biostatistik i - isa.uni-stuttgart.de · biostatistik i jürgen dippon institut für stochastik und...
TRANSCRIPT

Biostatistik I
Jürgen Dippon
Institut für Stochastik und Anwendungen (ISA)Universität Stuttgart
11. Dezember 2012
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 1 / 435
Teil I
Deskriptive Statistik
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 2 / 435

Deskriptive Statistik
1 Einführung
2 Deskriptive Statistik univariater Daten
3 Deskriptive Statistik multivariater Daten
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 3 / 435
1. Einführung
1 Einführung
2 Deskriptive Statistik univariater Daten
3 Deskriptive Statistik multivariater Daten
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 4 / 435

1. Einführung
Einführung
Grundaufgabe der Statistik
Beschreiben (Deskription)
Suchen (Exploration)
Schlieÿen (Induktion)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 5 / 435
1. Einführung
Die deskriptive Statistik dient zur beschreibenden und graschenAufarbeitung und Komprimierung von Daten. Beschrieben werdenMerkmale oder Variablen, die gewisse Ausprägungen oder Werte besitzen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 6 / 435

1. Einführung
Unterschiedliche Typen von Variablen
Zielgröÿen
Einussgröÿen oder Faktoren
Störgröÿen oder latente Gröÿen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 7 / 435
1. Einführung
Deskriptive Statistik wird auch zur Datenvalidierung eingesetzt: Sind dieerhobenen Daten plausibel und vertrauenswürdig?Mögliche Probleme: Passt die Gröÿenordnung? Gibt es Ausreiser? Gibt esHinweise auf Übertragungs- oder Eingabefehler? Wurden die Dateneventuell gefälscht?
Deskriptive Statistik verwendet im Gegensatz zur induktiven Statistik keine Wahrscheinlichkeitstheorie.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 8 / 435

1. Einführung
Die explorative Statistik sucht Strukturen oder Besonderheiten in denDaten und dient zur Hypothesengewinnung.
Hypothesen können schlieÿlich in der induktiven Statistik formal mitwahrscheinlichkeitstheoretischen Methoden überprüft werden, z.B. kann mitgroÿer Sicherheit geschlossen werden, dass ein in der Stichprobe gefundenerZusammenhang auch in der Grundgesamtheit vorliegt ?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 9 / 435
1. Einführung
Wichtige Grundbegrie
Statistische Einheit: Objekte, an denen interessierende Gröÿen erfasstwerden
Grundgesamtheit, Population: Menge aller für die Fragestellungrelevanten statistischen Einheiten
Teilgesamtheit: Teilmenge der Grundgesamtheit
Stichprobe: tatsächlich untersuchte Teilmenge der Grundgesamtheit
Merkmal: interessierende Gröÿe, Variable
Merkmalsausprägung: konkreter Wert des Merkmals für eine statistischeEinheit
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 10 / 435

1. Einführung
Charakterisierung von Merkmalen
diskretes Merkmal: Menge der Merkmalsausprägung ist abzählbar
stetiges Merkmal: Merkmale nehmen Werte aus einem Intervall an
quasistetige Merkmale: Merkmal ist von seiner Natur her stetig,mögliche Werte aber, z.B. aufgrund des Messprozesses, abzählbar
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 11 / 435
1. Einführung
Unterscheidung von Merkmalen aufgrund ihrer Skalenniveaus:1 Nominalskala: Merkmalsausprägungen sind Namen oder Kategorien
(z.B. Haarfarbe, Religion) (endliche Menge)2 Ordinalskala: Ausprägungen können geordnet werden (z.B.
Tumorstadien, Schulnoten)3 Intervallskala: Abstände zwischen Ausprägungen können interpretiert
werden (z.B. Temperatur auf der Celsius-Skala, Jahreszahlen,IQ-Skala)
4 Verhältnisskala: Quotienten zwischen Ausprägungen könneninterpretiert werden (z.B. Temperatur in Kelvin, Gewicht in kg, Preisin Euro)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 12 / 435

1. Einführung
Weitere Unterscheidung:
Qualitative Merkmale (endlich viele Ausprägungen, höchstens ordinalskaliert)
versus
quantitative Merkmale (spiegeln eine Intensität wider)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 13 / 435
1. Einführung
Elemente der Versuchsplanung
Notwendigkeit eines Versuchsplans
Wie lautet das Ziel der Studie oder des Experiments ?
Wie soll das Ziel erreicht werden ?
Statistische Methoden
Fallzahl
Wie lassen sich Störvariablen kontrollieren ? (z.B. durchHomogenisierung, Randomisierung, Parallelisierung, Kontrolle derStörvariablen im Rahmen eines statistischen Modells)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 14 / 435

1. Einführung
Datengewinnung kann erfolgen
in einem Experimenteiner Erhebung
I im Rahmen einer VollerhebungI einer Stichprobe
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 15 / 435
1. Einführung
Verschiedene Methoden der Stichprobenbildung
einfache Zufallsstichprobe
systematische Ziehung (z.B. jeder siebte Patient)
geschichtete Zufallsstichproben (z.B. ziehe je eine Zufallsstichprobeaus der Gruppe der Männer und der Frauen)
Klumpenstichprobe (z.B. Vollerhebung aller Tiere aus zufälligausgewählten Herden).
mehrstuge Auswahlverfahren
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 16 / 435

1. Einführung
Studiendesigns
Querschnittstudie: mehrere Objekte werden zu einem Zeitpunktbeobachtet
Zeitreihe: ein Objekt wird zu mehreren Zeitpunkten beobachtet
Längsschnittstudie, Panel: mehrere Objekte und zwar immer diegleichen werden zu mehreren Zeitpunkten beobachtet
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 17 / 435
2. Deskriptive Statistik univariater Daten
1 Einführung
2 Deskriptive Statistik univariater DatenVerteilungen und ihre DarstellungenBeschreibung von VerteilungenLagemaÿeQuantile und Box-PlotStreuungsmaÿeMaÿzahlen für Schiefe und Wölbung
Dichtekurven und Normalverteilung
3 Deskriptive Statistik multivariater Daten
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 18 / 435

2. Deskriptive Statistik univariater Daten
Deskriptive Statistik univariater Daten
In diesem Kapitel betrachten wir Merkmalsträger mit nur einem Merkmal.
Im nächsten Kapitel betrachten wir auch Merkmalsträger mit mehrerenMerkmalen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 19 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Häugkeitsverteilung
Ein Merkmal X werde an n Untersuchungseinheiten beobachtet:x1, . . . , xn︸ ︷︷ ︸
sog. Urliste, Roh- oder Primärdaten
Problem: schon bei moderatem Stichprobenumfang unübersichtlich
Die dabei auftretenden verschiedenen Merkmalsausprägungen werden mita1, . . . , ak bezeichnet (k ≤ n)
h(aj) = hj absolute Häugkeit der Ausprägung aj d.h.Anzahl der xi aus x1, . . . , xn mit xi = aj
f (aj) = fj =hj
nrelative Häugkeit von aj
h1, . . . , fk absolute Häugkeitsverteilungf1, . . . , fk relative Häugkeitsverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 20 / 435

2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Grasche Methoden für univariate Daten
Stabdiagramm: Trage über a1, . . . , ak jeweils einen zur x-Achsesenkrechten Strich (Stab) mit Höhe h1, . . . , hk (oder f1, . . . , fk) ab.
Säulendiagramm: Wie Stabdiagramm, aber mit Rechtecken statt Strichen
Balkendiagramm: Wie Säulendiagramm, aber mit vertikal statt horizontalgelegter x-Achse
Kreisdiagramm: Flächen der Kreissektoren proportional zu denHäugkeiten: Winkel des Kreissektors j : fj · 360
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 21 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
## Anzahl der Tiere je Wurf in 12 Würfen
x <- c("2" ,"2" ,"3" ,"3" ,"3" ,"4" ,"2" ,"5" ,"5" ,"4" ,"4" ,"3")
n <- length(x)
h <- table(x) ## absolute Haeufigkeitsverteilung
f <- h/n ## relative Haeufigkeitsverteilung
## Stabdiagramm
plot(h)
plot(h/n)
## Säulendiagramm
barplot(h)
barplot(h/n)
## Balkendiagramm
barplot(h, horiz=TRUE)
## Kreisdiagramm
pie(h)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 22 / 435

2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Abbildung: Grasche Methoden zur DatenvisualisierungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 23 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Stamm-Blatt-Diagramm:Die Urliste wird bis auf Rundungen in einer dem Histogramm ähnlichenDarstellung reproduziert.Das Diagramm wird erzeugt mittels:
x <- c(2.46, 2.3, 3.1, 3.6, 3.8, 4.4, 2.7, 5.9, 5.9,
4.1, 4.4, 3.6)
stem(x)
Das ausgegebene Diagramm ist:
2 | 357
3 | 1668
4 | 144
5 | 99
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 24 / 435

2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Histogramm
Für gröÿere Datensätze besser geeignet:
Histogramme: Gruppiere die Daten in Klassen, bestehend aus benachbartenIntervallen [c0, c1), [c1, c2), . . . , [ck−1, ck)Zeichne über diesen Klassen Rechtecke mit:
Breite : dj = cj − cj−1
Höhe : gleich (oder proportional zu)hj
djbzw
fj
djFläche : gleich (oder proportional zu) hj bzw fj
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 25 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Histogramm ist so konstruiert, dass die dargestellten Flächen proportionalzu den absoluten bzw. relativen Häugkeiten (Prinzip der Flächentreue).
Wähle, falls möglich, die Klassenbreiten d1, . . . , dk gleich.
Faustregeln für die Klassenzahl:
k = [√n] oder k = 2[
√n] oder k = [10 log10 n] . . .
oder nach subjektivem Empnden.
Hierbei ist [x ] die gröÿte ganze Zahl kleiner gleich der reellen Zahl x .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 26 / 435
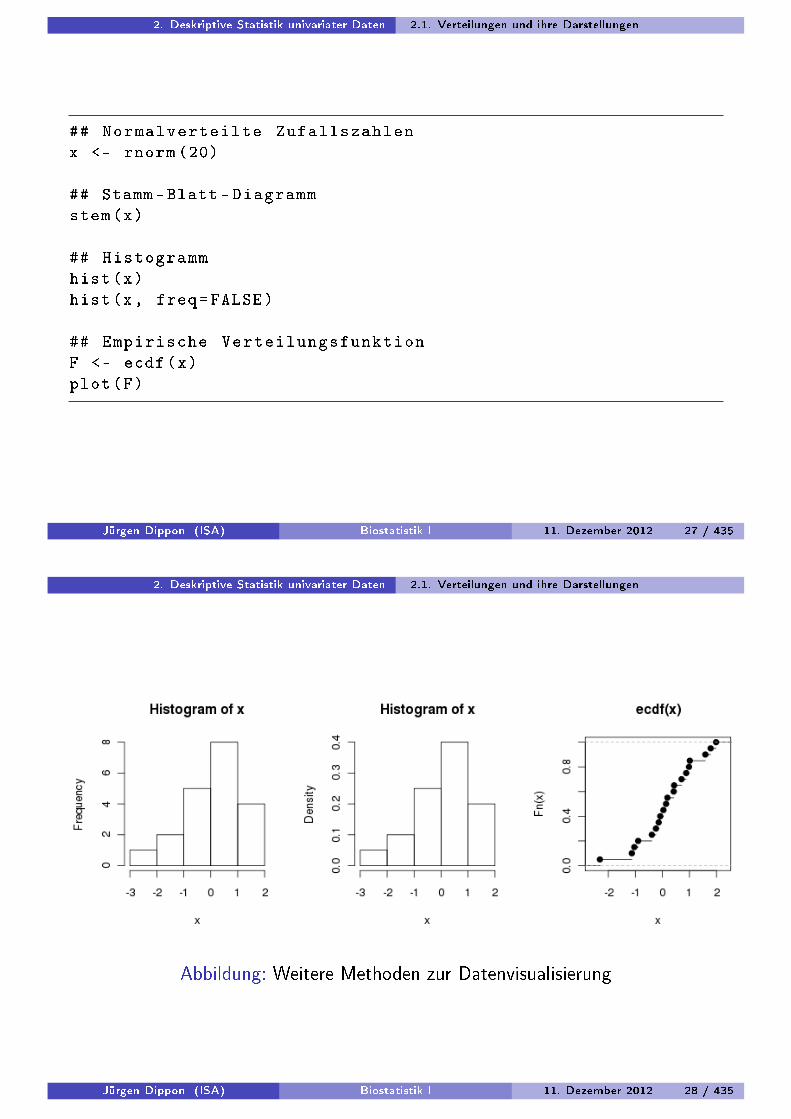
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
## Normalverteilte Zufallszahlen
x <- rnorm (20)
## Stamm -Blatt -Diagramm
stem(x)
## Histogramm
hist(x)
hist(x, freq=FALSE)
## Empirische Verteilungsfunktion
F <- ecdf(x)
plot(F)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 27 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Abbildung: Weitere Methoden zur Datenvisualisierung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 28 / 435

2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Viele empirische Verteilungen sind unimodal (eingipig), es sind aber auchbi- oder multimodale (zwei- oder mehrgipige) Verteilungen zu beobachten(z.B. bei geschichteten Daten)
Symmetrische Verteilung
linkssteile oder rechtsschiefe Verteilungen
rechtssteile oder linksschiefe Verteilungen
Ist das betrachtete Merkmal ordinalskaliert, so lassen sich die beobachtetenAusprägungen ordnen:
a1 < . . . < ak
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 29 / 435
2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Kumulierte Häugkeitsverteilung
Absolute kumulierte Häugkeitsverteilung:
∀x∈R
H(x) = Anzahl der Werte xi mit xi ≤ x
= h(a1) + . . .+ h(aj) =∑
i :ai≤x hi
Hierbei ist aj die gröÿte Ausprägung mit aj ≤ x (also ist aj+1 > x)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 30 / 435

2. Deskriptive Statistik univariater Daten 2.1. Verteilungen und ihre Darstellungen
Empirische Verteilungsfunktion
Wichtiger: Relative kumutierte Häugkeitsverteilung oder empirischeVerteilungsfunktion
F (x) =H(x)
n= relativer Anzahl der Werte xi mit xi ≤ x
= f (a1) + . . .+ f (aj) =∑
i : ai≤xfi
wobei aj ≤ x und aj+1 > x .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 31 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Lagemaÿe
Gesucht sind Maÿzahlen oder Parameter von Verteilungen
Ein Lagemaÿ (im engeren Sinne) ist eine Abbildung L : Rn → R, falls
∀a∈R
∀x1,...,xn∈R
L(x1 + a, . . . , xn + a) = L(x1, . . . , xn) + a
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 32 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Arithmetisches Mittel
Beispiele für Lagemaÿe:
Arithmetisches Mittel:
x =1n
(x1 + . . .+ xn) =1n
n∑i=1
xi
Für Häugkeitsdaten mit Ausprägungen a1, . . . , ak und relativenHäugkeiten f1, . . . , fk gilt
x = a1f1 + . . .+ ak fk =k∑
j=1
aj fj
(gewichtetes Mittel)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 33 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Das arithmetische Mittel ist i.a. nur für quantitative Merkmale sinnvolldeniert.
Für das arithmetische Mittel giltn∑
i=1
(xi − x) = 0
(Schwerpunkteigenschaft)
Stichprobe vom Umfang n, verteilt auf r Schichten mit jeweiligenUmfängen n1, . . . , nr und arith. Mitteln x1 . . . , xr , so gilt
x =1n
(n1x1 + . . .+ nr xr ) =1n
r∑i=1
ni xi
Beobachtung: arithmetische Mittel reagieren empndlich gegen Ausreiÿer,wohingegen der Median ein robustes Lagemaÿ ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 34 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
MedianUrliste x1, . . . , xn
geordnete Urliste x(1) ≤ . . . ≤ x(n)
Der (empirische) Median von x1, . . . , xn ist deniert durch
xmed =
x( n+1
2) für n ungerade
12(x( n
2) + x( n
2+1)) für n gerade
Denition sinnvoll für ordinale Merkmale (oder besser)
Eigenschaften des Medians:
Mindestens 50% der Daten sind
≤ xmed
≥ xmed
Median häug einfacher zu interpretieren als das arithmetische MittelJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 35 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Modus
Der Modus von x1, . . . , xn ist deniert durch
xmod = Ausprägung mit gröÿter Häugkeit
Modus nur eindeutig, falls die Häugkeitsverteilung ein eindeutigesMaximum besitzt.
Denition schon für nominalskalierte Merkmale sinnvoll.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 36 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Lageregeln
Symetrische Verteilungen x ≈ xmed ≈ xmod
Linkssteile Verteilungen x > xmed > xmod
Rechtssteile Verteilungen x < xmed < xmod
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 37 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Im Folgenden stellen wir noch weitere Maÿe für die Lage einer Verteilungvor, die jedoch keine Lageparameter im oben genannten Sinne sind
Zur Motivation ein Beispiel:Sei ri die Wachstumsrate einer Tierpopulation im i-ten JahrDann beträgt die Populationsgröÿe Pn im n-ten Jahr
Pn = P0(1 + r1) · . . . · (1 + rn)
= P0
n∏i=1
(1 + ri )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 38 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Geometrisches Mittel
Das geometrische Mittel zu den Faktoren x1, . . . , xn ist
xgeom = (x1 · . . . · xn)1n
Dann ist (n∏
i=1
(1 + ri )
) 1n
der mittlere Wachstumsfaktor und(n∏
i=1
(1 + ri )
) 1n
− 1
die mittlere Wachstumsrate.
Da xgeom ≤ x täuscht x statt xgeom überhöhte Wachstumsraten vor.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 39 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Harmonisches Mittel
Das harmonische Mittel
xharm =1
1n
∑ni=1
1xi
ist z.B. zur Ermittlung der Durchschnittsgeschwindigkeit geeignet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 40 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Quantile und Box-Plot
Jeder Wert xp mit 0 < p < 1, für den mindestens ein Anteil p der Daten≤ xp und mindestens ein Anteil 1− p der Daten ≥ xp ist, heiÿt(empirisches) p-Quantil der Stichprobe.Damit gilt für das p-Quantil:
xp = x([np]+1), wenn np nicht ganzzahlig
xp ∈ [x(np), x(np+1)], wenn np ganzzahlig
Dabei ist [np] die gröÿte ganze Zahl mit ≤ np
Speziell:
x0.25 = 25%-Quantil = unteres Quartil
x0.5 = 50%-Quantil = Median
x0.75 = 75%-Quantil = oberes Quartil
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 41 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Quantile und Box-Plot
Abbildung: Darstellung der Quantile
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 42 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Interquartilsabstand:dQ = x0.75 − x0.25
5-Punkte-Zusammenfassung einer Verteilung:
xmin, x0.25, xmed, x0.75, xmax
Grasche Darstellung der 5-Punkte-Zusammenfassung einer Verteilungmittels eines Box-Plots
Abbildung: Box-Plot
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 43 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
x <- airquality$Ozone
x
quantile(x,probs=c(0.25 ,0.75)) ## 25%- und 75%- Quantil
summary(x) ## 5-Punkte -Zusammenfassung einer Verteilung
boxplot(x)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 44 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Streuungsmaÿe
Ein Streuungsmaÿ (im engeren Sinne) ist eine Abbildung S : Rn → R, fürdie
∀a∈R
∀x1,...,xn
S(x1 + a, . . . , xn + a) = S(x1, . . . , xn)
Beispiele für Streuungsmaÿe:
Stichprobenspannweite x(n) − x(1)
Interquartilsabstand dQ = x0.75 − x0.25
Standardabweichung s
wobei
s2 =1n(x1 − x)2 + . . .+ (xn − x)2 =
1n
n∑i=1
(xi − x)2
die sog. empirische Varianz der Stichprobe.Beachte: s ist nur für metrische Merkmale deniert!
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 45 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Im Falle von Häugkeitsdaten gilt:
s2 = (a1 − x)2f1 + . . .+ (ak − x)2fk =k∑
j=1
(aj − x)2fj
Häug wird statt der empirischen Varianz s2 auch die Stichprobenvarianz
s2 =1
n − 1
n∑i=1
(xi − x)2
verwendet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 46 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Da∑
(xi − x) = 0, ist (xn − x) bereits durch die ersten (n − 1)Abweichungen festgelegt. (n − 1) ist deshalb auch die Anzahl derFreiheitsgrade.
Verschiebungssatz:
∀i∈R
n∑i=1
(xi − c)2 =n∑
i=1
(xi − x)2 + n(x − c)2
Für c = 0 folgt die praktische Darstellung
s2 =
1n
n∑i=1
x2i
− x2
Bei linearer Transformation der Daten xi zu yi = a + bxi folgt derTransformationssatz
s2y = b2s2x bzw. sy = |b|sx
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 47 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Standardabweichung und Varianz sind sehr empndlich gegen Ausreiÿer.Robuste Alternativen:Mittlere absolute Abweichung vom Median
1n
n∑i=1
|xi − x0.5|
Mediane absolute Abweichung vom Median
Median von |x1 − x0.5|, . . . , |xn − x0.5|
Ein Streumaÿ im weiteren Sinne ist der Variationskoezient
v =s
x
welcher für Merkmale mit nichtnegativen Ausprägungen und positivemarithmetischem Mittel sinnvoll deniert ist.Der Variationskoezient liefert ein maÿstabsunabhängiges Streumaÿ.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 48 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
max(x)-min(x) ## Stichprobenspannweite
iqr(x) ## Interquartilsabstand
sd(x) ## Standardabweichung (mit Nenner n-1)
var(x) ## Stichprobenvarianz (mit Nenner n-1)
var(x+10) ## Verschiebungsinvarianz der Varianz
mean(abs(x-median(x))) ## mittlere Abweichung vom Median
sd(x)/mean(x) ## Variationskoeffizient
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 49 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Maÿzahlen für Schiefe und Wölbung
Verteilungen können sich nicht nur hinsichtlich Lage und Schiefe, sondernauch in Bezug auf Symmetrie oder Schiefe und durch ihre Wölbung(Kurtosis) unterscheiden.(Empirischer) Quantilskoezient der Schiefe:
gp =(x1−p − xmed )− (xmed − xp)
x1−p − xpfür ein festes p ∈ (0, 0.5)
Für p = 0.25 erhält man den Quartilskoezienten.
Bei symmetrischen Verteilungen gilt gp ≈ 0linkssteilen gp > 0rechtssteilen gp < 0
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 50 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Maÿzahlen für Schiefe und Wölbung
Der Nenner in gp stellt sicher, dass −1 ≤ gp ≤ 1.Quantilskoezienten sind robust im Gegensatz zum Momentenkoezientder Schiefe:
gm =m3
s3mit m3 =
1n
n∑i=1
(xi − x)3
Interpretation wie beim Quantilskoezienten.Division mit s3 macht gm maÿstabsunabhängig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 51 / 435
2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
Wölbungsmaÿ von Fisher
Das (empirische) Wölbungsmaÿ von Fisher ist deniert durch
γ =m4
s4− 3 mit m4 =
1n
n∑i=1
(xi − x)4
Bei Normalverteilung gilt γ ≈ 0bei spitzeren Verteilungen gilt γ > 0bei acheren Verteilungen gilt γ < 0
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 52 / 435

2. Deskriptive Statistik univariater Daten 2.2. Beschreibung von Verteilungen
## Herzgewicht von Katzen
library(MASS)
help(cats)
attach(cats) ## ab jetzt Spalten direkt ansprechen
hist(Hwt); density(Hwt)
q12 <- quantile(Hwt ,c(0.25 ,0.75))
names(q12) <- NULL ## Kosmetik
dQ <- q12[2]-q12 [1] ## Interquartilsabstand
## Quartilskoeeffizient für die Schiefe
m <- median(Hwt)
((q12[2]-m)-(m-q12 [1]))/ dQ
## Momentenkoeffizient für die Schiefe
m3 <- mean((Hwt -mean(Hwt ))^3)
m3/sd(Hwt)^3 ## Daten linkssteil
## Wölbungsmaÿ von Fisher
m4 <- mean((Hwt -mean(Hwt ))^4)
m4/sd(Hwt)^4-3 ## Daten spitzer als Normalverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 53 / 435
2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Dichtekurven und NormalverteilungZur Darstellung der Verteilung eines metrischen Merkmals kann z.B. dieempirische Verteilungsfunktion oder instruktiver das Histogrammverwendet werden.
Abbildung: Empirische Verteilungsfunktion
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 54 / 435

2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Nachteil: selbst bei stetigen Merkmalen ist das Histogramm eineTreppenfunktion, die u.U. groÿe Sprünge ausweist.
Deshalb: Approximiere das Histogramm durch eine stetige Dichtefunktion.Eine stetige Funktion f ist eine Dichte(kurve), wenn f (x) ≥ 0 und∫R f (x)dx = 1
Für p ∈ (0, 1) ist xp das p-Quantil der Dichte f , falls
p =
∫ xp
−∞f (x)dx
(und 1− p =
∫ ∞xp
f (x)dx
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 55 / 435
2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Dichte der Normalverteilung
Wichtiges Beispiel einer Dichtekurve:
Dichte der Normalverteilung
f (x |µ, σ) =1
σ√2π
exp
(−12
(x − µσ
)2), x ∈ R
µ ∈ R heiÿt Mittelwert, σ > 0 Standardabweichung von f (x |µ, σ)(genaue Denitionen dieser beiden Begrie später)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 56 / 435

2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Viele in der Anwedung auftretende Verteilungen können unter Verwendungeiner Normalverteilung gut approximiert werden.
Sind x1, . . . , xn Beobachtungen eines solchen Merkmals, so wird µ durch x
und σ durch s approximiert.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 57 / 435
2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Ist f die Dichtekurve einer normalverteilten Variablen X mit Mittelwert µund Standardabweichung σ, dann besitzt die standardisierte Variable
Z =X − µσ
die Dichtekurve einer Normalverteilung mit µ = 0 und σ = 1
Diese Normalverteilung heiÿt Standardnormalverteilung und die VariableZ entsprechend standardnormalverteilt.Die zugehörige Dichtekurve wird mit φ bezeichnet, also
φ(z) =1√2π
exp
(−z
2
2
)Quantile der Standardnormalverteilung ndet man in Tabellen oder mittelsStatistiksoftware.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 58 / 435

2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Quantile xp einer Normalverteilung mit Mittelwert µ und Varianz σ stehenmit den den Quantilen zp der Standardnormalverteilung über die lineareTransformation
xp = µ+ σzp
in Beziehung.
Daraus ergibt sich die 3-σ-Regel für normalverteilte Merkmale:
68% der Beobachtungen liegen im Intervall µ± σ95% der Beobachtungen liegen im Intervall µ± 2σ
99, 7% der Beobachtungen liegen im Intervall µ± 3σ
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 59 / 435
2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Normal-Quantil-Plots
Statt die Häugkeitsverteilung der Beobachtungen einer Variablen X direktmit einer Normalverteilung zu vergleichen, werden bei Normal-Quantil-Plotsdie Quantile der Häugkeitsverteilung mit den entsprechenden Quantilender Standardnormalverteilung verglichen:
x(1), . . . , x(n) geordnete Stichprobez(1), . . . , z(n)
1n -Quantil, . . . ,
nn -Quantil oder besser
1−0,5n -Quantil, . . . , n−0,5
n -Quantil derStandardnormalverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 60 / 435

2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
Der Normal-Quantil-Plot besteht aus den Punkten
(z(1), x(1)), . . . , (z(n), x(n))
im z-x-Koordinatensystem.Ist die empirische Verteilung der Beobachtung approximativstandard-normalverteilt, liegen die Punkte (z(i), x(i)) des NQ-Plots nahe anoder auf der Winkelhalbierenden z = x
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 61 / 435
2. Deskriptive Statistik univariater Daten 2.3. Dichtekurven und Normalverteilung
## Erzeugung normalverteilter (Pseudo -) Zufallszahlen
x <- rnorm (100, mean=2, sd=2)
plot(ecdf(x),verticals=TRUE)
hist(x,freq=FALSE)
rug(x)
## Standardisieren
z <- (x-mean(x))/sd(x)
hist(z,freq=FALSE)
## Hinzufügen der Dichtekurve einer N(0,1)- Verteilung
g <- seq(-3,3,by =0.01)
lines(g,dnorm(g),col="blue")
## Normal -Quantil -Plot
qqnorm(x)
qqline(x)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 62 / 435

3. Deskriptive Statistik multivariater Daten
1 Einführung
2 Deskriptive Statistik univariater Daten
3 Deskriptive Statistik multivariater DatenDiskrete multivariate DatenQuantitative multivariate MerkmaleGrasche Darstellungen quantitativer MerkmaleZusammenhangsmaÿe bei quantitativen MerkmalenLineare RegressionR Beispiel
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 63 / 435
3. Deskriptive Statistik multivariater Daten
Deskriptive Statistik multivariater Daten
In diesem Abschnitt stellen wir grasche und rechnerische Methoden zurDarstellung multivariater Daten vor. Insbesondere geht es um die Frage,wie eventuelle Zusammenhänge von Merkmalen erkannt werden können.Gemäÿ dem deskriptive Ansatz können wir diese Frage hier nur rechtvorläug beantworten. Erst unter Verwendung vonwahrscheinlichkeitstheoretischen Methoden kann im Rahmen der induktivenStatistik diese Frage zufriedenstellend gelöst werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 64 / 435

3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Diskrete multivariate Daten
Eine Sonntagsfrage lieferte folgende Häugkeitstabelle oder Kontigenztafel:
CDU/CSU SPD FDP Grüne RestMänner 144 153 17 26 95 435Frauen 200 145 30 50 71 496
344 298 47 76 166 931
Besteht ein Zusammenhang zwischen dem Geschlecht X und derParteipräferenz Y ?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 65 / 435
3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Kontingenztafel der absoluten Häugkeitena1 . . . , ak Merkmalswerte der Variablen X
b1, . . . , bm Merkmalswerte der Variablen Y
(k ×m)-Kontingenztafel der absoluten Häugkeiten
Yb1 . . . bm
a1 h11 . . . h1m h1·
X...
......
...ak hk1 . . . hkm hk·
h·1 . . . h·m n
hij = h(ai , bj) absolute Häugkeit der Kombination (ai , bj)h1·, . . . , hk· Randhäugkeiten der Variablen X (Zeilensummen)h·1, . . . , h·m Randhäugkeiten der Variablen Y (Spaltensummen)n Stichprobenumfang
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 66 / 435

3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Kontingenztafel der relativen Häugkeiten
(k ×m)-Kontingenztafel der relativen Häugkeiten
Yb1 . . . bm
a1 f11 . . . f1m f1·
X...
......
...ak fk1 . . . fkm fk·
f·1 . . . f·m 1
fij =hijn relative Häugkeit der Kombination (ai , bj)
fi · =∑m
j=1 fij = hi·n relative Randhäugkeiten der Variablen X
(Zeilensummen)
f·j =∑k
i=1 fij =f·jn relative Randhäugkeiten der Variablen Y
(Spaltensummen)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 67 / 435
3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Grasche Darstellung von (k ×m)-Kontingenztafeln
Säulendiagramm Säulenhöhe proportional zu hij bzw. fijMosaikplot Flächeninhalt der Rechtecke proportional zu hij bzw. fij
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 68 / 435

3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
h <- matrix(c(144 ,153 ,17 ,26 ,95 ,200 ,145 ,30 ,50 ,71) ,
nrow=2,byrow=TRUE); h
f <- h/sum(h)
f
dimnames(h)[[1]] <- c(" Männer","Frauen ")
dimnames(h)[[2]] <- c("CDU/CSU","SPD","FDP","Grüne","Rest")
h
barplot(h,beside=TRUE)
mosaicplot(h,col=c("black","red","yellow","green","gray "))
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 69 / 435
3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Zusammenhangsanalyse in Kontingenztafeln
Wie kann ein Zusammenhang von nominalen Merkmalen quantiziertwerden?
Yb1 . . . bm
a1 h11 . . . h1m h1·
X...
......
...ak hk1 . . . hkm hk·
h·1 . . . h·m n
Sind die beiden Merkmale X und Y unabhängig, würde man erwarten, dassdie Spalten proportional proportional zur Spalte der Zeilensummen sind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 70 / 435

3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Also:
∀j∈1,...,m
h1j...hkj
≈ proportional zu
h1·...hk·
oder äquivalent
∀j∈1,...,m
h1j/h·j...
hkj/h·j
≈ proportional zu
h1·/n...
hk·/n
Denn dann wäre die Verteilung von X unabhängig von der AusprägungY = bj ·Kurz:
∀i ,j
hij ≈hi · · h·j
n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 71 / 435
3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Wir bezeichnen jetzt mit
hij die beobachteten Häugkeiten
hij =hi··h·jn die Häugkeiten, die zu erwarten sind, wenn kein
Zusammenhang zwischen den Merkmalen X und Yvorliegt
Der sog. χ2-Koezient ist deniert durch
χ2 =k∑
i=1
m∑j=1
(hij − hij)2
hij∈ [0,∞)
und dient zur Messung der Diskrepanz zwischen der beobachtetenVerteilung und der Verteilung, die man bei Unabhängigkeit der beidenMerkmale erwarten würde.
Der Nenner dient zur Normierung.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 72 / 435

