a problem space algorithm for single machine weighted tardiness problems
TRANSCRIPT

This article was downloaded by: [Ams/Girona*barri Lib]On: 16 October 2014, At: 05:53Publisher: Taylor & FrancisInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House,37-41 Mortimer Street, London W1T 3JH, UK
IIE TransactionsPublication details, including instructions for authors and subscription information:http://www.tandfonline.com/loi/uiie20
A problem space algorithm for single machine weightedtardiness problemsSELCUK AVCI a , M. SELIM AKTURK b & ROBERT H. STORER aa Department of Industrial and Systems Engineering, Lehigh University, Bethlehem, PA18015, USA E-mail: [email protected] Department of Industrial Engineering, Bilkent University, Ankara, Turkey E-mail:[email protected] online: 29 Oct 2010.
To cite this article: SELCUK AVCI , M. SELIM AKTURK & ROBERT H. STORER (2003) A problem space algorithm for singlemachine weighted tardiness problems, IIE Transactions, 35:5, 479-486, DOI: 10.1080/07408170304390
To link to this article: http://dx.doi.org/10.1080/07408170304390
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) containedin the publications on our platform. However, Taylor & Francis, our agents, and our licensors make norepresentations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose of theContent. Any opinions and views expressed in this publication are the opinions and views of the authors, andare not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be relied upon andshould be independently verified with primary sources of information. Taylor and Francis shall not be liable forany losses, actions, claims, proceedings, demands, costs, expenses, damages, and other liabilities whatsoeveror howsoever caused arising directly or indirectly in connection with, in relation to or arising out of the use ofthe Content.
This article may be used for research, teaching, and private study purposes. Any substantial or systematicreproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in anyform to anyone is expressly forbidden. Terms & Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

A problem space algorithm for single machine weightedtardiness problems
SELCUK AVCI1, M. SELIM AKTURK2 and ROBERT H. STORER1;*1Department of Industrial and Systems Engineering, Lehigh University, Bethlehem, PA 18015, USAE-mail: [email protected] of Industrial Engineering, Bilkent University, Ankara, TurkeyE-mail: [email protected]
Received March 2000 and accepted May 2002
We propose a problem space genetic algorithm to solve single machine total weighted tardiness scheduling problems. The proposedalgorithm utilizes global and time-dependent local dominance rules to improve the neighborhood structure of the search space.They are also a powerful exploitation (intensifying) tool since the global optimum is one of the local optimum solutions. Fur-thermore, the problem space search method significantly enhances the exploration (diversification) capability of the geneticalgorithm. In summary, we can improve both solution quality and robustness over the other local search algorithms reported in theliterature.
1. Introduction
In this paper we develop a Problem Space Genetic Al-gorithm (PSGA) for the single machine total weightedtardiness problem, 1j jPwjTj. The results are quite en-couraging relative to the best algorithm in the literature(Crauwels et al., 1998). In addition to developing an ef-fective algorithm for an important problem, we also in-vestigate some key questions regarding PSGA’s andprovide insight into their performance. PSGA’s have beenshown in previous research to be quite effective for avariety of scheduling problems (Storer et al., 1992, 1995).Intuitive explanations have been offered to account fortheir good performance, but little evidence exists to sub-stantiate these conjectures. In this paper we also provideinsight into the behavior of PSGA’s by investigating theeffect of various base heuristics on PSGA performance.In this section we first review research on the single ma-chine total weighted tardiness problem, followed by areview of PSGA.
1.1. The single machine total weighted tardiness problem
The single machine total weighted tardiness problem,1j jPwjTj, may be stated as follows. A set of jobs (in-dexed 1; . . . ; n) is to be processed without interruption on
a single machine that can process one job at a time. Alljobs become available for processing at time zero. Job jhas an integer processing time pj, a due date dj, and apositive weight wj. A weighted tardiness penalty is in-curred for each time unit of tardiness Tj if job j is com-pleted after its due date dj. The problem can be formallystated as: find a schedule S that minimizes f ðSÞ ¼Pn
j¼1 wjTj.Lawler (1977) showed that the problem is strongly NP-
hard. Emmons (1969) derived several dominance rulesthat restrict the search for an optimal solution to theunweighted problem. Rinnooy Kan et al. (1975) extendedthese results to the weighted tardiness problem. TheBranch and Bound (BB) algorithm of Potts and VanWassenhove (1985) can solve problems with up to 50jobs. Akturk and Yildirim (1998) proposed a new domi-nance rule and a lower bounding scheme for the1j jPwjTj problem that can be used to reduce the timecomplexity of any exact approach.Implicit enumerative algorithms for the total weighted
tardiness problem, such as the BB algorithm proposed byPotts and Wassenhove (1985), guarantee optimality butrequire considerable computational resources in terms ofboth computation time and memory. It is important tonote that due to the nature of the problem, the number oflocal minima is very large with respect to neighborhoodsbased on pairwise interchange. Therefore, several heu-ristics and dispatching rules have been proposed to gen-erate good, but not necessarily optimal solutions asdiscussed in Potts and Van Wassenhove (1991). The*Corresponding author
0740-817X � 2003 ‘‘IIE’’
IIE Transactions (2003) 35, 479–486
0740-817X � 2003 ‘‘IIE’’
0740-817X/03 $12.00+.00
DOI: 10.1080/07408170390187924
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

obvious disadvantage of these methods is that solutionsgenerated by simple heuristic methods may be far fromthe optimum. Crauwels et al. (1998) present several localsearch heuristics for the 1j jPwjTj problem. They in-troduce a new binary encoding scheme to represent so-lutions, together with a heuristic to decode the binaryrepresentations into actual sequences. This binary en-coding scheme is also compared to the usual permutationrepresentation for descent, simulated annealing, thres-hold accepting, tabu search and genetic algorithms on alarge set of problems.
