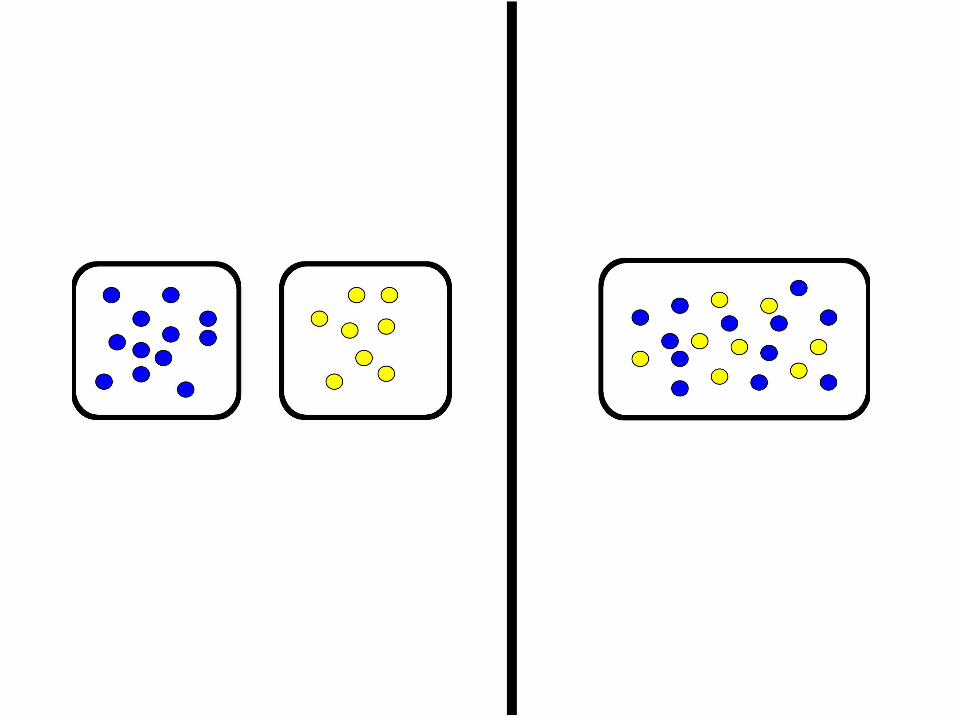
4:5 (blue:yellow) “scattered random”
Post on 21-Dec-2015
219 views
TRANSCRIPT


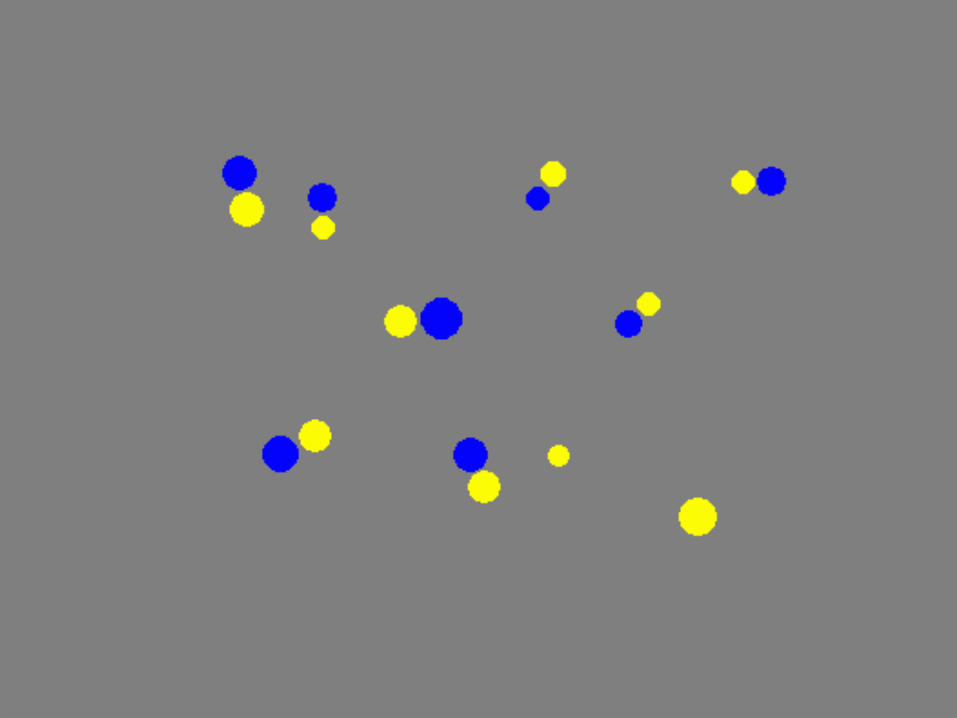





4:5 (blue:yellow)“scattered random”

