big data meets hpc: exploiting hpc technologies for ... · big data meets hpc: exploiting hpc...
TRANSCRIPT

Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Talk at HPCAC-Switzerland (April ‘17)
by

HPCAC-Switzerland (April ’17) 2Network Based Computing Laboratory
• Big Data has changed the way people understand
and harness the power of data, both in the
business and research domains
• Big Data has become one of the most important
elements in business analytics
• Big Data and High Performance Computing (HPC)
are converging to meet large scale data processing
challenges
• Running High Performance Data Analysis (HPDA) workloads in the cloud is gaining popularity
• According to the latest OpenStack survey, 27% of cloud deployments are running HPDA workloads
Introduction to Big Data Analytics and Trends
http://www.coolinfographics.com/blog/tag/data?currentPage=3
http://www.climatecentral.org/news/white-house-brings-together-big-data-and-climate-change-17194
HPCAC-Switzerland (April ’17) 3Network Based Computing Laboratory
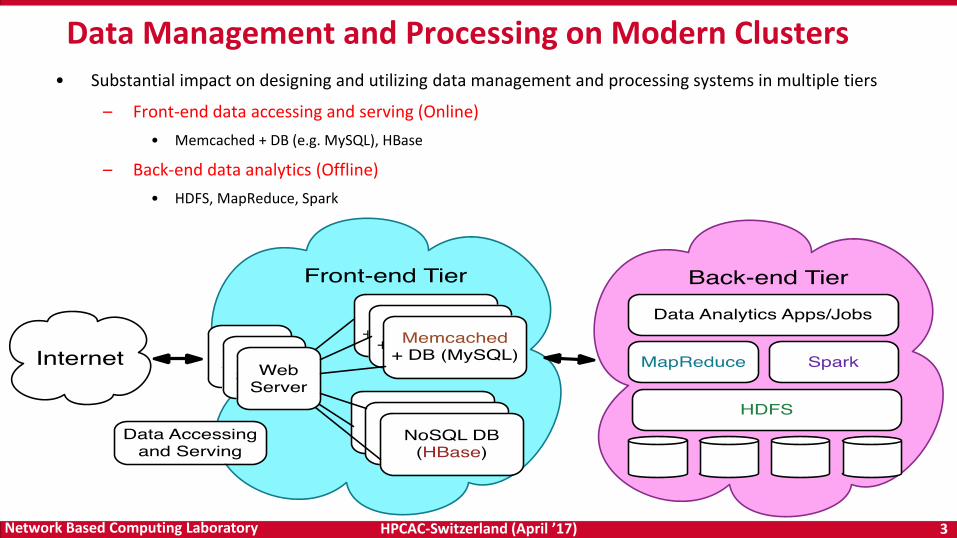
• Substantial impact on designing and utilizing data management and processing systems in multiple tiers
– Front-end data accessing and serving (Online)
• Memcached + DB (e.g. MySQL), HBase
– Back-end data analytics (Offline)
• HDFS, MapReduce, Spark
Data Management and Processing on Modern Clusters

HPCAC-Switzerland (April ’17) 4Network Based Computing Laboratory
Drivers of Modern HPC Cluster Architectures
Tianhe – 2 Titan Stampede Tianhe – 1A
• Multi-core/many-core technologies
• Remote Direct Memory Access (RDMA)-enabled networking (InfiniBand and RoCE)
• Solid State Drives (SSDs), Non-Volatile Random-Access Memory (NVRAM), NVMe-SSD
• Accelerators (NVIDIA GPGPUs and Intel Xeon Phi)
Accelerators / Coprocessors high compute density, high
performance/watt>1 TFlop DP on a chip
High Performance Interconnects -InfiniBand
<1usec latency, 100Gbps Bandwidth>Multi-core Processors SSD, NVMe-SSD, NVRAM
HPCAC-Switzerland (April ’17) 5Network Based Computing Laboratory
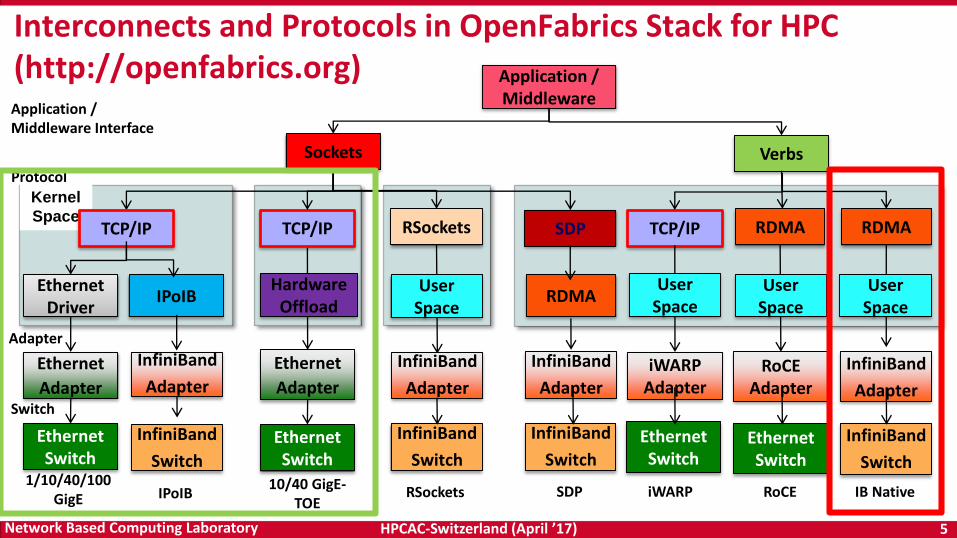
Interconnects and Protocols in OpenFabrics Stack for HPC(http://openfabrics.org)
Kernel
Space
Application / Middleware
Verbs
Ethernet
Adapter
EthernetSwitch
Ethernet Driver
TCP/IP
1/10/40/100 GigE
InfiniBand
Adapter
InfiniBand
Switch
IPoIB
IPoIB
Ethernet
Adapter
Ethernet Switch
Hardware Offload
TCP/IP
10/40 GigE-TOE
InfiniBand
Adapter
InfiniBand
Switch
User Space
RSockets
RSockets
iWARP Adapter
Ethernet Switch
TCP/IP
User Space
iWARP
RoCEAdapter
Ethernet Switch
RDMA
User Space
RoCE
InfiniBand
Switch
InfiniBand
Adapter
RDMA
User Space
IB Native
Sockets
Application / Middleware Interface
Protocol
Adapter
Switch
InfiniBand
Adapter
InfiniBand
Switch
RDMA
SDP
SDP
HPCAC-Switzerland (April ’17) 6Network Based Computing Laboratory
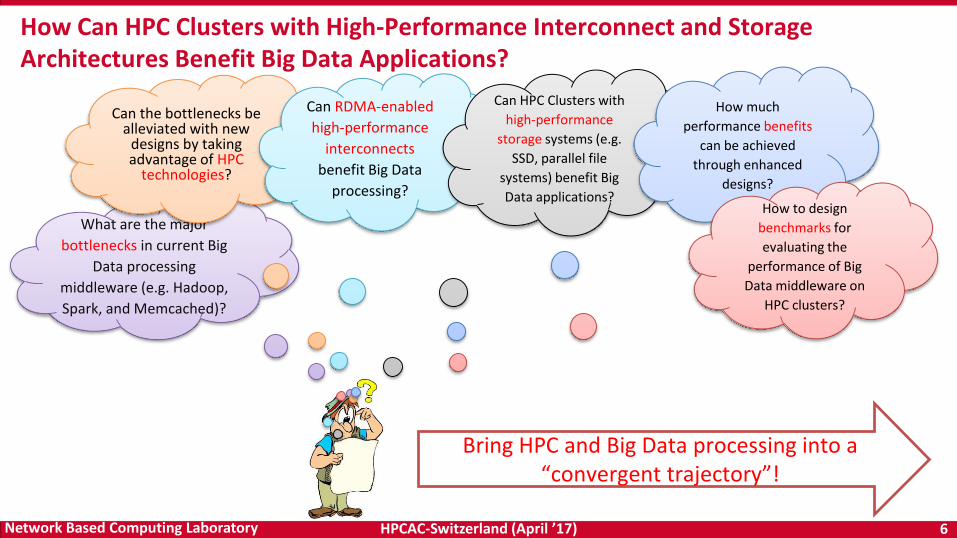
How Can HPC Clusters with High-Performance Interconnect and Storage Architectures Benefit Big Data Applications?
Bring HPC and Big Data processing into a “convergent trajectory”!
What are the major
bottlenecks in current Big
Data processing
middleware (e.g. Hadoop,
Spark, and Memcached)?
Can the bottlenecks be alleviated with new
designs by taking advantage of HPC
technologies?
Can RDMA-enabled
high-performance
interconnects
benefit Big Data
processing?
Can HPC Clusters with
high-performance
storage systems (e.g.
SSD, parallel file
systems) benefit Big
Data applications?
How much
performance benefits
can be achieved
through enhanced
designs?
How to design
benchmarks for
evaluating the
performance of Big
Data middleware on
HPC clusters?

HPCAC-Switzerland (April ’17) 7Network Based Computing Laboratory
Can We Run Big Data Jobs on Existing HPC Infrastructure?

HPCAC-Switzerland (April ’17) 8Network Based Computing Laboratory
Can We Run Big Data Jobs on Existing HPC Infrastructure?

