biwa2016 - enrich, transform and analyse big data using oracle big data discovery and oracle visual...
TRANSCRIPT

[email protected] www.rittmanmead.com @rittmanmead
Enrich, Transform and Analyse Big Data using Oracle Big Data Discovery and Oracle Visual Analyzer
Mark Rittman, CTO, Rittman Mead BIWA Summit 2016, San Francisco, January 2016

[email protected] www.rittmanmead.com @rittmanmead 2
•Mark Rittman, Co-Founder of Rittman Mead‣Oracle ACE Director, specialising in Oracle BI&DW‣14 Years Experience with Oracle Technology‣Regular columnist for Oracle Magazine
•Author of two Oracle Press Oracle BI books‣Oracle Business Intelligence Developers Guide‣Oracle Exalytics Revealed‣Writer for Rittman Mead Blog :http://www.rittmanmead.com/blog
•Email : [email protected]•Twitter : @markrittman
About the Speaker

[email protected] www.rittmanmead.com @rittmanmead 3
•Many Rittman Mead customers have asked us whether they need both Visual Analyzer, and Oracle Big Data Discovery, for data discovery against big data ‣They both provide “data discovery”‣OBIEE can access Hadoop + NoSQL datasets‣BDD is just Endeca, and we didn’t need that
•Why don’t we just use Visual Analyzer for this work?•Can we just give Big Data Discovery to all our users?•Well let’s find out…
I’m Analysing Oracle Big Data - Which Tool to Use?
Mr. Visual Analyzer
Mr. Big Data Discovery

[email protected] www.rittmanmead.com @rittmanmead 4
Business Scenario
•Rittman Mead want to understand drivers and audience for their website ‣What is our most popular content? Who are the most in-demand blog authors?
•Three data sources in scope ‣Mixture of event-based data (website page view), Social Media (Twitter) and Textual (blog)
RM Website Logs Twitter Stream Website Posts, Comments etc

[email protected] www.rittmanmead.com @rittmanmead 5
•Apache Flume is the standard way to transport log files from source through to target• Initial use-case was webserver log files, but can transport any file from A>B•Does not do data transformation, but can send to multiple targets / target types•Mechanisms and checks to ensure successful transport of entries
•Has a concept of “agents”, “sinks” and “channels”•Agents collect and forward log data•Sinks store it in final destination•Channels store log data en-route
•Simple configuration through INI files•Handled outside of ODI12c
Apache Flume : Distributed Transport for Log Activity

[email protected] www.rittmanmead.com @rittmanmead 6
•Twitter provides an API for developers to use to consume the Twitter “firehose”
•Can specify keywords to limit the tweets consumed•Free service, but some limitations on actions (number of requests etc)
• Install additional Flume source JAR (pre-built available, but best to compile from source)‣https://github.com/cloudera/cdh-twitter-example
•Specify Twitter developer API key and keyword filters in the Flume conf settings
Accessing the Twitter “Firehose”

[email protected] www.rittmanmead.com @rittmanmead
•Capture page view + Twitter activity using Apache Flume, land in HDFS•Analyse using Big Data SQL and OBIEE
Overall Project Architecture - Phase 1
Spark
Hive
HDFS
Spark
Hive
HDFS
Spark
Hive
HDFS
Cloudera CDH5.3 BDA Hadoop Cluster
Big Data SQL
Exadata Exalytics
Flume Flume
DimAttributes
SQL for BDA Exec
Filtered &Projected Rows / Columns
OBIEE
TimesTen
12c In-Mem Flume

