centro nacional de investigacion … leopoldo z... · consideraciones al distribuir la base de...
TRANSCRIPT

S.E.P. S.E.I.T. D G.T.I. - -_
CENTRO NACIONAL DE INVESTIGACION Y DESARROLLO TECNOLOGICO
cenidet .
'' MANEJADOR DE ARCHIVOS FRAGMENTADOS
PARA UN SISTEMA MANEJADOR DE BASES DE
DATOS DISTRIBUIDAS "
T E S 1 § OUE PARA OBTENER EL GRADO DE: CEN~'RODEI, . ,~~~~~,<
M A E S T R O E N C I E N C I A S D E L A
P R E S E N T A I
C E N I D E T C O M P U T A C I O N
LEOPOLDO 2. ZEPEDA SANCHEZ
CUERNAVACA, MOR. FEBRERO DE 1995

s@P SISTEMA NACIONAL DE INSTITUTOS TECNOLOGICOS
Centro Nacional de Investigación y Desarrollo Tecnológico ACADEMIA DE LA MAESTRIA EN CIENCIAS
DE LA COMPUTACION
Cuemavaca Mor., a 9 de febrero de 1995
Dr. Juan Manuel Ricaiio Castillo Director del CENiDET P r e s e n t e
At'n: M.C. Luis García Gutiérrez Jefe del Dpto. de Computación
Nos es grato comunicarle, que conforme a los Iineamientos establecidos para la obtención del grado de maestría de este centro, y después de haber sometido a revisión académica el trabajo de tesis titulado:
"MANEJADOR DE ARCHIVOS FRAGMENTADOS PARA UN SISTEMA MANEJADOR DE BASES DE DATOS DISTRIBUIDAS"
que presenta el Ing. Leopoldo Zepeda Sánchez, y habiendo cumplido con todas las correcciones que le fueron indicadas, estamos de acuerdo con su contenido, por io que aprobamos que el trabajo sea presentado en examen oral.
Sin más por el momento, quedamos de usted.
A t e n t a m e n t,e"
Inierior Internado palmira S/N C.P. 62490 Apartado Postal 5-164, C.P. 62050, Cuemvaca Mor., Mexico
Tels. (73) 18-7741 y 12-76-13, Fax. 12-2434 cenidetl

SIP SISTEMA NACIONAL DE INSTITUTOS TECNOLOGICOS
Centro Nacional de Investigación y Desarrollo Tecnológico DEPARTAMENTO DE CIENCIAS COMPUTACIONALES
Cuernavaca Mor., a 13 de febrero de 1995
Ing. Leopoldo 2. Zepeda Sanchez Candidato al grado de Maestro en Ciencias de la Computación
‘ P R E S E N T E
Después de haber revisado su expediente escolar, y considerando que cumple con los lineamientos establecidos en el reglamento académico para la obtención del grado de maestría de este centro, me es grato comunicarle que se le concede la autorización para que proceda con la impresión de su tesis. AI mismo tiempo, aprovecho para indicarle que, deberá acordar con los miembros del jurado la fecha y hora de presentación del examen respectivo.
Sin más por el momento, reciba mis felicitaciones por el término de su trabajo de tesis, deseandole éxito en el examen correspondiente.
~ ,-
Computacionales.
C.C.P. M.C. Wiiberth Alcocer R. Cubdireccibn Académica C.C.P. Ing. David Chávez A. Dpto. de Servicios Escolares
interior Internado wlmira S N C.P. 62490 Apartado Posh1 5-164, C.P. 62050, Cuemavcica Mur., Mkicn
Tels. (73) 18-77-31 y 12-76-13, Fax. 12-2434 cenidetl

Con iodo e1 caritlo y rcflsptto a mi Madre motivo de mi superucih.
A mis sobrinos Aliciu, Luis, José, Adriunu, Verónicu. Curlos y Naialia.

AGRADECIMIENTOS
Agradezco a mis hermanos Julio, José Luis, Estela, Rosa, Herlinda, y Mireya todo cuando hicieron y contribuyeron para llegar al final de mis estudios de maestría.
Agradezco de manera muy especial a mis cuñados Gilberto, Elvira, Liz, Angel, y Francisco por su gran apoyo.
Expreso mi agradecimiento al Centro Nacional de Investigación y Desarrollo Tecnológico.
Reconozco y agradezco el apoyo económico brindado por CONACYT para mis estudios de maestría y tesis de maestría.
Gracias al Instituto de Investigaciones Eléctricas por las facilidades dadas para la realización de este trabajo de tesis.
Agradezco a mi asesor de tesis Dr. Rodolfo Pazos Rangel, su apoyo, orientación y tiempo dedicado para la realización de la tesis.
Expreso mi agradecimiento ai M.C. Joaquín Pérez Ortega, su apoyo e interés para este trabajo.
Agradezco al M.C. Luis García Gutiérrez por el apoyo brindado durante la maestría.
Agradezco a mis maestros por su apoyo, orientación y por brindarme sus conocimientos.
Agradezco a mis compañeros y amigos de generación Elsa Juárez, Victor Sosa, Juan de Dios Viniegra, Leticia Santaolalla, y Ariel Lira por su amistad;
Agradezco de manera muy en especial a mi amiga Paula Ocaños por su incondicional ayuda, apoyo y confianza brindada.

TABLA DE CONTENIDO
CAPITULO 1
INTRODUCCION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1 . I . Bases de Datos Distribuidas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2. Descripción del Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.3. Beneficios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.4. Estado del Arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.5. Organización de la Tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
CAPITULO 2
CONCEPTOS SOBRE BDDs . . . . . ; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.1. Consideraciones al Distribuir la Base de Datos . . . . . . . . . . . . . . . . . . . 6
2.1.1. Ventajas de la Distribución de Datos . . . . . . . . . . . . . . . . . . . 6 2.2. Diseño de Bases de Datos Distribuidas . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1. Repetición de los Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 2.2.2. Fragmentación de los Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2.1. Fragmentación Horizontal . . . . . . . . . . . . . . . . . . . . . Y 2.2.2.2. Fragmentación Vertical . . . . . . . . . . . . . . . . . . . . . 1 1 2.2.2.3. Fragmentación Mixta . . . . . . . . . . . . . . . . . . . . . . . 13
2.4. Transparencia de Fragmentación . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 2.5. Razones para Fragmentar una Tabla . . . . . . . . . . . . . . . . . . . . . . . . . 14
CAPITULO 3
PLANTEAMIENTO Y ANALISIS DEL PROBLEMA . . . . . . . . . . . . . . . . . . . . . 1.5 3 . 1 . Planteamiento General del Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 3.2. Alcance de la Tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 3.3. Antecedentes del Proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.4. Estrategias de Definición de una BDD Fragmentada . . . . . . . . . . . . . . 19 3.5. Ubicación del Esquema de Fragnientación . . . . . . . . . . . . . . . . . . . . . . 20 3.6. Gramatica para la Definición de Fragmentos . . . . . . . . . . . . . . . . . . . . 21 3.7. Diccionario de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 3.8. Lenguaje de Definición de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
. .
I

3.8. 1 . Definición de Tablas Globales o de Fragmentos . . . . . . . . . . . 29 3.8.2. Definición de Fragmentos . . . . . . . . . . . . . . . . . . . . . . . . . . 30 3.8.3. Definición de índices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 3.8.4. Instrucción DROP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.8.4.1. DROP TABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 3.8.4.2. DROP FRAGMENT . . . . . . . . . . . . . . . . . . . . . . 32 3.8.4.2. DROP INDEX . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.9. Lenguaje de Manipulación de Datos . . . . . . . . . . . . . . . . . . . . . . . . . 33 3.9.1. instrucción INSERT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 3.9.2. instrucción DELETE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 3.9.3. Instrucción UPDATE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 3.9.4. Instrucción SELECT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3 .IO . Localización del Fragmento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
CAPITULO 4
METODOLOGIA DE SOLUCION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 4.1. Instrucción CREATE FRAGMENTED TABLE . . . . . . . . . . . . . . . . . . 37 4.2. Creación de Fragmentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 4.3. Instrucción CREATE INDEX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 4.4. Instrucción DROP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.4. 1 . DROP TABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 4.4.2. DROP INDEX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 4.4.3. DROP'FRAGMENT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.5. Instrucción INSERT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 4.6. Localización del Fragmento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 4.7. Instrucción UPDATE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 4.8. Instrucción DELETE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1 4.9. Instrucción SELECT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
CAPITULO 5
PRUEBAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 5.1. Objetivos de las pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 5.2. Condiciones de las pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 5.3. Presentación de las pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
I1

.
CAPITULO 6
COMENTARIOS FINALES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.1. Posibles Extensiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85 6.2. Comentarios Firisles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
ANEXOA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
BIBLIOGRAFIA Y REFERENCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
....
I11

CAPITULO 1
INTRODUCCION
En este capitulo se muestran los beneficios que se esperan obtener con el desarrollo del presente trabajo de tesis, y las características de algunos manejadores de bases de datos distribuid#, también se presenta la descripción del problema a resolver y se describe a grandes rasgos como está organizada la tesis.
1.1. Bases de Datos Distribuidas
Una base de datos distribuida (BDD) es una colección de datos que se encuentran distribuidos en diferentes computadoras de nna red. Cada máquina de la red posee capacidad de procesamiento autónomo y puede efectuar aplicaciones locales. Cada máquina de la red participa también en la ejecución de, cuando menos, una aplicación global que requiere accesar datos de varias máquinas por medio de un subsistema de comunicaciones I I J.
Algunas características deseables en una base de datos .distribuida son las siguientes:
Transparencia de Iocaüzación. Es aquella caractenstica que permite a los nsuarios accesar la información de un archivo cualquiera de la base de dalos sin necesidad de indicar en qué computadora se encuentra el archivo.
Transparencia de fragmentación. Es aquella caractenstica que le permite a los usuarios accesar la información de un archivo fragmentado como si todos los datos del archivo estuvieran en una inisina computadora. Es decir, cuando se crea transparencia de fragmentación, el sistema crea la ilusión de que los archivos no están fragmentados.
Transparencia de repetición. Es aquella característica que permite a los usuarios accesar la información de los archivos con múltiples copias, como si el archivo fuera Único. Es decir, cuando existe transparencia de repetición, los usuarios no necesitan manipular separadamente cada. copia de un archivo repetido, ya que el sistema crea la ilusión de que el archivo es único.
Uno de los grandes problemas a los que se enfrentan los sistemas manejadores de. bases de datos distribuidas es el de realizar de manera rápida las peticiones solicitadas por el usuario. Para lograrlo se han diseñado diferentes métodos de optimizacióii de consult&.
1

Uno de ellos consiste en definir un esquema de consultas distribuidas. Este método de optimización, al momento de identificar que la tabla que interviene en la consulta es foránea, envía la ejecución de la consulta a la máquina donde reside físicamente la tabla, de esta manera la consulta se realiza en el nodo remoto y el tráfico por la red se reduce.
otro método (que no es excluyente del anterior) consiste en diseñar un esquema de fragmentación, el cual permite definir fragmentos a una tabla, de tal manera que cada fragmento se coloca en el nodo de la red donde más se usa, así la búsqueda de registros se reduce al nodo local.
1.2. Descripción del Problema
El instituto de investigaciones Eléctricas (IIE) ha desarrollado un manejador de bases de datos distribuidas, que permite accesar archivos de una BDD por medio de programas escntos en Turbo Pascal con instrucciones de SQL inmerso. El manejador ofrece los servicios de transparencia de localización y trabaja con el modelo de bases de datos relacional.
El manejador sólo había considerado aquellos casos en los que todos los renglones de una misma tabla se encuentran en una misma computadora. Sin embargo, puede darse el caso en que los datos de una tabla se encuentren repartidos en dos o más máquinas.
Con el presente trabajo se pretende desarrollar un manejador de archivos fragmentados con la intención de agregarse al manejador de base de datos distribuidas que se desarrolla actualmente en el LIE.
El problema que se presenta al desarrollar un manejador de archivos fragmentados consiste no sólo en poder interpretar las cláusulas de fragmentación, sino que también debe ser lo suficientemente inteligente para determinar la localización física de cada fragmento sin necesidad de indicarlo en forma explícita, lo que se conoce como transparencia de fragmentación
Este problema (transparencia de fragmentación) se presenta en instrucciones como SELECT, UPDATE, DELETE e INSERT. Por ejemplo, cuando se realiza un UPDATE a un renglón (el mismo caso sucede para DELETE y SELECT), se debe hacer UM búsqueda del renglón hasta encontrarlo y realizar las operaciones sobre él, que en este caso es la de actualización.
Cuando se realiza una operación de selección (uso del SELECT), éste puede presentar dos casos: uno en cual sólo involucra una tabla, el cual se conoce como selección simple; y el otro en el cual interviene más de una tabla que se conoce como selección múltiple. Cuando se presenta una selección simple, es necesario localizar el fragmento de una sola tabla; en cambio cuando se presenta una selección múltiple, es necesario realizar la búsqueda en más de una tabla; en este Último caso es necesario poder interpretar las cláusulas de fragmentación y determinar los atributos de las cláusulas y de las tablas que intervienen en la selección.
2

Es necesario entonces desarrollar un algoritmo que permita encontrar el renglón a buscar en cualquier fragmento, uno de estos métodos podria ser el de fuerza bruta, el cual consiste en buscar el registro en cada uno de los fragmentos lo que se traduce en un aumento del tiempo de respuesta.
Un método más sofisticado consiste en hacer uso del esquema de fragmentación, el cual está defiido por las cláusulas que permitieron crear los fragmentos de la tabla, de esa manera se tiene un punto de referencia para i i i t a r la búsqueda a un cierto fragmento, con lo que se hace una optimización del tiempo de búsqueda.
1.3. Beneficios
Entre los principales beneficios que pueden obtenerse con el desarrollo del presente trabajo se encuentran los siguientes:
a) Eliminar la limitación de capacidad del disco duro, ya que si una tabla no cabe en su totalidad en éste, podrá ser fragmentada y almacenada en otra parte de la red.
b) Reducir el tiempo de acceso en búsquedas a renglones especificos, lo que se logra de la siguiente manera: las tablas al estar fragmentadas, pueden estar estratégicamente localizadas o almacenadas en diferentes localidades de la red (donde por motivos organizacionales resulte más práctico), de tal manera que se pueden acomodar los fragmentos de la tabla en aquella máquina cuya aplicación haga un uso más frecuente de ese fragmento, y de esa forma reducir el tiempo de búsqueda ya que sólo se realiza en los renglones de una soia máquina.
Permitir una mayor flexibilidad en el desarrollo del código, ya que el programador no deberá preocuparse por la localización física del fragmento, ni tampoco deberá preocuparse si se modifica el esquema de fragmentación; es decir, al escribir código para alguna aplicación no será necesario indicar la localización donde se encuentra el fragmento, ni tampoco deberá preocuparse si los fragmentos son cambiados de lugar.
c)
1.4. Estado del Arte
- POREL
POREL es un sistema de bases de datos distribuidas desarrollado en la Universidad de Stuttgart en Alemania. Este prototipo trabaja en una red de mini-computadoras y trabaja con el modelo de bases de datos relacional. POREL soporta la fragmentación horizontal, y proporciona transparencia de localización.
3

- SIRIUS DELTA
S i R i ü S DELTA usa el modelo relaciona1 para la descripción de datos. Las relaciones pueden ser fragmentadas en forma horizontal o vertical. Sin embargo, la fragmentación mixta está limitada a un árbol de fragmentación de profundidad dos en el cual la fragmentación horizontal puede ser aplicada a la fragmentación vertical.
La fragmentación horizontal derivada se puede definir con la cláusula "VIA", la cual especifica que las tuplas de una tabla dada o fragmentación vertical se almacenan en el mismo sitio de otra tabla que tiene las mismas columnas en la llave primaria. En la práctica, la tabla tiene UM fragmentación y almacenamiento autónomo.
- DDM
DDM soporta la fragmentación horizontal de un conjunto de entidades, la cual se define usando los siguientes dos métodos:
Fragmentación primaria. Las entidades de un mismo conjunto de entidades pueden ser fragmentadas de acuerdo a un conjunto completo de predicados basados en propiedades del conjunto de entidades.
Fragmentación derivada. La fragmentación de una entidad puede hacerse usando una función de valor singular, la cual mapea cada entidad del conjunto de entidades para la cual se ha defhdo la fragmentación.
La fragmentación en este prototipo puede incluir más de un conjunto de entidades. En DDM existe la fragmentación en grupo. Una fragmentación en grupo está constituida por uno o más subconjuntos de entidades de una o más entidades, así que UM de ellas tiene una fragmentación primaria y la otra tiene una fragmentación derivada.
- PROYECTO R*
El objetivo principal del proyecto R* es construir un sistema de bases de datos distribuidas constituido de sitios cooperativos autónomos, cada uno soportando un sistema de bases de datos relacional. R* no soporta fragmentación y redundancia, y las bases de datos deben estar en redes locales.
4

