aula inferencia
TRANSCRIPT

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
Prof. Luciana Nunes
INFERÊNCIAESTATÍSTICA
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
2
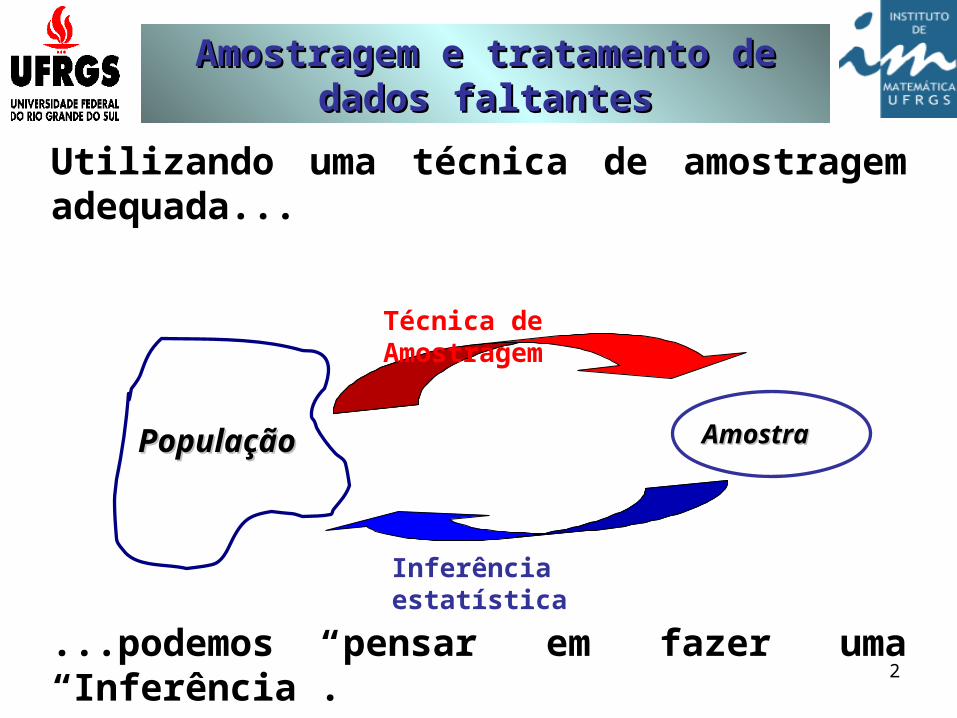
PopulaçãoPopulação AmostraAmostra
Técnica de Amostragem
Inferência estatística
Utilizando uma técnica de amostragem adequada...
...podemos pensar em fazer uma “Inferência”.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
3
InferênciaPodemos pensar em fazer
inferência de duas maneiras:
Testando hipóteses com base em amostras. TESTES DE HIPÓTESES
Generalizando resultados de uma amostra para a população de onde ela foi extraída. ESTIMAÇÃO

