cs2013 itinfrastruktura cs2013 itinfrastruktura l15
DESCRIPTION
ITInfrastrukturaTRANSCRIPT

Lekcija 15 - Uvod udistribuirane sisteme

| Contents | 2
Contents
LearningObject................................................................ 3L15 Distribuirani sistemi.................................................................................................. 3Uvod................................................................................................................................3Distribuirano računarsko okruženje - DCE......................................................................6DCE Directory service.....................................................................................................7DCE Security Service...................................................................................................... 9DCE Niti...........................................................................................................................9DCE Remote Procedure Call......................................................................................... 10Distributed Time Service.............................................................................................. 11Distributed File Service (DFS).......................................................................................12Konkurentni procesi i programiranje............................................................................ 13Distribuirani fajl sistemi................................................................................................15Organizacija Fajl Sistema..............................................................................................16Kоmprеsiјa pоdаtаkа.................................................................................................... 20Frekventno zavisni kodovi............................................................................................ 21Aritmetička kompresija................................................................................................. 24Run-Length kodiranje....................................................................................................28L15 Distribuirani sistemi............................................................................................... 32
LearningObject.............................................................. 33Kompjuterska forenzika................................................................................................ 33Kompjuterska forenzika..................................................................................................35

| LearningObject | 3
LearningObject
L15 Distribuirani sistemi
UvodOvo poglavlje razmatra osnovne koncepte iz oblasti distribuiranih sistema.
Uvod
Cilj• Uvodne napomene
UvodUvod
Primarni cilj distribuiranih sistema je sposobnost da se efikasnije koriste računarski resursi.Ovo je omogućeno korišćenjem sledećih tehnika• Deljenje resursa. To može biti od koristi usled nedovoljnih hardverskih komponenti ili
nedovoljnih podataka.• Raspoređivanje procesorskog opterećenja između više različitih mašina. To može dovesti
do znatnog ubrzanja proračunavanja.• Reflektovanje nasleđene distributivnosti nekih aplikacija. Na primer međunarodni lanac
hotela. Postoje razdvojeni lokalni računari, ali s vremena na vreme menadžment zahtevaglobalan pogled.
• Povećanje pouzdanosti. Poslovi koji su se izvršavali na krahiranoj mašini mogu biti preuzetiod strane druge mašine.
• Da bi se iskoristile mogućnosti distrubuiranih sistema, servisi ponuđeni od stranekonvencionalnih operativnih sistema moraju biti prošireni. Postoje dva osnovna pristupa:
• Prvi, nazvan monolotni kernel, baziran je na centralizovanom operativnom sistemu, npr.UNIX, bez podrške za mrežnu komunikaciju i integraciju udaljenih servisa.
• Drugi, mikrokernelski pristup je baziran na ideji da se obezbede samo neophodni servisikernela. Generalno, ovi servisi spadaju u četiri kategorije međuprocesne komunikacije,primitivnog upravljanja memorijom, U/I niskog nivoa, i mali deo upravljanja procesaniskog nivoa. Ostali servisi se nalaze izvan kernela i obezbeđeni su od strane sistemskihservera. Neki od tipičnih servera su procesni server, mrežni server, fajl server i serverautentičnosti. Ovi servisi su neophodni za implementaciju distribuiranih sistema. Dodatniservisi podržavaju distribuirane aplikacije i nalaze se na vrhu sistemskih servisa. Primeritakvih servera su grupni server, mail server i Veb server.
U distribuiranim sistemima je dostupno više procesora. Kako se procesori koriste, je glavnopitanje projektovanja. Procesori u distribuiranom sistemu mogu biti organizovani premamodelu radne stanice, procesorske liste ili njihovom kombinacijom.
Sledeći projektni zahtev bavi se osnovnim osobinama distribuiranih sistema. To sutransparentnost, fleksibilnost, pouzdanost i performanse.

| LearningObject | 4
Implementacija servisa distribuiranih operativnih sistema je podržana od strane distribuiranihalgoritama.Postoji mnoštvo centralizovanih algoritama, korišćenih od konvencionalnihoperativnih sistema, ali oni moraju biti ponovo provereni za distribuirano okruženje.Distribuirani algoritmi treba da uzmu u obzir sledeće karakteristike distribuiranih sistema:• nedostatak globalnih informacija• nepostojanje globalnog sata• algoritam treba da je u stanju da reši situaciju kada se izgubi poruka ili krahira mašinaOsnovni model organizacije procesa u distribuiranom sistemu je model radne stanice. Ovajmodel se prosto sastoji od međusobno povezanih radnih stanica. Ako je svaka od ovih radnihstanica kompletna mašina sa sposobnošću da kontaktira druge mašine, bliži smo mrežnomoperativnom sistemu. Druga mogućnost je da su neke mašine posvećene samo određenimservisima. Na primer, svim datotekama se centralizovano upravlja na malom broju fajlservera. Tada se model preciznije naziva model radne stanice - servera. Nasuprot modelusa kompletnim mašinama, neke radne stanice mogu biti bez diska, i ako se obavlja udaljenoprocesiranje te mašine postaju terminali.
Rešenje za nezaposlene mašine je da se procesori sakupe na jednom mestu i da se dinamičkidodeljuju korisnicima na osnovu zahteva. Ova organizacija procesora u distribuiranimsistemima naziva se model procesorske liste. U tom modelu korisnici imaju sliku virtuelnevišeprocesorske mašine. Umesto radnih stanica inteligentni terminali (poput X terminala) suna raspolaganju korisnicima da pristupe sistemu.
Dva pristupa, model radne stanice i model procesorske liste mogu biti kombinovani. Osnovninačin njihovog kombinovanja je da se model radne stanice proširi procesorskom listom. Utom hibridnom modelu korisnici mogu da obavljaju interaktivan rad na radnim stanicama, ida zahtevaju dodatnu procesorsku snagu iz procesorske liste za komplikovane proračune.Takođe je moguće da se procesori radnih stanica posmatraju kao oblik procesorske liste akosistem poseduje efikasnu implementaciju migracije procesa.
Transparentnost zaklanja fizičku podeljenost objekata, njihovo upravljanje u distribuiranimsistemima, od njihovih korisnika. U isto vreme koncept transparentnosti kreira željenu slikusistema. Kompletna transparentnost je ekstremna. Ona nije uvek poželjna. Korisnik koji želida odštampa dokument više bi voleo da sačeka da lokalni zauzeti štampač završi posao negoda štampa na 100 kilometara udaljenom slobodnom štampaču.
Postoji nekoliko tipova transparentnosti u distribuiranom sistemu:• Lokaciona transparentnost znači da korisnici nisu svesni gde se objekti nalaze. Objektima
se pristupa preko njihovih logičkih imena. Oni ne moraju da sadrže informaciju gde seobjekti nalaze.
• Migraciona transparentnost znači da se objektima pristupa preko njihovih logičkih imenačak i ako se oni prebace na drugu fizičku lokaciju bez menjanja njihovog logičkog imena.
• Replikaciona transparentnost znaši da korisnici nisu svesni postojanja višestrukih kopijaobjekata u sistemu.
• Konkurentna transparentnost znači da korisnici ne smetaju jedan drugom ako dele objekte.• Paralelna transparentnost omogućava paralelne aktivnosti bez znanja korisnika.
Fleksibilnost je jedan od glavnih projektnih zahteva u distribuiranim sistemima, zato štotreba da očekujemo razvoj novih tehnologija u budućnosti koje moraju da budu uključene utrenutno projektovane sisteme. Drugi razlog je moguća potreba za poboljšanjem distribuiranihsistema, čak i sa heterogenim komponentama. Drugim rečima moramo da oslikamomogućnost da se sistem razvija u vremenu i prostoru.
Koncept fleksibilnosti uključuje osobine poput modularnosti, skalabilnosti, portabilnosti imeđusaradnje.

| LearningObject | 5
Pouzdanost je očigledno bitniji zahtev u distribuiranim sistemima nego u centralizovanim,zbog njihove visoke kompleksnosti i geografske distribucije.
Može se desiti da korisnicima bude onemogućen rad zbog kvarova na komunikacionimlinkovima ili udaljenim serverima. U slučaju kad je mnogo resursa potrebno da bi se izvršiozadatak, krajnja pouzdanost je proizvod pouzdanosti komponenti. Ovo čini kvarove udistribuiranim sistemima češćim, jer je traženi servis dostupan samo ako sve komponentefunkcionišu. Sa druge strane moguće je organizovati distribuirani sistem tako da ako jednakomponenta otkaže druga preuzima njene poslove. Ova ideja povećava pouzdanost jer jeservis dostupan ako bar jedna komponenta radi. Pouzdanost ima više aspekata. Upravo smoraspravljali o jednom koji je nazvan dostupnost.
Povrh toga, ako servise obezbeđuje grupa kooperativnih servera, i ako servis nastavlja dabude dostupan kada jedan ili dva servera budu izgubljeni zbog nekog pada performansisistem je otporan na greške. Otpornost na greške je još jedan aspekt pouzdanosti.
Dok su kvarovi na komponentama u distribuiranim sistemima nenamerni, namerni upadi,ako je bezbednost narušena mogu izazvati ozbiljne štete. Bezbednost je novi važan aspektpouzdanosti.
Posedovanje transparentnog, fleksibilnog distribuiranog sistema, sa čestim preopterećenjimasistema, gde se aplikacije sporo izvršavaju bilo bi beskorisno. Nasuprot tome performanse bitrebalo da budu bolje ili bar jednake izvršavanju iste aplikacije na centralizovanom sistemu.
Poboljšanje performansi deljenjem posla među više procesora zahteva slanje poruka. Poputtoga, koordinacija nekoliko servera, koja obezbeđuje pouzdane servise, zahteva razmenuinformacija. Komunikaciona zadrška je činjenica koja je neizbežna u distribuiranim sistemima.Zbog toga komunikacioni sistem, uključujući komunikacione primitive i komunikacioneprotokole mora biti pažljivo projektovani.
Generalno uzevši algoritmi korišćeni u centralizovanim sistemima ne mogu biti direktnokorišćeni u distribuiranim sistemima. Sledeće činjenice se moraju uzeti u obzir:
Na različitim čvorovima je nepotpuna i nedosledna slika sistema, zbog nepostojanja deljenememorije i komunikacionih zadrški. Koordinacija između procesa na različitim čvorovima sepostiže slanjem poruka.Ne postoji globalan sat. Čak i ako postoji centralni sat u distribuiranom sistemu, vremenskokašnjenje prenošenja vremenske informacije različitim čvorovima će se razlikovati i moževarirati, na primer u zavisnosti od mrežnog saobraćaja.Distribuirani sistemi mogu imati menjajuću topologiju, na primer zbog povezivanja novogčvora. Kvarovi na komunikacionim linkovima i čvorovima mogu takođe izmeniti topologiju.
U zavisnosti od upravljanja kontrolom, distribuirani algoritmi mogu biti potpuno centralizovaniili decentralizovani. Kasnije, ako centalizovani kontroler doživi kvar, algoritam mora biti ustanju da ga oporavi.
Linkovi
Primer 1 http://www0.cs.ucl.ac.uk/staff/ucacwxe/lectures/ds98-99/dsee3.pdf
Primer 2 http://www.cl.cam.ac.uk/~rja14/Papers/SE-06.pdf

| LearningObject | 6
Primer 3 http://www.cs.helsinki.fi/u/jakangas/Teaching/DistSys/DistSys-08f-1.pdf
Primer 4 http://pdos.csail.mit.edu/6.824/
Primer 5 http://research.google.com/pubs/DistributedSystemsandParallelComputing.html
Primer 6 http://www.infosys.tuwien.ac.at/
Distribuirano računarsko okruženje - DCE
Cilj• Upoznavanje sa distribuiranim računarskim okruženjem - DCE
Distribuirano računarsko okruženje - DCEDistribuirano računarsko okruženje - DCE
Distribuirano računarsko okruženje je (DCE - Distributed computer environment) jearhitektura, skup otvorenih standardnih servisa i pratećih API-ja koji se koriste za razvoj iadministraciju distribuiranih aplikacija u okruženju različitih platformi i proizvođača.
DCE je rezultat rada Open Systems Foundation (sada pod imenom Open Group), udruženjavećeg broja proizvođača hardvera, softvera, korisnika i konsalting preduzeća. OSF je 1998godine počeo sa podrškom istraživanja, razvoja i isporuke industrijskih standarda i tehnologijanezavisnih od proizvođača. Jedan od razvijenih standarda je i DCE. Verzija 1.0 je izdata 1992.godine.
Slika 1 DCE arhitektura
DCE se sastoji od sledećih glavnih komponenti:

