comp 422: introduction to parallel computing - …vs3/comp422/lecture-notes/comp422-lec1-s...comp...
TRANSCRIPT

Vivek Sarkar
Department of Computer ScienceRice University
COMP 422: Introduction toParallel Computing
COMP 422 Lecture 1 8 January 2008

2 COMP 422, Spring 2008 (V.Sarkar)
Acknowledgments for today’s lecture
• Jack Dongarra (U. Tennessee) --- CS 594 slides from Spring2008—http://www.cs.utk.edu/%7Edongarra/WEB-PAGES/cs594-2008.htm
• John Mellor-Crummey (Rice) --- COMP 422 slides from Spring2007
• Kathy Yelick (UC Berkeley) --- CS 267 slides from Spring 2007—http://www.eecs.berkeley.edu/~yelick/cs267_sp07/lectures
• Slides accompanying course textbook—http://www-users.cs.umn.edu/~karypis/parbook/

3 COMP 422, Spring 2008 (V.Sarkar)
Course Information
• Meeting time: TTh 10:50-12:05• Meeting place: DH 1046
• Instructor: Vivek Sarkar—[email protected], x5304, DH 3131—office hours: Wednesdays 11am - 12noon, and by appointment
• TA: Raj Barik— [email protected], x2738, DH 2070—Office hours: Tuesdays & Thursdays, 1pm - 2pm, and by appointment
• Web site: http://www.owlnet.rice.edu/~comp422

4 COMP 422, Spring 2008 (V.Sarkar)
Prerequisites
• Programming in C, Fortran, or Java
• Basics of data structures
• Basics of machine architecture
• Required courses: Comp 212 and 320, or equivalent
• See me if you have concerns!

5 COMP 422, Spring 2008 (V.Sarkar)
TextIntroduction to ParallelComputing, 2nd Edition
Ananth Grama,Anshul Gupta,
George Karypis,Vipin Kumar
Addison-Wesley
2003
http://www-users.cs.umn.edu/~karypis/parbook/

6 COMP 422, Spring 2008 (V.Sarkar)
Topics• Introduction (Chapter 1) --- today’s lecture
• Parallel Programming Platforms (Chapter 2)—New material: homogeneous & heterogeneous multicore platforms
• Principles of Parallel Algorithm Design (Chapter 3)
• Analytical Modeling of Parallel Programs (Chapter 5)—New material: theoretical foundations of task scheduling
• Programming Shared Address Space Platforms (Chapter 7)—New material: new programming models (beyond threads and OpenMP) --- Java
Concurrency Utilities, Intel Thread Building Blocks, .Net Parallel Extensions (TaskParallel Library & PLINQ), Cilk, X10
• Dense Matrix Operations (Chapter 8)
• Graph Algorithms (Chapter 10)
• Programming Using the Message-Passing Paradigm (Chapter 6)—New material: Partitioned Global Address Space (PGAS) languages --- Unified
Parallel C (UPC), Co-array Fortran (CAF)
• New material: Programming Heterogeneous Processors and Accelerators
• New material: Problem Solving on Large Scale Clusters using MapReduce
• (Secondary references will be assigned for new material)

7 COMP 422, Spring 2008 (V.Sarkar)
Parallel Machines for the Course
• Ada—316 dual-core Opteron processors—dual processor nodes—Infiniband interconnection network—no global shared memory
• Additional nodes on Ada—Quad-core AMD Barcelona (denali)—Sun T2000 (yellowstone)
• Google/IBM cluster—Accounts to be obtained later in semester

8 COMP 422, Spring 2008 (V.Sarkar)
Assignments and Exams
• Coursework will be weighted as follows:—Homeworks: 5%—Programming Assignments: 55%
– to be done individually or in 2-person teams; the requirements willbe scaled accordingly
—Midterm Exam: 20% (one-hour written exam)—Final Exam: 20% (one-hour multiple-choice exam)

9 COMP 422, Spring 2008 (V.Sarkar)
Why is Parallel ComputingImportant?

10 COMP 422, Spring 2008 (V.Sarkar)
Computing and Science• “Computational modeling and simulation are among the most significant
developments in the practice of scientific inquiry in the 20th Century. Within thelast two decades, scientific computing has become an important contributor toall scientific disciplines.
• It is particularly important for the solution of research problems that areinsoluble by traditional scientific theoretical and experimental approaches,hazardous to study in the laboratory, or time consuming or expensive to solveby traditional means” — “Scientific Discovery through Advanced Computing”
DOE Office of Science, 2000

11 COMP 422, Spring 2008 (V.Sarkar)
Simulation: The Third Pillar of Science
• Traditional scientific and engineering paradigm:1) Do theory or paper design.2) Perform experiments or build system.
• Limitations:—Too difficult -- build large wind tunnels.—Too expensive -- build a throw-away passenger jet.—Too slow -- wait for climate or galactic evolution.—Too dangerous -- weapons, drug design, climate
experimentation.
• Computational science paradigm:3) Use high performance computer systems to
simulate the phenomenon– Base on known physical laws and efficient numerical methods.

