big data paradigms in python - kevin...
TRANSCRIPT

Big Data Paradigms in Python San Diego Data Science and R Users Group | January 2014
Thank you to our sponsors:
Kevin Davenport!http://kldavenport.com [email protected] @KevinLDavenport

San Diego Data Science: Largish Data in Python
Setting up your environmentCompletely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing
Spend time writing code, not working to set up a system. Create interactive plots in your browser with Bokeh or D3.

http://ipython.org/notebook.html http://docs.continuum.io/anaconda/index.html http://pandas.pydata.org http://scikit-learn.org/stable/
San Diego Data Science: Largish Data in Python

San Diego Data Science: Largish Data in Python
Anaconda$ conda update conda
$ conda update anaconda
$ conda update numpy
$ conda update bokeh
$ conda update numba
$ conda install ggplot
San Diego Data Science: Largish Data in Python
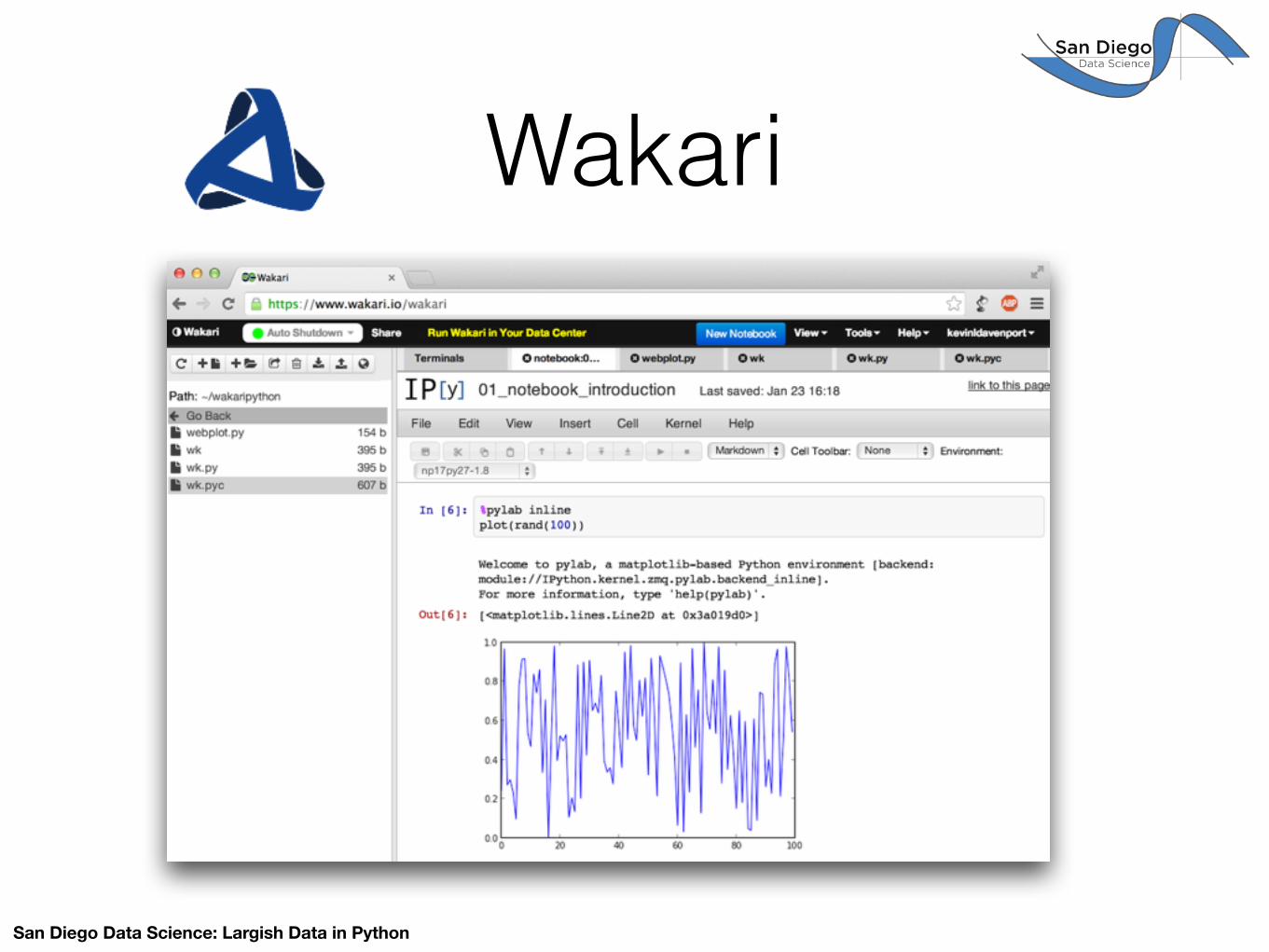
Wakari
San Diego Data Science: Largish Data in Python
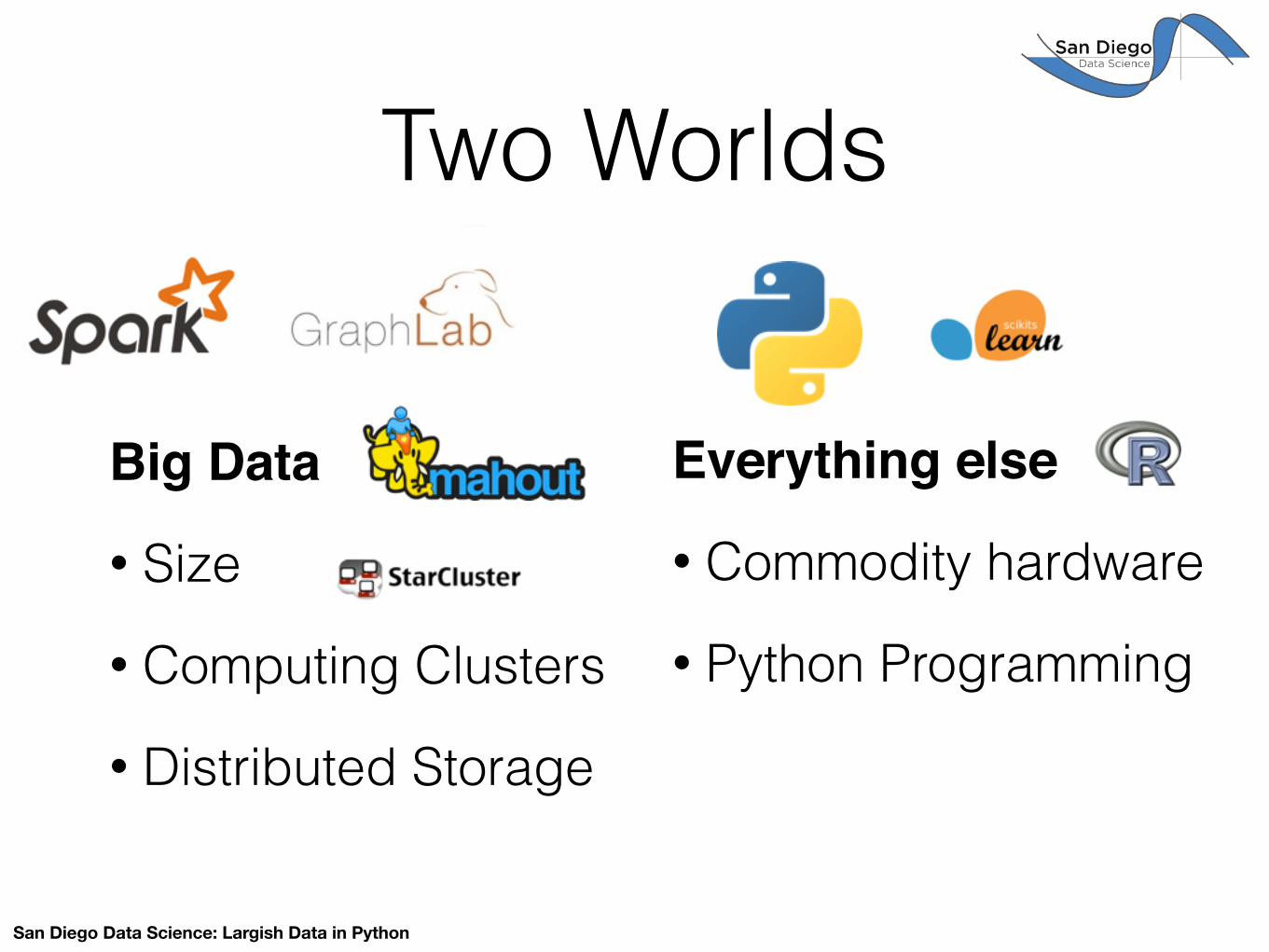
Two Worlds
Big Data!
• Size
• Computing Clusters
• Distributed Storage
Everything else!
• Commodity hardware
• Python Programming

