cits7212 computational intelligence ci technologies
TRANSCRIPT

CITS7212 Computational Intelligence
CI Technologies

Particle swarm optimisation
• A population-based stochastic optimisation technique
• Eberhart and Kennedy, 1995
• Inspired by bird-flocking
• Imagine a flock of birds searching a landscape for food
• Each bird is currently at some point in the landscape
• Each bird flies continually over the landscape
• Each bird remembers where it has been and how much food was there
• Each bird is influenced by the findings of the other birds
• Collectively the birds explore the landscape and share the resulting food

PSO
• For our purposes
• The landscape represents the possible solutions to a problem (i.e. the search space)
• Time moves in discrete steps called generations
• At a given generation, each bird has a position in the landscape and a velocity
• Each bird knows
• Which point it has visited that scored the best (its personal best pbest)
• Which point visited by any bird that scored the best (the global best gbest)
• At each generation, for each bird
• Update (stochastically) its velocity v, favouring pbest and gbest
• Use v to update its position
• Update pbest and gbest as appropriate

PSO
• Initialisation can be by many means, but often is just done randomly
• Termination criteria also vary, but often termination is either
• After a fixed number of generations, or
• After convergence is “achieved”, e.g. if gbest doesn’t improve for a while
• After a solution is discovered that is better than a given standard
• Performance-wise
• A large population usually gives better results
• A large number of generations gives better results
• But both obviously have computational costs
• Clearly an evolutionary searching algorithm, but co-operation is via gbest, rather than via crossover and survival as in EAs

Ant colony optimisation
• Another population-based stochastic optimisation technique
• Dorigo et al., 1996
• Inspired by colonies of ants communicating via pheromones
• Imagine a colony of ants with a choice of two paths around an obstacle
• A shorter path ABXCD vs. a longer path ABYCD
• Each ant chooses a path probabilistically wrt the amount of pheromone on each
• Each ant lays pheromone as it moves along its chosen path
• Initially 50% of ants go each way, but the ants going via X take a shorter time, therefore more pheromone is laid on that path
• Later ants are biased towards ABXCD by this pheromone, which reinforces the process
• Eventually almost all ants will choose ABXCD
• Pheromone evaporates over time to allow adaptation to changing situations

ACO
• The key points are that
• Paths with more pheromone are more likely to be chosen by later ants
• Shorter/better paths are likely to have more pheromone
• Therefore shorter/better paths are likely to be favoured over time
• But the stochastic routing and the evaporation means that new paths can be explored

ACO
• Consider the application of ACO to the Traveling Salesman Problem
• Given n cities, find the shortest tour that visits each city exactly once
• Given m ants, each starting from a random city
• In each iteration, each ant chooses a city it hasn’t visited yet
• Ants choose cities probabilistically, favouring links with more pheromone
• After n iterations (i.e. one cycle), all ants have done a complete tour, and they all lay pheromone on each link they used
• The shorter an ant’s tour, the more pheromone it lays on each link
• In subsequent cycles, ants tend to favour links that contributed to short tours in earlier cycles
• The shortest tour found so far is recorded and updated appropriately
• Initialisation and termination are performed similarly to PSO

Learning Classifier Systems
Reading:
M. Butz and S. Wilson, “An algorithmic description of XCS”, Advances in Learning Classifier Systems, 2001
O. Sigaud and S. Wilson, “Learning classifier systems: a survey”, Soft Computing – A Fusion of Foundations, Methodologies and Applications 11(11), 2007
R. Urbanomwicz and J. Moore, “Learning classifier systems: a complete introduction, review, and roadmap”, Journal of Artificial Evolution and Applications, 2009

LCSs
• Inspired by a model of human learning:
• frequent update of the efficacy of existing rules
• occasional modification of governing rules
• ability to create, remove, and generalise rules
• LCSs simulate adaptive expert systems – adapting both the value of individual rules and the structural composition of rules in the rule set
• LCSs are hybrid machine learning techniques, combining reinforcement learning and EAs
• reinforcement learning used to update rule quality
• an EA used to update the composition of the rule set

