a timed mobile agent planning approach for distributed information retrieval in dynamic network...
TRANSCRIPT

Information Sciences 176 (2006) 3347–3378
www.elsevier.com/locate/ins
A timed mobile agent planning approachfor distributed information retrievalin dynamic network environments
Jin-Wook Baek *, Heon Y. Yeom
School of Computer Science and Engineering, Seoul National University, San 56-1,
Sinlim-Dong, Kwanak-Gu, Seoul 151-742, Republic of Korea
Received 19 May 2004; received in revised form 8 January 2006; accepted 13 January 2006
Abstract
The number of mobile agents and total execution time are two factors used to rep-resent the system overhead that must be considered as part of mobile agent planning(MAP) for distributed information retrieval. In addition to these two factors, the timeconstraints at the nodes of an information repository must also be taken into accountwhen attempting to improve the quality of information retrieval. In previous studies,MAP approaches could not consider dynamic network conditions, e.g., variable net-work bandwidth and disconnection, such as are found in peer-to-peer (P2P) computing.For better performance, mobile agents that are more sensitive to network conditionsmust be used. In this paper, we propose a new MAP approach that we have namedTimed Mobile Agent Planning (Tmap). The proposed approach minimizes the numberof mobile agents and total execution time while keeping the turnaround time to a min-imum, even if some nodes have a time constraint. It also considers dynamic networkconditions to reflect the dynamic network condition more accurately. Moreover, we
0020-0255/$ - see front matter � 2006 Elsevier Inc. All rights reserved.doi:10.1016/j.ins.2006.01.005
* Corresponding author. Tel.: +82 2 876 2159; fax: +82 2 871 4912.E-mail addresses: [email protected] (J.-W. Baek), [email protected] (H.Y. Yeom).

3348 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
incorporate a security and fault-tolerance mechanism into the planning approach to bet-ter adapt it to real network environments.� 2006 Elsevier Inc. All rights reserved.
Keywords: Mobile agents; Distributed information retrieval; Internet and mobile computing;Distributed computing; P2P computing
1. Introduction
Using mobile agents has become an important alternative to conventionalapproaches, such as remote procedure calls (RPCs) for Internet and mobilecomputing applications. Many researchers have attempted to utilize mobileagents in various distributed applications, such as network management,mobile wireless communication, electronic and mobile commerce, distributedinformation retrieval, and peer-to-peer (P2P) computing. In particular, dueto the migratory characteristics of mobile agents, which are able to travel fromone node to another to accomplish their task, mobile agent technology can helpto reduce network traffic, overcome network latencies, and enhance the robust-ness and fault-tolerance capabilities of distributed applications [19].
Distributed information retrieval is a major potential application area formobile agents. In this application, information is spread over several nodes,which are commonly geographically separated [22]. Mobile agents migrate tothe nodes where the data are located to perform their retrieval tasks thereinstead of transmitting data across the network. Consequently, the mobileagent can utilize the bandwidth of the network much more efficiently thanwhen simply accessing the distributed database using a direct connection froma remote area, especially when data transmission is the task bottleneck [16,49].
Since mobile agents consume network bandwidth as they visit a designatedset of nodes, it is necessary to carefully determine the best visit sequence for thenodes that will constitute the itinerary of each agent. This process is calledmobile agent planning, or MAP [14,34,33]. The number of mobile agentsand the total execution time are two of the factors used to represent the systemoverhead that must be considered as a part of MAP for distributed informationretrieval [4,42]. These two factors must be minimized for optimal performance.However, it is also essential to minimize the system turnaround time because aretrieval service must be able to supply the required information to users asquickly as possible.
In addition to the number of mobile agents and the total execution time, thetime constraints that may exist at nodes also have to be considered in MAP.When performing a retrieval task for distributed information, various time-con-straint problems are encountered. Agents may have advance information aboutnodes that are going to be shut down or isolated due to link disconnection, as

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3349
mentioned in [33]. Time constraints are particularly important for improvingthe quality of the information retrieved in certain environments, such as finan-cial, defense-related, or decision-supported systems [41,40,46,45]. Consider thecase of nodes that present information that is valid only for a certain time win-dow, such as those providing news reports, stock exchange information, or cur-rency rates. If the mobile agent cannot retrieve the requested information withina specified time window, the information may no longer be useful to the user.Therefore, in a distributed information-retrieval environment, the problem oftime constraints has to be addressed.
In a dynamic network environment, such as a P2P network, the connectionsbetween nodes, also called peers, are frequently broken or reconnected. Fur-thermore, latency times can increase or users may be removed from the systemwithout notice [31]. Previous MAP techniques are not the best approaches fordynamic network environments, as they do not consider changing networkcharacteristics. For optimal performance, mobile agents that can adapt dynam-ically to changing network conditions must be employed.
In this paper, we propose a new MAP algorithm for distributed informationretrieval, which we call Timed Mobile Agent Planning (Tmap). The proposedalgorithm has two goals: to minimize the two factors noted above under the con-dition that the turnaround time is minimized, even if some nodes have a timeconstraint, and to consider dynamic network conditions that reflect real networkconditions more accurately. To achieve these goals, the algorithm uses static anddynamic planning. Static planning is used to determine an efficient itinerary foragents to process a required set of network nodes. This itinerary is computed byusing predetermined statistical information about network traffic before theagents start their traversal of the network. Dynamic planning is then used toadjust the agents’ itineraries continually in accordance with changing networkconditions. Furthermore, the MAP approach is further adapted for real networkenvironments by providing a security and fault-tolerance mechanism.
The remainder of this paper is organized as follows. In Section 2, wedescribe related works. Sections 3 and 4 describe the system model and theTmap problem, respectively. The proposed planning algorithms are outlinedin Section 5. In Section 6, simulation results are presented and analyzed, andthe paper’s conclusions are given in Section 7.
2. Related works
2.1. Mobile agents and mobile agent planning
Recently, much research has examined mobile agents in distributed comput-ing. In particular, many authors have argued that mobile agents are betteradapted for distributed applications in a system environment with a low

3350 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
network bandwidth and frequent disconnections, such as the Internetand mobile computing. Many agent research groups have tried to supportmobile agents in this type of execution environment, such as Aglets [32], Ara[36], D’agents [25], Messenger [10], Mole [7], and Tacoma [29]. The use ofmobile agents has become one of the most important distributed computingtechniques in the last few years, and their importance has increased with theemergence of P2P computing, which has the goal of achieving global resourcesharing.
P2P networks are also a recent domain of interest for agent researchers.There are many P2P systems being developed worldwide, including Napster,Gnutella, Freenet, KaZaA, and Morpheus [27]. Looking at the recent trendin P2P agent computing, P2P agent systems such as Anthill [1], A-peer [30],and P2P-DIET [27] have attempted to combine mobile agent technology withP2P systems, allowing mobile agents to move and communicate over P2P sys-tems and utilize their resources worldwide. Many researchers [44,50,21] havebeen working on improving the information-retrieval efficiency of such sys-tems. Thanks to the current research in mobile agent technology, which isattempting to solve the problems noted above and to apply them to agentsin P2P networks and information retrieval, mobile agent applications will bewidely used in the near future.
MAP is a planning technology that performs a given task in a distributedagent application efficiently [14,34,33,18]. For MAP, mobile agents must haveknowledge of the network conditions so that they can adapt to the networkenvironment. With this perception of network status, mobile agents must alsoconsider the history of network conditions, which can facilitate their efforts toachieve the expected performance. It is very important for mobile agents to havea planning mechanism that is sensitive to the performance of the agent system.MAP is used to establish a plan for the mobile agents before they are sent out,i.e., it allows the travel path (itinerary) of each agent and the number of agentsto be determined according to the policy of the agent system. In most of the lit-erature [14,34,33], MAP is regarded as an ordinary scheduling problem, like thetraveling salesman problem (TSP). The TSP seeks to find the cheapest way for asalesman to visit a specified list of cities and return to the starting point whileconsidering the cost of traveling between each pair of cities. It is claimed thatif the agent’s task is to visit all the nodes, then the problem is reduced to theclassical TSP. Since the TSP is clearly nondeterministic polynomial-time hard(NP-hard) [26], many heuristic algorithms have been proposed to determinethe optimal scheduling solution. Brewington et al. [14] formulated a MAP prob-lem, the traveling agent problem (TAP), which is analogous to the TSP, indeciding the sequence of nodes to visit in order to minimize the total executiontime until the desired information is found. Moizumi et al. [34,33] explored howagents can efficiently spend their time traveling throughout the network to com-plete sets of tasks. These previous studies have regarded MAP as a classical

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3351
problem similar to the TSP, in which distances represent latencies. These studiesused dynamic programming to determine an approximate solution in polyno-mial time by fixing the latencies as constants [13].
Although MAP and the TSP have similar concepts with respect to determin-ing an optimal schedule, the characteristics of mobile agents, such as theirmigration capability, must be considered carefully to find the best solution.First, clones of agents are allowed to perform their task. We must considerthe number of agents for a task, because the number should be allowed to varyfor system flexibility. Therefore, there should be a partitioning method todecide the number of agents, and then the TSP can be solved for each agent.Second, agents can visit any node more than once. An agent can choose anindirect link instead of a direct link between any pair of nodes to minimizeits execution time, if the latency of an indirect link is smaller than that of adirect link. Consequently, MAP is more flexible and dynamic than the TSP.In previous studies [5,3,6], we developed MAP algorithms that deal with thenumber of agents and the total execution times of participating agents andresolve the MAP problem in an efficient manner.
Many researchers [41,40,46,45] have considered time constraints an impor-tant factor for improving retrieval capacity and reducing information over-head. In particular, Alfredo Sanchez et al. [40] emphasized the importance oftimed planning methods, such as that presented in [2], and planned to explorethese methods further in future works to improve their Mobile Agent in DigitalLibraries (MAIDL) system. MAP approaches must consider time constraintsand dynamic network conditions to realize better system performance andquality of service. Therefore, we present a new MAP problem, called the TimedMobile Agent Planning (Tmap) problem, and effectively solve the problem ofminimizing both the number of agents and the total execution time under thecondition that the turnaround time is minimized, even if some nodes have atime constraint. The proposed solution also considers dynamic network condi-tions that reflect dynamic network environments, such as a P2P network, moreaccurately.
2.2. Security and fault-tolerance issues
Recently, security and fault-tolerance issues for mobile agents have been avery active research field. Some difficult problems related to these issues haveprevented the wider development of mobile agents [24]. Agent mobility com-monly raises important security issues concerning the authentication of bothmobile agents and nodes. These security issues can be broadly divided intotwo types: node protection against hostile agents and agent protection againstmalicious nodes [48]. Many techniques have been developed for the first type ofproblem, such as access control, password protection, and sand boxes [51,9,15].The problem of malicious nodes is a serious security problem for mobile