3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
Zur Interpretation des χ2-Koezienten:
Hängen X und Y voneinander ab, sollte χ2 groÿ sein.Hängen X und Y nicht voneinander ab, sollte χ2 nahe bei Null sein.
Erst die induktive Statistik stellt Methoden zur Verfügung, um zuentscheiden, ob die beobachteten Daten Anlass geben, an derUnabhängigkeit der Merkmale X und Y zu zweifeln.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 73 / 435
3. Deskriptive Statistik multivariater Daten 3.1. Diskrete multivariate Daten
h <- matrix(c(144 ,153 ,17 ,26 ,95 ,200 ,145 ,30 ,50 ,71) ,
nrow=2,byrow=TRUE); h
f <- h/sum(h); f
dimnames(h)[[1]] <- c(" Männer","Frauen ")
dimnames(h)[[2]] <- c("CDU/CSU","SPD","FDP","Grüne","Rest")
h
z.sum <- apply(h,1,sum) # Zeilensummen; z.sum
s.sum <- apply(h,2,sum) # Spaltensummen; s.sum
n <- sum(h)
htilde <- z.sum %*% t(s.sum)/n # erw. Häufigkeiten bei Unabh.
htilde
chisquare.coeff <- sum((h-htilde )^2/ htilde) # chi^2-Koeff.
chisquare.coeff
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 74 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Multivariate quantitative Merkmale
Zur Untersuchung quantitativer multivariater Daten sind die im letztenAbschnitt vorgestellten Methoden zur Untersuchung qualitativermultivariater Daten meist ungeeignet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 75 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Grasche Darstellungen quantitativer Merkmale
Für bivariate Daten:
Streudiagramme
2-dimensionale Histogramme und Dichten
Für multivariate Daten:
Matrix von Streudiagrammen
Matrix von 2-dimensionalen Histogrammen und Dichten
pairs(trees)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 76 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Zusammenhangsmaÿe bei quantitativen MerkmalenDer Bravais-Pearson-Korrelationskoezient zur Stichprobe(x1, y1), . . . , (xn, yn) ist deniert durch
r =
∑ni=1(xi − x)(yi − y)√∑n
i=1(xi − x)2√∑n
i=1(yi − y)2∈ [−1, 1]
Der Bravais-Pearson-Korrelationskoezient ist ein Maÿ für die Stärke deslinearen Zusammenhangs zweier metrischer Merkmale.r > 0 positive Korrelation, gleichsinniger linearer
Zusammenhangr < 0 negative Korrelation, gegensinniger linearer
Zusammenhangr = 0 keine Korrelation, kein linearer Zusammenhang|r | < 0.5 schwache Korrelation0.5 < |r | < 0.8 mittlere Korrelation0.8 < |r | starke Korrelation
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 77 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Beispiel
Obwohl der Bravais-Pearson-Koezient nur für metrische Variablendeniert ist, liefert er auch für dichotome, d.h. binäre, Variablen X und Yein sinnvolles Ergebnis, falls man 0 und 1 als Kodierung für dieMerkmalsvariable verwendet. Damit lassen sich die Ergebnisse in einer(2× 2)-Tabelle zusammenfassen:
Y0 1
X0 h11 h12 h1·1 h21 h22 h2·
h·1 h·2 n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 78 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Bemerkung
In diesem Fall besteht ein Zusammenhang mit dem χ2-Koezienten fürHäugkeitstabellen:
r =h11h22 − h12h21√
h1·h2·h·1h·2=
√χ2
n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 79 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Korrelationskoezient von Spearman
Stichprobe x1, ..., xnGeordnete Stichprobe x(1), ..., x(n)
Der Rang rg(xi ) von xi ist deniert als die Position von xi in dergeordneten Stichprobe. Es gilt also:
rg(x(i)) = i
Beispiel:Stichprobe 4, 2, 5, 0geordnete Stichprobe 0, 2, 4, 5Ränge der Stichprobe 3, 2, 4, 1Ränge der geordneten Stichprobe 1, 2, 3, 4
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 80 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Korrelationskoezient von Spearman
Treten gewisse Werte mehrfach in der Stichprobe auf, verwendet man denmittleren Rang:
Stichprobe 4, 3, 2, 3, 5geordnete Stichprobe 2, 3, 3, 4, 5Ränge 1, 2.5, 2.5, 4, 5
Ersetzt man im Korrelationskoezienten von Bravais-Pearson die X- undY-Werte durch ihre Ränge und x und y durch die Mittelwerte der Ränge(= n+1
2 ), so erhält man den Korrelationskoezient von Spearman:
rsp =
∑ni=1
(rg(xi )− n+1
2
)·(rg(yi )− n+1
2
)√∑ni=1
(rg(xi )− n+1
2
)2 ·√∑ni=1
(rg(yi )− n+1
2
)2 ∈ [−1, 1]
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 81 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Korrelationskoezient von Spearman
Der Korrelationskoezient von Spearman ist ein Maÿ für die Stärke desmonotonen Zusammenhangs zweier ordinaler Merkmale.
rsp > 0 gleichsinniger monotoner Zusammenhangrsp < 0 gegensinniger monotoner Zusammenhangrsp = 0 kein monotoner Zusammenhang
Der Spearmansche Korrelationskoezient eignet sich oensichtlich auch fürMessungen, die nur als Rangreihen vorliegen.Beispiel: Vergleich zweier Weinkenner, die zehn Weinproben der Qualitätnach ordnen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 82 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Invarianzeigenschaften
Werden die ursprünglichen Merkmale x und y linear transformiert, so bleibtder Korrelationskoezient von Bravais-Pearson (betragsmäÿig) invariant.
Werden die ursprünglichen Merkmale x und y mittels zweier strengmonotoner (wachsender oder fallender) Transformationen transformiert, sobleibt der Korrelationskoezient von Spearman-Korrelation (betragsmäÿig)invariant.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 83 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Korrelation und Kausalität
Korrelation ist ein Maÿ für die Stärke des Zusammenhangs zwischen x undy . Über die Richtung der Wirkung falls überhaupt vorhanden kanndamit prinzipiell keine Aussage getroen werden.
Probleme
Scheinkorrelation: Eine hohe Korrelation zweier Merkmale x und y
entsteht dadurch, dass x und y über ein drittes Merkmal hochkorreliert sind.Beispiel:Gesundheitszustand ∼ Abstand zur Hochspannungsleitung
Verdeckte Korrelation: Obwohl keine statistische Korrelationberechnet wurde, besteht sachlich eine eindeutige Korrelation.Beispiel: Blutdrucksenkung und Dosierung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 84 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Beispiel
Abbildung: Blutdrucksenkung und Dosierung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 85 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
help(trees)
attach(trees)
## Scatterplot -Matrix
pairs(trees)
## Korrelation zweier Merkmale
cor(Girth , Volume , method =" pearson ")
cor(Girth , Volume , method =" spearman ")
## Korrelations -Matrizen
cor(trees , method =" pearson ")
cor(trees , method =" spearman ")
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 86 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Lineare Regression
Problem: Gesucht ist eine Funktion f : R→ R, welche das metrischeMerkmal Y in Abhängigkeit des Merkmals X beschreibt.
Y = f (X )
Im Allgemeinen existiert jedoch kein solch klarer Zusammenhang. Deshalb:Suche f so, dass obiger Zusammenhang nur ungefähr erfüllt ist:
Y = f (X ) + ε
mit einem Fehlerterm ε, wobei ein möglichst groÿer Anteil der Variabilitätvon Y durch f erklärt werden soll.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 87 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Ein solches Modell heiÿt Regressionsmodell.
Bei einem linearen Regressionsmodell nimmt man
f (X ) = α + βX
an.
Für eine Stichprobe (x1, y1), . . . , (xn, yn) sind also ein y -Achsenabschnitt αund eine Steigung β gesucht, so dass
yi = α + βxi︸ ︷︷ ︸yi
+εi
mit möglichst kleinen Fehlern (Residuen) εi .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 88 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Methode der kleinsten Quadrate
Wähle α und β so, dass
Q(α, β) =1n
n∑i=1
ε2i
=1n
n∑i=1
(yi − yi )2
=1n
n∑i=1
(yi − (α + βxi ))2
minimal.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 89 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Ermittle die Kleinste-Quadrate-Schätzer α und β von α bzw. β alsNullstellen der partiellen Ableitung von Q nach α und β:
∂Q(α, β)
∂α= −2
n
n∑i=1
(yi − (α + βxi ))!
= 0 (1)
∂Q(α, β)
∂β= −2
n
n∑i=1
(yi − (α + βxi )) xi!
= 0 (2)
(sog. Normalengleichungen).Also
1n
n∑i=1
yi − α−1nβ
n∑i=1
xi = 0 (3)
1n
n∑i=1
yixi −1nα
n∑i=1
xi −1nβ
n∑i=1
x2i = 0 (4)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 90 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Aus (3):α = y − βx
Eingesetzt in (4):
1n
n∑i=1
yixi −1ny
n∑i=1
xi +1nβx
n∑i=1
xi −1nβ
n∑i=1
x2i = 0
Dies ist äquivalent zu
1n
n∑i=1
yixi − y x =1nβ
(n∑
i=1
x2i − nx2
)
Also
β =
∑ni=1 yixi − y x∑ni=1 x
2i − nx2
=1n
∑ni=1(xi − x)(yi − y)1n
∑ni=1(xi − x)2
=sxy
s2x
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 91 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Bestimmtheitsmaÿ und Residualanalyse
Zerlegung der Gesamtstreuung (sum of squares total)
SQT =n∑
i=1
(yi − y)2
=n∑
i=1
(yi − yi + yi − y)2
=n∑
i=1
(yi − yi )2 +
n∑i=1
(yi − y)2 + 2n∑
i=1
(yi − yi )(yi − y)︸ ︷︷ ︸= 0 mit (1) und (2)
= SQR + SQE
in die Residualstreuung (sum of squares residual) unddie erklärte Streuung (sum of squares explained).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 92 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Der dritte Term ist gleich Null, da
n∑i=1
(yi − yi )y = y
n∑i=1
(yi − yi ) = 0 mit (1)
n∑i=1
(yi − yi )yi =n∑
i=1
(yi − yi )α +n∑
i=1
(yi − yi )βxi
= α
n∑i=1
(yi − yi )︸ ︷︷ ︸= 0 mit (1)
+βn∑
i=1
(yi − yi )xi︸ ︷︷ ︸= 0 mit (2)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 93 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Das Bestimmtheitsmaÿ
R2 =SQE
SQT=
∑ni=1(yi − y)2∑ni=1(yi − y)2
∈ [0, 1]
gibt den relativen Anteil der erklärten Streuung an der Gesamtstreuung an.
Beziehung zum Korrelationskoezienten:
R2 = r2xy
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 94 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Begründung: Es gilt
¯y =1n
n∑i=1
yi =1n
n∑i=1
(α + βxi ) = α + βx
= (y − βx) + βx mit (3)
= y
daraus
n∑i=1
(yi − y)2 =n∑
i=1
(yi − ¯y)2
=n∑
i=1
(α + βxi − α− βx)2
= β2n∑
i=1
(xi − x)2
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 95 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
und schlieÿlich
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
=β2∑n
i=1(xi − x)2∑ni=1(yi − y)2
=s2xy s
2x
(s2x )2 s2y=
(sxy
sx sy
)2
= r2xy
Je näher R2 bei 1 liegt, umso besser ist die Modellanpassung.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 96 / 435

3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
Graphische Methode zur Überprüfung der Modellanpassung
Residualplots (xi , εi ) : i ∈ 1, . . . , n eignen sich zur Untersuchung derFrage, ob
die Daten durch ein lineares Modell hinreichend gut erklärt werdenkönnen
die Residuen von der erklärenden Variablen abhängen
eine Transformation einer Variablen sinnvoll sein könnte
Ausreiÿer vorliegen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 97 / 435
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
attach(trees)
## Lineare Regression
plot(Volume~Girth ,ylim=c(0 ,80))
mymodel <- lm(Volume~Girth)
mymodel
abline(mymodel)
## Bestimmtheitskoeffizient
summary(mymodel)$r.squared
## Residualanalyse
plot(Girth ,mymodel$residuals)
abline(h=0)
## In im folgenden Fall ist das lineare Modell ungeeignet
plot(Girth~Height)
mymodel <- lm(Girth~Height)
mymodel
summary(mymodel)$r.squared
plot(Girth ,mymodel$residuals)
abline(h=0)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 98 / 435
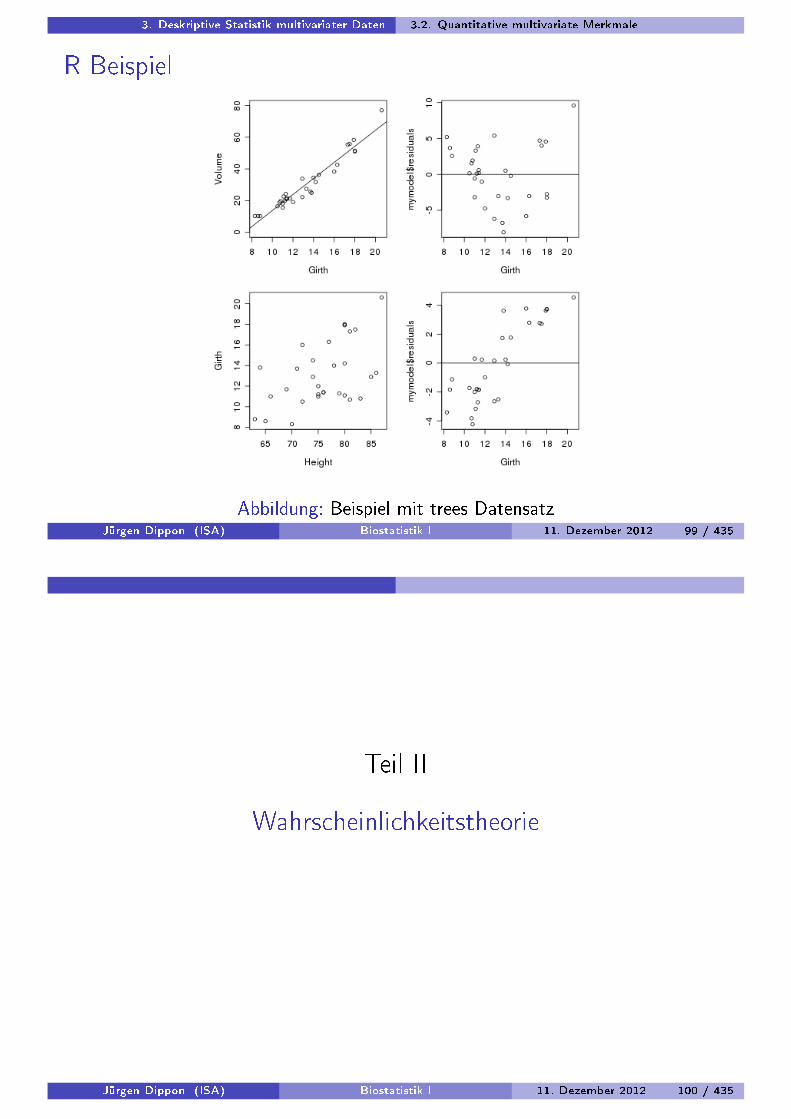
3. Deskriptive Statistik multivariater Daten 3.2. Quantitative multivariate Merkmale
R Beispiel
Abbildung: Beispiel mit trees DatensatzJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 99 / 435
Teil II
Wahrscheinlichkeitstheorie
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 100 / 435

Wahrscheinlichkeitstheorie
4 Wahrscheinlichkeitsrechnung
5 Diskrete Zufallsvariablen
6 Stetige Zufallsvariablen
7 Grenzwertsätze
8 Mehrdimensionale Zufallsvariablen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 101 / 435
4. Wahrscheinlichkeitsrechnung
4 WahrscheinlichkeitsrechnungDenition und Begri der WahrscheinlichkeitLaplace-ExperimenteKombinatorikModell mit ZurücklegenModell ohne ZurücklegenPermutationModell ohne Zurücklegen und ohne Berücksichtigung der ReihenfolgeModell mit Zurücklegen und ohne Berücksichtigung der Reihenfolge
Bedingte WahrscheinlichkeitenUnabhängigkeit von zwei EreignissenTotale WahrscheinlichkeitDer Satz von BayesUnendliche Grundgesamtheit
5 Diskrete Zufallsvariablen
6 Stetige Zufallsvariablen
7 Grenzwertsätze
8 Mehrdimensionale Zufallsvariablen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 102 / 435

4. Wahrscheinlichkeitsrechnung
Wahrscheinlichkeitsrechnung
Problem der Generalisierung: Besteht eine oensichtliche Korrelation zweierMerkmale (oder eine andere Eigenschaft) nur zufällig in der Stichprobeoder aber auch mit hoher Sicherheit in der Gesamtpopulation?
Dieses Problem kann nur gelöst werden, wenn man in der Lage ist,zufälligen Ereignissen eine Wahrscheinlichkeit zuzuweisen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 103 / 435
4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Denition und Begri der Wahrscheinlichkeit
Ein Zufallsvorgang führt zu einem von mehreren sich gegenseitigausschlieÿenden Ereignissen. Es ist vor der Durchführung ungewiss, welchesErgebnis tatsächlich eintreten wird.
Der Ergebnisraum oder Stichprobenraum Ω ist die Menge allerErgebnisse ω des Zufallsvorgangs.
Teilmengen von Ω heiÿen (Zufalls-) Ereignisse. Die einelementigenTeilmengen ω von Ω werden als Elementarereignisse bezeichnet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 104 / 435

4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Denition und Begri der Wahrscheinlichkeit
Sei A ⊂ Ω ein Ereignis. Das Ergebnis ω ∈ Ω werde beobachtet.
Falls ω ∈ A, so sagt man, dass das Ereignis A eintritt.
Falls ω ∈ A, so sagt man A tritt nicht ein.
Falls A = ∅, ist A das unmögliche Ereignis
Falls A = Ω, ist A das sichere Ereignis
A = Ω \ A ist das Ereignis, dass A nicht eintritt.A ∪ B ist das Ereignis, dass A oder B eintritt (im nichtexklusiven Sinne).A ∩ B ist das Ereignis, dass A und B eintritt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 105 / 435
4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Denition und Begri der Wahrscheinlichkeit
Beispiel:Einmaliges Werfen eines Würfels.
Ω = 1, 2, 3, 4, 5, 6 Grundraum, gleichzeitig das sichere EreignisA = 2, 4, 6 Ereignis, dass eine gerade Zahl geworfen wirdB = 1, 2 Ereignis, dass eine Zahl ≤ 2 geworfen wirdA ∩ B = 4, 6 Ereignis, dass eine gerade Zahl ≥ 3 geworfen wird
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 106 / 435

4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Denition und Begri der WahrscheinlichkeitUm den unsicheren Ausgang eines Zufallsvorganges zu bewerten, ordnetman jedem Ereignis A ⊂ Ω eine reelle Zahl ∈ [0, 1] zu:
P : A : A ⊂ Ω → [0, 1]
A 7→ P(A)
P(A) heiÿt Wahrscheinlichkeit des Ereignisses A.
Diese Abbildung P, das sog. Wahrscheinlichkeitsmaÿ, muss die Axiomevon Kolmogorov erfüllen (hier für Ω endlich)(K1) P(A) ≥ 0(K2) P(Ω) = 1(K3) Falls A ∩ B = ∅, dann gilt P(A ∪ B) = P(A) + P(B)
Diese Axiome werden motiviert durch die Eigenschaften relativerHäugkeiten, die zur Interpretation der Wahrscheinlichkeit herangezogenwerden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 107 / 435
4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Beispiel
Beispiel:n-malige unabhängige Wiederholung eines Würfelexperiments, das denErgebnissraum Ω = 1, ..., 6 besitzt.
fi relative Häugkeit, dass die Zahl i oben liegt
A = eine Zahl ≤ 3 liegt oben = 1, 2, 3f (A) relative Häugkeit des Eintretens von Ereignis A
f (A) = f1 + f2 + f3
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 108 / 435

4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Beispiel
Oder für allgemeines A ⊂ Ω:
f (A) =∑i∈A
fi︸︷︷︸≥0
∈ [0, 1]
f (Ω) = 1
Für wachsendes n erwarten wir, dass sich f(A) bei einem gewissen Wertstabilisiert (empirisches Gesetz der groÿen Zahlen). Dieser Wert wird alsWahrscheinlichkeit P(A) des Eintretens von A angesehen (frequentistischeoder objektivistische Interpretation des Wahrscheinlichkeitsbegris).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 109 / 435
4. Wahrscheinlichkeitsrechnung 4.1. Denition und Begri der Wahrscheinlichkeit
Rechenregeln für Wahrscheinlichkeiten
1 0 ≤ P(A) ≤ 1 für alle A ⊂ Ω
2 P(∅) = 03 P(A) ≤ P(B) falls A ⊂ B und A,B ⊂ Ω
4 P(A) = 1− P(A) mit A = Ω \ A5 P(A1 ∪ ... ∪ An) = P(A1) + ...+ P(An) falls A1, ...,An paarweise
disjunkt und Ai ⊂ Ω
6 P(A ∪ B) = P(A) + P(B)− P(A ∩ B) für beliebige A,B ⊂ Ω
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 110 / 435

4. Wahrscheinlichkeitsrechnung 4.2. Laplace-Experimente
Laplace-ExperimenteBei manchen Zufallsexperimenten mit endlichem Grundraum (alsoΩ = 1, ...,N) ist es sinnvoll davon auszugehen, dass alleElementarereignisse dieselbe Wahrscheinlichkeit, die sog.Laplace-Wahrscheinlichkeit, besitzen:
P(j) = pj =1N
=1|Ω|
für alle j ∈ 1, ...,N
Unter Verwendung der 5. Rechenregel folgt für jedes Ereignis A in einemLaplace-Experiment
P(A) =∑j∈A
P(j) =|A||Ω|
=Anzahl der für A günstigen ErgebnisseAnzahl aller möglichen Ergebnisse
Achtung: Es gibt viele Zusallsexperimente, in denen dieElementarereignisse nicht gleichwahrscheinlich sind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 111 / 435
4. Wahrscheinlichkeitsrechnung 4.2. Laplace-Experimente
Laplace-ExperimenteBeispiel:Wie groÿ ist die Wahrscheinlichkeit bei dreimaligem Münzwurf mindestenseinmal Wappen zu erzielen.
Ergebnisraum: Ω = (W ,W ,W ), (W ,W ,Z ), ..., (Z ,Z ,Z )|Ω| = 8
∀ω∈Ω
P(ω) =1|Ω|
=18
A = mindestens einmal Wappen, |A| = 7. Also
P(A) =|A||Ω|
=78
A = keinmal Wappen, |A| = 1. Also
P(A) = 1− P(A) = 1− 78
=18
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 112 / 435

4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Zufallsvariablen und Kombinatorik
Modell:N Kugeln mit Nummern 1,...,N benden sich in einer Urne. Ziehe inzufälliger Weise n Kugeln, entweder mit oder ohne Zurücklegen.
Ergebnis: geordnetes n-Tupel (E1, ...,En) mit Ei ∈ G = 1, ...,N.
Besitzt jede dieser Stichproben vom Umfang n dieselbe Wahrscheinlichkeit,so spricht man von einer einfachen Stichprobe.
Aufgabe: Bestimme diese Wahrscheinlichkeit
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 113 / 435
4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Modell mit Zurücklegen
Bei einer Ziehung mit Zurücklegen aus einer Grundgesamtheit vom UmfangN ist die Anzahl der möglichen Stichproben vom Umfang n gegeben als:
N · N · ... · N︸ ︷︷ ︸n−mal
= Nn
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 114 / 435

4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Modell ohne Zurücklegen
Bei einer Ziehung ohne Zurücklegen aus einer Grundgesamtheit vomUmfang N ist die Anzahl der möglichen Stichproben vom Umfang n
gegeben als:
N · (N − 1) · ... · (N − n + 1)︸ ︷︷ ︸n−Faktoren
=N · (N − 1) · ... · 1
(N − n) · ... · 1
=N!
(N − n)!
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 115 / 435
4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Permutation
Werden alle N Kugeln aus der Urne ohne Zurücklegen gezogen und gemäÿder Reihenfolge des Ziehens angeordnet, so ist (E1, ...,EN) einePermutation der Nummern 1, ...,N.
Bei N unterscheidbaren Objekten gibt es
N · (N − 1) · · · · · 1 = N!
verschiedene Permutationen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 116 / 435

4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Modell ohne Zurücklegen und ohne Berücksichtigung derReihenfolge
Bei einer Ziehung ohne Zurücklegen aus einer Grundgesamtheit vomUmfang N ist die Anzahl der möglichen Stichproben vom Umfang n beiNichtbeachten der Reihenfolge:
N · (N − 1) · ... · (N − n + 1)
n!=
N · (N − 1) · ... · 1n!(N − n)!
=
(N
n
)(Nn
)heiÿt Binomialkoezient und es gilt:(
N
0
)= 1,
(N
N
)= 1,
(N
1
)= N,
(N
n
)= 1, falls N < n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 117 / 435
4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Beispiel
Ziehung der Lottozahlen
Anzahl der Möglichkeiten 6 Zahlen aus 49 Zahlen zu ziehen, wobei dieReihenfolge nicht beachtet wird,(
496
)=
49!
43!6!= 13983816
Alle diese(496
)Zahlen können als gleichwahrscheinliche Elementarereignisse
angesehen werden. Damit
P(6 Richtige) =Anzahl der günstigen ErgebnisseAnzahl der möglichen Ergebnisse
=1
13983816= 0.000000072
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 118 / 435

4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Modell mit Zurücklegen und ohne Berücksichtigung derReihenfolge
Bei einer Ziehung mit Zurücklegen aus einer Grundgesamtheit vom UmfangN ist die Anzahl der möglichen Stichprobem vom Umfang n beiNichtbeachten der Reihenfolge gegeben durch:(
N + n − 1n
)Begründung: Durch N − 1 Trennzeichen können N verschiedene Zellenvoneinander abgegrenzt werden. Auf diese N Zellen werden insgesamt nKreuze verteilt, wobei Mehrfachbesetzungen erlaubt sind. Die Anzahl derKreuze gibt an, wieviele Kugeln vom Typ Ei in Zelle i liegen, z.B.
×|| × ×| × | . . . | × ×|
Die Anzahl solcher Aufteilungen der n Kreuze ist(N+n−1
n
).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 119 / 435
4. Wahrscheinlichkeitsrechnung 4.3. Kombinatorik
Übersicht
ohne Zurücklegen mit Zurücklegenmit Berücksichtigender Reihenfolge
N!(N−n)! Nn
ohne Berücksichtigender Reihenfolge
(Nn
) (N+n−1
n
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 120 / 435

4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Bedingte Wahrscheinlichkeiten
Analog zum (empirischen) Begri der bedingten relativen Häugkeitdenieren wir den (theoretischen) Begri der bedingten Wahrscheinlichkeiteines Ereignisses A gegeben ein Ereignis B .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 121 / 435
4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Beispiel: einmaliges Werfen eines Würfels
A Ereignis, dass Augenzahl geradeB Ereignis, dass Augenzahl ≤ 3
P(A) =36
=12
Wie groÿ ist die Wahrscheinlichkeit von A, wenn bekannt ist, dassAugenzahl ≤ 3?
P(A|B) =Anzahl der für A und B günstigen Ergebnisse
Anzahl der für B möglichen Ergebnisse
=13
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 122 / 435

4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Allgemein denieren wir (unter Verwendung der Beziehung zwischenrelativen Häugkeiten und Wahrscheinlichkeiten):
Seien A,B ⊂ Ω und P(B) > 0. Dann ist die bedingte Wahrscheinlichkeitvon A unter B deniert als
P(A|B) =P(A ∩ B)
P(B)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 123 / 435
4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Rechenregeln für bedingte Wahrscheinlichkeiten
Seien A,B ⊂ Ω und P(B) > 0. Dann gilt bei fest gehaltenem B
P(·|B) : A : A ⊂ Ω → [0, 1]
A 7→ P(A|B)
ist wieder eine Wahrscheinlichkeit mit P(B|B) = 1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 124 / 435

4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Die Axiome von Kolmogorov gelten entsprechend für bedingteWahrscheinlichkeiten
Zu (K3): A1,A2,B ⊂ Ω,A1 ∩ A2 = ∅,P(B) > 0:
P(A1 ∪ A2|B) =P((A1 ∪ A2) ∩ B)
P(B)
=P((A1 ∩ B) ∪ (A2 ∩ B))
P(B)
=P(A1 ∩ B) + P(A2 ∩ B)
P(B)
= P(A1|B) + P(A2|B)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 125 / 435
4. Wahrscheinlichkeitsrechnung 4.4. Bedingte Wahrscheinlichkeiten
Aus der Denition der bedingten Wahrscheinlichkeit folgt sofort der
Produktsatz: Seien A,B ⊂ Ω und P(B) > 0. Dann gilt
P(A ∩ B) = P(A|B) · P(B)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 126 / 435

4. Wahrscheinlichkeitsrechnung 4.5. Unabhängigkeit von zwei Ereignissen
Unabhängigkeit von zwei Ereignissen
Ist die Wahrscheinlichkeit des Ereignisses A unabhängig davon, ob dasEreignis B eingetreten ist, d.h.
P(A|B) = P(A) (1)
so werden die Ereignisse A und B als stochastisch unabhängig angesehen.Da
(1)⇐⇒ P(A ∩ B)
P(B)= P(A)⇐⇒ P(A ∩ B) = P(A) · P(B)
denieren wir:
Zwei Ereignisse A ⊂ Ω und B ⊂ Ω heiÿen (stochastisch) unabhängig,falls
P(A ∩ B) = P(A) · P(B)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 127 / 435
4. Wahrscheinlichkeitsrechnung 4.5. Unabhängigkeit von zwei Ereignissen
Beispiel: Zweimaliges Würfeln
Ω = (1, 1), . . . , (1, 6), (2, 1), . . . , (6, 6)|Ω| = 36∀
ω∈ΩP(ω) = 1
36
A = (1, 1), . . . , (1, 6) eine 1 im ersten WurfB = (1, 1), . . . , (6, 1) eine 1 im zweiten WurfP(A) = P(B) = 6
36 = 16
A ∩ B = (1, 1) eine 1 im ersten und im zweiten Wurf
P(A ∩ B)︸ ︷︷ ︸136
= P(A)︸ ︷︷ ︸16
·P(B)︸ ︷︷ ︸16
⇒ A und B sind stochastisch unabhängige Ereignisse
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 128 / 435

4. Wahrscheinlichkeitsrechnung 4.5. Unabhängigkeit von zwei Ereignissen
Beispiel: Urne mit den Zahlen 1, 2, 3, 4
Zweimaliges Ziehen mit Zurücklegen:Ω = (1, 1), (1, 2), . . . , (4, 4) mit |Ω| = 16
Zweimaliges Ziehen ohne Zurücklegen: Ω = (1, 2), (1, 3), . . . , (4, 3) mit|Ω| = 12
A = Die Eins wird beim ersten Mal gezogenB = Die Zwei wird beim zweiten Mal gezogen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 129 / 435
4. Wahrscheinlichkeitsrechnung 4.5. Unabhängigkeit von zwei Ereignissen
Ziehen mit Zurücklegen Ziehen ohne ZurücklegenP(A) 4
16 = 14
312 = 1
4P(B) 4
16 = 14
312 = 1
4P(A) · P(B) 1
16116
P(A ∩ B) 116
112
Also sind A und B beim Ziehen mit Zurücklegen stochastisch unabhängig,nicht jedoch beim Ziehen ohne Zurücklegen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 130 / 435

4. Wahrscheinlichkeitsrechnung 4.6. Totale Wahrscheinlichkeit
Totale Wahrscheinlichkeit
Ist Ω = A1 ∪ A2 eine disjunkte Zerlegung des Ergebnisraumes Ω(A1 ∩ A2 = ∅), so gilt für ein Ereignis B ⊂ Ω
B = (B ∩ A1) ∪ (B ∩ A2) wobei (B ∩ A1) ∩ (B ∩ A2) = ∅
und mit Axiom (K3)
P(B) = P(B ∩ A1) + P(B ∩ A2)
= P(B|A1) · P(A1) + P(B|A2) · P(A2)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 131 / 435
4. Wahrscheinlichkeitsrechnung 4.6. Totale Wahrscheinlichkeit
Etwas allgemeiner gilt der Satz der totalen Wahrscheinlichkeit:
Sei A1, . . . ,Ak eine disjunkte Zerlegung von Ω.Dann gilt für B ⊂ Ω
P(B) =k∑
i=1
P(B|Ai ) · P(Ai )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 132 / 435