HPCAC-Switzerland (April ’17) 9Network Based Computing Laboratory
Can We Run Big Data Jobs on Existing HPC Infrastructure?
HPCAC-Switzerland (April ’17) 10Network Based Computing Laboratory
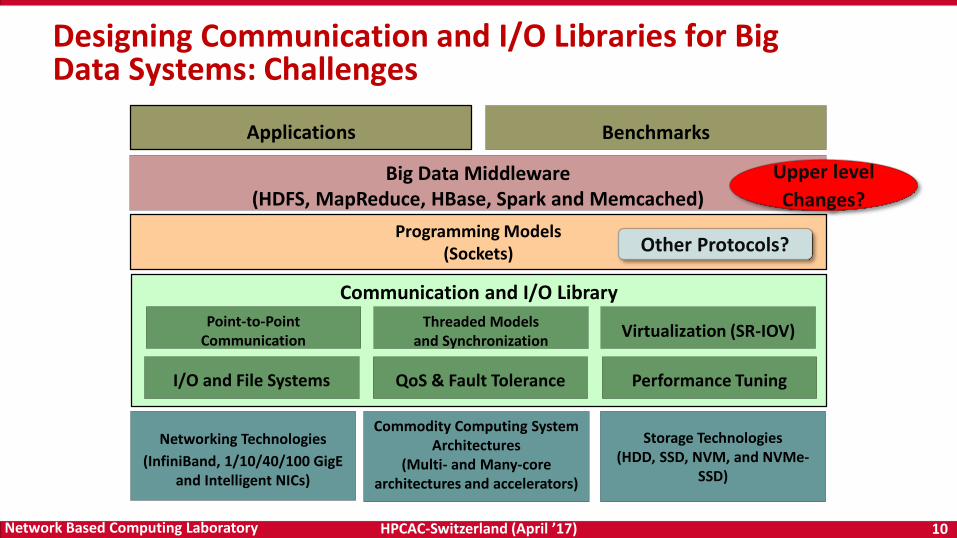
Designing Communication and I/O Libraries for Big Data Systems: Challenges
Big Data Middleware(HDFS, MapReduce, HBase, Spark and Memcached)
Networking Technologies
(InfiniBand, 1/10/40/100 GigE and Intelligent NICs)
Storage Technologies(HDD, SSD, NVM, and NVMe-
SSD)
Programming Models(Sockets)
Applications
Commodity Computing System Architectures
(Multi- and Many-core architectures and accelerators)
Other Protocols?
Communication and I/O Library
Point-to-PointCommunication
QoS & Fault Tolerance
Threaded Modelsand Synchronization
Performance TuningI/O and File Systems
Virtualization (SR-IOV)
Benchmarks
Upper level
Changes?
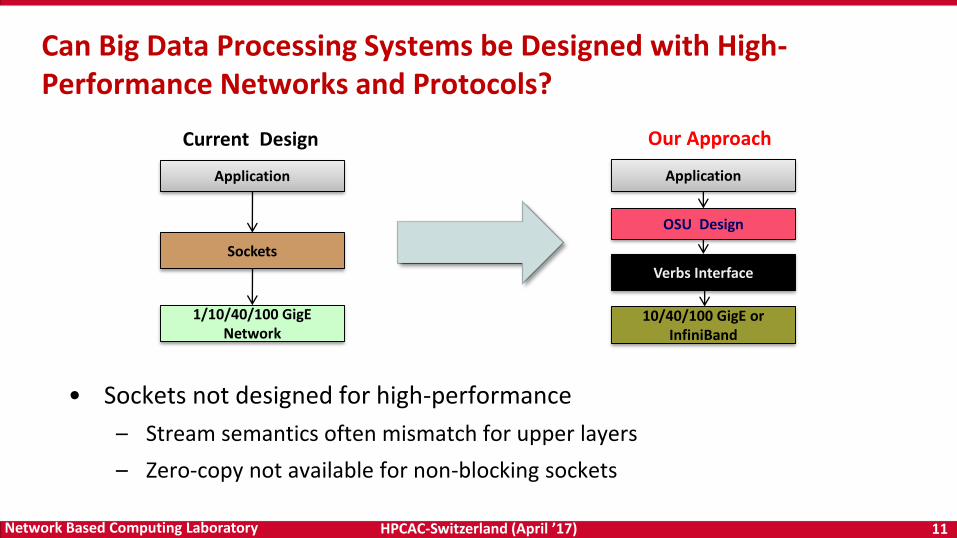
HPCAC-Switzerland (April ’17) 11Network Based Computing Laboratory
• Sockets not designed for high-performance
– Stream semantics often mismatch for upper layers
– Zero-copy not available for non-blocking sockets
Can Big Data Processing Systems be Designed with High-Performance Networks and Protocols?
Current Design
Application
Sockets
1/10/40/100 GigENetwork
Our Approach
Application
OSU Design
10/40/100 GigE or InfiniBand
Verbs Interface

HPCAC-Switzerland (April ’17) 12Network Based Computing Laboratory
• RDMA for Apache Spark
• RDMA for Apache Hadoop 2.x (RDMA-Hadoop-2.x)
– Plugins for Apache, Hortonworks (HDP) and Cloudera (CDH) Hadoop distributions
• RDMA for Apache HBase
• RDMA for Memcached (RDMA-Memcached)
• RDMA for Apache Hadoop 1.x (RDMA-Hadoop)
• OSU HiBD-Benchmarks (OHB)
– HDFS, Memcached, HBase, and Spark Micro-benchmarks
• http://hibd.cse.ohio-state.edu
• Users Base: 215 organizations from 29 countries
• More than 21,100 downloads from the project site
The High-Performance Big Data (HiBD) Project
Available for InfiniBand and RoCE
Also run on Ethernet

HPCAC-Switzerland (April ’17) 13Network Based Computing Laboratory
• High-Performance Design of Hadoop over RDMA-enabled Interconnects
– High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for HDFS, MapReduce, and
RPC components
– Enhanced HDFS with in-memory and heterogeneous storage
– High performance design of MapReduce over Lustre
– Memcached-based burst buffer for MapReduce over Lustre-integrated HDFS (HHH-L-BB mode)
– Plugin-based architecture supporting RDMA-based designs for Apache Hadoop, CDH and HDP
– Easily configurable for different running modes (HHH, HHH-M, HHH-L, HHH-L-BB, and MapReduce over Lustre) and different
protocols (native InfiniBand, RoCE, and IPoIB)
• Current release: 1.1.0
– Based on Apache Hadoop 2.7.3
– Compliant with Apache Hadoop 2.7.1, HDP 2.5.0.3 and CDH 5.8.2 APIs and applications
– Tested with
• Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR)
• RoCE support with Mellanox adapters
• Various multi-core platforms
• Different file systems with disks and SSDs and Lustre
RDMA for Apache Hadoop 2.x Distribution
http://hibd.cse.ohio-state.edu

HPCAC-Switzerland (April ’17) 14Network Based Computing Laboratory
• HHH: Heterogeneous storage devices with hybrid replication schemes are supported in this mode of operation to have better fault-tolerance as well
as performance. This mode is enabled by default in the package.
• HHH-M: A high-performance in-memory based setup has been introduced in this package that can be utilized to perform all I/O operations in-
memory and obtain as much performance benefit as possible.
• HHH-L: With parallel file systems integrated, HHH-L mode can take advantage of the Lustre available in the cluster.
• HHH-L-BB: This mode deploys a Memcached-based burst buffer system to reduce the bandwidth bottleneck of shared file system access. The burst
buffer design is hosted by Memcached servers, each of which has a local SSD.
• MapReduce over Lustre, with/without local disks: Besides, HDFS based solutions, this package also provides support to run MapReduce jobs on top
of Lustre alone. Here, two different modes are introduced: with local disks and without local disks.
• Running with Slurm and PBS: Supports deploying RDMA for Apache Hadoop 2.x with Slurm and PBS in different running modes (HHH, HHH-M, HHH-
L, and MapReduce over Lustre).
Different Modes of RDMA for Apache Hadoop 2.x

HPCAC-Switzerland (April ’17) 15Network Based Computing Laboratory
• High-Performance Design of Spark over RDMA-enabled Interconnects
– High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for Spark
– RDMA-based data shuffle and SEDA-based shuffle architecture
– Support pre-connection, on-demand connection, and connection sharing
– Non-blocking and chunk-based data transfer
– Off-JVM-heap buffer management
– Easily configurable for different protocols (native InfiniBand, RoCE, and IPoIB)
• Current release: 0.9.4
– Based on Apache Spark 2.1.0
– Tested with
• Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR)
• RoCE support with Mellanox adapters
• Various multi-core platforms
• RAM disks, SSDs, and HDD
– http://hibd.cse.ohio-state.edu
RDMA for Apache Spark Distribution

HPCAC-Switzerland (April ’17) 16Network Based Computing Laboratory
• High-Performance Design of HBase over RDMA-enabled Interconnects
– High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level
for HBase
– Compliant with Apache HBase 1.1.2 APIs and applications
– On-demand connection setup
– Easily configurable for different protocols (native InfiniBand, RoCE, and IPoIB)
• Current release: 0.9.1
– Based on Apache HBase 1.1.2
– Tested with
• Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR)
• RoCE support with Mellanox adapters
• Various multi-core platforms
– http://hibd.cse.ohio-state.edu
RDMA for Apache HBase Distribution

HPCAC-Switzerland (April ’17) 17Network Based Computing Laboratory
• High-Performance Design of Memcached over RDMA-enabled Interconnects
– High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for Memcached and
libMemcached components
– High performance design of SSD-Assisted Hybrid Memory
– Non-Blocking Libmemcached Set/Get API extensions
– Support for burst-buffer mode in Lustre-integrated design of HDFS in RDMA for Apache Hadoop-2.x
– Easily configurable for native InfiniBand, RoCE and the traditional sockets-based support (Ethernet and InfiniBand with
IPoIB)
• Current release: 0.9.5
– Based on Memcached 1.4.24 and libMemcached 1.0.18
– Compliant with libMemcached APIs and applications
– Tested with
• Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR)
• RoCE support with Mellanox adapters
• Various multi-core platforms
• SSD
– http://hibd.cse.ohio-state.edu
RDMA for Memcached Distribution

