adaptive cyclic scheduling of nested loops
DESCRIPTION
Adaptive Cyclic Scheduling of Nested Loops. Florina M. Ciorba , Theodore Andronikos and George Papakonstantinou. National Technical University of Athens Computing Systems Laboratory. [email protected] www.cslab.ece.ntua.gr. Outline. Introduction Definitions and notations - PowerPoint PPT PresentationTRANSCRIPT

Adaptive Cyclic Scheduling Adaptive Cyclic Scheduling of Nested Loopsof Nested Loops
Florina M. Ciorba, Theodore Andronikos andGeorge Papakonstantinou
National Technical University of Athens
Computing Systems Laboratory

September 24, 2005 HERCMA'05 2
OutlineOutline
• IntroductionIntroduction
• Definitions and notations
• Adaptive cyclic scheduling
• ACS for homogeneous systems
• ACS for heterogeneous systems
• Conclusions
• Future work

September 24, 2005 HERCMA'05 3
IntroductionIntroduction
Motivation:
• A lot of work has been done in
parallelizing loops with dependencies,
but very little work exists on explicitly
minimizing the communication incurred
by certain dependence vectors

September 24, 2005 HERCMA'05 4
IntroductionIntroduction Contribution:
• Enhancing the data locality for loops with
dependencies
• Reducing the communication cost by mapping
iterations tied by certain dependence vectors
to the same processor
• Applicability to both homogeneous &
heterogeneous systems, regardless of their
interconnection network

September 24, 2005 HERCMA'05 5
OutlineOutline
• Introduction
• Definitions and notationsDefinitions and notations
• Adaptive cyclic scheduling
• ACS for homogeneous systems
• ACS for heterogeneous systems
• Conclusions
• Future work

September 24, 2005 HERCMA'05 6
Definitions and notationsDefinitions and notations
Algorithmic model:FOR (i1=l1; i1<=u1; i1++) FOR (i2=l2; i2<=u2; i2++) … FOR (in=ln; in<=un; in++)
Loop Body ENDFOR … ENDFORENDFOR• Perfectly nested loops
• Constant flow data dependencies

September 24, 2005 HERCMA'05 7
Definitions and notationsDefinitions and notations
• J – the index space of an n-dimensional loop
• ECT – earliest computation time of an iteration point
• Rk – set of points (called region) of J with ECT k
• R0 – contains the boundary (pre-computed) points
• Con(d1,..., dq) – a cone, the convex subspace formed by q dependence
vectors of the m+1 dependence vectors of the problem
• Trivial cones – the cones defined by dependence vectors and at least one
unitary axis vector
• Non-trivial cones – the cones defined exclusively by dependence vectors
• Cone vectors – are those dependence vectors di (i≤q) that define the
hyperplane in a cone
• Chain of computations – a sequence of iterations executed by the same
processor

September 24, 2005 HERCMA'05 8
Definitions and notationsDefinitions and notations
• Index space of a loop with d1=(1,7), d2=(2,4), d3=(3,2), d4=(4,4) and d5=(6,1)
• The cone vectors are d1, d2, d3 and d5
• The first three regions and few chains of computations are shown

September 24, 2005 HERCMA'05 9
Definitions and notationsDefinitions and notations• dc – the communication vector (one of the cone vectors)
• j = p + λdc is the family of lines of J formed by dc
• Cr = is a chain formed by dc
• |Cr| is the number of iteration points of Cr
• r – is a natural number indicating the relative offset between chain
C(0,0) and chain Cr
• C – is the set of Cr chains and |C| is the number of Cr chains
• |CM| – is the cardinality of the maximal chain
• Drin – the volume of “incoming” data for Cr
• Drout – the volume of “outgoing” data for Cr
• Drin + Dr
out is the total communication associated with Cr
• #P – the number of available processors
• m – the number of dependence vectors, except dc
}{ R λ some for,λ | cJ drjj

September 24, 2005 HERCMA'05 10
Definitions and notationsDefinitions and notations
• Communication vector is dc = d3 = (3,2)
• Chains are formed along dc

September 24, 2005 HERCMA'05 11
OutlineOutline
• Introduction
• Definitions and notations
• Adaptive cyclic schedulingAdaptive cyclic scheduling
• ACS for homogeneous systemsACS for homogeneous systems
• ACS for heterogeneous systemsACS for heterogeneous systems
• Conclusions
• Future work