3352 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
agents, since nodes have complete control over all programs. To solve the mali-cious node problem, a number of approaches have been proposed, such asJiang et al. [28], Vijil and Sridhar Iyer [47], and Cubaleska et al. [20]. Recentlydeveloped agent systems try to provide flexible mechanisms to grant the mostsuitable security level, while integrating with public key infrastructures [11,43].
Fault-tolerance is the ability of a system to continue normal operationdespite the presence of hardware or software faults. In the context of mobileagents, fault-tolerance prevents partial or complete loss of the agent, i.e., itensures that the agent arrives at its destination [37]. Several mobile agent sys-tems provide a mechanism that makes mobile agents persistent, since persis-tency is helpful in critical situations, such as a connectivity loss or a powershortage; it provides fault-tolerance by duplicating and storing agent copiesbefore starting critical operations. Although this mechanism achieves a triviallevel of fault-tolerance, persistence on its own is insufficient [8,39]. There havebeen several suggestions for ways to implement fault-tolerance in mobile agents,e.g., the exception handling approach [35], Fatomas [38]. Most approaches relyon replication to enable fault-tolerant mobile agent execution. However, elect-ing a new leader and sending replicas to a set of redundant nodes at each stage ofthe itinerary still entail overhead. Among recent studies to solve the problem inwhich two or more malicious nodes collude, Vijil and Sridhar Iyer [47] incorpo-rated and extended the notion of the AppendOnlyContainer. Jiang et al. [28]incorporated two methods, agent integrity verification and agent fault-toler-ance, and presented an agent migration fault-tolerance model based on integrityverification to detect tampering with an agent and to carry out fault-tolerantexecution.
All of these techniques may eventually produce useful tools for agent protec-tion. Since these issues still need much work in the agent community, manyresearch groups are working to solve problems related to these issues, and itis probable that within a few years mobile agents will be completely secure, per-sistent, and fault-tolerant.
3. System model
In this section, we present the system model required for Tmap. First, wedescribe the system structure of mobile agents to which the proposed planningalgorithms are applied, and we then present the planning model in detail. Table1 summarizes the notations used in this paper.
3.1. Structure of a mobile agent system
All of the nodes on which the mobile agents are executable can assist theactions of a mobile agent, such as creating, planning, executing, cloning,

Table 1Notations used in this paper
Symbol Definition
d Turnaround time, i.e., execution time to complete a taskdmin Minimum turnaround timen Number of nodes excluding the home nodeNi, 0 6 i 6 n Node identifiersH Home node, such as H = N0 = Nn+1
r Number of agents employed for a taskAj, 1 6 j 6 r Agent identifierstour Sequence of nodes to be processed by an agent. It is described
by hNi,Ni+1,Ni+2, . . . ,NkiSl, l = 1,2, . . . tour identifiers
R(Ni) ‘‘ready-time’’: the time when the information required becomesavailable at node Ni
D(Ni) ‘‘deadline’’ of information pickup at node Ni
L(Ni,Nj) Smallest latency between nodes Ni and Nj via shortest pathC(Ni) Computation (retrieval) time of node Ni
Tour(Aj) tour of agent Aj, i.e., itinerary for agent Aj
U(Ni) Arrival time of an agent at node Ni
TourTime(Sl) Execution time for tour Sl, called the routing timeUnion(Sl, . . . ,Sl+m) Concatenation of tours Sl, . . . , and Sl+m, e.g, Union(hN1i,
hN2, . . . ,Nk�1i, hNki) is a tour hN1,N2, . . . ,NkiDepart(Aj) Departure time: the time at which agent Aj departs from H
First(Sl) First entry of tour Sl, e.g., First(hNk,Nk+1,Nk+2i) = Nk
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3353
communicating, waiting, and migrating. Therefore, each node can play the roleof either a home node or a resource node. Agents running on these nodes canbe classified into two groups: static agents and mobile agents. The function of astatic agent is to provide a mobile agent with node resources, whereas a mobileagent can migrate to the node where a service is being provided.
Fig. 1 depicts the state transition diagram (STD) of a mobile agent. Thehome node usually creates the agent (Creation). Before deploying agents, aroute is planned at the home node (Static Planning). The agent moves to a des-ignated node (Migration). This state may have a transition to itself because theagent can migrate to another node without any computational operations. Theagent runs a given retrieval task using services provided by static agents (Exe-cution). To perform a given task, the agent can clone itself (Cloning) and com-municate with other participating agents (Communication). The execution ofthe mobile agent can be stopped temporarily (Waiting). After the agent hasacquired resources, or if some event occurs, the agent continues. While themobile agent is roaming, it can plan a new itinerary (Dynamic Planning).The agent is terminated after performing its given task successfully (Termina-tion). In special cases, the agent may be terminated by the user or by itself.
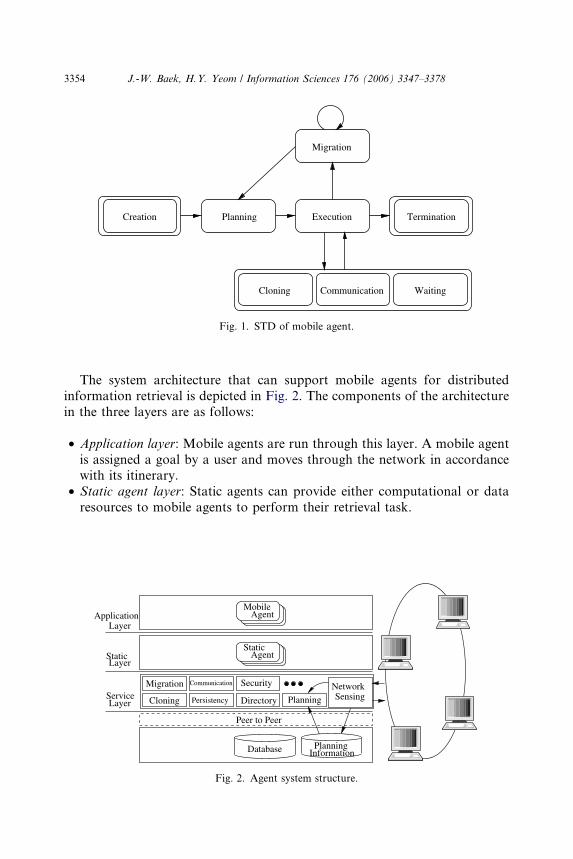
WaitingCommunicationCloning
Planning ExecutionCreation Termination
Migration
Fig. 1. STD of mobile agent.
3354 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
The system architecture that can support mobile agents for distributedinformation retrieval is depicted in Fig. 2. The components of the architecturein the three layers are as follows:
• Application layer: Mobile agents are run through this layer. A mobile agentis assigned a goal by a user and moves through the network in accordancewith its itinerary.
• Static agent layer: Static agents can provide either computational or dataresources to mobile agents to perform their retrieval task.
MobileAgent
StaticAgent
NetworkSensing
Security
PlanningPersistency
CommunicationMigration
Cloning DirectoryLayerService
LayerStatic
LayerApplication
Database
Peer to Peer
InformationPlanning
Fig. 2. Agent system structure.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3355
• Service layer: This layer includes services such as a directory, network sens-ing, planning, migration, cloning, communication, security, and persistency.
The directory service can identify the nodes at which mobile agents can exe-cute. A network-sensing service periodically collects information about networkconditions. This information is stored on a disk and is provided to the planningservice in the form of network statistics. Collecting network statistics (i.e., net-work sensing) is a very important topic for distributed applications, and manyschemes have been proposed in the literature. The planning service at the homenode uses planning information to determine the number of mobile agents andeach itinerary. The planning service at resource nodes is consulted by the mobileagents directly and determines new paths between nodes using dynamic networkcharacteristics, such as variable latencies and node or link failure. Mobile agentscan migrate to other nodes, make cloned agents, communicate with otheragents, and perform other services based on the data at resource nodes. Thesecurity service authenticates both incoming agents and nodes. The persistencyservice maintains the state of agents as they travel around the network. The per-sistency service can be used in the event of critical situations, such as a connec-tivity loss, agent loss, or power shortage involving the checkpoint and restartingagents. Mobile agents can perform their tasks using the mechanisms of P2P sys-tems, which can constitute the base layer of the mobile agent system.
Example 1. Consider an information-retrieval task using mobile agents. Usinga planning service supported by a directory service and a network-sensingservice in accordance with the system and user requirements, the system can setthe number of mobile agents and a route for each agent at the home node. Theplanning service asks the directory service to list the nodes at which the mobileagent might complete its tasks, i.e., where it can find the desired information.After obtaining the list of nodes, the planning service passes the list to thenetwork-sensing service, which prepares the planning information. Thenetwork-sensing module keeps track of these network statistics by probingthe network at a fixed interval. As soon as the network statistics are returned,the system at the home node determines the number of agents and theiritineraries using a static planning algorithm. The system sends the agents toevery designated node. When a mobile agent arrives at a node, it interacts withthe static agent. The mobile agent gives its identity to the static agent forsecurity reasons, and provided that the mobile agent is valid the static agentthen performs the given task. If it needs to talk to other cooperating agents, itdoes so through the communication service. In addition, a mobile agent canclone itself using the cloning service and assign certain tasks to the clonedagent. After a mobile agent has performed its task at a resource node, it thendecides whether to follow its predefined itinerary or to find an alternative pathusing the dynamic planning algorithm.

