deep dive: amazon dynamodb - amazon web serviceslondon-summit-slides-2017.s3.amazonaws.com/deep...
TRANSCRIPT

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Richard Westby-Nunn – Technical Account Manager, Enterprise Support
28 June 2017
Deep Dive:Amazon DynamoDB

Agenda
DynamoDB 101 - Tables, PartitioningIndexesScalingData ModelingDynamoDB StreamsScenarios and Best PracticesRecent Announcements

Amazon DynamoDB
Document or Key-Value Scales to Any WorkloadFully Managed NoSQL
Access Control Event Driven ProgrammingFast and Consistent

Tables, Partitioning

TableTable
Items
Attributes
PartitionKey
SortKey
MandatoryKey-value access patternDetermines data distribution Optional
Model 1:N relationshipsEnables rich query capabilities
Allitemsforapartitionkey==,<,>,>=,<=“beginswith”“between”sortedresultscountstop/bottomNvaluespagedresponses

00 55 A954 AA FF
Partition tablePartition key uniquely identifies an itemPartition key is used for building an unordered hash indexTable can be partitioned for scale
00 FF
Id = 1Name = Jim
Hash (1) = 7B
Id = 2Name = AndyDept = EnggHash (2) = 48
Id = 3Name = KimDept = Ops
Hash (3) = CD
Key Space

Partition-sort key tablePartition key and sort key together uniquely identify an ItemWithin unordered partition key-space, data is sorted by the sort keyNo limit on the number of items (∞) per partition key
• Except if you have local secondary indexes
00:0 FF:∞
Hash (2) = 48
Customer# = 2Order# = 10Item = Pen
Customer# = 2Order# = 11Item = Shoes
Customer# = 1Order# = 10Item = Toy
Customer# = 1Order# = 11Item = Boots
Hash (1) = 7B
Customer# = 3Order# = 10Item = Book
Customer# = 3Order# = 11Item = Paper
Hash (3) = CD
55 A9:∞54:∞ AA
Partition 1 Partition 2 Partition 3

Partitions are three-way replicated
Id = 2Name = AndyDept = Engg
Id = 3Name = KimDept = Ops
Id = 1Name = Jim
Id = 2Name = AndyDept = Engg
Id = 3Name = KimDept = Ops
Id = 1Name = Jim
Id = 2Name = AndyDept = Engg
Id = 3Name = KimDept = Ops
Id = 1Name = Jim
Replica 1
Replica 2
Replica 3
Partition 1 Partition 2 Partition N

Eventually Consistent Reads
Partition A1000 RCUs
Partition A1000 RCUs
Partition A1000 RCUs
Rand(1,3)
Replica 1 Replica 2 Replica 3

Strongly Consistent Reads
Partition A1000 RCUs
Partition A1000 RCUs
Partition A1000 RCUs
Primary
Locate Primary
Replica 1 Replica 2 Replica 3

Indexes

Local secondary index (LSI)
Alternate sort key attributeIndex is local to a partition key
A1(partition)
A3(sort)
A2(tablekey)
A1(partition)
A2(sort)
A3 A4 A5
LSIs A1(partition)
A4(sort)
A2(tablekey)
A3(projected)
Table
KEYS_ONLY
INCLUDE A3
A1(partition)
A5(sort)
A2(tablekey)
A3(projected)
A4(projected) ALL
10 GB max per partition key, i.e. LSIs limit the # of sort keys!

Global secondary index (GSI)Alternate partition (+sort) keyIndex is across all table partition keys
GSIsA5
(part.)A4
(sort)A1
(tablekey)A3
(projected)
Table
INCLUDE A3
A4(part.)
A5(sort)
A1(tablekey)
A2(projected)
A3(projected) ALL
A2(part.)
A1(tablekey) KEYS_ONLY
RCUs/WCUs provisioned separately for GSIs
Online Indexing
A1(partition)
A2 A3 A4 A5

LSI or GSI?
LSI can be modeled as a GSIIf data size in an item collection > 10 GB, use GSIIf eventual consistency is okay for your scenario, use GSI!