- SDD-1.
SDD-1 soporta el modelo relaciona1 de bases de datos. UM base de datos puede ser fragmentada en dos pasos: primero horizontal y luego vertical, y los fragmentos pueden ser almacenados de manera redundante. SDD-1 también sopoita transparencia de fragmentación. La manipulación de sus relaciones se hace usando un Datalenguaje, que es un lenguaje procedimental de alto nivel disponible en Datacomputers.
- D-INGRES.
DJNGRES proporciona al usuario la posibilidad de manejar un esquema relacional con fragmentos y transparencia de localización. La fragmentación horizontal es soportada mientras que la vertical no. Los fragmentos pueden estar duplicados, donde cada fragmento se define por una operación de selección.
1.5. Organización de la Tesis
El material que se presenta en esta tesis está organizado de la manera siguiente:
En el Capitulo 2 se introducen los conceptos sobre bases de datos distribuidas, y se analizan las ventajas y desventajas de la distribución de los datos. También se presentan los diferentes tipos de fragmentación y algunas consideraciones que deben tomarse en cuenta al fragmentar una tabla.
En el Capítulo 3 se presentan los antecedentes del proyecto y se describen los problemas que se estudian en esta tesis, despues se aborda la solución conceptual de cada uno de los ellos y se determina la factibilidad de solución. En este capítulo se describen también algunas de las estructuras que se emplean para la solucion del problema y se define el alcance de la tesis.
En el Capítulo 4 se explican con detalle los algoritmos que permiten la transparencia de fragmentación para cada una de las instrucciones que soparta el manejador de bases de datos distribuidas.
En el Capítulo 5 se muesúan las pruebas efectuadas al sistema manejador de bases de datos distribuidas experimental con las que se demuestra la equivalencia semántica de los estatutos SQL-Pascal y la transparencia de fragmentación y de localización.
Por útimo, en el Capítulo 6 se describen los beneficios obtenidos con esta tesis, las posibles extensiones al trabajo y las conclusiones del mismo.
5

CAPITULO 2
CONCEPTOS SOBRE BDDs
En este capitulo se muestran los conceptos sobre bases de datos distribuidas, y se explican las ventajas y desventajas de la distribución de los datos.
También se muestran las consideraciones que deben tomarse en cuenta al diseñar un sistema de bases de datos distribuida y se defmen los diferentes tipos de fragmentación.
2.1. Consideraciones al Distribuir la Base de Datos
Existen varias razones para construir sistemas distribuidos de bases de datos que incluyen compartimiento de información, fiabilidad y disponibilidad, y agilización del procesamiento de las consultas. Sin embargo estas ventajas vienen acompañadas de varias desventajas, como son mayores costos del desarrollo de software, mayor posibilidad de errores y el aumento en el costo extra de procesamiento.
2.1.1. Ventajas de la Distribución de Datos
La principal ventaja de los sistemas distribuidos de base de datos es la capacidad de compartir y accesar información de una manera fiable y eficaz.
Utilización compartida de los datos y distribución de control
Si varias localidades diferentes están conectadas entre sí, entonces un usuario de una localidad puede accesar datos en otra localidad. La ventaja principai de compartir los datos por medio de una distribución es que cada localidad pueda controlar hasta cierto punto los datos almacenados localmente y si la organización crece adicionando nuevas unidades organizacionales, el enfoque de BDDs soporta un crecimiento incremental más suave con un grado mínimo de impacto sobre unidades ya existentes.
El control de los datos aimacenados localmente se conoce como autonomía local, y la responsabilidad se delega a un administrador local; sin embargo, debe existir un administrador global que se encarga de todo el sistema. La posibilidad de contar con autonom’a local es en muchos casos una ventaja importante de las bases de datos distribuidas.
6

Fiabilidad y disponibiüdad
Si se produce UM falla en UM localidad de un sistema didbuido, es posible que las demás localidades puedan seguir trabajando. En particular si los datos se repiten en varias localidades, una transacción que requiere un dato específico puede encontrarlo en más de una localidad; así, la falla de una localidad no implica la desactivación del sistema.
El sistema debe detectar cuándo falla una localidad y tomar las medidas necesarias para recuperarse de la falla. Por último, cuando se recupere o repare esta localidad, debe de contar con mecanismos para reintegrarla al sistema con el mínimo de complicaciones.
Aunque la recuperación de fallas es más compleja en los sistemas distribuidos que en íos centralizados, la capacidad que tiene el sistema para seguir trabajando, a pesar de la falla de una localidad, da como resultado una mayor disponibilidad. La disponibilidad es fundamental para los sistemas de bases de datos que se utilizan en aplicaciones de tiempo real.
El tener cierto grado de redundancia puede resultar conveniente, ya que la localidad de las aplicaciones puede incrementarse si los datos se duplican en todos los sitios donde las aplicaciones los necesiten.
Desventajas de la distribución de los datos
La desventaja principal de los sistemas distribuidos de bases de datos es la mayor complejidad que se requiere para garantizar una coordinación adecuada entre localidades. El aumento de la complejidad se refleja en los siguientes puntos:
Costo de desarrollo de software. Es más difícil estructurar un sistema de bases de datos distribuidas y, por tanto, su costo es mayor.
Mayor posibiüdad de errores. Puesto que las localidades del sistema distribuido operan en paralelo, es más difícil garantizar que los algoritmos sean correctos.
Mayor tiempo extra de procesamiento. El intercambio de mensajes y cálculos adicionales que se requieren para coordinar las localidades son una carga de tiempo que no existe en los sistemas centralizados.
22. Diseño de Bases de Datos Distribuidas
Considérese una relación R que se va a almacenar en la base de datos. Hay varios factores que deben tomarse en cuenta ai almacenar esta relación en la base de datos distribuida. Tres de ellos son los siguientes: .

- Repetición. El sistema mantiene varias copias idénticas de la relación. Cada copia se almacena en una localidad diferente, lo que resulta en una repetición de la información.
Fragmentación. La relación se divide en varios fragmentos y cada fragmento se almacena en UM localidad diferente.
-
- Repetición y fragmentación. Esta es UM combinación de los dos conceptos antes mencionados. La relación se divide en vanos fragmentos y el sistema mantiene varias copias idénticas de cada uno de los fragmentos.
2.2.1. Repetición de los Datos
Si la relación R está repetida, se almacena UM copia en dos o más localidades. En el caso extremo se tiene rcpehción total en el que se almacena una copia de la relación en cada una de las localidades del sistema. La repetición tiene vanas ventajas y desventajas.
Disponibilidad. Si falla una de las localidades que contiene una copia de R, puede disponerse de ésta en otra localidad. Así, el sistema puede continuar procesando las consultas que involucren a la relación R a pesar de haber fallado una localidad.
Mayor paralelismo. En el caso en que la mayor parte de los accesos a la relación R resulten sólo para lectura, varias localidades podrán procesar en paralelo consultas que involucren a R. Mientras m á s copias de R existan, mayor será la probabilidad de que los datos requeridos se encuentren en la localidad donde se está ejecutando la transacción. Por tanto, la repetición de los datos reduce al minimo el movimiento de información entre localidades y reduce al mínimo el uso de la red por lo que las consultas se agilizan.
Mayor tiempo para actualizaciones. El sistema debe asegurarse de que todas las copias de la relación R sean congruentes, pues de otra manera la información requerida puede ser errónea. Esto implica que cada vez que se actualice R, la actualización debe propagarse a todas las localidades que contengan copias, lo que resulta en un mayor tiempo extra de ejecución.
En general, la repetición mejora el rendimiento de las operaciones y aumenta la disponibilidad de datos sólo para las operacioncs de lectura.
2.2.2. Fragmentación de los Datos
Si la relación R está fragmentada, R se dividirá en variosfragmentos r,, ru ..., r,. Estos fragmentos deben contener información suficiente para reconstruir la relación R original. Esta reconstrucción puede llevarse a cabo de diferente manera, dependiendo del tipo de fragmentación. Existen dos esquemas diferentes para fragmentar UM relación: fragmentación horizontal y fragmentación vertical.

La fragmentación horizontal divide a una relación R en base a una selección de las tuplas y las asigna a uno o más fragmentos, la fragmentación vertical divide a la relación descomponiendo el esquema de la relación R en base a UM proyección.
2.2.2.1. Fragmentación Borizontal
La fragmentación horizontal consiste en patticionar las tuplas de una relación global en subconjuntos; ésto es claramente Útil en bases de datos distribuidas, donde cada subconjunto puede contener datos con propiedades comunes.
Esto se puede definir expresando cada fragmento como una operación de selección (SL), de una relación global R. Es decir, se utiliza un predicado de la forma P, para construir el fragmento de la siguiente manera:
rj = SLp, (R)
la reconstrucción de la relación R puede obtenerse al calcular la unión de todos los fragmentos, es decir:
R = r, U r, U ... U ro
Supongamos que la relación R es la relación depósito de la Figura 2.1. Esta relación puede dividirse en n fragmentos diferentes, cada uno de los cuales consiste en tuplas de cuentas que pertenecen a una sucursal determinada por ejemplo: Si el sistema bancario tiene dos sucursales, Jalisco y México, entonces existen dos fragmentos diferentes
Depósito, = SLNombemm~,,dsm ,, (Depósito) Depósito2 = SLNombmmcd~~~,,,dmm (Depósito)
Estos dos fragmentos se muestran en la Figura 2.2. El fragmento Depósito, se almacena en la localidad Jalisco y el Depósito, se almacena en la localidad México.
9

Figura 2.1. Relación Depósito.
205 905 750 700
Figura 2.2. Fragmentación Horizontal de la Relación Depósito.
Fragmentación horizontal derivada
En algunos casos la fragmentación de una relación no puede hacerse en base a sus atributos, pero se deriva de la fragmentación horizontal de otra relación. Por ejemplo: si se nos pide que hagamos una fragmentación de R que contenga las tuplas de las sucursales que están en cierta ciudad, pero ciudad no es un atributo de R, pero es un atributo de otra relación S, donde S contiene los atributos que se muestran el la Figura 2.3.
10

Jaiiaoo
Quedaiapra
JlSW Jal
Fig.2.3. Relación S.
La fragmentación horizontal derivada de Depósifo para este caso puede definirse como sigue: es necesario hacer un Join, con los fragmentos horizontales resultantes de la relación S. Por ejemplo:
El efecto del Join es seleccionar las tuplas que satisfacen la condición entre S I , S, y Depósito. La reconstrucción de la relación global Depdsifo puede realizarse por medio de la operación de unión entre los fragmentos.
2.2.2.2. Fragmentación Vertical
En su forma más simple, la fragmentación vertical es igual a la descomposición de sus atributos en grupos. La fragmentación vertical de R involucra la definición de varios subconjuntos, los cuales se obtienen por proyecciones (PJ) de la relación global R, tales que cada fragmento r, de R se defme por
la relación R puede reconstruirse a partir de los fragmentos realizando la reunión natural. De manera más general, la fragmentación vertical se lieva a cabo añadiendo un atributo especial, llamado identificador de tupla (id-tupla), al esquema R. Un identificador de tupla es una dirección fisica-lógica de una tupla. Puesto que cada tupla en R debe tener una dirección única, el atributo identificador de tupla es una clave del esquema ampliado.

En la Figura 2.4 vemos la relación Depósito, que es el esquema ampliado de la relación Depósito de la Figura 2.1 con su identificador de tupla. En la Figura 2.5 vemos una descomposición vertical del esquema Depdsito en los siguientes fragmentos:
... mo
esquema- depdsito- 3 =(Nombre-sucursa/,Nombe cJientejd- tupa) esquema- depósit~-4=~Núrn~cuen~,Sddo,id-tup~a)
. .. 7m I
Figura 2.4. Relación Depósito con id-tupla.
las dos relaciones que se muestran el la Figura 2.5 resultan de calcular
Depkito, = PJ (esquema-depósito-3) DeMsito Depkito., = PJ (esquema- depósito-4) Depósito
Figura 2.5. Fragmentación Vertical de la Relación Depósito.
12

Para reconstruir la relación Depósito original a partir de los fragmentos, se calcula
Cabe hacer notar que la expresión anterior es una forma especial de la reunión nahiral. El atributo de la reunión es id-tupla, puesto que el valor de id-tupla representa una dirección, es posible formar una pareja con una tupla de Depósito, y la tupla correspondiente al Depósiro, empleando la dirección dada por id-tupla. Esta dirección permite recuperar de manera directa la tupla sin necesidad de un índice. Así, la reunión natural puede calcularse de manera más eficiente que las reuniones naturales normales.
Aunque el atributo identificador de tupla facilita la implementación de la fragmentación vertical, también es importante que los usuarios no puedan ver este atributo. Si los usuarios tienen acceso al identificador de tuplas, el sistema no podrá cambiar las direcciones de las tuplas. Además, el acceso a direcciones internas viola el concepto de independencia de los datos, que es UM de las virtudes del modelo relacional.
2.2.2.3. Fragmentación Mixta
La relación R se divide en varios fragmentos que constituyen las relaciones rl, r ) ..., r,. Cada fragmento se obtiene de la aplicación del esquema de fragmentación, ya sea horizontal o vertical, sobre la relación R, o sobre un fragmento de R que se haya obtenido con anterioridad; es decir, la fragmentación mixta consiste en definir cláusulas para fragmentos verticales en base a cláusulas para fragmentos horizontales.
Para ilustrar lo anterior, suponemos que R es la relación Depósito de la Figura 2.1, que se divide inicialmente en los fragmentos Depósito, y Depósito, arriba definidos. Ahora podemos dividir, además, el fragmento Depósito, utilizando el esquema de fragmentación horizontal en dos fragment os.
Depósito3, = SL"*~~~,,d=.McuEo,,(Depdsjto3) Depósito3, = SLmbm.sucud.~t,d- ,,(Depósito3)
Así, la relación R se divide en tres fragmentos Depósito,, Depósito,, y Depósito,; donde cada uno de ellos puede residir en una localidad diferente.
La fragmentación mixta se puede representar por un árbol de fragmentación, en donde la raiz corresponde a la relación global, los niveles corresponden a los fragmentos, y los nodos intermedios corresponden a los resultados intermedios de la expresión de defmición del fragmento. El conjunto de nodos, los cuales son hijos de un nodo dado, representan la descomposición de este nodo por UM operación de fragmentación.
13

2.4. Transparencia de Fragmentación
Cuando una relación se encuentra fragmentada no es necesario que el usuario de la aplicación haga referencia de manera explícita a un fragmento específico de la relación. El sistema debe ser el que determine a qué fragmento accesar. El que un usuario no se percate de la existencia de fragmentos se le conoce como transparencia de fragmentación.
Por ejemplo, si la relación Depósito (Figura 2.1) se fragmenta en dos (Figura 2.2.), y cada fragmento se coloca en sitios diferentes, el usuario de la aplicación al hacer una manipulación sobre la tabla no necesita indicar el nombre del(los) hgmento(s) que involucran la operación, ya que el sistema manejador de base de datos debe determinarlo automáticamente. Si la operación es una selección, donde el nombre de sucursal sea igual a "México", el código a realizar sería el siguiente:
$SELECT * INTO Ns, Nc, Ncl, S FROM Depósito WHERE Nombre-sucursal = "México";
2.5. Razones para Fragmentar una Tabla
Cuando una relación se desea fragmentar se debe tener en cuenta en qué nodos de la red se utilizan con m á s frecuencia los datos de cada fragmento, para que en ese nodo sea colocado AI residir el fragmento de manera local, el tráfico por la red disminuye y los accesos sobre las relaciones son más rápidos, en particular sobre la relación fragmentada
Cabe señalar que SI los fragmentos son colocados de manera errónea, los accesos a la tabla fragmentada serán más lentos debido a los cálculos adicionales que el manejador de bases de datos distribuidas debe realizar para determinar el fragmento al que se hace referencia en la operación.
Otros beneficios importantes que presenta la fragmentación' es que los datos son controlados de manera local; es decir, los departamentos de las empresas tienen un control de los datos que manejan específicamente. También el espacio en disco duro puede aprovecharse al mhimo, ya que si una tabla no cabe en su totalidad, puede fragmentarse y repartirse en varios sitios.
14

CAPITULO 3
PL. NTEAMIENTO Y ANALISIS DEL PROBLEMA
En este capítulo se. muestra una descripción detallada de los problemas que involucm el fragmentar una base de datos y se describe. la metodología de solución de una manera conceptual, evitando al máximo entrar en detalles de implementación (los cuales se explican en el capítulo 4).
Además se presentan los antecedentes previos a esta tesis con el fui de ubicar este trabajo dentro de la infraestructura de software ya existente, también se fija el alcance y se presenta un análisis sobre la ubicación del esquema de fragmentación dentro de la arquitectura ANSYSPARC.
3.1. Planteamiento General del Problema
El objetivo principal de esta tesis es agregar las rutinas que permitan a un manejador de bases de datos distribuidas experimental (que se está desarrollando en el Instituto de Investigaciones Eléctricas) ofrecer transparencia de fragmentación.
La BDD experimental tiene las siguientes caracteristicas:
a) Soporta el modelo relacional.
b)
c)
d)
e)
Utiliza la red IBM-PC Network.
Utiliza el sistema operativo DOS versión 3.3.
La red está constituida por tres computadoras personales AT.
L a forma como opera la red, es a través de aplicaciones escritas en Turbo Pascal con SQL intercalado.
f ) Las instrucciones de SQL para el lenguaje de defuiición de datos son CREATE TABLE, CREATE INDEX, DROP TABLE, y DROP INDEX, y para el lenguaje de manipulación de datos son INSERT, SELECT, UPDATE, DELETE, y la manipulación de CURSORES.
15

3.2. Alcance de la Tesis
El alcance de la tesis comprende solamente el tipo de fragmentación horizontal con las
Fragmentar una base de datos en base a uno de sus atributos.
siguientes caractensticas:
-
- Fragmentar una base de datos en base a dos o más de sus atributos.
Realizar búsquedas simples sobre una tabla (donde intervengan uno o varios de sus atributos) y búsquedas más complejas donde intervengan más de una tabla.
Las herramientas utilizadas para llevar a cabo el trabajo son las siguientes:
-
- Turbo Pascal versión 6.0.
- Red local de computadoras con el paquete de comunicaciones IBM PC Network.
3.3. Antecedentes del Proyecto
Antes de exponer el análisis del problema, se presenta a continuación una descripción breve de los trabajos que han sido desarrollados por el instituto de investigaciones Eléctricas (HE) en materia de bases de datos distribuidas (BDD), con el objeto de situar en ellos el presente trabajo. Asimismo, se describe parte del software que se tenía antes de este trabajo con el propósito de conocer los servicios de este software.
El primer trabajo relacionado con BDD desarrollado en el departamento de Sistemas de información del IIE consistió en el desarrollo de un paquete de rutinas que permiten el acceso a los archivos de UM base de datos distribuida por medio de programas escritos en Turbo Pascal. Estas primitivas permiten el acceso concurrente y trasparente a la bases de datos distribuida. Lo anterior quiere decir que un programa en Pascal que hace uso de estas rutinas, puede accesar los archivos desde cualquier máquina de la BDD, sin necesidad de especificar en qué computadora de la red residen dichos archivos (a esto se le conoce como transparencia de localización). Las rutinas fueron escritas en lenguaje ensamblador y en Turbo Pascal, para trabajar con sistema operativo DOS versión 3.30. El paquete está constituido por dos niveles de programas (véase la Figura 3. I .).
Para facilitar la implementación del paquete, se consideró conveniente desarrollar un grupo de rutinas (nivel I ) que permiten abrir y cerrar archivos, así como leer, escribir, reservar y liberar registros en cualquier computadora de la red. Estos servicios se ofrecen como funciones del sistema operativo (denominados interrupciones), los cuales pueden ser invocados por medio del lenguaje ensamblador.