| LearningObject | 7
• Directory service• Security service• Distributed time service• Distributed file service• Threads• Remote procedure call
Svi navedeni servisi imaju API-je koji programeru omogućavaju da koristi ove funkcije. Servisisu detaljnije objašnjeni u nastavku
Linkovi
Primer 1 http://www0.cs.ucl.ac.uk/staff/ucacwxe/lectures/ds98-99/dsee3.pdf
Primer 2 http://www.cl.cam.ac.uk/~rja14/Papers/SE-06.pdf
Primer 3 http://www.cs.helsinki.fi/u/jakangas/Teaching/DistSys/DistSys-08f-1.pdf
Primer 4 http://pdos.csail.mit.edu/6.824/
Primer 5 http://research.google.com/pubs/DistributedSystemsandParallelComputing.html
Primer 6 http://www.infosys.tuwien.ac.at/
DCE Directory service
Cilj• DCE Directory service
DCE Directory serviceDCE Directory service
Prilikom rada u velikim i složenim mrežnim okruženjima, važno je održati podatke olokacijama, imenima i servisima (i mnogim drugim detaljima) učesnika i resursima utoj mreži. Takođe je važno da se ovim informacijama može lako pristupati. Da bi se ovoomogućilo, informacije moraju biti smeštene u logičkom, centralnom mestu i moraju imatistandardne interfejse za pristup podacima. Za to je zadužen DCE Cell Directory Service.Glavne komponente koje čine DCE Directory Sevice su:DCE Directory service
Prilikom rada u velikim i složenim mrežnim okruženjima, važno je održati podatke olokacijama, imenima i servisima (i mnogim drugim detaljima) učesnika i resursima utoj mreži. Takođe je važno da se ovim informacijama može lako pristupati. Da bi se ovoomogućilo, informacije moraju biti smeštene u logičkom, centralnom mestu i moraju imati

| LearningObject | 8
standardne interfejse za pristup podacima. Za to je zadužen DCE Cell Directory Service.Glavne komponente koje čine DCE Directory Sevice su:
• Cell Directory Service (CDS)• Global Directory Service (GDS)• Global Directory Agent (GDA)• Application Program Interface (API)Cell Directory Service
Cell Directory Service upravlja bazom podataka sa informacijama o resursima u grupi hostovau bliskoj saradnji, koja se naziva ćelija (eng. cell). DCE ćelija je veoma skalabilna i možeda sadrži više hiljada entiteta. Tipično, čak i prilično velike kompanije će biti organizovanekao jedna ćelija, koja može da pokriva nekoliko država. Baza podataka Directory Service-a sadrži hijerarhijski skup imena koja predstavljaju logički pogled na mašine, aplikacije,korisnike i resurse u okviru ćelije. Ova imena su uglavnom ulazi jedinice direktorijuma. Čestose ovaj hijerarhijski skup imena naziva namespace. Svaka ćelija zahteva bar jedan DCE serverkonfigurisan sa Cell Directory Service (server direktorijuma).
CDS ima dve veoma važne karakteristike: može biti distribuiran i može biti repliciran. Osobinadistribuiranosti znači da baza podataka ne mora biti cela na jednoj fizičkoj mašini u ćeliji.Baza podataka moće biti logički particionisana u više sekcija (replika) i svaka od njih može bitipostavljena na posebnoj mašini. Prva instanca replike je master replika koja ima read/writepristup. Mogućnost da cell direktorijum bude podeljen na nekoliko master replika dozoljavaopciju distribuirane odgovornosti u upravljanju resursima različitih delova ćelije. Ovo može bitiod velikog značaja ako je ćelija veoma velika.
Svaka master replika može biti replicirana. To jest, kopija ove replike može biti napravljena ndrugoj mašini (koja je takođe server direktorijuma). Takva replika se zove read-only replika.Ovakve replike obezbeđuju elastičnost i poboljšanje performansi na taj način što se mašinidomaćinu dozvoljava da vrši pretraživanja u najbližoj dostupnoj replici. Prilikom inicijalizacijeCDS-a, mora se izvršiti autentifikacija korišćenjem DCE Security Sservice-a. Ovo sprečava dalažni CDS učestvuje u postojećoj ćeliji.
Ne smeštaju se sva DCE imena direktno u DCE directory service. Resursi koje koristeneki servisi, kao servisi zaštite i distribuirani fajl sistem, se povezuju u namespace u viduspecijalizovanih CDS ulaza, sa imenom spoj (eng. junction). Spoljni ulaz sadrži informacijekoje omogućavaju klijentu da se poveže sa serverom direktorijuma van servisa direktorijuma.
Global Directory Service i Agent
Cell Directory servis je odgovoran za poznavanje rasporeda resursa u okviru ćelije. Međutim,u mreži sa više ćelija, svaka ćelija je deo većeg hijerarhijskog namespace-a, koji se nazivaGloba Directory namespace. Global Directory Service (GDS) nam dozvoljava da odredimolokaciju resursa spoljnih ćelija.
Da bi se ostvarila međućelijska komunikacija potrebna je još jedna komponenta – globaldirectory agent (GDA). GDA se nalazi između lokalne ćelije i GDS-a. Kada CDS ne zna lokacijuresursa koji mu je potreban, on traži pomoć od GDA. GDA zna na koji globalni namespace jepovezan i traži od GDS-a ime spoljnog cell directory servera sa kojim hoće da komunicira.Kada se komunikacija uspostavi može se pronaći mrežno ime traženog resursa.
Linkovi
Primer 1 http://iase.disa.mil/gds/

| LearningObject | 9
Primer 2 http://en.wikipedia.org/wiki/Global_Directory_Server
Primer 3 http://msdn.microsoft.com/en-us/library/windows/desktop/aa379192(v=vs.85).aspx
Primer 4 http://mtrax.com/cell-phone-directory.html
Primer 5 http://pic.dhe.ibm.com/infocenter/zos/v1r12/index.jsp?topic=%2Fcom.ibm.zos.r12.euvma00%2Feuva2a0031.htm
Primer 6 http://www.webopedia.com/TERM/A/API.html
DCE Security Service
Cilj• Upoznavanje sa DCE Security servisom
DCE Security ServiceDCE Security Service
DCE Security servis obezbeđuje sigurne komunikacije i kontrolisani pristup resursima udistribuiranom okruženju. DCE Security servis mora biti u mogućnosti da proverava korisnikei servise, te mora imati bazu podataka koja sadrži ove podatke. U bazi podataka koju DCESecurity servis održava se nalaze podaci o nalozima, grupama, organizacijama, politikama,svojstvima i atributima. Ova baza podataka se naziva registry. Registry je deo cell directorynamespace-a, iako je smeštena na različitom serveru.DCE Security servis se sastoji od nekoliko komponenti:• Authentication Service - Vrši proces verifikacije da su korisnici korektno identifikovani.
Takođe sadrži Ticket Granting Service koji dozvoljava upotrebu sigurnih komunikacija.• Privilege Service - Dostavlja korisnikove atribute privilegija da bi mogli biti poslani DCE
serverima.• Registry Service - Održava registry bazu podataka, koja sadrži naloge, grupe organizacije
i politika.• Access Control List Facility - Obezbeđuje mehanizam upoređivanja zahteva za
pristupom i kontrolom pristupa za dati resurs.• Login Facility - Obezbeđuje okruženje za korisničko logovanje i inicijalizuje sigurnosno
okruženje.Ovi servisi omogućuju proveru autentičnosti korisnika, sigurnu komunikaciju, autorizovanpristup resursima i odgovarajuću primenu zaštite.
DCE Security servis komunicira sa Cell Direktory servisom da bi prijavio svoje postojanjeostalim sistemima koji su deo ćelije. DCE Security servis takođe koristi i Distributed TimeService da bi dobio potrebne podatke o vremenu.
DCE Niti

| LearningObject | 10
Cilj• Upoznavanje sa DCE nitima
DCE NitiDCE Niti
Tradicionalne aplikacije (pisane u jezicima C, Fortran, itd.) sadrže veliki broj linijaprogramskog koda koji se često izvršava na sekvencijalan način. U bilo kom trenutku, nalazise tačno jedna tačka u programu koja se izvršava. Ovo može biti definisano kao jednanit. Nit je jedna jedinica izvršnog toka unutar procesa. Bolje performanse aplikacije mogubiti postignute kada je program struktuiran tako da nekoliko delova može biti izvršenokonkurentno. Ovo se naziva višenitno izvršavanje. Mogućnost višenitnog izvršavanja zavisi odoperativnog sistema.
U distribuiranim računarskim okruženjima u okviru klijent/server modela, nitno izvršavanjeobezbeđuje izvršavanje više procedura u isto vreme. Posao se može nastaviti u okviru drugeniti dok odgovarajuća nit čekanja za drugi odgovor blokirana (čekanje odgovora u mreži, naprimer). Dok serverska nit čeka za U/I operaciju, nit drugog servera može biti nastavljena nadrugom zahtevu.
Podrška niti treba da je integrisana u operativni sistem. Ako je nit implementirana u aplikacijuumesto u operativni sistem, performanse više-niti aplikacija su sporije.
DCE niti mogu da se mapiraju ka OS/2 nitima kroz posebne programerske konstrukcije. Usvakom slučaju, u pokušaju da se napiše aplikacija koja se može pokrenuti na različitimplaformama, samo DCE nit može da se koristi. U mnogim slučajevima, male su razlikeperformansi kao rezultat mapiranja.
DCE Remote Procedure Call
Cilj• Upoznavanje sa DCE Remote Procedure Call konceptom
DCE Remote Procedure CallDCE Remote Procedure Call
DCE Remote Procedure Call (RPC) arhitektura je baza komunikacije između klijenta i serverabez DCE okruženja.
RPC daje mogućnost aplikacijama za distribuciju na više sistema, koji mogu biti bilo gde namreži. Aplikacije pisana korišćenjem DCE RPC-a ima klijentski deo, koji obično upućuje RPCzahtev, i serverski deo, koji prima RPC zahteve, procesira ih i vraća rezultat klijentu. RPCposeduje tri glavna dela:
• Interface Definition Language (IDL) i njegov kompajler. Iz specificiranog fajla (idl), ongeneriše heder fajlove, klijentski i serverski stub. Ovo omogućava aplikaciji da upućuje RPCzahteve na isti način kao što poziva lokalne procedure.
• Reprezentacija podataka koji se prosleđuju putem mreže, kojom se definiše formatpodataka kao što su ulazni i izlazni parametri. Ovo garantuje da će niz bitova biti pravilno

| LearningObject | 11
konvertovan kada bude primljen na ciljnom računaru. Ovaj proces pripreme podataka zaRPC naziva se ustrojavanje (eng. marshaling).
• Izvršna biblioteka, koja sakriva od aplikacije detalje mrežne komunikacije između servera iklijenta.
Programeri mogu upotrebljavati višestruke niti kada vrše RPC pozive. Ovo je mogućeiz razloga što je RPC sinhron; tj. kada usledi RPC poziv, nit koja je uputila zahtev se“zaštićuje”od drugih procesiranja dok se ne primi odgovor.
RPC mogu biti uotrebljeni za razvoj aplikacija koje koriste druge DCE servise, kao što su CellDirectory Service (CDS) i Security Service. CDS se može koristiti za pronalaženje serveraili za publikovanje adrese servera za klijentski pristup. Security Service se može koristitiza izvršenje autentifikovanog RPC-a koji omogućuje različite nivoe integriteta podataka,enkripciju koristeći Commercial Data Masking Facility (CDMF), Data Encryption Standard(DES), i razne druge funkcije kao identifikacija, itd.
Linkovi
Primer 1 http://www.cs.cf.ac.uk/Dave/C/node33.html
Primer 2 http://searchsoa.techtarget.com/definition/Remote-Procedure-Call
Primer 3 http://www.cs.princeton.edu/courses/archive/fall03/cs518/papers/rpc.pdf
Primer 4 http://whatis.techtarget.com/definition/IDL-interface-definition-language
Primer 5 http://msdn.microsoft.com/en-us/library/windows/desktop/aa367091(v=vs.85).aspx
Primer 6 http://en.wikipedia.org/wiki/CDMF
Distributed Time Service
Cilj• Upoznavanje sa Distributed Time servisom
Distributed Time ServiceDistributed Time Service
Očuvanje sinhronizovanosti satova na različitim host-ovima je veoma težak zadatak. Ovoje problem za distribuirane aplikacije koje zavise od redosleda događaja tokom njihovogizvršavanja. Problem je naročito izražen ako ćelija sadrži servere u različitim vremenskimzonama.
DCE Distributed Time Service (DTS) daje standardne softverske mehanizme da bisinhronizovao satove na različitim host-ovima u distribuiranom okruženju. Takođe, onobezbeđuje način za čuvanje host-ovog vremena blizu apsolutnog vremena. DTS je opcioni
| LearningObject | 12
servis. Međutim, ako DTS nije implementovan, administrator mora koristiti neki drugi načinsinhronizacije satova svih sistema u ćeliji. DTS ima nekoliko komponenti:
• Local time server• Global time server• Courier and backup courier time server
Linkovi
Primer 1 http://www.cs.cf.ac.uk/Dave/C/node33.html
Primer 2 http://searchsoa.techtarget.com/definition/Remote-Procedure-Call
Primer 3 http://www.cs.princeton.edu/courses/archive/fall03/cs518/papers/rpc.pdf
Primer 4 http://whatis.techtarget.com/definition/IDL-interface-definition-language
Primer 5 http://msdn.microsoft.com/en-us/library/windows/desktop/aa367091(v=vs.85).aspx
Primer 6 http://en.wikipedia.org/wiki/CDMF
Distributed File Service (DFS)
Cilj• Upoznavanje sa Distributed File Service-DFS
Distributed File Service-DFSDistributed File Service-DFS
Distributed File Service-DFS nije stvarno komponenta DCE, već aplikacija koja je integrisanasa njim i koristi ostale DCE servise. DFS obezbeđuje globalnu podelu fajlova. Pristup fajlovimalociranim bilo gde u povezanim DCE ćelijama je transparentan za korisnika. Korisnik imautisak da pristupa fajlovima na lokalnom disku. DFS serveri i klijenti mogu biti heterogeni iraditi pod različitim operativnim sistemima.
DFS je izgrađen na i integrisan sa svim ostalim DCE servisima i razvijen je da bi odgovorio napotrebe distribuiranog fajl sistema, kao što su:
• Transparentnost lokacije• Uniformni nazivi• Dobre performanse• Zaštita• Visoka dostupnost• Kontrola konzistentnosti fajlova• NFS interoperabilnost.