1:2 (blue:yellow)“scattered random”
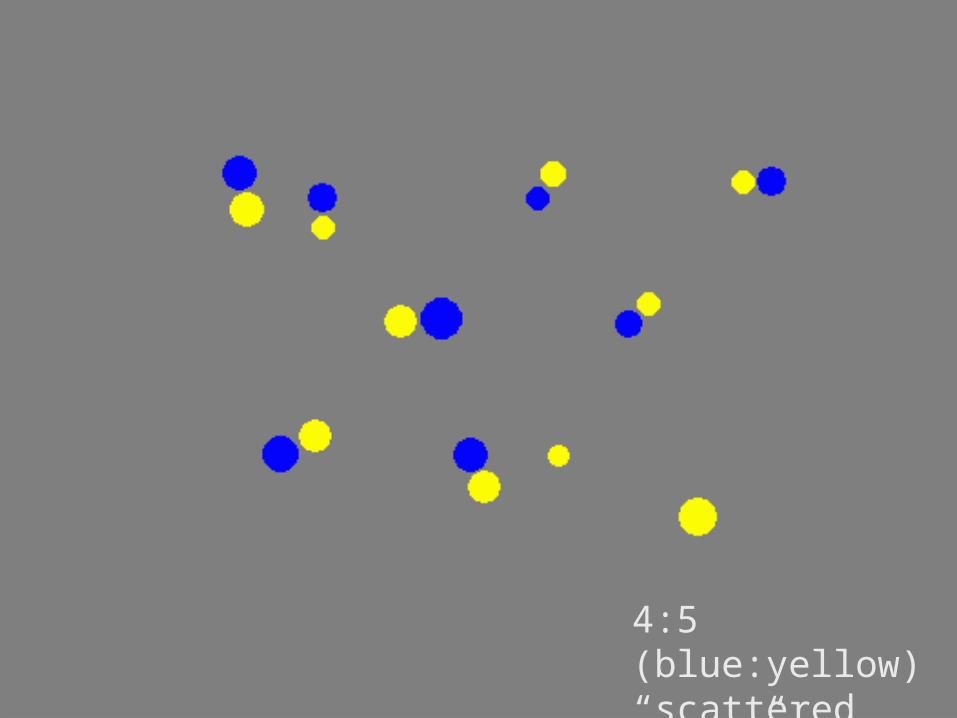
4:5 (blue:yellow)“scattered pairs”

9:10 (blue:yellow)“scattered random”

4:5 (blue:yellow)“sorted columns”

4:5 (blue:yellow)“mixed columns”

5:4 (blue:yellow)“mixed columns”
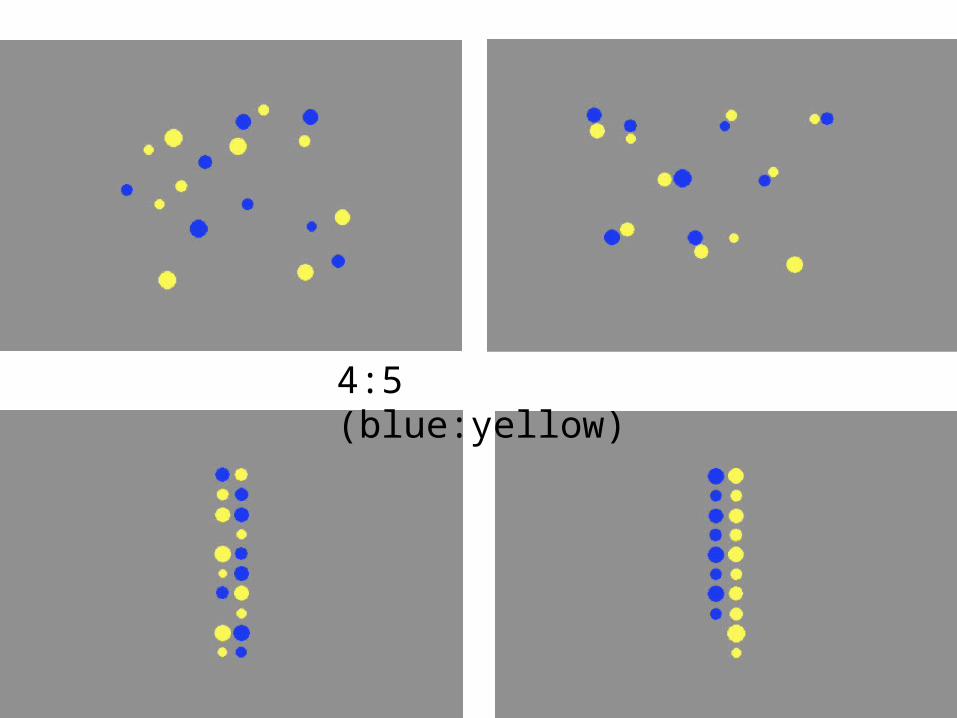
4:5 (blue:yellow)

Basic Design
• 12 naive adults, 360 trials for each participant• 5-17 dots of each color on each trial • trials varied by ratio (from 1:2 to 9:10) and type• each “dot scene” displayed for 200ms • target sentence: Are most of the dots yellow?• participants answered ‘yes’ or ‘no’ by pressing
buttons on a keyboard.• correct answer randomized, relevant controls for
area (pixels) vs. number, yada yada…

