cosc 6339 big data analytics python mapreduce and 1...
TRANSCRIPT

1
COSC 6339
Big Data Analytics
Python MapReduce and
1st homework assignment
Edgar Gabriel
Spring 2018
pydoop
• Python interface to Hadoop that allows you to write
MapReduce applications in pure Python
• Offers several features interesting features:
– MapReduce API that allows to write pure Python mappers, reducers, record readers, record
writers, partitioners and combiners
• No python method for creating your own InputFormat, but possible to include java
InputFormats
- Support for HDFS API

2
Wordcount in pydoop
#!/usr/bin/env python
import pydoop.mapreduce.api as api
import pydoop.mapreduce.pipes as pp
class Mapper(api.Mapper):
def map(self, context):
words = context.value.split()
for w in words:
context.emit(w, 1)
class Reducer(api.Reducer):
def reduce(self, context):
s = sum(context.values)
context.emit(context.key, s)
def __main__():
pp.run_task(pp.Factory(Mapper, Reducer))
Executing a pydoop job
• pydoop submit --num-reducers 5 --upload-file-to-
cache wordcount_pydoop.py wordcount_pydoop
/gabriel/books/ /gabriel/output
• pydoop submit --num-reducers 5 --input-
format=org.apache.hadoop.mapreduce.lib.input.KeyVa
lueTextInputFormat --upload-file-to-cache
book_per_line.py book_per_line
/gabriel/booklists.txt /gabriel/output8

3
pydoop submit -h
usage: pydoop submit [-h] [--num-reducers INT] [--no-override-home]
[--no-override-env] [--no-override-ld-path]
[--no-override-pypath] [--no-override-path]
[--set-env VAR=VALUE] [-D NAME=VALUE]
[--python-zip ZIP_FILE] [--upload-file-to-cache FILE]
[--upload-archive-to-cache FILE] [--log-level LEVEL]
[--job-name NAME] [--python-program PYTHON] [--pretend]
[--hadoop-conf HADOOP_CONF_FILE]
[--disable-property-name-conversion] [--mrv1]
[--local-fs] [--do-not-use-java-record-reader]
[--do-not-use-java-record-writer] [--input-format CLASS]
[--output-format CLASS]
[--job-conf NAME=VALUE [NAME=VALUE ...]]
[--libjars JAR_FILE] [--cache-file HDFS_FILE]
[--cache-archive HDFS_FILE] [--entry-point ENTRY_POINT]
[--avro-input k|v|kv] [--avro-output k|v|kv]
MODULE INPUT OUTPUT
gabriel@whale:> pydoop submit < omitting list of arguments>
17/02/12 08:38:33 INFO client.RMProxy: Connecting to ResourceManager at
whale/192.168.3.253:10040
17/02/12 08:38:34 WARN mapreduce.JobResourceUploader: No job jar file set.
User classes may not be found. See Job or Job#setJar(String).
17/02/12 08:38:34 INFO input.FileInputFormat: Total input paths to process
: 1
17/02/12 08:38:35 INFO mapreduce.JobSubmitter: number of splits:1
…
17/02/12 08:38:49 INFO mapreduce.Job: map 0% reduce 0%
17/02/12 08:39:02 INFO mapreduce.Job: map 100% reduce 0%
17/02/12 08:39:12 INFO mapreduce.Job: map 100% reduce 100%
17/02/12 08:39:13 INFO mapreduce.Job: Job job_1486767070254_0001 completed
successfully
17/02/12 08:39:13 INFO mapreduce.Job: Counters: 51
File System Counters
FILE: Number of bytes read=2008
FILE: Number of bytes written=246163
…
4
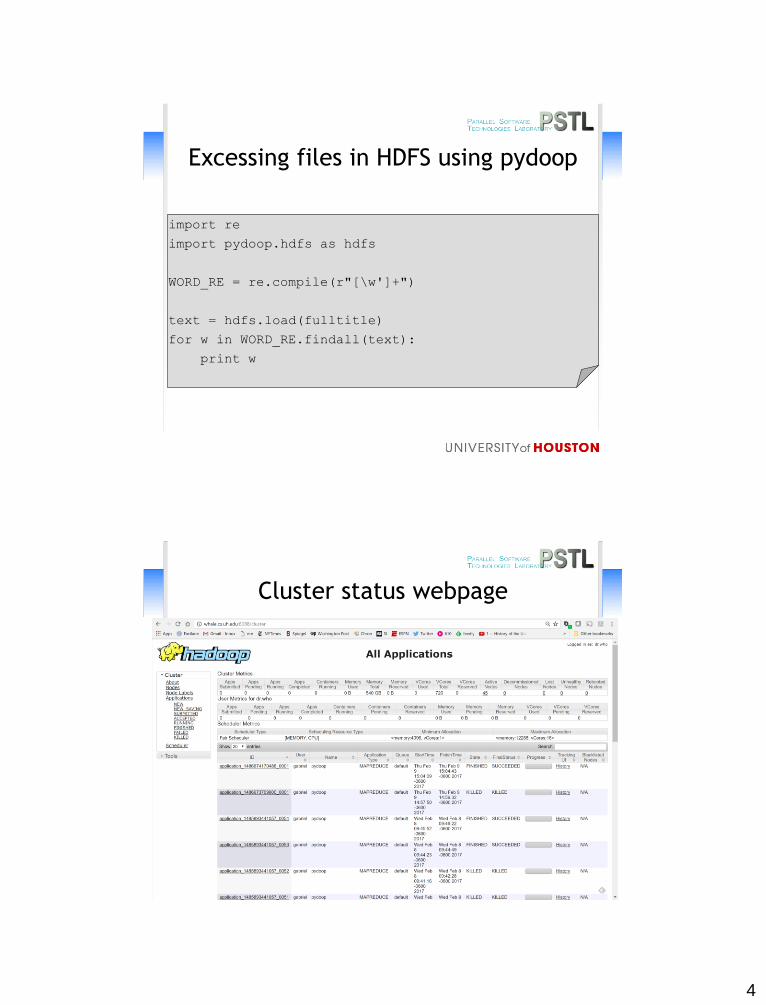
import re
import pydoop.hdfs as hdfs
WORD_RE = re.compile(r"[\w']+")
text = hdfs.load(fulltitle)
for w in WORD_RE.findall(text):
print w
Excessing files in HDFS using pydoop
Cluster status webpage
5
Debugging your application
• Major parts of your python application can first be tested using the
interactive python shell
gabriel@whale> python
>>> import re
>>> import pydoop.hdfs as hdfs
>>> WORD_RE = re.compile(r"[\w']+")
>>> text = hdfs.load("/cosc6339_s17/books-
shortlist/9055_bad+medicine.txt")
>>> for w in WORD_RE.findall(text):
... print w
...
a
vlendish
manner
The
How to kill a job if it is hangingbigd65@whale:> yarn application -list
16/02/05 17:01:23 INFO client.RMProxy: Connecting to ResourceManager at whale/192.168.3.253:10040
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-
State Progress Tracking-URL
application_1391622275771_0007 wordcount MAPREDUCE gabriel default RUNNING
UNDEFINED 5% http://whale-001:58572
bigd65@whale:> yarn application -kill
application_1391622275771_000716/02/05 17:01:38 INFO client.RMProxy: Connecting to ResourceManager at whale/192.168.3.253:10040
Killing application application_1391622275771_0007
14/02/05 17:01:38 INFO impl.YarnClientImpl: Killing application application_1391622275771_0007

