3-1 chapter 3: describing syntax and semantics introduction terminology formal methods of describing...
TRANSCRIPT

3-1
Chapter 3: Describing Syntax and Semantics
• Introduction• Terminology• Formal Methods of Describing Syntax• Attribute Grammars – Static Semantics• Describing the Meanings of Programs:
Dynamic Semantics

3-2
Introduction
• Syntax: the form or structure of the expressions, statements, and program units, e.g., DD/DD/ DDDD– lexical specification – grammar
• Semantics: the meaning of the expressions, statements, and program units, e.g., 先月後日
• Syntax and semantics provide a language’s definition– Users of a language definition
• Other language designers• Implementers• Programmers (the users of the language)

3-3
Terminology
• A sentence is a string of characters over some alphabet
• A language is a set of sentences• A lexeme is the lowest level syntactic unit
of a language (e.g., *, sum, x), given by the lexical specification
• A token is a category of lexemes (e.g., identifier)

3-4
Formal Methods of Describing Syntax• Context-Free Grammars
– Developed by Noam Chomsky in the mid-1950s– meant to describe the syntax of natural languages– Define a class of languages called context-free
languages
• Backus-Naur Form (1959)– Invented by John Backus to describe Algol 58– BNF is equivalent to context-free grammars– The Most widely known metalanguage, which is used
to describe another language
• Extended BNF– Improves readability and writability of BNF

3-5
Four parts of a Context-Free Grammar
• a set of terminals: lexemes and tokens, the atomic symbols in the language,
• a set of nonterminals: abstractions, used to represent constructs in the language;
they act like syntactic variables• a set of rules (or called productions):
– identifying the components of a construct– A rule has a nonterminal as the left-hand side (LHS),
and the right-hand side (RHS) may consist of terminal and nonterminal symbols
– Examples of a BNF rule:<if_stmt> → if <logic_expr> then <stmt>
• A nonterminal chosen as the starting nonterminal.

3-6
BNF Rules
• Nonterminals are enclosed between symbols “ < ” and “ > ”. • An abstraction (or nonterminal symbol) can
have more than one RHS. Each alternative separated by “|” is a distinct rule.
• “ ” is read as “can be”. “|” is read as “or”.• Example:
<stmt> <single_stmt> | begin <stmt_list> end
• It sometimes uses subscripts, like [1], on the right side to distinguish between occurrences of a construct.

3-7
Describing Lists
• Syntactic lists are described using recursion <ident_list> ident | ident, <ident_list>
• Example: BNF rules for real numbers <real-number> <integer-part > . <fraction> <integer-part> <digit> | <integer-part><digit> <fraction> <digit> |<digit><fraction> <digit> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9

3-8
Derivation
• A derivation is a repeated application of rules, starting with the start symbol and ending with a sentence (all terminal symbols)
• Every string of symbols in the derivation is a sentential form, which may consist of nonterminals.
• A leftmost derivation is one in which the leftmost nonterminal in each sentential form is the one that is expanded
• A derivation may be neither leftmost nor rightmost

3-9
Example
• An Example Grammar <program> <stmts>
<stmts> <stmt> | <stmt> ; <stmts> <stmt> <var> = <expr> <var> a | b | c | d <expr> <term> + <term> | <term> - <term> <term> <var> | const
• Example of deviation: <program> => <stmts> => <stmt> => <var> = <expr>
=> a = <expr> => a = <term> + <term> => a = <var> + <term> => a = b + <term> => a = b + const

3-10
Parse Tree
• A hierarchical representation of a derivation
<program>
<stmts>
<stmt>
const
a
<var> = <expr>
<var>
b
<term> + <term>
<program> => <stmts> => <stmt> => <var> = <expr> => a =<expr> => a = <term> + <term> => a = <var> + <term> => a = b + <term> => a = b + const

3-11
Parse Tree (cont)
• Each leaf is labeled with a terminal. • Each non leaf node is labeled with a nonterminal.• The label of a non leaf node is the left side of
some rule, and the labels of the children of the node, from left to right, form the right side of that production.
• The root is labeled with the starting nonterminal.• A parse tree generates the sentence formed by
reading the terminals at its leaves from left to right.
• The construction of a parse tree is called parsing.

