chapter 4. the genomic biologist’s...
TRANSCRIPT
Chapter 4. The Genomic Biologist’s Toolkit
Contents
4. Genomic Biologists tool kit 4.1. Restriction Endonucleases – making “sticky ends” 4.2. Cloning Vectors
4.2.1. Simple Cloning Vectors 4.2.2. Expression Vectors 4.2.3. Shuttle Vectors 4.2.4. Phage Vectors 4.2.5. Artificial Chromosome Vectors
4.3. Methods for Sequence Amplification 4.3.1. Polymerase Chain Reaction 4.3.2. Cloning Recombinant DNA 4.3.3. Cloning DNA in Expression Vectors 4.3.4. Making Complementary DNA (cDNA) 4.3.5. Cloning a cDNA Library
4.4. Genomic Libraries 4.4.1. Cloning in YAC Vectors 4.4.2. Cloning in BAC Vectors
4.5. DNA sequencing 4.5.1. Electrophoresis 4.5.2. Sanger Dideoxy Sequencing 4.5.3. Capillary Sequencers 4.5.4. Next Generation Sequencing 4.5.5. 3rd Generation Sequencing
4.6. DNA Sequencing Strategies 4.6.1. Map-based Strategies 4.6.2. Whole Genome Shotgun Sequencing
4.7. Genome Annotation 4.7.1. Using Bioinformatic Tools to Identify Putative
Protein Coding Genes 4.7.2. Comparison of predicted sequences with known
sequences (at NCBI) 4.7.3. Published Genomes

CONCEPTS OF GENOMIC BIOLOGY Page 4-1
Genomic Biology has 3 important branches, i.e. Structural Genomics, Comparative genomics, and Functional genomics. The ultimate goal of these branches is, respectively; the sequencing of genes and genomes; the comparison of these sequenced genes and genomes, and an understanding of how genes and genomes work to produce the complex phenotypes of all organisms.
A set of molecular genetic technologies was/is critical to our ability to pursue the goals described above. The Genomic Biologists Tool Kit is provides a brief understanding of these critical tools, and how they are used in the investigation of genomes. While the techniques are intrinsically laboratory tools, the nature of what they can do and how they work can be readily studied using bioinformatic resources.
Restriction endonucleases (restriction enzymes) each
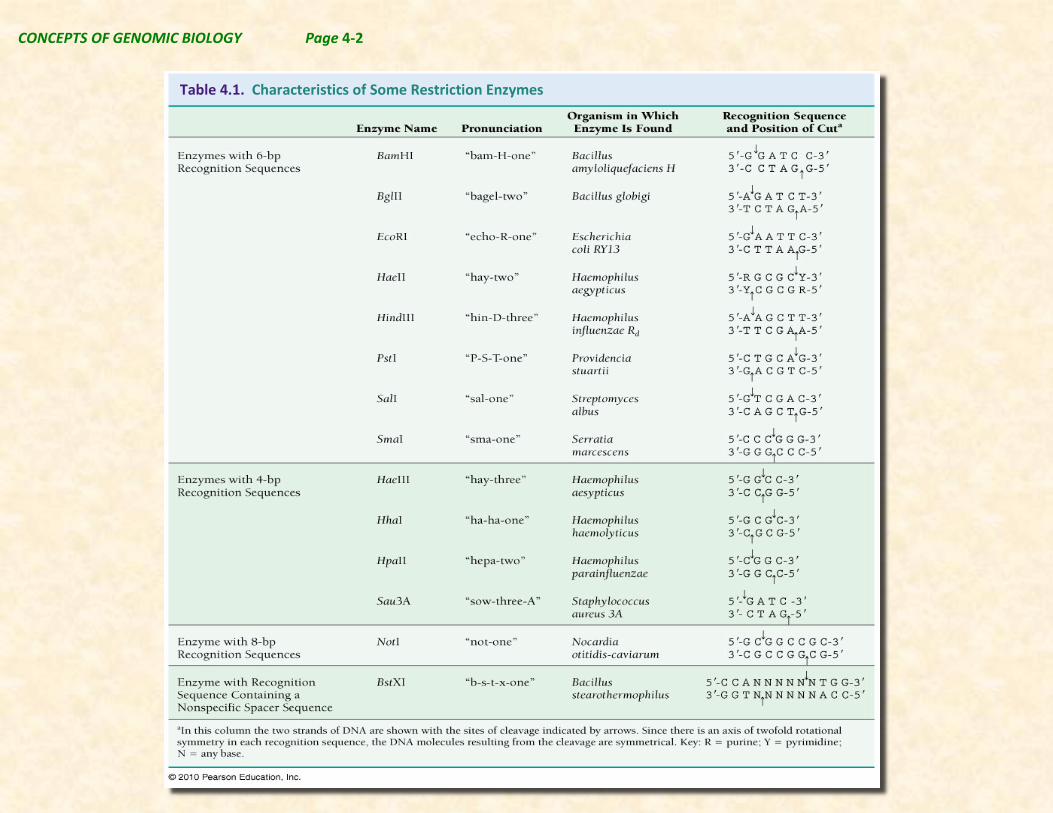
recognize a specific DNA sequence (restriction site), and break a phosphodiester linkage between a 3’ carbon and phosphate within that sequence. Restriction enzymes are used to create DNA fragments for cloning and to analyze positions of restriction sites in cloned or genomic DNA. A specific restriction enzyme digests cut DNA at the same sites in every molecule if allowed to cut to completion. Thus, this is a method whereby all copies of genomes or any other longer sequence can be reproducibly cut into identical fragments.
The first three letters of the name of a restriction enzyme are derived from the genus and species of the organism from which it was isolated. Additional letters often denote the bacterial strain from which the restriction enzyme was isolated, and if multiple enzymes are isolated from the same strain, they are given Roman numerals. For example, the restriction enzyme EcoRI, is the first enzyme isolated from the RY13-strain of Escherichia coli.
Bacteria produce restriction endonucleases to defend against bacteriophages (viruses), and each restriction
CHAPTER 4. THE GENOMIC BIOLOGIST’S
TOOLKIT (RETURN)
4.1. RESTRICTION ENDONUCLEASES (RETURN)
CONCEPTS OF GENOMIC BIOLOGY Page 4-2
Table 4.1. Characteristics of Some Restriction Enzymes

CONCEPTS OF GENOMIC BIOLOGY Page 4-3
enzyme recognizes a completely unique DNA sequence where it cuts the DNA strands (see Table 4.1 & Figure 4.1). The specific restriction enzyme recognition sites in the bacterial DNA are often limited in the genome of the organism from which it comes, but they are abundant in the genome of the bacteriophage. Also the DNA of the host cell can be modified by methylation, which prevents the restriction enzymes of the host cell
from degrading host cell DNA, while invading bacter-iophage DNA is unmethylated and readily degraded.
Many restriction sites are sequences of 4, 6, or 8 base pairs in length and have identical sequences from 5’ to 3’ on each strand. These sequences are referred to as palindromic DNA sequences. Other restriction sites are not completely symmetrical and/or differ in length from 4, 6, or 8 nucleotide pairs (Table 4.1 & Figure 4.1). As shown in the figure on the left, the nature of the fragment ends produced when a restriction enzyme produces DNA fragments can vary. Some enzymes produce fragments where the two strands are equal in length. This is referred to as blunt ends. Other enzymes produce fragments where the two strands are unequal in length. These are referred to as either 5’ sticky ends, or 3’ sticky ends. Overhanging sticky ends provide a basis for combining DNA fragments produced by the same restriction enzyme from different DNA sources. This process was the original method used to produce recombinant DNA molecules.
The application of restriction endonucleases to the cloning of DNA is further discussed in DNA Cloning video that can be viewed by clicking on the link. Note that part of this video will be discussed in detail in the next section of the Genomic Biologist’s Toolkit, but the first part of the video is a good demonstration of how
Figure 4.1. Restriction site sequences and cut locations of: a) SmaI; b) BamHI, and c) PstI.
CONCEPTS OF GENOMIC BIOLOGY Page 4-4
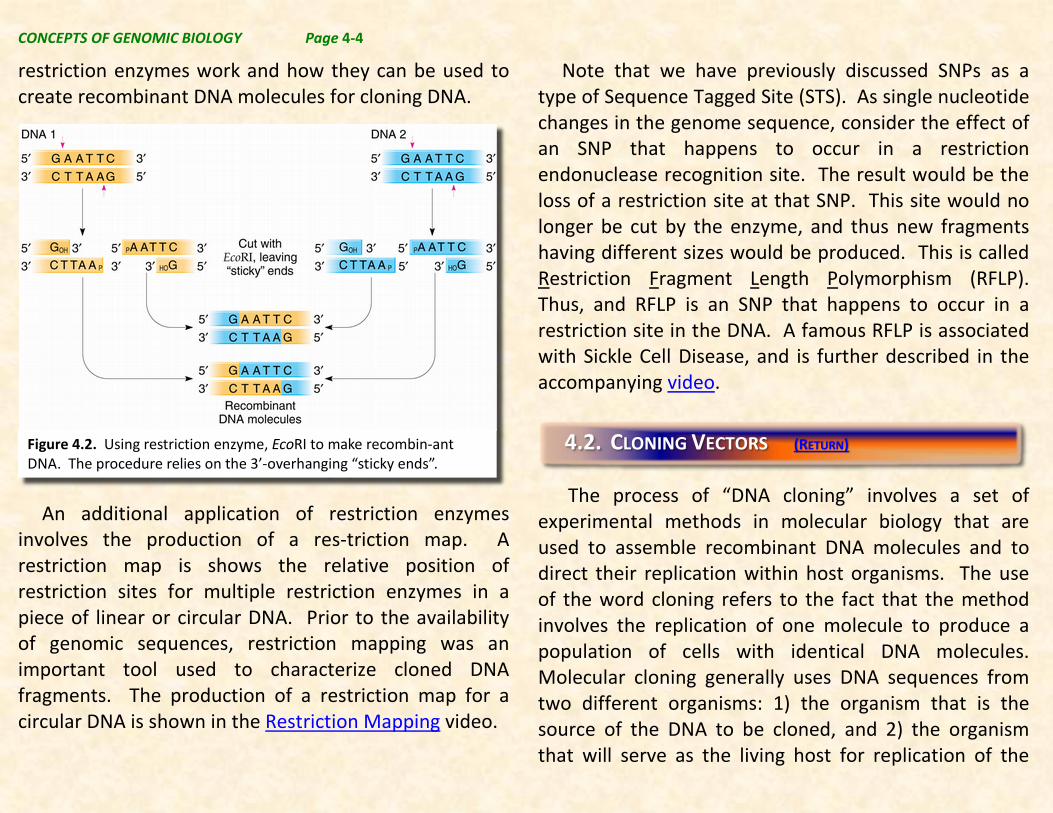
restriction enzymes work and how they can be used to create recombinant DNA molecules for cloning DNA.
An additional application of restriction enzymes
involves the production of a res-triction map. A restriction map is shows the relative position of restriction sites for multiple restriction enzymes in a piece of linear or circular DNA. Prior to the availability of genomic sequences, restriction mapping was an important tool used to characterize cloned DNA fragments. The production of a restriction map for a circular DNA is shown in the Restriction Mapping video.
Note that we have previously discussed SNPs as a type of Sequence Tagged Site (STS). As single nucleotide changes in the genome sequence, consider the effect of an SNP that happens to occur in a restriction endonuclease recognition site. The result would be the loss of a restriction site at that SNP. This site would no longer be cut by the enzyme, and thus new fragments having different sizes would be produced. This is called Restriction Fragment Length Polymorphism (RFLP). Thus, and RFLP is an SNP that happens to occur in a restriction site in the DNA. A famous RFLP is associated with Sickle Cell Disease, and is further described in the accompanying video.
The process of “DNA cloning” involves a set of
experimental methods in molecular biology that are used to assemble recombinant DNA molecules and to direct their replication within host organisms. The use of the word cloning refers to the fact that the method involves the replication of one molecule to produce a population of cells with identical DNA molecules. Molecular cloning generally uses DNA sequences from two different organisms: 1) the organism that is the source of the DNA to be cloned, and 2) the organism that will serve as the living host for replication of the
Figure 4.2. Using restriction enzyme, EcoRI to make recombin-ant DNA. The procedure relies on the 3’-overhanging “sticky ends”.
4.2. CLONING VECTORS (RETURN)