SERWCIOS DE ACCESO A *RCHIVos Y 71 RE01SlFSS EN FORMA lRANSPAr(EHTE NIVEL?
Figura 3.1 Arquitectura del Manejador de Archivos.
Finalmente el nivel 2 ofrece los servicios de transparencia de localización como un conjunto de rutinas cuya característica es que permite a los programas de aplicación accew información de un archivo cualquiera de una base de datos distribuida, sin necesidad de indicar en qué computadora o disco se encuentra el archivo.
E1 hecho de que un manejador posea transparencia de localización implica que, dado el nombre de un archivo, los servicios de acceso a archivos del manejador deben determinar dónde se encuentra el archivo.
Esto se logra por medio del Diccionario de Archivos Distribuidos (DAD). El DAD contenia entre otras cow, una lista de los nombres de los archivos que constituyen la BDD junto con la localización de cada archivo (o sea, la máquina donde se encuentra cada archivo) y la descripción del registro.
El DAD se dividía en varios fragmentos y cada uno de éstos se colocaba en una computadora diferente; es decir, la información que contenía el DAD acerca de las tablas que participan en las bases de datos se encontraba distribuida en todos los nodos que participan en la red.
EL segundo trabajo desarrollado en el IIE consistió en un precomplidor del lenguaje SQL, el cual facilita el uso del manejador de archivos (descrito anteriormente), por parte de cualquier desarrollador de aplicaciones que conozca de bases de datos. Este precompilador está basado en el estándar de SQL[2], el cual consta de I ) un lenguaje de manipulación de datos (LMD) que sirve para manipular las tablas con operaciones tales como insertar, borrar o consultar renglones de las tablas y 2) un lenguaje de deffición de datos (LDD) que efectúa la creación, definición y eliminación de las tablas de una base de datos. De esta manera, los desarrolladores familiarizados con SQL pueden definir y manipular una BDD sin necesidad de conocer las rutinas y los argumentos del manejador de archivos.
El precompilador está constituido por un r e c o n d o r de proposiciones de SQL y un traductor (el cual consiste a su vez de un analizador y un generador de código).
17

El m m c e d o r de proposiciones de SQL tiene la función de buscm el programa fuente
El analizador se encarga de identificar los elementos del lenguaje SQL agrupándolos en
de SQL inmerso en k b o Pascal y reconocer cuándo se inicia proposicibn de SQL.
construcciones lógicas, y consta de tres partes:
1.- El analizador léxico que se encarga de leer las instrucciones en SQL del programa fuente (carácter por carácter) para reconocer los elementos mínimos del lenguaje llamados "tokens".
El analizador sintáctico que verifica que la secuencia de los "tokens" sean legales de acuerdo a las reglas sintácticas especificadas por la gramática independiente del contexto del lenguaje SQL.
El analizador semántico que se encarga de verificar que las construcciones sintácticas tengan una semántica o significado correcto.
El generador de código produce código en Turbo Pascal que es semánticamente equivalente a la instrucción de SQL analizada. El código generado incluye llamados a los servicios del manejador de archivos descrito anteriormente.
2.-
3.-
Todas estas partes actúan en un solo paso de la siguiente maneia: cuando se detecta el símbolo "$", que indica el inicio del código SQL, el precompilador transfiere el control al analizador sintáctico (Figura 3.2). éste utiliza un esquema de traducción dingido por sintaxis, ei cual está basado en la idea de que las reglas de producción de la gramática del lenguaje SQL se usen para dirigir el tipo de procesamiento que se va a efectuar en las construcciones del lenguaje.
De esta forma, para cada regla de producción, el analizador sintáctico puede llamar el análisis semántico apropiado y la rutina de generación de código para generar código Turbo Pascal correcto.
Programa hlenle I enpesca mn I SQC inmerso
Figura 3.2. Diagrama a Bloques del Precompilador.
18

3.4. Estrategias de Defición de ma BDD kagmentada
Existen dos enfoques para la definición de bases de datos con tablas fragmentadas. En uno de los enfoques, primero se definen los fragmentos y después la tabla global; mientras que en el otro, primero se define la tabla global y después los fragmentos. A continuación se explican estos dos enfoques y se muestran sus ventajas y desventajas.
El primer enfoque de fragmentación consiste en integrar tablas ya existentes en una tabla global, donde la tabla global se comporta como una vista de las tablas que le dieron origen, pero a diferencia de las vistas tradicionales la tabla global no presenta ninguna restricción para poder ser actualizada.
Con este tipo de enfoque se complica el logro de la transparencia de fragmentación ya que puede darse el caso de que los atributos que forman las diferentes tablas sean de diferente tipo, por lo tanto es necesario realizar la conversión de tipos para lograr la transparencia de fragmentación.
Por ejemplo si la tabla R, contiene los siguientes atributos:
Num-Emp: CHAR(4) Nombre: CHAR(30) Sueldo: FLOAT Ciudad: CHAR( 1 O)
y la tabla R, contiene los atributos
Num-Emp: INTEGER Nombre: CHAR(30) Sueldo: FLOAT Ciudad: CHAR(I0)
y se desea integrar a ambas tablas en la tabla global R ver Figura 3.3, al momento de hacer la integración existe un conflicto en el tipo de dato de la columna Nun-Emp, por lo tanto es necesario realizar un procedimiento para hacer la conversión de tipos al momento de tratar de identificar a qué fragmento se hace referencia en una operación de manipulación de datos.
El otro enfoque de fragmentación se logra defmiendo primero lógicamente la tabla, es decir se almacena solamente su estructura en el DAD, y definiendo después fragmentos sobre la tabla. Estos fragmentos se crean fisica y iógicamente de tal manera que, al momento de insertar datos sobre la tabla global, se procede a identificar en cuál de los fragmentos asociados a la tabla serán colocados.
19

- 'i
En este tipo de metodología los fragmentos heredan la estructura de la tabla global, de tal manera que no se presenta el problema de diferencia de tipos (ya que cada fragmento tiene la misma estructura).
Ya que esta metodología facilita la identificación de los fragmentos de manera transparente; por esto, fue considerada para el desarrollo de esta tesis.
CIUDAD NDMBRE SUELW NUM-EMP
1 w I
RELACION GLOBAL R
I CIUDAD I NOMBRE I SUELDO I NUMJMP I I -I 1.'
MEXICO ncToR - FRAGMENTO R1
FRAGMENTO R:! Figura 3.3 Esquema de Fragmentación.
3.5. Ubicación del Esquema de Fragmentación
Es importante determinar la ubicación del esquema de fragmentación dentro de la arquitectura ANSl/SPARC, para comprender mejor la manera como se implementó el lenguaje de definición de datos en esta tesis y la relación que existe con el lenguaje de maiiipulación de datos.
La arquitectura ANSYSPARC para sistemas de bases de datos define tres niveles para lograr la independencia de datos: nivel interno, nivel conceptual y nivel externo.
En el nivel interno se percibe la base de datos completa con los detalles de almacenamiento de los datos. En el nivel conceptual se percibe la base de datos completa en forma abstracta; es decir, solamente se perciben sus aspectos esenciales y se ignoran los detalles de almacenamiento. En el nivel externo se percibe la base de datos en el nivel conceptual de manera transformada (en donde esta transformación generalmente se concreta en una percepción limitada). Mientras que en el nivel interno y conceptual se percibe la base de datos de una sola manera, en el nivel externo pueden existir tantas percepciones como transformaciones puedan definirse.
2 0

para el diseño del lenguaje de defhción de datos es n e c e b o dete-, en quk nivel de la arquitectura ANsusPARC se ubican los esquemas de las tablas globales Y 10s fragmentos.
como el esquema de las tablas globales es una representación abstracta, es razonable suponer que el esquema de una tabla global se ubique en el nivel conceptual o en el extemo. sin embargo ya que una tabla global no está destinada a un usUano o un gnipo de usuarios, sino a todos los usuarios de la base datos, puede descartarse el nivel extemo; y por lo tanto, el esquema de una tabla global debe ubicarse en el nivel conceptual (a semejanza de una tabla base).
El esquema de los fragmentos también es UM representación abstracta, ya que no incluye . los detalles de almacenamiento que normalmente se asocian al nivel físico. Sin embargo, el
concepto de fragmentación introduce en el esquema un aspecto de repartición de datos que no es esencial y que puede considerarse un detalle de almacenamiento.
Ya que el esquema de un fragmento tiene muchas características del nivel conceptual y un poco del nivel interno; es conveniente ubicarlo en un subnivel del nivel conceptual.
Este análisis sugiere los siguientes lineamientos para el diseño de las instrucciones del lenguaje de definición de datos:
- ~a Yistmcción para la definición de tablas globales debe ser semejante a la definición de tablas base (ya que pertenecen al mismo nivel).
~a hstmcción para la defición de tablas globales no debe involucrar la defición de fragmentos (ya que pertenecen a diferentes niveles).
~a instmcción para la definición de fragmentos debe parecerse a la definición de índices para sugerir su proximidad al nivel conceptual.
-
-
3.6. Gramática para la Definición de Fragmentos
Ya que SQL no presenta una sintaxis que permita definir fragmentos se desarrolló una extensión a la norma del SQL, específicamente al lenguaje de definición de datos para definir fragmentos.
La gramática está basada en la notación Backus-Naur-Form (BNF), y se implementó en el analizador sintáctico y semántico del precompilador, el cual usa el esquema de traducción dirigido por suitaxis.
Las extensiones realizadas tuvieron como objetivo permitir la creación de tablas de fragmentos y la definición de fragmentos sobre una tabla específica. También fue necesario implementar la instrucción que permite borrar fragmentos y tablas de fragmentos.
2 1
CENTRO DE INFoRMACLON .+
c EN1 DET -

La sintaxis de la gramática para la definición de fragmentos se muestra a continuación:
- Definición de una Tabla Global
Función.- Permite definir una tabla global o de fragmentos.
<Defmición de tabla global>::= CREATE FRAGMENTED TABLE <Identificado@- (<Elemento de tabla> [ ,<Elemento de tabla> ... ,<Elemento de tabla>]);
- Elemento de Tabla
Función.- Define una columna de una tabla global.
<Elemento de tabla*::= <Identificador> <Tip0 de dato> [<Cláusula default>] [<Restricción de columna> ... I
- Tipo de Dato
Función.- Especifica un tipo de dato.
<Tipo de dato>::= CHAR [(Valor numérko)] I NUMERIC [(Valor numérico) [,<Valor numérico~l)] I DECIMAL [(<Valor numérico> [,<Valor numérico>])] I MTEGER I SMALLFLOAT I FLOAT
- Cláusula Default
Función.- Especifica un valor por omisión para una definición de columna.
<Cláusula default>::= DEFAULT <Valor por omisión>
22

.. .
- Valor por omisión
Función.- Especifica un valor para la cláusula default.
<Valor por omisión>::= <Literal* NULL
- Restricción de Columna
Función.- Especifica restricciones de unicidad a una columna.
<Restricción de columna>::=NOT NULL [<Restricción de unicidad>]
- Restricción de Unicidad
Función.- Especifica valores Únicos para una o varias columnas.
<Restricción de unicidad>::= UNIQUE I PRIMARY KEY(<Lista de columnas de unicidad>)
- Lisia de Columnas de Unicidad
Función.- únicos.
Establece los identificadores de columnas que contendrán valores
<Lista de columnas de unicídad>::=<Identificador> [ ,<Identificador>. .. ,<ldentificador>]
- Defmición de Fragmento
Función.- Permite crear fragmentos bajo una cláusula de fragmentación.
<Defmición de fragmento>::= CREATE FRAGMENT <Identificador> ON <Identificador> WHERE <Condición de fragmentación> IN [Identificador];
23

- Condición de Fragmentación
. -
Función.- Permite definir ~ O S elementos que contendrá un fragmento.
<Condición de fragmentación>::= <Término booleano> I <Término booleano> AND <Condición de fragmen- tación> I <Término Booleano> OR <Condición de fragmentación>
-Término Bodeano
Función.- Establece un predicado de comparación el cual puede estar negado o no estarlo.
<Término booleano>::= [NOT] <Predicado de comparación>
- Predicado de Comparación
Función.- Especifica una comparación de dos valores.
<Predicado de comparación>::= <Identiticador> <Operador de comparación> <Especificación de valor>
- Especificación de Valor
Función.- Permite definir valores numéricos o alfanuméricos.
<Especificación de valor>::= <Valor numérico> I <Cadena de caracteres>
- Literal
Función.- Establece valores numéricos o alfanumérkos.
<Literal> ::= Valor numérico I Cadena de caracteres
2 4

- Valor Numérico
Función.- Establece un conjunto de dígitos.
<Valor numerico>::= Dígito I <Valor numérico> Dígito
- Cadena de Caracteres
Función.- Establece un conjunto de caracteres alfanuméricos.
<Cadena de caracteres>::= Letra I <Cadena de caracteres’ Letra
- Jdentificador
Función.- Especifica unidades Iéxicas.
<Identificador>::= Letra I Letra <Identificador> I <Letra> <Dígito> I <Letra> <Digito><Identificador>
- Letra
Función.- Especifica un conjunto de letras mayúsculas y/o minúsculas.
<Letra>::= <Letra mayúscula> I <Letra minúscula>
- Relación de Símbolos Terminales
<Letra mayúscula>::= A ; B I C I DI E I F I G H I I J I K L I M I N I Ñ O I P I Q I R
25

3.7. Diccionario de Datos
El diccionario de archivos distribuidos (DAD) constituye una de las estructuras más importantes usadas por el sistema manejador de bases de datos distribuidas (SiMBaDD). El DAD contiene información acerca de las tablas y de los fragmentos de la BDD. Esta información es utilizada por los programas de aplicación y gracias ella se logra la transparencia de fragmentación y de localización.
Al inicio de la tesis, la estructura con la que contaba el DAD ofrecía toda la información referente a la estructura, de las tablas y a la localización física de éstas.
La forma como se almacenaba el DAD consistía en que por cada máquina de la red existía un registro del tipo TRegTabla, la información que contenía se manejaba de manera descentralizada (no repetía la información de las tablas).
Por ejemplo, si se creaba la tabla S en el nodo ALFA de la red, la información acerca de la tabla se almacenaba solamente en ese nodo; de tal manera, que cuando se realizaba una manipulación de la tabla en un nodo foráneo al nodo ALFA, era necesario buscarla en el DAD de todos los nodos de la red, para determinar la localización física de la tabla en la red y su estructura; este mecanismo presenta las siguientes desventajas:
- Mayor tiempo de procesamiento al momento de realizar una manipulación de los datos.
El sistema depende del nodo donde reside la tabla a buscar, ya que si este no está funcionando, queda la incertidumbre de si la tabla que interviene en la operación existe o no.
Debido a ésto se determinó modificar la estructura del DAD, primeramente para que pemiita lograr la transparencia de fragmentación se agregó un nuevo archivo TRegFrag y posteriormente se modificó la estructura del archivo TRegTabla. Además se agregaron las rutinas que p e d t e n repetir la información del DAD en todos los nodos de la red al momento de usar el lenguaje de definición de datos con el fin de evitar las desventajas antes mencionadas
-
1 .-
2.-
3.-
La forma en que se maneja el DAD es la siguiente:
Por cada máquina de la red se tiene un DAD, el cual consiste en dos archivos TRegTabla y TRegFrag.
Por cada tabla (convencional o global) que participa en la base de datos, se utiliza un registro del archivo TRegTabla para almacenar la definición de la tabia y la localización de ésta.
Por cada fragmento definido en la bases de datos, se emplea un registro del archivo
2 6

TRegFrag para almacenar la definición del fragmento y su localización
La estructura asociada con los registros del archivo TRegTabla es la siguiente:
TRegTabla=RECORD NombreT TipoT ActivaT Dirección TotalCois Totalindst PrimKey ColsF'rimKey Colst indst Nun-Frg Nodos
END;
donde
NombreT
TipoT
ActivaT
Dirección
TotalColst
Totabds t
PrimKey
Colst
indst
STRING[ 121; CHAR; BOOLEAN; STRING; l..Maxcols; O..Maxindices; BOOLEAN; ARRAY[l..Maxcols] OF BYTE ARRAY[I..Maxcols] OF Twiumna; ARRAY [ 1 ..Muindices1 OF Tindice; INTEGER, STRING;
Es el nombre de la tabla con la extensión ".BDI".
Es el tipo de tabla la cual piiede ser "F" si se trata de una tabla de fragmentos o una " B si se trata de una tabla base convencional.
indica si la tabla está dada de alta en el archivo o no.
indica el nombre del nodo donde reside la tabla.
Número de columnas que tiene definida la tabla.
Número de índices que tiene definidos una tabla.
indica si la tabla tiene definida alguna llave primaria.
Arreglo que contiene para cada elemento, la información para cada UM de las columnas de la tabla.
Arreglo que contiene para cada elemento, la información para cada uno de los índices de la tabla.
2 1

