digital signal processing: architettura dei...
TRANSCRIPT

Corso di Elettronica dei sistemi programmabili
Digital Signal Processing:Digital Signal Processing:
Architettura dei DSP
Stefano Salvatori

2
Sommario
● Introduzione● DSP vs altri processori
– Manipolazione dei dati
– Elaborazione dei segnali
● Considerazioni sull'hardware di un DSP– Elaborazione off-line
– Elaborazione real-time
– Buffer circolare
● Architettura per un DSP– Von Neumann
– Harvard
● Famiglia SHARC di Analog Devices

3
Introduzione
● L'elaborazione digitale prevede l'uso di funzioni matematiche;
● Una elaborazione di testi prevede il semplice arrangiamento di dati memorizzati;
● => un processore progettato per un computer non è ottimizzato per l'elaborazione di segnali (come ad esempio il calcolo della FFT)
● I DSP sono processori specificamente progettati per task di calcolo che si riferiscono all'elaborazione di dati estratti da un segnale

4
Origine
● Negli ultimi due decenni lo sviluppo dei DSP è stato piuttosto repentino per le vaste aree di applicazione:
– dalla telefonia alla strumentazione scientifica● verranno illustrate le differenze che i processori DSP
presentano rispetto ad altri processori
● successivamente sarà presentato un esempio di DSP prodotto dalla Analog Devices appartenente alla famiglia SHARC

5
Differenze con altri processori
● Lo sviluppo dell'elaborazione digitale comincia intorno al 1960. Dopo un ventennio cominciano a svilupparsi i primi home computer e il calcolo automatico comincia a invadere la nostra cultura;
● I computer dimostrarono le loro capacità in due grosse aree:
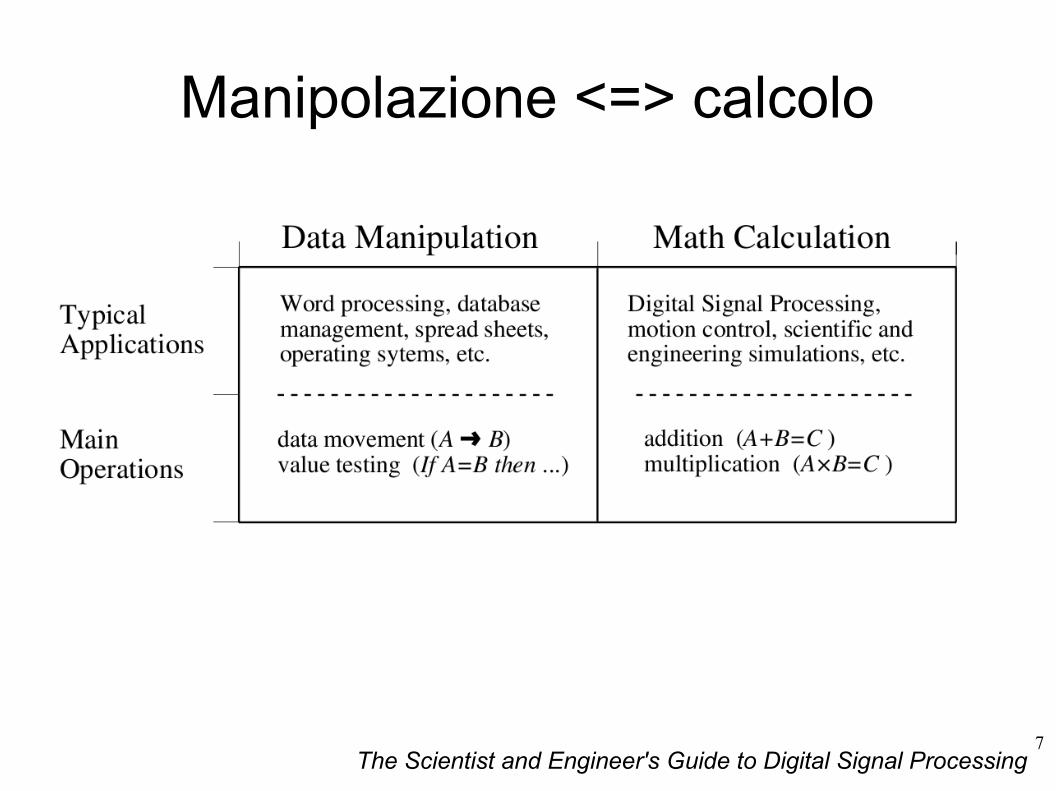
– Manipolazione dei dati (word-processing, database, …);
– Calcoli matematici (scienze, ecomomia, …).
Digital Signal ProcessingDigital Signal Processing

