Typisierung, die eine Programmiersprache lie-fert wie z.B. Java. Dort kann es z.B. der Fall sein, das eine Subklasse gebildet wird,die nicht dem Liskov-Substitution-Principle entspricht.
Interface-Segregation-Principle
Das Interface-Segregation-Principle wird beschrieben in [Mey97] als: „Clients shouldnot be forced to depend upon interfaces that they do not use“. Das Prinzip besagt,dass eine Klasse, die von sehr unterschiedlichen Klassen benutzt wird, auch unter-schiedliche Schnittstellen anbieten muss.
Wenn diese Trennung über die Schnittstelle nicht wäre, dann müssten alle abhän-gigen Klassen des Anbieters auch angepasst werden.
Common-Closure Principle
Die Klassen in einem Package sollen geschlossen gegenüber Veränderungen sein.Eine Veränderung soll nur Auswirkungen innerhalb eines Packages haben. DiesesPrinzip ist die Verallgemeinerung des Single-Responsibility-Principle von Seite 10.Genau wie beim Single-Responsibility-Principle eine Klasse nur einen Grund habensollte für eine Veränderung, sollten alle Klassen eines Packages nur einen Grund ha-ben angepasst zu werden. Das Prinzip besagt somit auch, dass ein Package genaueine Verantwortung haben sollte. Eine Änderung an dieser Verantwortlichkeit soll-te auch nur dieses Package betreffen. Durch diese Forderung wird Wartbarkeit vorWiederverwendbarkeit gestellt.
Mit diesem Prinzip ist für die Arbeit eine geeignete Größe für die Definition allerzusammenhängenden Klassen gefunden, wie sie im Abschnitt Testbarkeit auf Seite 9gesucht wurde. Zu einem Modul gehören also alle Klassen in einem Package beieinem Komponenten-Test, damit ist der Komponenten-Test ausreichend klein. Alle

2.3. ZUSAMMENFASSUNG 13
anderen Klassen außerhalb dieses Packages gehören nicht zu einem Komponenten-Test.
YAGNI
Das Prinzip YAGNI ist eine Abkürzung und steht für „You ain’t gonna need it“. Esbezeichnet den Ausdruck, wenn Software auf Vorrat gebaut wird. Es sollte nichtsprogrammiert werden, für das aktuell keine fachliche oder technische Notwendig-keit besteht.
2.3 Zusammenfassung
In diesem Kapitel wurden die Grundlagen der Arbeit beschrieben, um in den wei-teren Kapiteln der Arbeit darauf verweisen zu können. Der Begriff Qualität wurdeanhand bekannter Definitionen vorgestellt. Testbarkeit ist als wichtigster Faktor fürdie Qualität von Softwaresystemen erkannt und beschrieben worden. Dabei wur-de die Wichtigkeit möglichst einfacher Initialisierung von Softwaretests festgestellt.Wenn es möglich ist Komponenten-Tests zu schreiben ohne abhängige Klassen an-derer Komponenten zu benutzen, zeigt das direkt die Erweiterbarkeit und Qualitätder Software. In diesem Fall kann die Komponente auch in einem anderen Kontextbenutzt werden.
Abschliessend wurden aus der Literatur entlehnte, in der Softwaretechnik eta-blierte Designprinzipien vorgestellt. Insbesondere mit dem Common-Closure-Principleist eine geeignete Größe gefunden worden, um zu definieren, wieviele und welcheKlassen zu einem Komponenten-Test gehören: Nur die Klassen in einem Packagegehören zu einem Komponenten-Test, dann ist der Test ausreichend klein.

Kapitel 3
Gegenstand der Arbeit
In diesem Kapitel wird das CommSy genauer beschrieben. Zuerst wird das CommSyfachlich erläutert und dabei die Frage geklärt, welchen Zweck es erfüllt. Der techni-sche Hintergrund wird erläutert, der Unterschied zwischen CommSy und dem Ge-genstand der Arbeit, dem JCommSy, sowie die Technologien, mit denen das JCommSyrealisiert ist.
Im zweiten Abschnitt wird die vorgefundene Architektur des CommSys beschrie-ben. Dabei wird neben einer abstrakten Beschreibung der Software, insbesonderedie Erzeugung von Objekten betrachtet. Hierbei werden auch die Probleme der vor-gefundenen Architektur bzgl. der direkten Erzeugung von Objekten für Testbarkeitund Erweiterbarkeit gezeigt.
Dabei wird das CommSy mit Metriken vermessen und untersucht, ob das JCommSydie im vorigen Kapitel vorgestellten Designprinzipien beachtet.
3.1 Das CommSy
Das Community System, kurz CommSy, ist aus einem universitären Projekt zumWissensmanagement entstanden, in dem unterstützende Dienste zur Projektarbeitund für Arbeitsgruppen entwickelt wurden. Sein technischer Kern ist eine dyna-mische Webserver-Applikation, die die Kommunikation zwischen den Mitgliederneines Projektes erlaubt. Das System wurde in einer großen Anzahl von Projektenbenutzt und wissenschaftlich ausgewertet. Die Entwicklung des Prototypen begannmit zwei bis fünf Personen. Seitdem haben viele Lehrveranstalter das CommSy inVeranstaltungen unterschiedlicher Universitätskontexte verwendet, u.a. bei der In-ternationalen Frauenuniversität.
Fachlicher Hintergrund
Das CommSy ist eine Webanwendung zur Unterstützung der Kommunikation vonLehrveranstaltungen. Das Ziel ist gemeinsames Lernen. Das CommSy benutzt dieMetapher der Räume. So gibt es einen Gemeinschaftsraum, auf den alle eingetrage-nen Benutzers des CommSys zugreifen können. Für einzelnen Lehrveranstaltungen
14
3.1. DAS COMMSY 15
Abbildung 3.1: Screenshot CommSy
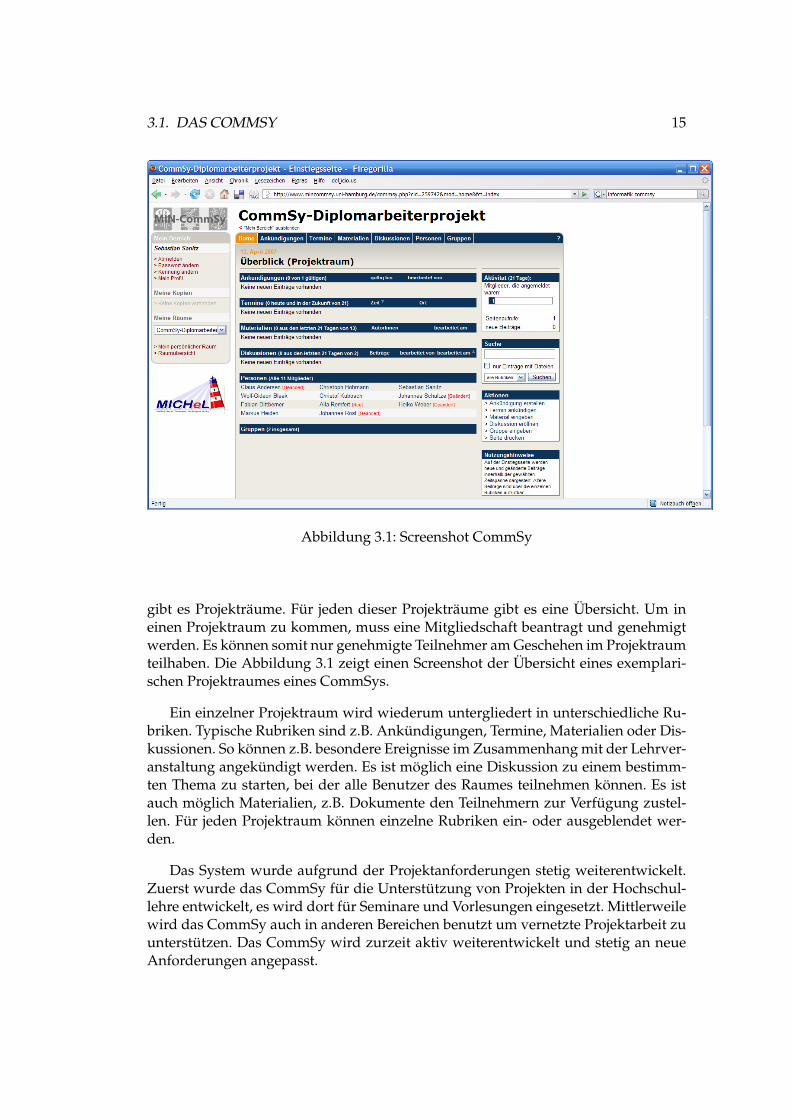
gibt es Projekträume. Für jeden dieser Projekträume gibt es eine Übersicht. Um ineinen Projektraum zu kommen, muss eine Mitgliedschaft beantragt und genehmigtwerden. Es können somit nur genehmigte Teilnehmer am Geschehen im Projektraumteilhaben. Die Abbildung 3.1 zeigt einen Screenshot der Übersicht eines exemplari-schen Projektraumes eines CommSys.
Ein einzelner Projektraum wird wiederum untergliedert in unterschiedliche Ru-briken. Typische Rubriken sind z.B. Ankündigungen, Termine, Materialien oder Dis-kussionen. So können z.B. besondere Ereignisse im Zusammenhang mit der Lehrver-anstaltung angekündigt werden. Es ist möglich eine Diskussion zu einem bestimm-ten Thema zu starten, bei der alle Benutzer des Raumes teilnehmen können. Es istauch möglich Materialien, z.B. Dokumente den Teilnehmern zur Verfügung zustel-len. Für jeden Projektraum können einzelne Rubriken ein- oder ausgeblendet wer-den.
Das System wurde aufgrund der Projektanforderungen stetig weiterentwickelt.Zuerst wurde das CommSy für die Unterstützung von Projekten in der Hochschul-lehre entwickelt, es wird dort für Seminare und Vorlesungen eingesetzt. Mittlerweilewird das CommSy auch in anderen Bereichen benutzt um vernetzte Projektarbeit zuunterstützen. Das CommSy wird zurzeit aktiv weiterentwickelt und stetig an neueAnforderungen angepasst.

16 KAPITEL 3. GEGENSTAND DER ARBEIT
Abbildung 3.2: Architektur PHP-CommSy
Technischer Hintergrund
Das Projekt CommSy ist ursprünglich in der Programmiersprache PHP realisiert. Esbenutzt für die Speicherung der Daten eine MySQL-Datenbank. Die Architektur desPHP-CommSys wird in Abbildung 3.2 gezeigt. Ein Webserver mit PHP-Engine be-antwortet die Anfragen der Webbrowser. Das CommSy bezieht seine Informationenaus der Datenbank, aktualisiert diese und schreibt dorthin je nach Anfrage auch neueInformationen.
Seit 2004 wird das CommSy schrittweise umgestellt auf die Plattform Java unterdem Namen JCommSy. Hier werden die Technologien Servlets und JavaServer Pages(JSP) benutzt. Es erfolgt eine schrittweise Umstellung der einzelnen Kategorien. Fürdie schrittweise Umstellung wird die aktuelle Session, der Zustand der Anwendung,vom PHP-System in die Datenbank serialisert. Der Zugriff auf die Daten und dieSynchronisation erfolgt über eine Session-ID und die gleiche MySQL-Datenbank. EinFilter deserialisiert diese Informationen vor jedem Zugriff für die Java-Anwendung.Diese Information beinhaltet den aktuellen Benutzer und seine Rechte.
3.2 Die vorhandene Architektur
Das vorhandene CommSy besteht aus zwei großen Teilprojekten, der Version in PHPund der migrierten Version in Java. Das alte CommSy ist geschrieben in PHP undwird in dieser Arbeit nicht detailliert betrachtet. Die abstrakte Beschreibung aus demvorigen Kapitel ist für die Arbeit und den praktischen Teil ausreichend.
Für die Arbeit ist der neue in Java realisierte Teil von Interesse, das JCommSy.Die dort vorgefundene Architektur entspricht dem Muster Model-View-Controller.Bei diesem Muster ist die Anwendung in drei Komponenten aufgeteilt, das Model,die View und den Controller.
Das Model beinhaltet im Muster die Anwendungslogik und Daten. Ein typischesBeispiel für ein Model im JCommSy ist das Objekt Room. Das Objekt modelliert einenRaum im JCommSy, dort sind der Name und weitere Informationen gespeichert. ImModel werden mit Objekten die fachlichen Entitäten und die Geschäftslogik model-liert.
Die Benutzungsschnittstelle, das User Interface (UI), wird durch View und Con-troller repräsentiert. Der Controller verarbeitet die Eingaben des Programms undaktualisiert das Model.
Die View ist zuständig für die Darstellung der Ausgabe. Meistens registriert sichdie View als Callback beim Model für inhaltliche Änderungen am fachlichen Modell,

3.2. DIE VORHANDENE ARCHITEKTUR 17
Abbildung 3.3: MVC - Architektur
damit diese Änderungen sofort angezeigt werden können. Die Trennung zwischenModel, View und Controller soll die Erweiterbarkeit und Testbarkeit erhöhen. DerUrsprung des MVC-Musters sind Desktopanwendungen. Das komplette Muster istin der Abbildung 3.3 gezeigt.
Bei einer Webanwendung wie dem JCommSy ist die View meist mit JavaServerPages (JSPs) realisiert. Beim JCommSy wird der Controller durch ein Servlet rea-lisiert. Das Servlet bearbeitet die Eingaben, die durch einen Webbrowser geschicktwerden, und liest dafür aus dem HTTP-Request die Parameter aus.
Im Bereich der Webandwendungen wird noch weiter unterschieden zwischenMVC1 und MVC2. Die Unterscheidung liegt in der Geschichte der Webanwendun-gen, die in Java geschrieben wurden. In Abbildung 3.4 ist die MVC1-Architekturdargestellt. Hier waren noch View und Controller in der JSP vereint. Somit ist hierdie JSP nicht nur für die Darstellung zuständig, dort werden auch die Aufgaben desControllers übernommen. In JSP-Seiten wird mit HTML die Darstellung definiert.Zusätzlich kann in den JSP-Seiten auch Java-Code aufgerufen werden. Da MVC1 dieView und den Controller in der JSP-Seite vereint, wird diese bei komplexeren An-wendungen schnell unübersichtlich. Aus diesem Grund ist MVC1 keine vollständigeMVC-Architektur, es entstammt nur der Zeit, in der die ersten Präsentationsframe-works für Java entwickelt wurden.
Bei der MVC2 Architektur, wie in Abbildung 3.5 gezeigt, wurden der Controllerund die View getrennt, um so wenig wie möglich ausführbaren Code im View zu be-nutzen. Der Controller ist als Servlet realisiert und leitet die Anfragen an das Modelweiter. Die View in MVC2 benutzt JSP als Technologie für die Ausgabe. Durch dieTrennung von View und Controller handelt es sich bei MVC2 um ein vollständigesModel-View-Controller-Muster.
Für die weitere Betrachtung der Architektur wurde der Kontrollfluss innerhalbder Anwendung betrachtet. Der Kontrollfluss geht vom Servlet aus, ausgelöst durcheine Anfrage von einem Browser. Das CommSy-Servlet analysiert die Anfrage. ZumBeispiel wird geprüft, ob aktuell ein Benutzer angemeldet ist oder welche Funkti-on der Benutzer ausgewählt hat. Das CommSy-Servlet leitet die Anfrage weiter anActions oder ComponentCommands, entsprechend der Funktion, die der Benutzerausgewählt hat. Die Actions oder ComponentCommands lesen die Parameter aus,

18 KAPITEL 3. GEGENSTAND DER ARBEIT
Abbildung 3.4: MVC1 - Architektur
Abbildung 3.5: MVC2 - Architektur

3.2. DIE VORHANDENE ARCHITEKTUR 19
stoßen entsprechende fachliche Funktionen an und leiten anschließend weiter an ei-ne JSP-Seite. Das JCommSy ist also als klassische MVC2-Architektur realisiert.
Neben dieser statischen Analyse muss auch der dynamische Aspekt der Anwen-dung betrachtet werden. Damit wird jetzt ein zentrales Thema dieser Arbeit behan-delt, es wird die Fragestellung beantwortet, welche Objekte zu welchem Zeitpunktandere Objekte erzeugen bzw. wie sie auf andere Objekte zugreifen können. Hierfürwerden der Kontrollfluß und anschließend die fachlichen Services genauer betrach-ten.
Kontrollfluss
Für eine Analyse des Systems ist eine genaue Betrachtung des Kontrollflusses wich-tig. Es muss analysiert werden, an welchen Stellen durch das Servlet-Frameworkbzw. den Applikations-Server der JCommSy-Code aufgerufen wird. Die Frage nachden Einstiegspunkten des Kontrollflusses ist für die Analyse der Objekterzeugungwichtig und für die Planung einer Umstellung auf eine der möglichen Lösungen vonNöten.
Eine genauere Betrachtung des Sourcecodes hat gezeigt, dass nicht nur durchServlets der Kontrollfluss vom Servlet-Container bzw. dem Servlet-Framework andas JCommSy-System weitergereicht wird. Es werden im JCommSy auch Filter ein-gesetzt, z.B. für die Migration. Die Filter werden vor und nach dem Aufruf des Serv-lets durch den Servlet-Container aufgerufen. Dort liest ein Filter den angemeldetenBenutzer aus der aktuellen Session und prüft, ob die angefragte Funktionalität über-haupt durch das Java-System behandelt werden kann. Damit sind nicht nur Services,sondern auch die Filter ein Einstiegspunkt für den Kontrollfluss im JCommSy.
Neben diesen direkten Einstiegspunkten in den Kontrollfluss fallen bei der Ana-lyse des Sourcecodes die Component Commands auf. Sie wurden durch die Arbeit vonChristoph Hohmann [Hoh07] als Erweiterung der Architektur eingeführt.
Bei der Erzeugung einer darzustellenden Seite im JCommSy wird dynamisch zurLaufzeit ein Baum von Component Commands erstellt. Dieser Baum entspricht inseiner Struktur dem Aufbau der Seite. Für jede Darstellungskomponente findet sichein Pendent im erstellten Baum der Component Commands. Diese Component Com-mands stellen die Funktion bereit die in der Darstellung angeboten werden. Durchdiese Architektur sollen häufig verwendete Elemente in der Darstellung einfacherwieder zu verwenden sein bei der Implementierung neuer Funktionalitäten. DieseKomponenten sind für diese Arbeit von Interesse, denn diese Bäume werden beijedem Zugriff auf das JCommSy entsprechend der Anfrage neu erzeugt. Es findetalso Objekterzeugung statt. Diese Objekte benutzen für die Erledigung ihrer Auf-gaben Services. Für die Services greifen sie auf die ServiceRegistry bzw. dasServiceRegistrySingleton zu. Das Singleton und weitere Muster werden wirspäter noch auf Seite 22 und folgend betrachten. Die Component Commands unter-scheiden sich aber im Bezug auf die Erzeugung von den Services. Ein solches Com-ponent Command wird bei jeder Anfrage neu erzeugt. Für einen Service muss fürdie gesamte Laufzeit der Anwendung nur einmal ein Objekt erzeugt werden.
Der dahinter liegende Unterschied zwischen den Services und den Component

