curso topicos usach
DESCRIPTION
Metodos numéricosTRANSCRIPT

Indice
1. Introduccion 4
1.1. Error. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2. Dıgitos significativos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3. Polinomios de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3.1. Formula de Euler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2. Ecuaciones No lineales. 10
2.1. Metodo de Biseccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2. Metodo de la secante. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.3. Estudio de la convergencia del metodo de Newton-Raphson. . . . . . . . . . . . . . 142.4. Velocidad de convergencia del metodo de Newton- Raphson . . . . . . . . . . . . . 152.5. Metodos de punto fijo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.6. Convergencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.7. Velocidad de Convergencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.8. Convergencia del Metodo de Newton-Raphson . . . . . . . . . . . . . . . . . . . . . 22
3. Ceros de las funciones Polinomicas. 25
3.1. Sistemas de Ecuaciones No lineales. . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.2. Metodo de Newton- Raphson Generalizado. . . . . . . . . . . . . . . . . . . . . . . 28
4. Sistemas de Ecuaciones Lineales. 33
4.1. Metodos directos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.1.1. Metodo de Gauss. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.1.2. Eliminacion gaussiana con y sin pivoteo. . . . . . . . . . . . . . . . . . . . 35
4.2. Factorizacion LU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.2.1. Matrices definidas positivas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2.2. Matrices diagonal dominante. . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5. Metodos iterativos. 41
5.1. Normas vectoriales y matriciales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.1.1. Preliminares. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.1.2. Normas matriciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.1.3. Otros resultados importantes para el estudio de los metodos iterativos. . . . 43
5.2. Metodos iterativos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 445.2.1. Metodo de Jacobi. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.3. Metodo de Gauss-Seidel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
1

5.4. Metodo de sobrerelajacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475.5. Resultados importantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485.6. Analisis de error y Numero de Condicion . . . . . . . . . . . . . . . . . . . . . . . . 49
6. Resolucion Numerica del Problema de Valor de Contorno de orden 2. 53
6.1. Metodo de diferencias finitas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7. Sistemas de Ecuaciones No lineales. 56
7.1. Metodo de Newton- Raphson Generalizado. . . . . . . . . . . . . . . . . . . . . . . 577.2. Metodo de Broyden. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
8. Interpolacion Polinomica. 66
8.1. Metodo de los coeficientes indeterminados. . . . . . . . . . . . . . . . . . . . . . . . 668.2. Metodo de Lagrange. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 678.3. Forma de Newton para el Polinomio de Interpolacion . . . . . . . . . . . . . . . . . 69
8.3.1. Diferencias Divididas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 708.4. El problema de Hermite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 748.5. ¿Como obtener el polinomio de Hermite ? . . . . . . . . . . . . . . . . . . . . . . . 74
9. Integracion Numerica. 78
9.1. Formulas de Newton-Cotes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 789.1.1. Metodo del Trapecio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 789.1.2. Metodo de Simpson. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
9.2. Cuadratura Gaussiana. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 829.3. Integrales Indefinidas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 879.4. Integrales Impropias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 889.5. Integrales Multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 899.6. Diferenciacion Numerica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 909.7. Mınimos cuadrados Discretos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 939.8. Algo sobre Normas de funciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 959.9. Aproximacion de Mınimos Cuadrados Continuos. . . . . . . . . . . . . . . . . . . . 97
9.9.1. Metodo Generalizado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 999.9.2. Sistemas Ortonormales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1049.9.3. Proceso de ortonormalizacion de Gramm-Schmidt. . . . . . . . . . . . . . . 106
10.Aproximacion Minimax. 108
10.0.4. Caso Discreto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10810.1. Algoritmo de Remez. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
2

10.1.1. Caso Continuo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11010.2. Propiedad mınimax de los polinomios de Tchebyshev . . . . . . . . . . . . . . . . . 11310.3. Potencias de xn en terminos de {Tn(x)} . . . . . . . . . . . . . . . . . . . . . . . . 116
11.Metodos de un paso. 117
11.0.1. Metodos de solucion por serie de Taylor. . . . . . . . . . . . . . . . . . . . . 11711.0.2. Metodos por serie de Taylor de orden superior. . . . . . . . . . . . . . . . . 12011.0.3. Metodos de Runge-Kutta.(R-K) . . . . . . . . . . . . . . . . . . . . . . . . 121
12.METODOS MULTIPASOS. 122
12.1. Deduccion de las formulas predictor corrector . . . . . . . . . . . . . . . . . . . . . 123
13.Metodos predictor - corrector. 124
13.0.1. Formulas de Adams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
14.Ecuaciones elıpticas. 128
14.1. La ecuacion de Laplace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12814.2. Solucion Numerica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
14.2.1. La Ecuacion de Laplace. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13114.2.2. El metodo de Liebmann. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
14.3. Condiciones en la frontera. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
15.La ecuacion de conduccion de calor. 136
15.0.1. Metodos Explıcitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13715.0.2. Convergencia y estabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . 13915.0.3. Aproximaciones temporales de orden superior . . . . . . . . . . . . . . . . . 139
15.1. Un metodo implıcito simple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13915.2. El metodo de Crank-Nicholson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
16.La ecuacion de ondas. 143
16.1. Construccion de la ecuacion en diferencias. . . . . . . . . . . . . . . . . . . . . . . 14316.2. Condiciones Iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
3

UNIVERSIDAD DE SANTIAGO DE CHILE
Topicos I.
1. Introduccion
Profesor : Marıa Angelica Vega U.
El proposito de estos modulos es entregar los conceptos teoricos necesarios y las aplica-ciones en forma dirigida, de modo que el estudiante pueda participar en forma activa,en el proceso ensenanza - aprendizaje, elaborando su propio material de estudio. Ellogro deseable es que el estudiante aprenda a aprender.
1.1. Error.
En el analisis de un algoritmo, es necesario considerar el error en la aproximacion obtenida ala solucion del problema. Este error puede producirse por varios factores, en el ejemplo 1.1 porredondeo de la aritmetica y termino del proceso infinito. Estos errores son parte inevitable delproceso de solucion y no deben confundirse con los errores cometidos por el usuario, como falla enel algoritmo o error en la programacion.Para cada algoritmo podemos conocer una cota de error, esto es una cota sobre el error en lasolucion calculada.Una cota que no depende de la solucion y puede ser calculada previamente, se llama cota de errora priori. Cuando una cota no puede ser calculada hasta despues de la completacion de la parteprincipal de los calculos es llamada una cota a posteriori. La cota de error es mas grande que elerror, por tal razon debemos desarrollar metodos alternativos de estimacion de error para algunosproblemas. Las cotas de error y estimativos son a menudo calculables y nos dan informacion tantodel comportamiento asintotico del error como del mejoramiento de las aproximaciones.Existen dos formas de medir o cuantificar la magnitud de un error.
Definicion 1.1 . Sea x∗ una aproximacion del valor exacto x. Un indicador natural es la distanciaentre el valor exacto y el aproximado.Definimos,
El error absoluto como la distancia,
EA(x∗) = |x− x∗|
Observamos que el error absoluto no permite comparar la precision entre aproximaciones dediferentes ordenes de magnitudes.
4

El error relativo como,
ER(x∗) =EA(x∗)|x|
=|x− x∗||x|
Este error es mas significativo para comparar aproximaciones.
El error porcentual es el error relativo multiplicado por 100,
EP (x∗) = 100 · ER(x∗)
Estos conceptos de error tienen solo un valor formal,puesto que no se conoce el valor exacto x. Enla practica, se determina una cota o estimativo del error.
Otro concepto importante es el de intervalo precision, diremos que [a, b] es un intervalo precisionde x, que denotaremos por I(x), si
P (x ∈ [a, b]) = 1
es decir, la probabilidad que x este en el intervalo de precision es la cierta.Relacion entre error absoluto e intervalo de precision
Dada una cota del error absoluto de x∗, es posible determinar el intervalo de precision de x.
Sea ε una cota del error absoluto,
EA(x∗) ≤ ε ⇔ |x− x∗| ≤ ε ⇔ x∗ − ε ≤ x ≤ x∗ + ε
es decir, x ∈ [x∗ − ε, x∗ + ε] , luego I(x) = [x∗ − ε, x∗ + ε].
Inversamente, dado I(x) = [a, b] un intervalo de precision de x, es posible determinar unacota del error absoluto de cualquier aproximacion x∗ en [a, b].
Sea x∗ ∈ [a, b] ⇒ |x− x∗| ≤ max (x∗ − a, b− x∗) = ε
de donde,EA(x∗) ≤ ε.
Si x∗ = a+b2 ε = b−a
2 .
Observamos que el error absoluto no es significativo, a menos que tengamos algun conocimientode la magnitud de x. A menudo se usa el error relativo en termino de porcentajes.Otro punto importante de considerar al seleccionar un algoritmo es la eficiencia, que se mide deacuerdo al numero de operaciones aritmeticas basicas requeridas para dar una exactitud en elresultado.
5

1.2. Dıgitos significativos.
El uso de la aritmetica de las computadoras lleva al concepto de dıgitos significativos. El dıgitoprincipal o mas significativo de un numero real x 6= 0, es el dıgito no nulo mas a la izquierdade su expresion decimal. Todos los dıgitos, incluyendo los ceros a la derecha del dıgito significativoprincipal, son significativos y el ultimo de la serie es el menos significativo. Sin embargo, los cerosa la izquierda del dıgito significativo principal no son significativos. Por ejemplo, si x = 0.0670 eldıgito significativo principal es 6 y el dıgito menos significativo es el cuarto de izquierda a derechacero.
Definicion 1.2
Diremos que x∗ aproxima a x con λ dıgitos significativos (o cifras) ssi λ es el entero masgrande no negativo tal que:
|x− x∗||x|
< 5× 10−λ o |x− x∗| < 5× 10−λ|x|. (1)
i)ii) Diremos que x∗ aproxima a x con λ dıgitos significativos (o cifras) ssi λ es el entero masgrande no negativo tal que:
|x− x∗| < 0.5× 10σ−λ
donde σ es el exponente de la potencia de 10 que resulta al transformar x∗ a la notacioncientıfica normalizada.
Ejemplo 1.1 Para que x∗ aproxime a 1000 con cuatro cifras significativas, debe satisfacer :
|x∗ − 1000||1000|
< 5× 10−4. (2)
Es decir, 999.5 < x∗ < 1000.5
Ejemplo 1.2
Si x∗ = 5.98 la notacion normalizada de x∗ = 0.598× 101, es decir, σ = 1.
i)ii) Si x = 0.5 y x∗ = 4.9, determine el numero de dıgitos significativos de la aproximacion.
Ejemplo 1.3 Aproxime con 4 dıgitos significativos de precision el cero de la funcion f(x) =x− cos(x) que se encuentra en el intervalo [0, pi
2 ], usando metodo de Newton.Raphson.
sol. Graficamos en el intervalo [0, pi2 ]
6

Figura 1: f(x) = x− cos(x) x ∈ [0, π2 ]
Algoritmo de Newton-Raphson: Dada una aproximacion inicial x0, generamos una sucesion{xn)}∞n=1, tal que xn se determina por:
xk+1 = xk −(f(xk)f ′(xk)
. (3)
Observando el grafico podemos seleccionar x0 = 0.7854, presentamos los resultados de cada itera-cion en la siguiente tabla
n xn|xn+1 − xn||xn+1|
< 5× 10−4 |xn+1 − xn| < 0.5× 10σ−4
0 0.7854 − −1 0.7395361684 0.06201702305 > 0.0005 0.0458638 > 0.000052 0.7390851781 0.0006102007094 > 0.0005 0.00045099033 > 0.000053 0.7390851332 0.0000006075078226 < 0.0005 0.0000000449 < 0.00005
Luego la aproximacion requerida es x3 = 0.7390851
Actividades Libres 1.1
1. Use el metodo de Newton para aproximar con precision 10−4las raıces dex− 0.8− 0.2 sin (x) = 0 en [0, π
2 ].
2. Aproxime con precision 10−5 las raıces deex + 2−x + 2cos(x)− 6 = 0.
7

1.3. Polinomios de Taylor
Teorema 1.1 Sean
i) f ∈ Cn[a, b] y f (n+1) existe en [a, b).
ii) x0 ∈ [a, b]
entonces para toda x ∈ [a, b] existe ξ(x) entre x0 y x tal que :
f(x) = Pn(x) +Rn(x)
donde:
Pn(x) = f(x0) + f ′(x0)(x− x0) + f ′′(x0)(x− x0)2
2!+ f ′′′(x0)
(x− x0)3
3!+ · · ·
+f (n)(x0)(x− x0)n
n!y
Rn(x) = f (n+1)(ξ(x))(x− x0)(n+1)
(n+ 1)!
Pn(x) se llama el polinomio de Taylor de grado n para f alrededor de x0 y Rn(x) se llamael residuo o error de truncamiento asociado con Pn(x). La serie infinita que se obtiene altomar el lımite de Pn(x), cuando n → ∞ se denomina serie de Taylor para f alrededor de x0.El termino de error de truncamiento se refiere generalmente al error involucrado al usar sumasfinitas o truncadas para aproximar la suma de una serie infinita.
1.3.1. Formula de Euler
Un metodo numerico para de resolver el Problema de valor inicial :
P.V.I.
{y′ = f(x, y)y(x0) = y0.
es el metodo de Euler. Si escribimos la serie de Taylor, con respecto a algun punto xi de la soluciony(x), entonces tenemos:
y(x) = yi + y′i(x− xi) + y′′i(x− xi)2
2!+ y′′′i
(x− xi)3
3!+ · · ·
Entonces, podemos aproximar la solucion en xi+1 por:
yi+1 = yi + y′ih+ y′′ih2
2!+ y′′′i
h3
3!+ · · ·
8

donde, h = xi+1 − xi. Es claro que mientras mas terminos se consideren en el desarrollo de Taylormejor sera la aproximacion. Si consideramos dos terminos del desarrollo, obtenemos:
yi+1 = yi + y′ih⇔ yi+1 = yi + f(xi, yi)h i = 0, 1, 2, · · · (4)
Observese que (197) es el metodo de Euler, con un error de orden O(h2), esto significa que losterminos no considerados contienen potencias de h con exponente mayor o igual que 2.Error de local del metodo de Euler.
Consideramos:yi+1 = yi + hf(xi, yi)
y suponemos y(x) en serie de Taylor con segunda derivada continua en un intervalo que contienea xi
y(xi+1) = y(xi) + y′(xi)h+ y′′(ξ) · h2
2!(5)
donde ξ ∈ (xi, xi+1). Restando ambas ecuaciones :
y(xi+1)− yi+1 = y(xi)− yi + h[f(xi, y(xi))− f(xi, yi)] +(h2)2y′′(ξ)
suponiendo yi = y(xi), obtenemos la formula para el error local:
ei+1 = y(xi+1)− yi+1 =(h2)2y′′(ξ). (6)
Como generalmente no se conoce el valor de ξ, aunque teoricamente exista, no se puede calculareste error , pero es posible determinar un estimativo, acotando esta expresion por el maximo quealcanza la segunda derivada en el intervalo, es decir
|ei+1| ≤M · h2
2!(7)
conM = max
x∈(xi,xi+1)|y′′(x)|
Observemos que el maximo M no depende de h, luego si se reduce h en un factor de 12 , la cota
derror se reduce en 14 y una reduccion de h en un factor de 1
10 , la cota derror se reduce en 1100 .
Actividades 1.1 Para el problema de valor inicial siguiente
y′ = 0.2xy , y(1) = 1
Use el metodo de Euler para obtener una aproximacion a y(1.5) usando h = 0.1 y h = 0.05.Resuelva esta ecuacion analıticamente usando alguno de los metodos ya estudiados y elabore unatabla que incluya en los puntos seleccionados (Use h = 0.1 ) el valor exacto, el valor aproximadoy el error relativo para cada aproximacion .
9

2. Ecuaciones No lineales.
Modulo 2Prof. M.Angelica Vega
2.1. Metodo de Biseccion
Problema 1. Dada una funcion f(x) no lineal y continua en el intervalo [a, b]. Determinar unaraız α ∈ [a, b] de la ecuacion f(x) = 0.
Ante el problema planteado surgen las siguientes interrogantes :1. ¿Existe solucion?2. Si existe solucion . ¿Es unica ?3. ¿Como determinarla ?1.- Existencia : Teorema de Bolzano.
La existencia de solucion esta garantizada por el teorema de Bolzano, cuyo enunciado afirma quebajo las hipotesis :i) f continua en [a, b].ii) f(a) y f(b) de distinto signo. (es decir, f(a) · f(b) < 0 )entonces,existe α ∈ (a, b) tal que f(α) = 0.
2.- Unicidad :
La existencia de una unica solucion en el intervalo de precicion queda garantizada por el siguienteteorema visto en Calculo Diferencial .
Teorema 2.1 Si f es una funcion que satisface las hipotesis :i) f continua en [a, b].ii) f(a) · f(b) < 0.iii) f es diferenciable en (a, b)iv) Signo de f ′(x) es constante en (a, b) entonces,existe un unico α ∈ (a, b) tal que, f(α) = 0.
Metodo de Biseccion. Se basa en el teorema de Bolzano, por lo tanto se supone :i) f continua en I(α) = [a, b].ii) f(a) · f(b) < 0Algoritmo de la Biseccion .
1.- Dividir el intervalo de precision I(α) por la mitad, obteniendose:
x1 =(a + b)
2
8

2.- Analizar f(x1)Si f(x1) = 0 , entonces α = x1 y detener el proceso.Si f(x1) 6= 0 , entonces
Si f(x1) · f(a) < 0 , f(x) tiene un cero en el intervalo [a, x1].
Si f(x1) · f(a) > 0 , f(x) tiene un cero en[x1, b].
3.- Repitiendo los pasos 1 y 2 se genera una sucesion de aproximaciones, hasta que se satisfaga unacondicion de termino.Ventajas y desventajas.Es posible demostrar que si f(x) es continua en [a, b] y f(a)·f(b) < 0, el procedimiento de bisecciongenera una sucesion que converge a la raız α y
|xn − α| ≤ (b− a)2n
. (8)
Sin embargo este metodo tiene la desventaja que la convergencia es lenta .Del resultado anterior, se puede deducir una formula para determinar el numero de iteraciones,dada una cierta tolerancia ε.
n ≥ln ((b−a)
ε
ln(2). (9)
Actividades 2.1
Demuestre que de (8) puede obtener (9).
Sea f(x) = x3 + 4x2 − 10, encuentre una raız aproximada.
a) ¿Como podrıa verificar si es la unica?
b) Determine I(x).
c) ¿Cuantas iteraciones se deben realizar para que la aproximacion sea correcta a lo menosen 4 cifras significativas?
2.2. Metodo de la secante.
Se basa en encontrar una aproximacion a la raız mediante rectas secantes a la grafica de f(x), demodo que, si (xk−1, f(xk−1)) y (xk, f(xk)) son dos puntos de la grafica de f(x) una aproximaciona la raız α es, xk+1 interseccion de la recta secante que une los puntos mencionados con el eje X.De donde se deduce :
xk+1 = xk −(f(xk) · (xk − xk−1))(f(xk)− f(xk−1))
. (10)
9

Figura 2:
Algoritmo de la Secante .
1.- Dadas dos aproximaciones x0 y x1.2.- Generamos una sucesion de aproximaciones {xk+1} definida por:
xk+1 = xk −(f(xk) · (xk − xk−1))(f(xk)− f(xk−1))
.
Metodo de la Regula Falsi.
Este algoritmo es una mezcla de los metodos de biseccion y secante.1.- Si [a, b] es el intervalo de precision, unimos (a, f(a)) y (b, f(b)) para obtener x1 como interseccionde la recta secante que pasa por los puntos precedentes y el eje X.
2.- Trazamos la recta secante por (x1, f(x1)) y (b, f(b)) cuya interseccion sobre el eje X determinados subintervalos, escogemos aquel que contiene a la raız, verificando :Si f(x1) · f(b) < 0 , la raız esta en [x1, b] , de lo contrario la raız pertenece al intervalo [a, x1] .3.- Supongamos que f(x1) · f(b) < 0 , repetimos el paso 1 considerando el intervalo [x1, b] , demodo que se obtiene la aproximacion x2, como interseccion de la secante y el eje X.
4.- Procediendo ası sucesivamente obtenemos la sucesion {xk+1} definida por :
xk+1 = xk −(f(x[k]) · (b− xk))
(f(b)− f(xk))(11)
Graficamente,
Actividades 2.2
10

Figura 3:
Usando el metodo de la secante, obtener el cero de
f = x− 2 senx
que esta en el intervalo [1,5, 2]
Dada f = x3 + x2 − 3x− 3 , determine en forma aproximada la raız que se encuentra en elintervalo [0,3] .
Metodo de Newton-Raphson.
El metodo de Newton-Raphson es uno de los metodos numericos mas conocidos en la resoluciondel problema de busqueda de raıces de la ecuacion :
f(x) = 0
Existen tres formas de derivar este metodo, un enfoque basado en el polinomio de Taylor, comoun procedimiento para obtener una convergencia mas rapida que la que se obtiene con los otrosmetodos y el metodo grafico.Discutiremos este ultimo. Geometricamente consiste en dada una funcion dos veces continuamentediferenciable, nos aproximamos a la raız mediante rectas tangentes, de modo que si ((xk, f(xk)) esun punto de la grafica de f(x), trazamos la recta tangente en este punto y donde la tangente cortaal eje X obtenemos la aproximacion xk+1, es decir, geometricamentede donde deducimos
xk+1 = xk −(f(xk))(f ′(xk))
. (12)
11

Figura 4:
Actividades 2.3 Use el metodo de Newton-Raphson para determinar una aproximacion de lamayor raız negativa de la ecuacion f(x) = 0 con
f(x) = x5 + 0,85x4 + 0,70x3 − 3,45x2 − 1,10x + 1,265
use como aproximacion inicial x0 = −0,1.
2.3. Estudio de la convergencia del metodo de Newton-Raphson.
Definicion 2.1 Si {xn} es una sucesion de numeros reales que converge a la raız r, diremos quela razon de convergencia es de orden α si existen dos constantes C y α y un entero N tal que,
|xn+1 − r| ≤ C|xn − r|α ,∀n ≥ N o lımn→∞
|xn+1 − r||xn − r|α
= C. (13)
Observacion 2.1 i) Si usamos la notacion |en+1| = |xn+1 − r| (error absoluto cometido en la(n+1)- esima aproximacion), el lımite puede abreviarse por
lımn→∞
|en+1||en|α
= C.
ii) Si C < 1 y N es un entero tal que
|xn+1 − r| ≤ C|xn − r| ∀n ≥ N
diremos que la convergencia es a lo menos lineal .
12

iii) Si existen C no necesariamente menor que 1 y un entero N tal que
|xn+1 − r| ≤ C|xn − r|2 ∀n ≥ N
diremos que la convergencia es a lo menos cuadratica.
2.4. Velocidad de convergencia del metodo de Newton- Raphson
Comentamos antes, que otra forma de obtener Newton-Raphson consiste en derivarlo a partir deldesarrollo en serie de Taylor de la funcion f(x).En efecto, supongamos que desarrollamos en serie la funcion no lineal f(x) en torno del punto xk
f(x) = f(xk) + f ′(xk)(x− xk) + f ′′(ξ)2! (x− xk)2 evaluamos en xk+1
f(xk+1) = f(xk) + f ′(xk)(xk+1 − xk) + f ′′(ξ)2! (xk+1 − xk)2.
(14)
donde, ξ ∈ (xk, xk+1). Truncando el tercer termino, queda
f(xk+1) = f(xk) + f ′(xk)(xk+1 − xk). (15)
En la interseccion con el eje X, f(xk+1) = 0, luego
0 = f(xk) + f ′(xk)(xk+1 − xk). (16)
Ordenando, se obtiene
xk+1 = xk −f(xk)f ′(xk)
. (17)
La formula del metodo de Newton.Ademas este desarrollo permite estimar el error de la formula y la velocidad de convergencia delmetodo.En efecto, supongamos que en el desarrollo anterior xk+1 es xr el valor exacto, entonces f(xr) = 0.y
0 = f(xk) + f ′(xk)(xr − xk) +f ′′(ξ)
2!(xr − xk)2. (18)
Restando (16) y (18) se obtiene :
0 = f ′(xk)(xr − xk+1) + f ′′(ξ)2! (xr − xk)2
0 = ek+1f′(xk) + f ′′(ξ)
2! (ek)2.
ek+1 =−f ′′(xk)2f ′(xk)
e2k
De esta ultima igualdad se deduce que el error es casi proporcional al cuadrado del error anteriorlo que significa que el numero de cifras decimales correctas se duplica en cada iteracion.
13

Tomando valor absoluto y lımite cunado k →∞, se tiene que
lımk→∞
|ek+1||ek|2
=|f ′′(ξ)|
2|f ′(xk)|. (19)
De aquı deducimos que el metodo converge cuadraticamente, si f ′(xk) 6= 0, es decir si la raız essimple.
Teorema 2.2 Si f ∈ C2[a, b] y r es una raız es simple en [a, b] (es decir, f(r) = 0 y f ′(r) 6= 0 )entonces, existe un δ > 0 tal que el metodo de Newton-Raphson generara una sucesion que convergecuadraticamente a r para cualquier aproximacion inicial x0 ∈ [r − δ, r + δ] .
Observacion 2.2 Deducimos que no ocurre necesariamente convergencia cuadratica si laraız no es simple.
El metodo de Newton-Raphson en general es muy eficiente, sin embargo hay situaciones enque no es aplicable o se comporta en forma deficiente. Uno de estos casos es cuando la funcionposee raıces multiples.
La siguiente figura muestra graficamente, un ejemplo donde no es posible aplicar Newton-Raphson. ¿Podrıa explicar porque ?
Figura 5: f(x) = x− cos(x) x ∈ [0, π2 ]
Actividades 2.4 Los problemas que se presentan a continuacion son 2 casos especiales, donde noes posible aplicar Newton-Raphson
14

Dada la funcion
f(x) = −12x3 +
52x
aproxime la raız positiva, use como aproximacion inicial x0 = 1. y realice 6 iteraciones.¿Que sucede ? ¿Porque ocurre esto ?
Dada la funcionf(x) = (x− 1)3(x− 2)
aproxime la menor raız, use como aproximacion inicial x0 = 1,75
¿Que sucede ? ¿A que atribuye este hecho ?
Raıces multiples.
Las raıces multiples presentan algunas dificultades para los metodos que hemos analizado.
i) Si una funcion no cambia de signo en raıces multiples pares impide el uso de los metodoscerrados que usan intervalos y los metodos abiertos tienen la limitacion que pueden serdivergentes.
ii) Otra dificultad que puede presentarse, es el hecho que f(x) y f ′(x) tiendan a cero. En estoscasos, hay dificultades con el metodo de Newton-Raphson y el de la secante (aproximacionde f ′(x)) que provocan una division por cero.
iii) Ralston y Rabinowitz demostraron que los metodos de Newton-Raphson y secante conver-gen linealmente cuando hay raıces multiples y han propuesto algunas modificaciones que seobtienen a partir del metodo de newton-Raphson para problemas con funciones que tienenraıces multiples.
iv) El siguiente metodo es una modificacion de Newton-Raphson, tiene convergencia cuadratica:
xk+1 = xk −mf(xk)f ′(xk)
. (20)
donde, m es la multiplicidad de la raız, es decir m = 2 si la raız tiene multiplicidad 2.
v) Otra modificacion de Newton-Raphson, se obtiene definiendo una nueva funcion
u(x) =f(x)f ′(x)
,
que tiene raıces en las mismas proporciones que la funcion original. Se sustituye u(x) en (17)y se obtiene:
xk+1 = xk −f(xk) · f ′(xk)
[f ′(xk)]2 − f(xk) · f ′′(xk). (21)
15

Actividades 2.5 Usar metodo de Newton-Raphson y el modificado (21)para aproximar la raızmultiple de :
f(x) = x3 − 5x2 + 7x− 3
use como aproximacion inicial x0 = 0. Realice a lo menos 5 iteraciones con el metodo de Newton-Raphson.
Nota 2.1 El material bibliografico usado para la elaboracion de este taller :
Analisis Numerico. R.L. Burden-J.D. Faires
Metodos numericos. S.C. Chapra- R.P. Canale
16