6
Differenze con altri processori
● Tuttavia, realizzare un processore che sia ottimizzato sia per la manipolazione che per il calcolo diviene un oggetto troppo sofisticato e costoso.
● I compromessi a cui si deve giungere nel progetto di un processore sono ad esempio:
● Dimensione (e quindi consumo);● Quantità e tipo di istruzioni;● Gestione delle interruzioni; …
● Ancor più determinanti sono poi i motivi economici:
● Costo;● Tempi di sviluppo;● Competitività; ...
7
Manipolazione <=> calcolo
The Scientist and Engineer's Guide to Digital Signal Processing

8
Manipolazione dati
● Nella manipolazione dei dati è importante gestire la memoria per leggere e scrivere dati che un operatore immette o richiede;
● L'organizzazione delle informazioni prevede copia, tagli, incolla, check ortografico, impostazione pagina, ...
● Il movimento dei dati prevede semplici calcoli di tipo ordinale (ordine alfabetico, possibile grazie alla codifica numerica dei caratteri alfanumerici);
● L'elaborazione prevede l'applicazione di operatori logici (IF A=B THEN …).

9
Manipolazione dati
● Per esempio, nella stampa di un testo, le operazioni svolte dal processore sono di semplice manipolazione dei dati memorizzati:
– I dati vengono letti dalla memoria;
– E vengono sequenzialmente inviati alla stampante;
– L'operazione prevede un “leggero” scambio di informazioni (stampante pronta, fine carta, ...)
10
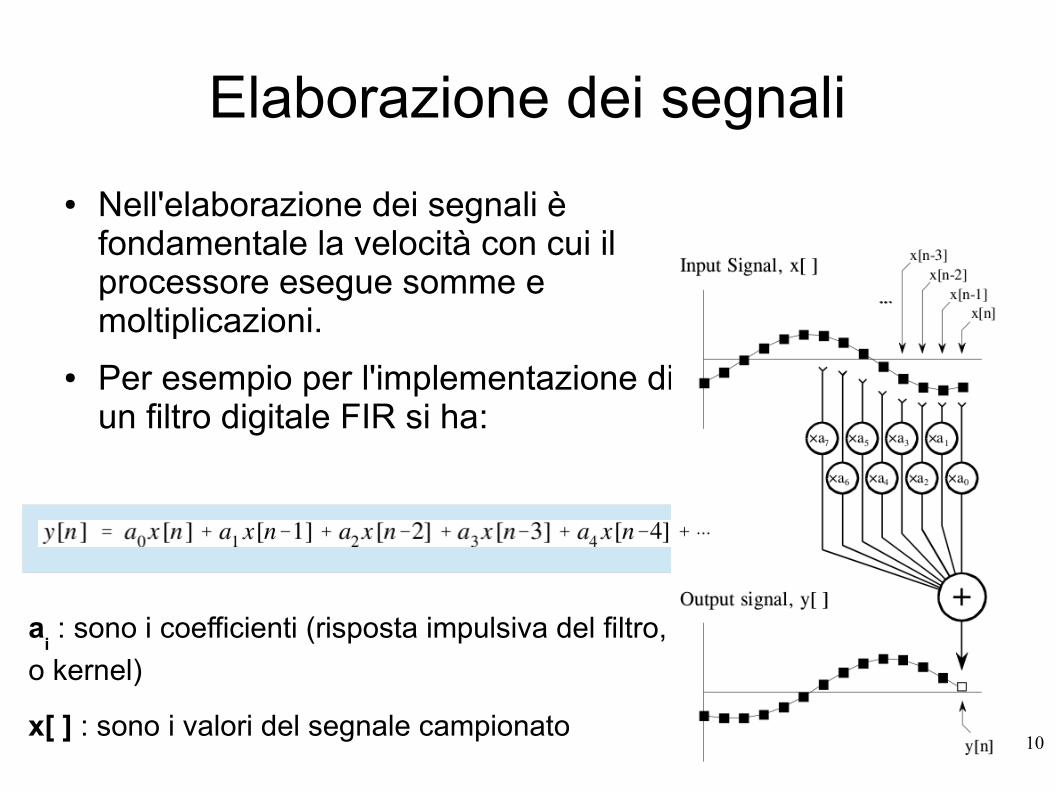
Elaborazione dei segnali
● Nell'elaborazione dei segnali è fondamentale la velocità con cui il processore esegue somme e moltiplicazioni.
● Per esempio per l'implementazione di un filtro digitale FIR si ha:
ai : sono i coefficienti (risposta impulsiva del filtro,
o kernel)
x[ ] : sono i valori del segnale campionato