20 KAPITEL 3. GEGENSTAND DER ARBEIT
1 public void execute(Item item, CallContext cc, CHttpServletRequest request) throws CommsyException {
2 // Load topics which are attached to the item3 List<Link> links = ServiceRegistrySingleton.getLinkServiceC
().getItems(item.getItemID(), ItemType.TOPIC);4 Map<ItemID, Topic> topics = ServiceRegistrySingletonC
.getTopicService().getItemsMap(ItemCollectionUtilC
.linkedIDs(links, item));5 Map<ItemID, User> creators = C
ServiceRegistrySingleton.getUserService().CgetItemsMap(ItemCollectionUtil.creatorIDs(links))C;
6 // Der Rest der Methode ist hier nicht von Interesse ...7 }
Listing 3.1: Zugriff auf Services im DetailedTopicsCommand
Commands ist der Zustand dieser Objekte. Die Services im JCommSy sind zustands-los implementiert. Außerhalb der Methoden sind keine Variablen definiert, die durcheine Anfrage verändert werden. Die Services benutzen selber nur zustandslose an-dere Services. Aus diesem Grund kann ein Exemplar eines Services gleichzeitig fürviele unterschiedliche Anfragen genutzt werden. Die Commands haben einen Zu-stand entsprechend der konkreten Anfrage, in dessen Kontext sie gerade benutztwerden. Daher kann ein Exemplar eines Commands nur für eine Anfrage erzeugtund benutzt werden.
Aus der Beobachtung von Services und Component Commands lässt sich fest-stellen, dass Exemplare dieser Objekte abhängig von Kontexten unterschiedlich häu-fig erzeugt werden. Es gibt Objekte, die nur einmal pro Anwendung erzeugt werden,und Objekte, die nur in einem bestimmten Kontext, wie z.B. einer Session oder einemKomponenten-Baum, jeweils einmal erzeugt werden.
Services
Fachliche Funktionen sind häufig in Services gekapselt. Services sind neben Fachwer-ten und Geschäftsobjekten eine der wichtigsten Abstraktionen die beim JCommSygenutzt werden. Es gibt z.B. Services, die Objekte in der Datenbank persistieren,suchen oder aktualisieren1. Diese Services benötigen Ressourcen, z.B. eine Daten-bankanbindung oder sie benutzen weitere Services. Um auf Services zuzugreifen,wird eine Singeleton-Factory benutzt. Hier wird mit dem Muster Singleton, sieheauch [GHJV94], der Zugriff auf die Services ermöglicht. Ein statisches Attribut ver-weist auf die einzige vorhandene Instanz. Der Zugriff auf diese Instanz erfolgt übereine statische Methode.
1Diese Serviceobjekte werden auch DAO genannt, für Data Access Object

3.3. MUSTER IM JCOMMSY 21
Abbildung 3.6: Abhängigkeiten über das ServiceRegistrySingleton
Um die Architektur genauer zu beurteilen, muss der Kontrollfluss an einem kon-kreten Beispiel betrachtet werden. Ein Beispiel ist der Zugriff in einer Methode ausder Klasse DetailedTopicsCommand auf den LinkServicewie gezeigt in Listing3.1. Dort werden alle Verweise geladen. Hierfür wird der LinkService benötigt.Der wird über die Klasse ServiceRegistrySingleton bezogen, diese hat einestatische Methode getLinkService. Nach dem selben Muster wird für die Bear-beitung der Anfrage auf den TopicService und den UserService zugegriffen.
Die Abhängigkeiten ausgehend von der Klasse DetailedTopicsCommand sindin Abbildung 3.6 gezeigt. Das Command greift auf das ServiceRegistrySingle-ton zu. Das hat ein statische Feld mit einer ServiceRegistry. Daher wurde sie alsSingleton bezeichnet, denn sie erzeugt nur einmal diese Registry. Diese Registry wirdbenutzt bei der Abfrage zum aktuellen LinkService. Die Registry selber ist keinSingleton. Sie erzeugt aber bei der Initialisierung einen LinkService. Dafür mussdie Registry eine konkrete Implementierung benutzen, den LinkServiceImpl.
Alle Klassen benutzen das Interface LinkService, bis auf die ServiceRegistry.Diese erzeugt initial die konkrete Implementierung für den LinkService und kenntdaher die Implementation LinkServiceImpl. Somit hat auch das DetailedTo-picsCommand eine implizite Abhängigkeit zu dieser konkreten Implementierung.Der Ursprung dieser Abhängigkeit ist die direkte Objekterzeugung in der Registryund das dadurch entstandene Wissen um die konkrete Implementierung dieses Ser-vices.
3.3 Muster im JCommSy
Um einen Einblick in die Architektur des JCommSy zu bekommen, wird diese mitEntwurfsmustern beschrieben. Zuerst werden die benutzten Muster erläutert undanschließend wird die Benutzung und Anpassung dieser Muster im JCommSy be-schrieben.

22 KAPITEL 3. GEGENSTAND DER ARBEIT
1 public class Singleton {2 private Singleton() {}3 private static Singleton instance = null;4 public static Singleton instance() {5 if (instance == null)6 instance = new Singleton();7 return instance;8 }9
10 // weitere fachliche Methoden11 }
Listing 3.2: Singleton-Muster
Singletons
Das Entwurfsmuster Singleton ist in [GHJV94] beschrieben. Dort wird es als Erzeu-gungsmuster kategorisiert. Ein Singleton soll sicher stellen, dass ein Objekt nur ein-mal erzeugt werden kann. Das Singleton liefert dabei den Zugriff auf dieses Exem-plar des Objektes. Im Listing 3.2 ist dargestellt wie in Java ein Singleton implemen-tiert wird. Das einzige Exemplar der Klasse wird in einer statischen Klassenvaria-ble gespeichert. Der Zugriff auf dieses Exemplar erfolgt über eine statische Methode.Diese Methode liefert das einzige Objekt dieser Klasse zurück. Falls noch kein Objektdieser Klasse erzeugt wurde, wird eines erzeugt und der statischen Klassenvariablezugewiesen. Bei einem weiteren Zugriff über die Methode instance wird genauwieder dieses Exemplar zurück gegeben. Die Sichtbarkeit des Konstruktor wird alsprivate deklariert, somit können nur Methoden aus dieser Klasse ein Exemplarerzeugen.
Singletons haben den Vorteil, dass sie einen zentralen Zugriffpunkt haben undnur genau ein Exemplar dieser Klasse zulassen. Genau dieses Verhalten kann auchals nachteilig angesehen werden. Ein Singleton hat mindestens zwei Verantwortun-gen. Einmal bietet es die fachlichen Funktionen der Klasse an und zum anderen stelltes sicher, dass nur ein Exemplar dieser Klasse erzeugt wird. Damit widerspricht dasSingleton einer strikten Auslegung des Single-Responsibility-Principles.
Singletons sind für die Testbarkeit von Nachteil. Greift das getestete Objekt aufein Singleton zu, besteht keine einfache Möglichkeit das Singleton vom Test zu iso-lieren. Das Singleton gehört dann immer zu den Klassen die mit dem eigentlich zutestenden Objekt mitgetestet werden.
Service Locator
Das Muster Service Locator wird beschrieben in [ACM03]. In diesem Buch werdengängige Muster in J2EE-Umgebungen beschrieben. Das Klassendiagramm zum Mus-ter Service Locator ist in Abbildung 3.7 dargestellt. Der Service Locator soll die auf-

3.3. MUSTER IM JCOMMSY 23
Abbildung 3.7: Klassendiagramm J2EE Service Locator, aus [ACM03]
wendige Suche nach verteilten Services in diesen J2EE-Umgebungen kapseln undvereinfachen. Der Service Locator übernimmt die Lokalisierung der Komponenten,sucht mit einem InitialContext nach einer Factory für den gesuchten Service.Diese Factory erzeugt oder lokalisiert den Service und der Service Locator gibt die-sen Service als Ergebnis der Suche zurück.
Wenn keine J2EE-Komponenten wie z.B. EJBs verwendet werden und auch Ser-vices nicht über einen InitialContext verteilt werden, kann ein vereinfachterService Locator benutzt werden. Diese vereinfachte Beschreibung befindet sich auchin [Fow04]. In diesem Fall erzeugt der Service Locator die Services selber, anstatt die-se über einen InitialContext o.ä. zu beziehen. In Abbildung 3.8 ist ein Klassen-diagramm dargestellt, das die Benutzung eines einfachen Service Locators darstellt.Hier bezieht der BuecherService das benötigte BuecherRepository über einenService Locator.
Der Service Locator bietet somit eine Abstraktion über die Lokalisierung oderErzeugung des benutzten Services an. Es besteht nur noch eine indirekte Beziehungvom benutzenden Klienten und dem konkreten Anbieter. Im Beispiel kennt der Bue-cherService direkt nur die Schnittstelle BuecherRepository, nicht aber die kon-krete Implementierung. Die Implementierung des konkreten BuecherService istim Service Locator verankert, dieser erzeugt im Beispiel bei Bedarf das konkreteBuecherRepositoryImpl.
Die Benutzung eines Service Locators wirkt sich im Vergleich zu Singletons bes-ser auf Tests aus. Für den Test kann der Service Locator programmatisch konfiguriertwerden, so das er eine gewünschte Implementierung beim Zugriff liefert. Der Nach-teil dieser Lösung liegt darin, das die Möglichkeit den Service Locator programma-tisch zu konfigurieren nur für Tests implementiert werden muss, diese Funktionalität

24 KAPITEL 3. GEGENSTAND DER ARBEIT
Abbildung 3.8: Klassendiagramm eines einfachen Service Locators
1 public static void setDatabaseService(DatabaseService Cservice) {
2 ServiceRegistrySingleton.getInstance().CsetDatabaseService(service);
3 }4
5 // usw.
Listing 3.3: Ausschnitt aus der Klasse ServiceConfigurator
ist für den Einsatz der Software nicht unbedingt notwendig.
Einsatz der Muster im JCommSy
Betrachtet man die Nutzung der Muster Singleton und Service Locator im JCommSyfällt sofort das ServiceRegistrySingleton auf, siehe Abbildung 3.6. Die Klassehat eine statische Klassenvariable, die genau eine ServiceRegistry referenziert undbietet eine statische Methode als einzigen Zugriffspunkt zu dieser ServiceRegis-try an. Die Klasse ServiceRegistrySingleton hat nur statische Methoden fürden Zugriff und verwaltet eine ServiceRegistry, somit ist diese Klasse im eigent-lichen Sinne kein Singleton. Hier entspricht die Klasse dem Single-Responsibility-Principle. Die Klasse ist nur für die Verwaltung der ServiceRegistry zuständig.Sie verhindert, dass mehrerer Exemplare der Registry vorhanden sind und bieteteinen gemeinsamen Zugriffspunkt an.
Für die Konfiguration der Tests gibt es im JCommSy die Klasse ServiceConfi-gurator. Mit Hilfe dieser Klasse können Tests einen eigenen Service setzen. In Lis-ting 3.3 ist die Methode setDatabaseService exemplarisch aufgeführt. Für alleServices, die im JCommSy verwendet werden, bietet der Configurator eine Methodezum Austausch des jeweiligen Service an.

3.4. ERGEBNISSE DER VERMESSUNG 25
3.4 Ergebnisse der Vermessung
Für die Vermessung des Sourcecodes sind die Metriken von Robert C. Martin aus[Mar03] benutzt worden, die dort als „stability metrics“ bezeichnet werden. Die wich-tigsten Maße dieser Metriken sind afferent couplings, efferent couplings, abstractness undinstability. Diese Metriken werden in dieser Arbeit benutzt, um die Abhängigkei-ten zwischen den Packages zu analysieren. Bei der Erläuterung der einzelnen Maßewird jeweils mit angegeben, welches Design-Ziel durch die jeweilige Metrik über-prüft werden kann.
Metriken von Robert C. Martin
Für die Metriken von Robert C. Martin werden Packages analysiert und es werdendie Kennzeichnungen eines Packages als stabil oder instabil und konkret oder ab-strakt eingeführt. In einem Package in Java werden eine oder mehrere Klassen undInterfaces gebündelt. Jedes Package hat einen eindeutigen Namen. Im Namensraumdes Packages sind Klassen eindeutig. Packages werden benutzt um in größeren Pro-jekten Klassen zu gruppieren.
Für die Metriken werden die Abhängigkeiten der Klassen eines Packages betrach-tet. Es wird ein Package als stabil definiert, wenn es von Klassen anderer Packagesbenutzt wird. In Abbildung 3.9 ist das Package D stabil, es wird von Klassen derPackages B und C benutzt. Das Package D hat keine Abhängigkeiten, es ist unabhän-gig. Daher muss es nicht angepasst werden, wenn sich andere Packages verändern.Andere Packages sind abhängig vom stabilen Package.
Im Gegensatz dazu ist Package C instabil gekennzeichnet. Es ist abhängig vonden Packages D, E und F, denn Package C müsste auf Änderungen in einem derPackages D, E oder F angepasst werden.
Ob ein Package als stabil oder instabil bezeichnet wird, ist somit unabhängigvon der Reife oder der Qualität der Software. Vielmehr beschreibt die Stabilität, wieaufwendig es ist, Klassen innerhalb eines Packages anzupassen. Sind andere Packa-ges abhängig von einem Package und müssen bei Änderungen angepasst werden,dann wird dieses Package als stabil gekennzeichnet, denn es erschwert die Änderun-gen. Sind keine anderen abhängigen Packages vorhanden, so wird dieses als instabilgekennzeichnet, da Änderungen an dem Package keine Anpassungen in anderenPackages erfordern.
Ein stabiles Package sollte möglichst abstrakt sein. Warum? Nach dem Open-Closed-Principle, siehe Seite 11, soll ein Modul geschlossen sein für Änderungen undoffen für Anpassungen. Diese Problematik wird durch Schnittstellen gelöst. Abhän-gige Module sollen die Schnittstellen benutzen. Diese Schnittstellen sind geschlossenfür Änderungen. Anpassungen können in dem Package in konkreten Klassen dieserSchnittstelle implementiert werden. Nach dem Open-Closed-Principle sollten alsoabhängige Klassen anderer Packages möglichst abstrakte Klassen oder Schnittstellenbenutzen. Somit sollten Packages abstrakter sein, je mehr sie von anderen Packagesbenutzt werden. Oder anders ausgedrückt, so stabil wie ein Package ist, so abstrakt

26 KAPITEL 3. GEGENSTAND DER ARBEIT
Abbildung 3.9: Abhängigkeiten zwischen Packages
soll es sein. Dieses wird in [Mar03] auch als stable-abstractions principle (SAP) bezeich-net.
Ein Package gilt als abstrakt, wenn die dort definierten Klassen nicht direkt in-stanzierbar sind, es sich also um Interfaces oder abstrakte Klassen handelt. Das Packa-ge gilt als konkret, wenn es sich bei den Klassen in dem Package um konkrete Klas-sen handelt, die instanzierbar sind.
Um für diese Begriffe Messwerte und Dimension zu benutzen, müssen die Be-griffe afferent couplings, efferent couplings definiert werden:
Afferent Couplings Ca Die Anzahl der Klassen, die außerhalb des Packages vonKlassen innerhalb des Packages abhängig sind.
Efferent Couplings Ce Die Anzahl der Klassen die innerhalb des Packages abhängigsind von Klassen anderer Packages.
Instabilty I Wird berechnet aus der Formel:
I =Ce
Ca + Ce
Die Werte dieser Metrik in dem Intervall von 0 bis 1. Ein Package mit dem WertI = 1 wird als maximal instabil benannt und ein Package mit dem Wert I = 0ist maximal stabil.
Um den Grad der Abstraktheit eines Packages zu benennen, müssen die Anzahlder konkreten und der abstrakten Klassen gezählt werden, dafür werden die MaßeNc, Na und A definiert:
Anzahl der Klassen Nc Die Anzahl der Klassen innerhalb des Packages.