HPCAC-Switzerland (April ’17) 18Network Based Computing Laboratory
• Micro-benchmarks for Hadoop Distributed File System (HDFS)
– Sequential Write Latency (SWL) Benchmark, Sequential Read Latency (SRL) Benchmark,
Random Read Latency (RRL) Benchmark, Sequential Write Throughput (SWT) Benchmark,
Sequential Read Throughput (SRT) Benchmark
– Support benchmarking of
• Apache Hadoop 1.x and 2.x HDFS, Hortonworks Data Platform (HDP) HDFS, Cloudera Distribution of
Hadoop (CDH) HDFS
• Micro-benchmarks for Memcached
– Get Benchmark, Set Benchmark, and Mixed Get/Set Benchmark, Non-Blocking API Latency
Benchmark, Hybrid Memory Latency Benchmark
• Micro-benchmarks for HBase
– Get Latency Benchmark, Put Latency Benchmark
• Current release: 0.9.1
• http://hibd.cse.ohio-state.edu
OSU HiBD Micro-Benchmark (OHB) Suite – HDFS, Memcached, and HBase

HPCAC-Switzerland (April ’17) 19Network Based Computing Laboratory
Using HiBD Packages on Existing HPC Infrastructure

HPCAC-Switzerland (April ’17) 20Network Based Computing Laboratory
Using HiBD Packages on Existing HPC Infrastructure

HPCAC-Switzerland (April ’17) 21Network Based Computing Laboratory
• RDMA for Apache Hadoop 2.x and RDMA for Apache Spark are installed and
available on SDSC Comet.
– Examples for various modes of usage are available in:
• RDMA for Apache Hadoop 2.x: /share/apps/examples/HADOOP
• RDMA for Apache Spark: /share/apps/examples/SPARK/
– Please email [email protected] (reference Comet as the machine, and SDSC as the
site) if you have any further questions about usage and configuration.
• RDMA for Apache Hadoop is also available on Chameleon Cloud as an
appliance
– https://www.chameleoncloud.org/appliances/17/
HiBD Packages on SDSC Comet and Chameleon Cloud
M. Tatineni, X. Lu, D. J. Choi, A. Majumdar, and D. K. Panda, Experiences and Benefits of Running RDMA Hadoop and Spark on SDSC
Comet, XSEDE’16, July 2016

HPCAC-Switzerland (April ’17) 22Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• RDMA-Hadoop with DDN IME Burst Buffer Technology
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
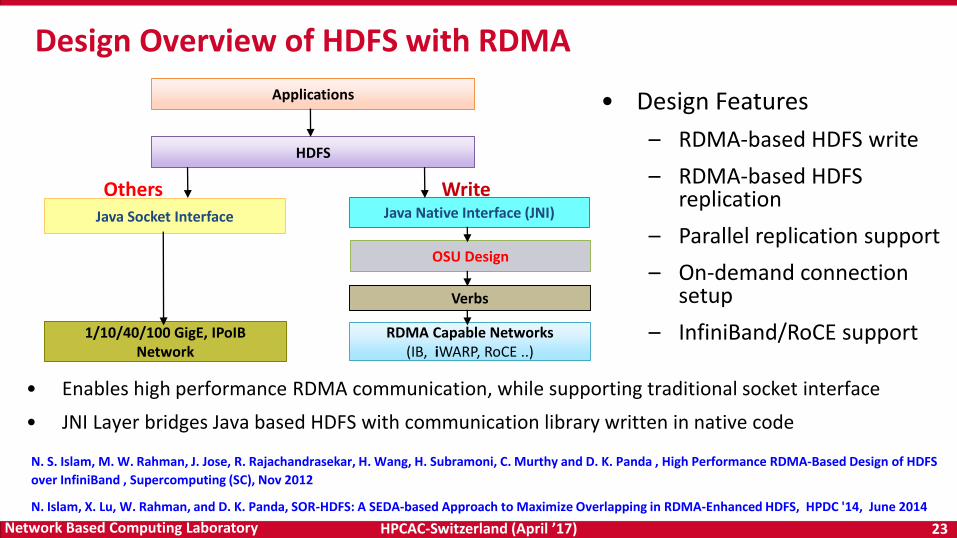
HPCAC-Switzerland (April ’17) 23Network Based Computing Laboratory
• Enables high performance RDMA communication, while supporting traditional socket interface
• JNI Layer bridges Java based HDFS with communication library written in native code
Design Overview of HDFS with RDMA
HDFS
Verbs
RDMA Capable Networks(IB, iWARP, RoCE ..)
Applications
1/10/40/100 GigE, IPoIB Network
Java Socket Interface Java Native Interface (JNI)
WriteOthers
OSU Design
• Design Features
– RDMA-based HDFS write
– RDMA-based HDFS replication
– Parallel replication support
– On-demand connection setup
– InfiniBand/RoCE support
N. S. Islam, M. W. Rahman, J. Jose, R. Rajachandrasekar, H. Wang, H. Subramoni, C. Murthy and D. K. Panda , High Performance RDMA-Based Design of HDFS
over InfiniBand , Supercomputing (SC), Nov 2012
N. Islam, X. Lu, W. Rahman, and D. K. Panda, SOR-HDFS: A SEDA-based Approach to Maximize Overlapping in RDMA-Enhanced HDFS, HPDC '14, June 2014
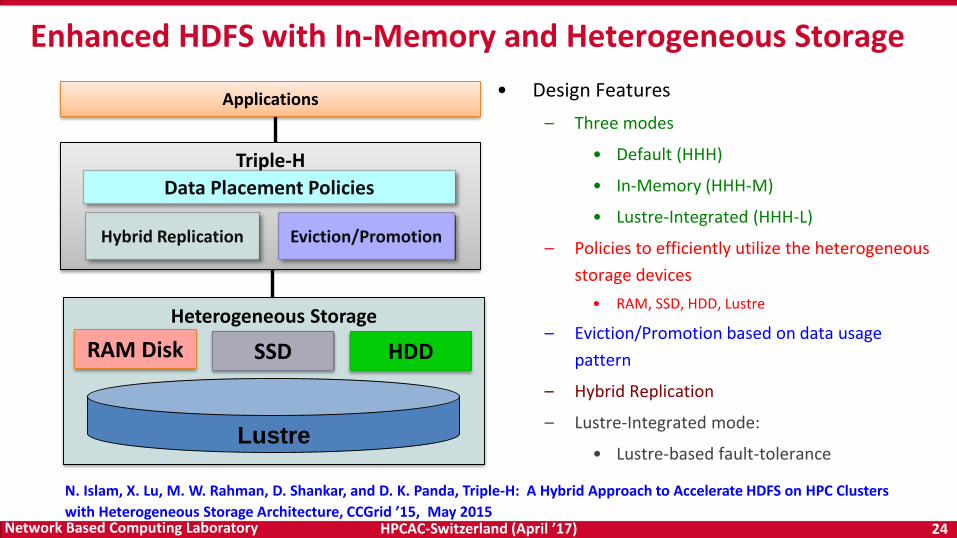
HPCAC-Switzerland (April ’17) 24Network Based Computing Laboratory
Triple-H
Heterogeneous Storage
• Design Features
– Three modes
• Default (HHH)
• In-Memory (HHH-M)
• Lustre-Integrated (HHH-L)
– Policies to efficiently utilize the heterogeneous
storage devices
• RAM, SSD, HDD, Lustre
– Eviction/Promotion based on data usage
pattern
– Hybrid Replication
– Lustre-Integrated mode:
• Lustre-based fault-tolerance
Enhanced HDFS with In-Memory and Heterogeneous Storage
Hybrid Replication
Data Placement Policies
Eviction/Promotion
RAM Disk SSD HDD
Lustre
N. Islam, X. Lu, M. W. Rahman, D. Shankar, and D. K. Panda, Triple-H: A Hybrid Approach to Accelerate HDFS on HPC Clusters
with Heterogeneous Storage Architecture, CCGrid ’15, May 2015
Applications
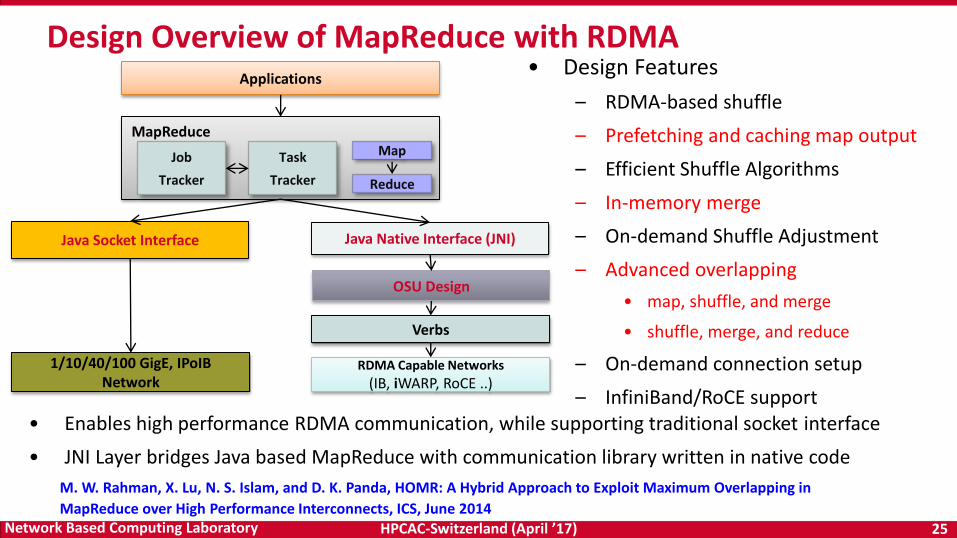
HPCAC-Switzerland (April ’17) 25Network Based Computing Laboratory
Design Overview of MapReduce with RDMA
MapReduce
Verbs
RDMA Capable Networks
(IB, iWARP, RoCE ..)
OSU Design
Applications
1/10/40/100 GigE, IPoIB Network
Java Socket Interface Java Native Interface (JNI)
Job
Tracker
Task
Tracker
Map
Reduce
• Enables high performance RDMA communication, while supporting traditional socket interface
• JNI Layer bridges Java based MapReduce with communication library written in native code
• Design Features
– RDMA-based shuffle
– Prefetching and caching map output
– Efficient Shuffle Algorithms
– In-memory merge
– On-demand Shuffle Adjustment
– Advanced overlapping
• map, shuffle, and merge
• shuffle, merge, and reduce
– On-demand connection setup
– InfiniBand/RoCE support
M. W. Rahman, X. Lu, N. S. Islam, and D. K. Panda, HOMR: A Hybrid Approach to Exploit Maximum Overlapping in
MapReduce over High Performance Interconnects, ICS, June 2014