12 COMP 422, Spring 2008 (V.Sarkar)
Some Particularly Challenging Computations• Science
—Global climate modeling—Biology: genomics; protein folding; drug design—Astrophysical modeling—Computational Chemistry—Computational Material Sciences and Nanosciences
• Engineering—Semiconductor design—Earthquake and structural modeling—Computation fluid dynamics (airplane design)—Combustion (engine design)—Crash simulation
• Business—Financial and economic modeling—Transaction processing, web services and search engines
• Defense—Nuclear weapons -- test by simulations—Cryptography

13 COMP 422, Spring 2008 (V.Sarkar)
Units of Measure in HPC• High Performance Computing (HPC) units are:
—Flop: floating point operation—Flops/s: floating point operations per second—Bytes: size of data (a double precision floating point number is 8)
• Typical sizes are millions, billions, trillions…Mega Mflop/s = 106 flop/sec Mbyte = 220 = 1048576 ~ 106 bytesGiga Gflop/s = 109 flop/sec Gbyte = 230 ~ 109 bytesTera Tflop/s = 1012 flop/sec Tbyte = 240 ~ 1012 bytesPeta Pflop/s = 1015 flop/sec Pbyte = 250 ~ 1015 bytesExa Eflop/s = 1018 flop/sec Ebyte = 260 ~ 1018 bytesZetta Zflop/s = 1021 flop/sec Zbyte = 270 ~ 1021 bytesYotta Yflop/s = 1024 flop/sec Ybyte = 280 ~ 1024 bytes
• See www.top500.org for current list of fastest machines

14 COMP 422, Spring 2008 (V.Sarkar)
Global Climate Modeling Problem• Problem is to compute:
f(latitude, longitude, elevation, time) temperature, pressure, humidity, wind velocity
• Approach:—Discretize the domain, e.g., a measurement point every 10
km—Devise an algorithm to predict weather at time t+δt given t
• Uses:- Predict major events,
e.g., El Nino- Use in setting air
emissions standards
Source: http://www.epm.ornl.gov/chammp/chammp.html