September 24, 2005 HERCMA'05 12
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)
Assumptions
All points of a chain Cr are mapped to the same processor
Each chain is mapped to a different processor
a) Homogeneous case: in round-robin fashion, load balanced
b) Heterogeneous case: according to the available computation
power of every processor
#P is arbitrarily chosen to be fixed
The Master-Slave model is used in both cases

September 24, 2005 HERCMA'05 13
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)The ACS Algorithm
IINPUTNPUT: An n-dimensional nested loop with terminal point U.
Master:
(1) Determine the cone vectors.
(2) Compute cones.
(3) Use QuickHull to find the optimal hyperplane.
(4) Choose the dc.
(5) Form and count the chains.
(6) Compute the relative offsets between C(0,0) and the m dependence
vectors.
(7) Divide #P so as to cover most successfully the relative offsets below as
well as above dc. If no dependence vector exists below (or above) dc,
then choose the closest offset to #P above (or below) dc, and use the
remaining number of processors below (or above) dc.
(8) Assign chains to slave:
a) (homogeneous sys) in cyclic fashion.
b) (heterogeneous sys) according to their available computational power (i.e.
longer/more chains are mapped to faster processors, whereas shorter/fewer
chains to slower processors).

September 24, 2005 HERCMA'05 14
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)
The ACS Algorithm (continued)
Slave:
(1) Send request for work to master (and communicate the available
computational power if in heterogeneous system).
(2) Wait for reply; store all chains and sort the points by the region they
belong to.
(3) Compute points region by region, and along the optimal hyperplane.
Communicate only when needed points are not locally computed.
OOUTPUTUTPUT:
(Slave) When no more points in the memory, notify the master and
terminate.
(Master) If all slaves sent notification, collect results and terminate.
September 24, 2005 HERCMA'05 15
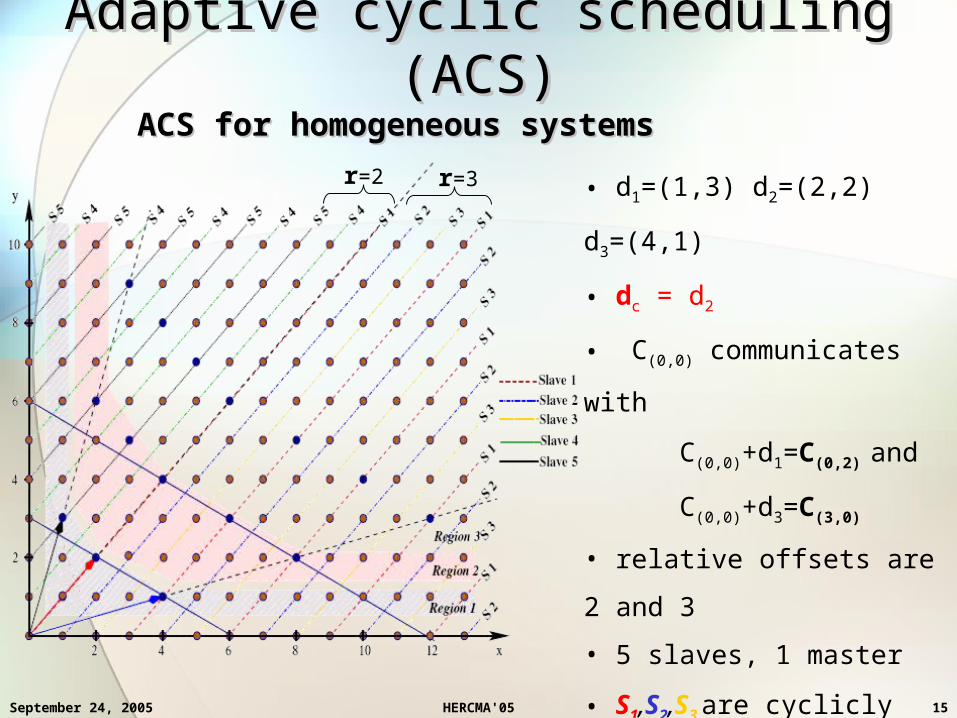
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)ACS for homogeneous systemsACS for homogeneous systems
r=2 r=3 • d1=(1,3) d2=(2,2) d3=(4,1)
• dc = d2
• C(0,0) communicates with
C(0,0)+d1=C(0,2) and
C(0,0)+d3=C(3,0)
• relative offsets are 2 and 3
• 5 slaves, 1 master
• S1,S2,S3 are cyclicly assigned
chains below dc
• S4,S5 are cyclicly assigned
chains above dc