4. Wahrscheinlichkeitsrechnung 4.6. Totale Wahrscheinlichkeit
Beispiel: Alarmanalyse
A = Alarm, E = Einbruch, E = kein Einbruch
P(A|E ) = 0, 99 W für Alarm bei EinbruchP(A|E ) = 0, 005 W für FehlalarmP(E ) = 0, 001 W für Einbruch
Wie groÿ ist die Wahrscheinlichkeit für einen Alarm?
P(A) = P(A|E ) · P(E ) + P(A|E ) · P(E )
= 0, 99 · 0, 001 + 0, 005 · (1− 0, 001)
≈ 0, 006
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 133 / 435
4. Wahrscheinlichkeitsrechnung 4.7. Der Satz von Bayes
Der Satz von Bayes
Ist A1 ∪ · · · ∪ Ak = Ω eine Zerlegung von Ω mit P(Ai ) > 0 und B einEreignis, so gilt für jedes j ∈ 1, . . . , k
P(Aj |B) =P(Aj ∩ B)
P(B)
=P(B|Aj) · P(Aj)
P(B)
=P(B|Aj) · P(Aj)∑ki=1 P(B|Ai ) · P(Ai )
wobei im letzten Schritt der Satz von der totalen Wahrscheinlichkeitverwendet wurde.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 134 / 435

4. Wahrscheinlichkeitsrechnung 4.7. Der Satz von Bayes
Satz von Bayes
A1, . . . ,Ak disjunkte Zerlegung von Ω mit P(A1) > 0, . . . ,P(Ak) > 0B ⊂ Ω ein Ereignis mit P(B) > 0Dann gilt für alle j ∈ 1, . . . , k
P(Aj |B) =P(B|Aj) · P(Aj)∑ki=1 P(B|Ai ) · P(Ai )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 135 / 435
4. Wahrscheinlichkeitsrechnung 4.7. Der Satz von Bayes
Interpretation:
Werden die Ereignisse A1, . . . ,Ak als mögliche Ursachen für das Ereignis Bangesehen, so gibt P(B|Ai ) die (bedingte) Wahrscheinlichkeit an, dass beiVorliegen von Ereignis Ai die Wirkung B eintritt.
Die Formel von Bayes erlaubt jetzt einen wahrscheinlichkeitstheoretischenRückschluss von der Wirkung B auf die mögliche Ursache Aj
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 136 / 435

4. Wahrscheinlichkeitsrechnung 4.7. Der Satz von Bayes
Beispiel: Fortsetzung Alarmanalyse
Wie groÿ ist die Wahrscheinlichkeit, dass ein Einbruch im Gange ist, wennein Alarm ertönt?
P(E |A) =P(A|E ) · P(E )
P(A|E ) · P(E ) + P(A|E ) · P(E )
≈ 0, 99 · 0, 0010, 006
≈ 0.165
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 137 / 435
4. Wahrscheinlichkeitsrechnung 4.8. Unendliche Grundgesamtheit
Unendliche Grundgesamtheit
Beispiel: Anzahl der Würfe eines Würfels bis zur ersten 6
Ω = 1, 2, 3, ..., also |Ω| =∞
P(2 Würfe bis zur ersten 6)= P(1. Wurf keine 6) · P(2. Wurf eine 6|1. Wurf keine 6)
= P(1. Wurf keine 6) · P(2. Wurf eine 6)
=56· 16
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 138 / 435

4. Wahrscheinlichkeitsrechnung 4.8. Unendliche Grundgesamtheit
Unendliche GrundgesamtheitAllgemeiner:Ai = i-ter Wurf keine 6Bi = i-ter Wurf eine 6Ci = Spiel endet nach i Würfen
P(Ci ) = P(A1 ∩ ... ∩ Ai−1 ∩ Bi )
= P(A1) · P(A2) · ... · P(Ai−1) · P(Bi )
=56· 56· ...5
6· 16
=
(56
)i−1· 16
Da hier i beliebig groÿ werden kann, sollte das 3. Axiom von Kolmogorovauch für abzählbar unendliche Vereinigungen von Ereignissenverallgemeinert werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 139 / 435
4. Wahrscheinlichkeitsrechnung 4.8. Unendliche Grundgesamtheit
Axiome von Kolmogorov
Axiome von Kolmogorov für unendliche Ergebnisräume:(K1) P(A) ≥ 0 für alle Ereignisse A ⊂ Ω(K2) P(Ω) = 1
(K3) Für paarweise disjunkte Ereignisse A ⊂ Ω gilt:P(A1 ∪ A2 ∪ ...) =
∑∞i=1 P(Ai )
Alle bislang hergeleiteten Rechenregeln gelten auch für unendlicheErgebnisräume.
Später werden wir sehen, dass sich die Wahrscheinlichkeit einesüberabzählbaren Ereignisses nicht als Summe der Wahrscheinlichkeiten dereinzelnen Ergebnisse darstellen lässt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 140 / 435

5. Diskrete Zufallsvariablen
4 Wahrscheinlichkeitsrechnung
5 Diskrete ZufallsvariablenZufallsvariablenVerteilungen und Parameter von diskreten ZufallsvariablenSpezielle diskrete VerteilungsmodelleDie BinomialverteilungDie hypergeometrische VerteilungDie Poisson-Verteilung
6 Stetige Zufallsvariablen
7 Grenzwertsätze
8 Mehrdimensionale Zufallsvariablen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 141 / 435
5. Diskrete Zufallsvariablen
Diskrete Zufallsvariablen
In den Kapiteln 57 werden grundlegende Begrie und Eigenschaften vonunivariaten (d.h. eindimensionalen) Zufallsvariablen eingeführt.
Insbesondere wird zwischen diskreten und stetigen Zufallsvariablenunterschieden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 142 / 435

5. Diskrete Zufallsvariablen 5.1. Zufallsvariablen
Zufallsvariablen
Beispiel: 2-maliges Würfeln
Ω = (1, 1), . . . , (6, 6), |Ω| = 36Summe der Augenzahlen werde beschrieben durch die Variable:
X : Ω→ 2, . . . , 12ω︸︷︷︸
(i ,j)
7→ X (ω) = i + j
X ist Beispiel einer Zufallsvariablen, die jedem Ergebnis ω ∈ Ω eine reelleZahl zuordnet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 143 / 435
5. Diskrete Zufallsvariablen 5.1. Zufallsvariablen
Zufallsvariablen
Frage: Wie groÿ ist die Wahrscheinlichkeit, dass die Augensumme ≤ 4 ist?Gesucht ist also P(A) mit:
A = X ≤ 4 = (1, 1), (1, 2), (2, 1), . . . , (1, 3), (2, 2), (3, 1)
P(A) = P(X = 2)︸ ︷︷ ︸136
+P(X = 3)︸ ︷︷ ︸236
+P(X = 4)︸ ︷︷ ︸336
=16
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 144 / 435

5. Diskrete Zufallsvariablen 5.1. Zufallsvariablen
Zufallsvariablen
Eine Variable oder ein Merkmal X, dessen Werte oder Ausprägungen dieErgebnisse eines Zufallsvorgangs sind, heiÿt Zufallsvariable X.
Die Zahl x ∈ R, die X bei Durchführung des Zufallsvorgangs annimmt,heiÿt Realisierung oder Wert von X.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 145 / 435
5. Diskrete Zufallsvariablen 5.1. Zufallsvariablen
Zufallsvariablen
Von Interesse sind oft Ereignisse der Form:
X = x = ω ∈ Ω|X (ω) = xX 6= x = ω ∈ Ω|X (ω) 6= xX ≤ x = ω ∈ Ω|X (ω) ≤ x
oder allgemein für einen Bereich B ⊂ R:
X ∈ B = ω ∈ Ω|X (ω) ∈ B
Die Menge aller Wahrscheinlichkeiten P(X ∈ B) für Bereiche B nennt manWahrscheinlichkeitsverteilung von X.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 146 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Verteilungen und Parameter von diskreten Zufallsvariablen
Eine Zufallsvariable X heiÿt diskret, falls sie nur endlich oder abzählbarunendlich viele Werte x1, x2, . . . annehmen kann. DieWahrscheinlichkeitsverteilung von X ist durch die Wahrscheinlichkeiten:
P(X = xi ) = pi = f (xi ), i = 1, 2, ..
gegeben. Die Folge (pi ) bzw. die Funktion f heiÿt auch Zähldichte von X .Die Wertemenge von X wird auch als Träger von X bezeichnet:
T = x1, x2, . . .
Ist B eine Teilmenge des Trägers von X, so folgt mit Axiom (K3):
P(X ∈ B) =∑i :xi∈B
pi
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 147 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Verteilungen und Parameter von diskreten Zufallsvariablen
Bei einem endlichen Wertebereich x1, . . . , xk ist dieWahrscheinlichkeitsverteilung (Zähldichte) p1, . . . pk daswahrscheinlichkeitstheoretische Analogon zur relativen Häugkeitsverteilungf1, . . . , fk .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 148 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Bernoulli-Verteilung
Besitzt der Wertebereich von X nur zwei Werte x1 und x2, so ist X einebinäre oder dichothome Zufallsvariable.
Beispiel:
X =
1, falls Kunde kreditwürdig0, falls Kunde nicht kreditwürdig
Sei A = Kunde kreditwürdig. Dann
P(A) = P(X = 1) = p und P(A) = P(X = 0) = 1− p
X ist eine Bernoulli-Variable, kurz X ∼ Bin(1, p). Die dazugehörigeVerteilung heiÿt Bernoulli-Verteilung.
Grasche Darstellung durch ein Stab- oder Säulendiagramm oder einWahrscheinlichkeitsdiagramm.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 149 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Verteilungsfunktion
Verteilungsfunktion einer diskreten Zufallsvariable:
F (x) = P(X ≤ x) =∑i :xi≤x
f (xi )
Diese Verteilungsfunktion besitzt viele Eigenschaften der empirischenVerteilungsfunktion:
monoton wachsende Treppenfunktion
F (x)→ 0 für x → −∞F (x)→ 1 für x →∞F (x) macht Sprünge der Höhe f (xi ) = pi an xi
F (x) rechtsstetig an den Sprungstellen
(Die empirische Verteilungsfunktion macht Sprünge der Höhe 1n oder
Vielfache davon.)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 150 / 435
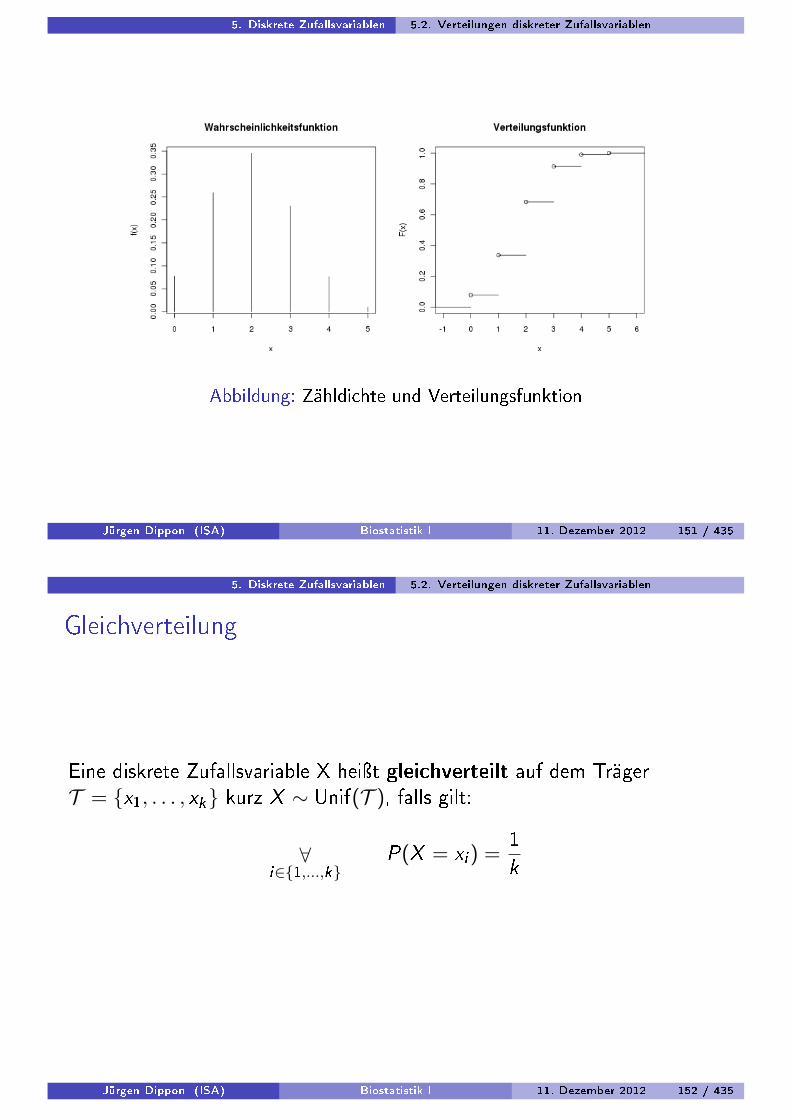
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Abbildung: Zähldichte und Verteilungsfunktion
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 151 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Gleichverteilung
Eine diskrete Zufallsvariable X heiÿt gleichverteilt auf dem TrägerT = x1, . . . , xk kurz X ∼ Unif(T ), falls gilt:
∀i∈1,...,k
P(X = xi ) =1k
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 152 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Geometrische Verteilung
Eine diskrete Zufallsvariable X heiÿt geometrisch(p)-verteilt, kurzX ∼ Geo(p), falls gilt:
∀i∈N0
P(X = i) = (1− p)i−1p
Eine Geo(p)-verteilte Zufallvariable X zählt die Anzahl der Versuche ineiner Folge von unabhängigen Zufallsexperimenten mit jeweiligerErfolgswahrscheinlichkeit p ∈ (0, 1) bis zum ersten Erfolg:
A = ( 0, 0, . . . , 0︸ ︷︷ ︸i−1 Misserfolge
, 1︸︷︷︸1. Erfolg
)
P(A) = (1− p) · (1− p) · . . . · (1− p) · p = (1− p)i−1p
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 153 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Unabhängigkeit
Zwei diskrete Zufallsvariablen X und Y mit den Trägern TX = x1, x2, . . .und TY = y1, y2, . . . heiÿen unabhängig, wenn für beliebige x ∈ TX undy ∈ TY gilt:
P(X = x ,Y = y) = P(X = x) · P(Y = y)
Allgemeiner heiÿen n diskrete Zufallsvariablen X1, . . . ,Xn unabhängig,wenn für beliebige Werte x1, . . . , xn aus den jeweiligen Trägern gilt:
P(X1 = x1, . . . ,Xn = xn) = P(X1 = x1) · . . . · P(Xn = xn)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 154 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Unabhängigkeit
Sind zwei diskrete Zufallsvariablen X und Y unabhängig, folgt dieUnabhängigkeit der Ereignisse X ∈ A und Y ∈ B, d.h.
P(X ∈ A,Y ∈ B) = P(X ∈ A) · P(Y ∈ B)
Nachweis mit Axiom (K3).
Beispiel: Unabhängigkeit beim Werfen zweier WürfelX Augenzahl im 1. Wurf, Y Augenzahl im 2. Wurf
P(X = i ,Y = j)︸ ︷︷ ︸136
= P(X = i)︸ ︷︷ ︸16
·P(Y = j)︸ ︷︷ ︸16
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 155 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Lageparamter einer diskreten Verteilung
Analog zum arithmetischen Mittel einer Stichprobe denieren wir:
Der Erwartungswert E (X ) einer diskreten Zufallsvariable mit den Wertenx1, x2, . . . und der Wahrscheinlichkeitsverteilung p1, p2, . . . bzw. derWahrscheinlichkeitsfunktion f (x) ist deniert durch:
E (X ) =∑i∈N
xipi
=∑i∈N
xi f (xi )
Der Erwartungswert einer Zufallsvariable X ist damit das mit derWahrscheinlichkeit des Auftretens gewichtete Mittel der Werte.
Beim arithmetischen Mittel x einer Stichprobe wird statt pi bzw. f (xi ) dierelative Häugkeit fi von xi in der Stichprobe verwendet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 156 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Beispiel
Beispiel: Erwartungswert beim WürfelDie Variable X gebe die Augenzahlen an
E (X ) =∑
xipi =6∑
i=1
i · 16
=16
(1 + . . .+ 6) =216
= 3, 5
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 157 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Beispiel
Beispiel: Mittlere Anzahl der Versuche bis zum 1. Erfolg bei unabhängigenBernoulli-Versuchen mit jeweiliger Erfolgswahrscheinlichkeit p ∈ (0, 1)
X ∼ Geo(p), d.h. P(X = i) = (1− p)i−1p, i ∈ 1, 2, . . .
E (X ) =∞∑i=0
i(1− p)i−1p = p
∞∑i=0
i(1− p)i−1
= −p∞∑i=0
d
dp(1− p)i = −p d
dp
∞∑i=0
(1− p)i
= −p d
dp
11− (1− p)
= −p d
dp
1p
= p · 1p2
=1p> 1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 158 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
ErwartungswertIst g(x) eine reelle Funktion, dann gilt für die Zufallsvariable Y = g(X ):
E (Y ) = E (g(X )) =∑i≥1
g(xi )pi =∑i≥1
g(xi )f (xi )
Beispiel: g(x) = x2
E (X 2) =∑i≥1
x2i pi = x21p1 + x22p2 + . . .
Beispiel: g(x) = ax + b
E (aX + b) =∑i≥1
(axi + b)pi = a∑i≥1
xipi︸ ︷︷ ︸E(X )
+b∑i≥1
pi︸ ︷︷ ︸1
= aE (x) + b
Erwartungswertbildung ist also linear.Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 159 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Beispiel
Beispiel: Ist die Wahrscheinlichkeitsfunktion f (x) symmetrisch um c, sogilt:
E (X ) = E (X − c) + Ec
=∑i≥1
(xi − c)f (xi )︸ ︷︷ ︸0
+c
= c
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 160 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Weitere Eigenschaften
Die folgende Tatsache ist aufwändig zu zeigen:
Für zwei diskrete Zufallsvariablen X und Y gilt:
E (X + Y ) = E (X ) + E (Y )
und allgemeiner für beliebige Konstanten a1, . . . , an:
E (a1X1 + . . .+ anXn) = a1E (X1) + . . .+ anE (Xn)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 161 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Produktregel
Für zwei unabhängige diskrete Zufallsvariablen gilt die Produktregel:
E (X · Y ) = E (X ) · E (Y )
Beispiel: Beim 2-maligen Würfeln gilt für die Augenzahlen X (erster Wurf)und Y (zweiter Wurf):
E (X · Y ) = E (X ) · E (Y ) =72· 72
=494
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 162 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Weitere Lageparameter
Der Modus xmod ist derjenige x-Wert, der f (x) = P(X = x) maximalmacht.
Für jeden Wert p ∈ (0, 1) ist xp ein p-Quantil, falls
P(X ≤ xp) = F (xp) ≥ p und P(X ≥ xp) ≥ 1− p
Mit dieser Denition ist xp u.U. nicht eindeutig deniert. Sind mehrereWerte möglich, so kann man z.B. den mittleren Wert wählen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 163 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Streungsparameter für eine diskrete Zufallsvariable X
Die Varianz einer diskreten Zufallsvariable ist:
σ2 = Var(X ) =∑i≥1
(xi − µ)2f (xi ) = E ((X − µ)2)
wobei µ = E (X ).
Die Standardabweichung ist:
σ = +√Var(X )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 164 / 435

5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Streuungsparameter für eine diskrete Zufallsvariable X
Wie bei empirischen Varianzen gilt die Verschiebungsregel:
Var(X ) = E (X 2)− (E (X ))2 = E (X 2)− µ2
und für Y = aX + b
Var(Y ) = Var(aX + b) = a2Var(X ) und σY = |a|σX
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 165 / 435
5. Diskrete Zufallsvariablen 5.2. Verteilungen diskreter Zufallsvariablen
Beispiel
Augenzahl X beim Würfeln
Var(X ) = E (X 2)− (E (X ))2
= 12 · 16
+ 22 · 16
+ . . .+ 62 · 16−(72
)2
=16· (12 + 22 + . . .+ 62)︸ ︷︷ ︸
91
−(72
)2
= . . . =7024
= 2, 92
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 166 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Die BinomialverteilungFolge von n unabhängigen Bernoulli-Versuchen X1, . . . ,Xn mit jeweiligenErfolgswahrscheinlichkeiten p, wobei
Xi =
0 mit Wahrscheinlichkeit 1− p
1 mit Wahrscheinlichkeit p
Gesucht ist nun die Wahrscheinlichkeit für genau k Erfolge:
0 . . . 0︸ ︷︷ ︸n−k
1 . . . 1︸ ︷︷ ︸k
Wahrscheinlichkeit für genau dieses Ergebnis: (1− p)n−k · pk
Anzahl verschiedener Permutationen:(nk
)Alle Permutatonen sind gleich wahrscheinlich. Also:
P(k Erfolge bei n Versuchen) =
(n
k
)pk(1− p)n−k
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 167 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Die Binomialverteilung
X = X1 + . . .+ Xn sei die Anzahl der Erfolge bei n Versuchen. Dann ist:
E (X ) = E (X1 + . . .+ Xn) = E (X1) + . . .+ E (Xn) = n E (X1)︸ ︷︷ ︸0·(1−p)+1·p
= np
Wegen Unabhängigkeit der X1, . . . ,Xn folgt:
Var(X ) = Var(X1 + . . .+ Xn) = Var(X1) + . . .+ Var(Xn) = nVar(X1)
= n(E (X 21 )− (E (X1))2)
= n(02 · (1− p) + 12 · p − p2) = np(1− p)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 168 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Die Binomialverteilung
Additionseigenschaft der BinomialverteilungSind X ∼ Bin(n, p) und Y ∼ Bin(m, p) unabhängig, so gilt:
X + Y ∼ Bin(n + m, p)
SymmetrieeigenschaftSei X ∼ Bin(n, p) und Y = n − X , dann gilt
Y ∼ Bin(n, 1− p)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 169 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Beispiel
Beispiel: QualitätskontrolleIn einer Zucht von Austern entstehen mit Wahrscheinlichkeit p = 0.9fehlerfreie Perlen.Aus der Population werden n = 20 Perlen entnommen. Sei X die Anzahlder fehlerfreien Perlen, also:
X ∼ Bin(20, 0.9) und Y = n − X ∼ Bin(20, 0.1)
Wie groÿ ist die Wahrscheinlichkeit, dass höchstens 18 der 20 Perlenfehlerfrei sind?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 170 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Beispiel
P(X ≤ 18) = 1− P(X = 19 oder X = 20)
= 1−(2019
)0.919 · 0.11 −
(2020
)0.920 · 0.10
= 1− 20 · 0.919 · 0.1− 0.920
≈ 0.61
P(X = 18) =
(2018
)· 0.918 · 0.12 ≈ 0.285
E (X ) = n · p = 20 · 0.9 = 18
Var(X ) = n · p(1− p) = 20 · 0.9 · 0.1 = 1.8, also σ ≈ 1.34
Im Zusammenhang mit dem zentralen Grenzwertsatz werden wir sehen,dass X ungefähr normalverteilt ist mit Erwartungswert 18 und Varianz 1.8
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 171 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Die hypergeometrische VerteilungIn einem Aquarium benden sich N Fische, M davon sind männlich.
00 . . . 0︸ ︷︷ ︸M
11 . . . 1︸ ︷︷ ︸N−M︸ ︷︷ ︸
N
Es werden n Fische ohne Zurücklegen herausgezogen.Wie groÿ ist die W., genau X = k männliche Fische zu ziehen?Stichprobe
0 . . . 0︸ ︷︷ ︸k
1 . . . 1︸ ︷︷ ︸n−k︸ ︷︷ ︸
n
P(X = k) =Anzahl der günstigen ErgebnisseAnzahl der möglichen Ergebnisse
=
(Mk
)·(N−Mn−k
)(Nn
)Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 172 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
X kann nicht gröÿer werden als
n, falls n ≤ M
M, falls n > M
X kann nicht kleiner werden als
0,
n − (N −M),
Also gilt für den Träger von X :T = max (0, n − (N −M)) , . . . ,min(n,M)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 173 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Eine Zufallsvariable heiÿt hypergeometrisch verteilt mit Parameternn,M,N, kurz X ∼ Hyp(n,M,N), wenn sie die Wahrscheinlichkeitsfunktion
f (k) =
(Mk )(N−Mn−k )
(Nn), falls x ∈ T
0 , sonst
Es gilt
E (X ) = nM
N, Var(X ) = n
M
N
(1− M
N
)N − n
N − 1
Ist N groÿ im Vergleich yu n (Faustregel nN ≤ 0.05), so kann X als nahezu
Bin(N, MN )-verteilt angesehen werden.Zum Vergleich: Sei Y ∼ Bin
(N, MN
). Dann
E (Y ) = nM
N= E (X )
Var(Y ) = nM
N
(1− M
N
)> Var(X )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 174 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Abbildung: Zähldichte- und Verteilungsfunktion der Hyp(6, 6, 10)-Verteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 175 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Die Poisson-Verteilung
Binomial- und hypergeometrisch verteilte Zufallsvariablen zählen, wie oftbei n-maligem Ziehen ein bestimmtes Ereignis eintritt: T = 0, 1, . . . , n
Die geometrische Verteilung zählt, wie lange man warten muss bis einbestimmtes Ereignis zum ersten Mal eintrit: T = N
Eine Poisson-verteilte Zufallsvariable zählt, wie oft ein bestimmtesEreignis innerhalb eines (Zeit-)Intervalles eingetreten ist: T = N0
Die Poisson-Verteilung lässt sich herleiten1 als Grenzfall der Binomial-Verteilung oder2 aus den Poisson-Annahmen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 176 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
zu 1): Die Wahrscheinlichkeit, dass das Erbgut eines Einzellers nachRöntgenbestrahlung eine Mutation aufweist, sei p = 1
1000 .
In einer Kultur benden sich n = 500000 Einzeller.
Wie groÿ ist die Wahrscheinlichkeit, dass sich in der Kultur nachRöntgenbestrahlung k mutierte Individuen benden?
X = Anzahl der Mutationen
P(X = k) =
(n
k
)pk(1− p)n−k
=n · . . . · (n − k + 1)
k!︸ ︷︷ ︸≈ nk
k!
pk (1− p)n︸ ︷︷ ︸[(1−p)
1p
]np (1− p)−k︸ ︷︷ ︸≈1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 177 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Da(1 + 1
n
)n → e für n→∞ folgt für kleines p und groÿes n und λ = np
P(X = k) ≈ λk
k!e−λ , k ∈ 0, 1, . . . , n
Eine Zufallsvariable X mit der Wahrscheinlichkeitsfunktion
f (k) = P(X = k) =
λk
k! e−λ für k ∈ N0
0 sonst
heiÿt Poisson-verteilt mit Parameter (oder Rate) λ > 0, kurz X ∼ Pois(λ)Es gilt
E (X ) = λ, Var(X ) = λ
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 178 / 435

5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Finden im Zeitintervall [0, 1] zufällig Ereignisse statt, so ist die Anzahl Xder in [0, 1] beobachteten Ereignisse Pois(λ)-verteilt, falls die folgendenPoisson-Annahmen gelten:
Zwei Erreignisse können nicht gleichzeitig auftreten
P (Anzahl der Ereignisse in [t, t + ∆t]) ≈ λ∆t für ∆t kein
P (Anzahl der Ereignisse in [t, t + ∆t]) nur abhängig von ∆t
Für zwei disjunkte Intervalle I1, I2 ⊂ [0, 1] gilt:N1 und N2 sind zwei unabhängige Zufallsvariablen, wobei Ni = Anzahlder Ereignisse in Ii
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 179 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Ähnlich wie bei der Binomial-Verteilung gilt eine Additionseigenschaft fürPoisson-verteilte Zufallsvariablen sind X ∼ Pois(λ) und Y ∼ Pois(µ)unabhängig, so gilt
X + Y ∼ Pois(λ+ µ)
Damit lässt sich dann zeigen:Ist die Anzahl X von Ereignissen in [0, 1] Pois(λ)-verteilt, so ist die AnzahlZ von Ereignissen in [0, t] Pois(λt)-verteilt.
Beispiele für Poisson-verteilten Zufallsvariablen:
Anzahl radioaktiver Zerfälle in einem gegebenen Zeitintervall
Anzahl der durch Blitzschlag in einem Jahr getöteten Personen
Anzahl von Morden in einer Groÿstadt
Anzahl von HIV-Inzierten in einem Stadtteil
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 180 / 435
5. Diskrete Zufallsvariablen 5.3. Spezielle diskrete Verteilungsmodelle
Abbildung: Zähldichte- und Verteilungsfunktion der Pois(3)-Verteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 181 / 435
6. Stetige Zufallsvariablen
4 Wahrscheinlichkeitsrechnung
5 Diskrete Zufallsvariablen
6 Stetige ZufallsvariablenSpezielle stetige VerteilungsmodelleGleichverteilungExponentialverteilung
Lageparameter, Quantile und Varianz von stetigen ZufallsvariablenErwartungswertModus, Quantil und MedianVarianz und Standardabweichung
Normalverteilung
7 Grenzwertsätze
8 Mehrdimensionale Zufallsvariablen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 182 / 435

6. Stetige Zufallsvariablen
Stetige Zufallsvariablen
Zur Erinnerung: Eine diskrete Zufallsvariable X nimmt Werte in einerendlichen oder abzählbaren, also diskreten, Menge T = x1, x2, . . . an.
Für deren Verteilungsfunktion F gilt
F (x) = P(X ≤ x) =∑
i : xi≤xf (xi ) (1)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 183 / 435
6. Stetige Zufallsvariablen
Eine stetige Zufallsvariable X nimmt Werte in einer überabzählbarenkontinuierlichen Menge T , z.B. T = R, T = [0, 1] oder T = (0,∞) an.
Für deren Verteilungsfunktion kann die Gleichung (1) jetzt NICHT mehrgelten.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 184 / 435

6. Stetige Zufallsvariablen
Stattdessen und genauer:
Eine Zufallsvariable X heiÿt stetig, wenn es eine Funktion f (t) ≥ 0 gibt, sodass für jedes x ∈ R
F (x) = P(X ≤ x) =
∫ x
−∞f (t) dt
f (x) heiÿt (Wahrscheinlichkeits-)Dichte von X .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 185 / 435
6. Stetige Zufallsvariablen
Für stetige Zufallsvariablen gilt:
P(a ≤ X ≤ b) = P(a < X < b)
= P(a ≤ X < b)
= P(a < X ≤ b) =
∫ b
a
f (t) dt = F (b)− F (a)
und P(X = x) = 0 für jedes x ∈ R
Da P(−∞ < X <∞) = 1 gilt auch∫ ∞−∞
f (t) dt = 1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 186 / 435

6. Stetige Zufallsvariablen
Weitere Eigenschaften der Verteilungsfunktion einer stetigen Zufallsvariable:
1 F (x) ist stetig und monoton wachsend mit Werten in [0, 1]
2 limx→−∞F (x) = 0, limx→∞F (x) = 13 Für Werte x , an denen f (x) stetig ist, gilt
F ′(x) =dF (x)
dx= f (x)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 187 / 435
6. Stetige Zufallsvariablen
Zwei stetige Zufallsvariablen X und Y sind unabhängig, wenn für allex ∈ R und y ∈ R
P(X ≤ x ,Y ≤ y) = P(X ≤ x) · P(Y ≤ y) = FX (x) · FY (y)
Allgemeiner: Die stetigen Zufallsvariablen X1, . . . ,Xn sind unabhängig, fallsfür alle x1, . . . , xn ∈ R
P(X1 ≤ x1, . . . ,Xn ≤ xn) = P(X1 ≤ x1) · . . . · P(Xn ≤ xn)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 188 / 435

6. Stetige Zufallsvariablen 6.1. Spezielle stetige Verteilungsmodelle
Gleichverteilung
Eine stetige Zufallsvariable heiÿt gleichverteilt auf dem Intervall [a, b],kurz X ∼ Unif ([a, b]), wenn sie eine Dichte
f (x) =
1
b−a für a ≤ x ≤ b
0 sonst
besitzt.
Dazugehörige Verteilungsfunktion
F (x) =
0 x < a
x−ab−a a ≤ x ≤ b
1 x > b
An den Knickstellen x = a und x = b ist F nicht dierenzierbar.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 189 / 435
6. Stetige Zufallsvariablen 6.1. Spezielle stetige Verteilungsmodelle
Abbildung: Dichte- und Verteilungsfunktion der Gleichverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 190 / 435