11
Elaborazione dei segnali
● Un'altra caratteristica fondamentale dei DSP, oltre alla velocità, è che il tempo di esecuzione dev'essere predicibile:
– È necessario che il tempo di calcolo della risposta sia adeguato all'applicazione
– In un'applicazione tipo word-processing che la risposta all'utente giunga dopo millisecondi o secondi non è detrminante: l'utente attenderà comunque il termine dell'elaborazione;
– In un DSP il rate della risposta deve essere in accordo (e costante) con l'applicazione: per l'audio, ad esempio, se si hanno 44000 campioni in un secondo, non è possibile che la risposta intervenga ad un rate diverso.

12
Elaborazione dei segnali
● Infine, l'elaborazione di un DSP dev'essere continua:
– Mentre per una applicazione software si ha una elaborazione che prevede un inizio (ingresso dati) e una fine (produzione del risultato, per un DSP l'elaborazione deve avvenire continuamente senza che si abbiano un inizio e una fine definiti.

13
Considerazioni sull'hardware
● Per la loro natura, i DSP prevedono soluzioni circuitali dedicate;
● Per comprendere l'hardware di un DSP dobbiamo pensare al tipo di algoritmi che essi tipicamente svolgono;
● I tipi sono:
– Elaborazione di tipo off-line:● L'intero set di dati da elaborare risiedono nel computer;
– Elaborazione di tipo real-time:● L'elaborazione è svolta nello stesso tempo in cui è
acquisito il segnale da elaborare.

14
Considerazioni sull'hardware
● Elaborazione off-line
– Per esempio nell'elaborazione meteo, le informazioni sono raccolte nel computer e l'elaborazione è svolta successivamente;
– Per l'elaborazione di immagini tramite tecniche di risonanza magnetica, i dati sono raccolti durante le misurazioni mentre le immagini sono formate successivamente grazie all'elaborazione dei dati stessi.
Tutte le informazioni sono simultaneamente disponibili al programma di elaborazione.
Caso tipico per strumentazione scientifica ma assente nell'elettronica di consumo.

15
Considerazioni sull'hardware
● Elaborazione real-time
– In questo tipo di elaborazione il risultato è fornito negli stessi istanti di tempo in cui il segnale è acquisito.
– Il tempo finito di elaborazione prevede, ovviamente, un ritardo tra segnale di ingresso e segnale di uscita. Il tempo di ritardo (elaborazione) dipenderà dall'applicazione (per un radar, se l'operatore osserva il fenomeno con 1 s di ritardo, non si hanno problemi, mentre lo stesso ritardo in una comunicazione telefonica può ritenersi drammatico).