3356 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
3.2. Planning model
We introduce four important definitions in Table 1 as follows:
Definition 1 (Tour of an agent: Tour(Aj)). Tour(Aj) is the tour of agent Aj,which involves a sequence of resource nodes to be processed by agent Aj, e.g.,Tour(Aj) = hN1,N2,N3, . . . ,Nki means that agent Aj starts from its home node,migrates to and performs its task on the nodes N1,N2,N3, . . . , and Nk in thatorder, and then returns results to the home node.
Definition 2 (Shortest latency between nodes Ni and Nj: L(Ni,Nj)). L(Ni,Nj) isthe minimum latency of all possible paths from Ni to Nj found by evaluatingthe all-pairs shortest-paths algorithm [26].
Definition 3 (Arrival time: U(Ni)). U(Ni) is the arrival time of an agent at nodeNi. The arrival time is defined by the following equation where U(N0) =C(N0) = 0:
UðNiÞ ¼ maxfUðNi�1Þ;RðNi�1Þg þ CðNiþ1Þ þ LðNi�1;NiÞ ð1Þ
Definition 4 (Routing time for tour Sl: TourTime(Sl)). The routing time fortour Sl is the execution time for the specific tour Sl. The routing time of tour
Sl is defined by the following equation where tour Sl consists of hN1,N2,N3, . . . ,Nki.
TourTimeðSlÞ ¼ maxfUðN kÞ;RðN kÞg þ CðN kÞ þ LðN k;HÞ ð2ÞFig. 3 depicts an instance of a planning model with three resource nodes and
two agents (n = 3, r = 2, tour(A1) = hN1,N2i and tour(A2) = hN3i). Time flowsfrom left to right and the notation ti, i = 0,1,2, . . . , represents the relativeamount of time from the home node. The notation C(Ni), 1 6 i 6 3, markedby the bold box, represents the computation time at node Ni. Two of threenodes, N2 and N3, have time constraints. Node N2 has a ready-time and a dead-line, whereas node N3 has only a ready-time. The arrow represents agent migra-tion between nodes. The system sends two mobile agents from the home nodeat time t0. It takes time t1 for the first agent to reach node N1 from the homenode. Therefore, U(N1) = t1. After the first agent has processed node N1, itmigrates from node N1 to node N2. The first agent starts computation at nodeN2 at time t3, since it arrives at the node after the ready-time t2. The secondagent arrives at node N3 at time t1, waits until t2, and starts computation attime t2. Times t5 and t6 are the turnaround times of agents A1 and A2, respec-tively. Time d (= t6 in this example) on the right-hand side represents the turn-around time required to complete a task.

2D(N )2R(N )
3U(N )
1U(N )
2U(N )
H
R(N )3wait
timet t 2 t 4 t 5 t 6t 31t 0
δ
N1
N2
N3
C(N )1
C(N )2
C(N )3
Fig. 3. The planning model.
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3357
4. The Tmap problem
In this section, we describe the Tmap problem in detail. Before we describethe planning problem, we discuss some assumptions that are related to the net-work configuration and to the behavior of mobile agents. First, the planninginformation, such as the latency and bandwidth of links and the computationtime and time constraint at each node, are known statistically. Next, an agentcan pass through several nodes on its way to a target node. In this case, theagent affects network latency only during migration through a bypass node.Note that the first assumption is already described in previous MAP studies[14,34,33].
As mentioned in Brewington et al. [14], planning information can be pro-vided by a more advanced directory service and a network-sensing service.The list of possible nodes is provided by the directory service. The networkconditions include information regarding the connectivity of links, operabilityof machines in the network, latency and available bandwidth of links, and thecomputation time and time constraint of each node. These statistics are col-lected by the network-sensing service and are used in planning. Under theseassumptions, Tmap can be informally described as follows.
4.1. Tmap problem
There are n + 1 nodes, of which one is the home node (H) and the others areresource nodes (N1,N2,N3, . . . ,Nn). Each node has a computation timerequired for a mobile agent to perform its task at that node. The latenciesfor a mobile agent moving between nodes Ni and Nj are also known. Some

3358 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
nodes may have time constraints. A mobile agent can perform its retrieval taskonly during the time window of the node. Note that the time window can bezero. The computation time at the home node is zero. Mobile agents mustretrieve information from all the resource nodes, and each node must be pro-cessed exactly once. Note that an agent can bypass several nodes to reach a tar-get node and does not consume time at bypassed nodes. The Tmap problem isto minimize both the number of mobile agents and the total execution times ofthe agents under the condition that the minimum turnaround time is guaran-teed, even if some nodes have time constraints imposed by a time window.
When the issue of time constraints is considered, only two types of nodesexist in the information-retrieval system: naive nodes and timed nodes. A timednode differs from a naive node in that it provides correct information onlywithin a certain time window. This time window consists of a ‘‘ready-line’’(lower bound) and a ‘‘deadline’’ (upper bound). The ready-line refers to whenthe server finishes producing the required information, and the deadline refersto the time by which an agent must finish its retrieval process.
As stated below, the agent can define the turnaround time (d) based on thelongest routing time for all of the agents used for a retrieval task
d ¼ maxfTourTimeðTourðAjÞÞg; 1 6 j 6 r ð3Þ
The minimum turnaround time (dmin) for a task is the turnaround time for thespecial case in which n agents are sent to n different nodes (r = n). The turn-around time of a node Ni can be written as the following equation, by includingthe ‘‘ready-time’’
TourTimeðhNiiÞ ¼ maxfLðH ;NiÞ;RðN iÞg þ CðNiÞ þ LðNi;HÞ ð4Þ
Therefore, the minimum turnaround time (dmin) is dependent only on the nodewith the longest routing time among all the nodes that an agent can visit (Eq.(5))
dmin ¼ maxfTourTimeðhN iiÞg; 1 6 i 6 n ð5Þ
At a timed node, a mobile agent must retrieve the requested information at atime that is between the ready-time and the deadline. If the agent arrives at thenode before the ready-time, it must wait until the ready-time. The fact that amobile agent must satisfy the time constraint of each node is described bythe following equation:
maxfUðNiÞ;RðN iÞg þ CðNiÞ 6 DðN iÞ ð6Þ
The Tmap problem can also be defined formally as follows.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3359
4.2. Formal Tmap problem
minimize r ^Xr
j¼1
TourTimeðTourðAjÞÞ( )
ð7Þ
subject to TourTimeðTourðAjÞÞ 6 dmin; 1 6 j 6 r ð8Þ[r
j¼1
TourðAjÞ�����
����� ¼ n ð9Þ
TourðAiÞ \ TourðAjÞ ¼ /; i 6¼ j ð10ÞmaxfLðH ;NiÞ;RðN iÞg þ CðNiÞ 6 DðNiÞ; 1 6 i 6 n ð11Þwhere dmin ¼ maxfTourTimeðhN iiÞg; 1 6 i 6 n ð12Þ
In Eq. (7), the objective function consists of two terms: the number of agentsand the total execution time. Therefore, Eq. (7) has two targets: the minimumnumber of agents and the minimum total execution time. Eqs. (8)–(11) are con-straints for this objective function. In Eq. (8), the routing time of each agent isalways smaller than the minimum turnaround time, i.e., dmin. This means that agiven task can always be completed within the minimum time, which is deter-mined by the node with the longest routing time in Eq. (12). Eq. (9) means thatthe size of the union of the agents’ tours equals the number of nodes. Note thatthe absolute symbol (j j) returns the number of elements that compose a tour.Eqs. (9) and (10) require that all nodes are processed and that each node is pro-cessed exactly once. Eq. (11) imposes the time constraint on each node in thisplanning problem, i.e., an agent should complete retrieval before the deadline.
5. Proposed planning algorithms
The first static planning algorithm determines the number of agents andtheir itineraries using network statistics at the home node before sending theagents. The second dynamic planning algorithm is used to adjust the agents’itineraries continually using dynamic network characteristics, such as variablelatency and node/link failures at the resource nodes while the agent is roaming.
5.1. Static planning
5.1.1. Preprocessing: construction of the shortest latency network
During preprocessing, before executing the static planning algorithm, we con-struct a Shortest Latency Network (SLN) from the given network configuration.Preprocessing is conducted only once, and it can be used in each static planning