6. Stetige Zufallsvariablen 6.1. Spezielle stetige Verteilungsmodelle
Exponentialverteilung
Die geometrische Verteilung dient zur Beschreibung der Wartezeit bis zueinem bestimmten Ereignis. Ein stetiges Analogon hierzu ist dieExponentialverteilung:
Eine stetige Zufallsvariable X mit nichtnegativen Werten heiÿtexponentialverteilt mit dem Parameter λ > 0, kurz X ∼ Exp(λ), wenn siedie Dichte
f (x) =
λe−λx für x ≥ 00 für x < 0
besitzt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 191 / 435
6. Stetige Zufallsvariablen 6.1. Spezielle stetige Verteilungsmodelle
Exponentialverteilung
Dazugehörige Verteilungsfunktion
F (x) =
1− e−λx für x ≥ 0
0 für x < 0
Man kann zeigen, dass die Anzahl von Ereignissen in einem Zeitintervall derLänge t Pois(λt)-verteilt ist, wenn die Zeitdauern zwischen aufeinanderfolgenden Ereignissen unabhängig und exponentialverteilt mit Parameter λsind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 192 / 435
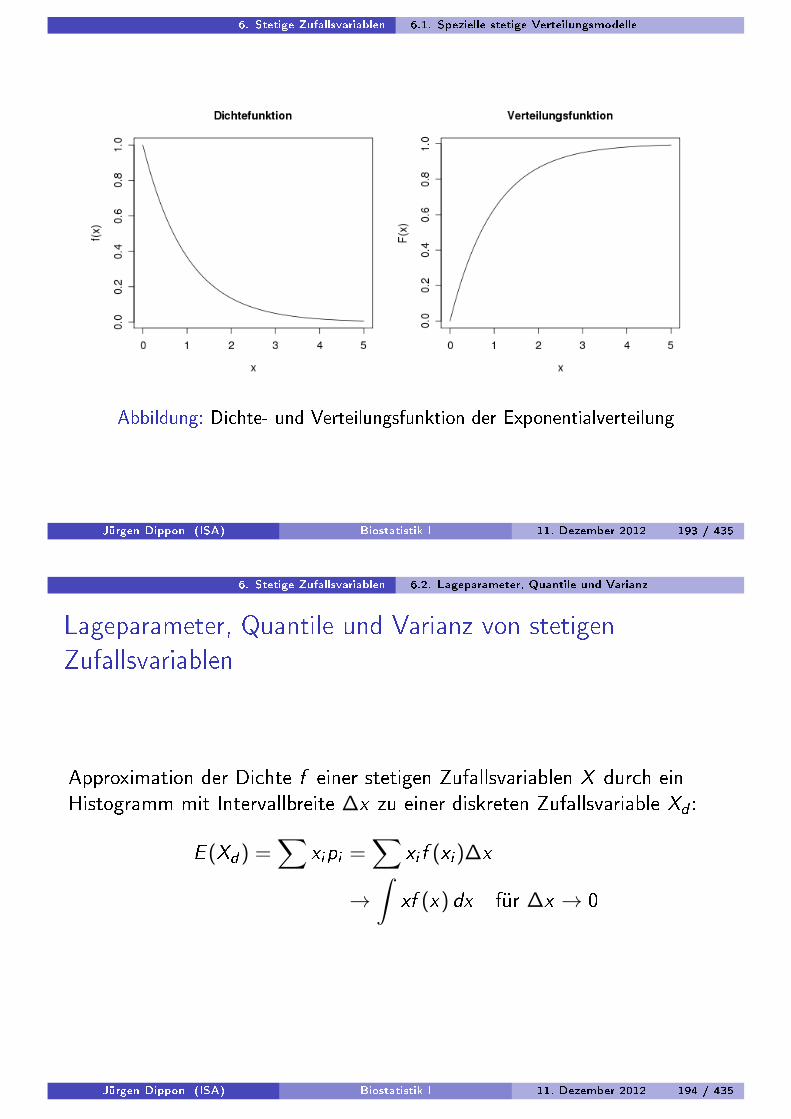
6. Stetige Zufallsvariablen 6.1. Spezielle stetige Verteilungsmodelle
Abbildung: Dichte- und Verteilungsfunktion der Exponentialverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 193 / 435
6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Lageparameter, Quantile und Varianz von stetigenZufallsvariablen
Approximation der Dichte f einer stetigen Zufallsvariablen X durch einHistogramm mit Intervallbreite ∆x zu einer diskreten Zufallsvariable Xd :
E (Xd ) =∑
xipi =∑
xi f (xi )∆x
→∫
xf (x) dx für ∆x → 0
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 194 / 435
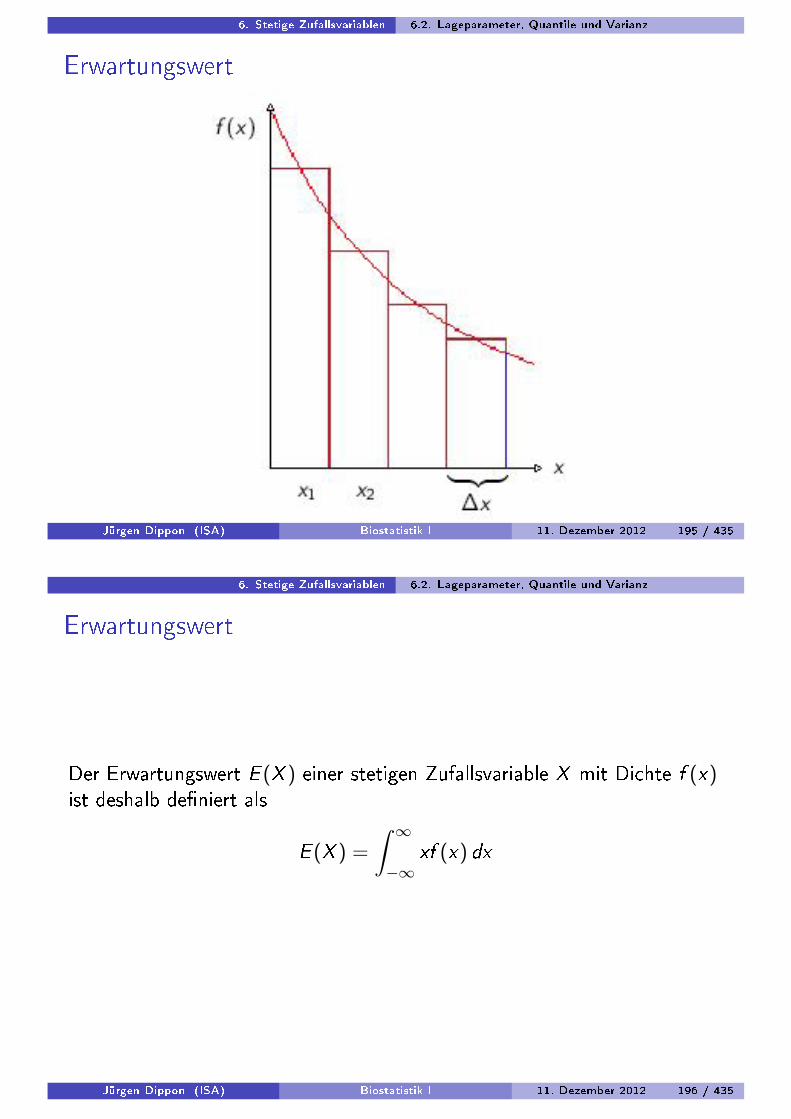
6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Erwartungswert
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 195 / 435
6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Erwartungswert
Der Erwartungswert E (X ) einer stetigen Zufallsvariable X mit Dichte f (x)ist deshalb deniert als
E (X ) =
∫ ∞−∞
xf (x) dx
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 196 / 435

6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Eigenschaften von Erwartungswerten1 Ist g(x) eine reelle Funktion, dann gilt für Y = g(X )
E (Y ) = E (g(X )) =
∫ ∞−∞
g(x)f (x) dx
2 Für Y = aX + b gilt
E (Y ) = E (aX + b) = aE (X ) + b
3 Ist f symmetrisch um c , d.h. f (c − x) = f (c + x), so gilt
E (X ) = c
4 Additivität: Für zwei Zufallsvariablen X und Y gilt
E (X + Y ) = E (X ) + E (Y )
5 Linearität: Für beliebige Konstanten a1, . . . , an gilt
E (a1X1 + . . .+ anXn) = a1E (X1) + . . .+ anE (Xn)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 197 / 435
6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Beispiele
1 X gleichverteilt auf [a, b]. Dann
E (X ) =
∫ ∞−∞
xf (x) dx =
∫ b
a
x1
b − adx
=1
b − a
(b2
2− a2
2
)=
(b − a)(b + a)
2(b − a)
=a + b
2
2 X ∼ Exp(λ)
E (X ) =
∫ ∞−∞
xf (x) dx =
∫ ∞0
xe−λx dx
= · · · =1λ
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 198 / 435

6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Modus, Quantil und Median
Ist X eine stetige Zufallsvariable mit Dichte f (x), so heiÿt der Wert, andem f (x) ein (lokales) Maximum annimmt, Modus von X , kurz xmod .
Für 0 < p < 1 heiÿt der Wert xp mit
F (xp) = p
p-Quantil von X . Der Median xmed ist das 50%-Quantil, also
F (xmed ) = 0.5
Ist F streng monoton, so sind das p-Quantil und der Median eindeutig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 199 / 435
6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Varianz und Standardabweichung
Die Varianz einer stetigen Zufallsvariable ist deniert als die mittlere odererwartete quadratische Abweichung vom Erwartungswert µ = E (X ):
σ2 = Var(X ) = E ((X − µ)2) =
∫ ∞−∞
(x − µ)2f (x) dx
Die Standardabweichung ist
σ = +√Var(X )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 200 / 435

6. Stetige Zufallsvariablen 6.2. Lageparameter, Quantile und Varianz
Wie im diskreten Fall gelten
1 Var(X ) = E (X 2)− (E (X ))2 = E ((X − c)2)− (µ− c)2
2 Var(aX + b) = a2Var(X )
3 für unabhängige Zufallsvariablen X und Y
Var(X + Y ) = Var(X ) + Var(Y )
Beispiel: Sei X auf [a, b] gleichverteilt
Var(X ) = E (X 2)︸ ︷︷ ︸∫ bax2 1
b−a dx
− (E (X ))2︸ ︷︷ ︸( a+b
2 )2
= · · · =(b − a)2
12
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 201 / 435
6. Stetige Zufallsvariablen 6.3. Normalverteilung
Normalverteilung
Eine Zufallsvariable X mit Dichte
f (x) =1√2πσ
exp
(−(x − µ)2
2σ2
), x ∈ R,
heiÿt normalverteilt mit den Parametern µ ∈ R und σ2 > 0, kurzX ∼ N(µ, σ2).
Es gilt
E (X ) =1√2πσ
∫ ∞−∞
xe(x−µ)2
2σ2 dx = · · · = µ
Var(X ) = E (X 2)− (E (X ))2 = · · · = σ2
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 202 / 435
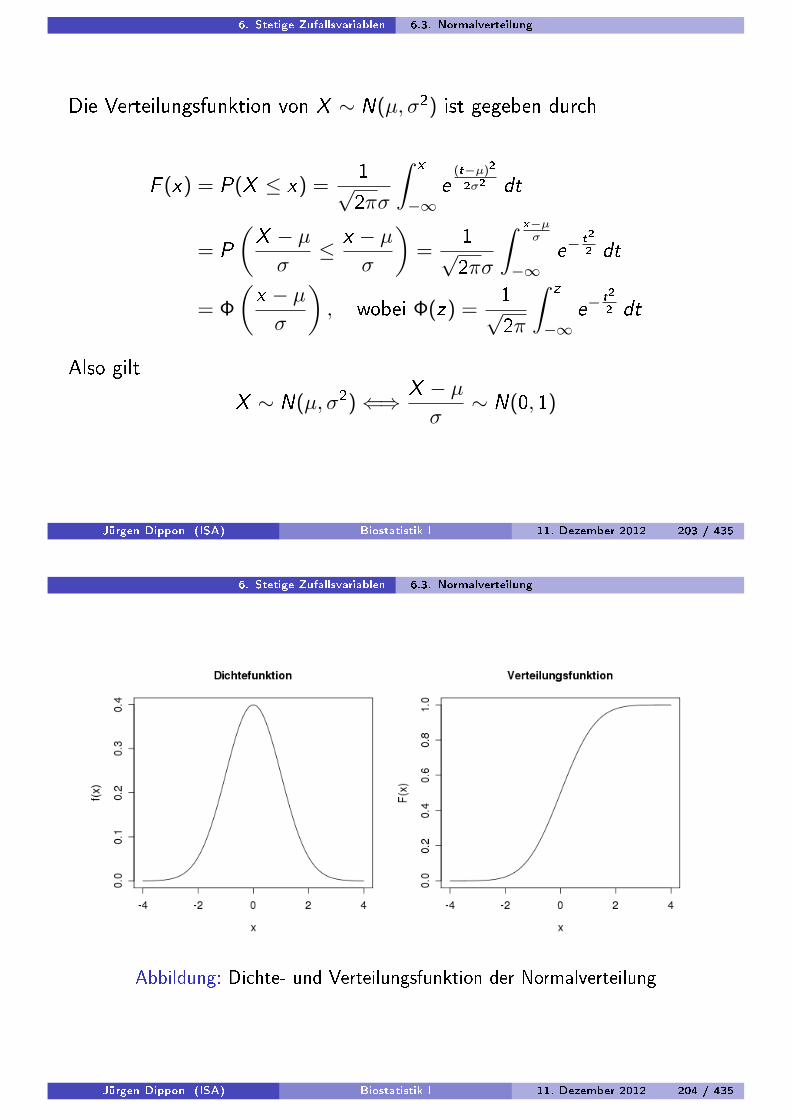
6. Stetige Zufallsvariablen 6.3. Normalverteilung
Die Verteilungsfunktion von X ∼ N(µ, σ2) ist gegeben durch
F (x) = P(X ≤ x) =1√2πσ
∫ x
−∞e
(t−µ)2
2σ2 dt
= P
(X − µσ≤ x − µ
σ
)=
1√2πσ
∫ x−µσ
−∞e−
t2
2 dt
= Φ
(x − µσ
), wobei Φ(z) =
1√2π
∫ z
−∞e−
t2
2 dt
Also gilt
X ∼ N(µ, σ2)⇐⇒ X − µσ∼ N(0, 1)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 203 / 435
6. Stetige Zufallsvariablen 6.3. Normalverteilung
Abbildung: Dichte- und Verteilungsfunktion der Normalverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 204 / 435

7. Grenzwertsätze
4 Wahrscheinlichkeitsrechnung
5 Diskrete Zufallsvariablen
6 Stetige Zufallsvariablen
7 GrenzwertsätzeGesetz der groÿen ZahlenDer zentrale Grenzwertsatz
8 Mehrdimensionale Zufallsvariablen
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 205 / 435
7. Grenzwertsätze
Grenzwertsätze
Fragen:
1 Unter welchen Voraussetzungen liegt die relative Häugkeit für dasEintreten eines Ereignisses nahe bei der Wahrscheinlichkeit für dasEreignis?
2 Unter welchen Voraussetzungen kann die Verteilung einer Summe vonZufallsvariablen durch eine einfachere Verteilung approximiert werden?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 206 / 435

7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Gesetz der groÿen Zahlen
Sei X eine binäre Zufallsvariable und A ein Ereignis mit
X =
1 falls A eintritt0 falls A nicht eintritt
Also X ∼ Bin(1, p) mit p = P(A) = P(X = 1).
Wir nehmen an, dass das Zufallsexperiment n-mal und in identischer Weisewiederholt werden kann:
Xi =
1, falls A im i-ten Versuch eintritt0, falls A im i-ten Versuch nicht eintritt
Klar: Xi ∼ Bin(1, p) für alle i ∈ 1, . . . , n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 207 / 435
7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Empirisches Gesetz der groÿen Zahlen
Für groÿes n liegt die relative Häugkeit fn(A) für das Eintreten von A
nahe bei der Wahrscheinlichkeit von A:
fn(A)→ P(A) für n→∞ (1)
Da fn(A) = 1n
∑ni=1 Xi = Xn und P(A) = E (X ) kann (1) auch in die Form
Xn → E (X ) für n→∞ (2)
gebracht werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 208 / 435

7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Fragen:
1 Wie ist die Konvergenz in (1) und (2) zu verstehen?2 Gilt (2) auch für nicht-binäre Zufallsvariablen?
Auf beide Fragen gibt das Gesetz der groÿen Zahlen eine Antwort.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 209 / 435
7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Sei X eine Zufallsvariable mit Erwartungswert µ = EX und Varianzσ2 = Var(X ).Seien X1, . . . ,Xn unabhängige wie X verteilte Zufallsvariablen.Dann gilt
EXn = E
(1n
n∑i=1
Xi
)=
1n
n∑i=1
EXi =1n
n∑i=1
µ = µ
Var(Xn) = Var
(1n
n∑i=1
Xi
)=
1n2
n∑i=1
Var(Xi ) =1n2
n∑i=1
σ2 =σ2
n
Für groÿe n ist Xn damit immer mehr um µ herum konzentriert.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 210 / 435

7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Gesetz der groÿen Zahlen
Für beliebig kleines c > 0 gilt
P(|Xn − µ| < c)→ 1 für n→∞
In Worten: Xn konvergiert nach Wahrscheinlichkeit gegen µ.
Zum Beweis verwenden wir die Ungleichung von Tschebyschev
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 211 / 435
7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Ungleichung von Tschebyschev
Für jede Zufallsvariable X mit endlicher Varianz gilt
∀c>0
P(|X − E (X )| ≥ c) ≤ Var(X )
c2(3)
Beweis: Setze
Y =
0, falls |X − E (X )| < c
1, falls |X − E (X )| ≥ c
Damit
P(|X − E (X )| ≥ c) = E (Y ) = E (Y 2)
≤ E
(|X − E (X )|2
c2
)=
1c2Var(X )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 212 / 435

7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Beweis des Gesetzes der groÿen Zahlen
P(|Xn − µ| < c) = 1− P(|Xn − µ| ≥ c)︸ ︷︷ ︸(3)
≤ 1
c2Var(Xn)= 1
c2σ2
n→0
→ 1 (n→∞)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 213 / 435
7. Grenzwertsätze 7.1. Gesetz der groÿen Zahlen
Satz von Bernoulli
Spezialfall des starken Gesetzes der groÿen Zahlen:
Die relative Häugkeit, mit der ein Ereignis A bei n unabhängigenWiederholungen eines Zufallsvorgangs eintritt, konvergiert nachWahrscheinlichkeit gegen P(A).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 214 / 435

7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Der zentrale Grenzwertsatz
Die Zufallsvariable X sei Bin(1, p)-verteilt.Die Zufallsvariablen X1, . . . ,Xn seien unabhängig wie X verteilt. Dann
Sn = X1 + · · ·+ Xn ∼ Bin(n, p)
E (Sn) = np
Var(Sn) = np(1− p)
Man stellt experimentell leicht fest, dass die Dichte einerBin(n, p)-verteilten Zufallsvariablen durch die Dichte einerN(np, np(1− p))-verteilten Zufallsvariablen approximiert werden kann. Derformale Beweis ist jedoch schwierig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 215 / 435
7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Approximation von Summen von Zufallsvariablen
Standardisierung von Sn:
Zn =Sn − E (Sn)√
Var(Sn)
Dann gilt:
E (Zn) = 0, Var(Zn) =1
Var(Sn)Var(Sn) = 1
Damit kann obige Beobachtung reformuliert werden:
Die Dichte von Zn kann für groÿe n gut durch die Dichte der
N(0, 1)-Verteilung, also f (x) = 1√2πe−
x2
2 , approximiert werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 216 / 435

7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Daraus folgt:
Die Verteilungsfunktion Fn(z) = P(Zn ≤ z) von Zn kann für groÿe n gut
durch die Verteilungsfunktion Φ(z) =∫ z−∞
1√2πe−
x2
2 dx einer
N(0, 1)-verteilten Zufallsvariablen approximiert werden.
Diese Tatsache gilt nicht nur für Summen von unabhängigenBin(1, p)-verteilten Zufallsvariablen, sondern unter viel allgemeinerenVoraussetzungen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 217 / 435
7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Zentraler GrenzwertsatzX1, . . . ,Xn seien unabhängig identisch verteilte Zufallsvariablen mit
E (Xi ) = µ und Var(Xi ) = σ2
Dann konvergiert die Verteilungsfunktion Fn(z) = P(Zn ≤ z) derstandardisierten Summe
Zn =X1 + · · ·+ Xn − nµ√
nσ=
1√n
n∑i=1
Xi − µσ
für n→∞ an jeder Stelle z ∈ R gegen die Verteilungsfunktion Φ(z) derStandardnormalverteilung
Fn(z)→ Φ(z) (n→∞)
Unter den Voraussetzungen dieses Satzes gilt deshalb:
Sn = X1 + · · ·+ Xn ist approximativ N(nµ, nσ2)-verteilt
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 218 / 435

7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Grenzwertsatz von Moivre-Laplace
Als Spezialfall des zentralen Grenzwertsatzes gilt damit für die Summe vonunabhängigen Bin(1, p)-verteilten Zufallsvariablen X1, . . . ,Xn der
Grenzwertsatz von Moivre-Laplace
∀z∈R
P
(Sn − np√np(1− p)
≤ z
)→ Φ(z) für n→∞
oder
Sn = Anzahl der Erfolge in n unabhänigen Bernoulli-Versuchen
ist approximativ N(np, np(1− p))-verteilt
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 219 / 435
7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Approximation der Binomialverteilung mitStetigkeitskorrektor
Für moderate n wird die Approximation besser, wenn die Treppenfunktiondes Wahrscheinlichkeitshistogramms von der Dichtekurve derN(0, 1)-Verteilung etwa in der Mitte getroen wird.
Sei Sn ∼ Bin(n, p)-verteilt. Falls np und n(1− p) groÿ genug sind, gilt
P(Sn ≤ x) = Bin(x |n, p) ≈ Φ
(x+0.5− np√np(1− p)
)
P(Sn = x) ≈ Φ
(x+0.5− np√np(1− p)
)− Φ
(x−0.5− np√np(1− p)
)
Faustregel: Die Approximation ist für praktische Zwecke gut, falls np ≥ 5und n(1− p) ≥ 5
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 220 / 435

7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
Beispiel
Eine Tierart trägt mit Wahrscheinlichkeit 0.1 einen Gendefekt. Es werdeeine Stichprobe vom Umfang n = 100 der Population untersucht.
Sn sei die Anzahl der gesunden Tiere.
Also Sn ∼ Bin(n, p) = Bin(100, 0.9).
Wegen np = 90 und n(1− p)=10 ist die Faustregel erfüllt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 221 / 435
7. Grenzwertsätze 7.2. Der zentrale Grenzwertsatz
BeispielWie groÿ ist die Wahrscheinlichkeit, dass höchstens x = 88 Tiere gesundsind?
P(Sn ≤ 88) ≈ Φ
(88+0.5− 90√100 · 0.9 · 0.1
)= Φ
(−1.53
)= Φ(−0.5) = 0.309
Die Addition von 0.5 verbessert die Approximation (Stetigkeitskorrektur).
Wie groÿ ist die Wahrscheinlichkeit, dass genau x = 90 = E (Sn) Tieregesund sind?
P(Sn = 90) = P(Sn ≤ 90)− P(Sn ≤ 89)
≈ Φ
(0.53
)− Φ
(−0.53
)︸ ︷︷ ︸1−Φ( 0.5
3 )
= 2 · Φ(0.53
)− 1 = 0.134
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 222 / 435

8. Mehrdimensionale Zufallsvariablen
4 Wahrscheinlichkeitsrechnung
5 Diskrete Zufallsvariablen
6 Stetige Zufallsvariablen
7 Grenzwertsätze
8 Mehrdimensionale ZufallsvariablenBegri mehrdimensionale ZufallsvariablenZweidimensionale diskrete ZufallsvariablenZweidimensionale stetige ZufallsvariablenUnabhängigkeit von ZufallsvariablenKovarianz und KorrelationDie zweidimensionale Normalverteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 223 / 435
8. Mehrdimensionale Zufallsvariablen
Mehrdimensionale Zufallsvariablen
In vielen Anwendungen interessiert nicht nur ein Merkmal, sondern mehrereMerkmale, welche überdies oft nicht unabhängig sind. Das Studium derAbhängigkeit ist häug von zentralem Interesse.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 224 / 435

8. Mehrdimensionale Zufallsvariablen 8.1. Begri mehrdimensionale Zufallsvariablen
Begri mehrdimensionale Zufallsvariablen
Bei einer reellen, also 1-dimensionalen Zufallsvariablen, wird jedemErgebnis ω eines Zufallsvorganges genau eine reelle Zahl X (ω) zugeordnet.
Bei einer n-dimensionalen Zufallsvariablen X werden jedem Ergebnis ωeines Zufallsvorganges genau n reelle Zahlen X1(ω), . . . ,Xn(ω) zugeordnet:
X = (X1, . . . ,Xn) : Ω −→ Rn
ω 7−→ (X1(ω), . . . ,Xn(ω))
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 225 / 435
8. Mehrdimensionale Zufallsvariablen 8.2. Zweidimensionale diskrete Zufallsvariablen
Zweidimensionale diskrete Zufallsvariablen
Seien X und Y zwei diskrete Zufallsvariablen mit Werten x1, x2, . . . bzw.y1, y2, . . .
Die gemeinsame Wahrscheinlichkeitsfunktion oder gemeinsame diskreteDichte der bivariaten diskreten Zufallsvariable (X ,Y ) ist bestimmt durch
f (x , y) =
P(X = x ,Y = y) für x ∈ x1, x2, . . . ,
y ∈ y1, y2, . . . 0 sonst
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 226 / 435

8. Mehrdimensionale Zufallsvariablen 8.2. Zweidimensionale diskrete Zufallsvariablen
Die gemeinsame Verteilungsfunktion zu X und Y ist gegeben durch
F (x , y) = P(X ≤ x ,Y ≤ y) =∑xi≤x
∑yj≤y
f (xi , yj)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 227 / 435
8. Mehrdimensionale Zufallsvariablen 8.3. Zweidimensionale stetige Zufallsvariablen
Zweidimensionale stetige Zufallsvariablen
Die Zufallsvariablen X und Y sind gemeinsam stetig verteilt, wenn eseine auf R2 denierte Dichtefunktion f (x , y) gibt, so dass
P(a ≤ X ≤ b, c ≤ Y ≤ d) =
∫ b
a
∫ d
c
f (x , y)dxdy
Diese Wahrscheinlichkeit entspricht dem Volumen des Körpers über demRechteck [a, b]× [c , d ] bis zur durch z = f (x , y) gegebenen Fläche.
Die gemeinsame Verteilungsfunktion zu X und Y ist gegeben durch
F (x , y) =
∫ x
−∞
∫ y
−∞f (s, t)dsdt
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 228 / 435

8. Mehrdimensionale Zufallsvariablen 8.4. Unabhängigkeit von Zufallsvariablen
Unabhängigkeit von Zufallsvariablen
Die Zufallsvariable Y kann als unabhängig von der Zufallsvariablen X
angesehen werden, falls
fY |X (y |x) =f (x , y)
fX (x)= fY (y)
(vorausgesetzt fX (x) > 0).In diesem Fall gilt f (x , y) = fX (x) · fY (y)
Deshalb deniert man:
Die Zufallsvariablen X und Y heiÿen (stochastisch) unabhängig, falls
∀x∀y
f (x , y) = fX (x) · fY (y)
Ansonsten heiÿen X und Y (stochastisch) abhängig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 229 / 435
8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Kovarianz und Korrelation
Die Wahrscheinlichkeitsfunktion f (x , y) liefert alle Informationen über diebeiden Zufallsvariablen X und Y , auch über deren mögliche Abhängigkeit.
Kovarianz und Korrelation sind zwei Begrie zur Beschreibung der linearenAbhängigkeit von X und Y unter Verwendung einer einzigen Maÿzahl.
Sind X und Y unabhängig, so gilt
E (X · Y ) = E (X ) · E (Y )
(ohne Beweis)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 230 / 435

8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Sind die Zufallsvariablen X und Y abhängig, so liefert die Dierenz
E (XY )− E (X ) · E (Y ) = E [(X − E (X )) · (Y − E (Y ))]
eine Maÿzahl für die Stärke der Abhängigkeit.
Wir denieren deshalb:
Die Kovarianz der Zufallsvariablen X und Y ist gegeben durch
Cov(X ,Y ) = E ((X − E (X )) · (Y − E (Y )))
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 231 / 435
8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Die Kovarianz liefert ein Maÿ für die lineare Abhängigkeit und lässt sichberechnen durch
Cov(X ,Y ) =∑i
∑j
f (xi , yj)(xi − E (X ))(yj − E (Y ))
falls X und Y diskret sind, bzw.
Cov(X ,Y ) =
∫ ∞−∞
∫ ∞−∞
f (x , y)(x − E (X ))(y − E (Y ))dxdy
falls X und Y stetig sind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 232 / 435

8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Werden die Zufallsvariablen X und Y linear transformiert zu X = aX + b
und Y = cY + d , so gilt
Cov(X , Y ) = a · c · Cov(X ,Y )
Da die Kovarianz oensichtlich maÿstabsabhängig ist, wird in der Praxisder durch
% = %(X ,Y ) =Cov(X ,Y )√
Var(X ) ·√Var(Y )
denierte Korrelationskoezient bevorzugt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 233 / 435
8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Eigenschaften des Korrelationskoezienten:
−1 ≤ %(X ,Y ) ≤ 1
|%(X ,Y )| = 1⇔ Y = aX + b für Konstanten a, b
X = aX + b, Y = cY + d mit a, c 6= 0:
|%(X , Y )| = |%(X ,Y )|
Zwei Zufallsvariablen X und Y heiÿen unkorreliert, falls
%(X ,Y ) = 0
Ist %(X ,Y ) 6= 0, so heiÿen sie korreliert.
Man kann zeigen, dass zwei unabhängige Zufallsvariablen auch immerunkorreliert sind.Die Umkehrung gilt im Allgemeinen nicht.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 234 / 435

8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Varianz der Summe zweier u.U. abhängigen Zufallsvariablen:
Var(X1 + X2) = E(
(X1 + X2 − E (X1)− E (X2))2)
= E(
(X1 − E (X1))2)
+ 2E ((X1 − E (X1)) (X2 − E (X2)))
+ E(
(X2 − E (X2))2)
= Var(X1) + Var(X2) + 2Cov(X1,X2)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 235 / 435
8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Linearkombination von Zufallsvariablen
Sei X z.B. die zufallsabhängige Tagesproduktion von Hefe in einemBioreaktor mit n verschiedenen Hefekulturen, die sich pro Tag um denzufälligen Faktor Xi vermehren und deren relativen Anteile zu Tagesbeginnai betragen:
X = a1X1 + · · ·+ anXn
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 236 / 435

8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Dann gilt:
E (X ) = a1E (X1) + · · ·+ anE (Xn)
Var(X ) = E ((X − E (X ))2)
= E
( n∑i=1
ai (Xi − E (Xi ))
)2
= E
n∑i=1
a2i (Xi − E (Xi ))2 +∑i 6=j
aiaj(Xi − E (Xi ))(Xj − E (Xj))
=
n∑i=1
a2i Var(Xi ) + 2∑i<j
aiajCov(Xi ,Xj)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 237 / 435
8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Beispiel: Optimierung eines Bioreaktors
Zwei Hefekulturen werden in den Anteilen a1 und a2 mit a1 + a2 = 1 ineinen Bioreaktor eingebracht. X1,X2 seien die zufallsabhängigenVermehrungsraten (pro Tag) der beiden Hefearten. Der gesamteTagesertrag ist somit
X = a1X1 + a2X2
Und der zu erwartende Tagesertrag ist
E (X ) = a1E (X1) + a2E (X2)
Die Varianz der Tagesertrages kann als ein Risikomaÿ für den Tagesertraginterpretiert werden:
Var(X ) = a21Var(X1) + a22Var(X2) + 2a1a2Cov(X1,X2)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 238 / 435