3.4. ERGEBNISSE DER VERMESSUNG 27
Anzahl der abstrakten Klassen Na Die Anzahl der abstrakten Klassen innerhalb desPackages.
Abstractness A Wird berechnet aus der Formel
A =Nc
Na
Die Werte dieser Metrik liegen innerhalb des Intervalls von 0 bis 1. Ein Packagemit dem Wert A = 1 hat nur abstrakte Klassen bzw. Schnittstellen. Dagegen hat einPackage mit dem Wert A = 0 gar keine abstrakten Klassen.
Aus den beiden Maßen Abstractness und Instability lässt sich ein Diagrammerstellen. Auf der X-Achse wird der Grad der Abstraktion gekennzeichnet, auf derY-Achse wird die Stabilität eingetragen.
Jedes Package der Software lässt sich jetzt in diesem Diagramm eintragen. Dieeinzelnen Packages werden dabei in drei Gruppen unterteilt. Entweder sie befindensich in der Hauptreihe zwischen den Punkten A = 0, I = 1 und A = 1, I = 0,darunter oder darüber. Der Bereich über dieser Reihe bis zum Punkt A = 0, I = 0wird als zone of pain gekennzeichnet. Es deutet an, dass viele Klassen in dem Packagenicht abstrakt sind und trotzdem viele andere Klassen von diesem Package abhängig.Das erschwert eine Anpassung dieses Packages, denn sie erfordert die Anpassungder Klassen in den abhängigen Packages.
Der Bereich unter der Hauptlinie bis zum Punkt A = 1, I = 1 wird zone of useless-ness genannt. Ein Package in diesem Bereich hat viele abstrakte Klassen und wird vonwenig Klassen anderer Packages benutzt. Es sind sehr wahrscheinlich viele unnötigeSchnittstellen und abstrakte Klassen in diesem Package.
Für die Packages aus dem Beispiel sind die Werte in Abbildung 3.10 markiert.Der Abstand zu dieser Hauptreihe wird als Distance bezeichnet. Je größer der
Abstand zu der Hauptreihe, desto mehr ist das Package entweder in der zone of painoder in der zone of uselessness. Für die Berechnung der Distance gilt folgende Formel:
D – Distance Beschreibt den Abstand zur Hauptreihe
D =A + I − 1√
2
D′ – Normalized Distance Ist der normalisierte Abstand zur Hauptreihe. Die Wertebefinden sich im Intervall von 0 bis 1.
D′ = |A + I − 1|
Für die Packages aus der Abbildung 3.9 sind die entsprechenden Werte für Ca,Ce, Nc, Na, A, I und D′ in Tabelle 3.1 eingetragen.
Betrachtet man aus der Tabelle 3.1 die Packages mit dem größten Abstand zurHauptlinie findet man die Packages B mit D′ = 0, 75 und D mit D′ = 0, 5. PackageB befindet sich in der zone of uselessness. Es hat sechs abstrakte Klassen von insge-samt acht und es gibt keine Klasse aus einem anderen Package das von B abhängt.

28 KAPITEL 3. GEGENSTAND DER ARBEIT
abstractness
instability
0.2
0.4
0.6
0.8
0.2 0.4 0.6 0.8
main sequence
A
BC
D
E
Abbildung 3.10: A-I-Diagramm
Package Ca Ce Nc Na A I D’
A 0 2 4 0 0 1 0B 0 3 8 6 0,75 1 0,75C 3 2 5 4 0,8 0,4 0,2D 2 2 4 0 0 0,5 0,5E 4 0 5 4 0,8 0 0,2
Tabelle 3.1: Messwerte für das Beispiel

3.4. ERGEBNISSE DER VERMESSUNG 29
Package Ca Ce Nc Na A I D’
domainvalue 29 0 14 0 0,00 0,00 1,00item.search 11 2 2 0 0,00 0,15 0,85util 22 4 5 0 0,00 0,15 0,85presentation 14 4 34 1 0,03 0,22 0,75service.persistence 4 6 4 4 1,00 0,60 0,60
Tabelle 3.2: Messwerte für JCommSy sortiert
Das deutet an, das unnötig viele abstrakte Klassen in B benutzt werden. Package Dbefindet sich in der zone of pain. Es hat vier Klassen und keine davon ist abstrakt. Esgibt aber zwei Klassen aus anderen Packages die von D abhängen. Das deutet an, daseine Änderung von D aufwendig wird, da mindestens die zwei abhängigen Klassenangepasst werden müssen.
Messwerte aus dem JCommSy
Das JCommSy wurde vor der Umstellung gemessen. Die Werte für das JCommSybefinden sich in Tabelle A-1 auf Seite 66.
Bei den Werten fallen ein paar Packages durch eine höhere Distanz auf. In Tabelle3.2 sind fünf Packages mit der höchsten Distanz absteigend sortiert aufgelistet. Dasentsprechende Diagramm dazu ist in Abbildung 3.11 dargestellt.
Anhand der Grafik und der Messwerte ist sofort zu erkennen, dass das Packa-ge service.persistence sich im Bereich der zone of uselessness befindet. Es hatnur abstrakte Klassen. Trotzdem wird es nicht von vielen Klassen anderer Packagesbenutzt. Die anderen Packages befinden sich in der zone of pain.
Es muss nicht unbedingt ein schlechtes Zeichen sein, wenn sich ein Package indieser Zone befindet. Ein typisches Beispiel sind Klassen mit Hilfsmethoden, die sichsehr wahrscheinlich niemals verändern werden, z.B. String-Utils. Falls es sich umsolche Klassen handelt, kann man diese kennzeichnen als non-volatile, also als nichtflüchtig oder permanent. So gekennzeichnete Packages werden in dieser Metrik nichtmehr berücksichtigt.
Typischerweise hat das Package mit den Fachwerten, hier domainvalues, einenschlechten Wert in der Distanz und ist in der zone of pain. Fachwerte sind häufigals konkrete Klassen implementiert, es gibt in diesen Packages also relativ wenig ab-strakte Klassen. Es stellt sich die Frage, ob Fachwerte als non-volatile markiert werdenkönnen, weil sie von ihrer Natur aus unveränderlich sind. Eine andere Sicht ist es fürFachwerte nur noch Interfaces zu benutzen, und diese über statische Methoden oderFactories zu erzeugen. Die Definition eines Fachwertes wird sich wie die Anforde-rung eines Kunden an die Software auch verändern können. Desweiteren könnteman fordern Fachwerte nicht mehr universell im ganzen System einzusetzen, son-dern spezielle Fachwerte nur für bestimmte Schichten oder Bereiche des Systems zubenutzen.

30 KAPITEL 3. GEGENSTAND DER ARBEIT
abstractness
instability
0.2
0.4
0.6
0.8
0.2 0.4 0.6 0.8
main sequence
domainvalue
item.search,util presentation
service.persistence
Abbildung 3.11: A-I-Diagramm für ausgewählte Packages aus dem JCommSy
Tests im JCommSy
Die indirekte Abhängigkeit der Servlets und Commands zu den konkreten Serviceszeigt sich in den Tests als Hindernis. In den meisten Tests für Klassen die von Ser-vices abhängig sind, werden auch alle abhängigen Services mitbenutzt. Sie könnennicht einfach ausgetauscht werden. Alle Tests im JCommSy benutzen daher implizitsämtliche abhängigen Objekte mit. Es handelt sich also nicht um Komponententestsim eigentlichen Sinne. Es wird nicht nur das Verhalten einer einzelnen Komponentegeprüft, sondern implizit auch das Verhalten der anderen abhängigen Objekte.
Das bereitet allen Tests einen enormen Aufwand, einen zuverlässigen Zustandvor dem Test bereitzustellen. Es werden im JCommSy-Code in der Vorbereitung derTests die abhängigen Services der zu testenden Klasse aufgerufen und versucht, die-se in einen definierten Zustand zu bringen. Bei den eigentlichen Tests wird indirektauch die Funktionalität der abhängigen Services mit getestet. Als Beispiel hierfürwird in Listing 3.4 die Methode setUp aus dem Test MaterialServiceHiber-nate gezeigt, die vor jedem Test in diesem Testfall aufgerufen wird. Für jeden Testwerden hier die beiden Services für Links und Materialen explizit gesetzt am Ser-viceConfigurator gesetzt.
Durch diese Abhängigkeiten sind fast alle Tests sehr aufwändig in ihrer Beschrei-bung und in der Ausführung sehr langsam. Die komplette Testsuite mit ca. 900 Testsdauert in der Ausführung fast fünf Minuten. Viele der Tests initalisieren aufwendigdie Service Registry, nur um Funktionen des getesteten Objektes zu prüfen. Diese In-

3.4. ERGEBNISSE DER VERMESSUNG 31
1 protected void setUp() throws Exception {2 setUpJUnitDatabaseService();3 Persister.deleteAll(Material.class); // usw..4 _service = new MaterialServiceHibernate();5 ServiceConfigurator.setMaterialService(_service);6 ServiceConfigurator.setLinkService(new C
LinkServiceHibernate()); // usw.7 }
Listing 3.4: Ausschnitt aus dem Test MaterialServiceHibernate
itialisierung kostet viel Zeit und ist für den eigentlichen Test nicht notwendig. DamitEntwickler Tests häufig ausführen, sollte die Ausführung der Tests möglichst schnellsein. An diesem Punkt gibt es somit Potential zur Verbesserung.
Neben dem umständlichen Aufsetzen der Tests ist die Fehlersuche bei fehlschla-genden Tests ein Problem. Bei der Suche muss nicht nur die getestete Klasse unter-sucht werden, warum nicht das vom Test erwartete Ergebnis liefert. Auch die ab-hängigen Objekte und Services können einen Grund für das Fehlschlagen des Testssein.
Im folgenden beschreibe ich die Gründe, warum mit dieser Architektur das Tes-ten erschwert ist:
• Verschleppen von Zuständen
• Reihenfolge der Ausführung
• Abhängigkeiten der Objekte unklar
Die Architektur ermöglicht das Verschleppen von Zuständen, wenn ein Test einenungewollten Zustand hinterlässt, z.B. in dem er einen Service über den Service Confi-gurator ausgetauscht hat. Der folgende Test kann ggf. einen anderen Zustand erwar-ten und fehlschlagen. Die Tests können ungewollt abhängig werden von der Reihen-folge der Ausführung der Tests. Dass Tests Zustände verschleppen, liegt unter anderemdaran, dass die Abhängigkeiten der Objekte unklar sind. Ein Test muss alle abhängigenKlassen der zu testenden Klasse kennen und eventuell austauschen. Direkte Abhän-gigkeiten zu anderen Services sind nur erkennbar über den Aufruf am Service Loca-tor. Indirekte Abhängigkeiten sind schon viel schwerer zu erkennen, hierfür muss inden abhängigen Services nach Aufrufen am Service Locator gesucht werden.
Das Testen wird im JCommSy weiterhin dadurch erschwert, das drei unterschied-liche aber zentrale Datenbanken mit unterschiedlichem Inhalt für die Tests benutztwerden. Diese Datenbanken werden nicht an einem zentralen Ort konfiguriert. Zu-dem ist bei ihnen auf den ersten Blick auch nicht ersichtlich, mit welchen Daten fürwelchen Zwick sie gefüllt sind.
Auf Grund dieser komplizierten Randbedingungen für Tests werden für vieleKlassen im JCommSy gar keine Komponententests geschrieben. Das ist eindeutig

32 KAPITEL 3. GEGENSTAND DER ARBEIT
ein Nachteil, denn Tests sind ein Voraussetzung für die Qualität der Software, wieschon in Kapitel 2.1 beschrieben. Das Ziel dieser Arbeit sollte also die Vereinfachungdes Erstellens von Komponententests beinhalten.
3.5 Zusammenfassung
In diesem Kapitel wurde das JCommSy vorgestellt. Dabei wurde der fachliche Hin-tergrund gezeigt. Es wurde beschrieben, wer das System benutzt und welche Auf-gaben damit erledigt werden. Die Migration des PHP-Systems CommSy zum Java-basierten System JCommSy wurde gezeigt. Im JCommSy wird eine typische MVC2-Architektur benutzt. Der vorhandene Code wurde an Beispielen gezeigt.
Das JCommSy-System wurde vor der Umstellung vermessen. Für die Vermessun-gen wurden die Metriken von Robert C. Martin über stabile und abstrakte Packagesverwandt. Die wichtigsten Ergebnisse sind vorgestellt worden.
Die Muster Singleton und Service Locator wurden vorgestellt. Mit diesen Mus-tern wurde der Zugriff im JCommSy auf Services veranschaulicht. Hierbei wurdenbesonders die Abhängigkeiten der Services durch das Singleton-Muster betrachtet.Die Schwierigkeiten, die aus diesen Abhängigkeiten für die Tests und damit für dieQualität der Software entstehen, wurden erläutert. Der Kontrollfluss und insbeson-dere die Einstiegspunkte wurden gezeigt, denn sie sind für die Analyse der Objek-terzeugung und die Planung einer Umstellung von Bedeutung.

Kapitel 4
Lösungsansätze
Neben den notwendigen Grundlagen wurde der Gegenstand der Arbeit, das JCommSy,beschrieben. Der Code wurde vermessen und die Tests wurden vorgestellt. Dabeiwurde gezeigt, dass auch indirekte Abhängigkeiten von Klienten zu Anbietern die-se miteinander koppeln und sich negativ auf die Testisolation und Testbarkeit aus-wirken. Im Rahmen des JCommSy sind konkret die Aufrufe an der Service Registryaufgefallen. Nur diese Aufrufe zeigen, welche Services von einer Klasse benutzt wer-den. Diese Abhängigkeiten zu Anbietern sind nicht sofort im Klienten ersichtlich, dasie im Sourcecode der Klasse verteilt sind.
Diese Services sind nur mit erhöhtem Aufwand für Tests durch andere Imple-mentierungen zu ersetzen. Bei Änderungen und Erweiterungen, z.B. durch geänder-te fachliche Anforderungen, können diese Services auch nur mit größerem Aufwanddurch eine andere Implementierung ersetzt werden.
Dieses Kapitel wird Lösungen zu den beschriebenen Problematiken vorstellen.Zuerst wird eine Lösung vorgestellt, wie Abhängigkeiten explizit gemacht werden kön-nen. Der zweite Abschnitt zeigt eine mächtigere Lösung, wie Abhängigkeiten mit De-pendency Injection ausdrücklich dargestellt und verwaltet werden können. Abschlie-ßend wird beschrieben, warum Dependency Injection die Testbarkeit im JCommSyvereinfachen kann.
4.1 Explizite Abhängigkeiten
Bei der Betrachtung des Gegenstandes ist aufgefallen, das Abhängigkeiten zu ande-ren Objekten, insbesondere Services, im JCommSy nicht explizit gemacht sind. Umabhängige Services zu finden, reicht die Suche in den Import-Statements nicht aus.Die Abhängigkeiten sind nur innerhalb der Klasse zu finden - durch die Suche nacheinem Aufruf des Service Locators.
In allen vorgestellten Lösungen in Kapitel 3.3 hat der Klient den Anbieter selbererzeugt oder versucht, ihn über ein Singleton oder einen Service Locator ausfindigzu machen. In beiden Fällen ist der Klient aktiv, um den Service zu lokalisieren oderzu erzeugen, um ihn anschließend benutzen zu können. Genau dort setzt die ersteLösung an. Der Klient kümmert sich nicht selber um die Referenz zum benötigten
33

34 KAPITEL 4. LÖSUNGSANSÄTZE
Abbildung 4.1: Beispiel für abhängige Klassen
1 public class A {2 private A a;3 private B b;4 public A (B b, C c) {5 this.a = a;6 this.b = b;7 }8 // fachliche Methoden usw.
Listing 4.1: Klasse A mit direkten Abhängigkeiten im Konstruktor
Anbieter, sie kann ihm gesetzt werden. Der Klient würde eine Schnittstelle anbieten,an der der Anbieter gesetzt werden kann (und muss). Das bedeutet, dass der Klientnicht mehr selber versucht den Anbieter zu lokalisieren, sondern eine andere Instanzdiese Aufgabe erledigen muss. Der Klient selber hat nur eine Referenz über eineExemplarvariable auf den Anbieter. Diese Referenz benutzt der Klient für Aufrufeam Anbieter.
Um die Lösung zu verdeutlichen, wird als Beispiel das Klassendiagramm in Ab-bildung 4.1 benutzt. Hier wird gezeigt das die Klasse A direkt von der Klasse B undC abhängt. Indirekt gibt es eine Abhängigkeitsbeziehung von A auch zu den KlassenD, E und F. In dem Beispiel würde die Klasse A z.B. eine Methode anbieten, um Bund um C zu setzen. Hierfür bieten sich zwei Möglichkeiten an. Entweder werdendie abhängigen Anbieter über Methoden gesetzt, z.B:public setServices(B b, C c)
Die Objekte können auch im Konstruktor übergeben werden, dann würde dieKlasse im Konstruktor als Parameter B und C haben, das ist beispielhaft in Listing 4.1dargestellt. Durch diese Methoden werden die Abhängigkeiten zu den benötigtenAnbietern sichtbar. Um abhängige Services zu erkennen, sind nicht mehr die Aufrufean einem Service Locator oder deren direkte Erzeugung zu suchen. Schon an denSignaturen der Methoden einer Klasse lässt sich erkennen, welche Objekte benötigtwerden.