CONCEPTS OF GENOMIC BIOLOGY Page 4-5
recombinant DNA. Molecular cloning methods are central to many areas of biology, biotechnology, and medicine, including DNA sequencing.
The DNA from host organism in a cloning experiment, often called a vector, typically has 3 things:
1) Sequences necessary to produce recombinant DNA and facilitate entry into the host organism. Typically, this can be one or more “unique” restriction sites. “Unique” in this context means that these are restriction sites will permit cutting the vector at only one location. Most vectors contain unique restriction sites for a number of different restriction enzymes. This is called a polylinker or multiple cloning site, and can make the use of the vector much easier.
2) An origin of replication for the host organism to facilitate replication of the recombinant DNA in the host cell. Typically this sequence controls the number of copies of the vector that can be made in one cell.
3) In order to facilitate identification of cells that contain the vector containing recombinant DNA, a gene that can be expressed in the host and that provides a “selectable” marker for the presence of recombinant DNA is provided. Often the selectable marker gene will be a gene that makes cells resistant to a specific
antibiotic or that permits cells to make an amino acid required for growth. These are the basic requirements that all modern
cloning vectors contain, but beyond these basic requirements, there can be a number of additional features that make specific vectors useful for various purposes. Thus, several types of cloning vectors have been constructed, each with different molecular properties and cloning capacities.
4.2.1. Simple Cloning Vectors (RETURN)
The most common vectors are used to clone recombinant DNA in bacterial cells, typically E. coli. Simple cloning vectors are constructed from plasmids common in many bacterial cells. In fact plasmids are circles of dsDNA (double stranded) much smaller than the bacterial chromosome that include replication origins (ori sequence) needed for replication in bacterial cells that naturally carry DNA between different bacteria. An example of a typical E. coli cloning vector is pUC19 (2,686bp). The more modern version of pUC19 is pBluescript II. The features of this plasmid are shown in Figrue 4.2.
More information about cloning DNA in plasmid vectors can be found in Molecular Cell Biology, 4th edition, Section 7.1. This can be downloaded from NCBI by clicking on the link. The use of simple cloning vectors

CONCEPTS OF GENOMIC BIOLOGY Page 4-6
to clone recombinant DNA made via the use of DNA restriction and overhanging sticky ends can be seen in the attached Steps in DNA Cloning video. The use of simple cloning to obtain a collection of clones representing all sequences that can be cut from a longer piece of DNA is called creating a clone library (see video) of sequences. Libraries can be useful in several ways.
One of these might be to create a expression library that makes specific proteins from each clone. This requires an expression vector.
4.2.2. Expression Vectors (RETURN)
Expression vectors contain all of the same elements that simple cloning vectors contain, i.e. an ori, a selectable marker, and a multiple cloning site; but the
Figure 4.3. The features of pUC19 and pBluescrip II include: 1) High copy number in E. coli, with nearly 100 copies
per cell, provides a good yield of cloned DNA.
2) Its selectable marker is ampR.
3) It has a cluster of unique restriction sites, called the polylinker (multiple cloning site).
4) The polylinker is part of the lacZ (b-galacto-sidase) gene. The plasmid will complement a lacZ- mutation, allowing it to become lacZ+. When DNA is cloned into the polylinker, lacZ is disrupted, preventing complementation of the lacZ- from occurring.
5) X-gal, a chromogenic analog of lactose that turns blue when -galactosidase is present, and remains white in the absence of -galactosidase, so blue-white screening can indicate which colonies contain recombinant plasmids.

CONCEPTS OF GENOMIC BIOLOGY Page 4-7
MCS is flanked by a promoter sequence, and a terminator sequence that works in the host organism. This permits the cloned sequence to be transcribed, and if the vector contains a Shine-Delgarno sequence (not shown in Figure 4.4.), to be translated into a protein if there is an start and stop code word in the sequence. Note that Figure 4.4. illustrates how the cloned
sequence can insert randomly in two orientations. However, only one of the orientations will produce a translatable mRNA. The other orientation will produce an apparent RNA that will be the complementary strand of the mRNA (called an antisense RNA). In section 4.5. dealing with this issue will be considered. t
4.2.3. Shuttle Vectors (RETURN)
A cloning vector capable of replicating in two or more types of organism (e.g., E. coli and yeast) is called
Figure 4.4. An example of a simple expression vector.
Figure 4.5. Shuttle vectors like pRS426 can be used to move cloned DNA into 2 different organisms. In this case, the plasmid moves into E. coli and Yeast. Note that the vector contains an origin of replication for yeast (yeast 2 u ARS) and E. coli (ori), a selectable marker gene for E. coli (ampr) and yeast (Ura3, does not require Uracil for growth as does the yeast strain used), and a multiple cloning site with a yeast promoter and terminator on either side. Thus, this shuttle vector can work in both E. coli and yeast.

