"big data" bioinformatics
TRANSCRIPT

"BIG DATA" BIOINFORMATICSMODELS FOR DISTRIBUTED, PARALLEL AND CONCURRENT PROCESSING
Brian RepkoDecember 4, 2014

AGENDAWhat does this have to do with me?High Performance Computing modelsTraditional Software Engineering modelsDistributed Systems Architecture

WHAT DOES THIS HAVE TO DO WITH ME?Existing tools designed as single flow / single machineProgramming languages have limits (R, python)CPUs moving to multi-core
Single flow can't make use of thisSome processes hit CPU/memory issues
Data volume in bioinformatics4 "V"s of "Big Data"Volume, Velocity, Variety and Veracity
Limits on single node CPU / memory

TERMINOLOGYConcurrent - dealing with a lot of thingsParallel - doing a lot of thingsWhy parallelize / use concurrency?Throughput and Responsiveness
Distributed - anything non-sharedWhy distribute?Scalability and Availability
Goal is concurrent, distributed, resilient, simple

HPC MODELSVon Neumann MachineOpenMPMPIGeneral Purpose GPUBeyond HPC (HTC/MTC)

VON NEUMANN MACHINEJohn von Neumann 1945CPU, Memory, I/OProgram AND data in memorySISD, SIMD, MIMD modelsMulti-levels/types of cache, UMA/ccNUMAThreading, pipelining, vectorization

VON NEUMANN MACHINE

OPENMP (MULTI-PROCESSING)Shared memory programming modelBased on threads, fork/join and a known "memory model"C/C++ pragmas, Fortran compiler directivesOpenMP directive categories:
control, work-sharing, data visibility, synchronization andcontext / environment
Pros/Cons with use of directivesOptimizations very architecture-specificCan be difficult to get correct
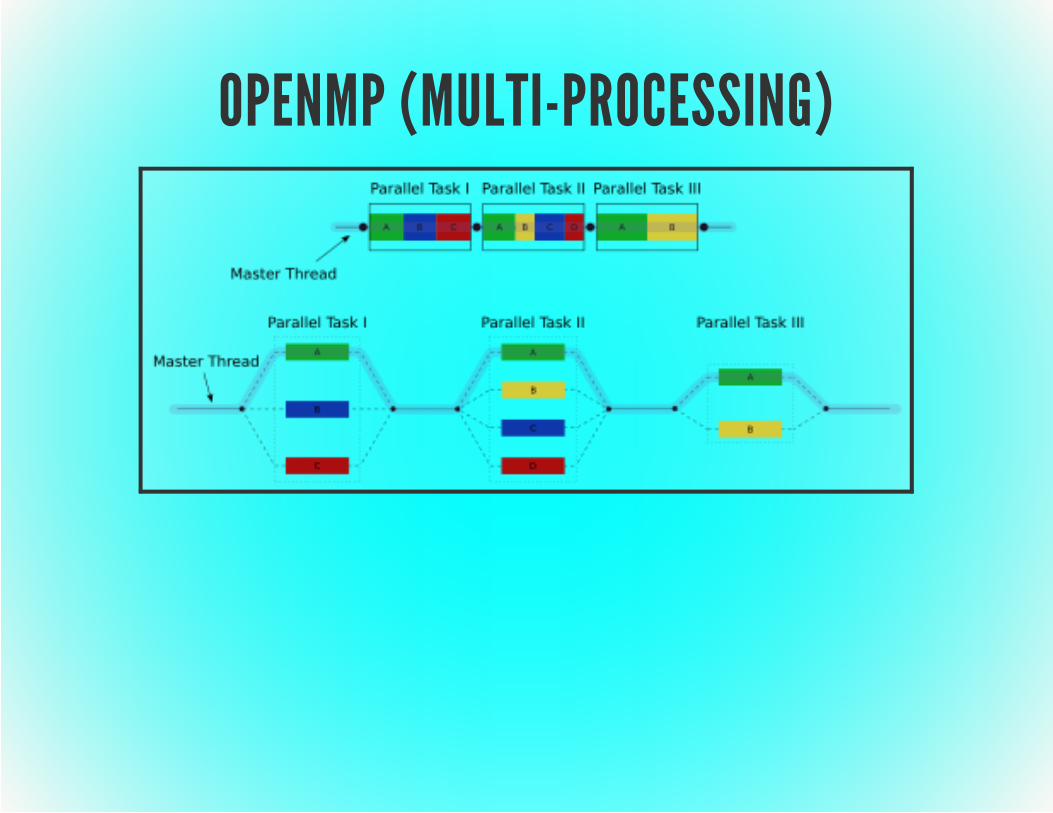
OPENMP (MULTI-PROCESSING)