2.5. Metodos de punto fijo.
Modulo 3Prof: Marıa Angelica Vega U.
Sea f(x) = 0 una ecuacion no lineal. Los metodos para determinar una raız de esta ecuacion, quese expresan en la forma
x = g(x)
se denominan Metodos de Iteracion Funcional o Metodos de punto fijo. Una solucion deesta ecuacion se llama punto fijo de g y la funcion g(x) se llama funcion de iteracion . Frenteal problema de buscar los puntos fijos de la ecuacion x = g(x), surgen las siguientes interrogantes :1.- ¿Cuando una funcion g(x) tiene un punto fijo ?2.- ¿Si existe, es unico ?3.- ¿ Como determinarlo ?Las respuestas a la primera y segunda interrogante, es el resultado que veremos a continuacionformalizado como Teorema de existencia y unicidad.
Teorema 2.3 Teorema de Existencia y unicidad. Si
i) g(x) es continua en [a, b].
ii) g(x) pertenece a [a, b], para todo x que pertenece al intervalo [a, b]. entonces, existe un puntofijo para g(x) en (a, b).
Si ademas,
iii) g(x) es diferenciable en (a, b)
iv) |g(x)| ≤ k < 1 , para todo x perteneciente al intervalo (a, b), entonces , g(x) tiene un unicopunto fijo en [a, b].
Demostracion.
1) Existencia. Si g(a) = a y g(b) = b la existencia de un punto fijo es trivial.
Suponemos entonces,
a < g(a) y b > g(b) (Por hipotesis g(x) ∈ [a, b]).
Definimos:h(x) = g(x)− x
observamos que,
i) h(x) es continua en [a, b]
ii)
h(a) = g(a)− a > 0h(b) = g(b)− b < 0
}⇒ h(a) · h(b) < 0.
17
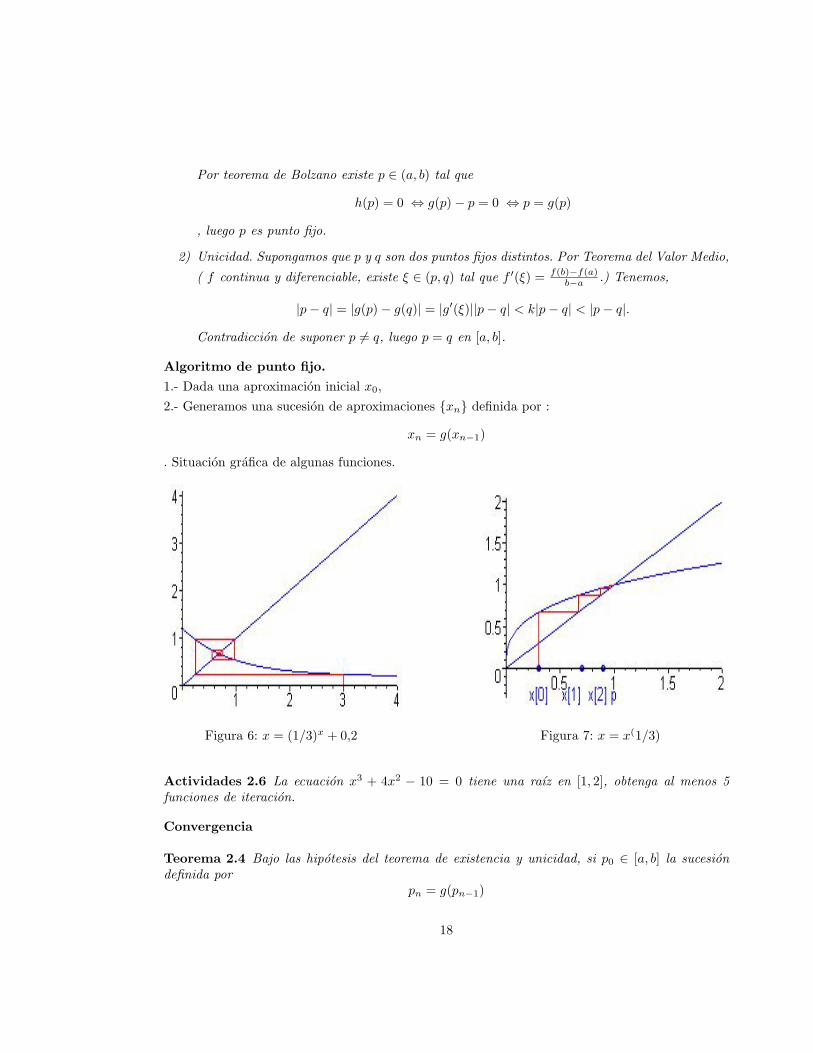
Por teorema de Bolzano existe p ∈ (a, b) tal que
h(p) = 0 ⇔ g(p)− p = 0 ⇔ p = g(p)
, luego p es punto fijo.
2) Unicidad. Supongamos que p y q son dos puntos fijos distintos. Por Teorema del Valor Medio,
( f continua y diferenciable, existe ξ ∈ (p, q) tal que f ′(ξ) = f(b)−f(a)b−a .) Tenemos,
|p− q| = |g(p)− g(q)| = |g′(ξ)||p− q| < k|p− q| < |p− q|.
Contradiccion de suponer p 6= q, luego p = q en [a, b].
Algoritmo de punto fijo.
1.- Dada una aproximacion inicial x0,2.- Generamos una sucesion de aproximaciones {xn} definida por :
xn = g(xn−1)
. Situacion grafica de algunas funciones.
Figura 6: x = (1/3)x + 0,2 Figura 7: x = x(1/3)
Actividades 2.6 La ecuacion x3 + 4x2 − 10 = 0 tiene una raız en [1, 2], obtenga al menos 5funciones de iteracion.
Convergencia
Teorema 2.4 Bajo las hipotesis del teorema de existencia y unicidad, si p0 ∈ [a, b] la sucesiondefinida por
pn = g(pn−1)
18

Figura 8: x = (3/2)x
converge al unico punto fijo. Ademas se cumple
i)|pn − p| ≤ kn
1− k|p0 − p1| ∀n ≥ 1.
ii)|pn − p| ≤ kn|p0 − p| ≤ kn max {p0 − a, b− p0},
puesto que, p ∈ [a, b].Demostracion. Hacerla como ejercicio. Se utilizan las hipotesis del Teorema de existencia yunicidad y el Teorema del Valor Medio.
Actividades 2.7 Sea g(x) = (x2−1)3 en [−1, 1] . Demostrar que g(x) tiene un unico punto fijo en
(−1, 1).
Velocidad de Convergencia.
Teorema 2.5 Sea p un punto fijo de g(x), tal que p ∈ I y sea
xk = g(xk−1) para k = 1, 2, ...
i) Si g ∈ C1(I(p)) y g′(p) 6= 0, entonces
|xk+1 − xk| ≈ g′(p)|xk − xk−1|
de modo que, si x0 ∈ I(p) entonces,{xk} converge linealmente a p con C = g′(p) si 0 < |g′(p)| < 1.
19

{xk} diverge linealmente a p con C = g′(p) si |g′(p)| > 1.ii) Si g′′(x) es continua y g′(p) = 0 entonces,
|xk+1 − xk| ≈ −12g′′(p)|xk − xk−1|
si x0 ∈ I(p) entonces,{xk} converge cuadraticamente a p con C = − 1
2g′′(p).Si g′(p) = ±1 , {xk} puede converger o diverger muy lentamente.Demostracion. Consultar Analisis Numerico de M.J.Maron-R.J.Lopez.
2.6. Convergencia del Metodo de Newton-Raphson
Teorema 2.6 Si α es una raız simple de f(x) = 0, entonces el algoritmo de Newton Raphsontiene convergencia Cuadratica.Sol. α raız simple de f(x) = 0 implica que:
f(x) = (x− α) · h(x) con h(α) 6= 0
f ′(x) = h(x) + (x− α) · h′(x)
f ′(α) = h(α) 6= 0
Desarrollando f(x) en serie de Taylor alrededor de x = α se tiene :
f(x) = f(α) + f ′(α)(x− α) +f ′′(α)(x− α)2
2!+
f ′′′(ξ)(x− α)2
3!
Para algun ξ en un entorno de α. Consideremos el algoritmo de Newton-Raphson:
xn+1 = xn −f(xn)f ′(xn)
xn+1 − α = xn − α− 1f ′(xn)
(f ′(α)(xn − α) +
f ′′(α)(xn − α)2
2!+
f ′′′(ξ)(xn − α)3
3!
)
xn+1 − α =(xn − α)2
f ′(xn)
[f ′(xn)− f ′(α)
(xn − α)− f ′′(α)
2!− f ′′′(ξ)(xn − α)
3!
]
lımn→∞|xn+1 − α||xn − α|2
=∣∣∣∣ 1f ′(α)
(f ′′(α)− f ′′(α)2
)∣∣∣∣ =
∣∣∣∣ 12f ′(α)
∣∣∣∣ = cte
(22)Luego el metodo de Newton tiene orden de convergencia 2 para α raız simple.
Teorema 2.7 Si α es una raız multiplicidad p de f(x) = 0, entonces el algoritmo de NewtonRaphson tiene convergencia lineal.Dem. α raız simple de f(x) = 0 implica que:
20

f(x) = (x− α)p · g(x) con g(α) 6= 0
f ′(x) = p(x− α)p−1 · g(x) + (x− α)p · g′(α)
En efecto,
xn+1 = xn −f(xn)f ′(xn)
xn+1 − α = xn − α− (xn − α)p · g(xn)p(xn − α)p−1 · g(xn) + (xn − α)p · g′(xn)
xn+1 − α = (xn − α)− (xn − α)p · g(xn)(xn − α)p−1(pg(xn) + (xn − α) · g′(xn))
xn+1 − α = (xn − α)(
1− g(xn)pg(xn) + (xn − α)g′(xn)
)
lımn→∞|xn+1 − α||xn − α|2
= lımn→∞
∣∣∣∣1− g′(α)pg(α)
∣∣∣∣ g(α) 6= 0
= 1− 1p
=p− 1
p, con p > 1
(23)
Luego el metodo de Newton-Raphson tiene orden convergencia 1 o lineal para α raız multiple.
Actividades 2.8
1. Considere la ecuacion:e
x2 − 2x = 0 (24)
i) Verifıque la ecuacion (24) tiene una raız en el intervalo [4, 5].ii) Demuestre que en el intervalo [4, 5] esta la mayor raız positiva de la ecuacion (24).iii) Para obtener la raız que esta en [4, 5], se propone el siguiente algoritmo de punto fijo:
xk+1 =e
xk2
2(25)
Determine justificadamente , si es posible garantizar la convergencia del algoritmo parahallar la raız . Usando (25) y una aproximacion x0, adecuada, trate de obtener unaaproximacion de la citada raız.
iv) Proponga un algoritmo de punto fijo convergente, y uselo con x0 conveniente, paradeterminar una aproximacion de la raız de (24) en [4, 5].
2. Puede demostrarse que la forma que adopta un cable suspendido de sus extremos es catenaria.Una ecuacion de una catenaria esta dada por:
y = coshx
a
21

donde a es una constante por determinar. El eje Y equidista de sus puntos extremos. Uncable telefonico esta suspendido, a la misma altura, de dos postes que estan a 200 pies unodel otro. El cable tiene una caıda maxima de 10 pies en el punto medio del cable. Determineel valor de a. (Recuerde que cosh0 = 1.)
Nota 2.2 El material bibliografico usado para la elaboracion de este taller :
Analisis Numerico. R.L. Burden-J.D. Faires
Analisis Numerico. M.J. Maron - R.J. Lopez.
22

3. Ceros de las funciones Polinomicas.
Una expresion de la forma:
Pn(x) = anxn + an−1xn−1 + · · · a1x + a0
donde, los ai son constantes, an 6= 0, se llama polinomio de grado n.Recordamos el metodo de Horner:
Teorema 3.1 Metodo de Horner.Sea
Pn(x) =n∑
k=0
akxk , anneq0 , an = bn
i) Si bk = ak + bk+1x0 , ∀k = n− 1, · · · 1, 0 entonces
P (x0) = b0
ii) Ademas si,Qn−1(x) = bnxn−1 + bn−1x
n−2 + · · · b2x + b1
entoncesPn(x) = (x− x0)Qn−1(x) + b0
Dem.
ii) Desarrollamos Q(x) en la expresion :
(x− x0)Qn−1(x) + b0 = (x− x0)(bnxn−1 + bn−1xn−2 + · · · b2x + b1) + b0
= bnxn + bn−1xn−1 + · · · b2x
2 + b1x)− (bnx0xn−1 + bn−1x0x
n−2 + · · · b2x0x + b1x0) + b0
= bnxn + (bn−1 − bnx0)xn−1 + · · ·+ (b2 − b3x0)x2 + (b1 − b2x0)x + (b0 − b1x0)= anxn + an−1x
n−1 + · · · a1x + a0 = Pn(x).
i) Usando ii)Pn(x) = (x− x0)Qn−1(x) + b0 ⇐ P (x0) = b0
Corolario. P ′(x0) = Q(x0)Dem.
P (x) = (x− x0)Q(x) + b0
= Q(x) + (x− x0)Q′(x)P ′(x0) = Q(x0)
Observacion 3.1 Si se usa el metodo de Newton - Raphson para determinar las raıces de unpolinomio P (x), para evaluar P (xk) y P ′(xk) puede usarse el metodo de Horner.
23

Ejemplo 3.1 Usando Newton - Raphson y Metodo de Horner, aproximar la mayor raız negativade
2x4 − 3x2 − 3x− 4
Usando x0 = −2 como aproximacion inicial, relizar 3 iteraciones.Solucion .
Primera iteracion.
i) Calculo de P (x0)
ai a4 a3 a2 a1 a0
2 0 −3 3 −4−4 8 −10 14
bi 2 −4 5 −7 10
Por teorema de Horner:
P (−2) = 10 y Q(x) = 2x3 − 4x2 + 5x− 7
ii) Calculo de P ′(x0)Para determinar P ′(−2) = Q(−2), usamos nuevamente metodo de Horner.
2 −4 5 −7−4 16 −42
2 −8 21 −49
Luego P ′(−2) = −49 Usamos Metodo de Newton-Raphson
x1 = −2− 10−49
≈ −1,796
Segunda y Tercera iteracion.
Actividades 3.1 Separar las raıces de los siguientes polinomios:a) P3(x) = 3x3 + 2x− 1c) P4(x) = x4 − 2x2 + 1
24

UNIVERSIDAD DE SANTIAGO DE CHILE
CALCULO NUMERICO
Ecuaciones No lineales.
Modulo 5
Prof: Marıa Angelica Vega U.
3.1. Sistemas de Ecuaciones No lineales.
Un sistema de n ecuaciones con n incognitas x1, x2, ..., xn se dice no lineal si una o mas ecuacioneses no lineal.Notacion.
f1(x1, ..., xn) = 0f2(x1, ..., xn) = 0
... =...
fn(x1, ..., xn) = 0
o
f1(x) = 0f2(x) = 0
... =...
fn(x) = 0
donde x =
x1
x2
...xn.
Este sistema puede escribirse abreviadamente como, ~F ( ~X) = ~0 (o F(x) = 0 .) Notese que lasolucion es un vector que debe satisfacer simultaneamente todas las ecuaciones del sistema.
Ejemplo 3.2 Analizar, si es posible determinar la solucion de :i)
yex − 2 = 0x2 + y − 4 = 0
ii)xey − x5 + y + 3 = 0
x + y + tanx− sen y = 0
Solucion.
i) Segun la notacion anterior:
f1(x, y) = yex − 2 = 0f2(x, y) = x2 + y − 4 = 0
25

Figura 9: x = (1/3)x + 0,2
Graficamente, Una forma simple de resolver este sistema es, usar los metodos empleados en laresolucion de sistemas lineales, es decir, despejar y en ambas ecuaciones, obteniendose:
x2 + 2e−x − 4 = 0
Usando cualquier metodo para aproximar raıces de ecuaciones no lineales se obtiene:
x1 ≈ (−0,6, 3,7)T y x2 ≈ (1,9, 0,4)T
ii) ¿Es posible usar el metodo anterior para determinar una solucion de:
f1(x, y) = xey − x5 + y + 3 = 0f2(x, y) = x + y + tanx− sen y = 0
Justificar la respuesta.
3.2. Metodo de Newton- Raphson Generalizado.
La idea es ahora extender el metodo de Newton- Raphson, visto para funciones de una variablereal a funciones de dos o mas variables, para resolver el sistema:
F(x) = 0 ⇔
{f(x, y) = 0g(x, y) = 0
(26)
Analizaremos el caso mas simple, es decir, funciones de dos variables. Para ello recordamos elteorema de Taylor, para funciones de 2 variables .Sea u = f(x, y) y todas sus derivadas parciales de orden menor o igual a (n + 1) continuas enuna region D = {(x, y)/a ≤ x ≤ b c ≤ y ≤ d}. Sea (x0, y0) ∈ D, para todo (x, y) ∈ D existen
26

ξ ∈ (x, x0) y η ∈ (y, y0) tal que:
Pn(x, y) = f(x0, y0) + (x− x0)∂f
∂x(x0, y0) + (y − y0)
∂f
∂y(x0, y0)+
=(x− x0)2
2!∂2f
∂x2(x0, y0) +
(x− x0)(y − y0)2!
∂2f
∂x∂y(x0, y0)+
=(y − y0)2
2!∂2f
∂y2(x0, y0) + · · ·+
=1n!
n∑j=0
(nj
)(x− x0)n−j(y − y0)j ∂nf
∂xn−j∂yj(x0, y0)+
=1
(n + 1)!
n+1∑j=0
(n + 1
j
)(x− x0)n+1−j(y − y0)j ∂n+1f
∂xn+1−j∂yj(ξ, η).
(27)
Pn(x, y) se llama Polinomio de Taylor de grado n en dos variables para la funcion f alrededorde (x0, y0). El ultimo termino corresponde al termino de error.Deduccion del metodo.
Aplicamos (27) para desarrollar las funciones no lineales f y g del sistema (26) en torno del punto(xk, yk).
f(x, y) = f(xk, yk) + (x− xk)∂f
∂x(xk, yk) + (y − yk)
∂f
∂y(xk, yk)+
=(x− xk)2
2∂2f
∂x2(ξ, η) +
(x− xk)(y − yk)2
∂2f
∂x∂y(ξ, η)+
=(y − yk)2
2∂2f
∂y2(ξ, η) + · · ·
g(x, y) = g(xk, yk) + (x− xk)∂g
∂x(xk, yk) + (y − yk)
∂g
∂y(xk, yk)+
=(x− xk)2
2∂2g
∂x2(ξ, η) +
(x− xk)(y − yk)2
∂2g
∂x∂y(ξ, η)+
=(y − yk)2
2∂2g
∂y2(ξ, η) + · · ·
(28)
Evaluando en (xk+1, yk+1) y trucando el termino de error se tiene:
f(xk+1, yk+1) = f(xk, yk) + (xk+1 − xk)∂f
∂x(xk, yk) + (yk+1 − yk)
∂f
∂y(xk, yk)
g(xk+1, yk+1) = g(xk, yk) + (xk+1 − xk)∂g
∂x(xk, yk) + (yk+1 − yk)
∂g
∂y(xk, yk).
(29)
27

Como la aproximacion (xk+1, yk+1) corresponde donde,
f(xk+1, yk+1) = 0 = g(xk+1, yk+1),
reordenando se obtiene:
(xk+1 − xk)∂f
∂x(xk, yk) + (yk+1 − yk)
∂f
∂y(xk, yk) = −f(xk, yk)
(xk+1 − xk)∂g
∂x(xk, yk) + (yk+1 − yk)
∂g
∂y(xk, yk) = −g(xk, yk).
(30)
Con el fın de simplificar la notacion, escribimos el sistema en forma matricial
Jk ·∆ = −xk. (31)
donde,
Jk =
∂f
∂x(xk)
∂f
∂y(xk)
∂g
∂x(xk)
∂g
∂y(xk)
es la matriz jacobiana, en
xk =(
xk
yk
)para xk =
(f(xk)g(xk)
)y ∆ =
(∆x∆y
)=
(xk+1 − xk
yk+1 − yk
)De (31) podemos escribir
∆ = −J−1F(xk)xk+1 = xk − J−1F(xk) (32)
Esta ultima ecuacion es una generalizacion de la formula de Newton-Raphson para funciones nolineales de una variable real.
Ejemplo 3.3 Resolver el ejemplo 1.1 i) usando metodo de Newton.Raphson generalizado.Solucion. Consideremos:
f(x, y) = yex − 2 = 0g(x, y) = x2 + y − 4 = 0 (33)
sabemos que tiene dos raıces, aproximaremos la raız positiva, usando
x0 =(−0,63,7
)Determinamos:
F(x) =(
yex − 2x2 + y − 4
), J =
(yex ex
2x 1
)
28

Evaluando en el dato inicial x0, tenemos
F(x0) =(
3,7e−0,6 − 2(−0,6)2 + 3,7− 4
), J0 =
(3,7e−0,6 e−0,6
2(−0,6) 1
)de donde, (
2,03060 0,548812−1,2 1
)·(
∆x∆y
)= −
(0,0306031
0,006
)De aquı (
∆x∆y
)=
−12,68917
(1 −0,548812
1,2 2,03060
)·
(0,0306031
0,006
)luego, (
∆x∆y
)=
(0,000865−0,05896
)Como
x1 − x0 = ∆x0 ⇒ x1 = x0 + ∆x0
entonces,
x1 =(−0,63,7
)+
(0,000865−0,05896
)=
(−0,5991353,64104
)Si realizamos una segunda iteracion, se obtiene:
x2 = x1 + ∆x1 =(−0,5991253,64105
)Actividades 3.2 Use el metodo de Newton-Raphson para determinar la aproximacion x3 de lasolucion del sistema no lineal √
x + 12cosz = ln 1
y
y ln 4x + 1 = 2z + ez
4x + y sen z = 1(34)
use como aproximacion inicial
x0 =
13
13
π6
Ayuda. Programando el algoritmo de Newton Raphson generalizado, en MAPLE se obtiene:
x1 =
,2399765202,3506602354
,551268419 · 10−1
, x2 =
0,24974296630,3672616918
0,26800671 · 10−3
, x3 =
0,24999997230,3678789014
−0,1485685 · 10−6
x4 =
0,2500000000,3678794411
−,1098834 · 10−9
, x5 =
0,25000000000,3678794411
−,7324581877 · 10−10
29

Nota 3.1 Observese que el metodo converge a
x =
14
1e
0
30

Método de Müller Es un método de interpolación que aproxima la función f(x) cuya raíz interesa por un polinomio cuadrático. Para determinar dicho polinomio se consideran tres puntos cercanos a la raíz de la ecuación f(x) = 0. Sean
20 0 1 1 2 2( , ) , ( , ) .( , ) dichos puntos y sea ( ) el polinomio
que interpola a ( ) en dichos puntos.A x f B x f y C x f P u au bu c
f x= + +
Para simplificar la obtención del polinomio cuadrático se supone que el origen pasa por el punto que esta en medio de los otros dos. Sea
1 1 0 2 0 2
20 0
21 1 1 1
Sea , Los coeficientes , , del polinomio ( ) se determinan resolviendo el sistema (0) (0) (0)
( )
h x x h x xa b c P uP f a b c f
P h f ah bh c
= − = −
= ⇒ + + =
= ⇒ + + 12
2 2 2 2 2
2 0 1 0
2
1
1 00
( )( en este desarrollo se considera , es decir, es el punto del medio)
Se obtiene,con :
· (1 )· ,
f
P h f ah bh c fx x x x
hdh
d f d fc f a
=
= ⇒ − + =< <
=
− += =
22 1 0 1
21 1
2
·,(1 )· ·
Con los valores determinados de , , se resuelve ( ) 0
f f f a hbd d h h
a b c P u au bu c
+ − −=
+
= + + =
eligiendo la raíz más cercana a 0x . Este valor es:
0 2
2 4
El signo del denominador se toma de modo que coincida con el de : si 0 se considera el signo + y si 0 se elig
cr xb b ac
b bb
= −± −
>< e el signo - en el denominador.
De ese modo el denominador toma su mayor valor absoluto.El valor calculado es uno de los tres puntos a considerar en el siguiente paso,es decir,si queda a la derecha
rr 0 0 1 0
0 2
0
de x se toman los puntos , , y si queda a la izquierda de ,los puntos a considerar son , , .En ambos casos los puntos se redefinen de modo que sea el punto del medio de los tres esco
x x r r xx x r
x gidos.
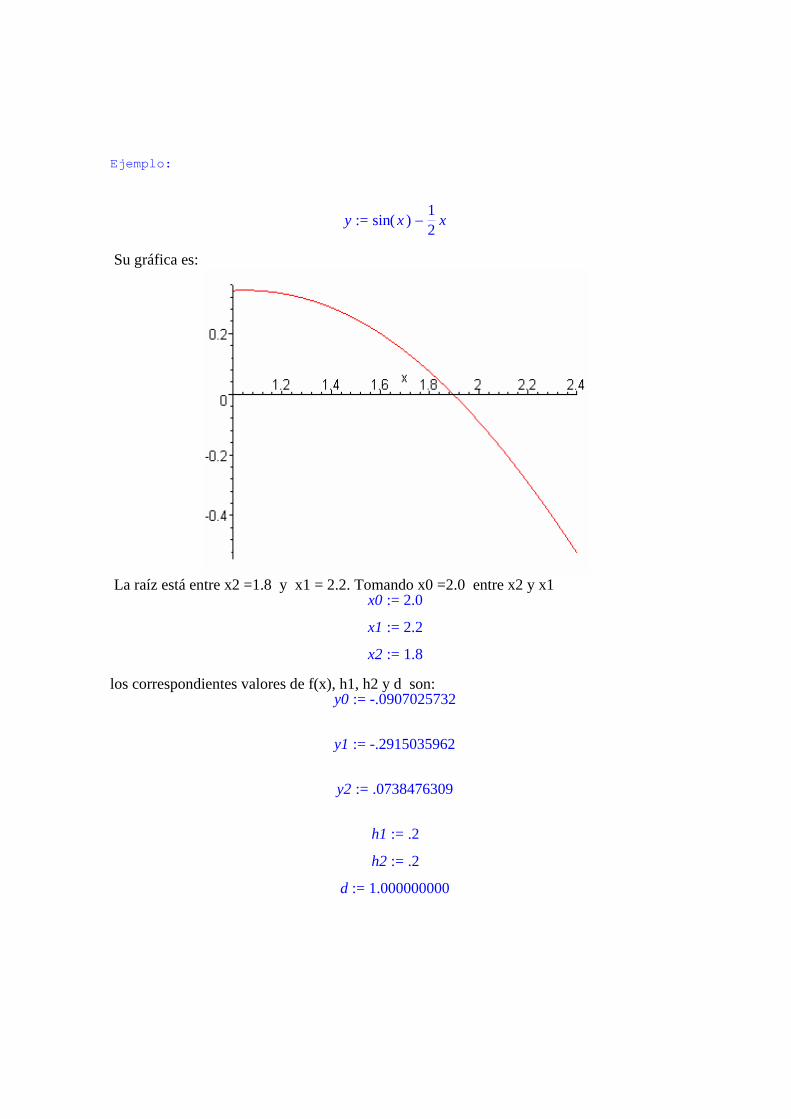
Ejemplo:
:= y − ( )sin x 12 x
Su gráfica es:
La raíz está entre x2 =1.8 y x1 = 2.2. Tomando x0 =2.0 entre x2 y x1
:= x0 2.0 := x1 2.2 := x2 1.8
los correspondientes valores de f(x), h1, h2 y d son: := y0 -.0907025732
:= y1 -.2915035962
:= y2 .0738476309
:= h1 .2 := h2 .2
:= d 1.000000000

Resolviendo el sistema se obtienen los coeficientes del polinomio cuadrático:
:= a -.4531352362
:= b -.9133780680
:= c -.0907025732
Por ser b < 0 se considera el signo (-) en el denominador de la expresión para r, raíz del polinomio ( r es una primera aproximación a la raíz de f(x) )
:= r 1.895252107
La raíz r del polinomio se encuentra a la izquierda de x0. Los nuevos valores son
:= x00 1.895252107 := x11 2.0 := x22 1.8
:= h11 .104747893 := h22 .095252107
:= d1 .9093462816
y los nuevos valores de la función son:
:= y00 .0001983067 := y11 -.0907025732 := y22 .0738476309
Los valores de los nuevos coeficientes del polinomio son:
:= a1 -.4730106876 := b1 -.8182594122 := c1 .0001983067
Con dichos valores se obtiene una nueva aproximación a la raíz resolviendo el polinomio cuadrático:
:= r1 1.895494425
El valor de la función en r1 es: := y3 -.1294 10-6

y la solución “exacta” (obtenida con Maple) de la ecuación propuesta es:
:= rexac 1.895494267
La magnitud del error absoluto en r1 es: := er .158 10-6
Ejemplo 2: Calcular la raíz en el segundo cuadrante de la ecuación:
:= y − ( ) + 1 x ( )sin x 1 = 0
:= x2 2.8 := x0 2.9 := x1 3.0 := h1 .1 := h2 .1
:= d 1.000000000 := y2 1.726773367 := y0 -.0669276161 := y1 -.4355199676 := a 71.25543160 := b -10.81146668 := c -.0669276161 := r 2.894043416

:= y3 -.0458478202 := x22 2.894043416
:= x00 2.9 := x11 3.0 := h11 .1
:= h22 .005956584 := d1 .05956584000 := y22 -.0458478202 := y00 -.0669276161 := y11 -.4355199676 := a1 -1.387518017 := b1 -3.547171713 := c1 -.0669276161
Una segunda aproximación a la raíz es r1 y la raíz "exacta" es rexac:
:= r1 2.880990772 := rexac 2.880986321
El valor de la función en x = r1 es: := y33 -.0000155441