3360 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
process. This is not a simple task, as we must search all the combinatorial links ofany two selected nodes. Nevertheless, without this information, there is no way todetermine the minimum turnaround time and shortest latencies of all pairs ofnodes. Therefore, the static algorithms, before entering the main body, processthe all-pairs shortest-path algorithm [26] and construct an SLN graph.
Example 2. Fig. 4 shows a network configuration and the results that arecalculated by the proposed static planning. Fig. 4(a) describes the networkconfiguration. The weight of a link between nodes represents the latency. Theweight of a node has two components. The first represents the computationtime, and the second describes the time window at the corresponding node. Thetime window consists of the ready-time and the deadline in parentheses. Forexample, for node N3, an agent should process information between 41 and50 ms. We can obtain an SLN graph as shown in Fig. 4(b) from Fig. 4(a) byusing the all-pairs shortest-path algorithm. Fig. 4(c) details how an agentbypasses node N2. Although the latency on the direct link between nodes N4
and N3 is known, the agent can take the indirect link (N4,N2,N3) instead of(N4,N3), using the SLN graph. This is because the latency of the indirect link is10 ms (= 4 + 6), whereas the latency of the direct link is 100 ms. Therefore, anagent can move from node N4 to N3 in 10 ms. Note that the computation timeof the bypassed node (N2) is not included in the indirect latency.
5.1.2. Planning algorithms
Provided that all the planning information is available, as described in theprevious section, the static algorithm proceeds as follows:
(1) Set the minimum turnaround time (dmin) as the longest routing timeamong all of the nodes. The routing time of each node Ni, Tour-
Time(hNii), is calculated using Eq. (4).
N2
N4
N3
N1
4
6
16
1516
1025
8 10
H
510
55
(16,30)
100
(41,50)N2
N4
N3
N1
4
6
16
1516
1025
8 10
H
510
55
(16,30)
10
(41,50)N2
N4
N3
N1
10
16
1516
10
H
510
55
(16,30)
25
4
6
8
10
(41,50)
(a) (b) (c)
Fig. 4. An example (a) original network configuration; (b) SLN graph; (c) calculating minimumturnaround time, partitioning, assigning, optimizing, and sending.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3361
(2) Partition the given network into several parts by gathering nodes so thatthe routing time of each part does not exceed time dmin and build a rout-ing path for each partition.
(3) First, set each agent’s departure time if the first node in the tour of thatagent has a time constraint. Next, run a TSP algorithm to optimize eachagent’s local routing path.
We developed two algorithms, Tmap1 and Tmap2 (Fig. 5), which performsimilar tasks but use slightly different partitioning methods. They differ inthe method that they use to find the next node to visit from the node wherethe agent currently resides. Tmap2 is more dynamic than Tmap1. Tmap1 triesto find the next possible node by always considering the routing time from thehome node, whereas Tmap2 searches for the next possible node from the nodewhere the agent currently resides. Therefore, Tmap1 always selects the nodefarthest from home (with the longest routing time), while Tmap2 selects thenode nearest the current node (with the smallest L value).
The first algorithm, Tmap1, is presented in the form of Algorithm 1. In step1, all of the nodes are sorted in decreasing order of routing time from home,and the minimum turnaround time is equal to the routing time of the first nodein the sorted list (lines 3, 4). The routing time for a given node is the round-triptime from home to that node. In the middle step of the algorithm (step 2), eachagent’s tour is decided (lines 5–10). The partitioning process starts from the firstassigned node in the subroutine AssignNode( ). The first node in the sorted listis assigned to the tour of the first agent, and Tend is dmin initially. After assign-ing this node, two different time windows are available. The subroutineAssignNode( ) is called recursively for each time window in order to select nodesfor the current tour from among those nodes that have not yet been assigned(lines 31–34). Tmap1 estimates the agents’ routing times by adding the costsof the next adjacent set of nodes in the sorted list. Exceeding the upper boundof the time constraint (the threshold ‘‘Tend’’), i.e., the impossibility of perform-ing the task at the node within the time window, is not allowed when assigningan adjacent node to the tour (lines 22, 23, 26). In this manner, the path of theagents can be decided using the sorted list. When we create a tour for agents,nodes that have already been assigned are not considered as candidate nodesfor the agents’ tours. If unassigned nodes remain, the algorithm continues (lines20, 21). Each unassigned node is eliminated from the sorted list if it satisfies thecondition in line 26.
At the end of the algorithm (step 3), the departure time of each agent is set,if the first visited node in this agent’s tour has a ready-time and the L valuefrom home to this node is smaller than the ready-time (lines 14, 15). Next, itcalls a TSP program (line 16). We use the 2OPT algorithm [12] because it issimple and effective. The 2OPT is the best known of the classical optimizationalgorithms for the TSP. It produces an optimal routing path asymptotically for

Fig. 5. Static planning algorithm.
3362 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
each given network partition. In 2OPT, two edges are deleted from the tour,breaking the tour into two paths, and those paths are reconnected in other pos-sible ways. Attempts to improve the tour are made repeatedly by deleting andadding two edges until all pairs of edges are considered. The other well-knownTSP algorithms, e.g., 3OPT and LK, can be replaced with 2OPT for better per-formance. Algorithm 2 is the algorithm corresponding to Tmap2. In compar-

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3363
ison with Tmap1, Tmap2 considers the costs of a different set of nodes when itgenerates a tour. The nodes selected by Tmap2 always have the shortestlatency, i.e., L time, from the last added node, rather than from home (line22 in Algorithm 2). Therefore, the results of these two algorithms may have dif-ferent routing paths for a given agent.
Example 3. Fig. 6 describes how nodes are assigned for particular partitions.The vertical lines represent the times taken by each agent in the sequence. First,we show how Tmap1 operates. In step 1, the routing time for node N1 is 55(= 25 + 5 + 25) ms, whereas the routing times for nodes N2, N3, and N4 are 30(= 10 + 10 + 10), 54 (= max{8,41} + 5 + 8), and 31 (= max{10, 16} + 5 +10) ms, respectively. Therefore, dmin = 55 ms and Tour(A1) = hN1i (Fig. 6(a)).In step 2, we start the partitioning process from the assigned node N1. Thesecond agent covers node N3, as its routing time is the greatest, except for thatof the node already assigned as node N1. We have two available time windowsafter assigning N3 (Fig. 6(b)). The first is from 0 to 41 ms, and the second isfrom 46 to 55 ms. The first time window is selected and processing continues toassign additional nodes to include in the current partition. Since the routingtime for node N4 is the greatest among the unassigned nodes, the second
34<N ,N >
0
(a) (b) (c)
3243<N > <N ,N ,N >
(d)
Tour(A ) Tour(A )
Candidate
Tour
1 2
2
not changed
(e)
0
55
H
H
45
50
55
40
35
30
25
20
15
10
5
0
T
T
N
N
start
end
start
end
HHH
H
N
41 16 41
2100
55
1N
<N >1
N3 N4
3N N4 N3
N4
N2
1N
3N 3N 3N 3N
N4 N4 N4
N2
55
0 0
41
0 0
16
41
21
16
21
31
25
35
6
46
54
0
6
16
21
31
545454
41
46 46 46
30
25
33
41
Computation
Latency
Fig. 6. Assignment of nodes for partitions: (a) assigning N1, (b) assigning N3, (c) assigning N4, (d)not assigned and (e) assigning N2.

3364 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
agent’s tour so far is hN4,N3i. Two time windows, 0–16 and 21–41 ms, arenewly available after the assignment of N4 (Fig. 6(c)). The last node, N2, isconsidered and assigned not to the first new time window (Fig. 6(d)), but to thesecond new time window, and we obtain Fig. 6(e). Consequently, the networkcan be partitioned into two parts: hN1i and hN4,N2,N3i. In step 3, the 2OPTalgorithm can optimize these two partitions. As a result, the number of agentsfor this example is two, and the total execution time is 103 (= 55 + 48) ms.Therefore, r = 2, Tour(A1) = hN1i, and Tour(A2) = hN4,N2,N3i (Fig. 4(c)).Next, we show how Tmap2 operates. The two algorithms perform the sametask in assigning the first node in the sorted list to the first agent’s tour. Thesecond agent covers node N3 because it has the shortest latency from node N1,which is the last node assigned in the tour of the first agent. Tmap1 and Tmap2produce identical results in this example. We need to consider the secondagent’s departure time since the first node (N4) has a time window. Therefore,the mobile agent should depart from the home node at 6 ms.
5.2. Dynamic planning
We are proposing two dynamic planning algorithms. The first is for the ori-ginal agent (Algorithm 3), and the second is for its clone (Algorithm 4), asshown in Fig. 7. Table 2 summarizes the notations used in dynamic planning.The dynamic planning algorithms try to satisfy the given minimum turnaroundtime by replacing an original itinerary with an alternative path. When a mobileagent arrives at node Ni, the computations for that node begins. Note that itwaits for a while until the ready-time if it arrives at the node before theready-time. In addition, the values of Lr(Ni,Ni+1) and Lr(Ni,Ni+k) are deter-mined concurrently (lines 3–7). If the term Ur(Ni+1) + Cr(Ni) + Lr(Ni,Ni+1) isequal to, or less than U(Ni+1), the original agent follows its given itinerary(lines 8–9, 16). If an agent decides to follow an alternative path in the middleof its itinerary (in the case of either node/link failure or low network connec-tion), it clones itself to cover any skipped nodes before its starts off to the nextnode (lines 10–14, 16). However, if the next node is the home node, then theagent sends results to the home node and destroys itself at the current node(line 15). As described in Algorithm 4, the cloned agent waits for an availableconnection before moving to the target node (line 2). If the clone waits aftertime hi, then it sends results to the home node and destroys itself (line 3). Other-wise, it moves on and processes the next node (lines 4–5). This procedure is per-formed k � 1 times (line 6). The clone sends results to the home at the end ofthe algorithm (line 7).
Example 4. Fig. 8 is an example that shows how the agents work. The originalagent uses the original itinerary that was determined statically in the first static

Fig. 7. Dynamic planning algorithm.
Table 2Notations used in dynamic planning
Symbol Definition
k Factor k: number of skipped nodes, i.e., an agent skips k � 1 nodeshi Waiting time: the time after which an agent sends result from node
Ni to the home, i.e., hi = dmin � Ur(Ni)Rr(Ni) Actual ‘‘ready-time’’ at node Ni
Dr(Ni) Actual deadline at node Ni
Lr(Ni,Nj) Smallest actual latency between nodes Ni and Nj via shortest pathCr(Ni) Actual computation time of node Ni
Ur(Ni) Actual arrival time of an agent at node Ni, i.e., Ur(Ni) = Ur(Ni�1) +Cr(Ni�1) + Lr(Ni�1,Ni), where Ur(N0) = C(N0) = 0
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3365
planning algorithm. The original agent checks the current conditions to decidewhether to move to N1 while it is at the first node, N0. For simplicity, weassume that Cr = C, k = 3, R 6 Rr, and D 6 Dr.