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
4
EstimaçãoPara entendermos a ideia da estimação é
preciso que vejamos alguns conceitos:
Parâmetro É uma quantidade que resume na população a informação relativa a uma variável.Estatística É uma quantidade que resume na amostra a informação de uma variável.
Estimativa valor da estatística calculado com base na amostra efetivamente observada.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
5
Exemplos de parâmetros
Média É uma quantidade que resume na população a informação relativa a uma variável quantitativa. Por exemplo, podemos estar interessados em estimar a média de altura de uma determinada população.
Proporção É uma quantidade que resume na população a informação relativa a uma variável qualitativa. Por exemplo, podemos querer estimar a proporção de homens que têm diabete.
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
6
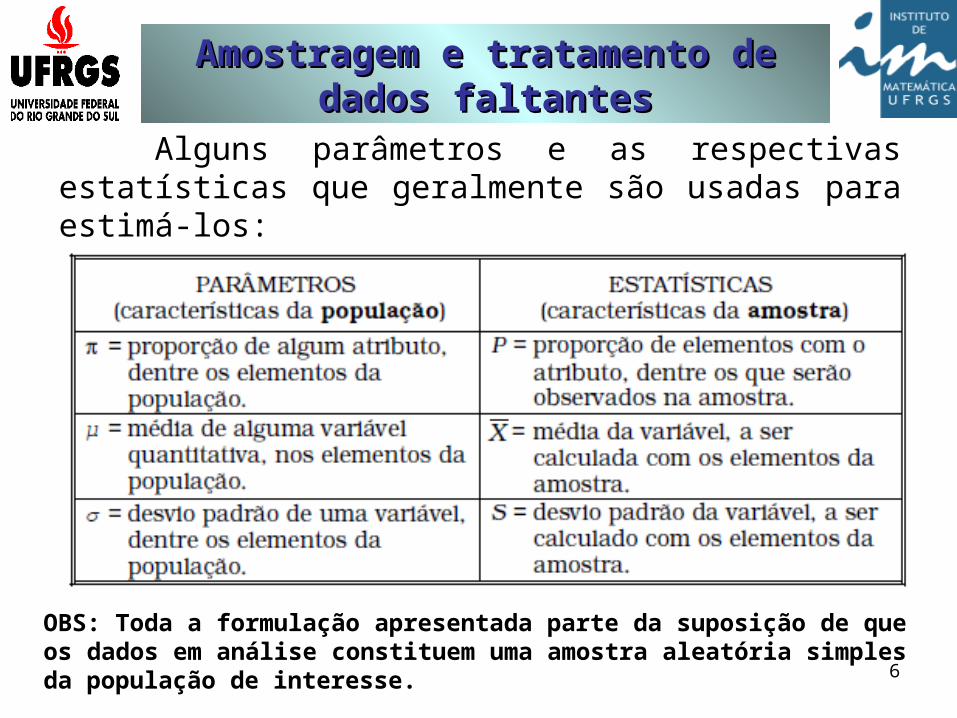
Alguns parâmetros e as respectivasestatísticas que geralmente são usadas para estimá-los:
OBS: Toda a formulação apresentada parte da suposição de que os dados em análise constituem uma amostra aleatória simples da população de interesse.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
7
Em geral, os parâmetros são números desconhecidos (somente serão conhecidos se for feito um censo – pesquisa de toda a população).
Já as estatísticas são variáveis aleatórias, pois seus valores dependem dos elementos a serem sorteados na amostragem. Ao observar efetivamente uma amostra, a estatística se identifica com um valor (resultado do cálculo), chamado de estimativa.Por exemplo, se em uma amostra de n = 90 sujeitos, encontrarmos 72 sujeitos com a característica de interesse, então temos a seguinte estimativa para o parâmetro :
8090
72,P (ou, 80%)

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
8
Quanto ao erro amostralComo as informações provêm de um conjunto
menor que a população, cometem-se erros amostrais ao se fazer uma inferência.
Esses erros são quantificados por um valor numérico, denominado probabilidade.
O erro amostral mencionado neste contexto não deve ser confundido com os erros não amostrais (vieses), que são, por exemplo, erro de medida, erro de digitação, respondente não ter entendido a pergunta, etc . O erro amostral é conseqüência inevitável da tentativa de generalizações ou da flutuação de amostra para amostra, enquanto os erros não amostrais devem ser evitados (por exemplo, por treinamento dos entrevistadores, controle de qualidade da digitação, aplicação de questionários testados, instrumentos de medida calibrados...).

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
9
Há duas formas para se fazer a estimação de parâmetros:
1. ESTIMATIVAS PONTUAIS
Valor numérico único usado para fazer uma inferência sobre um parâmetro desconhecido da população.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
10
2. ESTIMATIVAS POR INTERVALO
Um intervalo de valores é usado para fazer uma inferência sobre um parâmetro desconhecido da população. A idéia do intervalo de confiança (IC) é um refinamento da estimativa pontual, de modo que este intervalo tenha uma probabilidade de conter o parâmetro.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
Exemplo
SILVA, R.M.G.; KUPEK, E.; PERES, K. G. "Prevalência de doação de sangue e fatores associados em Florianópolis, Sul do Brasil: estudo de base populacional." Cadernos de Saúde Pública v.29 n.10 (2013): 2008-2016.
11

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
A prevalência de doação alguma vez na vida foi
30,6% (IC95%:28,4;32,8%), e doação nos últimos
12 meses 6,2% (IC95%:5,1;7,4%). Entre os
participantes que referiram doação nos últimos 12
meses 80,4% (IC95%:72,7;88,0%) declararam
doação espontânea; 15,9% (IC95%:8,8;22,9%)
doação de sangue para reposição; e 31,8%
(IC95%:22,8;40,7%) doação de repetição.
12

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
13
Estimação para proporção
•Por ponto: P•Por intervalo:
com (1-)% de confiançaOnde,
n
PPzP
12/
(n)a amostra unidades dnúmero de
terísticaom a caracunidades cnúmero de P