1.2. Problem space genetic algorithms
Problem Space Genetic Algorithms have been used suc-cessfully in the past on various scheduling problems(Storer et al., 1995). Embedded within a PSGA is aconstructive base heuristic H : P ! S which maps aproblem instance data vector P to a solution sequence S.Given any solution sequence S, the objective functionV ðSÞ (total weighted tardiness) can be calculated. Let dbe a vector of perturbations. One can then define anoptimization problem on d 2 RN, the space of pertur-bations:
mind
V ½HðPþ dÞ�:
A PSGA uses the perturbation vector as the encodingof a solution (or chromosome). A chromosome (pertur-bation vector) d is ‘decoded’ into a sequence by apply-ing HðPþ dÞ, and its value obtained by applyingV ½HðPþ dÞ�. Unlike many applications of genetic algo-rithms to sequencing problems, standard crossover op-erators may be applied under this encoding.The reason for the success of PSGA’s has, in the past,
been explained intuitively by observing that good solu-tions will tend to lie near the point d ¼ 0 in problemspace. This makes sense since we expect the heuristic toprovide reasonable solutions to the original problemwhen perturbations are small. Since the neighborhoodaround d ¼ 0 consists mainly of good solutions, searchingthis neighborhood yields good results. In this paper weprovide empirical evidence of this observation by em-bedding various base heuristics within the PSGA.In Section 2 we develop a set of PSGA’s for the
problem that differ from each other by the embeddedbase heuristic, and by the search algorithm employed.The reason for developing these different versions of thePSGA is to show the effect of the base heuristic onproblem space neighborhood quality, and to provide in-sight into what makes the algorithm successful. In Section3 we conduct tuning experiments, then describe thecomputational testing in Section 4. In Section 5 we pre-sent the results, including a comparison to the results ofCrauwels et al. (1998) and a discussion of the insightgained about the PSGA.
2. Algorithm development
In this section we develop a set of PSGA’s for the1j jPwjTj problem. Version one uses the simple Ap-parent Tardiness Cost (ATC) dispatching rule by Mortonand Pentico (1993) as the base heuristic. The secondversion augments ATC with the Global Dominance (GD)rules of Rinnooy Kan et al. (1975). The final version ofthe base heuristic uses Local Dominance Rules (LDR)proposed by Akturk and Yildirim (1998) in addition tothe global dominance rules. The properties of the domi-nance rules guarantee that the solution generated byversion 2 is at least as good as that generated by version1, and similarly that version 3 solutions dominate version2. An algorithmic description of version 3 (ATC +GD + LDR) is discussed below. For version 1 (ATC),we skip Steps 2.1, 2.2, 2.3 and 2.8. For version 2(ATC + GD), we skip Steps 2.1 and 2.8. We first presentthe algorithm then describe each of the steps.
Algorithm:
Step 0. (Problem reduction pre-processing): Apply theglobal dominance rules of Rinnooy Kan et al.(1975). Let b be the set of jobs that are assignedto the first positions due to this rule, B be thecompletion time of set b, and the position indexk ¼ jbj.
Step 1. (Problem space genetic algorithm): Create theinitial population by randomly generating theperturbation vectors as chromosomes.
Step 2. (Base heuristic): For each individual perturba-tion vector i (or equivalently for every chromo-some in the GA population), set the current timet ¼ B, k ¼ k þ 1 and solve the following baseheuristic.Step 2.1. If t > tl then the remaining unsched-
uled jobs are sequenced using theSWPT rule, i.e., in non-increasingorder of wj=pj, and go to Step 2.8.