8. Mehrdimensionale Zufallsvariablen 8.5. Kovarianz und Korrelation
Mit σ2i = Var(Xi ), ρ = Cor(X1,X2) ist:
Var(X ) = a21σ21 + a22σ
22 + 2a1a2σ1σ2ρ
Je nachdem, ob die Wachstumsfaktoren der beiden Hefekulturen positivoder negativ korreliert sind, ist das Risikomaÿ für den Tagesertrag gröÿeroder kleiner als die Summe der Einzelrisiken.
Spezialfall: σ = σ1 = σ2, ρ = 1
Var(X ) = a21σ2 + a22σ2 + 2a1a2σ
2 = (a1 + a2)2σ2 = σ2
Spezialfall: σ = σ1 = σ2, ρ = −1
Var(X ) = a21σ2 + a22σ2− 2a1a2σ
2 = (a1 − a2)2σ2
Falls a1 = a2 = 0.5, ist das Gesamtrisiko gleich Null.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 239 / 435
8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Die zweidimensionale Normalverteilung
Dichte einer 1-dimensional normalverteilten Zufallsvariablen X :
f (x) =1√2πσ
exp
−12
(x − µσ
)2, x ∈ R,
wobei µ = E (X ), σ2 = Var(X ).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 240 / 435
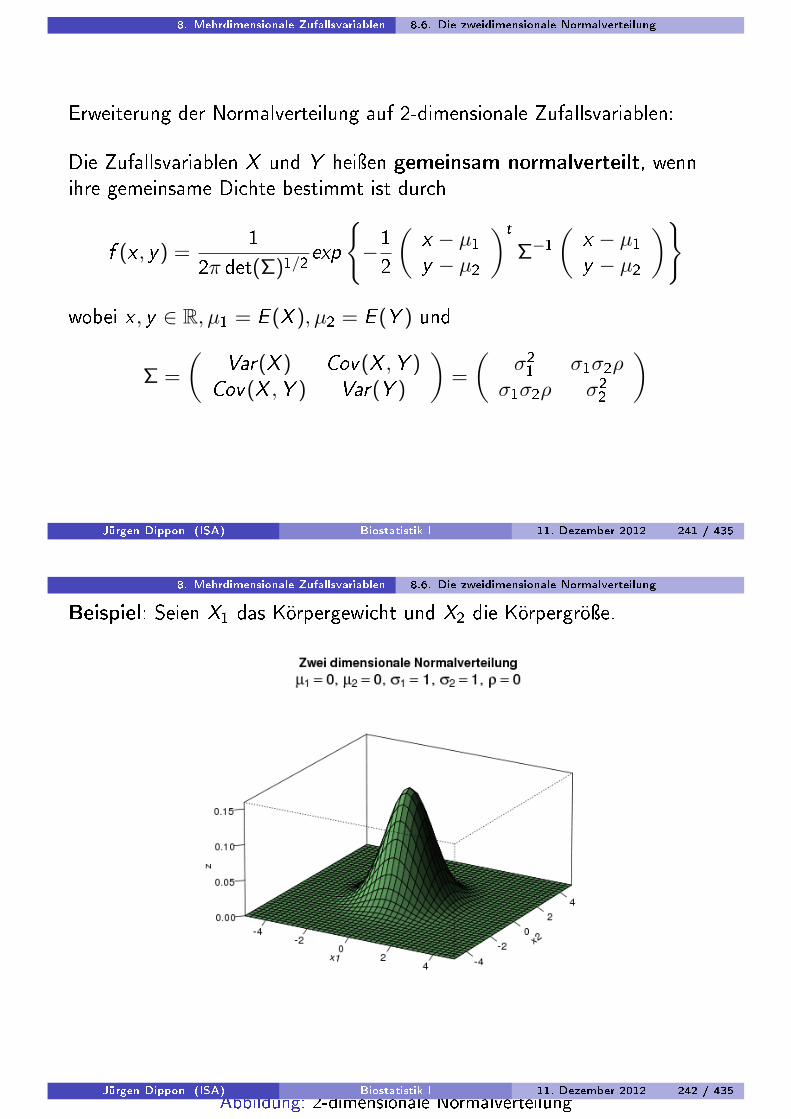
8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Erweiterung der Normalverteilung auf 2-dimensionale Zufallsvariablen:
Die Zufallsvariablen X und Y heiÿen gemeinsam normalverteilt, wennihre gemeinsame Dichte bestimmt ist durch
f (x , y) =1
2π det(Σ)1/2exp
−12
(x − µ1y − µ2
)t
Σ−1(
x − µ1y − µ2
)
wobei x , y ∈ R, µ1 = E (X ), µ2 = E (Y ) und
Σ =
(Var(X ) Cov(X ,Y )
Cov(X ,Y ) Var(Y )
)=
(σ21 σ1σ2ρ
σ1σ2ρ σ22
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 241 / 435
8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Beispiel: Seien X1 das Körpergewicht und X2 die Körpergröÿe.
Abbildung: 2-dimensionale NormalverteilungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 242 / 435
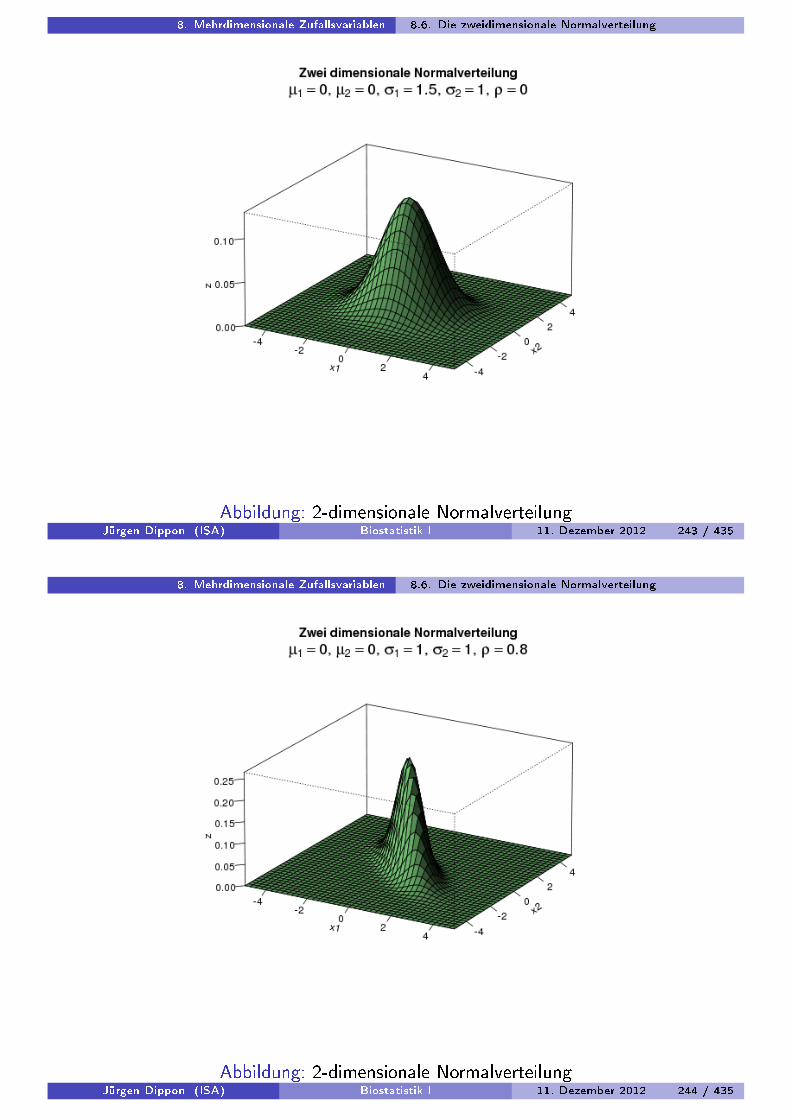
8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Abbildung: 2-dimensionale NormalverteilungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 243 / 435
8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Abbildung: 2-dimensionale NormalverteilungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 244 / 435

8. Mehrdimensionale Zufallsvariablen 8.6. Die zweidimensionale Normalverteilung
Der unkorrelierte Fall
Sind die Zufallsvariablen X und Y mit gemeinsamer Normalverteilungunkorreliert, d.h. ρ = 0, so ist X und Y sogar unabhängig, da in diesemFall:
Σ =
(σ21 00 σ22
), det(Σ) = σ21σ
22, Σ−1 =
(σ−21 00 σ−22
)
f (x , y) =1
2πσ1σ2exp
−12
(x − µ1σ1
)2
− 12
(x − µ2σ2
)2
=1√2πσ1
exp
−12
(x − µ1σ1
)2· 1√
2πσ2exp
−12
(y − µ2σ2
)2
= fX (x) · fY (y)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 245 / 435
Teil III
Induktive Statistik
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 246 / 435

Induktive Statistik
9 Parameterschätzung
10 Testen von Hypothesen
11 Einfache lineare Regression
12 Varianzanalyse
13 Versuchsplanung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 247 / 435
Schlieÿende Statistik
Wie kann man basierend auf einer Stichprobe Informationen über dieVerteilung eines interessierenden Merkmals erhalten?
Schätzverfahren dienen zur näherungsweisen Ermittlung unbekannterParameter der Verteilung
Testverfahren dienen zur Überprüfung von Hypothesen über dieunbekannte Verteilung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 248 / 435

9. Parameterschätzung
9 ParameterschätzungParameterschätzungEigenschaften von SchätzstatistikenErwartungstreueErwartete mittlere quadratische Abweichung und Konsistenz
Konstruktion von SchätzfunktionenMaximum-Likelihood-SchätzungKleinste-Quadrate-Schätzung
IntervallschätzungKondenzintervalle für Erwartungswert und Varianz
10 Testen von Hypothesen
11 Einfache lineare Regression
12 Varianzanalyse
13 VersuchsplanungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 249 / 435
9. Parameterschätzung
Beispiel: Wie hoch ist der relative Anteil von Frauen unter denHochschullehrern in Deutschland?
Da eine Totalerhebung viel zu aufwändig wäre, bestimmt man den relativenAnteil der Frauen in einer Zufallsstichprobe. Dieser relative Anteil in derStichprobe ist ein Schätzer für den wahren Anteil in der Grundgesamtheit.
Da eine zweite Stichprobe einen anderen Schätzwert liefern würde, stelltsich u.a. die Frage nach der Qualität des Schätzers.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 250 / 435

9. Parameterschätzung 9.1. Parameterschätzung
Parameterschätzung
Einer Schätzfunktion oder Schätzstatistik für den Parameter θ derVerteilung der Grundgesamtheit ist eine Funktion
T = g(X1, . . . ,Xn)
der Stichprobenvariablen X1, . . . ,Xn.Der aus den Realisationen x1, . . . , xn resultierende numerische Wert
g(x1, . . . , xn)
ist der zugehörige Schätzwert.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 251 / 435
9. Parameterschätzung 9.1. Parameterschätzung
Beispiele:
X = g(X1, . . . ,Xn) = 1n
∑ni=1 Xi
Schätzfunktion für den Erwartungswert µ = E (X )x zugehörige Realisation der Stichprobe
S2 = g(X1, . . . ,Xn) = 1n−1
∑ni=1(Xi − X )2
Schätzfunktion für die Varianz σ2 = Var(X )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 252 / 435

9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Eigenschaften von SchätzstatistikenErwartungstreueEine Schätzstatistik T = g(X1, . . . ,Xn) heiÿt erwartungstreu oderunverzerrt für den Parameter θ, falls
Eθ(T ) = θ
Sie heiÿt asymptotisch erwartungstreu für θ, falls
limn→∞
Eθ(T ) = θ
Die Verzerrung oder der Bias ist deniert durch
Biasθ(T ) = Eθ(T )− θ
Das tief gestellte θ in Eθ soll andeuten, dass der Erwartungswert von T
bezüglich der Verteilung berechnet werden soll, die θ als wahren Parameterbesitzt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 253 / 435
9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Beispiele:
Eµ(X ) = Eµ( 1n∑n
i=1 Xi ) = 1n
∑ni=1 Eµ(Xi )︸ ︷︷ ︸
µ
= µ
Also ist X ein erwartungstreuer Schätzer für den Erwartungswert µ
Eσ2(S2) = Eσ2( 1n−1
∑ni=1(Xi − X )2) = · · · = σ2
Also ist S2 ein erwartungstreuer Schätzer für die Varianz
Eσ2(S2) = Eσ2( 1n∑n
i=1(Xi − X )2) = · · · = n−1n σ2
Also ist S2 kein erwartungstreuer Schätzer für die Varianz σ2
Biasσ2(S2) = Eσ2(S2)− σ2 = − 1nσ
2
Also ist S2 asymptotisch erwartungstreu für σ2
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 254 / 435

9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Frage: Wie genau schätzt X den Erwartungswert?
Var(X ) = Var
(1n
n∑i=1
Xi
)=
1n2
n∑i=1
Var(Xi ) =σ2
n
Der Standardfehler einer Schätzstatistik ist bestimmt durch dieStandardabweichung der Schätzstatistik
σg =√Var(g(X1, . . . ,Xn))
Achtung: Der Begri des Standardfehlers ist nur sinnvoll fürerwartungstreue Schätzstatistiken!
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 255 / 435
9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Der Standardfehler von X ist damit
σX =σ√n
Da σ2 meist unbekannt sein dürfte, muss es geschätzt werden. EinSchätzer für den Standardfehler σX von X ist
σX =
√S2
n=
√1
n−1∑n
i=1(Xi − X )2
n
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 256 / 435

9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Erwartete mittlere quadratische Abweichung und Konsistenz
Die erwartete mittlere quadratische Abweichung (mean squared error)ist bestimmt durch
MSE =E((T − θ)2
)=E
((T − E (T ) + E (T )− θ)2
)=E ((T − E (T ))2 + 2E ((T − E (T )) ((E (T )− θ))︸ ︷︷ ︸
=0
+ E ((E (T )− θ)2))
=Var(T ) + (Bias(T ))2
Diese Zerlegung des MSE zeigt, dass der Standardfehler nur dann einbrauchbares Vergleichsmaÿ für die Güte eines Schätzers ist, wenn derSchätzer erwartungstreu ist, d.h. Bias(T ) = 0.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 257 / 435
9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Eine Schätzstatistik heiÿt konsistent im quadratischen Mittel, falls
MSE = E ((T − θ)2)→ 0 für n→∞
und schwach konsistent, falls
∀ε>0
P(|T − θ| ≥ ε)→ 0 für n→∞
Konsistenz im quadratischen Mittel impliziert schwache Konsistenz.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 258 / 435

9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Beispiel: Arithmetisches Mittel
X1, . . . ,Xn ∼ N(µ, σ2) unabhängige ZufallsvariablenSchätzen des Erwartungswertes µ mittels
X =1n
n∑i=1
Xi
Da EX = · · · = µ, ist X erwartungstreu.
Da Var(X ) = · · · = σ2
n → 0 (n→∞) ist X konsistent im quadratischenMittel.
Ferner gilt
X ∼ N
(µ,σ2
n
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 259 / 435
9. Parameterschätzung 9.2. Eigenschaften von Schätzstatistiken
Also
P(|X − µ| ≤ ε) = P
(∣∣∣∣∣ X − µσ√n
∣∣∣∣∣ ≤ εσ√n
)
= Φ
(εσ√n
)− Φ
(− ε
σ√n
)
= 2 Φ
(εσ√n
)︸ ︷︷ ︸→1 für n→∞
−1
→ 1 für n→∞
Damit ist X auch schwach konsistent.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 260 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Konstruktion von Schätzfunktionen
Wir diskutieren drei Ideen zur Konstruktion von Schätzfunktionen:
Maximum-Likelihood-Schätzung
Kleinste-Quadrate-Schätzung
Intervallschätzung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 261 / 435
9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Maximum-Likelihood-Schätzung
Beispiel: Gesucht ist die Wahrscheinlichkeit p für das Auftreten einesEreignisses A im Rahmen eines Experiments
X =
0 falls A nicht eintritt1 falls A eintritt
Die Ausgänge von n unabhängigen Wiederholungen des Experimenteswerden dann beschrieben durch die n unabhängigen wie X verteiltenZufallsvariablen X1, . . . ,Xn
Klar:∑n
i=1 Xi ∼ Bin(n, p)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 262 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Hierbei ist n natürlich bekannt, nicht jedoch die Erfolgswahrscheinlichkeit p
L(p) = P
(n∑
i=1
Xi = k
)=
(n
k
)pk(1− p)n−k
Das Maximum-Likelihood-Prinzip wählt als Schätzwert p für dieunbekannte Wahrscheinlichkeit p den Wert, welcher L(p) maximiert.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 263 / 435
9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Allgemein: Sei θ der gesuchte ein- oder mehrdimensionale Parameter einer(diskreten oder stetigen) Dichte f (x |θ).Dann ist die gemeinsame Dichte von n unabhängigen identischenWiederholungen gegeben durch
f (x1, . . . , xn|θ) = f (x1|θ) · . . . · f (xn|θ)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 264 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Anstatt diese Dichte als eine Funktion zu beliebigen Werten x1, . . . , xn undeinem festen Parameter θ zu interpretieren, interpretieren wir die sog.Likelihoodfunktion
L(θ) = f (x1, . . . , xn|θ)
als eine Funktion von θ zu den gegebenen festen Realisationen x1, . . . , xnund wählen als Parameterschätzung denjenigen Parameter θ, für welchendie Likelihood maximal ist, d.h.
L(θ) = maxθ
L(θ)
Eine so konstruierte Schätzfunktion T = θ(x1, . . . , xn) heiÿtMaximum-Likelihood-Schätzer.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 265 / 435
9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Das Maximum bestimmt man meist durch Ableiten und Nullsetzen derAbleitung. Häug ist es jedoch geschickter, die sog. Log-Likelihood
ln L(θ) =n∑
i=1
ln f (xi |θ)
in θ zu maximieren, welche an denselben Stellen maximal wird, da dieLogarithmusfunktion ln eine streng monoton wachsende Funktion ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 266 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Beispiel: Poisson-VerteilungGesucht: Parameter λ einer Pois(λ)-verteilten Zufallsgröÿe XGegeben: Realisationen x1, . . . , xn von unabhängigen identisch wie Xverteilten Zufallsvariablen X1, . . . ,Xn
Likelihoodfunktion
L(λ) = e−λλx1
x1!· . . . · e−λλ
xn
xn!
Log-Likelihoodfunktion
ln L(λ) =n∑
i=1
ln e−λλxi
xi !=
n∑i=1
(−λ+ xi lnλ− ln (xi !))
∂ ln L(λ)
∂λ=
n∑i=1
(−1 +xi
λ) = 0
=⇒ λ =
∑ni=1 xi
n= x
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 267 / 435
9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Beispiel: Normalverteilung
Gesucht: Parameter µ, σ einer N(µ, σ2)-verteilten Zufallsgröÿe XX1, . . . ,Xn unabhängige Wiederholungen einer wie X -verteiltenZufallsgröÿe.Likelihoodfunktion zu den Realisierungen
L(µ, σ) =1√2πσ
e− (x1−µ)2
2σ2 · . . . · 1√2πσ
e− (xn−µ)2
2σ2
ln L(µ, σ) =n∑
i=1
(ln
(1√2πσ
)− (xi − µ)2
2σ2
)
=n∑
i=1
(− ln√2π − lnσ − (xi − µ)2
2σ2
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 268 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Partielles Dierenzieren nach µ und σ und Nullsetzen
∂ ln L(µ, σ)
∂µ=
n∑i=1
xi − µσ2
= 0 (1)
∂ ln L(µ, σ)
∂σ=
n∑i=1
(− 1σ
+2(xi − µ)2
2σ3
)= 0 (2)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 269 / 435
9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Aus (1):n∑
i=1
xi − nµ = 0,
alsoµ = x
Aus (2):
−nσ
+n∑
i=1
2(xi − µ)2
2σ3= 0
also
σ =
√√√√1n
n∑i=1
(xi − µ)2 =
√√√√1n
n∑i=1
(xi − x)2
Oensichtlich erhält man die bereits bekannten Schätzstatistiken X und S .
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 270 / 435

9. Parameterschätzung 9.3. Konstruktion von Schätzfunktionen
Kleinste-Quadrate-Schätzung
Prinzip der kleinsten Quadrate:Wähle den Parameter so, dass die Summe der quadrierten Abweichungenzwischen Beobachtungswert und geschätztem Wert minimal wird.Wichtig im Rahmen der Regressionsanalyse.
Beispiel: Schätze den Lageparameter µ so, dass
Q(µ) :=n∑
i=1
(Xi − µ)2 minimal
dQ
dµ= 2
n∑i=1
(Xi − µ) = 0
=⇒ µ =1n
n∑i=1
Xi = X
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 271 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Intervallschätzung
Wie der Name schon sagt, liefert die Punktschätzung einen (zufälligen)Wert θ für den gesuchten Parameter θ, der aber in den meisten Fällen mitdem gesuchten Wert nicht übereinstimmt.
Ist der Schätzer erwartungstreu, liefert der Standardfehler ein sinnvollesMaÿ für die Präzision des Schätzverfahrens.
Ein alternatives Vorgehen steht in Form der Intervallschätzung zurVerfügung, welches ein (zufallsabhängiges) Intervall angibt, in dem dergesuchte Parameter mit einer vorgegebenen (Mindest-)Wahrscheinlichkeitliegt:
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 272 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Zu vorgegebener Irrtumswahrscheinlichkeit α werden aus denStichprobenvariablen X1, . . . ,Xn Schätzstatistiken
Gu = gu(X1, . . . ,Xn) ≤ Go = go(X1, . . . ,Xn)
so konstruiert, dassP(θ ∈ [Gu,Go ]) ≥ 1− α
d.h. P(Gu ≤ θ ≤ Go) ≥ 1− α.Dann heiÿt [Gu,Go ] (1− α)-Kondenzintervall (oder(1− α)-Vertrauensintervall) für den unbekannten Parameter θ.
Typische Werte für α: 0.1, 0.05, 0.01.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 273 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Setzt man prinzipiell Gu = −∞ oder Go =∞ (für alle Werte vonX1, . . . ,Xn) erhält man ein einseitiges (1− α)-Kondenzintervall
P(θ ≤ Go) ≥ 1− α
mit der oberen Kondenzschranke Go , bzw.
P(Gu ≤ θ) ≥ 1− α
mit der unteren Kondenzschranke Gu.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 274 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Ist x1, . . . , xn eine Realisation von X1, . . . ,Xn, so ergibt sich durch
[gu(x1, . . . , xn), go(x1, . . . , xn)]
ein realisiertes Kondenzintervall, das den unbekannten Parameter θentweder enthält oder nicht enthält.
Das (1− α)-Kondenzintervall [Gu,Go ] für θ muss so interpretiert werden,dass [Gu,Go ] in (1− α) · 100% der Fälle, in denen Kondenzintervallegeschätzt werden, die resultierenden Kondenzintervalle den wahren Wert θenthalten.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 275 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Kondenzintervalle für Erwartungswert und Varianz
X1, . . . ,Xn unabhängige Wiederholungen von X ∼ N(µ, σ2).
Gesucht: Kondenzintervalle für den unbekannten Erwartungswert µ.
1. Fall: σ2 bekannt
X ist ein Schätzer für µ
X ∼ N
(µ,σ2
n
)X − µ
σ√n
∼ N(0, 1)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 276 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Sei z1−α2das (1− α
2 )-Quantil der N(0, 1)-Verteilung.Dann gilt
1− α = P
(−z1−α
2≤ X − µ
σ√n
≤ z1−α2
)
= P
(−z1−α
2
σ√n≤ X − µ ≤ z1−α
2
σ√n
)= P
(X − z1−α
2
σ√n≤ µ ≤ X + z1−α
2
σ√n
)Damit ist
[Gu,Go ] =
[X − z1−α
2
σ√n, X + z1−α
2
σ√n
]ein (1− α)-Kondenzintervall für µ.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 277 / 435
9. Parameterschätzung 9.4. Intervallschätzung
n→∞: Breite von [Gu,Go ]→ 0
α→ 0: Breite von [Gu,Go ]→∞
In ähnlicher Weise ndet man die einseitigen Kondenzintervalle für µ:(−∞, X + z1−α
2
σ√n
]bzw.
[X − z1−α
2
σ√n,∞)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 278 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Beispiel: Proteingehalt eines Biolms in mg/g Trockenmasse
Modellannahme: Proteingehalt ist N(µ, σ2)-verteiltStichprobe (n=80)
x <- c(321 ,334 ,356 ,398 ,376 ,343 ,312 ,334 ,365 ,376 ,334 ,355 ,388 ,
322 ,311 ,388 ,339 ,350 ,354 ,334 ,324 ,323 ,345 ,376 ,352 ,383 ,
326 ,327 ,334 ,385 ,332 ,312 ,385 ,360 ,398 ,399 ,360 ,310 ,334 ,
323 ,335 ,372 ,383 ,372 ,382 ,389 ,389 ,311 ,325 ,327 ,373 ,382 ,
314 ,315 ,317 ,318 ,311 ,390 ,380 ,370 ,385 ,392 ,399 ,373 ,335 ,
336 ,335 ,335 ,335 ,335 ,334 ,335 ,334 ,336 ,334 ,331 ,339 ,335 ,
331 ,338)
Punktschätzung für den unbekannten Erwartungswert µ: µ = x = 349.25Punktschätzung für die unbekannte Varianz σ2: σ2 = s2 = 27.12(Stichprobenvarianz)
Schätzer für den Standardfehler von x : σx =√
s2
n = 3.03
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 279 / 435
9. Parameterschätzung 9.4. Intervallschätzung
95%-Kondenzintervall für den Erwartungswert bei bekannterStandardabweichung (die hier nicht bekannt ist, deshalb nehmen wir malσ = 27 an): [
x − z1−α2
σ√n, x + z1−α
2
σ√n
]=
[349.25− 1.96 · 27√
80, 349.25 + 1.96 · 27√
80
]= [343.31, 355.19]
Berechnung des konkreten 95%-Kondenzintervalles in R:
> mean(x)-qnorm (0.975)* sd(x)/sqrt(length(x))
[1] 343.3061
> mean(x)+ qnorm (0.975)* sd(x)/sqrt(length(x))
[1] 355.1939
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 280 / 435

9. Parameterschätzung 9.4. Intervallschätzung
In einer kleinen Simulationsstudie überprüfen wir, ob das oben angegebene(theoretische) Kondenzintervall das vorgeschriebene Niveau einhält:
in.conf.int <- rep(FALSE ,1000)
for (i in 1:1000)
x <- rnorm (80, mean =350, sd=27)
lower <- mean(x)-qnorm (0.975)* sd(x)/sqrt(length(x))
upper <- mean(x)+qnorm (0.975)* sd(x)/sqrt(length(x))
cat("i=",i,":",c(lower ,upper), "\n")
if (lower <= 350 & 350 <= upper )
in.conf.int[i] <- TRUE
table(in.conf.int )/1000
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 281 / 435
9. Parameterschätzung 9.4. Intervallschätzung
2. Fall: σ2 unbekannt
Da σ2 unbekannt ist, ist auch die Verteilung von X−µσ√n
unbekannt. Deshalb
wird σ durch
S =
√√√√ 1n − 1
n∑i=1
(Xi − X )2
geschätzt. Die ZufallsvariableX − µ
S√n
ist jetzt allerdings nicht mehr normalverteilt, sondern tn−1- verteilt mit(n − 1) Freiheitsgraden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 282 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Sind Z ,Z1, . . . ,Zn unabhängige N(0, 1)-verteilte Zufallsvariablen, dannheiÿt die Verteilung von
T =Z√
Z21 +···+Z2
n
n
t- oder Student-verteilt mit n Freiheitsgraden.
Die Tails (Flanken) der Dichten fallen nur ∼ x−n und nicht ∼ exp(− x2
2 )wie bei der Normalverteilung.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 283 / 435
9. Parameterschätzung 9.4. Intervallschätzung
tn−1,1−α2sei das (1− α
2 )-Quantil der tn−1-Verteilung.
Konstruktion eines (1− α)-Kondenzintervalles für den Erwartungswert µ:
1− α = P
(−tn−1,1−α
2≤ X − µ
S√n
≤ tn−1,1−α2
)
= P
(X − tn−1,1−α
2
S√n≤ µ ≤ X + tn−1,1−α
2
S√n
)Damit ist
[Gu,Go ] =
[X − tn−1,1−α
2
S√n, X + tn−1,1−α
2
S√n
]ein (1− α)-Kondenzintervall für den Erwartungswert µ, falls σ2
unbekannt ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 284 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Da für groÿe Stichprobenumfänge n das arithmetische Mittel Xapproximativ N(µ, σ
2
n )-verteilt ist, kann man zeigen, dass für n ≥ 30
[Gu,Go ] =
[X − z1−α
2
S√n, X + z1−α
2
S√n
]ein approximatives (1− α)-Kondenzintervall für den Erwartungswert µ ist,falls σ2 unbekannt ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 285 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Konstruktion eines (1− α)-Kondenzintervalles für die Varianz beinormalverteilter Grundgesamtheit:
σ2 kann mittels S2 geschätzt werden.
Sind Z1, . . . ,Zn unabhängige N(0, 1)-verteilte Zufallsvariablen, so besitzt
Z 21 + · · ·+ Z 2
n
eine so genannte χ2-Verteilung mit n Freiheitsgraden.
Man kann zeigen, dassn − 1σ2
S2 ∼ χ2n−1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 286 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Seien χ2n−1,α2und χ2
n−1, 1−α2
die α2 - bzw. (1− α
2 )-Quantile der χ2-Verteilung
mit (n − 1) Freiheitsgraden.Dann gilt:
1− α = P
(χ2n−1,α
2≤ n − 1
σ2S2 ≤ χ2n−1,1−α
2
)= P
((n − 1)S2
χ2n−1,1−α
2
≤ σ2 ≤ (n − 1)S2
χ2n−1,α
2
)
Also ist [(n − 1)S2
χ2n−1,1−α
2
,(n − 1)S2
χ2n−1,α
2
]ein (1− α)-Kondenzintervall für die Varianz bei einer normalverteiltenGrundgesamtheit.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 287 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Bei einem dichotomen Merkmal X wird die Auftretenswahrscheinlichkeit
p = P(X = 1)
bei Vorliegen der Stichprobe X1, . . . ,Xn von unabhängigenBin(1, p)-verteilten Zufallsvariablen mittels
p =1n
n∑i=1
Xi
geschätzt. Da∑n
i=1 Xi ∼ Bin(n, p), ist nach dem zentralen Grenzwertsatz
X − E (X )√Var(X )
=p − p√p(1−p)
n
approximativ N(0, 1)-verteilt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 288 / 435

9. Parameterschätzung 9.4. Intervallschätzung
Da p unbekannt ist, wird p durch p geschätzt. Dann gilt
1− α ∼ P
−z1−α2≤ p − p√
p(1−p)n
≤ z1−α2
= P
(p − z1−α
2
√p(1− p)
n≤ p ≤ p + z1−α
2
√p(1− p)
n
)
Also ist
[Gu,Go ] =
[p − z1−α
2
√p(1− p)
n, p + z1−α
2
√p(1− p)
n
]
ein approximatives (1− α)-Kondenzintervall für die Wahrscheinlichkeit pin einer Bernoulli-verteilten Grundgesamtheit.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 289 / 435
9. Parameterschätzung 9.4. Intervallschätzung
Beispiel: Sonntagsfrage
Von n = 496 befragte Frauen zeigten∑n
i=1 Xi = 200 eine Präferenz für dieUnionsparteien. Also ist p = 200
496 .Bei einer Sicherheitswahrscheinlichkeit von 1− α = 0.95 erhält man fürp = P(X = 1) ein approximatives 95%-Kondenzintervall
[p − z1−α
2
√p(1− p)
n, p + z1−α
2
√p(1− p)
n
]
=
[0.403− 1.96
√0.403 · 0.597
496, · · ·+ . . .
]= [0.360, 0.446]
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 290 / 435