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
14
Estimação para média•Por ponto:
•Por intervalo:
Ou
n
zX
2/com (1-)% de confiança
n
stX n )2/;1(
Quando a amostra é pequena e é desconhecido.
Geralmente, vale 0,1, 0,05 ou 0,01, gerando intervalos de 90%, 95% ou 99% de confiança.
X
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
15
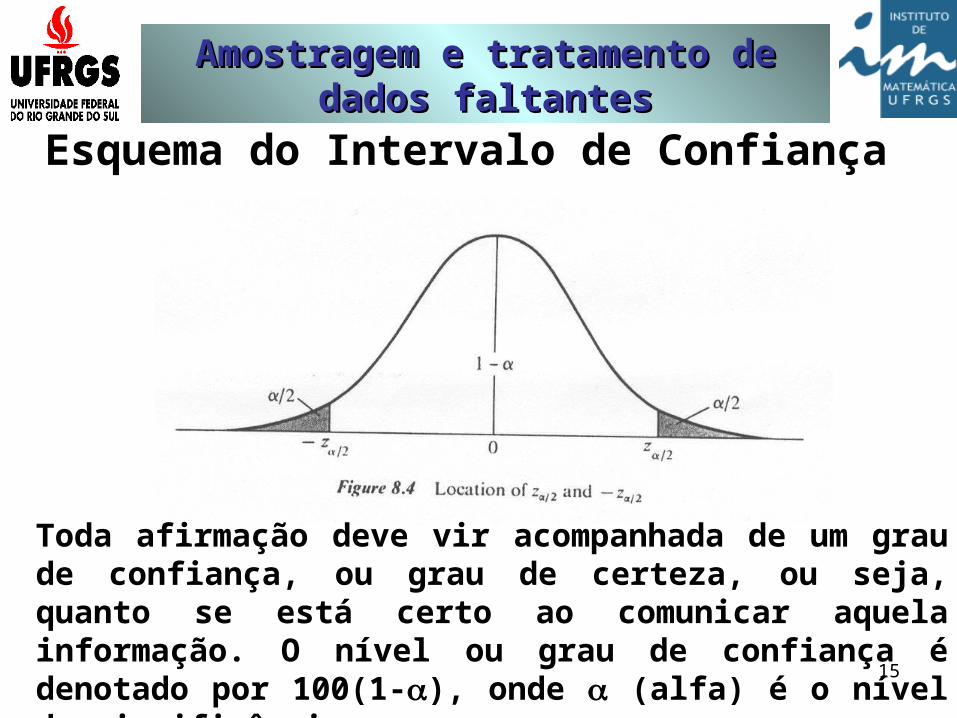
Esquema do Intervalo de Confiança
Toda afirmação deve vir acompanhada de um grau de confiança, ou grau de certeza, ou seja, quanto se está certo ao comunicar aquela informação. O nível ou grau de confiança é denotado por 100(1-), onde (alfa) é o nível de significância.
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
16
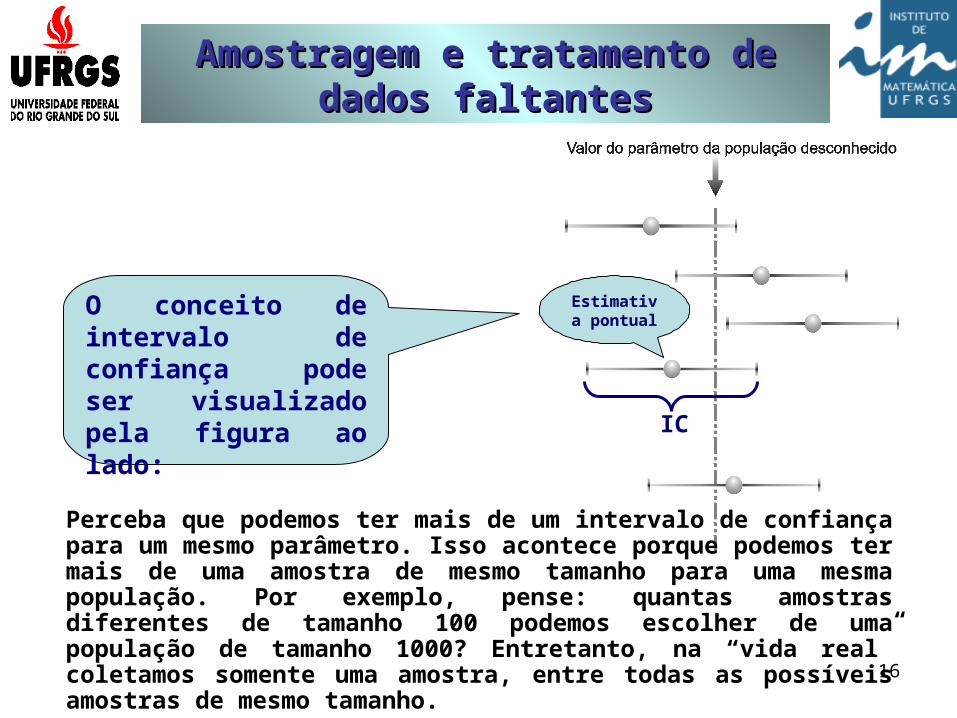
Perceba que podemos ter mais de um intervalo de confiança para um mesmo parâmetro. Isso acontece porque podemos ter mais de uma amostra de mesmo tamanho para uma mesma população. Por exemplo, pense: quantas amostras diferentes de tamanho 100 podemos escolher de uma população de tamanho 1000? Entretanto, na “vida real” coletamos somente uma amostra, entre todas as possíveis amostras de mesmo tamanho.
O conceito de intervalo de confiança pode ser visualizado pela figura ao lado:
Estimativa pontual
IC