Step 2.2. For all unscheduled jobs at time t, de-termine the set of eligible jobs usingthe global dominance rule.
Step 2.3. If only one job is eligible, i.e., job m,then schedule job m at position k, andset t ¼ t þ pm and k ¼ k þ 1, otherwisego to Step 2.4. If there are no otherjobs remaining then go to Step 2.8,otherwise go to Step 2.1.
Step 2.4. For each eligible job j at time t, calculatethe ATC priorities as follows:
ajðtÞ ¼ wj
pj� exp �max ð0; dj � t� pjÞ
�
=ðl� �ppÞÞ:Step 2.5. The ATC priorities, ajðtÞ, are normali-
zed into the interval [0,1] yielding njðtÞ
480 Avci et al.
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

as follows. Let aminðtÞ ¼ minj
ajðtÞ andamaxðtÞ ¼ max
jajðtÞ then
njðtÞ ¼ ðajðtÞ � aminðtÞÞ = ðamaxðtÞ� aminðtÞÞ:
Step 2.6. Perturb the job priorities as follows:njðtÞ ¼ njðtÞ þ dj.
Step 2.7. Select the job j which has the highestperturbed normalized priority njðtÞþdj, and schedule it next in the se-quence. Set t ¼ t þ pj and k ¼ k þ 1. Ifthere are any unscheduled jobs go toStep 2.1.
Step 2.8. (Local dominance rule): Improve thesequence generated above for a givenperturbation vector i by applying theLocal Dominance Rule (LDR) basedon the Adjacent Pairwise Interchange(API) method proposed by AkturkandYildirim (1998). Calculate the totalweighted tardiness for the given per-turbation vector, denoted by V ðiÞ.
Step 3. If the generation number is less than the limitcontinue, otherwise stop.
Step 4. Calculate a fitness f ðiÞ for each perturbationvector i of the current generation as follows:
Let Vmax ¼ maxi
V ðiÞ; then
f ðiÞ ¼ ðVmax � V ðiÞÞp� X
i
ðVmax � V ðiÞÞp:
Step 5. Perform ‘evolutionary processes’ to get the nextgeneration using the fitness distribution and up-dated perturbation vectors. Go to Step 2.
In Step 0, we generate a n� n 0-1 global dominancematrix, in which an entry of one indicates that the job inrow i globally dominates the job in column j due to theglobal dominance theorem by Rinnooy Kan et al. (1975).Whenever jobs i and j satisfy this theorem, an arc ði; jÞ isadded to the precedence graph along with any other arcsthat are implied by the transitive property. In this matrix,RowSumðiÞ and ColSumðiÞ give the number of jobsguaranteed to be succeeding or preceding job i, respec-tively, in an optimum sequence. Let N be the number ofunscheduled jobs. If RowSumðiÞ ¼ N � 1 then job i willbe scheduled to the first available position. Similarly, ifColSumðjÞ ¼ N � 1 then job j will be scheduled to thelast available position. If we proceed iteratively in thesame manner, we can fix certain jobs to the first and lastpositions. As a result, we can reduce the problem size forcertain problem instances, and implement the local searchon this reduced set of jobs. We also use this globaldominance matrix to find a set of eligible jobs in Step 2.1.A job is called eligible if it is not globally dominated bysome other unscheduled job at time t.
Potts and Van Wassenhove (1991) applied an APImethod starting with the heuristic sequence obtained byapplying the ATC rule. The ATC rule is a compositedispatching rule that combines the Shortest WeightedProcessing Time (SWPT) rule and the minimum slackrule. Under the ATC rule jobs are scheduled one at atime; that is, every time the machine becomes free, apriority index is computed for each remaining job j. Thejob with the highest priority index is then selected to beprocessed next. The priority index is a function of thetime t at which the machine becomes free as well as pj, wj,and dj of the remaining jobs. We set the look-ahead pa-rameter l ¼ 2 as suggested by Morton and Pentico (1993),and �pp is the average processing time of the remainingunscheduled jobs.We use the global dominance theorem as a static
dominance rule, and also employ a time-dependent localdominance rule proposed by Akturk and Yildirim (1998)in Step 2.8 to improve the initial sequence given by theATC + GD rule. They show that the arrangement ofadjacent jobs in an optimal schedule depends on theirstart times. For each pair of jobs i and j that are adjacentin an optimal schedule, there can be a critical value tij(denoted as breakpoint) such that i precedes j if pro-cessing of this pair starts earlier than tij and j precedes i ifprocessing of this pair starts after tij. As a result, theystate a general rule that provides a sufficient condition forschedules that cannot be improved by adjacent job in-terchanges. They show that if any sequence violates theproposed dominance rule, then switching these jobs eitherreduces the total weighted tardiness or leaves it un-changed. Furthermore, let tl be the maximum breakpoint.Akturk and Yildirim (1998) also show that if t > tl thenthe SWPT rule gives an optimum sequence for the re-maining unscheduled jobs. Therefore, we use this rule inStep 2.1 to find an optimal sequence for the remainingjobs on hand after a time point tl.