50
60
70
80
90
100
1 1.5 2Ratio (Weber Ratio)
Perc
en
t C
orr
ect
Scattered Random
Scattered Pairs
Column Pairs Mixed
Column Pairs Sorted
better performance on easier ratios: p < .001
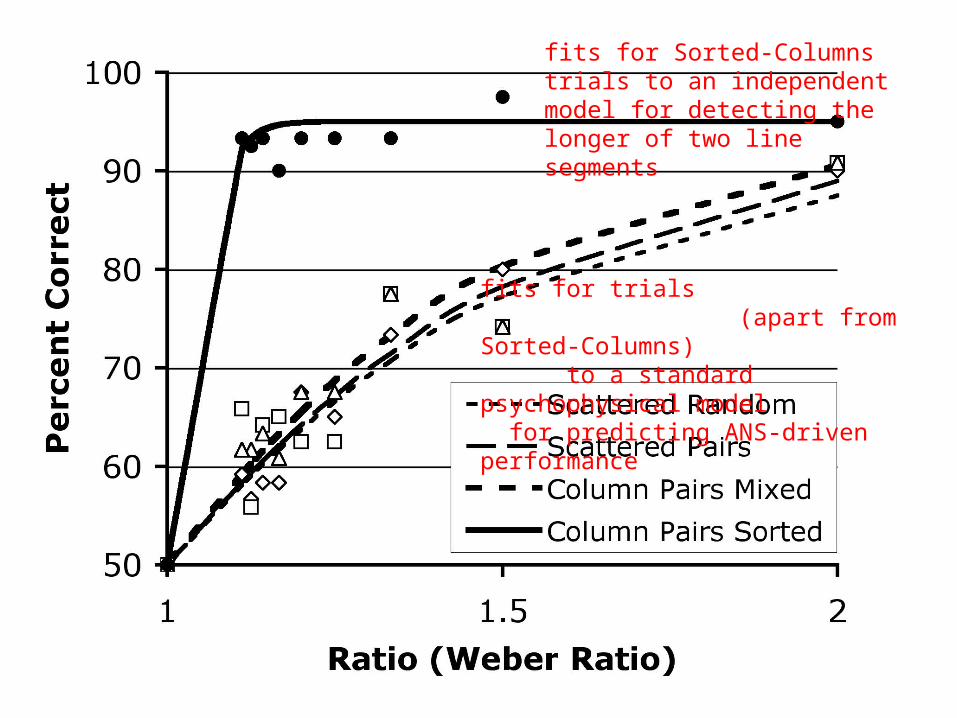
fits for trials (apart from Sorted-Columns) to a standard psychophysical model for predicting ANS-driven performance
fits for Sorted-Columns trials to an independent model for detecting the longer of two line segments


‘Most’ as a Case Study
‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x) & ~Blue(x)}
#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
{x:Dot(x) & Blue(x)} 1-To-1-Plus {x:Dot(x) & ~Blue(x)}
Could it be that speakers use ‘most’ to access a complex 1-To-1-Plus concept…but our task made it too hard to use a 1-To-1-Plus verification strategy?
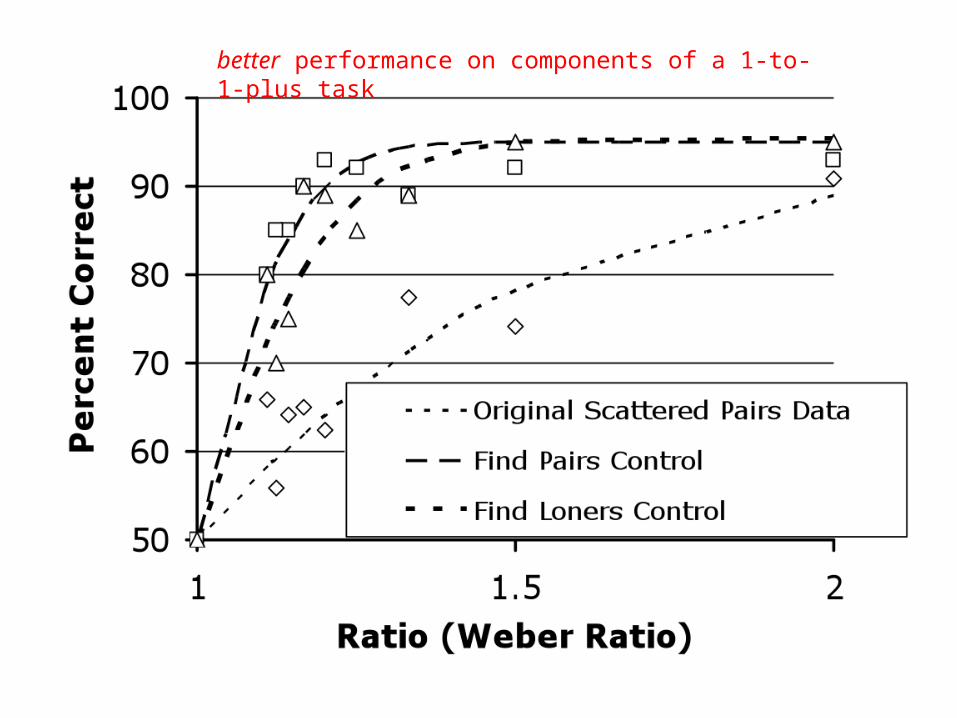
better performance on components of a 1-to-1-plus task

