büyük, dağıtık, veri yoğunluklu uygulamalarda programlama ... file yaratır ve hafızasında...
TRANSCRIPT

18/10/11 GRID ÇALIŞTAYI 2007 1
Büyük, Dağıtık, Veri Yoğunluklu Uygulamalarda Programlama
Paradigmaları
Güven FidanAGMLAB Bilişim Teknolojileri

18/10/11 GRID ÇALIŞTAYI 2007 2
MapReduce Nedir?
• Büyük data kümelerini işlemek ve oluşturmak için bir programlama modelidir.
• Map ve Reduce fonksiyonlarını içerir.
• Büyük bilgisayar kümelerinde çalışır.
• Paralel olarak birçok MapReduce uygulaması bu kümeler üzerinde aynı anda çalışabilir.

18/10/11 GRID ÇALIŞTAYI 2007 3
MapReduce Nedir?
• İlk programlama kütüphanesi Google tarafından oluşturuldu.– Web içeriğini crawl etme– İçeriği parse etme– Inverted indeks oluşturma– Web grafı oluşturma ve işleme– Kullanıcı kullanım log verilerini işleme– Kümelendirme, sınıflama, vb.
• Apache MapReduce kütüphanesi: Hadoop

18/10/11 GRID ÇALIŞTAYI 2007 4
Programlama Modeli?
• <Input key,value> ikililerinden <Output key, value> ikilileri üretilir.
• İki temel fonksiyon belirtilir:– Map(input_key,input_value) -> (out_key,
intermediate_value)• input key/value ikilileri üzerinde çalışır
• Ara key/value ikilileri yaratır
– Reduce (out_key, intermediate_value) -> list(out_value)• Ara key/value ikilileri üzerinde çalışır
• Birleştirilmiş output değerleri kümesini yaratır

18/10/11 GRID ÇALIŞTAYI 2007 5
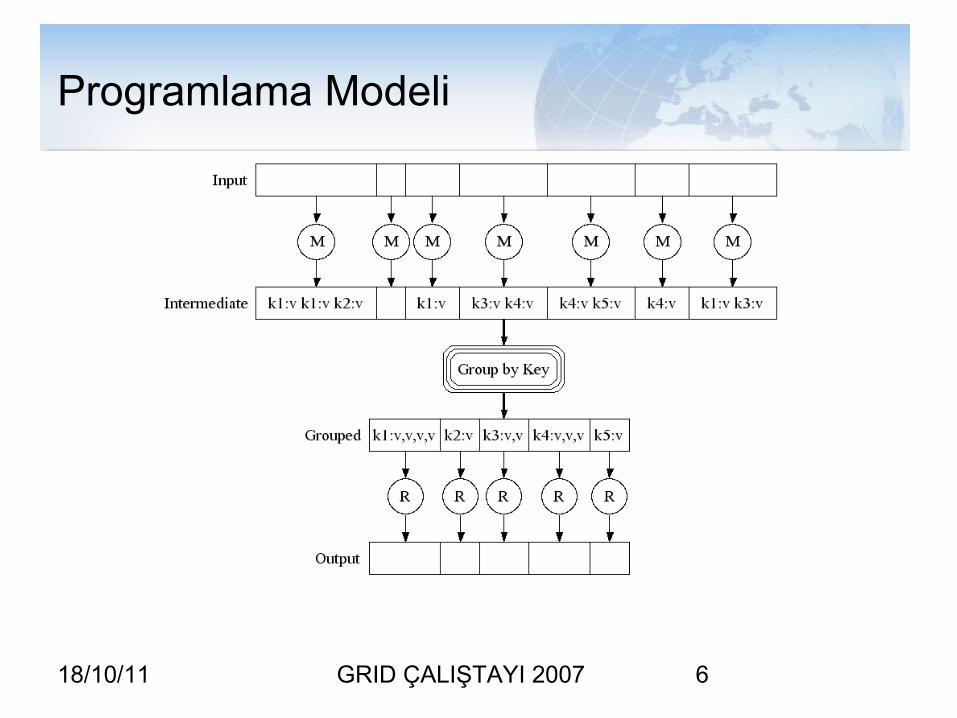
Programlama Modeli?
• Tipler:map (k1,v1) -> list(k2,v2)reduce (k2, list(v2)) -> list(v2)
• Örnek: Bir grup doküman içerisindeki her bir kelimenin frekansının hesaplanması.map(String key, String value){
// key: doküman adı// value: document içeriğifor each word w in value
EmitIntermediate(w,”1”);}reduce(String key, Iterator values){
// key: kelime// values: frekans listesiint result = 0;for each v in values
result += parseInt(v);Emit(AsString(result));
}
18/10/11 GRID ÇALIŞTAYI 2007 6
Programlama Modeli
18/10/11 GRID ÇALIŞTAYI 2007 7
Akış Modeli

