deep learning: changing the playing field of artificial intelligence - mars global leadership
TRANSCRIPT

Deep Learning
Ruslan Salakhutdinov
Department of Computer Science
University of Toronto
Images & Video
Relational Data/ Social Network
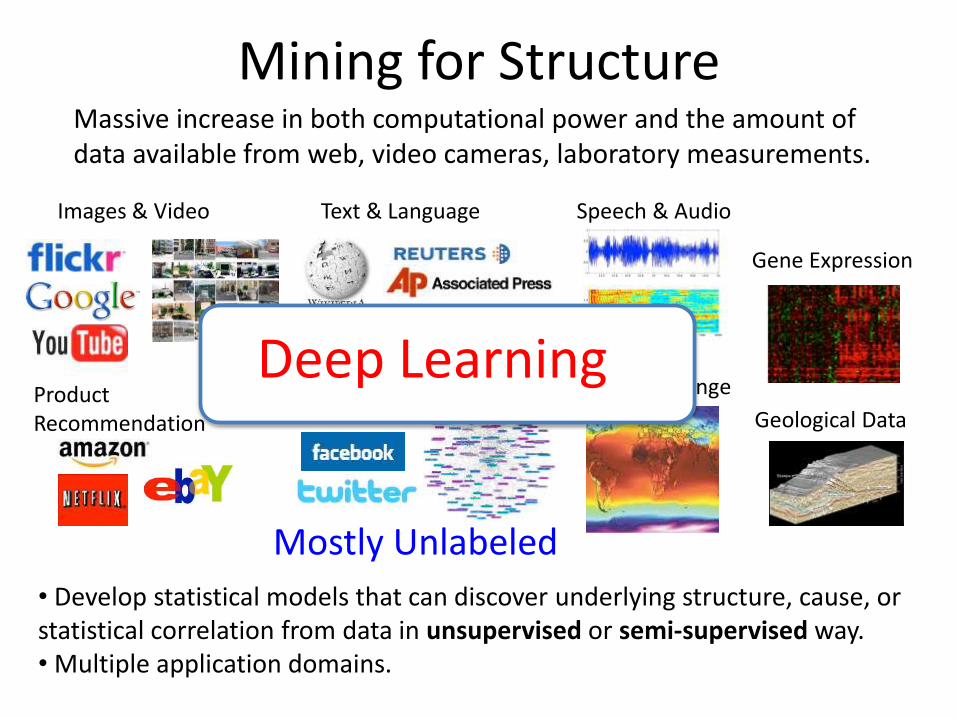
Massive increase in both computational power and the amount of data available from web, video cameras, laboratory measurements.
Mining for Structure
Speech & Audio
Gene Expression
Text & Language
Geological DataProduct Recommendation
Climate Change
Mostly Unlabeled
• Develop statistical models that can discover underlying structure, cause, or statistical correlation from data in unsupervised or semi-supervised way. • Multiple application domains.
Deep Learning

Impact of Deep Learning
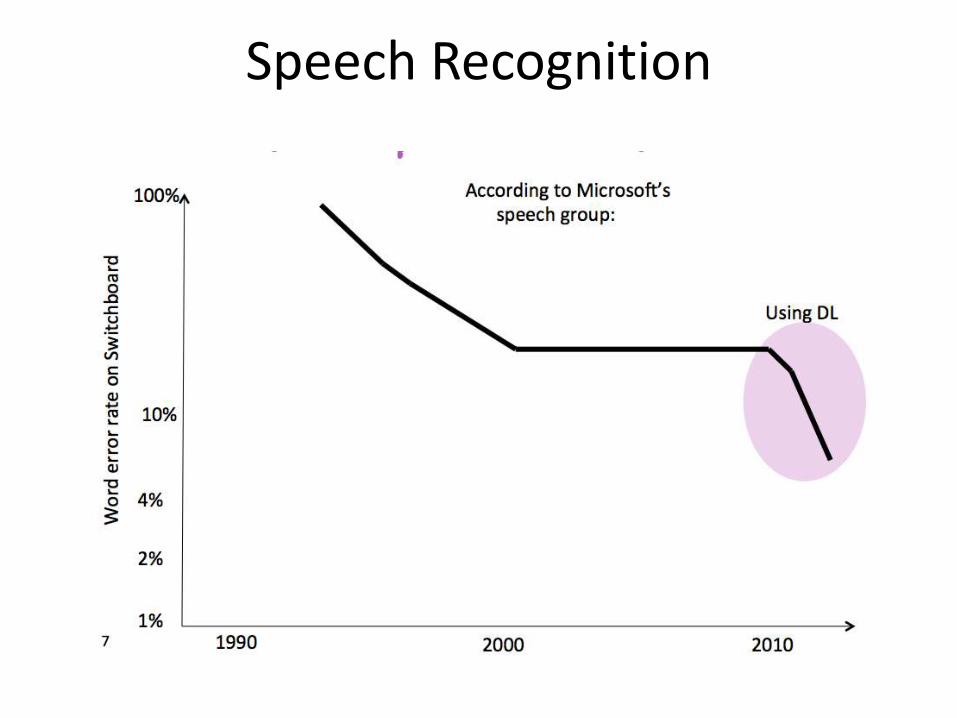
• Speech Recognition
• Computer Vision
• Language Understanding
• Recommender Systems
• Drug Discovery and Medical Image Analysis

Deep Learning in Action • Achieves state-of-the-art on many object recognition tasks! Try it at deeplearning.cs.toronto.edu!

Example: Understanding Images
Model Samples
• a group of people in a crowded area .• a group of people are walking and talking .• a group of people, standing around and talking .• a group of people that are in the outside .
strangers, coworkers, conventioneers, attendants, patrons
TAGS:
Nearest Neighbor Sentence:
people taking pictures of a crazy person

Image Tagging and Retrievalmosque, tower, building, cathedral,dome, castle
kitchen, stove, oven,refrigerator, microwave
ski, skiing, skiers, skiiers,snowmobile
bowl, cup, soup, cups, coffee
beach
snow
Speech Recognition

Merck Molecular Activity Challenge
• Deep Learning technique: Predict biological activities of different molecules, given numerical descriptors generated from their chemical structures.
• To develop new medicines, it is important to identify molecules that are highly active toward their intended targets.
Toronto team takes first place!