MESSAGE PASSING INTERFACEDistributed memory programming modelSingle-Program Multiple-Data (SPMD)P2P and Broadcast, Synch and AsynchDatatypes for message contentCommunicators / network topologyProgram instance gets rank / size
Rank 0 typically a coordinator / reducerAll others do work and send result to rank 0
Dynamic process management in MPI-2Hybrid models with OpenMPBioinformatics example: Trinity (transcript assembly) on Cray

GENERAL PURPOSE GPUOpenCL (computing language)
CUDA (specific to NVIDIA)Standard library and device-specific driver (ICD)Kernel routine written in OpenCL CGlobal / Work-group / Work-item memory modelDevices are sent streams of work-groupsKernel runs in parallel on work-itemsVery useful together with OpenGLExtension of this idea to custom chips (ASIC/FPGA)
BEYOND HPC (HTC/MTC)High-Throughput Computing
Long-running, parallel jobsMany-Task Computing
Mix of job size, WorkflowsCluster/Grid Computing (Grid Engine)Lots of workflow solutions
YAP (MPI)Swift scripting languagebpipe (workflow DSL)celery / gridmap (Python)
Process-level failure / error handling

TRADITIONAL ENGINEERING MODELS
Threads, Locks and Fork/JoinFunctional ProgrammingCommunicating Sequential Processes (CSP)Actors

THREADS, LOCKS AND FORK/JOINThese are the general termsOpenMP is a particular style (via macros)Support varies by programming language
May or may not use multiple coresFor C, choose OpenMP or pthreads
Concurrency model (non-deterministic)Difficult to get correct
The problem is shared mutable state

FUNCTIONAL PROGRAMMINGAlonzo Church 1930
Lambda CalculusSystem for maths / computation
Declarative (vs Imperative)Computation is the evalutation of functionsAvoids mutable stateHaskell (pure), Lisp (Scheme, Clojure, Common Lisp), Erlang,ML (OCaml), Javascript, C#, F#, Groovy, Scala, Java 8, Python,R, Julia,...

FUNCTIONAL PROGRAMMINGFirst-class functionsHigher-order functionsPure functions (no side effects)
Referential transparency and beta-reduction in any orderincluding parallel
(Tail) recursion, partial functions, curryingStrict (eager) vs non-strict (lazy) evaluationTyped or Untyped - Category theory when typedSoftware Transactional Memory (Clojure)

FUNCTIONAL PROGRAMMINGexpr = "28+32+++32++39"res = 0for t in expr.split("+"): if t != "": res += int(t)
print res
expr = "28+32+++32++39"print reduce(map(filter(expr.split("+"), isNonBlank), toInteger), add)

