david shotton - opencon oxford, 1st dec 2017
TRANSCRIPT

Oxford e-Research Centre
University of Oxford, UK
OpenCon 2017 OxfordWeston Library
1 December 2017
© David Shotton 2017 Published under the Creative Commons Attribution-Noncommercial-Share Alike 3.0 Licence
David Shotton
Open publication – current progress Bibliographic resources and
bibliographic citations

What proportion of academic papers are open?
Heather Piwowar et al. recently estimated that at least 28% of the scholarly
literature is now Open Access, and for 2015, the most recent year they analyzed,
the proportion is 47% Open Access
Piwowar, H. et al. The State of OA: A large-scale analysis of the prevalence
and impact of Open Access articles. PeerJ Prepr. (2017).
https://doi.org/10.7287/peerj.preprints.3119v1
They determined the so-called open-access citation advantage:
Accounting for age and discipline, Open Access articles receive
18% more citations than average
Many funders, including the US National Institutes of Health, the US National
Science, the European Commission, the Wellcome Trust, and the Bill and
Melinda Gates Foundation, make Open Access mandatory for grantees
For biomedical papers, this is achieved by putting articles in PubMed Central
PMC (https://www.ncbi.nlm.nih.gov/pmc/) holds ~4.5 million full text articles
Of these, over 1.6 million comprise the PMC open access subset
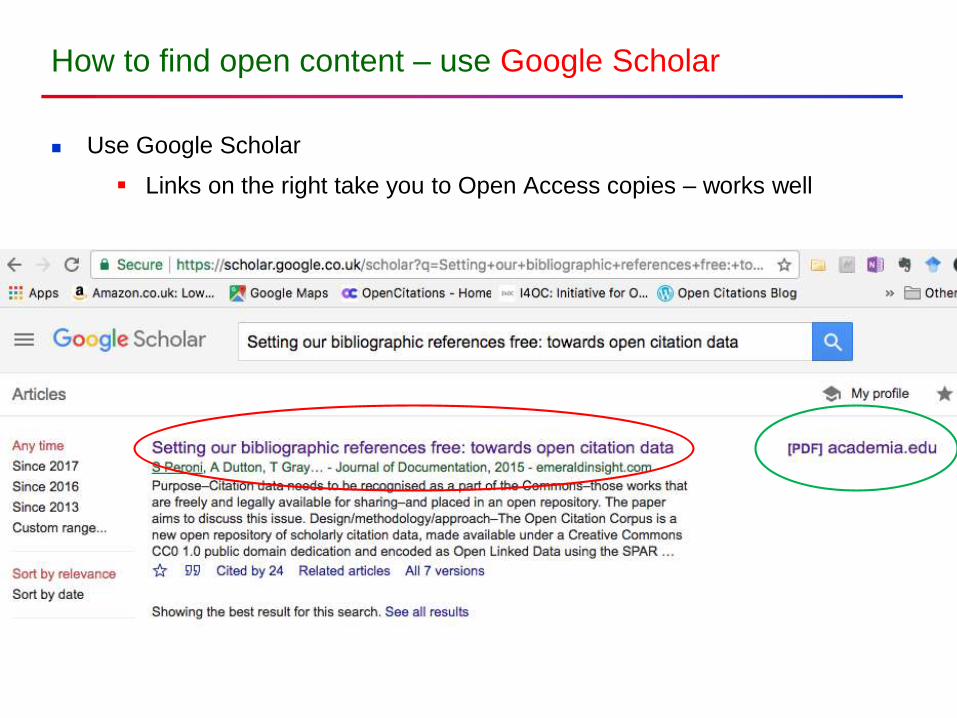
How to find open content – use Google Scholar
Use Google Scholar
Links on the right take you to Open Access copies – works well
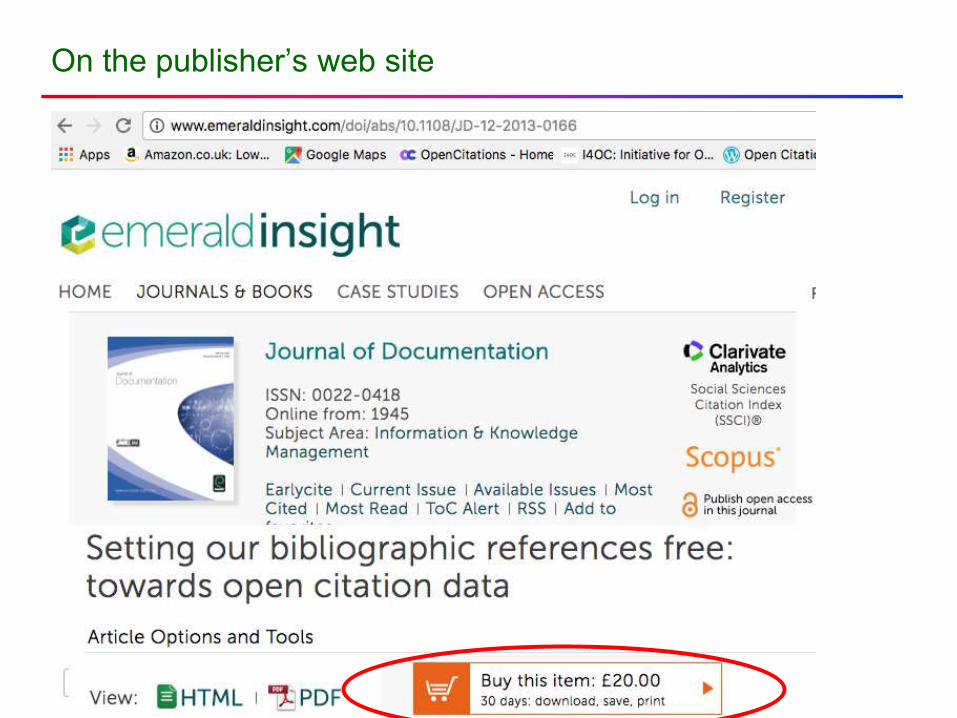
On the publisher’s web site
Use Google Scholar
Links on the right take you to Open Access copies
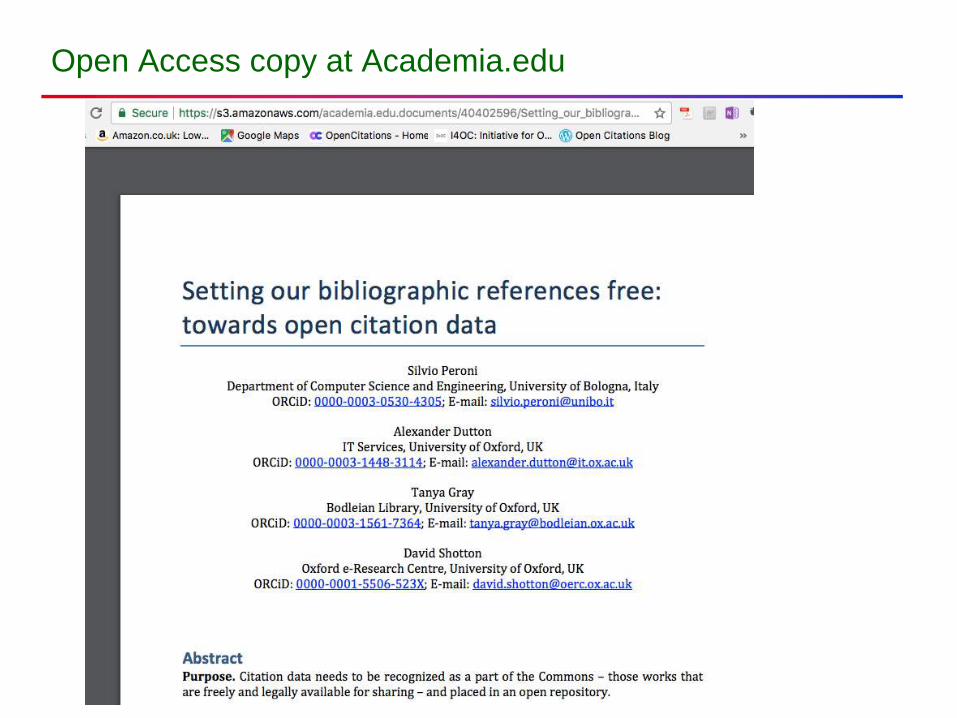
Open Access copy at Academia.edu
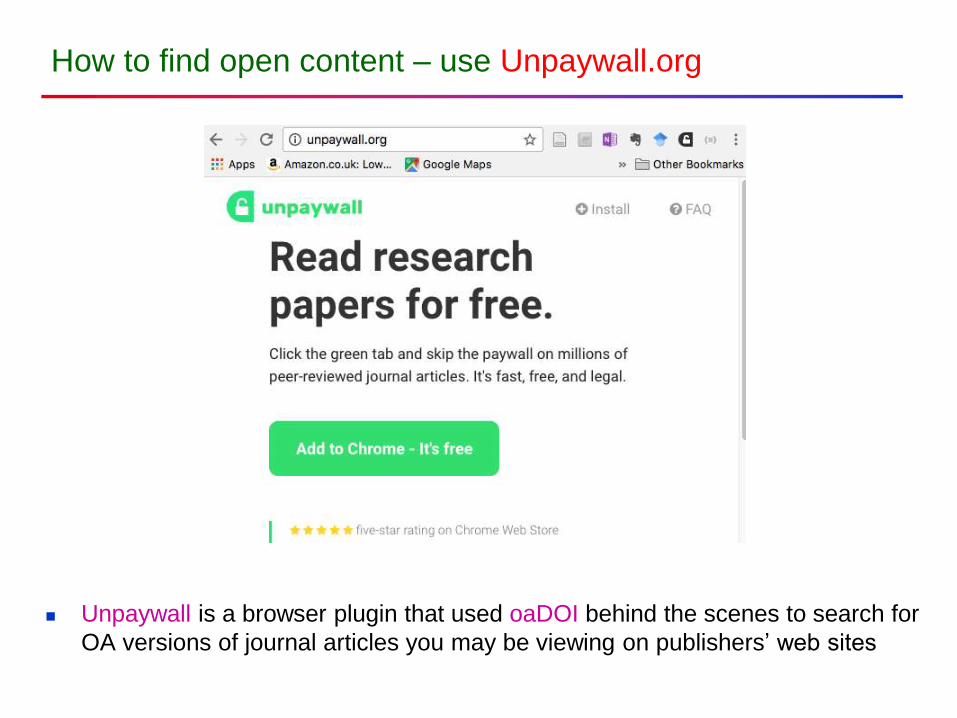
How to find open content – use Unpaywall.org
Unpaywall is a browser plugin that used oaDOI behind the scenes to search for
OA versions of journal articles you may be viewing on publishers’ web sites