[email protected] www.rittmanmead.com @rittmanmead 8
•Data landed into Hadoop is considered “raw”‣At best, semi-structured‣No data quality checks‣Typically in non-tabular format‣Isolated datasets, no joins‣No data dictionary‣Real-time and immediate, but raw
Raw Data Landed into Hadoop Data Reservoir
[email protected] www.rittmanmead.com @rittmanmead
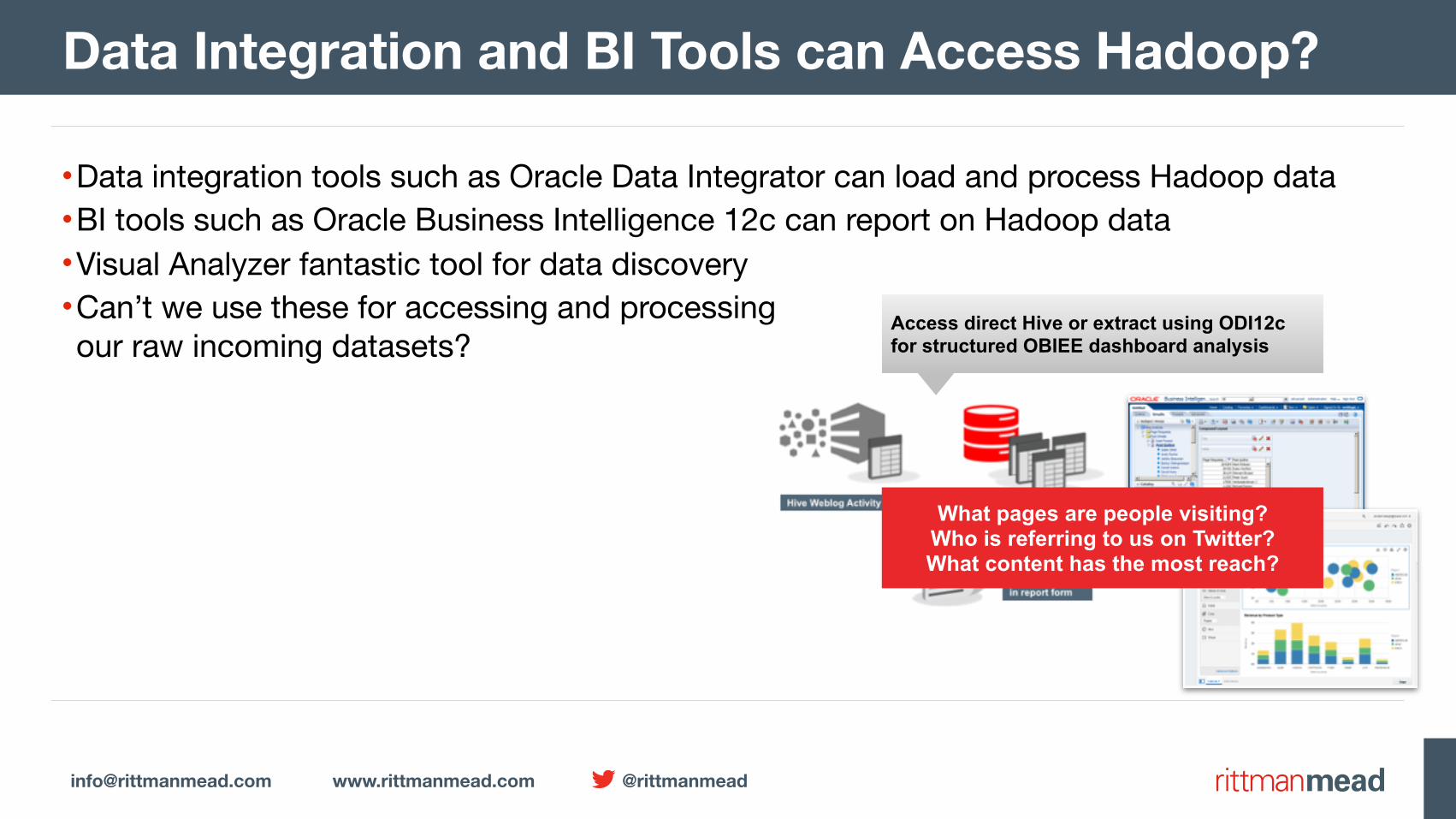
•Data integration tools such as Oracle Data Integrator can load and process Hadoop data•BI tools such as Oracle Business Intelligence 12c can report on Hadoop data•Visual Analyzer fantastic tool for data discovery•Can’t we use these for accessing and processingour raw incoming datasets?
Data Integration and BI Tools can Access Hadoop?
Access direct Hive or extract using ODI12c for structured OBIEE dashboard analysis
What pages are people visiting? Who is referring to us on Twitter? What content has the most reach?

[email protected] www.rittmanmead.com @rittmanmead 10
•Visual Analyzer and Answers both require a BI Repository (RPD) as their main datasource ‣Provides a structured, curated baseline for reporting, can be supplemented by mashups
•But is this the right time to be curating data? ‣Do we understand it well enough yet?
Understand the Work Involved in Creating an RPD

[email protected] www.rittmanmead.com @rittmanmead 11
•Data in the data reservoir typically is raw, hasn’t been organised into facts, dimensions yet•Often you don’t want to it to be - “data scientists like it raw”
•Later on though, users will benefit from structure and hierarchies being added to data•So how do we initially understand raw data, enrich and make is suitable for Visual Analyzer?
Hadoop Data is Typically “Schema-on-Read”