4.1. EXPLIZITE ABHÄNGIGKEITEN 35
Abbildung 4.2: Explizite Abhängigkeiten am Beispiel des Bücherservices
Um das gesamte System zu erzeugen, hat die Klasse B dann auch eine Methodeum D und E zu setzen usw. Die zentrale Konfiguration muss dann die benötigtenObjekte in umgekehrter Reihenfolge ihrer Abhängigkeiten erzeugen. Zuerst wird esdie Objekte erzeugen die keine weiteren Abhängigkeiten besitzen. In diesem Fallsind das D, E und F. Anschließend kann diese Konfiguration dann B und C erzeugenund deren Abhängigkjeiten setzen. Zum Schluss könnte A erzeugt werden und diebenötigten B und C gesetzt bekommen.
Für die Zusammenstellung der Objekte wird ein neues Objekt benötigt. SeineAufgabe ist genau diese Zusammenstellung. In [Fow04] wird diese Klasse daherauch Assembler genannt. Häufig findet sich auch die Bezeichnung Container für solcheObjekte. Die Abbildung 4.2 zeigt die Lösung angewandt auf das in den vorigen Ka-piteln benutzte Beispiel mit dem Bücherservice. An diesem Bild ist durch die Pfeilefür Abhängigkeitsbeziehungen zu erkennen, dass keine indirekte Verbindung mehrzwischen dem Bücherservice und der konkreten Implementierung des Bücherrepo-sitories besteht.
Bei der Zusammenstellung der Klassen ist zu beachten, ob dem Objekt nur direk-te Abhängigkeiten gesetzt werden oder ob dem Objekt auch alle indirekten Abhän-gigkeiten übergeben werden müssen. Es ist einfacher den Objekten nur die direk-ten Abhängigkeiten zu setzen. In dem Beispiel aus Abbildung 4.1 muss dem Objektder Klasse A nur ein Exemplar von B und eines von C gesetzt werden. Das Objektder Klasse A benötigt in dem Fall nicht die indirekten Abhängigkeiten D, E und F.Entsprechend muss vorher dem Exemplar von B jeweils ein Exemplar von D und Eübergeben werden usw.
Nur die expliziten Abhängigkeiten zu verwalten ist einfacher als auch die im-

36 KAPITEL 4. LÖSUNGSANSÄTZE
pliziten Abhängigkeiten den Objekten übergeben zu müssen. Die Schnittstelle einerKlasse würde sich erweitern um Methoden oder Parameter für die Exemplare derKlassen, die auch indirekt abhängig sind. Im Beispiel müsste dann die Klasse A alleAbhängigkeiten in der Schnittstelle aufweisen, also B, C, D, E und F. Diese indirektenAbhängigkeiten würde das Exemplar A nicht selber benutzen, sondern nur „weiter-schleifen“ und sie den Objekten B und C übergeben.
Es kann notwendig sein, dass bei einer Umstellung eines Systems nicht alle Klas-sen sofort angepasst werden können. Es kann auch sein, dass aus technischen oderorganisatorischen Gründen nicht alle Klassen durch einen Assembler bzw. Containerverwaltet werden können. Dann wäre man gezwungen, auch indirekte Abhängigkei-ten zu setzen, diese würden man durch den Code „weiterschleifen“.
Eine weiteres Problem beim Setzen der indirekten Abhängigkeiten ist aus demBild 4.1 ersichtlich. Die Klassen B und C sind beide abhängig von E. In diesem Fallmuss geklärt sein, ob B und C das gleiche Exemplar von E gesetzt bekommen. DieKlasse E hat noch eine Abhängigkeit zu G. Diese wird es zweimal gesetzt bekom-men, von B und von E. Für diesen Fall muss geregelt sein, nach welcher Semantikdies passiert, also ob G bei E zweimal gesetzt wird oder ob G nur gesetzt wird, wennE noch kein G hat. Es erweitert nicht nur die Schnittstelle der Klassen, sondern kom-pliziert zudem noch die Semantik der Anwendung, wenn explizite Abhängigkeitenübergeben werden müssen.
Explizite Abhängigkeiten und Tests
Wie schon in Abbildung 4.2 gezeigt, besteht keine direkte Verbindung mehr zwi-schen dem Klienten und dem Anbieter. Das Listing 4.1 deutet an, wieviel einfacheres ist diese Klasse zu testen. Der Test muss die abhängigen Exemplare B und C imKonstruktor übergeben, um ein Exemplar der Klasse A zu erzeugen. Dadurch sindnicht nur die Abhängigkeiten sofort ersichtlich, sondern der Test kann diese Abhän-gigkeiten auch durch eigene Implementierungen für die Testisolation ersetzen.
Programmatisch ist es möglich diese Konfiguration und Zusammenstellung derbenötigten Objekte zu verwalten. Ein Problem wird von dieser Lösung noch nichtadressiert. In dieser Lösung gibt es von einer Klasse, die durch diese Lösung verwal-tet wird, immer nur ein Exemplar. Das Verhalten entspricht dem eines Singletons. Eswurde im vorigen Kapitel festgestellt, dass manche der Objekte im JCommSy, ins-besondere die Commands, abhängig vom verwendeten Kontext neu erzeugt werdenmüssen. Desweitern ist die Auflösung der Abhängigkeiten nicht trivial, zuerst mussder Assembler alle Objekte instanzieren, die keine Abhängigkeiten haben, anschlie-ßend die Objekte, die von diesen abhängen usw.
Wie diese Probleme gelöst werden können, zeigt der nächste Abschnitt über De-pendency Injection, der eine erweiterte Form dieser Zusammenstellung und Konfigu-ration anbietet.

4.2. DEPENDENCY INJECTION 37
4.2 Dependency Injection
Das Thema Dependency Injection ist unterteilt in Erzeugung und Initialisierung, Kon-figuration und Benutzung. Die Erzeugung und Initialisierung der Objekte beschreibtwie ein Dependency Injection Framework Abhängigkeiten verwaltet und diese denObjekten übergibt. Die Konfiguration gibt die verwalteten Objekte und deren Ab-hängigkeiten an. Die Benutzung beschreibt, wie die verwalteten Objekte von einemDependency Injection Framework bezogen werden.
Häufig werden die Begriffe Dependency Injection (DI) und Inversion of Control (IoC)in einem Zusammenhang benutzt, doch beschreiben beide unterschiedliche Prinzi-pien. Diese Unterscheidung soll zuerst geklärt werden, sie ist wichtig für das Ver-ständnis von Dependency Injection.
Inversion of Control
Das Prinzip Inversion of Control beschreibt eine Änderung des Kontrollflusses. Esist der wesentliche Unterschied zwischen einem Framwork und einer Bibliothek. Beieiner Bibliothek kommt der Programmfluss aus dem eigenen Code und ruft an derBibiliothek Funktionen auf, erzeugt Objekte die von der Bibliothek angeboten wer-den und schickt diesen Objekten Nachrichten. Die Bibliothek wird vom Programmbenutzt und der Kontrollfluss kommt vom eigenen Programm.
Anders ist es bei einem Framework. Dort kommt der Kontrollfluss vom Frame-work. Das Framework ruft eine überschriebene Funktionen auf, der Kontrollfluss istsomit umgekehrt. Ein typisches Beispiel sind GUI-Frameworks. Dort wird z.B. füreinen Button ein Listener geschrieben und als Callback beim Framework registriert.Der Kontrollfluss kommt vom Framework, dieses ruft den Listener auf, wenn ein Be-nutzer auf diesen Button drückt. Zusammen mit dem Ausspruch „Don’t call us, we’llcall you!“ wird das Prinzip Inversion of Control auch Hollywood Principle genannt.
Erzeugung und Initialisierung von Objekten
Das Prinzip der Inversion of Control (IoC) findet Anwendung bei Dependency In-jection. Es bezieht sich auf die Erzeugung und Initialisierung von Objekten. Die Ver-antwortung Objekte zu erzeugen und zu initialisieren wird somit dem Dependen-cy Injection Framework übergeben. Dependency Injection Frameworks werden indrei Kategegorien unterteilt. Sie unterscheiden sich jeweils wie das Framework dieabhängigen Objekte dem Klienten setzt. Sie werden in [Fow04] entweder als SetterInjection, Interface Injection und Constructor Injection, beschrieben.
Interface Injection Dependency Injection Frameworks dieser Art werden auch alsTyp 1 IoC umschrieben. Hier muss ein Klient ein Interface implementieren,wenn es ein abhängiges Objekt gesetzt bekommen soll. In dem Listing 4.2 wirddies anhand des Bücherservices gezeigt, der ein Repository gesetzt bekommt.Dafür implementiert der Bücherservice das Interface InjectRepositoryC. Diese Schnittstelle definiert nur die Methode:void injectRepository(BuecherRepository r)

38 KAPITEL 4. LÖSUNGSANSÄTZE
1 public interface InjectRepository {2 public void injectRepository(BuecherRepository r);3 }4
5 public class BuecherService implements InjectRepository {6 private BuecherRepository repository;7
8 public void injectRepository(BuecherRepository r) {9 this.repository = r;
10 } //..
Listing 4.2: Beispiel für Interface Injection
1 public class BuecherService {2
3 private BuecherRepository repository;4
5 public void setRepository(BuecherRepository r) {6 this.repository = r;7 } //..
Listing 4.3: Beispiel für Setter Injection
Mit dieser Methode wird vom Framework das Bücherrepository dem Bücher-service gesetzt. Ein Dependency Injection Framework kann anhand der Schnitt-stelle leicht über Meta-Objektprotokolle wie Reflection erkennen, welche ver-walteteten Objekte ein Bücherrepository gesetzt bekommen müssen. Jedes vomFramework verwaltetete Objekt, das diese Schnittstelle implementiert, wird einRepository gesetzt bekommen.
Setter Injection Wird auch als Typ 2 IoC umschrieben. Hier muss ein Klient keinInterface implementieren, dafür aber eine Methode anbieten zum Setzen desbenötigten Objekts. Solche Methoden werden auch Setter gennant. In Listing 4.3ist der Bücherservice mit einer Setter-Methode für ein Repository abgebildet.
Constructor Injection Wenn sämtliche Abhängigkeiten einer Klasse über den Kon-struktor übergeben werden, spricht man von Constructor Injection, oder auchTyp 3 IoC. Bei dieser Art der Zusammenstellung muss ein verwaltetes Objekt inder Signatur des Konstruktors alle Abhängigkeiten als Parameter angeben. Einverwaltetes Objekt kann demnach nur instantiiert werden, wenn alle Abhän-gigkeiten bei der Erzeugung des Objekts übergeben werden. Das Listing 4.4zeigt den Bücherservice mit einem Konstruktor der das abhängige Repositoryals Parameter beinhaltet.

4.2. DEPENDENCY INJECTION 39
1 class BuecherService {2
3 private final BuecherRepository repository;4
5 public BuecherService (BuecherRepository r) {6 this.repository = r;7 } //..
Listing 4.4: Beispiel Constructor Injection
Die Methode des Interface Injections, bzw. Typ 1 IoC, hat den Vorteil, dass schonanhand des Typs der Klasse die Abhängigkeiten erkannt werden können. Die ent-sprechenden Schnittstellen zum Setzen der Abhängigkeiten markieren diesen Typsehr eindeutig mit seinen Abhängigkeiten. Der Nachteil dieser Methode liegt genauin diesen Schnittstellen. Für jede mögliche Abhängigkeit muss ein zusätzliches In-terface geschrieben werden. Zudem wird die Schnittstelle der fachlichen Klasse er-weitert um technische Schnittstellen, denn diese Schnittstellen werden nur für dieErzeugung des Objektes benötigt. Aus diesen Gründen bieten aktuelle und die hiervorgestellten Dependency Injection Frameworks die Methode die Interface Injecti-on nicht an. Die Methode ist in den ersten Dependency Injection Frameworks fürJava benutzt worden, da auch schon mit frühen Versionen von Java über das Meta-objektprotokoll und Reflection die Schnittstellen einer Klasse leicht erkannt werdenkonnten.
Die Erzeugung der Objekte mit Setter Injection, bzw. Typ 2 IoC, benötigt keinzusätzliches Interface. Dem Framework muss nur über die Konfiguration oder perKonventionen die Methode zum Setzen der Abhängigkeiten bekannt gemacht wer-den. Ein weiterer Vorteil von Setter Injection im Vergleich zu Constructor Injectionist es, das Objekt ohne seine Abhängigkeiten erzeugen zu können. Wenn ein Objektsehr viele und aufwendig zu erzeugende Abhängigkeiten besitzt, kann dadurch dasTesten erleichtert werden. Ein Test braucht nur die Objekte zu setzen, die von demObjekt im entsprechenden Test aufgerufen werden. Bei Setter Injection ist es schwereran der Klasse (bzw. ihrer Schnittstelle) ihre Abhängigkeiten zu erkennen. Um dieseausfindig zu machen, müssen alle Setter-Methoden betrachtet werden. Beim Zugriffinnerhalb der Klasse auf die Abhängigkeiten ist nicht eindeutig, ob das abhängigeObjekt auch wirklich schon gesetzt wurden. Die Referenz auf das abhängige Objektkann eventuell noch null sein, wenn sie z.B. nicht konfiguriert wurde und ein Zu-griff würde dann einen Fehler verursachen. Ein weiterer Nachteil liegt darin, dassüber die Setter-Methode auch nach der Erzeugung und Initialisierung das abhängi-ge Objekt fälschlicherweise überschrieben werden kann. Die Setter-Methode wird indem Fall nur für das Dependency Injection Framework an der Klasse angeboten underweitert somit deren Schnittstelle ohne fachliche Motivierung.
Bei Constructor Injection (bzw. Typ 3 IoC) müssen alle abhängigen Objekte alsParameter im Konstruktor der Klasse übergeben werden. Die Abhängigkeiten derKlasse sind mit einem Blick sofort am Konstruktor zu erkennenen. Die übergebe-

40 KAPITEL 4. LÖSUNGSANSÄTZE
nen Objekte können sofort an Klassenvariablen gebunden werden, somit kann jedeMethode davon ausgehen, dass sämtliche Abhängigkeiten gesetzt wurden. Es mussnicht wie bei Setter Injection im Zweifel geprüft werden, ob die Referenz wirklichgesetzt ist. Die Referenz kann mit dem Stichwort final als unveränderlich markiertwerden, da sie im Konstruktor gesetzt wird. Diese Abhängigkeit kann dann nichtmehr aus Versehen überschrieben werden. Diese Methode ist nachteilig, wenn ei-ne Klasse sehr viele Abhängigkeiten hat. Dann wird der Konstruktor dieser Klasseschnell unübersichtlich1. Um ein Objekt dieser Klasse für einen Tests zu erzeugenmuss jede Abhängigkeit mit übergeben werden, auch wenn diese durch den Testnicht benutzt wird.
Scopes - Gültigkeitsbereiche für verwaltete Objekte
Die Aufgabe von Dependency Injection Frameworks ist die Erzeugung und Konfi-guration von Objekten. Hier liegt einer der großen Vorteil von Dependency Injecti-on gegenüber der in Abschnitt 4.1 beschriebenen Lösung rein programmatisch dieObjekte zu konfigurieren. Für die Erzeugung können Dependency Injection Frame-works konfiguriert werden, ob immer dasselbe Objekt oder bei jeder Anfrage einneues Objekt geliefert werden soll. Wird jedesmal dasselbe Objekt vom Frameworkgeliefert, entspricht das dem Verhalten eines Singletons. Wenn bei jeder Anfrage einneues Objekt geliefert werden soll, dann ist das Verhalten ähnlich einer Erzeugungdes Objekts mit new. Zwischen beiden Varianten gibt es bei manchen Frameworksnoch Abstufungen. Dort wird abhängig vom Kontext jeweils ein neues Objekt gelie-fert, ein verwaltetes Objekt ist dann nur innerhalb eines Bereiches gültig.
Als Beispiel kann man sich vorstellen, das ein Objekt nur innerhalb eines HTTP-Requests gültig sein soll. Innerhalb des selben Requests soll immer wieder das glei-che Objekt vom Container geliefert werden. Innerhalb eines anderen Requests ist einanderes Objekt gültig. In diesem Beispiel ist die Anfrage, bzw. der HTTP-Request,der entscheidende Kontext. Dieser Kontext wird im Zusammenhang mit Dependen-cy Injection auch Scope genannt. Dieser Kontext beschreibt den Gültigkeitsbereichfür ein Objekt. Ein weiterer möglicher Gültigkeitsbereich, bzw. Scope für Webanwen-dungen ist z.B. die aktuelle Session.
Die Gültigkeitsbereiche von Scopes sind unterschiedlich groß und schließen zumTeil auch andere Scopes mit ein. Die Benutzung von Scopes führt zu Einschränkun-gen. Objekte dürfen abhängig sein von Objekten mit dem gleichen oder einem grö-ßeren Scope. So darf ein Objekt, das im Kontext einer Session erzeugt wird, abhängigsein von Objekten mit Singleton-Verhalten oder anderen Objekten, die mit dem ScopeSession konfiguriert wurden. Das Objekt mit dem Scope Session darf nicht abhängigsein von einem Objekt mit einem kleineren Scope, z.B. einem Objekt mit Request-Scope.
1Nach meiner Meinung ist das kein Nachteil. Es ist nur ein Zeichen das die Klasse zu viele Abhän-gigkeiten hat und durch ein Refactoring aufgeteilt werden muss!

4.2. DEPENDENCY INJECTION 41
Konfiguration und Benutzung
Bei Dependency Injection wird unterschieden zwischen der Konfiguration und derBenutzung. In diesem Abschnitt werden beide Begriff geklärt und abschließend ge-zeigt, warum diese Trennung die Entwicklung von Software erleichtert. DependencyInjection baut ein Netzwerk von verwalteteten Klassen auf. Die Konfiguration gibtan welche Klassen verwaltet werden sollen und wie das Framework Abhängigkei-ten auflöst. Mit der Benutzung eines Dependency Injection Frameworks durch eineAnwendung ist der Zugriff auf die verwalteten Objekte gemeint.
Bei der Konfiguration wird dem Dependency Injection Framework angegeben,welche Klassen verwaltet werden sollen. In der Konfiguration werden abhängige Ob-jekte dieses Netzwerks von Objekten einander zugewiesen. Damit Objekte verwaltetwerden, müssen sie dem Framework bekannt gemacht werden. Hierfür gibt es diefolgenden Möglichkeiten der Konfiguration. Für konkrete Konfigurationen zeigt diespätere Vorstellung der einzelnen Frameworks Beispiele.
• Die Objekte werden anhand eines Typs registriert, den sie implementieren. Sokann man z.B. die konkrete Implementierung des Bücherrepositories anhandder abstrakten Schnittstelle BuecherRepository registrieren. Objekte, dieein Bücherrepository benötigen, kennen nur diese Schnittstelle. Sie werden sokonfiguriert, dass sie das Objekt zugewiesen bekommen, das unter dieser Schnitt-stelle registriert wird.
• Als Alternative können verwaltete Objekte unter einem symbolischen Namenregistriert werden. Auch hier muss angegeben werden, welche Abhängigkei-ten das angegebene Objekt benötigt. Hierfür werden die in der Konfigurationangegebenen Namen benutzt. Der Vorteil einer textuellen Konfiguration liegtdarin, dass für eine Schnittstelle mehrere unterschiedliche Objekte registriertwerden können.
Unabhängig ob die Objekte anhand eines Typs oder textuellen Namens verwaltetwerden, muss dem Framework zusätzlich angegeben werden, ob das Objekt per Set-ter Injection oder mit Constructor Injection erzeugt werden soll. Desweiteren mussangegeben werden, ob ein Objekt nur einmal erzeugt werden soll oder nur innerhalbeines bestimmten Kontexts wiederverwendet werden soll und ansonsten immer wie-der neu erzeugt wird.
Dependency Injection Frameworks unterscheiden auch noch in der Art wie dieseKonfiguration geschrieben wird. Auch hier gibt es zwei Ansätze:
• Die programmatische Konfiguration ist die einfachste Möglichkeit. Hier wird mitAufrufen an einer Klasse die Konfigration der zu verwalteten Objekte angeben.Der Vorteil dieser Konfiguration ist die Typsicherheit. Es können in diesem Fallnur Klassen registriert werden, die auch im Projekt wirklich vorhanden sind.Werden Klassen registriert, die nicht vorhanden sind, beschwert sich der Com-piler.