COMMUNICATING SEQUENTIAL PROCESSESTony Hoare 1978One of multiple process calculi
Verifiable lack of deadlocksAvoids shared stateSynchronous message passing via shared channelsConcurrently executing elements - send / receiveFunctions can use and return channelsImplemented in Ada, Go and Clojure core.asyncDistribution is possible but difficult
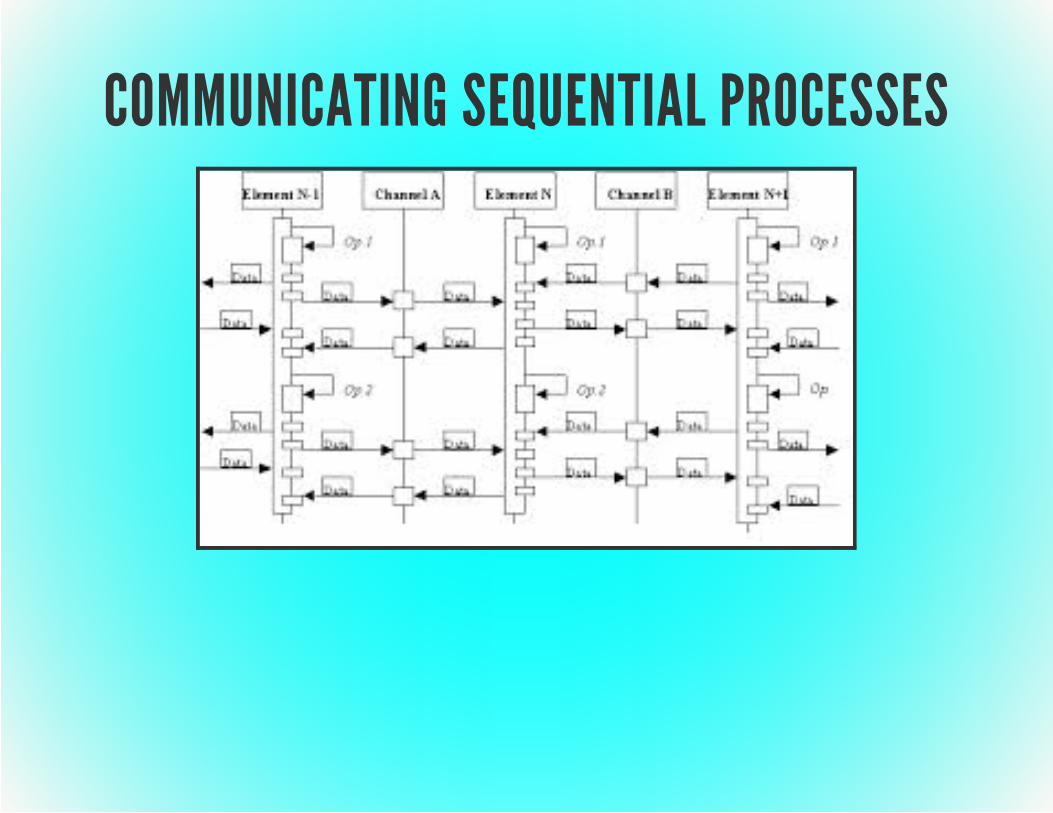
COMMUNICATING SEQUENTIAL PROCESSES