3. Tuning experiments
With many GA tuning parameters, it is necessary toconduct separate experiments to determine appropriatevalues for each parameter and to assure that the final re-sults are not biased by tuning. To maintain unbiasedness,we generated a set of problems used for tuning indepen-dent of the problems ultimately used in testing. Based onsome initial trials, an experiment was designed to studythe tuning parameters at the levels given in Table 1.The last two factors in the experiment are range of due
date ‘RDD’ and tardiness factor ‘TF’. These factors de-termine the type of problem generated. By varying theRDD and TF factors, the experiments cover a broadrange of problem types. This will help find tuning pa-rameter values that work well across the range of possibleproblem types. For each of the 25 combinations of RDD
Single machine weighted tardiness problems 481
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

and TF, one instance with 100 jobs was generated. A fullfactorial experiment was conducted over all tuning fac-tors. For each combination of tuning parameters and foreach test problem, two algorithm runs were made withdifferent random number seeds, yielding two replicates(note that five replicates are used later in testing).In our first pass analysis of the results of the experi-
ment we observed that the variance was not constantacross the factors RDD and TF. As non-constant vari-ance violates the basic assumptions of the Analysis OfVariance (ANOVA), remedial measures were necessary.The reason for non-constant variance was readily ap-parent. Some combinations of RDD and TF producedeasy problems with ‘loose’ due dates. Regardless of thetuning parameter values, the PSGA easily found a solu-tion with zero total weighted tardiness for these easyproblems. Other combinations of RDD and TF producedproblems with a spectrum of difficulty levels. In generalwe observed higher variance on harder problems. Withineach of the 25 cells formed by combinations of RDD andTF, we had 192 responses. To stabilize the variance wetransformed each response to ‘percentage from best so-lution’ among the 192 in each cell. We then performed anANOVA on the transformed data.From the results of an ANOVA, we first note that
crossover type and selectivity parameter p have no sig-nificant effect on the results. We also note the percentsexual reproduction has little effect. Perturbation mag-nitude h, population size, and mutation probability allshowed significant effects. It is expected that populationsize would be significant since twice as many solutions aregenerated with POPSIZE 100 as opposed to 50. As onewould expect, both solution quality and computationtime to increase with population size. In the testing phasewe use both population sizes to examine the marginalbenefits of generating more solutions.The perturbation magnitude h was also significant as
expected. The experimental results show that h ¼ 0:5performed poorly, and that h ¼ 1 was marginally betterthan h ¼ 2. Our experience with problem space searchmethods indicates that performance is poor when h is toosmall, but that performance is reasonably robust when his larger than its optimal value. The experimental results
match precisely what we have learned from experience.Since h ¼ 1 provided the best results, we chose this levelin subsequent testing.The final significant tuning parameter was mutation
probability. A closer examination revealed an interactionbetween population size and mutation probability. Whenboth mutation probability and population size were attheir low levels (0.01 and 50 respectively), algorithmperformance was poor. At all other combinations oflevels, performance was roughly the same. Mutation isnecessary to maintain diversity in the gene pool of a ge-netic algorithm. This is especially true in problem spacegenetic algorithms where we have found that aggressiveselectivity works well. Our conclusion is that when bothPOPSIZE and MUTPROB are at their low levels, di-versity is lost too quickly leading to poor performance.Since we test with both small and large population sizes,and since mutation probability interacts with POPSIZE,we decided not to fix MUTPROB a priori, but rather toexamine its effects in testing as well. For a further dis-cussion on the use of different genetic operators in thePSGA framework, such as how the perturbation vectorsare found in each generation and how mutation is per-formed on each perturbation vector, we refer to Storeret al. (1992, 1995).We proceeded to the testing phase having fixed the
following tuning parameters: perturbation magnitudeh ¼ 1:0, selectivity p ¼ 4, and the crossover type is singlepoint. We also investigated the merits of several short GAruns (five runs of 200 generations) against a single longerrun (1000 generations). The performance did not varysignificantly thus we will use one long run in testing.To summarize, we will test various PSGA algorithms
by varying the parameters listed in Table 2.