42 KAPITEL 4. LÖSUNGSANSÄTZE
1 // Konfiguration2 MutablePicoContainer pico = new DefaultPicoContainer();3 pico.registerComponentImplementation(BuecherService.class)C
;4 pico.registerComponentImplementation(C
RdbmsBuecherRepository.class);5
6 // .... die Benutzung an anderer Stelle7 BuecherService service = (BuecherService) pico.C
getComponentInstance(BuecherService.class);8 // Aufrufe am BuecherService usw...
Listing 4.5: Beispiel für die Konfiguration und Benutzung mit PicoContainer
• Die alternative Konfiguration erfolgt in einer Text-Datei. Das Format dieser Da-tei kann z.B. XML, oder das in Java typische Property-Format sein. Hier werdendie Objekte angegeben, die vom Framework zu erzeugen sind, welche Namenoder Typen sie implementieren und welche Abhängigkeiten sie besitzen.
Die Konfiguration ist immer der erste Schritt, wenn Dependency Injection be-nutzt wird. Die Konfiguration erfolgt meist nur einmal zur Startzeit der Anwendung.Um anschließend auf die konfigurierten Objektnetze zuzugreifen, muss ein Depen-dency Injection Framework eine Methode anbieten, um verwaltete Objekte benutzenzu können. Die Frameworks bieten je nach Konfiguration eine Methode an, um an-hand eines angefragten Namens oder Typs ein Objekt mit seinen Abhängigkeiten zuliefern.
Die wichtigsten Konzepte von Dependency Injection sind erklärt worden. Dernächste Abschnitt wird die Ausgestaltung dieser Konzepte anhand konkreter Fra-meworks zeigen.
4.3 Dependency Injection Frameworks
In diesem Abschnitt werden die gängigsten Frameworks für Dependency Injectionim Java-Umfeld kurz beschrieben, PicoContainer und das Spring-Framework. Aus his-torischen Gründen wird auch Apache Avalon vorgestellt.
Apache Avalon
Apache Avalon ist das erste DI-Framework im Java-Umfeld gewesen. Das Frame-work wurde geschrieben als Grundlage und Komponentenmodell für das ApacheCocoon-System. Es ist mittlerweil eingestellt worden, siehe [Ava04]. Es wird hier nurerwähnt da es das erste Framework dieser Art ist und das einzige das Typ 1 IoCanbietet.

4.3. DEPENDENCY INJECTION FRAMEWORKS 43
PicoContainer
PicoContainer ist ein Opensource-Framework, siehe [Pic06]. Das Framework wirdunter der BSD-Lizenz bereitgestellt. Die Nutzung ist somit kostenlos und verpflich-tet nicht den benutzenden Code auch unter eine Opensource-Lizenz zu stellen. DasFramework bietet eine einfache Lösung für Dependency Injection an. Für die Erzeu-gung wird Constructor Injection benutzt. Die Konfiguration des Containers erfolgtprogrammatisch. Das Beispiel mit PicoContainer in Listing 4.5 zeigt eine einfacheKonfiguration und die Benutzung eines Objekts mit Bücherservice und Bücherre-pository. Das Beispiel geht davon aus, das der Bücherservice wie in Listing 4.4 inseinem Konstruktor einen Parameter für das benötigte Repository anbietet. BeideKlassen werden in Zeile 3 und 4 mit ihrem Typ, dem Class-Objekt, beim Containerregistriert. Später in Zeile 7 wird der Container nach einem Bücherservice gefragt.Der Container liefert einen Bücherservice der mit dem angegebenen Repository kon-figuriert ist.
PicoContainer ist ein Framework ausschließlich für Dependency Injection. DerVorteil von PiocoContainer ist die Einfacheit des Frameworks, es wird keine zusätz-liche und eventuell nicht benötigte Funktionalität angeboten. PicoContainer bietetnur Constructor Injection an. Die verwalteteten Objekte verhalten sich wie Single-tons, sie werden nur ein einziges mal erzeugt. Neben dem Singleton-Scope werdenkeine weiteren Scopes vom Framework angeboten, auch über eigene Erweitungen istes nicht möglich, neue Scopes zu definieren.
Spring-Framework
Das Spring-Framework, siehe [Spr07a], ist auch ein Opensource-Projekt. Mit der Apa-che Lizenz kann das Framework ohne Kosten benutzt werden, sie zwingt auch nichtden benutzenden Code als Opensource zu deklarieren. Das Framework ist entstan-den aus dem Bedürfnis, die Entwicklung von J2EE-Anwendungen zu vereinfachen.Das Framework integriert viele existierende Technologien anstatt eigene Lösungenanzubieten. Das Framework ist unabhängig von einem eingesetzten Application Ser-ver. Die Entwicklung mit Spring wird in[JHA+05] als minimal invasiv beschrieben,denn der Anwendungscode ist (meist) nicht abhängig von Spring APIs. Das Frame-work ist modular aus unabhängig einsetzbaren Paketen aufgebaut. In der folgendenListe sind die wichtigsten Pakete aus dem Spring Framework beschrieben:
Spring Core Das Core-Paket beitet die Basisinfrastruktur mit Unterstützung für Be-ans und Dependency Injection.
Spring AOP Mit dem AOP-Paket2 werden mittels Aspekten deklarative Dienste un-tertützt. Die Aspekte können u.a. bei der Verwaltung von Transaktionen, derBehandlung von Exceptions, für Zugriffs- oder Architekturkontrollen benutztwerden.
2AOP = Aspect-Oriented Programming

44 KAPITEL 4. LÖSUNGSANSÄTZE
Spring DAO Das DAO-Paket3 bietet Abstraktionen für den Zugriff auf Datenban-ken. Hier werden viele Hilfsmethoden und abstrakte Klassen für den Umgangmit JDBC angeboten.
Spring ORM Für die Unterstützung von Persistenztechnologien wie Hibernate, Ja-va Data Objects (JDO) oder Java Persistence Architecture (JPA) bietet das PaketSpring ORM4 Techniken zur Integration.
Spring Transaction Für die Verwaltung von Transaktionen, unabhängig ob von ei-ner Datenbank, einem Transaktionsserver oder einem Application Server, bietetSpring eine Abstraktion mit dem Paket Spring Transaction.
Spring Web Mit dem Paket Spring Web bietet Spring eine Anbindung an bestehendeFrontend-Technologien (Struts, JSF, usw.).
Spring MVC Das Spring-Framework bietet ein eigenes Web-Framework im PaketSpring MVC an.
Neben dem Framework gibt es mehrere Subprojekte wie z.B. Web Flow, Web Ser-vices, Security (Acegi Security), LDAP, Rich Client, Extensions (Modules), IDE forEclipse, BeanDoc, OSGi, JavaConfig, .NET und Batch. Die Möglichkeiten mit Springneue Technologien mit wenig Integrationsaufwand einzubinden sind groß. Dabei istman nicht gezwungen, eines dieser Pakte oder Projekte zu benutzen.
Die Konfiguration kann bei Spring mit XML oder programmatisch erfolgen, wo-bei die programmatische Konfiguration sehr umständlich ist. In Listing 4.6 wird ge-zeigt wie das Beispiel mit dem Bücherservice mit Spring in XML konfiguriert wird.Die Konfiguration geht davon aus, dass ein Setter an der Klasse des Bücherservicesexistiert, wie in Listing 4.3 gezeigt. Die einzelnen Objekte werden bei Spring Beansgenannt. Diese Beans bekommen in der Konfiguration einen symbolischen Namenanhand dessen sie referenziert werden. Das Bücherrepository wird hier buecher-Repository genannt. Dieser Name wird bei der Benutzung verwendet, um eineReferenz auf das verwaltete Objekt zu bekommen. Vorher muss der Container er-zeugt werden wie in Listing 4.7 in Zeile 1, in der zweiten Zeile wird an dem Con-tainer nach dem Bücherrepository gefragt. Bei Spring wird der Container, der dasObjektnetz verwaltet, Application Context oder Bean Factory genannt.
Das Spring-Framework bietet eine Unterstützung für Scopes an. Es gibt zweiScope-Typen, die ohne Erweiterungen benutzt werden können. Der Standard ist dasSingleton-Verhalten, hierfür kann die Bean auch bei der Konfiguration explizit mitdem Scope singleton markiert werden. Wird eine Klasse bei der Konfigurationmit dem Scope prototype angemeldet, dann erzeugt jede Anfrage nach einem Ob-jekt an dem Container ein neues Objekt. Spring hat auch noch die Scopes sessionund request. Für diese gilt jeweils der Gültigkeitsbereich einer Session oder einerHTTP-Anfrage. Des weitern können für Spring weitere Scopes implementiert wer-den, das Framework hat eine eigene API für diesen Zweck.
3DAO = Data Access Objects4ORM = Objekt-Relationales Mapping

4.4. VEREINFACHUNG DER TESTS DURCH MOCK-OBJEKTE 45
1 <?xml version="1.0" encoding="UTF-8" ?>2
3 <beans>4 <bean id="buecherRepository" class="BuecherRepository" />5 <bean id="buecherService" class="BuecherService">6 <property name="repository" ref="buecherRepository" />7 </bean>8 </beans>
Listing 4.6: Beispiel Konfiguration Spring Framework
1 ApplicationContext ctx = new ClassPathXmlApplicationContext(C"context.xml");
2 BuecherService service = (buecherService) ctx.getBean("CbuecherService");
3 // Aufrufe am BuecherService usw...
Listing 4.7: Beispiel Spring Framework
4.4 Vereinfachung der Tests durch Mock-Objekte
Bisher wurde gezeigt wie die Abhängigkeiten für die Objekte explizit gemacht wer-den können, indem sie an der Signatur eines Objektes erkennbar sind. Die Abhän-gigkeiten lassen sich durch die Setter oder besser anhand des Konstruktors ablesen.Die Konfiguration und Erzeugung der Objekte lässt sich mit einem Dependency In-jection Framework wie Spring oder PicoContainer erledigen. Es ist noch die Frage zuklären, wie sich die Tests vereinfachen lassen. Hierfür werden in diesem AbschnittMock-Objekte vorgestellt.
Dummies und Mock-Objekte
Um für Objekte oder kleine Gruppen von Objekte Komponenten-Tests zu schreiben,müssen diese von allen anderen Klassen, die sie benötigen, isoliert werden. Werdendiese nicht von den abhängigen Klassen getrennt, werden die abhängien Klassenimplizit immer mit getestet. Ein Verhalten, wie es im JCommSy (siehe Abschnitt 3.4)über die Tests aufgefallen ist.
Dummies5 sind eine Lösung, um für Komponenten-Test die zu testende Klassezu isolieren. Eine abhängige Klasse wird dabei nur für den Test rudimentär imple-mentiert. Der Dummy muss die selbe öffentliche Schnittstelle implementieren wiedas Objekt, das es ersetzt. Es braucht dabei nicht die Funktionalität des ersetzten Ob-jektes anzubieten, sondern nur ein einfaches Verhalten, das für den Test ausreicht.Auch hat ein Dummy keine weiteren Abhängigkeiten, selbst wenn das Objekt, wel-ches es ersetzt, welche hätte. Für den Test kann jetzt das Objekt erzeugt werden,
5auch Attrappen genant

46 KAPITEL 4. LÖSUNGSANSÄTZE
das dabei seine Abhängigkeiten als Dummy-Objekte gesetzt bekommt. Dieser An-satz ist für abhängige Klassen mit einer kleinen Schnittstelle einfach zu realisieren.Sind abhängige Klassen nicht unter der eigenen Kontrolle und lassen sich somit dieSchnittstellen dieser Klassen nicht klein halten, dann wird die Implementation sol-cher Dummy-Objekte sehr aufwendig.
Mock-Objekte bieten noch mehr Funktionalität für das Testen an. Sie implemen-tieren nicht nur die Schnittstelle eines abhängien Objektes, sie haben zusätzlicheFunktionalität für das Testen. Einem Mock-Objekt kann vor dem Test sein Verhaltenim Test programmiert werden. Das Mock-Objekt wird vor dem eigentlichen Test mitden zu erwarteten Aufrufen programmiert. Zu den Aufrufen, die am Mock-Objektim Test erwartet werden, wird festgelegt wie das Mock-Objekt darauf reagieren soll.Der eigentliche Test ruft an dem Objekt Methoden auf. Diese Methoden führen zuAufrufen an dem abhängigen Objekt. Dieses ist im Test das Mock-Objekt. Das Mock-Objekt reagiert, wie es vor dem Test programmiert wurde. Der Test überprüft dieRückgaben des getesteten Objekts. Anschließend wird geprüft, ob das Mock-Objektvom getestetem Objekt so benutzt wurde, wie es vor dem Test programmiert wur-de. Diese Methode des Testens wird auch endoskopisches Testen genannt. Der Namestammt aus dem Artikel [MFC01].
Für die Erstellung von Mock-Objekten gibt es Frameworks wie JMock oder Ea-syMock. Für diese Arbeit wird EasyMock von Tammo Freese [Fre07] vorgestellt. DasBeispiel in Listing 4.8 zeigt einen Test für den Bücherservice mit einem Mock-Objekt.Mit EasyMock wird ein Mock für das Bücherrepository erstellt. Der Mock soll einenAufruf an der Methode getBuecherFuerAutor erwarten. Dabei bekommt der Mockdas Verhalten bei diesem Aufruf programmiert, er muss dann die übergebene Listezurück geben. Mit der Methode replay wird der Mock in den Wiedergabemodusversetzt. Anschließend startet der eigentliche Test, indem am Service eine Methodeaufgerufen und der Rückgabewert überprüft wird. Mit der Methode verify über-prüft EasyMock, ob die programmierten Aufrufe auch durch den Test an das Mockgesendet wurden. An dem Beispiel ist zu beachten, dass nur die aufgerufenen Metho-den am Mock-Objekt programmiert werden müssen, nicht aber die gesamte Schnitt-stelle des ersetzten Objektes!
Neben den einfachen Funktionen bieten die Frameworks für Mock-Objekte vielmehr Funktionalität. Zum Beispiel kann ein Mock-Objekt auch programmiert wer-den, um eine Exception zu werfen bei einem Aufruf. Zudem werden Algorithmenangeboten, mit denen die dem Mock-Objekt übergebenen Parameter leichter vergli-chen werden können. Eine gute Quelle zu dem Thema Testen mit Mock-Objektenist das Buch von Johannes Link [Lin05] und die Dokumentation zu dem FrameworkEasyMock [Fre07].
4.5 Zusammenfassung
In diesem Kapitel wurden Lösungen zu den in den vorigen Kapiteln beschriebenenProblemen vorgestellt. Es wurde gezeigt wie Abhängigkeiten einer Klasse über de-ren Schnittstelle explizit gemacht werden können. Dabei wurde deutlich, wie auf-

4.5. ZUSAMMENFASSUNG 47
1 BuecherRepository mock = EasyMock.createMock(CBuecherRepository);
2 BuecherRepository service = new BuecherService(mock);3
4 List<Buch> erwartet = new ArrayList<Buch>();5
6 EasyMock.expect(mock.getBuecherFuerAutor("floyd")).andReturnC(erwartet);
7
8 EasyMock.replay(mock);9
10 List<Buch> ergebnis = service.buecherDesAutors("floYd");11
12 assertEquals(ergebnis, erwartet);13
14 EasyMock.verify(mock);
Listing 4.8: Beispiel EasyMock
wendig eine programmatische Zusammenstellung abhängiger Klassen werden kann.Es wurde vorgestellt, wie Dependency Injection Abhängigkeiten verwaltet. Die ty-pischen Merkmale und Unterschiede von Dependency Injection Frameworks sindgezeigt worden. Dabei wurden vorhandene Frameworks vorgestellt. Abschließendwurde gezeigt, wie Dependency Injection und Mock-Objekte die Testbarkeit im Pro-jekt JCommSy vereinfachen können.