15 COMP 422, Spring 2008 (V.Sarkar)
Global Climate Modeling Computation• One piece is modeling the fluid flow in the atmosphere
—Solve Navier-Stokes equations– Roughly 100 Flops per grid point with 1 minute timestep
• Computational requirements:—To match real-time, need 5 x 1011 flops in 60 seconds = 8 Gflop/s—Weather prediction (7 days in 24 hours) 56 Gflop/s—Climate prediction (50 years in 30 days) 4.8 Tflop/s—To use in policy negotiations (50 years in 12 hours) 288 Tflop/s
• To double the grid resolution, computation is 8x to 16x
• State of the art models require integration of atmosphere,ocean, sea-ice, land models, plus possibly carbon cycle,geochemistry and more
• Current models are coarser than this
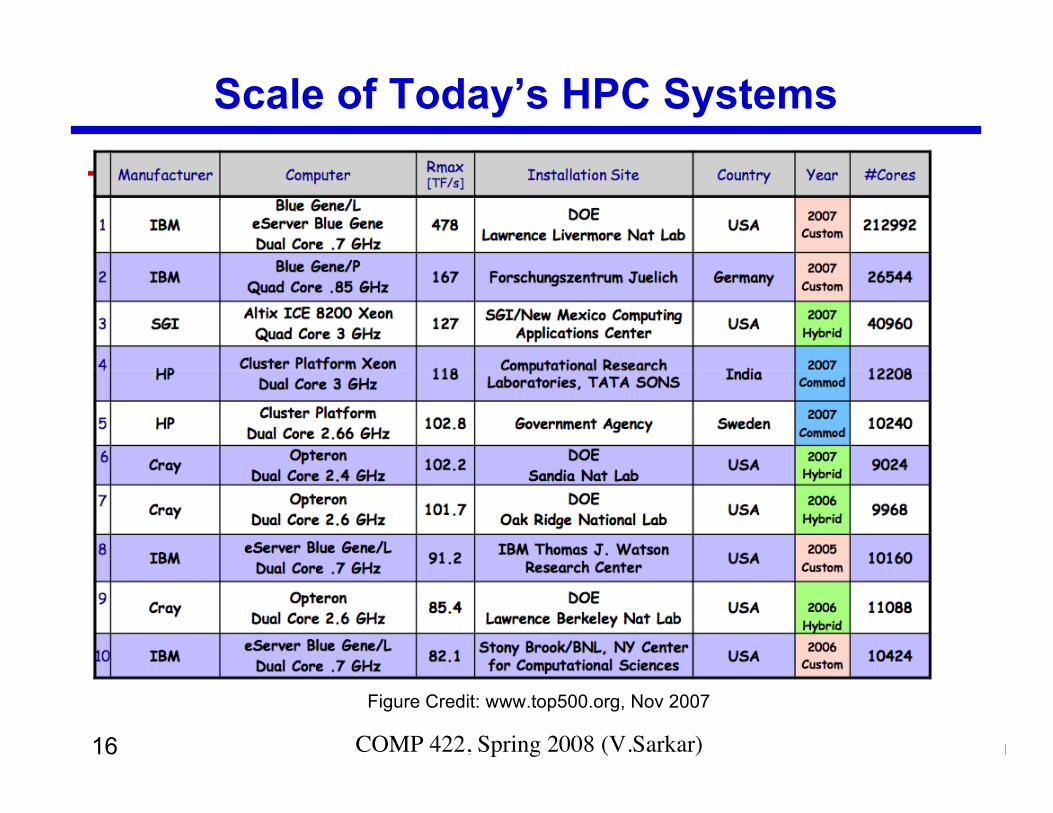
16 COMP 422, Spring 2008 (V.Sarkar)
Scale of Today’s HPC Systems
Figure Credit: www.top500.org, Nov 2007
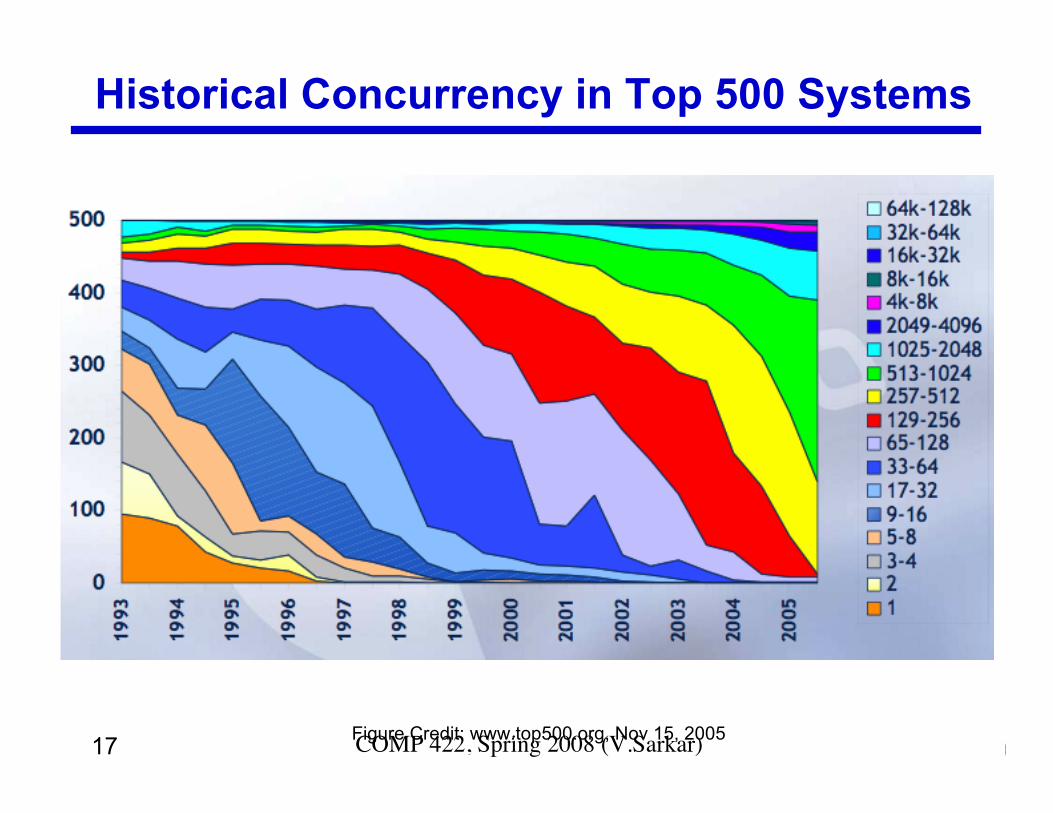
17 COMP 422, Spring 2008 (V.Sarkar)