6
• Retrieve the ID of your application
bigd65@whale:> yarn application -list
• Retrieve also the log files from across the cluster associated with
your application after it finished or was killed, e.g.
bigd65@whale:> yarn logs -applicationId yourID
– Might want to redirect it into an output file, since logs can be
large and exceed the buffering capability of your terminal, e.g.
yarn logs –applicationId yourid > output.log
Using HDFS
• If you want to run a MapReduce job on the cluster, you
have to have the input data in HDFS and the result also
will be in HDFS
– Input data set is already available with read-only
permission for all students in hdfs:///cosc6339_hw1/
• Similar commands for HDFS as for a local UNIX file
systemhdfs dfs –ls /
hdfs dfs –ls /cosc6339_hw1/
hdfs dfs –mkdir /bigd65/newdir
hdfs dfs –rm /bigd65/file.txt
hdfs dfs –rm -r /bigd65/newdir

7
Using HDFS (II)
• Copying a file into hdfs
hdfs dfs –put <localfilename> /bigd65/<remotefilename>
• Copying a file from hdfs into local directory
hdfs dfs –get /bigd65/output/part-r-00000 .
• Looking at the content of a file in hdfs
hdfs dfs –cat /bigd65/filename.txt
• Merging multiple output file (each reducer produces a separate
output file!)
hdfs dfs –getmerge /bigd65/output/part-* allparts.out
1st Homework• Rules
– Each student should deliver
• Source code (.py files) compressed to a zip or tar.gz
file
• Source code has to be using python 2.7
• Documentation (.pdf, .docx, or .txt file)
– explanations to the code
– answers to questions
– Deliver electronically on blackboard
– Expected by Friday, September 28, 11.59pm
– In case of questions: ask early!