San Diego Data Science: Largish Data in Python
Toolsscikit-learn!
• Python ML library based on (NumPy, SciPy, matplotlib)!
joblib!
• Pipeline jobs with python functions
Learn a model from the data: estimator.fit(X train, Y train)!
Predict using learned model estimator.predict(X test)!
Test goodness of fit estimator.score(X test, y test)!
Apply change of representation estimator.transform(X, y)

San Diego Data Science: Largish Data in Python
Design1. Debugging:!
%debug, %time, %timeit, %lprun, %prun,%mprun,%memit!
2. Dependency Hell:!
HomeBrew, Anaconda, Enthought!
3. Get to NumPy as fast possible:!
Optimized C drivers/connectors

San Diego Data Science: Largish Data in Python
Efficient Data Handling
1. On the fly data reduction!
2. On-line algorithms!
3. Parallel Processing patterns!
4. Caching

San Diego Data Science: Largish Data in Python
Efficient Data Handling
1. On the fly data reduction!
2. On-line algorithms!
3. Parallel Processing patterns!
4. Caching

San Diego Data Science: Largish Data in Python
Simpler Case for ML
“Data-driven” work needs ML because of the curse of dimensionality
San Diego Data Science: Largish Data in Python
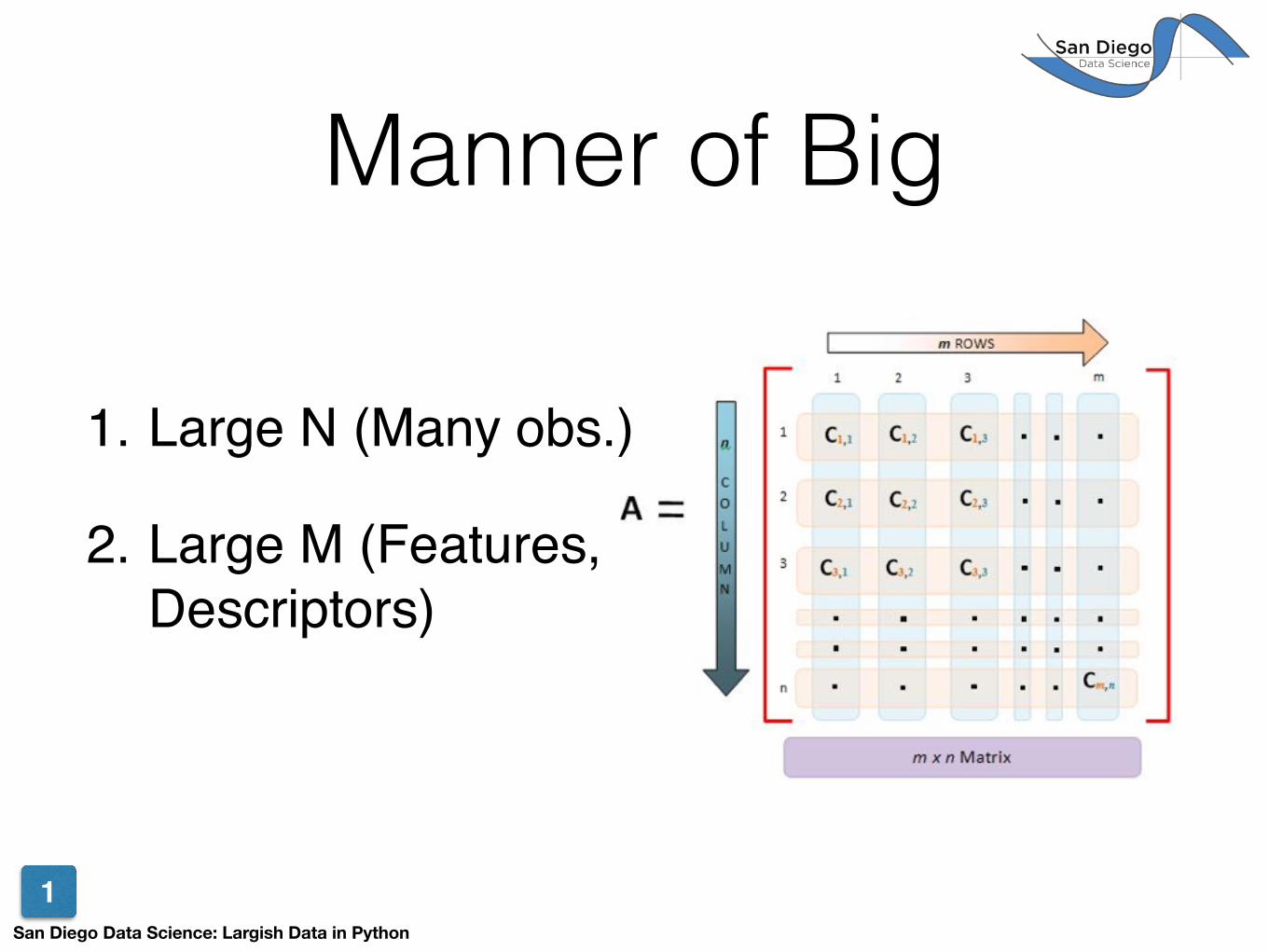
Manner of Big
1. Large N (Many obs.)!
2. Large M (Features, Descriptors)
1