• From their blog:
- Restricted Boltzmann machines - Probabilistic Matrix Factorization
(Salakhutdinov et. al. ICML, 2007, Salakhutdinov and Mnih, 2008)
To put these algorithms to use, we had to work to overcome some limitations, for instance that they were built to handle 100 million ratings, instead of the more than 5 billion that we have, and that they were not built to adapt as members added more ratings. But once we overcame those challenges, we put the two algorithms into production, where they are still used as part of our recommendation engine.
Netflix uses:
Both of these algorithms were developed by us at Toronto!


Deep Learning in the News

Key Computational Challenges
- Learning from billions of (unlabeled) data points
- Developing new parallel algorithms
Building bigger models using more data improves performance of deep learning algorithms!
Scaling up our deep learning algorithms:
- Scaling up Computation using clusters of GPUs and FPGAs

Building Artificial Intelligence
Develop computer algorithms that can:
- See and recognize objects around us
- Perceive human speech
- Understand natural language
- Navigate around autonomously
- Display human like Intelligence
Personal assistants, self-driving cars, etc.

Talk Roadmap
• Introduction
• Key Deep Learning Models
• Applications: Multimodal Learning and Language Modeling

Learning Feature Representations
pixel 1
pixel 2 Learning
Algorithm
pixel 2
pix
el 1
SegwayNon-SegwayInput Space
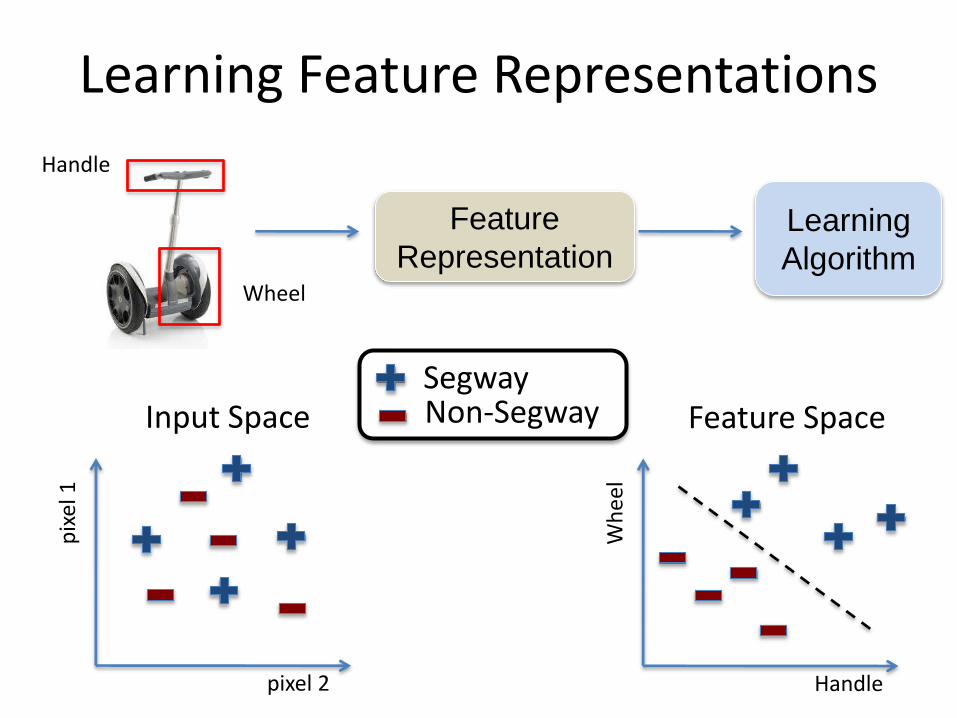
Learning Feature Representations
pixel 2
pix
el 1
SegwayNon-SegwayInput Space
Handle
Wheel
Learning
Algorithm
Feature
Representation
Handle
Wh
eel
Feature Space