September 24, 2005 HERCMA'05 16
ACS for heterogeneous systemsACS for heterogeneous systems
Assumptions
Every process running on a heterogeneous computer
takes an equal share of its computing resources
Notations
ACPi – the available computational power of slave i
VCPi – the virtual computational power of slave i
Qi – the number of running processes in the queue of slave i
ACP – the total available computational power of the
heterogeneous system
ACPi = VCPi / Qi and ACP = Σ ACPi
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)

September 24, 2005 HERCMA'05 17
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS)ACS for heterogeneous systemsACS for heterogeneous systems
r=2 r=3• d1=(1,3) d2=(2,2) d3=(4,1)
• dc = d2
• C(0,0) communicates with
C(0,0)+d1=C(0,2) and
C(0,0)+d3=C(3,0)
• 5 slaves, 1 master
• S3 has the lowest ACP
• S3 is assigned 4 chains
• S1,S2, S4,S5 are assigned 5
chains each
• oversimplified example

September 24, 2005 HERCMA'05 18
Adaptive cyclic scheduling (ACS)Adaptive cyclic scheduling (ACS) Advantages
It zeroes the communication cost imposed by as many dependence
vectors as possible
#P is divided into two groups of processors used in the area above dc, and
below dc respectively, such that chains above dc are cyclically mapped to
one group of processors, whereas chains below dc are cyclically mapped to
the other
This way communication cost is additionally zeroed along one
dependence vector in the area above dc, and along another dependence
vector in the area below dc
Suitable for
Homogeneous systems (an arbitrary chain is mapped to an arbitrary
processor)
Heterogeneous systems (longer/more chains are mapped to faster
processors, whereas shorter/fewer chains to slower processors)

September 24, 2005 HERCMA'05 19
OutlineOutline
• Introduction
• Definitions and notations
• Adaptive cyclic scheduling
• ACS for homogeneous systems
• ACS for heterogeneous systems
• ConclusionsConclusions
• Future work

September 24, 2005 HERCMA'05 20
ConclusionsConclusions
• The total communication cost can be
significantly reduced if the communication
incurred by certain dependence vectors is
eliminated
• Preliminary simulations show that the
adaptive cyclic mapping outperforms
other mapping schemes (e.g. cyclic
mapping) by enhancing the data locality

September 24, 2005 HERCMA'05 21
OutlineOutline
• Introduction
• Definitions and notations
• Adaptive cyclic scheduling
• ACS for homogeneous systems
• ACS for heterogeneous systems
• Conclusions
• Future workFuture work

September 24, 2005 HERCMA'05 22
Future work
• Simulate the algorithm on various
architectures (such as shared memory
systems, SMPs and MPP systems) and for
real-life test cases

September 24, 2005 HERCMA'05 23
Thank you
Questions?

September 24, 2005 HERCMA'05 24
Selected references[12] I. Drositis, T. Andronikos, M. Kalathas, G.
Papakonstantinou, and N. Koziris, “Optimal loop parallelization in n-dimensional index spaces”, in Proc. of the 2002 Int’l Conf. on Par. and Dist. Proc. Techn. and Appl. (PDPTA’02)
[13] F.M. Ciorba, T. Andronikos, D. Kamenopoulos, P. Theodoropoulos, and G. Papakonstantinou, “Simple code generation for special UDLs”, in Proc. of the 1st Balkan Conference in Informatics (BCI’03)
[14] N. Manjikian and T. Abdelrahman, “Exploiting Wavefront Parallelism on Large-Scale Shared-Memory Multiprocessors,” IEEE Trans. on Par. and Dist. Sys., vol. 12, no. 3, pp. 259-271, 2001
[15] G. Papakonstantinou, T. Andronikos, I. Drositis, “On the parallelization of UET/UET-UCT loops”, Journal of Neural Parallel & Scientific Computations, 2001