concurrent q-learning: reinforcement learning for dynamic goals and environments
TRANSCRIPT

Concurrent Q-Learning: ReinforcementLearning for Dynamic Goalsand EnvironmentsRobert B. Ollington,* Peter W. Vamplew†
School of Computing, University of Tasmania, Churchill Avenue,Sandy Bay, Hobart, Tasmania 7001, Australia
This article presents a powerful new algorithm for reinforcement learning in problems wherethe goals and also the environment may change. The algorithm is completely goal independent,allowing the mechanics of the environment to be learned independently of the task that is beingundertaken. Conventional reinforcement learning techniques, such as Q-learning, are goal depen-dent. When the goal or reward conditions change, previous learning interferes with the new taskthat is being learned, resulting in very poor performance. Previously, the Concurrent Q-Learningalgorithm was developed, based on Watkin’s Q-learning, which learns the relative proximity ofall states simultaneously. This learning is completely independent of the reward experienced atthose states and, through a simple action selection strategy, may be applied to any given rewardstructure. Here it is shown that the extra information obtained may be used to replace the eligi-bility traces of Watkin’s Q-learning, allowing many more value updates to be made at each timestep. The new algorithm is compared to the previous version and also to DG-learning in tasksinvolving changing goals and environments. The new algorithm is shown to perform signifi-cantly better than these alternatives, especially in situations involving novel obstructions. Thealgorithm adapts quickly and intelligently to changes in both the environment and reward struc-ture, and does not suffer interference from training undertaken prior to those changes. © 2005Wiley Periodicals, Inc.
1. INTRODUCTION
Reinforcement learning ~RL! techniques, such as temporal difference ~TD!learning,1 have been shown to display good performance in tasks involving navi-gation to a fixed goal.2,3 However, if the goal location is moved, the previouslylearned information interferes with the task of finding the new goal location andperformance suffers accordingly.2
*Author to whom all correspondence should be addressed: e-mail: [email protected].
†e-mail: [email protected].
INTERNATIONAL JOURNAL OF INTELLIGENT SYSTEMS, VOL. 20, 1037–1052 ~2005!© 2005 Wiley Periodicals, Inc. Published online in Wiley InterScience~www.interscience.wiley.com!. • DOI 10.1002/int.20105

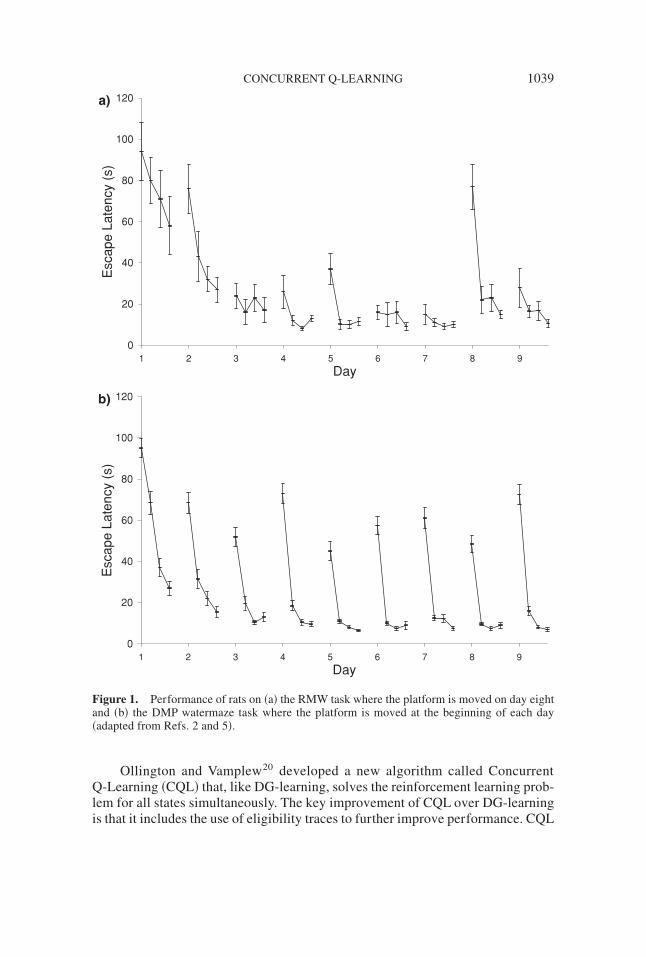
Rats do not exhibit this limitation and have been shown to achieve “one-triallearning” in tasks where the goal location is moved after learning to navigate to aprevious location. In the reference memory watermaze ~RMW! task,2,4,5 rats aretrained to find the location of a hidden platform in a circular pool over a period ofseveral days, undergoing four trials per day. After this initial training period, theplatform is moved to a new location. Once the new platform location is discov-ered, the rats are able to navigate directly to the new location on subsequent trials.
