budapest big data meetup nov 26 2015
TRANSCRIPT

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
After Dark 1.5 Budapest Big Data Meetup
Chris Fregly Principal Data Solutions Engineer
We’re Hiring - Only Nice People!
Nov 26th, 2015

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Who Am I?
2
Streaming Data Engineer Open Source Committer
Data Solutions Engineer
Apache Contributor
Principal Data Solutions Engineer IBM Technology Center
Founder Advanced Apache Meetup
Author Advanced .
Due 2016
My Ma’s First Time in California

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Random Slide: More Ma “First Time” Pics
3
In California Using Chopsticks Using “New” iPhone

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Advanced Apache Spark Meetup Meetup Metrics 1600+ Members in just 4 mos! Top 5 Most Active Spark Meetup!! Meetup Goals Dig deep into codebase of Spark and related projects Study integrations of Cassandra, ElasticSearch,
Tachyon, S3, BlinkDB, Mesos, YARN, Kafka, R Surface and share patterns and idioms of these
well-designed, distributed, big data components

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
All Slides and Code Are Available!
advancedspark.com slideshare.net/cfregly
github.com/fluxcapacitor hub.docker.com/r/fluxcapacitor
5
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
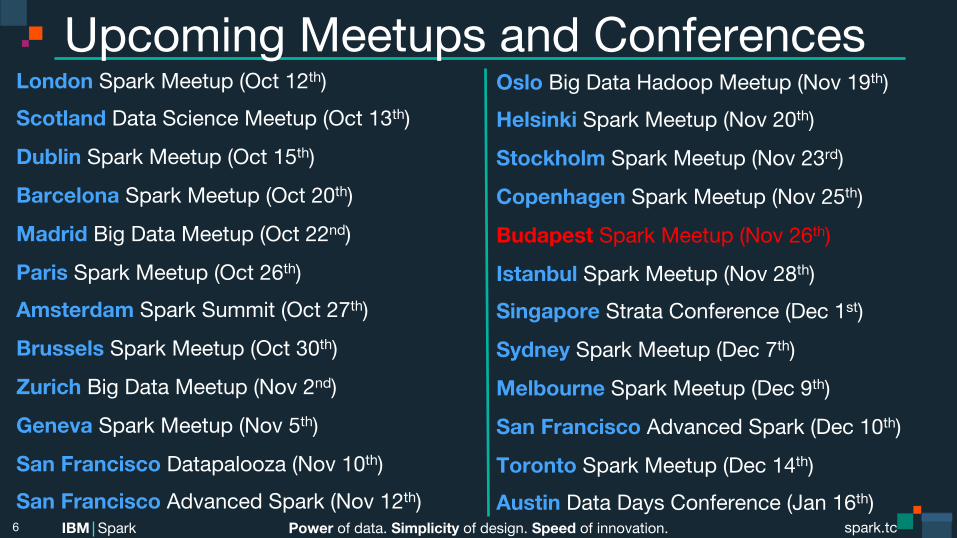
Upcoming Meetups and Conferences London Spark Meetup (Oct 12th) Scotland Data Science Meetup (Oct 13th)
Dublin Spark Meetup (Oct 15th)
Barcelona Spark Meetup (Oct 20th)
Madrid Big Data Meetup (Oct 22nd)
Paris Spark Meetup (Oct 26th) Amsterdam Spark Summit (Oct 27th)
Brussels Spark Meetup (Oct 30th)
Zurich Big Data Meetup (Nov 2nd)
Geneva Spark Meetup (Nov 5th)
San Francisco Datapalooza (Nov 10th) San Francisco Advanced Spark (Nov 12th)
6
Oslo Big Data Hadoop Meetup (Nov 19th) Helsinki Spark Meetup (Nov 20th)
Stockholm Spark Meetup (Nov 23rd)
Copenhagen Spark Meetup (Nov 25th)
Budapest Spark Meetup (Nov 26th)
Istanbul Spark Meetup (Nov 28th) Singapore Strata Conference (Dec 1st)
Sydney Spark Meetup (Dec 7th)
Melbourne Spark Meetup (Dec 9th)
San Francisco Advanced Spark (Dec 10th)
Toronto Spark Meetup (Dec 14th) Austin Data Days Conference (Jan 16th)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
What is “ After Dark”? Spark-based, Advanced Analytics Reference App End-to-End, Scalable, Real-time Big Data Pipeline Demo Spark and Related Open Source Projects
7
github.com/fluxcapacitor

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Tools of This Talk
8
Kafka Redis Docker Ganglia Cassandra Parquet, JSON, ORC, Avro Apache Zeppelin Notebooks Spark SQL, DataFrames, Hive ElasticSearch, Logstash, Kibana Spark ML, GraphX, Stanford CoreNLP
…
github.com/fluxcapacitor hub.docker.com/r/fluxcapacitor

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Themes of this Talk Filter Off-Heap Parallelize Approximate Find Similarity Minimize Seeks Maximize Scans Customize Data Structs Tune Performance At Every Layer
9
Be Nice, Collaborate! Like my Ma!!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Live, Interactive Demo! sparkafterdark.com
10

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Audience Participation Needed!!
11
You -> Audience Instructions Go to sparkafterdark.com Click 3 actresses and 3 actors
Wait for us to analyze together!
Links To Do This Yourself! github.com/fluxcapacitor hub.docker.com/r/fluxcapacitor
Data -> Scientist
EU Safe Harbor DisclaimerThis is Totally Anonymous!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline
Spark Core: Tuning & Mechanical Sympathy
Spark SQL: Query Optimizing & Catalyst
12

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Spark Core: Tuning & Mechanical Sympathy Understand and Acknowledge Mechanical Sympathy
Study AlphaSort and 100TB GraySort Challenge
Dive Deep into Project Tungsten
13

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Mechanical Sympathy Hardware and software working together in harmony. - Martin Thompson http://mechanical-sympathy.blogspot.com
Whatever your data structure, my array will beat it. - Scott Meyers Every C++ Book, basically
14
Hair Sympathy
- Bruce Jenner

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spark and Mechanical Sympathy
15
Project Tungsten (Spark 1.4-1.6+)
GraySort Challenge (Spark 1.1-1.2)
Minimize Memory and GC Maximize CPU Cache Locality
Saturate Network I/O Saturate Disk I/O