10. Testen von Hypothesen
9 Parameterschätzung
10 Testen von HypothesenBinomial- und Gauÿ-TestApproximativer BinomialtestGauÿ-Test
Prinzipien des TestensFehlentscheidungenZusammenhang zwischen statistischen Tests und KondenzintervallenÜberschreitungswahrscheinlichkeitGütefunktion
Durchführung eines Tests mit R
11 Einfache lineare Regression
12 Varianzanalyse
13 VersuchsplanungJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 291 / 435
10. Testen von Hypothesen
Testen von Hypothesen
Neben dem Schätzen von Parametern theoretischer Verteilungen ist es oftvon Interesse, Vermutungen über einen Parameter oder eine Verteilung inder Grundgesamtheit zu überprüfen.
Die Vermutung wird in Bezug auf die Grundgesamtheit aufgestellt, derenÜberprüfung jedoch unter Verwendung einer Stichprobe durchgeführt.Inwieweit der Schluss von der Stichprobe auf die Grundgesamtheit zulässigist, ist Teil des statistischen Tests.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 292 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Binomial- und Gauÿ-Test
Beispiel: Eine Klausur besteht aus n = 30 Aufgaben, bei der jeweils einevon zwei Antworten auszuwählen ist. Ein Student beantwortet 19 Fragenkorrekt und 11 Fragen falsch.
Frage: Hat der Student geraten oder tatsächlich etwas gewusst?
Xi =
1, falls i-te Antwort des Studenten richtig0, sonst
X1, ...,X30 seien unabhängige Bin(1, p)-verteilte Zufallsvariablen.Also ist S =
∑30i=1 Xi Bin(30, p)-verteilt.
Wenn der Student nichts weiÿ, ist p = 12 .
Besitzt der Student gewisse Kenntnisse, so ist p > 12
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 293 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Auf Grundlage der Daten (S = 19) wollen wir uns zwischen derNullhypothese
Ho : p =12
und der Alternativhypothese
H1 : p >12
entscheiden.
Ist die Prüfgröÿe oder Teststatistik
S =30∑i=1
Xi
gröÿer als ein kritischer Wert c , entscheiden wir uns für H1.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 294 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Wie ist der kritische Wert c nun zu wählen?
c = 16, c = 17, c = 18, . . .?
c wird so gewählt, dass H0 höchstens mit Wahrscheinlichkeit α = 0.05fälschlicherweise abgelehnt wird:
α = 0.05 > P( S > c︸ ︷︷ ︸H0 wird abgelehnt
|H0)
= 1− P(S ≤ c|H0)
= 1−c∑
i=0
(30i
)(12
)i (1− 1
2
)30−i
Es ist also die kleinste natürliche Zahl c gesucht, so dass
c∑i=0
(30i
)(12
)30
> 0.95
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 295 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Bestimmung des kritischen Wertes c mittels R:
> qbinom (0.95 , size=30, prob =0.5)
> 19
Damit wählen wir c = 19 als kritischen Wert.
Da S = 19, können wir H0 nicht ablehnen, wenn wir sicherstellen wollen,dass H0 höchstens mit Wahrscheinlichkeit α = 0.05, dem sogenanntenNiveau, fälschlicherweise abgelehnt wird.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 296 / 435
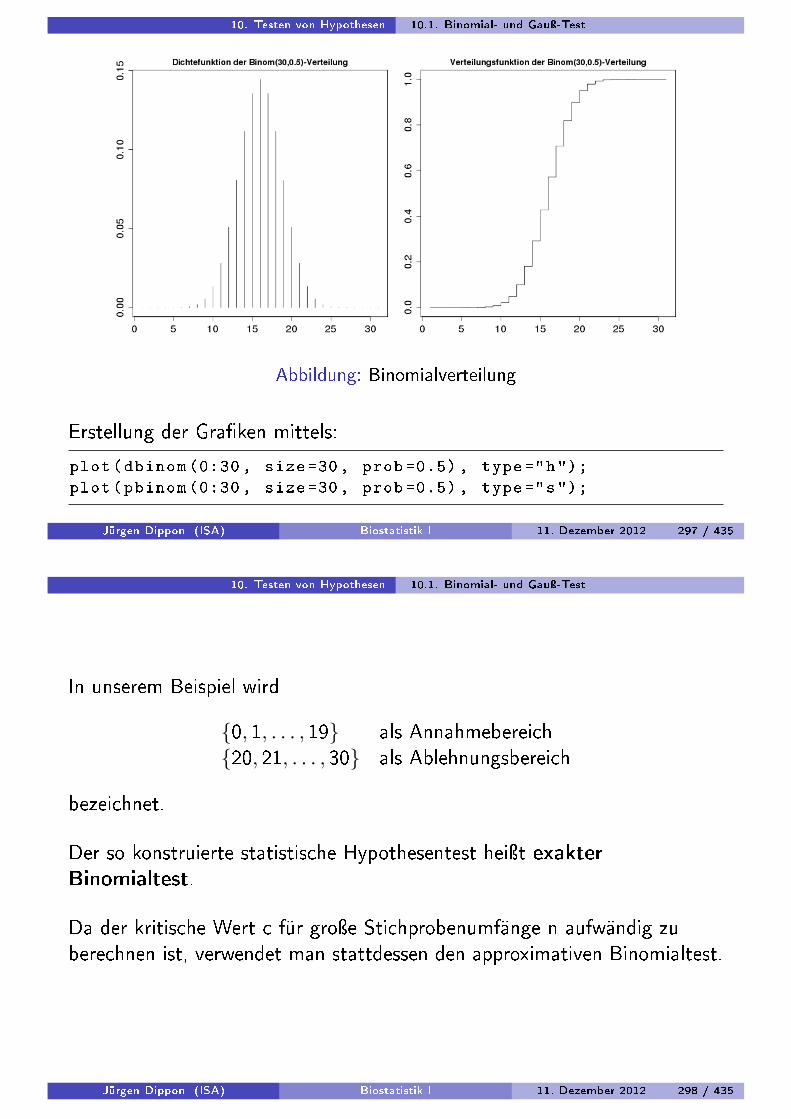
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Abbildung: Binomialverteilung
Erstellung der Graken mittels:
plot(dbinom (0:30 , size=30, prob =0.5), type="h");
plot(pbinom (0:30 , size=30, prob =0.5), type="s");
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 297 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
In unserem Beispiel wird
0, 1, . . . , 19 als Annahmebereich20, 21, . . . , 30 als Ablehnungsbereich
bezeichnet.
Der so konstruierte statistische Hypothesentest heiÿt exakterBinomialtest.
Da der kritische Wert c für groÿe Stichprobenumfänge n aufwändig zuberechnen ist, verwendet man stattdessen den approximativen Binomialtest.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 298 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Approximativer Binomialtest
Beispiel: statistische QualitätskontrolleBei der Produktion von Speicherchips entstehen 10% unbrauchbare Chips.Anhand einer Stichprobe mit Umfang n = 1000 soll überprüft werden, obder Produktionsprozess sich verschlechtert hat, also mehr als 10%Ausschuss entsteht.
Wie oben seien
Xi =
1, falls i-tes Stichprobenelement Ausschuss ist0, sonst
und X1, ...,Xn unabhängige Bin(1, p)-verteilte Zufallsvariablen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 299 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Dann ist
S =n∑
i=1
Xi ∼ Bin(n, p)
und nach dem zentralen Grenzwertsatz von Moivre-Laplace
Z =S − np√np(1− p)
ungefähr N(0, 1)-verteilt
Das Testproblem ist:
H0 : p = p0 = 0.1 gegen H1 : p > p0 = 0.1
Der eigentlich interessierende Sachverhalt wird durch dieAlternativhypothese ausgedrückt.
Wir lehnen H0 ab, falls S bzw. Z zu groÿ ist. Dabei soll sichergestelltwerden, dass die Abweichung von S zu E (S) = np0 bei Vorliegen derNullhypothese nicht alleine durch den Zufall erklärt werden kann.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 300 / 435
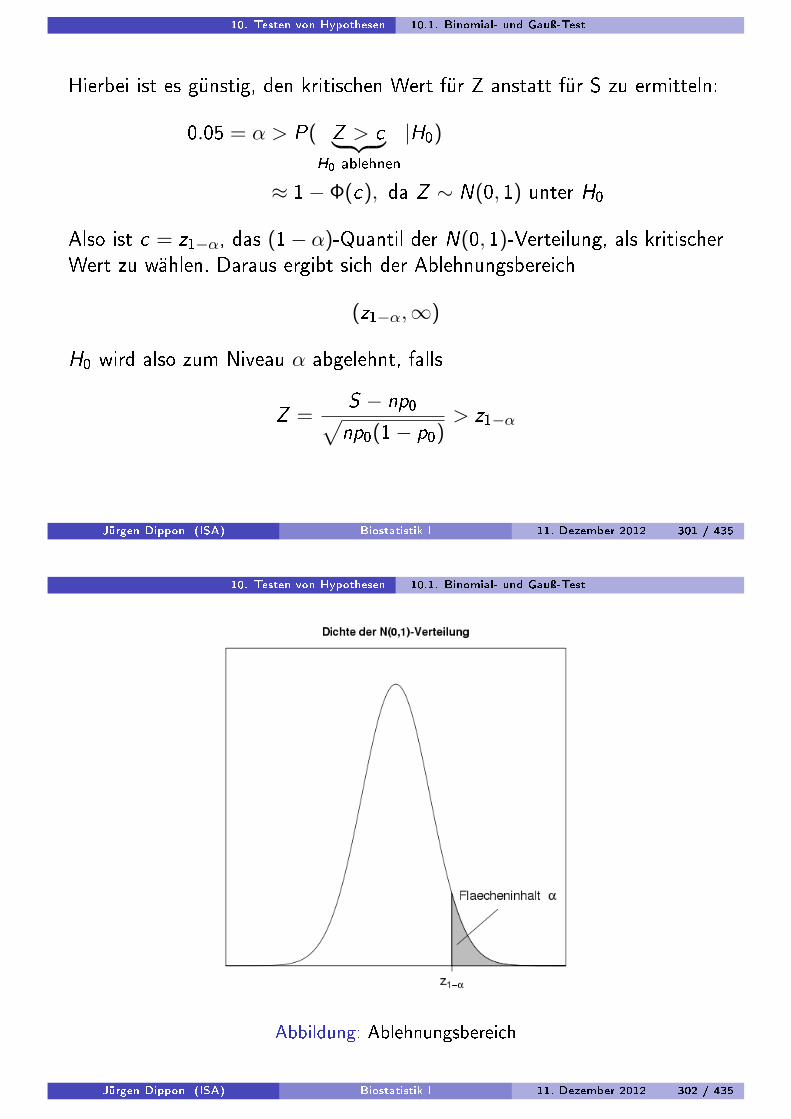
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Hierbei ist es günstig, den kritischen Wert für Z anstatt für S zu ermitteln:
0.05 = α > P( Z > c︸ ︷︷ ︸H0 ablehnen
|H0)
≈ 1− Φ(c), da Z ∼ N(0, 1) unter H0
Also ist c = z1−α, das (1− α)-Quantil der N(0, 1)-Verteilung, als kritischerWert zu wählen. Daraus ergibt sich der Ablehnungsbereich
(z1−α,∞)
H0 wird also zum Niveau α abgelehnt, falls
Z =S − np0√np0(1− p0)
> z1−α
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 301 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Abbildung: Ablehnungsbereich
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 302 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Für n = 1000, p = 0.1, α = 0.05 wird H0 abgelehnt, falls
Z =S − 100√
90> 1.64
d.h.S > 115.56
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 303 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Soll überprüft werden, ob sich der Produktionsprozess hinsichtlich derErgebnisqualität verbessert hat, ist das Testproblem:
H0 : p = p0 gegen H1 : p < p0
zu betrachten. Der dazugehörige Ablehnungsbereich lautet
(−∞,−z1−α) = (−∞, zα)
Soll überprüft werden, ob sich der Produktionsprozess hinsichtlich derErgebnisqualität verändert hat, ist das Testproblem:
H0 : p = p0 gegen H1 : p 6= p0
zu betrachten. Der dazugehörige Ablehnungsbereich lautet
c = (−∞, zα/2) ∪ (z1−α/2,∞)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 304 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Abbildung: Beidseitiger Ablehnungsbereich
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 305 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Zusammenfassung: Approximativer BinomialtestGegeben seien folgende Testprobleme über den Parameter p in einerBin(n, p)-Verteilung:
(a) H0 : p = p0 gegen H1 : p 6= p0(b) H0 : p = p0 gegen H1 : p < p0(c) H0 : p = p0 gegen H1 : p > p0
Basierend auf der Prüfgröÿe
Z =S − np0√np0(1− p0)
welche unter H0 näherungsweise N(0, 1)-verteilt ist, und dem vorgegebenenNiveau α entscheidet man sich für H1 im Testproblem
(a), falls |z | > z1−α/2(b), falls z < −z1−α(c), falls z > z1−α
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 306 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Gauÿ-TestBeispiel: KontrollkartenEs sei bekannt, dass ein Produktionsprozess Bleistifte produziert, derenLängen X approximativ N(µ, σ2)-verteilt sind mit Erwartungswertµ = 17[cm] und bekannter Varianz σ2 = 2.25[cm2]
Um zu überprüfen, ob die produzierten Bleistifte dem Sollwert (miterlaubter zufälliger Abweichung) entsprechen, d.h. EX = µ0 = 17,betrachtet man das Testproblem
H0 : µ = µ0 = 17 gegen H1 : µ 6= 17
Dazu entnimmt man der laufenden Produktion Bleistifte mit LängenX1, ...,Xn ∼ N(µ, σ2) und untersucht die Prüfgröÿe X oder diestandardisierte Prüfgröÿe
Z =X − µ0σ
√n
welche unter H0 N(0, 1)-verteilt ist.Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 307 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
H0 wird dann zum Niveau α abgelehnt, falls
|Z | > z1−α/2
Zahlenbeispiel: n = 5, x = 18.1, α = 0.01
z =x − µ0σ
√n =
18.1− 171.5
√5 = 1.64
z1−α/2 = 2.5758
Da |z | ≤ z1−α/2 kann H0 zum Niveau α = 0.01 nicht abgelehnt werden.Ein Eingri in den Produktionsprozess ist also nicht nötig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 308 / 435

10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
In der statistischen Qualitätskontrolle werden für jede Stichprobe dieMittelwerte x über der Stichprobennummer in einer Grak eingetragen undmit den Kontrollgrenzen
µ0 − z1−α/2 ·σ√n
und µ0 + z1−α/2 ·σ√n
verglichen. Bendet sich x auÿerhalb dieses dadurch deniertenhorizontalen Streifens, gilt der Prozess als statistisch auÿer Kontrolle.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 309 / 435
10. Testen von Hypothesen 10.1. Binomial- und Gauÿ-Test
Zusammenfassung: Gauÿ-TestUnabhängige Zufallsvariablen X1, ...Xn jeweils N(µ, σ2)-verteilt mitbekannter Varianz σ2 oder, falls n groÿ (Faustregel: n ≥ 30) mit beliebigerstetiger Verteilung, E (Xi ) = µ,Var(Xi ) = σ2. Betrachte folgendeTestprobleme:
(a) H0 : µ = µ0 gegen H1 : µ 6= µ0(b) H0 : µ = µ0 gegen H1 : µ < µ0(c) H0 : µ = µ0 gegen H1 : µ > µ0
Unter H0 (d.h. µ = µ0) ist
Z =X − µ0σ
√n N(0, 1)-verteilt bzw. näherungsweise N(0, 1)-verteilt
Basierend auf der Prüfgröÿe Z fällt die Entscheidung für H1 im Testproblem
(a), falls |z | > z1−α/2(b), falls z < −z1−α(c), falls z > z1−α
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 310 / 435

10. Testen von Hypothesen 10.2. Prinzipien des Testens
Prinzipien des Testens
1. Schritt: Quantizierung der Fragestellung
2. Schritt: Formulierung der Modellannahmen
3. Schritt: Festlegung der Null- und Alternativhypothese
4. Schritt: Wahl des Signikanzniveaus
5. Schritt: Wahl einer Prüfgröÿe (Teststatistik), die in der Lage ist,zwischen H0 und H1 zu dierenzieren. Bestimmung derVerteilung der Prüfgröÿe unter der Nullhypothese.Konstruktion des Ablehnungsbereiches.
6. Schritt: Berechnung des Wertes der Prüfgröÿe für die konkreteStichprobe
7. Schritt: Testentscheidung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 311 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Falls Abweichungen nach oben und unten interessieren, wie im Fall (a) imGauÿ-Test, heiÿt das Testproblem zweiseitig, falls nur Abweichungen ineine Richtung interessieren, wie im Fall (b) und (c) im Gauÿ-Test, heiÿt dasTestproblem einseitig.
Besteht die Hypothese H0 oder H1 nur aus einem Punkt, nennt man H0
bzw. H1 einfach, sonst zusammengesetzt
Tests, die keine genaueren Annahmen über die Verteilung derZufallsvariablen X1, ... Xn machen, heiÿen nichtparametrisch. WerdenAnnahmen über den Verteilungstyp gemacht, so heiÿen die Testsparametrisch.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 312 / 435

10. Testen von Hypothesen 10.2. Prinzipien des Testens
FehlentscheidungenBei einem statistischen Testproblem H0 gegen H1 und einem geeignetenstatistischen Test spricht man von einem
Fehler 1. Art, wenn H0 verworfen wird, obwohl H0 wahr ist
Fehler 2. Art, wenn H0 beibehalten wird, obwohl H1 wahr ist
Es sind dehalb folgende Ausgänge bei einem statistischen Test denkbar:
Entscheidung fürH0 H1
falschH0 wahr richtig Fehler 1. Art
(α-Fehler)falsch
H1 wahr Fehler 2. Art richtig(β-Fehler)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 313 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Ein statistischer Test heiÿt Test zum Signikanzniveau α (wobei0 < α < 1) oder Signikanztest, falls:
P(H1 annehmen |H0 wahr) ≤ α
d.h.P(Fehler 1. Art) ≤ α
Typische Werte für das Signikanzniveau α sind 0.1, 0.05, 0.01.
Interpretation: Es werden 100 Stichproben vom Umfang n gezogen und esgelte die Nullhypothese. Bei 100 Tests zum Niveau α wird dieNullhypothese dann im Mittel höchstens in 5% der Fälle (fälschlicherweise)abgelehnt werden.
Im Falle einer Ablehnung der Nullhypothese sagt man, dass das Ergebnisstatistisch signikant zum Niveau α sei. Die Wahrscheinlichkeit für einenFehler 2. Art kann man meist nicht kontrollieren. DieseUngleichbehandlung der Fehler 1. und 2. Art ist der Grund dafür, dass diezu sichernde Behauptung als Alternativhypothese formuliert wird.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 314 / 435

10. Testen von Hypothesen 10.2. Prinzipien des Testens
Zusammenhang zwischen statistischen Tests undKondenzintervallenBeispiel Gauÿ-Test
Verwerfe H0, falls |z | =∣∣ x−µ0
σ
√n∣∣ > z1−α/2
Behalte H0, falls |z | =
∣∣∣∣ x − µ0σ
√n
∣∣∣∣ ≤ z1−α/2︸ ︷︷ ︸⇔ |x − µ0| ≤ z1−α/2 · σ√
n
⇔ µ0 ∈[x − z1−α/2 · σ√
n, x + z1−α/2 · σ√
n
]Damit ist H0 genau dann beizubehalten, wenn µ0 im(1− α)-Kondenzintervall für µ liegt.
Allgemein: Ein 2-seitiges (1− α)-Kondenzintervall entspricht demAnnahmebereich des zugehörigen 2-seitigen Signikanztests zum Niveau α.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 315 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Überschreitungswahrscheinlichkeit
Der p-Wert oder die Überschreitungswahrscheinlichkeit ist deniert alsdie Wahrscheinlichkeit den beobachteten Prüfgröÿenwert oder einen inRichtung der Alternative extremeren Wert zu beobachten:
Ist der p-Wert kleiner oder gleich dem vorgegebenen Signikanzniveau,wird H0 verworfen, andernfalls beibehalten.
Fortsetzung des Beispiels zum Gauÿ-Test:Dort wurde die Teststatistik |z | betrachtet, welche für die Stichprobe denWert z = 1.64 lieferte. Der p-Wert ist jetzt gegeben durch
p = P(|Z | ≥ 1, 64|H0) = 2(1− Φ(1.64)) ≈ 0.1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 316 / 435

10. Testen von Hypothesen 10.2. Prinzipien des Testens
Abbildung: P-Wert (Inhalt der hellgrauen Fläche beträgt α− p. Inhalt derdunkleren Fläche ist p)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 317 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Gütefunktion
Für vorgegebenes Signikanzniveau α und festen Stichprobenumfang n gibtdie Gütefunktion g die Wahrscheinlichkeit für einen statistischen Test an,die Nullhypothese zu verwerfen:
g(µ) = P(H0 verwerfen| µ︸︷︷︸wahrer Parameter
)
Ist µ ∈ H0, so ist g(µ) ≤ αIst µ ∈ H1, so ist 1− g(µ) die Wahrscheinlichkeit für den Fehler 2. Art
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 318 / 435
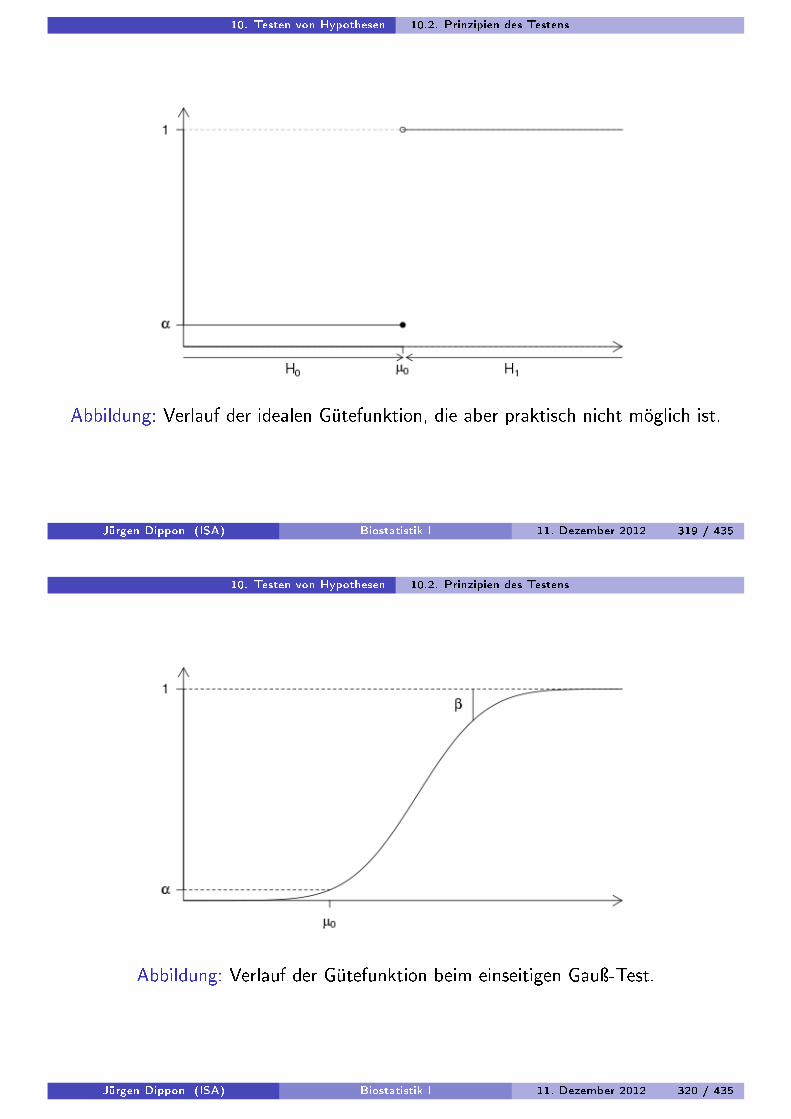
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Abbildung: Verlauf der idealen Gütefunktion, die aber praktisch nicht möglich ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 319 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Abbildung: Verlauf der Gütefunktion beim einseitigen Gauÿ-Test.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 320 / 435
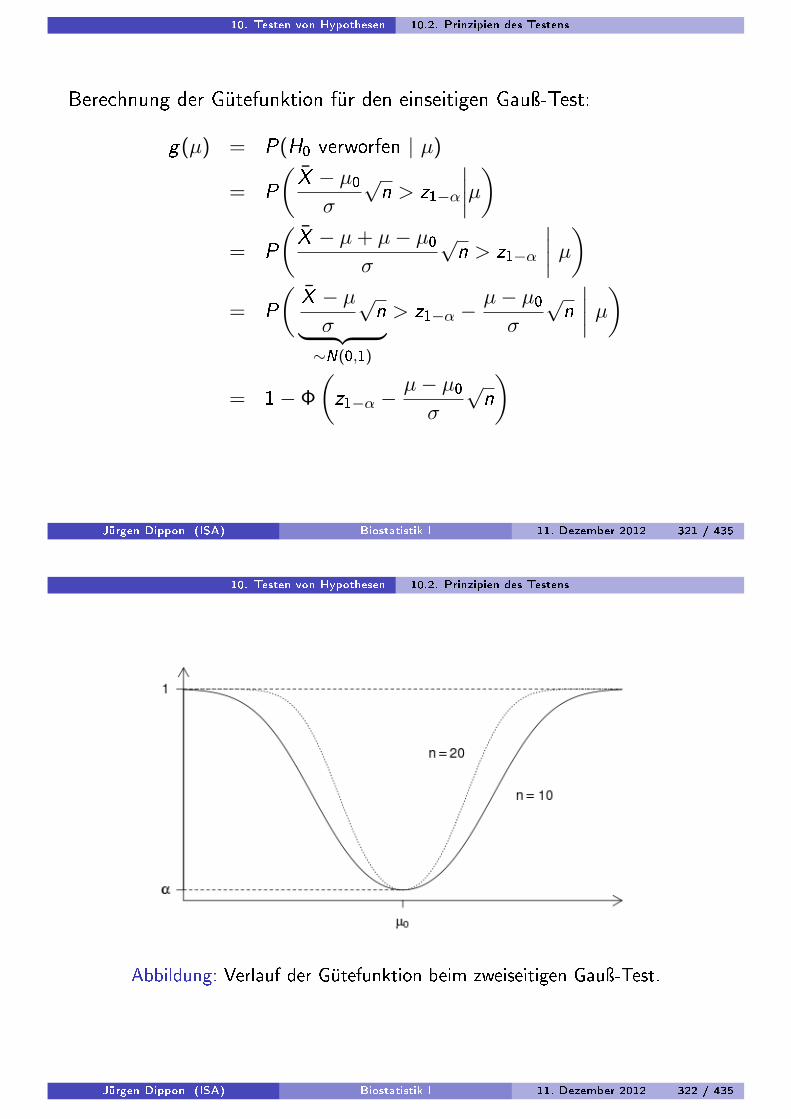
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Berechnung der Gütefunktion für den einseitigen Gauÿ-Test:
g(µ) = P(H0 verworfen | µ)
= P
(X − µ0σ
√n > z1−α
∣∣∣∣µ)= P
(X − µ+ µ− µ0
σ
√n > z1−α
∣∣∣∣ µ)= P
(X − µσ
√n︸ ︷︷ ︸
∼N(0,1)
> z1−α −µ− µ0σ
√n
∣∣∣∣ µ)
= 1− Φ
(z1−α −
µ− µ0σ
√n
)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 321 / 435
10. Testen von Hypothesen 10.2. Prinzipien des Testens
Abbildung: Verlauf der Gütefunktion beim zweiseitigen Gauÿ-Test.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 322 / 435

10. Testen von Hypothesen 10.2. Prinzipien des Testens
Eigenschaften der Gütefunktionen eines statistischen Tests
Für Werte aus H1 heiÿt die Gütefunktion Trennschärfe oder Macht
Für Werte aus H0 ist die Gütefunktion kleiner oder gleich α
Für wachsendes n wird die Macht eines Tests gröÿer, d.h. dieGütefunktion wird steiler
Für wachsendes α wird die Macht eines Tests gröÿer
Für einen wachsenden Abstand zwischen Werten aus H1 und H0 wirddie Macht eines Tests gröÿer.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 323 / 435
10. Testen von Hypothesen 10.3. Durchführung eines Tests mit R
Durchführung eines Tests mit R
Beispiel: Eine Klausur besteht aus n = 30 Aufgaben, bei der jeweils einevon zwei Antworten auszuwählen ist. Ein Student beantwortet 19 Fragenkorrekt und 11 Fragen falsch.
> binom.test(x=19, n=30, p=0.5, alternative =" greater ")
Exact binomial test
data: 19 and 30
number of successes = 19, number of trials = 30, p-value = 0.1002
alternative hypothesis: true probability of success is greater than 0.5
95 percent confidence interval:
0.4669137 1.0000000
sample estimates:
probability of success
0.6333333
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 324 / 435

11. Einfache lineare Regression
9 Parameterschätzung
10 Testen von Hypothesen
11 Einfache lineare RegressionEinfache lineare RegressionMethode der kleinsten QuadrateGütemaÿ für die Anpassung der GeradenStochastisches Modell
12 Varianzanalyse
13 Versuchsplanung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 325 / 435
11. Einfache lineare Regression 11.1. Einfache lineare Regression
Einfache lineare Regression
Beispiel: Rohöl und BenzinpreiseDie folgenden Daten geben die mittleren Rohöl-Preise xi (in Dollar/Barrel)und Benzinpreise yi (in Cent/Gallone) wieder:
i Jahr i yi xi1 1980 125 28.072 1981 138 35.243 1982 129 31.87...
......
...21 2000 151 28.2622 2001 146 22.96
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 326 / 435
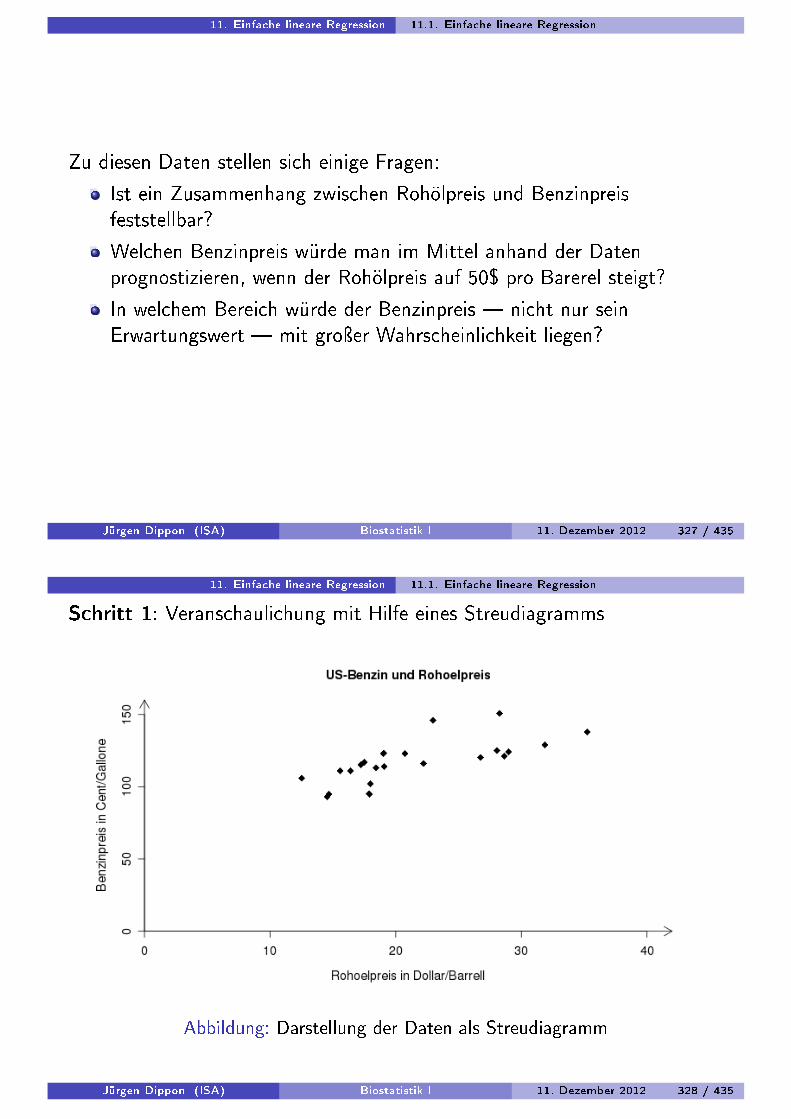
11. Einfache lineare Regression 11.1. Einfache lineare Regression
Zu diesen Daten stellen sich einige Fragen:
Ist ein Zusammenhang zwischen Rohölpreis und Benzinpreisfeststellbar?
Welchen Benzinpreis würde man im Mittel anhand der Datenprognostizieren, wenn der Rohölpreis auf 50$ pro Barerel steigt?
In welchem Bereich würde der Benzinpreis nicht nur seinErwartungswert mit groÿer Wahrscheinlichkeit liegen?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 327 / 435
11. Einfache lineare Regression 11.1. Einfache lineare Regression
Schritt 1: Veranschaulichung mit Hilfe eines Streudiagramms
Abbildung: Darstellung der Daten als Streudiagramm
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 328 / 435