Traditional Approaches
Image vision features Recognition
Object detection
Audio classification
Audio audio featuresSpeaker
identification
DataFeature
extraction
Learning
algorithm
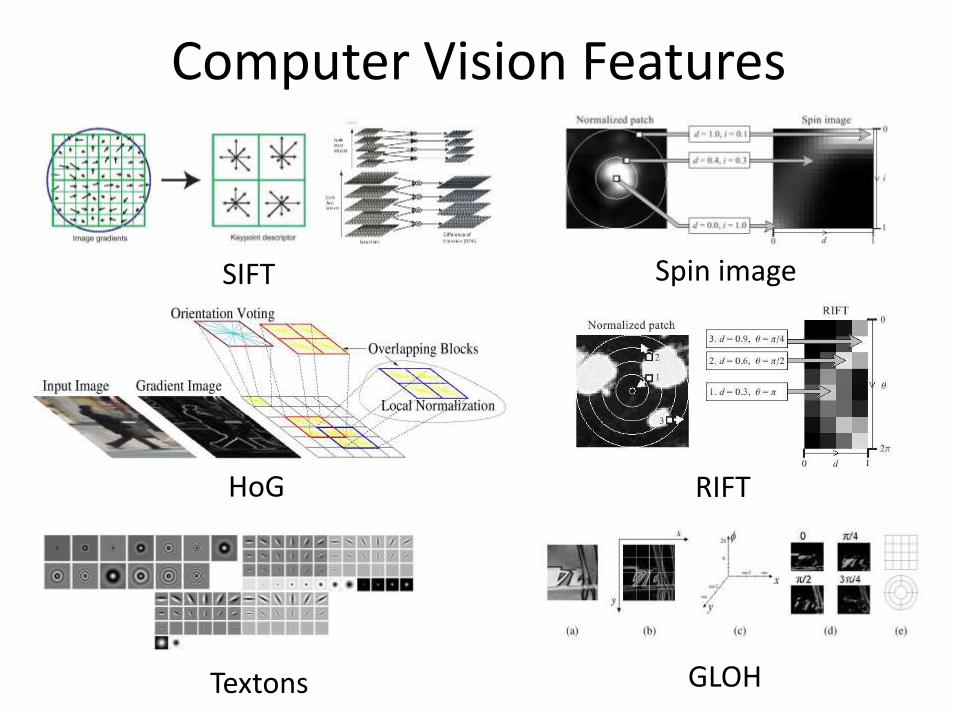
Computer Vision Features
SIFT Spin image
HoG RIFT
Textons GLOH
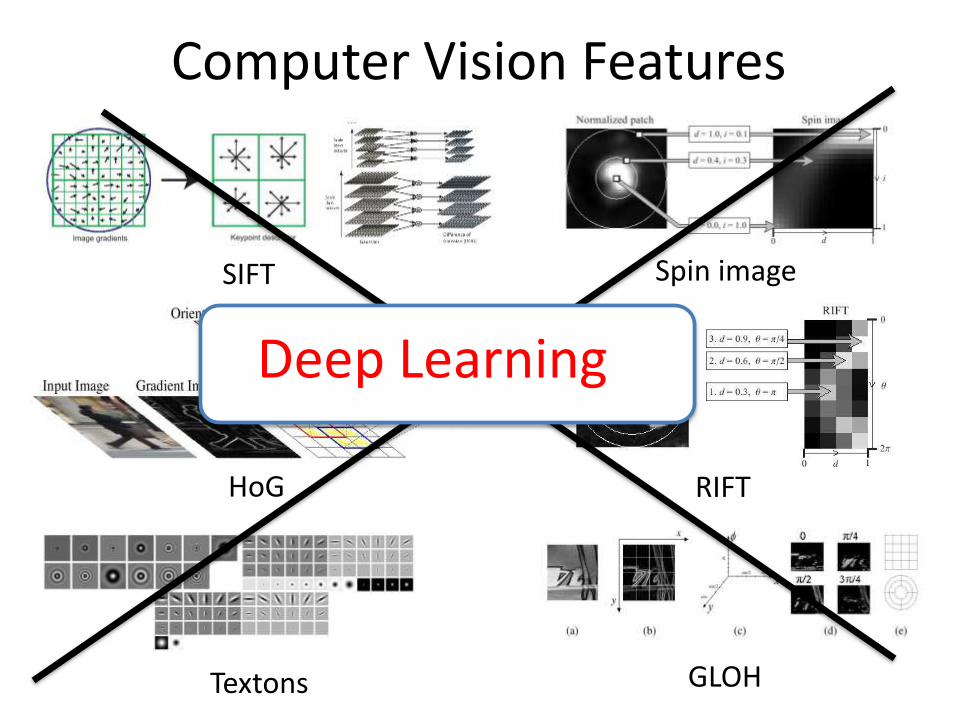
Computer Vision Features
SIFT Spin image
HoG RIFT
Textons GLOH
Deep Learning
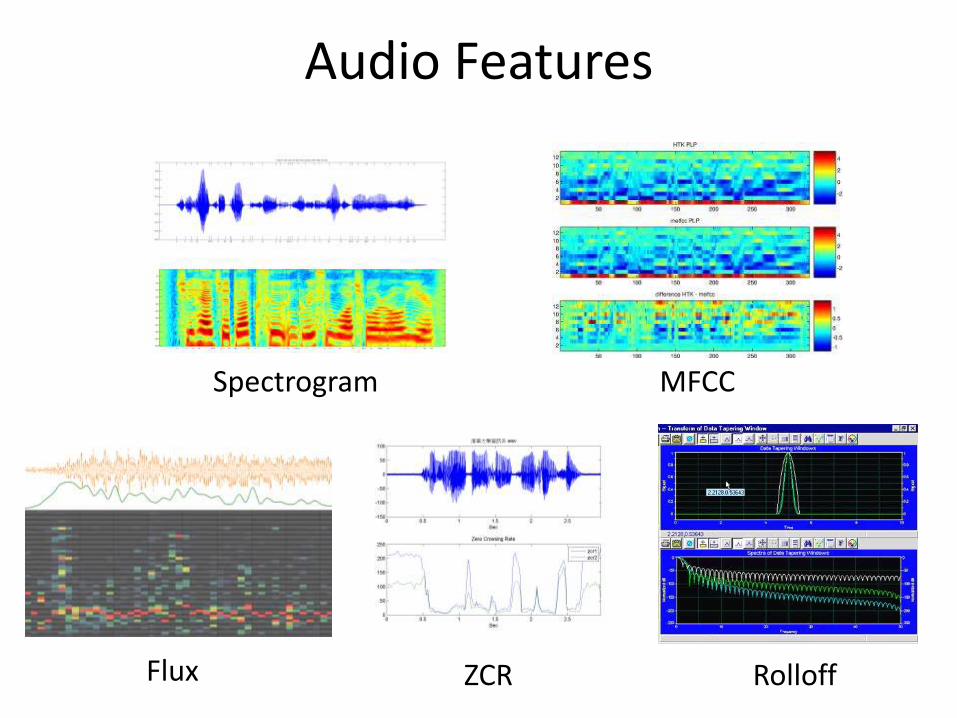
ZCR
Spectrogram MFCC
RolloffFlux
Audio Features
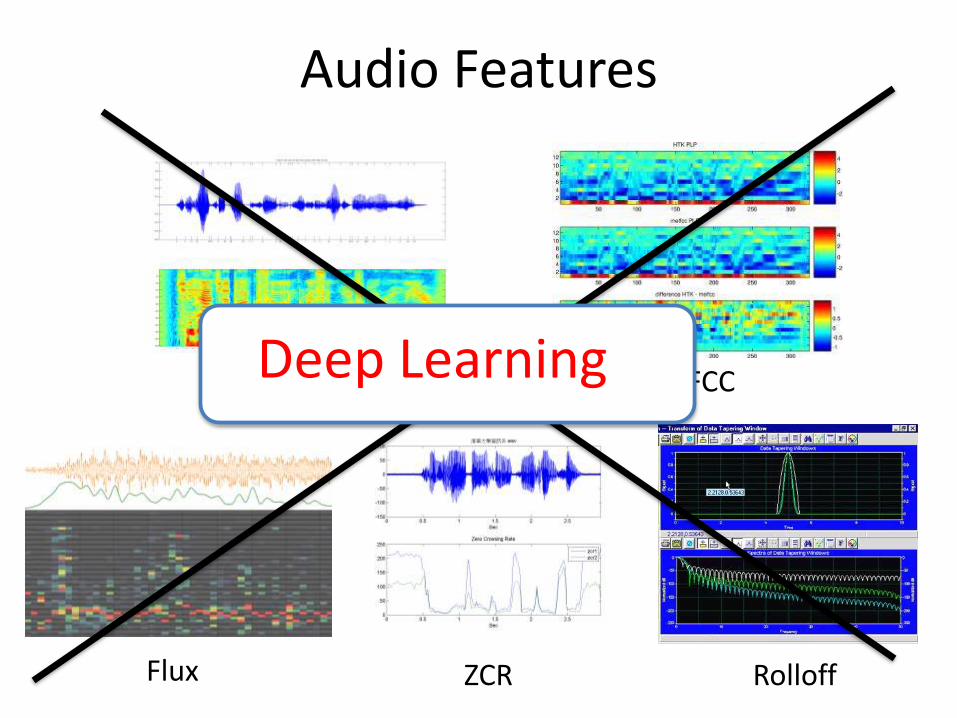
Audio Features
ZCR
Spectrogram MFCC
RolloffFlux
Deep Learning
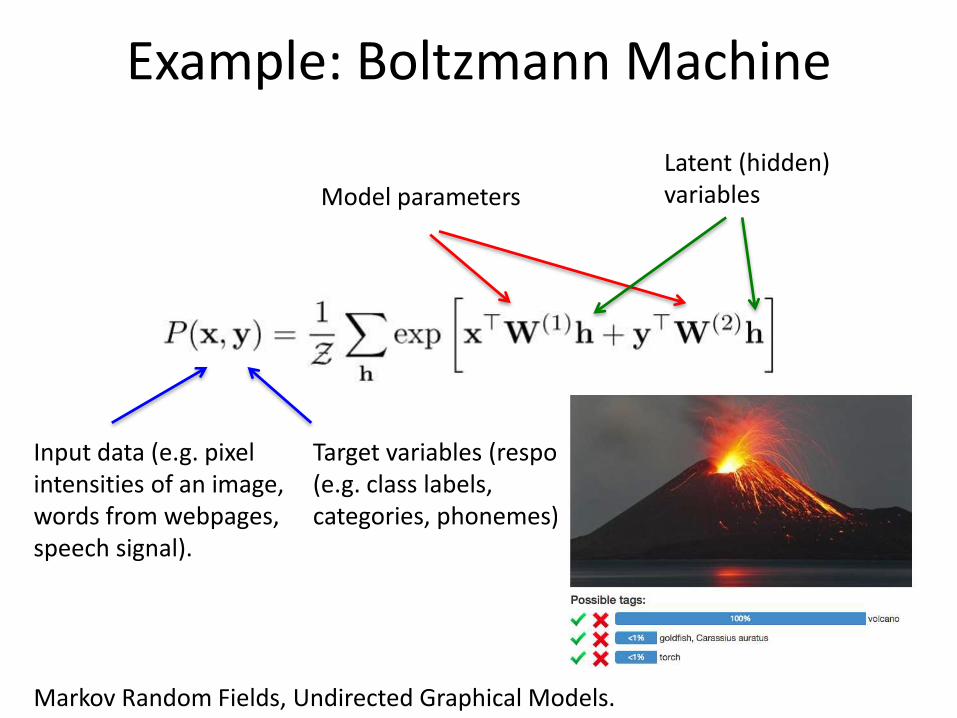
Example: Boltzmann Machine
Input data (e.g. pixel intensities of an image, words from webpages, speech signal).
Target variables (response) (e.g. class labels, categories, phonemes).
Model parameters
Latent (hidden) variables
Markov Random Fields, Undirected Graphical Models.