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
17
Comentários... Quando se retira uma amostra e se calcula um intervalo de confiança, não se sabe, na verdade, se o parâmetro da população se encontra naquele intervalo calculado. Trabalhamos com um “nível de confiança” para fazermos afirmações sobre nossas estimativas. Essas afirmações baseiam-se na teoria da probabilidade e, nesse caso, podemos afirmar com probabilidade (1-) que o intervalo obtido com essa amostra deve conter o verdadeiro valor do parâmetro. O importante é reconhecer que se está usando um método com 100(1-)% de probabilidade de sucesso: em uma seqüência grande de repetições, 100(1-)% dos intervalos assim construídos conterão o verdadeiro valor do parâmetro, embora não se saiba exatamente quanto ele vale.
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
18
Testes de Hipóteses
Muitas vezes o pesquisador tem interesse no comportamento de uma variável ou de uma possível associação entre variáveis. Essas afirmações provisórias são hipóteses de pesquisa.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
19
Hipóteses EstatísticasA partir das hipóteses de pesquisa,
podemos elaborar as hipóteses estatísticas.Por definição, as hipóteses estatísticas
são suposições feitas sobre o valor dos parâmetros nas populações. Elas são duas:
Hipótese nula (H0) estabelece a ausência de diferença entre os parâmetros. É sempre a primeira a ser formulada. Hipótese alternativa (H1 ou Ha) é a hipótese contrária à hipótese nula. Geralmente, é a que o pesquisador quer ver confirmada.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
20
Testes de hipóteses
O teste de hipóteses é um procedimento estatístico através do qual se aceita ou se rejeita uma hipótese, nesse caso, aceitamos ou rejeitamos a hipótese nula (H0). Nos baseamos na amostra para tomar tal decisão. Por isso, o teste de hipóteses é um método estatístico inferencial.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
21
Testes de hipóteses
Para a verificação das hipóteses, as decisões envolverão um risco máximo admissível para o erro de afirmar que existe uma diferença, quando ela, efetivamente, não existe, chamado (alfa) que é o nível de significância. O pesquisador estabelece antes de realizar o teste de hipóteses.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
22
Região crítica do testePara seguirmos o raciocínio sobre o teste
de hipóteses é preciso que o conceito de região crítica do teste seja estabelecido.
Suponhamos, inicialmente, H0 como verdadeira. H0 somente vai ser rejeitada em favor de H1, se houver evidência suficiente que a contradiga. A existência dessa possível evidência será verificada num conjunto de observações relativas ao problema em estudo (amostra).