Modulo 6
Prof. M.Angelica Vega U.
4. Sistemas de Ecuaciones Lineales.
4.1. Metodos directos
Estos metodos consisten en sustituir la matriz A por una sucesion de matrices elementales, demanera que se obtiene un sistema sea mas facil de resolver.
4.1.1. Metodo de Gauss.
El metodo de eliminacion gaussiana es uno de los metodos directos clasico para resolver el sistemaAx = b, consiste de dos etapas.Etapa 1. Triangularizacion.Para efectos de la operatoria, resulta mas simple, efectuar las operaciones sobre la matriz aumen-tada A en lugar de A.El metodo consiste en obtener una sucesion de sistemas equivalentes
A(k)x = b(k) , (k = 1, 2, ... , n)
mediante operaciones elementales de fila, tal que para cada k = 2, 3 , . . . , n.
A(k) =
a(1)11 a
(1)12 . . . . . . . . . . . . a
(1)1 n
... a(1)1 n+1
0 a(2)22 . . . . . . . . . . . . a
(2)2n
... a(2)2 n+1
0 0. . .
......
...
0 0 . . . a(k)kk a
(k)k k+1 . . . a
(k)k n
... a(k)k n+1
0 0 . . . a(k)k+1 k a
(k)k+1 k+1 . . . a
(k)k+1 n
... a(k)k+1 n+1
...... . . .
...... . . .
......
0 0 . . . a(k)n k a
(k)n k+1 . . . a
(k)n n
... a(k)n n+1.
(35)
donde,
b(k) =
a(1)1 n+1
...a(k)n n+1
...a(k)n n+1.
(36)
conA(1) = A ,
31

A(k) = (a(k)ij ) se obtiene de la siguiente manera:
a(k)ij =
a(k−1)ij si, i = 1, 2, . . . k − 1 ; j = 1, 2, . . . n + 1
0 si, i = k, k + 1, . . . n ; j = 1 . . . k − 1 ,
a(k−1)ij − a
(k−1)i k−1
a(k−1)k−1 k−1
a(k−1)k−1 j sii = k, k + 1 . . . n ; j = k, k + 1 . . . n + 1 ..
(37)
El proceso termina cuando A(n) es triangular superior, teniendose el sistema A(n)x = b(n).Notese que en esta etapa solo se obtiene una matriz triangular superior. En la etapa siguiente, seresuelve el sistema.Etapa 2. Retrosustitucion.Resolvemos la n-esima ecuacion
xn =a(n)n n+1
a(n)n n
.
Usando xn se puede despejar xn−1 de la n− 1-ecuacion
xn−1 =a(n−1)n−1 ,n+1 − a
(n−1)n−1 n xn
an−1 n−1;
continuando con este proceso, se tiene que, para cadai = n− 1, n− 2, . . . , 2, 1 ,
xi =ai
i ,n+1 − aii nxn − ai
i n−1xn−1 − · · · · · · · · · − aii i+1xi+1
aii=
aii ,n+1 −
∑nj=i+1 ai
ijxj
aii(38)
Nota 4.1 Denotaremos por :
mi k =ai k
ak k
al numero que produce un cero en la fila i columna k, denominado multiplicador y a los elementosai i le llamaremos elementos pivotes.
Observemos que, a(k)i j , se obtiene de :
a(k)i j = a
(k−1)i j −mk−1
i k−1 · a(k−1)k−1 j
Actividades 4.1
i) Ejemplo 4.1 Use eliminacion de Gauss para resolver:
3x1 − 0,1x2 − 0,2x3 = 7,85 ,
0,1x1 + 7x2 − 0,3x3 = −19,4 ,
0,3x1 − 0,2x2 + 10x3 = 71,4 ,
efectuar los calculos con 6 cifras significativas.
32

Solucion : la matriz aumentada es
A =
3 −0,1 −0,2 7,850,1 7 −0,3 −19,40,3 −0,2 10 71,4
luego,los multiplicadores que producen ceros en la primera columna son :
m2 1 =a2 1
a1 1=
0,13
= 0,03333333
y
m3 1 =a3 1
a1 1=
0,33
= 0,09999999
ii) Ejemplo 4.2 Use eliminacion de Gauss para resolver los siguientes sistemas: a)
0,0003x1 + 3,0000x2 = 2,0001 ,
1,0000x1 + 1,0000x2 = 1,0000 ,
b)
1,0000x1 + 1,0000x2 = 1,0000 ,
0,0003x1 + 3,0000x2 = 2,0001 ,
c) Compare los resultados de a) y b) al considerar 3, 4 y 5 cifras significativas. ¿A que con-clusion llega ?
4.1.2. Eliminacion gaussiana con y sin pivoteo.
De la Actividad I.ii), se observa que pueden surgir dificultades en algunos casos, como cuando elpivote es pequeno en relacion a los otros elementos de la columna a la que pertenece el elementopivote. Una forma de mejorar las soluciones se usa como estrategia pivotear. El llamado pivoteoparcial consiste en seleccionar el elemento de mayor valor absoluto ubicado en la misma columnaque el pivote, bajo la diagonal e intercambiar filas. Al procedimiento de buscar el elemento demayor valor absoluto tanto en las columnas como en las filas y luego intercambiar se conoce comopivoteo total.El pivoteo completo o total no es muy usado puesto que el intercambio de columnas implica unintercambio de las incognitas, lo que agrega complejidad injustificada.
Actividades 4.2 1. Use eliminacion de Gauss para resolver el sistema :
x1 + x2 − x3 = −3 ,
6x1 + 2x2 + 2x3 = 2 ,
−3x1 + 4x2 + x3 = 1 ,
usando,
33

Gauss simple.
Eliminacion gaussiana con pivoteo parcial.
Eliminacion gaussiana con pivoteo total.
2. Para k = 0, 1, 2, ..., sea x(k) = [xk, yk, zk]T generada por :
4xk+1 = −xk − yk + 2 ,
6yk+1 = +2xk + yk − zk − 1 ,
−4xk+1 = −xk + yk − zk + 4 ,
a) Demuestre que la sucesion de vectores {x(k)}∞k=1 es convergente para cualquier vectorinicial x(0).
b) Determine el vector x al cual converge usando Gauss con pivote parcial.
c) Encuentre el vector x iterando el sistema dado.
3. Suponga que trabaja con una maquina que redondea a dos decimales para resolver el siguientesistema :
0,10 · 10−1x + y = 1x− y = 0
Use el metodo de eliminacion de Gauss para encontrar la solucion.
Efectue un pivoteo parcial y compare con la solucion anterior. La solucion exacta delsistema es x = y = 100
101 .
34

4.2. Factorizacion LU
A = LU
Una primera interrogante es ¿Existe tal factorizacion? . Un primer resultado que garantiza laexistencia de esta factorizacion dice,
Teorema 4.1 Si puede aplicarse la eliminacion gaussiana al sistema Ax = b sin intercambio defilas, entonces la matriz A puede factorizarse como
A = LU ,
donde
U =
a(1)11 a
(1)12 . . . a
(1)1n
0 a(2)22
. . ....
.... . . . . . a
(n−1)n−1 n−1
0 . . . 0 a(n)nn
y
L =
1 0 . . . 0
m21 1. . .
......
. . . . . . 0mn1 . . . mn n−1 1
(39)
Notese que al factorizar A en LU ,
Ax = b ⇔ L(Ux) = b
entonces, es posible resolver el sistema utilizando dos sistemas que involucran matrices triangulares,se resuelve primero Ly = b y luego Ux = y. De modo que si L = (lij), entonces se obtiene elvector y por sustitucion hacia adelante,
y1 =b1
l11
y los yi para cada i = 2, 3, . . . n, mediante
yi =1lii
[bi −
i−1∑j=1
lijyj
].
Ası conociendo el vector y podemos obtener en el sistema Ux = y el vector x por retrosustitucion.El Teorema 1 proporciona una factorizacion de la matriz A, observe que los elementos de la matrizL son los elementos multiplicadores mi j que se obtuvieron al realizar la eliminacion gaussiana,excepto los elementos de la diagonal principal que son 1. Esta factorizacion se conoce como Fac-torizacion de Doolitle.Queda analizar una segunda interrogante . si A admite una factorizacion LU , ¿ esta sera unica?
35

Analicemos el problema general, el factorizar A como LU , significa que hay que resolver las ecua-ciones
a11 a12 . . . a1n
a21 a22 . . . a2n
......
. . ....
an1 an2 . . . ann
=
l11 0 0 . . . 0l21 l22 0 . . . 0l31 l32 l33 . . . 0...
......
. . ....
ln1 ln2 ln3 . . . lnn
·
u11 u12 u13 . . . u1n
0 u22 u23 . . . u2n
0 0 u33 . . . u3n
......
.... . .
...0 0 0 . . . unn.
(40)
Notemos que las ecuaciones anteriores, no determinan a L y a U en forma unica. Para cada i sepuede asignar un valor no nulo lii o uii (pero no a ambos). ¿Porque ? Justifique . Por ejemplo, silii = 1 para i = 1, 2, . . . , n, es la descomposicion de Doolitle que se obtiene como vimos al aplicareliminacion gaussiana. Otra eleccion simple es uii = 1 para cada i en este caso la factorizacion esla de Crout, o bien asumir que lii = uii en cual caso tenemos la factorizacion de Choleski
Actividades 4.3
i) Descomponer la matriz A usando la factorizacion de Crout, en el sistema :
x1 + x2 − x3 = −3 ,
6x1 + 2x2 + 2x3 = 2 ,
−3x1 + 4x2 + x3 = 1 ,
ii) Problema N◦3 de la PEP1 (Sem II-2000) Para determinar la temperatura en cuatro puntosinteriores equidistantes de una barra, hay que resolver la ecuacion :
Atk+1 = tk , k = 0, 1, 2, ...
donde,
A =
3 −1 0 0−1 3 −1 00 −1 3 −10 0 −1 3
, t0 =
10121210
(41)
(tk es la distribucion de la temperatura en los puntos interiores de la barra en el instante k.
a) Mediante el metodo de Gauss (sin pivote) determine t1.
b) Obtenga t2 y t3, usando una descomposicion A = LU .
iii) Resolver el sistema −x1 + 2x2 + 3x3 + x4 = 12x1 − 4x2 − 5x3 − x4 = 0−3x1 + 8x2 + 8x3 + x4 = 2x1 + 2x2 − 6x3 + 4x4 = −1
(42)
iv) Investigue como a partir de la factorizacion de Doolitle puede obtener la factorizacion deCrout ? Ilustre el metodo con un ejemplo.
36

4.2.1. Matrices definidas positivas.
Definicion 4.1 Una matriz A simetrica es definida positiva si y solo si
xT Ax > 0 ,∀x ∈ Rn − {0} (43)
Ejemplo 4.3 Verifique si la matriz dada es definida positiva. 2 −1 0−1 2 −10 −1 2
(44)
En la practica puede resultar difıcil determinar si una matriz es definida positiva a partir de ladefinicion, el siguiente resultado constituye un criterio de gran utilidad para este proposito.
Teorema 4.2 A es simetrica y definida positiva, si y solo si Dk > 0 , ∀ k = 1, ..., n, donde Dk esel determinante:
Dk =
∣∣∣∣∣∣∣a11 · · · a1k
.... . .
...ak1 · · · akk
∣∣∣∣∣∣∣Dem. Consultar, Introduction to Numerical Analysis de Stoer - Bulirsch.
Teorema 4.3 Si A es simetrica y definida positiva, entonces :i) A es no singularii) aii > 0, para cada i = 1, 2, ..., n.Dem.
i) Supongamos A no invertible, entonces exite x 6= 0 tal que el sistema Ax = 0, de dondexT Ax = 0, lo que contradice el hecho de A definida positiva. Por tanto, A es no singular.
ii) Ejercicio
Teorema 4.4 Si A es una matriz real, simetrica y definida positiva, entonces A = LLT , donde Les una matriz triangular inferior con diagonal positiva.Dem. Consultar Analisis Numerico de Burden - Faires o Kincaid - Cheney
4.2.2. Matrices diagonal dominante.
Definicion 4.2 Sea A una matriz cuadrada de orden n, diremos que A es diagonal dominantesi
|aii| ≥n∑
j=1j 6=i
|aij |,∀i, 1 ≤ i ≤ n (45)
Veamos algunos resultados importantes,
37

Teorema 4.5 Si A es diagonal dominante, entonces A es invertible.
Teorema 4.6 Si A es diagonal dominante y todos los elementos de la diagonal son reales positivos, entonces la parte real de cada valor propio es positiva. Dem. Algebra Lineal. Grossman. Mc GrawHill.
Teorema 4.7 Si A es simetrica, diagonal dominante, con los coeficientes diagonales positivos,entonces A es definida positiva.Dem. Usando el teorema anterior, si λi > 0 deduciremos que xtAx > 0. Como A es simetrica,tiene un conjunto de autovectores ortonormales (teorema espectral), entonces cualquier vector xpuede escribirse como una combinacion lineal de ellos,
x = c1x1 + c2x2 + ... + cnxn,
entoncesAx = c1Ax1 + c2Ax2 + ... + cnAxn = c1λ1x1 + c2λ2x2 + ... + cnλnxn.
De la ortogonalidad y la normalizacion xtixi = 1. Luego,
xtAx = (c1xt1 + c2x
t2 + ... + cnxt
n)(c1λ1x1 + c2λ2x2 + ... + cnλnxn)
= c21λ1x1 + c2
2λ2x2 + ... + c2nλnxn
como λi > 0, se tiene que ∀i xtAx > 0.
Observacion 4.1 El recıproco del teorema anterior es falsa, es decir existen matrices simetricasdefinidas positivas que no son diagonal dominante. De un contraejemplo.
38

Modulo 7Prof : Marıa Angelica Vega U.
5. Metodos iterativos.
5.1. Normas vectoriales y matriciales.
5.1.1. Preliminares.
Actividades 5.1
i) Si V es un espacio vectorial, ¿Que es una norma sobre V ? , ¿Como se define la distanciaentre dos vectores ? ¿Cuando una sucesion de vectores es convergente ?
ii) Sea V = IRn, las normas de uso frecuente en IRn son,
‖x‖1 =∑n
i=1 |xi| , llamada norma 1
‖x‖2 =(∑n
i=1 x2i
)1/2, llamada norma euclıdea o norma 2
‖x‖∞ = max1≤i≤n |xi| , llamada norma infinito o del maximo.
Ejemplo 5.1 Compare la longitud de los siguientes tres vectores en IR4, usando cada una de lasnormas anteriores.
x = (4, 4,−4, 4)T y = (0, 5, 5, 5)T w = (6, 0, 0, 0)T
Definicion 5.1 Diremos que dos normas son equivalentes si existen dos numeros α y β positivostales que
α‖v‖q ≤ ‖v‖p ≤ β‖v‖q.
Demuestre las siguientes afirmaciones.(Haga una en clases ).
iv) Las normas ‖v‖∞ y ‖v‖1 son equivalentes, en efecto
‖v‖∞ ≤ ‖v‖1 ≤ n‖v‖∞
v) Las normas ‖v‖∞ y ‖v‖2 son equivalentes
‖v‖∞ ≤ ‖v‖2 ≤√
n‖v‖∞ o1√n‖v‖2 ≤ ‖v‖∞ ≤ ‖v‖2 .
vi) Las normas ‖v‖1 y ‖v‖2 son equivalentes
‖v‖2 ≤ ‖v‖1 ≤√
n‖v‖2.
Observacion 5.1 ¿Por que es importante que las normas estudiadas sean equivalentes ?
Porque se puede utilizar cualquiera de ellas. Ası si, por ejemplo, se tiene una sucesion de vectoresque tiende a v para una cierta norma, entonces la sucesion tambien converge a v para las otrasnormas (equivalentes).
40

5.1.2. Normas matriciales
Definicion 5.2 Sea An el conjunto de las matrices de orden n, con las operaciones habituales,definidas sobre IR (o CI ). Definiremos una norma matricial como una aplicacion
‖ · ‖ : An → IR
que verifica las siguientes propiedades :
i) ‖A‖ ≥ 0 , ∀ A ∈ An y ‖A‖ = 0 ⇐⇒ A = 0ii) ‖αA‖ = |α|‖A‖ , ∀ α ∈ IR y A ∈ An
iii) ‖A + B‖ ≤ ‖A‖+ ‖B‖ , ∀ A,B ∈ An
iv) ‖AB‖ ≤ ‖A‖‖B‖ , ∀ A,B ∈ An.
Comentarios:
i) An puede ser considerado como un espacio vectorial de dimension n2, Ası las cosas, las tresprimeras propiedades son similares a las correspondientes de una norma vectorial; mientrasque la ultima propiedad es propia de las normas matriciales.
ii) Un concepto importante para nuetros propositos es norma matricial inducida, puesto quepermite relacionar las normas vectoriales con las normas matriciales, pilar fundamental parael estudio de convergencia y analisis de error en el calculo numerico.
Definicion 5.3 Sean A una matriz n×n y ‖ ·‖v una norma vectorial definida en IRn, llamaremosnorma matricial inducida o norma matricial subordinada, con respecto a la norma vectorial dadaal numero:
‖A‖ = supv 6=0
‖Av‖v
‖v‖v= sup
‖v‖=1
‖Av‖.
Actividades 5.2 Investigue, como demostrar los siguientes resultados importantes.
i) Para toda norma matricial inducida, se cumple
‖Ax‖v ≤ ‖A‖‖x‖v , x ∈ IRn. (46)
En este caso se dice que la norma matricial y la norma vectorial son compatibles.
ii) Sea A = (aij) una matriz cuadrada real, entonces
‖A‖1 = sup‖Av‖1‖v‖1
= max1≤j≤n
n∑i=1
|aij |
‖A‖2 = sup‖Av‖2‖v‖2
=√
ρ(AT A) =√
ρ(AAT ) = ‖AT ‖2 (norma espectral)
‖A‖∞ = sup‖Av‖∞‖v‖∞
= max1≤i≤n
n∑j=1
|aij | (norma del maximo.)
41

Nota 5.1 Si A es una matriz de orden n, ρ(A) denota el radio espectral de A, es decir
ρ(A) = maxλi∈σ(A)
|λi|
Observacion 5.2 Existen normas matriciales que no son subordinadas a ninguna norma vectorial,por ejemplo, la norma
‖A‖E =
∑i,j
|aij |21/2
= (tr(A∗A))1/2
es una norma matricial no subordinada.
Nota 5.2 La matriz aumentada de un sistema lineal Ax = b en general se almacena con un errorde redondeo, si la solucion calculada se obtiene usando una estrategia de pivoteo que limita el error,entonces la solucion calculada y la solucion exacta son iguales hasta alrededor de la exactitud dela maquina usada. Por lo tanto es util saber si la matriz de los coeficientes esta mal condicionada.Se entiende por matriz mal condicionada si pequenos cambios en los elementos de la matrizA, pueden producir grandes cambios en el vector solucion.
Un indicador de mal condicionamiento es el llamado numero de condicion de la matriz A quese define como
K(A) = ‖A‖ · ‖A−1‖
Este numero tiene la propiedad que, K(A) ≥ 1, luego un numero de condicion de una matrizcercano a 1 es indicador de buen condicionamiento y un numero de condicion muy grande, esindicador de mal condicionamiento.
Actividades 5.3
i) Determine ‖x‖ , ‖A‖ y ‖A−1‖ para las ‖ · ‖1 y ‖ · ‖∞, si
x =
2−53
y A =
−1 1 −42 2 03 3 2
(47)
ii) ¿Cual es el numero de condicion de la matriz A.
iii) Determine la norma espectral de A. (Para entretenerse fuera de la clase ).
5.1.3. Otros resultados importantes para el estudio de los metodos iterativos.
Si A es una matriz real de orden n, se tiene
i) ρ(A) ≤ ‖A‖, para cualquier norma ‖ · ‖.
42

ii) Diremos que A es una matriz convergente, si
lımk→∞
(ak)ij = 0 para cada i = 1, 2, ..., n y j = 1, 2, ..., n.
Las siguientes afirmaciones son equivalentes:
i) A es una matriz convergente.ii) lım
n→∞‖(An)‖ = 0, para alguna norma natural ‖ · ‖.
iii) ρ(A) < 1.
iv) lımn→∞
Anx = 0.
Actividades 5.4 !’ Entretengase ! , demuestre que A es una matriz convergente si
A =(
12 014
12
)(48)
Teorema 5.1 Las siguientes afirmaciones son equivalentes:
i) A es una matriz convergente.ii) lım
n→∞‖(An)‖ = 0, para alguna norma natural ‖ · ‖.
iii) ρ(A) < 1.
iv) lımn→∞
Anx = 0.
5.2. Metodos iterativos.
Los metodos directos requieren alrededor de 2n3/3 operaciones aritmeticas para resolver un sistemalineal de n×n, lo que limita el tamano de los sistemas que pueden ser resueltos de manera directa.Por ejemplo cuando se resuelven numericamente ecuaciones diferenciales pueden surgir sistemasde 20000 variable.Una alternativa que puede lograr gran exactitud para n grande son los metodos iterativos.Para obtener un metodo iterativo procedemos como antes, re-escribimos el sistema de ecuacionescomo una iteracion de punto fijo. Es decir,
Ax = b. (49)
lo escribimos, en la forma
x(k+1) = Mx(k) + c para cadak ≥ 1. (50)
donde la matriz M , se llama matriz de iteracion. Relacionando nuestros conocimientos sobrenormas con estos metodos, existen algunos resultados importantes que garantizan la convergenciade estos metodos. ( Se sugiere cosultar la demostracion en los textos de la bibliografıa entregada.)
43

1) El radio espectral de la matriz M , ρ(M) cumple
ρ(M) ≤ ‖M‖
para cualquier norma matricial inducida.
2) Sea M matriz n × n, el proceso iterativo (61) converge para cada k ≥ 1 y c 6= 0 a la unicasolucion si y solo si ρ(M) < 1.
Para transformar (49) en un problema de punto fijo, se descompone la matriz A en la suma,
A = L + D + U
donde, D es la diagonal principal de A, L es la parte diagonal inferior de la matriz A y U es laparte triangular superior de A con ceros en las diagonales.
5.2.1. Metodo de Jacobi.
i) Forma matricial
Transformamos el sistema,
Ax = b ⇔ (D + L + U)x = b⇔ Dx = b− (L + U)x⇔ x = D−1[b− (L + U)x]⇔ x = −D−1(L + U)x + D−1b⇔ x = MJACx + c.
(51)
De aquı que la matriz de de iteracion de Jacobi es,
MJAC = −D−1(L + U).
y c = D−1b.
ii) Forma en terminos de las componentes
La i-esima componente del vector correspondiente a (k + 1)-esima iteracion es,
x(k+1)i =
1aii
bi −n∑
j=1j 6=i
aijx(k)j
. (52)
44

5.3. Metodo de Gauss-Seidel.
i) Forma matricial
En este caso se hace la transformacion,
Ax = b ⇔ (D + L + U)x = b⇔ (D + L)x = b− Ux⇔ x = (D + L)−1[b− Ux]⇔ x = −(D + L)−1Ux + (D + L)−1b⇔ x = MGSx + c.
(53)
De aquı que la matriz de de iteracion de Gauss-Seidel es,
MGS = −(D + L)−1U.
y el vector c = (D + L)−1b.
ii) Forma en terminos de las componentes
Este metodo es un mejoramiento del metodo de Jacobi, que consiste en calcular la compo-nente x
(k)i a partir de las componentes de x(k−1) en la forma siguiente, para i > 1, han
sido calculadas las x(k)1 , ..., x
(k)i−1 que supuestamente son mejores aproximaciones que las
x(k−1)1 , ..., x
(k−1)i−1 a las componentes x1, ..., xi−1, de la solucion real , por lo tanto se usa esta
idea al resolver la i-esima ecuacion,
x(k)i =
−∑i−1
j=1
(aijx
(k)j
)−
∑nj=i+1
(aijx
(k−1)j
)+ bi
aiipara i = 1, 2, ..., n.
Actividades 5.5
i) Dado el sistema lineal: x1 − 0x2 + 3x3 = 25x1 + x2 + 2x3 = −5x1 + 6x2 + 2x3 = −11
(54)
a) Es Definida positiva la matriz A. Justifique.
b) Determine la solucion exacta del sistema.
c) Comenzando con x(0) = 0 determine cuatro iteraciones usando el metodo de Jacobi ycuatro iteraciones usando Gauss-Seidel
ii) El metodo iterativo de Jacobi puede expresarse como :
x(k+1) = MJACx(k) + c. (55)
donde = MJAC es la correspondiente matriz de iteracion.
45

a) Verifique que (55) puede escribirse como:
x(k+1) = x(k) + z(k). (56)
donde,
z(k) = c−BJACx(k) con BJAC = I −MJAC
(z(k) se llama vector de correccion)
b) Para obtener un metodo de relajacion, se introduce en (56) el coeficiente ω para obtener:
x(k+1) = x(k) + ωz(k). (57)
Use el metodo (57) con ω = 0,5 para estimar la aproximacion x(2) del sistema :3 −1 0 0−1 3 −1 00 −1 3 −10 0 −1 3
x1
x2
x3
x4
=
10121210
(58)
con x(0) = 0.
5.4. Metodo de sobrerelajacion
Estos metodos se obtienen modificando el metodo de Jacobi o el de Gauss-Seidel, introduciendoun parametro ω llamado parametro de relajacion.
i) Forma matricial
En efecto, la forma matricial del esquema, se obtiene considerando la siguiente descomposicionpara la matriz A.
A =D
ω+ L−
[(1− ω)
ωD
]+ U. (59)
donde :
ω es un parametro
D,L,U son las matrices diagonal y triangulares inferior y superior definidas anteri-ormente.
sustituyendo (59) en Ax = b, se tiene :
D
ωx + Lx +
[−(1− ω)
ωD + U
]x = b. (60)
multiplicando (60) por ω :
Dx + ωLx + [−(1− ω)D + ωU ]x = ωb
46

y de aquı :x = (D + ωL)−1[(1− ω)D − ωU ]x + ω(D + ωL)−1b
que en forma recursiva puede expresarse en la forma :
x(k) = Mωx(k−1) + c (1)
con :Mω = (D + ωL)−1[(1− ω)D − ωU ]c = ω(D + ωL)−1b
ii) En termino de componentesPara fines computacionales la ecuacion matricial, puede escribirse:
x(k)i = (1− ω)x(k−1)
i +ω
aii
bi −i−1∑j=1
aijx(k)j −
n∑j=i+1
aijx(k−1)j
, (2)
para i = 1, 2, ..., n.
Si ω = 1 , tenemos el metodo de Gauss-Seidel.Si 0 < ω < 1, los metodos de relajacion se denominan metodos de sub-relajacion y se pueden usaren sistemas que no son convergentes por el metodo de Gauss-Seidel.Si ω > 1 los metodos se denominan metodos de sobre-relajacion y se pueden usar para acelerar laconvergencia en sistemas que son convergentes mediante el metodo de Gauss-Seidel.
5.5. Resultados importantes
i) Para cualquier x(0) ∈ Rn, la sucesion definida por
x(k+1) = Mx(k) + c para cadak ≥ 1. (61)
converge a la solucion unica si y solo si ρ(M) < 1.
ii) Si ‖M‖ < 1 para cualquier norma matricial subordinada, la sucesion generada por (61)converge para cualquier x(0) ∈ Rn y se satisafacen las cotas de error:
• ‖x− x(k)‖ ≤ ‖M‖k‖x(0) − x‖
• ‖x− x(k)‖ ≤ ‖M‖k
1− ‖M‖‖x(1) − x(0)‖
iii) Si A es diagonal dominante, entonces para cualquier eleccion de x(0) los metodos de Jacobiy Gauss-Seidel convergen a la solucion exacta del sistema.
iv) Si A es definida positiva y 0 < ω < 2, entonces el metodo SOR converge para cualquieraproximacion inicial.
v) Si A es definida positiva y tridiagonal, entonces ρ(MGS) = ρ(MJAC)2 < 1 y la eleccionoptima de ω, es
ω =2
1 +√
1− ρ(MJAC)2.
47