Historical Concurrency in Top 500 Systems
Figure Credit: www.top500.org, Nov 15, 2005
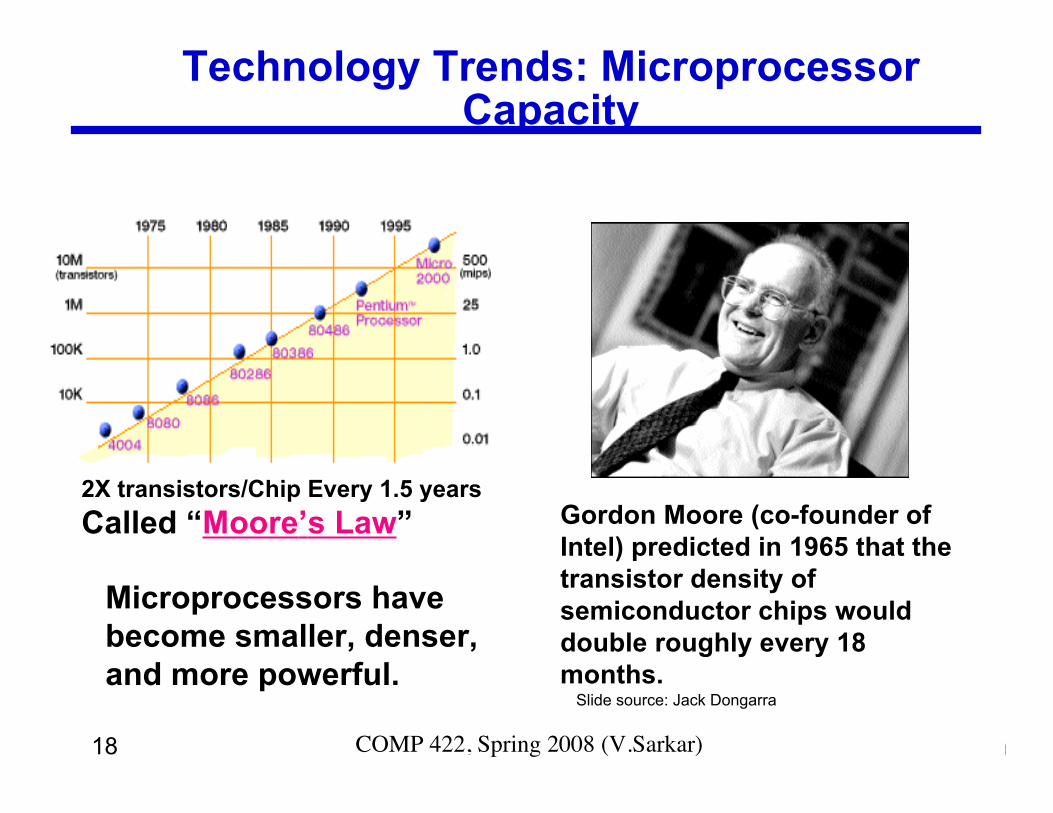
18 COMP 422, Spring 2008 (V.Sarkar)
Technology Trends: MicroprocessorCapacity
2X transistors/Chip Every 1.5 yearsCalled “Moore’s Law”
Moore’s Law
Microprocessors havebecome smaller, denser,and more powerful.
Gordon Moore (co-founder ofIntel) predicted in 1965 that thetransistor density ofsemiconductor chips woulddouble roughly every 18months.
Slide source: Jack Dongarra
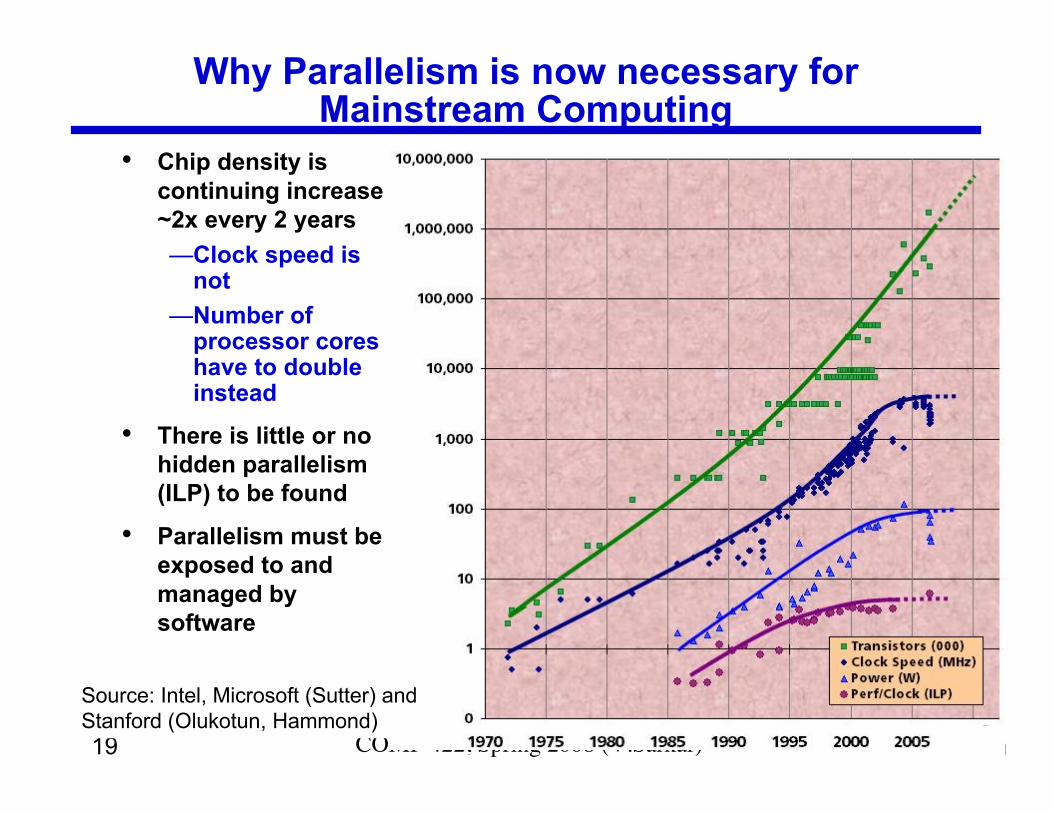
19 COMP 422, Spring 2008 (V.Sarkar)
Why Parallelism is now necessary forMainstream Computing
• Chip density iscontinuing increase~2x every 2 years—Clock speed is
not—Number of
processor coreshave to doubleinstead
• There is little or nohidden parallelism(ILP) to be found
• Parallelism must beexposed to andmanaged bysoftware
Source: Intel, Microsoft (Sutter) andStanford (Olukotun, Hammond)