CONCEPTS OF GENOMIC BIOLOGY Page 4-8
a shuttle vector. Shuttle vectors may replicate autonomously in both hosts, or integrate into the host genome.
4.2.4. Phage Vectors (RETURN)
Beside plasmid-based simple cloning vectors, there are a number of other vectors that are not based on
plasmids. These often have specific uses that take advantage of their unique properties. Among the types of non-plasmid vectors, bacteriophage λ vectors (shown in Figure 4.6) are among the most frequently used. Phage λ vectors can be used to make expression libraries and to convenient for selection of clones as the bacteriophage lyses cells releasing the contents to the cell to the medium. Thus RNAs and proteins derived from the inserted fragment can be investigated using these vectors.
4.2.5. Artificial Chromosome Vectors (RETURN)
The typical simple cloning vector will accommodate DNA fragments up to about 3,000 bp in length. However, there are needs to clone significantly longer fragments of DNA for study. Typically DNA genomic sequencing is easiest with the longest fragments possible. Two vector systems, i.e. BAC vectors (bacterial artificial chromosome) and YAC vectors (yeast artificial chromosome), are useful choices for cloning DNA fragments. In BACs fragments up about 350 kbp (350,000 bp) can be cloned while in YACs fragments up 1,000,000 bp have been reported. Both of these methods have been used in the original human genome sequencing project. However, it was found that YACs are relatively unstable, meaning that they frequently self-modified loosing DNA in the process, and thus, they Figure 4.6. Phage λ Vector.
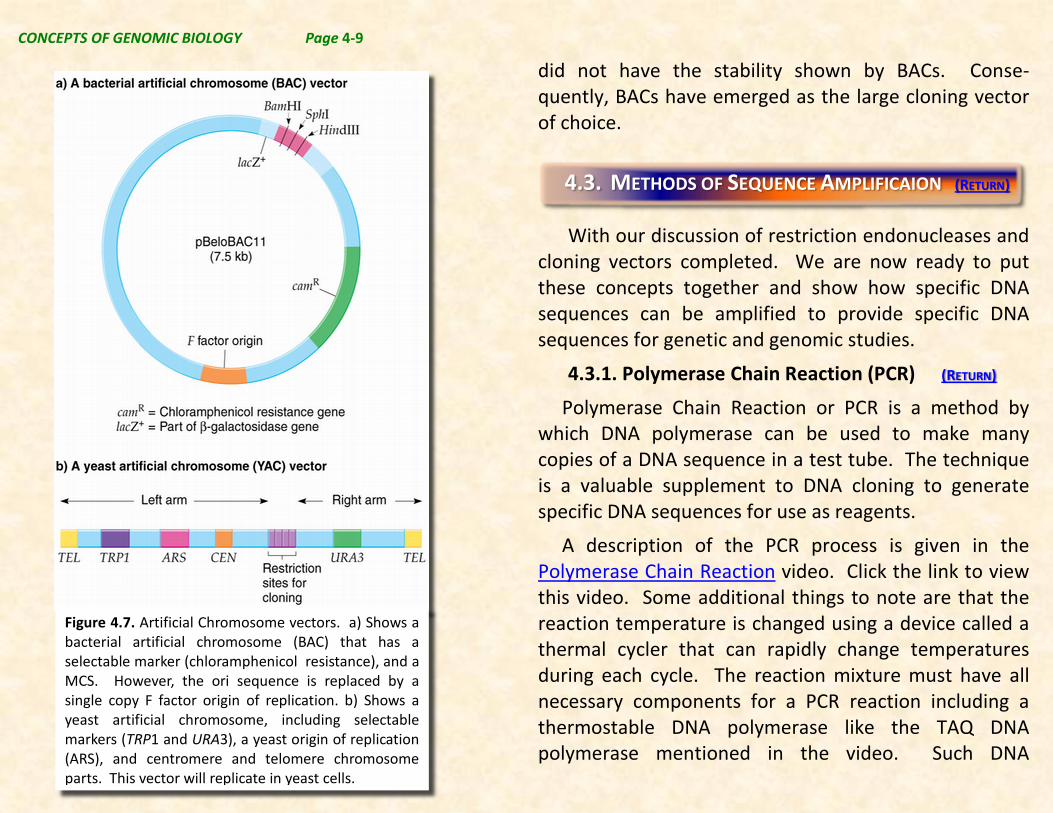
CONCEPTS OF GENOMIC BIOLOGY Page 4-9
did not have the stability shown by BACs. Conse-quently, BACs have emerged as the large cloning vector of choice.
With our discussion of restriction endonucleases and
cloning vectors completed. We are now ready to put these concepts together and show how specific DNA sequences can be amplified to provide specific DNA sequences for genetic and genomic studies.
4.3.1. Polymerase Chain Reaction (PCR) (RETURN)
Polymerase Chain Reaction or PCR is a method by which DNA polymerase can be used to make many copies of a DNA sequence in a test tube. The technique is a valuable supplement to DNA cloning to generate specific DNA sequences for use as reagents.
A description of the PCR process is given in the Polymerase Chain Reaction video. Click the link to view this video. Some additional things to note are that the reaction temperature is changed using a device called a thermal cycler that can rapidly change temperatures during each cycle. The reaction mixture must have all necessary components for a PCR reaction including a thermostable DNA polymerase like the TAQ DNA polymerase mentioned in the video. Such DNA
4.3. METHODS OF SEQUENCE AMPLIFICAION (RETURN)
Figure 4.7. Artificial Chromosome vectors. a) Shows a bacterial artificial chromosome (BAC) that has a selectable marker (chloramphenicol resistance), and a MCS. However, the ori sequence is replaced by a single copy F factor origin of replication. b) Shows a yeast artificial chromosome, including selectable markers (TRP1 and URA3), a yeast origin of replication (ARS), and centromere and telomere chromosome parts. This vector will replicate in yeast cells.

CONCEPTS OF GENOMIC BIOLOGY Page 4-10
polymerases are obtained from organisms called extremophiles that grow in very hot water like that found in geysers (e.g. Old Faithful in Yellowstone National park) or thermal vents on the floor of the ocean. The reaction also contains the deoxyNTP (deoxy nucleotide triphosphates, e.g. dATP, dGTP, dCTP, & dTTP), and the primers which define each end of the sequence to be amplified.
DNA sequences amplified via PCR typically contain an extra A on the 3’-end the molecule, i.e. a single overhanging 3’-A that makes ligation of the PCR amplified fragment into a PCR cloning vector much easier (see Figure 4.6).
4.3.2. Cloning in a Simple Cloning Vector (RETURN)
DNA cloning is the for a number of genomic biology experiments. Large amounts of DNA are needed for analysis, sequencing, and numerous experimental approaches. As we saw above multiple copies of a known DNA sequence can be made and cloned using PCR and a PCR vector. However, an alternative is necessary when the sequence to be cloned is unknown (i.e. PCR primers cannot be determined). To introduce this principle we will outline the steps to clone a DNA fragment of unknown sequence in a simple cloning vector.
To get multiple copies of a gene or other piece of DNA you must isolate, or ‘cut’, the DNA from its source using restriction enzymes, and then ‘paste’ it into a simple cloning vector that can be amplified in a host cell, typically E. coli.
The four main steps in PCR DNA cloning are:
Step 1. DNA is purified from the donor cells using a standard DNA purification technique.
Step 2. A chosen fragment of DNA is ‘cut’ from the purified genomic DNA of the source organism using a restriction enzyme.
+
Recont
pGEM-T Easy PCR Vector (3015 bp)
pGEM-T Easy PCR Vector (3015 bp)
PCR Amplified DNA (1191 bp)
pGEM-Teasy+ PCR Amplified DNA (4206 bp)
DNA Ligase +
Figure 4.8. PCR Cloning vectors. Note that the vector comes linearized with overhanging 3’-T’s. PCR products typically have single over-hanging A’s at their 3’-ends. This provides a convenient way of making a circular plasmid with the inserted PCR product.

CONCEPTS OF GENOMIC BIOLOGY Page 4-11
Step 3. The piece of DNA is ‘pasted’ into a vector and the ends of the DNA are joined with the vector DNA by DNA ligase (joins Okazaki fragments) in the DNA
replication section.
Step 4. The vector is introduced into a host cell, often a bacterium, by a process called bacterial transformation. The transformed host cells copy the vector DNA + recombinant DNA along with their own DNA, creating multiple copies of the inserted DNA. DNA that has been ‘cut’ and ‘pasted’ from an organism into a vector is called recombinant DNA. Because of this, DNA cloning is also called recombinant DNA technology.
Step 5. The vector DNA is isolated (or separated) from the host cells’ DNA and purified.
4.3.3. Cloning DNA in Expression Vectors (RETURN)
In section 4.2., we discussed expression vectors, and showed that when a restricted DNA sequence is cloned
Figure 4.9. Insertion of restricted DNA into a simple cloning vector.
Figure 4.10. Using PCR to obtain only the forward orientation of a sequence in an expression vector. Primers are designed with a restriction site added such that they anneal at each end of the fragment of interest. Following PCR an amplified fragment will be produced with a KpnI site at the 5’ end of the intended coding sequence and a SalI site at the 3’ end. The expression vector is then opened by cutting with both KpnI and SalI. Since the KpnI site is closer to the promoter in the expression vector’s MCS, while the SalI site is closer to the terminator. This construct will go into the vector in the sense orientation so that a message is produced that makes the protein of interest rather than its antisense equivalent.

CONCEPTS OF GENOMIC BIOLOGY Page 4-12
in an expression vector, it can be ligated into the vector in both a “forward” or a “reverse” configuration (Figure 4.4). In the forward configuration the fragment is positioned so that it makes an mRNA that codes for a protein, while in the reverse configuration, the DNA fragment does not make an mRNA, but makes an RNA from the opposite strand called an antisense RNA.
It is possible using a PCR strategy to insert a DNA fragment into an expression vector such that it can only insert in the “forward” orientation. This strategy is shown in Figure 4.10.
4.3.4 Making complementary DNA (cDNA) (RETURN)
A double stranded DNA copy of an mRNA is called a cDNA. Making cDNA is a way to convert a relatively labile single-stranded RNA into a relatively stable double-stranded DNA. It is possible to make a DNA copy of an RNA by employing an enzyme involved in replic-ation of certain viruses called reverse transcriptase. The other aspect of Eukaryotic mRNAs that makes producing cDNAs relatively facile is the polyA tail as we will see below. cDNAs can be made in several ways, but the method described here is a traditional method.
Step 1. Total RNA is extracted from cells using a standard technique for the organism in question.
Step 2. An oligo-dT primer is hybridized with the polyA tail of a Eukaryotic mRNA. Then an enzyme called
reverse transcriptase (makes a DNA strand from an RNA strand) is used to make a first-strand DNA copy of the mRNA strand.
Figure 4.11. The process for making cDNA in a simple cloning vector.