San Diego Data Science: Largish Data in Python
Less data = less work1. Big Data often I/O Bound!
2. Layer Memory Access!
• CPU cache!• RAM!• Local disks!• Distant Storage
1

San Diego Data Science: Largish Data in Python
Dropping Data in a Loop
1. Take a random subset/sample of the data!
2. Apply algorithm on given subset!
3. aggregate results across subsets
-Run the loop in parallel -Exploit redundancy across obs.
1

San Diego Data Science: Largish Data in Python
2
2 22
Resample the sample with replacement
Sample
Bootstrap Aggregating (Bagging):
1

San Diego Data Science: Largish Data in Python
Dimension Reduction• Random Projections (averaging features)!
sklearn.random_projection!
• Fast (sub-optimal) clustering of features:!
sklearn.cluster.WardAgglomeration!
• Hashing (obs. of varying size, e.g. words)!
sklearn.feature_extraction.text.HashingVectorizer
1

San Diego Data Science: Largish Data in Python
Gaussian Random Projection
1

San Diego Data Science: Largish Data in Python
PCA using randomized SVD
1

San Diego Data Science: Largish Data in Python
Efficient Data Handling Schemes
1. On the fly data reduction!
2. On-line algorithms!
3. Parallel Processing patterns!
4. Caching

San Diego Data Science: Largish Data in Python
Convergence
1. i.i.d. converges to expectations of distribution of interest!
2. Mini-batch: bunch observationsTrade-off between memory usage and vectorization
2
San Diego Data Science: Largish Data in Python
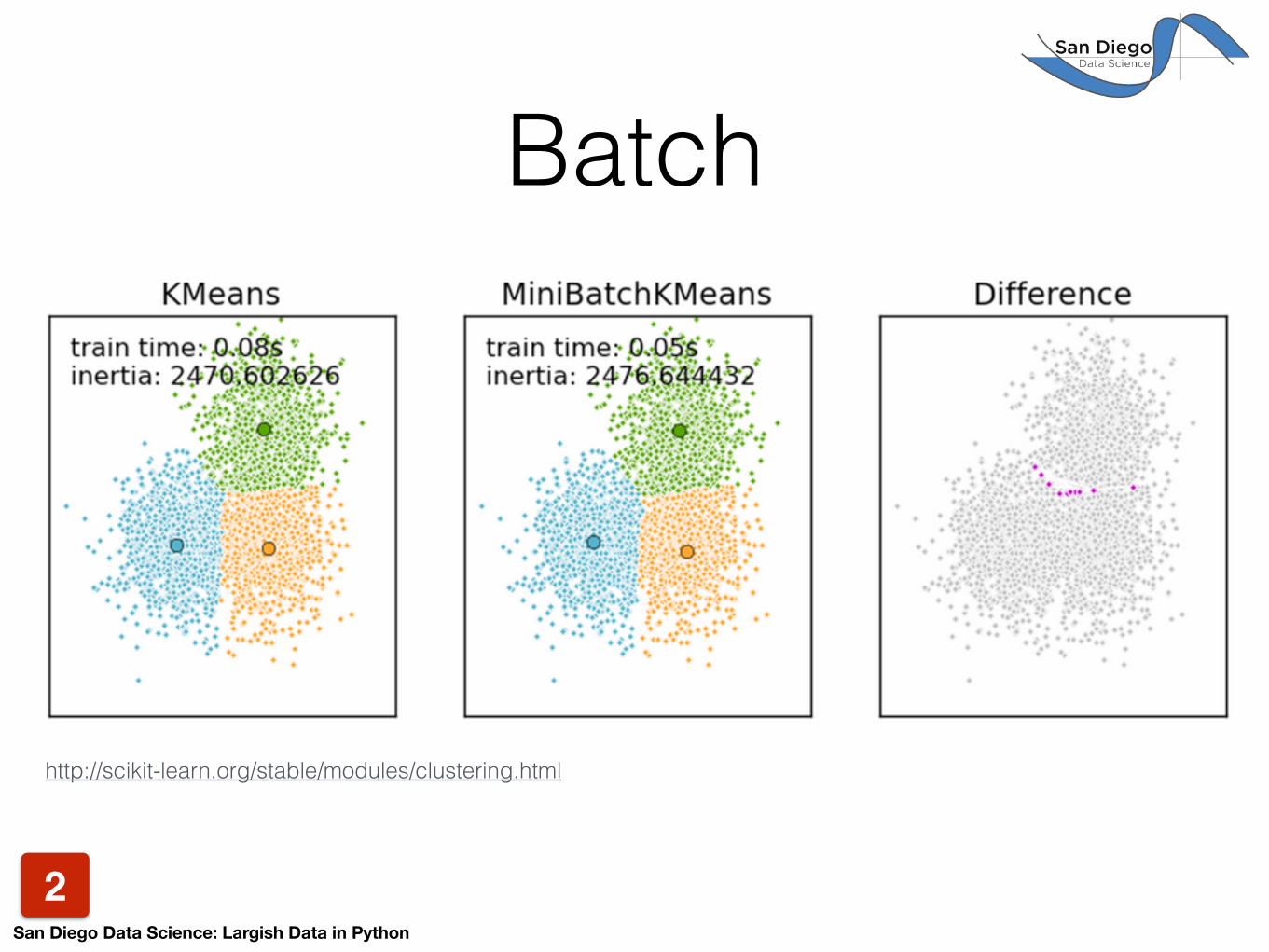
Batch
2
http://scikit-learn.org/stable/modules/clustering.html