16
Considerazioni sull'hardware
● Elaborazione real-time
– Possiamo avere due tecniche:● Il DSP campiona il segnale di ingresso, elabora il
singolo campione e fornisce il campione risultato dell'elaborazione;
● Analogamente, il DSP potrebbe acquisire un gruppo di campioni, elaborare il gruppo e fornire un gruppo di campioni in uscita.
– In entrambi i casi il risultato non cambia. Ciò che cambia è il tipo di elaborazione che il DSP dovrà svolgere.
17
Elaborazione real-time
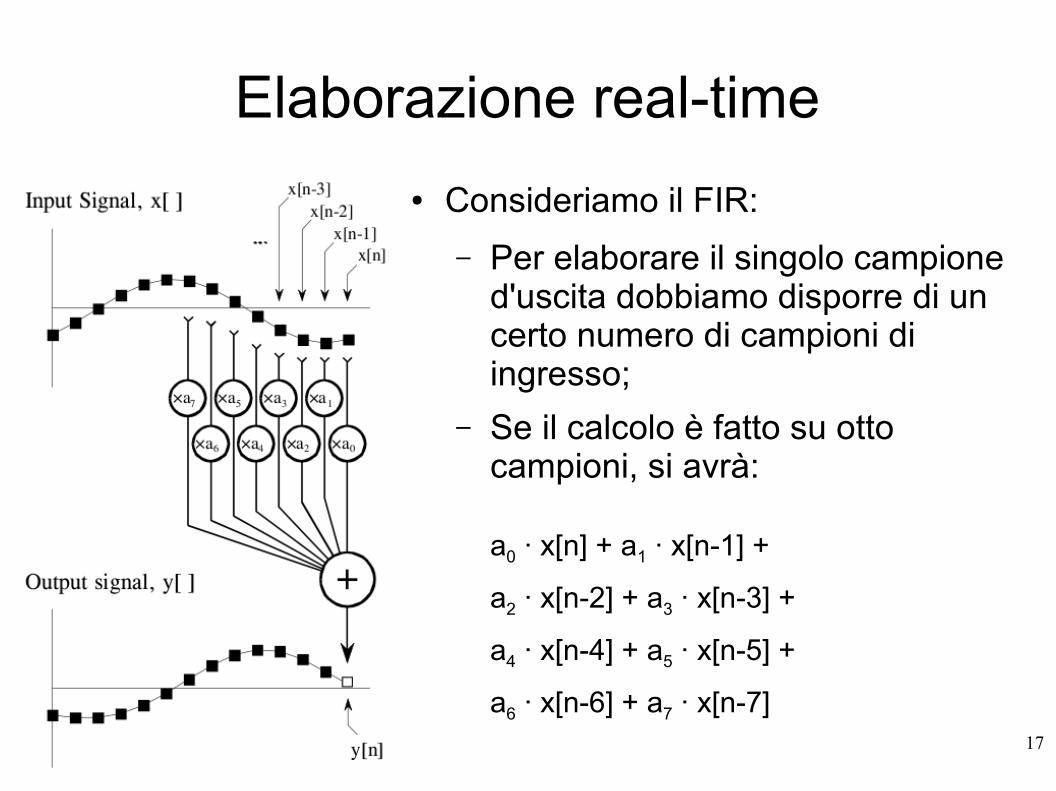
● Consideriamo il FIR:
– Per elaborare il singolo campione d'uscita dobbiamo disporre di un certo numero di campioni di ingresso;
– Se il calcolo è fatto su otto campioni, si avrà:
a0 · x[n] + a1 · x[n-1] +
a2 · x[n-2] + a3 · x[n-3] +
a4 · x[n-4] + a5 · x[n-5] +
a6 · x[n-6] + a7 · x[n-7]