CONCEPTS OF GENOMIC BIOLOGY Page 4-13
Step 3. The RNA is then partially degraded with RNase H, and RNA fragments are randomly annealed to the newly made DNA strand. These RNA fragments act is primers for DNA polymerase I.
Step 4. DNA polymerase I is then used to make a complementary DNA strand, and replace the RNA primers with DNA nucletoides.
Step 5. All pieces are then ligated together using DNA ligase. Completing the synthesis of a double stranded DNA copy of the mRNA.
At completion of the procedure above you will have prepared a cDNA copy of each mRNA that was present in the cells from which you extracted the RNA. If there were 10,000,000 polyA tails on 10,000,000 mRNAs you should make 10,000,000 cDNAs. In other words if there were 10,000 mRNAs in the preparation that coded for a given protein like myosin, but only 500 mRNAs coding for hexokinase and 10 mRNAs for tyrosyl-tRNA synthetase, you might expect that your cDNA library of sequences obtained from the cells you used would have 10,000, 500, and 10 cDNAs for the 3 proteins respectively. The frequency of occurrence of each mRNA is represented by the frequency of cDNAs in the cDNA library obtained from a given set of cells. Thus, information about the frequency of occurrence of mRNAs in cells can be obtained from analysis of such a
cDNA library. A similar cDNA library from different cells (e.g. different tissues, or cells treated with a drug, or grown in a different environment, etc.) will show different levels of each cDNA present based on the mRNAs found in a tissue. The frequency of mRNAs found in a tissue is considered information about the expression of a gene. Gene expression information relates directly to the function of transcription machinery in cells, and is critical functional genomic information, as we will see in a subsequent section of the book.
In order to store and subsequently utilize a cDNA library it is useful to produce a clone of each sequence in the library. Typically this involved putting the cDNAs into vectors, and putting the vectors into host cells, typically E. coli such that each cell gets a single cDNA which is amplified in that cell and all it’s clones.
4.3.5. Cloning a cDNA Library (RETURN)
A cDNA clone library is a useful tool to identify specific mRNAs found in a tissue and to obtain the sequences of identified genes. To do this a cDNA clone library (i.e. to clone all cDNAs into a vector, and put one vector containing an individual cDNA in each cell) can be created. These cells can be screened to determine which clones express genes of interest.

CONCEPTS OF GENOMIC BIOLOGY Page 4-14
Various types of vectors can be used to create a cDNA clone library. These include phage expression vectors, plasmid expression vectors, or shuttle vectors depending on the intended use of the clone library. We will look at a protocol for incorporation of cDNA into a plasmid expression vector, using a simple strategy. Note that kits are now available that provide everything you require and outline specific strategies for most types of vectors should you ever need to accomplish this task.
Step 1. Prepare a cDNA library as outlined in section 4.3.4.
Step 2. Manipulating the cDNAs so that each one has a unique (not contained in any cDNA) restriction site at both ends. To do this, the cDNAs are frequently methylated with a specific methyl transferase that incorporates a methyl group into particular restriction sites to protect them from the restriction enzyme that will be used later.
Step 3. A synthetic double stranded oligonucleotide linker is then ligated to the ends of this cDNA. The linker should correspond to a restriction site in the MCS of the vector to be used. Blunt end ligation is generally a low efficiency process; but, by using a high concentration of these synthetic oligonucleotides, it is possible to drive the reaction to near completion.
Step 4. Digest the cDNAs with internal sites protected and linkers attached with the restriction enzyme to generate the appropriate overhanging sticky ends).
Figure 4.12. Procedure of inserting a cDNA into a cloning vector involving ligation of linkers on the ends of the cDNA.
Step 3
Step 4
Step 5
CONCEPTS OF GENOMIC BIOLOGY Page 4-15
Step 5. Mix the digested cDNAs with the predigested vector, and add DNA ligase to ligate to make cDNA recombinant vectors
Step 6. Transform the recombinant vectors into host cells, and grow up clones.
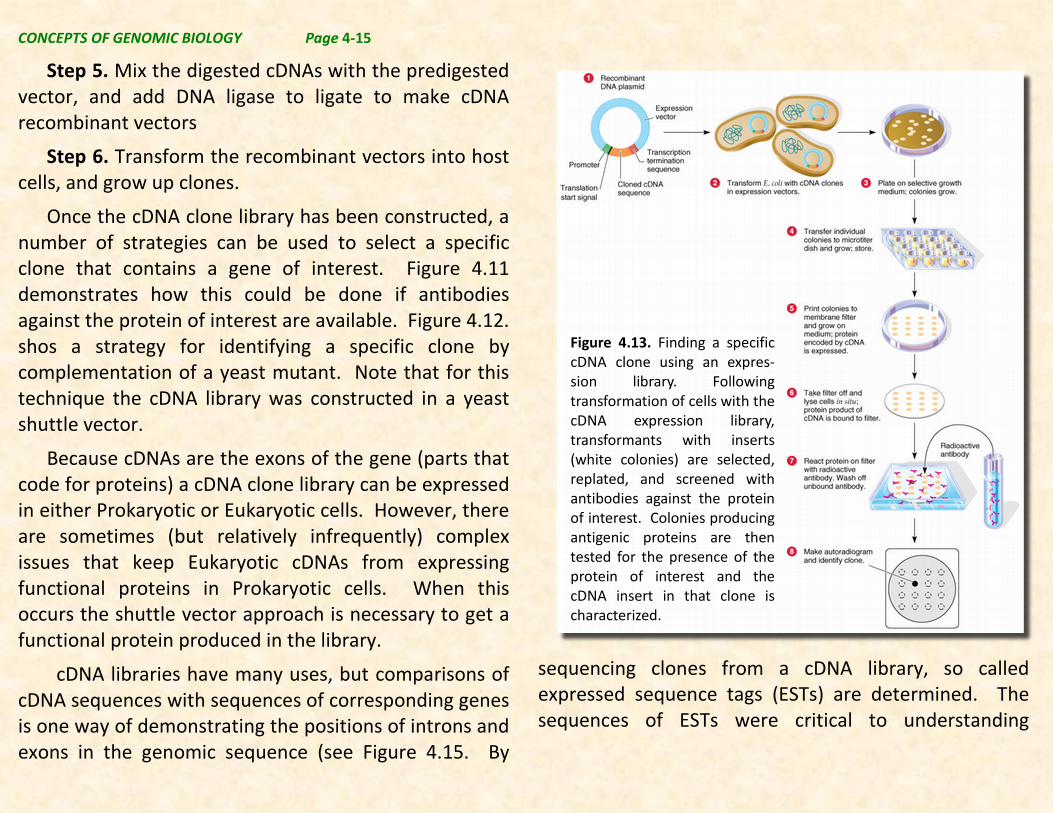
Once the cDNA clone library has been constructed, a number of strategies can be used to select a specific clone that contains a gene of interest. Figure 4.11 demonstrates how this could be done if antibodies against the protein of interest are available. Figure 4.12. shos a strategy for identifying a specific clone by complementation of a yeast mutant. Note that for this technique the cDNA library was constructed in a yeast shuttle vector.
Because cDNAs are the exons of the gene (parts that code for proteins) a cDNA clone library can be expressed in either Prokaryotic or Eukaryotic cells. However, there are sometimes (but relatively infrequently) complex issues that keep Eukaryotic cDNAs from expressing functional proteins in Prokaryotic cells. When this occurs the shuttle vector approach is necessary to get a functional protein produced in the library.
cDNA libraries have many uses, but comparisons of cDNA sequences with sequences of corresponding genes is one way of demonstrating the positions of introns and exons in the genomic sequence (see Figure 4.15. By
sequencing clones from a cDNA library, so called expressed sequence tags (ESTs) are determined. The sequences of ESTs were critical to understanding
Figure 4.13. Finding a specific cDNA clone using an expres-sion library. Following transformation of cells with the cDNA expression library, transformants with inserts (white colonies) are selected, replated, and screened with antibodies against the protein of interest. Colonies producing antigenic proteins are then tested for the presence of the protein of interest and the cDNA insert in that clone is characterized.
CONCEPTS OF GENOMIC BIOLOGY Page 4-16
functional components of genomes as they were being sequenced.
A genomic clone library or Genomic Library is a set of
cloned sequences made by cloning the entire genome of an organism or organelle. One of several ways this can be done by cutting the genomic DNA with one or more restriction enzymes, and ligating the pieces into a simple cloning vector as shown in Figure 4.9. A limitation of simple cloning vectors is the size of DNA that can be introduced into the cell by transformation. This presents problems when you are trying to create a Genomic Library of a large genome such as that of most Eukaryotes.
Remember that a genomic library contains all of the DNA found in the cells of the organism. If you digest
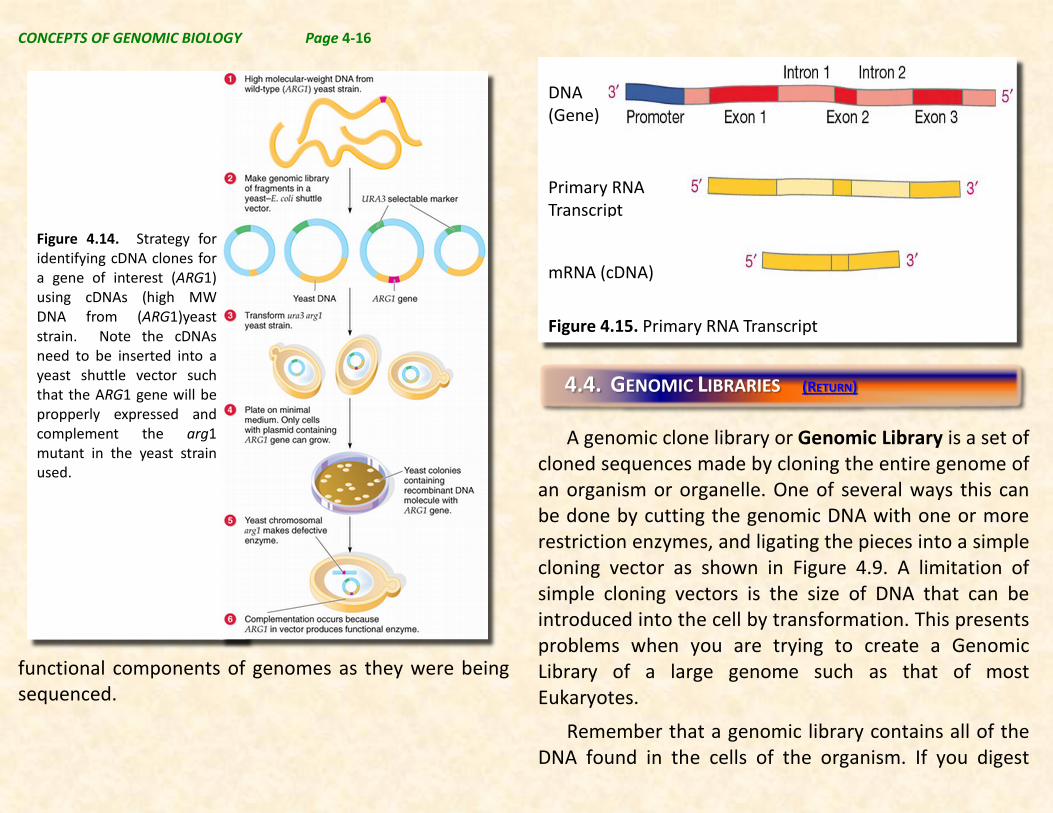
Figure 4.15. Primary RNA Transcript
DNA
(Gene)
Primary RNA Transcript
mRNA (cDNA)
4.4. GENOMIC LIBRARIES (RETURN)
Figure 4.14. Strategy for identifying cDNA clones for a gene of interest (ARG1) using cDNAs (high MW DNA from (ARG1)yeast strain. Note the cDNAs need to be inserted into a yeast shuttle vector such that the ARG1 gene will be propperly expressed and complement the arg1 mutant in the yeast strain used.

