a dynamic caching mechanism for hadoop using …web.engr.illinois.edu/.../hadoop_plus_memcached.pdf1...
TRANSCRIPT

1
A Dynamic Caching Mechanism for Hadoopusing Memcached
Rashid Tahir Gurmeet Singh Puneet Chandra Department of Computer Science
University of Illinois at Urbana Champaign
Abstract—Advancements in disk capacity havegreatly surpassed those in disk access time and band-width. As a result disk-based storage systems arefinding it increasingly difficult to cope up with the per-formance demands of large cluster-based systems. Inan attempt to eradicate this bottleneck we present thedesign of a proactive fetching and caching mechanismbased on Memcahed and integrate it with Hadoop.The contribution of this paper is three fold. First wepresent several practical design choices for integratingHadoop with Memcached servers which would storemeta-data about objects cached at datanodes. Theblocks to be cached are decided on the basis of two-level greedy approach. Then we compare several opensource memcached server and client implementations,and find out the best one for our requirements. Finallywe simulate caching in Hadoop based on the possibledesign choices of using Memcached as the metadatastore of the cached objects. The simulation resultsare promising and indicate multi-fold of speedup forcertain workloads of MapReduce jobs.
I. INTRODUCTION
Disk technology has evolved rapidly in the pastdecade leading to the design of complex storage sys-tems that can house petabytes of data. Data-intensiveframeworks, such as MapReduce [10], Hadoop [4]and Dryad [16], rely on disk-based file systems tomeet their exponential storage demands. The GoogleFile System (GFS) [14] and the Hadoop DistributedFile System (HDFS) [19], [9] are classic specimensof such storage structures that have the capability tostore colossal amounts of data. However, the indus-try has focused largely on disk capacity rather thandisk access time [18]. Consequently contemporarydisk-based systems fail to meet the performance de-mands of large scale applications. Disk access timehas surfaced as the primary bottleneck obstructingclouds from unlocking their true potential.
To compensate for access latencies serviceproviders resort to various mechanisms and heuris-tics. Jobs are scheduled on the same node thathouses the associated data [10], [16], [20]. In addi-tion data is replicated and placed in numerous waysto improve throughput and job completion times [6].This provides a twofold benefit: Firstly concurrentaccesses to data blocks can be serviced in parallelthus reducing contention and secondly data localityis improved by assigning more replicas to populardata. However additional replicas further complicatematters by elevating the storage needs of the system.
On the other extreme of the spectrum, Ousterhoutet al. [18] have suggested to do away with disk-based systems in their entirety. They propose a de-sign, called RAMClouds, which provides a storagemechanism based solely on main memory. RAM-Clouds exploits the fact that access time for DRAMsis 10-100 orders of magnitude faster than disk accesstime resulting in considerably lower latency andgreater throughput. The obvious disadvantage of thisapproach is the high cost both in terms of per bitstorage and the energy usage.
We propose a pseudo caching mechanism thatfinds a balance between the aforementioned ap-proaches. Our goal is to develop a design thatwould provide users with enhanced throughput andminimalist job completion time while maintainingthe ability to store vast amounts of data. We combinedata replication and placement algorithms, such asDARE [6] , with a proactive fetching and cachingmechanism based on Memcached [5]. Memcachedis a distributed caching system which provides an in-memory key-value store. We wish to integrate ourdesign with Hadoop and test our system with variouscache management and replacement algorithms.

II. RELATED WORK
Cutting down the tasks completion time can beachieved by either replication or by caching, hencefirst we briefly discuss all the work that has beendone on caches and in-memory storage and laterdraw our attention towards replication.
There has been a humble amount of work on in-memory storage and caches to improve job perfor-mance: such as PACMan [12], presents a cachingservice that coordinates access to the distributedcaches. The key features of this service is that it (i)operates in a datacenter setting with parallel jobs,thereby leading to a coordinated system, and (ii)focuses on job speed up as opposed to hit-ratio.Unlike PACMan, Global memory caching systemssuch as the GMS project [2], NOW project [3] andothers [11] have coordinated caching among nodesby using the memory of a remote machine insteadof spilling to disk. Our work differs from that ofPACMan in that while PACMan proposes the use ofa central coordinator for managing caching of data,we rely on distributed memcached servers to manageour distributed cache.
RAMCloud [18] and other prior work ondatabases such as MMDB [13] propose storing alldata in RAM. While this is suited for web servers,it is unlikely to work in data-intensive clusters dueto capacity reasons.
Distributed filesystems such as Zebra [15] andxFS [8] developed for the Sprite file system [17]make use of client-side in-memory block caching,also suggesting using the cache only for smallfiles. However, these systems make use of relativelynaÃrve and simple eviction policies as a result ofwhich they fail to improve the job performance bythe order of magnitudes.