10/1010/1010/555 11 16 13 9
N N N N N N086 754
10/1010/5
Original Agent
Cloned Agent
Agent moves
Clone moveslink/node failurexL/Lr*/*10/5010/10
10
N N10
10/9x
10/–
wait for20 ms
10
N2
5
N35/5
Fig. 8. An example of dynamic planning.
3366 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
• from N0 to N1: Ur(N0) + Cr(N0) + Lr(N0,N1) = 0 + 0 + 9 = 9 < U(N1) =
10) move to N1.• from N1 to N2: link/node failure) create clone; cannot move to N2; deter-mine N4 (next = i + k).
• from N1 to N4: Ur(N1) + Cr(N1) + Lr(N1,N4) = 9 + 10 + 10 = 29 < U(N4) =55) move to N4.
• from N4 to N5: Ur(N4) + Cr(N4) + Lr(N4,N5) = 29 + 5 + 5 = 39 < U(N5) =70) move to N5.
• from N5 to N6: Ur(N5) + Cr(N5) + Lr(N5,N6) = 39 + 11 + 55 = 105 >U(N6) = 91) create clone; cannot move to N6; determine N8 (next = i + k).
• from N5 to N8: Ur(N5) + Cr(N5) + Lr(N5,N8) = 39 + 11 + 50 = 100 <U(N8) = 140) move to N8.
• at N8: send results to H.
The original agent then follows three paths in the original itinerary and twopaths in the alternative path. Two cloned agents are produced at nodes N1 andN5. The cloned agents then follow the paths that are shown in Fig. 8 in order toprocess the nodes excluded by the original agent. The first cloned agent acts asfollows:
• from N1 to N2: reconnect after 10 ms; move to N2; Ur(N2) = Ur(N1) +Cr(N1) + Lr(N1,N2) = 9 + 10 + 20 = 39.
• from N2 to N3: move to N3; Ur(N3) = Ur(N2) + Cr(N2) + Lr(N2,N3) =39 + 10 + 5 = 54.
• at N3: send results to H.
The second cloned agent proceeds in the following steps:
• from N5 to N6: move to N6; Ur(N6) = Ur(N5) + Cr(N5) + Lr(N5,N6) = 39 +11 + 55 = 105.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3367
• from N6 to N7: move to N7; Ur(N7) = Ur(N6) + Cr(N6) + Lr(N6,N7) = 105 +16 + 10 = 131.
• at N7: send results to H.
5.3. Security and fault-tolerance mechanism
In this subsection, we propose a security and fault-tolerance mechanism forTmap/dynamic, which protects mobile agents from malicious nodes and makesmobile agents fault-tolerant. As agents move in real networks, such as theInternet, they are exposed to untrustworthy environments and may also beexposed to malicious nodes. Moreover, fault-tolerance problems can preventthem from operating. Therefore, we present a security and fault-tolerancemechanism for the proposed MAP in order to adapt it better to dynamicenvironments.
We assume that nodes are allowed to store an agent, recover, and restart theagent; the next node to be moved is determined by the proposed planning algo-rithm; and a set of redundant nodes at each stage in the itinerary is not consid-ered. In the following, we explain the security and fault-tolerance mechanismfor Tmap/dynamic, as shown in Fig. 9. We assume that the itinerary of anagent is hN1,N2,N3, . . . ,Nni and that the agent resides at Ni.
First, let us consider the case of the original agent, as shown in Fig. 9(a). Theoriginal agent migrates from Ni to Ni+1 (1). After the agent has executed onNi+1, Ni verifies its integrity (2). If the integrity is verified, then Ni+1 stores acopy of the agent in a persistent disk in order to verify the agent in the nextround (3,3-a). The next node to be visited is determined using dynamic plan-ning, and the above steps are repeated until the next node becomes the home(3-b,5). If the next node is the home, then the agent immediately sends theresults to the home (6). When verification fails at Ni+1, the node is malicious,and the agent is terminated (4, 4-a). Node Ni has to recover a new agent usingthe stored agent’s information (4-b). Then, the agent skips k � 1 nodes andjumps to the new node, i.e., Ni+k, along the alternative path. The clone ofthe agent created at Ni can process the skipped k � 1 nodes (4-c). If Ni+k ismalicious, then Ni reselects the next node in the order of the itinerary; e.g.,Ni+k+1, Ni+k+2, etc. (4-d).
Second, consider the case of a clone, as shown in Fig. 9(b). Let a clone becreated at Ni. Note that the clone does not execute on its originating node.If Ni+1 is already known to be malicious (as already identified by the originalagent), then the clone moves to node Ni+2, skipping the malicious node (1, 2).After the clone has completed its task at Ni+2, Ni again verifies its integrity, asfor the original agent (3). If verified, Ni then stores a copy of the clone, andthe clone moves to the next node in the itinerary (4, 4-a,4-b). Otherwise, theclone at Nnext is terminated, and Ni recovers a new clone with the stored copy

Fig. 9. The security and fault-tolerance mechanism.
3368 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
information (5, 5-a,5-b). The new clone skips the malicious node and selects thenext node from the itinerary (5-c). These steps are repeated until the next nodebecomes Ni+k (6). At the last node, i.e., Ni+k�1, agent integrity is verifiedbetween the last node and Ni+k, which has already been processed or will beprocessed by the original agent (7). It is possible that the original agent hasnot arrived at Ni+k when the clone seeks verification using the agent informa-tion at Ni+k, in which case the clone has to wait for the original agent to finishits execution at Ni+k. Of course, if Ni+k+1 is malicious, then the comparingnode is reselected from the itinerary to verify the integrity of the clone (7-a).If verification fails, then there are colluding malicious nodes between Ni+1
and Ni+k�1 (7-b).
Example 5. Fig. 10 shows how the proposed mechanism works. Note that thenext node to move to is determined by the proposed dynamic planning. First,consider the original agent, as shown Fig. 10(a). The original agent at N1
moves to N2. After the agent has completed its task at N2, node N1 verifies itsintegrity (1). Since N2 is a malicious node, the original agent is terminated at

N0
N1
N4
N5
N6N2
N3
N7
: Uncovered nodes: Nodes covered by original agent
: Original agent: Clone
: Malicious node
1
3
4
2
5
7
6
high
: Uncovered nodes: Nodes covered by original agent
: Original agent: Clone
: Malicious node
N0
N1
N4
N5
N6N2
N3
N7
1
2
3
4
5
7
89
6
(a) Original Agent (b) Cloned Agents
Fig. 10. An example of security and fault-tolerance.
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3369
that node (2). Node N1 recovers a new agent using the stored information (3).The agent makes a clone that will process the skipped nodes before movingalong an alternative path (4, 5). As shown in Fig. 10(a), N4 creates a clone sincethe path between N4 and N5 is a high-traffic path. The agent moves to N7 andsends the results home after verification. Next, let us consider how clones work,as shown in Fig. 10(b). The first clone at N1 moves to N3, because N2 ismalicious (1). Node N3 verifies its integrity with N4 when the clone completesits task at N3, and then reports home after verification (2, 3). Consider thesecond clone. The clone arrives at N6 (4, 5,6,7); after verification between N6
and N7, N6 knows that two consecutive cooperative malicious nodes, i.e., N5
and N6, exist, and reports home (8, 9).
The proposed mechanism tries to solve the problem of consecutive andcooperative malicious nodes and to act as a fault-tolerant mobile agent inthe case of fault-tolerance problems with some level of security and fault-toler-ance. It is possible for a malicious node to compromise agent integrity afterintegrity verification has finished, but the proposed mechanism can easily beimproved by delaying the time of agent verification, as Jiang et al. [28] does.Although we do not consider a set of redundant nodes at each stage in the itin-erary (due to the difficulty in making redundant systems in real environments)for practical implementation purposes, the mechanism achieves a higher levelof fault-tolerance at an overhead cost of some redundancy. In a real environ-ment, e.g., the Internet, there are no bounds on verification time delays; eachnode can specify a time-out value and denote the maximum waiting time forverification. The method also has the exactly-once property by storing a copyof the agent after an agent’s normal execution. Consequently, the proposedsolution can easily be extended and modified for an advanced security andfault-tolerant protocol to make the MAP increasingly secure and fault-tolerant.