Kapitel 5
Beschreibung der praktischenLösung
Nach der Beschreibung der Grundlagen und der Analyse des vorhandenen Sys-tems wurde im Abschnitt 4.5 mit den Techniken Dependency Injection und Mock-Objekten eine Lösung vorgeschlagen. Dieses Kapitel beschreibt die praktische Um-setzung der Diplomarbeit. Der erste Teil der Umsetzung ist eine Definition der Zie-larchitektur des Systems. Anhand dieser Zielarchitektur wird ein Plan erstellt für dieUmstellung, das Refactoring. Bei der Beschreibung der praktische Umstellung desSystems werden auch die Besonderheiten betrachtet, die bei einem Refactoring die-ser Größe zu beachten sind.
5.1 Ziele der Umstellung
Zuerst wird beschrieben welche Ziele mit dem Refactoring erreicht werden sollen.Anschließend folgt eine Beschreibung der Architektur des JCommSy nach der Um-stellung.
Konzept
In diesem Abschnitt wird das Konzept der Zielarchitektur des JCommSy beschrie-ben. Dabei wird auf die Unterschiede zur vorhanden Architektur eingegangen. DieZielarchitektur soll die Testbarkeit des Systems vereinfachen. Es soll einfacher wer-den, Komponenten-Tests zu schreiben für Komponenten, die abhängige Komponen-ten besitzen.
Der wichtigste Punkt ist die Einführung von Dependency Injection. Hier stelltsich die Frage, welche der Objekte aus dem JCommSy durch den Dependency In-jection Container verwaltet werden sollen und welche Objekte unberührt durch dieUmstellung bleiben sollen. Es wurde in der Analyse festgestellt, dass besonders dieServices und der Zugriff über die Serviceregistry problematisch in Bezug auf dasTesten sind. Die Services werden in der Zielarchitektur durch einen Dependency In-
48

5.1. ZIELE DER UMSTELLUNG 49
jection Container verwaltet. Nicht betroffen von der Umstellung auf DependencyInjection sollten die Fachwerte und Materialien des Systems sein.
An so wenig Stellen wie möglich sollte auf die API des Dependency InjectionFrameworks zugegriffen werden. Die Verantwortung für die Konfiguration und Er-zeugung der verwalteteten Objekte soll zentral gebündelt werden.
Es gibt konzeptionell zwei Stellen, an denen das gewählte Framework benutztwerden muss, die Konfiguration und die Benutzung. Der Container muss beim Startender Anwendung konfiguriert werden, dafür ist ein Zugriff notwendig. Der zweiteZugriff auf das Framework ist die Benutzung. Bei der Benutzung geht es um denZugriff auf Objekte, die der Dependency Injection Container erzeugt und verwaltet.Benötigt eine Klasse ein Objekt, das von dem Dependency Injection Container ver-waltet wird, dann muss eine Abhängigkeit zu diesem Objekt konfiguriert werden.Diese Abhängigkeit wird in der Konfiguration beschrieben. Im Sourcecode wird imKonstruktor oder im Setter keine Abhängigkeit zu der API des Dependency InjectionFrameworks eingeführt. An dieser Stelle wird nur beschrieben, dass ein Objekt desangegebenen Typs benötigt wird. Beim Starten der Anwendung muss mindestenseinmal ein Objekt von dem Dependency Injection Container bezogen werden, damitder Kontrollfluss an die verwalteten Objekte übergeben werden kann. Die verwalte-ten Objekte werden unter einem Typen oder einem Namen beim Framework in derKonfiguration registriert. Mit diesem Namen bzw. Typen kann der Dependency In-jection Container nach dem verwalteten Objekt gefragt werden. Dieses Objekt wirdinklusive seiner Abhängigkeiten geliefert und der Kontrollfluss kann durch einenMethodenaufruf übergeben werden.
Wenn sämtliche Abhängigkeiten in der Konfiguration explizit gemacht wurden,dann ist nur eine Benutzung des Frameworks beim Starten notwendig. Das führtzu expliziten Abhängigkeiten und der Zugriff auf die API des Frameworks auf dieKonfiguration und die initiale Benutzung beschränkt.
Zielarchitektur
Dieser Abschnitt beschreibt die Architektur, die nach der Umstellung erreicht wer-den soll. Es ist für das JCommSy geplant, Dependency Injection mit textueller Kon-figuration zu benutzen. Sämtliche bestehende Services werden dabei durch einenDependency Injection Container verwaltet. Es werden sämtliche Services umgestellt.Die Services werden im Konstruktor ihre Abhängigkeiten als Parameter darstellen.Die Vorteile von Constructor Injection sind in Kapitel 4.2 beschrieben.
Als Framework für Dependency Injection wird das Spring-Framework benutzt.Die Konfiguration erfolgt mit XML-Dateien. Für die Erzeugung der Objekte wirdConstructor-Injection benutzt. Die API des Spring-Frameworks wird nur von derService Factory benutzt. Diese greift auf den Container zu, um Objekte zu beziehenoder neu zu erzeugen. Die Services im JCommSy sollen sich verhalten wie Singletons,es gibt im System jeweils nur ein Exempar von ihnen. Die Component-Commandswerden zur Laufzeit zum Aufbau der Seite entsprechend der Anfrage benötigt. Siemüssen pro Anfrage neu erzeugt werden. Den Component-Commands werden beider Erzeugung durch den Container im Konstruktor die benötigten Services injiziert.

50 KAPITEL 5. BESCHREIBUNG DER PRAKTISCHEN LÖSUNG
Abbildung 5.1: Zielarchitektur - Sequenzdigramm
Abbildung 5.2: Zielarchitektur - Klassendiagramm

5.2. PLANUNG 51
5.2 Planung
Refactoringplan
Zuerst muss der Ansatz für das Refactoring analysiert und das Ziel des Refactoringsgenau beschrieben werden. Das definierte Ziel muss erreichbar und messbar sein.Die Bestimmung eines Ziels mit diesen beiden Eigenschaften ist wichtig, damit ge-nau bestimmt werden kann, ob das Refactoring erledigt ist, oder nicht. Das Vorge-hen beschreibt in groben Schritten, wie das System mit kleinen Änderungen in derStruktur auf die neue Architektur angepasst werden soll. Jeder dieser groben Schritteentspricht einem Etappenziel.
Zieldefinition
Für den Refactoring-Plan muss das vorhande System analysiert werden, wie be-schrieben in Kapitel3.2.
Für die Umstellung auf Dependency Injection wurde der Kontrollfluss betrach-tet. An einer zentralen Stelle muss der Container einmal initialisert werden, damitihm alle zu verwaltenden Klassen konfiguriert werden. Diese Konfiguration musszu einem frühen Zeitpunkt geschehen, bevor die Anwendung auf Objekte zugreift,die durch den Container initialisiert werden. Zudem muss bei der Analyse betrachtetwerden, wie die Anwendung auf den Container für die Erzeugung von Objekten zu-greift. Außerdem soll dieser Zugriff nur an möglichst wenigen und zentralen Stellenim System erfolgen.
Das JCommsy ist zurzeit ein webbasiertes System, implementiert mit Servlets.Der Kontrollfluss der Applikation geht immer durch diese Servlets. Diese Servletsgreifen mit statischen Methoden auf eine Service-Registry zu, um entsprechend deraktuellen Aufgabe einen Service zu benutzen. Sie erzeugt den angefragten Service,wenn er noch nicht vorhanden ist. Diese Erzeugung erfolgt direkt mit einem Kon-struktor und die exakte Typdefinition ist somit der Service-Registry bekannt. DieService-Registry ist dabei als Singleton implementiert, wie in Kapitel 3.3 beschrie-ben. Der Zugriff auf die Service-Registry muss ersetzt werden durch DependencyInjection.
Anhand der XML-Konfigurationsdateien erzeugt das Spring-Framework einenApplikationskontext. Dieser Applikationskontext ist ein Dependency-Injection-Container,er ist für die konkrete Erzeugung der Objekte verantwortlich.
Ein Ziel des Refactorings ist, dass sämtliche in der Service-Registry instanzier-ten Klassen von einem Applikationkontext durch Spring erzeugt werden. Der Ap-plikationskontext verwaltet sämtliche durch Spring erzeugten Objekte, und löst da-bei transitiv die Abhängigkeiten auf. Ein Applikationskontext kann einen anderenApplikationskontext benutzen. Mit dieser Technik kann die Definition der Kontextevereinfacht und eine simple Schichtenarchitekturen definiert werden.
Ein weiteres Ziel des Refactorings ist die Ablösung von Singletons durch die Ein-führung von Dependency Injection für das JCommsy-System. Eine Analyse hat ge-zeigt, dass es zwei große Singletons im System gibt, die Service-Registry und den

52 KAPITEL 5. BESCHREIBUNG DER PRAKTISCHEN LÖSUNG
ServiceManager. Diese Singletons müssen bei der Einführung ersetzt werden.Durch eine hierarchische Aufteilung der verwalteten Objekte mit mehreren Ap-
plikationskontexten wird deren Beschreibung übersichtlicher für die weitere Ent-wicklung. Die Aufteilung in die Applikationskontexte erfolgt anhand der Analysedes Systems. Ein Kontext beschreibt z.B. den Zugriff auf die Datenbank. Dieser Kon-text lässt sich dann in Tests für den Zugriff auf eine andere Testdatenbank leicht er-setzen. Ein Applikationskontext beschreibt die im JCommsy vorhandenen fachlichenServices. Ein weiterer Applikationskontext definiert die Component-Commands undderen Abhängigkeiten.
Vor der praktischen Arbeit wurde genau beschrieben, wann diese als erledigt er-klärt werden kann. Hierfür muss ein messbares Ziel definiert werden. Die beschrie-benen Anforderungen führen zusammengefasst zur folgenden Zieldefinition. DasRefactoring gilt als beendet, wenn:
• die beiden Singleton-Klassen ersetzt wurden durch Dependency Injection
• und dabei eine simple mehrschichtige Architektur durch Applikationskontextedefiniert wurde.
Vorgehen
Jeder der folgenden Schritte im Refactoring wird abgeschlossen mit der Durchfüh-rung aller JUnit-Tests und einem händischen Integrations-Test an der Anwendung(„durchklicken“). Sind diese Tests erfolgreich, wird der Zwischenstand in das Source-Repository eingecheckt. Somit wird in kleinen Schritt gearbeitet, die immer wiederzu einem korrekten und laufenden System führen.
1. Ein zentraler Applikationskontext von Spring muss eingeführt werden. Diesermuss zur Startzeit der Anwendung initialisiert werden.
(a) Für die Initialisierung wird das Spring-Servlet oder der Spring-Context-Listener benutzt. Diese werden beim Start der Anwendung einmal aus-geführt und stellen dann in einem zentralen Kontext den Container zurVerfügung.
(b) Für den Zugriff aus dem JCommSy-Servlet auf die zur Verfügung gestell-ten Services muss eine Zugriffsmethode erstellt werden. Diese Methodeabstrahiert von der Spring-API und ist der einzige zentrale Zugriff aufalle Services.
(c) Sämtliche Einstiegspunkte in den Kontrollfluss müssen identifiziert wer-den. Wenn an diesen Punkten verwaltete Objekte benutzt werden, so müs-sen diese die neue Zugriffsmethode für Services nutzen können. Damitwird ein schrittweiser Umstieg auf Dependency Injection ermöglicht.
2. Die Zugriffsmethoden für Services an der ServiceRegistry werden abgelöst.Hierbei wird mit Services angefangen die keine Abhängigkeiten haben, oder

5.3. UMSTELLUNG 53
Abhängigkeiten, die schon durch Dependency Injection verwaltet werden. Fürjede Zugriffsmethode wird wie folgt vorgegangen:
(a) Die Zugriffsmethode für den Service wird an der Service Registry auf „de-precated“ gesetzt. Hiermit sind alle abzulösenden Zugriffe bei der Ent-wicklung sofort zu erkennen.
(b) Falls der benutzte Service noch keine Trennung in Schnittstelle und Im-plementation hat, wird diese eingeführt.
(c) Objekte, die in dem abzulösenden Service benutzt werden, müssen tran-sitiv durch Dependency Injection erzeugt werden.
(d) Abhängige Objekte werden im Service mit „final“ markiert und durch denKonstruktor gesetzt.
(e) Die Tests, die Zugriffsmethoden benutzen, müssen angepasst werden undeventuell mit EasyMock neu geschrieben werden.
(f) Die Zugriffsmethode und das Feld für den Service kann in der ServiceRe-gistry gelöscht werden.
3. Der vorige Schritt wird für alle Zugriffsmethoden an der Service-Registry wie-derholt, bis keine Klasse mehr auf die Service-Registry zugreift.
4. Die Klasse ServiceRegistry kann gelöscht werden.
5. Die Zugriffsmethoden des Service-Manageres werden analog zu der Service-Registry durch Dependency Injection abgelöst.
6. Die Klasse ServiceManager kann gelöscht werden.
Dieser Plan ist die Leitlinie für die Umstellung des Systems. Der Plan ist vor derUmstellung erstellt worden. Im nächsten Abschnitt wird gezeigt, welche Schritte ge-nau umgesetzt werden konnten und welche Schritte angepasst werden mussten.
5.3 Umstellung
Dieser Abschnitt beschreibt die Erfahrung, die bei der Umstellung des Systems ge-macht wurden.
Das wichtigste Hilfsmittel bei der Umstellung waren die automatischen Tests, diemit JUnit geschrieben worden waren. Vor jeder kleinen Änderungen wurden dieseTests ausgeführt. Nach jeder kleinen Änderung wurden diese Tests wieder ausge-führt. Dadurch wurden trotz der strukturellen Änderung unerwünschte Seiteneffek-te vermieden. Verliefen die Tests auch nach den Änderungen erfolgreich, wurden dieveränderten Dateien sofort in der zentralen Versionsverwaltung Subversion (SVN)bekannt gemacht. Das häufige Abgleichen mit dem aktuellen Stand der Entwick-lung war besonders wichtig, da Änderungen anderer Entwickler einbezogen werdenmussten, die zur gleichen Zeit an JCommSy arbeiteten. Jeder Stand der über SVN be-kannt gemacht wurde, hat das System zwar verändert, war aber komplett getestet.

54 KAPITEL 5. BESCHREIBUNG DER PRAKTISCHEN LÖSUNG
Abbildung 5.3: Vorgehen bei der Umstellung
Das JCommSy wurde zu keiner Zeit für eine Umstellung dieser Größe soweit verän-dert, dass es nicht mehr funktionsfähig war.
Das typische Vorgehen lässt sich in Abbildung 5.3 ablesen. Der erste Schritt ist,die nächste Aufgabe aus der Liste auf Seite 52 zu suchen. Im nächster Schritt Testenmuss ein neuer Test für die Aufgabe formuliert werden. Sämtliche Tests werden aus-geführt, dabei werden die neu formulierten Tests, die die neue Aufgabe beschreiben,fehlschlagen. Im folgenden Abschnitt Programmieren sind die eigentlichen Tätigkei-ten für die Umstellung zusammengefasst. Hier wurden die Methoden für den Zugriffauf die Services geschrieben und die vorhandenen Services auf Constructor Injecti-on umgestellt. Der Schritt der Programmierung wird immer wieder unterbrochenvon Testausführungen. Erst wenn die Tests erfolgreich durchlaufen und die Aufga-be durch die neuen und umgeschriebenen Tests überprüft wurde, kann die Aufgabeals erledigt angesehen werden. Es folgt der Schritt Update und es wird der aktuelleStand auf dem Entwicklungsrechner mit dem aktuellen Stand der Versionsverwal-tung abgeglichen. Falls Änderungen von anderen Entwicklern eingespielt wurden,muss das System erst aktualisiert und dann wieder getestet werden. Befindet sichkeine neue Version in der Versionsverwaltung, können die Änderungen in die Ver-sionsverwaltung im dem Schritt Einchecken eingespielt werden. Das Vorgehen wardurch die vorherige Absicherung durch Tests testgetrieben, wie in [Bec02] beschrie-ben.
Ein weiterer Aspekt ist die Größe der gewählten Aufgabe. Wenn für eine längereZeit bei der Umstellung der Code nicht kompilierbar oder die Tests nicht erfolg-reich waren, kann nicht eingecheckt werden. Das führt zu Problemen, wenn andereEntwickler zeitgleich an dem System arbeiten und dabei an den selben Dateien Än-derungen durchführen. Die Größe der Aufgaben lässt sich nicht immer im Vorwegeabschätzen. Aufgaben, die vorher als gering und schnell durchgeführt erscheinen,können sich als sehr langwierig herausstellen. Im Laufe der praktischen Arbeit habensich Zeitboxen als nützlich herausgestellt. Ein Beispiel: Wenn die gewählte Aufgabenicht in einer halben Stunde zu lösen ist, dann wurden alle Änderungen rückgängiggemacht und ein kleinerer Schritt für die Aufgabe gewählt.
Im Sourcecode des JCommSy ist mehrfach Source- und Testcode aufgefallen, dernicht benutzt wurde. Vielfach wurde dort schon für eventuell kommende neue Fea-tures programmiert, die aber nicht benutzt wurden. Im Laufe des Refactorings habe

5.4. ZUSAMMENFASSUNG 55
ich diesen Code gelöscht und mich an das YAGNI-Prinzip gehalten, siehe Seite 2.2.Der nicht benutzte und gelöschte Sourcecode lässt sich bei Bedarf immer wiederdurch die Versionsverwaltung beschaffen.
Aufwand
Das JCommSy wurde in acht Wochen auf Dependency Injection umgestellt. Mit derVersionsverwaltung Subversion können Zahlen ermittelt werden, die die Größe desRefactorings verdeutlichen. Bei der Umstellung wurden insgesamt 928 Dateien ver-ändert. Pro Woche wurden durchschnittlich 128 Dateien, maximal 477 Dateien ange-passt.
Über die Service Registry konnte vor der Umstellung auf 18 Services zugegrif-fen werden. Nach der Umstellung werden mit dem Spring-Framework 24 Servicesund 33 Commands verwaltet. Insgesamt gab es vor dem Refactoring 903 Tests beieiner Abdeckung von 78%. Nach der Umstellung sind 798 Tests übrig geblieben, dieinsgesamt 76% Sourcecodes abdecken.
5.4 Zusammenfassung
Das Kapitel hat die praktische Umsetzung der Diplomarbeit beschrieben. Für dieUmsetzung wurde eine Definition der Zielarchitektur des Systems erstellt. Anhandder Zielarchitektur und der Unterschied zur bestehenden Architektur wurde einRefactoringplan erstellt. Mit diesem Refactoringplan wurde die Umstellung durch-geführt. Bei der Umstellung wurde testgetrieben vorgegangen. Es hat sich gezeigtdas ein Refactoring dieser Größe nur in sehr kleinen Schritten durchgeführt werdenkann.