Algorithm Structure
• An LCS maintains a population of condition-action-prediction rules called classifiers
• the condition defines when the rule matches
• the action defines what action the system should take
• the prediction indicates the expected reward of the action
• At each step (input), the LCS:
• forms a match set of classifiers whose conditions are satisfied by the input
• chooses the action from the match set with the highest average reward, weighted by classifier fitness (reliability)
• forms the action set – the subset of classifiers from the match set who suggest the chosen action
• executes the action and observes the returned payoff

Algorithm Structure
• Simple reinforcement learning is used to update prediction and fitness values for each classifier in the action set
• A steady-state EA is used to evolve the composition of the classifiers in the LCS
• the EA executes at regular intervals to replace the weakest members of the population
• the EA operates on the condition and action parts of classifiers
• Extra phases for rule subsumption (generalisation) and rule creation (covering) are used to ensure a minimal covering set of classifiers is maintained
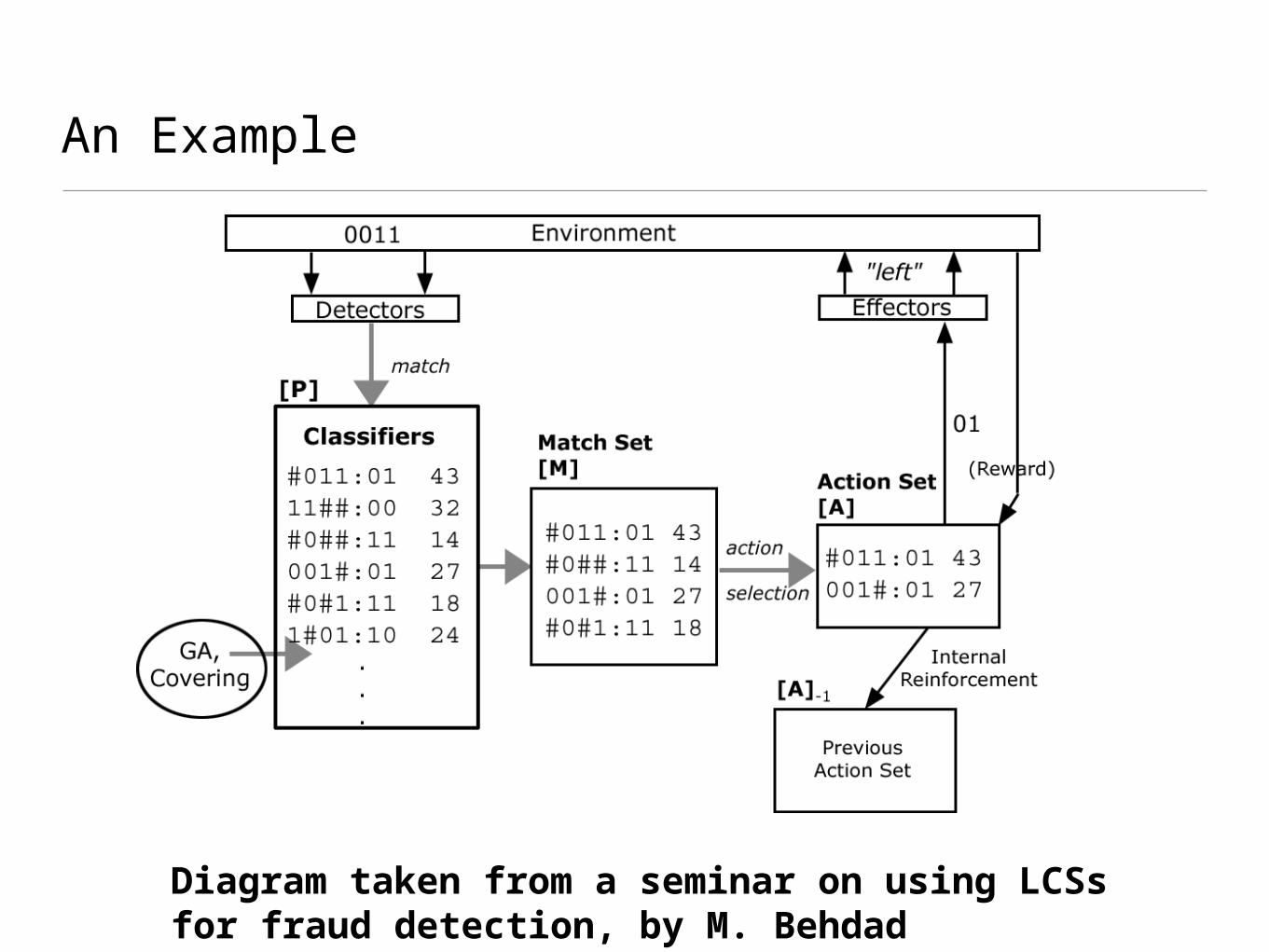
An Example
Diagram taken from a seminar on using LCSs for fraud detection, by M. Behdad