Table 1. The values of the tuning parameters
Factors Number of levels Values
POPSIZE 2 50 100Perturbation magnitude h 3 0.5 1.0 2.0Selectivity p 2 2 4% SEXUAL 2 80% 100%Crossover type 2 Single point UniformMUTPROB 2 0.01 0.05RDD 5 0.2 0.4 0.6 0.8 1.0TF 5 0.2 0.4 0.6 0.8 1.0
Table 2. The parameters used in testing the PSGA algorithms
Parameter Level 1 Level 2 Level 3
Base heuristic ATC ATC þ GD ATC þ GD þ LDRPOPSIZE 50 100MUTPROB 0.01 0.05
482 Avci et al.
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

4. Description of experiments
To test the efficiency of the proposed PSGA’s, the re-quired programs were coded in the C language, compiledwith a Borland compiler, and run on a Gateway 2000model GP6-400 PC Pentium II 400 MHz with a memoryof 96 MB RAM. The proposed algorithms were tested ona series of randomly generated problems developed byCrauwels et al. (1998). In addition, we also generated 125new test problems for n ¼ 200 using the same uniformdistributions for pj, wj, RDD and TF. These new testproblems and the computer codes for the PSGA andLDR methods may be obtained from the authors.For each problem instance and factor combination, the
algorithmwas run five timeswith different randomnumberseeds. The various algorithmswere then compared in termsof the average deviation and the maximum deviation fromthe optimum (or best known) solution. The average andmaximumwere taken over the entire set of five replicates ofeach of 25 problem instances. The number of times (out of125) that an optimum (or best known) solution was foundwas denoted as total match, and the average CPU times inseconds was also reported. Results are summarized inTable 3 for each value of n. We also report the averagenumber of generations in which the best solution is found.The best solution values appearing in Crauwels et al.
(1998) for the 100 job problems are given on J.E. Beas-ley’s OR-Library web site (http://mscmga.ms.ic.ac.uk/jeb/orlib/wtinfo.html) as file wtbest100a. Subsequent unpub-lished research has found slightly better solutions forsome problems. These solutions are also available on thesame web site. In our tables, comparison to the publishedresults of Crauwels et al. (1998) appear in the row labeledn ¼ 100 (A). Comparisons to the best known (unpub-lished) solutions to date appear in the row labeledn ¼ 100 (B). In some cases we found better solutions tothe 100 job problems than those of Crauwels et al. (1998)(n ¼ 100 (A)). These are indicated as the ‘number of im-provements’. The total match values in row n ¼ 100 (A)indicate the number of times we found the exact samesolution as Crauwels et al. (1998).In order to find a ‘best known solution’ to each one of
the 125 instances for the 200 job problems, we took a verylong run with our best PSGA (using the LDR method).We used POPSIZE = 100, number of generations =5000 (as opposed to 200 in all experiments), %SEXUAL =0.8, MUTPROB = 0.01, h ¼ 1:0, p ¼ 4, and single pointcrossover. The algorithm was then run 10 times usingdifferent random number seeds, and the best solutionfound is reported as the best known.
5. Discussion of results
We begin by discussing the importance of the baseheuristic in the performance of the PSGA, and then
compare our results to the best known algorithms in theliterature.
5.1. Effects of the base heuristic
We developed PSGA’s with three different base heuris-tics, ATC, ATC + GD, and ATC + GD + LDR. Oneobvious question is how well each heuristic performs onits own when they run on the original problem data.Therefore, we present their results in parentheses in Table3, which indicate that the ATC + GD + LDR methodprovides a significant improvement over the ATC rule interms of average and maximum deviation. Furthermore,each successive base heuristic dominates the previous one.For each version, we tried several sets of GA parametervalues. The results were quite striking. As the base heu-ristic improves, the overall PSGA algorithm performancealso improves significantly. By improving the base heu-ristic, we were able to improve the quality of the neigh-borhood searched by the GA, and thus significantlyimprove the overall solution quality in all measures.Moreover, all of the PSGA’s provide a significant im-provement over the corresponding single pass heuristics.It is also worth noting that this improved performancecomes with a relatively small increase in the CPU time. Interms of the overall solution quality, the best solution isgiven by the parameter setting of MUTPROB = 0.01and POPSIZE = 100 for the ATC + GD + LDR baseheuristic. Crauwels et al. (1998) also note that a geneticalgorithm with the permutation representation performedso poorly compared to other local search heuristics, thatthey did not even report their results. This gives furthercredence to our observation that the neighborhoodstructure and encoding are far more important than thesearch mechanism.