11. Einfache lineare Regression 11.1. Einfache lineare Regression
Schritt 2: Vermutung über Zusammenhang anstellen.Nicht unerwartet korrespondieren gröÿere Ölpreise mit höherenBenzinpreisen. Man könnte näherungsweise einen linearen Zusammenhangmutmaÿen. Seien (xi , yi ) die Datenpaare, wobei xi den Rohölpreisen und yiden Benzinpreisen entspricht, dann gilt:
yi = a + bxi + ei
wobei die ei die Abweichungen von der Gerade a + bx beschreiben.
Schritt 3: Ermittlung einer Geraden, die den Zusammenhang zwischen denDaten möglichst gut beschreibt. Dazu wird die Methode der kleinstenQuadrate verwendet.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 329 / 435
11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Methode der kleinsten Quadrate
Ausgehend von der Beziehung:
yi = a + bxi + ei , ei = yi − (a + bxi ) Fehler (Residuum)
sucht man nach einer Gerade, für die alle Fehlerterme (error) ei möglichstklein werden. Das erreicht man z.B. in dem man
Q(a, b) :=n∑
i=1
e2i =n∑
i=1
[yi − (a + bxi )]2
minimiert. Wir gehen im Folgenden davon aus, dass die xi nicht alleidentisch sind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 330 / 435
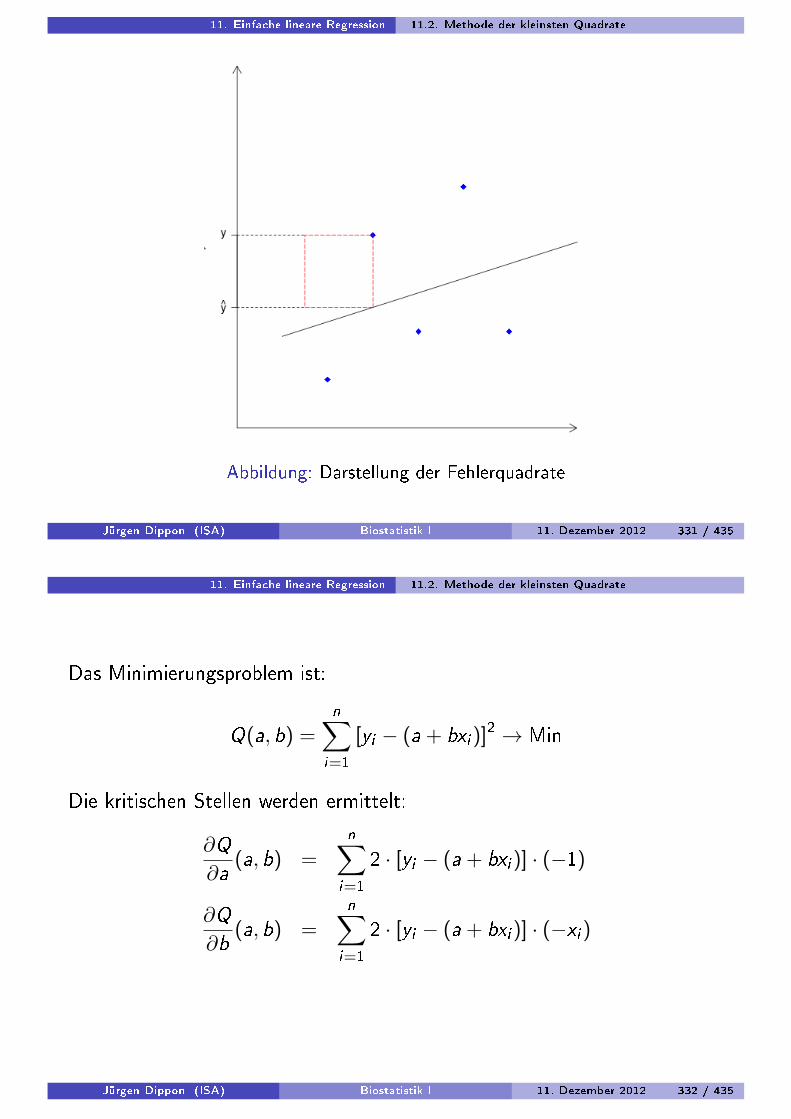
11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Abbildung: Darstellung der Fehlerquadrate
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 331 / 435
11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Das Minimierungsproblem ist:
Q(a, b) =n∑
i=1
[yi − (a + bxi )]2 → Min
Die kritischen Stellen werden ermittelt:
∂Q
∂a(a, b) =
n∑i=1
2 · [yi − (a + bxi )] · (−1)
∂Q
∂b(a, b) =
n∑i=1
2 · [yi − (a + bxi )] · (−xi )
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 332 / 435

11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Die Lösung des linearen Gleichungssystems
∂Q
∂a(a, b) = 0
∂Q
∂b(a, b) = 0
führt auf genau eine Lösung a, b, die Q minimiert:
b =
∑ni=1 xiyi − nx y∑ni=1 x
2i − nx2
, a = y − bx
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 333 / 435
11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Einfache lineare Regression und Kleinste-Quadrate-Methode
Gegeben seien die reellwertigen Beobachtungswerte (x1, y1), ..., (xn, yn).Dann heiÿt
yi = a + bxi + ei , i = 1, ..., n
einfache lineare Regressionsgleichung wobei a den Achsenabschnitt, bden Steigungsparameter und ei die Residuen (Fehler) bezeichnen. Unter derAnnahme s2X > 0 sind die Kleinste-Quadrate-Koezienten für a und b
gegeben durch:
a = y − bx , b =
∑ni=1 xiyi − nx y∑ni=1 x
2i − nx2
=1
n−1∑n
i=1(xi − x)(yi − y)1
n−1∑n
i=1(xi − x)2
Die Kleinste-Quadrate-Gerade (KQ-Gerade) ergibt sich durchy(x) = a + bx . Die Werte yi = a + bxi und ei = yi − yi bezeichnen wir alsKQ-gettete Werte bzw. KQ-Residuen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 334 / 435

11. Einfache lineare Regression 11.2. Methode der kleinsten Quadrate
Eigenschaften
Die KQ-Gerade geht durch den Mittelpunkt (x , y).
a = y − bx ⇒ y = a + bx = y/(x).
Die Summe der KQ-Residuen ist gleich 0:
n∑i=1
ei = 0
¯y = y
Wenn alle Punkte (xi , yi ) auf der Geraden a + bx liegen, dann sind:
a = a, b = b, yi = yi , ei = 0
Eine Prognose wird mit der KQ-Geraden vorgenommen. Für einenWert x prognostiziert man den y-Wert:
y(x) = a + bx
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 335 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Gütemaÿ für die Anpassung der Geraden
Wie gut lassen sich die Daten mit einer Geraden beschreiben?Streuungszerlegung der Regression
n∑i=1
(yi − y)2 =n∑
i=1
(yi − y)2 +n∑
i=1
(yi − yi )2
Ansatz:
Die Residualstreuung ist die Summe der verbliebenen quadriertenFehler nach Anpassung der Geraden.
Die Anpassung ist gut, falls der Anteil der erklärten Streuung an derGesamtstreuung groÿ ist:
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
=Erklärte StreuungGesamtstreuung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 336 / 435

11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
BestimmtheitsmaÿGegeben seien die reellwertigen Beobachtungswerte (x1, y1), ..., (xn, yn) mit
s2X > 0 und s2Y > 0
Dann ist das Bestimmtheitsmaÿ der KQ-Regression gegeben durch:
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
= 1−∑n
i=1(yi − yi )2∑n
i=1(yi − y)2
Eigenschaften
0 ≤ R2 ≤ 1
R2 = r2XYR2 = 1 genau dann, wenn alle Punkte (xi , yi ) auf einer Geraden liegen.
R2 = 0 genau dann, wenn sXY = 0 ist.
Eine gute Beschreibung der Daten durch eine Gerade liegt bei groÿenWerten von R2 (nahe 1) vor, eine schlechte bei kleinen Werten von R2
(nahe 0).Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 337 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Beispiel (fortgesetzt): ÖlpreiseDirekte Berechnung der Regressionsgeraden:
x = 21.572, y = 117.635,∑i
x2i = 11078.277
∑i
y2i = 309218,∑i
xiyi = 57284.35
s2X =
∑i x
2i − nx2
n − 1=
11078.277− 22 · 21.5722
21= 40.026
s2Y =
∑i y
2i − ny2
n − 1=
57284.35− 22 · 117.6362
21= 227.475
sXY =
∑i xiyi − nx y
n − 1=
57284.35− 22 · 21.572 · 117.63621
= 69.342
Daher:
b =sXY
s2X=
69.34240.026
= 1.732, a = y−bx = 117.636−1.732·21.572 = 80.273
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 338 / 435

11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Und für das Bestimmtheitsmaÿ ergibt sich:
rXY =sXY√s2X s
2Y
=69.342√
40.026 · 227.475= 0.727, R2 = r2XY = 0.529
Prognose für x = 50 durch Einsetzen in KQ-Gleichung
y(x) = a + bx ,
x = 50 ergibt y(50) ≈ 166.9.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 339 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
In R lässt sich die Regressionsgerade mit eine paar einfachen Kommandosberechnen und in das Streudiagramm einzeichnen:
plot(oelpreis ,benzinpreis) ## Scatterplot
myregression <- lm(benzinpreis~oelpreis)
myregression ## zeigt Ergebnis der Regressionsrechnung an
abline(myregression) ## zeichnet Regressionsgerade
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 340 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Abbildung: Streudiagramm mit Regressionsgeraden
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 341 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Vorhersage des BlutdrucksFür 15 zufällig ausgewählte Frauen wurde das Alter (xi ) festgestellt und derBlutdruck (yi ) gemessen.Wie kann zu gegebenem Alter der zu erwartende Blutdruck vorhergesagtwerden?
i Alter (xi ) Blutdruck (yi )1 47 1292 52 1393 30 1124 35 1195 59 1456 44 1337 63 1528 38 1179 49 14510 41 13611 32 11512 55 13713 46 13414 51 14115 63 157
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 342 / 435
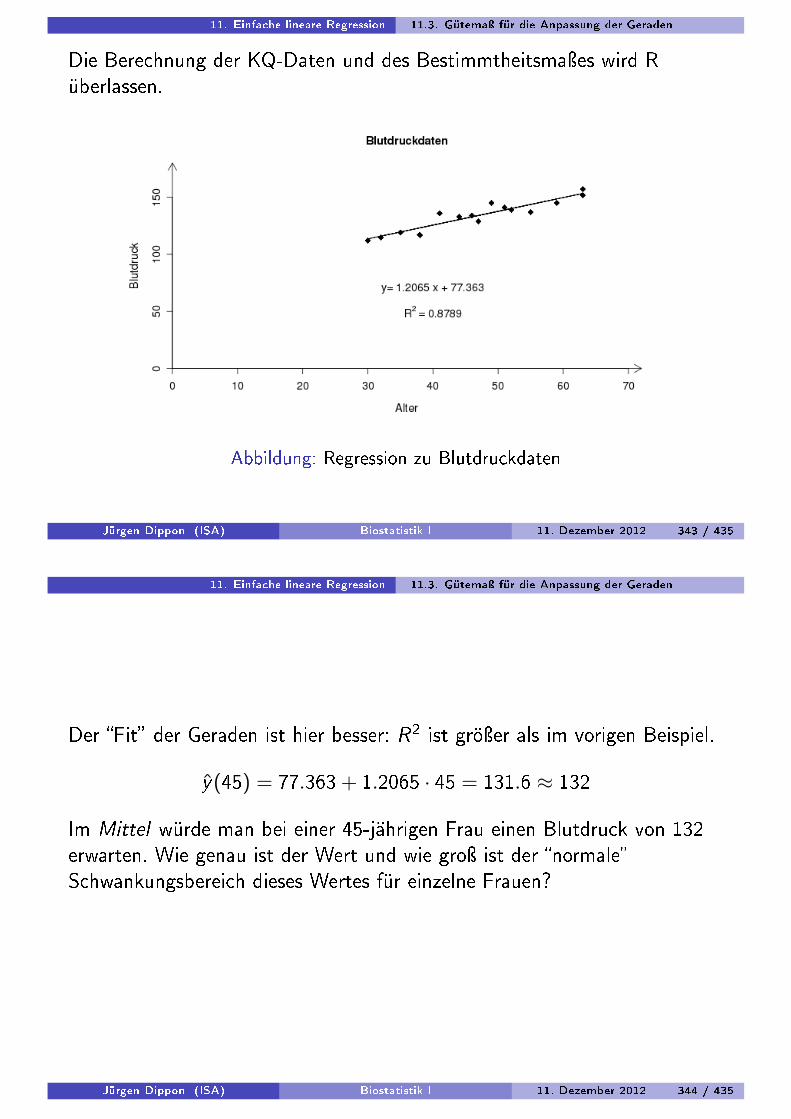
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Die Berechnung der KQ-Daten und des Bestimmtheitsmaÿes wird Rüberlassen.
Abbildung: Regression zu Blutdruckdaten
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 343 / 435
11. Einfache lineare Regression 11.3. Gütemaÿ für die Anpassung der Geraden
Der Fit der Geraden ist hier besser: R2 ist gröÿer als im vorigen Beispiel.
y(45) = 77.363 + 1.2065 · 45 = 131.6 ≈ 132
Im Mittel würde man bei einer 45-jährigen Frau einen Blutdruck von 132erwarten. Wie genau ist der Wert und wie groÿ ist der normaleSchwankungsbereich dieses Wertes für einzelne Frauen?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 344 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Stochastisches ModellUm für Datenpaare (xi , yi ), i = 1, ..., n, für die man lineareZusammenhänge zwischen den xi und yi -Werten vermutet,Wahrscheinlichkeitsaussagen ableiten zu können, muss man sie mit einemgeeigneten statistischen Modell breschreiben. Wie im letzten Abschnittsollen die Daten durch eine Geradenbeziehung
yi = α + βxi + ei
beschrieben werden.
Wenn die yi funktional beschrieben werden durch die xi bezeichnet manyi als abhängige oder endogene Variablenxi als unabhängige oder exogene Variablen oder Regressoren unddieei als latente Variablen oder Störvariablen.
Die ei können nicht beobachtet werden und die Parameter α und β sindunbekannt.
Wo gibt es im Modell zufällige Komponenten?Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 345 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Beispiel: College-AbsolventenDie folgenden Daten geben die Anzahl der Absolventen eines kleinenColleges an, die im Jahr (xi ) ihres Abschlusses einen Job gefunden haben.Die Anzahl (yi ) der Absolventen soll über die Jahre etwa gleich groÿgewesen sein.
Jahr 1 2 3 4 5 6Berufseinsteiger 121 138 115 162 160 174
Die Jahre xi sind nichtzufällig, während die konkretenBerufseinsteigerzahlen yi nicht vorhersehbar waren und als zufälliginterpretiert werden können.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 346 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Streudiagramm
Abbildung: Berufseinsteiger
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 347 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Modell mit deterministischen Regressoren
xi sind deterministisch und yi sind als Realisierungen von ZufallsvariablenYi aufzufassen. Dann sind aber auch die ei = yi − α− βxi alsRealisierungen von Zufallsvariablen εi = Yi − α− βxi aufzufassen.
Modellansatz:Yi = α + βxi + εi
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 348 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Beispiel (fortgesetzt): BlutdruckdatenIm Rahmen der Datenerhebung wurden 15 Frauen ausgewählt. Im Vorfeldder Erhebung ist i.A. sowohl das Alter (xi ) als auch der Blutdruck (yi )nicht bekannt und muss als Realisierung von Zufallsvariablen Xi bzw. Yi
aufgefasst werden.
Modell mit stochastischen Regressoren:Das zufällige Verhalten der Beobachtung xi und yi sowie ei werdenbeschrieben mit Zufallsvariablen Xi ,Yi und εi , die in folgender Beziehungstehen:
Yi = α + βXi + εi
Dabei wird die Zusatzannahme getroen, dass
Xi und εi unabhängig
sind.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 349 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Beide Regressionsmodelle haben groÿe Gemeinsamkeiten:
Die Schätzer für die Parameter α und β werden mit den gleichenFormeln berechnet, s.u.
Die bedingte Verteilung von Yi gegeben Xi = xi ist gleich derVerteilung, die sich aus dem deterministischen Ansatz ergibt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 350 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Wir beschränken uns im Folgenden auf die nähere Untersuchung desModells mit deterministischen Regressoren.
Standardmodell der linearen Einfachregressionx1, . . . , xn seien reelle Zahlen und Y1, . . . ,Yn seien reelle Zufallsvariablen.Die Vektoren (x1,Y1), . . . , (xn,Yn) erfüllen das Standardmodell der linearenEinfachregression mit den Parametern α, β und σ2 > 0, wenn
Yi = α + βxi + εi , i = 1, . . . , n
gilt, wobei εi u.i.v. Zufallsvariablen sind, für die E (εi ) = 0 undVar(εi ) = σ2 gilt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 351 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Anmerkungen:
Die Zufallsvariablen εi können nicht beobachtet werden. Siebeschreiben die Abweichungen der Yi -Werte von derRegressionsgeraden α + βx .
Die xi -Werte sind entweder als einstellbare deterministische, d.h. nichtzufällige, Regressoren oder als Realisierungen von Zufallsvariablen Xi
aufzufassen.
Der Parameter β beschreibt die lineare Abhängigkeit der yi - von denxi -Werten. Ist β = 0, gibt es keine (lineare) Abhängigkeit.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 352 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Die Schätzer im Standardmodell berechnen wir wie oben durchMinimierung von
Q(α, β) :=n∑
i=1
[Yi − (α + β · xi )]2 → Minα,β
Als Ergebnis erhalten wir in Analogie zu oben:Wenn s2X > 0 ergeben sich als Schätzer α und β im Standardmodell
α = Yn − β · x ,
β =
∑ni=1 xiYi − nxYn∑ni=1 x
2i − nx2
=1
n−1∑n
i−1(xi − x)(Yi − Yn)1
n−1∑n
i=1(xi − x)2=
sXY
s2X.
α und β sind erwartungstreue Schätzer von α bzw. β, d.h.
E (α) = α und E (β) = β .
Anmerkung zur Bezeichnung: Wie in der Literatur gebräuchlich bezeichnenα und β i.F. sowohl die Schätzer als auch die Schätzwerte für α und β. Diejeweilige Bedeutung erschlieÿt sich aus dem Kontext.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 353 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Beispiel (fortgesetzt): College-Absolventen.
x = 3.5, y = 145,∑i
x2i = 91,∑i
y2i = 129030,∑i
xiyi = 3234
s2X =
∑i x
2i − n · x2
n − 1=
91− 6 · 3.52
5= 3.5
s2Y =
∑i y
2i − n · y2
n − 1=
29030− 6 · 1452
5= 576
sXY =
∑i xiyi − n · x · y
n − 1=
3234− 6 · 3.5 · 1455
= 37.8
Daher
β =sXY
s2X=
37.53.5
= 10.8
α = y − β · x = 145− 10.8 · 3.5 = 107.2
rXY =sXY√s2X · s2Y
=37.5√3.5 · 576
= 0.8419 R2 = r2XY = 0.84192 = 0.788
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 354 / 435
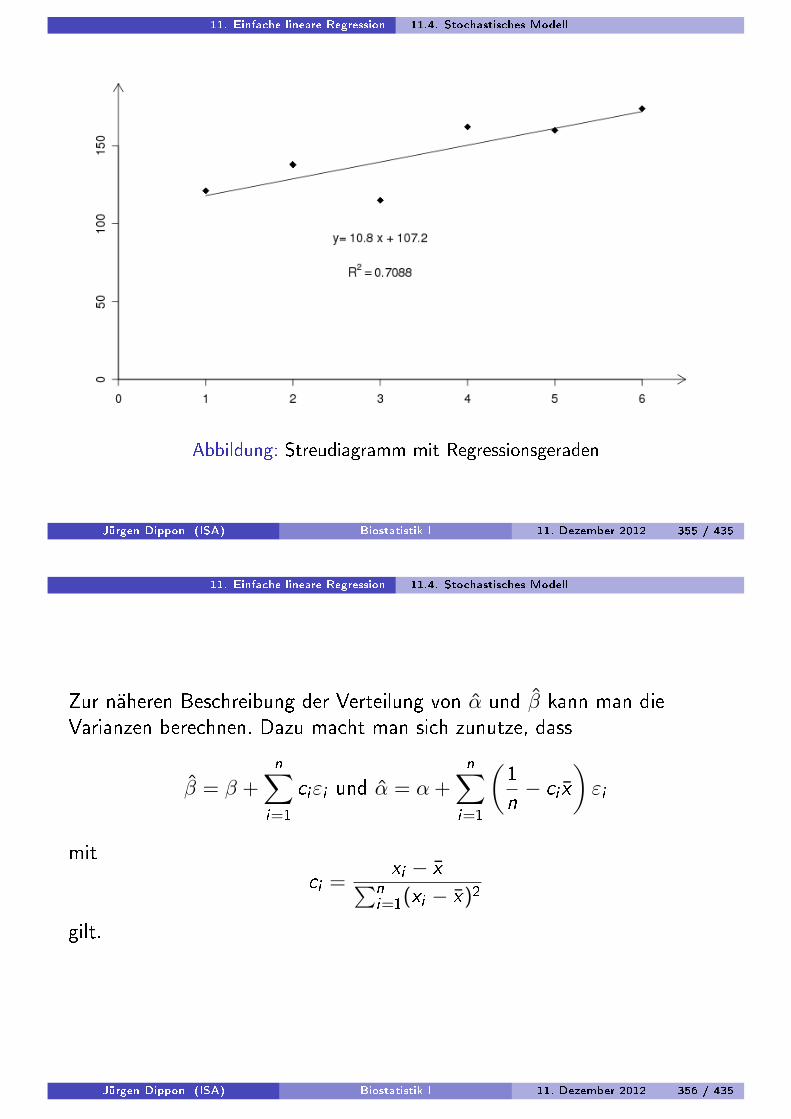
11. Einfache lineare Regression 11.4. Stochastisches Modell
Abbildung: Streudiagramm mit Regressionsgeraden
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 355 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Zur näheren Beschreibung der Verteilung von α und β kann man dieVarianzen berechnen. Dazu macht man sich zunutze, dass
β = β +n∑
i=1
ciεi und α = α +n∑
i=1
(1n− ci x
)εi
mit
ci =xi − x∑n
i=1(xi − x)2
gilt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 356 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Die Varianzen berechnen sich als
Var(β) = σ2β
=σ2∑n
i=1(xi − x)2
Var(α) = σ2α =σ2∑n
i=1 x2i
n ·∑n
i=1(xi − x)2
Diese Varianzen kann man nicht direkt berechnen, da sie noch vomunbekannten Parameter σ2 abhängen.
Aber: α bzw. β sind MSE- und schwach konsistent für α bzw. β, wenn dieKonsistenzbedingung
n∑i=1
(xi − x)2 →∞ für n→∞
gilt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 357 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Ausgehend von der Denition des Bestimmtheitsmaÿ kann man dieKonstruktion eines erwartungstreuen Schätzers σ2 von σ2 auf bekannteGröÿen zurückführen:
R2 = 1−∑2
i=1(yi − yi )2∑n
i=1(yi − y)2
⇒n∑
i=1
(yi − yi )2 = (1− R2)
n∑i=1
(yi − y)2 = (1− R2)(n − 1)s2Y
Damit denieren wir
σ2 :=1
n − 2
n∑i=1
(yi − yi )2 =
n − 1n − 2
(1− R2)s2Y =n − 1n − 2
(s2Y −
sXY
s2X
)Die letzte Identität folgt wegen R2 = r2XY = sXY /(s2X s
2Y ).
Beispiel (fortgesetzt): Für die College-Daten gilt dann
σ2 =n − 1n − 2
s2Y (1− R2) =54576 · (1− 0.7088) = 209.664
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 358 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Mit dem Schätzer für σ2 kann man die Varianzen bzw. Standardfehler vonα und β schätzen
σ2α =σ2∑n
i=1 x2i
n ·∑n
i=1(xi − x)2σα =
√σ2α
σ2β
=σ2∑n
i=1(xi − x)2σβ =
√σ2β
Unter präziseren Verteilungsannahmen kann auch die Verteilung derSchätzer genauer beschrieben werden und es können Tests konstruiertwerden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 359 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Normalverteilungsannahme: Die Störvariablen sind normalverteilt, also εiu.i.v. und εi ∼ N(0, σ2).
Unter der Normalverteilungsannahme gilt
α und β sind gemeinsam normalverteilt.
(n − 2) · σ2/σ2 ist χ2-verteilt mit n − 2 Freiheitsgraden.
α und σ2 bzw. β und σ2 sind unabhängig.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 360 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Aus der Normalverteilungsannahme und der Denition der t-Verteilungfolgt
α− ασα
=α− ασα
/σασα
=α− ασα
/σ
σ
=α− ασα
/√(n − 2)σ2
σ2(n − 2)= Z
/√W 2
(n − 2)∼ tn−2
mit Z =α
σα∼ N(0, 1), W 2 =
(n − 2)σ2
σ2∼ χ2n−1.
Eine analoge Aussage gilt für βUnter der Normalverteilungsannahme gilt
α− ασα
∼ tn−2 undβ − βσβ
∼ tn−2
Mit Hilfe dieser Aussagen lassen sich Tests für α und β konstruieren:
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 361 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Tests für die RegressionskoezientenGegeben sei das Standardmodell der linearen Einfachregression mitNormalverteilungsvorraussetzung sowie s2X > 0. Wir betrachten folgendeTestprobleme über die Parameter α und β:a) H0:α = α0 gegen H1:α 6= α0 , d) H0:β = β0 gegen H1:β 6= β0,b) H0:α ≥ α0 gegen H1:α < α0 , e) H0:β ≥ β0 gegen H1:β < β0,c) H0:α ≤ α0 gegen H1:α > α0 , f) H0:β ≤ β0 gegen H1:β > β0.
Basierend auf der Teststatistik
Tα0 =α− α0√
σ2α
bzw. Tβ0 =β − β0√
σ2β
und dem vorgegebenen Signikanzniveau α∗ fällt die Entscheidung für H1
im Testproblema) , falls |Tα0 | > tn−2,1−α∗/2, d) , falls |Tβ0 | > tn−2,1−α∗/2b) , falls Tα0 < −tn−2,1−α∗ , e) , falls Tβ0 < −tn−2,1−α∗c) , falls Tα0 > tn−2,1−α∗ , f ) , falls Tβ0 > tn−2,1−α∗
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 362 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Insbesondere der Test H0 : β = 0 ist wichtig, da hiermit überprüft wird, obes einen linearen Zusammenhang zwischen den yi - und xi -Werten gibt.
Beispiel (fortgesetzt) College-Daten.Wir wollen überprüfen, ob β = 0 ist. Das Signikanzniveau sei α∗ = 0.05.Dazu berechnen wir den Schätzer für den Standardfehler von β.
σ2β
=σ2∑n
i=1(xi − x)2=
σ2
(n − 1)s2X=
209.6645 · 3.5
= 11.9808⇒ σβ = 3.4613.
Damit ist
t =β − β0√
σ2β
=10.8− 03.4613
= 3.12.
Der kritische Wert ist tn−2,1−α∗/2 = t4,0.975 = 2.7764. Wegen 3.12 > 2.7ist die Nullhypothese β = 0 abzulehnen. Es gibt also einen signikantenlinearen Trend bei den Berufseinsteigerzahlen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 363 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Statistische Tests für die Regressionsparameter mit R
> x <- 1:6
> y <- c(121 ,138 ,115 ,162 ,160 ,174)
> mymodel <- lm(y~x)
> summary(mymodel)
Call:
lm(formula = y ~ x)
Residuals:
1 2 3 4 5 6
3.0 9.2 -24.6 11.6 -1.2 2.0
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 107.200 13.481 7.952 0.00135 **
x 10.800 3.462 3.120 0.03553 *
Residual standard error: 14.48 on 4 degrees of freedom
Multiple R-squared: 0.7087 , Adjusted R-squared: 0.6359
F-statistic: 9.734 on 1 and 4 DF, p-value: 0.03553
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 364 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Kondenzintervalle für die RegressionsparameterAusgehend von der Verteilungsaussage zu α und β kann manKondenzintervalle für die Parameter α und β herleiten:Gegeben sei das Standardmodell der linearen Einfachregression mitNormalverteilungsvorraussetzung. Dann sind[
α− tn−2,1−α∗/2σα, α + tn−2,1−α∗/2σα]
bzw. [β − tn−2,1−α∗/2σβ, β + tn−2,1−α∗/2σβ
](1− α∗)-Kondenzintervalle für die Parameter α bzw. β.
Anmerkung: Diese Struktur von Kondenzintervallen ist sehr typisch.θ sei ein Parameterschätzer für einen Parameter θ und σθ seinStandardfehler.
θ − θσθ∼ N(0, 1) für alle zulässigen θ
⇒[θ − z1−α/2σθ, θ + z1−α/2σθ
]ist (1− α)-Kondenzintervall für θ
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 365 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Beispiel: Kondenzintervall für µ bei bekanntem σ2.X1, . . . ,Xn ∼ N(µ, σ2).Dann gilt für den Schätzer Xn für µ : Var(Xn) = σ2/n:[
Xn − z1−α/2
√σ2/n, Xn + z1−α/2
√σ2/n
]=[Xn − z1−α/2σXn
, Xn + z1−α/2σXn
]θ sei ein Parameterschätzer für einen Parameter θ und σθ ein Schätzer fürseinen Standardfehler.
θ − θσθ∼ tm für alle zullässigen θ
⇒[θ − tm,1−α/2σθ, θ + tm,1−α/2σθ
]ist (1− α)-Kondenzintervall für θ
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 366 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Anmerkung: i.A. m = n Anzahl der geschätzten Parameter.
Beispiel: Kondenzintervall für µ bei unbekanntem σ2.X1, . . . ,Xn ∼ N(µ, σ2). Dann gilt für den Schätzer Xn fürµ : Var(Xn) = σ2/n und σ2
Xn= S2
n/n,[Xn − tn−1,1−α/2
√S2n/n, Xn + tn−1,1−α/2
√S2n/n
]=[Xn − t−1,1−α/2σXn
, Xn + tn−1,1−α/2σXn
]
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 367 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Viele Statistikprogramme liefern als Ergebnis von komplexeren statistischenModellen Schätzwerte für die Parameter und Standardfehler. Wenn diezugehörigen standardisierten Schätzer t-verteilt oder asymptotisch normalverteilt sind, kann man obige Kondenzintervallkonstruktion direktverwenden.
Beispiel: College-Absolventen.Wir berechnen ein 0.95-Kondenzintervall für β. σβ = 3.4613 und β = 10.8wurde bereits früher berechnet. Mit tn−2,1−α∗ = t4,0.975 = 2.7764 gilt[
β − tn−2,1−α∗/2σβ, β + tn−2,1−α∗/2σβ
]= [10.8− 2.7764 · 3.4613, 10.8 + 2.7764 · 3.4613]
= [1.19, 20.41]
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 368 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Falls die Normalverteilungsannahme εi ∼ N(0, σ2) verletzt, aber dieKonsistenzbedingung
n∑i=1
(xi − x)2 →∞ für n→∞
erfüllt ist, gelten die Verteilungsaussagen für die standardisierten Schätzerauch approximativ. Dann gelten auch die angegebenen Tests undKondenzintervalle approximativ.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 369 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Beispiel (Fortsetzung): College-Daten.Die nächste Tabelle bezieht sich auf die Streuungszerlegung bei der linearenRegression,
n∑i=1
(yi − y)2︸ ︷︷ ︸Gesamtstreuung
(SQT)
=n∑
i=1
(yi − y)2︸ ︷︷ ︸Erklärte Streuung
(SQE)
+n∑
i=1
(yi − yi )2
︸ ︷︷ ︸Reststreuung
(SQR)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 370 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Kondenzintervalle für die Regressionsparameter mit R
> x <- 1:6
> y <- c(121 ,138 ,115 ,162 ,160 ,174)
> mymodel <- lm(y~x)
> confint(mymodel)
2.5 % 97.5 %
(Intercept) 69.770472 144.62953
x 1.188984 20.41102
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 371 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
PrognoseAusgehend vom Regressionsmodell
Yi = α + βxi + εi
interessiert man sich für die Regressionsgerade
y(x) = α + βx
für einen Vorgabewert x .Schätzung von y(x) : Y (x) = α + β · xDann gilt
E (Y (x)) = E (α + β · x) = E (α) + E (β) · x = α + β · x = y(x)
σ2Y (x)
= Var(Y (x)) = Var(α + β · x) = . . . = σ2(1n
+(x − x)2∑i (xi − x)2
).
Y (x) ist also erwartungstreu und MSE- bzw. schwach konsistent.Die Varianz können wir schätzen mit
σ2Y (x)
= σ2(1n
+(x − x)2∑i (xi − x)2
).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 372 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Prognose für y(x):Y (x) = α + β · x ist der Schätzer für y(x). Unter derNormalverteilungsannahme ist[
Y (x)− tn−2,1−α∗/2σY (x), Y (x) + tn−2,1−α∗/2σY (x)
]ein (1− α)-Kondenzintervall für y(x).
y(x0) beschreibt nur die Mittellage einer Zufallsvariable Y0, die zu einemRegressor x0 erhoben wird. Interessant ist häug der Wertebereich, in demwir Y0 mir groÿer Wahrscheinlichkeit nden. Dazu muss nicht nur dieMittellage y(x0), sondern auch der Schwankung um diese Mittellage miteinem Störterm ε0 Rechnung getragen werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 373 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Ansatz:
Y0 = α + β · x0 + ε0 = Y (x0) + ε0, E (ε0) = 0, Var(ε0) = σ2,
wobei ε0 unabhängig von ε1, . . . , εn.Damit ist
Var(Y0) = Var(Y (x0)) + Var(ε0) = σ2(1 +
1n
+(x0 − x)2∑i (xi − x)2
)und
σ2Y0
= σ2(1 +
1n
+(x0 − x)2∑i (xi − x)2
).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 374 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Prognose der Werte der Zufallsvariablen Y0 zu gegebenen x0:Unter der Normalverteilungsannahme ist[
Y (x0)− tn−2,1−α∗/2σY0 , Y (x0) + tn−2,1−α∗/2σY0
]ein (1− α)-Kondenz- oder Prognoseintervall für Y0.
Beispiel: College-Absolventen.Wir berechnen ein 0.95-Kondenzintervall für y(x0) und Y0 zu x0 = 7. Aus
x = 3.5, s2x = 3.5, σ = 14.461, t4,0.975 = 2.7764
ergibt sich
σ2Y (7)
= σ2(1n
+(x0 − x)2∑i (xi − x)2
)= 209.7 ·
(16
+(7− 3.5)2
5 · 3.5
)= 181.74
σ2Y0
= σ2 + σ2Y (7)
= 391.44, σY (7) = 13.4811, σY0 = 19.7848
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 375 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
Damit sind Y (7) = α + β · 7 = 107.2 + 10.8 · 7 = 182.8, t4,0.975 = 2.7764,und[
Y (7)− t6−2,0.975σY (7), Y (7) + t6−2,0.975σY (7)
]= [145.37, 220.23]
das gesuchte 95%-Kondenzintervall für den unbekannten Erwartungswerty(7) und[
Y (7)− t6−2,0.975σY0 , Y (7) + t6−2,0.975σY0
]= [127.87, 237.73]
das 95%-Prognoseintervall für die zufälligen Werte von Y0 an der Stellex = 7.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 376 / 435
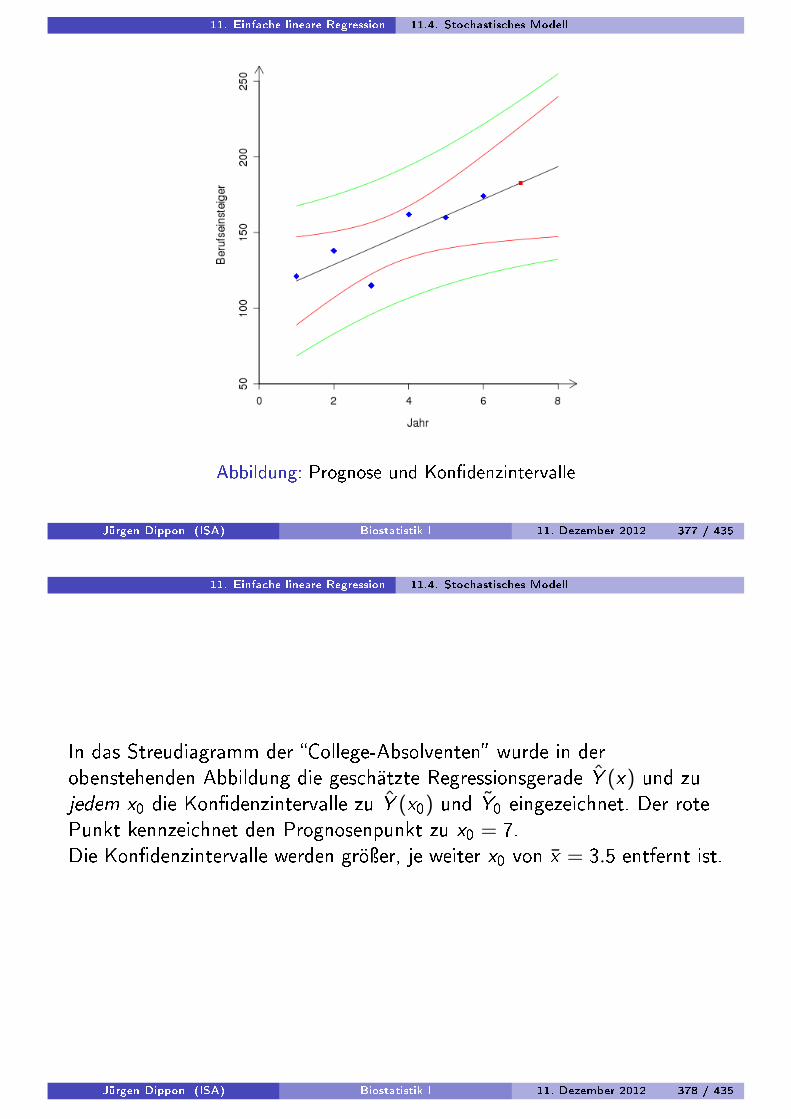
11. Einfache lineare Regression 11.4. Stochastisches Modell
Abbildung: Prognose und Kondenzintervalle
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 377 / 435
11. Einfache lineare Regression 11.4. Stochastisches Modell
In das Streudiagramm der College-Absolventen wurde in derobenstehenden Abbildung die geschätzte Regressionsgerade Y (x) und zujedem x0 die Kondenzintervalle zu Y (x0) und Y0 eingezeichnet. Der rotePunkt kennzeichnet den Prognosenpunkt zu x0 = 7.Die Kondenzintervalle werden gröÿer, je weiter x0 von x = 3.5 entfernt ist.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 378 / 435