San Diego Data Science: Largish Data in Python
Batch
2
Minibatch
Vanilla50.9 ms
15.1 ms

San Diego Data Science: Largish Data in Python
Efficient Data Handling Schemes
1. On the fly data reduction!
2. On-line algorithms!
3. Parallel Processing patterns!
4. Caching
San Diego Data Science: Largish Data in Python
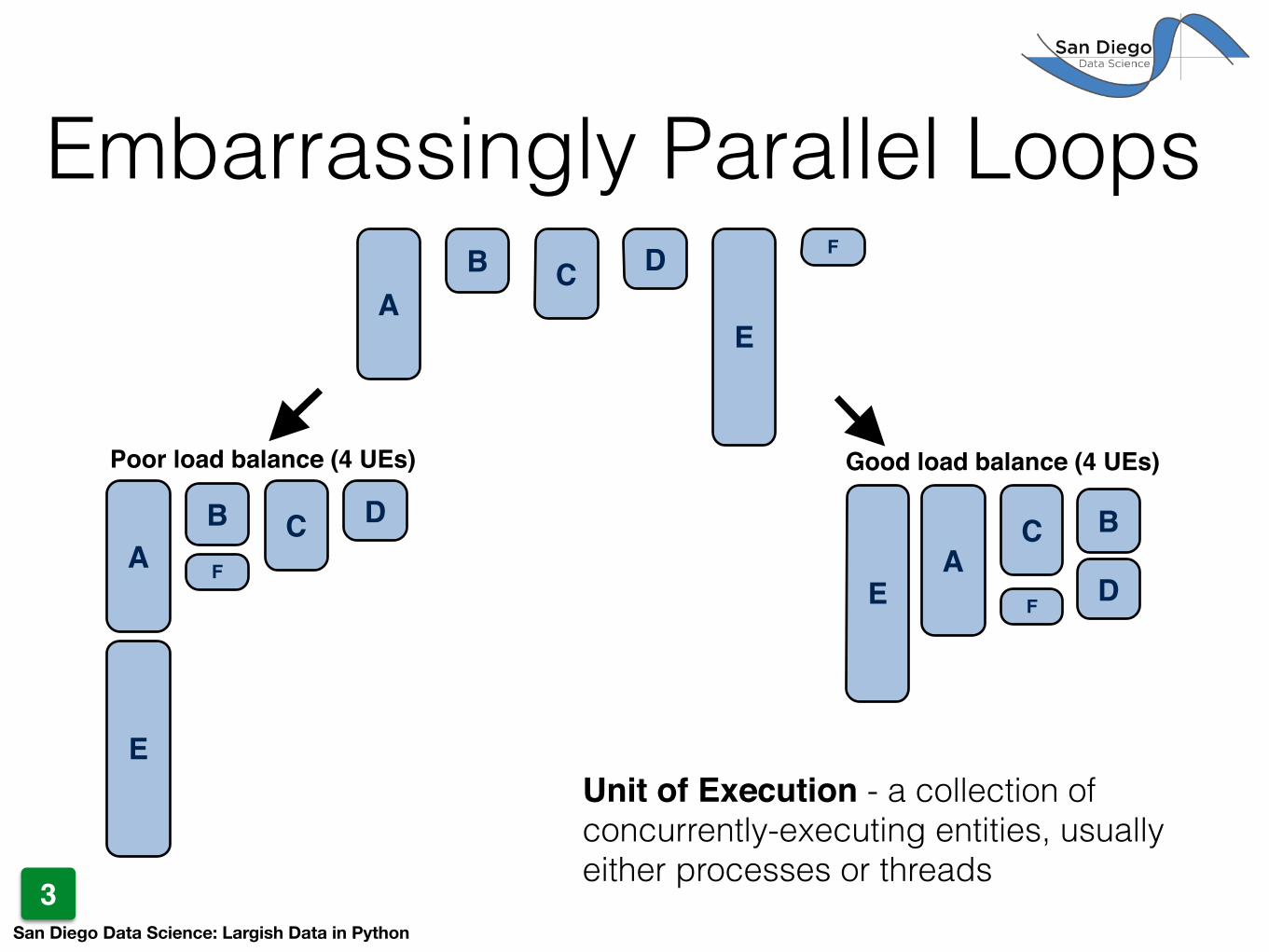
Embarrassingly Parallel Loops
3
AB C D
E
F
A
E
BF
C D
Poor load balance (4 UEs)
E
B
F
C
D
Good load balance (4 UEs)
A
Unit of Execution - a collection of concurrently-executing entities, usually either processes or threads

San Diego Data Science: Largish Data in Python
joblibRunning Python functions as pipeline jobs!
• Don’t change your code!
• No dependencies
3

San Diego Data Science: Largish Data in Python
Return vs Yield Quick Review
3

San Diego Data Science: Largish Data in Python
scikit-learn Integration
3
• Random Projections (averaging features)!
cross_val(model, X, y, n_jobs=4,cv=3)!
• Grid Search:!
GridsearchCV(model, n_jobs=4,cv=3).fit(X,y) !
• Random Forests!
RandomForestClassifier(n_jobs=4).fit(X,y)!
ExtraTreesClassifier(n_jobs=4).fit(X,y)

San Diego Data Science: Largish Data in Python
3
All Data
All Labels to Predict
All Data
All Labels
All Data
All Labels