In the delayed matching-to-place ~DMP! task,2,5 the platform is moved at theend of every day. Even in this more complex task, the rats are able to achieveone-trial learning after very few days. Typical results for the RMW and DMP tasksare shown in Figure 1.
A crucial component of the rat’s spatial ability is the hippocampus, and inparticular place cells, which are found predominantly in areas CA1 and CA3.6,7
These cells fire whenever the rat is located at or near a particular location withinits environment, or more accurately, they predict the future location of the rat on ashort timescale ~;100 ms!.8 The region where the activity of a place cell is high iscalled the cell’s place field.
Recently, neurons have been found in the basal ganglia whose firing patternsshow a striking similarity to the TD error term.9–11 Moreover, it is known thatthere is considerable connectivity between the hippocampus and the basal ganglia.Thus, it is tempting to assume that the rat uses a TD-like technique to infer amap-like representation of its environment from the activity of hippocampal placecells.
Foster et al.2 explored the use of place cells for navigation in the watermazetasks using TD-learning. It was found that the performance of the actor-critic archi-tecture12 was qualitatively similar to that of a rat when the platform location wasnot moved. But, as expected, it was not able to achieve “one-trial” learning whenthe platform was moved.
To overcome this problem, Foster and colleagues2 used TD-learning in a novelway to learn a mapping from the place cells to a coordinate system. As the coordi-nate mapping became more accurate, the system was able to utilize this informa-tion to compute direct paths to the goal location. The coordinate learning was goalindependent and could be used to achieve one-trial learning when the platformwas moved.
A limitation of this method is the inability to deal appropriately with complexenvironments involving barriers and dead ends. In such environments computingthe direction to a goal location may not provide any useful information and mayeven be counterproductive. In the worst case scenario, this system will revert tousing the goal-dependent RL technique only and will not be able to achieve “one-trial” learning.
Previous work in the field of reinforcement learning has examined other meth-ods of achieving some degree of goal independence. DG-learning13 learns actionvalues to all goals simultaneously, and it was shown that for a nonfixed goal loca-tion this method was considerably faster than conventional reinforcement learningtechniques. Researchers have also explored methods of transferring knowledgebetween tasks.14–19
1038 OLLINGTON AND VAMPLEW
Ollington and Vamplew20 developed a new algorithm called ConcurrentQ-Learning ~CQL! that, like DG-learning, solves the reinforcement learning prob-lem for all states simultaneously. The key improvement of CQL over DG-learningis that it includes the use of eligibility traces to further improve performance. CQL
Figure 1. Performance of rats on ~a! the RMW task where the platform is moved on day eightand ~b! the DMP watermaze task where the platform is moved at the beginning of each day~adapted from Refs. 2 and 5!.
CONCURRENT Q-LEARNING 1039

was compared to the method of Foster and colleagues and to traditional Q-learningin the watermaze tasks. It was found that CQL was able to achieve “one-trial”learning in the RMW and DMP tasks in watermazes both with and without barri-ers. Furthermore, the new method learned faster than traditional Q-learning evenfor a fixed goal location.
Here a further refinement of the CQL algorithm is developed and comparedto the previous version and to DG-learning. The enhanced algorithm is tested onthe watermaze tasks and on grid-world tasks involving changing environmentsthat test the algorithm’s ability to deal with shortcuts and detours.
1.1. Temporal Difference Learning
TD learning1 is a form of RL that is able to update its estimate of the value ofa state based only on the observed reward upon reaching the next state and theestimated value of that state. The error at time t, dt , in a state-value prediction V iscalculated using Equation 1.
dt � Rt � gV~st�1!� V~st ! ~1!
where Rt is the observed reward, st and st�1 are the current and next state, and g isa discounting factor. Critically, the value function being learned is the value ofeach state with respect to the current policy. The policy is typically based on thevalue function, and so the value function and policy are being learned simulta-neously. This is referred to as an on-policy method.3
Sarsa21 is an extension of the TD concept that explicitly learns the values ofactions associated with states. That is, the task is to learn the action-value functionQ~s, a!. The error function is given in Equation 2.
dt � Rt � gQ~st�1, at�1!� Q~st , at ! ~2!