Num-Frg
Nodo
Numero de fragmentos asociados a la tabla.
Nodo donde reside físicamente la tabla.
A continuación se describen los tipos de registros asociados Tcolumna y Tindice usados en TRegTabla.
TColumna=RECORD NombreC STRING[ 121; TipoC Tipocolumna; LongC INTEGER DesplazC: INTEGER NuloC: BOOLEAN;
END;
NombreC Contiene el nombre de la columna.
TipoC
LongC
Contiene el tipo de columna: integer, longint, real o string.
Contiene la longitud de la columna en bytes, dependiendo del tipo de dato de la misma.
Posición donde se encuentra la columna a partir del inicio del contenedor para transferencia entre variables anfhionas y disco.
indica si la columna acepta valores nulos.
DespiazaC
NuloC
Tindice=RECORD Nombreind: STRING[ 121 LongLlaveind: íNTEGER TotalColstind: 1 ..Maxcols Colsind: ARRAY[l..Maxcols] OF BYTE
END;
NombreInd
LongLlaveInd
TotalCoistInd Número de columnas que participan en el índice. .
Coisind
Nombre del archivo asociado con el índice con extensión ".IDX.
Contiene la longitud en bytes de la llave del índice.
Contiene los números de las columnas sobre las que e& definido el índice.
2 8

La estructura asociada con los registros del archivo TRegFrag es la siguiente:
TRegFrag=RECORD NombreF STRiNG[12]; TablaP STRING[ 121; ActivoF: BOOLEAN, CondFrag : STRING. CondFraiPos: ARRAY[l..30] OF STRING;
END;
NombreF Es el nombre del fragmento.
T a b l a
ActivoF
CondFrag
CondFragPos
Tabla a la que pertenece el fragmento.
indica si el fragmento está dado de alta en el archivo.
Contiene la condición de fragmentación bajo la cual se creó el fragmento.
Arreglo que contiene la cláusula de fragmentación en la forma posfija.
3.8 Lenguaje de Definición de Datos
3.8.1. Definición de Tablas Globales o de Fragmentos
Como se explicó anteriormente la creación de una tabla de fragmentos es lógica, lo que quiere decir que su estructura se almacena en el diccionario de archivos distribuidos solamente.
$ CREATE FRAGMENTED TABLE E (Num-Emp INTEGER, Nombre CHAR(301, Sueldo FLOAT NOT NULL, Ciudad CHAR(l0));
Figura 3.4. Relación Global E.
Por ejemplo, si creamos la tabla de fragmentos E de la Figura 3.4 los datos a almacenar en el DAD, después de verificar que no exista la tabla serían los siguientes:
2 9

Se deben almacenar cada una de las columnas que pertenecen a la tabla, para io cual se afecta el registro Tcolumna, en donde se almacena el nombre de la columna, el tipo de dato de la columna, la longitud y el desplazamiento de la columna; este desplazamiento, como se explicará más adelante, ayuda a determinar la posición que ocupa la columna dentro de un contenedor de memoria que contendrá los datos asociados con el registro de la tabla.
También se almacenan otros datos acerca de la tabla como son el nombre de la tabla, el tipo de tabla que puede ser de fragmentos o base, la longitud del registro de la tabla. Otros datos que se almacenan son los referentes a los índices y a la llave primaria.
Después que se registró la información en el DAD en el nodo local, se copia la información del registro en todos los nodos de la red; ésto se hace con la finaidad de que ai momento de realizar una búsqueda de la tabla, se limite al nodo local evitando de esta manera realizar la búsqueda a través de los nodos de la red (como se hacía en una versión anterior).
Esta información de la tabla sirve como esqueleto de la estructura de los futuros fragmentos que sobre ella se definan.
3.8.2. Definición de Fragmentos
Si se crea un fragmento (Figura 3.5) de la tabla de la Figura 3.4, es necesario realizar una búsqueda de la tabla sobre la que se define el fragmento en el DAD local para verificar prhero que exista y segundo que el tipo de tabla sea de fragmentos.
$ CREATE FRAGMENT E, ON E WHERE Sueldo <= 900 iN "Aifa\Alfa4';
Figura 3.5 Defuiición del Fragmento E,.
Una vez identificada la tabla, se obtiene su estructura y se usa para el fragmento que se está creando. En el caso especifico de este ejemplo es necesario realizar una búsqueda en el DAD de la tabla global E y obtener su estructura, para posteriormente asignarla al fragmento E,.
Como puede verse. la definición del fragmento va acompañada de la cláusula WHERE, a la cual se le conoce como clriuruiu de fragmentacidn, con base en ella el usuario define que renglones se almacenarán en los fragmentos. La cláusula de fragmentación está formada por atributos que pertenecen a la tabla global, lo que obliga a realizar un análisis semhtico de la expresión para verificar la concordancia entre tipos.
30

Una restricción de los atributos que participan en la cláusula de fragmentación es que no deben permitir valores NULOS ya que de contenerlos no se podría determinar a qué fragmento(s) se hace referencia en una operación de manipulación de datos.
Los fragmentos deben ser mutuamente excluyentes (no permitir intersección de valores) para que se conserve la integridad de la tabla. El proceso para identifiw la intersección de fragmentos es complejo, por lo que no se considera dentro del alcance de esta tesis. ~
Antes de crear el fragmento físicamente, es necesario almacenar su definición en el DAD:
En primer término se incrementa el número de fragmentos de la tabla global, en nuestro caso se incrementa el número de fragmentos de la tabla E, específicamente el campo Num-Frg, posteriormente se modifica el registro asociado TRegFrag donde se almacenan los datos del fragmento: el nombre del fragmento, la tabla a la que pertenece, el estado del fragmento que puede ser activo o inactivo, y la cláusula de fragmentación tanto en la forma idija como posfija.
3.8.3. Definición de índices
Cuando se define un índice sobre una tabla de fragmentos, es necesario almacenar su definición en el arreglo de índices del registro TRegTabla de la tabla a la que pertenece. Los datos a almacenar del índice son el nombre, el tipo que puede ser Único o duplicado, y las columnas bajo la cual se define el índice. Después de almacenar su definición en el DAD se verifica cuántos fragmentos están asociados a la tabla, ya que el número de índices a crear será igual que el número de fragmentos; es decir se crea un índice físico por cada fragmento.
En el caso de que todavía no se hayan definido fragmentos a la tabla, la creación del índice será lógica (solamente se registran sus datos en el DAD). Cuando ya existen fragmentos definidos sobre la tabla, se debe localizar a cada uno de ellos en la red, para crear su respectivo índice en el nodo donde existe físicamente el fragmento. Si los fragmentos contienen información se debe hacer un vaciado de los datos sobre su índice; al momento de efectuar este vaciado debe determinarse si el tipo de índice sobre el que se actúa es Único o duplicado.
Cuando el tipo de índice es Único, se debe llevar a cabo un procedimiento que garantice la integridad de la tabla, una manera de hacerlo consiste en realizar una búsqueda de la clave en todos los indices asociados con los fragmentos para asegurar que no se repita en otro fragmento. Otra manera consiste en analizar la cláusula de fragmentación y verificar si dentro de ella intervienen una o más columnas que participan en la definición del índice, si es así la verificación de la integridad se realiza en el índice local al fragmento y se evita realizar la búsqueda de la clave en los demás nodos de la red. Si se detecta que se está violando la integridad de la tabla ei índice no se crea.
31

Por ejemplo, si definimos dos fragmentos sobre la tabla E de la Figura 3.4, en donde el fragmento E, está definido bajo la cláusula de fragmentación WHERE Num_Emp>100 y el fragmento & bajo la cláusula WHERE Numemp<I00 y se crea el siguiente índice sobre la tabla de fragmentos E
S CREATE INDEX UNIQUE Num-idx (Num-Emp) ON E;
Como se ve, la columna que participa en la cláusula de fragmentación, participa también en la definición del índice, por lo que al momento de realizar el vaciado de la información del fragmento E, sobre su índice, la verificación de la integridad será de manera local, lo mismo sucede para el fragmento &.
3.8.4 Instrucción DROP
La cláusula DROP se utiliza para borrar de la base de datos una tabla, un índice, o un fragmento.
3.8.4.1 DROP TABLE
Cuando se borra una tabla de fragmentos, es necesario eliminar los índices y fragmentos asociados a ella. Para ésto es necesario determinar el número de índices y de fragmentos de la tabla, para después determinar la ubicación física de éstos para eliminarlos del DAD y de la base de datos (ver el Capítulo 4 para una explicación detallada).
3.8.4.2 DROP FRAGMENT
Ai momento de borrar un fragmento de UM tabla global, se debe decrementar el campo Num-Frg del registro de la tabla global a la que pertenece el fragmento. Antes de eliminar el fragmento, se deben borrar los índices asociados ai fragmento (ver el Capitulo 4 para una explicación detallada).
3.8.4.3 DROP INDEX
Cuando se borra un índice se debe decrementar el total de índices de la tabla, si la tabla contiene además fragmentos, se deben eliminar el índice asociado a cada uno de los fragmentos (ver Capitulo 4 para UM explicación detallada).
32

39. Lenguaje de Manipulación de Datos
3.9.1. Instrucción INSERT
Para r e a l i r la inserción de un renglón a una tabla específica, se deben proporcionar los valores correspondientes a cada columna de la tabla. Por ejemplo, si se desea insertar un nuevo renglón a la tabla de fragmentos E con la siguiente instrucción de SQL
S INSERT INTO E VALUES (500, "Luis", 700, "MEXICO");
cada valor especificado debe ser mapeado a su correspondiente campo del registro que representa a la tabla y llevado a un contenedor (buffer) de memoria.
La manera de identificar el fragmento al que se debe agregar el registro es la siguiente: por cada fragmento asociado con la tabla global se debe obtener la cláusula de fragmentación en la forma posfija y llevarla a memoria, una vez en memoria se efectúa una evaluación de los valores que están en el contenedor contra la cláusula de fragmentación que se encuentra en memoria, si el registro cumple con la cláusula de fragmentación se inserta en ese fragmento.
Si se agregan nuevos registros a una tabla de fragmentos o base que contiene índices únicos o llave primaria, es necesario garantizar la integridad de los datos que se almacenan en la tabla. En ciertos c a m es suficiente con efectuar la búsqueda del valor de la llave en el índice del fragmento, pero si en la cláusula de fragmentación no interviene al menos una columna que participe en la definición de un índice único o una llave primaria, la búsqueda debe extenderse al índice de los demás fragmentos asociados a la tabla global.
3.9.2. Instrucciún DELETE
Para suprimir registros de una tabla, es necesario ejecutar u& instrucción DELETE de SQL. Por ejemplo, si ejecutamos la siguiente cláusula sobre la tabla de fragmentos E.
$ DELETE FROM E WHERE Ciudad="MEXICO";
El problema consiste en identificar qué fragmentos están asociados a la tabla global y llevar sus cláusulas de fragmentación a memoria; una vez en memona es necesario realizar una comparación de las cláusulas de fragmentación contra la cláusula de selección de la instrucción DELETE, para determinar a qué fragmento se hace referencia (la manera como se logra se explica en la sección 4.6).
Para eliminar un renglón de UM tabla, únicamente se cambia el valor del campo Alta a uno, el borrado del registro es lógico. Cuando existen indices relacionados a la tabla se debe efectuar UM actualización de los datos del índice de tal manera que también se debe eiiminar del índice el valor de la clave asociada con el registro a eliminar de la tabla.
33

3.9.3. instrucción UPDATE
La instrucción UPDATE presenta los mismos problemas que los de la ciáusula DELETE al momento de determinar de manera transparente a qué fragmento se hace referencia en la cláusula WHERE. Por ejemplo, si se desea actualizar la tabla global E, con la siguiente insüucción:
S UPDATE E SET Sueldo=Sueldo*S WHERE Sueldw700 AND Ciudad="MEXICO";
La secuencia del proceso de actualización de registros sería la siguiente: Es necesario buscar en el DAD los fragmentos asociados con la tabla global E; de esta búsqueda se obtiene el nombre del fragmento, su ubicación en la red, la cláusula de fragmentación, y la cláusula de fragmentación en la forma posfija.
Una vez que se obtuvo el(los) fragmento($ involucrado(s) en la operación de actualización, se seleccionan los renglones que cumplan con la cláusula WHERE, para ésto el registro que se lee del fragmento se lleva a un contenedor de memoria (buffer); después de que el contenedor se encuentra en memoria se aplica la cláusula SET del UPDATE y se actualiza.
Cuando se actualiza el contenedor, se compara con la cláusula de fragmentación que se obtuvo del DAD, para constatar que el renglón actualizado cumpla con la cláusula de fragmentación. Si cumple se graba el renglón en ese fragmento; de lo contrario, es necesario buscar en el DAD qué fragmento cumple con el renglón actualizado, para grabarlo en él. En el proceso de actualización es necesario actualizar también los índices relacionados con cada fragmento.
3.9.4. instruccihn SELECT
La instnicción que se encarga de realizar la recuperación (selección) de información de la BDD es el SELECT. Esta instrucción designa una tabla vhtual cuyos renglones serán accesibles dentro de un programa de aplicación mediante el mecanismo de los cursores.
Si por ejemplo, se quiere consultar la tabla global E, y saber qué empleado tiene un salario mayor que iO00, se debe identificar de la misma manera que para el UPDATE y DELETE qué fragmento cumple con la cláusula de selección; una vez identificado el fragmento, se somete a un proceso de selección el cual regresa un conjunto de renglones que cumplan con la condición salario > 1m.
Como Pascal no tiene un mecanismo para manejar conjuntos de renglones como un solo objeto, entonces se debe establecer el mecanismo de cursores. Un cursor es un mecanismo de SQL cuyo propósito es recorrer el conjunto de renglones que se obtiene de una operación de selección, uno a la vez.
34

Antes de recorrer el cursor, es necesario mantenerlo en estado abierto, para lo cual se usa la instrucción OPEN. La instrucción FETCH se usa para recuperar información de un cursor en estado abierto; esta instrucción se ejecuta hasta que se terminan los registros de la tabla virtual. Una vez finalizado el recorrido se debe usar la instrucción CLOSE para cenar el cursor.
3.10. Localización del Fragmento
Para identificar a qué fragmento se hace referencia en una operación de selección (involucrada en las instrucciones DELETE, UPDATE y SELECT), se debe comparar la cláusula de fragmentación contra la cbdusula de selección, para ver si el conjunto de valores solicitados en la selección corresponde al fragmento.
Para lograr esto se deben hacer algunas consideraciones a la cláusula de fragmentación, ya que se permite el uso de operadores lógicos y de operadores relacionales. Cuando en una cláusula de fragmentación existe un operador lógico OR, el proceso de evaluación se complica ya que en términos generales podríamos ver a una expresión separada por OR como dos expresiones independientes (o más dependiendo del número de ORs).
Por ejemplo, si tenemos la cláusula de fragmentación
WHERE Sueldo>1000 OR Ciudad="MEXICO AND Nurn_Emp>"001"
podríamos verla como dos cláusulas independientes: la cláusula WHERE Sueldo>1000 y la cláusula WHERE Ciudad="MEXlCO" AND Nurn_Emp>"001", donde el resultado global de las dos será el que arroje la evaluación de ambas por el operador OR.
AI momento que se soliciten registros de UM tabla global, se debe verificar primero que las columnas que intervienen en la cláusula de selección estén en la cláusula de fragmentación, de lo contrario no existe un punto de referencia que permita determinar si el fragmento cumple o no con la petición.
Si al menos existe una columna que participa en la cláusula de fragmentación, se lleva a cabo UM comparación de los operadores relacionales y de los valores que intervienen en ambas cláusulas. Este resultado (que puede ser falso o verdadero) se introduce a una pila de resultados, donde posteriormente se evaltía con el operador lógico que le corresponde (el operador lógico de la cláusula de selección). De tal manera que al final de la evaluación se tendrá en la pila de resultados un solo valor que indica si el fragmento cumple o no con la selección.
35

Por ejemplo, si se solicitan los registros donde
Sueldo400 AND Ciudad="MEXICO
y se tiene la cláusula de fragmentación
Sueldob1000 OR Ciudad="COLiMA"
Antes de evaluar la cláusula de selección contra la cláusula de fragmentación, la cláusula de selección se debe transformar a su equivalente en posfijo, ya que esta forma de manejar las expresiones asigna la prioridad correspondiente a los operadores lógicos AND y OR. El equivalente de la expresión anterior en posfijo es
Sueldo=500 Ciudad="MEXICO AND
Ya que en la cláusula de fragmentación aparece un OR, se debe separar; en este caso, en dos condiciones: a) Sueldo> IO00 y b) Ciudad="COLIMA".
Como se mencionó anteriormente, debe verificarse si al menos una columna de la cláusula de selección aparece en la cláusula de fragmentación; en este caso aparecen ambas columnas, el valor de cada columna de esta cláusula debe ser comparado con su correspondiente valor de la cláusula de fragmentación. Puesto que la cláusula de fragmentación fue dividida en dos, se debe comparar la cláusula de selección contra cada una de las cláusulas de fragmentación.
Por ejemplo, debe compararse primero la cláusula de selección contra la subcláusula Sueldo>1000. El resultado de esta comparación es FALSO, este valor se introduce a una pila de resultados. El mismo procedimiento se sigue para evaluar la subcláusula de fragmentación (b). El valor del resultado de esta evaluación es FALSO y se introduce también a la pila de resultados. UM vez finalizado el proceso se evalúan ambos valores por el operador lógico OR de la cláusula de fragmentación; de esta última evaluación se obtiene el valor del resultado final (en el capítulo 4 se explican a detalle los pseudocódigos que permiten la transparencia de fragmentación).
36