Unpaywall uses oaDOI
oaDOI is a service that finds Open Access copies of articles
identified by a DOI (Digital Object Identifier)
If it finds one, it puts an Unpaywall Open Access logo on
the right of the article page
Clicking on that takes you to the Open Access version of the paper
A cool idea
However, in my experience it fails to catch many OA copies
because it uses BASE – the Bielefeld Academic Search Engine
(https://www.base-search.net/), which only searches official Green
Open Access repositories

Sci-Hub provides illegal access to subscription content
The pirate website Sci-Hub provides access to scholarly literature via full text
PDFs illegally downloaded from behind publishers' paywalls
Its stated goal is to make research papers free, to aid academia
But several science journals have taken it to court for breach of copyright
Daniel Himmelstein et al. determined that Sci-Hub contains 70% of all
~81.6 million scholarly articles
This rises to 85% for those published in subscription-access journals, and
97% for articles published by Elsevier, the largest and least open publisher
Himmelstein, D. S., Romero, A. R., McLaughlin, S. R., Tzovaras, B. G. & Greene, C. S. Sci-
Hub provides access to nearly all scholarly literature. PeerJ Prepr. (2017).
https://peerj.com/preprints/3100/

The fight for open access can get nasty
Sci-Hub’s founder, Alexandra Elbakyan, is a fugitive from justice
Elsevier won a $15 million court order against her in June
Sci-Hub’s domain names sci-hub.io, sci-hub.ac and sci-hub.cc have recently
been blocked, following another court order earlier this month
https://www.theregister.co.uk/2017/11/23/scihubs_become_inactive_ following_court_order/
But http://sci-hub.bz/, http://80.82.77.83/ and http://80.82.77.84/ still work
Martin Eve, Professor of Literature, Technology and Publishing at Birkbeck
College, University of London, said:
“I think domain blocking is going to prove an ineffective technique to
shutdown Sci-Hub permanently.
“Academic publishers would do better to reroute their efforts into
developing business models for scholarly communications that allow open
dissemination of educational research content and that are, therefore,
immune to initiatives such as SciHub.”