20 COMP 422, Spring 2008 (V.Sarkar)
Fundamental limits on Serial Computing:Three “Walls”
• Power Wall—Increasingly, microprocessor performance is limited by
achievable power dissipation rather than by the number ofavailable integrated-circuit resources (transistors and wires).Thus, the only way to significantly increase the performance ofmicroprocessors is to improve power efficiency at about thesame rate as the performance increase.
• Frequency Wall—Conventional processors require increasingly deeper instruction
pipelines to achieve higher operating frequencies. This techniquehas reached a pointof diminishing returns, and even negativereturns if power is taken into account.
• Memory Wall—On multi-gigahertz symmetric processors --- even those with
integrated memory controllers --- latency to DRAM memory iscurrently approaching 1,000 cycles. As a result, programperformance is dominated by the activity of moving data betweenmain storage (the effective-address space that includes mainmemory) and the processor.

21 COMP 422, Spring 2008 (V.Sarkar)
Illustration of Power Wall
22 COMP 422, Spring 2008 (V.Sarkar)
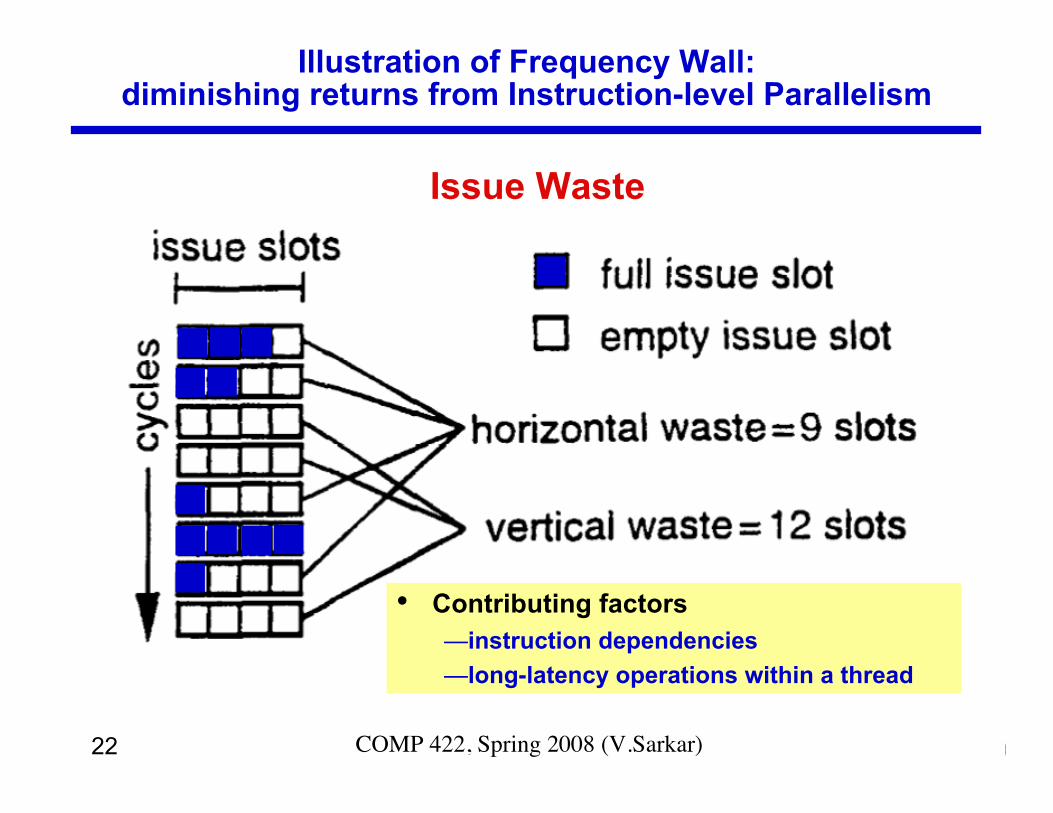
Issue Waste
Illustration of Frequency Wall:diminishing returns from Instruction-level Parallelism
• Contributing factors—instruction dependencies—long-latency operations within a thread
23 COMP 422, Spring 2008 (V.Sarkar)
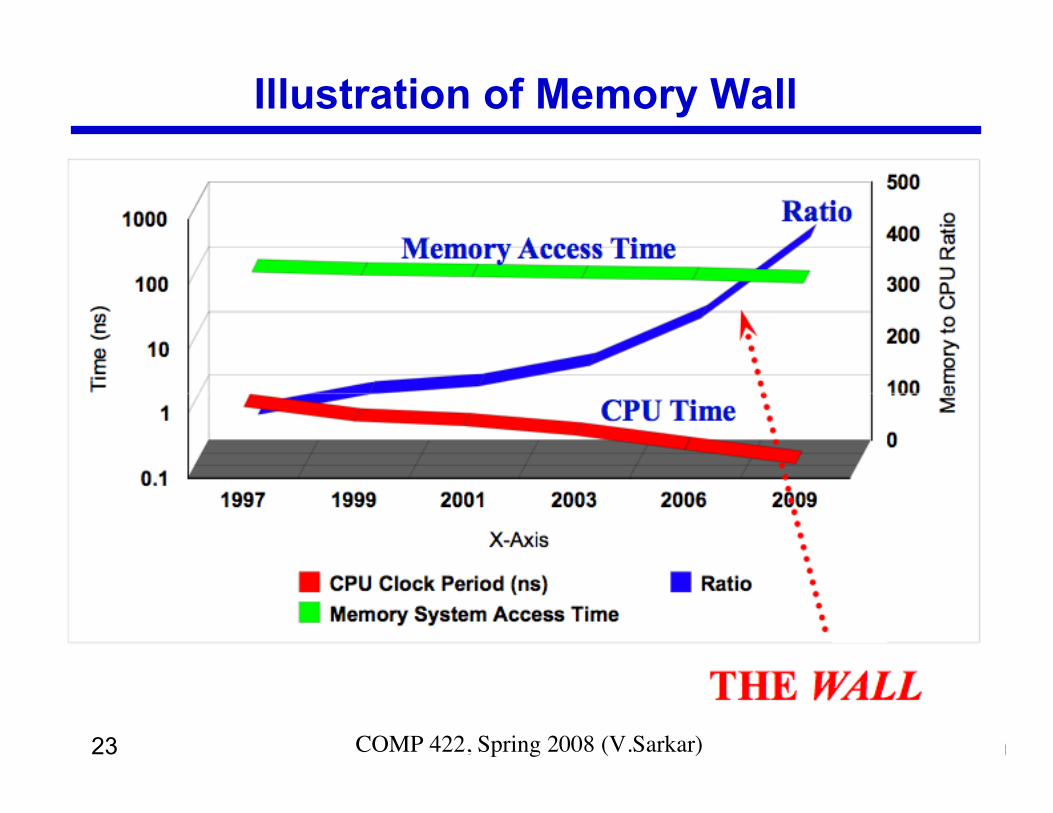
Illustration of Memory Wall
24 COMP 422, Spring 2008 (V.Sarkar)
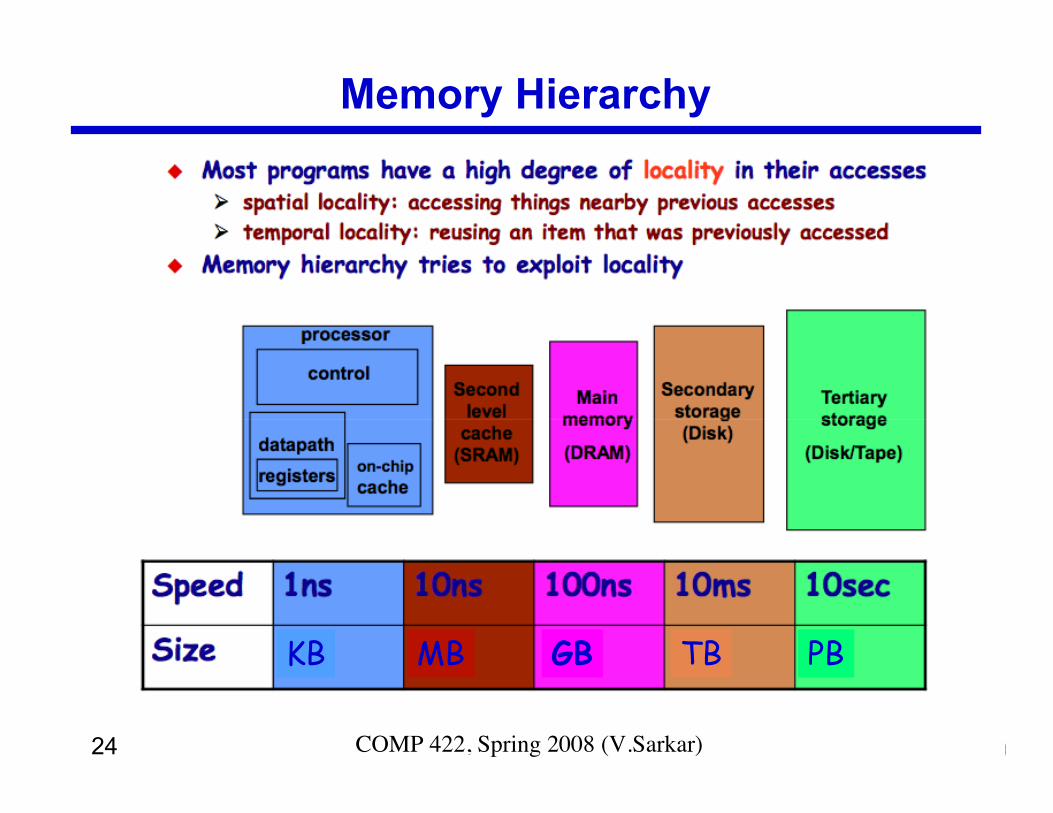
Memory Hierarchy
KB MB GB TB PB