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
23
Região crítica do testeEntão, a partir dos dados amostrais,
se calcula uma estatística chamada de “estatística do teste”.
Essa estatística do teste, supondo H0 verdadeira, deve seguir uma distribuição de probabilidades que será a referência básica para analisarmos o resultado da amostra e decidirmos sobre aceitar ou rejeitar H0.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
24
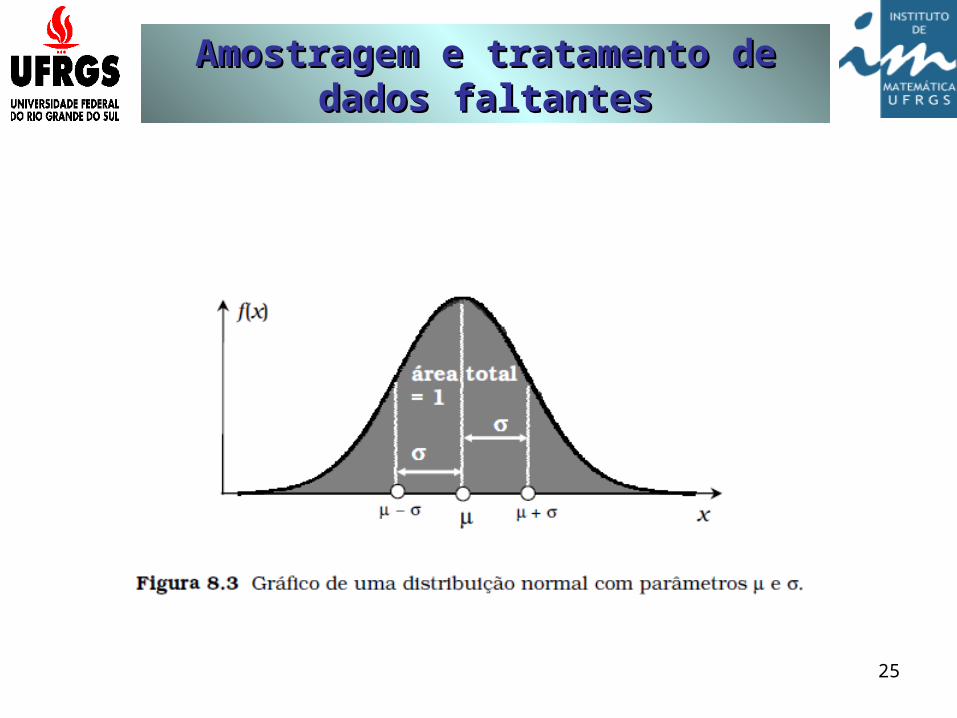
Um exemplo de região crítica
Com a distribuição de probabilidades da estatística do teste, podemos avaliar melhor a adequação de H0 com o resultado da estatística calculada com base na amostra.
Suponha que, por exemplo, a estatística do teste tem distribuição Normal. Nesse caso, a distribuição tem a forma como apresentada a seguir:
Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
25

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
26
Testes bilaterais e unilaterais
A região crítica (indicada pelas setas na figura) na respectiva distribuição de probabilidades vai depender da hipótese alternativa. No exemplo abaixo foi considerado =0,05.
95%95%

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
27
Região crítica Com a distribuição de referência podemos definir qual a região crítica do teste. Ou seja, a decisão do teste se baseia no seguinte: se o valor da estatística do teste cai na região crítica (região hachurada na figura anterior), rejeita-se H0, se o valor cai fora da região crítica, aceita-se H0. Repare que a probabilidade () associada a região crítica (de rejeição) é bem menor que seu complemento (1- ). Essa probabilidade deve ser previamente estabelecida.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
28
Erros Ainda na fase do planejamento de uma pesquisa, quando desejamos confirmar ou refutar alguma hipótese, é comum estabelecer o valor da probabilidade tolerável de incorrer no erro de rejeitar H0, quando H0 é verdadeira. Este valor é conhecido como nível de significância do teste e é designado pela letra grega . É comum se adotar nível de significância de 5%, isto é, = 0,05.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
29
ErrosQuando o teste rejeita H0, a probabilidade de
se estar tomando a decisão errada é, no máximo, igual ao nível de significância adotado. Desta forma, temos certa garantia da veracidade de H1.
Uma interpretação um pouco diferente é dada quando o teste aceita a hipótese nula H0. Neste caso, podemos dizer: os dados estão em conformidade com a hipótese nula! Isto não implica, contudo, que H0 seja realmente a hipótese verdadeira, mas que os dados não mostraram evidência suficiente para rejeitá-la e, por isso, continuamos acreditando em sua veracidade.

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
30
ErrosEstabelecido um nível de significância antes
da observação dos dados, temos as seguintes possibilidades:

Amostragem e tratamento de Amostragem e tratamento de dados faltantesdados faltantes
31
ConclusãoObservamos no esquema que, se o teste
rejeitar H0, temos controle do risco de erro (probabilidade igual a ). Por outro lado, se o teste aceitar H0, não temos controle do risco de erro. No esquema, representamos a probabilidade de ocorrer o erro tipo II como β, mas, ao contrário de , a probabilidade β não é fixada a priori. Em razão disso, usamos uma linguagem mais enfática quando o teste rejeita H0 (p. ex., os dados provaram estatisticamente que existe diferença entre...) e uma linguagem mais suave quando o teste aceita H0
(p. ex., os dados não mostraram evidência suficiente para que se diga que há diferença entre...).