Scaling

Scaling
Throughput§ Provision any amount of throughput to a table
Size§ Add any number of items to a table
- Max item size is 400 KB- LSIs limit the number of range keys due to 10 GB limit
Scaling is achieved through partitioning

Throughput
Provisioned at the table level• Write capacity units (WCUs) are measured in 1 KB per second• Read capacity units (RCUs) are measured in 4 KB per second
• RCUs measure strictly consistent reads• Eventually consistent reads cost 1/2 of consistent reads
Read and write throughput limits are independent
WCURCU

Partitioning Math
Number of Partitions
By Capacity (Total RCU / 3000) + (Total WCU / 1000)
By Size Total Size / 10 GB
Total Partitions CEILING(MAX (Capacity, Size))

Partitioning Example
Table size = 8 GB, RCUs = 5000, WCUs = 500
RCUs per partition = 5000/3 = 1666.67WCUs per partition = 500/3 = 166.67Data/partition = 10/3 = 3.33 GB
RCUs and WCUs are uniformly spread across partitions
Number of Partitions
By Capacity (5000 / 3000) + (500 / 1000) = 2.17
By Size 8 / 10 = 0.8
Total Partitions CEILING(MAX (2.17, 0.8)) = 3

Burst capacity is built-in
0
400
800
1200
1600
Cap
acity
Uni
ts
Time
Provisioned Consumed
“Save up” unused capacity
Consume saved up capacity
Burst: 300 seconds(1200 × 300 = 360k CU)

Burst capacity may not be sufficient
0
400
800
1200
1600
Cap
acity
Uni
ts
Time
Provisioned Consumed Attempted
Throttled requests
Don’t completely depend on burst capacity… provision sufficient throughput
Burst: 300 seconds(1200 × 300 = 360k CU)

What causes throttling?
Non-uniform workloads• Hot keys/hot partitions• Very large bursts
Dilution of throughput across partitions caused by mixing hot data with cold data
• Use a table per time period for storing time series data so WCUs and RCUs are applied to the hot data set

Example: Key Choice or Uniform Access
Parti
tion
Time
Heat

Getting the most out of DynamoDB throughput
“To get the most out of DynamoDBthroughput, create tables where the partition key has a large number of distinct values, and values are requested fairly uniformly, as randomly as possible.”
—DynamoDB Developer Guide
1. Key Choice: High key cardinality (“uniqueness”)
2. Uniform Access: access is evenly spread over the key-space
3. Time: requests arrive evenly spaced in time

Example: Time-based Access

Example: Uniform access

Data Modeling
Store data based on how you will access it!

1:1 relationships or key-values
Use a table or GSI with a partition keyUse GetItem or BatchGetItem API
Example: Given a user or email, get attributes
UsersTablePartition key AttributesUserId=bob [email protected],JoinDate=2011-11-15UserId=fred [email protected],JoinDate=2011-12-01
Users-Email-GSIPartitionkey [email protected] UserId=bob,[email protected] UserId=fred,JoinDate=2011-12-01

1:N relationships or parent-children
Use a table or GSI with partition and sort keyUse Query API
Example: Given a device, find all readings between epoch X, Y
Device-measurementsPart.Key Sortkey AttributesDeviceId=1 epoch=5513A97C Temperature=30,pressure=90DeviceId=1 epoch=5513A9DB Temperature=30,pressure=90

N:M relationships
Use a table and GSI with partition and sort key elements switchedUse Query API Example: Given a user, find all games. Or given a game, find all users.
User-Games-TablePart.Key SortkeyUserId=bob GameId=Game1UserId=fred GameId=Game2UserId=bob GameId=Game3
Game-Users-GSIPart.Key SortkeyGameId=Game1 UserId=bobGameId=Game2 UserId=fredGameId=Game3 UserId=bob

Documents (JSON)
Data types (M, L, BOOL, NULL) introduced to support JSONDocument SDKs
• Simple programming model• Conversion to/from JSON• Java, JavaScript, Ruby, .NET
Cannot create an Index on elements of a JSON object stored in Map
• They need to be modeled as top-level table attributes to be used in LSIs and GSIs
Set, Map, and List have no element limit but depth is 32 levels
Javascript DynamoDBstring S
number Nboolean BOOL
null NULLarray Lobject M

Rich expressions
Projection expression• Query/Get/Scan: ProductReviews.FiveStar[0]
Filter expression• Query/Scan: #V > :num (#V is a place holder for keyword VIEWS)
Conditional expression • Put/Update/DeleteItem: attribute_not_exists (#pr.FiveStar)
Update expression• UpdateItem: set Replies = Replies + :num

DynamoDB Streams

Stream of updates to a tableAsynchronousExactly onceStrictly ordered
• Per item
Highly durable
• Scale with table24-hour lifetimeSub-second latency
DynamoDB Streams