Unsupervised Learning
Vector of word counts on a webpage
Latent variables: semantic topics
804,414 newswire stories
(Hinton & Salakhutdinov, Science 2006)

Talk Roadmap
• Introduction
• Key Deep Learning Models
• Applications: Multimodal Learning and Language Modeling.

Restricted Boltzmann Machines
- Can characterize uncertainty.
Pair-wise Unary
Markov random fields, Boltzmann machines, log-linear models.
Image visible variables
Feature Detectors
Define a proper probabilistic model:
- Deal with missing or noisy data.
- Can simulate from the model.
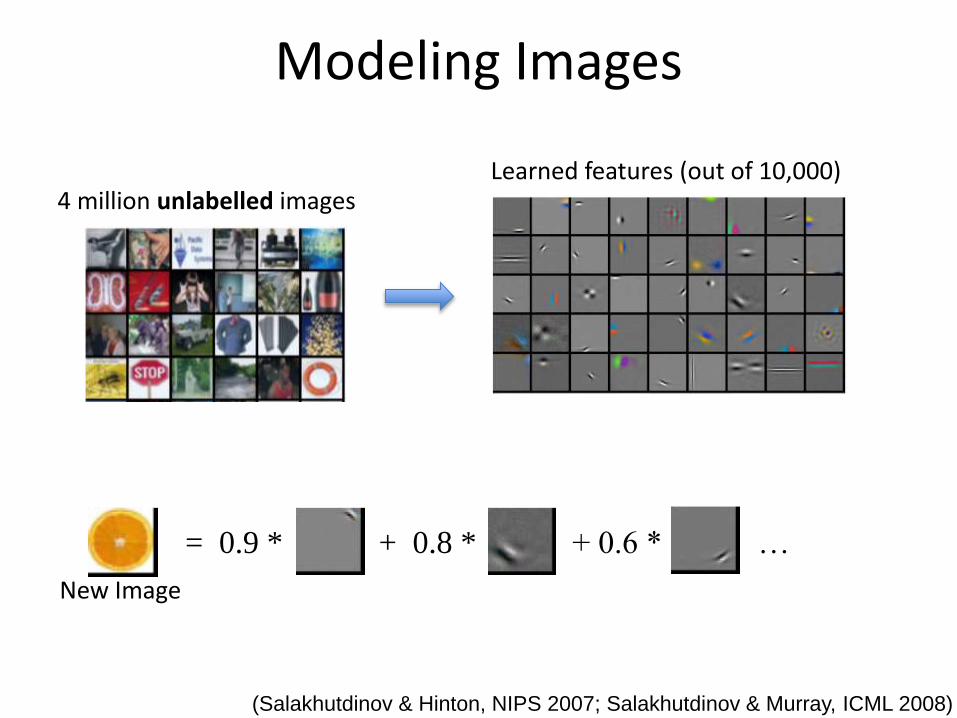
Modeling Images
(Salakhutdinov & Hinton, NIPS 2007; Salakhutdinov & Murray, ICML 2008)
Learned features (out of 10,000)4 million unlabelled images
= 0.9 * + 0.8 * + 0.6 * …
New Image