5.6. Analisis de error y Numero de Condicion
Consideremos el sistema A−→x =−→b y supongamos que A es una matriz invertible, analicemos las
siguientes situaciones:
1. Si se perturba la matriz A−1 para obtener una nueva matriz B la solucion x = A−1b resultaperturbada y la escribiremos x = Bb. Nos preguntamos ¿Que tan grande es la solucionperturbada en terminos absolutos y relativos ? sol. Consideremos || · ||p una norma vectorialy su correspondiente norma matricial subordinada, determinamos
i) el error absoluto
||x− x|| = ||x−Bb|| = ||x−BAx|| = ||(I −BA)x|| ≤ ||I −BA|| · ||x||
ii) el error relativo
||x− x||||x||
≤ ||I −BA||
representan las medidas de los errores en terminos absolutos y relativos.
2. Consideremos ahora que se perturba el vector b para obtener el vector b. Si x y x satisfacen
respectivamente Ax =−→b y Ax = b. ¿En cuanto difiere x y x en terminos absolutos y
relativos ?
i) En terminos absolutos
||x− x|| =‖ A−1b−A−1b ‖=‖ A−1(b− b) ‖≤‖ A−1 ‖‖ b− b ‖
ii) En terminos relativos
||x− x|| ≤ ||A−1|| · ||b− b|| = ||A−1|| · ||b− b|| ||b||||b||
||A−1|| · ||Ax|| ||b− b||||b||
||x− x||||x||
≤ ||A−1|| · ||A|| ||b− b||||b||
es decir, el error relativo de la solucion x esta acotado por κ(A) veces el error relativo de−→b .
Observacion 5.3
i) El numero de condicion depende de la norma vectorial seleccionada.
48

ii) Si κ(A) es pequeno, entonces pequenas perturbaciones en−→b conducen a pequenas perturba-
ciones en x.
Ejemplo 5.2 Analizar el condicionamiento de la matriz A =(
1 1 + ε1− ε 1
)con ε > 0.
Sol. Determinamos A−1
A−1 =(
1 −1− ε−1 + ε 1
)Usando norma infinito, tenemos,
||A||∞ = 2 + ε , ||A−1||∞ = ε−2(2 + ε)
κ(A) =[(2 + ε)
ε
]2
=4 + 4ε + ε2
ε2>
4ε2
Si ε ≤ 0,01, entonces κ(A) ≥ 40000. Esto significa que una pequena perturbacion sobre b puedeinducir una perturbacion o error relativo de 40000 veces mayor en la solucion del sistema Ax = b.
Observacion 5.4 En el caso de los metodos iterativos, podemos medir que tan buena es la solucionaproximada x, calculando
i) Ax
ii) y r = b−Ax. Este vector se denomina vector residual.
Observamos ademas que la diferencia e = x− x se llama vector residual.
Podemos resumir una relacion importante entre vector error y vector residual.
Teorema 5.2 Si x es la solucion exacta de Ax = b, donde b = b− r implica r = − b.
1κA)
||r||||b||
≤ ||e||||x||
≤ κ(A)||r||||b||
Criterios de parada.
Se define el vector el residual r(k) = b−Ax(k) y el vector error e(k) = x− x(k).
Criterio 1. Dada una tolerancia ε, iterar hasta que,
‖r(k)‖‖r(0)‖
< ε.
Criterio 2. Sean, b , x , x(0) ∈ Rn y A una matriz no singular, entonces:
‖e(k)‖‖e(0)‖
≤ κ(A)‖r(k)‖‖r(0)‖
.
donde, κ(A) es el numero de condicion de la matriz A.
49

Criterio 3. El criterio 1, depende del valor inicial x(0), de modo que si la aproximacion inicialno es buena, los resultados pueden ser grotescos. Se recomienda usar en su lugar,
‖r(k)‖‖b‖
< ε.
Actividades 5.6
i) Demuestre el teorema anterior
ii) Demuestre que si ||A|| < 1 entonces
• I −A es invertible.• ||(I + A)−1|| ≤ (1− ||A||)−1
• (I + A)−1 = I −A + A2 −A3 + · · ·
• ||(I + A)−1|| ≥ 11 + ||A||
Teorema 5.3 El radio espectralρ(A) = inf
||.||||A||
es el ınfimo sobre todas las normas matriciales subordinadas.
Actividades 5.7
1) Contra los deseos de su corredor Jeanette compra x tıtulos de acciones de ENDESA, y tıtulosde acciones de CTC Chile y z tıtulos de acciones de Chilgener . A inicios de Enero, Febreroy Marzo, las acciones de ENDESA valıan $5,18 , $3,14 y $3,01 por tıtulo, las acciones deCTC Chile $2,10 , $6,03 y $2,18 por tıtulo y las acciones de Chilgener, $2,90 , $2,80 y $5,53por tıtulo, respectivamente.
a) Determine el vector (x(2), y(2), z(2)) mediante el metodo de Gauss-Seidel, si Jeanettegasto en total $2945,30 , $4113,85 y $3417,00 en Enero, Febrero y Marzo, respectiva-mente. (x(0) = (150, 150, 150)T ).(Justifique).
b) Determine una estimacion del error absoluto de la aproximacion anterior.c) De acuerdo a lo obtenido en a), ¿Cuantos tıtulos de cada empresa adquirio Jeanette ?
2) El sistema de ecuaciones Ax = b, donde
A =(
3 21 2
),x =
(x1
x2
),b =
(12
)(62)
puede resolverse mediante el siguiente metodo iterativo :
x(k+1) = x(k) + α(Ax(k) − b),
x(0) =(
11
), (63)
50

a) Determinar todos los valores de α para los cuales se puede garantizar la convergenciadel algoritmo.
b) Determinar si para α = −0,4 el algoritmo es convergente.
51

1

2
Aproximacion de funciones.Modulo 10
Prof. Marıa Angelica Vega U.
El proposito de estos modulos es entregar los conceptos teoricos basicosnecesarios y algunas aplicaciones en forma dirigida, de modo que el estudian-te pueda participar en forma activa, en el proceso ensenanza - aprendizaje,elaborando su propio material de estudio. El logro deseable es que el estudian-te aprenda a aprender. Es claro que este material debe ser complementadocon el apoyo de la bibliografıa sugerida.
2.1 Interpolacion Polinomica.
El Problema :Dado el conjunto de (n+ 1) puntos, del grafico de una funcion f , deno-
tados por(x0, f(x0)) , (x1, f(x1)) . . . (xx, f(xn)),
se requiere encontrar una funcion polinomica P (x) al que llamaremos poli-nomio interpolante para f , de a lo mas grado n que satisfaga la condicionde interpolacion, expresada por
P (xi) = f(xi) , ∀i = 0, 1, ...n. (2.1)
Soluciones al Problema :
Inspirandonos en el criterio de Taylor, de acuerdo a (2.1), observemosque el polinomio de Taylor es combinacion lineal de los elementos de la base
{1, (x− x0), (x− x0)2, (x− x0)3...(x− x0)n...}
para el espacio vectorial de los polinomios de una variable real sobre IR. Esobvio que los polinomios de Taylor son utiles para aproximar una funcionsobre intervalos pequenos alrededor del punto x0, pero en la practica este nosiempre es el caso y es necesario usar un metodo mas eficiente que incluyainformacion en otros puntos.

2.1. INTERPOLACION POLINOMICA. 3
2.1.1 Metodo de los coeficientes indeterminados.
Tomando en cuenta lo anterior, podemos proponer que el polinomio inter-polante sea una combinacion lineal de los elementos de la base canonica delespacio de los polinomios por la sencillez en los calculos, es decir
Pn(x) =n∑
i=0
aixi = a0 + a1x+ a2x
2 + ...+ anxn. (2.2)
Ası el problema se reduce a encontrar los coeficientes de las potencias dex, de donde se obtiene un sistema de ecuaciones cuyas incognitas son estoscoeficientes. Veamos estas ideas aplicadas a un problema practico.
Actividad I.
Suponga que una empresa contrata servicios y entrega la siguiente infor-macion exacta,
Piezas Vendidas (en millones) 1 2 3 4 5Ganancia Neta (en millones) 11.2 15.3 17.1 16.9 15.0
Tabla 1.
se pide determinar cuantas piezas deben venderse para maximizar laganancia neta, dejando estipulado en las bases del contrato que no habrafuturas contrataciones si la respuesta es equıvoca . Se debe hacer una re-comendacion y justifıcarla.
♣Consideraciones sobre el metodo.♣
Este metodo que resulta muy simple en este caso, presenta la dificultadque la matriz de los coeficientes asociada al sistema de ecuaciones que seobtiene al aplicar la condicion de interpolacion, es la matriz de Vandermonde,que se caracteriza por volverse rapidamente mal condicionada cuando n, elorden de la matriz crece en funcion del grado del polinomio, por tanto estemetodo no es conveniente para hallar polinomios interpolantes.
De aquı que es importante estudiar otra forma de escribir este polinomio,de modo de obviar el que tengamos que resolver un sistema de ecuacioneslineales mal condicionado. Los metodos de Lagrange y de Newton son losque tradicionalmente se estudian en cualquier curso de calculo numerico,ambos se basan en escribir el polinomio de interpolacion como combinacionlineal de elementos de alguna base del espacio vectorial de los polinomiosdistinta de la canonica.

4
2.1.2 Metodo de Lagrange.
Sea Pn(x) el polinomio que interpola a la funcion f en los (n+ 1) puntos
(x0, f(x0)) , (x1, f(x1)) , (x2, f(x2)) , · · · , (xn, f(xn))
y supongamos que segun una cierta base
{l0(x), l1(x), ..., ln(x)},
para el espacio vectorial de los polinomios, el polinomio interpolante se es-cribe :
Pn(x) =n∑
i=0
f(xi)li(x) = f(x0)l0(x) + ...+ f(xn)ln(x). (2.3)
Si resolvemos de esta forma el problema, nuestro trabajo consistira en en-contrar los polinomios li(x) de modo que se verifique
f(xi) = Pn(xi) = f(x0)l0(xi) + · · ·+ f(xi)li(xi) + · · ·+ f(xn)ln(xi). (2.4)
Observemos que para que se verifique la condicion (2.4) para cada i, essuficiente que el polinomio li(x) verifique que:
li(xj) = 0 ∀0 ≤ j ≤ n , i 6= j (2.5)
li(xi) = 1 (2.6)
De la condicion (2.5) se deduce que las raıces del polinomio li(x) son los
x = xj , 0 ≤ j ≤ n , i 6= j ,
por lo tanto podrıamos escribir este polinomio como :
li(x) = (x− x0)...((x− xi−1)(x− xi+1)...(x− xn). (2.7)
Pero este polinomio no cumple con la condicion (2.6), puesto que si lo eval-uamos en el nodo xi vale:
li(xi) = (xi − x0)...((xi − xi−1)(xi − xi+1)...(xi − xn). (2.8)
Luego si dividimos el polinomio li(x) por el valor li(xi), obtenemos el poli-nomio :
li(x) =n∏
j=0 j 6=i
(x− xj)(xi − xj)
=(x− x0)...((x− xi−1)(x− xi+1)...(x− xn)
(xi − x0)...(xi − xi−1)(xi − xi+1)...(xi − xn).
(2.9)Que por construccion cumple las condiciones (2.5)y (2.6).
Los polinomios li(x) se conocen con el nombre polinomios de Lagrange,mientras que Pn(x) recibe el nombre de polinomio interpolante de Lagrangepara f(x) en los puntos (x0, f0) , (x1, f1) , ..., (xn, fn), que suele denotarsegeneralmente Ln(x).
Aplicaremos la idea de Lagrange al problema del ejemplo anterior con elfın de obtener algun tipo comparacion entre ambos metodos.
Actividad II.
Solucione el problema planteado en la actividad I, usando un polinomiode Lagrange para interpolar la funcion representada por los datos dados.

2.1. INTERPOLACION POLINOMICA. 5
Observacion 2.1 • Sabemos que si el polinomio interpolante existe, esunico, por lo tanto es obvio pensar que el polinomio es el mismo usandocualesquiera de los dos metodos anteriores, mas aun usando cualquierotro metodo.
• El metodo de Lagrange para determinar el polinomio interpolante com-parado con el metodo de coeficientes indeterminados, es un tanto labo-rioso por la cantidad de calculos involucrados al calcular los elementosde la base, pero tiene un valor teorico importante en la deduccion deotros metodos numericos, como por ejemplo formulas de integracionnumerica, aproximacion de soluciones de ecuaciones diferenciales, etc.
Si en la formula (2.3), n = 1 el polinomio interpolante adopta la forma,
P1(x) = f(x0)(x− x1)(x0 − x1)
+ f(x1)(x− x0)(x1 − x0)
.(2.10)
o (2.10) en forma simplificada,
P1(x) = f(x0)l0(x) + f(x1)l1(x) (2.11)
con,
l0(x) =x− x1
(x0 − x1), l1(x) =
x− x0
(x1 − x0).
cuya grafica es la recta que pasa por los puntos dados por lo que este prob-lema se conoce como Interpolacion lineal.
Otra situacion particular es el caso en que n = 2, es decir se tienen lospuntos,
(x0, f(x0)) , (x1, f(x1)) , (x2, f(x2)),
el polinomio P2(x) que interpola a la funcion f(x) en los tres puntos es
P2(x) = f(x0)(x− x1)(x− x2)
(x0 − x1)(x0 − x2)+ f(x1)
(x− x0)(x− x2)(x1 − x0)(x1 − x2)
+f(x2)(x− x0)(x− x1)
(x2 − x0)(x2 − x1).
.
(2.12)
Simplificando la notacion igual que antes,
P2(x) = f(x0)l0(x) + f(x1)l1(x) + f(x2)l2(x) (2.13)

6
con,
l0(x) =(x− x1)(x− x2)
(x0 − x1)(x0 − x2), l1(x) =
(x− x0)(x− x2)(x1 − x0)(x1 − x2)
.
La grafica corresponde a la parabola que pasa por los puntos dados, eneste caso hablamos de interpolacion cuadratica.
♣Consideraciones sobre el metodo.♣
Uno de los inconvenientes que tiene la forma de Lagrange para el poli-nomio de interpolacion, es que al agregar otro ” punto de interpolacion ” o” nodo ”, los elementos de la base polinomios de Lagrange,
li(x) , para i = 0, 1, ..., n+ 1.
deben ser calculados nuevamente uno a uno. Surge entonces la inquietudde como construir el polinomio de interpolacion en forma mas eficiente, demodo de aprovechar la informacion ya procesada al agregar nuevos nodos.Este hecho amerita que busquemos otra forma de escribir el polinomio deinterpolacion, es decir expresarlo en otra base del espacio vectorial.

2.1. INTERPOLACION POLINOMICA. 7
2.1.3 Forma de Newton para el Polinomio de Interpolacion
En la forma de Newton el polinomio interpolante Pn(x) es escrito usando unabase parecida a la usada para expresar el polinomio de Taylor, observemosambas bases :
{1 , (x− x0) , (x− x0)2 , · · · , (x− x0)n}. (2.14)
base usada para definir el polinomio de Taylor y
{1 , (x−x0) , (x−x0)(x−x1) , · · · , (x−x0)(x−x1) · · · (x−xn−1)}. (2.15)
base usada para definir el polinomio de Newton. De aquı podemos expresarel polinomio en la forma,
Pn(x) = a0+a1(x−x0)+a2(x−x0)(x−x1)+· · · an(x−x0)(x−x1) · · · (x−xn−1).(2.16)
Notemos que por construccion este polinomio es de grado a lo mas n yes logico pensar los coeficientes ai , para i = 0, 1, ..., n deben determinarsede modo que se verifique la condicion de interpolacion. Para ello evaluamosPn(x) en cada xi.
Para x0 obtenemos:
Pn(x0) = f(x0) = a0.
Analogamente si evaluamos Pn(x) en x1 tenemos:
a1 =f(x1)− f(x0)
x1 − x0
Pn(x) evaluado en x2
a2 =f(x2)− f(x0)
(x2 − x0)(x2 − x1)− f(x1)− f(x0)
(x2 − x1)(x1 − x0).
Ası obtenemos sucesivamente los otros valores de las constantes a3, · · · , an.Para simplificar la escritura de los coeficientes ai, introducimos el con-
cepto de diferencias divididas lo que permite escribir el polinomio de Newtonen una forma mas simple.
Diferencias Divididas
Consideremos (n+1) puntos cualesquiera Pi(xi, f(xi)) , i = 0...n, nonecesariamente equiespaciados, definimos :
1. diferencias divididas de orden cero por:
f [xi] = f(xi).
2. Si consideramos un par de puntos indexados cualesquiera
Pi(xi, f(xi)) y Pi+1(xi+1, f(xi+1))

8
definimos la primera diferencia dividida o diferencia dividida de orden1 como el numero :
f [xi, xi+1] =f(xi+1)− f(xi)
xi+1 − xi.
Al relacionar f [xi, xi+1] con su significado geometrico, sabemos quecorresponde a la pendiente del segmento lineal que une Pi y Pi+1,entonces si f [xi, xi+1] > 0 implica que f(x) es creciente en [xi, xi+1]y si f [xi, xi+1] < 0 implica que f(x) es decreciente en [xi, xi+1]. Esdecir, este concepto nos proporciona informacion adicional acerca dela grafica de la funcion.
3. Consideremos ahora un trıo de puntos consecutivos
Pi(xi, f(xi)) , Pi+1(xi+1, f(xi+1)) y Pi+2(xi+2, f(xi+2))
definimos la segunda diferencia dividida o diferencia dividida de orden2 como el numero :
f [xi, xi+1, xi+2] =f [xi+1, xi+2]− f [xi, xi+1]
xi+2 − xi.
Como f [xi, xi+1, xi+2] es el cuociente entre el cambio de pendiente yel cambio en x, de modo que si f [xi, xi+1, xi+2] > 0 geometricamentela grafica de f(x) es concava hacia arriba y si f [xi, xi+1, xi+2] < 0 lagrafica de f(x) es concava hacia abajo en el intervalo [xi, xi+2].
O sea, tenemos ademas informacion acerca de la concavidad de lafuncion.
4. En general considerando los n+ 1 puntos consecutivos
(xi, fi) , (xi+1, fi+1) , ..., (xi+n, fi+n)
podemos definir recursivamente la n-esima diferencia dividida o difer-encia dividida de orden n por :
f [xi, ..., xi+n] =f [xi+1, xi+n]− f [xi, xi+n−1]
xi+n − xi.
Vemos que hay una relacion entre las diferencias divididas y el valor delos coeficientes del polinomio de Newton (2.16).
Los calculos para determinar las diferencias divididas pueden facilitarsemucho, si estas se representan abreviadamente en una tabla.

2.1. INTERPOLACION POLINOMICA. 9
xi f [xi] f [xi, xi+1] f [xi, xi+1, xi+2] f [xi, xi+1, xi+2, xi+3] · · ·x0 f [x0]
f [x0, x1]x1 f [x1] f [x0, x1, x2]
f [x1, x2] f [x0, x1, x2, x3] · · ·x2 f [x2] f [x1, x2, x3]
f [x2, x3] f [x1, x2, x3, x4] · · ·x3 f [x3] f [x2, x3, x4]
f [x3, x4] f [x2, x3, x4, x5] · · ·x4 f [x4] f [x3, x4, x5]
f [x4, x5]x5 f [x5]
f [x5, x6]x6 f [x6]
Tabla 2. Diferencias Divididas
Al observar la tabla 2 podemos darnos cuenta que las diferencias divididasque aparecen en la diagonal que va desde el extremo superior izquierdo alextremo inferior derecho son precisamente los coeficientes de (2.16), usandoeste hecho el polinomio interpolante puede expresarse en forma simplificadacomo:
Pn(x) = f [x0] + f [x0, x1](x− x0) + f [x0, x1, x2](x− x0)(x− x1) + · · ·+f [x0, x1, ..., xn](x− x0)(x− x1) · · · (x− xn−1).
Actividad III.
Consideremos nuestro ejemplo modelo y construyamos el polinomio in-terpolante en la forma de Newton.
¿Como medimos que tan buena es la aproximacion ?
Cuando en calculo diferencial se estudia el polinomio de Taylor de gradon para aproximar una funcion f ∈ C(n+1)[a, b] en un punto x0 ∈ [a, b] su de-sarrollo involucra el termino Rn(x) llamado residuo o error de truncamientoy que se define como :
Rn(x) =f (n+1)(ξ)(n+ 1)!
(x− x0)(n+1) , ξ ∈ (x0, x). (2.17)
Cabe pensar entonces que al aproximar una funcion mediante un polinomiode interpolacion usando mas de un punto, tambien existe un termino de errorinvolucrado y de hecho es una extension de (2.17). En el siguiente resultadoformalizamos este hecho.
Teorema 2.1 Si x0, x1, ..., xn son (n + 1) puntos distintos en [a, b] y f ∈C(n+1)[a, b] entonces, para cada x ∈ [a, b] existe un ξ(x) en (a, b) tal que :

10
E(x) = f(x)− Pn(x) =f (n+1)(ξ)(n+ 1)!
(x− x0)(x− x1)...(x− xn). (2.18)
donde Pn(x) es el polinomio interpolante de Lagrange.
Demostracion. Se deja como inquietud, sin embargo podemos comentarque se usa como parte del argumento el teorema de Rolle.
Observacion 2.2 • Es posible obtener una relacion entre diferencia di-vidida y el termino
f (n+1)(ξ)(n+ 1)!
,
de modo que podemos expresar la formula de error en terminos dediferencias divididas. Para ello consideremos :
Pn(x) = f [x0] + f [x0, x1](x− x0) + f [x0, x1, x2](x− x0)(x− x1) + · · ·+f [x0, x1, ..., xn](x− x0)(x− x1) · · · (x− xn−1)
si agregamos un punto mas (xn+1, f(xn+1)) de modo que ahora tenemos(n+ 2) puntos y usamos la notacion :
xn+1 = x , f(xn+1) = f(x) x 6= xi ∀i = 0, ..., n
entonces de la formula de Newton
f(x) = Pn+1(x) = Pn(x) + f [x0, x1, ..., xn, x]w(x)
of(x)− Pn(x) = f [x0, x1, ..., xn, x]w(x)
de aquı y (2.18), obtenemos
f [x0, x1, ..., xn, x] =f (n+1)(ψ)(n+ 1)!
para algun ξ ∈ I
luego reemplazando f [x0, x1, ..., xn, x] en (2.18) tenemos,
E(x) = f(x)− Pn(x) = f [x0, x1, ..., xn, x]w(x). (2.19)
que es otra forma de expresar el error de interpolacion.
• El polinomio de Newton puede expresarse para datos equiespaciados,usando el concepto de diferencias progresivas y regresivas, para may-ores detalles consultar la bibliografıa recomendada al final.

2.1. INTERPOLACION POLINOMICA. 11
2.1.4 El problema de Hermite
El problema mas simple de Hermite es encontrar el polinomio H(x) delmenor grado posible, tal que interpole a la funcion f(x) y a su derivadaf ′(x) en (n+ 1) puntos x0, · · · , xn , es decir, el polinomio debe satisfacer
H(xi) = f(xi) , ∀i = 0, ..., n
H ′(xi) = f ′(xi) , ∀i = 0, ..., n
y el Problema General consiste en suponer que :
1. En el nodo i se conocen los valores
p(j)(xi) , p(j−1)(xi) , p′(xi) , p(xi).
2. Sea ki el numero de condiciones de interpolacion sobre el nodo xi.
3. Si x0, ..., xn son los nodos entonces
p(j)(xi) = f (j)(xi) , ∀ j = 0, 1, · · · ki−1 , i = 0, ..., n
De los dos problemas presentados estudiaremos el caso simple, aquellospolinomios que geometricamente se parecen a la funcion en los puntos deinterpolacion (xi, f(xi)) en el sentido que las rectas tangentes al polinomioy a la funcion tienen el mismo valor, es decir poseen misma derivada en unavecindad del punto de interpolacion.
2.1.5 ¿ Como obtener el polinomio de Hermite ?
Podemos determinar el polinomio de Hermite basandonos en la forma deLagrange o extendiendo la forma de Newton.
1. Polinomio de Hermite basado en la forma de Lagrange.
Consideremos los nodos x0, ..., xn y supongamos que en cada nodo ten-emos:
p(xi) = f(xi) , ∀i = 0, ..., n
p′(xi) = f ′(xi) , ∀i = 0, ..., n
Observemos que tenemos (n+1) condiciones sobre f(x) y (n+1) condicionessobre f ′(x) en total (2n + 2) condiciones, por lo que el polinomio es degrado (2n+ 1). Procediendo en forma similar a la usada para determinar laforma del polinomio interpolante de Lagrange, se propone que la forma delpolinomio de Hermite es :
H2n+1(x) =∑n
i=0 f(xi)hi(x) +∑n
i=0 f′(xi)hi(x). (2.20)

12
Con hi(x) y hi(x) elementos de una base para el espacio vectorial de lospolinomios, tales que,
hi(xj) = δij , hi(xj) = 0.
h′i(xj) = 0 , h′i(xj) = δij .(2.21)
Al aplicar las condiciones de interpolacion y las relaciones (2.21) el lectorpuede comprobar que se obtiene que :
hi(x) = [1 − 2(x− xi) · l′i(xi)]l2i (x) , ∀i = 0, ..., n
hi(x) = (x− xi) · l2i (x) , ∀i = 0, ..., n.(2.22)
Notese aquı, que hi(x) y hi(x) son de grado (2n+ 1) y como antes li(x)es el polinomio de Lagrange de grado n definido anteriormente, por:
li(x) =n∏
j=0 j 6=i
(x− xj)(xi − xj)
.
Resumiendo estas ideas el El polinomio de Hermite de grado (2n+1) queinterpola a una funcion f(x) y a su derivada en (n+ 1) puntos es :
H2n+1(x) =∑n
i=0 f(xi)hi(x) +∑n
i=0 f′(xi)hi(x). (2.23)
con,
hi(x) = [1 − 2(x− xi) · l′i(xi)]l2i (x) , ∀i = 0, ..., n.
hi(x) = (x− xi) · l2i (x) , ∀i = 0, ..., n.(2.24)
¿ Que podemos decir del error cometido ?
Deberıa deducirse en forma analoga a como se obtiene el error del poli-nomio interpolante de Lagrange. En efecto,
Si x0, ..., xn son (n + 1) puntos distintos en [a, b] y f ∈ C(2n+2)[a, b] yH(x) es el polinomio de grado ≤ (2n+ 1) tal que :
H(xi) = f(xi) , ∀i = 0, ..., n
H ′(xi) = f ′(xi) , ∀i = 0, ..., n
entonces, a cada x ∈ [a, b] le corresponde ξ(x) ∈ [a, b] tal que,
E(x) = f(x)−H(x) =f (2n+2)(ξ(x))
(2n+ 2)!
n∏i=0
(x− xi)2. (2.25)

2.1. INTERPOLACION POLINOMICA. 13
Observacion 2.3 Es conveniente senalar que en el caso particular que ex-iste un solo nodo x0, se conoce la funcion f(x) y sus n derivadas el polinomiode Hermite es el polinomio de Taylor, es decir
H(x) = P (x)
= P (x0) + P ′(x0)(x− x0) + P ′′(x0)(x− x0)2
2!+ · · ·+ P (n)(x0)
(x− x0)n
n!.
(2.26)
2. Polinomio de Hermite basado en la forma de Newton.
La idea es ahora extender el metodo de las diferencias divididas de New-ton para resolver el problema de interpolacion de Hermite. Ello se lograconstruyendo la tabla como antes, con la variante de incluir un nodo en latabla tantas veces como condiciones dadas existan sobre el. Para ilustraresta situacion consideraremos a modo de ejemplo el caso en que se tienendos puntos de interpolacion x0 y x1 y se conocen los valores de la funcion ysu derivada. Inspirandonos en el polinomio de Taylor podemos intuir que elpolinomio que interpola la funcion y su derivada en los nodos dados es de laforma :
H3(x) = a0 + a1(x− x0) + a2(x− x0)2 + a3(x− x0)2(x− x1). (2.27)
donde obviamente los coeficientes a0, a1, a2 y a3 se pueden obtener de lasiguiente tabla :
xi f [xi] f [xi, xi+1] f [xi, xi+1, xi+2] f [xi, xi+1, xi+2, xi+3]x0 f [x0]
f [x0, x0] = f ′(x0)x0 f [x0] f [x0, x0, x1]
f [x0, x1] f [x0, x0, x1, x1]x1 f [x1] f [x0, x1, x1]
f [x1, x1] = f ′(x1)x1 f [x1]
Tabla 4. Diferencias Divididas para el polinomio de Hermite
Veremos ahora porque,
f [x0, x0] = f ′(x0) y f [x1, x1] = f ′(x1).
En efecto,
f [x0, x0] = limx→x0
f [x0, x] = limx→x0
f(x)− f(x0)x− x0
= f ′(x0). (2.28)

14
Un razonamiento similar es valido para:
f [x1, x1] = limx→x1
f [x1, x] = limx→x1
f(x)− f(x1)x− x1
= f ′(x1). (2.29)
De donde el polinomio de Hermite es,
H3(x) = f(x0)+f ′(x0)(x−x0)+f [x0, x0, x1](x−x0)2+f [x0, x0, x1, x1](x−x0)2(x−x1).(2.30)
Observacion 2.4 En general se puede demostrar que, si los puntos xi sondistintos y f (n)(x) es continua en el nodo xk, entonces :
limxk+n→xk
f [xk, · · · , xk+n] =f (n)(xk)
n!, xk = xk+1 = · · · = xk+n. (2.31)
Actividad I.
1) Encuentre un polinomio p(x) de grado menor o igual que 4 que cumplacon las condiciones :
f(0) = 0 , f ′(0) = 0 , f(2) = 16 , f ′(2) = 32 , f ′′(2) = 48
Usando
– el primer nodo como pivote
– el ultimo nodo como pivote.
2) PEP 2 (Problema 3). Segundo Semestre del 2000.
Un automovil recorrio 160 km en un camino que une dos ciudades, yempleo, en este trayecto, 2 hora y 20 minutos. Use los datos de latabla adjunta para determinar :
a) La distancia recorrida en los primeros 45 minutos de viaje. (Useun polinomio cubico.)
b) El tiempo empleado en llegar a la mitad del camino recorrido.
Tiempo (en min) Distancia (en Km)0 0.0010 8.0030 27.0060 58.0090 100.00120 145.00140 160.00
3 ) PEP 2 (Problema 1). Segundo Semestre del 2001.
Considere la funcion f(x) = ex + senx+ 2 definida en [0, π].