5.2. Algorithm effectiveness
In the paper by Crauwels et al. (1998), the best resultswere obtained with tabu search. Their genetic algorithmwith a binary encoding scheme was comparable and usedless computation time than the other local search heu-ristics, but tabu search still gave the best overall results interms of average and maximum deviation. The resultsreported in Crauwels et al. (1998) were quite good. Basedon comparisons to optimal solutions for 40 and 50 jobproblems, there is little margin for improvement. Never-theless, our computational results show that our bestPSGA provided the largest total match, and the smallestaverage and maximum deviation (which also indicates itsrobustness) when compared to the best algorithm re-ported in Crauwels et al. (1998).Another important feature of the PSGA is its running
time behavior as a function of the number of jobs. InCrauwels et al. (1998), the local search heuristics were runon a HP 9000 - G50 computer. In their study, the genetic
Single machine weighted tardiness problems 483
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

Table 3. Computational Results
Base heuristic MUTPROB = 0.01
POPSIZE = 50 POPSIZE = 100
ATC ATC + GD ATC + GD +LDR
ATC ATC +GD
ATC +GD + LDR
n = 40 Total Match 72 (19) 81 (19) 122 (45) 79 86 125Ave. Dev. 0.31% (18.3) 0.26% (17.1) 0.00% (5.4) 0.18% 0.18% 0.00%Max. Dev. 9.4% (275) 8.1% (355) 0.20% (107) 8.3% 6.7% 0.0%Ave. Gen. 276.3 225.3 25.9 257.1 224.4 9.7CPU Time 31.4 (0.001) 13.3 (0.000) 14.7 (0.000) 62.9 26.3 29.3
n = 50 Total Match 53 (18) 57 (18) 119 (30) 59 66 121Ave. Dev. 0.52% (50.3) 0.43% (12.2) 0.01% (5.6) 0.23% 0.21% 0.00%Max. Dev. 10.7% (4200) 9.7% (182) 0.7% (128) 8.1% 8.1% 0.15%Ave. Gen. 373.5 274.3 54.5 388.6 238.9 33.8CPU Time 49.2 (0.002) 18.4 (0.000) 20.8 (0.000) 98.4 36.3 41.5
n = 100 (A) Total Match 38 (18) 40 (18) 95 (25) 41 39 101Ave. Dev. 4.73% (41.5) 1.0% (39.5) 0.02% (10.7) 4.7% 0.13% 0.0%Max. Dev. 552% (2225) 82% (2225) 0.97% (162) 552% 2.7% 0.1%Ave. Gen. 617.2 557.8 211.1 591.6 565.9 148.2Number of Improvements 0 0 3 0 0 0CPU Time 186.4 (0.007) 52.3 (0.001) 60.8 (0.001) 368.3 103.9 120.8
n = 100 (B) Total Match 38 (18) 40 (18) 94 (25) 41 39 103Ave. Dev. 4.73% (41.5) 1.00% (39.5) 0.02% (10.7) 4.70% 0.13% 0.00%Max. Dev. 552% (2225) 82% (2225) 0.97% (161.8) 552% 2.7% 0.1%Ave. Gen. 617.2 557.8 211.1 591.6 565.9 148.2Number of Improvements 0 0 0 0 0 0CPU Time 186.4 (0.007) 52.3 (0.001) 60.8 (0.001) 368.3 103.9 120.8
n = 200 Total Match 30 (21) 30 (21) 55 (24) 32 33 62Ave. Dev. 0.48% (16.2) 0.85% (15.5) 0.14% (12.0) 0.33% 0.40% 0.04%Max. Dev. 10.1% (154) 16.8% (157) 4.6% (142) 2.9% 7.8% 1.2%Ave. Gen. 689.6 709.3 429.3 692.9 685.4 418.9CPU Time 719 (0.026) 149.3 (0.004) 182 (0.003) 1414.5 297.4 362.1
MUTPROB=0.05
n = 40 Total Match 64 73 125 66 79 125Ave. Dev. 0.23% 0.06% 0.00% 0.11% 0.05% 0.00%Max. Dev. 9.38% 0.84% 0.00% 1.75% 0.56% 0.00%Ave. Gen. 389.12 244.31 5.97 415.73 277.18 4.78CPU Time 31.40 12.85 14.48 62.62 25.84 29.11
n = 50 Total Match 44 56 121 43 57 124Ave. Dev. 0.43% 0.25% 0.01% 0.39% 0.21% 0.00%Max. Dev. 8.09% 8.09% 1.27% 8.09% 8.09% 0.02%Ave. Gen. 495.30 405.3 34.15 510.15 365.57 42.11CPU Time 49.18 17.83 20.54 97.92 35.89 41.02
n = 100 (A) Total Match 37 39 86 32 42 83Ave. Dev. 4.39% 0.35% 0.01% 2.79% 0.27% 0.02%Max. Dev. 455.56% 11.42% 0.22% 266.67% 2.11% 0.30%Ave. Gen. 602.32 618.26 208.38 601.14 604.62 233.98Number of Improvements 0 0 0 0 0 0CPU Time 185.83 50.46 59.17 370.13 101.54 118.97
n = 100 (B) Total Match 37 39 86 32 42 83Ave. Dev. 4.39% 0.35% 0.01% 2.79% 0.27% 0.02%Max. Dev. 455.56% 11.42% 0.22% 266.67% 2.11% 0.30%Ave. Gen. 602.32 618.26 208.38 601.14 604.62 233.98Number of Improvements 0 0 0 0 0 0CPU Time 185.83 50.46 59.17 370.13 101.54 118.97