Kapitel 6
Ergebnis
In diesem Kapitel wird die praktische Arbeit analysiert. Anhand der Vorgehensweiseund der Messergebnisse werden die vorgestellten Lösungsansätze bewertet. DieseRetrospektive soll zudem Verbesserung bei der Vorgehensweise für ein Refactoringdieser Art vorstellen.
6.1 Bewertung der Vorgehensweise
Die Umstellung des System wurde durch einen Refactoringplan vorbereitet. Bei derUmstellung konnte der Plan eingehalten werden. Nicht vorhersehbar war die Größeder einzelnen Aufgaben. Die Benutzung von festen Zeitabschnitten, in denen eineAufgabe zu erledigt werden musste, war sehr hilfreich für die Erledigung. DiesesVorgehen führte zu kleinen Schritten beim Umbau. Das war besser, als wenn eine zugroße Aufgabe zu lange ohne Ergebnis gearbeitet bearbeteit worden wäre.
Nur durch Analyse des Sourcecodes waren die Abhängigkeiten der Objekte er-sichtlich, die mit Dependency Injection verwaltet werden sollten ersichtlich. Hierfürwurde kein spezielles Werkzeug verwendet. Es wurden nur die Mittel einer inte-grierten Entwicklungsumgebung (IDE) wie z.B. Eclipse benutzt. Dabei kann die Ent-wicklungsumgebung anzeigen, an welchen Stellen in einem System eine Klasse odereine Schnittstelle benutzt wird. Mit einer ausführlicheren Analyse vor dem Umbauhätte man einen Graphen der Abhängigkeiten verwalteter Objekte erstellen können.Dieser Graph hätte zudem noch zeigen können in welchem Sichtbarkeitsbereich bzw.Scope diese Objekte jeweils gültig sind.
Diese Übersicht der Abhängigkeiten sämtlicher verwalteten Objekte sind erst mitder XML-Konfiguration explizit gegeben. Das XML-Format eignet sich nur bedingtfür die Analyse der Abhängigkeiten, zumindest bietet sie keine gute Übersicht. Ab-hilfe schafft hier die Erweiterung der Eclipse Entwicklungsumgebung, die SpringIDE, siehe [Spr07b]. In der Abbildung 6.1 ist ein Ausschnitt einer Ansicht dieser IDEdargestellt. Dieser Ausschnitt zeigt die verwalteteten Objekte und deren Abhängig-keiten. Für die Sichtbarkeit der Objekte, die nicht als Singleton verwaltet werden,wird ein extra Symbol angezeigt. Die Commands, die bei jedem Request erzeugtwerden, sind in der Ansicht mit einem roten Sternchen markiert.
56

6.1.BEW
ERT
UN
GD
ERV
OR
GEH
ENSW
EISE57Abbildung 6.1: Spring IDE mit einem Ausschnitt der Abhängigkeiten im JCommSy

58 KAPITEL 6. ERGEBNIS
Package Ca Ce Nc Na A I D’
domainvalue 31 0 14 0 0,00 0,00 1,00item.search 15 2 2 0 0,00 0,12 0,88util 23 6 6 0 0,00 0,21 0,79presentation 14 4 35 1 0,03 0,22 0,75item 28 7 32 11 0,34 0,20 0,46
Tabelle 6.1: Messwerte für JCommsy nach der Umstellung
6.2 Bewertung der Umstellung
Dieser Abschnitt wird die Umstellung bewerten. Dabei wird der Code vor und nachdem Refactoring betrachtet. Es werden die Meßergebnisse nach den Robert C. MartinMetriken bewertet und die Testbarkeit betrachtet.
Bewertung der Meßergebnisse
Nach der erfolgreichen Umstellung auf Dependency Injection wurde das Systemwieder vermessen nach den Metriken von Robert C. Martin. Sämtliche Ergebnissewie instability und abstractness der Vermessung sind in Tabelle A-2 auf Seite 67 ab-gebildet. Die Tabelle 6.1 zeigt die Pakete mit den höchsten Werten für den AbstandD.
Durch das Refactoring haben sich die Werte leicht verändert. Die grafische Dar-stellung der Meßwerte ist in Abbildung 6.2. Die Ergebnisse vor der Umstellung ste-hen in der Tabelle 3.2 auf Seite 29. Im Vergleich befindet sich das Package ser-vice.persistence nicht mehr im Bereich der zone of uselessness und es gehört auchnicht mehr zu den fünf Packages mit der größten Distance. Aus diesem Package wur-den nicht benutzte abstrakte Klassen und Schnittstellen gelöscht. Die Vererbungs-hierarchie wurde für die Persistenzschicht vereinfacht. Diese Änderung steht somitnicht im Zusammenhang mit der Einführung von Dependency Injection. Bei denweiteren Meßwerten sind keine Verbesserungen oder auffällige Änderungen aufge-treten. Wie schon in der Vermessung vor der Umstellung gibt es Ausreißer in denErgebnissen, aber keine weiteren signifikanten Veränderungen der Werte. Es gibtzwei Gründe für die Änderung der Werte ohne messbaren Erfolg der Umstellung.Das Kapitel 3.4 beschreibt die Werte vor der Vermessung genauer. Der Abstand wirdbestimmt aus abstractness und instability. Anhand dieser beiden Maße kann geklärtwerden, warum die Umstellung keine größeren Änderungen hervorgebracht hat.
Die meisten Services, die durch Dependency Injection verwaltet werden, warenschon unterteilt in eine Schnittstelle und eine Implementation. Dadurch gab es keineVeränderung der Werte für abstractness. Da es keine Analyse der Package-Strukturund Verschiebung der Klassen und Schnittstellen gab, wurden die Werte für instabi-lity auch nur wenig verändert. Die Werte haben sich nur geändert, da ungenutzterCode gelöscht wurde. Außerdem wurden die Abhängigkeiten zur Service Registrygelöscht, manche Objekte haben eine Abhängigkeit zu der neu eingeführten Service

6.2. BEWERTUNG DER UMSTELLUNG 59
abstractness
instability
0.2
0.4
0.6
0.8
0.2 0.4 0.6 0.8
main sequence
domainvalue
item.search
util
presentation
item
Abbildung 6.2: A-I-Diagramm für ausgewählte Packages aus dem JCommsy nachder Umstellung
Factory bekommen. Diese Änderungen haben aber an der gesamten Struktur nurkleine Auswirkungen gehabt. Hierfür hätte die Paket-Struktur analysiert und um-strukturiert werden müssen. Diese Änderung hätte auch unabhängig von der Ein-führung von Dependency Injection geschehen können.
Bewertung der Testbarkeit
Vor der Umstellung wurde bei der Betrachtung des Gegenstandes in Kapitel 3.4 dieerschwerte Testbarkeit bemängelt. Durch die Einführung von Dependency Injectionhat sich die Testbarkeit im JCommSy verbessert. Die Verbesserung der Tests lässtssich in die folgenden Kategorien einteilen:
• Abhängigkeiten der getesteten Objekte sind eindeutig geworden
• Die Tests sind einfacher und schneller geworden
• Die Tests haben eine eindeutige Zuordnung zu Komponenten-, Integrations-oder Akzeptanztests.
Die Abhängigkeiten der getesteten Objekte lassen sich durch die Einführung vonDependency Injection sehr leicht erkennen. Im JCommSy wurde Constructor Injec-tion eingeführt. Daher können die abhängigen Objekte der verwalteten Objekten an

60 KAPITEL 6. ERGEBNIS
deren Konstruktor leicht abgelesen werden. Vielfach wurden in den Tests viele ande-re nicht abhängige Objekte für einen Test vorbereitet.
Durch die eindeutigen Abhängigkeiten konnten viele Tests vereinfacht werden,da nicht benötigten abhängige Objekte aus dem Setup der Tests gelöscht werdenkonnten. Durch die Benutzung von Mock-Objekten in den Tests sind die Tests vieleinfacher geworden. Anhand der programmierten Aufrufe der Mocks lässt sich imTest genau ablesen, welche Methoden das getestete Objekt an dem abhängigen Ob-jekt während des Tests aufruft. Die Tests haben durch die Vereinfachung im Setupkeine Funktionalität verloren, denn der eigentliche Test ruft immer noch dieselbenMethoden auf und überprüft die Ergebnisse. Es wurden viele Tests gelöscht, dieSourcecode referenziert haben, der ansonsten im System nicht benutzt wurde. Ins-gesamt gab es vor dem Refactoring 903 Tests bei einer Abdeckung von 78%. Nachder Umstellung sind 798 Tests übrig geblieben, die insgesamt 76% des Sourcecodesabdecken. Die Tests haben vor der Umstellung ca. 9 Minuten Ausführungszeit benö-tigt. Nach der Umstellung dauert die Ausführung der Tests des JCommSy nur nochknapp unter einer Minute.
Ein weiterer Effekt der Umstellung ist eine einfache Kategorisierung der Tests.Die Tests haben jetzt eine eindeutige Zuordnung, ob es sich um einen Komponenten-,Integrations- oder Akzeptanztest handelt! Komponententests im JCommSy sind di-rekte Subklassen der Oberklasse TestCase von JUnit. Manche der Tests prüfen meh-rere Objekte im Zusammenspiel, es sind Integrationstests. Für diese Integrationstestsgibt es im JCommSy eine Oberklasse, die eine ServiceFactory anbietet. Die Fac-tory benutzt einen DI-Container, konfiguriert durch mehrere Applikationskontex-te. Der einzige Unterschied zu dem DI-Container in der Anwendung ist ein ausge-tauschter Applikationskontext für die Anbindung zur Datenbank. Mit dieser Factorykann der Test sämtliche durch Spring verwalteten Objekte beziehen, initialisiert mitallen abhängigen Klassen. Diese Oberklasse heißt im JCommSy DatabaseTestCa-se1 und markiert somit alle Integrationstests. Im JCommSy werden Akzeptanztestsmit HttpUnit [Gol07] geschrieben. Mit dieser Erweiterung für JUnit wird die Anwen-dung mit HTTP-Anfragen aufgerufen und getestet. Sämtliche Tests dieser Kategoriebefinden sich in einem Package und lassen sich dadurch unterschieden.
6.3 Zusammenfassung
Die vorgestellten Lösungsansätze wurden bewertet. Bei einem Refactoring dieserGröße ist eine Planung notwendig gewesen. Das Refactoring wurde durch die Ent-wicklungsumgebung Eclipse und deren Erweiterung Spring IDE unterstützt. Bei demRefactoring war die Einhaltung von festen Zeitabschnitten für die die Einteilung undErledigung von Aufgaben hilfreich. Die Ergebnisse der Metriken von Robert C. Mar-tin haben sich nach dem Refactoring verändert, aber nicht verbessert. Sie sind keinegeeignetes Maß um die Testbarkeit zu bestimmen. Nur die vereinfachten Tests, die
1Der Name der Klasse sollte seine Verantwortung besser kommunizieren undIntegrationTestCase heißen.

6.3. ZUSAMMENFASSUNG 61
explizite Markierung von Abhängigkeiten im Konstruktor und die kürzeren Testlauf-zeiten konnten die Verbesserung der Testbarkeit zeigen. Zudem lassen sich nach demUmbau Tests einfacher Komponenten-, Integrations- oder Akzeptanztest zuordnen.

Kapitel 7
Ausblick
Zum Abschluss der Arbeit möchte ich auf Themen blicken, die mir im Laufe derDiplomarbeit aufgefallen sind, aber in dieser Arbeit nicht adressiert wurden. DieseThemen beziehen sich auf zwei Gebiete: Zum einen gibt es Techniken, die für die wei-tere Entwicklung, Qualität und Architektur des JCommSy von Nutzen sein könnten.Dann möchte ich einen Ausblick geben auf weitere Themen, die im Zusammenhangmit der These der Arbeit stehen.
Ausblick JCommSy
Bei der weiteren Entwicklung des JCommSy könnten die Tests unterschiedlicher Ty-pen noch eindeutiger voneinander getrennt werden. Das könnte durch eigene Source-Verzeichnisse jeweils für Komponenten-, Integrations- und Akzeptanztests erreichtwerden. Eine weitere Trennung könnte erreicht werden, wenn die verschiedenenTesttypen in eigene Projekte ausgelagert werden. Diese Trennung hätte den Vorteil,dass durch Einstellung dieser Projekte nur die Tests vom eigentlichen Code abhän-gen und Abhängigkeiten von produktiven Code zu Testklassen unmöglich wären.
Das JCommSy wird zurzeit als ein Quellcode-Projekt realisiert. Dabei werdenKlassen Packages zugeordnet. Abhängigkeiten oder zyklische Beziehungen zwischenden Packages können nicht ohne weiteren Aufwand erkannt werden. Eine automati-sche Prüfung im Rahmen der Tests könnte mit einem Werkzeug wie JDepend [Cla07]erfolgen. Mit JDepend können Bedingungen und Regeln für eine Architektur unddie erlaubten Beziehungen zwischen Packages als Textdatei definiert werden. JDe-pend kann mit dieser Definition in einem JUnit-Test die aktuellen Beziehungen ana-lysieren und Verstöße gegen die Regeln anzeigen. Ein weiterer Schritt wäre die Auf-teilung des JCommSy in mehrere Quelltext-Projekte anhand der Zugehörigkeit zuArchitektur-Schichten. Die Abhängigkeiten zwischen den Projekte müssten nach denRegeln der Architektur konfiguriert werden. Zum Beispiel dürften Zugriffe aus derDatenbankschicht nicht auf die Oberfläche erlaubt werden. Eine Verletzungen die-ser Regeln wäre dann nicht mehr möglich. Die Aufteilung des JCommSy in einzelneKomponenten wäre ein weiterer Schritt. Als Basis für die Definition von Komponen-
62

63
ten müsste ein Komponentenmodell benutzt werden, wie zum Beispiel OSGi1, siehe[Gon01] und [GHM+05].
Weiterer Ausblick
Die Arbeit hat gezeigt, dass die benutzten Metriken kein Indikator sind für die Test-barkeit eines Systems. Die Verbesserung der Testbarkeit konnte nur anhand der Ver-einfachung der Tests und der kürzeren Testlaufzeiten gezeigt werden. Für die Test-barkeit sind Singletons problematisch. Um die Testbarkeit im JCommSy zu verbes-sern, wurden die Singletons durch Dependency Injection ersetzt. Singletons sind fürdie Testbarkeit problematisch, da ein globaler Zustand über mehrere Testfälle hin-weg „verschleppt“ werden kann. Dieser Zustand wird bei Singletons über eine sta-tischen Variable gehalten. Um die Testbarkeit zu prüfen kann man sich eine Metrikvorstellen, die Abhängigkeiten zu statischen Variablen überprüft. Diese Metrik könn-te prüfen, über wieviele Referenzen hinweg die Abhängigkeit besteht und wievieleAbhängigkeiten zu statischen Variablen bestehen. Ein erster Ansatz in diese Rich-tung ist der Google Singleton Detector [Rub07].
1Open Services Gateway initiative

64 KAPITEL 7. AUSBLICK

Messergebnisse
Package Ca Ce Nc Na A I D’
control 9 19 15 7 0,47 0,68 0,15control.action 2 4 3 0 0,00 0,67 0,33control.announcement 1 14 10 0 0,00 0,93 0,07control.appointment 1 15 6 0 0,00 0,94 0,06control.appointment.action 1 14 8 2 0,25 0,93 0,18control.appointment.command 2 8 5 0 0,00 0,80 0,20control.common 3 15 22 7 0,32 0,83 0,15control.group 3 8 6 0 0,00 0,73 0,27control.label 2 7 3 0 0,00 0,78 0,22control.material 2 9 5 0 0,00 0,82 0,18control.topic 3 8 6 0 0,00 0,73 0,27control.util 1 1 3 1 0,33 0,50 0,17domainvalue 29 0 14 0 0,00 0,00 1,00domainvalue.filter 12 1 8 1 0,12 0,08 0,80domainvalue.util 6 1 1 0 0,00 0,14 0,86item 24 7 30 11 0,37 0,23 0,41item.search 11 2 2 0 0,00 0,15 0,85item.util 10 2 1 0 0,00 0,17 0,83migration 0 15 10 0 0,00 1,00 0,00presentation 14 4 34 1 0,03 0,22 0,75presentation.components 6 1 30 2 0,07 0,14 0,79presentation.tags 0 4 7 0 0,00 1,00 0,00service 16 4 18 18 1,00 0,20 0,20service.filter 4 12 7 1 0,14 0,75 0,11service.filter.announcement 1 2 2 0 0,00 0,67 0,33service.filter.appointment 1 4 4 0 0,00 0,80 0,20service.filter.discussion 1 2 1 0 0,00 0,67 0,33service.hibernate 2 22 43 3 0,07 0,92 0,01service.impl 3 10 5 1 0,20 0,77 0,03service.mem 0 13 19 3 0,16 1,00 0,16service.persistence 4 6 4 4 1,00 0,60 0,60service.registry 16 3 4 1 0,25 0,16 0,59
65