[email protected] www.rittmanmead.com @rittmanmead 12
Where Can We Find This Type of Developer…?
+ =
[email protected] www.rittmanmead.com @rittmanmead 13
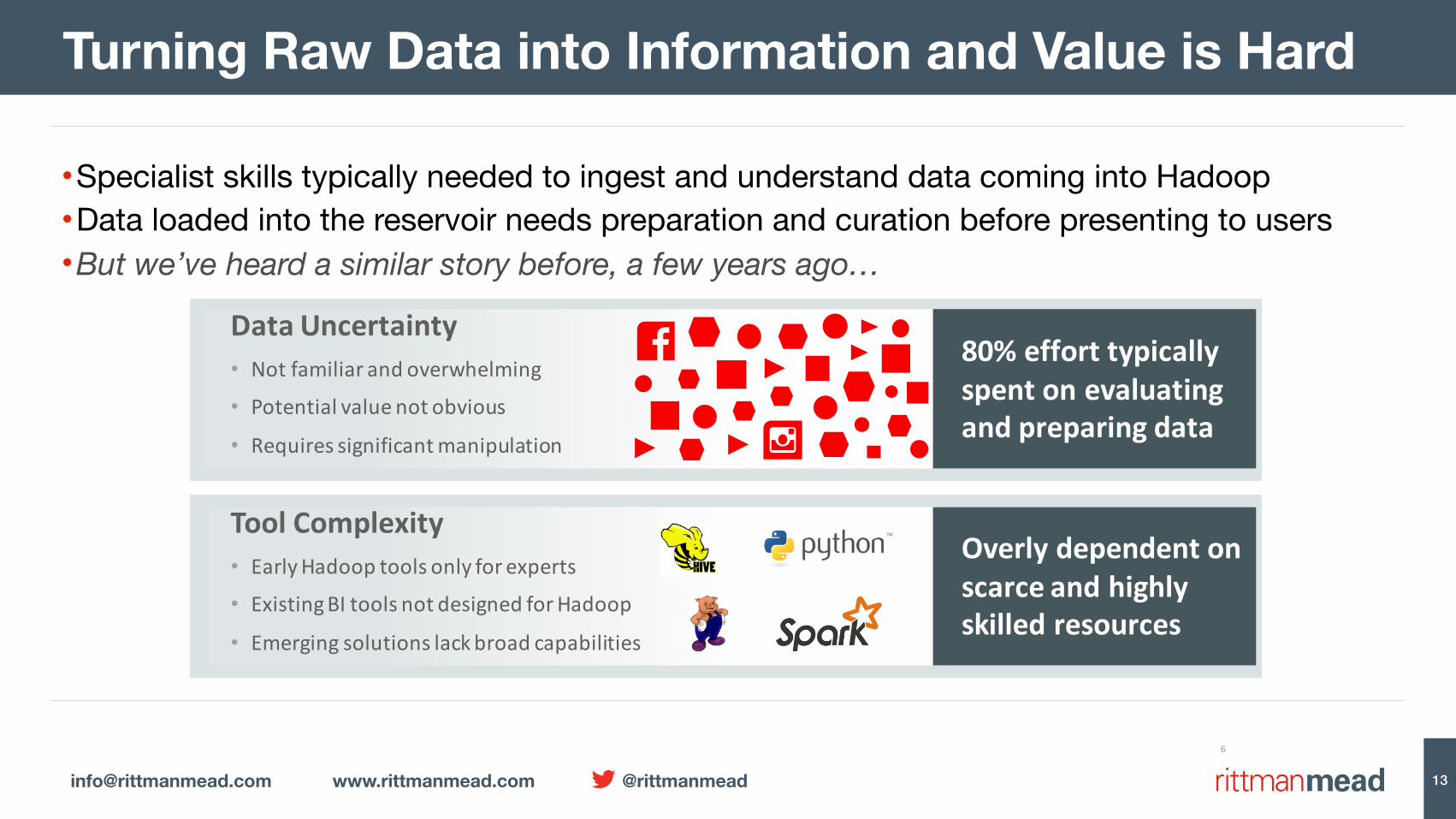
•Specialist skills typically needed to ingest and understand data coming into Hadoop•Data loaded into the reservoir needs preparation and curation before presenting to users•But we’ve heard a similar story before, a few years ago…
Turning Raw Data into Information and Value is Hard
6
ToolComplexity• EarlyHadooptoolsonlyforexperts• ExistingBItoolsnotdesignedforHadoop
• Emergingsolutionslackbroadcapabilities
80%efforttypicallyspentonevaluatingandpreparingdata
DataUncertainty• Notfamiliarandoverwhelming• Potentialvaluenotobvious
• Requiressignificantmanipulation
Overlydependentonscarceandhighlyskilledresources


[email protected] www.rittmanmead.com @rittmanmead 15
•Part of the acquisition of Endeca back in 2012 by Oracle Corporation
•Based on search technology and concept of “faceted search”
•Data stored in flexible NoSQL-style in-memory database called “Endeca Server”
•Added aggregation, text analytics and text enrichment features for “data discovery”‣Explore data in raw form, loose connections, navigate via search rather than hierarchies‣Useful to find out what is relevant and valuable in a dataset before formal modeling
What Was Oracle Endeca Information Discovery?