Side Point Worth Noting…

‘Most’ as a Case Study
‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x) & ~Blue(x)}#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• if there are only two colors to worry about, blue and red, the non-blues can be identified reds
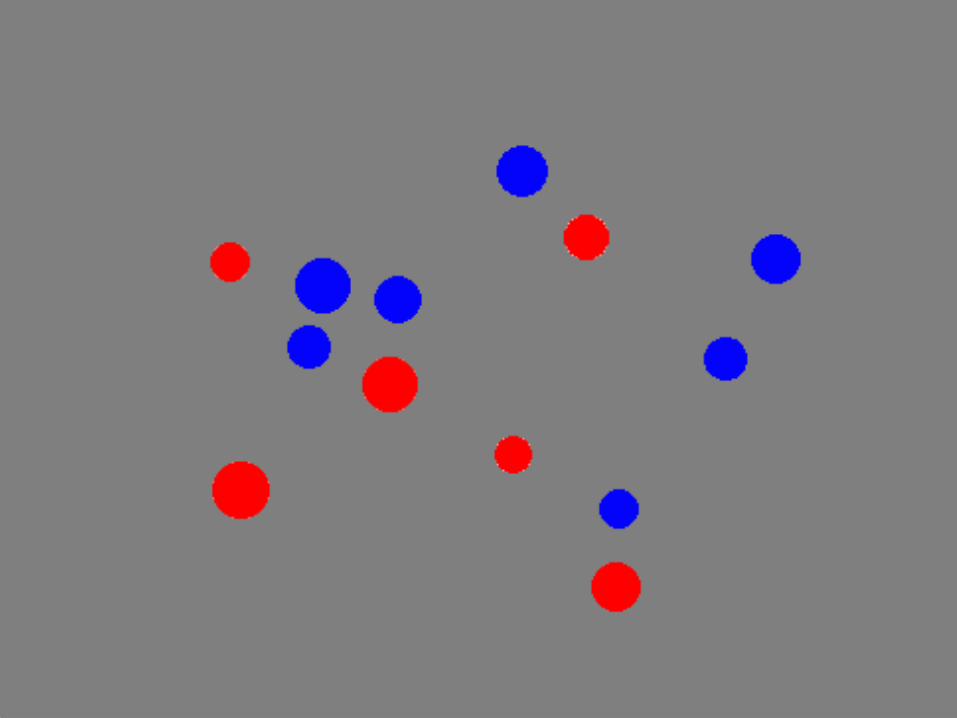

‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x) & ~Blue(x)}#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• if there are only 2 colors to worry about, blue and red, the non-blues can be identified reds
• the visual system can (and will) “select” the dots, the blue dots, and the red dots;
so the ANS can estimate these three cardinalities• but adding more colors will make it harder (and with 5 colors,
impossible) for the visual system to make enough “selections” for the ANS to operate on