| LearningObject | 13
Linkovi
Primer 1 http://www.cs.cf.ac.uk/Dave/C/node33.html
Primer 2 http://searchsoa.techtarget.com/definition/Remote-Procedure-Call
Primer 3 http://www.cs.princeton.edu/courses/archive/fall03/cs518/papers/rpc.pdf
Primer 4 http://whatis.techtarget.com/definition/IDL-interface-definition-language
Primer 5 http://msdn.microsoft.com/en-us/library/windows/desktop/aa367091(v=vs.85).aspx
Primer 6 http://en.wikipedia.org/wiki/CDMF
Konkurentni procesi i programiranje
Cilj• Upoznavanje sa konkurentnim procesima i programiranjem
Konkurentni procesi i programiranjeKonkurentni procesi i programiranje
Konkurentni procesi
Procesi su sekvencijalni programi koji se izvršavaju. Sekvencijalni procesi imaju jednu nitkontrole izvršenja i adresni prostor.
Konkurentni procesi su sekvencijalni procesi koji se simultano izvršavaju. Svaki od tih procesaima svoj adresni prostor i oni su asinhroni. Neki od konkurentnih procesa se mogu razdvojitii izvršiti konkurentno. Ostalima može biti potrebna koordinacija u obliku komunikacije ilisinhronizacije.
U nekim situacijama, računanje mora biti podeljeno u višestruke kontrolne niti koje dele istepodatke. To dovodi do sjedinjavanja višestrukih kontrolnih niti (eng. treads), prosto nazvanihniti, ili sitnih procesa, koji se izvršavaju u deljenom adresnom prostoru. Na taj način drugi nivokonkurentnosti se formira konkurentnim izvršavanjem niti u procesu.Korišćenje nitiOtkriće niti dozvoljava kombinovanje sekvencijalnih procesa, paralelno izvršavanje i blokiranjeprocesa. Tipičan primer njihovog korišćenja su serveri, poput terminala ili fajl servera.
Serverski procesi su potrebni da bi se dobili slični servisi za više klijenata. Klijenti moguzahtevati te servise paralelno. Ako serverski proces ima jednu kontrolnu nit i trenutno jesuspendovan čekajući neki događaj, zahtevi ostalih klijenta ne mogu biti obrađeni i procesiklijenata su blokirani. Kreiranjem niti za svaki zahtev omogućava da se procesi klijenata neblokiraju, ako je zahtevani proces suspendovan i niti u serverskim procesima mogu deliti

| LearningObject | 14
uobičajene podatke. Serverski proces obrađuje zahteve klijenata konkurentno, ali se svaka nitizvršava sekvencijalno.
Postoje dva osnovna pristupa implementaciji niti: u prostoru korisničkog programa i u kernelu.Kombinacija ova dva pristupa je takođe moguća.
Implementacija niti u prostoru korisničkog programaVišenitni procesi su u potpunosti u prostoru korisničkog programa, i oni operativnom sistemuizgledaju kao običan jednonitni proces. Operativni sistem dodeljuje procesorsko vremeprocesu na uobičajen način.Taj dodeljeni vremenski period je razdeljen među nitima uprocesu.
Niti se izvršavaju preko izvršne biblioteke, koja je kolekcija procedura koje upravljajuizvršavanjem niti. Kad nit koja se izvršava napravi blokirajući sistemski poziv, ona pozivaizvršnu proceduru, koja snima registre niti iz koje je pozvana (programski brojač, registar,pokazivač na stek), odabira nit spremnu za izvršavanje i učitava vrednosti koje suuskladištene u niti u registre. Efektivno se ne pojavljuje blokiranje procesa, izvršavanjeprocesa se nastavlja izvršavanjem odabrane niti. Menjanje niti na ovaj način zahteva veomamalo dodatnog opterećenja.Raspoređivanje niti se obavlja podrškom izvršnog sistema, i uglavnom je neprekidno, zbognedostatka vremenskih prekida u okviru procesa. To znači da ako nit počne da se izvršava,ona se izvršava dok ne bude blokirana.
Implementacija niti u kerneluNiti se stvaraju i uništavaju pozivima kernela i kernel ih stvara i uništava. Niti su tretiranekao jednonitni procesi. Kada se nit blokira kernel može odabrati da pokrene novu nit izistog procesa ili nit iz nekog drugog procesa. Pošto niti raspoređuje kernel, dozvoljeno jeraspoređivanje sa izbacivanjem. Nizak trošak menjanja niti je izbačen.
Kombinacija implementacije u prostoru korisničkog programa i kernelu (npr. Sun-ov Solaris)zadržava prednosti oba pristupa. Na primer na Solarisu postoji srednji nivo niti nazvanjednostavniji proces (engl. light weight proces), koji služe kao veza između niti kernela ikorisničkih niti. Light weight procese kreiraju korisnički procesi. Korisničke niti su razdeljenelight weight procesima, a light weight procesi su razdeljeni na procese kernela, formirajući trinivoa konkurentnosti. Tada blokirajući poziv korisničkog procesa može blokirati povezani lightweight proces, ali korisnički proces može nastaviti izvršavanje izvršenjem niti povezane sadrugim light weight procesom u istom korisničkom procesu. Raspoređivanje korisničkih niti saizbacivanjem je moguće jer light weight procesi mogu biti izbačeni od strane kernela.Klijent - Server model
Ideja ovog modela je da se napravi kooperacija procesa između servera koji obezbeđujuservise i klijenata koji servise zahtevaju. Ova paradigma se koristi na nivou aplikacijepodjednako kao i na nivou operativnog sistema. Svaki proces u interakciji igra ili uloguservera ili ulogu klijenta. Sa druge strane, proces koji se ponaša kao server može zahtevatiservis od drugog servera da bi izvršio neki zadatak, time dobijajući i ulogu klijenta. Mašinamože biti jedan klijent, jedan server, više klijenata ili servera ili mešavina klijenata i servera.Logička komunikacija između klijenata i servera je bazirana na razmeni zahteva i odgovora:
• Klijent šalje zahtev serveru i blokira se• Server prima zahtev, obavlja traženi posao, i vraća odgovor klijentu• Klijent prima odgovor i nastavlja izvršavanje

| LearningObject | 15
Fizički, zahtevi i odgovori se prosleđuju dotičnom kernelu, i šalju kroz komunikacionu mrežuciljnim kernelima i procesima. Iz jednostavnosti ovog modela proizilazi potreba za samo dvakomunikaciona sistemska poziva kernelu: pošalji (send) i primi (receive) poruku.
Važno pitanje je kako klijent locira server ako on promeni lokaciju ili ako postoji više servera.Zbog fleksibilnosti serveri se identifikuju preko imena. Serveri, nazvani vezujući serveri (engl.binder servers) spajaju klijente i servere. Procedura koja izvršava ovo spajanje je nazvanadinamičko povezivanje (engl. dynamic binding). Kada se server startuje, on šalje povezivačupodatke o svojoj lokaciji. Tada klijenti preko povezivača znaju lokaciju odgovarajućeg servera.Kao dodatak, povezivač može pomagati u autentifikaciji klijenata za servere.
Linkovi
Primer 1 http://www.ipd.uka.de/JavaParty/threads.html
Primer 2 www.news.cs.nyu.edu/~jinyang/fa08/notes/ds-lec2.ppt
Primer 3 http://homepage.lnu.se/staff/daweaa/papers/2002ISPDC.pdf
Distribuirani fajl sistemi
Cilj• Upoznavanje sa distribuiranim datote;nim sistemima
Distribuirani fajl sistemiDistribuirani fajl sistemi
Fajl (datoteka) sistem je ključna komponenta svakog distribuiranog sistema. Uloga fajlsistema je da skladišti postojane imenovane objekte podataka zvane fajlovi, i da omogućida budu dostupni kada je to potrebno. Fajl sistem je dakle odgovoran za kreiranje, brisanje,povraćaj, izmene i zaštitu fajlova.
Distribuirani fajl sistem (DFS) predstavlja implementaciju fajl sistema u distribuiranomsistemskom okruženju koje se sastoji od fizički razdvojenih (distribuiranih u smislulokacije) skladišta podataka, ali koji obezbeđuje tradicionalnu preglednost fajl sistema zakorisnike. Zato se mnogi važni koncepti u izradi distribuiranih sistema mogu demonstriratiimplementacijom DFS-a:1. Distribuirani fajl sistemi primenjuju koncept transparentnosti2. Način adresiranja u DFS-u je primer ''opsluživanja imenovanja''3. Korišćenje keširanja i replikacije fajlova radi povećanja performansi i bolje dostupnosti
faljova4. Kontrola pristupa i zaštita podataka u DFS-u predstavlja problem.Aspekti DFS-aVeliki broj korisnika i fajlova je ključni aspekt fajl sistema, a distribuiranom okruženju je ovajaspekt još izraženiji. Novi aspekt DFS-a je disperzija korisnika i fajlova (npr. korisnik u DFS-u može da pristupa svojim podacima koji se nalaze na hard disku nekog drugog računara umreži). Disperziju i mnoštvo (korisnika i fajlova) bi trebalo sakriti od korisnika.
| LearningObject | 16
• DISTRIBUIRANI KLIJENTI. DFS bi trebao da omogući transparentno logovanje tj. korisniktreba da vidi sistem jedinstveno nezavisno od servera ("HOST" računar) uključujući iproceduru za logovanje i transparentan pristup. Mehanizam pristupa fajlu je jedinstven,bez obzira da li su fajlovi na lokalnom ili udaljenom serveru.
• DISTRIBUIRANI FAJLOVI. DFS bi trebalo da omogući trasparentnost lokacije, tj. imenafajlova ne treba da sadrže informacije o njihovoj fizičkoj lokaciji i nezavisnoj lokaciji, tj.fajlovi se mogu premeštati sa jedne lokacije na drugu bez promene imena.
• VELIKI BROJ KORISNIKA. DFS bi trebao da omogući transparentnu konkurentnost, tj. fajlukoji deli više korisnika može se pristupiti bez greške od strane bilo kog korisnika.
• VELIKI BROJ FAJLOVA. DFS bi trebalo da omogući transparentnost replikacije tj. ažuriranjereplika se vrši na atomskom nivou i korisnici nisu ni svesni postojanja više od jedne kopije.
Drugi aspekti uključuju otpornost na greške, skalabilnost, heterogenost DFS-a.
Linkovi
Primer 1 http://www0.cs.ucl.ac.uk/staff/ucacwxe/lectures/ds98-99/dsee3.pdf
Primer 2 http://www.cl.cam.ac.uk/~rja14/Papers/SE-06.pdf
Primer 3 http://www.cs.helsinki.fi/u/jakangas/Teaching/DistSys/DistSys-08f-1.pdf
Primer 4 http://pdos.csail.mit.edu/6.824/
Primer 5 http://research.google.com/pubs/DistributedSystemsandParallelComputing.html
Primer 6 http://www.infosys.tuwien.ac.at/
Organizacija Fajl Sistema
Cilj• Upoznavanje sa organizacijom fajl sistema
Organizacija Fajl SistemaOrganizacija Fajl SistemaPosmatrano funkcijski, fajl sistem se sastoji od četiri glavne komponente:• servis direktorijuma• servis autorizacije• servis fajlova• servisi sistema
SERVIS DIREKTORIJUMA. Glavna funkcija je mapiranje tekstualnih imena fajlova u adrese.Mapiranje je dosta nezavisno od trenutnih operacija nad fajlom. Zbog toga, uobičajenoje odvajanje servisa direktorijuma od servisa fajlova kako bi se podržala modularnost i