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
AlphaSort Technique: Sort 100 Bytes Recs
16
Value
Ptr Key Dereference Not Required! AlphaSort
List [(Key, Pointer)] Key is directly available for comparison
Naïve List [Pointer] Must dereference key for comparison
Ptr Dereference for Key Comparison
Key
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
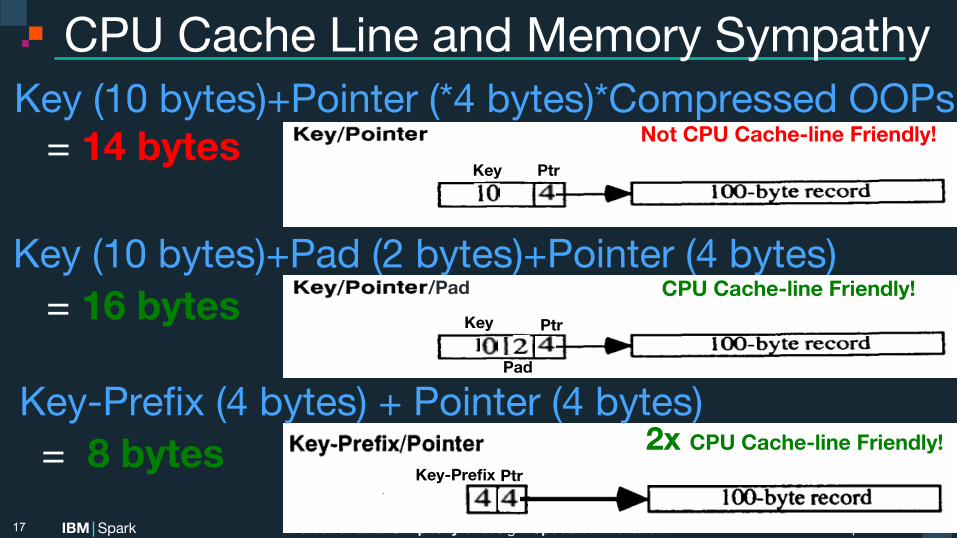
CPU Cache Line and Memory Sympathy Key (10 bytes)+Pointer (*4 bytes)*Compressed OOPs = 14 bytes
17
Key Ptr
Not CPU Cache-line Friendly!
Ptr Key-Prefix
2x CPU Cache-line Friendly! Key-Prefix (4 bytes) + Pointer (4 bytes) = 8 bytes
Key (10 bytes)+Pad (2 bytes)+Pointer (4 bytes) = 16 bytes Key Ptr
Pad
/Pad CPU Cache-line Friendly!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Performance Comparison
18
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
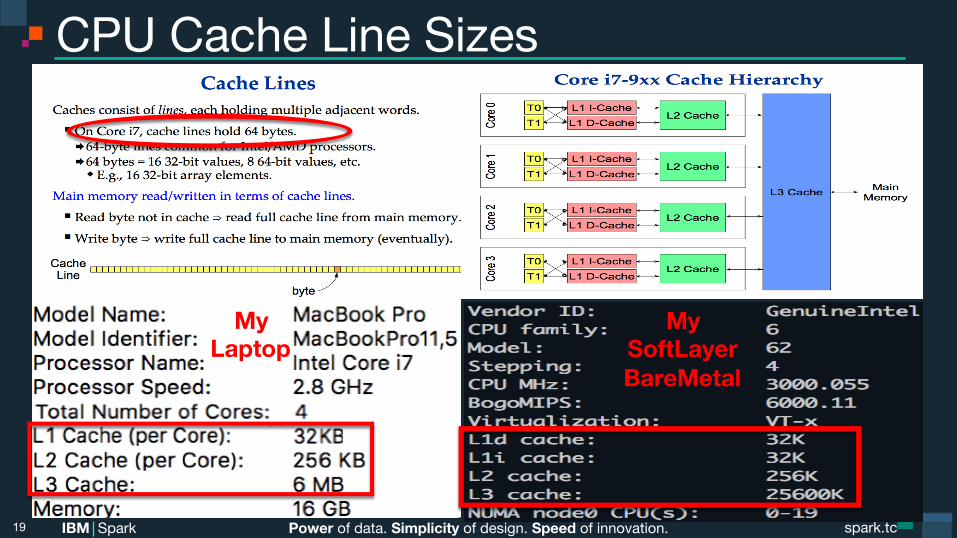
CPU Cache Line Sizes
19
MyLaptop
MySoftLayerBareMetal
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
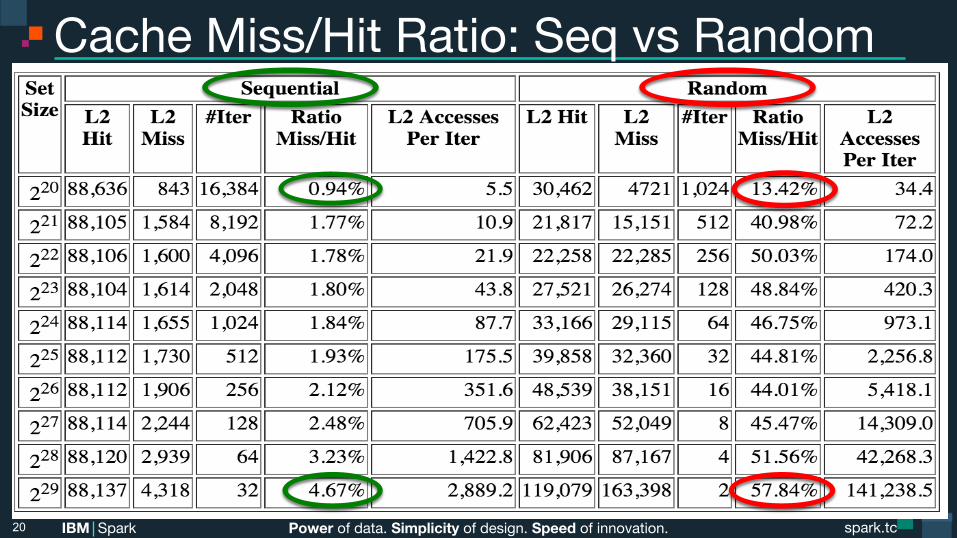
Cache Miss/Hit Ratio: Seq vs Random
20

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Mechanical Sympathy Improving Performance with CPU Cache Line Affinity
Matrix Multiplication
21

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
CPU Cache Naïve Matrix Multiplication
// Dot product of each row & column vector for (i <- 0 until numRowA) for (j <- 0 until numColsB) for (k <- 0 until numColsA) res[ i ][ j ] += matA[ i ][ k ] * matB[ k ][ j ];
22
Bad: Row-wise traversal, not using CPU cache line,
ineffective pre-fetching

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
CPU Cache Friendly Matrix Multiplication // Transpose B for (i <- 0 until numRowsB) for (j <- 0 until numColsB) matBT[ i ][ j ] = matB[ j ][ i ];
// Modify dot product calculation for B Transpose for (i <- 0 until numRowsA) for (j <- 0 until numColsB) for (k <- 0 until numColsA) res[ i ][ j ] += matA[ i ][ k ] * matBT[ j ][ k ];
23
Good: Full CPU cache line, effective prefetching
OLD: res[ i ][ j ] += matA[ i ][ k ] * matB [ k ] [ j ];
Reference jbefore k

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Instrumenting and Monitoring CPU Use Linux perf command!
24
http://www.brendangregg.com/blog/2015-11-06/java-mixed-mode-flame-graphs.html

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! CPU Cache Line Affinity & Matrix Multiplication
25

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Results of Matrix Multiplication
Cache-Friendly Matrix Multiply
26
Naive Matrix Multiply
perf stat –event \ L1-dcache-load-misses,L1-dcache-prefetch-misses,LLC-load-misses, \
LLC-prefetch-misses,cache-misses,stalled-cycles-frontend
4% 7% 7%
47%
L1-dcache-load-misses 7916379222 21448286305227.0935559
1
L1-dcache-prefetch-misses 4248568884 114878389282.70393142
8
LLC-load-misses 336612743 449261229613.3465306
6
LLC-prefetch-misses 4300544980 497580590.01157017
5cache-misses 320086472 4447068200 13.8933338
stalled-cycles-frontend 1575227969401 52463114772913.33050934
8
elapsed@me 1073 22982.14163124
6
% of Naive

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Mechanical Sympathy Improving Performance with Lock-Free Thread Synchronization
2-Counter Atomic Increment
27

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Naïve Case Class 2-Counter Increment case class Counters(left: Int, right: Int) object NaiveCaseClass2CounterIncrement { var counters = new Counters(0,0) … def increment(leftIncrement: Int, rightIncrement: Int) : MyTuple = { this.synchronized { counters = new Counters(counters.left + leftIncrement, counters.right + rightIncrement)
counters } } }
28

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Naïve Tuple 2-Counter Increment object NaiveTuple2CounterIncrement { var counters = (0,0) … def increment(leftIncrement: Int, rightIncrement: Int) : (Int, Int) = { this.synchronized { counters = (counters._1 + leftIncrement, counters._2 + rightIncrement)
counters } } }
29

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Lock-Free AtomicLong 2-Counter Incr object LockFreeAtomicLong2CounterIncrement { // a single Long (8-bytes) will maintain 2 separate Ints (4-bytes each) val counters = new AtomicLong() … def increment(leftIncrement: Int, rightIncrement: Int) : Long = { var originalCounters = 0L var updatedCounters = 0L do { originalCounters = counters.get()
… // Store two 32-bit Int into one 64-bit Long // Use >>> 32 and << 32 to set and retrieve each Int from the Long // Retry lock-free, optimistic compareAndSet() until AtomicLong update succeeds ...
} while (tuple.compareAndSet(originalCounters, updatedCounters) == false) updatedCounters } }
30
Q: Why not @volatile long? A: JVM Java Memory Modeldoes not guarantee atomicupdates of 64-bit long, double.
** Must use AtomicLong!! **