3370 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
6. Simulation
6.1. Simulation environment
The simulation is based on a practical perspective of the mobile agent envi-ronment for a distributed information-retrieval system. The network model isbased on the network topology model proposed by Doar [23] and Calver et al.[17], which can be used to generate a realistic network model. The network iscomposed of several subnetworks, such as local area networks (LANs), thatare distributed over a wide area network (WAN). The major parameters cho-sen for this model are:
• NL, the number of subnetworks, and SL, the number of nodes per subnetwork.• NT, the number of time windows. Since the number of nodes (n) in the
network is given by NL * SL, 0 6 NT 6 n (= NL * SL).
We classify the network topology into three types: LAN, WAN, and Clus-tered-LAN.
• LAN: All nodes are located in a subnetwork (NL = 1 and SL = n).• WAN: The subnetwork includes exactly one node (NL = n and SL = 1).• Clustered-LAN: Each subnetwork includes more than one node (NL < n and
SL > 1).
The network topology is related to the way that latencies are assigned toeach pair of nodes in a network. When all of the nodes that agents must visitare in a subnetwork (LAN), the standard deviation of the latencies betweeneach pair of nodes in the network is very small. In contrast, if all of the nodesare scattered across a WAN, the latencies will be arbitrary and large. The lasttopology (Clustered-LAN) involves a mixture of the two topologies. Thistopology consists of several subnetworks distributed over a WAN. Any twonodes in this topology can be located in either the same subnetwork or differentones. The latency within a subnetwork varies between 10 and 15 ms. Thelatency between subnetworks varies between 1000 and 1150 ms. Query behav-iors can be classified into two types: Simple and Complex.
• Simple query: This type of query requires little computation time. Gatheringheadline news is an example of this type. A simple query has a computationtime of 1–50 ms.
• Complex query: A complex query requires a relatively long computationtime. Let us consider a meta-search. The search system has an extensivesearch and summarizing process. This type of query consumes 500–10,000 ms.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3371
The network latencies between any pair of nodes and the computation timeat each node are generated randomly. The time window at each node is depen-dent on the latency and computation at that node in order to process all nodes.The time window is composed of a ready-time and a deadline. The ready-timeR(Ni) at node Ni varies between 0 and L(H,Ni) + C(Ni) ms. The deadline D(Ni)at node Ni varies between max{R(Ni), L(H,Ni)} and1 ms. The number of timewindows cannot exceed the number of nodes. Every time window from 0 to n ina given network configuration is simulated.
A simulation was performed in the described environment using three net-work topologies (LAN, WAN, and Clustered-LAN), two query types (Simpleand Complex), and a varying number of time windows. Since the optimal solu-tion for more than 16 nodes requires a tremendous amount of search space andtime, it is difficult to perform in reality. The simulation results therefore fellinto two groups. For systems up to 16 nodes in size, we were able to computethe optimum results and compare the results of the proposed algorithms withthe optimum values. For larger systems, up to 300 nodes, in which computa-tion of the optimum was prohibitive, the simulations found the number ofmobile agents, total execution time, and actual planning time using the pro-posed algorithm. We evaluated the performance of the proposed planningalgorithm by comparing the results of the simulation with those for a case,called BroadCast, which launches as many agents as there are nodes.
The simulation was performed on a PC with an Intel Pentium IV 2.41-GHzprocessor and 768 MB RAM. All of the results obtained using this machinewas averaged to reflect the average computing environment. If the compu-ting power were increased, the calculated performance would definitelyimprove.
6.2. Simulation results
When the problem was small (n 6 16), we compared the performance of bothalgorithms by comparing results with the optimal case (Optimal). Table 3 showsthe number of agents and the total execution time required for each combina-torial configuration, as found using three different algorithms Tmap1, Tmap2,and Optimal; the number of nodes; and the number of time windows. The totalexecution time in the table is the sum of the computation times, network laten-cies, and wait times caused by the ready-time. As the number of timed nodesincreases in a network, the number of agents and total execution time graduallyincrease. This occurs because the ready-time at each timed node acts as a con-straint because an agent that arrives early must wait until the ready-time beforeit can obtain the required information.
Table 3 shows that the difference in the average numbers of agents betweenOptimal and Tmap2 was almost less than one, and the total execution time of
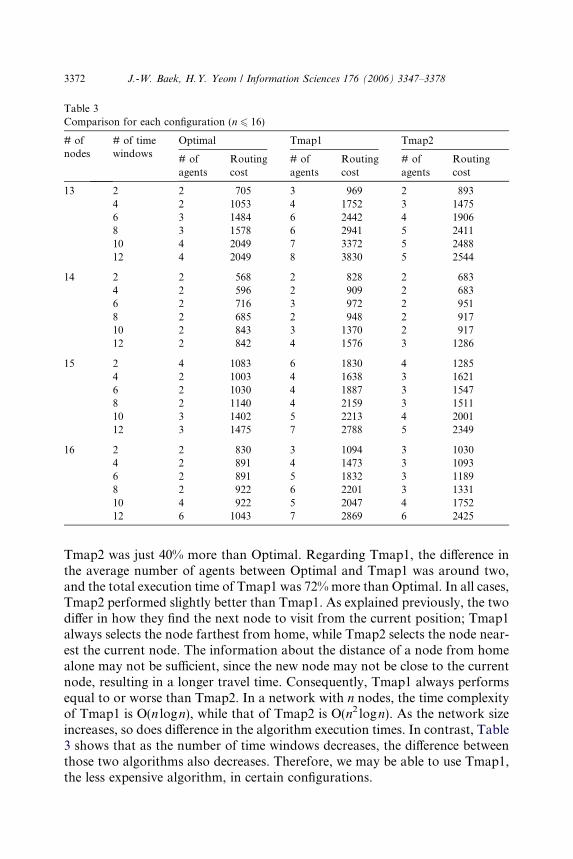
Table 3Comparison for each configuration (n 6 16)
# ofnodes
# of timewindows
Optimal Tmap1 Tmap2
# ofagents
Routingcost
# ofagents
Routingcost
# ofagents
Routingcost
13 2 2 705 3 969 2 8934 2 1053 4 1752 3 14756 3 1484 6 2442 4 19068 3 1578 6 2941 5 241110 4 2049 7 3372 5 248812 4 2049 8 3830 5 2544
14 2 2 568 2 828 2 6834 2 596 2 909 2 6836 2 716 3 972 2 9518 2 685 2 948 2 91710 2 843 3 1370 2 91712 2 842 4 1576 3 1286
15 2 4 1083 6 1830 4 12854 2 1003 4 1638 3 16216 2 1030 4 1887 3 15478 2 1140 4 2159 3 151110 3 1402 5 2213 4 200112 3 1475 7 2788 5 2349
16 2 2 830 3 1094 3 10304 2 891 4 1473 3 10936 2 891 5 1832 3 11898 2 922 6 2201 3 133110 4 922 5 2047 4 175212 6 1043 7 2869 6 2425
3372 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
Tmap2 was just 40% more than Optimal. Regarding Tmap1, the difference inthe average number of agents between Optimal and Tmap1 was around two,and the total execution time of Tmap1 was 72% more than Optimal. In all cases,Tmap2 performed slightly better than Tmap1. As explained previously, the twodiffer in how they find the next node to visit from the current position; Tmap1always selects the node farthest from home, while Tmap2 selects the node near-est the current node. The information about the distance of a node from homealone may not be sufficient, since the new node may not be close to the currentnode, resulting in a longer travel time. Consequently, Tmap1 always performsequal to or worse than Tmap2. In a network with n nodes, the time complexityof Tmap1 is O(n logn), while that of Tmap2 is O(n2 logn). As the network sizeincreases, so does difference in the algorithm execution times. In contrast, Table3 shows that as the number of time windows decreases, the difference betweenthose two algorithms also decreases. Therefore, we may be able to use Tmap1,the less expensive algorithm, in certain configurations.
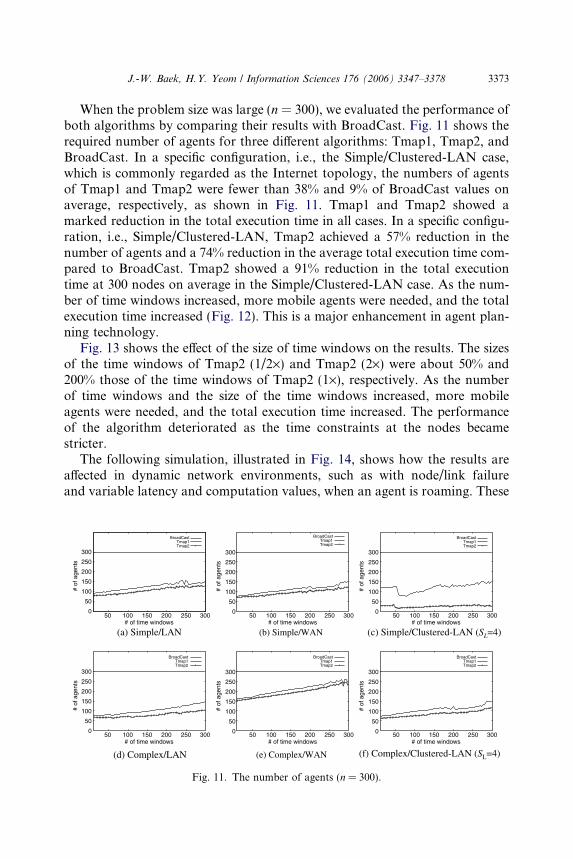
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3373
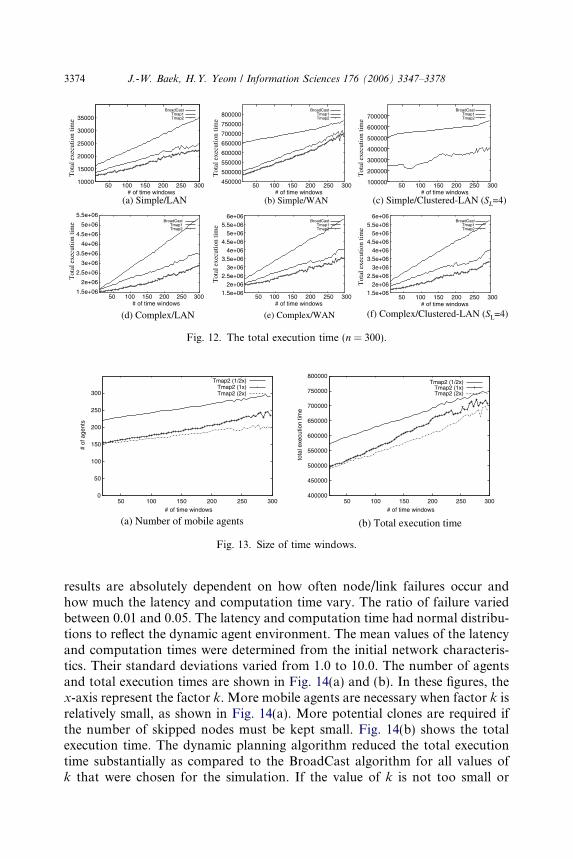
When the problem size was large (n = 300), we evaluated the performance ofboth algorithms by comparing their results with BroadCast. Fig. 11 shows therequired number of agents for three different algorithms: Tmap1, Tmap2, andBroadCast. In a specific configuration, i.e., the Simple/Clustered-LAN case,which is commonly regarded as the Internet topology, the numbers of agentsof Tmap1 and Tmap2 were fewer than 38% and 9% of BroadCast values onaverage, respectively, as shown in Fig. 11. Tmap1 and Tmap2 showed amarked reduction in the total execution time in all cases. In a specific configu-ration, i.e., Simple/Clustered-LAN, Tmap2 achieved a 57% reduction in thenumber of agents and a 74% reduction in the average total execution time com-pared to BroadCast. Tmap2 showed a 91% reduction in the total executiontime at 300 nodes on average in the Simple/Clustered-LAN case. As the num-ber of time windows increased, more mobile agents were needed, and the totalexecution time increased (Fig. 12). This is a major enhancement in agent plan-ning technology.
Fig. 13 shows the effect of the size of time windows on the results. The sizesof the time windows of Tmap2 (1/2·) and Tmap2 (2·) were about 50% and200% those of the time windows of Tmap2 (1·), respectively. As the numberof time windows and the size of the time windows increased, more mobileagents were needed, and the total execution time increased. The performanceof the algorithm deteriorated as the time constraints at the nodes becamestricter.
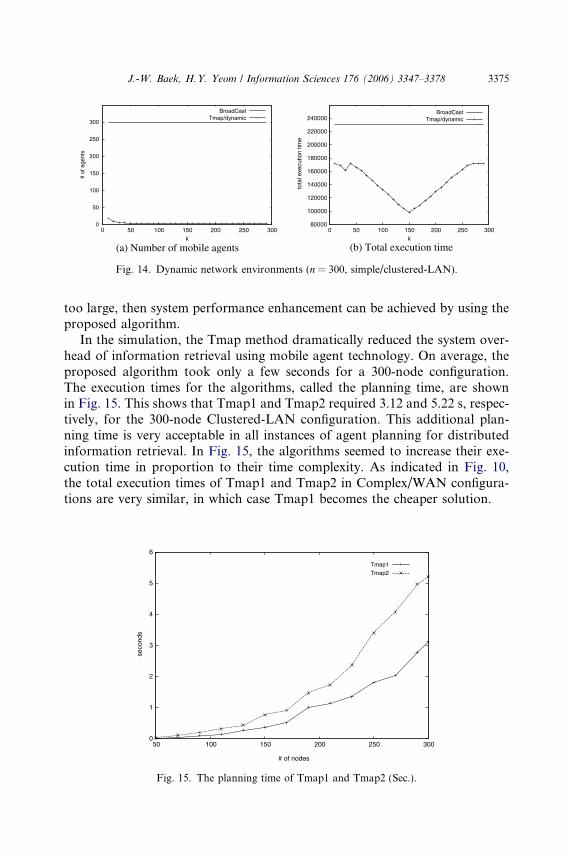
The following simulation, illustrated in Fig. 14, shows how the results areaffected in dynamic network environments, such as with node/link failureand variable latency and computation values, when an agent is roaming. These
0
50
100
150
200
250
300
50 100 150 200 250 300
# of
age
nts
0
50
100
150
200
250
300
# of
age
nts
0
50
100
150
200
250
300
# of
age
nts
0
50
100
150
200
250
300
# of
age
nts
0
50
100
150
200
250
300
# of
age
nts
0
50
100
150
200
250
300
# of
age
nts
# of time windows50 100 150 200 250 300
# of time windows50 100 150 200 250 300
# of time windows
50 100 150 200 250 300# of time windows
50 100 150 200 250 300# of time windows
50 100 150 200 250 300# of time windows
(a) Simple/LAN (b) Simple/WAN (c) Simple/Clustered-LAN (SL=4)
(d) Complex/LAN (e) Complex/WAN (f) Complex/Clustered-LAN (SL=4)
Fig. 11. The number of agents (n = 300).
10000
15000
20000
25000
30000
35000
50 100 150 200 250 300
Tot
al e
xecu
tion
time
Tot
al e
xecu
tion
time
Tot
al e
xecu
tion
time
Tot
al e
xecu
tion
time
Tot
al e
xecu
tion
time
Tot
al e
xecu
tion
time
# of time windows50 100 150 200 250 300
# of time windows
50 100 150 200 250 300# of time windows
50 100 150 200 250 300# of time windows
50 100 150 200 250 300# of time windows
450000
500000
550000
600000
650000
700000
750000
800000
100000
200000
300000
400000
500000
600000
700000
1.5e+06
2e+06
2.5e+06
3e+06
3.5e+06
4e+06
4.5e+06
5e+06
5.5e+06
50 100 150 200 250 300# of time windows
1.5e+062e+06
2.5e+063e+06
3.5e+064e+06
4.5e+065e+06
5.5e+066e+06
1.5e+062e+06
2.5e+063e+06
3.5e+064e+06
4.5e+065e+06
5.5e+066e+06
(a) Simple/LAN (b) Simple/WAN (c) Simple/Clustered-LAN (SL=4)
(d) Complex/LAN (e) Complex/WAN (f) Complex/Clustered-LAN (SL=4)
Fig. 12. The total execution time (n = 300).
0
50
100
150
200
250
300
50 100 150 200 250 300
# of
age
nts
# of time windows
Tmap2 (1/2x)Tmap2 (1x)Tmap2 (2x)
400000
450000
500000
550000
600000
650000
700000
750000
800000
50 100 150 200 250 300
tota
l exe
cutio
n tim
e
# of time windows
Tmap2 (1/2x)Tmap2 (1x)Tmap2 (2x)
(a) Number of mobile agents (b) Total execution time
Fig. 13. Size of time windows.
3374 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
results are absolutely dependent on how often node/link failures occur andhow much the latency and computation time vary. The ratio of failure variedbetween 0.01 and 0.05. The latency and computation time had normal distribu-tions to reflect the dynamic agent environment. The mean values of the latencyand computation times were determined from the initial network characteris-tics. Their standard deviations varied from 1.0 to 10.0. The number of agentsand total execution times are shown in Fig. 14(a) and (b). In these figures, thex-axis represent the factor k. More mobile agents are necessary when factor k isrelatively small, as shown in Fig. 14(a). More potential clones are required ifthe number of skipped nodes must be kept small. Fig. 14(b) shows the totalexecution time. The dynamic planning algorithm reduced the total executiontime substantially as compared to the BroadCast algorithm for all values ofk that were chosen for the simulation. If the value of k is not too small or
0
50
100
150
200
250
300
0 50 100 150 200 250 300
# of
age
nts
k
BroadCastTmap/dynamic
80000
100000
120000
140000
160000
180000
200000
220000
240000
0 50 100 150 200 250 300
tota
l exe
cutio
n tim
e
k
BroadCastTmap/dynamic
(a) Number of mobile agents (b) Total execution time
Fig. 14. Dynamic network environments (n = 300, simple/clustered-LAN).
J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3375
too large, then system performance enhancement can be achieved by using theproposed algorithm.
In the simulation, the Tmap method dramatically reduced the system over-head of information retrieval using mobile agent technology. On average, theproposed algorithm took only a few seconds for a 300-node configuration.The execution times for the algorithms, called the planning time, are shownin Fig. 15. This shows that Tmap1 and Tmap2 required 3.12 and 5.22 s, respec-tively, for the 300-node Clustered-LAN configuration. This additional plan-ning time is very acceptable in all instances of agent planning for distributedinformation retrieval. In Fig. 15, the algorithms seemed to increase their exe-cution time in proportion to their time complexity. As indicated in Fig. 10,the total execution times of Tmap1 and Tmap2 in Complex/WAN configura-tions are very similar, in which case Tmap1 becomes the cheaper solution.
0
1
2
3
4
5
6
50 100 150 200 250 300
seco
nds
# of nodes
Tmap1
Tmap2
Fig. 15. The planning time of Tmap1 and Tmap2 (Sec.).

