a tabu search algorithm for parallel machine total tardiness problem
TRANSCRIPT

Available online at www.sciencedirect.com
Computers & Operations Research 31 (2004) 397–414www.elsevier.com/locate/dsw
A tabu search algorithm for parallel machine total tardinessproblem
&Umit Bilge∗, Furkan K-ra.c, M&ujde Kurtulan, Pelin Pekg&un
Department of Industrial Engineering, Bo�gazic�i University, Bebek, 80815 Istanbul, Turkey
Received 1 April 2001; received in revised form 1 July 2002
Abstract
In this study, we consider the problem of scheduling a set of independent jobs with sequence dependentsetups on a set of uniform parallel machines such that total tardiness is minimized. Jobs have non-identicaldue dates and arrival times. A tabu search (TS) approach is employed to attack this complex problem. In orderto obtain a robust search mechanism, several key components of TS such as candidate list strategies, tabuclassi<cations, tabu tenure and intensi<cation/diversi<cation strategies are investigated. Alternative approachesto each of these issues are developed and extensively tested on a set of problems obtained from the literature.The results obtained are considerably better than those reported previously and constitute the best solutionsknown for the benchmark problems as to date.
Scope and purpose
Several surveys on parallel machine scheduling with due date related objectives (Oper. Res. 38(1) (1990)22; EJOR 38 (1989) 156; Oper. Res. 42 (1994) 1025) reveal that the NP-hard nature of the problem rendersit a challenging area for many researchers who studied various versions. However, most of these studiesmake the assumption that jobs are available at the beginning of the scheduling period, which is an importantdeviation form reality. In this study, as well as distinct due dates and ready times, features such as sequencedependent setup times and diCerent processing rates for machines are incorporated into the classical model.These enhancements approach the model to the actual practice at the expense of complicating the problemfurther. For this complex problem, we present a tabu search (TS) algorithm to minimize total tardiness andprovide the best solutions known for a set of benchmark problems.? 2003 Elsevier Ltd. All rights reserved.
Keywords: Scheduling; Parallel machines; Total tardiness problem; Sequence dependent setup times; Tabu search
∗ Corresponding author. Tel.: +90-212-263-1500; fax: +90-212-265-1800.E-mail address: [email protected] ( &U. Bilge).
0305-0548/04/$ - see front matter ? 2003 Elsevier Ltd. All rights reserved.doi:10.1016/S0305-0548(02)00198-3

398 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
1. Introduction
The classical parallel machine total tardiness problem (PMTP) can be stated as follows [1–3]: Aset of independent jobs is to be processed on a number of continuously available identical parallelmachines. Each machine can process only one job at a time, and each job can be processed on onemachine. Each job is ready at the beginning of the scheduling horizon and has a distinct processingtime and a distinct due date. The objective is to determine a schedule such that total tardiness isminimized, where tardiness of a job is the amount of time its completion time exceeds its duedate. The problem is NP-hard even for a single machine (Du and Leung [4]) and exact methodsin which the dimensionality problem is acute are mostly limited to special cases like common duedates and equal processing times (i.e. Root [5], Lawler [6], Elmaghraby and Park [7], Dessouky [8]).A large class of heuristics is based on list scheduling where the jobs are <rst prioritised accordingto some rule and then dispatched in this order to the machine with the earliest <nish time. Suchheuristics are proposed by Wilkerson and Irwin [9], Dogramaci and Surkis [10], Ho and Chang [11]and Koulamas [3]. Koulamas [12] also developed a decomposition heuristic and a hybrid simulatedannealing heuristic, while Bean [13] applied a genetic algorithm (GA) heuristic to the PMTP.
In all the studies cited above it is assumed that machines are identical, all jobs are available attime zero and setup times are non-existent. However, in many real-world situations there exist (i)distinct job ready dates, (ii) uniform parallel machines that are capable of processing these jobs atdiCerent speeds (i.e. new machines versus old machines) and (iii) sequence dependent setups. Inthis paper, these features are also incorporated into the model so as to de<ne a problem closer toreality albeit far more complex than the classical one.
In this generalized version of parallel machine total tardiness problem (GPMTP), there are n jobsto be processed on m machines of k types. Machines belonging to the same type are identical whereasmachines belonging to diCerent types are uniform. Each job i has an integer processing time pki ona type k machine, an integer ready time ri, a distinct due date di and a sequence dependent setuptime skji of processing job i immediately after job j on a type k machine. For a given processingorder of the jobs, the earliest completion time Ci and the tardiness Ti can be computed for each job,where tardiness is de<ned as Ti = max{0; Ci − di}. The objective is to <nd the processing order ofthe jobs that minimizes the sum of the tardiness of all the jobs.
This paper presents a tabu search (TS) approach to the GPMTP de<ned above. Tabu search (Gloverand Laguna [14], Reeves [15]) is a meta-heuristic that guides a local heuristic search procedure toexplore the solution space beyond local optimality. TS allows intelligent problem solving by theincorporation of adaptive memory and responsive exploration. Key elements of the search pathare selectively remembered and strategic choices are made to guide the search out of local optimaand into diverse regions of the solution space. The adaptive memory usage is a clever compromisebetween the rigid memory structure of exact techniques like Branch & Bound and the memorylessheuristics like local search procedures.
A large number of successful applications of TS for scheduling problems can be found in literature.Laguna et al. [16] study the single machine scheduling problem with the objective of minimizing thesum of setup costs and delay penalties and propose a TS algorithm that uses a hybrid neighbourhood.James and Buchanan [17] develop enhanced TS strategies for the single machine early/tardy schedul-ing problem. H&ubscher and Glover [18] apply a candidate list strategy and introduce an inOuentialdiversi<cation to parallel machine scheduling to minimize the makespan. Nowicki and Smutnicki

&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 399
[19] present a TS to minimize makespan in a Oow shop with parallel machines, and employ aneighbourhood based on blocks of operations on a critical path. A similar block approach is usedby Liaw [20] for makespan minimization in an open shop. Park and Kim [21] compare simulatedannealing and TS for a parallel machine scheduling problem where jobs have equal due dates andequal ready times for minimizing holding costs.
When jobs are allowed to have distinct arrival times as well as due dates, diCerent processingrates on machines and sequence dependent setup times, the literature becomes really sparse. Thereare only two studies reported on this more general problem to our knowledge and both of them dealwith minimizing the total earliness-tardiness costs: S.erifoPglu and Ulusoy [22] present a GA witha new crossover operator, while Balakrishnan et al. [23] report a compact mathematical model tosolve small sized (up to 10 jobs) problems.
The TS algorithm proposed here is tested using the problem set given in Serifoglu and Ulusoy[22] and the results are compared to their results for the case where the weight of the earlinesspenalty is zero (In this case their problem also reduces to total tardiness problem).
The next section describes the key aspects of the TS approach used. Section 3 compares sev-eral alternative approaches leading towards a robust TS algorithm tailored to solve the problem athand, and evaluates the performance of this algorithm through numerical experimentation. The paperconcludes with discussion of results and further studies in Section 4.