Sarsa is also an on-policy method since the value Q~st�1, at�1! depends on theaction chosen; that is, it depends on the current policy.
It has been shown that TD performance is improved by the inclusion of eli-gibility trace updates, which allow not only the value of the current state, but alsopreviously visited states to be updated at each time step. As each state or state-action pair is visited, a trace is initiated. If replacing traces22 are being used ~as inthe current work!, the trace is set to one as each state or state-action pair is visited.The trace decays over time according to a parameter l. At each time step all val-ues are updated in proportion to the corresponding trace.
None of these on-policy methods are suitable for goal-independent learning.In order to be goal independent, the algorithm must also be policy-independent.While similar to the Sarsa algorithm, Q-learning is an off-policy method. The errorterm is based on the best action value from the subsequent location rather than theaction value of the action chosen from that location. The Q-learning algorithm isindependent of the policy being followed but is not independent of the currentgoal.
1040 OLLINGTON AND VAMPLEW

Dyna-Q23 is a reinforcement algorithm that learns a model of the environ-ment. The model is used to generate simulated experiences, hence allowing addi-tional value updates. Dyna-Q is able to deal more successfully with dynamic goalsbecause many simulated experiences may be generated when changes to the modelare identified. However, the Dyna-Q algorithm is not goal independent. When thegoal changes, all values are adjusted to meet the new conditions and previouslylearned values are lost.
2. CONCURRENT REINFORCEMENT LEARNING
Foster and colleagues2 suggest that rodents learn a spatial representation thatis goal independent, allowing the rat to acquire one-trial learning when the loca-tion of the goal is moved, as in the watermaze task. Concurrent Q-Learning20 is agoal-independent learning method that produces similar performance to Foster andcolleagues’ model in the RMW and DMP watermaze tasks. However, it is alsoable to achieve one-trial learning in a watermaze task where an obstacle is intro-duced, an environment where coordinate learning, as used by Foster and col-leagues, will be of little benefit.
As with DG-learning, CQL solves the reinforcement learning problem for allpossible goal locations ~place fields! concurrently. Having learned this map-likerepresentation, it is possible to navigate from any location directly to any otherlocation, even if the desired destination has never been a goal.
Also in common with DG-learning, we make use of the relaxation procedureoutlined in Kaelbling,13 which enforces consistency by applying the triangularinequality:
AC � AB � BC ~3!
This equation can be converted to the Q representation:
Q sC ~sA , a! � Q sB ~sA , a!� maxa ' Q sC ~sB , a ' ! ~4!
This rule would ideally be applied to all possible state and action combinations foreach iteration of the learning algorithm. However, Kaelbling suggests that the com-plexity of the full relaxation procedure, O~S 3 � A!, would make this impractical.Therefore, we apply relaxation only for paths involving the most recently experi-enced state transition, reducing the complexity to O~S 2 � A!.
As with other forms of TD-learning, the learning rate of CQL may be signif-icantly improved if eligibility traces are included. Two methods of implementingeligibility traces for Q-learning are Watkins’ Q~l!24 and Peng’s Q~l!.25 The methodmost appropriate for CQL is Watkins’ Q~l! since Peng’s Q~l! is not truly an off-policy method.3
The implementation of Watkin’s Q~l! into CQL requires an eligibility tracebe kept for each state-action-goal combination. All traces for a state-action pairare set to 1 whenever that action is chosen from that state. Whenever a nonoptimalaction is chosen with respect to a particular goal, the eligibility trace for that goal
CONCURRENT Q-LEARNING 1041

is set to zero. The eligibility trace for the current location is also set to zero for allstate-action pairs. The new algorithm, denoted CQL-e, is given in Figure 2.
The major advantage of CQL-e over DG-learning is that the eligibility traces,when available, allow action values to be updated in either direction, whereas relax-ation alone can only find shorter paths. If a novel obstruction is introduced intothe environment, CQL-e should find an alternative route more quickly thanDG-learning, as DG-learning will take longer to learn that the length of the previ-ous path has now increased and will therefore be slower to begin exploring foralternate routes.
If an agent using DG-learning encountered the situation in Figure 3, the valuefor the action Er F would be updated. Even if full relaxation were then performed,
Figure 2. The CQL-e algorithm.