CONCEPTS OF GENOMIC BIOLOGY Page 4-17
organismal DNA to completion with a restriction enzyme, ligate those fragments into a plasmid vector and transform bacterial cells, only a portion of those fragments will be represented in the final transformation products. If a gene of interest is larger that the clonalbe fragment length, then you will not be able to isolate that gene in tact from a plasmid library.
But what can be done to increase the probability of obtaining a clone that contains the entire gene. First you need to use a vector that can accept large fragments of DNA. Examples of these are bacteriophage and cosmid vectors, and the relatively popular yeast artificial chromosome (YAC) vectors (see Figure 4.7b) and the bacterial artificial chromosome (BAC) vetors (see Figure 4.7a). While longer fragments of genomic DNA can be cloned in YAC vectors, these are less stable than the BAC vectors, making BACs the vectors most frequently used for genomic cloning.
4.4.1. Cloning in YAC Vectors (RETURN)
A goal of genomic sequencing is to obtain physical data about the genomic organization of DNA in a genome. Traditionally, this data has been obtained by a technique called chromosome walking. Walking can performed by subcloning the ends of DNA inserted in a phage λ vector or cosmid vector and screening a library for new clones that contain the end-sequences
previously obtained. If this new clone overlaps a portion of the original clone, then the length of the DNA of interest is extended by the length of DNA in the second clone that is not found in the original clone. By performing these steps successive times, a long distance map can be obtained. To claify this concept, please view the Chromosome Walking short video.
This technique though has difficulties. First, each step is technically slow. Second, if you use phage λ or cosmid clones, you might only extend the region of interest by 5-10 kb in each step of the walk. Finally, if any of the clones that are obtained contain repeated sequences, the subclone could lead you to another region of the genome that is not contiguous with the region of interest. This is because Eukaryotic genomes have so called repeated sequence DNA interspersed throughout their genomes.
Yeast artificial chromosomes can alleviate some of these problems because of the large (100-1000kb) amount of DNA that can be cloned. Howver, YACs cannot speed up each step of the walk because the subcloning and screening steps cannot be accellerated. But YACs can easily extend the region of interest by 50-100 kb and up to as much as 500 kb per walking cycle. Thus a long distance map of the region can be obtained in several steps. Secondly, although repetitive regions

CONCEPTS OF GENOMIC BIOLOGY Page 4-18
may be 10-20 kb in length they are rarely, longer than 50 kb. Thus a YAC with 100kb will contain some region that is single copy which can be used for further steps in the walk.
While YACs allow the cloning of the largest fragments possible, their relative stability has allowed the more stable BACs, which bear shorter recombinant fragments, to become the vector of choice for chromosome walking and subsequent sequencing.
4.4.2. Cloning in BAC Vectors (RETURN)
During the Human Genome Project, researchers had to find a way to reduce the entire human genome into chunks, as it was too large to be sequenced in one go. To do this they created a store of DNA fragments called a BAC library, specifically a human genome BAC library.
BAC stands for Bacterial Artificial Chromosome. These are small pieces of bacterial DNA that can be identified and copied within a bacterial cell and act as a vector, to artificially carry recombinant DNA into the cell of a bacterium, such as Escherichia coli.
In general BAC clones carry inserts of DNA up to 300,000 bp in length. The bacteria are then grown to produce colonies that contain the same fragment of DNA in each cell of the colony. This is a BAC clone
library. Individual BAC clone colonies can be stored until needed.
Making a BAC library
To make a genomic Bacterial Artificial Chromosome (BAC) library:
Step 1. Isolate the cells containing the DNA you want to store. For animals BAC libraries come from white blood cells.
Step 2. These isolated cells are then mixed with warm agarose, a jelly-like substance. The whole mixture is then poured into a mold and allowed to cool to produce a set of small blocks, each containing thousands of the isolated cells.
Step 3. The cells are then treated with enzymes to dissolve their cell membranes and release the DNA into the agarose gel. A restriction endonuclease is used to chop the DNA into pieces around 200,000 base pairs in length (partial digestion versus complete digestion producing smaller fragments).
Step 4. These blocks of gel containing chopped up DNA are then inserted into holes in a slab of agarose gel. The DNA fragments are then separated according to size by electrophoresis.
CONCEPTS OF GENOMIC BIOLOGY Page 4-19
Step 5. Fragments of a particular size class (200,000 to 300,000 bp) selected, removed from the agarose gel
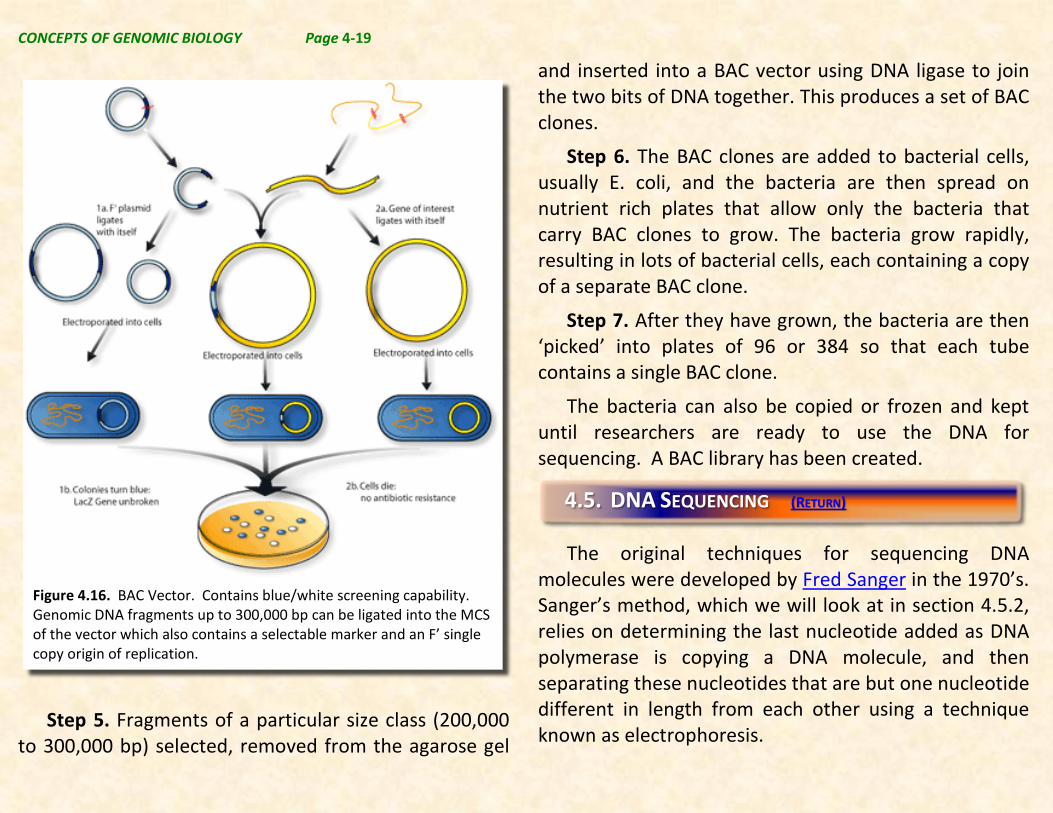
and inserted into a BAC vector using DNA ligase to join the two bits of DNA together. This produces a set of BAC clones.
Step 6. The BAC clones are added to bacterial cells, usually E. coli, and the bacteria are then spread on nutrient rich plates that allow only the bacteria that carry BAC clones to grow. The bacteria grow rapidly, resulting in lots of bacterial cells, each containing a copy of a separate BAC clone.
Step 7. After they have grown, the bacteria are then ‘picked’ into plates of 96 or 384 so that each tube contains a single BAC clone.
The bacteria can also be copied or frozen and kept until researchers are ready to use the DNA for sequencing. A BAC library has been created.
The original techniques for sequencing DNA
molecules were developed by Fred Sanger in the 1970’s. Sanger’s method, which we will look at in section 4.5.2, relies on determining the last nucleotide added as DNA polymerase is copying a DNA molecule, and then separating these nucleotides that are but one nucleotide different in length from each other using a technique known as electrophoresis.
4.5. DNA SEQUENCING (RETURN)
Figure 4.16. BAC Vector. Contains blue/white screening capability. Genomic DNA fragments up to 300,000 bp can be ligated into the MCS of the vector which also contains a selectable marker and an F’ single copy origin of replication.