18/10/11 GRID ÇALIŞTAYI 2007 8
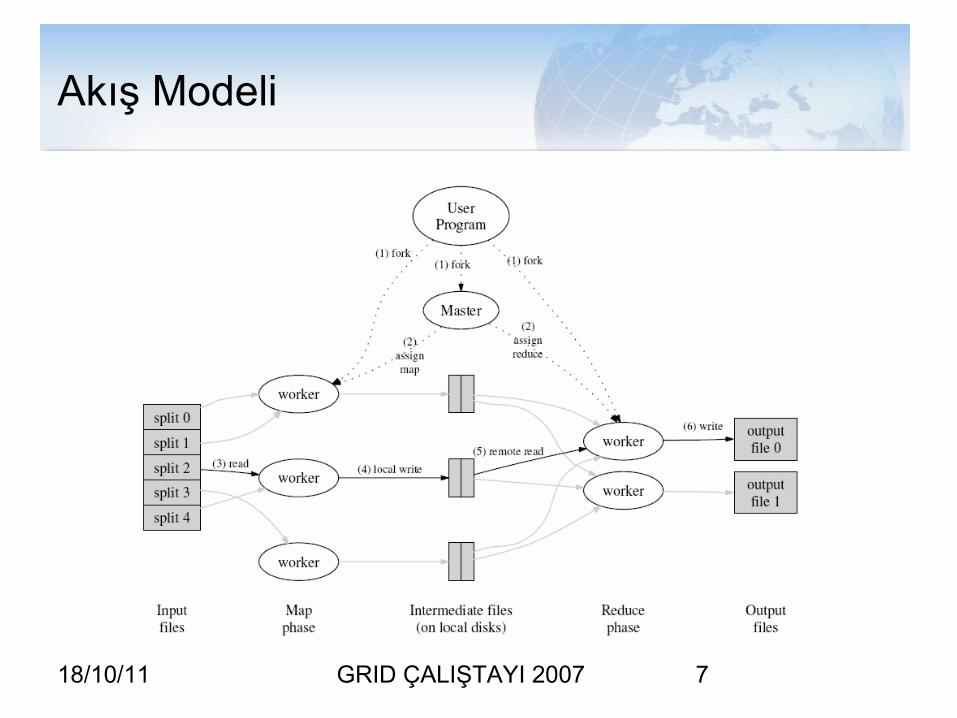
Akış Modeli
1. Input M parçaya ayrılır.2. Master M map taski ve R reduce taski workerlara atar.3. Map workeri atanmış parçayı parçalar,
<intermediate_key,value> yaratır ve hafızasında saklar.
4. Düzenli olarak bu key/value ikilileri, lokal diskte R alana bölünmüş bir yerde saklanır. Master bu alanlardan haberdar edilir.
5. Reduce workeri bu geçici alanlardaki veriyi alır, sıralar.

18/10/11 GRID ÇALIŞTAYI 2007 9
Akış Modeli
6. Reduce workeri bu data üzerinde hareket ederek ara keyler üzerindeki valueleri gruplar ve Reduce fonksiyonunu çağırır. Sonuç sisteme yazılır.
7. Bütün map ve reduce işlemleri bitince master clienta bilgi verir.