HPCAC-Switzerland (April ’17) 26Network Based Computing Laboratory
0
50
100
150
200
250
300
350
400
80 120 160
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)OSU-IB (EDR)
0
100
200
300
400
500
600
700
800
80 160 240
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)OSU-IB (EDR)
Performance Numbers of RDMA for Apache Hadoop 2.x –RandomWriter & TeraGen in OSU-RI2 (EDR)
Cluster with 8 Nodes with a total of 64 maps
• RandomWriter
– 3x improvement over IPoIB
for 80-160 GB file size
• TeraGen
– 4x improvement over IPoIB for
80-240 GB file size
RandomWriter TeraGen
Reduced by 3x Reduced by 4x
HPCAC-Switzerland (April ’17) 27Network Based Computing Laboratory
0
100
200
300
400
500
600
700
800
80 120 160
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)
OSU-IB (EDR)
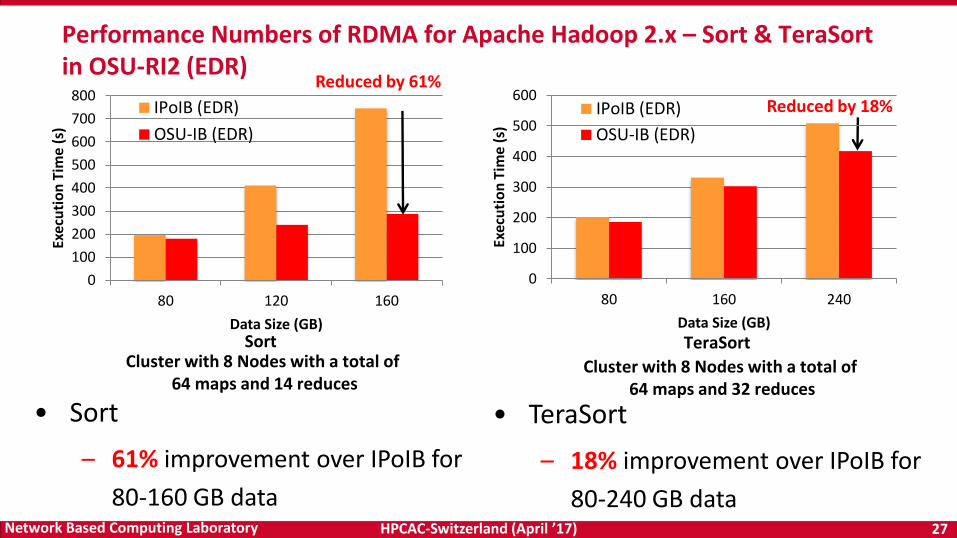
Performance Numbers of RDMA for Apache Hadoop 2.x – Sort & TeraSort in OSU-RI2 (EDR)
Cluster with 8 Nodes with a total of 64 maps and 32 reduces
• Sort
– 61% improvement over IPoIB for
80-160 GB data
• TeraSort
– 18% improvement over IPoIB for
80-240 GB data
Reduced by 61%
Reduced by 18%
Cluster with 8 Nodes with a total of 64 maps and 14 reduces
Sort TeraSort
0
100
200
300
400
500
600
80 160 240
Exec
uti
on
Tim
e (s
)
Data Size (GB)
IPoIB (EDR)
OSU-IB (EDR)
HPCAC-Switzerland (April ’17) 28Network Based Computing Laboratory
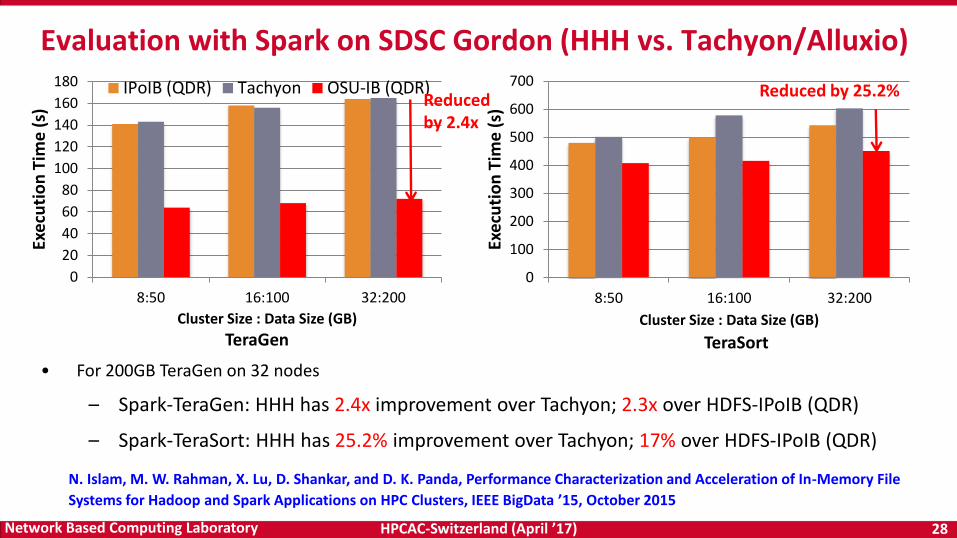
Evaluation with Spark on SDSC Gordon (HHH vs. Tachyon/Alluxio)
• For 200GB TeraGen on 32 nodes
– Spark-TeraGen: HHH has 2.4x improvement over Tachyon; 2.3x over HDFS-IPoIB (QDR)
– Spark-TeraSort: HHH has 25.2% improvement over Tachyon; 17% over HDFS-IPoIB (QDR)
0
20
40
60
80
100
120
140
160
180
8:50 16:100 32:200
Exe
cuti
on
Tim
e (
s)
Cluster Size : Data Size (GB)
IPoIB (QDR) Tachyon OSU-IB (QDR)
0
100
200
300
400
500
600
700
8:50 16:100 32:200
Exe
cuti
on
Tim
e (
s)
Cluster Size : Data Size (GB)
Reduced by 2.4x
Reduced by 25.2%
TeraGen TeraSort
N. Islam, M. W. Rahman, X. Lu, D. Shankar, and D. K. Panda, Performance Characterization and Acceleration of In-Memory File
Systems for Hadoop and Spark Applications on HPC Clusters, IEEE BigData ’15, October 2015

HPCAC-Switzerland (April ’17) 29Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• RDMA-Hadoop with DDN IME Burst Buffer Technology
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
HPCAC-Switzerland (April ’17) 30Network Based Computing Laboratory
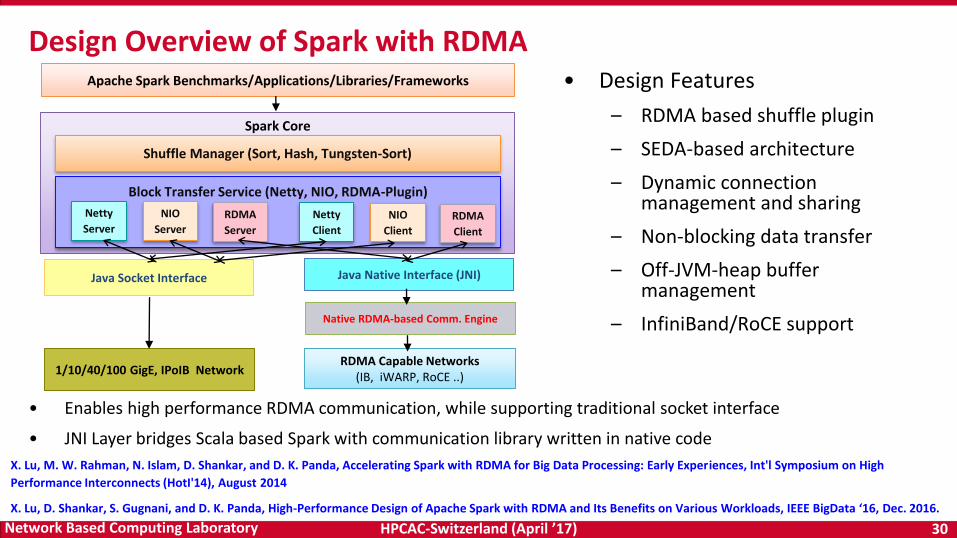
• Design Features
– RDMA based shuffle plugin
– SEDA-based architecture
– Dynamic connection management and sharing
– Non-blocking data transfer
– Off-JVM-heap buffer management
– InfiniBand/RoCE support
Design Overview of Spark with RDMA
• Enables high performance RDMA communication, while supporting traditional socket interface
• JNI Layer bridges Scala based Spark with communication library written in native code
X. Lu, M. W. Rahman, N. Islam, D. Shankar, and D. K. Panda, Accelerating Spark with RDMA for Big Data Processing: Early Experiences, Int'l Symposium on High
Performance Interconnects (HotI'14), August 2014
X. Lu, D. Shankar, S. Gugnani, and D. K. Panda, High-Performance Design of Apache Spark with RDMA and Its Benefits on Various Workloads, IEEE BigData ‘16, Dec. 2016.
Spark Core
RDMA Capable Networks(IB, iWARP, RoCE ..)
Apache Spark Benchmarks/Applications/Libraries/Frameworks
1/10/40/100 GigE, IPoIB Network
Java Socket Interface Java Native Interface (JNI)
Native RDMA-based Comm. Engine
Shuffle Manager (Sort, Hash, Tungsten-Sort)
Block Transfer Service (Netty, NIO, RDMA-Plugin)
Netty
Server
NIO
ServerRDMA
Server
Netty
Client
NIO
ClientRDMA
Client