ACTORSCarl Hewitt 1973Avoids shared state (share nothing!)Actor (the processing element) has
an identity, non-shared state, and a mailboxasynchronous messaging
Actors cando work, send messages, and create other actors
Built-into some programming languages - Erlang, ScalaFrameworks available for almost all languages - AkkaConcurrency and (somewhat easier) DistributionBioinformatics example - MetaRay (MPI) to BioSAL/Thorium
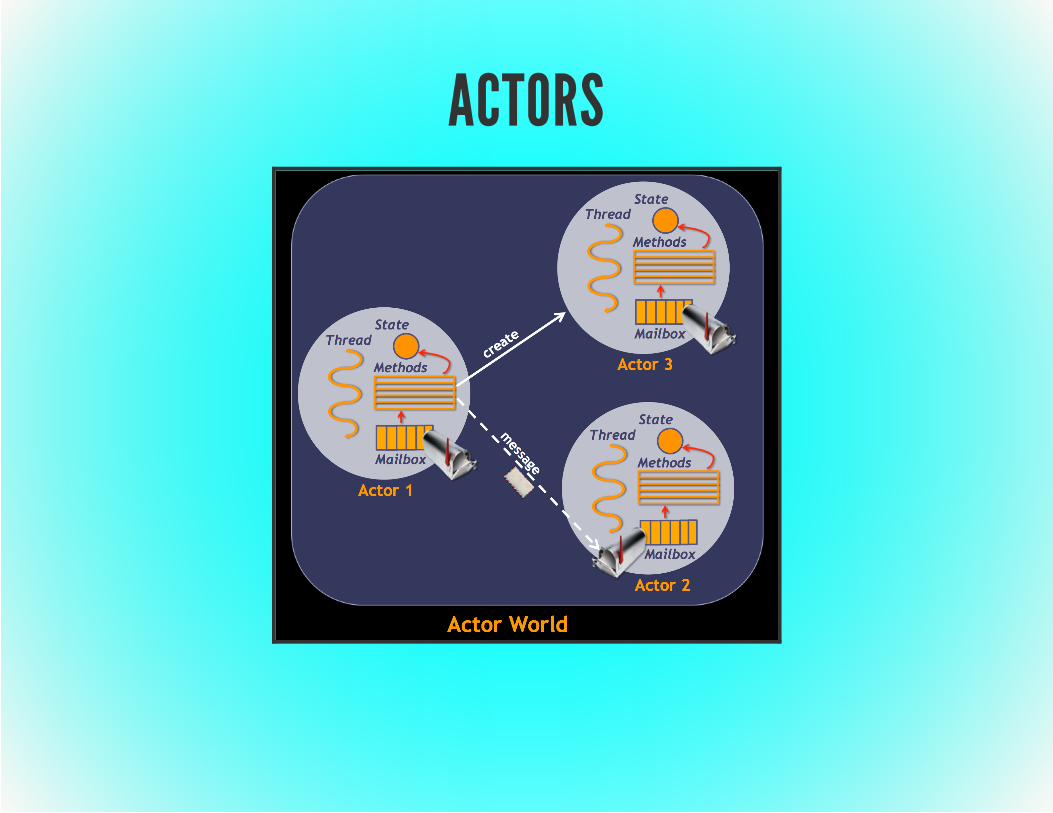
ACTORS

DISTRIBUTED SYSTEM ARCHITECTUREDistributed Storage (Filesystems/NoSQL)HadoopMap-ReduceApache SparkLambda Architecture

DISTRIBUTED STORAGE (FS/NOSQL)Filesystems
Lustre, GlusterFS (Redhat), OneFS (Isilon)Hadoop HDFSTachyon
NoSQL / NewSQLDistribution one of the main reasons for NoSQLKey-value (Dynamo, Redis, Riak, Voldemort)Document (MongoDB, Couchbase)Column (Cassandra, Accumulo, HBase, Vertica)Graph (Neo4J, Allegro, InfiniteGraph, OrientDB)Relational (NuoDB, Teradata)
These all have to deal with standard distribution problems

HADOOPDistributed storage AND computingHDFS (file system storage)
NameNodes and DataNodesMap-Reduce (computing model)
JobTrackers and TaskTrackersHadoop "ecosystem":
HBase or Parquet (NoSQL DB)Pig (Hadoop job DSL / scripting)Hadwrap (scripting / workflow)Hive (data warehouse)Drill or Impala (SQL query engine)Sqoop (ETL - DB to Hadoop)