18/10/11 GRID ÇALIŞTAYI 2007 10
Hataya Duyarlılık
• Durum Bilgileri:– Idle, In-progress, Completed.
• Worker Hatası– Heartbeat– Map Worker Hatası– Reduce Worker Hatası
• Master Hatası– Single Master Problemi
• Network Hataları
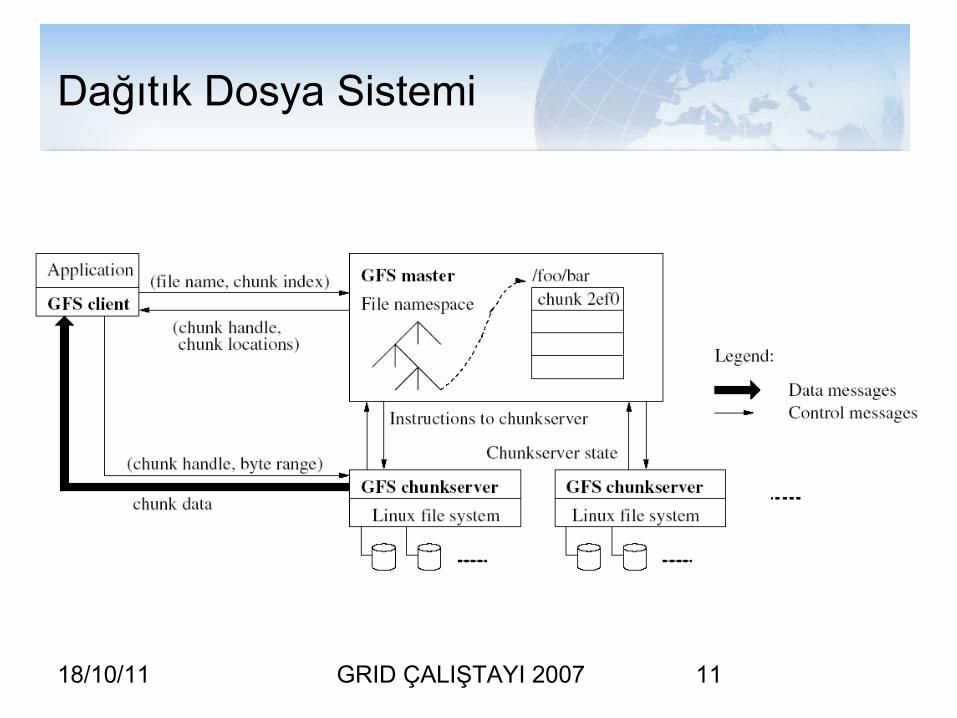
18/10/11 GRID ÇALIŞTAYI 2007 11
Dağıtık Dosya Sistemi

18/10/11 GRID ÇALIŞTAYI 2007 12
Performans
• Lokal dataya ulaşım– DFS üzerinde lokal data nodelarına iş atama
• Hatalı input problemleri
• Ara çıktıların sıkıştırılması
• Deterministic iş parçacıkları
• Backup workerlar

18/10/11 GRID ÇALIŞTAYI 2007 13
MapReduce
• Client-Server Model & RPC
• Üst seviyede soyutlama– Yük Dağıtımı
– Yerel Optimizasyon
– Paralelleştirme
– Hataya Tolerans
• Yeni bir programlama modeli
• Büyük verileri işleme kolaylığı
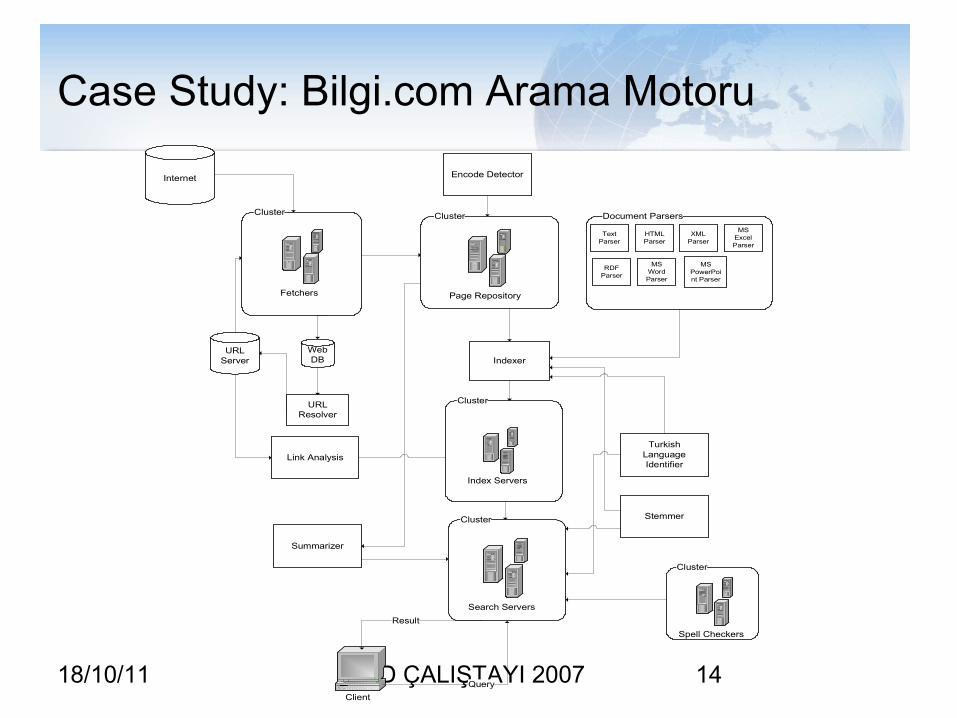
18/10/11 GRID ÇALIŞTAYI 2007 14
Case Study: Bilgi.com Arama Motoru
Cluster
Fetchers
URL Server
Document Parsers
Text Parser
HTML Parser
XML Parser
RDF Parser
MS Word Parser
MS PowerPoint Parser
MS Excel Parser
Internet
Web DB
URL Resolver
Cluster
Page Repository
Indexer
Link Analysis
Cluster
Index Servers
Stemmer
Turkish Language Identifier
Encode Detector
Cluster
Search Servers
Cluster
Spell Checkers
Summarizer
Client
Query
Result