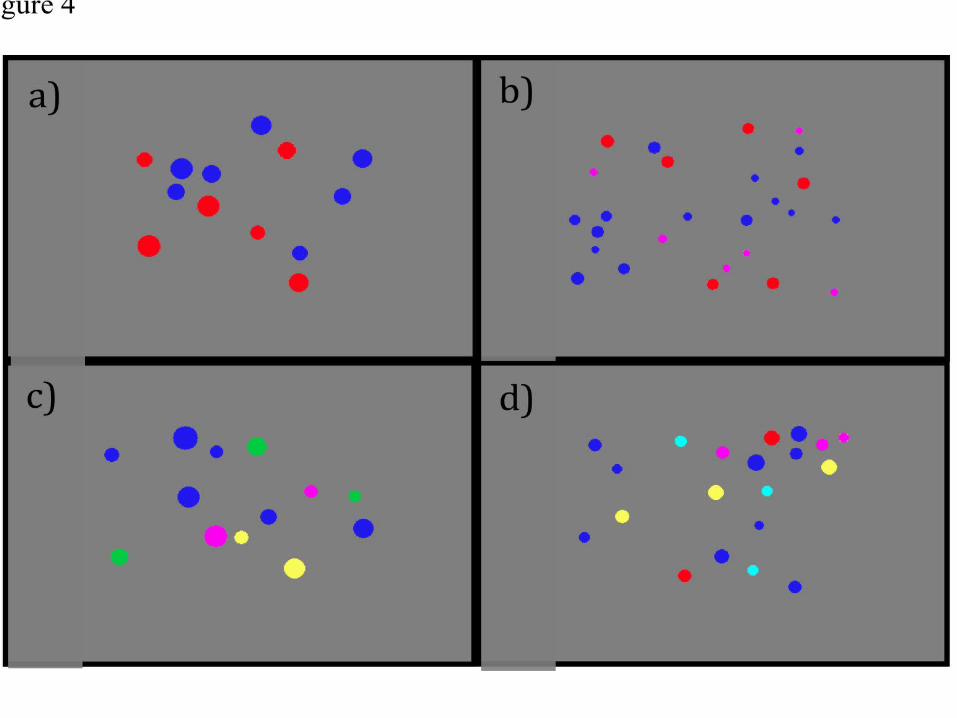

‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x) & ~Blue(x)}#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• adding alternative colors will make it harder (and eventually impossible) for the visual system to make enough “selections” for the ANS to operate on