All Data
All Labels
Replicate Dataset
All Data
All Labels
All Data
All Labels
All Data
All Labels
Train Forest Models in Parallel
http://ogrisel.com/ http://scikit-learn.org/dev/modules/ensemble.html#random-forests
Seed each model with a different random state integerclf_1 clf_1 clf_1
clf = (clf_1 + clf_2 + clf_2)
In-memory

San Diego Data Science: Largish Data in Python
3
All Data
All Labels to Predict
Data 1
Labels 1
Data 2
Labels 2
Data 3
Labels 3
Replicate Partition Dataset Train Forest Models in Parallel
http://ogrisel.com/ http://scikit-learn.org/dev/modules/ensemble.html#random-forests
Data 1
Labels 1
Data 2
Labels 2
Data 3
Labels 3
Seed each model with a different random state integer
clf_1 clf_2 clf_3
clf = (clf_1 + clf_2 + clf_3)
Too large for memory

San Diego Data Science: Largish Data in Python
Efficient Data Handling
1. On the fly data reduction!
2. On-line algorithms!
3. Parallel Processing patterns!
4. Caching

San Diego Data Science: Largish Data in Python
Memoize
3

San Diego Data Science: Largish Data in Python
Don’t underestimate the cost of complexity whether it be cognitive, maintenance, mutability, portability, etc.!
"We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil” - Donald Knuth