1042 OLLINGTON AND VAMPLEW

no additional values would be updated. In the case of CQL-e, the action values forDr E, Cr D, and Br C would also be updated. Ar B would not be updatedbecause the trace would have been set to zero as this action is not optimal withrespect to the goal G. However, the CQL-e algorithm still does not fully utilize allthe additional information now available; the number of updated values is far lessthan is conceptually possible. The major change to the CQL algorithm proposedby this paper is to increase the number of updates made per action.
To perform all possible updates in Figure 3, we need a method for determin-ing that an action is on an optimal path to a given goal. If ~s, a! is the state actionpair for which an error has just been observed, and if
Qsd~s o, ao ! � Qs~s o, ao !� Qsd
~s, a! ~5!
then the state-action pair ~s, a! must be on the shortest path from so , via ao , to sd .Therefore, any error observed in the action value for ~s, a! must also be appli-cable to ~so, ao !. To make the appropriate update, we can replace the eligibilitytrace esd
~s o, ao ! with the corresponding action value and apply the update rule
Figure 3. A navigational problem consisting of a grid of states with possible actions to eachadjacent state; a wall with two “doorways” divides the environment into two regions. An agentfamiliar with the environment has just moved along the path A-B-C-D-E and attempts to moveto F, but the doorway, previously open, has been blocked. Clearly the value of taking the actionEr F, with respect to the goal G, should be reduced. But any action for which the optimal pathto G previously included the action Er F should also have its value reduced. The actions forwhich this is the case are identified in bold.
CONCURRENT Q-LEARNING 1043

whenever Equation 5 holds, as shown in the new algorithm denoted CQL-q ~seeFigure 4!.
While the new update rule largely eliminates the need for relaxation, in cer-tain situations CQL-q may make value updates that are unduly pessimistic. Forexample, if two independent paths of equal length exist to a given goal, then if onepath becomes blocked the values for actions leading to the origin of both pathswill be reduced. Therefore, relaxation is still required to correct action values thatmay have been trained too low. However, relaxation now only needs to be per-formed for the current state, prior to action selection.
2.1. Inverse Actions
While not an integral component of the CQL algorithm, in many cases it ispossible to compute the inverse of any action and use this as though it were a realexperience. For example, in most navigational tasks it is possible to backtrack to aprevious location simply by reversing the direction of movement. In the case ofCQL-e, the action values Qsd
~s ', a�1 !, where a�1 is the inverse of the action achosen at s, can be updated for all sd , using Equation 6 to calculate the error d�1 .
Figure 4. The CQL-q algorithm.
1044 OLLINGTON AND VAMPLEW

d�1 R r sd� gmaxa Qsd
~s, a!� Qsd~s ', a�1 ! ~6!
A similar rule may also be used with DG-learning. When using CQL-e, alleligibility traces are clearly invalid for the inverse action, and therefore furtherinverse updates are not possible with this algorithm. When using CQL-q, how-ever, full updates may be made in the reverse direction by using the error calcu-lated in Equation 6, and applying the new update rule with Qs ' ~s o, ao ! in place ofQs~so, ao !.
Inverse action updates were used for all algorithms and experiments reportedin this article.
2.2. Choosing an Action
Having learned a “map” of the environment, all that remains is to choose anappropriate action. That is, a state must be chosen as an ultimate goal and an actionmust be chosen to move toward this goal. To do this, the agent must first have anestimate of the expected reward r s for each state s. Given the reward vector, theexpected return, Rs~s ', a!, of moving toward state s via an action a from the cur-rent state s ' can be calculated. The state-action pair with the highest expected returncan be chosen as a current goal and action as shown in Figure 5.
This greedy action selection algorithm may easily be modified to use an«-greedy ~as in the current work! or similar strategy. The method used to estimatethe expected reward for each state should be chosen based on the nature of theproblem faced by the learning agent. This issue will be revisited in the discussionof the test problems later in Sections 3 and 4.
3. WATERMAZE EXPERIMENT
The CQL method was tested for its ability to solve the RMW and DMP tasksas described in Steele and Morris.5 Input to the learning system was via 400 sim-ulated place cells, which is comparable to the number of place cells in Foster et al.2
Unlike Foster and colleagues, the environment was discretized into 400 correspond-ing locations in a square 20 � 20 grid ~note that some locations are not reachable!.Movement was restricted to the eight adjacent locations, with the action beingperformed in one time step.
Figure 5. Action selection for CQL.
CONCURRENT Q-LEARNING 1045

The platform was the same size as a single place field, making it proportion-ately the same size as in Steele and Morris.5 Platform locations were chosen to min-imize the possibility of straight-line movement between platform and start locations.