| LearningObject | 17
prenosivost. Obično je opsluživanje fajlova na usluzi različitim strukturama direktorijuma.Operacije nad direktorijumima uključuju pregled, dodavanje i brisanje sadržaja direktorijuma.
SERVIS AUTORIZACIJE. Uloga servisa autorizacije je da obezbedi kontrolu pristupanjafajlu. U implementaciji, autorizacija se može realizovati u sklopu servisa direktorijuma iliservisa fajlova. U prethodnom slučaju, komponenta za servis direktorijuma čuva informacijeo pristupima fajlovima i direktorijumima. Ako je korisnik autorizovan za pristup fajlu ilidirektorijumu, njemu se omogućava obrada željenog fajla, i određene mogućnosti, koje sedefinišu pravima korisnika pri korišćenju fajla. Kada se kasnije pristupa fajlu, prava pristupase proveravaju preko fajl servera. Kasnije komponenta za servis direktorijuma obezbeđujesamo obradu fajla. Klijent mora biti autorizovan od strane fajl sistema svaki put kada izvodineku operaciju nad fajlom.
SERVIS FAJLOVA. Fajl sistemi koji podržavaju transakcije dele fajl servise na transakcionei osnovne fajl servise. Transakcioni servisi sprovode upravljanje konkurentnom obradomi upravljanje replikacijama. Osnovni fajl servisi su ''read/write'' i ''get/set''. Servis fajlovatakođe podržava kreiranje i brisanje fajlova. Servis fajlova je u interakciji sa sistemskimopsluživanjem kod poslova dodeljivanja i oslobađanja prostora bafera i fajla.
SERVISI SISTEMA. Funkcije koje obezbeđuje sistem obuhvataju trenutne ''read/write''operacije, mapiranje logičkih u fizički blok adresa, i upravljanje prostorom (memorijom) kojizauzima fajl. Upravljanje kešom i odzivima je takođe usluga sistemskih servisa fajl sistema.Fajl ServeriServisi se implementiraju procesima zvanim serveri. Servis može biti implementiran od stranesamo jednog servera ili većeg broja kooperativnih servera. Server može obezbediti mnoštvousluga. Veliki fajl sistemi su sastavljeni od različitih fajl servera.
Montiranje fajlova (maunting) je koristan koncept za projektovanje velikih fajl sistema.Operacija montiranja od strane klijenta spaja udaljeni imenovani fajl sistem za klijentovuhierarhiju fajl sistema u trenutku identifikacije preko imenovane putanje. Tačka (mesto)montiranja je obično prazan poddirektorijum. Specificiranje fajl sistema koji će se montirativrši se prema konvenciji imenovanja udaljenog fajl sistema. Na ovaj način se ostvarujetransparentnost lokacije. Korišćenjem mehanizma montiranja različiti klijenti mogu dobitirazličite poglede fajl sistema.
Fajl server može zabraniti montiranje celog ili dela njegovog fajl sistema predefinisan skupomservera (host računari) zbog bezbednosnih razloga. Montiranje fajl sistema može se sprovestina tri načina:
• EKSPLICITNO MONTIRANJE. Klijenti zahtevaju operaciju montiranja eksplicitno kada imzatreba. "Pogled" fajl sistema je definisan od strane korisnika.
• BOOT – MONTIRANJE. Propisani skup se montira u vreme "boot-ovanja" korisnika. Klijentiimaju jedinstven statičan pogled celog fajl sistema, čak i ako nekima od njih neće trebatisvi propisani montirani serveri.
• AUTO MONTIRANJE. Server se bezuslovno montira kada klijent po prvi put otvori fajl.Pogled fajl sistema je dinamičan, kao kod eksplicitnog montiranja, ali bez potrebe zapozivima eksplicitnog montiranja.
• Montiranje zahteva poznavanje lokacija fajl servera. Fajl server se može locirati na dvanačina:
• Klijenti se konsultuju sa registracionim serverom tamo gde se serveri moraju registrovatiza svoje usluge. Registracioni server dodeljuje, po nekom kriterijumu, najbolji server.
• Klijenti emituju zahteve za montiranjem, a fajl serveri odgovore na te zahteve. Sada klijentmože da bira jedan od servera, koji su se javili, primenom neke strategije.

| LearningObject | 18
Fajl Serveri sa i bez informacija o postojećem stanju (engč. Stateful and Stateless)
Klijentovi ''read/write'' zahtevi mogu biti jednopotezne operacije. Obično, klijent pokrećetakozvanu fajl sesiju putem operacije otvaranja, nakon koje slede kasniji ''read-write'' zahtevi.U ovom slučaju postoji informacija o stanju za svaku fajl-sesiju. Na primer informacije o stanjumogu obuhvatiti:• koji klijent je otvorio fajl• fajl-deskriptore zbog identifikacije fajla u predstojećim operacijama• pokazivače trenutne pozicije fajla za sledeći sekvencijalni pristup• montiranje informacija zbog daljinskog pristupa• lock status zbog koordiniranja deljenja fajla• jednokratne sesijske ključeve zbog bezbedne komunikacije• sadržaj keša ili bafera radi poboljšanja performansi
Jasno je da informacije o stanju fajl-sesije mogu biti podeljene između klijenta i fajl servera.
Fajl server sa informacijama o stanju je onaj koji sadrži neke bitne informacije o stanju fajla.Na primer; kada se fajl otvori, klijent prima fajl deskriptor za sledeći pristup. Tabela mapiranjafajl deskriptora za fajlove održava se od strane servera. Slično tome, pokazivač pozicije fajlačuva se za svakog klijenta tokom sekvencijalnog pristupa fajlu, osim u slučaju "nasleđivanja".
''Stateless'' fajl server se zove tako zato što ne čuva informacije o stanju. U ovom slučaju,svaki zahtev bi sadržao puno ime fajla i pokazivač pozicije fajla. Informacije o stanju koje senalaze u zahtevima stateless servera (bez informacija o stanju) povećavaju dužinu poruke imoraju biti izvršene od strane servera svaki put kada se pristupi fajlu.
Čuvanje informacija u statefull serveru omogućava postizanje boljih performansi. Sa drugestrane ako statefull fajl server "padne", informacija o stanju za svaku fajl-sesiju je zauvekizgubljena, a oporavak ako je uopšte moguć, zavisi isključivo od klijenta. "Pad" stateless fajlservera je lako povratiti, a javlja se kao kašnjenje odziva.Semantika Deljenja FajlaDeljenje fajla od strane više klijenata pokreće dva važna problema. Operacije pristupa moguse preklopiti ako postoji više kopija istog fajla. To omogućava simultani pristup deljenompodatku. Svaki čvor (računar u mreži) koji ima kopiju fajla može imati različito viđenjepodatka. Ovaj problem naziva se kontrola postojanosti (koherencije).
Višestruki pristupi od strane klijenata istom deljenom fajlu imaju formu povezanihjednostavnih read/write operacija, a iluzija simultanosti može se postići preplitanjem izvršenjaovih sekvenci. Primarni razlog je postizanje postojanog stanja podataka nakon preplitanja uizvršavanju sekvenci, na primer, rezultat je jednak nekom serijskom izvršavanju ovih sekvencibez preplitanja. Rešenje pomenutog problema zavisi od semantike čitanja i pisanja.
UNIX SEMANTIKA. Read operacija će vratiti ''poslednju'' upisanu vrednost. Ova semantikapotiče od sistema sa jednim procesorom, gde se podaci keširaju po fajl osnovama. Udistribuiranim sistemima može postojati mnoštvo keša istog fajl podatka i problemkonzistentnosti keša mora da se reši.
UNIX semantika modelira poslove sa prostim read/write operacijama i pokušava da postigneglobalni konzistentni pogled deljenog podatka i može se posmatrati na dva načina, tako da seodnosi na semantiku transakcije i semantiku sesije.
SEMANTIKA TRANSAKCIJE: Jedinica pristupa fajlu ili grupi fajlova je nedeljiva sekvenca read iwrite operacija. Operacije transakcije su obuhvaćene parom naredbi: početak transakcije/kraj
| LearningObject | 19
transakcije. Izvršavanje transakcije se ne ometa od strane drugih konkurentnih transakcija. Toznači da zahtev za izvršavanje dve ili više konkurentnih transakcija je isti kao da se izvršavajujedna za drugom (sekvencijalno). Jedino se održava konzistentnost podataka, stalne izmenefajla se sprovode samo na kraju uspešne transakcije.
SEMANTIKA SESIJE: Izmene na otvorenom fajlu su fizički vidljive samo lokalnom klijentu. Samokada je fajl zatvoren izmenjeni fajl se kopira na fajl server i promena je trajno izvršena. Takoda je sesija obuhvaćena parom naredbi: ''open/close'' i deljenje fajla postoji samo izmeđuuspešnih sesija.KeširanjeKeširanje od strane korisnika klijent-server sistema eliminiše prenos kroz mrežu kada klijentpristupi fajlu. Na ovaj način se može postići prednost u izvršavanju, ali keširanje klijenta unosinekonzistentnost u sistem. Ako klijent lokalno vrši izmene keširanog fajla i ubrzo zatim drugikljient pročita fajl sa servera, drugi klijent dobija zastareo fajl.
''WRITE-TROUGH'' STRATEGIJA pokušava da reši problem nekonzistentnosti trenutnim slanjem''write'' naredbi fajl serveru. Shodno tome, kada drugi klijent čita fajl sa fajl servera, dobijanovu vrednost. Ipak promene se neće videti od strane drugih procesa koji imaju isti fajl usvom kešu.
''WRITE-INVALIDATE'' ili ''WRITE-UPDATE'' protokoli se mogu koristiti za rešenje ovogproblema. Poništavanje keševa od strane fajl servera obaveštava sve klijente da su njihovikeševi "zastareli" i da se moraju ponovo učitati za predstojeće korišćenje.
''Write-trough'' i ''write-invalidate'' simuliraju Unix semantiku. Jasno je da sa ''write-trough''kešom prenos mrežom je eliminisan samo za čitanje. Kako bi se snizio promet write naredbikroz mrežu promene se mogu prikupiti na strani klijenta i da se periodično šalje writenaredba. Ova strategija kontrole se naziva ''WRITE-BACK'' i nije podržana od strane Unixsemantike.
Dalja olakšanja u radu sa keširanjem traže usvajanje semantike sesije. Izmenjeni fajl seažurira (slanjem "write" naredbe) posle zatvaranja. Ova strategija se zove ''WRITE-ON-CLOSE''.
Linkovi
Primer 1 http://www0.cs.ucl.ac.uk/staff/ucacwxe/lectures/ds98-99/dsee3.pdf
Primer 2 http://www.cl.cam.ac.uk/~rja14/Papers/SE-06.pdf
Primer 3 http://www.cs.helsinki.fi/u/jakangas/Teaching/DistSys/DistSys-08f-1.pdf
Primer 4 http://pdos.csail.mit.edu/6.824/
Primer 5 http://research.google.com/pubs/DistributedSystemsandParallelComputing.html
Primer 6 http://www.infosys.tuwien.ac.at/