18
Elaborazione real-time
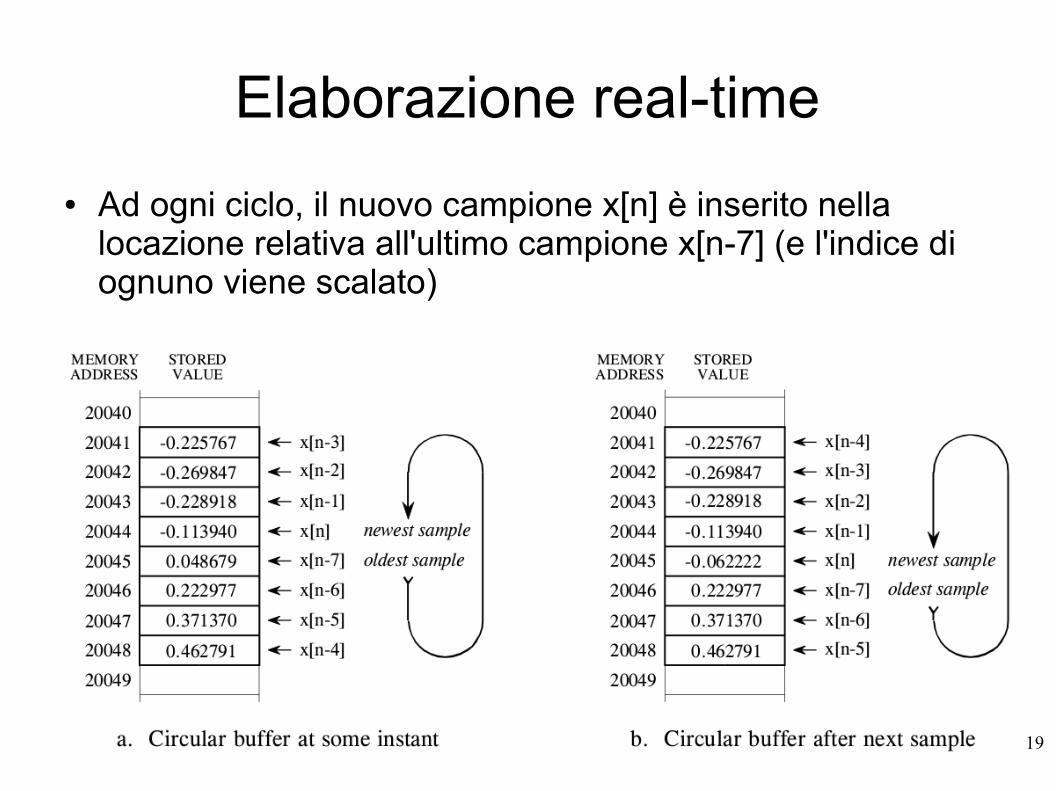
● Gli otto campioni devono essere presenti in memoria per essere aggiornati ad ogni iterazione.
● Per disporre di tali dati è conveniente allora ricorrere a buffer di tipo circolare:
a0 · x[n] + a
1 · x[n-1] +
a2 · x[n-2] + a
3 · x[n-3] +
a4 · x[n-4] + a
5 · x[n-5] +
a6 · x[n-6] + a
7 · x[n-7]
19
Elaborazione real-time
● Ad ogni ciclo, il nuovo campione x[n] è inserito nella locazione relativa all'ultimo campione x[n-7] (e l'indice di ognuno viene scalato)

20
Buffer circolare
● È necessario:
– Un puntatore che indica l'inizio del buffer;
– Un puntatore per la fine del buffer (o una variabile che indica la lunghezza del buffer);
– Dimensione di ciascuna locazione (dimensione dei dati);
– Puntatore al campione più recente
Non cambiano
Cambia
La logica che controlla un tale buffer è piuttosto semplice ma dev'essere veloce.

21
Buffer circolare per filtro FIR
● Le operazioni che il DSP svolgerà sono:
– Acquisire un campione dall'ADC;– Spostare il campione nel buffer;– Aggiornare il puntatore;– Azzerare l'accumulatore;– Loop con i coefficienti:
● Prelevare il coefficiente;● Aggiornare il puntatore del buffer dei coefficienti;● Prelevare il campione dal buffer dei dati;● Aggiornare il puntatore;● Eseguire la moltiplicazione;● Addizionare il risultato all'accumulatore;
– Spostare il contenuto dell'accumulatore verso il buffer d'uscita;– Spostare il contenuto del buffer d'uscita verso il DAC.

22
Buffer circolare per filtro FIR
● L'esecuzione dev'essere “rapida” (att.ne al loop);
● Un μP tradizionale esegue l'algoritmo sequenzialmente;
● un DSP lo svolge con diverse operazioni in parallelo.
● In molti casi il tempo di esecuzione di un tale algoritmo per un DSP si riduce a un solo ciclo di clock.

23
Architettura di un DSP
● Nell'eseguire un algoritmo il tempo maggiore speso da un processore è quello relativo all'accesso alla memoria:
Instruction type Dynamic usage
Data movement 43%
Control flow 23%
Arithmetic operations 15%
Comparisons 13%
Logical operations 5%
Other 1%
Frber “ARM system on chip architecture”, Wiley

24
Architettura DSP
● L'accesso alla memoria è relativo sia al reperimento dei dati da elaborare (campione e coefficiente), sia all'istruzione che dice cosa deve essere fatto con i dati.
Architettura di Von Neumann (una sola memoria: dati e programma)

25
Architettura DSP
● L'architettura di Von Neumann, cun bus dati e uno per gli indirizzi, va bene nei casi in cui il processo è sequenziale;
● Per il singolo calcolo del FIR servono tre accessi alla memoria: istruzione, campione e coefficiente => nel caso migliore servono tre cicli di clock;
● Per aumentare la velocità, cioè ridurre il numero di cicli di clock necessari all'esecuzione dell'elaborazione, è necessario ideare nuove architetture in grado di ridurre il numero di accessi alla memoria.