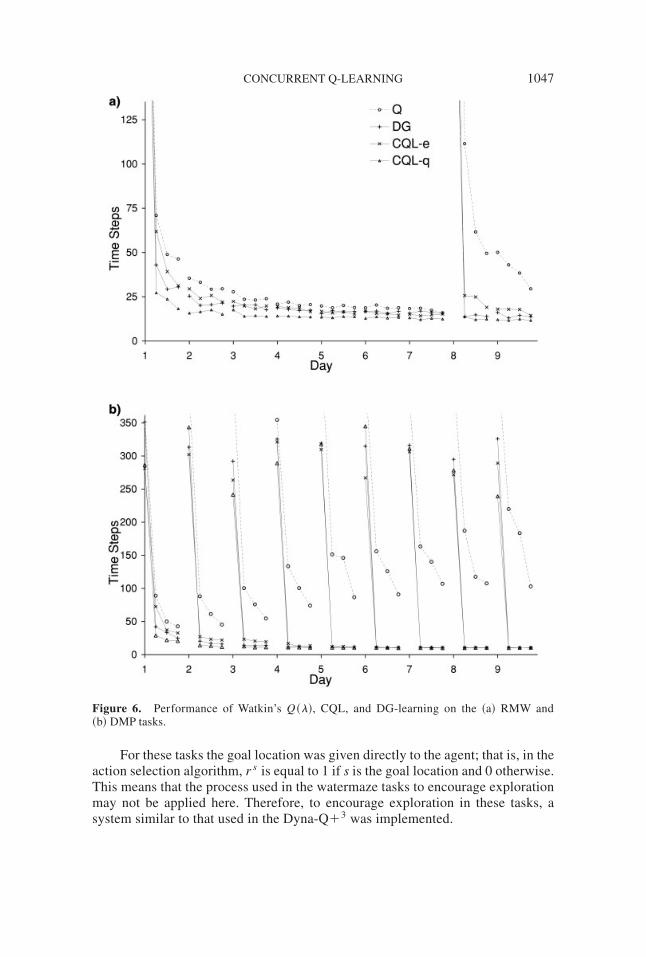
For the watermaze task, each location was assigned an initial estimate req ofthe expected reward for that state. At each time step, the reward for the currentlocation was updated to the experienced reward ~that is; 1 if the platform is reached,and 0 otherwise!. The value for all other locations decayed toward req at somesmall rate. In combination with the action selection algorithm, this process achievesa good balance between exploration and exploitation. In addition, to improve theefficiency of searching when the platform location is unknown, the system wasgiven a slight preference for traveling in the same direction as chosen at the pre-vious time step. This is similar to Foster and colleagues’ decision to add mo-mentum to their system. In addition, nongreedy actions were limited to the twodirections adjacent to the greedy action. Figure 6 compares the performance ofQ~l!, CQL-e, CQL-q, and DG-learning in the RMW and DMP tasks.
Like the actor-critic architecture in Foster et al.,2 Q~l! was able to learn theinitial goal location quite quickly, but performance suffered when the goal loca-tion changed. This was particularly noticeable in the DMP task where repeatedinterference from previous platform locations caused a progressive degradation inperformance. The improved performance over the actor-critic architecture in Fos-ter et al.2 was primarily due to the inclusion of eligibility traces.
The CQL-e algorithm learned faster than Q~l! and also showed very goodone-trial learning when the platform location changed in the RMW task. In theDMP task, CQL-e was able to achieve one-trial learning by day four to five.DG-learning performed slightly better than CQL-e, presumably this was due tothe alternate representation used. CQL-q learned faster than all other algorithms,due to the increased number of updates made at each time step.
4. CHANGING ENVIRONMENTS
To test the performance of the CQL algorithm in changing environments, agrid-world task was devised similar to those used by Sutton and Barto.3 A 10 �10square environment was divided into two equal sized “rooms”. The two roomswere connected by two doors, which could be opened or closed. The goal locationalternated between random locations in each room so that the agent had to navi-gate through the doors for each episode. Movement was allowed only in the North,South, East, and West directions.
The detour experiment started with both doors open. After the task had beenlearned by the agent, one door was closed. The blocking experiment started withone door open. After the task had been learned, this door was closed and the otherdoor opened. The shortcut experiment started with one door open. After a periodof time, the other door was opened to create a potential shortcut. Since these tasksrequire goal-independent learning, conventional reinforcement learning techniqueswill fail. Therefore, the three experiments were conducted for DG-learning, CQL-e,and CQL-q, only.