484 Avci et al.
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4
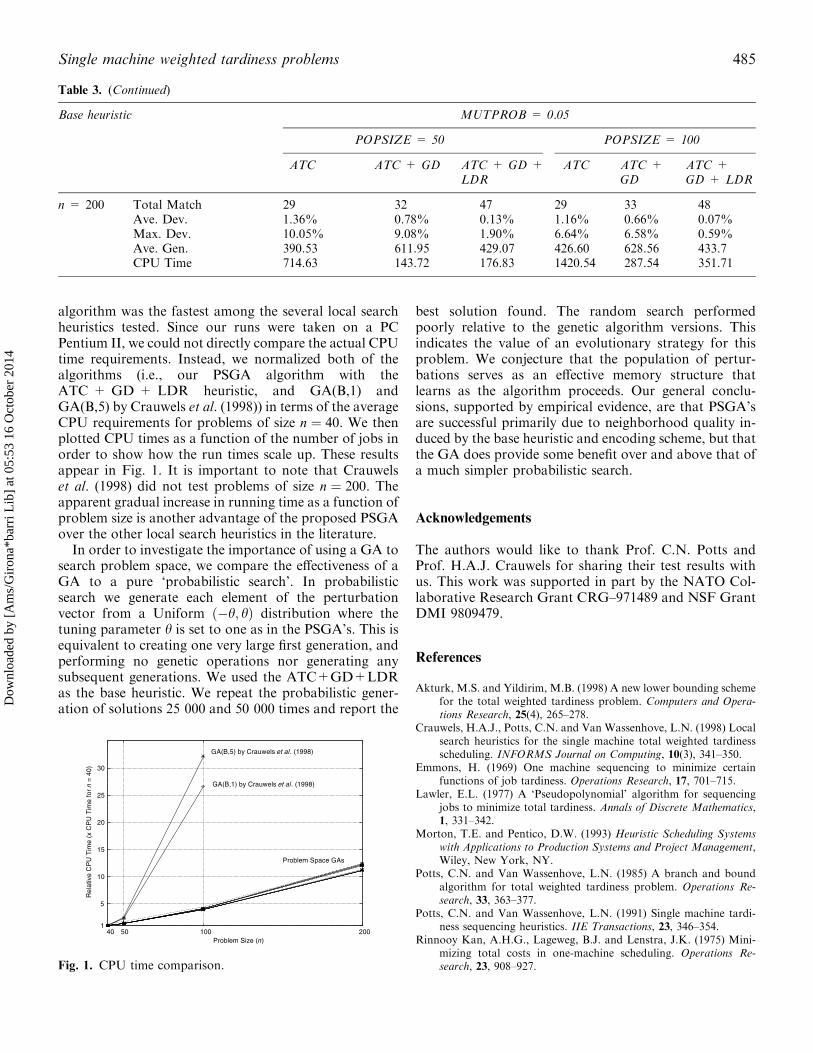
algorithm was the fastest among the several local searchheuristics tested. Since our runs were taken on a PCPentium II, we could not directly compare the actual CPUtime requirements. Instead, we normalized both of thealgorithms (i.e., our PSGA algorithm with theATC + GD + LDR heuristic, and GA(B,1) andGA(B,5) by Crauwels et al. (1998)) in terms of the averageCPU requirements for problems of size n ¼ 40. We thenplotted CPU times as a function of the number of jobs inorder to show how the run times scale up. These resultsappear in Fig. 1. It is important to note that Crauwelset al. (1998) did not test problems of size n ¼ 200. Theapparent gradual increase in running time as a function ofproblem size is another advantage of the proposed PSGAover the other local search heuristics in the literature.In order to investigate the importance of using a GA to
search problem space, we compare the effectiveness of aGA to a pure ‘probabilistic search’. In probabilisticsearch we generate each element of the perturbationvector from a Uniform ð�h; hÞ distribution where thetuning parameter h is set to one as in the PSGA’s. This isequivalent to creating one very large first generation, andperforming no genetic operations nor generating anysubsequent generations. We used the ATC+GD+LDRas the base heuristic. We repeat the probabilistic gener-ation of solutions 25 000 and 50 000 times and report the
best solution found. The random search performedpoorly relative to the genetic algorithm versions. Thisindicates the value of an evolutionary strategy for thisproblem. We conjecture that the population of pertur-bations serves as an effective memory structure thatlearns as the algorithm proceeds. Our general conclu-sions, supported by empirical evidence, are that PSGA’sare successful primarily due to neighborhood quality in-duced by the base heuristic and encoding scheme, but thatthe GA does provide some benefit over and above that ofa much simpler probabilistic search.