26
Architettura DSP
● Una prima soluzione è rappresentata dall'architettura Harvard (sviluppata nell'omonima università negli anni 1940):
● La CPU gestisce indipendentemente due coppie di bus per memoria dati e memoria programma:

27
Architettura DSP
● Un'ulteriore modifica porta all'architettura di tipo Super Harvard, termine conato dalla Analog Devices, per denominare i dispositivi della famiglia ADSP-2106x (SHARC®, Super Harvard ARChitecure).

28
Architettura DSP
● Nei dispositivi SHARC sono inseriti due elementi di novità:
● Una chace per le istruzioni● Un controllore per I/O.

29
Architettura DSP
● Per la struttura Harvard, ad ogni istruzione si ha il prelievo di due dati (coefficiente e campione):
● I coefficienti sono trasferiti nella memoria programma (secondary data);
● Ora però per ogni dato sono necessari due accessi alla memoria programma (istruzione e coefficiente):
● Questo solo se il prelievo delle istruzioni fosse “casuale”.

30
Architettura DSP
● In realtà i DSP spendono la maggior parte del tempo di calcolo nell'eseguire dei loop, cioè un ristretto gruppo di istruzioni → la CPU riceve periodicamente sempre le stesse istruzioni;
● La cache contiene allora solo un certo numero di istruzioni più recenti e, se di dimensione adeguata, conterrà già tutte le istruzione del loop.
● A parte il primo ciclo, tutto è poi svolto con un solo colpo di clock:
● Prelievo del campione dalla memoria dati;● Prelievo del coefficiente dalla memoria programma;● Prelievo dell'istruzione dalla cache.
coefficiente campione
istruzione