1046 OLLINGTON AND VAMPLEW
For these tasks the goal location was given directly to the agent; that is, in theaction selection algorithm, r s is equal to 1 if s is the goal location and 0 otherwise.This means that the process used in the watermaze tasks to encourage explorationmay not be applied here. Therefore, to encourage exploration in these tasks, asystem similar to that used in the Dyna-Q�3 was implemented.
Figure 6. Performance of Watkin’s Q~l!, CQL, and DG-learning on the ~a! RMW and~b! DMP tasks.
CONCURRENT Q-LEARNING 1047

In the Dyna-Q� algorithm, state-action pairs are assigned an additional rewardbased on the time since this action was last performed. This additional reward isused for training in both the learning and planning stages of the algorithm. In con-trast, we assign an additional value during action selection only and do not use thisexploration bonus to update values. In accordance with Sutton and Barto,3 theCQL algorithms will be denoted CQL-q� and CQL-e� when this strategy is used,and DG� when used with DG-learning. The action selection algorithm for theaction-based exploration strategy for CQL-q� and CQL-e� is shown in Figure 7.The environments and results for the detour, blocking, and shortcut experimentsare shown in Figure 8.
Figure 8a shows that CQL-q was able to solve the task more efficiently thanboth DG-learning and CQL-e. Most importantly, when the door was closed, CQL-qwas able to adjust to the new environment very quickly compared to DG-learningand CQL-e, both of which continued to try using the South door long after it wasclosed.
With DG-learning, relaxation updates are not applicable in this case, as theycan not be used to increase the estimated distance of the path via the South door.Hence, much exploration is required to correct previously learned values. Asexpected, the eligibility trace updates of CQL-e offered some improvement. Amore dramatic improvement is seen with the CQL-q algorithm, which is able toupdate all relevant action values as soon as the closed door is found. These pessi-mistic updates are then corrected as the agent searches for a shorter path via therelaxation updates.
For the blocking and shortcut tasks, the CQL-q�, CQL-e�, and DG� algo-rithms were used. Without the exploratory bonus given during the action selectionphase of these algorithms, the CQL and DG-learning algorithms find these prob-lems difficult to solve, as do goal-dependent algorithms such as Dyna-Q.3
Figure 8b shows a similar performance for all algorithms before the doorstates changed. When the doors were switched, however, CQL-q� was able tolocate and utilize the new path much more quickly than CQL-e� or DG�.
When the door is closed, CQL-q� quickly updates all values close to zero.With low action values the exploration bonus dominates, and an exploratory sweepof the room commences. Once the new door is discovered, CQL-q� immediatelyupdates all relevant action values and almost immediately returns to optimalbehavior. In contrast, action values are updated much more slowly by CQL-e�,
Figure 7. Action selection for CQL-q� and CQL-e�.
1048 OLLINGTON AND VAMPLEW
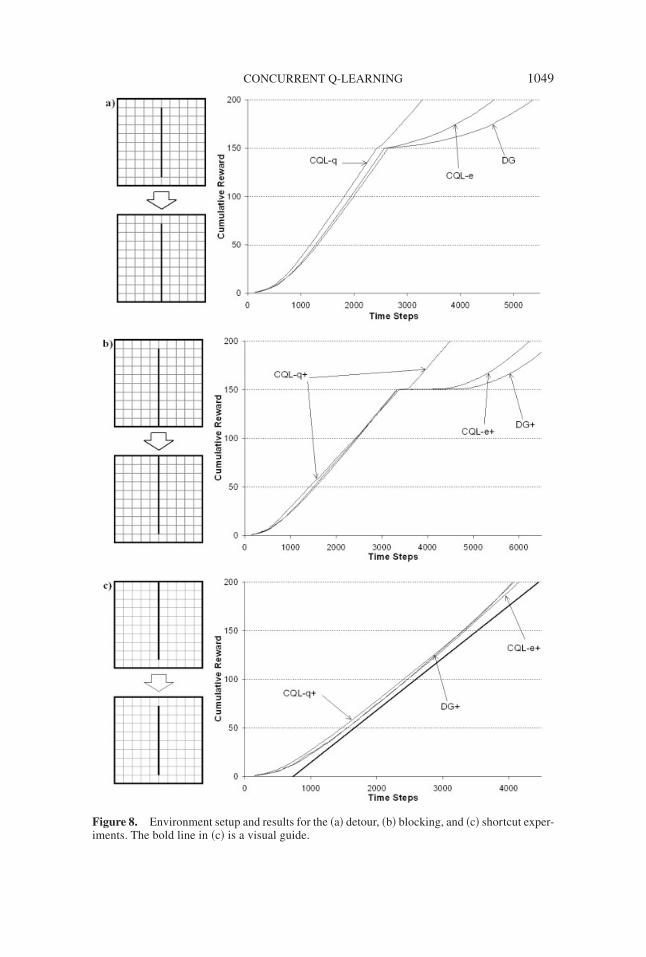
Figure 8. Environment setup and results for the ~a! detour, ~b! blocking, and ~c! shortcut exper-iments. The bold line in ~c! is a visual guide.
CONCURRENT Q-LEARNING 1049

and even more slowly by DG�. As a result the exploration bonus is not able todominate the now incorrect action values, and the agent begins a period of erraticbehavior.
The shortcut task in Figure 8c does not involve a novel obstruction, and there-fore all algorithms show similar performance in this task. The slight upward cur-vature of the graphs in the latter half of the experiment indicates that all threealgorithms correctly learn to exploit the shortcut.
5. CONCLUSION
Ollington and Vamplew20 developed a goal-independent reinforcement learn-ing method called Concurrent Q-Learning ~CQL-e!. Here that method was refinedby replacing the eligibility traces with an explicit measure of the distance betweenstates, as stored in the action values. This method dramatically increases the num-ber of value updates that may be made at each time step and also significantlyreduces the memory requirements by eliminating the need to maintain eligibilitytraces. The new method, CQL-q, was compared with both the previous versionand with Kaelbling’s DG-learning.
Testing was first conducted in a watermaze simulation where the goal loca-tion changes during training. Conventional reinforcement learning techniques areunable to deal with changing reward conditions in an intelligent way, while thecoordinate-based approach of Foster et al.2 is not suitable for more complex envi-ronments. CQL-q, CQL-e, and DG-learning are all able to solve this task withoutrequiring the use of a coordinate system and perform better than conventionalreinforcement learning techniques even when the goal location does not change.While this does not exclude the possibility that rodents and other mammals have acoordinate system, it does demonstrate an alternative solution in complex environ-ments where coordinates may be of little use. CQL-q performed slightly betterthan DG-learning and CQL-e in these tasks.
CQL-q, CQL-e, and DG-learning were also tested in grid-world tasks involv-ing changing environments. The tasks required the agent to find alternate routeswhen environmental changes blocked an existing route and/or opened a new route.
The detour task required the agent to use an existing alternate route when theshorter route was blocked. CQL-q performed significantly better than CQL-e andDG-learning on this task. The more complete updates of CQL-q quickly propagatethe effects of this environmental change throughout the entire set of action values,allowing the agent to adapt almost immediately to the changed conditions, whereasCQL-e and DG-learning continue to try the old route.
The blocking task required the agent to discover a new route that opens whenthe old route closes. To accomplish this task the agent used a structured explora-tion strategy, similar to the exploration bonus used in the Dyna-Q� algorithm.These tasks showed that CQL-q�, the CQL-q algorithm with an exploration bonus,performed significantly better than CQL-e� and DG�, the equivalent CQL-eand DG-learning algorithms, respectively. As with the detour task, CQL-e� andDG� suffer interference from values learned under the previous environmental
1050 OLLINGTON AND VAMPLEW

conditions. In contrast, CQL-q� quickly trains all action values close to zero whenthe existing route is blocked, allowing for more efficient exploration. This allowsthe new route to be found consistently quicker than for the other algorithms.
In summary, the main advantage of CQL-q over previous goal-independenttechniques, such as CQL-e and DG-learning, is that the algorithm is able toupdate many more action values per time step. This is particularly true whenaction values need to be revised downward due to a novel obstruction beingencountered. Under these circumstances the relaxation technique used by CQL-eand DG-learning is not applicable, unlike the action value based updates of CQL-q.
The major disadvantage of CQL-e and CQL-q, as well as DG-learning, is thatthe time complexity of the algorithm is O~6S 62 � 6A6!, which may be problematicfor tasks involving a large number of possible states. Future work will also con-sider techniques such as fast online Q~l!26 and hierarchical reinforcement learn-ing14,15,18,19,27 to reduce the dimensionality of CQL.
References
1. Sutton RS. Learning to predict by the methods of temporal differences. Mach Learn1988;3:9– 44.
2. Foster DJ, Morris RGM, Dayan P. A model of hippocampally dependent navigation, usingthe temporal difference learning rule. Hippocampus 2000;10~1!:1–16.
3. Sutton RS, Barto AG. Reinforcement learning: An introduction. Cambridge, MA: MITPress; 1998.
4. Morris RGM. Spatial localization does not require the presence of local cues. Learn Motiv1981;12:239–260.
5. Steele RJ, Morris RGM. Delay-dependent impairment of a matching-to-place task withchronic and intrahippocampal infusion of the NMDA-Antagonist D-AP5. Hippocampus1999;9~2!:118–136.
6. O’Keefe J. Place units in the hippocampus of the freely moving rat. Exp Neurol 1976;51:78–109.
7. O’Keefe J, Dostrovsky J. The hippocampus as a spatial map. Preliminary evidence fromthe unit activity in the freely-moving rat. Brain Res 1971;34:171–175.
8. Muller RU, Kubie JL. The firing of hippocampal place cells predicts the future position offreely moving rats. J Neurosci 1989;9~12!:4101– 4110.
9. Joel D, Niv Y, Ruppin E. Actor-critic models of the basal ganglia: New anatomical andcomputational perspectives. Neural Netw 2002;15:535–547.
10. Schultz W, Dickinson A. Neuronal coding of prediction errors. Ann Rev Neurosci 2000;23:473–500.
11. Schultz W, Tremblay L, Hollerman JR. Reward processing in primate orbitofrontal cortexand basal ganglia. Cereb Cortex 2000;10:272–283.
12. Barto AG, Sutton RS, Anderson CW. Neuronlike adaptive elements that can solve difficultlearning control problems. IEEE Trans Syst Man Cyber 1983;13~5!:834–846.
13. Kaelbling LP. Learning to achieve goals. Chambéry, France: Morgan Kaufmann; 1993.14. Dayan P, Hinton GE. Feudal reinforcement learning. In: Giles CL, Hanson SJ, Cowan JD,
editors. Advances in neural information processing systems 5. San Mateo, CA: MorganKaufmann; 1993.
15. Dietterich TG. The MAXQ method for hierarchical reinforcement learning. In: Proc Fif-teenth Int Conf on Machine Learning. San Francisco, CA: Morgan Kaufmann; 1998. pp118–126.
CONCURRENT Q-LEARNING 1051

16. Digney BL. Emergent hierarchical control structures: Learning reactive/hierarchical rela-tionships in reinforcement environments. In: Proc Fourth Conf on Simulation of AdaptiveBehavior. Cambridge, MA: MIT Press; 1996.
17. Drummond C. Accelerating reinforcement learning by composing solutions of automati-cally identified subtasks. J Artif Intell Res 2002;16:59–104.
18. Parr R, Russell S. Reinforcement learning with hierarchies of machines. In: Jordan MI,Kearns MJ, Solla SA, editors. Advances in neural information processing systems. Cam-bridge, MA: The MIT Press; 1997.
19. Singh SP. Reinforcement learning with a hierarchy of abstract models. In: Proc TenthNational Conf on Artificial Intelligence, San Jose, CA; 1992. pp 202–207.
20. Ollington RB, Vamplew PW. Concurrent Q-learning for autonomous mapping and naviga-tion. In: Vadakkepat P, Tan WW, Tan WC, Loh AP, editors. Proc 2nd Int Conf on Compu-tational Intelligence, Robotics and Autonomous Systems, Singapore. National Universityof Singapore; 2003.
21. Rummery GA, Niranjan M. On-line Q-learning using connectionist systems. Report CUED/F-INFENG/TR 166, Cambridge University Engineering Department; 1994.
22. Singh SP, Sutton RS. Reinforcement learning with replacing eligibility traces. Mach Learn1996;22:123–158.
23. Sutton RS. Integrated architectures for learning, planning, and reacting based on approx-imating dynamic programming; San Mateo, CA: Morgan Kaufmann; 1990. pp 216–224.
24. Watkins CJCH, Dayan P. Q-learning. Mach Learn 1992;8~3– 4!:279–292.25. Peng J, Williams RJ. Incremental multi-step Q-learning. Mach Learn 1996;22~1–3!:
283–290.26. Wierling M, Schmidhuber J. Fast online Q~l!. Mach Learn 1998;33:105–115.27. Kaelbling LP. Hierarchical learning in stochastic domains: Preliminary results. In: Proc
Tenth Int Conf on Machine Learning. San Francisco, CA: Morgan Kaufmann; 1993.pp 167–173.
1052 OLLINGTON AND VAMPLEW