CAPITULO 4
METODOLOGIA DE SOLUCION
En este capítulo se muestran de manera detaiiada algunos de los procedimientos y funciones más importantes utilizados en esta tesis para lograr la transparencia de fragmentación, para cada una de las instrucciones del lenguaje SQL soportadas por el precompilador.
Para la explicación de cada una de las instrucciones se explica un ejemplo tratando de abarcar en él los aspectos más sobresalientes de la instrucción.
4.1. Instrucción CREATE FRAGMENTED TABLE
En la Sección 3.5 se definió la sintaxis para crear una tabla global o de fragmentos. Cuando se ejecuta la instrucción CREATE FRAGMENTED TABLE, se almacena en un registro del DAD la descripción de la tabla.
Como se menciono en la Sección 3.3, el prototipo usa un precompilador el cual genera código equivalente semánticamente a la instrucción SQL en Pascal, en este caso para la instrucción de la Fig 3.4. Para generar el código en Pascal de esta instrucción es necesario realizar el análisis sintáctico y semántico de ésta.
El procedimiento CREATE-FRAGMENTED es el encargado de realizar el análisis sintáctico y semántico de la instrucción. A continuación se muestra el código equivalente en Pascal de la instrucción que permite definir lógicamente una tabla global E (de acuerdo a la instrucción que aparece en la Figura 3.4).
Uses SQL - SQL-INI-TABLA; - SQL-SET-NODO("L0CAL"); -SQL-SET-TABLA("E ","F",4,0); - SQL-SET-COLUMNA( 1 ,"Num-Emp",3,4,0,FALSE,FALSE,FALSE,""); - SQL~SET~COLUMNA(2,"Nombre",l,30,O,TRUE,FALSE,FALSE,""); - SQL~SET~COLUMNA(3,"Sueldo",3,4,0,FALSE,FALSE,FALSE,""); - SQL-SET-COLUM NA(4,"Ciudad". 1,30,0,TRUE,FALSE,FALSE,""); CREA-TABLA;
37

De la linea 2 a la 8 son llamados a procedimientos que se encuentran en el módulo principal SQL. Estos procedimientos se encargan de llenar la estructura de datos a almacenar en el DAD. La línea 4 indica que el tipo de tabla a crear es de fragmentos, gracias a esta indicación el sistema manejador de bases de datos distribuidas determina que debe almacenar la estructura de la tabla global en el DAD solamente.
42. Creación de Fragmentos
La instrucción CREATE FRAGMENT tiene por objeto permitir d e f i i fragmentos. Para implementar esta gramática fue necesario modificar el precompilador en la etapa del análisis sintáctico y semántico. El procedimiento que se encarga de realizar el análisis sintáctico y semántico se muestra a continuación.
FUNCION CreaFrag( Nodo, FTregfrag) q:=q3 REPITE SI NO ES PyC ENTONCES Get-Token (PyC: Constante que representa al punto y coma) CON LA ESTRUCTURA F HACER EN EL CASO DE QUE Q SEA q3: SI T(1dentüicador) ENTONCES (Si T regresa un identificador de fragmento]
Nombrefr:=iexval (Lexval variable global arrojada por Get-Token) q:=q4
DE LO CONTRARIO Error()
DE LO CONTRARIO Error() q4: SI R(0N) ENTONCES q:=qS (Si el siguiente Tokens es la palabra reservada ON)
qS: SI T(identificador) ENTONCES (Si T regresa un identificador de tabla] Busca-TablaF(lexva1) [Ver ANEXO A ) SI Regis-Arch.tipot=F ENTONCES (Si el tipo de tabla es de fragmentos) Buildhedft(Regis-Arch) (Ver ANEXO A) q:=q6
DE LO CONTRARIO Error() q6: SI R(Where) ENTONCES q:=q7
DE LO CONTRARIO Error() 97: SI NO Verifica-Condicion ENTONCES Error(); {Si existe error de sintaxis en la cláusula
Where entonces error) DE LO CONTRARIO q:=q8
q8: SI R(JN) ENTONCES q:=q9 DE LO CONTRARIO Error()
q9: Nodo:=Lexval q:=qlO: Genera-Codigo-Fragmento {Ver ANEXO A )
HASTA (q:=qlO);
38

Cuando el precompilador reconoce el signo que identifica el inicio de una instrucción de SQL ($), transfiere el control al analizador sintáctico y semántico. Una vez que identifica que se trata de crear un fragmento, transfiere el control a la función CreaFrag, que es la encargada de realizar el análisis del fragmento.
El tipo de análisis realizado es dirigido por sintaxis, en el pseudocódigo se observa el conjunto de estados necesarios para realizar el anSlisis de la creaci6n del fragmento. Los datos a evaluar son tomados del archivo fuente y mientras no se encuentre un punto y coma (pyC), el cual indica el fin de la instrucción en SQL, se continúan tomando "tokens" del archivo de entrada usando la función Get-Token.
Antes de que el precompilador transfiera el control a esta función, tuvo que haber analizado previamente la instrucción hasta identificar que io que se está analizando es una instrucción CREATE FRAGMENT, así que el siguiente "token" después de FRAGMENT es el nombre del fragmento. El estado 4 3 se encarga de identificar si el "token" regresado es un identificador de fragmento para lo cual hace uso de la función T, que regresa el tipo de dato leído por Get-Token (a continuación se muestra el autómata para la instrucción CREATE FRAGMENT).
CREATE
F W M E N T
IN N O W IDLTeBlP WHERE ID-FRAG ON
Se hace un cambio de estado a Q4 y se evalúa si lo que sigue es la palabra reservada ON, el control se transfiere a Q5, donde se verifica que además de seguir un identificador de tabla, ésta se haya defindo como tabla global, para lo cual se hace uso del procedimiento Busca-TablaF. Este procedimiento nos regresa la estructura de la tabla de fragmentos, en la variable global Regis-arch, la cual está declarada como tipo TRegFrag (ver sección 3.3).
39

De esta estructura se verifica si la tabla global contiene llave primaria o indices para asociarle a cada fragmento sus respectivos indices o llave primaria. Una vez que se obhivo la estructura global se evalúa la correspondencia en tipos de la cláusula WHERE en el estado 47 para lo cual se hace uso de la función Verifica-Condicion que además de hacer el análisis sintáctico y semántico transforma la cláusula de fragmentación a su equivalente en posfijo.
En caso de que no presente error el flujo del análisis, cambia al estado Q9 donde se verifica la localización física del fragmento. Una vez analizada la instrucción, se genera su código equivalente en Pascal.
Al momento de ejecutar el código, se crea físicamente el fragmento en el nodo especificado y se guarda su estructura en el DAD especificamente en el registro TRegFrag.
43. Instrucción CREATE INDEX
Para crear un índice se hace uso de la instrucción CREATE INDEX. Debido a que la creación de una tabla global es lógica, ai momento de crear un indice pueden suceder dos cosas: a) que la tabla global no tenga asociados fragmentos y b) que la tabla global tenga asociados fragmentos. Por ejemplo considérese la creación del indice SNo-ldx mediante la siguiente instrucción
$ CREATE INDEX SNo-Idx ON E(NumEmp);
AI momento de precompilar esta instrucción, se realiza una búsqueda de la tabla global E, usando el procedimiento Busca-archivos3, el cual recibe como parámetro de entrada el nombre de la tabla, y regresa un estado que indica si la búsqueda fue exitosa o no. En caso de encontrar la tabla, regresa la estructura de ésta en la variable global Regis-arch.
Si el campo Regis-arch.Numfrg de la tabla global es mayor que cero, indica que la tabla global contiene fragmentos. Cuando el número de fragmentos es cero, se almacena la estructura del índice en el DAD usando la función Almacena-lndice, la cual incrementa el campo Regis-arch.totalíndst en uno y además almacena la estructura del índice en el DAD.
Posteriormente se realiza una copia de la información en todos los nodos de la red usando el procedimiento Replica-Dad, que se encarga de copiar la información en el DAD.
A continuación se presenta el pseudocódigo que permite la creación de índices a los fragmentos cuando el número de fragmentos en mayor que cero.
4 0

PROCEDIMIENTO Create-IndexOVombre-Index, Nombre-Tabla) EMPIEZA Busca-archivos3(Nombre-Tabla,Estado); (Ver ANEXO A ) SI Estado=l ENTONCES Enor() DE LO CONTRARIO SI Regis-arch.num-frg>O ENTONCES (Si la tabla Nombre-Tabla contiene fragmentos) EMPIEZA Busca-fragmentos(Nombre-Tabla); (Ver ANEXO A) MIENTRAS AptFrag SEA DIFERENTE DE NiL
Busca-archivos3( AptfragA .nombrefrg,edo); Sql_AddJndex(Nombre-hdex); (Ver ANEXO A}
EMPIEZA
FIN; FIN;
FIN.
La función Create-index recibe como entrada el nombre del índice y el nombre de la tabla sobre la que se crea el índice. Si el total de fragmentos es mayor que cero, se identifican los fragmentos asociados a la tabla usando la función Busca-Fragmentos que regresa el apuntador AptFrag, el cual contiene la dirección inicial de una lista donde se almacenan los nombres de los fragmentos.
El siguiente paso es determinar la ubicación de cada fragmento, para lo cual se debe realizar un banido de todos los nodos de la lista apuntada por AptFrag. Mientras no se llegue al fin de la lista, se ejecuta el procedimiento Busca-archivos3, el cual se encarga de buscar el fragmento; una vez que se tiene la localización física del fragmento, se crea el índice usando la función Sql-Add-Index.
Sql-Add-Index identifica el número de registros que contiene el fragmento, si el número de registros es mayor que cero, se debe realizar un vaciado de los valores que forman la clave al índice. Para no hacer una búsqueda de la clave en todos los nodos donde residen los fragmentos, la función Sql-Add-lndex hace uso de la función Existe-Col-en-hd, la cual verifica si en la cláusula de fragmentación existe una columna que participa en la definición del indice, en caso de que encuentie que una llave se repite es necesario destruir los índices creados y eliminar su definición del DAD.
4 1

4.4. instrucción DROP
La instrucción Drop se encafga de eliminar lógica y físicamente una tabla, un índice o un fragmento.
4.4.1. DROP TABLE
La instrucción DROP TABLE se encarga de eliminar una tabla global o una tabla base
Cuando el manejador detecta que se desea borrar una tabla de fragmentos, debe realizar un búsqueda de los fragmentos asociados a la tabla de fragmentos y de los indices en el DAD, una vez que tiene identificados los fragmentos se realiza una búsqueda de cada uno de ellos en los nodos de la red hasta localizarlos físicamente ya localizados se elimina la información de la tabla y de los fragmentos del DAD.
del diccionario de archivos distribuidos y del nodo donde reside físicamente la tabla.
Para eliminar físicamente la tabla, se usa la rutina de bajo nivel Elimina-a (ver explicación detallada en la referencia [3]), que recibe como parámetro el nombre del archivo y la ubicación física de éste.
4.4.2 DROP INDEX
Al momento de borrar el indice es necesario identificar a qué tabla pertenece para reducir del registro TRegArch, el número de indices de la tabla. La eliminación delhdice se hace por medio de la rutina de bajo nivel Elimina-a (ver explicación detallada en la referencia [3]). Cuando el indice a borrar pertenece también a una tabla fragmentada, es necesario eliminar de cada fragmento el índice asociado a él.
4.4.3 DROP FRAGMENT
Cuando se borra un fragmento, se debe detectar a qué tabla pertenece para decrementar el número de fragmentos asociados con ella. Después se determina la ubicación del fragmento y el número de indices asociados a él; el fragmento es borrado físicamente de la base de datos y los indices asociados a él también por medio de la rutina Elimina-a (ver explicación detallada en la referencia 131).
4.5. hstruccion INSERT
Cuando se inserta un registro a UM tabla global, es necesario buscar los fragmentos en el DAD. Lo cual se hace usando el procedimiento Busca-fragmentos, que como se explicó anteriormente regresa un apuntador de los fragmentos asociados a la tabla global (AptFrag).
4 2

una vez que se tienen los fragmentos, es necesario ejecutar la cláusula de fragmentación en posfijo (la cual se almacenó en el DAD al momento de crear el fragmento) de cada uno de los fragmentos de manera secuencial.
Ya que la cláusula de fragmentación está en memoria, se verifica que cumpla con el registro a insertar; para lo cual se hace uso de la función RegCumpleWhere. Esta función recibe un apuntador a una lista de tipo estructura que contiene la cláusula de fragmentación en posfijo del fragmento; si la función regresa un valor verdadero, significa que el fragmento activo cumple y se inserta el registro en él usando la función AddRec (para UM explicación del procedimiento ver referencia [4]); de lo contrario se continúa con la búsqueda en los demás fragmentos.
Si el fragmento tiene índices, es necesario buscar en el índice la clave correspondiente al valor a insertar; para ésto se hace uso del procedimiento Existe-Col-en-ind que (como se explicó anteriormente) verifica si, en los índices definidos como Únicos, existe una columna que paiticipa en la cláusula de fragmentación para reducir la búsqueda de la clave al fragmento local. Para realizar la búsqueda de la clave en el índice, el procedimiento INSERT usa la función Tuplacumplerequisitos, la cual se encarga de verificar si en el índice no existen claves repetidas.
4.6. Localización del Fragmento
Para lograr la transparencia de fragmentación se hacen uso de diversas estructuras, a continuación se explica cómo se resuelve el problema de identificación de fragmentos en esta tesis para las instrucción UPDATE, DELETE y SELECT, ya que la manera de identificar fragmentos para la instrucción INSERT se explicó en la Sección 4.5.
Cuando el sistema verifica que la tabla que interviene en la operación de manipulación de datos es de fragmentos el manejador, realiza una bíisqueda de los fragmentos activos asociados a la tabla de fragmentos en el archivo de registros del tipo TRegFrag (descrito en la sección 3.7.), de él se obtiene el nombre del fragmento y la condición de selección bajo la cual se creó el fragmento.
fragmentos con su respectiva cláusula de fragmentación la cual es apuntada por APTLCF. Cada uno de los fragmentos asociados a la tabla global se introducen a una lista de
Para determinar a que fragmento se hace referencia en la operación de manipulación de datos se recorre la lista de fragmentos de manera secuencial, hasta encontrar al fragmento que cumpla con la cláusula de selección.
A continuación se muestra el pseudocódigo que se encarga de recorrer la lista y llamar al procedimiento que determina si el fragmento cumple o no con la cláusula de selección.
4 3

MIENTRAS APTLCF NO SEA NULO EMPIEZA
Eva1 ua-Fragmento( AptlCf^. CondFrag ,Apt) SI NO Cumple-Fragmento AVANZA EL APUNTADOR APTLCF
TERMINA
AI momento de entrar al ciclo se toma el primer fragmento de la lista (siempre es el fragmento local al nodo donde se efectúa la aplicación) con su cláusula de fragmentación la cual se envía como parámetro de entrada al procedimiento Evalua-Fragmento (que se explica a continuación) donde se compara contra la cláusula de selección que interviene en la operación de manipulación.
Ya que la cláusula de fragmentación puede contener separadores lógicos (AND y OR); entonces, como se explicó en la sección 3.9, la cláusula de fragmentación se separa en tantas cláusulas como ORs existan.
El procedimiento que se encarga de realizar esta descomposición y la evaluación del fragmento se llama Evalua-Fragmento, el cual recibe la cláusula de fragmentación y un apuntador a una lista de cláusulas cuya estructura se describe más adelante. A Continuación se presenta y se explica el pseudocódigo que permite identificar fragmentos
PROCEDIMIENTO Evalua-Fragmento (Clausula-Frag Apt:TpointerListaFrag); SI Existe_Or(Clausula-Frag) ENTONCES (Si existe al menos un OR en la cláusula de frag. I Separa-Clausula(Cf,Num-Or) (Separa la cláusula dependiendo del número de ORs)
DE LO CONTRARIO Cf[ 11: =Clausula-Frag Num-Or:= 1
REPITE T=T+ 1 [Incrementa la variable T que actúa como índice del arreglo Cf I Apunta-Clausula(Cf[t]) [Procedimiento que genera una lista apuntada por APF) Evaluafragmento-Tabla(APT) [Evalúa lo apuntado por APF y la cláusula de selección APT]
HASTA T=Num-Or (Hasta que las divisiones de la cláusula de fragmentación se hayan evaluado en su totalidad termina)
Este procedimiento se encarga de dividir la cláusula de fragmentación en tantas como ORs aparezcan en ella, para lo cual usa la función Separa-Clausula que regresa como salida un vector, el cual contiene los elementos ya separados de la cláusula de fragmentación. Por ejemplo, si la cláusula de fragmentación es
WHERE Sueldo<=900 OR Estado=1000,
!