| LearningObject | 20
Kоmprеsiјa pоdаtаkа
Cilj• Kоmprеsiјa pоdаtаkа
Kоmprеsiјa pоdаtаkаKоmprеsiјa pоdаtаkа
Kompjuter ne misli, ne oseća ništa. Nema ni memoriju, samo prostor za skladištenje. Kadgod mu se obratite, ili dobijate kompletan odgovor, ili ništa. Neodređenost, inteligentnakonfuzija, originalno baratanje rečima, ili idejama se nikada ne dešava, a inteme veze su uveknepromenljive; uspostavljene su jednom od istinskih umova koji su kreirali mašinu i program.Kada se uključi, i najjednostavniji kompjuter sigurno može da obavi posao u skladu sa svojimmaksimalnim mogućnostima; najvećim umovima ne mogu da se povere takvi poslovi zbogjednog jednostavnog razloga - zbog njihove promenljivosti, koja ih čini toliko superiornim.Uvod
Da li ste nekada slušali MP3 audio fajl? Da li ste nekada preuzeli filmski triler snimljen uformi MPG, ili MPEG fajla? Da li ste nekada koristili faks (faksimil) mašinu? Sasvim sigurnoste izveli neke od ovih akcija. Medutim, ništa od ovoga ne bi bilo praktično bez sofisticiranematematike i rutina za kompresovanje. Sa tolikim brojem novih aplikacija koje zahtevajuelektronske komunikacije očigledan trend je kreiranje bržih i jeftinijih načina za slanjepodataka.
Neke aplikacije ipak ne mogu da čekaju na nov razvoj. Njihovi zahtevi su primorali ljude dapotraže nove načine za postizanje brzih i jeftinih komunikacija. Na primer, razmotrite faksmašinu, jedan od najznačajnijih izuma iz 80-ih prošlog veka. Tipična faks mašina koristi40.000 tačaka po kvadratnom inču, što daje skoro četiri miliona tačaka po stranici. Ako sekoristi 56 Kbps modem, potrebno je više od jednog minuta da se prenesu ove informacije. Akoste ikada koristili faks mašinu, znate da to, ipak, ne traje toliko dugo.
Sledeći primer je video. Ono što mi vidimo kao kretanje je standardni TV ekran, koji, u stvari,prikazuje 30 slika (kadrova) u sekundi (isti princip na kome se zasnivaju pokretne slike).
Osim toga, svaka slika sadrži aproksimativno 20.000 tačaka, ili piksela - svaki piksel imarazličitu jačinu osnovnih boja plave, zelene i crvene. Različite kombinacije omogućavajugenerisanje različitih boja spektra. Ako se svaka osnovna boja jednog piksela predstavlja saosam bitova, onda je za svaku sliku potrebno 20.000x24 = 4.800.000 bitova. Dvočasovni filmbi zahtevao oko 216.000 zasebnih slika, ili 216.000x4.800.000 = 1.0368 1012 bitova, mnogoviše od kapaciteta jednog DVD-a. Ipak, na DVD staje dvočasovni film.
Oba primera pokazuju da mogu da se zaobidu fizička ograničenja medijuma. Kako? Odgovorje pomoću kompresije podataka, načina da se obavi redukovanje broja bitova u okviru, ada se, pri tom, zadrži značenje. Na taj način se smanjuje cena i skraćuje vreme prenosa.Kompresija podataka se koristi u različitim oblastima, kao što su faks mašine, DVD tehnologijai V.42 modemi. Koristi se i prilikom smeštanja na disk, a mnogi proizvodači softverakompresuju svoje programe na diskovima i CD-ima radi uštede prostora.
Sledeće logično pitanje je kako eliminisati bitove, a, pri tom, zadržati neophodne informacije.Na primer, pretpostavite da imate podatke u fajlu koji se u potpunosti sastoji od niza velikihslova. Ako pošaljete fajl e-mailom, koliko će bitova biti preneto? Ako se karakteri smeštaju
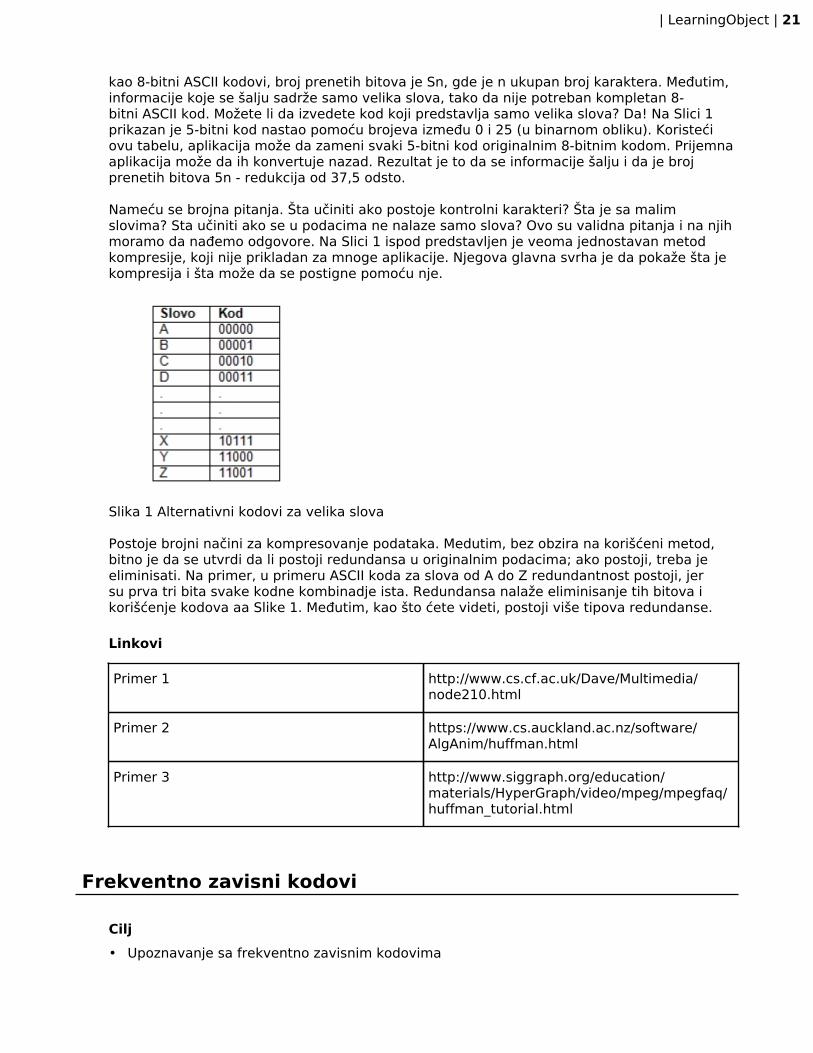
| LearningObject | 21
kao 8-bitni ASCII kodovi, broj prenetih bitova je Sn, gde je n ukupan broj karaktera. Međutim,informacije koje se šalju sadrže samo velika slova, tako da nije potreban kompletan 8-bitni ASCII kod. Možete li da izvedete kod koji predstavlja samo velika slova? Da! Na Slici 1prikazan je 5-bitni kod nastao pomoću brojeva između 0 i 25 (u binarnom obliku). Koristećiovu tabelu, aplikacija može da zameni svaki 5-bitni kod originalnim 8-bitnim kodom. Prijemnaaplikacija može da ih konvertuje nazad. Rezultat je to da se informacije šalju i da je brojprenetih bitova 5n - redukcija od 37,5 odsto.
Nameću se brojna pitanja. Šta učiniti ako postoje kontrolni karakteri? Šta je sa malimslovima? Sta učiniti ako se u podacima ne nalaze samo slova? Ovo su validna pitanja i na njihmoramo da nađemo odgovore. Na Slici 1 ispod predstavljen je veoma jednostavan metodkompresije, koji nije prikladan za mnoge aplikacije. Njegova glavna svrha je da pokaže šta jekompresija i šta može da se postigne pomoću nje.
Slika 1 Alternativni kodovi za velika slova
Postoje brojni načini za kompresovanje podataka. Medutim, bez obzira na korišćeni metod,bitno je da se utvrdi da li postoji redundansa u originalnim podacima; ako postoji, treba jeeliminisati. Na primer, u primeru ASCII koda za slova od A do Z redundantnost postoji, jersu prva tri bita svake kodne kombinadje ista. Redundansa nalaže eliminisanje tih bitova ikorišćenje kodova aa Slike 1. Međutim, kao što ćete videti, postoji više tipova redundanse.
Linkovi
Primer 1 http://www.cs.cf.ac.uk/Dave/Multimedia/node210.html
Primer 2 https://www.cs.auckland.ac.nz/software/AlgAnim/huffman.html
Primer 3 http://www.siggraph.org/education/materials/HyperGraph/video/mpeg/mpegfaq/huffman_tutorial.html
Frekventno zavisni kodovi
Cilj• Upoznavanje sa frekventno zavisnim kodovima
| LearningObject | 22
Frekventno zavisni kodoviFrekventno zavisni kodovi
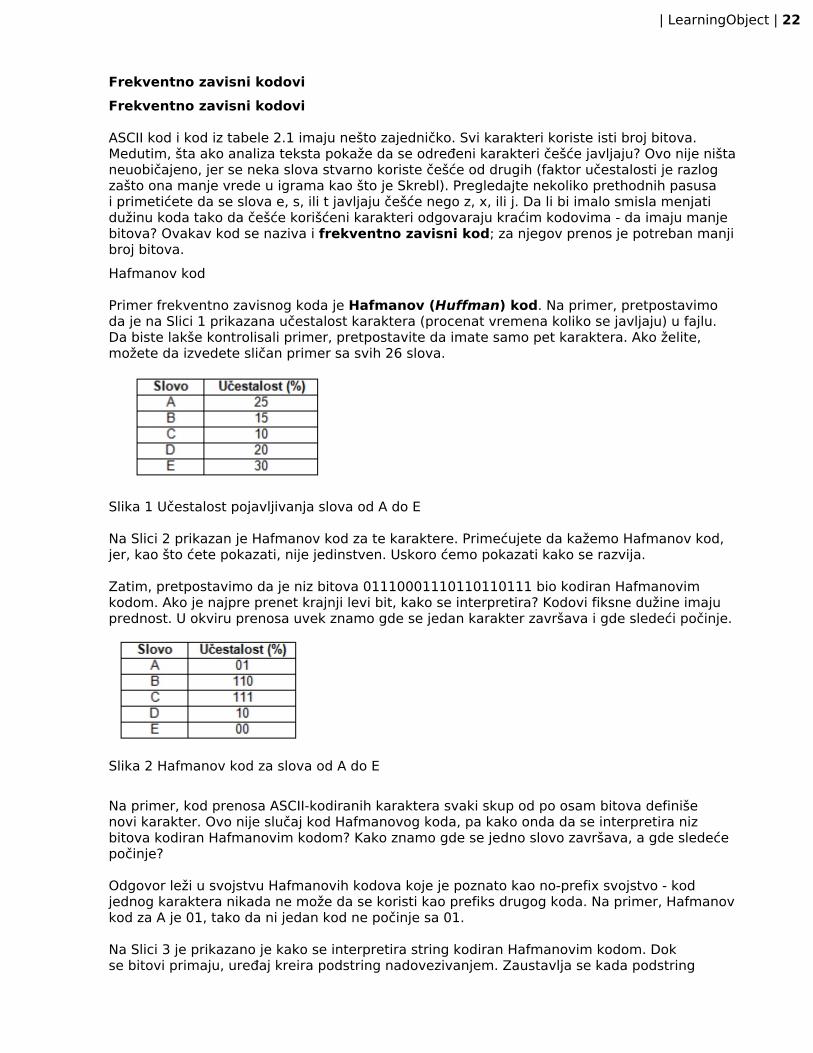
ASCII kod i kod iz tabele 2.1 imaju nešto zajedničko. Svi karakteri koriste isti broj bitova.Medutim, šta ako analiza teksta pokaže da se određeni karakteri češće javljaju? Ovo nije ništaneuobičajeno, jer se neka slova stvarno koriste češće od drugih (faktor učestalosti je razlogzašto ona manje vrede u igrama kao što je Skrebl). Pregledajte nekoliko prethodnih pasusai primetićete da se slova e, s, ili t javljaju češće nego z, x, ili j. Da li bi imalo smisla menjatidužinu koda tako da češće korišćeni karakteri odgovaraju kraćim kodovima - da imaju manjebitova? Ovakav kod se naziva i frekventno zavisni kod; za njegov prenos je potreban manjibroj bitova.Hafmanov kod
Primer frekventno zavisnog koda je Hafmanov (Huffman) kod. Na primer, pretpostavimoda je na Slici 1 prikazana učestalost karaktera (procenat vremena koliko se javljaju) u fajlu.Da biste lakše kontrolisali primer, pretpostavite da imate samo pet karaktera. Ako želite,možete da izvedete sličan primer sa svih 26 slova.
Slika 1 Učestalost pojavljivanja slova od A do E
Na Slici 2 prikazan je Hafmanov kod za te karaktere. Primećujete da kažemo Hafmanov kod,jer, kao što ćete pokazati, nije jedinstven. Uskoro ćemo pokazati kako se razvija.
Zatim, pretpostavimo da je niz bitova 01110001110110110111 bio kodiran Hafmanovimkodom. Ako je najpre prenet krajnji levi bit, kako se interpretira? Kodovi fiksne dužine imajuprednost. U okviru prenosa uvek znamo gde se jedan karakter završava i gde sledeći počinje.
Slika 2 Hafmanov kod za slova od A do E
Na primer, kod prenosa ASCII-kodiranih karaktera svaki skup od po osam bitova definišenovi karakter. Ovo nije slučaj kod Hafmanovog koda, pa kako onda da se interpretira nizbitova kodiran Hafmanovim kodom? Kako znamo gde se jedno slovo završava, a gde sledećepočinje?
Odgovor leži u svojstvu Hafmanovih kodova koje je poznato kao no-prefix svojstvo - kodjednog karaktera nikada ne može da se koristi kao prefiks drugog koda. Na primer, Hafmanovkod za A je 01, tako da ni jedan kod ne počinje sa 01.
Na Slici 3 je prikazano je kako se interpretira string kodiran Hafmanovim kodom. Dokse bitovi primaju, uređaj kreira podstring nadovezivanjem. Zaustavlja se kada podstring