[email protected] www.rittmanmead.com @rittmanmead 16
•Proprietary database engine focused on search and analytics•Data organized as records, made up of attributes stored as key/value pairs•No over-arching schema, no tables, self-describing attributes
•Endeca Server hallmarks:‣Minimal upfront design‣Support for “jagged” data‣Administered via web service calls‣“No data left behind”‣“Load and Go”
•But … limited in scale (>1m records)‣… what if it could be rebuilt on Hadoop?
Endeca Server Technology Combined Search + Analytics

[email protected] www.rittmanmead.com @rittmanmead 17
•A visual front-end to the Hadoop data reservoir, providing end-user access to datasets•Catalog, profile, analyse and combine schema-on-read datasets across the Hadoop cluster•Visualize and search datasets to gain insights, potentially load in summary form into DW
Oracle Big Data Discovery

[email protected] www.rittmanmead.com @rittmanmead 18
• Initial catalog view of the raw datasets in Hadoop•Lightweight, user-driven data transformations (“data wrangling”)
•Enrichment of raw data to add sentiment scores, extract nouns etc
•User-driven addition of file and RDBMS datasets for reference data
•Understand potential columns for joins, and for hierarchies to go into RPD
Where Oracle Big Data Discovery Can Add Value

[email protected] www.rittmanmead.com @rittmanmead 19
•Relies on datasets in Hadoop being registered with Hive Catalog •Presents semi-structured and other datasets as tables, columns•Hive SerDe and Storage Handler technologies allow Hive to run over most datasets•Hive tables need to be defined before dataset can be used by BDD