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! Lock-Free Thread Synchronization & 2-Counter Atomic Increment
31

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Results of Atomic 2-Counter Increment Naïve Case Class Counters
Naïve Tuple Counters
32
Cache Friendly, Lock-Free Counters
28%
50%
17%
65%
perf stat –event \ context-switches,L1-dcache-load-misses,L1-dcache-prefetch-misses, \
LLC-load-misses, LLC-prefetch-misses,cache-misses,stalled-cycles-frontend
% of Naïve

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Profiling Visualizations: Flame Graphs
33 Example: Spark Word Count
Java Stack Traces are Good! (-XX:-Inline -XX:+PreserveFramePointer)
Plateausare Bad!!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
100TB GraySort Challenge Sort 100TB of 100-Byte Records with 10-byte Keys
Custom Data Structs & Algos for Sort & Shuffle
Saturate Network and Disk I/O Controllers 34

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
100TB GraySort Challenge Results
35
Performance Goals Saturate Network I/O Saturate Disk I/O Maximize Throughput
(2013) (2014)
EC2 (i2.8xlarge)
(2014)
28,000 partitions!
250,000 partitions!!
EC2 (i2.8xlarge)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Winning Hardware Configuration Compute 206 Workers, 1 Master (AWS EC2 i2.8xlarge) 32 Intel Xeon CPU E5-2670 @ 2.5 Ghz 244 GB RAM, 8 x 800GB SSD, RAID 0 striping, ext4 3 GBps mixed read/write disk I/O per node
Network AWS Placement Groups, VPC, Enhanced Networking Single Root I/O Virtualization (SR-IOV) 10 Gbps, low latency, low jitter (iperf: ~9.5 Gbps)
36
Q: Why only 206? A: Network is saturated @ 206
Allowed andEncouraged

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Winning Software Configuration Spark 1.2, OpenJDK 1.7 Disable caching, compression, spec execution, shuffle spill Force NODE_LOCAL task scheduling for optimal data locality HDFS 2.4.1 short-circuit local reads, 2x replication Overprovision between 4-6 partitions per core 206 nodes * 32 cores = 6592 cores 6592 cores * 4 = 26,368 partitions 6592 cores * 6 = 39,552 partitions 6592 cores * 4.25 = 28,000 partitions (empirical best)
Range partitioning co-locates keys and minimize shuffle Required ~10s of sampling 79 keys from in each partition
37
GraySort Challenge
Requirement
1000 TB Sort used 250,000
partitions

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
New Sort Shuffle Manager for Spark 1.2 Original “hash-based” New “sort-based” ① Use less OS resources (socket buffers, file descriptors) ② TimSort partitions in-memory ③ MergeSort partitions on-disk into a single master file ④ Serve partitions from master file: seek once, sequential scan
38
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
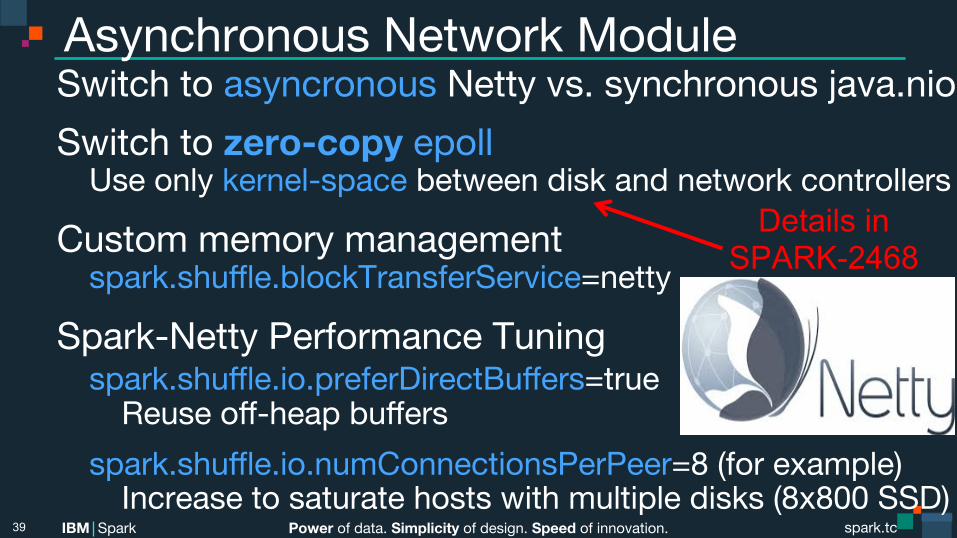
Asynchronous Network Module Switch to asyncronous Netty vs. synchronous java.nio Switch to zero-copy epoll Use only kernel-space between disk and network controllers
Custom memory management spark.shuffle.blockTransferService=netty
Spark-Netty Performance Tuning spark.shuffle.io.preferDirectBuffers=true Reuse off-heap buffers spark.shuffle.io.numConnectionsPerPeer=8 (for example) Increase to saturate hosts with multiple disks (8x800 SSD)
39
Details in SPARK-2468

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Custom Algorithms and Data Structures Optimized for sort & shuffle workloads o.a.s.util.collection.TimSort[K,V] Based on JDK 1.7 TimSort Performs best with partially-sorted runs Optimized for elements of (K,V) pairs Sorts impl of SortDataFormat (ie. KVArraySortDataFormat)
o.a.s.util.collection.AppendOnlyMap Open addressing hash, quadratic probing Array of [(K, V), (K, V)] Good memory locality No deletes, only append
40

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Daytona GraySort Challenge Goal Success
1.1 Gbps/node network I/O (Reducers) Theoretical max = 1.25 Gbps for 10 GB ethernet
3 GBps/node disk I/O (Mappers)
41
Aggregate Cluster
Network I/O!
220 Gbps / 206 nodes ~= 1.1 Gbps per node

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Shuffle Performance Tuning Tips Hash Shuffle Manager (Deprecated) spark.shuffle.consolidateFiles (Mapper) o.a.s.shuffle.FileShuffleBlockResolver
Intermediate Files Increase spark.shuffle.file.buffer (Reducer) Increase spark.reducer.maxSizeInFlight if memory allows
Use Smaller Number of Larger Executors Minimizes intermediate files and overall shuffle More opportunity for PROCESS_LOCAL
SQL: BroadcastHashJoin vs. ShuffledHashJoin spark.sql.autoBroadcastJoinThreshold Use DataFrame.explain(true) or EXPLAIN to verify
42
Many Threads (1 per CPU)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Project Tungsten Data Struts & Algos Operate Directly on Byte Arrays
Maximize CPU Cache Locality, Minimize GC
Utilize Dynamic Code Generation
43
SPARK-7076 (Spark 1.4)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Why is CPU the Bottleneck? CPU is used for serialization, hashing, compression GraySort optimizations improved network & shuffle Network and Disk I/O bandwidth are relatively high More partitioning, pruning, predicate pushdowns Better columnar formats reduce disk I/O bottleneck
44