Modeling Images and Text
(Salakhutdinov & Hinton, NIPS 2007; Salakhutdinov & Murray, ICML 2008)
Learned ``strokes’’Data: Handwritten characters
Learned features: ``topics’’
russianrussiamoscowyeltsinsoviet
clintonhousepresidentbillcongress
computersystemproductsoftwaredevelop
tradecountryimportworldeconomy
stockwallstreetpointdow
Reuters dataset: 804,414 unlabeled newswire stories
Bag-of-Words

Learned features: ``genre’’
Fahrenheit 9/11Bowling for ColumbineThe People vs. Larry FlyntCanadian BaconLa Dolce Vita
Independence DayThe Day After TomorrowCon AirMen in Black IIMen in Black
Friday the 13thThe Texas Chainsaw MassacreChildren of the CornChild's PlayThe Return of Michael Myers
Scary MovieNaked Gun Hot Shots!American Pie Police Academy
Netflix dataset: 480,189 users 17,770 movies Over 100 million ratings
State-of-the-art performance on the Netflix dataset.
Recommender Engine
(Salakhutdinov, Mnih, Hinton, ICML 2007)
Multinomial visible: user ratings
Binary hidden: user preferences

Image
Low-level features:Edges
Input: Pixels
(Salakhutdinov & Hinton, Neural Computation 2012)
Deep Boltzmann Machines: Learning Hierarchies of Features
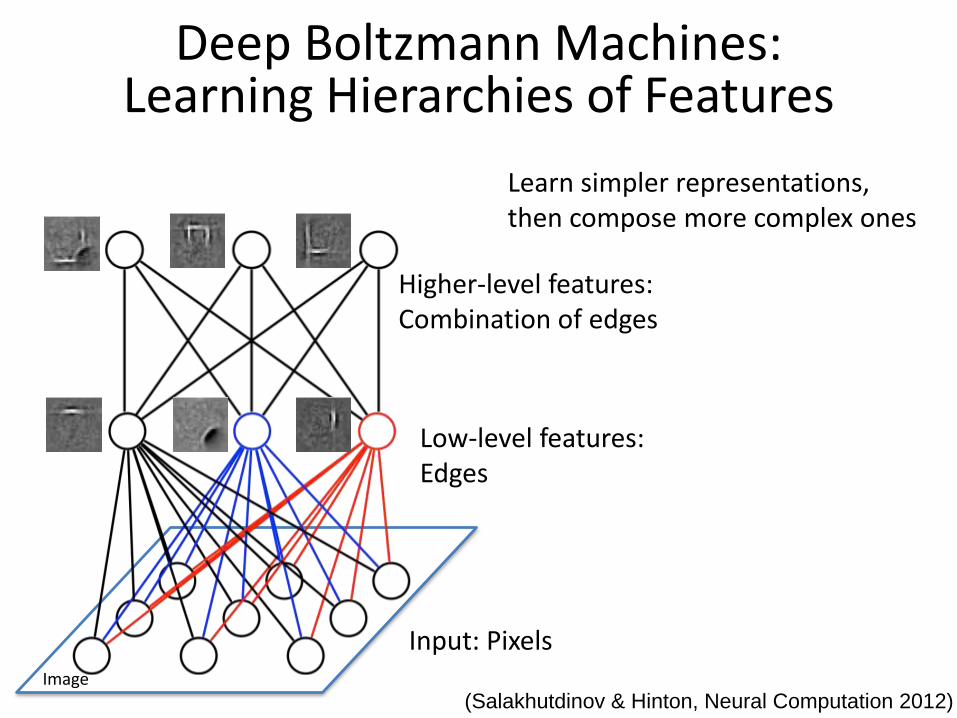
Image
Higher-level features:Combination of edges
Low-level features:Edges
Input: Pixels
Learn simpler representations,then compose more complex ones
(Salakhutdinov & Hinton, Neural Computation 2012)
Deep Boltzmann Machines: Learning Hierarchies of Features
Learning Multiple Layers• Biological and theoretical justification for learning multiple layers of representation
• Biologically inspired learning:
- Brain has hierarchical architecture
- Cortex appears to have a generic learning algorithm
- Humans learn simpler representations, then compose more complex ones
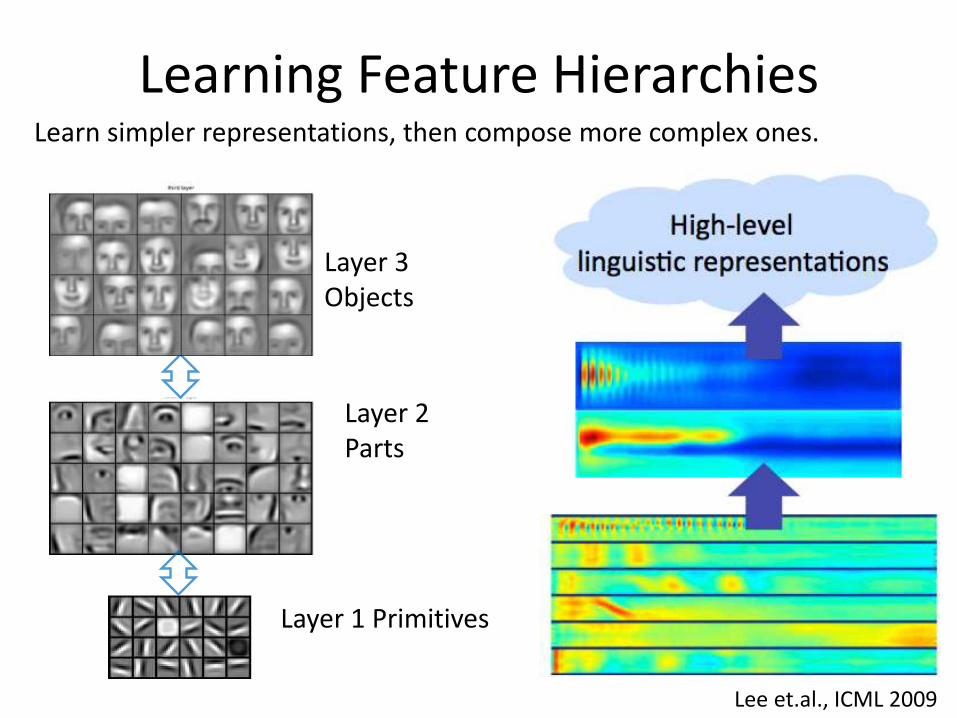
Learning Feature Hierarchies
Layer 1 Primitives
Lee et.al., ICML 2009
Layer 2 Parts
Layer 3 Objects
Learn simpler representations, then compose more complex ones.