Enabling Raw Data for Access by Big Data Discovery
CREATE external TABLE apachelog_parsed( host STRING, identity STRING, … agent STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \”]*|\"[^\"]*\")(-|[0-9]*) (-|[0-9]*)(?: ([^ \"] *|\".*\") ([^ \"]*|\".*\"))?" ) STORED AS TEXTFILE LOCATION '/user/flume/rm_website_logs;
[email protected] www.rittmanmead.com @rittmanmead 20
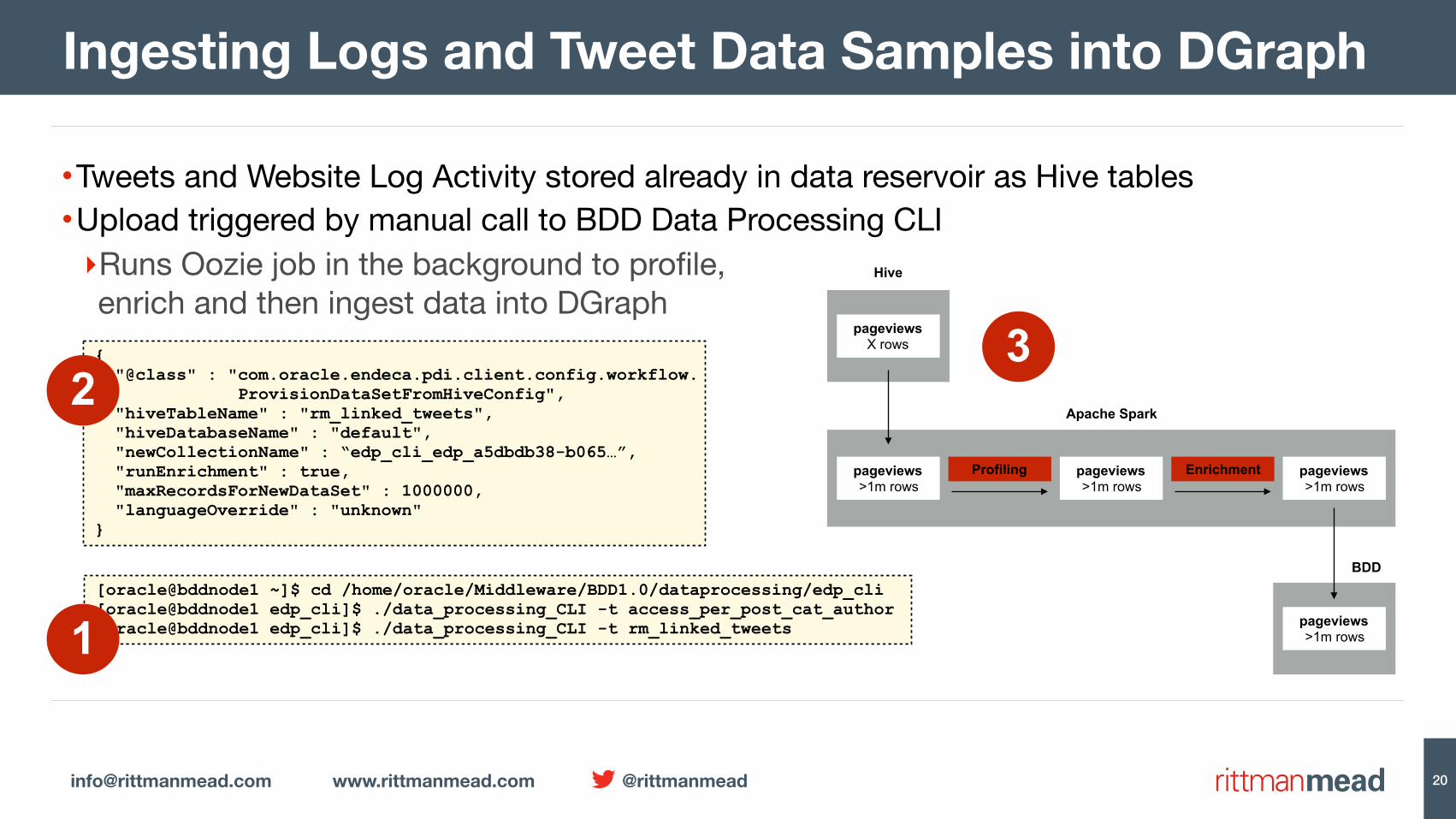
•Tweets and Website Log Activity stored already in data reservoir as Hive tables•Upload triggered by manual call to BDD Data Processing CLI‣Runs Oozie job in the background to profile,enrich and then ingest data into DGraph
Ingesting Logs and Tweet Data Samples into DGraph
[oracle@bddnode1 ~]$ cd /home/oracle/Middleware/BDD1.0/dataprocessing/edp_cli [oracle@bddnode1 edp_cli]$ ./data_processing_CLI -t access_per_post_cat_author [oracle@bddnode1 edp_cli]$ ./data_processing_CLI -t rm_linked_tweets
Hive
Apache Spark
pageviews X rows
pageviews >1m rows
Profiling pageviews >1m rows
Enrichment pageviews >1m rows
BDD
pageviews >1m rows
{ "@class" : "com.oracle.endeca.pdi.client.config.workflow. ProvisionDataSetFromHiveConfig", "hiveTableName" : "rm_linked_tweets", "hiveDatabaseName" : "default", "newCollectionName" : “edp_cli_edp_a5dbdb38-b065…”, "runEnrichment" : true, "maxRecordsForNewDataSet" : 1000000, "languageOverride" : "unknown" }
1
23
[email protected] www.rittmanmead.com @rittmanmead 21
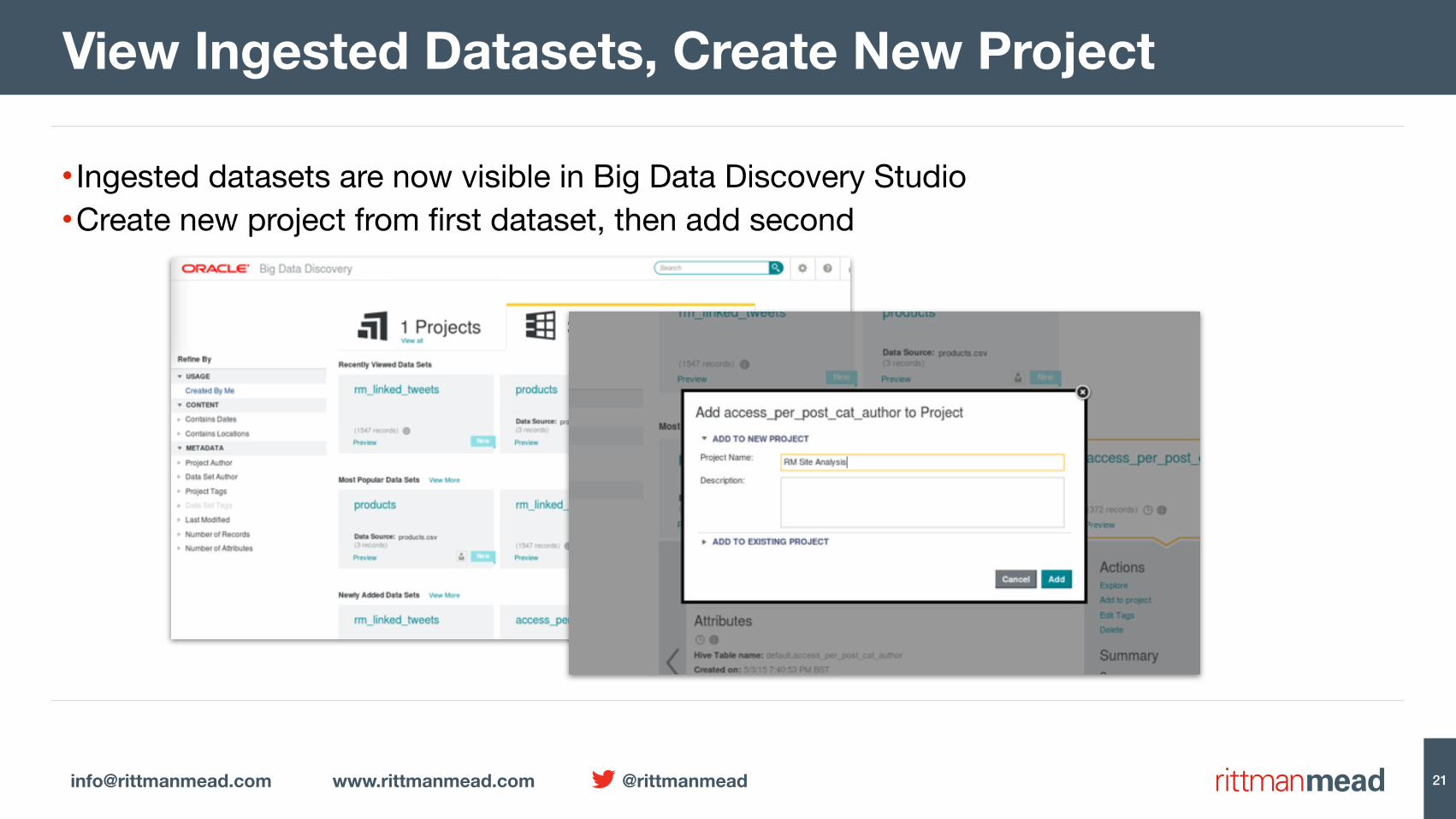
• Ingested datasets are now visible in Big Data Discovery Studio•Create new project from first dataset, then add second
View Ingested Datasets, Create New Project

