comparable corpora and its application presented by srijit dutt(10305056) janardhan singh(10305067)...
TRANSCRIPT

COMPARABLE CORPORAAND ITS APPLICATION
Presented by
Srijit Dutt(10305056)Janardhan Singh(10305067)Ashutosh Nirala(10305906)
Brijesh Bhatt(10405301)
1
Guide: Dr. Pushpak Bhattacharya

Outline
Motivation Comparable Corpora (Non-parallel
Corpora) Basic Architecture Geometrical view Improvements
2

Motivation
Corpus is holy grail in NLP Bilingual Dictionary Generation Parallel Corpora
One to one correspondence in content Parallel corpora is rare
Resource constraint language (Punjabi - Spanish)
Monolingual corpus readily available World Wide Web(Non-parallel corpus)
Techniques to work on non-parallel corpus
3

Non-parallel corpora
Characteristics No parallel sentence No parallel paragraphs Fewer overlapping terms and words
Four dimension Author Domain Topic Time
Finding terminology translations from non parallel corpora, Fung et al, 1997
4
Comparable Corpora5
OneIndia.in

Comparable Corpora
Navbharat Times
6

Postulates for non-parallel corpora Basic postulate (Fung et al. 1997)
7
If a domain specific term A is related to another term B in some text T then its counterpart A' is related to B' in some other text T'
EA
D
CB
E’D’
C’
B’
A’
T T’
Finding terminology translations from non parallel corpora, Fung et al, 1997
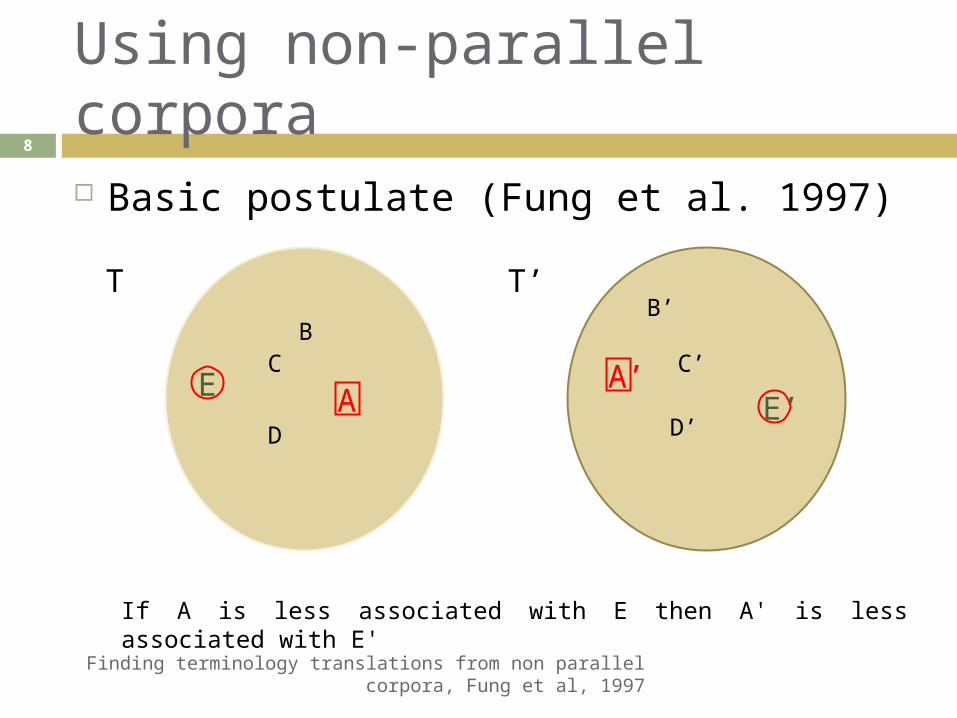
Using non-parallel corpora
Basic postulate (Fung et al. 1997)
8
If A is less associated with E then A' is less associated with E'
E AD
CB
E’D’
C’
B’
A’
T T’
Finding terminology translations from non parallel corpora, Fung et al, 1997