11. Einfache lineare Regression 11.4. Stochastisches Modell
Kondenz- und Prognosestreifen mit R
x <- 1:6; y <- c(121 ,138 ,115 ,162 ,160 ,174)
plot(x,y,xlim=c(0,8.5), ylim=c(50,260),
xlab="Jahr",ylab=" Berufseinsteiger",col="blue")
mymodel <- lm(y~x)
y0 <- sum(mymodel$coefficients*c(1,0))
y8 <- sum(mymodel$coefficients*c(1,8))
lines(matrix(c(0,y0 ,8,y8),byrow=TRUE ,ncol =2))
newx <- data.frame(x=seq(0,8,by =0.1))
predEY <- predict(mymodel , newx , interval =" confidence ")
lines(data.matrix(newx), data.matrix(predEY [,2]),col="red")
lines(data.matrix(newx), data.matrix(predEY [,3]),col="red")
predY <- predict(mymodel , newx , interval =" prediction ")
lines(data.matrix(newx), data.matrix(predY[,2]),col="green ")
lines(data.matrix(newx), data.matrix(predY[,3]),col="green ")
points(7,predict(mymodel , data.frame(x=7)),col="red", pch =15)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 379 / 435
12. Varianzanalyse
9 Parameterschätzung
10 Testen von Hypothesen
11 Einfache lineare Regression
12 VarianzanalyseEinfache KlassikationEinfache Varianzanalyse mit R
13 Versuchsplanung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 380 / 435

12. Varianzanalyse
Varianzanalyse
Modelle der Varianzanalyse (ANOVA Analysis of Variance) dienen zurUntersuchung der Frage, ob eine oder mehrere kategoriale Gröÿen(Faktoren) einen Einuss auf die metrische Kriteriumsvariable besitzen.
Je nach Anzahl der Faktoren spricht man von einer Varianzanalyse mitEinfach-, Zweifach-, . . . Klassikation.
Ausprägungen eines Faktors werden als Stufen des Faktors bezeichnet.
Ist jede Stufe eines Faktors mit jeder Stufe eines anderen kombiniert, sospricht man von (einem Versuchsplan mit) Kreuzklassikation, andernfallsvon hierarchischer Klassikation.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 381 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Einfache Klassikation
Welchen (Mittelwert-) Einuss haben die k Stufen eines Faktors auf dieKriteriumsvariable Y ?
Gruppe EW Umfang Stichprobe Mittelwert(=Faktorstufe)
1 µ1 n1 Y11 . . . Y1n1 Y1...
......
......
...i µi ni Yi1 . . . Yini Yi...
......
......
...k µk nk Yk1 . . . Yknk Yk
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 382 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Yi =1ni
ni∑j=1
Yij Mittelwert der Gruppe i
n = n1 + · · ·+ nk Umfang der gesamten Stichprobe
Y =1n
k∑i=1
ni∑j=1
Yi ,j
=1n
k∑i=1
ni Yi
Mittelwert der gesamten Stichprobe
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 383 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Modell 1
Yij = µi + eij i = 1, . . . , k , j = 1, . . . , ni
mit unabhängigen Zufallsvariablen e11, . . . , ek,nk (Fehlervariablen) undGruppen-Erwartungswerten µ1, . . . , µk .
Annahmen:E(eij) = 0Var(eij) = σ2 (Varianzhomogenität)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 384 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Matrixschreibweise der Modellgleichungen:
Y = Xβ + e
mit
Y =
Y11...
Yknk
n-dim. Beobachtungsvektor
β =
µ1...µk
k-dim. Vektor der unbekannten Parameter
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 385 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
X =
1 0 · · · 0...
......
1 0 · · · 00 1 · · · 0...
......
0 1 · · · 0...
...0 0 · · · 1...
......
0 0 · · · 1
n1 Zeilen
n2 Zeilen
...nk Zeilen
X ist eine n × k-Matrix mit Rang(X ) = k , die sog. Designmatrix.
e =
e11...
ek,nk
n-dim. Fehlervektor
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 386 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Andere Parametrisierung
µi = µ0︸︷︷︸ + αi︸︷︷︸:= 1
n
∑ki=1 niµi := µi − µ0
mittlerer EW Eekt der Gruppe i
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 387 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Modell 2 (Eektdarstellung)
Yij = µ0 + αi + eij i = 1, . . . , k , j = 1, . . . , ni
Hier gilt∑k
i=1 niαi = 0 (Reparametrisierungsbedingung).
Aufgabe: Schreibe das Modell in Matrixschreibweise
Y = Xβ + e
mit geeigneter Designmatrix X und Parametervektor β.
Schätzen des Parametervektors β in Modell 1 mittels Methode derkleinsten Quadrate:
Minimierek∑
i=1
ni∑j=1
(Yij − µi )2
liefert die Schätzwerte µi = Yi
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 388 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Für Modell 2 erhält man:
µ0 = Yi und αi = Yi − Y
Schätzung der Varianz in beiden Modellen durch:
σ2 =SSE
n − k(mittlere Fehlerquadratsumme)
wobei
SSE :=k∑
i=1
ni∑j=1
(Yij − Yi )2
(Sum of Squares due to Errors Summe der quadrierten Residuen).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 389 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Es gilt die folgende Streuungszerlegung:
k∑i=1
ni∑j=1
(Yij − Y )2 =k∑
i=1
ni (Yi − Y )2 +k∑
i=1
ni∑j=1
(Yij − Yi )2
Kurz:
SST = SSA + SSE
Sum of Squares Sum of Squares Sum of SquaresTotal due to factor A due to Errors
Die Variation der gesamten Stichprobe (SST) ist also die Summe derVariation zwischen den Gruppen und der Variation innerhalb der Gruppen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 390 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Begründung:
SST =k∑
i=1
ni∑j=1
(Yij − Y )2
=k∑
i=1
ni∑j=1
(Yij − Yi + Yi − Y )2
=k∑
i=1
ni∑j=1
((Yij − Yi )
2 + 2(Yij − Yi )(Yi − Y ) + (Yi − Y )2)
= SSA + 2k∑
i=1
(Yi − Y )
ni∑j=1
(Yij − Yi )︸ ︷︷ ︸=0
+SSE
= SSA + SSE
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 391 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Man sagt auch, dass die Gesamtvariation SST der Daten sich aus dererklärten Variation SSA und der unerklärten Restvariation SSEzusammensetzt.
Zur Überprüfung der globalen Nullhypothese
H0 : µ1 = · · · = µk (oder äquivalent α1 = · · · = αk = 0)
vergleicht man SSA und SSE, genauer
MSA :=SSA
k − 1und MSE :=
SSE
n − k
Haben die Faktorstufen von A keinen unterschiedlichen Einuss auf dieZielgröÿe, dann ist SSA/(k − 1) klein im Vergleich zu SSE/(n − k).
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 392 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Sind die Fehlervariablen ei normalverteilt (also N(0, σ2)-verteilt), so ist
F :=SSA/(k − 1)
SSE/(n − k)=
MSA
MSE
unter der Nullhypothese F-verteilt mit den Freiheitsgraden k − 1 und n − k
Denition: Seien Z1, . . . ,Zm, Z1, . . . , Zn unabhängige N(0, 1)-verteilteZufallsvariablen. Dann heiÿt die Verteilung von
F :=(Z 2
1 + · · ·+ Z 2m)/m
(Z 21 + · · ·+ Z 2
n )/n
F-verteilt mit den Freiheitsgraden m und n.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 393 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
F-Test
Damit ergibt sich der F-Test der einfaktoriellen (oder einfachen)Varianzanalyse:
Lehne H0 zum Niveal α ab, fallsF > Fk−1,n−k;1−α︸ ︷︷ ︸
(1− α)-Quantil der F-Verteilung mit (k − 1) und(n − k) Freiheitsgraden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 394 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Zur Beurteilung der Teststatistik von F verwendet man idealerweise diefolgende Tafel der einfachen Varianzanalyse:
Quadrat- mittlere
Variationsursache summen Freiheitsgrade Quadratsummen
zwischen den Stufen SSA (k − 1) MSA
des Faktors A
innerhalb der Stufen SSE (n − k) MSE
des Faktors A
Gesamt SST (n − 1) F =MSA
MSE
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 395 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Überprüfung der Vorraussetzung zur Varianzhomogenität
Grasch mit parallelen BoxplotsInferenzstatistisch mit
I Levene-Test oderI Bartlett-Test
zur Überprüfung der Nullhypothese:
H0 : σ21 = · · · = σ2k wobei σ2i = Var(Yij)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 396 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Multiple Mittelwertvergleiche
Führt der F-Test zur Ablehnung der globalen Nullhypothese, so sindzumindest nicht alle Gruppen-Erwartungswerte identisch.
Welche (Kombination von) Gruppen sind für die Ablehnung verantwortlich?
Zur Beantwortung dieser Frage gibt es mehrere Methoden:
Scheé-Test: Lehne H0 : µi = µj zum Niveau α ab, falls:
|µi − µj |se(µi − µj)
>√
(k − 1)Fk−1,n−k,1−α
wobei
se(µi − µj) =
√SSE
n − k·
√1ni
+1nj
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 397 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Den Scheé-Test gibt es auch in einer allgemeineren Version für lineareKontraste zur Überprüfung von Hypothesen der Form
H0 :k∑
i=1
ciµi = 0 wobeik∑
i=1
ci = 0.
Wichtiges Beispiel (s.o.): ci = 1, cj = −1, alle übrigen c ′s = 0.
Anderer populärer Test zum simultanen Vergleich von Mittelwerten:Tukey-Test.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 398 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Kumulierung der Fehlerwahrscheinlichkeit beim multiplenTesten
Werden alle Nullhypothesen:
Hij0 : µi = µj
z.B. mittels 2-Stichproben-t-Test durchgeführt, so sind insgesamt
l =
(k
2
)=
k · (k − 1)
2
Einzeltests erforderlich. Wird jeder Einzeltest zum Niveau α durchgeführt,so führt dies zu einer Ination des multiplen α-Fehlers (auchexperimentwise oder familywise error rate), deniert durch
p = P(mindestens eine Nullhypothese H ij0 fälschlicherweise ablehnen)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 399 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Sei Aij das Ereignis, H ij0 fälschlicherweise abzulehnen:
p = P(A12 ∪ A13 ∪ · · · ∪ A(i−1)j)
= P
⋃i 6=j
Aij
= 1− P
⋂i 6=j
Aij
︸ ︷︷ ︸≥∏i 6=j
P(Aij)︸ ︷︷ ︸=1−α
≤ 1− (1− α)l
wobei l die Gesamtzahl der Einzeltests zum Niveau α.Bei Unabhängigkeit der Ereignisse Aij gilt Gleichheit.
Beispiel: α = 0.05, k = 5, also l = 10 ⇒ p ≤ 1− (1− 0.05)10 ≈ 0.4Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 400 / 435

12. Varianzanalyse 12.1. Einfache Klassikation
Paarvergleiche nach dem Bonferroni-Verfahren
Nach der Bonferroni-Ungleichung gilt:
P(∩Aij
)≥ 1−
∑P(Aij)︸ ︷︷ ︸
l ·α
Also gilt für die multiple Fehlerrate p:
α ≤ p ≤ lα
Werden die Einzelvergleiche statt zum Niveau α zum Niveau α/ldurchgeführt, so ist die multiple Fehlerrate höchstens gleich α!
Die Bonferroni-Korrektur ist jedoch sehr konservativ, der resultierendemultiple Test besitzt eine geringe Power!
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 401 / 435
12. Varianzanalyse 12.1. Einfache Klassikation
Äquivalente Formulierung des Bonferroni-Verfahrens: Seien pij die p-Wertezu den Tests mit den Hypothesen H
ij0 : µi = µj
Dann ist der Bonferroni-korrigierte multiple p-Wert gegeben durch:
pBonf = l ·maxi 6=j
pij
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 402 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Einfache Varianzanalyse mit R
Im Datensatz survey aus dem Paket MASS nden sich die Variablen Pulse
(Pulsrate pro Minute), Smoke (Rauchverhalten) und weitere.
Frage: Besteht ein Zusammenhang zwischen Pulsrate und Rauchverhalten?
> library(MASS)
> attach(survey)
> summary(Pulse)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA 's
35.00 66.00 72.50 74.15 80.00 104.00 45.00
> summary(Smoke)
Heavy Never Occas Regul NA's
11 189 19 17 1
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 403 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
> boxplot(Pulse ~ Smoke)
> aov(Pulse ~ Smoke)
Call:
aov(formula = Pulse ~ Smoke)
Terms:
Smoke Residuals
Sum of Squares 127.433 25926.797
Deg. of Freedom 3 187
Residual standard error: 11.77480
Estimated effects may be unbalanced
46 observations deleted due to missingness
> summary(aov(Pulse ~ Smoke))
Df Sum Sq Mean Sq F value Pr(>F)
Smoke 3 127.4 42.478 0.3064 0.8208
Residuals 187 25926.8 138.646
46 observations deleted due to missingness
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 404 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Abbildung: Puls in Abhängigkeit vom Rauchverhalten
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 405 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Besteht ein Zusammenhang zwischen Pulsrate und Geschlecht?
Überprüfen Sie, dass die Varianzanalyse bei einem Merkmal mit zweiGruppen der Vergleich der Gruppenmittel identisch ist zum2-Stichproben-t-Test:
> summary(aov(Pulse ~ Sex))
Df Sum Sq Mean Sq F value Pr(>F)
Sex 1 177.6 177.56 1.2953 0.2565
Residuals 189 25909.7 137.09
46 observations deleted due to missingness
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 406 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
> t.test(Pulse ~ Sex , var.equal=TRUE)
Two Sample t-test
data: Pulse by Sex
t = 1.1381 , df = 189, p-value = 0.2565
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.413995 5.270794
sample estimates:
mean in group Female mean in group Male
75.12632 73.19792
Wird im linearen Modell für die Gruppenmittel angenommen, dass
µi = µ+ αi , i = 1, . . . , I
mit unbekannten µ und αi , so sind diese Parameter nicht eindeutigbestimmt.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 407 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
In R wird standardmäÿig angenommen, dass
α1 = 0 (Berechne die Behandlungskontraste)
α2, . . . αI sind dann die Abweichungen vom ersten Gruppenmittel in denGruppen 2, . . . , I .
> lm(Pulse ~ Smoke)
Call:
lm(formula = Pulse ~ Smoke)
Coefficients:
(Intercept) SmokeNever SmokeOccas SmokeRegul
78.286 -4.292 -4.348 -4.598
> mean(Pulse[Smoke == "Heavy"], na.rm=TRUE)
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 408 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Eine andere Wahl der Parametrisierung liefert die Nebenbedingung:
I∑i=1
αi = 0 Berechne die Kontraste so, dass deren Summe = 0
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 409 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
In R:
> model1 <- lm(Pulse ~ Smoke ,
+ contrasts=list(Smoke=" contr.treatment "));
> dummy.coef(model1)
Full coefficients are
(Intercept ): 78.28571
Smoke: Heavy Never Occas Regul
0.000000 -4.292293 -4.348214 -4.598214
> model2 <- lm(Pulse ~ Smoke ,
+ contrasts=list(Smoke="contr.sum"))
> dummy.coef(model2)
Full coefficients are
(Intercept ): 74.97603
Smoke: Heavy Never Occas Regul
3.3096805 -0.9826128 -1.0385338 -1.2885338
> sum(dummy.coef(model2)$Smoke)
[1] 1.110223e-16
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 410 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Die Faktorstufen werden in R standardmäÿig in alphabetischer Reihenfolgedargestellt. Referenzkategorie (Baseline) ist damit die Faktorstufe, welchealphabetisch gesehen als erste auftaucht. In obigem Beispiel ist dies dieFaktorstufe Heavy. Vermutlich ist es jedoch sinnvoller, Never alsReferenzkategorie zu wählen:
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 411 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
> levels(Smoke)
[1] ``Heavy '' ``Never '' ``Occas '' ``Regul ''
> levels(Smoke) <- c(``Never '',''Occas '',''Regul '',''Heavy '')
> levels(Smoke)
[1] ``Never '' ``Occas '' ``Regul '' ``Heavy ''
> model1 <- lm(Pulse~Smoke , contrasts=list(Smoke=''contr.treatment ''))
> dummy.coef(model1)
Full coefficients are
(Intercept ): 78.28571
Smoke: Never Occas Regul Heavy
0.000000 -4.292293 -4.348214 -4.598214
> model2 <- lm(Pulse~Smoke , contrasts=list(Smoke=''contr.sum ''))
> dummy.coef(model2)
Full coefficients are
(Intercept ): 74.97603
Smoke: Never Occas Regul Heavy
3.3096805 -0.9826128 -1.0385338 -1.2885338
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 412 / 435

12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Überprüfung auf gleiche Varianzen:
> bartlett.test(Pulse ~ Smoke)
Bartlett test of homogeneity of variances
data: Pulse by Smoke
Bartlett 's K-squared = 2.8627 , df = 3, p-value = 0.4133
> library(car)
> leveneTest(Pulse ~ Smoke , data=survey)
Levene 's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 3 0.6535 0.5817
187
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 413 / 435
12. Varianzanalyse 12.2. Einfache Varianzanalyse mit R
Multipler paarweiser Vergleich von Hypothesen:
> pairwise.t.test(Pulse , Smoke , pool.sd=FALSE)
Pairwise comparisons using t tests with non -pooled SD
data: Pulse and Smoke
Heavy Never Occas
Never 1 - -
Occas 1 1 -
Regul 1 1 1
P value adjustment method: holm
Hier könnte die Varianz auch aus der gesamten Stichprobe ermitteltwerden: pool.sd=TRUE.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 414 / 435

13. Versuchsplanung
9 Parameterschätzung
10 Testen von Hypothesen
11 Einfache lineare Regression
12 Varianzanalyse
13 VersuchsplanungWahl geeigneter MerkmaleBedeutung der Versuchsplanung in der biowissenschaftlichenForschungGrundlegende Aspekte der VersuchsplanungVarianzquellen in biowissenschaftlichen UntersuchungenAllgemeine Prinzipien der VersuchsplanungTypen von StichprobenEinige wichtige Versuchspläne
Bestimmung optimaler StichprobenumfängeJürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 415 / 435
13. Versuchsplanung
Versuchsplanung
Die folgende Darstellung orientiert sich an Köhler et alt., Biostatistik, 2007,und Rudolf et alt., Biostatistik, 2008.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 416 / 435

13. Versuchsplanung 13.1. Wahl geeigneter Merkmale
Wahl geeigneter Merkmale
Objektivität, Reliabilität, ValiditätLiegt dem Fachwissenschaftler eine Fragestellung vor, so muss er sichentscheiden, welche Merkmale er zur Beantwortung seiner Fragesinnvollerweise untersucht. Dazu sollte er zunächst die folgenden dreiKriterien bei der Auswahl seiner Merkmale beachten:
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 417 / 435
13. Versuchsplanung 13.1. Wahl geeigneter Merkmale
Objektivität
Die Ausprägung des zu ermittelnden Merkmals ist unabhängig von derPerson des Auswerters eindeutig festzustellen.
Beispiel: die Bewertung von Deutsch-Aufsätzen ist oft stark vombeurteilenden Lehrer abhängig und somit wenig objektiv.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 418 / 435

13. Versuchsplanung 13.1. Wahl geeigneter Merkmale
Reliabilität
Das Merkmal gestattet reproduzierbare Mess- (bzw. Beobachtungs-)Ergebnisse, bei Wiederholung liegen also gleiche Resultate vor. StattReliabilität wird auch von Zuverlässigkeit gesprochen.
Beispiel: Beim Test einer neuen Methode zur Messung der Enzymaktivitätwurde das untersuchte Homogenat in mehrere gleiche Proben aufgeteiltund jeweils gemessen. Die erhaltenen Ergebnisse unterschieden sichteilweise um eine Gröÿenordnung (Faktor 10). Die Methode musste alsunzuverlässig verworfen werden.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 419 / 435
13. Versuchsplanung 13.1. Wahl geeigneter Merkmale
Validität
Das Merkmal in seinen Ausprägungen spiegelt die für die Fragestellungwesentlichen Eigenschaften wider. Statt Valitität wird auch von Gültigkeitoder Aussagekraft gesprochen.
Beispiel: Bei der Zulassung zum Medizin-Studium spielt dieDurchschnittsnote im Abitur eine wichtige Rolle. Hat dieses Merkmaltatsächlich eine zentrale Bedeutung für die Beurteilung, ob die Fähigkeitzum Arztberuf vorliegt?
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 420 / 435

13. Versuchsplanung 13.1. Wahl geeigneter Merkmale
Grundlegende Elemente der fachwissenschaftlichen Planung
Ableitung einer durch einen Versuch zu bearbeitenden Fragestellung.
Überführung dieser Fragestellung in ein biowissenschaftliches Modellmit entsprechenden Forschungshypothesen.
Erarbeitung einer Untersuchungsmethode zur Überprüfung derHypothese.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 421 / 435
13. Versuchsplanung13.2. Bedeutung der Versuchsplanung in der
biowissenschaftlichen Forschung
Grundlegende Elemente der biostatistischen Versuchsplanung
Formalisierung des biowissenschaftlichen Modells durch einentpsrechendes mathematisch-statistisches Modell mit denentsprechenden statistischen Hypothesen.
Festlegung der Stichprobengewinnung.
Detaillierte Festlegung des Versuchsplanes (zum Beispiel Anzahl derFaktorstufen, Anzahl der Wiederholungen, Umgang mit Störvariablen,Verteilung der Untersuchungseinheiten auf die unterschiedlichenVersuchsbedingungen).
Festlegung der Verfahren zur Datenanalyse einschlieÿlich derUntersuchung der notwendigen Voraussetzungen.
Bestimmung des optimalen Stichprobenumfangs.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 422 / 435

13. Versuchsplanung13.2. Bedeutung der Versuchsplanung in der
biowissenschaftlichen Forschung
Zusammenhang von fachwissenschaftlicher undbiostatistischer Versuchsplanung
Eine abgestimmte fachwissenschaftliche und biostatistischeVersuchsplanung schat die Voraussetzungen für
die Genauigkeit der Versuchsergebnisse und ihre Kontrolle bei derAuswertung
die Kontrolle oder die Elimination vor Störgröÿen
die sachgerechte Beschreibung der Versuchsergebnisse durch grascheDarstellungen und statistische Maÿzahlen
die Quantizierung und kritischen Wertung charakteristischerBeziehungen (Zusammenhänge, Unterschiede) und
die ökonomische Durchführung des Versuchs.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 423 / 435
13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Grundlegende Aspekte der Versuchsplanung
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 424 / 435

13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Varianzquellen in biowissenschaftlichen Untersuchungen
Denition: Als Primärvarianz wird der Varianzanteil der Zielvariablenbezeichnet, der auschlieÿlich auf die Variation der experimentellenBedingungen zurückgeführt werden kann.
Die biostatistische Versuchsplanung soll die Voraussetzungen dafürschaen, dass dieser Varianzanteil möglichst groÿ sein kann, damit dieinteressierenden Eekte nachgewiesen werden können.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 425 / 435
13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Denition: Als Sekundärvarianz wird der Varianzanteil bezeichnet, derdurch die Wirkung von Störvariablen hervorgerufen wird.
Die biostatistische Versuchsplanung soll eine Kontrolle potentiellerStörvariablen sicherstellen.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 426 / 435

13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Denition: Als Fehlervarianz wird der aus zufälligen Unterschiedenzwischen den Untersuchungseinheiten oder aus unsystematischen, zufälligenEinüssen der Untersuchung resultierende Varianzanteil bezeichnet.
Die biostatistische Versuchsplanung hat die Aufgabe, diesen Varianzanteilso gering wie möglich zu halten.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 427 / 435
13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Merksatz: ein wichtiges Ziel der biostatistischen Versuchsplanung bestehtdarin, die Primärvarianz zu maximieren, die Sekundärvarianz zukontrollieren und die Fehlervarianz zu minimieren.
Das Verhältnis der Anteil von Primär-, Sekundär- und Fehlervarianz ist engmit dem Begri der internen Validität einer Untersuchung verbunden.
Denition: eine Untersuchung ist intern valide (nach innen gültig), wenndie Unterschiede in der abhängigen Variablen (dem interessierendenMerkmal) zwischen den verschiedenen Versuchbedingungen eindeutig aufdie Veränderungen der unabhängigen Variablen, d.h. auf dieunterschiedlichen Versuchsbedingungen zurückgeführt werden können.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 428 / 435

13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Denition: Eine Untersuchung ist extern valide (nach auÿen gültig), wenndie Ergebnisse der Untersuchung auf die Population und auf andereSituationen übertragen werden können.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 429 / 435
13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Allgemeine Prinzipien der Versuchsplanung
Maximieren der Primärvarianz
Konstanthalten von Störgröÿen
Randomisierung von Versuchsbedingungen
Matching
Blockbildung
Verblindung (einfach oder mehrfach)
Wiederholungen
mehrfaktorielle Strukturen
statistische Kontrolle von Störfaktoren mittels Regressionsmethoden
Einbeziehung einer Kontrollgruppe
Symmetrie
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 430 / 435

13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Typen von Stichproben
Einfache Zufallsstichproben
Geschichtete Stichproben (zB hinsichtlich Alter und/oder Geschlecht)
Klumpenstichproben (zB Herden oder Familien)
Mehrstuge zufällige Auswahlverfahren
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 431 / 435
13. Versuchsplanung 13.3. Grundlegende Aspekte der Versuchsplanung
Einige wichtige Versuchspläne
Einfaktorielle Randomisierungspläne für groÿe Stichprobenumfänge,dreifache Zufallszuordnung
Blockversuchspläne
Messwiederholungspläne
Mehrfaktorielle Pläne
Mischversuchspläne
Unvollständige Versuchspläne wie hierarchische Pläne oder LateinischeQuadrate
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 432 / 435

13. Versuchsplanung 13.4. Bestimmung optimaler Stichprobenumfänge
Bestimmung optimaler StichprobenumfängeEinfaches Beispiel: 1-Stichproben-GauÿtestX1, . . . ,Xn unabhängige Zufallsgröÿen, verteilt wie N(µ, σ2) mitunbekanntem Erwartungswert µ und bekannter Varianz σ2 > 0.Zu testen ist
H0 : µ ≤ µ0 gegen H1 : µ > µ0 (Signikanztest)
mit dem rechtsseitigen Gauÿ-Test: Lehne H0 zum Niveau α ∈ (0, 1) ab, falls
√nx − µ0σ
> z1−α := Φ−1(1− α)
Gütefunktion dieses Tests:
G (µ) = Φ
(√nµ− µ0σ
− z1−α
)Die Wahrscheinlichkeit für einen Fehler 2. Art liegt damit für ein µ, das nurwenig gröÿer ist als µ0, knapp unterhalb von 1− α.
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 433 / 435
13. Versuchsplanung 13.4. Bestimmung optimaler Stichprobenumfänge
Sind wir nur an µ-Werten interessiert sind, die um mindestens eine von unsgewählte Gröÿe ∆ > 0 von µ0 abweichen, testen wir die Hypothesen
H0 : µ ≤ µ0 gegen H∆ : µ > µ0 + ∆ (Relevanztest)
Für diesen Test kann die Wahrscheinlichkeit β für einen Fehler 2. Artkontrolliert werden:
β = 1− G (µ0 + ∆) = Φ
(z1−α −
√n
∆
σ
)Diese Beziehung ist äquivalent mit
∆ =σ√n
(z1−α − zβ)
Zu vorgegebenen Wahrscheinlichkeiten α und β für einen Fehler 1. bzw. 2.Art, Streuung σ (geschätzt z.B. im Rahmen einer Pilotstudie) undminimaler relevanter Abweichung (Mindesteekt) ∆ ergibt sich für denminimalen Stichprobenumfang
n ≥σ2(z21−α + z21−β)
∆2
Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 434 / 435

14. Literatur
Literatur
L. Fahrmeir et al.: Statistik Der Weg zur Datenanalyse, 7. Auage,Springer 2010.
J. Groÿ: Grundlegende Statistik mit R Eine anwendungsorientierte
Einführung in die Verwendung der Statistik Software R,Vieweg+Teubner 2010.
J. Hain: Statistik mit R Grundlagen der Datenanalyse,RRZN-Handbuch, Leibniz Universität Hannover 2011 (erhältlich in derBenutzerberatung des RUS).
W. Köhler, G. Schachtel, P. Voleske: Biostatistik: Eine Einführung für
Biologen und Agrarwissenschaftler, Springer 2007.
M. Rudolf und W. Kuhlisch: Biostatistik eine Einführung für
Biowissenschaftler, Pearson Studium 2008
B. Shababa: Biostatistics with R An Introduction to Statistics
Through Biological Data, Springer 2012.Jürgen Dippon (ISA) Biostatistik I 11. Dezember 2012 435 / 435