Good Generative Model?
Handwritten Characters

Good Generative Model?
Handwritten Characters

Good Generative Model?
Handwritten Characters
Real DataSimulated

Good Generative Model?
Handwritten Characters
Real Data Simulated

Good Generative Model?
Handwritten Characters

Good Generative Model?
MNIST Handwritten Digit Dataset

Talk Roadmap
• Introduction
• Key Deep Learning Models
• Applications: Multimodal Learning and Language Modeling.

Data – Collection of Modalities
• Multimedia content on the web -image + text + audio.
• Product recommendation systems.
• Robotics applications.
AudioVision
Touch sensorsMotor control
sunset, pacificocean, bakerbeach, seashore, ocean
car, automobile
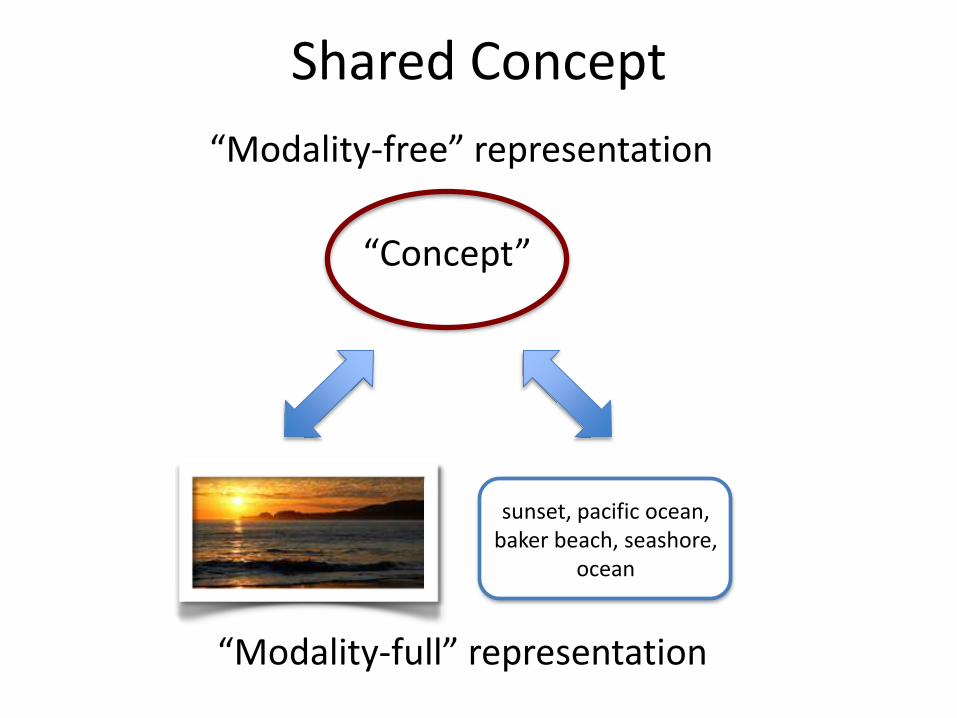
Shared Concept
“Modality-free” representation
“Modality-full” representation
“Concept”
sunset, pacific ocean, baker beach, seashore,
ocean