25 COMP 422, Spring 2008 (V.Sarkar)
Memory Hierarchy (contd)

26 COMP 422, Spring 2008 (V.Sarkar)
Another Limit: Speed of Light!
• Consider a hypothetical 1 Tflop/s sequential machine:—Data must travel some distance, r, to get from memory to
CPU.—To get 1 data element per cycle, this means 1012 times per
second at the speed of light, c = 3x108 m/s. Thus r < c/1012 =0.3 mm.
• Now put 1 Tbyte of storage in a 0.3 mm x 0.3 mm area:—Each bit occupies about 1 square Angstrom, or the size of a
small atom.
• No choice but parallelism
r = 0.3mm
1 Tflop/s, 1Tbyte sequentialmachine

27 COMP 422, Spring 2008 (V.Sarkar)
Why is Parallel ComputingHard?

28 COMP 422, Spring 2008 (V.Sarkar)
Impediments to Parallel Computing
• Algorithm development is harder—complexity of specifying and coordinating concurrent activities
• Software development is much harder—lack of standardized & effective development tools, programming
models, and environments
• Rapid pace of change in computer system architecture—today’s hot parallel algorithm may not be suitable for tomorrow’s
parallel computer!

29 COMP 422, Spring 2008 (V.Sarkar)
Principles of Parallel Computing• Finding enough parallelism (Amdahl’s Law)
• Granularity
• Locality
• Load balance
• Coordination and synchronization
• Performance modeling
All of these things makes parallel programmingeven harder than sequential programming.