2.1. INTERPOLACION POLINOMICA. 15
a) Aproxime la funcion dada, utilizando interpolacion lineal por
tramos y los puntos xi =iπ
4, i=0,1,2,...,4.
b) Mediante la aproximacion encontrada en el punto anterior, estimeel valor de la funcion en el punto x = 1.25 y determine su errorabsoluto comparando el valor aproximado con el exacto.
4) PEP 2 (Problema 2). Segundo Semestre del 2001. Usando mınimoscuadrados, se desea determinar una funcion que represente los datosde la siguiente tabla:
k 0 1 2 3 4xk 1 3 6 9 15
f(xk) 5.12 3.00 2.48 2.34 2.18
a) Encuentre una aproximacion de mınimos cuadrados usando lafuncion
h(x) = α+β
x
b) Utilizando los datos de la tabla y la aproximacion anterior, calcule:
max{|h(xk)− f(xk)|/k = 0, 1, ..., 4}
¿ Que interpretacion puede darle a este numero ?
5) Determine un polinomio P (x) tal que
p(−1) = −10 , p′(−1) = 11 , p′′(−1) = 22 , p(3) = 18 , p′(3) = 83.

Modulo 11
Prof. Marıa Angelica Vega U.
9.2. Polinomios de Tchebyshev y economizacion de series.
El estudio de lo polinomios de Tchebyshev conduce a los resultados siguientes:
i) Permiten una colocacion optima de los puntos de interpolacion para minimizar el error en lainterpolacion de lagrange.
ii) Permiten reducir el grado del interpolante con una perdida mınima de precision.
Definicion 9.1 Se definen los polinomios de Tchebyshev por
Tn(x) = cos(n arc cos (x)) − 1 ≤ x ≤ 1 y n = 0, 1, 2, · · · (142)
la sustitucion θ = arc cos (x) implica que:
Tn(x) = cos(n θ) − 1 ≤ x ≤ 1 (143)
Usando identidades trigonometricas la ecuacion 143 se transforma en
Tn+1(x) = 2xTn(x)− Tn−1)(x) para cada n = 1, 2, · · · y x ∈ [−1, 1] (144)
con T0(x) = 1 y T1(x) = x. Esta relacion de recurrencia implica que para cada n ≥ 1, Tn es unpolinomio de grado n con coeficiente principal 2n−1.
9.2.1. Propiedades o Teoremas importantes
Propiedad 9.1 El polinomio de Tchebyshev Tn d egrado n ≥ 1 tiene n ceros simplesn en [−1, 1]
xk = cos(
(2k − 1)π(2n)
)para k = 1, 2, · · · , n. (145)
Ademas tiene extremos absolutos en
xk = cos(
(k)π(n)
)para k = 0, 1, · · · , n. (146)
con
Tn(xk) = cos(
(k)π(n)
)para k = 0, 1, · · · , n. (147)
Las graficas de algunos polinomios de Tchebyshev se presentan en la siguiente figura: En estosgraficos se puede observar las siguientes 3 propiedades de los polinomios de Chebyshev:
1. |Tn(x)| ≤ 1 ∀ − 1 ≤ x ≤ 1.
81

Figura 11: Graficas de T1 , ..., T5
2. Tn tiene n ceros reales distintos en el interior de [−1, 1].
3. |Tn(x)| alcanza su maximo modulo de 1 en [−1, 1] en n+1 puntos, incluyendo ambos extremos±1 y Tn(x) toma los valores ±1 alternadamente en estos puntos.
Observacion 9.1 i) Los polinomios monicos (coeficiente inicial 1) Tn de Tchebyshev, sepueden deducir de los polinomio de Tchebyshev Tn, dividiendo por 2n−1,
T0(x) = 1 , Tn(x) = 21−nTn(x) para cada n ≥ 1.
ii) Estos polinomios satisfacen la relacion de recurrencia,
T2(x) = xT1(x)−12T0(x) , Tn+1(x) = xTn(x)− 1
4Tn−1(x)
para cada n ≥ 2.
iii) Debido a la relacion lineal entre Tn y Tn la propiedad 8.1, implica que los ceros de Tnocurrentambien en,
xk = cos(
(2k − 1)π(2n)
)para k = 1, 2, · · · , n. (148)
y que los valores extremos de los Tn ocurren en
xk = cos(kπ
(n)
)para k = 0, 1, · · · , n. (149)
82

iv) En estos valores extremos para n ≥ 1
Tn(xk) =(−1)k
2n−1para cada k = 0, 1, 2, · · · , n
De esto ultimo, se deduce la siguiente propiedad
Propiedad 9.2 Los polinomios de la forma Tn, cuando n ≥ 1, tienen la propiedad
12n−1
= maxx∈[−1,1]
|Tn(x)| ≤ maxx∈[−1,1]
|Pn(x)| para toda Pn ∈∏
n
En esta ultima expresion, se produce la igualdad si y solo sı Pn = Tn
Observacion 9.2 1. La respuesta a la interrogante ¿donde colocar los nodos interpolantes paraminimizar el error en la interpolacion de Lagrange? Recordemos que: Si f ∈ Cn+1[−1, 1] yx − 0, · · · , xn son numeros distintos en el intervalo [−1, 1], entonces para cada x ∈ [−1, 1]existe ξ(x) en (−1, 1) tal que,
f(x) = P (x) +f (n+1)(ξ(x))
(n+ 1)!(x− x0)(x− x1) · · · (x− xn), (150)
donde P es el poinomio interpolante de Lagrange. Vimos que una alternativa de minimizarel error es ubicar los nodos de una forma optima, lo equivale a encontrar los nodos queminimizan la expresion.
|(x− x0)(x− x1) · · · (x− xn)|sobre todo el intervalo [−1, 1]. Como
(x− x0)(x− x1) · · · (x− xn). (151)
es un polinomio monico de grado (n+ 1), la propiedad anterior implica que este mınimo seobtiene ssı
(x− x0)(x− x1) · · · (x− xn) = Tn+1(x). (152)
Luego si se escoge xk como el (k + 1) cero de Tn+1 para cada k = 0, 1, · · ·n, es decir cuandoxk se escoja como
xk+1 = cos(
(2k + 1)π(2(n+ 1))
)para k = 1, 2, · · · , n. (153)
el valor maximo de |(x− x0)(x− x1) · · · (x− xn)| sera minimizado. Como,
maxx∈[−1,1] |Tn+1(x)| = 2−n ⇒ 12n
= maxx∈[−1,1]
|(x− x0)(x− x1) · · · (x− xn+1)|
≤ maxx∈[−1,1] |(x− x0)(x− x1) · · · (x− xn)|.
(154)
para cualquier eleccion de x0, x1, · · · , xn en el intervalo [−1, 1]
83

2. Esta tecnica de eleccion de puntos que minimizan el error interpolante puede extendersefacilmente a un intervalo cerrado general [a, b] usando el cambio de variables
x =12[(b− a)x+ a+ b]
para transformar los numeros xk, en el intervalo [−1, 1] en los numeros correspondientes xk
en el intervalo [a, b].
Ejemplo 9.1 Sea f(x) = xex en [0, 1,5]. Construir dos polinomios interpolantes de grado a lo mastres.
i) Usando los nodos igualmente espaciados x0 = 0, x1 = 0,5, x2 = 1, x3 = 1,5
ii) Usando los nodos de Tchebyshev.
iii) Hacer una tabla comparativa entre los valores exactos de la funcion, el polinomio usandonodos igualmente espaciados y el polinomio de Tchebyshev T4 y entre los errores absolutosde los dos polinomios.
Sol.
i) Usando los nodos igualmente espaciados se obtiene:
l0(x) = −1,3333x3 + 4,0000x2 − 3,6667x+ 1,l1(x) = 4,000x3 − 10,000x2 + 6,0000x,l2(x) = −4,000x3 + 8,0000x2 − 3,0000x,l3(x) = 1,3333x3 − 2,0000x2 + 0,66667x.
De aquı el polinomio interpolante es
P3(x) = 1,3875x3 + 0,057570x2 + 1,2730x.
ii) Usando los nodos de Tchebyshev. Transformamos los ceros xk = cos( (2k+1)π8 , k = 0, 1, 2, 3
de T4 de [−1, 1] a [0, 1,5], usando la transformacion lineal
xk = 0,75 + 0,75xk
obteniendose,
x0 = 1,44291 , x1 = 1,03701 , x2 = 0,46299 , x3 = 0,05709
Los polinomios de Lagrange para estos nodos son:
l0(x) = −1,8142x3 − 2,8249x2 + 1,0264x− 0,049728,l1(x) = −4,3799x3 + 8,5977x2 − 3,4026x+ 0,16705,l2(x) = 4,3799x3 − 11,112x2 + 7,1738x− 0,37415,l3(x) = −1,8142x3 + 5,3390x2 − 4,7976x+ 1,2568.
y el polinomio interpolante de grado a lo mas 3 es:
P3(x) = 1,3811x3 + 0,044445x2 + 1,3030x− 0,014357.
84

7. Integracion Numerica.
Modulo 7
Prof. Marıa Angelica Vega U.
7.1. Formulas de Newton-Cotes.
Problema. Se trata de encontrar el valor de
∫ b
a
f(x)dx
especialmente cuando no puede ser resuelta por metodos analıticos.
Se obtiene aproximando f(x) en [a, b] mediante un polinomio de interpolacion, es decir,
f(x) = Pn(x) + E(x) , entonces∫ b
af(x)dx =
∫ b
aPn(x)dx+
∫ b
aE(x)dx
de modo que si
Pn(x) =n∑
i=0
f(xi)li(x)
es el polinomio interpolante de Lagrange,∫ b
a
f(x)dx =n∑
i=0
f(xi)∫ b
a
pi(x)dx. (106)
En general, si el integrando es:∫ b
a
w(x)f(x)dx =n∑
i=0
Hi(x)f(xi) + Eint. (107)
donde w(x) es una funcion peso, losHi(x) se determinan imponiendo que Ec , el error de cuadraturasea cero, si f es un polinomio de grado menor o igual que n.
7.1.1. Metodo del Trapecio.
Si en la formula, (??), n=1 entonces los puntos de interpolacion son x0 y x1∫ x1
x0
f(x)dx =1∑
i=0
Hi(x)f(xi) = H0f(x0) +H1f(x1).

luego hay que calcular, H0 y H1, en efecto
H0 =∫ x1
x0
l0(x)dx =∫ x1
x0
x− x1
x0 − x1dx =
−1h
∫ x1
x0
(x− x1)dx =h
2.
Analogamente resulta:
H1 =h
2.
Luego,
∫ x1
x0f(x)dx =
h
2[f(x0) + f(x1)]. (108)
denominada Regla del trapecio.
¿Que representa graficamente esta formula ?
Error de cuadratura
¿Que podemos decir del error cometido ? Para ello integramos el error de la aproximacion polino-mial, en efecto
E = f(x)− P1(x) =f ′′(ξ)
2(x− a)(x− b)
utilizando el teorema del valor medio para integrales, se tiene que
ET =∫ b
a
E(x)dx = − 112
(b− a)3f ′′(ξ). (109)
Notese aquı que b−a = h es la longitud del intervalo y que la formula (??) proporciona un resultadoexacto para polinomios de grado a lo mas 1. Esta formula se conoce con elnombre de metodo deltrapecio simple.
Una forma de disminuir el error de cuadratura, es considerar mas puntos de interpolacion porejemplo (n + 1), en este caso el intervalo [a, b]lo dividimos en n subintervalos de longitud h y encada subintervalo aplicamos el metodo anterior , obteniendose,
∫ b
af(x)dx =
b− a
2n[f(x0) + f(xn) + 2
n−1∑i=1
f(x0 + ih)]. (110)
denominada metodo del trapecio generalizada y el termino de error
ET =−112
h3
n2f ′′(ξ)
de donde un estimativo del error es :
|ET | ≤h3
12n2max
a≤x≤b|f ′′(x)|

7.1.2. Metodo de Simpson.
Si en la formula, (??), n=2 entonces los puntos de interpolacion son x0, x1 y x2 y
∫ x2
x0
f(x)dx =2∑
i=0
Hi(x)f(xi) = H0f(x0) +H1f(x1) +H2f(x2).
luego hay que calcular, H0, H1 y H2, en efecto
∫ x1
x0f(x)dx =
∫ x2
x0(
(x− x1)(x− x2)(x0 − x1)(x0 − x2)
f(x0) +(x− x0)(x− x2)
(x1 − x0)(x1 − x2)f(x1))dx
+∫ x2
x0
(x− x0)(x− x1)(x2 − x0)(x2 − x1)
f(x2)dx+∫ x2
x0
(x− x0)(x− x1)(x− x2)6
f (3)(ξ(x))dx.
evaluando las integrales (Consultar Analisis Numerico de Burden-Faires.) se obtiene :∫ x1
x0
f(x)dx =h
3[f(x0) + 4f(x1) + f(x2)]−
h5
90f (4).
denominada Regla de Simpson simple. Como la derivada involucrada en el error es de cuartoorden, entonces la formula sera exacta para polinomios de grado menor que 4.
Observemos que si queremos generalizar este metodo a n subintervalos, el metodo requiere de dos
intervalos consecutivos, por lo que n debe ser par. Generalizamos definiendo: n = 2m , h =b− a
2mtenemos
a = x0 < x1 < ... < x2m = b , xi = x0 + ih , i = 0, ..., 2m
entonces ∫ b
af(x)dx =
h
3
[+f(x0) + 2
m−1∑i=1
f(x2i) + 4m∑
i=1
f(x2i−1) + f(x2m)
]
−h5
90
m∑i=1
f (4)(ξi).
(111)
Un concepto importante, es saber determinar el grado de exactitud o de precision de una formulade cuadratura. El grado de exactitud o precision de una formula de cuadratura es el enteropositivo n tal que E(Pk) = 0, para todos los polinomios Pk de grado menor o igual que n, peroE(Pn+1) 6= 0 para algun polinomio de grado (n+ 1).
Actividades 7.1 Problema 1. (PEP No 3. Sem I - 2000) Una partıcula con masa m = 20 kg semueve a traves de un fluido y esta sometida a una resistencia viscosa dada por:
R(v) = −v3/2

donde v es su velocidad. La relacion entre el tiempo t, la velocidad v, y la resistencia R esta dadapor:
t =∫ v(t)
v0
m
R(v)dv (en segundos)
donde v0 es la velocidad inicial.
a) Suponiendo que v0 = 15 m/seg y usando cuatro intervalos de igual longitud, determinar eltiempo T que se requiere para que la partıcula llegue a v(T ) = 7,0 m/seg.
b) Estime el error cometido en (a)
Problema 2. Considere la siguiente formula de integracion numerica:∫ 2
−2
f(x)dx =29[5f(−2
√0,6) + 8f(0) + 5f(2
√0,6)] (1)
a) Usando la formula (1), estime el valor de la siguiente integral:∫ 1
0
2[0,2969√x− 0,126x− 0,3516x2 + 0,2843x3 − 0,1015x4]dx
b) Determine el polinomio de mayor grado para el que la formula (1) es exacta.

7.2. Cuadratura Gaussiana.
Recordamos que las formulas de Newton-Cotes se obtuvieron al integrar los polinomios inter-polantes de Lagrange. Como el termino de error en el polinomio interpolante involucra la derivadade orden (n+ 1) de la funcion que se esta aproximando, la formula es exacta cuando se aproximacualquier polinomio de grado menor o igual a n. Luego las formulas de Newton-Cotes tienen gradode precision de a lo menos n.
Todas las formulas de Newton-Cotes requieren que se conozcan los valores de la funcion que seva a integrar, en puntos equiespaciados ( datos tabulados), sin embargo si la funcion esta dadaexplıcitamente, los puntos para evaluar la funcion pueden escogerse de modo que la aproximaciontenga una mayor precision.
La cuadratura Gaussiana consiste en escoger los puntos de evaluacion de la funcion de modoque la aproximacion sea optima.
Problema. Se trata de escoger los puntos x∗0, x∗1, ..., x
∗n en [a, b] y las constantes H0,H1, ...,Hn de
modo que el error obtenido en: ∫ b
a
f(x)dx ≈n∑
i=0
Hif(x∗i )
sea mınimo, para cualquier f . La mejor eleccion es la que maximice el grado de precision de laformula.
Como los valores de los Hi son arbitrarios y los x∗i solo a que la funcion cuya integral se estaaproximando, debe estar definida en estos puntos , hay (2n + 2) parametros involucrados. Si loscoeficientes de un polinomio se consideran tambien como parametros, entonces la clase mas grandede polinomios para la cual es exacta la formula sera 2n+ 1.
Actividades 7.2 Se considera la formula de cuadratura:∫ 1
−1
f(x)dx = A[f(x1) + f(x2) + f(x3)) + E
i) Determinar las ecuaciones que permiten calcular A , x1 , x2 , x3 de modo que la formulasea exacta para polinomios del mayor grado posible.
ii) Si en la formula anterior se impone x2 = 0. Determinar A , x2 , x3. ¿Cual es el mayorgrado del polinomio para el que la formula obtenida es exacta?
Sol.
x2 = 0 , x1 = −√
22
, x3 =√
22
, A =23.
La formula es exacta para polinomios de grado ≤ 3.

De la actividad anterior , es claro que para aplicar cuadratura Gaussiana, necesitaremos algunosconceptos relacionados con conjuntos ortogonales de funciones.
Definicion 7.1 Diremos que un conjunto de funciones {Φ0,Φ1, · · · ,Φn} es ortogonal en [a, b],con respecto a la funcion peso w(x) ≥ 0, si
∫ b
aΦ0kΦjw(x)dx = 0 , cuando j 6= k y∫ b
aΦ0kΦjw(x)dx > 0 , cuando j = k

Algunas Propiedades importantes.
1) Si {Φ0,Φ1, · · · ,Φn} es un conjunto ortogonal de polinomios definidos en [a, b] y Φi es degrado i para cada i = 0, 1, · · · , n, entonces para cualquier polinomio Q(x) de grado a lo masn, existen constantes unicas α0, α1, · · · , αn}, tales que:
Q(x) =n∑
i=0
αiΦi(x)
2) Si {Φ0,Φ1, · · · ,Φn} es un conjunto ortogonal de polinomios definidos en [a, b] con respecto auna funcion de peso continua w y Φk es un polinomio de grado k para cada k = 0, 1, · · · , n,entonces Φk tiene k raıces en el intervalo (a, b).
Resumen Polinomios Ortogonales.
Polinomios de Legendre.
i) Son ortogonales con respecto a la funcion peso w(x) = 1 en [a, b] = [−1, 1]
ii) Formula Recursiva.
Pn+1 =(
2n+ 1n+ 1
)xPn(x)−
(n
n+ 1
)Pn−1(x)
para todo n ≥ 1, P0(x) = 1, P1(x) = x.
iii) Formula para los pesos.
Wj =−2
(n+ 1)Pn+1(xj)P ′n(xj), j = 1, ..., n
En esta formula n representa el grado del polinomio.
iv) Formula para el error.
E(f) =22n+1(n!)4
(2n+ 1)[(2n)!]3f (2n)(ξ).
con ξ ∈ [−1, 1] y n grado del polinomio.
Polinomios de Laguerre.
i) Son ortogonales con respecto a la funcion peso w(x) = e−x en [a, b] = [0,∞)

ii) Formula Recursiva.
Ln+1 =(
1n+ 1
)(2n+ 1− x)Ln(x)−
(n
n+ 1
)Ln−1(x)
para todo n ≥ 1, L0(x) = 1, L1(x) = 1− x.
iii) Formula para los pesos.
Wj =[(n)!]2
Ln+1(xj)L′n(xj).
iv) Formula para el error.
E(f) =(n!)2f (2n)(ξ)
(2n)!.
con ξ ∈ [0,∞).
Polinomios de Hermite.
i) Son ortogonales con respecto a la funcion peso w(x) = e−x2en [a, b] = (−∞,∞)
ii) Formula Recursiva.Hn+1 = 2xHn(x)− 2nHn−1(x)
para todo n ≥ 1, H0(x) = 1, H1(x) = 2x.
iii) Formula para los pesos.
Wj =2(n+1)(n)!
√π
[H ′n(xj)]2
.
iv) Formula para el error.
E(f) =n!√πf (2n)(ξ)
2n[(2n)!].
con ξ ∈ (−∞,∞).
Polinomios de Tchebyshev.
i) Son ortogonales con respecto a la funcion peso w(x) = (1− x2)−1/2 en [a, b] = [−1, 1]
ii) Formula Recursiva.Tn+1(x) = 2xTn(x)− Tn−1(x)
para todo n ≥ 1, T0(x) = 1, T1(x) = x.
iii) Formula para los pesos.
Wj =π
n.
donde n representa el numero de ceros del polinomio.

iv) Formula para el error.
E(f) =2π
22n(2n)!f (2n)(ξ).
con ξ ∈ (−1, 1).
Actividades 7.3 1. Estimar ∫ 3
1
dx
x
usando un polinomio de Legendre de grado 3. Estimar ademas el error.
Sol.
x0 = −√
(35) , x1 = 0 , x2 =
√(35)
H0 =59, H1 =
89, H2 =
59
g(y) =1
y + 2, I ≈ 1,098039 , |E| < 0,045714
2. Estimar ∫ ∞
−∞e−x2
x2dx ,
usando un polinomio de Hermite de grado 2.
Sol.
x1 = −√
22
, x2 =√
22
, H1 = H2 =√π
2, I =
sqrtπ
2
3. Calcular : ∫ 1
−1
cosx√1− x2
dx
uasndo un polinomio de Tchebyshev de grado 2.
Sol. I ≈ 2,38884
4. La formula de Gauss - Tchebyshev,∫ 1
−1
f(x)√1− x2
dx approxπ
n
n∑i=1
f(xi)
es exacta para polinomios de grado 2n-1.
a) Demuestrelo para el caso n=3.
b) Aproxime usando lo anterior: ∫ π
0
cosx√π2 − x2
dx.

7.3. Integrales Indefinidas
Supongamos que desamos evaluar la integral:
F (x) =∫ x
a
f(t)dt. (112)
para a ≤ x ≤ b. Podemos escoger un adecuado paso de h para aproximar el lado derecho de (112),para x = a+ h , x = a+ 2h , ... cada integral puede estimarse por alguna regla de cuadratura porejemplo trapecio. Los valores intermedios de F (x) pueden estimarse por interpolacion.
Otro metodo es reemplazar f por algun polinomio de aproximacion p y aproximar F integrando p.
Si |f(x)− p(x)| < ε para a ≤ x ≤ b entonces,∣∣∣∣F (x)−∫ x
a
p(t)dt∣∣∣∣ < ∫ x
a
εdx ≤ (b− a)ε
para a ≤ x ≤ b. Tomando [a, b] como [−1, 1] una adecuada eleccion de p es la serie de Tchebyshev
b∑r=0
αrTr(x). (113)
donde,
αr =2N
N∑j=0
f(xj)Tr(xj). (114)
y xj = cos(πjN ), con N > n. Para integrar la expresion (113), es necesario integrar Tr(x), cuya
integral indefinida es un polinomio de grado r+1. Por lo tanto, queda una suma de T0 , T1, ..., Tr+1.Para evaluar en general la integral de Tr(x) es mas facil usar t = cos(θ), de modo que:∫
Tr(x)dx = −∫
cosrθ sin θdθ
=12
∫[sin (r − 1)θ − sin (r + 1)θ]dθ
=12
(cos(r + 1)θ
r + 1− cos(r − 1)θ
r − 1
)+ C
Si r 6= 1, escogemos C de modo que se cumpla la condicion Tr(−1) = (−1)r , de modo que:∫ x
−1
Tr(t)dt =12
(Tr+1(x)r + 1
− Tr−1(x)r − 1
)+
(−1)r+1
r2 − 1. (115)
donde r > 1. Ademas, ∫ x
−1T0(t)dt =
14T1(x) + 1
∫ x
−1T1(t)dt =
14T1(x)−
14

Luego integrando (113), tenemos:
∫ x
−1
(n∑
r=0
αrTr(t)
)dt =
n+1∑j=0
βjTj(x). (116)
De (115) se deduce que :
βj =12j
(αj+1 − αj−1) , 1 ≤ j ≤ n− 1. (117)
y
β0 =12α0 −
14α1 +
n∑r=2
(−1)r+1αr
r2 − 1
Si se define αn+1 = αn+2 = 0, la expresion (117) se cumple para j = n y n+ 1.
7.4. Integrales Impropias
Recordando como se definen las integrales impropias de primera y segunda clase, tenemos los dosproblemas siguientes:
i) Estimar∫ b
af(x)dx, donde f tiene una singularidad en x = b, entonces definimos sobre el
intervalo [a, b− ε], con 0 < ε < b− a. Suponemos que
lımε→0
∫ b−ε
a
f(x)dx
existe. Por ejemplo,∫ 1
0(1− x)
12 dx
ii) Estimar∫∞
af(x)dx, donde f esta definida sobre cualquier intervalo [a, b] y
lımb→∞
∫ b
a
f(x)dx
existe. Por ejemplo,∫∞1x−2dx
Una tecnica que es util algunas veces en ambos casos es hacer un cambio de variables adecuado.Ası la sustitucion t = (1−x2)
12 transforma la integral impropia i)
∫ 1
0(1−x)− 1
2 sinxdx en la integral
propia 2∫ 1
0sin 1− t2dt que puede estimarse usando alguna regla de cuadratura estandard .
Otra tecnica usada es remocion de la singularidad. Consideremos la integral impropia
I =∫ 1
0
x−pcosxdx , 0 < p < 1

con singularidad en x = 0. Podemos aproximar cosx por el primer termino de la serie de Tayloralrededor de x = 0, nos da
I =∫ 1
0
x−pdx+∫ 1
0
x−p(cosx− 1)dx.
La primera integral tiene el valor (1 − p)−1. La segunda integral puede calcularse mediante unmetodo numerico, puesto que su integrando no tiene singularidad, ya que cosx − 1 se comportacomo − 1
2x2 en x = 0. Sin embargo, x−p(cosx − 1) se comporta como − 1
2x2−p, cuya segunda
derivada y las derivadas de orden superior son singulares en x = 0. Por lo tanto no es posiblegarantizar que la integracion numerica de resultados exactos.
Ejemplo 7.1
7.5. Integrales Multiples
Dscutiremos integrales sobre una region rectangular. Mediante un cambio de variables, el rectangulopuede transformarse en cuadrado. Usando cualquier cuadratura en una dimension, tenemos :∫ b
a
(∫ b
af(x, y)dx
)dy =
∫ b
a
(∑Ni=0 ωif(xi, y)
)dy
=∑N
i=0 ωi
∫ b
af(xi, y)dy
=∑N
i=0 ωi
(∑Nj=0 ωjf(xi, yj)
),
donde, en realidad xi = yi . Los numeros xi ωi representan los puntos y los pesos respectivamente,en una dimension. Luego para dos dimensiones tenemos:
∫ b
a
(∫ b
a
f(x, y)dx
)dy =
N∑i,j=0
ωiωjf(xi, yj). (118)
denominada unaregla de integracion del producto. Por ejemplo, para un producto con la reglade Simpso compuesta en dos dimensiones con 4 subintervalos en cada direccion, el valor relativo alos pesos 1, 4, 2, 4, 2, 1, son multiplicados, los resultados de muestran en la siguiente tabla:
Tabla relativa a los pesos de un producto usando Simpson
1 4 2 4 14 16 8 16 42 8 4 8 24 16 8 16 41 4 2 4 1