2. Description of the tabu search approach
This section outlines the totally deterministic TS algorithm tailored to the GPMTP by discussingseveral of the key concepts such as solution encoding, initial solutions, tabu classi<cations, candidatelist structures, tabu tenure and intensi<cation/diversi<cation strategies.
2.1. Solution representation
Considering a schedule with nj jobs on each machine j, where n =∑m
j=1 nj, the solution isrepresented as m partial schedules as shown in Fig. 1. The objective value of a solution representedin this manner is obtained by going through the sequence of jobs over each machine and summingup the tardiness of each job, calculated by taking into account the distinct ready times, due dates,diCerent processing times on diCerent types of machines, and sequence dependent setup times.
2.2. Initial solutions
In the presence of distinct ready times, sequence dependent set up times and uniform machines,list scheduling heuristics using priority rules such as shortest processing time or minimum slack timedo not produce good results. Due to the same reason, more sophisticated list scheduling heuristicsdeveloped for the classical PMTP [3,9,11] cannot be readily used, either. Earliest Due Date (EDD)based list scheduling, however, performs agreeably well and is used to generate starting solutionsfor TS. Here, jobs are ordered with respect to their EDD and then scheduled on the machine thatwill complete them earliest.

400 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Machine 1 1 2 3 .. .. .. .. .. .. n1
Machine 2 1 2 3 .. .. .. .. .. .. .. n2
:
:
:
Machine j 1 2 3 .. .. .. .. nj
:
:
:
Machine m 1 2 3 .. .. .. nm
Fig. 1. Solution representation.
2.3. Neighbourhood generation
Insert moves and pairwise exchanges (swaps) are two of the frequently used move types inpermutation problems. An insert move identi<es two particular jobs and places the <rst job in thelocation that directly precedes the location of the second job. A swap move, on the other hand,places each job in the location previously occupied by the other, and can be considered as a movethat combines two insert moves. In the parallel machine scheduling problem the new locations maybe on diCerent machines as well as on the same machine. Swap moves involving jobs on diCerentmachines do not cause a change in the number of jobs on machines.
The neighbourhood used in this study has a “hybrid” structure. It consists of the complete “insertneighbourhood” where all the intra-machine and inter-machine insert moves are considered, withthe addition of a partial “swap neighbourhood” which consists of inter-machine swap moves only.In other words, only those swaps that involve two jobs each on diCerent machines are considered.Hence, the neighbourhood includes also the moves that create diCerent sequences without changingthe number of jobs on machines.
2.4. Candidate list strategies
For situations where the neighbourhood of a solution is large or its elements are expensive toevaluate, candidate list strategies are essential to restrict the number of solutions examined on a giveniteration [16]. The purpose of these rules is to screen the neighbourhood so as to concentrate onpromising moves at each iteration. When the aggressive nature of TS in selecting the next solution isconsidered, rules for generating and evaluating good candidates become critical for the eSciency of

&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 401
the search process. Since jobs have distinct ready times, diCerent processing times on diCerent typesof machines and sequence dependent setup times, calculation of total tardiness for a given move is atedious task. Although this is implemented in an eScient way by <rst determining the aCected jobsand updating the tardiness values for only those jobs, move value calculation is still time consuming.Therefore, a good candidate list strategy, which saves time, is critical for the eSciency of the TSalgorithm.
In this study three candidate list strategies, which are described below, are tested. Since the swapneighbourhood is already small, these strategies are applied only for insert moves.
2.4.1. The maximum tardy vs. maximum early approachIn this approach, only the jobs on “the machine with the highest contribution to total tardiness” are
chosen as candidates for inserting on “the machine with the highest contribution to total earliness”,as explained below:
• Calculate the contribution of each machine j to total tardiness as∑
i∈Ij Ti, where Ij is the set ofjobs scheduled on machine j.
• Select the machine with highest contribution to total tardiness, and call it machine kT .• Calculate the contribution of each machine j to total earliness as
∑i∈Ij Ei, where Ei is the earliness
of job i given by Ei = max{0; di − Ci}.• Select the machine with highest contribution to total earliness, and call it machine kE .• Consider every job on machine kT for an insertion on machine kE .
Since this approach has been shown to be quite fast and decreases the size of the neighbourhoodconsiderably, it is called the ‘High Candidate List Strategy’.
2.4.2. The maximum tardy approachIn this approach, “the machine with the highest contribution to total tardiness” is speci<ed as
explained above. Then, only the jobs on this machine are considered for an insert operation on anyother machine. Since the neighbourhood screening introduced is less, this approach is slower and itis called the ‘Low Candidate List Strategy’.
2.4.3. The ready time closeness approachIn this approach, job i is allowed to be inserted after job j only if the completion time of job j in
the current schedule is within a range of the ready time of job i, i.e. |ri − Cj|6 a threshold value.Thus, the amount of time job i spends waiting (when ri ¡Cj) or the inserted idleness on the machine(when Cj ¡ri) is bounded. The threshold value is a measure of closeness of the two jobs. Sincethe aim of candidate list strategy is to save time, the threshold value has to be simple and easy tocompute. Moreover, it should not be too restrictive, and it should be dependent on data speci<c tothe problem instance. For these reasons, instead of trying to develop sophisticated bounds that applyunder diCerent cases, the threshold value is chosen to be the sum of the maximum processing timeand the maximum setup time of all the jobs. This strategy is called the ‘Closeness Candidate ListStrategy’.

402 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
2.5. Tabu classi<cation
In this study, two alternatives for tabu classi<cations are used. Tabu classi<cation 1 (TC1) isposition related and therefore has an arc approach, which classi<es all schedules that include arc((i− 1); i) as tabu, where i is the job that moves and (i− 1) is its immediate predecessor before themove. Thus TC1 prohibits a recently moved job i from becoming the immediate successor of job(i− 1) again during tabu duration. This requires all newly added arcs by a move to be checked fortheir tabu status. Tabu classi<cation 2 (TC2) on the other hand, is related to the path of the search,banning employed moves to be repeated within tabu tenure. If the move just performed is to insertjob i after job (j − 1), “inserting job i after job j − 1” becomes tabu-active, while on swappingjob i with job j, “swapping job i with job j” becomes tabu-active. Evidently, this tabu classi<cationrequires only a single check for each candidate move and introduces computational speed.
The last element to be mentioned here is the aspiration criterion, which allows the tabu status ofa move to be overridden if it yields a solution better than the best obtained so far.
2.6. Tabu tenure
Two approaches for tenure selection are employed in this study: using a single tenure valuethroughout the search versus systematically varying the tenure among a number of values.
For the <rst approach, the range of tenure values that provides good performance for each problemsize are identi<ed and then an empirical rule that depends on the size of the problem instance andyields a <xed tenure value within these ranges is determined.
The systematic dynamic tenure strategy tested in this paper consists of creating a sequence of small(S), medium (M) and large (L) tabu tenure values all in the ranges determined as stated above andrepeating this sequence throughout the search. Varying tabu tenure in this manner actually providesa balance between intensi<cation and diversi<cation. Short tabu tenures allow close examination ofa region, while long tenures help moving to diCerent parts of the solution space [24].