3-12
Parser
• top - down parser : from the root of a parse tree toward the leaves;
• bottom - up parser:from leaves of a parse tree toward the root;

3-13
Ambiguity in Grammars
• A grammar is ambiguous if and only if it generates a sentential form that has two or more distinct parse trees
• Ambiguity can be resolved by establishing conventions.
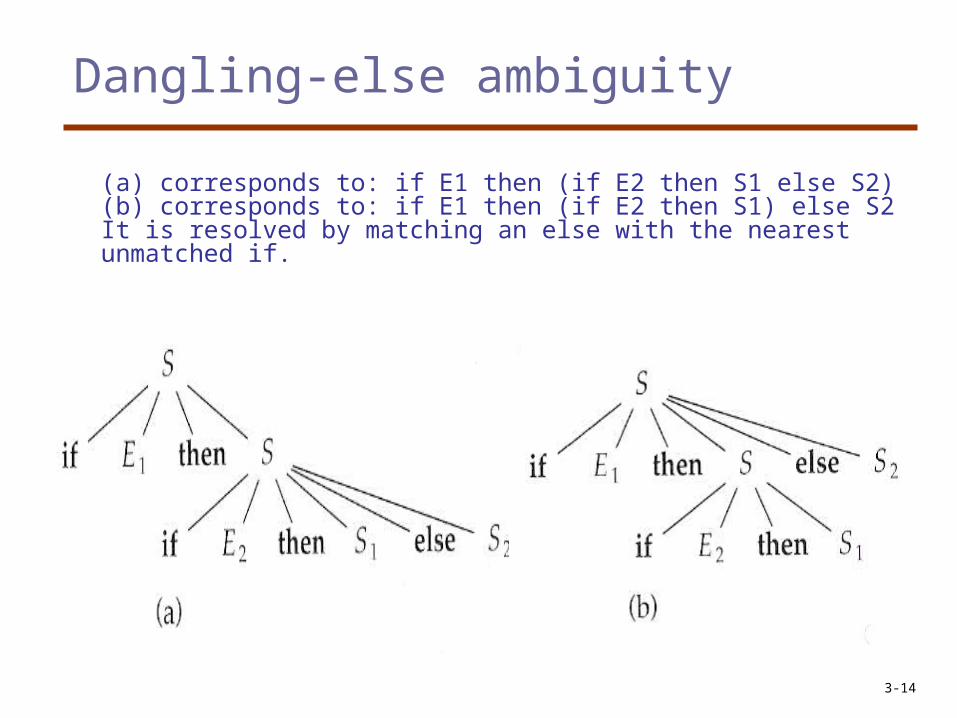
• Example: dangling-else ambiguity
Consider the following grammar: <S> if <E> then <S> <S> if <E> then <S> else <S>
Consider the sentential form: if E1 then if E2 then S1 else S2
3-14
Dangling-else ambiguity
(a) corresponds to: if E1 then (if E2 then S1 else S2) (b) corresponds to: if E1 then (if E2 then S1) else S2It is resolved by matching an else with the nearest unmatched if.

3-15
Expression notations
• prefix notation: op E1 E2, e.g., * + 20 30 60 = * 50 60 = 3000; easy to decode during a left-to-right scan of an expression.• postfix notation: E1 E2 op, e.g., 20 30 + 60 *=50 60 *=3000; can be mechanically evaluated with a stack data
structure.