LCS Variants
• There are two main styles of LCS algorithms:
1. Pittsburgh-style: each population member represents a separate rule set, each forming a permanent “team”
2. Michigan-style: a single population of rules is maintained; rules form ad-hoc “teams” as required
• LCS variants differ on the definition of fitness:
• strength-based (ZCS): classifier fitness is based on the predicted reward of the classifier and not its accuracy
• accuracy-based (XCS): classifier fitness is based on the accuracy of the classifier and not its predicted reward, thus promoting the evolution of accurate classifiers
• XCS generally has better performance, although understanding when remains an open question

• Fuzzy logic facilitates the definition of control systems that can make good decisions from noisy, imprecise, or partial information
• Zadeh, 1973
• Two key concepts
• Graduation: everything is a matter of degree e.g. it can be “not cold”, or “a bit cold”, or “a lot cold”, or …
• Granulation: everything is “clumped”, e.g. age is young, middle-aged, or old
Fuzzy systems
age
1
0
old
middle-aged
young

Fuzzy Logic
• The syntax of Fuzzy logic typically includes propositions ("It is raining", "CITS7212 is difficult", etc.), and Boolean connectives (and, not, etc.)
• The semantics of Fuzzy logic differs from propositional logic; rather than assigning a True/False value to a proposition, we assign a degree of truth between 0 and 1, (e.g. v("CITS7212 is difficult") = 0.8)
• Typical interpretations of the operators and and not are
• v(not p) = 1 – v(p)
• v(p and q) = min { v(p), v(q) } (Godel-Dummett norm)
• Different semantics may be given by varying the interpretation of and (the T-norm). Anything commutative, associative, monotonic, continuous, and with 1 as an identity is a T-norm. Other common T-norms are:
• v(p and q) = v(p)*v(q) (product norm) and
• v(p and q) = max{v(p) + v(q) -1, 0} (Lukasiewicz norm)

Vagueness and Uncertainty
• The product norm captures our understanding of probability or uncertainty with a strong independence assumption
• prob(Rain and Wind) = prob(Rain) * prob(Wind)
• The Godel-Dummett norm is a fair representation of Vagueness:
• If it’s a bit windy and very rainy, it’s a bit windy and rainy
• Fuzzy logic provides a unifying logical framework for all CI Techniques, as CI techniques are inherently vague
• Whether or not it is actually implemented is another question