CONCEPTS OF GENOMIC BIOLOGY Page 4-20
From Sanger’s original work, the process was automated, and such robotic sequencers were used to generate the first human genome sequence obtained by the original Human Genome Project. Subsequently, sequencing technology has been dramatically changed to both lower the cost of sequencing and increase the speed of sequencing using so called “Next Generation Sequencing”.
We will look at these techniques in today’s lab.
4.5.1. Electrophoresis (RETURN)
Nucleic acid electrophoresis is an analytical technique used to separate DNA or RNA fragments by size and reactivity. Nucleic acid molecules to be analyzed are separated in a viscous medium, typically a gel of some type. An electric field is appled across the gel causing the nucleic acids to migrate toward the anode due to the net negative charge of the sugar-phosphate backbone of the nucleic acid chain. The separation of nucleic acid fragments is accomplished by exploiting the different mobility of different sized molecules as they are passing through the gel. Longer molecules migrate more slowly because they experience more resistance within the gel. Smaller fragments migrate further in the same time and end up nearer to the anode than longer ones (see figure 4.17).
For highest reolution of similar sized fragments as required for DNA sequencing, either the voltage or run time can be varried. Extended runs across a low voltage gel yield the most accurate resolution, and sequencing gels can be 1 m in length.
Figure 4.17. Electrophoretogram showing the migration of smaller molecules to the anode (+) at the bottom of the gel,. The molecules to be separated are loaded at the top of the gel near the cathode (-). Larger molecules remain near the cathode. On the right side of the gel, a set of moleucles of known molecular size (length) are run. By comparing the mobility of an unknown molecule with the molecules of known length the size of the unknown fragments can be estimated.

CONCEPTS OF GENOMIC BIOLOGY Page 4-21
4.5.2. Sanger Dideoxy Sequencing (RETURN)
The method of DNA sequencing invented by Fred Sanger is a truly revolutionary technique. He was rewarded for his ingenuity with the Nobel Prize in 1980.
The specific steps of Sanger’s method are given below. Note that you can also view a video that describes this process:
Step 1. The DNA double helix is ‘denatured’ (broken down) with heat or chemicals to separate the two
strands. These will then act as templates for DNA synthesis using DNA polymerase and a primer similar to what is used in PCR.
Step 2. To the mixture of template, primer, DNA polymerase, dNTP (nucleotide bases (dA, dC, dG and dT) are added. One or more of these bases is radioactively labelled so that any DNA that is synthesised can be detected.
Step 3. Once the sequencing reaction has begun versions of the dNTP containing a hydrogen atom on both the 2’ and 3’ carbons of deoxyribose (see Figure 4.18) known as dideoxy-nucletotides (ddNTP) or chain terminators are also added in small amounts. Four identical reactions are run at the same, but ddA is added to one, ddG to the second, ddC to the third, and ddT to the last reaction. Terminators stop DNA synthesis since they lack a 3’-OH group for the next nucleotide to fasten to. So, the 'A' terminator will stop DNA synthesis when an 'A' base is added (the 'C' terminator will stop DNA synthesis when a 'C' base is added and so on…)
Step 4. This results in a mixture of pieces of radioactive DNA of various lengths but all ending in the same base, i.e. the ddBase added to each reaction.
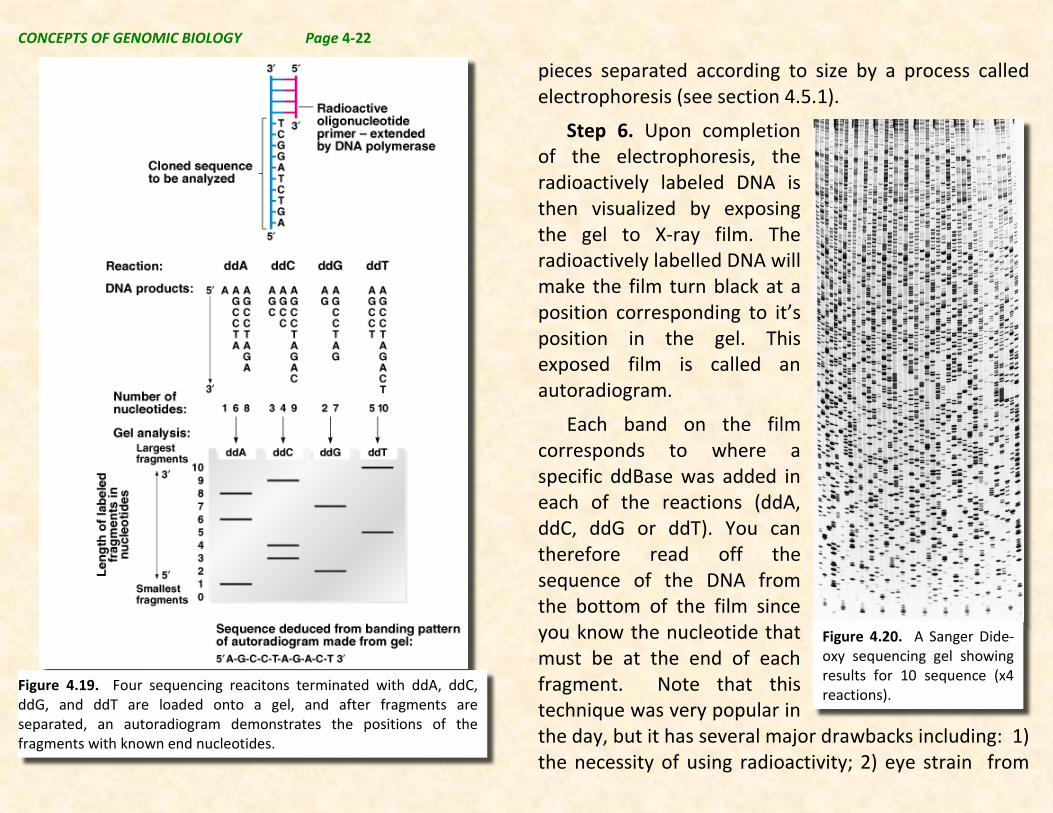
Step 5. The four different reactions are then loaded on to separate lanes of an acrylamide gel and the DNA
Figure 4.18. a) A regular deoxynucleotide triphosphate (dNTP) with a 3’-OH Group. B) A dideoxynucleotide triphosphate ddNTP. Since ddNTP have no 3’-OH group it is not possible for DNA polymerase to add more nucleotides to the growing nucleotide chain and DNA synthesis is terminated at that base.
CONCEPTS OF GENOMIC BIOLOGY Page 4-22
pieces separated according to size by a process called electrophoresis (see section 4.5.1).
Step 6. Upon completion of the electrophoresis, the radioactively labeled DNA is then visualized by exposing the gel to X-ray film. The radioactively labelled DNA will make the film turn black at a position corresponding to it’s position in the gel. This exposed film is called an autoradiogram.
Each band on the film corresponds to where a specific ddBase was added in each of the reactions (ddA, ddC, ddG or ddT). You can therefore read off the sequence of the DNA from the bottom of the film since you know the nucleotide that must be at the end of each fragment. Note that this technique was very popular in the day, but it has several major drawbacks including: 1) the necessity of using radioactivity; 2) eye strain from
Figure 4.19. Four sequencing reacitons terminated with ddA, ddC, ddG, and ddT are loaded onto a gel, and after fragments are separated, an autoradiogram demonstrates the positions of the fragments with known end nucleotides.
Figure 4.20. A Sanger Dide-oxy sequencing gel showing results for 10 sequence (x4 reactions).

CONCEPTS OF GENOMIC BIOLOGY Page 4-23
reading the gel manually leading to frequent errors; 3) fragments near the top of the gel cannot accurately be read, and in general discontinuities in the gel can create errors; 4) the method was not easily automated because it was tedious and time consuming. In general with great effort it was possible to obtain about 500-700 nt of sequence from most gels, this often took months to obtain.
Imagine that this the “state of the art” at the time the Human Genome Sequencing Project began. Obtaining 3.2 billion bp of human sequence taking 3 man-months per 700 bp would require about 1 million man-years of labor. Thus, improved technology was required to make the project successful. Though not really appreciated by the general population, this project was the biological equivalent of putting a man on the moon.
4.5.3. Capillary Sequencing (RETURN)
Two significant innovations made it possible to automate DNA sequencing, reduce costs, and increase efficiency making whole genome sequencing of virtually any genome a reality.
The first of these innovations was the addition of fluorescent chromophores to the dideoxy NTPs. These chromophores are attached such that different chromophores are attached to each base, and each
chromophore fluoresces at a different color. This means that only one reaction is needed instead of four, and as the differently colored ddNTPs terminate the reactions the molecules will have different fluorescent colors depending on the terminating nucleotide (see Figure 4.21., left pannel).
The second innovation was the replacement of gel electrophoresis, with electrophoresis through long thin acrylic-fiber capillaries (tubes with very narrow pores through which liquids can pass). These capillaries are far more uniform and consistent as an electrophoresis medium, and because they are less temperature sensitive higher voltages can be employed making separation faster and more reproducible. Additionally a laser can be used to generate the fluorescence and this can be done while the nucleotides remain in the capillary.
In capillary sequencing machines, DNA fragments are separated by size through a long, thin, acrylic-fibre capillary. A sample containing fragments of DNA labeled with the different chromophores described above is injected into the capillary. Once the sample has been injected, an electric field can be applied, to drive the DNA fragments through the capillary toward the anode as in gel electrophoresis.