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Yet Another Spark Shuffle Manager! spark.shuffle.manager = hash (Deprecated) < 10,000 reducers Output partition file hashes the key of (K,V) pair Mapper creates an output file per partition Leads to M*P output files for all partitions sort (GraySort Challenge) > 10,000 reducers Default from Spark 1.2-1.5 Mapper creates single output file for all partitions Minimizes OS resources, netty + epoll optimizes network I/O, disk I/O, and memory Uses custom data structures and algorithms for sort-shuffle workload Wins Daytona GraySort Challenge tungsten-sort (Project Tungsten) Default since 1.5 Modification of existing sort-based shuffle Uses com.misc.Unsafe for self-managed memory and garbage collection Maximize CPU utilization and cache locality with AlphaSort-inspired binary data structures/algorithms Perform joins, sorts, and other operators on both serialized and compressed byte buffers
45
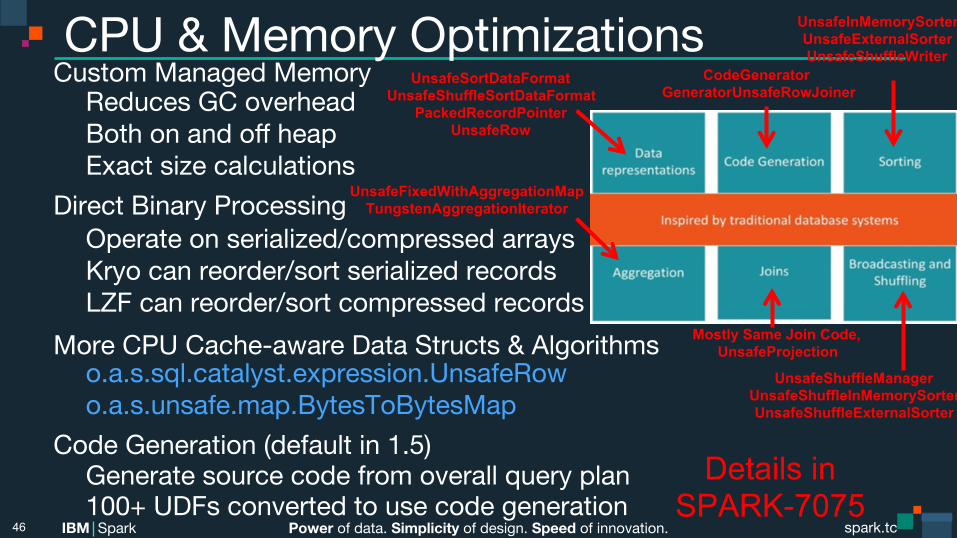
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
CPU & Memory Optimizations Custom Managed Memory Reduces GC overhead Both on and off heap Exact size calculations
Direct Binary Processing Operate on serialized/compressed arrays Kryo can reorder/sort serialized records LZF can reorder/sort compressed records
More CPU Cache-aware Data Structs & Algorithms o.a.s.sql.catalyst.expression.UnsafeRow o.a.s.unsafe.map.BytesToBytesMap
Code Generation (default in 1.5) Generate source code from overall query plan 100+ UDFs converted to use code generation
46
UnsafeFixedWithAggregationMap TungstenAggregationIterator
CodeGenerator GeneratorUnsafeRowJoiner
UnsafeSortDataFormat UnsafeShuffleSortDataFormat
PackedRecordPointer UnsafeRow
UnsafeInMemorySorter UnsafeExternalSorter UnsafeShuffleWriter
Mostly Same Join Code, UnsafeProjection
UnsafeShuffleManager UnsafeShuffleInMemorySorter UnsafeShuffleExternalSorter
Details in SPARK-7075

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
sun.misc.Unsafe
47
Info addressSize() pageSize()
Objects allocateInstance() objectFieldOffset()
Classes staticFieldOffset() defineClass() defineAnonymousClass() ensureClassInitialized()
Synchronization monitorEnter() tryMonitorEnter() monitorExit() compareAndSwapInt() putOrderedInt()
Arrays arrayBaseOffset() arrayIndexScale()
Memory allocateMemory() copyMemory() freeMemory() getAddress() – not guaranteed after GC getInt()/putInt() getBoolean()/putBoolean() getByte()/putByte() getShort()/putShort() getLong()/putLong() getFloat()/putFloat() getDouble()/putDouble() getObjectVolatile()/putObjectVolatile()
Used by Tungsten
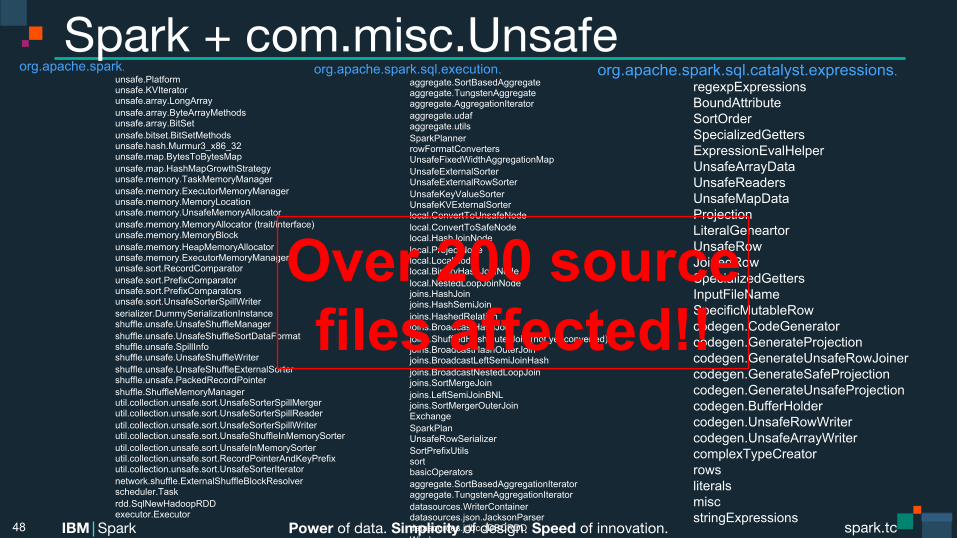
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spark + com.misc.Unsafe
48
org.apache.spark.sql.execution. aggregate.SortBasedAggregate aggregate.TungstenAggregate aggregate.AggregationIterator aggregate.udaf aggregate.utils SparkPlanner rowFormatConverters UnsafeFixedWidthAggregationMap UnsafeExternalSorter UnsafeExternalRowSorter UnsafeKeyValueSorter UnsafeKVExternalSorter local.ConvertToUnsafeNode local.ConvertToSafeNode local.HashJoinNode local.ProjectNode local.LocalNode local.BinaryHashJoinNode local.NestedLoopJoinNode joins.HashJoin joins.HashSemiJoin joins.HashedRelation joins.BroadcastHashJoin joins.ShuffledHashOuterJoin (not yet converted) joins.BroadcastHashOuterJoin joins.BroadcastLeftSemiJoinHash joins.BroadcastNestedLoopJoin joins.SortMergeJoin joins.LeftSemiJoinBNL joins.SortMergerOuterJoin Exchange SparkPlan UnsafeRowSerializer SortPrefixUtils sort basicOperators aggregate.SortBasedAggregationIterator aggregate.TungstenAggregationIterator datasources.WriterContainer datasources.json.JacksonParser datasources.jdbc.JDBCRDD Window
org.apache.spark. unsafe.Platform unsafe.KVIterator unsafe.array.LongArray unsafe.array.ByteArrayMethods unsafe.array.BitSet unsafe.bitset.BitSetMethods unsafe.hash.Murmur3_x86_32 unsafe.map.BytesToBytesMap unsafe.map.HashMapGrowthStrategy unsafe.memory.TaskMemoryManager unsafe.memory.ExecutorMemoryManager unsafe.memory.MemoryLocation unsafe.memory.UnsafeMemoryAllocator unsafe.memory.MemoryAllocator (trait/interface) unsafe.memory.MemoryBlock unsafe.memory.HeapMemoryAllocator unsafe.memory.ExecutorMemoryManager unsafe.sort.RecordComparator unsafe.sort.PrefixComparator unsafe.sort.PrefixComparators unsafe.sort.UnsafeSorterSpillWriter serializer.DummySerializationInstance shuffle.unsafe.UnsafeShuffleManager shuffle.unsafe.UnsafeShuffleSortDataFormat shuffle.unsafe.SpillInfo shuffle.unsafe.UnsafeShuffleWriter shuffle.unsafe.UnsafeShuffleExternalSorter shuffle.unsafe.PackedRecordPointer shuffle.ShuffleMemoryManager util.collection.unsafe.sort.UnsafeSorterSpillMerger util.collection.unsafe.sort.UnsafeSorterSpillReader util.collection.unsafe.sort.UnsafeSorterSpillWriter util.collection.unsafe.sort.UnsafeShuffleInMemorySorter util.collection.unsafe.sort.UnsafeInMemorySorter util.collection.unsafe.sort.RecordPointerAndKeyPrefix util.collection.unsafe.sort.UnsafeSorterIterator network.shuffle.ExternalShuffleBlockResolver scheduler.Task rdd.SqlNewHadoopRDD executor.Executor
org.apache.spark.sql.catalyst.expressions. regexpExpressions BoundAttribute SortOrder SpecializedGetters ExpressionEvalHelper UnsafeArrayData UnsafeReaders UnsafeMapData Projection LiteralGeneartor UnsafeRow JoinedRow SpecializedGetters InputFileName SpecificMutableRow codegen.CodeGenerator codegen.GenerateProjection codegen.GenerateUnsafeRowJoiner codegen.GenerateSafeProjection codegen.GenerateUnsafeProjection codegen.BufferHolder codegen.UnsafeRowWriter codegen.UnsafeArrayWriter complexTypeCreator rows literals misc stringExpressions
Over 200 source files affected!!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Traditional Java Object Row Layout 4-byte String
Multi-field Object
49