18/10/11 GRID ÇALIŞTAYI 2007 15
Teknoloji Alanları
• Information Retrieval
• Web Mining
• Machine Learning
• Natural Language Processing
• High Speed Parallel Computing
• Distributed File Systems
• Linux Clustering

18/10/11 GRID ÇALIŞTAYI 2007 16
Bilgisayar Kümesi

18/10/11 GRID ÇALIŞTAYI 2007 17
Altyapısı
• Ölçeklenebilir.• Sistem Özellikleri:
– 120 çift çekirdek işlemcili ve 4GB RAM– 200 TeraByte disk alanı– Gigabit network altyapısı– MapReduce– Dağıtık Dosya Sistemi– Linux Cluster– Tamamı geliştirilmiş veya açık kaynak kodlar
kullanılmıştır– Geliştirilmeye devam edilmektedir
18/10/11 GRID ÇALIŞTAYI 2007 18
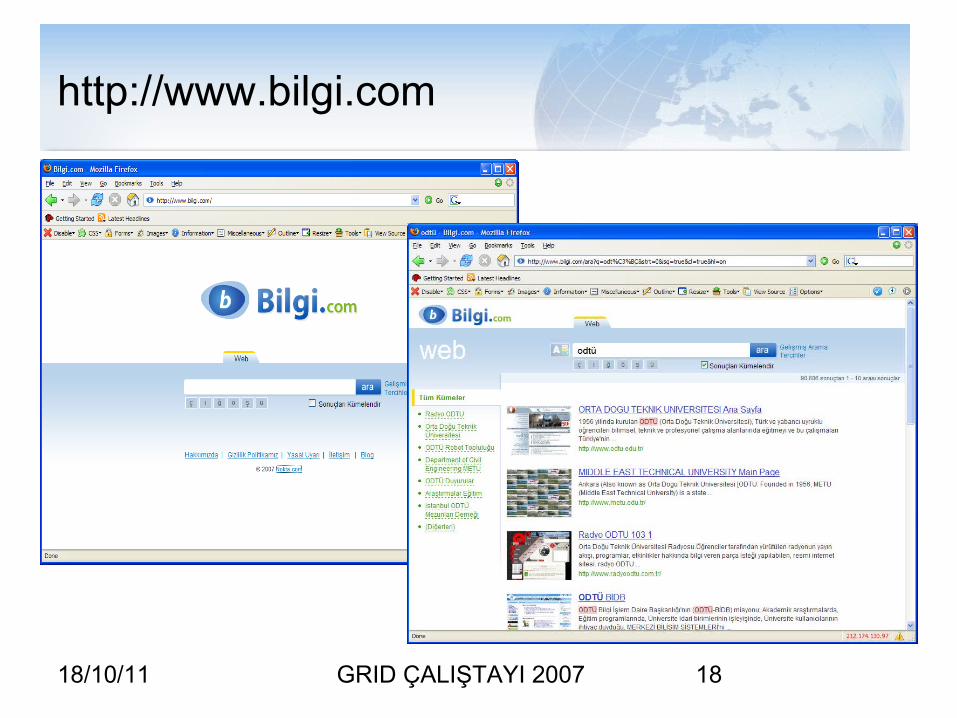
http://www.bilgi.com