La suma de los numeros en la tabla es (1 + 4 + 2 + 4 + 1)2 Consideraremos la funcion f(x, y) ≡ 1,por lo tanto la regla integrara la funcion sobre la region con area (b−a)2, cada numero en la tabla
debe ser multiplicado por(b− a)2
144para obtener los pesos ωiωj de (118).
El estimativo de error de las reglas del producto, da un error estimado para la regla unidimensional.Se puede obtener una cota de error basados en la regla de Simpson , con paso h. Si R denota laregion cuadrada a ≤ x ≤ b , a ≤ y ≤ b, entonces:
∫ b
a
f(x, y)dx =N∑
i,j=0
ωif(xi, y)− (b− a)h4
180f (iv)
x (ξy, y). (119)
7.6. Diferenciacion Numerica
Se trata de encontrar metodos para aproximar f ′ dados los valores de x en ciertos puntos. Si pes una aproximacion polinomial a f , podemos usar p′ como una aproximacion a f ′. Sin embargo,puede ocurrir que el modulo maximo de f ′(x)− p′(x) sobre el intervalo [a, b] puede ser mucho masgrande que el modulo maximo de f(x)− p(x). Por lo tanto se buscaran otros metodos. La formuladel error es:
f(x)− pn(x) =∏n+1
(x)f (n+1)(ξx)(n+ 1)!
. (120)
donde,∏
n+1(x) = (x− x0) · · · (x− xn). Derivando,
f ′(x)− p′n(x) = Π′n+1(x)f (n+1)(ξx)(n+ 1)!
+Π(n+1)(x)(n+ 1)!
d
dxf (n+1)(ξx). (121)
Recordamos la formula de diferencias avanzadas:
pn(x) = pn(x0 + sh) = f0 +(s1
)4f0 + · · ·+
(sn
)4nf0 (122)
De x = x0 + sh se tienedx
ds= h, por lo tanto,
p′n(x) =ds
dx
d
dspn(x0 + sh) =
1h
d
dspn(x0 + sh). (123)
Ası
p′n(x) =1h
[4f0 +
12(2s− 1)42f0 + · · ·+ d
ds
(sn
)4nf0
]. (124)
Para calcular Π′n+1(xr) escribimos:
Πn+1(x) = (x− xr)Πj 6=r(x− xj). (125)

De aquı obtenemos:
Π′n+1(x) =(d
dx(x− xr)
)Πj 6=r(x− xj) + (x− xr)
d
dxΠj 6=r(x− xj). (126)
En x = xr, el segundo termino sera cero y obtenemos:
Π′n+1(xr) =∏j 6=r
(xr − xj) = (−1)n−rhnr!(n− r)!. (127)
ya que xr − xj = (r − j)h. Por lo tanto, (121) puede expresarse como:
f ′(xr)− p′n(xr) = (−1)n−rhn r!(n− r)!(n+ 1)!
f (n+1)(ξx)r. (128)
De aquı podemos deducir algunas reglas:
Con n = 1 en (124) obtenemos:
p′1(x) =f1 − f0h
− . (129)
y con r = 0 en (128) tenemos:
f ′(x0) =1h4f0 =
f1 − f0h
− 12hf ′′(ξ0). (130)
Con n = 2 en (124) y r = 1 obtenemos la derivada centrada en x1, interpolando los puntos x0 , x1
y x2, si x = x1 entonces s = 1 y la formula (124) se transforma en :
p′2(x1) =1h
[4f0 +1242f0] =
f2 − f02h
. (131)
Esta es una aproximacion a f ′(x1), con error (128).
f ′(x1)−f2 − f0
2h= −1
6h2f ′′′(ξ1). (132)
Se pueden obtener las formulas de diferencia progresiva , centrada y regresiva respectivamente:
f ′(x) ≈ f(x+ h)− f(x)h
. (133)
y
f ′(x) ≈ f(x+ h)− f(x− h)2h
. (134)
f ′(x) ≈ f(x+ h)− f(x− h)2h
. (135)

Las derivadas de orden superior de f son aproximadas por las derivadas de orden superior delpolinomio interpolante pn. Si procedemos como antes, tenemos:
p′′n(x) =1h2
d2
ds2pn(x0 + sh)
y de (124) tenemos:
p′′n(x) =1h2
[42f0 +
d2
ds2
(s3
)43f0 + · · ·+ d2
ds2
(sn
)4nf0
]. (136)
donde x = x0 + sh y n ≤ 2. Para n = 2 encontramos que:
p′′2(x) =1h242f0
Consideramos esto como una aproximacion a f ′′(x) en x = x1. Ası
f ′′(x1) ≈f2 − 2f1 + f0
h2. (137)
Generalizando esta estrategia para cualquier k ≤ n obtenemos:
p(k)n (x) =
1hk
[dk
dsk
(sk
)4kf0 + · · ·+ dk
dsk
(sn
)4nf0
]. (138)
De aquı se obtiene,
f (k)(x) ≈ 4kf0hk
. (139)
Si consideramos la formula (139) para aproximar f (k)(x) para un x centrado en el intervalo [x0, xk]y si k = 2m, entonces tenemos:
f (2m)(xm) ≈ 42mf0h2m
. (140)
Si k = 2m−1, el intervalo [x0, x2m−1] no tiene un punto central tabulado, en este caso se generalizael procedimiento adaptado para la estimacion de la primera derivada. Usamos (140) con n = k+1 =2m, encontrando
f (2m−1)(xm) ≈ 1h2m−1
(42m−1f0 +1242mf0). (141)
Ya que,42mf0 = 4(42m−1f0) = 42m−1f1 −42m−1f0. (142)
obtenemos:
f (2m−1)(xm) ≈ 42m−1f0 +42m−1f12h2m−1
. (143)

De (143) y (140) se pueden obtener aproximaciones para la tercera y cuarta derivada:
f (3)(x2) ≈1h3
(f4 − 2f3 + 2f1 − f0). (144)
y
f (4)(x2) ≈1h4
(f4 − 4f3 + 6f2 − 4f1 + f0). (145)
Se pueden obtener otras reglas de derivacion considerando mas terminos en (138)

y de (154) tenemos:
p′′n(x) =1h2
[42f0 +
d2
ds2
(s3
)43f0 + · · ·+ d2
ds2
(sn
)4nf0
]. (166)
donde x = x0 + sh y n ≤ 2. Para n = 2 encontramos que:
p′′2(x) =1h242f0
Consideramos esto como una aproximacion a f ′′(x) en x = x1. Ası
f ′′(x1) ≈f2 − 2f1 + f0
h2. (167)
Generalizando esta estrategia para cualquier k ≤ n obtenemos:
p(k)n (x) =
1hk
[dk
dsk
(sk
)4kf0 + · · ·+ dk
dsk
(sn
)4nf0
]. (168)
De aquı se obtiene,
f (k)(x) ≈ 4kf0hk
. (169)
Si consideramos la formula (169) para aproximar f (k)(x) para un x centrado en el intervalo [x0, xk]y si k = 2m, entonces tenemos:
f (2m)(xm) ≈ 42mf0h2m
. (170)
Si k = 2m−1, el intervalo [x0, x2m−1] no tiene un punto central tabulado, en este caso se generalizael procedimiento adaptado para la estimacion de la primera derivada. Usamos (170) con n = k+1 =2m, encontrando
f (2m−1)(xm) ≈ 1h2m−1
(42m−1f0 +1242mf0). (171)
Ya que,42mf0 = 4(42m−1f0) = 42m−1f1 −42m−1f0. (172)
obtenemos:
f (2m−1)(xm) ≈ 42m−1f0 +42m−1f12h2m−1
. (173)
De (173) y (170) se pueden obtener aproximaciones para la tercera y cuarta derivada:
f (3)(x2) ≈1h3
(f4 − 2f3 + 2f1 − f0). (174)
y
f (4)(x2) ≈1h4
(f4 − 4f3 + 6f2 − 4f1 + f0). (175)
Se pueden obtener otras reglas de derivacion considerando mas terminos en (168)
90

Modulo de clases
Prof. Marıa Angelica Vega U.
9.7. Mınimos cuadrados Discretos.
Consiste en buscar una una funcion aproximada que ajuste la forma de la tendencia que siguen losdatos sin pasar necesariamente por los puntos dados. Un modo de hacer esto es determinar unacurva que minimice la diferencia entre los puntos dados y la curva. Este metodo se conoce comoregresion por mınimos cuadrados. El caso mas simple de una aproximacion por mınimos cuadradoses el ajuste de las observaciones mediante una lınea recta. La figura siguiente muestra la mejorlınea recta.Regresion lineal. Este problema clasico puede enunciarse : Dada una funcion continua f sobreun intervalo [a, b] y un conjunto de n observaciones (x1, y1), (x2, y2), · · · , (xn, yn), buscamos unalınea recta de ecuacion
f(x) = a0 + a1x
tal que la diferencia entre el valor real de y y el valor aproximado obtenido por f(x) sea el menorposible. Recordemos que se definio el error o residuo entre la funcion y) y su aproximacion como :
e = y − a0 − a1x.
¿Como obtener la recta de regresion ? La regresion lineal es un metodo poderoso en el sentidoque ajusta los datos a la mejor lınea. Sabemos que este es un problema de optimizacion y debemosencontrar los valores a0 y a1 de f(x) = a0 + a1x de modo que la suma
Er =n∑
i=1
(ei)2 =n∑
i=1
(yi − f(xi))2. (176)
sea mınima. Para ello derivamos la ecuacion (176) con respecto a cada coeficiente e igualamos acero, de donde tenemos :
∂Er
∂a0= −2
∑ni=1(yi − a0 − a1xi) = 0
∂Er
∂a1= −2
∑ni=1(yi − a0 − a1xi)xi = 0
De aquı se tiene el sistema de ecuaciones lineales, escrito en la forma Aa = b:( ∑ni=1 1
∑ni=1 xi∑n
i=1 xi
∑ni=1 x
2i
)(a0
a1
)=( ∑n
i=1 yi∑ni=1 xiyi
)o equivalentemente
(n
∑ni=1 xi∑n
i=1 xi
∑ni=1 x
2i
)(a0
a1
)=( ∑n
i=1 yi∑ni=1 xiyi
)Resolviendo el sistema matricial obtenemos los valores de a0 y a1.
91

Ejemplo 9.2 Ajuste a una lınea recta los siguientes cinco puntos. ¿Que puede decir del error quese obtiene
P1(1, 5,12) , P2(3, 3) , P3(6, 2,48) , P4(9, 2,34) , P5(15, 2,18).
Solucion. Determinamos cada uno de los terminos que aparecen en (9.7)
Calculo de las sumas.
n = 5 ,∑5
i=1 xi = 34∑5i=1 xi = 34 ,
∑5i=1 yi = 15,12∑5
i=1 yi = 15,12 ,∑5
i=1 xiyi = 82,76∑5i=1 x
2i = 352 ,
∑5i=1 y
2i = 51,5928
de donde tenemos el sistema de ecuaciones :
Sistema de ecuaciones (5 3434 352
)(a0
a1
)=(
15,1282,76
)Usando eliminacion gaussiana encontramos los valores del vector a
a0 = 4,15298 , a1 = −0,166027.
de donde la ecuacion de la recta es:
L(x) = 4,15− 0,17 ∗ x
Actividades 9.4
i) Encuentre el sistema matricial que se obtiene al ajustar, usando:
f(x) = P (x) = a0 + a1x+ a2x2.
ii) Dado un conjunto de m observaciones (x1, y1), ..., (xm, ym). aproximar los datos con un poli-nomio de grado n, usando el procedimiento de mınimos cuadrados. Observe que el polinomioes ahora
f(x) = P (x) =n∑
i=1
aixi.
Problema 2. Supongamos que queremos ajustar n datos, P1(x1, y1), · · · , Pn(xn, yn) con una fun-cion g(x) de dos parametros γ1 y γ2 , es decir
g(x) = γ1Φ1(x) + γ2Φ2(x).
Notemos que Φ1(x) y Φ(x) son funciones conocidas elementales de x que no son necesariamenteelementos de una base para los polinomios. Obviamente para encontrar la g(x) que minimiza elcuadrado de los errores hay que determinar los parametros γ1 y γ2. En efecto,
E(g) =n∑
i=1
(yi − g(xi))2. (177)
92

Derivando parcialmente con respecto a γ1 y γ2, igualando a cero y reordenando se obtiene elsiguiente sistema de ecuaciones en forma matricial Aγ = b( ∑n
i=1 Φ1(xi)Φ1(xi)∑n
i=1 Φ2(xi)Φ1(xi)∑ni=1 Φ1(xi)Φ2(xi)
∑ni=1 Φ2(xi)Φ2(xi)
)(γ1
γ2
)=( ∑n
i=1 Φ1(xi)yi∑ni=1 Φ2(xi)yi
)Las ecuaciones del sistema se denominan ecuaciones normales y cualquier modelo lineal (sumaponderada de dos funciones) de dos parametros pueden ajustarse a un sistema de ecuacioneslineales. El error en este caso puede determinarse luego de encontrar γ1 y γ2, usando:
E(g) =n∑
i=1
(yi)2 −
(γ1
n∑i=1
Φ1(xi)yi + γ2
n∑i=1
Φ2(xi)yi
)(178)
Para ilustrar este modelo, tomemos el ejemplo 0.2 y ajustemos los datos usando una funcion dedos parametros como sigue.
Ejemplo 9.3 Ajustar mediante el metodo de mınimos cuadrados, los datos del ejemplo 1.15 con
una hiperbola desplazada del tipo g(x) = γ1 +γ2
x. Determine el error cometido al ajustar los datos
con la recta y con la parabola.
9.8. Algo sobre Normas de funciones.
Definicion 9.2 La norma de una funcion f que pertenece a alguna clase de funciones continuasC es una funcion de C al conjunto de los numeros reales no negativos :
|| · || : C → R+
f 7→ ||f || ≥ 0
tal que verifica las siguientes propiedades :
i) ||f || > 0 , ||f || = 0 ⇔ f = 0
ii) ∀ λεR y fεC ||λf || = |λ||f ||
iii) ∀ f, g εC ||f + g|| ≤ |||f ||+ ||g||
Algunas normas conocidas con fεC
i)||f ||∞ = max
a≥x≥b|f(x)|. (179)
Esta norma definida sobre [a, b] es llamada norma del maximo, norma infinito o normade Tchebyshev. Verificar como ejercicio que satisface las propiedades de una norma.
93

ii)
||f ||p =
{∫ b
a
|f(x)|pdx
} 1p
. (180)
conocida como p− norma, donde f ∈ C[a, b] y p ≥ 1. Obviamente cada valor de p ≥ 1 esuna norma, aunque en la practica se utiliza p = 1 y p = 2.
Normas Discretas (es decir para fεC(X))
i)||f ||∞ = max
0≤i≤N|f(xi)|. (181)
llamada norma infinito discreta.
ii)
||f ||p ={ΣN
i=0|f(xi)|pdx} 1
p . (182)
conocida como p− norma discreta, siendo p ≥ 1.
La desigualdad triangular es difıcil de demostrar para esta ultima norma, excepto para p = 1 yp = 2.
Nota 9.1 i) Observemos que se ha usado ||f ||∞ para denotar dos normas diferentes (179) sobreC[a, b] y (181) analogamente sucede con ||f ||p.
ii) Existe la siguiente relacion entre la norma (181) y las p− normas (182) dada por :
lımp→∞
{ΣN
i=0|f(xi)|pdx} 1
p = max0≥ix≥N
|f(xi)|. (183)
iii) La mejor aproximacion respecto a la norma infinito se llama aproximacion minimax,puesto que esta aproximacion minimiza el error maximo ||f − q||∞ sobre todo q ∈ Pn(x)
iv) La mejor aproximacion respecto a la norma 2 se llama aproximacion mınimo cuadrado.
94

Modulo N◦ 9
Profesores : Edgard Shipley - Marıa Angelica Vega U.Erklarungen: Zusammengestohlen aus Verschiedenem diesem und jenem
Ludwig van Beethoven.
9.9. Aproximacion de Mınimos Cuadrados Continuos.
Problema 2. Sea f ∈ C[a, b] , queremos determinar un polinomio Pn de grado ≤ n que minimiceel error : ∫ b
a
(f(x)− Pn(x))2dx
Sean Pn(x) =n∑
k=0
akxk y E(a0, ..., an) =
∫ b
a
(f(x)− Pn(x))2dx. (184)
es decir, la funcion error es,
E(a0, ..., an) =∫ b
a
(f(x)−n∑
k=0
akxk)2dx. (185)
Para determinar los coeficientes ak, k = 0, 1, 2, ..., n, debemos resolver el siguiente sistema:
∂E
∂aj= 0 para j = 0, 1, 2, ..., n.
De (??), obtenemos
E(a0, ..., an) =∫ b
a
f(x)2dx− 2n∑
k=0
ak
∫ b
a
f(x)xkdx+∫ b
a
(n∑
k=0
akxk
)2
dx. (186)
Luego,∂E
∂aj= −2
∫ b
af(x)xjdx+
∫ b
a2(∑n
k=0 akxk)xjdx
= −2∫ b
af(x)xjdx+ 2
∑nk=0 ak
∫ b
axj+kdx = 0 , j = 0, 1, ..., n.
De aquı el sistema es:
n∑k=0
ak
∫ b
a
xj+kdx =∫ b
a
f(x)xjdx , j = 0, 1, ..., n. (187)
Las ecuaciones (??) son las ecuaciones normales y tienen solucion unica si f ∈ C[a, b]. La matrizde los coeficientes de este sistema es:
H = (hi,j) =(bj+k+1 − aj+k+1
j + k + 1
)
95

que es una matriz de Hilbert mal condicionada que produce dificultades con el error de redondeo.Observemos que al dar valores a j en (??), se obtiene:
j = 0, −2(∫ b
af(x)dx+
∫ b
a
(∑nk=0 akx
k)dx)
= 0
j = 1, −2(∫ b
af(x)xdx+
∫ b
a
(∑nk=0 akx
k)xdx
)= 0
......
j = n, −2(∫ b
af(x)xndx+
∫ b
a
(∑nk=0 akx
k)xndx
)= 0
Ejemplo 9.4 (Burden) Determinar el polinomio de grado dos que aproxima por mınimos cuadra-dos a la funcion f(x) = sin (πx) en el intervalo [0, 1].Sol. El sistema (??) queda:
1 1
213
12
13
14
13
14
15
a0
a1
a2
=
∫ 1
0sinπxdx∫ 1
0x sinπxdx∫ 1
0x2 sinπxdx
=
2π
1π
π2−4π3
El polinomio aproximante de grado dos para f(x) = sin (πx) en el intervalo [0, 1] es
P2(x) = −0,050465 + 4,12251x− 4,12251x2
9.9.1. Metodo Generalizado
Podemos usar en lugar de la base canonica para polinomios,{1, x, x2, ..., xn} , cualquier base defamilia de polinomios ortogonales en el intervalo [a, b] respecto de una funcion peso w(x). Para ellodebemos tener presente los siguientes conceptos:
Definicion 9.3 Un espacio con producto interno (E.P.I.) es un (E, 〈 , 〉) donde:
〈f, h〉 = 〈h, f〉
〈f, ah+ bg〉 = a〈f, h〉+ b〈f, g〉
〈f, f〉 = ||f ||2 > 0
96

Propiedad 9.1 Algunas propiedades importantes en un E.P.I.
〈∑n
1 aifi, g〉 =∑n
1 ai〈fi, g〉
||f + g||2 = ||f ||2 + 2〈f, g〉+ ||g||2
Si f⊥g ⇒ ||f + g||2 = ||f ||2 + ||g||2
|〈f, g〉| = ||f ||||g||
||f + g||2 + ||f − g||2 = 2(||f ||2 + ||g||2)
Teorema 9.1 Sea G un subespacio de un espacio con producto interno E. Para toda f ∈ E , g ∈ Gson equivalentes las proposiciones:
i) g es una mejor aproximacion a f ∈ G
ii) f − g ⊥ G si 〈f − g, h〉 = 0
Definicion 9.4 Si B = {ϕ0, ϕ1, ϕ2, ..., ϕn} es una base de los polinomios ortogonales en [a, b]respecto de w(x) se cumple:
〈ϕj , ϕk〉 =∫ b
a
w(x)φj(x)ϕk(x)dx =
{0, si j 6= k
γk, si j = k
Observacion 9.1 Recordemos que,
Un conjunto de funciones ψ0, ψ1, ..., ψn es linealmente independiente en [a, b] si
n∑j=0
cjϕj = 0 ⇒ cj = 0 para cada j = 0, 1, ..., n
De lo contrario decimos que el conjunto es linealmente dependiente.
Sea ϕj un polinomio de grado j para cada j = 0, 1, ..., n y sea ψ0, ψ1, ..., ϕn un conjunto lin-ealmente independiente. Si Πn es el conjunto de todos los polinomios de grado ≤ n, entoncescualquier polinomio de Πn puede expresarse como
Pn(x) = Σnj=0cjϕj(x)
.
De modo que el problema de determinar un polinomio Pn(x) =∑n
j=0 cjϕj(x) de grado n queminimice el error
E(c0, ..., cn) =∫ b
a
w(x)[f(x)− Pn(x)]2dx. =∫ b
a
w(x)
f(x)−n∑
j=0
cjϕj
2
dx. (188)
97

se reduce a determinar la solucion del sistema de ecuaciones lineales obtenido mediante
∂E
∂ci= 0 ⇔
∫ b
aw(x)
[f(x)−
∑nj=0 cjϕj(x)
]ϕi(x)dx = 0
∂E
∂ci= 0 ⇔
∑nj=0 cj〈ϕj , ϕi〉 = 〈f, ϕi〉 ⇒ ciγi = 〈f, ϕi〉 , i = 0, 1, ..., n
Por tanto los coeficientes de Pn(x) estan dados por:
cj =〈f, ϕj〉γj
=
∫ b
aω(x)f(x)ϕj(x)dx∫ b
aω(x)ϕ2
j (x)dxj = 0, 1, ..., n.. (189)
El producto interior definido por 〈f, g〉 =∫ b
aω(x)f(x)g(x)dx permite definir la llamada Norma-2
que esta dada por
||f ||2 =√〈f, f〉 =
(∫ b
a
ω(x)f(x)2dx
) 12
.[a, b] (190)
Con lo anterior,el problema de minimizar el error (??), puede expresarse como:Problema 2. Determinar
mın ||f − Pn||2 , con Pn ∈ Πn
donde Πn es el espacio de los polinomios generados por B.
Ejemplo 9.5 Sean ϕ0(x) = 3 , ϕ1(x) = x+ 2 , ϕ2(x) = x2 + 4x− 6. ExpresarP (x) = a+ bx+ cx2 como Σn
j=0cjϕj(x) En efecto,
13ϕ0(x) = 1 , x = ϕ1(x)− 2 = ϕ1(x)−
23ϕ0(x)
y
x2 = ϕ2(x)− 4(ϕ1(x)−23ϕ0(x)) + 2ϕ0(x)
Luego,
P (x) = a
(13ϕ0(x)
)+ b
(ϕ1(x)−
23ϕ0(x)
)+ c
(ϕ2(x)− 4ϕ1(x) +
143ϕ0(x)
)y
P (x) =13(a− 2b+ 14)ϕ0(x) + (b− 4c)ϕ1(x)− cϕ2(x)
Proceso de Gramm-Schmidt
Existe un metodo para generar una familia de polinomios ortogonales en un intervalo dado, respectode una funcion peso ω(x). Este metodo es el llamado metodo de Gramm-Schmidt que consiste endeterminar los polinomios de la siguiente manera:
98

1. ϕ0(x) = 1 , ϕ1(x) = (x−B1)ϕ0(x)
2. B1 se determina de modo que 〈ϕ1, ϕ0〉 = 0. Se obtiene ;
B1 =
∫ b
aω(x)xϕ0(x)2dx∫ b
aω(x)ϕ2
0(x)dx
3. Para k ≥ 2, ϕk(x) = (x−Bk)ϕk−1 − Ckϕk−2
Bk =
∫ b
aω(x)xϕ2
k−1(x)dx∫ b
aω(x)ϕ2
k−1(x)dx, Ck =
∫ b
aω(x)xϕk−1(x)ϕk−2dx∫ b
aω(x)ϕ2
k−2(x)dx
Ejemplo 9.6 Los polinomios de Legendre son ortogonales en [−1, 1] con funcion peso ω(x) = 1 yse define ϕ0(x) = 1. Aplicando la formula anterior recursivamente, se obtiene
ϕ1(x) = x , ϕ2(x) = x2 − 13, ϕ3(x) = x2 − 3
5x
.
Ejemplo 9.7 Encontrar la aproximacion de mınimos cuadrados de grado dos, de la funcion f(x) =e−x con x ∈ [−1, 1] usando polinomios de Legendre.Sol.: Sea P2(x) = aϕ0(x) + bϕ1(x) + cϕ2(x) el polinomio que minimiza ||f − P2||22. En este casolas ecuaciones que determinan los coeficientes son:
a =
∫ 1
−1e−xϕ0(x)dx∫ 1
−1ϕ2
0(x)dx=
12[−e−x]1−1 =
12(e− e−1)
b =
∫ 1
−1e−xϕ1(x)dx∫ 1
−1ϕ2
1(x)dx=
∫ 1
−1e−xxdx∫ 1
−1x2dx
=3(−2)
2e= −3
e= −3e−1
c =
∫ 1
−1e−xϕ2(x)dx∫ 1
−1ϕ2
2(x)dx=
∫ 1
−1e−x(x2 − 1
3 )dx∫ 1
−1(x2 − 1
3 )dx =
154
(e− 7e−1)
El polinomio cuadratico que minimiza la aproximacion por mınimos cuadrados es:
P2(x) = aϕ0(x) + bϕ1(x) + cϕ2(x)
= 12 (e− e−1)ϕ0(x)− 3e−1ϕ1(x) + 15
4 (e− 7e−1)ϕ2(x)
En el grafico, se muestra la funcion y su aproximacion : El error es 0,001440569656, luego ||e−x−P2(x)||2 = 0,3795483706e−1
99

Figura 11: f(x) = e−x
Ejemplo 9.8 Encontrar las aproximaciones por mınimos cuadrados ay(t) = t2 en (0, 1), usando polinomios de Legendre de grado 1.Sol.
1) El polinomio de Legendre de grado 0 es P0(x) = 1 y P1(x) = x
2) Transformacion del intervalo (0, 1) a (−1, 1).
Consideremos la recta x = at+ b, si t = 0 ⇒ x = −1 ⇒ b = −1
luego x = at− 1 y si t = 1 ⇒ x = 1 ⇒ a = 2
luego, la recta de transformacion es x = 2t− 1 t = x+12 , es decir (0, 1) ↔ (−1, 1) y
y =(x+ 1)2
4ademas P0(x) = 1 P1(x) = x
Usando (4)
ak =2k + 1
2
∫ 1
−1
y(x)Pk(x)dx
a0 =12
∫ 1
−1
(x+ 1)2
4dx =
13
a1 =32
∫ 1
−1
(x+ 1)2
4xdx =
12.
Luego,
y(x) =13P0(x) +
12P1(x) =
13
+x
2
100

y
y(t) = t− 16
Ejemplo 9.9 Dada f(x) = e−2x en [1, 3]. Determinar la mejor aproximacion ag(x) = a+ bx2 + cx4.
Sol. La base {1, x2, x4} genera el subespacio G ≤ E, consideremos g ∈ G , f ∈ E y recordemosque
〈f − g, h〉 = 0 ⇔ 〈f, h〉 = 〈g, h〉.Si h = 1, x2, x4 entonces,
h = 1 , 〈e−2x, 1〉 = 〈a+ bx2 + cx4, 1〉∫ 3
1e−2dx = 〈a, 1〉+ 〈bx2dx, 1〉+ 〈cx4, 1〉
=∫ 3
1adx+
∫ 3
1bx2dx+
∫ 3
1cx4dx
e−2x
−2
∣∣31 = 2a+ b
x3
3
∣∣∣∣31 + cx5
5
∣∣∣∣31
.
0,0664 = 2a+263b+ 48,4c
h = x2 , 〈e−2x, x2〉 = 〈a+ bx2 + cx4, x2〉∫ 3
1e−2x2dx = 〈a, x2〉+ 〈bx2dx, x2〉+ 〈cx4, x2〉
= a∫ 3
1x2dx+ b
∫ 3
1x4dx+ c
∫ 3
1cx6dx
0,153 =263a+ 48,4b+ 312,92c
h = x4 , 〈e−2x, x4〉 = 〈a+ bx2 + cx4, x4〉∫ 3
1e−2x4dx = a
∫ 3
1x4dx+ b
∫ 3
1x6dx+ c
∫ 3
1cx8dx
0,4967 = 48,4a+ 312,24b+ 2186,8c
Resolviendo el sistemaa = 0,144 , b = −0,045 , c = 0,0034
Luego g(x) = 0,144− 0,045x2 + 0,0034x4.
9.9.2. Sistemas Ortonormales.
Existe otro enfoque de los problemas de aproximacion en un E.P.I, que consiste en construirun sistema ortonormal.
101