3376 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
7. Conclusions
Previous MAP approaches are inappropriate for dynamic network environ-ments, such as P2P networks, because they do not consider time constraints ordynamic network conditions. The proposed approach tries to minimize thenumber of mobile agents and the total execution time, even when some nodeshave time constraints, in order to realize better system performance and qualityof service. Furthermore, the proposed approach can take advantage ofdynamic network environments, continually adjusting the itineraries of mobileagents by monitoring and adapting to changing network conditions. The sim-ulation study showed that overall system performance is markedly better usingthe algorithm than one that uses as many mobile agents as there are nodes inthe network. The proposed approach greatly enhances system performanceusing mobile agents for distributed information retrieval in dynamic networkenvironments. We also provide a security and fault-tolerance mechanism tobetter adapt to actual network environments.
References
[1] O. Babaoglu, H. Meling, A. Montresor, Anthill: a framework for the development of agent-based peer-to-peer systems, in: Proceedings of the 22nd International Conference onDistributed Computing Systems, Vienna, Austria, 2002, pp. 15–22.
[2] J.-W. Baek, G.-T. Kim, H.Y. Yeom, Timed mobile agent planning for distributed informationretrieval, in: Proceedings of the International Conference on Autonomous Agent, Montreal,Canada, 2001, pp. 120–121.
[3] J.-W. Baek, G.-T. Kim, H.Y. Yeom, Cost effective planning of timed mobile agent, in:Proceedings of the 22nd International Conference on Information Technology, Las Vegas,USA, 2002, pp. 536–542.
[4] J.-W. Baek, J.-H. Yeo, G.-T. Kim, H.Y. Yeom, Cemap: cost-effective mobile agent planning,International Journal of Cooperative Information Systems 13 (2) (2004) 159–181.
[5] J.-W. Baek, J.-H. Yeo, G.-T. Kim, H.Y. Yeom, Cost effective mobile agent planning fordistributed information retrieval, in: Proceedings of the 21st International Conference onDistributed Computing Systems, Phoenix, Arizona, USA, 2001, pp. 65–72.
[6] J.-W. Baek, J.-H. Yeo, H.Y. Yeom, Agent chaining: an approach to mobile agent planning, in:Proceedings of the 22nd International Conference on Distributed Computing Systems, Vienna,Austria, 2002, pp. 579–585.
[7] J. Baumann, F. Hohl, K. Rothermel, M. Straer, W. Theilmann, Mole: a mobile agent system,Software-Practice & Experience 32 (6) (2002) 575–603.
[8] P. Bellavista, A. Corradi, C. Stefanelli, Mobile agent middleware for mobile computing, IEEEComputer 34 (3) (2001) 73–81.
[9] E.Z. Bem, Protecting mobile agents in a hostile environment, in: Proceedings of the ICSCSymposia on Intelligent Systems and Applications, Sydney, Australia, 2000.
[10] L.F. Bic, M. Fukuda, M.B. Dillencourt, F. Merchant, Messengers: distributed programmingusing mobile agents, Journal of Integrated Design and Process Science 5 (4) (2001) 95–112.
[11] N. Borselius, Mobile agent security, Electronics and Communication Engineering Journal 14(5) (2002) 211–218.