Data replication in distributed file systems hasalso been studied in the context of cutting downthe tasks completion time: such as DARE [6] whichsmartly builds data replicas to achieve maximum jobperformance and proposes a two-phased solution tothe replica allocation and placement problem: First,analyze the existing production systems to obtain ef-fective bandwidth, data popularity distributions, anduncover characteristics of access patterns, Seconduse distributed adaptive data replication approachwhich inherently uses probabilistic sampling and acompetitive aging algorithm to accomplish the taskof determining the appropriate number of replicas
that should be allocated for each data file and whereshould they be placed. CDRM [21] which is a replicaplacement scheme for Hadoop, aims to improve fileavailability by centrally determining the ideal num-ber of replicas for a file, and an adequate placementstrategy based on the blocking probability.
However, the effects of increasing locality are notstudied. Along the same lines as DARE, Scarlett [7]is an off-line system that replicates blocks basedon their observed access probability in a previousepoch. Scarlett computes a replication factor foreach file and creates budget limited replicas dis-tributed among the cluster with the goal of mini-mizing hotspots. Replicas are aged to make spacefor new replicas. While Scarlett uses a proactivereplication scheme that periodically replicates filesbased on predicted popularity, DARE proposes areactive approach that is able to adapt to popularitychanges at smaller time scales and can help alleviaterecurrent as well as non-recurrent hotspots.
III. DESIGN
This section presents the design choices we maketo get faster access to blocks in HDFS. The designgiven here might evolve over the duration of thecourse.
To allow caching of data blocks by each datanodeof HDFS and facilitate reads of these blocks byother datanodes, we propose the use of memcached.Memcached is a high performance distributed mem-ory object caching system, typically used to speedup dynamic database driven websites by cachingmemory objects in RAM and hence reducing thenumber of times the database must be read. In ourscenario, a block cached at a data node is registeredin to the hash table of the Memcached Server.
The APIs of Memcached provide a large hash ta-ble distributed across several machines. Memcachedservers store each entry as a key-value pair, wherekey is the block-id to be accessed and value is thedatanode-id where the block is cached. Since thevalue field can be up to 1 Megabyte long, it canpotentially store a list of datanode identifiers whenmultiple nodes cache the same block for localityoptimization. Figure 2 shows the Memcached In-frastructure of our system. We reserve 30% RAMat each node to serve as our cache. This value issubject to change and will eventually be determinedempirically.
2

Namenode
HadoopDatanodes
HadoopDatanodes
MemcachedServers
Fig. 1. The preliminary architecture of our proposed system. Standalone Memcached Servers are added to Hadoop’s architecture.The Data Nodes will now be able to communicate with the Namenode as well as the Memcached Servers. The Servers and theNamenode in turn will be communicating to manage the system.
Fig 1 shows our preliminary design based on theintegration of Memcached with Hadoop. As shown,we plan to set aside some of the datanodes to be usedas dedicated Memcached Servers. These serverskeep a log of the most recently cached blocks in theentire system with the corresponding node where theblock is cached. When a particular node is in need ofa data block it generates two simultaneous requests:One is directed at Memcached which returns theaddress of the node that has a cached version ofthe block in question and the other is forwardedto the namenode that provides the requester withthe whereabouts of a replica of the block. Thenumber of servers that must be used for Memcachedis a parameter to be adjusted for the system towork efficiently. Another meaningful parameter isthe amount of memory to be reserved at each nodefor caching blocks. The two parameters intuitivelydepend upon each other, and we plan to empiricallydetermine their values for our particular design.
HadoopDatanode
HadoopDatanode
MemcachedServer
MemcachedServer
Memory
HadoopDatanode
HadoopDatanode
30% Memory Reserved for Caching
Memory
MemcachedService
Hash TableBlock ID Block Location
….. …..
….. …..
….. …..
Fig. 2. The Memcached Infrastructure of our system
A. Two-Level Greedy Caching
In this paper, we adopt a policy of caching thatwe call Two-Level greedy caching strategy. This is acombination of two simple greedy caching policies.The first one is to cache an object locally whenevera node needs it and it is unavailable in its localcache. This caching information is then propagated
3

to the memcached servers. This is called Receiver-Only greedy caching policy and it helps to servefuture block requests for the same block at the samenode. The second is for a node to cache an objectwhenever some other node requests for it and theobject is in the filesystem but not in the cache. Thenthis update about the object cached at the datanodeis sent to the memcached servers. This technique,termed as Sender-Only greedy Caching in this paper,facilitates the reuse of the cached datablock when afuture request for the block arrives at that datanode.