DynamoDB Streams and AWS Lambda

Scenarios and Best Practices

Event Logging
Storing time series data

Time series tables
Events_table_2016_AprilEvent_id(Partition key)
Timestamp(sort key)
Attribute1 …. Attribute N
Events_table_2016_MarchEvent_id(Partition key)
Timestamp(sort key)
Attribute1 …. Attribute N
Events_table_2016_FeburaryEvent_id(Partition key)
Timestamp(sort key)
Attribute1 …. Attribute N
Events_table_2016_JanuaryEvent_id(Partition key)
Timestamp(sort key)
Attribute1 …. Attribute N
RCUs = 1000WCUs = 100
RCUs = 10000WCUs = 10000
RCUs = 100WCUs = 1
RCUs = 10WCUs = 1
Current table
Older tables
Hot
dat
aC
old
data
Don’t mix hot and cold data; archive cold data to Amazon S3

DynamoDB TTL
RCUs = 10000WCUs = 10000
RCUs = 100WCUs = 1
Hot
dat
aC
old
data
Use DynamoDB TTL and Streams to archive
Events_table_2016_AprilEvent_id(Partition key)
Timestamp(sort key)
myTTL1489188093
…. Attribute NCurrent table
Events_ArchiveEvent_id(Partition key)
Timestamp(sort key)
Attribute1 …. Attribute N

Isolate cold data from hot data
Pre-create daily, weekly, monthly tablesProvision required throughput for current tableWrites go to the current tableTurn off (or reduce) throughput for older tablesOR move items to separate table with TTL
Dealing with time series data

Real-Time Voting
Write-heavy items

Partition 11000 WCUs
Partition K1000 WCUs
Partition M1000 WCUs
Partition N1000 WCUs
Votes Table
Candidate A Candidate B
Scaling bottlenecks
Voters
Provision 200,000 WCUs

Write sharding
Candidate A_2
Candidate B_1
Candidate B_2
Candidate B_3
Candidate B_5
Candidate B_4
Candidate B_7
Candidate B_6
Candidate A_1
Candidate A_3
Candidate A_4Candidate A_7 Candidate B_8
UpdateItem: “CandidateA_” + rand(0, 10)ADD 1 to Votes
Candidate A_6 Candidate A_8
Candidate A_5
Voter
Votes Table

Votes Table
Shard aggregation
Candidate A_2
Candidate B_1
Candidate B_2
Candidate B_3
Candidate B_5
Candidate B_4
Candidate B_7
Candidate B_6
Candidate A_1
Candidate A_3
Candidate A_4
Candidate A_5
Candidate A_6 Candidate A_8
Candidate A_7 Candidate B_8
Periodic Process
Candidate ATotal: 2.5M
1. Sum2. Store Voter

Trade off read cost for write scalabilityConsider throughput per partition key and per partition
Shard write-heavy partition keys
Your write workload is not horizontally scalable

Product Catalog
Popular items (read)

Partition 12000 RCUs
Partition K2000 RCUs
Partition M2000 RCUs
Partition 502000 RCU
Scaling bottlenecks
Product A Product B
Shoppers
ProductCatalog Table
100,000$%&50()*+,+,-./
≈ 𝟐𝟎𝟎𝟎𝑅𝐶𝑈𝑝𝑒𝑟𝑝𝑎𝑟𝑡𝑖𝑡𝑖𝑜𝑛
SELECT Id, Description, ...FROM ProductCatalogWHERE Id="POPULAR_PRODUCT"

Req
uest
s Pe
r Sec
ond
Item Primary Key
Request Distribution Per Partition Key
DynamoDB Requests

Partition 1 Partition 2
ProductCatalog Table
User
DynamoDB
User
SELECT Id, Description, ...FROM ProductCatalogWHERE Id="POPULAR_PRODUCT"

Req
uest
s Pe
r Sec
ond
Item Primary Key
Request Distribution Per Partition Key
DynamoDB Requests Cache Hits

Amazon DynamoDB Accelerator (DAX)
Highly Scalable Fully ManagedExtreme Performance
Flexible SecureEase of Use