Using non-parallel corpora
Basic postulate (Fung et al. 1997)
9
Given a large set of words, a words is only associated with some of the words.
EA
D
CB
E’D’
C’
B’
A’
T T’
Finding terminology translations from non parallel corpora, Fung et al, 1997

Using non-parallel corpora
Basic postulate (Fung et al. 1997)
10
If A is closely associated with word B, C in varying degree then A' is also closely associated with the same varying degrees to B’ and C’.
EA
D
CB
E’D’
C’
B’
A’
T T’
Finding terminology translations from non parallel corpora, Fung et al, 1997
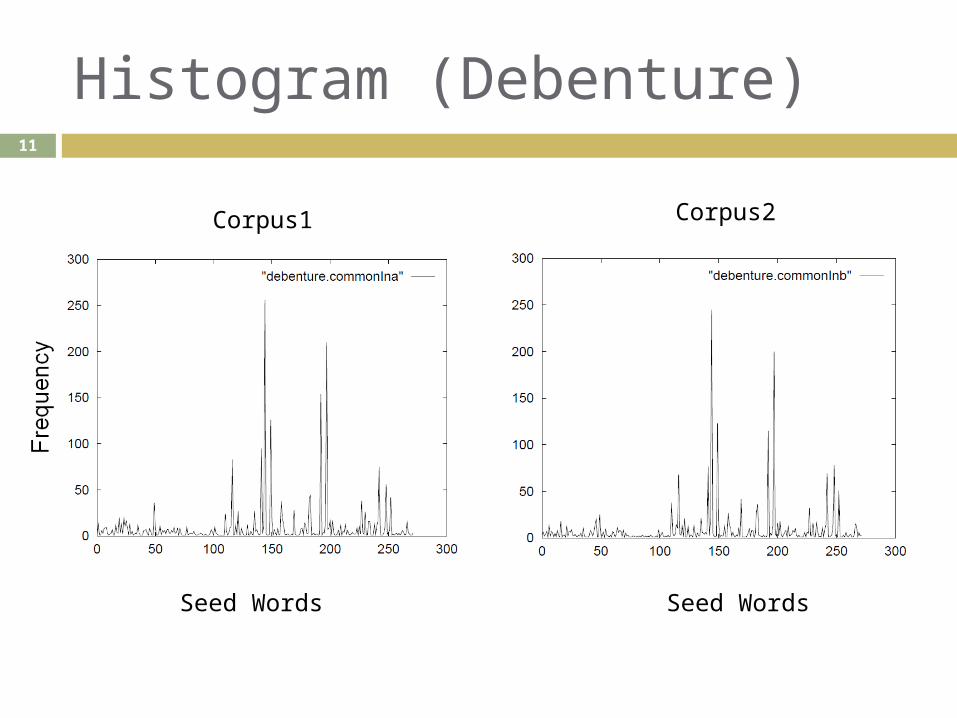
Histogram (Debenture)11
Seed Words
Corpus1 Corpus2
Seed Words

Histogram (Administration)12
Seed Words Seed Words
Corpus1 Corpus2

Co-occurrence Relation13
Known seed words of both languages(Online dictionary)
bookकि�ता�ब
English Hindi
Library पु�स्ता���लय
knowledge
ज्ञा�न
school पु�ठशा�ल�

Co-occurrence matrix14
Base Lexicon/Dictionary
Words inCorpus Book
Knowledge
1 … 0 … 1
Tree Library
Word in source language
1 0 1 Co-occurence vector
Base Lexicon/Dictionary
Target LanguageMatrix
कि�ता�ब
ज्ञा�न पु�स्ता���लयपु�ड़

Improvements on Basic Architecture Co-occurrence Counts Similarity Measure Window Size
Is it same for all words ? Dictionary
Polysemous and Synonym Words What if dictionary is not available ?
15