31
Architettura per gli SHARCArchitettura per gli SHARC
di Analog Devicesdi Analog Devices

32
SHARC

33
SHARCIl controllore I/O interfaccia, ad alta velocità, la memoria dati con ADC e DAC e dispone anche di porte di tipo seriale e parallelo:
p.es. A 40 MHz, con sei porte parallele (40 Mbyte/s) si ha un trasferimento totale di 240 Mbyte/s.
L'accesso è direttamente verso la memoria (senza impegnare la CPU) cioè di tipo DMA, Direct Memory Access.
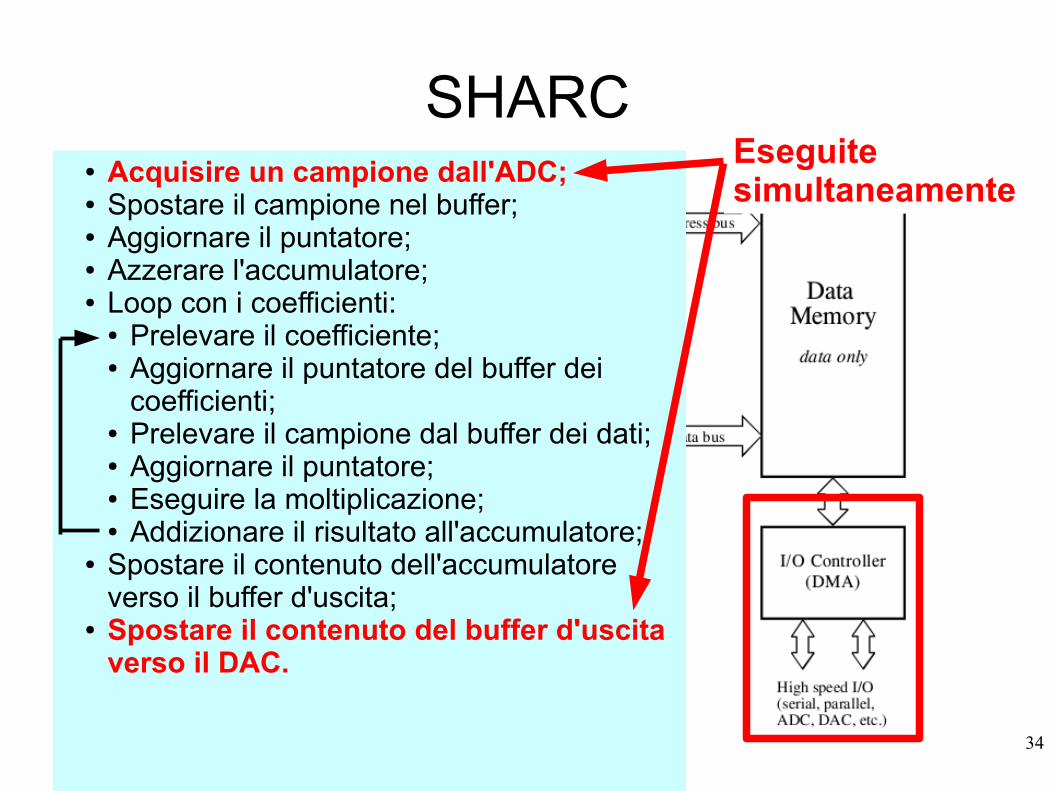
34
SHARC● Acquisire un campione dall'ADC;● Spostare il campione nel buffer;● Aggiornare il puntatore;● Azzerare l'accumulatore;● Loop con i coefficienti:
● Prelevare il coefficiente;● Aggiornare il puntatore del buffer dei
coefficienti;● Prelevare il campione dal buffer dei dati;● Aggiornare il puntatore;● Eseguire la moltiplicazione;● Addizionare il risultato all'accumulatore;
● Spostare il contenuto dell'accumulatore verso il buffer d'uscita;
● Spostare il contenuto del buffer d'uscita verso il DAC.
Eseguite simultaneamente
35
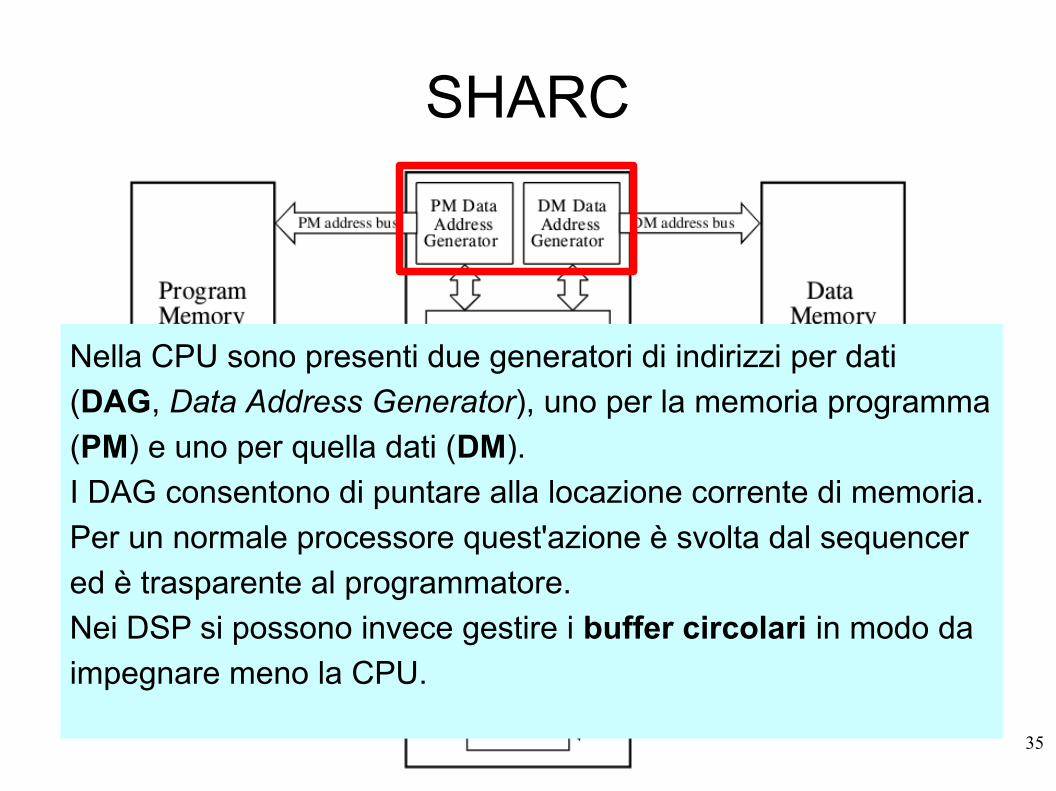
SHARC
Nella CPU sono presenti due generatori di indirizzi per dati
(DAG, Data Address Generator), uno per la memoria programma
(PM) e uno per quella dati (DM).
I DAG consentono di puntare alla locazione corrente di memoria.
Per un normale processore quest'azione è svolta dal sequencer
ed è trasparente al programmatore.
Nei DSP si possono invece gestire i buffer circolari in modo da
impegnare meno la CPU.