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Custom Data Structures for Workload UnsafeRow
(Dense Binary Row)
TaskMemoryManager (Virtual Memory Address)
BytesToBytesMap (Binary, Append-Only Map)
50
Dense, 8-bytes per field (word-aligned)
Key Ptr
AlphaSort-Style (Key + Pointer)
OS-Style Memory Paging
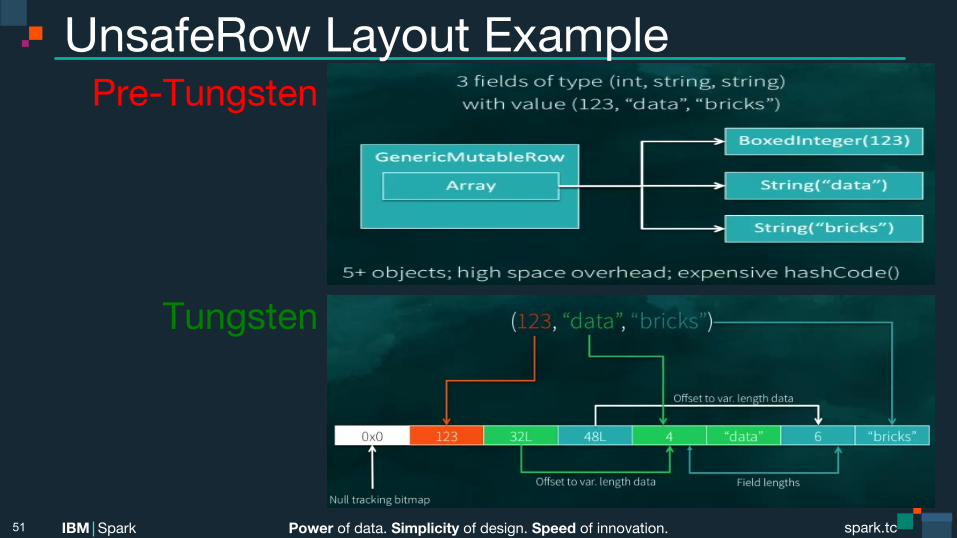
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
UnsafeRow Layout Example
51
Pre-Tungsten
Tungsten

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Custom Memory Management o.a.s.memory. TaskMemoryManager & MemoryConsumer Memory management: virtual memory allocation, pageing Off-heap: direct 64-bit address On-heap: 13-bit page num + 27-bit page offset
o.a.s.shuffle.sort. PackedRecordPointer 64-bit word (24-bit partition key, (13-bit page num, 27-bit page offset))
o.a.s.unsafe.types. UTF8String Primitive Array[Byte]
52
2^13 pages * 2^27 page size = 1 TB RAM per Task

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
UnsafeFixedWidthAggregationMap
Aggregations o.a.s.sql.execution. UnsafeFixedWidthAggregationMap Uses BytesToBytesMap In-place updates of serialized data No object creation on hot-path Improved external agg support No more OOM’s for large, single key aggs
o.a.s.sql.catalyst.expression.codegen. GenerateUnsafeRowJoiner Combine 2 UnsafeRows into 1
o.a.s.sql.execution.aggregate. TungstenAggregate & TungstenAggregationIterator Operates directly on serialized, binary UnsafeRow 2 Steps: hash-based agg (grouping), then sort-based agg Avoids OOMs with spill + external merge sort
53

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Equality Bitwise comparison on UnsafeRow No need to calculate equals(), hashCode() Row 1
Equals! Row 2
54

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Joins Surprisingly, not many code changes o.a.s.sql.catalyst.expressions. UnsafeProjection Converts InternalRow to UnsafeRow
55

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Sorting o.a.s.util.collection.unsafe.sort. UnsafeSortDataFormat UnsafeInMemorySorter UnsafeExternalSorter RecordPointerAndKeyPrefix UnsafeShuffleWriter
AlphaSort-Style Cache Friendly
56
Ptr Key-Prefix
2x CPU Cache-line Friendly!
Warning: Using multiple subclasses of SortDataFormat simultaneously will prevent JIT inlining. (Affects sort & shuffle performance.)
Supports merging compressed records (if compression CODEC supports it, ie. LZF)
Uses format compatible with BytesToBytesMap

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spilling More Efficient Spilling Exact data size is known vs. approximate No need to guess or traverse entire object tree Reduces amount of unnecessary spilling
External Merge of Compressed Records!! (If compression CODEC supports it - ie. LZF)
57
UnsafeFixedWidthAggregationMap.getPeakMemoryUsedBytes()
Exact Memory Byte Count

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Code Generation Problem Boxing creates excessive objects Expression tree evaluations are costly JVM can’t inline polymorphic impls Lack of polymorphism == poor code design
Solution Codegen by-passes virtual functions
Defer source code generation to each operator, UDF, UDAF Rewrite and optimize code for overall plan, 8-byte align, etc Uses Scala quasiquote macros for Scala AST source code gen Use Janino to compile generated code into bytecode
58

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc IBM | spark.tc
Spark SQL UDF Code Generation 100+ UDFs now generating code
More to come in Spark 1.6+
Details in SPARK-8159, SPARK-9571
Each UDF implements Expression.genCode() !

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Creating a Custom UDF with Codegen Study existing implementations https://github.com/apache/spark/pull/7214/files
Extend base trait o.a.s.sql.catalyst.expressions.Expression.genCode()
Register the function o.a.s.sql.catalyst.analysis.FunctionRegistry.registerFunction()
Augment DataFrame with new UDF (Scala implicits) o.a.s.sql.functions.scala
Don’t forget about Python! python.pyspark.sql.functions.py 60

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Who Benefits from Project Tungsten? Users of DataFrames All Spark SQL Queries Catalyst
All RDDs Serialization, Compression, and Aggregations
61
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
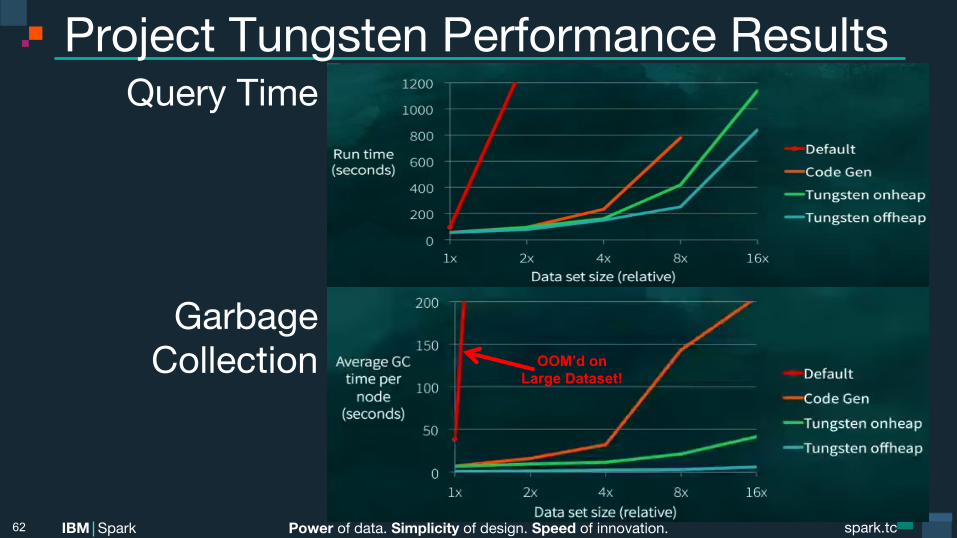
Project Tungsten Performance Results Query Time
Garbage Collection
62
OOM’d on Large Dataset!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Autoscaling Spark Workers (Spark 1.5+) spark-submit Job Submission --max-executors=4 Spark will add Executor JVMs until max is reached
SparkContext API addExecutors() & removeExecutors()
Scaling up is easy J Scaling down is tricky L Lose RDD cache inside Executor JVM Must rebuild RDD partitions in another Executor JVM
Separate External Shuffle Service (Spark 1.2) Enables Executor JVM autoscaling When Executor JVM dies, External Shuffle Service keeps shufflin’ 63