Context vector16
A X B
A B X
X B A
B X A
Window Size : 3
Word A
B occurs in dictionaryX is any word
Word Co-occurrence Count
Automatic Identification of Word Translations, Rapp, 1999

Co-occurrence Counts
Mutual Information (Church et al 1989) Conditional Probability (Fung et al 1996) Chi-Square Test (Dunning et al 1993) Log-likelihood Ratio (Rapp 1998) TF-IDF (Fung et al 1997)
17

Conditional Probability
k11= frequency of common occurrence of word ws and word wt
k12 = corpus frequency of word ws – k11
k21 = corpus frequency of word wt – k11
k22 = size of corpus (no. of tokens) – corpus frequency of ws - corpus frequency of wt
Marginal and joint probability
18
Finding terminology translations from non parallel corpora, Fung et al, 1997
22211211
1211)1Pr(kkkk
kkws
22211211
2111)1Pr(kkkk
kkwt
22211211
11)1,1Pr(kkkk
kww ss

Co-occurrence Counts
Mutual information
TF-IDF
19
)1Pr()1Pr(
)1,1Pr(log)1,1Pr(),( 2
sx
sxsxsx ww
wwwwwwW
Finding terminology translations from non parallel corpora, Fung et al, 1997

Co-occurrence Counts
Log Likelihood k11= frequency of
common occurrence of word ws and word wt
k12 = corpus frequency of word ws – k11
k21 = corpus frequency of word wt – k11
k22 = size of corpus (no. of tokens) – corpus frequency of ws - corpus frequency of wt
20
Automatic Identification of Word Translations, Rapp, 1999
}2,1{,
loglog2ji ji
ijij RC
Nkk
22
2222
12
2121
21
1212
11
1111
loglog
loglog
RC
Nkk
RC
Nkk
RC
Nkk
RC
Nkk
where
12111 kkC 22212 kkC
21111 kkR 12222 kkR
22211211 kkkkN

Similarity Measures
Cosine Similarity
Jaccard Similarity
Euclidian\L2
Manhattan\L1\City-Block
21
BA
BABAJ
),(
BA
BAcos
n
iii qpqpd
1
2)(),(
n
iii qpqpd
1
),(

Window Size
What is ideal context size ? Same window size
“amount” : more frequent “debenture” : less frequent
Window Size
22
)(
1
sWfrequency

Dependency Tree23
Improving Translation Lexicon Induction from Monolingual Corpora via dependency context and POS equivalence, N
Garera et al. , 2009

Modeling context using dependency tree
24
The four vectors for positions are mapped as follows:
-1 – Immediate parent +1 – Immediate child -2 – grand parent +2 – grand child
Improving Translation Lexicon Induction from Monolingual Corpora via dependency context and POS equivalence, N
Garera et al. , 2009

Context vector v/s dependency parsing
25
Improving Translation Lexicon Induction from Monolingual Corpora via dependency context and POS equivalence, N
Garera et al. , 2009

Dependency Tree
Context is better captured in dependency information rather than adjacent words
Long distance dependencies capture associated words
Languages with different word orders : parent and child relationship
Higher Accuracy
26
Improving Translation Lexicon Induction from Monolingual Corpora via dependency context and POS equivalence, N Garera et al. , 2009

Dictionary as seed word list (issues)
27
Multiple translation Polysemous words Words in one text may not be present in
other Word may not be in dictionary format
Finding terminology translations from non parallel corpora, Fung et al, 1997

Geometrical View
(translation)
A Geometric View on Bilingual Lexicon Extraction from Comparable Corpora, E. Gaussier,J M Renders, I Matveeva,
C Goutte, H Dejean,2004
28

Geometric View (Extended Approach)
29
(translation)
A Geometric View on Bilingual Lexicon Extraction from Comparable Corpora, E. Gaussier,J M Renders, I Matveeva,
C Goutte, H Dejean,2004

Translation without dictionary What if dictionary is not available? Find language for which dictionary is
available. Use that language as intermediate
language between source and target language.
30

Use of pivot language
Unavailability of bilingual lexiconUse pivot language for which bilingual lexicon
is available.
31
Bilingual Lexicon Generation Using Non-Aligned Signatures, Shezaf et al,
X Y Z
Source Language Pivot Language Target Language
What if Y is polysemous???