Multiplayer Online Gaming
Query filters vs.composite key indexes

Secondary index
Opponent Date GameId Status HostAlice 2014-10-02 d9bl3 DONE DavidCarol 2014-10-08 o2pnb IN_PROGRESS BobBob 2014-09-30 72f49 PENDING AliceBob 2014-10-03 b932s PENDING CarolBob 2014-10-03 ef9ca IN_PROGRESS David
BobPartition key Sort key
Multivalue sorts and filters
Secondary Index
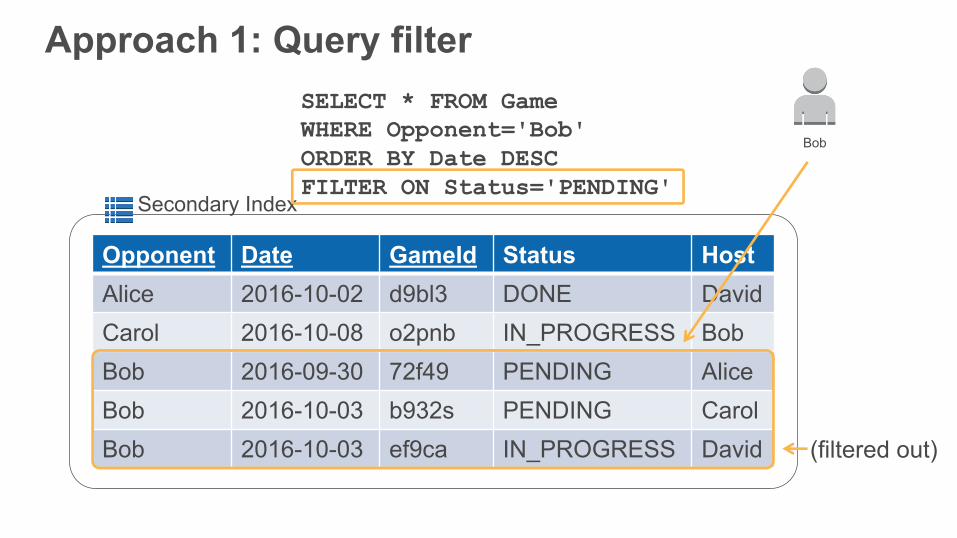
Approach 1: Query filter
Bob
Opponent Date GameId Status HostAlice 2016-10-02 d9bl3 DONE DavidCarol 2016-10-08 o2pnb IN_PROGRESS BobBob 2016-09-30 72f49 PENDING AliceBob 2016-10-03 b932s PENDING CarolBob 2016-10-03 ef9ca IN_PROGRESS David
SELECT * FROM GameWHERE Opponent='Bob' ORDER BY Date DESCFILTER ON Status='PENDING'
(filtered out)

Send back less data “on the wire”Simplify application codeSimple SQL-like expressions
• AND, OR, NOT, ()
Use query filter
Your index isn’t entirely selective

Approach 2: Composite key
StatusDateDONE_2016-10-02IN_PROGRESS_2016-10-08IN_PROGRESS_2016-10-03PENDING_2016-09-30PENDING_2016-10-03
StatusDONEIN_PROGRESSIN_PROGRESSPENDINGPENDING
Date2016-10-022016-10-082016-10-032016-10-032016-09-30

Secondary Index
Approach 2: Composite key
Opponent StatusDate GameId HostAlice DONE_2016-10-02 d9bl3 DavidCarol IN_PROGRESS_2016-10-08 o2pnb BobBob IN_PROGRESS_2016-10-03 ef9ca DavidBob PENDING_2016-09-30 72f49 AliceBob PENDING_2016-10-03 b932s Carol

Opponent StatusDate GameId HostAlice DONE_2016-10-02 d9bl3 DavidCarol IN_PROGRESS_2016-10-08 o2pnb BobBob IN_PROGRESS_2016-10-03 ef9ca DavidBob PENDING_2016-09-30 72f49 AliceBob PENDING_2016-10-03 b932s Carol
Secondary Index
Approach 2: Composite key
Bob
SELECT * FROM GameWHERE Opponent='Bob'
AND StatusDate BEGINS_WITH 'PENDING'

Sparse indexes
Id(Part.) User Game Score Date Award
1 Bob G1 1300 2015-12-232 Bob G1 1450 2015-12-233 Jay G1 1600 2015-12-244 Mary G1 2000 2015-10-24 Champ5 Ryan G2 123 2015-03-106 Jones G2 345 2015-03-20
Game-scores-table
Award(Part.) Id User Score
Champ 4 Mary 2000
Award-GSI
Scan sparse partition GSIs

Concatenate attributes to form useful secondary index keys
Take advantage of sparse indexes
Replace filter with indexes
You want to optimize a query as much as possible