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline
Spark Core: Tuning & Mechanical Sympathy
Spark SQL: Query Optimizing & Catalyst
64

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Spark SQL: Query Optimizing & Catalyst Explore DataFrames/Datasets/DataSources, Catalyst
Review Partitions, Pruning, Pushdowns, File Formats
Create a Custom DataSource API Implementation
65

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
DataFrames Inspired by R and Pandas DataFrames Schema-aware
Cross language support SQL, Python, Scala, Java, R Equal performance between all languages
DataFrame is container for logical plan Lazy transformations represented as tree Only logical plan is sent from Python -> JVM Only results returned from JVM -> Python
Supports existing Hive metastore Small, file-based Hive metastore created by default
DataFrame.rdd returns underlying RDD if needed
66
Use DataFrames instead of RDDs!!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Custom UDF and UDAF Support Study existing implementations https://github.com/apache/spark/pull/7214/files
Extend base trait o.a.s.sql.catalyst.expressions.Expression.genCode()
Register the function o.a.s.sql.catalyst.analysis.FunctionRegistry.registerFunc()
Augment DataFrame with new UDF (Scala implicits) o.a.s.sql.functions.scala
Don’t forget about Python! python.pyspark.sql.functions.py
67

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spark and Hive Shark: “Hive on Spark” Spork: “Pig on Spark” Catalyst Optimizer replaces Hive Optimizer Always use HiveContext No Hive? No problem. Spark SQL creates small, file-based Hive metastore
Spark 1.5+ supports all Hive versions 0.12+ Separate classloaders for internal vs user Hive spark.sql.hive.metastore.version=1.2.1 spark.sql.hive.metastore.jars=[builtin|maven]
68
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
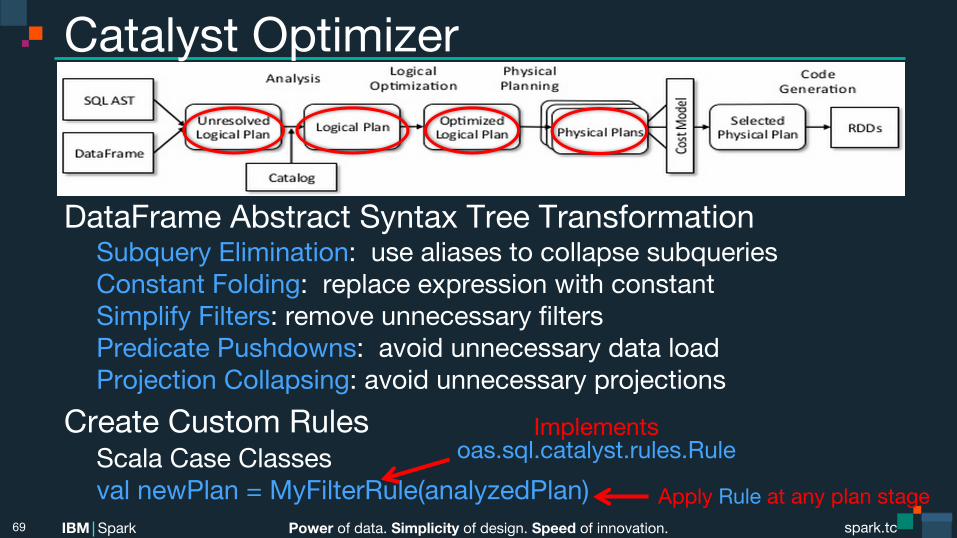
Catalyst Optimizer DataFrame Abstract Syntax Tree Transformation Subquery Elimination: use aliases to collapse subqueries
Constant Folding: replace expression with constant Simplify Filters: remove unnecessary filters Predicate Pushdowns: avoid unnecessary data load Projection Collapsing: avoid unnecessary projections Create Custom Rules Scala Case Classes val newPlan = MyFilterRule(analyzedPlan) 69
Implements oas.sql.catalyst.rules.Rule
Apply Rule at any plan stage

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Parquet Columnar File Format Based on Google Dremel
Collaboration with Twitter and Cloudera
Self-describing, evolving schema
Fast columnar aggregation
Supports filter pushdowns
Columnar storage format
Excellent compression
70
Min/Max Heuristics For Chunk Skipping

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Types of Compression Run Length Encoding: Repeated data Dictionary Encoding: Fixed set of values
Delta, Prefix Encoding: Sorted data
71

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! Demonstrate File Formats, Partition Schemes, and Query Plans
72

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Partitions Partition Data Access Patterns /genders.parquet/gender=M/… /gender=F/… <-- Use case: access users by gender /gender=U/…
Partition Discovery On read, infer partitions from organization of data (ie. gender=F)
Dynamic Partitions Upon insert, dynamically create partitions Specify column to for each partition (ie. Gender)
SQL: INSERT TABLE genders PARTITION (gender) SELECT … DF: gendersDF.write.format(”parquet").partitionBy(”gender”).save(…)
73

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Pruning Partition Pruning Filter out rows by partition
SELECT id, gender FROM genders where gender = ‘U’ Column Pruning Filter out columns by column filter Extremely useful for columnar storage formats (Parquet, ORC) Skip entire blocks of columns
SELECT id, gender FROM genders
74

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Pushdowns Predicate Pushdowns aka. Filter Pushdowns
Predicate returns [true|false] for given function Filter rows deep into the data source Reduce amount of data returned
Data Source must implement PrunedFilteredScan
def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row]
75

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
DataSources API Relations (o.a.s.sql.sources.interfaces.scala)
BaseRelation (abstract class): Provides schema of data TableScan (impl): Read all data from source PrunedFilteredScan (impl): Column pruning & predicate pushdowns InsertableRelation (impl): Insert/overwrite data based on SaveMode RelationProvider (trait/interface): Handle options, BaseRelation factory
Execution (o.a.s.sql.execution.commands.scala) RunnableCommand (trait/interface): Common commands like EXPLAIN ExplainCommand(impl: case class) CacheTableCommand(impl: case class)
Filters (o.a.s.sql.sources.filters.scala) Filter (abstract class): Handles all predicates/filters supported by this source EqualTo (impl) GreaterThan (impl) StringStartsWith (impl)
76

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Native Spark SQL DataSources
77

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Cartesian vs. Inner Join
78

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Broadcast vs. Normal Shuffle
79

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Partitioned and Unpartitioned Join
80

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Both Partitioned Join
81

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Visualizing the Query Plan
82
Effectiveness of Filter
CPU Cache Friendly
Binary Format Cost-based Join Optimization
Similar to MapReduce
Map-side Join
Peak Memory for Joins and Aggs

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
JSON Data Source DataFrame val ratingsDF = sqlContext.read.format("json")
.load("file:/root/pipeline/datasets/dating/ratings.json.bz2") -- or – val ratingsDF = sqlContext.read.json ("file:/root/pipeline/datasets/dating/ratings.json.bz2")
SQL Code CREATE TABLE genders USING json OPTIONS (path "file:/root/pipeline/datasets/dating/genders.json.bz2") 83
json() convenience method