The Two-Level greedy caching combinesreceiver-only greedy caching and sender-onlygreedy caching. Hence the block cached can bereused by future block requests of the same blockat any node. We compare and evaluate the threestrategies in the section on Simulation Results. Asthe intuition suggests, it has been observed that thetwo-level greedy caching strategy performs betterthan the other two, in that it results in less cachemisses per job execution. Although it would beconsuming more resources than either of the other,we adopt this policy since the focus of this paperis to maximize the performance of mapreduce tasksusing caching policies. In the future however, weplan to come up with more sophisticated policysuitable for our scenario. One such possibility isthe use of machine learning techniques based onprevious access patterns of the workload to decidewhich objects to cache in memory.
B. Fetching a Cached Block
At this stage, we discuss two design patterns forour system, which we plan to compare and evalu-ate by experimentation. The first scenario activelyinvolves both Memcached and namenode when arequest for a block is generated, whereas the sec-ond approach places more emphasis on the roleof Memcached, enforcing the namenode to comeinto play only when a cache miss is detected. Bothdesigns have their associated pros and cons whichwe discuss after explaining them in more detail.Note that in the following discussion, we assumefault free communication for the sake of simplicity.
In the first design pattern that we callSimultaneous-Requesting, which is illustratedas a sequence of events in Fig 3, when a datanodeN1 needs a block B1, it sends simultaneous requests
to both namenode and Memcached. Both namenodeand Memcached check for availability of theblock in their respective stores- filesystem and thedistributed cache base, and reply back to N1 withthe locations of B1. In the event that Memcachedreturns a positive response to N1, the data block isaccessed from the cache base irrespective of whatthe namenode returns. However if the Memcachedreports a cache miss the node has no option but toturn to the namenode and will need to access theblock from a replica. This design choice assumesthat Memcached will be able to perform as good asnamenode and that N1 gets back the replies withina reasonable time duration.
The second approach begins just like the first,where datanode N1 sends request for B1 simulta-neously to both namenode and Memcached. Bothcheck for availability of B1 in their respective datastores, but namenode does not reply back imme-diately, while Memcached does. In case there wasa cache miss, Memcached informs the datanode aswell as namenode about that. Namenode at this stagewould be ready with nodes that have replicas ofB1, and tells one of them (say node N2) to cachethe block B1 into its memory and replies back toMemcached with this update. Namenode also repliesto N1 that N2 has started caching the block. N1 thenaccesses N2 for read of the block, which is nowavailable for faster read from cache in contrast toslower read from disk in the previous design pattern.We call this design choice as the Memcached-Firstdesing.
Although the Memcached-First design seems toreduce read latency of block B1 by node N1, it isbased on the assumption that the sequence of oper-ations «message from namenode to N2, caching B1
from disk to RAM at N2»is faster than (or at leastcomparable to) the sequence of communications «re-ply from namenode to N1, request from N1 to N2»,and hence N1 does not have to wait for caching tobe complete. Memcached First design will performbetter than the Simultaneous Requesting one if thesummation of the total time taken to exchange theextra set of messages, caching the block B1, andaccessing the block from the cache via the networkis less than the total time taken to read the replicaof block B1 from the disk over the network.
Among the two strategies proposed, we evaluateand find the better one using either simulation and
4

Namenode
MemcachedMemcached
N 1N 1
N 2N 2
1 – Block Request
1 – Block Request
2 - Reply
2 - Reply
3 – Block Access
Fig. 3. A typical use case for our system
the results are presented in the section V.
C. Replacement at the Memcached Servers
When a Memcached Server gets filled up, itreplaces the Least Recently Used (LRU) entry fromthe hash table and informs the node that has cachedthe block. This node, however, need not deletethis block from its cache. But it should flag thisblock as deleted from Memcached, so that whenthis block is again accessed it can unflag it andinform Memcached about current use of this block.Memcached then inserts this block’s entry back intothe hash table.
D. Global Cache Replacement Policy
In order for our system to be effective we need aglobal cache replacement policy. Our initial policywas local in the sense that nodes would replace theirLeast Recently Used (LRU) block whenever a datablock had to be evicted. This leads to a problem thatcan be observed in the following use case. Considernode N1 which has cached Blocks 110, 115, 120 and125 and Node N2 which has cached Blocks 50, 55,60 and 65. Furthermore suppose that each node onlyhas enough cache to house 4 blocks hence if eitherNode N1 or N2 receives a cache request from theserver it will need to evict one of the blocks based onan LRU policy. The blocks at N1 were all used morerecently as compared to the blocks at N2 howeverif N1 receives a cache request it will evict the block
that was used the earliest which is not actually theearliest access block in the entire Hadoop cluster.Effectively the system evicts a block that is not theblock that was accessed earliest globally but whichwas accessed earliest at a particular node only.