HPCAC-Switzerland (April ’17) 31Network Based Computing Laboratory
• InfiniBand FDR, SSD, 64 Worker Nodes, 1536 Cores, (1536M 1536R)
• RDMA vs. IPoIB with 1536 concurrent tasks, single SSD per node.
– SortBy: Total time reduced by up to 80% over IPoIB (56Gbps)
– GroupBy: Total time reduced by up to 74% over IPoIB (56Gbps)
Performance Evaluation on SDSC Comet – SortBy/GroupBy
64 Worker Nodes, 1536 cores, SortByTest Total Time 64 Worker Nodes, 1536 cores, GroupByTest Total Time
0
50
100
150
200
250
300
64 128 256
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
0
50
100
150
200
250
64 128 256
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
74%80%
HPCAC-Switzerland (April ’17) 32Network Based Computing Laboratory
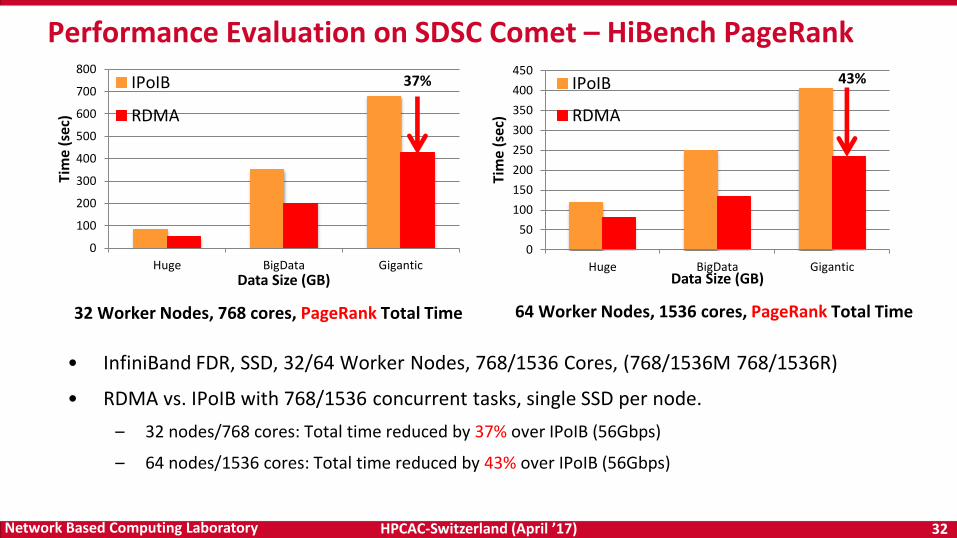
• InfiniBand FDR, SSD, 32/64 Worker Nodes, 768/1536 Cores, (768/1536M 768/1536R)
• RDMA vs. IPoIB with 768/1536 concurrent tasks, single SSD per node.
– 32 nodes/768 cores: Total time reduced by 37% over IPoIB (56Gbps)
– 64 nodes/1536 cores: Total time reduced by 43% over IPoIB (56Gbps)
Performance Evaluation on SDSC Comet – HiBench PageRank
32 Worker Nodes, 768 cores, PageRank Total Time 64 Worker Nodes, 1536 cores, PageRank Total Time
0
50
100
150
200
250
300
350
400
450
Huge BigData Gigantic
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
0
100
200
300
400
500
600
700
800
Huge BigData Gigantic
Tim
e (s
ec)
Data Size (GB)
IPoIB
RDMA
43%37%
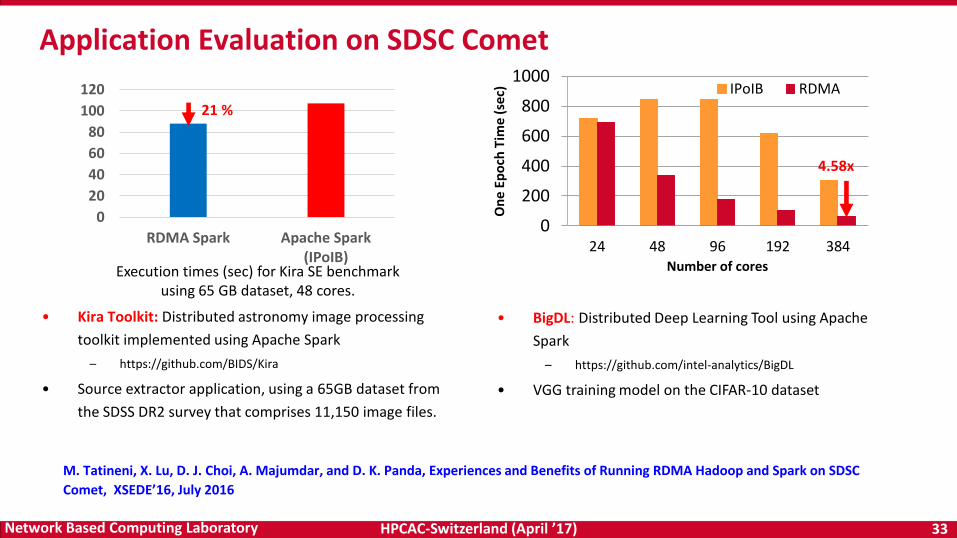
HPCAC-Switzerland (April ’17) 33Network Based Computing Laboratory
Application Evaluation on SDSC Comet
• Kira Toolkit: Distributed astronomy image processing
toolkit implemented using Apache Spark
– https://github.com/BIDS/Kira
• Source extractor application, using a 65GB dataset from
the SDSS DR2 survey that comprises 11,150 image files.
0
20
40
60
80
100
120
RDMA Spark Apache Spark(IPoIB)
21 %
Execution times (sec) for Kira SE benchmark using 65 GB dataset, 48 cores.
M. Tatineni, X. Lu, D. J. Choi, A. Majumdar, and D. K. Panda, Experiences and Benefits of Running RDMA Hadoop and Spark on SDSC
Comet, XSEDE’16, July 2016
0
200
400
600
800
1000
24 48 96 192 384
On
e E
po
ch T
ime
(se
c)
Number of cores
IPoIB RDMA
• BigDL: Distributed Deep Learning Tool using Apache
Spark
– https://github.com/intel-analytics/BigDL
• VGG training model on the CIFAR-10 dataset
4.58x