Definicion 9.5 Un conjunto {ϕ1, · · · , ϕn} es ortonormal ssi 〈ϕi, ϕj〉 = δij
Teorema 9.2 Sea {ϕ1, ϕ2, · · · , ϕn} un sistema ortonormal en un E.P.I. que denotaremos (E, 〈, 〉).La mejor aproximacion a f mediante un elemento
∑ni=1 ciϕi se obtiene ssi ci = 〈f, ϕi〉.
〈f −n∑
i=1
ciϕi, ϕj〉 = 〈f, ϕj〉 −n∑
i=1
ci〈ϕi, ϕj〉 = 〈f, ϕi〉 − ci = 0
Es decir, la mejor aproximacion de f(x) se puede escribir en la forma
f(x) =n∑
i=1
〈f(x), ϕi(x)〉ϕi(x) con {ϕi(x)} base ortonormal.
El procedimiento sugerido de estos conceptos para aproximar elementos de un espacio E medianteelementos de un subespacio G es :
i) Obtener una base ortonormal {ϕ1, ϕ2, ..., ϕn}. para G
ii) Determinar la mejor aproximacion a partir de
n∑i=1
ci〈ϕi, ϕj〉 =n∑
i=1
ciδi
Ejemplo 9.10 Obtener la aproximacion de la forma g(x) = c1 + c2x2 + c3x
3, a f(x) = sen (x),usando la base ortonormal: x√
23
,5x3 − 3x√
27
,63x5 − 70x3 + 15x√
211
Sol.
i) Determinamos cada ci, i = 1, 2, 3
c1 =√
32
∫ 1
−1x sen (x)dx = 2
√32 (sen (1)− cos(1))
c2 =√
72
∫ 1
−1(5x3 − 3x) sen (x)dx = 2
√72 (−18 sen (1)− 28cos(1))
c3 =√
112
∫ 1
−1(63x5 − 70x3 + 15x) sen (x)dx = 2
√112 (4320 sen (1)− 6728cos(1))
ii) La mejor aproximacion es
g(x) = 2
√32(sen (1)−cos(1))x+2
√72(−18 sen (1)+28cos(1))x2+2
√112
(4320 sen (1)−6728cos(1)).
Actividades 9.5 Determina la mejor aproximacion de la funcion f(x) = sen (x) mediante unpolinomio g(x) = c1x+ c2x
3 + c3x5 en [−1, 1]. (Usando || · ||∞).
102

9.9.3. Proceso de ortonormalizacion de Gramm-Schmidt.
1. Definimosu1 =
v1||v1||
, luego ||u1|| = 1 , w1 = u|
2. Se define w2 = v2 − 〈v2, u1〉u1
〈w2, u1〉 = 〈v2 − 〈v2, u1〉u1, u1〉= 〈v2, u1〉 − 〈v2, u1〉〈u1, u1〉1 = 0 ⇒ w2⊥u1.
w2⊥u1, pero w2 no tiene necesariamente norma 1. Por tanto ,
u2 =w2
||w2||=v2 − 〈v2, u1〉u1
v2 − 〈v2, u1〉u1
3. Se define w3 = v3 − 〈v3, u1〉u1 − 〈v3, u2〉u2 ortogonal a u1 y u2.
〈w3, u1〉 = 〈v3 − 〈v3, u1〉u1 − 〈v3, u2〉u2, u1〉= 〈v3, u1〉 − 〈v3, u1〉〈u1, u1〉 − 〈v3, u2〉〈u2, u1〉
〈w3, u1〉 = 〈v3, u1〉 − 〈v3, u1〉 = 0.
Luego w3⊥u1 y w3⊥u2 se comprueba en forma analoga. Como w3⊥u1 y w3⊥u2, definimos
u3 =w3
||w3||
Por tanto {u1, u2, u3} son ortonormales.
4. Generalizamos a un =wn
||wn||con
wn = vn − 〈vn, u1〉u1 − 〈vn, u2〉u2 − · · · − 〈vn, un−1〉un−1.
Ejemplo 9.11 Ilustrativo. Sea f(x) = e−2x con x ∈ [1, 3] encontrar la mejor aproximacion a f(x)
i) respecto de la base β = {x, 3x2 + 1} con w(x) = 1 en || · ||2.
ii) respecto de la base β∗ = {x+ 1, x2} con w(x) = e−x en || · ||∞.
Sol. i) Nuestro proposito es encontrar g(x) =∑〈f(x), gi(x)〉gi(x). Para ello
Se debe ortonormalizar, para obtener g1(x) y g2(x) respecto a β = {v1(x) = x, v2(x) =3x2 + 1}
103

g1(x) =v1(x)
||v1(x)||2, y
||v1(x)||22 = 〈v1(x), v1(x)〉 =∫ 3
1
1 · (v1(x))2dx =∫ 3
1
x2dx =x3
3|31 =
263
de donde, ||v1(x)||2 =√
263 y
g1(x) =x√263
=
√326x
g2(x) =w2(x)
||w2(x)||2, donde w2(x) = v2(x)− 〈v2(x), g1(x)〉g1(x)
〈v2(x), g1(x)〉 =∫ 3
1
(3x2 + 1)
√326xdx = 21,74
Luego, w2(x) = (3x2+1)−21,74√
326x es ortonormal a g1(x), perono necesariamente unitario.
Falta determinar
||w2(x)||22 =∫ 3
1
(w2(x))2dx =∫ 3
1
[(3x2 + 1)− 21,74
√326x]2dx = 16,98
Luego, ||w2(x)||2 =√
16,98 y
g2(x) =(3x2 + 1)− 21,74
√326x
4,12
Luego, β∗ = {g1(x), g2(x)} es ortonormal segun la norma || · ||2 y la mejor aproximacion es
g(x) = 〈f(x), g1(x)〉g1(x) + 〈f(x), g2(x)〉g2(x)
y
〈f(x), g1(x)〉 =∫ 3
1e−2x
√326xdx = 0,033
〈f(x), g2(x)〉 =∫ 3
1e−2x
(3x2 + 1)− 21,74√
326x
4,12xdx = 0,045
,
entonces la mejor aproximacion es:
g(x) = 0,033
√326x− 0,045
(3x2 + 1)− 21,74√
326x
4,12
104

Modulo N◦ 10
Profesores : Marıa Angelica Vega U.Erklarungen: Zusammengestohlen aus Verschiedenem diesem und jenem
Ludwig van Beethoven.
10. Aproximacion Minimax.
10.0.4. Caso Discreto.
Problema Este problema no es directo como el metodo de mınimos cuadrados. Por ejemplo siqueremos encontrar el polinomio minimax P1(x) = a0 + a1x que aproxima a f(x) = x
12 en un
intervalo [ 14 , 1]
E = mın[a0,a1]
max14≤x≤1
|x 12 − (a0 + a1x)|
La mejor lınea recta es aquella para la cual el error maximo ocurre en x = 14 , x = 1 y en algun
punto interior x = ξ. Entoncesa0 + a1
4 − ( 14 )
12 = E
a0 + a1ξ − ξ12 = −E
a0 + a1 − 1 = E.
Observamos que hay 3 ecuaciones y 4 incognitas, a0, a1, E y ξ. La cuarta ecuacion se obtiene delhecho que la derivada es cero en x = ξ para el error E = f(x)− (a0 + a1x). Es decir,
12ξ−
12 − b = 0
Ya que E en x = ξ
a0 + a14 − ( 1
4 )12 = E
a0 + a1 − 1 = E.
De aquı,
b =23, ξ =
916
, a =1748
, E =148
Luego la mejor aproximacion es y(x) =1748
+23x, que aproxima con un error no mejor que
148.
10.1. Algoritmo de Remez.
Permite construir aproximaciones minimax, debido al mate´matico ucraniano E.Ya. Remez.Algoritmo de Remez Calcula iterativamente el polinomio minimax p ∈ Pn, para f ∈ C[a, b] enun conjunto de (n+2) puntos. La sucesion de polinomios p converge al polinomio minimax p∗ ∈ Pn
y la sucesion de conjuntos X converge a X∗ sobre el cual f − p∗ es equioscilante.
105

Paso 1. Escoger un conjunto X = {x1, x2, ..., xn+2}.
Paso 2. Resolver el sistema de ecuaciones lineales,
f(xi)− p(xi = (−1)ie , 1 ≤ i ≤ n+ 2 (191)
para determinar un numero real e y un polinomio p ∈ Pn.
Paso 3. Cambiar el conjunto X, de la siguiente manera:
• Cuando [a, b] es [−1, 1], una forma comun de elegir el conjunto X en paso 1 es el con-junto de puntos extremos de Tn+1. Para este conjunto inicial, el paso 2 da el polinomiominimax inmediatamente cuando f(x) = xn+1. En el caso general las ecuaciones linealesdel paso 2 siempre tienen una unica solucion.
• Para llevar a cabo el paso 3, necesitamos primero estimar ||f − p||∞ , donde p ∈ Pn esel polinomio que ha sido calculado en el paso 2.
• Si ||f − p||∞ es suficientemente cercana a |e| entonces por teorema 4.3 p es proximo alpolinomio minimax y terminamos el proceso iterativo.
• De otra forma, sea ξ un punto tal que
|f(ξ)− p(ξ)| = ||f − p||∞.
Incluimos el punto ξ en el conjunto X y borramos uno de los puntos existentes de modoque f − p tenga signos alternados sobre los (n+ 2) puntos de X.
• Si ξ esta entre a y x1, descartamos x1 o xn+2 y anaalogamente si ξ esta entre xn+2 y b,descartamos x1 o xn+2. De otra forma, ξ esta entre dos xi consecutivos y en este casodescartamos uno de ellos apropiadamente.
Ejemplo 10.1 Encontrar el polinomio minimax de grado 2, para f(x) = ( 38x+ 5
8 )12 en [−1, 1].
Sol. Escogemos X = {−1,−0,5, 0,5, 1} inicialmente, los puntos extremos de T3 y resolvemos elsistema de ecuaciones lineales (??) de donde obtenemos:
p(x) = 0,79188 + 0,24665x− 0,04188x2 , |e| = 0,00335 (192)
con 5 cifras decimales.Evaluando f − p en intervalos intervalos de 0,01, encontramos que hay maximo y mınimo local en−1 , −0,61 , 0,40 y 1 y f − p tiene signos alternados en estos puntos, los que tomamos como elnuevo conjunto X. Resolviendo el sistema(??) nos da otra vez
p(x) = 0,79196 + 0,24650x− 0,04196x2 , |e| = 0,00350 (193)
Encontramos que ||f −p||∞ = 0,00350 con 5 cifras decimales y por lo tanto aceptamos este p comopolinomio minimax.
106

10.1.1. Caso Continuo.
En los espacios con Producto Interno (E.P.I.)se pueden definir las siguientes normas:
1. Norma uniforme o norma minimax o norma de Tchebyshev.
||f || = ||f ||∞ = maxa≤x≤b
|f(x)|
.
2. Norma Euclideana o norma 2.
||f ||2 =
√∫ b
a
w(x)f2(x)dx.
3. Norma 1.
||f ||1 =∫ b
a
w(x)|f(x)|dx.
4. Norma minimax ponderada. ||f || = maxa≤x≤b w(x)|f(x)|
Recordemos que, p ∈ Pn es una mejor aproximacion de f ∈ C con respecto a una normadada si
||f − g|| = infq∈Pn
||f − g||
Las aproximaciones con respecto a la norma infinito se denominan aproximacionesminimax, porque es la mejor aproximacion que minimiza el error maximo ||f −q||∞ ∀q ∈ Pn
Problema 10.1 i) Determinar ||√x||2.
ii) Hallar un polinomio g(x) = a0 + a1x ortogonal a f(x) = 1.
iii) Encontrar el polinomio minimax para f(x) =√
1 + x2 en [0, 1].Sol.
i)
||√x||2 = 〈
√x,√x〉 =
∫ e
1
x ln |x|dx =e2
2− e2
4+
14.
ii)
g(x)⊥f(x) ⇔ 〈g(x), f(x)〉 = 0
⇔ 〈a0 + a1x, 1)〉 = 0 ⇔ 〈a0, 1〉+ a1〈x, 1〉 = 0
⇔∫ e
1a0 · 1 · ln |x|dx+ a1
∫ e
1x · 1 · ln |x|dx = 0
⇔ a0
∫ e
1ln |x|dx+ a1
∫ e
1x ln |x|dx = 0
⇔ a0 + a1
(e2
2− e2
4+
14
)= 0
107

Tenemos infinitas soluciones. En terminos de a0,
a0 = −a1
(e2
2− e2
4+
14
)⇒ a0 = a1
(e2
4− e2
2− 1
4
),
luego g(x) = a1
(e2
4− e2
2− 1
4
)+ a1x es ortogonal a 1.
iii) Polinomio minimax. De (??).
a1 =f(1)− f(0)
1=√
2− 1
a0 =1 + f(c)
2− (√
2− 1)( c
2
)donce c es tal que, f ′(c) = a1
f ′(x) =x√
1 + x2⇒ f ′(c) =
c√1 + c2
luego,c√
1 + c2=√
2− 1 ⇒ c√1 + c2
= 0,42 ⇒ c = 0,455 ⇒ f(c) = 1,0986
luego,
a0 =(
1 + 1,09862
)− (√
2− 1)(
1,09862
)= 0,955
Por tanto, la aproximacion minimax lineal a f(x) en [0, 1] es:
P1(x) = 0,955 + (√
2− 1)x.
Observacion 10.1 Observamos que puede haber mas de una mejor aproximacion a f .Determinar la mejor aproximacion polinomial a f ∈ L∞[a, b] equivale a resolver elproblema : ”minimizar max |f(x) − pn(x)| si x ∈ [a, b] y pn ∈ Πn”, es decir, se debedeterminar el polinomio de grado ≤ n que minimiza el valor maximo de |f(x)− pn(x)|.
Proposicion 10.1 Existe una unica mejor aproximacion que resuelve el problema mıni-max.
Teorema 10.1 (Teorema de la alternancia para polinomios) Para cualquier funcionf(x) ∈ C[a, b] existe una unica mejor aproximacion polinomial mınimax pn(x) queesta caracterizada por la propiedad alternante de que hay (a lo menos) n+2 puntos en[a, b] en los cuales f(x)− pn(x) obtiene sus valores maximos absolutos (nominalmente||f − pn||∞) con signos alternados.
108

Este teorema se atribuye a Tchebyshev. Pero Borel (1905) establecio que la condicionde alternancia es una condicion necesaria y suficiente y que existe solo un polinomioque cumple con dicha caracterizacion
Ejemplo 10.2 La funcion f(x) = x2 se aproxima por f∗ = p1(x) = x − 0,125 en [0, 1].Entonces, el error f(x) − p1(x) = x2 − x + 0,125 tiene un valor maximo absoluto enlos puntos 0, 0,5 y 1 y alcanza los valores 0,125,−0,125, 0,125 que tienen signos alterna-dos. Por lo tanto, es la unica aproximacion mınimax. La grafica de la funcion y laaproximacion es:
Figura 12: f(x) = x2
109

10.2. Propiedad mınimax de los polinomios de Tchebyshev
Los polinomios de Tchebyshev, Tn(x) con x = cosθ tiene (n+1) valores extremos en lospuntos x = yk = cos
(kπn
)con k = 0, 1, 2, ..., n
Proposicion 10.2 Los polinomios de Tchebyshev alcanzan su valor maximo en mag-nitud igual a 1 en [−1, 1] en los (n + 1) puntos x = yk = cos
(kπn
)con k = 0, 1, 2, ..., n y
presenta signos alternados en dichos puntos.
La proposicion evoca el teorema de la alternancia y se puede aplicar de la siguienteforma:
Sea f(x) = xn y sea pn−1(x) su aproximacion polinomial mınimax de grado n−1 enel intervalo [−1, 1]. Por el teorema de la alternancia f(x)− pn−1(x) = xn − pn−1(x),debe tener dicha propiedad en n+ 1 puntos.
El coeficiente principal de Tn(x) es 2n−1 de modo que 21−nTn(x) es de la mismaforma que f(x)−pn−1(x) = xn−pn−1(x) y con la misma propiedad de la alternancia.
Se sigue de lo anterior que
xn − pn−1(x) = 21−nTn(x)
Claramente 21−nTn(x) es un polinomio monico de grado n. Del Teorema de la alter-nancia y de lo anterior es el siguiente corolario.
Corolario 10.1 La aproximacion polinomial mınimax de grado n− 1 a la funcion
f(x) = xn en [−1, 1] es pn−1(x) = 21−nTn(x)
Corolario 10.2 (Propiedad mınimax de Tn(x) ) La aproximacion polinomial mınimaxen [−1, 1] mediante un polinomio monico de grado n a la funcion cero es 21−nTn(x)
Ejemplo 10.3 . La aproximacion mınimax a la funcion cero en [−1, 1], mediante unpolinomio monico de grado 4 es,
2−3T4(x) = 2−3(8x4 − 8x2 + 1) = x4 − x2 + 0,125
Este polinomio tiene la propiedad de la alternancia y tiene valores extremos0,125 , −0,125 , 0,125 , −0,125 y 0,125 respectivamente, en los cinco puntos dados por
yk = cosπ
4, k = 0, 1, 2, 3, 4
De aquı,
yk = 1 ,1√(2)
, 0 , − 1√(2)
,−1
Tambien por el corolario 1, la aproximacion mınimax por un polinomio cubico a lafuncion f(x) = x4 es p3(x) = x4 − (x4 − x2 + 0,125) = x2 − 0,125.
110

El error f(x)−p3(x) tiene la propiedad alternante en los puntos yk, obtenidos anterior-mente. Se debe destacar que x2−0,125 es una aproximacion polinomial cuadratica a lafuncion x4 en [−1, 1] y tambien presenta cinco extremos. El teorema de la alternanciase cumple en n+ 3 puntos.
El teorema senala que la alternancia de los signos se cumple para a lo menos n + 2puntos.
Si el intervalo de aproximacion es [0, 1] en vez de [−1, 1], se debe redefinir los polinomiosde Tchebyshev a dicho intervalo. Estos polinomios trasladados se denotan por T ∗n(x) ysu recorrido es [0, 1]. Para obtener T ∗n(x) a partir de Tn(x) se debe efectuar un cambiode intervalo, usando la transformacion:
s = 2x− 1 o bien x =12(1 + s) , x ∈ [0, 1] , s ∈ [−1, 1]
Se obtiene:T ∗n(x) = Tn(s) = Tn(2x− 1)
Luego:
T ∗0 (x) = 1 , T ∗1 (x) = x , T ∗2 (x) = 8x2 − 8x+ 1 , T ∗3 (x) = 32x3 − 48x2 + 18x− 1
y ası sucesivamente. En general el polinomio monico de aproximacion mınimax degrado n a cero es
21−2nT ∗n(x)
Por ejemplo el polinomio de aproximacion mınimax de grado dos a la funcion cero en[0, 1] es:
2−3T ∗2 (x) = 2−3(8x2 − 8x+ 1) = x2 − x+ 0,125
Ejemplo 10.4 Ilustrativo.(Aproximacion Minimax en una base ortonormal.)
Sea f(x) = e−2x con x ∈ [1, 3] encontrar la mejor aproximacion a f(x) respecto de labase β∗ = {x+ 1, x2} con w(x) = e−x en || · ||∞.Sol.
Se debe ortonormalizar, para obtener g1(x) y g2(x) respecto a β∗.
g1(x) =v1(x)
||v1(x)||∞=
x+ 1||v1(x)||∞
, y
||v1(x)||∞ = maxx∈[1,3]
|v1(x)| = 4 ⇒ g1(x) =x+ 1
4
g2(x) =w2(x)
||w2(x)||∞, donde w2(x) = v2(x)− 〈v2(x), g1(x)〉g1(x)⊥g1(x)
〈v2(x), g1(x)〉 =∫ 3
1
exx2x+ 14
dx =174e3 +
14e = 86,04
111

Luego, w2(x) = x2 − 86,04x+ 1
4.
Falta determinar
||w2(x)||∞ = maxx∈[1,3]
|w2(x)| = maxx∈[1,3]
|x2 − 86,04x
4− 86,04
4|
Sea p2(x) = x2 − 86,04x
4− 86,04
4entonces
p′2(x) = 2x− 86,044
= 0 ⇒ x = 10,755
p′′2(10,755) > 0 ⇒ (10,755, f(10,755) es un mınimo. El maximo se alcanza en x = 1.Luego
||w2(x)||∞ = |1− 86,044
− 86,044
| = 42
y
g2(x) =x2 − 86,04
x+ 14
42
Luego, la mejor aproximacion es
g(x) = 〈f(x), g1(x)〉g1(x) + 〈f(x), g2(x)〉g2(x)
〈f(x), g1(x)〉 =∫ 3
1e−2xexx+ 1
4dx = 0,21
〈f(x), g2(x)〉 =∫ 3
1e−2xex
x2 − 86,04x+14
42dx = −0,41
entonces la mejor aproximacion es:
g(x) = 0,21x+ 1
4x− 0,41
(x2 − 86,04x+1
4
42
)
112

10.3. Potencias de xn en terminos de {Tn(x)}
Se puede demostrar que:
xn = 21−n
k=[n2 ]∑
k=0
(nk
)Tn−2k(x). (194)
donde [m] representa la parte entera de m y senala que el k-esimo termino de la sumadebe dividirse por dos si n es par y k = n
2 .
Ejemplo 10.5 Ilustrar para el caso n = 4. En efecto, tenemos
x4 = 2−3∑2
k=0
(4k
)T4−2k(x)
= 2−3[T4(x) +(
41
)T2(x) + 1
2
(42
)T0(x)
= 18T4(x) + 1
2T2(x) + 38T0 = (x)
Esto ultimo se usa en la Economizacion de Tchebyshev cuando una funcion se aproxi-ma por Taylor (Maclaurin) hasta un cierto grado y se rebaja dicho grado manteniendoun cierto orden de exactitud.
Ejemplo 10.6 f(x) = e(x) en [−1, 1], con un error tolerable de 0,05, reemplazando eltermino del desarrollo que contiene a x4 por los polinomios de Tchebyshev de gradomenor o igual a 4.
113

Metodo de Diferencias Finitas
Prof: Marıa Angelica Vega U.
Modulo 12
12. Resolucion Numerica del Problema de Valor
de Contorno de orden 2.
Hemos visto dos metodos para determinar la solucion particular yp de la
solucion general de una ecuacion diferencial no homogenea con coeficientes
constantes y = yc + yp. Ambos metodos tienen sus ventajas y desventajas,
ademas de no ser aplicables para cualquier expresion de g(x).
El metodo que analizaremos ahora denominado Metodo de diferen-
cias finitas, tiene la ventaja de ser aplicable a cualquier problema de con-
torno, desde no lineal a ecuaciones diferenciales parciales para las que no
siempre existe un metodo analıtico para determinar su solucion, pero tiene la
desventaja de dar un valor aproximado de la solucion exacta en algunos pun-
tos del dominio de definicion de la solucion que son elegidos por el usuario.
Problema. Se trata de resolver el siguiente Problema de Valor de Con-
196

torno (P.V.C)
y′′(x) = P (x)y′(x) +Q(x)y(x) + r(x) , 0 ≤ x ≤ 1
y(0) = 0.
y(1) = 0.
(211)
con P (x), Q(x), r(x), funciones continuas en un intervalo abierto I.
Observemos que en el problema (211), la ecuacion diferencial es no ho-
mogenea con coeficientes variables.
12.1. Metodo de diferencias finitas.
Este metodo consiste en
Dividir el intervalo [0, 1] en N + 1 subintervalos de igual longitud, de
modo que:
xi = i · h , i = 0, 1, · · · , N + 1 (212)
donde,
h =1
N + 1
En cada nodo xi, se aproximan las derivadas de la ecuacion:
y′′(xi) = P (xi)y′(xi) +Q(xi)y(xi) + r(xi) , i = 0, 1, · · · , N + 1.
(213)
197

Existen varias formas de aproximar las derivadas, pero es recomend-
able usar diferencias centradas , puesto que resulatan aproximaciones
mejores,
y′′(xi) =y(xi+1)− 2y(xi) + y(xi−1)
h2
y′(xi) =y(xi+1)− y(xi−1)
2h.
(214)
Reemplazamos las expresiones de (214) en (213), simplificamos la no-
tacion escribiendo yi en lugar de y(xi) y reordenamos los terminos de
la ecuacion en la siguiente forma :
−r(xi)h2 = −(
1 +h
2p(xi)
)yi−1+(2+h2Q(xi))yi−
(1− h
2p(xi)
)yi+1 , i = 1, · · · , N.
(215)
Observacion 12.1 Observemos que (215) es un sistema de ecua-
ciones lineales, cuyas incognitas son los valores de la solucion aproxi-
mada evaluada en los siguientes puntos (extremos de intervalos),
xi , i = 1, · · · , N.
Ejemplo 12.1 Use el metodo de diferencias finitas para resolver el
(P.V.C.):
y′′ =−2t
(y′ − 2) , y(12) = 3 , y(1) = 3
198

Solucion. Notemos que en esta ecuacion P (t) =−2t, Q(t) = 0 , r(t) =
4t.
La ecuacion (215) en forma discreta queda,
−(
2− 2h
ti
)yi−1 − (4 + 2h2 · 0)yi +
(2 + 2
h
ti
)yi+1 =
8h2
ti, i = 1, · · · , N.
(216)
Si tomamos h = 0,1, tenemos que t0 = 0,5 , t1 = 0,6 , t2 = 0,7 , t3 = 0,8 y
t4 = 0,9 , t5 = 1,0. Sustituimos en (216) y obtenemos el sistema matricial :
−473
0 0
127
−4167
0
074
−494
0 0169
−4
;
y1
y2
y3
y4
=
860− 2(
56) · 3
870880
890− 2(
109
) · 3
=
−7315435110
−26945
.
(217)
De aquı la solucion aproximada es,
y1 =4315
, y2 =167, y3 =
5720
, y4 =26290
Actividades 12.1
Escriba el sistema de ecuaciones (215) en la forma matricial Ay = b
Dado el P.V.C.
y′′ + y + x = 0 , 0 < x < 1 con
y(0) = y(1) = 0.
• Determine la solucion exacta del problema.
199

• Use el metodo de diferencias finitas, con N=3, para obtener una
solucion aproximada del problema.
Resuelva el P.V.C.
y′′ = −3y′ + 2y + 2x+ 3 , 0 < x < 1 con
y(0) = 2.
y(1) = 1.
use h=0.25 y compare los resultados con la solucion exacta.
200

Metodos Numericos para resolver Ecuaciones Diferenciales
Parciales.
Prof. Marıa Angelica Vega U.
Modulo 14
Observacion 15.2 Este tema ha sido desarrollado, usando el texto Metodos
Numericos para Ingenieros. Steven C. Chapra - Raymond P.Canale
16. Ecuaciones elıpticas.
Se usan para caracterizar problemas en estado estacionario con valores
en la frontera.
16.1. La ecuacion de Laplace
La ecuacion de Laplace, se utiliza para modelar diversos problemas que
tienen que ver con el potencial de una variable desconocida. Se usara una
placa calentada para deducir y resolver esta EDP elıptica. En la figura se
muestra la placa y un elemento sobre la cara de una placa rectangular del-
gada de espezor 4z. La placa esta totalmente aislada excepto en sus ex-
tremos, donde la temperatura puede ajustarse a un nivel preestablecido. El
aislamiento y el espesor de la placa permiten que la transferencia de calor
222

Figura 12: Placa delgada de espesor 4z
esta limitada solamente a las dimensiones de x y y. En estado estacionario el
flujo de calor hacia el elemento en una unidad de tiempo 4t debe ser igual
al flujo de salida , es decir,
q(x)4y4z4t+ q(y)4x4z4t = q(x+4x)4y4z4t+ q(y +4y)4x4z4t
(247)
donde q(x) y q(y) son los flujos de calor en x y y, respectivamente [ calcm2·s ]
Dividiendo entre 4z y 4t y reagrupando terminos, se obtiene
[q(x)− q(x+4x)]4y + [q(y)− q(y +4y)]4x = 0
Multiplicando el primer termino por 4x4x y el segundo por 4y
4y se obtiene
q(x)− q(x+4x)4x
4x4y +q(y)− q(y +4y)
4y4y4x = 0 (248)
223