3-16
Expression notations (cont)
• infix notation: E1 op E2 – familiar and easy to read; – without rules for specifying the relative “precedence” of
operators, parentheses would be needed in expressions to make explicit the operands of an infix operator,
e.g., a+b*c a+(b*c).• An operator is “ left associate” if subexpressions
containing multiple occurrences of the operator are grouped from left to right, – e.g. 4-2-1 (4-2)-1
• An operator is “ right associate” if subexpressions containing multiple occurrences of the operator are grouped from right to left, – e.g. x=y=3 x=(y=3)
3-17
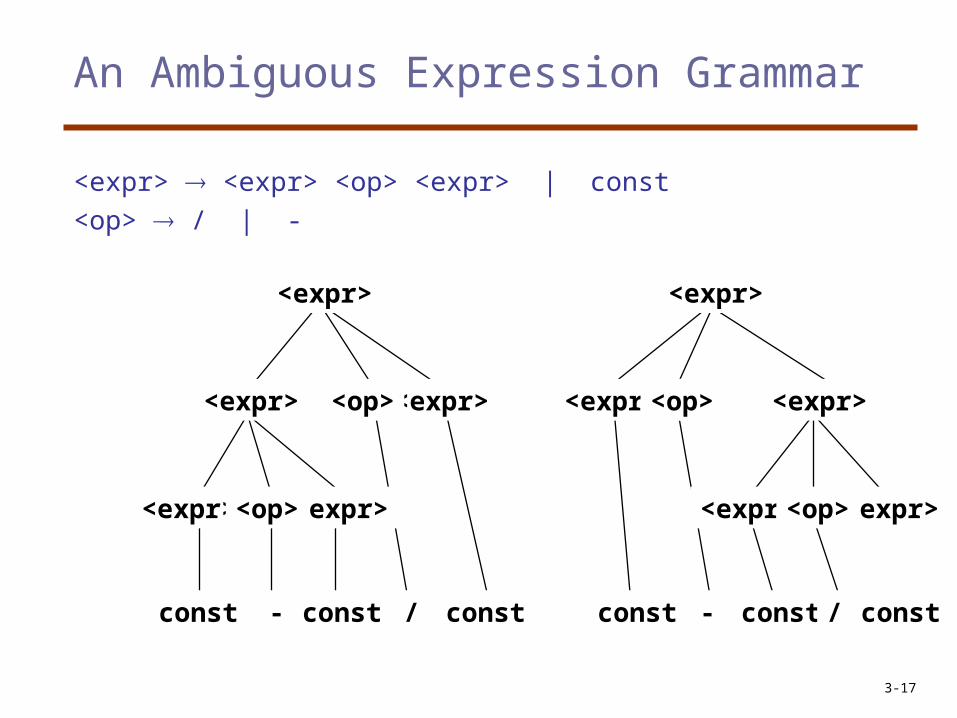
An Ambiguous Expression Grammar
<expr> <expr> <op> <expr> | const<op> / | -
<expr>
<expr> <expr>
<expr> <expr>
<expr>
<expr> <expr>
<expr> <expr>
<op>
<op>
<op>
<op>
const const const const const const- -/ /
<op>

3-18
An Unambiguous Expression Grammar
• If we use the parse tree to indicate precedence levels of the operators, we cannot have ambiguity
<expr> <expr> - <term> | <term><term> <term> / const| const
<expr>
<expr> <term>
<term> <term>
const const
const/
-
3-19
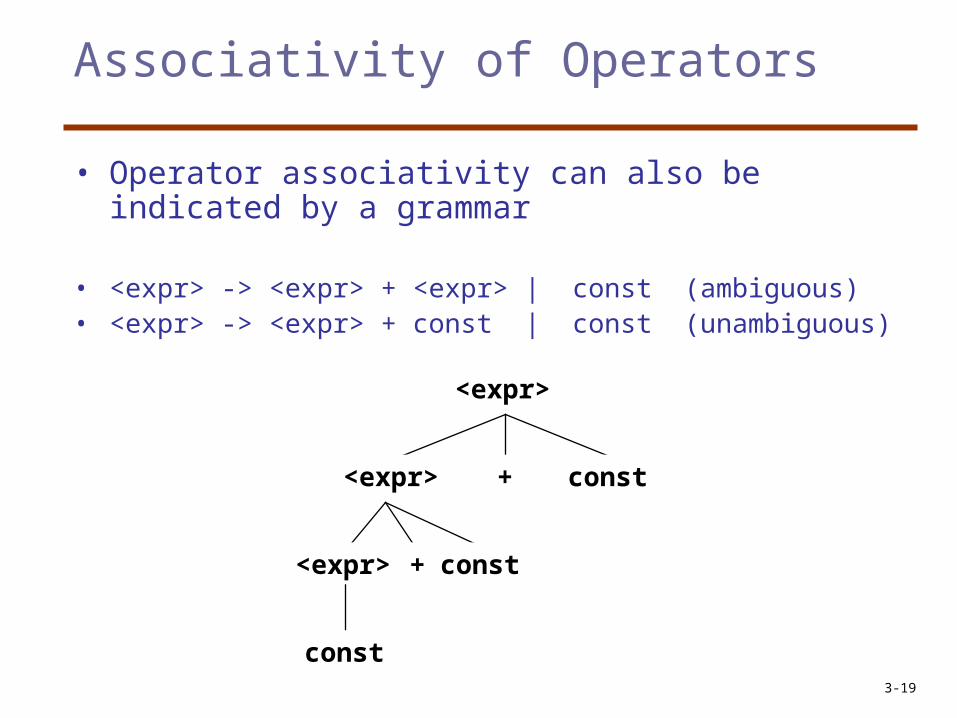
Associativity of Operators
• Operator associativity can also be indicated by a grammar
• <expr> -> <expr> + <expr> | const (ambiguous)• <expr> -> <expr> + const | const (unambiguous)
<expr><expr>
<expr>
<expr> const
const
const
+
+