8
1. Given a data set containing all flights which occurred
between 2006 and 2008 in the US
– ~21 Million flights listed in the file
– small file for code development with 286 flights available
in HDFS
– each line is one flight with information as listed on the
next pages
a. Implement a MapReduce job which determines the
percentage of delayed flights per Origin Airport
b. Implement a MapReduce job which determines the
percentage delayed flights per Origin Airport and Month
c. Determine the execution time of code developed in part
a. and b. for the large data set using 1, 2, 4, and 8
reducers. Comment on the results.
Description of the input file
• Comma separated list of data, the elements of which are explained
on the next page
• more information available at
http://stat-computing.org/dataexpo/2009/the-data.html
2008,1,3,4,NA,905,NA,1025,WN,469,,NA,80,NA,NA,NA,LAX,SFO,337,NA,NA,1,A,0,NA,NA,NA,NA,NA
2008,1,3,4,1417,1345,1717,1645,WN,2524,N458WN,120,120,105,32,32,MDW,MHT,838,4,11,0,,0,28,0,0,0,4
2008,1,3,4,852,855,959,1015,WN,3602,N737JW,67,80,57,-16,-3,ONT,SMF,389,4,6,0,,0,NA,NA,NA,NA,NA
2008,1,3,4,1726,1725,1932,1940,WN,563,N285WN,306,315,291,-8,1,RDU,LAS,2027,5,10,0,,0,NA,NA,NA,NA,NA
2008,1,3,4,2014,1935,2129,2045,WN,1662,N461WN,75,70,47,44,39,SLC,BOI,291,3,25,0,,0,0,0,6,0,38
2008,1,4,5,1617,1610,1813,1810,WN,2374,N344SW,56,60,46,3,7,ABQ,MAF,332,3,7,0,,0,NA,NA,NA,NA,NA
2008,1,4,5,839,820,1019,1010,WN,535,N761RR,100,110,82,9,19,BWI,IND,515,5,13,0,,0,NA,NA,NA,NA,NA
2008,1,4,5,814,810,930,930,WN,502,N641SW,76,80,62,0,4,ELP,PHX,347,3,11,0,,0,NA,NA,NA,NA,NA
• Some values can be numeric or NA, some values are missing (i.e.
there are two ,, in a row)

9
Variable descriptions
Name Description
Year 1987-2008
Month 1-12
DayofMonth 1-31
DayOfWeek 1 (Monday) - 7 (Sunday)
DepTime actual departure time (local, hhmm)
CRSDepTime scheduled departure time (local, hhmm)
ArrTime actual arrival time (local, hhmm)
CRSArrTime scheduled arrival time (local, hhmm)
UniqueCarrier unique carrier code
FlightNum flight number
TailNum plane tail number
ActualElapsedTime in minutes
CRSElapsedTime in minutes
AirTime in minutes
Variable descriptions
ArrDelay arrival delay, in minutes
DepDelay departure delay, in minutes
Origin origin IATA airport code
Dest destination IATA airport code
Distance in miles
TaxiIn taxi in time, in minutes
TaxiOut taxi out time in minutes
Cancelled was the flight cancelled?
CancellationCode reason for cancellation (A = carrier, B = weather,
C= NAS, D = security)
Diverted 1 = yes, 0 = no
CarrierDelay in minutes
WeatherDelay in minutes
NASDelay in minutes
SecurityDelay in minutes
LateAircraftDelay in minutes

10
Input files
• Small input available in hdfs in for development and
testing/cosc6339_hw1/flights-shortlist/sample-
flights.csv
• Large input available in hdfs in /cosc6339_hw1/flights-longlist/allflights.csv
– Only use large input file after you have confirmed that
your code runs correctly with the small input file
• In fact, for the very first steps, you can probably
initially create an even smaller test case with just a
couple of lines/entries
Output
• Every student has one directory in hdfs, please create
subdirectories only in that directory!
hdfs dfs –ls /bigd65/

11
Documentation
• The Documentation should contain
– (Brief) Problem description
– Solution strategy
– Description of how to run your code
– Results section
• Description of resources used
• Description of measurements performed
• Results (graphs/tables + findings)
• The document should not contain
– Replication of the entire source code – that’s why you
have to deliver the sources
– Screen shots of every single measurement you made
• Actually, no screen shots at all.
– The output files

12
Using the cluster
• Access of the cluster only through ssh , e.g.
ssh –l bigd65 whale.cs.uh.edu
• Change the default password given to you upon first login:
every other student knows your password as well!
use the passwd command
• Cluster will block your IP address for one hour after 5
unsuccessfull login attempts
• Copying of data files : use scp or sftp, e.g.
scp thisfile.py [email protected]:
scp [email protected]:thatfile.py .
– Be careful with editing files on windows and then
transferring it to the linux cluster (end of line marker is
different!)
Additional resources
• Python: https://docs.python.org/2.7/tutorial/
• Pydoop: https://crs4.github.io/pydoop/index.html
• Whale cluster: http://pstl.cs.uh.edu/resources/whale
• Hadoop status: https://whale.cs.uh.edu:8088/cluster
– Webpage only available inside of the University network
or when using a VPN connection from the outside of the
university campus!