[email protected] www.rittmanmead.com @rittmanmead 22
• Ingestion process has automatically geo-coded host IP addresses•Other automatic enrichments run after initial discovery step, based on datatypes, content
Automatic Enrichment of Ingested Datasets

[email protected] www.rittmanmead.com @rittmanmead 23
•For the ACCESS_PER_POST_CAT_AUTHORS dataset, 18 attributes now available•Combination of original attributes, and derived attributes added by enrichment process
Initial Data Exploration On Uploaded Dataset Attributes

[email protected] www.rittmanmead.com @rittmanmead 24
•Click on individual attributes to view more details about them•Add to scratchpad, automatically selects most relevant data visualisation
Explore Attribute Values, Distribution using Scratchpad
1
2

[email protected] www.rittmanmead.com @rittmanmead 25
•Data ingest process automatically applies some enrichments - geocoding etc•Can apply others from Transformation page - simple transformations & Groovy expressions
Data Transformation & Enrichment

[email protected] www.rittmanmead.com @rittmanmead 26
•Uses Salience text engine under the covers•Extract terms, sentiment, noun groups, positive / negative words etc
Transformations using Text Enrichment / Parsing
[email protected] www.rittmanmead.com @rittmanmead 27
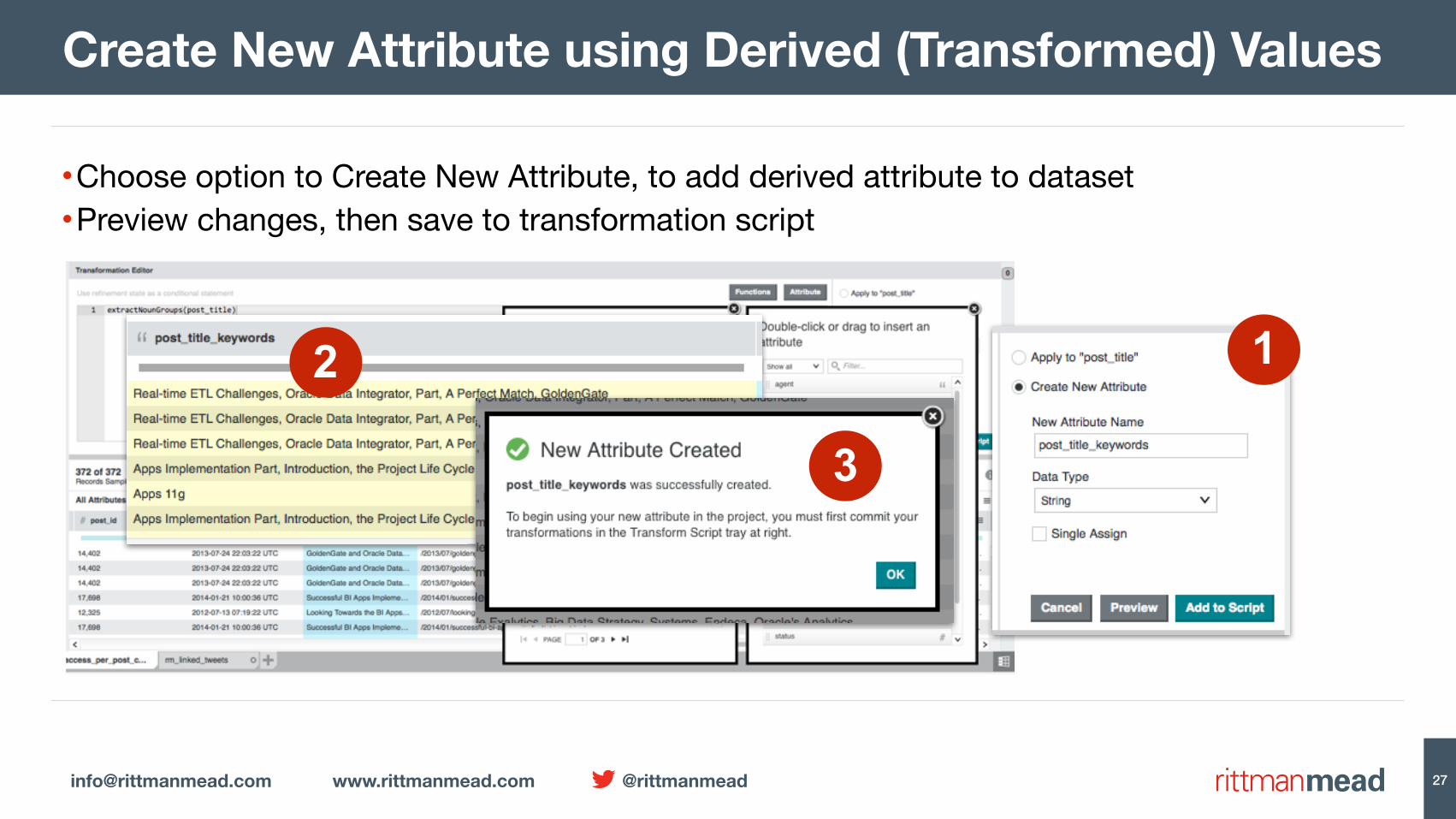
•Choose option to Create New Attribute, to add derived attribute to dataset•Preview changes, then save to transformation script
Create New Attribute using Derived (Transformed) Values
12
3