To solve this problem we propose a global cacheeviction policy. Our policy builds on an assumptionthat the namenode keeps track of all get requestsit receives. When a Memcached server asks thenamenode to issue a cache request to a data nodeit forwards the request to all three data nodes thathouse a replica of the data block in question. If allthree of the data nodes respond with a “memory full”reply, the server asks a data block that has cached theblock with the earliest access time to first retrieve thedata block and then cache it. If any of the three datablocks sends the namenode a “cached successfully”message then the namenode simply updates the hashtable of the associated Memcached Server for thecached blocks location.
E. Prefetching
Prefetching, which extends the idea of temporallocality of caching to spatial locality, is a gen-eral technique used in many practical systems. Inprefetching, when a data block is cached after it wasrequested by a node, its neighboring data blocks arealso brought into cache to avoid a future cache miss.We propose integrating a prefetching mechanisminto the caching designs described earlier.
5

In our scenario, we prefetch at the stage whenblocks in the neighbourhood of the requested blockare missing. This is illustrated in the Fig 4. Whenthe node N1 requests for a block with ID 110,Memcached looks up for the availability of allneighboring blocks of the requested block ( In ourexample IDs in the range 108-112). For the blocksthat are missing, a cache request is initiated proac-tively by asking the namenode to find replicas ofthose blocks. If those blocks have replicas availablein the system (that is, if these block ID’s are valid),namenode requests a replica to cache the data blockand informs Memcached of the location of this node.
In the figure shown, blocks 109 and 112 are miss-ing from the Memcached hash tables so a request tocache these blocks is sent to namenode. Namenodeselects one replica of these blocks (perhaps thereplica closest to N1 to reduce latency)- N3 forblock ID 109 and N4 for block ID 112. It thensimultaneously request these nodes to cache therespective blocks and informs Memcached of theMemcached new cache entries.
The system parameter that needs to be adjustedfor prefetching based system is how many blocksmust be prefetched when there is a request fora block. In the description above, we assumed 4block-prefetching and two blocks prefetched in bothdirections of the requested block. In a more practi-cal scenario, this may or may not be very useful.Although we propose the prefetching design basedon its potential advantages, due to lack of time wecompletely leave the prefetching part of the reportfor future work.
IV. PROGRESS
This section details our progress in the project sofar.
A. Memcached
We have successfully managed to deploy theMemcached infrastructure for our project. Mem-cached, being distributed in nature, is based on aclient-server architecture. We had numerous choicesfor both ends of the system. Our final choice is basedon performance and deployment metrics such asease of use, request and response latency, availabilityof documentation, simplicity of debugging etc.
1) Memcached Server: For the server side ofMemcached we had the following options to choosefrom:
• Quickcached• Memcached Implementation in JGroups• Jmemcached-DaemonQuickcaced is a Memcached Server implementa-
tion based on the Quick Server. It is a generic objectmemory caching system, which is highly distributedand scalable because of the small memory footprintof the server daemons. We were able to dig upsignificant documentation on the usage of Quick-cached and found that it was still being developedactively with an open source stable release availablefor usage. The simplicity, ease of modification andperformance statistics of Quickcached forced us tochoose it for the purposes of our project.
Memcached Implementation in JGroups workswith PartitionedHashMaps on top of the JGroupMulticast Communication Toolkit. It has numerousadvantages over Memcached such as the fact thatPartitionedHashMaps are aware of each others’ pres-ence in the system, unlike Memcached Servers, andcan therefore make smart well-informed decisionssuch as key migration in case of a server crash.Furthermore the PartitionedHashMaps can be con-figured to use the L1 cache, which significantlyimproves access latencies.
However, for the purpose of this project we weremore interested in simplicity and basic Memcachedfunctionality for which reason we found Partitioned-HashMaps to be overkill. The extra baggage associ-ated with Memcached Implementation in JGroupsadded more complexity to the development andintegration phase which we wanted to avoid as wewished to build our system on top of Hadoop’sdefault interconnect layer.