2.7. Long-term strategies
Although some intensi<cation and diversi<cation aspects are introduced in the TS mechanismthrough the use of systematic dynamic tenure, these concepts are further investigated by developingsome long-term strategies.
The diversi<cation strategy used in this study is diCerent than what is usually employed in literaturein that it does not use frequency based information but rather relies on realizing that the search istrapped in some undesirable region (i.e. a deep valley or a large plateau) and forcing it out byresorting to a very large tenure which literally means remembering the whole search history. Thediversi<cation phase commences by multiplying the current tenure value by a large multiplier after apre-speci<ed number of non-improving iterations during the normal course of TS. After a speci<ednumber of diversi<cation iterations a major disruption is achieved and the short-term memory TS isresumed.
The intensi<cation strategy employed consists of keeping a bounded length sequential list of elitesolutions during the short-term memory TS and, after erasing all memory, restarting and carrying

&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 403
Fig. 2. Sample screen for ‘WinMeta’.
out a search of a given length from each of these solutions. An elite solution is de<ned as a solutionthat can survive as the best-so-far for a given number of iterations.
3. Computational studies
A software called “WinMeta” is implemented by the authors in Visual C++ to conduct thenecessary experimentation. WinMeta can generate new problem instances with speci<c parameters inuser-de<ned ranges, or take previously created problems as inputs. All the strategies developed in thisstudy are provided in a menu-format. The solution scheme for a problem instance can be speci<ed bythe user by selecting a combination of these strategies and providing a set of parameters via a userfriendly Graphical User Interface. WinMeta produces an on-line total tardiness-total earliness graphof the run, which enables the user to get a clear idea of the topology of the search space. A samplescreen of WinMeta is provided in Fig. 2. These features of the software allow Oexible experimentaldesign and easy tuning of the parameters employed. Taking full advantage of the capabilities of thesoftware developed, extensive experimentation is performed. The experiments are conducted on a

404 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Table 1Problem design parameters
Number of jobs: n 20, 40, 60Number of machines: m 2, 4Maximum setup duration: Amax 4,8
Pentium 4- 1:6 GHz CPU, Host Bus 133 MHz with 512 MB RAM. The problem set and the resultsobtained are presented in the next sections.
3.1. Example problems
Although WinMeta can be used to generate a new set of problems, in this study the benchmarkproblem set due to S.erifoPglu and Ulusoy [22] is used. Their test problems were generated using thedesign in Table 1 with 20 instances for each combination. The details regarding the generation ofproblems are as follows: The machines considered belong to one of two diCerent types, Types Iand II, which have the same characteristics except that they have diCerent processing rates. Type IImachines are older technology machines and the processing time of a job on Type II machine is 10–20% larger than on a Type I machine. Likewise, setup times on a Type II machine are 20–40% largerthan the corresponding setup times on a Type I machine. The processing times on a Type I machine,pIi , are obtained from the uniform distribution U [4,20], and to generate the processing times for the
Type II machine, pIIi , multipliers are chosen from the interval [1:10; 1:20] randomly and applied to
the corresponding processing time on machine Type I. Setup times on a Type I machine, sIji, are ob-
tained from the uniform distribution U [1; Amax], where two levels of maximum setup time, Amax, areutilized. Multipliers are randomly chosen from the interval [1:20; 1:40] and used to obtain the corre-sponding setup time on machine Type II. Ready times, ri, have the uniform distribution U [1; Rmax],where Rmax is the maximum ready time. Rmax is computed as �( XpII + XsII)(n=m− 1)�, where the <rstterm in parentheses is the sum of the average processing time and average setup time on machineType II, and the smallest integer greater than or equal to the entire expression is used. The slack timefor the jobs is set to XpII + XsII. Lastly, due dates are computed as di = ri + maxj sIIji +p
IIi + slack [22].
From this set of problems, the 40-job and 60-job problem sets with maximum set-up durationof 4 time-units are used in our study. The 20-job set is discarded because it turned out to betrivial for the total tardiness measure. Thus the test set used consists of 80 problems. The <rst twodigits in the problem name encoding correspond to the number of jobs, third digit to the numberof machines, the fourth to maximum setup length and the last two digits give the instance number.As an example, problem “40247” is the seventh instance of the 40 jobs-2 machines case with amaximum setup duration of 4 time units. The data for the problem sets is scaled up by 100 to avoiddecimal numbers.
3.2. Designing the short-term memory TS algorithm
The experiments performed at this phase are aimed at designing a short-term memory TS for theproblem under consideration by comparing the alternative approaches discussed previously. For allthe experiments a stopping criterion of 5000 non-improving iterations is applied.

&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 405
Table 2Comparison of the candidate list strategies
Problem type Average % improvement over EDD-based initial solution for 10 problem instances
Candidate list strategy
Low High Closeness
60 jobs—2 machines 53.43 50.21 51.3260 jobs—4 machines 77.19 67.90 63.97
The <rst step is to compare the performances of the two tabu classi<cation methods. These ex-periments are restricted to the <rst 10 problems of the 60-job set. Each method is employed overa tenure range of [0–250] in increments of 10. For each problem, the percent improvement of theTS result from the EDD-based initial solution (i.e. (EDD-result)/EDD) at each tenure value andthe average of the percent improvements over the stated range of tenure values are computed. TC2gives quite competitive results with those of TC1, 61.79% versus 62.28%, respectively. Furthermore,TC2 is faster. Thus, TC2 is selected as the tabu classi<cation to be used for the rest of the study.
As the second step, the <rst 10 problems in the 60-job and 40-job sets are tested with tabutenures over the range [0–250] in increments of 10 in order to determine a good tabu tenure value.This extensive experimentation reveals that no single tenure value can give the best solutions to allproblem instances, but good sub-ranges of tenure values can be located. So the eCorts are turned todesigning an empirical formula depending on problem size that yields an eCective tenure for eachclass of problems. As a result, k × n
√n turns out to be a reasonable compromise with k = 0:5.
However, the same formula performs poorly when applied with a candidate list strategy since acandidate list strategy reduces the neighbourhood size considerably and the tenure value has to bediscounted accordingly. After further experimentation, the tenure formula to be used along with acandidate list strategy is determined as k × n√n=(m− 0:5), where again, k = 0:5.
The last step is the comparison of the candidate list strategies using this empirical formula. Theresults for the <rst 10 problems in the 60-job set are summarized in Table 2. It can be concludedfrom these results that the “Low” candidate list strategy dominates the others.
3.3. Performance evaluation for the short-term memory TS algorithm
The short-term memory TS algorithm developed above is used in solving all 80 problems in theproblem set and the results are presented in the second and third columns of Tables 3–6.