• A fuzzy control system is a collection of rules
• IF X [AND Y] THEN Z
• e.g. IF cold AND ¬warming-up THEN open heating valve slightly
• Such rules are usually derived empirically from experience, rather than from the system itself
• Attempt to mimic human-style logic
• Granulation means that the exact values of any constants (e.g. where does cold start/end?) are less important
• The fuzzy rules typically take observations, and according to these observations’ membership of fuzzy sets, we get a fuzzy action
• The fuzzy action then needs to be defuzzified to become a precise output
Fuzzy Controllers
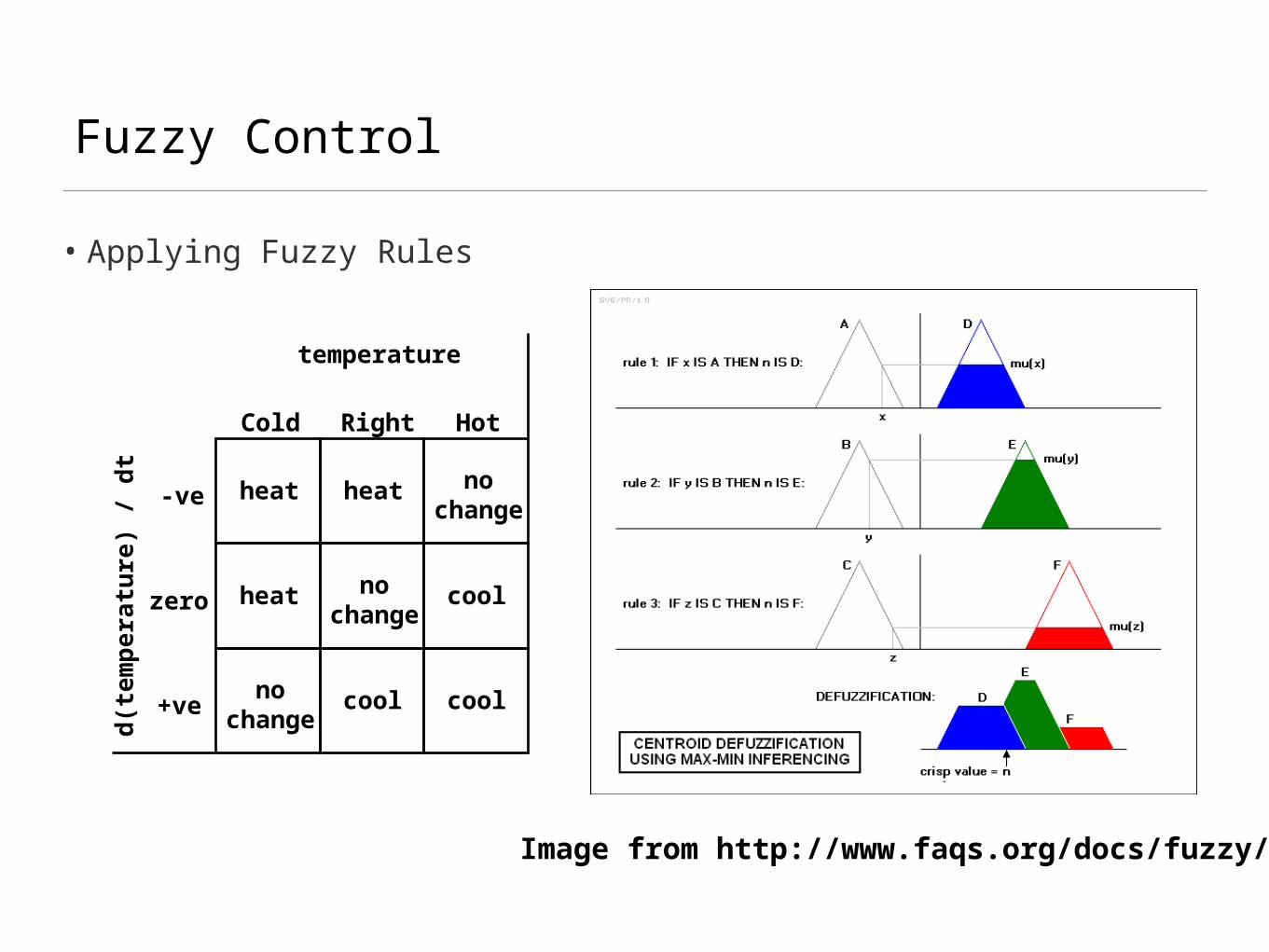
Fuzzy Control
temperature
d(t
em
pera
ture
) /
dt
Cold
zero
Right
+ve
Hot
-ve
heat
cool cool
cool
heatheat
no chang
e
no chang
e
no chang
e
• Applying Fuzzy Rules
Image from http://www.faqs.org/docs/fuzzy/