The Jmemcached-Daemon is quite similar to stan-dard Memcached implementations except that it usesthe JBoss Netty Client Server Socket Framework forcommunication between the clients and the servers.The functional similarity of Jmemcached-Daemonmade it a suitable candidate for integration withHadoop however as Jmemcached-Daemon was onlyabout 50% as efficient as Memcached V-1.4.1 (de-veloped in C) we chose to disregard it in favor ofQuickcached. It is unclear whether the performancedifferences lie in the way caching is managed in-side Jmemcached-Daemon or if its protocol/Netty
6

Namenode
1 – Block Request for ID 110
1 – Block Request for ID 110
2 - Reply
2 - Reply3 – Block
Access
MemcachedBlock ID 108
Block ID 110
Block ID 111
….
….
….
….
Node ID N1
Node ID N2
Node ID N3
….
….
….
….
………
3- Initiate cache request for Block IDs
109, 112
4- Node IDs for Block IDs 109, 112
N1N1 N3N3
N4N4
4- Cache request for Block ID 109
4- Cache request for Block ID 112
N2N2
Fig. 4. The sequence of calls under the proposed prefecting mechanism
related.
2) Memcached Client: As far as the clients go,there are three commonly used clients that are opensource:
• Spymemcached• Xmemcached• Memcached Java Client
Our initial goal was to use Xmemcached as itwas found to be sufficiently fast in experiments per-formed in [1]. However we were facing difficultiesin setting up Xmemcached with Quickcached so wegave up Xmemcachedc in favor of Spymemcached.The Memcached Java Client which gave good per-formance for most values of packet sizes, resultedin zero performance for large number of threads dueto an exception [1].
Spymemcached’s performance is comparable toXmemcached [1] for packet sizes over 4096 Bytes. Ithas also been observed that Spymemcached is easyto work with. We found substantial documentationfor extending the design of Spymemcached in orderto be used with custom code bases as in our case.Like Quickcached, Spymemcached is also in activedevelopment with many stable releases available fordownload.
B. Hadoop Modification
Modifications have been made within Hadoop inorder to integrate it with Quickcached Server andSpymemcached Client architectures. As proposed inSection III, whenever tasks are initiated at the datan-odes, the DFSClient initiates get requests for datablocks either simultaneously from the namenode andthe Memcached Servers or first from MemcachedServers and then Namenode in case MemcachedServers retrurns a cache miss. In response to the getrequests, the servers successfully respond with theIP address of datanode where the requested block iscached.
Towards creating a cached copy of the datablocks,we realized that this involved reading from thefilesystem filestream using granularities of pack-ets and required serialzation and deserialization ofpackets to construct a block in cache. To avoidthese complications and to efficiently utilize thelimited available time, at this stage we have as-sumed that a datablock can be cached into memoryand constructed a dummy object in memory calledCachedBlock which imitates the behavior of thetraditional Block but does not actually contain thedata per se.
Whenever a block has to be cached in memory,we cache this dummy object and assign it the sameblockId as the original block. Use of CachedBlock
7

Fig. 5. Comparison of three caching approaches.
in simulations instead of the block allows us tomeasure performance parameters like Cache Hitsand Network Overhead due to our proposed designs.It does not however allow us to measure block fetchlatency improvement due to caching of data andhence map-reduce task completion time improve-ment. Although the latter can not be quantified atthis stage, the former must be positive since memorylatency is many times less than disk latency. Thiswill be discussed in more details in the section onExperimental Results.
At this point we have implemented a two-levelgreedy approach to cache objects. This means thatwhenever a datanode needs an object which isnot cached locally, it requests the block from cor-responding datanode and cache it. The datanodeserving the requesting datanode can be either the onereturned by Memcached Server by a cache hit or theone returned by Namenode which would be used incase Memcached returned a miss. In the latter case,the second level of greedy approach comes into playand the serving datanode creates a cached copy ofthe object it is serving from its disk to allow fasteraccess to the block in future.
Implementing this two-level greedy caching algo-rithm involved modifications mostly in datanode anddfsclient modules of Hadoop. When the dfsclientsends request to namemode to fetch a block’s repli-cas, another request is sent to memcached serverswhich respond with the datanodes that have the
block cached. Whenever a datanode serves the re-quest of a block it first needs to check with its localcache if the block’s cached object is in memory.
Then we implemented the two design choicesdescribed earlier- Simultaneous-Requesting designand Memcached-First design. This included modi-fying dfsclient to send requests for required blocksto namenode as well as memcached servers. Forthe Simultaneous-Requesting design two threadswere launched which simultaneously sent requeststo namenode and memcached servers. In case mem-cached replied with a hit the client sends fetch-datarequest to the datanode identified by memcached.Else the datanodes returned by namenode are used tofetch data from. Implementation of the Memcached-First design was fairly straight forward, with se-quentially requesting the two meta-data servers asdescribed earlier.