CONCEPTS OF GENOMIC BIOLOGY Page 4-24
A fluorescence-detecting laser, built into the automated sequencing machine, then shoots through the capillary fiber at the end, causing the colored tags on the DNA fragments, to fluoresce. Each fluorescent terminator base produces a different color: A = Green, C
= Blue, G = Yellow and T = Red. The color of the fluorescent bases is detected by a camera as they migrate through the capilary, and the bases are recorded by the sequencing machine as the electrophoresis proceeds. The colors of the bases are
Figure 4.21. On the right is a capillary sequencer trace showing the nucleotides seen by the laser scan. On the left is a classical gel made using fluorescent nucleotides rather than radioactivity to demonstrate the principle of the cappliary sequencer.

CONCEPTS OF GENOMIC BIOLOGY Page 4-25
then displayed on a computer as a graph of different colored peaks (see Figure 4.21., right panel).
This technology is readily amenable to mechanization, and modern capillary sequences can dependably run dozens of samples in parallel through multiple capillaries simultaneously. Also the process is much faster, and thus multiple runs can be made daily through each capillary. The robots automating these sequencers also work 24-7, and data is collected and stored directly with no tedious human gel read involved. The human genome took about 10 years to sequence 3.2 billion bases at a cost of approximately $3 billion.
Today we have even faster sequencers that do not use electrophoresis, and generate sequences even faster and more inexpensively. This is ….
4.5.4. Next Generation Sequencing (RETURN)
Next-generation sequencing (NGS) is a fundamen- tally different approach to DNA sequencing, cutting the time and cost needed to sequence a genome. Using capillary sequencing it costs about $1 million to sequence 1 million bp, and it took about 10 years to sequence the first human genome. NGS costs about $0.60 per million bp, and can do the job in about 1 day.
The principles of NGS are in some ways similar to capillary sequencing where the bases of a small section of DNA are identified and recorded. However, rather
than being limited to just a few DNA fragments, next-generation sequencing extends this process so that millions of samples can be sequenced, all at the same time. For this reason it is sometimes called massively parallel sequencing (MPS). As a result, large amounts of DNA can be sequenced at rapid speed. With some next-generation sequencing machines researchers can sequence more than five human genomes per machine in just under a week.
Next-generation sequencing gives scientists the ability to compare the genomes of many different individuals. With the latest technologies, we can study the genomes from all sorts of people to provide us with the data needed to compare them and uncover the genetic causes of cancer, diabetes, schizophrenia and other diseases. We can also explore the genomes of things that cause human disease such as viruses, bacteria and other pathogens.
There are at least 4 different NGS sequencing technologies. Each has it’s advantages and disadvantages, but 2 technologies have emerged as the most useful, e.g. Illumina sequencing-by-synthesis, and the Roche 454 sequencing technology. All of the NGS sequencing technologies share several features as illustrated a video (click link); these are:

CONCEPTS OF GENOMIC BIOLOGY Page 4-26
1. Sample preparation. Fragments of uniform length are generated and adapter sequences are ligated onto the ends of the fragments.
2. Attachment of sequences to a matrix using a technique called “bridge PCR” that amplifies a sequence in a specific region of the support matrix in a cluster. This produces millions to billions of sequence locations where specific clusters of sequences are attached to a solid support matrix.
3. Raw sequence data collection is accomplished by various techniques depending on the particular technology that is employed. In general the data collection process records the sequence being generated from each cluster at each of the millions of locations on the matrix simultaneously, and saves these sequences for subsequent analysis.
Each sequencing technology involves different chemistry leading to the generation of sequences. The specific chemistries that can be used include: pyrosequencing chemistry used by Roche 454 Sequencers, sequencing-by-synthesis chemistry used by Illumina sequencers, ion semi-conductor sequencing used by Ion Torrent Sequencers, and sequen-cing-by-ligation used by ABI SoLID sequencers (this technology is
longer available although it is described in the video above).
Note that each of these sequencing technologies, delivers millions to billions of base paris of reads in a relatively short period of time (days), and does so at varying, but relatively low costs per base sequenced. Read length varies according to the technology used, but is typically 100 to 400 bases are obtained per read. The data generated are very large data files that must be used to generate the longer genomic or cDNA sequences that are biologically meaningful.
NGS technology regardless of type has revolutionized DNA sequencing, but simultaneously places a burden on available computational technology in order to assemble billions of short reads into whole genomic sequences. Nevertheless, the ability to generate such massive amounts of sequence has made this very successful technology.
4.5.5. Third Generation Sequencing (RETURN)
Although this technology is emerging, it could soon be a reality further advancing the role of DNA sequencing in all branches of the life sciences.
With third generation sequencing, sequencing a genome will become a cheaper, faster and more sophisticated process. No sooner had next-generation
CONCEPTS OF GENOMIC BIOLOGY Page 4-27
sequencing reached the market than a third generation of sequencing was being developed.
One of these new technologies was developed by Pacific Biosciences and is called Single-Molecule Sequencing in Real Time (SMRT). This system involves a single-stranded molecule of DNA that attaches to a DNA polymerase enzyme. The DNA is sequenced as the DNA polymerase adds complementary fluorescently-labelled bases to the DNA strand. As each labelled base is added, the fluorescent color of the base is recorded before the fluorescent label is cut off. The next base in the DNA chain can then be added and recorded.
SMRT is very efficient which means that fewer expensive chemicals have to be used. It is also incredibly sensitive, enabling scientists to effectively ‘eavesdrop’ on DNA polymerase and observe it making a strand of DNA.
SMRT can generate very long reads of sequence (10-15 kilobases) from single molecules of DNA, very quickly. Producing long reads is very important because it is easier to assemble genomes from longer fragments of DNA.
With the introduction of such sensitive and cheap sequencing methods scientists can now begin to re-sequence genomes that have already been sequenced to achieve a higher level of accuracy. For example, using
SMRT, Escherichia coli has now been sequenced to an accuracy of 99.9999 per cent!
Sequencing the human genome in this way won’t be possible for a while, but when it is, scientists predict that it will be possible to sequence an entire human genome in about an hour. Imagine the clinical applications of this technology. A doctor or pharmacist may be able to identify a critical gene that leads to an accurate drug prescription by sequencing your genome in the office while you wait
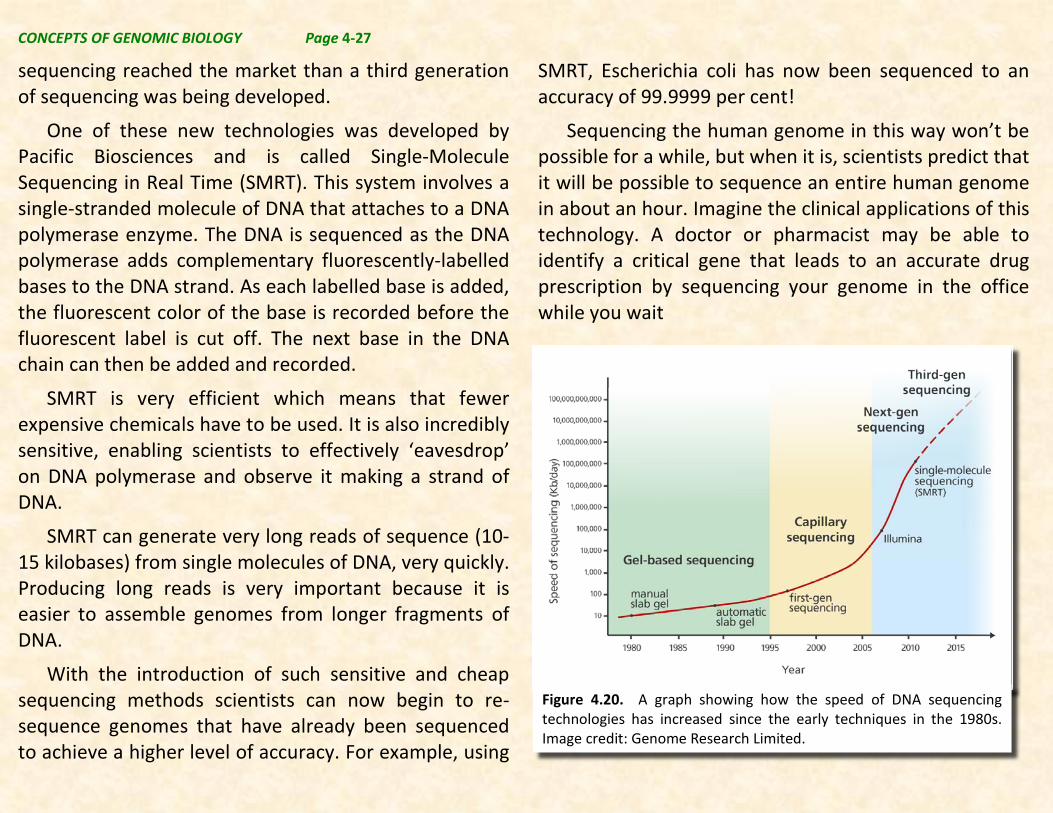
Figure 4.20. A graph showing how the speed of DNA sequencing technologies has increased since the early techniques in the 1980s. Image credit: Genome Research Limited.