| LearningObject | 23
odgovara podstringu 01, što znači da je A prvi karakter koji je poslat. Da bi bio nađen sledećikarakter, odbacuje se tekući string i počinje kreiranje novog sa prijemom svakog se kadapodstring odgovara kodiranom karakteru sledećeg bita. U ovom slučaju sledeća tri bita (110)odgovaraju karakteru B. Napomenimo da string ne odgovara ni jednom Hafmanovom kodusve dok se ne prime tri bita. Ovo je posledica no-prefiks svojstva. Uređaj nastavlja u ovom"maniru" sve dok se ne prime svi bitovi.
Podaci sa Slike 3 sadrže string ABECADBC.
Slika 3 Prijem i interpretiranje poruke kodirane Hafmanovim kodom
Sledeći koraci pokazuju kako se kreira Hafmanov kod.1. Svakom karakteru se dodeljuje binarno stablo koje se sastoji samo iz jednog čvora.
Svakom stablu je dodeljena učestalost pojavljivanja karaktera, koju nazivamo težina stabla(engl. tree's height).
2. Potražite dva najlakša stabla. Ako ih ima više od dva, izaberite bilo koja dva. Spojite ih ujedno sa novim korenom, da levo i desno podstablo odgovara ranijim stablima. Dodelitesumu težina spojenih stabala kao sumu novog stabla.
3. Ponovite sledeći korak sve dok ne budete imali samo jedno stablo.
Kada se stablo kompletira, svi originalni čvorovi predstavljaju listove u finalnom binarnomstablu. Kao i kod bilo kog binarnog stabla, postoji jedinstvena putanja od korena do lista. Zasvaki list putanja do njega definiše Hafmanov kod. Putanja se određuje tako što se dodeljuje 0svaki put kada se sledi levi pokazivač i 1 za svaki desni pokazivač.
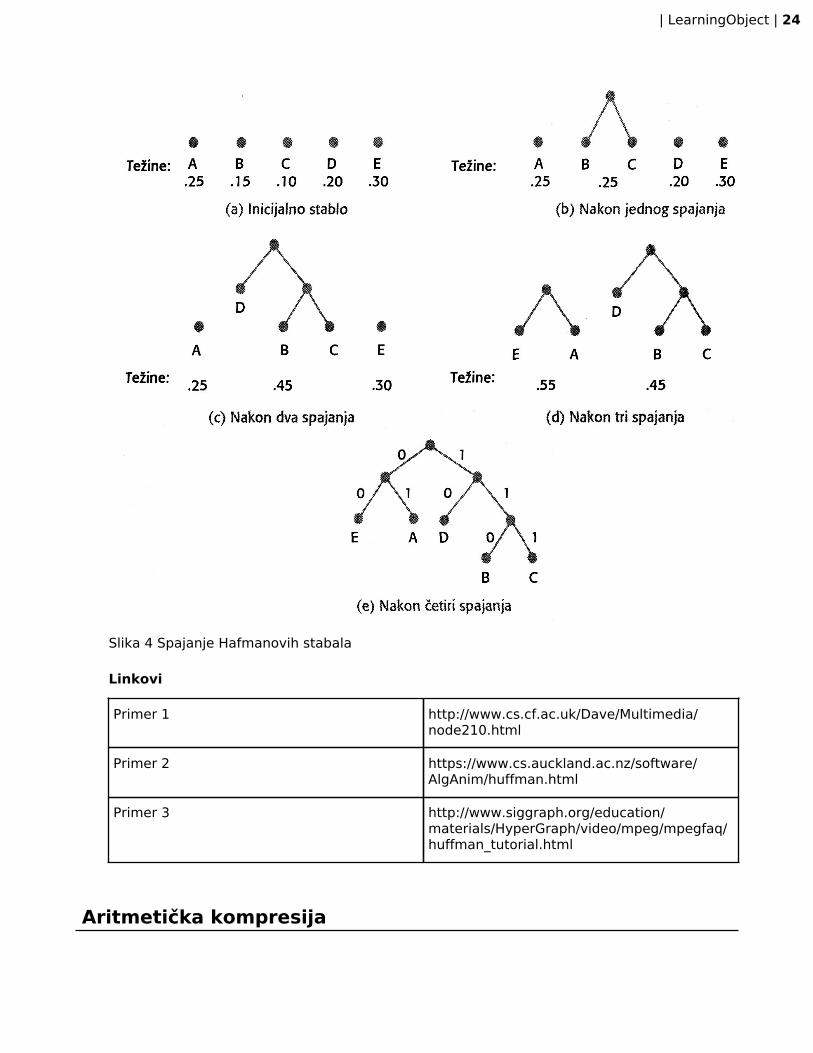
Na Slici 4 (delovi od a do e) prikazana je konstrukcija Hafmanovog koda, a prikazano je jednostablo sa pet samostalnih čvorova sa njihovim težinama. Stabla za slova B i C imaju manjetežine, tako da se njihovim spajanjem dobija rezultat sa Slike 4b. Kod drugog spajanja postojedve mogućnosti: spajanje novog stabla sa D, ili spajanje A sa D. U ovom slučaju proizvoljnobiramo prvo spajanje; rezultat je prikazan na Slici 4c. Nastavljajući na ovaj način, eventualnodobijate stablo kao na Slici 4e.
Kod njega možete da vidite da su svakom levom i desnom pokazivaču dodeljene 0 i 1.Praćenjem pokazivača do čvora lista dobija se Hafmanov kod za pridruženi karakter. Naprimer, praćenjem levog (0) pokazivača, pa desnog (1), dolazimo do lista čvora A. Ovo jekonzistentno sa Hafmanovim kodom 01 za slovo A.
| LearningObject | 24
Slika 4 Spajanje Hafmanovih stabala
Linkovi
Primer 1 http://www.cs.cf.ac.uk/Dave/Multimedia/node210.html
Primer 2 https://www.cs.auckland.ac.nz/software/AlgAnim/huffman.html
Primer 3 http://www.siggraph.org/education/materials/HyperGraph/video/mpeg/mpegfaq/huffman_tutorial.html
Aritmetička kompresija

| LearningObject | 25
Cilj• Upoznavanje sa aritmetičkom kompresijom
Aritmetička kompresijaSledeći primer metoda za kompresovanje podataka koji generiše frekventno zavisni kod jearitmetička kompresija, koja je zasnovana na interpretiranju stringa kao jednog realnogbroja. Ovo nije neuobičajen koncept; na primer, mogli bismo da interpretiramo Hafmanovimkodom kodirane nule i jedinice u stringu kao bitsku reprezentaciju za veoma veliki ceo broj.Više karaktera u stringu znači više bitova i, samim, tim veći broj.Aritmetička kompresijafunkcioniše tako što se definiše asocijacija izmedu stringa karaktera i realnog broja izmedu0 i 1. Pošto postoji beskonačno mnogo brojeva između 0 i 1 i beskonačno mnogo stringova,možemo da definišemo algoritam koji pridružuje realni broj bilo kom stringu.
Ilustracije radi, koristićemo ista slova i učestalost koji su bili korišćeni u prethodnom primeruza Hafmanov kod. Razlika je u tome što dodeljujemo opseg brojeva (podinterval intervala[0, 1]) na osnovu učestalosti pojavljivanja svakog karaktera. Dužina podintervala odgovaraučestalosti simbola. Na slici 1 prikazano je kako ovo funkcioniše. Slovo A ima učestalostpojavljivanja 25 odsto i dodeljujemo mu interval [0, 0.25]. Ovo predstavlja 25 odsto intervalai dužine je 0.22. Zatim, pošto B ima učestalost 15 odsto, dodeljujemo mu sledećih 15odsto intervala (nakon podintervala [0, 0.25]). Dakle, podinterval [0.25, 0.40], dužine 0.15,odgovara slovu B. Pošto C ima učestalost pojavljivanja 10 odsto, dodeljuje mu se sledećih 10odsto, što odgovara podintervalu [0.40, 0.50], dužine 0.10. Prateći ovaj šablon, dodeljujemosledećih 20 odsto intervala slovu D i preostalih 30 odsto slovu E. Pošto je suma učestalosti100 odsto, ukupna suma podintervala je 1. Osim toga, kolekcija podintervala kompletno"pokriva" originalni interval [0, 1].
Kako ovo može da pomogne u našem slučaju? Pretpostavite da imate string karaktera.Osnovna ideja je u sledećem.1. Startujte od intervala [x, y] = [0, 1]2. Pogledajte prvi karakter i utvrdite odgovarajući podinterval od [x, y], koji se zasniva na
učestalosti karaktera.3. Redefinišite interval [x, y] koji će predstavljati taj podinterval, tj. smanjite [x, y].4. Ispitajte sledeći karakter i ponovo utvrdite odgovarajući podinterval [x, y], u zavisnosti
od učestalosti karaktera. Ovo je identično onome što ste uradili u koraku 2, osim što sadaradite sa manjim intervalom [x, y], umesto sa [0, 1].
5. Ponovljamo korake 3 i 4 za svaki karakter u stringu.
Slika 1 Pridruživanje opsega individualnim slovima
Verovatno je najbitniji korak izračunavanje novog intervala na osnovu starog, uzimajućivrednosti za p i q. Osnovna ideja je predstavljena na slici 2.3. Počinjemo od intervala [x, y]širine w = y - x. Zatim, postoje podintervali zasnovani na p i q za svaki karakter. Vrednosti p iq predstavljaju procenat rastojanja od x do y. Nakon toga se za novu vrednost za x postavljavrednost p, a za y vrednost q. Dakle, pretpostavimo da je [x, y] = [0.3, 0.9], w = 0.9 - 0.3 =0.6 i da je [p, q] = [0.25, 0.50]. Nova vrednost za x je 25 odsto rastojanja od tekuće vrednostix ka y. Drugim rečima, sledeća vrednost x = tekuća vrednost za x + w x p = 0.3 + 0.6 x 0.25

| LearningObject | 26
= 0.42. Nova vrednost za y = tekuća vrednost za x + w x q = 0.3 + 0.6 x 0.5 = 0.6. Sledećinačin na koji ovo može da se zamisli je da se pretpostavi da 0.45 iznosi 25 odsto rastojanja od0.3 do 0.9, a da 0.6 predstavlja 50 odsto rastojanja od 0.3 do 0.9.
Slika 2 Utvrđivanje novog intervala na osnovu starog
U osnovi, ovaj proces opisuje generisanje podintervala sa manjom dužinom. Osim toga,podintervali na jedinstven način zavise od karaktera u stringu i učestalosti njihovogpojavljivanja. Što je veći broj karaktera u stringu, to su podintervali manji (oni se smanjujusa svakim novim karakterom u stringu). Kada se obradi poslednji karakter u stringu, birajterealni broj u finalnom intervalu (na primer, središnju tačku). Birajte bitsku reprezentaciju togbroja, a to je kompresovani kod.
Pretpostavimo da važe učestalosti sa Slike 3 i da se koristi string CABA-CADA. Na slici 2.4prikazano je prvih nekoliko koraka procesa. Koristeći izračunavanja koja smo prethodnonaveli, generišete sledeću sekvencu intervala: [0, 1], [0.4, 0.5], [0.4, 0.425], [0.40625, 0.41],[0.40625, 0.4071875] i [0.406625, 04067187]. Trebalo bi da uklopite vrednosti iz svakogkoraka na slici sa odgovarajućim koracima u tabeli i da potvrdite da su tačne. Još uvek nismoprošli kroz ceo string, tako da možete sami da izvežbate ostatak. Pretpostavite da ste sezaustavili nakon petog koraka. Onda možete da izaberete bilo koji broj iz intervala [0.406625,04067187], kao na primer, 0.4067, za predstavljanje stringa CABAC.
Slika 3 Koraci u procesu aritmetičkog kodiranja
Kako sada obrnuti proces? Osnovna ideja je da se najpre utvrdi u kom delu intervala [0,1] se nalazi broj. Tako se utvrđuje prvi karakter u stringu. Na primer, pretpostavite da stepredstavili broj N = 0.4067. i da znate samo sadržaj na slici 4.