V. EXPERIMENTS AND RESULTS
We have performed experiments in three sets.The first one involved looking for a memcachedserver and memcached client for our experiments.In the second phase we focused on familiarizingourselves with the way Hadoop works in generaland integration of Hadoop with Memcached Clientand Server in particular. Finally we stepped ahead torun the experiments on the two-level greedy cachingmechanism described earlier.
8

(a) Cache Hit Ratio vs Cache Size (b) Network Overhead vs Cache Size
Fig. 6. Plot showing variation of Network Overhead and Cache Hit Ratio with increasing Cache Size for a WordCount job.
a) Memcached Servers and Clients: The nextset of experiments was targeted at the MemcachedServers and Clients. We started off by deploying thevarious Memecached Servers available to us. Aftersuccessfully setting up the memcached servers, weset up the client side of Memcached. As explainedin Section IV we successfully managed to setup theSpymemcached Client.
We ran numerous tests on the servers to determinethe most suitable server for our case. We did run into some problems as the clients could not connectwith all active servers and at times showed only asubset of the total servers to be available at a giveninstance in time. This erratic behavior continuedthroughout our experiments even when we executedthe servers and the clients on the same network andthe same Virtual Private Network. However, whenthe servers were all executed on the same machine,listening on different ports, the problem went away.Our subsequent experiments were carried out withthis design modification. Our experiments concludedthat Spymemcached and Quickcached work per-fectly with each other to form our MemcachedInfrastructure.
b) Hadoop and its integration with Mem-cached: The second set of experiments aimed atfamiliarizing us with the Hadoop environment. Wesetup various different versions of Hadoop on dif-ferent machines and IDEs such as Eclipse. We alsotried a virtual setup of Hadoop in order to determineif it was feasible for our case. After setting upHadoop, we ran various examples such as WordCount, Random Writer, Sorting etc on differentinputs and investigated the logs to understand in
more detail how Hadoop functions.This was followed by experiments on top of
HDFS which we were initially not using as we weredirectly feeding files to Hadoop from the native filesystem instead of HDFS. Experiments on HDFSgave us the insight to finalize the detailed designfor our system. Hence, we chose the DFSClientof HDFS to be the optimal place to inject ourMemcached code. We were successfully able tointegrate DFSClient with Spymemcached and ranthe Word Count example to make sure that the newcode base was functional.
c) Simulation Results: Towards simulation re-sults, we first validated our use of Two-Level greedyapproach by comparing with the two other simplegreedy protocols- Receiver-Only greedy protocoland Sender-Only greedy protocol described earlier.Both the simple protocols offer their own advantagestowards increasing the hit ratio of cache entries. Forthe Receiver-Only protocol, the block fetched fromthe other datanode is then cached locally for furtherfuture use. Whereas for the Sender-Only greedycaching protocol the receiver upon future requestsof the same block then relies on the sender to sendthe cached block instead of the replicated block.Hit ratio resulting from these strategies are plottedagainst the cache size for a word-count job and canbe found in the Figure IV-B.
The final set of experiments conducted were toevaluate the performance of our caching mechanismfor the Hadoop-Memcached scenario. For this weran several map-reduce jobs like wordcount, grep,sort, join and random writer on the top of the systemwe built. At this stage since only the meta-data of
9
(a) Cache Hit Ratio vs Cache Size (b) Network Overhead vs Cache Size