18/10/11 GRID ÇALIŞTAYI 2007 19
Bilgi.com Özellikleri
• Türkçe NLP Uygulamaları
– Türkçe Dil Belirleme
– Sözcük Kökü Belirleme
– Named Entity Belirleme
– Tamlamalar ve Sık Kullanılan Kalıplar
– Sözcük Denetimi

18/10/11 GRID ÇALIŞTAYI 2007 20
Bilgi.com Özellikleri
• Sonuç Kümelendirme(Clustering)
• Sayfa Sınıflandırma
• Benzer Aramalar
• Site Resimleri (Thumbnail)
• Spam Belirleme

18/10/11 GRID ÇALIŞTAYI 2007 21
GRID Entegrasyonu ve Uygulamaları
• EU 7. Çerçeve Çağrıları: Dijital Kütüphaneler ve Info Grid
• ULAKBIM Dijital Kütüphane Uygulaması– ULAKBIM Grid altyapısına entegrasyon– Dijital akademik kaynakların arama servisine taşınması– Bu kaynaklar üzerinde gelişmiş kullanıcı odaklı
özelliklerin eklenmesi– Gerçek bir dijital kütüphane uygulaması altyapısının
oluşturulması– Uygulamanın genişletilmesi
18/10/11 GRID ÇALIŞTAYI 2007 22
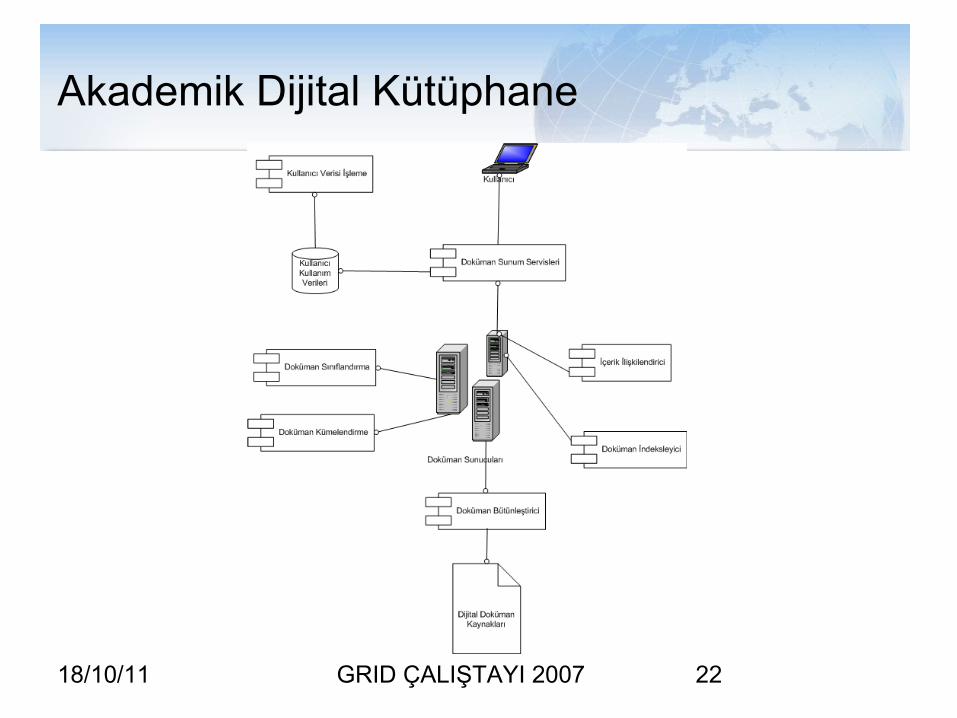
Akademik Dijital Kütüphane

18/10/11 GRID ÇALIŞTAYI 2007 23
TEŞEKKÜRLER...