MAP-REDUCEA Map-Reduce job has
an input data-set and an output directorya mapper, reducer and optional combiner (classes)all classes get and produce kv-pairs
The job runs as1. The input is converted to kv-pairs (key=line#, value=text)2. Mapper gets and processes kv-pairs (data locality)3. Sort/Shuffle phase on mapper output4. Reducers get all kv-pairs for a given key (sorted)5. Reducers output is stored in output directory
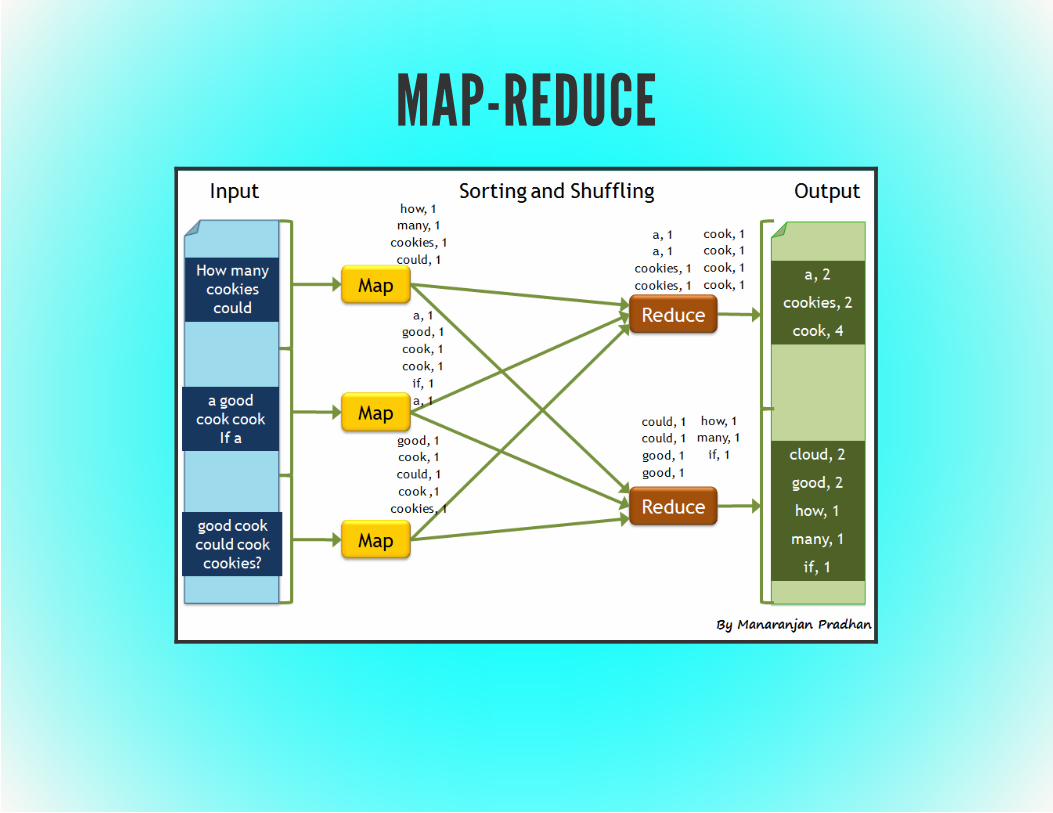
MAP-REDUCE

APACHE SPARKNew computing modelRDD - Resilient Distributed Datasets
Read-only, distributed collection of objectsStored on disk (HDFS/Cassandra) or in-memoryMemory usage on shared clusters can be an issue
Computation is transformations and actions on RDDsTransformations convert data or RDD into an RDDActions convert RDD to object / dataFunctional programming (immutability) paradigmDAG (lineage) for how RDD was built (scheduling, failover)Lazy evaluation of tasksActor-based (Akka) distribution of code
Faster than Hadoop, more expressive than MR