It is not possible to obtain the optimal results for the benchmark problems by means of an exactmethod. A good lower bound for the PMTP with setup times and ready times is not available either.Therefore, the best solutions known for the problems are used for performance evaluation. The bestknown solution to each instance is obtained as the minimum of EDD-based list scheduling heuristic,the GA solution reported in [22], and the best TS result encountered throughout this study includingpreliminary analyses and parameter <ne-tuning under any combination of parameters and strategies.It is important to note that the latter always gives the minimum. These best-known solutions tobenchmark problems are reported in Table 7.

406 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Table 3Final results for problems with 40 jobs and 2 machines
Cycle string M M LMMSMM M MStrategies None Low Low+ Low+ Low+
dynamic diversi<cation intensi<cationNon-improving 5000 5000 5000 8000 8000iterations
Problem Result % Dev Result % Dev Result % Dev Result % Dev Result % Dev
40241 14 079 0.00 14 079 0.00 14 079 0.00 14 079 0.00 14 079 0.0040242 3946 0.00 4013 1.67 3946 0.00 3946 0.00 3946 0.0040243 3335 0.00 3335 0.00 3335 0.00 3335 0.00 3335 0.0040244 10 758 6.16 10 095 0.00 10 095 0.00 10 095 0.00 10 095 0.0040245 19 703 0.04 19 748 0.27 19 722 0.14 19 748 0.27 19 703 0.0440246 26 767 1.48 26 372 0.00 26 372 0.00 26 372 0.00 26 372 0.0040247 18 565 0.00 18 565 0.00 19 324 3.93 18 565 0.00 18 565 0.0040248 37 513 0.00 37 658 0.39 37 789 0.73 37 658 0.39 37 658 0.3940249 1142 7.62 1055 0.00 1055 0.00 1055 0.00 1055 0.00402410 1270 18.27 1038 0.00 1038 0.00 1038 0.00 1038 0.00402411 1726 0.00 1835 5.94 1869 7.65 1726 0.00 1726 0.00402412 8288 1.07 8331 1.58 8465 3.14 8331 1.58 8199 0.00402413 8382 0.00 8382 0.00 8382 0.00 8382 0.00 8382 0.00402414 5860 0.00 5869 0.15 5869 0.15 5869 0.15 5860 0.00402415 21 977 1.88 22 378 3.64 22 134 2.58 22 134 2.58 22 190 2.83402416 43 502 0.00 43 502 0.00 43 502 0.00 43 502 0.00 43 502 0.00402417 15 816 0.00 15 816 0.00 15 976 1.00 15 816 0.00 15 816 0.00402418 6391 8.21 5866 0.00 6430 8.77 5866 0.00 5866 0.00402419 27 258 0.00 27 258 0.00 28 192 3.31 27 258 0.00 27 258 0.00402420 2934 1.60 2934 1.60 2974 2.93 2934 1.60 2934 1.60
Average % deviation 2.32 0.76 1.72 0.33 0.24
Average CPU 18.50 14.20 11.50 19.05 22.50
Hence, in all the tables below presenting the experimental results, the “% dev” column indicatesthe value ((result − best-known)=result × 100), where “best-known” is the solution given in Table7 and “result” is the solution given by TS under the corresponding strategy. Those problems withzero initial solution are skipped and this situation is indicated by a “—” in the percent deviationcolumns. The CPU times are reported in seconds.
The second column in Tables 3–6, referred as “None”, represents the case when there is nocandidate list strategy, while the third column represents the case when the candidate list strategyis “Low”. The results indicate that the “Low” candidate list strategy is very powerful, not onlyimproving the performance but also dramatically decreasing the CPU time. As problem size isincreased from 40 jobs-2 machines (Table 3) to 60 jobs-4 machines (Table 6) the complexityincreases in both sequencing and allocation aspects of the problem. Average percentage of deviationfrom the best solution known comply with this fact.
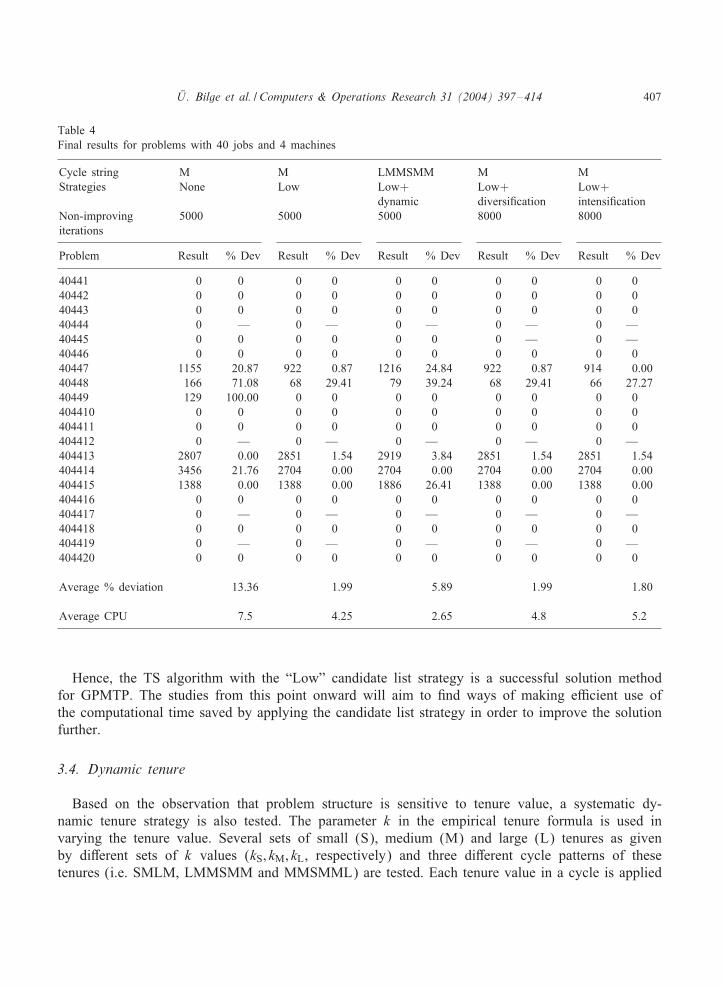
&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 407
Table 4Final results for problems with 40 jobs and 4 machines
Cycle string M M LMMSMM M MStrategies None Low Low+ Low+ Low+
dynamic diversi<cation intensi<cationNon-improving 5000 5000 5000 8000 8000iterations
Problem Result % Dev Result % Dev Result % Dev Result % Dev Result % Dev
40441 0 0 0 0 0 0 0 0 0 040442 0 0 0 0 0 0 0 0 0 040443 0 0 0 0 0 0 0 0 0 040444 0 — 0 — 0 — 0 — 0 —40445 0 0 0 0 0 0 0 — 0 —40446 0 0 0 0 0 0 0 0 0 040447 1155 20.87 922 0.87 1216 24.84 922 0.87 914 0.0040448 166 71.08 68 29.41 79 39.24 68 29.41 66 27.2740449 129 100.00 0 0 0 0 0 0 0 0404410 0 0 0 0 0 0 0 0 0 0404411 0 0 0 0 0 0 0 0 0 0404412 0 — 0 — 0 — 0 — 0 —404413 2807 0.00 2851 1.54 2919 3.84 2851 1.54 2851 1.54404414 3456 21.76 2704 0.00 2704 0.00 2704 0.00 2704 0.00404415 1388 0.00 1388 0.00 1886 26.41 1388 0.00 1388 0.00404416 0 0 0 0 0 0 0 0 0 0404417 0 — 0 — 0 — 0 — 0 —404418 0 0 0 0 0 0 0 0 0 0404419 0 — 0 — 0 — 0 — 0 —404420 0 0 0 0 0 0 0 0 0 0
Average % deviation 13.36 1.99 5.89 1.99 1.80
Average CPU 7.5 4.25 2.65 4.8 5.2
Hence, the TS algorithm with the “Low” candidate list strategy is a successful solution methodfor GPMTP. The studies from this point onward will aim to <nd ways of making eScient use ofthe computational time saved by applying the candidate list strategy in order to improve the solutionfurther.