30 COMP 422, Spring 2008 (V.Sarkar)
“Automatic” Parallelism in Modern Machines• Bit level parallelism
—within floating point operations, etc.
• Instruction level parallelism (ILP)—multiple instructions execute per clock cycle
• Memory system parallelism—overlap of memory operations with computation
• OS parallelism—multiple jobs run in parallel on commodity SMPs
Limits to all of these -- for very high performance, need userto identify, schedule and coordinate parallel tasks

31 COMP 422, Spring 2008 (V.Sarkar)
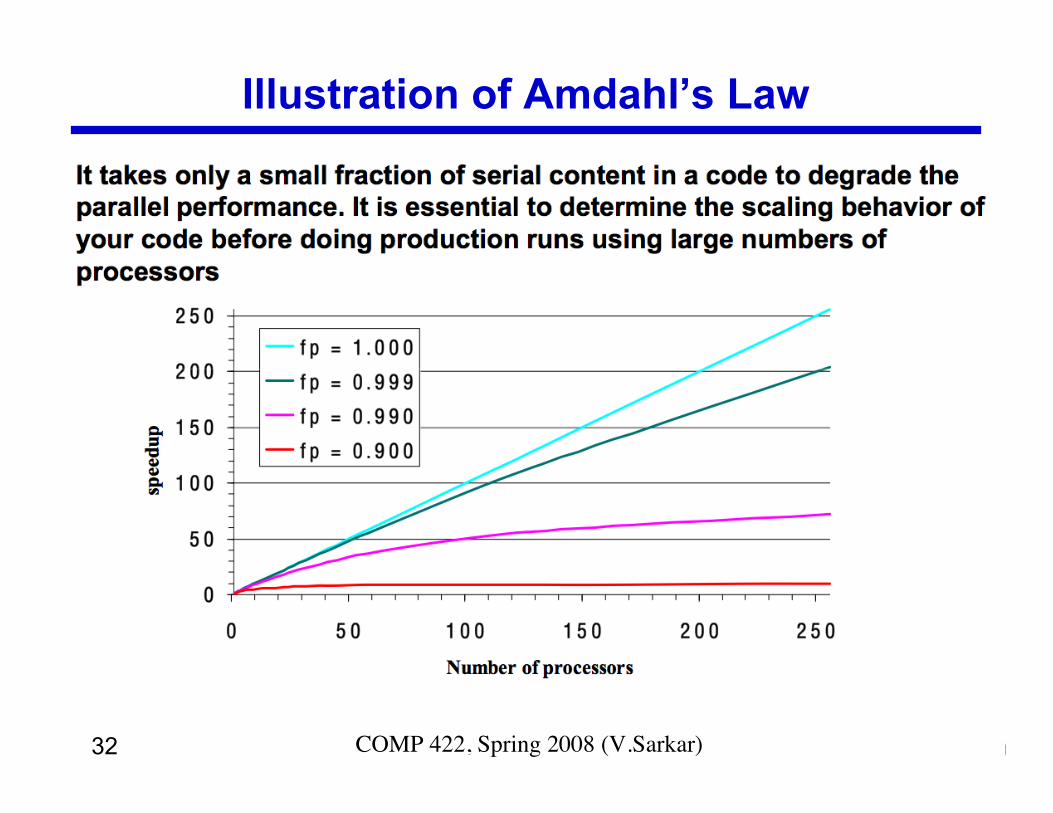
Amdahl’s Law
32 COMP 422, Spring 2008 (V.Sarkar)
Illustration of Amdahl’s Law

33 COMP 422, Spring 2008 (V.Sarkar)
Overhead of Parallelism• Given enough parallel work, this is the biggest barrier
to getting desired speedup
• Parallelism overheads include:—cost of starting a thread or process—cost of communicating shared data—cost of synchronizing—extra (redundant) computation
• Each of these can be in the range of milliseconds(=millions of flops) on some systems
• Tradeoff: Algorithm needs sufficiently large units ofwork to run fast in parallel (I.e. large granularity), butnot so large that there is not enough parallel work

34 COMP 422, Spring 2008 (V.Sarkar)
Load Imbalance• Load imbalance is the time that some processors in the
system are idle due to—insufficient parallelism (during that phase)—unequal size tasks
• Examples of the latter—adapting to “interesting parts of a domain”—tree-structured computations—fundamentally unstructured problems
• Algorithm needs to balance load

35 COMP 422, Spring 2008 (V.Sarkar)
Reading List for Thursday & Homework #1
• Reading list for next lecture—Sections 2.1, 2.2, 2.3 and 2.4 of textbook
• Homework #1 (due Jan 15, 2008)—Apply for an account on the Ada cluster, if you don’t already have one
– Go to https://rcsg.rice.edu/apply– Click on "Apply for a class user account”
—Send email to TA ([email protected]) with– Your userid on Ada– Your preference on whether to do assignments individually or in two -
person teams (in which case you should also include your team partner’sname)
– A ranking of C, Fortran, and Java as your language of choice forprogramming assignments This is for planning purposes; we cannot guarantee that your top
choice will suffice for all programming assignments