• Improve Classification
Multi-Modal Input
pentax, k10d, kangarooislandsouthaustralia, sa australiaaustraliansealion 300mm
SEA / NOT SEA
• Retrieve data from one modality when queried using data from another modality
beach, sea, surf, strand, shore, wave, seascape, sand, ocean, waves
• Fill in Missing Modalitiesbeach, sea, surf, strand, shore, wave, seascape, sand, ocean, waves
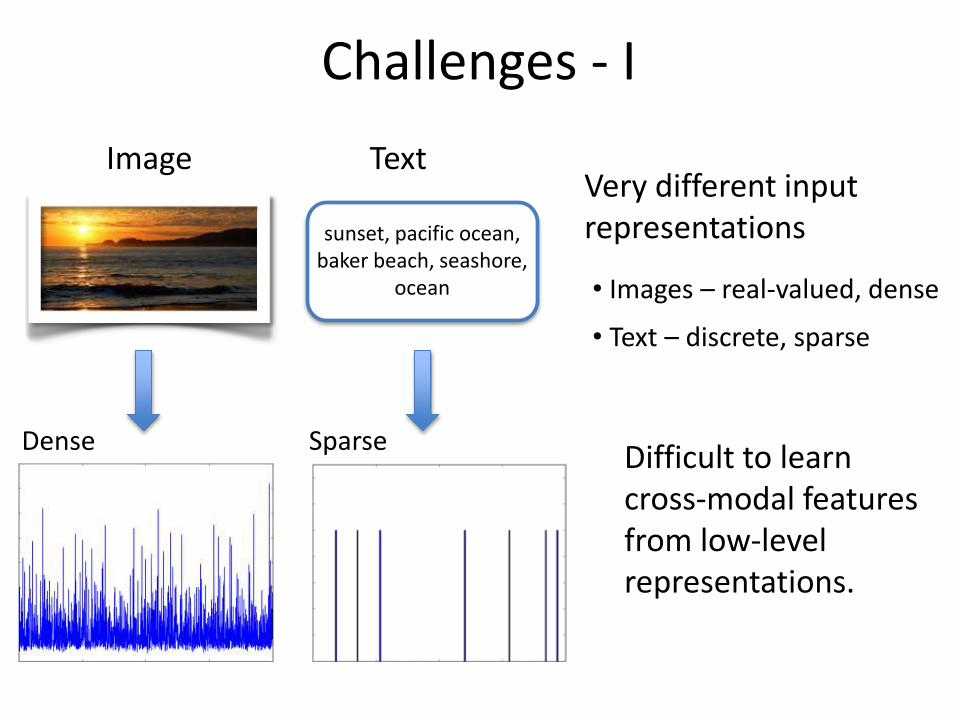
Challenges - I
Very different input representations
Image Text
sunset, pacific ocean, baker beach, seashore,
ocean • Images – real-valued, dense
Difficult to learn cross-modal features from low-level representations.
Dense
• Text – discrete, sparse
Sparse

Challenges - II
Noisy and missing data
Image Textpentax, k10d, pentaxda50200, kangarooisland, sa, australiansealion
mickikrimmel, mickipedia, headshot
unseulpixel, naturey
< no text>

Challenges - II Image Text Text generated by the model
beach, sea, surf, strand, shore, wave, seascape, sand, ocean, waves
portrait, girl, woman, lady, blonde, pretty, gorgeous, expression, model
night, notte, traffic, light, lights, parking, darkness, lowlight, nacht, glow
fall, autumn, trees, leaves, foliage, forest, woods, branches, path
pentax, k10d, pentaxda50200, kangarooisland, sa, australiansealion
mickikrimmel, mickipedia, headshot
unseulpixel, naturey
< no text>
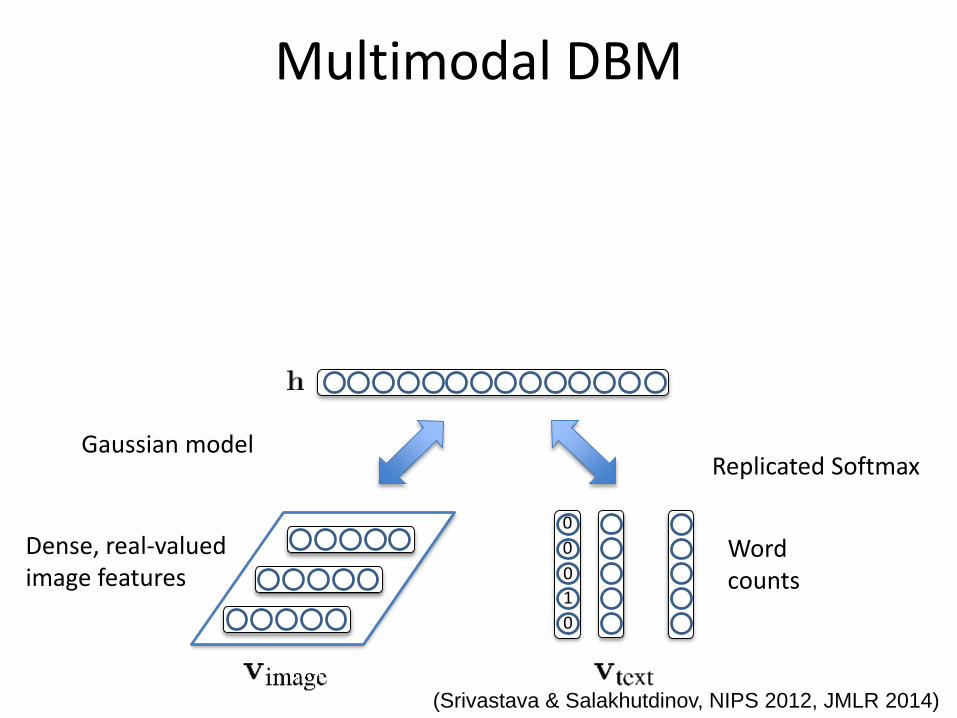
0
0
1
0
0
Dense, real-valued image features
Gaussian modelReplicated Softmax
Multimodal DBM
Word counts
(Srivastava & Salakhutdinov, NIPS 2012, JMLR 2014)