J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378 3377
[12] H. Braun, On solving traveling salesman problems by genetic algorithms, in: Proceedings ofthe 1st Workshop on Parallel Problem Solving from Nature, Berlin, Germany, 1991, pp. 129–133.
[13] J. Bredin, Market-based control of mobile-agent systems, Ph.D. Thesis, Dartmouth College,2001.
[14] B. Brewington, R. Gray, K. Moizumi, D. Kotz, G. Cybenko, D. Rus, Mobile agents indistributed information retrieval, in: M. Klusch (Ed.), Intelligent Information Agents,Springer-Verlag, Heidelberg, Germany, 1999, pp. 355–395.
[15] R. Brooks, Mobile code paradigms and security issues, IEEE Internet Computing 8 (3) (2004)54–59.
[16] G. Cabri, L. Leonardi, F. Zambonelli, Agents for information retrieval: issues of mobility andcoordination, Journal of Systems Architecture 46 (15) (2000) 1419–1433.
[17] K.L. Calvert, M.B. Doar, E.W. Zegura, Modeling internet topology, IEEE CommunicationsMagazine 35 (6) (1997) 160–163.
[18] W. Caripe, G. Cybenko, K. Moizumi, R. Gray, Network awareness and mobile agent systems,IEEE Communications Magazine 36 (7) (1998) 44–49.
[19] W.R. Cockayne, M. Zyda, Mobile Agents, Manning Publications Co., Greenwich, CT, USA,1997.
[20] B. Cubaleska, M. Schneider, Applying trust policies for protecting mobile agents against dos,in: Proceedings of the 3rd International Workshop on Policies for Distributed Systems andNetworks, Monterey, USA, 2002, pp. 198–201.
[21] P. Dasgupta, Improving peer-to-peer resource discovery using mobile agent based referrals, in:Proceedings of the 2nd International Workshop on Agents and Peer-to-Peer Computing,Melbourne, Australia, 2003, pp. 186–197.
[22] O. de Kretser, A. Moffat, T. Shimmin, J. Zobel, Methodologies for distributed informationretrieval, in: Proceedings of the 18th International Conference on Distributed ComputingSystems, Amsterdam, The Netherlands, 1998, pp. 26–29.
[23] M.B. Doar, A better model for generating test networks, in: Proceedings of the IEEE GlobalTelecommunications Conference, London, United Kingdom, 1996, pp. 86–93.
[24] V. Felmetsger, G. Vigna, Exploiting OS-level mechanisms to implement mobile code security,in: Proceedings of the 10th IEEE International Conference on Engineering of ComplexComputer Systems, Shanghai, China, 2005, pp. 234–243.
[25] R.S. Gray, G. Cybenko, D. Kotz, R.A. Peterson, D. Rus, D’agents: applications andperformance of a mobile-agent system, Software-Practice & Experience 32 (6) (2002) 543–573.
[26] E. Horowitz, S. Sahni, Fundamentals of Computer Algorithms, Computer Science Press, 1989.[27] S. Idreos, M. Koubarakis, P2p-diet: ad-hoc and continuous queries in peer-to-peer networks
using mobile agents, in: Proceedings of the 3rd Hellenic Conference on Artificial Intelligence,Samos, Greece, 2004, pp. 23–32.
[28] Y. Jiang, Z. Xia, Y. Zhong, S. Zhang, Defend mobile agent against malicious hosts inmigration itineraries, Microprocessors and Microsystems 28 (10) (2004) 531–546.
[29] D. Johansen, K.J. Lauvset, R. van Renesse, F.B. Schneider, N.P. Sudmann, K. Jacobsen, ATacoma retrospective, Software-Practice & Experience 32 (6) (2002) 605–619.
[30] T. Li, Z. Zhao, S. You, A-peer: an agent platform integrating peer-to-peer network, in:Proceedings of the 3rd International Symposium on Cluster Computing and the Grid, Tokyo,Japan, 2003, pp. 614–618.
[31] B.T. Loo, J.M. Hellerstein, R. Huebsch, S. Shenker, I. Stoica, Enhancing p2p file-sharing withan internet-scale query processor, in: Proceedings of the 30th International Conference onVery Large Data Bases, Toronto, Ontario, Canada, 2004, pp. 432–443.
[32] F. Lu, K. Bubendorfer, A RMI protocol for Aglets, in: Proceedings of the 27th Conference onAustralasian Computer Science, Dunedin, New Zealand, 2004, pp. 249–253.
[33] K. Moizumi, Mobile agent planning problems, Ph.D. Thesis, Dartmouth College, 1998.

3378 J.-W. Baek, H.Y. Yeom / Information Sciences 176 (2006) 3347–3378
[34] K. Moizumi, G. Cybenko, The traveling agent problem, Mathematics of Control, Signals, andSystems 14 (3) (2001) 213–232.
[35] S. Pears, J. Xu, C. Boldyreff, Mobile agent fault tolerance for information retrievalapplications: an exception handling approach, in: Proceedings of the 6th InternationalSymposium on Autonomous Decentralized Systems, Pisa, Italy, 2003, pp. 115–121.
[36] H. Peine, Application and programming experience with the Ara mobile agent system,Software-Practice & Experience 32 (6) (2002) 515–541.
[37] S. Pleisch, A. Schiper, Fatomas: a fault-tolerant mobile agent system based on the agent-dependent approach, in: Proceedings of the International Conference on Dependable Systemsand Networks, Goteborg, Sweden, 2001, pp. 215–224.
[38] S. Pleisch, A. Schiper, Fault-tolerant mobile agent execution, IEEE Transactions onComputers 52 (2) (2003) 209–222.
[39] S. Pleisch, A. Schiper, Approaches to fault-tolerant and transactional mobile agentexecution—an algorithm view, ACM Computing Surveys 36 (3) (2004) 219–262.
[40] J.A. Sanchez, S.N. Munoz, L.F. Ramirez, G.C. Duenas, Distributed information retrievalfrom web-accessible digital libraries using mobile agents, The European Journal for theInformatics Professional 3 (3) (2002) 37–43.
[41] J. Savoy, Information retrieval on the web: a new paradigm, The European Journal for theInformatics Professional 3 (3) (2002) 9–11.
[42] A. Selamat, M.H. Selamat, Analysis on the performance of mobile agents for query retrieval,Information Sciences 172 (3–4) (2005) 281–307.
[43] E. Sultanik, D. Artz, G. Anderson, M. Kam, W.C. Regli, M. Peysakhov, J. Sevy, N. Belov, N.Morizio, A. Mroczkowski, Secure mobile agents on ad hoc wireless networks, in: Proceedingsof the 15th Innovative Applications of Artificial Intelligence Conference, Acapulco, Mexico,2003, pp. 129–136.
[44] E.A. Sultanik, Mobile agent-based search for service discovery on dynamic peer-to-peernetworks, in: Proceedings of the 19th National Conference on Artificial Intelligence, San Jose,California, USA, 2004, pp. 974–975.
[45] C.-C. Tseng, P.J. Gmytrasiewicz, Time sensitive sequential myopic information gathering, in:Proceedings of the 32nd Annual Hawaii International Conference on System Sciences, Maui,Hawaii, 1999.
[46] Y. Tzitzikas, P. Constantopoulos, A decision theoretic model for information retrievalsupporting time constraints, in: Proceedings of the BCS-IRSG European Colloquium on IRResearch, Darmstadt, Germany, 2001.
[47] E. Vijil, S. Iyer, Identifying collusions: co-operating malicious hosts in mobile agent itineraries,in: Proceedings of the 2nd International Workshop on Security in Mobile Multi-AgentSystems, Bologna, Italy, 2002, pp. 60–65.
[48] S.T. Vuong, P. Fu, A security architecture and design for mobile intelligent agent systems,ACM SIGAPP Applied Computing Review 9 (3) (2001) 21–30.
[49] K.G. Zerfridis, H.D. Karatza, Brute force web search for wireless devices using mobile agents,Journal of Systems and Software 69 (1–2) (2004) 195–206.
[50] H. Zhang, W.B. Croft, B. Levine, V. Lesser, A multi-agent approach for peer-to-peer-basedinformation retrieval systems, in: Proceedings of the 3rd International Joint Conference onAutonomous Agents and Multi-Agent Systems, New York, USA, 2004, pp. 456–464.
[51] C. Zhou, Y. Sun, Spmh: a solution to the problem of malicious hosts, Journal of ComputerScience and Technology 17 (6) (2002) 738–748.