la función regresaría mi ]:=Ciudad=”Sueldo<=900”, Cfl2]:=Estado:= lm, y en la vanable Num-Or el numero de divisiones de la cláusula original (en e se ejemplo ~ ~ - 0 ~ ~ 2 ) .
En el Pseudmódigo se observa un ciclo que se repite hasta que la vanable T sea igual al de la variable N w - 0 1 (regresada por el procedimiento Separa-Clausula) esta vanable (T)
se Utiliza como índice del vector Cf (también regresado por Sepam-Clusula).
En este ejemplo al inicio del ciclo la variable T es igual a uno el contenido del arreglo Cf en su posición uno (en su posición T) es enviado como parámetro al procedimiento Apunta-Clausula.
Antes de evaluar la cláusula de fragmentación, el procedimiento Apunta-Clausula(Cf[t]), introduce a una lista el pedazo de la cláusula de fragmentación contenido en Cf[T] esta lista es apuntada por el apuntador global APF (en este caso APF apunta al pedazo de cláusula de fragmentación Sueldo<=900).
Una vez que se tiene direccionada @or el apuntador APF) la cláusula de fragmentación, se evalúa contra la cláusula de selección usando el procedimiento evaluafragmento-tabla, al que se le envía como parámetro el apuntador APT. Este apuntador contiene la dirección de la cláusula de selección en la forma posfija que se desea evaluar en una operación de manipulación de datos (UPDATE, SELECT, DELETE).
A continuación se describe la estructura de datos empleada en el proceso de identificación del fragmento. ~a pafie principal consiste de una lista de cláusulas denominada StackStatutos, cuyos elementos sirven para almacenar la cláusula de la instrucción que se ejecuta. La estructura de la lista es la siguiente:
TpointerStackStatutos=StackStatutos; StackStatutos = RECORD Cláusula: STRING; Headpl: PointerPrimaryList; Sigclaus: TpointerStackStatutos;
END;
Donde
Cláusula Contiene el tipo de operación a realizar y puede se un UPDATE, INSERT, SELECT, DELETE, WHERE, FROM.
Es un apuntador a la estructura PointerPrimaryList que se describe a continuación.
Es un apuntador al siguiente elemento de la lista TpointerStackStatutos.
Headpl
Sigclaus
4 5

Cada uno de los elementos de la lista StackStatutos apunta a SU vez a otra lista denominada PrimaryNodo, cuyos elementos se usan para almacenar las columnas, constantes y operadores de cada cláusula. La estructura de esta lista es la siguiente:
PointerPrimaryList = TrimaryNodo; RimaryNodo = RECORD
Itemp: Tprimary Sigp: PointerPrimaryList;
END;
Donde
Itemp Es una variable del tipo estructura Tprimary (que se describe a continuación) donde se especifica si la siguiente operación a realizar dentro de la lista es un predicado, el tipo de predicado (IN, BETWEEN, ESCALAR), el valor de comparación, la columna que participa en la evaluación, etc.
SkP Es un apuntador al siguiente elemento de la lista PointerPrimaryList.
El registro Tprimary, usado en PrimaryNodo, tiene la siguiente estructura:
Tprimary = RECORD ClaseP: Tprimary Clase; NuloP BOOLEAN; DesdeP INTEGER NombreP STRING[ 121; LongP: BYTE, CASE TipoP:
BYTE OF 1: (CharP STRING); 2: (Intp: INTEGER); 3: (LintP: LONGINT); 4: (RealP: REAL); 10: (OperadorP: CHAR); 2 0 (OperRelP BYTE); 30: (OperLogP CHAR); 40: (PredicadoP: BYTE);
END,
46

Donde
ClaseP
NuloP
Desedp
NombreP
LongP
TipoP
Contiene la clase de operación a realizar que se describe en el conjunto Tprimary Clase.
Contiene el valor TRUE si la columna acepta valores nulos de lo contrano contiene el valor FALSE.
Contiene la posición inicial de la columna dentro del buffer de memoria.
Contiene el nombre de la columna que se evalúa.
Contiene la longitud de la columna que se evalúa.
Registro de tipo variable que indica el tipo de operador lógico que interviene en la operación o bien indica el tipo de dato que se está evaluando.
TprimaryClase Es un conjunto que contiene los siguientes datos (Predicado, Espcol, Espvar, Oprlog, Oprel), los cuales se usan para determinar el tipo de operación a realizar.
Si se realiza una operación de manipulación de datos donde la cláusula de selección es
WHERE Sueldo>100 AND Ciudad="MEXICO
el estado de la lista apuntada por APT seria el que se muestra en la Figura 4.1.
WHERE 0
I"(P.lW0
Figura 4.1. Lista de la Cláusula de Selección.
4 7

apuntador APT apunta a kt posición inicial de la lista de la Figura 4.1, y es envido como P-e@O al procedimiento Evaluafragmento-Tabla donde se comparan (La cláusula de selección apuntada por APT y ei pedazo de cláusula de fragmentación apuntada POI APF). En este Proceso de evaluación, es necesario considerar el tipo de dato, los o p e ~ o r e s Iógicos que aparecen, 10s operadores relacionales, los nombres de las coi^ participantes, y los valores que intervienen en ias ciáusuias.
El procedimiento Evaluafragmento-Tabla, recorre la cláusula de selección apuntada por APT, la cual se encuentra en la forma posfija, ad que al momento que identifica UM columna que pertenece a la tabla a evaluar verifica si ésta participa en la cláusula de fragmentación apuntada por APF. Después es necesario verificar el operador relacional de ambas columnas, para determinar si probablemente en este fragmento está el valor solicitado. Ya que se tiene un valor de verdad resultante de la evaluación anterior se introduce a una pila de resultados donde posteriormente se evalúa con el operador lógico correspondiente.
El siguiente paso es incrementar el valor de la variable T (seguir con el ciclo Repite-Hasta del pseudocódigo) e introducir a la lista apuntada por APF el siguiente pedazo de la cláusula de fragmentación y evaluar como se explico anteriormente a la cláusula de selección contra io apuntado por APF.
Como se observa en el pseudocódigo del procedimiento Evaluafragmento, este Proceso se repetirá hasta que se evaluen todas las divisiones de la ciáusula de fragmentación apuntadas PO' APF. bs resultados finales que aparezcan en la pila serán evaluados Por el operador Iógico OR siempre y cuando éste aparezca en la cláusula de fragmentación.
~1 resultado final es mojado en la variable Cumple-Fragmento la Cual contiene el valor TRUE si el fragmento cumple con la cláusula de selección de 10 contrario regrew el valor FALSE.
4.7. Instrucción UPDATE
Cuando se realiza una actualización sobre una tabla no es necesario indicar el nombre del fragmento que se desea actualizar. En el ejemplo que se describe a continuación, se desea actualizar de manera transparente la tabla global E, de la Figura 3.4.
S UPDATE E SET Sueldo = Sueldo * 5 WHERE Sueldo>1000 AND Ciudad="MEXICO";
Para poder ejecutar la instrucción anterior, primeramente es necesario procesar el programa con el precompilador del manejador. El código equivalente en Turbo Pascal que genera el precompilador es el siguiente:
4 a

USES SQL; BEGIN
1 -MTOPSTATS('UPDATE); 2 -MTOPC('E.SUELDO,6,41 ,6,TRUE); 3 -MTOPL2(5); 4 -MTOPO('*'); 5 -MTOPUPDCOL(6,41,6,TRUE); 6 -MTOPSTATS('WHERE '); 7 -MTOPRED( 1); 8 -MTOPC('E.SUELDO,6,41,ó,TRUE); 9 -MTOPOR('*'); 10 -MTOPL2(1OOO); 11 -MTOPPRED( I); 12 -MTOPC('E.CIUDAD,I,48,1l,TRUE); 13 -MTOPOR('='); 14 -MTOPL 1 ('MEXICO); 15 -MTOPOL('@'); 16 -MTOPSTATS('FXOM E '); 17 -TIPOT('F); 18 -EXEC-SELEW,
END.
De la línea 1 a la 16, los valores enviados como parámetros a los procedimientos son los elementos de la estructura de datos TpointerStackStatutos (ver estructura en Sección 4.5), la cual se usa también para realizar manipulaciones de datos en los renglones correspondientes de los fragmentos involucrados en la actualización.
En el ejemplo que nos ocupa, los elementos que se introducirían en la lista serían las cláusulas UPDATE, WHERE y FROM, indicadas en la Iheas 1, 6 y 16 del código equivalente. Cada elemento de la lista StackStatutos apunta a su vez a otra lista denominada PrimaryNodo, cuyos elementos se usan para almacenar las columnas, variables, constantes y operadores de cada cláusula. La apariencia física de la lista al terminar la ejecución de la linea 18 se muestra en la Fig. 4.2.
Al ejecutar la línea 18, el manejador procede a actualizar los renglones de la tabla E como se describe a continuación.
De la estructura de datos se extrae el nombre de la tabla, de la cual sabemos, gracias a la línea 17 del código, que se trata de una tabla global. El siguiente paso es buscar en el DAD los fragmentos asociados con la tabla global E; de esta búsqueda se obtienen el nombre del fragmento, su ubicación en la red, la clausula de fragmentación original y la cláusula de fragmentación en la forma posfija.
4 9

Ciaeep=Espvar
Nulop=False CtmrnMEXlCO
. . I
Figura 4.2. Lisia de Clausuias para Ejecución del UPDATE.
El siguiente paso es determinar ei(1os) fragmentob) involucrado(s) con la operación de manipulación de datos, lo cual se logra por medio del procedimiento Evalua-Fragmento descrito en la sección anterior. Una vez que se obtuvo el(los) fragmentob) involucrado(s), se seleccionan los renglones que cumplan con la cláusula WHERE de la lista; para ésto el registro que se lee se introduce a un contenedor de memoria.
Después de que el renglón se encuentra en memoria, se aplica la operación de la lista correspondiente a la cláusula WHERE, en esta pane de la estructura se encuentran la condición de selección en la forma posfija, el desplazamiento de la columna que participa en la selección dentro del contenedor, y los operadores lógicos y relacionales de la condición. Si el renglón cumple con la cláusula de selección, se procede a su modificación. La siguiente cláusula de la lista indica que se trata de UM actualización y que debe actualizarse el contenedor de memoria con los nuevos valores que en ella se indican.
Cuando se actualiza el contenedor, se compara con la cláusula de fragmentación que se obtuvo del DAD para verificar que el renglón actualizado cumpla con la cláusula de fragmentación. Si cumple se graba el renglón en el fragmento, de lo contrario es necesario buscar en el DAD qué fragmento corresponde al renglón actualizado. En el proceso de actualización es necesario actualizar también los indices relacionados con cada fragmento.
50

4.8. Instrucción DELETE
La instrucción DELETE tiene como función suprizni~ los renglones de una tabla que cumplan con una cláusula de selección. La sintaxis se mostró en la Sección 3.4. Para lograr la transparencia de fragmentación se hace uso del procedimiento Evalua-Fragmento descrito en la Sección 4.6.
El borrado de un registro es lógico, se cambia solamente el indicador de activo a falso; cuando se hace un borrado del registro es necewio actualizar el(los) índice(s) del fragmento. Esta actualización se hace por medio del procedimiento Actualiza-índixes, el cual se encarga de borrar del índice que pertenece al fragmento la clave relacionada con el registro borrado del fragmento.
4.9. Instrucción SELECT
La instrucción SELECT se encarga de recuperar un conjunto de renglones o un renglón de una tabla. Cuando se desean recuperar renglones de una tabla de fragmentos se usa el procedimiento Evalua-Fragmento, para determinar de manera transparente eloos) fragmento(s) involucrado(s) en la selección.
Cuando en la selección interviene más de una tabla (JOIN), el proceso de identificación de fragmentos varía. Para deteminar el(los) fragmento(s) de una de las tablas que intervienen en el JOIN, es necesario realizar una separación de la cláusula de selección de todas las columnas que pertenecen a la tabla que se evalúa y de todos sus operadores lógicos y relacionales. Este proceso de descomposición se realiza en el procedimiento Evaiuafragmento-Tabla.
Por ejemplo, si tenemos el siguiente JOIN,
$ SELECT E.SNo FROM E,P,SP WHERE E.SNo=SP.SNo AND SP.PNo=P.PNo AND P.Ciudad="MEXICO";
para determinar el fragmento que corresponde a cada una de las tablas, se descompone la cláusula de selección de este ejemplo en tres subcláusulas (ya que el número de tablas paaicipantes en la selección son tres).
A).- E.SNo=SP.SNo B).- SP.PNo=P.PNo AND P.Ciudad="MEXICO" C).- E.SNo=SP.SNo AND SP.PNo=P.PNo
51

La cláusula mostrada en el inciso A corresponde a la tabla global E, la cláusula del inciso B corresponde a la tabla global P y la cláusula del inciso C corresponde a la tabla global SP.
Una vez separadas se identifica de manera independiente a cada fragmento, usando el procedimiento Evalua-Fragmento. Después de identificar cada uno de los fragmentos, se realiza el producto cartesiano de los fragmentos involucrados en la selección. A este producto cartesiano se le aplica la cláusula de selección que interviene en la operación de selección.
Existe otra variante cuando se presentan consultas anidadas como en el siguiente ejemplo:
$ SELECT SNo FROM E WHERE SNo IN
(SELECT SNo FROM Sp WHERE PNo IN
(SELECT PNO FROM P WHERE Ciudad="MEXICO")) ;
En este tipo de evaluación, primero se identifican los fragmentos que corresponden a la tabla del nivel más interno con el procedimiento Evalua-Fragmento. En este ejemplo se evalúa primero la tabla P, y se seleccionan los registros que cumplan que la ciudad sea igual a MEXICO.
Estos registros son almacenados en un archivo temporal, del cual se obtienen los datos al momento de evaluar la condición de selección de los fragmentos relacionados con la tabla SP. El mismo procedimiento se usa al momento de evaluar la tabla global E del nivel más externo.
52

CAPITULO 5
PRUEBAS
En este capítulo se presentan las pruebas realizadas al sistema manejado1 de bases de datos distribuidas experimental con el fui de comprobar los resultados obtenidos con el desarrollo del presente trabajo de tesis. Las pruebas consisten en ejecutar una serie de programas en Pascal con instrucciones de SQL intercaladas y verificar que el resultado de cada ejecución sea equivalente a la semántica de las proposiciones en el programa fuente. El número de pruebas efectuadas al precompilador fueron aproximadamente 70, tratando de abarcar todos los puntos sintácticos de la gramática SQL soportada por el precompilador. Por cuestiones de espacio se presentan en este capítulo sólo aquellas pruebas que se consideran más representativas.
5.1 Objetivos de Las Pruebas
Los objetivos de las pruebas al precompilador son principalmente los siguientes:
Verificar que las acciones semánticas efectuadas por el programa que resulten de la precompilación, sean equivalentes a las instrucciones del lenguaje SQL intercalado en el lenguaje anfitrión.
Verificar que los programas ejecutables cumplan con la transparencia de localización
Verificar que los programas ejecutables cumplan con la transparencia de fragmentación.
I )
2)
3)
Para lograr el punto 1), se implemento una serie de programas fuentes en Turbo Pascal y SQL. Cada programa corresponde a un ejercicio del Capitulo 7 de la referencial51. Se seleccionaron aquellos ejercicios que involucren el uso del las instrucciones más representativas de SQL.
Para lograr el punto 2), se verificó que las instrucciones de SQL utilizadas en los programas de entrada, no especificaran el nodo donde se encontraba@) lab) tablab) involucrada(s) en cada programa, con excepción de la instrucción CREATE TABLE, Y CREATE FRAGMENT, ya que estas instrucciones requieren especificar el nodo donde se desea crear la tabla.
53

Para lograr el punto 3), se verificó que las instrucciones de SQL utilizadas en los programas de entrada, no especificaran eloos) nombre(s) deloos) fragmento(s) involucrados en la operación de manipulaciÓn, a excepción de la instrucción DROP FRAGMENT, ya que esta requiere especificar explícitamente el nombre del fragmento; además f ie necesario modificar algunos ejercicios para comprobar la transparencia de fragmentación.
5.2 Condiciones de las h e b a s
Las pruebas se efectuaron en una red formada por 3 computadoras AT, en donde por cada computadora se creó una tabla global y por cada tabla global se crearon tres fragmentos; es decir, un fragmento por computadora.
5.3. Presentación de las Pruebas
A continuación se presentan los listados de los programas fuente en Pascal y SQL correspondientes a las pruebas junto con los resultados impresos cuando sea el caso, además se presentan los archivos de donde se obtienen los datos a insertar en los fragmentos y también se presentan los fragmentos con los registros que contendrán cada uno de ellos dependiendo de la cláusula de fragmentación.
- Datos del archivo DatosP.Dat.
54
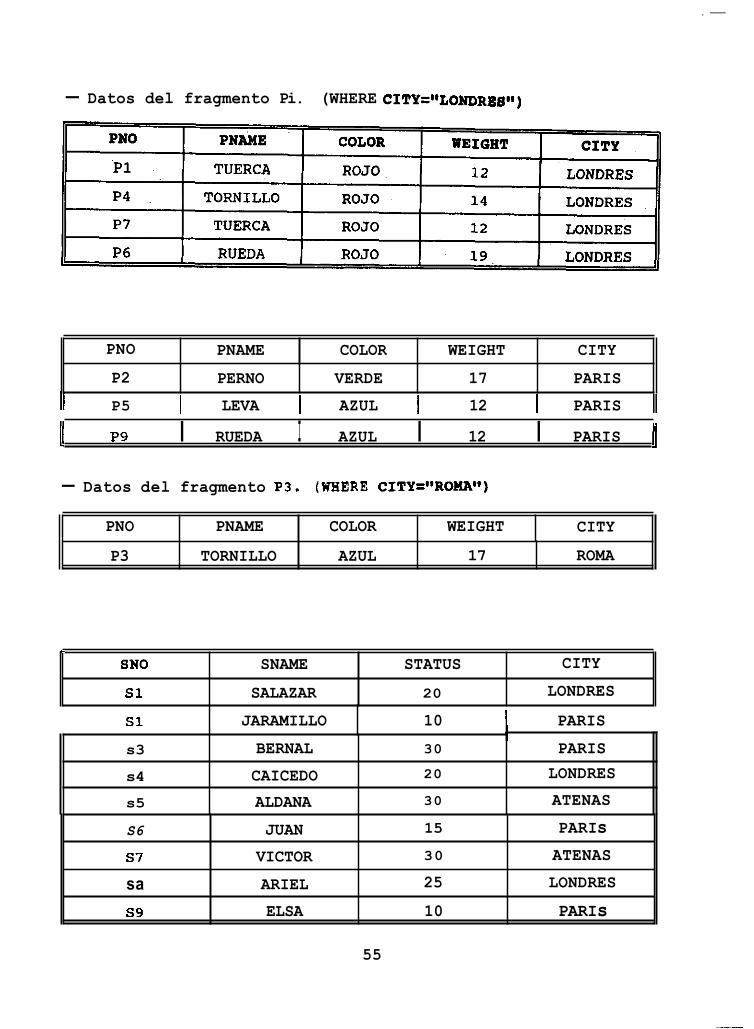
. -
PNO
- Datos del fragmento Pi. (WHERE CITY=iiLOmRESi~)
PNAME COLOR WEIGHT CITY
P2
II P5 I LEVA I AZUL I 12 I PARIS 11 PERNO VERDE 17 PARIS
P9 I RUEDA I AZUL I 12 I PARIS
PNO PNAME COLOR WEIGHT
- Datos del fragmento Pí. (W?IERE CITY=ivROMAii)
CITY
P3 TORNILLO AZUL 17 ROMA
- SNO SNAME STATUS
S1 SALAZAR 20
CITY
LONDRES
S1
55
JARAMILLO 10 PARIS
s3
s4
s5
BERNAL 30 PARIS
CAICEDO 20 LONDRES
ALDANA 30 ATENAS
S6
57
sa S9
JUAN 15 PARI s
VICTOR 30 ATENAS
ARIEL 25 LONDRES
ELSA 10 PARI s