| LearningObject | 27
Slika 4 Intervali kod aritmetičkog kodiranja
Uočavamo da se nalazi u intervalu [0.4, 0.5]. To znači da je prvi korak u procesu kompresijemorao da počne intervalom [0.4, 0.5]. Dakle, prvi karakter je bio C, a svi ostali su morali daimaju broj iz nekog drugog podintervala. Kuda idemo dalje?
Na Slici 5 dati su koraci procesa dekompresije. Sada treba da utvrdite u kom delu intervala[0.4, 0.5] se nalazi vrednost N. Tako ćete utvrditi sledeći karakter. Primećujete da je N mnogobliže 0.4 nego 0.2. Koliko bliže? Da biste to izračunali, oduzmite p od N, čime se dobija 0.0067(korak 1 na Slici 5), i podelite to širinom intervala, tako da se dobija 0.067. To ukazuje da Niznosi samo 6,7 odsto rastojanja od p do q. Ako ovo uporedite sa mogućim [p,q] intervalima,videćete da se vrednost nalazi u prvoj četvrtini intervala [0.4, 0.5 ]. Drugim rečima, drugikorak procesa kompresije je morao da koristi [p, q] = [0, 0.25], što znači da je drugi karaktermorao da bude A.
U kom delu intervala [0, 0.25 ] se nalazi 0.067? Izgleda da je na četvrtini puta od 0 do 0.25,ali treba da budete malo precizniji. Izvodeći ista izračunavanja kao i malopre, oduzimajući p= 0 od N = 0.067 da bi se dobilo 0.067 i deleći sa širinom intervala 0.25, dobija se 0.268, štoznači da se N = 0.067 nalazi na oko 26,8 odsto rastojanja od p = 0 do q = 0.22. Na taj način,treći korak procesa kompresije pokazuje da se mora koristiti interval [0.25, 0.40], odnosno daje treći karakter bio B.

| LearningObject | 28
Slika 5 Koraci u procesu aritmetickog kodiranja
Ako nastavite na ovaj način, dobijate da je četvrti karakter bio A,. Zajedničkim postavljanjemkaraktera koje ste generisali dobijate string CABAC, tačno ono što je generisala i tabela
Postoji jedan manji problem kod ovog metoda - kada treba da se zaustavite. Kada se vršidekompresija, sve što predstavljate je broj i slično onome što se nalazi u tabeli. Da ste izvelialgoritam kompresije još nekoliko koraka dalje, generisali biste manji interval u kome bi senašao broj 0.4067. Ne postoji ništa što bi ukazalo da se treba zauslaviti u određenoj tački.
Algoritmi aritmetičke kompresije obično rešavaju ovaj problem dodavanjem jednog karaktera,terminalnog karaktera, na kraj originalnog stringa. Tretira se kao i ostali karakteri. Međutim,kada se generiše za vreme kompresije, proces se zaustavlja. Ovo je slično kompresovanjurečenica promenljive dužine, jedne po jedne, kada se zaustavljamo u slučaju da se generišetačka.
Postoji još nešto što treba da istaknemo. Jednostavno smo opisali kako da pridružimorealan broj stringu. Pošto smo pretpostavili da će string biti kompresovan, moramo da sezapitamo kako je ovo povezano sa uzorcima bitova. Odgovor leži u metodima koji se koristeza smeštanje realnih brojeva. Ovde nećemo navoditi raspravu o uzorcima bitova za brojeve upokretnom zarezu. Glavna ideja je da se bilo koji realni broj izmedu 0 i 1 može predstaviti sapreciznošću od sedam cifara pomoću 32-bitne reprezentacije. Na osnovu tabele, svaki broj izintervala [0.406625, 0.4067187] lako može da se predstavi sa željenom tačnošću pomoću 32bita. U stvari, mogli bismo da obradimo još nekoliko karaktera, a da se i dalje koristi 32-bitnareprezentacija.
Medutim, da je string bio duži, subintervali bi bili manji nego što je potrebno za tačnost odsedam cifara. U ovom slučaju je potrebna proširena preciznost. Detalji bi bili prikladniji zaknjigu o organizaciji kompjutera, ali moguće je pokazati da bilo koji broj izmedu 0 i 1 možeda se predstavi uz preciznost od 16 decimalnih mesta pomoću 64 bita. Ako 16 cifara nijedovoljno, onda bismo mogli da pređemo na sledeći nivo.
U opštem slučaju, interval [x, y] postaje manji dok se broj karaktera povećava. Osim toga,postoje procedure koje mogu da aproksimiraju bilo koji realni broj do određene tačnosti akose koristi dovoljan broj bitova.
Run-Length kodiranje
Cilj• Upoznavanje sa Run-Length kodiranjem

| LearningObject | 29
Run-Length kodiranjeRun-Length kodiranje
Hafmanovi kodovi redukuju broj bitova koji se šalju, ali je kod njih neophodno znati vrednostučestalosti pojavljivanja. Kao što smo opisali, kod njih je pretpostavljeno da su bitovi grupisaniu karaktere, ili neke druge jedinice koje se ponavljaju. Mnogi elementi koji putuju prekokomunikacionog medijuma, uključujući binarne (mašinski kodirane) fajlove, podatke koji sešalju faksom i video signale, ne ubrajaju se u tu kategoriju.
Na primer, bitovi koji se prenose preko faksa odgovaraju rasporedu svetlih i tamnih oblasti naparčetu papira. Nema direktnog prenosa karaktera. Zbog toga, postoji potreba za opštijomtehnikom koja može da kompresuje proizvoljne nizove bitova. Jedan pristup, poznat podnazivom run-length kodiranje, koristi jednostavan i očigledan koncept: niz bitova se analizirada bi se pronašli dugački nizovi nula ili, jedinica. Umesto svi bitovi, šalje se samo njihov broj unizu.
Ova tehnika je posebno korisna prilikom prenosa podataka pomoću faksa. Ako pažljivijeproučite prostor na korne je otkucan jedan karakter, videćete da je 70 do 80 odsto prostorabele boje. Naravno, tačna količina zavisi od fonta i samog karaktera. Konkretna tamna mestaotkucanog karaktera učestvuju sa veoma malim procentom u prenosu pomoću faksa. Naprimer, primetićete količinu belog prostora kod uvećane reprezentacije malog slova f najednoj štampanoj poziciji.Nizovi istog bitaPostoji nekoliko načina za implementaciju run-length kodiranja. Prvi je posebno koristankod binarnih stringova, kod kojih se u većini nizova javlja isti bit. U primeru stringa kojise prenosi preko faksa imamo string koji je sastavljen prvenstveno od karaktera i zato ćepostojati dugački nizovi 0 (uz pretpostavku da 0 odgovara svetlim mestima). Ovaj pristuppodrazumeva slanje dužine svakog niza u vidu binarno izraženog celog broja fiksne dužine.Prijemni uredaj prihvata dužinu svakog niza i generiše odgovarajući broj bitova u nizu,umećući drugi bit izmedu tih nizova.
Na primer, pretpostavimo da se za predstavljanje dužine niza koriste grupe od po četiri bita.Razmotrimo niz sa Slike 1a. Na Slici 1b prikazan je poslati kompresovani string.
Originalni string počinje sa 14 nula, tako da su prva četiri bita kompresovanog stringa 1110(binarno 14). Sledeća četiri bita u kompresovanom stringu su 1001 (binarno 9 za sledeći nizod devet 0). Nakon drugog niza postoje dve uzastopne jedinice. Medutim, kod ovog pristupasmatra se da između uzastopnih jedinica postoji niz bez nula. Zato se u trećoj grupi od četiribita koristi kombinacija 0000.
U četvrtom nizu postoji 20 nula. Medutim, broj 20 ne može binarno da se predstavi sa četiribita. U tom slučaju, koristi se još jedna grupa od četiri bita. Dva 4-bitna broja se nakon togasabiraju i dobija se ukupna dužina niza. Na slici 1b, 1111 (binarno 15) i 0101 (binarno 5)određuju niz dužine 20.

| LearningObject | 30
Slika 1 String pre kompresije i nakon run-length kodiranjaAko je dužina niza suviše velika da bi se izrazila kao suma dve 4-bitne grupe, koristi seonoliko grupa koliko je potrebno za defmisanje te sume. Prijemni uređaj mora da zna dagrupa sa svim jedinicama ukazuje da iza nje sledi još jedna grupa koja definiše dužinu niza.Tako se nastavlja sumiranje sve dok se ne dođe do grupe u kojoj se ne nalaze sve jedinice.Na primer, niz dužine 30 je predstavljen sa 1111, 1111 i 0000. U ovom slučaju je neophodnagrupa sa svim nulama da bi se uredaju "saopštilo" da se niz završava nakon 30 nula.
Kako bi izgledao kompresovani string da je originalni string sa Slike 1a počeo jedinicom?Slično slučaju sa dve uzastopne jedinice, metod "smatra" da string počinje nizom nula dužine0. Dakle, prva četiri bita su 0000.
Ova tehnika je najefikasnija kada postoji veliki broj dugačkih nizova 0. Kako se povećavaučestalost pojavljivanja jedinica, tako se smanjuje efikasnost ovog metoda. U stvari, mogućeje iskoristiti ovaj princip za kodiranje dugačkih nizova nekog drugog karaktera.Nizovi sa različitim karakterima
Ako znate da se u stringu često javlja isti bit, okolnosti se pojednostavljuju, jer je potrebnoslati samo dužinu niza. Šta je sa slučajevima kada postoje nizovi različitih bitova, ili, čak,karaktera? Verovatno pretpostavljate rešenje za te slučajeve: šalje se konkretni karakter,zajedno sa dužinom njegovog niza. Na primer, string
HHHHHHHUFFFFFFFFFFFFFFYYYYYYYYYYYYYYYYYYYYDGGGGGGGGGGG
može da se prenese naizmeničnim slanjem broja pojavljivanja u nizu i karaktera 7, H; 1, U;14, F; 20, Y; 1, D; i 11, G.Faksimil kompresija
Duži niz godina (pre pojave WinZipa i Interneta) jedan od najčešće korišćenih primerakorišćenja kompresije bio je prenos podataka pomoću faksa. U opštem slučaju, crno-belaslika je sastavljena od velikog broja piksela, koji predstavljaju bele i crne tačke na stranici.U stvari, ITU je definisao operacione standarde za različite grupe mašina. Ovde se nećemobaviti razlikama izmedu tih grupa, već ćemo se fokusirati na šeme kompresije da bismo senadovezali na prethodnu raspravu.
Za našu diskusiju relevantna su dva ITU standarda - T.4 i T.6, koji definišu kompresiju zaono što nazivamo mašinama Grupe 3 i Grupe 4. U osnovi, to su mašine koje koriste digitalnemetode za prenos slika preko telefonske mreže. Iako su moguće različite veličine stranica, mićemo se fokusirati samo na A4 dokumente, tj. stranice veličine 210x297 mm.