Use of pivot language
Source : Hindi Pivot: EnglishX = प्र��शा Y = light
32
Bilingual Lexicon Generation Using Non-Aligned Signatures, Shezaf et al,
X Y Z
Source Language Pivot Language Target Language
Lexicons are intransitive.Results in noisy translation.
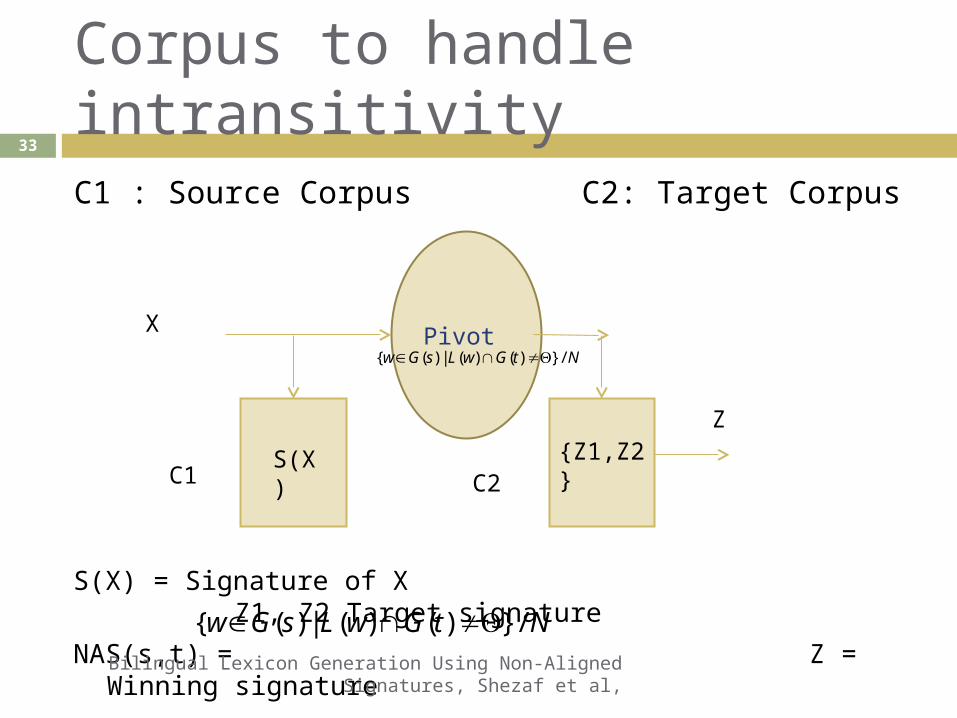
Corpus to handle intransitivityC1 : Source Corpus C2: Target Corpus
33
Pivot X
Z
S(X) {Z1,Z2}C1 C2
S(X) = Signature of X Z1, Z2 Target signature
NAS(s,t) = Z = Winning signature
Bilingual Lexicon Generation Using Non-Aligned Signatures, Shezaf et al,
NtGwLsGw /})()(|)({
NtGwLsGw /})()(|)({

Limitation of Context-based Approach
Lexical context around translation candidates. Words may appear in similar context but are
not translation of each other. So leads to false translation.
E.g.# using Chinese English comparable corpus we get (using definition of Fung 1995)
Distance between vector 1 & 2 is 0.084 > distance between vector 1 and 3 which is 0.075
Does not use rich syntactic information other than bag-of-words.
34
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
No WordContext Heterogeneity
Vector
1经济学
(economics)(0.185, 0.006)
2 economics (0.101, 0.013)
3 medicine (0.113,0.028)