/OcadoTechnology
Scaling with DynamoDB at Ocado


/OcadoTechnology
Who is OcadoOcado is the world’s largest dedicated online grocery retailer.Here in the UK we deliver to over 500,000 active customers shopping with us.Each day we pick and pack over 1,000,000 items for 25,000 customers

/OcadoTechnology
What does Ocado Technology Do?We create the websites and webapps for Ocado, Morrisons, Fetch, Sizzled, Fabled and moreDesign build robotics and software for our automated warehouses.Optimise routes for thousands of miles of deliveries each week

/OcadoTechnology
Ocado Smart PlatformWe’ve also developed a proprietary solution for operating an online retail business.This has been built with the Cloud and AWS in mind.Allows us to offer our solutions international retailers and scale to serve customers around the globe.


/OcadoTechnology
Our ChallengesStarting from scratch, how do we design a modern application suite architecture?How do we minimise bottlenecks and allow ourselves to scale? How can we support our customers (retailers) and their customers without massively increasing our size?

How about them microservices?
Application Architecture

/OcadoTechnology
Applications as masters of their own stateIn the past we had ETLs moving data aroundWe wanted to control how data moved through the platformFor us this mean RESTful services or asynchronous messaging

/OcadoTechnology
Name-spaced MicroservicesUsing IAM policies each application can have it’s own name-spaced AWS resourcesApplications need to stateless themselves, all state must be stored in the databaseDecouple how data is stored from how it’s accessed.

/OcadoTechnology
Opting for DynamoDBEvery microservice needs it’s own database.Easy to manage by developers themselvesNeed to be highly available and as fast as needed

/OcadoTechnology
Things we wanted to avoidShared resources or infrastructure between appsManual intervention in order to scaleDowntime

/OcadoTechnology
RecommendationsAllow applications to create their own DynamoDB tables.Allowing them to tune their own capacity tooUse namespacing to control access arn:aws:dynamodb:region:account-id:table/mymicroservice-*

While managing costs
Scaling Up

/OcadoTechnology
Managed Service vs DIYWe’re a team of 5 engineersSupporting over 1,000 developersWorking on over 200 applications

/OcadoTechnology
Scaling With DynamoDBUse account level throughput limits as a cost safety control no as planned usage.Encourage developers to scale based on a metric using the SDK.Make sure scale down is happening too.

/OcadoTechnology
DynamoDB Autoscaling NEW!
Recently released is the DynamoDB Autoscaling feature.It allows you to set min and max throughput and a target utilisation

/OcadoTechnology
Total Tables: 2,045Total Storage: 283.42 GiBNumber of Items: 1,000,374,288Total Provisioned Throughput (Reads): 49,850Total Provisioned Throughput (Writes): 20,210
Some Stats - Jan 2017

/OcadoTechnology
Total Tables: 3,073Total Storage: 1.78 TiBNumber of Items: 2,816,558,766Total Provisioned Throughput (Reads): 63,421Total Provisioned Throughput (Writes): 32,569
Some Stats - Jun 2017

What additional features do we want
Looking to the Future

/OcadoTechnology
BackupDespite DynamoDB being a managed service we still have a desire to backup our dataHighly available services don’t protect you from user errorHaving a second copy of live databases makes everyone feel confident

/OcadoTechnology
Introducing HippolyteHippolyte is an at-scale DynamoDB backup solutionDesigned for point-in-time backups of hundreds of tables or moreScales capacity up to complete as fast as needed.

/OcadoTechnology
Available NowGithub: https://github.com/ocadotechnology/hippolyte
Blog Post: http://hippolyte.oca.do

Thank you

Recent AnnouncementsAmazon DynamoDB now Supports Cost Allocation Tags
AWS DMS Adds Support for MongoDB and Amazon DynamoDB
Announcing VPC Endpoints for Amazon DynamoDB (Public Preview)
Announcing Amazon DynamoDB Auto Scaling

Amazon DynamoDB AutoScalingAutomate capacity management for tables and GSIs
Enabled by default for all new tables and indexes
Can manually configure for existing tables and indexes
Requires DynamoDBAutoScale Role
Full CLI / API Support
No additional cost beyond existing DynamoDB and Cloudwatch alarms

Amazon DynamoDB Resources
Amazon Dynamo FAQ: https://aws.amazon.com/dynamodb/faqs/
Amazon DynamoDB Documentation (includes Developers Guide):
https://aws.amazon.com/documentation/dynamodb/
AWS Blog: https://aws.amazon.com/blogs/aws/

Thank you!