Dividiendo entre 4x4y y tomando lımite, se llega a
−∂q∂x
− ∂q
∂y= 0 (249)
La ecuacion (249) es una ecuacion diferencial parcial, que es una expresion
de la conservacion de la energıa en la placa. Sin embargo no puede resolverse,
a menos que se especifiquen los flujos de calor en los extremos de la placa.
Debido a que las condiciones de frontera se dan para la temperatura, la
ecuacion (249) debe reformularse en terminos de la temperatura. la relacion
entre flujo y temperatura esta dada por la ley de Fourier de conduccion
del calor, que se representa como,
qi = −kρC ∂T∂t
(250)
donde,
qi es el flujo de calor en la direccion de la dimension i [ calcm2·s ]
k es el coeficiente de difusividad termica cm2
s
ρ es la densidad del material gcm3
C es la capacidad calorica del material [ calg·◦C ]
T es la temperatura del material ◦C que se define por
T =H
ρCV
224

donde,
H es el calor (cal)
V es el volumen en cm3
Algunas veces, el termino que esta multiplicando a la derivada parcial en la
ecuacion (250) se trata como un solo termino.
k′ = kρC (251)
donde, k′ es el coeficiente de conductividad termica [ cals·cm·◦C ]. En ambos
casos k y k′ son parametros que determinan, que tan bien el material conduce
calor.
La ley de Fourier se conoce tambien como ecuacion constitutiva, de-
bido a que proporciona un mecanismo que define las interacciones internas
del sistema. Inspeccionando la ecuacion (250) indica que la ley de Fourier es-
pecifica que el flujo de calor perpendicular al eje i es proporcional a gradiente
o pendiente de la temperatura en la direccion i. El signo negativo asegura
que un flujo positivo en la direccion i resulta de una pendiente negativa de
alta a baja temperatura. En la figura 13 se ilustra la representacion grafica
de un gradiente de temperatura, recpordamos que el calor se transfiere hacia
abajo, desde una temperatura alta a una baja, el flujo en a) va de izquierda
225

a derecha en la direccion i y en este caso la pendiente es negativa, es decir
un gradiente negativo se relaciona con un flujo positivo. En la figura 14 se
representa el caso inverso, donde el gradiente positivo se relaciona con un
flujo de calor negativo de derecha a izquierda. Sustituyendo, (250) en (249)
Figura 13: ∂T∂i < 0 Figura 14: ∂T
∂i > 0
se obtiene,
∂2T
∂x2+∂2T
∂y2= 0 (252)
conocida como ecuacion de Laplace. En el caso donde hay fuentes o perdi-
das de calor, dentro del dominio bidimensional, tenemos la ecuacion
∂2T
∂x2+∂2T
∂y2= f(x, y) (253)
226

donde la funcion f(x, y) describe las fuentes o perdidas de calor. La ecuacion
(253) se conoce como ecuacion de Poisson.
16.2. Solucion Numerica
La solucion numerica, se basa en el metodo de diferencias finitas. En el
caso bidimensional tratamos la placa como una malla de puntos discretos.
-
6
(x0, y0) x1 xi−1 xi xi+1 (xm+1, y0) X
(xi, yj)
(xi, yj−1)
(xi, yj+1)
yj
yj−1
yj+1
...
(x0, yn+1)(xm+1, yn+1)
Y
• • •• • ••
• • • • • • •
• • •• • • •
• ••• • • •
• ••• • • •
• ••• • • •
• •• •• • •
• ••• • • •
Luego aproximamos las derivadas parciales en cada punto de la malla
transformando la ecuacion diferencial en una ecuacion algebraica en difer-
encias.
227

16.2.1. La Ecuacion de Laplace.
Las diferencias centrales basadas en la malla de la figura son:
∂2T
∂x2=Ti+1,j − 2Ti,j + Ti−1,j
4x2(254)
y
∂2T
∂y2=Ti,j+1 − 2Ti,j + Ti,j−1
4y2(255)
las cuales tienen errores de O(4x2) y O(4y2) respectivamente. Sustituyendo
en la ecuacion (252) se obtiene,
Ti+1,j − 2Ti,j + Ti−1,j
4x2+Ti,j+1 − 2Ti,j + Ti,j−1
4y2= 0 (256)
En la malla cuadrada de la figura anterior, 4x = 4y, reagrupando terminos
la ecuacion queda,
Ti+1,j + Ti−1,j + Ti,j+1 + Ti,j−1 − 4Ti,j = 0 (257)
Esta relacion, que se satisface por todos los puntos interiores de la placa, se
conoce como ecuacion laplaciana en diferencias. Debemos ademas es-
pecificar las condiciones de frontera en los extremos de la placa para obtener
una solucion unica. El caso mas simple es aquel donde la temperatura en la
frontera es un valor fijo. Este tipo de condicion se denomina condicion de
frontera de Dirichlet. En la figura siguiente , se tiene una placa con este
tipo de condicion. En esta figura un balance en el nodo (1, 1) es de acuerdo
228

Figura 15: Condicion Dirichlet
con la ecuacion (257), se obtiene
T21 + T01 + T12 + T10 − 4T11 = 0 (258)
Sin embargo, T01 = 75 y T10 = 0, por lo tanto (258) se expresa como
−4T11 + T12 + T21 = −75
Analogamente, se pueden desarrollar ecuaciones para los otros interiores.
229

El resultado es el sistema siguiente de nueve ecuaciones y nueve incognitas:+
4T11 −T21 −T12 = 75
−T11 +4T21 −T31 −T22 = 0
−T21 +4T31 −T32 = 50
−T11 +4T12 −T22 −T13 = 75
−T21 −T12 +4T22 −T32 −T23 = 0
−T31 −T22 +4T32 −T33 = 50
−T12 4T13 −T23 = 175
−T22 −T13 +4T23 −T33 = 100
−T32 −T23 +4T33 = 150
(259)
16.2.2. El metodo de Liebmann.
En la mayorıa de las soluciones numericas de la ecuacion de Laplace se
tienen sistemas que son muchos mas grandes, por ejemplo para una mal-
la de 10 por 10 nodos se tiene un sistema de 100 ecuaciones lineales. El
metodo comunmente usado es el de Gauss-Seidel, que cuando se aplica a las
ecuaciones diferenciales parciales, tambien se conoce como el metodo de
Liebmann.
230

Con este metodo la ecuacion la ecuacion (258) se expresa como
Tij =Ti+1,j + Ti−1,j + Ti,j+1 + Ti,j−1
4(260)
que se resuelve de manera iterativa para j = 1...n y i = 1...m. Como la matris
asociada al sistema (257) es diagonal dominante, la sucesion de aproxima-
ciones convergeraa a una solucion estable.
Como en el metodo coveccional de Gauus- Seidel las iteraciones se repiten
hasta alcanzar una presicion estipulada.
Ejemplo 16.1 Usando metodo de Liebmann, calcular la temperatura de la
placa calentada de la figura 15. Use sobrerrelajacion con ω = 1,5 e itere
hasta que e = 1%.
Sol. La ecuacion (260) para i = 1 , j = 1 es
Tij =0 + 75 + 0 + 0
4= 18,75, (261)
aplicando sobrerrelajacion se obtiene,
T11 = 1,5(18,75) + (1− 1,5)0 = 28,125 (262)
Para i = 2 , j = 1
T21 =0 + 28,125 + 0 + 0
4= 7,03125
T21 = 1,5(7,03125) + (1− 1,5)0 = 10,54688
(263)
231

Para i = 3 , j = 1
T31 =50 + 10,54688 + 0 + 0
4= 15,13672
T31 = 1,5(15,13672) + (1− 1,5)0 = 22,70508
(264)
calculando sucesivamente se obtiene
T12 = 38,67188 T22 = 18,45703 T32 = 34,18579
T13 = 80,12696 T23 = 74,46900 T33 = 96,99554(265)
Como los Tij son cero, inicialmente entonces los errores en la primera it-
eracion sera 100 % En la segunda iteracion los resultados son:
T11 = 32,51953 T21 = 22,35718 T31 = 28,60108
T12 = 57,95288 T22 = 61,63333 T32 = 71,86833
T13 = 75,21973 T23 = 87,95872 T33 = 67,68736
(266)
El error T1,1 se estima como sigue
|e11| = |32,51953− 28,1250032,51953
|100 % = 13,5 % (267)
La novena iteracion da como resultado:
T11 = 4300061 T21 = 33,29755 T31 = 33,88506
T12 = 63,21152 T22 = 56,11238 T32 = 52,33999
T13 = 78,58718 T23 = 76,06402 T33 = 69,71050
(268)
donde el error maximo es 0,71 % En la figura siguiente se muestran los
resultados.
232

Figura 16: Distribucion de temperatu-
ra
16.3. Condiciones en la frontera.
La condicion de frontera fija o de Dirichlet es una alternativa comun en
las ecuaciones diferenciales parciales, otro tipo de condicion es la condicion
de frontera de Newmann la que se tiene como dato la derivada en la frontera.
En el caso de la placa calentada, esto corresponde a especificar el flujo de
calor, mas que la temperatura en la frontera.
Un ejemplo es el caso donde el extremo esta aislado, en tal caso que
denominamos condicion de frontera natural la derivada es cero. Esta con-
clusion se obtiene de la ecuacion (250), ya que aislar una frontera significa
233

que el flujo de calor debe ser cero.
El esquema siguiente muestra un nodo (0, j) en el extremo izquierdo de
una placa calentada, aplicando la ecuacion (257) se obtiene
T1,j + T−1,j + T0,j+1 + T0,j−1 − 4T0,j = 0 (269)
Observese que para aesta ecuacion se necesita un punto (−1, j) que esta fuera
de la placa. Aunque parezca un pun to ficticio sirve para incorporar la deriva-
da de la condicion de frontera en el problema, lo que se logra representando
la primera derivada en la dimension x en (0, j) por la diferencia dividida
finita
∂T
∂x=T1,j − T−1,j
24x2(270)
despejando
T−1,j = T1,j − 24x∂T∂x
(271)
Ahora tenemos una relacion para T−1,j que incluye la derivada, sustituyendo
en la relacion (269) se obtiene
2T1,j − 24x∂T∂x
+ T0,j+1 + T1,j−1 − 4T0,j = 0 (272)
De esta forma se ha incorporado la derivada a la ecuacion.
234

Ecuaciones Hiperbolicas.
Prof. Marıa Angelica Vega U.
Modulo 16
18. La ecuacion de ondas.
La ecuacion de ondas es un ejemplo de una ecuacion en derivadas par-
ciales
∂2u
∂t2= c2
∂2u
∂x2para 0 < x < a y 0 < t < b (293)
o en forma mas simple
utt(x, t) = c2uxx(x, t) para 0 < x < a y 0 < t < b (294)
con las condiciones de contorno,
u(0, t) = 0 u(a, t) = 0 0 ≤ t ≤ b,
u(x, 0) = f(x) 0 ≤ x ≤ a,
ut(0, t) = g(x) 0 < x ≤ a,
(295)
La ecuacion de ondas modela el desplazamiento u desde su posicion de equi-
librio de una cuerda elastica vibrante cuyos extremos, de coordenadas x = 0
y x = a estan fijos. Aunque es posible determinar la solucion de ondas
por medio de las series de Fourier, se usara este problema como modelo de
ecuaciones hiperbolicas.
248

18.1. Construccion de la ecuacion en diferencias.
Hacemos una particion del rectangulo R = {(x, t)/0 ≤ x ≤ a , 0 ≤ t ≤
b} en una malla que consta de n− 1 por m− 1 rectangulos de lados 4x = h
y 4t = k, como la figura,
-
6
xi−1 xi xi+1 xn X
tj
tj−1
tj+1
...
tm
t
•• •
•
•
comenzamos por la fila de abajo, donde t = t1 = 0 y sabemos que la
solucion es u(xi, t1) = f(xi). Ahora usaremos una ecuacion en diferencias
para calcular, en las filas sucesivas, las aproximaciones a la solucion exacta,
que en los puntos de la malla u(xi, tj). Denotaremos para cada j = 2, 3, · · ·m
uij ≈ u(xi, tj)
Usaremos para aproximar utt(x, t) y uxx(x, t) las formulas:
utt(x, t) =u(x, t+ k)− 2u(x, t) + u(x, t− k)
k2+ O(k2) (296)
249

y
uxx(x, t) =u(x+ h, t)− 2u(x, t) + u(x− h, t)
h2+ O(h2) (297)
El espaciado entre los puntos de la malla es uniforme en todas las filas
xi+1 = xi + h y xi−1 = xi − h
y tambien uniforme en todas las columnas
tj+1 = ti + k y tj−1 = tj − k
Sustituyendo (295) y (296) y usando la notacion mencionada tenemos,
ui,j+1 − 2ui,j + ui,j−1
k2= c2
ui+1,j − 2ui,j + ui−1,j
h2(298)
que es la ecuacion en diferencias que se usara como aproximacion a la
ecuacion diferencial (293) o (294). Llamemos r =ck
h, luego tenemos:
ui,j+1 − 2ui,j + ui,j−1 = r2(ui+1,j − 2ui,j + ui−1,j) (299)
Reordenando los terminos, determinaremos las aproximaciones a la solucion
en los puntos de la fila (j + 1)-esima de la malla, supuesto que conocemos
las aproximaciones a la solucion en los puntos de los puntos de las dos filas
anteriores, la j-esima y la (j − 1)-esima.
ui,j+1 = (2− 2r2)ui,j + r2(ui+1,j + ui−1,j)− ui,j−1 (300)
250

para i = 2, 3, · · · , n − 1. En la figura siguiente se muestra la posicion en la
malla de los cuatro valores conocidos , que aparecen en el miembro derecho
de (298) que se usan para determinar la aproximacion ui,j+1
r2ui+1,j
ui,j−1
(2− 2r2)ui,j
−ui,j−1
r2ui−1,j ••
•
•
•
18.2. Condiciones Iniciales
Si se desea usar (296) para calcular las aproximaciones en los puntos de
la tercera fila de la malla, se necesitan las aproximaciones en los puntos de
la primera y segunda fila.
Los valores de la primera fila vienen dados por la funcion f(x), pero
no ası los valores de la segunda fila, por lo que se usa la funcion g(x) para
determinar las aproximaciones en dichos puntos. Supongamos que x = xi
en la frontera inferior de R, aplicando teorema de Taylor de orden 1, para
251

desarrollar u(x, t) alrededor de (xi, 0) para el valoru(xi, k) , se verifica
u(xi, k) = u(xi, 0) + ut(xi, 0)k +©(k2) (301)
Ahora se usa uxi,0 = f(xi) = fi y uxi,0 = g(xi) = gi en (301) para obtener
las aproximaciones numericas en los puntos de la segunda fila t2 = k
ui,2 = fi + kgi para i = 2, 3, · · · , n− 1 (302)
En general, u(xi, t2) 6= ui,2 por lo que el error introducido al usar (302)
se propagara a toda la malla cuando se use el esquema dado por (299).
Para contrarrestar esta situacion es aconsejable escoger un tamano de k
muy pequeno. Comunmente se da el caso de que la funcion f(x) dada en el
contorno es dos veces derivable en el intervalo, con lo cual uxx(x, 0) = f ′′(x).
Esta igualdad nos permite usar la formula de Taylor de orden 2 para obtener
una aproximacion mejorada a los valores de la segunda fila de la malla. Para
ello volvemos a la ecuacion de ondas y usamos la relacion entre las derivadas
parciales segundas, obteniendo:
utt(xi, 0) = c2uxx(xi, 0) = c2f ′′(xi) = c2fi+1 − 2fi + fi−1
h2+ O(h2) (303)
Recordamos que la formula de Taylor de orden 2 es
u(x, k) = u(x, 0) + ut(x, 0)k +utt(x, 0)k2
2+ O(k2) (304)
252

y aplicando (304), (303)y (302) en el punto x = xi se obtiene:
u(xi, k) = fi + kgi +c2k2
2h2(fi+1 − 2fi + fi−1) + O(k2) + O(k3) (305)
Como r = ckh , la ecuacion (305) se puede simplificar obteniendose la sigu-
iente formula que proporciona aproximaciones numericas mejoradas a los
elementos de la segunda fila.
ui,2 = (1− r2)fi + kgi +r2
2(fi+1 + fi−1), para i = 2, 3, · · ·n− 1 (306)
Ejemplo 18.1 Se ilustrara el metodo de diferencias finitas en la resolucion
de la ecuacion de ondas de una cuerda vibrante.
utt(x, t) = 4uxx(x, t). para 0 < x < 1sn− 1 y 0 < t < 0,5 (307)
con las condiciones de contorno:
u(0, t) = 0 y u(1, t) = 0 0 ≤ t ≤ 0,5,
u(x, 0) = f(x) = sin (πx) + sin (2πx) 0 ≤ x ≤ 1,
ut(x, 0) = g(x) = 0 0 ≤ x ≤ 1,
(308)
Por conveniencia tomaremos h = 0,1 y k = 0,05. Como c = 2 entonces
r = 2(0,05)0,1 = 1. Como g(x) = 0 y r = 1, la formula (306) para calcular los
valores de la segunda queda
ui,2 =fi−1 + fi+1
2, para i = 2, 3, · · · 9 (309)
253

Sustituyendo r = 1 en la ecuacion (299) obtenemos la ecuacion en diferen-
cias ya simplificada
ui,j+1 = ui+1,j + ui−1,j − ui,j−1) (310)
Usando (309) y (310) generamos las aproximaciones a los valores de u(x, t)
que aparecen en la tabla de aproximaciones para 0 < xi < 1 y 0 ≤ tj ≤ 0,50
que coinciden en mas de seis cifras decimales con los correspondientes a la
solucion exacta
u(x, t) = sin (πx)cos(2πt) + sin (2πx)cos(4πt) (311)
Tabla de aproximaciones
254

tj x2 x3 x4 x5 x6 x7 x8 x9 x10
0,00 0,896802 1,538842 1,760074 1,538842 1,000000 0,363271 −0,142040 −0,363271 −0,278768
0,05 0,769421 1,328438 1,538842 1,380037 0,951056 0,428980 0,000000 −0,210404 −0,181636
0,10 0,431636 0,769421 0,948401 0,951056 0,809017 0,587785 0,360616 0,181636 0,068364
0,15 0,000000 0,051599 0,181636 0,377381 0,587785 0,740653 0,769421 0,639384 0,363271
0,20 −0,380037 −0,587785 −0,519421 −0,181636 0,309017 0,769421 1,019421 0,951056 0,571020
0,25 −0,587785 −0,951056 −0,951056 −0,587785 0,000000 0,587785 0,951056 0,951056 0,587785
0,30 −0,571020 −0,951056 −1,019421 −0,769421 −0,309017 0,181636 0,519421 0,587785 0,380037
0,35 −0,363271 −0,639384 −0,769421 −0,740653 −0,587785 −0,377381 −0,181636 −0,051599 0,000000
0,40 −0,068364 −0,181636 −0,3606161 −0,587785 −0,809017 −0,951056 −0,948401 −0,769421 −0,431636
0,45 0,181636 0,210404 0,000000 −0,428980 −0,951056 −0,380037 −0,538842 −1,328438 −0,769421
0,50 0,278768 0,363271 0,142040 −0,363271 −1,000000 −1,538842 −1,760074 −1,538842 −0,896802
255

Ecuaciones Parabolicas.
Prof. Marıa Angelica Vega U.
Modulo 15
17. La ecuacion de conduccion de calor.
Analogamente a la deduccion de la ecuacion de Laplace, se puede uti-
lizar la conservacion del calor para desarrollar un balance de calor en una
barra larga aislada como en la siguiente figura Ademas de examinar el ca-
Figura 17: Barra aislada excepto en los
extremos.
235

so estacionario , este balance tambien considera la cantidad de calor que
se almacena en el elemento en el periodo 4t. El balance entonces es de la
forma:
Entradas - Salida = Acumulacion
es decir,
q(x)4y4z4t− q(x+4x)4y4z4t = 4x4y4zρC4T (273)
dividiendo por 4x4y4z y 4t se obtiene
q(x)− q(x+4x)4x
= ρC4T4t
(274)
tomando lımite,
−∂q∂x
= ρC∂T
∂t(275)
Sustituyendo la ley de Fourier para la conduccion del calor, se obtiene
k∂2T
∂x2=∂T
∂t(276)
que es la ecuacion del calor.
En el caso de una ecuacion parabolica en dos variables independientes,
la malla esta abierta en los extremos en la dimension temporal.
236

-
66 6 6 6 6 6
(x0, y0) xi−1 xi xi+1 (xm+1, y0) X
(xi, yj)
(xi, yj−1)
(xi, yj+1)
yj
yj−1
yj+1
Y
• • •• • ••
• • • • • • •
• • •• • • •
• ••• • • •
• ••• • • •
• ••• • • •
• •• •• • •
• ••• • • •
Analogamente al caso elıptico, las ecuaciones parabolicas se resuelven
sustituyendo las derivadas parciales por diferencias finitas. La diferencia rad-
ica en que las ecuaciones elıpticas estan acotadas en todas las dimensiones,
las ecuaciones parabolicas estan abiertas en la variable temporal
17.0.1. Metodos Explıcitos
Usamos una diferencia centrada para aproximar la segunda derivada
espacial,
∂2T
∂x2=T j
i+1 − 2T ji + T j
i+1
42(277)
que tiene un error O(4x2) y los superındices denotan el tiempo. La derivada
en tiempo la aproximamos por un diferencia progresiva:
∂T
∂t=T j+1
i − T ji
4t(278)
237

que tiene un error O(4t). Sustituyendo en la ecuacion (276) se obtiene
kT j
i+1 − 2T ji + T j
i−1
4x2=T j+1
i − T ji
4t. (279)
de donde resulta
T j+1i = T j
i + λ(T ji+1 − 2T j
i + T ji−1) (280)
donde λ = k4t
(4x)2. Esta ecuacion permite calcular explıcitamente los val-
ores de la funcion en cada nodo para un tiempo posterior j + 1 a partir
de la informacion en el nodo j y los nodos vecinos. Observemos que este
metodo es un analogo del metodo de Euler para resolver sistemas de ecua-
ciones diferenciales ordinarias. Un esquema de lo que ocurre en los nodos
esta representado en la siguiente figura,
Ejemplo 17.1 Usando em metodo explıcito determine la distribucion de
temperatura en una barra larga y delgada que tiene una longitud de 10 cm
y los siguientes valores k′ = 0,49 [ calseg·cm·◦C ], 4x = 2 cm y 4t = 0,1 seg.
En t = 0 la temperatura de la barra es cero y las condiciones de frontera
en T (0) = 100◦C y T (10) = 50◦C. Considere que la barra es de aluminio
con C = 0,2174 [ calg·◦C ] y ρ = 2,7 g
cm3 . Por lo tanto, k =0,49
2,7 · 0,2174=
0,835(cm2
seg
)y λ = 0,8350,1
22 = 0,020875
238

Figura 18: Metodo Explıcito
Sol. Aplicando la ecuacion (280) se obtiene el siguiente valor en t = 0,1
seg para el nodo en x = 2 cm
T 11 = 0 + 0,020875(0− 2(0) + 100) = 2,0875
En los otros nodos interiores, x = 4,6 y 8 cm, los resultados son
T 12 = 0 + 0,020875(0− 2(0) + 0) = 0
T 13 = 0 + 0,020875(0− 2(0) + 0) = 0
T 12 = 0 + 0,020875(50− 2(0) + 0) = 1,0438
239

En t = 0,2 se obtiene para los cuatro nodos interiores
T 21 = 2,0875 + 0,020875(0− 2(2,0875) + 100) = 4,0878
T 22 = 0 + 0,020875(0− 2(0) + 2,0875) = 0,043577
T 23 = 0 + 0,020875(1,0438− 2(0) + 0) = 0,021788
T 24 = 1,0438 + 0,020875(50− 2(1,0438) + 0) = 2,0439
El aumento general de la temperatura con el tiempo indica que la difusion
del calor desde las fronteras al interior de la barra.
17.0.2. Convergencia y estabilidad
La Convergencia significa que si 4x y 4y tienden a cero, entonces los
valores obtenidos por el metodo se aproximan a la solucion exacta.
La Estabilidad significa que los errores en cualquier etapa del calculo, no
se amplifican en etapas posteriores sino disminuyen.
Un resultado importante es que el meetodo explıcito es convergente y
estable si λ ≤ 12 o
4t ≤ 124x2
k(281)
17.0.3. Aproximaciones temporales de orden superior
La idea general es volver expresar la EDP como un sistema de EDO se
denomina metodo de lıneas. En efecto, una manera de mejorar el metodo
240

de Euler usado antes serıa emplear un esquema de integracion mas exacto
para resolver las EDO. Por ejemplo, el metodo de Heun puede utilizarse
para obtener una exactitud temporal de segundo orden.
17.1. Un metodo implıcito simple
Las formulas explıcitas por diferencias finitas tienen problemas con la
estabilidad. Los metodos implıcitos son mas estables, pero usan algoritmos
mas complicados.
La diferencia fundamental entre ambos metodos radica en la forma de
tomar los nodos, se ilustra en la siguiente figura
Figura 19: Puntos malla
241

En un esquema explıcito, aproximamos la derivada espacial para un nivel
de tiempo j, (figura a) en cambio en los esquemas implıcitos la derivada
espacial se aproxima en un nivel de tiempo posterior j + 1 (figura b). Por
ejemplo la segunda derivada se aproximara por
∂2T
∂x2=T j+1
i+1 − 2T j+1i + T j+1
i−1
(4x)2(282)
que tiene una exactitud de segundo orden. Al sustituir en la ecuacion origi-
nal, se obtiene
kT j+1
i+1 − 2T j+1i + T j+1
i−1
(4x)2=T j+1
i − T ji
4t(283)
que se puede escribir como
−λT j+1i−1 + (1 + 2λ)T j+1
i − λT j+1i+1 = T j
i (284)
donde λ =k4t
(4x)2. Esta ecuacion se aplica a todos los nodos excepto al
primero y al ultimo de los nodos interiores, los cuales se modifican al con-
siderar las condiciones de frontera. La condicion de frontera en el extremo
izquierdo de la barra (i = 0) se expresa:
T j+10 = f0(tj+1) (285)
donde f0(tj+1) es una funcion que describe como cambia con el tiempo
la temperatura de la frontera. Sustituyendo (285) en (284) se obtiene la
ecuacion en diferencias para el primer nodo interior (i = 1)
(1 + 2λ)T j+11 − λT j+1
2 = T j1 + λf0(tj+1) (286)
242

Analogamente para (i = m)
−λT j+1m−1 + (1 + 2λ)T j+1
m = T jm + λfm+1(tj+1) (287)
donde fm+1(tj+1) describe los cambios especıficos de temperatura en el ex-
tremo derecho de la barra (i = m+1). observamos que el sistema resultante
de m ecuaciones lineales con m incognitas es tridiagonal.
Ejemplo 17.2 Resolver el ejemplo anterior usando diferencias finitas im-
plıcitas. Para este caso λ = 0,020875 .
para t = 0 la ecuacion para el primer nodo interior es
1,04175T 11 − 0,020875T 1
2 = 0 + 0,020875(100)
o
1,04175T 11 − 0,020875T 1
2 = 2,0875
Analogamente,
1,04175 −0,020875 0 0
−0,020875 1,04175 −0,020875 0
0 −0,020875 1,04175 −0,020875
0 0 −0,020875 1,04175
T 11
T 12
T 13
T 14
=
2,0875
0
0
1,04375
243

En t = 0,1 seg
T 11 = 2,0047
T 12 = 0,0406
T 13 = 0,0209
T 14 = 1,0023
En t = 0,2 seg
T 21 = 3,9305
T 22 = 0,1190
T 23 = 0,0618
T 24 = 1,9653
El metodo implıcito descrito es estable y convergente, pero tiene la desventa-
ja que la aproximacion en diferencias temporal tiene una exactitud de primer
orden y con diferencia espacial de oreden 2. Hay que mencionar que aunque
este metodo es incondicionalmente estable hay un lımite de exactitud para
el uso de pasos tiempo grande. Por tanto no es mucho mas eficiente que los
metodos explıcitos para la mayorıa de los problemas variables en el tiempo.
17.2. El metodo de Crank-Nicholson
El metodo de Crank-Nicholson es un esquema implıcito alternativo que
tiene una exactitud de segundo orden, tanto para la aproximacion espacial,
244

como para la temporal. Para alcanzar esta exactitud en el tiempo se desar-
rollan diferencias en el punto medio del incremento tiempo, por lo tanto la
primera derivada temporal se aproxima en tj+12 por
∂T
∂t=T j+1
i − T ji
4t(288)
La segunda derivada en el espacio puede determinarse en el punto medio
promediando las aproximaciones por diferencias al principio tj y al final
tj+1 del incremento del tiempo.
∂2T
∂x2=
12
[T j
i+1 − 2T ji + T j
i−1
(4x)2+T j+1
i+1 − 2T j+1i + T j+1
i−1
(4x)2
](289)
sustituyendo las ecuaciones (288) y (289) en la ecuacion wwwwwww , se
obtiene
−λT j+1i+1 + 2(1 + λ)T j+1
i − λT j+1i−1 = λT j
i+1 + 2(1− λ)T ji + λT j
i−1 (290)
donde λ =k4t
(4x)2. Como en el caso del metodo implıcito simple, se determi-
nan las condiciones de fronteea T j+10 = f0(tj+1) y T j+1
m+1 = fm+1(tj+1) para
obtene las ecuaciones para los nodos interiores primero y ultim o.
Para el primer nodo interior se obtiene
2(1 + λ)T j+11 − λ)T j+1
2 = λf0(tj) + 2(1− λ)T j1 + λT j
2 + λf0(tj+1) (291)
245

y para el ultimo nodo interior
−λT j+1m−1 + 2(1 + λ)T j+1
m = λfm+1(tj) + 2(1− λ)T jm + λT j
m−1 + λfm+1(tj+1)
(292)
observamos que los sistemas de ecuaciones involucrados son tridiagonales,
lo que hace eficiente el proceso.
Ejemplo 17.3 Resolver el ejemplo anterior, usando el metodo de Crank-
Nicholson.
2,04175 −0,020875 0 0
−0,020875 2,04175 −0,020875 0
0 −0,020875 2,04175 −0,020875
0 0 −0,020875 2,04175
T 11
T 12
T 13
T 14
=
4,175
0
0
2,0875
En t = 0,1 seg
T 11 = 2,0450
T 12 = 0,0210
T 13 = 0,0107
T 14 = 1,0225
246

De las ecuaciones se obtiene
T 21 = 4,0073
T 22 = 0,0826
T 23 = 0,0422
T 24 = 2,0036
247