3.4. Dynamic tenure
Based on the observation that problem structure is sensitive to tenure value, a systematic dy-namic tenure strategy is also tested. The parameter k in the empirical tenure formula is used invarying the tenure value. Several sets of small (S), medium (M) and large (L) tenures as givenby diCerent sets of k values (kS; kM; kL, respectively) and three diCerent cycle patterns of thesetenures (i.e. SMLM, LMMSMM and MMSMML) are tested. Each tenure value in a cycle is applied
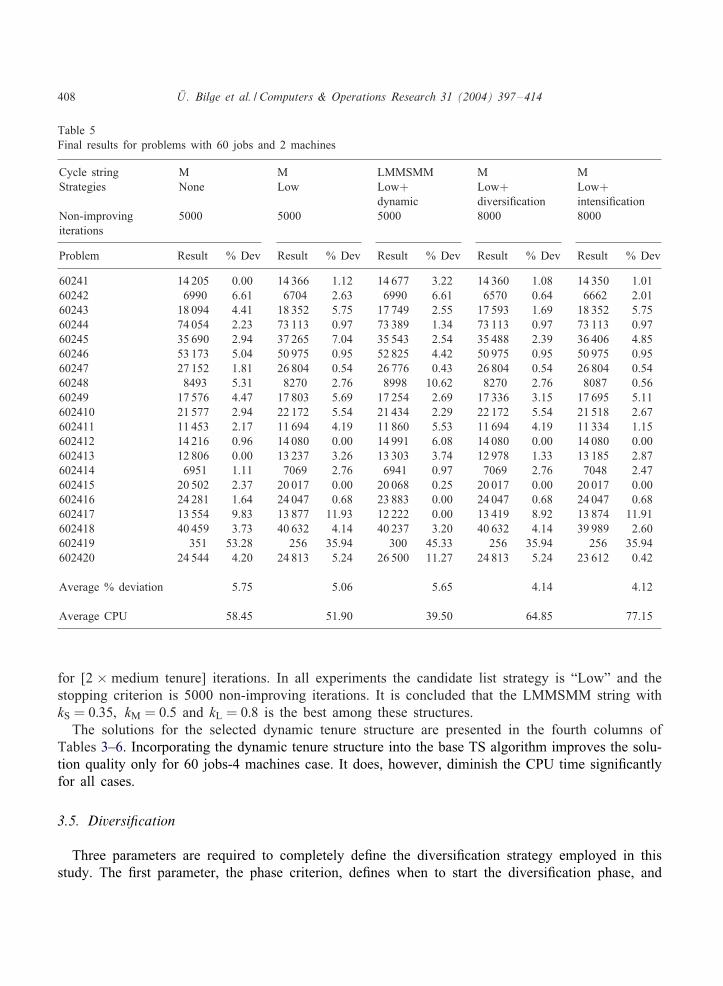
408 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Table 5Final results for problems with 60 jobs and 2 machines
Cycle string M M LMMSMM M MStrategies None Low Low+ Low+ Low+
dynamic diversi<cation intensi<cationNon-improving 5000 5000 5000 8000 8000iterations
Problem Result % Dev Result % Dev Result % Dev Result % Dev Result % Dev
60241 14 205 0.00 14 366 1.12 14 677 3.22 14 360 1.08 14 350 1.0160242 6990 6.61 6704 2.63 6990 6.61 6570 0.64 6662 2.0160243 18 094 4.41 18 352 5.75 17 749 2.55 17 593 1.69 18 352 5.7560244 74 054 2.23 73 113 0.97 73 389 1.34 73 113 0.97 73 113 0.9760245 35 690 2.94 37 265 7.04 35 543 2.54 35 488 2.39 36 406 4.8560246 53 173 5.04 50 975 0.95 52 825 4.42 50 975 0.95 50 975 0.9560247 27 152 1.81 26 804 0.54 26 776 0.43 26 804 0.54 26 804 0.5460248 8493 5.31 8270 2.76 8998 10.62 8270 2.76 8087 0.5660249 17 576 4.47 17 803 5.69 17 254 2.69 17 336 3.15 17 695 5.11602410 21 577 2.94 22 172 5.54 21 434 2.29 22 172 5.54 21 518 2.67602411 11 453 2.17 11 694 4.19 11 860 5.53 11 694 4.19 11 334 1.15602412 14 216 0.96 14 080 0.00 14 991 6.08 14 080 0.00 14 080 0.00602413 12 806 0.00 13 237 3.26 13 303 3.74 12 978 1.33 13 185 2.87602414 6951 1.11 7069 2.76 6941 0.97 7069 2.76 7048 2.47602415 20 502 2.37 20 017 0.00 20 068 0.25 20 017 0.00 20 017 0.00602416 24 281 1.64 24 047 0.68 23 883 0.00 24 047 0.68 24 047 0.68602417 13 554 9.83 13 877 11.93 12 222 0.00 13 419 8.92 13 874 11.91602418 40 459 3.73 40 632 4.14 40 237 3.20 40 632 4.14 39 989 2.60602419 351 53.28 256 35.94 300 45.33 256 35.94 256 35.94602420 24 544 4.20 24 813 5.24 26 500 11.27 24 813 5.24 23 612 0.42
Average % deviation 5.75 5.06 5.65 4.14 4.12
Average CPU 58.45 51.90 39.50 64.85 77.15
for [2 × medium tenure] iterations. In all experiments the candidate list strategy is “Low” and thestopping criterion is 5000 non-improving iterations. It is concluded that the LMMSMM string withkS = 0:35; kM = 0:5 and kL = 0:8 is the best among these structures.
The solutions for the selected dynamic tenure structure are presented in the fourth columns ofTables 3–6. Incorporating the dynamic tenure structure into the base TS algorithm improves the solu-tion quality only for 60 jobs-4 machines case. It does, however, diminish the CPU time signi<cantlyfor all cases.