Multimodal DBM
0
0
1
0
0
Dense, real-valued image features
Gaussian modelReplicated Softmax
Word counts
(Srivastava & Salakhutdinov, NIPS 2012, JMLR 2014)
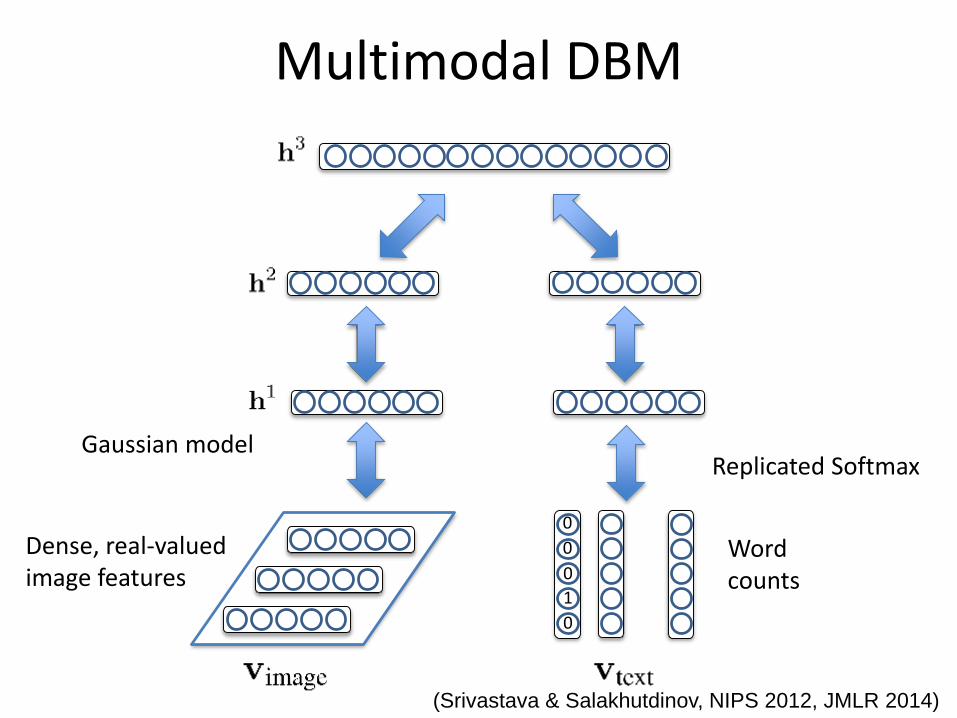
Gaussian modelReplicated Softmax
0
0
1
0
0
Multimodal DBM
Word counts
Dense, real-valued image features
(Srivastava & Salakhutdinov, NIPS 2012, JMLR 2014)

Text Generated from Images
canada, nature, sunrise, ontario, fog, mist, bc, morning
insect, butterfly, insects, bug, butterflies, lepidoptera
graffiti, streetart, stencil, sticker, urbanart, graff, sanfrancisco
portrait, child, kid, ritratto, kids, children, boy, cute, boys, italy
dog, cat, pet, kitten, puppy, ginger, tongue, kitty, dogs, furry
sea, france, boat, mer, beach, river, bretagne, plage, brittany
Given Generated Given Generated

Text Generated from Images
Given Generated
water, glass, beer, bottle, drink, wine, bubbles, splash, drops, drop
portrait, women, army, soldier, mother, postcard, soldiers
obama, barackobama, election, politics, president, hope, change, sanfrancisco, convention, rally

Images from Text
water, red, sunset
nature, flower, red, green
blue, green, yellow, colors
chocolate, cake
Given Retrieved

MIR-Flickr Dataset
Huiskes et. al.
• 1 million images along with user-assigned tags.
sculpture, beauty, stone
nikon, green, light, photoshop, apple, d70
white, yellow, abstract, lines, bus, graphic
sky, geotagged, reflection, cielo, bilbao, reflejo
food, cupcake, vegan
d80
anawesomeshot, theperfectphotographer, flash, damniwishidtakenthat, spiritofphotography
nikon, abigfave, goldstaraward, d80, nikond80

Results• Logistic regression on top-level representation.
• Multimodal Inputs
Learning Algorithm MAP Precision@50
Random 0.124 0.124
LDA [Huiskes et. al.] 0.492 0.754
SVM [Huiskes et. al.] 0.475 0.758
DBM-Labelled 0.526 0.791
Deep Belief Net 0.638 0.867
Autoencoder 0.638 0.875
DBM 0.641 0.873
Mean Average Precision
Labeled 25K examples
+ 1 Million unlabelled
State-of-the-art performance

Generating Sentences
Input
A man skiing down the snow covered mountain with a dark sky in the background.
Output
• More challenging problem.
• How can we generate complete descriptions of images?
Learning Semantic Representation
• Key Idea: Each word w is represented as a D-dimensional real-valued vector rw 2 RD.
Dimension 2
Dim
ensi
on
2
Semantic Space
table
chair
dolphinwhale
November

Joint Feature space
A castle and reflecting water
A ship sailing in the ocean
A plane flying in the sky
Multimodal Neural Language Models (Kiros, et.al., ICML 2014)
Learning Semantic Representation

Tagging and Retrievalmosque, tower, building, cathedral,dome, castle
kitchen, stove, oven,refrigerator, microwave
ski, skiing, skiers, skiiers,snowmobile
bowl, cup, soup, cups, coffee
beach
snow

Multimodal Linguistic RegularitiesNearest Images
Ryan Kiros, 2014

Multimodal Linguistic RegularitiesNearest Images
Ryan Kiros, 2014

Caption Generation

Caption Generation
Model Samples
• Two men in a room talking on a table .• Two men are sitting next to each other .• Two men are having a conversation at a table .• Two men sitting at a desk next to each other .
colleagues waiters waiter entrepreneurs busboy
TAGS:

More Examples
spider, spiders, arachnid, insects, insect
creepy, spooky, elfin
Model Samples
Giant spider found in the Netherlands.Look at the new spider web.This was near the black spider web.I like the spider.The pattern of one spider web.
TAGS:

Multi-Modal Models
Laser scans
Images
Video
Text & Language
Time series data
Speech & Audio
Develop learning systems that come closer to displaying human like intelligence

Summary• Efficient learning algorithms for Hierarchical Generative Models.
Learning more adaptive, robust, and structured representations.
• Deep models can improve current state-of-the art in many application domains: Object recognition and detection, text and image retrieval, handwritten
character and speech recognition, and others.
Text & image retrieval / Object recognition
Learning a Category Hierarchy
Dealing with missing/occluded data
HMM decoder
Speech Recognition
sunset, pacific ocean, beach, seashore
Multimodal Data
Object Detection

Our Toronto Lab
We collaborate with and consult for various organizations

Thank you