Acknowledgements
The authors would like to thank Prof. C.N. Potts andProf. H.A.J. Crauwels for sharing their test results withus. This work was supported in part by the NATO Col-laborative Research Grant CRG–971489 and NSF GrantDMI 9809479.
References
Akturk, M.S. and Yildirim, M.B. (1998) A new lower bounding schemefor the total weighted tardiness problem. Computers and Opera-tions Research, 25(4), 265–278.
Crauwels, H.A.J., Potts, C.N. and Van Wassenhove, L.N. (1998) Localsearch heuristics for the single machine total weighted tardinessscheduling. INFORMS Journal on Computing, 10(3), 341–350.
Emmons, H. (1969) One machine sequencing to minimize certainfunctions of job tardiness. Operations Research, 17, 701–715.
Lawler, E.L. (1977) A ‘Pseudopolynomial’ algorithm for sequencingjobs to minimize total tardiness. Annals of Discrete Mathematics,1, 331–342.
Morton, T.E. and Pentico, D.W. (1993) Heuristic Scheduling Systemswith Applications to Production Systems and Project Management,Wiley, New York, NY.
Potts, C.N. and Van Wassenhove, L.N. (1985) A branch and boundalgorithm for total weighted tardiness problem. Operations Re-search, 33, 363–377.
Potts, C.N. and Van Wassenhove, L.N. (1991) Single machine tardi-ness sequencing heuristics. IIE Transactions, 23, 346–354.
Rinnooy Kan, A.H.G., Lageweg, B.J. and Lenstra, J.K. (1975) Mini-mizing total costs in one-machine scheduling. Operations Re-search, 23, 908–927.
Table 3. (Continued)
Base heuristic MUTPROB = 0.05
POPSIZE = 50 POPSIZE = 100
ATC ATC + GD ATC + GD +LDR
ATC ATC +GD
ATC +GD + LDR
n = 200 Total Match 29 32 47 29 33 48Ave. Dev. 1.36% 0.78% 0.13% 1.16% 0.66% 0.07%Max. Dev. 10.05% 9.08% 1.90% 6.64% 6.58% 0.59%Ave. Gen. 390.53 611.95 429.07 426.60 628.56 433.7CPU Time 714.63 143.72 176.83 1420.54 287.54 351.71
Fig. 1. CPU time comparison.
Single machine weighted tardiness problems 485
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4

Storer, R.H., Wu, S.D. and Vaccari, R. (1992) New search spaces forsequencing problems with application to job shop scheduling.Management Science, 38(10), 1495–1509.
Storer, R.H., Wu, S.D. and Vaccari, R. (1995) Local search in problemand heuristic space for job shop scheduling. ORSA Journal onComputing, 7(4), 453–467.
Biographies
Selcuk Avci is a research staff member in the CASTLE Laboratory inthe Department of Operations Research and Financial Engineering atPrinceton University. He received his B.S. in Mechanical Engineeringfrom the Middle East Technical University, Turkey, M.S. in IndustrialEngineering from the Bilkent University, Turkey, and Ph.D. in In-dustrial Engineering from Lehigh University. His current research in-terests include production planning and scheduling, transportationplanning and logistics, inventory theory and modern optimizationheuristics.
M. Selim Akturk is an Associate Professor of Industrial Engineering atBilkent University, Turkey. He holds a Ph.D. in Industrial Engineeringfrom Lehigh University, USA and B.S.I.E. and M.S.I.E. degrees fromthe Middle East Technical University, Turkey. His current researchinterests include hierarchical planning of large scale systems, produc-tion scheduling, cellular manufacturing systems, and advanced manu-facturing technologies. He is a senior member of IIE and member ofINFORMS.
Robert H. Storer is Professor of Industrial and Systems Engineering,Co-Director of the Manufacturing Logistics Institute, and Co-Directorof the Integrated Business and Engineering Honors Program at LehighUniversity. He received his B.S in Industrial and Operations Engi-neering from the University of Michigan in 1979, and M.S. and Ph.D.degrees in Industrial and Systems Engineering from the Georgia In-stitute of Technology in 1982 and 1986 respectively. His interests lie inoperations research and applied statistics with particular interest inheuristic optimization, scheduling and logistics.
Contributed by the Scheduling Department
486 Avci et al.
Dow
nloa
ded
by [
Am
s/G
iron
a*ba
rri L
ib]
at 0
5:53
16
Oct
ober
201
4