3.5. Diversi<cation
Three parameters are required to completely de<ne the diversi<cation strategy employed in thisstudy. The <rst parameter, the phase criterion, de<nes when to start the diversi<cation phase, and
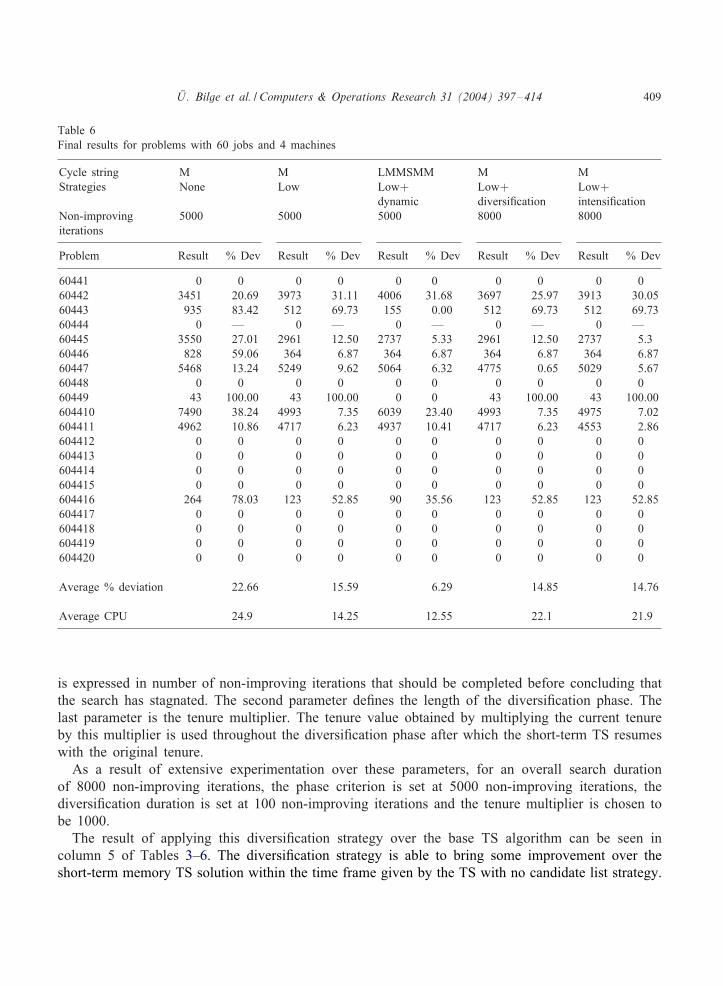
&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 409
Table 6Final results for problems with 60 jobs and 4 machines
Cycle string M M LMMSMM M MStrategies None Low Low+ Low+ Low+
dynamic diversi<cation intensi<cationNon-improving 5000 5000 5000 8000 8000iterations
Problem Result % Dev Result % Dev Result % Dev Result % Dev Result % Dev
60441 0 0 0 0 0 0 0 0 0 060442 3451 20.69 3973 31.11 4006 31.68 3697 25.97 3913 30.0560443 935 83.42 512 69.73 155 0.00 512 69.73 512 69.7360444 0 — 0 — 0 — 0 — 0 —60445 3550 27.01 2961 12.50 2737 5.33 2961 12.50 2737 5.360446 828 59.06 364 6.87 364 6.87 364 6.87 364 6.8760447 5468 13.24 5249 9.62 5064 6.32 4775 0.65 5029 5.6760448 0 0 0 0 0 0 0 0 0 060449 43 100.00 43 100.00 0 0 43 100.00 43 100.00604410 7490 38.24 4993 7.35 6039 23.40 4993 7.35 4975 7.02604411 4962 10.86 4717 6.23 4937 10.41 4717 6.23 4553 2.86604412 0 0 0 0 0 0 0 0 0 0604413 0 0 0 0 0 0 0 0 0 0604414 0 0 0 0 0 0 0 0 0 0604415 0 0 0 0 0 0 0 0 0 0604416 264 78.03 123 52.85 90 35.56 123 52.85 123 52.85604417 0 0 0 0 0 0 0 0 0 0604418 0 0 0 0 0 0 0 0 0 0604419 0 0 0 0 0 0 0 0 0 0604420 0 0 0 0 0 0 0 0 0 0
Average % deviation 22.66 15.59 6.29 14.85 14.76
Average CPU 24.9 14.25 12.55 22.1 21.9
is expressed in number of non-improving iterations that should be completed before concluding thatthe search has stagnated. The second parameter de<nes the length of the diversi<cation phase. Thelast parameter is the tenure multiplier. The tenure value obtained by multiplying the current tenureby this multiplier is used throughout the diversi<cation phase after which the short-term TS resumeswith the original tenure.
As a result of extensive experimentation over these parameters, for an overall search durationof 8000 non-improving iterations, the phase criterion is set at 5000 non-improving iterations, thediversi<cation duration is set at 100 non-improving iterations and the tenure multiplier is chosen tobe 1000.
The result of applying this diversi<cation strategy over the base TS algorithm can be seen incolumn 5 of Tables 3–6. The diversi<cation strategy is able to bring some improvement over theshort-term memory TS solution within the time frame given by the TS with no candidate list strategy.

410 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Table 7The best solutions known for the benchmark problems
Problem Best-known Problem Best-known Problem Best-known Problem Best-known
40241 14 079 40441 0 60241 14 205 60441 040242 3946 40442 0 60242 6528 60442 273740243 3335 40443 0 60243 17 296 60443 15540244 10 095 40444 0 60244 72 406 60444 040245 19 695 40445 0 60245 34 640 60445 259140246 26 372 40446 0 60246 50 492 60446 33940247 18 565 40447 914 60247 26 660 60447 474440248 37 513 40448 48 60248 8042 60448 040249 1055 40449 0 60249 16 790 60449 0
402410 1038 404410 0 602410 20 943 604410 4626402411 1726 404411 0 602411 11 204 604411 4423402412 8199 404412 0 602412 14 080 604412 0402413 8382 404413 2807 602413 12 806 604413 0402414 5860 404414 2704 602414 6874 604414 0402415 21 563 404415 1388 602415 20 017 604415 0402416 43 502 404416 0 602416 23 883 604416 58402417 15 816 404417 0 602417 12 222 604417 0402418 5866 404418 0 602418 38 948 604418 0402419 27 258 404419 0 602419 164 604419 0402420 2887 404420 0 602420 23 514 604420 0
When those 60-job problems that give non-zero solutions under base TS are examined, it is observedthat nine out of 29 are improved in this way. Therefore, this is an eScient way of using the timesaved by applying the “Low” candidate list strategy especially for larger sized problems.
3.6. Intensi<cation
The number and nature of the elite solutions to be stored during the short-term memory TSshould be speci<ed in order to fully describe the intensi<cation strategy used in this study. Also,the duration of intensi<cation around each local optimum and the search strategy to be used duringthe intensi<cation phase have to be de<ned. Through experimentation, it is decided that intensifyingaround two elite solutions, where an elite solution is de<ned as a best solution that cannot beimproved for at least 300 iterations, provides good results. The intensi<cation phase is adopted after5000 non-improving iterations of short-term memory TS and lasts for 1500 non-improving iterationsaround each elite solution.