• so given the first proposal (with negation), verification should get harder as the number of colors increases
• but the second proposal (with subtraction) predicts relative indifference to the number of alternative colors
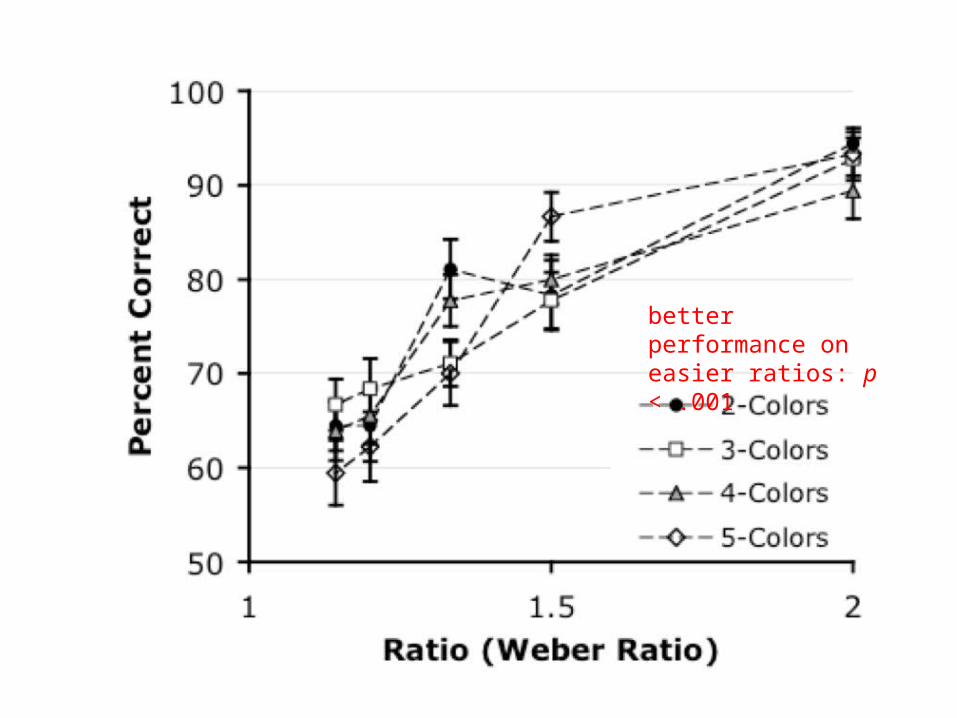
better performance on easier ratios: p < .001
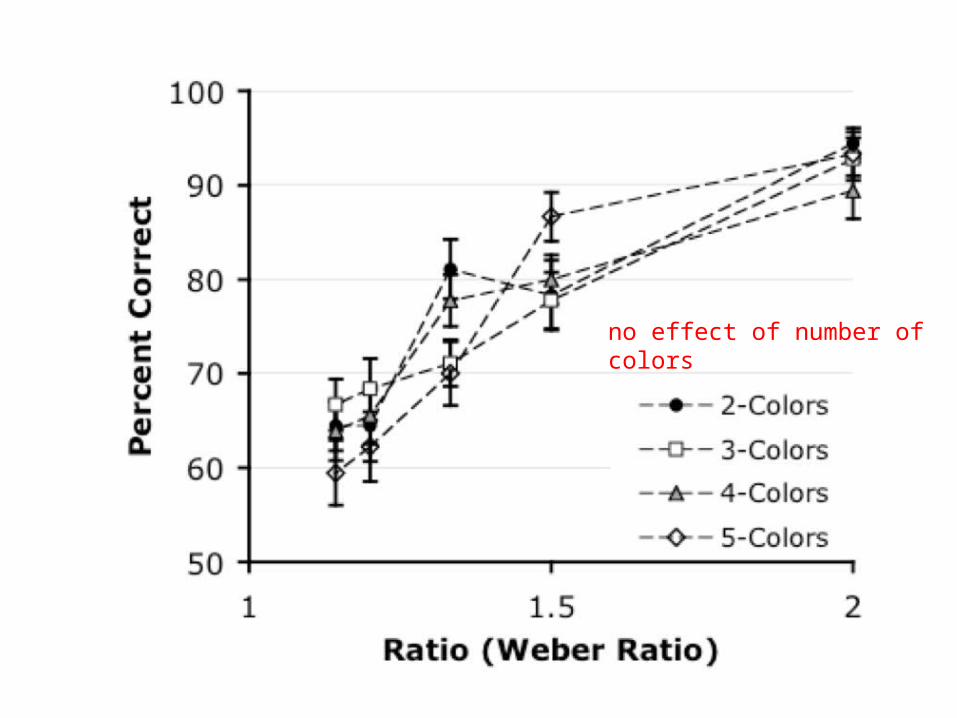
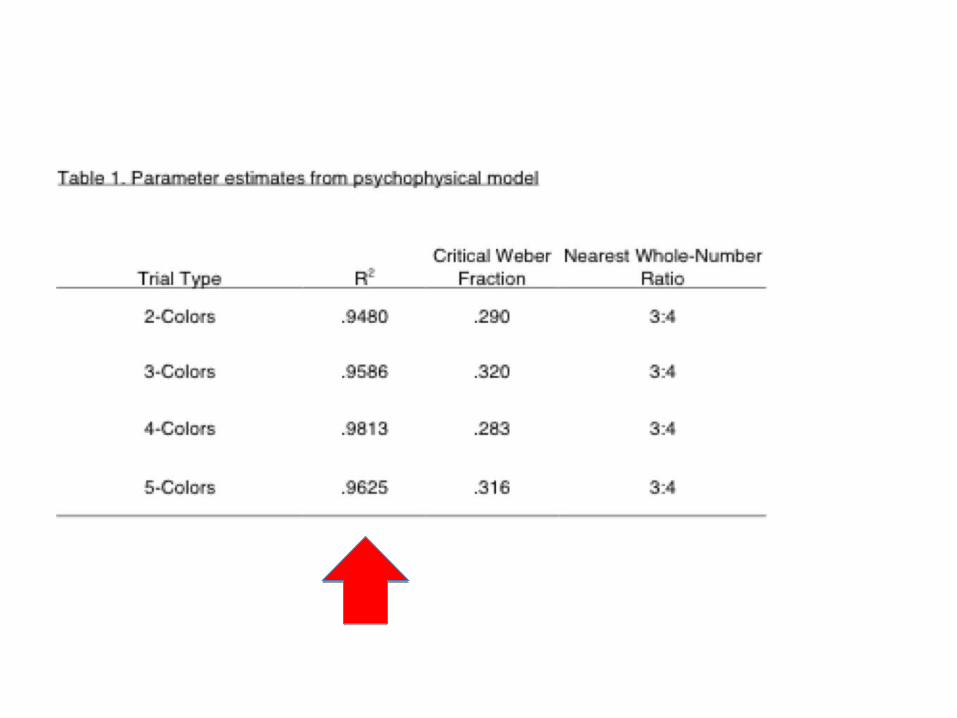
no effect of number of colors