- Datos del fragmento 81 (WHERE CITY="LONDRES" AND 8TATU8=20)
8NO SNAME STATUS CITY
s9 ELSA 10 PARIS 2
STATUS CITY SALAZAR 20 LONDRES CAICEDO 20 LONDRES
s1
54
s5
s7
ALDANA 3 0 ATENAS
VICTOR 3 0 ATENAS
- Datos del fragmento 83 (WHERE CITY="ATENAS" AND STATUS=30)
SNO SNAME STATUS
- Datos del archivo DatosSP.dat
56
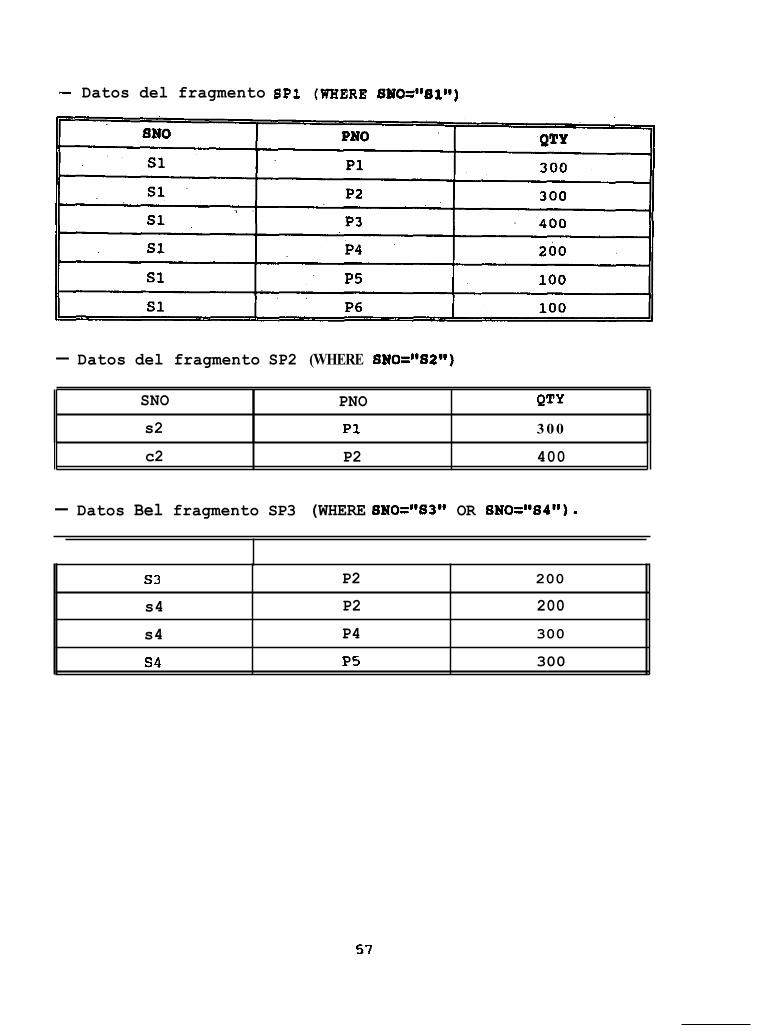
' - Datos del fragmento SP1 (WHERE S N O P O = ~ ~ S ~ ~ ~ )
SNO
s2
- Datos del fragmento SP2 (WHERE SNO=*eS2ee)
PNO QTY
P1 300
c2 P2 400
- Datos Bel fragmento SP3 (WHERE BNO=veS3ee OR SN0=eeS4ee).
53
s4
s4
s4
P2 200
P2 200
P4 300
P5 300
51

{------------------------------------------------ Prueba No. 1. Para el precompilador de SQL. Objetivo : Crear la tablas de fragmentos S, P, SP. Fecha : 17 de Enero DE 1995.
}
USES SQL;
................................................
BEGIN
$ CREATE FRAGMENTED TABLE S( SNo CHAR(5) NOT NULL PRIMARY KEY, SName CHAR(2O) NOT NULL, Status SMALLINT NOT NULL, City CHAR(20) NOT NULL);
$ CREATE FRAGMENTED TABLE P( PNo CHAR(5) NOT NULL PRIMARY KEY, PName CHAR(20) NOT NULL, Color CHAR(20) NOT NULL, Weight INTEGER NOT NULL, City CHAR(20) NOT NULL);
$ CREATE FRAGMENTED TABLE SP( SNo CHAR(30) NOT NULL,
Qty INTEGER NOT NULL); PNO CHAR(30) NOT NULL,
END ;
58

{------------------------------------------------------- Prueba No. 2. Para el precompilador de SQL. Objetivo : Crear los fragmentos para la tabla global S. Fecha : 17 de Enero DE 1995.
> ........................................................
USES SQL;
BEGIN
$ CREATE FRAGMENT S1 ON S WHERE City='Londresf AND Status=2O;
WHERE City='Parisf AND Status=lO IN 'BETA\BETA-C';
WHERE City='Atenas' AND Status=30 IN 'GAMA\GAMA-C';
$ CREATE FRAGMENT 52 ON S
$ CREATE FRAGMENT S3 ON S
END.
59

{-------------------------------------------------------- Prueba No. 3. Para el precompilador de SQL. Objetivo : Crear loa fragmentos para la tabla global P. Fecha : 17 de Enero DE 1995. ........................................................
USES CQL;
BEGIN
$ CREATE FRAGMENT P1 ON P WHERE City='Londres';
$ CREATE FRAGMENT P2 ON P WHERE City='Paric' IN 'BETA\BETA-C';
$ CREATE FRAGMENT P3 ON P WHERE City='Roma' IN 'GIMA\GAMA-C';
END.
60

(-------------------------------------------------------- Prueba No. 4. Para el precompilador de SQL. Objetivo : Crear los fragmentos para la tabla global SP. Fecha : 17 de Enero DE 1995. ........................................................
USES SQL;
BEGIN
$ CREATE FRAGMENT SP1 ON SP WHERE SNo='Cl';
$ CREATE FRAGMENT SP2 ON SP WHERE SNoz'S2' IN 'BETA\BETA-C';
$ CREATE FRAGMENT SP3 ON SP WHERE SNo='S3' OR SNO='S4' IN 'GAMA\GAMA-C';
END.
61

{---------------------------------------------------------- Prueba No. 5. Para el precompilador de SQL. Objetivo : Insertar los valores de los renglones de la
tabla de ragmentos S , los datos se leen del archivo de datos Datoss.dat.
Fecha : 17 de Enero DE 1995. }
......................................................... USES SQL,PRINTER;
TYPE
Datos = RECORD Numero :STRING[5]; Nombrer:STRING[20]; Estado :INTEGER; Ciudad :STRING[20]; END ;
VAR F :FILE OF Datos; X :Datos;
SBEGIN DECLARE SECTION
UsName : STRING[20]; Ustatus: INTEGER;
USNO : STRING[5];
UCity : STRING[20]; END DECLARE SECTION;
BEGIN WRITELN(LST,'-------- DATOS DE S --------'); ASSIGN(F.'C:\DatosS.dat'); ~~~ ~
RESET(F) i WHILE NOT EOF (F) DO BEGIN READ(F,X) ; USno :=X.Numero; USname :=X.Nombrer; KJStatus:=X. Estado; -~ UCity :=X.Ciudad: WRITELN(LST,USno:10,UsName:lO,UStatus:lO,UC~ty:lO);
$. INSERT INTO S VALUES(:USno,:UsName,:UStatus,:UCity);
END ; CLOSE(F) ;
END.
62

{------------------------------------------- r------ Prueba No. 6 . Para el precompilador de SQL. Objetivo :Insertar los valores de los renglones de
Fecha : 17 de Enero DE 1995.
la tabla de fragmentos P, los datos se leen del archivo de datos DatosP.dat.
} .......................................................... USES SQL,PRINTER;
TYPE
Datos = RECORD Numero :STRING[5]; Nombre :STRING[ZO]; Color :CTRING[LO]; Ancho :INTEGER; Ciudad :STRING[LO];
END ;
VAR F :FILE OF Datos; X :Datos;
$ BEGIN DECLARE SECTION UPno :STRING[5]; UpName :STRING[ZO]; UpColor :STRING[ZO]; UpWeight:Integer; UpCity :STRING[LO];
END DECLARE SECTION;
BEGIN WRITELN(LST,'------ DATOS DE P -------'I ;} ASSIGN(F,'C:\DatosP.dat'); RESET (F) ; WHILE NOT EOF(F) DO BEGIN READ(F,X) ; UPno :=X.Numero; UpName :=X.Nombre; upcolor :=X.Color; UpWeight:=X.Weight; Upcity :=X.Ciudad; $INSERT INTO P VALUES(:UPnO,:UpName,:upcolor,:UpWeight,:upCitY);
END; CLOSE (F) ;
END.
63

{---------------------------------------------------------- Prueba No. 7. Para el precompilador de SQL. Objetivo : Insertar los valores de los renglones
de la tabla S , los datos son leidos de archivo de datos DatoSSP.dat.
Fecha : 17 de Enero DE 1995. } ..........................................................
USES SQL, PRIENTER;
TYPE
Datos = RECORD SNumero :STRING[S]; PNUmerO :STRING[5]; Qty : INTEGER; END;
VAR F :FILE OF Datos; X :Datos;
$BEGIN DECLARE SECTION Usno :STRING[5]; UPno :STRING[5]; UQty : INTEGER;
END DECLARE SECTION;
BEGIN WRITELNILST,'------- DATOS DE SP --------'); ASSIGN(F, 'C: \DatosSP.dat') ; RESET(F) f WHILE NOT EOF(F) DO BEGIN READ (F ,,X) ; USno :=X.SNumero; UPno :=X.PNumero; UQty : =X. Qty ; WRITELN(LST,USno:lO,UPno:lO,UQty:lO);
$INSERT INTO SP VALUES(:USno,:UPno,:UQtY);
END; CLOSE (F) ;
END.
64

{--------------------------------------------------------- Prueba No. 0 . Pare el precompilador de SQL. Objetivo : Obtener los números de partes para todas las
Fecha : 17 de Enero DE 1995. partes suministradas eliminando duplicados.
> ..........................................................
USES SQL,PRINTER;
$ BEGIN DECLARE SECTION
END DECLARE SECTION; UPno :STRING[S];
BEGIN
$DECLARE CURSOR Testcur FOR SELECT DISTINCT PNO FROM SP;
$ OPEN Testcur; WRITELN(' Resultado de la prueba No. 8 ' ) ; WRITELN (LST) ; WRITELN(LST, tResultado de la prueba NO. 8 ' ) ; WRITELN;WRITELN(LST); REPEAT
$ FETCH Testcur INTO : UPno;
IF SQLCODE=O THEN BEGIN WRITELN(UPno:15); WRITELN(LST,UPno: 15) ; END;
UNTIL SQLCODEoO;
$ CLOSE Testcur; END.
65

Resultado de la prueba 8.
Cumple el fragmento CPl.BD1, SPL.BD1, SP3.BD1
PI P2 P3 P4 P5 P6
66

. {---------------------------------------------------------- Prueba No. 9 . Para el precompilador de SQL. Objetivo : Obtener los detalles completos de todos los
proveedores donde el Status=20. Fecha : 17 de Enero DE 1995. '
} .......................................................... USES CQL,PRINTER;
$BEGIN DECLARE SECTION USno :STRING[S]; UsName :STRING[20]; IndName :INTEGER; UStatus :INTEGER; IndStatus :INTEGER; UCity :STRING[LO]; IndCity :INTEGER;
END DECLARE SECTION:
BEGIN
$ DECLARE CURSOR Testcur FOR SELECT * FROM S WHERE Status=20;
$ OPEN Testcur; WRITELN('Resu1tado de la Prueba Numero 9:'); WRITELN(LST,'Resultado de la Prueba Numero 9:'); REPEAT
$ FETCH Testcur INTO :USno,:UsName,:lndName,:uStatus,:IndStatus, :UCity,:IndCity;
IF SQLCODE=O THEN BEGIN WRITE(USno:5,UsName:lO,lndName:5,UStatus:5,
:IndStatus:5,:UCity,:IndCity); WRITE(LST,USno:5,UsName:1O,IndName:5,UStatus:5,
:IndStatus:5,:UCity,:IndCity); END;
UNTIL SQLCODE<>O; $CLOSE Testcur; END.
67

Resultado de la prueba 9.
Cumple el fragmento Sl.BD1
sl s a l a z a r 2 0 Londres c4 Caicedo 20 Londres
68

{-------------------------------------------------------- Prueba No. 10. Para el precompilador de SQL. Objetivo : Obtener la informacion de todas las combinaciones
de partes y proveedores tal que el proveedor y parte en cuestion esten localizados en la misma ciudad pero omitiendo proveedores con Status=20.
Fecha : 17 de Enero DE 1995.
USES SQL, PRINTER; 1 ..........................................................
$ BEGIN DECLARE SECTION USno :STRING[5]; USname :STRING[20]; UStatUS :INTEGER; Uscity :STRING[ZO]; UPno :STRING[3]; UpName :STRING[LO]; Ucolor :STRING[ZO]; Weight :REAL; upcity :STRING[ZO];
END DECLARE SECTION;
BEGIN $ DECLARE CURSOR Testcur FOR SELECT * FROM S,P WHERE S.City=P.City AND S.Statuso20 AND P.City=ttParistt;
$ OPEN Testcur; WRITELN('Resu1tado de La prueba No. 10'); WRITELN(LST,'Resultado de la prueba No. 10'); REPEAT $FETCH Testcur INTO
:USno,:UsName,:UStatus,:UsCity, :UPno,:UpName,:UColor,:Uweight,:UpCity;
IF SQLCODE = O THEN BEGIN
WRITELN(USno:4,UsName:1O,UStatus:5,UsCity:8, UPn0:4,UpName:8,UColor:E,UWeight:7:2, Upcity: 8 ) ;
UPn0:4,UpName:8,UColor:E,Weight:7:2, Upcity:8) ;
WRITELN(LST,USno:4,UsName:10,UStatus:5,UsCity:8,
END ; UNTIL SQLCODEoO; $CLOSE Testcur;
END.
69

.
Resultado de la prueba lo.
Cumple el fragmento S2.BD1, s3.BD1, p2.BDl
s9 Elsa 10 Paris p2 Perno Verde 17.00 Paris s9 Elsa 10 Paris p5 Leva Azul 12.00 Paris
70

{---------------------------------------------------------- Prueba NO. 11. Para el precompilador de SQL. Objetivo : Obtener todos los pares de nombre de ciudades
tal que el proveedor situado en la primera ciudad suministre una parte almacenada en la segunda ciudad.
Fecha : 17 de Enero DE 1995. > ..........................................................
USES SQL,PRINTER;
$ BEGIN DECLARE SECTION
UpCity:STRING[ZO]; uscity,
END DECLARE SECTION;
BEGIN
$ DECLARE CURSOR Testcur FOR SELECT DISTINCT S.City,P.City FROM S,Sp,P WHERE S.SNo=SP.SNo AND Sp.PNo=P.PNo AND
P.City="Londres"AND S.Status=LO AND SP.SNo>"OOSt8;
$ OPEN Testcur;
WRITELN('Resultad0 de la prueba No.11');
WRITELN(LST,'Recuitado de la prueba No. 11'); WRITELN (LST) ;
REPEAT
$FETCH Testcur INTO :UsCity,:upcity;
IF SQLCODE=O THEN BEGIN WRITELN(UsCity:lO,UpCity:lO); WRITELN(LST,USCity:l9,UpCity:19); END ;
UNTIL SQLCODE<>O;
$ CLOSE Testcur;
END.
71

Resultado de l a prueba 11.
Cumple e l fragmento Cl.BD1, CP.BD1, Pl.BD1
Londres Londres
7 2