| LearningObject | 31
A4 dokument sadrži 1.728 piksela u svakoj liniji. Ako bismo poslali po jedan bit za svakipiksel, morali bismo da prenesemo više od tri miliona bitova za svaku stranicu - to je ogromnakoličina informacija za veoma jednostavne slike. Standardi T.4 i T.6 koriste činjenicu datipična slika sadrži mnogo uzastopnih belih, ili crnih piksela, tako da postoji veliki brojnizova sa uzastopnim nulama, ili jedinicama. Ovo je definitivno dobra osnova za korišćenjerun-length kompresije. Ipak, postoje dve "stvari" koje treba istaći. Prvo, dužina niza možeda varira izmedu 0 i 1.728, kreirajući razne moguće kombinacije. Medutim, ovaj metodispoljava određenu dozu neefikasnosti prilikom postavljanja formata za predstavljanje bilokog broja iz ovog opsega. Drugo, neki nizovi mogu da se jave sa veoma visokom učestalošćupojavljivanja. Na primer, većina otkucanih stranica sadrži uglavnom bele piksele, možda čak80 odsto, ako ne i više.
Razmak između susednih slova, ili pre prvog slova u liniji obično je konstantan. I između linijamožete da očekujete da nema crnih piksela - drugim rečima, postoje samo dugački nizovibelih piksela. Posle svake linije teksta možete da očekujete nekoliko linija (u zavisnosti odproreda) od po 1.728 belih piksela.
Krajnji zaključak je da se kod mnogih faks slika može predvideti, prilično pouzdano,verovatnoća da će se određeni nizovi pojaviti. Ovo nalaže korišćenje nekog tipa frekventnozavisnog kodiranja koje se zasniva na dužini niza. Standardi T.4 i T.6 za faksimil kompresijukoriste, u stvari, kombinaciju nizova sa belim i cmim pikselima, poštujući frekventno zavisnikod koji je definisan učestalošću pojavljivanja tih nizova - naziva se modifikovani Hafmanovkod. Pretpostavke i proces se sastoje u sledećem:
1. Svaka linija sadrži naizmenične nizove belih i cmih piksela.2. Svaka linija počinje nizom belih piksela. Čak i kada se prenosi slika koja ima crne ivice,
proces poznat pod nazivom overscanning dodaje po jedan beli piksel na početak i na krajsvake linije.
3. Izračunavaju se kodovi za naizmenične nizove belih i crnih piksela, a zatim se prenosekodirani bitovi.
Na Slici 2 je prikazan podskup kodova koji definišu dužine nizova belih i crnih piksela.Kompletna tabela definiše kod za nizove dužine izmedu 0 i 63, zaključno, i za dužine 64, 128,192, 256 i tako redom. Nakon 64, ITU definiše samo kodove za dužine koje predstavljajuumnožak broja 64. Tako se smanjuje ukupan broj potrebnih kodova. Kodovi za nizove čijaje dužina manja od 64 nazivaju se konačni kodovi (engl. terminating codes), a oni čija jedužina umnožak broja 64 nazivaju se kodovi "doterivanja" (engl. makeup codes). Svaki nizčija je dužina manja od 64 piksela kodira se pomoću konačnog koda. Ako je dužina veća od64 piskela, metod koristi kod "doterivanja" za najduži niz koji se u potpunosti može smestiti uoriginalni niz i konačni kod za preostale bitove.
Na primer, niz koji se sastoji od 50 belih piksela može da se kodira kao 01010011. Zatim,uzmimo primer niza koji ima 572 bela piksela. On se interpretira kao niz dužine 512 piksela,iza koga sledi niz od još 60 piksela. Pridruženi kod je 01100101-01001011. U ovoj instanci 512bitova je kompresovano na 16 bitova, što predstavlja redukciju od skoro 97 odsto.

| LearningObject | 32
Slika 2 Neki kodovi faksimil kompresije
Naravno, veći broj manjih nizova neće imati toliko veliki procenat kompresije, ali nijeneuobičajeno postići kompresiju od 90 odsto. Sledi nekoliko opažanja na osnovu Slike 2.• Kodovi za nizove belih piksela su kraći od nizova crnih piksela, jer su beli nizovi češći.• I za bele i za crne nizove koriste se run-length kodovi sa no-prefix svojstvom.• Kompresija je bolja kod slika sa dužim nizovima.
Iako ovo važi i za T.4 i za T.6 standard, postoje razlike izmedu njih. Na primer, šema koju smoopisali dobro funkcioniše za tipične kucane stranice. Obično postoji dovoljno nizova u svakojliniji da bi se efikasno iskoristili kodovi za kompresiju. Medutim, ako slika sadrži složeneuzorke, ili je, možda, reč o fotografiji, nekoliko dugačkih nizova može da se nađe bilo gde naslici, a ostatak obično čine veoma kratki nizovi. Pošto se kratki nizovi kompresuju sa manjimprocentom redukcije, ovaj pristup (bar ovaj koji smo ovde opisali) ne funkcioniše baš najbolje.
Alternativa koju je usvojio standard T.6 koristi činjenicu da se dve uzastopne linije verovatnone razlikuju isuviše. Zbog toga, umesto da se kompresuje svaka linija nezavisno, standard T.6uspostavlja osnovnu liniju, pa utvrduje razliku izmedu nje i sledeće linije. Ako je razlika veomamala, sledeća linija može da se kodira sa manjom količinom dodatnih informacija; tako možeda se postigne zadovoljavajuća kompresija. Pošto u sledećem delu objašnjavamo kompresijukoja se zasniva na utvrđivanju različitosti, ovde se nećemo baviti detaljima.
L15 Distribuirani sistemi
Zaključak*Studenti stiču razumevanje i solidna znanja iz oblasti distribuiranih sistema.

| LearningObject | 33
LearningObject
Kompjuterska forenzika
Cilj• Upoznavanje sa kompjuterskom forenzikom
Kompjuterska forenzikaUvod
Kompjuterska forenzika je grana nauke forenzika koja se odnosi na sudske pravne dokazepronađene na računaru i digitalnim sredstvima za skladištenje podataka. Kompjuterskaforenzika je takođe, poznata kao digitalna forenzika
Cilj kompjuterske forenzike je istražni postupak nad računarskim sistemom u kome seutvrđuju uzroci nekog incidenta.
Kompjuterska forenzika je primjena nauke i inženjeringa na pravni problem digitalnih dokazaKompjuterska forenzika je naučno ispitivanje i analiza zadržanih podataka ili preuzetih samedija za skladištenje na računaru tako da se informacije mogu koristiti kao dokaz na sudu.
Alati i tehnike koje ova disciplina zahtjeva su relativno lako dostupne svakome ko želi dasprovede forenzičku analizu. Od kompjuterskih istražitelja se zahtijeva ispitivanje na svakojfizičkoj lokaciji, a ne samo u kontrolisanim uslovima. Prikupljanje digitalnih dokaza počinjekada se informacija i/ili fizički objekt prikupe ili skladište u očekivanju ispitivanja.
Termin dokaz implicira da je onaj koji je dokaz prikupio prepoznat od strane suda i da jeproces prikupljanja takođe prepoznat kao legalan proces, u skladu sa lokalitetom sa kogaje prikupljen. Podatak ili fizički objekt postaje dokaz jedino kada je prikupljen od straneovlašćenog lica.
Forenzičku analizu obavljaju stručni timovi. Timovi rade u oblasti visokih tehnologija, i toponekad može biti analiza samih računarskih i informacionih sistema i mreža, a ponekadmože biti samo deo veće istrage ili pomoćna analiza. Timovi za forenzičku analizu formirajuse po potrebi za određeni slučaj
Sakupljanje digitalnih dokaza
Jedan od najosetljivijih postupaka i greške u ovom postupku dovode do gubitka i/ili oštećenjadokaza, ili ih mogu učiniti nepouzdanim, pa čak i neupotrebljivim. Pre prikupljanja dokazatreba detaljno proceniti razmatrani slučaj i na osnovu toga odrediti smer postupanja.
U takvu procenu ulaze nalog za pretraživanje, detalji slučaja, vrsta ispitivane hardverske iprogramske podrške, potencijalni dokazi koji se traže i uslovi njihovog prikupljanja.
Posebna pažnja mora se voditi pri obradi kompjuterskih dokaza:• Većinu digitalnih informacija je lako promijeniti, a nakon što je promjenjena obično je
nemoguće prepoznati da je promjena izvršena.

| LearningObject | 34
• Iz tog razloga je uobičajena praksa da se izračunati kriptografski izvod (engl. hash)dokazne datoteke snimi na drugom mjestu, obično u istraživačke sveske, tako da se možedokazati kasnije da nije izmijenjen.
• Druge specifične prakse u obradi digitalnih dokaza uključuju:• Snimanje medija pomoću računarskih alata za zabranu upisivanja (engl.writeblocking) kako
bi se osiguralo da nema dodatih podataka sa sumljivog uređaja.• Uspostaviti i održavati lanac nadzora.• Dokumentovanje svega što je učinjeno.• Koristite samo sredstva i metode koje su ispitane i procenjene za njihove tačnost i
pouzdanosti.
Tri osnovna formata log datoteka
1. System log: Sistem logovi sadrže podatke o događajima i aktivnostima koji izazivajukomponente sistema. Tipovi događaja koji odgovaraju svakom od ovih logovapredefinisanisu od strane samog sistema.
2. Security log: Logovi ovog tipa sadrže informacije o validnim i ne validnim pokušajimalogovanja kao i događaje koji regulišu korišćenje resursa. Logovi ovog tipa dostupni susamo administratoru sistema i adminsitrator određuje koje će aktivnosti nadzirati.
3. Application log: Aplikacioni logovi su najbrojniji logovi i beleže aktivnosti aplikacija.Tvorci aplikacija određuju šta će se nadzirati i logovati.
Analiza
• Najizazovniji i najinteresantniji dio forenzičkog procesa.• Da bi uspešno izvršio analizu, istražitelj mora poznavati način rada operativnog sistema i
aplikacije koja je predmet istrage.• Svi digitalni dokazi moraju biti analizirani kako bi se utvrdila vrsta informacija koje se
čuvaju na njoj.• Poželjno je da se dokazni materijali analiziraju u kontrolisanim uslovima, koji postoje u
posebnim forenzičkim laboratorijama.• Kada je moguće treba analizirati kopije dokaza da bi se izbjeglo nenamjerno oštećenje
orginala.• Redoslijed ispitivanja dokaza može se utvrditi prema mjestu pronalaska ili stabilnosti
medijuma na kojima su smješteni.
Metode analiza
Mogu se klasifikovati u četiri grupe:
• Analiza vremenskog redoslijeda događaja - utvrđuje se redoslijed događaja i povezujuse sa korisnicima sistema.
• Pronalaženje skrivenih podataka - utvrđuje se postoje li podaci koji su šifrovani,zaštićeni lozinkama, sakriveni komprimovanjem ili primjenom steganografije.
• Analiza programa i datoteka. Iz analize podataka i programa koji se nalaze naračunaru, može se saznati o korisniku, njegovom nivou znanja, navikama u radu i slično.
• Analiza vlasništva nad datotekama. Identifikovanje korisnika koji je napravio određenudatoteku, izmijenio je ili joj pristupio može biti veoma značajno za istragu
Izveštaji
Nakon završetka analize, izrađuje se izveštaj i predaje se nadležnoj instituciji ili organizacijipo čijem je nalogu urađena računarska forenzička analiza.

| LearningObject | 35
Ukoliko je namijenjen dokaznom ili sudskom postupku izveštaj ima propisanu formu i sadržaj.Završni izvještaj o incidentu sadrži:
• relevantne podatke o incidentu• prepoznavanje izvora napada• prepoznavanja i uklanjanje sigurnosnih propustaKoristiti se u sklopu procesa za upravljanje sigurnosnim incidentima
Evidencija prikupljenih podataka
Evidencija prikupljenih dokaza predstavlja dnevnik u kome se upisuju svi podaci oprikupljenim dokazima. Kvalitetna evidencija obezbjeđuje punu vjerodostojnost dokaza.
U njoj se moraju nalaziti podaci koji mogu dati odgovor na slijedeća pitanja:
• Ko je prikupio dokaz?• Kako i gde je dokaz prikupljen?• Kome i kada (vrijeme i datum) je dokaz dat?• Kako je dokaz uskladišten i zaštićen?• Ko je izuzeo dokaz iz skladišta i zbog čega?Profesionalni istražni organi završavaju specijalnu obuku radi spriječavanja kompromitovanjadokaza.
Kompromitovani dokazi obično nisu prihvatljivi u sudu.
Obezbjeđenje dokaza
• Mora se ograničiti pristup dokazima da bi bili obezbijeđeni.• Policija i druge zakonske institucije koriste zasebne prostorije za čuvanje dokaza, sa
ograničenim pravima pristupa; jedno lice je zaduženo za kontrolu pristupa.• Dokazi u vidu elektronskih medijumima čuvaju se u prostorijama koja nisu izložena dejstvu
neuobičajenih temperatura i promjeni vlažnosti.• Poželjno je da se dokazi pakuju u plastične vrećice sa naljepnicama na kojima seispisani
datum i vrijeme prikupljanja i lice koje je prikupilo dokaz.
Kompjuterska forenzika
Kompjuterska forenzikaZadatak:
Ukratko opisati osnove “EnCase Guidance Software” alata za kompijutersku forenziku.
Napomena: Domaći zadatak je potrebno uraditi u MS Word (doc) ili LibreOffice (odf) formatui poslati predmetnom profesoru na: [email protected]
Naziv zadatka treba da bude: IT270-DZ15-ime_prezime_brojIndexa
Subjekat mail-a treba da bude: IT270-DZ15