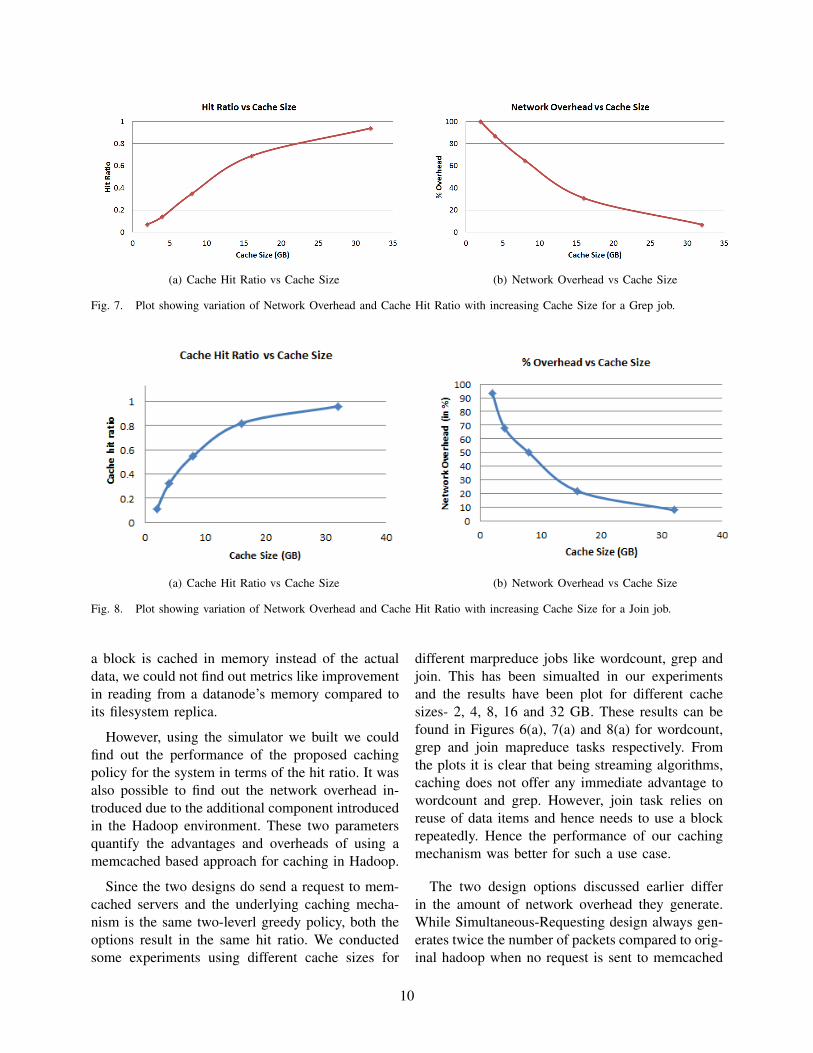
Fig. 7. Plot showing variation of Network Overhead and Cache Hit Ratio with increasing Cache Size for a Grep job.
(a) Cache Hit Ratio vs Cache Size (b) Network Overhead vs Cache Size
Fig. 8. Plot showing variation of Network Overhead and Cache Hit Ratio with increasing Cache Size for a Join job.
a block is cached in memory instead of the actualdata, we could not find out metrics like improvementin reading from a datanode’s memory compared toits filesystem replica.
However, using the simulator we built we couldfind out the performance of the proposed cachingpolicy for the system in terms of the hit ratio. It wasalso possible to find out the network overhead in-troduced due to the additional component introducedin the Hadoop environment. These two parametersquantify the advantages and overheads of using amemcached based approach for caching in Hadoop.
Since the two designs do send a request to mem-cached servers and the underlying caching mecha-nism is the same two-leverl greedy policy, both theoptions result in the same hit ratio. We conductedsome experiments using different cache sizes for
different marpreduce jobs like wordcount, grep andjoin. This has been simualted in our experimentsand the results have been plot for different cachesizes- 2, 4, 8, 16 and 32 GB. These results can befound in Figures 6(a), 7(a) and 8(a) for wordcount,grep and join mapreduce tasks respectively. Fromthe plots it is clear that being streaming algorithms,caching does not offer any immediate advantage towordcount and grep. However, join task relies onreuse of data items and hence needs to use a blockrepeatedly. Hence the performance of our cachingmechanism was better for such a use case.
The two design options discussed earlier differin the amount of network overhead they generate.While Simultaneous-Requesting design always gen-erates twice the number of packets compared to orig-inal hadoop when no request is sent to memcached
10

servers. This is because for this design a request issent both to namenode and memcached even whenboth of them return a hit. Hence the network trafficoverhead due to this design is always 100%. Onthe other hand, the Memcached-First design onlysends request to namenode when memcached returnsa miss, hence reducing the network overhead bysome fraction. These results can be found in Figures6(b), 7(b) and 8(b) for wordcount, grep and joinmapreduce tasks respectively. The fall in networkoverhead with the increasing cache size is due toincrease in hit ratio because a cache hit stops thecorresponding block request from being sent to thenamenode.
VI. CHALLENGES
At the moment the biggest challenge facing usis to come up with a comprehensive caching mech-anism augmented with a cache replacement policythat favors Hadoop’s data access patterns. Settingup a system that provides caching is not enough asbatch computing based on clusters is a completelydifferent ball game even from traditional distributedcache management approaches. We are in the pro-cess of acquiring logs that will shed more lighton this issue. Meanwhile we can only speculate orinvestigate logs from the Cloud Computing Testbedhere at UIUC to figure out access patterns of work-loads similar to those that we would expect to runon top of Hadoop. For this purpose we are alsoexploring the use Swim Workload Generator.
Another challenge that we foresee at this pointis increased traffic overhead that will be generatedfrom the new components that we have added toHadoop. Not only that, the design places more re-sponsibility on an already stressed out namenode asit is part of the cache management infrastructure. Weare looking in to the possibility of offloading someof the computation to the secondary namenode orstandalone namenode “helpers” that will relieve theprimary namenode of some of the responsibilities.