HPCAC-Switzerland (April ’17) 34Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• RDMA-Hadoop with DDN IME Burst Buffer Technology
• Advanced Designs and Studies
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
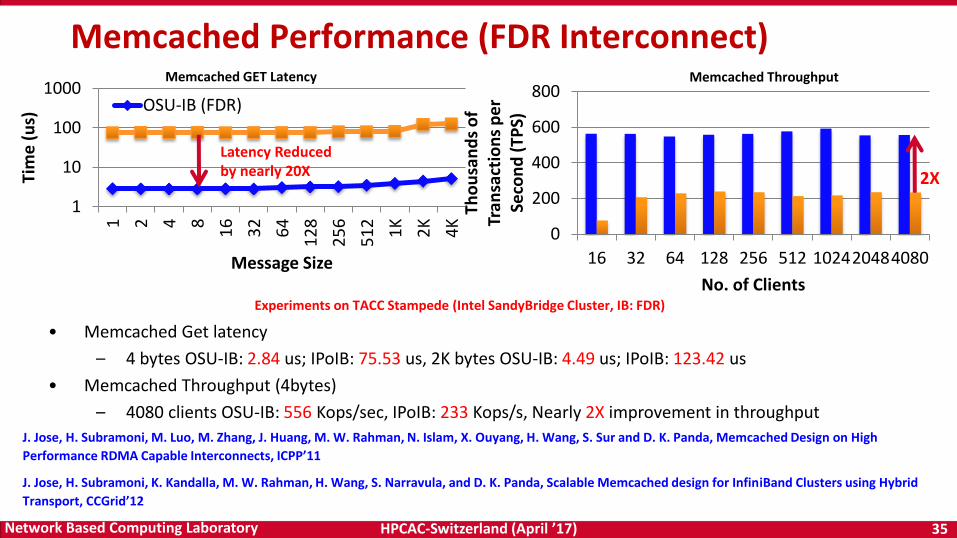
HPCAC-Switzerland (April ’17) 35Network Based Computing Laboratory
1
10
100
1000
1 2 4 8
16
32
64
12
8
25
6
51
2
1K
2K
4K
Tim
e (
us)
Message Size
OSU-IB (FDR)
0
200
400
600
800
16 32 64 128 256 512 102420484080
Tho
usa
nd
s o
f Tr
ansa
ctio
ns
pe
r Se
con
d (
TPS)
No. of Clients
• Memcached Get latency
– 4 bytes OSU-IB: 2.84 us; IPoIB: 75.53 us, 2K bytes OSU-IB: 4.49 us; IPoIB: 123.42 us
• Memcached Throughput (4bytes)
– 4080 clients OSU-IB: 556 Kops/sec, IPoIB: 233 Kops/s, Nearly 2X improvement in throughput
Memcached GET Latency Memcached Throughput
Memcached Performance (FDR Interconnect)
Experiments on TACC Stampede (Intel SandyBridge Cluster, IB: FDR)
Latency Reduced by nearly 20X 2X
J. Jose, H. Subramoni, M. Luo, M. Zhang, J. Huang, M. W. Rahman, N. Islam, X. Ouyang, H. Wang, S. Sur and D. K. Panda, Memcached Design on High
Performance RDMA Capable Interconnects, ICPP’11
J. Jose, H. Subramoni, K. Kandalla, M. W. Rahman, H. Wang, S. Narravula, and D. K. Panda, Scalable Memcached design for InfiniBand Clusters using Hybrid
Transport, CCGrid’12
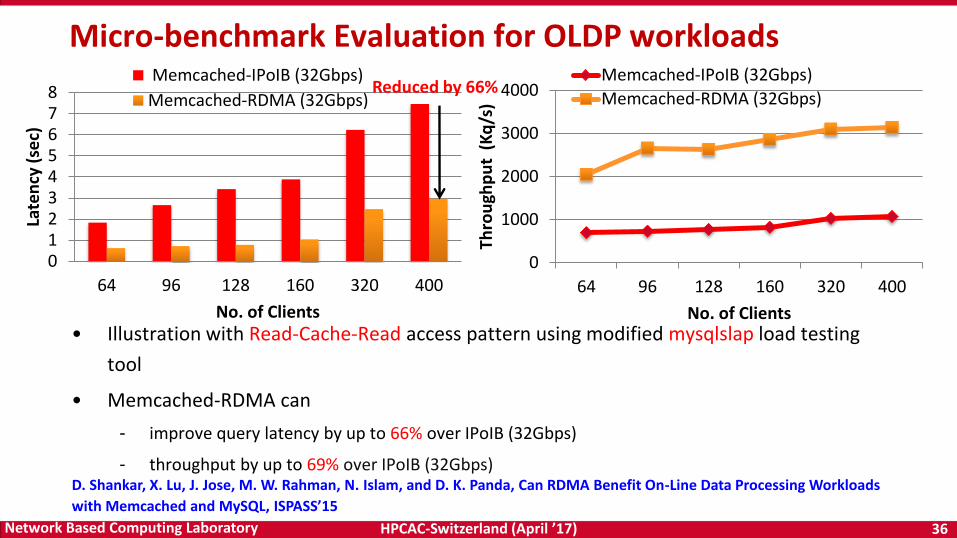
HPCAC-Switzerland (April ’17) 36Network Based Computing Laboratory
• Illustration with Read-Cache-Read access pattern using modified mysqlslap load testing
tool
• Memcached-RDMA can
- improve query latency by up to 66% over IPoIB (32Gbps)
- throughput by up to 69% over IPoIB (32Gbps)
Micro-benchmark Evaluation for OLDP workloads
012345678
64 96 128 160 320 400
Late
ncy
(se
c)
No. of Clients
Memcached-IPoIB (32Gbps)
Memcached-RDMA (32Gbps)
0
1000
2000
3000
4000
64 96 128 160 320 400
Thro
ugh
pu
t (
Kq
/s)
No. of Clients
Memcached-IPoIB (32Gbps)
Memcached-RDMA (32Gbps)
D. Shankar, X. Lu, J. Jose, M. W. Rahman, N. Islam, and D. K. Panda, Can RDMA Benefit On-Line Data Processing Workloads
with Memcached and MySQL, ISPASS’15
Reduced by 66%

HPCAC-Switzerland (April ’17) 37Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• RDMA-Hadoop with DDN IME Burst Buffer Technology
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
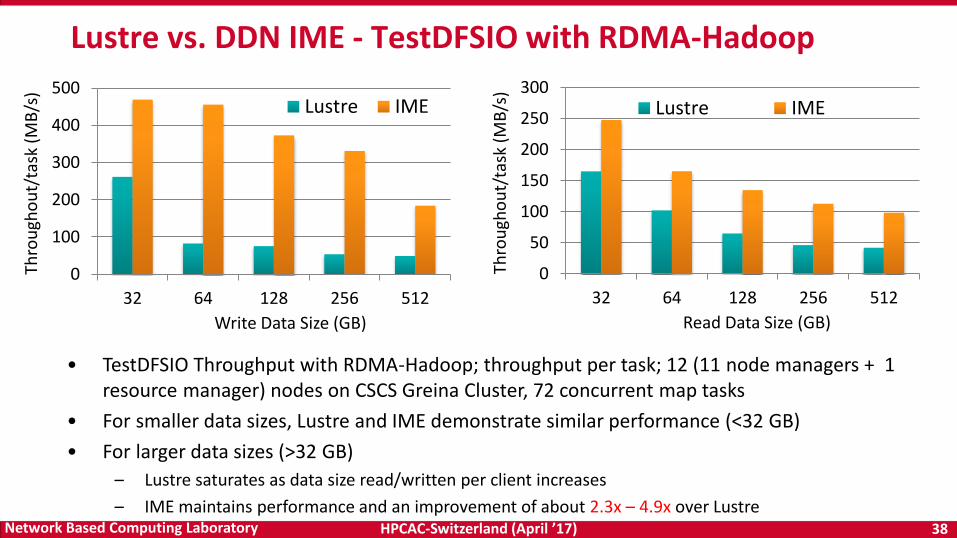
HPCAC-Switzerland (April ’17) 38Network Based Computing Laboratory
0
100
200
300
400
500
32 64 128 256 512
Thro
ugh
ou
t/ta
sk (
MB
/s)
Write Data Size (GB)
Lustre IME
Lustre vs. DDN IME - TestDFSIO with RDMA-Hadoop
• TestDFSIO Throughput with RDMA-Hadoop; throughput per task; 12 (11 node managers + 1 resource manager) nodes on CSCS Greina Cluster, 72 concurrent map tasks
• For smaller data sizes, Lustre and IME demonstrate similar performance (<32 GB)
• For larger data sizes (>32 GB)
– Lustre saturates as data size read/written per client increases
– IME maintains performance and an improvement of about 2.3x – 4.9x over Lustre
0
50
100
150
200
250
300
32 64 128 256 512
Thro
ugh
ou
t/ta
sk (
MB
/s)
Read Data Size (GB)
Lustre IME
HPCAC-Switzerland (April ’17) 39Network Based Computing Laboratory
0
20
40
60
80
100
32 64 72 96 128
Job
Tim
e (s
)
TeraGen Data Size (GB)
Lustre IME
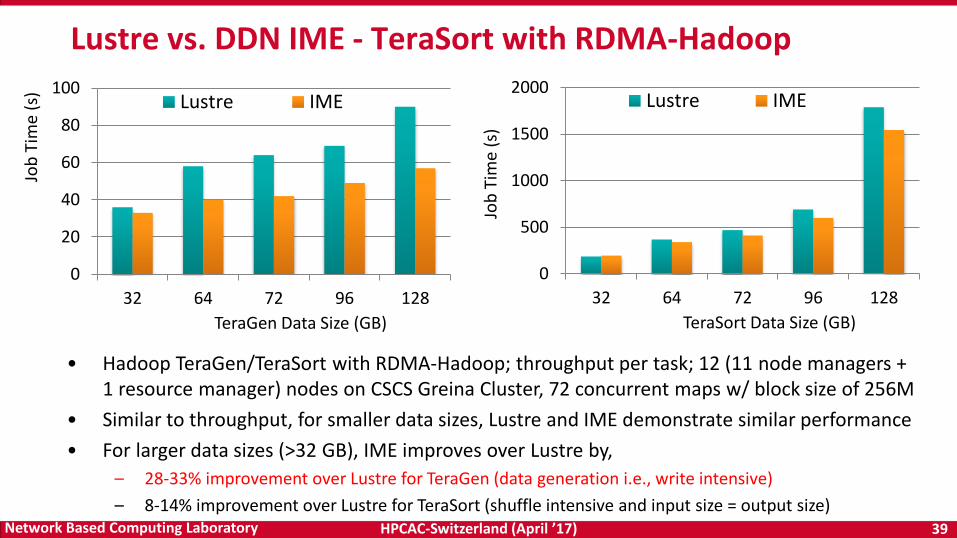
Lustre vs. DDN IME - TeraSort with RDMA-Hadoop
• Hadoop TeraGen/TeraSort with RDMA-Hadoop; throughput per task; 12 (11 node managers + 1 resource manager) nodes on CSCS Greina Cluster, 72 concurrent maps w/ block size of 256M
• Similar to throughput, for smaller data sizes, Lustre and IME demonstrate similar performance
• For larger data sizes (>32 GB), IME improves over Lustre by,
– 28-33% improvement over Lustre for TeraGen (data generation i.e., write intensive)
– 8-14% improvement over Lustre for TeraSort (shuffle intensive and input size = output size)
0
500
1000
1500
2000
32 64 72 96 128
Job
Tim
e (s
)
TeraSort Data Size (GB)
Lustre IME

HPCAC-Switzerland (April ’17) 40Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• RDMA-Hadoop with DDN IME Burst Buffer Technology
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation

HPCAC-Switzerland (April ’17) 41Network Based Computing Laboratory
– Memcached latency test with Zipf distribution, server with 1 GB memory, 32 KB key-value pair size, total
size of data accessed is 1 GB (when data fits in memory) and 1.5 GB (when data does not fit in memory)
– When data fits in memory: RDMA-Mem/Hybrid gives 5x improvement over IPoIB-Mem
– When data does not fit in memory: RDMA-Hybrid gives 2x-2.5x over IPoIB/RDMA-Mem
Performance Evaluation on IB FDR + SATA/NVMe SSDs (Hybrid Memory)
0
500
1000
1500
2000
2500
Set Get Set Get Set Get Set Get Set Get Set Get Set Get Set Get
IPoIB-Mem RDMA-Mem RDMA-Hybrid-SATA RDMA-Hybrid-NVMe
IPoIB-Mem RDMA-Mem RDMA-Hybrid-SATA RDMA-Hybrid-NVMe
Data Fits In Memory Data Does Not Fit In Memory
Late
ncy
(u
s)
slab allocation (SSD write) cache check+load (SSD read) cache update server response client wait miss-penalty
HPCAC-Switzerland (April ’17) 42Network Based Computing Laboratory
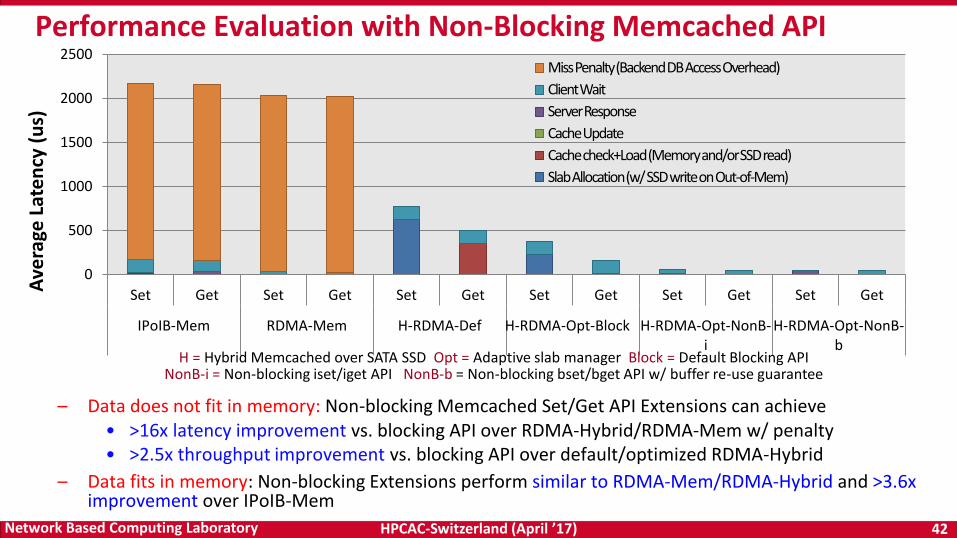
– Data does not fit in memory: Non-blocking Memcached Set/Get API Extensions can achieve• >16x latency improvement vs. blocking API over RDMA-Hybrid/RDMA-Mem w/ penalty• >2.5x throughput improvement vs. blocking API over default/optimized RDMA-Hybrid
– Data fits in memory: Non-blocking Extensions perform similar to RDMA-Mem/RDMA-Hybrid and >3.6x improvement over IPoIB-Mem
Performance Evaluation with Non-Blocking Memcached API
0
500
1000
1500
2000
2500
Set Get Set Get Set Get Set Get Set Get Set Get
IPoIB-Mem RDMA-Mem H-RDMA-Def H-RDMA-Opt-Block H-RDMA-Opt-NonB-i
H-RDMA-Opt-NonB-b
Ave
rage
Lat
en
cy (
us)
Miss Penalty (Backend DB Access Overhead)
Client Wait
Server Response
Cache Update
Cache check+Load (Memory and/or SSD read)
Slab Allocation (w/ SSD write on Out-of-Mem)
H = Hybrid Memcached over SATA SSD Opt = Adaptive slab manager Block = Default Blocking API NonB-i = Non-blocking iset/iget API NonB-b = Non-blocking bset/bget API w/ buffer re-use guarantee

HPCAC-Switzerland (April ’17) 43Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
HPCAC-Switzerland (April ’17) 44Network Based Computing Laboratory
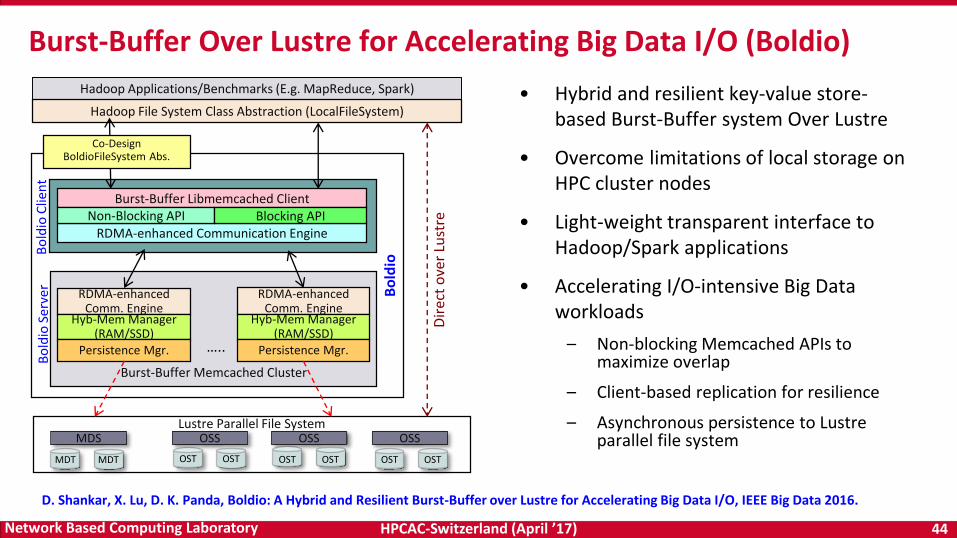
• Hybrid and resilient key-value store-based Burst-Buffer system Over Lustre
• Overcome limitations of local storage on HPC cluster nodes
• Light-weight transparent interface to Hadoop/Spark applications
• Accelerating I/O-intensive Big Data workloads
– Non-blocking Memcached APIs to maximize overlap
– Client-based replication for resilience
– Asynchronous persistence to Lustre parallel file system
Burst-Buffer Over Lustre for Accelerating Big Data I/O (Boldio)
D. Shankar, X. Lu, D. K. Panda, Boldio: A Hybrid and Resilient Burst-Buffer over Lustre for Accelerating Big Data I/O, IEEE Big Data 2016.
Dir
ect
ove
r Lu
stre
Hadoop Applications/Benchmarks (E.g. MapReduce, Spark)
Hadoop File System Class Abstraction (LocalFileSystem)
Burst-Buffer Memcached Cluster
Burst-Buffer Libmemcached Client
RDMA-enhanced Communication EngineNon-Blocking API Blocking API
RDMA-enhanced Comm. Engine
Hyb-Mem Manager (RAM/SSD)
Persistence Mgr.
RDMA-enhanced Comm. Engine
Hyb-Mem Manager (RAM/SSD)
Persistence Mgr.
Bo
ldio
…..
Co-Design BoldioFileSystem Abs.
Lustre Parallel File SystemMDS OSS OSS OSS
MDT MDT OST OST OST OST OST OST
Bo
ldio
Ser
ver
Bo
ldio
Clie
nt
HPCAC-Switzerland (April ’17) 45Network Based Computing Laboratory
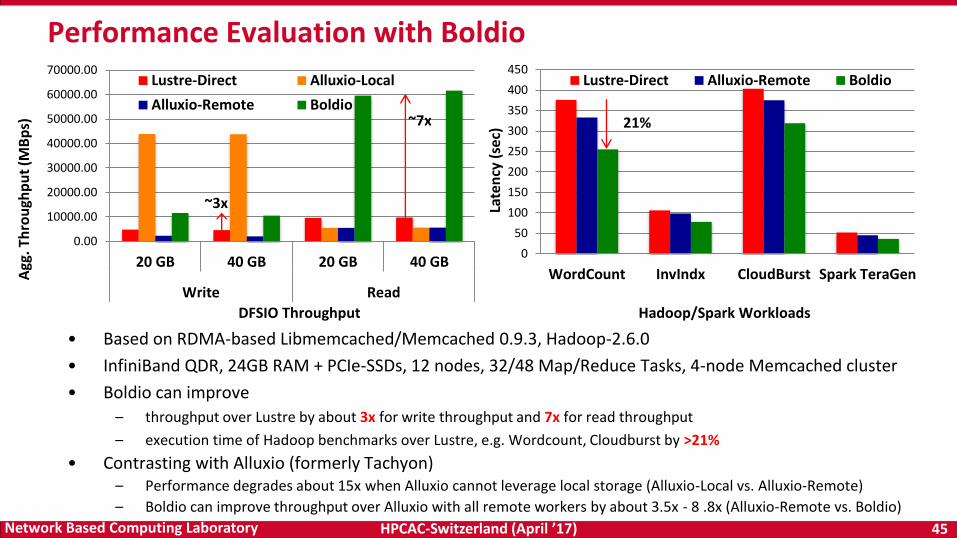
• Based on RDMA-based Libmemcached/Memcached 0.9.3, Hadoop-2.6.0
• InfiniBand QDR, 24GB RAM + PCIe-SSDs, 12 nodes, 32/48 Map/Reduce Tasks, 4-node Memcached cluster
• Boldio can improve
– throughput over Lustre by about 3x for write throughput and 7x for read throughput
– execution time of Hadoop benchmarks over Lustre, e.g. Wordcount, Cloudburst by >21%
• Contrasting with Alluxio (formerly Tachyon) – Performance degrades about 15x when Alluxio cannot leverage local storage (Alluxio-Local vs. Alluxio-Remote)
– Boldio can improve throughput over Alluxio with all remote workers by about 3.5x - 8 .8x (Alluxio-Remote vs. Boldio)
Performance Evaluation with Boldio
Hadoop/Spark Workloads
21%
0
50
100
150
200
250
300
350
400
450
WordCount InvIndx CloudBurst Spark TeraGen
Late
ncy
(se
c)
Lustre-Direct Alluxio-Remote Boldio
DFSIO Throughput
0.00
10000.00
20000.00
30000.00
40000.00
50000.00
60000.00
70000.00
20 GB 40 GB 20 GB 40 GB
Write Read
Agg
. Th
rou
ghp
ut
(MB
ps)
Lustre-Direct Alluxio-Local
Alluxio-Remote Boldio
~3x
~7x