36
SHARC
Ogni DAG degli SHARC gestisce 8 buffer circolari: cioè un
totale di 32 variabili per DAG (4 variabili per buffer: inizio, fine,
dimensione dato, puntatore).
Un elevato numero di buffer circolari consente di implementare
sistemi a più stadi (p. es. IIR sono stabili se composti dalla
cascata di filtri bi-quadratici)
37
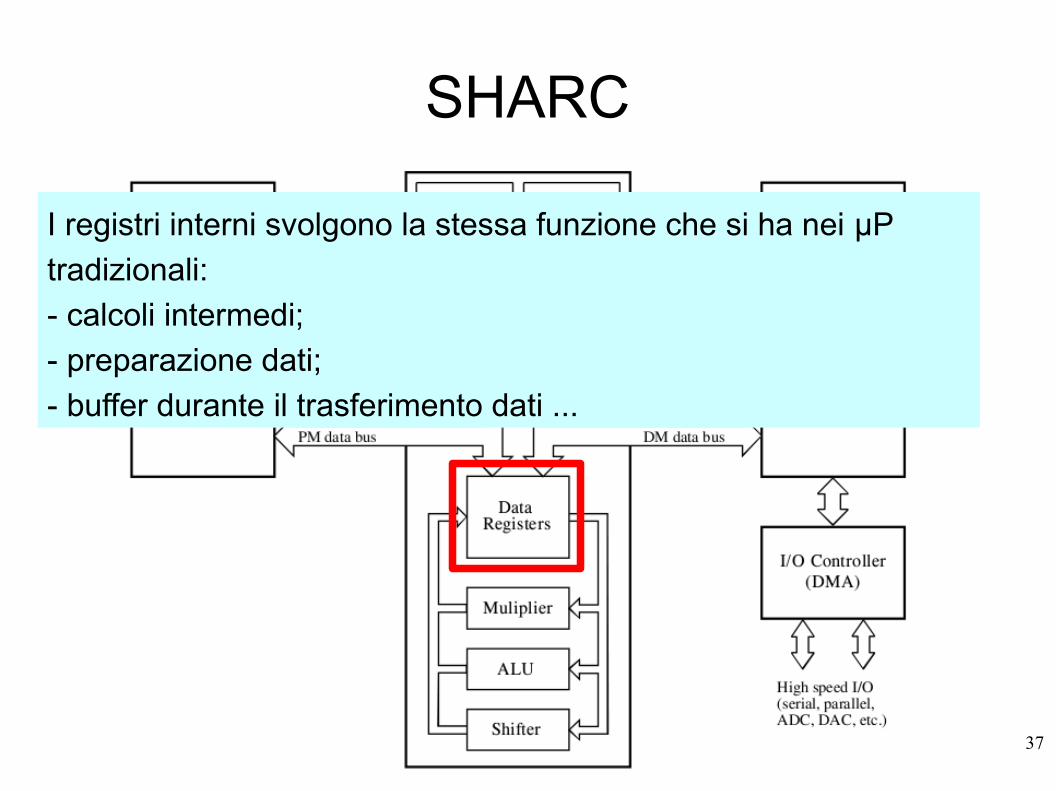
SHARC
I registri interni svolgono la stessa funzione che si ha nei μP
tradizionali:
- calcoli intermedi;
- preparazione dati;
- buffer durante il trasferimento dati ...

38
SHARC
Per l'elaborazione si hanno:
- moltiplicatore;
- ALU;
- barrel shifter
In un singolo ciclo di clock, la ALU può accedere a un gruppo di
registri mentre il moltiplicatore accede a un altro. I due risultati
sono memorizzati in altri registri.
Tutti indipendenti

39
SHARC
● Altre caratteristiche degne di nota:
– Accumulatore a 80 bit per superare problemi di arrotondamento nelle operazioni tra numeri interi;
– Registri raddoppiati (shadow registers), il cui contenuto viene salvato in un solo ciclo di clock, per rispondere più rapidamente alle interruzioni

40
Di nuovo il filtro FIR
Tutte svolte in parallelo
Se abbiamo un filtro con 100 coefficienti saranno sufficienti 105-110 cicli di clock
5% di un processore tradizionale