Prueba No. 12. Para el precompilador de SQL. Objetivo: Obtener los nombres de proveedores para
Provedores que suministran al menos una parte roja.
Fecha : 17 de Enero DE 1995. 1 .........................................................
USES SQL,PRINTER;
$ BEGIN DECLARE SECTION UsName:STRING[20
END DECLARE SECTION
BEGIN
$ DECLARE CURSOR Te SELECT SName FROM S
,
tcur FOR
~~
WHERE S.City='Londres' AND SNO IN (SELECT SNo FROM SP WHERE SP.SNo='sl' AND PNo IN (SELECT PNo FROM P WHERE Color='Rojo'));
$ OPEN Testcur;
WRITELN('Recu1tado de la prueba No. 12'); WRITELN (LST) ; WRITELN(LST,'Resultado de la prueba No. 12'); REPEAT
$FETCH Testcur INTO : UsName ;
IF SQLCODE=O THEN BEGIN WRITELN(UsName:lO); WRITELN(LST,UsName:l8); END;
UNTIL SQLCODE<>O; END.
73

Resultado de la prueba 12.
Cumple el fragmento Pl.BD1, PZ.BD1, P3.BD1 Cumple el fragmento SPl.BD1, SPZ.BD1, SP3.BD1 Cumple el fragmento Sl.BD1
Salazar
74

Prueba No. 13. Para el precompilador de SQL. Objetivo : Cambiar el valor del atributo Status de la tabla
de fragmentos S para el proveedor S5. Fecha : 17 de Enero DE 1995.
} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . USES SQL;
BEGIN
$ UPDATE S SET Status=20 WHERE SNo='s5'; WRITELN('SQLC0DE = ',Sqlcode);
END.
,
75

Resultado de l a prueba 1 3 .
SQLCODE = O
76

USES SQL;
BEGIN
$ DELETE FROM S WHERE SNo=’sl’; WRITELN(’SQLC0DE = ‘,Sqlcode);
END.
77

Resultado de l a prueba 14.'
SQLCODE = O
78

USES SQL,PRINTER;
$ BEGIN DECLARE SECTION USno :STRING[5]; UsName :STRING[ZO]; IndName :INTEGER; UStatus :INTEGER; IndStatus :INTEGER; UCity :STRING[LO]; Indcity :INTEGER; END DECLARE SECTION;
BEGIN
$ DECLARE CURSOR Testcur FOR SELECT * FROM S WHERE Status IN (10,20,50);
$ OPEN Testcur;
WRITELN('Resu1tado de la Prueba Numero 15:'); WRITELN(lst,'Resultado de la Prueba Numero 15'); WRITELN;WRITELN(LST); REPEAT
$ FETCH Testcur INTO :USno, :UsName:IndName, :UStatus:IndStatus,:UCity:IndCity;
WRITE(USno:5,UsName:lO,IndName:5,UStatus:5, :IndStatus:5,:UCity,:IndCity);
WRITE(LST,USno:5,UsName:lO,IndName:5,UStatus:5, :IndStatus:5,:UCity,:IndCity);
UNTIL SQLCODE<>O;
$ CLOSE Testcur; End.
79

Resultado de la prueba 15.
Fragmento que cumple Sl.BD1, S2.BD1
sl Calazar 20 Londres s4 Caicedo 20 Londres s9 Elsa 10 Paris
80

$BEGIN DECLARE SECTION USno :STRING[5]; UcName :STRING[LO]; IndName :INTEGER; UStatuc :INTEGER; IndStatus :INTEGER; UCity :STRING[LO]; IndCity :INTEGER; X : INTEGER;
END DECLARE SECTION;
BEGIN READ (X) ; $ DECLARE CURSOR Testcur FOR SELECT * FROM S WHERE Status=:X;
$ OPEN Testcur;
WRITELN('Resultad0 de la Prueba Numero 16:'); WRITELN (LST) ; WRITELN(LST,'Resultado de la Prueba Numero 16');
REPEAT $FETCH Testcur into :USno, :UcName:IndName,:UStatus :IndStatus,:UCity:IndCity;
WRITE(USno:5,UsName:lO,IndName:5,UStatus:5, :IndStatus:5,:UCity,:IndCity);
WRITE(LST,USno:S,UsName:1O,IndName:5,UStatus:5, :IndStatus:5,:UCity,:IndCity);
UNTIL SQLCODEoO;
$CLOSE Testcur; END.
81

Resultado de la prueba 16.
Valor de X ..: 30 Cumple el fragmento S3.BD1
s5 Aldana 30 Atenas s? Victor 30 Atenas
C a2

CAPITULO 6
COMENTARIOS FINALES
Actualmente existe un enorme interés por parte de la comunidad investigadora así como del mercado comercial en el área de bases de datos distribuidas, sin embargo, a la fecha no se sabe de un producto comercial que cumpla con todas las características que un sistema manejador de bases de datos distribuidas debe poseer [6 ] . Esto se debe en gran parte a los numerosos problemas de carácter técnico asociados con la implementación de bases de datos distribuidas.
El desarrollo de este proyecto tuvo como propósito dar solución a algunos de los problemas relacionados con bases de datos disiribuidas con el fin de asimilar esta tecnología y estar en condiciones de ofrecerla al sector educativo y al sector eléctrico.
A continuación se describen los problemas y soluciones obtenidas con el desarrollo del presente trabajo:
- Para identificar un fragmento el sistema debe realizar UM serie de cálculos para localizarlo de manera transparente. Lo óptimo para un sistema manejador de bases de datos distribuidas, es que el fragmento sea local al nodo donde se realiza la operación de manipulación de la tabla de fragmentos, ya que de no estarlo debe viajar a través de los nodos de la red hasta localizar su ubicación, con lo cual el tiempo de consulta es mayor que el tiempo que se emplearía en manipulaciones realizadas sobre tablas convencionales, foráneas al nodo donde se realiza la aplicación este es un problema del diseño del esquema de la base de datos y no es responsabilidad del manejador solucionar este tipo de situaciones.
EI método empleado en esta tesis para determinar la ubicación física del fragmento consiste en comparar las columnas en común que aparecen en la cláusula de selección y las columnas que aparecen en la cláusula de fragmentación, el hecho de que existan columnas comunes (en la cláusula de fragmentación y la cláusula de selección) indica que posiblemente en el fragmento que se evalúa está el valor solicitado en la operación de manipulación de datos; el siguiente paso consiste en verificar el tipo de operadores relacionales que aparecen en las cláusulas para determinar si existe intersección de datos entre ambas condiciones. Una vez identificadas las columnas en común y los operadores relacionales se comparan los valores que se desean seleccionar contra los valores con que se creo el fragmento. Así el método garantiza que el fragmento localizado sea el solicitado en la cláusula de selección.
8 3

- Otro problema que presenta la fragmentación, cuando una base de datos está mal diseñada, es el cambio de registros de un fragmento a otro cuando se realiza una actualización sobre una tabla de fragmentos. Este caso se presenta cuando se modifica el valor de ia(s) columna(s) de un registro que participa(n) en la cláusula de fragmentación de tal manera que los nuevos valores no concuerdan con dicha cláusula, en este caso el tiempo empleado se incrementa considerablemente ya que debe determinar una nueva ubicación para el registro actualizado. En algunas aplicaciones la fragmentación se presenta de manera natural (empresas con departamentos, bancos, etc.) lo que hace que el diseño de la base de datos se facilite y se identifiquen de manera rápida en que nodos de la red se usan con más frecuencia los datos, en este caso es poco probable que se presente el caso antes mencionado (cambio de registros de un fragmento a otro), pero en otras aplicaciones no es nada fácil identificar en que nodos de la red se usan con más frecuencia los datos lo que lleva a un mal diseño de la base de datos y hace que se presenten situaciones similares a la mencionada; posiblemente ésta sea una causa del por qué la mayoría de los manejadores comerciales no presentan la característica de transparencia de fragmentación.
La manera como se maneja el cambio de registros de un fragmento a otro en esta tesis consiste en almacenar el registro a actualizar en un contenedor de memoria, una vez en memoria se actualiza con los valores especificados en la cláusula UPDATE; después es necesario verificar si los nuevos valores del contenedor en memoria cumplen con la cláusula de fragmentación a la que pertenece el registro actualizado. Esta evaluación se hace comparando el registro actualizado con la cláusula de fragmentación en la forma posfija; si el registro actualizado cumple con la cláusula de fragmentación, se actualiza el fragmento; de lo contrario es necesario realizar una búsqueda en el DAD de los fragmentos asociados a la tabla de fragmentos y ejecutar su cláusula de fragmentación hasta enconcm aquél que cumpla con el registro actualizado.
- Un problema importante que se encontró al momento de implementar las rutinas que permiten la transparencia de fragmentación, y que no se señala en la literatura es el referente a la integridad de los datos de la tabla de fragmentos. Esto básicamente se presenta cuando los fragmentos de una tabla tienen asociados índices únicos o llave primaria. Para evitar que se viole la integridad de la tabla es necesario realizar una serie de procedimientos que garanticen que los datos que se introducen al fragmento y que participan en un índice único o llave primaria no se repitan, para ésto se debe verificar si ia(s) columna(s) que participan en la definición del índice único, participa(n) también en la cláusula de fragmentación; de ser así la búsqueda de la clave se efectúa únicamente en el nodo donde reside el fragmento, de lo contrario la búsqueda de la clave se realiza en todos los índices de los fragmentos asociados con la tabla.
84

- También se llegó a la conclusión de que un esquema de fragmentación puede ser tratado de dos maneras diferentes. La primera consiste en percibir la tabla global como una vista de los fragmentos, este caso se presenta cuando se integran tablas en una relación de tal manera que las tablas se convierten en fragmento de la relación. La segunda consiste en descomponer una tabla global en fragmentos, los cuales se comportan como vistas de la relación global..
6.1 Posibles Extensiones
Actualmente el mecanismo de transparencia de fragmentación sólo permite manejar la fragmentación horizontal, y por lo tanto quedm’a por desarrollar el manejo de los siguientes puntos:
- Fragmentación vertical . Consiste en descomponer una relación global en base a sus atributos en grupos, lo cual se obtiene por proyecciones de la relación global, la relación puede reconstruirse realizando la reunión natural de los grupos. Sin embargo, la fragmentación vertical presenta problemas más dificiles que los de la fragmentación horizontal; ya que en ésta las columnas de la llave primaria de una tabla fragmentada deben estar presentes en cada uno de los fragmentos, lo cual ocasiona el problema de mantener la congruencia de dichas columnas cuando se hacen altas y bajas de renglones.
- Fragmentacih mixta. En este tipo de fragmentación cada fragmento se obtiene de la aplicación del esquema de fragmentación ya sea horizontal o vertical, sobre un fragmento que se haya obtenido con anterioridad.
- Fragmentación horizontal derivada. Consiste en fragmentar horizontalmente UM relación global en base a los atributos de otra relación. Para lograrlo es necesario realizar una selección de las tuplas que cumplan con la cláusula de fragmentación y posteriormente realizar el producto cartesiano del resultado obtenido con la selección y con la tabla que se desea fragmentar.
- Algoritmos para determinar la intersección entre fragmentos. Ya que los fragmentos deben ser disjuntos es necesario realizar un método que sea capaz de determinar cuando dos fragmentos presentan intersección, lo cual se logra en base a comparaciones de las cláusulas de fragmentación, estos algoritmos son de gran importancia ya que evitan problemas de duplicidad de datos.
85

6.2. Observaciones
En esta tesis se han presentado los resultados de un proyecto relacionado con el desarrollo de un mecanismo que permite ofrecer transparencia de fragmentación en el SiMBaDD.
Conviene destaw que este proyecto es sólo uno de una larga serie que tiene por objeto estudiar problemas y desarrollar tecnología relacionados con manejadores de bases de datos distribuidas.
El manejador SiMBaDD cuenta actualmente con un manejador de archivos y un precompilador para SQL. El manejador de archivos proporciona funciones básicas para el acceso transparente a los archivos de una base de datos distribuida.
El precompilador permite a los usuarios escribir programas en Turbo Pascal con instrucciones SQL intercaladas. Tomando como entrada dichos programas, el precompilador genera programas semánticamente equivalentes con instrucciones de Turbo Pascal exclusivaniente.
Recientemente se agregó al SiMBaDD un módulo para el manejo de transacciones que proporciona un control de concurrencia y recuperación de la base de datos. Los primeros módulos han sido ampliamente probado con el desarrollo de proyectos en cursos de maestría en el Centro Nacional de investigación y Desarrollo Tecnológico y en inst. Tecnológico de Estudios Superiores de Monterrey (Campus Morelos).
Se tiene planeado agregar al SiMBaDD (a) un manejador de vistas y control de acceso para usuarios, (b) una interfaz gráfica para la formulación de consultas mediante ejemplos, (c) un manejador de dominios compuestos, (d) u n manejador de apuntadores entre tablas, y (e) un generador automático de código para altas, bajas, cdmbios, e informes.
8 6

ANEXO A
En este anexo se explican de manera narrada los procedimientos y funciones mencionados en los pseudocódigos del Capítulo 4. También se muestra el uso de algunas variables globales, con el fin de comprender mejor el funcionamiento de estos pseudocódigos.
Funciones.
- CreaFrag(Nod0,TregFrag). Recibe como parámetro de entrada el nombre de la computadora donde se desea crear el fragmento en la variable Nodo y la estructura del fragmento en TregFrag, su función es crear un fragmento en el nodo especificado..
- Existe-Or(Clausu1a-Frag). Esta función regresa un valor verdadero si en la cláusula de fragmentación interviene al menos un operador lógico OR.
- T(ld). Regresa un valor verdadero si el parámetro de entrada Id, es un identificador (columna, fragmento, indice, tabla global), de lo contrario regresa un valor falso.
- R(Pal). Regresa un valor verdadero si el parhmetro de entrada Pal, es una palabra reservada, de lo contrario regresa un valor falso.
- RegCumpleWhere. Regresa un valor verdadero si la condición de la cláusula WHERE cumple con el registro activo (almacenado en él contenedor de memoria).
TuplacumpleRequisitos. Regresa un valor verdadero si los valores a insertar en una tabla o fragmento cumplen con los requisitos (concordancia en tipos de datos, longitud, etc.).
-
Procedimientos.
- Apunta-Ciausula(Cf). Este procedimiento se encarga de introducis a una lista apuntada por APF, los elementos que contiene el vector Cf que se recibe como parámetro de entrada.
87

- EvaluaFragmento-Tabla(Apt). Este procedimiento se encarga de evaluar la cláusula de fragmentación descompuesta (apuntada por APF), contra la cláusula de selección apuntada por APT que se recibe como parámetro de entrada; del resultado de la comparación se determina si el fragmento cumple o no con la cláusula de selección.
Busca-Archivos3(Nombre-Tabla, Estado). Realiza UM búsqueda de la tabla (recibida como parámetro en Nombre-Tabla) en el DAD, regresa un valor de uno en la variable de salida Estado en caso de que la tabla no exista y un valor de cero en caso contrario, si la tabla existe regresa su estructura en la variable global Regis-Arch.
-
- Bu-Fragmentos(Nombre-Frag). Realiza un búsqueda de los fragmentos en el DAD y regresa el apuntador global AptFrag, el cual apunta a una lista donde se incluyen todos los fragmentos asociados a la tabla de fragmentos que se recibe como parámetro de entrada en la variable Nombre-Frag.
- Sql-Add-lndex(Nombre-index). Este procedimiento se encarga de modificar la información de la tabla en el DAD, es decir registra el nuevo índice asociado a la tabla.
- Separa-Clausula(Cf, Num-Or). Regresa el número de operadores lógicos OR que intervienen en la cláusula de fragmentación en la variable de salida Num-Or y . divide la cláusula de fragmentación dependiendo del número de operadores lógicos OR, regresando estas divisiones en el vector Cf.
- Create-Index(Nombre-Index, Nombre-Tabla). Recibe como parámetro el nombre del índice en la variable Nombre-index, y el nombre de tabla sobre la que se crea el índice en la variable Nombre-Tabla, su función es crear el índice especificado.
- Evalua-Fragmento(C1ausula-Frag, Apt). El procedimiento Evalua-Fragmento se encarga de descomponer la cláusula de fragmentación (Clausula-Frag) y compararla contra la cláusula de selección apuntada por Apt para determinar si el fragmento cumple con la solicitud de la cláusula de selección.
- GetToken. Este procedimiento se encarga de leer los "Tokens" de manera secuencia1 del programa fuente.
88

- Busca-Tablaf(Tab1a). Identifica si la tabla a la que se hace referencia en el parámetro de entrada Tabla es global o de fragmentos, el valor lo regresa en la variable global Regis-Arch.Tipot (Regis-Arch.Tipot toma el valor de "B" para las tablas base y " F para las tablas de fragmento).
- Genera-Codigo-Fragmento. Genera el código en Pascal equivalente a la instrucción SQL para la creación de fragmentos después de que se verifico sintáctica y semánticamente la instrucción.
- Existe-Col-En-Ind. Verifica si, en los índices definidos como únicos o en la llave primaria existe una columna que participa en la cláusula de fragmentación.
Variables Globales.
Regis-Arch. Variable tipo estructura TregTabla que contiene la descripción general de la tabla
Verifica-Condición. Variable tipo booleana que indica si la cláusula Where no contiene errores sintácticos; regresa un valor verdadero si la cláusula Where está bien escrita, de lo contrario regresa un valor falso.
Estado. Variable de salida en algunos procedimientos que regresa un valor cero si existe la tabla, de lo contrario regresa un valor igual a uno.
AptFrag. Apuntador global que apunta a una lista que contiene la cláusula de fragmentación completa.
Apf. Apuntador a una lista que contiene una división de la cláusula de fragmentación.
Apt. Apuntador a una lista que contiene la cláusula de selección en la forma posfija.
Lexval. Variable que toma su valor en el procedimiento Get-Token y contiene un lexema.
CumpieFragmento. Variable booleana que indica si cumple o no el fragmento.
AptlCf. Apuntador a una lista que contiene los fragmentos asociados a la tabla de fragmentos
89 .- * I' n. 0.
CENTRO DE INFORMACION' - I - ,
C E N i n F T