HPCAC-Switzerland (April ’17) 46Network Based Computing Laboratory
• Basic Designs for HiBD Packages
– HDFS and MapReduce
– Spark
– Memcached
• Advanced Designs
– Memcached with Hybrid Memory and Non-blocking APIs
– Accelerating Big Data I/O (Lustre + Burst-Buffer)
• High-Performance Hadoop over Cloud
Acceleration Case Studies and Performance Evaluation
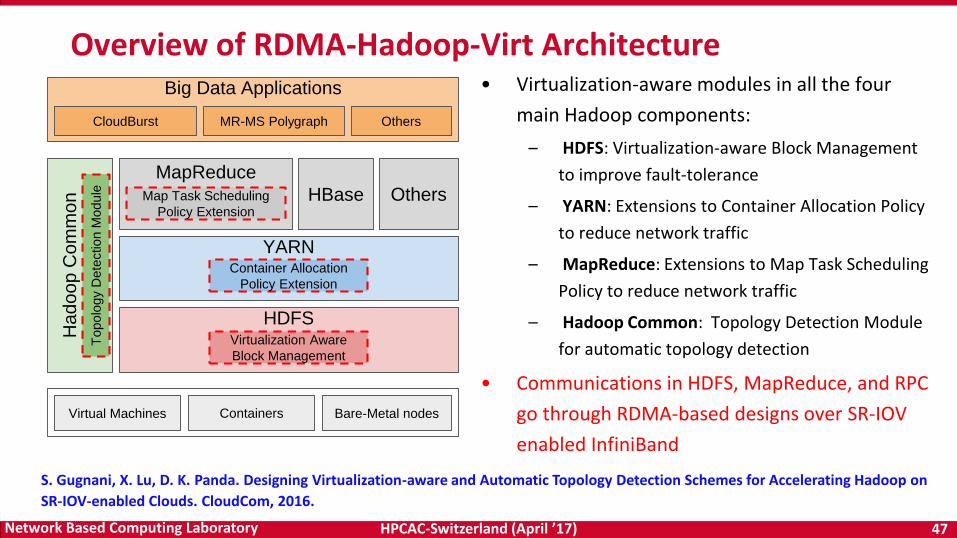
HPCAC-Switzerland (April ’17) 47Network Based Computing Laboratory
Overview of RDMA-Hadoop-Virt Architecture• Virtualization-aware modules in all the four
main Hadoop components:
– HDFS: Virtualization-aware Block Management
to improve fault-tolerance
– YARN: Extensions to Container Allocation Policy
to reduce network traffic
– MapReduce: Extensions to Map Task Scheduling
Policy to reduce network traffic
– Hadoop Common: Topology Detection Module
for automatic topology detection
• Communications in HDFS, MapReduce, and RPC
go through RDMA-based designs over SR-IOV
enabled InfiniBand
HDFS
YARN
Ha
do
op
Co
mm
on
MapReduce
HBase Others
Virtual Machines Bare-Metal nodesContainers
Big Data ApplicationsT
opolo
gy D
ete
ction M
odule Map Task Scheduling
Policy Extension
Container Allocation
Policy Extension
CloudBurst MR-MS Polygraph Others
Virtualization Aware
Block Management
S. Gugnani, X. Lu, D. K. Panda. Designing Virtualization-aware and Automatic Topology Detection Schemes for Accelerating Hadoop on
SR-IOV-enabled Clouds. CloudCom, 2016.

HPCAC-Switzerland (April ’17) 48Network Based Computing Laboratory
Evaluation with Applications
– 14% and 24% improvement with Default Mode for CloudBurst and Self-Join
– 30% and 55% improvement with Distributed Mode for CloudBurst and Self-Join
0
20
40
60
80
100
Default Mode Distributed Mode
EXEC
UTI
ON
TIM
ECloudBurst
RDMA-Hadoop RDMA-Hadoop-Virt
0
50
100
150
200
250
300
350
400
Default Mode Distributed Mode
EXEC
UTI
ON
TIM
E
Self-Join
RDMA-Hadoop RDMA-Hadoop-Virt
30% reduction
55% reduction
Will be released in future

HPCAC-Switzerland (April ’17) 49Network Based Computing Laboratory
• Upcoming Releases of RDMA-enhanced Packages will support
– Upgrades to the latest versions of Hadoop and Spark
– Streaming
– MR-Advisor
– Impala
– Virtualization support
• Upcoming Releases of OSU HiBD Micro-Benchmarks (OHB) will support
– MapReduce, RPC
• Advanced designs with upper-level changes and optimizations
– Boldio
– Efficient Indexing
On-going and Future Plans of OSU High Performance Big Data (HiBD) Project

HPCAC-Switzerland (April ’17) 50Network Based Computing Laboratory
Funding Acknowledgments
Funding Support by
Equipment Support by

HPCAC-Switzerland (April ’17) 51Network Based Computing Laboratory
Personnel AcknowledgmentsCurrent Students
– A. Awan (Ph.D.)
– R. Biswas (M.S.)
– M. Bayatpour (Ph.D.)
– S. Chakraborthy (Ph.D.)
Past Students
– A. Augustine (M.S.)
– P. Balaji (Ph.D.)
– S. Bhagvat (M.S.)
– A. Bhat (M.S.)
– D. Buntinas (Ph.D.)
– L. Chai (Ph.D.)
– B. Chandrasekharan (M.S.)
– N. Dandapanthula (M.S.)
– V. Dhanraj (M.S.)
– T. Gangadharappa (M.S.)
– K. Gopalakrishnan (M.S.)
– R. Rajachandrasekar (Ph.D.)
– G. Santhanaraman (Ph.D.)
– A. Singh (Ph.D.)
– J. Sridhar (M.S.)
– S. Sur (Ph.D.)
– H. Subramoni (Ph.D.)
– K. Vaidyanathan (Ph.D.)
– A. Venkatesh (Ph.D.)
– A. Vishnu (Ph.D.)
– J. Wu (Ph.D.)
– W. Yu (Ph.D.)
Past Research Scientist
– K. Hamidouche
– S. Sur
Past Post-Docs
– D. Banerjee
– X. Besseron
– H.-W. Jin
– W. Huang (Ph.D.)
– N. Islam (Ph.D.)
– W. Jiang (M.S.)
– J. Jose (Ph.D.)
– S. Kini (M.S.)
– M. Koop (Ph.D.)
– K. Kulkarni (M.S.)
– R. Kumar (M.S.)
– S. Krishnamoorthy (M.S.)
– K. Kandalla (Ph.D.)
– P. Lai (M.S.)
– J. Liu (Ph.D.)
– M. Luo (Ph.D.)
– A. Mamidala (Ph.D.)
– G. Marsh (M.S.)
– V. Meshram (M.S.)
– A. Moody (M.S.)
– S. Naravula (Ph.D.)
– R. Noronha (Ph.D.)
– X. Ouyang (Ph.D.)
– S. Pai (M.S.)
– S. Potluri (Ph.D.)
– M.-W. Rahman (Ph.D.)
– C.-H. Chu (Ph.D.)
– S. Guganani (Ph.D.)
– J. Hashmi (Ph.D.)
– H. Javed (Ph.D.)
– J. Lin
– M. Luo
– E. Mancini
Current Research Scientists
– X. Lu
– H. Subramoni
Past Programmers
– D. Bureddy
– M. Arnold
– J. Perkins
Current Research Specialist
– J. Smith– M. Li (Ph.D.)
– D. Shankar (Ph.D.)
– H. Shi (Ph.D.)
– J. Zhang (Ph.D.)
– S. Marcarelli
– J. Vienne
– H. Wang

HPCAC-Switzerland (April ’17) 52Network Based Computing Laboratory
The 3rd International Workshop on High-Performance Big Data Computing (HPBDC)
HPBDC 2017 will be held with IEEE International Parallel and Distributed Processing
Symposium (IPDPS 2017), Orlando, Florida USA, May, 2017
Keynote Speaker: Prof. Satoshi Matsuoka, Tokyo Institute of Technology, Japan
Panel Moderator: Prof. Jianfeng Zhan (ICT/CAS)Panel Topic: Sunrise or Sunset: Exploring the Design Space of Big Data Software Stack
Panel Members (Confirmed so far): Prof. Geoffrey C. Fox (Indiana University Bloomington); Dr. Raghunath Nambiar (Cisco); Prof. D. K. Panda (The Ohio State University)
Six Regular Research Papers and One Short Research PapersSession I: High-Performance Graph Processing
Session II: Benchmarking and Performance Analysis
http://web.cse.ohio-state.edu/~luxi/hpbdc2017

HPCAC-Switzerland (April ’17) 53Network Based Computing Laboratory
Birds of Feather (BoF) at ISC ‘17
A BoF on
Accelerating Big Data Processing System Software on
Modern HPC Clusters
will be held at Int’l Supercomputing Conference (ISC 2017), Frankfurt
Date/Time: The schedule is being finalized

HPCAC-Switzerland (April ’17) 54Network Based Computing Laboratory
http://www.cse.ohio-state.edu/~panda
Thank You!
Network-Based Computing Laboratoryhttp://nowlab.cse.ohio-state.edu/
The High-Performance Big Data Projecthttp://hibd.cse.ohio-state.edu/