[email protected] www.rittmanmead.com @rittmanmead 28
•Transformation changes have to be committed to DGraph sample of dataset‣Project transformations kept separate from other project copies of dataset
•Transformations can also be applied to full dataset, using Apache Spark ‣Creates new Hive table of complete dataset
Commit Transforms to DGraph, or Create New Hive Table

[email protected] www.rittmanmead.com @rittmanmead 29
•Users can upload their own datasets into BDD, from MS Excel or CSV file•Uploaded data is first loaded into Hive table, then sampled/ingested as normal
Combine with User-Uploaded Reference Data
12
3

[email protected] www.rittmanmead.com @rittmanmead 30
•Used to create a dataset based on the intersection (typically) of two datasets•Not required to just view two or more datasets together - think of this as a JOIN and SELECT
Join Datasets On Common Attributes

[email protected] www.rittmanmead.com @rittmanmead 31
•BDD Studio dashboards support faceted search across all attributes, refinements•Auto-filter dashboard contents on selected attribute values - for data discovery•Fast analysis and summarisation through Endeca Server technology
Search and Analyse Schema-on-Read Data using BDD Studio
Further refinement on“OBIEE” in post keywords
3Results now filteredon two refinements
4

[email protected] www.rittmanmead.com @rittmanmead 32
•Can’t we now just use Oracle Big Data Discovery to do our data discovery & dashboarding?•Basic BI-type reporting against datasets, joined together, filtered, transformed etc•But … lack of structure, hierarchies, free form joins etc will cause issues for non-tech users
•They need structure, hierarchies, measures•They need … Dan
Can’t We Keep Using BDD for End-User Reporting?

[email protected] www.rittmanmead.com @rittmanmead 33
•Transformations within BDD Studio can then be used to create curated fact + dim Hive tables•Can be used then as a more suitable dataset for use with OBIEE RPD + Visual Analyzer•Or exported then in to Exadata or Exalytics to combine with main DW datasets
Export Onboard Datasets Back to Hive, for OBIEE + VA

[email protected] www.rittmanmead.com @rittmanmead 34
•Now is the time to invest time into creating the RPD•We understand the data, have added enrichments, discovered the hierarchies•The next set of users will benefit from time taken to curate the data into an RPD
Create the RPD Against Curated, Enriched Hive Tables