VII. FURTHER WORK
As a baseline project for the course, we planto integrate memcached with Hadoop and come upwith a system having good performance. However,we are also interested to observe the effect of severalother optimization techniques. Primarily we are in-terested in investigating the effect of various cache
management and replacement policies. At presentwe plan to implement basic LRU, but in future wewould want to evaluate which replacement policyworks for the kinds of workload seen in Hadoop.
Given the diversity of workloads possible in theHadoop scenario, we also would like to exploitmachine learning techniques to find out an optimalcaching strategy for a given workload. Towards thatend, we would train a learner using different work-loads, each with several possible caching policies,and find which policy gives the best performancefor what kind of workload.
REFERENCES
[1] Performance Benchmark for Vari-ous Memcached Clients in Java.http://xmemcached.googlecode.com/svn/trunk/benchmark/benchmark.html.
[2] The Global Memory System (GMS) Project. http://www.cs.washington.edu/homes/levy/gms/.
[3] The NOW Project. http://now.cs.berkeley.edu.[4] Apache Hadoop. http://hadoop.apache.org/, March 2012.[5] Memcached. http://www.memcached.org/, March 2012.[6] C. L. Abad, Y. Lu, and R. H. Campbell. DARE: Adaptive
Data Replication for Efficient Cluster Scheduling. InCLUSTER, pages 159–168. IEEE, 2011.
[7] G. Ananthanarayanan, S. Agarwal, S. Kandula, A. G.Greenberg, I. Stoica, D. Harlan, and E. Harris. Scarlett:coping with skewed content popularity in mapreduce clus-ters. In C. M. Kirsch and G. Heiser, editors, EuroSys,pages 287–300. ACM, 2011.
[8] T. E. Anderson, M. Dahlin, J. M. Neefe, D. A. Patterson,D. S. Roselli, and R. Y. Wang. Serverless Network FileSystems. In SOSP’95, pages 109–126, 1995.
[9] D. Borthakur. The Hadoop Distributed File System: Ar-chitecture and Design. The Apache Software Foundation,2007.
[10] J. Dean and f. S. Ghemawat. MapReduce: Simplified DataProcessing on Large Clusters. In Symposium on OperatingSystem Design and Implementation (OSDI), pages 137–150, 2004.
[11] M. J. Franklin, M. J. Carey, and M. Livny. Global MemoryManagement in Client-Server Database Architectures. InVLDB’92, pages 596–609, 1992.
[12] A. W. D. B. S. K. S. S. G. Ananthanarayanan, A. Ghodsiand I. Stoica. PACMan: Coordinated Memory Caching forParallel Jobs. In NSDI, 2012.
[13] H. Garcia-Molina and K. Salem. Main Memory DatabaseSystems: An Overview. IEEE Trans. Knowl. Data Eng.,pages 509–516, 1992.
[14] S. Ghemawat, H. Gobioff, and S.-T. Leung. The GoogleFile System. In SOSP’03, pages 29–43, 2003.
[15] J. H. Hartman and J. K. Ousterhout. The Zebra StripedNetwork File System. In SOSP’93, pages 29–43, 1993.
[16] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly.Dryad: distributed data-parallel programs from sequentialbuilding blocks. In EuroSys’07, pages 59–72, 2007.
11

[17] M. N. Nelson, B. B. Welch, and J. K. Ousterhout. Cachingin the Sprite Network File System. ACM Trans. Comput.Syst., pages 134–154, 1988.
[18] J. K. Ousterhout, P. Agrawal, D. Erickson, C. Kozyrakis,J. Leverich, D. Mazires, S. Mitra, A. Narayanan, G. M.Parulkar, M. Rosenblum, S. M. Rumble, E. Stratmann,and R. Stutsman. The case for RAMClouds: scalablehigh-performance storage entirely in DRAM. OperatingSystems Review, pages 92–105, 2009.
[19] K. Shvachko, H. Kuang, S. Radia, and R. Chansler. TheHadoop Distributed File System. Mass Storage Systemsand Technologies, IEEE / NASA Goddard Conference on,0:1–10, 2010.
[20] M. Tang, B.-S. Lee, X. Tang, and C. K. Yeo. The impactof data replication on job scheduling performance in theData Grid. Future Generation Comp. Syst., pages 254–268, 2006.
[21] Q. Wei, B. Veeravalli, B. Gong, L. Zeng, and D. Feng.CDRM: A Cost-Effective Dynamic Replication Manage-ment Scheme for Cloud Storage Cluster. In CLUSTER’10,pages 188–196, 2010.
12