CONCEPTS OF GENOMIC BIOLOGY Page 4-28
Beyond the method for generating DNA sequences, it
is necessary to have a strategy for how to emply DNA sequencing technology. Strategies for DNA sequencing depend on the features and size of the genome that is being sequenced and the available technology for doing the sequencing. As part of the Human Genome Project two general approaches emerged as most useful and valuable. One of these strategies the Map-based approach was employed by the publicly funded sequencing effort that involved scientists from around the world. The other strategy that was developed by a privately funded group at Celera Genomics, called whole genome shotgun sequencing was perhaps faster and cheaper than the map-based approach, but does not work efficiently with large genomes though it is very useful for smaller genomes. In fact today these approaches are “hybridized” or combined to obtain the advantages of both strategies.
4.6.1. Map-based Sequencing (RETURN)
The map-based or clone-contig mapping sequencing approach was the method originally developed by the publically funded Human Genome Project sequencing effort. The rationale for this method is that it is the
“best” method for obtaining the sequence of most eukaryotic genomes, and it has also been used with those microbial genomes that have previously been mapped by genetic and/or physical means. Though it is relatively slow and expensive, this method provides dependable high-quality sequence information with a high level of confidence.
In the clone-contig approach, the genome is broken into fragments of up to 1.5 Mb, usually by partial digestion with a restriction endonuclease (section 4.1), and these cloned in a high-capacity vector such as a BAC or a YAC vector (section 4.2.5). A clone contig map is made by identifying clones containing overlapping fragments bearing mapped sequence markers. These markers were originally identified using a combination of conventional genetic mapping, FISH cytogenetic mapping, and radiation hybrid mapping. Subsequently, common practice is to use chromosome walking as an approach to making a clone-contig library using this approach sequence markers are generated from BAC-ends, and a map of BAC-end sequences is subsequently made. Ideally the cloned fragments are anchored onto a genetic and/or physical map of the genome, so that the sequence data from the contig can be checked and interpreted by looking for features (e.g. STSs, SSLPs, RFLPs, and genes) known to be present in a particular region.
4.6. DNA SEQUENCING STRATEGIES (RETURN)
CONCEPTS OF GENOMIC BIOLOGY Page 4-29
Once the clone library and contig map have been developed, relevant clones are sequenced, using shotgun method below. These sequenced contigs are then alighned using the markers and overlapping seuqences on the clones to position each clone.
4.6.2. Whole Genome Shotgun Sequencing (RETURN)
In the whole genome shotgun approach, smaller randomly produced fragments (1,500-2,000 bp) were produced, cloned, and sequenced. These sequences were then assembled based on random overlap into a genome sequence. Typically, some regions are not well sequenced, and specific sequencing is done to fill in the gaps that cannot be assembled from the randomly made pieces.
Figure 4.21. Schematic diagram of sequencing strategy used by the publicly funded Human Genome Project. The DNA was cut into 150 Mb fragments and arranged into overlapping contiguous fragments. These contigs were cut into smaller pieces and sequenced completely..
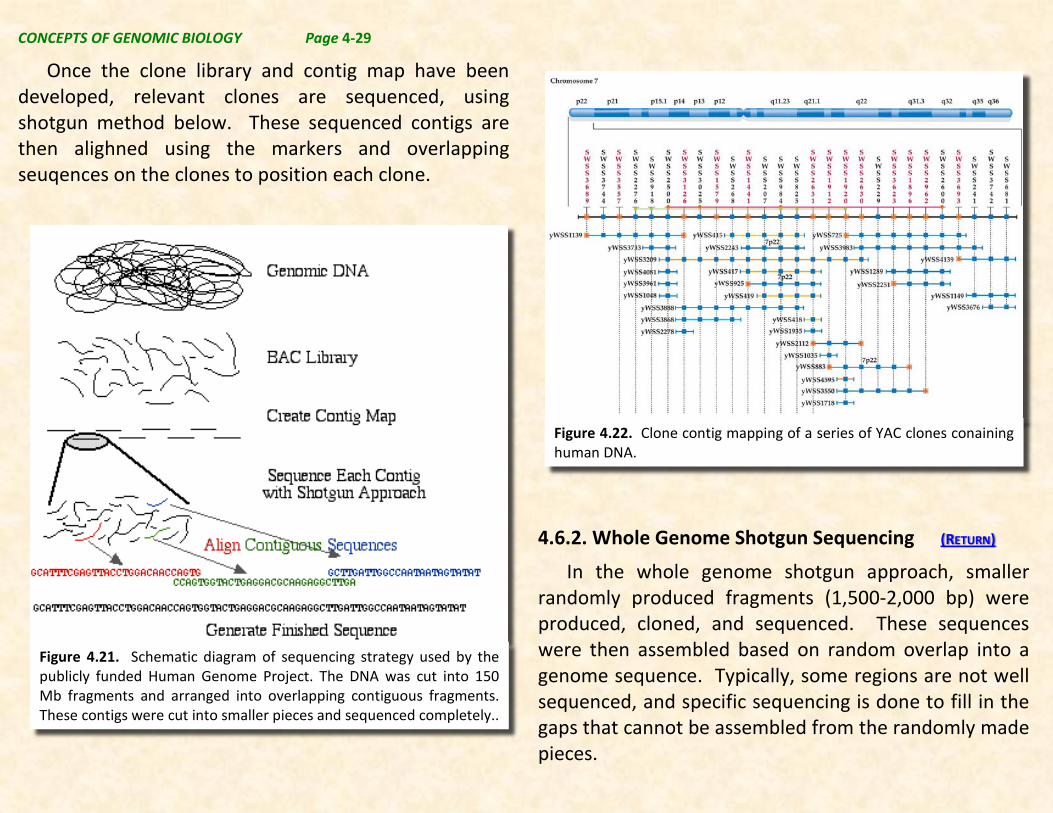
Figure 4.22. Clone contig mapping of a series of YAC clones conaining human DNA.

CONCEPTS OF GENOMIC BIOLOGY Page 4-30
The shotgun method is faster and less expensive than the map-based approach, but the shotgun method is more prone to errors due to incorrect assembly of the random fragments, especially in larger genomes. For example, if a 500 kb portion of a chromosome is duplicated and each duplication is cut into 2kb fragments, then it would be difficult to determine where a particular 2 kb piece should be located in the finished
sequence. This might seem trivial, but duplications seldom retain their original sequences. They tend to develop SNPs over time, and this can generate difficulties in the proper assembly of these duplicated sequences.
Which method is better? It depends on the size and complexity of the genome. With the human genome, each group involved believed its approach was superior to the other, but a hybrid approach is now being used routinely. The advent of next generation sequencing allows the use of fragment-end short read sequencing with much more powerful computer-based assemblers generating finished sequences. However, the method still requires at least some second round sequencing to obtain a completely sequenced genome.
Once a genome sequence is obtained via sequencing
using one or more strategies outlined in the preceding sections. The hard work of deciding what the sequence means begins. Typically to make such tasks easier some type of database is created that ultimately shows the entire sequence, the location of specific genes in that sequence, and some functional annotation as to the role that each gene has in an organism. The databases at
4.7. GENOME ANNOTATION (RETURN)
Figure 4.23. Schematic diagram of sequencing strategy used by Celera Genomics. The DNA was cut into small pieces and sequenced completely. These fragments were organized into contigs based on overlapping sequences.

CONCEPTS OF GENOMIC BIOLOGY Page 4-31
NCBI are a critical repository for these types of information, but there are many other specific and perhaps more detailed repositories of this type of information.
The process routinely begins with the implementation of what is termed a Gene Finding bioinformatic pipeline. The separate parts of such a pipeline are described below.
4.7.1. Using Bioinformatic Tools to Identify Putative Protein Coding Genes (RETURN)
A first approximation of gene locations in the genomic sequence is usually made using a gene prediction program to predict gene beginning and ending points, transcriptional and translational start and stop sites, intron and exon locations, and polyA addition sites. Often such programs produce sequences of the putative transcript produced, and/or the mature mRNA and protein amino acid sequence coded for by the gene as well.
Many gene prediction programs are so called neural network programs that are capable of “learning” what algorithms to use to decide the sequence of a gene. Such programs are trained on known sequences, and then once trained used to predict gene regions, and then after predicting, input is given back concerning
errors that were made. As the programs are used they refine and improve their predictive power.
4.7.2. Comparison of predicted sequences with known sequences (at NCBI) (RETURN)
Once putative coding genes are predicted, the next step is to compare the predicted mRNA (cDNA) sequences with known coding sequences, in publically available libraries.
This can be done with a number of possible tools, but one of the best for doing this is the Basic Local Alignment Search Tool (BLAST) utility at NCBI. By taking your predicted peptide and/or nucleotide sequence and submitting it to a BLAST search of the nr (proteins) or nt (nucleotide) sequence database you can learn what sequences available at NCBI are most similar to your sequence. When you do a BLASTP (protein) comparison, you are also shown conserved domains found in your protein.
Recall that conserved domains are amino acid sequences that are conserved in various types of proteins. Thus, BLAST searches can inform you a number of interesting and useful sequence features that are found in your submitted sequence. Also note that if a cDNA sequence library or libraries is/are available from the organism you are working with, and if a related sequence from a previously cloned gene is available at

CONCEPTS OF GENOMIC BIOLOGY Page 4-32
NCBI you can also learn about previously known cDNA or other sequences found in all of the databases at NCBI from this BLAST search. This becomes a critical method for learning what your gene does.
Also note that if you are working with a rare organism where little sequence information is available, you can construct and sequence your own cDNA library, to provide information about protein coding genes in your organism.
The other things you can learn from inspection of the predicted cDNA sequence and the actual sequence found in databases is how accurate the prediction was that was made by the prediction program. This can lead to editing the predicted gene to show the actual sequence that is found by BLAST searching when this is appropriate based on the available data.
As we learn more information about each gene, more literature is published related to your gene, and appears in the PubMed database at NCBI or in other NCBI databases. Since you have an interlocking series of databases at NCBI, the BLAST search itself gives you access to a large body of information about sequences related to your predicted sequence and to the actual gene that you discovered in the genome that was sequenced.
4.7.3. Published Genomes (RETURN)
Once such preliminary analyses have been performed the data needs to be shared with the applicable communities (scientific, medical, clinical, students, the interested public, etc) to whom the information is useful. The Genomes database at NCBI is a resource where this is done.
Note that genomic databases at NCBI and elsewhere are continually evolving, and new information is added as it comes available. This can make it difficult to understand what you find, but with care you can follow the process and wind up with the best information available.