Research publishing has changed very little over 350 years
We still have a linear narrative, with references
While the article has moved online, and may indeed be Open Access, the norm is to publish a static PDF file, mimicking the printed page
This is totally antithetical to the spirit of the Web, and ignores its great potential
Rather, we need lively journal content
Semantic mark-up of text
Interactive figures
Links between papers and datasets
Actionable numerical data
. . . what I have called Semantic Publishing

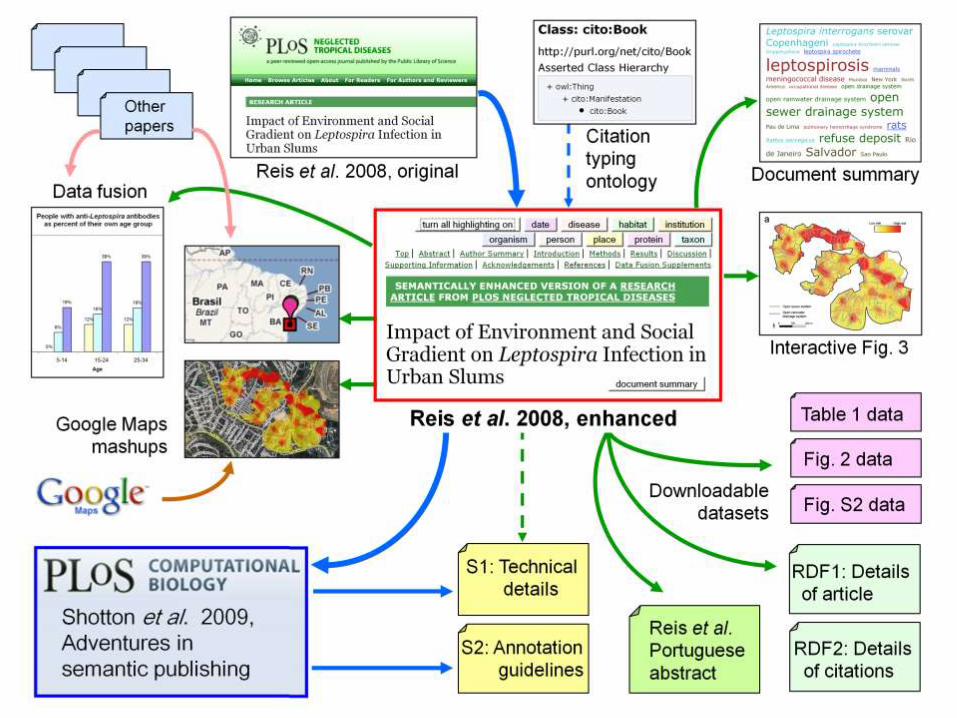
Our experiment in semantic enhancement of articles
To provide a compelling existence proof of the possibilities of semantic
publication, we took an ordinary research article from PLoS Neglected Tropical
Diseases and enhanced it as an exemplar
The results can be seen at http://dx.doi.org/10.1371/journal.pntd.0000228.x001

The Five Stars of Online Journal Articles
Shotton D (2012). The Five Stars of Online Journal Articles — a Framework for Article Evaluation.
D-Lib Magazine 18 (1/2) (January/February 2012 issue). http://dx.doi.org/10.1045/january2012-shotton

The Reis et al. PLoS article, before and after enhancement
Before After
The article already scored well for open access (O) and peer review (P)
Our semantic enhancements gave considerable improvement in enhanced
content (E), available datasets (A) and machine-readable metadata (M)
P
M A
E
O
P
M A
E
O

Citations - Crossref provides the fundamental infrastructure
https://www.crossref.org/
Crossref is the registration agency of Digital Object Identifiers (DOIs) for
scholarly publications (journal articles, conference papers, books, etc.)
Its head office is here in Oxford, at the Oxford Centre for Innovation
Most scholarly publishers are members, paying annual fees
For all scholarly publications that have DOIs
Crossref hold metadata (record of authors, title, publication year, etc.)
and also reference lists, if these are submitted by the publishers
Crossref presently holds over one billion references!
But the records on CrossRef are raw data, not organized or structured so
that non-experts can query them in useful ways, such as asking for the
highest-cited paper published by a particular university in a particular year

The importance of citations
A citation permits an author to give credit to another person's endeavours
Direct citation is a key indicator of a cited publication’s significance
Citations also integrate our independent acts of scholarship into a global
knowledge network
Bibliometric analysis of the citation network can reveal patterns of
communication between scholars and the development and demise of
academic disciplines
But aggregated citation data have been hidden behind subscription firewalls
In this Open Access age, it is a scandal that all citation data are not freely
available for use by the scholars who created them
Citations now need to be recognized as a part of the Commons – basic facts
that should be freely and legally available for sharing and reuse by all
The Initiative for Open Citations (I4OC) is working to achieve this

The Initiative for Open Citations
The Initiative for Open Citations is a collaboration between scholarly publishers,
researchers and others to promote unrestricted availability of scholarly citations
Launched on April 6, 2017 Web site https://i4oc.org
Within a short space of time, I4OC has persuaded most of the major scholarly
publishers to make their reference lists submitted to Crossref open
Before I4OC, only 1% of these were open
By the I4OC launch last April, that proportion was 40%
By September 2017, more that 50% of the almost one billion journal
article references stored in Crossref were open
However, there is much more that publishers could do
52% of the journal articles documented at Crossref lack references
And of these that are submitted, almost 50% are yet not open
See https://opencitations.wordpress.com/2017/11/24/
milestone-for-i4oc-open-references-at-crossref-exceed-50/