[email protected] www.rittmanmead.com @rittmanmead 35
•Users in Visual Analyzer then havea more structured dataset to use
•Data organised into dimensions, facts, hierarchies and attributes
•Can still access Hadoop directlythrough Impala or Big Data SQL
•Big Data Discovery though was key to initial understanding of data
Further Analyse in Visual Analyzer for Managed Dataset
[email protected] www.rittmanmead.com @rittmanmead 36
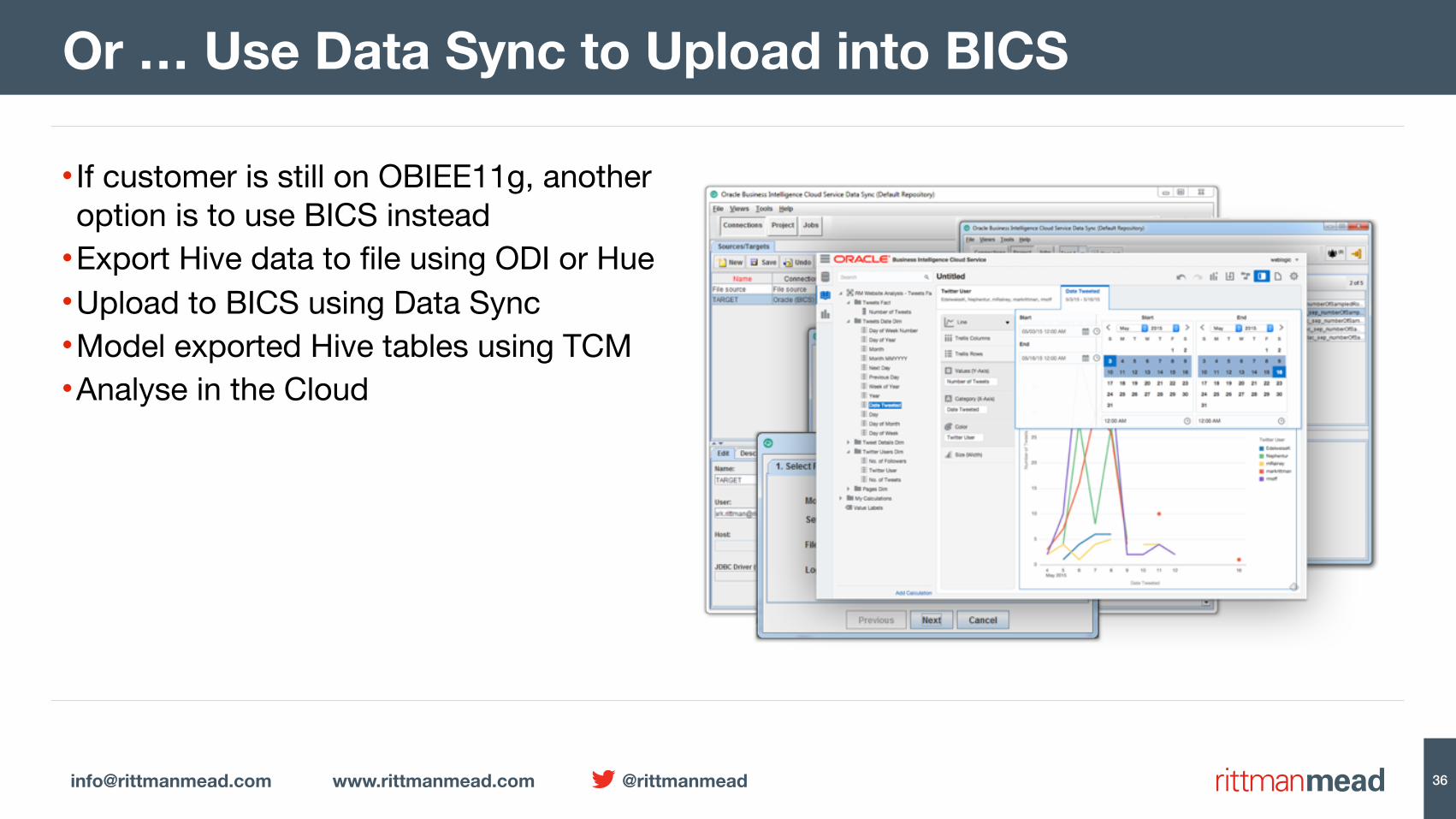
• If customer is still on OBIEE11g, anotheroption is to use BICS instead
•Export Hive data to file using ODI or Hue•Upload to BICS using Data Sync•Model exported Hive tables using TCM•Analyse in the Cloud
Or … Use Data Sync to Upload into BICS

[email protected] www.rittmanmead.com @rittmanmead 37
•Both tools play a key role in analysing Hadoop data•Big Data Discovery adds significant value for data on boarding‣Initial catalog view of data‣Data Wrangling and Enrichment‣Discover hierarchies, measures and attributes
•But BDD isn’t a sensible BI tool for non-analyst users‣OBIEE’s RPD provides much needed structure‣Visual Analyzer enables “managed data discovery”‣But only make this investment when it’s needed, andonce the data is understood and ready for curation
So Who Will it Be? VA or Big Data Discovery?
Mr. Visual Analyzer
Mr. Big Data Discovery

[email protected] www.rittmanmead.com @rittmanmead
Oracle Big Data Spatial & GraphSocial Media Analysis - Case StudyMark Rittman, CTO, Rittman Mead BIWA Summit 2016, San Francisco, January 2016