66 KAPITEL 7. AUSBLICK
Package Ca Ce Nc Na A I D’
service.webservice 1 3 10 5 0,50 0,75 0,25service.webservice.impl 0 7 5 1 0,20 1,00 0,20service.webservice.item 2 0 5 0 0,00 0,00 1,00util 22 4 5 0 0,00 0,15 0,85util.axis.servlet 0 2 1 0 0,00 1,00 0,00util.components 1 4 5 0 0,00 0,80 0,20util.hibernate 3 6 13 0 0,00 0,67 0,33util.hibernate.domainvalue 1 5 4 2 0,50 0,83 0,33util.hibernate.domainvalue.mapper 3 7 9 0 0,00 0,70 0,30util.hibernate.servlet 9 8 9 4 0,44 0,47 0,08util.jmx 4 2 9 7 0,78 0,33 0,11
Tabelle A-1: Meßwerte für JCommsy vor der Umstellung
Package Ca Ce Nc Na A I D’
control 16 18 16 7 0,44 0,53 0,03control.action 1 4 2 0 0,00 0,80 0,20control.announcement 1 14 10 0 0,00 0,93 0,07control.appointment 1 14 12 0 0,00 0,93 0,07control.appointment.command 0 7 4 0 0,00 1,00 0,00control.common 10 22 25 9 0,36 0,69 0,05control.discussion 1 12 6 0 0,00 0,92 0,08control.group 8 13 6 0 0,00 0,62 0,38control.label 2 3 1 0 0,00 0,60 0,40control.material 1 12 6 0 0,00 0,92 0,08control.profiling 0 0 2 0 0,00 0,00 1,00control.system 1 7 2 0 0,00 0,88 0,12control.todo 1 13 7 0 0,00 0,93 0,07control.topic 8 13 6 0 0,00 0,62 0,38control.user 1 12 6 0 0,00 0,92 0,08control.util 1 1 3 1 0,33 0,50 0,17domainvalue 31 0 14 0 0,00 0,00 1,00domainvalue.filter 15 1 10 1 0,10 0,06 0,84domainvalue.util 6 1 1 0 0,00 0,14 0,86item 28 7 32 11 0,34 0,20 0,46item.search 15 2 2 0 0,00 0,12 0,88migration 0 13 9 0 0,00 1,00 0,00presentation 14 4 35 1 0,03 0,22 0,75presentation.components 13 1 37 2 0,05 0,07 0,87presentation.tags 1 4 8 0 0,00 0,80 0,20service 16 4 17 17 1,00 0,20 0,20service.file 0 3 1 0 0,00 1,00 0,00
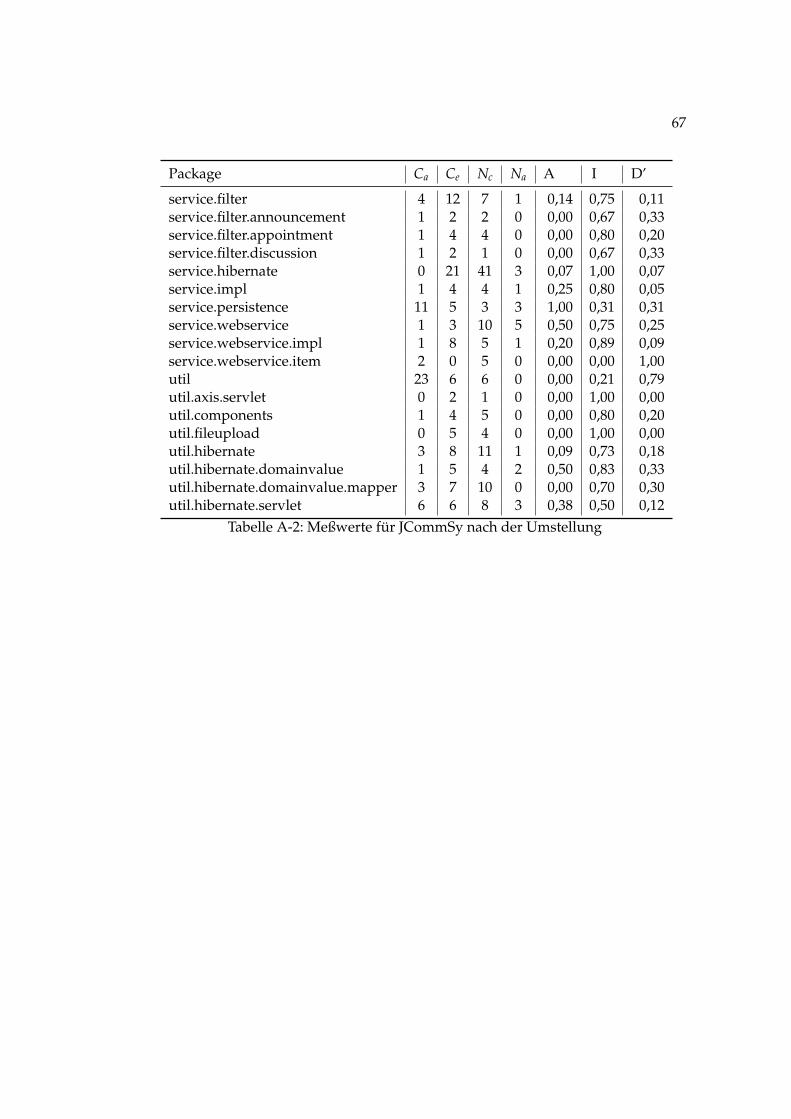
67
Package Ca Ce Nc Na A I D’
service.filter 4 12 7 1 0,14 0,75 0,11service.filter.announcement 1 2 2 0 0,00 0,67 0,33service.filter.appointment 1 4 4 0 0,00 0,80 0,20service.filter.discussion 1 2 1 0 0,00 0,67 0,33service.hibernate 0 21 41 3 0,07 1,00 0,07service.impl 1 4 4 1 0,25 0,80 0,05service.persistence 11 5 3 3 1,00 0,31 0,31service.webservice 1 3 10 5 0,50 0,75 0,25service.webservice.impl 1 8 5 1 0,20 0,89 0,09service.webservice.item 2 0 5 0 0,00 0,00 1,00util 23 6 6 0 0,00 0,21 0,79util.axis.servlet 0 2 1 0 0,00 1,00 0,00util.components 1 4 5 0 0,00 0,80 0,20util.fileupload 0 5 4 0 0,00 1,00 0,00util.hibernate 3 8 11 1 0,09 0,73 0,18util.hibernate.domainvalue 1 5 4 2 0,50 0,83 0,33util.hibernate.domainvalue.mapper 3 7 10 0 0,00 0,70 0,30util.hibernate.servlet 6 6 8 3 0,38 0,50 0,12
Tabelle A-2: Meßwerte für JCommSy nach der Umstellung

Literaturverzeichnis
[ACM03] ALUR, Deepak ; CRUPI, John ; MALKS, Dan: Core J2EE Patterns: Best Prac-tices and Design Strategies. 2nd. Prentice Hall and Sun MicrosystemsPress, 2003. – ISBN 0–131–42246–4
[Ava04] Apache Avalon. Website. http://avalon.apache.org/.Version: 2004, Abruf: 2007-07-01
[Bec02] BECK, Kent: Test-Driven Development: By example. Boston, MA, USA :Addison-Wesley Longman Publishing Co., Inc., 2002. – ISBN 0–321–14653–0
[Bin99] BINDER, Robert V.: Testing Object-Oriented Systems: Models, Patterns, andTools. Boston, MA, USA : Addison-Wesley Longman, Inc., 1999. – ISBN0–201–80938–9
[CKM94] CHIDAMBER, SR ; KEMERER, CF ; MIT, C.: A metrics suite for objectoriented design. In: Software Engineering, IEEE Transactions on 20 (1994),Nr. 6, S. 476–493
[Cla07] CLARK, Mike: JDepend. Website. http://www.clarkware.com/software/JDepend.html. Version: 2007, Abruf: 2007-07-01
[Dij72] DIJKSTRA, Edsger W.: Notes on Structured Programming. In: DAHL, O. J.(Hrsg.) ; DIJKSTRA, E. W. (Hrsg.) ; HOARE, C. A. R. (Hrsg.): StructuredProgramming. London : Academic Press, 1972
[Eva03] EVANS, Eric: Domain-Driven Design: Tacking Complexity In the Heart ofSoftware. Boston, MA, USA : Addison-Wesley Longman Publishing Co.,Inc., 2003. – ISBN 0–321–12521–5
[For06] FORSTER, Florian: Measuring The Quality Of Inferred Interfaces. In:IWSM/MetriKon 2006, 2006
[Fow99] FOWLER, Martin: Refactoring: improving the design of existing code. Boston,MA, USA : Addison-Wesley Longman, Inc., 1999. – ISBN 0–201–48467–2
[Fow03] FOWLER, Martin: Patterns of Enterprise Application Architecture. Boston,MA, USA : Addison-Wesley Longman Publishing Co., Inc., 2003. – ISBN0–321–12742–0
68

LITERATURVERZEICHNIS 69
[Fow04] FOWLER, Martin: Inversion of Control Containers and the Dependen-cy Injection pattern. http://www.martinfowler.com/articles/injection.html. Version: Januar 2004, Abruf: 2007-07-01
[Fre02] FREESE, Tammo: EasyMock: Dynamic Mock Objects for JUnit. In: MAR-CHESI, M. (Hrsg.) ; SUCCI, G. (Hrsg.): Proceedings of the 3nd InternationalConference on Extreme Programming and Flexible Processes in Software Engi-neering (XP2002), 2002, S. 2–5
[Fre07] FREESE, Tammo: EasyMock. Website. http://www.easymock.org/.Version: 2007, Abruf: 2007-07-01
[FS97] FOWLER, Martin ; SCOTT, Kendall: UML Distilled: Applying the StandardObject Modeling Language. Boston, MA, USA : Addison-Wesley Longman,Inc., 1997. – ISBN 0–201–32563–2
[GHJV94] GAMMA, Erich ; HELM, Richard ; JOHNSON, Ralph ; VLISSIDES, John: De-sign Patterns: Elements of Reusable Object-Oriented Software. Boston, MA,USA : Addison-Wesley Longman, Inc., 1994. – ISBN 0–201–63361–2
[GHM+05] GRUBER, O. ; HARGRAVE, B. J. ; MCAFFER, J. ; RAPICAULT, P. ; WATSON,T.: The Eclipse 3.0 platform: Adopting OSGi technology. In: IBM SystemsJournal 44 (2005), Nr. 2, S. 289–299. – ISSN 0018–8670
[Gol07] GOLD, Russell: HttpUnit. Website. http://httpunit.sourceforge.net/. Version: 2007, Abruf: 2007-07-01
[Gon01] GONG, Li: A Software Architecture for Open Service Gateways. In: IEEEInternet Computing 5 (2001), Nr. 1, S. 64–70
[HO02] HERCZEG, Michael (Hrsg.) ; OBERQUELLE, Horst (Hrsg.): Mensch & Com-puter 2002: Vom interaktiven Werkzeug zu kooperativen Arbeits- und Lernwel-ten, 2. bis 5. September 2002 in Hamburg. B.G. Teubner Verlag, 2002 . – ISBN3–519–00364–3
[Hoh07] HOHMANN, Christoph: Softwarearchitektur von J2EE Web Applikationenmit Web Components am Beispiel von AJAX, Universität Hamburg, Fachbe-reich Informatik, Arbeitsbereich Softwaretechnik, Diplomarbeit, 2007
[JB02] JANNECK, Michael ; BLEEK, Wolf-Gideon: Project-based Learning withCommSy. In: [Sta02], S. 509–510
[JHA+05] JOHNSON, Rod ; HOELLER, Juergen ; ARENDSEN, Alef ; RISBERG, Tho-mas ; SAMPALEANU, Colin: Professional Java Development with the SpringFramework. Indianapolis, IN, USA : Wiley Publishing, Inc., 2005. – ISBN0–7645–7483–3
[JJP02] JACKEWITZ, Iver ; JANNECK, Michael ; PAPE, Bernd: Vernetzte Projekt-arbeit mit CommSy. In: [HO02], S. 35–44

70 LITERATURVERZEICHNIS
[KFBR06] KOZIOLEK, Heiko ; FIRUS, Viktoria ; BECKER, Steffen ; REUSSNER, Ralf; REUSSNER, Ralf (Hrsg.) ; HASSELBRING, Wilhelm (Hrsg.): Hand-buch der Software-Architektur. 1. Auflage. Heidelberg, Deutschland :dpunkt.verlag GmbH, 2006. – ISBN 3–989864–372–2
[Lin05] LINK, Johannes: Softwaretests mit JUnit, Techniken der testgetriebenen Ent-wicklung. 2. Auflage. Heidelberg, Deutschland : dpunkt.verlag GmbH,2005. – ISBN 3–89864–325–5
[LW94] LISKOV, Barbara H. ; WING, Jeannette M.: A Behavioral Notion of Sub-typing. In: ACM Transactions on Programming Languages and Systems 16(1994), November, Nr. 6, S. 1811–1841
[Mar96] MARTIN, Robert C.: The Dependency Inversion Principle. In: C++ Report8 (1996), Mai, 61-66. http://www.objectmentor.com/resources/articles/dip.pdf, Abruf: 2007-07-01
[Mar03] MARTIN, Robert C.: Agile Software Development: Principles, Patterns, andPractices. Prentice Hall PTR Upper Saddle River, NJ, USA, 2003. – ISBN0–13–597444–5
[Mey97] MEYER, Bertrand: Object-Oriented Software Construction. 2nd Edition.Prentice Hall, 1997. – ISBN 0–13–629155–4
[MFC01] MACKINNON, Tim ; FREEMAN, Steve ; CRAIG, Philip: Endo-Testing: UnitTesting with Mock Objects. (2001), S. 287–301. ISBN 0–201–71040–4
[MSM06] MAYER, Philip ; STEIMANN, Friedrich ; MEISSNER, Andreas: DecouplingClasses with Inferred Interfaces. In: Proceedings of the 2006 ACM Sympo-sium on Applied Computing, 2006, S. 1404–1408
[Par72] PARNAS, D.L.: On the criteria to be used in decomposing systems intomodules. In: Communications of the ACM 15 (1972), Nr. 12, S. 1053–1058
[Pic06] PicoContainer - IoC component container. Website. http://www.picocontainer.org/. Version: 2006, Abruf: 2007-07-01
[RL04] ROOCK, Stefan ; LIPPERT, Martin: Refactoring in großen Softwareprojekt. 1.Auflage. Heidelberg, Deutschland : dpunkt.verlag GmbH, 2004. – ISBN3–89864–207–0
[Rub07] RUBEL, David: google-singleton-detector - Find singletons and globalstate in Java programs. Website. http://code.google.com/p/google-singleton-detector/. Version: 2007, Abruf: 2007-09-01
[Sie04] SIEDERSLEBEN, Johannes: Moderne Software-Architektur. Heidelberg,Deutschland : dpunkt.verlag GmbH, 2004. – ISBN 3–89864–292–5
[Spr07a] Spring Framework. Website. http://www.springframework.org/.Version: 2007, Abruf: 2007-07-01

LITERATURVERZEICHNIS 71
[Spr07b] Spring IDE. Website. http://www.springide.org/. Version: 2007,Abruf: 2007-07-01
[Sta02] STAHL, G. (Hrsg.): Computer Support for Collaborative Learning: Foundati-ons for a Cscl Community(Cscl 2002 Proceedings). Lawrence Erlbaum AssocInc, 2002 . – ISBN 0–8058–4443–0
[TH02] THOMAS, Dave ; HUNT, Andy: Mock Objects. In: IEEE Software 19 (2002),Nr. 3, S. 22–24. – ISSN 0740–7459
[YC79] YOURDON, Edward ; CONSTANTINE, Larry L.: Structured Design: Fun-damentals of a Discipline of Computer Program and Systems Design. UpperSaddle River, NJ, USA : Prentice-Hall, Inc., 1979. – ISBN 0–13–854471–9

Abbildungsverzeichnis
1.1 Direkte Abhängigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Lösung mit Factory-Muster . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Lösung mit Dependency Injection . . . . . . . . . . . . . . . . . . . . . 3
2.1 Qualitätsmerkmale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Klient ist nicht offen und geschlossen . . . . . . . . . . . . . . . . . . . 112.3 Klient ist beides, offen und geschlossen (Strategy-Muster) . . . . . . . . 12
3.1 Screenshot CommSy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.2 Architektur PHP-CommSy . . . . . . . . . . . . . . . . . . . . . . . . . . 163.3 MVC - Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.4 MVC1 - Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.5 MVC2 - Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.6 Abhängigkeiten über das ServiceRegistrySingleton . . . . . . . 213.7 Klassendiagramm J2EE Service Locator, aus [ACM03] . . . . . . . . . . 233.8 Klassendiagramm eines einfachen Service Locators . . . . . . . . . . . 243.9 Abhängigkeiten zwischen Packages . . . . . . . . . . . . . . . . . . . . 263.10 A-I-Diagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.11 A-I-Diagramm für ausgewählte Packages aus dem JCommSy . . . . . 30
4.1 Beispiel für abhängige Klassen . . . . . . . . . . . . . . . . . . . . . . . 344.2 Explizite Abhängigkeiten am Beispiel des Bücherservices . . . . . . . . 35
5.1 Zielarchitektur - Sequenzdigramm . . . . . . . . . . . . . . . . . . . . . 505.2 Zielarchitektur - Klassendiagramm . . . . . . . . . . . . . . . . . . . . 505.3 Vorgehen bei der Umstellung . . . . . . . . . . . . . . . . . . . . . . . . 54
6.1 Spring IDE mit einem Ausschnitt der Abhängigkeiten im JCommSy . . 576.2 A-I-Diagramm für ausgewählte Packages aus dem JCommsy nach der
Umstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
72

Tabellenverzeichnis
3.1 Messwerte für das Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2 Messwerte für JCommSy sortiert . . . . . . . . . . . . . . . . . . . . . . 29
6.1 Messwerte für JCommsy nach der Umstellung . . . . . . . . . . . . . . 58
A-1 Meßwerte für JCommsy vor der Umstellung . . . . . . . . . . . . . . . 66A-2 Meßwerte für JCommSy nach der Umstellung . . . . . . . . . . . . . . 67
73

74 TABELLENVERZEICHNIS
Danksagung
Hiermit möchte ich mich bedanken bei Dr. Wolf-Gideon Bleek und Prof. Dr. Win-fried Lamersdorf für die Betreuung dieser Arbeit. Für die zahlreichen Hinweise, diekonstruktive Kritik und Diskussionen bedanke ich mich bei Alexander Pokahr, LarsBraubach, Henning Wolf und Stefan Roock. Auch bei Jennifer Wirsching, Kai Rüst-mann, Robert F. Beeger und Ekkehart Opitz bedanke ich mich für die vielen Hinweiseund das Korrekturlesen.

Erklärung
Ich versichere, dass ich die vorstehende Arbeit selbstständig und ohne fremde Hilfeangefertigt und mich anderer als der im beigefügten Verzeichnis angegebenen Hilfs-mittel nicht bedient habe. Alle Stellen, die wörtlich oder sinngemäß aus Veröffentli-chungen entnommen wurden, sind als solche kenntlich gemacht.
Ich bin mit einer Einstellung in den Bestand der Bibliothek des Fachbereicheseinverstanden. Hamburg, September 2007.
Sebastian SanitzWohlwillstr. 120359 Hamburg