fit to psychophysical model of ANS-driven performance

‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• we need to think about the form-dependence of a priori knowledge, since given the proposed analysis…
• speakers of English know a priori that: if most of the dots are blue, then the number blue dots exceeds the result
of subtracting that number from the number of dots
• this is so, even if speakers cannot put it this way
• and speakers could fail to know that most of the dots are blue, even if they knew that: there are 8 blue dots, and 7 yellow dots, and 8 is more than 7

‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• determiner/adjectival flexibility (for another day)I saw the most dots
• mass/count flexibilityMost of the dots are blue
Most of the goo is blue



‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• mass/count flexibilityMost of the dots are brown
Most of the goo is brown
• are mass nouns disguised count nouns? #{x:GooUnits(x) & BlueUnits(x)} > #{x:GooUnits(x)} − #{x:GooUnits(x) & BlueUnits(x)}

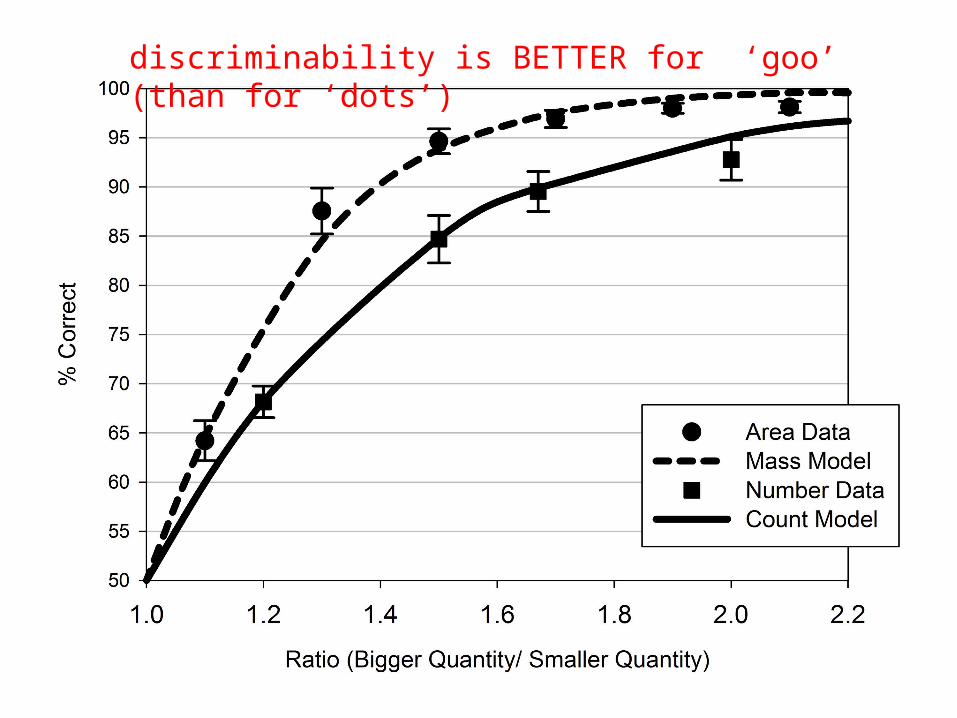
discriminability is BETTER for ‘goo’ (than for ‘dots’)

‘Most’ as a Case Study‘Most of the dots are blue’
#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
• mass/count flexibilityMost of the dots are brown
Most of the goo is brown
• I wouldn’t bet that mass nouns disguised count nouns #{x:GooUnits(x) & BlueUnits(x)} > #{x:GooUnits(x)} − #{x:GooUnits(x) & BlueUnits(x)} #
• work remains

‘Most of the dots are blue’#{x:Dot(x) & Blue(x)} > #{x:Dot(x)} − #{x:Dot(x) & Blue(x)}
If this hypothesis about the form of the assembled thought is on the right track, it provides some insight into how quantificational expressions interface with the (presumably older) cognitive systems that make it possible to have thoughts with quantificational content.
If ‘most’ fetches a complex concept specified in terms of conjunction, cardinalities and subtraction, perhaps that is because these concepts are basic, so far as prelinguistic cognition is concerned—or at least more natural than other concepts that are equivalent for purposes of logic/math.
In which case, the modern study of perception can help revive an ancient research program: study the “logical” vocabulary and its relation to meaning/analyticity/verification, to gain insights about the forms of human judgment. The trick is to pursue this program, and work out its implications for human knowledge, without spoiling semantics by confusing it with epistemology.