APACHE SPARKSub-projects
Spark SQL (was "Shark" - Spark for Hive)GraphX (graph data)MLlib (machine learning)Spark Streaming (events)
Multiple languages - Java 8, Scala, Python, RBioinformatics examples:
gData Integration and Analytics LayersADAM (AMPlab and bdgenomics.org)Why is Bioinformatics a Good Fit for Spark?Real-time Image Processing and Analytics using SparkWhy Apache Spark is a Crossover Hit for Data Scientists
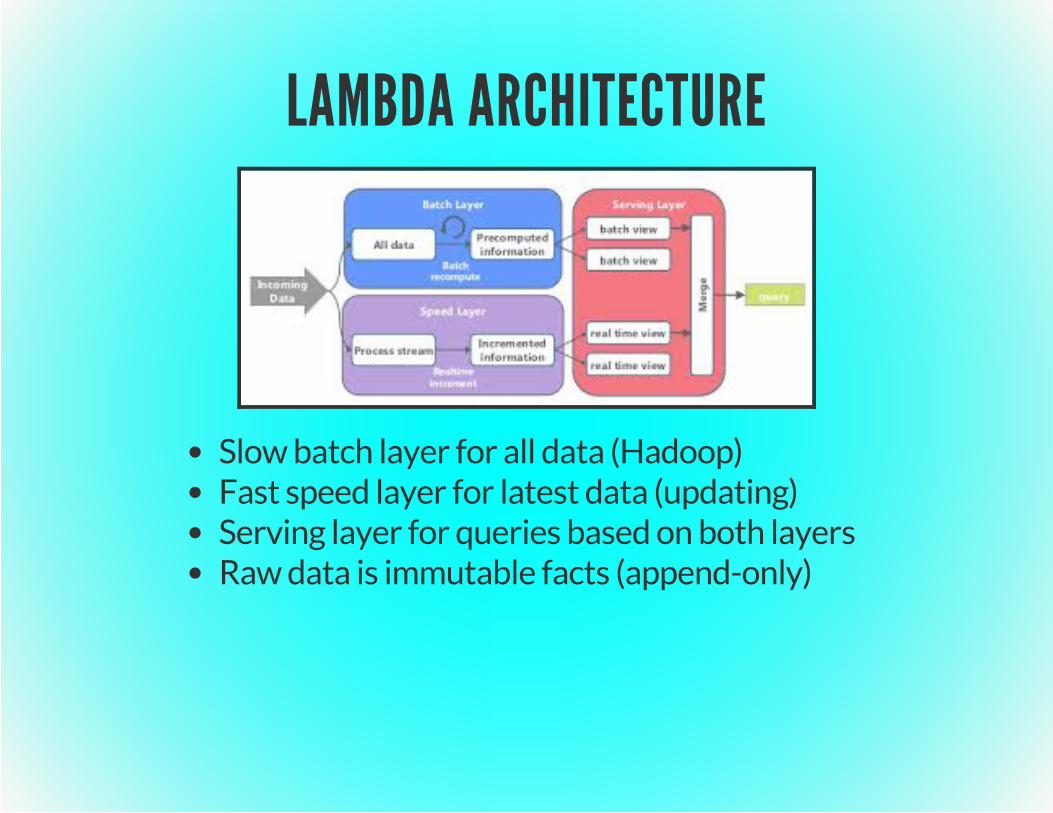
LAMBDA ARCHITECTURE
Slow batch layer for all data (Hadoop)Fast speed layer for latest data (updating)Serving layer for queries based on both layersRaw data is immutable facts (append-only)

WHAT DOES THIS HAVE TO DO WITH ME(AGAIN)?
Bioinformatics has/will have a volume constraintSome algorithms have a CPU constraintFor volume, move to distributed dataFor computation on distributed data
Parallelize over standard data partitions (position, samples)Distribute that computation
Actors > MPI and Spark > Map-ReduceFunctional programming as an algorithm goal
Additional advantages with Apache SparkAvailability of intermediate processing steps for workflowsAvailability of graph and ML algorithms

THANK YOU! QUESTIONS?Special thanks to Ken Robbins, Dave Tester, Steve Litster, NickHolway, Timothy Danford, Laurent Gautier and Jason CalvertOpenMP/MPI/Hadoop/Spark is available inSciComp/DataEng clustersWhat are your data / computation challenges?