Interestingly, the best results are obtained when the candidate list strategy is dropped duringintensi<cation. This is expected because including the moves previously screened by the candidatelist strategy allows closer examination of the neighbourhood around the local optima and launchesa new search path.
In Tables 3–6 where the <nal results are summarized, the intensi<cation column (column 6) usesthe above combination of parameters. Generally, the intensi<cation strategy performs better than the
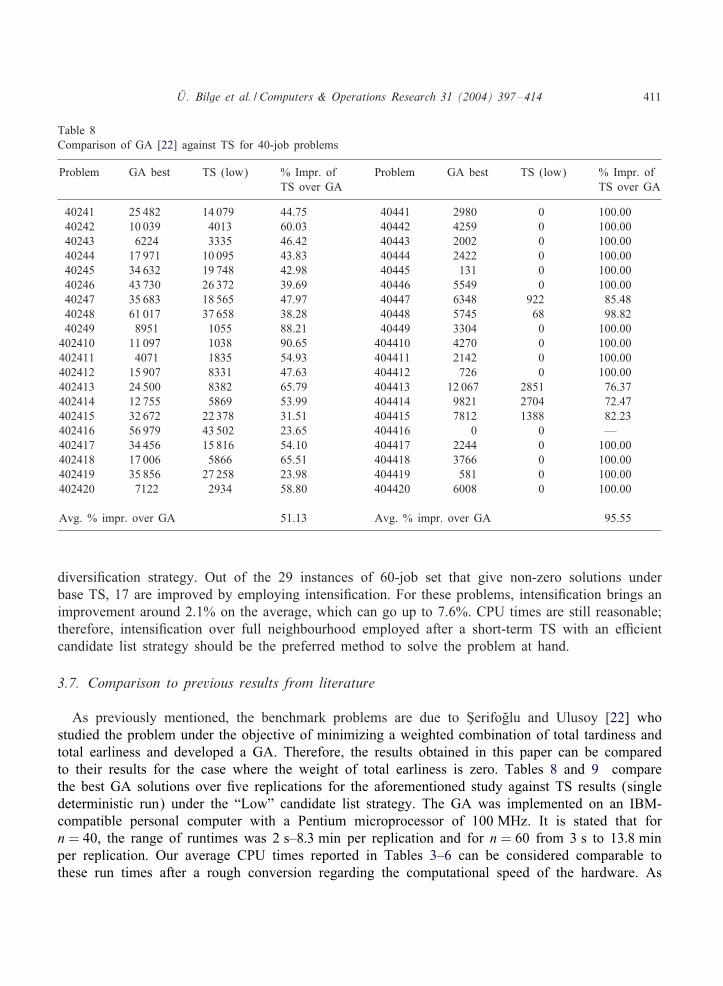
&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 411
Table 8Comparison of GA [22] against TS for 40-job problems
Problem GA best TS (low) % Impr. of Problem GA best TS (low) % Impr. ofTS over GA TS over GA
40241 25 482 14 079 44.75 40441 2980 0 100.0040242 10 039 4013 60.03 40442 4259 0 100.0040243 6224 3335 46.42 40443 2002 0 100.0040244 17 971 10 095 43.83 40444 2422 0 100.0040245 34 632 19 748 42.98 40445 131 0 100.0040246 43 730 26 372 39.69 40446 5549 0 100.0040247 35 683 18 565 47.97 40447 6348 922 85.4840248 61 017 37 658 38.28 40448 5745 68 98.8240249 8951 1055 88.21 40449 3304 0 100.00
402410 11 097 1038 90.65 404410 4270 0 100.00402411 4071 1835 54.93 404411 2142 0 100.00402412 15 907 8331 47.63 404412 726 0 100.00402413 24 500 8382 65.79 404413 12 067 2851 76.37402414 12 755 5869 53.99 404414 9821 2704 72.47402415 32 672 22 378 31.51 404415 7812 1388 82.23402416 56 979 43 502 23.65 404416 0 0 —402417 34 456 15 816 54.10 404417 2244 0 100.00402418 17 006 5866 65.51 404418 3766 0 100.00402419 35 856 27 258 23.98 404419 581 0 100.00402420 7122 2934 58.80 404420 6008 0 100.00
Avg. % impr. over GA 51.13 Avg. % impr. over GA 95.55
diversi<cation strategy. Out of the 29 instances of 60-job set that give non-zero solutions underbase TS, 17 are improved by employing intensi<cation. For these problems, intensi<cation brings animprovement around 2.1% on the average, which can go up to 7.6%. CPU times are still reasonable;therefore, intensi<cation over full neighbourhood employed after a short-term TS with an eScientcandidate list strategy should be the preferred method to solve the problem at hand.
3.7. Comparison to previous results from literature
As previously mentioned, the benchmark problems are due to S.erifoPglu and Ulusoy [22] whostudied the problem under the objective of minimizing a weighted combination of total tardiness andtotal earliness and developed a GA. Therefore, the results obtained in this paper can be comparedto their results for the case where the weight of total earliness is zero. Tables 8 and 9 comparethe best GA solutions over <ve replications for the aforementioned study against TS results (singledeterministic run) under the “Low” candidate list strategy. The GA was implemented on an IBM-compatible personal computer with a Pentium microprocessor of 100 MHz. It is stated that forn= 40, the range of runtimes was 2 s–8:3 min per replication and for n= 60 from 3 s to 13:8 minper replication. Our average CPU times reported in Tables 3–6 can be considered comparable tothese run times after a rough conversion regarding the computational speed of the hardware. As

412 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
Table 9Comparison of GA [22] against TS for 60-job problems
Problem GA best TS (low) % Impr. of Problem GA best TS (low) % Impr. ofTS over GA TS over GA
60241 72 860 14 366 80.28 60441 27 626 0 100.0060242 74 948 6704 91.06 60442 23 326 3973 82.9760243 93 203 18 352 80.31 60443 40 861 512 98.7560244 127 175 73 113 42.51 60444 18 057 0 100.0060245 110 234 37 265 66.19 60445 13 608 2961 78.2460246 148 363 50 975 65.64 60446 9732 364 96.2660247 59 213 26 804 54.73 60447 22 731 5249 76.9160248 69 940 8270 88.18 60448 33 076 0 100.0060249 98 100 17 803 81.85 60449 25 279 43 99.83
602410 91 911 22 172 75.88 604410 36 781 4993 86.43602411 58 755 11 694 80.10 604411 42 430 4717 88.88602412 54 686 14 080 74.25 604412 17 914 0 100.00602413 102 444 13 237 87.08 604413 30 541 0 100.00602414 88 232 7069 91.99 604414 9370 0 100.00602415 90 994 20 017 78.00 604415 20 035 0 100.00602416 84 974 24 047 71.70 604416 14 276 123 99.14602417 37 049 13 877 62.54 604417 32 919 0 100.00602418 81 804 40 632 50.33 604418 13 761 0 100.00602419 55 911 256 99.54 604419 13 442 0 100.00602420 119 553 24 813 79.25 604420 29 440 0 100.00
Avg. % impr. over GA 75.07 Avg. % impr. over GA 95.34
demonstrated in Tables 8 and 9, the short-term TS with the “Low” candidate list strategy yieldsmuch superior results. The diCerence in the performance can be attributed to the possibility ofearly convergence of the GA. The GA starts with a random population without seeding in any goodsolution, and most of the time the results are inferior to the solution given by the EDD list schedulingheuristic. It seems that the authors concentrated on the new crossover operator they proposed ratherthan aggressively searching for the best results to the problem set they have generated.