3-20
Associativity of Operators (cont)
(1) <L> -> <L> + number (2) <R> -> number + <R> | <L> - number | number - <R> | number | number
Although both grammars are unambiguous, (1) is more suitable for left associate operators, because its parse tree grows down and to the left, which is close to the
semantics. L
L
L
number 1
number 2
number 4
-
-
R
R
R
-
-
number 1
number 2
number 4

3-21
Handling Associativity and Precedence
• The syntax of expressions in a language can be characterized by a table giving the associativity and precedence of operators.
• Suppose we have a table, where all operators on the same line have the same associativity and precedence. (see the next page)
• A grammar for expressions can be designed by choosing a nonterminal for each precedence level, and an additional nonterminal for the smallest subexpression (factors).

3-22
Handling Associativity and Precedence (cont)
• Example of three-level operators: [A] = right associative [E] + - left associative [T] * / left associative [F] factors• The grammar is: <A> -> <E> = <A> | <E> <E> -> <E> + <T> | <E> – <T> | <T> <T> -> <T > * <F> | <T> / <F> | <F> <F> -> (< E> ) | name | number

3-23
Extended BNF
• Optional parts are placed in brackets [ ]<proc_call> -> ident [(<expr_list>)]
• Alternative parts of RHSs are placed inside parentheses and separated via vertical bars <term> → <term> (+|-) const
• Repetitions (0 or more) are placed inside braces { }<ident> → letter {letter|digit}

3-24
BNF and EBNF
• BNF <expr> <expr> + <term> | <expr> - <term> | <term> <term> <term> * <factor> | <term> / <factor> | <factor>
• EBNF <expr> <term> {(+ | -) <term>} <term> <factor> {(* | /) <factor>}

3-25
Attribute Grammars
• Context-free grammars (CFGs) cannot describe all of the syntax of programming languages. For example, all variables must be declared before they are referenced.
• attribute grammars (AGs): additions to CFGs to carry some static semantic information along parse trees
• Static semantics are related to the legal form of a program, not directly related to the meaning of programs during execution. Many static semantic rules state the type constraints of a language.
• Primary value of attribute grammars (AGs)– Static semantics specification– Compiler design (static semantics checking)

3-26
Attribute Grammars : Definition
• An attribute grammar is a context-free grammar with the following additions:– For each grammar symbol x there is a set A(x)
of attribute values– Each rule has a set of semantic functions that
define certain attributes of the nonterminals in the rule
– Each rule has a (possibly empty) set of predicates to check for attribute consistency

3-27
Attribute Grammars: Definition (cont)
• Let X0 X1 ... Xn be a rule
• Functions of the form S(X0) = f(A(X1), ... , A(Xn)) define synthesized attributes, which are used to pass semantic information up a parse tree.
• Functions of the form I(Xj) = f(A(X0), ... , A(Xn)), for 1<= j <= n, define inherited attributes, which pass semantic information down and across a tree.
• Initially, there are intrinsic attributes on the leaves, whose values are determined outside the parse tree. For example, the types of variables come from the symbol table.

3-28
Attribute Grammars: An Example
• Syntax<assign> -> <var> = <expr><expr> -> <var> + <var> | <var><var> -> A | B | C
• Attributes– actual_type: synthesized for <var> and <expr> – expected_type: inherited for <expr>
• We assume the variables can be one of two types: int or real.
• In the next page, the look-up function looks up a given variable name in the symbol table and returns the type.