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
JDBC Data Source Add Driver to Spark JVM System Classpath $ export SPARK_CLASSPATH=<jdbc-driver.jar>
DataFrame val jdbcConfig = Map("driver" -> "org.postgresql.Driver", "url" -> "jdbc:postgresql:hostname:port/database", "dbtable" -> ”schema.tablename") df.read.format("jdbc").options(jdbcConfig).load()
SQL CREATE TABLE genders USING jdbc OPTIONS (url, dbtable, driver, …)
84

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Parquet Data Source Configuration
spark.sql.parquet.filterPushdown=true spark.sql.parquet.mergeSchema=false (unless your schema is evolving) spark.sql.parquet.cacheMetadata=true (requires sqlContext.refreshTable()) spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo]
DataFrames val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet") gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet")
SQL CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")
85

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
ORC Data Source Configuration spark.sql.orc.filterPushdown=true
DataFrames val gendersDF = sqlContext.read.format("orc") .load("file:/root/pipeline/datasets/dating/genders") gendersDF.write.format("orc").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders")
SQL CREATE TABLE genders USING orc OPTIONS (path "file:/root/pipeline/datasets/dating/genders")
86
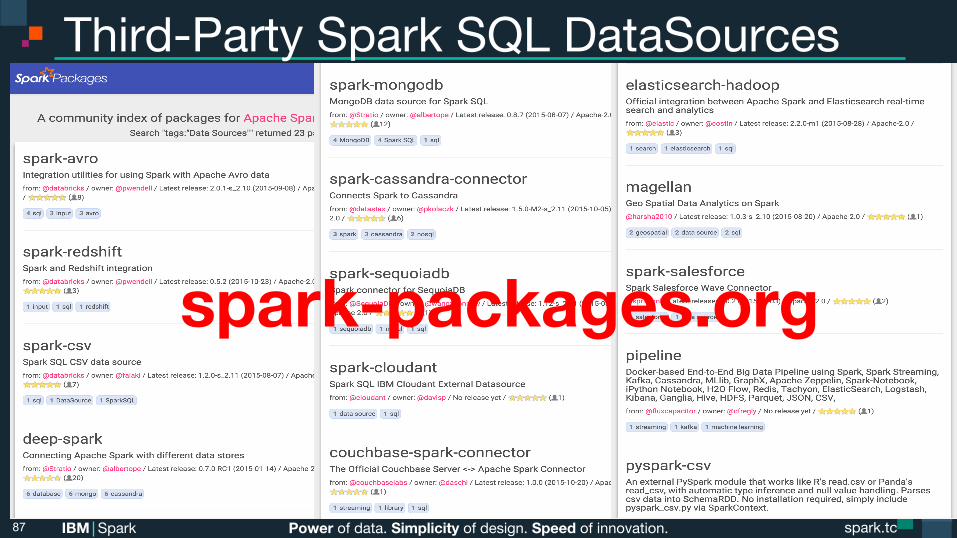
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Third-Party Spark SQL DataSources
87
spark-packages.org

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
CSV DataSource (Databricks) Github https://github.com/databricks/spark-csv
Maven com.databricks:spark-csv_2.10:1.2.0
Code val gendersCsvDF = sqlContext.read .format("com.databricks.spark.csv") .load("file:/root/pipeline/datasets/dating/gender.csv.bz2") .toDF("id", "gender")
88
toDF() is required if CSV does not contain header

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
ElasticSearch DataSource (Elastic.co) Github https://github.com/elastic/elasticsearch-hadoop
Maven org.elasticsearch:elasticsearch-spark_2.10:2.1.0
Code
val esConfig = Map("pushdown" -> "true", "es.nodes" -> "<hostname>", "es.port" -> "<port>") df.write.format("org.elasticsearch.spark.sql”).mode(SaveMode.Overwrite) .options(esConfig).save("<index>/<document-type>")
89

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Elasticsearch Tips Change id field to not_analyzed to avoid indexing
Use term filter to build and cache the query
Perform multiple aggregations in a single request
Adapt scoring function to current trends at query time
90

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
AWS Redshift Data Source (Databricks) Github https://github.com/databricks/spark-redshift
Maven com.databricks:spark-redshift:0.5.0
Code val df: DataFrame = sqlContext.read
.format("com.databricks.spark.redshift") .option("url", "jdbc:redshift://<hostname>:<port>/<database>…") .option("query", "select x, count(*) my_table group by x") .option("tempdir", "s3n://tmpdir") .load(...)
91
UNLOAD and copy to tmp bucket in S3 enables
parallel reads

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
DB2 and BigSQL DataSources (IBM) Coming Soon!
92

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Cassandra DataSource (DataStax) Github https://github.com/datastax/spark-cassandra-connector
Maven com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M1
Code
ratingsDF.write .format("org.apache.spark.sql.cassandra") .mode(SaveMode.Append) .options(Map("keyspace"->"<keyspace>", "table"->"<table>")).save(…)
93
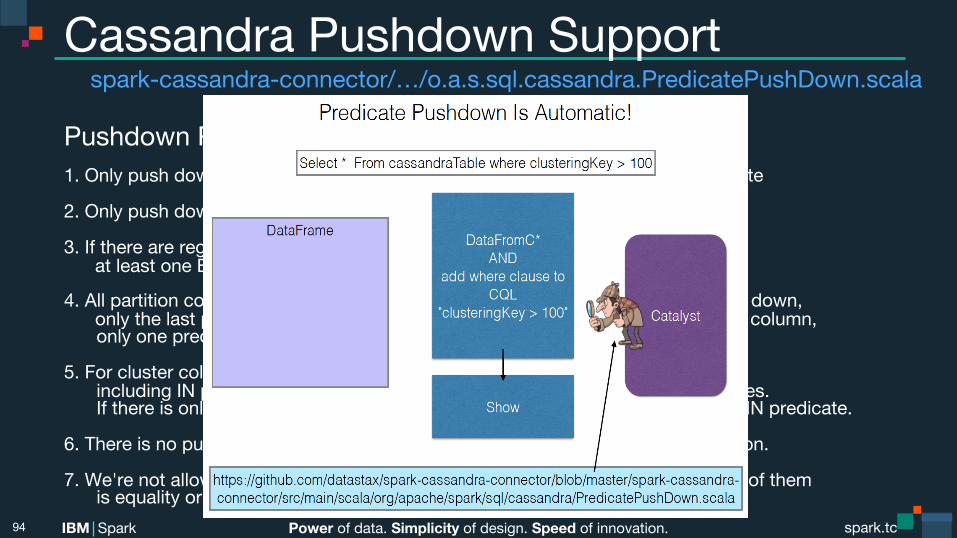
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Cassandra Pushdown Support spark-cassandra-connector/…/o.a.s.sql.cassandra.PredicatePushDown.scala
Pushdown Predicate Rules 1. Only push down no-partition key column predicates with =, >, <, >=, <= predicate 2. Only push down primary key column predicates with = or IN predicate. 3. If there are regular columns in the pushdown predicates, they should have at least one EQ expression on an indexed column and no IN predicates. 4. All partition column predicates must be included in the predicates to be pushed down, only the last part of the partition key can be an IN predicate. For each partition column,
only one predicate is allowed. 5. For cluster column predicates, only last predicate can be non-EQ predicate
including IN predicate, and preceding column predicates must be EQ predicates. If there is only one cluster column predicate, the predicates could be any non-IN predicate.
6. There is no pushdown predicates if there is any OR condition or NOT IN condition. 7. We're not allowed to push down multiple predicates for the same column if any of them
is equality or IN predicate.
94

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
New Cassandra DataSource (?) By-pass CQL optimized for transactional data Instead, do bulk reads/writes directly on SSTables Similar to 5 year old Netflix Open Source project Aegisthus
Promotes Cassandra to first-class Analytics Option Potentially only part of DataStax Enterprise?! Please mail a nasty letter to your local DataStax office
95

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Rumor of REST DataSource (Databricks) Coming Soon?
Ask Michael Armbrust Spark SQL Lead @ Databricks
96