4. Conclusions
In this paper, a robust TS algorithm for the solution of a very complex parallel machine schedulingproblem where jobs have sequence dependent setup times, distinct due dates and ready times isinvestigated. The major components of TS are tackled through extensive experimentation and as aresult, a completely deterministic TS algorithm is developed. The performance of the algorithm istested using an existing set of problems from literature, and the obtained results are far better thanthose that were previously reported.
Moreover, this paper establishes the benchmark solutions for the problem set used under the totaltardiness criterion (Table 7). These best-known values are obtained by collating the best tabu search

&U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414 413
results encountered throughout the study including preliminary analyses under any combination ofparameters and strategies.
The most critical TS component in this algorithm is its context related candidate list strategy. Theso-called “Low” candidate list strategy considers job insertions from the machine with the maximumcontribution to total tardiness to each of the other machines. The results reveal that this candidatelist strategy is very successful in isolating desirable regions of the neighbourhood, thus not onlyincreases the speed of the search, but also improves the solution quality with its power to overcometopological traps and direct the search to good regions.
Generally, the proposed intensi<cation strategy performs better than the diversi<cation strategy forthese problems. However, both strategies are able to bring some improvement over the short-termmemory TS solution within the time frame given by the TS with no candidate list strategy. Therefore,this has been an eScient way of using the time saved by applying the “Low” candidate list strategy.Application of a dynamic tenure structure, to reduce the sensitivity to tenure value and to introducesystematic intensi<cation and diversi<cation, becomes promising as both number of jobs and numberof machines increase thereby increasing the complexity in both sequencing and allocation aspects ofthe problem.
The diversi<cation and intensi<cation strategies employed in this paper do not use any frequency-information and they are context-independent strategies that can be applied to any problem. It maybe an interesting further research to try to incorporate some problem dependent information increating inOuential moves towards some elite solutions or away from already searched regions forintensi<cation and diversi<cation purposes, respectively.
References
[1] Baker KR, Scudder GD. Sequencing with earliness and tardiness penalties: a review. Operations Research1990;38(1):22–35.
[2] Cheng TCE, Gupta MC. Survey of scheduling research involving due date determination decisions. EJOR 1989;38:156–66.
[3] Koulamas CP. The total tardiness problem: review and extensions. Operations Research 1994;42:1025–41.[4] Du J, Leung JYT. Minimizing total tardiness on one machine is NP-hard. Mathematics of Operations Research
1990;15:483–95.[5] Root JG. Scheduling with deadlines and loss functions on k parallel machines. Management Science 1965;11:
460–75.[6] Lawler EL. A ‘pseudopolynomial’ algorithm for sequencing jobs to minimize total tardiness. Annals of Discrete
Mathematics 1977;1:331–42.[7] Elmaghraby SE, Park SH. Scheduling jobs on a number of identical machines. AIIE Transactions 1974;6:1–13.[8] Dessouky MM. Scheduling identical jobs with unequal ready times on uniform parallel machines to minimize the
maximum lateness. Computers and Industrial Engineering 1998;34(4):793–806.[9] Wilkerson LJ, Irwin JD. An improved algorithm for scheduling independent tasks. AIIE Transactions 1971;3:
239–45.[10] Dogramaci A, Surkis J. Evaluation of a heuristic for scheduling independent jobs on parallel identical processors.
Management Science 1979;25:1208–16.[11] Ho JC, Chang YL. Heuristics for minimizing mean tardiness for m parallel machines. Naval Research Logistics
1991;38:367–81.[12] Koulamas C. Decomposition and hybrid simulated annealing heuristics for the parallel-machine total tardiness
problem. Naval Research Logistics 1997;44:109–25.

414 &U . Bilge et al. / Computers & Operations Research 31 (2004) 397–414
[13] Bean JC. Genetic algorithms and random keys for sequencing and optimization. ORSA Journal on Computing1994;6:154–60.
[14] Glover F, Laguna M. Tabu search. London: Kluwer Academic Publishers, 1997.[15] Reeves CR. Modern heuristic techniques for combinatorial problems. New York: John Wiley & Sons, 1993.[16] Laguna M, Barnes JW, Glover F. Tabu search methods for a single machine scheduling problem. Journal of Intelligent
Manufacturing 1991;2:63–74.[17] James RJW, Buchanan JT. Performance enhancements to tabu search for the early/tardy scheduling problem. EJOR
1998;106:254–65.[18] H&ubscher R, Glover F. Applying tabu search with inOuential diversi<cation to multiprocessor scheduling. Computers
Operations Research 1994;21(8):877–84.[19] Nowicki E, Smutnicki C. The Oow shop with parallel machines: a tabu search approach. EJOR 1998;106:226–53.[20] Liaw, Ching-Fang. A tabu search algorithm for the open shop scheduling problem. Computers Operations Research
1999;26:109–26.[21] Park M-W, Kim Y-D. Search heuristics for a parallel machine scheduling problem with ready times and due dates.
Computers and Industrial Engineering 1997;33(3–4):793–6.[22] Sivrikaya-S.erifoPglu F, Ulusoy G. Parallel machine scheduling with earliness and tardiness penalties. Computers
Operations Research 1999;26:773–87.[23] Balakrishnan N, Kanet JJ, Sridharan SV. Early/tardy scheduling with sequence dependent setups on uniform parallel
machines. Computers Operations Research 1999;26:127–41.[24] Costamagna E, Fanni A, Giacinto G. A tabu search algorithm for the optimization of telecommunication networks.
EJOR 1998;106:357–72.
�Umit Bilge is an Associate Professor of Industrial Engineering at BoPgazi.ci University, Istanbul. Her research and teach-ing interests include machine scheduling, production planning and control, design and analysis of advanced manufacturingsystems, and automated material handling systems. She has published research articles in Operations Research, Interna-tional Journal of Production Research, Computers & OR and Journal of Manufacturing Systems.
M�ujde Kurtulan who received her MS in Industrial Engineering from BoPgazi.ci University (2002) is currently workingfor European Patent OSce, Munich.
Pelin Pekg�un holds her MSIE from BoPgazi.ci University (2001). She is currently a Ph.D. student in Industrial andSystems Engineering in Georgia Institute of Technology.
Furkan K'ra(c received his MS in Systems and Control Engineering in 2002 and is currently studying towards a Ph.D.degree in Computer Engineering in BoPgazi.ci University. He is the developer of the software used in this study.