Dependency Heterogeneity
Dependency Heterogeneity phenomena: a word in source language shares similar head and modifiers with its translation in target language, no matter whether they occur in similar context or not. Uses rich syntactic information. E.g.#
big(MOD) brown(MOD) dog(HEAD) Bird(MOD) song(HEAD) Song(MOD) bird(HEAD)
35
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009

Does it work?36
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
Frequently used Modifier Frequently used Head
经济学(economics)
economicsmedici
ne
微观 /micro keynesianphysiolo
gy
宏观 /macro new Chinese
计量 /computation institutionaltradition
al
新 /new positive biology
政治 /politics classical internal
大学 /university labor science
古典派 /classicists
development
clinical
发展 /developmen
tengineering
veterinary
理论 /theory finance western
实证 /demonstration
international
agriculture
经济学(economics)
economics
medicine
是 /is is is
均衡 /average has tends
毕业 /graduate wasinclud
e
承认 /admitemphasizes
moved
能 /cannon-
rivaledmeans
分化 /split becamerequir
es
剩下 /leave assumeinclud
es
比 /compare relies were
成为 /become can has
偏重 /emphasize
replaces may

Comparable Corpora Preprocessing
37
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
Raw corpora: Chinese and English pages from Wikipedia with inter-language links
Morphological Analyzer
POS tagger
MaltParser to get syntactic dependency.
Refinements1. Stemming on translation candidate.2. Removal of stop words.3. Sentences having more than k (= 30) words are removed.
Focus is on Chinese-English bilingual dictionary extraction for single-nouns
Refinement to get preprocessed corpora.

Dependency Heterogeneity Vector Calculation
Where: • NMOD : noun modifier• SUB : subject• OBJ : object, are the dependency labels produced by
MaltParser.
38
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
No Bilingual Dictionary is needed

Bilingual Dictionary Extraction (contd)
39
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
From this method distance(DH) between DH( 经济学 , economics) = 0.222 & DH( 经济学 , medicine) = 0.496.
Word Dependency Heterogeneity Vector
经济学(economics)
(0.398, 0.677, 0.733, 0.471)
economics (0.466, 0.500, 0.625, 0.432)
medicine (0.748, 0.524, 0.542, 0.220)

Results of Bilingual Dictionary Extraction40
Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity, Kun Yu & Junichi Tsujii, 2009
Performed on 250 Chinese/English single-noun pairs
Average, accuracy
forContext
Dependency
only-mod
only-head
only-NMODs
Top 5 0.1320.208
(↑ 57.58%)
0.156 0.176 0.200
Top 10 0.2960.380
(↑ 28.38%)
0.336 0.336 0.364 only-mod: (HNMODMod )
only-head: (HNMODHead ,HSUBHead ,HOBJHead )
only-NMOD: (HNMODHead ,HNMODMod )
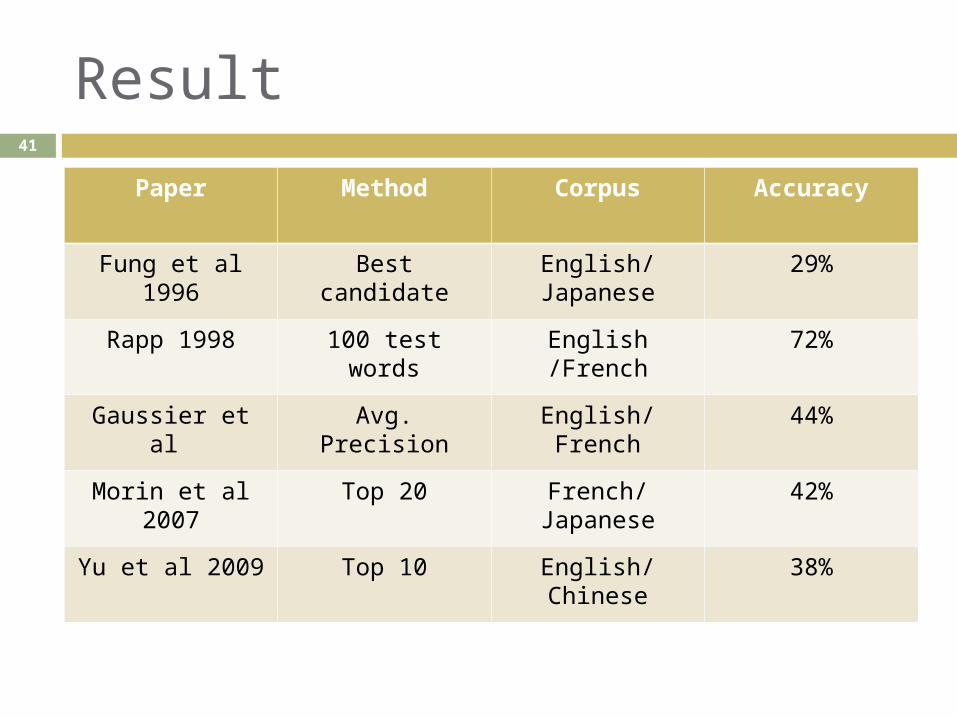
Result
Paper Method Corpus Accuracy
Fung et al 1996 Best candidate English/Japanese
29%
Rapp 1998 100 test words English /French 72%
Gaussier et al Avg. Precision English/French 44%
Morin et al 2007
Top 20 French/Japanese
42%
Yu et al 2009 Top 10 English/Chinese 38%
41

Conclusion42
Use of non-parallel corpora is inevitable and reduces the efforts of development of parallel corpora.
Modern techniques achieve accuracy upto 70% with non-parallel corpora.
Polysemy and sense disambiguation remains major challenge.
It becomes difficult to compare different implementation due to different nature of language and corpus.

References43
Fung, P.; McKeown, K. (1997). Finding terminology translations from non-parallel corpora. Proceedings of the 5th Annual Workshop on Very Large Corpora,Hong Kong, 192-202.
Fung, P.; Yee, L. Y. (1998). An IR approach for translating new words from nonparallel, comparable texts. In: Proceedings of COLING-ACL 1998,Montreal, Vol. 1,414-420.
R. Rapp. 1999. Automatic Identification of Word Translations from Unrelated English and German Corpora. In Proc. of the ACL-99. pp. 1–17. College Park, USA.

References
Gaussier, Eric, Jean-Michel Renders, Irina Matveeva, Cyril Goutte, and Herve Dejean. 2004. A geometric view on bilingual lexicon extraction from comparable corpora. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, pages 527–534, Barcelona, Spain.
X.Robitaille, Y.Sasaki, M.Tonoike, S.Sato and T.Utsuro. 2006. Compiling French Japanese Terminologies from the Web. Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics.
E.Morin, B.Daille, K.Takeuchi and K.Kageura. 2007. Bilingual Terminology Mining – Using Brain, not Brawn Comparable Corpora. Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics. pp. 664-671.
44

References
Nikesh Garera, Chris Callison-Burch, and David Yarowsky. 2009. Improving translation lexicon induction from monolingual corpora via dependency contexts and part-of-speech equivalences. In Proceedings of the Conference on Natural Language Learning (CoNLL), Boulder, Colorado.
K.Yu and J.Tsujii. 2009. Extracting Bilingual Dictionary from Comparable Corpora with Dependency Heterogeneity. Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics – Human Language Technologies (NAACL-HLT 2009).
Daphna Shezaf, Ari Rappoport, Bilingual lexicon generation using non-aligned signatures Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 98–107, Uppsala, Sweden, 11-16 July 2010. c 2010 Association for Computational Linguistics
45

46
THANK YOU
Questions ?