The problem with Elsevier
The largest scholarly publisher is Elsevier
It has about 15 million journal article records in Crossref
References from journal articles published by Elsevier constitute 32% of all
journal articles references stored at Crossref
While 75% of such references from other publishers are open
NONE of the ~300 million references from Elsevier articles are open
As a consequence, of all journal article references deposited at Crossref that
are not yet open, 65% are from journals published by Elsevier
I have just submitted an article to Nature that discusses this problem, entitled
Open Citations – The Elephant in the Room
to be published in the New Year
See https://opencitations.wordpress.com/2017/11/24/
elsevier-references-dominate-those-that-are-not-open-at-crossref/

Enhancing citation data - the OpenCitations Corpus
OpenCitations (http://opencitations.net) is an infrastructure organization directed
by myself and by Silvio Peroni of the University of Bologna
Its primary purpose is to host and develop the OpenCitations Corpus (OCC), a
Linked Open Data repository of bibliographic citation data covering all disciplines
The first OCC prototype was created here in Oxford in 2011
A new instance of the OCC, based on our revised OpenCitations Metadata Model,
was then set up with my colleague Silvio Peroni at the University of Bologna
It has been ingesting scholarly references continuously since early July 2016
OCC provides the largest Linked Open Data collection of citations on the Web
Currently holds references from ~285,000 citing bibliographic resources
Provides >12 million citation links to over 6 million cited resources
These data are freely available under a CC0 public domain waiver

The SPAR (Semantic Publishing and Referencing) Ontologies
FaBiO, the FRBR-aligned Bibliographic Ontology - an ontology for
describing bibliographic entities (books, articles, etc.)
CiTO, the Citation Typing Ontology - an ontology that enables the
characterization of citations, both factually and rhetorically
BiRO, the Bibliographic Reference Ontology - an ontology to define
bibliographic records and references, and their compilation into
bibliographic collections and reference lists, respectively
http://www.sparontologies.net/
OCC data are described in RDF (JSON-LD) using, with other standard
vocabularies, the SPAR (Semantic Publishing and Referencing) ontologies
These SPAR ontologies include

The OpenCitations ingestion rate
The OpenCitations Corpus is current ingesting ~8 million new citations per year
With new hardware funded by the Sloan Foundation OpenCitations
Enhancement Project, this rate will increase thirty-fold early in 2018 to
~240 million new citations per year
By the end of 2018, the OpenCitations Corpus should hold
~250 million citations, compared to Web of Knowledge’s ~1.25 billion
Even this partial coverage will include citations of all important papers
A further five-fold increase in ingest rate - significant but achievable with
additional resources (and funding!) - would enable us to reach parity by 2020

Where will the references come from?
We will quickly consume all 1.6 million OA articles in PubMed Central
We will then start harvesting the half-billion references from the ~18 million
articles already made open at Crossref in response to The Initiative for Open
Citations, of which OpenCitations is a founding member
Other possible sources of open citation data include
ArXiv (1.3 million preprints, mainly in physics and the hard sciences)
CiteSeerX (>120 million references from >6 million documents)
CitEc (11 million references from a million Economics papers)
References from pre-digital publications extracted by text mining, e.g.
From Bodleian catalogues of its holdings of illuminated manuscripts
In the Social Sciences, from the LOC-DB at the University of Mannheim
In Biological Taxonomy, mined into BioStor from the Biodiversity
Heritage Library, e.g. http://biostor.org/reference/105357

Adopting the OpenCitations Data Model
The OpenCitations data model provides the possibility of interoperability between
independent citation collections
Several other organizations and projects have adopted, or are considering
adoption of the OpenCitations data model
This will provide immediate interoperability of RDF citation data
and will enable seamless import into the OpenCitations Corpus
In this way, we hope that OpenCitations can become a global hub for open
citation data structured in RDF

2017 The year of success - citation data are freed!
Two fantastic success stories
The Initiative for Open Citations https://i4oc.org/
The OpenCitations Corpus http://opencitations.net
Two Italian heros: Dario Taraborelli and Silvio Peroni

Thank you!
David Shotton
Website: http://opencitations.netEmail: [email protected]: @opencitationsBlog: https://opencitations.wordpress.com