3-29
Example of an Attribute Grammar (cont)
1. Syntax rule: <assign> <var> = <expr>Semantic rules: <expr>.expected_type
<var>.actual_type2. Syntax rule: <expr> <var>[2] + <var>[3]
Semantic rules: <expr>.actual_type if (<var>[2].actual_type == int) and (<var>[3].actual_type == int) then int else real end if Predicate: <expr>.actual_type == <expr>.expected_type
3. Syntax rule: <expr> <var>Semantic rules: <expr>.actual_type <var>.actual_type
Predicate: <expr>.actual_type == <expr>.expected_type
4. Syntax rule: <var> A | B | C Semantic rule:
<var>.actual_type lookup (<var>.string)

3-30
Computing Attribute Values
• How are attribute values computed?– If all attributes were inherited, the tree could
be decorated in top-down order.– If all attributes were synthesized, the tree
could be decorated in bottom-up order.– In many cases, both kinds of attributes are
used, and it is some combination of top-down and bottom-up that must be used.

3-31
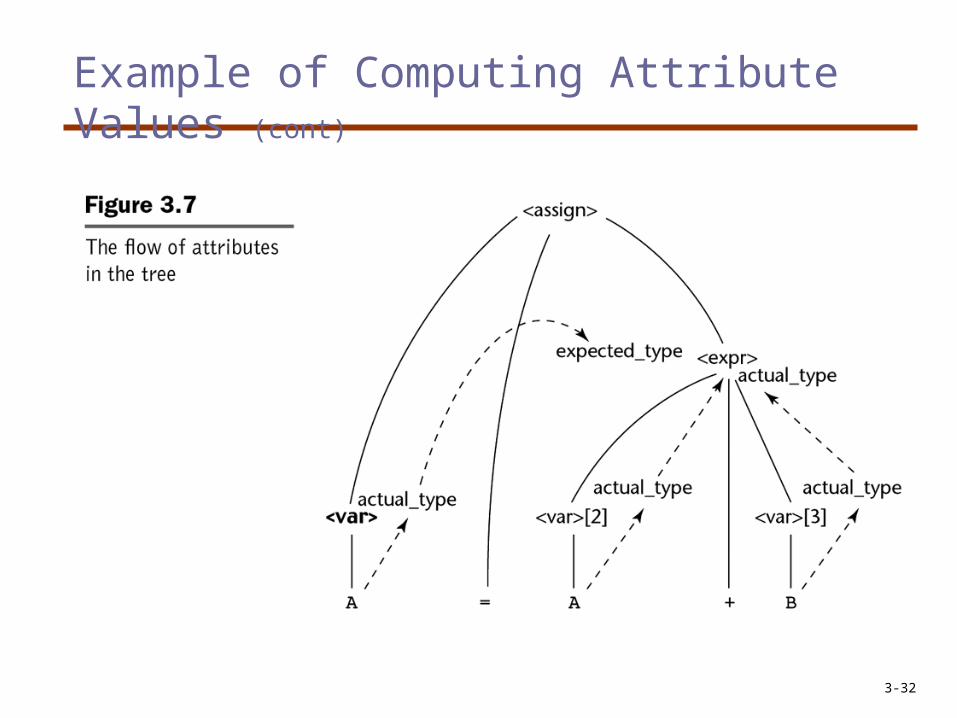
Example of Computing Attribute Values• For the sentence: A = A + B
1. <var>.actual_type look-up(A) (Rule4)2. <expr>.expected_type <var>.actual_type
(Rule1)
3. <var>[2].actual_type lookup (A) (Rule4)<var>[3].actual_type lookup (B) (Rule4)
4. <expr>.actual_type either int or real (Rule2)
5. <expr>.expected_type == <expr>.actual_type is either TRUE or FALSE (Rule2)
3-32
Example of Computing Attribute Values (cont)

3-33
Semantics
• There is no single widely acceptable notation or formalism for describing semantics
• Axiomatic Semantics– Based on formal logic (predicate calculus)– Axioms or inference rules are defined for each
statement type in the language, to state the meaning of statements and programs.
– The main purpose is for formal program verification. We will talk about this in Chapter 8.