TimHunter
DarkoOdic
JeffLidz
JustinHalberda
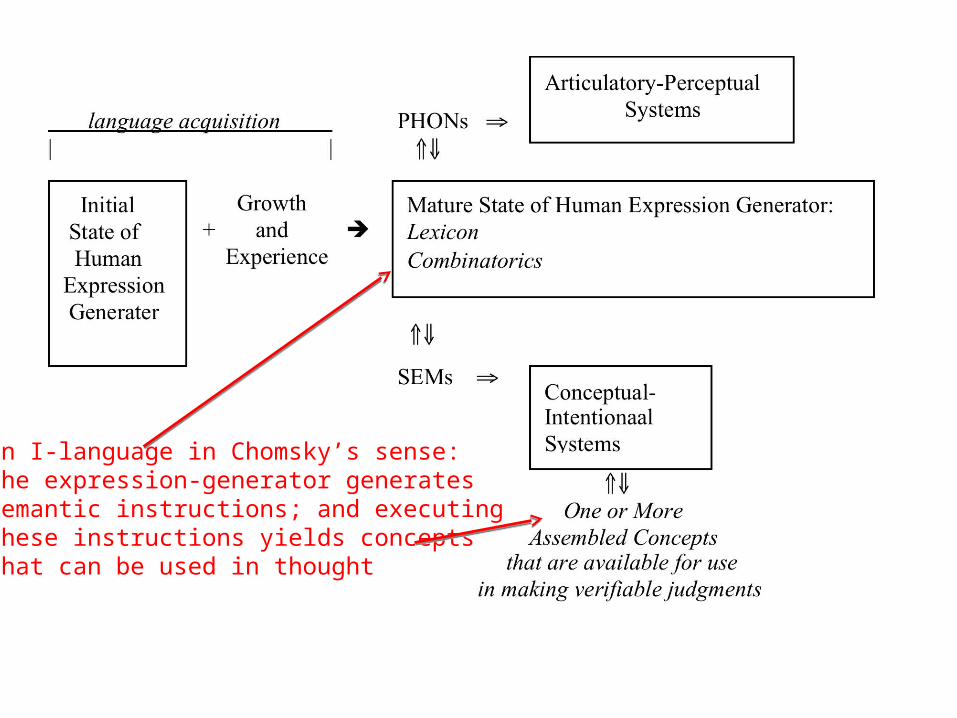
an I-language in Chomsky’s sense:the expression-generator generates semantic instructions; and executing these instructions yields concepts that can be used in thought
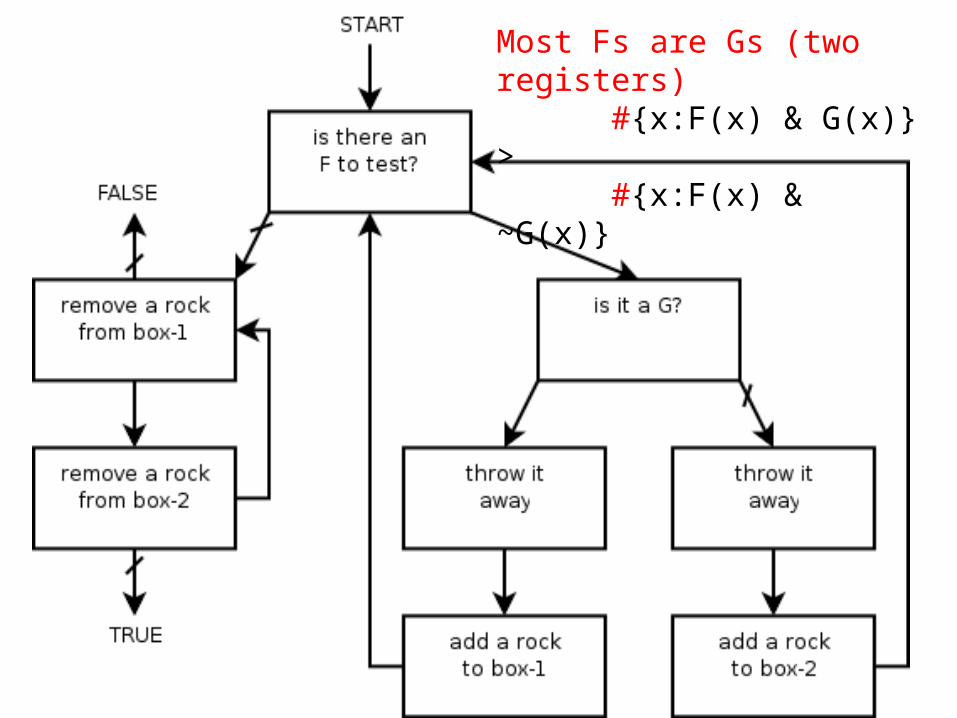
Most Fs are Gs (two registers) #{x:F(x) & G(x)} > #{x:F(x) & ~G(x)}
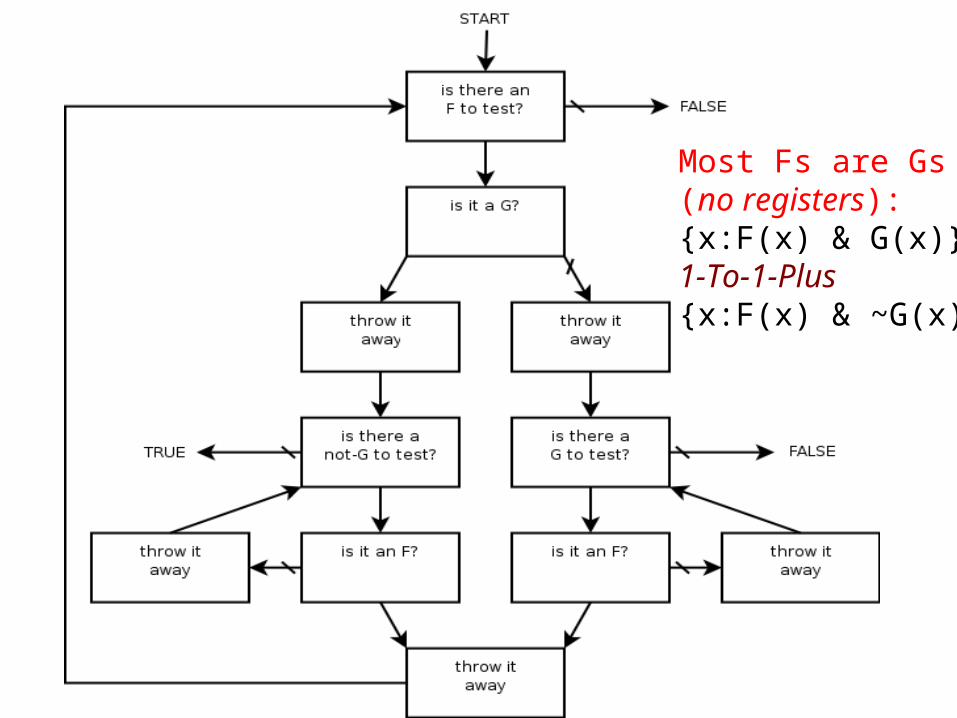
Most Fs are Gs (no registers): {x:F(x) & G(x)} 1-To-1-Plus {x:F(x) & ~G(x)}