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Custom DataSource (Me and You!) Coming Right Now!
97
DEMO ALERT!!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Create a Custom DataSource Study Existing Native & Third-Party Data Sources Native Spark JDBC (o.a.s.sql.execution.datasources.jdbc) class JDBCRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation
Third-Party DataStax Cassandra (o.a.s.sql.cassandra) class CassandraSourceRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation!
98

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! Create a Custom DataSource
99

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Contribute a Custom Data Source spark-packages.org Managed by Contains links to external github projects Ratings and comments Declare supported Spark version per package Kind of like a package manager Custom Maven Repo ---->
Examples https://github.com/databricks/spark-csv https://github.com/datastax/spark-cassandra-connector
100

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Hive JDBC ODBC ThriftServer Allow BI Tools to Query and Process Spark Data Register Permanent Table CREATE TABLE ratings(fromuserid INT, touserid INT, rating INT) USING org.apache.spark.sql.json OPTIONS (path "datasets/dating/ratings.json.bz2")
Register Temp Table ratingsDF.registerTempTable("ratings_temp")
Configuration spark.sql.thriftServer.incrementalCollect=true spark.driver.maxResultSize > 10gb (default)
Configuration Multi-session mode is default Separate SQL configuration & temporary function registry Cached tables shared across session optionspark.sql.hive.thriftServer.singleSession=true
101

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demo! Query and Process Spark Data from Beeline and/or Tableau
102

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Thank You!!! Chris Fregly IBM Spark Technology Center San Francisco, California (Find me on LinkedIn, Twitter, Github) Relevant Links advancedspark.com Signup for the book & global meetup! github.com/fluxcapacitor/pipeline Clone, contribute, and commit code! hub.docker.com/r/fluxcapacitor/pipeline/wiki Run all demos in your own environment with Docker! 103

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
More Relevant Links http://meetup.com/Advanced-Apache-Spark-Meetup http://advancedspark.com http://github.com/fluxcapacitor/pipeline http://hub.docker.com/r/fluxcapacitor/pipeline http://sortbenchmark.org/ApacheSpark2014.pd https://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html http://0x0fff.com/spark-architecture-shuffle/ http://www.cs.berkeley.edu/~kubitron/courses/cs262a-F13/projects/reports/project16_report.pdf http://stackoverflow.com/questions/763262/how-does-one-write-code-that-best-utilizes-the-cpu-cache-to-improve-performance http://www.aristeia.com/TalkNotes/ACCU2011_CPUCaches.pdf http://mishadoff.com/blog/java-magic-part-4-sun-dot-misc-dot-unsafe/ http://docs.scala-lang.org/overviews/quasiquotes/intro.html http://lwn.net/Articles/252125/ (Memory Part 2: CPU Caches) http://lwn.net/Articles/255364/ (Memory Part 5: What Programmers Can Do) https://www.safaribooksonline.com/library/view/java-performance-the/9781449363512/ch04.html http://web.eece.maine.edu/~vweaver/projects/perf_events/perf_event_open.html http://www.brendangregg.com/perf.html https://perf.wiki.kernel.org/index.php/Tutorial http://techblog.netflix.com/2015/07/java-in-flames.html http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html#Java http://sortbenchmark.org/ApacheSpark2014.pdf https://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html http://0x0fff.com/spark-architecture-shuffle/ http://www.cs.berkeley.edu/~kubitron/courses/cs262a-F13/projects/reports/project16_report.pdf http://stackoverflow.com/questions/763262/how-does-one-write-code-that-best-utilizes-the-cpu-cache-to-improve-performance http://www.aristeia.com/TalkNotes/ACCU2011_CPUCaches.pdf http://mishadoff.com/blog/java-magic-part-4-sun-dot-misc-dot-unsafe/ http://docs.scala-lang.org/overviews/quasiquotes/intro.html 104
http://lwn.net/Articles/252125/ <-- Memory Part 2: CPU Caches http://lwn.net/Articles/255364/ <-- Memory Part 5: What Programmers Can Do http://antirez.com/news/75 http://esumitra.github.io/algebird-boston-spark/#/ https://github.com/fluxcapacitor/pipeline http://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf http://blog.echen.me/2011/10/24/winning-the-netflix-prize-a-summary/ http://spark.apache.org/docs/latest/ml-guide.html http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.html (part 1) http://techblog.netflix.com/2012/06/netflix-recommendations-beyond-5-stars.html (part 2) http://www.brendangregg.com/blog/2015-11-06/java-mixed-mode-flame-graphs.html

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
What’s Next?
105
After Dark 1.6

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Incorporate New Features of Spark 1.6
https://docs.cloud.databricks.com/docs/spark/1.6/
106

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
What’s Next? Autoscaling Docker/Spark Workers Completely Docker-based Docker Compose, Google Kubernetes
Lots of Demos and Examples More Zeppelin & IPython/Jupyter notebooks More advanced analytics use cases
Performance Tuning and Profiling Work closely with Netflix & Databricks Identify & fix Spark performance bottlenecks
107
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
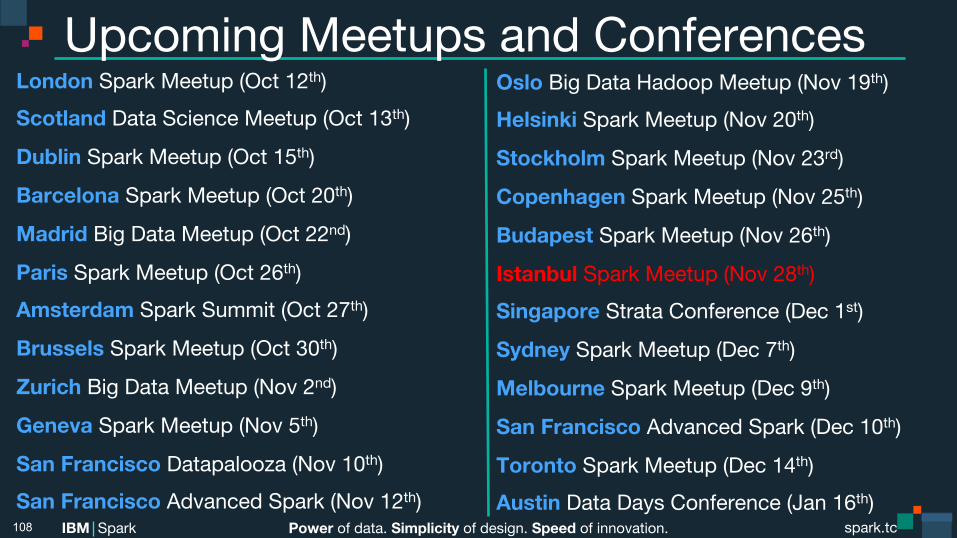
Upcoming Meetups and Conferences London Spark Meetup (Oct 12th) Scotland Data Science Meetup (Oct 13th)
Dublin Spark Meetup (Oct 15th)
Barcelona Spark Meetup (Oct 20th)
Madrid Big Data Meetup (Oct 22nd)
Paris Spark Meetup (Oct 26th) Amsterdam Spark Summit (Oct 27th)
Brussels Spark Meetup (Oct 30th)
Zurich Big Data Meetup (Nov 2nd)
Geneva Spark Meetup (Nov 5th)
San Francisco Datapalooza (Nov 10th) San Francisco Advanced Spark (Nov 12th)
108
Oslo Big Data Hadoop Meetup (Nov 19th) Helsinki Spark Meetup (Nov 20th)
Stockholm Spark Meetup (Nov 23rd)
Copenhagen Spark Meetup (Nov 25th)
Budapest Spark Meetup (Nov 26th)
Istanbul Spark Meetup (Nov 28th) Singapore Strata Conference (Dec 1st)
Sydney Spark Meetup (Dec 7th)
Melbourne Spark Meetup (Dec 9th)
San Francisco Advanced Spark (Dec 10th)
Toronto Spark Meetup (Dec 14th) Austin Data Days Conference (Jan 16th)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark